針對腦機接口中運動想象任務的特征選擇問題,提出一種基于互信息與主成分分析的腦電特征選擇算法。該算法融入類別信息,用不同運動想象類別條件下特征間的互信息矩陣之和取代傳統主成分分析算法中的協方差矩陣,其特征向量表示新的主成分空間內各主成分的方向,特征值則作為評價準則判斷主成分維數。對2005年國際BCI競賽數據集,聯合功率譜估計、連續小波變換、小波包分解、Hjorth參數四種方法進行特征提取,采用所提出的算法進行特征選擇并與主成分分析算法對比,實驗結果表明,所提出算法的降維效果更好,以支持向量機為分類器,相同維數的主成分,所得分類正確率更高。
引用本文: 徐佳琳, 左國坤. 基于互信息與主成分分析的運動想象腦電特征選擇算法. 生物醫學工程學雜志, 2016, 33(2): 201-207. doi: 10.7507/1001-5515.20160036 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
腦機接口(brain-computer interface,BCI)是不依賴于腦的正常神經與肌肉輸出通路,在人腦與計算機或外部設備間建立起來的一種通信系統[1]。腦電(electroencephalogram,EEG)信號記錄簡單、無創,可以反映腦的不同狀態,且能夠有效提取意識特征信息,因此基于EEG信號的BCI技術具有較高的研究及應用價值[2-3]。研究表明[4]當進行單側肢體動作或運動想象時,大腦對側激活腦區的μ(8~12 Hz)、 β(18~26 Hz)波段EEG成分在功率譜密度上產生降低現象,稱為事件相關去同步(event related desynchronization,ERD),大腦同側則產生升高現象,稱為事件相關同步(event related synchronization,ERS)[5],利用EEG信號的這種節律性差異可實現BCI技術。
EEG信號處理是BCI技術的核心,其關鍵問題涉及特征提取、特征選擇和特征分類等。其中,特征選擇的任務就是從得到的特征中挑選最有效的特征進行模式識別,將高維特征空間降到低維空間,同時提高分類的性能[6-7]。主成分分析(principal component analysis,PCA)[8]是當前被廣泛應用的一種特征選擇方法,該方法計算特征數據集的協方差矩陣,并用矩陣的特征向量確定主成分方向,用矩陣的特征值判斷主成分的維數。一般在進行主成分分析前先對特征數據集進行標準化處理,消除各特征之間由于不同量綱和量綱單位而造成的差異,因此計算特征間的協方差即計算相關,但是相關僅能反映特征之間的線性關系,無法度量非線性關系。而互信息[9]可衡量特征間相互關聯的程度,表示特征之間共同擁有信息的含量,且這種度量對于特征之間的線性、非線性關系均能進行評估。主要利用信息熵[10]等量化特征相對于分類類別的不確定性程度來判定其包含的類別信息。
針對主成分分析特征選擇算法中協方差矩陣僅能衡量特征之間線性關系的局限性,本文提出一種基于互信息與主成分分析的運動想象EEG信號特征選擇算法。該算法從互信息的角度進行主成分計算,可提供更多特征之間的線性、非線性關系信息,轉換后的主成分與傳統的主成分相比所需維數更低,并且保留了更多的原始信息。對2005年國際BCI競賽的Ⅲb數據集[11]進行實驗分析,采用自回歸模型(autoregressive model,AR模型)功率譜估計、連續小波變換、小波包分解這三種頻域分析法和Hjorth參數時域分析法對運動想象EEG信號進行特征提取,在此基礎上用所提出的特征選擇算法進行特征選擇,并以支持向量機(support vector machine,SVM)作為分類器進行分類,從主成分維數、累積貢獻率、分類正確率等方面與主成分分析算法進行對比,驗證了所提出算法的有效性和優越性。
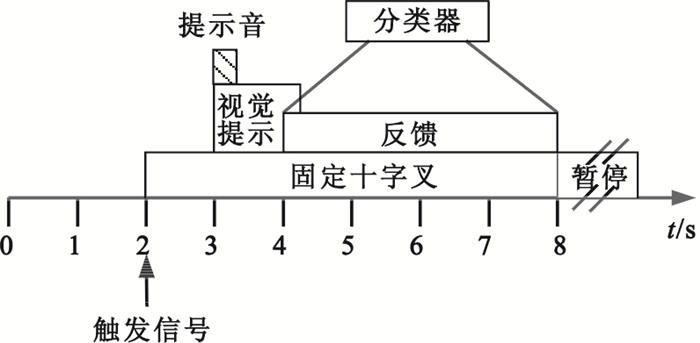
1 實驗數據
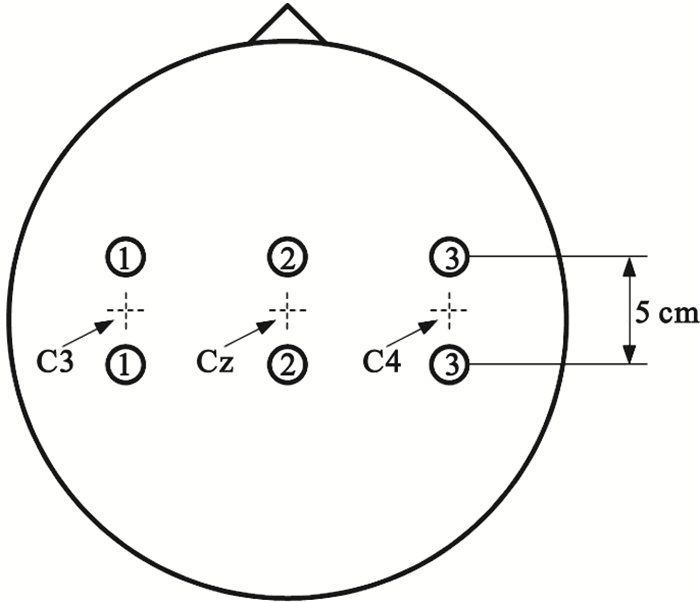
采用2005年國際BCI競賽中由奧地利Graz科技大學提供的Ⅲb數據集,其實驗過程如圖 1所示。該數據集包括三名被試O3、S4和X11,均采用想象左、右手運動這兩類意識任務。EEG數據共C3、C4兩導,參考電極為Cz,電極位置如圖 2所示。EEG信號采樣率為125 Hz,并進行了0.5~30 Hz的帶通濾波處理。被試O3采用頭戴式顯示器通過虛擬現實場景進行反饋,反饋信號提供時間為4~8 s,包含480次實驗數據,其中訓練數據為278次,測試數據為202次;被試S4和X11均采用小球移動進行反饋,反饋信號提供時間均為4~7 s,均包含1 080次實驗數據,其中訓練數據、測試數據各為540次。
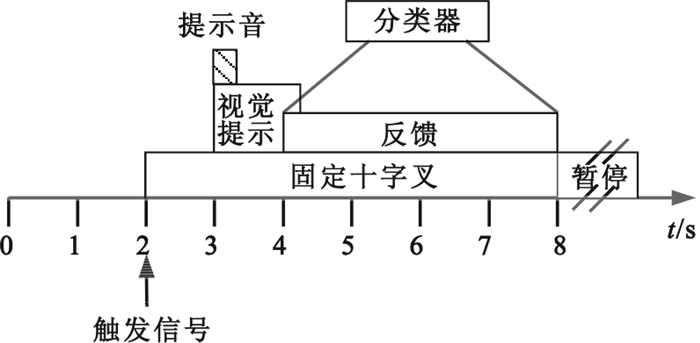 圖1
實驗過程
Figure1.
Experimental process
圖1
實驗過程
Figure1.
