腦機接口(BCI)腦電圖(EEG)分類能實現人腦直接與外部環境的信息交互。提出了基于輔助訓練思想的半監督稀疏表示分類器方法在BCI EEG分類中的應用。首先采用稀疏表示分類器從未標記樣本中選擇部分相關度較高的樣本。其次采用Fisher線性分類器作為判別分類器得到已選樣本的邊界信息。通過距離大小和方向判別條件進一步選出高置信度樣本。本文對三組基準數據集BCIⅠ、BCIⅡ_Ⅳ和USPS分別進行仿真實驗,分類正確率分別為97%、82%和84.7%,運算速度最快的僅需約0.2s。在分類正確率和運算效率兩個方面,均優于自訓練半監督SVM、有導師SVM兩種方法。
引用本文: 賈敏, 王金甲, 李靜, 洪文學. 基于輔助訓練的半監督稀疏表示分類器用于腦電圖分類. 生物醫學工程學雜志, 2014, 31(1): 1-6. doi: 10.7507/1001-5515.20140001 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
腦電圖(electroencephalogram,EEG)信號是從頭表通過電極采集得到的腦電生理信號,在腦機接口(brain-computer interface,BCI)的研究中具有很重要的作用。只有對EEG信號進行分析和分類,才能實現大腦信號直接控制外部設備。目前,對EEG信號進行分類的常用方法有:有監督分類方法[1-2]、半監督分類方法[3]。常用的EEG分類方法有:感知器、線性判別分析、Fisher分類器和線性支持向量機(support vector machine,SVM)等線性分類器,神經網絡、K近鄰、學習矢量量化、二次判別分析、非線性SVM等非線性分類器。半監督學習[4]可以從未標記樣本中選擇有用信息樣本來改善有監督學習,基于這種優點,半監督學習用于EEG分類已經成為一個研究熱點。
在半監督學習中,如何挑選出置信度較高的未標記樣本是極其關鍵的一個環節,將其稱為標記過程。不同的標記策略衍生出了不同的半監督方法。比如:直推式SVM方法[5]是根據未標記樣本的判別函數輸出值進行標記;漸進直推式SVM[5]是用成對標注法和標簽重置法進行標記。Co-training[6]是利用兩個不同類型的分類器完成學習,確定未標記樣本的標記置信度,但這種方法比較費時。Tri-training[7]是通過判斷三個分類器的預測一致性來對未標記樣本的不同標記置信度進行比較。最小二乘SVM的半監督學習算法[8]是采用區域標注法和標簽重置法進行標記。以上提到的對未標記樣本的標記方法中都用的是判別式分類器,只考慮了邊界信息,而沒有充分利用樣本的密度分布情況。
自訓練半監督學習[9]首先用少量有標記樣本訓練出一個初始SVM 分類器,然后分類器再對無標記樣本進行標記,最后通過選取置信度最高的標記過的無標記樣本,并將其加入到訓練集中重新訓練SVM 分類器。這就會存在某些問題。比如:假設樣本點x1、x2是兩個未標記樣本,它們的真實標簽分別為y1=+1、y2=-1,用標記樣本訓練得到的SVM對兩者進行分類,發現兩個未標記樣本離決策平面的距離都比較大也就是都具有很高的置信度,但是得到的分類結果卻是y1=-1、y2=+1,出現兩個樣本被完全錯分的情況。簡單來說就是兩個未標記樣本都具有很高的置信度,但是如果只考慮邊界信息,用SVM對其進行分類很可能出現以上錯分情況。輔助訓練半監督學習方法[10]改進了自訓練的問題,將密度分布和邊界這兩種信息結合起來,來完成半監督訓練過程中的標記任務。其中生成式分類器考慮每類的密度分布情況,利用樣本分布信息輔助得到數據的真實內在結構,判別式分類器使用SVM。由于這兩種分類器在解決分類任務時具有互補性,通過使用生成式分類器輔助判別式分類器做出決定,從而選出高置信度的未標記樣本,這樣就可以解決以上的錯分問題。
