針對現有的多生理參數實時監測系統中,由于終端用戶數量增加和上傳數據加大所導致的服務后臺數據一致性無法保證、生理參數存儲與處理能力不足、實時性較差以及數據利用率低等問題,提出了基于云計算的多生理參數監測后臺數據集群存儲與并行處理新模式。通過對監測系統云平臺的基礎設施即服務層資源虛擬化、平臺即服務層實時計算平臺的構建、軟件即服務層數據流的接收與分析,以及多生理參數流傳輸通路瓶頸問題等方面的研究,實現了生理信息大數據量的實時傳輸、存儲與集群處理,并可利用批處理對患者的歷史數據實現縱向分析。仿真測試結果表明:基于云平臺的遠程多生理參數監測系統在集群數據處理時間和負載平衡方面,比傳統的服務器模式具有明顯的優勢。該平臺解決了傳統遠程醫療服務中數據周轉時間長、實時分析算法誤差較大和架構拓展困難等問題,為多生理參數無線監測以專業的"穿戴式無線傳感+移動終端無線傳輸+云計算服務"模式走向家庭健康監測提供了技術支撐。
引用本文: 朱凌云, 李連杰, 孟春艷. 遠程多生理參數實時監測云服務平臺的構建與分析. 生物醫學工程學雜志, 2014, 31(6): 1377-1383. doi: 10.7507/1001-5515.20140261 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
目前,基于無線通信終端的多生理參數監測系統在醫院患者集群監控、亞健康人群生命體征在線監測以及疾病預警等方面發揮了重要的作用。隨著監測人數和監測生理參數類別的不斷增加,需要傳輸的數據量日益龐大。但是,現有遠程實時監控的數據處理及服務端大多設在醫院,多生理參數監測模式則是將數據傳輸至醫院進行集中分析和管理。這種模式存在如下問題:首先,大多數醫院工作站采用計算機單機或者簡單的計算機集群,存在數據分析能力不足、存儲空間受限等問題;其次,現有的模式是將數據上傳至服務器,再轉發至醫院監護中心進行分析和處理,不同的監測系統、不同的醫院都有一套自身的數據傳輸模式、監測模式和數據管理模式,導致用戶在不同醫院的數據一致性不能得到保障;再次,數據從終端到工作站要經過多次中轉才能分析與處理,存在數據延遲,影響系統的實時性,無形中為監測結果的實時性服務設置了技術障礙。另外,在現代多生理參數實時監測中,由于手機的運用,數據規模在后臺數據存儲中呈爆炸式增長,特別是當數據基數達到一定程度成為大數據(Big Data)后,在考慮如何高效分析集群實時海量數據的同時,如何對每位患者的大量歷史數據進行縱向分析、對區域及特定年齡段患者的大數據進行關聯分析,以生成可供參考及決策的報表,也日益成為醫院大數據庫亟待解決的問題。
近年來,移動互聯網、無線體域網(Wireless Body Area Network,WBAN)及針對大數據處理的云端并行計算高速發展,使得無線數據高速采集、并行計算和實時處理性能得到進一步的提升[1]。這些都為多生理參數架構向普適性、大數據量、強實時性以及高準確率方向發展提供了技術支持,同時也對傳統遠程多生理參數服務平臺提出了更高的要求。因此,針對當前環境,研究面向手機用戶的,提供實時集群分析、大數據存儲和處理的生理參數監測與服務平臺是非常必要的。
1 面向大數據實時處理的多生理參數監測架構
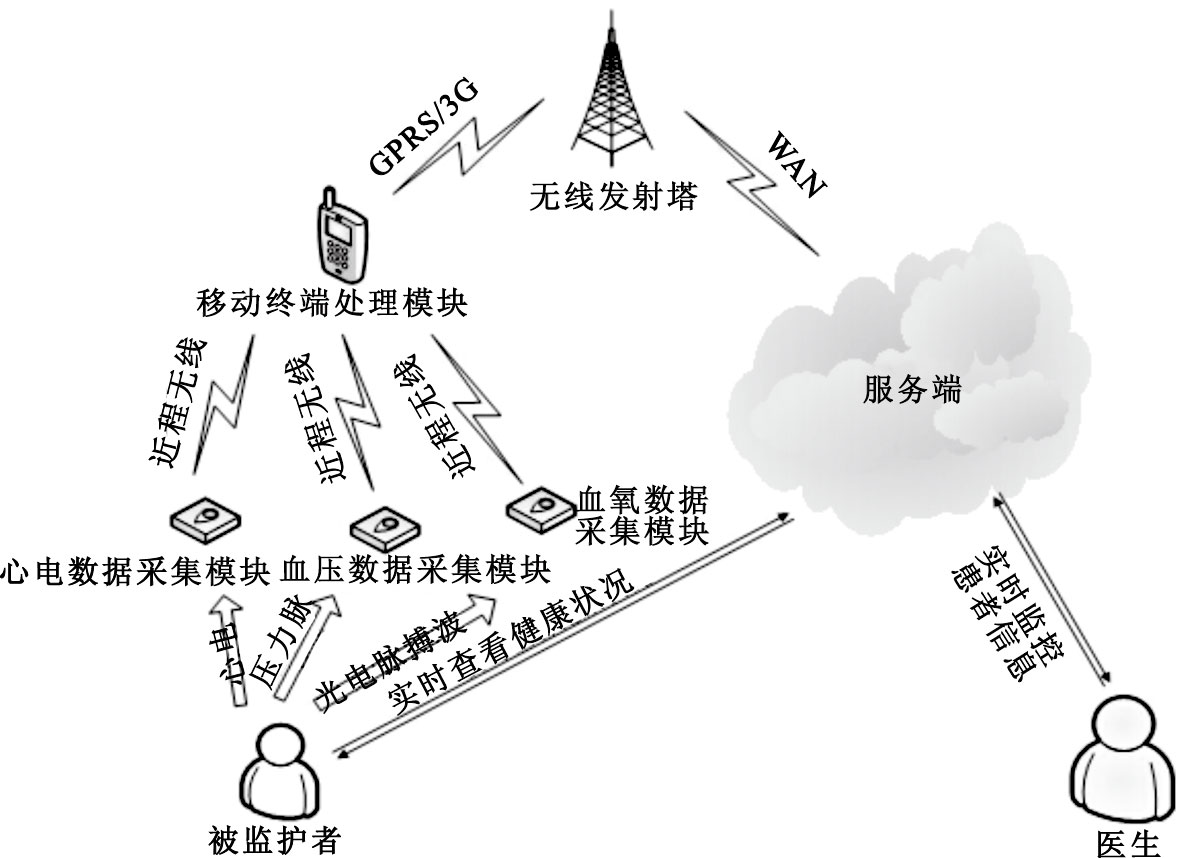
