提出一種基于低頻帶非均勻采樣的電子耳蝸編碼策略,即低頻帶精細結構(LFFS)過零刺激方案(簡稱LFFS方案),以提高電子耳蝸漢語聲調和語音識別魯棒性。根據頻帶選擇法則,在人耳基頻感知范圍內,采用精細結構過零刺激脈沖序列。聲學模擬結果表明:在安靜環境下,LFFS方案和連續交替采樣(CIS)方案語音識別率差別不大;在噪聲環境下,LFFS方案在漢語聲調、詞匯和句子方面要明顯優于CIS方案,同時采用改進指數分布模型得到較好的漢語識別因素分布圖。LFFS方案包含了更多的漢語聲調信息,所以能有效地提高電子耳蝸植入患者漢語識別魯棒性。
引用本文: 倪賽華, 孫文業, 孫寶印, 周強, 王振明, 顧濟華, 陶智. 基于低頻帶非均勻采樣策略提高電子耳蝸漢語識別魯棒性. 生物醫學工程學雜志, 2014, 31(3): 520-526. doi: 10.7507/1001-5515.20140097 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
電子耳蝸是目前惟一能恢復重度、急重度或全聾患者部分聽覺的醫學裝置[1],全球已經有超過十萬電子耳蝸使用者重新回到了聲音世界。現有的電子耳蝸編碼方案主要針對非聲調語言設計,在安靜環境下,患者幾乎可以進行正常的電話交流;但是在噪聲環境下,患者對聲調、基頻感知、音樂旋律以及說話者識別能力急劇下降[2-5]。
目前研究者們對于時間精細結構也只是一個模糊的定位,更多的是將語音信號的瞬時相位一階導數,即頻率調制,定義為時間精細結構[6]。也有研究者用語音信號的某些特殊時間點作為時間精細結構的表現形式,如過零點、峰值點等等[7]。本文綜合研究者的觀點將時間精細結構定義為:語音合成模型中的微觀部分但對聲調語言識別起至關作用的頻率表現形式。
語音契合實驗[8]表明,時間精細結構(fine structure,FS)和時間包絡信息對漢語語音識別起同等作用。在安靜環境下,對于非聲調語言,應用時間包絡信號足以取得很高的語音識別率,這就是目前連續交替采樣(continuous interleaved sampling,CIS)方案[9]取得巨大成功的原因;但是對于聲調語言,尤其在背景噪聲下,時間精細結構在聲調識別、基頻感知、音樂旋律識別、說話者認證方面卻占取主要作用[8, 10-11]。
漢語是有聲調的語言,而且四個聲調具有明確的詞匯意義,研究已經表明,時間精細結構對聲調識別起著決定作用,所以研究者們致力于更加精確的提取時間精細結構以及對之合理的編碼,使患者能夠使用這些信息。Smith等[8]的語音契合實驗首先提出了時間精細結構的重要性; Rubinstein等[12]通過“噪聲調制時間精細結構”,進一步說明時間精細結構對于聲調,旋律的重要性;Lan等[13]基于人耳基頻感知和語音信號基音頻率一致性,采用基頻調制子帶脈沖序列方案來提高漢語聲調識別率;但是由于患者感知基頻范圍大致在0~1 000 Hz[14],在高頻帶所加的基頻偏量已經失效,反而降低了算法的時間效率[15];Nie等[6]提出了基于幅頻調制編碼算法,采用正交調制模型提取緩慢變換的精細結構,并調制緩慢變換的包絡信號以提高漢語識別率;最近基于過零點方案在聲調語言以及語音識別上取得較大突破,Wang等[16-17]采用子波過零點及其改進方案;Chen 等[7, 18]利用語音信號的過零點時刻表現時間精細結構;過零點方案也用于泰語聲調研究[19]。實驗結果表明,語音信號的過零點可以傳遞聲調信息,具有很好的抗噪性。但在中高頻部分,由于語音信號變化很快,所以,一方面語音信號的過零點檢測很困難,另一方面由于聲學模擬采用高速正弦波調制,這樣使得很多鄰近過零點處的正負脈沖相互抵消了,從而丟失很多中高頻信息。
基于以上研究基礎,本文提出了一種低頻帶精細結構(fine structure in low frequency,LFFS)過零刺激方案(簡稱LFFS方案),一方面將時間精細結構編碼到電子耳蝸語音處理算法中,另一方面利用語音信號的過零點時刻非均勻采樣脈沖刺激序列,進一步提高漢語電子耳蝸的識別率以及電子耳蝸編碼策略的抗噪性能。
1 基于低頻帶非均勻采樣聲學合成模型
1.1 多頻帶聲道共振模型
目前電子耳蝸主流波形編碼策略多采用如下聲學模型,即
