麥克風陣列的方法在近年來被逐漸應用在電子耳蝸前端語音增強和提高言語識別率的研究里。該方法通過在空間不同的位置上放置若干麥克風,可以采集包含大量空間位置和方位信息的多通道信號,并形成增強目標信號和抑制干擾信號的特定波束指向模式。該方法更加適合用于電子耳蝸增強面對面交流的應用場景,其應用價值受到越來越多研究人員的關注。本文對麥克風陣列波束形成的原理進行闡述,并對目前文獻中基于麥克風陣列的語音增強技術進行分析,歸納和總結了其中的技術難點和發展趨勢。
引用本文: 陳又圣, 陳偉芳, 張璞, 陳培培. 電子耳蝸前端麥克風陣列語音增強技術的研究與進展. 生物醫學工程學雜志, 2019, 36(4): 696-704. doi: 10.7507/1001-5515.201805050 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
世界衛生組織(World Health Organization,WHO)官網 2018 年 3 月 15 日的統計數據表明:全球已有 4.66 億人患有聽力損失,其中成年人有 4.32 億,兒童有 3 400 萬[1]。遺傳性的疾病、傳染病、分娩綜合征、慢性耳部感染、藥物服用不當、過量噪音以及衰老等因素均能導致聽力損失,其中,12~35 歲年輕人群的聽力損失的重要致病原因是經常處于娛樂環境中的過量噪音之中,而 65 歲以上老年人中有三分之一患有殘疾性聽力損失。聽力損失引起患者不同程度的耳聾,如輕度耳聾、中度耳聾、重度耳聾和極重度耳聾等。第二次全國殘疾人抽樣調查的數據顯示,我國聽力殘疾人數有 2 780 萬人,其中重度和極重度耳聾患者高達 739 萬人[2]。
不同的聽力損失可依據病因及程度來選取相應的治療模式,常見的方法包括藥物治療、手術治療、佩戴助聽設備和植入電刺激設備[3]。其中,植入電子耳蝸是極重度耳聾以及全聾患者恢復聽力感知能力的有效方式。對于正常人來說,外耳和中耳是外界聲音信號的機械傳導裝置,其中,外耳用來收集聲音,中耳的聽小骨鏈用來放大機械振動。由中耳放大后的信號傳送到內耳,通過毛細胞把聲信號轉成生物電信號,再由生物電信號刺激聽覺神經來產生聽覺感知。耳聾患者的耳蝸內殘留的聽神經可以通過電刺激的模式使其興奮,該興奮沿聽覺通路傳遞至大腦從而產生類似正常人的聽覺感知能力。因此,電子耳蝸作為一種替代裝置,直接將語音信號轉換為電脈沖信號,刺激聽神經來產生相似的神經發放模式和聽覺感知。美國國立耳聾與其他交流障礙性疾病研究所(National Institute on Deafness and Other Communication Disorders,NIDCD)于 2017 年 3 月 6 日公布的數據表明:目前全球電子耳蝸植入數已達 324 200 個[4]。
為了提高電子耳蝸的言語識別率,目前的熱點研究方法包括精細結構編碼[5]、電流導引[6]、電場聚焦[7]、光學耳蝸[8-10]、虛擬電極[11-13]、麥克風陣列[14-17]等。其中,麥克風陣列的方法通過多個信號采集點獲取空間信息,適合應用于電子耳蝸使用場景中目標信號和干擾信號方位不同的情形。通過提高前端信號采集的信噪比或者結合語音增強的算法來提升電子耳蝸言語識別率,是近年來受到較多關注的重要研究方法。
本文詳細介紹了近年來利用麥克風陣列進行電子耳蝸前端語音增強的主要方法和研究進展,并針對麥克風陣列存在的問題進行分析和探討,歸納和總結了目前存在的研究難點,最后指出了未來的發展方向。
1 麥克風陣列信號采集和波束形成原理
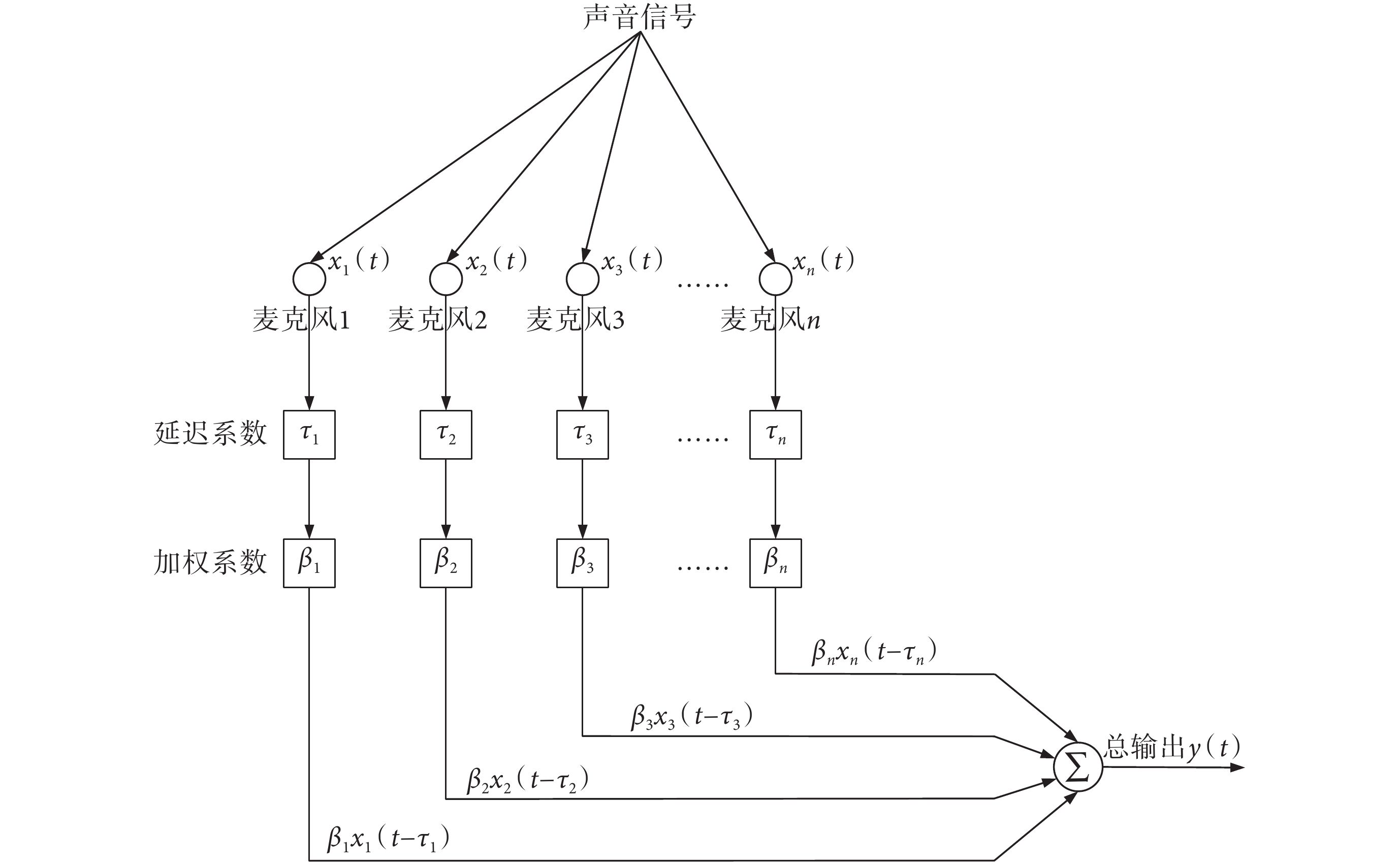
在空間不同位置以特定排列的方式來放置麥克風,形成麥克風陣列的信號采集模式,其原理如圖 1 所示。
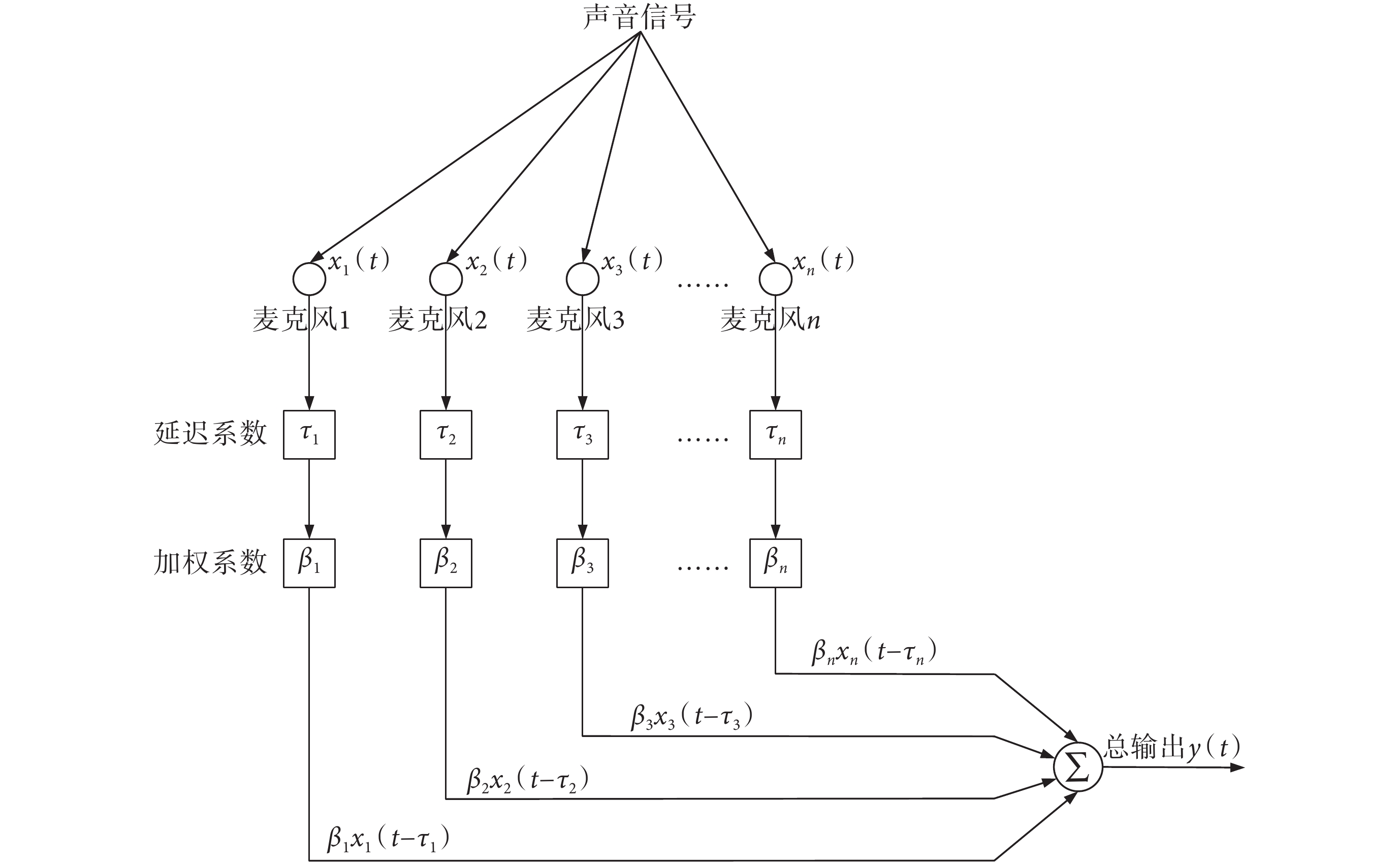 圖1
麥克風陣列信號采集原理圖
Figure1.
Schematic diagram of signal acquisition principle in microphone array
圖1
麥克風陣列信號采集原理圖
Figure1.
