糖尿病和高血壓等疾病會引起視網膜血管的形狀發生變化,眼底圖像血管分割是疾病定量分析過程中的關鍵步驟,對臨床疾病的分析和診斷具有指導意義。本文提出一種結合深度可分離卷積與通道加權的全卷積神經網絡(FCN)視網膜圖像血管分割方法。首先,對眼底圖像的綠色通道進行 CLAHE 及 Gamma 校正以增強對比度;然后,為了適應網絡訓練,對增強后的圖像進行分塊以擴充數據;最后,以深度可分離卷積代替標準的卷積方式以增加網絡寬度,同時引入通道加權模塊,以學習的方式顯式地建模特征通道的依賴關系,提高特征的可分辨性。將二者結合應用于 FCN 網絡中,以專家手動標識結果作為監督在 DRIVE 數據庫進行實驗。結果表明,本文方法在 DRIVE 庫的分割準確性能夠達到 0.963 0,AUC 達到 0.983 1,在 STARE 庫的分割準確性可以達到 0.962 0,AUC 達到 0.983 0。在一定程度上,本文方法具有更好的特征分辨性,分割性能較好。
引用本文: 耿磊, 邱玲, 吳駿, 肖志濤, 張芳. 結合深度可分離卷積與通道加權的全卷積神經網絡視網膜圖像血管分割. 生物醫學工程學雜志, 2019, 36(1): 107-115. doi: 10.7507/1001-5515.201801054 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
糖尿病視網膜病變、動脈硬化、白血病等疾病都會對眼底血管產生影響[1-3],導致其長度、寬度、角度的變化以及血管增生[4]。臨床上經常通過眼底視網膜圖像對疾病進行篩查、分析和診斷。因此,為了對疾病進行定量分析,眼底血管分割成為視網膜相關工作中的關鍵步驟,對人類疾病的診斷有著指導意義,是科學技術造福人類的體現。
眼底圖像血管分割問題已被廣泛關注,也存在一些難點:① 對于存在組織損傷的病理圖片,其中的病變區域對血管的分割起到很大的干擾。② 在有些眼底圖片中,血管的中心線呈現高亮狀態,類似拍照反光現象,這種現象對血管分割也造成了一定的難度。③ 眼底圖像中微細血管與背景的低對比度給毛細血管的識別帶來了困難。人工手動的分割方法依賴操作者的技術經驗,受主觀因素影響較大,重復性低,效率也較低[5]。隨著眼科疾病計算機輔助診斷系統的發展,眼底血管的自動分割技術也在逐步提高。國內外已經提出了大量的視網膜血管分割算法,根據分割時是否采用標準圖像提供的特征數據,可以分為無監督和有監督的兩大類分割方法。
無監督的分割方法不需要先驗標記信息,根據圖像處理方法不同,細分為:基于模型方法、血管追蹤方法、匹配濾波方法和數學形態學方法。基于模型的血管分割方法主要依據眼底圖像中血管的灰度變化,對于圖像中亮的或者暗的病變[6]以及血管分支點和交叉點等其他組織則需要建立更加復雜的模型。基于血管追蹤的分割方法首先確定初始種子點,然后通過血管中心線跟蹤血管[7]。此類方法可以比較全面地描述血管網絡結構,自適應性良好,但是運算量大而且依賴于初始種子點和方向的選擇,也無法有效分割血管的分支點以及低對比度血管。基于匹配濾波的方法是將濾波器與圖像進行卷積[8]來提取目標對象,對于健康圖片有較好的分割效果,但是對于病理圖片的分割效果,其假陽性率偏大[9]。基于數學形態學的視網膜血管分割方法主要針對的是灰度級以及二值圖像。此類方法快速高效,能夠比較好地抑制噪聲,但沒有充分考慮血管剖面等顯著特征,而且對結構元素的選取比較嚴格[10],通常與其他方法相結合進行視網膜血管分割。
有監督的方法主要基于提取的特征訓練分類器達到血管與非血管分類的目的。Ricci 等[11]采用線操作結合支持向量機(support vector machine,SVM)完成對樣本的學習,特征提取簡單,所需樣本較少。Marin 等[12]提出基于神經網絡的視網膜血管檢測方法,首先預處理原始眼底圖以實現灰度均勻和血管增強。然后對圖像中的每個像素構建基于灰度值和基于不變矩的特征向量,接著設計多層前饋神經網絡,該神經網絡可以只在一個數據庫上訓練卻在多個數據庫上得到很好的血管分割結果。Wang 等[13]提出一種分層次的視網膜血管分割方法,該方法首先用直方圖均衡化和高斯濾波來對綠色通道的眼底圖進行圖像增強。然后用簡單的線性迭代聚類(simple linear iterative cluster,SLIC)方法進行超像素分割,從每個超像素中隨機選中一個像素點代表整個超像素作為樣本進行特征提取。最后,用卷積神經網絡(convolutional neural networks,CNN)完成層次特征提取,并用隨機森林進行分類。此類監督方法都是在得到相應的標定的血管分割結果后,提取出相關特征,再使用分類器訓練。這些分類模型依賴于手動特征選取的好壞,并且需要大量的預先分割好的視網膜血管圖像作為訓練樣本來保證模型的精確度,對醫學圖像要求比較高。
近年來,深度學習算法取得了重大突破,通過組合淺層特征形成抽象的深層特征,并據此發現數據的分布式特征。和傳統方法相比,深度學習讓計算機從觀測數據中學習,根據學習結果自行解決問題。Liskowski 等[14]從大圖中提取圖像塊進行數據擴充,利用深度神經網絡進行視網膜血管分割。Fu 等[15]提出基于 CNN 和條件隨機場(conditional random field,CRF)的視網膜圖像血管分割方法,將血管分割作為邊界檢測問題處理,利用 CNN 產生分割概率圖,再結合 CRF 得到二值分割結果。Khalaf 等[16]將 CNN 結構簡化對眼底圖像中的大血管、小血管以及背景進行區分,并采用不同尺寸的卷積核進行調整,在數字視網膜圖像血管提取庫(Digital Retinal Images for Vessel Extraction,DRIVE)[17]得到了良好的分割結果。Ngo 等[18]提出一種 max-resizing 技術用于改善網絡訓練,在 DRIVE 庫得到了很好的分割效果。全卷積神經網絡(fully convolutional network,FCN)[19]作為深度學習的一支,是基于語義級別圖像分割問題提出的。以 GroundTruth 作為監督信息訓練網絡,讓網絡作像素級別的預測,使圖像級別的分類進一步延伸到像素級別的分類。U-net[20]模型是基于 FCN 的語義分割網絡,適合醫學圖像分割。該網絡采用編碼器-解碼器結構,利用編碼器逐漸減少池化層的空間維度,利用解碼器逐步修復物體的細節和空間維度。另外,為幫助解碼器更好地修復目標的細節,編碼器和解碼器之間還采用了跳躍式連接方式。本文首先以 DRIVE 庫眼底圖像為實驗對象,對圖像的綠色通道采用對比度受限的自適應直方圖均衡化(Contrast Limited Adaptive Histogram Equalization,CLAHE)和伽瑪(Gamma)校正增強對比度。然后,對 DRIVE 庫中訓練集圖像進行分塊實現數據擴充。接著在 U-net 網絡部分結構的基礎上,以深度可分離卷積(depthwise separable convolution)代替標準的卷積方式,增加網絡的寬度。同時,在每個跳躍式連接處引入一個通道加權模塊,以學習的方式自動獲取每個特征通道的重要程度,并依照重要程度自適應地調整各通道的特征響應,完成通道特征的重新標定。最后,以訓練好的分割模型對測試集圖像進行測試,實現圖像中血管與背景二分。
1 結合深度可分離卷積與通道加權的 FCN
1.1 深度可分離卷積
卷積層的主要作用是特征提取,標準的卷積將三維的卷積核作用在一組特征圖上,需要同時學習空間上的相關性和通道間的相關性。深度可分離卷積 [21]在執行空間卷積的同時,保持通道之間分離,然后按照深度方向進行卷積。如圖 1 所示,首先執行深度卷積(Depthwise convolution),即輸入的每個通道獨立執行空間卷積,然后執行 1 × 1 卷積(Pointwise convolution),將深度卷積的通道輸出映射到新的通道空間。
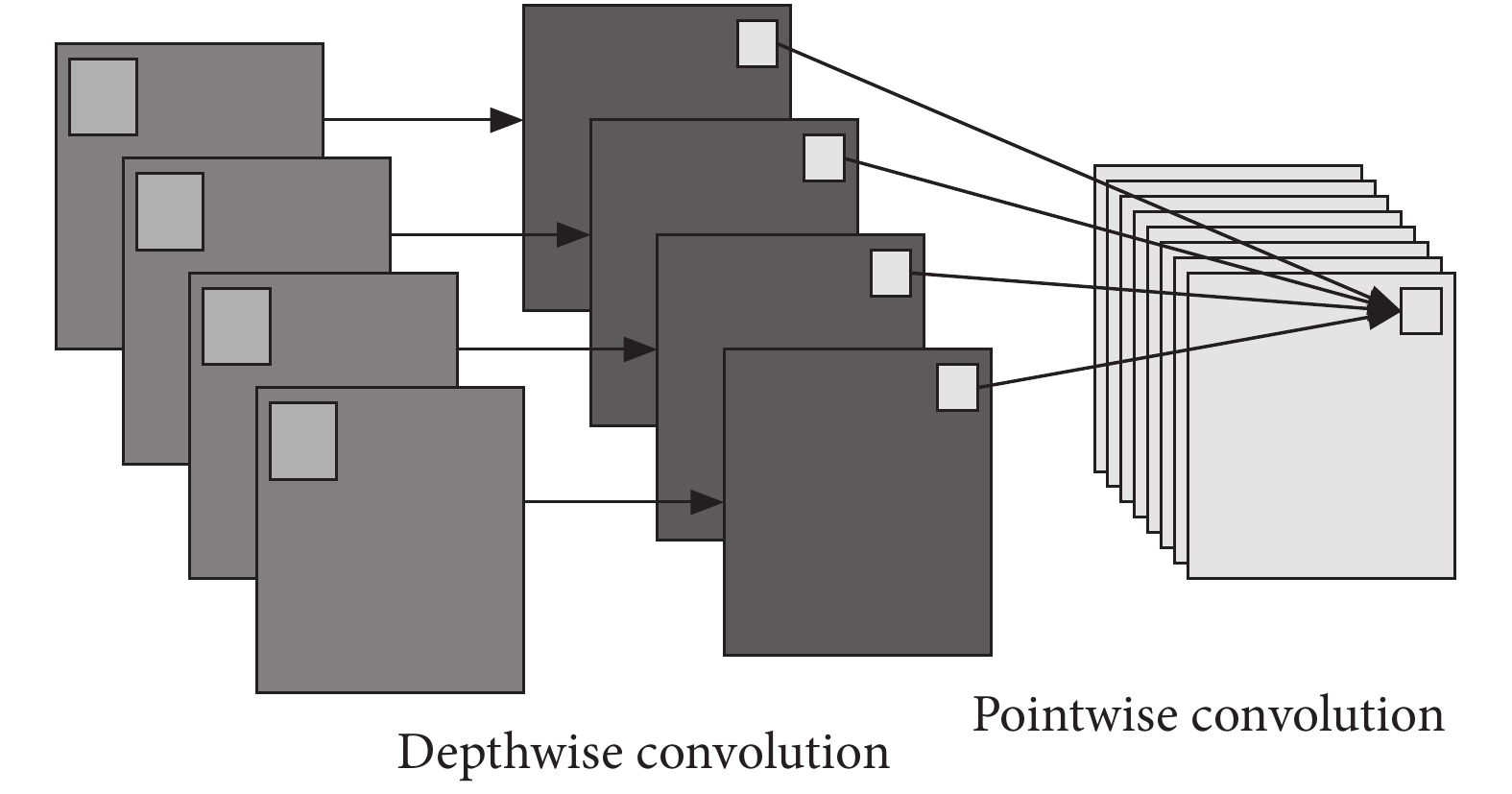 圖1
Depthwise separable 卷積示意圖
Figure1.
