認知重評是一種重要的情緒調控策略。研究表明,即使是健康的人群也不能保證重評的成功執行,但是從行為學上觀察到的重評成功或失敗,其背后的神經機制卻不清晰。本文招募了 28 名健康大學生進行認知重評的情緒調控實驗,實驗前完成認知心理問卷,實驗過程中同步采集行為學評分和頭皮腦電信號。接著,按照效價評分將受試者分為重評成功與失敗兩個組,然后分別分析兩組人員的問卷結果,不同條件下的事件相關電位早期成分 N200、P200 和晚正電位(LPP),以及效價評分之差與 LPP 幅值之差的相關性。結果發現,無論重評成功與否,與負性觀看相比,重評都誘發出更大的 N200 和 P200 成分,并且對 LPP 早期(刺激開始后 300~1 000 ms)幅值的調制作用都表現為“增加”和“減小”兩種模式。進一步相關分析顯示,在重評成功的受試者中,重評與負性觀看的效價評分之差越大,兩者的 LPP 早期幅值之差也越大,表現出顯著正相關;而失敗組中沒有發現這種效應。該結果表明,重評成功與否對 ERP 的早期成分沒有顯著影響,對早期 LPP 的影響存在不同的模式;重評成功與失敗之間的差異主要體現在 LPP 的早期,重評成功的受試者其早期 LPP 與行為學評分之間具有顯著正相關性。更進一步地,小樣本分析發現這種相關性僅存在于具有“LPP 幅值升高”這一模式的人群中。未來可以針對這種調制模式進行深入研究,以發現更穩定的成功實施情緒調節腦電的特征。
引用本文: 連海鵬, 曹丹, 李穎潔. 成功實施情緒認知重評策略的腦電特征. 生物醫學工程學雜志, 2020, 37(4): 579-586. doi: 10.7507/1001-5515.201909042 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
對情緒的良好調節是人類具備完整社會功能的基本前提,研究指出情緒調節包含多種策略,可以作用于情緒產生的不同階段。其中,認知重評策略指的是通過在情緒產生的早期改變對刺激事件的理解以及調整刺激對自身意義的認知來降低(負性)情緒感受的一種調節策略[1]。研究表明,認知重評策略具有長期的效應影響力[2],是臨床上抑郁癥、焦慮癥認知(行為)療法的核心策略[3]。但是,并不是每一個人都能成功地執行該策略[4-7],深入研究認知重評策略的神經機制,對今后的個性化臨床干預具有重要意義。
認知重評策略包括對事物重新進行解釋、換位思考等方式,來增加或者減少情緒感受,進而影響情緒反應,這一過程相關的神經活動具有顯著的動力學特征[8]。事件相關電位(event-related potential,ERP)是通過疊加平均技術從頭皮腦電(electroencephalogram,EEG)中提取的電位,由事件刺激誘發,能夠實時反映受到刺激后大腦高速的信息加工處理過程[9],在認知重評的神經機制研究中占據著重要的地位[10-11]。已有研究表明晚正電位(late positive potential,LPP)對情緒刺激具有很高的敏感性,與中性視覺刺激相比,LPP 幅值在情緒視覺刺激呈現后更大[12-14]。進一步的研究發現,在觀看負性情緒圖片并采取認知重評策略時誘發的 LPP 幅值比觀看負性圖片誘發的幅值小,比觀看中性圖片誘發的幅值大[15-16]。但是,并不是所有的研究都取得了一致性的研究結果。例如,Gardener 等[5]在認知重評任務下并未發現 LPP 幅值的變化,而 Langeslag 等[17]在實驗中卻發現相對負性圖片觀看,執行重評策略后觀看圖片反而增加了 LPP 幅值。研究結果的不同究竟是因何而起目前還沒有明確的結論,是實驗范式不同導致的,還是 LPP 幅值的變化與認知重評之間并不存在穩定的相互關系還需要進一步探究。此外,目前認知重評策略的研究大多關注受試者整體的情緒調節情況,只有少數研究關注到認知重評的成功問題[4-7]。本文通過行為學評分將所有受試者劃分為重評成功組與重評失敗組,分析比較了兩組人員的腦電信號,以及腦電與行為學結果之間的相關性,旨在探尋成功執行情緒認知重評策略的腦電特征尤其是對 LPP 的調制作用,以及重評成功與重評失敗表現出的電生理差異。
1 實驗方法
1.1 受試者信息
