針對帕金森病語音檢測問題,本文提出了一種基于時頻混合域局部統計的帕金森病語音障礙分析方法。該方法首先將語音信號從時域轉化為時頻混合域,即進行時頻化表示。在時頻化表示方法中將語音信號進行分幀處理,再將每幀的語音進行傅里葉變換,通過計算得到能量譜,并將能量譜通過映射關系映射到圖像空間進行可視化;其次統計信號每個能量數據在時間軸上和頻率軸上的差分值,根據差分值計算該能量的梯度統計特征,用梯度統計特征來表示其不同時域與頻域的能量值的突變情況;最后利用 KNN 分類器對提取的梯度統計特征進行分類。本文在不同的帕金森病語音數據集上進行實驗,發現本文所提取的梯度統計特征在分類時有更強的聚類性。與基于傳統特征與深度學習特征的分類結果相比,本文所提取的梯度統計特征在分類準確率、特異性和靈敏性上均優于前二者。實驗證明了本文所提出的梯度統計特征在帕金森病語音分類診斷中的可行性。
引用本文: 張濤, 蔣培培, 張亞娟, 曹玉陽. 基于時頻混合域局部統計的帕金森病語音障礙分析方法研究. 生物醫學工程學雜志, 2021, 38(1): 21-29. doi: 10.7507/1001-5515.202001024 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
帕金森病是人類常見的中老年人神經系統變性疾病,其主要癥狀表現為震顫、肌肉僵直和行為緩慢等。目前雖然有輔酶 Q10[1]、5-羥胺再攝取抑制劑[2]和雷沙吉蘭[3]等方法治療帕金森病,但由于病因尚未完全明確,疾病無法完全治愈,所以對帕金森病的早期診斷顯得尤為重要。在帕金森病的早期檢測研究中,研究人員根據帕金森病的癥狀表現提出了一些檢測方法,其中包括步態分析[4]、可穿戴傳感器[5]、腦電信號分析[6]、生理信號分析[7]、語音信號分析[8]等。研究表明,在 200 名帕金森病患者實驗研究中,發現 74.00% 的帕金森病患者受到不同程度的言語障礙影響[9-11],因此,帕金森病的語音信號檢測分析引起了人們極大的關注[10-13]。
目前在帕金森病的語音研究中,主要集中在特征提取、特征選擇和分類三個方面。在特征提取領域,主要包括傳統的時域或頻域特征以及時頻混合域特征。傳統特征提取的方法主要是從語音信號中提取時域和頻域中的各種特征,在此方面有大量的研究者做出了巨大的貢獻。Little 等[14]根據語音的時頻和頻域分別提出了基本頻率變化測量 Jitter 和振幅變化測量 Shimmer,同時也提出了諧波噪聲比(harmonics to noise ratio,HNR)來顯示語音信號的噪聲特征,還研究了語音信號中的幾種非線性測量特征包括動態復雜度和基頻變化測量等。Sakar 等[15]增加了不同的音調特征、周期特征和無聲中斷的特征。提取時域信息或者頻域信息的傳統方法,在帕金森病語音研究中取得了一定的成就,但是由于只針對時域或者頻域提取特征,因而忽略了語音中其他因素帶來的直接影響。近年來,越來越多的學者開始關注時域與頻域的聯合特征描述,促進了以時頻混合分析為代表的變換域特征提取的研究。時頻混合域是描述信號在時間、頻率方面特性時用到的一種二維坐標系。Sakar 等[16]提取了時頻特征梅爾頻率倒譜系數(Mel-frequency cepstral coefficients,MFCC)、基于小波變換的特征聲音折疊特征和可調 Q 因子小波變換特征(tunable Q-factor wavelet transform,TQWT)。Naranjo 等[17-18]增加了不同階數的 MFCC。這些報道顯示越來越多的學者開始關注時頻混合域。此外,有些學者在時頻混合域中用深度學習的方法來解決帕金森病分類問題,以時頻混合域為基礎通過神經網絡進行訓練,該類方法取得了很好的分類效果[19-20]。
近年來針對時頻混合域的研究逐步增多,提示我們在時頻混合域進行帕金森病檢測可能會有新的突破。因此本文提出了一種基于時頻混合域局部統計的帕金森病語音障礙分析方法,該方法基于時頻混合域,從能量突變的角度出發,提取了時頻混合域能量的梯度統計特征,全面提取了帕金森病語音的時頻域能量突變信息,并將提取的梯度統計特征通過 KNN 分類器進行分類,以期實現帕金森病的檢測。
1 材料和方法
1.1 數據集描述
在帕金森病語音分析中,大多數學者的研究數據均源于 Little 和 Sakar 提取的語音特征數據[21-24]。但是根據目前國際上對帕金森病原始語音障礙數據的公開情況,Little 并沒有公開帕金森語音數據集,因此本文采用的數據集為 Sakar 團隊[15]采集的土耳其語帕金森病語音數據集(Sakar’s Parkinson Detection Dataset,SPDD)和本團隊[25]采集的漢語發音的帕金森病語音數據集(Chinese Pronunciation Parkinson Detection Dataset,CPPDD)。
SPDD 數據集包括原始語音數據與提取的傳統特征數據兩部分。該數據集中包括 20 例帕金森病患者(6 例女性,14 例男性)和 20 例健康人(10 例男性,10 例女性),每例受試者分別采集 6 例語音片段(持續元音“a”與持續元音“o”的發音各三遍)。為了確保語音數據的一致性與平穩性,本文將原始語音信號截取 1.5 s 的平穩語音信號作為樣本,并對截取的語音信號作進一步篩選,最終得到符合實驗標準的語音樣本數 411 例。SPDD 數據集中包含原始語音聲學特征 Jitter、Shimmer、HNR 等 26 個傳統特征[15]如表1 所示,共包含傳統特征樣本數 1 040 例。
CPPDD 數據集中包含 36 例帕金森病患者(19 例男性,17 例女性)和 32 例健康人(16 例男性,16 例女性)的原始語音數據。其母語均為漢語,對每個受試者采集漢語發音(“a”和“o”),每個音節發音 3 次,每次持續發音 3 s。同樣截取 1.5 s 的平穩語音,并對信號進一步篩選,得到的 CPPDD 數據集共包含符合實驗標準的語音樣本數為 821 例。
1.2 方法
本文通過對語音數據進行時頻化表示,將語音數據的時域信息、頻域信息、時頻混合域信息進行同窗可視化,把語音的時域信號轉化到時頻混合域,然后通過局部梯度統計方法提取時頻混合域能量數據的時域特征、頻域特征以及時頻混合域特征。最后通過分類器將提取的特征進行訓練,將訓練好的分類器用于帕金森病語音檢測。該算法的整體流程圖如圖1 所示。
 圖1
算法整體流程圖
Figure1.