基于云服務平臺的遠程多生理參數實時監測系統,主要由用戶前端體域網、移動監護終端機(智能手機)以及云計算(Cloud Computing)數據管理與服務中心組成,其系統架構如圖 1所示。云計算數據中心接收到前端采集模塊的患者生理數據流后,將完成用戶現有數據的實時分析、現有數據與歷史數據的關聯分析以及其它統計段數據的實時分析,以充分利用云服務端較強的并行處理能力。云端還可對前端數據采集模塊和移動監護終端進行反饋控制,可實現多用戶集群數據的云端存儲、數據分析結果分級推送、用戶綜合信息管理,并能根據數據處理結果由醫生給出全面的醫療決策與服務。在這種設計模式中,云端不但為用戶、醫生和醫院構建了一個公共的數據池,同時也為三者提供了技術共享與更好的專業服務。
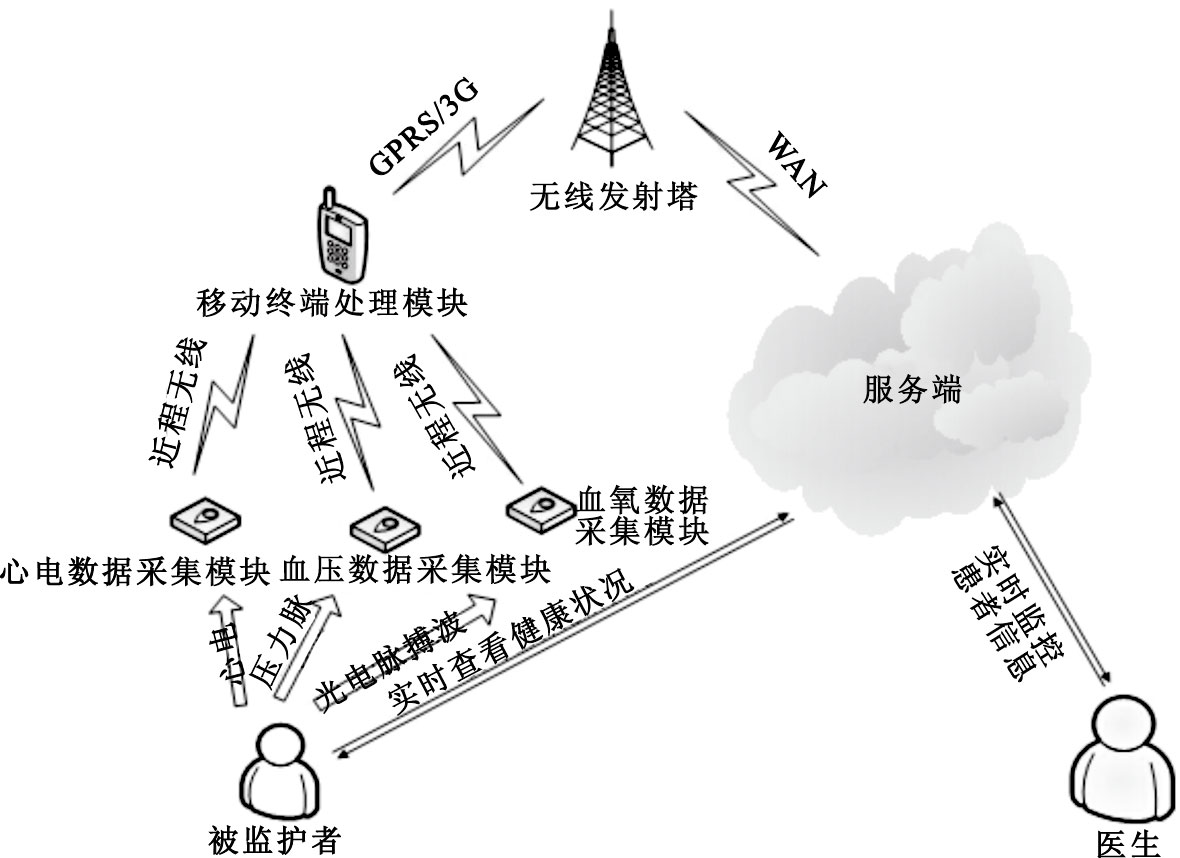 圖1
多生理參數云端監測架構
Figure1.
Cloud computing architecture for multiple physiological parameters
圖1
多生理參數云端監測架構
Figure1.
Cloud computing architecture for multiple physiological parameters
2 多生理參數實時監測云服務平臺的相關技術
2.1 云計算及Storm實時計算框架
云計算將計算任務分布在多臺計算機構成的資源池上,使各種應用系統能夠根據需要獲取計算能力、存儲空間和信息服務[2]。云計算一般包括多種層次的服務:基礎設施即服務(Infrastructure as a Service,IaaS)、平臺即服務(Platform as a Service,PaaS)和軟件即服務(Software as a service,SaaS)。目前,應用最廣泛的開源云平臺是Google的Hadoop云平臺[3]。但是,Hadoop及其相關技術都不是針對數據流實時處理系統的,對于多生理參數監測這種集群用戶數據流并行處理要求較高的情況不太適用。隨著終端用戶的急劇增長,大規模實時數據處理已經成為移動互聯網亟待解決的問題。特別是對于實時性要求比較高的多生理參數在線監測系統,Storm以其獨特的設計風格顯示了實時處理的技術優勢[4]。與其他大數據解決方案不同,Storm對于數據處理的方式存在較大差別:支持創建拓撲結構來轉換沒有終點的數據流,并可持續處理到達的數據;數據從外部來源流入Storm拓撲結構中,根據具體分析算法來處理數據。這種與MapReduce截然不同的設計風格,使得Storm能夠保證大數據處理的實時性[5]。
2.2 多生理參數實時監測私有云的資源虛擬化
構成云計算的核心部分之一就是虛擬化(Virtualization)技術,也是將各種計算資源及存儲資源充分整合和高效利用的關鍵技術[6]。虛擬化是云計算區別于其它并行計算的重要特征,通過虛擬化可以為一組類似資源提供通用的抽象接口集,從而隱藏屬性和操作之間的差異,并允許采用通用的方式來查看和維護資源[7]。由于虛擬機是一類特殊的軟件,能夠完全模擬硬件的執行,因此可在虛擬機上運行操作系統,進而能夠保留一整套運行環境語義[8]。將虛擬化技術應用到云計算平臺,可以獲得普通并行計算所不具備的良好特性。多生理參數監測云平臺屬于私有云規模,其資源的虛擬化則應根據監測用戶的規模、用戶上傳數據規模以及所提供的服務內容來確定。
2.3 Topology編程模型
