麥克風陣列語音增強的方法是通過采用多個麥克風同時進行語音信號采集,從而增加了空間方位的信息,因此有助于提高電子耳蝸在噪聲環境下的言語識別率。鑒于尺寸的限制,電子耳蝸使用的麥克風數量不能太多,從而限制了麥克風陣列形成波束的設計。為了兼顧電子耳蝸尺寸的限制條件并增加信號采集空間方位信息,本文提出了一種采用兩個超薄單指向/全向組合型麥克風(TP)的語音增強和波束形成算法,每個 TP 麥克風均單獨包含兩個聲管用于信號采集,達到了增加整體空間方位信息的目的。本文探討了不同增益向量條件下波束形成的特性和雙麥克風間距對波束的影響,為雙麥克風語音增強技術在電子耳蝸的應用提供有價值的理論分析和工程參數。
引用本文: 陳又圣, 陳艷. 電子耳蝸前端雙麥克風語音增強及波束形成算法研究. 生物醫學工程學雜志, 2019, 36(3): 468-477. doi: 10.7507/1001-5515.201810025 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
電子耳蝸是一種通過電信號刺激聽覺神經并使耳聾患者產生聽覺感知的電子裝置,是目前治療重度聾和全聾患者的有效方法[1-3]。美國國立耳聾與其他交流障礙性疾病研究所(National Institute on Deafness and Other Communication Disorders,NIDCD)官網 2017 年 3 月 6 日公布的數據表明:目前全球電子耳蝸植入數已有 32 萬余個。經過近幾十年的發展,電子耳蝸的價格逐漸降低,進一步促進了電子耳蝸的廣泛應用。據 Zeng[4]的研究報道,2017 年國內外電子耳蝸生產廠商在我國政府招標采購中的投標價格均有了大幅度的下降。從 2011-2016 年,其售價由 25 000 美元/個降到 6 030 美元/個,而到 2017 年時僅為 5 490 美元/個。同時,技術的發展提高了電子耳蝸的性能,使用者已經能夠順暢地進行打電話、面對面說話等日常溝通和交流,但是電子耳蝸在噪聲環境和各種失配場景條件下的言語識別率仍然較低[5-7]。提高電子耳蝸前端信號采集的質量有助于提升電子耳蝸識別率,目前的研究方法有兩類,分別是單通道的語音增強方法和基于麥克風陣列的語音增強方法。
由于電子耳蝸體積的限制,麥克風陣列中實際能采用的麥克風數量有限,常見的方法是雙麥克風波束形成方法[8-10]或雙耳模式的語音增強方法[11-13]。在電子耳蝸前端語音增強應用中,固定波束形成方法是常見的語音增強方法,通過延遲或者增益向量來實現特定的波束指向[14],其特點是計算量少,適合電子耳蝸的低功耗要求,缺點是極性圖固定,信噪比提高有限。而對于運動噪聲來說,自適應波束形成方法是另一種常見的語音增強方法,該方法通過對噪聲的方位進行估計可使系統的最小輸出跟隨噪聲方位變化,其優點是適宜于運動噪聲的情形,缺點是僅通過延遲等參數調整極性圖,波束指向簡單并且計算量過大[8, 10]。為了進一步提高噪聲去除的效果,現已將單通道的語音增強技術用于麥克風陣列語音增強算法中,Lockwood 等[11]采用非因果最優濾波器來設計頻域波束形成器,Kate 等[15]則把最小方差無畸變響應的自適應波束形成技術用于由 5 個麥克風所組成的信號采集陣列,可較好地適應復雜噪聲的去除,但過多的麥克風數量不能滿足電子耳蝸較小的體積限制要求。本文前期研究工作里提出了一種采用兩個全向性麥克風的基于實時譜估計的雙通道語音增強算法[16],該算法可用于去除方向性噪聲和競爭性語音噪聲,具有高信噪比的特點。但是,前期所提出的雙全向性麥克風模式在空間上只有兩個信號采集點,所能獲取的空間方位信息有限,不利于設計復雜的具有多種波束指向的語音增強系統。考慮到電子耳蝸尺寸的限制和復雜波束設計的需求,本文選用具有兩個聲管的超薄單指向/全向組合型麥克風(thin uni-directional/omni-directional microphone pair,TP)來設計雙麥克風信號采集系統,并進一步通過增益向量的選取來設計可滿足使用者特定需求的雙麥克風系統,然后探討了麥克風間距對系統響應的影響,并歸納了本系統的應用條件。本文研究在雙麥克風波束形成算法、小間距條件的波束設計和電子耳蝸語音增強方面進行了理論探索,或對今后的電子耳蝸前端語音增強的研究和工程應用奠定理論基礎并提供技術參數。