Experimental process
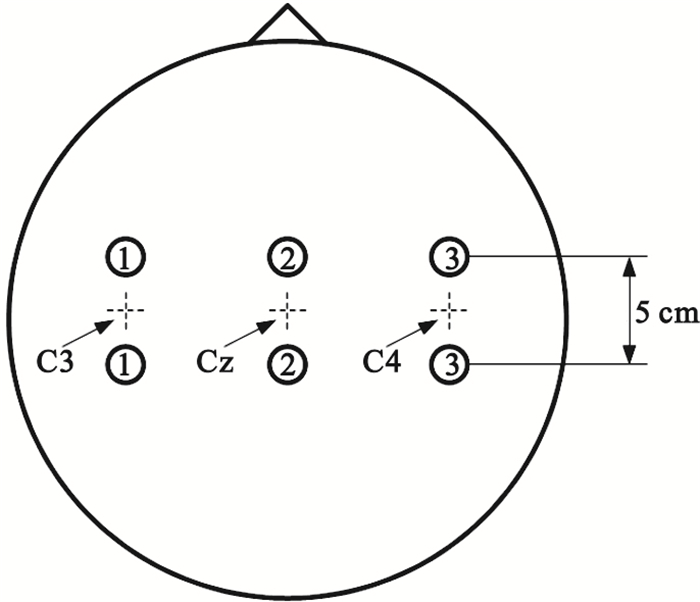 圖2
電極位置圖
Figure2.
Electrode positions
圖2
電極位置圖
Figure2.
Electrode positions
2 方法
2.1 特征提取
本文利用目前運動想象BCI技術中常用的AR模型功率譜估計、連續小波變換、小波包分解這三種頻域分析法及Hjorth參數時域分析法對運動想象EEG信號進行特征提取[12-16]。
2.1.1 功率譜估計
EEG信號可認為是由白噪聲激勵某一確定系統而產生的,當激勵白噪聲的功率和系統參數已知時,就可利用白噪聲通過此系統后形成的輸入、輸出關系來研究EEG信號。因此采用AR模型對各導聯EEG信號進行功率譜估計,某一EEG信號序列x(n)可用式(1)的差分方程表示:
| $ x\left( n \right)=-\sum\limits_{k=1}^{p}{{{a}_{k}}x\left( n-k \right)+w\left( n \right)} $ |
其中w(n)表示均值為零、方差為σω2的白噪聲序列,k表示AR模型的階數。因此EEG信號序列x(n)可看作是白噪聲序列ω(n)輸入AR模型后的輸出,AR模型的傳遞函數如式(2),從而得到AR模型功率譜估計公式如式(3)所示:
| $ H\left( z \right)=\frac{1}{1+\sum\limits_{k=1}^{p}{{{a}_{k}}{{z}^{-k}}}} $ |
| $ {{P}_{x}}\left( \omega \right)=\frac{\sigma _{\omega }^{2}}{{{\left| A\left( {{\text{e}}^{jw}} \right) \right|}^{2}}}=\frac{\sigma _{\omega }^{2}}{{{\left| 1+\sum\limits_{k=1}^{p}{{{a}_{k}}{{\text{e}}^{-jwk}}} \right|}^{2}}} $ |
多數實驗表明6~8階的AR模型對EEG信號處理效果較好[17],因此本文采用6階AR模型,AR模型參數估計采用使EEG信號序列x(n)的前后預測誤差功率之和最小的Burg算法,其具有較好的譜估計質量的同時算法復雜度也較小。為減少特征維數,本文提取功率譜密度值的2范數、均值、方差三個統計特征。
2.1.2 連續小波變換
小波變換通過可變的時頻窗口對信號進行局部化處理,在一定程度上能增強隱藏在EEG信號中的瞬態信息,對EEG信號x(t)進行連續小波變換所得小波系數用式(4)表示:
| $ {{W}_{x}}\left( a,\tau \right)=\left\langle x\left( t \right),{{\psi }_{a,\tau }}\left( t \right) \right\rangle =\frac{1}{\sqrt{\left| a \right|}}\int{_{R}x\left( t \right)\psi \left( \frac{t-\tau }{a} \right)}\text{d}t $ |
其中a為尺度因子,τ為平移因子,ψa,τ(t)為小波函數,t為時間。
尺度a與頻率Fa之間的關系如式(5)所示,Δ表示EEG信號采樣頻率,Fc表示小波的中心頻率:
| $ {{F}_{a}}=\frac{\vartriangle \cdot {{F}_{c}}}{a} $ |
本文采用Morlet小波函數,Morlet小波是頻域的高斯濾波器,在頻域具有很好的局部化特性。小波尺度的選定依據具體信號的有用成分及采樣頻率。為減少特征維數,本文提取小波系數的最大值、均值、方差三個統計特征。
2.1.3 小波包分解
與小波變換相比,小波包分解是一種更為精細的分解方法,該方法對低頻、高頻信號均進行分解,可在所有頻率范圍聚焦,能很好地將頻率分辨率調整到與EEG節律特性相一致,具有更好的濾波特性。
小波包分解的二尺度方程如式(6)所示:
| $ \left\{ \begin{matrix} {{w}_{2n}}\left( t \right)=\sqrt{2}\sum\limits_{k\in z}{{{h}_{0k}}{{w}_{n}}\left( 2t-k \right)} \\ {{w}_{2n+1}}\left( t \right)=\sqrt{2}\sum\limits_{k\in z}{{{h}_{1k}}{{w}_{n}}\left( 2t-k \right)} \\ \end{matrix} \right. $ |
其中,h0k、h1k分別是多分辨率分析的濾波器系數;當n=0時,w0(t)=?(t)為尺度函數,w1(t)=ψ(t)為小波函數;定義函數序列{wn(t)}n∈z為由w0(t)=?(t)所確定的小波包。
小波包系數遞推公式如式(7)所示:
| $ \left\{ \begin{matrix} d_{k}^{j+1,2n}=\sum\limits_{l}{{{h}_{0\left( 2l-k \right)}}d_{l}^{j,n}} \\ d_{k}^{j+1,2n+1}=\sum\limits_{l}{{{h}_{1\left( 2l-k \right)}}d_{l}^{j,n}} \\ \end{matrix} \right. $ |
其中,dkj+1,2n、dkj+1,2n+1分別為小波包分解系數;h0(2l-k)、h1(2l-k)分別為小波包分解的低通、高通濾波器組。
本文采用Daubechies 4小波,該小波具有正交性、時頻緊支撐性、高正則性,并且能用Mallat快速算法實現,對非平穩信號的靈敏性較高。將EEG信號進行小波包分解時,分解層數決定了用于特征提取的各節點信號的頻率范圍,各特征值所覆蓋的頻率范圍隨著分解層數的增加而縮小,分解層數依據具體信號的有用成分及采樣頻率而定。同2.1.2節,本文提取小波系數的最大值、均值、方差三種統計特征。
2.1.4 Hjorth參數
時域Hjorth參數包含活動性Ac、移動性Mo和復雜度Co,可分別描述EEG信號x(t)在時域上的幅度、斜率及斜率變化率三個特性。計算公式見式(8)~式(10):
| $ {{A}_{c}}=\operatorname{var}\left( x\left( t \right) \right) $ |
