血糖濃度的近紅外光譜分析中, 奇異樣本的存在會影響多元校正模型的精度。本研究建立了基于蒙特卡洛交互驗證法(MCCV)的奇異樣本去除方法, 通過人體離體血漿實驗和人體在體試驗, 驗證了該方法在血糖近紅外光譜分析中的應用效果, 并與基于改進的無信息變量消除的無信息樣本去除方法(MUVE-USE)進行了比較研究。實驗結果表明, 基于MCCV的奇異樣本去除方法, 除了與MUVE-USE一樣可去除由于粗大誤差(如樣品損壞)或系統誤差(如儀器漂移)產生的奇異樣本外, 還能同時去除對模型精度有影響的由于不確定原因產生的隨機誤差等奇異樣本。去除多種奇異樣本后建立的多元校正模型的精度明顯提高。
引用本文: 林永忠, 李麗娜, 林添良. 血糖近紅外光譜分析中奇異樣本去除方法研究. 生物醫學工程學雜志, 2015, 32(6): 1323-1328, 1334. doi: 10.7507/1001-5515.20150234 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
糖尿d病及其并發癥是嚴重威脅人類健康的現代疾病之一, 目前還沒有徹底根治糖尿病的醫學手段。世界衛生組織推薦糖尿病患者進行血糖的自我監測,通過頻繁地監測血糖濃度并以此為依據精確及時地調整口服降糖藥物和胰島素的用量,實現血糖值的精確管理,以達到有效預防糖尿病并發癥發生的目的。現有的血糖自我監測方法屬于有創檢測,是通過抽取血樣,然后應用一次性的試藥以化學方法來實現,不但操作繁瑣且頻繁地針刺取血給患者造成了極大的痛苦,增加了感染的幾率。因此人體血糖濃度無創檢測方法的研究是國內外研究的熱點之一,許多研究者認為血糖的近紅外檢測是較有前景的無創檢測方法之一[1-3]。
血糖近紅外檢測必須要通過大量實驗建立多元校正模型,以表達血糖濃度與光譜的數學關系,對于測量得到的未知血糖濃度的光譜數據,代入該模型即可計算出血糖濃度的預測值。在近紅外檢測實驗的過程中,由于操作錯誤、實驗室環境異常變化、被測樣品被破壞等,會獲得奇異的光譜樣本。多元校正模型中若包含奇異的光譜樣本,則會嚴重影響模型的預測精度。因此在建模前剔除各種奇異樣本,是建立預測能力好的校正模型的關鍵步驟之一[4-5]。
奇異樣本的來源一般大致可分為兩類:一類為測量方法中存在問題,例如在近紅外光譜掃描過程中,由于操作錯誤、實驗室環境(包括溫度、電流)突然變化、儀器噪聲和漂移等,產生異常光譜形成了奇異樣本,經發現后可以通過重新掃描等方法糾正;另一類為被測樣的問題,即由于被測樣品本身存在問題,導致采集的光譜為奇異樣本,因而不能通過重新掃描糾正[5]。奇異樣本的存在將影響多元校正模型的質量,當研究人員不能通過肉眼直接分辨這兩類樣本時,需要采用數學方法進行檢測,從建模樣本中剔除奇異樣本后,再重新建立校正模型,從而提高模型的準確性[6]。