Topology是Storm云平臺的主要編程模型,由多個spout和bolt組成,是任務運行時所有計算節點拓撲結構的集合[9]。消息源spout是Topology的消息生產者,可從外部源讀取數據并且向topology發出消息tuple,而所有的消息處理邏輯都封裝在bolts里面。bolts可以完成過濾、聚合、查詢數據庫等操作,也可以傳遞簡單的消息流。而對于復雜的消息流處理,如多生理參數的監測處理,往往需要較多步驟,也就需要多個bolts協同完成[10]。因此,可以將多生理參數的分析算法拆分為多個細粒度的子分析過程,從而為規模數據與復雜算法的并行化處理提供技術支撐。
3 多生理參數監測云平臺數據中心的構建
3.1 多生理參數云端硬件資源的虛擬化設計
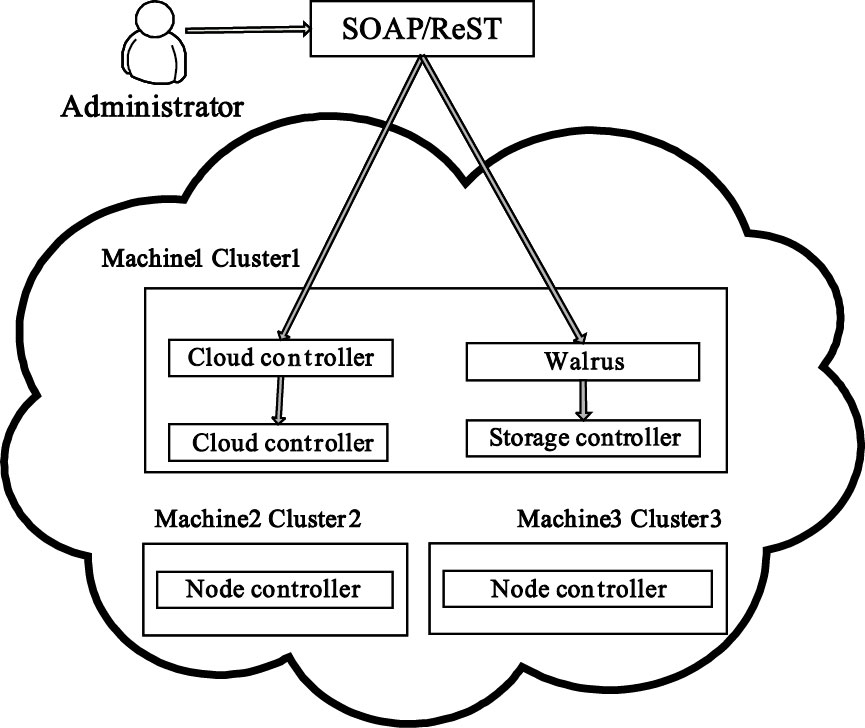
云服務平臺IaaS層的主要任務是把計算和存儲等物理資源虛擬為可供調度的資源池,并為用戶以云計算的模式提供使各種資源。IaaS層主流開源平臺有Eucalyptus、OpenStack和ConVirt等[11]。Eucalyptus 是一種開源GPL協議下,通過計算集群或服務集群上的部署,實現云計算環境彈性需求的軟件基礎結構。結合多生理參數實時監測的需求,數據中心選擇Eucalyptus作為資源虛擬化工具,其云平臺IaaS層架構如圖 2所示。通過虛擬化設計,可構建符合多生理參數監測等特定需求的私有云及混合云,將電腦、網絡和存儲等數據中心資源納入可控制的云,用戶在該平臺上可運行和控制部署在各種虛擬物理資源上的應用實例。Eucalyptus管理系統的服務最終依賴于底層云計算資源提供,搭建底層云計算環境的目的在于為資源的虛擬化管理應用提供支持環境,使用戶可以通過中間件訪問底層云計算資源。多生理參數云端的這種設計,不僅讓醫院從投資、維護龐大的遠程醫療平臺硬件中解脫出來,使得醫生和監護者不再擔心平臺運行的穩定性和可靠性,更重要的是使得不同醫院監護者的數據在實現共享的同時,也保證了其數據資源的一致性。同時,也使得監護者、醫院和醫生更加關注云端的服務內容和服務質量。
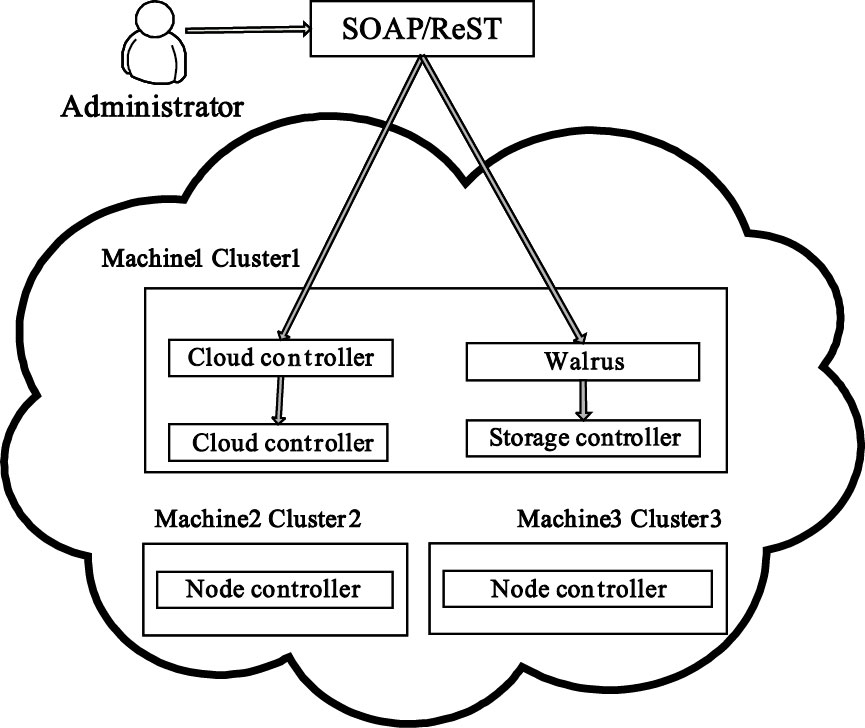 圖2
IaaS層架構示意圖
Figure2.
Schematic diagram of IaaS layer architecture
圖2
IaaS層架構示意圖
Figure2.
Schematic diagram of IaaS layer architecture
3.2 多生理參數云端數據中心的架構設計
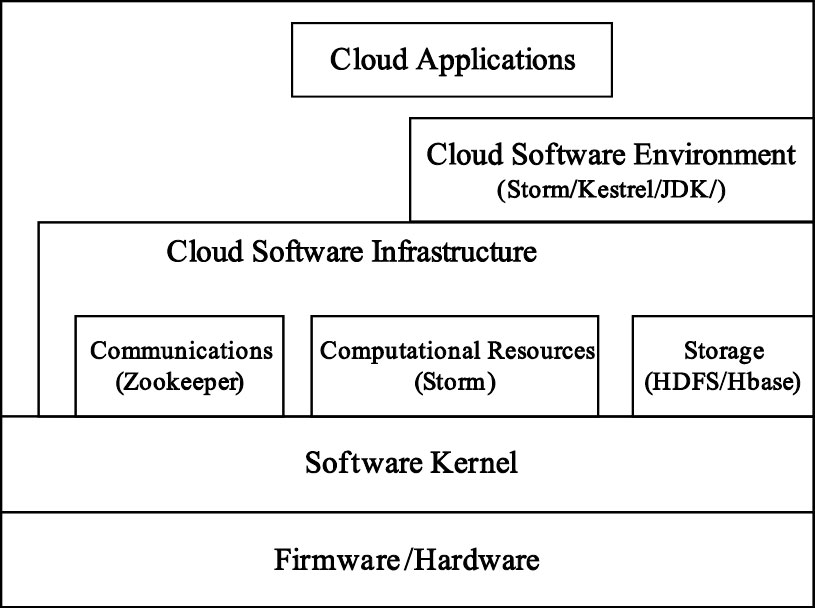
多生理參數監測服務平臺數據中心采用典型的層次化服務模型架構,其體系構成如圖 3所示。數據中心將從IaaS、PaaS、SaaS三個層次分別提供多生理參數監測的云端數據存儲、管理和服務。IaaS提供數據中心的基礎設施共享和虛擬化服務,其中的基礎設施包括各種提供計算和存儲能力的硬件資源;PaaS提供數據管理的平臺服務,如安全數據訪問、高效數據存儲、實時計算等;SaaS則提供遠程醫療的智能化信息服務,如海量數據接收、智能化數據分析和診斷結果前端推送等。為滿足多生理參數實時監測的需求,選用Twitter公司的Storm云平臺提供實時計算基礎服務,以此為基礎在SaaS層整合了Hbase分布式數據庫和Kestrel分布式隊列,以便安全、高效地實現監測數據的實時分析與存儲。
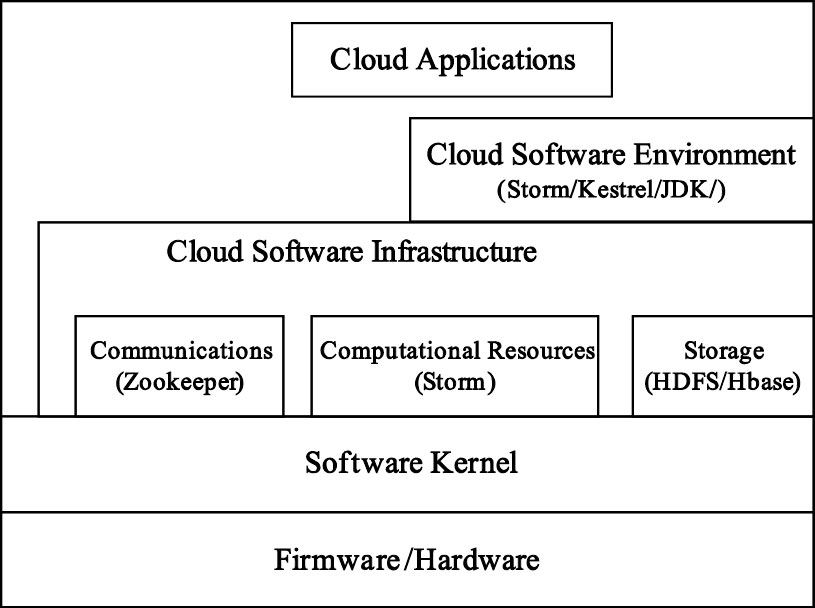 圖3
數據中心整體架構示意圖
Figure3.
