臨床上原發性腦部淋巴瘤(PCNSL)和膠質母細胞瘤(GBM)的治療方案存在很大差異,因此治療前對二者的精確鑒別具有重要臨床價值。本文提出一套基于稀疏表示體系的腫瘤自動鑒別方法,利用 PCNSL 和 GBM T1 加權磁共振成像(MRI)圖像紋理細節信息的差異鑒別這兩種腫瘤。首先,基于影像組學的思想,設計一種基于字典學習和稀疏表示的腫瘤紋理特征提取方法,將不同體積、不同形狀的腫瘤區域轉化為 968 維紋理特征;其次,針對提取特征存在的冗余問題,建立迭代稀疏表示方法選擇少數高穩定性高分辨力的特征;最后,將選擇的關鍵特征送入稀疏表示分類器(SRC)分類。利用十折法對數據集進行交叉驗證,鑒別結果的準確率為 96.36%,敏感度為 96.30%,特異性為 96.43%。實驗結果表明,本文方法不僅能夠有效地鑒別 PCNSL 和 GBM,還避免了使用先進 MRI 鑒別腫瘤時存在的參數提取問題,在實際應用中具有較強的魯棒性。
引用本文: 吳國慶, 李澤櫸, 汪源源, 余錦華, 陳銀生, 陳忠平. 基于稀疏表示體系的原發性腦部淋巴瘤和膠質母細胞瘤圖像鑒別. 生物醫學工程學雜志, 2018, 35(5): 754-760. doi: 10.7507/1001-5515.201705061 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
臨床上原發性腦部淋巴瘤(primary central nervous system lymphoma,PCNSL)和膠質母細胞瘤(glioblastoma,GBM)的治療方案存在較大差異。PCNSL 常采用化療和全腦放射治療,而 GBM 通常采用外科手術切除的方法治療,因此治療前對 PCNSL 和 GBM 的準確鑒別,能指導臨床醫師制定合理的治療方案,具有重要的臨床價值[1-2]。然而,由于這兩種腫瘤在一些傳統模態核磁共振成像(magnetic resonance imaging,MRI)圖像,如 T1 加權、T1 增強、T2 加權和 T2 FLAIR 上呈現許多相似的特性,因此準確鑒別二者十分困難[3]。近年來,一些研究提出利用先進的 MRI 方式如擴散加權成像(diffusion-weighted imaging,DWI)和動態磁化率增強灌注成像(dynamic susceptibility contrast-enhanced perfusion-weighted imaging,DSC-PWI)等來鑒別這兩種腫瘤[4-5],但這些方法或多或少還存在一些問題。一方面這些模態的成像還主要用于實驗研究,臨床上常規檢查很少使用;另一方面這些方法本身也存在一些鑒別參數提取的問題[6-7]。
在過去十年中,隨著模式識別工具的發展和數據集的擴大,利用工程上的圖像處理技術進行醫學疾病的診斷研究成為新的趨勢。這些進步促進了量化特征高通量抽取過程的發展,并致使圖像向高維數據特征轉化以及隨后利用這些數據進行決策支持,這種做法被稱為影像組學[8]。影像組學的高維數據特征與患者的其他數據結合能夠進一步提高診斷和預后的準確性。2014 年《自然》期刊上發表文章提出利用圖像的高通量特征進行腫瘤亞型鑒別[9],隨后一些研究者相繼提出利用高通量特征進行腫瘤分子標記物的預測[10]和腫瘤分類等[11],并取得了更好的效果。這些方法在疾病預測診斷時,不僅提取醫生肉眼可直接觀察的特征進行分類預測,如形狀、體素、灰度等,還提取了一些難以直接觀測但對分類預測至關重要的紋理特征信息。
稀疏表示理論認為自然信號可由字典中少數原子線性組合而成,這些原子包含了信號的最本質特征[12]。稀疏表示在信號表達分析方面的優勢使其在數據壓縮、信號降噪、信號分離、圖像恢復和分類識別等領域取得廣泛應用[12-14]。利用字典對含噪圖像或信號進行稀疏表示,然后將表示系數重構可得到降噪后的圖像或信號[12]。在分類識別問題中,利用已知標簽特征對測試樣本特征進行表示,然后通過殘差比較,可準確預測待測樣本類別[13];將圖像像素點的鄰域像素值作為該點特征,稀疏表示分類(sparse representation classification,SRC)可被進一步用于圖像分割。Li 等[14]利用樣本特征對樣本標簽稀疏表示,并根據獲得的稀疏表示系數對樣本特征進行重要性排序,有效選擇了精神分裂癥的生物標記特征。稀疏表示對圖像及數據的表達分析優勢,使其成為影像組學中圖像分割、特征提取、特征選擇以及分類判別的重要工具。
既往臨床文獻報道,PCNSL 與 GBM 的影像形態學表現存在許多差異,如囊變壞死、邊緣、瘤周水腫和強化方式等。這些差異反映在圖像上為紋理細節信息的差異,因此受影像組學思想啟發,結合稀疏表示理論基礎,本文提出一種基于稀疏表示紋理特征提取、特征選擇、分類識別的 PCNSL 和 GBM 鑒別方法。為提取腫瘤區域紋理特征,首先訓練紋理特征字典,然后利用該字典對測試樣本腫瘤區域抽取的圖像塊集合進行稀疏表示,最后平均所有圖像塊的稀疏表示系數得到每個腫瘤樣本對應的紋理特征。由于直接提取的紋理特征具有一定冗余性,因此建立迭代稀疏表示方法選擇少數高穩定性和高分辨力的特征,并且迭代求解的過程有效克服了特征選擇時訓練樣本不足和訓練樣本信息利用不徹底的問題。最后,利用 SRC 方法對選擇后的腫瘤特征進行分類鑒別。
1 基于稀疏表示的腫瘤紋理特征提取
1.1 圖像分割
腫瘤區域的分割是后續特征提取和分類識別的前提和基礎。為獲得精確的分割腫瘤區域,首先對 T1 增強 MRI 圖像進行腦殼剝離預處理,然后利用文獻[15]的方法訓練卷積神經網絡分割 MRI 圖像中的腫瘤區域,該方法在 2015 年與 2016 年的 Brain Tumor Segmentation Challenge 中獲得了良好的分割效果。
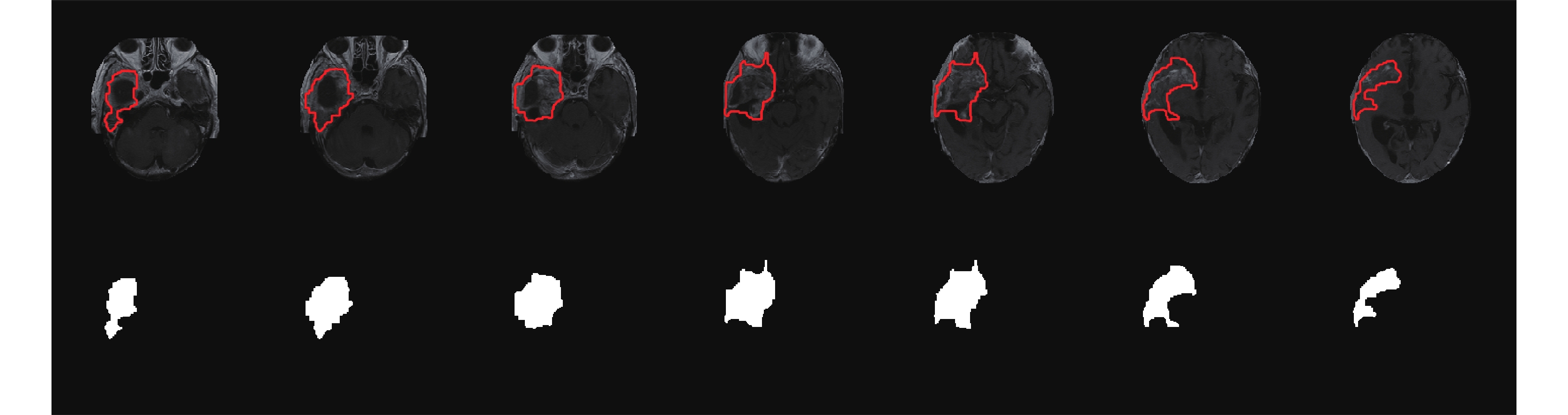
圖 1 為膠質瘤患者(60 歲,男性)T1 增強圖像利用卷積神經網絡分割的結果,第一行為剝去腦殼原圖,紅色封閉曲線內部為腫瘤部分,第二行為腫瘤區域對應標簽。此外,對于一些腫瘤區域較小的圖像,先由經驗豐富的醫生畫定感興趣區域(region of interest,ROI),然后再利用卷積神經網絡進行分割,以保證腫瘤分割的精度。
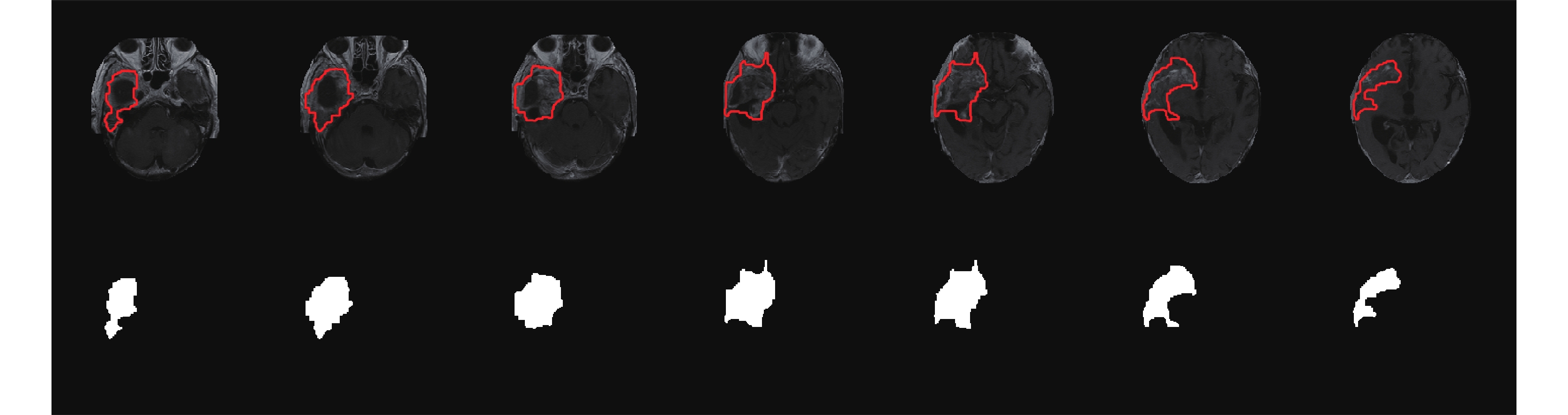 圖1
T1 增強圖像卷積神經網絡分割結果
Figure1.
