將卷積神經網絡(CNN)用于肺部腫瘤正電子發射計算機斷層掃描(PET)/電子計算機斷層掃描(CT)計算機輔助診斷,不僅可以提供精確的定量分析以彌補人眼惰性及對灰階不敏感的缺陷,也能輔助醫生準確診療。本文首先采用參數遷移的方法初始構建三個 CNN(CT-CNN、PET-CNN、PET/CT-CNN)分別用于肺部腫瘤 CT、PET、PET/CT 的識別;然后以 CT-CNN 為例探討迭代次數、批次大小和輸入圖像大小對識別率和訓練時間的影響,從而選擇合適的模型參數訓練單一 CNN;最后集成三個單一 CNN,采用“相對多數投票法”完成肺部腫瘤 PET/CT 計算機輔助診斷,進而對比集成 CNN 與單個 CNN 的性能。實驗結果表明集成 CNN 模型比單一 CNN 模型對于肺部腫瘤計算機輔助診斷的性能更優。
引用本文: 王媛媛, 周濤, 陸惠玲, 吳翠穎, 楊鵬飛. 基于集成卷積神經網絡的肺部腫瘤計算機輔助診斷模型. 生物醫學工程學雜志, 2017, 34(4): 543-551. doi: 10.7507/1001-5515.201607003 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
肺癌是世界上發病率和死亡率最高的惡性腫瘤之一[1],吸煙和空氣污染是其主要誘因,由于肺癌的病理學特征復雜難辨,發病時間短,惡性程度高,早期癥狀不易被發現,使得 80% 以上的患者確診時已處于肺癌晚期,所以早發現早治療對于肺癌患者至關重要。目前臨床上常見的肺癌診斷方法有纖維支氣管鏡刷檢查、電子計算機斷層掃描(computed tomography,CT)引導下的肺穿刺組織病理學檢查、痰細胞學檢查或多種手段聯合檢查等[2]。隨著影像學的發展,X 線成像、CT、磁共振成像、正電子發射計算機斷層掃描(positron emission tomography,PET)等影像檢查被廣泛應用,尤其 PET/CT 不僅能通過圖像發現肺部病灶的存在,而且能準確定位病灶在全肺的位置,還能觀察病灶的大小、形態及密度等物理特征。但是,海量圖像在提供更加詳細、準確的診斷信息時,也給讀片醫生增加了工作負擔,容易因診斷疲勞導致疾病漏診和誤診,并且醫生憑借閱片經驗對病灶進行定性分析具有較大的主觀性,所以肺部腫瘤計算機輔助診斷不僅可以為放射科醫生提供精確的定量分析以彌補人眼惰性及對灰階不敏感的缺陷[3],而且可以減少放射科醫生因主觀因素對閱片結果造成的不利影響,從而幫助醫師發現病灶,提高診斷率。
目前,肺部腫瘤計算機輔助診斷主要集中在肺部感興趣區域(region of interest,ROI)分割、病灶檢測和良惡性識別三方面,關鍵技術包括圖像增強、圖像分割、特征提取和分類器設計。劉慧等[4]提出了快速模糊 C 均值聚類肺結節分割方法,可有效提高局部鄰域像素自適應程度并實現對病變組織的正確、快速分割;姜慧研等[5]提出了基于一幅 CT 圖像快速識別肺癌的方法和基于序列圖像的準確識別方法,建立了面向不同需求的肺癌識別模型;吳遂愿[6]提出了基于形狀特征矩和三維細化的 CT 腫瘤識別方法,達到了 77.55% 的腫瘤檢出率;王晉[7]構建了 PET-CT 孤立型肺結節特征集,研究了基于信息論的特征選擇方法,提高結節的良惡性分類器性能。近年,基于圖像傳統特征提取的神經網絡廣泛用于肺癌計算機輔助診斷中,王克全等[8]探討了肺癌 CT 診斷中應用模糊神經網絡輔助診斷的效果;聶永康等[9]從腫瘤的 CT 特征和 PET 特征角度出發,提出了一種人工神經網絡輔助診斷系統。目前,將深度神經網絡與計算機輔助診斷結合,提取圖像語義信息成為研究熱點。
卷積神經網絡[10](convolutional neural network,CNN)作為深度學習經典模型之一,可以直接輸入原始圖像并具有局部感受野、權值共享、下采樣特點,對于圖像平移、比例縮放、傾斜或其他形式的變形表現出良好的魯棒性。集成學習[11]作為機器學習領域的研究熱點,利用多個(通常是同質的)學習機來解決同一個問題,在保證每個學習機具有良好的識別精度和較大差異時,提高網絡的泛化能力。所以,本文首先通過參數遷移的方法初始構建三個單一 CNN(CT-CNN、PET-CNN、PET/CT-CNN)分別用于肺部腫瘤 CT、PET 和 PET/CT 圖像的識別,參數遷移可以保證單個 CNN 具有快速學習的能力;然后集成三個單一 CNN,由于本文采用 CT、PET、PET/CT 不同模態的輸入數據使得樣本集處于不同空間的分布,正好滿足集成網絡中個體分類器的差異性,最后采用“少數服從多數”投票法形成最優決策,完成肺部腫瘤圖像的識別。
1 基礎理論
1.1 卷積神經網絡
CNN 是受視覺神經機制啟發而設計的一個多層感知器,是一種有監督學習下的深度學習模型,主要由卷積層和池化層兩種特殊的結構層組成,可以直接輸入原始圖像,避免前期對圖像復雜的預處理過程,在二維圖像識別領域取得了廣泛應用。
