準確區分生理序列隨機性與混沌性,且不受序列長度與參數的影響是衡量復雜度算法的關鍵。本文提出了一種編碼式Lempel-Ziv(LZ)算法,分別從序列隨機性與混沌性的區分、長度的影響、動力學性質突變的敏感性、高斯白與粉紅噪聲復雜度測量等4個方面與經典LZ算法、多狀態LZ算法、樣本熵以及排列熵進行比較。結果顯示,在短、中、長時(100、500、5 000點)下,編碼式LZ算法均能準確區分隨機與混沌性,正確測度高斯噪聲的復雜度低于粉紅噪聲,并能準確響應序列動力學性質的改變。本文采用美國麻省理工學院(MIT)和波士頓貝斯以色列醫院(BIH)聯合建立的的MIT-BIH心電數據庫中的充血性心力衰竭RR間期(CHF-RR)數據和正常竇性心律RR間期(NSR-RR)數據進行測試,實驗結果顯示,在各種時長下,編碼式LZ復雜度算法均能準確地得出心力衰竭的復雜度低于竇性心律(P<0.01)的結果,且不受長度與參數影響,具有較強的泛化能力。
引用本文: 張亞濤, 劉澄玉, 劉海, 魏守水. 一種編碼式Lempel-Ziv復雜度用于生理信號復雜度分析. 生物醫學工程學雜志, 2016, 33(6): 1176-1182. doi: 10.7507/1001-5515.20160186 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
時間序列的復雜度反應了序列所含的非線性動力學特征,而生理信號的復雜度也反映了人體相關特征與身體病癥的改變[1],因此準確分析生理信號的復雜度,對于信號的非線性分析以及生理、病理特征的識別具有重要意義。
目前經典的Lempel-Ziv(classic Lempel-Ziv,CLZ)復雜度及其變形算法,如多狀態LZ(multi-state LZ,MLZ)復雜度算法[2-5]以及熵方法,如樣本熵(sample entropy,SampEn)[6-7]、排列熵(pecmutation entropy,PE)[8-9]與多尺度熵[10-12]等已被廣泛用于時間序列復雜度分析。其中CLZ表征了時間序列中新模式隨序列長度增加的速率,其值越大說明新模式出現的概率越高,序列越趨向于隨機[2, 5]。CLZ是將序列進行2狀態的符號化,其過程是把原始時間序列與一個預設閾值(序列的中值或均值)進行比較,大于該閾值則為1,否則為0;最終將原序列轉換為一個0/1符號序列。然而該過程會丟失大量原始序列信息,易造成“過粗粒化”,混淆序列的隨機性與混沌特性,甚至改變原序列的動力學特征,造成復雜度分析結果不準確。而MLZ復雜度算法[3-4],即包含了3狀態[13-14];以及其他更多狀態的LZ算法,則因盡可能地保留原序列信息而得到廣泛的應用,然而這種算法的精度受到狀態數的影響較大。文獻[3-4]指出狀態數量在40以上時才能保證MLZ算法得到較好結果,這樣就可能導致狀態數的無限制增長。事實上,狀態數并非越多越好,因此MLZ算法的關鍵是選擇最佳狀態數,而最佳狀態數的選擇方法尚未有明確依據,僅依靠經驗,這就限制了MLZ的使用。
另一類常用的時間序列復雜度分析方法,如SampEn、PE、多尺度熵等都以香農熵為基礎,均是序列中新信息產生的測度。其中SampEn和PE都是在一維方向計算序列的復雜度,因計算簡單、具有較高的魯棒性而得到廣泛的應用。然而它們混淆了時間序列的隨機性與混沌特性,且不能正確度量高斯白噪聲與1/f粉紅噪聲的復雜度,造成復雜性度量不準確。多尺度熵引入了不同的時間尺度,然而在實際應用中,過高的尺度會導致心電波形湮滅和信息的丟失,從而缺乏實際意義。而且因為尺度的引入,致使序列長度必須足夠長,才能保證尺度化后的新序列仍有足夠的原始序列信息,因此限制了其在生物醫學領域的應用,這是因為在臨床診斷中采集的生理信號常常會有時長的限制。同時,熵方法的性能受參數,如嵌入維數m、相似性容限r與延遲時間τ等影響較大[7, 15-16]。
為此,本文提出了一種新的編碼式LZ(encoding LZ,ELZ)復雜度算法,相對CLZ、MLZ、SampEn和PE,ELZ能夠準確地區分時間序列的隨機性與非線性混沌特征,也能正確地度量高斯白噪聲與1/f粉紅噪聲復雜度。最后,將這些方法應用于美國麻省理工學院(massachusetts institute of technology,MIT)和波士頓貝斯以色列醫院(Beth Israel hospital,BIH)聯合建立的的MIT-BIH心電數據庫中的充血性心力衰竭RR間期數據庫(congestive heart failure RR interval database,CHF-RR)和正常竇性心律RR間期數據庫(normal sinus rhythm RR interval database,NSR-RR)的復雜性分析中,結果表明ELZ復雜度算法能夠正確分析充血性心力衰竭數據和正常竇性心律心電數據的復雜度,并且在不同長度時間序列中均保持穩定的性能。本文的研究結果不僅解決了其他LZ復雜度算法對含噪聲過多信號與正常信號的復雜度混淆的問題,而且對普遍意義下的各種非線性復雜性測度尤其是LZ算法在時間序列復雜性與隨機性,隨機性與混沌性的解釋和區分能力上有極大促進作用。
1 ELZ復雜度算法