Segmentation results by convolutional neural networks on T1 contrast image
圖1
T1 增強圖像卷積神經網絡分割結果
Figure1.
Segmentation results by convolutional neural networks on T1 contrast image
1.2 紋理特征提取
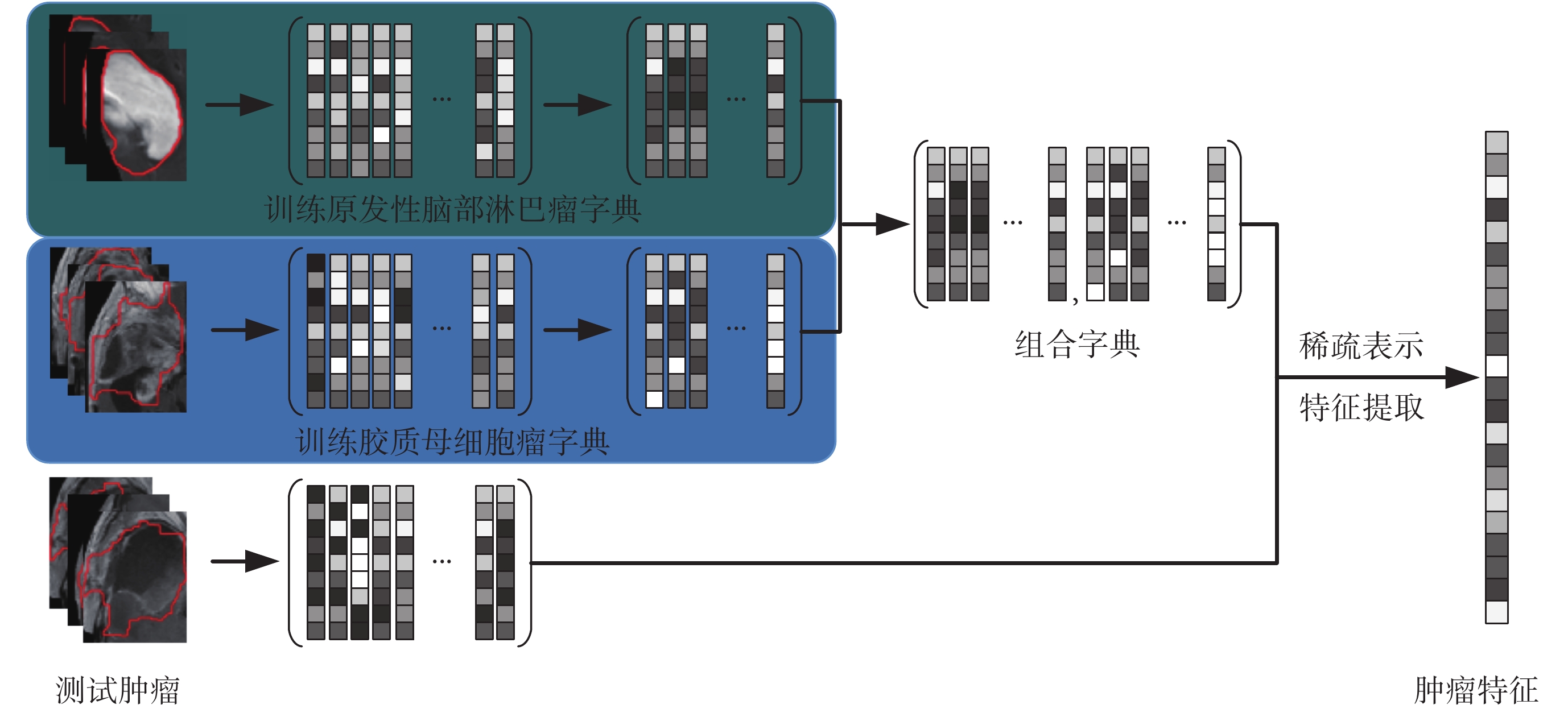
由于不同患者腫瘤大小形狀存在較大差異,因此采用基于圖像塊的處理方式提取腫瘤紋理特征。圖 2 展示了基于稀疏表示圖像紋理特征提取的流程圖。首先提取腫瘤區域圖像塊集合
 ,
,
 ,
,
 ,yi 表示第 i 個圖像塊,N 為腫瘤區域所包含的圖像塊的個數。分別選擇多個 PCNSL 圖像塊集合和多個 GBM 圖像塊集合,并采用文獻中 K-奇異值分解(K-singular value decomposition,KSVD)方法分別訓練 PCNSL 字典
,yi 表示第 i 個圖像塊,N 為腫瘤區域所包含的圖像塊的個數。分別選擇多個 PCNSL 圖像塊集合和多個 GBM 圖像塊集合,并采用文獻中 K-奇異值分解(K-singular value decomposition,KSVD)方法分別訓練 PCNSL 字典
 和 GBM 字典
和 GBM 字典
 [12],將訓練字典組合得到紋理特征提取字典
[12],將訓練字典組合得到紋理特征提取字典

 。圖 3 展示了訓練的 PCNSL 字典和 GBM 字典。
。圖 3 展示了訓練的 PCNSL 字典和 GBM 字典。
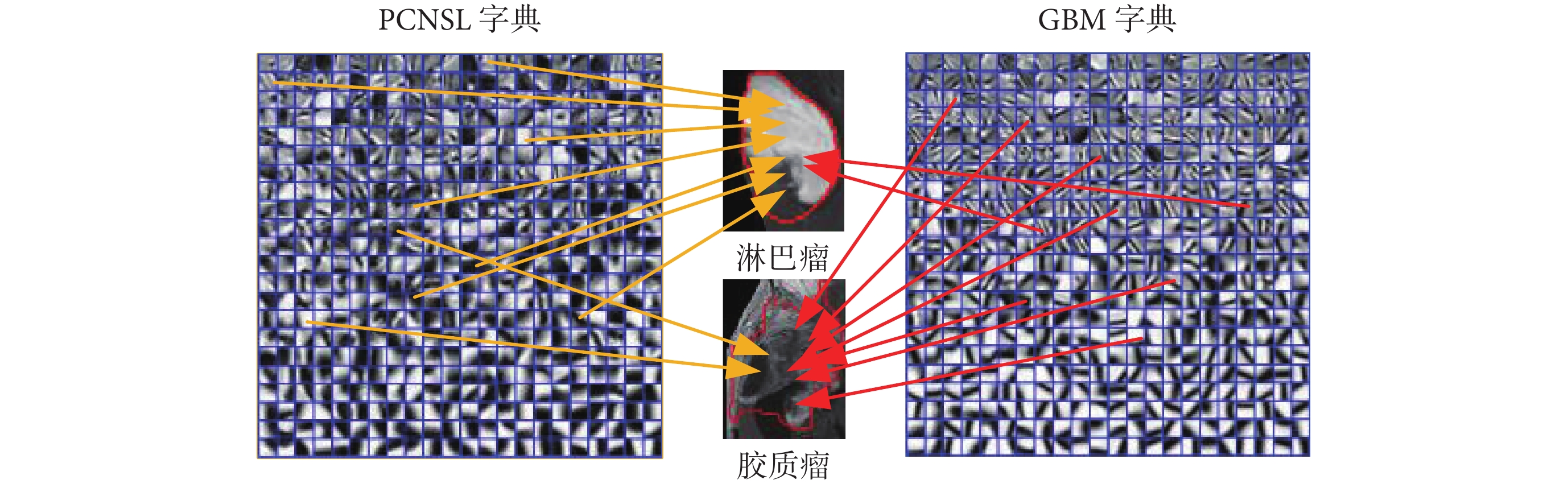
字典中的原子,即圖 3 中藍線圍成的小正方形區域,表示著圖像的微小紋理細節,而腫瘤圖像是由這些小細節疊加構成。對比兩個字典可以明顯看出組成淋巴瘤圖像的紋理細節和組成膠質瘤圖像的紋理細節差距較大,因此一個直觀的鑒別 PCNSL 和 GBM 的想法是利用字典中原子(即紋理)來表達待檢測圖像,比較構成待檢測圖像所使用原子的統計差異來鑒別腫瘤,即利用字典對待檢測腫瘤圖像進行稀疏表示,然后將稀疏表示系數(構成腫瘤區域所使用的紋理信息的描述)作為對應特征輸入分類器來判別腫瘤。
