為了實現血液中肝癌細胞的自動識別,本文基于主成分分析(PCA)和反向傳播(BP)神經網絡算法對三種細胞(小鼠的白細胞、紅細胞和人體肝癌細胞 HepG2)進行了識別研究。利用光纖共聚焦后向散射(FCBS)光譜儀獲取光譜數據后進行 PCA,選取前兩個主成分作為光譜的特征,建立一個具有 2 個輸入層節點、11 個隱層節點、3 個輸出節點的神經網絡模式識別模型。選取 195 例對象數據訓練該模型,隨機抽取 150 組數據作為訓練集,45 組數據作為測試集,驗證模型給出的細胞是否識別準確。結果顯示三種細胞的整體識別準確率在 90% 以上,平均相對偏差只有 4.36%。實驗結果預示采用 PCA+BP 算法能夠從紅細胞和白細胞中自動識別肝癌細胞,這將為研究肝癌的轉移與肝癌的生物代謝特性提供有利的工具。
引用本文: 楊靜, 王成, 謝成穎, 翁小阜, 魏勛斌. 基于主成分分析和反向傳播神經網絡的肝癌細胞后向散射顯微光譜判別. 生物醫學工程學雜志, 2017, 34(2): 246-252. doi: 10.7507/1001-5515.201605008 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
目前,世界上死亡率排名第三的腫瘤為肝細胞癌(hepatocellular carcinoma,HCC),同時也是第 6 位常見的惡性腫瘤[1]。HCC 治療的難點為初期檢測困難、擴散速度快、復發轉移率高,其術后轉移與復發已經成為影響患者預后的重要因素,臨床上迫切需要能夠有效預測肝癌轉移的檢測手段。循環腫瘤細胞(circulating tumor cell,CTC)出現于癌癥患者的外周血中,是一種重要的游離態組織樣本,在早期診斷、早期治療、判斷預后和制定個體化治療方案等方面具有重要意義[2]。最新的研究表明,肝癌患者病情狀態與血液中 CTC 的數量顯示出極強的相關性[3]。因此實現循環腫瘤細胞在體檢測,對研究許多疾病,特別是癌癥的早期診斷和早期治療具有重要意義。
目前 CTC 探測主要可以分成熒光標記分析和無熒光標記分析兩個大類。基于熒光標記的在體流式細胞儀(in vivo flow cytometry,IVFC)可分為單光子共焦熒光[4]和多光子熒光[5]分析兩類。無標記的在體流式細胞儀又分為基于光熱(photother-mal technique,PT)/光聲技術(photoacoustic technology,PA)[6-7]、基于拉曼散射[8]和基于后向散射[9]三種。標記分析方法,在老鼠模型中,需要通過尾靜脈將體外標記后的腫瘤細胞輸入體內,再研究其循環特征。由于循環腫瘤細胞非常稀少,目前還無法實現在體腫瘤細胞的直接標記,因此無法模擬真實的循環腫瘤細胞環境來研究腫瘤的轉移問題。而無標記的方式將直接探測循環系統中的腫瘤細胞,這樣可以不改變任何環境。
當使用基于 PA/PT 技術的 IVFC 時,利用細胞中吸收光的分子來產生探測信號,從具有相似生物分子的正常細胞中不易區分腫瘤細胞。基于拉曼散射的 IVFC[8],雖然具有在無標記腫瘤細胞監測中應用的前景,但這個技術目前只能在慢流率和小直徑的靜脈管中計數 CTCs,而且需要獨特的生物化學特性(如高血脂)來探測靶細胞。Irene Georga-koudi 團隊最近報道了基于后向散射光的 IVFC[10],表明細胞后向散射光可以作為本征信號源區分循環腫瘤細胞。細胞結構與后向散射光譜的特性有直接關系,細胞光散射光譜具有的天然特點使其非常適合于解決在體細胞計數的問題:① 微米-納米結構的光散射信號展現出了波長和散射角與散射體結構的特征關系,是一個本征的信號源;② 細胞中一些固有的吸收體,如血紅蛋白在散射光譜中也具有獨特的光譜特性;③ 光散射光譜的檢測成本極低,操作簡單;④ 與熒光光譜相比較,不存在熒光“淬滅”等固有缺陷。
本文提出使用光纖共聚焦后向散射(fiber confocal back-scattering,FCBS)光譜儀結合神經網絡模式識別模型進行肝癌細胞的檢測識別。本文采集小鼠白細胞、紅細胞及人體肝癌細胞的散射光譜,進行主成分分析(principle component analysis,PCA),提取三種細胞散射光譜的 2 個主成分,將其作為神經網絡的輸入,將測試細胞的編碼作為神經網絡的輸出,并對該神經網絡模式識別模型進行訓練和測試。
1 材料和方法
1.1 實驗裝置
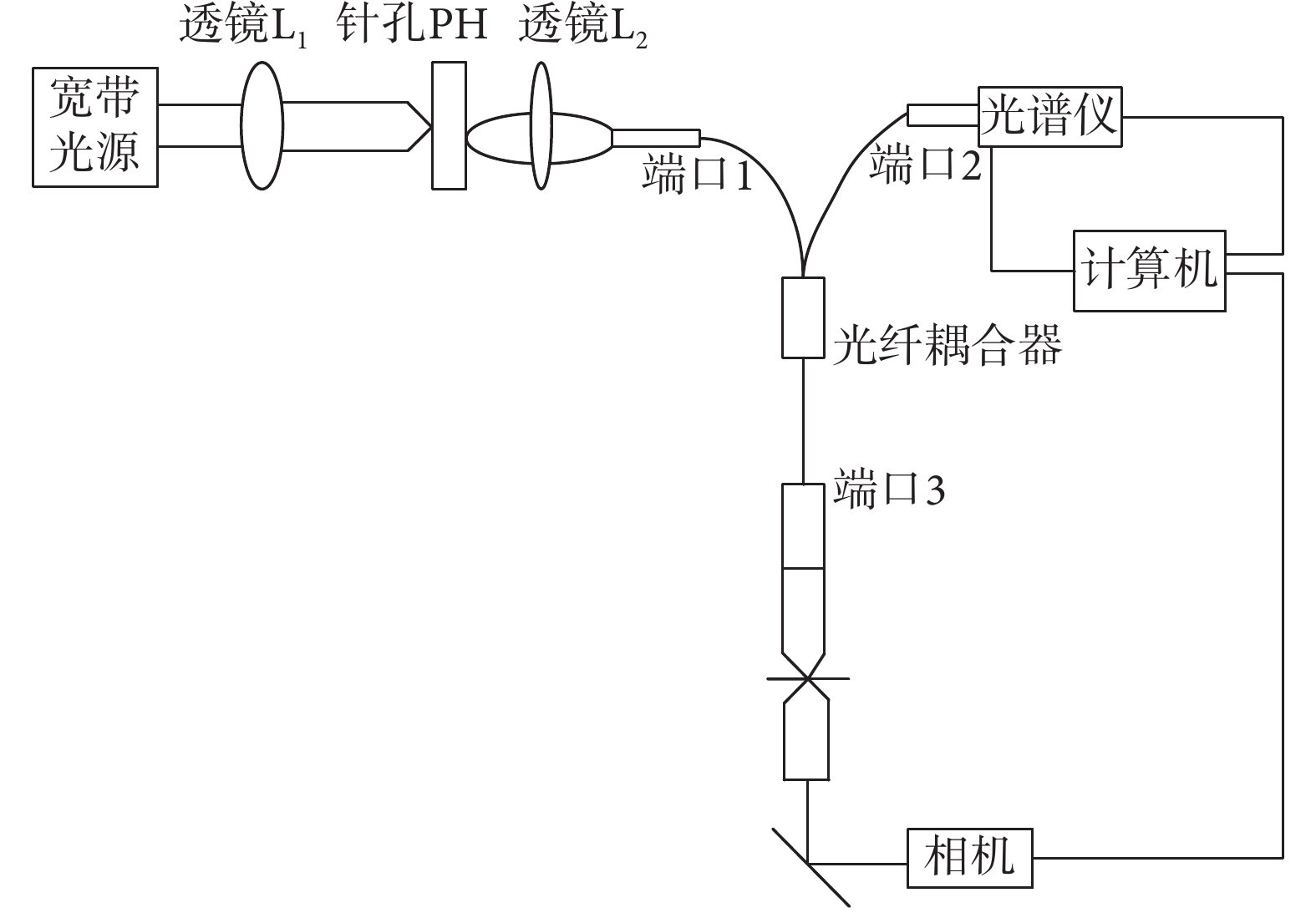
本實驗采用 FCBS 光譜儀,它由光纖共焦顯微鏡和彈性散射光譜儀組成,能獲得單細胞后向散射光譜,同時還能得到該單細胞的圖像。如圖 1 所示,整個系統主要由寬帶光源、透鏡 L1 和 L2、光纖耦合器、光學探頭、光譜儀、主控電腦組成。其中,光學探頭由兩個消色差物鏡組成,一個消色差物鏡用于準直,其數值孔徑為 0.25,10×;另一個消色差物鏡用于聚焦,其數值孔徑為 0.4,20×。實驗所用光譜儀響應較好的光譜寬帶為 600 nm(400~1 000 nm),光譜分辨率為 4 nm。
寬帶光源出射的光經過透鏡 L1 和 L2 準直后進入到光纖耦合器的端口 1 中,然后從耦合器的端口 3 輸出。端口 3 不僅作為光線傳輸的通道,還成為共焦系統中的探測針孔。光纖耦合器的端口 3 把光源的光線耦合到光學探頭,兩光學探頭之間放置硅片和實驗樣品(細胞)。硅片反射和細胞散射的光線將被探頭接收,進入到耦合器的端口 3 中,并最終從耦合器的端口 2 中出射,進入到光譜儀中。光譜儀探測的數據傳輸到計算機進行分析并顯示光譜曲線。FCBS 光譜儀系統設置了一個觀察功能,確保物鏡探測的是單個細胞而非其他物質。因此我們可以觀測目標的視覺圖像,確定細胞的位置,確定被檢測的對象是單個細胞[11]。
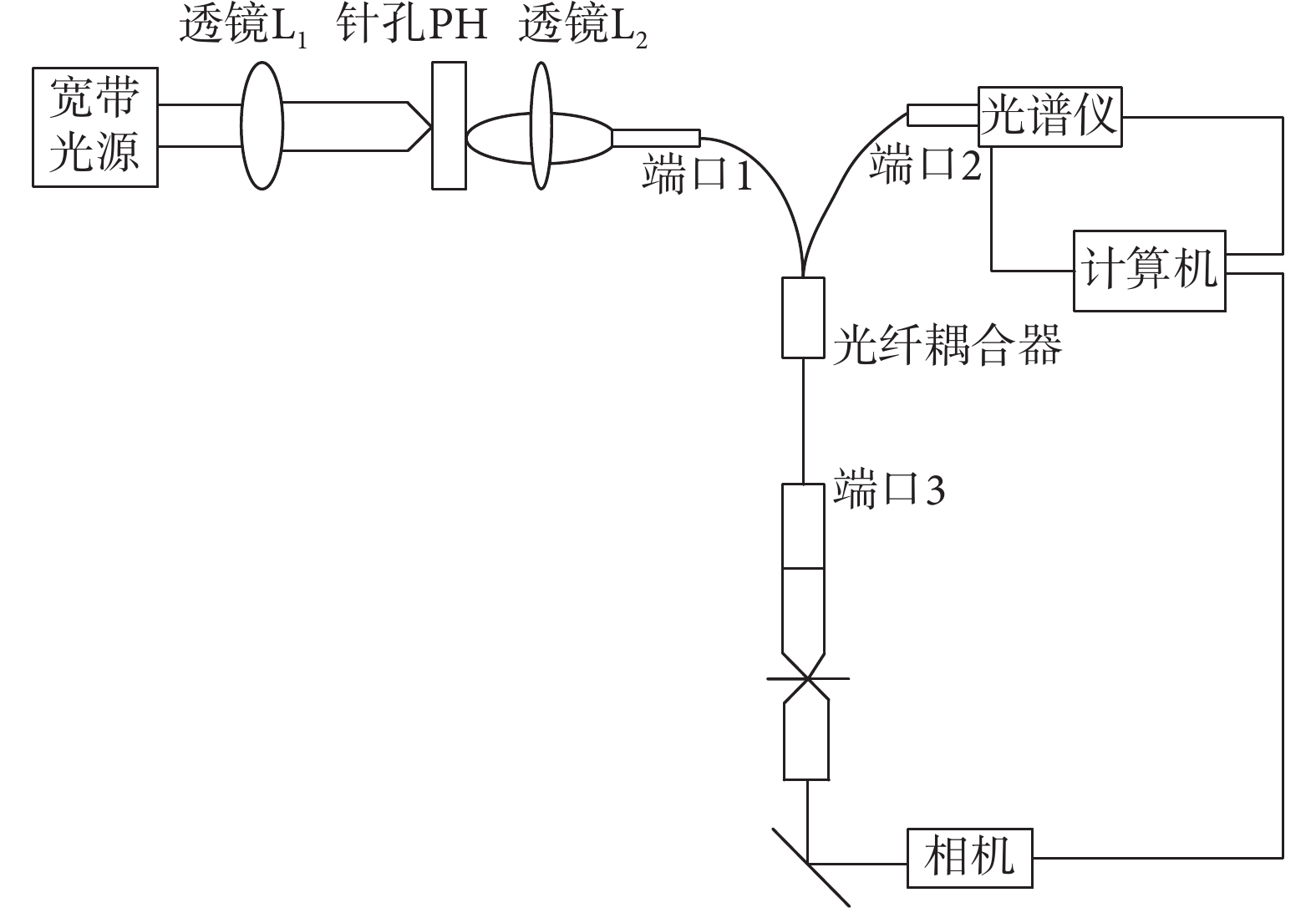 圖1
光纖共聚焦后向散射顯微光譜儀
Figure1.
