在小動物計算機斷層掃描(CT)實驗中, 因需考慮小動物存活率以及實驗的連續性等問題, 一般較少采用高劑量的X射線進行實驗; 而低劑量的X射線會導致重建圖像被噪聲污染, 影響圖像質量, 不利于后續實驗分析。為解決此問題, 本文介紹了一種基于全局字典學習的降噪方法, 并將其應用于提升低劑量小動物CT重建圖像質量的研究中。針對真實的小動物CT重建數據, 選擇高劑量的小動物CT重建圖像作為訓練樣本, 利用逐列更新的字典學習算法(K-SVD), 構建包含圖像信息的全局字典; 利用正交匹配追蹤算法(OMP)將低劑量重建圖像利用全局字典進行稀疏分解, 分離噪聲, 最后將重建圖像復原, 達到降噪、提升圖像質量、降低小動物CT實驗的拍攝劑量、提高小動物存活率的目的。實驗結果表明, 本文提出的方法能夠有效減少低劑量動物CT圖像的噪聲, 并能夠較好地保留圖像細節。
引用本文: 李中源, 李光, 孫翌, 陳功, 羅守華. 一種基于全局字典學習的小動物低劑量計算機斷層掃描降噪方法. 生物醫學工程學雜志, 2016, 33(2): 279-286. doi: 10.7507/1001-5515.20160048 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
動物模型是現代生物醫學研究中的重要組成部分。通過對動物接種腫瘤觀察其生理變化、利用各類新型造影劑進行動物實驗、研究藥物對動物生理的影響等[1],能夠有效地幫助人類認識疾病發生規律,并采取相應的防治措施。近年來,各類醫學影像技術廣泛地應用于各類動物實驗中,其中計算機斷層掃描(computed tomography,CT)技術由于具有分辨率高、成像時間短等特點,成為動物醫學影像研究的重要手段之一。
與傳統的臨床CT相比,小動物CT具有更高的分辨率,但卻受到射線劑量方面的限制。小動物本身十分脆弱,高劑量的X射線輻射往往會對諸如小鼠之類的動物造成損傷,甚至死亡,不利于實驗的連續性,因此低劑量小動物CT將是未來研究的一個發展趨勢。但是低劑量的CT重建圖像會被噪聲干擾,影響圖像質量,因而如何提高低劑量小動物CT的重建圖像質量,成為了亟待解決的問題。
傳統的低劑量CT重建問題的解決方案主要分為三類,分別應用于重建過程的三個部分:重建前處理(對CT投影圖或者Sinogram圖進行降噪處理)、重建(對CT重建過程中的算法進行改進以抑制噪聲)以及重建后處理(對CT重建結果進行降噪處理)。在前處理過程中,由于投影圖是通過X射線直接掃描得到的,因而噪聲類型較好統計,如基于懲罰加權的最小二乘(penalized weighted least-squares,PWLS)算法通過統計方法獲得投影圖像噪聲模型,針對噪聲模型進行降噪處理[2];此外也有對Sinogram圖像進行噪聲統計,并利用非線性濾波進行降噪處理的辦法[3]。由于此類方法應用于重建算法之前,有可能會造成圖像信息的丟失或者引發圖像的畸變。另外,由于投影圖的數據量非常龐大,統計過程耗時較長。而圖像重建過程中,對重建算法進行改進的一種基本思路是通過在傳統的濾波反投影過程中添加平滑窗函數來獲取較為平滑的結果,比如信號處理領域中常見的漢寧窗、海明窗等。此外,也有采用基于統計迭代圖像重建的算法,這類算法通過將CT重建圖像數據與投影數據相關聯,對投影數據的噪聲模型建模,在迭代過程中引入權重,達到圖像降噪的目的[4-5]。雖然迭代類算法對噪聲的抑制作用比較明顯,但其計算量龐大、耗時長,在臨床上應用并不廣泛。在重建圖像的后處理中,一般將重建圖像視為普通圖像,采用傳統的線性或非線性濾波方法,例如利用核函數的辦法對圖像進行降噪濾波,以及利用總變分最小化(total variation,TV)的辦法對圖像進行降噪等[6-7];也有學者提出將圖像變換到小波域進行降噪處理[8],但是由于重建圖像需要通過反投影等復雜計算才能得到,噪聲模型不便統計,傳統的圖像處理辦法很難取得一個好的結果。
近階段興起的信號稀疏表示與字典學習等方法為上述問題提供了新的解決方案。字典的概念最早由1993年Mallat等[9]提出。1998年Chen等[10]提出利用一范數評估稀疏性以及利用凸函數求解系數問題,推進了該理論的發展。2001年,Donoho等[11]驗證了追蹤算法的確定性,使得稀疏表示理論取得長足發展,并廣泛應用于圖像的降噪、壓縮與恢復等各個領域。在圖像降噪方面,基本的算法思路可以概括為將圖像利用字典稀疏的表達,在給定噪聲誤差的前提下,利用稀疏化的參數和字典將圖像稀疏重構,達到濾除噪聲的目的。字典解決方案直接應用于重建圖像,保證了圖像結果的真實性,也省去了前處理龐大的計算量,十分具有應用前景。
本文利用字典降噪的基本思路,使用高劑量圖像作為訓練樣本,利用逐列更新的字典學習算法(K-means singular value decomposition, K-SVD)獲取合適的全局字典,并將其應用于低劑量小動物CT的圖像降噪研究之中。
1 算法
在小鼠低劑量CT圖像降噪過程中,主要會涉及全局字典的訓練學習、圖像降噪算法實現以及小鼠CT應用框架搭建等具體操作問題。
1.1 K-SVD字典訓練
利用K-SVD算法進行字典訓練的過程可以歸結于求解如下目標函數[12]