對于待檢測腫瘤區域,利用字典 D 對其對應的圖像塊集合 Y 進行稀疏表示:
 |
其中
 ,
,
 為 yi 對應的稀疏表示系數,
為 yi 對應的稀疏表示系數,
 為稀疏約束函數,λ 為權重控制參數。由于不同腫瘤抽取圖像塊個數不同,得到對應的 Λ 大小不同,不利于后續設計分類器,因此對圖像塊集合中圖像塊單獨稀疏表示,并將稀疏表示系數的絕對值平均作為腫瘤的紋理特征,即:
為稀疏約束函數,λ 為權重控制參數。由于不同腫瘤抽取圖像塊個數不同,得到對應的 Λ 大小不同,不利于后續設計分類器,因此對圖像塊集合中圖像塊單獨稀疏表示,并將稀疏表示系數的絕對值平均作為腫瘤的紋理特征,即:
 |
其中
 為最終獲得的腫瘤紋理特征,正交匹配追蹤(orthogonal matching pursuit,OMP)算法可快速有效地求解式(2)中的稀疏表示模型。
為最終獲得的腫瘤紋理特征,正交匹配追蹤(orthogonal matching pursuit,OMP)算法可快速有效地求解式(2)中的稀疏表示模型。
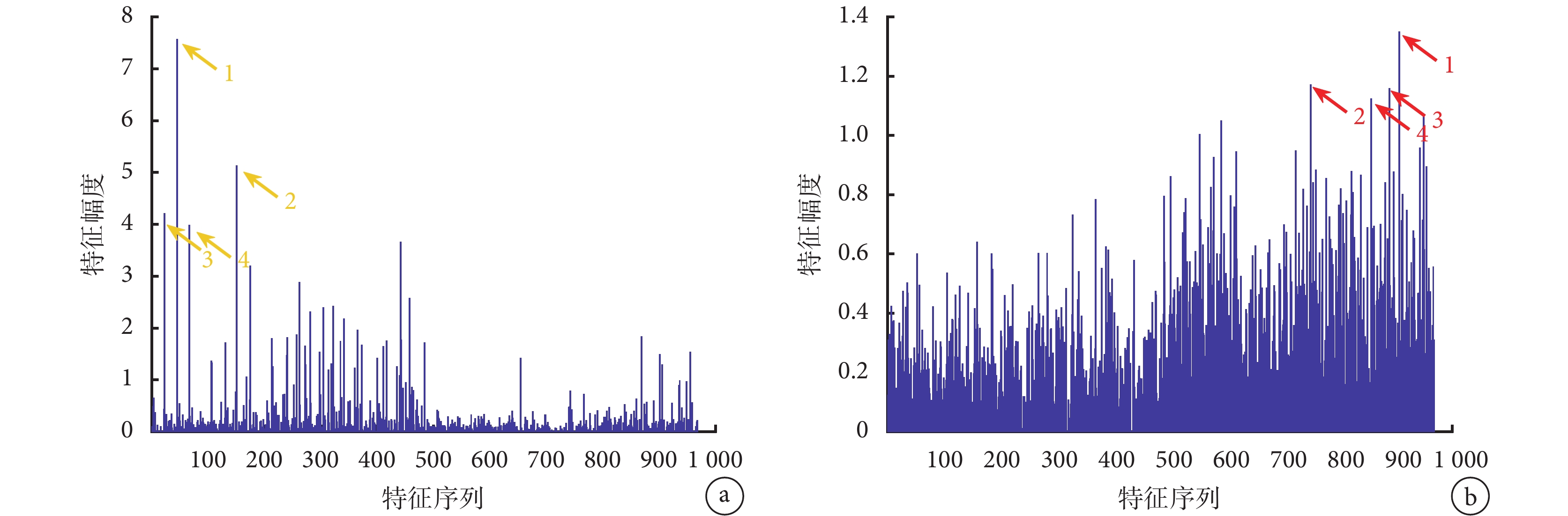
圖 4a 和圖 4b 分別為 PCNSL 和 GBM 的紋理特征,可見二者差異明顯,PCNSL 特征的前 K 個特征系數(1~484,PCNSL 字典對應系數)總體大于后面 K 個特征系數(485~968,GBM 字典對應系數),而 GBM 特征情況相反。即如圖 3 所示,PCNSL 圖像更多地被 PCNSL 字典中紋理所表示,而 GBM 圖像更多地被 GBM 字典中原子所表示。此外,如圖 4a 所示,PCNSL 用到頻率最高的 4 個紋理信息(黃色箭頭指向的特征系數),來自于 PCNSL 字典;而如圖 4b 所示,GBM 用到最多的 4 個紋理信息(紅色箭頭指向的特征系數),來自于 GBM 字典,可以看出二者存在明顯差異。因此構成兩種腫瘤紋理信息的統計分布差異,即式(2)獲得的紋理特征,對腫瘤的鑒別有關鍵意義。
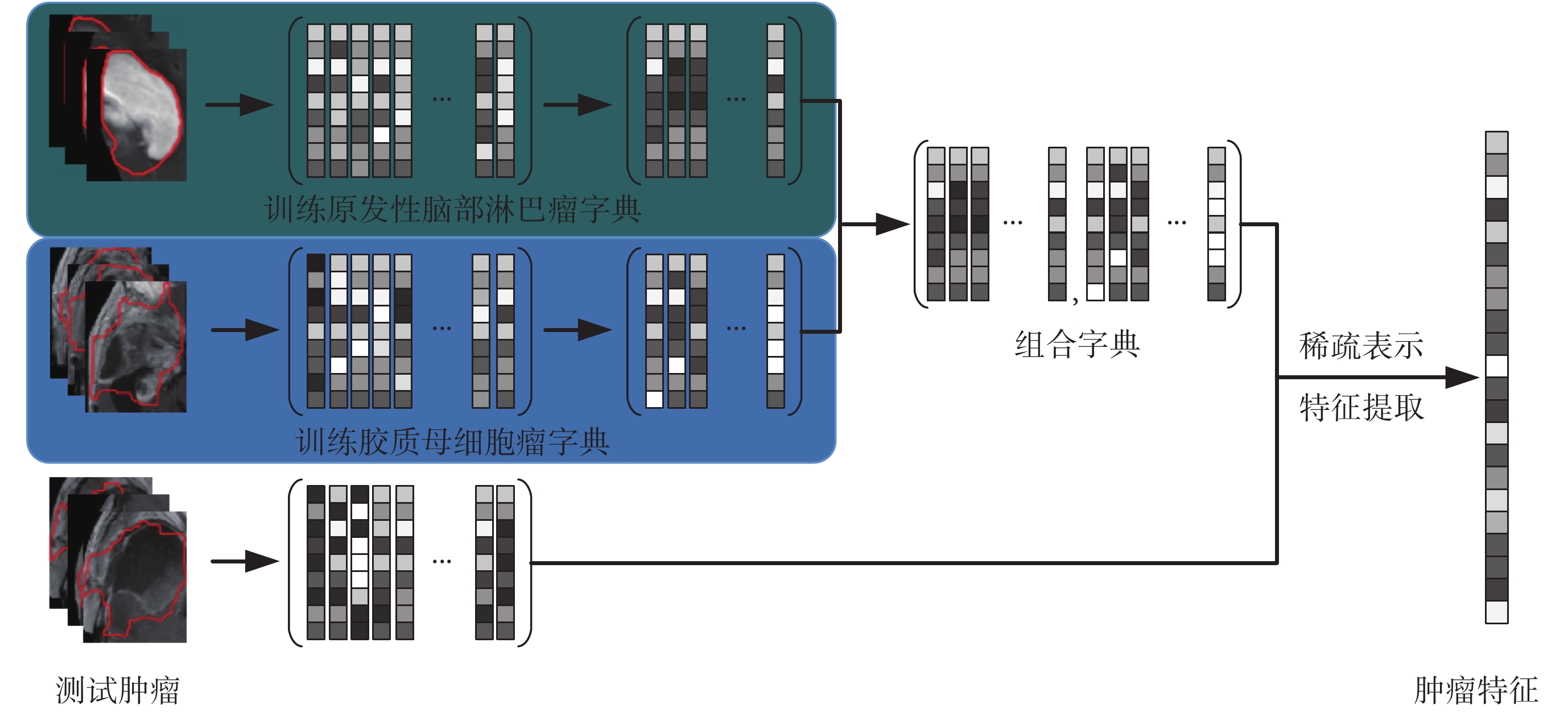 圖2
基于稀疏表示的腫瘤紋理特征提取
Figure2.