本次實驗共招募了 28 名大學生作為志愿者,其中男生 15 名,女生 13 名,年齡為(21.6 ± 2.8)歲,受教育年限為(15.6 ± 1.9)年。所有參與者均為右利手,視力正常或矯正后正常,無精神及神經類疾病史。在正式實驗前,所有受試者簽署了知情同意書,并填寫了自評焦慮量表(Self-Rating Anxiety Scale,SAS)、自評抑郁量表(Self-Rating Depression Scale,SDS)、Gross 情緒調節習慣問卷、大五人格量表、情緒調節自我效能感問卷和認知情緒調節習慣問卷。根據 SAS 和 SDS 量表標準,所有受試者 SAS 評分(正常范圍 ≤ 50)和 SDS 評分(正常范圍 ≤ 53)都在正常范圍之內。實驗完成后,受試者均獲得了適當的志愿者費用。本實驗通過了上海市臨床研究倫理委員會批準,并遵從赫爾辛基宣言。
1.2 刺激材料
本文從國際情感圖片系統(International Affective Picture System,IAPS)中選取了 75 張圖片用作刺激材料[18]。這些圖片均為彩色場景圖片,大小為 260 像素 × 195 像素,無特殊標記或雜質。其中負性場景圖片 50 張,中性場景圖片 25 張。每一張圖片附有一句文字描述性話語:25 張中性圖片附有中性描述語,50 張負性圖片中隨機選取 25 張附有負性描述語,剩下 25 張附有中性或正性的重評描述語。所有描述語及圖片均在 17 寸液晶顯示屏正中央出現,呈水平和垂直大約 30° 視角。其中 15 張用于預實驗,60 張用于正式實驗。
1.3 實驗流程
研究發現,通過在負性圖片刺激出現之前播放或呈現中性或正性的描述語,能夠調節負性情緒感受[19-21]。本文參考 Foti 等[21]的實驗范式,在負性圖片出現之前給受試者呈現一句中性或正性的描述語(以下簡稱“重評描述語”)來重新解釋圖片的含義,以此讓受試者執行認知重評策略。在每一張圖片之后,要求受試者根據自身的真實感受對圖片的效價和喚醒度進行評分。為減少噪聲干擾,整個實驗過程中,受試者坐在隔音封閉房間里的靠背椅上,正視屏幕,雙眼距離屏幕大約 80 cm。
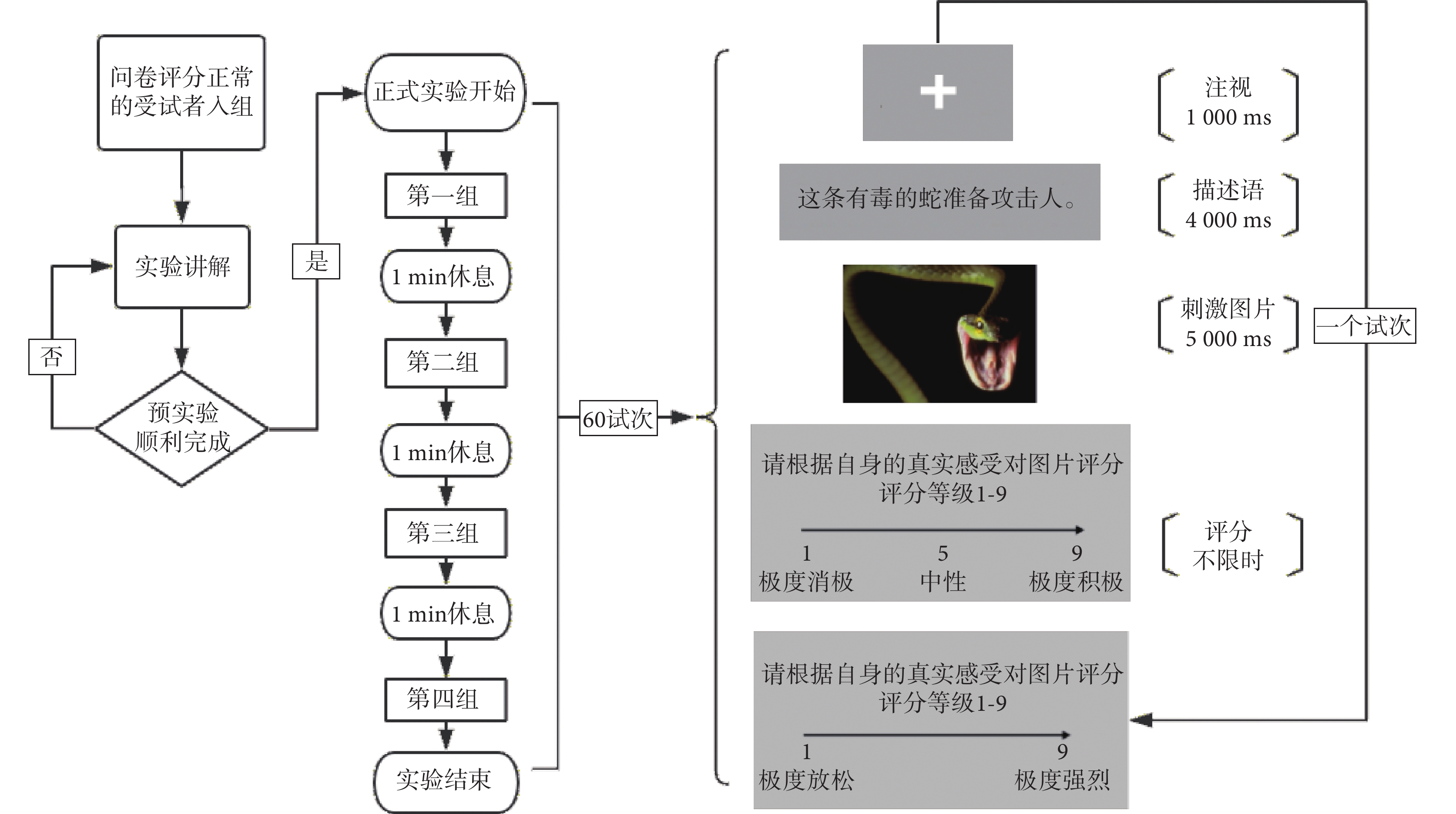
實驗流程如圖1 所示,正式實驗有 60 個試次,每一個試次對應一張刺激圖片。所有試次分為 4 個組,每個組包含中性圖片 5 張、負性圖片 10 張,圖片均為隨機選取、隨機出現。實驗正式開始前,受試者通過預實驗熟悉流程。正式開始后,受試者閱讀屏幕上顯示的實驗說明,按任意鍵進入第一個試次:屏幕中央依次出現一個小十字、文字描述語和相對應的刺激圖片,要求受試者根據描述語來理解圖片;圖片消失后受試者需要根據自身的真實感受先對圖片的效價進行評分,數字 1~9 對應從“極度消極”到“極度積極”九個等級,然后再對圖片的喚醒度進行評分,數字 1~9 對應“極度放松”到“極度強烈”九個等級。評分完成后自動進入下一個試次。實驗程序采用 E-Prime 2.0 軟件(Psychology Software Tools 等,美國)編寫。
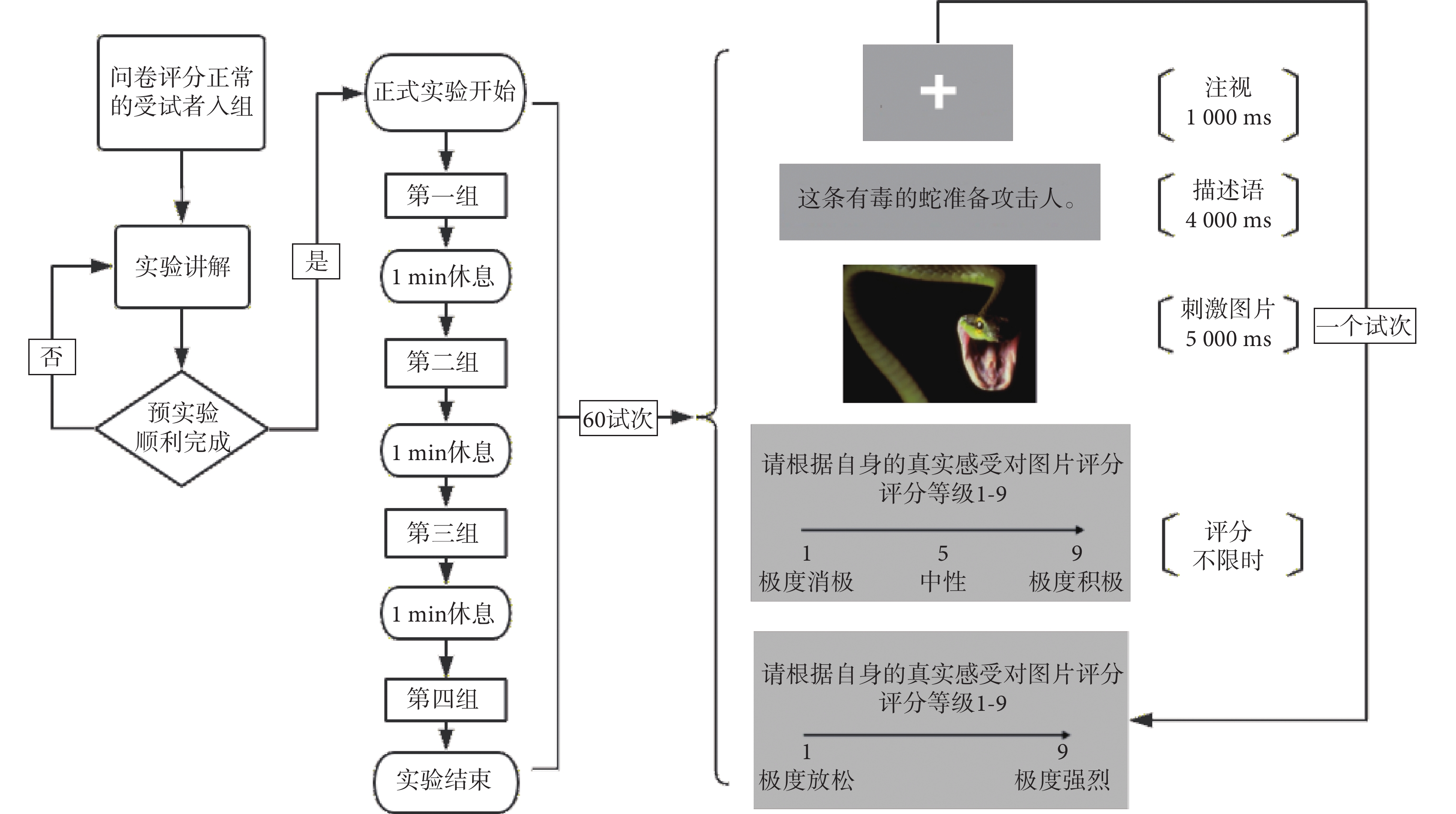 圖1
實驗流程圖
Figure1.
Experimental flow chart
圖1
實驗流程圖
Figure1.
Experimental flow chart
根據描述語與圖片的匹配,本實驗分為了三種任務條件(condition):中性描述語與中性圖片(中性觀看,neutral)、負性描述語與負性圖片(負性觀看,negative)以及重評描述語與負性圖片(重評,reappraisal)。
1.4 EEG 數據采集與預處理
受試者在完成認知重評任務的同時進行腦電數據的采集,采集設備為 32 導 EEG/ERP 檢測儀(Neuroscan,美國),符合 10-20 國際標準。參考電極放置在右側乳突,接地電極位于 AFz,兩個附加電極分別放置在左眼下方和右眼上方來記錄垂直眼電。實驗開始前,電極帽上每個導聯的阻抗均通過涂抹導電膏的方式降至 5 000 Ω 以下。采集過程中采樣率為 1 000 Hz,同時用陷波濾波去除 50 Hz 的工頻干擾。