Overall algorithm flowchart
圖1
算法整體流程圖
Figure1.
Overall algorithm flowchart
1.2.1 時頻化表示方法
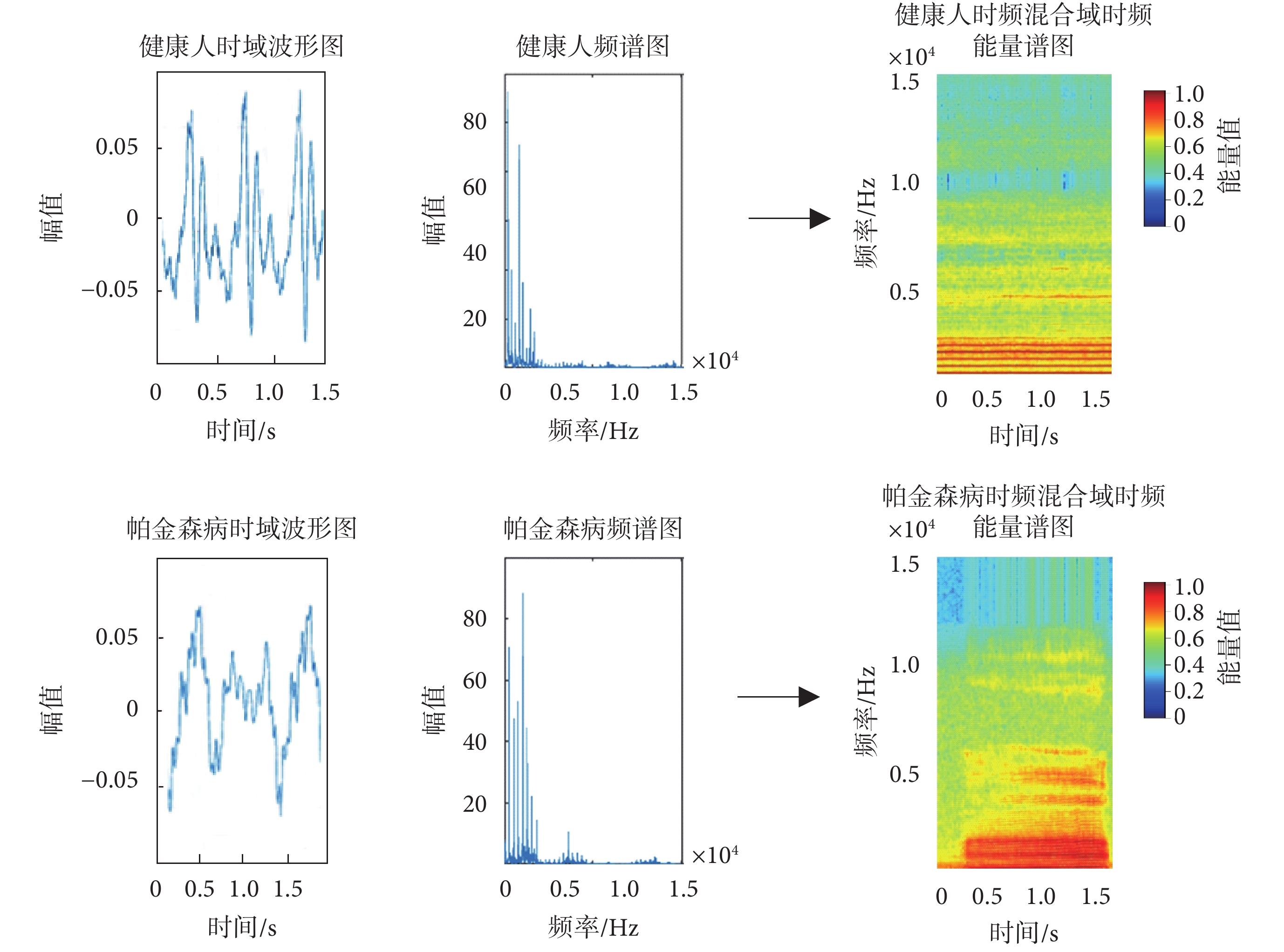
時域分析和頻域分析是語音信號分析的兩種重要方法,但這兩種方法均具有局限性:在進行時域分析時,無法直觀地展示語音信號的頻域特性;在進行頻域分析時,語音信號隨時間的變換關系也無從展現,因此將時域、頻域同時進行展示顯得尤為重要。本文通過使用短時傅里葉變換,將語音的時域信息和頻域信息同時轉換到時頻混合域,從而實現時頻化表示,如圖2 所示。
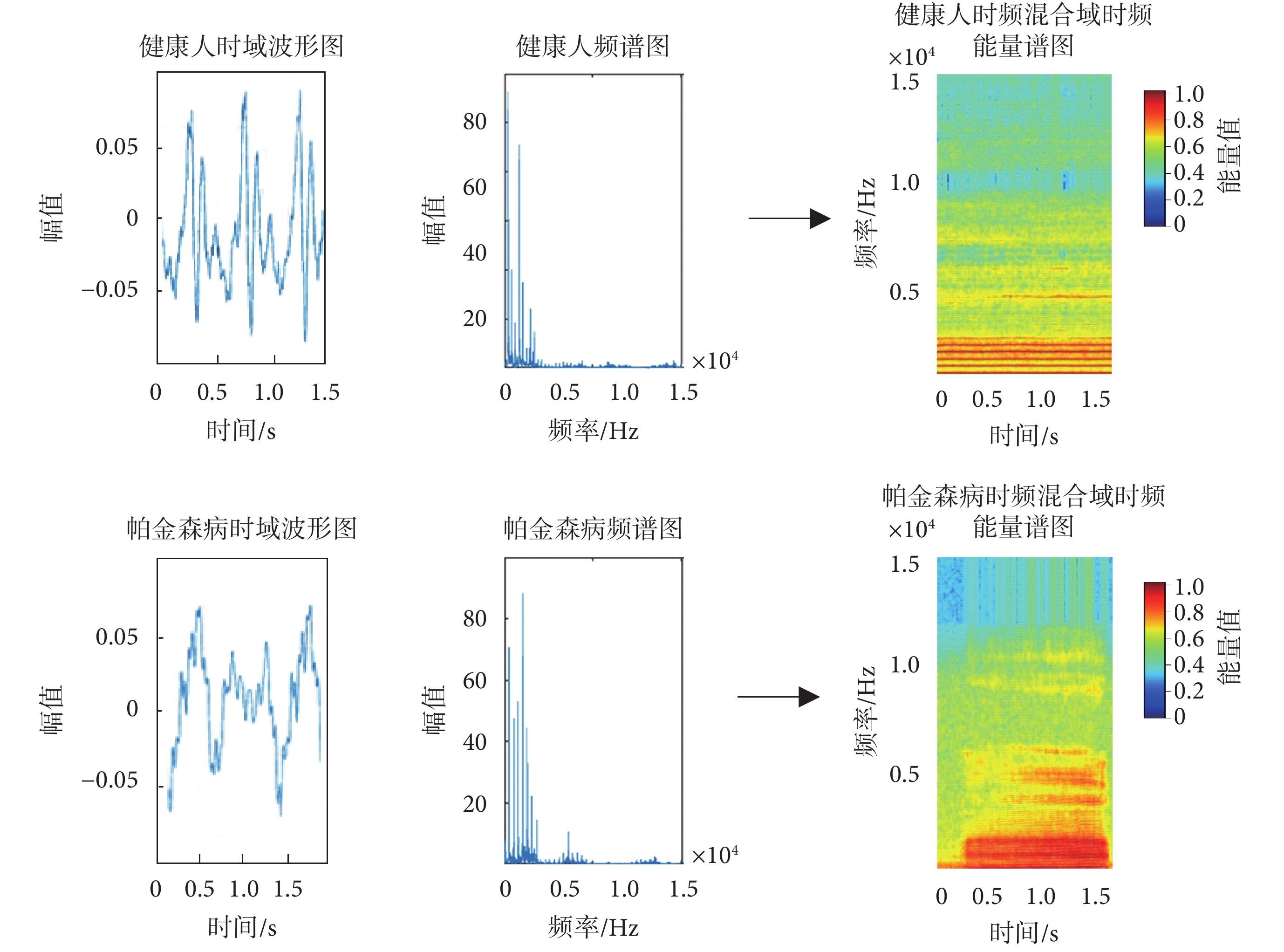 圖2
健康人與帕金森病患者語音時域、頻域及時頻混合域比較
圖2
健康人與帕金森病患者語音時域、頻域及時頻混合域比較
兩組在時域圖中信號周期、頻域中頻譜分布及時頻混合域圖中能量分布均勻性與分布范圍表現出明顯差異
Figure2. Comparison of speech in time domain, frequency domain and time-frequency domain between healthy and patients with Parkinson’s diseasethere are significant differences in signal period, spectrum distribution and energy distribution uniformity and distribution range in the time domain