1.1.1 網絡結構 CNN 的隱藏層是特征提取的核心,隱藏層包括卷積層和下采樣層。卷積層進行卷積運算,每個神經元的輸入與前一層的局部感受野相連,前一層的特征圖與一個可學習的卷積核進行卷積,然后通過激活函數,輸出這一層的特征圖,表達式為:
 |
其中,I 代表層數,k 是卷積核,Mj 代表輸入特征圖的一個選擇,每個輸出圖有一個偏置 b;由于 CNN 采取的是非全連接方式,所以每一個輸出的特征圖可能包含多個輸入圖的卷積。子采樣層對輸入進行 Pooling 運算,如果輸入的特征圖為 n 個,則經過下采樣層后的特征圖的個數仍然為 n,但特征圖大小為原圖的一半,下采樣層的表達式為:
 |
其中 down(·)表示次抽樣函數,β 和 b 分別為下采樣層的乘性偏置和加性偏置。
1.1.2 訓練算法 CNN 的學習過程主要包括兩個階段:① 前向傳播:即卷積和下采樣依次進行的過程,上一層的輸出作為下一層的輸入,并通過激活函數逐層傳遞,最后得到實際輸出;② 反向傳播和權值更新:即通過實際輸出與理想輸出間的誤差反向傳播,得到各個網絡層的誤差函數,然后采用隨機梯度下降法對網絡權值和偏置進行優化調整。假設一個多分類問題包括 N 個訓練樣本和 C 個類別,其誤差函數為:
 |
其中
 表示第 n 個輸入樣本中第 k 維對應的類別標簽,
表示第 n 個輸入樣本中第 k 維對應的類別標簽,
 表示第 n 個輸入樣本中第 k 維對應的預測輸出值。
表示第 n 個輸入樣本中第 k 維對應的預測輸出值。
1.2 集成學習
集成學習是一種機器學習范式,其本質是利用多個(通常是同質的)學習機來解決同一個問題,最后采用“集體決策”的思想決定最終的輸出結果,目的是更有效地提高學習模型的泛化能力,泛化能力越強,處理新數據的能力就越好。神經網絡集成方法最早是在 1990 年由 Hansen 和 Salamon 提出,證明了可以簡單地通過訓練多個神經網絡將其結果進行合成,并且對于神經網絡分類器采用集成方法能夠有效提高系統的泛化能力。
神經網絡集成實現方法的研究主要集中在兩個方面,即如何生成集成中的個體網絡和怎樣將多個神經網絡的輸出結論進行結合[12]。在生成集成中個體網絡方面,最重要的技術是 Boosting 和 Bagging,Freund 和 Schapire 對 Boosting 類方法進行了分析,并證明該類方法產生的最終預測函數 H 的訓練誤差滿足:
 |
 |
從式(5)可以看出,只要學習算法略好于隨機猜測,訓練誤差將隨 t 以指數級下降。對于結論生成方法通常采用絕對多數投票法和相對多數投票法,假設集成由 N 個獨立的神經網絡分類器構成,采用絕對多數投票法,再假設每個網絡以 1–p 的概率給出正確的分類結果,并且網絡之間錯誤不相關,則該網絡集成發生錯誤的概率 P 為:
 |
在 p<1/2 時,P 隨 N 的增大而單調遞減。因此,如果每個神經網絡的預測精度都高于 50%,并且各網絡之間錯誤不相關,則神經網絡集成中的網絡數目越多,集成的精度就越高,當 N 趨向于無窮時,集成的錯誤率趨向于 0。所以,要想構建一個好的網絡模型,一方面應盡可能提高個體網絡的泛化能力,另一方面要增大集成中各網絡之間的差異。
2 基于集成 CNN 的肺部腫瘤 PET/CT 輔助診斷模型
2.1 算法思想
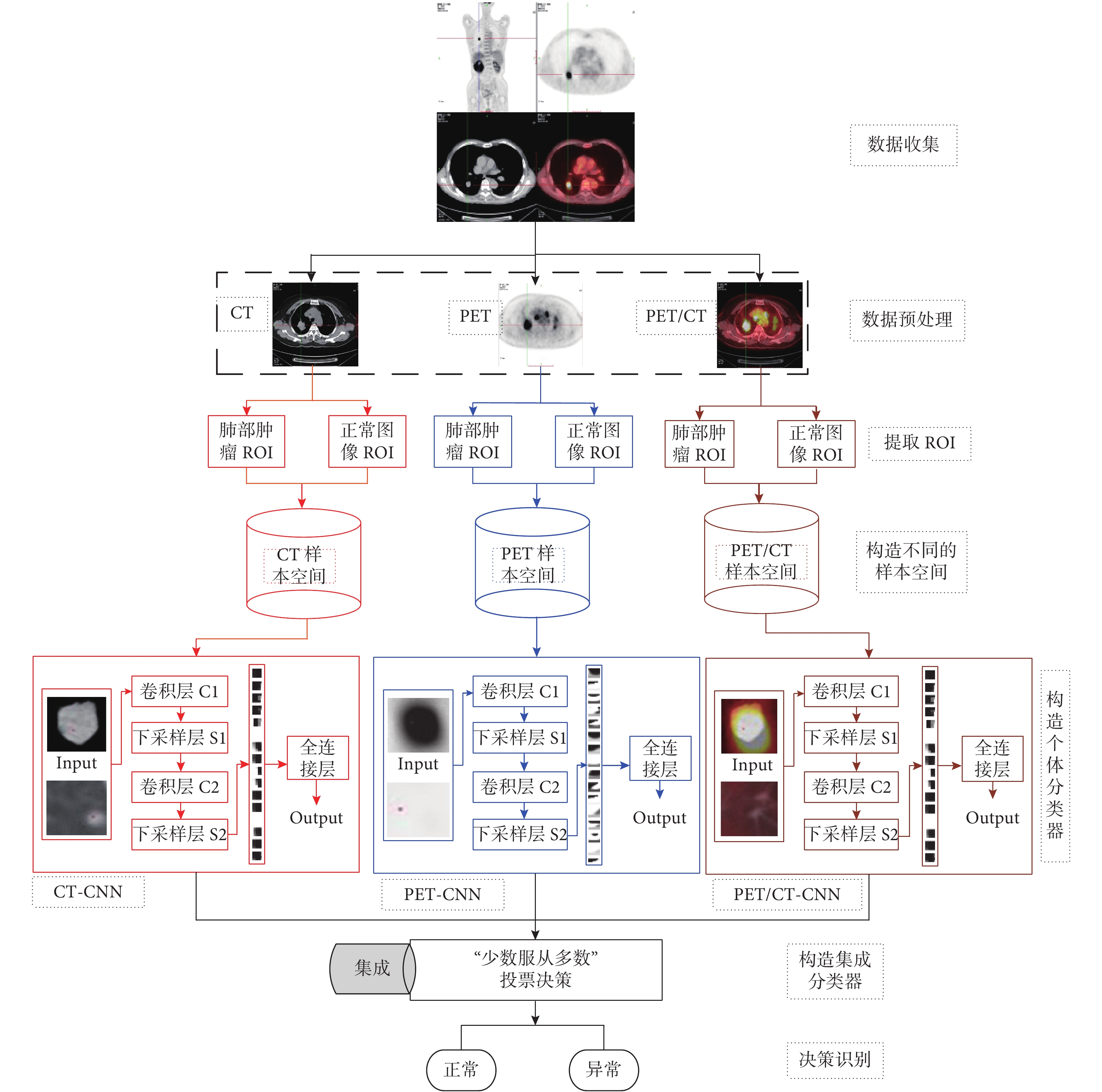
本文首先采用參數遷移 LeNet-5 模型結構的方法構建三個單一 CNN(CT-CNN、PET-CNN、PET/CT-CNN),分別用于肺部腫瘤 CT、PET、PET/CT 圖像的識別,然后以 CT-CNN 為例探討模型參數即迭代次數、批次大小和輸入圖像大小對識別率和訓練時間的影響,從而選擇合適的模型參數訓練三個單一 CNN,對比其識別性能;最后集成三個單一 CNN,采用“相對多數投票法”形成最優決策完成肺部腫瘤 PET/CT 計算機輔助診斷,對比分析集成 CNN 與單一 CNN 對于肺部腫瘤輔助診斷的整體性能。本文算法流程如圖 1 所示。
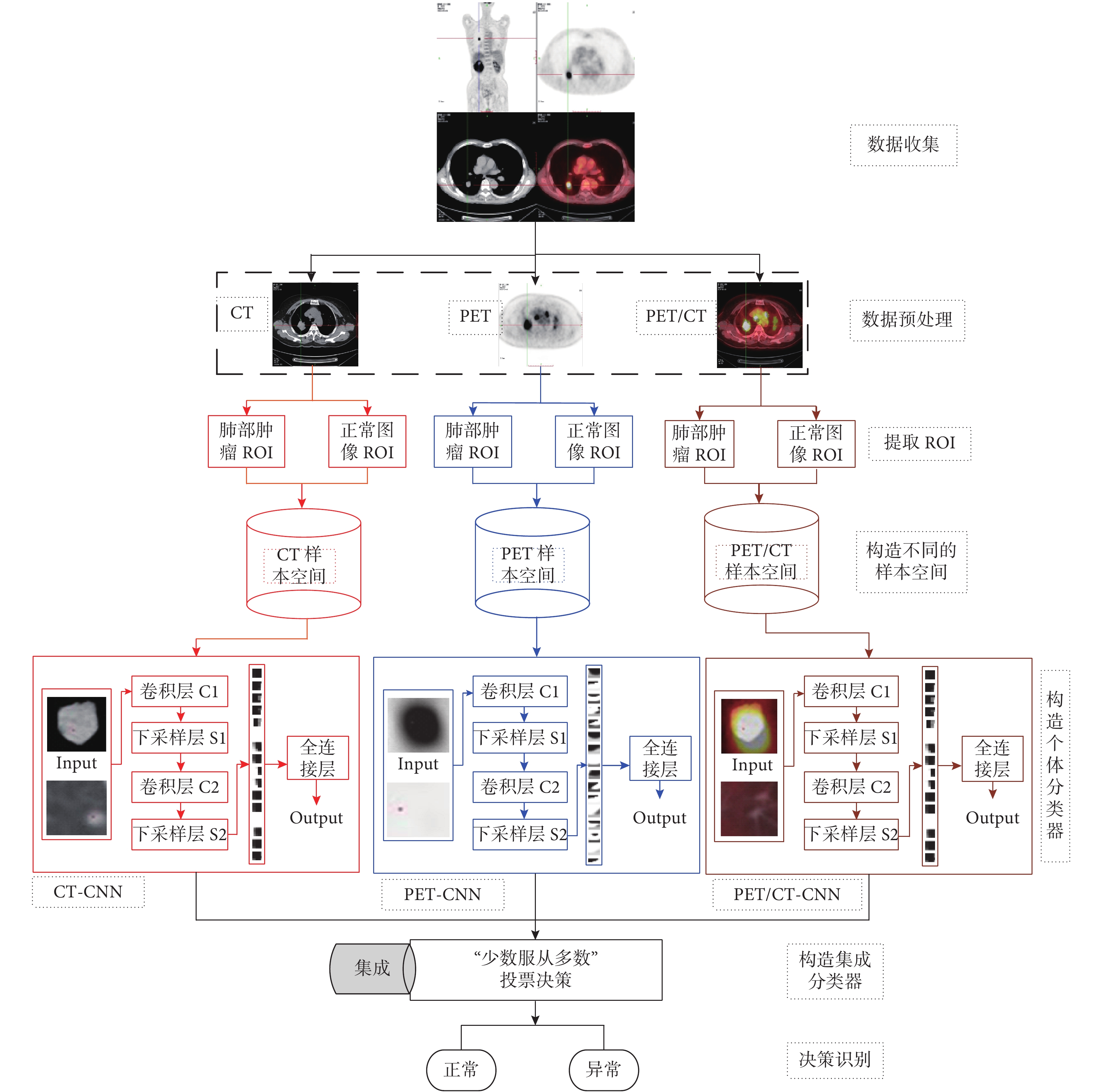 圖1
算法流程圖
Figure1.
Flow diagram of algorithm
圖1
算法流程圖
Figure1.
Flow diagram of algorithm
基于集成 CNN 的肺部腫瘤 PET/CT 計算機輔助診斷模型構建的具體步驟如下:
(1)數據收集:從醫院收集 9 000 例原始肺部 CT、PET、PET/CT 三種模態的圖像,其中每種模態圖像各 3 000 例,包括經專家標記為肺部腫瘤的 1 500 例和正常的 1 500 例;
(2)圖像預處理:首先對 PET/CT 融合圖像去偽彩,轉化為灰度圖像;然后對三個模態圖像一一對應手動提取專家標記的 ROI 作為肺部腫瘤數據,提取同一患者肺部正常的區域作為正常圖像的 ROI,從而保證肺部腫瘤圖像與正常圖像本身的可對比性和區分性;最后將提取的三模態圖像歸一化為 28*28 和 50*50 大小的實驗圖像,保證數據本身的統一性便于后續實驗;
