超聲檢查是甲狀腺病變檢查中的常用手段,其檢查結果主要由甲狀腺超聲圖像和檢查所見文本報告組成。實現醫療圖像與文本報告的互相檢索(簡稱:互檢)可以為醫生及患者提供極大的便利,但目前尚未有將甲狀腺超聲圖像與文本報告相關聯的互檢方法。本文提出一種基于深度學習的跨模態甲狀腺圖文互檢方法,并在跨模態生成對抗網絡的基礎上提出改進方法:① 將原網絡中用于構建公共表示空間的部分全連接層之間的權重共享約束改為余弦相似度約束,能使網絡更好地學習不同模態數據的公共表示;② 在跨模態判別器前加入全連接層,將權重共享的原網絡中圖像和文本全連接層合并在一起,在繼承了原網絡權重共享的優點基礎上實現語義正則化。實驗結果表明,本文方法的甲狀腺超聲圖像與文本報告互檢平均精度均值可以達到 0.508,較傳統跨模態方法有較大提升,為甲狀腺超聲圖像和文本報告的跨模態檢索提供了新手段。
引用本文: 徐峰, 馬小萍, 劉立波. 基于生成對抗網絡的甲狀腺超聲圖像文本跨模態檢索方法. 生物醫學工程學雜志, 2020, 37(4): 641-651. doi: 10.7507/1001-5515.201812042 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
甲狀腺結節是內分泌系統的常見病和多發病,發病率在成人中高達 50%,其中惡性結節占 7%[1]。超聲影像是目前甲狀腺檢查中最常用的方法。甲狀腺超聲報告包括超聲圖像和文本內容,這兩類不同模態數據為同一病例提供了不同的視角。實現甲狀腺超聲圖像和文本報告之間的跨模態互相檢索(簡稱:互檢),不僅可以方便醫生與患者查閱病歷,還可以針對現有數據檢索相似病例,為診斷提供極大便利。但目前針對甲狀腺超聲診斷的研究主要是針對圖像或文本報告的獨立方法,尚未有將跨模態檢索方法應用于兩者聯系的研究。
現階段跨模態檢索方法的主要思想是學習不同模態間的公共表示,并將不同模態的數據用距離聯系起來,主要分為傳統方法和基于深度學習的方法。① 傳統方法通過學習線性投影來最大化不同模態數據間的聯系,將不同模態數據的特征投影至公共空間來生成一個公共語義表示,其中一類方法主要是通過優化統計值進行相關性分析,具有代表性的是典型關聯分析(canonical correlation analysis,CCA)[2]。CCA 通過構建低維公共空間來實現聯系不同模態間的數據,后續有研究在該方法基礎上提出了很多改進,比如使用核函數、整合語義標簽、加入高級語義的多視 CCA 等[3-5]。與 CCA 類似的還有跨模態因子分析方法(cross-modal factor analysis,CFA)[6]。CFA 通過最小化不同模態數據間的 F 范數,學習將不同模態數據投影至公共空間。另一類方法則將圖正則化整合至跨模態關聯學習中,主要是在公共語義空間中構建不同模態數據的圖[7-9]。② 深度學習憑借著其強大的非線性關聯建模能力,在許多單模態問題上取得了很好的應用,例如圖像分類和目標檢測等[10-11]。因此,一些深度學習網絡也被應用在多模態關聯性建模問題中[12],例如 Feng 等[13]提出了一種自動編碼器(correspondence autoencoder,Corr-AE)來對跨模態關聯和信息重建進行建模;此外還有采用深度網絡和 CCA 相結合的方法——深度典型關聯分析(deep canonical correlation analysis,DCCA)[14]。這些網絡一般包含兩個子網絡,通過聯合層(joint layer)來聯系不同模態的數據[15]。目前還有整合細粒度信息與多任務學習策略并以此來提高性能的方法,例如跨模態關聯學習方法(cross-modal correlation learning,CCL)[16]。
上述方法在構建公共表示空間的過程中,往往缺少對不同模態數據特征之間的相似性關聯約束,對于公共表示空間缺少深層語義關聯。由于甲狀腺超聲圖像相似度較高,且醫生給出的文本報告格式統一,由這些數據提取出的特征往往也較為相似,所以在這些特征基礎上構建公共表示空間時,上述問題所帶來的檢索準確率較低的影響尤為凸出。
隨著 Ian 等[17]提出生成對抗網絡(generative adversarial network,GAN)以后,越來越多的學者提出了基于 GAN 的跨模態數據生成方法[18-20],但大多數方法只能由一種模態生成另一種模態。Peng 等[21]將 GAN 應用在跨模態數據公共表示建模問題中,提出了跨模態 GAN(cross-modal GAN,CM-GAN)網絡。CM-GAN 網絡通過使用深度網絡提取數據特征,再利用 GAN 強大的學習能力來構建跨模態的公共表示空間。
本文針對上述問題,提出基于 CM-GAN 的跨模態方法來實現甲狀腺超聲圖像與文本報告圖文互檢,并在原有網絡基礎上進行兩點改進:① 將原網絡中用于構建公共表示空間的部分全連接層之間的權重共享約束改為余弦相似度約束,使網絡更好地學習不同模態數據的公共表示;② 在跨模態判別器前加入全連接層,將權重共享的原圖像和文本全連接層合并在一起,在繼承了原網絡權重共享的優點基礎上實現語義正則化。本文以銀川市第一人民醫院提供的甲狀腺超聲圖像與文本報告為基礎數據,所有數據均經過脫敏處理,而本文研究僅使用圖像與文本報告,不使用任何患者信息與設備信息。本文所提出的方法實現了甲狀腺超聲圖像與文本報告的互檢,為甲狀腺超聲檢查數據的臨床應用拓展、減少醫生工作量以及方便患者檢索數據奠定了理論與實驗基礎。
1 方法
本文采用 CM-GAN 為基礎網絡,對甲狀腺超聲圖像與文本報告進行關聯建模,并實現跨模態檢索。具體包括三個工作:① 構建 CM-GAN 網絡;② 改進 CM-GAN 網絡;③ 對本文方法進行對比測試。
1.1 CM-GAN 結構
本文方法基于 GAN,以 CM-GAN 為基礎網絡。目前,基于 GAN 的基本結構,衍生出非常多的網絡模型,其中包括 CM-GAN。
GAN 主要由兩部分組成,一部分為生成器(以符號 G 表示),另一部分為判別器(以符號 D 表示)。生成器主要用于學習真實數據的分布,生成接近真實的數據,而判別器主要用于判別數據是真實的還是由生成器生成的。一個典型的 GAN 網絡結構如圖 1 所示。在訓練時,GAN 可以看作是 G 和 D 的極大極小博弈,如式(1)所示:
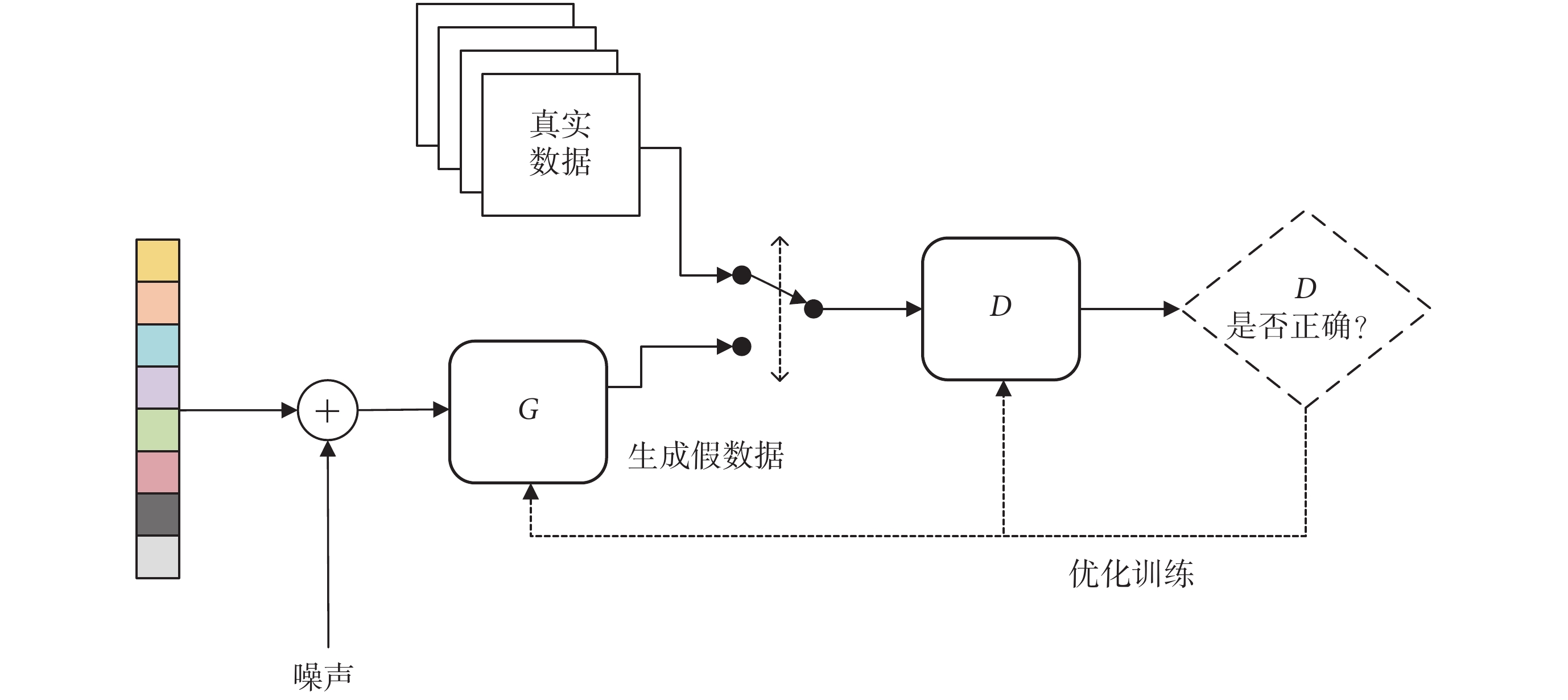 圖1
典型的 GAN 結構
Figure1.
Typical structure of GAN
圖1
典型的 GAN 結構
Figure1.
