目前電子耳蝸在漢語的應用環境下會丟失音調信息,導致言語識別率的降低。為了便于針對性地研究適合漢語特征的電子耳蝸言語處理算法并提高言語識別率,本文在改進的電子耳蝸前端信號采集平臺上研究了不同電子耳蝸言語處理策略的波形特性以及語譜分布、能量強度、基頻和共振峰等譜相關參數,通過分析和提取參數特征,研究了兩大類電子耳蝸言語處理策略的特征。因此,本文的研究目的是期望通過本文結果能夠有助于擴展基于漢語特征的電子耳蝸言語處理策略的研究。
引用本文: 陳又圣, 王健, 陳偉芳, 管明祥. 電子耳蝸言語處理策略的頻譜特征研究. 生物醫學工程學雜志, 2017, 34(5): 760-766. doi: 10.7507/1001-5515.201702020 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
據世界衛生組織(world health organization,WHO)2015 年的官網報道數據(第 300 號)顯示:全球約有 3.6 億人患有聽力損失,其中包含 3.28 億成人和 3 200 萬兒童。世界衛生組織的媒體中心描述該聽力損失的標準是:成人聽力較好的那只耳朵聽力喪失超過 40 分貝,兒童聽力較好的那只耳朵聽力喪失超過 30 分貝。如果按這個標準以及類似的比例估計(3.6 億約占全球人口的 5%),中國的聽力損失患者接近 7 000 萬。聽力損失患者需要根據聽力的損失狀況來佩帶助聽器或者植入電子耳蝸,而電子耳蝸是目前治療重度耳聾或者全聾(尤其是毛細胞損傷所引起的聽力嚴重受損情形)的有效聽力裝置。電子耳蝸包括體外機和體內機兩部分,體內機的核心部分是接收線圈、相關電路和刺激電極;體外機主要包括麥克風、言語處理器和發射線圈及相關輔助器件等;其中,體外言語處理器所嵌入的電子耳蝸言語處理算法是最核心和關鍵的部分。目前國外有三大電子耳蝸生產廠商,即澳大利亞的 Cochlear Corporation,奧地利的 MED-EL 和美國的 Advanced Bionics(簡稱 AB)。國外開發電子耳蝸的經驗豐富,而且有大量的電子耳蝸植入者,因此現有的電子耳蝸在英語環境下性能較好,使用者已經能夠便利地進行電話聊天或者面對面的交流了。但國外的基于英語語系和特征的電子耳蝸直接應用于漢語人群則丟失了語調特征,因此造成漢語里不同音調的語義辨識出錯和言語識別率低的后果。
近年來,國內的聲學研究所和研究型大學開展了基于漢語特征的電子耳蝸相關研究工作,杭州的諾爾康神經電子科技有限公司也開發了國產化的電子耳蝸,相關的產品研制和臨床性能正進行試驗和評估中。同時,為了便于進行算法研究,近年來國外也相繼開發出了電子耳蝸算法移植和研究平臺。比如,美國 AB 公司開發了一款聲學處理算法集成開發環境(sound-processing algorithm integrated development environment,SPAIDE)的研究平臺用于設置特定的語音處理模式和電刺激策略參數[1],美國德克薩斯大學開發了基于掌上電腦(personal digital assistant,PDA)和智能手機的電子耳蝸研究平臺[2-3],澳大利亞的企業(HEARworks Pty Ltd)開發了基于語音處理器(SPEAR3,HEARworks/AUS)的信號處理研究平臺,通過匯編編程方式對 22 通道的電子耳蝸植入體(Nucleus CI22,HEARworks/AUS)Nucleus CI22 和 24 通道的電子耳蝸植入體(Nucleus CI24,HEARworks/AUS)進行刺激參數設置和植入新的言語處理算法[4],Fatemeh[5]和 Mirzahasanloo[6-7]等學者開發了基于 PDA 的電子耳蝸研究平臺并進行語音處理算法的研究。國內學者也開發了電子耳蝸信號采集平臺用于算法研究[8-10]。
不同廠商的電子耳蝸產品在尺寸,體外機佩帶方式,麥克風數量及配置陣型,體外機的語音處理器,信號編碼方式等方面差別很大,而電子耳蝸言語處理算法則是其中最核心的技術之一。連續交替采樣策略(continuous interleaved sampling,CIS)是一種經典的言語處理方法,目前流行的很多算法基本都是以該策略為基礎改進和發展起來的,例如連續交替等間隔多刺激策略(multiple stimulation continuous interleaved sampling,MCIS),最大譜峰策略(spectral peak,SPEAK)[11],聯合編碼策略(advanced combined encoder,ACE)[12],頻帶劃分和最大譜峰可調策略(n of m strategy,NOM)[13-14]等,其中,MCIS 策略的瞬時刺激數本身不固定,常見的有連續交替雙刺激策略(double stimulation continuous interleaved sampling,DCIS)和連續交替四刺激策略(four stimulation continuous interleaved sampling,FCIS)。在這 6 類電子耳蝸言語處理策略中,CIS 策略出現最早,該策略通過連續交替傳遞一個通道的參數到電極并形成交替電刺激,刺激速率范圍是 740~2 400 脈沖/秒(pulse per second,PPS)。后來發展了非等間隔刺激的言語處理策略,即 SPEAK 策略和 ACE 策略,這兩類言語處理策略提取的是能量信息最大的頻帶信息并用于電極刺激,所提取的頻帶不是等間隔的,也并不連續交替刺激。另外,由于語音信號的能量主要集中在低頻段,因此 SPEAK 策略和 ACE 策略主要提取并傳遞低頻段的通道信息。SPEAK 策略和 ACE 策略的差別一方面體現在刺激速率上,ACE 策略的刺激速率更高,另一方面是電子耳蝸通道數及通道選取的數量上的差別,SPEAK 策略設置 20 個通道并選取其中對應的最大的 5~10 個頻帶用于電極刺激,而 ACE 策略則設置 22 個通道并選取其中對應的 20 個以內的最大的頻帶用于電極刺激。之后出現的 NOM 策略則進一步增加了電子耳蝸通道數和用于電極刺激頻帶數的可調性,是一種電子耳蝸通道數劃分和最大譜峰數均可設置的言語處理策略。本文研究了基于 CIS 算法架構的電子耳蝸言語處理策略的算法處理流程及信號特征變化,通過漢語四聲調的信號采集實驗并提取了波形、語譜、能量強度、基頻和共振峰等信號特征和參數,分析了漢語中不同聲調信號經過電子耳蝸言語處理策略處理后的特征變化。漢語是音調語言,本文所研究的基頻和共振峰等參數特征有助于反映漢語經過電子耳蝸算法處理后的失配特性,為基于漢語特征的電子耳蝸言語處理算法的進一步研究提供有價值的參數和研究基礎。
1 算法架構及實驗系統
1.1 基于 CIS 策略的算法架構
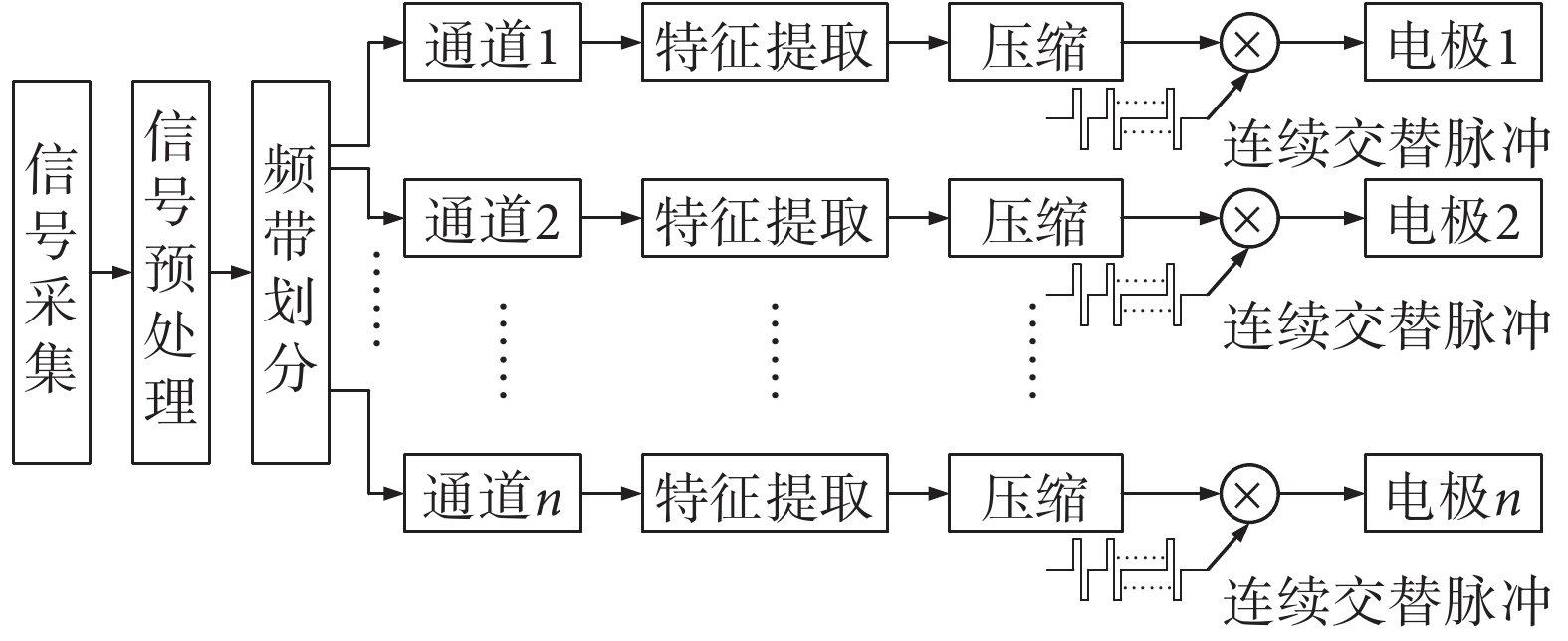
CIS 策略是通過濾波器組把信號進行頻帶劃分,每一段信號可認為是一段窄帶信號。通過特定的算法提取每個頻帶的包絡等關鍵信息,并用一組純音信號來調制(可選取對應濾波器組中心頻率作為純音信號頻率),并通過無線方式傳遞到對應體內電極上。電極刺激的時候不是同時進行的,而是通過交替的方式來完成,即每個時刻只有一個電極以特定的刺激速率刺激相應的位置,然后其他電極依次等間隔進行,如圖 1 所示是 CIS 策略的算法工作原理示意圖。
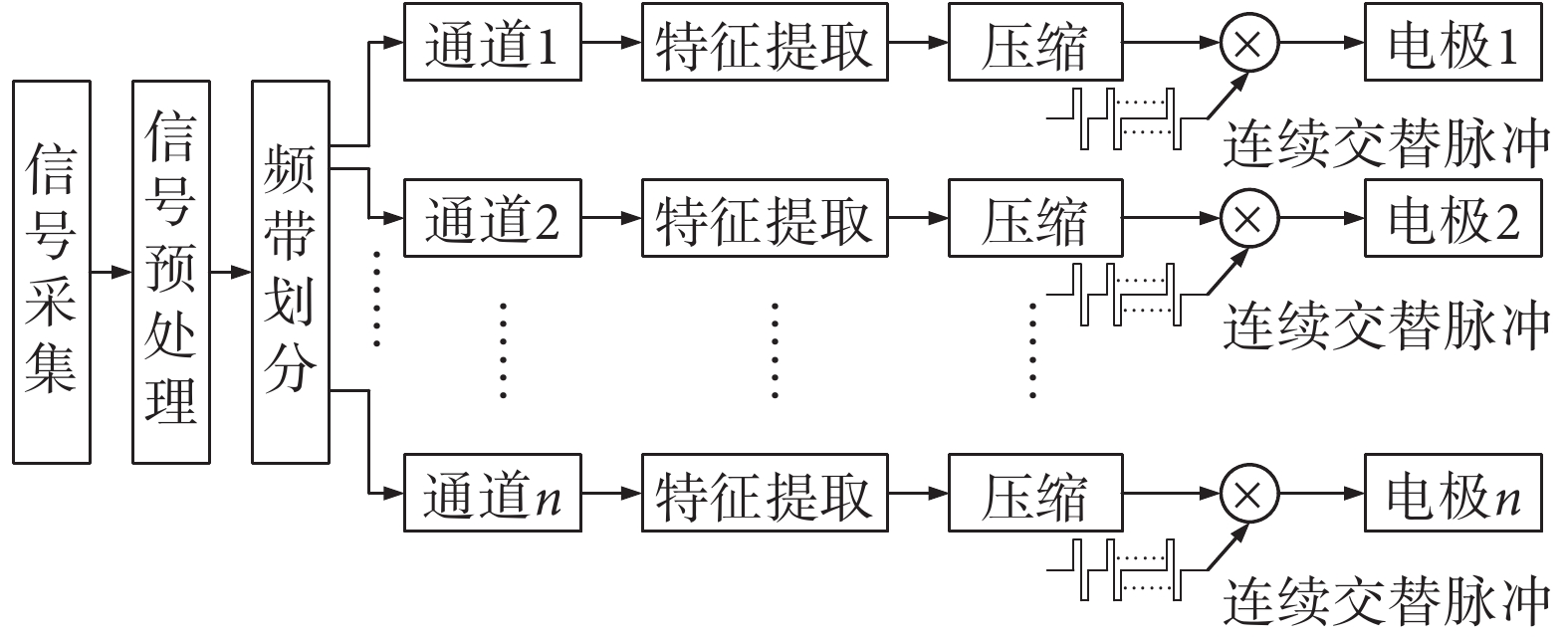 圖1
CIS 策略的算法工作原理示意圖
Figure1.