基于輔助訓練的半監督學習的過程如下。在輔助訓練的第一階段:用生成式分類器先選部分可靠的未標記樣本組成樣本集S′;在第二階段:用判別式分類器從S′中進一步選出置信度高的樣本組成樣本集S。兩個階段是輔助的關系,即第一階段幫助第二階段選擇高置信度樣本,所以將其稱為輔助訓練。在最后的分類階段,由已知的標記樣本和S中的高置信度樣本共同訓練主分類器,并對測試樣本進行分類,得到最終的分類結果。
在本文中嘗試了不同的方法完成輔助訓練的半監督學習過程并用于EEG信號分類,同時根據判別分類器自身的特點制定配套的選擇策略。在輔助訓練的第一階段采用稀疏表示分類器;在第二階段中采用Fisher線性分類器,制定合理策略來進一步選擇高置信度未標記樣本。EEG信號分類實驗表明,新算法表現出良好的性能,分類準確率高而且運行速度也快,達到了預期的效果。
1 稀疏表示分類器
稀疏表示方法是以壓縮感知理論為依據的。近年來基于l1范數最小化的稀疏表示分類器[11]已經成為模式識別領域的一個重要研究成果。稀疏表示分類是直接根據測試樣本在全部訓練樣本上的投影系數來進行識別的。當訓練樣本較好地反映所屬類別的特征分布時,稀疏表示的分類性能就比較高。
訓練樣本集記為A,其中屬于第i類的訓練樣本集記為Ai=[υi,1,υi,2,…,υi,ni]∈Rm×ni,其中一列表示一個樣本,相應的樣本個數記為ni,特征維數記為m。也就是說Ai中的樣本均是屬于同一類別的,可以把Ai當做一個線性子空間。任意一個測試樣本記為y∈Rm,如果y和Ai是屬于同一類別的,那么y就可以用ni個訓練樣本的線性組合來表示y=αi,1υi,1+αi,2υi,2+…αi,niυi,ni,其中系數αi,j∈R,j=1,2,…,ni。
稀疏表示分類器的算法步驟如下:
(1) 輸入:訓練樣本矩陣:A=[A1,A2,…,Ak]∈Rm×n,其中一共包含k個類別;一個新的測試樣本記為y∈Rm;ε是一個可調的允許誤差。
(2) 正則化:以l2范數為單位,對矩陣A的列進行正則化。
(3) l1范數最小化:求解式范數最小化問題:
(4) 計算殘差:
(5) 輸出:把測試樣本y所屬的類別歸為殘差最小對應的類別。
2 輔助訓練的半監督稀疏表示分類器
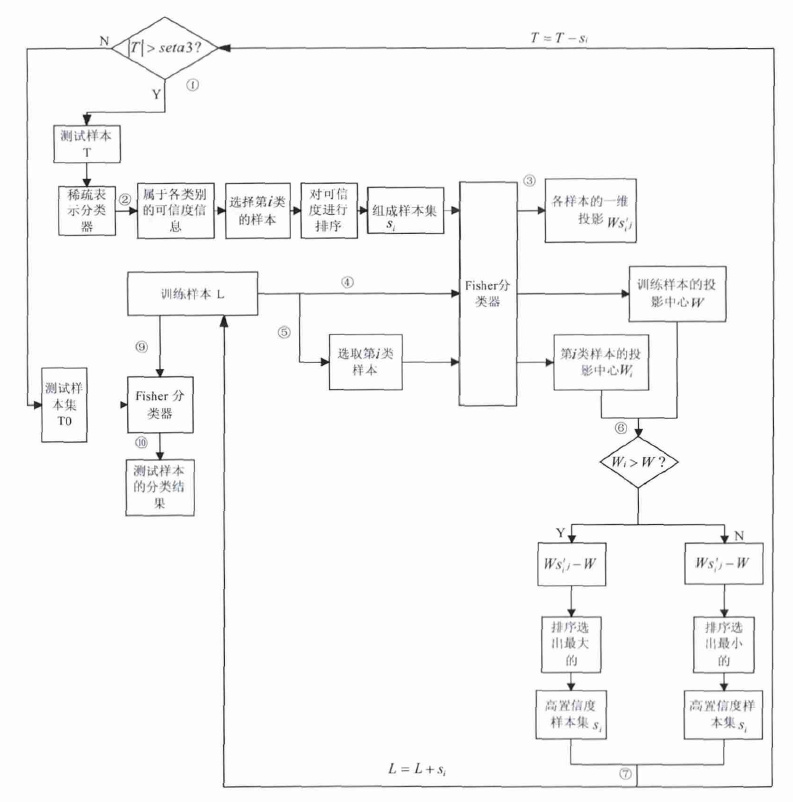
在輔助階段采用了稀疏表示分類器,它可以提供樣本的類別信息,同時還可以知道各個未標記樣本屬于某類的可靠程度。在判別階段使用了Fisher線性分類器,要針對該分類器設計相應的選擇策略。本文方法采用的是通過樣本的投影值來進行判斷,投影維數d和樣本類別數c關系如下:d=c-1。本文提出的基于輔助訓練思想的半監督分類方法對于多分類情況同樣是適用的,我們以兩分類問題為例進行詳細說明,通過Fisher線性分類器得到的投影也就是一維的投影。通過投影之間的距離最終選出置信度較高的未標記樣本。基于輔助訓練的半監督稀疏表示分類器的框圖如圖 1所示。
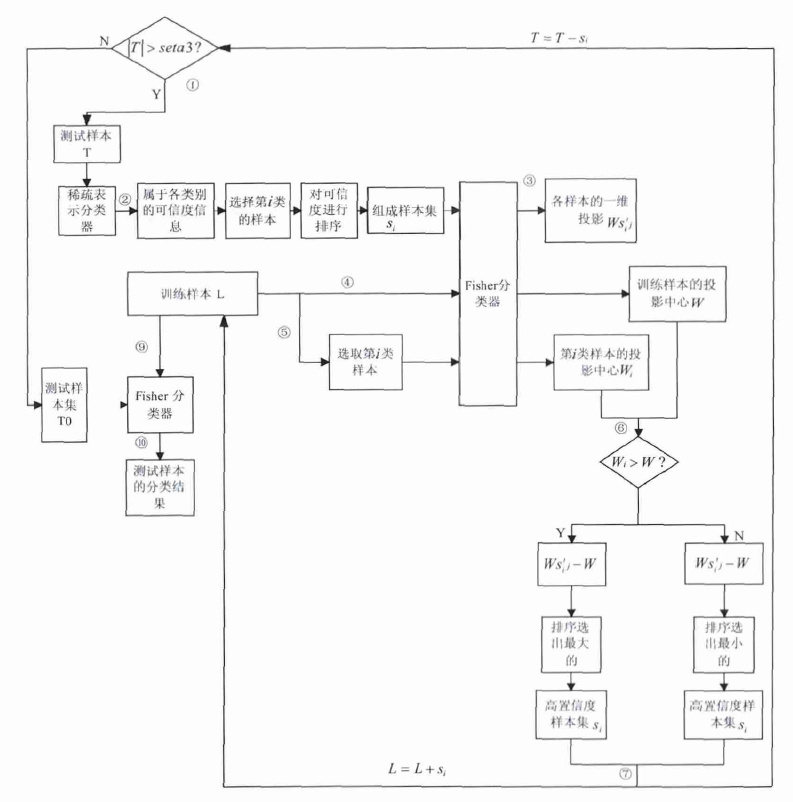 圖1
基于輔助訓練的半監督稀疏表示分類器的框圖
Figure1.