Typical structure of GAN
 |
其中,x 為真實數據,z 為噪聲輸入, 代表在訓練中 G 減少 V 的值、D 增加 V 的值,訓練網絡的最終目標是在 D 與 G 之間尋找平衡點,使得 V 的值最大,E 代表目標函數,GAN 的主要目的是訓練生成器且最小化 D(G(z)),即讓判別器無法判斷數據是由生成器生成的還是真實的。交替訓練生成器與判別器,G 與 D 互相博弈,最終得到一個在給定數據分布下的最優 G。
代表在訓練中 G 減少 V 的值、D 增加 V 的值,訓練網絡的最終目標是在 D 與 G 之間尋找平衡點,使得 V 的值最大,E 代表目標函數,GAN 的主要目的是訓練生成器且最小化 D(G(z)),即讓判別器無法判斷數據是由生成器生成的還是真實的。交替訓練生成器與判別器,G 與 D 互相博弈,最終得到一個在給定數據分布下的最優 G。
CM-GAN 將 GAN 的思想應用于跨模態數據公共空間建模中,利用 GAN 的生成器與判別器博弈的原理,對特征數據及不同模態數據的公共表示進行判別,從而更好地構建跨模態數據公共空間,實現更高的跨模態檢索準確度。
CM-GAN 網絡結構如圖 2 所示,該網絡主要包含兩大部分,一部分是生成模型,另一部分是判別模型。從水平方向看又可分為同模態通路與跨模態通路。對于生成模型,將跨模態自動編碼器應用其中,使用共享權重來約束跨模態的自動編碼器,并以此構建不同模態間的公共表示空間。對于判別模型,設計模態內和模態間的判別模型,不僅對生成公共表示進行判別,還對生成的重構表示進行判別,從而加速訓練過程。生成模型和判別模型同時進行訓練,從而實現不同模態數據的相互關聯。
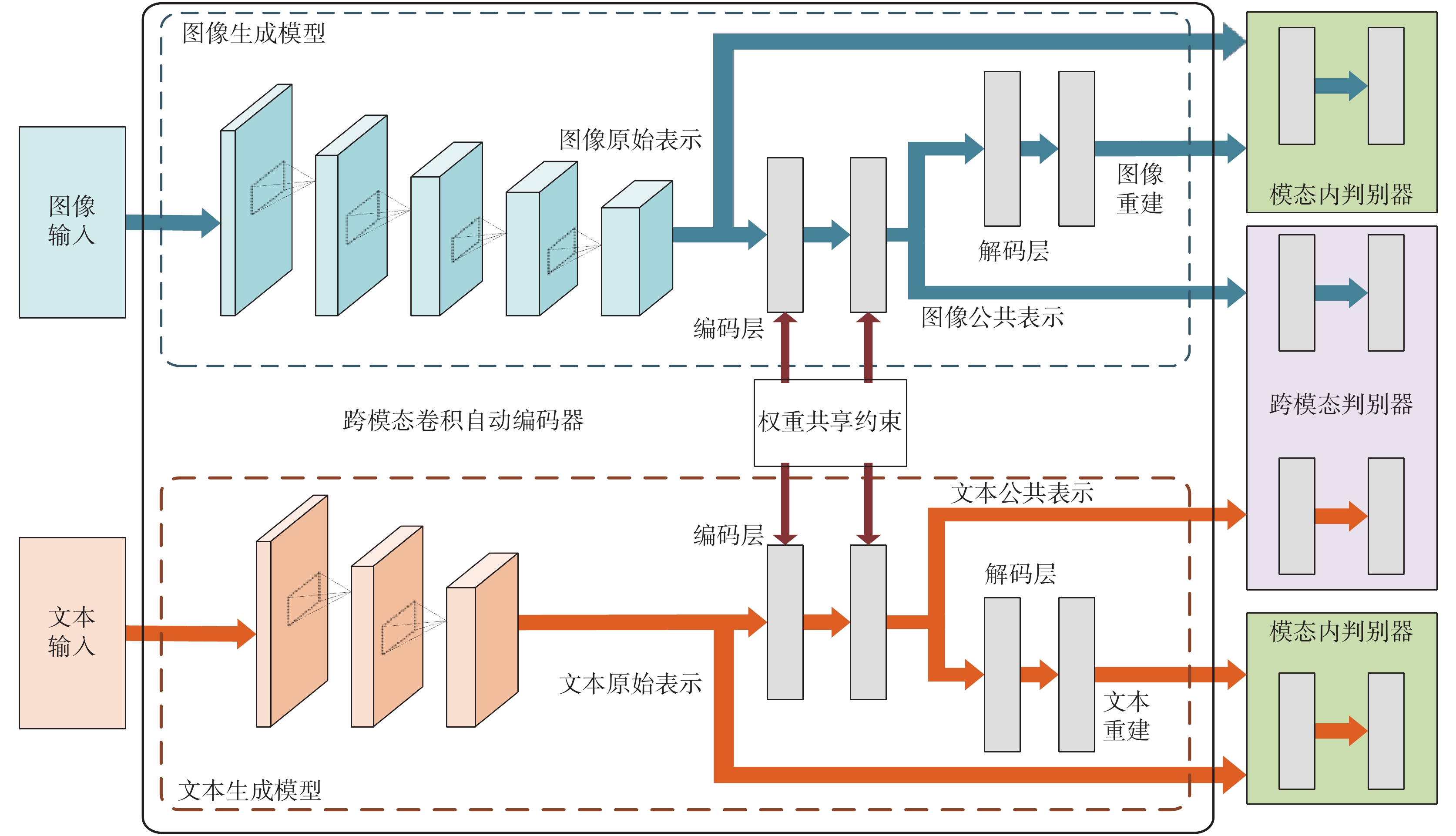 圖2
CM-GAN 網絡結構
Figure2.
Structure of CM-GAN network
圖2
CM-GAN 網絡結構
Figure2.
Structure of CM-GAN network
生成模型部分主要由兩種生成器組成,一種是圖片生成器(以符號 GI 表示),一種為文本生成器(以符號 GT 表示),而每種生成器又是由編碼器和解碼器兩部分組成,即對應于 GI 的編碼器(以符號 GIenc 表示)和解碼器(以符號 GIdec 表示)以及對應于 GT 的編碼器(以符號 GTenc 表示)和解碼器(以符號 GTdec 表示)。編碼器主要由卷積神經網絡組成,主要用于學習每種模態的特征信息,與之相連接的是全連接層,而 GIenc 和 GTenc 的最后一個全連接層由共享權重和語義約束構成,從而實現公共表示的學習。對于解碼器,其功能主要是將從編碼器的卷積神經網絡中獲取的高級語義表示重建,來保持每種模態的語義一致性。
判別模型部分有兩種判別器同時對跨模態和模態內的公共表示信息進行判別。模態內的判別器由圖片判別器(以符號 DI 表示)和文本判別器(以符號 DT 表示)組成,主要是將生成器重構的表示信息與提取到的特征作以判別;跨模態判別器(以符號 DC 表示),是一個由兩個子判別器(通路)構成的網絡,即圖像通路(以符號 DCi 表示)與文本通路(以符號 DCt 表示),這兩個子判別器的目的是判斷公共表示是來自圖像還是文本。DCi 以圖像公共表示(以符號 spi 表示)為真數據,以文本公共表示(以符號 spt 表示)與不匹配的圖像公共表示(以符號  表示)為假數據,spi 與
表示)為假數據,spi 與  都來自圖像的高級語義特征(分別對應以符號 hpi 與
都來自圖像的高級語義特征(分別對應以符號 hpi 與  表示)。與 DCi 類似,DCt 以 spt 為真數據,以 spt 與不匹配的文本公共表示(以符號
表示)。與 DCi 類似,DCt 以 spt 為真數據,以 spt 與不匹配的文本公共表示(以符號  表示)為假數據。
表示)為假數據。
對于跨模態判別器(以符號 DC 表示),構成其網絡的兩個子判別器均連接自公共表示空間,并以公共表示空間作為輸入數據。每個子判別器都由兩個全連接層構成。第一個全連接層是由 512 個單元的全連接層,后接一個批正則化層和線性修正單元(rectified linear unit,ReLU)激活函數組成。第二個全連接層將第一個全連接層的輸出作為輸入,并將輸出送入緊隨其后的 S 形激活函數(sigmoid)層來生成一個預測值。對于圖像通路,圖像的公共表示被標示為 1,與其匹配的文本公共表示和與其不匹配的圖像公共表示被標示為 0。對于文本通路,文本的公共表示被標示為 1,與其匹配的圖像公共表示和與其不匹配的文本公共表示被標示為 0。
CM-GAN 網絡的目標函數可以表示如式(2)所示:
 |
其中, 與
與 分別對應同模態通路與跨模態通路,其表示如式(3)~(4)所示:
分別對應同模態通路與跨模態通路,其表示如式(3)~(4)所示:
 |
 |
本文在直接使用 CM-GAN 網絡用于甲狀腺超聲圖像與文本報告跨模態檢索時,其收斂速度并不高,平均精度均值(mean average precision,mAP)只能達到 0.487,與其他現有方法比較提升不高。分析其可能原因,主要有兩點:① 采用相同角度采集的甲狀腺超聲圖像在空間上往往是相似的,且醫生給出的文本報告用詞相似、格式統一,這些大量在空間上相似的數據經過編碼器提取后其特征數據也較為相似,這給解碼器生成公共表示空間以及判別器對正負樣本的判別造成了困難;② CM-GAN 中加入了對全連接層的權重共享,實現了一定的語義關聯限制,但與其相連的跨模態判別器之間并無語義上的關聯,這對于公共表示空間的生成也造成了影響。因此,針對以上問題,本文對 CM-GAN 進行了改進。
1.2 改進的 CM-GAN
本文提出的改進的 CM-GAN 在原網絡基礎上,取消了原有編碼器之后的第二個全連接層之間的權重共享約束(weight-sharing constraints),使用余弦相似度約束(cosine similarity constraints)對全連接層的參數進行約束。
原網絡中,圖像數據經由 GIenc,即由 19 層全卷積神經網絡組成的視覺幾何組—19 網絡(visual geometry group,VGG-19)生成特征向量 hpi,再由權重共享的全連接層生成 spi[22]。而文本數據則通過 GTenc,先由詞嵌入(word to vector, Word2Vec)方法轉換成詞向量,然后經卷積神經網絡形成特征向量(以符號 hpt 表示),再經過權重共享的全連接層生成 spt[23]。權重共享約束的作用是在為每種模態數據生成公共表示空間的同時增加語義限制,使得成對的圖像與文本的公共表示盡可能相近。而且在原網絡中,在權重共享的每個全連接層之后還加入了批正則化層和 ReLU 激活函數,最后公共表示空間 spi 和 spt 還被送入歸一化(softmax)層,使得不同模態的數據關聯更緊密。