Schematic diagram of algorithm principle for CIS strategy
圖1
CIS 策略的算法工作原理示意圖
Figure1.
Schematic diagram of algorithm principle for CIS strategy
如圖 1 所示是 CIS 策略的算法工作原理示意圖,首先用麥克風采集原始信號,接著經過預處理之后進行頻帶劃分,并用特定的濾波器組(與電極對應)來對信號頻帶進行劃分。然后進一步通過電子耳蝸言語處理策略提取每個子帶信號中的特征參數,其中,包絡參數和能量參數是所需提取的基本信息,而更復雜的算法則需要進一步提取基頻參數及時變信息。考慮到電子耳蝸采集到的聲信號幅度的范圍與電極所接收到的電刺激強度范圍的不同,因此需要把經過前面算法處理后的信號進行壓縮,然后把壓縮后的信號通過連續交替脈沖的方式傳遞到電極上。為了防止不同電極間的刺激干擾,CIS 策略在每個特定的時刻只傳遞一個電極的電流刺激信息,因而通常采用的方法是固定時長并連續交替刺激。
1.2 硬件平臺及實驗方案
為驗證上述策略,本文搭建了實驗平臺,在前期搭建的電子耳蝸前端采集系統基礎上進行了改進[8]。我們選取了尺寸更小的樓氏圓筒型聲電麥克風模塊(FG23329C36,Knowles/馬來西亞)作為信號采集端,該麥克風的圓筒直徑僅為 2.59 mm 并且具有平坦頻率響應特性。麥克風模塊直接輸出的是電信號,但信號微弱,因此硬件系統中設計了放大和濾波電路,并通過在電路中覆銅、電源供電采用穩壓電源模塊、麥克風的供電采用穩壓芯片、整個硬件電路外部加裝金屬外殼等方式以減少信號采集的噪聲干擾。另一方面,設計了用于連接和固定麥克風模塊的印制電路板(printed circuit board,PCB),這樣便于調節麥克風采集端的位置。但是,PCB 本身有尺寸,會導致信號采集受到影響,因此本系統設計的連接麥克風的 PCB 為更小的橢圓形尺寸,麥克風聲管突出在 PCB 的外部,接線更緊湊,目的是減少采集端 PCB 本身尺寸對信號采集的影響。
考慮到漢語語音的特點,音源選取的是一段含四個音調的漢語聲音(語料為女生標準普通話發音的詞語“大學本科”,對應的聲調分別是:去聲、陽平、上聲和陰平),以便于后續的信號參數特征的提取和分析。同時,為了更清晰分析信號特征,本次實驗的發音語料是慢讀的方式。實驗環境是在一個尺寸約 12×9×3 m3 的靜音房間內進行,音箱離地面的高度為 1.5 m,播放選取的目標信號源在水平距離 1 m 處等高位置(距地面 1.5 m)放置硬件平臺,麥克風模塊圓筒位置正對著音箱并且精確調整麥克風聲管到音源的距離。
信號采集使用基于矩陣數值計算的數學軟件 Matlab(MathWorks,美國)編寫的程序來控制,FG23329C36 麥克風采集的兩路信號經過放大和濾波后通過 USB 接口傳輸到計算機中,所保存的音頻信息用于信號特征研究。本文的程序設置了可選時間間隔的循環信號采集,可實時連續采集信號。
1.3 言語處理算法調制前后的波形特征
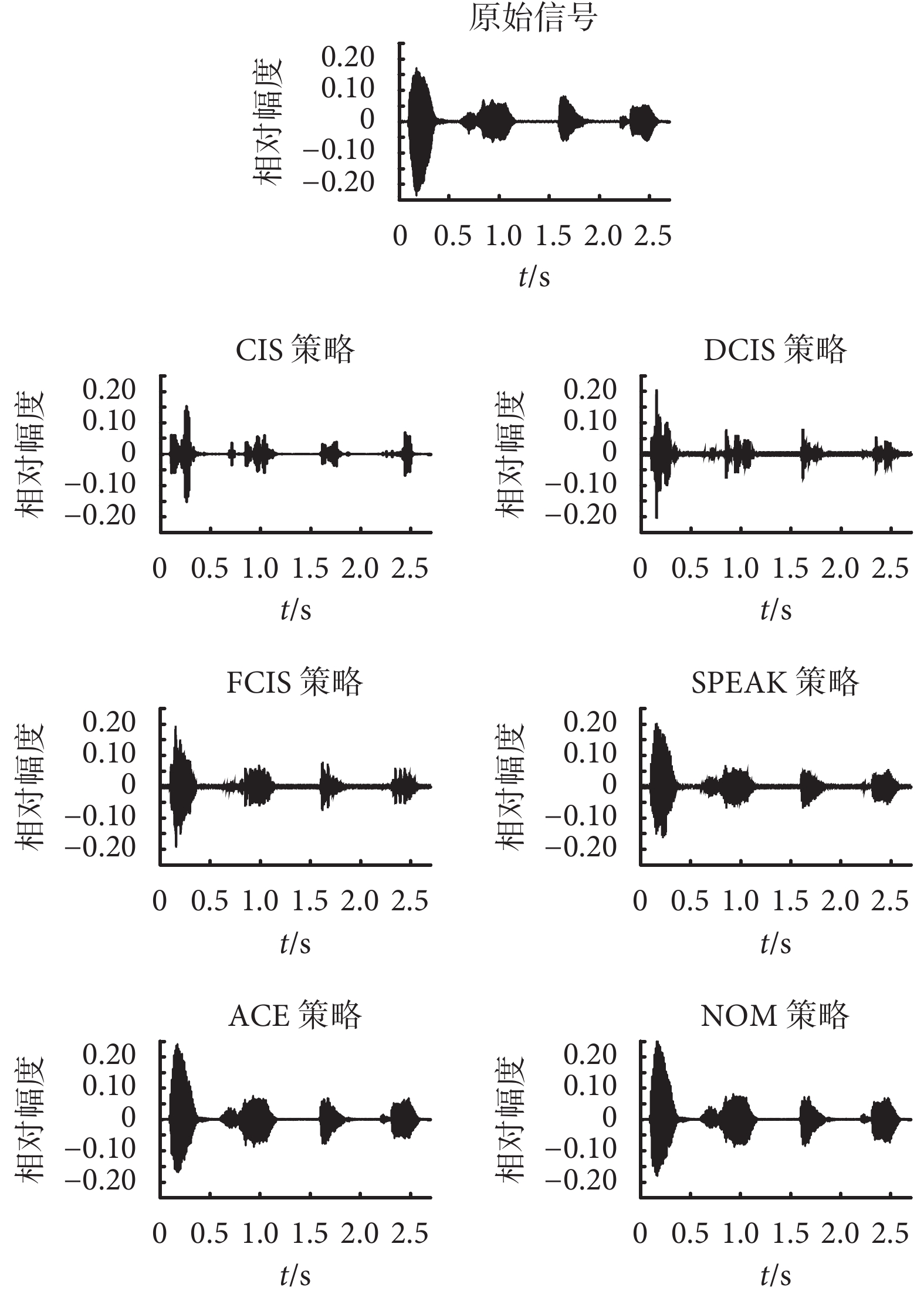
在所搭建的平臺上采集真實的原始信號波形并經過 6 種不同策略處理原始信號后的信號波形如圖 2 所示,本文所選取的是常見的電子耳蝸言語處理策略,包括基于等間隔交替刺激方法的 DCIS 策略和 FCIS 策略以及基于特征提取方法的 SPEAK 策略、ACE 策略和 NOM 策略。
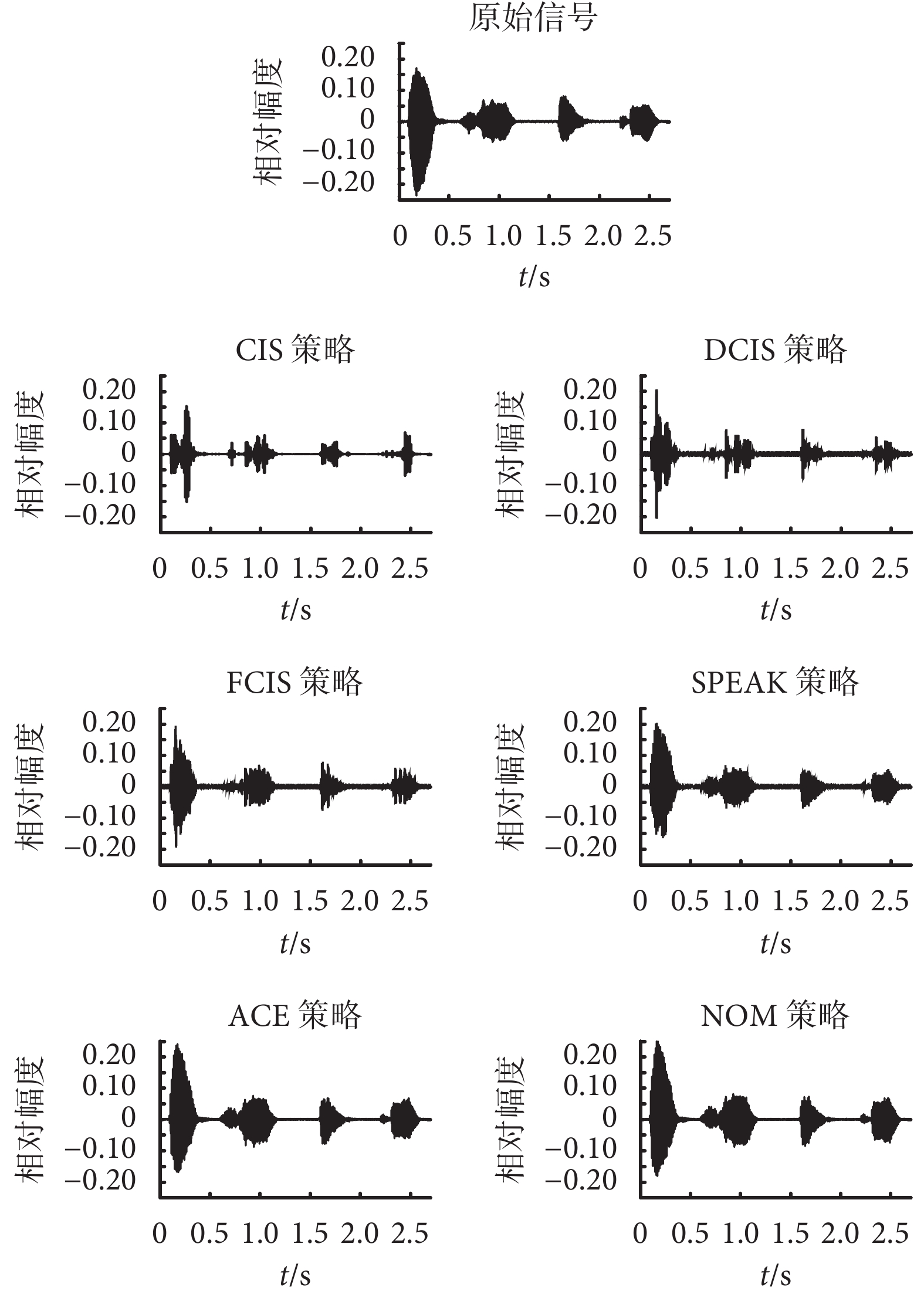 圖2
電子耳蝸言語處理策略的波形特征對比
Figure2.
Waveform comparison of speech processing strategy of cochlear implant
圖2
電子耳蝸言語處理策略的波形特征對比
Figure2.
