傳統語音信號檢測方法是將噪聲作為干擾信號來線性濾除, 而在強噪聲背景下, 這些方法在去除噪聲的同時也丟失了部分原始語音信號。隨機共振能夠利用噪聲能量放大弱信號而抑制噪聲, 基于此原理, 提出一種基于自適應隨機共振提取弱語音信號的方法, 并與二次采樣相結合, 實現強噪聲背景下弱語音信號的檢測。該方法通過評價系統輸出信號的信噪比, 自適應調節系統參數a、b, 從而最優地檢測出弱語音信號。實驗仿真分析表明, 強噪聲背景下, 輸出信號的信噪比由初始信噪比-7 dB提高到0.86 dB, 信噪比增益為7.86 dB。該方法明顯提高了輸出語音信號的信噪比, 為弱語音信號的檢測提供了新的思路。
引用本文: 盧歡歡, 王輔忠, 張慧春. 基于自適應隨機共振理論強噪聲背景下的弱語音信號檢測. 生物醫學工程學雜志, 2016, 33(2): 357-361. doi: 10.7507/1001-5515.20160060 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
語音信號是人類傳播信息、感情交流的重要媒介,是人類最重要、最有效、最常用、最方便的通信方式。然而,在通信中,語音信號將不可避免地受到外界噪聲的干擾,最終使接收到的語音信號并非純凈的原始信號,而是已被噪聲污染過的含噪語音信號。含噪語音信號不利于對語音信號的分析,所以,語音信號增強的主要目的是從含噪語音信號中提取出較為純凈的原始語音信號,改善其質量。
由于噪聲特性各異,語音信號增強方法有很多。目前常用的語音信號增強的算法包括自適應噪聲抵消法、維納濾波器法、譜減法及小波變換法等。但上述方法都是將噪聲作為一種干擾信號,通過噪聲估計等方法,將其從含噪語音信號中去除。隨著信噪比(signal-to-noise ratio, SNR)不斷減小,上述方法的降噪效果也隨之變差,同時也會使語音信號丟字,或者波形失真。
隨機共振(stochastic resonance, SR)理論自1981年由Benzi等[1]提出,成功解釋了古氣象學中冷暖氣候交替出現的現象。隨機共振是弱信號、噪聲、非線性系統三者協同產生的一種非線性動力學行為,在發生隨機共振時,噪聲能量轉化為信號能量從而抑制了噪聲,提高了系統輸出信噪比,該理論在弱信號檢測中得到了廣泛的應用。但經典隨機共振理論須滿足絕熱近似條件,它只適用于小參數信號(幅值、頻率、噪聲強度均小于1),而在現實生活中,待檢測的弱信號一般都不滿足絕熱近似條件,所以一些學者嘗試對其進行預處理。文獻[2-6]提出了二次采樣、移頻或變尺度、結構參數自尋優算法,對信號頻率進行線性壓縮,使其滿足絕熱近似理論。文獻[7]采用將陣列傳感器與隨機共振相結合,處理多頻弱信號的檢測。在實際工程中,信號與噪聲通常是未知的,這就要求隨機共振系統能夠根據現場信號和噪聲強度,自動地調節系統自身的參數來達到隨機共振狀態,達到抑制噪聲提取信號的目的。1998年,Mitaim等[8]提出了自適應隨機共振。目前,參數優化方法針對單一參數進行優化,而假定其它參數不變。如,文獻[9]提出一種基于時頻的自適應算法,文獻[10]提出了尺度變換和調幅信號調制聯合應用自適應的方法,但這兩種方法都是令系統參數b和噪聲強度D不變,對參數a進行優化。文獻[11]中將系統參數a、b設置為常數,自適應改變噪聲強度,使輸出SNR達到最優。當固定參數值選取不當時,對某一參數的優化可能會失去意義,亦即系統始終無法達到最優共振。
本文以強噪聲背景下的語音信號為研究對象,采用二次采樣算法,對語音信號進行頻率壓縮,使其滿足絕熱近似理論,再通過自適應調節系統參數a、b,以系統輸出的SNR為評價函數,對多個系統參數同步優化,從而最優地檢測出語音信號。
1 雙穩態隨機共振基本理論
1.1 雙穩態隨機共振模型
隨機共振一般包含三個必不可缺的因素:輸入信號、雙穩或多穩態非線性系統、噪聲。經典的非線性雙穩態系統可由郎之萬方程描述:
| $ \frac{{{\rm{d}}x}}{{{\rm{d}}t}}=ax-b{x^3} + A\sin \left({2\pi ft} \right) + n\left(t \right) $ |
其中,E[n(t)]=0;E[n(t)n(t-τ)]=2Dδ(τ)。雙穩SR系統模型如圖 1所示。
 圖1
雙穩SR系統模型
Figure1.