| $S\left( t \right)=\sum\limits_{i=1}^{N}{{{A}_{i}}\left( t \right)}cos(2\pi {{f}_{ci}}t+{{\theta }_{i}}),$ |
式中N為濾波通道數目,Ai(t)為通道的時間包絡,fci為第i通道濾波器的中心頻率,θi為第i通道語音的初始相位,S(t)為合成語音。
本文引入改進的波形編碼策略模型,也稱為多頻帶聲道共振模型[20],即
| $S\left( t \right)=\sum\limits_{i=1}^{N}{{{A}_{i}}\left( t \right)}cos(2\pi {{f}_{ci}}t+2\pi \int\limits_{0}^{t}{{{g}_{i}}(\tau )d\tau +{{\theta }_{i}})}~,$ |
式中引入了頻率調制gi(τ),表征頻率調制對漢語聲調,語音識別以及魯棒性的重要性。
1.2 希爾伯特變換
希爾伯特變換可以將語音信號分解為緩慢變化的時間包絡信號調制高速變化的頻率信號[21]。而解析信號可以從實信號中得到,即
| $s\left( t \right)={{s}_{r}}\left( t \right)+i{{s}_{i}}\left( t \right),$ |
式中sr(t)為實信號,si(t)為sr(t)的希爾伯特變換,s(t)為解析信號,i=-1;由希爾伯特變換可得
| ${{s}_{i}}\left( t \right)=-\frac{1}{\pi }\int\limits_{-\infty }^{+\infty }{\frac{{{s}_{r}}(\tau )}{t-\tau }d\tau }$ |
定義解析信號的相位即為希爾伯特的相位φ(t),相位導數為頻率調制gi(t),即:
| $\varphi \left( t \right)=atan(\frac{{{s}_{i}}\left( t \right)}{{{s}_{r}}\left( t \right)})$ |
| ${{g}_{i}}\left( t \right)=\frac{1}{2\pi }~\frac{d(\varphi \left( t \right))}{dt}$ |
本文定義希爾伯特相位的余弦為精細結構,即:
| $FS=cos(\varphi \left( t \right))$ |
1.3 基于低頻帶非均勻采樣刺激聲學合成模型
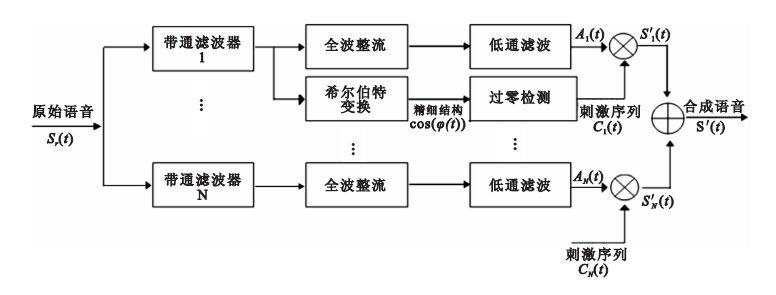
本文提出的聲學合成模型如圖 1所示。第一步:將預處理過的語音信號通過帶通濾波器組,帶通濾波器的頻帶劃分按照人耳基底膜模型[22],使之更加符合正常聽覺感知;第二步:采用整流低通提取每個濾波通道的時間包絡Ai;第三步:依據頻帶選擇原則,在低頻帶采用希爾伯特變換提取子帶語音信號時間精細結構;第四步:檢測低頻帶時間精細結構的過零點時刻ti;第五步:用得到的脈沖序列調制緩慢變換的時間包絡,并將所有通道的語音相加得到合成語音,即
| ${{C}_{low}}\left( t \right)=\sum\limits_{i}{C}(t-{{t}_{i}}),$ |
| ${{C}_{high}}\left( t \right)=cos(2\pi {{f}_{ck}}t)~,$ |
| $S\prime \left( t \right)=\sum\limits_{j=1}^{M}{{{A}_{j}}}Clow\left( t \right)+\sum\limits_{k=M+1}^{N}{{{A}_{k}}Chigh\left( t \right),}$ |
式中Clow(t)為低頻帶脈沖序列,Chigh(t)為中高頻帶脈沖序列,fck為濾波器中心頻率。本文聲學合成模型中,低頻帶采用的脈沖序列為T=0.5 ms周期的正弦波列,中、高頻帶采用的脈沖序列頻率為該濾波通道中心頻率的正弦波列。低頻范圍定義為0~1 000 Hz,所以取值M=4。
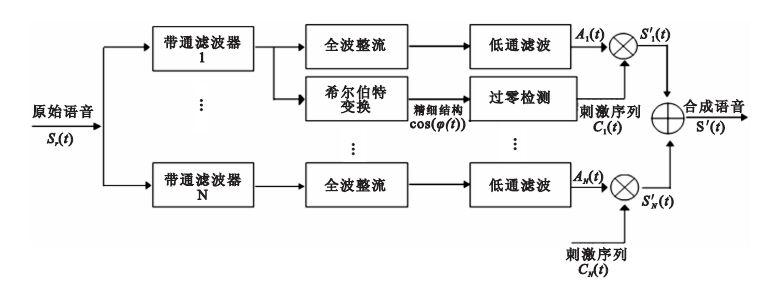 圖1
基于低頻帶精細結構過零刺激聲學合成模型
Figure1.
Acoustic synthesis model based on the zero-crossing time of fine structure of low frequency
圖1
基于低頻帶精細結構過零刺激聲學合成模型
Figure1.