數據采集完畢后,使用軟件 Matlab 2016(MathWorks,美國)的工具箱 EEGLAB 進行數據的預處理,帶通濾波 0.1~30 Hz,以刺激圖片出現時刻為 0 ms,將數據按 ? 200~5 000 ms 分段,剔除明顯的壞數據,設置幅值范圍 ± 100 μV,刪除超出范圍的數據段,運用獨立成分分析進行偽跡排除,去除眨眼、眼飄和肌電偽跡,得到干凈的數據后導入 REST 工具箱[22],進行重參考[23]。Chella 等[24]明確指出,這種零參考方式的誤差顯著小于全腦平均參考、雙側乳突平均參考和 Cz 參考等方式。預處理完成后,每個受試者剩余的平均有效試次數目為 53.96(標準差為 4.12,約占總試次的 90%)。將這些試次進行疊加平均,得到三種任務條件下的 ERP 波形。最后用刺激圖片出現前 200 ms 的數據進行基線校正。
1.5 成功實施策略的行為學指標
研究表明,通過重評可以減小負面情緒感受,表現在行為學指標上,通常就是顯著減少受試者自我報告中對負性刺激的不愉悅度(效價評分升高)、降低對刺激的喚醒度(喚醒度評分降低)[25-26]。當然,認知重評的方式有很多,例如通過增加積極情緒就可以有效實施重評。有研究指出增加積極情緒主要影響受試者對效價的評分,對喚醒度評分影響較小[27]。本實驗使用的范式是通過刺激圖片出現前增加重評描述語來引導受試者有效實現重評,這些描述語可以有效增加積極情緒,因此,本文將受試者的效價評分作為分組指標,用來判斷受試者是否成功執行了認知重評策略。若受試者的重評評分與負性觀看評分相比顯著提升了,則該受試者被分為重評“成功組”,否則為“失敗組”。
我們對每一名受試者的負性觀看評分和重評評分進行配對 t 檢驗,在 28 名受試者中,有 15 名的效價評分是重評顯著大于負性觀看的(P < 0.05),入組“成功組”,其余的 13 名受試者入組“失敗組”。成功組中男 8 名、女 7 名,年齡為(21.7 ± 3.7)歲,受教育年限為(15.5 ± 2.0)年。失敗組中男 7 名、女 6 名,年齡為(21.6 ± 2.1)歲,受教育年限為(15.7 ± 1.9)年。兩組人的基本信息無顯著差異。失敗組比成功組的 SAS 得分更高(P = 0.005)。
1.6 統計檢驗
本文使用了配對 t 檢驗、相關性分析以及重復測量方差分析(repetitive measure analysis of variance,rmANOVA)分析方法,均在軟件 SPSS 22.0(IBM,美國)中完成數據的統計分析。進行重復測量方差分析時,多重比較校正采用 Bonferroni 校正,若所分析因素不滿足球形檢驗,再對其進行 Greenhouse-Geisser 校正。相關性分析使用斯皮爾曼相關分析法(Spearman’s correlation)。所有統計分析的顯著性水平為 0.05。
2 結果
2.1 ERP 早期成分
根據文獻,本文對 ERP 早期成分的時間窗和對應電極位置進行了選擇,具體來說,選擇圖片刺激出現時刻之后的 200~300 ms 作為刺激誘發的早期注意和反應過程的時間窗,來分析 N200 和 P200 的特性[12];選取額區(F3、FZ 和 F4)來計算 N200 成分[28],選取顳區(T5 和 T6)來計算 P200 成分[29]。分別對 N200 和 P200 的幅值和潛伏期進行 rmANOVA,組間因素為 group(成功和失敗),組內因素為 condition(中性觀看、負性觀看和重評)。結果發現了顯著的重評效應,無論是成功組還是失敗組,重評比負性觀看誘發了更大的 N200 和 P200 成分(見表1)。關于潛伏期則沒有發現任何統計效應。
2.2 LPP 成分
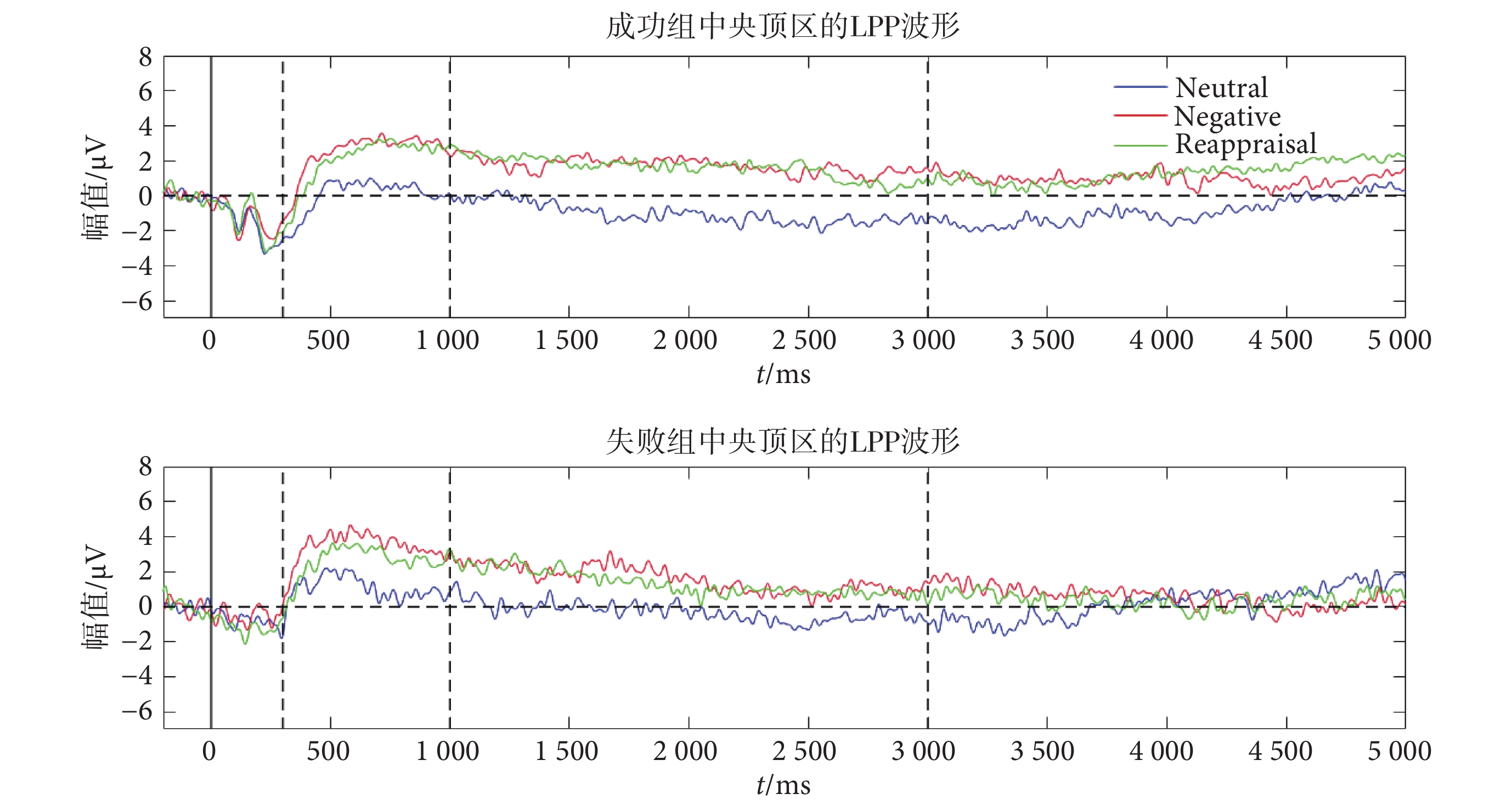
我們將圖片刺激出現后 300~5 000 ms 的 LPP 劃分為三個時間窗:早期 300~1 000 ms、中期 1 000~3 000 ms 和后期 3 000~5 000 ms,再把每一個時間窗內的 ERP 均值作為該時期的 LPP 幅值。選擇以下三個區域(area)來計算 LPP 幅值:額區(F3、FZ 和 F4)、中央頂區(CZ 和 CPZ)和顳區(T5 和 T6)。圖2 為中央頂區疊加平均后的 LPP 波形。
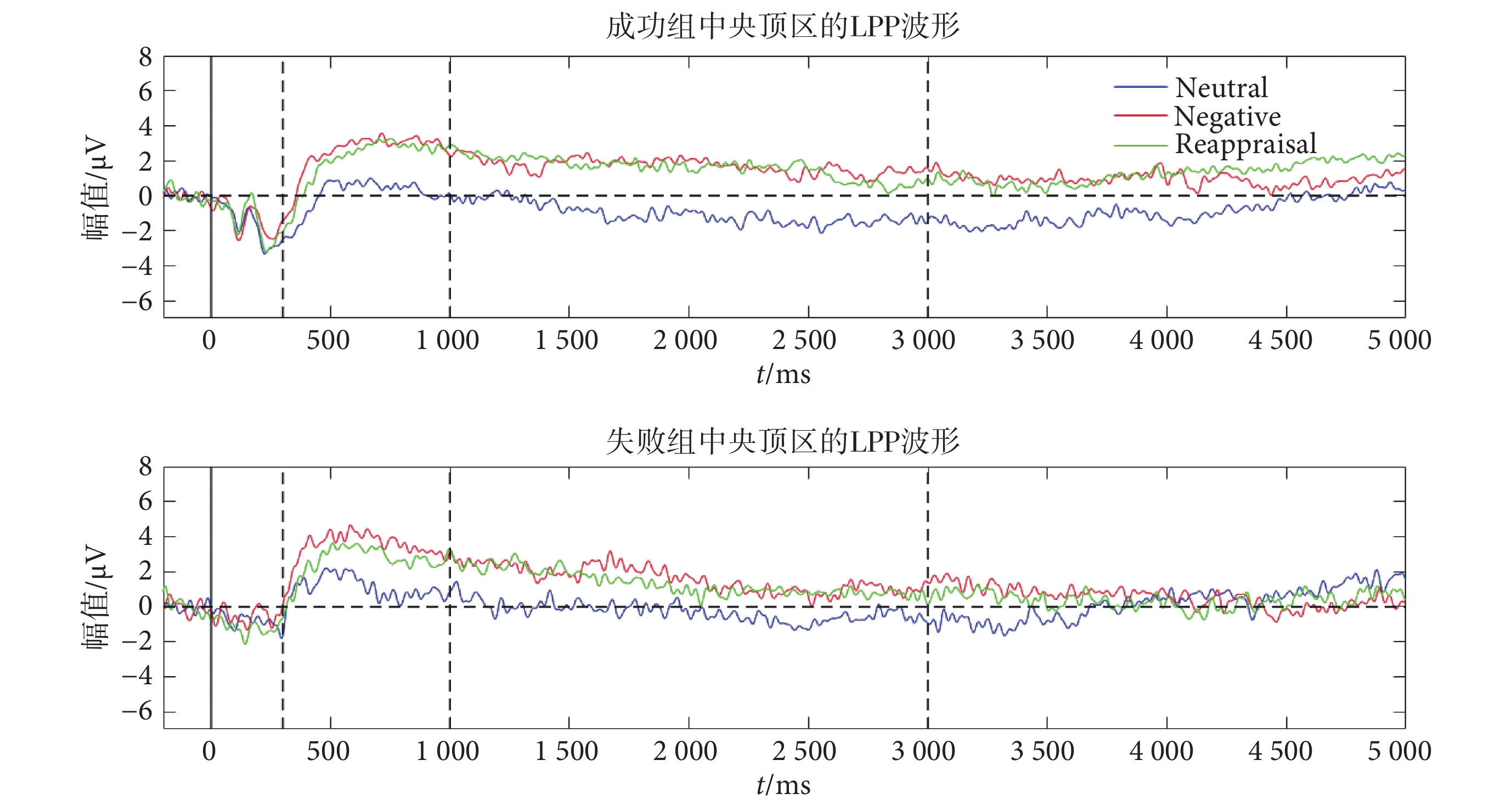 圖2
兩組人員在中央頂區的 LPP 總平均波形
Figure2.