| $ {{M}_{o}}=\sqrt{\operatorname{var}\left( x'\left( t \right) \right)/\operatorname{var}\left( x\left( t \right) \right)} $ |
| $ {{C}_{o}}={{M}_{o}}\left( x'\left( t \right) \right)/{{M}_{o}}\left( x\left( t \right) \right) $ |
其中,活動性代表EEG信號平均功率即方差,移動性用于測算EEG信號的平均頻率,復雜性則用于測算EEG信號的帶寬。本文提取各定長時間窗下EEG信號的活動性、移動性和復雜度,并統計各自的最大值、均值、方差作為特征。
將以上四種方法所提取的EEG信號的各特征組合成特征數據集FR×D(D=N*Q),其中R為單次實驗的次數,D為一次單次實驗的特征總數,N為導聯數,Q為一次單次實驗某一導聯處特征數。
2.2 特征選擇
互信息可衡量特征數據集FR×D中各特征間相互關聯的程度,表示特征間共同擁有信息的含量。例如,對于特征Fi|fiu,u=1,2,…,R的可能取值集合記為{fi1,fi2,…,fiMI},fi1,fi2,…,fiMI表示MI個子集,特征Fj|fju,u=1,2,…,R的可能取值集合記為{fj1,fj2,…,fjMJ},fj1,fj2,…fjMJ表示MJ個子集,R為單次實驗的次數即R個觀察值,則特征Fi的熵定義如式(11)所示,特征Fi與特征Fj的聯合熵定義如式(12)所示:
| $ H\left( {{\boldsymbol{F}}_{i}} \right)=-\sum\limits_{m=1}^{{{M}_{I}}}{p\left( f_{i}^{m} \right)\log p\left( f_{i}^{m} \right)} $ |
| $ H\left( {{\boldsymbol{F}}_{i}},{{\boldsymbol{F}}_{j}} \right)=-\sum\limits_{m=1}^{{{M}_{I}}}{\sum\limits_{n=1}^{{{M}_{J}}}{p\left( f_{i}^{m},f_{j}^{n} \right)\log p\left( f_{i}^{m},f_{j}^{n} \right)}} $ |
其中p(fim)表示fim的邊緣概率,p(fim,fjn)表示fim與fjn的聯合概率。
Fi和Fj之間的互信息MI(Fi,Fj)定義如式(13)所示,互信息與熵的關系如式(14)所示:
| $ MI\left( {{\boldsymbol{F}}_{i}},{{\boldsymbol{F}}_{j}} \right)=\sum\limits_{m=1}^{{{M}_{I}}}{\sum\limits_{n=1}^{{{M}_{J}}}{p\left( f_{i}^{m},f_{j}^{n} \right)\log \frac{p\left( f_{i}^{m},f_{j}^{n} \right)}{p\left( f_{i}^{m} \right),p\left( f_{j}^{n} \right)}}} $ |
| $ MI\left( {{\boldsymbol{F}}_{i}},{{\boldsymbol{F}}_{j}} \right)=H\left( {{\boldsymbol{F}}_{i}} \right)+H\left( {{\boldsymbol{F}}_{j}} \right)-H\left( {{\boldsymbol{F}}_{i}},{{\boldsymbol{F}}_{j}} \right)\ge 0 $ |
當特征Fi和Fj完全無關時,互信息的值為0,達到最小,意味著兩特征之間不存在重疊信息;反之,兩特征間的相互關聯程度越高,互信息的值越大,重疊信息也越多。
鑒于主成分分析算法用相關或相關系數反映特征之間的線性關系,無法衡量特征之間的非線性關系,而互信息可從信息論的角度評估特征間共有信息量的多少,且不局限于線性關系,提出一種基于互信息與主成分分析的算法用于運動想象EEG信號的特征選擇,該算法融入類別信息,用不同運動想象類別條件下特征之間的互信息矩陣之和計算主成分,如式(15)所示:
| $ \boldsymbol{B},{{\boldsymbol{\psi}}_{{{I}_{F}}}}\boldsymbol{B}=\boldsymbol{\Lambda } $ |
其中,B為特征向量(β1,β2,…,βγ )組成的矩陣,Λ為特征值(μ1,μ2,…,μγ)組成的對角陣。ΨIF表示不同運動想象類別條件下特征之間的互信息矩陣之和,計算公式見式(16):
| $ {{\mathbf{\psi }}_{{{I}_{F}}}}=\sum\limits_{c=1}^{l}{MI\left( \boldsymbol{F}\left| C \right. \right)} $ |
其中,l表示類別總數,MI(F|C)矩陣第i行第j列的元素為I(Fi,Fj|C),表示類別C條件下特征Fi和Fj之間的互信息。ΨIF中非對角線元素表示特征間的互信息,對角線元素表示特征的自信息。互信息與自信息均為非負實數,當兩特征之間不相關即相互獨立時,互信息為0,反之為正數,且互信息具備對稱性,因此ΨIF為非負實數對稱陣,其特征值為實數,特征向量兩兩正交。
本文算法的主成分q,如式(17)所示:
| $ \boldsymbol{q}=\boldsymbol{B}'{{\boldsymbol{f}}^{u}} $ |
其中,第d維主成分qd=β′dfu(d=1,2,…,γ),且兩兩正交。
定義本文算法的第d維主成分貢獻率σd為該主成分占總體主成分信息量的比率,第d
| $ {{\sigma }_{d}}=\frac{{{\mu }_{d}}}{\sum\limits_{d=1}^{r}{{{\mu }_{d}}}},{{\delta }_{d}}=\sum\limits_{r=1}^{d}{{{\sigma }_{d}}} $ |
選擇δd為85%~95%的前v個主成分作為新的特征。