由圖2 可知,健康人和帕金森病患者的語音信號在時域波形和頻譜圖上均存在差異。在時域上,二者語音信號波形的周期不同,振幅的相對變化也不同;在頻域上,二者的頻譜在高頻和低頻的分布也存在差異。故本文綜合語音信號的時域和頻域信息,在時頻混合域分析信號的時頻能量譜。從圖2 中可直觀看出,健康人語音信號的能量分布與帕金森病患者相比,能量分布更加均勻,更具規律性;從語音信號主要能量的分布范圍來看,與帕金森病患者相比,健康人語音信號能量分布的范圍更加集中。
1.2.2 局部梯度統計
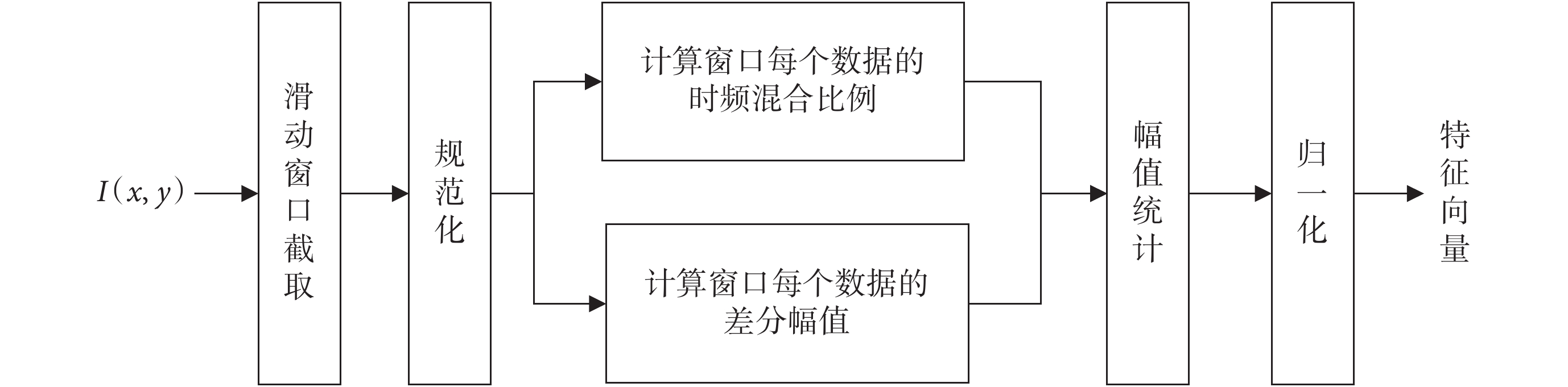
針對時頻混合域中的能量分布情況,本文采用局部梯度統計方法進行分析。該方法通過滑動窗口選擇局部數據,并對其進行差分化梯度統計處理,從而得到局部數據的統計信息。最后按照滑動窗口的滑動順序對每個窗口的梯度特征進行統計,得到時頻混合域的梯度統計特征。梯度統計特征的具體提取方法如圖3 所示。
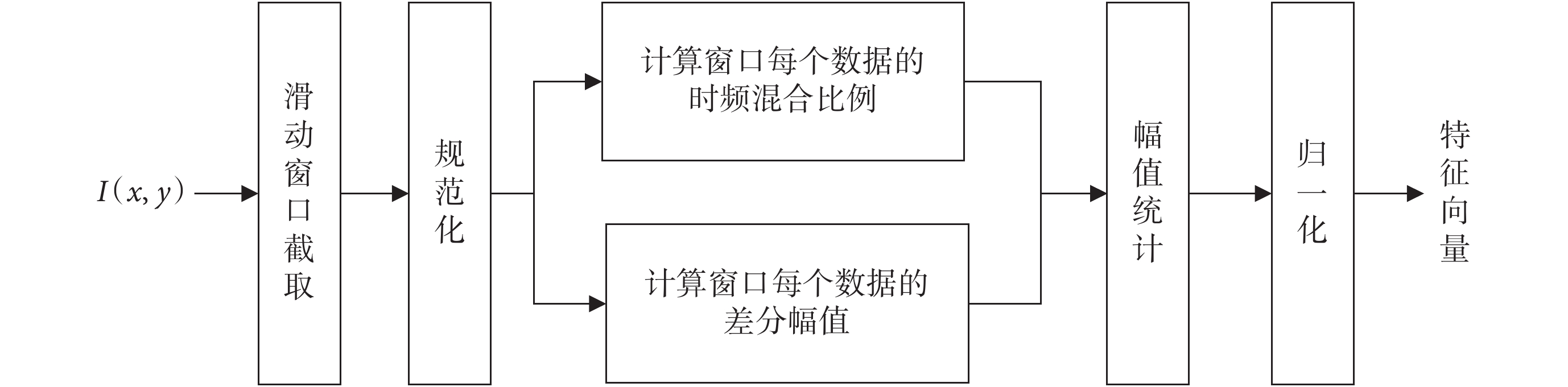 圖3
局部梯度統計流程圖
Figure3.
Local gradient statistical flowchart
圖3
局部梯度統計流程圖
Figure3.
Local gradient statistical flowchart
在圖3 局部梯度統計方法中,首先將時頻混合域能量數據 進行滑窗處理,得到其局部數據,然后對該數據進行規范化處理。處理方法如式(1)所示。
進行滑窗處理,得到其局部數據,然后對該數據進行規范化處理。處理方法如式(1)所示。
 |
在式(1)中, 表示時頻混合域能量數據指數化的值,
表示時頻混合域能量數據指數化的值, 、
、 表示窗口的頂點位置,
表示窗口的頂點位置, ,
, 。其中l和w分別表示窗口的長度與寬度。
。其中l和w分別表示窗口的長度與寬度。 表示頂點為
表示頂點為 的窗口內的局部數據。窗移與窗口大小相同。在局部能量數據內進行差分化梯度統計,其統計步驟如下所示:
的窗口內的局部數據。窗移與窗口大小相同。在局部能量數據內進行差分化梯度統計,其統計步驟如下所示:
步驟 1:計算滑動窗口內每個能量數據點 在
在 軸時間分量和
軸時間分量和 軸頻率分量的差分值,分別為
軸頻率分量的差分值,分別為 、
、 ,其計算方法如式(2)、式(3)所示。為了能夠提取邊界的時頻混合域能量數據點的差分值,本文在時頻混合域能量數據
,其計算方法如式(2)、式(3)所示。為了能夠提取邊界的時頻混合域能量數據點的差分值,本文在時頻混合域能量數據 的外圍補充數值為 0 的能量數據。
的外圍補充數值為 0 的能量數據。
 |
 |
步驟 2:計算滑動窗口內每個能量數據的梯度值大小,其梯度值用周邊能量點差分值的模值大小來表示,梯度值的計算方法如式(4)所示。 表示坐標位置為
表示坐標位置為 的數據點的梯度值。
的數據點的梯度值。
 |
步驟 3:能量數據點的時域分量與頻域分量的比值表示該能量點時域與頻域信息的混合程度,即用角度表示不同程度的時頻混合程度。時頻混合程度的計算方法如式(5)所示。
 |
步驟 4:根據局部能量數據的梯度值和時頻混合程度統計局部窗口內能量的梯度,構建包含時頻信息的局部梯度統計特征。將時頻混合程度進行量化,如式(6)所示。根據能量數據時頻化混合程度對應的量化級別統計能量數據的梯度值。
 |
 |
式(6)、式(7)表示滑窗內局部梯度統計特征的統計方法, 表示量化的單位,
表示量化的單位, 表示量化級別,
表示量化級別, 表示不同量化級別的梯度統計特征。對梯度統計特征進行歸一化,歸一化方法如式(8)所示。
表示不同量化級別的梯度統計特征。對梯度統計特征進行歸一化,歸一化方法如式(8)所示。 為一個極小且不為零的常數,
為一個極小且不為零的常數, 表示 1 范數。
表示 1 范數。 即為一個滑動窗口內歸一化后的梯度統計特征。
即為一個滑動窗口內歸一化后的梯度統計特征。
 '/> '/> |
設實驗中所用語音對應的時頻混合域 的時間長度為
的時間長度為 、頻率長度為