Acoustic synthesis model based on the zero-crossing time of fine structure of low frequency
2 實驗流程設計
本實驗采用聽覺仿真實驗來評估LFFS方案對電子耳蝸漢語識別的效果,并與CIS方案對比。兩種方案各通道濾波器的中心頻率、頻率帶寬以及濾波范圍如表 1所示,實驗中將通道數目設定為8,低通濾波器截止頻率為400 Hz。實驗一:主要評估在三種信噪比(即安靜、5 dB和0 dB)條件下漢語聲調識別率;實驗二:主要評估在上述三種信噪比條件下元音(見表 2)和輔音(見表 3)識別率;實驗三:主要評估在上述三種信噪比條件下漢語詞匯和語句識別率。實驗采用單因素方差分析(P值檢驗)比較兩種方案的差異。
本實驗所采用的漢語語音庫由Emily Shannon Fu Foundation提供,本語音庫包含日常漢語詞匯5 000多個,日常漢語句子500多句,并由兩男兩女朗讀。本實驗從中挑選160個詞匯和160個句子。
本實驗在蘇州大學招募12名本科生和6名研究生,其中男女生各9名,年齡為(22±2.3)歲,所有受試者雙耳聽力正常。受試者隨機分為三組,每組6人,隨機分配兩種方案同一信噪比下的三個實驗。本實驗得到蘇州大學允許并在全封閉聲學實驗室進行,實驗軟件平臺為MATLAB,硬件為DELL臺式機,耳機型號為高保真頭戴式Edifier k380。
2.1 實驗一(漢語聲調識別)
將160個漢語詞匯隨機分成4組,每組包含40個詞匯。每組受試者隨機挑選一組測試,采用四選一方法,將所聽到的聲調標注出來(示例見表 4)。
2.2 實驗二 漢語元音、輔音識別
2.2.1 漢語元音識別
從160個詞匯中挑選4個詞組成一個小測試集。挑選原則:保證該測試集中4個單詞的聲調和輔音一樣,而元音不同。每大組包含40個小測試集,一共隨機組成4大組。每組受試者隨機挑選一大組測試,采用四選一方法,將所聽到的元音標注出來(示例見表 4)。
2.2.2 漢語輔音識別
從160個詞匯中挑選4個詞組成一個小測試集。挑選原則:保證該測試集中4個單詞的聲調和元音一樣,而輔音不同。每大組包含40個小測試集,一共隨機組成4大組。每組受試者隨機挑選一組測試,采用四選一方法,將所聽到的輔音標注出來(示例見表 4)。
2.3 實驗三(漢語詞匯、語句識別)
2.3.1 漢語詞匯識別
將160個漢語詞匯隨機分成4組,每組包含40個。受試者隨機挑選一組測試,將所聽到的詞匯記錄下,也可記錄下拼音(標注聲調)。
2.3.2 漢語語句識別
從160句中隨機挑選100句,組成10組,每組句子各不相同,但包含的總漢字數相同,大約為80個漢字。每組受試者隨機挑選一組測試,要求盡可能多的記錄下聽到的詞匯。
3 聽覺仿真實驗結果
3.1 漢語聲調識別
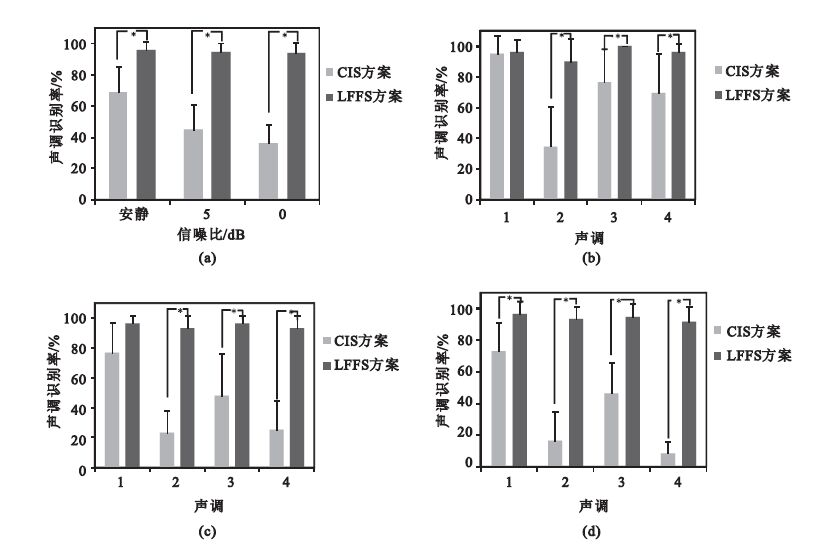
圖 2為三種信噪比條件下漢語聲調識別率。從圖 2(a)看出,在三種信噪比條件下,LFFS方案在聲調識別率上明顯優于CIS方案,安靜環境下平均高出27.08%、5 dB環境下平均高出50.08%、0 dB環境下平均高出58.09%,且在三種信噪比條件下兩種方案的差異有統計學意義(P<0.05)。進一步我們可以看出CIS方案在噪聲環境下聲調識別率很差,而LFFS方案具有很強的抗噪性。圖 2(b)~(d)分別為三種信噪比條件下漢語4個聲調的識別率,從中可以更加清楚地看出LFFS方案在噪聲環境下的優越性。
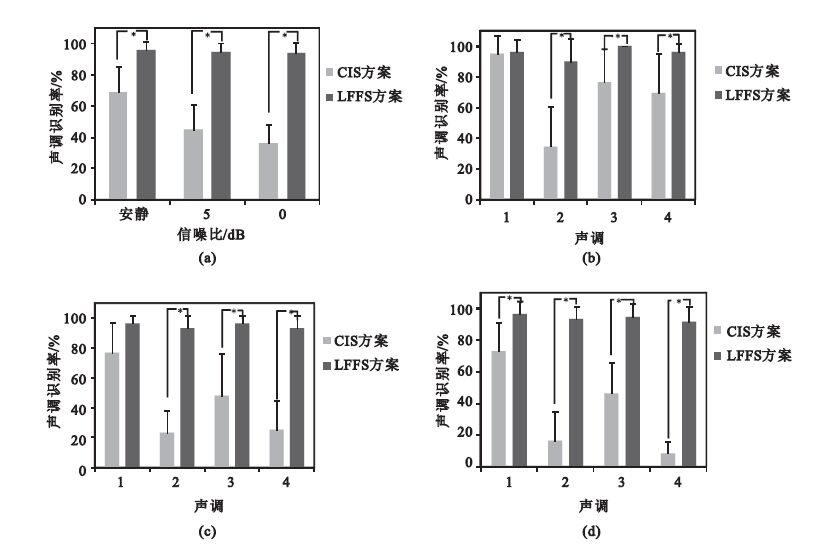 圖2
三種信噪比條件下漢語聲調識別率(*表示兩種方案差異具有統計學意義)
圖2
三種信噪比條件下漢語聲調識別率(*表示兩種方案差異具有統計學意義)
(a)三種信噪比條件下的聲調識別率;(b)安靜條件下4個聲調的識別率;(c) 5 dB條件下4個聲調的識別率;(d) 0 dB條件下4個聲調的識別率
Figure2. Chinese tone recognition rate in three signal to noise ratio (SNR) (* shows statistically significant difference)(a) Chinese tone recognition rate in three SNR; (b) four tones recognition in quiet background; (c) four tones recognition in 5 dB; (d) four tones recognition in 0 dB
3.2 漢語元音和輔音識別
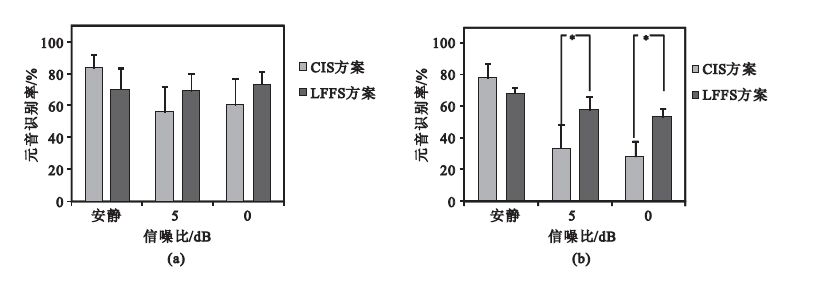
