從核磁共振成像分析儀上直觀采集到的信號無法直接反映樣品屬性,必須采用反演算法獲取弛豫時間及這種弛豫分量所對應回波的初始幅度之間的關系。因此,正確的反演算法結果直接影響核磁共振信號的解釋和應用。本文基于不適定反問題正則化理論,優化了正則化因子的選取方法,通過Matlab7.0數值模擬,設計了一套低場核磁共振弛豫譜反演正則化算法。構造譜反演和樣品實測回波串反演表明本算法能夠滿足核磁共振成像分析儀測試和科研的需要。
引用本文: 陳珊珊, 汪紅志, 楊培強, 張學龍. 低場核磁共振弛豫譜反演算法研究. 生物醫學工程學雜志, 2014, 31(3): 682-685,713. doi: 10.7507/1001-5515.20140127 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
低場脈沖核磁共振測量技術是一種新興技術,與目前可知的其他技術相比,具有無損、精確、快速等諸多優勢,在農業與生物材料、食品安全、生命科技與制藥行業、石油能源和新材料等領域具有廣闊的應用前景[1]。低場脈沖核磁共振與高場核磁共振譜儀直接檢測大分子之間相互作用導致的頻率差異不同,它主要通過對待測樣品的氫質子的弛豫特性分析,來實現對樣品中水分、油分的定性定量研究。低場脈沖核磁共振測量技術是一種間接測量技術,我們所需的反映樣品屬性的信息是從核磁共振分析儀上采集到的原始核磁共振信號中提取出來的,而提取這些信息的關鍵是對原始核磁共振信號進行弛豫譜反演,因此,弛豫譜反演是核磁共振信號正確解釋和應用的關鍵[2]。
目前已提出的幾種反演算法主要有奇異值分解反演算法(singular value decomposition,SVD)、非負最小二乘法反演算法(non-negative least squares,NNLS)、聯合迭代反演算法(solid iteration rebuilding technique,SIRT)和遺傳反演算法(genetic algorithm,GA),這些方法或對回波信噪比要求高,或反演時間長,或實現非負約束的過程較復雜,而且反演的結果受算法參數如弛豫布點數、布點方式、信噪比等的影響[2-20]。本文基于正則化理論,提出一種尋找正則化因子的新方法,通過加入正則化因子求得反演問題的解,不僅抑制了解的不穩定性,還使得反演結果更接近真實值。本文通過Matlab數值模擬,設計了一套低場核磁共振弛豫譜反演正則化算法,分別對構造的和實際的核磁共振回波信號進行反演,反演運算結果表明:本文提出的算法反演速度快、穩定性好。
1 原理
在實際的測量過程中,從低場核磁共振分析儀上檢測到的核磁共振信號y是由一系列滿足指數衰減規律的弛豫組分的信號疊加而成的,同時不可避免地混入了隨機噪聲,因此y可以描述為
| $\begin{align} & y\left( {{t}_{i}} \right)=\sum\limits_{j=1}^{m}{{{x}_{j}}}\cdot {{e}^{-\frac{{{t}_{1}}}{{{T}_{2j}}}}}+\varepsilon \left( t \right) \\ & \left( 1\le i\le n;\text{ }1\le j\le m \right) \\ \end{align}$ |