但對于甲狀腺超聲圖像與文本報告來說,在空間上相似的數據較多,如果僅使用權重共享的全連接層是無法很好地將不同模態的正負樣本數據進行區分的,從而影響公共表示空間的建立。本文使用余弦相似度約束來保證網絡在相似數據較多的情況下仍可以良好完成對公共表示空間的建立。
余弦相似度(cosine similarity)指兩個成角度的 d 維向量 a,b∈Rd 的余弦值,其計算如式(5)所示:
 |
其中 表示點積,
表示點積, 表示 Lp 范數。
表示 Lp 范數。
令 x∈X 為一種模態的數據(圖片或文本),y∈C 為另一種模態的數據。令 ?θ:X→Rd 為一種參數為 θ 的從輸入 x 到 d 維特征空間的變換。gρ:C→Sd 為一種參數為 ρ 的從輸入 C 到 d 維特征空間的變換。其中 ?θ 與 gρ 在深度學習中一般為特征提取。而 ψ:Rd→P 與 φ:Sd→P 這兩種變換定義為 Rd 與 Sd 到公共表示空間 P 的映射。
一種簡單的映射,以獨熱編碼(one hot)的向量為例,如式(6)所示:
 |
在深度學習中,可以理解為 φ 的目標是通過參數為 θ 的神經網絡 ?θ 通過最大化圖像特征和文本特征的余弦相似度來學習公共表示空間。定義損失(loss)值函數訓練神經網絡,如式(7)所示:
 |
在實際運用中通過兩個操作的序列實現這一方法,首先由神經網絡提取的特征被 L2 歸一化(L2 normalized),即  ,這保證了公共空間被限制在單位超球面(the unit hypersphere),這里余弦相似度可以等價于點積,如式(8)所示:
,這保證了公共空間被限制在單位超球面(the unit hypersphere),這里余弦相似度可以等價于點積,如式(8)所示:
 |
其次,φ(gρ)也需要位于單位超球面上來保證等式成立。以獨熱編碼的向量為例,它在定義上就滿足了單位正則化,所以不需要再進行 L2 歸一化。
在改進的 CM-GAN 網絡中,編碼器之后的第一層全連接層仍使用權重共享約束以保證 hpi 以及 hpt 在公共空間中的關聯性。而對于第二層全連接層取消權重共享約束,取而代之的是在該層之后加入余弦相似度約束。對于從編碼器得到的特征數據 hpi 以及 hpt,經過全連接層得到的公共空間特征 spi 與 spt,在訓練過程中,此處將采用加入余弦相似度約束的 loss 值函數,其表達式如式(9)所示:
 |
其中 cos()為余弦相似度計算公式,α 為邊界條件,在訓練中取 0.1。
在加入余弦相似度約束之后,改進的網絡繼承了原有 CM-GAN 在構建公共表示空間中權重共享對不同模態特征數據在語義上關聯的優點,還能降低由于存在大量相似度較高的數據集導致所獲得到的特征數據也較為相似所帶來的影響。
在訓練多個批(batches)的數據時,計算所有批(batch)的平均 loss 值,從而約束網絡構建更好的公共表示空間。
1.3 改進網絡結構
在經過上述改進之后,雖然網絡對于大量相似的數據具有了一定的魯棒性,但其對不同模態特征數據的公共表示空間的構建仍不理想,原因是在構建公共表示空間的全連接層之后,公共表示 spi 與 spt 被送入跨模態判別器中,在原網絡中,跨模態判別器主要用于判別某模態數據的公共表示和另一模態與之對應的公共表示以及不匹配的數據。判別器由兩部分組成,每一部分都由兩層網絡組成,第一層由維度 512 的隱藏層以及批正則化層和 ReLU 激活函數組成,第二層為單值輸出層。該網絡結構雖然可以實現對不同模態的公共表示進行語義上的關聯,但判別器互相獨立,圖像和文本判別器分別對 spi 與 spt 進行獨立判別,這在一定程度上影響了跨模態數據公共表示空間的語義統一性。
在改進的網絡結構中,在跨模態判別器 DC 前加入了兩層全連接層(以符號 GIT 表示),第一層由含有 1 024 個單元的隱藏層與批正則化和 ReLU 激活函數組成,第二層為含有 512 個單元的全連接層,該層維度與 DC 的第一層全連接層一致。在此基礎上,對數據加入圖像語義標簽(以符號 ci 表示)與文本語義標簽(以符號 ct 表示),從而進一步對不同模態數據的語義關聯。
在跨模態判別器中,為了達到更好的判別效果,讓 spi 作為正樣本,讓  與 spt 作為負樣本,并且將 hpi 與
與 spt 作為負樣本,并且將 hpi 與  連接在一起。其中 spt 與
連接在一起。其中 spt 與  作為負樣本被標記為 0,這樣可以使判別器在連接 hpi 或
作為負樣本被標記為 0,這樣可以使判別器在連接 hpi 或  時有更好的效果,對于圖像判別器的梯度計算,如式(10)所示:
時有更好的效果,對于圖像判別器的梯度計算,如式(10)所示:
 |
其中,(spi,hpi)與( ,
, )表示鏈接公共表示與高級語義特征。對于文本判別器,其梯度計算如式(11)所示:
)表示鏈接公共表示與高級語義特征。對于文本判別器,其梯度計算如式(11)所示:
 |
在整個網絡模型中,生成器需要最小化目標方程來生成真正的關聯分布,在訓練時使用梯度下降法,并凍結判別器,其中圖像生成器的梯度計算如式(12)所示:
 |
其中,(spi,hpt)表示串聯公共表示與高級語義特征。對于文本生成器也可以用類似的公式計算梯度,如式(13)所示:
 |
在此基礎上,兩個生成器使用語義標簽結合 softmax loss 值函數進行進一步優化,如式(14)所示:
 |
其中,sp 表示模型學習到的公共表示空間 spi 或 spt,cp 代表與它們對應的標簽,當 cp = q 時,1{cp = q}為 1,其他情況為 0。經過這種方法的優化,可以使語義在不同模態間保持連續性。
結合前文對權重共享約束的全連接層的改進,整體公共表示空間構造部分的 loss 值函數如式(15)所示:
 |
其中,spi 和 spt 仍為圖像與文本的公共表示,ci 和 ct 為語義標簽,當 spi 與 spt 為匹配的文本與圖像時,ci 和 ct 是相同的,y 為加入余弦相似度約束的 loss 值函數 Lcos 的參數,當 spi 和 spt 為匹配的文本與圖像時,y 的值為 1,當 spi 和 spt 不匹配時,y 的值為 ?1。Lfc 表示全連接層的 loss 值函數。
1.4 最終網絡結構
將前文中提出的加入的余弦相似度約束與跨模態判別器前增加的全連接層結合在一起,得到了總體改進后的網絡,其結構如圖 3 所示。由于增加的全連接層將原網絡中構建的公共空間 spi 與 spt 結合在了一起,并加入了語義標簽,所以改進后的網絡中跨模態判別器的 loss 值函數也做出了相應改變,如式(16)所示:
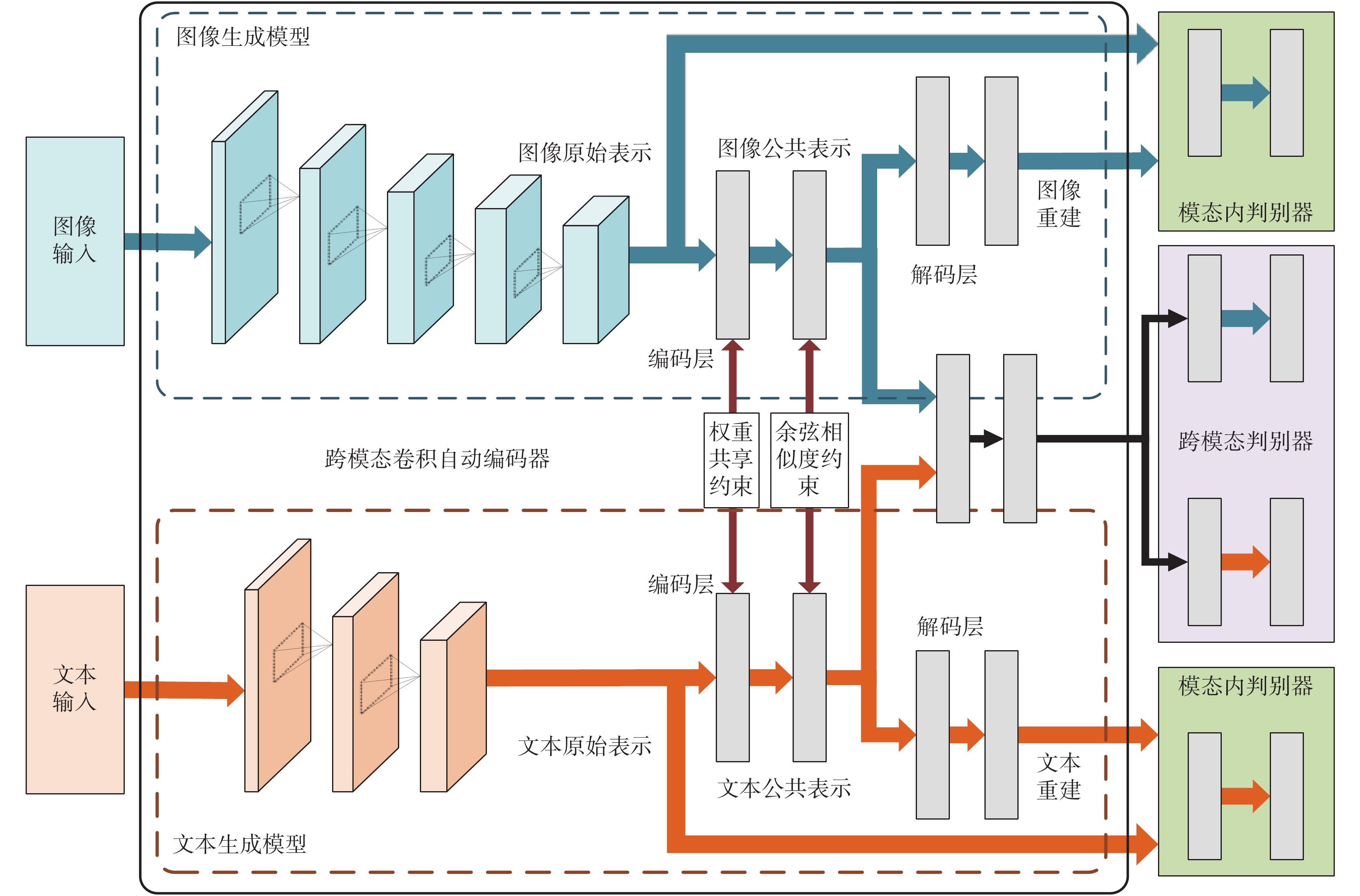 圖3
改進后網絡結構
Figure3.
The structure of improved CM-GAN network
圖3
改進后網絡結構
Figure3.