1 雙 TP 麥克風陣列結構及信號采集分析
本文選用具有雙聲管的 TP 型麥克風模塊用于電子耳蝸前端信號采集。TP 型麥克風包含兩個聲管,兩個聲管的指向相互垂直。根據尺寸資料可以計算出兩個聲管中心點之間的距離(d)。需注意的是,來自不同方位的聲音信號被同一個 TP 型麥克風的兩個聲管采集到的時間是不同的,存在一個延遲時間,延遲時間與聲音信號的方位角度有關。此外,兩個聲管采集到信號后,TP 型麥克風模塊還會對其中一個聲管采集到的信號進行一個額外的延遲,并由此形成不同方位的波束指向。按照 TP 型麥克風技術說明,該麥克風可以產生兩路輸出信號,既可輸出全向性信號,也可輸出心型極性圖(cardioid beam pattern)的指向性信號。其中,全向性信號為其中一個采集聲管的信號,而心型極性圖的指向性信號所設置的額外延遲時間(τ)是通過 τ = d/c 計算得到的,其中 d 為前面計算得到的兩個聲管中心點之間的距離,本文取 5.24 × 10?3 m;c 為聲音在空氣中的傳播速度,本文取 340 m/s;因此本文計算得到的 τ 的參數值是 1.54 × 10?5 s。麥克風兩個聲管之間的距離 d 是固定的,但兩個 TP 型麥克風之間的間距(L)則是可調的。
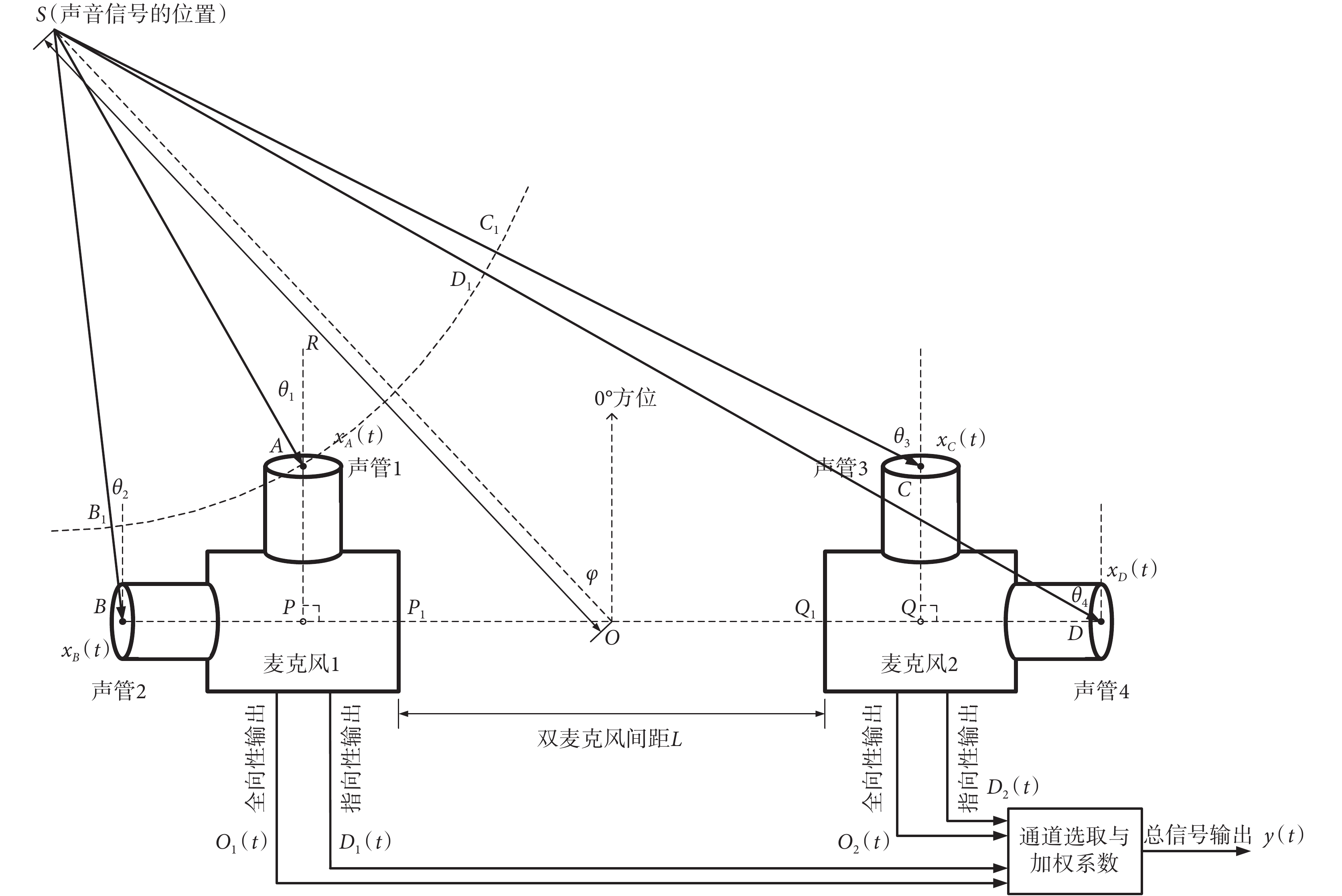
本文所設計的雙麥克風信號采集模式如圖 1 所示。在圖 1 中,TP 型麥克風 1 包含聲管 1 和聲管 2,麥克風 2 包含聲管 3 和聲管 4。定義聲管 1 和聲管 3 所面向的方位是 0°(正向,對應電子耳蝸使用者所面對的方位),按逆時針定義其他各個方位,左側半圈的角度范圍是 0°~180°,右側半圈的角度范圍是 0°~? 180°,則聲管 2 對應的方位是 90°,聲管 4 對應的方位是 ? 90°。用極坐標方式定義所要采集聲音信號的位置 S,S 點距離兩個麥克風中心點 O 的距離為 R,與 0° 方位所在直線的夾角為 φ。4 個聲管分別采集從 S 處傳輸過來的聲音信號,并分別形成全向性輸出信號[O1(t)和 O2(t)]和指向性輸出信號[D1(t)和 D2(t)],然后形成 4 路輸出信號,對信號進行通道選擇和給予增益向量形成總的輸出信號[y(t)],不同的增益向量可用于設計具有特定波束指向的語音增強系統。
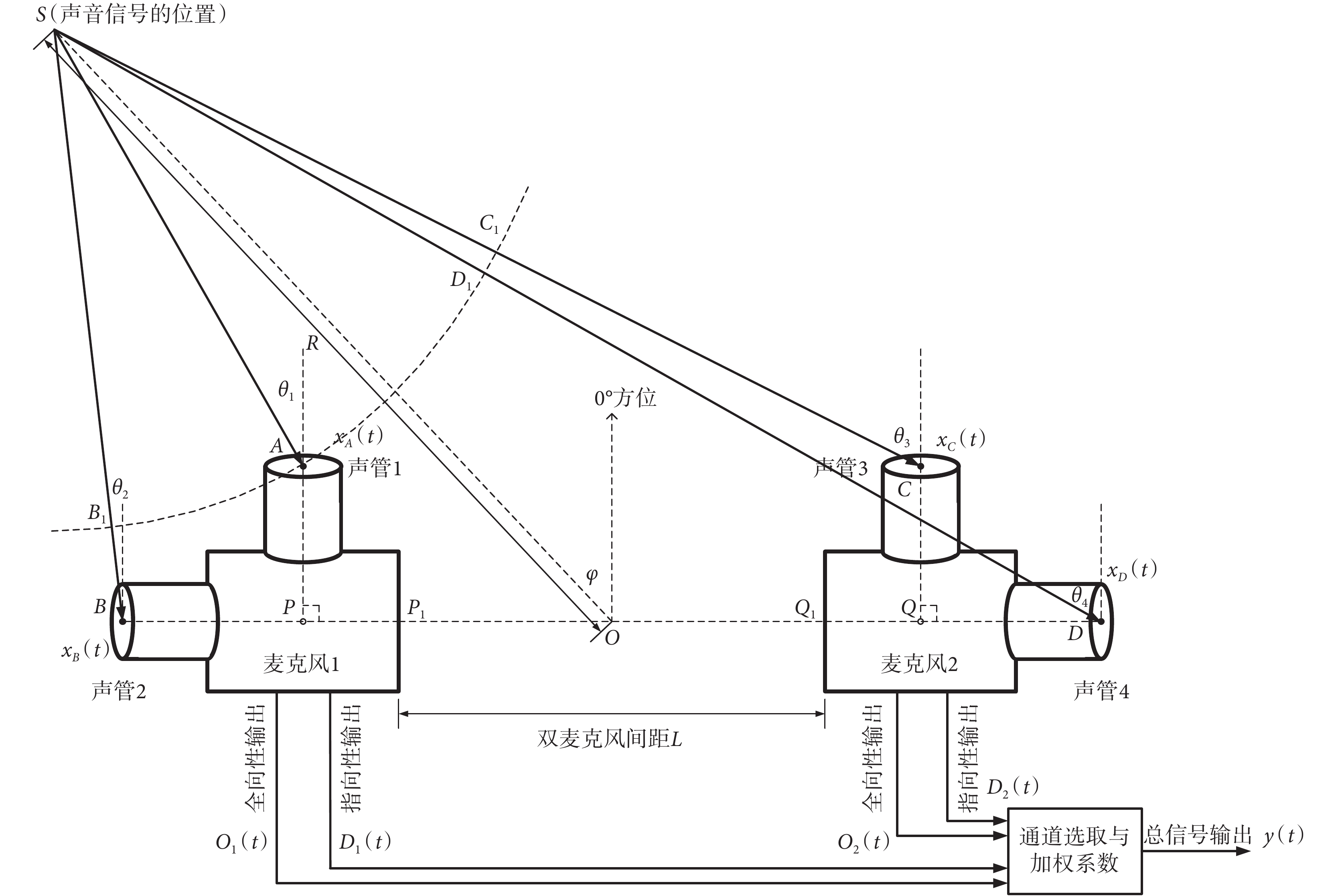 圖1
雙麥克風系統信號采集原理圖
Figure1.
Schematicdiagram of signal acquisition principle in dual-microphone system
圖1
雙麥克風系統信號采集原理圖
Figure1.
Schematicdiagram of signal acquisition principle in dual-microphone system
如圖 1 所示,標記了聲管 1、2、3、4 的中心位置為 A、B、C 和 D,與 S 點連線和 0° 方位所在直線的夾角分別是 θ1、θ2、θ3 和 θ4,標記麥克風 1 兩個垂直聲管中軸線交點為 P,麥克風 2 兩個垂直聲管中軸線交點為 Q,BP 延長線與麥克風 1 的外殼交點為 P1,DQ 延長線與麥克風 2 的外殼交點為 Q1,P1Q1 為雙麥克風的間距,標記為 L,而圖中的∠PBA = ∠QDC = 51.21°。假設 A 處采集到的聲音信號為 xA(t),則 B、C 和 D 處由于距離不同所采集到的聲音信號 xB(t)、xC(t)和 xD(t)也不同,信號之間存在延遲時間。在圖中,B、C 和 D 處采集到的聲音信號相對于 A 點采集到的聲音分別有延遲距離 BB1、CC1 和 DD1,用 x(t)簡化表示 xA(t),則根據圖中的幾何關系,可以得到信號 xB(t)、xC(t)和 xD(t)的表達式如式(1)~式(3)所示:
 |
 |
 |
式中,t 為信號表達式所對應函數的時間變量,c 為聲音在空氣中的傳播速度。