Sparse representation-based texture feature extraction
圖2
基于稀疏表示的腫瘤紋理特征提取
Figure2.
Sparse representation-based texture feature extraction
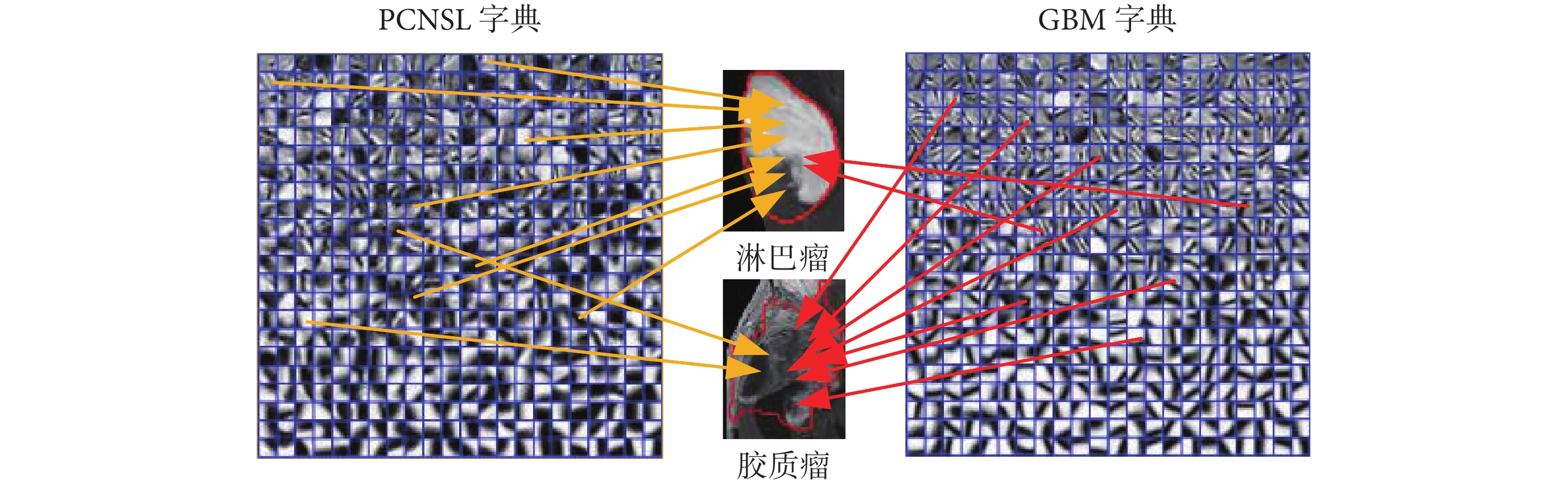 圖3
字典訓練結果
Figure3.
The learned dictionary
圖3
字典訓練結果
Figure3.
The learned dictionary
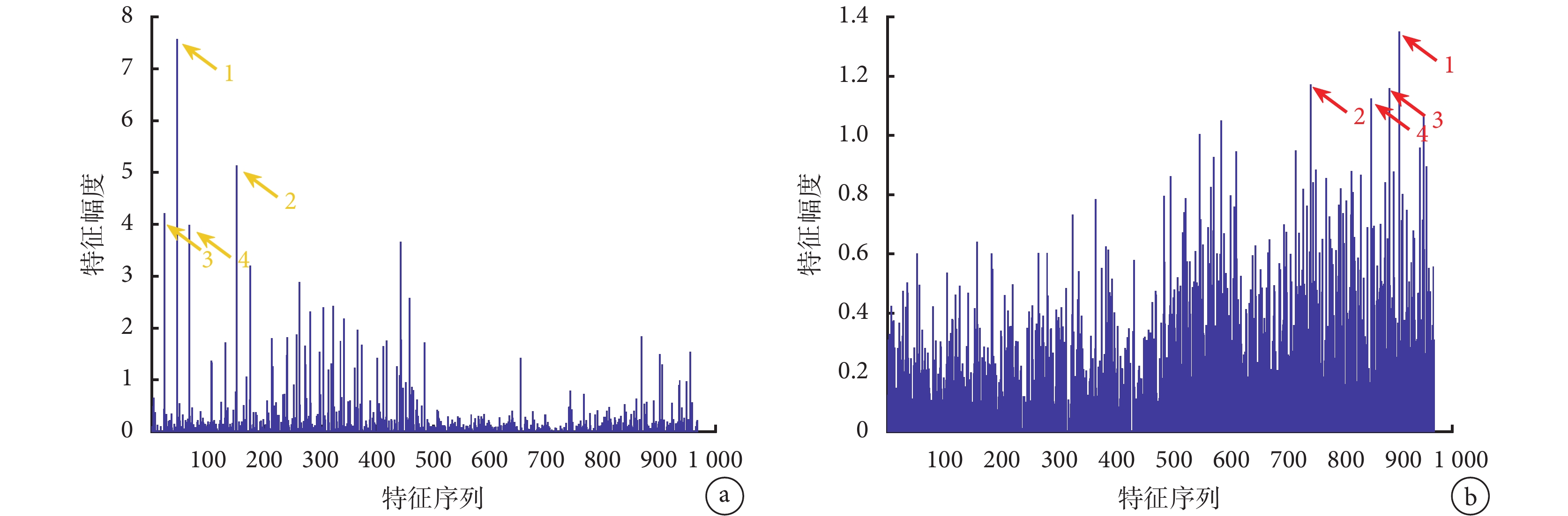 圖4
提取的腫瘤紋理特征
圖4
提取的腫瘤紋理特征
a. PCNSL 紋理特征;b. GBM 紋理特征
Figure4. The extracted texture featurea. PCNSL texture feature; b. GBM texture feature
2 基于稀疏表示的特征選擇
利用式(2)提取的紋理特征中存在大量的冗余信息,這些冗余特征不僅增加了后續分類識別的計算量,還可能影響識別精度,因此建立稀疏表示特征選擇模型選擇少量高分辨力特征:
 |
其中
 是訓練樣本標簽,m 為訓練樣本個數,
是訓練樣本標簽,m 為訓練樣本個數,
 為訓練樣本特征集合,η 為稀疏表示控制參數,稀疏表示系數 w 中元素絕對值對應特征的重要性。當求得 w,通過簡單的閾值比較可選擇出關鍵特征。
為訓練樣本特征集合,η 為稀疏表示控制參數,稀疏表示系數 w 中元素絕對值對應特征的重要性。當求得 w,通過簡單的閾值比較可選擇出關鍵特征。
值得注意的是,在實際特征選擇時,樣本個數 m 會對選擇結果產生重要影響,一方面當
 時,求解式(3)可獲得有效的稀疏系數解,但此時由于樣本個數太少,一次迭代求解獲得的稀疏表示系數不能很好地反映一些特征的重要性;另一方面,當 m > 2 K 時,式(3)不再適合此時的超定問題。此外,對于式(3)特征選擇,特征選擇的性能應隨樣本數量的增加而增加,因此本文構建如下迭代的特征選擇算法:
時,求解式(3)可獲得有效的稀疏系數解,但此時由于樣本個數太少,一次迭代求解獲得的稀疏表示系數不能很好地反映一些特征的重要性;另一方面,當 m > 2 K 時,式(3)不再適合此時的超定問題。此外,對于式(3)特征選擇,特征選擇的性能應隨樣本數量的增加而增加,因此本文構建如下迭代的特征選擇算法:
輸入:樣本標簽 l,樣本特征集合 F;
初始化:小正整數 ε,最大迭代次數 K0,隨機選擇樣本個數 M,
 ,k = 1;
,k = 1;
循環:
① 隨機選擇 M 個樣本,對應樣本標簽為 lk,樣本特征集為 Fk;
② 求解
 ;
;
③ 更新
 ;
;
④ 若
 或 k = K0 結束循環,否則執行步驟①。
或 k = K0 結束循環,否則執行步驟①。
輸出:

迭代稀疏表示特征選擇方法有效地解決了特征選擇中樣本個數的問題。每次迭代從樣本集中隨機選擇
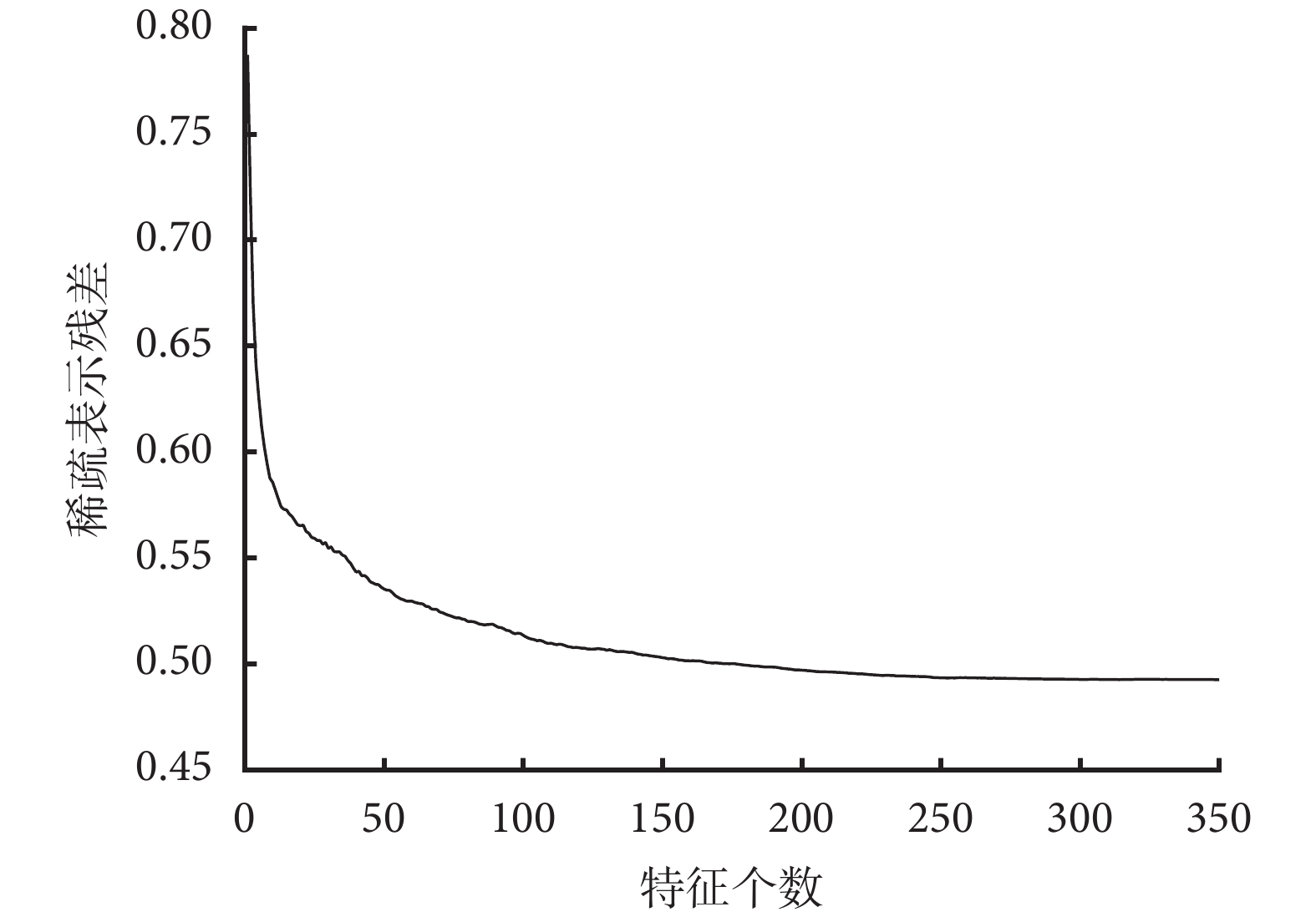
 個樣本進行稀疏表示,確保了式(3)中稀疏解的有效性。此外,多次隨機選擇樣本集中數據進行稀疏,并將獲得的系數平均,不僅利用了所有樣本數據的信息,還增加了稀疏解的魯棒性,保障了選擇特征的有效性。圖 5 為稀疏表示對特征排序后,特征對樣本標簽表示的殘差隨樣本個數增加的變化情況,可以看出在提取的特征中,僅前 200 個特征對標簽的表示作用比較明顯。
個樣本進行稀疏表示,確保了式(3)中稀疏解的有效性。此外,多次隨機選擇樣本集中數據進行稀疏,并將獲得的系數平均,不僅利用了所有樣本數據的信息,還增加了稀疏解的魯棒性,保障了選擇特征的有效性。圖 5 為稀疏表示對特征排序后,特征對樣本標簽表示的殘差隨樣本個數增加的變化情況,可以看出在提取的特征中,僅前 200 個特征對標簽的表示作用比較明顯。
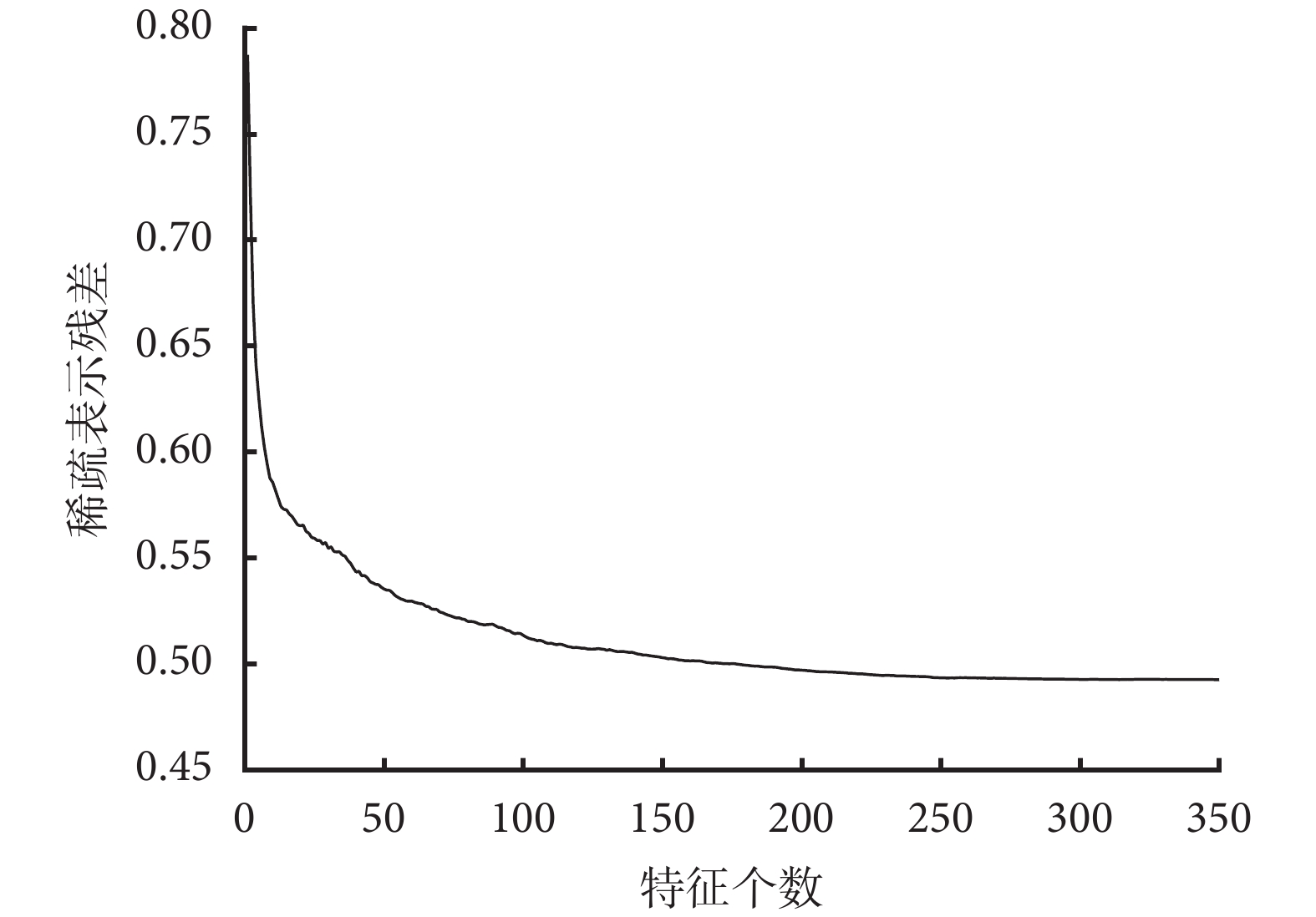 圖5
殘差收斂曲線
Figure5.