對于奇異樣本識別和處理的數學方法一般有兩類[7]:一類為經典診斷的方法,如主成分分析法、馬氏距離判別法、光譜殘差的F檢驗法、凈信號處理方法、基于改進的無信息變量消除的無信息樣本去除方法(uninformative sample elimination based on modified uninformative variable elimination,MUVE-USE)等[8-12],通過樣本間距離或預測誤差的離散程度來識別奇異樣本;另一類為穩健回歸的方法,如偏穩健M回歸(the partial robust M-regression, PRM)、基于主靈敏度矢量(principal sensitivity vectors, PSV)的穩健主成分回歸、基于橢球多變量整理法(ellipsoidal multivariate trimming,MVT)的穩健主成分回歸等[13-17],異常點的穩健診斷方法可較好地診斷出X和Y空間的異常點,并具有一定的穩健性。這些診斷方法對于粗大誤差產生的奇異樣本識別一般具有可靠的識別能力,但是當樣本較為集中且存在系統誤差、隨機誤差等原因而產生多種奇異樣本時,識別效率有時會不理想,且這些方法的操作往往需借助一定的識別經驗。
蒙特卡洛交互驗證法(Monte-Carlo cross validation,MCCV)是一種隨機統計的數學方法[18],由于奇異樣本出現在校正集和驗證集時會對校正模型的預測誤差影響較大,因此可通過MCCV方法,以大量隨機抽樣的方式,統計各樣本在校正集和驗證集中出現頻次的規律,并根據各樣本在不同集合中建立的校正模型預測殘差平方和的差異情況判別奇異樣本。因此本研究建立了基于MCCV的可同時去除多種奇異樣本的方法,用于血糖近紅外光譜分析。該方法通過樣本的統計規律可自動進行多個奇異點的分析和剔除,無需借助特別的經驗,分析過程簡單、直觀;可解決血糖近紅外檢測中由于測量條件變化、參考值誤差、樣品損壞等復雜原因所產生的多種奇異點同時去除的問題,從而提高多元校正模型的精度。
本研究通過兩組血糖近紅外檢測實驗(人體離體血漿近紅外實驗和人體在體近紅外試驗),分別獲得簡單樣本光譜集和復雜樣本光譜集,驗證基于MCCV的奇異樣本去除模型在血糖近紅外光譜分析中的效果,并與MUVE-USE方法進行比較研究,討論這兩種方法在復雜的血糖近紅外光譜分析中對不同類型奇異樣本去除的效果。
1 奇異樣本去除算法
1.1 MUVE-USE算法
MUVE-USE算法是Jun等[12]在提出MUVE方法之后于2001年再一次擴展用于奇異樣本剔除而得到的。依據該算法,建立偏最小二乘(partial least squares,PLS)模型,并由留一法(leave one out,LOO)計算每一個樣本的預測誤差e(i)和預測誤差的標準差σ(i),當樣本i的預測誤差e(i)的絕對值大于3倍的σ(i)(記為3σ(i))的絕對值,則判定樣本i為奇異樣本。MUVE-USE的具體算法參見文獻[12]描述。
1.2 MCCV算法