雙麥克風模塊放置在耳朵旁,由于電子耳蝸體積的限制,麥克風的間距 L 不能太大(一般設置為 1 cm 左右)。而圖 1 中的 R 為聲源距離,一般面對面交流的距離為 1~2 m,而會議、電影院等場景的距離則可以超過 10 m。因此,相對于雙麥克風極小的間距來說,本文所探討的聲源可認為是遠場的情形,該情形有助于本文對信號采集進行簡化。當聲源距離相對較遠時,聲音信號可近似認為是平行傳播,圖 1 中的信號采集角 θ1、θ2、θ3 和 θ4 與聲源信號的方位角 φ 相同。近場時聲源信號的位置需要由方位角 φ 和距離 R 確定,而遠場時聲源信號簡化為用方位角 φ 來表征。對式(1)~式(3)進行簡化,分別得到簡化后的 xB(t)、xC(t)和 xD(t)。對于 TP 型麥克風來說,指向性輸出信號對應的內部固定延遲時間是 τ = d/c,進而得到麥克風 1 的全向性輸出信號 O1(t)、指向性輸出信號 D1(t)和麥克風 2 的全向性輸出信號 O2(t)、指向性輸出信號 D2(t),分別如式(4)~式(7)所示:
 |
 |
 |
 |
式(4)~式(7)是通過幾何關系計算出的全向性輸出信號和指向性輸出信號的通用公式,由于 TP 型麥克風有具體的尺寸(PP1 = 1.55 × 10?3 m、QQ1 = 1.55 × 10?3 m、PP1 + QQ1 = 3.10 × 10?3 m、BP = 3.62 × 10?3 m、PA = 2.91 × 10?3 m)以及相關參數( = 51.21°、d = 5.24 × 10?3 m、c = 340 m/s),進一步代入對應的參數可以對全向性輸出信號和指向性輸出信號的公式進行簡化,得到如式(8)~式(11)所示的結果:
= 51.21°、d = 5.24 × 10?3 m、c = 340 m/s),進一步代入對應的參數可以對全向性輸出信號和指向性輸出信號的公式進行簡化,得到如式(8)~式(11)所示的結果:
 |
 |
 |
 |
對麥克風 1 的全向性輸出信號 O1(t)、指向性輸出信號 D1(t)和麥克風 2 的全向性輸出信號 O2(t)、指向性輸出信號 D2(t)給予通道選取和增益向量,可以得到式(12)中的總的信號輸出 y(t):
 |
式中 βi(i = 1,2,3,4)是增益向量的 4 個系數,系數取不同數值可組成不同的增益向量,進而形成特定波束指向的極性圖,而當 βi 直接取值 0 時,表示該通道信號沒有被選取,取值 1 時,則表示該通道的信號無失真地被直接選取,取值其他值時,表示該通道的信號以一定比例被選取。
2 雙 TP 型麥克風的波束指向設計和特征
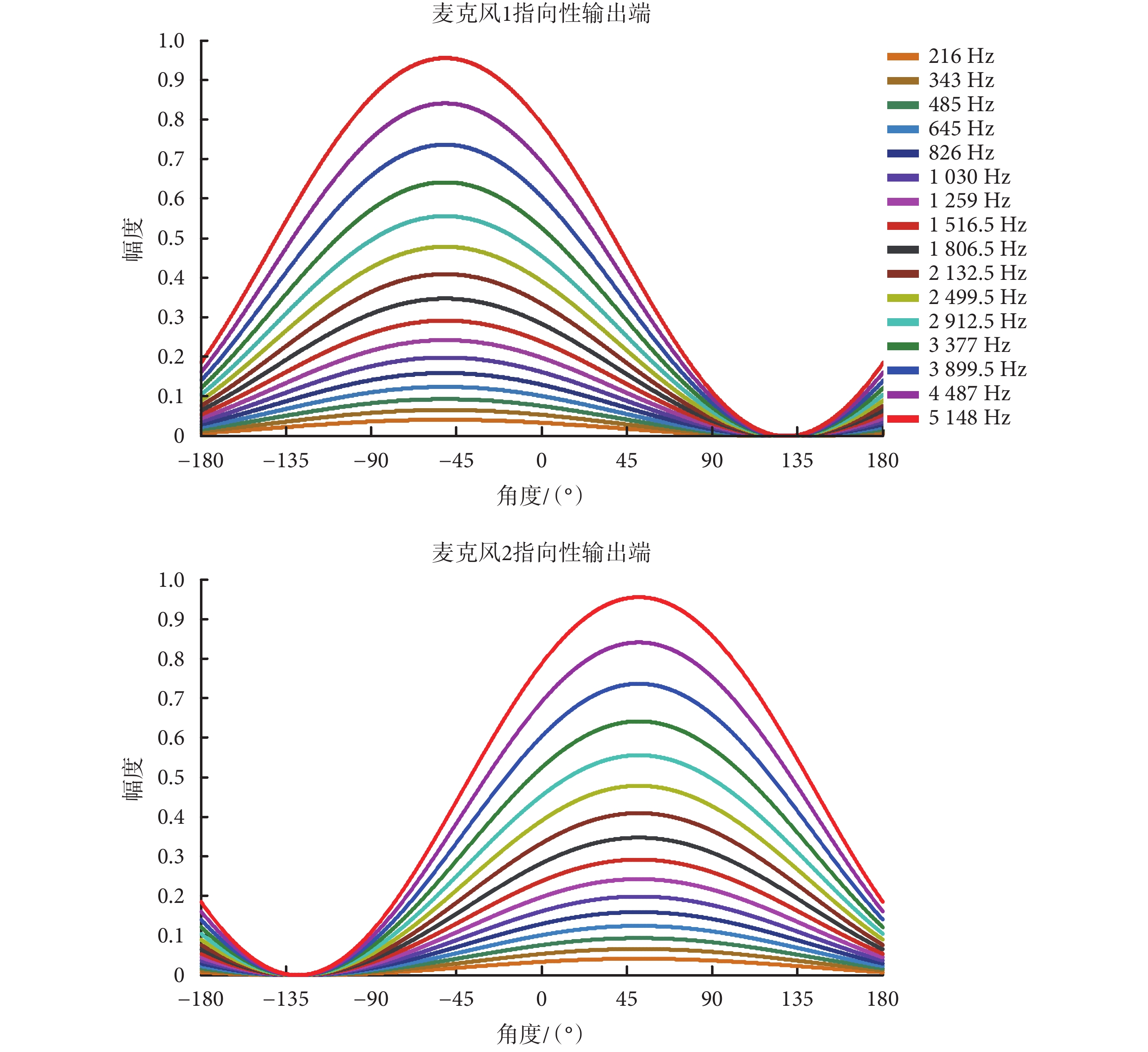
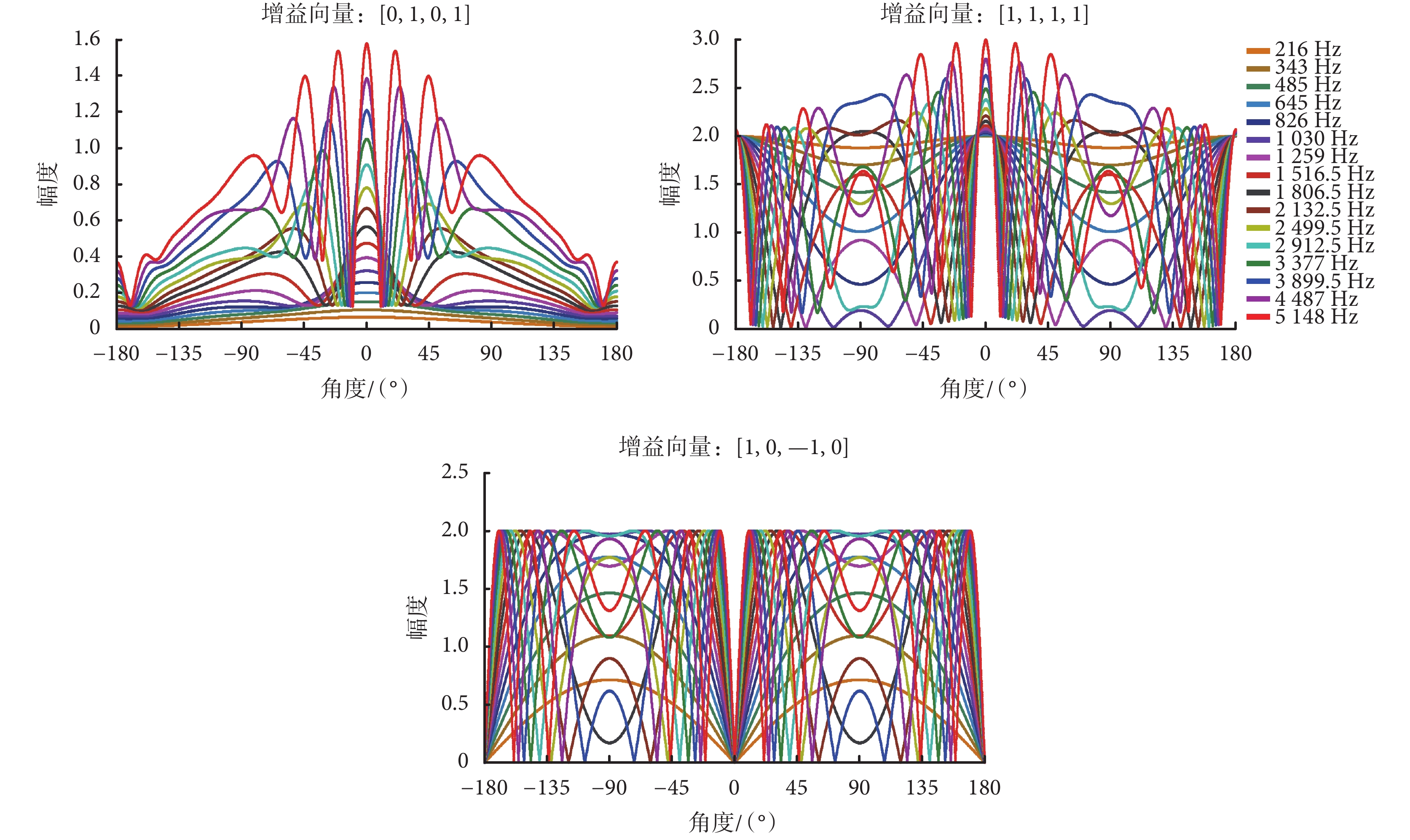
不同方位的系統幅頻響應可用于表征麥克風系統的波束指向特征,TP 型麥克風本身具有全向性輸出信號和指向性輸出信號。全向性輸出信號對應相同的系統響應,即不同方位的系統幅頻響應相同;而指向性輸出信號則在特定位置有最大的系統幅頻響應和最小的系統幅頻響應。在電子耳蝸應用場景中,需要對目標信號給予大的系統響應,對干擾噪聲給予小系統響應或者零系統響應。本文選取 16 通道電子耳蝸的中心頻率用于矩陣實驗室數學軟件(Matlab)的仿真實驗,該 16 通道電子耳蝸的中心頻率分別是:216、343、485、645、826、1 030、1 259、1 516.5、1 806.5、2 132.5、2 499.5、2 912.5、3 377、3 899.5、4 487、5 148 Hz,TP 型麥克風指向性輸出端的系統幅頻響應曲線如圖 2 所示。
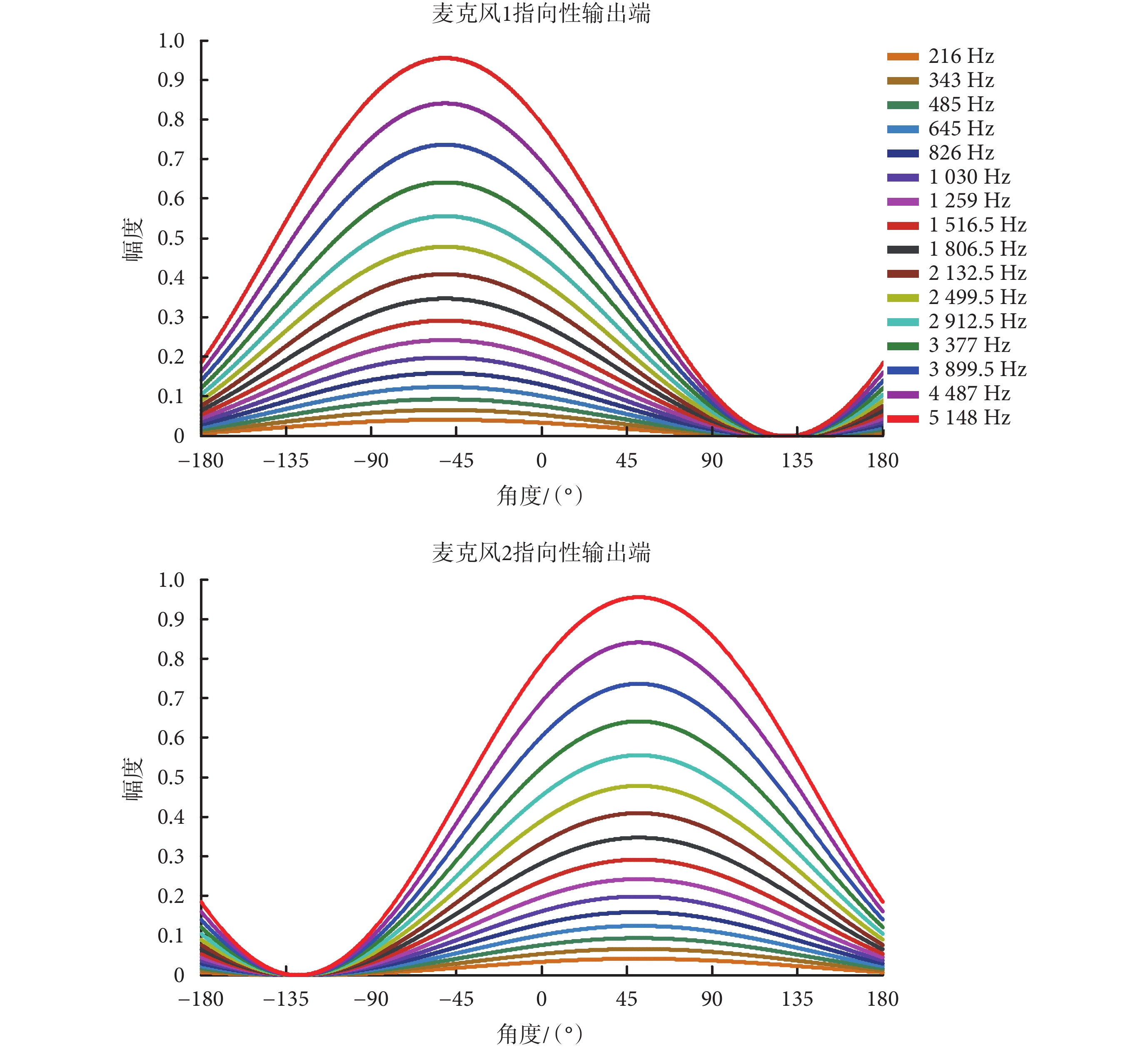 圖2
不同頻率條件下 TP 麥克風指向性輸出端的系統響應曲線
Figure2.
System response curves for TP microphone directional outputs based on different frequencies
圖2
不同頻率條件下 TP 麥克風指向性輸出端的系統響應曲線
Figure2.