圖 3為三種信噪比條件下漢語元音和輔音識別率。從圖 3(a)看出,在安靜環境下,LFFS方案對元音的識別效果并不優于CIS方案;但是在噪聲環境下,5 dB時,LFFS方案的元音識別率比CIS方案高出13.42%;0 dB時,LFFS方案的元音識別率比CIS方案高出12.58%。雖然在元音識別上兩種方案的差異無統計學意義(P>0.05),但是在加噪條件下,LFFS方案對元音識別率好于CIS方案。從圖 3(b)看出,在安靜環境下,LFFS方案對輔音的識別效果并不優于CIS方案;但是在噪聲環境下,5 dB時,LFFS方案的輔音識別率比CIS方案高出24.25%;0 dB時,LFFS方案的輔音識別率比CIS方案高出25.08%,而且在噪聲條件下LFFS方案與CIS方案差異有統計學意義(P<0.05)。因為CIS方案主要是針對非聲調語言設計,而且患者能在安靜下正常交流,所以對于安靜環境下元音和輔音的識別率會很高;但是噪聲環境下,CIS方案的元音和輔音識別率會大幅下降,而LFFS方案因為保留了更多低頻帶的信息,并采用非均勻采樣脈沖刺激序列,所以具有相對較強的抗噪性能。
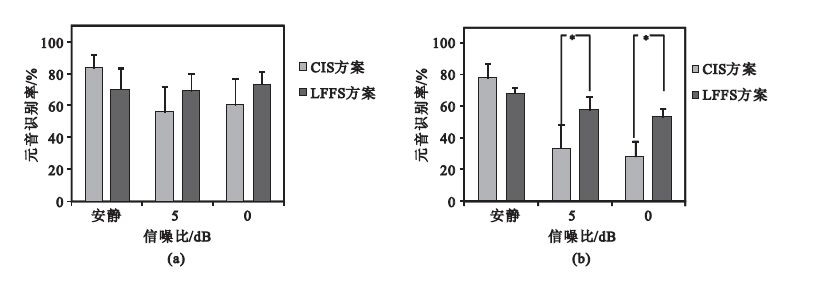 圖3
三種信噪比條件下元音和輔音識別率(*表示兩種方案差異具有統計學意義)
圖3
三種信噪比條件下元音和輔音識別率(*表示兩種方案差異具有統計學意義)
(a)三種信噪比條件下元音識別率;(b)三種信噪比條件下輔音識別率
Figure3. Vowel and consonant recognition rates in three SNR (* shows statistically significant difference)(a) vowel recognition rate in three SNR; (b) consonant recognition rate in three SNR
3.3 漢語詞匯和語句識別
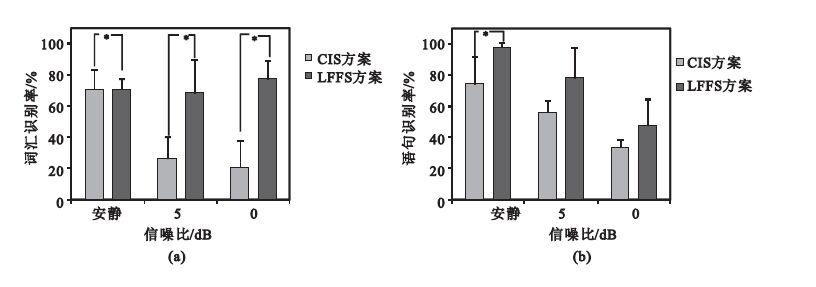
圖 4為三種信噪比條件下漢語詞匯和語句識別率。從圖 4(a)看出,安靜環境下CIS方案和LFFS方案的詞匯識別率相當;但是在噪聲環境下,5 dB時,LFFS方案比CIS方案高出41.67%,0 dB時,LFFS方案比CIS方案高出57.17%,而且在三種信噪比條件下兩種方案差異有統計學意義(P<0.05)。因為漢字4個聲調代表不同的詞匯意義,而CIS方案丟失了很多聲調信息,LFFS方案保留了更多的低頻帶信息,即包含了聲調信息。所以,在噪聲環境下LFFS方案詞匯識別率遠遠高于CIS方案。 從圖 4(b)看出,安靜環境下,LFFS方案的語句識別率比CIS方案高出23.37%,且差異具有統計學意義(P<0.05);5 dB時,LFFS方案比CIS方案高出22%;0 dB時,LFFS方案比CIS方案高出14.5%。在這兩種噪聲條件下,LFFS方案對漢語語句的識別率好于CIS方案,進一步體現了低頻帶信息對漢語語句識別的重要性。
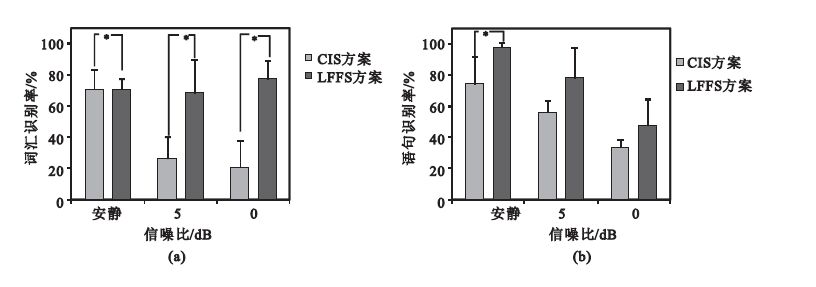 圖4
三種信噪比條件下漢語詞匯和句子識別率(*表示兩種方案差異具有統計學意義)
圖4
三種信噪比條件下漢語詞匯和句子識別率(*表示兩種方案差異具有統計學意義)
(a)三種信噪比條件下詞匯識別率;(b)三種信噪比條件下語句識別率
Figure4. Vocabulary and sentence recognition rate in three SNR (* shows statistically significant difference)(a) vocabulary recognition rate in three SNR; (b) sentence recognition rate in three SNR
3.4 改進的指數權重分布模型
從結果分析可以看出,對于元音和輔音識別,并不是在所有信噪比情況下兩種方案都有顯著性差異。但是,在聲調和詞匯識別上有顯著性差異,說明聲調對詞匯識別的重要性,所以采用改進的指數權重分布模型[23-24]定量分析漢語電子耳蝸聲調、元音、輔音、詞匯、語句之間的關系,該模型步驟如下:
第一步
| ${{p}_{w}}={{p}_{p}}^{j}={{({{p}_{v}}^{{{w}_{v}}}\cdot {{p}_{c}}^{{{w}_{c}}}\cdot {{p}_{t}}^{{{w}_{t}}})}^{j}},$ |
式中pw為孤立詞匯的識別概率,pp為音素識別概率,pv為元音識別概率,pc為輔音識別概率,pt為聲調識別概率,wv為元音權重,wc為輔音權重,wt為聲調權重,j為詞匯和音素的相關系數。
第二步
| ${{p}_{s}}=1-{{(1-{{p}_{w}})}^{k}},$ |