Schematic diagram of signal acquisition principle in microphone array
圖 1 中,在空間里以線性或者特定結構排列 n 個麥克風用于采集聲音信號。由于空間位置的差異,所采集到的 n 個通道的信號是不同的。麥克風陣列的方法對每個通道的信號分別給予延遲系數和加權系數,然后將所有信號疊加來形成總的輸出信號。對于整個麥克風陣列系統來說,延遲系數和加權系數決定著極性圖。該方法可以通過系數調整來設計滿足電子耳蝸特定應用場景的極性圖,以實現目標信號的增強和干擾信號的抑制。對于 n 個麥克風來說,麥克風陣列系統的總輸出 y(t) 的表達式如式 (1) 所示:
 |
式中 βi 和 τi 分別是第 i 個麥克風的加權系數和延遲系數。
對于不同的加權系數和延遲系數,可以形成不同的波束指向。在電子耳蝸應用中,由于尺寸的限制,雙麥克風信號采集是常見的模式,在該模式下可產生全向型、雙極型、超心型和心型等常規波束。
2 電子耳蝸麥克風陣列語音增強的方法
2.1 固定波束形成方法
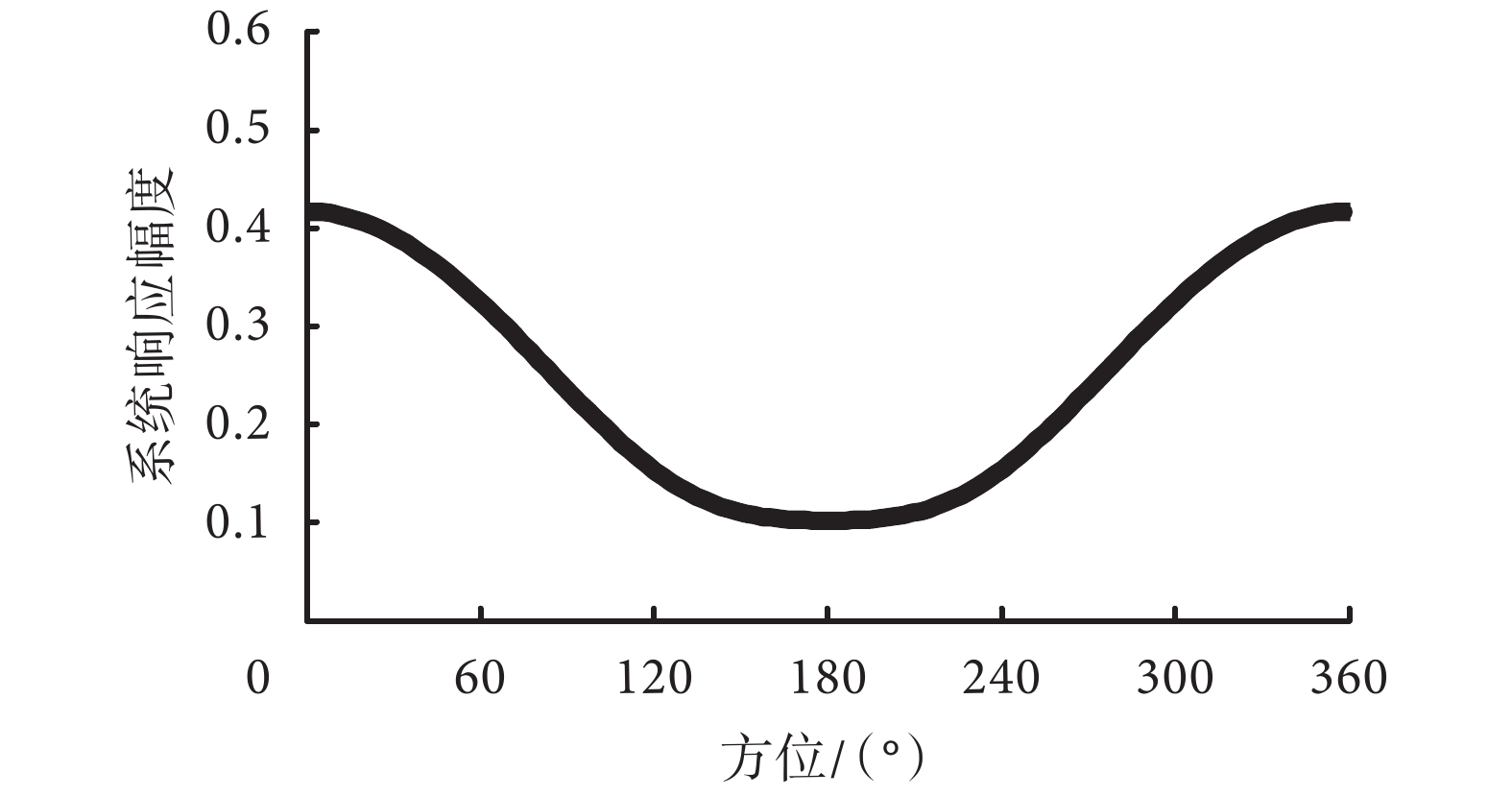
固定波束形成方法適合應用在固定方位的目標聲源的情形,所設計波束的極性圖固定。在電子耳蝸實際使用的場景中,面對面交談時的正向方位是目標信號的方位,而干擾噪聲則來源于其他方位。在此場景中,所設計的波束需要對正向方位的信號有最大的系統響應,其他方位的系統響應則應該較小。由于電子耳蝸尺寸的限制,目前文獻中電子耳蝸信號采集一般采用雙麥克風模式,可形成雙極型、超心型和心型等常見的波束,這三類波束最大的系統響應方位均在正向。如果對其中一個麥克風增加一個增益參數,則可形成更加多樣的極性圖,例如,可形成從正向到后向單調平滑過渡的極性圖[18]。該極性圖所對應的不同方位的系統幅頻響應如圖 2 所示。
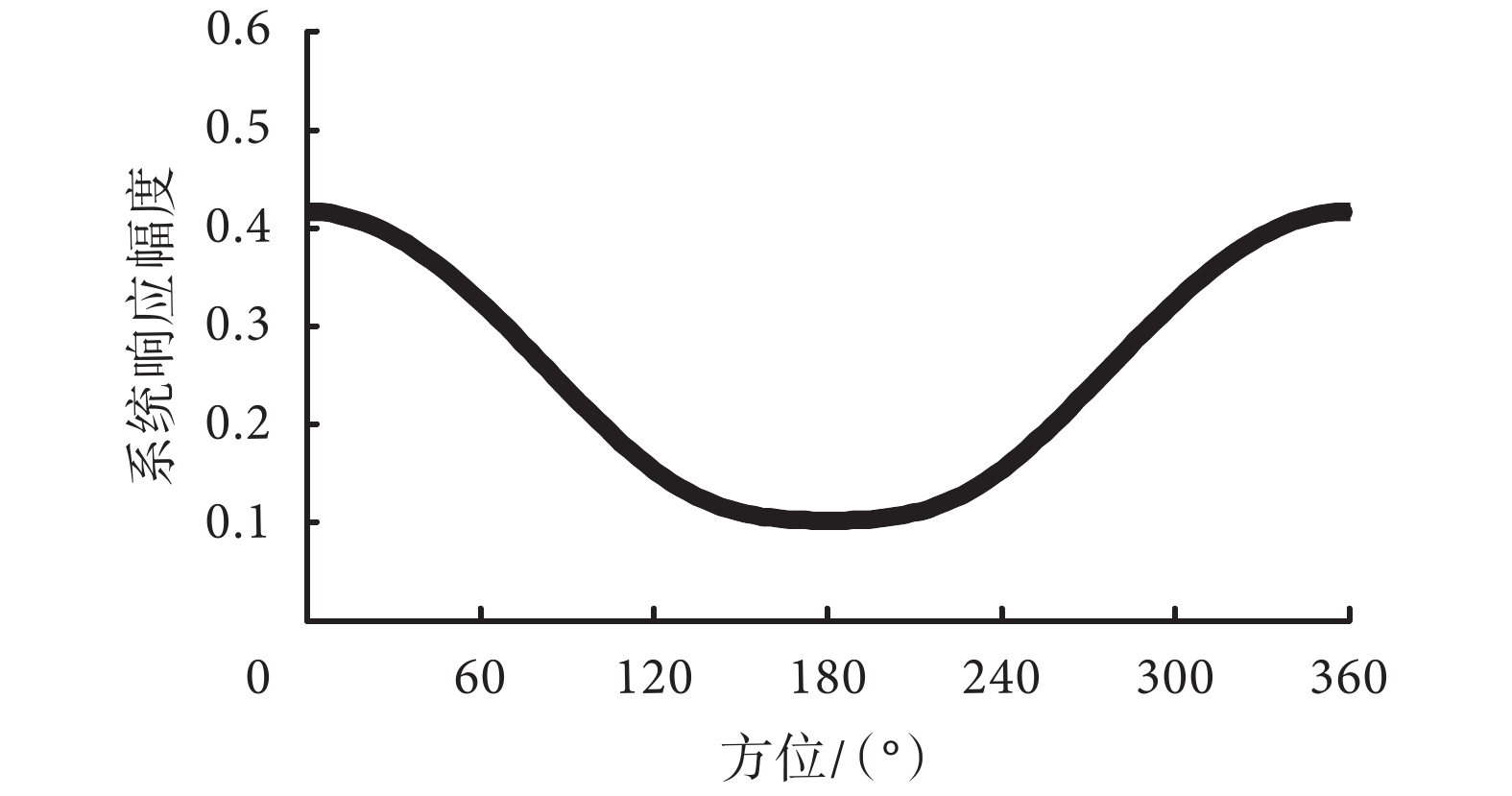 圖2
特定參數條件下的不同方位的系統幅頻響應曲線
Figure2.
System amplitude based on specific parameters
圖2
特定參數條件下的不同方位的系統幅頻響應曲線
Figure2.
System amplitude based on specific parameters
雙極型、超心型和心型是常見的極性圖,共同特點是正向方位的系統響應最大,區別在于系統零點的位置。雙極型極性圖的系統零點在 90° 和 270° 方位,可用于去除兩側的干擾信號;心型極性圖的系統零點在 180° 方位,可用于去除后向的干擾信號;超心型的系統零點在側向和后向之間,可用于去除側后向的干擾信號。圖 2 是針對特定場景設計極性圖所對應的系統幅頻響應曲線,可以看到,正向方位的系統響應最大,側向和后向的系統響應單調平緩降低。該極性圖可用于增強方位為正向的目標信號,同時可以減少其他方位信號的突然變化,有助于提高電子耳蝸的舒適度。從上面的分析可以看到,各類固定波束形成方法的參數固定,極性圖固定,主要針對特定的應用場景。
2.2 自適應波束形成方法
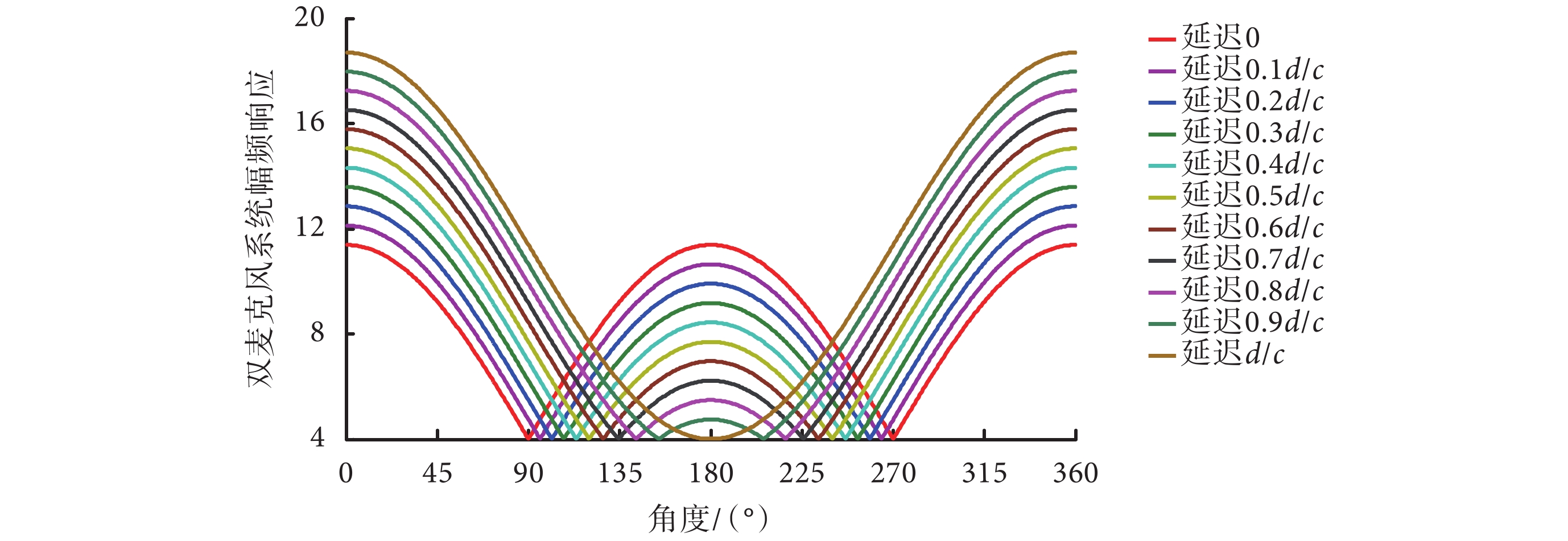
對于單一噪聲源和噪聲源方位時變的情形來說,可采用自適應波束形成的方法。雙麥克風系統可通過延遲參數的設置,形成特定波束指向的極性圖。在該極性圖中,存在一個系統幅頻響應為零的點,不同的延遲參數對應的零點方位不同。自適應波束形成方法是通過對噪聲特征和方位進行參數提取,自適應地調整延遲參數,讓零點的方位一直跟隨著干擾噪聲的方位,從而抑制干擾噪聲和增強目標信號[19-21]。以雙麥克風系統為例,不同的延遲參數所對應的極性圖和系統零點如圖 3 所示。
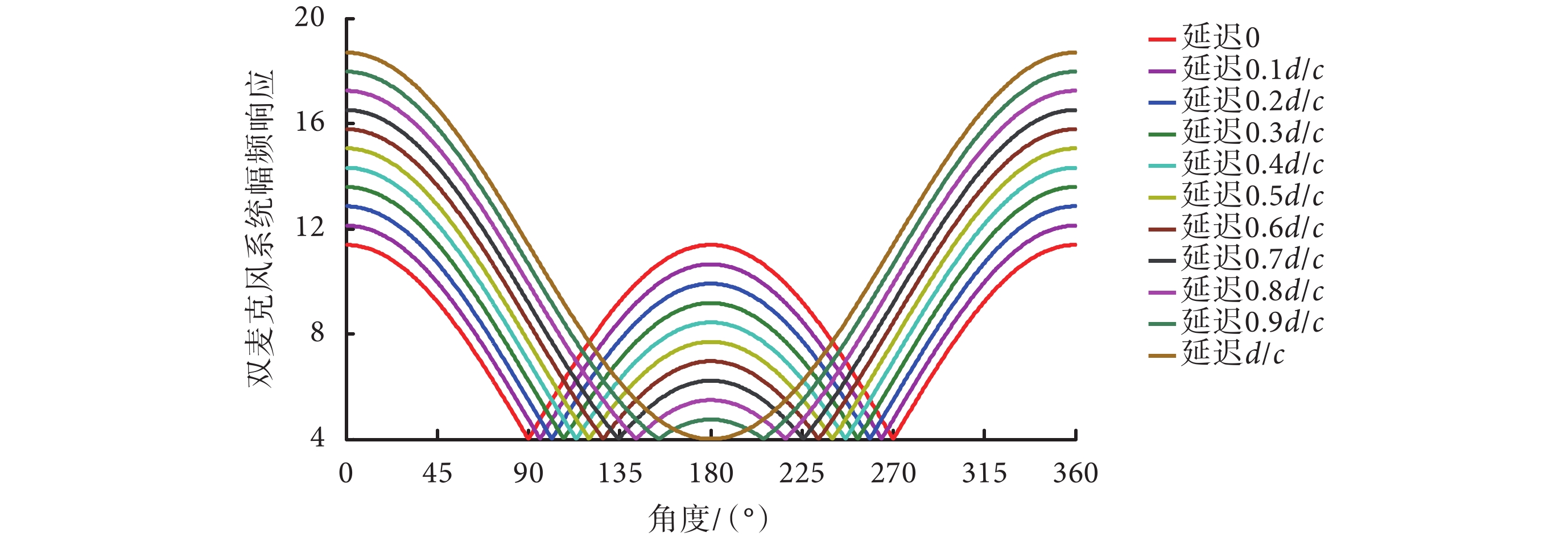 圖3
不同延遲參數值的極性圖和系統零點
Figure3.