The schematic of depthwise separable convolution
圖1
Depthwise separable 卷積示意圖
Figure1.
The schematic of depthwise separable convolution
標準卷積同時學習空間信息及通道間的相關性,然后對輸出進行非線性激活;深度可分離卷積首先進行深度卷積,增加了網絡的寬度,使得特征提取更加豐富,然后直接進行 1 × 1 卷積,對 1 × 1 卷積結果進行非線性激活。在參數量方面,假設有一個卷積核大小為 3 × 3 的卷積層,其輸入通道為 4,輸出通道為 2。具體為,2 個 3 × 3 大小的卷積核遍歷 4 個通道中的每個數據,從而產生 4 × 2 = 8 個特征圖,進而通過疊加每個輸入通道對應的特征圖再融合得到 1 個特征圖,最后可得到所需的 2 個輸出通道。而應用深度可分離卷積,用 4 個 3 × 3 大小的卷積核分別遍歷 4 通道的數據,得到了 4 個特征圖。在融合操作之前,接著用 2 個 1 × 1 大小的卷積核遍歷這 4 個特征圖,進行相加融合。這個過程使用了 4 × 3 × 3 + 4 × 2 × 1 × 1 = 44 個參數,少于標準卷積的 4 × 2 × 3 × 3 = 72 個參數。若采用相同的網絡結構,當通道數量增加時,應用深度可分離卷積比采用標準卷積方式減少的參數量也會增加。因此,深度可分離卷積不但能夠拓展網絡寬度,而且在一定程度上減少了參數量。
1.2 通道加權結構
SE(Squeeze-and-Excitation)[22]模塊利用卷積層后特征圖的全局信息動態地對各通道的依賴性進行非線性建模,提升網絡的特征學習能力。該模塊建立在特征維度的基礎上,顯式地建模特征通道之間的相互依賴關系。通過學習的方式自動獲取每個特征通道的重要程度,依照重要程度讓網絡有選擇性地增強有用特征,使有用特征得到更充分的利用。SE 模塊具體實現主要包括:① 使用全局平均池化(global average pooling)對卷積層輸出的各通道特征進行壓縮,獲取輸入特征通道的全局感受野信息。② 采用含有 sigmoid 激活函數的門限機制為每個特征通道生成可學習的權重,顯式地對各特征通道之間的相關性進行建模。為了限制模型復雜度并增強泛化能力,門限機制中使用兩個全連接層(fully connected layer,FC),第一個 FC 降維為 1/16,通過一個修正線性單元(Rectified Linear Units,ReLU)之后,第二個 FC 恢復其維度。這種方式既引入了非線性,能夠更好地擬合維度間復雜的相關性,同時也會減少參數量和計算量。③Sigmoid 函數輸出的權重是對每個特征通道重要程度的衡量,將權重通過乘法逐通道加權到先前的通道特征上,完成在通道維度上對原始特征的重新標定。SE 模塊結構如圖 2 所示。
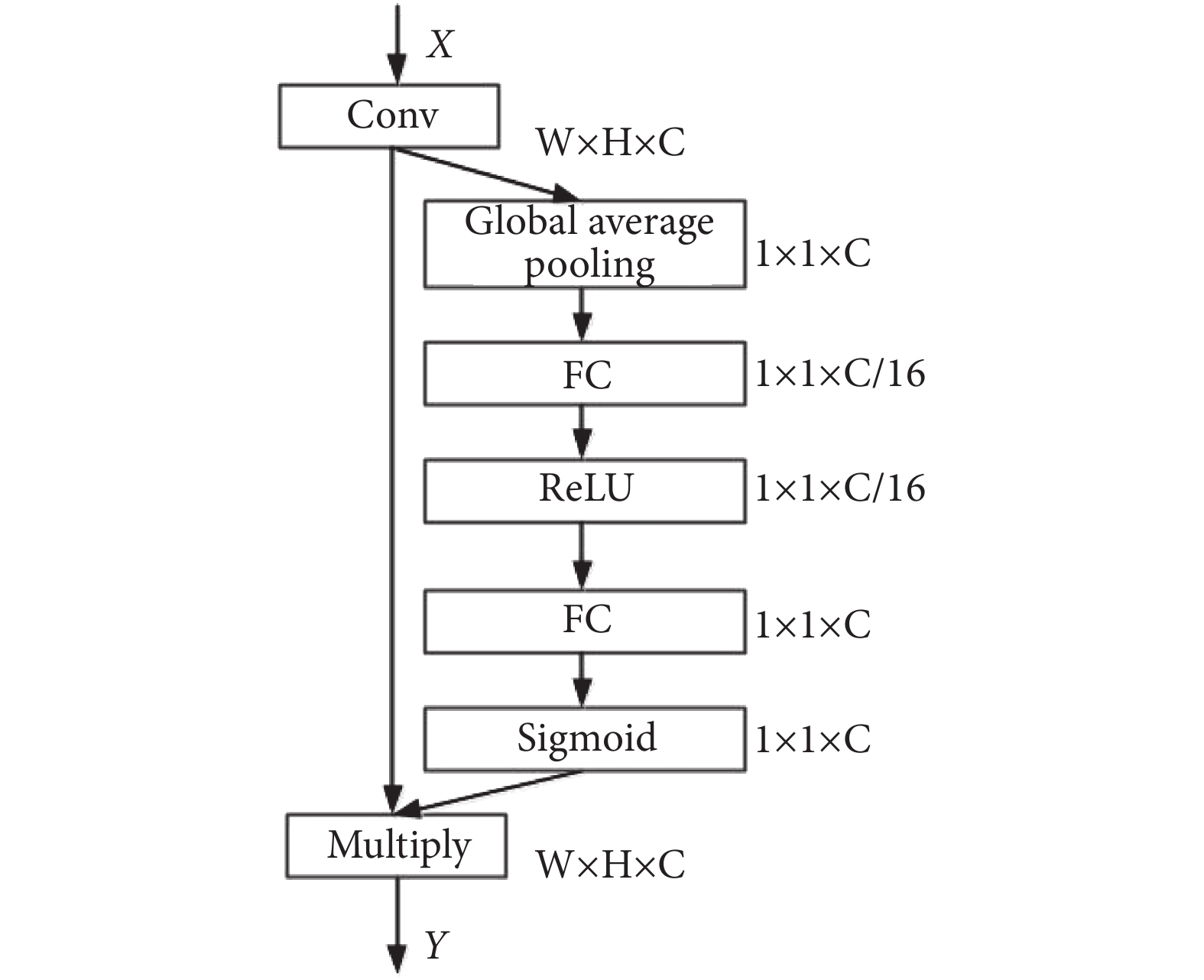 圖2
SE 模塊結構圖
Figure2.
Thestructure diagram of SE module
圖2
SE 模塊結構圖
Figure2.