MCCV算法是根據奇異樣本的統計規律來識別奇異樣本。由于奇異樣本出現在校正集和驗證集時對校正模型預測誤差的差異明顯,因此可通過MCCV方法,以多次隨機抽樣的方式,隨機產生大量的樣本集模型,其中每個樣本集模型中包含的校正集和驗證集是隨機組合而成的,然后建立PLS模型,計算每個樣本集模型的預測殘差平方和(predictive residual error sum of squares,PRESS),將PRESS按從小到大的順序排序,并統計各樣本在排序后的樣本集模型中出現的累計頻次,若某樣本在具有小PRESS的PLS模型(或在具有大PRESS的模型)中的出現頻次明顯偏離,則判定該樣本為奇異樣本。MCCV的具體算法參見文獻[18]描述。
2 實驗和數據
2.1 人體離體血漿近紅外實驗
儀器與試劑:傅里葉變換紅外光譜儀(Spectrum GX,Perkin-Elmer,美國),液態氮冷卻的InSb檢測器,光譜采集范圍900~3 600 nm,1 mm石英樣品池,蠕動泵自動進樣系統。采用全自動生化分析儀(TBA30,TOSHIBA,日本)測量血糖參考值。
實驗步驟:在全血中加入肝素抗凝劑,1 500 rpm,離心10 min分離出血漿,并在血漿中加入葡萄糖使其產生具有一定濃度變化的血糖值,然后用全自動生化分析儀和葡萄糖氧化酶法標定血糖值。其中,全血來源于天津醫院,葡萄糖由北京市燕京制藥廠生產。
樣本數據:血漿實驗中共配制了39個樣品。本研究選用的波段為2 083.3 nm~2 381.0 nm(4 800~4 200 cm-1),共計601個波長變量。
2.2 人體在體近紅外試驗
儀器與試劑:采用光柵光譜儀(NIR 256-2.5,Ocean Optics,美國),HL-2000光源、R400-7-VIS-NIR Y型反射光纖探頭,光譜掃描范圍870~2 565 nm,掃描分辨率6.6 nm,積分時間13 ms。采用便攜式血糖儀(Onetouch Ultra2,強生,美國)測量血糖參考值。
試驗步驟:采用口服葡萄糖耐量試驗(oral glucose tolerance test,OGTT)以獲得一定數量的具有血糖濃度變化的光譜樣本。受試者為1位33歲女性健康志愿者,試驗前已禁食8 h以上,試驗時5 min內飲入100 ml含75 g葡萄糖的水溶液,約每10 min采集手指指腹的近紅外光譜,試驗時保持檢測位置、壓力、受試者心理狀態等盡可能恒定。光纖探頭與指腹接觸壓力約壓入0.5 mm,接觸30 s后開始采集光譜。同時采用便攜式血糖儀測血糖作為建模參考值。
樣本數據:該次試驗共采集了11個樣本。本研究選用波段為掃描的全部255個變量的波長范圍。
3 結果與討論
3.1 人體離體血漿近紅外實驗結果與討論
3.1.1 MUVE-USE算法結果
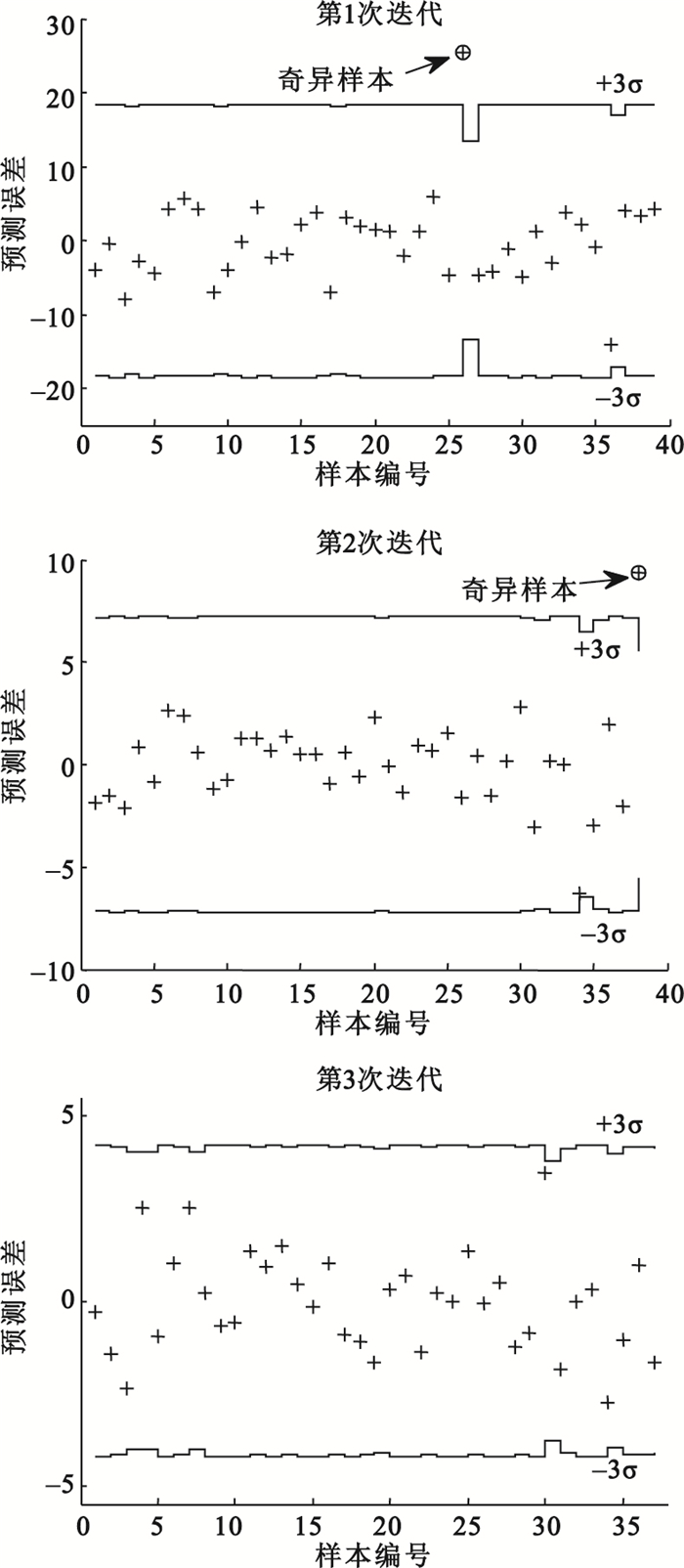
對于人體離體血漿近紅外實驗獲得的簡單樣品光譜數據,建立PLS模型,主成分個數為8,并由LOO法計算每一個樣本的預測誤差e(i)和預測誤差的標準差的3倍即3δ(i),結果如圖 1所示。應用MUVE-USE算法經第1次迭代計算后,根據MUVE-USE算法的3σ判據,判定樣本26應作為奇異樣本剔除。去除了樣本26后,進行了MUVE-USE算法的第2次迭代計算,由圖可見,樣本39應作為奇異樣本剔除。剔除樣本26和樣本39后,進行了第3次迭代計算,結果顯示,依據MUVE-USE算法的3σ判據無其他奇異樣本。