計算LZ復雜度,一般需先對原始時間序列進行粗粒化處理,將其轉換為一個用少量符號表示的新序列,然后計算新序列復雜度值。CLZ的粗粒化過程采用原始序列與序列均值或中值做比較,當信號的數據點大于均值或中值時,該點映射為1,否則映射為0,最終得到新的時間序列。這種粗粒化處理往往造成“過粗粒化”現象,即丟失大量原始序列信息,甚至改變原序列的動力學特征,致使其復雜度分析的精度降低。本文中,則使用序列均值作為粗粒化閾值。
MLZ復雜度的計算是先使用多個狀態將原始序列符號化[3-4],再計算新序列復雜度值。其粗粒化過程是將原始序列X=x1,x2,…,xn轉換為一個具有0,1,2,…,γ-1個符號的序列S,其中γ是大于3的整數。該算法首先獲得信號的上下界li和ls。然后γ+1個門限在li和ls區間內等間隔的平分。最終,序列S包含γ個狀態,其遵循下列的規則[3-4]:
| $S\left( i \right)=\left\{ \begin{array}{*{35}{l}} 0if\text{ } & \text{ }{{U}_{1}}{{x}_{i}}\le {{U}_{2}} & {} \\ 1if & \text{ }{{U}_{2}}{{x}_{i}}\le {{U}_{3}} & ,i=1,2,\ldots ,n \\ \cdots & \cdots & {} \\ \gamma -1\text{ }if & {{U}_{\gamma }}{{x}_{i}}\le {{U}_{\gamma +1}} & {} \\ \end{array} \right.$ |
其中U是γ+1個門限,n是信號的長度。本文設置γ為90用于計算MLZ。
本文提出的編碼式LZ算法使用一種新的粗粒化方法將原始信號X=x1,x2,…,xn中的每一個xi轉換成一個由3個二進制位組成的符號b1(i)b2(i)b3(i)。新的粗粒化過程如下:
(1) 第一個二進制位b1(i)由xi和門限值Tmean比較來確定。門限值Tmean是信號X的均值。b1(i)的定義如下:
| ${{b}_{1}}\left( i \right)=\left\{ \begin{array}{*{35}{l}} 0\text{ }if\text{ }{{x}_{i}}{{T}_{\text{mean}}} \\ 1\text{ }if\text{ }{{x}_{i}}\ge {{T}_{\text{mean}}}~ \\ \end{array} \right.\text{, }i=1,2,\ldots ,n$ |
可以看出,b1反映了信號的整體變化趨勢,然而丟掉了信號的大量細節信息。
(2) 第二個二進制位b2(i)通過xi和它的前一個點xi-1的差來確定,定義如下:
| ${{b}_{2}}\left( i \right)=\left\{ \begin{array}{*{35}{l}} 0\text{ }if\text{ }{{x}_{i}}-{{x}_{i-1}}0 \\ 1\text{ }if\text{ }{{x}_{i}}-{{x}_{i-1}}\ge 0 \\ \end{array} \right.\text{, }i=1,2,3,\ldots ,n$ |
其中,b2(1)是0,b2反映了信號的改變趨勢和細節信息。
(3) 第三個二進制位b3(i)的確定分為兩步進行:首先,計算序列中兩個相鄰點的距離的均值。同時,定義一個標志變量Flag表示兩相鄰點的距離遠近程度,當x(i)和前一個點x(i-1)的距離大于等于均值時,則該標志變量Flag為1,否則為0。Flag定義如下:
| $Flag\left( i \right)=\left\{ \begin{array}{*{35}{l}} 0\text{ }if|{{x}_{i}}-{{x}_{i-1}}|dm \\ 1\text{ }if|{{x}_{i}}-{{x}_{i-1}}\ge dm\text{ } \\ \end{array} \right.\text{,}i=1,2,3,\ldots ,n$ |
其中,dm是信號X中相鄰點距離的均值。Flag(i)反映了當前點x(i)與前一個點x(i-1)距離遠近的程度,如Flag(i)是0,則意味著x(i)是相對接近于點x(i-1)的,否則這兩個點是相對較遠的。其次,第三個二進制位b3(i)計算公式如下:
| ${{b}_{3}}\left( i \right)=NOT[{{b}_{2}}\left( i \right)XOR\text{ }flag\left( i \right)],i=2,3,\ldots ,n$ |
其中,b3(1) 等于0。可以看出,b2和b3的組合反映了x(i)大于或小于x(i-1)的程度,如b2等于1且Flag(i)也等于1,則x(i)是相對更大于x(i-1)的。這是因為x(i)不僅僅大于x(i-1)而且相對遠離x(i-1)。同樣地,若b2等于0并且Flag(i)等于1,則x(i)相對更小于x(i-1),因為x(i)不僅僅小于x(i-1) 而且相對遠離x(i-1)。
總體上,新的編碼式粗粒化方式不僅反映了時間序列變化的整體趨勢(b1位),也包含了序列變化的細節信息(b2,b3位),同時弱化了序列中細節變化微小的改變,而強化了細節變化較大的改變(b3位)。通過上述步驟將原始時間序列轉換為一個新的8狀態時間序列。計算該序列ELZ復雜度值的過程如下[5, 17-18]:
設S和Q分別為兩個符號序列,SQ是S和Q的連接。SQπ表示把SQ中最后一個字符去掉后所得到字符串(π表示刪除最后一個字符的操作)。令v(SQπ)表示SQπ中所有不同子串的集合。初始時,令c(n)=1,S=s1,Q=s2,SQπ=s1。假定S=s1,s2,…,sr,Q=sr+1,則SQπ=s1,s2,…,sr;如果Q屬于v(SQπ),則sr+1是S=s1,s2,…,sr字符串的一個子串,即Q是SQπ的一個子串,那么S不變,只需要將Q更新為sr+1,sr+2,接著判斷Q是否為SQπ的子串。重復該過程直到Q不屬于v(SQπ)。此時,Q=sr+1,sr+2,…,sr+i,不是SQπ=s1,s2,…,sr,sr+1,…,sr+i-1的子串,則c(n)加1。此后,更新S為S=s1,s2,…,sr+i,并且Q=sr+i+1;重復這個上述過程直到Q的最后一個字符。此時,c(n)是包含于R中的不同子串的個數,其反映了序列中新模式的個數,且c(n)的值與時間序列長度相關,因此應將c(n)標準化處理,以減少其與長度相關性[5, 13, 17]。
| $c\left( n \right)\frac{n}{(1-{{\varepsilon }_{n}}){{\log }_{\alpha }}\left( n \right)},$ |
其中n是序列的長度,α是序列R中可能的符號個數。對于CLZ,α是2。εn是一個很小的量,且εn→0 (n→∞)。因此有
| $\underset{n\to \infty }{\mathop{Lim}}\,c\left( n \right)=b\left( n \right)=\frac{n}{{{\log }_{\alpha }}\left( n \right)}.$ |
最后,將c(n)標準化為C(n),即通常意義上的LZ復雜度值:
| $C\left( n \right)=c\left( n \right)\frac{{{\log }_{\alpha }}\left( n \right)}{n},$ |
其中n是序列長度,α是序列R中可能的符號個數,C(n)是標準化后的LZ復雜度,表示了序列中新模式的產生率,且僅在序列長度較短時與長度相關[5]。詳細LZ復雜度算法可參見文獻[13, 17]。
為了進一步驗證ELZ性能,本文還對比了SampEn和PE。針對不同類型的序列,PE的參數設置各不相同[15]。因此本文根據文獻[15],選擇適合大多數序列的參數取值,其中嵌入維數m為5,延遲時間τ為1。依據經驗,本文課題組將SampEn的嵌入維數m與相似容忍度為0.15×SD,SD是序列標準差。
2 實驗結果與性能分析
2.1 序列隨機性和非線性混沌特征的區分能力
為了分析ELZ對時間序列隨機性和非線性混沌特征的區分能力,本文分別使用100點(短時)、500點(中時)和5 000點(長時)三種長度的序列組,每組序列均包括高斯噪聲(gauss noise,Gau),混合噪聲(mixed noise,MIX),Logistic(Logi)映射和周期序列。其中Gau由MATLAB的wgn函數產生。MIX(p)序列是在長度為N的正弦信號中,隨機選擇N×p個數據點替換為獨立同分布的隨機噪聲。本文設定p分別為0.2和0.4。對于Logi映射序列xn+1=μ×xn×(1-xn),1<μ≤4,本文選擇μ=3.8,4.0作為混沌序列;μ=3.5作為周期序列。我們分別計算三種時長的序列組的ELZ、CLZ、MLZ、SampEn和PE。同時為了盡可能保證實驗結果的合理性,每一類信號均用20樣本。
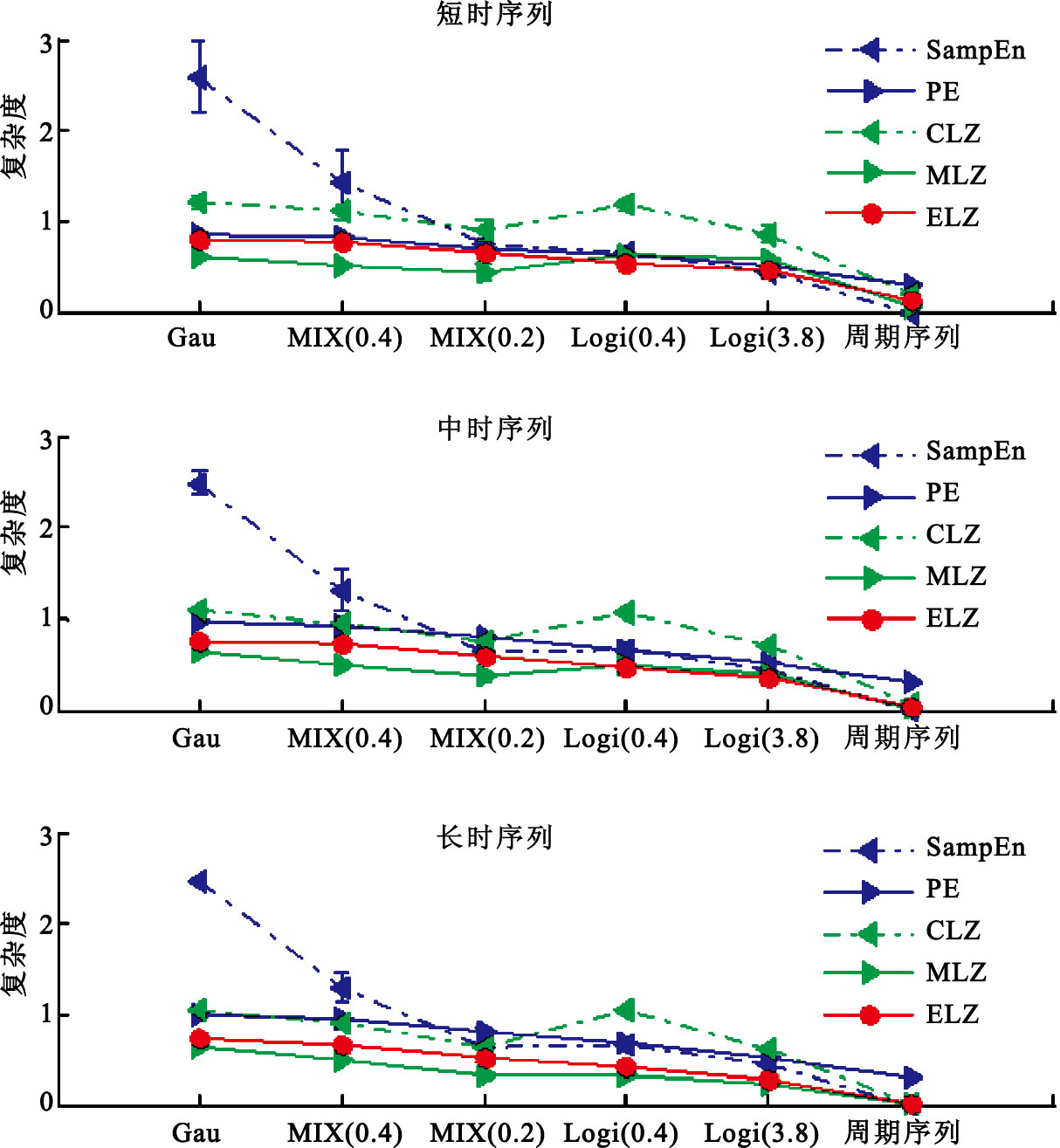
非線性研究發現,混沌與隨機并不一樣,混沌是介于有序與無序、隨機性與確定性之間的一種偽隨機狀態[19],因此從Gau, MIX(0.4), MIX(0.2), Logi(4.0), Logi(3.8)到周期序列,隨機性或無序性逐漸降低,而有序性逐漸增大。如圖 1所示,ELZ與PE在短時、中時、長時序列中,隨序列隨機性降低,依次按照由Gau,MIX(0.4),MIX(0.2),Logi(4.0),Logi(3.8)到周期序列的順序遞減。因此ELZ與PE均能夠區分序列的隨機性與混沌特性,能夠準確反映序列隨機性降低,有序性增強的趨勢。然而,ELZ的計算與參數無關,其泛化能力與客觀性更強;而PE的計算受到嵌入維數m和延遲時間τ的影響較大,不同的參數所得結果并不一致。如圖 1所示,ELZ在短時、中時與長時序列中均能保持穩定的性能,因此ELZ與序列長度無關。對于CLZ與MLZ而言,在三種時長的序列組中,均在噪聲序列與Logi混沌序列間產生波動,即Logi(4.0)的值高于MIX(0.2),因此它們混淆了序列的隨機性與混沌特性。在短時序列組中,SampEn隨著序列隨機性降低,熵值依次降低,能夠正確區分序列隨機性與混沌性,然而在中時和長時序列組中,SampEn未能準確測量,即Logi(4.0)的值略高于MIX(0.2)。
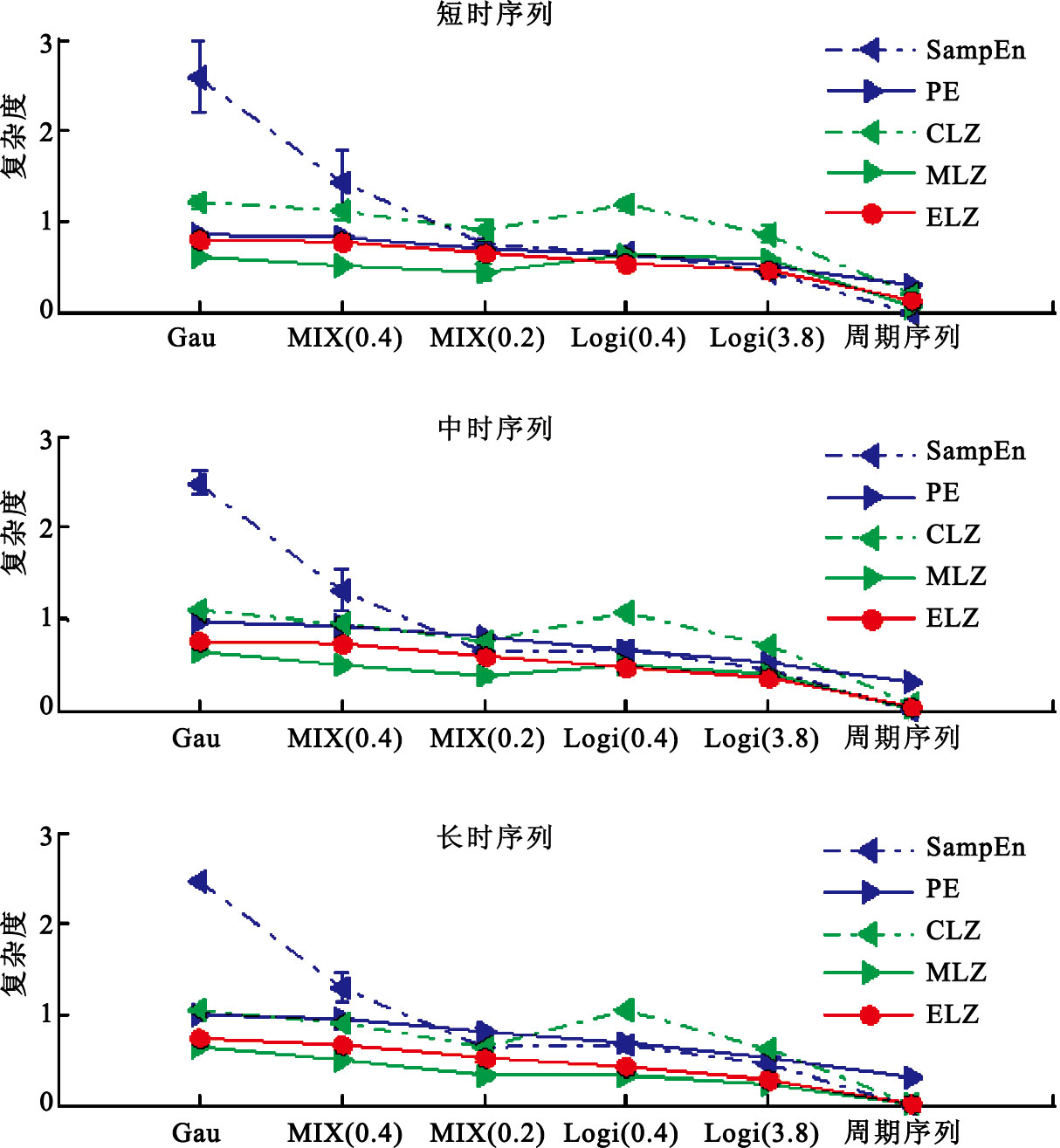 圖1
六類時間序列的SampEn、PE、CLZ、MLZ和ELZ的值
Figure1.