The block diagram of the semi-supervised sparse representation classifier based on help training
圖1
基于輔助訓練的半監督稀疏表示分類器的框圖
Figure1.
The block diagram of the semi-supervised sparse representation classifier based on help training
具體步驟如下:
(1) 測試樣本集為T,初始的測試樣本集為T0,當測試樣本集個數|T|大于預先設定的剩余測試樣本個數seta 3,即|T|>seta 3,將測試樣本集送入稀疏表示分類器中;
(2) 由稀疏表示分類器得到所有測試樣本的類別信息,先選出屬于第i類的測試樣本,其中i={1,2}。稀疏表示分類器同時可以提供各樣本屬于各個類別的可信度信息,即殘差,根據殘差的大小進行選擇,選出最小seta 1的個可信樣本,組成樣本集s′i;
(3) 將樣本集si中的樣本送入Fisher分類器中,得到各個可信樣本的一維投影值Ws′ij;其中j的表示預選樣本集s′i中各樣本的標號;
(4) 訓練樣本集為L,初始的訓練樣本集為L0,將訓練樣本全部送入Fisher分類器中,得到所有訓練樣本的一維投影值,通過計算得到全部訓練樣本的投影中心W;
(5) 從訓練樣本中選出屬于第i類的樣本,送入Fisher分類器中得到各樣本的一維投影值,通過計算得到第i類訓練樣本的投影中心Wi;
(6) 比較全部訓練樣本的投影中心值W、第i類訓練樣本的投影中心Wi。如果Wi>W,將各個可信樣本的一維投影值Ws′ij與全部訓練樣本的投影中心值W做差(Ws′ij-W),排序選出差值最大并且差值是大于0的,差值最大保證距離最遠,大于0可以避免錯分,將符合該條件的樣本組成高置信度樣本集si;如果Wi<W,同樣將Ws′ij、W做差(Ws′ij-W),排序選出差值最小并且是小于0的,差值最小保證了距離最遠,小于0可以避免錯分,將符合該條件的樣本組成高置信度樣本集si;
(7) 對訓練樣本和測試樣本集進行更新,L=L+si,T=T-si;
(8) 重復以上步驟,依次交替選出各類高置信度樣本,直到測試樣本個數小于規定的測試樣本個數時即|T|<seta 3時,以上步驟的循環迭代停止,終止高置信度樣本的選擇過程;
(9) 用更新過的訓練樣本訓練Fisher線性分類器,也就是用初始訓練樣本和加入的高置信度未標記樣本共同進行訓練;
(10) 把初始的測試樣本集T0送入最終的Fisher分類器中,最后得到測試樣本的分類結果。
算法涉及到一些細節問題,高置信度樣本的選擇策略討論如下:① 在第(2) 步驟中,對由稀疏表示分類器得到的未標記樣本的可信度進行排序選擇的時候,選出seta 1個可信樣本。seta 1的取值人工設定,如果seta 1的值取的過大,超過了未標記樣本的個數,就把所有的未標記樣本做為高置信度樣本的候選樣本;如果seta 1的取值小于未標記樣本的個數,則把優選出的前seta 1個未標記樣本作為高置信度樣本的候選樣本。② 在步驟(6) 中,投影值進行比較的時候,高置信度未標記樣本要滿足兩個條件,首先要保證s′i中的各個樣本的投影Ws′ij與所有訓練樣本的投影W的距離最大;其次還要有方向信息,當第i類訓練樣本的投影大于所有訓練樣本的投影時即Wi>W,說明選擇的第i類訓練樣本是正類,即s′i中的樣本也應該都是正類,所以在保證Ws′ij-W差值最大的同時,還要保證差是正的;同理,如果第i類訓練樣本的投影小于所有訓練樣本的投影時即Wi<W,說明選擇的第i類訓練樣本是負類,即s′i中的樣本也應該都是負類,所以在保證Ws′ij-W差值最小的同時還要保證差值是負。雙重條件可以保證樣本的不錯分。這樣將滿足以上兩個條件的樣本組成高置信度樣本集si。③ 在實驗中預先設定參數seta 2,表示最終選出的高置信度未標記樣本個數,因為我們不知道實驗中實際選出的高置信度樣本個數setatemp,所以如果我們設定的參數seta 2的值超過了setatemp,即seta 2>setatemp,就會出錯,為了避免這種情況的發生,我們采取如下措施:setamin=min(stea2,steatemp),參數steamin就是在實驗中真正的高置信度樣本的個數。所以一般來說,實驗中真正的高置信度樣本個數setamin和實驗中預先設定seta 2的不一定是相等的。但如果seta 2的值設定比較小時,使seta 2=setamin。這部分工作是我們的創新。