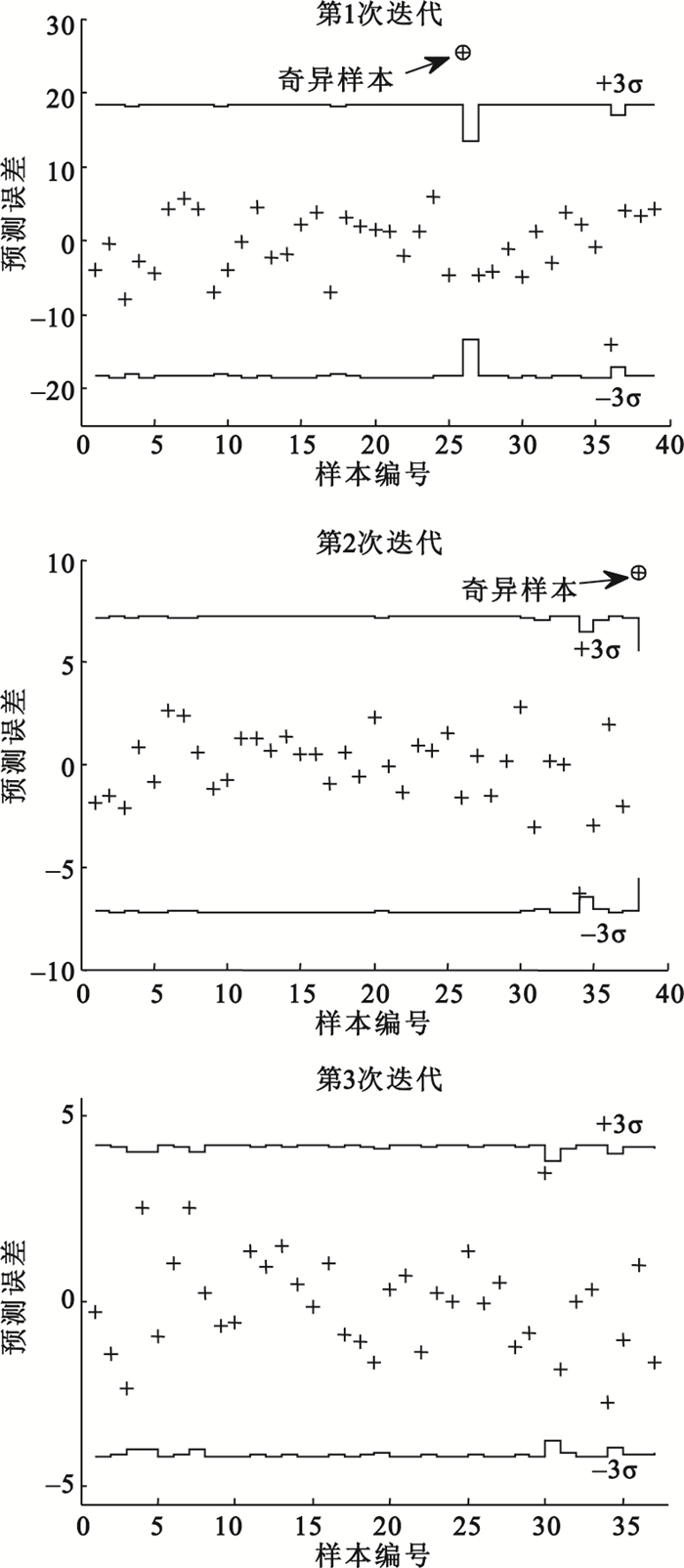 圖1
人體離體血漿近紅外實驗中應用MUVE-USE算法的結果
Figure1.
Results of MUVE-USE for the plasma near-infrared experiment in vitro
圖1
人體離體血漿近紅外實驗中應用MUVE-USE算法的結果
Figure1.
Results of MUVE-USE for the plasma near-infrared experiment in vitro
3.1.2 MCCV算法結果
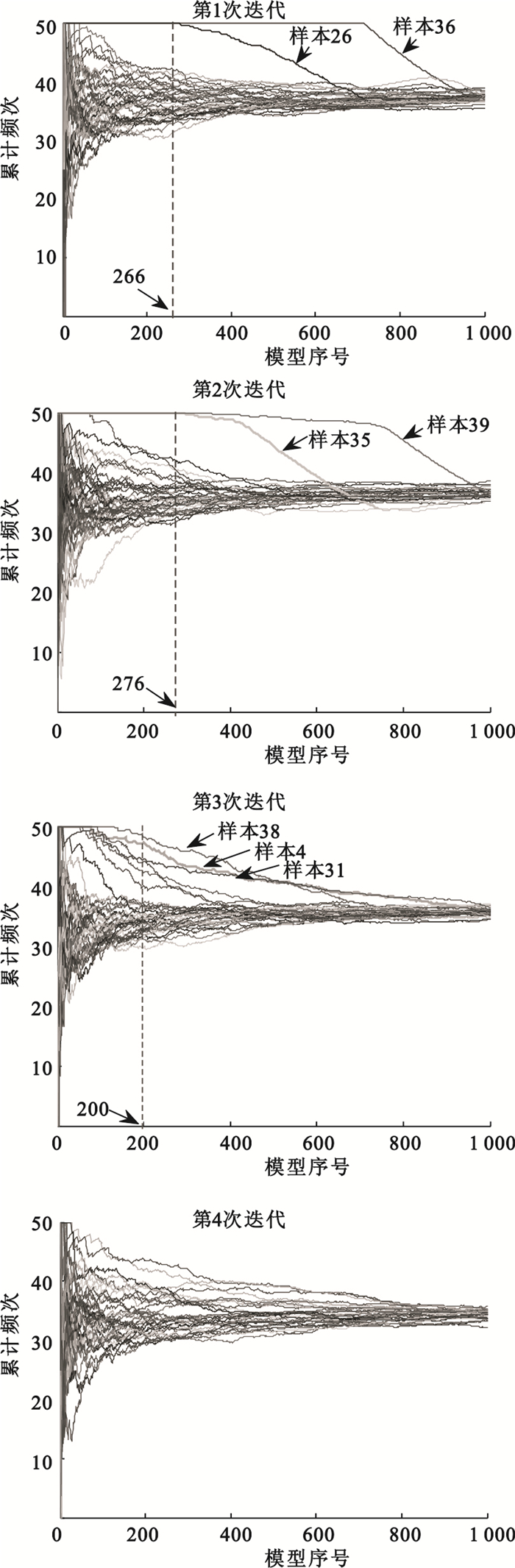
對于人體離體血漿近紅外實驗數據,根據MCCV算法,隨機組合產生1 000個樣本集模型,其中每個隨機組合產生的樣本集中,有10個隨機選取的樣本作為驗證集,其余樣本作為校正集。隨機組合產生的樣本集模型的個數不能過少,也不能過多;過少會導致隨機模型的信息不充分,過多會影響應用和分析的效率。因此,本實驗中依據經驗設計隨機產生的樣本集模型個數為1 000。對于隨機組合產生的1 000個樣本集,分別建立PLS模型,并計算每個模型的PRESS,根據PRESS大小將模型排序,統計每個樣本在模型中出現的累計頻次。如圖 2所示,采用MCCV算法進行第1次迭代計算,結果顯示,在第266號模型以后,樣本26和36的累計頻次出現了明顯的偏離,因此判定樣本26和36為奇異樣本。為了進一步確定奇異點,去除樣本26和36后再次采用MCCV算法進行第2次迭代計算,結果顯示,在第276號模型以后,樣本35和39的累計頻次出現了明顯的偏離,因此判定樣本35和39為奇異樣本。同樣的,采用MCCV算法進行了第3次迭代計算,結果顯示,在第200號模型以后,樣本38、4和31的累計頻次出現了明顯的偏離,因此判定樣本38、4和31為奇異樣本。而進行第4次迭代計算的結果顯示無其他奇異樣本。
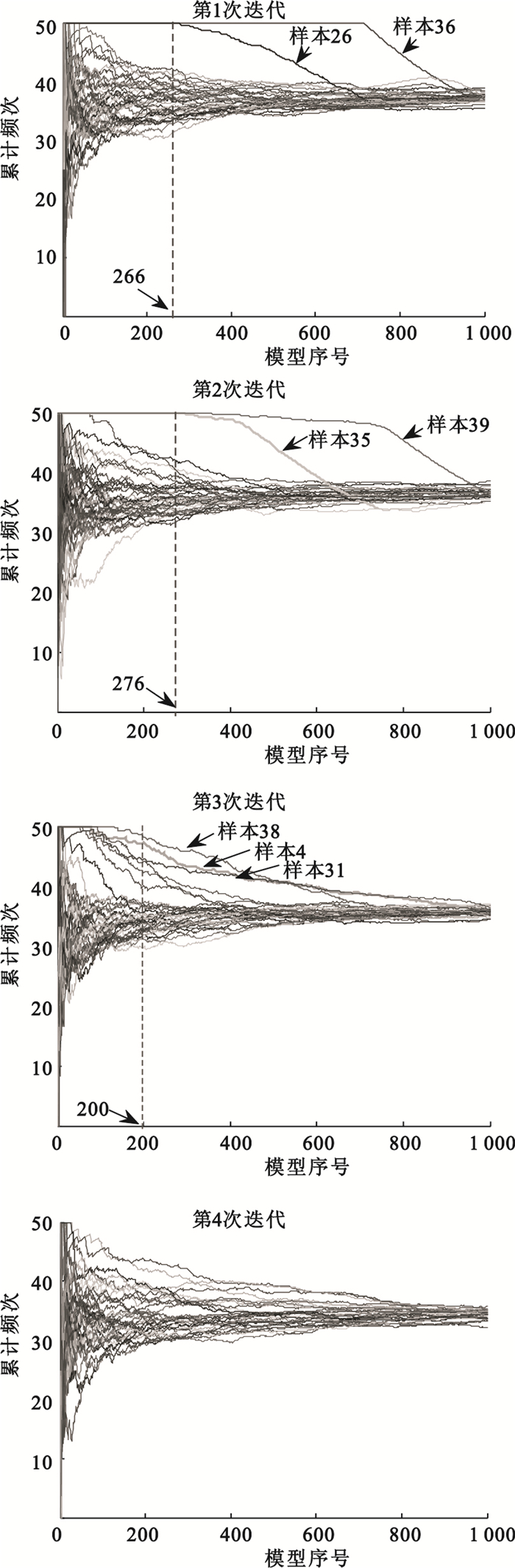 圖2
人體離體血漿近紅外實驗中應用MCCV算法的結果
Figure2.
Results of MCCV for the plasma near-infrared experiment in vitro
圖2
人體離體血漿近紅外實驗中應用MCCV算法的結果
Figure2.
Results of MCCV for the plasma near-infrared experiment in vitro
3.1.3 MUVE-USE和MCCV算法的比較