Fiber confocal back-scattering micro-spectrometer
圖1
光纖共聚焦后向散射顯微光譜儀
Figure1.
Fiber confocal back-scattering micro-spectrometer
1.2 細胞樣品
本次實驗細胞樣品為小鼠的白細胞和紅細胞、人體肝癌細胞 HepG2。實驗總樣本數達到 195 例,隨機選取 150 例(紅細胞 50 例,白細胞 50 例,肝癌細胞 50 例)作為訓練集,45 例(紅細胞 15 例,白細胞 15 例,肝癌細胞 15 例)作為測試集。其中白細胞、紅細胞在上海交通大學團隊實驗室分離獲得,肝癌細胞 HepG2 由中科院細胞庫獲得。所有細胞學樣本無血凝塊,并且在常溫、24 h 內完成實驗。
小鼠采血及白細胞的分離方法:balb/c 小鼠毛細管采用 1.5% EDTA 抗凝液預處理,從眼外眥靜脈叢取血 100 μL 置于抗凝液處理過的離心管中,離心 5 min 去除上清,將細胞重懸于 1 mL 紅細胞裂解液中,混勻室溫靜置 5 min,加入 5 mL 磷酸緩沖鹽溶液(phosphate buffer saline,PBS),400g 離心去除上清及紅細胞碎片,然后重懸于 PBS 中離心去除紅細胞碎片。若紅細胞裂解不完全可重復一次裂解洗滌步驟。最后獲得的細胞沉淀重懸于 PBS 中,鏡下觀察。
紅細胞:采血后抗凝處理,無需裂紅步驟,重懸于 PBS 鏡下觀察,紅細胞的典型形態為雙凹圓盤狀。
1.3 光譜采集與預處理
本次實驗利用已經搭建的 FCBS 平臺測量人體肝癌細胞以及小鼠正常的紅細胞、白細胞的后向散射光譜。如圖 1 所示,耦合透鏡組接收到經光纖耦合器耦合的光線,將其直接照射到細胞表面,同時透鏡組接收到細胞散射光,光譜儀接收經光纖耦合器耦合的細胞散射光,從而獲得細胞光譜。
由于硅片在可見光和近紅外波段的反射率為 30%,細胞散射光強度比較低,能真實反映所測樣品的光譜特性,因此在細胞后向散射光譜的分析中,所有光譜的標準均采用拋光良好的硅片[11]。分別滴取適量白細胞和紅細胞、人體肝癌細胞 HepG2 于載玻片上,依次放在顯微鏡的載物臺上,手動調節載物臺使其沿四周移動,使會聚光點全方面掃描細胞,從而測量出樣品在該點的顯微光譜信息。
1.4 光譜 PCA 法降維
上述方法采集到的光譜每隔 4 nm 為一個采樣點,即一個維數,所以光譜維度較高,如此高的維數進行自動識別非常困難。因此本研究采用 PCA 法進行降維處理。20 世紀 30 年代霍特林提出了 PCA 法,它是一種多元統計分析技術[12]。采用 PCA 法實現降維,通過對數據去相關,提取出數據的最主要特征,經變換后得到的新變量作為主成分,按信息量的大小排序后,得到三種細胞散射光譜數據的新變量,實現光譜數據降維[13]。
PCA 算法的主要步驟如下:
設光譜數據 為n 維向量。
(1)對數據進行標準化處理:
將原始待觀察數據組成樣本矩陣 x ,每一行為一個觀察樣本,每一列代表一維數據。計算每一維的均值,即計算樣本矩陣 x 中每一列的均值,并對矩陣中的每個樣本進行歸一化處理:
| $x({λ})= \frac{{{x_i} - {x_{\min }}}}{{{x_{\max }} - {x_{\min }}}}$ |
該方法可實現對原始數據的等比例縮放,其中x( )為歸一化后的光譜數據,xi 為光譜原始數據,xmax、xmin 分別為光譜原始數據集的最大值和最小值。