The grand average LPPs in central parietal area of two groups
圖2
兩組人員在中央頂區的 LPP 總平均波形
Figure2.
The grand average LPPs in central parietal area of two groups
分別對 LPP 早中后三個時期進行 group*area*condition 的 rmANOVA,一個組間因素 group(成功和失敗),兩個組內因素為 area(額區、中央頂區和顳區)和 condition(中性觀看、負性觀看和重評)。結果未發現重評效應和組間差異,發現在 LPP 早期與中期均具有顯著的 area*condition 交互效應[早期 F(4,22)= 13.30,P < 0.001;中期 F(4,30)= 8.03,P < 0.001],分別進行簡單效應分析,結果如下(詳見表2):LPP 早期(300~1 000 ms),在額區、中央頂區和顳區都發現 condition 主效應;到 LPP 中期(1 000~3 000 ms),condition 主效應在中央頂區和顳區仍然存在,而額區的 condition 效應消失。成對比較顯示負性觀看顯著大于中性觀看,在中央頂區還發現重評顯著大于中性觀看。在 LPP 后期(3 000~5000 ms)則未發現任何統計效應。
2.3 重評的 LPP 模式
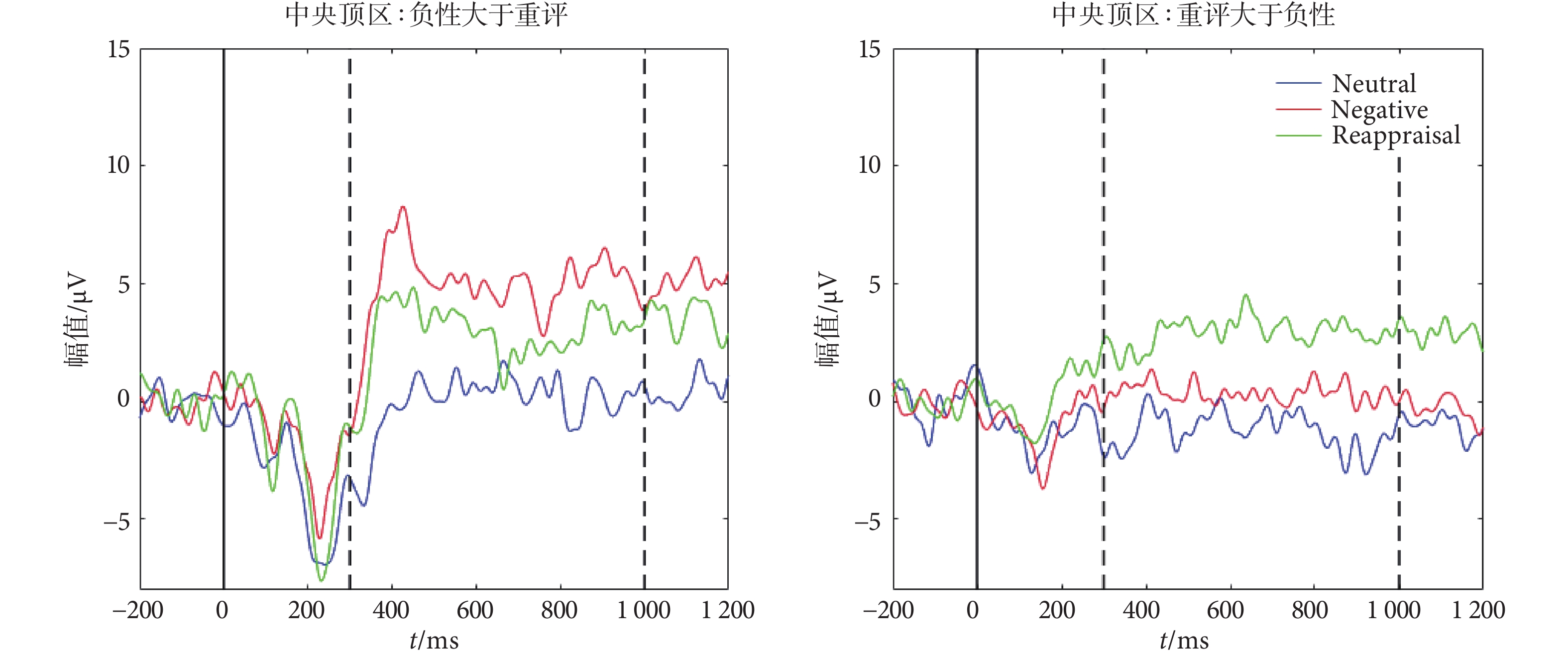
我們目測發現不管是成功組還是失敗組,在中央頂區處早期(300~1 000 ms)LPP 幅值都存在兩種變化模式:重評的 LPP 幅值高于負性觀看(簡稱為“增加模式”),重評的 LPP 幅值低于負性觀看(簡稱為“減小模式”)。兩種模式的波形參見圖3。而在中期和后期兩者的 LPP 幅值目測未發現差異,或者說沒有發現類似的模式。
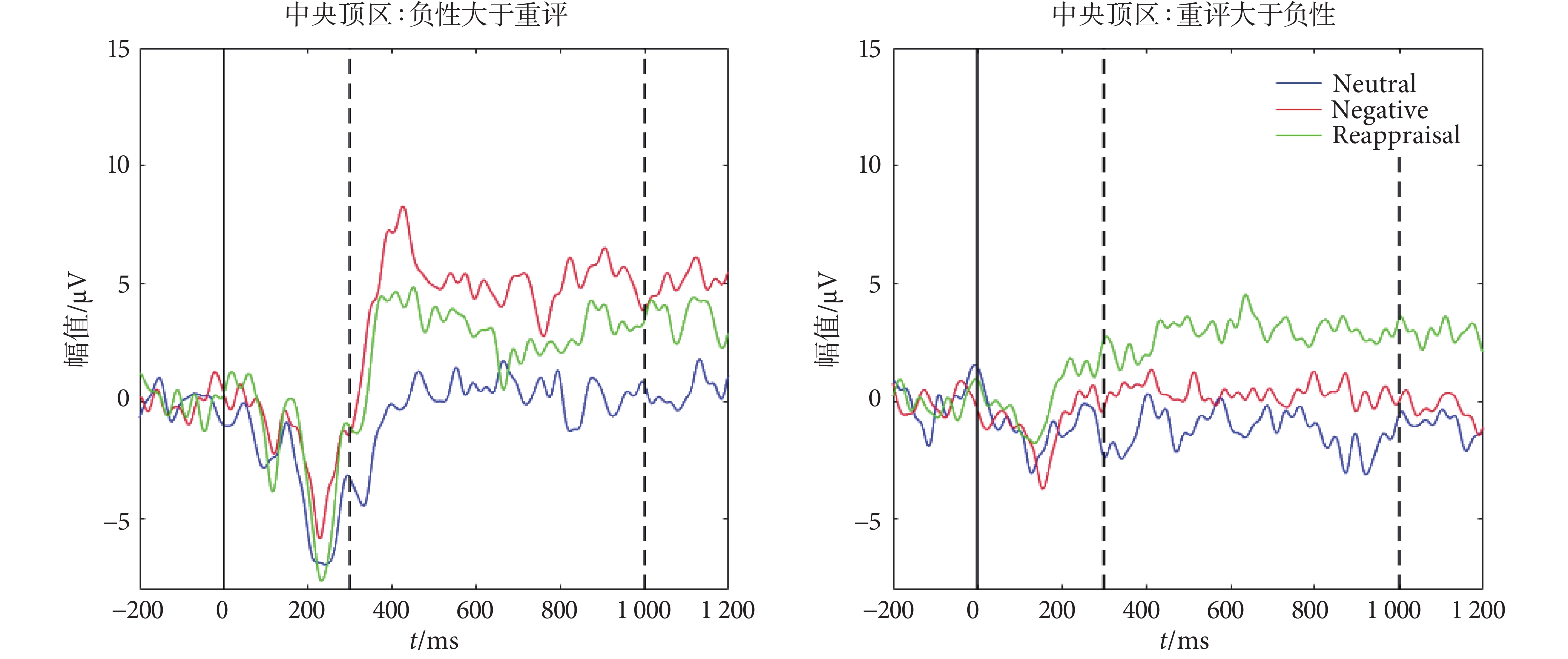 圖3
LPP 早期模式
Figure3.
The modes of early LPP
圖3
LPP 早期模式
Figure3.