Waveform comparison of speech processing strategy of cochlear implant
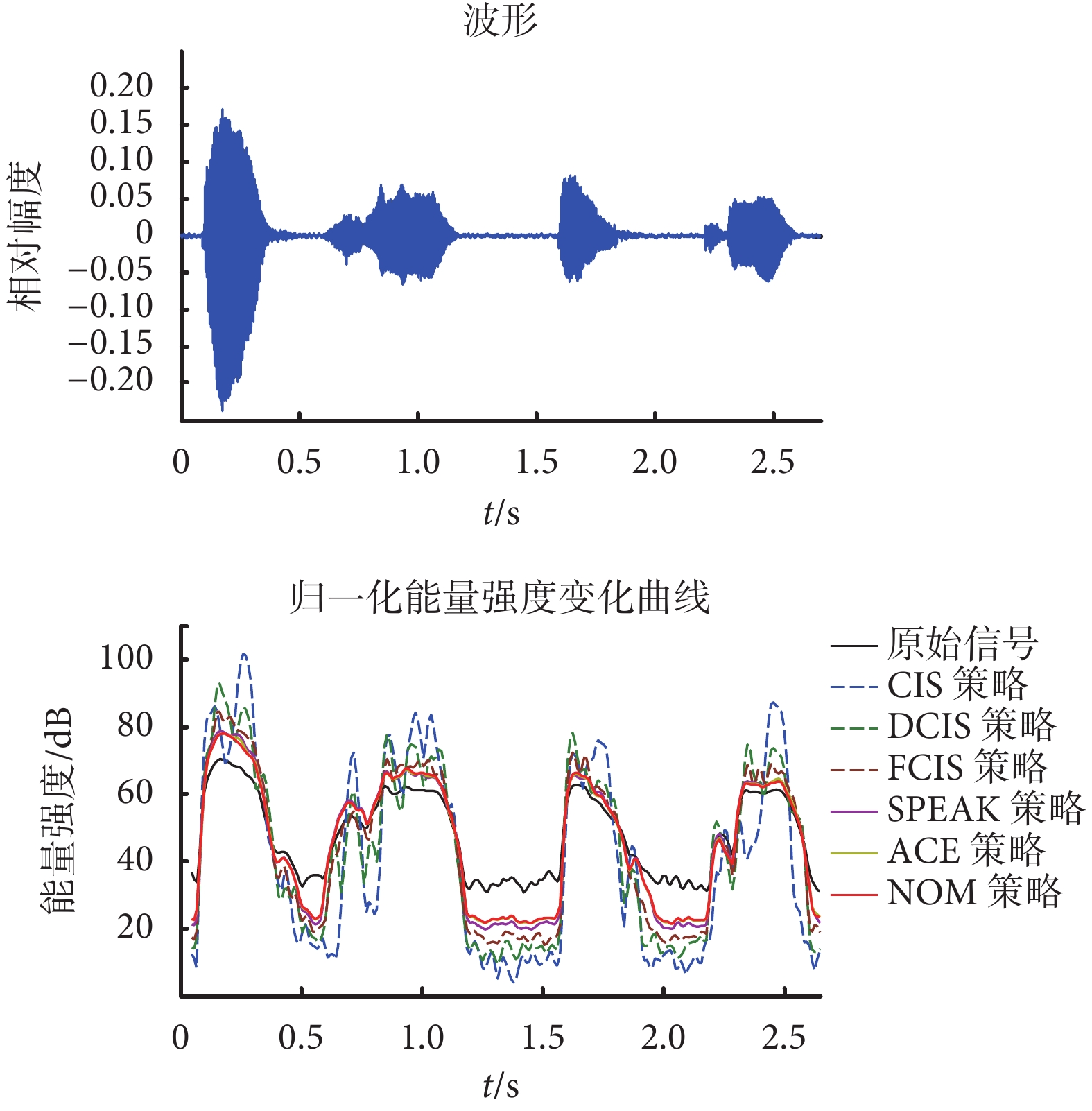
如圖 2 所示為原始信號的波形以及經過 6 種不同策略處理后的信號波形。在波形顯示中,本文所選用的 Matlab 軟件讀出聲音文件并顯示出來,該軟件自動把波形顯示為相對幅度,范圍限制在–1~1 之間。范圍通過原始信號波形圖和電子耳蝸 CIS 策略的信號波形圖對比結果可以看出,信號波形發生了較大的變化。這是由于 CIS 策略把信號按濾波器組劃分為若干頻帶后,在特定的某一時刻只傳遞一個電極的信息,也就是在特定的每個時間片斷只傳遞一個純音正弦信號,因而造成目標信號的大量信息發生丟失。對比 DCIS 和 FCIS 策略處理后的波形,由于特定時刻刺激電極更多,包含的信息比單刺激豐富,因此從波形看,DCIS 和 FCIS 策略更加接近原始波形,瞬時刺激數越多,波形越接近。當然,實際電子耳蝸產品中并不是同時刺激數越多越好的。電子耳蝸的刺激電極用的是電流刺激,電極之間距離非常小,相互之間會有干擾和電流泄露,這也是 CIS 策略每一時刻只傳遞一個電極刺激的實際考慮。實驗表明,CIS 策略比同時刺激的言語識別率更高,但與等間隔多刺激模式的 DCIS 和 FCIS 策略相比是否更好,則有待更進一步的實驗驗證。另外,從算法本身來說,SPEAK 策略和 ACE 策略都可以看成是 NOM 策略的特定情形。SPEAK 是一種最大譜峰策略,ACE 是一種聯合編碼策略,NOM 是一種頻帶劃分和最大譜峰可選策略。這 3 種策略都是選擇電子耳蝸濾波器組頻帶里的若干個最大幅度的信號包絡用于刺激序列并分時進行刺激。不同之處,一方面是頻帶不同,SPEAK 策略一般把信號劃分 20 個子帶并且選擇其中 5~10 個最大的子帶進行脈沖的調制;ACE 策略則劃分為 22 個子帶并且選擇 20 個以內的子帶;NOM 策略所劃分的頻帶以及選取的子帶數量則沒有特別規定。另一方面的差異是刺激速率的不同,ACE 和 NOM 策略的刺激速率高,而 SPEAK 策略則較低。因此,本文實驗結果的通道選取是按照不同言語處理策略的特性確定的,比如選取了典型的 SPEAK 的 20 通道策略,ACE 的 22 通道策略和 NOM 策略的 24 通道策略。如圖 2 所示的這 3 種電子耳蝸言語策略的信號波形來看,算法所生成的信號波形都和原始信號波形非常接近,波形細節的分布也基本一致。但波形一致性不是算法性能的唯一參數,算法所選取的頻帶所對應的電極可能比較接近,需要通過譜特征來進一步分析。
2 特征參數分析
2.1 譜特征
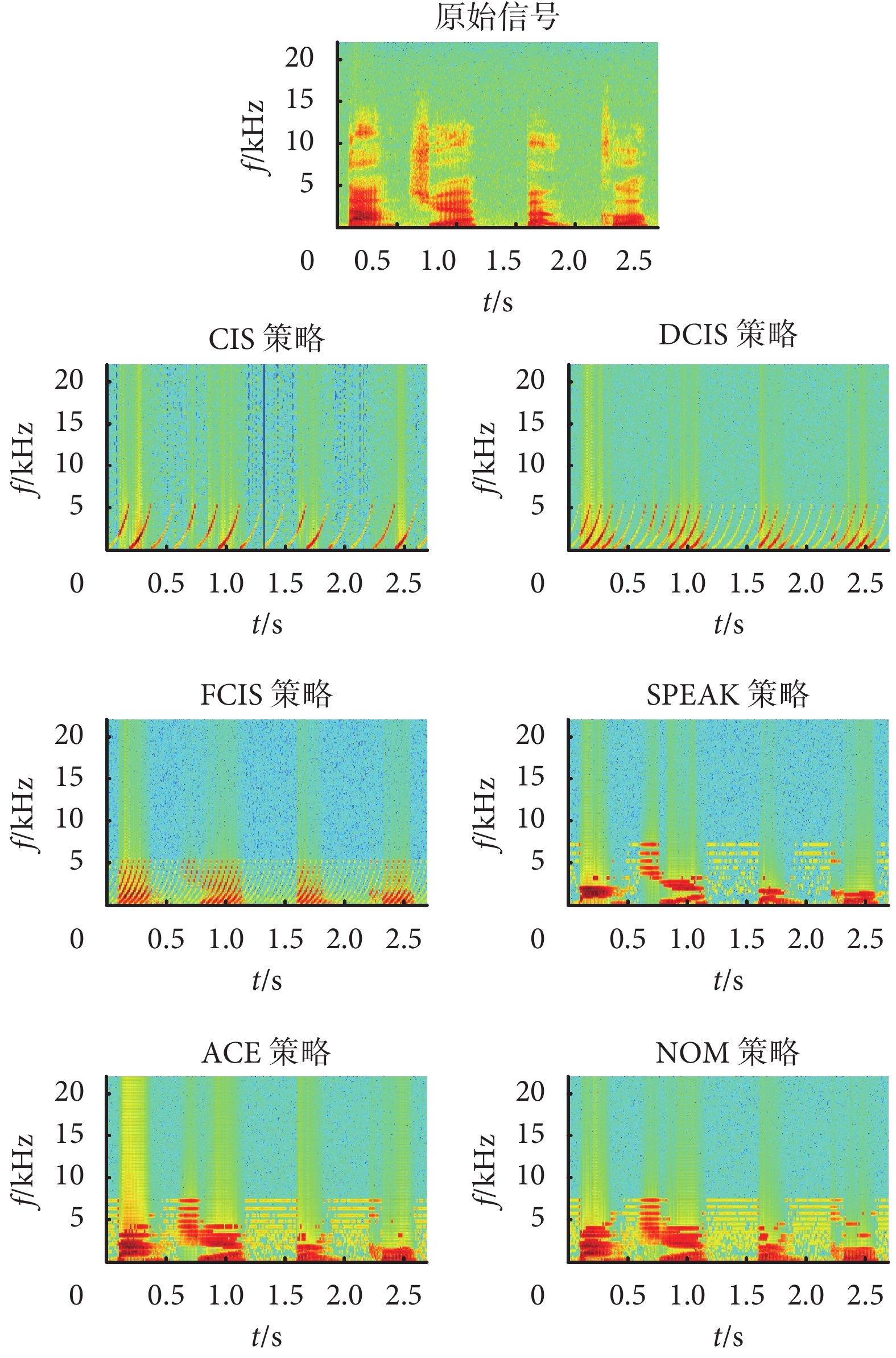
與波形特征對應的,經 6 種不同策略處理原始信號后的語譜圖如圖 3 所示。
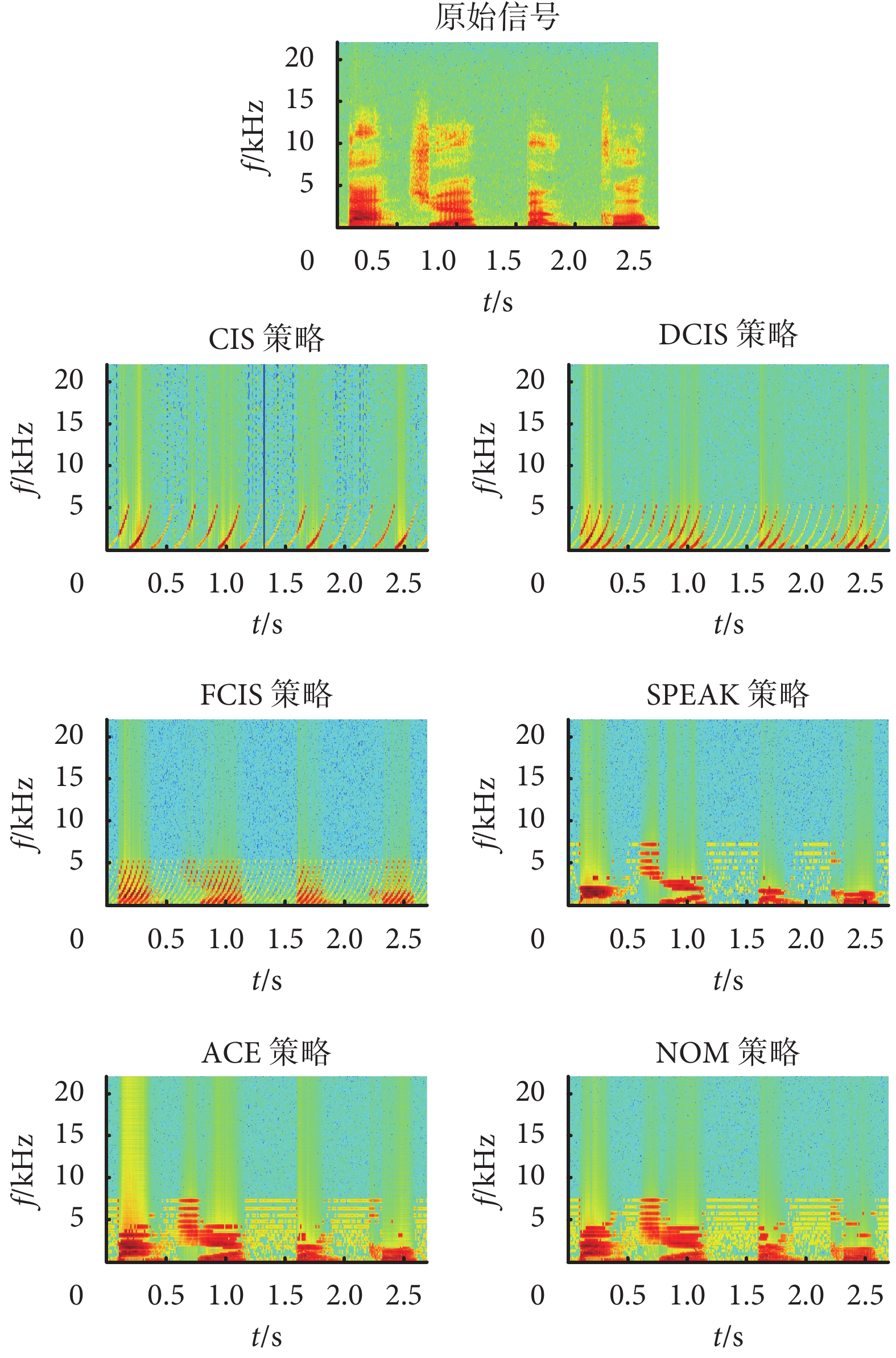 圖3
電子耳蝸言語處理策略的語譜特征對比
Figure3.