Thestructure diagram of SE module
1.3 結合深度可分離卷積與通道加權的 FCN
本文將深度可分離卷積與 SE 模塊相結合。對于深度可分離卷積,首先執行深度卷積,增加網絡寬度,然后進行 1 × 1 卷積,融合通道信息;采用 SE 模塊,以學習的方式調整通道的依賴關系,實現通道特征的重標定。
網絡結構如圖 3 所示,網絡的左半部分包含兩組 Separable 卷積層,Depthwise 卷積核大小均為 3 × 3,在每層 Separable 卷積后使用 ReLU 函數進行激活,每組 Separable 卷積后連接步長為 2 的 2 × 2 最大值池化(max pooling)。為了減少特征信息的丟失,每次降采樣后都將通道數量加倍。網絡的右半部分包含兩組反卷積(Transposed)層,核大小為 3 × 3。由于網絡淺層提取的特征包含許多細節,深層的特征更加抽象,利用 SE 對淺層特征通道進行加權,以學習的方式對通道特征重新標定,增強有用特征,抑制不重要的成分,然后再將上采樣的結果與通道加權后的淺層高分辨率信息進行連接(concatenate)。每組連接后再進行兩次 Separable 卷積,Separable 卷積通道的數量相比上采樣的通道數量進行了減半處理,Depthwise 卷積核大小均為 3 × 3,同樣在每層 Separable 卷積后使用 ReLU 函數進行激活。最后一層,使用卷積核大小為 1 × 1 的標準卷積(conv)將 32 個特征圖(feature map)映射為 2 個特征圖(feature map),實現眼底圖像血管以及背景二分類。
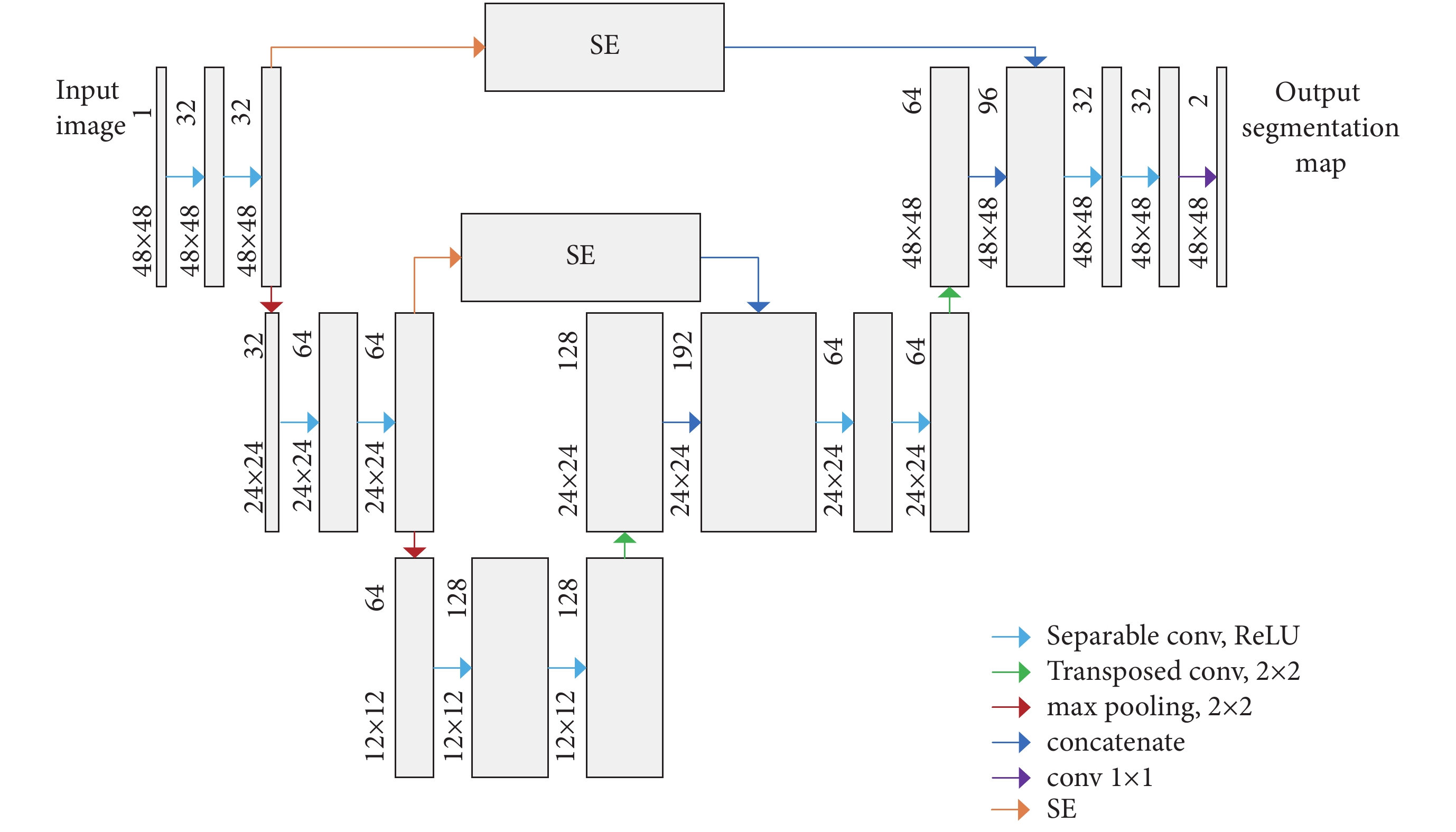 圖3
結合深度可分離卷積與通道加權的 FCN 網絡結構圖
Figure3.
The network architecture of the FCN with depthwise separable convolution and channel weighting
圖3
結合深度可分離卷積與通道加權的 FCN 網絡結構圖
Figure3.
The network architecture of the FCN with depthwise separable convolution and channel weighting
2 實驗結果與分析
2.1 實驗對象
本文的實驗對象包括公開數據庫 DRIVE 庫和視網膜結構化分析庫(Structured Analysis of the Retina,STARE)[23]。DRIVE 庫由 Niemeijer 等收集,包括 40 張彩色眼底圖像,訓練集和測試集各 20 張圖像,圖像尺寸為 565 × 584(單位為像素),每張圖像都配有顯示有效區域的二值圖像 mask。訓練集中相應地還包括第一專家標注的眼底血管二值圖,測試集中包括第一專家和第二專家標注的眼底血管二值圖。通常將一組標注圖作為金標準,另外一組用于與其他方法進行比較。進行手動標注的專家均是由經驗豐富的眼科醫生進行指導和訓練的[24]。STARE 庫由 Hoover 等收集,其中 20 幅圖像含有對應的第一專家(Adam Hoover)和第二專家(Valentina Kouznetsova)標注結果,圖像尺寸為 700 × 605。由于該數據庫沒有 mask,本文根據規則[25],生成這 20 張圖像的 mask。
2.2 圖像預處理
2.2.1 圖像增強
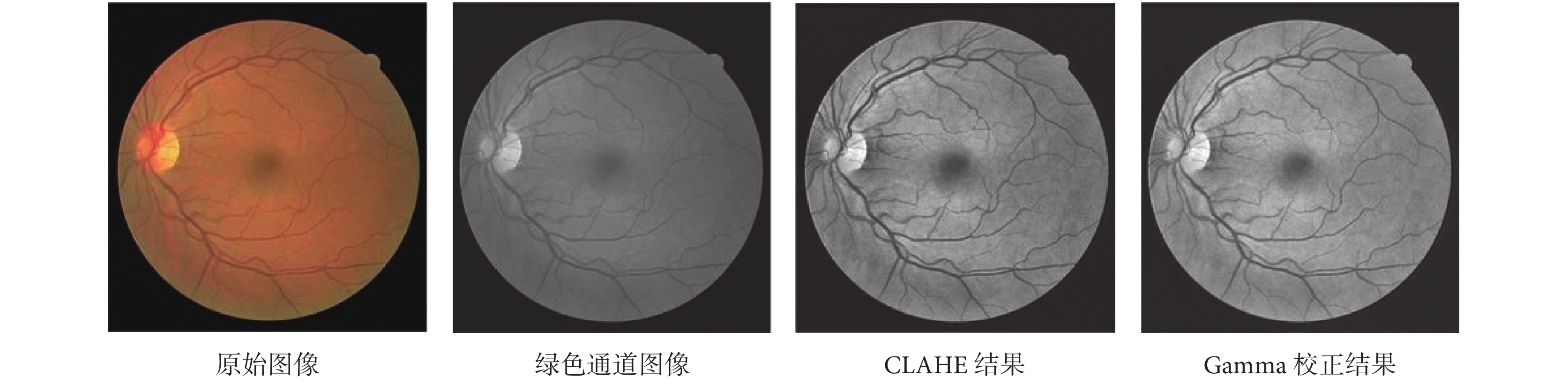
圖像增強算法旨在提升圖片質量,使圖像在內容上更加清晰。為了加快網絡訓練速度,本文選取 DRIVE 庫眼底視網膜圖像對比度較高的綠色通道進行處理。由于光照不均衡以及拍照過程中眼部的移動,導致圖像質量不佳,為了使網絡盡快收斂,故對綠色通道圖像進行了歸一化操作。之后采用 CLAHE 對歸一化的圖像進行處理,實現自適應直方圖均衡化和對比度限幅,提高視網膜圖像血管的對比度和清晰度。最后對 CLAHE 的結果進行 Gamma 校正,提高圖像的動態范圍,實現對比度拉伸,增強圖像對比度。原始圖像預處理結果如圖 4 所示。
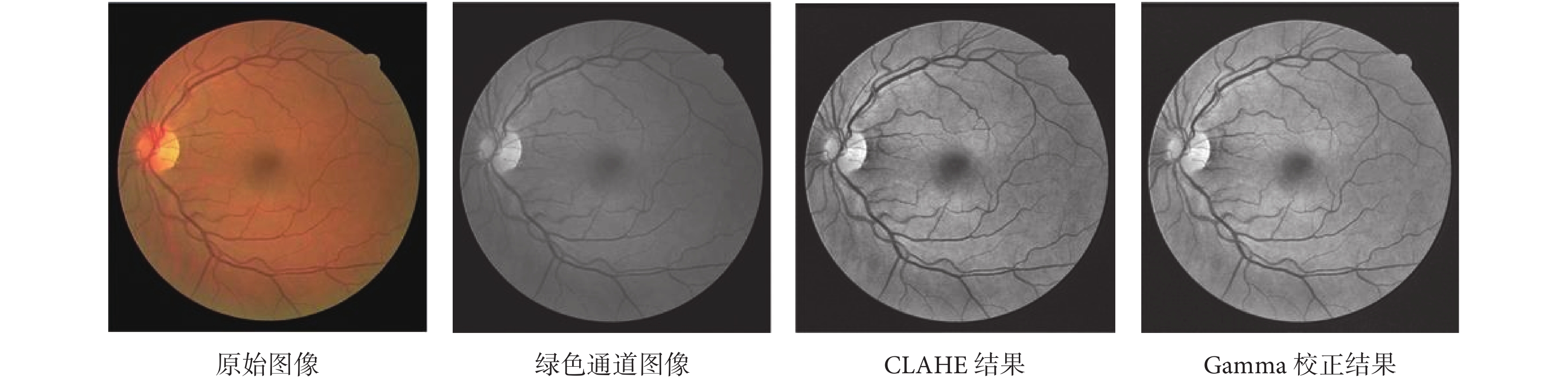 圖4
原始圖像預處理結果
Figure4.