The modes of early LPP
為了進一步分析驗證重評時 LPP 的不同模式,我們將每一個受試者負性觀看和重評兩種條件下的早期 LPP(300~1 000 ms)內每個時間點的幅度作為樣本,進行配對 t 檢驗,只有滿足顯著差異(P < 0.05),才認為與負性觀看相比,重評效應使得 LPP 幅值發生了改變。按照這種原則,本文驗證了無論成功組還是失敗組,都存在上述波形圖圖3 中觀察到的“增加模式”和“減小模式”。經過統計,成功“增加模式”組 8 人,記為 S1,成功“減小模式”組 7 人,記為 S2;失敗“增加模式”組 5 人,記為 F1,失敗“減小模式”組 8 人,記為 F2。由于中央頂區處的早期 LPP 在重評上有特異性結果,我們針對這些數據進行 rmANOVA 檢驗,組間因素為 pattern(四水平:S1、S2、F1 和 F2),組內因素為 condition(中性觀看、負性觀看和重評)。結果發現了顯著的 pattern*condition 交互效應(P < 0.001),簡單效應分析顯示,四種模式下都發現了顯著的重評和負性觀看的統計差異(S1,P = 0.003;S2,P = 0.003;F1,P = 0.003;F2,P = 0.020)。按照早期 LPP 的這四個分組,我們再對他們的 LPP 中后期進行統計檢驗。結果發現,在 LPP 中期(1 000~3 000 ms)只剩下 S1(P = 0.041)和 F1(P = 0.048)兩種模式有重評效應;而在 LPP 后期(3 000~5 000 ms),前述早期 LPP 的變化模式消失了。
進一步地,我們不考慮成功和失敗分組,分別對“增加模式”的 13 人和“減小模式”的 15 人早期 LPP 繼續進行重評效應的 rmANOVA 檢驗,組內因素為 condition(中性觀看、負性觀看和重評)。兩種模式的檢驗結果均成功發現了顯著的重評效應(P < 0.001),重評 LPP 與負性觀看 LPP 顯著不同。進一步分析,“減小模式”下重評 LPP 和中性觀看 LPP 沒有發現顯著差異,而“增加模式”下重評 LPP 顯著大于中性觀看 LPP(P < 0.001)。
2.4 相關分析
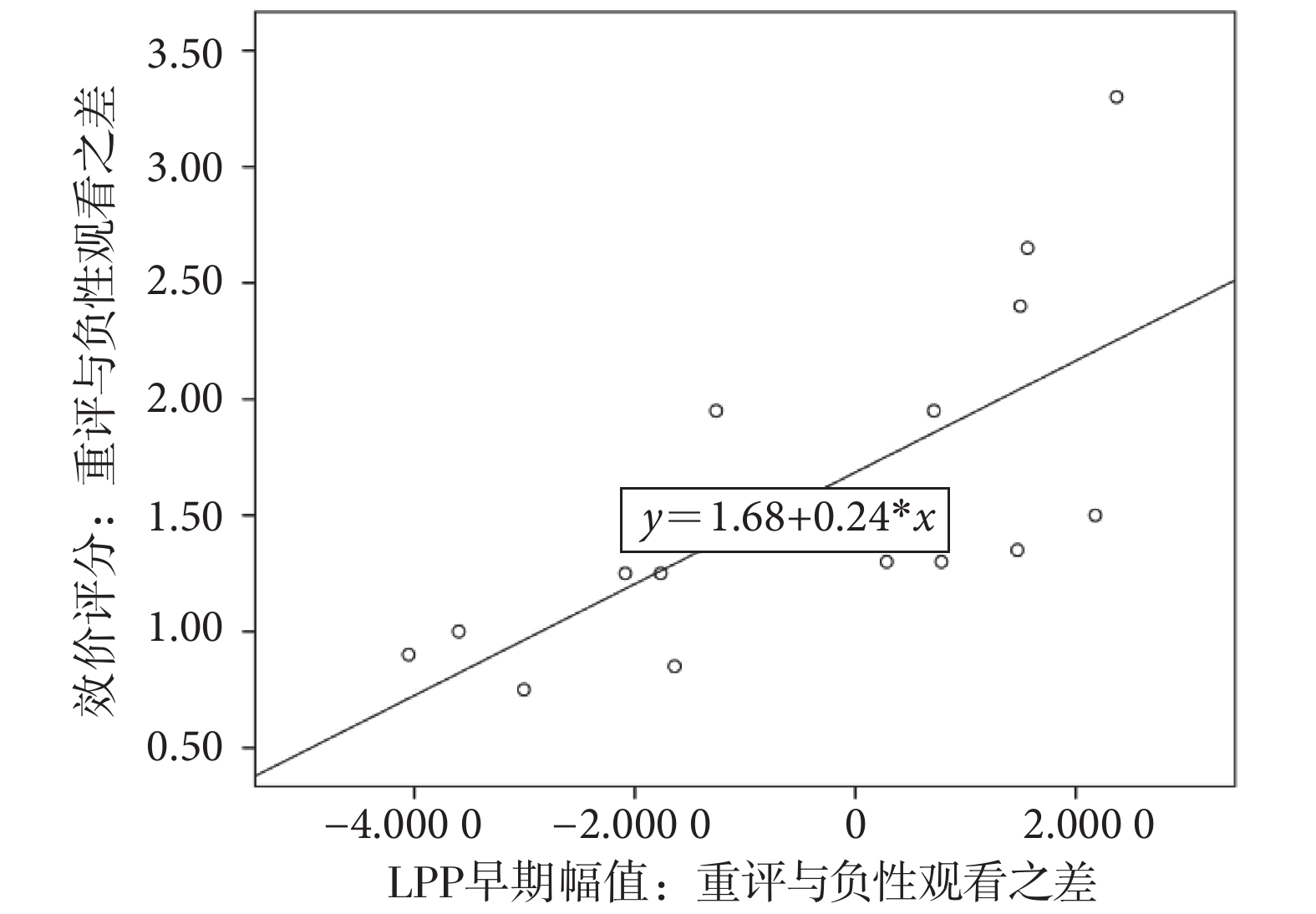
上述結果表明,重評的 LPP 幅值在成功組和失敗組之間并沒有直接發現組間差異,但是具有兩種變化模式。我們通過分析行為學評分與電生理信號之間的相關性,即受試者重評與負性觀看的效價評分之差與對應任務條件下 LPP 早期幅值之差的關系,進一步探究成功組和失敗組的差異。首先,我們對 15 例成功組和 13 例失敗組分別進行斯皮爾曼相關分析。結果發現,對于成功組,兩者具有顯著的正相關性(ρ = 0.847,P < 0.001;見圖4),重評與負性觀看的效價評分之差越大,這兩種任務條件下的 LPP 早期幅值之差也越大;而對于失敗組,沒有發現兩者之間的相關性。
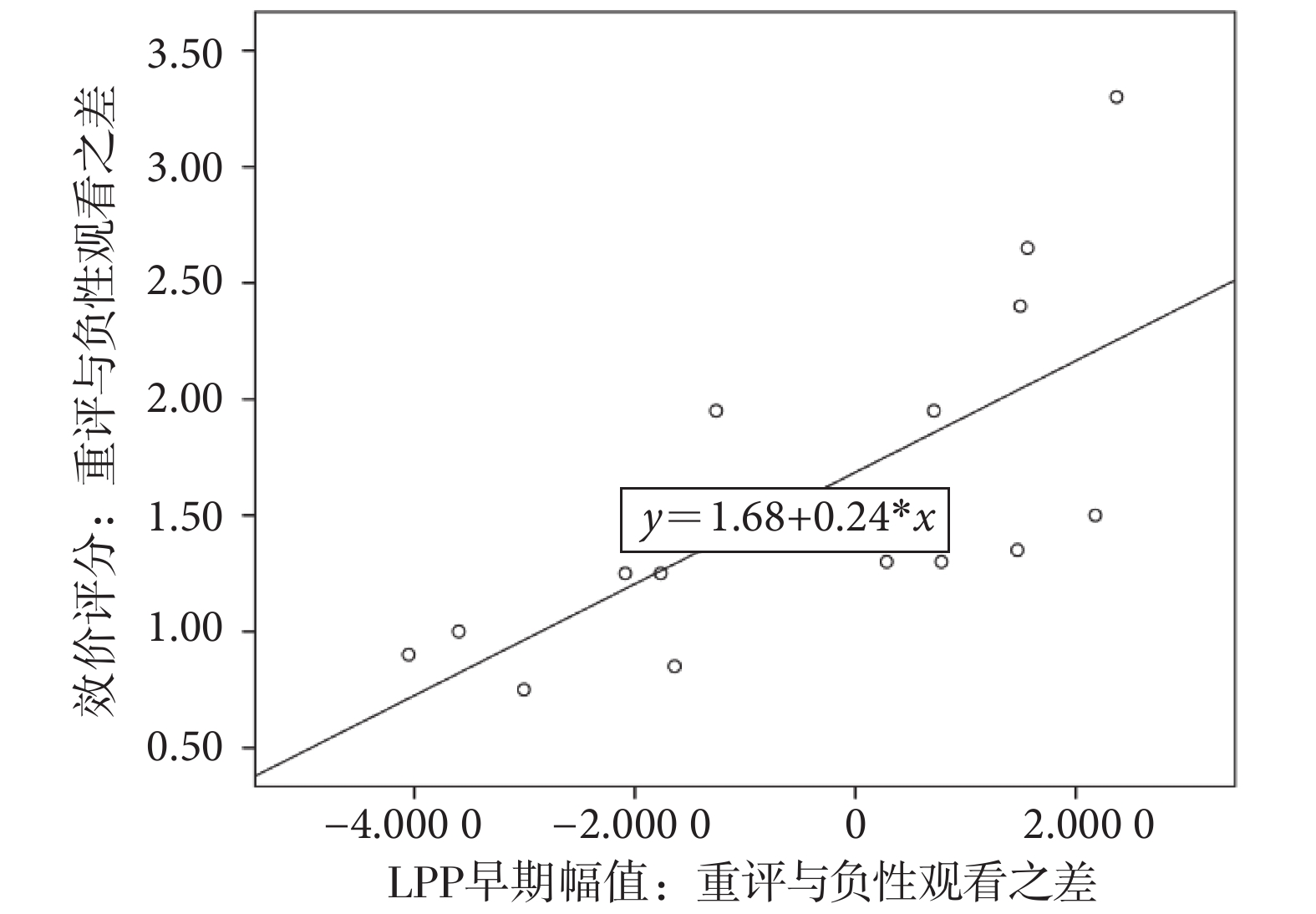 圖4
成功組效價評分之差與 LPP 早期幅值之差的斯皮爾曼 相關性分析
Figure4.