、頻率長度為 ,則時頻混合域對應的窗口數量如式(9)所示。
,則時頻混合域對應的窗口數量如式(9)所示。
 |
通過統計每個窗口內的梯度統計特征可得到時頻混合域能量數據 的梯度統計特征,如式(10)所示。
的梯度統計特征,如式(10)所示。
 '/> '/> |
因此, 的時頻混合域梯度統計特征的維數為
的時頻混合域梯度統計特征的維數為 。
。
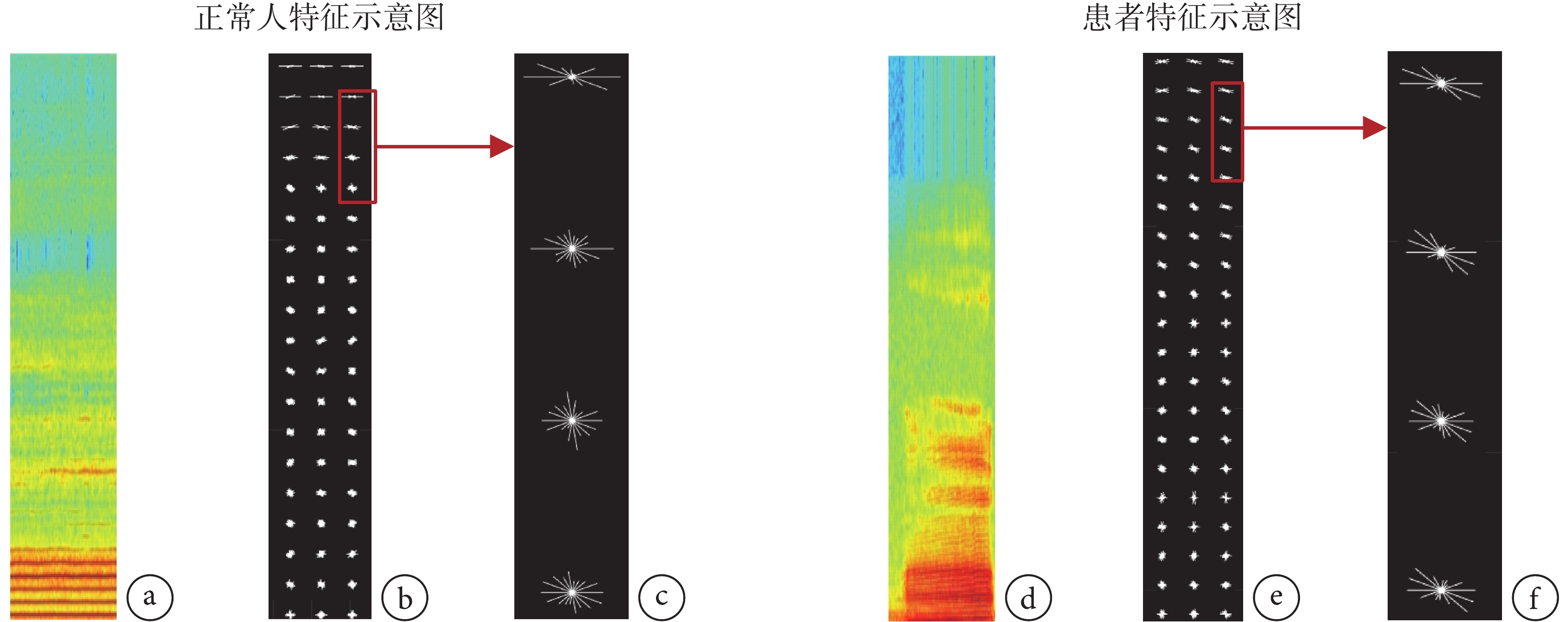
時頻混合域梯度統計特征包含了不同時頻混合程度的梯度統計特征值。圖4 為梯度統計特征示意圖。以一個可視化窗口內的梯度統計特征為例,圖中每條線段的長度表示梯度統計值的大小,線段與水平線的夾角表示時域頻域的混合程度。
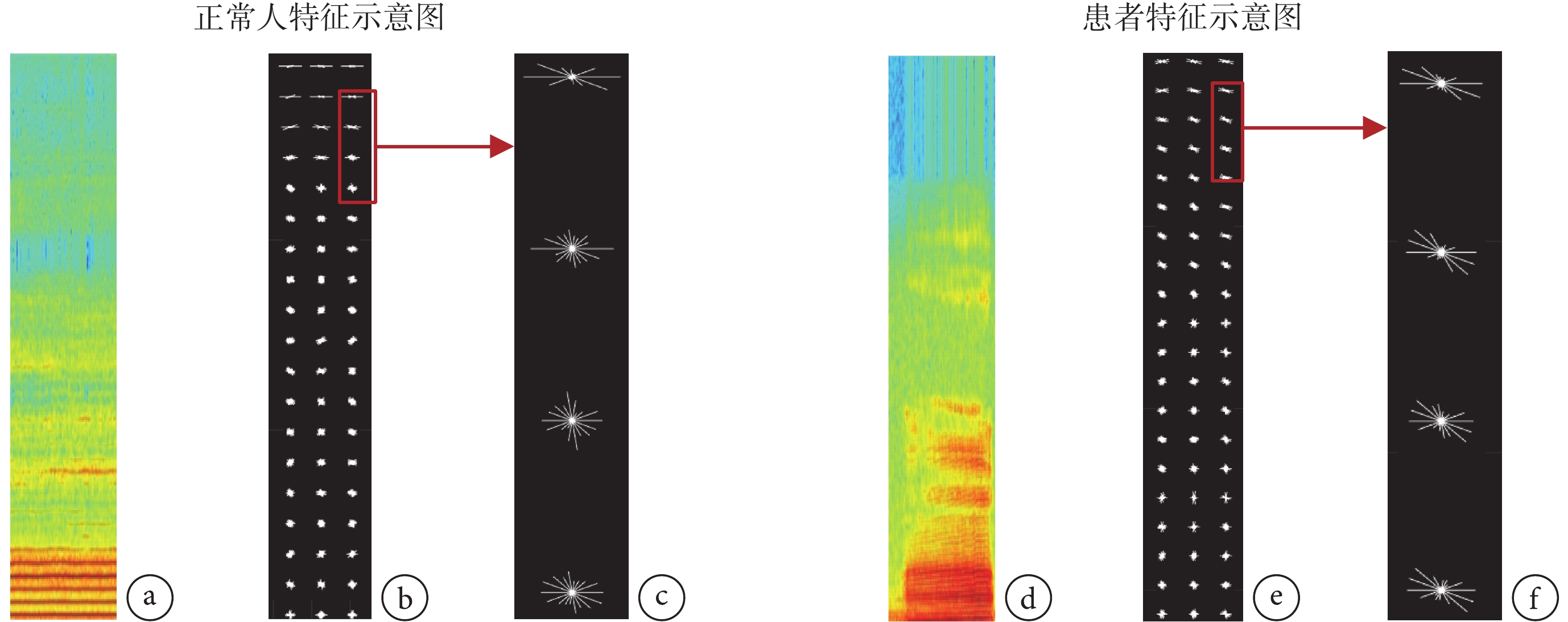 圖4
梯度統計特征示意圖特征
圖4
梯度統計特征示意圖特征
a 和 d. 時頻混合域能量可視化圖;b 和 e. 時頻混合域梯度統計特征圖;c 和 f. 四個可視化窗口內的梯度統計
Figure4. Sketch of gradient statistical featuresa & d. visualization of time-frequency domain energy; b & e. gradient statistical features charts in time-frequency domain; c & f. gradient statistical features charts in time-frequency domain in four visual windows
1.3 評估指標
為了說明分類器的分類性能,本文使用準確率(accuracy)、靈敏性(sensitivity)、特異性(specificity)三個指標對分類器進行評估。準確率的計算公式如式(11)所示。
 |