Beam patterns and system nulls for different delay parameters
圖3
不同延遲參數值的極性圖和系統零點
Figure3.
Beam patterns and system nulls for different delay parameters
圖 3 中的 d 為雙麥克風的間距,c 為聲音在空氣中的傳播速度,本文取 340 m/s。從圖 3 可以看到,當改變延遲值時,系統幅頻響應最小值(即系統零點)的方位會發生變化。例如,延遲 0 時,系統零點在 90° 和 270° 方位;延遲 d/c 時,系統零點在 180° 方位;而當延遲在 0 和 d/c 之間時,系統零點分別在 90~180° 和 180~270° 區間內有兩個對稱的系統零點。自適應波束形成方法是通過對干擾信號的估計和方位的判斷,自適應地實時調整參數,讓系統零點始終跟隨著干擾噪聲方位,從而實現噪聲去除。
2.3 雙耳電子耳蝸的方法
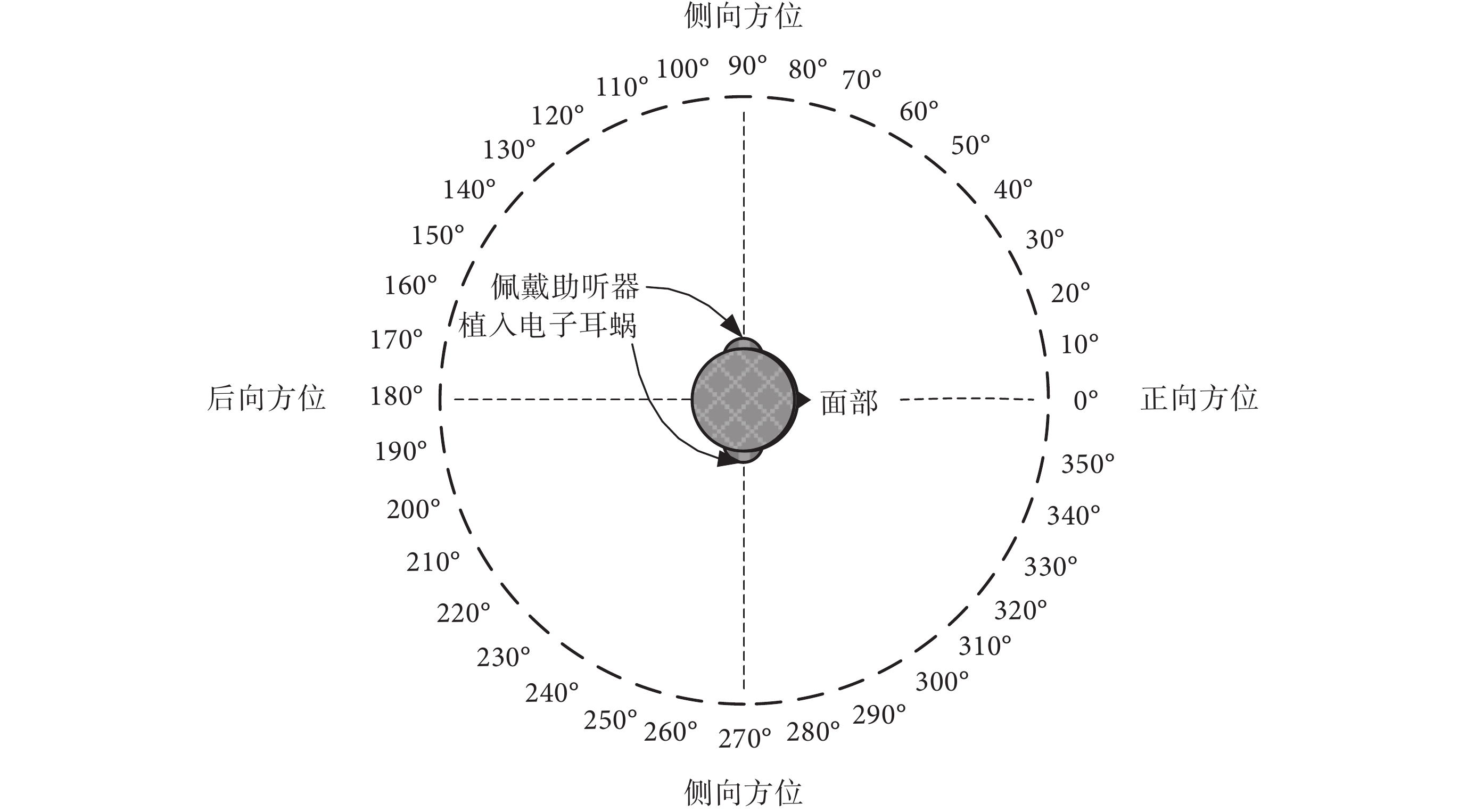
Zeng[22]在報道中指出,在目前的方向性麥克風或者噪聲去除技術用于前端聲音處理的方法上,最為成功的是兩個方面:一是雙邊或者雙耳電子耳蝸的應用;二是結合助聽器和電子耳蝸的使用,尤其是對于殘存少量低頻聲音聽力的情形。雙耳佩戴助聽器和電子耳蝸的示意圖如圖 4 所示。
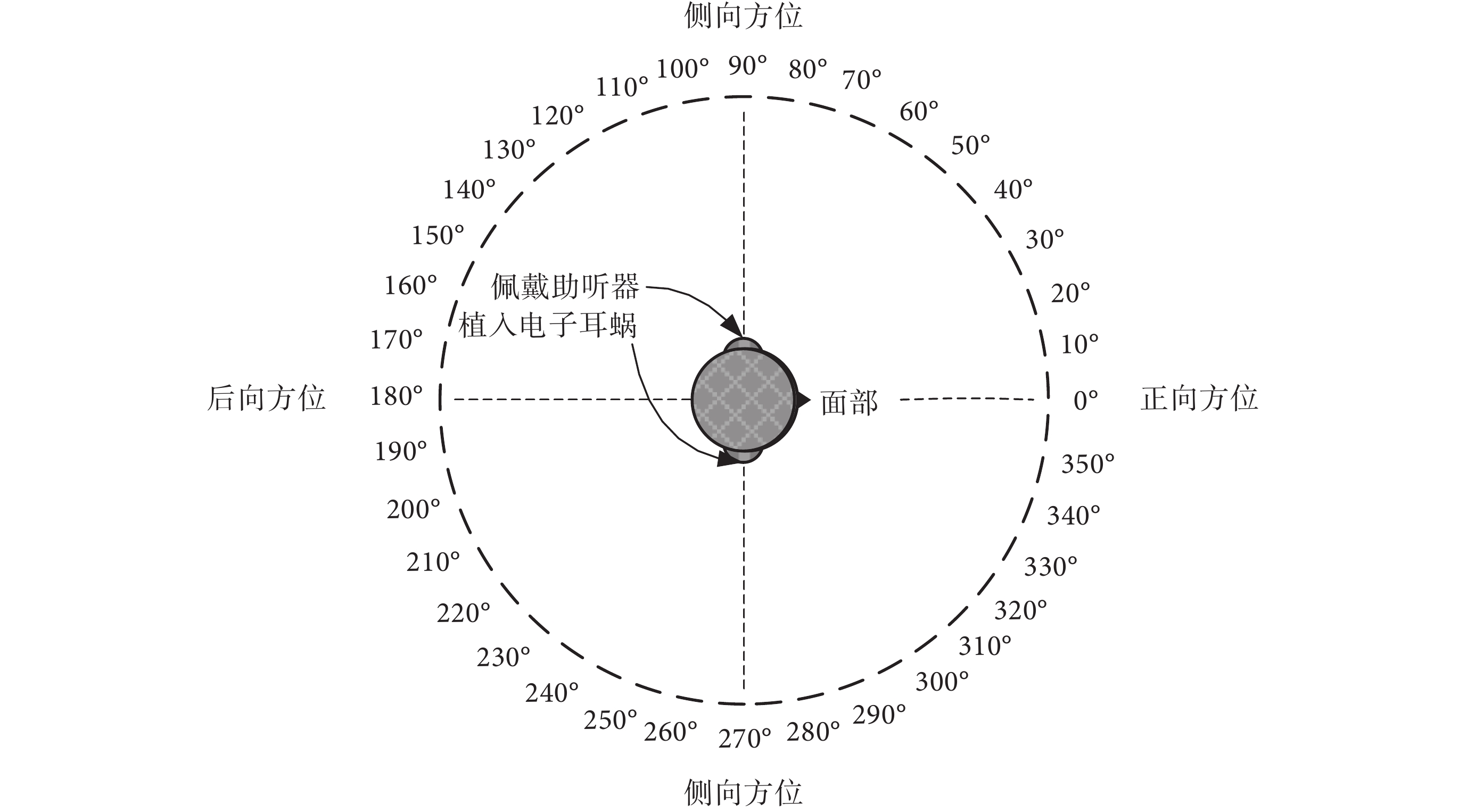 圖4
雙耳佩戴電子耳蝸和助聽器的示意圖
Figure4.
A schematic diagram of binaural cochlear and hearing aids
圖4
雙耳佩戴電子耳蝸和助聽器的示意圖
Figure4.