Spearman’s correlation between the valence scores difference and the early amplitude difference of LPP in successful group
圖4
成功組效價評分之差與 LPP 早期幅值之差的斯皮爾曼 相關性分析
Figure4.
Spearman’s correlation between the valence scores difference and the early amplitude difference of LPP in successful group
接著,我們再對四種重評模式分別進行同樣的相關性分析。結果發現,對于 S1 模式(成功組“增加模式”),兩者具有顯著的正相關性(ρ = 0.719,P = 0.045);而對于另外三種模式,均沒有發現兩者之間的相關性。
3 討論
N200 成分在前額幅值最大,反映了對視覺刺激的自動注意捕獲[30],同時若刺激誘發的情緒感受和語義矛盾,則會產生沖突效應,誘發出更大的 N200 成分[31]。本文采用的重評描述語的語義與負性圖片原本誘發的負性情緒是矛盾的,從而產生了沖突效應,導致重評比負性觀看誘發出更負的 N200 幅值。
P200 成分對情緒內容敏感,與選擇性關注有關[11]。情緒相關刺激的注意力捕獲被稱為“動機關注(motivated attention)”,指的是選擇性關注的自然狀態[32]。觀看情緒圖片刺激時,頂葉 P200 幅值的增大反映了更多的動機關注[33]。本文發現,在頂葉和顳葉交界處(T5 和 T6),重評比負性觀看誘發了更大的 P200 幅值。我們推測重評任務引起了受試者更多的注意力,即動機關注的增大,才導致了 P200 幅值的增大。
中央頂葉處的 LPP 對情緒刺激敏感。與中性圖片相比,情緒圖片能誘發出更大的 LPP 幅值[12-14]。Cuthbert 等[12]發現,LPP 幅值在情緒圖片出現后約 1 s 時達到最大,之后在圖片呈現的剩余 5 s 內緩慢下降。本文同樣發現,與額區和顳區相比,中央頂區(Cz 和 CPz)處的 LPP 對情緒刺激敏感。與中性刺激相比,負性刺激和重評刺激均增大了 LPP 在 300~3 000 ms 內的幅值,而在 3 000~5 000 ms 內這種顯著差異消失,我們推測是刺激造成的效應減弱引起的。
以上 ERP 成分中均未發現組間差異,說明從腦電數據看無論是成功組還是失敗組都正常地執行了三種實驗任務。值得討論的是,本文并未發現重評與負性觀看在 LPP 幅值上的差異性(重評效應)。究其原因,我們發現在本實驗中重評對 LPP 的調制模式不是唯一的,有時升高,有時降低,如引言所述,即使同樣是認知重評的任務,研究結果也不一致,有的發現重評后的 LPP 升高,有的則發現是降低的。我們推測是這種并非唯一的變化模式導致最終平均后的重評效應“抵消”了。
本文結果顯示,受重評效應的調制作用,在中央頂區處,成功組和失敗組的 LPP 早期幅值均有兩種變化模式,即升高和降低。當我們把不同模式的受試者分開統計時,成功發現了重評效應。根據 Kalisch[34]提出的認知重評的執行-維持模型(implementation-maintenance model),早期階段指選擇和執行初步的重評策略,晚期階段指對該策略的成功維持,我們的結果體現了重評在 LPP 早期(300~1 000 ms)的執行,但并未成功維持到 LPP 后期(3 000~5 000 ms)。Hajcak 等[16]的實驗中重評引起的 LPP 幅值變化至少持續了 2 s,而本文結果中重評效應引起的變化模式在 LPP 中期(1 000~3 000 ms)就不再顯著,我們推測持續時間在 2 s 左右。
本文結果還表明,成功組和失敗組的行為學和電生理活動是具有差異的。在正式實驗前進行的問卷調查中,失敗組的 SAS 得分更高,說明失敗組在進行實驗的那段時期比成功組焦慮感更強,這也可能導致最終重評的失敗。此外,本研究中的重評成功組和失敗組是按照他們實驗之后的效價評分標準來區分,只說明他們在實驗結束時情緒體驗是否達到標準。進入失敗組是否就意味著在整個實驗過程中沒有執行認知重評策略?
根據我們對電生理數據的分析,失敗組在 ERP 早期與成功組具有一致的特性,說明早期加工未發現不同;同時我們發現在兩組人員中重評效應對早期 LPP 的調制作用模式一致,說明失敗組也嘗試使用了重評策略,但重評效應對于兩組人員 LPP 的調制機制不同。我們推測失敗組之所以失敗是由于他們執行策略后的情緒體驗未持續到行為評分時刻。在我們的另一份研究工作中,發現成功組和失敗組執行認知重評策略時增加了 LPP 早期幅值,成功組維持了這一調制作用至 LPP 晚期,而失敗組并未發現相同的調制作用[35]。雖然兩個研究的實驗不一樣,但仍然為我們的推測提供了依據。最后,我們通過將成功組和失敗組再進行兩種模式的分組,發現了成功組“增加模式”與行為之間的顯著相關,提示這種模式在重評過程中具有特殊意義。需要說明的是,這樣分組后每一種模式的受試者例數較少,因此究竟具有怎樣的意義還需要更深入的研究。
4 結論
綜上所述,我們的研究表明無論重評成功與否,執行認知重評策略都會影響情緒加工的早期成分,重評對 LPP 早期成分的調制作用都表現為“增加”和“減小”兩種模式。但是,小樣本分析顯示只有對 LPP 早期成分的“增加”調制與重評成功顯著相關,反映了認知重評電生理特性與情緒反應的正相關性。未來可以針對這種調制模式進行深入研究,以發現更穩定的成功實施情緒調節的電生理特征。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
對情緒的良好調節是人類具備完整社會功能的基本前提,研究指出情緒調節包含多種策略,可以作用于情緒產生的不同階段。其中,認知重評策略指的是通過在情緒產生的早期改變對刺激事件的理解以及調整刺激對自身意義的認知來降低(負性)情緒感受的一種調節策略[1]。研究表明,認知重評策略具有長期的效應影響力[2],是臨床上抑郁癥、焦慮癥認知(行為)療法的核心策略[3]。但是,并不是每一個人都能成功地執行該策略[4-7],深入研究認知重評策略的神經機制,對今后的個性化臨床干預具有重要意義。
認知重評策略包括對事物重新進行解釋、換位思考等方式,來增加或者減少情緒感受,進而影響情緒反應,這一過程相關的神經活動具有顯著的動力學特征[8]。事件相關電位(event-related potential,ERP)是通過疊加平均技術從頭皮腦電(electroencephalogram,EEG)中提取的電位,由事件刺激誘發,能夠實時反映受到刺激后大腦高速的信息加工處理過程[9],在認知重評的神經機制研究中占據著重要的地位[10-11]。已有研究表明晚正電位(late positive potential,LPP)對情緒刺激具有很高的敏感性,與中性視覺刺激相比,LPP 幅值在情緒視覺刺激呈現后更大[12-14]。進一步的研究發現,在觀看負性情緒圖片并采取認知重評策略時誘發的 LPP 幅值比觀看負性圖片誘發的幅值小,比觀看中性圖片誘發的幅值大[15-16]。但是,并不是所有的研究都取得了一致性的研究結果。例如,Gardener 等[5]在認知重評任務下并未發現 LPP 幅值的變化,而 Langeslag 等[17]在實驗中卻發現相對負性圖片觀看,執行重評策略后觀看圖片反而增加了 LPP 幅值。研究結果的不同究竟是因何而起目前還沒有明確的結論,是實驗范式不同導致的,還是 LPP 幅值的變化與認知重評之間并不存在穩定的相互關系還需要進一步探究。此外,目前認知重評策略的研究大多關注受試者整體的情緒調節情況,只有少數研究關注到認知重評的成功問題[4-7]。本文通過行為學評分將所有受試者劃分為重評成功組與重評失敗組,分析比較了兩組人員的腦電信號,以及腦電與行為學結果之間的相關性,旨在探尋成功執行情緒認知重評策略的腦電特征尤其是對 LPP 的調制作用,以及重評成功與重評失敗表現出的電生理差異。
1 實驗方法
1.1 受試者信息