Model of bistable SR system
圖1
雙穩SR系統模型
Figure1.
Model of bistable SR system
s(t)=Asin(2πft)為被檢測微弱周期信號,為白噪聲,D是噪聲強度,g(t)是均值為0,方差為1的白噪聲,勢函數表示非線性雙穩態系統,x(t)是系統輸出信號。圖 1說明:信號s(t)和噪聲n(t)通過雙穩態非線性系統V(x)后,信號、噪聲及非線性系統之間達到某種匹配時,一部分噪聲能量將轉化到信號身上,從而使信號放大形成隨機共振。
1.2 雙穩態隨機共振的SNR評價
對于語音信號,常用的評價語音增強算法有效性的方法是SNR,SNR定義如下[12]
| $ SNR=10\lg \frac{{\sum {s{{\left(t \right)}^2}} }}{{\sum {{{\left[ {y\left(t \right)s\left(t \right)} \right]}^2}} }} $ |
式中,s(t)表示含噪語音信號,y(t)表示增強后的語音信號。
2 含噪弱語音信號自適應隨機共振模型
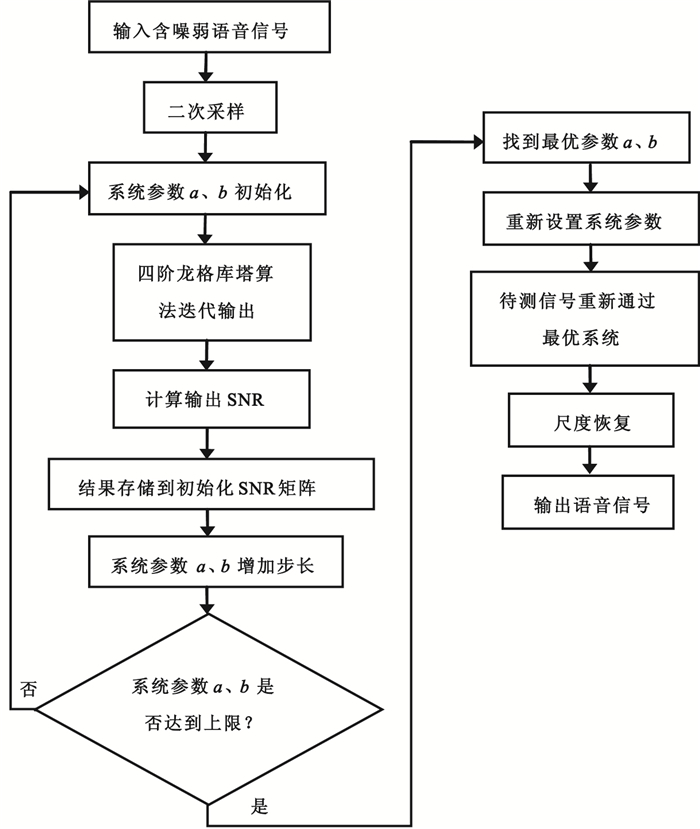
本文對輸出信號的SNR進行分析,將SNR作為隨機共振的測度指標,對系統參數a、b同步優化,實現含噪語音信號自適應隨機共振。具體流程如圖 2所示。
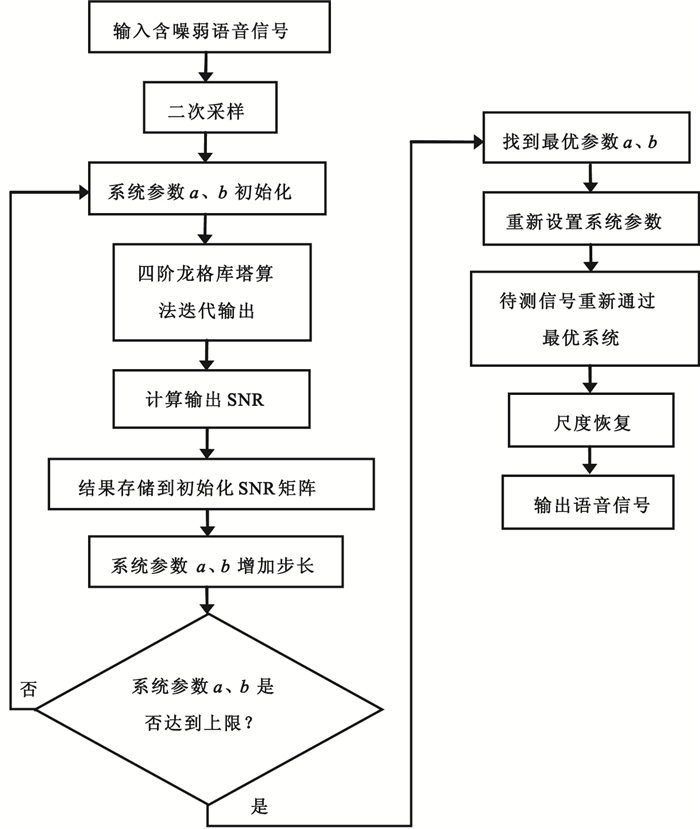 圖2
含噪語音信號自適應隨機共振流程圖
Figure2.