Spectrogram comparison of speech processing strategy of cochlear implant
圖3
電子耳蝸言語處理策略的語譜特征對比
Figure3.
Spectrogram comparison of speech processing strategy of cochlear implant
如圖 3 所示為各個電子耳蝸言語處理策略的信號語譜圖,該語譜圖是通過軟件 Matlab 自帶的時頻工具箱編程得到的。通過對比看到,經過電子耳蝸 6 種言語處理策略處理后的信號語譜圖均與原始信號的語譜圖差異很大。從譜特征來看,各種算法都會損失較多信號的信息,語音處理算法只能以一定的方式來描述信號主要特征并通過電極刺激來產生聲學感知。對 CIS、DCIS 和 FCIS 策略來說,選取的刺激通道(與濾波器頻帶對應)是按規律選取的,這樣就能保證特定時刻的電極刺激不會很近,避免刺激電流的擴散效應。但同時,按規律的選取并不是基于信號的,因而選取的頻帶并不是能量最大的。以圖 3 中 CIS 策略處理圖為例,在 1.312~1.323 s 的位置有一條細藍線,藍色為能量很低的部位,由于 CIS 策略的電極選取是按規律而不是基于信號特征參數,因而往往選取了不是最能表征該幀的電極參數。而從 SPEAK 策略、ACE 策略和 NOM 策略處理的語譜分布則主要選取了深紅色區域(能量集中的地方),這類言語處理策略可以選取最能表征目標信號的子帶并傳遞到電極上,但是從分布結果來看,能量成片集中,表明算法所選取的刺激電極集中在少數低頻電極上而且相互靠近,容易引起電極間刺激電流的干擾。
2.2 能量強度特征
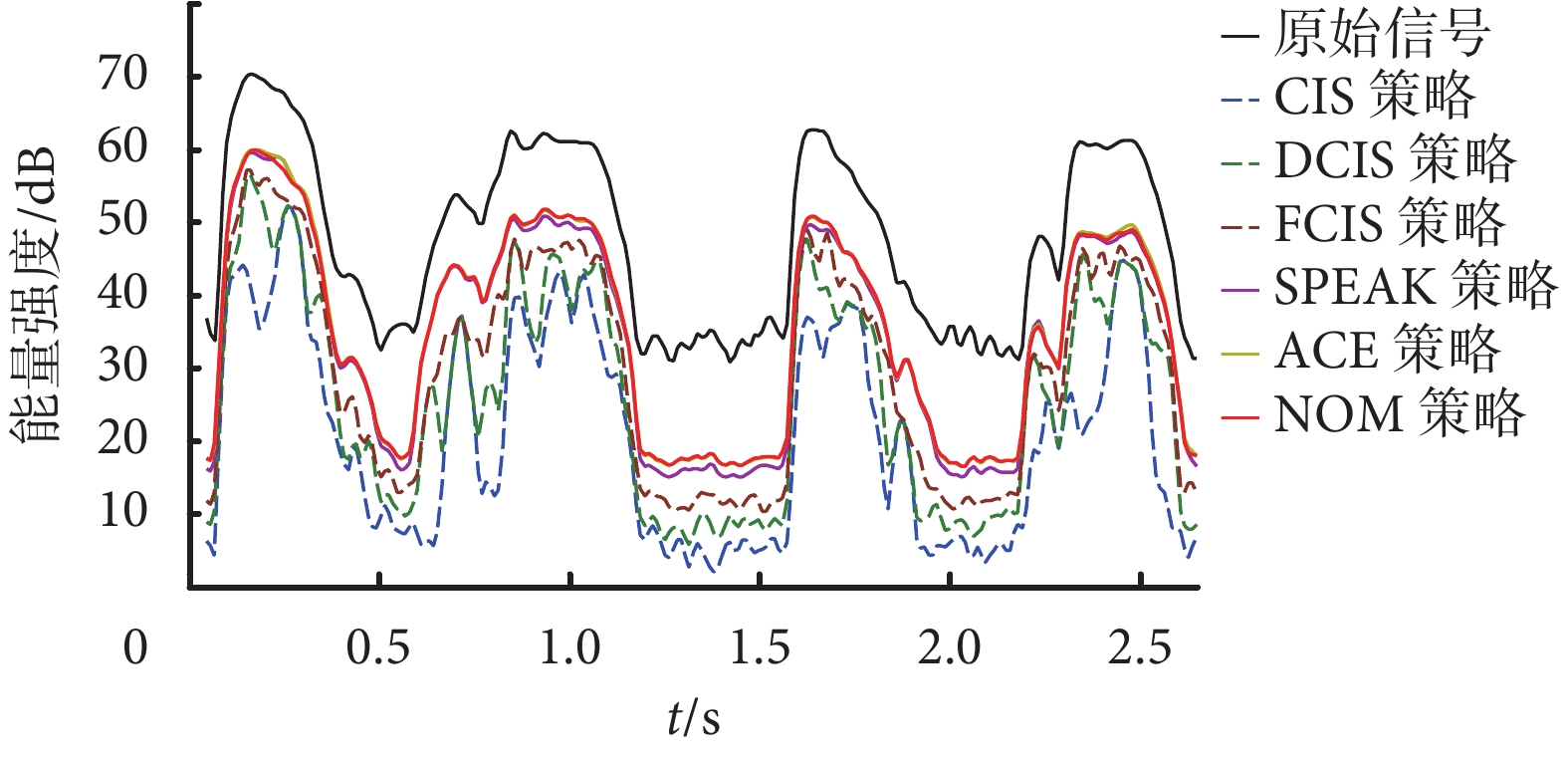
電子耳蝸刺激速率對應體外言語處理器的濾波器組頻帶,而電刺激強度對應所在語音幀的包絡及能量。能量強度為單位時間內信號的能量(單位:dB)。對原始信號及上面所用的 6 種言語處理策略的信號能量密度進行計算,結果如圖 4 所示。
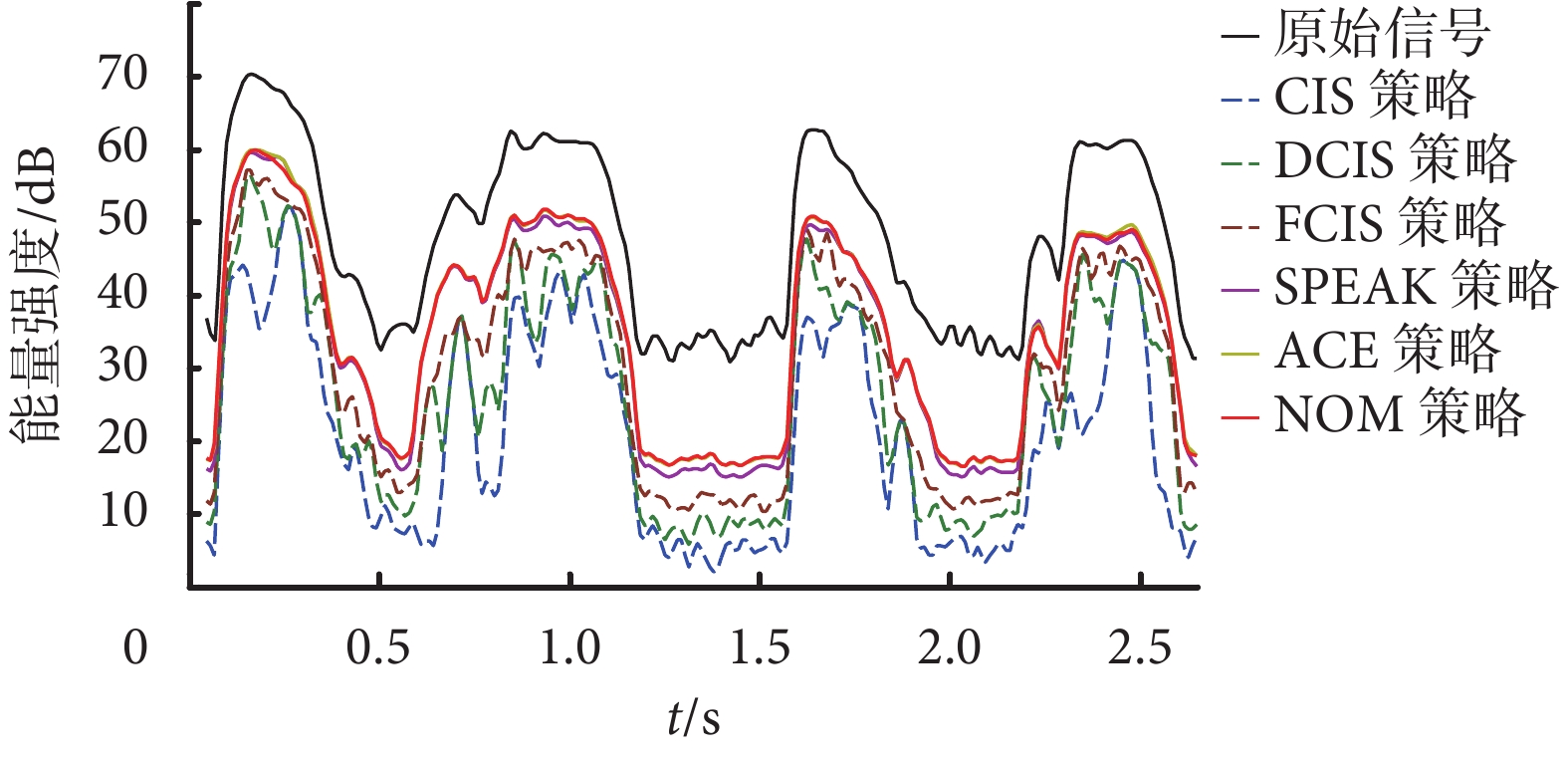 圖4
電子耳蝸言語處理策略的能量強度特征對比
Figure4.
Energy intensity comparison of speech processing strategy of cochlear implant
圖4
電子耳蝸言語處理策略的能量強度特征對比
Figure4.