| $ \mathop {\min }\limits_{D, \alpha } \left\{ {\left\| {\boldsymbol{Y}-\boldsymbol{D}\alpha } \right\|_F^2} \right\}, st.{\forall _i}, \left\| {{\alpha _i}} \right\| \le T $ |
其中,Y是用于訓練的樣本集,Y的每一個列向量都為一個訓練樣本;D是初始字典,一般為大小為n×K的一個矩陣,K表示字典總共包含K個原子,n表示樣本的維度。常用的初始字典有離散余弦字典或者小波字典;α是對樣本集Y進行稀疏分解后獲得的稀疏編碼系數,T為式(1)的稀疏度約束,表明表達式中每一次稀疏表示的過程使用的字典原子數量不能超過T個。由于K-SVD算法是對字典D逐個原子進行更新,稀疏編碼計算也是針對單個訓練樣本進行計算,因此我們將式(1)細化到每一個信號,重新改寫為:
| $ \mathop {\min }\limits_{{\alpha _I}} \left\{ {\left\| {{\boldsymbol{y}_i}-\boldsymbol{D}{\alpha _i}} \right\|_2^2} \right\}, st.\left\| {{\alpha _i}} \right\| \le T $ |
其中i代表樣本序號,K-SVD算法的目的在于使得式(2)取得最小值,聯合兩式可以將目標函數繼續修改進行求解:
| $ \left\| {\boldsymbol{Y}-\boldsymbol{D}\alpha } \right\|_F^2=\left\| {\boldsymbol{Y}-\sum\limits_{j=1}^K {{\boldsymbol{d}_j}\alpha _T^j} } \right\|_2^2=\left\| {\left({\boldsymbol{Y}-\sum\limits_{j \ne k} {{\boldsymbol{d}_j}\alpha _T^j} } \right)-{\boldsymbol{d}_k}\alpha _T^k} \right\|_F^2 $ |
其中dj表示第j個字典原子,為一個列向量。令Ek表示,則Ek代表了在字典中去除第k個原子后式(3)所產生的誤差,對Ek進行奇異值分解(singular value decomposition,SVD),求解最大的滿秩列向量,并利用該向量對原字典中第k個原子進行更新;將字典中所有原子遍歷一次,便可得到迭代一次后更新的字典,為了使字典更為平滑、有效地抑制噪聲信息,一般需要迭代多次。
1.2 圖像降噪框架
通過K-SVD算法獲取合適的全局字典后,則可以利用全局字典對噪聲圖像進行降噪處理[13],利用全局字典進行降噪的問題可以表述為:
| $ \left\{ {{{\hat \alpha }_{ij}},\boldsymbol{\hat X}} \right\} = \mathop {{\rm{argmin}}\lambda }\limits_{{\alpha _{ij}},X} \left\| {\boldsymbol{X} - \boldsymbol{Y}} \right\|_2^2 + \sum\limits_{ij} {{\mu _{ij}}} {\left\| {{\alpha _{ij}}} \right\|_0} + \sum\limits_{ij} {\left\| {{\boldsymbol{R}_{ij}}\boldsymbol{X} - \boldsymbol{D}{\alpha _{ij}}} \right\|_2^2} $ |
其中,式(4)右側第一項衡量的是原始圖像X與噪聲圖像Y之間的整體相似程度,λ為拉格朗日系數;第二項為字典降噪過程中的稀疏度約束,其中μij為約束項的權重系數,由于整圖較大,所以需要將原圖劃分為一塊塊的小圖像并重排為與全局字典的原子維度一致的列向量;第三項中的RijX表示了原圖中的第ij幅子圖像,Rij是用于提取子圖的矩陣,ij為子圖像序列下標,Dαij為對應子圖像的稀疏表達,第三項用于衡量這兩者之間的誤差,它們的誤差越小越好。
由于已經通過K-SVD算法獲取到了合適的全局字典D,為了獲取每張子圖的稀疏表達系數,需要求解下式最優化問題:
| $ {\alpha _{ij}}=\mathop {{\mathop{\rm a}\nolimits} \hat rgmin{\mu _{ij}}}\limits_\alpha {\left\| \alpha \right\|_0} + \sum\limits_{ij} {\left\| {\boldsymbol{D}{\alpha _{ij}}-{\boldsymbol{R}_{ij}}\boldsymbol{X}} \right\|_2^2} $ |
式(5)一般通過貪婪算法來求解。本文采用正交匹配追蹤(orthogonal matching pursuit,OMP)來求解式(5)的問題[14],其基本思路是對每一次逼近的殘差進行新一輪的逼近,直到滿足設定的誤差限或者稀疏度要求,得到近似解aij。如此,式(5)的求解更新即可轉換為如下形式:
| $ \boldsymbol{\hat X}=\mathop {{\mathop{\rm argmin}\nolimits} \lambda }\limits_\boldsymbol{X} \left\| {\boldsymbol{X}-\boldsymbol{Y}} \right\|_2^2 + \sum\limits_{ij} {\left\| {\boldsymbol{D}{{\hat \alpha }_{ij}}-{\boldsymbol{R}_{ij}}\boldsymbol{X}} \right\|_2^2} $ |
這是一個簡單的凸函數問題,對其進行求解得到降噪后的圖像:
| $ \boldsymbol{\hat X}={\left({\lambda \boldsymbol{I} + \sum\limits_{ij} {\boldsymbol{R}_{ij}^T{\boldsymbol{R}_{ij}}} } \right)^{-1}}\left({\lambda \boldsymbol{Y} + \sum\limits_{ij} {\boldsymbol{R}_{ij}^T\boldsymbol{D}{{\hat \alpha }_{ij}}} } \right) $ |
其中,I為單位矩陣,為降噪后的結果圖像。
1.3 基于全局字典降噪的小動物CT低劑量圖像降噪框架
在Aharon等[12]的工作中,利用噪聲圖像自身作為訓練集,經過K-SVD算法訓練過后的字典在降噪方面比初始字典更有優勢。這主要是因為經由噪聲圖像訓練自身得到的字典原子包含了圖像的結構信息,這使得圖像在做稀疏表達時能夠獲得更好的稀疏度,從而取得更好的結果。但是在實際應用中,如果對每一幅噪聲圖像都進行字典訓練,無疑大大增加了計算量,并不可取。考慮到同種類的小動物CT圖像結構相對比較接近,同種類動物的不同個體在CT圖像上的結構差異更多地體現于結構整體的不同,比如組織的輪廓或者位置等,但是其組織及其骨骼等構成成分都類似,因而在圖像細節方面表現大多類似,比如組織的邊緣、灰度級、骨骼內部細微結構等,因此通過提前對高劑量的同種類CT圖像進行字典訓練獲取包含結構信息的全局字典,對同種類小動物的低劑量噪聲圖像進行降噪處理,既能達到噪聲圖像自身訓練字典的降噪效果,也能省去單獨每幅圖像全局字典訓練的時間,使得全局字典在低劑量小動物CT上的應用具有了可行性。
因此,基于全局字典降噪的低劑量小動物CT降噪方案可以歸納為如下幾個步驟:
(1)?獲取訓練樣本集:利用高劑量X射線拍攝小動物獲得質量好的小動物的CT圖像;
(2)?獲取全局字典:對高劑量小動物的CT圖像進行處理,利用K-SVD算法獲取合適的全局字典D;
(3)?低劑量圖像稀疏分解:將低劑量圖像分割為圖像子集,利用D以及OMP算法對低劑量圖像進行稀疏分解,獲取每一個子集的稀疏編碼α;
(4)?低劑量圖像重構:利用式(7)以及步驟(3)中獲得結果對低劑量圖像進行重構,獲取降噪后的純凈圖像。
2 實驗與結果分析
本文實驗主要分為兩個部分,模擬實驗以及小動物CT數據實驗。為了驗證全局字典降噪的有效性,本文采用小波軟閾值、TV算法降噪進行對比實驗。實驗結果通過峰值信噪比(peak signal-noise ratio,PSNR)以及結構相似度(structure similarity index measurement,SSIM)兩個評價指標進行衡量[15]。PSNR以及SSIM都是圖像客觀評價的標準,其中PSNR反映的是最大值信號與噪聲之間的關系,單位為dB,PSNR值越大,噪聲濾除效果越好;而SSIM則綜合考量兩幅圖像之間亮度、對比度以及結構相似度作為整體評判指標,SSIM值越接近1,代表兩幅圖像越相似。
2.1 模擬數據實驗結果
為了盡可能地接近小動物CT實驗的真實情況,模擬實驗采用人體胸腔CT圖像作為模擬數據(數據來源于文獻[16]),圖像大小為512×512。CT圖像噪聲是由于到達探測器的光子數量不同(被掃描物體各部分對X光吸收不一致)并且有暗電流背景噪聲等因素影響而形成。為了使模擬實驗更加接近真實情況,對CT重建圖像的噪聲產生過程進行模擬,首先圖像進行正投影后,投影圖添加泊松噪聲再進行重建[17],重建后的CT圖像利用全局字典、小波軟閾值以及TV算法進行降噪處理,并計算處理后的結果與無噪聲標準重建CT圖像之間的PSNR值與SSIM值,觀察實驗結果。
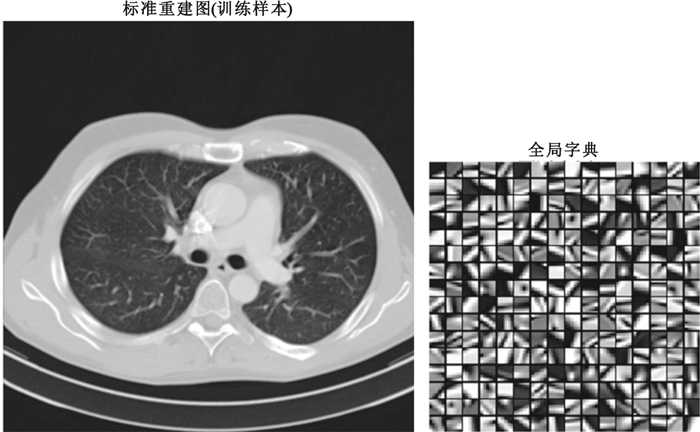
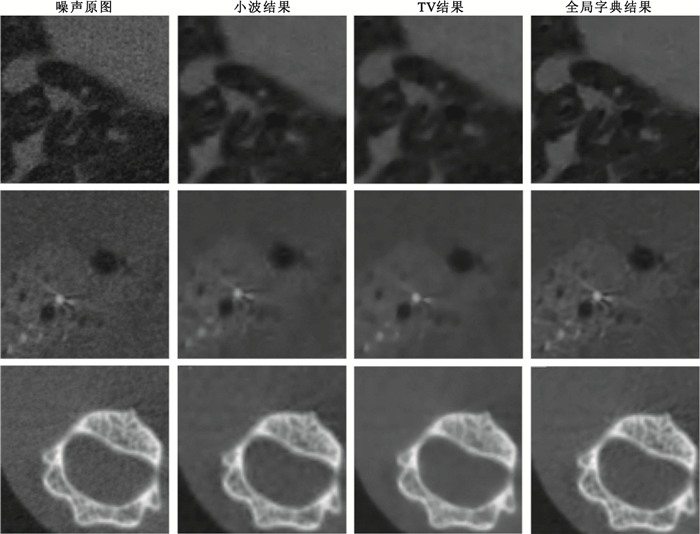
其中,全局字典由無噪聲標準重建圖像訓練而來,以8×8圖像塊大小對原圖像素點進行采樣,總共獲取255 025個訓練樣本構成全局字典的訓練集。全局字典訓練參數稀疏度設置為3,迭代20次。字典大小為64×256,表示總共256個原子,每個原子代表了8×8大小的圖像塊。原圖與全局字典如圖 1所示。不同方法的降噪結果如圖 2所示。
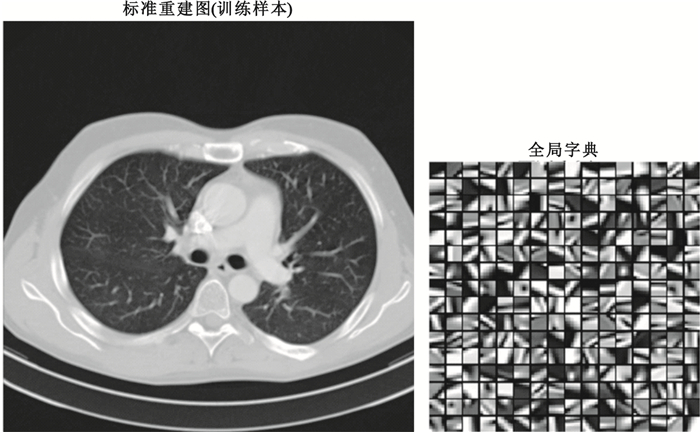 圖1
模擬實驗全局字典
Figure1.
The globe dictionary of simulation experiments
圖1
模擬實驗全局字典
Figure1.
The globe dictionary of simulation experiments
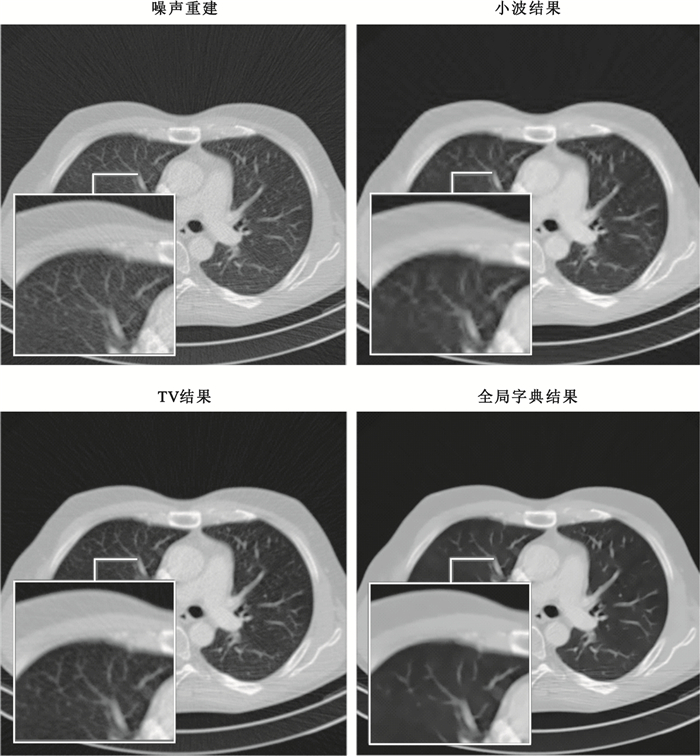 圖2
模擬實驗降噪結果(1 000 000光子)
Figure2.