Values of the six kinds of time sequence for SampEn,PE,CLZ,MLZ and ELZ
圖1
六類時間序列的SampEn、PE、CLZ、MLZ和ELZ的值
Figure1.
Values of the six kinds of time sequence for SampEn,PE,CLZ,MLZ and ELZ
2.2 對Gau與1/f粉紅噪聲的復雜度分析
研究發現[11, 20-21]1/f粉紅噪聲序列比白噪聲具有更為復雜的結構。于是對粉紅噪聲與白噪聲復雜度的測量也被用于檢測ELZ算法的性能,同時本文仍然對比了CLZ、MLZ、SampEn和PE。該實驗仍然使用100、500和5 000點三種長度的序列組,每組序列均包括Gau和1/f粉紅噪聲,且每類序列的樣本數為20。
如表 1所示為ELZ與CLZ、MLZ、SampEn和PE方法在Gau與1/f粉紅噪聲上的均值與標準差,以(x±s)表示,以及Gau與1/f粉紅噪聲復雜度值之間的差異分析結果。可以看出只有ELZ方法所得到粉紅噪聲復雜度高于Gau噪聲復雜度,且兩組間的差異具有統計學意義(P<0.01)。而其余4種方法所得結果均為高斯噪聲復雜度大于1/f噪聲復雜度。這個結果同樣表明,ELZ復雜度算法在對不同時長序列度量均保持穩定的性能,且能夠正確反映序列復雜度。
2.3 ELZ對序列突變的敏感性分析
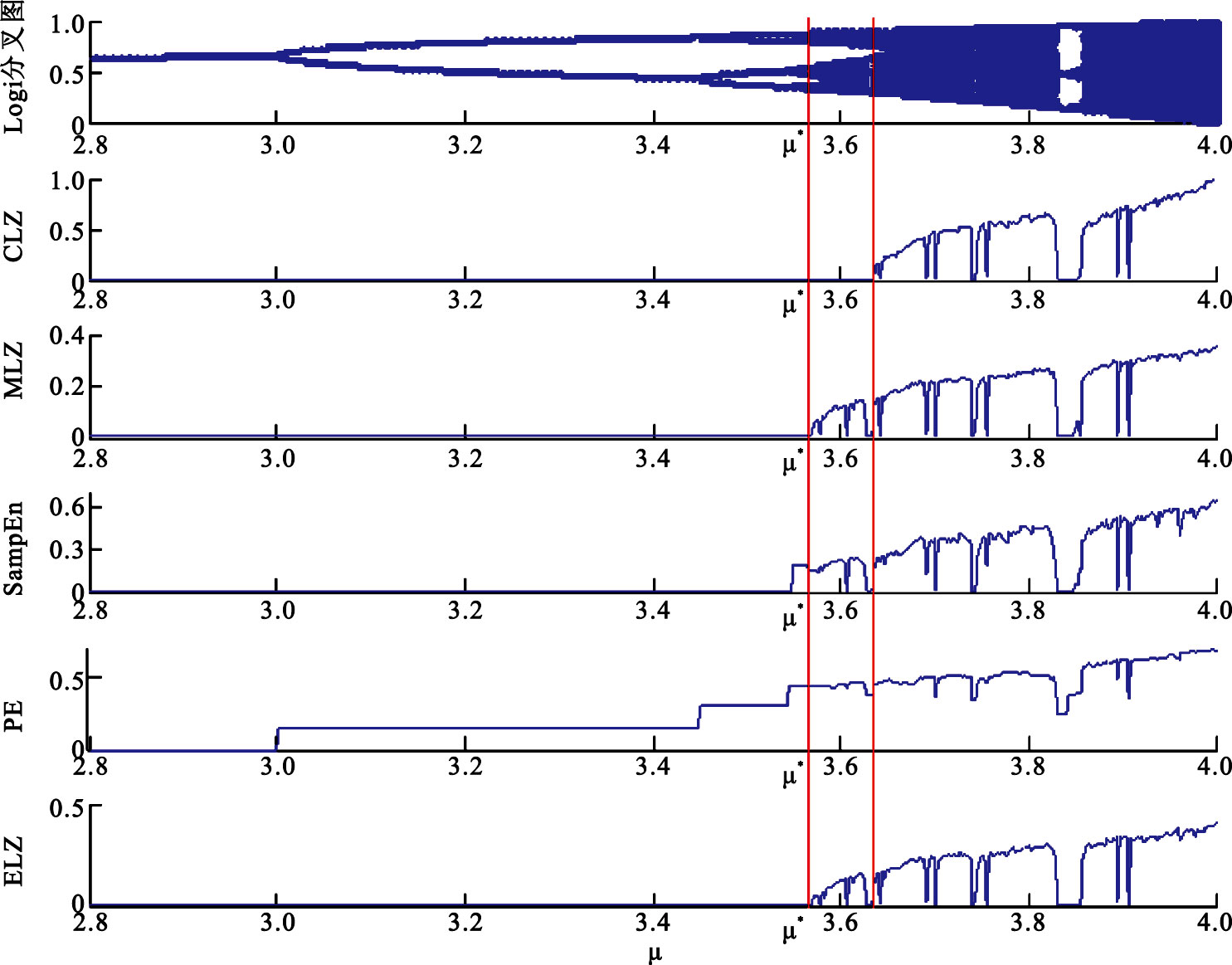
為了檢驗ELZ方法對序列動力學性質突變的響應能力。我們將CLZ、MLZ、SampEn、 PE和ELZ方法分別對Logi映射中的突變進行檢測。在Logi映射中,當μ=μ*=3.569 945 672時,Logi序列由倍周期突變為混沌,此時序列的動力學性質發生改變,不規則性應發生明顯變化。
如圖 2所示,Logi映射的分叉圖與上述5種方法針對Logi序列數據突變的敏感性分析結果表明了CLZ方法在μ*時刻并不能及時檢測數據由倍周期到混沌的突變。MLZ和ELZ方法的敏感性分析表明,這兩種方法都能夠在μ*時刻,及時檢測到數據到混沌狀態的突變。如圖 2所示的SampEn和PE的實驗結果,顯示出這兩種熵算法對序列的突變較為敏感。同時SampEn在Logi序列參數μ尚未達到μ*時,就已經檢測到信號倍周期改變;而PE更為敏感,其能夠檢測到Logi序列的信號周期倍增的每一次改變[22-23]。相比而言,CLZ在檢測信號動力學特性突變中,有明顯的延遲;SampEn與PE對序列的狀態變化尤為敏感,然而這兩種熵算法對序列的倍周期變化也具有較強的敏感性,這樣就混淆了周期與混沌的動力學特征,而這恰恰是我們所不希望看到的;ELZ與MLZ都能較好地在Logi映射的μ接近μ*時(即序列由倍周期變為混沌時),則可及時檢測到序列變化。
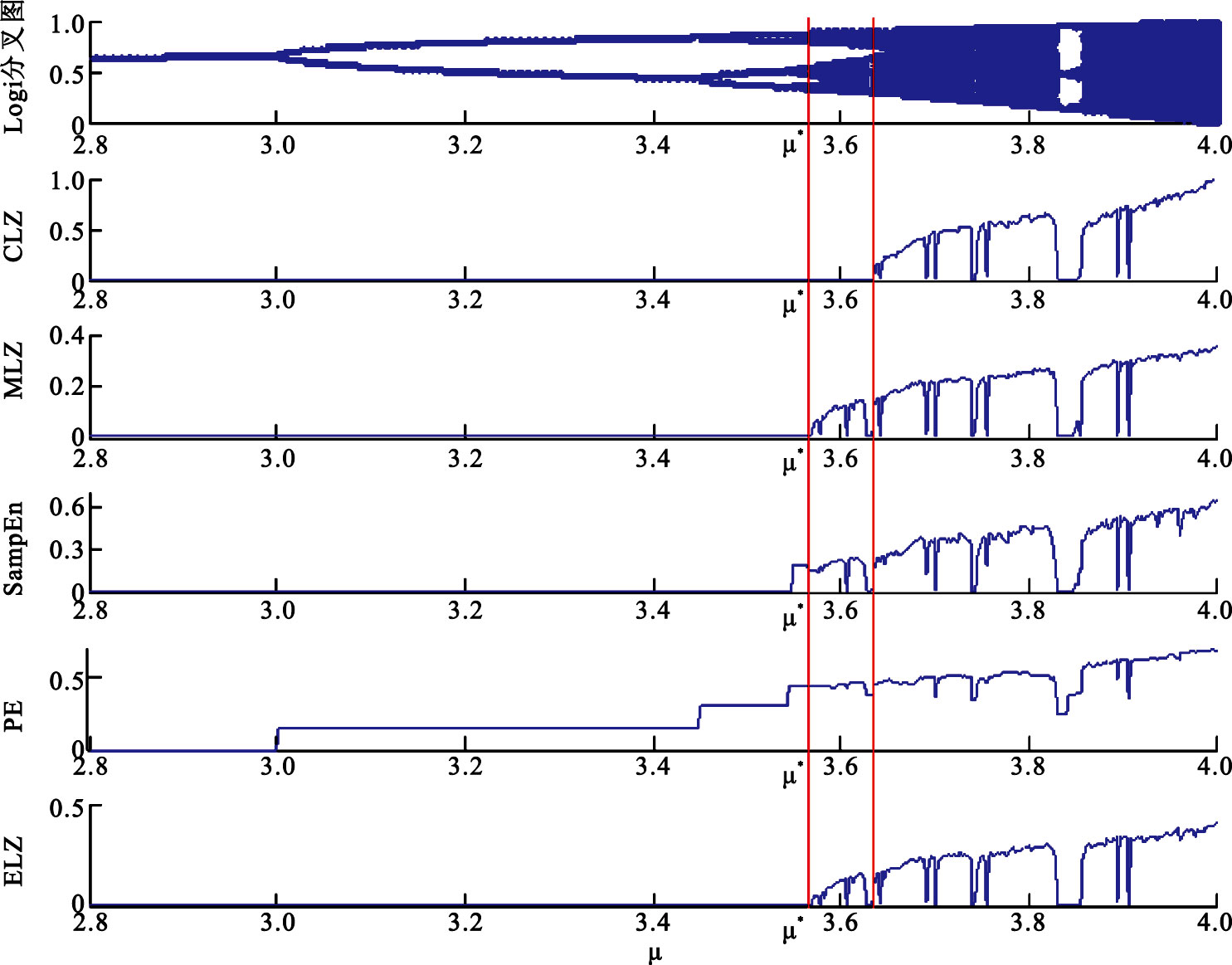 圖2
ELZ、CLZ、MLZ、SampEn和PE對Logi序列數據突變的敏感性的分析
Figure2.
Analysis of sensitivity of data change of the logistic mapping for ELZ,CLZ,MLZ,SampEn and PE on the logistic mapping
圖2
ELZ、CLZ、MLZ、SampEn和PE對Logi序列數據突變的敏感性的分析
Figure2.
Analysis of sensitivity of data change of the logistic mapping for ELZ,CLZ,MLZ,SampEn and PE on the logistic mapping
2.4 ELZ對生理時間序列復雜度分析
本文繼續將ELZ用于實際診斷數據的復雜性度量,同時也對比了CLZ、MLZ、SampEn和PE在實際數據上的結果。數據來源于MIT-BIH提供的CHF-RR和NSR-RR數據庫 [24-25]。其中CHF-RR數據庫是充盈性心衰數據庫,采集年齡34~79歲之間的29組心電數據。NSR-RR數據庫是包括54個長時正常竇性心律心電數據庫,數據來源于30位男性(年齡28~76歲),24位女性(年齡58~73歲)。兩組數據庫采樣率均為128 Hz,采樣時間在18~24 h之間。這些心電數據在使用之前必須進行預處理,首先刪除了RR間期大于2 s的心電數據,這是因為超過2 s的RR間期一般是由信號質量較差的段的斷裂信息形成[16]。原始數據中每個心拍都被標注為正常(‘N’)或者病變,其中病變數據常常是因為室上性心率過速和室早造成。為了得到正常心電數據,我們也刪除了這些心律失常的心拍。同時,RR間期中存在的不平穩趨勢也會影響到實驗結果,因此我們用一種快速算法提取RR間期的基線并進行了矯正[26-27]。最終RR間期數據被按100、500、5 000點的窗口長度分段。