Energy intensity comparison of speech processing strategy of cochlear implant
如圖 4 所示的黑色曲線為原始信號的能量強度曲線,其他顏色為不同言語處理策略的能量強度曲線分布。為了區分不同算法的特性,CIS、DCIS 和 FCIS 這 3 種言語處理策略的能量曲線是虛線,而基于信號特征的 SPEAK、ACE 和 NOM 策略則以實線表示。從曲線的變化趨勢來說,實線的 3 種策略的波形相似度更高,變化模式基本匹配原始信號,而虛線的 3 類策略則相似度較低,而且曲線的變化和幅度抖動更大。
另一方面,從能量幅度來說,原始信號的能量強度比經各個言語處理策略處理后的信號能量強度都大,這個結果可以從圖 3 的語譜圖看到原因。這是由于所使用的 6 種電子耳蝸言語處理策略都只是抽取部分通道的頻帶,包括按規律抽取和按語音特征抽取(如圖 3 所示),因此經過電子耳蝸言語處理算法調制后的信號總體能量是減少的。為了描述算法調制后信號的相對能量強度變化情況,需要對信號進行能量歸一化。用 xori(n)表示硬件系統采集到的原始信號,xCI-i(n)表示用某個電子耳蝸言語處理策略調制形成的信號,則能量歸一化信號 xnor-i(n)需要在 xCI-i(n)基礎上給予增益因子 Ai,如式(1)所示:
 |
其中,增益因子 Ai 的計算方法為:
 ,式中 N 表示采集到的語音信號的總長度(全部采集點的數量),i=1,2,3,
,式中 N 表示采集到的語音信號的總長度(全部采集點的數量),i=1,2,3,
 ,6,代表不同言語處理策略。
,6,代表不同言語處理策略。
歸一化后的能量強度曲線如圖 5 所示,同時為了分析信號不同位置的特性,原始信號的波形圖以相同的時間軸顯示在圖 5 中。
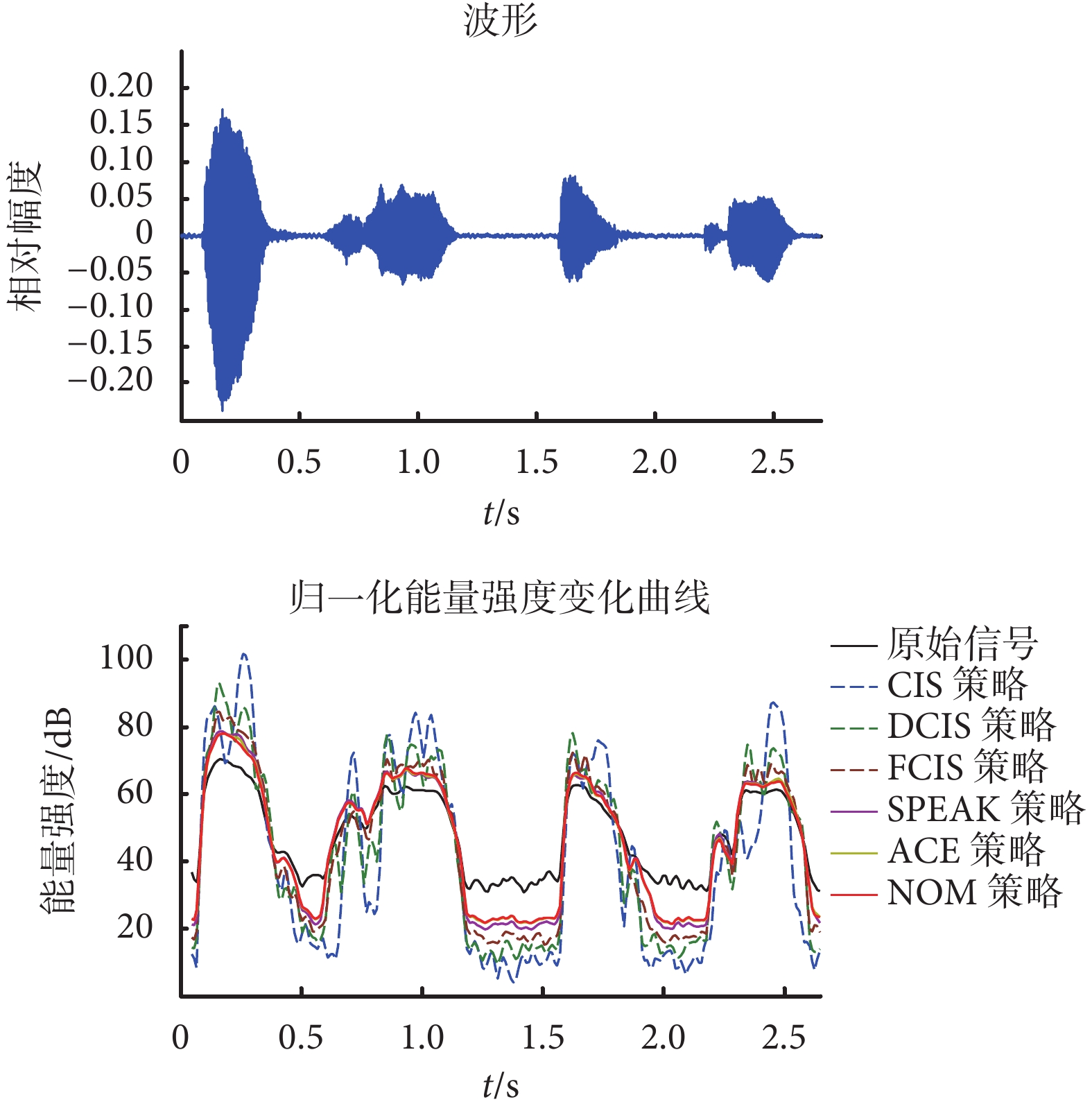 圖5
電子耳蝸言語處理策略的歸一化能量強度特征對比
Figure5.
Normalized energy intensity comparison of speech processing strategy of cochlear implant
圖5
電子耳蝸言語處理策略的歸一化能量強度特征對比
Figure5.
Normalized energy intensity comparison of speech processing strategy of cochlear implant
如圖 5 所示,對比各個歸一化能量強度曲線,可以看到,SPEAK、ACE 和 NOM 這 3 種策略(實線)要比 CIS、DCIS 和 FCIS 策略(虛線)與原始信號的能量強度曲線(黑色實線)差異小,而且變化趨勢更一致。原始波形圖中分為 4 個子波形,分別對應“大”、“學”、“本”、“科”四個字的發音,子波之間是發音間隔和尾音。對比原始信號在發音字部位和字間部位的歸一化能量強度,可以看到,電子耳蝸言語處理策略調制后的信號的能量強度在發音字部位的幅度大,而在發音字的間隔和尾音部位幅度小。言語處理策略提取信號的特征,對發音間隔的信號及靜音段的噪聲信號有一定的消減作用,但同時也對尾音產生損傷,降低了發音識別性能。而對比 6 種言語處理策略的能量強度的曲線變化細節,可以看到,基于語音特性建立的 SPEAK、ACE 和 NOM 策略(實線)與原始信號一致性更好,更有助于反映信號主要能量的變化。
2.3 基頻特征
基頻是語音的主要特征參數之一,反映人體喉部產生濁輔音的振動頻率,是影響音高的主要參數,本文采用自相關方法計算語音信號的基頻參數。對于一個數據長度為 N 的信號 x(n),延遲長度為 M 時的自相關函數 R(M)的計算如式(2)所示:
 |
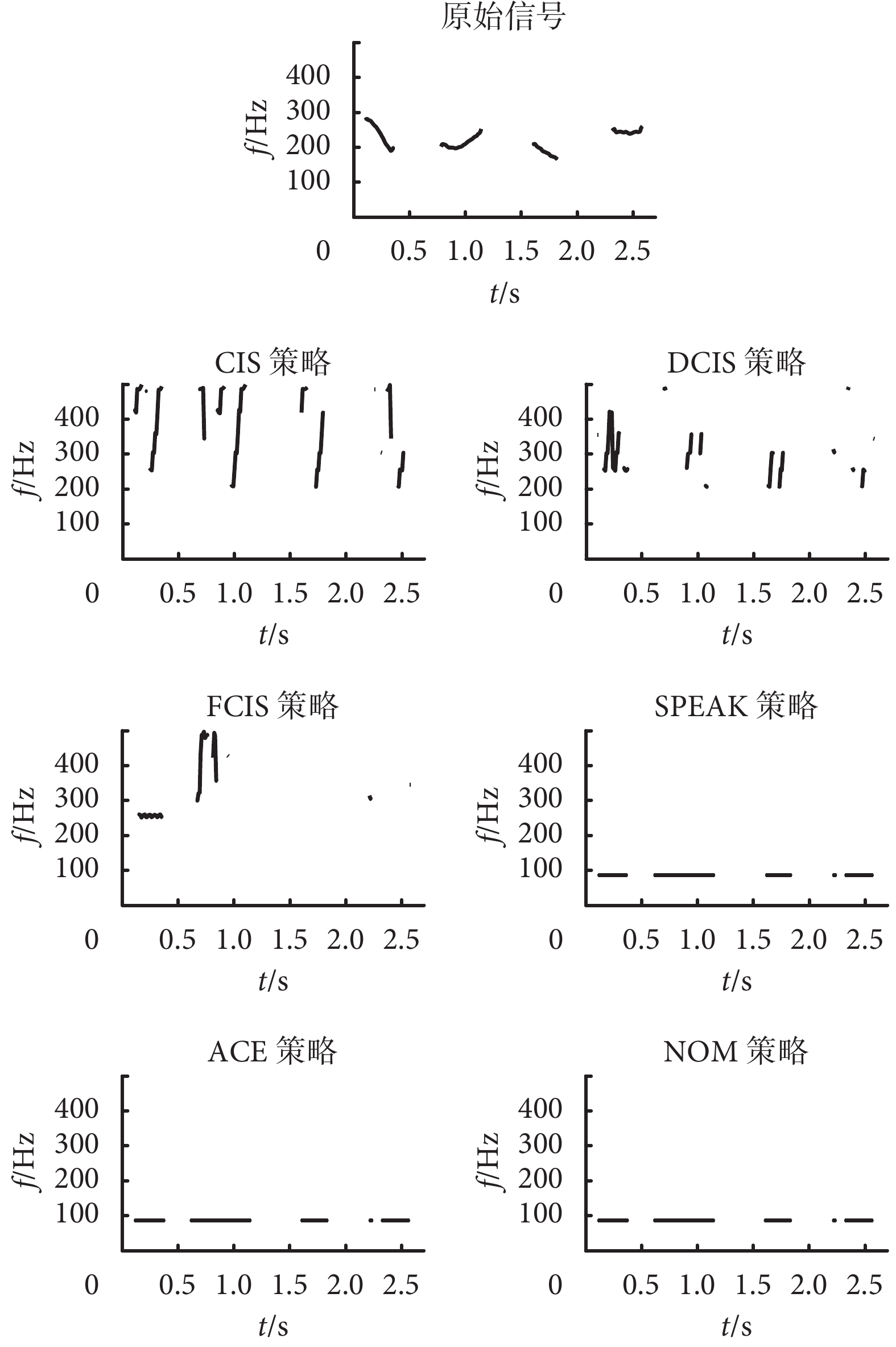
正常人發音的基頻范圍大概是 100~300 Hz,電子耳蝸言語處理算法對信號產生了較大的畸變,為了便于比較,本文設置的基頻范圍要適當大一些,設置為 75~500 Hz,計算得到的各言語處理策略的基頻曲線如圖 6 所示。
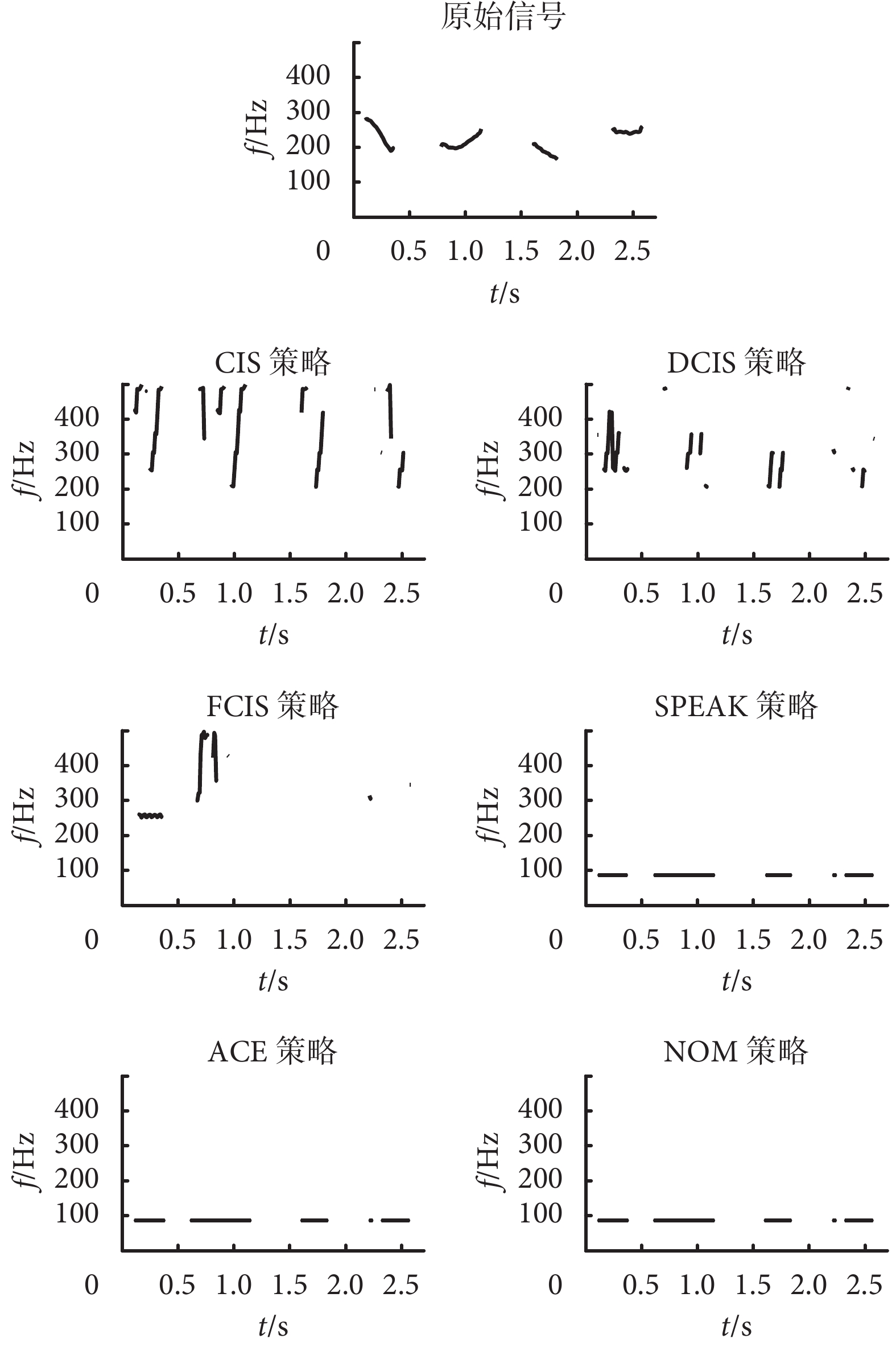 圖6
基頻曲線特征對比
Figure6.