The structure of improved CM-GAN network
 |
整合改進后的網絡不僅對相似數據的跨模態公共空間的生成有了魯棒性,還增加了對公共空間在語義上的關聯,使得網絡對于甲狀腺超聲圖像與文本的跨模態公共空間建模能力有所提升。
2 實驗
在實驗部分,主要討論實驗所用數據集、評價指標以及所對比的方法。本文中使用了來自銀川市第一人民醫院授權使用的甲狀腺超聲診斷數據。評價指標主要使用 mAP 值評價網絡跨模態檢索的能力,并以此評價指標為準,與 5 種經典的跨模態檢索方法比較。本文中還將優化后的網絡與原網絡進行收斂速度對比,以此評價網絡優化效果。
2.1 數據集和預處理
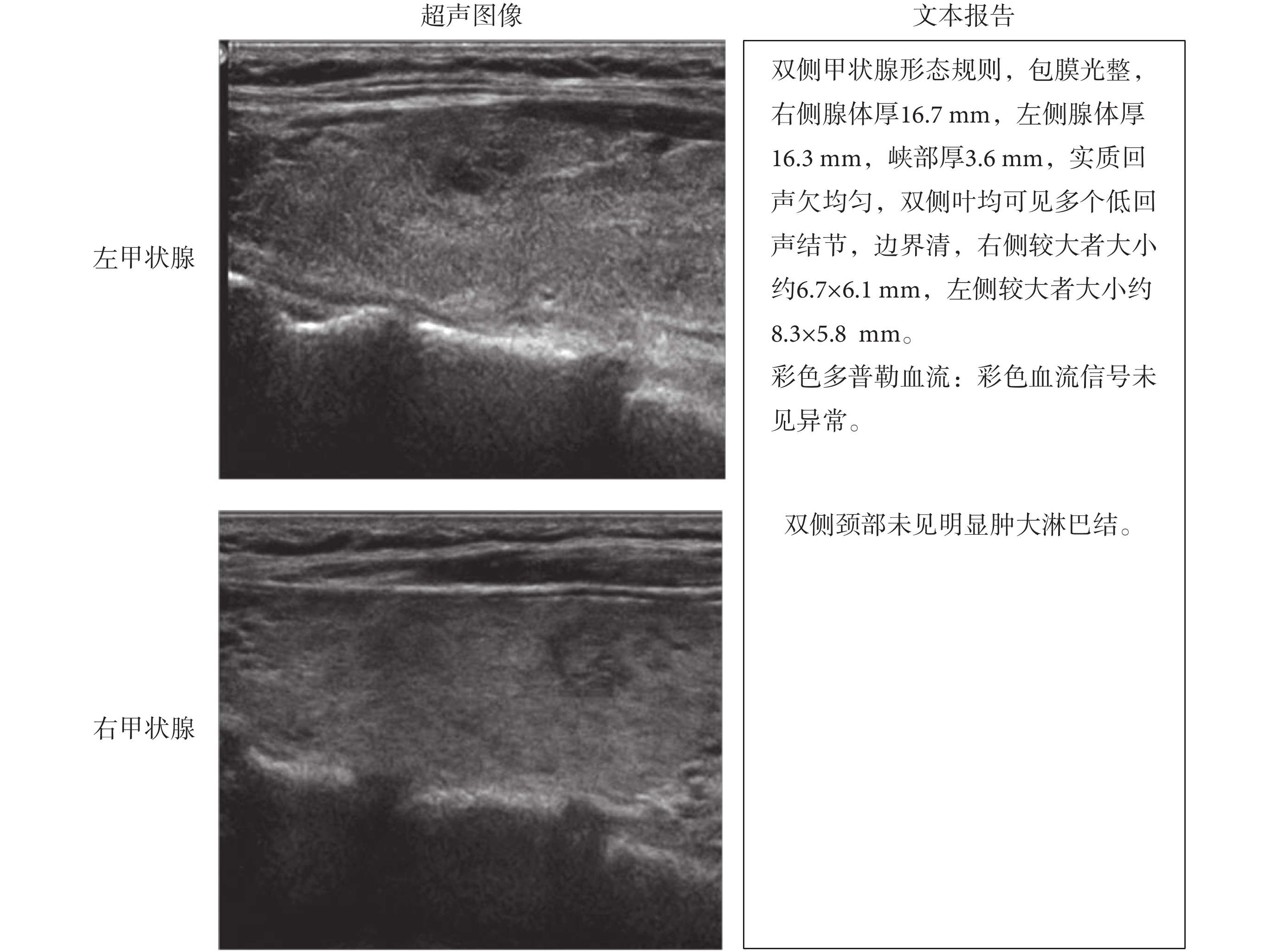
本文使用了來自銀川市第一人民醫院授權的 700 例(共 2 800 張)甲狀腺超聲圖像數據以及對應的文本報告(檢查所見),圖像數據原始格式為醫學影像成像和通訊標準格式(digital imaging and communications in medicine,DICOM)。首先,將原始數據進行脫敏處理,然后轉換為灰度圖像,再將圖像中含有敏感信息的部分截去,只保留甲狀腺超聲圖像區域。文本報告(檢查所見)來自于專業醫生對甲狀腺超聲圖像的客觀描述,原始數據保存在數據庫中,首先從數據庫中導出文本數據,然后將文本數據進行脫敏處理,并且只使用針對圖像的文本描述部分。如圖 4 所示,為甲狀腺超聲圖像與文本報告數據樣例,左側為兩張屬于同一個患者同一次檢查所得到的圖像,右側為對應的文本報告。
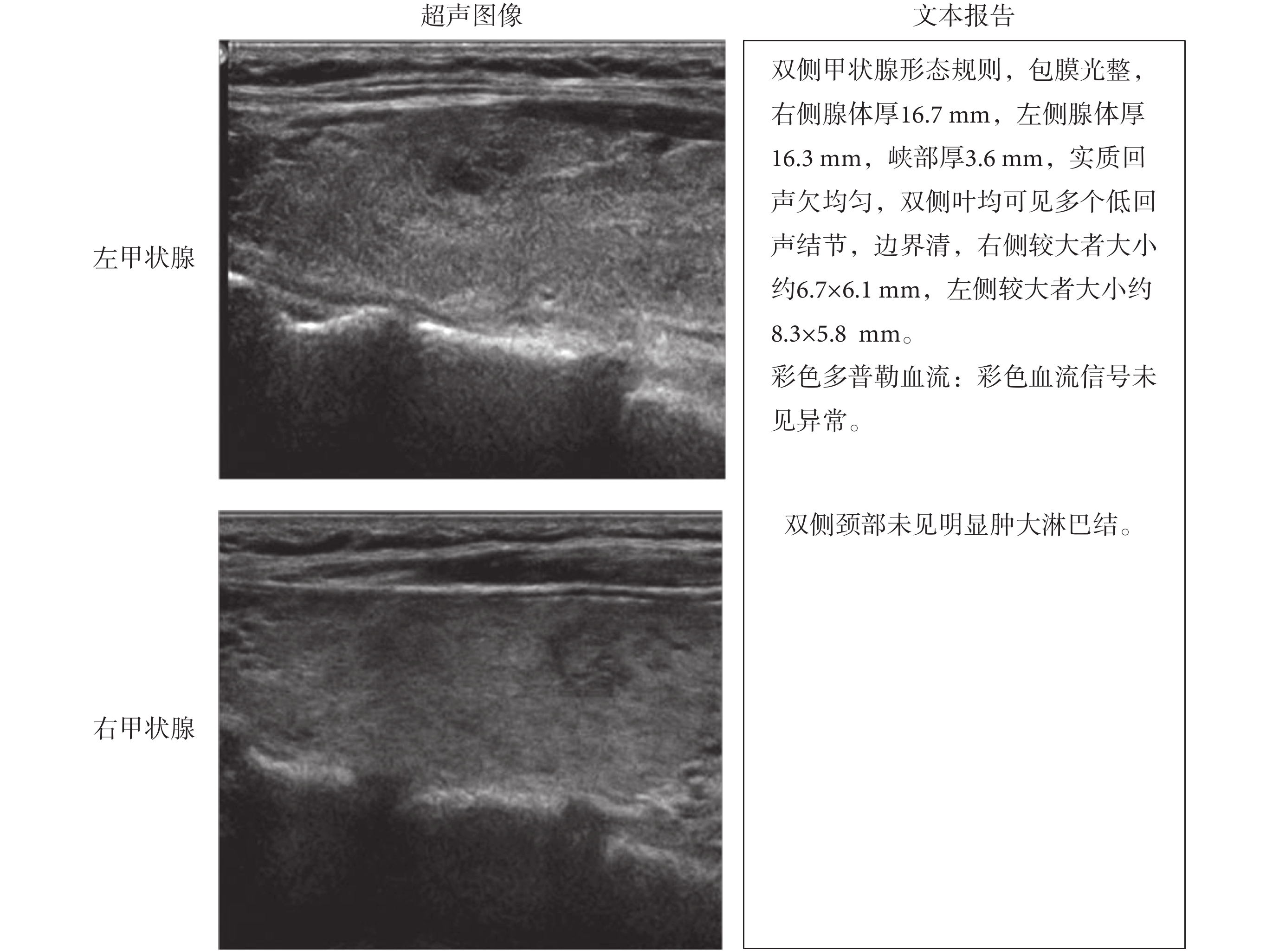 圖4
甲狀腺超聲圖像與文本數據
Figure4.
Thyroid ultrasonic images and text
圖4
甲狀腺超聲圖像與文本數據
Figure4.
Thyroid ultrasonic images and text
由于網絡訓練需要大量樣本,因此本文對甲狀腺超聲圖像和文本報告都做了一定的數據增廣處理。對于圖像數據采用縮放圖像、旋轉圖像、截取圖像區域方法對數據集進行擴充。對于每一對圖像—文本來說,不存在一個圖像對應多個文本,或者一個文本對應多個圖像的情況,但是對于同一次超聲檢查來說,往往有多個圖像—文本對。對于文本數據,采用調整語序或摘取部分文本的方法進行擴充。最終得到共 9 400 組圖像與文本。
2.2 評價指標
不同模態數據可以用相似度矩陣與 CM-GAN 學習到的公共表示聯系在一起。本文主要考慮 CM-GAN 在甲狀腺超聲圖像與文本的雙模態檢索能力,即以圖像檢索文本與以文本檢索圖像的能力。對于以圖像檢索文本,采用圖像作為檢索輸入數據來檢索文本數據并計算它們的相似度。對于以文本檢索圖像,采用文本作為檢索輸入數據來檢索圖像并計算它們的相似度。
本文采用 mAP 來對 CM-GAN 的檢索結果進行評價,該評價指標是檢索、識別任務中常用的評價指標,代表每個檢索(或識別)的準確率的均值,該指標反映了網絡的優良程度。
查準率(precision)是指正確的檢索結果在所有檢索結果中的占比。查準率可以考慮到所有獲取的結果,也可以指定考慮結果中排名前 k 的結果,這種情況下查準率稱為前 k 查準率。查全率(recall)是指正確的查詢結果的數量在所有正確數據中的比例。查準率和查全率雖然可以在一定程度上反應檢索方法的有效性,但這兩種指標并沒有考慮檢索方法給出的結果在順序上的重要性,所以需要引入平均準確率。
平均準確率(average precision, AveP)(以符號 AveP 表示)的計算方法如式(17)所示:
 |
其中,P(k)指前 k 查準率,Δr(k)= r(k)? r(k ? 1)。如果令合集 Ω 為查詢第 k 個結果的集合,如式(18)所示:
 |
為提高計算準確率,使用相鄰兩次查的前 k 查詢準確率進行計算,如式(19)所示:
 |
對于每一次查詢所得到的 AveP 取均值,即得到了 mAP 值。
2.3 實驗結果
為了驗證本文方法在甲狀腺超聲圖像與文本報告跨模態檢索任務中的性能,通過將本文方法與 CM-GAN、CCL、DCCA、Corr-AE、CFA 以及 CCA 共 6 種跨模態檢索方法對比,選取 10 組樣本對以上方法進行多次實驗,得出結果如表 1 所示。在測試過程中,所有的數據均采用相同的 CNN 網絡結構來提取數據特征。對于圖像數據,采用 VGG-19,對于文本數據,采用詞卷積神經網絡(word convolutional neural network,WordCNN)。由實驗結果數據不難發現,CM-GAN 在以圖檢文、以文檢圖以及平均的 mAP 值方面,均優于其他方法。相對于原 CM-GAN 方法,本文方法以圖檢文精度均值從 0.503 提高到了 0.519,以文檢圖從 0.471 提高到了 0.497,而平均值從 0.487 提高到了 0.508。CM-GAN 利用深度學習的特征提取優勢與 GAN 在跨模態領域中優異的異質數據關聯性建模能力,在圖文跨模態互檢任務中取得了更好的效果。