Schematic diagram of data center architecture
圖3
數據中心整體架構示意圖
Figure3.
Schematic diagram of data center architecture
3.3 多生理參數監測云端的數據存儲
遠程多生理參數監測服務平臺需要存儲多種類型的數據,包括生理數據和系統管理中各實體信息。為此,其數據存儲采用分布式數據庫和關系型數據庫的雙數據庫設計。分布式數據庫主要負責大數據的存儲,其底層采用HDFS實現,數據庫則采用Hbase。HDFS采用master/slave架構,主要設計部署在大量廉價機器上的分布式文件系統。每個HDFS集群由一個NameNode節點和一組DataNode節點組成,適合多生理參數等大數據集的應用程序。醫療信息管理系統的數據庫則采用MySql實現,可適應復雜的數據邏輯關系,并使云平臺與java主流的web框架集成度顯著增加。
3.4 多生理參數集的關聯分析
大數據或稱海量數據,是指所涉及的數據量規模巨大,無法通過目前主流軟件工具在合理時間內進行擷取、管理、處理[8]。云端存儲的多生理參數監測用戶較多,而用戶的數據記錄也較多,除了需要實現某一時段的集群用戶不同數據段的分析外,還要求實現用于預測單個用戶健康態勢的現有數據與歷史數據的關聯分析,以及某年齡段或某區域人群的感興趣數據分析。對于上述大數據關聯分析需求,現有的遠程醫療軟件平臺和醫院服務器集群都無法實現。為此,鑒于上述數據分析的時效性要求不太苛刻,對其采用Hadoop批處理平臺以滿足上述需求,并通過運用MapReduce編程模型,實現患者海量歷史數據的不同需求分析。例如,在對不同年齡段數據進行分析時,可用Map函數接受患者生理數據并將其轉換為一個鍵/值對列表,輸入域中的每個元素對應一個鍵/值對,Reduce函數接受Map函數生成的列表,然后根據不同年齡段的鍵值縮小鍵/值對列表,最后輸出每一年齡組的分析結果。
3.5 多生理參數監測云平臺的數據流程
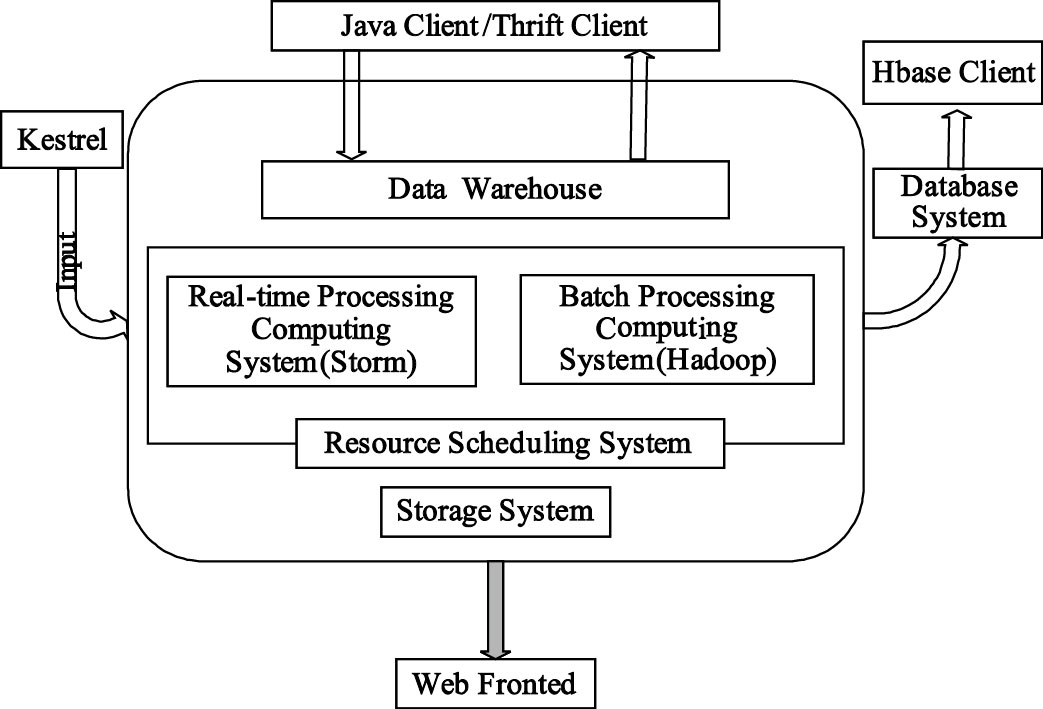
云端數據中心服務流程如圖 4所示,主要分為數據輸入、數據計算、數據持久化與前端展示三部分。數據輸入端負責處理患者監控節點的數據傳輸請求,并把接收到的生理數據放入分布式隊列,作為數據中心的待處理數據源。數據中心可根據當前待處理數據量的大小合理分配資源,并把處理后的數據存放在分布式數據庫或者前端進行展示。
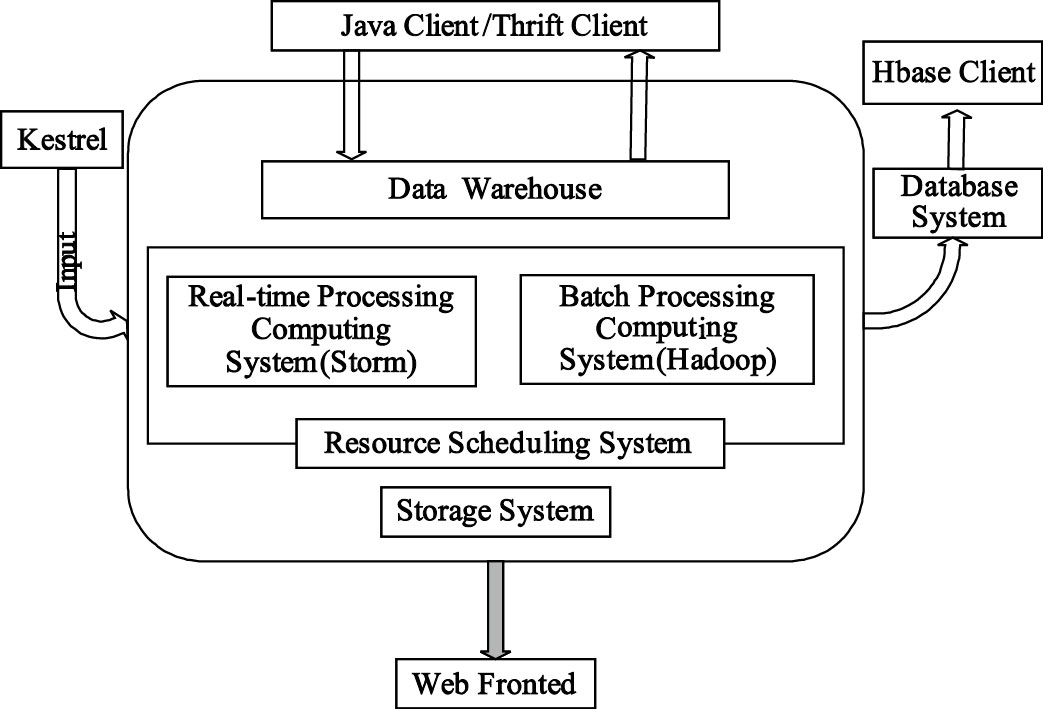 圖4
云平臺服務流程圖
Figure4.