(2)計算樣本矩陣 的協方差矩陣:
| ${{{c}}_{{x}}} = {\mathop{\rm cov}} ({{x}}) = \left[ {\begin{array}{*{20}{c}}{{c_{11}}} & \cdot \! \cdot \! \cdot & {{c_{1n}}}\\ \vdots & \ddots & \vdots \\{{c_{n1}}} & \cdot \! \cdot \! \cdot & {{c_{nn}}}\end{array}} \right]$ |
(3)計算協方差矩陣 c x 的特征值xj 及相應特征向量 vi 。
(4)計算前m 個主元的累計貢獻率 。
按特征值xj 的大小順序排列后,截取特征值大于某個閾值r 的前m 個主元[14]。一般主成分選取標準是按照累計貢獻率達到 80% 以上[15],其依據是選取方差最大的前幾個主成分,實現將多個相關變量壓縮為少數幾個不相關的綜合變量,并且獲得包含大部分原變量信息的新綜合變量,達到降維的效果。
| $\phi (m) = \frac{{\sum\limits_{j = 1}^m {{x_j}} }}{{\sum\limits_{i = 1}^m {{x_i}} }}$ |
1.5 反向傳播神經網絡與光譜分類識別
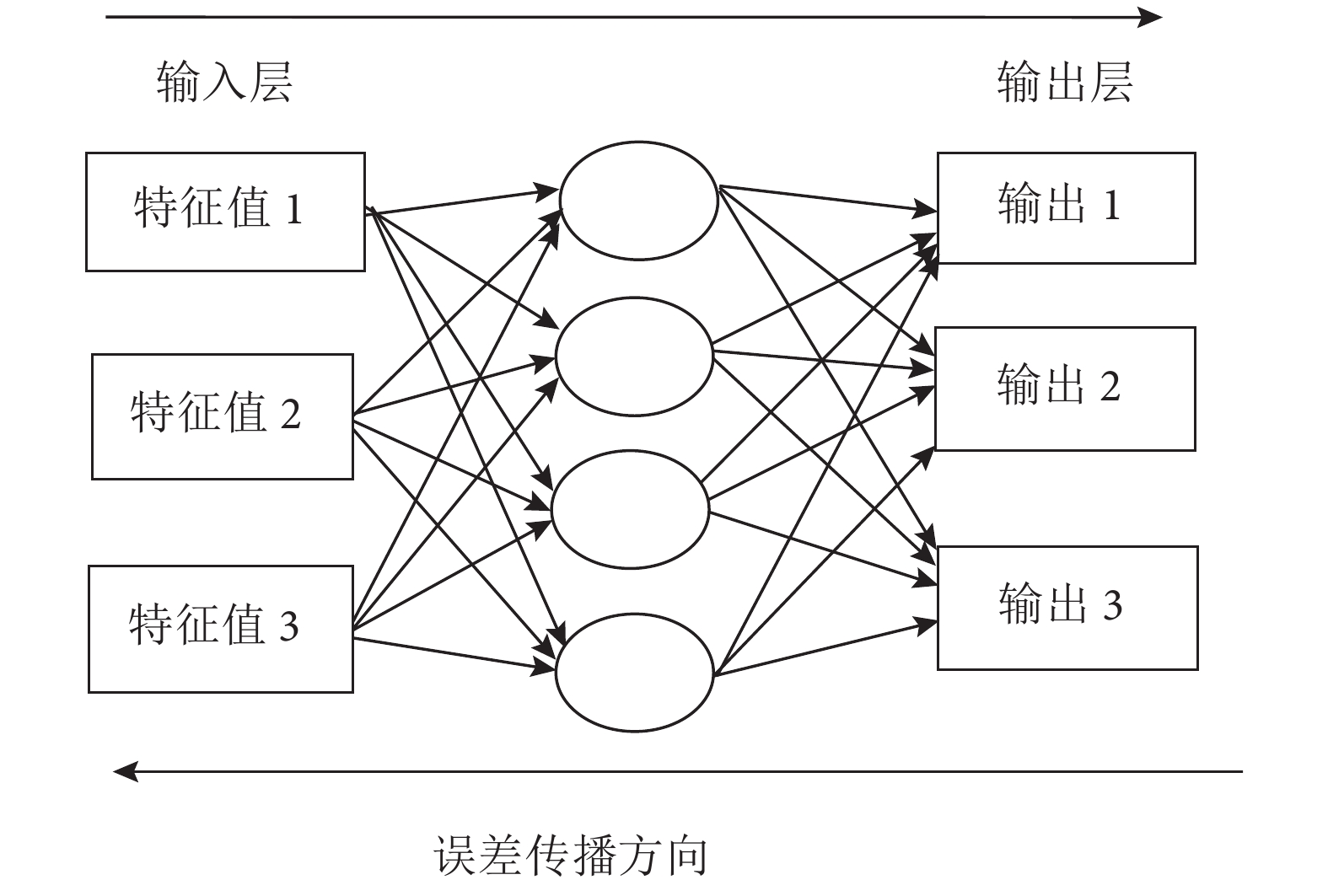
網絡學習算法中,最常見的就是反向傳播(back propagation,BP)神經網絡。它是一種按誤差逆傳播算法訓練的多層前饋網絡。其基本思想是使用最速下降法,通過反向傳播,獲得網絡權值和閾值的不斷調整,從而得到最小的網絡誤差平方和[16]。根據 PCA 包含主要信息的判斷,將包含主要信息的主成分值xj 作為 BP 神經網絡輸入節點j 的輸入值,對三種細胞的后向散射光譜進行自動識別[15]。BP神經網絡結構如圖 2 所示。
BP 神經網絡的學習算法步驟如下[16]:
(1)計算隱層和輸出層節點的輸出:
| ${y_i} = f(\sum\limits_j {{w_{ij}}} {x_j} - {\theta _i}) = f(ne{t_i})$ |
公式(4)中,yi 為隱層第i 個節點的計算輸出,wij 為輸入節點j 至隱含層節點i 的連接權重,xj 為輸入節點j 的輸入值,θi 為隱含層節點的閾值,f 為激活函數,即 S 型的 Sigmoid 函數。
隱含層節點數設計:
| $i = \sqrt {j + l} + {{a}$ |
a 為 1~10 之間的調節常數。
(2)計算輸出點l 的輸出ol :
| ${o_l} = f(\sum\limits_i {{T_{li}}} {y_i} - {\theta _l}) = f(ne{t_l})$ |
式(6)中,ol 為輸出節點l 的計算輸出,Tli 為隱層節點i 至輸出節點l 的連接權重,θl 為輸出節點l 的閾值,其它參數含義同前面。
(3)計算誤差:
總誤差E 按式(7)進行計算。
| $\begin{aligned}E = & \frac{1}{2}\sum\limits_l {({t_l}} - {o_l}{)^2}= \\& \frac{1}{2}\sum\limits_l {({t_l} - f(\sum\limits_i {{T_{li}}} } {y_i} - {\theta _l}){)^2}= \\& \frac{1}{2}\sum\limits_l {({t_l}} - f(\sum\limits_i {{T_{li}}} f(\sum\limits_j {{w_{ij}}} {x_j} - {\theta _i}) - {\theta _l}){)^2}\end{aligned}$ |