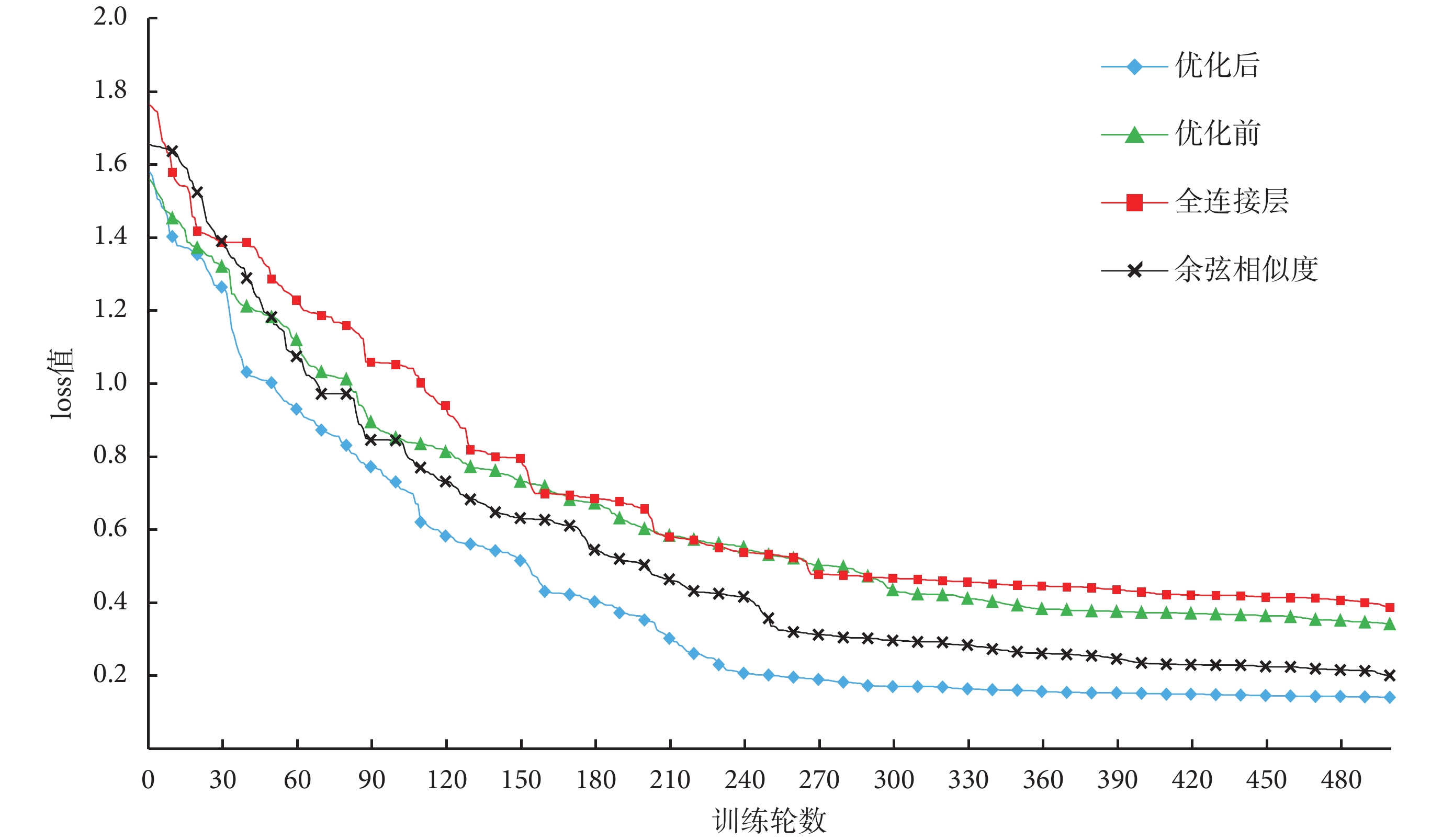
本文實驗還驗證了對 CM-GAN 網絡的優化效果,如圖 5 所示,虛線為優化前的網絡 loss 值曲線,實線為優化后網絡 loss 值曲線,縱坐標為 loss 值,橫坐標為迭代次數。從圖 5 中可知在迭代訓練大于 400 次時,優化后的網絡 loss 值下降更快。優化后的網絡在 250 次迭代后基本趨于收斂,最終 loss 值穩定在 0.14 左右,而優化前的網絡則在 360 次左右區域穩定,收斂速度相對較慢,最終穩定在 0.35 左右。通過比較可知,優化后的網絡收斂速度更快,收斂時 loss 值更低。
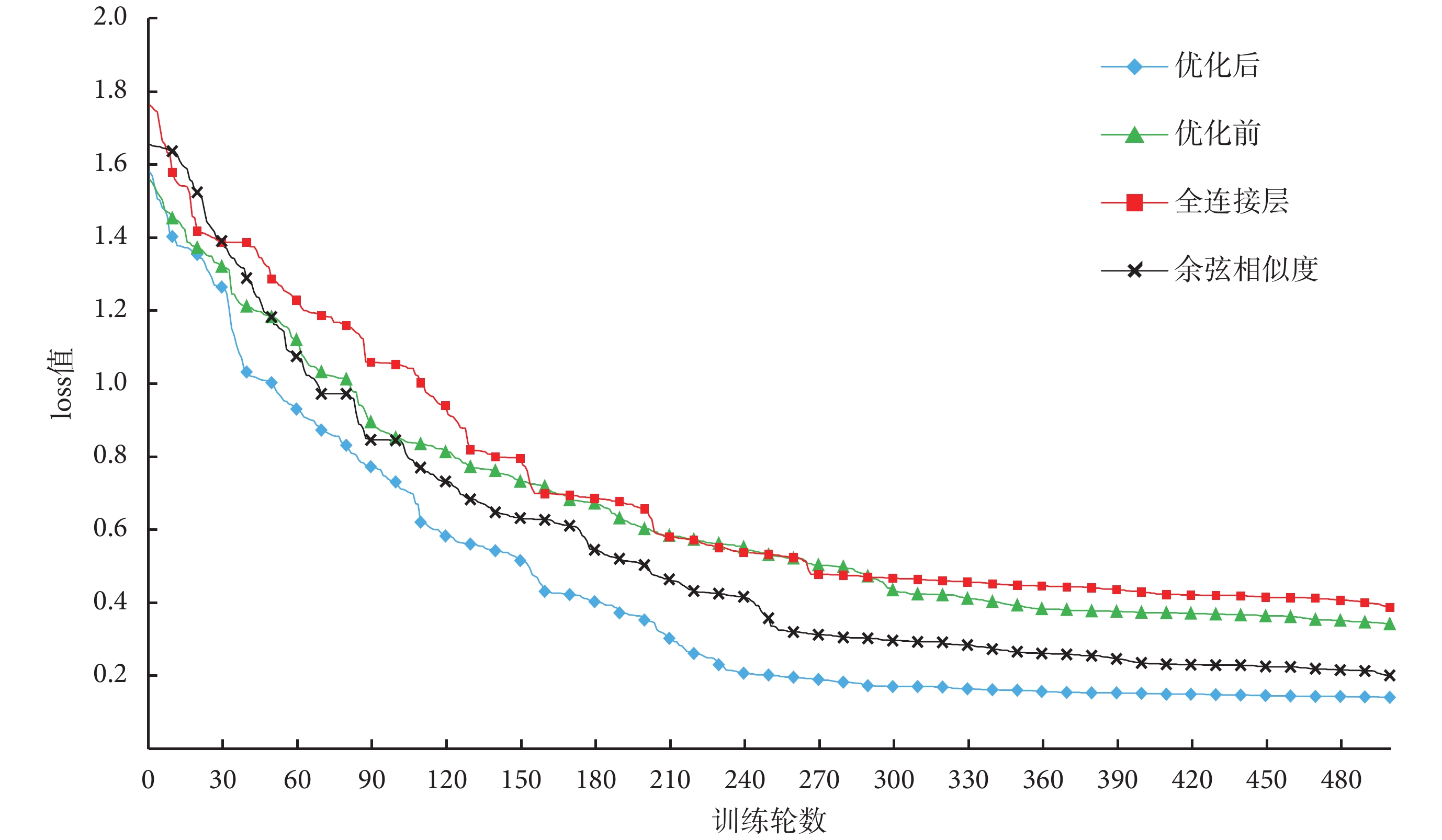 圖5
訓練時 loss 值對比
Figure5.
Comparison of loss value in training
圖5
訓練時 loss 值對比
Figure5.
Comparison of loss value in training
本文還針對兩種改進方式分別進行了對比,使用與上文相同的圖像與文本特征提取方法與數據集,分別對只加入全連接層與只加入余弦相似度的網絡進行了測試。通過實驗結果發現,如果只加入全連接層,增加了網絡中隱藏節點的數量,對網絡訓練效率有較大影響,收斂速度低于改進前的網絡結構,而網絡的 mAP 值并沒有隨著網絡復雜度的提升而提高。只加入余弦相似度的網絡結構,減少了一層權重共享的全連接層,在訓練效率上有所提高,收斂速度優于原網絡結構,但缺少全連接層,導致 mAP 值無法提高。余弦相似度和全連接層形成互補關系,相對于使用權重共享的全連接層,訓練效率更高,網絡檢索效果更好。
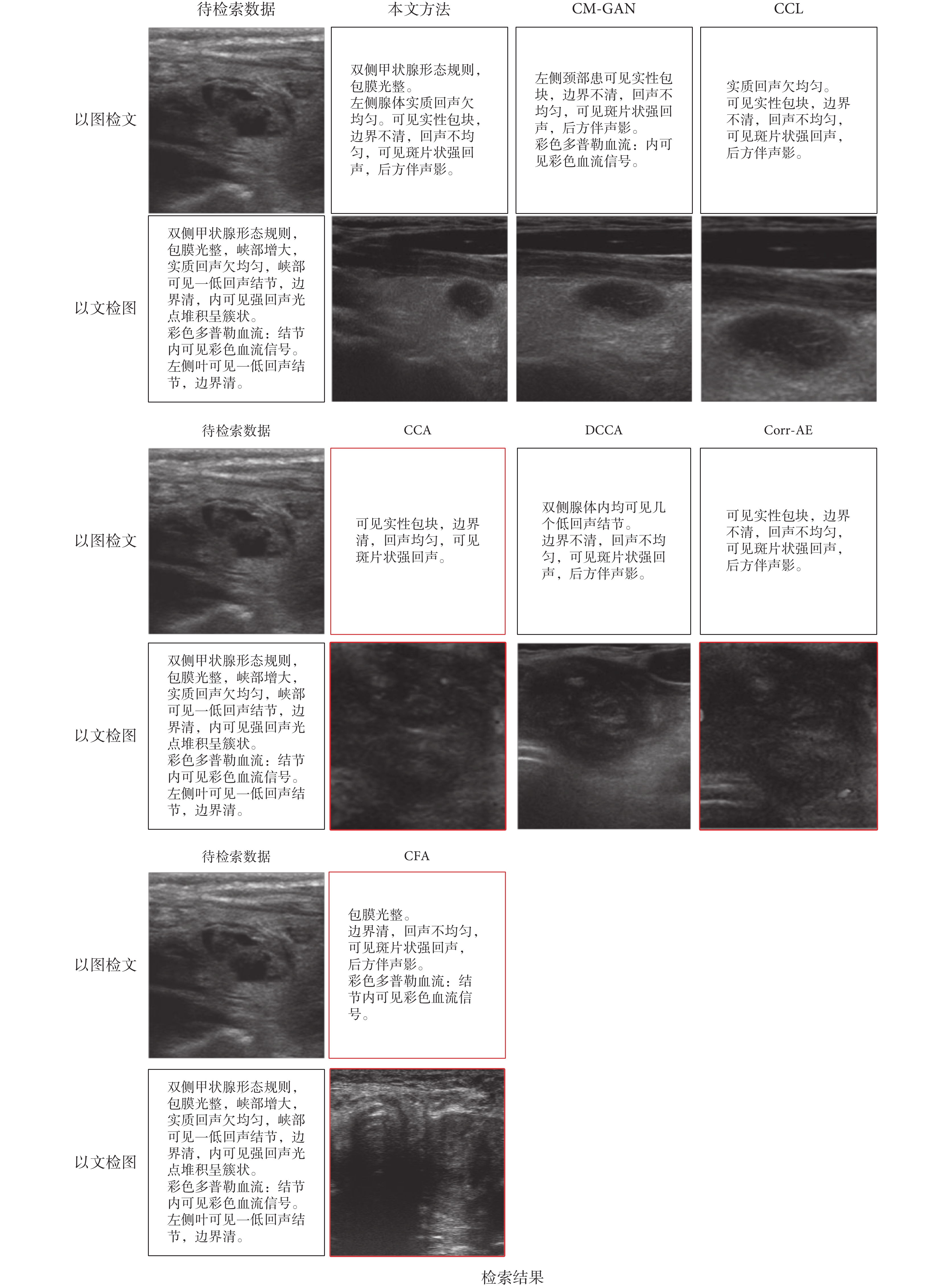
如圖 6 所示,為本文與 6 種跨模態檢索方法的結果對比,分別以圖像和文本為輸入數據,各個算法得出的檢索結果各有不同,其中檢索結果有誤的用紅色框線標出。
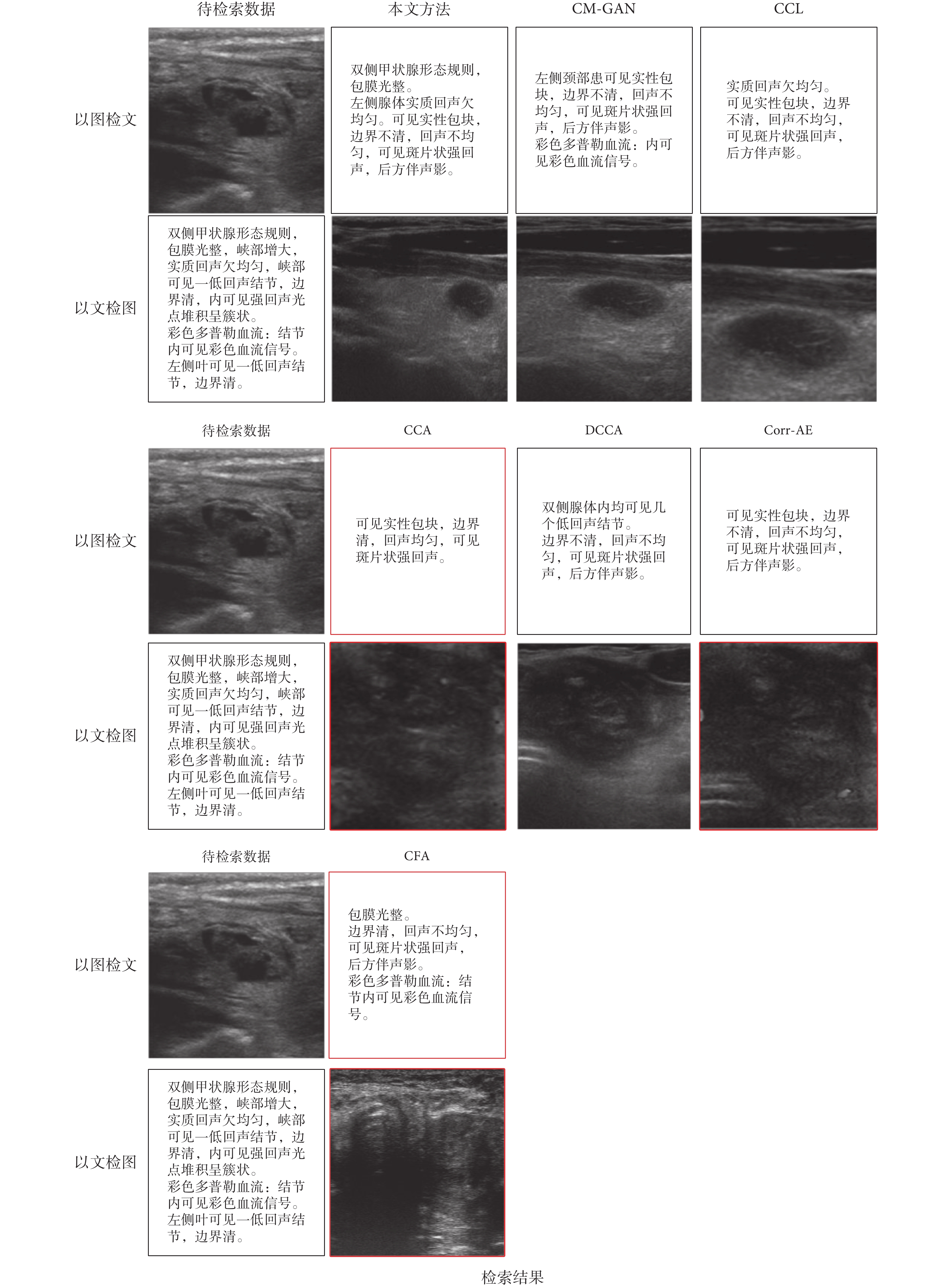 圖6
本文 7 種方法檢索結果對比
Figure6.
Comparison between retrieval results of 7 methods
圖6
本文 7 種方法檢索結果對比
Figure6.
Comparison between retrieval results of 7 methods
圖 6 中,以圖像檢索文本的結果,圖中顯示為待檢索甲狀腺結節超聲圖像檢索到的文本描述,該甲狀腺結節為 25 × 11 mm2 大小的實性結節,邊界不清晰,回聲不均勻,可見斑片狀強回聲,后方伴有聲影。從檢索結果來看,CM-GAN、CCL、Corr-AE 與 DCCA 方法可以較為準確地得到該甲狀腺結節的描述;而 CFA 與 CCA 方法對邊界的描述為不清晰;CCA 方法得到的結果較少,描述不完整。
圖 6 中,以文本檢索圖像的結果,圖中顯示為待檢索文本檢索到的甲狀腺超聲圖像,從結果可以發現 CM-GAN、CCL 與 DCCA 方法可以準確地檢索到相關圖像,其中 CM-GAN 與 CCL 檢索到的圖像為增廣處理后的甲狀腺超聲圖像;Corr-AE 與 CCA 檢索到的圖像來自同一個甲狀腺,但不對應于描述;CFA 方法沒有正確檢索到圖像。
通過檢索結果對比可以發現,本文方法可以較好地完成甲狀腺超聲圖像與文本報告的跨模態檢索任務。
3 結束語
本文將 CM-GAN 應用于甲狀腺超聲圖像與文本報告的跨模態檢索任務中,實現了甲狀腺超聲圖像與文本報告的互相檢索,不僅利用了醫院數據庫中長久保存而不用的大量數據,還利用跨模態檢索方法,探索了從醫療圖像生成文本報告,以及從文本報告生成醫療圖像的方法,為減輕醫生工作壓力,方便患者了解和使用醫療圖像奠定了理論與實驗基礎。通過實驗證明,CM-GAN 不僅可以在公開數據集上取得良好的效果,在醫療影像與醫療文本報告數據集上同樣可以取得較好結果。目前,本文只使用了圖像與文本數據,但醫院中還有大量的數據是基于視頻和音頻的,所以在后續工作中,如何將跨模態檢索方法應用于其他醫療數據模態上也將成為未來的研究方向之一。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