式中ps為句中詞匯的識別概率,參數k為句中上下文因數。
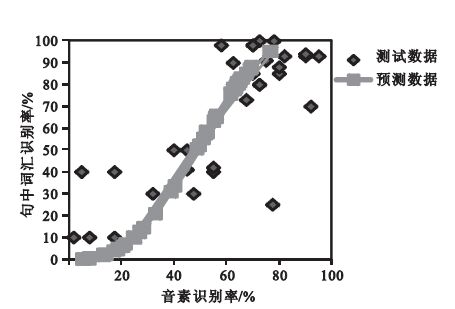
根據文獻[24-25],對于漢語識別,式中參數沒有參考指標。所以,本文根據以上實驗數據,取定wt=0.9、wv=0.7、wc=0.5、j=2.67、k=4.5。從圖 5可以看出,基于改進的指數權重分布模型可定量分析音素、句中詞匯識別率之間的關系。當預測數據和測試數據的相關系數r為0.7時,能很好地說明聲調、元音和輔音對漢語識別起著同等的作用。
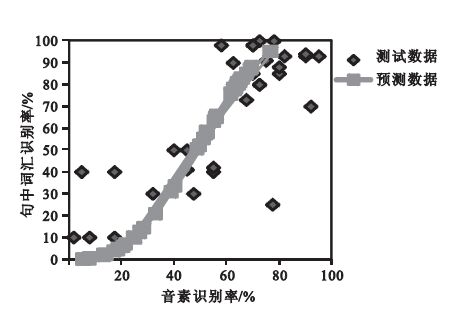 圖5
音素與句中詞匯識別預測指數曲線
Figure5.
Predicted exponential curve between phonemes and sentence vocabulary recognition rate
圖5
音素與句中詞匯識別預測指數曲線
Figure5.
Predicted exponential curve between phonemes and sentence vocabulary recognition rate
4 結論
本文根據語音聲道共振模型,在已有的研究基礎上,利用LFFS方案提高漢語識別魯棒性,與傳統的CIS方案相比有三大優越性,其一:將時間精細結構編碼到電子耳蝸語音算法中,有利于提高漢語聲調識別率;其二:在過零點時刻產生刺激脈沖,這樣整個脈沖序列是非均勻的、不連續的,可能更加符合正常人耳的聽神經沖動發放方式;其三:采用頻帶選擇原則,只在低頻帶選擇過零點刺激,一方面符合人耳的基頻感知局限性,另一方面提高算法的時間效率。
聽覺仿真實驗結果表明:在安靜環境下,LFFS方案在聲調和語句識別上優于CIS方案,尤其是在背景噪聲下,LFFS方案具有很強的魯棒性。當然本方案還存在以下幾方面不足之處:由于希爾伯特變換提取的頻率調制變化太快,頻率帶寬太寬,人耳可能不能全部加以利用,所以期待找到更好的時間精細結構提取算法;由于語音信號的非平穩、非線性特點,所以如何精確確定過零點時刻也是關鍵;漢語語音庫的進一步完善以及實驗流程的科學化設計也對識別結果有重要影響,等等。隨著本文算法的進一步優化,LFFS方案可以為漢語電子耳蝸語音編碼策略的設計提供一定的參考。
引言
電子耳蝸是目前惟一能恢復重度、急重度或全聾患者部分聽覺的醫學裝置[1],全球已經有超過十萬電子耳蝸使用者重新回到了聲音世界。現有的電子耳蝸編碼方案主要針對非聲調語言設計,在安靜環境下,患者幾乎可以進行正常的電話交流;但是在噪聲環境下,患者對聲調、基頻感知、音樂旋律以及說話者識別能力急劇下降[2-5]。
目前研究者們對于時間精細結構也只是一個模糊的定位,更多的是將語音信號的瞬時相位一階導數,即頻率調制,定義為時間精細結構[6]。也有研究者用語音信號的某些特殊時間點作為時間精細結構的表現形式,如過零點、峰值點等等[7]。本文綜合研究者的觀點將時間精細結構定義為:語音合成模型中的微觀部分但對聲調語言識別起至關作用的頻率表現形式。
語音契合實驗[8]表明,時間精細結構(fine structure,FS)和時間包絡信息對漢語語音識別起同等作用。在安靜環境下,對于非聲調語言,應用時間包絡信號足以取得很高的語音識別率,這就是目前連續交替采樣(continuous interleaved sampling,CIS)方案[9]取得巨大成功的原因;但是對于聲調語言,尤其在背景噪聲下,時間精細結構在聲調識別、基頻感知、音樂旋律識別、說話者認證方面卻占取主要作用[8, 10-11]。
漢語是有聲調的語言,而且四個聲調具有明確的詞匯意義,研究已經表明,時間精細結構對聲調識別起著決定作用,所以研究者們致力于更加精確的提取時間精細結構以及對之合理的編碼,使患者能夠使用這些信息。Smith等[8]的語音契合實驗首先提出了時間精細結構的重要性; Rubinstein等[12]通過“噪聲調制時間精細結構”,進一步說明時間精細結構對于聲調,旋律的重要性;Lan等[13]基于人耳基頻感知和語音信號基音頻率一致性,采用基頻調制子帶脈沖序列方案來提高漢語聲調識別率;但是由于患者感知基頻范圍大致在0~1 000 Hz[14],在高頻帶所加的基頻偏量已經失效,反而降低了算法的時間效率[15];Nie等[6]提出了基于幅頻調制編碼算法,采用正交調制模型提取緩慢變換的精細結構,并調制緩慢變換的包絡信號以提高漢語識別率;最近基于過零點方案在聲調語言以及語音識別上取得較大突破,Wang等[16-17]采用子波過零點及其改進方案;Chen 等[7, 18]利用語音信號的過零點時刻表現時間精細結構;過零點方案也用于泰語聲調研究[19]。實驗結果表明,語音信號的過零點可以傳遞聲調信息,具有很好的抗噪性。但在中高頻部分,由于語音信號變化很快,所以,一方面語音信號的過零點檢測很困難,另一方面由于聲學模擬采用高速正弦波調制,這樣使得很多鄰近過零點處的正負脈沖相互抵消了,從而丟失很多中高頻信息。