3 實驗仿真結果與分析
本實驗的環境為:Intel Xeon(R)2CPU、 2 GHz、內存2 GB、 MATLAB語言實現。采用的EEG信號數據是腦機接口競賽一的BCIⅠ數據集和競賽二的BCIⅡ_Ⅳ數據集[12],將測試樣本當作未標記樣本。還考慮了真實數據集USPS[13],USPS是手寫體數字集,也是真實數據集,從1~10每個數字都隨機抽取150張圖片,數字‘2’、‘5’被歸為+1類,其余數字被歸為-1類。如表 1所示。
在實驗中會涉及到三個可調參數,分別是預選的未標記樣本個數seta 1、選擇的高置信度未標記樣本個數seta 2、剩余的未標記樣本個數seta 3。限于篇幅,以下仿真實驗均列出部分實驗結果進行討論。
BCIⅠ數據集的仿真實驗結果如表 2所示。從表 2可以看出,第一,固定參數seta 2=5、seta 3=80,調整參數seta 1的取值。仿真結果表明:預選樣本個數seta 1的取值在一定范圍內對正確率是有影響的,從seta 1=20,以5為一個單位逐漸增大,對正確率沒有影響,均可以達到95%;以同樣單位逐漸減小時,正確率有偏高的趨勢,當seta 1=10時,正確率可以達到96%,當seta 1=5時,正確率可以達到97%,達到了理想的效果。第二,固定參數seta 1=20、seta 2=5,調整參數seta 3的取值。在其它兩個參數確定的前提下,seta 3是很重要的一個參數,對正確率和時間都有一定影響:(1) 取值變小時說明選擇的高置信度樣本增多,其中部分樣本不一定是有效的,所以正確率不會有明顯變化,但是花費的時間明顯變長,如表 2中所示,當seta 3的取值從80變為70、60時,正確率沒有發生變化,均為95%;當seta 3=60時,需要的時間是154.968 8 s,明顯比seta 3=80時所需的時間要長;(2) 當seta 3的取值變大時說明選擇的高置信度樣本減小,其中有效樣本所占的比例是增大的,所以正確率會明顯變化,所花費的時間也會明顯縮短。參數seta 3的取值從80變為90時,正確率從95%提高到97%,運算時間也從82.796 9 s縮短到50.109 4 s。 第三,固定參數seta 1=20、seta 3=90,調整參數seta 2的取值,如表 2所示也可以達到97%的分類效果,當然這個結果和seta 3=90是有很大關系的。
BCIⅡ_Ⅳ數據集的仿真實驗結果如表 3所示。從表 3可以看出,固定參數seta 2=5、seta 3=80,調整參數的取值,當seta 1=20最優,正確率可以達到82%;固定參數seta 1=20、seta 3=80,調整參數seta 2的取值,正確率同樣可以達到82%,其中當seta 2=20時,運算效率也是最高的,只需要5.468 8 s;固定seta 1=20、seta 2=5,可調參數seta 3=90時,正確率降低到80%,這和表 2所呈現的規律是不太一致的。另外,在BCIⅠ數據集上運行所需的時間整體都比在BCIⅡ_Ⅳ數據集上花費的時間要長很多,在BCIⅡ_Ⅳ數據集上正確率最高且時間最少的只需要5.468 8 s,在BCIⅠ數據集上效果最好所需的運行時間是50.109 4 s。這與數據集本身的復雜度是有很大關系的。數據集不同,相應的最優參數也不相同。