Iterative convergence curves of residual
圖5
殘差收斂曲線
Figure5.
Iterative convergence curves of residual
事實上,稀疏表示特征選擇的實質是選擇與樣本標簽相關性高的少數特征,并且當利用 OMP 算法求解式(3)時,正交化過程消除了所選特征間的冗余性,因此最終選擇的特征滿足最大相關最小冗余特性。
3 SRC
對篩選后的特征,利用 SRC 方法[13]進行分類驗證。稀疏表示模型可表示為:
 |
其中 f 表示待測腫瘤特征;
 ,
,

 為訓練樣本中 PCNSL 特征集合,m1 為 PCNSL 個數,
為訓練樣本中 PCNSL 特征集合,m1 為 PCNSL 個數,
 為訓練樣本中 GBM 特征集合,m2 為 GBM 個數;γ 為稀疏表示控制參數。當獲得稀疏表示系數 β 后,計算殘差:
為訓練樣本中 GBM 特征集合,m2 為 GBM 個數;γ 為稀疏表示控制參數。當獲得稀疏表示系數 β 后,計算殘差:
 |
 表示選擇第 c 類特征對應的系數。最終待測樣本類別
表示選擇第 c 類特征對應的系數。最終待測樣本類別
 。
。
4 實驗結果與討論
為驗證提出方法的有效性,對 55 例患者(PCNSL 27 例,GBM 28 例)進行十折驗證。本實驗所使用 T1 增強 MRI 圖像以及臨床資料由中山大學附屬腫瘤醫院神經外科提供,并且本實驗已被大學倫理委員會所允許,同時涉及的患者也知悉并允許數據的使用。患者詳細信息匯總見表 1。
每次選擇 90% 的訓練樣本特征作為字典 F,剩下樣本特征進行測試。本文方法中,圖像塊大小為 11*11,抽取圖像塊滑動距離為 5*5,訓練 PCNSL 和 GBM 字典大小均為 121*484,因此字典 D 大小為 121*968,對應提取的特征為 968 個。特征選擇過程中 ε、K0 和 M 分別設置為:ε = 0.000 1,K0 = 300 和 M = 5,最終選擇 66 個特征用于分類,SRC 中系數采用 lp = 0.5 范數約束。計算分類結果的準確率(accuracy,Acc)、敏感度(sensitivity,Sen)、特異性(specificity,Spe)來評價分類性能。其中敏感度表示被正確判別的 PCNSL 例數與 PCNSL 總例數的比值,特異性表示被正確判別的 GBM 例數與 GBM 總例數的比值。選擇支持向量機(support vector machine,SVM)方法作為分類比較[16],并將本文方法結果與近期利用先進 MRI 參數提取鑒別的方法進行比較,各方法的鑒別結果見表 2。
Ahn 等[6]分析了 25 例 PCNSL 與 62 例 GBM 的 DWI 圖像,提取表觀擴散系數(apparent diffusion coefficients,ADC)區分這兩種腫瘤,結果如表 2 所示,準確率、敏感度和特異性分別為 87.36%、87.10% 和 88.00%。Xing 等[4]分析了 20 例 PCNSL 與 26 例 GBM 的 DSC-PWI 圖像,提取相對腦血容量(relative cerebral blood volume,rCBV)對腫瘤進行鑒別,準確率、敏感度和特異性分別為 93.48%、96.15% 和 90.00%。雖然這兩種方法取得了良好的效果,但其本身均具有一定的局限性。一方面,在實際臨床應用中,這些先進的 MRI 成像,患者常規檢查時不經常使用;另一方面,一些鑒別參數的提取與 ROI 區域的選擇十分相關,實際鑒別的魯棒性不高,實驗結果的可重復性較差[17]。傳統 MRI 圖像上 PCNSL 與 GBM 的影像形態學表現存在許多差異,因此本文將這些差異轉化為構建腫瘤區域所使用紋理細節的統計情況差異,并建立稀疏表示特征選擇方法選擇一些關鍵細節差異來鑒別腫瘤。表 2 列出了兩種分類器分類的結果,其中稀疏表示方法的分類正確率、敏感度、和特異性分別達到了 96.36%、96.30% 和 96.43%。對比表中其他方法結果可見,本文方法腫瘤鑒別準確性較高,并且由于本文方法是通過算法自動提取腫瘤特征,在實際應用中具有較強的魯棒性。
受影像組學思想啟發,本文通過提取兩種腫瘤所獨有的深層圖像特征來提高腫瘤鑒別的性能。對信號的稀疏約束和稀疏表示能夠有效提取信號本質特征,因此本文利用稀疏表示字典訓練來學習兩種腫瘤獨有的紋理結構。圖 3 展示了訓練的 PCNSL 紋理基底和 GBM 紋理基底,可以直觀地看出組成這兩種腫瘤的紋理信息間的差異,即 PCNSL 圖像包含許多無規則的深層紋理結構,而 GBM 包含許多結構性較強的深層紋理結構。當找到兩種腫瘤的差異性特征后,本文設計了一種基于稀疏表示的方法來具體量化這些特征,即利用訓練的紋理基底的組合來表示腫瘤圖像。由于兩種腫瘤主要由對應的紋理基底來表示,因此如圖 4 所示,兩種腫瘤的表示系數會出現很大差異。將這些差異性的系數作為腫瘤特征進行分類,有利于獲得更高精度的鑒別結果。由于兩種腫瘤中存在一些相似的紋理結構,對應的表示系數中會出現相近的值,這些系數作為特征進行分類,不僅不能幫助提升分類效果還增加了計算量,因此本文利用稀疏表示方法對提取的特征進行篩選,最終選擇 66 個高分辨力特征進行后續分類。對于相同的特征,表 2 中 SVM 分類器分類結果差于 SRC 結果的原因包括:一方面,特征選擇時采用基于稀疏表示的特征進行選擇,其結果會更有利于 SRC 的分類;另一方面,十折法測試時,本實驗中訓練樣本數量不充分導致 SVM 分類器在訓練階段產生了過度擬合現象。
5 結論
針對 PCNSL 和 GBM 的鑒別,本文提出一套基于稀疏表示體系的腫瘤自動鑒別方法。對于 T1 增強 MRI 圖像,首先利用卷積神經網絡分割方法分割腫瘤區域。由于 PCNSL 和 GBM 腫瘤區域紋理信息存在差異,因此利用稀疏表示方法提取腫瘤紋理信息來鑒別腫瘤。此外,為進一步提高腫瘤鑒別精度,本文建立了迭代稀疏表示特征選擇方法,有效選擇了少數高區分力紋理特征,并最終利用 SRC 對其進行鑒別。實驗結果表明,本文所提出方法能夠有效地鑒別 PCNSL 和 GBM。
傳統 MRI 圖像包含 T1 加權、T1 增強、T2 加權和 T2 FLAIR 四種模態圖像,不同模態圖像體現腫瘤不同特征,因此下一步工作將考慮結合 MRI 圖像多模態信息進行分類,從而進一步提高腫瘤鑒別精度。
引言
臨床上原發性腦部淋巴瘤(primary central nervous system lymphoma,PCNSL)和膠質母細胞瘤(glioblastoma,GBM)的治療方案存在較大差異。PCNSL 常采用化療和全腦放射治療,而 GBM 通常采用外科手術切除的方法治療,因此治療前對 PCNSL 和 GBM 的準確鑒別,能指導臨床醫師制定合理的治療方案,具有重要的臨床價值[1-2]。然而,由于這兩種腫瘤在一些傳統模態核磁共振成像(magnetic resonance imaging,MRI)圖像,如 T1 加權、T1 增強、T2 加權和 T2 FLAIR 上呈現許多相似的特性,因此準確鑒別二者十分困難[3]。近年來,一些研究提出利用先進的 MRI 方式如擴散加權成像(diffusion-weighted imaging,DWI)和動態磁化率增強灌注成像(dynamic susceptibility contrast-enhanced perfusion-weighted imaging,DSC-PWI)等來鑒別這兩種腫瘤[4-5],但這些方法或多或少還存在一些問題。一方面這些模態的成像還主要用于實驗研究,臨床上常規檢查很少使用;另一方面這些方法本身也存在一些鑒別參數提取的問題[6-7]。