The preprocess results of the original image
圖4
原始圖像預處理結果
Figure4.
The preprocess results of the original image
2.2.2 數據擴充
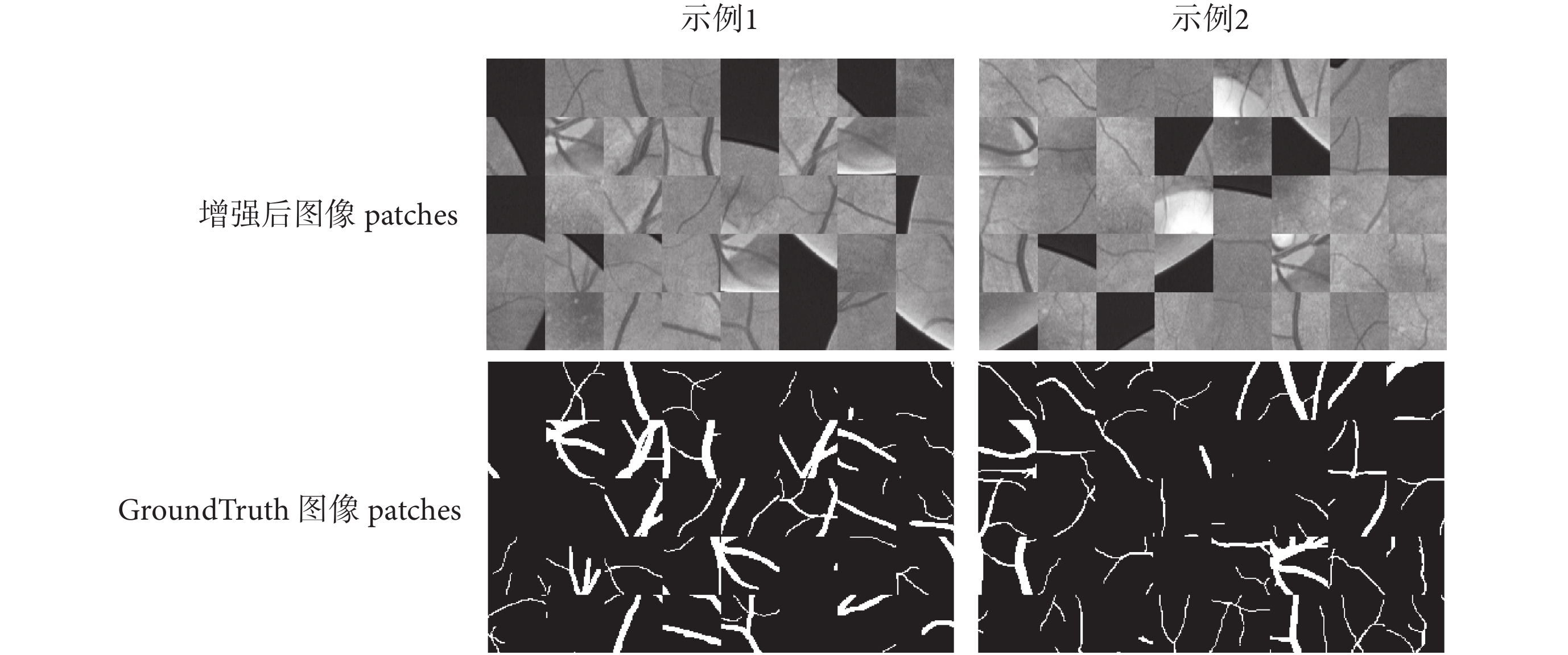
數據規模對訓練網絡的性能影響很大,由于視網膜圖像比較少,標注工作耗時耗力,而且視網膜圖像血管寬度由一個像素到十幾個像素變化,因此,本文提出的網絡訓練是基于圖像塊即 patch 的處理。以 DRIVE 庫中訓練集 20 幅圖像為樣本,在增強后的圖像中提取 48 × 48 的圖像 patch,每幅圖像提取 10 000 幅圖像 patch。相應地,GroundTruth 圖像也進行同樣的 patch 提取操作。圖像 patch 如圖 5 所示。
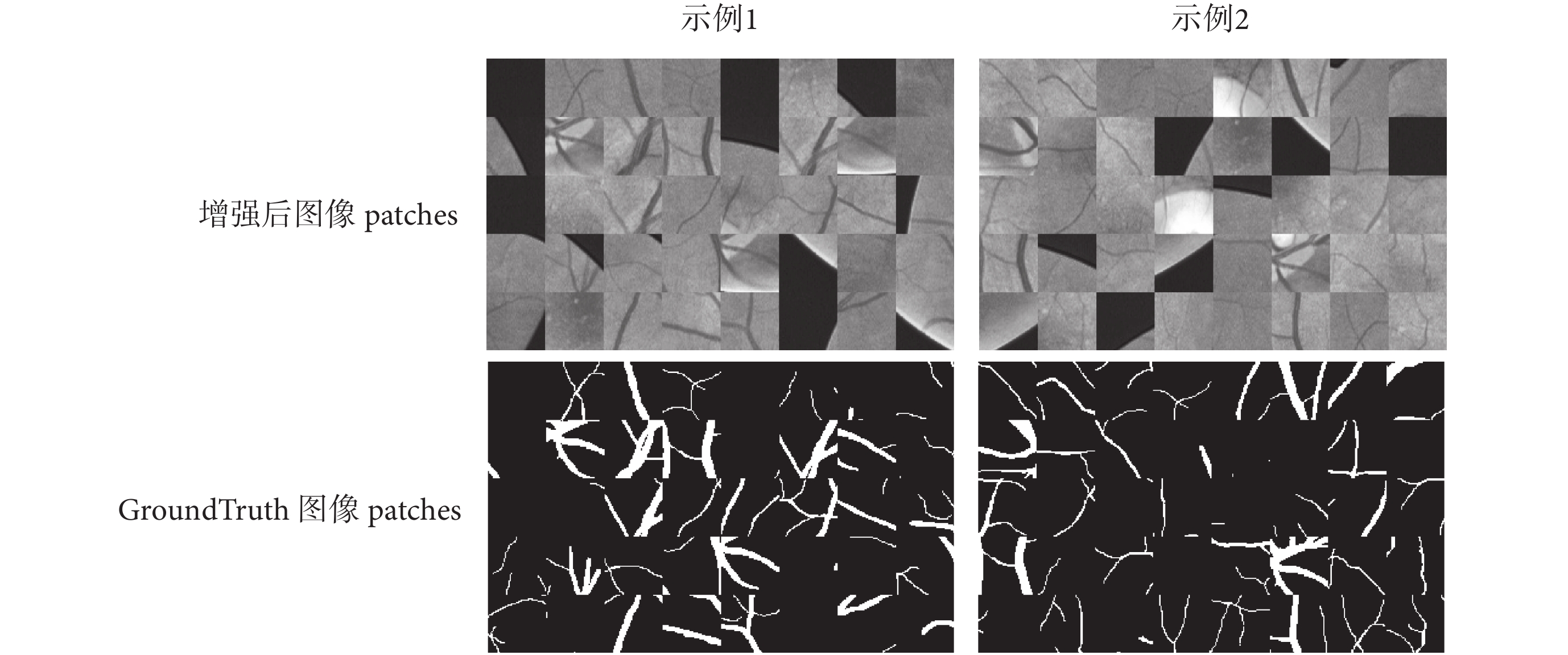 圖5
增強后圖像 patches 和 GroundTruth 圖像 patches
Figure5.
The patches of the enhanced image and the patches of the GroundTruth image
圖5
增強后圖像 patches 和 GroundTruth 圖像 patches
Figure5.