USPS數據集的仿真實驗結果如表 4所示。在該數據集上,我們對可調參數進行了多次調整,選擇有效數據進行說明。實驗中采用的USPS數據集的維數特別高,其維數d=241,遠遠超過了標記樣本個數,標記樣本個數為100,稀疏表示分類器對維數是比較敏感的,因為稀疏表示分類器在對未標記樣本進行分類時,是一個一個送入分類器進行處理,送入的每個待分類樣本分別和所有的標記樣本作用,計算殘差,在計算過程中,如果維數過高遠遠超過樣本個數,一次一次迭代過程是非常復雜的,所以我們固定參數seta 3的值且令seta 3=400。結果表明,改變其它兩個參數的值對分類正確率幾乎沒什么影響,只是對運行效率有一定影響。
我們將BCIⅠ、BCIⅡ_Ⅳ數據集中選出高置信度樣本的真實標簽與學習到的標簽進行比較分析。BCIⅠ數據集中選用的是seta 1=20、seta 2=5、seta 3=90,最終選出的高置信度樣本個數是10個,學習標簽全部和真實標簽一致。BCIⅡ_Ⅳ數據集中選用的是seta 1=20、seta 2=20、seta 3=90,最終選出的高置信度樣本個數是20個,其中18個學習標簽和真實標簽一致,這種誤差導致了分類性能下降。
4 討論
本文方法與自訓練SVM[3, 9]、輔助訓練SVM[10]和有導師SVM[3]三種方法在分類正確率和運算效率兩方面進行了比較分析,仿真結果如表 5所示。實驗中用高斯核對三種方法進行了仿真實驗,參數c的取值范圍為10-3~103,高斯核參數為0.02。仔細調整高斯核參數效果更好。SVM分類這三個數據時只考慮訓練集和測試集,不考慮未標志樣本。從表 5中可以看到,本文方法的實驗結果優于自訓練SVM、輔助訓練SVM和有導師SVM的實驗結果。
文獻[3]采用的是自訓練SVM方法,文獻[9]采用的是改進的自訓練SVM方法,文獻[10]采用的是輔助訓練SVM方法。本文方法采用的是稀疏表示分類器輔助訓練Fisher線性分類器,和文獻[3, 9]主要區別是訓練方式不同和使用的分類器不同,和文獻[10]主要區別是使用的分類器不同并且提出了避免錯分策略。實驗結果說明輔助訓練思想要優于自訓練思想,也說明半監督方法不要局限于SVM。
5 結論
以輔助訓練思想為框架,提出了一種新的稀疏表示分類器半監督方法。本文方法的創新點如下:首先用稀疏表示分類器所提供的信息選擇高置信度樣本。其次用Fisher線性分類器作為判別分類器,并提出相匹配的距離和方向選擇策略。仿真實驗結果表明本文提出的方法對EEG信號分類具有很好的性能,證明本文方法是十分有效的。可以說EEG信號分類任務為半監督方法提供了應用背景。進一步研究輔助訓練用于多分類問題,在判別階段中具體的多分類問題用到的判別條件可能還會有更加復雜的形式。進一步研究其他輔助階段和判別階段所選用的分類方法,進行實驗并設計相匹配的選擇策略,以達到更好的分類性能。
引言
腦電圖(electroencephalogram,EEG)信號是從頭表通過電極采集得到的腦電生理信號,在腦機接口(brain-computer interface,BCI)的研究中具有很重要的作用。只有對EEG信號進行分析和分類,才能實現大腦信號直接控制外部設備。目前,對EEG信號進行分類的常用方法有:有監督分類方法[1-2]、半監督分類方法[3]。常用的EEG分類方法有:感知器、線性判別分析、Fisher分類器和線性支持向量機(support vector machine,SVM)等線性分類器,神經網絡、K近鄰、學習矢量量化、二次判別分析、非線性SVM等非線性分類器。半監督學習[4]可以從未標記樣本中選擇有用信息樣本來改善有監督學習,基于這種優點,半監督學習用于EEG分類已經成為一個研究熱點。
在半監督學習中,如何挑選出置信度較高的未標記樣本是極其關鍵的一個環節,將其稱為標記過程。不同的標記策略衍生出了不同的半監督方法。比如:直推式SVM方法[5]是根據未標記樣本的判別函數輸出值進行標記;漸進直推式SVM[5]是用成對標注法和標簽重置法進行標記。Co-training[6]是利用兩個不同類型的分類器完成學習,確定未標記樣本的標記置信度,但這種方法比較費時。Tri-training[7]是通過判斷三個分類器的預測一致性來對未標記樣本的不同標記置信度進行比較。最小二乘SVM的半監督學習算法[8]是采用區域標注法和標簽重置法進行標記。以上提到的對未標記樣本的標記方法中都用的是判別式分類器,只考慮了邊界信息,而沒有充分利用樣本的密度分布情況。