在過去十年中,隨著模式識別工具的發展和數據集的擴大,利用工程上的圖像處理技術進行醫學疾病的診斷研究成為新的趨勢。這些進步促進了量化特征高通量抽取過程的發展,并致使圖像向高維數據特征轉化以及隨后利用這些數據進行決策支持,這種做法被稱為影像組學[8]。影像組學的高維數據特征與患者的其他數據結合能夠進一步提高診斷和預后的準確性。2014 年《自然》期刊上發表文章提出利用圖像的高通量特征進行腫瘤亞型鑒別[9],隨后一些研究者相繼提出利用高通量特征進行腫瘤分子標記物的預測[10]和腫瘤分類等[11],并取得了更好的效果。這些方法在疾病預測診斷時,不僅提取醫生肉眼可直接觀察的特征進行分類預測,如形狀、體素、灰度等,還提取了一些難以直接觀測但對分類預測至關重要的紋理特征信息。
稀疏表示理論認為自然信號可由字典中少數原子線性組合而成,這些原子包含了信號的最本質特征[12]。稀疏表示在信號表達分析方面的優勢使其在數據壓縮、信號降噪、信號分離、圖像恢復和分類識別等領域取得廣泛應用[12-14]。利用字典對含噪圖像或信號進行稀疏表示,然后將表示系數重構可得到降噪后的圖像或信號[12]。在分類識別問題中,利用已知標簽特征對測試樣本特征進行表示,然后通過殘差比較,可準確預測待測樣本類別[13];將圖像像素點的鄰域像素值作為該點特征,稀疏表示分類(sparse representation classification,SRC)可被進一步用于圖像分割。Li 等[14]利用樣本特征對樣本標簽稀疏表示,并根據獲得的稀疏表示系數對樣本特征進行重要性排序,有效選擇了精神分裂癥的生物標記特征。稀疏表示對圖像及數據的表達分析優勢,使其成為影像組學中圖像分割、特征提取、特征選擇以及分類判別的重要工具。
既往臨床文獻報道,PCNSL 與 GBM 的影像形態學表現存在許多差異,如囊變壞死、邊緣、瘤周水腫和強化方式等。這些差異反映在圖像上為紋理細節信息的差異,因此受影像組學思想啟發,結合稀疏表示理論基礎,本文提出一種基于稀疏表示紋理特征提取、特征選擇、分類識別的 PCNSL 和 GBM 鑒別方法。為提取腫瘤區域紋理特征,首先訓練紋理特征字典,然后利用該字典對測試樣本腫瘤區域抽取的圖像塊集合進行稀疏表示,最后平均所有圖像塊的稀疏表示系數得到每個腫瘤樣本對應的紋理特征。由于直接提取的紋理特征具有一定冗余性,因此建立迭代稀疏表示方法選擇少數高穩定性和高分辨力的特征,并且迭代求解的過程有效克服了特征選擇時訓練樣本不足和訓練樣本信息利用不徹底的問題。最后,利用 SRC 方法對選擇后的腫瘤特征進行分類鑒別。
1 基于稀疏表示的腫瘤紋理特征提取
1.1 圖像分割
腫瘤區域的分割是后續特征提取和分類識別的前提和基礎。為獲得精確的分割腫瘤區域,首先對 T1 增強 MRI 圖像進行腦殼剝離預處理,然后利用文獻[15]的方法訓練卷積神經網絡分割 MRI 圖像中的腫瘤區域,該方法在 2015 年與 2016 年的 Brain Tumor Segmentation Challenge 中獲得了良好的分割效果。
圖 1 為膠質瘤患者(60 歲,男性)T1 增強圖像利用卷積神經網絡分割的結果,第一行為剝去腦殼原圖,紅色封閉曲線內部為腫瘤部分,第二行為腫瘤區域對應標簽。此外,對于一些腫瘤區域較小的圖像,先由經驗豐富的醫生畫定感興趣區域(region of interest,ROI),然后再利用卷積神經網絡進行分割,以保證腫瘤分割的精度。
圖1
T1 增強圖像卷積神經網絡分割結果
Figure1.
Segmentation results by convolutional neural networks on T1 contrast image
1.2 紋理特征提取
由于不同患者腫瘤大小形狀存在較大差異,因此采用基于圖像塊的處理方式提取腫瘤紋理特征。圖 2 展示了基于稀疏表示圖像紋理特征提取的流程圖。首先提取腫瘤區域圖像塊集合
,
,
,yi 表示第 i 個圖像塊,N 為腫瘤區域所包含的圖像塊的個數。分別選擇多個 PCNSL 圖像塊集合和多個 GBM 圖像塊集合,并采用文獻中 K-奇異值分解(K-singular value decomposition,KSVD)方法分別訓練 PCNSL 字典
和 GBM 字典
[12],將訓練字典組合得到紋理特征提取字典
。圖 3 展示了訓練的 PCNSL 字典和 GBM 字典。
字典中的原子,即圖 3 中藍線圍成的小正方形區域,表示著圖像的微小紋理細節,而腫瘤圖像是由這些小細節疊加構成。對比兩個字典可以明顯看出組成淋巴瘤圖像的紋理細節和組成膠質瘤圖像的紋理細節差距較大,因此一個直觀的鑒別 PCNSL 和 GBM 的想法是利用字典中原子(即紋理)來表達待檢測圖像,比較構成待檢測圖像所使用原子的統計差異來鑒別腫瘤,即利用字典對待檢測腫瘤圖像進行稀疏表示,然后將稀疏表示系數(構成腫瘤區域所使用的紋理信息的描述)作為對應特征輸入分類器來判別腫瘤。
對于待檢測腫瘤區域,利用字典 D 對其對應的圖像塊集合 Y 進行稀疏表示:
|
其中
,
為 yi 對應的稀疏表示系數,
為稀疏約束函數,λ 為權重控制參數。由于不同腫瘤抽取圖像塊個數不同,得到對應的 Λ 大小不同,不利于后續設計分類器,因此對圖像塊集合中圖像塊單獨稀疏表示,并將稀疏表示系數的絕對值平均作為腫瘤的紋理特征,即:
|
其中
為最終獲得的腫瘤紋理特征,正交匹配追蹤(orthogonal matching pursuit,OMP)算法可快速有效地求解式(2)中的稀疏表示模型。
圖 4a 和圖 4b 分別為 PCNSL 和 GBM 的紋理特征,可見二者差異明顯,PCNSL 特征的前 K 個特征系數(1~484,PCNSL 字典對應系數)總體大于后面 K 個特征系數(485~968,GBM 字典對應系數),而 GBM 特征情況相反。即如圖 3 所示,PCNSL 圖像更多地被 PCNSL 字典中紋理所表示,而 GBM 圖像更多地被 GBM 字典中原子所表示。此外,如圖 4a 所示,PCNSL 用到頻率最高的 4 個紋理信息(黃色箭頭指向的特征系數),來自于 PCNSL 字典;而如圖 4b 所示,GBM 用到最多的 4 個紋理信息(紅色箭頭指向的特征系數),來自于 GBM 字典,可以看出二者存在明顯差異。因此構成兩種腫瘤紋理信息的統計分布差異,即式(2)獲得的紋理特征,對腫瘤的鑒別有關鍵意義。
圖2
基于稀疏表示的腫瘤紋理特征提取
Figure2.
Sparse representation-based texture feature extraction
圖3
字典訓練結果
Figure3.