Flow chart of cloud platform services
圖4
云平臺服務流程圖
Figure4.
Flow chart of cloud platform services
集群處理分為實時計算和批處理計算兩個部分。實時計算Storm平臺根據節點處理功能的不同又將節點分為兩類:控制節點(master node)和工作節點(worker node)。控制節點上面運行后臺程序Nimbus,負責代碼在集群里面的分布,給機器分配工作,并且監控運行狀態。每一個工作節點上面運行一個Supervisor的節點,以監聽相應的機器,并根據需要啟動/關閉工作進程。計算任務可根據具體算法流程封裝成相應的Topology,患者數據流入Topology后由工作進程負責每一步具體的數據計算,每個工作進程都執行一個Topology的子集;而每個Topology都由運行在大量機器上的很多工作進程組成,患者的數據流在這些工作進程上進行計算,完成實時分析與處理。
在批處理方面,Hadoop平臺存在兩類節點:JobTracer和TaskTracker。JobTracer是Hadoop 集群中唯一負責控制MapReduce應用程序的系統。在應用程序提交之后,將提供包含在HDFS中的輸入和輸出目錄。MapReduce應用程序被復制到每個出現輸入文件塊的節點,將為特定節點上的每個文件塊創建唯一的從屬任務,每個TaskTracker將狀態和完成信息報告給JobTracker。在特定的時間段,如每天或者每個星期,Hadoop集群會定時啟動,以完成用戶數據關聯分析,并生成報表供參考或者決策。這樣,既充分利用數據資源,實現了對多生理參數實時分析的補充,也使得生理數據分析的準確度性和完備性進一步提高。
多生理參數監測狀況前端展示主要面向監護者和醫院。由于兩類用戶所要求展示信息有所區別,例如監護者更關注自己有無疾病、身體是否健康,而醫院和醫生可能更關注數據分析的結果以及數據分析本身,因此推送的結果和內容存在差異。多生理參數監測狀況前端展示設計有兩種模式,一種是面向醫院所采用的富客戶端B/S模式,另一種是面向監護者智能手機的App模式。考慮到醫生對心電、血壓、血氧飽和度等重要參數的實時波形顯示等特殊需求,web前端采用javascript和flex等工具實現富客戶端,從而增加本地數據處理邏輯,并減少服務器負載水平。
4 多生理參數監測云平臺服務性能的優化
4.1 高性能網絡服務器的優化
引入云平臺之后,多生理參數監測過程中數據實時計算能力得到提高,數據資源的有效利用率得到了大幅度提升,但平臺入口接收實時數據的能力還有待改進。由于在實際應用中可能存在數以千計的移動終端同時連接服務器申請服務,因此,需要針對并發連接進行優化。Netty是由JBOSS提供的一個java開源框架,提供異步的、事件驅動的網絡應用程序框架和工具,吸收了多種協議的實現經驗,包括FTP、SMTP、HTTP、各種二進制以及文本協議等,使其穩定性和伸縮性得到提高。因此,多生理參數監測云服務平臺采用Netty快速開發高性能、高可靠性的網絡服務器和客戶端程序。
4.2 分布式消息隊列
由于醫療行業必須保證數據的可靠性與完整性,因此系統引入了分布式隊列來作為技術保障。分布式消息隊列可提供更好的可靠性和安全性,主要表現在如下幾方面:消息會被持久化到分布式存儲中,避免了單臺機器存儲的消息由于機器問題導致消息的丟失;當網絡環境不佳時,保證只有當消息的接收者確實收到消息時才從隊列中刪除該消息;各業務的消息內容是安全存儲的,其它業務不能訪問到非自身業務的數據;當訪問量和數據量增大時,分布式消息隊列服務可以自動擴展。
上述設計使得當服務器負載水平顯著增加時,可在不改動體系架構的情況下迅速增強系統的處理能力。
5 系統仿真與結果分析
為驗證多生理參數實時監測云端平臺構建的效果與合理性,對云服務器的相關性能進行了系統仿真與測試。在測試環境構建時,所采用的Eucayptus版本是最新的開源版本2.0.2版,虛擬機版本為Xen3.4.2,采用源碼方式安裝;各物理機安裝的JDK版本為JDK1.6.0_13,使用的操作系統均為Ubuntu10.04。其中一臺物理機安裝Eucayptus的CLC、CC、WS3和SC節點,共有四臺虛擬機安裝在NC節點,每臺均安裝了Ubuntu10.04操作系統、Storm云平臺及其它支撐軟件。將其中的一臺虛擬機設置為主服務器,負責接收手機端發送的數據并管理Storm集群。
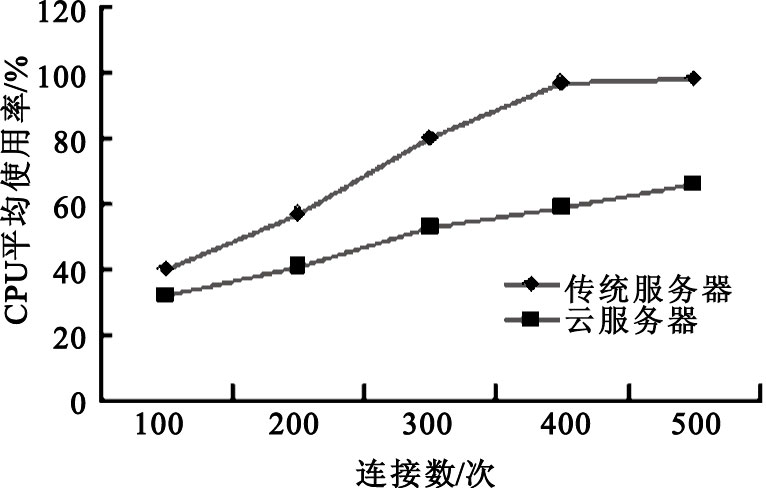
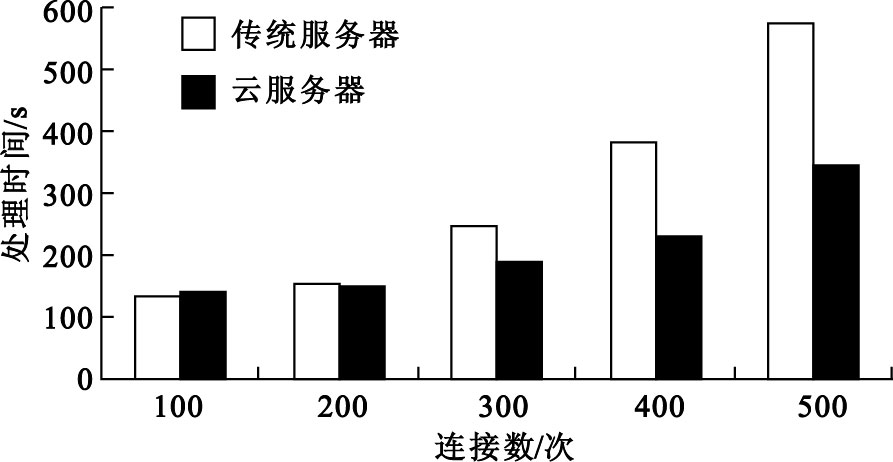
為了測試云服務器的性能,在手機端分別模擬100~500個請求同時連接服務器并發送數據,云平臺則對生理參數進行FFT變換,以實現多生理參數的預處理。在測試數據序列長度N=1 024、每臺終端連續發送3 min的情況下,云服務器與傳統服務器處理情況對比效果如圖 5和圖 6所示。
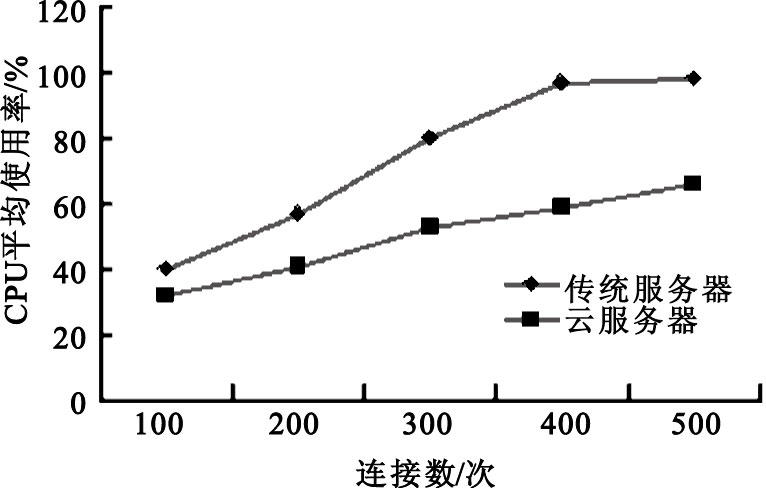 圖5
云服務器與傳統服務器負載水平對比
Figure5.