System response curves for TP microphone directional outputs based on different frequencies
對于不同的頻率來說,TP 型麥克風均包含全向性輸出端和指向性輸出端,其中理想的全向性信號輸出端在 ? 180°~180° 范圍內的系統幅頻響應與頻率無關,理想情形下各個頻率對應的系統幅頻響應值均為 1,呈現平坦的系統幅頻響應曲線。而對于指向性輸出來說,不同頻率的系統幅頻響應不同,通過對比發現,頻率越高,幅頻響應越大。如圖 2 所示,第 16 通道頻率(5 148 Hz)的幅頻響應曲線的各個值最大,第 1 通道頻率(216 Hz)的幅頻響應最小,該結果表明高頻信號的指向性輸出有著更大的系統響應。進一步比較不同頻率的幅頻響應曲線的形狀,可以看到不同頻率的波束雖然大小不同,但形狀高度相似,并且波束中的最大指向都指向同一個方位。對于麥克風 1 來說,系統幅頻響應曲線在 ? 51.21° 位置有最大值,而麥克風 2 的系統幅頻響應曲線在 51.21° 位置有最大值。對比圖 1 中的方位角∠PBA 和∠QDC,這兩個方位角與系統幅頻響應曲線最大值的角度相同,因此指向性輸出最大輸出信號方向是兩個聲管連線的延長線所指向的方向。
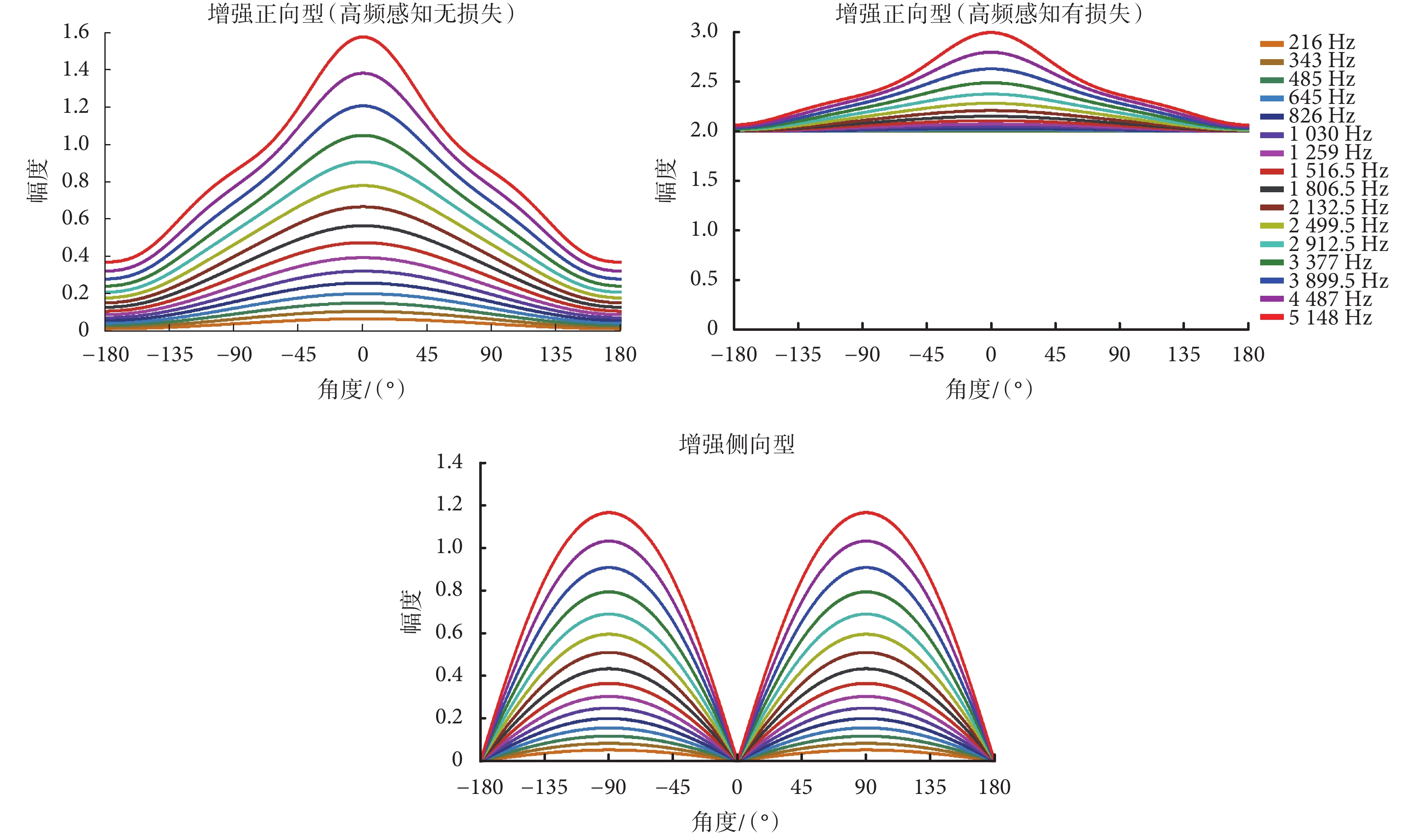
如式(8)~式(11)所示,麥克風不同聲管采集到的聲音信號是關于間距 L 的函數。由于電子耳蝸尺寸的限制,L 一般設置為 1 cm 左右。在式(12)中,增益向量的系數 βi 取不同數值時可形成特定波束指向的極性圖。電子耳蝸應用場景很多,這里選取電子耳蝸應用場景中三種常見的語音增強需求來進行分析,對應的增益向量的系數值如表 1 所示。
在 L = 1 cm 的間距條件下,對應的系統幅頻響應曲線如圖 3 所示。
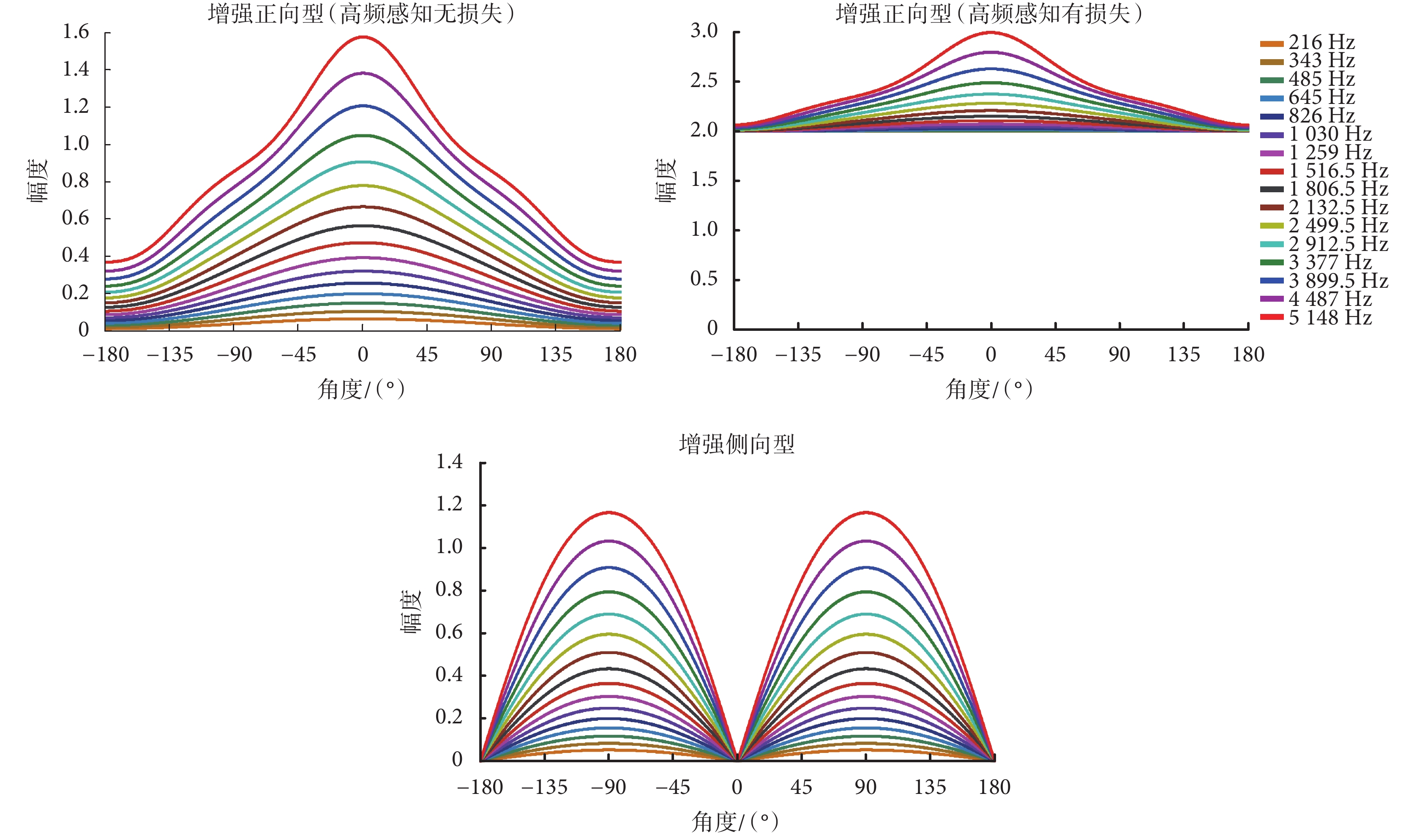 圖3
不同增益向量條件下的系統幅頻響應曲線
Figure3.
System response curves for different gain vectors
圖3
不同增益向量條件下的系統幅頻響應曲線
Figure3.
System response curves for different gain vectors
如圖 3 所示為選取的適合應用于電子耳蝸前端語音增強的常見幾種增益向量及對應的系統幅頻響應曲線。其中,圖中的 0° 表示佩帶電子耳蝸的使用者所面對的正向位置,? 90° 和 90° 表示兩側方位。對于電子耳蝸的日常使用者來說,最期望的是增強正向和側向的目標信號,其中對增強來源于正向方位的信號的需求最迫切,而對后向的信號則要求降低,因此所設計的雙麥克風系統的最大指向方位應該是正側向(尤其是正向方位)。圖 3 中 3 個子圖的系統幅頻響應曲線有著不同的波束指向,可應用于特定的場景,而在實際應用中可以通過設置在電子耳蝸體外機中的按鈕讓使用者依據具體的使用場景來切換。其中,子圖“增強正向型(高頻感知無損失)”的增益向量為[0,1,0,1],具有增強正向型的波束指向特征,在該系統幅頻響應曲線中,所有頻率條件下均是 0° 方位的系統響應最大,因此用該增益向量所設計的系統可用于增強所有頻率信號在電子耳蝸使用者正向方位的目標信號。子圖“增強正向型(高頻感知有損失)”的增益向量為[1,1,1,1],用該增益向量所設計的系統同樣具有增強正向型的波束指向特征,但對于低頻信號來說,從該子圖中可以看到,系統幅頻響應曲線趨向于幅值恒為 2 的水平直線。系統幅頻響應值恒定,表明系統對低頻信號在各個方位的響應相同,不具有特定方位波束指向的特征,因此對低頻信號來說,用該增益向量所設計的系統具有全向性的特征,而對于高頻信號來說,正向 0° 方位的信號響應最大,正向的高頻信號得到增強。該系統屬于增強正向型(高頻感知有損失)系統,主要針對使用者高頻信號損失和高頻識別困難的場景,可用于增強正向方位目標信號的高頻信號,而不影響低頻信號的采集。因此按照增益向量為[1,1,1,1]所設計的雙麥克風系統可針對具有高頻信號損失的人群(如老年人),用于增強正向信號并補償高頻感知損失的情形。子圖“增強側向型”的增益向量為[1,0,? 1,0],其波束最大指向側向位置(? 90° 和 90°),可用于增強兩側的目標信號,即源于兩耳正對的兩側方位的目標信號得到增強。
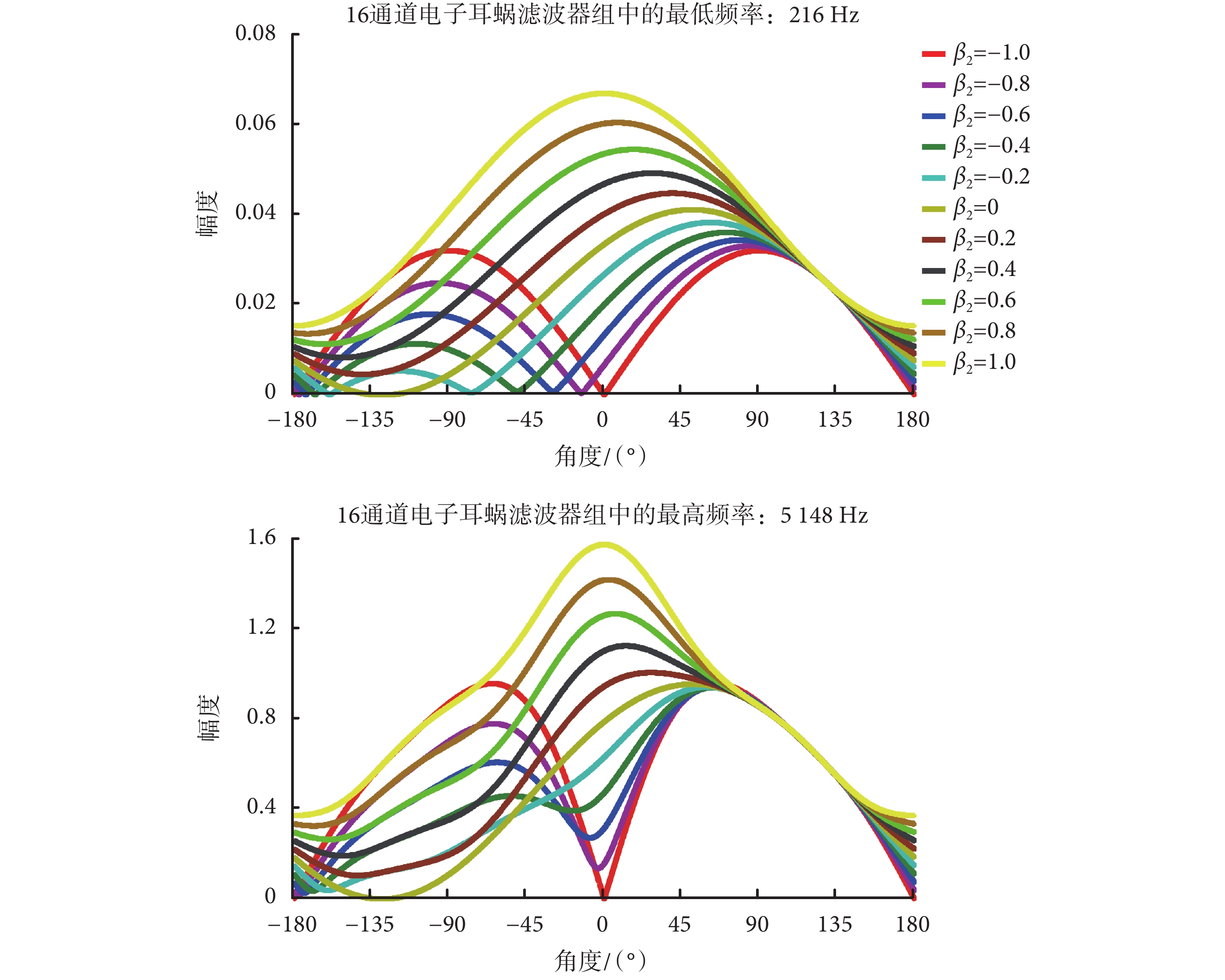
前面所列舉的這三種增益向量所設計的雙麥克風波束主要應用于電子耳蝸使用者最常見的語音增強場景,如果有更特定的需求,可依據需求進一步設置增益向量里的系數值,設計出更復雜和多樣的特定波束指向系統。增益向量的系數 βi(i = 1,2,3,4)的取值范圍是 ? ∞~∞,假設 βi(i = 1~4)中絕對值最大的是 βmax,則增益向量[β1,β2,β3,β4]= βmax[β1/βmax,β2/βmax,β3/βmax,β4/βmax]。因此,給予增益向量的系數 βi 等同于先給予增益向量的系數 βi/βmax,然后再給予整體相同的增益向量的系數 βmax。對雙麥克風系統來說,給予相同的增益向量的系數(不同通道的信號以同樣比例擴大或者縮小)不會改變波束形狀,僅僅是擴大總體的幅度,因此增益向量的系數的范圍只需考慮 ? 1~1 的情形。前面只分析了系數為 0、? 1 和 1 的情形,實際上,系數的取值是可以在 ? 1~1 范圍內連續取值的,可根據應用場景的需要調整和選取增益向量的系數值。由于 4 個增益向量的系數連續取值的排列組合很多,僅以其中一個增益向量的系數 β2 在 ? 1~1 范圍里以 0.2 為間隔連續取值為例(其他增益向量的系數為 β1 = 0,β3 = 0,β4 = 1),最低頻率(216 Hz)和最高頻率(5 148 Hz)的系統幅頻響應曲線如圖 4 所示。
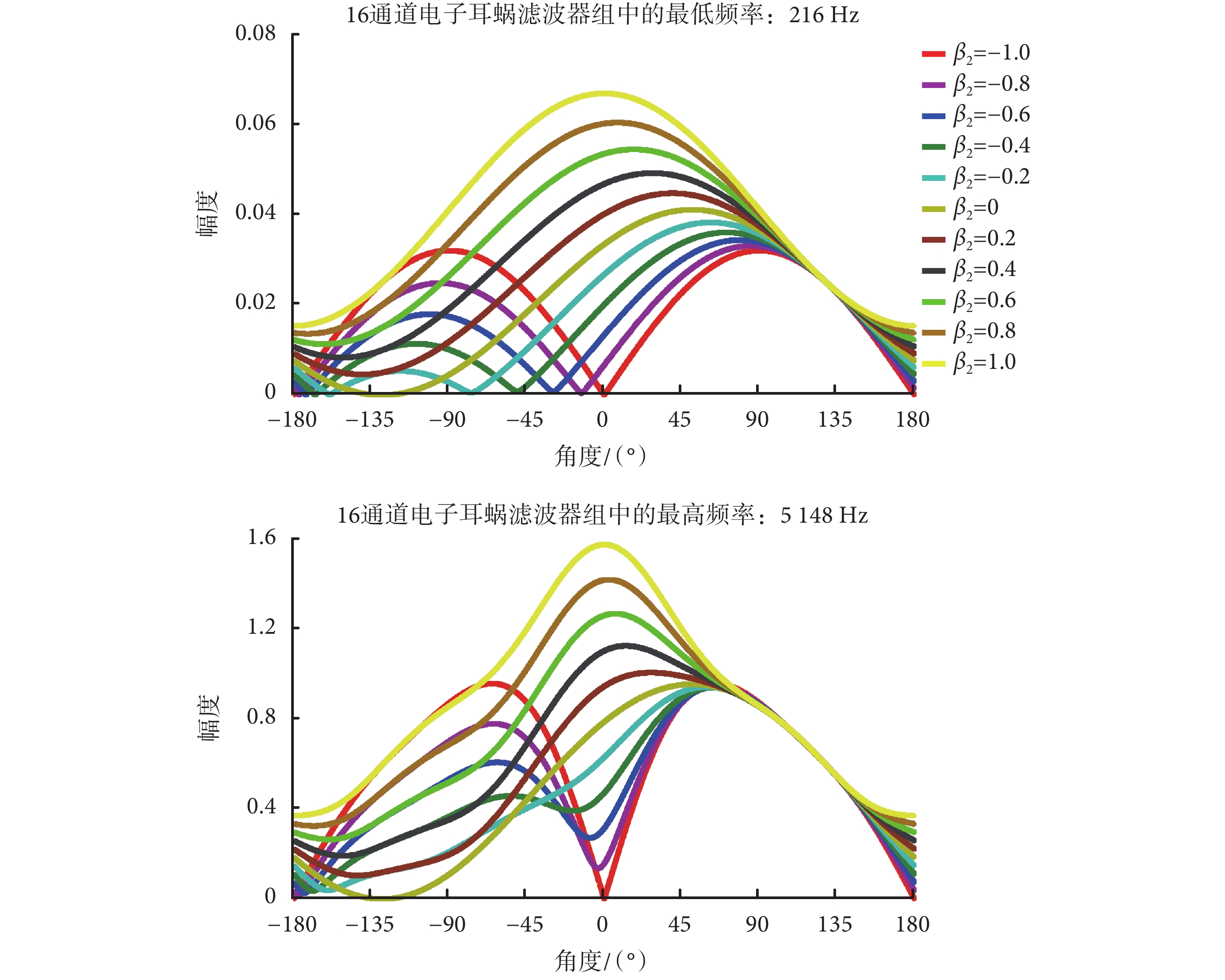 圖4
不同的 β2 取值條件下的最低頻率和最高頻率的系統幅頻響應曲線
Figure4.
System response curves for minimal frequency and maximal frequency based on different β2
圖4
不同的 β2 取值條件下的最低頻率和最高頻率的系統幅頻響應曲線
Figure4.
System response curves for minimal frequency and maximal frequency based on different β2