Process of adaptive stochastic resonance of noisy speech signal
圖2
含噪語音信號自適應隨機共振流程圖
Figure2.
Process of adaptive stochastic resonance of noisy speech signal
隨機共振絕熱近似理論要求信號的幅度和頻率均小于1,因此對于大參數信號,需要對這些大參數進行尺度變換,以滿足隨機共振的條件。
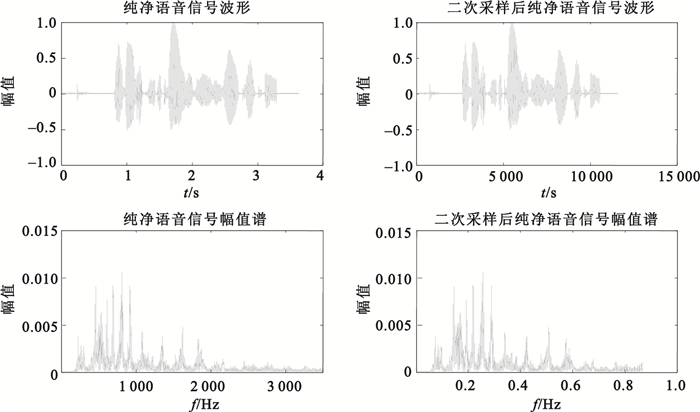
一般而言,語音信號的頻率范圍為300~3 500 Hz,頻率不滿足絕熱近似條件,無法通過雙穩態非線性系統達到隨機共振。因此本文會先通過二次采樣算法,將語音信號的頻率范圍線性壓縮到0~1 Hz,如圖 3所示,然后再通過自適應隨機共振得到最優輸出信號。
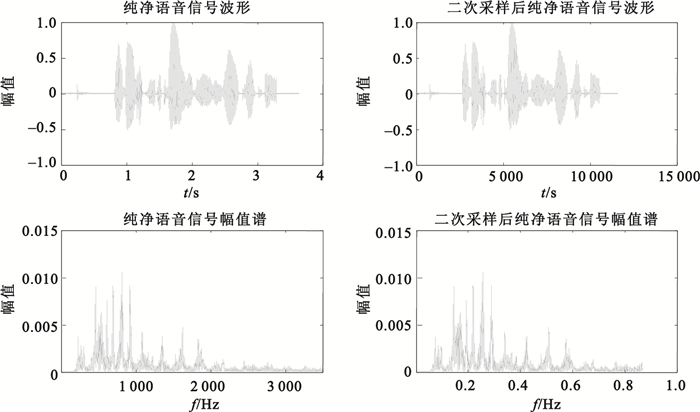 圖3
純凈語音信號二次采樣前后時域及頻域圖
Figure3.
Time domain and frequency domain of original speech before and after twice sampling
圖3
純凈語音信號二次采樣前后時域及頻域圖
Figure3.