本次實驗共招募了 28 名大學生作為志愿者,其中男生 15 名,女生 13 名,年齡為(21.6 ± 2.8)歲,受教育年限為(15.6 ± 1.9)年。所有參與者均為右利手,視力正常或矯正后正常,無精神及神經類疾病史。在正式實驗前,所有受試者簽署了知情同意書,并填寫了自評焦慮量表(Self-Rating Anxiety Scale,SAS)、自評抑郁量表(Self-Rating Depression Scale,SDS)、Gross 情緒調節習慣問卷、大五人格量表、情緒調節自我效能感問卷和認知情緒調節習慣問卷。根據 SAS 和 SDS 量表標準,所有受試者 SAS 評分(正常范圍 ≤ 50)和 SDS 評分(正常范圍 ≤ 53)都在正常范圍之內。實驗完成后,受試者均獲得了適當的志愿者費用。本實驗通過了上海市臨床研究倫理委員會批準,并遵從赫爾辛基宣言。
1.2 刺激材料
本文從國際情感圖片系統(International Affective Picture System,IAPS)中選取了 75 張圖片用作刺激材料[18]。這些圖片均為彩色場景圖片,大小為 260 像素 × 195 像素,無特殊標記或雜質。其中負性場景圖片 50 張,中性場景圖片 25 張。每一張圖片附有一句文字描述性話語:25 張中性圖片附有中性描述語,50 張負性圖片中隨機選取 25 張附有負性描述語,剩下 25 張附有中性或正性的重評描述語。所有描述語及圖片均在 17 寸液晶顯示屏正中央出現,呈水平和垂直大約 30° 視角。其中 15 張用于預實驗,60 張用于正式實驗。
1.3 實驗流程
研究發現,通過在負性圖片刺激出現之前播放或呈現中性或正性的描述語,能夠調節負性情緒感受[19-21]。本文參考 Foti 等[21]的實驗范式,在負性圖片出現之前給受試者呈現一句中性或正性的描述語(以下簡稱“重評描述語”)來重新解釋圖片的含義,以此讓受試者執行認知重評策略。在每一張圖片之后,要求受試者根據自身的真實感受對圖片的效價和喚醒度進行評分。為減少噪聲干擾,整個實驗過程中,受試者坐在隔音封閉房間里的靠背椅上,正視屏幕,雙眼距離屏幕大約 80 cm。
實驗流程如圖1 所示,正式實驗有 60 個試次,每一個試次對應一張刺激圖片。所有試次分為 4 個組,每個組包含中性圖片 5 張、負性圖片 10 張,圖片均為隨機選取、隨機出現。實驗正式開始前,受試者通過預實驗熟悉流程。正式開始后,受試者閱讀屏幕上顯示的實驗說明,按任意鍵進入第一個試次:屏幕中央依次出現一個小十字、文字描述語和相對應的刺激圖片,要求受試者根據描述語來理解圖片;圖片消失后受試者需要根據自身的真實感受先對圖片的效價進行評分,數字 1~9 對應從“極度消極”到“極度積極”九個等級,然后再對圖片的喚醒度進行評分,數字 1~9 對應“極度放松”到“極度強烈”九個等級。評分完成后自動進入下一個試次。實驗程序采用 E-Prime 2.0 軟件(Psychology Software Tools 等,美國)編寫。
圖1
實驗流程圖
Figure1.
Experimental flow chart
根據描述語與圖片的匹配,本實驗分為了三種任務條件(condition):中性描述語與中性圖片(中性觀看,neutral)、負性描述語與負性圖片(負性觀看,negative)以及重評描述語與負性圖片(重評,reappraisal)。
1.4 EEG 數據采集與預處理
受試者在完成認知重評任務的同時進行腦電數據的采集,采集設備為 32 導 EEG/ERP 檢測儀(Neuroscan,美國),符合 10-20 國際標準。參考電極放置在右側乳突,接地電極位于 AFz,兩個附加電極分別放置在左眼下方和右眼上方來記錄垂直眼電。實驗開始前,電極帽上每個導聯的阻抗均通過涂抹導電膏的方式降至 5 000 Ω 以下。采集過程中采樣率為 1 000 Hz,同時用陷波濾波去除 50 Hz 的工頻干擾。
數據采集完畢后,使用軟件 Matlab 2016(MathWorks,美國)的工具箱 EEGLAB 進行數據的預處理,帶通濾波 0.1~30 Hz,以刺激圖片出現時刻為 0 ms,將數據按 ? 200~5 000 ms 分段,剔除明顯的壞數據,設置幅值范圍 ± 100 μV,刪除超出范圍的數據段,運用獨立成分分析進行偽跡排除,去除眨眼、眼飄和肌電偽跡,得到干凈的數據后導入 REST 工具箱[22],進行重參考[23]。Chella 等[24]明確指出,這種零參考方式的誤差顯著小于全腦平均參考、雙側乳突平均參考和 Cz 參考等方式。預處理完成后,每個受試者剩余的平均有效試次數目為 53.96(標準差為 4.12,約占總試次的 90%)。將這些試次進行疊加平均,得到三種任務條件下的 ERP 波形。最后用刺激圖片出現前 200 ms 的數據進行基線校正。
1.5 成功實施策略的行為學指標
研究表明,通過重評可以減小負面情緒感受,表現在行為學指標上,通常就是顯著減少受試者自我報告中對負性刺激的不愉悅度(效價評分升高)、降低對刺激的喚醒度(喚醒度評分降低)[25-26]。當然,認知重評的方式有很多,例如通過增加積極情緒就可以有效實施重評。有研究指出增加積極情緒主要影響受試者對效價的評分,對喚醒度評分影響較小[27]。本實驗使用的范式是通過刺激圖片出現前增加重評描述語來引導受試者有效實現重評,這些描述語可以有效增加積極情緒,因此,本文將受試者的效價評分作為分組指標,用來判斷受試者是否成功執行了認知重評策略。若受試者的重評評分與負性觀看評分相比顯著提升了,則該受試者被分為重評“成功組”,否則為“失敗組”。
我們對每一名受試者的負性觀看評分和重評評分進行配對 t 檢驗,在 28 名受試者中,有 15 名的效價評分是重評顯著大于負性觀看的(P < 0.05),入組“成功組”,其余的 13 名受試者入組“失敗組”。成功組中男 8 名、女 7 名,年齡為(21.7 ± 3.7)歲,受教育年限為(15.5 ± 2.0)年。失敗組中男 7 名、女 6 名,年齡為(21.6 ± 2.1)歲,受教育年限為(15.7 ± 1.9)年。兩組人的基本信息無顯著差異。失敗組比成功組的 SAS 得分更高(P = 0.005)。
1.6 統計檢驗
本文使用了配對 t 檢驗、相關性分析以及重復測量方差分析(repetitive measure analysis of variance,rmANOVA)分析方法,均在軟件 SPSS 22.0(IBM,美國)中完成數據的統計分析。進行重復測量方差分析時,多重比較校正采用 Bonferroni 校正,若所分析因素不滿足球形檢驗,再對其進行 Greenhouse-Geisser 校正。相關性分析使用斯皮爾曼相關分析法(Spearman’s correlation)。所有統計分析的顯著性水平為 0.05。
2 結果
2.1 ERP 早期成分
根據文獻,本文對 ERP 早期成分的時間窗和對應電極位置進行了選擇,具體來說,選擇圖片刺激出現時刻之后的 200~300 ms 作為刺激誘發的早期注意和反應過程的時間窗,來分析 N200 和 P200 的特性[12];選取額區(F3、FZ 和 F4)來計算 N200 成分[28],選取顳區(T5 和 T6)來計算 P200 成分[29]。分別對 N200 和 P200 的幅值和潛伏期進行 rmANOVA,組間因素為 group(成功和失敗),組內因素為 condition(中性觀看、負性觀看和重評)。結果發現了顯著的重評效應,無論是成功組還是失敗組,重評比負性觀看誘發了更大的 N200 和 P200 成分(見表1)。關于潛伏期則沒有發現任何統計效應。
2.2 LPP 成分
我們將圖片刺激出現后 300~5 000 ms 的 LPP 劃分為三個時間窗:早期 300~1 000 ms、中期 1 000~3 000 ms 和后期 3 000~5 000 ms,再把每一個時間窗內的 ERP 均值作為該時期的 LPP 幅值。選擇以下三個區域(area)來計算 LPP 幅值:額區(F3、FZ 和 F4)、中央頂區(CZ 和 CPZ)和顳區(T5 和 T6)。圖2 為中央頂區疊加平均后的 LPP 波形。
圖2
兩組人員在中央頂區的 LPP 總平均波形
Figure2.