其中 y(ti) 為ti時刻觀測到的回波幅度; xj為第j種弛豫分量的回波初始幅度;m為弛豫分量的個數,n為回波的個數;ti為回波間隔時間的整數倍;T2j(j=1,2,…,m)為預先設定的T2 布點,為第j種弛豫分量的橫向弛豫時間,考慮譜的覆蓋范圍從0.1~10 000 ms,超過三個數量級,隨著時間的增大,信號基本衰減完畢,T2組分會減少,因此T2采用先疏后密的對數均勻布點;ε表示隨機噪聲。
核磁共振分析測量技術的關鍵是如何從方程(1)中求解出樣品中各個T2弛豫時間及各個弛豫時間所對應的回波初始幅值。求解方程(1),實際上是求解第一類fredholm線性積分方程,這類方程的解具有不唯一性,同時輸入數據攜帶的噪聲又會影響解的結果,也就是說,在允許的測量誤差范圍內,存在不同的弛豫時間分布函數都能相當好地擬合原始回波衰減曲線,這種相容性增大了反演過程的難度[2]。因此我們必須利用一些先驗知識(數據信噪比、非負約束、解的連續性)來最大限度地恢復我們需要的樣品的弛豫時間分量與其所對應回波的初始幅度之間的關系。本文主要采用正則化思想來求解方程,通過尋找合適的算子來逼近原問題,使由適定算子確定的問題的解可以逼近原問題的解,本文將解的2-范數最小作為附加條件加入到原問題中,轉化為
| $min(\|y-Ax{{\|}^{2}}+{{\lambda }^{2}}\|Lx{{\|}^{2}})~,$ |
其中λ為正則化參數。它控制著殘差的范數與附加條件之間的權重。對式(2)求導令其為0,即得到方程組:
| ${{x}_{\lambda }}={{({{A}^{T}}A+{{\lambda }^{2}}{{L}^{T}}L)}^{-1}}{{A}^{T}}y$ |
求解方程組的過程即為正則化的過程[21]。公式中L的選取有以下三種方法(模型參數的三種解估計),分別為最小能量解估計、最光滑解估計、最平滑解估計。本文確定L采取最小能量解估計,即取單位矩陣。其次在正則化問題中,λ的選取是個重要問題,選取不當會影響算法的收斂性和收斂速度。正則化參數λ的選取是最終反演結果正確與否的關鍵,本文兼顧求解結果的平滑性和非負性,先計算λ為0時方程(3)的解,并得到方差χ2范圍,其中,χ2定義如方程(4):
| ${{\chi }^{2}}=\sum\limits_{j=1}^{n}{{{\left[ y({{t}_{j}})-\sum\limits_{i=1}^{m}{{{x}_{i}}}{{e}^{-\frac{{{t}_{i}}}{{{T}_{2j}}}}} \right]}^{2}}}$ |
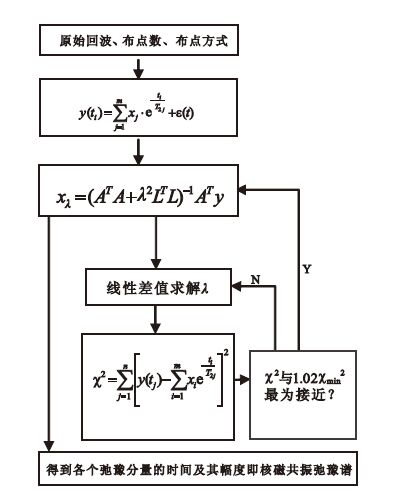
假設每個點的測量誤差是隨機獨立的,且標準差都一樣,然后通過線性改變λ的值以觀察感興趣范圍內χ2的改變,采用插值法找到最合適的正則化因子λ, 并代入方程(3)中求得弛豫時間分量與其所對應回波的初始幅度之間的關系。具體算法的實現過程如下:① 確定布點數、布點方式,并將原始回波數據代入方程,得出方程的正則化解;② 取正則化參數為0,得到正則化解代入方差方程,得到最小方差,再通過線性插值法取得最佳正則化參數;③ 將最佳正則化參數代入方程最終得到各個弛豫分量的時間及其幅度。算法流程如圖 1所示。
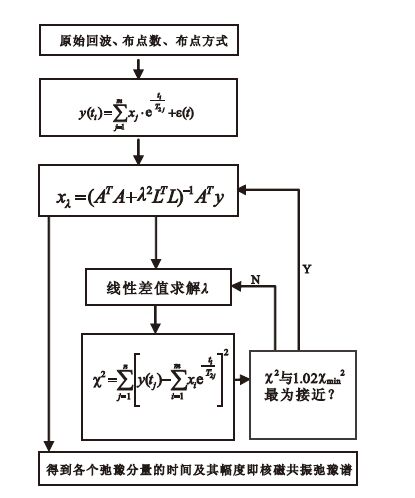 圖1
核磁共振反演算法流程圖
Figure1.
Flowchart of NMR inversion algorithm
圖1
核磁共振反演算法流程圖
Figure1.