The patches of the enhanced image and the patches of the GroundTruth image
2.3 分割結果
2.3.1 評價指標
為了定量比較分割結果和人工標定結果,引入四種量化統計指標:① 真陽性(true positives,TP)指實際是血管也被準確識別為血管的像素點;② 假陰性(false negatives,FN)指實際是血管卻被識別為非血管的像素點;③ 真陰性(true negatives,TN)指實際是非血管也被準確識別為非血管的像素點;④ 假陽性(false positives,FP)指實際是非血管卻被識別為血管的像素點。在此基礎上通過定義靈敏度(Sensitivity,Se)、特異性(Specificity,Sp)、準確率(Accuracy,Acc)等參數評價算法的優劣,具體見式(1)–(3):
 |
 |
 |
另外,根據 Se 與 1–Sp 之間的變化關系繪制受試者工作特征(receiver operating characteristic,ROC)曲線,ROC 曲線下的面積(area under curve,AUC)反映了分割方法的性能,AUC 為 1 的分類器就是完美的分類器。
2.3.2 不同網絡的分割結果
本文利用深度可分離卷積,結合通道加權模塊,設計了一個學習能力更強的網絡。網絡基于圖像 patch,采用第一專家結果作為參考進行有監督訓練,其中 80% 即 160 000 張 patch 用于訓練,20% 即 40 000 張圖像 patch 用于驗證。訓練中 batch_size 設置為 64,訓練集每訓練一次 Epoch,對驗證集進行一次整體評測,訓練過程持續了 100 次 Epoch。實驗測試結果與第二專家結果作比較,采用測試圖片定量評價的平均值作為定量分析的結果。
對于 DRIVE 數據庫的測試結果,本文從 Se、Sp 和 Acc 三個方面進行比較。由表 1 可以看出本文使用的 4 種網絡在這三種性能上均高于第二專家結果。對比 4 種網絡,可以看出,通道加權(Conv-SE)以及深度可分離卷積(SeparableConv)在靈敏度上低于標準卷積(Conv)方式,但在特異性上均比標準的卷積方式要高。由于靈敏度和特異性的互補,使得兩者結合的結果在特異性以及準確性上有所提升。
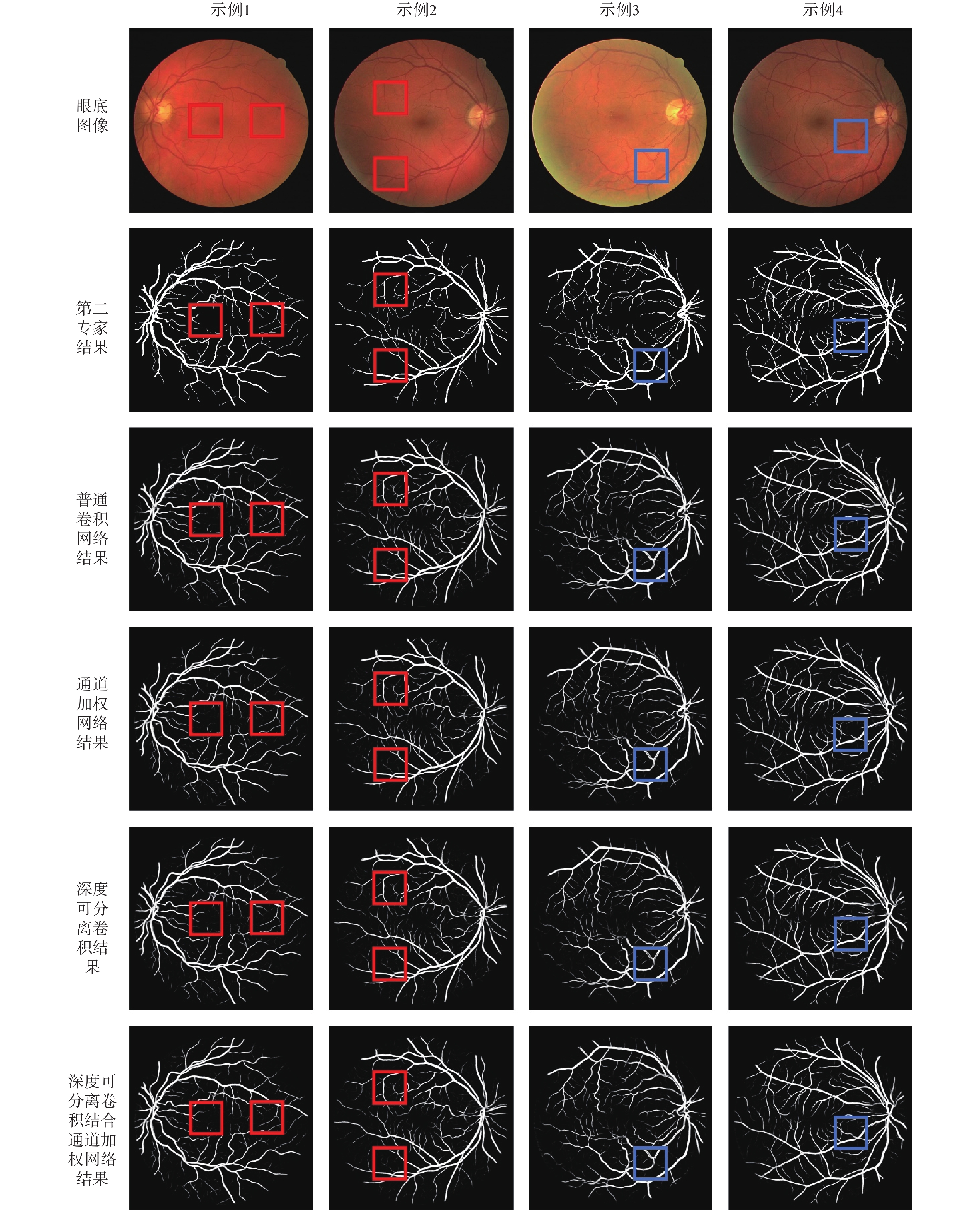
圖 6 展示了不同網絡在 DRIVE 庫的分割結果,從圖中可以看出本文使用的網絡模型均有較好的分割效果。對網絡進行通道加權以及深度可分離卷積比標準的卷積方式在展示血管細節方面更加突出,如圖中紅框標注所示,兩者結合對于細小血管的分割結果更加精細。另外,對于帶有中心線反射現象的血管,如圖中藍框標注所示,結合深度可分離卷積與通道加權的網絡也有較好的分割結果。
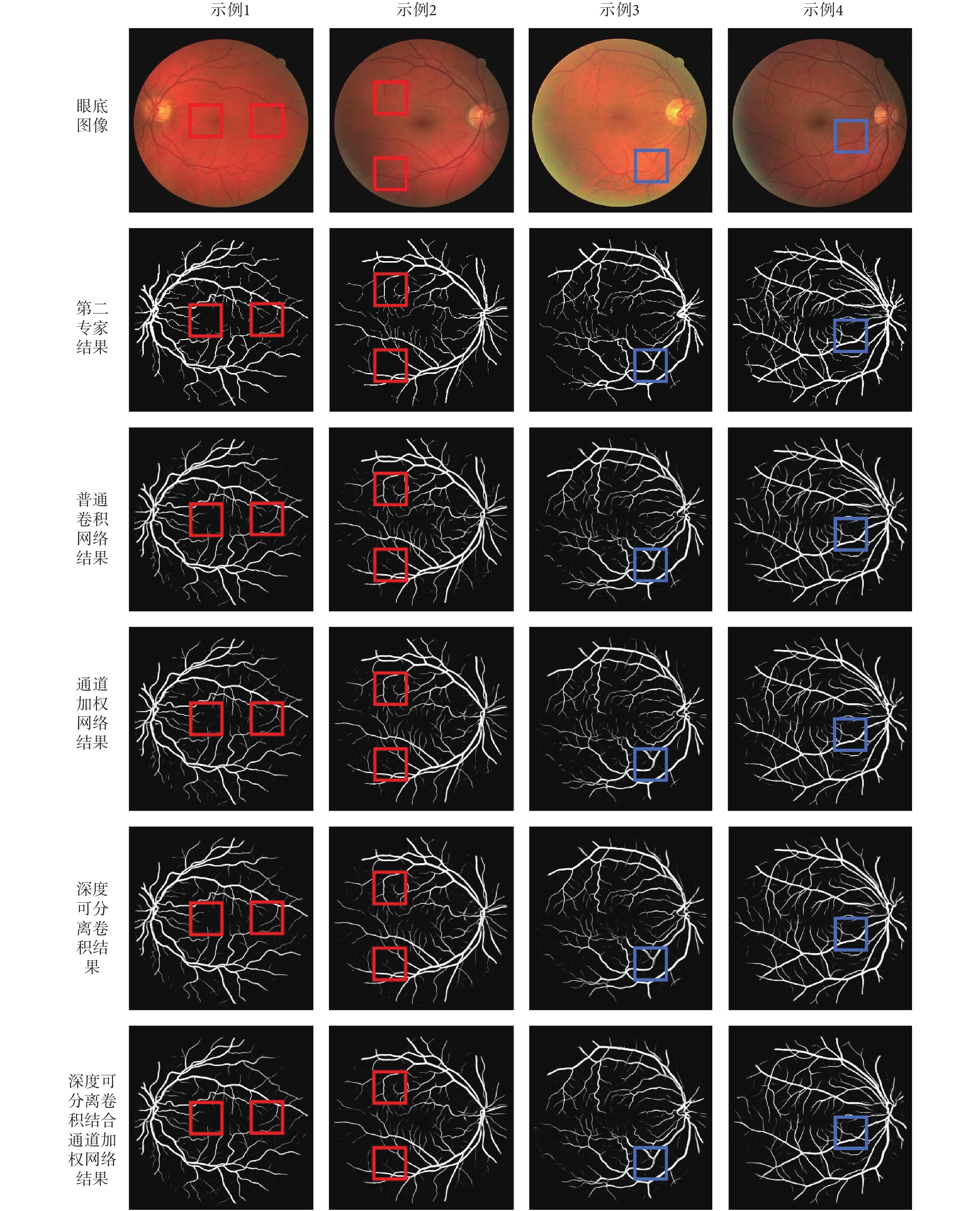 圖6
不同網絡分割結果
Figure6.
The segmentation results with different networks
圖6
不同網絡分割結果
Figure6.