從圖 4 可以看到,當增益向量的系數 β2 在? 1~1 范圍里以 0.2 為間隔連續取值時,系統幅頻響應曲線的幅度最大值和幅度最小值的方位發生移動。幅度最大值的方位及附近的位置可用于增強目標信號,而幅度最小值的方位及附近的位置可用于削減干擾噪聲信號。對于噪聲源復雜的情況(如多聲源的應用場景),則需要結合本系統和常規的聲源估計方法來調整參數,讓系統的輸出特性跟隨噪聲源變化,例如以譜估計的方法[16]結合到本系統中用于特定場景的方向性噪聲的聲源定位和語音增強。對于不同的應用場景來說,選取的語音增強方法和模式不同,而本文提出的雙 TP 麥克風系統和波束形成方法可通過調整增益向量的系數來自適應地改變系統幅頻響應最大值和最小值的方位,有助于電子耳蝸前端語音信號的增強。對于常見的應用場景來說,其對應的增益向量可以通過固定增益向量的系數的數值并嵌入電子耳蝸體外言語處理器中的方式,以開關轉換來選取不同模式,例如圖 3 中所闡述的 3 種最常見的語音增強需求,采用該方法的計算量低,有助于降低電池的功耗。而復雜運動噪聲源和多噪聲源的情形則需要自適應調整增益向量的系數的方法,缺點是計算量大。在具體的算法植入中,本文所提出的雙 TP 麥克風波束形成算法中的固定增益向量的系數的方法應設置為常規模式,而自適應參數更新方法則應設置為特殊模式,以便適應電子耳蝸嚴格的功耗限制。
本文提出的算法和模型對噪聲的消除主要基于信源方向的增強和非聲源方向的削減以符合電子耳蝸使用者所面臨的應用場景。與正常人的語音增強需求不同,電子耳蝸使用者本來獲取的是有限的失真信息。通過前端言語處理器進行特征提取和編碼,最終傳遞到電子耳蝸電極陣列的也只有最多 24 通道的信息,目標信號已經損失了大量的細節特征,因此電子耳蝸使用者聽到的是畸變的信號,易導致言語識別率的降低。目前電子耳蝸使用者最為迫切的需求是當他們在面對面交談等情形下,如何更好地去除其他方位的干擾噪聲。Nelson 等[17]的實驗研究表明,在面對面交流時,要達到能正確識別 50% 的句子識別率來說,正常人所需要的信噪比約 ? 10 dB,而植入電子耳蝸的人所需的信噪比是 5~15 dB。如果想讓面對面交談時電子耳蝸的識別率達到正常人的水平,則需要將信噪比提高 15~25 dB[17]。因此,本文所提出的算法正是基于此場景和目前電子耳蝸使用者迫切的需求應運而生,主要是通過基于信源方向的增強和非聲源方向的削減來提高信噪比,讓電子耳蝸恢復工作在“安靜”的環境下,進而提高言語識別率。
3 麥克風佩帶間距的影響及系統指向性特征
由于電子耳蝸尺寸的限制,如果兩個麥克風是嵌入到電子耳蝸體外機里的,則間距不能太大。前面的分析是基于間距 1 cm 的情形下進行分析的。如果兩個麥克風不直接嵌入,而是通過線路的方式放置在兩耳處,則可以增大兩個麥克風之間的距離。按照目前電子耳蝸的設計特點和使用習慣,外置麥克風通過耳背式、耳道式和耳內式等方式佩帶在耳朵上,而雙麥克風信號采集的模式則可以把兩個麥克風放置在一個耳朵上,也可以分別放置在兩個耳朵上。如果兩個麥克風都放置在一個耳朵上,常見的麥克風間距是 1 cm,考慮到佩帶的舒適度和穩定度,麥克風間距雖然可以超過 1 cm,但不宜過大。如果麥克風分別放置在兩個耳朵上,則間距可以較大幅度地增大,正常人兩耳的距離約為 18 cm,因此,下面的有關雙耳佩帶模式是基于 18 cm 間距來進行仿真分析的,在此間距條件下的不同增益向量所對應的系統幅頻響應曲線圖如圖 5 所示。
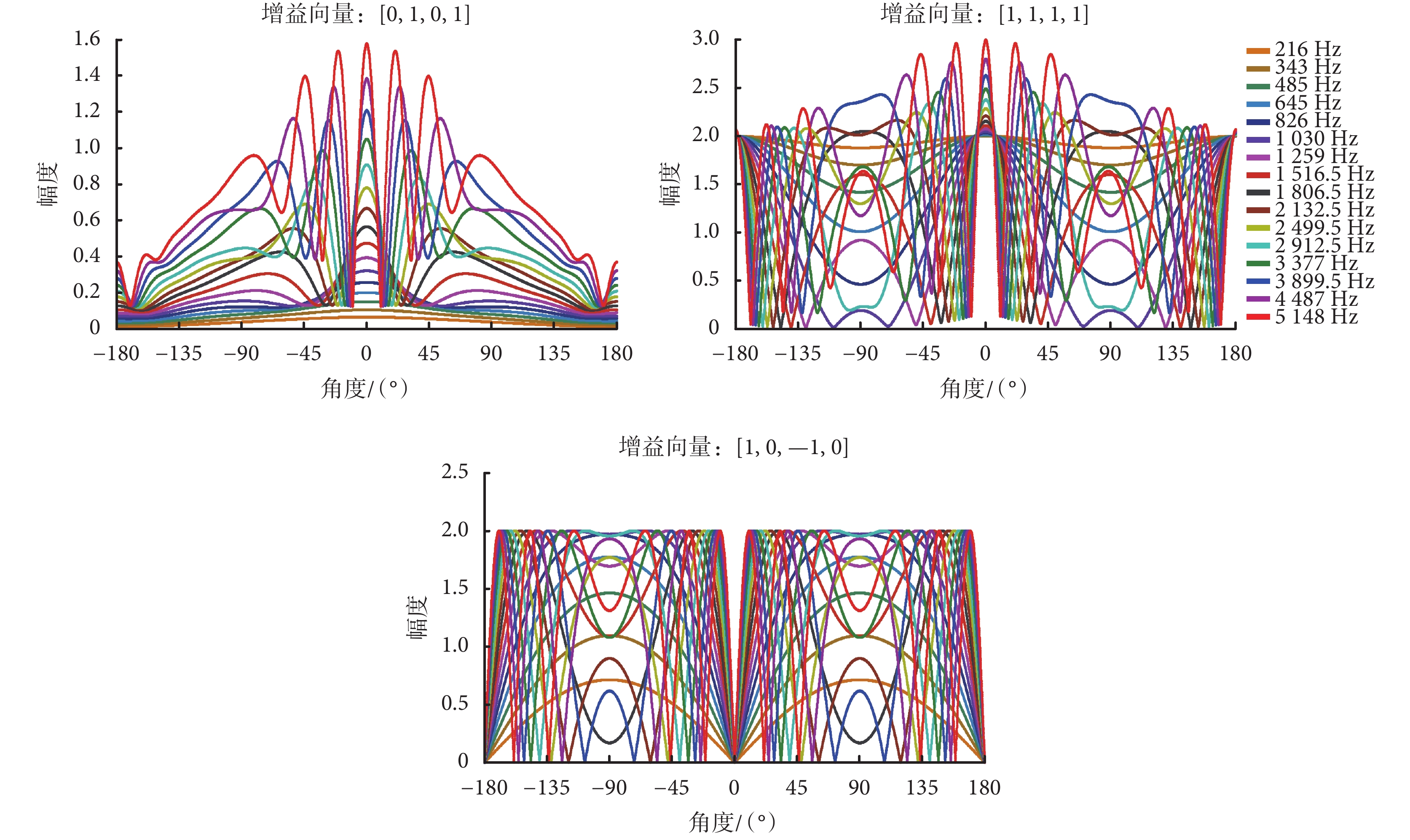 圖5
雙耳佩帶麥克風時(間距 18 cm)不同增益向量條件的系統幅頻響應曲線
Figure5.
System response curves for different gain vectors when wearing microphones in both ears (inter-microphone distance of 18 cm)
圖5
雙耳佩帶麥克風時(間距 18 cm)不同增益向量條件的系統幅頻響應曲線
Figure5.
System response curves for different gain vectors when wearing microphones in both ears (inter-microphone distance of 18 cm)
從圖 5 可以看到,當麥克風間距增大到 18 cm 時(即對應兩個麥克風分別放置在兩個耳朵上),不同增益向量條件下所對應的系統幅頻響應曲線都發生很大的變化。尤其是高頻信號,其系統幅頻響應曲線在多個方位已經出現多個波束指向,與 1 cm 小間距的情形有著巨大差別。電子耳蝸最為迫切的需求是當使用者在面對面交談等情形下去除其他方位的干擾噪聲,因此在具體的波束設計中要求有一個最大的系統幅頻響應方位,該方位應與目標信號方位一致,而其他方位的系統幅頻響應較小。同時,由于目標信號和干擾噪聲在一定范圍內會移動,因此對波束的設計要求系統幅頻響應的幅度變化不宜起伏過快,不宜出現過多的波束旁瓣,例如針對特定應用場景可以設計一種從正向到后向系統幅頻響應具有單調下降特征的極性圖[14]。對于不同的應用場景,波束的指向特征不同,但在電子耳蝸的應用里,平穩的系統幅頻響應曲線有助于提高使用者的舒適度[14]。在圖 5 中,當麥克風間距是 18 cm 時,系統幅頻響應曲線的幅度值變化過快,并且出現了多個峰值和旁瓣,不適合用于電子耳蝸前端的信號采集中。因此,本文所探討的雙 TP 型四聲道信號采集的波束形成方式不適合在把兩個麥克風分別放置兩耳位置。麥克風間距過大導致目標波束發生嚴重的畸變,如果進一步減少麥克風間距,則可以降低所設計波束的失真,系統幅頻響應的變化趨緩。通過 Matlab 仿真實驗來觀察當麥克風間距由 18 cm 逐漸減少時的系統幅頻響應曲線,可以得到以下結論,麥克風間距減少到 2.5 cm 時,目標的系統波束才不會產生較大的差異,因此本文方法適用于麥克風間距在 1~2.5 cm 的范圍內。另一方面,當麥克風間距小于 1 cm 時,系統幅頻響應曲線也會發生變化。極限的最小的間距為 0,此時兩個麥克風互相貼在一起放置。通過仿真實驗可以知道,此時系統幅頻響應曲線變化不太大,主要特征是一致的。因此,結合前面的有關麥克風間距大于 1 cm 和小于 1 cm 的兩種情形的分析,可以得到以下的結論,本文所探討的應用于電子耳蝸前端語音增強的雙 TP 型麥克風波束形成算法對間距有要求,其范圍適用于 0~2.5 cm。對于麥克風固定安裝在電子耳蝸體外機的情形,可選取該范圍內的間距進行放置,而對于通過線路連接的麥克風可移動的情形,麥克風的間距以及由于運動或者震動偏移產生的間距也要限制在 0~2.5 cm 之間。