(3)構造不同樣本空間:由于 CT、PET、PET/CT 三模態的圖像一一對應(即來自于同一患者的不同影像數據),通過前期預處理后構建 CT、PET、PET/CT 不同的樣本空間集;
(4)單個 CNN 構建:采用參數遷移法初始構建三個單一 CNN 模型(CT-CNN、PET-CNN、PET/CT-CNN),然后探討 CNN 模型中迭代次數、批次大小和不同輸入圖像大小對識別率和訓練時間的影響,最后選取合適的模型參數進行后續實驗;
(5)集成 CNN 構建:通過三個單一 CNN 構建集成 CNN 模型;
(6)決策識別:采用“相對多數投票法”決策識別肺部正常圖像和肺部腫瘤圖像,綜合對比三個單一 CNN 和集成 CNN 用于肺部腫瘤 PET/CT 識別的性能。
2.2 關鍵技術
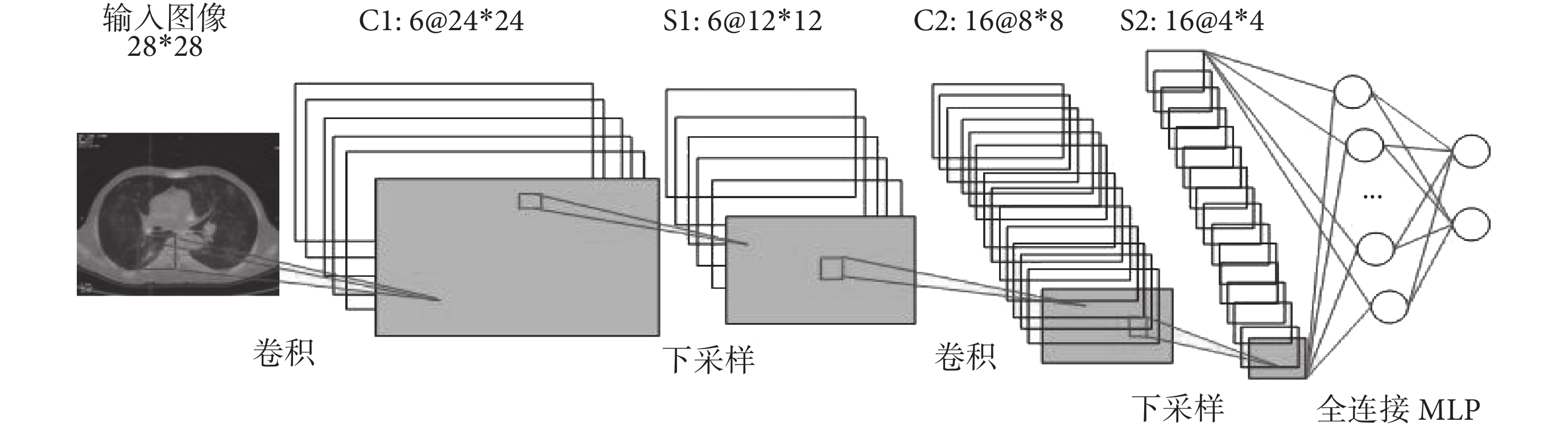
2.2.1 單個 CNN 結構設計 參數遷移[13]是指利用現有的預先訓練好的具有強大學習能力的網絡模型參數初始化某個小型訓練集模型參數,參數初始化方法可以將已有的強大的學習能力遷移到另一個網絡中,Lecun 等[14]提出的 LeNet-5 是典型的 CNN 模型,共有七層(不包括輸入層),所有層都帶有參數,本文采用參數遷移 LeNet-5 模型的方法初次構建單個 CNN。
本文設計的單個 CNN 結構由 5 層組成,具體結構如圖 2 所示,其中包含兩個卷積層、兩個下采樣層和一個全連接層,每一層都包括可訓練的參數。
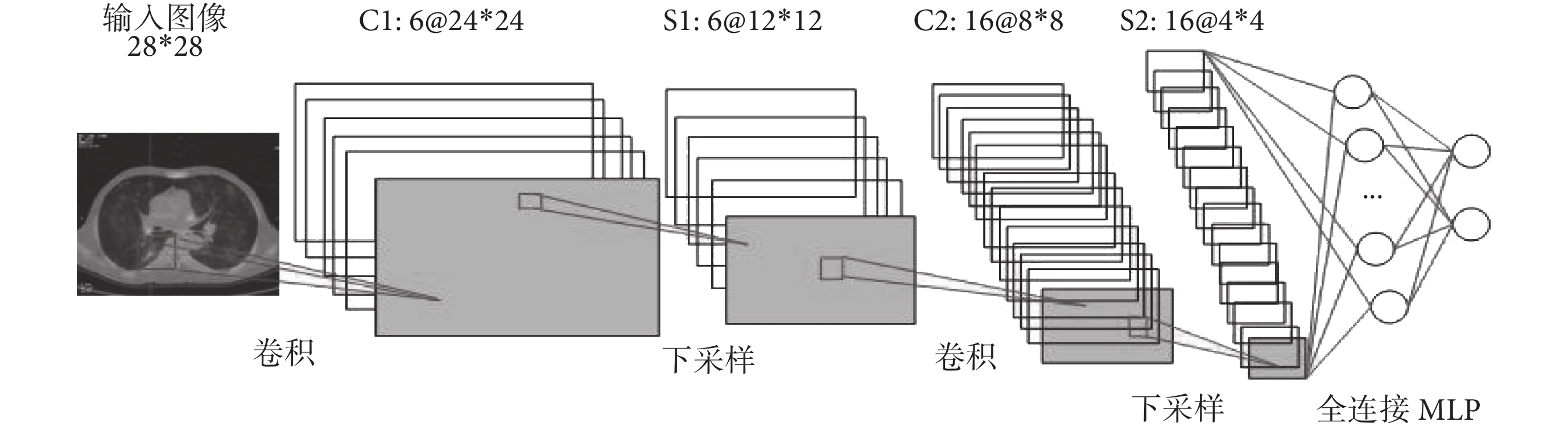 圖2
單個卷積神經網絡結構
Figure2.
Single convolutional neural network architecture
圖2
單個卷積神經網絡結構
Figure2.
Single convolutional neural network architecture
(1)輸入層:輸入大小為 28*28 的 CT、PET 和 PET/CT 圖像;
(2)卷積層 C1:由輸入圖像經過六個 5*5 的卷積核卷積而成的 6 個特征圖組成,每個特征圖的大小為 24*24;
(3)下采樣層 S1:對 C1 層的每個特征圖進行尺度為 2 的下采樣,由 6 個 12*12 的下采樣特征圖組成;
(4)卷積層 C2:由 16 個大小為 8*8 的特征圖組成;
(5)下采樣層 S2:由 16 個大小為 4*4 的特征圖組成,特征圖的每個神經元與 C2 層的一個大小為 2*2 的鄰域連接;
(6)全連接層 F1:即輸出層前一層的全連接層,每個特征圖全連接到 S2 層的所有特征圖;
(7)輸出層:輸出類別為兩類即是否為肺部腫瘤,激活函數選擇 Sigmoid 函數。
2.2.2 集成 CNN 模型構建 神經網絡集成通過訓練多個神經網絡并將其結論進行合成,可以顯著地提高學習模型的泛化能力。本文在單個 CNN 模型結構的基礎上,集成三個不同的單一 CNN(CT-CNN、PET-CNN、PET/CT-CNN)用于肺部腫瘤識別,最后采用集成算法投票法進行最終的圖像識別,也就是三個不同的單一 CNN 模型都進行分類識別,然后根據識別結果用“少數服從多數”的投票原則進行投票表決,得票數多的那個分類 Yi 作為對應輸入圖像 X 的最終分類[15],因為本文集成模型的輸入是 CT、PET、PET/CT 三種不同模態圖像,并且三種模態采取“一一對應”的方式進行局部特征提取,既滿足三個學習機間的差異性,也保證了最終投票決策的公平性。
3 算法仿真實驗
3.1 實驗環境
軟件環境:Windows 7 操作系統,Matlab R2014b;硬件環境:Intel Xeon CPU E5-2407 v2@2.40 GHz,32.0 GB 內存,3.5 TB 硬盤。
3.2 實驗數據
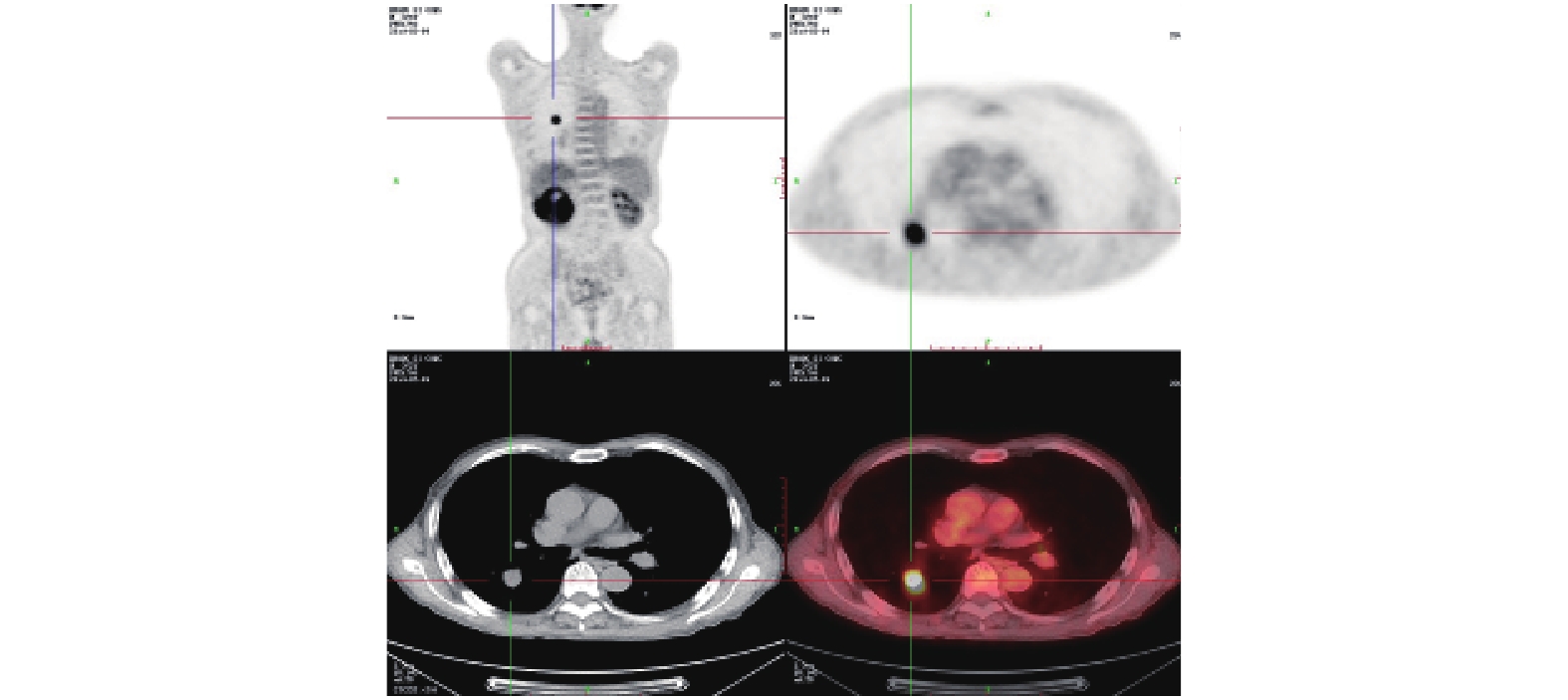
數據來源:從寧夏醫科大學總醫院影像科獲取 CT、PET 和 PET/CT 三種模態的肺部影像數據 9 000 例,其中每種模態圖像各 3 000 例,包括經專家標記為肺部腫瘤的 1 500 例和正常的 1 500 例。為了避免因數據集太小而造成的過擬合現象,本文肺部腫瘤不限于具體的某一種肺部腫瘤,只要專家標記為肺部腫瘤的影像數據都作為實驗數據。圖 3 為其中一幅原始數據,左上圖為全身 CT 影像,左下圖為肺部腫瘤 CT 影像,右上圖為肺部腫瘤 PET 影像,右下圖為加偽彩的肺部腫瘤 PET/CT 融合影像。
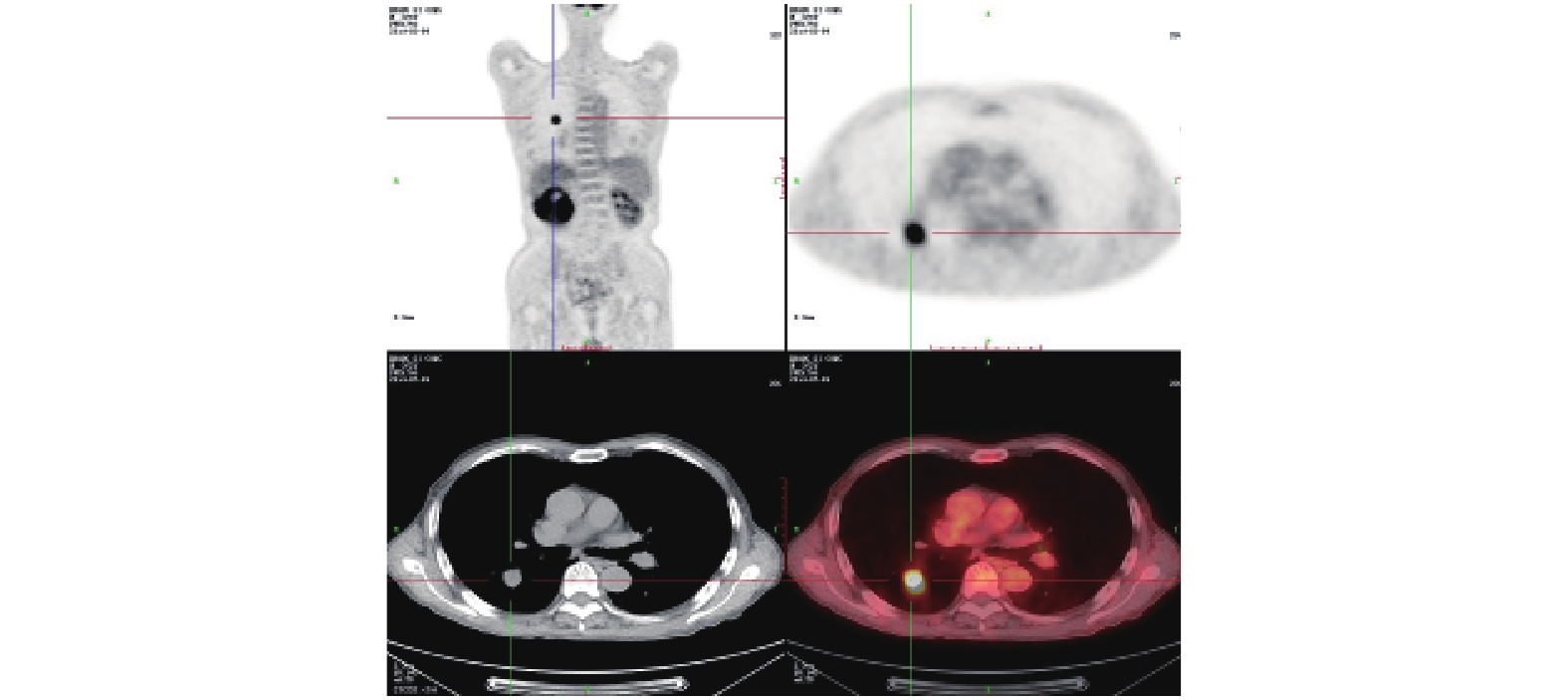 圖3
CT、PET、PET/CT 原始圖像
Figure3.