The segmentation results with different networks
2.3.3 本文方法與其他方法結果對比
本文從 Se、Sp、Acc 和 AUC 四個方面與其他方法進行了比較,如表 2 所示。Azzopardi 等[8]采用一系列濾波器響應的組合提取血管,特異性應相對較高。Ricci 等[11]的方法中涉及模板匹配,對模板的輕微變形比較敏感,準確性相對較好。Khalaf 等[16]采用 CNN 對圖像中的大血管、小血管以及背景進行區分,靈敏度很好。Ngo 等[18]采用 max-resizing 技術,融合了尺度信息,特異性較好,AUC 的值較高。Cheng 等[26]采用隨機森林方法融合情景感知特征,得到了較好的特異性。綜合來看,本文方法在少量數據的基礎上進行有監督的學習,避免了復雜的圖像處理過程,在靈敏度、特異性以及準確性上相比其他方法較優,而且 AUC 達到了 0.983 1,說明本文方法有很好的分割性能。
2.3.4 本文方法在 STARE 庫的分割結果
STARE 庫中許多眼底圖像含有病變,對血管分割有干擾作用。對病理圖像的有效分割,能夠說明模型對血管分割的魯棒性。
為了驗證本文方案的有效性,對 STARE 數據庫進行了訓練驗證。綜合 Se、Sp、Acc 以及 AUC,由表 3 可以看出本文方法在靈敏度方面與第二專家結果有一定差距,但均高于其他方法,對于其他指標,本文方法的效果均優于其他方法。
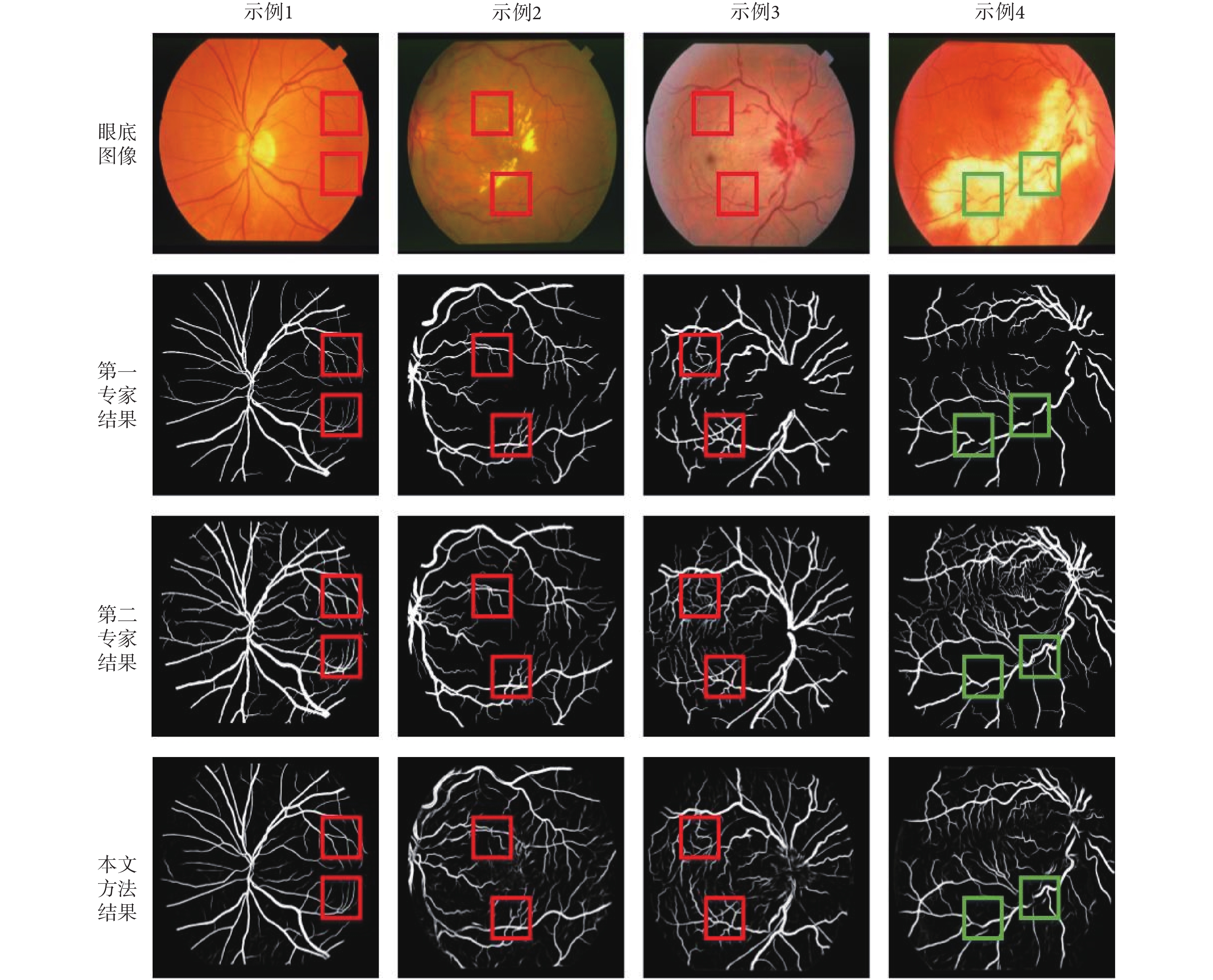
對于 SATRE 庫,不同專家的標注結果差異較大,圖 7 展示了兩個專家的部分標注結果以及本文方法的分割結果,從圖中可以看出對于病變不多的圖像,本文方法血管分割效果較好,如圖 7 示例 1 所示。圖 7 示例 2 是有糖尿病視網膜病變背景的眼底圖像,圖像中的亮斑和暗斑,極大地干擾了血管分割的過程;圖 7 中示例 3 是患有視網膜中央靜脈阻塞的眼底圖像,視盤周圍有淤血現象;圖 7 示例 4 中視網膜血管炎的眼底圖像上有一個大的亮斑,產生明顯的背景差異,許多血管圖像不連續。對于這些病理圖像,本文方法也能較好地分割出細小血管,如圖中紅框標注所示,對于背景差異造成的血管不連續,本文方法存在一定誤差,但也能分割出一部分血管。綜合分析,本文方法對于病理圖像也有較好的分割結果,相對于專家結果,特異性和準確性都比較高,但靈敏度相差較大,主要原因是各類病理樣本過少,在模型訓練過程中沒有很好地獲得病理圖像中血管的分布規律。
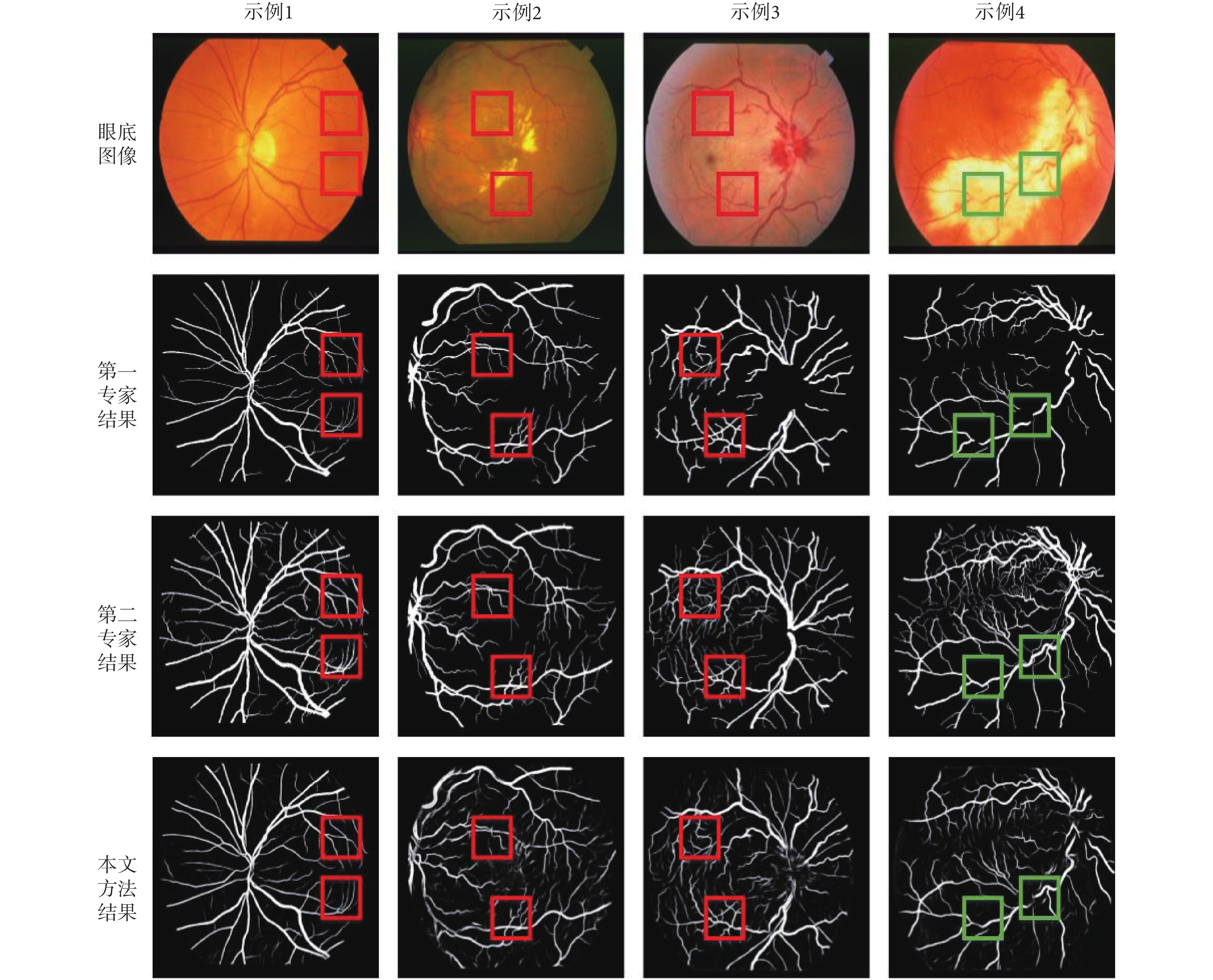 圖7
本文方法在 STARE 庫分割結果
Figure7.
The segmentation results of STARE database using the proposed method
圖7
本文方法在 STARE 庫分割結果
Figure7.