Time domain and frequency domain of original speech before and after twice sampling
3 實驗結果與分析
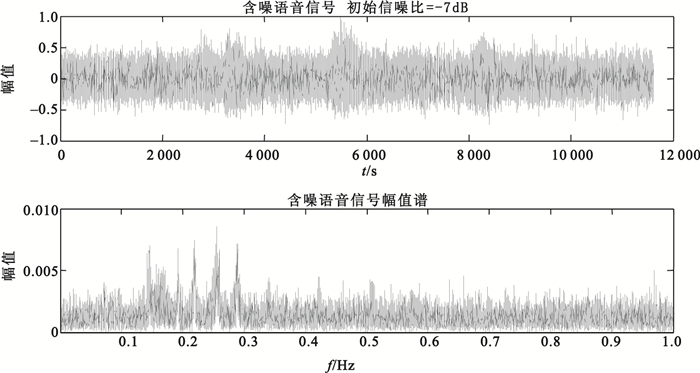
本文實驗對象采用TIMIT標準語音數據庫,語音樣本的采樣頻率為16 kHz。語音樣本所含背景白噪聲來源于NOISE92標準噪聲數據庫。取語音樣本1,設頻率壓縮比R=3 200,二次采樣頻率fsr=fs/R=5。
圖 4表示含噪語音樣本1二次采樣后的波形及其頻譜圖,語音信號的頻率被壓縮到0~1 Hz范圍內,設初始SNR為-7 dB。從圖中可以看到,語音信號淹沒在噪聲中,且在整個頻域范圍都有很強的噪聲,只能在低頻段看到部分信號分布。
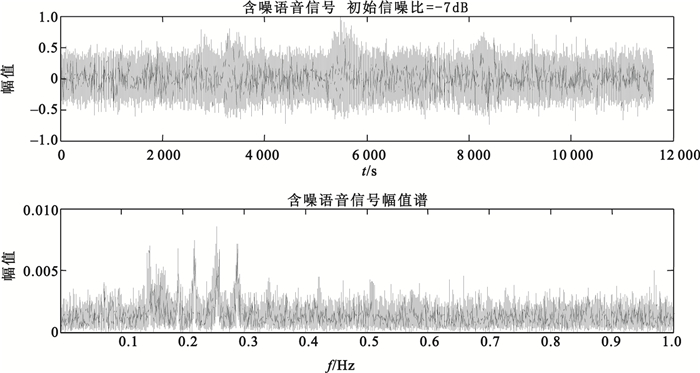 圖4
含噪語音樣本1二次采樣后時域和頻域圖
Figure4.
Time domain and frequency domain of noisy speech 1 after twice sampling
圖4
含噪語音樣本1二次采樣后時域和頻域圖
Figure4.
Time domain and frequency domain of noisy speech 1 after twice sampling
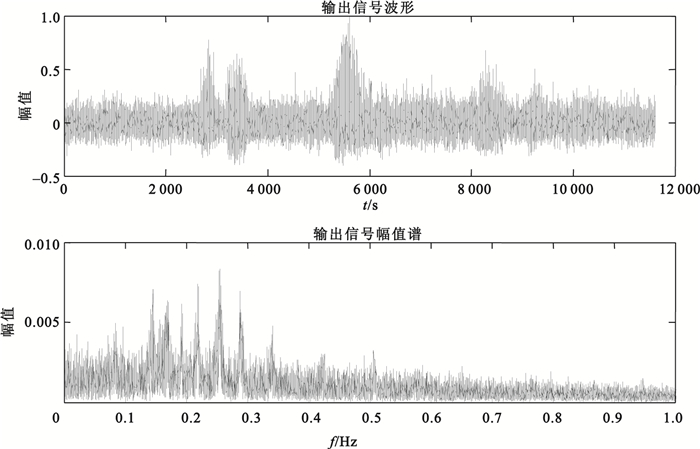
將含噪語音信號通過郎之萬方程(1),步長h=1/fsr=0.2,采用四階龍格-庫塔(Runge-Kutta)法求解該常微分方程。設參數a、b搜索范圍為[0.1, 4.1],循環步長為0.02,使其產生隨機共振,得到最優的輸出SNR,及最優參數a、b。經過系統參數自適應優化,當a=1.2,b=2.42時,輸出SNR最優達到0.86 dB,系統最優的輸出效果,如圖 5所示。含噪語音的SNR由初始值-7 dB提高到了0.86 dB,SNR增益為7.86 dB。從圖 5中可以看出,噪聲能量向低頻區發生了轉移,低頻區的語音信號被增強,含噪語音信號得到很大的改善。
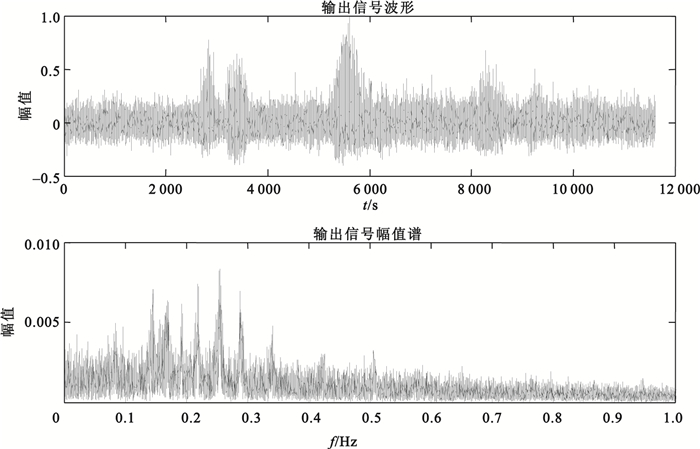 圖5
最優SNR輸出語音信號時域波形及頻譜圖
Figure5.