心電信號分析中,正常竇性心律信號的復雜度低于心力衰竭信號的復雜度已經是一種共識[11, 20, 28]。如表 2所示,顯示了ELZ、CLZ、MLZ、SampEn和PE在心律失常與正常竇性心律上的實驗結果以及兩組數據間差異性分析結果。其中,CLZ得出心力衰竭信號復雜度值高于竇性心律的值,并不能反映真實情況。而SampEn和PE雖然都能正確度量心力衰竭組復雜度低于與竇性心律組復雜度,然而在短時(100點)情況下,兩組的差異不具有統計學意義(P>0.05)。這說明信號長度對SampEn和PE有一定影響,對短時生理信號的分析效果相對于ELZ方法并不理想,而在臨床診斷中,短時生理信號則較為常見。ELZ與MLZ在各種長度的信號中,都能正確分析心力衰竭組與竇性心律組的復雜度,且兩組間差異具有統計學意義(P<0.01)。與ELZ方法相比,MLZ需要憑經驗設置狀態個數,而SampEn和PE的性能均與參數設置有關,其中SampEn受嵌入維數m和相似容忍度r影響較大;PE受嵌入維數m和延遲時間τ的影響較大,而且對于不同種類的序列,最優的參數并不一致[15-16]。然而ELZ方法,無需任何參數設置,減少了其他因素對性能的影響,具有較強的泛化能力。
3 結論
本文提出了一種ELZ復雜度算法,該方法在短時、中時與長時序列中,均能有效地區分序列隨機性與混沌性,較其他算法相比,避免了將兩者混淆;并可正確地度量Gau與1/f粉紅噪聲的復雜度,同時能夠及時反映信號動力學特征變化。來自MIF-BIH數據庫的真實數據實驗表明,該方法在短時、中時與長時的心電信號中,均能正確度量心力衰竭與竇性心律的復雜度。這也反映出,ELZ方法不僅在不同長度序列能保持性能穩定,同時也避免了粗粒化過程中量化狀態的無限制增長,并可避免熵方法中參數對算法性能的影響,因此具有較強的泛化能力,對于各種時長的生理信號極具應用價值。
引言
時間序列的復雜度反應了序列所含的非線性動力學特征,而生理信號的復雜度也反映了人體相關特征與身體病癥的改變[1],因此準確分析生理信號的復雜度,對于信號的非線性分析以及生理、病理特征的識別具有重要意義。
目前經典的Lempel-Ziv(classic Lempel-Ziv,CLZ)復雜度及其變形算法,如多狀態LZ(multi-state LZ,MLZ)復雜度算法[2-5]以及熵方法,如樣本熵(sample entropy,SampEn)[6-7]、排列熵(pecmutation entropy,PE)[8-9]與多尺度熵[10-12]等已被廣泛用于時間序列復雜度分析。其中CLZ表征了時間序列中新模式隨序列長度增加的速率,其值越大說明新模式出現的概率越高,序列越趨向于隨機[2, 5]。CLZ是將序列進行2狀態的符號化,其過程是把原始時間序列與一個預設閾值(序列的中值或均值)進行比較,大于該閾值則為1,否則為0;最終將原序列轉換為一個0/1符號序列。然而該過程會丟失大量原始序列信息,易造成“過粗粒化”,混淆序列的隨機性與混沌特性,甚至改變原序列的動力學特征,造成復雜度分析結果不準確。而MLZ復雜度算法[3-4],即包含了3狀態[13-14];以及其他更多狀態的LZ算法,則因盡可能地保留原序列信息而得到廣泛的應用,然而這種算法的精度受到狀態數的影響較大。文獻[3-4]指出狀態數量在40以上時才能保證MLZ算法得到較好結果,這樣就可能導致狀態數的無限制增長。事實上,狀態數并非越多越好,因此MLZ算法的關鍵是選擇最佳狀態數,而最佳狀態數的選擇方法尚未有明確依據,僅依靠經驗,這就限制了MLZ的使用。
另一類常用的時間序列復雜度分析方法,如SampEn、PE、多尺度熵等都以香農熵為基礎,均是序列中新信息產生的測度。其中SampEn和PE都是在一維方向計算序列的復雜度,因計算簡單、具有較高的魯棒性而得到廣泛的應用。然而它們混淆了時間序列的隨機性與混沌特性,且不能正確度量高斯白噪聲與1/f粉紅噪聲的復雜度,造成復雜性度量不準確。多尺度熵引入了不同的時間尺度,然而在實際應用中,過高的尺度會導致心電波形湮滅和信息的丟失,從而缺乏實際意義。而且因為尺度的引入,致使序列長度必須足夠長,才能保證尺度化后的新序列仍有足夠的原始序列信息,因此限制了其在生物醫學領域的應用,這是因為在臨床診斷中采集的生理信號常常會有時長的限制。同時,熵方法的性能受參數,如嵌入維數m、相似性容限r與延遲時間τ等影響較大[7, 15-16]。
為此,本文提出了一種新的編碼式LZ(encoding LZ,ELZ)復雜度算法,相對CLZ、MLZ、SampEn和PE,ELZ能夠準確地區分時間序列的隨機性與非線性混沌特征,也能正確地度量高斯白噪聲與1/f粉紅噪聲復雜度。最后,將這些方法應用于美國麻省理工學院(massachusetts institute of technology,MIT)和波士頓貝斯以色列醫院(Beth Israel hospital,BIH)聯合建立的的MIT-BIH心電數據庫中的充血性心力衰竭RR間期數據庫(congestive heart failure RR interval database,CHF-RR)和正常竇性心律RR間期數據庫(normal sinus rhythm RR interval database,NSR-RR)的復雜性分析中,結果表明ELZ復雜度算法能夠正確分析充血性心力衰竭數據和正常竇性心律心電數據的復雜度,并且在不同長度時間序列中均保持穩定的性能。本文的研究結果不僅解決了其他LZ復雜度算法對含噪聲過多信號與正常信號的復雜度混淆的問題,而且對普遍意義下的各種非線性復雜性測度尤其是LZ算法在時間序列復雜性與隨機性,隨機性與混沌性的解釋和區分能力上有極大促進作用。