Original image of CT,PET and PET/CT
圖3
CT、PET、PET/CT 原始圖像
Figure3.
Original image of CT,PET and PET/CT
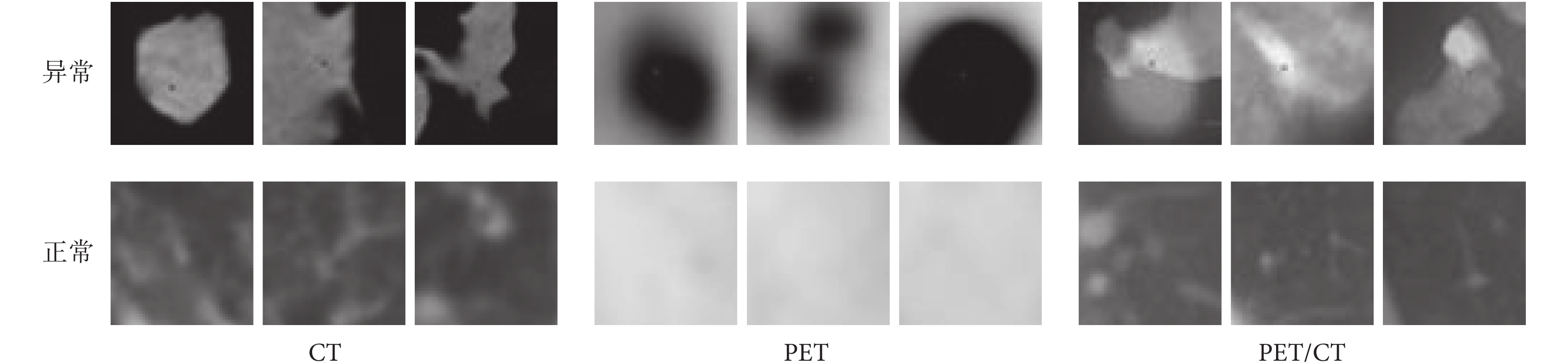
數據預處理:首先,對 PET/CT 圖像去偽彩,并將 CT、PET 和 PET/CT 三種模態圖像轉化成灰度圖像,保持三種模態圖像的一致性;然后,對三模態肺部腫瘤原始數據一一對應手動提取局部特征即 ROI 區域,接著提取同一患者肺部正常的區域作為正常圖像的 ROI,并將實驗圖像大小歸一化為 28*28 和 50*50,在保證數據本身統一性的同時更好地探討 CNN 的整體性能,預處理后的部分實驗數據如圖 4 所示。
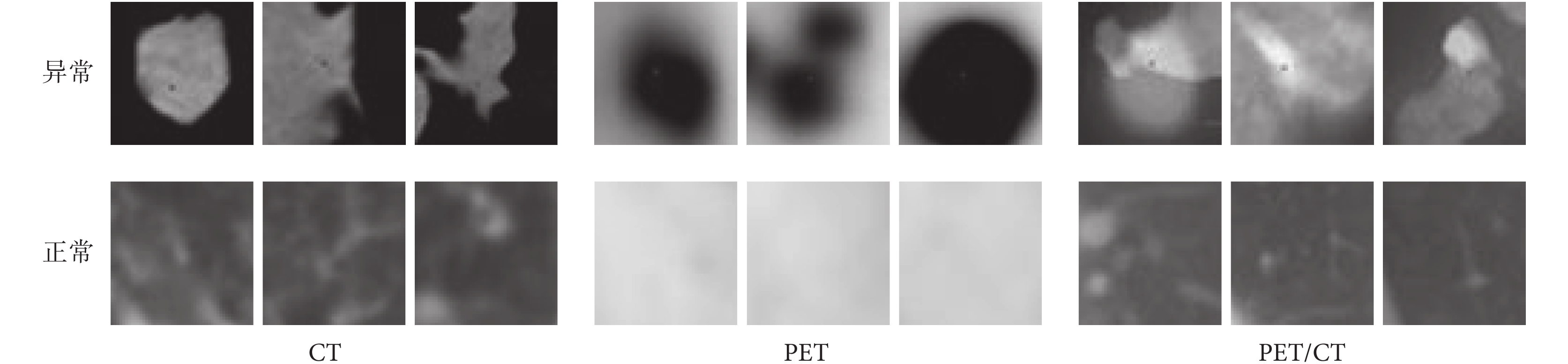 圖4
預處理后部分圖像
Figure4.
Some images after preprocessing
圖4
預處理后部分圖像
Figure4.
Some images after preprocessing
3.3 實驗結果分析
實驗一:CNN 中模型參數探討
本實驗以 CT-CNN 為研究對象探討模型參數對識別性能的影響,由于本文三模態的圖像是來自于同一患者同一部位的不同影像,并且初始構建的三個單一 CNN 采用參數遷移 LeNet-5 的模型結構,所以以 CT-CNN 模型為例探討迭代次數、批次大小、輸入圖像大小與 CNN 識別率、訓練時間的關系可以作為后續研究的基礎。
(1)迭代次數和批次大小對識別率和訓練時間的影響
在 CT-CNN 模型結構不變的前提下,控制批次大小為 10、20、50,探討迭代次數為 1、5、10、20、30、40、50、100 次的 CNN 識別率和訓練時間,實驗結果見表 1。
從表 1 可以看出,隨著迭代次數的增加,CNN 的識別率越來越高。當迭代次數超過 40 次時,識別率達到 98% 左右。隨著訓練次數的繼續增加,識別率維持在較高的水平,基本不會出現過訓練的情況,從而體現了 CNN 的良好性能。不論批次大小為多少,隨著迭代次數的增加,CNN 的訓練時間呈明顯上升趨勢,尤其當迭代 100 次時,需要半個多小時的訓練時間,所以時間消耗是目前深度神經網絡研究中存在的一個問題。在相同迭代次數下,批次大小越小,訓練時間越長,識別率相對較高;但是在迭代 50 次后,不論批次大小,訓練時間繼續升高,識別率基本維持在較高水準,所以在迭代次數達到一定條件后,可以選擇大批量的數據進行訓練,在降低時間復雜度的同時保證較高的識別率。
(2)輸入圖像大小對識別率和訓練時間的影響
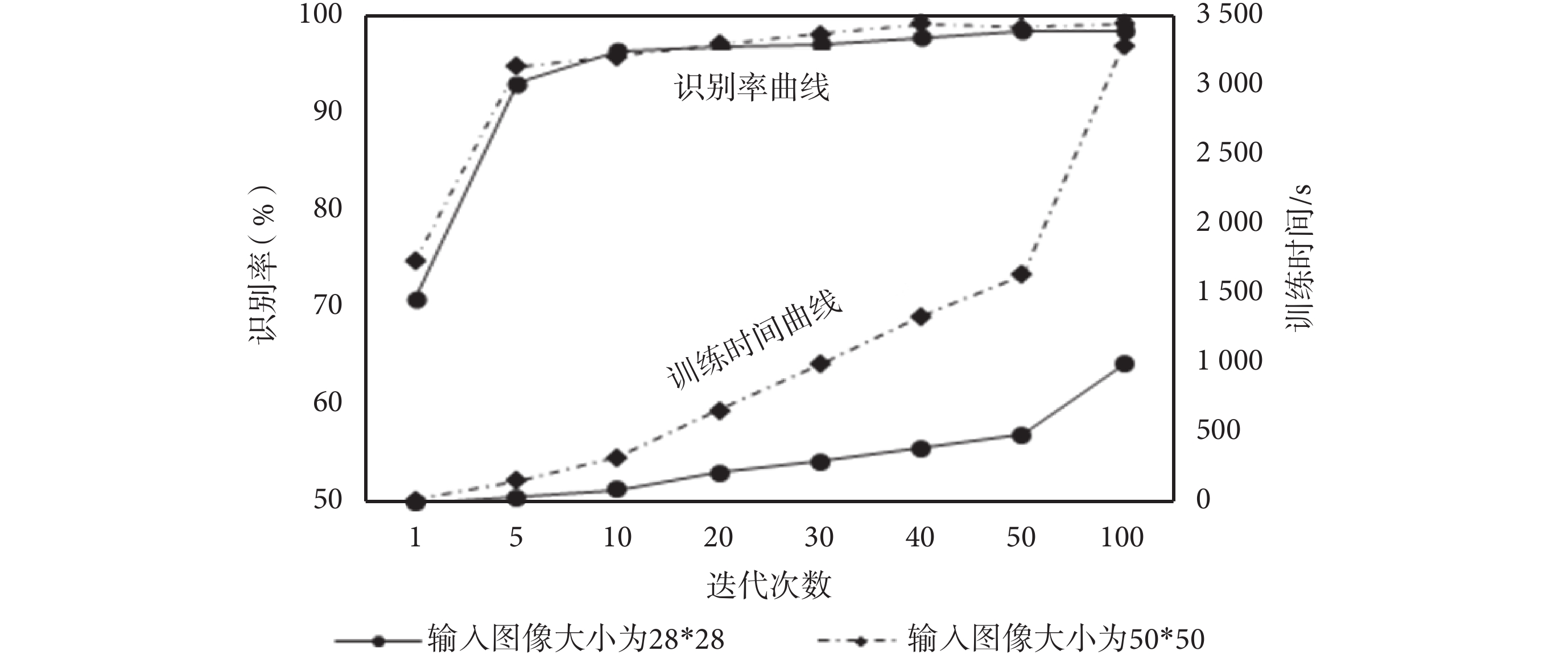
CNN 可以將整幅圖像作為輸入,既避免了對圖像前期復雜的預處理過程,也保證了圖像本身的完整信息,本實驗選取 28*28 和 50*50 不同大小的圖像作為 CNN 的輸入,探討圖像大小與識別率、訓練時間的關系,實驗結果如圖 5 所示。
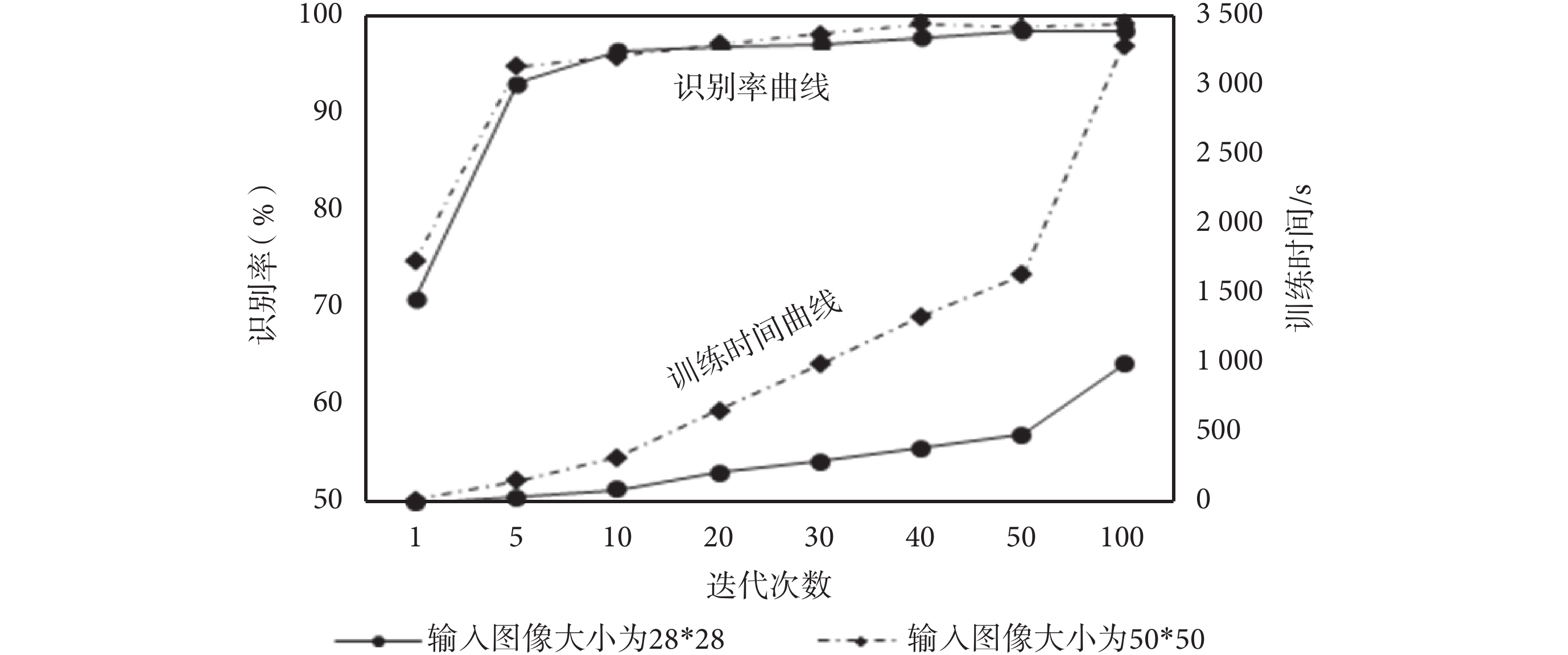 圖5
輸入圖像大小與識別性能的關系
Figure5.
Relation between input image scale and recognition performance
圖5
輸入圖像大小與識別性能的關系
Figure5.
Relation between input image scale and recognition performance
從圖 5 可以看出,不管是 28*28 還是 50*50 大小的輸入圖像,隨著迭代次數的增加,識別率都在上升并維持在較高的識別水準,整體而言 50*50 圖像的識別率稍高于 28*28 圖像,因為尺度相對大的圖像保留了更多完整的圖像信息,而小尺度圖像預處理后會損失部分信息;但是輸入圖像越大,訓練時間越長,并且隨著迭代次數增加,訓練時間上升趨勢更加明顯,因為 CNN 在識別復雜的、尺度較大的圖像時,卷積核會依次卷積整幅圖像,所以在其他條件恒定的情況下,圖像尺寸越大,卷積所需時間越長。
通過對模型參數與 CNN 識別性能的探討,迭代次數、批次大小和輸入圖像大小對 CNN 的識別率和訓練時間的影響程度不同,為了保證后續實驗的可操作性和對比性,在時間復雜度較低的基礎上,統一選擇批次大小為 20、輸入圖像大小為 28*28 的模型參數,用于三個單一 CNN 和集成 CNN 的對比研究。
實驗二:集成 CNN 與單個 CNN 的性能比較
為了對比集成 CNN 與單個 CNN 的性能,本實驗首先探討了 CT-CNN、PET-CNN 和 PET/CT-CNN 三個單一 CNN 的識別性能,然后集成三個單一 CNN,通過識別率、靈敏度、特異度和訓練時間四個指標刻畫不同 CNN 的識別性能,最后對比分析集成 CNN 模型和單一 CNN 模型對于肺部腫瘤計算機輔助診斷的性能。