The denoising results of simulation expreriments (with 1 000 000 photons)
圖2
模擬實驗降噪結果(1 000 000光子)
Figure2.
The denoising results of simulation expreriments (with 1 000 000 photons)
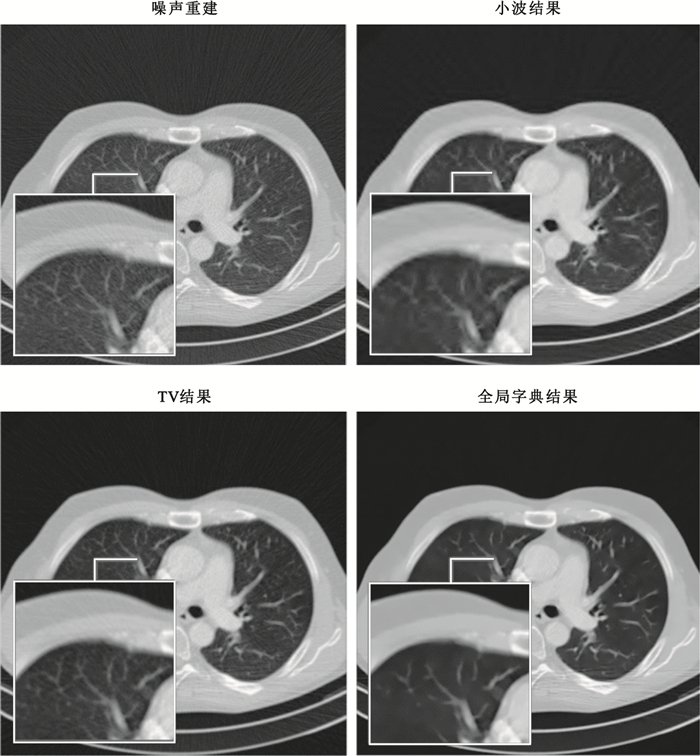
如圖 2所示,小波軟閾值在濾除噪聲的同時,使得胸腔邊界模糊并且產生了偽影,TV算法對于重建產生的條紋噪聲不能很好地抑制,而全局字典獲得了相對平滑的效果。從局部放大圖中可以看出,胸腔的邊緣以及肺葉部分,小波軟閾值處理結果模糊不清,TV算法處理結果仍然保留了許多放射條紋噪聲,同時也導致了邊緣一定程度的模糊,全局字典在去除噪聲的同時很好地保留了邊緣細節信息。不同量級噪聲的處理結果如表 1所示。
由模擬數據的實驗結果可以看出,全局字典降噪的效果,不僅在噪聲濾除方面,在結構性保持方面也優于目前較為流行的一些降噪算法。
2.2 動物實驗結果
本節中所有小動物的實際CT圖像數據由蘇州海斯菲德信息科技有限公司Hiscan M-1000型CT拍攝小鼠獲得。圖像大小為884×884,像素的空間分辨率為50 μm。CT掃描管電壓40 kVp,由于CT的X射線劑量與管電流成線性正比關系,實驗過程中高劑量的CT圖像管電流為200 μA,低劑量CT圖像的管電流依次為100 μA、50 μA以及20 μA。CT圖像的數據位數為12位,顯示窗寬為900,窗位為600。
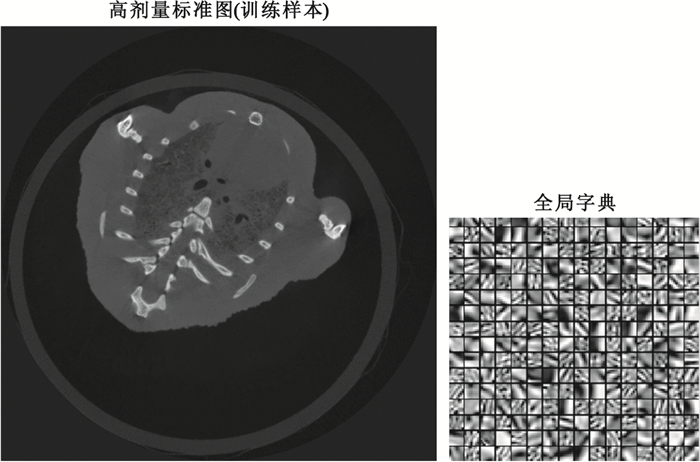
全局字典參數設置與模擬實驗一致,選取高劑量掃描圖序列中結構較為豐富的一幅圖像作為訓練樣本,同樣以8×8大小的圖像塊對高劑量圖像進行采樣,構成包含777 899個訓練樣本的訓練集;字典大小為64×256,訓練時稀疏度為3,迭代20次。訓練樣本及全局字典如圖 3所示。需要特別說明的是,在實際實驗中,由于需要計算PSNR以及SSIM值對實驗結果進行分析,這要求不同劑量組別的CT圖像結構一致。小老鼠活體CT實驗由于小鼠呼吸及運動等因素難以做到這一點,考慮CT圖像反映的是不同組織對X射線的吸收率,組織凋亡與否對吸收率影響并不明顯,因此包含數值計算驗證實驗可行性的小鼠實驗是利用剛死亡的小鼠進行拍攝的。在一次實驗過程中,對小鼠尸體分別進行劑量從高到低的連續四組拍攝,每組重建20層,對低劑量的三組CT圖像利用全局字典、小波軟閾值以及TV算法進行處理并與高劑量組進行對比;總共重復3次實驗,并觀察實驗結果。實驗結果如圖 4及表 2所示。其中圖 4展示了一次實驗中一層圖像的處理結果;表 2展示為三次試驗不同劑量組每組各60幅圖像的PSNR與SSIM數值的平均值。驗證方法的可行性后,再對活體小鼠進行降噪方法的實驗對比,保證實驗的完整性。
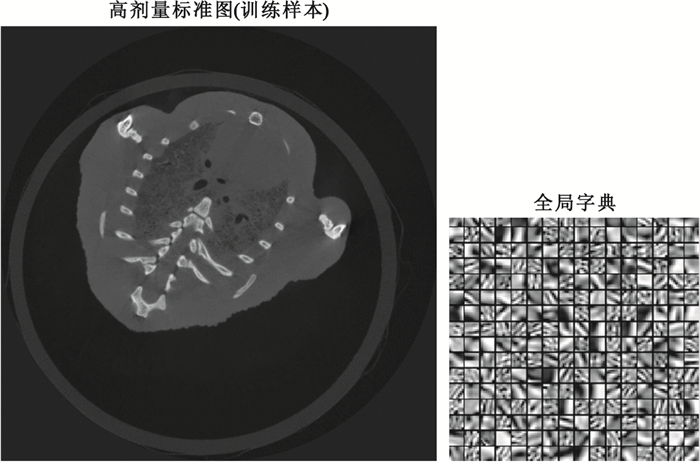 圖3
動物實驗全局字典
Figure3.