輸出平均值:
| $t = \sum\limits_{i = 1}^n {{t_i}} $ |
平均相對偏差:
| $z = \frac{1}{{nt}}\sqrt {\sum\limits_{i = 1}^n {{{({t_i} - t)}^2}} } * 100\% $ |
式(7)中ti 為輸出節點l 的期望輸出值。式(8)中t 為輸出節點的平均值,式(9)中z 為輸出層的平均相對偏差。
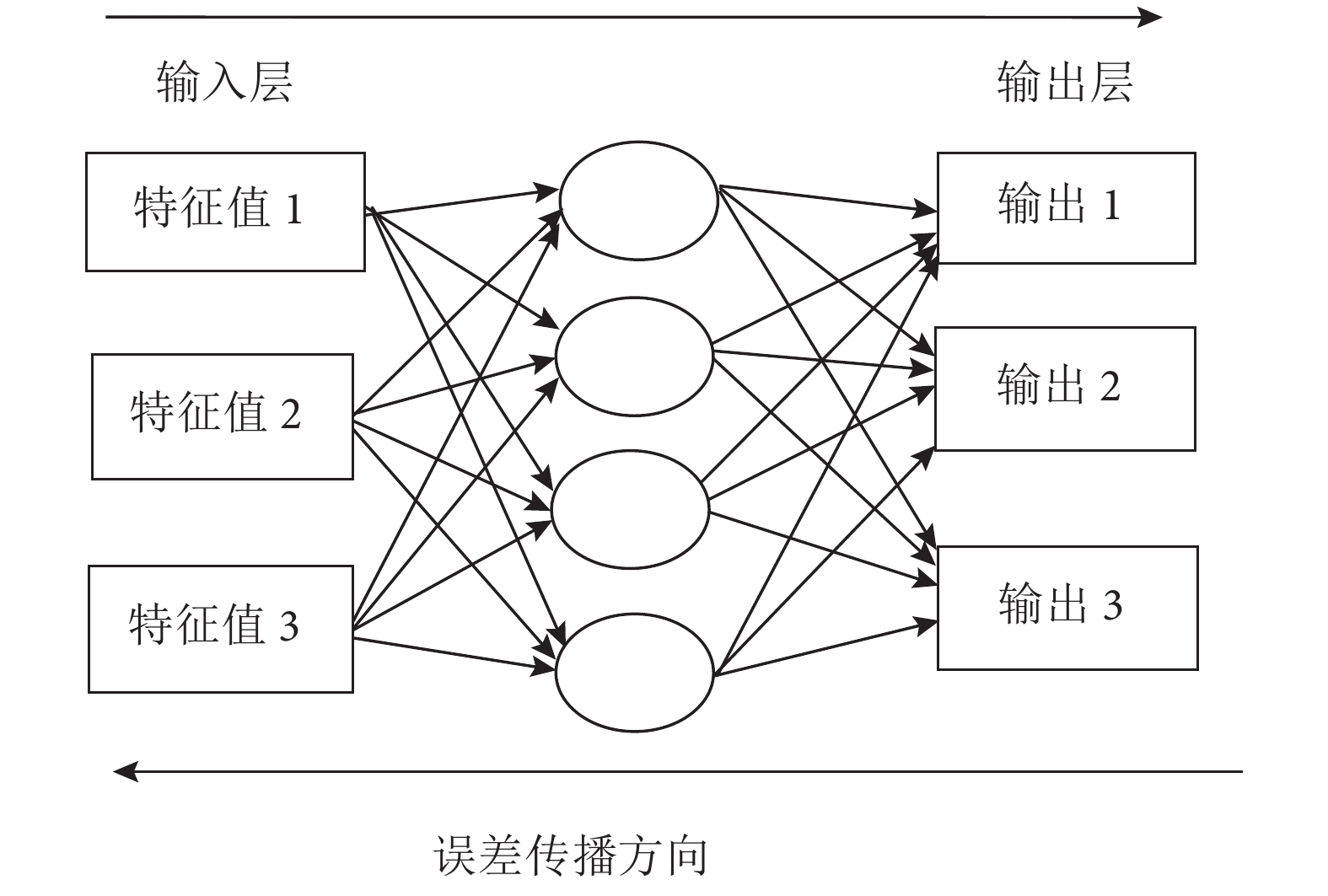 圖2
BP 神經網絡結構
Figure2.
Back propagation neural network structure
圖2
BP 神經網絡結構
Figure2.
Back propagation neural network structure
2 結果與分析
2.1 光譜分析結果
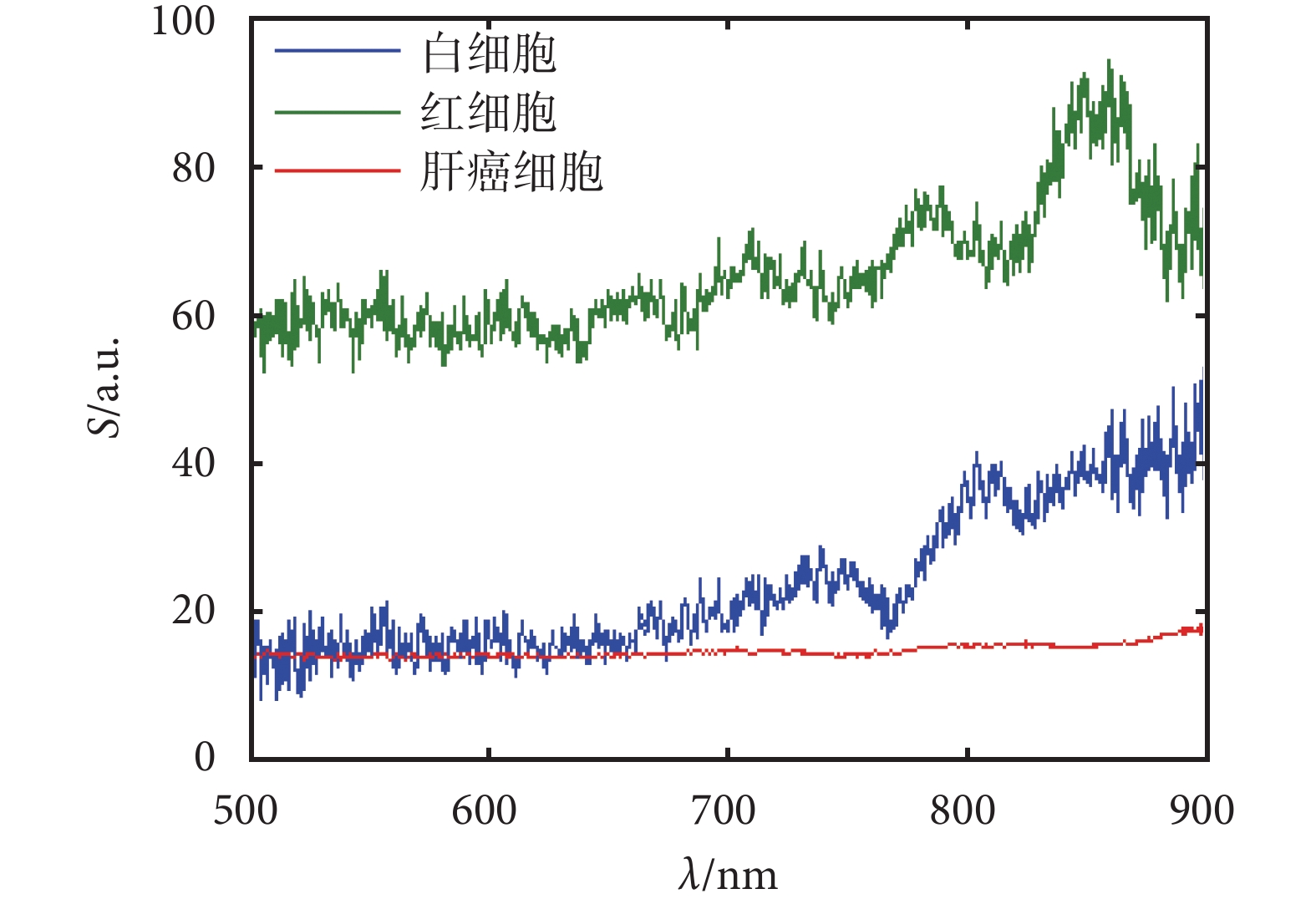
圖 3 為實驗所得到的三種細胞的后向散射顯微光譜數據。圖中紅色、藍色、綠色曲線分別代表肝癌細胞、白細胞、紅細胞的后向散射光譜曲線。其中橫坐標是波長(nm);縱坐標是相對后向散射光強度S(a.u.),即細胞后向散射光譜相對參考硅片反射。研究選取可見光波段到近紅外波段,即波長范圍在 500~900 nm 間。
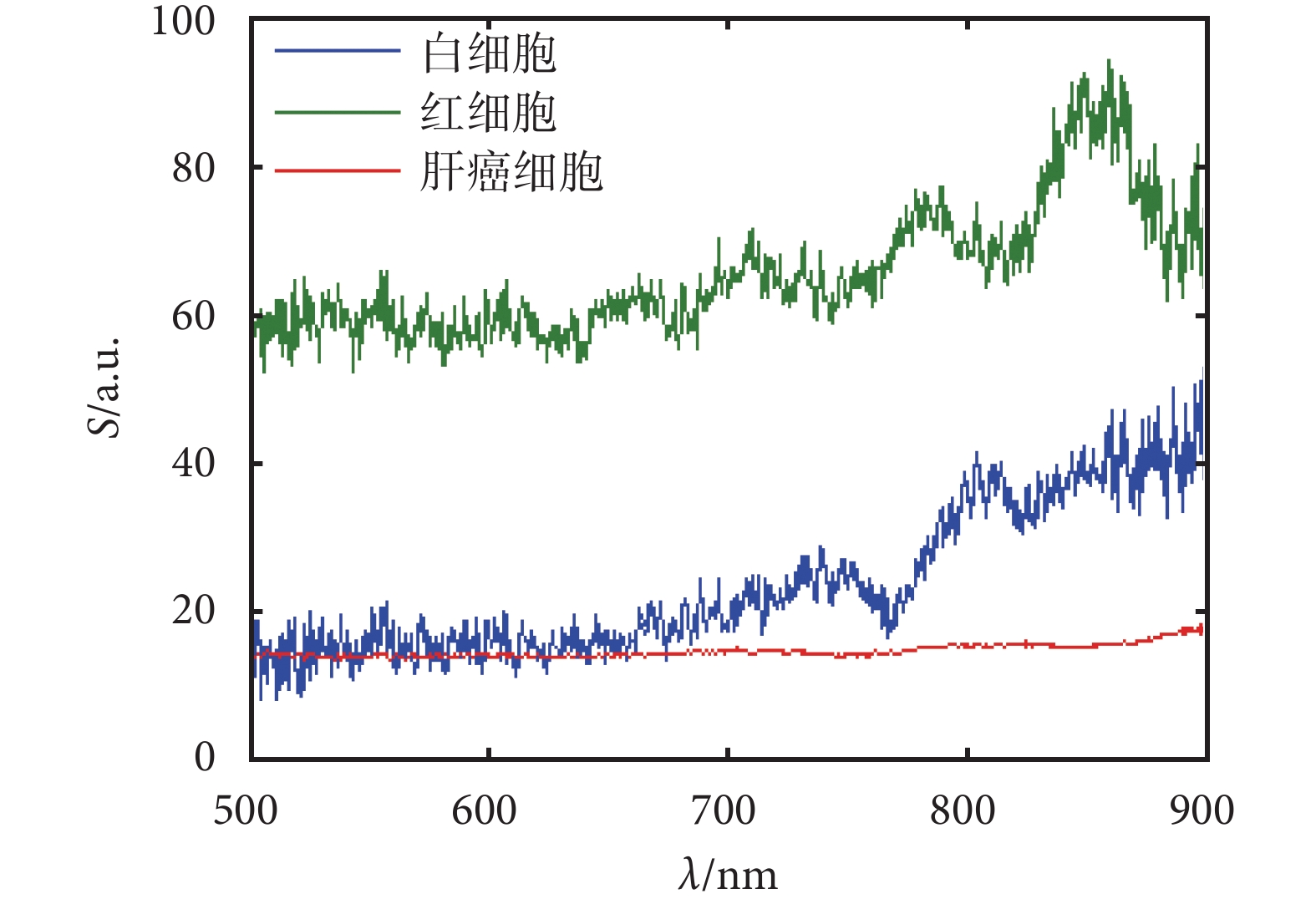 圖3
白細胞、紅細胞、肝癌細胞平均光譜
Figure3.
Average spectra of white blood cells, red blood cells, and liver cancer cells
圖3
白細胞、紅細胞、肝癌細胞平均光譜
Figure3.
Average spectra of white blood cells, red blood cells, and liver cancer cells
由圖 3 可看出,在 500~900 nm 波長范圍內,三種細胞中肝癌細胞的散射光強最低,其次是白細胞,紅細胞散射光強最高。三種細胞在整體曲線趨勢上區別很明顯。因此,后向散射光譜系統可以初步對這三種細胞進行區分檢測。為了進一步對三種細胞實現自動識別,采用了 PCA 分析法,對采集樣本的光譜數據進行降維分析。
2.2 光譜降維的 PCA 結果
紅細胞、白細胞和肝癌細胞共焦后向散射光譜主成分得分如表 1 所示。前兩個主成分的累計貢獻率已經達到 89.5%,說明它們已經包含了原變量的主要信息。
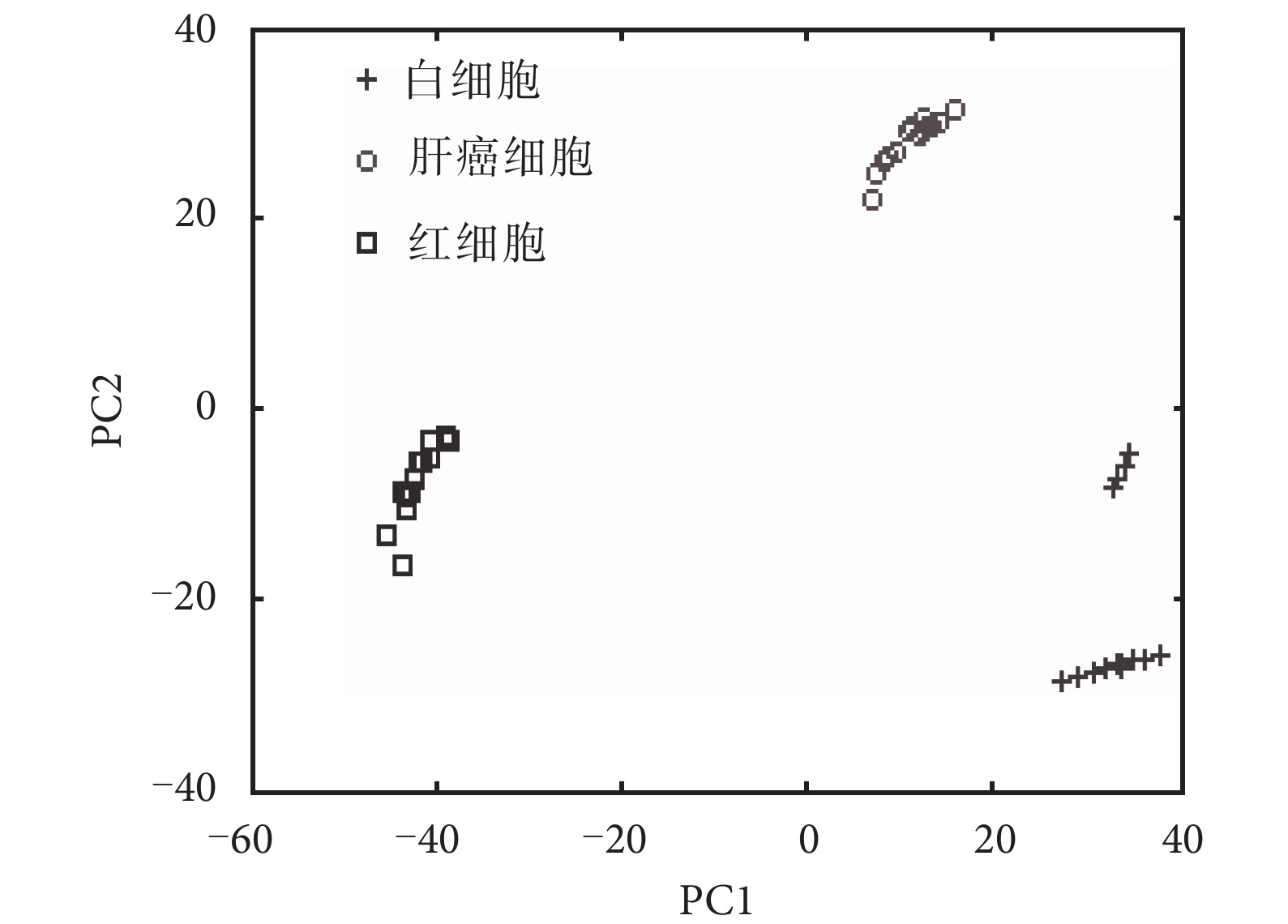
如圖 4 所示,測試集樣本為 45 個樣本的光譜數據,其中 15 組紅細胞、15 組白細胞和 15 組肝癌細胞。紅細胞主要分布在 PC1 與 PC2 的負半軸。肝癌細胞主要分布在 PC1 的 0~20 處,PC2 的正半軸。白細胞分布在 PC1 的正半軸。三種細胞分布區域的差別較明顯,說明通過前兩個主成分已經完全可以區分出紅細胞、白細胞和肝癌細胞。
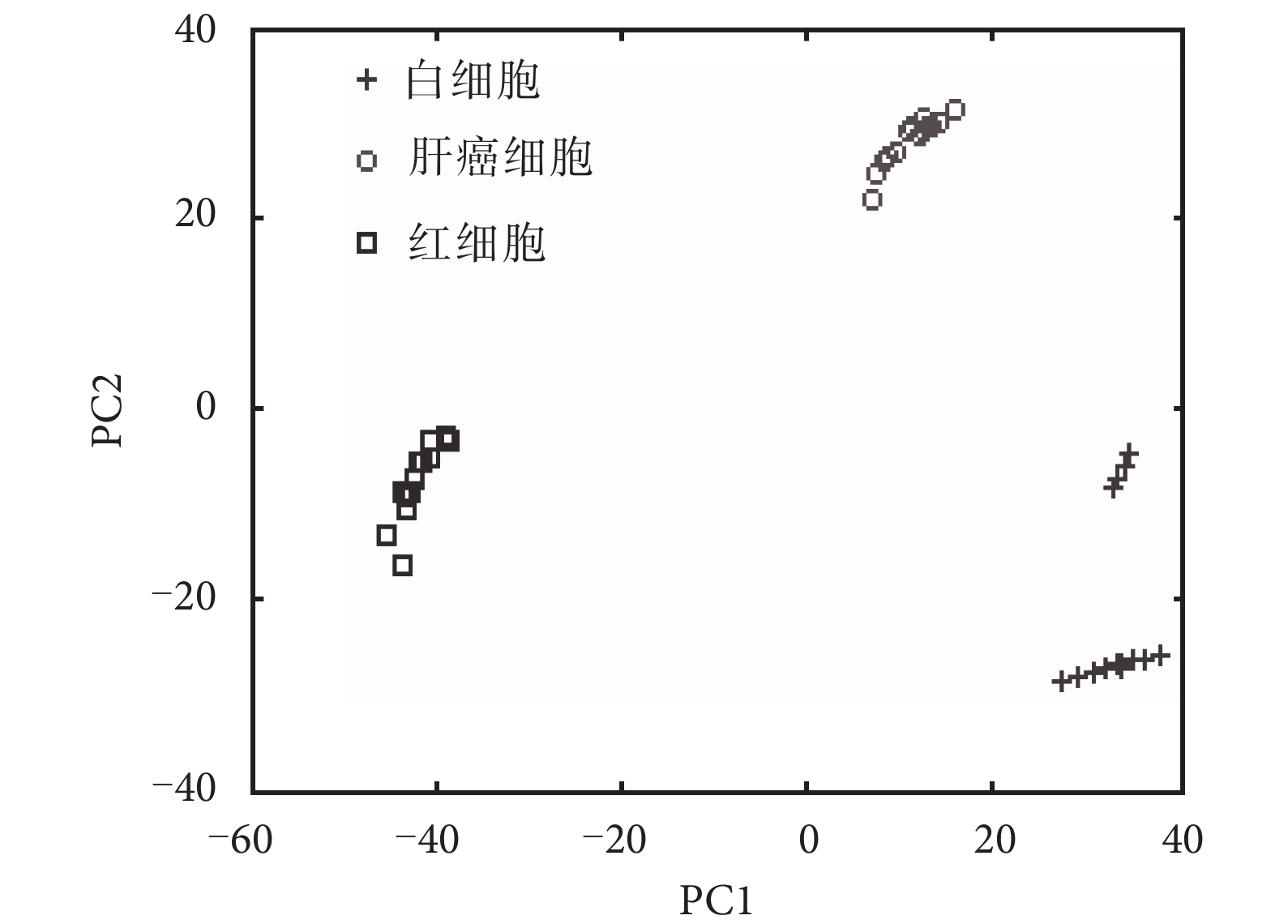 圖4
三種細胞前 2 個主成分得分圖
Figure4.