(1)單個 CNN 中間特征圖的輸出
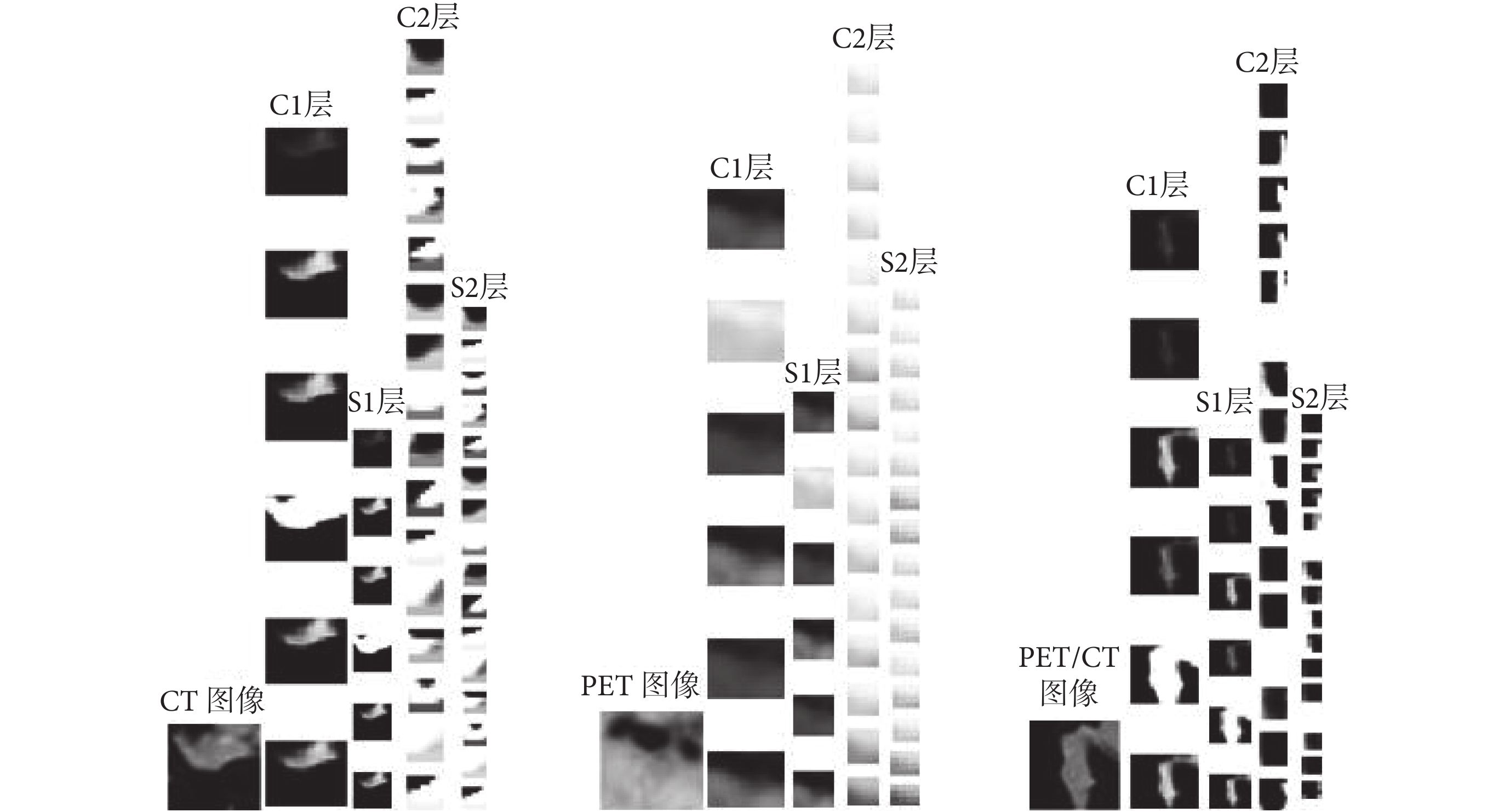
三種不同模態(CT、PET、PET/CT)肺部腫瘤輸入圖像在單個 CNN 訓練過程中每一層的輸出特征圖如圖 6 所示,其中最左邊是輸入圖像,從左向右依次為 C1 層、S1 層、C2 層、S2 層的輸出特征圖,可以看出,前兩層特征圖有效保留了圖像整體輪廓,是對原圖像邊緣信息的提取,而 C2、S2 層是對原圖像細節特征和更高級特征的提取,已經無法用肉眼清晰識別,最后全連接最后一層所有輸出特征圖用于分類識別。
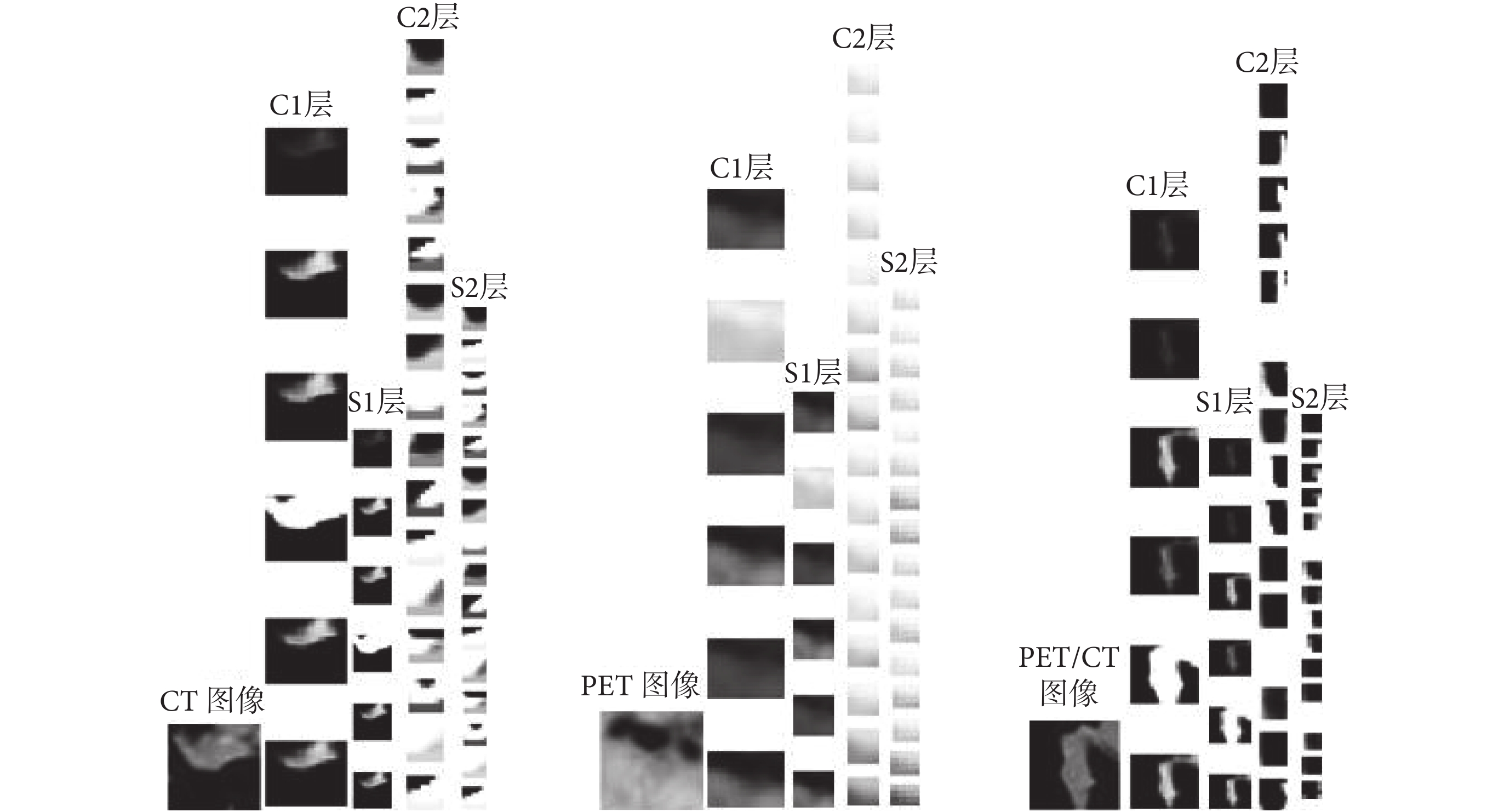 圖6
CT、PET、PET/CT 輸入圖像及中間特征圖輸出
Figure6.
Input images and feature maps of CT, PET and PET/CT
圖6
CT、PET、PET/CT 輸入圖像及中間特征圖輸出
Figure6.
Input images and feature maps of CT, PET and PET/CT
(2)單一 CNN 與集成 CNN 的識別性能比較
本實驗通過參數遷移的方法構建三個單一 CNN(CT-CNN、PET-CNN 和 PET/CT-CNN)用于不同模態肺部腫瘤圖像的識別,然后集成三個單一 CNN,采用“相對多數投票法”完成肺部腫瘤 PET/CT 計算機輔助診斷,每個模型訓練數據為 2 700 例,測試數據為 300 例,模型參數選擇批次大小為 20、輸入圖像大小為 28*28 進行實驗,四個模型的實驗結果見表 2。
從表 2 可以看出:CT-CNN 在迭代次數高于 10 次后基本達到 96% 的識別率,隨著迭代次數的增加,識別率稍有浮動,靈敏度稍低于特異度,說明肺部腫瘤患者被診斷為陰性的概率較高。PET-CNN 的識別率較高,基本達到 98% 的識別準確率,在迭代次數達到 30 次之后基本收斂,識別率不再隨著迭代次數的增加而增加。PET 肺部腫瘤圖像達到如此高的識別率原因在于 PET 圖像屬于功能圖像,對于病灶部位表現出明顯的亮斑,清晰可辨,而正常組織 PET 圖像無亮斑,基本保持同一灰度,所以肺部腫瘤 PET 圖像更易于識別。PET/CT-CNN 對于融合的 PET/CT 圖像達到了 98% 的識別準確率,因為融合的圖像本身就提高了病變部位的可辨識度,圖像更加清晰,視覺感更強,所以增強了 CNN 對肺部腫瘤的識別效果,其特異度相對較低。
單個 CNN 達到很高識別率的主要原因在于:① 數據預處理時,手動提取三種模態肺部腫瘤 ROI 區域對最終識別率有一定的貢獻;② 參數遷移方法使得初始構建的 CNN 具有快速學習能力,當訓練的數據集規模不夠大時,可避免隨機初始化 CNN 對小樣本數據過擬合現象的發生,同時保證網絡具有較強的泛化能力;③ CNN 自身具有很強的特征學習能力,對于圖像語義信息的提取具有明顯優勢。
通過對集成 CNN 和單一 CNN 的對比分析發現,即使單個 CNN 取得了良好的識別效果,但是集成 CNN 的總體性能都高于單個傳統的 CNN 模型,在相同迭代次數的基礎上,集成 CNN 的識別率都高于單一 CNN 的識別率,對肺部腫瘤的 PET/CT 識別能達到 99% 的識別率。雖然集成 CNN 的訓練時間明顯高于單一 CNN,但可以通過提升實驗環境和改變模型參數來優化實驗,在保證較高識別準確率的同時有效控制總體訓練時間,降低時間復雜度。
集成 CNN 的結果優于單個 CNN 識別結果的原因在于:假定 CT-CNN、PET-CNN、PET/CT-CNN 三個神經網絡互不相關,它們在各自網絡模型訓練過程中會陷入不同的局部極小,如 PET-CNN 在訓練過程中不論迭代次數或批次大小如何變化識別率總不變,而當三個 CNN 模型集成在一起后,各個神經網絡局部極小的負作用可以相互抵消,所以,集成 CNN 可以進行信息補償和強化,比單個 CNN 更能準確識別肺部腫瘤,從而為影像醫生提供了輔助診斷。
4 總結
本文采用參數遷移的方法初始構建了三個 CNN(CT-CNN、PET-CNN、PET/CT-CNN) 用于肺部腫瘤圖像識別,在保證了網絡良好訓練性能的同時增加了泛化能力,也避免了小樣本數據易出現過擬合現象的發生,集成 CNN 能對單個的 CT-CNN、PET-CNN 和 PET/CT-CNN 各自擁有的信息進行補償和強化,通過“相對多數投票決策”完成肺部腫瘤的識別,結果表明,集成的 CNN 比單個傳統的 CNN 對 PET/CT 肺部腫瘤的識別率更高、性能更加優越。
引言