The segmentation results of STARE database using the proposed method
3 結論
本文提出了一種結合深度可分離卷積與通道加權的 FCN 網絡視網膜圖像血管分割方法。首先對 DRIVE 庫的部分圖像進行預處理以增強對比度;然后對預處理后的圖像進行數據擴充以適應網絡訓練的數據規模;接著,以深度可分離卷積代替標準的卷積方式,同時考慮到特征通道之間的相互依賴程度,引入通道加權模塊,將其嵌入 FCN 網絡結構中進行訓練,以專家手動標識結果作為金標準測試網絡模型的分割性能。實驗結果表明采用深度可分離卷積結合通道加權的網絡模型具有更好的特征分辨性,分割性能較好。
引言
糖尿病視網膜病變、動脈硬化、白血病等疾病都會對眼底血管產生影響[1-3],導致其長度、寬度、角度的變化以及血管增生[4]。臨床上經常通過眼底視網膜圖像對疾病進行篩查、分析和診斷。因此,為了對疾病進行定量分析,眼底血管分割成為視網膜相關工作中的關鍵步驟,對人類疾病的診斷有著指導意義,是科學技術造福人類的體現。
眼底圖像血管分割問題已被廣泛關注,也存在一些難點:① 對于存在組織損傷的病理圖片,其中的病變區域對血管的分割起到很大的干擾。② 在有些眼底圖片中,血管的中心線呈現高亮狀態,類似拍照反光現象,這種現象對血管分割也造成了一定的難度。③ 眼底圖像中微細血管與背景的低對比度給毛細血管的識別帶來了困難。人工手動的分割方法依賴操作者的技術經驗,受主觀因素影響較大,重復性低,效率也較低[5]。隨著眼科疾病計算機輔助診斷系統的發展,眼底血管的自動分割技術也在逐步提高。國內外已經提出了大量的視網膜血管分割算法,根據分割時是否采用標準圖像提供的特征數據,可以分為無監督和有監督的兩大類分割方法。
無監督的分割方法不需要先驗標記信息,根據圖像處理方法不同,細分為:基于模型方法、血管追蹤方法、匹配濾波方法和數學形態學方法。基于模型的血管分割方法主要依據眼底圖像中血管的灰度變化,對于圖像中亮的或者暗的病變[6]以及血管分支點和交叉點等其他組織則需要建立更加復雜的模型。基于血管追蹤的分割方法首先確定初始種子點,然后通過血管中心線跟蹤血管[7]。此類方法可以比較全面地描述血管網絡結構,自適應性良好,但是運算量大而且依賴于初始種子點和方向的選擇,也無法有效分割血管的分支點以及低對比度血管。基于匹配濾波的方法是將濾波器與圖像進行卷積[8]來提取目標對象,對于健康圖片有較好的分割效果,但是對于病理圖片的分割效果,其假陽性率偏大[9]。基于數學形態學的視網膜血管分割方法主要針對的是灰度級以及二值圖像。此類方法快速高效,能夠比較好地抑制噪聲,但沒有充分考慮血管剖面等顯著特征,而且對結構元素的選取比較嚴格[10],通常與其他方法相結合進行視網膜血管分割。
有監督的方法主要基于提取的特征訓練分類器達到血管與非血管分類的目的。Ricci 等[11]采用線操作結合支持向量機(support vector machine,SVM)完成對樣本的學習,特征提取簡單,所需樣本較少。Marin 等[12]提出基于神經網絡的視網膜血管檢測方法,首先預處理原始眼底圖以實現灰度均勻和血管增強。然后對圖像中的每個像素構建基于灰度值和基于不變矩的特征向量,接著設計多層前饋神經網絡,該神經網絡可以只在一個數據庫上訓練卻在多個數據庫上得到很好的血管分割結果。Wang 等[13]提出一種分層次的視網膜血管分割方法,該方法首先用直方圖均衡化和高斯濾波來對綠色通道的眼底圖進行圖像增強。然后用簡單的線性迭代聚類(simple linear iterative cluster,SLIC)方法進行超像素分割,從每個超像素中隨機選中一個像素點代表整個超像素作為樣本進行特征提取。最后,用卷積神經網絡(convolutional neural networks,CNN)完成層次特征提取,并用隨機森林進行分類。此類監督方法都是在得到相應的標定的血管分割結果后,提取出相關特征,再使用分類器訓練。這些分類模型依賴于手動特征選取的好壞,并且需要大量的預先分割好的視網膜血管圖像作為訓練樣本來保證模型的精確度,對醫學圖像要求比較高。
近年來,深度學習算法取得了重大突破,通過組合淺層特征形成抽象的深層特征,并據此發現數據的分布式特征。和傳統方法相比,深度學習讓計算機從觀測數據中學習,根據學習結果自行解決問題。Liskowski 等[14]從大圖中提取圖像塊進行數據擴充,利用深度神經網絡進行視網膜血管分割。Fu 等[15]提出基于 CNN 和條件隨機場(conditional random field,CRF)的視網膜圖像血管分割方法,將血管分割作為邊界檢測問題處理,利用 CNN 產生分割概率圖,再結合 CRF 得到二值分割結果。Khalaf 等[16]將 CNN 結構簡化對眼底圖像中的大血管、小血管以及背景進行區分,并采用不同尺寸的卷積核進行調整,在數字視網膜圖像血管提取庫(Digital Retinal Images for Vessel Extraction,DRIVE)[17]得到了良好的分割結果。Ngo 等[18]提出一種 max-resizing 技術用于改善網絡訓練,在 DRIVE 庫得到了很好的分割效果。全卷積神經網絡(fully convolutional network,FCN)[19]作為深度學習的一支,是基于語義級別圖像分割問題提出的。以 GroundTruth 作為監督信息訓練網絡,讓網絡作像素級別的預測,使圖像級別的分類進一步延伸到像素級別的分類。U-net[20]模型是基于 FCN 的語義分割網絡,適合醫學圖像分割。該網絡采用編碼器-解碼器結構,利用編碼器逐漸減少池化層的空間維度,利用解碼器逐步修復物體的細節和空間維度。另外,為幫助解碼器更好地修復目標的細節,編碼器和解碼器之間還采用了跳躍式連接方式。本文首先以 DRIVE 庫眼底圖像為實驗對象,對圖像的綠色通道采用對比度受限的自適應直方圖均衡化(Contrast Limited Adaptive Histogram Equalization,CLAHE)和伽瑪(Gamma)校正增強對比度。然后,對 DRIVE 庫中訓練集圖像進行分塊實現數據擴充。接著在 U-net 網絡部分結構的基礎上,以深度可分離卷積(depthwise separable convolution)代替標準的卷積方式,增加網絡的寬度。同時,在每個跳躍式連接處引入一個通道加權模塊,以學習的方式自動獲取每個特征通道的重要程度,并依照重要程度自適應地調整各通道的特征響應,完成通道特征的重新標定。最后,以訓練好的分割模型對測試集圖像進行測試,實現圖像中血管與背景二分。
1 結合深度可分離卷積與通道加權的 FCN
1.1 深度可分離卷積
卷積層的主要作用是特征提取,標準的卷積將三維的卷積核作用在一組特征圖上,需要同時學習空間上的相關性和通道間的相關性。深度可分離卷積 [21]在執行空間卷積的同時,保持通道之間分離,然后按照深度方向進行卷積。如圖 1 所示,首先執行深度卷積(Depthwise convolution),即輸入的每個通道獨立執行空間卷積,然后執行 1 × 1 卷積(Pointwise convolution),將深度卷積的通道輸出映射到新的通道空間。
圖1
Depthwise separable 卷積示意圖
Figure1.
The schematic of depthwise separable convolution
標準卷積同時學習空間信息及通道間的相關性,然后對輸出進行非線性激活;深度可分離卷積首先進行深度卷積,增加了網絡的寬度,使得特征提取更加豐富,然后直接進行 1 × 1 卷積,對 1 × 1 卷積結果進行非線性激活。在參數量方面,假設有一個卷積核大小為 3 × 3 的卷積層,其輸入通道為 4,輸出通道為 2。具體為,2 個 3 × 3 大小的卷積核遍歷 4 個通道中的每個數據,從而產生 4 × 2 = 8 個特征圖,進而通過疊加每個輸入通道對應的特征圖再融合得到 1 個特征圖,最后可得到所需的 2 個輸出通道。而應用深度可分離卷積,用 4 個 3 × 3 大小的卷積核分別遍歷 4 通道的數據,得到了 4 個特征圖。在融合操作之前,接著用 2 個 1 × 1 大小的卷積核遍歷這 4 個特征圖,進行相加融合。這個過程使用了 4 × 3 × 3 + 4 × 2 × 1 × 1 = 44 個參數,少于標準卷積的 4 × 2 × 3 × 3 = 72 個參數。若采用相同的網絡結構,當通道數量增加時,應用深度可分離卷積比采用標準卷積方式減少的參數量也會增加。因此,深度可分離卷積不但能夠拓展網絡寬度,而且在一定程度上減少了參數量。
1.2 通道加權結構
SE(Squeeze-and-Excitation)[22]模塊利用卷積層后特征圖的全局信息動態地對各通道的依賴性進行非線性建模,提升網絡的特征學習能力。該模塊建立在特征維度的基礎上,顯式地建模特征通道之間的相互依賴關系。通過學習的方式自動獲取每個特征通道的重要程度,依照重要程度讓網絡有選擇性地增強有用特征,使有用特征得到更充分的利用。SE 模塊具體實現主要包括:① 使用全局平均池化(global average pooling)對卷積層輸出的各通道特征進行壓縮,獲取輸入特征通道的全局感受野信息。② 采用含有 sigmoid 激活函數的門限機制為每個特征通道生成可學習的權重,顯式地對各特征通道之間的相關性進行建模。為了限制模型復雜度并增強泛化能力,門限機制中使用兩個全連接層(fully connected layer,FC),第一個 FC 降維為 1/16,通過一個修正線性單元(Rectified Linear Units,ReLU)之后,第二個 FC 恢復其維度。這種方式既引入了非線性,能夠更好地擬合維度間復雜的相關性,同時也會減少參數量和計算量。③Sigmoid 函數輸出的權重是對每個特征通道重要程度的衡量,將權重通過乘法逐通道加權到先前的通道特征上,完成在通道維度上對原始特征的重新標定。SE 模塊結構如圖 2 所示。
圖2
SE 模塊結構圖
Figure2.