A schematic diagram of binaural cochlear and hearing aids
Lockwood 等[23]采用了非因果最優濾波器方法設計頻域波束形成器,把兩個麥克風放在兩側雙耳位置(相隔約 15 cm)。該算法可以較低失真地提取目標信號,并具有計算量較小的優點。對于電子耳蝸使用者來說,植入電子耳蝸往往是因為該側耳存在重度聾或者極重度聾的情況。如果對側耳還存有部分殘余的毛細胞,則可在該對側耳佩戴助聽器,形成雙耳的模式[24-25]。研究表明,雙耳模式的電子耳蝸有助于提高使用者的言語識別能力和聲源定位能力;另一方面,當對側耳朵中存有殘留的聲音感知能力,則雙側耳朵同時佩戴助聽器和植入電子耳蝸有助于改善噪聲環境中的言語識別[26-27]。中國科學技術大學等機構的研究表明:具有正常聽力的被試者收聽電子耳蝸聲學模擬語音時,如果在他們的另一側耳朵中加入低頻語音信息,則能夠顯著提升語音成形噪聲中的中文語音識別[28]。
2.4 單通道語音增強技術和麥克風陣列結合方法
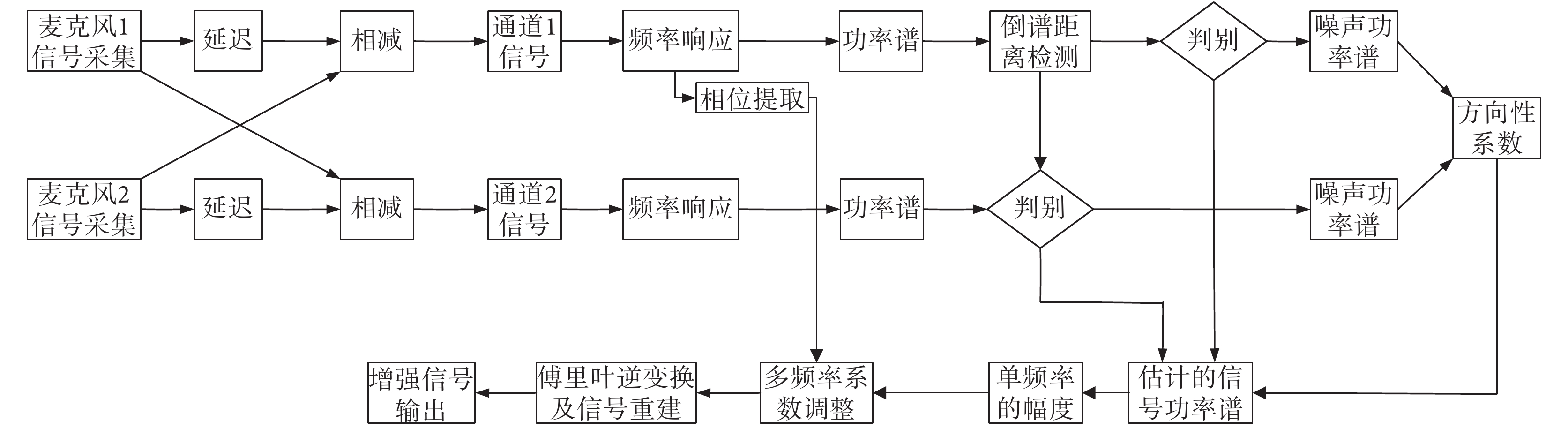
單通道的語音增強技術對平穩噪聲有較好的去除效果,而麥克風陣列的方法則適合應用在目標信號和干擾噪聲在空間方位上分離的情形,兩者的結合是近年來電子耳蝸前端語音增強技術的熱點方法之一。單通道語音增強技術和雙麥克風陣列相結合的方法可增加方位信息,有助于更大幅度地提高信噪比。傳統的方法是用線性約束最小方差來改進維納濾波器,而雙耳頻域最小方差算法則把失真最小化從時域應用到了頻域[23]。Kates 等[29]則設計了一個 5 麥克風的陣列,并結合了最小方差無畸變響應的自適應波束形成技術,最大限度地抑制噪聲并實現了自適應的噪聲控制。針對小間距的電子耳蝸實際應用場景,清華大學聲學與認知工程實驗室的宮琴團隊[30]提出了基于譜參數分析和估計的雙通道語音增強算法。該算法適合用于去除單一噪聲源的音樂噪聲和語音噪聲,如圖 5 所示。
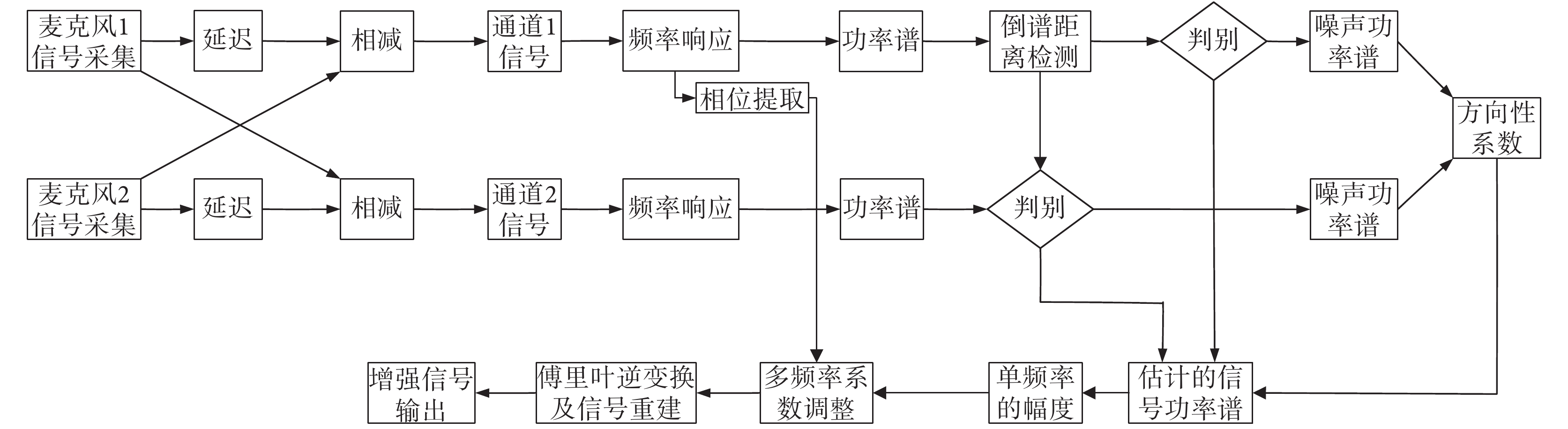 圖5
單通道語音增強技術和麥克風陣列結合的去噪方法
Figure5.
Noise suppression method based on the combination of single channel speech enhancement technology and microphone array technology
圖5
單通道語音增強技術和麥克風陣列結合的去噪方法
Figure5.
Noise suppression method based on the combination of single channel speech enhancement technology and microphone array technology
圖 5 描述的是一種典型的單通道語音增強技術和麥克風陣列結合方法。該方法通過前端的兩個麥克風來采集目標信號,對其中一個麥克風給予延遲,然后組合形成兩路輸出。兩路信號由于包含了空間方位信息,它們的目標信號和干擾噪聲信號的成分不同,再結合單通道語音增強技術則可以實現不同方位干擾信號的消除。
2.5 麥克風陣列語音增強方法的總結和言語識別率的關聯分析
前面闡述了目前在電子耳蝸應用里最為常用的語音增強算法,其共同特征是通過空間中放置若干個聲音傳感器來增加空間方位信息,主要區別是所結合的語音增強技術和具體的應用場景。在日常使用場景中,電子耳蝸使用者最迫切的應用需求是提高面對面交談時的言語識別率,源于正向的信號被認為是目標信號,而干擾噪聲則源于其他方位。因此,麥克風陣列的方法通過空間不同位置的信號采集來獲取方位信息,再結合特定的語音處理技術分離出目標信號。在上述的四大類語音增強技術中,固定波束形成方法的參數固定,因此波束指向也固定,主要應用在噪聲方位固定的場合,計算量低。自適應波束形成方法的參數不固定,參數需要依據噪聲方位的變化而實時更新,計算量大,適合應用在移動噪聲源和非確定噪聲源的場合。雙耳電子耳蝸的方法則主要是用于患者存有部分殘余毛細胞的情形,該方法通過兩耳同時佩戴助聽器和植入電子耳蝸來增加一個聲音信號的獲取渠道,充分利用了患者殘存的少量低頻聲音聽力感知能力,有助于提升使用者的聲音定位能力。單通道語音增強技術和麥克風陣列結合方法則非常多樣,主要目標是提高信噪比和去除干擾噪聲。由于單通道語音增強技術已經比較成熟,將該技術與麥克風陣列所提供的空間方位信息相結合,有助于提高去噪的性能,缺點是計算量較大。
言語識別率是電子耳蝸語音增強技術評價的重要指標,在具體實驗研究中,字出錯率、詞出錯率和句子出錯率等都是測試指標。目前的麥克風陣列語音增強技術是通過設計特定的極性圖和提高信噪比來實現的,其實驗基礎是前期學者對電子耳蝸使用者的言語識別率和信噪比的關聯性研究。例如,曾凡鋼的研究表明,植入電子耳蝸的耳聾患者在安靜環境下的言語識別率較高,在噪聲環境下的言語識別率大幅度降低。Nelson 的實驗研究表明,要達到 50% 的句子識別率,正常人所需要的信噪比約 ? 10 dB,而植入電子耳蝸的耳聾患者需要的信噪比則是 5~15 dB。因此,通過設計指向目標信號的極性圖或者通過語音增強算法來提高信噪比,都可以讓電子耳蝸使用者恢復在類似“安靜”環境的使用場景,有助于提高言語識別率。
3 麥克風陣列語音增強技術在電子耳蝸應用中存在的問題
3.1 低頻滾降失真
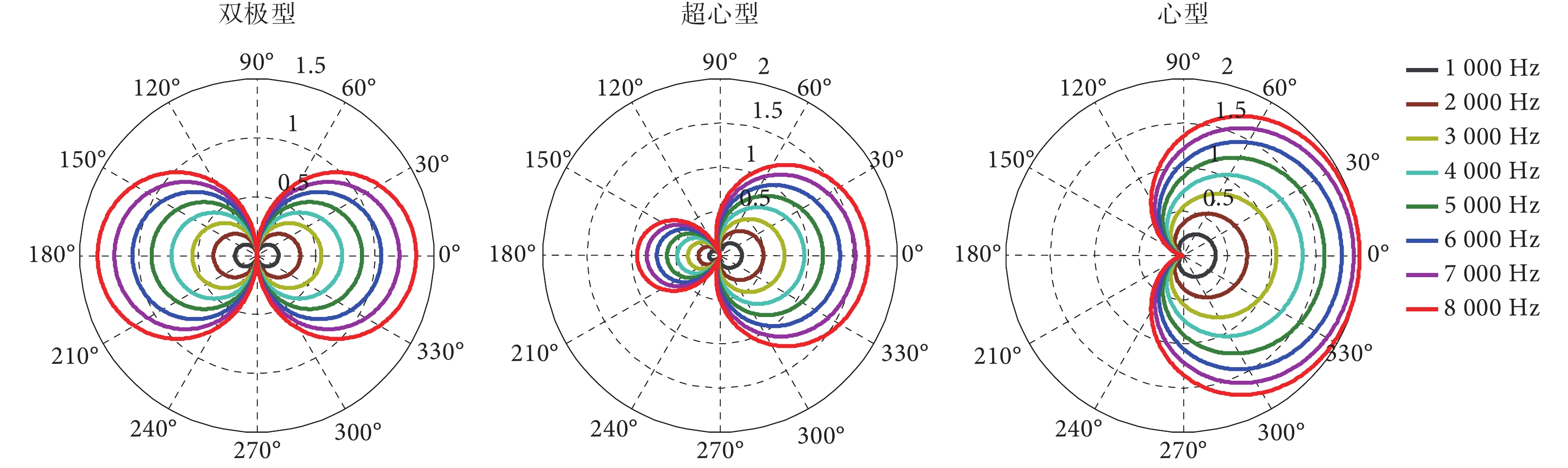
麥克風陣列的系統響應表達式是一個多參數的函數,其中頻率是影響系統響應的主要參數之一。以雙麥克風在間距為 1 cm 為例,選取 1 000~ 8 000 Hz(間隔 1 000 Hz)的 8 個頻率來描述其波束特征,如圖 6 所示。
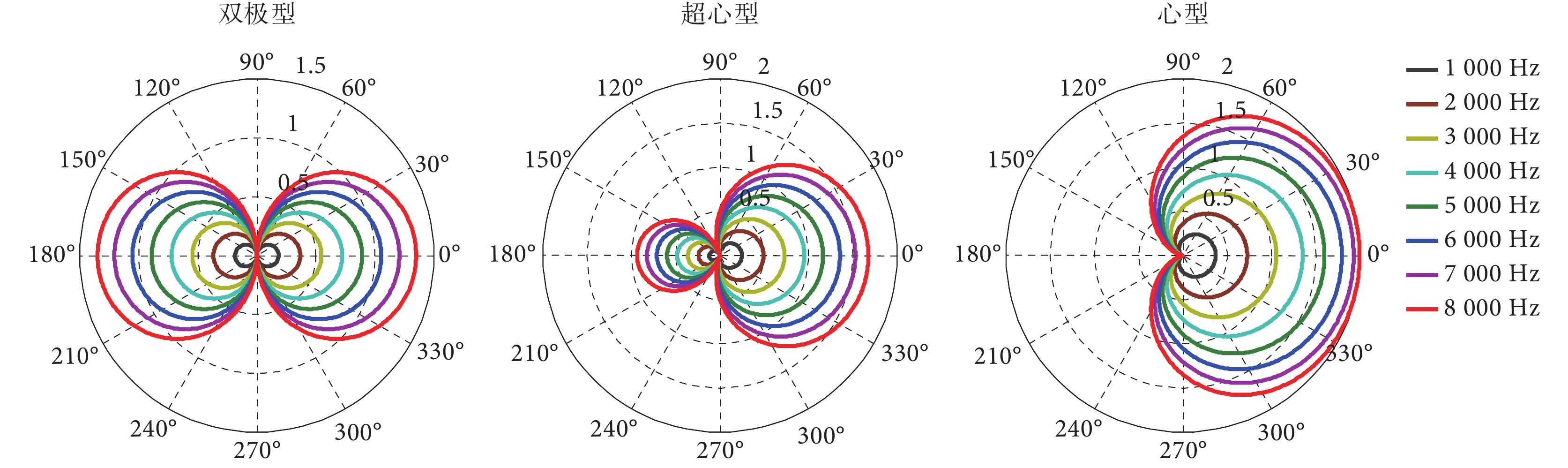 圖6
不同頻率條件下的雙麥克風極性圖
Figure6.