互信息估計的常用方法有直方圖法、核密度估計法、K鄰近法等,而本文采用B樣條法,該方法通過初始點的輪換降低了直方圖法中因初始點選擇問題所帶來的影響,同時避免了核密度估計法中的數值積分過程,時間消耗較小,計算效率較高,而與K鄰近法相比,計算時間更少。B樣條函數的遞歸定義見式(19)~式(21):
| $ {{B}_{m,1}}\left( z \right)=\left\{ \begin{matrix} 1\ \ \ \ {{t}_{m}}\le z\le {{t}_{m+1}} \\ 0\ \ \ 其他 \\ \end{matrix} \right. $ |
| $ \begin{matrix} {{B}_{m,k}}\left( z \right)={{B}_{m,k-1}}\left( z \right)\frac{z-{{t}_{m}}}{{{t}_{m+k-1}}-{{t}_{m}}}+ \\ {{B}_{m+1,k-1}}\left( z \right)\frac{{{t}_{m+k}}-z}{{{t}_{m+k}}-{{t}_{m+1}}} \\ \end{matrix} $ |
| $ {t_m} = \left\{ {\begin{array}{*{20}{c}} {0\;\;\;\;\;m < k}\\ {m - k + 1\;\;\;\;\;\;\;\;\;k \le m \le M - 1}\\ {M - 1 - k + 2\;\;\;\;\;m > M - 1} \end{array}} \right. $ |
其中tm、k=1,…,M-1分別為B樣條函數的節點矢量和階數,z∈[0,M-k+1],m=1,…,M,M為某特征可能取值集合中子集的個數。
因此,對于特征Fi|fiu,u=1,2,…,R、Fj|fju,u=1,2,…,R、fim、fjn各自邊緣概率和聯合概率計算如式(22)~式(26)所示:
| $ p\left( {f_i^m} \right) = \frac{1}{R}\sum\limits_{u = 1}^R {{{\tilde B}_{m,k}}\left( {f_i^u} \right)} $ |
| $ {{\tilde B}_{m,k}}\left( {f_i^u} \right) = {B_{m,k}}\left( {f_i^u - \min \left( {f_i^u} \right)\frac{{{M_I} - k + 1}}{{\max \left( {f_i^u} \right)\min \left( {f_i^u} \right)}}} \right) $ |
| $ p\left( {f_j^n} \right) = \frac{1}{R}\sum\limits_{u = 1}^R {{{\tilde B}_{n,k}}\left( {f_j^u} \right)} $ |
| $ {{\tilde B}_{n,k}}\left( {f_j^n} \right) = {B_{n,k}}\left( {f_j^u - \min \left( {f_j^u} \right)\frac{{{M_J} - k + 1}}{{\max \left( {f_j^u} \right)\min \left( {f_j^u} \right)}}} \right) $ |
| $ p\left( {f_i^m,f_j^n} \right) = \frac{1}{R}\sum\limits_{u = 1}^R {{{\tilde B}_{m,k}}\left( {f_i^u} \right)} \times {{\tilde B}_{n,k}}\left( {f_j^u} \right) $ |
最終由式(13)求得特征Fi和Fj之間的互信息。
3 實驗分析
對Ⅲb數據集的O3、S4和X11三名被試,每名被試取其訓練數據中270次單次實驗的有效EEG信號進行實驗分析。
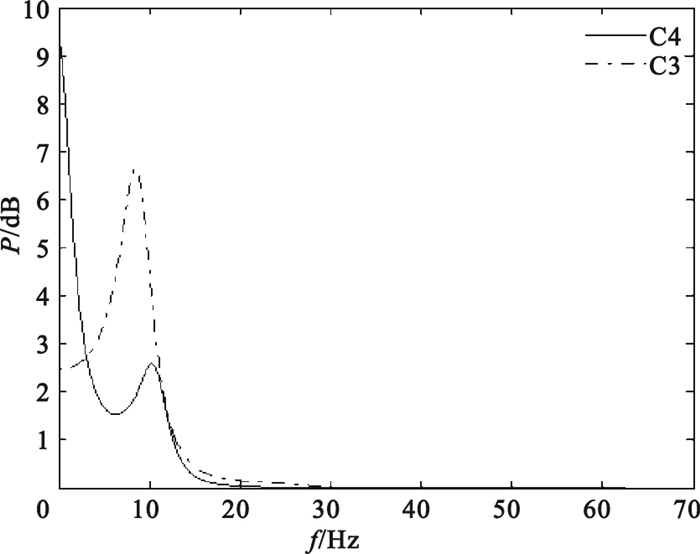
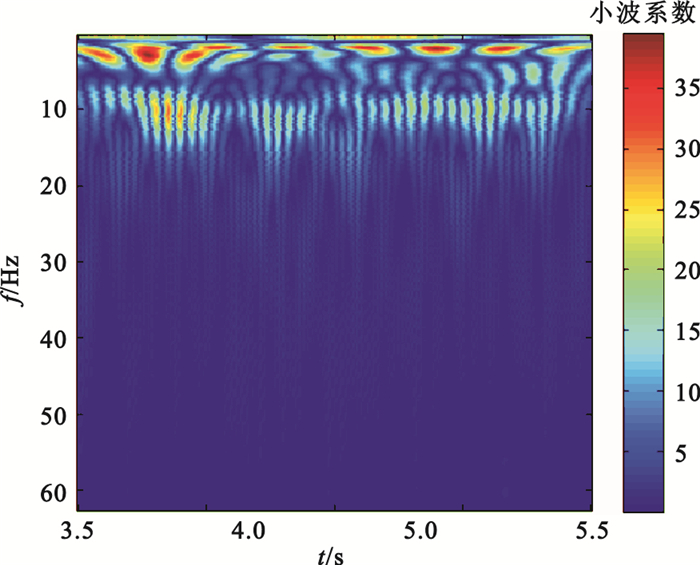
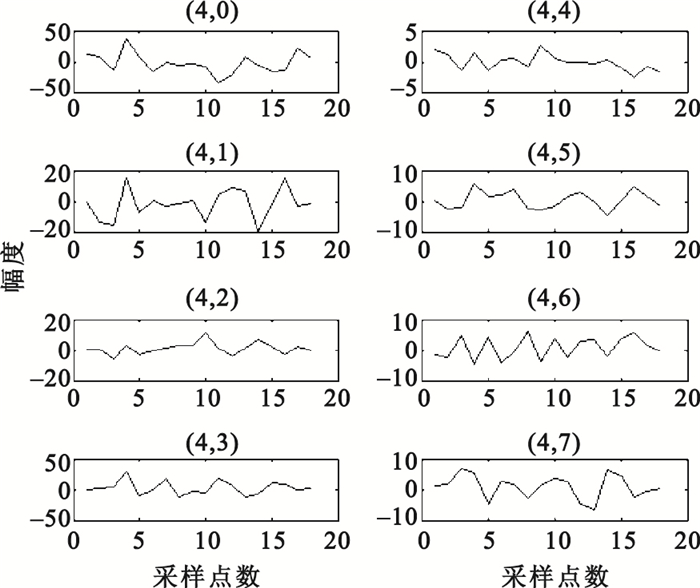
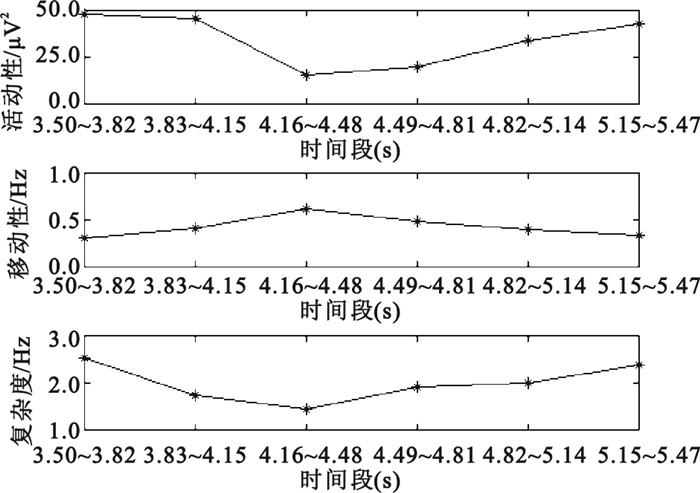
對C3、C4導聯EEG信號,提取3.5~5.5 s時間窗數據進行特征提取。首先,用6階AR模型進行功率譜估計,AR模型參數估計采用Burg算法,分別提取各導聯在μ、β波段的功率譜估計值的2范數、均值、方差共12個特征,例如圖 3為被試S4的一單次實驗EEG信號經AR模型功率譜估計后得到的頻譜曲線;其次,用Morlet小波進行連續小波變換,提取各導聯在μ、β波段的小波系數的最大值、均值、方差共12個特征,例如圖 4為被試S4的一單次實驗某通道EEG信號的小波時頻圖;隨后,用Daubechies 4小波進行四層小波包分解,各小波包系數所對應的頻率范圍如表 1所示,可以看出d (4,3)(7.82~11.71 Hz)在EEG信號的μ波段范圍之內,d(4,7)(19.55~23.44 Hz)在EEG信號的β波段之內,因此分別提取各導聯d(4,3)、d(4,7)小波系數的最大值、均值、方差共12個特征,例如圖 5為被試S4的一單次實驗某通道EEG信號經小波包分解后的波形;最后,對3.50~3.82 s、3.83~4.15 s、4.16~4.48 s、4.49~4.81 s、4.82~5.14 s、5.15~5.47 s各時間窗數據,均提取Hjorth參數活動性、移動性和復雜度,統計出各Hjorth參數的最大值、均值、方差共18個特征,例如圖 6為被試S4的一單次實驗某通道EEG信號的Hjorth參數曲線。
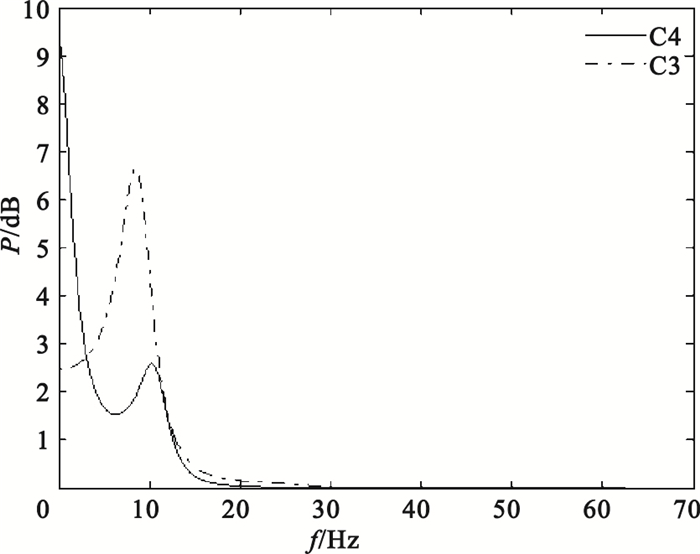 圖3
EEG信號經AR模型功率譜估計后的頻譜曲線
Figure3.
Frequency spectrum curves of AR model power spectrum estimation on EEG signals
圖3
EEG信號經AR模型功率譜估計后的頻譜曲線
Figure3.
Frequency spectrum curves of AR model power spectrum estimation on EEG signals
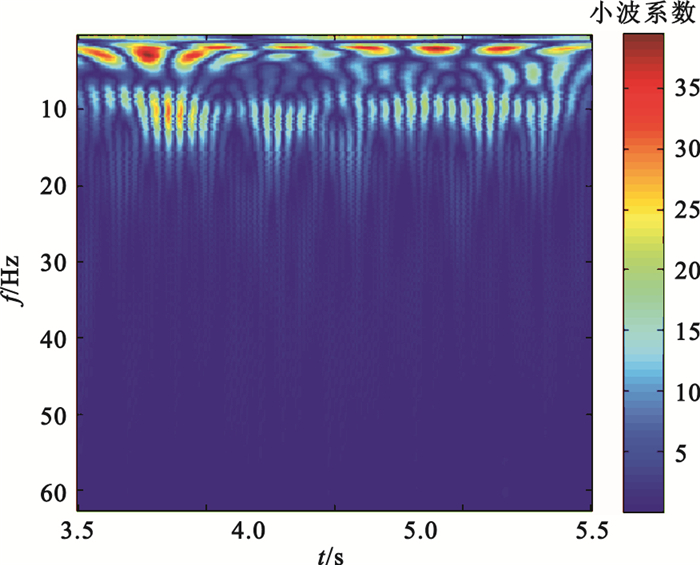 圖4
EEG信號經連續小波變換后的時頻圖
Figure4.