1 ELZ復雜度算法
計算LZ復雜度,一般需先對原始時間序列進行粗粒化處理,將其轉換為一個用少量符號表示的新序列,然后計算新序列復雜度值。CLZ的粗粒化過程采用原始序列與序列均值或中值做比較,當信號的數據點大于均值或中值時,該點映射為1,否則映射為0,最終得到新的時間序列。這種粗粒化處理往往造成“過粗粒化”現象,即丟失大量原始序列信息,甚至改變原序列的動力學特征,致使其復雜度分析的精度降低。本文中,則使用序列均值作為粗粒化閾值。
MLZ復雜度的計算是先使用多個狀態將原始序列符號化[3-4],再計算新序列復雜度值。其粗粒化過程是將原始序列X=x1,x2,…,xn轉換為一個具有0,1,2,…,γ-1個符號的序列S,其中γ是大于3的整數。該算法首先獲得信號的上下界li和ls。然后γ+1個門限在li和ls區間內等間隔的平分。最終,序列S包含γ個狀態,其遵循下列的規則[3-4]:
| $S\left( i \right)=\left\{ \begin{array}{*{35}{l}} 0if\text{ } & \text{ }{{U}_{1}}{{x}_{i}}\le {{U}_{2}} & {} \\ 1if & \text{ }{{U}_{2}}{{x}_{i}}\le {{U}_{3}} & ,i=1,2,\ldots ,n \\ \cdots & \cdots & {} \\ \gamma -1\text{ }if & {{U}_{\gamma }}{{x}_{i}}\le {{U}_{\gamma +1}} & {} \\ \end{array} \right.$ |
其中U是γ+1個門限,n是信號的長度。本文設置γ為90用于計算MLZ。
本文提出的編碼式LZ算法使用一種新的粗粒化方法將原始信號X=x1,x2,…,xn中的每一個xi轉換成一個由3個二進制位組成的符號b1(i)b2(i)b3(i)。新的粗粒化過程如下:
(1) 第一個二進制位b1(i)由xi和門限值Tmean比較來確定。門限值Tmean是信號X的均值。b1(i)的定義如下:
| ${{b}_{1}}\left( i \right)=\left\{ \begin{array}{*{35}{l}} 0\text{ }if\text{ }{{x}_{i}}{{T}_{\text{mean}}} \\ 1\text{ }if\text{ }{{x}_{i}}\ge {{T}_{\text{mean}}}~ \\ \end{array} \right.\text{, }i=1,2,\ldots ,n$ |
可以看出,b1反映了信號的整體變化趨勢,然而丟掉了信號的大量細節信息。
(2) 第二個二進制位b2(i)通過xi和它的前一個點xi-1的差來確定,定義如下:
| ${{b}_{2}}\left( i \right)=\left\{ \begin{array}{*{35}{l}} 0\text{ }if\text{ }{{x}_{i}}-{{x}_{i-1}}0 \\ 1\text{ }if\text{ }{{x}_{i}}-{{x}_{i-1}}\ge 0 \\ \end{array} \right.\text{, }i=1,2,3,\ldots ,n$ |
其中,b2(1)是0,b2反映了信號的改變趨勢和細節信息。
(3) 第三個二進制位b3(i)的確定分為兩步進行:首先,計算序列中兩個相鄰點的距離的均值。同時,定義一個標志變量Flag表示兩相鄰點的距離遠近程度,當x(i)和前一個點x(i-1)的距離大于等于均值時,則該標志變量Flag為1,否則為0。Flag定義如下:
| $Flag\left( i \right)=\left\{ \begin{array}{*{35}{l}} 0\text{ }if|{{x}_{i}}-{{x}_{i-1}}|dm \\ 1\text{ }if|{{x}_{i}}-{{x}_{i-1}}\ge dm\text{ } \\ \end{array} \right.\text{,}i=1,2,3,\ldots ,n$ |
其中,dm是信號X中相鄰點距離的均值。Flag(i)反映了當前點x(i)與前一個點x(i-1)距離遠近的程度,如Flag(i)是0,則意味著x(i)是相對接近于點x(i-1)的,否則這兩個點是相對較遠的。其次,第三個二進制位b3(i)計算公式如下:
| ${{b}_{3}}\left( i \right)=NOT[{{b}_{2}}\left( i \right)XOR\text{ }flag\left( i \right)],i=2,3,\ldots ,n$ |
其中,b3(1) 等于0。可以看出,b2和b3的組合反映了x(i)大于或小于x(i-1)的程度,如b2等于1且Flag(i)也等于1,則x(i)是相對更大于x(i-1)的。這是因為x(i)不僅僅大于x(i-1)而且相對遠離x(i-1)。同樣地,若b2等于0并且Flag(i)等于1,則x(i)相對更小于x(i-1),因為x(i)不僅僅小于x(i-1) 而且相對遠離x(i-1)。