甲狀腺結節是內分泌系統的常見病和多發病,發病率在成人中高達 50%,其中惡性結節占 7%[1]。超聲影像是目前甲狀腺檢查中最常用的方法。甲狀腺超聲報告包括超聲圖像和文本內容,這兩類不同模態數據為同一病例提供了不同的視角。實現甲狀腺超聲圖像和文本報告之間的跨模態互相檢索(簡稱:互檢),不僅可以方便醫生與患者查閱病歷,還可以針對現有數據檢索相似病例,為診斷提供極大便利。但目前針對甲狀腺超聲診斷的研究主要是針對圖像或文本報告的獨立方法,尚未有將跨模態檢索方法應用于兩者聯系的研究。
現階段跨模態檢索方法的主要思想是學習不同模態間的公共表示,并將不同模態的數據用距離聯系起來,主要分為傳統方法和基于深度學習的方法。① 傳統方法通過學習線性投影來最大化不同模態數據間的聯系,將不同模態數據的特征投影至公共空間來生成一個公共語義表示,其中一類方法主要是通過優化統計值進行相關性分析,具有代表性的是典型關聯分析(canonical correlation analysis,CCA)[2]。CCA 通過構建低維公共空間來實現聯系不同模態間的數據,后續有研究在該方法基礎上提出了很多改進,比如使用核函數、整合語義標簽、加入高級語義的多視 CCA 等[3-5]。與 CCA 類似的還有跨模態因子分析方法(cross-modal factor analysis,CFA)[6]。CFA 通過最小化不同模態數據間的 F 范數,學習將不同模態數據投影至公共空間。另一類方法則將圖正則化整合至跨模態關聯學習中,主要是在公共語義空間中構建不同模態數據的圖[7-9]。② 深度學習憑借著其強大的非線性關聯建模能力,在許多單模態問題上取得了很好的應用,例如圖像分類和目標檢測等[10-11]。因此,一些深度學習網絡也被應用在多模態關聯性建模問題中[12],例如 Feng 等[13]提出了一種自動編碼器(correspondence autoencoder,Corr-AE)來對跨模態關聯和信息重建進行建模;此外還有采用深度網絡和 CCA 相結合的方法——深度典型關聯分析(deep canonical correlation analysis,DCCA)[14]。這些網絡一般包含兩個子網絡,通過聯合層(joint layer)來聯系不同模態的數據[15]。目前還有整合細粒度信息與多任務學習策略并以此來提高性能的方法,例如跨模態關聯學習方法(cross-modal correlation learning,CCL)[16]。
上述方法在構建公共表示空間的過程中,往往缺少對不同模態數據特征之間的相似性關聯約束,對于公共表示空間缺少深層語義關聯。由于甲狀腺超聲圖像相似度較高,且醫生給出的文本報告格式統一,由這些數據提取出的特征往往也較為相似,所以在這些特征基礎上構建公共表示空間時,上述問題所帶來的檢索準確率較低的影響尤為凸出。
隨著 Ian 等[17]提出生成對抗網絡(generative adversarial network,GAN)以后,越來越多的學者提出了基于 GAN 的跨模態數據生成方法[18-20],但大多數方法只能由一種模態生成另一種模態。Peng 等[21]將 GAN 應用在跨模態數據公共表示建模問題中,提出了跨模態 GAN(cross-modal GAN,CM-GAN)網絡。CM-GAN 網絡通過使用深度網絡提取數據特征,再利用 GAN 強大的學習能力來構建跨模態的公共表示空間。
本文針對上述問題,提出基于 CM-GAN 的跨模態方法來實現甲狀腺超聲圖像與文本報告圖文互檢,并在原有網絡基礎上進行兩點改進:① 將原網絡中用于構建公共表示空間的部分全連接層之間的權重共享約束改為余弦相似度約束,使網絡更好地學習不同模態數據的公共表示;② 在跨模態判別器前加入全連接層,將權重共享的原圖像和文本全連接層合并在一起,在繼承了原網絡權重共享的優點基礎上實現語義正則化。本文以銀川市第一人民醫院提供的甲狀腺超聲圖像與文本報告為基礎數據,所有數據均經過脫敏處理,而本文研究僅使用圖像與文本報告,不使用任何患者信息與設備信息。本文所提出的方法實現了甲狀腺超聲圖像與文本報告的互檢,為甲狀腺超聲檢查數據的臨床應用拓展、減少醫生工作量以及方便患者檢索數據奠定了理論與實驗基礎。
1 方法
本文采用 CM-GAN 為基礎網絡,對甲狀腺超聲圖像與文本報告進行關聯建模,并實現跨模態檢索。具體包括三個工作:① 構建 CM-GAN 網絡;② 改進 CM-GAN 網絡;③ 對本文方法進行對比測試。
1.1 CM-GAN 結構
本文方法基于 GAN,以 CM-GAN 為基礎網絡。目前,基于 GAN 的基本結構,衍生出非常多的網絡模型,其中包括 CM-GAN。
GAN 主要由兩部分組成,一部分為生成器(以符號 G 表示),另一部分為判別器(以符號 D 表示)。生成器主要用于學習真實數據的分布,生成接近真實的數據,而判別器主要用于判別數據是真實的還是由生成器生成的。一個典型的 GAN 網絡結構如圖 1 所示。在訓練時,GAN 可以看作是 G 和 D 的極大極小博弈,如式(1)所示:
圖1
典型的 GAN 結構
Figure1.