Comparison of pitch curve feature
圖6
基頻曲線特征對比
Figure6.
Comparison of pitch curve feature
如圖 6 所示為基頻變化曲線,曲線中斷開部位為基頻不存在的時段。從原始信號圖可以看到,原始信號的基頻是平緩變化且有規律的,分為四段曲線(對應“大學本科”的各字發音的基頻),基頻曲線的變化與漢字的聲調變化基本一致。在“大學本科”的各個字的發音中,第一個字“大”的音調為去聲,對應基頻平緩下降,第二和第四個字“學科”的音調分別是陽平和陰平,也和基頻的變化一致,只有第三個字“本”的音調有一些差異,該字為上聲,基頻變化只有下降過程,少了上升過程,但總體原始信號的基頻變化是匹配音調的。而對比經過電子耳蝸言語處理策略得到的基頻,則這些特征消失。具體可分為兩類,CIS、DCIS 和 FCIS 這 3 種策略的基頻是沒有明顯規律的變化的,損失了信號的基頻匹配特征,而 SPEAK、ACE 和 NOM 的 3 種策略的基頻則是平穩直線,即基頻數值是恒定的 86 Hz 左右。這種平穩恒定的基頻也不能匹配原始信號導致信號失真,具體來說,由于漢字的四種聲調無法區別,進而會引起對漢語的言語識別率的降低。
2.4 共振峰特征
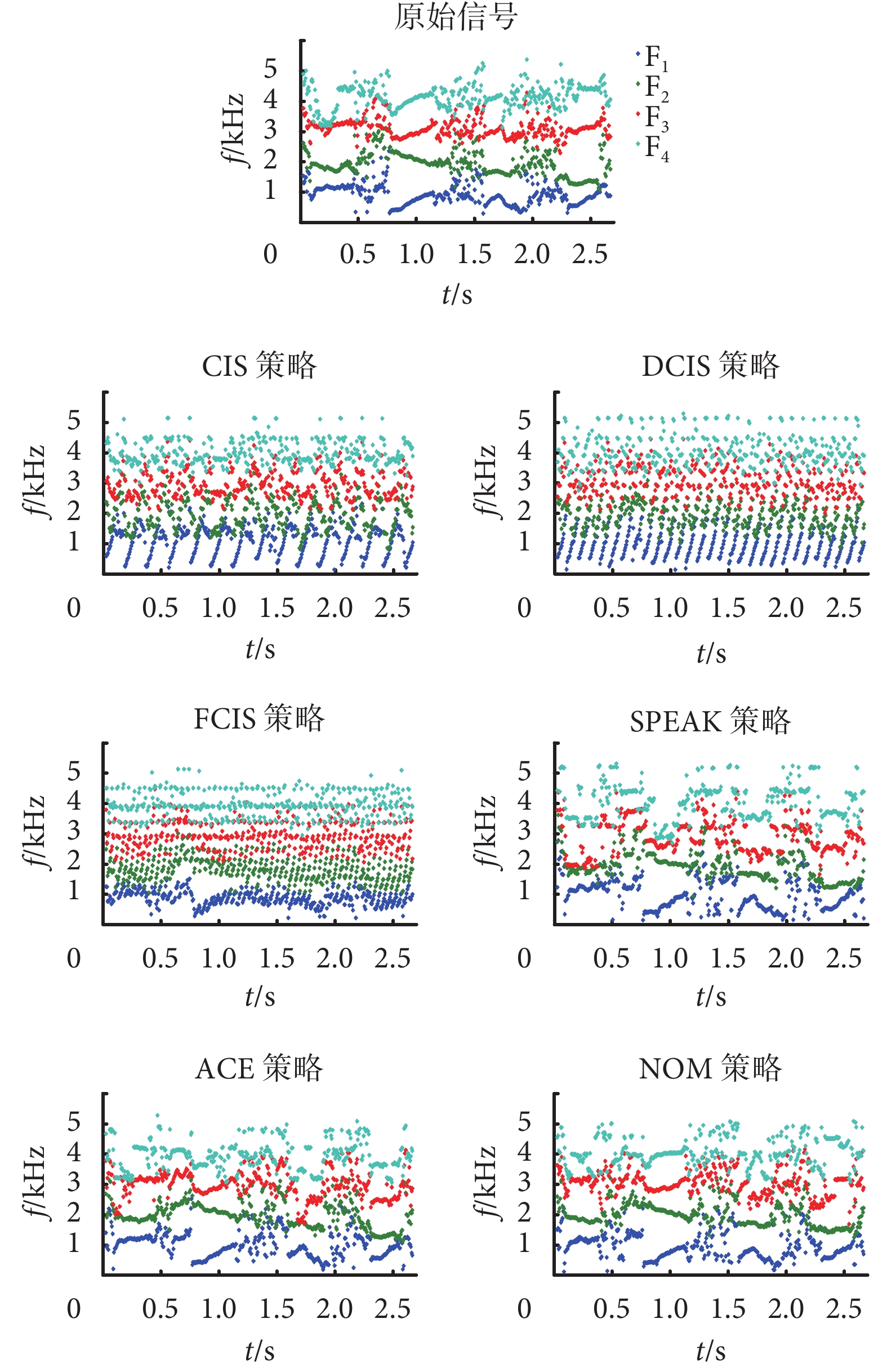
共振峰反映人體聲道的諧振特性,是影響音色的主要參數,本文采用倒譜的方法計算語音信號的共振峰特征參數。本文提取 F1、F2、F3、F4 共四個峰,計算得到的原始信號以及經過 6 種電子耳蝸言語處理策略處理后的共振峰曲線如圖 7 所示。
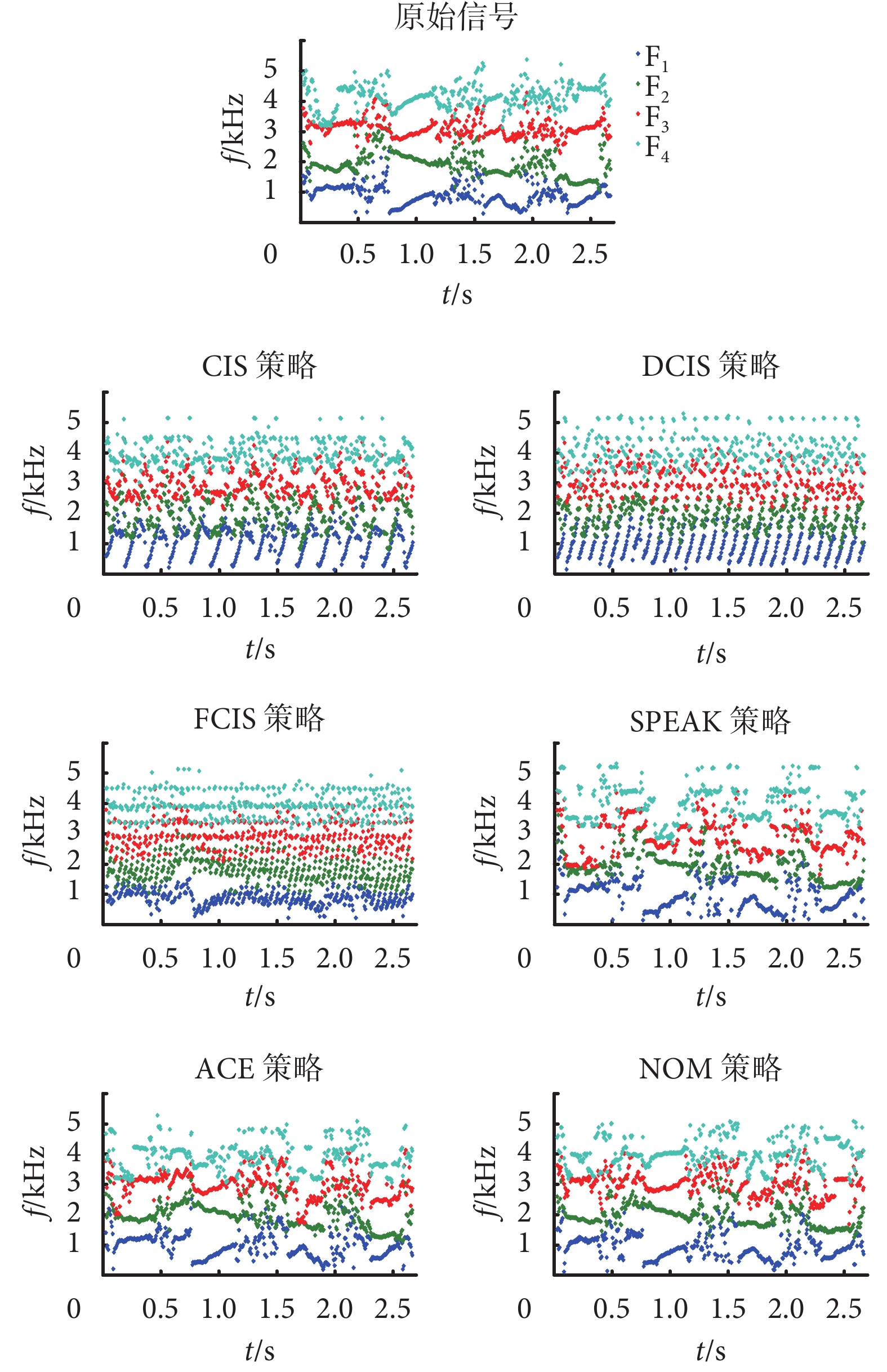 圖7
電子耳蝸言語處理策略的共振峰特征對比
Figure7.
Formant comparison of speech processing strategy of cochlear implant
圖7
電子耳蝸言語處理策略的共振峰特征對比
Figure7.