Beam patterns of dual-microphone system based on different frequencies
圖6
不同頻率條件下的雙麥克風極性圖
Figure6.
Beam patterns of dual-microphone system based on different frequencies
從圖 6 可以看到,不同頻率條件下的系統極性圖是不同的。在電子耳蝸應用場景條件下(間距 1 cm)可以看到:頻率越大則系統響應越大,頻率越小則系統響應越小。對輸入為低頻信號來說,經過麥克風系統后的不同方位的增益系數均比高頻信號小,由此產生了麥克風陣列中的低頻滾降現象[31-33]。低頻滾降是麥克風陣列波束形成里的特有現象,其結果是導致信號在不同頻段的能量重新分布,并且主要是衰減了低頻信號的能量從而產生了信號失真,為此,需要對低頻信號給予額外的增益來調整和均衡不同頻段的信號輸出。從理論上說,一階差分麥克風的低頻滾降是 6 dB/倍頻程,而二階差分麥克風的低頻滾降是 12 dB/倍頻程。從圖 6 可以看到,雖然不同頻率條件下的波束大小不同,但波束之間存在較大的相似性,通過適當的信號補償方法可以實現不同頻率條件下的各個波束重新匹配。基于電子耳蝸實際的參數特征,清華大學等研究機構提出了基于雙麥克風的歸一化波束形成方法和多參數條件下的低頻滾降補償算法,這些算法采用線性化的方式進行低頻滾降補償,具有計算復雜度低的特點[34]。
3.2 信號補償中的噪聲過度放大
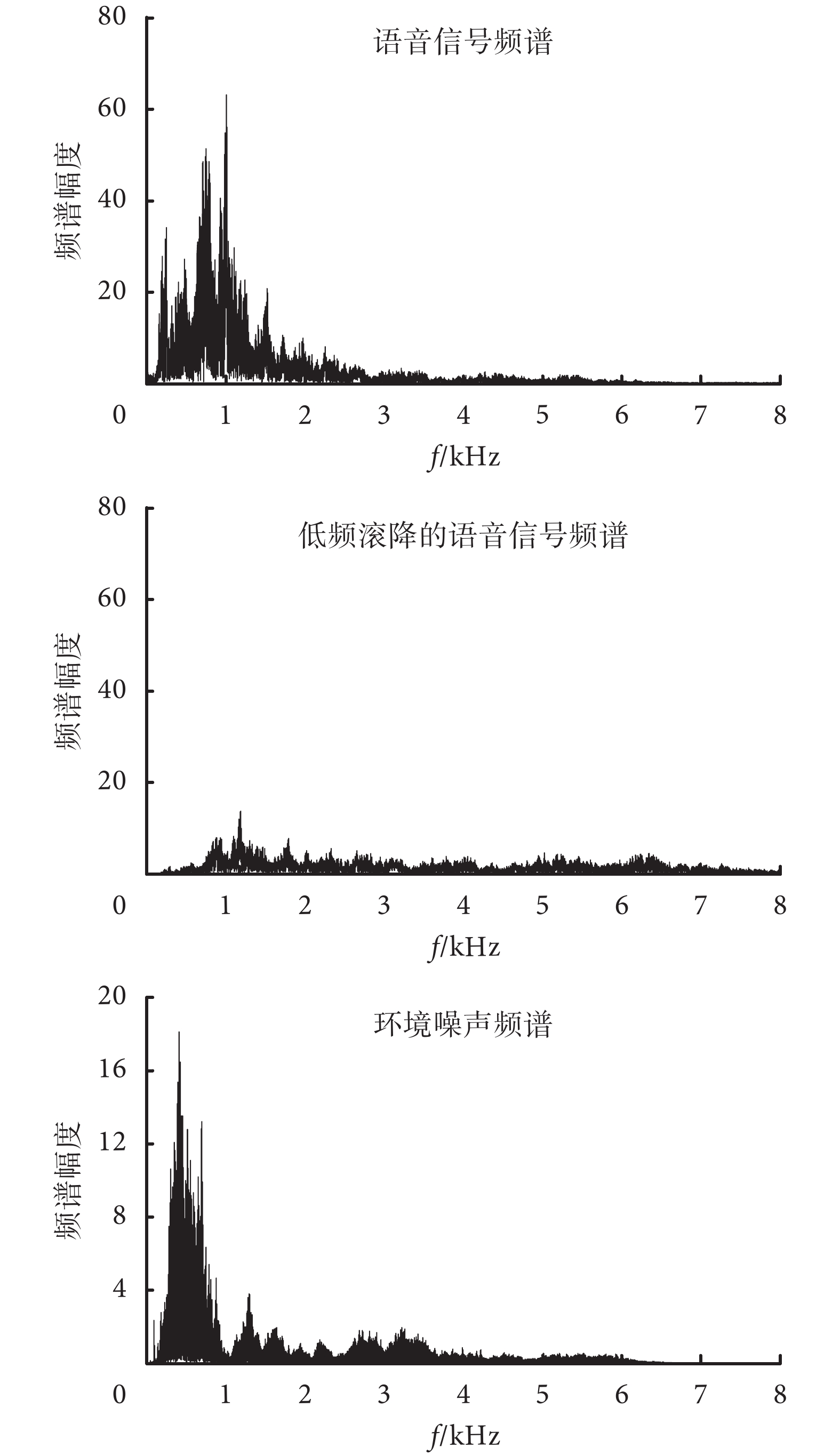
對于麥克風陣列所存在的低頻滾降問題,目前的方法是調整不同頻段的增益。由于低頻信號的系統響應小,因而給予低頻信號的增益會更大。但是,電子耳蝸所采集的信號既包含目標語音信號,也包含環境噪聲信號,而日常應用場景中的環境噪聲信號則主要以低頻信號為主。以實際采集的語音信號和在餐廳場景下的噪聲信號為例來進行說明,其頻譜對比如圖 7 所示。
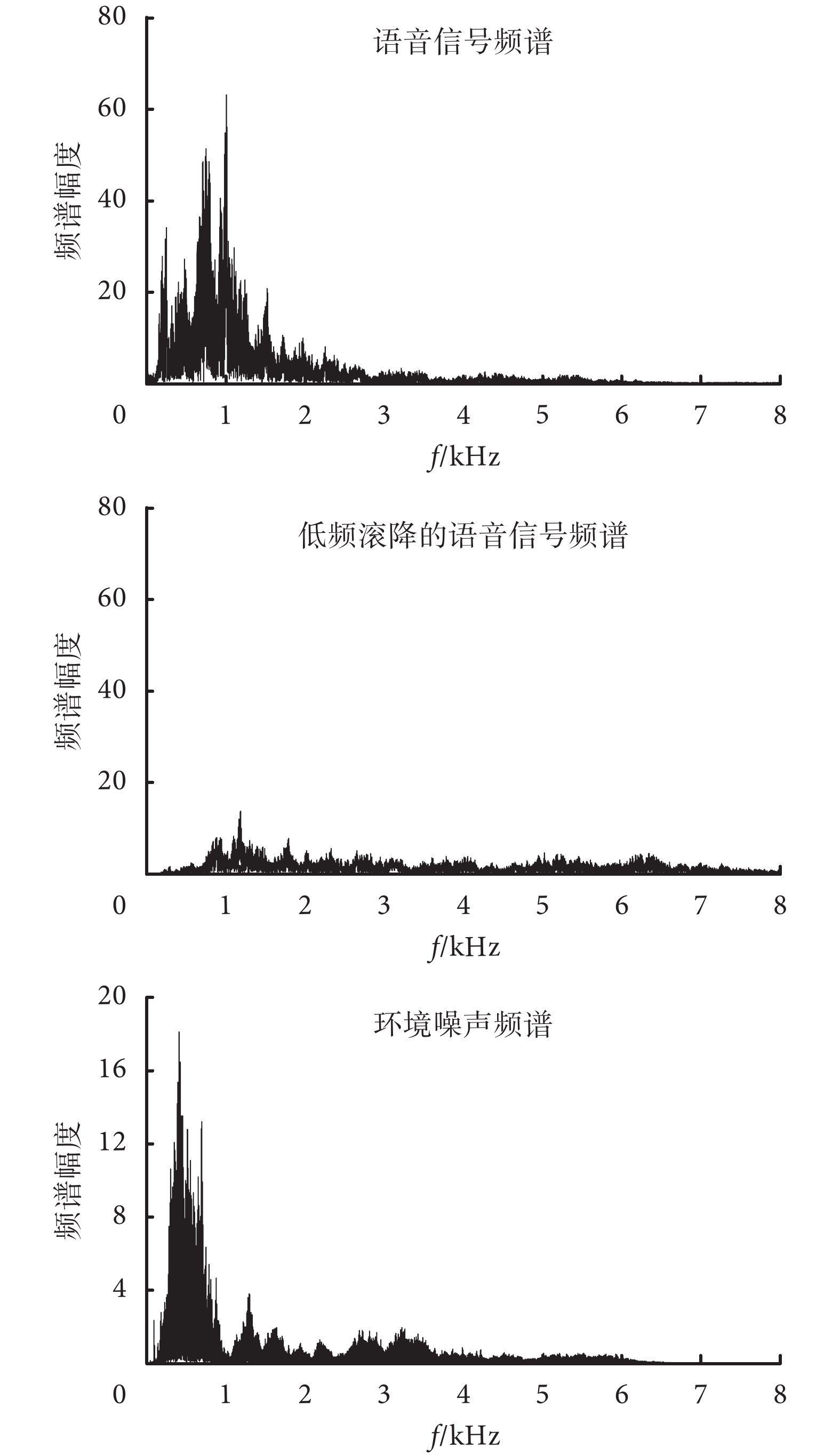 圖7
語音信號和環境噪聲的頻譜對比
Figure7.
Spectrum comparison of speech signal and environ mental noise
圖7
語音信號和環境噪聲的頻譜對比
Figure7.