肺癌是世界上發病率和死亡率最高的惡性腫瘤之一[1],吸煙和空氣污染是其主要誘因,由于肺癌的病理學特征復雜難辨,發病時間短,惡性程度高,早期癥狀不易被發現,使得 80% 以上的患者確診時已處于肺癌晚期,所以早發現早治療對于肺癌患者至關重要。目前臨床上常見的肺癌診斷方法有纖維支氣管鏡刷檢查、電子計算機斷層掃描(computed tomography,CT)引導下的肺穿刺組織病理學檢查、痰細胞學檢查或多種手段聯合檢查等[2]。隨著影像學的發展,X 線成像、CT、磁共振成像、正電子發射計算機斷層掃描(positron emission tomography,PET)等影像檢查被廣泛應用,尤其 PET/CT 不僅能通過圖像發現肺部病灶的存在,而且能準確定位病灶在全肺的位置,還能觀察病灶的大小、形態及密度等物理特征。但是,海量圖像在提供更加詳細、準確的診斷信息時,也給讀片醫生增加了工作負擔,容易因診斷疲勞導致疾病漏診和誤診,并且醫生憑借閱片經驗對病灶進行定性分析具有較大的主觀性,所以肺部腫瘤計算機輔助診斷不僅可以為放射科醫生提供精確的定量分析以彌補人眼惰性及對灰階不敏感的缺陷[3],而且可以減少放射科醫生因主觀因素對閱片結果造成的不利影響,從而幫助醫師發現病灶,提高診斷率。
目前,肺部腫瘤計算機輔助診斷主要集中在肺部感興趣區域(region of interest,ROI)分割、病灶檢測和良惡性識別三方面,關鍵技術包括圖像增強、圖像分割、特征提取和分類器設計。劉慧等[4]提出了快速模糊 C 均值聚類肺結節分割方法,可有效提高局部鄰域像素自適應程度并實現對病變組織的正確、快速分割;姜慧研等[5]提出了基于一幅 CT 圖像快速識別肺癌的方法和基于序列圖像的準確識別方法,建立了面向不同需求的肺癌識別模型;吳遂愿[6]提出了基于形狀特征矩和三維細化的 CT 腫瘤識別方法,達到了 77.55% 的腫瘤檢出率;王晉[7]構建了 PET-CT 孤立型肺結節特征集,研究了基于信息論的特征選擇方法,提高結節的良惡性分類器性能。近年,基于圖像傳統特征提取的神經網絡廣泛用于肺癌計算機輔助診斷中,王克全等[8]探討了肺癌 CT 診斷中應用模糊神經網絡輔助診斷的效果;聶永康等[9]從腫瘤的 CT 特征和 PET 特征角度出發,提出了一種人工神經網絡輔助診斷系統。目前,將深度神經網絡與計算機輔助診斷結合,提取圖像語義信息成為研究熱點。
卷積神經網絡[10](convolutional neural network,CNN)作為深度學習經典模型之一,可以直接輸入原始圖像并具有局部感受野、權值共享、下采樣特點,對于圖像平移、比例縮放、傾斜或其他形式的變形表現出良好的魯棒性。集成學習[11]作為機器學習領域的研究熱點,利用多個(通常是同質的)學習機來解決同一個問題,在保證每個學習機具有良好的識別精度和較大差異時,提高網絡的泛化能力。所以,本文首先通過參數遷移的方法初始構建三個單一 CNN(CT-CNN、PET-CNN、PET/CT-CNN)分別用于肺部腫瘤 CT、PET 和 PET/CT 圖像的識別,參數遷移可以保證單個 CNN 具有快速學習的能力;然后集成三個單一 CNN,由于本文采用 CT、PET、PET/CT 不同模態的輸入數據使得樣本集處于不同空間的分布,正好滿足集成網絡中個體分類器的差異性,最后采用“少數服從多數”投票法形成最優決策,完成肺部腫瘤圖像的識別。
1 基礎理論
1.1 卷積神經網絡
CNN 是受視覺神經機制啟發而設計的一個多層感知器,是一種有監督學習下的深度學習模型,主要由卷積層和池化層兩種特殊的結構層組成,可以直接輸入原始圖像,避免前期對圖像復雜的預處理過程,在二維圖像識別領域取得了廣泛應用。
1.1.1 網絡結構 CNN 的隱藏層是特征提取的核心,隱藏層包括卷積層和下采樣層。卷積層進行卷積運算,每個神經元的輸入與前一層的局部感受野相連,前一層的特征圖與一個可學習的卷積核進行卷積,然后通過激活函數,輸出這一層的特征圖,表達式為:
|
其中,I 代表層數,k 是卷積核,Mj 代表輸入特征圖的一個選擇,每個輸出圖有一個偏置 b;由于 CNN 采取的是非全連接方式,所以每一個輸出的特征圖可能包含多個輸入圖的卷積。子采樣層對輸入進行 Pooling 運算,如果輸入的特征圖為 n 個,則經過下采樣層后的特征圖的個數仍然為 n,但特征圖大小為原圖的一半,下采樣層的表達式為:
|
其中 down(·)表示次抽樣函數,β 和 b 分別為下采樣層的乘性偏置和加性偏置。
1.1.2 訓練算法 CNN 的學習過程主要包括兩個階段:① 前向傳播:即卷積和下采樣依次進行的過程,上一層的輸出作為下一層的輸入,并通過激活函數逐層傳遞,最后得到實際輸出;② 反向傳播和權值更新:即通過實際輸出與理想輸出間的誤差反向傳播,得到各個網絡層的誤差函數,然后采用隨機梯度下降法對網絡權值和偏置進行優化調整。假設一個多分類問題包括 N 個訓練樣本和 C 個類別,其誤差函數為:
|
其中