為了分析奇異樣本對模型的影響,本研究應用不同樣本集建立PLS模型的效果來進行討論,通過交互驗證均方根誤差(root mean square error of cross validation,RMSECV)來比較模型的精度。如表 1所示,列出了應用不同樣本集建立校正模型的預測參數,其中主成分個數為PLS模型的參數。由表 1結果分析可知:①樣本35和39的剔除對模型的影響最大,若模型中包含了該樣本的信息,模型預測能力較低,預測準確度不高,而在前期實驗過程中,第35和39號樣品因人為操作不當受到不同程度的污染,樣品渾濁,樣本35和39屬于粗大誤差產生的壞樣本,本研究中采用的MUVE-USE算法能辨別出樣本39,但未能識別出樣本35,而MCCV算法可識別出這兩個由于粗大誤差產生的無用信息樣本;②MCCV算法還選出了其他由于不確定原因產生的隨機誤差對模型精度有影響的樣本,表中所列結果表明這些樣本的剔除可進一步提高模型的預測能力。
3.2 人體在體近紅外試驗結果與討論
3.2.1 MUVE-USE算法結果
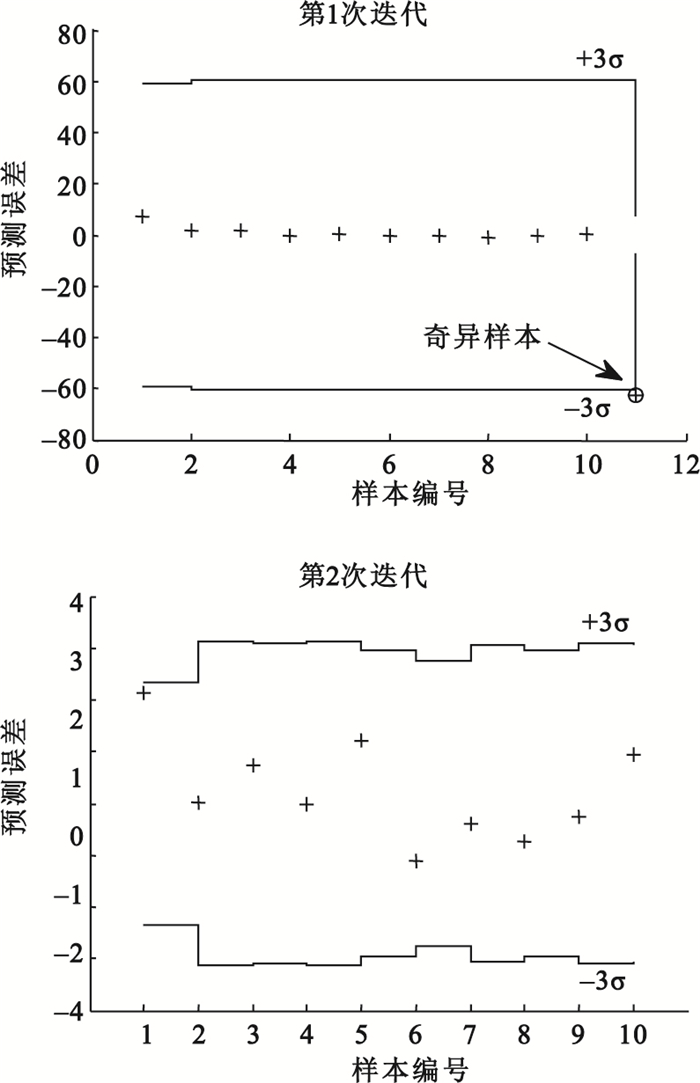
對于人體在體近紅外試驗獲得的復雜樣品光譜數據,建立主成分個數為4的PLS模型,采用MUVE-USE算法的結果如圖 3所示。經MUVE-USE算法第1次迭代的結果圖形顯示,根據3σ判據樣本11應作為奇異樣本剔除,不能用于建模。為了進一步確定還有沒有其他的奇異樣本,去除了樣本11后,進行了MUVE-USE算法的第2次迭代計算,第2次迭代的結果圖形顯示沒有奇異樣本了,不過可以看出樣本1接近3σ判據的臨界線,是一個可懷疑的奇異樣本點,該樣本是否應去除的判別則依賴于研究人員的經驗。
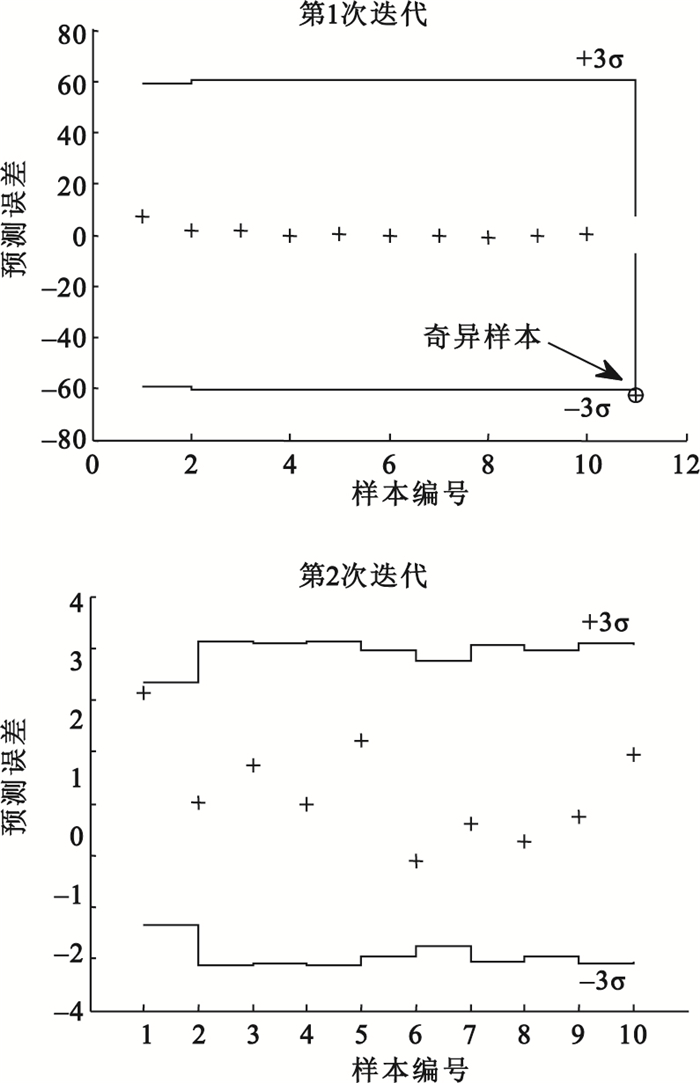 圖3
人體在體近紅外試驗中應用MUVE-USE算法的結果
Figure3.
Results of MUVE-USE for the human body near-infrared experiment in vivo
圖3
人體在體近紅外試驗中應用MUVE-USE算法的結果
Figure3.
Results of MUVE-USE for the human body near-infrared experiment in vivo
3.2.2 MCCV算法結果
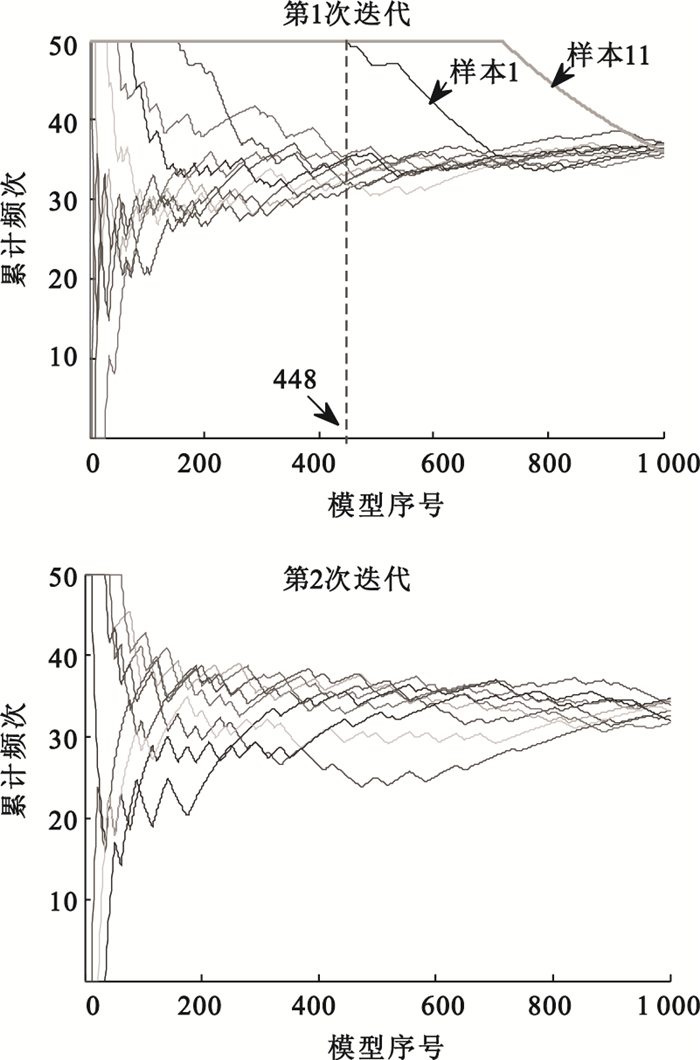
與人體離體血漿近紅外實驗類似的,對于人體在體近紅外試驗數據,隨機組合產生1 000個樣本集,其中每個樣本集中隨機選擇3個樣本作為驗證集,分別建立PLS模型,并計算每個模型的PRESS,根據PRESS大小將模型排序,統計每個樣本在模型中出現的累計頻次。如圖 4所示,采用MCCV算法第1次迭代的結果顯示,在第448號模型以后,樣本1和11的累計頻次出現了明顯的偏離,因此判定樣本1和11為奇異樣本。去除樣本1和11后,采用MCCV算法進行第2次迭代,結果未見明顯奇異樣本。
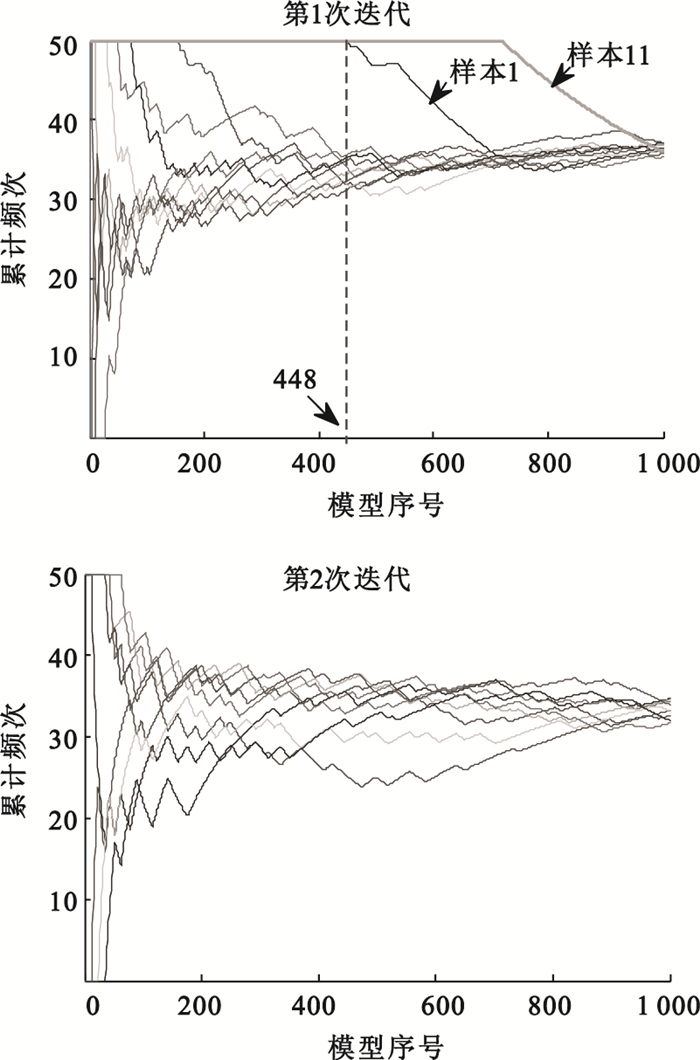 圖4
人體在體近紅外試驗中應用MCCV算法的結果
Figure4.