基于以上研究基礎,本文提出了一種低頻帶精細結構(fine structure in low frequency,LFFS)過零刺激方案(簡稱LFFS方案),一方面將時間精細結構編碼到電子耳蝸語音處理算法中,另一方面利用語音信號的過零點時刻非均勻采樣脈沖刺激序列,進一步提高漢語電子耳蝸的識別率以及電子耳蝸編碼策略的抗噪性能。
1 基于低頻帶非均勻采樣聲學合成模型
1.1 多頻帶聲道共振模型
目前電子耳蝸主流波形編碼策略多采用如下聲學模型,即
| $S\left( t \right)=\sum\limits_{i=1}^{N}{{{A}_{i}}\left( t \right)}cos(2\pi {{f}_{ci}}t+{{\theta }_{i}}),$ |
式中N為濾波通道數目,Ai(t)為通道的時間包絡,fci為第i通道濾波器的中心頻率,θi為第i通道語音的初始相位,S(t)為合成語音。
本文引入改進的波形編碼策略模型,也稱為多頻帶聲道共振模型[20],即
| $S\left( t \right)=\sum\limits_{i=1}^{N}{{{A}_{i}}\left( t \right)}cos(2\pi {{f}_{ci}}t+2\pi \int\limits_{0}^{t}{{{g}_{i}}(\tau )d\tau +{{\theta }_{i}})}~,$ |
式中引入了頻率調制gi(τ),表征頻率調制對漢語聲調,語音識別以及魯棒性的重要性。
1.2 希爾伯特變換
希爾伯特變換可以將語音信號分解為緩慢變化的時間包絡信號調制高速變化的頻率信號[21]。而解析信號可以從實信號中得到,即
| $s\left( t \right)={{s}_{r}}\left( t \right)+i{{s}_{i}}\left( t \right),$ |
式中sr(t)為實信號,si(t)為sr(t)的希爾伯特變換,s(t)為解析信號,i=-1;由希爾伯特變換可得
| ${{s}_{i}}\left( t \right)=-\frac{1}{\pi }\int\limits_{-\infty }^{+\infty }{\frac{{{s}_{r}}(\tau )}{t-\tau }d\tau }$ |
定義解析信號的相位即為希爾伯特的相位φ(t),相位導數為頻率調制gi(t),即:
| $\varphi \left( t \right)=atan(\frac{{{s}_{i}}\left( t \right)}{{{s}_{r}}\left( t \right)})$ |
| ${{g}_{i}}\left( t \right)=\frac{1}{2\pi }~\frac{d(\varphi \left( t \right))}{dt}$ |
本文定義希爾伯特相位的余弦為精細結構,即:
| $FS=cos(\varphi \left( t \right))$ |
1.3 基于低頻帶非均勻采樣刺激聲學合成模型
本文提出的聲學合成模型如圖 1所示。第一步:將預處理過的語音信號通過帶通濾波器組,帶通濾波器的頻帶劃分按照人耳基底膜模型[22],使之更加符合正常聽覺感知;第二步:采用整流低通提取每個濾波通道的時間包絡Ai;第三步:依據頻帶選擇原則,在低頻帶采用希爾伯特變換提取子帶語音信號時間精細結構;第四步:檢測低頻帶時間精細結構的過零點時刻ti;第五步:用得到的脈沖序列調制緩慢變換的時間包絡,并將所有通道的語音相加得到合成語音,即
| ${{C}_{low}}\left( t \right)=\sum\limits_{i}{C}(t-{{t}_{i}}),$ |
| ${{C}_{high}}\left( t \right)=cos(2\pi {{f}_{ck}}t)~,$ |
| $S\prime \left( t \right)=\sum\limits_{j=1}^{M}{{{A}_{j}}}Clow\left( t \right)+\sum\limits_{k=M+1}^{N}{{{A}_{k}}Chigh\left( t \right),}$ |
式中Clow(t)為低頻帶脈沖序列,Chigh(t)為中高頻帶脈沖序列,fck為濾波器中心頻率。本文聲學合成模型中,低頻帶采用的脈沖序列為T=0.5 ms周期的正弦波列,中、高頻帶采用的脈沖序列頻率為該濾波通道中心頻率的正弦波列。低頻范圍定義為0~1 000 Hz,所以取值M=4。
圖1
基于低頻帶精細結構過零刺激聲學合成模型
Figure1.