Time domain waveform and frequency domain of the output speech with optimal SNR
圖5
最優SNR輸出語音信號時域波形及頻譜圖
Figure5.
Time domain waveform and frequency domain of the output speech with optimal SNR
比較圖 4與圖 5可以看出,強噪聲背景下通過弱語音信號、噪聲及非線性系統的協同作用,噪聲被有效抑制,進而檢測出弱語音信號。雙穩態隨機共振將噪聲作為有用信號,有效抑制噪聲的同時仍存在噪聲殘留。
為進一步說明該方法在強噪聲背景下檢測弱語音信號的有效性,對多個語音信號在不同輸入SNR的情況下進行實驗。取語音數據庫里的另外3個語音信號分別作為語音樣本2、語音樣本3、語音樣本4,與語音樣本1做同樣的自適應隨機共振處理,實驗數據見表 1。比較表 1中的數據可以看到,不同含噪語音信號經過自適應隨機共振系統后,輸出SNR都有明顯的提高,且初始SNR越小,弱語音信號的檢測效果越好,說明該方法在強噪聲背景下檢測弱語音信號的有效性及魯棒性。
4 結論
本文研究了基于自適應隨機共振強噪聲背景下弱語音信號的檢測。以非線性系統輸出的SNR為評價函數,將自適應隨機共振與二次采樣相結合,同步優化參數a、b,成功實現了大參數條件下弱信號的自適應檢測。與傳統語音增強方法相比,該方法不是將噪聲作為一種干擾信號,通過削弱噪聲來增強語音信號,而是將噪聲能量轉化為有用信號的能量來提取弱語音信號。實驗分析表明,強噪聲背景下,該方法明顯調高了輸出語音信號的SNR,為提取弱語音信號提供了新的方法。
本文研究了基于自適應隨機共振強噪聲背景下弱語音信號的檢測。以非線性系統輸出的SNR為評價函數,將自適應隨機共振與二次采樣相結合,同步優化參數a、b,成功實現了大參數條件下弱信號的自適應檢測。與傳統語音增強方法相比,該方法不是將噪聲作為一種干擾信號,通過削弱噪聲來增強語音信號,而是將噪聲能量轉化為有用信號的能量來提取弱語音信號。實驗分析表明,強噪聲背景下,該方法明顯調高了輸出語音信號的SNR,為提取弱語音信號提供了新的方法。
引言
語音信號是人類傳播信息、感情交流的重要媒介,是人類最重要、最有效、最常用、最方便的通信方式。然而,在通信中,語音信號將不可避免地受到外界噪聲的干擾,最終使接收到的語音信號并非純凈的原始信號,而是已被噪聲污染過的含噪語音信號。含噪語音信號不利于對語音信號的分析,所以,語音信號增強的主要目的是從含噪語音信號中提取出較為純凈的原始語音信號,改善其質量。
由于噪聲特性各異,語音信號增強方法有很多。目前常用的語音信號增強的算法包括自適應噪聲抵消法、維納濾波器法、譜減法及小波變換法等。但上述方法都是將噪聲作為一種干擾信號,通過噪聲估計等方法,將其從含噪語音信號中去除。隨著信噪比(signal-to-noise ratio, SNR)不斷減小,上述方法的降噪效果也隨之變差,同時也會使語音信號丟字,或者波形失真。