Flowchart of NMR inversion algorithm
2 Matlab數值實驗
根據上述思路,在Matlab 7.0平臺下編譯了程序,并分別利用構造譜和實驗室采集到的核磁信號進行數值實驗。
2.1 構造譜反演
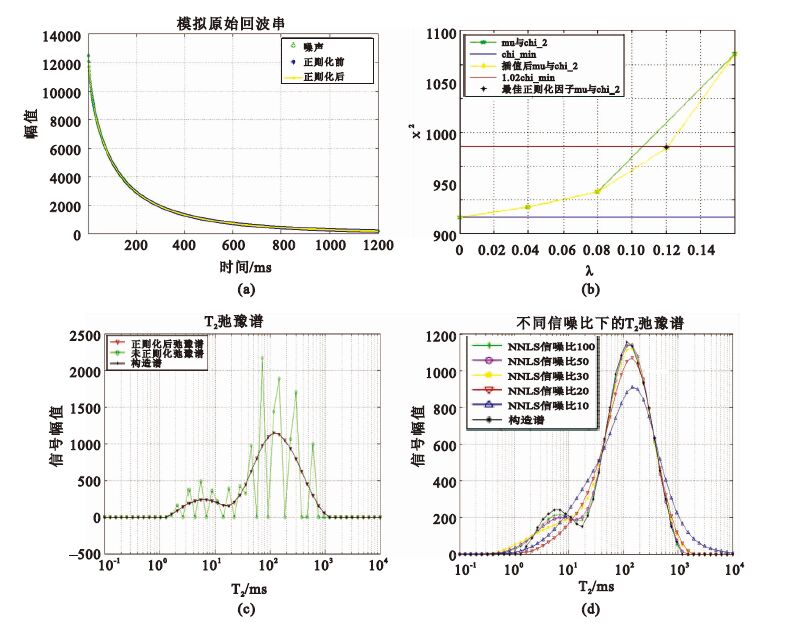
首先構造典型的雙峰結構的T2 譜,回波間隔時間τ=1.2 ms,回波數N=1 024,再代入方程(1)正演得到無噪聲核磁共振回波信號,后逐點加入隨機噪聲,生成一個具有一定信噪比的模擬回波串信號,代入算法得到反演結果,并分析與原始構造譜的差別驗證算法的準確性。
利用上述思路,得到的模擬原始回波串數據以及反演結果如圖 2所示:圖 2(a)表示構造譜正演并加入隨機噪聲后的回波;圖 2(b)表示λ與χ2關系,即線性插值選取λ的過程;圖 2(c)為正則化因子選取不當時反演結果(綠色圓圈)以及本算法反演結果(紅色三角)。實驗結果表明:反演譜與構造譜(黑色點線)完全吻合,表明本文提出的算法能夠精確地反演出構造譜。
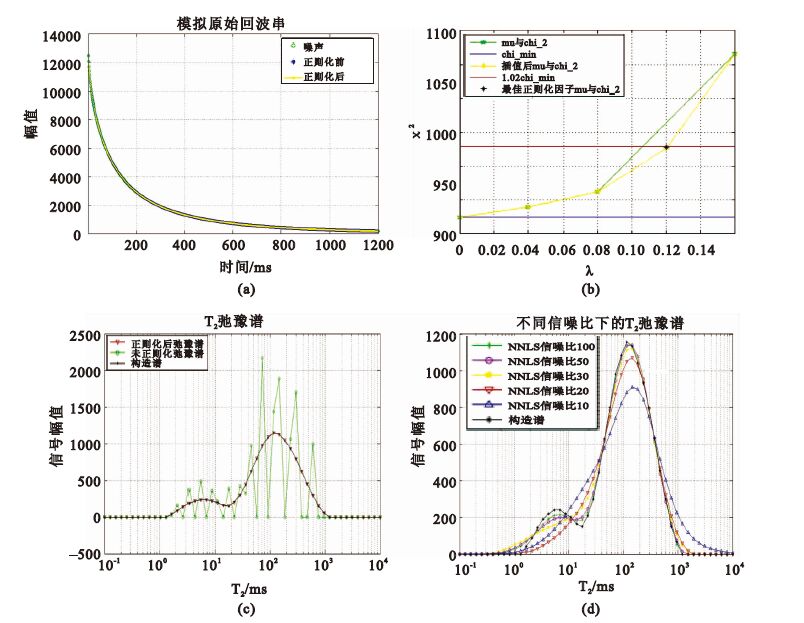 圖2
正則化反演算法結果
圖2
正則化反演算法結果
(a)核磁共振CPMG脈沖回波數據;(b)chi平方與正則化因子之間關系;(c)核磁共振弛豫譜反演結果;(d)信噪比對反演算法的影響
Figure2. NMR relaxation inversion result by regularization method(a) original CPMG echo data from configure spectrum; (b) variation of chi_2,as a function of regularization factor; (c) NMR relaxation inversion result; (d) T2 inversion spectrum after adding the white Gaussian noise with different
為了測試本算法的抗噪能力,采用對原始回波串依次添加不同程度的高斯白噪聲(信噪比依次取10、20、30、50、100),運行程序后,得到的反演結果如圖 2(d)所示:可以看到在信噪比大于30時,本文算法可以得到較真實的磁共振反演譜;在信噪比低于30時,反演譜逐漸偏離真實譜。筆者認為,在信噪比較低時可以對采集到的原始回波串數據進行指數濾波處理后再代入算法,以得到真實的反演譜。
2.2 實測回波反演