Acoustic synthesis model based on the zero-crossing time of fine structure of low frequency
2 實驗流程設計
本實驗采用聽覺仿真實驗來評估LFFS方案對電子耳蝸漢語識別的效果,并與CIS方案對比。兩種方案各通道濾波器的中心頻率、頻率帶寬以及濾波范圍如表 1所示,實驗中將通道數目設定為8,低通濾波器截止頻率為400 Hz。實驗一:主要評估在三種信噪比(即安靜、5 dB和0 dB)條件下漢語聲調識別率;實驗二:主要評估在上述三種信噪比條件下元音(見表 2)和輔音(見表 3)識別率;實驗三:主要評估在上述三種信噪比條件下漢語詞匯和語句識別率。實驗采用單因素方差分析(P值檢驗)比較兩種方案的差異。
本實驗所采用的漢語語音庫由Emily Shannon Fu Foundation提供,本語音庫包含日常漢語詞匯5 000多個,日常漢語句子500多句,并由兩男兩女朗讀。本實驗從中挑選160個詞匯和160個句子。
本實驗在蘇州大學招募12名本科生和6名研究生,其中男女生各9名,年齡為(22±2.3)歲,所有受試者雙耳聽力正常。受試者隨機分為三組,每組6人,隨機分配兩種方案同一信噪比下的三個實驗。本實驗得到蘇州大學允許并在全封閉聲學實驗室進行,實驗軟件平臺為MATLAB,硬件為DELL臺式機,耳機型號為高保真頭戴式Edifier k380。
2.1 實驗一(漢語聲調識別)
將160個漢語詞匯隨機分成4組,每組包含40個詞匯。每組受試者隨機挑選一組測試,采用四選一方法,將所聽到的聲調標注出來(示例見表 4)。
2.2 實驗二 漢語元音、輔音識別
2.2.1 漢語元音識別
從160個詞匯中挑選4個詞組成一個小測試集。挑選原則:保證該測試集中4個單詞的聲調和輔音一樣,而元音不同。每大組包含40個小測試集,一共隨機組成4大組。每組受試者隨機挑選一大組測試,采用四選一方法,將所聽到的元音標注出來(示例見表 4)。
2.2.2 漢語輔音識別
從160個詞匯中挑選4個詞組成一個小測試集。挑選原則:保證該測試集中4個單詞的聲調和元音一樣,而輔音不同。每大組包含40個小測試集,一共隨機組成4大組。每組受試者隨機挑選一組測試,采用四選一方法,將所聽到的輔音標注出來(示例見表 4)。
2.3 實驗三(漢語詞匯、語句識別)
2.3.1 漢語詞匯識別
將160個漢語詞匯隨機分成4組,每組包含40個。受試者隨機挑選一組測試,將所聽到的詞匯記錄下,也可記錄下拼音(標注聲調)。
2.3.2 漢語語句識別
從160句中隨機挑選100句,組成10組,每組句子各不相同,但包含的總漢字數相同,大約為80個漢字。每組受試者隨機挑選一組測試,要求盡可能多的記錄下聽到的詞匯。
3 聽覺仿真實驗結果
3.1 漢語聲調識別
圖 2為三種信噪比條件下漢語聲調識別率。從圖 2(a)看出,在三種信噪比條件下,LFFS方案在聲調識別率上明顯優于CIS方案,安靜環境下平均高出27.08%、5 dB環境下平均高出50.08%、0 dB環境下平均高出58.09%,且在三種信噪比條件下兩種方案的差異有統計學意義(P<0.05)。進一步我們可以看出CIS方案在噪聲環境下聲調識別率很差,而LFFS方案具有很強的抗噪性。圖 2(b)~(d)分別為三種信噪比條件下漢語4個聲調的識別率,從中可以更加清楚地看出LFFS方案在噪聲環境下的優越性。
圖2
三種信噪比條件下漢語聲調識別率(*表示兩種方案差異具有統計學意義)
(a)三種信噪比條件下的聲調識別率;(b)安靜條件下4個聲調的識別率;(c) 5 dB條件下4個聲調的識別率;(d) 0 dB條件下4個聲調的識別率
Figure2. Chinese tone recognition rate in three signal to noise ratio (SNR) (* shows statistically significant difference)(a) Chinese tone recognition rate in three SNR; (b) four tones recognition in quiet background; (c) four tones recognition in 5 dB; (d) four tones recognition in 0 dB
3.2 漢語元音和輔音識別
圖 3為三種信噪比條件下漢語元音和輔音識別率。從圖 3(a)看出,在安靜環境下,LFFS方案對元音的識別效果并不優于CIS方案;但是在噪聲環境下,5 dB時,LFFS方案的元音識別率比CIS方案高出13.42%;0 dB時,LFFS方案的元音識別率比CIS方案高出12.58%。雖然在元音識別上兩種方案的差異無統計學意義(P>0.05),但是在加噪條件下,LFFS方案對元音識別率好于CIS方案。從圖 3(b)看出,在安靜環境下,LFFS方案對輔音的識別效果并不優于CIS方案;但是在噪聲環境下,5 dB時,LFFS方案的輔音識別率比CIS方案高出24.25%;0 dB時,LFFS方案的輔音識別率比CIS方案高出25.08%,而且在噪聲條件下LFFS方案與CIS方案差異有統計學意義(P<0.05)。因為CIS方案主要是針對非聲調語言設計,而且患者能在安靜下正常交流,所以對于安靜環境下元音和輔音的識別率會很高;但是噪聲環境下,CIS方案的元音和輔音識別率會大幅下降,而LFFS方案因為保留了更多低頻帶的信息,并采用非均勻采樣脈沖刺激序列,所以具有相對較強的抗噪性能。