Time-frequency map of continuous wavelet transform on EEG signals
圖4
EEG信號經連續小波變換后的時頻圖
Figure4.
Time-frequency map of continuous wavelet transform on EEG signals
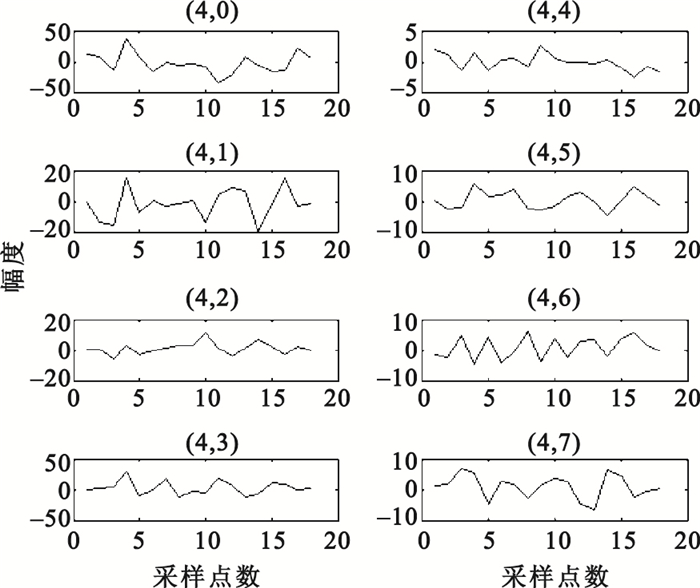 圖5
EEG信號經小波包分解后的波形
Figure5.
Waveform of wavelet packet decomposition on EEG signals
圖5
EEG信號經小波包分解后的波形
Figure5.
Waveform of wavelet packet decomposition on EEG signals
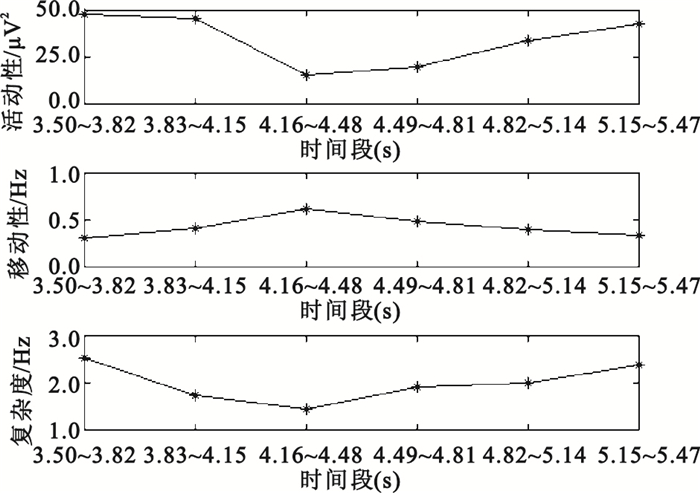 圖6
EEG信號的Hjorth參數曲線
Figure6.
Hjorth parameter curves of EEG signals
圖6
EEG信號的Hjorth參數曲線
Figure6.
Hjorth parameter curves of EEG signals
接下來,采用本文的特征選擇算法對以上的特征數據集F270×54進行分析,得到主成分貢獻率和累積貢獻率,隨后與主成分分析算法比較。表 2為對被試S4的特征數據集分別進行兩種算法分析后,各主成分對應的貢獻率及累積貢獻率。
從表 2可以看出,維數相同的情況下,本文算法計算得到的主成分所含的累積貢獻率大于主成分分析算法得到的結果,以同樣的主成分累積貢獻率為限度,采用本文算法較之主成分分析算法降低了數據的維數,但降維后的主成分能否取得較好的分類效果呢?對此,本文分析了上述兩種算法得到的主成分的分類效果,以各算法降維后的主成分作為新特征,選擇主成分累積貢獻率達85%、90%、95%三種情況時的主成分維度,采用SVM分類器,隨機抽取270組訓練數據中的60%作為訓練集對SVM分類器進行訓練,剩余40%作為測試集用于測試分類器,保證訓練集與測試集之間不存在任何交集。選擇徑向基函數作為SVM的核函數,采用5階交叉驗證對訓練集進行網格搜索以確定誤差懲罰因子和核參數。最終,分類結果如表 3所示,以相同的主成分累積貢獻率為原則計算所得的主成分維數作為新特征,分類正確率相近;而維數相同的情況下,采用本文算法計算出的主成分作為SVM分類器輸入得到的分類正確率大于主成分分析算法得到的結果,或者說在相同分類正確率下,本文算法所需主成分更少,降維效果優于主成分分析算法。綜上,可以得出以式(16)和式(17)為依據判斷選擇主成分是合理、可行的。
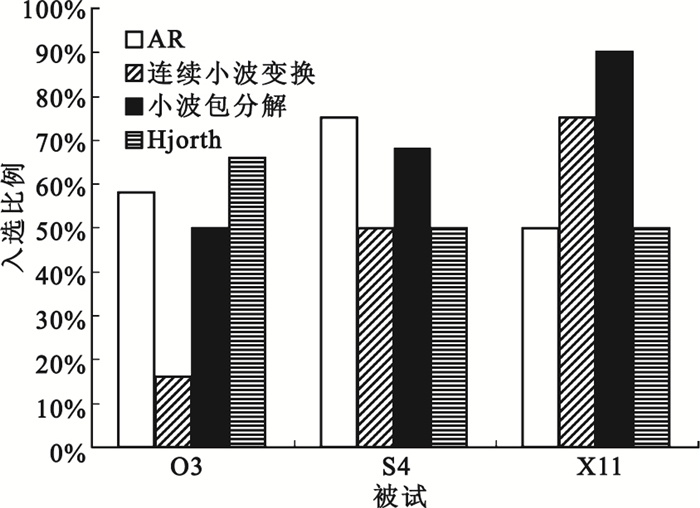
進一步地,本文統計了主成分累積貢獻率達90%的情況下,對于每名被試,本文的四種特征提取方法各自提取特征的入選比例,如圖 7所示。可以看出,對于不同的被試,其適合的特征提取方法有所不同,對于被試O3,AR模型功率譜估計、Hjorth參數方法所提取特征的入選比例較高;對于被試S4,AR模型功率譜估計、小波包分解方法所提取特征的入選比例較高;對于被試X11,連續小波變換、小波包分解方法所提取特征的入選比例較高。因此,在實際運用中要因人而異。例如對于被試O3,當構建最終的實時在線BCI系統時應選擇AR模型功率譜估計或Hjorth參數方法進行特征提取,也可將兩種方法綜合考慮以提高系統的穩定性。
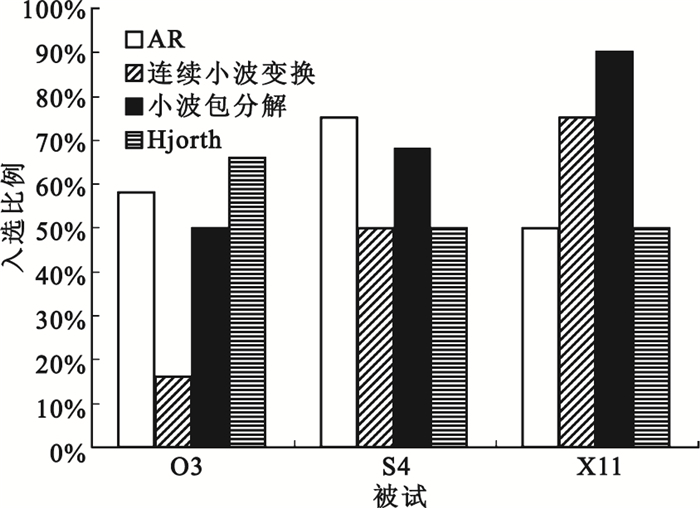 圖7
各種特征提取方法所提取特征的入選比例
Figure7.