總體上,新的編碼式粗粒化方式不僅反映了時間序列變化的整體趨勢(b1位),也包含了序列變化的細節信息(b2,b3位),同時弱化了序列中細節變化微小的改變,而強化了細節變化較大的改變(b3位)。通過上述步驟將原始時間序列轉換為一個新的8狀態時間序列。計算該序列ELZ復雜度值的過程如下[5, 17-18]:
設S和Q分別為兩個符號序列,SQ是S和Q的連接。SQπ表示把SQ中最后一個字符去掉后所得到字符串(π表示刪除最后一個字符的操作)。令v(SQπ)表示SQπ中所有不同子串的集合。初始時,令c(n)=1,S=s1,Q=s2,SQπ=s1。假定S=s1,s2,…,sr,Q=sr+1,則SQπ=s1,s2,…,sr;如果Q屬于v(SQπ),則sr+1是S=s1,s2,…,sr字符串的一個子串,即Q是SQπ的一個子串,那么S不變,只需要將Q更新為sr+1,sr+2,接著判斷Q是否為SQπ的子串。重復該過程直到Q不屬于v(SQπ)。此時,Q=sr+1,sr+2,…,sr+i,不是SQπ=s1,s2,…,sr,sr+1,…,sr+i-1的子串,則c(n)加1。此后,更新S為S=s1,s2,…,sr+i,并且Q=sr+i+1;重復這個上述過程直到Q的最后一個字符。此時,c(n)是包含于R中的不同子串的個數,其反映了序列中新模式的個數,且c(n)的值與時間序列長度相關,因此應將c(n)標準化處理,以減少其與長度相關性[5, 13, 17]。
| $c\left( n \right)\frac{n}{(1-{{\varepsilon }_{n}}){{\log }_{\alpha }}\left( n \right)},$ |
其中n是序列的長度,α是序列R中可能的符號個數。對于CLZ,α是2。εn是一個很小的量,且εn→0 (n→∞)。因此有
| $\underset{n\to \infty }{\mathop{Lim}}\,c\left( n \right)=b\left( n \right)=\frac{n}{{{\log }_{\alpha }}\left( n \right)}.$ |
最后,將c(n)標準化為C(n),即通常意義上的LZ復雜度值:
| $C\left( n \right)=c\left( n \right)\frac{{{\log }_{\alpha }}\left( n \right)}{n},$ |
其中n是序列長度,α是序列R中可能的符號個數,C(n)是標準化后的LZ復雜度,表示了序列中新模式的產生率,且僅在序列長度較短時與長度相關[5]。詳細LZ復雜度算法可參見文獻[13, 17]。
為了進一步驗證ELZ性能,本文還對比了SampEn和PE。針對不同類型的序列,PE的參數設置各不相同[15]。因此本文根據文獻[15],選擇適合大多數序列的參數取值,其中嵌入維數m為5,延遲時間τ為1。依據經驗,本文課題組將SampEn的嵌入維數m與相似容忍度為0.15×SD,SD是序列標準差。
2 實驗結果與性能分析
2.1 序列隨機性和非線性混沌特征的區分能力
為了分析ELZ對時間序列隨機性和非線性混沌特征的區分能力,本文分別使用100點(短時)、500點(中時)和5 000點(長時)三種長度的序列組,每組序列均包括高斯噪聲(gauss noise,Gau),混合噪聲(mixed noise,MIX),Logistic(Logi)映射和周期序列。其中Gau由MATLAB的wgn函數產生。MIX(p)序列是在長度為N的正弦信號中,隨機選擇N×p個數據點替換為獨立同分布的隨機噪聲。本文設定p分別為0.2和0.4。對于Logi映射序列xn+1=μ×xn×(1-xn),1<μ≤4,本文選擇μ=3.8,4.0作為混沌序列;μ=3.5作為周期序列。我們分別計算三種時長的序列組的ELZ、CLZ、MLZ、SampEn和PE。同時為了盡可能保證實驗結果的合理性,每一類信號均用20樣本。
非線性研究發現,混沌與隨機并不一樣,混沌是介于有序與無序、隨機性與確定性之間的一種偽隨機狀態[19],因此從Gau, MIX(0.4), MIX(0.2), Logi(4.0), Logi(3.8)到周期序列,隨機性或無序性逐漸降低,而有序性逐漸增大。如圖 1所示,ELZ與PE在短時、中時、長時序列中,隨序列隨機性降低,依次按照由Gau,MIX(0.4),MIX(0.2),Logi(4.0),Logi(3.8)到周期序列的順序遞減。因此ELZ與PE均能夠區分序列的隨機性與混沌特性,能夠準確反映序列隨機性降低,有序性增強的趨勢。然而,ELZ的計算與參數無關,其泛化能力與客觀性更強;而PE的計算受到嵌入維數m和延遲時間τ的影響較大,不同的參數所得結果并不一致。如圖 1所示,ELZ在短時、中時與長時序列中均能保持穩定的性能,因此ELZ與序列長度無關。對于CLZ與MLZ而言,在三種時長的序列組中,均在噪聲序列與Logi混沌序列間產生波動,即Logi(4.0)的值高于MIX(0.2),因此它們混淆了序列的隨機性與混沌特性。在短時序列組中,SampEn隨著序列隨機性降低,熵值依次降低,能夠正確區分序列隨機性與混沌性,然而在中時和長時序列組中,SampEn未能準確測量,即Logi(4.0)的值略高于MIX(0.2)。
圖1
六類時間序列的SampEn、PE、CLZ、MLZ和ELZ的值
Figure1.