圖3
三種信噪比條件下元音和輔音識別率(*表示兩種方案差異具有統計學意義)
(a)三種信噪比條件下元音識別率;(b)三種信噪比條件下輔音識別率
Figure3. Vowel and consonant recognition rates in three SNR (* shows statistically significant difference)(a) vowel recognition rate in three SNR; (b) consonant recognition rate in three SNR
3.3 漢語詞匯和語句識別
圖 4為三種信噪比條件下漢語詞匯和語句識別率。從圖 4(a)看出,安靜環境下CIS方案和LFFS方案的詞匯識別率相當;但是在噪聲環境下,5 dB時,LFFS方案比CIS方案高出41.67%,0 dB時,LFFS方案比CIS方案高出57.17%,而且在三種信噪比條件下兩種方案差異有統計學意義(P<0.05)。因為漢字4個聲調代表不同的詞匯意義,而CIS方案丟失了很多聲調信息,LFFS方案保留了更多的低頻帶信息,即包含了聲調信息。所以,在噪聲環境下LFFS方案詞匯識別率遠遠高于CIS方案。 從圖 4(b)看出,安靜環境下,LFFS方案的語句識別率比CIS方案高出23.37%,且差異具有統計學意義(P<0.05);5 dB時,LFFS方案比CIS方案高出22%;0 dB時,LFFS方案比CIS方案高出14.5%。在這兩種噪聲條件下,LFFS方案對漢語語句的識別率好于CIS方案,進一步體現了低頻帶信息對漢語語句識別的重要性。
圖4
三種信噪比條件下漢語詞匯和句子識別率(*表示兩種方案差異具有統計學意義)
(a)三種信噪比條件下詞匯識別率;(b)三種信噪比條件下語句識別率
Figure4. Vocabulary and sentence recognition rate in three SNR (* shows statistically significant difference)(a) vocabulary recognition rate in three SNR; (b) sentence recognition rate in three SNR
3.4 改進的指數權重分布模型
從結果分析可以看出,對于元音和輔音識別,并不是在所有信噪比情況下兩種方案都有顯著性差異。但是,在聲調和詞匯識別上有顯著性差異,說明聲調對詞匯識別的重要性,所以采用改進的指數權重分布模型[23-24]定量分析漢語電子耳蝸聲調、元音、輔音、詞匯、語句之間的關系,該模型步驟如下:
第一步
| ${{p}_{w}}={{p}_{p}}^{j}={{({{p}_{v}}^{{{w}_{v}}}\cdot {{p}_{c}}^{{{w}_{c}}}\cdot {{p}_{t}}^{{{w}_{t}}})}^{j}},$ |
式中pw為孤立詞匯的識別概率,pp為音素識別概率,pv為元音識別概率,pc為輔音識別概率,pt為聲調識別概率,wv為元音權重,wc為輔音權重,wt為聲調權重,j為詞匯和音素的相關系數。
第二步
| ${{p}_{s}}=1-{{(1-{{p}_{w}})}^{k}},$ |
式中ps為句中詞匯的識別概率,參數k為句中上下文因數。
根據文獻[24-25],對于漢語識別,式中參數沒有參考指標。所以,本文根據以上實驗數據,取定wt=0.9、wv=0.7、wc=0.5、j=2.67、k=4.5。從圖 5可以看出,基于改進的指數權重分布模型可定量分析音素、句中詞匯識別率之間的關系。當預測數據和測試數據的相關系數r為0.7時,能很好地說明聲調、元音和輔音對漢語識別起著同等的作用。
圖5
音素與句中詞匯識別預測指數曲線
Figure5.
Predicted exponential curve between phonemes and sentence vocabulary recognition rate
4 結論
本文根據語音聲道共振模型,在已有的研究基礎上,利用LFFS方案提高漢語識別魯棒性,與傳統的CIS方案相比有三大優越性,其一:將時間精細結構編碼到電子耳蝸語音算法中,有利于提高漢語聲調識別率;其二:在過零點時刻產生刺激脈沖,這樣整個脈沖序列是非均勻的、不連續的,可能更加符合正常人耳的聽神經沖動發放方式;其三:采用頻帶選擇原則,只在低頻帶選擇過零點刺激,一方面符合人耳的基頻感知局限性,另一方面提高算法的時間效率。
聽覺仿真實驗結果表明:在安靜環境下,LFFS方案在聲調和語句識別上優于CIS方案,尤其是在背景噪聲下,LFFS方案具有很強的魯棒性。當然本方案還存在以下幾方面不足之處:由于希爾伯特變換提取的頻率調制變化太快,頻率帶寬太寬,人耳可能不能全部加以利用,所以期待找到更好的時間精細結構提取算法;由于語音信號的非平穩、非線性特點,所以如何精確確定過零點時刻也是關鍵;漢語語音庫的進一步完善以及實驗流程的科學化設計也對識別結果有重要影響,等等。隨著本文算法的進一步優化,LFFS方案可以為漢語電子耳蝸語音編碼策略的設計提供一定的參考。