Results of MCCV for the human body near-infrared experiment in vivo
圖4
人體在體近紅外試驗中應用MCCV算法的結果
Figure4.
Results of MCCV for the human body near-infrared experiment in vivo
3.2.3 MUVE-USE和MCCV算法的比較
與人體離體血漿近紅外實驗類似,為了分析奇異樣本對模型的影響,本研究應用不同樣本集建立的PLS模型的效果來進行討論,通過RMSECV來比較模型的精度。如表 2所示,列出了應用不同樣本集建立校正模型的預測參數,其中,主成分個數為PLS模型的參數。由表 2所列結果分析可知:①樣本11的剔除對模型的影響最大,若模型中包含了樣本11的信息,所建立的校正模型基本是錯誤的,不能用于預測,而在實際試驗過程中,樣本11為關閉光譜儀后重新開啟光譜儀測量的樣品光譜,該樣本包含了儀器漂移信息,為系統誤差原因產生的無用信息樣本,而本研究所采用的兩種方法均能識別出該樣本;②樣本1的剔除可進一步提高模型的預測能力,樣本1為該次試驗中,志愿者喝糖水之前測得的樣本,該樣本由于不確定原因產生的隨機誤差影響了校正模型的模型精度,而MCCV算法同時也能識別這類樣本,對于人體血糖近紅外檢測中多種奇異樣本的同時剔除、提高模型的預測精度具有實際參考價值。
另外,兩組實驗結果顯示,奇異樣本出現在校正集或驗證集時,模型的PRESS值有顯著不同。因此,根據MCCV方法,通過統計各個樣本出現在校正集或驗證集時的累計頻次,并依據各個樣本累計頻次隨PRESS值變化的曲線圖形,可直觀地判定,若樣本在具有較小PRESS值的PLS模型(或在具有較大PRESS值的PLS模型)中出現的頻次明顯偏離時,該樣本即為奇異樣本。
需要注意的是,通過MCCV方法識別的奇異樣本是對模型或預測結果具有較大影響的樣本,這種影響可能是正面的,也可能是負面的[7, 18]。因此通常為了確認所識別的奇異樣本,可以利用獨立的外部預測集來進行檢驗。其方法是,從模型中刪除所識別的奇異樣本,如果預測均方根誤差(Root mean square error of prediction,RMSEP)顯著減小,說明模型的預測精度有明顯提高,則表明所識別的奇異樣本對模型有負面的影響,即確定該奇異樣本是應該去除的樣本;如果去除奇異樣本后模型的RMSEP增大,則說明所識別的奇異樣本對模型是正面的影響點,是應保留的含信息的樣本。
4 結論
本研究通過人體離體血漿近紅外實驗和人體在體近紅外試驗,對MCCV和MUVE-USE兩種奇異樣本去除方法進行了比較研究,分析了這兩種奇異樣本去除方法在血糖近紅外光譜分析中的效果。實驗結果表明:
①對于兩組實驗獲得的樣品光譜,基于距離特征的MUVE-USE算法能識別出部分不利于校正模型的樣本;
②無論對于人體離體實驗獲得的簡單樣品光譜,還是人體在體試驗獲得的復雜樣品光譜,基于統計特征的MCCV方法,能同時識別出由于測量條件異常變化、參考值誤差、樣品損壞以及不確定原因等對模型精度有影響的多種奇異樣本;
③在本研究中,相比MUVE-USE算法,MCCV算法更適用于血糖近紅外檢測中的奇異樣本去除,該方法通過樣本的統計規律可自動進行由于粗大誤差、隨機誤差、系統誤差等原因產生的多個奇異樣本的同時識別和去除,無需借助特別的經驗,圖形化的分析過程簡單、直觀,這對于提高血糖近紅外檢測精度具有實際應用意義。
0 引言
糖尿d病及其并發癥是嚴重威脅人類健康的現代疾病之一, 目前還沒有徹底根治糖尿病的醫學手段。世界衛生組織推薦糖尿病患者進行血糖的自我監測,通過頻繁地監測血糖濃度并以此為依據精確及時地調整口服降糖藥物和胰島素的用量,實現血糖值的精確管理,以達到有效預防糖尿病并發癥發生的目的。現有的血糖自我監測方法屬于有創檢測,是通過抽取血樣,然后應用一次性的試藥以化學方法來實現,不但操作繁瑣且頻繁地針刺取血給患者造成了極大的痛苦,增加了感染的幾率。因此人體血糖濃度無創檢測方法的研究是國內外研究的熱點之一,許多研究者認為血糖的近紅外檢測是較有前景的無創檢測方法之一[1-3]。
血糖近紅外檢測必須要通過大量實驗建立多元校正模型,以表達血糖濃度與光譜的數學關系,對于測量得到的未知血糖濃度的光譜數據,代入該模型即可計算出血糖濃度的預測值。在近紅外檢測實驗的過程中,由于操作錯誤、實驗室環境異常變化、被測樣品被破壞等,會獲得奇異的光譜樣本。多元校正模型中若包含奇異的光譜樣本,則會嚴重影響模型的預測精度。因此在建模前剔除各種奇異樣本,是建立預測能力好的校正模型的關鍵步驟之一[4-5]。
奇異樣本的來源一般大致可分為兩類:一類為測量方法中存在問題,例如在近紅外光譜掃描過程中,由于操作錯誤、實驗室環境(包括溫度、電流)突然變化、儀器噪聲和漂移等,產生異常光譜形成了奇異樣本,經發現后可以通過重新掃描等方法糾正;另一類為被測樣的問題,即由于被測樣品本身存在問題,導致采集的光譜為奇異樣本,因而不能通過重新掃描糾正[5]。奇異樣本的存在將影響多元校正模型的質量,當研究人員不能通過肉眼直接分辨這兩類樣本時,需要采用數學方法進行檢測,從建模樣本中剔除奇異樣本后,再重新建立校正模型,從而提高模型的準確性[6]。
對于奇異樣本識別和處理的數學方法一般有兩類[7]:一類為經典診斷的方法,如主成分分析法、馬氏距離判別法、光譜殘差的F檢驗法、凈信號處理方法、基于改進的無信息變量消除的無信息樣本去除方法(uninformative sample elimination based on modified uninformative variable elimination,MUVE-USE)等[8-12],通過樣本間距離或預測誤差的離散程度來識別奇異樣本;另一類為穩健回歸的方法,如偏穩健M回歸(the partial robust M-regression, PRM)、基于主靈敏度矢量(principal sensitivity vectors, PSV)的穩健主成分回歸、基于橢球多變量整理法(ellipsoidal multivariate trimming,MVT)的穩健主成分回歸等[13-17],異常點的穩健診斷方法可較好地診斷出X和Y空間的異常點,并具有一定的穩健性。這些診斷方法對于粗大誤差產生的奇異樣本識別一般具有可靠的識別能力,但是當樣本較為集中且存在系統誤差、隨機誤差等原因而產生多種奇異樣本時,識別效率有時會不理想,且這些方法的操作往往需借助一定的識別經驗。