為了進一步驗證本文算法的可行性,取光明酸奶、花生油、色拉油(加幾滴純水)、大豆油為測試樣品,利用上海紐邁電子科技有限公司0.51T PQ001臺式核磁共振分析儀[22],采用CPMG序列測得樣品的原始回波數據,CPMG序列參數為:采樣點數:60 150;回波數:1 000;重復采樣次數:16;半回波時間:300 μs;采樣率:100 kHz。
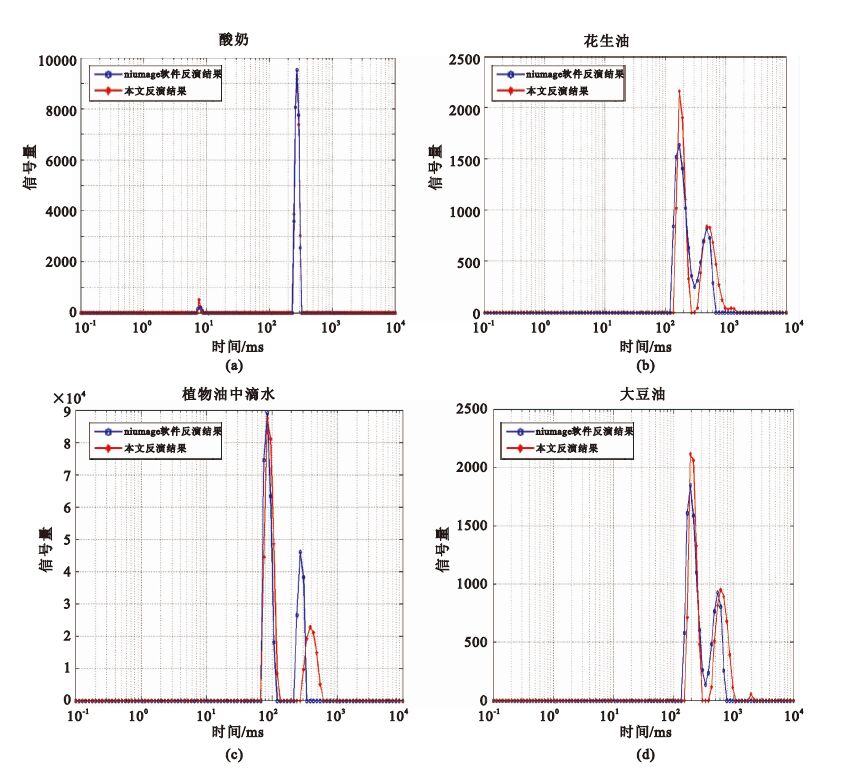
該原始回波通過儀器上Niumag T1/T2 inversion分別得到4種樣品的T2弛豫譜(此軟件采用聯合迭代算法反演),反演參數為:峰點數:1 000;迭代次數:2 000 000;布點數:100;布點方式:對數布點;最小弛豫時間:0.1 ms;最大弛豫時間:10 000 ms,取出此弛豫譜數據代入Matlab,結果如圖 3(藍色圓圈);然后將原始回波代入本文算法,得到4種樣品的T2弛豫譜,如圖 3(紅色點線)。
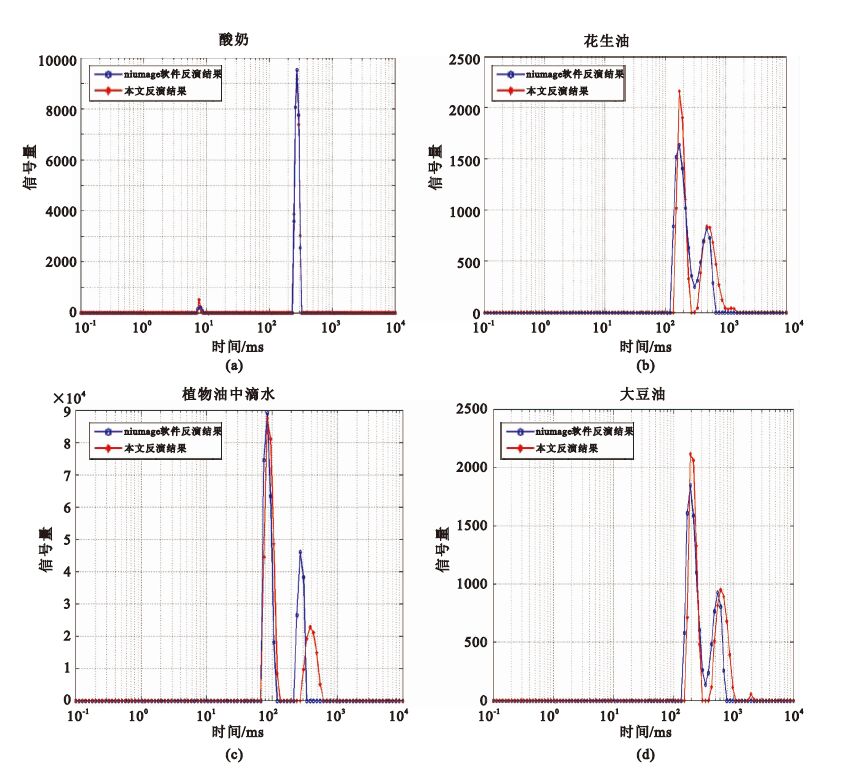 圖3
本文算法得到的T2譜與商業反演軟件得到的T2譜對比
Figure3.
T2 inversion spectrum (red asterisk) with the algorithm suggested by this paper and the spectrum (blue circle) obtained by the NMR instrument
圖3
本文算法得到的T2譜與商業反演軟件得到的T2譜對比
Figure3.
T2 inversion spectrum (red asterisk) with the algorithm suggested by this paper and the spectrum (blue circle) obtained by the NMR instrument
通過對比發現,對于酸奶、花生油和大豆油樣品,本文算法結果和商業軟件結果接近,對于色拉油(加入幾滴水),弛豫譜中大峰基本一致,小峰有微小差別。本文算法缺點是抗噪聲能力有待進一步提高,優點是比商業軟件用時短,本文算法耗時約為商業軟件的十分之一,同時本文算法的可行性和穩定性可滿足核磁共振成像分析儀測試和科研的需要。
3 結論
(1)本方法基于不適定反問題的正則化求解思想,能夠準確有效地得出構造數據和實測數據的核磁共振弛豫譜。(2)本方法通過數值實驗平臺自帶非負最小二函數實現弛豫譜的非負約束,且其中正則化參數的選取不同于傳統的迭代法,這種通過插值找到最佳正則化因子的方法對其他不適定問題的求解具有參考價值。(3)該方法速度快,可靠性和穩定性較好,可以用于生產檢測、實驗科研中。
引言