自訓練半監督學習[9]首先用少量有標記樣本訓練出一個初始SVM 分類器,然后分類器再對無標記樣本進行標記,最后通過選取置信度最高的標記過的無標記樣本,并將其加入到訓練集中重新訓練SVM 分類器。這就會存在某些問題。比如:假設樣本點x1、x2是兩個未標記樣本,它們的真實標簽分別為y1=+1、y2=-1,用標記樣本訓練得到的SVM對兩者進行分類,發現兩個未標記樣本離決策平面的距離都比較大也就是都具有很高的置信度,但是得到的分類結果卻是y1=-1、y2=+1,出現兩個樣本被完全錯分的情況。簡單來說就是兩個未標記樣本都具有很高的置信度,但是如果只考慮邊界信息,用SVM對其進行分類很可能出現以上錯分情況。輔助訓練半監督學習方法[10]改進了自訓練的問題,將密度分布和邊界這兩種信息結合起來,來完成半監督訓練過程中的標記任務。其中生成式分類器考慮每類的密度分布情況,利用樣本分布信息輔助得到數據的真實內在結構,判別式分類器使用SVM。由于這兩種分類器在解決分類任務時具有互補性,通過使用生成式分類器輔助判別式分類器做出決定,從而選出高置信度的未標記樣本,這樣就可以解決以上的錯分問題。
基于輔助訓練的半監督學習的過程如下。在輔助訓練的第一階段:用生成式分類器先選部分可靠的未標記樣本組成樣本集S′;在第二階段:用判別式分類器從S′中進一步選出置信度高的樣本組成樣本集S。兩個階段是輔助的關系,即第一階段幫助第二階段選擇高置信度樣本,所以將其稱為輔助訓練。在最后的分類階段,由已知的標記樣本和S中的高置信度樣本共同訓練主分類器,并對測試樣本進行分類,得到最終的分類結果。
在本文中嘗試了不同的方法完成輔助訓練的半監督學習過程并用于EEG信號分類,同時根據判別分類器自身的特點制定配套的選擇策略。在輔助訓練的第一階段采用稀疏表示分類器;在第二階段中采用Fisher線性分類器,制定合理策略來進一步選擇高置信度未標記樣本。EEG信號分類實驗表明,新算法表現出良好的性能,分類準確率高而且運行速度也快,達到了預期的效果。
1 稀疏表示分類器
稀疏表示方法是以壓縮感知理論為依據的。近年來基于l1范數最小化的稀疏表示分類器[11]已經成為模式識別領域的一個重要研究成果。稀疏表示分類是直接根據測試樣本在全部訓練樣本上的投影系數來進行識別的。當訓練樣本較好地反映所屬類別的特征分布時,稀疏表示的分類性能就比較高。
訓練樣本集記為A,其中屬于第i類的訓練樣本集記為Ai=[υi,1,υi,2,…,υi,ni]∈Rm×ni,其中一列表示一個樣本,相應的樣本個數記為ni,特征維數記為m。也就是說Ai中的樣本均是屬于同一類別的,可以把Ai當做一個線性子空間。任意一個測試樣本記為y∈Rm,如果y和Ai是屬于同一類別的,那么y就可以用ni個訓練樣本的線性組合來表示y=αi,1υi,1+αi,2υi,2+…αi,niυi,ni,其中系數αi,j∈R,j=1,2,…,ni。
稀疏表示分類器的算法步驟如下:
(1) 輸入:訓練樣本矩陣:A=[A1,A2,…,Ak]∈Rm×n,其中一共包含k個類別;一個新的測試樣本記為y∈Rm;ε是一個可調的允許誤差。
(2) 正則化:以l2范數為單位,對矩陣A的列進行正則化。
(3) l1范數最小化:求解式范數最小化問題:
(4) 計算殘差:
(5) 輸出:把測試樣本y所屬的類別歸為殘差最小對應的類別。
2 輔助訓練的半監督稀疏表示分類器
在輔助階段采用了稀疏表示分類器,它可以提供樣本的類別信息,同時還可以知道各個未標記樣本屬于某類的可靠程度。在判別階段使用了Fisher線性分類器,要針對該分類器設計相應的選擇策略。本文方法采用的是通過樣本的投影值來進行判斷,投影維數d和樣本類別數c關系如下:d=c-1。本文提出的基于輔助訓練思想的半監督分類方法對于多分類情況同樣是適用的,我們以兩分類問題為例進行詳細說明,通過Fisher線性分類器得到的投影也就是一維的投影。通過投影之間的距離最終選出置信度較高的未標記樣本。基于輔助訓練的半監督稀疏表示分類器的框圖如圖 1所示。
圖1
基于輔助訓練的半監督稀疏表示分類器的框圖
Figure1.