蒙特卡洛交互驗證法(Monte-Carlo cross validation,MCCV)是一種隨機統計的數學方法[18],由于奇異樣本出現在校正集和驗證集時會對校正模型的預測誤差影響較大,因此可通過MCCV方法,以大量隨機抽樣的方式,統計各樣本在校正集和驗證集中出現頻次的規律,并根據各樣本在不同集合中建立的校正模型預測殘差平方和的差異情況判別奇異樣本。因此本研究建立了基于MCCV的可同時去除多種奇異樣本的方法,用于血糖近紅外光譜分析。該方法通過樣本的統計規律可自動進行多個奇異點的分析和剔除,無需借助特別的經驗,分析過程簡單、直觀;可解決血糖近紅外檢測中由于測量條件變化、參考值誤差、樣品損壞等復雜原因所產生的多種奇異點同時去除的問題,從而提高多元校正模型的精度。
本研究通過兩組血糖近紅外檢測實驗(人體離體血漿近紅外實驗和人體在體近紅外試驗),分別獲得簡單樣本光譜集和復雜樣本光譜集,驗證基于MCCV的奇異樣本去除模型在血糖近紅外光譜分析中的效果,并與MUVE-USE方法進行比較研究,討論這兩種方法在復雜的血糖近紅外光譜分析中對不同類型奇異樣本去除的效果。
1 奇異樣本去除算法
1.1 MUVE-USE算法
MUVE-USE算法是Jun等[12]在提出MUVE方法之后于2001年再一次擴展用于奇異樣本剔除而得到的。依據該算法,建立偏最小二乘(partial least squares,PLS)模型,并由留一法(leave one out,LOO)計算每一個樣本的預測誤差e(i)和預測誤差的標準差σ(i),當樣本i的預測誤差e(i)的絕對值大于3倍的σ(i)(記為3σ(i))的絕對值,則判定樣本i為奇異樣本。MUVE-USE的具體算法參見文獻[12]描述。
1.2 MCCV算法
MCCV算法是根據奇異樣本的統計規律來識別奇異樣本。由于奇異樣本出現在校正集和驗證集時對校正模型預測誤差的差異明顯,因此可通過MCCV方法,以多次隨機抽樣的方式,隨機產生大量的樣本集模型,其中每個樣本集模型中包含的校正集和驗證集是隨機組合而成的,然后建立PLS模型,計算每個樣本集模型的預測殘差平方和(predictive residual error sum of squares,PRESS),將PRESS按從小到大的順序排序,并統計各樣本在排序后的樣本集模型中出現的累計頻次,若某樣本在具有小PRESS的PLS模型(或在具有大PRESS的模型)中的出現頻次明顯偏離,則判定該樣本為奇異樣本。MCCV的具體算法參見文獻[18]描述。
2 實驗和數據
2.1 人體離體血漿近紅外實驗
儀器與試劑:傅里葉變換紅外光譜儀(Spectrum GX,Perkin-Elmer,美國),液態氮冷卻的InSb檢測器,光譜采集范圍900~3 600 nm,1 mm石英樣品池,蠕動泵自動進樣系統。采用全自動生化分析儀(TBA30,TOSHIBA,日本)測量血糖參考值。
實驗步驟:在全血中加入肝素抗凝劑,1 500 rpm,離心10 min分離出血漿,并在血漿中加入葡萄糖使其產生具有一定濃度變化的血糖值,然后用全自動生化分析儀和葡萄糖氧化酶法標定血糖值。其中,全血來源于天津醫院,葡萄糖由北京市燕京制藥廠生產。
樣本數據:血漿實驗中共配制了39個樣品。本研究選用的波段為2 083.3 nm~2 381.0 nm(4 800~4 200 cm-1),共計601個波長變量。
2.2 人體在體近紅外試驗
儀器與試劑:采用光柵光譜儀(NIR 256-2.5,Ocean Optics,美國),HL-2000光源、R400-7-VIS-NIR Y型反射光纖探頭,光譜掃描范圍870~2 565 nm,掃描分辨率6.6 nm,積分時間13 ms。采用便攜式血糖儀(Onetouch Ultra2,強生,美國)測量血糖參考值。
試驗步驟:采用口服葡萄糖耐量試驗(oral glucose tolerance test,OGTT)以獲得一定數量的具有血糖濃度變化的光譜樣本。受試者為1位33歲女性健康志愿者,試驗前已禁食8 h以上,試驗時5 min內飲入100 ml含75 g葡萄糖的水溶液,約每10 min采集手指指腹的近紅外光譜,試驗時保持檢測位置、壓力、受試者心理狀態等盡可能恒定。光纖探頭與指腹接觸壓力約壓入0.5 mm,接觸30 s后開始采集光譜。同時采用便攜式血糖儀測血糖作為建模參考值。
樣本數據:該次試驗共采集了11個樣本。本研究選用波段為掃描的全部255個變量的波長范圍。
3 結果與討論
3.1 人體離體血漿近紅外實驗結果與討論
3.1.1 MUVE-USE算法結果
對于人體離體血漿近紅外實驗獲得的簡單樣品光譜數據,建立PLS模型,主成分個數為8,并由LOO法計算每一個樣本的預測誤差e(i)和預測誤差的標準差的3倍即3δ(i),結果如圖 1所示。應用MUVE-USE算法經第1次迭代計算后,根據MUVE-USE算法的3σ判據,判定樣本26應作為奇異樣本剔除。去除了樣本26后,進行了MUVE-USE算法的第2次迭代計算,由圖可見,樣本39應作為奇異樣本剔除。剔除樣本26和樣本39后,進行了第3次迭代計算,結果顯示,依據MUVE-USE算法的3σ判據無其他奇異樣本。
圖1
人體離體血漿近紅外實驗中應用MUVE-USE算法的結果
Figure1.