The learned dictionary
圖4
提取的腫瘤紋理特征
a. PCNSL 紋理特征;b. GBM 紋理特征
Figure4. The extracted texture featurea. PCNSL texture feature; b. GBM texture feature
2 基于稀疏表示的特征選擇
利用式(2)提取的紋理特征中存在大量的冗余信息,這些冗余特征不僅增加了后續分類識別的計算量,還可能影響識別精度,因此建立稀疏表示特征選擇模型選擇少量高分辨力特征:
|
其中
是訓練樣本標簽,m 為訓練樣本個數,
為訓練樣本特征集合,η 為稀疏表示控制參數,稀疏表示系數 w 中元素絕對值對應特征的重要性。當求得 w,通過簡單的閾值比較可選擇出關鍵特征。
值得注意的是,在實際特征選擇時,樣本個數 m 會對選擇結果產生重要影響,一方面當
時,求解式(3)可獲得有效的稀疏系數解,但此時由于樣本個數太少,一次迭代求解獲得的稀疏表示系數不能很好地反映一些特征的重要性;另一方面,當 m > 2 K 時,式(3)不再適合此時的超定問題。此外,對于式(3)特征選擇,特征選擇的性能應隨樣本數量的增加而增加,因此本文構建如下迭代的特征選擇算法:
輸入:樣本標簽 l,樣本特征集合 F;
初始化:小正整數 ε,最大迭代次數 K0,隨機選擇樣本個數 M,
,k = 1;
循環:
① 隨機選擇 M 個樣本,對應樣本標簽為 lk,樣本特征集為 Fk;
② 求解
;
③ 更新
;
④ 若
或 k = K0 結束循環,否則執行步驟①。
輸出:
迭代稀疏表示特征選擇方法有效地解決了特征選擇中樣本個數的問題。每次迭代從樣本集中隨機選擇
個樣本進行稀疏表示,確保了式(3)中稀疏解的有效性。此外,多次隨機選擇樣本集中數據進行稀疏,并將獲得的系數平均,不僅利用了所有樣本數據的信息,還增加了稀疏解的魯棒性,保障了選擇特征的有效性。圖 5 為稀疏表示對特征排序后,特征對樣本標簽表示的殘差隨樣本個數增加的變化情況,可以看出在提取的特征中,僅前 200 個特征對標簽的表示作用比較明顯。
圖5
殘差收斂曲線
Figure5.
Iterative convergence curves of residual
事實上,稀疏表示特征選擇的實質是選擇與樣本標簽相關性高的少數特征,并且當利用 OMP 算法求解式(3)時,正交化過程消除了所選特征間的冗余性,因此最終選擇的特征滿足最大相關最小冗余特性。
3 SRC
對篩選后的特征,利用 SRC 方法[13]進行分類驗證。稀疏表示模型可表示為:
|
其中 f 表示待測腫瘤特征;
,
為訓練樣本中 PCNSL 特征集合,m1 為 PCNSL 個數,
為訓練樣本中 GBM 特征集合,m2 為 GBM 個數;γ 為稀疏表示控制參數。當獲得稀疏表示系數 β 后,計算殘差:
|
表示選擇第 c 類特征對應的系數。最終待測樣本類別
。
4 實驗結果與討論
為驗證提出方法的有效性,對 55 例患者(PCNSL 27 例,GBM 28 例)進行十折驗證。本實驗所使用 T1 增強 MRI 圖像以及臨床資料由中山大學附屬腫瘤醫院神經外科提供,并且本實驗已被大學倫理委員會所允許,同時涉及的患者也知悉并允許數據的使用。患者詳細信息匯總見表 1。
每次選擇 90% 的訓練樣本特征作為字典 F,剩下樣本特征進行測試。本文方法中,圖像塊大小為 11*11,抽取圖像塊滑動距離為 5*5,訓練 PCNSL 和 GBM 字典大小均為 121*484,因此字典 D 大小為 121*968,對應提取的特征為 968 個。特征選擇過程中 ε、K0 和 M 分別設置為:ε = 0.000 1,K0 = 300 和 M = 5,最終選擇 66 個特征用于分類,SRC 中系數采用 lp = 0.5 范數約束。計算分類結果的準確率(accuracy,Acc)、敏感度(sensitivity,Sen)、特異性(specificity,Spe)來評價分類性能。其中敏感度表示被正確判別的 PCNSL 例數與 PCNSL 總例數的比值,特異性表示被正確判別的 GBM 例數與 GBM 總例數的比值。選擇支持向量機(support vector machine,SVM)方法作為分類比較[16],并將本文方法結果與近期利用先進 MRI 參數提取鑒別的方法進行比較,各方法的鑒別結果見表 2。
Ahn 等[6]分析了 25 例 PCNSL 與 62 例 GBM 的 DWI 圖像,提取表觀擴散系數(apparent diffusion coefficients,ADC)區分這兩種腫瘤,結果如表 2 所示,準確率、敏感度和特異性分別為 87.36%、87.10% 和 88.00%。Xing 等[4]分析了 20 例 PCNSL 與 26 例 GBM 的 DSC-PWI 圖像,提取相對腦血容量(relative cerebral blood volume,rCBV)對腫瘤進行鑒別,準確率、敏感度和特異性分別為 93.48%、96.15% 和 90.00%。雖然這兩種方法取得了良好的效果,但其本身均具有一定的局限性。一方面,在實際臨床應用中,這些先進的 MRI 成像,患者常規檢查時不經常使用;另一方面,一些鑒別參數的提取與 ROI 區域的選擇十分相關,實際鑒別的魯棒性不高,實驗結果的可重復性較差[17]。傳統 MRI 圖像上 PCNSL 與 GBM 的影像形態學表現存在許多差異,因此本文將這些差異轉化為構建腫瘤區域所使用紋理細節的統計情況差異,并建立稀疏表示特征選擇方法選擇一些關鍵細節差異來鑒別腫瘤。表 2 列出了兩種分類器分類的結果,其中稀疏表示方法的分類正確率、敏感度、和特異性分別達到了 96.36%、96.30% 和 96.43%。對比表中其他方法結果可見,本文方法腫瘤鑒別準確性較高,并且由于本文方法是通過算法自動提取腫瘤特征,在實際應用中具有較強的魯棒性。
受影像組學思想啟發,本文通過提取兩種腫瘤所獨有的深層圖像特征來提高腫瘤鑒別的性能。對信號的稀疏約束和稀疏表示能夠有效提取信號本質特征,因此本文利用稀疏表示字典訓練來學習兩種腫瘤獨有的紋理結構。圖 3 展示了訓練的 PCNSL 紋理基底和 GBM 紋理基底,可以直觀地看出組成這兩種腫瘤的紋理信息間的差異,即 PCNSL 圖像包含許多無規則的深層紋理結構,而 GBM 包含許多結構性較強的深層紋理結構。當找到兩種腫瘤的差異性特征后,本文設計了一種基于稀疏表示的方法來具體量化這些特征,即利用訓練的紋理基底的組合來表示腫瘤圖像。由于兩種腫瘤主要由對應的紋理基底來表示,因此如圖 4 所示,兩種腫瘤的表示系數會出現很大差異。將這些差異性的系數作為腫瘤特征進行分類,有利于獲得更高精度的鑒別結果。由于兩種腫瘤中存在一些相似的紋理結構,對應的表示系數中會出現相近的值,這些系數作為特征進行分類,不僅不能幫助提升分類效果還增加了計算量,因此本文利用稀疏表示方法對提取的特征進行篩選,最終選擇 66 個高分辨力特征進行后續分類。對于相同的特征,表 2 中 SVM 分類器分類結果差于 SRC 結果的原因包括:一方面,特征選擇時采用基于稀疏表示的特征進行選擇,其結果會更有利于 SRC 的分類;另一方面,十折法測試時,本實驗中訓練樣本數量不充分導致 SVM 分類器在訓練階段產生了過度擬合現象。
5 結論
針對 PCNSL 和 GBM 的鑒別,本文提出一套基于稀疏表示體系的腫瘤自動鑒別方法。對于 T1 增強 MRI 圖像,首先利用卷積神經網絡分割方法分割腫瘤區域。由于 PCNSL 和 GBM 腫瘤區域紋理信息存在差異,因此利用稀疏表示方法提取腫瘤紋理信息來鑒別腫瘤。此外,為進一步提高腫瘤鑒別精度,本文建立了迭代稀疏表示特征選擇方法,有效選擇了少數高區分力紋理特征,并最終利用 SRC 對其進行鑒別。實驗結果表明,本文所提出方法能夠有效地鑒別 PCNSL 和 GBM。
傳統 MRI 圖像包含 T1 加權、T1 增強、T2 加權和 T2 FLAIR 四種模態圖像,不同模態圖像體現腫瘤不同特征,因此下一步工作將考慮結合 MRI 圖像多模態信息進行分類,從而進一步提高腫瘤鑒別精度。