低場脈沖核磁共振測量技術是一種新興技術,與目前可知的其他技術相比,具有無損、精確、快速等諸多優勢,在農業與生物材料、食品安全、生命科技與制藥行業、石油能源和新材料等領域具有廣闊的應用前景[1]。低場脈沖核磁共振與高場核磁共振譜儀直接檢測大分子之間相互作用導致的頻率差異不同,它主要通過對待測樣品的氫質子的弛豫特性分析,來實現對樣品中水分、油分的定性定量研究。低場脈沖核磁共振測量技術是一種間接測量技術,我們所需的反映樣品屬性的信息是從核磁共振分析儀上采集到的原始核磁共振信號中提取出來的,而提取這些信息的關鍵是對原始核磁共振信號進行弛豫譜反演,因此,弛豫譜反演是核磁共振信號正確解釋和應用的關鍵[2]。
目前已提出的幾種反演算法主要有奇異值分解反演算法(singular value decomposition,SVD)、非負最小二乘法反演算法(non-negative least squares,NNLS)、聯合迭代反演算法(solid iteration rebuilding technique,SIRT)和遺傳反演算法(genetic algorithm,GA),這些方法或對回波信噪比要求高,或反演時間長,或實現非負約束的過程較復雜,而且反演的結果受算法參數如弛豫布點數、布點方式、信噪比等的影響[2-20]。本文基于正則化理論,提出一種尋找正則化因子的新方法,通過加入正則化因子求得反演問題的解,不僅抑制了解的不穩定性,還使得反演結果更接近真實值。本文通過Matlab數值模擬,設計了一套低場核磁共振弛豫譜反演正則化算法,分別對構造的和實際的核磁共振回波信號進行反演,反演運算結果表明:本文提出的算法反演速度快、穩定性好。
1 原理
在實際的測量過程中,從低場核磁共振分析儀上檢測到的核磁共振信號y是由一系列滿足指數衰減規律的弛豫組分的信號疊加而成的,同時不可避免地混入了隨機噪聲,因此y可以描述為
| $\begin{align} & y\left( {{t}_{i}} \right)=\sum\limits_{j=1}^{m}{{{x}_{j}}}\cdot {{e}^{-\frac{{{t}_{1}}}{{{T}_{2j}}}}}+\varepsilon \left( t \right) \\ & \left( 1\le i\le n;\text{ }1\le j\le m \right) \\ \end{align}$ |
其中 y(ti) 為ti時刻觀測到的回波幅度; xj為第j種弛豫分量的回波初始幅度;m為弛豫分量的個數,n為回波的個數;ti為回波間隔時間的整數倍;T2j(j=1,2,…,m)為預先設定的T2 布點,為第j種弛豫分量的橫向弛豫時間,考慮譜的覆蓋范圍從0.1~10 000 ms,超過三個數量級,隨著時間的增大,信號基本衰減完畢,T2組分會減少,因此T2采用先疏后密的對數均勻布點;ε表示隨機噪聲。