The global dictionary of animal experiments
圖3
動物實驗全局字典
Figure3.
The global dictionary of animal experiments
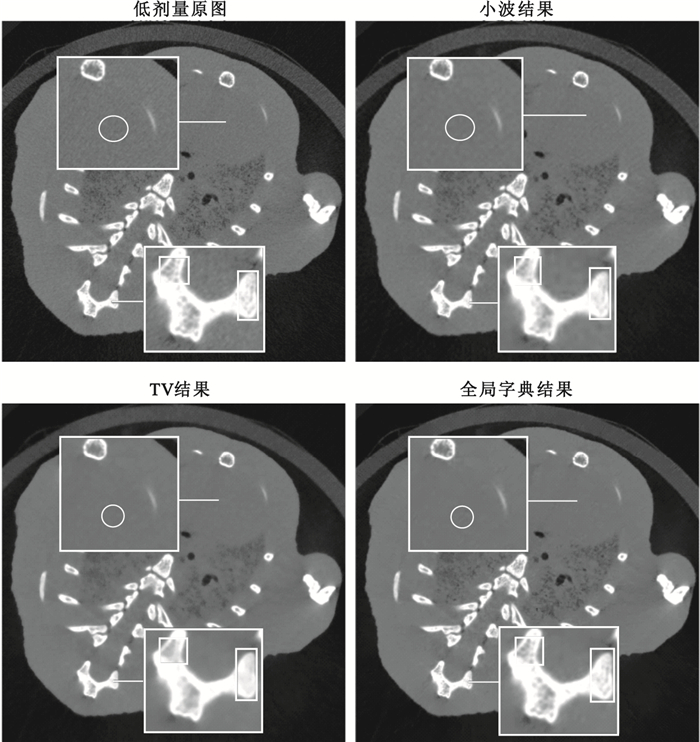 圖4
動物實驗結果(100 μA)
Figure4.
Results of animal experiments (100 μA)
圖4
動物實驗結果(100 μA)
Figure4.
Results of animal experiments (100 μA)
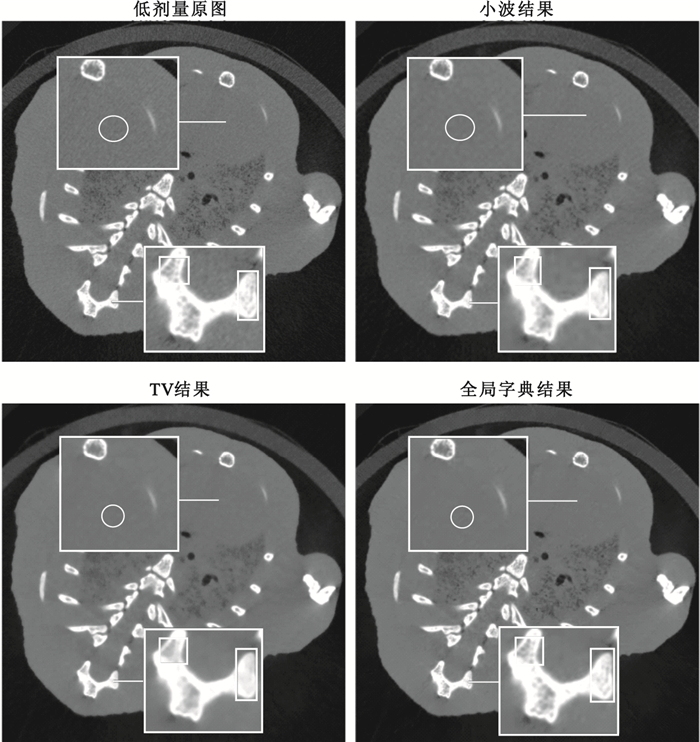
從實驗結果中可以看出,小波軟閾值法并不能很好地將噪聲濾除,因此PSNR提升并不明顯;TV降噪算法能夠有效地將噪聲濾除,并較為明顯地提高PSNR,但在濾除噪聲的過程中,圖像的邊緣變得平滑,部分有效信息被濾除,不能很好地保持圖像的結構信息,因此在指標SSIM上的表現結果不盡如人意。全局字典降噪的效果相較于對比算法,在提高相同水平的PSNR的前提下,能夠更好地保持結構信息,在PSRN以及SSIM兩項衡量標準下都取得了較為滿意的結果。如圖 4所示的局部放大圖中可以發現,原圖噪聲中微小的臟器間隙(圈內區域)以及骨骼內部的細小結構(方框內)在小波軟閾值與TV算法的降噪過程中,細節信息被一并濾除了,全局字典算法則很好地將間隙及骨小梁結構保留了下來。活體小鼠實驗的細節對比結果如圖 5所示,可以看出全局字典算法在結構保持、邊緣保留上均具有較好的結果,也說明了全局字典降噪算法在活體實驗中的可行性。
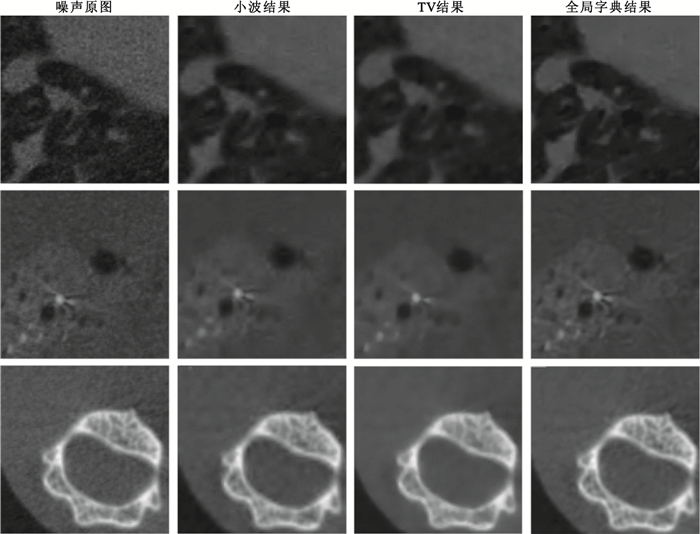 圖5
動物實驗結果(活體)
Figure5.
Results of animal experiments(in vivo)
圖5
動物實驗結果(活體)
Figure5.