Two principal component score of three kinds of cells
圖4
三種細胞前 2 個主成分得分圖
Figure4.
Two principal component score of three kinds of cells
2.3 BP 神經網絡的設計與光譜分類結果
選取 195 例對象數據訓練該模型,隨機抽取 150 組數據(紅細胞 50 例、白細胞 50 例、肝癌細胞 50 例)作為訓練集,45 組數據(紅細胞 15 例、白細胞 15 例、肝癌細胞 15 例)作為測試集。BP 神經網絡由輸入層、隱含層和輸出層組成[17]。輸入層對應輸入向量空間,在本文中對應采集到的細胞顯微光譜經 PCA 降維后的有效光譜分量;為了更穩妥地預測細胞類型,選擇前 2 個 PCA 主成分向量為神經網絡的輸入[18],即 BP 神經網絡的輸入節點為 2 個。由公式(2)知訓練集樣本的隱含層節點數為 12 時,網絡誤差最小,故隱含層由 12 個神經元組成。輸出值為不同細胞類型的編碼,設定編碼 –1 為紅細胞,編碼 0 為白細胞,編碼 1 為肝癌細胞,此代碼在訓練集中為目標值,在預測集中為相應的編碼,因此 BP 神經網絡的輸出節點為 3。設定預測結果偏差在±0.15 內為預測正確,反之,誤測情況有兩種:① 當結果不在設置的值區間說明誤測,但沒有被識別為其他類的細胞;② 當預測值在別的細胞值區間就會被識別為別的細胞。計算輸入層到隱含層和隱含層到輸入層的校正誤差,選取下一個輸入反復訓練,直到網絡輸出誤差達到要求結束訓練。本文采用的訓練次數為 1 000 次,目標誤差為 0.01。
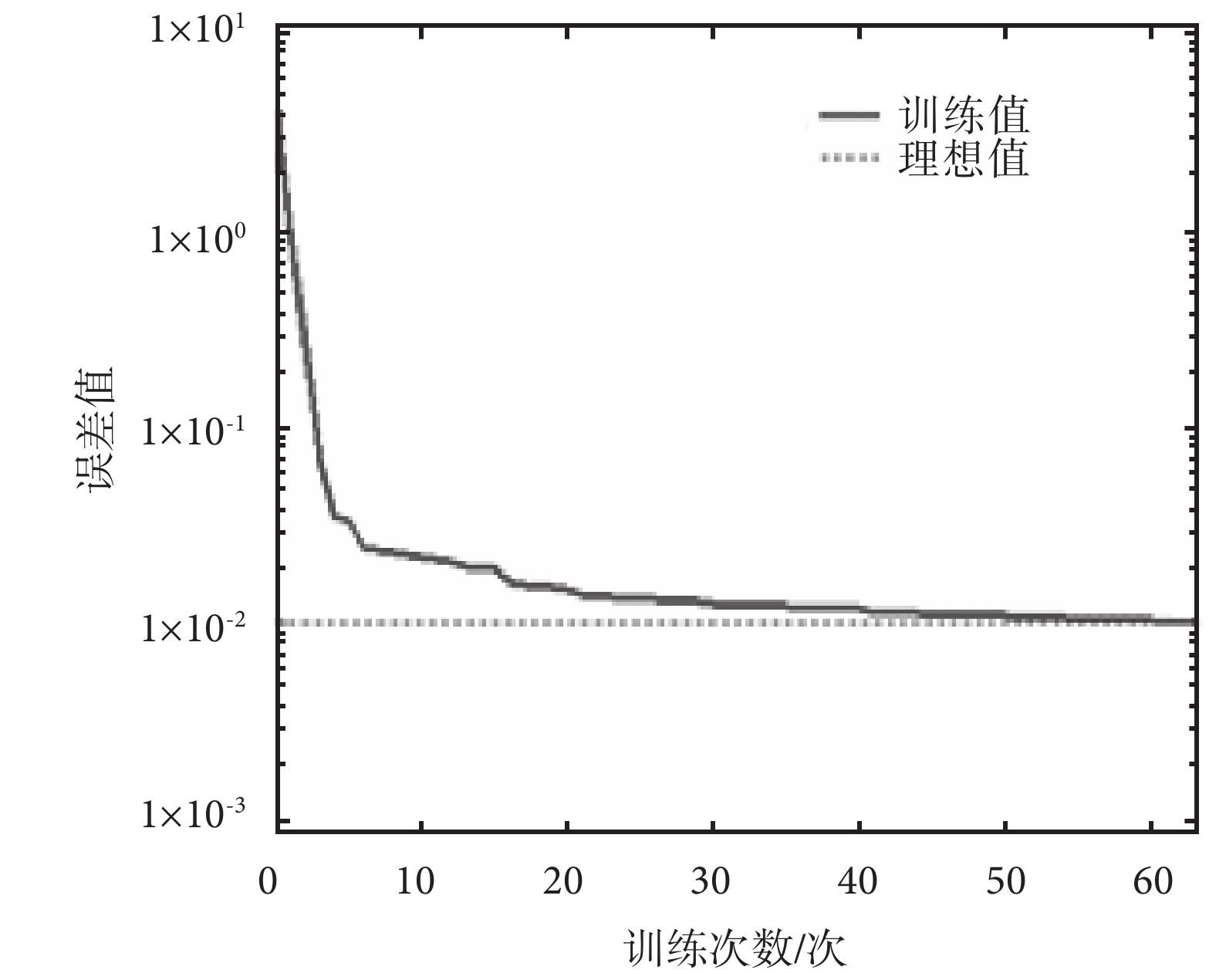
光譜數據經 PCA 處理得到主成分分量,然后取前 2 個主成分作為輸入信息進行訓練,訓練結果如圖 5 所示,經過 63 次訓練后,網絡的目標誤差達到要求。
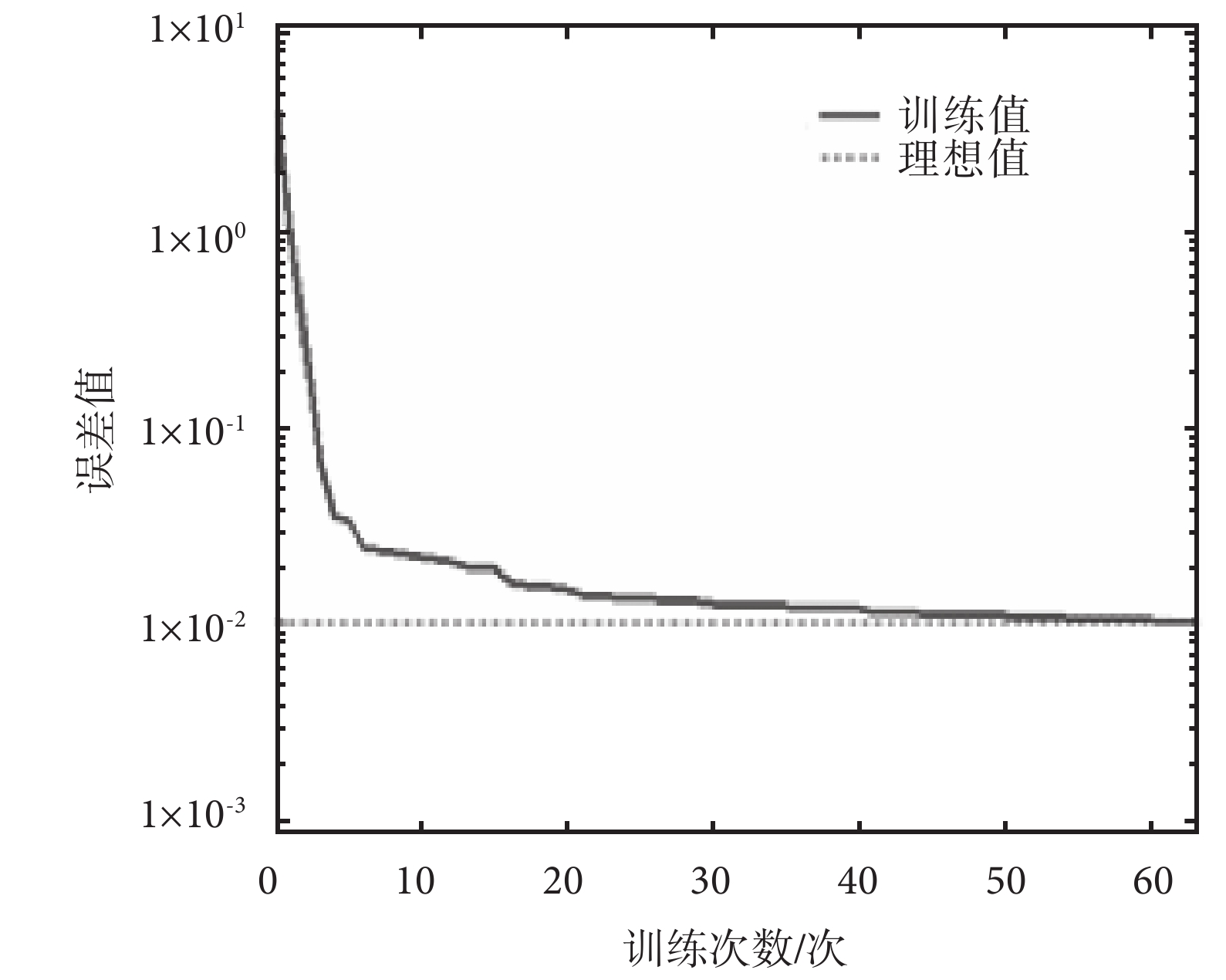 圖5
訓練結果
Figure5.