表示第 n 個輸入樣本中第 k 維對應的類別標簽,
表示第 n 個輸入樣本中第 k 維對應的預測輸出值。
1.2 集成學習
集成學習是一種機器學習范式,其本質是利用多個(通常是同質的)學習機來解決同一個問題,最后采用“集體決策”的思想決定最終的輸出結果,目的是更有效地提高學習模型的泛化能力,泛化能力越強,處理新數據的能力就越好。神經網絡集成方法最早是在 1990 年由 Hansen 和 Salamon 提出,證明了可以簡單地通過訓練多個神經網絡將其結果進行合成,并且對于神經網絡分類器采用集成方法能夠有效提高系統的泛化能力。
神經網絡集成實現方法的研究主要集中在兩個方面,即如何生成集成中的個體網絡和怎樣將多個神經網絡的輸出結論進行結合[12]。在生成集成中個體網絡方面,最重要的技術是 Boosting 和 Bagging,Freund 和 Schapire 對 Boosting 類方法進行了分析,并證明該類方法產生的最終預測函數 H 的訓練誤差滿足:
|
|
從式(5)可以看出,只要學習算法略好于隨機猜測,訓練誤差將隨 t 以指數級下降。對于結論生成方法通常采用絕對多數投票法和相對多數投票法,假設集成由 N 個獨立的神經網絡分類器構成,采用絕對多數投票法,再假設每個網絡以 1–p 的概率給出正確的分類結果,并且網絡之間錯誤不相關,則該網絡集成發生錯誤的概率 P 為:
|
在 p<1/2 時,P 隨 N 的增大而單調遞減。因此,如果每個神經網絡的預測精度都高于 50%,并且各網絡之間錯誤不相關,則神經網絡集成中的網絡數目越多,集成的精度就越高,當 N 趨向于無窮時,集成的錯誤率趨向于 0。所以,要想構建一個好的網絡模型,一方面應盡可能提高個體網絡的泛化能力,另一方面要增大集成中各網絡之間的差異。
2 基于集成 CNN 的肺部腫瘤 PET/CT 輔助診斷模型
2.1 算法思想
本文首先采用參數遷移 LeNet-5 模型結構的方法構建三個單一 CNN(CT-CNN、PET-CNN、PET/CT-CNN),分別用于肺部腫瘤 CT、PET、PET/CT 圖像的識別,然后以 CT-CNN 為例探討模型參數即迭代次數、批次大小和輸入圖像大小對識別率和訓練時間的影響,從而選擇合適的模型參數訓練三個單一 CNN,對比其識別性能;最后集成三個單一 CNN,采用“相對多數投票法”形成最優決策完成肺部腫瘤 PET/CT 計算機輔助診斷,對比分析集成 CNN 與單一 CNN 對于肺部腫瘤輔助診斷的整體性能。本文算法流程如圖 1 所示。
圖1
算法流程圖
Figure1.
Flow diagram of algorithm
基于集成 CNN 的肺部腫瘤 PET/CT 計算機輔助診斷模型構建的具體步驟如下:
(1)數據收集:從醫院收集 9 000 例原始肺部 CT、PET、PET/CT 三種模態的圖像,其中每種模態圖像各 3 000 例,包括經專家標記為肺部腫瘤的 1 500 例和正常的 1 500 例;
(2)圖像預處理:首先對 PET/CT 融合圖像去偽彩,轉化為灰度圖像;然后對三個模態圖像一一對應手動提取專家標記的 ROI 作為肺部腫瘤數據,提取同一患者肺部正常的區域作為正常圖像的 ROI,從而保證肺部腫瘤圖像與正常圖像本身的可對比性和區分性;最后將提取的三模態圖像歸一化為 28*28 和 50*50 大小的實驗圖像,保證數據本身的統一性便于后續實驗;
(3)構造不同樣本空間:由于 CT、PET、PET/CT 三模態的圖像一一對應(即來自于同一患者的不同影像數據),通過前期預處理后構建 CT、PET、PET/CT 不同的樣本空間集;
(4)單個 CNN 構建:采用參數遷移法初始構建三個單一 CNN 模型(CT-CNN、PET-CNN、PET/CT-CNN),然后探討 CNN 模型中迭代次數、批次大小和不同輸入圖像大小對識別率和訓練時間的影響,最后選取合適的模型參數進行后續實驗;
(5)集成 CNN 構建:通過三個單一 CNN 構建集成 CNN 模型;
(6)決策識別:采用“相對多數投票法”決策識別肺部正常圖像和肺部腫瘤圖像,綜合對比三個單一 CNN 和集成 CNN 用于肺部腫瘤 PET/CT 識別的性能。
2.2 關鍵技術
2.2.1 單個 CNN 結構設計 參數遷移[13]是指利用現有的預先訓練好的具有強大學習能力的網絡模型參數初始化某個小型訓練集模型參數,參數初始化方法可以將已有的強大的學習能力遷移到另一個網絡中,Lecun 等[14]提出的 LeNet-5 是典型的 CNN 模型,共有七層(不包括輸入層),所有層都帶有參數,本文采用參數遷移 LeNet-5 模型的方法初次構建單個 CNN。
本文設計的單個 CNN 結構由 5 層組成,具體結構如圖 2 所示,其中包含兩個卷積層、兩個下采樣層和一個全連接層,每一層都包括可訓練的參數。
圖2
單個卷積神經網絡結構
Figure2.