Selected features in percentage from each feature extraction method
圖7
各種特征提取方法所提取特征的入選比例
Figure7.
Selected features in percentage from each feature extraction method
4 結論
本文提出基于互信息與主成分分析的運動想象EEG信號特征選擇算法,利用互信息矩陣取代主成分分析算法中的協方差矩陣計算主成分方向,確定主成分維數。采用2005年國際腦機接口競賽中的Ⅲb數據集分析并驗證了本文特征選擇算法的性能。實驗表明:以累積貢獻率為準則判斷選擇主成分維數,本文算法較之主成分分析算法可得到更少的主成分維數,從而可減少后端分類的計算量,若選擇相同的主成分維數,則本文算法所得的主成分的累積貢獻率更高;以SVM為分類器,相同維數的主成分,采用本文算法較之主成分分析算法可得到更高的分類正確率。
引言
腦機接口(brain-computer interface,BCI)是不依賴于腦的正常神經與肌肉輸出通路,在人腦與計算機或外部設備間建立起來的一種通信系統[1]。腦電(electroencephalogram,EEG)信號記錄簡單、無創,可以反映腦的不同狀態,且能夠有效提取意識特征信息,因此基于EEG信號的BCI技術具有較高的研究及應用價值[2-3]。研究表明[4]當進行單側肢體動作或運動想象時,大腦對側激活腦區的μ(8~12 Hz)、 β(18~26 Hz)波段EEG成分在功率譜密度上產生降低現象,稱為事件相關去同步(event related desynchronization,ERD),大腦同側則產生升高現象,稱為事件相關同步(event related synchronization,ERS)[5],利用EEG信號的這種節律性差異可實現BCI技術。
EEG信號處理是BCI技術的核心,其關鍵問題涉及特征提取、特征選擇和特征分類等。其中,特征選擇的任務就是從得到的特征中挑選最有效的特征進行模式識別,將高維特征空間降到低維空間,同時提高分類的性能[6-7]。主成分分析(principal component analysis,PCA)[8]是當前被廣泛應用的一種特征選擇方法,該方法計算特征數據集的協方差矩陣,并用矩陣的特征向量確定主成分方向,用矩陣的特征值判斷主成分的維數。一般在進行主成分分析前先對特征數據集進行標準化處理,消除各特征之間由于不同量綱和量綱單位而造成的差異,因此計算特征間的協方差即計算相關,但是相關僅能反映特征之間的線性關系,無法度量非線性關系。而互信息[9]可衡量特征間相互關聯的程度,表示特征之間共同擁有信息的含量,且這種度量對于特征之間的線性、非線性關系均能進行評估。主要利用信息熵[10]等量化特征相對于分類類別的不確定性程度來判定其包含的類別信息。
針對主成分分析特征選擇算法中協方差矩陣僅能衡量特征之間線性關系的局限性,本文提出一種基于互信息與主成分分析的運動想象EEG信號特征選擇算法。該算法從互信息的角度進行主成分計算,可提供更多特征之間的線性、非線性關系信息,轉換后的主成分與傳統的主成分相比所需維數更低,并且保留了更多的原始信息。對2005年國際BCI競賽的Ⅲb數據集[11]進行實驗分析,采用自回歸模型(autoregressive model,AR模型)功率譜估計、連續小波變換、小波包分解這三種頻域分析法和Hjorth參數時域分析法對運動想象EEG信號進行特征提取,在此基礎上用所提出的特征選擇算法進行特征選擇,并以支持向量機(support vector machine,SVM)作為分類器進行分類,從主成分維數、累積貢獻率、分類正確率等方面與主成分分析算法進行對比,驗證了所提出算法的有效性和優越性。
1 實驗數據
采用2005年國際BCI競賽中由奧地利Graz科技大學提供的Ⅲb數據集,其實驗過程如圖 1所示。該數據集包括三名被試O3、S4和X11,均采用想象左、右手運動這兩類意識任務。EEG數據共C3、C4兩導,參考電極為Cz,電極位置如圖 2所示。EEG信號采樣率為125 Hz,并進行了0.5~30 Hz的帶通濾波處理。被試O3采用頭戴式顯示器通過虛擬現實場景進行反饋,反饋信號提供時間為4~8 s,包含480次實驗數據,其中訓練數據為278次,測試數據為202次;被試S4和X11均采用小球移動進行反饋,反饋信號提供時間均為4~7 s,均包含1 080次實驗數據,其中訓練數據、測試數據各為540次。
圖1
實驗過程
Figure1.
Experimental process
圖2
電極位置圖
Figure2.
Electrode positions
2 方法
2.1 特征提取
本文利用目前運動想象BCI技術中常用的AR模型功率譜估計、連續小波變換、小波包分解這三種頻域分析法及Hjorth參數時域分析法對運動想象EEG信號進行特征提取[12-16]。
2.1.1 功率譜估計
EEG信號可認為是由白噪聲激勵某一確定系統而產生的,當激勵白噪聲的功率和系統參數已知時,就可利用白噪聲通過此系統后形成的輸入、輸出關系來研究EEG信號。因此采用AR模型對各導聯EEG信號進行功率譜估計,某一EEG信號序列x(n)可用式(1)的差分方程表示:
| $ x\left( n \right)=-\sum\limits_{k=1}^{p}{{{a}_{k}}x\left( n-k \right)+w\left( n \right)} $ |
其中w(n)表示均值為零、方差為σω2的白噪聲序列,k表示AR模型的階數。因此EEG信號序列x(n)可看作是白噪聲序列ω(n)輸入AR模型后的輸出,AR模型的傳遞函數如式(2),從而得到AR模型功率譜估計公式如式(3)所示:
| $ H\left( z \right)=\frac{1}{1+\sum\limits_{k=1}^{p}{{{a}_{k}}{{z}^{-k}}}} $ |
| $ {{P}_{x}}\left( \omega \right)=\frac{\sigma _{\omega }^{2}}{{{\left| A\left( {{\text{e}}^{jw}} \right) \right|}^{2}}}=\frac{\sigma _{\omega }^{2}}{{{\left| 1+\sum\limits_{k=1}^{p}{{{a}_{k}}{{\text{e}}^{-jwk}}} \right|}^{2}}} $ |
多數實驗表明6~8階的AR模型對EEG信號處理效果較好[17],因此本文采用6階AR模型,AR模型參數估計采用使EEG信號序列x(n)的前后預測誤差功率之和最小的Burg算法,其具有較好的譜估計質量的同時算法復雜度也較小。為減少特征維數,本文提取功率譜密度值的2范數、均值、方差三個統計特征。
2.1.2 連續小波變換
小波變換通過可變的時頻窗口對信號進行局部化處理,在一定程度上能增強隱藏在EEG信號中的瞬態信息,對EEG信號x(t)進行連續小波變換所得小波系數用式(4)表示:
| $ {{W}_{x}}\left( a,\tau \right)=\left\langle x\left( t \right),{{\psi }_{a,\tau }}\left( t \right) \right\rangle =\frac{1}{\sqrt{\left| a \right|}}\int{_{R}x\left( t \right)\psi \left( \frac{t-\tau }{a} \right)}\text{d}t $ |
其中a為尺度因子,τ為平移因子,ψa,τ(t)為小波函數,t為時間。
尺度a與頻率Fa之間的關系如式(5)所示,Δ表示EEG信號采樣頻率,Fc表示小波的中心頻率:
| $ {{F}_{a}}=\frac{\vartriangle \cdot {{F}_{c}}}{a} $ |
本文采用Morlet小波函數,Morlet小波是頻域的高斯濾波器,在頻域具有很好的局部化特性。小波尺度的選定依據具體信號的有用成分及采樣頻率。為減少特征維數,本文提取小波系數的最大值、均值、方差三個統計特征。
2.1.3 小波包分解
與小波變換相比,小波包分解是一種更為精細的分解方法,該方法對低頻、高頻信號均進行分解,可在所有頻率范圍聚焦,能很好地將頻率分辨率調整到與EEG節律特性相一致,具有更好的濾波特性。
小波包分解的二尺度方程如式(6)所示:
| $ \left\{ \begin{matrix} {{w}_{2n}}\left( t \right)=\sqrt{2}\sum\limits_{k\in z}{{{h}_{0k}}{{w}_{n}}\left( 2t-k \right)} \\ {{w}_{2n+1}}\left( t \right)=\sqrt{2}\sum\limits_{k\in z}{{{h}_{1k}}{{w}_{n}}\left( 2t-k \right)} \\ \end{matrix} \right. $ |
其中,h0k、h1k分別是多分辨率分析的濾波器系數;當n=0時,w0(t)=?(t)為尺度函數,w1(t)=ψ(t)為小波函數;定義函數序列{wn(t)}n∈z為由w0(t)=?(t)所確定的小波包。
小波包系數遞推公式如式(7)所示:
| $ \left\{ \begin{matrix} d_{k}^{j+1,2n}=\sum\limits_{l}{{{h}_{0\left( 2l-k \right)}}d_{l}^{j,n}} \\ d_{k}^{j+1,2n+1}=\sum\limits_{l}{{{h}_{1\left( 2l-k \right)}}d_{l}^{j,n}} \\ \end{matrix} \right. $ |
其中,dkj+1,2n、dkj+1,2n+1分別為小波包分解系數;h0(2l-k)、h1(2l-k)分別為小波包分解的低通、高通濾波器組。
本文采用Daubechies 4小波,該小波具有正交性、時頻緊支撐性、高正則性,并且能用Mallat快速算法實現,對非平穩信號的靈敏性較高。將EEG信號進行小波包分解時,分解層數決定了用于特征提取的各節點信號的頻率范圍,各特征值所覆蓋的頻率范圍隨著分解層數的增加而縮小,分解層數依據具體信號的有用成分及采樣頻率而定。同2.1.2節,本文提取小波系數的最大值、均值、方差三種統計特征。
2.1.4 Hjorth參數
時域Hjorth參數包含活動性Ac、移動性Mo和復雜度Co,可分別描述EEG信號x(t)在時域上的幅度、斜率及斜率變化率三個特性。計算公式見式(8)~式(10):
| $ {{A}_{c}}=\operatorname{var}\left( x\left( t \right) \right) $ |
| $ {{M}_{o}}=\sqrt{\operatorname{var}\left( x'\left( t \right) \right)/\operatorname{var}\left( x\left( t \right) \right)} $ |
| $ {{C}_{o}}={{M}_{o}}\left( x'\left( t \right) \right)/{{M}_{o}}\left( x\left( t \right) \right) $ |
其中,活動性代表EEG信號平均功率即方差,移動性用于測算EEG信號的平均頻率,復雜性則用于測算EEG信號的帶寬。本文提取各定長時間窗下EEG信號的活動性、移動性和復雜度,并統計各自的最大值、均值、方差作為特征。
將以上四種方法所提取的EEG信號的各特征組合成特征數據集FR×D(D=N*Q),其中R為單次實驗的次數,D為一次單次實驗的特征總數,N為導聯數,Q為一次單次實驗某一導聯處特征數。
2.2 特征選擇
互信息可衡量特征數據集FR×D中各特征間相互關聯的程度,表示特征間共同擁有信息的含量。例如,對于特征Fi|fiu,u=1,2,…,R的可能取值集合記為{fi1,fi2,…,fiMI},fi1,fi2,…,fiMI表示MI個子集,特征Fj|fju,u=1,2,…,R的可能取值集合記為{fj1,fj2,…,fjMJ},fj1,fj2,…fjMJ表示MJ個子集,R為單次實驗的次數即R個觀察值,則特征Fi的熵定義如式(11)所示,特征Fi與特征Fj的聯合熵定義如式(12)所示:
| $ H\left( {{\boldsymbol{F}}_{i}} \right)=-\sum\limits_{m=1}^{{{M}_{I}}}{p\left( f_{i}^{m} \right)\log p\left( f_{i}^{m} \right)} $ |
| $ H\left( {{\boldsymbol{F}}_{i}},{{\boldsymbol{F}}_{j}} \right)=-\sum\limits_{m=1}^{{{M}_{I}}}{\sum\limits_{n=1}^{{{M}_{J}}}{p\left( f_{i}^{m},f_{j}^{n} \right)\log p\left( f_{i}^{m},f_{j}^{n} \right)}} $ |
其中p(fim)表示fim的邊緣概率,p(fim,fjn)表示fim與fjn的聯合概率。
Fi和Fj之間的互信息MI(Fi,Fj)定義如式(13)所示,互信息與熵的關系如式(14)所示:
| $ MI\left( {{\boldsymbol{F}}_{i}},{{\boldsymbol{F}}_{j}} \right)=\sum\limits_{m=1}^{{{M}_{I}}}{\sum\limits_{n=1}^{{{M}_{J}}}{p\left( f_{i}^{m},f_{j}^{n} \right)\log \frac{p\left( f_{i}^{m},f_{j}^{n} \right)}{p\left( f_{i}^{m} \right),p\left( f_{j}^{n} \right)}}} $ |
| $ MI\left( {{\boldsymbol{F}}_{i}},{{\boldsymbol{F}}_{j}} \right)=H\left( {{\boldsymbol{F}}_{i}} \right)+H\left( {{\boldsymbol{F}}_{j}} \right)-H\left( {{\boldsymbol{F}}_{i}},{{\boldsymbol{F}}_{j}} \right)\ge 0 $ |
當特征Fi和Fj完全無關時,互信息的值為0,達到最小,意味著兩特征之間不存在重疊信息;反之,兩特征間的相互關聯程度越高,互信息的值越大,重疊信息也越多。
鑒于主成分分析算法用相關或相關系數反映特征之間的線性關系,無法衡量特征之間的非線性關系,而互信息可從信息論的角度評估特征間共有信息量的多少,且不局限于線性關系,提出一種基于互信息與主成分分析的算法用于運動想象EEG信號的特征選擇,該算法融入類別信息,用不同運動想象類別條件下特征之間的互信息矩陣之和計算主成分,如式(15)所示:
| $ \boldsymbol{B},{{\boldsymbol{\psi}}_{{{I}_{F}}}}\boldsymbol{B}=\boldsymbol{\Lambda } $ |
其中,B為特征向量(β1,β2,…,βγ )組成的矩陣,Λ為特征值(μ1,μ2,…,μγ)組成的對角陣。ΨIF表示不同運動想象類別條件下特征之間的互信息矩陣之和,計算公式見式(16):
| $ {{\mathbf{\psi }}_{{{I}_{F}}}}=\sum\limits_{c=1}^{l}{MI\left( \boldsymbol{F}\left| C \right. \right)} $ |
其中,l表示類別總數,MI(F|C)矩陣第i行第j列的元素為I(Fi,Fj|C),表示類別C條件下特征Fi和Fj之間的互信息。ΨIF中非對角線元素表示特征間的互信息,對角線元素表示特征的自信息。互信息與自信息均為非負實數,當兩特征之間不相關即相互獨立時,互信息為0,反之為正數,且互信息具備對稱性,因此ΨIF為非負實數對稱陣,其特征值為實數,特征向量兩兩正交。
本文算法的主成分q,如式(17)所示:
| $ \boldsymbol{q}=\boldsymbol{B}'{{\boldsymbol{f}}^{u}} $ |
其中,第d維主成分qd=β′dfu(d=1,2,…,γ),且兩兩正交。
定義本文算法的第d維主成分貢獻率σd為該主成分占總體主成分信息量的比率,第d
| $ {{\sigma }_{d}}=\frac{{{\mu }_{d}}}{\sum\limits_{d=1}^{r}{{{\mu }_{d}}}},{{\delta }_{d}}=\sum\limits_{r=1}^{d}{{{\sigma }_{d}}} $ |
選擇δd為85%~95%的前v個主成分作為新的特征。
互信息估計的常用方法有直方圖法、核密度估計法、K鄰近法等,而本文采用B樣條法,該方法通過初始點的輪換降低了直方圖法中因初始點選擇問題所帶來的影響,同時避免了核密度估計法中的數值積分過程,時間消耗較小,計算效率較高,而與K鄰近法相比,計算時間更少。B樣條函數的遞歸定義見式(19)~式(21):