隨機共振(stochastic resonance, SR)理論自1981年由Benzi等[1]提出,成功解釋了古氣象學中冷暖氣候交替出現的現象。隨機共振是弱信號、噪聲、非線性系統三者協同產生的一種非線性動力學行為,在發生隨機共振時,噪聲能量轉化為信號能量從而抑制了噪聲,提高了系統輸出信噪比,該理論在弱信號檢測中得到了廣泛的應用。但經典隨機共振理論須滿足絕熱近似條件,它只適用于小參數信號(幅值、頻率、噪聲強度均小于1),而在現實生活中,待檢測的弱信號一般都不滿足絕熱近似條件,所以一些學者嘗試對其進行預處理。文獻[2-6]提出了二次采樣、移頻或變尺度、結構參數自尋優算法,對信號頻率進行線性壓縮,使其滿足絕熱近似理論。文獻[7]采用將陣列傳感器與隨機共振相結合,處理多頻弱信號的檢測。在實際工程中,信號與噪聲通常是未知的,這就要求隨機共振系統能夠根據現場信號和噪聲強度,自動地調節系統自身的參數來達到隨機共振狀態,達到抑制噪聲提取信號的目的。1998年,Mitaim等[8]提出了自適應隨機共振。目前,參數優化方法針對單一參數進行優化,而假定其它參數不變。如,文獻[9]提出一種基于時頻的自適應算法,文獻[10]提出了尺度變換和調幅信號調制聯合應用自適應的方法,但這兩種方法都是令系統參數b和噪聲強度D不變,對參數a進行優化。文獻[11]中將系統參數a、b設置為常數,自適應改變噪聲強度,使輸出SNR達到最優。當固定參數值選取不當時,對某一參數的優化可能會失去意義,亦即系統始終無法達到最優共振。
本文以強噪聲背景下的語音信號為研究對象,采用二次采樣算法,對語音信號進行頻率壓縮,使其滿足絕熱近似理論,再通過自適應調節系統參數a、b,以系統輸出的SNR為評價函數,對多個系統參數同步優化,從而最優地檢測出語音信號。
1 雙穩態隨機共振基本理論
1.1 雙穩態隨機共振模型
隨機共振一般包含三個必不可缺的因素:輸入信號、雙穩或多穩態非線性系統、噪聲。經典的非線性雙穩態系統可由郎之萬方程描述:
| $ \frac{{{\rm{d}}x}}{{{\rm{d}}t}}=ax-b{x^3} + A\sin \left({2\pi ft} \right) + n\left(t \right) $ |
其中,E[n(t)]=0;E[n(t)n(t-τ)]=2Dδ(τ)。雙穩SR系統模型如圖 1所示。
圖1
雙穩SR系統模型
Figure1.
Model of bistable SR system
s(t)=Asin(2πft)為被檢測微弱周期信號,為白噪聲,D是噪聲強度,g(t)是均值為0,方差為1的白噪聲,勢函數表示非線性雙穩態系統,x(t)是系統輸出信號。圖 1說明:信號s(t)和噪聲n(t)通過雙穩態非線性系統V(x)后,信號、噪聲及非線性系統之間達到某種匹配時,一部分噪聲能量將轉化到信號身上,從而使信號放大形成隨機共振。
1.2 雙穩態隨機共振的SNR評價
對于語音信號,常用的評價語音增強算法有效性的方法是SNR,SNR定義如下[12]
| $ SNR=10\lg \frac{{\sum {s{{\left(t \right)}^2}} }}{{\sum {{{\left[ {y\left(t \right)s\left(t \right)} \right]}^2}} }} $ |
式中,s(t)表示含噪語音信號,y(t)表示增強后的語音信號。
2 含噪弱語音信號自適應隨機共振模型
本文對輸出信號的SNR進行分析,將SNR作為隨機共振的測度指標,對系統參數a、b同步優化,實現含噪語音信號自適應隨機共振。具體流程如圖 2所示。
圖2
含噪語音信號自適應隨機共振流程圖
Figure2.