Values of the six kinds of time sequence for SampEn,PE,CLZ,MLZ and ELZ
2.2 對Gau與1/f粉紅噪聲的復雜度分析
研究發現[11, 20-21]1/f粉紅噪聲序列比白噪聲具有更為復雜的結構。于是對粉紅噪聲與白噪聲復雜度的測量也被用于檢測ELZ算法的性能,同時本文仍然對比了CLZ、MLZ、SampEn和PE。該實驗仍然使用100、500和5 000點三種長度的序列組,每組序列均包括Gau和1/f粉紅噪聲,且每類序列的樣本數為20。
如表 1所示為ELZ與CLZ、MLZ、SampEn和PE方法在Gau與1/f粉紅噪聲上的均值與標準差,以(x±s)表示,以及Gau與1/f粉紅噪聲復雜度值之間的差異分析結果。可以看出只有ELZ方法所得到粉紅噪聲復雜度高于Gau噪聲復雜度,且兩組間的差異具有統計學意義(P<0.01)。而其余4種方法所得結果均為高斯噪聲復雜度大于1/f噪聲復雜度。這個結果同樣表明,ELZ復雜度算法在對不同時長序列度量均保持穩定的性能,且能夠正確反映序列復雜度。
2.3 ELZ對序列突變的敏感性分析
為了檢驗ELZ方法對序列動力學性質突變的響應能力。我們將CLZ、MLZ、SampEn、 PE和ELZ方法分別對Logi映射中的突變進行檢測。在Logi映射中,當μ=μ*=3.569 945 672時,Logi序列由倍周期突變為混沌,此時序列的動力學性質發生改變,不規則性應發生明顯變化。
如圖 2所示,Logi映射的分叉圖與上述5種方法針對Logi序列數據突變的敏感性分析結果表明了CLZ方法在μ*時刻并不能及時檢測數據由倍周期到混沌的突變。MLZ和ELZ方法的敏感性分析表明,這兩種方法都能夠在μ*時刻,及時檢測到數據到混沌狀態的突變。如圖 2所示的SampEn和PE的實驗結果,顯示出這兩種熵算法對序列的突變較為敏感。同時SampEn在Logi序列參數μ尚未達到μ*時,就已經檢測到信號倍周期改變;而PE更為敏感,其能夠檢測到Logi序列的信號周期倍增的每一次改變[22-23]。相比而言,CLZ在檢測信號動力學特性突變中,有明顯的延遲;SampEn與PE對序列的狀態變化尤為敏感,然而這兩種熵算法對序列的倍周期變化也具有較強的敏感性,這樣就混淆了周期與混沌的動力學特征,而這恰恰是我們所不希望看到的;ELZ與MLZ都能較好地在Logi映射的μ接近μ*時(即序列由倍周期變為混沌時),則可及時檢測到序列變化。
圖2
ELZ、CLZ、MLZ、SampEn和PE對Logi序列數據突變的敏感性的分析
Figure2.
Analysis of sensitivity of data change of the logistic mapping for ELZ,CLZ,MLZ,SampEn and PE on the logistic mapping
2.4 ELZ對生理時間序列復雜度分析
本文繼續將ELZ用于實際診斷數據的復雜性度量,同時也對比了CLZ、MLZ、SampEn和PE在實際數據上的結果。數據來源于MIT-BIH提供的CHF-RR和NSR-RR數據庫 [24-25]。其中CHF-RR數據庫是充盈性心衰數據庫,采集年齡34~79歲之間的29組心電數據。NSR-RR數據庫是包括54個長時正常竇性心律心電數據庫,數據來源于30位男性(年齡28~76歲),24位女性(年齡58~73歲)。兩組數據庫采樣率均為128 Hz,采樣時間在18~24 h之間。這些心電數據在使用之前必須進行預處理,首先刪除了RR間期大于2 s的心電數據,這是因為超過2 s的RR間期一般是由信號質量較差的段的斷裂信息形成[16]。原始數據中每個心拍都被標注為正常(‘N’)或者病變,其中病變數據常常是因為室上性心率過速和室早造成。為了得到正常心電數據,我們也刪除了這些心律失常的心拍。同時,RR間期中存在的不平穩趨勢也會影響到實驗結果,因此我們用一種快速算法提取RR間期的基線并進行了矯正[26-27]。最終RR間期數據被按100、500、5 000點的窗口長度分段。
心電信號分析中,正常竇性心律信號的復雜度低于心力衰竭信號的復雜度已經是一種共識[11, 20, 28]。如表 2所示,顯示了ELZ、CLZ、MLZ、SampEn和PE在心律失常與正常竇性心律上的實驗結果以及兩組數據間差異性分析結果。其中,CLZ得出心力衰竭信號復雜度值高于竇性心律的值,并不能反映真實情況。而SampEn和PE雖然都能正確度量心力衰竭組復雜度低于與竇性心律組復雜度,然而在短時(100點)情況下,兩組的差異不具有統計學意義(P>0.05)。這說明信號長度對SampEn和PE有一定影響,對短時生理信號的分析效果相對于ELZ方法并不理想,而在臨床診斷中,短時生理信號則較為常見。ELZ與MLZ在各種長度的信號中,都能正確分析心力衰竭組與竇性心律組的復雜度,且兩組間差異具有統計學意義(P<0.01)。與ELZ方法相比,MLZ需要憑經驗設置狀態個數,而SampEn和PE的性能均與參數設置有關,其中SampEn受嵌入維數m和相似容忍度r影響較大;PE受嵌入維數m和延遲時間τ的影響較大,而且對于不同種類的序列,最優的參數并不一致[15-16]。然而ELZ方法,無需任何參數設置,減少了其他因素對性能的影響,具有較強的泛化能力。
3 結論
本文提出了一種ELZ復雜度算法,該方法在短時、中時與長時序列中,均能有效地區分序列隨機性與混沌性,較其他算法相比,避免了將兩者混淆;并可正確地度量Gau與1/f粉紅噪聲的復雜度,同時能夠及時反映信號動力學特征變化。來自MIF-BIH數據庫的真實數據實驗表明,該方法在短時、中時與長時的心電信號中,均能正確度量心力衰竭與竇性心律的復雜度。這也反映出,ELZ方法不僅在不同長度序列能保持性能穩定,同時也避免了粗粒化過程中量化狀態的無限制增長,并可避免熵方法中參數對算法性能的影響,因此具有較強的泛化能力,對于各種時長的生理信號極具應用價值。