核磁共振分析測量技術的關鍵是如何從方程(1)中求解出樣品中各個T2弛豫時間及各個弛豫時間所對應的回波初始幅值。求解方程(1),實際上是求解第一類fredholm線性積分方程,這類方程的解具有不唯一性,同時輸入數據攜帶的噪聲又會影響解的結果,也就是說,在允許的測量誤差范圍內,存在不同的弛豫時間分布函數都能相當好地擬合原始回波衰減曲線,這種相容性增大了反演過程的難度[2]。因此我們必須利用一些先驗知識(數據信噪比、非負約束、解的連續性)來最大限度地恢復我們需要的樣品的弛豫時間分量與其所對應回波的初始幅度之間的關系。本文主要采用正則化思想來求解方程,通過尋找合適的算子來逼近原問題,使由適定算子確定的問題的解可以逼近原問題的解,本文將解的2-范數最小作為附加條件加入到原問題中,轉化為
| $min(\|y-Ax{{\|}^{2}}+{{\lambda }^{2}}\|Lx{{\|}^{2}})~,$ |
其中λ為正則化參數。它控制著殘差的范數與附加條件之間的權重。對式(2)求導令其為0,即得到方程組:
| ${{x}_{\lambda }}={{({{A}^{T}}A+{{\lambda }^{2}}{{L}^{T}}L)}^{-1}}{{A}^{T}}y$ |
求解方程組的過程即為正則化的過程[21]。公式中L的選取有以下三種方法(模型參數的三種解估計),分別為最小能量解估計、最光滑解估計、最平滑解估計。本文確定L采取最小能量解估計,即取單位矩陣。其次在正則化問題中,λ的選取是個重要問題,選取不當會影響算法的收斂性和收斂速度。正則化參數λ的選取是最終反演結果正確與否的關鍵,本文兼顧求解結果的平滑性和非負性,先計算λ為0時方程(3)的解,并得到方差χ2范圍,其中,χ2定義如方程(4):
| ${{\chi }^{2}}=\sum\limits_{j=1}^{n}{{{\left[ y({{t}_{j}})-\sum\limits_{i=1}^{m}{{{x}_{i}}}{{e}^{-\frac{{{t}_{i}}}{{{T}_{2j}}}}} \right]}^{2}}}$ |
假設每個點的測量誤差是隨機獨立的,且標準差都一樣,然后通過線性改變λ的值以觀察感興趣范圍內χ2的改變,采用插值法找到最合適的正則化因子λ, 并代入方程(3)中求得弛豫時間分量與其所對應回波的初始幅度之間的關系。具體算法的實現過程如下:① 確定布點數、布點方式,并將原始回波數據代入方程,得出方程的正則化解;② 取正則化參數為0,得到正則化解代入方差方程,得到最小方差,再通過線性插值法取得最佳正則化參數;③ 將最佳正則化參數代入方程最終得到各個弛豫分量的時間及其幅度。算法流程如圖 1所示。
圖1
核磁共振反演算法流程圖
Figure1.