Results of animal experiments(in vivo)
3 結語
本文提出了一種基于K-SVD字典學習的全局字典小動物CT圖像降噪方法。通過對高劑量小動物CT圖像進行訓練獲得全局字典,并將其用于低劑量小動物CT圖像的稀疏分解中,最后利用稀疏分解獲得的稀疏編碼對低劑量圖像進行重建。實驗結果表明,與傳統的主流算法相比,本文提出的算法在降噪的同時,能夠較好地保留小動物CT圖像中的結構信息,較為顯著地提升低劑量小動物CT圖像質量,有利于動物模型實驗的順利進行。
需要指出的是,在低劑量情況下,小動物CT圖像不僅會被噪聲干擾,也會由于X射線光子不足而產生放射狀偽影,如何利用全局字典算法將偽影去除,進一步提升低劑量小動物CT圖像質量,將是課題組今后的研究方向。
引言
動物模型是現代生物醫學研究中的重要組成部分。通過對動物接種腫瘤觀察其生理變化、利用各類新型造影劑進行動物實驗、研究藥物對動物生理的影響等[1],能夠有效地幫助人類認識疾病發生規律,并采取相應的防治措施。近年來,各類醫學影像技術廣泛地應用于各類動物實驗中,其中計算機斷層掃描(computed tomography,CT)技術由于具有分辨率高、成像時間短等特點,成為動物醫學影像研究的重要手段之一。
與傳統的臨床CT相比,小動物CT具有更高的分辨率,但卻受到射線劑量方面的限制。小動物本身十分脆弱,高劑量的X射線輻射往往會對諸如小鼠之類的動物造成損傷,甚至死亡,不利于實驗的連續性,因此低劑量小動物CT將是未來研究的一個發展趨勢。但是低劑量的CT重建圖像會被噪聲干擾,影響圖像質量,因而如何提高低劑量小動物CT的重建圖像質量,成為了亟待解決的問題。
傳統的低劑量CT重建問題的解決方案主要分為三類,分別應用于重建過程的三個部分:重建前處理(對CT投影圖或者Sinogram圖進行降噪處理)、重建(對CT重建過程中的算法進行改進以抑制噪聲)以及重建后處理(對CT重建結果進行降噪處理)。在前處理過程中,由于投影圖是通過X射線直接掃描得到的,因而噪聲類型較好統計,如基于懲罰加權的最小二乘(penalized weighted least-squares,PWLS)算法通過統計方法獲得投影圖像噪聲模型,針對噪聲模型進行降噪處理[2];此外也有對Sinogram圖像進行噪聲統計,并利用非線性濾波進行降噪處理的辦法[3]。由于此類方法應用于重建算法之前,有可能會造成圖像信息的丟失或者引發圖像的畸變。另外,由于投影圖的數據量非常龐大,統計過程耗時較長。而圖像重建過程中,對重建算法進行改進的一種基本思路是通過在傳統的濾波反投影過程中添加平滑窗函數來獲取較為平滑的結果,比如信號處理領域中常見的漢寧窗、海明窗等。此外,也有采用基于統計迭代圖像重建的算法,這類算法通過將CT重建圖像數據與投影數據相關聯,對投影數據的噪聲模型建模,在迭代過程中引入權重,達到圖像降噪的目的[4-5]。雖然迭代類算法對噪聲的抑制作用比較明顯,但其計算量龐大、耗時長,在臨床上應用并不廣泛。在重建圖像的后處理中,一般將重建圖像視為普通圖像,采用傳統的線性或非線性濾波方法,例如利用核函數的辦法對圖像進行降噪濾波,以及利用總變分最小化(total variation,TV)的辦法對圖像進行降噪等[6-7];也有學者提出將圖像變換到小波域進行降噪處理[8],但是由于重建圖像需要通過反投影等復雜計算才能得到,噪聲模型不便統計,傳統的圖像處理辦法很難取得一個好的結果。
近階段興起的信號稀疏表示與字典學習等方法為上述問題提供了新的解決方案。字典的概念最早由1993年Mallat等[9]提出。1998年Chen等[10]提出利用一范數評估稀疏性以及利用凸函數求解系數問題,推進了該理論的發展。2001年,Donoho等[11]驗證了追蹤算法的確定性,使得稀疏表示理論取得長足發展,并廣泛應用于圖像的降噪、壓縮與恢復等各個領域。在圖像降噪方面,基本的算法思路可以概括為將圖像利用字典稀疏的表達,在給定噪聲誤差的前提下,利用稀疏化的參數和字典將圖像稀疏重構,達到濾除噪聲的目的。字典解決方案直接應用于重建圖像,保證了圖像結果的真實性,也省去了前處理龐大的計算量,十分具有應用前景。
本文利用字典降噪的基本思路,使用高劑量圖像作為訓練樣本,利用逐列更新的字典學習算法(K-means singular value decomposition, K-SVD)獲取合適的全局字典,并將其應用于低劑量小動物CT的圖像降噪研究之中。
1 算法
在小鼠低劑量CT圖像降噪過程中,主要會涉及全局字典的訓練學習、圖像降噪算法實現以及小鼠CT應用框架搭建等具體操作問題。
1.1 K-SVD字典訓練
利用K-SVD算法進行字典訓練的過程可以歸結于求解如下目標函數[12]
| $ \mathop {\min }\limits_{D, \alpha } \left\{ {\left\| {\boldsymbol{Y}-\boldsymbol{D}\alpha } \right\|_F^2} \right\}, st.{\forall _i}, \left\| {{\alpha _i}} \right\| \le T $ |
其中,Y是用于訓練的樣本集,Y的每一個列向量都為一個訓練樣本;D是初始字典,一般為大小為n×K的一個矩陣,K表示字典總共包含K個原子,n表示樣本的維度。常用的初始字典有離散余弦字典或者小波字典;α是對樣本集Y進行稀疏分解后獲得的稀疏編碼系數,T為式(1)的稀疏度約束,表明表達式中每一次稀疏表示的過程使用的字典原子數量不能超過T個。由于K-SVD算法是對字典D逐個原子進行更新,稀疏編碼計算也是針對單個訓練樣本進行計算,因此我們將式(1)細化到每一個信號,重新改寫為:
| $ \mathop {\min }\limits_{{\alpha _I}} \left\{ {\left\| {{\boldsymbol{y}_i}-\boldsymbol{D}{\alpha _i}} \right\|_2^2} \right\}, st.\left\| {{\alpha _i}} \right\| \le T $ |
其中i代表樣本序號,K-SVD算法的目的在于使得式(2)取得最小值,聯合兩式可以將目標函數繼續修改進行求解:
| $ \left\| {\boldsymbol{Y}-\boldsymbol{D}\alpha } \right\|_F^2=\left\| {\boldsymbol{Y}-\sum\limits_{j=1}^K {{\boldsymbol{d}_j}\alpha _T^j} } \right\|_2^2=\left\| {\left({\boldsymbol{Y}-\sum\limits_{j \ne k} {{\boldsymbol{d}_j}\alpha _T^j} } \right)-{\boldsymbol{d}_k}\alpha _T^k} \right\|_F^2 $ |
其中dj表示第j個字典原子,為一個列向量。令Ek表示,則Ek代表了在字典中去除第k個原子后式(3)所產生的誤差,對Ek進行奇異值分解(singular value decomposition,SVD),求解最大的滿秩列向量,并利用該向量對原字典中第k個原子進行更新;將字典中所有原子遍歷一次,便可得到迭代一次后更新的字典,為了使字典更為平滑、有效地抑制噪聲信息,一般需要迭代多次。
1.2 圖像降噪框架