Training results
圖5
訓練結果
Figure5.
Training results
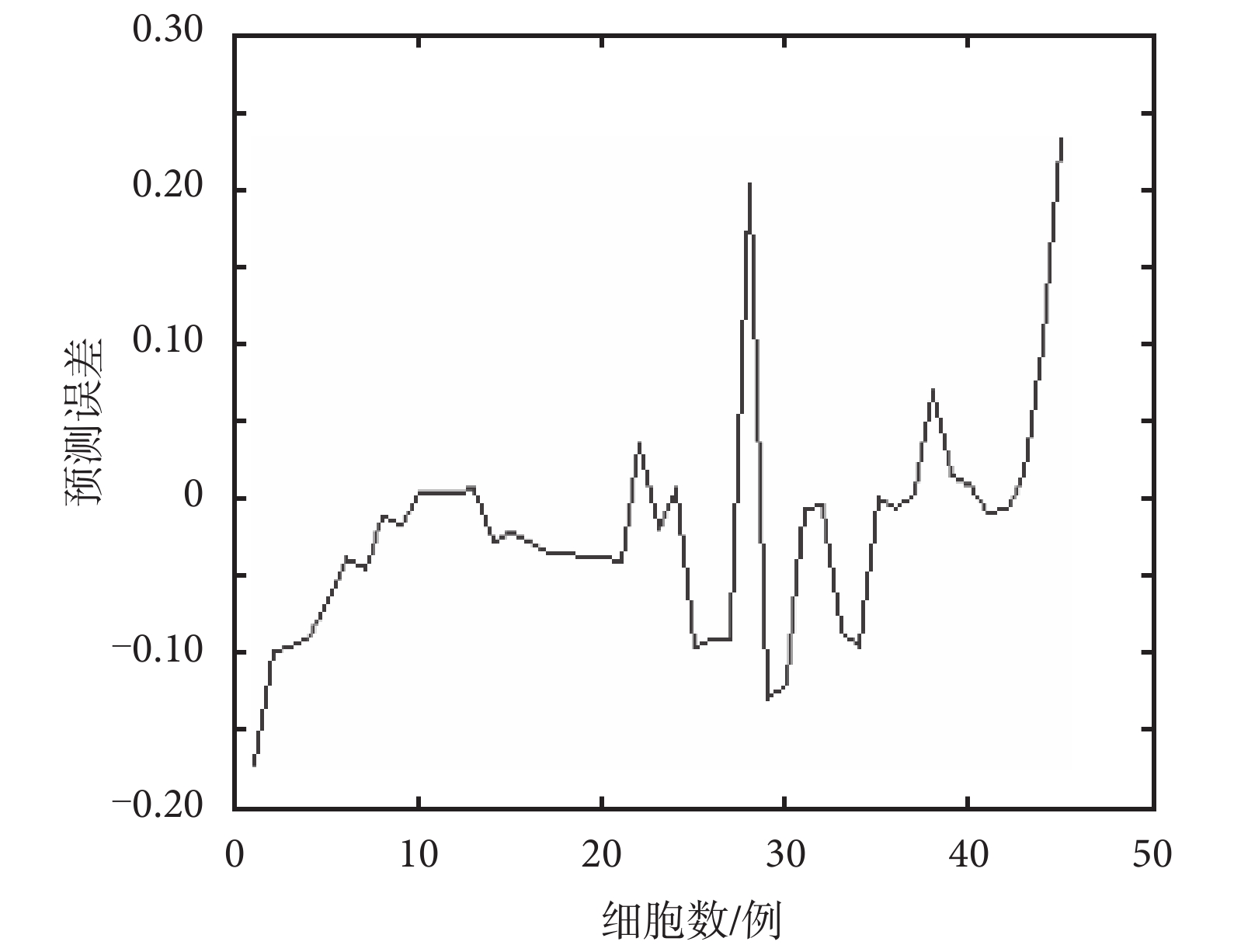
采集 45 組樣本數據作為測試集樣本,1~15 例為紅細胞光譜數據,16~30 例為白細胞光譜數據,31~45 例為肝細胞光譜數據。利用 BP 神經網絡對樣本的預測誤差結果如圖 6 所示。
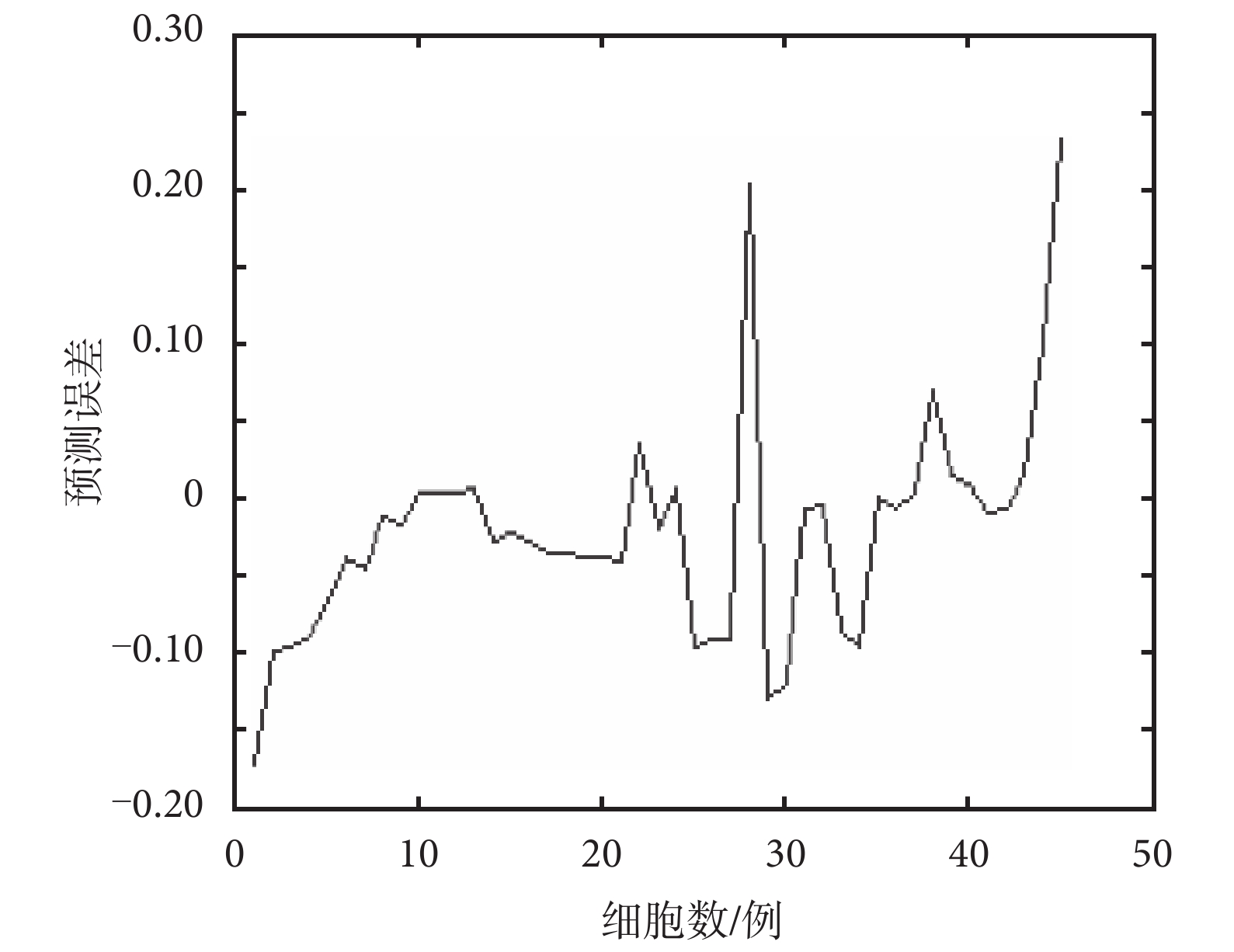 圖6
預測誤差
Figure6.
Prediction error
圖6
預測誤差
Figure6.