Cloud server load capacity compared with the traditional server
圖5
云服務器與傳統服務器負載水平對比
Figure5.
Cloud server load capacity compared with the traditional server
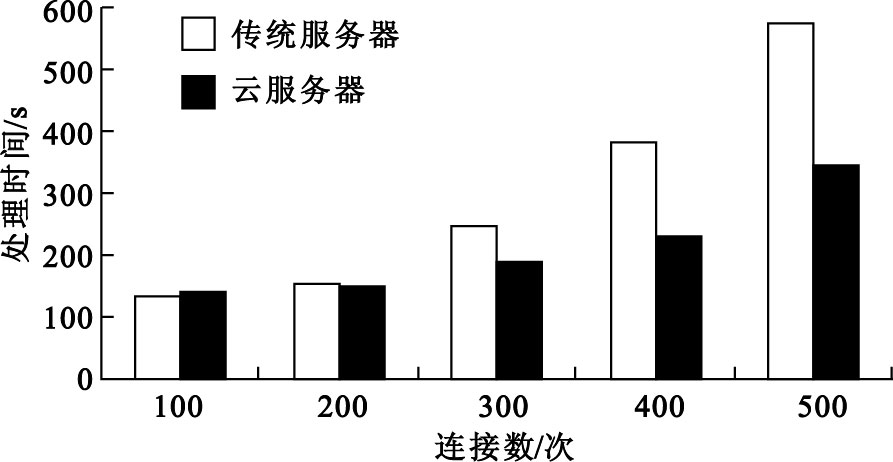 圖6
云服務器與傳統服務器處理時間對比
Figure6.
Cloud server processing time compared with the traditional server
圖6
云服務器與傳統服務器處理時間對比
Figure6.
Cloud server processing time compared with the traditional server
由此可以看出,在數據量比較小的時候,由于傳統服務器環境下數據都在本地處理,因此速度要快于集群云端。隨著數據量的增長,傳統服務器負載水平上升較快,而云服務器依賴負載均衡調度算法,把任務分給多個計算節點,提供了強大的服務能力,較好地解決了大數據量多生理參數的復雜計算問題。
6 結束語
針對多生理參數監測中數據量大和實時性高等特點進行了集群數據處理的云端平臺構建與設計。與傳統遠程醫療系統服務平臺相比,主要有以下特點:在彈性計算和存儲方面,數據中心對底層硬件資源進行了虛擬化,使其能根據系統實際的負載狀況合理分配資源,在運算任務較少的時間段可關閉部分服務器,降低運營成本;在數據庫構建方面,由于數據中心需要對大數據和關系緊密型數據進行分別處理,因此采用了關系型數據庫和非關系型數據庫共存的雙數據庫設計,解決了大數據的處理、存儲和內部實體關系復雜的醫療信息管理系統需求的矛盾,使系統的邏輯層和數據庫設計更加合理;在分布式計算方面,將實時計算與批處理計算共存,在Sorm實時計算的基礎上,引入Hadoop批處理用于對患者歷史數據的縱向分析,兩部分以HDFS分布式數據存儲作為結合點,使患者生理數據分析的準確性和完備性得到進一步的提高。上述平臺的構建,克服了傳統多生理參數監測平臺數據容量有限、分析能力不足、數據資源利用率低、共享數據的一致性較差等弊端,解決了傳統遠程醫療服務中數據周轉時間長、架構拓展困難等問題,為多生理參數無線監測以專業的“穿戴式無線傳感+移動終端無線傳輸+云計算服務”模式走向家庭健康監測提供了技術支撐。
引言
目前,基于無線通信終端的多生理參數監測系統在醫院患者集群監控、亞健康人群生命體征在線監測以及疾病預警等方面發揮了重要的作用。隨著監測人數和監測生理參數類別的不斷增加,需要傳輸的數據量日益龐大。但是,現有遠程實時監控的數據處理及服務端大多設在醫院,多生理參數監測模式則是將數據傳輸至醫院進行集中分析和管理。這種模式存在如下問題:首先,大多數醫院工作站采用計算機單機或者簡單的計算機集群,存在數據分析能力不足、存儲空間受限等問題;其次,現有的模式是將數據上傳至服務器,再轉發至醫院監護中心進行分析和處理,不同的監測系統、不同的醫院都有一套自身的數據傳輸模式、監測模式和數據管理模式,導致用戶在不同醫院的數據一致性不能得到保障;再次,數據從終端到工作站要經過多次中轉才能分析與處理,存在數據延遲,影響系統的實時性,無形中為監測結果的實時性服務設置了技術障礙。另外,在現代多生理參數實時監測中,由于手機的運用,數據規模在后臺數據存儲中呈爆炸式增長,特別是當數據基數達到一定程度成為大數據(Big Data)后,在考慮如何高效分析集群實時海量數據的同時,如何對每位患者的大量歷史數據進行縱向分析、對區域及特定年齡段患者的大數據進行關聯分析,以生成可供參考及決策的報表,也日益成為醫院大數據庫亟待解決的問題。
近年來,移動互聯網、無線體域網(Wireless Body Area Network,WBAN)及針對大數據處理的云端并行計算高速發展,使得無線數據高速采集、并行計算和實時處理性能得到進一步的提升[1]。這些都為多生理參數架構向普適性、大數據量、強實時性以及高準確率方向發展提供了技術支持,同時也對傳統遠程多生理參數服務平臺提出了更高的要求。因此,針對當前環境,研究面向手機用戶的,提供實時集群分析、大數據存儲和處理的生理參數監測與服務平臺是非常必要的。
1 面向大數據實時處理的多生理參數監測架構
基于云服務平臺的遠程多生理參數實時監測系統,主要由用戶前端體域網、移動監護終端機(智能手機)以及云計算(Cloud Computing)數據管理與服務中心組成,其系統架構如圖 1所示。云計算數據中心接收到前端采集模塊的患者生理數據流后,將完成用戶現有數據的實時分析、現有數據與歷史數據的關聯分析以及其它統計段數據的實時分析,以充分利用云服務端較強的并行處理能力。云端還可對前端數據采集模塊和移動監護終端進行反饋控制,可實現多用戶集群數據的云端存儲、數據分析結果分級推送、用戶綜合信息管理,并能根據數據處理結果由醫生給出全面的醫療決策與服務。在這種設計模式中,云端不但為用戶、醫生和醫院構建了一個公共的數據池,同時也為三者提供了技術共享與更好的專業服務。
圖1
多生理參數云端監測架構
Figure1.