其中 TP 是真陽性的數量,TN 為真陰性的數量,FP 是假陽性的數量,FN 為假陰性的數量。靈敏性和特異性分別為正確分類的陽性和陰性結果的統計測量值,如式(12)、(13)所示。
 |
 |
2 實驗結果與分析
為了證明本文方法所提特征的可行性與可靠性,分別在國際公開數據集 SPDD 和 CPPDD 數據集上,按照 1.2 所述的方法進行特征提取,并將提取的梯度統計特征輸入 KNN 分類器進行帕金森病分類診斷。在本文的實驗中,1.2.2 中各參數的選取如下:滑動窗口的大小為 ,即
,即 ,
, ,窗移為 8,量化的級別
,窗移為 8,量化的級別  ,
, 。
。
在 KNN 分類器中,本文使用歐氏距離進行度量,K 使用的參數為 1、3、5、7、15。由于在數據集的采集過程中,對每個受試者的語音記錄有多條,為了避免不同樣本之間帶來的誤差,在實驗方法上,采用N折交叉驗證與留一樣本法交叉驗證相結合的方法進行測試。其中N折交叉驗證的思路為將全部數據集樣本劃分為N份,每份互不相交,且每份包含的樣本數量相同,輪流將其中的N-1 份做訓練集,1 份做測試集;留一樣本法交叉驗證的思路為輪流將數據集中的 1 個樣本作為測試集,其余樣本作為訓練集。本文在 SPDD、CPPDD 兩個數據集上分別采用 5 折交叉(N=5)、10 折交叉(N=10)和留一樣本法進行交叉驗證。
由于 5 折交叉驗證和 10 折交叉驗證的結果會因數據集的劃分不同而不同,因此本文實驗采用多次交叉驗證求均值,分別記錄了準確率、靈敏性和特異性的均值及標準差,以確保結果的可信度。同時,由于留一樣本法交叉驗證為無偏估計[19],因此無標準差和最優值。
2.1 本文實驗結果及對比分析
表2 為使用 KNN 分類器采用本文的梯度提取方法對國際公開數據集 SPDD 和 CPPDD 中的原始語音信號提取梯度統計特征的分類結果。5 折交叉驗證和 10 折交叉驗證記錄了各項指標的均值和標準差;留一樣本法交叉驗證記錄了各項指標的結果值。