4 結論
本文采用了麥克風陣列的方法設計雙麥克風波束形成系統,考慮到電子耳蝸嚴格的體積限制,本系統采用雙聲管模式的麥克風。由于每個麥克風包含相互垂直的兩個聲管,因此本系統所設計的雙麥克風采集模式實際上包含了 4 個空間方位信息,有助于設計復雜的指向性波束。本文對雙麥克風多聲管信號采集進行理論的分析和計算,推導出系統輸出信號的表達式,然后根據電子耳蝸使用者常見的語音增強的應用場景,選取了對應的 3 個增益向量用于系統幅頻響應曲線的分析,并探討了增益向量的系數連續取值情形下的響應曲線變化特征和應用場景。所設計的系統能滿足常見電子耳蝸使用者多種狀態和場景的語音增強需求,同時分析了不同麥克風間距的影響,歸納了保持目標波束特征不變的間距范圍。本文所述理論分析以及結論尚需在以后的實驗中加以驗證,所提出的雙 TP 麥克風信號采集模式和多參數條件下所設計的波束需要結合單通道的語音增強技術來應對電子耳蝸復雜的語音增強的應用場景。
引言
電子耳蝸是一種通過電信號刺激聽覺神經并使耳聾患者產生聽覺感知的電子裝置,是目前治療重度聾和全聾患者的有效方法[1-3]。美國國立耳聾與其他交流障礙性疾病研究所(National Institute on Deafness and Other Communication Disorders,NIDCD)官網 2017 年 3 月 6 日公布的數據表明:目前全球電子耳蝸植入數已有 32 萬余個。經過近幾十年的發展,電子耳蝸的價格逐漸降低,進一步促進了電子耳蝸的廣泛應用。據 Zeng[4]的研究報道,2017 年國內外電子耳蝸生產廠商在我國政府招標采購中的投標價格均有了大幅度的下降。從 2011-2016 年,其售價由 25 000 美元/個降到 6 030 美元/個,而到 2017 年時僅為 5 490 美元/個。同時,技術的發展提高了電子耳蝸的性能,使用者已經能夠順暢地進行打電話、面對面說話等日常溝通和交流,但是電子耳蝸在噪聲環境和各種失配場景條件下的言語識別率仍然較低[5-7]。提高電子耳蝸前端信號采集的質量有助于提升電子耳蝸識別率,目前的研究方法有兩類,分別是單通道的語音增強方法和基于麥克風陣列的語音增強方法。
由于電子耳蝸體積的限制,麥克風陣列中實際能采用的麥克風數量有限,常見的方法是雙麥克風波束形成方法[8-10]或雙耳模式的語音增強方法[11-13]。在電子耳蝸前端語音增強應用中,固定波束形成方法是常見的語音增強方法,通過延遲或者增益向量來實現特定的波束指向[14],其特點是計算量少,適合電子耳蝸的低功耗要求,缺點是極性圖固定,信噪比提高有限。而對于運動噪聲來說,自適應波束形成方法是另一種常見的語音增強方法,該方法通過對噪聲的方位進行估計可使系統的最小輸出跟隨噪聲方位變化,其優點是適宜于運動噪聲的情形,缺點是僅通過延遲等參數調整極性圖,波束指向簡單并且計算量過大[8, 10]。為了進一步提高噪聲去除的效果,現已將單通道的語音增強技術用于麥克風陣列語音增強算法中,Lockwood 等[11]采用非因果最優濾波器來設計頻域波束形成器,Kate 等[15]則把最小方差無畸變響應的自適應波束形成技術用于由 5 個麥克風所組成的信號采集陣列,可較好地適應復雜噪聲的去除,但過多的麥克風數量不能滿足電子耳蝸較小的體積限制要求。本文前期研究工作里提出了一種采用兩個全向性麥克風的基于實時譜估計的雙通道語音增強算法[16],該算法可用于去除方向性噪聲和競爭性語音噪聲,具有高信噪比的特點。但是,前期所提出的雙全向性麥克風模式在空間上只有兩個信號采集點,所能獲取的空間方位信息有限,不利于設計復雜的具有多種波束指向的語音增強系統。考慮到電子耳蝸尺寸的限制和復雜波束設計的需求,本文選用具有兩個聲管的超薄單指向/全向組合型麥克風(thin uni-directional/omni-directional microphone pair,TP)來設計雙麥克風信號采集系統,并進一步通過增益向量的選取來設計可滿足使用者特定需求的雙麥克風系統,然后探討了麥克風間距對系統響應的影響,并歸納了本系統的應用條件。本文研究在雙麥克風波束形成算法、小間距條件的波束設計和電子耳蝸語音增強方面進行了理論探索,或對今后的電子耳蝸前端語音增強的研究和工程應用奠定理論基礎并提供技術參數。
1 雙 TP 麥克風陣列結構及信號采集分析
本文選用具有雙聲管的 TP 型麥克風模塊用于電子耳蝸前端信號采集。TP 型麥克風包含兩個聲管,兩個聲管的指向相互垂直。根據尺寸資料可以計算出兩個聲管中心點之間的距離(d)。需注意的是,來自不同方位的聲音信號被同一個 TP 型麥克風的兩個聲管采集到的時間是不同的,存在一個延遲時間,延遲時間與聲音信號的方位角度有關。此外,兩個聲管采集到信號后,TP 型麥克風模塊還會對其中一個聲管采集到的信號進行一個額外的延遲,并由此形成不同方位的波束指向。按照 TP 型麥克風技術說明,該麥克風可以產生兩路輸出信號,既可輸出全向性信號,也可輸出心型極性圖(cardioid beam pattern)的指向性信號。其中,全向性信號為其中一個采集聲管的信號,而心型極性圖的指向性信號所設置的額外延遲時間(τ)是通過 τ = d/c 計算得到的,其中 d 為前面計算得到的兩個聲管中心點之間的距離,本文取 5.24 × 10?3 m;c 為聲音在空氣中的傳播速度,本文取 340 m/s;因此本文計算得到的 τ 的參數值是 1.54 × 10?5 s。麥克風兩個聲管之間的距離 d 是固定的,但兩個 TP 型麥克風之間的間距(L)則是可調的。
本文所設計的雙麥克風信號采集模式如圖 1 所示。在圖 1 中,TP 型麥克風 1 包含聲管 1 和聲管 2,麥克風 2 包含聲管 3 和聲管 4。定義聲管 1 和聲管 3 所面向的方位是 0°(正向,對應電子耳蝸使用者所面對的方位),按逆時針定義其他各個方位,左側半圈的角度范圍是 0°~180°,右側半圈的角度范圍是 0°~? 180°,則聲管 2 對應的方位是 90°,聲管 4 對應的方位是 ? 90°。用極坐標方式定義所要采集聲音信號的位置 S,S 點距離兩個麥克風中心點 O 的距離為 R,與 0° 方位所在直線的夾角為 φ。4 個聲管分別采集從 S 處傳輸過來的聲音信號,并分別形成全向性輸出信號[O1(t)和 O2(t)]和指向性輸出信號[D1(t)和 D2(t)],然后形成 4 路輸出信號,對信號進行通道選擇和給予增益向量形成總的輸出信號[y(t)],不同的增益向量可用于設計具有特定波束指向的語音增強系統。