Spectrum comparison of speech signal and environ mental noise
從實測的常見環境噪聲(餐廳中嘈雜的場景)的頻譜圖中可以看到,常見環境噪聲的主要能量集中在低頻的頻段位置上。麥克風陣列會導致低頻滾降的產生,對于語音信號來說,其頻譜能量也是集中在低頻的位置。但是,低頻滾降后的信號其低頻能量會受到更大的削減,因此,需要對語音信號進行能量補償。由于環境噪聲來源多樣并且含有隨機噪聲,陣列中的各個麥克風采集到的噪聲信號具有較大的非相關性,因而噪聲的低頻滾降沒有語音信號明顯。電子耳蝸前端的麥克風采集的信號包含了目標語音信號,也包含應用場景中的環境噪聲信號。當麥克風陣列系統中發生低頻滾降失真后,對信號的調整主要是增大低頻信號的增益。此時由于環境噪聲主要集中在低頻段,其結果是環境噪聲會被過度地放大,導致信號補償后的信噪比并沒有相應地提高,因此影響了電子耳蝸的言語識別率[34]。對環境噪聲過度放大的抑制是麥克風陣列低頻滾降補償中的關鍵難點之一。由于信號過程中語音和噪聲同時被采集,頻譜間相互重疊,而且環境噪聲本身也具有多樣性,因而環境噪聲的抑制在技術上具有復雜性。
3.3 電極數量限制及信號分辨率問題
麥克風陣列應用在電子耳蝸前端信號采集中可以增加空間方位信息,但是濾波器組本身有限的頻帶限制了信號提取的質量,并導致目標信號的信息丟失。電子耳蝸濾波器組的頻帶數量是由電極陣列的數量決定的,濾波器組的每個頻帶與電子耳蝸的一個電極對應。電子耳蝸言語識別率難以提高的根源是電極設計方面在近年來幾乎沒有進展。近幾十年來,電子耳蝸中所使用的電極的變化主要是形狀從球形和環形到盤形(平面型)的變化和電極陣列長度和厚度的變化,但電極的尺寸和電極與神經元之間的數量失配卻沒有改變。有學者研究指出:從 1980 年到 1995 年這 15 年間,電子耳蝸相關文獻的發表速度很快,呈現指數增長的速度,相應地,電子耳蝸的句子識別率也提高很快,從 0% 到接近 80%;而在隨后的 20 年里(1995 年—2015 年),文獻發表速度仍很快,但句子識別率卻沒什么提高,其原因是缺乏耳蝸電極與耳蝸神經之間接口這方面的技術改進[22]。電極的尺寸是神經元尺寸的 1 000 倍以上,也就是說電極數量不到神經元數量的千分之一。目前電子耳蝸電極的特點是尺寸大和數量少,其結果是電極的刺激位置太寬和頻率分辨率太低,電子耳蝸電極與耳蝸神經的數量失配限制了電子耳蝸性能的提升。
3.4 麥克風間的增益失配和運動偏移失配問題
在多麥克風應用中,麥克風采集的信號存在傳輸衰減,并引起了不同麥克風間的增益失配問題。仿真實驗表明,當雙麥克風發生增益失配時,不同頻率的波束形狀的相似性變差,其中,低頻信號的波束逐漸趨向于具有全向性特征的圓形波束,而高頻信號的波束則影響相對較小。當增益匹配時,通過低頻滾降的補償可以得到一致的歸一化波束,而增益失配時,歸一化波束之間變得不一致,因此,增益失配會降低低頻滾降補償的效果。
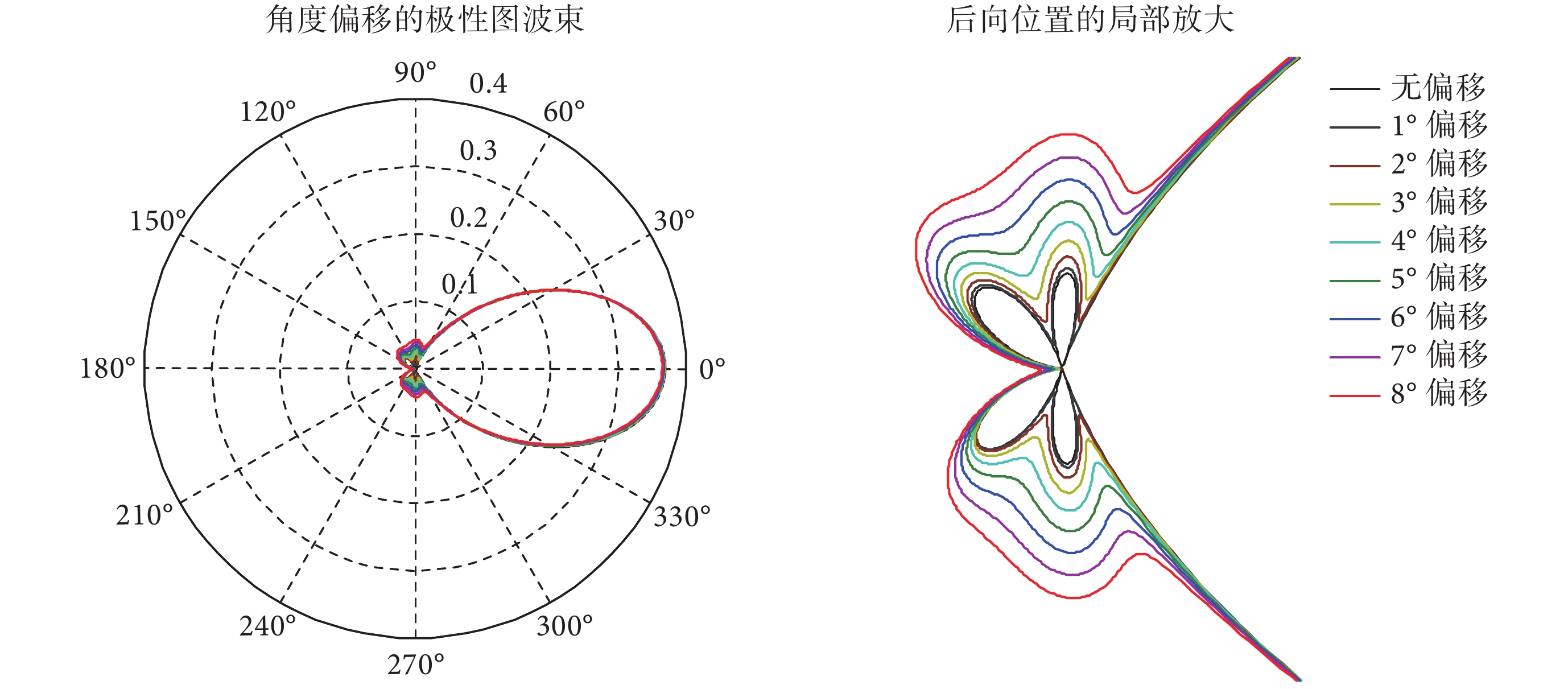
對于電子耳蝸來說,實際使用場景會存在使用者佩戴電子耳蝸時發生偏移以及在走動過程中麥克風產生震動等情形。運動偏移失配對單個全向性麥克風的影響很小,但對方向性麥克風的影響較大。以樓氏電子的超薄單指向/全向組合型麥克風(thin uni-directional/omni-directional microphone pair,TP)為例,每個 TP 型方向性麥克風包含兩個聲管用于信號采集,兩個聲管既可以垂直放置(型號為 TP-24612-000),也可以對稱放置(型號為 TP-24620-000)。聲管垂直放置和對稱放置的這兩類麥克風均可輸出具有心型波束特征的信號,該輸出信號的強弱與聲源方位有關。心型波束有一個方位的系統幅頻響應最大,該方位位于 TP 型麥克風兩個聲管中心點所連接成的幾何線段的一側(另一側是系統幅頻響應最小處)。當發生震動時,單個方向性麥克風的波束形狀本身沒有發生變化,只是束中最大幅頻響應的方位發生了偏移。對于兩個及以上的方向性麥克風組成的系統來說,其震動偏移情況更為復雜,系統的波束形狀本身也發生了變化。以聲管兩端對稱的兩個方向性麥克風為例,當發生震動偏移時(方位角度變化 1~8°),雙指向性麥克風系統的波束變化情況如圖 8 所示。
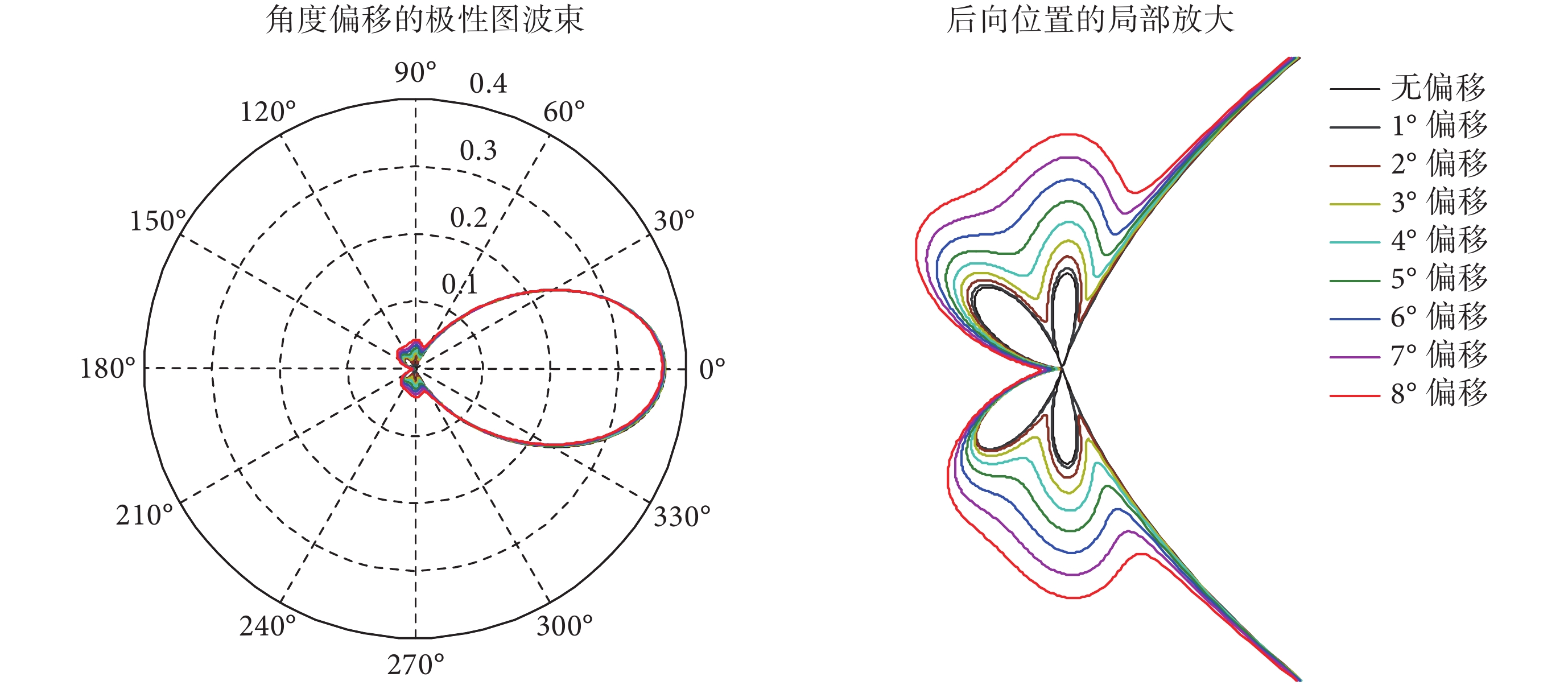 圖8
角度偏移 1~8° 的雙指向性麥克風極性圖對比
Figure8.
Comparison of beam patterns for 1–8° angle offset in dual-microphone system
圖8
角度偏移 1~8° 的雙指向性麥克風極性圖對比
Figure8.
Comparison of beam patterns for 1–8° angle offset in dual-microphone system
從圖 8 中的角度偏移 1~8° 的雙指向性麥克風極性圖對比來看,正向范圍(方位 0~60° 和 300~360° 范圍內)的各個波束互相重疊。該結果表明角度發生偏移后對正向及正向附近方位的系統幅頻響應影響不大,波束之間互相匹配。而側向和后向方位則不同,不同角度偏移所對應的波束差異較大,波束之間互相不一致。由于電子耳蝸使用者在行走或者移動狀態下麥克風會發生一定程度的偏移,從前面的分析可以看到,震動偏移對正向、側向和后向的信號影響不同。而對于電子耳蝸的具體應用場景來說,目標語音信號主要源于正向,也有部分信號源來自側向和后向,因此震動偏移對目標信號的影響及信號補償方式也是難點之一。
3.5 雙耳信號采集及波束變化問題
近年來,電子耳蝸雙耳信號采集受到研究者更多的關注。將兩個麥克風放置在雙耳位置進行信號采集,可以增大麥克風間距。如果雙麥克風佩戴在同一側耳朵,由于尺寸限制,麥克風間距一般設置為 1 cm;而如果放置于耳朵兩側,則麥克風間距可增大到 18 cm。但是,間距的增大會直接改變小間距條件下波束設計的模式,波束形狀會發生明顯變化。以圖 6 中的雙極型、超心型和心型三類波束為例,選取 1 000~8 000 Hz(間隔 1 000 Hz)的 8 個頻率來描述雙耳信號采集的波束特征,如圖 9 所示。
 圖9
雙耳佩戴麥克風的雙麥克風極性圖的波束變化
Figure9.
Changing of beams in beam patterns of dual-microphone system for situation of biauricular distance
圖9
雙耳佩戴麥克風的雙麥克風極性圖的波束變化
Figure9.