通過K-SVD算法獲取合適的全局字典后,則可以利用全局字典對噪聲圖像進行降噪處理[13],利用全局字典進行降噪的問題可以表述為:
| $ \left\{ {{{\hat \alpha }_{ij}},\boldsymbol{\hat X}} \right\} = \mathop {{\rm{argmin}}\lambda }\limits_{{\alpha _{ij}},X} \left\| {\boldsymbol{X} - \boldsymbol{Y}} \right\|_2^2 + \sum\limits_{ij} {{\mu _{ij}}} {\left\| {{\alpha _{ij}}} \right\|_0} + \sum\limits_{ij} {\left\| {{\boldsymbol{R}_{ij}}\boldsymbol{X} - \boldsymbol{D}{\alpha _{ij}}} \right\|_2^2} $ |
其中,式(4)右側第一項衡量的是原始圖像X與噪聲圖像Y之間的整體相似程度,λ為拉格朗日系數;第二項為字典降噪過程中的稀疏度約束,其中μij為約束項的權重系數,由于整圖較大,所以需要將原圖劃分為一塊塊的小圖像并重排為與全局字典的原子維度一致的列向量;第三項中的RijX表示了原圖中的第ij幅子圖像,Rij是用于提取子圖的矩陣,ij為子圖像序列下標,Dαij為對應子圖像的稀疏表達,第三項用于衡量這兩者之間的誤差,它們的誤差越小越好。
由于已經通過K-SVD算法獲取到了合適的全局字典D,為了獲取每張子圖的稀疏表達系數,需要求解下式最優化問題:
| $ {\alpha _{ij}}=\mathop {{\mathop{\rm a}\nolimits} \hat rgmin{\mu _{ij}}}\limits_\alpha {\left\| \alpha \right\|_0} + \sum\limits_{ij} {\left\| {\boldsymbol{D}{\alpha _{ij}}-{\boldsymbol{R}_{ij}}\boldsymbol{X}} \right\|_2^2} $ |
式(5)一般通過貪婪算法來求解。本文采用正交匹配追蹤(orthogonal matching pursuit,OMP)來求解式(5)的問題[14],其基本思路是對每一次逼近的殘差進行新一輪的逼近,直到滿足設定的誤差限或者稀疏度要求,得到近似解aij。如此,式(5)的求解更新即可轉換為如下形式:
| $ \boldsymbol{\hat X}=\mathop {{\mathop{\rm argmin}\nolimits} \lambda }\limits_\boldsymbol{X} \left\| {\boldsymbol{X}-\boldsymbol{Y}} \right\|_2^2 + \sum\limits_{ij} {\left\| {\boldsymbol{D}{{\hat \alpha }_{ij}}-{\boldsymbol{R}_{ij}}\boldsymbol{X}} \right\|_2^2} $ |
這是一個簡單的凸函數問題,對其進行求解得到降噪后的圖像:
| $ \boldsymbol{\hat X}={\left({\lambda \boldsymbol{I} + \sum\limits_{ij} {\boldsymbol{R}_{ij}^T{\boldsymbol{R}_{ij}}} } \right)^{-1}}\left({\lambda \boldsymbol{Y} + \sum\limits_{ij} {\boldsymbol{R}_{ij}^T\boldsymbol{D}{{\hat \alpha }_{ij}}} } \right) $ |
其中,I為單位矩陣,為降噪后的結果圖像。
1.3 基于全局字典降噪的小動物CT低劑量圖像降噪框架
在Aharon等[12]的工作中,利用噪聲圖像自身作為訓練集,經過K-SVD算法訓練過后的字典在降噪方面比初始字典更有優勢。這主要是因為經由噪聲圖像訓練自身得到的字典原子包含了圖像的結構信息,這使得圖像在做稀疏表達時能夠獲得更好的稀疏度,從而取得更好的結果。但是在實際應用中,如果對每一幅噪聲圖像都進行字典訓練,無疑大大增加了計算量,并不可取。考慮到同種類的小動物CT圖像結構相對比較接近,同種類動物的不同個體在CT圖像上的結構差異更多地體現于結構整體的不同,比如組織的輪廓或者位置等,但是其組織及其骨骼等構成成分都類似,因而在圖像細節方面表現大多類似,比如組織的邊緣、灰度級、骨骼內部細微結構等,因此通過提前對高劑量的同種類CT圖像進行字典訓練獲取包含結構信息的全局字典,對同種類小動物的低劑量噪聲圖像進行降噪處理,既能達到噪聲圖像自身訓練字典的降噪效果,也能省去單獨每幅圖像全局字典訓練的時間,使得全局字典在低劑量小動物CT上的應用具有了可行性。
因此,基于全局字典降噪的低劑量小動物CT降噪方案可以歸納為如下幾個步驟:
(1)?獲取訓練樣本集:利用高劑量X射線拍攝小動物獲得質量好的小動物的CT圖像;
(2)?獲取全局字典:對高劑量小動物的CT圖像進行處理,利用K-SVD算法獲取合適的全局字典D;
(3)?低劑量圖像稀疏分解:將低劑量圖像分割為圖像子集,利用D以及OMP算法對低劑量圖像進行稀疏分解,獲取每一個子集的稀疏編碼α;
(4)?低劑量圖像重構:利用式(7)以及步驟(3)中獲得結果對低劑量圖像進行重構,獲取降噪后的純凈圖像。
2 實驗與結果分析
本文實驗主要分為兩個部分,模擬實驗以及小動物CT數據實驗。為了驗證全局字典降噪的有效性,本文采用小波軟閾值、TV算法降噪進行對比實驗。實驗結果通過峰值信噪比(peak signal-noise ratio,PSNR)以及結構相似度(structure similarity index measurement,SSIM)兩個評價指標進行衡量[15]。PSNR以及SSIM都是圖像客觀評價的標準,其中PSNR反映的是最大值信號與噪聲之間的關系,單位為dB,PSNR值越大,噪聲濾除效果越好;而SSIM則綜合考量兩幅圖像之間亮度、對比度以及結構相似度作為整體評判指標,SSIM值越接近1,代表兩幅圖像越相似。
2.1 模擬數據實驗結果
為了盡可能地接近小動物CT實驗的真實情況,模擬實驗采用人體胸腔CT圖像作為模擬數據(數據來源于文獻[16]),圖像大小為512×512。CT圖像噪聲是由于到達探測器的光子數量不同(被掃描物體各部分對X光吸收不一致)并且有暗電流背景噪聲等因素影響而形成。為了使模擬實驗更加接近真實情況,對CT重建圖像的噪聲產生過程進行模擬,首先圖像進行正投影后,投影圖添加泊松噪聲再進行重建[17],重建后的CT圖像利用全局字典、小波軟閾值以及TV算法進行降噪處理,并計算處理后的結果與無噪聲標準重建CT圖像之間的PSNR值與SSIM值,觀察實驗結果。
其中,全局字典由無噪聲標準重建圖像訓練而來,以8×8圖像塊大小對原圖像素點進行采樣,總共獲取255 025個訓練樣本構成全局字典的訓練集。全局字典訓練參數稀疏度設置為3,迭代20次。字典大小為64×256,表示總共256個原子,每個原子代表了8×8大小的圖像塊。原圖與全局字典如圖 1所示。不同方法的降噪結果如圖 2所示。
圖1
模擬實驗全局字典
Figure1.