圖1
雙麥克風系統信號采集原理圖
Figure1.
Schematicdiagram of signal acquisition principle in dual-microphone system
如圖 1 所示,標記了聲管 1、2、3、4 的中心位置為 A、B、C 和 D,與 S 點連線和 0° 方位所在直線的夾角分別是 θ1、θ2、θ3 和 θ4,標記麥克風 1 兩個垂直聲管中軸線交點為 P,麥克風 2 兩個垂直聲管中軸線交點為 Q,BP 延長線與麥克風 1 的外殼交點為 P1,DQ 延長線與麥克風 2 的外殼交點為 Q1,P1Q1 為雙麥克風的間距,標記為 L,而圖中的∠PBA = ∠QDC = 51.21°。假設 A 處采集到的聲音信號為 xA(t),則 B、C 和 D 處由于距離不同所采集到的聲音信號 xB(t)、xC(t)和 xD(t)也不同,信號之間存在延遲時間。在圖中,B、C 和 D 處采集到的聲音信號相對于 A 點采集到的聲音分別有延遲距離 BB1、CC1 和 DD1,用 x(t)簡化表示 xA(t),則根據圖中的幾何關系,可以得到信號 xB(t)、xC(t)和 xD(t)的表達式如式(1)~式(3)所示:
|
|
|
式中,t 為信號表達式所對應函數的時間變量,c 為聲音在空氣中的傳播速度。
雙麥克風模塊放置在耳朵旁,由于電子耳蝸體積的限制,麥克風的間距 L 不能太大(一般設置為 1 cm 左右)。而圖 1 中的 R 為聲源距離,一般面對面交流的距離為 1~2 m,而會議、電影院等場景的距離則可以超過 10 m。因此,相對于雙麥克風極小的間距來說,本文所探討的聲源可認為是遠場的情形,該情形有助于本文對信號采集進行簡化。當聲源距離相對較遠時,聲音信號可近似認為是平行傳播,圖 1 中的信號采集角 θ1、θ2、θ3 和 θ4 與聲源信號的方位角 φ 相同。近場時聲源信號的位置需要由方位角 φ 和距離 R 確定,而遠場時聲源信號簡化為用方位角 φ 來表征。對式(1)~式(3)進行簡化,分別得到簡化后的 xB(t)、xC(t)和 xD(t)。對于 TP 型麥克風來說,指向性輸出信號對應的內部固定延遲時間是 τ = d/c,進而得到麥克風 1 的全向性輸出信號 O1(t)、指向性輸出信號 D1(t)和麥克風 2 的全向性輸出信號 O2(t)、指向性輸出信號 D2(t),分別如式(4)~式(7)所示:
|
|
|
|
式(4)~式(7)是通過幾何關系計算出的全向性輸出信號和指向性輸出信號的通用公式,由于 TP 型麥克風有具體的尺寸(PP1 = 1.55 × 10?3 m、QQ1 = 1.55 × 10?3 m、PP1 + QQ1 = 3.10 × 10?3 m、BP = 3.62 × 10?3 m、PA = 2.91 × 10?3 m)以及相關參數( = 51.21°、d = 5.24 × 10?3 m、c = 340 m/s),進一步代入對應的參數可以對全向性輸出信號和指向性輸出信號的公式進行簡化,得到如式(8)~式(11)所示的結果:
|
|
|
|
對麥克風 1 的全向性輸出信號 O1(t)、指向性輸出信號 D1(t)和麥克風 2 的全向性輸出信號 O2(t)、指向性輸出信號 D2(t)給予通道選取和增益向量,可以得到式(12)中的總的信號輸出 y(t):
|
式中 βi(i = 1,2,3,4)是增益向量的 4 個系數,系數取不同數值可組成不同的增益向量,進而形成特定波束指向的極性圖,而當 βi 直接取值 0 時,表示該通道信號沒有被選取,取值 1 時,則表示該通道的信號無失真地被直接選取,取值其他值時,表示該通道的信號以一定比例被選取。
2 雙 TP 型麥克風的波束指向設計和特征
不同方位的系統幅頻響應可用于表征麥克風系統的波束指向特征,TP 型麥克風本身具有全向性輸出信號和指向性輸出信號。全向性輸出信號對應相同的系統響應,即不同方位的系統幅頻響應相同;而指向性輸出信號則在特定位置有最大的系統幅頻響應和最小的系統幅頻響應。在電子耳蝸應用場景中,需要對目標信號給予大的系統響應,對干擾噪聲給予小系統響應或者零系統響應。本文選取 16 通道電子耳蝸的中心頻率用于矩陣實驗室數學軟件(Matlab)的仿真實驗,該 16 通道電子耳蝸的中心頻率分別是:216、343、485、645、826、1 030、1 259、1 516.5、1 806.5、2 132.5、2 499.5、2 912.5、3 377、3 899.5、4 487、5 148 Hz,TP 型麥克風指向性輸出端的系統幅頻響應曲線如圖 2 所示。
圖2
不同頻率條件下 TP 麥克風指向性輸出端的系統響應曲線
Figure2.
System response curves for TP microphone directional outputs based on different frequencies
對于不同的頻率來說,TP 型麥克風均包含全向性輸出端和指向性輸出端,其中理想的全向性信號輸出端在 ? 180°~180° 范圍內的系統幅頻響應與頻率無關,理想情形下各個頻率對應的系統幅頻響應值均為 1,呈現平坦的系統幅頻響應曲線。而對于指向性輸出來說,不同頻率的系統幅頻響應不同,通過對比發現,頻率越高,幅頻響應越大。如圖 2 所示,第 16 通道頻率(5 148 Hz)的幅頻響應曲線的各個值最大,第 1 通道頻率(216 Hz)的幅頻響應最小,該結果表明高頻信號的指向性輸出有著更大的系統響應。進一步比較不同頻率的幅頻響應曲線的形狀,可以看到不同頻率的波束雖然大小不同,但形狀高度相似,并且波束中的最大指向都指向同一個方位。對于麥克風 1 來說,系統幅頻響應曲線在 ? 51.21° 位置有最大值,而麥克風 2 的系統幅頻響應曲線在 51.21° 位置有最大值。對比圖 1 中的方位角∠PBA 和∠QDC,這兩個方位角與系統幅頻響應曲線最大值的角度相同,因此指向性輸出最大輸出信號方向是兩個聲管連線的延長線所指向的方向。
如式(8)~式(11)所示,麥克風不同聲管采集到的聲音信號是關于間距 L 的函數。由于電子耳蝸尺寸的限制,L 一般設置為 1 cm 左右。在式(12)中,增益向量的系數 βi 取不同數值時可形成特定波束指向的極性圖。電子耳蝸應用場景很多,這里選取電子耳蝸應用場景中三種常見的語音增強需求來進行分析,對應的增益向量的系數值如表 1 所示。
在 L = 1 cm 的間距條件下,對應的系統幅頻響應曲線如圖 3 所示。
圖3
不同增益向量條件下的系統幅頻響應曲線
Figure3.