The grand average LPPs in central parietal area of two groups
分別對 LPP 早中后三個時期進行 group*area*condition 的 rmANOVA,一個組間因素 group(成功和失敗),兩個組內因素為 area(額區、中央頂區和顳區)和 condition(中性觀看、負性觀看和重評)。結果未發現重評效應和組間差異,發現在 LPP 早期與中期均具有顯著的 area*condition 交互效應[早期 F(4,22)= 13.30,P < 0.001;中期 F(4,30)= 8.03,P < 0.001],分別進行簡單效應分析,結果如下(詳見表2):LPP 早期(300~1 000 ms),在額區、中央頂區和顳區都發現 condition 主效應;到 LPP 中期(1 000~3 000 ms),condition 主效應在中央頂區和顳區仍然存在,而額區的 condition 效應消失。成對比較顯示負性觀看顯著大于中性觀看,在中央頂區還發現重評顯著大于中性觀看。在 LPP 后期(3 000~5000 ms)則未發現任何統計效應。
2.3 重評的 LPP 模式
我們目測發現不管是成功組還是失敗組,在中央頂區處早期(300~1 000 ms)LPP 幅值都存在兩種變化模式:重評的 LPP 幅值高于負性觀看(簡稱為“增加模式”),重評的 LPP 幅值低于負性觀看(簡稱為“減小模式”)。兩種模式的波形參見圖3。而在中期和后期兩者的 LPP 幅值目測未發現差異,或者說沒有發現類似的模式。
圖3
LPP 早期模式
Figure3.
The modes of early LPP
為了進一步分析驗證重評時 LPP 的不同模式,我們將每一個受試者負性觀看和重評兩種條件下的早期 LPP(300~1 000 ms)內每個時間點的幅度作為樣本,進行配對 t 檢驗,只有滿足顯著差異(P < 0.05),才認為與負性觀看相比,重評效應使得 LPP 幅值發生了改變。按照這種原則,本文驗證了無論成功組還是失敗組,都存在上述波形圖圖3 中觀察到的“增加模式”和“減小模式”。經過統計,成功“增加模式”組 8 人,記為 S1,成功“減小模式”組 7 人,記為 S2;失敗“增加模式”組 5 人,記為 F1,失敗“減小模式”組 8 人,記為 F2。由于中央頂區處的早期 LPP 在重評上有特異性結果,我們針對這些數據進行 rmANOVA 檢驗,組間因素為 pattern(四水平:S1、S2、F1 和 F2),組內因素為 condition(中性觀看、負性觀看和重評)。結果發現了顯著的 pattern*condition 交互效應(P < 0.001),簡單效應分析顯示,四種模式下都發現了顯著的重評和負性觀看的統計差異(S1,P = 0.003;S2,P = 0.003;F1,P = 0.003;F2,P = 0.020)。按照早期 LPP 的這四個分組,我們再對他們的 LPP 中后期進行統計檢驗。結果發現,在 LPP 中期(1 000~3 000 ms)只剩下 S1(P = 0.041)和 F1(P = 0.048)兩種模式有重評效應;而在 LPP 后期(3 000~5 000 ms),前述早期 LPP 的變化模式消失了。
進一步地,我們不考慮成功和失敗分組,分別對“增加模式”的 13 人和“減小模式”的 15 人早期 LPP 繼續進行重評效應的 rmANOVA 檢驗,組內因素為 condition(中性觀看、負性觀看和重評)。兩種模式的檢驗結果均成功發現了顯著的重評效應(P < 0.001),重評 LPP 與負性觀看 LPP 顯著不同。進一步分析,“減小模式”下重評 LPP 和中性觀看 LPP 沒有發現顯著差異,而“增加模式”下重評 LPP 顯著大于中性觀看 LPP(P < 0.001)。
2.4 相關分析
上述結果表明,重評的 LPP 幅值在成功組和失敗組之間并沒有直接發現組間差異,但是具有兩種變化模式。我們通過分析行為學評分與電生理信號之間的相關性,即受試者重評與負性觀看的效價評分之差與對應任務條件下 LPP 早期幅值之差的關系,進一步探究成功組和失敗組的差異。首先,我們對 15 例成功組和 13 例失敗組分別進行斯皮爾曼相關分析。結果發現,對于成功組,兩者具有顯著的正相關性(ρ = 0.847,P < 0.001;見圖4),重評與負性觀看的效價評分之差越大,這兩種任務條件下的 LPP 早期幅值之差也越大;而對于失敗組,沒有發現兩者之間的相關性。
圖4
成功組效價評分之差與 LPP 早期幅值之差的斯皮爾曼 相關性分析
Figure4.
Spearman’s correlation between the valence scores difference and the early amplitude difference of LPP in successful group
接著,我們再對四種重評模式分別進行同樣的相關性分析。結果發現,對于 S1 模式(成功組“增加模式”),兩者具有顯著的正相關性(ρ = 0.719,P = 0.045);而對于另外三種模式,均沒有發現兩者之間的相關性。
3 討論
N200 成分在前額幅值最大,反映了對視覺刺激的自動注意捕獲[30],同時若刺激誘發的情緒感受和語義矛盾,則會產生沖突效應,誘發出更大的 N200 成分[31]。本文采用的重評描述語的語義與負性圖片原本誘發的負性情緒是矛盾的,從而產生了沖突效應,導致重評比負性觀看誘發出更負的 N200 幅值。
P200 成分對情緒內容敏感,與選擇性關注有關[11]。情緒相關刺激的注意力捕獲被稱為“動機關注(motivated attention)”,指的是選擇性關注的自然狀態[32]。觀看情緒圖片刺激時,頂葉 P200 幅值的增大反映了更多的動機關注[33]。本文發現,在頂葉和顳葉交界處(T5 和 T6),重評比負性觀看誘發了更大的 P200 幅值。我們推測重評任務引起了受試者更多的注意力,即動機關注的增大,才導致了 P200 幅值的增大。
中央頂葉處的 LPP 對情緒刺激敏感。與中性圖片相比,情緒圖片能誘發出更大的 LPP 幅值[12-14]。Cuthbert 等[12]發現,LPP 幅值在情緒圖片出現后約 1 s 時達到最大,之后在圖片呈現的剩余 5 s 內緩慢下降。本文同樣發現,與額區和顳區相比,中央頂區(Cz 和 CPz)處的 LPP 對情緒刺激敏感。與中性刺激相比,負性刺激和重評刺激均增大了 LPP 在 300~3 000 ms 內的幅值,而在 3 000~5 000 ms 內這種顯著差異消失,我們推測是刺激造成的效應減弱引起的。
以上 ERP 成分中均未發現組間差異,說明從腦電數據看無論是成功組還是失敗組都正常地執行了三種實驗任務。值得討論的是,本文并未發現重評與負性觀看在 LPP 幅值上的差異性(重評效應)。究其原因,我們發現在本實驗中重評對 LPP 的調制模式不是唯一的,有時升高,有時降低,如引言所述,即使同樣是認知重評的任務,研究結果也不一致,有的發現重評后的 LPP 升高,有的則發現是降低的。我們推測是這種并非唯一的變化模式導致最終平均后的重評效應“抵消”了。
本文結果顯示,受重評效應的調制作用,在中央頂區處,成功組和失敗組的 LPP 早期幅值均有兩種變化模式,即升高和降低。當我們把不同模式的受試者分開統計時,成功發現了重評效應。根據 Kalisch[34]提出的認知重評的執行-維持模型(implementation-maintenance model),早期階段指選擇和執行初步的重評策略,晚期階段指對該策略的成功維持,我們的結果體現了重評在 LPP 早期(300~1 000 ms)的執行,但并未成功維持到 LPP 后期(3 000~5 000 ms)。Hajcak 等[16]的實驗中重評引起的 LPP 幅值變化至少持續了 2 s,而本文結果中重評效應引起的變化模式在 LPP 中期(1 000~3 000 ms)就不再顯著,我們推測持續時間在 2 s 左右。
本文結果還表明,成功組和失敗組的行為學和電生理活動是具有差異的。在正式實驗前進行的問卷調查中,失敗組的 SAS 得分更高,說明失敗組在進行實驗的那段時期比成功組焦慮感更強,這也可能導致最終重評的失敗。此外,本研究中的重評成功組和失敗組是按照他們實驗之后的效價評分標準來區分,只說明他們在實驗結束時情緒體驗是否達到標準。進入失敗組是否就意味著在整個實驗過程中沒有執行認知重評策略?
根據我們對電生理數據的分析,失敗組在 ERP 早期與成功組具有一致的特性,說明早期加工未發現不同;同時我們發現在兩組人員中重評效應對早期 LPP 的調制作用模式一致,說明失敗組也嘗試使用了重評策略,但重評效應對于兩組人員 LPP 的調制機制不同。我們推測失敗組之所以失敗是由于他們執行策略后的情緒體驗未持續到行為評分時刻。在我們的另一份研究工作中,發現成功組和失敗組執行認知重評策略時增加了 LPP 早期幅值,成功組維持了這一調制作用至 LPP 晚期,而失敗組并未發現相同的調制作用[35]。雖然兩個研究的實驗不一樣,但仍然為我們的推測提供了依據。最后,我們通過將成功組和失敗組再進行兩種模式的分組,發現了成功組“增加模式”與行為之間的顯著相關,提示這種模式在重評過程中具有特殊意義。需要說明的是,這樣分組后每一種模式的受試者例數較少,因此究竟具有怎樣的意義還需要更深入的研究。
4 結論
綜上所述,我們的研究表明無論重評成功與否,執行認知重評策略都會影響情緒加工的早期成分,重評對 LPP 早期成分的調制作用都表現為“增加”和“減小”兩種模式。但是,小樣本分析顯示只有對 LPP 早期成分的“增加”調制與重評成功顯著相關,反映了認知重評電生理特性與情緒反應的正相關性。未來可以針對這種調制模式進行深入研究,以發現更穩定的成功實施情緒調節的電生理特征。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。