The block diagram of the semi-supervised sparse representation classifier based on help training
具體步驟如下:
(1) 測試樣本集為T,初始的測試樣本集為T0,當測試樣本集個數|T|大于預先設定的剩余測試樣本個數seta 3,即|T|>seta 3,將測試樣本集送入稀疏表示分類器中;
(2) 由稀疏表示分類器得到所有測試樣本的類別信息,先選出屬于第i類的測試樣本,其中i={1,2}。稀疏表示分類器同時可以提供各樣本屬于各個類別的可信度信息,即殘差,根據殘差的大小進行選擇,選出最小seta 1的個可信樣本,組成樣本集s′i;
(3) 將樣本集si中的樣本送入Fisher分類器中,得到各個可信樣本的一維投影值Ws′ij;其中j的表示預選樣本集s′i中各樣本的標號;
(4) 訓練樣本集為L,初始的訓練樣本集為L0,將訓練樣本全部送入Fisher分類器中,得到所有訓練樣本的一維投影值,通過計算得到全部訓練樣本的投影中心W;
(5) 從訓練樣本中選出屬于第i類的樣本,送入Fisher分類器中得到各樣本的一維投影值,通過計算得到第i類訓練樣本的投影中心Wi;
(6) 比較全部訓練樣本的投影中心值W、第i類訓練樣本的投影中心Wi。如果Wi>W,將各個可信樣本的一維投影值Ws′ij與全部訓練樣本的投影中心值W做差(Ws′ij-W),排序選出差值最大并且差值是大于0的,差值最大保證距離最遠,大于0可以避免錯分,將符合該條件的樣本組成高置信度樣本集si;如果Wi<W,同樣將Ws′ij、W做差(Ws′ij-W),排序選出差值最小并且是小于0的,差值最小保證了距離最遠,小于0可以避免錯分,將符合該條件的樣本組成高置信度樣本集si;
(7) 對訓練樣本和測試樣本集進行更新,L=L+si,T=T-si;
(8) 重復以上步驟,依次交替選出各類高置信度樣本,直到測試樣本個數小于規定的測試樣本個數時即|T|<seta 3時,以上步驟的循環迭代停止,終止高置信度樣本的選擇過程;
(9) 用更新過的訓練樣本訓練Fisher線性分類器,也就是用初始訓練樣本和加入的高置信度未標記樣本共同進行訓練;
(10) 把初始的測試樣本集T0送入最終的Fisher分類器中,最后得到測試樣本的分類結果。
算法涉及到一些細節問題,高置信度樣本的選擇策略討論如下:① 在第(2) 步驟中,對由稀疏表示分類器得到的未標記樣本的可信度進行排序選擇的時候,選出seta 1個可信樣本。seta 1的取值人工設定,如果seta 1的值取的過大,超過了未標記樣本的個數,就把所有的未標記樣本做為高置信度樣本的候選樣本;如果seta 1的取值小于未標記樣本的個數,則把優選出的前seta 1個未標記樣本作為高置信度樣本的候選樣本。② 在步驟(6) 中,投影值進行比較的時候,高置信度未標記樣本要滿足兩個條件,首先要保證s′i中的各個樣本的投影Ws′ij與所有訓練樣本的投影W的距離最大;其次還要有方向信息,當第i類訓練樣本的投影大于所有訓練樣本的投影時即Wi>W,說明選擇的第i類訓練樣本是正類,即s′i中的樣本也應該都是正類,所以在保證Ws′ij-W差值最大的同時,還要保證差是正的;同理,如果第i類訓練樣本的投影小于所有訓練樣本的投影時即Wi<W,說明選擇的第i類訓練樣本是負類,即s′i中的樣本也應該都是負類,所以在保證Ws′ij-W差值最小的同時還要保證差值是負。雙重條件可以保證樣本的不錯分。這樣將滿足以上兩個條件的樣本組成高置信度樣本集si。③ 在實驗中預先設定參數seta 2,表示最終選出的高置信度未標記樣本個數,因為我們不知道實驗中實際選出的高置信度樣本個數setatemp,所以如果我們設定的參數seta 2的值超過了setatemp,即seta 2>setatemp,就會出錯,為了避免這種情況的發生,我們采取如下措施:setamin=min(stea2,steatemp),參數steamin就是在實驗中真正的高置信度樣本的個數。所以一般來說,實驗中真正的高置信度樣本個數setamin和實驗中預先設定seta 2的不一定是相等的。但如果seta 2的值設定比較小時,使seta 2=setamin。這部分工作是我們的創新。
3 實驗仿真結果與分析
本實驗的環境為:Intel Xeon(R)2CPU、 2 GHz、內存2 GB、 MATLAB語言實現。采用的EEG信號數據是腦機接口競賽一的BCIⅠ數據集和競賽二的BCIⅡ_Ⅳ數據集[12],將測試樣本當作未標記樣本。還考慮了真實數據集USPS[13],USPS是手寫體數字集,也是真實數據集,從1~10每個數字都隨機抽取150張圖片,數字‘2’、‘5’被歸為+1類,其余數字被歸為-1類。如表 1所示。
在實驗中會涉及到三個可調參數,分別是預選的未標記樣本個數seta 1、選擇的高置信度未標記樣本個數seta 2、剩余的未標記樣本個數seta 3。限于篇幅,以下仿真實驗均列出部分實驗結果進行討論。