Single convolutional neural network architecture
(1)輸入層:輸入大小為 28*28 的 CT、PET 和 PET/CT 圖像;
(2)卷積層 C1:由輸入圖像經過六個 5*5 的卷積核卷積而成的 6 個特征圖組成,每個特征圖的大小為 24*24;
(3)下采樣層 S1:對 C1 層的每個特征圖進行尺度為 2 的下采樣,由 6 個 12*12 的下采樣特征圖組成;
(4)卷積層 C2:由 16 個大小為 8*8 的特征圖組成;
(5)下采樣層 S2:由 16 個大小為 4*4 的特征圖組成,特征圖的每個神經元與 C2 層的一個大小為 2*2 的鄰域連接;
(6)全連接層 F1:即輸出層前一層的全連接層,每個特征圖全連接到 S2 層的所有特征圖;
(7)輸出層:輸出類別為兩類即是否為肺部腫瘤,激活函數選擇 Sigmoid 函數。
2.2.2 集成 CNN 模型構建 神經網絡集成通過訓練多個神經網絡并將其結論進行合成,可以顯著地提高學習模型的泛化能力。本文在單個 CNN 模型結構的基礎上,集成三個不同的單一 CNN(CT-CNN、PET-CNN、PET/CT-CNN)用于肺部腫瘤識別,最后采用集成算法投票法進行最終的圖像識別,也就是三個不同的單一 CNN 模型都進行分類識別,然后根據識別結果用“少數服從多數”的投票原則進行投票表決,得票數多的那個分類 Yi 作為對應輸入圖像 X 的最終分類[15],因為本文集成模型的輸入是 CT、PET、PET/CT 三種不同模態圖像,并且三種模態采取“一一對應”的方式進行局部特征提取,既滿足三個學習機間的差異性,也保證了最終投票決策的公平性。
3 算法仿真實驗
3.1 實驗環境
軟件環境:Windows 7 操作系統,Matlab R2014b;硬件環境:Intel Xeon CPU E5-2407 v2@2.40 GHz,32.0 GB 內存,3.5 TB 硬盤。
3.2 實驗數據
數據來源:從寧夏醫科大學總醫院影像科獲取 CT、PET 和 PET/CT 三種模態的肺部影像數據 9 000 例,其中每種模態圖像各 3 000 例,包括經專家標記為肺部腫瘤的 1 500 例和正常的 1 500 例。為了避免因數據集太小而造成的過擬合現象,本文肺部腫瘤不限于具體的某一種肺部腫瘤,只要專家標記為肺部腫瘤的影像數據都作為實驗數據。圖 3 為其中一幅原始數據,左上圖為全身 CT 影像,左下圖為肺部腫瘤 CT 影像,右上圖為肺部腫瘤 PET 影像,右下圖為加偽彩的肺部腫瘤 PET/CT 融合影像。
圖3
CT、PET、PET/CT 原始圖像
Figure3.
Original image of CT,PET and PET/CT
數據預處理:首先,對 PET/CT 圖像去偽彩,并將 CT、PET 和 PET/CT 三種模態圖像轉化成灰度圖像,保持三種模態圖像的一致性;然后,對三模態肺部腫瘤原始數據一一對應手動提取局部特征即 ROI 區域,接著提取同一患者肺部正常的區域作為正常圖像的 ROI,并將實驗圖像大小歸一化為 28*28 和 50*50,在保證數據本身統一性的同時更好地探討 CNN 的整體性能,預處理后的部分實驗數據如圖 4 所示。
圖4
預處理后部分圖像
Figure4.
Some images after preprocessing
3.3 實驗結果分析
實驗一:CNN 中模型參數探討
本實驗以 CT-CNN 為研究對象探討模型參數對識別性能的影響,由于本文三模態的圖像是來自于同一患者同一部位的不同影像,并且初始構建的三個單一 CNN 采用參數遷移 LeNet-5 的模型結構,所以以 CT-CNN 模型為例探討迭代次數、批次大小、輸入圖像大小與 CNN 識別率、訓練時間的關系可以作為后續研究的基礎。
(1)迭代次數和批次大小對識別率和訓練時間的影響
在 CT-CNN 模型結構不變的前提下,控制批次大小為 10、20、50,探討迭代次數為 1、5、10、20、30、40、50、100 次的 CNN 識別率和訓練時間,實驗結果見表 1。
從表 1 可以看出,隨著迭代次數的增加,CNN 的識別率越來越高。當迭代次數超過 40 次時,識別率達到 98% 左右。隨著訓練次數的繼續增加,識別率維持在較高的水平,基本不會出現過訓練的情況,從而體現了 CNN 的良好性能。不論批次大小為多少,隨著迭代次數的增加,CNN 的訓練時間呈明顯上升趨勢,尤其當迭代 100 次時,需要半個多小時的訓練時間,所以時間消耗是目前深度神經網絡研究中存在的一個問題。在相同迭代次數下,批次大小越小,訓練時間越長,識別率相對較高;但是在迭代 50 次后,不論批次大小,訓練時間繼續升高,識別率基本維持在較高水準,所以在迭代次數達到一定條件后,可以選擇大批量的數據進行訓練,在降低時間復雜度的同時保證較高的識別率。
(2)輸入圖像大小對識別率和訓練時間的影響
CNN 可以將整幅圖像作為輸入,既避免了對圖像前期復雜的預處理過程,也保證了圖像本身的完整信息,本實驗選取 28*28 和 50*50 不同大小的圖像作為 CNN 的輸入,探討圖像大小與識別率、訓練時間的關系,實驗結果如圖 5 所示。
圖5
輸入圖像大小與識別性能的關系
Figure5.
Relation between input image scale and recognition performance
從圖 5 可以看出,不管是 28*28 還是 50*50 大小的輸入圖像,隨著迭代次數的增加,識別率都在上升并維持在較高的識別水準,整體而言 50*50 圖像的識別率稍高于 28*28 圖像,因為尺度相對大的圖像保留了更多完整的圖像信息,而小尺度圖像預處理后會損失部分信息;但是輸入圖像越大,訓練時間越長,并且隨著迭代次數增加,訓練時間上升趨勢更加明顯,因為 CNN 在識別復雜的、尺度較大的圖像時,卷積核會依次卷積整幅圖像,所以在其他條件恒定的情況下,圖像尺寸越大,卷積所需時間越長。
通過對模型參數與 CNN 識別性能的探討,迭代次數、批次大小和輸入圖像大小對 CNN 的識別率和訓練時間的影響程度不同,為了保證后續實驗的可操作性和對比性,在時間復雜度較低的基礎上,統一選擇批次大小為 20、輸入圖像大小為 28*28 的模型參數,用于三個單一 CNN 和集成 CNN 的對比研究。
實驗二:集成 CNN 與單個 CNN 的性能比較
為了對比集成 CNN 與單個 CNN 的性能,本實驗首先探討了 CT-CNN、PET-CNN 和 PET/CT-CNN 三個單一 CNN 的識別性能,然后集成三個單一 CNN,通過識別率、靈敏度、特異度和訓練時間四個指標刻畫不同 CNN 的識別性能,最后對比分析集成 CNN 模型和單一 CNN 模型對于肺部腫瘤計算機輔助診斷的性能。
(1)單個 CNN 中間特征圖的輸出
三種不同模態(CT、PET、PET/CT)肺部腫瘤輸入圖像在單個 CNN 訓練過程中每一層的輸出特征圖如圖 6 所示,其中最左邊是輸入圖像,從左向右依次為 C1 層、S1 層、C2 層、S2 層的輸出特征圖,可以看出,前兩層特征圖有效保留了圖像整體輪廓,是對原圖像邊緣信息的提取,而 C2、S2 層是對原圖像細節特征和更高級特征的提取,已經無法用肉眼清晰識別,最后全連接最后一層所有輸出特征圖用于分類識別。
圖6
CT、PET、PET/CT 輸入圖像及中間特征圖輸出
Figure6.
Input images and feature maps of CT, PET and PET/CT
(2)單一 CNN 與集成 CNN 的識別性能比較
本實驗通過參數遷移的方法構建三個單一 CNN(CT-CNN、PET-CNN 和 PET/CT-CNN)用于不同模態肺部腫瘤圖像的識別,然后集成三個單一 CNN,采用“相對多數投票法”完成肺部腫瘤 PET/CT 計算機輔助診斷,每個模型訓練數據為 2 700 例,測試數據為 300 例,模型參數選擇批次大小為 20、輸入圖像大小為 28*28 進行實驗,四個模型的實驗結果見表 2。
從表 2 可以看出:CT-CNN 在迭代次數高于 10 次后基本達到 96% 的識別率,隨著迭代次數的增加,識別率稍有浮動,靈敏度稍低于特異度,說明肺部腫瘤患者被診斷為陰性的概率較高。PET-CNN 的識別率較高,基本達到 98% 的識別準確率,在迭代次數達到 30 次之后基本收斂,識別率不再隨著迭代次數的增加而增加。PET 肺部腫瘤圖像達到如此高的識別率原因在于 PET 圖像屬于功能圖像,對于病灶部位表現出明顯的亮斑,清晰可辨,而正常組織 PET 圖像無亮斑,基本保持同一灰度,所以肺部腫瘤 PET 圖像更易于識別。PET/CT-CNN 對于融合的 PET/CT 圖像達到了 98% 的識別準確率,因為融合的圖像本身就提高了病變部位的可辨識度,圖像更加清晰,視覺感更強,所以增強了 CNN 對肺部腫瘤的識別效果,其特異度相對較低。
單個 CNN 達到很高識別率的主要原因在于:① 數據預處理時,手動提取三種模態肺部腫瘤 ROI 區域對最終識別率有一定的貢獻;② 參數遷移方法使得初始構建的 CNN 具有快速學習能力,當訓練的數據集規模不夠大時,可避免隨機初始化 CNN 對小樣本數據過擬合現象的發生,同時保證網絡具有較強的泛化能力;③ CNN 自身具有很強的特征學習能力,對于圖像語義信息的提取具有明顯優勢。
通過對集成 CNN 和單一 CNN 的對比分析發現,即使單個 CNN 取得了良好的識別效果,但是集成 CNN 的總體性能都高于單個傳統的 CNN 模型,在相同迭代次數的基礎上,集成 CNN 的識別率都高于單一 CNN 的識別率,對肺部腫瘤的 PET/CT 識別能達到 99% 的識別率。雖然集成 CNN 的訓練時間明顯高于單一 CNN,但可以通過提升實驗環境和改變模型參數來優化實驗,在保證較高識別準確率的同時有效控制總體訓練時間,降低時間復雜度。
集成 CNN 的結果優于單個 CNN 識別結果的原因在于:假定 CT-CNN、PET-CNN、PET/CT-CNN 三個神經網絡互不相關,它們在各自網絡模型訓練過程中會陷入不同的局部極小,如 PET-CNN 在訓練過程中不論迭代次數或批次大小如何變化識別率總不變,而當三個 CNN 模型集成在一起后,各個神經網絡局部極小的負作用可以相互抵消,所以,集成 CNN 可以進行信息補償和強化,比單個 CNN 更能準確識別肺部腫瘤,從而為影像醫生提供了輔助診斷。
4 總結
本文采用參數遷移的方法初始構建了三個 CNN(CT-CNN、PET-CNN、PET/CT-CNN) 用于肺部腫瘤圖像識別,在保證了網絡良好訓練性能的同時增加了泛化能力,也避免了小樣本數據易出現過擬合現象的發生,集成 CNN 能對單個的 CT-CNN、PET-CNN 和 PET/CT-CNN 各自擁有的信息進行補償和強化,通過“相對多數投票決策”完成肺部腫瘤的識別,結果表明,集成的 CNN 比單個傳統的 CNN 對 PET/CT 肺部腫瘤的識別率更高、性能更加優越。