由表2 可知,在 SPDD 數據集上,使用 KNN 對梯度統計特征分類時,得到的最優分類準確率為 97.27%,所對應的 K 值為 3;在 CPPDD 數據集上,使用 KNN 分類器對梯度統計特征分類時,得到的最優分類準確率為 90.81%,所對應的 K 值為 1。
表3 為利用文獻[15]所提的方法,將 SPDD 數據集中所提供的如表1 所示的傳統特征輸入 KNN 分類器進行分類診斷得到的分類結果。5 折交叉驗證和 10 折交叉驗證記錄了準確率、靈敏性和特異性的均值、標準差和最優值;留一樣本法交叉驗證記錄了各項指標的結果值。
由表3 可知,使用 KNN 分類器對 SPDD 數據集中的傳統特征分類時,得到的準確率的最優值為 83.45%,整體均值的最優值為 59.20%;而在文獻[15]中,采用 KNN 分類器對 SPDD 數據集中所提供的傳統特征分類,得到的準確率的最優值為 82.50%,得到的整體均值的最優值為 50.61%。可見,本文得到的實驗結果與文獻[15]的結果基本相當。
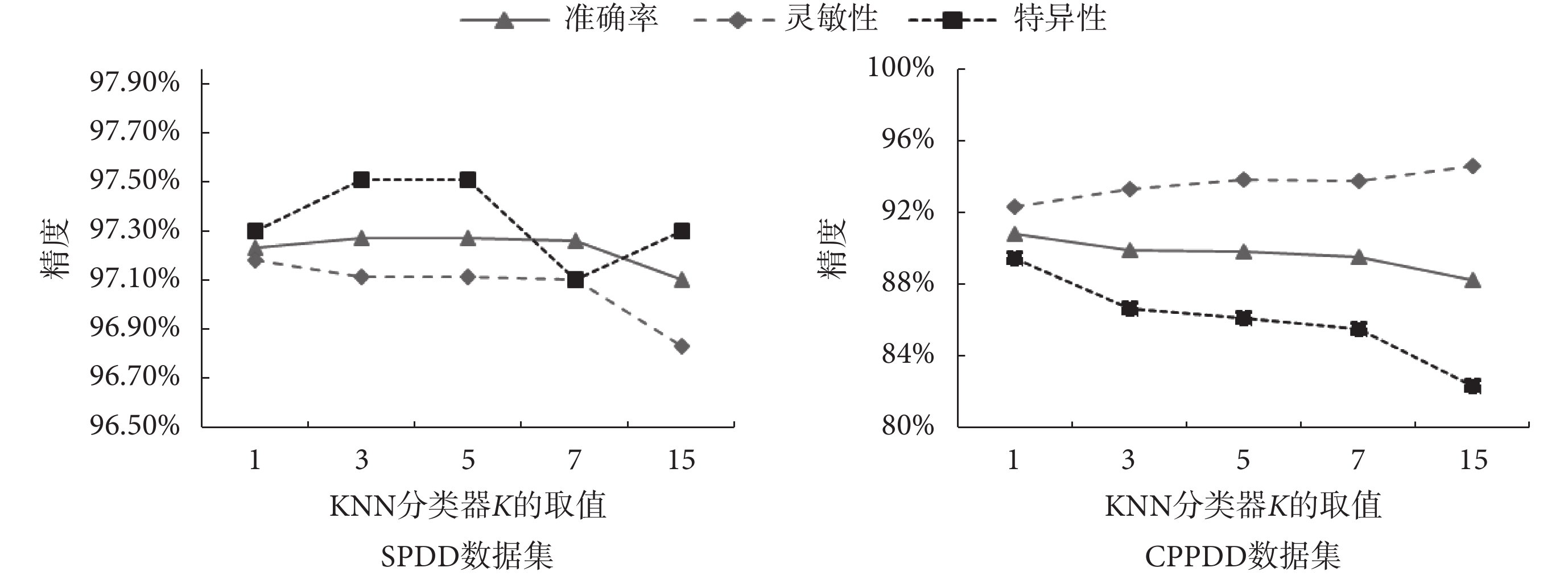
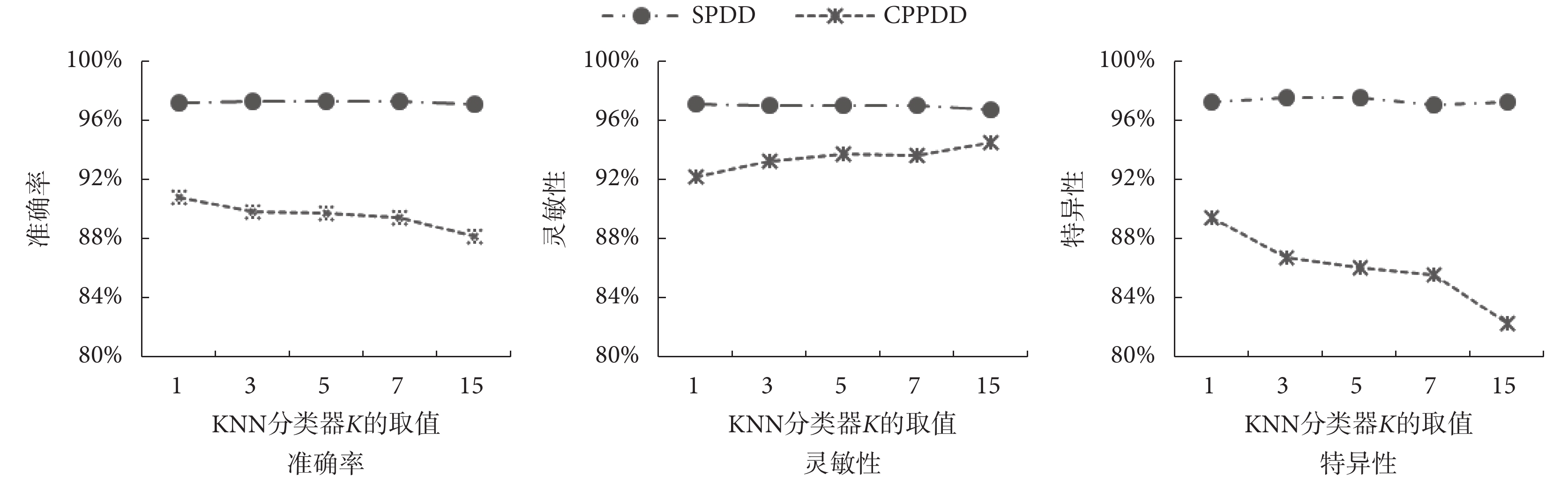
為了更清晰直觀地顯示 KNN 分類器的分類性能,圖5 繪制了表2 中 SPDD 和 CPPDD 數據集下的不同K值的準確率、靈敏性和特異性整體均值分布的折線圖。
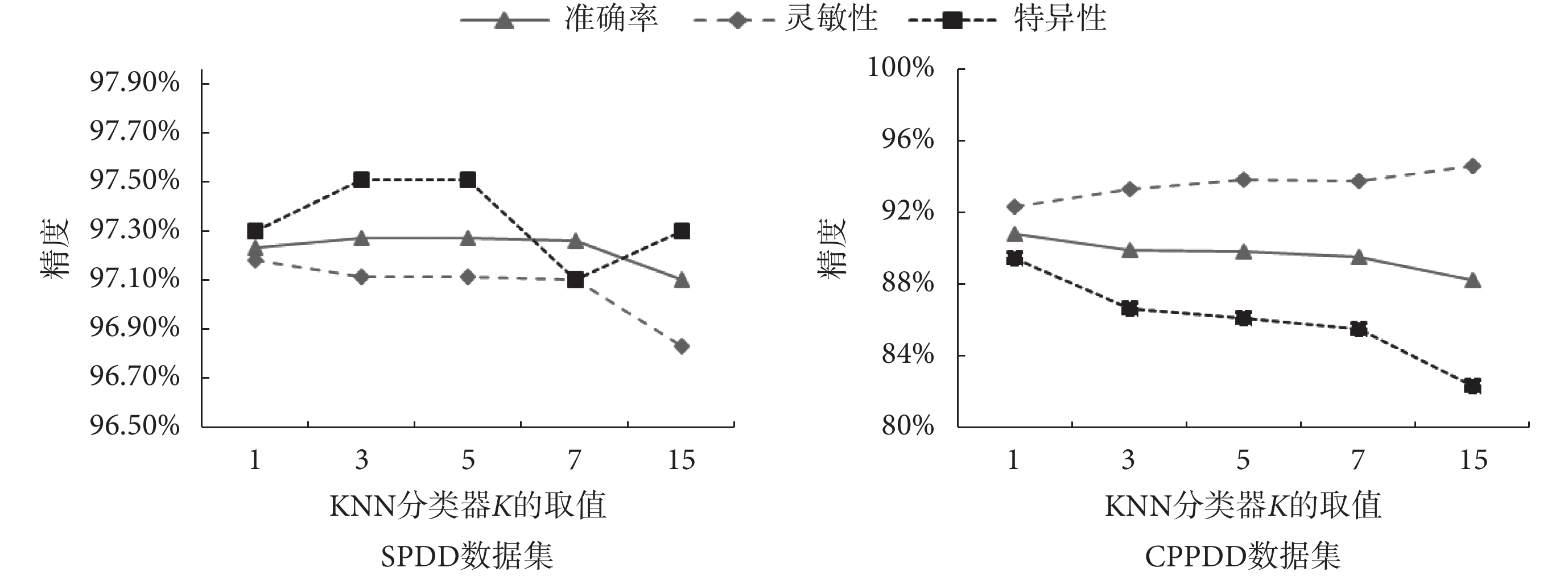 圖5
SPDD 數據集與 CPPDD 數據集基于梯度統計特征的 KNN 分類結果
Figure5.
KNN classification results based on gradient statistical features of SPDD and CPPDD datasets
圖5