Changing of beams in beam patterns of dual-microphone system for situation of biauricular distance
對比圖 6 和圖 9 可以看到,當雙麥克風的距離從小間距的 1 cm 擴展為雙耳間距 18 cm 時,系統所形成的極性圖的特征發生了巨大的變化。第一,小間距條件下的雙極型、超心型和心型波束特征已經不存在,雙耳間距條件下的波束出現了多個指向性的波束旁瓣與波束零點。第二,小間距條件下的雙極型、超心型和心型波束的最大系統幅頻響應的方位都是 0° 的方位,而雙耳間距條件下的波束最大系統幅頻響應的方位則并不一定在 0° 的方位,而且常常同時出現多個最大指向的位置。第三,小間距條件下波束存在低頻滾降特征以及不同頻率的波束之間存在相似性的特征,而在雙耳間距條件下,波束之間的相似性已經消失,而且低頻信號的幅頻響應并沒有比高頻信號的幅頻響應小,低頻滾降的特征也不存在。目前應用在電子耳蝸語音增強的算法往往是基于小間距條件下進行波束設計和噪聲抑制的研究,雙耳信號采集及波束變化問題限制了算法的有效性,因此雙耳間距條件下的算法需要重新進行修正和研究。
4 總結與展望
電子耳蝸在噪聲環境下的言語識別率仍然較低,提升言語識別率需要在電極工藝、言語處理策略和前端信號增強等方面有進一步的研究和技術突破。麥克風陣列波束形成技術和語音增強技術適合用于前端信號采集,并切合電子耳蝸使用者所面對的目標語音和干擾噪聲在空間方位上分離的應用場景。由于尺寸的限制,電子耳蝸實際上更多地采用雙麥克風信號采集的模式。然而,雙麥克風模式不利于獲取豐富的空間方位信息,不利于多噪聲源條件下的語音增強,這方面有待進一步的研究和算法上的突破。本文闡述了麥克風陣列信號采集的方法和波束設計的原理,歸納了目前國內外相關的應用于電子耳蝸的麥克風陣列語音增強方法,并進一步分析了目前存在的關鍵技術難點。本文重點闡述了低頻滾降失真、信號補償中的噪聲去除、電極數量和分辨率的工藝限制、麥克風失配、雙耳信號采集所產生的波束畸變等核心問題。結合近年來的文獻情況,目前有關的研究熱點和趨勢包括雙耳模式信號采集、麥克風失配及補償、虛擬電極陣列、高分辨率策略、去噪技術融合、算法實時性等方面的研究。就近年來的研究熱點和技術進展來看,可以預見,隨著新算法的提出以及關鍵技術難點的突破,麥克風陣列語音增強技術有望進一步提升電子耳蝸在噪聲環境下的言語識別率,從而拓展電子耳蝸在復雜環境下的使用性能,并推動電子耳蝸的廣泛應用和電子耳蝸產業的發展。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
世界衛生組織(World Health Organization,WHO)官網 2018 年 3 月 15 日的統計數據表明:全球已有 4.66 億人患有聽力損失,其中成年人有 4.32 億,兒童有 3 400 萬[1]。遺傳性的疾病、傳染病、分娩綜合征、慢性耳部感染、藥物服用不當、過量噪音以及衰老等因素均能導致聽力損失,其中,12~35 歲年輕人群的聽力損失的重要致病原因是經常處于娛樂環境中的過量噪音之中,而 65 歲以上老年人中有三分之一患有殘疾性聽力損失。聽力損失引起患者不同程度的耳聾,如輕度耳聾、中度耳聾、重度耳聾和極重度耳聾等。第二次全國殘疾人抽樣調查的數據顯示,我國聽力殘疾人數有 2 780 萬人,其中重度和極重度耳聾患者高達 739 萬人[2]。
不同的聽力損失可依據病因及程度來選取相應的治療模式,常見的方法包括藥物治療、手術治療、佩戴助聽設備和植入電刺激設備[3]。其中,植入電子耳蝸是極重度耳聾以及全聾患者恢復聽力感知能力的有效方式。對于正常人來說,外耳和中耳是外界聲音信號的機械傳導裝置,其中,外耳用來收集聲音,中耳的聽小骨鏈用來放大機械振動。由中耳放大后的信號傳送到內耳,通過毛細胞把聲信號轉成生物電信號,再由生物電信號刺激聽覺神經來產生聽覺感知。耳聾患者的耳蝸內殘留的聽神經可以通過電刺激的模式使其興奮,該興奮沿聽覺通路傳遞至大腦從而產生類似正常人的聽覺感知能力。因此,電子耳蝸作為一種替代裝置,直接將語音信號轉換為電脈沖信號,刺激聽神經來產生相似的神經發放模式和聽覺感知。美國國立耳聾與其他交流障礙性疾病研究所(National Institute on Deafness and Other Communication Disorders,NIDCD)于 2017 年 3 月 6 日公布的數據表明:目前全球電子耳蝸植入數已達 324 200 個[4]。
為了提高電子耳蝸的言語識別率,目前的熱點研究方法包括精細結構編碼[5]、電流導引[6]、電場聚焦[7]、光學耳蝸[8-10]、虛擬電極[11-13]、麥克風陣列[14-17]等。其中,麥克風陣列的方法通過多個信號采集點獲取空間信息,適合應用于電子耳蝸使用場景中目標信號和干擾信號方位不同的情形。通過提高前端信號采集的信噪比或者結合語音增強的算法來提升電子耳蝸言語識別率,是近年來受到較多關注的重要研究方法。
本文詳細介紹了近年來利用麥克風陣列進行電子耳蝸前端語音增強的主要方法和研究進展,并針對麥克風陣列存在的問題進行分析和探討,歸納和總結了目前存在的研究難點,最后指出了未來的發展方向。
1 麥克風陣列信號采集和波束形成原理
在空間不同位置以特定排列的方式來放置麥克風,形成麥克風陣列的信號采集模式,其原理如圖 1 所示。
圖1
麥克風陣列信號采集原理圖
Figure1.
Schematic diagram of signal acquisition principle in microphone array
圖 1 中,在空間里以線性或者特定結構排列 n 個麥克風用于采集聲音信號。由于空間位置的差異,所采集到的 n 個通道的信號是不同的。麥克風陣列的方法對每個通道的信號分別給予延遲系數和加權系數,然后將所有信號疊加來形成總的輸出信號。對于整個麥克風陣列系統來說,延遲系數和加權系數決定著極性圖。該方法可以通過系數調整來設計滿足電子耳蝸特定應用場景的極性圖,以實現目標信號的增強和干擾信號的抑制。對于 n 個麥克風來說,麥克風陣列系統的總輸出 y(t) 的表達式如式 (1) 所示:
|
式中 βi 和 τi 分別是第 i 個麥克風的加權系數和延遲系數。
對于不同的加權系數和延遲系數,可以形成不同的波束指向。在電子耳蝸應用中,由于尺寸的限制,雙麥克風信號采集是常見的模式,在該模式下可產生全向型、雙極型、超心型和心型等常規波束。
2 電子耳蝸麥克風陣列語音增強的方法
2.1 固定波束形成方法
固定波束形成方法適合應用在固定方位的目標聲源的情形,所設計波束的極性圖固定。在電子耳蝸實際使用的場景中,面對面交談時的正向方位是目標信號的方位,而干擾噪聲則來源于其他方位。在此場景中,所設計的波束需要對正向方位的信號有最大的系統響應,其他方位的系統響應則應該較小。由于電子耳蝸尺寸的限制,目前文獻中電子耳蝸信號采集一般采用雙麥克風模式,可形成雙極型、超心型和心型等常見的波束,這三類波束最大的系統響應方位均在正向。如果對其中一個麥克風增加一個增益參數,則可形成更加多樣的極性圖,例如,可形成從正向到后向單調平滑過渡的極性圖[18]。該極性圖所對應的不同方位的系統幅頻響應如圖 2 所示。
圖2
特定參數條件下的不同方位的系統幅頻響應曲線
Figure2.
System amplitude based on specific parameters
雙極型、超心型和心型是常見的極性圖,共同特點是正向方位的系統響應最大,區別在于系統零點的位置。雙極型極性圖的系統零點在 90° 和 270° 方位,可用于去除兩側的干擾信號;心型極性圖的系統零點在 180° 方位,可用于去除后向的干擾信號;超心型的系統零點在側向和后向之間,可用于去除側后向的干擾信號。圖 2 是針對特定場景設計極性圖所對應的系統幅頻響應曲線,可以看到,正向方位的系統響應最大,側向和后向的系統響應單調平緩降低。該極性圖可用于增強方位為正向的目標信號,同時可以減少其他方位信號的突然變化,有助于提高電子耳蝸的舒適度。從上面的分析可以看到,各類固定波束形成方法的參數固定,極性圖固定,主要針對特定的應用場景。
2.2 自適應波束形成方法
對于單一噪聲源和噪聲源方位時變的情形來說,可采用自適應波束形成的方法。雙麥克風系統可通過延遲參數的設置,形成特定波束指向的極性圖。在該極性圖中,存在一個系統幅頻響應為零的點,不同的延遲參數對應的零點方位不同。自適應波束形成方法是通過對噪聲特征和方位進行參數提取,自適應地調整延遲參數,讓零點的方位一直跟隨著干擾噪聲的方位,從而抑制干擾噪聲和增強目標信號[19-21]。以雙麥克風系統為例,不同的延遲參數所對應的極性圖和系統零點如圖 3 所示。
圖3
不同延遲參數值的極性圖和系統零點
Figure3.
Beam patterns and system nulls for different delay parameters
圖 3 中的 d 為雙麥克風的間距,c 為聲音在空氣中的傳播速度,本文取 340 m/s。從圖 3 可以看到,當改變延遲值時,系統幅頻響應最小值(即系統零點)的方位會發生變化。例如,延遲 0 時,系統零點在 90° 和 270° 方位;延遲 d/c 時,系統零點在 180° 方位;而當延遲在 0 和 d/c 之間時,系統零點分別在 90~180° 和 180~270° 區間內有兩個對稱的系統零點。自適應波束形成方法是通過對干擾信號的估計和方位的判斷,自適應地實時調整參數,讓系統零點始終跟隨著干擾噪聲方位,從而實現噪聲去除。
2.3 雙耳電子耳蝸的方法
Zeng[22]在報道中指出,在目前的方向性麥克風或者噪聲去除技術用于前端聲音處理的方法上,最為成功的是兩個方面:一是雙邊或者雙耳電子耳蝸的應用;二是結合助聽器和電子耳蝸的使用,尤其是對于殘存少量低頻聲音聽力的情形。雙耳佩戴助聽器和電子耳蝸的示意圖如圖 4 所示。
圖4
雙耳佩戴電子耳蝸和助聽器的示意圖
Figure4.
A schematic diagram of binaural cochlear and hearing aids
Lockwood 等[23]采用了非因果最優濾波器方法設計頻域波束形成器,把兩個麥克風放在兩側雙耳位置(相隔約 15 cm)。該算法可以較低失真地提取目標信號,并具有計算量較小的優點。對于電子耳蝸使用者來說,植入電子耳蝸往往是因為該側耳存在重度聾或者極重度聾的情況。如果對側耳還存有部分殘余的毛細胞,則可在該對側耳佩戴助聽器,形成雙耳的模式[24-25]。研究表明,雙耳模式的電子耳蝸有助于提高使用者的言語識別能力和聲源定位能力;另一方面,當對側耳朵中存有殘留的聲音感知能力,則雙側耳朵同時佩戴助聽器和植入電子耳蝸有助于改善噪聲環境中的言語識別[26-27]。中國科學技術大學等機構的研究表明:具有正常聽力的被試者收聽電子耳蝸聲學模擬語音時,如果在他們的另一側耳朵中加入低頻語音信息,則能夠顯著提升語音成形噪聲中的中文語音識別[28]。
2.4 單通道語音增強技術和麥克風陣列結合方法
單通道的語音增強技術對平穩噪聲有較好的去除效果,而麥克風陣列的方法則適合應用在目標信號和干擾噪聲在空間方位上分離的情形,兩者的結合是近年來電子耳蝸前端語音增強技術的熱點方法之一。單通道語音增強技術和雙麥克風陣列相結合的方法可增加方位信息,有助于更大幅度地提高信噪比。傳統的方法是用線性約束最小方差來改進維納濾波器,而雙耳頻域最小方差算法則把失真最小化從時域應用到了頻域[23]。Kates 等[29]則設計了一個 5 麥克風的陣列,并結合了最小方差無畸變響應的自適應波束形成技術,最大限度地抑制噪聲并實現了自適應的噪聲控制。針對小間距的電子耳蝸實際應用場景,清華大學聲學與認知工程實驗室的宮琴團隊[30]提出了基于譜參數分析和估計的雙通道語音增強算法。該算法適合用于去除單一噪聲源的音樂噪聲和語音噪聲,如圖 5 所示。
圖5
單通道語音增強技術和麥克風陣列結合的去噪方法
Figure5.