Prediction error
圖 6 顯示了 2∶12∶3 結構的前饋神經網絡在訓練階段誤差的趨勢。
網絡在 45 個預測樣本上的識別結果見表 2,設定預測結果偏差在±0.15 內為預測正確。從表中可以看出,經過訓練的網絡對 45 個預測樣本的判別結果與實際情況基本吻合。
表 3 為神經網絡在 45 個光譜測試樣本集的分類識別結果。實驗結果表明三種細胞的識別率均在 90% 以上,平均相對偏差為 4.36%,具有極高的精確度。這說明前饋神經網絡可以完成細胞識別的任務。
3 討論與結論
本研究基于光纖共聚焦后向散射顯微光譜系統,采集大量白細胞、紅細胞和肝癌細胞的后向顯微光譜數據,提出了一種有效的細胞識別分類算法,即 PCA 與 BP 神經網絡相結合。目前常用的分類識別算法有決策樹、人工神經網絡、遺傳算法、K-近鄰算法、支持向量機、樸素貝葉斯。相比較而言人工神經網絡對光譜數據分類的準確度更高、分布存儲及學習能力更強,并且能充分逼近復雜的非線性關系。將 BP 算法與 PCA 相結合,可以得到更精確的分類結果。而決策樹和 K-近鄰算法對于各類別樣本數量不一致的數據,信息增益的結果偏向于那些具有更多數值的特征。遺傳算法的編程實現比較復雜,算法的搜索速度比較慢,要得到較精確解需要較多的訓練時間。支持向量機對缺失數據敏感,對非線性問題沒有通用解決方案。樸素貝葉斯在屬性個數比較多或者屬性之間相關性較大時,分類效率比不上決策樹模型。因此本研究首先通過 PCA 方法對數據進行降維,對三種樣本細胞進行初步區分識別;其次采用 BP 神經網絡模型實現了三種細胞的分類識別,實驗結果表明三種細胞的識別率均在 90% 以上,平均相對偏差只有 4.36%。可以預見這種細胞識別分類算法能夠滿足人們對準確率和識別精度的要求。因此 PCA+BP 算法可以在實際應用中起到輔助診斷的作用,實用價值很高。
但是,本研究也有局限性。首先,BP 網絡收斂較慢,因此影響了該網絡在一些方面的實際應用。為了縮短訓練時間,防止局部值過小,下一步會對 BP 網絡的學習算法進行優化。其次,目前研究只針對離體白細胞、紅細胞和肝癌細胞的識別。采用離體細胞在方法學上主要是因為培養的腫瘤細胞株比較容易獲取,而原位的腫瘤和腫瘤細胞很難獲得,但兩者在細胞形態上是相同的,所以采用腫瘤細胞株來作為研究對象,這也是當前研究在體標記循環腫瘤細胞計數的主要方法[4];由于進一步實驗要在動物(老鼠)模型上展開,不會直接采用人體模型,所以對比腫瘤細胞與老鼠的紅細胞和白細胞將為下一步的研究提供基礎數據。下一步,還將在原位動物模型或微流通道下,開展原位循環到血液中的肝癌細胞等癌細胞的無損傷、無標記的識別探測,使其能應用到癌癥的臨床檢測和治療中。
因此,基于本研究,下一步將建立各種細胞的共焦后向散射光譜數據庫,實現細胞后向散射光譜的編碼,達到可以存儲多種類細胞光譜信息的目的;同時,結合共焦細胞后向散射顯微光譜技術、光纖色散技術、光域放大技術和高速探測器,建立高速光譜探測分析平臺,以微流通道技術為基礎,先實現循環狀態下識別單種細胞,再混合多種細胞以實現多種細胞的區分和計數。最終,根據我們建立的光譜數據庫,能夠有效地在流動細胞群中檢測識別出循環腫瘤細胞,為癌癥的早期診斷和治療提供識別檢測算法。
引言
目前,世界上死亡率排名第三的腫瘤為肝細胞癌(hepatocellular carcinoma,HCC),同時也是第 6 位常見的惡性腫瘤[1]。HCC 治療的難點為初期檢測困難、擴散速度快、復發轉移率高,其術后轉移與復發已經成為影響患者預后的重要因素,臨床上迫切需要能夠有效預測肝癌轉移的檢測手段。循環腫瘤細胞(circulating tumor cell,CTC)出現于癌癥患者的外周血中,是一種重要的游離態組織樣本,在早期診斷、早期治療、判斷預后和制定個體化治療方案等方面具有重要意義[2]。最新的研究表明,肝癌患者病情狀態與血液中 CTC 的數量顯示出極強的相關性[3]。因此實現循環腫瘤細胞在體檢測,對研究許多疾病,特別是癌癥的早期診斷和早期治療具有重要意義。
目前 CTC 探測主要可以分成熒光標記分析和無熒光標記分析兩個大類。基于熒光標記的在體流式細胞儀(in vivo flow cytometry,IVFC)可分為單光子共焦熒光[4]和多光子熒光[5]分析兩類。無標記的在體流式細胞儀又分為基于光熱(photother-mal technique,PT)/光聲技術(photoacoustic technology,PA)[6-7]、基于拉曼散射[8]和基于后向散射[9]三種。標記分析方法,在老鼠模型中,需要通過尾靜脈將體外標記后的腫瘤細胞輸入體內,再研究其循環特征。由于循環腫瘤細胞非常稀少,目前還無法實現在體腫瘤細胞的直接標記,因此無法模擬真實的循環腫瘤細胞環境來研究腫瘤的轉移問題。而無標記的方式將直接探測循環系統中的腫瘤細胞,這樣可以不改變任何環境。
當使用基于 PA/PT 技術的 IVFC 時,利用細胞中吸收光的分子來產生探測信號,從具有相似生物分子的正常細胞中不易區分腫瘤細胞。基于拉曼散射的 IVFC[8],雖然具有在無標記腫瘤細胞監測中應用的前景,但這個技術目前只能在慢流率和小直徑的靜脈管中計數 CTCs,而且需要獨特的生物化學特性(如高血脂)來探測靶細胞。Irene Georga-koudi 團隊最近報道了基于后向散射光的 IVFC[10],表明細胞后向散射光可以作為本征信號源區分循環腫瘤細胞。細胞結構與后向散射光譜的特性有直接關系,細胞光散射光譜具有的天然特點使其非常適合于解決在體細胞計數的問題:① 微米-納米結構的光散射信號展現出了波長和散射角與散射體結構的特征關系,是一個本征的信號源;② 細胞中一些固有的吸收體,如血紅蛋白在散射光譜中也具有獨特的光譜特性;③ 光散射光譜的檢測成本極低,操作簡單;④ 與熒光光譜相比較,不存在熒光“淬滅”等固有缺陷。
本文提出使用光纖共聚焦后向散射(fiber confocal back-scattering,FCBS)光譜儀結合神經網絡模式識別模型進行肝癌細胞的檢測識別。本文采集小鼠白細胞、紅細胞及人體肝癌細胞的散射光譜,進行主成分分析(principle component analysis,PCA),提取三種細胞散射光譜的 2 個主成分,將其作為神經網絡的輸入,將測試細胞的編碼作為神經網絡的輸出,并對該神經網絡模式識別模型進行訓練和測試。
1 材料和方法
1.1 實驗裝置
本實驗采用 FCBS 光譜儀,它由光纖共焦顯微鏡和彈性散射光譜儀組成,能獲得單細胞后向散射光譜,同時還能得到該單細胞的圖像。如圖 1 所示,整個系統主要由寬帶光源、透鏡 L1 和 L2、光纖耦合器、光學探頭、光譜儀、主控電腦組成。其中,光學探頭由兩個消色差物鏡組成,一個消色差物鏡用于準直,其數值孔徑為 0.25,10×;另一個消色差物鏡用于聚焦,其數值孔徑為 0.4,20×。實驗所用光譜儀響應較好的光譜寬帶為 600 nm(400~1 000 nm),光譜分辨率為 4 nm。
寬帶光源出射的光經過透鏡 L1 和 L2 準直后進入到光纖耦合器的端口 1 中,然后從耦合器的端口 3 輸出。端口 3 不僅作為光線傳輸的通道,還成為共焦系統中的探測針孔。光纖耦合器的端口 3 把光源的光線耦合到光學探頭,兩光學探頭之間放置硅片和實驗樣品(細胞)。硅片反射和細胞散射的光線將被探頭接收,進入到耦合器的端口 3 中,并最終從耦合器的端口 2 中出射,進入到光譜儀中。光譜儀探測的數據傳輸到計算機進行分析并顯示光譜曲線。FCBS 光譜儀系統設置了一個觀察功能,確保物鏡探測的是單個細胞而非其他物質。因此我們可以觀測目標的視覺圖像,確定細胞的位置,確定被檢測的對象是單個細胞[11]。
圖1
光纖共聚焦后向散射顯微光譜儀
Figure1.
Fiber confocal back-scattering micro-spectrometer
1.2 細胞樣品
本次實驗細胞樣品為小鼠的白細胞和紅細胞、人體肝癌細胞 HepG2。實驗總樣本數達到 195 例,隨機選取 150 例(紅細胞 50 例,白細胞 50 例,肝癌細胞 50 例)作為訓練集,45 例(紅細胞 15 例,白細胞 15 例,肝癌細胞 15 例)作為測試集。其中白細胞、紅細胞在上海交通大學團隊實驗室分離獲得,肝癌細胞 HepG2 由中科院細胞庫獲得。所有細胞學樣本無血凝塊,并且在常溫、24 h 內完成實驗。
小鼠采血及白細胞的分離方法:balb/c 小鼠毛細管采用 1.5% EDTA 抗凝液預處理,從眼外眥靜脈叢取血 100 μL 置于抗凝液處理過的離心管中,離心 5 min 去除上清,將細胞重懸于 1 mL 紅細胞裂解液中,混勻室溫靜置 5 min,加入 5 mL 磷酸緩沖鹽溶液(phosphate buffer saline,PBS),400g 離心去除上清及紅細胞碎片,然后重懸于 PBS 中離心去除紅細胞碎片。若紅細胞裂解不完全可重復一次裂解洗滌步驟。最后獲得的細胞沉淀重懸于 PBS 中,鏡下觀察。
紅細胞:采血后抗凝處理,無需裂紅步驟,重懸于 PBS 鏡下觀察,紅細胞的典型形態為雙凹圓盤狀。
1.3 光譜采集與預處理
本次實驗利用已經搭建的 FCBS 平臺測量人體肝癌細胞以及小鼠正常的紅細胞、白細胞的后向散射光譜。如圖 1 所示,耦合透鏡組接收到經光纖耦合器耦合的光線,將其直接照射到細胞表面,同時透鏡組接收到細胞散射光,光譜儀接收經光纖耦合器耦合的細胞散射光,從而獲得細胞光譜。
由于硅片在可見光和近紅外波段的反射率為 30%,細胞散射光強度比較低,能真實反映所測樣品的光譜特性,因此在細胞后向散射光譜的分析中,所有光譜的標準均采用拋光良好的硅片[11]。分別滴取適量白細胞和紅細胞、人體肝癌細胞 HepG2 于載玻片上,依次放在顯微鏡的載物臺上,手動調節載物臺使其沿四周移動,使會聚光點全方面掃描細胞,從而測量出樣品在該點的顯微光譜信息。
1.4 光譜 PCA 法降維
上述方法采集到的光譜每隔 4 nm 為一個采樣點,即一個維數,所以光譜維度較高,如此高的維數進行自動識別非常困難。因此本研究采用 PCA 法進行降維處理。20 世紀 30 年代霍特林提出了 PCA 法,它是一種多元統計分析技術[12]。采用 PCA 法實現降維,通過對數據去相關,提取出數據的最主要特征,經變換后得到的新變量作為主成分,按信息量的大小排序后,得到三種細胞散射光譜數據的新變量,實現光譜數據降維[13]。
PCA 算法的主要步驟如下:
設光譜數據 為n 維向量。
(1)對數據進行標準化處理:
將原始待觀察數據組成樣本矩陣 x ,每一行為一個觀察樣本,每一列代表一維數據。計算每一維的均值,即計算樣本矩陣 x 中每一列的均值,并對矩陣中的每個樣本進行歸一化處理:
| $x({λ})= \frac{{{x_i} - {x_{\min }}}}{{{x_{\max }} - {x_{\min }}}}$ |
該方法可實現對原始數據的等比例縮放,其中x( )為歸一化后的光譜數據,xi 為光譜原始數據,xmax、xmin 分別為光譜原始數據集的最大值和最小值。
(2)計算樣本矩陣 的協方差矩陣:
| ${{{c}}_{{x}}} = {\mathop{\rm cov}} ({{x}}) = \left[ {\begin{array}{*{20}{c}}{{c_{11}}} & \cdot \! \cdot \! \cdot & {{c_{1n}}}\\ \vdots & \ddots & \vdots \\{{c_{n1}}} & \cdot \! \cdot \! \cdot & {{c_{nn}}}\end{array}} \right]$ |
(3)計算協方差矩陣 c x 的特征值xj 及相應特征向量 vi 。
(4)計算前m 個主元的累計貢獻率 。
按特征值xj 的大小順序排列后,截取特征值大于某個閾值r 的前m 個主元[14]。一般主成分選取標準是按照累計貢獻率達到 80% 以上[15],其依據是選取方差最大的前幾個主成分,實現將多個相關變量壓縮為少數幾個不相關的綜合變量,并且獲得包含大部分原變量信息的新綜合變量,達到降維的效果。
| $\phi (m) = \frac{{\sum\limits_{j = 1}^m {{x_j}} }}{{\sum\limits_{i = 1}^m {{x_i}} }}$ |
1.5 反向傳播神經網絡與光譜分類識別
網絡學習算法中,最常見的就是反向傳播(back propagation,BP)神經網絡。它是一種按誤差逆傳播算法訓練的多層前饋網絡。其基本思想是使用最速下降法,通過反向傳播,獲得網絡權值和閾值的不斷調整,從而得到最小的網絡誤差平方和[16]。根據 PCA 包含主要信息的判斷,將包含主要信息的主成分值xj 作為 BP 神經網絡輸入節點j 的輸入值,對三種細胞的后向散射光譜進行自動識別[15]。BP神經網絡結構如圖 2 所示。
BP 神經網絡的學習算法步驟如下[16]:
(1)計算隱層和輸出層節點的輸出:
| ${y_i} = f(\sum\limits_j {{w_{ij}}} {x_j} - {\theta _i}) = f(ne{t_i})$ |
公式(4)中,yi 為隱層第i 個節點的計算輸出,wij 為輸入節點j 至隱含層節點i 的連接權重,xj 為輸入節點j 的輸入值,θi 為隱含層節點的閾值,f 為激活函數,即 S 型的 Sigmoid 函數。
隱含層節點數設計:
| $i = \sqrt {j + l} + {{a}$ |
a 為 1~10 之間的調節常數。
(2)計算輸出點l 的輸出ol :
| ${o_l} = f(\sum\limits_i {{T_{li}}} {y_i} - {\theta _l}) = f(ne{t_l})$ |
式(6)中,ol 為輸出節點l 的計算輸出,Tli 為隱層節點i 至輸出節點l 的連接權重,θl 為輸出節點l 的閾值,其它參數含義同前面。
(3)計算誤差:
總誤差E 按式(7)進行計算。
| $\begin{aligned}E = & \frac{1}{2}\sum\limits_l {({t_l}} - {o_l}{)^2}= \\& \frac{1}{2}\sum\limits_l {({t_l} - f(\sum\limits_i {{T_{li}}} } {y_i} - {\theta _l}){)^2}= \\& \frac{1}{2}\sum\limits_l {({t_l}} - f(\sum\limits_i {{T_{li}}} f(\sum\limits_j {{w_{ij}}} {x_j} - {\theta _i}) - {\theta _l}){)^2}\end{aligned}$ |
輸出平均值:
| $t = \sum\limits_{i = 1}^n {{t_i}} $ |
平均相對偏差:
| $z = \frac{1}{{nt}}\sqrt {\sum\limits_{i = 1}^n {{{({t_i} - t)}^2}} } * 100\% $ |
式(7)中ti 為輸出節點l 的期望輸出值。式(8)中t 為輸出節點的平均值,式(9)中z 為輸出層的平均相對偏差。
圖2
BP 神經網絡結構
Figure2.