Flowchart of NMR inversion algorithm
2 Matlab數值實驗
根據上述思路,在Matlab 7.0平臺下編譯了程序,并分別利用構造譜和實驗室采集到的核磁信號進行數值實驗。
2.1 構造譜反演
首先構造典型的雙峰結構的T2 譜,回波間隔時間τ=1.2 ms,回波數N=1 024,再代入方程(1)正演得到無噪聲核磁共振回波信號,后逐點加入隨機噪聲,生成一個具有一定信噪比的模擬回波串信號,代入算法得到反演結果,并分析與原始構造譜的差別驗證算法的準確性。
利用上述思路,得到的模擬原始回波串數據以及反演結果如圖 2所示:圖 2(a)表示構造譜正演并加入隨機噪聲后的回波;圖 2(b)表示λ與χ2關系,即線性插值選取λ的過程;圖 2(c)為正則化因子選取不當時反演結果(綠色圓圈)以及本算法反演結果(紅色三角)。實驗結果表明:反演譜與構造譜(黑色點線)完全吻合,表明本文提出的算法能夠精確地反演出構造譜。
圖2
正則化反演算法結果
(a)核磁共振CPMG脈沖回波數據;(b)chi平方與正則化因子之間關系;(c)核磁共振弛豫譜反演結果;(d)信噪比對反演算法的影響
Figure2. NMR relaxation inversion result by regularization method(a) original CPMG echo data from configure spectrum; (b) variation of chi_2,as a function of regularization factor; (c) NMR relaxation inversion result; (d) T2 inversion spectrum after adding the white Gaussian noise with different
為了測試本算法的抗噪能力,采用對原始回波串依次添加不同程度的高斯白噪聲(信噪比依次取10、20、30、50、100),運行程序后,得到的反演結果如圖 2(d)所示:可以看到在信噪比大于30時,本文算法可以得到較真實的磁共振反演譜;在信噪比低于30時,反演譜逐漸偏離真實譜。筆者認為,在信噪比較低時可以對采集到的原始回波串數據進行指數濾波處理后再代入算法,以得到真實的反演譜。
2.2 實測回波反演
為了進一步驗證本文算法的可行性,取光明酸奶、花生油、色拉油(加幾滴純水)、大豆油為測試樣品,利用上海紐邁電子科技有限公司0.51T PQ001臺式核磁共振分析儀[22],采用CPMG序列測得樣品的原始回波數據,CPMG序列參數為:采樣點數:60 150;回波數:1 000;重復采樣次數:16;半回波時間:300 μs;采樣率:100 kHz。
該原始回波通過儀器上Niumag T1/T2 inversion分別得到4種樣品的T2弛豫譜(此軟件采用聯合迭代算法反演),反演參數為:峰點數:1 000;迭代次數:2 000 000;布點數:100;布點方式:對數布點;最小弛豫時間:0.1 ms;最大弛豫時間:10 000 ms,取出此弛豫譜數據代入Matlab,結果如圖 3(藍色圓圈);然后將原始回波代入本文算法,得到4種樣品的T2弛豫譜,如圖 3(紅色點線)。
圖3
本文算法得到的T2譜與商業反演軟件得到的T2譜對比
Figure3.
T2 inversion spectrum (red asterisk) with the algorithm suggested by this paper and the spectrum (blue circle) obtained by the NMR instrument
通過對比發現,對于酸奶、花生油和大豆油樣品,本文算法結果和商業軟件結果接近,對于色拉油(加入幾滴水),弛豫譜中大峰基本一致,小峰有微小差別。本文算法缺點是抗噪聲能力有待進一步提高,優點是比商業軟件用時短,本文算法耗時約為商業軟件的十分之一,同時本文算法的可行性和穩定性可滿足核磁共振成像分析儀測試和科研的需要。
3 結論
(1)本方法基于不適定反問題的正則化求解思想,能夠準確有效地得出構造數據和實測數據的核磁共振弛豫譜。(2)本方法通過數值實驗平臺自帶非負最小二函數實現弛豫譜的非負約束,且其中正則化參數的選取不同于傳統的迭代法,這種通過插值找到最佳正則化因子的方法對其他不適定問題的求解具有參考價值。(3)該方法速度快,可靠性和穩定性較好,可以用于生產檢測、實驗科研中。