Results of MUVE-USE for the plasma near-infrared experiment in vitro
3.1.2 MCCV算法結果
對于人體離體血漿近紅外實驗數據,根據MCCV算法,隨機組合產生1 000個樣本集模型,其中每個隨機組合產生的樣本集中,有10個隨機選取的樣本作為驗證集,其余樣本作為校正集。隨機組合產生的樣本集模型的個數不能過少,也不能過多;過少會導致隨機模型的信息不充分,過多會影響應用和分析的效率。因此,本實驗中依據經驗設計隨機產生的樣本集模型個數為1 000。對于隨機組合產生的1 000個樣本集,分別建立PLS模型,并計算每個模型的PRESS,根據PRESS大小將模型排序,統計每個樣本在模型中出現的累計頻次。如圖 2所示,采用MCCV算法進行第1次迭代計算,結果顯示,在第266號模型以后,樣本26和36的累計頻次出現了明顯的偏離,因此判定樣本26和36為奇異樣本。為了進一步確定奇異點,去除樣本26和36后再次采用MCCV算法進行第2次迭代計算,結果顯示,在第276號模型以后,樣本35和39的累計頻次出現了明顯的偏離,因此判定樣本35和39為奇異樣本。同樣的,采用MCCV算法進行了第3次迭代計算,結果顯示,在第200號模型以后,樣本38、4和31的累計頻次出現了明顯的偏離,因此判定樣本38、4和31為奇異樣本。而進行第4次迭代計算的結果顯示無其他奇異樣本。
圖2
人體離體血漿近紅外實驗中應用MCCV算法的結果
Figure2.
Results of MCCV for the plasma near-infrared experiment in vitro
3.1.3 MUVE-USE和MCCV算法的比較
為了分析奇異樣本對模型的影響,本研究應用不同樣本集建立PLS模型的效果來進行討論,通過交互驗證均方根誤差(root mean square error of cross validation,RMSECV)來比較模型的精度。如表 1所示,列出了應用不同樣本集建立校正模型的預測參數,其中主成分個數為PLS模型的參數。由表 1結果分析可知:①樣本35和39的剔除對模型的影響最大,若模型中包含了該樣本的信息,模型預測能力較低,預測準確度不高,而在前期實驗過程中,第35和39號樣品因人為操作不當受到不同程度的污染,樣品渾濁,樣本35和39屬于粗大誤差產生的壞樣本,本研究中采用的MUVE-USE算法能辨別出樣本39,但未能識別出樣本35,而MCCV算法可識別出這兩個由于粗大誤差產生的無用信息樣本;②MCCV算法還選出了其他由于不確定原因產生的隨機誤差對模型精度有影響的樣本,表中所列結果表明這些樣本的剔除可進一步提高模型的預測能力。
3.2 人體在體近紅外試驗結果與討論
3.2.1 MUVE-USE算法結果
對于人體在體近紅外試驗獲得的復雜樣品光譜數據,建立主成分個數為4的PLS模型,采用MUVE-USE算法的結果如圖 3所示。經MUVE-USE算法第1次迭代的結果圖形顯示,根據3σ判據樣本11應作為奇異樣本剔除,不能用于建模。為了進一步確定還有沒有其他的奇異樣本,去除了樣本11后,進行了MUVE-USE算法的第2次迭代計算,第2次迭代的結果圖形顯示沒有奇異樣本了,不過可以看出樣本1接近3σ判據的臨界線,是一個可懷疑的奇異樣本點,該樣本是否應去除的判別則依賴于研究人員的經驗。
圖3
人體在體近紅外試驗中應用MUVE-USE算法的結果
Figure3.
Results of MUVE-USE for the human body near-infrared experiment in vivo
3.2.2 MCCV算法結果
與人體離體血漿近紅外實驗類似的,對于人體在體近紅外試驗數據,隨機組合產生1 000個樣本集,其中每個樣本集中隨機選擇3個樣本作為驗證集,分別建立PLS模型,并計算每個模型的PRESS,根據PRESS大小將模型排序,統計每個樣本在模型中出現的累計頻次。如圖 4所示,采用MCCV算法第1次迭代的結果顯示,在第448號模型以后,樣本1和11的累計頻次出現了明顯的偏離,因此判定樣本1和11為奇異樣本。去除樣本1和11后,采用MCCV算法進行第2次迭代,結果未見明顯奇異樣本。
圖4
人體在體近紅外試驗中應用MCCV算法的結果
Figure4.
Results of MCCV for the human body near-infrared experiment in vivo
3.2.3 MUVE-USE和MCCV算法的比較
與人體離體血漿近紅外實驗類似,為了分析奇異樣本對模型的影響,本研究應用不同樣本集建立的PLS模型的效果來進行討論,通過RMSECV來比較模型的精度。如表 2所示,列出了應用不同樣本集建立校正模型的預測參數,其中,主成分個數為PLS模型的參數。由表 2所列結果分析可知:①樣本11的剔除對模型的影響最大,若模型中包含了樣本11的信息,所建立的校正模型基本是錯誤的,不能用于預測,而在實際試驗過程中,樣本11為關閉光譜儀后重新開啟光譜儀測量的樣品光譜,該樣本包含了儀器漂移信息,為系統誤差原因產生的無用信息樣本,而本研究所采用的兩種方法均能識別出該樣本;②樣本1的剔除可進一步提高模型的預測能力,樣本1為該次試驗中,志愿者喝糖水之前測得的樣本,該樣本由于不確定原因產生的隨機誤差影響了校正模型的模型精度,而MCCV算法同時也能識別這類樣本,對于人體血糖近紅外檢測中多種奇異樣本的同時剔除、提高模型的預測精度具有實際參考價值。
另外,兩組實驗結果顯示,奇異樣本出現在校正集或驗證集時,模型的PRESS值有顯著不同。因此,根據MCCV方法,通過統計各個樣本出現在校正集或驗證集時的累計頻次,并依據各個樣本累計頻次隨PRESS值變化的曲線圖形,可直觀地判定,若樣本在具有較小PRESS值的PLS模型(或在具有較大PRESS值的PLS模型)中出現的頻次明顯偏離時,該樣本即為奇異樣本。
需要注意的是,通過MCCV方法識別的奇異樣本是對模型或預測結果具有較大影響的樣本,這種影響可能是正面的,也可能是負面的[7, 18]。因此通常為了確認所識別的奇異樣本,可以利用獨立的外部預測集來進行檢驗。其方法是,從模型中刪除所識別的奇異樣本,如果預測均方根誤差(Root mean square error of prediction,RMSEP)顯著減小,說明模型的預測精度有明顯提高,則表明所識別的奇異樣本對模型有負面的影響,即確定該奇異樣本是應該去除的樣本;如果去除奇異樣本后模型的RMSEP增大,則說明所識別的奇異樣本對模型是正面的影響點,是應保留的含信息的樣本。
4 結論
本研究通過人體離體血漿近紅外實驗和人體在體近紅外試驗,對MCCV和MUVE-USE兩種奇異樣本去除方法進行了比較研究,分析了這兩種奇異樣本去除方法在血糖近紅外光譜分析中的效果。實驗結果表明:
①對于兩組實驗獲得的樣品光譜,基于距離特征的MUVE-USE算法能識別出部分不利于校正模型的樣本;
②無論對于人體離體實驗獲得的簡單樣品光譜,還是人體在體試驗獲得的復雜樣品光譜,基于統計特征的MCCV方法,能同時識別出由于測量條件異常變化、參考值誤差、樣品損壞以及不確定原因等對模型精度有影響的多種奇異樣本;
③在本研究中,相比MUVE-USE算法,MCCV算法更適用于血糖近紅外檢測中的奇異樣本去除,該方法通過樣本的統計規律可自動進行由于粗大誤差、隨機誤差、系統誤差等原因產生的多個奇異樣本的同時識別和去除,無需借助特別的經驗,圖形化的分析過程簡單、直觀,這對于提高血糖近紅外檢測精度具有實際應用意義。