Back propagation neural network structure
2 結果與分析
2.1 光譜分析結果
圖 3 為實驗所得到的三種細胞的后向散射顯微光譜數據。圖中紅色、藍色、綠色曲線分別代表肝癌細胞、白細胞、紅細胞的后向散射光譜曲線。其中橫坐標是波長(nm);縱坐標是相對后向散射光強度S(a.u.),即細胞后向散射光譜相對參考硅片反射。研究選取可見光波段到近紅外波段,即波長范圍在 500~900 nm 間。
圖3
白細胞、紅細胞、肝癌細胞平均光譜
Figure3.
Average spectra of white blood cells, red blood cells, and liver cancer cells
由圖 3 可看出,在 500~900 nm 波長范圍內,三種細胞中肝癌細胞的散射光強最低,其次是白細胞,紅細胞散射光強最高。三種細胞在整體曲線趨勢上區別很明顯。因此,后向散射光譜系統可以初步對這三種細胞進行區分檢測。為了進一步對三種細胞實現自動識別,采用了 PCA 分析法,對采集樣本的光譜數據進行降維分析。
2.2 光譜降維的 PCA 結果
紅細胞、白細胞和肝癌細胞共焦后向散射光譜主成分得分如表 1 所示。前兩個主成分的累計貢獻率已經達到 89.5%,說明它們已經包含了原變量的主要信息。
如圖 4 所示,測試集樣本為 45 個樣本的光譜數據,其中 15 組紅細胞、15 組白細胞和 15 組肝癌細胞。紅細胞主要分布在 PC1 與 PC2 的負半軸。肝癌細胞主要分布在 PC1 的 0~20 處,PC2 的正半軸。白細胞分布在 PC1 的正半軸。三種細胞分布區域的差別較明顯,說明通過前兩個主成分已經完全可以區分出紅細胞、白細胞和肝癌細胞。
圖4
三種細胞前 2 個主成分得分圖
Figure4.
Two principal component score of three kinds of cells
2.3 BP 神經網絡的設計與光譜分類結果
選取 195 例對象數據訓練該模型,隨機抽取 150 組數據(紅細胞 50 例、白細胞 50 例、肝癌細胞 50 例)作為訓練集,45 組數據(紅細胞 15 例、白細胞 15 例、肝癌細胞 15 例)作為測試集。BP 神經網絡由輸入層、隱含層和輸出層組成[17]。輸入層對應輸入向量空間,在本文中對應采集到的細胞顯微光譜經 PCA 降維后的有效光譜分量;為了更穩妥地預測細胞類型,選擇前 2 個 PCA 主成分向量為神經網絡的輸入[18],即 BP 神經網絡的輸入節點為 2 個。由公式(2)知訓練集樣本的隱含層節點數為 12 時,網絡誤差最小,故隱含層由 12 個神經元組成。輸出值為不同細胞類型的編碼,設定編碼 –1 為紅細胞,編碼 0 為白細胞,編碼 1 為肝癌細胞,此代碼在訓練集中為目標值,在預測集中為相應的編碼,因此 BP 神經網絡的輸出節點為 3。設定預測結果偏差在±0.15 內為預測正確,反之,誤測情況有兩種:① 當結果不在設置的值區間說明誤測,但沒有被識別為其他類的細胞;② 當預測值在別的細胞值區間就會被識別為別的細胞。計算輸入層到隱含層和隱含層到輸入層的校正誤差,選取下一個輸入反復訓練,直到網絡輸出誤差達到要求結束訓練。本文采用的訓練次數為 1 000 次,目標誤差為 0.01。
光譜數據經 PCA 處理得到主成分分量,然后取前 2 個主成分作為輸入信息進行訓練,訓練結果如圖 5 所示,經過 63 次訓練后,網絡的目標誤差達到要求。
圖5
訓練結果
Figure5.
Training results
采集 45 組樣本數據作為測試集樣本,1~15 例為紅細胞光譜數據,16~30 例為白細胞光譜數據,31~45 例為肝細胞光譜數據。利用 BP 神經網絡對樣本的預測誤差結果如圖 6 所示。
圖6
預測誤差
Figure6.
Prediction error
圖 6 顯示了 2∶12∶3 結構的前饋神經網絡在訓練階段誤差的趨勢。
網絡在 45 個預測樣本上的識別結果見表 2,設定預測結果偏差在±0.15 內為預測正確。從表中可以看出,經過訓練的網絡對 45 個預測樣本的判別結果與實際情況基本吻合。
表 3 為神經網絡在 45 個光譜測試樣本集的分類識別結果。實驗結果表明三種細胞的識別率均在 90% 以上,平均相對偏差為 4.36%,具有極高的精確度。這說明前饋神經網絡可以完成細胞識別的任務。
3 討論與結論
本研究基于光纖共聚焦后向散射顯微光譜系統,采集大量白細胞、紅細胞和肝癌細胞的后向顯微光譜數據,提出了一種有效的細胞識別分類算法,即 PCA 與 BP 神經網絡相結合。目前常用的分類識別算法有決策樹、人工神經網絡、遺傳算法、K-近鄰算法、支持向量機、樸素貝葉斯。相比較而言人工神經網絡對光譜數據分類的準確度更高、分布存儲及學習能力更強,并且能充分逼近復雜的非線性關系。將 BP 算法與 PCA 相結合,可以得到更精確的分類結果。而決策樹和 K-近鄰算法對于各類別樣本數量不一致的數據,信息增益的結果偏向于那些具有更多數值的特征。遺傳算法的編程實現比較復雜,算法的搜索速度比較慢,要得到較精確解需要較多的訓練時間。支持向量機對缺失數據敏感,對非線性問題沒有通用解決方案。樸素貝葉斯在屬性個數比較多或者屬性之間相關性較大時,分類效率比不上決策樹模型。因此本研究首先通過 PCA 方法對數據進行降維,對三種樣本細胞進行初步區分識別;其次采用 BP 神經網絡模型實現了三種細胞的分類識別,實驗結果表明三種細胞的識別率均在 90% 以上,平均相對偏差只有 4.36%。可以預見這種細胞識別分類算法能夠滿足人們對準確率和識別精度的要求。因此 PCA+BP 算法可以在實際應用中起到輔助診斷的作用,實用價值很高。
但是,本研究也有局限性。首先,BP 網絡收斂較慢,因此影響了該網絡在一些方面的實際應用。為了縮短訓練時間,防止局部值過小,下一步會對 BP 網絡的學習算法進行優化。其次,目前研究只針對離體白細胞、紅細胞和肝癌細胞的識別。采用離體細胞在方法學上主要是因為培養的腫瘤細胞株比較容易獲取,而原位的腫瘤和腫瘤細胞很難獲得,但兩者在細胞形態上是相同的,所以采用腫瘤細胞株來作為研究對象,這也是當前研究在體標記循環腫瘤細胞計數的主要方法[4];由于進一步實驗要在動物(老鼠)模型上展開,不會直接采用人體模型,所以對比腫瘤細胞與老鼠的紅細胞和白細胞將為下一步的研究提供基礎數據。下一步,還將在原位動物模型或微流通道下,開展原位循環到血液中的肝癌細胞等癌細胞的無損傷、無標記的識別探測,使其能應用到癌癥的臨床檢測和治療中。
因此,基于本研究,下一步將建立各種細胞的共焦后向散射光譜數據庫,實現細胞后向散射光譜的編碼,達到可以存儲多種類細胞光譜信息的目的;同時,結合共焦細胞后向散射顯微光譜技術、光纖色散技術、光域放大技術和高速探測器,建立高速光譜探測分析平臺,以微流通道技術為基礎,先實現循環狀態下識別單種細胞,再混合多種細胞以實現多種細胞的區分和計數。最終,根據我們建立的光譜數據庫,能夠有效地在流動細胞群中檢測識別出循環腫瘤細胞,為癌癥的早期診斷和治療提供識別檢測算法。