Formant comparison of speech processing strategy of cochlear implant
如圖 7 所示是為共振峰特征的對比,從原始信號共振峰來看,在字發音的部分,共振峰 F1、F2、F3、F4 的變化曲線是清晰的,而在字間隔部位則呈現面狀的零散分布。對于 CIS 策略和 DCIS 策略來說,只有共振峰 F1 呈規律分布,并且與等間隔刺激的頻帶選取有一致性,這是因為 CIS 策略和 DCIS 策略都是依次按順序選取頻帶(由低頻到高頻),所以其特性在共振峰 F1 有所體現,而共振峰 F2、F3、F4 則無規律分布。對于 FCIS 策略來說,共振峰 F1 的分布已經與策略本身的頻帶選擇方式不一致,并且分布更寬,這是因為 FCIS 策略比 DCIS 策略選取了更多的頻帶,頻帶的增加會讓 F1 的分布接近語音本身的特性。而對比基于語音特性提取頻帶的 3 種策略(SPEAK、ACE 和 NOM 策略),在共振峰 F1、F2、F3 里的特征與原始信號一致性較好,而共振峰 F4 則有一定的模糊和失配。因此,通過對比電子耳蝸各個言語處理策略的共振峰特征可以看到,基于語音特性的電子耳蝸言語處理策略(SPEAK、ACE 和 NOM 策略)在共振峰 F1、F2、F3 的特征上能更好地匹配目標信號。
3 結論
針對不同電子耳蝸言語處理策略的差異,本文在原來開發的電子耳蝸前端硬件采集平臺上改進并進行實驗研究,重點研究基于連續交替等間隔刺激方式(CIS、DCIS 和 FCIS)和基于語音特性進行頻帶選取的方式(SPEAK、ACE 和 NOM)的兩類電子耳蝸言語處理策略對信號進行處理前后信號特征參數的變化。信號的波形反映語音隨時間變化的幅度變化,通過前面的比較可知,SPEAK、ACE 和 NOM 三種基于語音特性的言語處理策略具有更好的波形匹配度。能量強度特征能反映電子耳蝸所采集的信號能量傳遞到電極陣列并形成電刺激的強度,而 SPEAK、ACE 和 NOM 仍然比 CIS、DCIS 和 FCIS 三種基于連續交替等間隔刺激方式的言語處理策略有更高的能量強度匹配性。雖然在信號波形和能量強度兩個特征上 SPEAK、ACE 和 NOM 策略更能反映原始信號的特征,但這三種言語處理策略所選取的頻帶是基于信號特征的,通過選取能量最大的頻帶用于傳遞信號參數,因而會導致相鄰頻帶被同時選取的情形。選取鄰近頻帶會導致對應電極間刺激電流的干擾和擴散。總的來說,從信號匹配度和更準確反映目標語音信息的角度看,應該選取基于語音特性進行頻帶選取的言語處理策略(SPEAK、ACE 和 NOM),而從減少相鄰電極間刺激電流干擾的角度看,應該選取基于連續交替等間隔刺激方式的言語處理策略(CIS、DCIS 和 FCIS)。因此,兩類電子耳蝸言語處理策略的實際言語識別率有待進一步研究。基頻反映聲調特征,對于漢語這樣的聲調語言來說,聲調是字詞識別的重要特征,而從基頻曲線來看,6 種電子耳蝸言語處理策略均發生嚴重的基頻失配,這表明把常見的用于國外人群的電子耳蝸言語處理策略直接引入國內是不利于漢語識別的,后續的研究可嘗試通過可調的刺激速率的方式來跟隨音調的變化趨勢,并通過實驗來評估其有效性。本文通過研究電子耳蝸言語處理策略對目標信號的特征提取和變化規律,有助于針對性地開發適合漢語人群的電子耳蝸言語處理算法,具有較大的理論和實踐價值。
引言
據世界衛生組織(world health organization,WHO)2015 年的官網報道數據(第 300 號)顯示:全球約有 3.6 億人患有聽力損失,其中包含 3.28 億成人和 3 200 萬兒童。世界衛生組織的媒體中心描述該聽力損失的標準是:成人聽力較好的那只耳朵聽力喪失超過 40 分貝,兒童聽力較好的那只耳朵聽力喪失超過 30 分貝。如果按這個標準以及類似的比例估計(3.6 億約占全球人口的 5%),中國的聽力損失患者接近 7 000 萬。聽力損失患者需要根據聽力的損失狀況來佩帶助聽器或者植入電子耳蝸,而電子耳蝸是目前治療重度耳聾或者全聾(尤其是毛細胞損傷所引起的聽力嚴重受損情形)的有效聽力裝置。電子耳蝸包括體外機和體內機兩部分,體內機的核心部分是接收線圈、相關電路和刺激電極;體外機主要包括麥克風、言語處理器和發射線圈及相關輔助器件等;其中,體外言語處理器所嵌入的電子耳蝸言語處理算法是最核心和關鍵的部分。目前國外有三大電子耳蝸生產廠商,即澳大利亞的 Cochlear Corporation,奧地利的 MED-EL 和美國的 Advanced Bionics(簡稱 AB)。國外開發電子耳蝸的經驗豐富,而且有大量的電子耳蝸植入者,因此現有的電子耳蝸在英語環境下性能較好,使用者已經能夠便利地進行電話聊天或者面對面的交流了。但國外的基于英語語系和特征的電子耳蝸直接應用于漢語人群則丟失了語調特征,因此造成漢語里不同音調的語義辨識出錯和言語識別率低的后果。
近年來,國內的聲學研究所和研究型大學開展了基于漢語特征的電子耳蝸相關研究工作,杭州的諾爾康神經電子科技有限公司也開發了國產化的電子耳蝸,相關的產品研制和臨床性能正進行試驗和評估中。同時,為了便于進行算法研究,近年來國外也相繼開發出了電子耳蝸算法移植和研究平臺。比如,美國 AB 公司開發了一款聲學處理算法集成開發環境(sound-processing algorithm integrated development environment,SPAIDE)的研究平臺用于設置特定的語音處理模式和電刺激策略參數[1],美國德克薩斯大學開發了基于掌上電腦(personal digital assistant,PDA)和智能手機的電子耳蝸研究平臺[2-3],澳大利亞的企業(HEARworks Pty Ltd)開發了基于語音處理器(SPEAR3,HEARworks/AUS)的信號處理研究平臺,通過匯編編程方式對 22 通道的電子耳蝸植入體(Nucleus CI22,HEARworks/AUS)Nucleus CI22 和 24 通道的電子耳蝸植入體(Nucleus CI24,HEARworks/AUS)進行刺激參數設置和植入新的言語處理算法[4],Fatemeh[5]和 Mirzahasanloo[6-7]等學者開發了基于 PDA 的電子耳蝸研究平臺并進行語音處理算法的研究。國內學者也開發了電子耳蝸信號采集平臺用于算法研究[8-10]。
不同廠商的電子耳蝸產品在尺寸,體外機佩帶方式,麥克風數量及配置陣型,體外機的語音處理器,信號編碼方式等方面差別很大,而電子耳蝸言語處理算法則是其中最核心的技術之一。連續交替采樣策略(continuous interleaved sampling,CIS)是一種經典的言語處理方法,目前流行的很多算法基本都是以該策略為基礎改進和發展起來的,例如連續交替等間隔多刺激策略(multiple stimulation continuous interleaved sampling,MCIS),最大譜峰策略(spectral peak,SPEAK)[11],聯合編碼策略(advanced combined encoder,ACE)[12],頻帶劃分和最大譜峰可調策略(n of m strategy,NOM)[13-14]等,其中,MCIS 策略的瞬時刺激數本身不固定,常見的有連續交替雙刺激策略(double stimulation continuous interleaved sampling,DCIS)和連續交替四刺激策略(four stimulation continuous interleaved sampling,FCIS)。在這 6 類電子耳蝸言語處理策略中,CIS 策略出現最早,該策略通過連續交替傳遞一個通道的參數到電極并形成交替電刺激,刺激速率范圍是 740~2 400 脈沖/秒(pulse per second,PPS)。后來發展了非等間隔刺激的言語處理策略,即 SPEAK 策略和 ACE 策略,這兩類言語處理策略提取的是能量信息最大的頻帶信息并用于電極刺激,所提取的頻帶不是等間隔的,也并不連續交替刺激。另外,由于語音信號的能量主要集中在低頻段,因此 SPEAK 策略和 ACE 策略主要提取并傳遞低頻段的通道信息。SPEAK 策略和 ACE 策略的差別一方面體現在刺激速率上,ACE 策略的刺激速率更高,另一方面是電子耳蝸通道數及通道選取的數量上的差別,SPEAK 策略設置 20 個通道并選取其中對應的最大的 5~10 個頻帶用于電極刺激,而 ACE 策略則設置 22 個通道并選取其中對應的 20 個以內的最大的頻帶用于電極刺激。之后出現的 NOM 策略則進一步增加了電子耳蝸通道數和用于電極刺激頻帶數的可調性,是一種電子耳蝸通道數劃分和最大譜峰數均可設置的言語處理策略。本文研究了基于 CIS 算法架構的電子耳蝸言語處理策略的算法處理流程及信號特征變化,通過漢語四聲調的信號采集實驗并提取了波形、語譜、能量強度、基頻和共振峰等信號特征和參數,分析了漢語中不同聲調信號經過電子耳蝸言語處理策略處理后的特征變化。漢語是音調語言,本文所研究的基頻和共振峰等參數特征有助于反映漢語經過電子耳蝸算法處理后的失配特性,為基于漢語特征的電子耳蝸言語處理算法的進一步研究提供有價值的參數和研究基礎。
1 算法架構及實驗系統
1.1 基于 CIS 策略的算法架構
CIS 策略是通過濾波器組把信號進行頻帶劃分,每一段信號可認為是一段窄帶信號。通過特定的算法提取每個頻帶的包絡等關鍵信息,并用一組純音信號來調制(可選取對應濾波器組中心頻率作為純音信號頻率),并通過無線方式傳遞到對應體內電極上。電極刺激的時候不是同時進行的,而是通過交替的方式來完成,即每個時刻只有一個電極以特定的刺激速率刺激相應的位置,然后其他電極依次等間隔進行,如圖 1 所示是 CIS 策略的算法工作原理示意圖。
圖1
CIS 策略的算法工作原理示意圖
Figure1.
Schematic diagram of algorithm principle for CIS strategy
如圖 1 所示是 CIS 策略的算法工作原理示意圖,首先用麥克風采集原始信號,接著經過預處理之后進行頻帶劃分,并用特定的濾波器組(與電極對應)來對信號頻帶進行劃分。然后進一步通過電子耳蝸言語處理策略提取每個子帶信號中的特征參數,其中,包絡參數和能量參數是所需提取的基本信息,而更復雜的算法則需要進一步提取基頻參數及時變信息。考慮到電子耳蝸采集到的聲信號幅度的范圍與電極所接收到的電刺激強度范圍的不同,因此需要把經過前面算法處理后的信號進行壓縮,然后把壓縮后的信號通過連續交替脈沖的方式傳遞到電極上。為了防止不同電極間的刺激干擾,CIS 策略在每個特定的時刻只傳遞一個電極的電流刺激信息,因而通常采用的方法是固定時長并連續交替刺激。
1.2 硬件平臺及實驗方案
為驗證上述策略,本文搭建了實驗平臺,在前期搭建的電子耳蝸前端采集系統基礎上進行了改進[8]。我們選取了尺寸更小的樓氏圓筒型聲電麥克風模塊(FG23329C36,Knowles/馬來西亞)作為信號采集端,該麥克風的圓筒直徑僅為 2.59 mm 并且具有平坦頻率響應特性。麥克風模塊直接輸出的是電信號,但信號微弱,因此硬件系統中設計了放大和濾波電路,并通過在電路中覆銅、電源供電采用穩壓電源模塊、麥克風的供電采用穩壓芯片、整個硬件電路外部加裝金屬外殼等方式以減少信號采集的噪聲干擾。另一方面,設計了用于連接和固定麥克風模塊的印制電路板(printed circuit board,PCB),這樣便于調節麥克風采集端的位置。但是,PCB 本身有尺寸,會導致信號采集受到影響,因此本系統設計的連接麥克風的 PCB 為更小的橢圓形尺寸,麥克風聲管突出在 PCB 的外部,接線更緊湊,目的是減少采集端 PCB 本身尺寸對信號采集的影響。
考慮到漢語語音的特點,音源選取的是一段含四個音調的漢語聲音(語料為女生標準普通話發音的詞語“大學本科”,對應的聲調分別是:去聲、陽平、上聲和陰平),以便于后續的信號參數特征的提取和分析。同時,為了更清晰分析信號特征,本次實驗的發音語料是慢讀的方式。實驗環境是在一個尺寸約 12×9×3 m3 的靜音房間內進行,音箱離地面的高度為 1.5 m,播放選取的目標信號源在水平距離 1 m 處等高位置(距地面 1.5 m)放置硬件平臺,麥克風模塊圓筒位置正對著音箱并且精確調整麥克風聲管到音源的距離。
信號采集使用基于矩陣數值計算的數學軟件 Matlab(MathWorks,美國)編寫的程序來控制,FG23329C36 麥克風采集的兩路信號經過放大和濾波后通過 USB 接口傳輸到計算機中,所保存的音頻信息用于信號特征研究。本文的程序設置了可選時間間隔的循環信號采集,可實時連續采集信號。
1.3 言語處理算法調制前后的波形特征
在所搭建的平臺上采集真實的原始信號波形并經過 6 種不同策略處理原始信號后的信號波形如圖 2 所示,本文所選取的是常見的電子耳蝸言語處理策略,包括基于等間隔交替刺激方法的 DCIS 策略和 FCIS 策略以及基于特征提取方法的 SPEAK 策略、ACE 策略和 NOM 策略。
圖2
電子耳蝸言語處理策略的波形特征對比
Figure2.