Cloud computing architecture for multiple physiological parameters
2 多生理參數實時監測云服務平臺的相關技術
2.1 云計算及Storm實時計算框架
云計算將計算任務分布在多臺計算機構成的資源池上,使各種應用系統能夠根據需要獲取計算能力、存儲空間和信息服務[2]。云計算一般包括多種層次的服務:基礎設施即服務(Infrastructure as a Service,IaaS)、平臺即服務(Platform as a Service,PaaS)和軟件即服務(Software as a service,SaaS)。目前,應用最廣泛的開源云平臺是Google的Hadoop云平臺[3]。但是,Hadoop及其相關技術都不是針對數據流實時處理系統的,對于多生理參數監測這種集群用戶數據流并行處理要求較高的情況不太適用。隨著終端用戶的急劇增長,大規模實時數據處理已經成為移動互聯網亟待解決的問題。特別是對于實時性要求比較高的多生理參數在線監測系統,Storm以其獨特的設計風格顯示了實時處理的技術優勢[4]。與其他大數據解決方案不同,Storm對于數據處理的方式存在較大差別:支持創建拓撲結構來轉換沒有終點的數據流,并可持續處理到達的數據;數據從外部來源流入Storm拓撲結構中,根據具體分析算法來處理數據。這種與MapReduce截然不同的設計風格,使得Storm能夠保證大數據處理的實時性[5]。
2.2 多生理參數實時監測私有云的資源虛擬化
構成云計算的核心部分之一就是虛擬化(Virtualization)技術,也是將各種計算資源及存儲資源充分整合和高效利用的關鍵技術[6]。虛擬化是云計算區別于其它并行計算的重要特征,通過虛擬化可以為一組類似資源提供通用的抽象接口集,從而隱藏屬性和操作之間的差異,并允許采用通用的方式來查看和維護資源[7]。由于虛擬機是一類特殊的軟件,能夠完全模擬硬件的執行,因此可在虛擬機上運行操作系統,進而能夠保留一整套運行環境語義[8]。將虛擬化技術應用到云計算平臺,可以獲得普通并行計算所不具備的良好特性。多生理參數監測云平臺屬于私有云規模,其資源的虛擬化則應根據監測用戶的規模、用戶上傳數據規模以及所提供的服務內容來確定。
2.3 Topology編程模型
Topology是Storm云平臺的主要編程模型,由多個spout和bolt組成,是任務運行時所有計算節點拓撲結構的集合[9]。消息源spout是Topology的消息生產者,可從外部源讀取數據并且向topology發出消息tuple,而所有的消息處理邏輯都封裝在bolts里面。bolts可以完成過濾、聚合、查詢數據庫等操作,也可以傳遞簡單的消息流。而對于復雜的消息流處理,如多生理參數的監測處理,往往需要較多步驟,也就需要多個bolts協同完成[10]。因此,可以將多生理參數的分析算法拆分為多個細粒度的子分析過程,從而為規模數據與復雜算法的并行化處理提供技術支撐。
3 多生理參數監測云平臺數據中心的構建
3.1 多生理參數云端硬件資源的虛擬化設計
云服務平臺IaaS層的主要任務是把計算和存儲等物理資源虛擬為可供調度的資源池,并為用戶以云計算的模式提供使各種資源。IaaS層主流開源平臺有Eucalyptus、OpenStack和ConVirt等[11]。Eucalyptus 是一種開源GPL協議下,通過計算集群或服務集群上的部署,實現云計算環境彈性需求的軟件基礎結構。結合多生理參數實時監測的需求,數據中心選擇Eucalyptus作為資源虛擬化工具,其云平臺IaaS層架構如圖 2所示。通過虛擬化設計,可構建符合多生理參數監測等特定需求的私有云及混合云,將電腦、網絡和存儲等數據中心資源納入可控制的云,用戶在該平臺上可運行和控制部署在各種虛擬物理資源上的應用實例。Eucalyptus管理系統的服務最終依賴于底層云計算資源提供,搭建底層云計算環境的目的在于為資源的虛擬化管理應用提供支持環境,使用戶可以通過中間件訪問底層云計算資源。多生理參數云端的這種設計,不僅讓醫院從投資、維護龐大的遠程醫療平臺硬件中解脫出來,使得醫生和監護者不再擔心平臺運行的穩定性和可靠性,更重要的是使得不同醫院監護者的數據在實現共享的同時,也保證了其數據資源的一致性。同時,也使得監護者、醫院和醫生更加關注云端的服務內容和服務質量。
圖2
IaaS層架構示意圖
Figure2.
Schematic diagram of IaaS layer architecture
3.2 多生理參數云端數據中心的架構設計
多生理參數監測服務平臺數據中心采用典型的層次化服務模型架構,其體系構成如圖 3所示。數據中心將從IaaS、PaaS、SaaS三個層次分別提供多生理參數監測的云端數據存儲、管理和服務。IaaS提供數據中心的基礎設施共享和虛擬化服務,其中的基礎設施包括各種提供計算和存儲能力的硬件資源;PaaS提供數據管理的平臺服務,如安全數據訪問、高效數據存儲、實時計算等;SaaS則提供遠程醫療的智能化信息服務,如海量數據接收、智能化數據分析和診斷結果前端推送等。為滿足多生理參數實時監測的需求,選用Twitter公司的Storm云平臺提供實時計算基礎服務,以此為基礎在SaaS層整合了Hbase分布式數據庫和Kestrel分布式隊列,以便安全、高效地實現監測數據的實時分析與存儲。
圖3
數據中心整體架構示意圖
Figure3.
Schematic diagram of data center architecture
3.3 多生理參數監測云端的數據存儲
遠程多生理參數監測服務平臺需要存儲多種類型的數據,包括生理數據和系統管理中各實體信息。為此,其數據存儲采用分布式數據庫和關系型數據庫的雙數據庫設計。分布式數據庫主要負責大數據的存儲,其底層采用HDFS實現,數據庫則采用Hbase。HDFS采用master/slave架構,主要設計部署在大量廉價機器上的分布式文件系統。每個HDFS集群由一個NameNode節點和一組DataNode節點組成,適合多生理參數等大數據集的應用程序。醫療信息管理系統的數據庫則采用MySql實現,可適應復雜的數據邏輯關系,并使云平臺與java主流的web框架集成度顯著增加。
3.4 多生理參數集的關聯分析
大數據或稱海量數據,是指所涉及的數據量規模巨大,無法通過目前主流軟件工具在合理時間內進行擷取、管理、處理[8]。云端存儲的多生理參數監測用戶較多,而用戶的數據記錄也較多,除了需要實現某一時段的集群用戶不同數據段的分析外,還要求實現用于預測單個用戶健康態勢的現有數據與歷史數據的關聯分析,以及某年齡段或某區域人群的感興趣數據分析。對于上述大數據關聯分析需求,現有的遠程醫療軟件平臺和醫院服務器集群都無法實現。為此,鑒于上述數據分析的時效性要求不太苛刻,對其采用Hadoop批處理平臺以滿足上述需求,并通過運用MapReduce編程模型,實現患者海量歷史數據的不同需求分析。例如,在對不同年齡段數據進行分析時,可用Map函數接受患者生理數據并將其轉換為一個鍵/值對列表,輸入域中的每個元素對應一個鍵/值對,Reduce函數接受Map函數生成的列表,然后根據不同年齡段的鍵值縮小鍵/值對列表,最后輸出每一年齡組的分析結果。
3.5 多生理參數監測云平臺的數據流程
云端數據中心服務流程如圖 4所示,主要分為數據輸入、數據計算、數據持久化與前端展示三部分。數據輸入端負責處理患者監控節點的數據傳輸請求,并把接收到的生理數據放入分布式隊列,作為數據中心的待處理數據源。數據中心可根據當前待處理數據量的大小合理分配資源,并把處理后的數據存放在分布式數據庫或者前端進行展示。
圖4
云平臺服務流程圖
Figure4.