Noise suppression method based on the combination of single channel speech enhancement technology and microphone array technology
圖 5 描述的是一種典型的單通道語音增強技術和麥克風陣列結合方法。該方法通過前端的兩個麥克風來采集目標信號,對其中一個麥克風給予延遲,然后組合形成兩路輸出。兩路信號由于包含了空間方位信息,它們的目標信號和干擾噪聲信號的成分不同,再結合單通道語音增強技術則可以實現不同方位干擾信號的消除。
2.5 麥克風陣列語音增強方法的總結和言語識別率的關聯分析
前面闡述了目前在電子耳蝸應用里最為常用的語音增強算法,其共同特征是通過空間中放置若干個聲音傳感器來增加空間方位信息,主要區別是所結合的語音增強技術和具體的應用場景。在日常使用場景中,電子耳蝸使用者最迫切的應用需求是提高面對面交談時的言語識別率,源于正向的信號被認為是目標信號,而干擾噪聲則源于其他方位。因此,麥克風陣列的方法通過空間不同位置的信號采集來獲取方位信息,再結合特定的語音處理技術分離出目標信號。在上述的四大類語音增強技術中,固定波束形成方法的參數固定,因此波束指向也固定,主要應用在噪聲方位固定的場合,計算量低。自適應波束形成方法的參數不固定,參數需要依據噪聲方位的變化而實時更新,計算量大,適合應用在移動噪聲源和非確定噪聲源的場合。雙耳電子耳蝸的方法則主要是用于患者存有部分殘余毛細胞的情形,該方法通過兩耳同時佩戴助聽器和植入電子耳蝸來增加一個聲音信號的獲取渠道,充分利用了患者殘存的少量低頻聲音聽力感知能力,有助于提升使用者的聲音定位能力。單通道語音增強技術和麥克風陣列結合方法則非常多樣,主要目標是提高信噪比和去除干擾噪聲。由于單通道語音增強技術已經比較成熟,將該技術與麥克風陣列所提供的空間方位信息相結合,有助于提高去噪的性能,缺點是計算量較大。
言語識別率是電子耳蝸語音增強技術評價的重要指標,在具體實驗研究中,字出錯率、詞出錯率和句子出錯率等都是測試指標。目前的麥克風陣列語音增強技術是通過設計特定的極性圖和提高信噪比來實現的,其實驗基礎是前期學者對電子耳蝸使用者的言語識別率和信噪比的關聯性研究。例如,曾凡鋼的研究表明,植入電子耳蝸的耳聾患者在安靜環境下的言語識別率較高,在噪聲環境下的言語識別率大幅度降低。Nelson 的實驗研究表明,要達到 50% 的句子識別率,正常人所需要的信噪比約 ? 10 dB,而植入電子耳蝸的耳聾患者需要的信噪比則是 5~15 dB。因此,通過設計指向目標信號的極性圖或者通過語音增強算法來提高信噪比,都可以讓電子耳蝸使用者恢復在類似“安靜”環境的使用場景,有助于提高言語識別率。
3 麥克風陣列語音增強技術在電子耳蝸應用中存在的問題
3.1 低頻滾降失真
麥克風陣列的系統響應表達式是一個多參數的函數,其中頻率是影響系統響應的主要參數之一。以雙麥克風在間距為 1 cm 為例,選取 1 000~ 8 000 Hz(間隔 1 000 Hz)的 8 個頻率來描述其波束特征,如圖 6 所示。
圖6
不同頻率條件下的雙麥克風極性圖
Figure6.
Beam patterns of dual-microphone system based on different frequencies
從圖 6 可以看到,不同頻率條件下的系統極性圖是不同的。在電子耳蝸應用場景條件下(間距 1 cm)可以看到:頻率越大則系統響應越大,頻率越小則系統響應越小。對輸入為低頻信號來說,經過麥克風系統后的不同方位的增益系數均比高頻信號小,由此產生了麥克風陣列中的低頻滾降現象[31-33]。低頻滾降是麥克風陣列波束形成里的特有現象,其結果是導致信號在不同頻段的能量重新分布,并且主要是衰減了低頻信號的能量從而產生了信號失真,為此,需要對低頻信號給予額外的增益來調整和均衡不同頻段的信號輸出。從理論上說,一階差分麥克風的低頻滾降是 6 dB/倍頻程,而二階差分麥克風的低頻滾降是 12 dB/倍頻程。從圖 6 可以看到,雖然不同頻率條件下的波束大小不同,但波束之間存在較大的相似性,通過適當的信號補償方法可以實現不同頻率條件下的各個波束重新匹配。基于電子耳蝸實際的參數特征,清華大學等研究機構提出了基于雙麥克風的歸一化波束形成方法和多參數條件下的低頻滾降補償算法,這些算法采用線性化的方式進行低頻滾降補償,具有計算復雜度低的特點[34]。
3.2 信號補償中的噪聲過度放大
對于麥克風陣列所存在的低頻滾降問題,目前的方法是調整不同頻段的增益。由于低頻信號的系統響應小,因而給予低頻信號的增益會更大。但是,電子耳蝸所采集的信號既包含目標語音信號,也包含環境噪聲信號,而日常應用場景中的環境噪聲信號則主要以低頻信號為主。以實際采集的語音信號和在餐廳場景下的噪聲信號為例來進行說明,其頻譜對比如圖 7 所示。
圖7
語音信號和環境噪聲的頻譜對比
Figure7.
Spectrum comparison of speech signal and environ mental noise
從實測的常見環境噪聲(餐廳中嘈雜的場景)的頻譜圖中可以看到,常見環境噪聲的主要能量集中在低頻的頻段位置上。麥克風陣列會導致低頻滾降的產生,對于語音信號來說,其頻譜能量也是集中在低頻的位置。但是,低頻滾降后的信號其低頻能量會受到更大的削減,因此,需要對語音信號進行能量補償。由于環境噪聲來源多樣并且含有隨機噪聲,陣列中的各個麥克風采集到的噪聲信號具有較大的非相關性,因而噪聲的低頻滾降沒有語音信號明顯。電子耳蝸前端的麥克風采集的信號包含了目標語音信號,也包含應用場景中的環境噪聲信號。當麥克風陣列系統中發生低頻滾降失真后,對信號的調整主要是增大低頻信號的增益。此時由于環境噪聲主要集中在低頻段,其結果是環境噪聲會被過度地放大,導致信號補償后的信噪比并沒有相應地提高,因此影響了電子耳蝸的言語識別率[34]。對環境噪聲過度放大的抑制是麥克風陣列低頻滾降補償中的關鍵難點之一。由于信號過程中語音和噪聲同時被采集,頻譜間相互重疊,而且環境噪聲本身也具有多樣性,因而環境噪聲的抑制在技術上具有復雜性。
3.3 電極數量限制及信號分辨率問題
麥克風陣列應用在電子耳蝸前端信號采集中可以增加空間方位信息,但是濾波器組本身有限的頻帶限制了信號提取的質量,并導致目標信號的信息丟失。電子耳蝸濾波器組的頻帶數量是由電極陣列的數量決定的,濾波器組的每個頻帶與電子耳蝸的一個電極對應。電子耳蝸言語識別率難以提高的根源是電極設計方面在近年來幾乎沒有進展。近幾十年來,電子耳蝸中所使用的電極的變化主要是形狀從球形和環形到盤形(平面型)的變化和電極陣列長度和厚度的變化,但電極的尺寸和電極與神經元之間的數量失配卻沒有改變。有學者研究指出:從 1980 年到 1995 年這 15 年間,電子耳蝸相關文獻的發表速度很快,呈現指數增長的速度,相應地,電子耳蝸的句子識別率也提高很快,從 0% 到接近 80%;而在隨后的 20 年里(1995 年—2015 年),文獻發表速度仍很快,但句子識別率卻沒什么提高,其原因是缺乏耳蝸電極與耳蝸神經之間接口這方面的技術改進[22]。電極的尺寸是神經元尺寸的 1 000 倍以上,也就是說電極數量不到神經元數量的千分之一。目前電子耳蝸電極的特點是尺寸大和數量少,其結果是電極的刺激位置太寬和頻率分辨率太低,電子耳蝸電極與耳蝸神經的數量失配限制了電子耳蝸性能的提升。
3.4 麥克風間的增益失配和運動偏移失配問題
在多麥克風應用中,麥克風采集的信號存在傳輸衰減,并引起了不同麥克風間的增益失配問題。仿真實驗表明,當雙麥克風發生增益失配時,不同頻率的波束形狀的相似性變差,其中,低頻信號的波束逐漸趨向于具有全向性特征的圓形波束,而高頻信號的波束則影響相對較小。當增益匹配時,通過低頻滾降的補償可以得到一致的歸一化波束,而增益失配時,歸一化波束之間變得不一致,因此,增益失配會降低低頻滾降補償的效果。
對于電子耳蝸來說,實際使用場景會存在使用者佩戴電子耳蝸時發生偏移以及在走動過程中麥克風產生震動等情形。運動偏移失配對單個全向性麥克風的影響很小,但對方向性麥克風的影響較大。以樓氏電子的超薄單指向/全向組合型麥克風(thin uni-directional/omni-directional microphone pair,TP)為例,每個 TP 型方向性麥克風包含兩個聲管用于信號采集,兩個聲管既可以垂直放置(型號為 TP-24612-000),也可以對稱放置(型號為 TP-24620-000)。聲管垂直放置和對稱放置的這兩類麥克風均可輸出具有心型波束特征的信號,該輸出信號的強弱與聲源方位有關。心型波束有一個方位的系統幅頻響應最大,該方位位于 TP 型麥克風兩個聲管中心點所連接成的幾何線段的一側(另一側是系統幅頻響應最小處)。當發生震動時,單個方向性麥克風的波束形狀本身沒有發生變化,只是束中最大幅頻響應的方位發生了偏移。對于兩個及以上的方向性麥克風組成的系統來說,其震動偏移情況更為復雜,系統的波束形狀本身也發生了變化。以聲管兩端對稱的兩個方向性麥克風為例,當發生震動偏移時(方位角度變化 1~8°),雙指向性麥克風系統的波束變化情況如圖 8 所示。
圖8
角度偏移 1~8° 的雙指向性麥克風極性圖對比
Figure8.
Comparison of beam patterns for 1–8° angle offset in dual-microphone system
從圖 8 中的角度偏移 1~8° 的雙指向性麥克風極性圖對比來看,正向范圍(方位 0~60° 和 300~360° 范圍內)的各個波束互相重疊。該結果表明角度發生偏移后對正向及正向附近方位的系統幅頻響應影響不大,波束之間互相匹配。而側向和后向方位則不同,不同角度偏移所對應的波束差異較大,波束之間互相不一致。由于電子耳蝸使用者在行走或者移動狀態下麥克風會發生一定程度的偏移,從前面的分析可以看到,震動偏移對正向、側向和后向的信號影響不同。而對于電子耳蝸的具體應用場景來說,目標語音信號主要源于正向,也有部分信號源來自側向和后向,因此震動偏移對目標信號的影響及信號補償方式也是難點之一。
3.5 雙耳信號采集及波束變化問題
近年來,電子耳蝸雙耳信號采集受到研究者更多的關注。將兩個麥克風放置在雙耳位置進行信號采集,可以增大麥克風間距。如果雙麥克風佩戴在同一側耳朵,由于尺寸限制,麥克風間距一般設置為 1 cm;而如果放置于耳朵兩側,則麥克風間距可增大到 18 cm。但是,間距的增大會直接改變小間距條件下波束設計的模式,波束形狀會發生明顯變化。以圖 6 中的雙極型、超心型和心型三類波束為例,選取 1 000~8 000 Hz(間隔 1 000 Hz)的 8 個頻率來描述雙耳信號采集的波束特征,如圖 9 所示。
圖9
雙耳佩戴麥克風的雙麥克風極性圖的波束變化
Figure9.
Changing of beams in beam patterns of dual-microphone system for situation of biauricular distance
對比圖 6 和圖 9 可以看到,當雙麥克風的距離從小間距的 1 cm 擴展為雙耳間距 18 cm 時,系統所形成的極性圖的特征發生了巨大的變化。第一,小間距條件下的雙極型、超心型和心型波束特征已經不存在,雙耳間距條件下的波束出現了多個指向性的波束旁瓣與波束零點。第二,小間距條件下的雙極型、超心型和心型波束的最大系統幅頻響應的方位都是 0° 的方位,而雙耳間距條件下的波束最大系統幅頻響應的方位則并不一定在 0° 的方位,而且常常同時出現多個最大指向的位置。第三,小間距條件下波束存在低頻滾降特征以及不同頻率的波束之間存在相似性的特征,而在雙耳間距條件下,波束之間的相似性已經消失,而且低頻信號的幅頻響應并沒有比高頻信號的幅頻響應小,低頻滾降的特征也不存在。目前應用在電子耳蝸語音增強的算法往往是基于小間距條件下進行波束設計和噪聲抑制的研究,雙耳信號采集及波束變化問題限制了算法的有效性,因此雙耳間距條件下的算法需要重新進行修正和研究。
4 總結與展望
電子耳蝸在噪聲環境下的言語識別率仍然較低,提升言語識別率需要在電極工藝、言語處理策略和前端信號增強等方面有進一步的研究和技術突破。麥克風陣列波束形成技術和語音增強技術適合用于前端信號采集,并切合電子耳蝸使用者所面對的目標語音和干擾噪聲在空間方位上分離的應用場景。由于尺寸的限制,電子耳蝸實際上更多地采用雙麥克風信號采集的模式。然而,雙麥克風模式不利于獲取豐富的空間方位信息,不利于多噪聲源條件下的語音增強,這方面有待進一步的研究和算法上的突破。本文闡述了麥克風陣列信號采集的方法和波束設計的原理,歸納了目前國內外相關的應用于電子耳蝸的麥克風陣列語音增強方法,并進一步分析了目前存在的關鍵技術難點。本文重點闡述了低頻滾降失真、信號補償中的噪聲去除、電極數量和分辨率的工藝限制、麥克風失配、雙耳信號采集所產生的波束畸變等核心問題。結合近年來的文獻情況,目前有關的研究熱點和趨勢包括雙耳模式信號采集、麥克風失配及補償、虛擬電極陣列、高分辨率策略、去噪技術融合、算法實時性等方面的研究。就近年來的研究熱點和技術進展來看,可以預見,隨著新算法的提出以及關鍵技術難點的突破,麥克風陣列語音增強技術有望進一步提升電子耳蝸在噪聲環境下的言語識別率,從而拓展電子耳蝸在復雜環境下的使用性能,并推動電子耳蝸的廣泛應用和電子耳蝸產業的發展。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。