Thestructure diagram of SE module
1.3 結合深度可分離卷積與通道加權的 FCN
本文將深度可分離卷積與 SE 模塊相結合。對于深度可分離卷積,首先執行深度卷積,增加網絡寬度,然后進行 1 × 1 卷積,融合通道信息;采用 SE 模塊,以學習的方式調整通道的依賴關系,實現通道特征的重標定。
網絡結構如圖 3 所示,網絡的左半部分包含兩組 Separable 卷積層,Depthwise 卷積核大小均為 3 × 3,在每層 Separable 卷積后使用 ReLU 函數進行激活,每組 Separable 卷積后連接步長為 2 的 2 × 2 最大值池化(max pooling)。為了減少特征信息的丟失,每次降采樣后都將通道數量加倍。網絡的右半部分包含兩組反卷積(Transposed)層,核大小為 3 × 3。由于網絡淺層提取的特征包含許多細節,深層的特征更加抽象,利用 SE 對淺層特征通道進行加權,以學習的方式對通道特征重新標定,增強有用特征,抑制不重要的成分,然后再將上采樣的結果與通道加權后的淺層高分辨率信息進行連接(concatenate)。每組連接后再進行兩次 Separable 卷積,Separable 卷積通道的數量相比上采樣的通道數量進行了減半處理,Depthwise 卷積核大小均為 3 × 3,同樣在每層 Separable 卷積后使用 ReLU 函數進行激活。最后一層,使用卷積核大小為 1 × 1 的標準卷積(conv)將 32 個特征圖(feature map)映射為 2 個特征圖(feature map),實現眼底圖像血管以及背景二分類。
圖3
結合深度可分離卷積與通道加權的 FCN 網絡結構圖
Figure3.
The network architecture of the FCN with depthwise separable convolution and channel weighting
2 實驗結果與分析
2.1 實驗對象
本文的實驗對象包括公開數據庫 DRIVE 庫和視網膜結構化分析庫(Structured Analysis of the Retina,STARE)[23]。DRIVE 庫由 Niemeijer 等收集,包括 40 張彩色眼底圖像,訓練集和測試集各 20 張圖像,圖像尺寸為 565 × 584(單位為像素),每張圖像都配有顯示有效區域的二值圖像 mask。訓練集中相應地還包括第一專家標注的眼底血管二值圖,測試集中包括第一專家和第二專家標注的眼底血管二值圖。通常將一組標注圖作為金標準,另外一組用于與其他方法進行比較。進行手動標注的專家均是由經驗豐富的眼科醫生進行指導和訓練的[24]。STARE 庫由 Hoover 等收集,其中 20 幅圖像含有對應的第一專家(Adam Hoover)和第二專家(Valentina Kouznetsova)標注結果,圖像尺寸為 700 × 605。由于該數據庫沒有 mask,本文根據規則[25],生成這 20 張圖像的 mask。
2.2 圖像預處理
2.2.1 圖像增強
圖像增強算法旨在提升圖片質量,使圖像在內容上更加清晰。為了加快網絡訓練速度,本文選取 DRIVE 庫眼底視網膜圖像對比度較高的綠色通道進行處理。由于光照不均衡以及拍照過程中眼部的移動,導致圖像質量不佳,為了使網絡盡快收斂,故對綠色通道圖像進行了歸一化操作。之后采用 CLAHE 對歸一化的圖像進行處理,實現自適應直方圖均衡化和對比度限幅,提高視網膜圖像血管的對比度和清晰度。最后對 CLAHE 的結果進行 Gamma 校正,提高圖像的動態范圍,實現對比度拉伸,增強圖像對比度。原始圖像預處理結果如圖 4 所示。
圖4
原始圖像預處理結果
Figure4.
The preprocess results of the original image
2.2.2 數據擴充
數據規模對訓練網絡的性能影響很大,由于視網膜圖像比較少,標注工作耗時耗力,而且視網膜圖像血管寬度由一個像素到十幾個像素變化,因此,本文提出的網絡訓練是基于圖像塊即 patch 的處理。以 DRIVE 庫中訓練集 20 幅圖像為樣本,在增強后的圖像中提取 48 × 48 的圖像 patch,每幅圖像提取 10 000 幅圖像 patch。相應地,GroundTruth 圖像也進行同樣的 patch 提取操作。圖像 patch 如圖 5 所示。
圖5
增強后圖像 patches 和 GroundTruth 圖像 patches
Figure5.
The patches of the enhanced image and the patches of the GroundTruth image
2.3 分割結果
2.3.1 評價指標
為了定量比較分割結果和人工標定結果,引入四種量化統計指標:① 真陽性(true positives,TP)指實際是血管也被準確識別為血管的像素點;② 假陰性(false negatives,FN)指實際是血管卻被識別為非血管的像素點;③ 真陰性(true negatives,TN)指實際是非血管也被準確識別為非血管的像素點;④ 假陽性(false positives,FP)指實際是非血管卻被識別為血管的像素點。在此基礎上通過定義靈敏度(Sensitivity,Se)、特異性(Specificity,Sp)、準確率(Accuracy,Acc)等參數評價算法的優劣,具體見式(1)–(3):
|
|
|
另外,根據 Se 與 1–Sp 之間的變化關系繪制受試者工作特征(receiver operating characteristic,ROC)曲線,ROC 曲線下的面積(area under curve,AUC)反映了分割方法的性能,AUC 為 1 的分類器就是完美的分類器。
2.3.2 不同網絡的分割結果
本文利用深度可分離卷積,結合通道加權模塊,設計了一個學習能力更強的網絡。網絡基于圖像 patch,采用第一專家結果作為參考進行有監督訓練,其中 80% 即 160 000 張 patch 用于訓練,20% 即 40 000 張圖像 patch 用于驗證。訓練中 batch_size 設置為 64,訓練集每訓練一次 Epoch,對驗證集進行一次整體評測,訓練過程持續了 100 次 Epoch。實驗測試結果與第二專家結果作比較,采用測試圖片定量評價的平均值作為定量分析的結果。
對于 DRIVE 數據庫的測試結果,本文從 Se、Sp 和 Acc 三個方面進行比較。由表 1 可以看出本文使用的 4 種網絡在這三種性能上均高于第二專家結果。對比 4 種網絡,可以看出,通道加權(Conv-SE)以及深度可分離卷積(SeparableConv)在靈敏度上低于標準卷積(Conv)方式,但在特異性上均比標準的卷積方式要高。由于靈敏度和特異性的互補,使得兩者結合的結果在特異性以及準確性上有所提升。
圖 6 展示了不同網絡在 DRIVE 庫的分割結果,從圖中可以看出本文使用的網絡模型均有較好的分割效果。對網絡進行通道加權以及深度可分離卷積比標準的卷積方式在展示血管細節方面更加突出,如圖中紅框標注所示,兩者結合對于細小血管的分割結果更加精細。另外,對于帶有中心線反射現象的血管,如圖中藍框標注所示,結合深度可分離卷積與通道加權的網絡也有較好的分割結果。
圖6
不同網絡分割結果
Figure6.
The segmentation results with different networks
2.3.3 本文方法與其他方法結果對比
本文從 Se、Sp、Acc 和 AUC 四個方面與其他方法進行了比較,如表 2 所示。Azzopardi 等[8]采用一系列濾波器響應的組合提取血管,特異性應相對較高。Ricci 等[11]的方法中涉及模板匹配,對模板的輕微變形比較敏感,準確性相對較好。Khalaf 等[16]采用 CNN 對圖像中的大血管、小血管以及背景進行區分,靈敏度很好。Ngo 等[18]采用 max-resizing 技術,融合了尺度信息,特異性較好,AUC 的值較高。Cheng 等[26]采用隨機森林方法融合情景感知特征,得到了較好的特異性。綜合來看,本文方法在少量數據的基礎上進行有監督的學習,避免了復雜的圖像處理過程,在靈敏度、特異性以及準確性上相比其他方法較優,而且 AUC 達到了 0.983 1,說明本文方法有很好的分割性能。
2.3.4 本文方法在 STARE 庫的分割結果
STARE 庫中許多眼底圖像含有病變,對血管分割有干擾作用。對病理圖像的有效分割,能夠說明模型對血管分割的魯棒性。
為了驗證本文方案的有效性,對 STARE 數據庫進行了訓練驗證。綜合 Se、Sp、Acc 以及 AUC,由表 3 可以看出本文方法在靈敏度方面與第二專家結果有一定差距,但均高于其他方法,對于其他指標,本文方法的效果均優于其他方法。
對于 SATRE 庫,不同專家的標注結果差異較大,圖 7 展示了兩個專家的部分標注結果以及本文方法的分割結果,從圖中可以看出對于病變不多的圖像,本文方法血管分割效果較好,如圖 7 示例 1 所示。圖 7 示例 2 是有糖尿病視網膜病變背景的眼底圖像,圖像中的亮斑和暗斑,極大地干擾了血管分割的過程;圖 7 中示例 3 是患有視網膜中央靜脈阻塞的眼底圖像,視盤周圍有淤血現象;圖 7 示例 4 中視網膜血管炎的眼底圖像上有一個大的亮斑,產生明顯的背景差異,許多血管圖像不連續。對于這些病理圖像,本文方法也能較好地分割出細小血管,如圖中紅框標注所示,對于背景差異造成的血管不連續,本文方法存在一定誤差,但也能分割出一部分血管。綜合分析,本文方法對于病理圖像也有較好的分割結果,相對于專家結果,特異性和準確性都比較高,但靈敏度相差較大,主要原因是各類病理樣本過少,在模型訓練過程中沒有很好地獲得病理圖像中血管的分布規律。
圖7
本文方法在 STARE 庫分割結果
Figure7.
The segmentation results of STARE database using the proposed method
3 結論
本文提出了一種結合深度可分離卷積與通道加權的 FCN 網絡視網膜圖像血管分割方法。首先對 DRIVE 庫的部分圖像進行預處理以增強對比度;然后對預處理后的圖像進行數據擴充以適應網絡訓練的數據規模;接著,以深度可分離卷積代替標準的卷積方式,同時考慮到特征通道之間的相互依賴程度,引入通道加權模塊,將其嵌入 FCN 網絡結構中進行訓練,以專家手動標識結果作為金標準測試網絡模型的分割性能。實驗結果表明采用深度可分離卷積結合通道加權的網絡模型具有更好的特征分辨性,分割性能較好。