Waveform comparison of speech processing strategy of cochlear implant
如圖 2 所示為原始信號的波形以及經過 6 種不同策略處理后的信號波形。在波形顯示中,本文所選用的 Matlab 軟件讀出聲音文件并顯示出來,該軟件自動把波形顯示為相對幅度,范圍限制在–1~1 之間。范圍通過原始信號波形圖和電子耳蝸 CIS 策略的信號波形圖對比結果可以看出,信號波形發生了較大的變化。這是由于 CIS 策略把信號按濾波器組劃分為若干頻帶后,在特定的某一時刻只傳遞一個電極的信息,也就是在特定的每個時間片斷只傳遞一個純音正弦信號,因而造成目標信號的大量信息發生丟失。對比 DCIS 和 FCIS 策略處理后的波形,由于特定時刻刺激電極更多,包含的信息比單刺激豐富,因此從波形看,DCIS 和 FCIS 策略更加接近原始波形,瞬時刺激數越多,波形越接近。當然,實際電子耳蝸產品中并不是同時刺激數越多越好的。電子耳蝸的刺激電極用的是電流刺激,電極之間距離非常小,相互之間會有干擾和電流泄露,這也是 CIS 策略每一時刻只傳遞一個電極刺激的實際考慮。實驗表明,CIS 策略比同時刺激的言語識別率更高,但與等間隔多刺激模式的 DCIS 和 FCIS 策略相比是否更好,則有待更進一步的實驗驗證。另外,從算法本身來說,SPEAK 策略和 ACE 策略都可以看成是 NOM 策略的特定情形。SPEAK 是一種最大譜峰策略,ACE 是一種聯合編碼策略,NOM 是一種頻帶劃分和最大譜峰可選策略。這 3 種策略都是選擇電子耳蝸濾波器組頻帶里的若干個最大幅度的信號包絡用于刺激序列并分時進行刺激。不同之處,一方面是頻帶不同,SPEAK 策略一般把信號劃分 20 個子帶并且選擇其中 5~10 個最大的子帶進行脈沖的調制;ACE 策略則劃分為 22 個子帶并且選擇 20 個以內的子帶;NOM 策略所劃分的頻帶以及選取的子帶數量則沒有特別規定。另一方面的差異是刺激速率的不同,ACE 和 NOM 策略的刺激速率高,而 SPEAK 策略則較低。因此,本文實驗結果的通道選取是按照不同言語處理策略的特性確定的,比如選取了典型的 SPEAK 的 20 通道策略,ACE 的 22 通道策略和 NOM 策略的 24 通道策略。如圖 2 所示的這 3 種電子耳蝸言語策略的信號波形來看,算法所生成的信號波形都和原始信號波形非常接近,波形細節的分布也基本一致。但波形一致性不是算法性能的唯一參數,算法所選取的頻帶所對應的電極可能比較接近,需要通過譜特征來進一步分析。
2 特征參數分析
2.1 譜特征
與波形特征對應的,經 6 種不同策略處理原始信號后的語譜圖如圖 3 所示。
圖3
電子耳蝸言語處理策略的語譜特征對比
Figure3.
Spectrogram comparison of speech processing strategy of cochlear implant
如圖 3 所示為各個電子耳蝸言語處理策略的信號語譜圖,該語譜圖是通過軟件 Matlab 自帶的時頻工具箱編程得到的。通過對比看到,經過電子耳蝸 6 種言語處理策略處理后的信號語譜圖均與原始信號的語譜圖差異很大。從譜特征來看,各種算法都會損失較多信號的信息,語音處理算法只能以一定的方式來描述信號主要特征并通過電極刺激來產生聲學感知。對 CIS、DCIS 和 FCIS 策略來說,選取的刺激通道(與濾波器頻帶對應)是按規律選取的,這樣就能保證特定時刻的電極刺激不會很近,避免刺激電流的擴散效應。但同時,按規律的選取并不是基于信號的,因而選取的頻帶并不是能量最大的。以圖 3 中 CIS 策略處理圖為例,在 1.312~1.323 s 的位置有一條細藍線,藍色為能量很低的部位,由于 CIS 策略的電極選取是按規律而不是基于信號特征參數,因而往往選取了不是最能表征該幀的電極參數。而從 SPEAK 策略、ACE 策略和 NOM 策略處理的語譜分布則主要選取了深紅色區域(能量集中的地方),這類言語處理策略可以選取最能表征目標信號的子帶并傳遞到電極上,但是從分布結果來看,能量成片集中,表明算法所選取的刺激電極集中在少數低頻電極上而且相互靠近,容易引起電極間刺激電流的干擾。
2.2 能量強度特征
電子耳蝸刺激速率對應體外言語處理器的濾波器組頻帶,而電刺激強度對應所在語音幀的包絡及能量。能量強度為單位時間內信號的能量(單位:dB)。對原始信號及上面所用的 6 種言語處理策略的信號能量密度進行計算,結果如圖 4 所示。
圖4
電子耳蝸言語處理策略的能量強度特征對比
Figure4.
Energy intensity comparison of speech processing strategy of cochlear implant
如圖 4 所示的黑色曲線為原始信號的能量強度曲線,其他顏色為不同言語處理策略的能量強度曲線分布。為了區分不同算法的特性,CIS、DCIS 和 FCIS 這 3 種言語處理策略的能量曲線是虛線,而基于信號特征的 SPEAK、ACE 和 NOM 策略則以實線表示。從曲線的變化趨勢來說,實線的 3 種策略的波形相似度更高,變化模式基本匹配原始信號,而虛線的 3 類策略則相似度較低,而且曲線的變化和幅度抖動更大。
另一方面,從能量幅度來說,原始信號的能量強度比經各個言語處理策略處理后的信號能量強度都大,這個結果可以從圖 3 的語譜圖看到原因。這是由于所使用的 6 種電子耳蝸言語處理策略都只是抽取部分通道的頻帶,包括按規律抽取和按語音特征抽取(如圖 3 所示),因此經過電子耳蝸言語處理算法調制后的信號總體能量是減少的。為了描述算法調制后信號的相對能量強度變化情況,需要對信號進行能量歸一化。用 xori(n)表示硬件系統采集到的原始信號,xCI-i(n)表示用某個電子耳蝸言語處理策略調制形成的信號,則能量歸一化信號 xnor-i(n)需要在 xCI-i(n)基礎上給予增益因子 Ai,如式(1)所示:
|
其中,增益因子 Ai 的計算方法為:
,式中 N 表示采集到的語音信號的總長度(全部采集點的數量),i=1,2,3,
,6,代表不同言語處理策略。
歸一化后的能量強度曲線如圖 5 所示,同時為了分析信號不同位置的特性,原始信號的波形圖以相同的時間軸顯示在圖 5 中。
圖5
電子耳蝸言語處理策略的歸一化能量強度特征對比
Figure5.
Normalized energy intensity comparison of speech processing strategy of cochlear implant
如圖 5 所示,對比各個歸一化能量強度曲線,可以看到,SPEAK、ACE 和 NOM 這 3 種策略(實線)要比 CIS、DCIS 和 FCIS 策略(虛線)與原始信號的能量強度曲線(黑色實線)差異小,而且變化趨勢更一致。原始波形圖中分為 4 個子波形,分別對應“大”、“學”、“本”、“科”四個字的發音,子波之間是發音間隔和尾音。對比原始信號在發音字部位和字間部位的歸一化能量強度,可以看到,電子耳蝸言語處理策略調制后的信號的能量強度在發音字部位的幅度大,而在發音字的間隔和尾音部位幅度小。言語處理策略提取信號的特征,對發音間隔的信號及靜音段的噪聲信號有一定的消減作用,但同時也對尾音產生損傷,降低了發音識別性能。而對比 6 種言語處理策略的能量強度的曲線變化細節,可以看到,基于語音特性建立的 SPEAK、ACE 和 NOM 策略(實線)與原始信號一致性更好,更有助于反映信號主要能量的變化。
2.3 基頻特征
基頻是語音的主要特征參數之一,反映人體喉部產生濁輔音的振動頻率,是影響音高的主要參數,本文采用自相關方法計算語音信號的基頻參數。對于一個數據長度為 N 的信號 x(n),延遲長度為 M 時的自相關函數 R(M)的計算如式(2)所示:
|
正常人發音的基頻范圍大概是 100~300 Hz,電子耳蝸言語處理算法對信號產生了較大的畸變,為了便于比較,本文設置的基頻范圍要適當大一些,設置為 75~500 Hz,計算得到的各言語處理策略的基頻曲線如圖 6 所示。
圖6
基頻曲線特征對比
Figure6.
Comparison of pitch curve feature
如圖 6 所示為基頻變化曲線,曲線中斷開部位為基頻不存在的時段。從原始信號圖可以看到,原始信號的基頻是平緩變化且有規律的,分為四段曲線(對應“大學本科”的各字發音的基頻),基頻曲線的變化與漢字的聲調變化基本一致。在“大學本科”的各個字的發音中,第一個字“大”的音調為去聲,對應基頻平緩下降,第二和第四個字“學科”的音調分別是陽平和陰平,也和基頻的變化一致,只有第三個字“本”的音調有一些差異,該字為上聲,基頻變化只有下降過程,少了上升過程,但總體原始信號的基頻變化是匹配音調的。而對比經過電子耳蝸言語處理策略得到的基頻,則這些特征消失。具體可分為兩類,CIS、DCIS 和 FCIS 這 3 種策略的基頻是沒有明顯規律的變化的,損失了信號的基頻匹配特征,而 SPEAK、ACE 和 NOM 的 3 種策略的基頻則是平穩直線,即基頻數值是恒定的 86 Hz 左右。這種平穩恒定的基頻也不能匹配原始信號導致信號失真,具體來說,由于漢字的四種聲調無法區別,進而會引起對漢語的言語識別率的降低。
2.4 共振峰特征
共振峰反映人體聲道的諧振特性,是影響音色的主要參數,本文采用倒譜的方法計算語音信號的共振峰特征參數。本文提取 F1、F2、F3、F4 共四個峰,計算得到的原始信號以及經過 6 種電子耳蝸言語處理策略處理后的共振峰曲線如圖 7 所示。
圖7
電子耳蝸言語處理策略的共振峰特征對比
Figure7.
Formant comparison of speech processing strategy of cochlear implant
如圖 7 所示是為共振峰特征的對比,從原始信號共振峰來看,在字發音的部分,共振峰 F1、F2、F3、F4 的變化曲線是清晰的,而在字間隔部位則呈現面狀的零散分布。對于 CIS 策略和 DCIS 策略來說,只有共振峰 F1 呈規律分布,并且與等間隔刺激的頻帶選取有一致性,這是因為 CIS 策略和 DCIS 策略都是依次按順序選取頻帶(由低頻到高頻),所以其特性在共振峰 F1 有所體現,而共振峰 F2、F3、F4 則無規律分布。對于 FCIS 策略來說,共振峰 F1 的分布已經與策略本身的頻帶選擇方式不一致,并且分布更寬,這是因為 FCIS 策略比 DCIS 策略選取了更多的頻帶,頻帶的增加會讓 F1 的分布接近語音本身的特性。而對比基于語音特性提取頻帶的 3 種策略(SPEAK、ACE 和 NOM 策略),在共振峰 F1、F2、F3 里的特征與原始信號一致性較好,而共振峰 F4 則有一定的模糊和失配。因此,通過對比電子耳蝸各個言語處理策略的共振峰特征可以看到,基于語音特性的電子耳蝸言語處理策略(SPEAK、ACE 和 NOM 策略)在共振峰 F1、F2、F3 的特征上能更好地匹配目標信號。
3 結論
針對不同電子耳蝸言語處理策略的差異,本文在原來開發的電子耳蝸前端硬件采集平臺上改進并進行實驗研究,重點研究基于連續交替等間隔刺激方式(CIS、DCIS 和 FCIS)和基于語音特性進行頻帶選取的方式(SPEAK、ACE 和 NOM)的兩類電子耳蝸言語處理策略對信號進行處理前后信號特征參數的變化。信號的波形反映語音隨時間變化的幅度變化,通過前面的比較可知,SPEAK、ACE 和 NOM 三種基于語音特性的言語處理策略具有更好的波形匹配度。能量強度特征能反映電子耳蝸所采集的信號能量傳遞到電極陣列并形成電刺激的強度,而 SPEAK、ACE 和 NOM 仍然比 CIS、DCIS 和 FCIS 三種基于連續交替等間隔刺激方式的言語處理策略有更高的能量強度匹配性。雖然在信號波形和能量強度兩個特征上 SPEAK、ACE 和 NOM 策略更能反映原始信號的特征,但這三種言語處理策略所選取的頻帶是基于信號特征的,通過選取能量最大的頻帶用于傳遞信號參數,因而會導致相鄰頻帶被同時選取的情形。選取鄰近頻帶會導致對應電極間刺激電流的干擾和擴散。總的來說,從信號匹配度和更準確反映目標語音信息的角度看,應該選取基于語音特性進行頻帶選取的言語處理策略(SPEAK、ACE 和 NOM),而從減少相鄰電極間刺激電流干擾的角度看,應該選取基于連續交替等間隔刺激方式的言語處理策略(CIS、DCIS 和 FCIS)。因此,兩類電子耳蝸言語處理策略的實際言語識別率有待進一步研究。基頻反映聲調特征,對于漢語這樣的聲調語言來說,聲調是字詞識別的重要特征,而從基頻曲線來看,6 種電子耳蝸言語處理策略均發生嚴重的基頻失配,這表明把常見的用于國外人群的電子耳蝸言語處理策略直接引入國內是不利于漢語識別的,后續的研究可嘗試通過可調的刺激速率的方式來跟隨音調的變化趨勢,并通過實驗來評估其有效性。本文通過研究電子耳蝸言語處理策略對目標信號的特征提取和變化規律,有助于針對性地開發適合漢語人群的電子耳蝸言語處理算法,具有較大的理論和實踐價值。