BCIⅠ數據集的仿真實驗結果如表 2所示。從表 2可以看出,第一,固定參數seta 2=5、seta 3=80,調整參數seta 1的取值。仿真結果表明:預選樣本個數seta 1的取值在一定范圍內對正確率是有影響的,從seta 1=20,以5為一個單位逐漸增大,對正確率沒有影響,均可以達到95%;以同樣單位逐漸減小時,正確率有偏高的趨勢,當seta 1=10時,正確率可以達到96%,當seta 1=5時,正確率可以達到97%,達到了理想的效果。第二,固定參數seta 1=20、seta 2=5,調整參數seta 3的取值。在其它兩個參數確定的前提下,seta 3是很重要的一個參數,對正確率和時間都有一定影響:(1) 取值變小時說明選擇的高置信度樣本增多,其中部分樣本不一定是有效的,所以正確率不會有明顯變化,但是花費的時間明顯變長,如表 2中所示,當seta 3的取值從80變為70、60時,正確率沒有發生變化,均為95%;當seta 3=60時,需要的時間是154.968 8 s,明顯比seta 3=80時所需的時間要長;(2) 當seta 3的取值變大時說明選擇的高置信度樣本減小,其中有效樣本所占的比例是增大的,所以正確率會明顯變化,所花費的時間也會明顯縮短。參數seta 3的取值從80變為90時,正確率從95%提高到97%,運算時間也從82.796 9 s縮短到50.109 4 s。 第三,固定參數seta 1=20、seta 3=90,調整參數seta 2的取值,如表 2所示也可以達到97%的分類效果,當然這個結果和seta 3=90是有很大關系的。
BCIⅡ_Ⅳ數據集的仿真實驗結果如表 3所示。從表 3可以看出,固定參數seta 2=5、seta 3=80,調整參數的取值,當seta 1=20最優,正確率可以達到82%;固定參數seta 1=20、seta 3=80,調整參數seta 2的取值,正確率同樣可以達到82%,其中當seta 2=20時,運算效率也是最高的,只需要5.468 8 s;固定seta 1=20、seta 2=5,可調參數seta 3=90時,正確率降低到80%,這和表 2所呈現的規律是不太一致的。另外,在BCIⅠ數據集上運行所需的時間整體都比在BCIⅡ_Ⅳ數據集上花費的時間要長很多,在BCIⅡ_Ⅳ數據集上正確率最高且時間最少的只需要5.468 8 s,在BCIⅠ數據集上效果最好所需的運行時間是50.109 4 s。這與數據集本身的復雜度是有很大關系的。數據集不同,相應的最優參數也不相同。
USPS數據集的仿真實驗結果如表 4所示。在該數據集上,我們對可調參數進行了多次調整,選擇有效數據進行說明。實驗中采用的USPS數據集的維數特別高,其維數d=241,遠遠超過了標記樣本個數,標記樣本個數為100,稀疏表示分類器對維數是比較敏感的,因為稀疏表示分類器在對未標記樣本進行分類時,是一個一個送入分類器進行處理,送入的每個待分類樣本分別和所有的標記樣本作用,計算殘差,在計算過程中,如果維數過高遠遠超過樣本個數,一次一次迭代過程是非常復雜的,所以我們固定參數seta 3的值且令seta 3=400。結果表明,改變其它兩個參數的值對分類正確率幾乎沒什么影響,只是對運行效率有一定影響。
我們將BCIⅠ、BCIⅡ_Ⅳ數據集中選出高置信度樣本的真實標簽與學習到的標簽進行比較分析。BCIⅠ數據集中選用的是seta 1=20、seta 2=5、seta 3=90,最終選出的高置信度樣本個數是10個,學習標簽全部和真實標簽一致。BCIⅡ_Ⅳ數據集中選用的是seta 1=20、seta 2=20、seta 3=90,最終選出的高置信度樣本個數是20個,其中18個學習標簽和真實標簽一致,這種誤差導致了分類性能下降。
4 討論
本文方法與自訓練SVM[3, 9]、輔助訓練SVM[10]和有導師SVM[3]三種方法在分類正確率和運算效率兩方面進行了比較分析,仿真結果如表 5所示。實驗中用高斯核對三種方法進行了仿真實驗,參數c的取值范圍為10-3~103,高斯核參數為0.02。仔細調整高斯核參數效果更好。SVM分類這三個數據時只考慮訓練集和測試集,不考慮未標志樣本。從表 5中可以看到,本文方法的實驗結果優于自訓練SVM、輔助訓練SVM和有導師SVM的實驗結果。
文獻[3]采用的是自訓練SVM方法,文獻[9]采用的是改進的自訓練SVM方法,文獻[10]采用的是輔助訓練SVM方法。本文方法采用的是稀疏表示分類器輔助訓練Fisher線性分類器,和文獻[3, 9]主要區別是訓練方式不同和使用的分類器不同,和文獻[10]主要區別是使用的分類器不同并且提出了避免錯分策略。實驗結果說明輔助訓練思想要優于自訓練思想,也說明半監督方法不要局限于SVM。
5 結論
以輔助訓練思想為框架,提出了一種新的稀疏表示分類器半監督方法。本文方法的創新點如下:首先用稀疏表示分類器所提供的信息選擇高置信度樣本。其次用Fisher線性分類器作為判別分類器,并提出相匹配的距離和方向選擇策略。仿真實驗結果表明本文提出的方法對EEG信號分類具有很好的性能,證明本文方法是十分有效的。可以說EEG信號分類任務為半監督方法提供了應用背景。進一步研究輔助訓練用于多分類問題,在判別階段中具體的多分類問題用到的判別條件可能還會有更加復雜的形式。進一步研究其他輔助階段和判別階段所選用的分類方法,進行實驗并設計相匹配的選擇策略,以達到更好的分類性能。