Flow chart of cloud platform services
集群處理分為實時計算和批處理計算兩個部分。實時計算Storm平臺根據節點處理功能的不同又將節點分為兩類:控制節點(master node)和工作節點(worker node)。控制節點上面運行后臺程序Nimbus,負責代碼在集群里面的分布,給機器分配工作,并且監控運行狀態。每一個工作節點上面運行一個Supervisor的節點,以監聽相應的機器,并根據需要啟動/關閉工作進程。計算任務可根據具體算法流程封裝成相應的Topology,患者數據流入Topology后由工作進程負責每一步具體的數據計算,每個工作進程都執行一個Topology的子集;而每個Topology都由運行在大量機器上的很多工作進程組成,患者的數據流在這些工作進程上進行計算,完成實時分析與處理。
在批處理方面,Hadoop平臺存在兩類節點:JobTracer和TaskTracker。JobTracer是Hadoop 集群中唯一負責控制MapReduce應用程序的系統。在應用程序提交之后,將提供包含在HDFS中的輸入和輸出目錄。MapReduce應用程序被復制到每個出現輸入文件塊的節點,將為特定節點上的每個文件塊創建唯一的從屬任務,每個TaskTracker將狀態和完成信息報告給JobTracker。在特定的時間段,如每天或者每個星期,Hadoop集群會定時啟動,以完成用戶數據關聯分析,并生成報表供參考或者決策。這樣,既充分利用數據資源,實現了對多生理參數實時分析的補充,也使得生理數據分析的準確度性和完備性進一步提高。
多生理參數監測狀況前端展示主要面向監護者和醫院。由于兩類用戶所要求展示信息有所區別,例如監護者更關注自己有無疾病、身體是否健康,而醫院和醫生可能更關注數據分析的結果以及數據分析本身,因此推送的結果和內容存在差異。多生理參數監測狀況前端展示設計有兩種模式,一種是面向醫院所采用的富客戶端B/S模式,另一種是面向監護者智能手機的App模式。考慮到醫生對心電、血壓、血氧飽和度等重要參數的實時波形顯示等特殊需求,web前端采用javascript和flex等工具實現富客戶端,從而增加本地數據處理邏輯,并減少服務器負載水平。
4 多生理參數監測云平臺服務性能的優化
4.1 高性能網絡服務器的優化
引入云平臺之后,多生理參數監測過程中數據實時計算能力得到提高,數據資源的有效利用率得到了大幅度提升,但平臺入口接收實時數據的能力還有待改進。由于在實際應用中可能存在數以千計的移動終端同時連接服務器申請服務,因此,需要針對并發連接進行優化。Netty是由JBOSS提供的一個java開源框架,提供異步的、事件驅動的網絡應用程序框架和工具,吸收了多種協議的實現經驗,包括FTP、SMTP、HTTP、各種二進制以及文本協議等,使其穩定性和伸縮性得到提高。因此,多生理參數監測云服務平臺采用Netty快速開發高性能、高可靠性的網絡服務器和客戶端程序。
4.2 分布式消息隊列
由于醫療行業必須保證數據的可靠性與完整性,因此系統引入了分布式隊列來作為技術保障。分布式消息隊列可提供更好的可靠性和安全性,主要表現在如下幾方面:消息會被持久化到分布式存儲中,避免了單臺機器存儲的消息由于機器問題導致消息的丟失;當網絡環境不佳時,保證只有當消息的接收者確實收到消息時才從隊列中刪除該消息;各業務的消息內容是安全存儲的,其它業務不能訪問到非自身業務的數據;當訪問量和數據量增大時,分布式消息隊列服務可以自動擴展。
上述設計使得當服務器負載水平顯著增加時,可在不改動體系架構的情況下迅速增強系統的處理能力。
5 系統仿真與結果分析
為驗證多生理參數實時監測云端平臺構建的效果與合理性,對云服務器的相關性能進行了系統仿真與測試。在測試環境構建時,所采用的Eucayptus版本是最新的開源版本2.0.2版,虛擬機版本為Xen3.4.2,采用源碼方式安裝;各物理機安裝的JDK版本為JDK1.6.0_13,使用的操作系統均為Ubuntu10.04。其中一臺物理機安裝Eucayptus的CLC、CC、WS3和SC節點,共有四臺虛擬機安裝在NC節點,每臺均安裝了Ubuntu10.04操作系統、Storm云平臺及其它支撐軟件。將其中的一臺虛擬機設置為主服務器,負責接收手機端發送的數據并管理Storm集群。
為了測試云服務器的性能,在手機端分別模擬100~500個請求同時連接服務器并發送數據,云平臺則對生理參數進行FFT變換,以實現多生理參數的預處理。在測試數據序列長度N=1 024、每臺終端連續發送3 min的情況下,云服務器與傳統服務器處理情況對比效果如圖 5和圖 6所示。
圖5
云服務器與傳統服務器負載水平對比
Figure5.
Cloud server load capacity compared with the traditional server
圖6
云服務器與傳統服務器處理時間對比
Figure6.
Cloud server processing time compared with the traditional server
由此可以看出,在數據量比較小的時候,由于傳統服務器環境下數據都在本地處理,因此速度要快于集群云端。隨著數據量的增長,傳統服務器負載水平上升較快,而云服務器依賴負載均衡調度算法,把任務分給多個計算節點,提供了強大的服務能力,較好地解決了大數據量多生理參數的復雜計算問題。
6 結束語
針對多生理參數監測中數據量大和實時性高等特點進行了集群數據處理的云端平臺構建與設計。與傳統遠程醫療系統服務平臺相比,主要有以下特點:在彈性計算和存儲方面,數據中心對底層硬件資源進行了虛擬化,使其能根據系統實際的負載狀況合理分配資源,在運算任務較少的時間段可關閉部分服務器,降低運營成本;在數據庫構建方面,由于數據中心需要對大數據和關系緊密型數據進行分別處理,因此采用了關系型數據庫和非關系型數據庫共存的雙數據庫設計,解決了大數據的處理、存儲和內部實體關系復雜的醫療信息管理系統需求的矛盾,使系統的邏輯層和數據庫設計更加合理;在分布式計算方面,將實時計算與批處理計算共存,在Sorm實時計算的基礎上,引入Hadoop批處理用于對患者歷史數據的縱向分析,兩部分以HDFS分布式數據存儲作為結合點,使患者生理數據分析的準確性和完備性得到進一步的提高。上述平臺的構建,克服了傳統多生理參數監測平臺數據容量有限、分析能力不足、數據資源利用率低、共享數據的一致性較差等弊端,解決了傳統遠程醫療服務中數據周轉時間長、架構拓展困難等問題,為多生理參數無線監測以專業的“穿戴式無線傳感+移動終端無線傳輸+云計算服務”模式走向家庭健康監測提供了技術支撐。