Typical structure of GAN
|
其中,x 為真實數據,z 為噪聲輸入,代表在訓練中 G 減少 V 的值、D 增加 V 的值,訓練網絡的最終目標是在 D 與 G 之間尋找平衡點,使得 V 的值最大,E 代表目標函數,GAN 的主要目的是訓練生成器且最小化 D(G(z)),即讓判別器無法判斷數據是由生成器生成的還是真實的。交替訓練生成器與判別器,G 與 D 互相博弈,最終得到一個在給定數據分布下的最優 G。
CM-GAN 將 GAN 的思想應用于跨模態數據公共空間建模中,利用 GAN 的生成器與判別器博弈的原理,對特征數據及不同模態數據的公共表示進行判別,從而更好地構建跨模態數據公共空間,實現更高的跨模態檢索準確度。
CM-GAN 網絡結構如圖 2 所示,該網絡主要包含兩大部分,一部分是生成模型,另一部分是判別模型。從水平方向看又可分為同模態通路與跨模態通路。對于生成模型,將跨模態自動編碼器應用其中,使用共享權重來約束跨模態的自動編碼器,并以此構建不同模態間的公共表示空間。對于判別模型,設計模態內和模態間的判別模型,不僅對生成公共表示進行判別,還對生成的重構表示進行判別,從而加速訓練過程。生成模型和判別模型同時進行訓練,從而實現不同模態數據的相互關聯。
圖2
CM-GAN 網絡結構
Figure2.
Structure of CM-GAN network
生成模型部分主要由兩種生成器組成,一種是圖片生成器(以符號 GI 表示),一種為文本生成器(以符號 GT 表示),而每種生成器又是由編碼器和解碼器兩部分組成,即對應于 GI 的編碼器(以符號 GIenc 表示)和解碼器(以符號 GIdec 表示)以及對應于 GT 的編碼器(以符號 GTenc 表示)和解碼器(以符號 GTdec 表示)。編碼器主要由卷積神經網絡組成,主要用于學習每種模態的特征信息,與之相連接的是全連接層,而 GIenc 和 GTenc 的最后一個全連接層由共享權重和語義約束構成,從而實現公共表示的學習。對于解碼器,其功能主要是將從編碼器的卷積神經網絡中獲取的高級語義表示重建,來保持每種模態的語義一致性。
判別模型部分有兩種判別器同時對跨模態和模態內的公共表示信息進行判別。模態內的判別器由圖片判別器(以符號 DI 表示)和文本判別器(以符號 DT 表示)組成,主要是將生成器重構的表示信息與提取到的特征作以判別;跨模態判別器(以符號 DC 表示),是一個由兩個子判別器(通路)構成的網絡,即圖像通路(以符號 DCi 表示)與文本通路(以符號 DCt 表示),這兩個子判別器的目的是判斷公共表示是來自圖像還是文本。DCi 以圖像公共表示(以符號 spi 表示)為真數據,以文本公共表示(以符號 spt 表示)與不匹配的圖像公共表示(以符號 表示)為假數據,spi 與 都來自圖像的高級語義特征(分別對應以符號 hpi 與 表示)。與 DCi 類似,DCt 以 spt 為真數據,以 spt 與不匹配的文本公共表示(以符號 表示)為假數據。
對于跨模態判別器(以符號 DC 表示),構成其網絡的兩個子判別器均連接自公共表示空間,并以公共表示空間作為輸入數據。每個子判別器都由兩個全連接層構成。第一個全連接層是由 512 個單元的全連接層,后接一個批正則化層和線性修正單元(rectified linear unit,ReLU)激活函數組成。第二個全連接層將第一個全連接層的輸出作為輸入,并將輸出送入緊隨其后的 S 形激活函數(sigmoid)層來生成一個預測值。對于圖像通路,圖像的公共表示被標示為 1,與其匹配的文本公共表示和與其不匹配的圖像公共表示被標示為 0。對于文本通路,文本的公共表示被標示為 1,與其匹配的圖像公共表示和與其不匹配的文本公共表示被標示為 0。
CM-GAN 網絡的目標函數可以表示如式(2)所示:
|
其中,與 分別對應同模態通路與跨模態通路,其表示如式(3)~(4)所示:
|
|
本文在直接使用 CM-GAN 網絡用于甲狀腺超聲圖像與文本報告跨模態檢索時,其收斂速度并不高,平均精度均值(mean average precision,mAP)只能達到 0.487,與其他現有方法比較提升不高。分析其可能原因,主要有兩點:① 采用相同角度采集的甲狀腺超聲圖像在空間上往往是相似的,且醫生給出的文本報告用詞相似、格式統一,這些大量在空間上相似的數據經過編碼器提取后其特征數據也較為相似,這給解碼器生成公共表示空間以及判別器對正負樣本的判別造成了困難;② CM-GAN 中加入了對全連接層的權重共享,實現了一定的語義關聯限制,但與其相連的跨模態判別器之間并無語義上的關聯,這對于公共表示空間的生成也造成了影響。因此,針對以上問題,本文對 CM-GAN 進行了改進。
1.2 改進的 CM-GAN
本文提出的改進的 CM-GAN 在原網絡基礎上,取消了原有編碼器之后的第二個全連接層之間的權重共享約束(weight-sharing constraints),使用余弦相似度約束(cosine similarity constraints)對全連接層的參數進行約束。
原網絡中,圖像數據經由 GIenc,即由 19 層全卷積神經網絡組成的視覺幾何組—19 網絡(visual geometry group,VGG-19)生成特征向量 hpi,再由權重共享的全連接層生成 spi[22]。而文本數據則通過 GTenc,先由詞嵌入(word to vector, Word2Vec)方法轉換成詞向量,然后經卷積神經網絡形成特征向量(以符號 hpt 表示),再經過權重共享的全連接層生成 spt[23]。權重共享約束的作用是在為每種模態數據生成公共表示空間的同時增加語義限制,使得成對的圖像與文本的公共表示盡可能相近。而且在原網絡中,在權重共享的每個全連接層之后還加入了批正則化層和 ReLU 激活函數,最后公共表示空間 spi 和 spt 還被送入歸一化(softmax)層,使得不同模態的數據關聯更緊密。
但對于甲狀腺超聲圖像與文本報告來說,在空間上相似的數據較多,如果僅使用權重共享的全連接層是無法很好地將不同模態的正負樣本數據進行區分的,從而影響公共表示空間的建立。本文使用余弦相似度約束來保證網絡在相似數據較多的情況下仍可以良好完成對公共表示空間的建立。
余弦相似度(cosine similarity)指兩個成角度的 d 維向量 a,b∈Rd 的余弦值,其計算如式(5)所示:
|
其中表示點積,表示 Lp 范數。
令 x∈X 為一種模態的數據(圖片或文本),y∈C 為另一種模態的數據。令 ?θ:X→Rd 為一種參數為 θ 的從輸入 x 到 d 維特征空間的變換。gρ:C→Sd 為一種參數為 ρ 的從輸入 C 到 d 維特征空間的變換。其中 ?θ 與 gρ 在深度學習中一般為特征提取。而 ψ:Rd→P 與 φ:Sd→P 這兩種變換定義為 Rd 與 Sd 到公共表示空間 P 的映射。
一種簡單的映射,以獨熱編碼(one hot)的向量為例,如式(6)所示:
|
在深度學習中,可以理解為 φ 的目標是通過參數為 θ 的神經網絡 ?θ 通過最大化圖像特征和文本特征的余弦相似度來學習公共表示空間。定義損失(loss)值函數訓練神經網絡,如式(7)所示:
|
在實際運用中通過兩個操作的序列實現這一方法,首先由神經網絡提取的特征被 L2 歸一化(L2 normalized),即 ,這保證了公共空間被限制在單位超球面(the unit hypersphere),這里余弦相似度可以等價于點積,如式(8)所示:
|
其次,φ(gρ)也需要位于單位超球面上來保證等式成立。以獨熱編碼的向量為例,它在定義上就滿足了單位正則化,所以不需要再進行 L2 歸一化。
在改進的 CM-GAN 網絡中,編碼器之后的第一層全連接層仍使用權重共享約束以保證 hpi 以及 hpt 在公共空間中的關聯性。而對于第二層全連接層取消權重共享約束,取而代之的是在該層之后加入余弦相似度約束。對于從編碼器得到的特征數據 hpi 以及 hpt,經過全連接層得到的公共空間特征 spi 與 spt,在訓練過程中,此處將采用加入余弦相似度約束的 loss 值函數,其表達式如式(9)所示:
|
其中 cos()為余弦相似度計算公式,α 為邊界條件,在訓練中取 0.1。
在加入余弦相似度約束之后,改進的網絡繼承了原有 CM-GAN 在構建公共表示空間中權重共享對不同模態特征數據在語義上關聯的優點,還能降低由于存在大量相似度較高的數據集導致所獲得到的特征數據也較為相似所帶來的影響。
在訓練多個批(batches)的數據時,計算所有批(batch)的平均 loss 值,從而約束網絡構建更好的公共表示空間。
1.3 改進網絡結構
在經過上述改進之后,雖然網絡對于大量相似的數據具有了一定的魯棒性,但其對不同模態特征數據的公共表示空間的構建仍不理想,原因是在構建公共表示空間的全連接層之后,公共表示 spi 與 spt 被送入跨模態判別器中,在原網絡中,跨模態判別器主要用于判別某模態數據的公共表示和另一模態與之對應的公共表示以及不匹配的數據。判別器由兩部分組成,每一部分都由兩層網絡組成,第一層由維度 512 的隱藏層以及批正則化層和 ReLU 激活函數組成,第二層為單值輸出層。該網絡結構雖然可以實現對不同模態的公共表示進行語義上的關聯,但判別器互相獨立,圖像和文本判別器分別對 spi 與 spt 進行獨立判別,這在一定程度上影響了跨模態數據公共表示空間的語義統一性。
在改進的網絡結構中,在跨模態判別器 DC 前加入了兩層全連接層(以符號 GIT 表示),第一層由含有 1 024 個單元的隱藏層與批正則化和 ReLU 激活函數組成,第二層為含有 512 個單元的全連接層,該層維度與 DC 的第一層全連接層一致。在此基礎上,對數據加入圖像語義標簽(以符號 ci 表示)與文本語義標簽(以符號 ct 表示),從而進一步對不同模態數據的語義關聯。
在跨模態判別器中,為了達到更好的判別效果,讓 spi 作為正樣本,讓 與 spt 作為負樣本,并且將 hpi 與 連接在一起。其中 spt 與 作為負樣本被標記為 0,這樣可以使判別器在連接 hpi 或 時有更好的效果,對于圖像判別器的梯度計算,如式(10)所示:
|
其中,(spi,hpi)與(,)表示鏈接公共表示與高級語義特征。對于文本判別器,其梯度計算如式(11)所示:
|
在整個網絡模型中,生成器需要最小化目標方程來生成真正的關聯分布,在訓練時使用梯度下降法,并凍結判別器,其中圖像生成器的梯度計算如式(12)所示:
|
其中,(spi,hpt)表示串聯公共表示與高級語義特征。對于文本生成器也可以用類似的公式計算梯度,如式(13)所示:
|
在此基礎上,兩個生成器使用語義標簽結合 softmax loss 值函數進行進一步優化,如式(14)所示:
|
其中,sp 表示模型學習到的公共表示空間 spi 或 spt,cp 代表與它們對應的標簽,當 cp = q 時,1{cp = q}為 1,其他情況為 0。經過這種方法的優化,可以使語義在不同模態間保持連續性。
結合前文對權重共享約束的全連接層的改進,整體公共表示空間構造部分的 loss 值函數如式(15)所示:
|
其中,spi 和 spt 仍為圖像與文本的公共表示,ci 和 ct 為語義標簽,當 spi 與 spt 為匹配的文本與圖像時,ci 和 ct 是相同的,y 為加入余弦相似度約束的 loss 值函數 Lcos 的參數,當 spi 和 spt 為匹配的文本與圖像時,y 的值為 1,當 spi 和 spt 不匹配時,y 的值為 ?1。Lfc 表示全連接層的 loss 值函數。
1.4 最終網絡結構
將前文中提出的加入的余弦相似度約束與跨模態判別器前增加的全連接層結合在一起,得到了總體改進后的網絡,其結構如圖 3 所示。由于增加的全連接層將原網絡中構建的公共空間 spi 與 spt 結合在了一起,并加入了語義標簽,所以改進后的網絡中跨模態判別器的 loss 值函數也做出了相應改變,如式(16)所示:
圖3
改進后網絡結構
Figure3.