System response curves for different gain vectors
如圖 3 所示為選取的適合應用于電子耳蝸前端語音增強的常見幾種增益向量及對應的系統幅頻響應曲線。其中,圖中的 0° 表示佩帶電子耳蝸的使用者所面對的正向位置,? 90° 和 90° 表示兩側方位。對于電子耳蝸的日常使用者來說,最期望的是增強正向和側向的目標信號,其中對增強來源于正向方位的信號的需求最迫切,而對后向的信號則要求降低,因此所設計的雙麥克風系統的最大指向方位應該是正側向(尤其是正向方位)。圖 3 中 3 個子圖的系統幅頻響應曲線有著不同的波束指向,可應用于特定的場景,而在實際應用中可以通過設置在電子耳蝸體外機中的按鈕讓使用者依據具體的使用場景來切換。其中,子圖“增強正向型(高頻感知無損失)”的增益向量為[0,1,0,1],具有增強正向型的波束指向特征,在該系統幅頻響應曲線中,所有頻率條件下均是 0° 方位的系統響應最大,因此用該增益向量所設計的系統可用于增強所有頻率信號在電子耳蝸使用者正向方位的目標信號。子圖“增強正向型(高頻感知有損失)”的增益向量為[1,1,1,1],用該增益向量所設計的系統同樣具有增強正向型的波束指向特征,但對于低頻信號來說,從該子圖中可以看到,系統幅頻響應曲線趨向于幅值恒為 2 的水平直線。系統幅頻響應值恒定,表明系統對低頻信號在各個方位的響應相同,不具有特定方位波束指向的特征,因此對低頻信號來說,用該增益向量所設計的系統具有全向性的特征,而對于高頻信號來說,正向 0° 方位的信號響應最大,正向的高頻信號得到增強。該系統屬于增強正向型(高頻感知有損失)系統,主要針對使用者高頻信號損失和高頻識別困難的場景,可用于增強正向方位目標信號的高頻信號,而不影響低頻信號的采集。因此按照增益向量為[1,1,1,1]所設計的雙麥克風系統可針對具有高頻信號損失的人群(如老年人),用于增強正向信號并補償高頻感知損失的情形。子圖“增強側向型”的增益向量為[1,0,? 1,0],其波束最大指向側向位置(? 90° 和 90°),可用于增強兩側的目標信號,即源于兩耳正對的兩側方位的目標信號得到增強。
前面所列舉的這三種增益向量所設計的雙麥克風波束主要應用于電子耳蝸使用者最常見的語音增強場景,如果有更特定的需求,可依據需求進一步設置增益向量里的系數值,設計出更復雜和多樣的特定波束指向系統。增益向量的系數 βi(i = 1,2,3,4)的取值范圍是 ? ∞~∞,假設 βi(i = 1~4)中絕對值最大的是 βmax,則增益向量[β1,β2,β3,β4]= βmax[β1/βmax,β2/βmax,β3/βmax,β4/βmax]。因此,給予增益向量的系數 βi 等同于先給予增益向量的系數 βi/βmax,然后再給予整體相同的增益向量的系數 βmax。對雙麥克風系統來說,給予相同的增益向量的系數(不同通道的信號以同樣比例擴大或者縮小)不會改變波束形狀,僅僅是擴大總體的幅度,因此增益向量的系數的范圍只需考慮 ? 1~1 的情形。前面只分析了系數為 0、? 1 和 1 的情形,實際上,系數的取值是可以在 ? 1~1 范圍內連續取值的,可根據應用場景的需要調整和選取增益向量的系數值。由于 4 個增益向量的系數連續取值的排列組合很多,僅以其中一個增益向量的系數 β2 在 ? 1~1 范圍里以 0.2 為間隔連續取值為例(其他增益向量的系數為 β1 = 0,β3 = 0,β4 = 1),最低頻率(216 Hz)和最高頻率(5 148 Hz)的系統幅頻響應曲線如圖 4 所示。
圖4
不同的 β2 取值條件下的最低頻率和最高頻率的系統幅頻響應曲線
Figure4.
System response curves for minimal frequency and maximal frequency based on different β2
從圖 4 可以看到,當增益向量的系數 β2 在? 1~1 范圍里以 0.2 為間隔連續取值時,系統幅頻響應曲線的幅度最大值和幅度最小值的方位發生移動。幅度最大值的方位及附近的位置可用于增強目標信號,而幅度最小值的方位及附近的位置可用于削減干擾噪聲信號。對于噪聲源復雜的情況(如多聲源的應用場景),則需要結合本系統和常規的聲源估計方法來調整參數,讓系統的輸出特性跟隨噪聲源變化,例如以譜估計的方法[16]結合到本系統中用于特定場景的方向性噪聲的聲源定位和語音增強。對于不同的應用場景來說,選取的語音增強方法和模式不同,而本文提出的雙 TP 麥克風系統和波束形成方法可通過調整增益向量的系數來自適應地改變系統幅頻響應最大值和最小值的方位,有助于電子耳蝸前端語音信號的增強。對于常見的應用場景來說,其對應的增益向量可以通過固定增益向量的系數的數值并嵌入電子耳蝸體外言語處理器中的方式,以開關轉換來選取不同模式,例如圖 3 中所闡述的 3 種最常見的語音增強需求,采用該方法的計算量低,有助于降低電池的功耗。而復雜運動噪聲源和多噪聲源的情形則需要自適應調整增益向量的系數的方法,缺點是計算量大。在具體的算法植入中,本文所提出的雙 TP 麥克風波束形成算法中的固定增益向量的系數的方法應設置為常規模式,而自適應參數更新方法則應設置為特殊模式,以便適應電子耳蝸嚴格的功耗限制。
本文提出的算法和模型對噪聲的消除主要基于信源方向的增強和非聲源方向的削減以符合電子耳蝸使用者所面臨的應用場景。與正常人的語音增強需求不同,電子耳蝸使用者本來獲取的是有限的失真信息。通過前端言語處理器進行特征提取和編碼,最終傳遞到電子耳蝸電極陣列的也只有最多 24 通道的信息,目標信號已經損失了大量的細節特征,因此電子耳蝸使用者聽到的是畸變的信號,易導致言語識別率的降低。目前電子耳蝸使用者最為迫切的需求是當他們在面對面交談等情形下,如何更好地去除其他方位的干擾噪聲。Nelson 等[17]的實驗研究表明,在面對面交流時,要達到能正確識別 50% 的句子識別率來說,正常人所需要的信噪比約 ? 10 dB,而植入電子耳蝸的人所需的信噪比是 5~15 dB。如果想讓面對面交談時電子耳蝸的識別率達到正常人的水平,則需要將信噪比提高 15~25 dB[17]。因此,本文所提出的算法正是基于此場景和目前電子耳蝸使用者迫切的需求應運而生,主要是通過基于信源方向的增強和非聲源方向的削減來提高信噪比,讓電子耳蝸恢復工作在“安靜”的環境下,進而提高言語識別率。
3 麥克風佩帶間距的影響及系統指向性特征
由于電子耳蝸尺寸的限制,如果兩個麥克風是嵌入到電子耳蝸體外機里的,則間距不能太大。前面的分析是基于間距 1 cm 的情形下進行分析的。如果兩個麥克風不直接嵌入,而是通過線路的方式放置在兩耳處,則可以增大兩個麥克風之間的距離。按照目前電子耳蝸的設計特點和使用習慣,外置麥克風通過耳背式、耳道式和耳內式等方式佩帶在耳朵上,而雙麥克風信號采集的模式則可以把兩個麥克風放置在一個耳朵上,也可以分別放置在兩個耳朵上。如果兩個麥克風都放置在一個耳朵上,常見的麥克風間距是 1 cm,考慮到佩帶的舒適度和穩定度,麥克風間距雖然可以超過 1 cm,但不宜過大。如果麥克風分別放置在兩個耳朵上,則間距可以較大幅度地增大,正常人兩耳的距離約為 18 cm,因此,下面的有關雙耳佩帶模式是基于 18 cm 間距來進行仿真分析的,在此間距條件下的不同增益向量所對應的系統幅頻響應曲線圖如圖 5 所示。
圖5
雙耳佩帶麥克風時(間距 18 cm)不同增益向量條件的系統幅頻響應曲線
Figure5.
System response curves for different gain vectors when wearing microphones in both ears (inter-microphone distance of 18 cm)
從圖 5 可以看到,當麥克風間距增大到 18 cm 時(即對應兩個麥克風分別放置在兩個耳朵上),不同增益向量條件下所對應的系統幅頻響應曲線都發生很大的變化。尤其是高頻信號,其系統幅頻響應曲線在多個方位已經出現多個波束指向,與 1 cm 小間距的情形有著巨大差別。電子耳蝸最為迫切的需求是當使用者在面對面交談等情形下去除其他方位的干擾噪聲,因此在具體的波束設計中要求有一個最大的系統幅頻響應方位,該方位應與目標信號方位一致,而其他方位的系統幅頻響應較小。同時,由于目標信號和干擾噪聲在一定范圍內會移動,因此對波束的設計要求系統幅頻響應的幅度變化不宜起伏過快,不宜出現過多的波束旁瓣,例如針對特定應用場景可以設計一種從正向到后向系統幅頻響應具有單調下降特征的極性圖[14]。對于不同的應用場景,波束的指向特征不同,但在電子耳蝸的應用里,平穩的系統幅頻響應曲線有助于提高使用者的舒適度[14]。在圖 5 中,當麥克風間距是 18 cm 時,系統幅頻響應曲線的幅度值變化過快,并且出現了多個峰值和旁瓣,不適合用于電子耳蝸前端的信號采集中。因此,本文所探討的雙 TP 型四聲道信號采集的波束形成方式不適合在把兩個麥克風分別放置兩耳位置。麥克風間距過大導致目標波束發生嚴重的畸變,如果進一步減少麥克風間距,則可以降低所設計波束的失真,系統幅頻響應的變化趨緩。通過 Matlab 仿真實驗來觀察當麥克風間距由 18 cm 逐漸減少時的系統幅頻響應曲線,可以得到以下結論,麥克風間距減少到 2.5 cm 時,目標的系統波束才不會產生較大的差異,因此本文方法適用于麥克風間距在 1~2.5 cm 的范圍內。另一方面,當麥克風間距小于 1 cm 時,系統幅頻響應曲線也會發生變化。極限的最小的間距為 0,此時兩個麥克風互相貼在一起放置。通過仿真實驗可以知道,此時系統幅頻響應曲線變化不太大,主要特征是一致的。因此,結合前面的有關麥克風間距大于 1 cm 和小于 1 cm 的兩種情形的分析,可以得到以下的結論,本文所探討的應用于電子耳蝸前端語音增強的雙 TP 型麥克風波束形成算法對間距有要求,其范圍適用于 0~2.5 cm。對于麥克風固定安裝在電子耳蝸體外機的情形,可選取該范圍內的間距進行放置,而對于通過線路連接的麥克風可移動的情形,麥克風的間距以及由于運動或者震動偏移產生的間距也要限制在 0~2.5 cm 之間。
4 結論
本文采用了麥克風陣列的方法設計雙麥克風波束形成系統,考慮到電子耳蝸嚴格的體積限制,本系統采用雙聲管模式的麥克風。由于每個麥克風包含相互垂直的兩個聲管,因此本系統所設計的雙麥克風采集模式實際上包含了 4 個空間方位信息,有助于設計復雜的指向性波束。本文對雙麥克風多聲管信號采集進行理論的分析和計算,推導出系統輸出信號的表達式,然后根據電子耳蝸使用者常見的語音增強的應用場景,選取了對應的 3 個增益向量用于系統幅頻響應曲線的分析,并探討了增益向量的系數連續取值情形下的響應曲線變化特征和應用場景。所設計的系統能滿足常見電子耳蝸使用者多種狀態和場景的語音增強需求,同時分析了不同麥克風間距的影響,歸納了保持目標波束特征不變的間距范圍。本文所述理論分析以及結論尚需在以后的實驗中加以驗證,所提出的雙 TP 麥克風信號采集模式和多參數條件下所設計的波束需要結合單通道的語音增強技術來應對電子耳蝸復雜的語音增強的應用場景。