Process of adaptive stochastic resonance of noisy speech signal
隨機共振絕熱近似理論要求信號的幅度和頻率均小于1,因此對于大參數信號,需要對這些大參數進行尺度變換,以滿足隨機共振的條件。
一般而言,語音信號的頻率范圍為300~3 500 Hz,頻率不滿足絕熱近似條件,無法通過雙穩態非線性系統達到隨機共振。因此本文會先通過二次采樣算法,將語音信號的頻率范圍線性壓縮到0~1 Hz,如圖 3所示,然后再通過自適應隨機共振得到最優輸出信號。
圖3
純凈語音信號二次采樣前后時域及頻域圖
Figure3.
Time domain and frequency domain of original speech before and after twice sampling
3 實驗結果與分析
本文實驗對象采用TIMIT標準語音數據庫,語音樣本的采樣頻率為16 kHz。語音樣本所含背景白噪聲來源于NOISE92標準噪聲數據庫。取語音樣本1,設頻率壓縮比R=3 200,二次采樣頻率fsr=fs/R=5。
圖 4表示含噪語音樣本1二次采樣后的波形及其頻譜圖,語音信號的頻率被壓縮到0~1 Hz范圍內,設初始SNR為-7 dB。從圖中可以看到,語音信號淹沒在噪聲中,且在整個頻域范圍都有很強的噪聲,只能在低頻段看到部分信號分布。
圖4
含噪語音樣本1二次采樣后時域和頻域圖
Figure4.
Time domain and frequency domain of noisy speech 1 after twice sampling
將含噪語音信號通過郎之萬方程(1),步長h=1/fsr=0.2,采用四階龍格-庫塔(Runge-Kutta)法求解該常微分方程。設參數a、b搜索范圍為[0.1, 4.1],循環步長為0.02,使其產生隨機共振,得到最優的輸出SNR,及最優參數a、b。經過系統參數自適應優化,當a=1.2,b=2.42時,輸出SNR最優達到0.86 dB,系統最優的輸出效果,如圖 5所示。含噪語音的SNR由初始值-7 dB提高到了0.86 dB,SNR增益為7.86 dB。從圖 5中可以看出,噪聲能量向低頻區發生了轉移,低頻區的語音信號被增強,含噪語音信號得到很大的改善。
圖5
最優SNR輸出語音信號時域波形及頻譜圖
Figure5.
Time domain waveform and frequency domain of the output speech with optimal SNR
比較圖 4與圖 5可以看出,強噪聲背景下通過弱語音信號、噪聲及非線性系統的協同作用,噪聲被有效抑制,進而檢測出弱語音信號。雙穩態隨機共振將噪聲作為有用信號,有效抑制噪聲的同時仍存在噪聲殘留。
為進一步說明該方法在強噪聲背景下檢測弱語音信號的有效性,對多個語音信號在不同輸入SNR的情況下進行實驗。取語音數據庫里的另外3個語音信號分別作為語音樣本2、語音樣本3、語音樣本4,與語音樣本1做同樣的自適應隨機共振處理,實驗數據見表 1。比較表 1中的數據可以看到,不同含噪語音信號經過自適應隨機共振系統后,輸出SNR都有明顯的提高,且初始SNR越小,弱語音信號的檢測效果越好,說明該方法在強噪聲背景下檢測弱語音信號的有效性及魯棒性。
4 結論
本文研究了基于自適應隨機共振強噪聲背景下弱語音信號的檢測。以非線性系統輸出的SNR為評價函數,將自適應隨機共振與二次采樣相結合,同步優化參數a、b,成功實現了大參數條件下弱信號的自適應檢測。與傳統語音增強方法相比,該方法不是將噪聲作為一種干擾信號,通過削弱噪聲來增強語音信號,而是將噪聲能量轉化為有用信號的能量來提取弱語音信號。實驗分析表明,強噪聲背景下,該方法明顯調高了輸出語音信號的SNR,為提取弱語音信號提供了新的方法。
本文研究了基于自適應隨機共振強噪聲背景下弱語音信號的檢測。以非線性系統輸出的SNR為評價函數,將自適應隨機共振與二次采樣相結合,同步優化參數a、b,成功實現了大參數條件下弱信號的自適應檢測。與傳統語音增強方法相比,該方法不是將噪聲作為一種干擾信號,通過削弱噪聲來增強語音信號,而是將噪聲能量轉化為有用信號的能量來提取弱語音信號。實驗分析表明,強噪聲背景下,該方法明顯調高了輸出語音信號的SNR,為提取弱語音信號提供了新的方法。