The globe dictionary of simulation experiments
圖2
模擬實驗降噪結果(1 000 000光子)
Figure2.
The denoising results of simulation expreriments (with 1 000 000 photons)
如圖 2所示,小波軟閾值在濾除噪聲的同時,使得胸腔邊界模糊并且產生了偽影,TV算法對于重建產生的條紋噪聲不能很好地抑制,而全局字典獲得了相對平滑的效果。從局部放大圖中可以看出,胸腔的邊緣以及肺葉部分,小波軟閾值處理結果模糊不清,TV算法處理結果仍然保留了許多放射條紋噪聲,同時也導致了邊緣一定程度的模糊,全局字典在去除噪聲的同時很好地保留了邊緣細節信息。不同量級噪聲的處理結果如表 1所示。
由模擬數據的實驗結果可以看出,全局字典降噪的效果,不僅在噪聲濾除方面,在結構性保持方面也優于目前較為流行的一些降噪算法。
2.2 動物實驗結果
本節中所有小動物的實際CT圖像數據由蘇州海斯菲德信息科技有限公司Hiscan M-1000型CT拍攝小鼠獲得。圖像大小為884×884,像素的空間分辨率為50 μm。CT掃描管電壓40 kVp,由于CT的X射線劑量與管電流成線性正比關系,實驗過程中高劑量的CT圖像管電流為200 μA,低劑量CT圖像的管電流依次為100 μA、50 μA以及20 μA。CT圖像的數據位數為12位,顯示窗寬為900,窗位為600。
全局字典參數設置與模擬實驗一致,選取高劑量掃描圖序列中結構較為豐富的一幅圖像作為訓練樣本,同樣以8×8大小的圖像塊對高劑量圖像進行采樣,構成包含777 899個訓練樣本的訓練集;字典大小為64×256,訓練時稀疏度為3,迭代20次。訓練樣本及全局字典如圖 3所示。需要特別說明的是,在實際實驗中,由于需要計算PSNR以及SSIM值對實驗結果進行分析,這要求不同劑量組別的CT圖像結構一致。小老鼠活體CT實驗由于小鼠呼吸及運動等因素難以做到這一點,考慮CT圖像反映的是不同組織對X射線的吸收率,組織凋亡與否對吸收率影響并不明顯,因此包含數值計算驗證實驗可行性的小鼠實驗是利用剛死亡的小鼠進行拍攝的。在一次實驗過程中,對小鼠尸體分別進行劑量從高到低的連續四組拍攝,每組重建20層,對低劑量的三組CT圖像利用全局字典、小波軟閾值以及TV算法進行處理并與高劑量組進行對比;總共重復3次實驗,并觀察實驗結果。實驗結果如圖 4及表 2所示。其中圖 4展示了一次實驗中一層圖像的處理結果;表 2展示為三次試驗不同劑量組每組各60幅圖像的PSNR與SSIM數值的平均值。驗證方法的可行性后,再對活體小鼠進行降噪方法的實驗對比,保證實驗的完整性。
圖3
動物實驗全局字典
Figure3.
The global dictionary of animal experiments
圖4
動物實驗結果(100 μA)
Figure4.
Results of animal experiments (100 μA)
從實驗結果中可以看出,小波軟閾值法并不能很好地將噪聲濾除,因此PSNR提升并不明顯;TV降噪算法能夠有效地將噪聲濾除,并較為明顯地提高PSNR,但在濾除噪聲的過程中,圖像的邊緣變得平滑,部分有效信息被濾除,不能很好地保持圖像的結構信息,因此在指標SSIM上的表現結果不盡如人意。全局字典降噪的效果相較于對比算法,在提高相同水平的PSNR的前提下,能夠更好地保持結構信息,在PSRN以及SSIM兩項衡量標準下都取得了較為滿意的結果。如圖 4所示的局部放大圖中可以發現,原圖噪聲中微小的臟器間隙(圈內區域)以及骨骼內部的細小結構(方框內)在小波軟閾值與TV算法的降噪過程中,細節信息被一并濾除了,全局字典算法則很好地將間隙及骨小梁結構保留了下來。活體小鼠實驗的細節對比結果如圖 5所示,可以看出全局字典算法在結構保持、邊緣保留上均具有較好的結果,也說明了全局字典降噪算法在活體實驗中的可行性。
圖5
動物實驗結果(活體)
Figure5.
Results of animal experiments(in vivo)
3 結語
本文提出了一種基于K-SVD字典學習的全局字典小動物CT圖像降噪方法。通過對高劑量小動物CT圖像進行訓練獲得全局字典,并將其用于低劑量小動物CT圖像的稀疏分解中,最后利用稀疏分解獲得的稀疏編碼對低劑量圖像進行重建。實驗結果表明,與傳統的主流算法相比,本文提出的算法在降噪的同時,能夠較好地保留小動物CT圖像中的結構信息,較為顯著地提升低劑量小動物CT圖像質量,有利于動物模型實驗的順利進行。
需要指出的是,在低劑量情況下,小動物CT圖像不僅會被噪聲干擾,也會由于X射線光子不足而產生放射狀偽影,如何利用全局字典算法將偽影去除,進一步提升低劑量小動物CT圖像質量,將是課題組今后的研究方向。