The structure of improved CM-GAN network
|
整合改進后的網絡不僅對相似數據的跨模態公共空間的生成有了魯棒性,還增加了對公共空間在語義上的關聯,使得網絡對于甲狀腺超聲圖像與文本的跨模態公共空間建模能力有所提升。
2 實驗
在實驗部分,主要討論實驗所用數據集、評價指標以及所對比的方法。本文中使用了來自銀川市第一人民醫院授權使用的甲狀腺超聲診斷數據。評價指標主要使用 mAP 值評價網絡跨模態檢索的能力,并以此評價指標為準,與 5 種經典的跨模態檢索方法比較。本文中還將優化后的網絡與原網絡進行收斂速度對比,以此評價網絡優化效果。
2.1 數據集和預處理
本文使用了來自銀川市第一人民醫院授權的 700 例(共 2 800 張)甲狀腺超聲圖像數據以及對應的文本報告(檢查所見),圖像數據原始格式為醫學影像成像和通訊標準格式(digital imaging and communications in medicine,DICOM)。首先,將原始數據進行脫敏處理,然后轉換為灰度圖像,再將圖像中含有敏感信息的部分截去,只保留甲狀腺超聲圖像區域。文本報告(檢查所見)來自于專業醫生對甲狀腺超聲圖像的客觀描述,原始數據保存在數據庫中,首先從數據庫中導出文本數據,然后將文本數據進行脫敏處理,并且只使用針對圖像的文本描述部分。如圖 4 所示,為甲狀腺超聲圖像與文本報告數據樣例,左側為兩張屬于同一個患者同一次檢查所得到的圖像,右側為對應的文本報告。
圖4
甲狀腺超聲圖像與文本數據
Figure4.
Thyroid ultrasonic images and text
由于網絡訓練需要大量樣本,因此本文對甲狀腺超聲圖像和文本報告都做了一定的數據增廣處理。對于圖像數據采用縮放圖像、旋轉圖像、截取圖像區域方法對數據集進行擴充。對于每一對圖像—文本來說,不存在一個圖像對應多個文本,或者一個文本對應多個圖像的情況,但是對于同一次超聲檢查來說,往往有多個圖像—文本對。對于文本數據,采用調整語序或摘取部分文本的方法進行擴充。最終得到共 9 400 組圖像與文本。
2.2 評價指標
不同模態數據可以用相似度矩陣與 CM-GAN 學習到的公共表示聯系在一起。本文主要考慮 CM-GAN 在甲狀腺超聲圖像與文本的雙模態檢索能力,即以圖像檢索文本與以文本檢索圖像的能力。對于以圖像檢索文本,采用圖像作為檢索輸入數據來檢索文本數據并計算它們的相似度。對于以文本檢索圖像,采用文本作為檢索輸入數據來檢索圖像并計算它們的相似度。
本文采用 mAP 來對 CM-GAN 的檢索結果進行評價,該評價指標是檢索、識別任務中常用的評價指標,代表每個檢索(或識別)的準確率的均值,該指標反映了網絡的優良程度。
查準率(precision)是指正確的檢索結果在所有檢索結果中的占比。查準率可以考慮到所有獲取的結果,也可以指定考慮結果中排名前 k 的結果,這種情況下查準率稱為前 k 查準率。查全率(recall)是指正確的查詢結果的數量在所有正確數據中的比例。查準率和查全率雖然可以在一定程度上反應檢索方法的有效性,但這兩種指標并沒有考慮檢索方法給出的結果在順序上的重要性,所以需要引入平均準確率。
平均準確率(average precision, AveP)(以符號 AveP 表示)的計算方法如式(17)所示:
|
其中,P(k)指前 k 查準率,Δr(k)= r(k)? r(k ? 1)。如果令合集 Ω 為查詢第 k 個結果的集合,如式(18)所示:
|
為提高計算準確率,使用相鄰兩次查的前 k 查詢準確率進行計算,如式(19)所示:
|
對于每一次查詢所得到的 AveP 取均值,即得到了 mAP 值。
2.3 實驗結果
為了驗證本文方法在甲狀腺超聲圖像與文本報告跨模態檢索任務中的性能,通過將本文方法與 CM-GAN、CCL、DCCA、Corr-AE、CFA 以及 CCA 共 6 種跨模態檢索方法對比,選取 10 組樣本對以上方法進行多次實驗,得出結果如表 1 所示。在測試過程中,所有的數據均采用相同的 CNN 網絡結構來提取數據特征。對于圖像數據,采用 VGG-19,對于文本數據,采用詞卷積神經網絡(word convolutional neural network,WordCNN)。由實驗結果數據不難發現,CM-GAN 在以圖檢文、以文檢圖以及平均的 mAP 值方面,均優于其他方法。相對于原 CM-GAN 方法,本文方法以圖檢文精度均值從 0.503 提高到了 0.519,以文檢圖從 0.471 提高到了 0.497,而平均值從 0.487 提高到了 0.508。CM-GAN 利用深度學習的特征提取優勢與 GAN 在跨模態領域中優異的異質數據關聯性建模能力,在圖文跨模態互檢任務中取得了更好的效果。
本文實驗還驗證了對 CM-GAN 網絡的優化效果,如圖 5 所示,虛線為優化前的網絡 loss 值曲線,實線為優化后網絡 loss 值曲線,縱坐標為 loss 值,橫坐標為迭代次數。從圖 5 中可知在迭代訓練大于 400 次時,優化后的網絡 loss 值下降更快。優化后的網絡在 250 次迭代后基本趨于收斂,最終 loss 值穩定在 0.14 左右,而優化前的網絡則在 360 次左右區域穩定,收斂速度相對較慢,最終穩定在 0.35 左右。通過比較可知,優化后的網絡收斂速度更快,收斂時 loss 值更低。
圖5
訓練時 loss 值對比
Figure5.
Comparison of loss value in training
本文還針對兩種改進方式分別進行了對比,使用與上文相同的圖像與文本特征提取方法與數據集,分別對只加入全連接層與只加入余弦相似度的網絡進行了測試。通過實驗結果發現,如果只加入全連接層,增加了網絡中隱藏節點的數量,對網絡訓練效率有較大影響,收斂速度低于改進前的網絡結構,而網絡的 mAP 值并沒有隨著網絡復雜度的提升而提高。只加入余弦相似度的網絡結構,減少了一層權重共享的全連接層,在訓練效率上有所提高,收斂速度優于原網絡結構,但缺少全連接層,導致 mAP 值無法提高。余弦相似度和全連接層形成互補關系,相對于使用權重共享的全連接層,訓練效率更高,網絡檢索效果更好。
如圖 6 所示,為本文與 6 種跨模態檢索方法的結果對比,分別以圖像和文本為輸入數據,各個算法得出的檢索結果各有不同,其中檢索結果有誤的用紅色框線標出。
圖6
本文 7 種方法檢索結果對比
Figure6.
Comparison between retrieval results of 7 methods
圖 6 中,以圖像檢索文本的結果,圖中顯示為待檢索甲狀腺結節超聲圖像檢索到的文本描述,該甲狀腺結節為 25 × 11 mm2 大小的實性結節,邊界不清晰,回聲不均勻,可見斑片狀強回聲,后方伴有聲影。從檢索結果來看,CM-GAN、CCL、Corr-AE 與 DCCA 方法可以較為準確地得到該甲狀腺結節的描述;而 CFA 與 CCA 方法對邊界的描述為不清晰;CCA 方法得到的結果較少,描述不完整。
圖 6 中,以文本檢索圖像的結果,圖中顯示為待檢索文本檢索到的甲狀腺超聲圖像,從結果可以發現 CM-GAN、CCL 與 DCCA 方法可以準確地檢索到相關圖像,其中 CM-GAN 與 CCL 檢索到的圖像為增廣處理后的甲狀腺超聲圖像;Corr-AE 與 CCA 檢索到的圖像來自同一個甲狀腺,但不對應于描述;CFA 方法沒有正確檢索到圖像。
通過檢索結果對比可以發現,本文方法可以較好地完成甲狀腺超聲圖像與文本報告的跨模態檢索任務。
3 結束語
本文將 CM-GAN 應用于甲狀腺超聲圖像與文本報告的跨模態檢索任務中,實現了甲狀腺超聲圖像與文本報告的互相檢索,不僅利用了醫院數據庫中長久保存而不用的大量數據,還利用跨模態檢索方法,探索了從醫療圖像生成文本報告,以及從文本報告生成醫療圖像的方法,為減輕醫生工作壓力,方便患者了解和使用醫療圖像奠定了理論與實驗基礎。通過實驗證明,CM-GAN 不僅可以在公開數據集上取得良好的效果,在醫療影像與醫療文本報告數據集上同樣可以取得較好結果。目前,本文只使用了圖像與文本數據,但醫院中還有大量的數據是基于視頻和音頻的,所以在后續工作中,如何將跨模態檢索方法應用于其他醫療數據模態上也將成為未來的研究方向之一。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。