| $ {{B}_{m,1}}\left( z \right)=\left\{ \begin{matrix} 1\ \ \ \ {{t}_{m}}\le z\le {{t}_{m+1}} \\ 0\ \ \ 其他 \\ \end{matrix} \right. $ |
| $ \begin{matrix} {{B}_{m,k}}\left( z \right)={{B}_{m,k-1}}\left( z \right)\frac{z-{{t}_{m}}}{{{t}_{m+k-1}}-{{t}_{m}}}+ \\ {{B}_{m+1,k-1}}\left( z \right)\frac{{{t}_{m+k}}-z}{{{t}_{m+k}}-{{t}_{m+1}}} \\ \end{matrix} $ |
| $ {t_m} = \left\{ {\begin{array}{*{20}{c}} {0\;\;\;\;\;m < k}\\ {m - k + 1\;\;\;\;\;\;\;\;\;k \le m \le M - 1}\\ {M - 1 - k + 2\;\;\;\;\;m > M - 1} \end{array}} \right. $ |
其中tm、k=1,…,M-1分別為B樣條函數的節點矢量和階數,z∈[0,M-k+1],m=1,…,M,M為某特征可能取值集合中子集的個數。
因此,對于特征Fi|fiu,u=1,2,…,R、Fj|fju,u=1,2,…,R、fim、fjn各自邊緣概率和聯合概率計算如式(22)~式(26)所示:
| $ p\left( {f_i^m} \right) = \frac{1}{R}\sum\limits_{u = 1}^R {{{\tilde B}_{m,k}}\left( {f_i^u} \right)} $ |
| $ {{\tilde B}_{m,k}}\left( {f_i^u} \right) = {B_{m,k}}\left( {f_i^u - \min \left( {f_i^u} \right)\frac{{{M_I} - k + 1}}{{\max \left( {f_i^u} \right)\min \left( {f_i^u} \right)}}} \right) $ |
| $ p\left( {f_j^n} \right) = \frac{1}{R}\sum\limits_{u = 1}^R {{{\tilde B}_{n,k}}\left( {f_j^u} \right)} $ |
| $ {{\tilde B}_{n,k}}\left( {f_j^n} \right) = {B_{n,k}}\left( {f_j^u - \min \left( {f_j^u} \right)\frac{{{M_J} - k + 1}}{{\max \left( {f_j^u} \right)\min \left( {f_j^u} \right)}}} \right) $ |
| $ p\left( {f_i^m,f_j^n} \right) = \frac{1}{R}\sum\limits_{u = 1}^R {{{\tilde B}_{m,k}}\left( {f_i^u} \right)} \times {{\tilde B}_{n,k}}\left( {f_j^u} \right) $ |
最終由式(13)求得特征Fi和Fj之間的互信息。
3 實驗分析
對Ⅲb數據集的O3、S4和X11三名被試,每名被試取其訓練數據中270次單次實驗的有效EEG信號進行實驗分析。
對C3、C4導聯EEG信號,提取3.5~5.5 s時間窗數據進行特征提取。首先,用6階AR模型進行功率譜估計,AR模型參數估計采用Burg算法,分別提取各導聯在μ、β波段的功率譜估計值的2范數、均值、方差共12個特征,例如圖 3為被試S4的一單次實驗EEG信號經AR模型功率譜估計后得到的頻譜曲線;其次,用Morlet小波進行連續小波變換,提取各導聯在μ、β波段的小波系數的最大值、均值、方差共12個特征,例如圖 4為被試S4的一單次實驗某通道EEG信號的小波時頻圖;隨后,用Daubechies 4小波進行四層小波包分解,各小波包系數所對應的頻率范圍如表 1所示,可以看出d (4,3)(7.82~11.71 Hz)在EEG信號的μ波段范圍之內,d(4,7)(19.55~23.44 Hz)在EEG信號的β波段之內,因此分別提取各導聯d(4,3)、d(4,7)小波系數的最大值、均值、方差共12個特征,例如圖 5為被試S4的一單次實驗某通道EEG信號經小波包分解后的波形;最后,對3.50~3.82 s、3.83~4.15 s、4.16~4.48 s、4.49~4.81 s、4.82~5.14 s、5.15~5.47 s各時間窗數據,均提取Hjorth參數活動性、移動性和復雜度,統計出各Hjorth參數的最大值、均值、方差共18個特征,例如圖 6為被試S4的一單次實驗某通道EEG信號的Hjorth參數曲線。
圖3
EEG信號經AR模型功率譜估計后的頻譜曲線
Figure3.
Frequency spectrum curves of AR model power spectrum estimation on EEG signals
圖4
EEG信號經連續小波變換后的時頻圖
Figure4.
Time-frequency map of continuous wavelet transform on EEG signals
圖5
EEG信號經小波包分解后的波形
Figure5.
Waveform of wavelet packet decomposition on EEG signals
圖6
EEG信號的Hjorth參數曲線
Figure6.
Hjorth parameter curves of EEG signals
接下來,采用本文的特征選擇算法對以上的特征數據集F270×54進行分析,得到主成分貢獻率和累積貢獻率,隨后與主成分分析算法比較。表 2為對被試S4的特征數據集分別進行兩種算法分析后,各主成分對應的貢獻率及累積貢獻率。
從表 2可以看出,維數相同的情況下,本文算法計算得到的主成分所含的累積貢獻率大于主成分分析算法得到的結果,以同樣的主成分累積貢獻率為限度,采用本文算法較之主成分分析算法降低了數據的維數,但降維后的主成分能否取得較好的分類效果呢?對此,本文分析了上述兩種算法得到的主成分的分類效果,以各算法降維后的主成分作為新特征,選擇主成分累積貢獻率達85%、90%、95%三種情況時的主成分維度,采用SVM分類器,隨機抽取270組訓練數據中的60%作為訓練集對SVM分類器進行訓練,剩余40%作為測試集用于測試分類器,保證訓練集與測試集之間不存在任何交集。選擇徑向基函數作為SVM的核函數,采用5階交叉驗證對訓練集進行網格搜索以確定誤差懲罰因子和核參數。最終,分類結果如表 3所示,以相同的主成分累積貢獻率為原則計算所得的主成分維數作為新特征,分類正確率相近;而維數相同的情況下,采用本文算法計算出的主成分作為SVM分類器輸入得到的分類正確率大于主成分分析算法得到的結果,或者說在相同分類正確率下,本文算法所需主成分更少,降維效果優于主成分分析算法。綜上,可以得出以式(16)和式(17)為依據判斷選擇主成分是合理、可行的。
進一步地,本文統計了主成分累積貢獻率達90%的情況下,對于每名被試,本文的四種特征提取方法各自提取特征的入選比例,如圖 7所示。可以看出,對于不同的被試,其適合的特征提取方法有所不同,對于被試O3,AR模型功率譜估計、Hjorth參數方法所提取特征的入選比例較高;對于被試S4,AR模型功率譜估計、小波包分解方法所提取特征的入選比例較高;對于被試X11,連續小波變換、小波包分解方法所提取特征的入選比例較高。因此,在實際運用中要因人而異。例如對于被試O3,當構建最終的實時在線BCI系統時應選擇AR模型功率譜估計或Hjorth參數方法進行特征提取,也可將兩種方法綜合考慮以提高系統的穩定性。
圖7
各種特征提取方法所提取特征的入選比例
Figure7.
Selected features in percentage from each feature extraction method
4 結論
本文提出基于互信息與主成分分析的運動想象EEG信號特征選擇算法,利用互信息矩陣取代主成分分析算法中的協方差矩陣計算主成分方向,確定主成分維數。采用2005年國際腦機接口競賽中的Ⅲb數據集分析并驗證了本文特征選擇算法的性能。實驗表明:以累積貢獻率為準則判斷選擇主成分維數,本文算法較之主成分分析算法可得到更少的主成分維數,從而可減少后端分類的計算量,若選擇相同的主成分維數,則本文算法所得的主成分的累積貢獻率更高;以SVM為分類器,相同維數的主成分,采用本文算法較之主成分分析算法可得到更高的分類正確率。