SPDD 數據集與 CPPDD 數據集基于梯度統計特征的 KNN 分類結果
Figure5.
KNN classification results based on gradient statistical features of SPDD and CPPDD datasets
由圖5 可知,隨著 K 的增加,在兩個數據集上,分類器的評價指標前期變化幅度較小,當 K=7 時,分類器的評價指標下降幅度增加。說明利用本文所提取的梯度統計特征,有很強的聚類性。
為了比較不同語種發音對分類精度的影響,圖6 繪制了分別基于 SPDD 數據集與 CPPDD 數據集對梯度統計特征進行分類,分類器取不同 K 值時,準確率、靈敏性和特異性整體均值的折線對比圖。
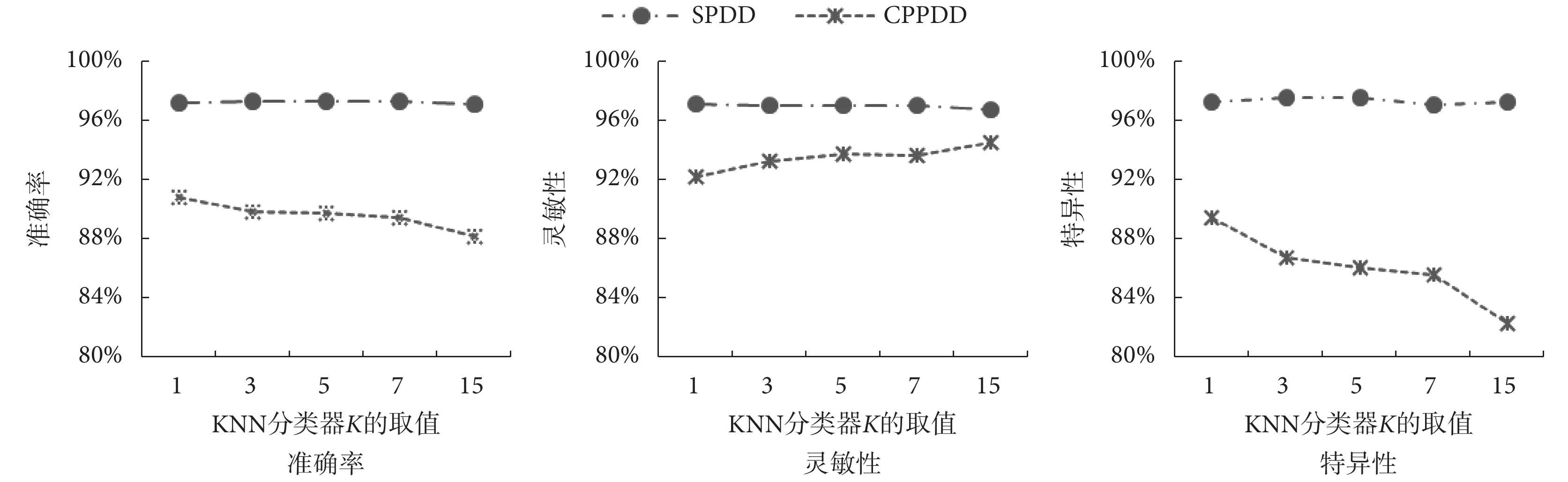 圖6
SPDD 數據集與 CPPDD 數據集梯度統計特征各項分類指標的均值對比圖
Figure6.
Comparison of the mean values of the classification indexes of the gradient features of SPDD and CPDDD dataset
圖6
SPDD 數據集與 CPPDD 數據集梯度統計特征各項分類指標的均值對比圖
Figure6.
Comparison of the mean values of the classification indexes of the gradient features of SPDD and CPDDD dataset
從圖6 中可以直觀地看出,對 SPDD 數據集上的梯度統計特征進行分類,其準確率、靈敏性和特異性的精度均高于 96.00%,而 CPPDD 數據集上的梯度統計特征分類,三個分類指標均低于 96.00%。從相同方法不同數據集的角度分析,對提取的梯度統計特征進行分類時,SPDD 數據集中的分類準確率、特異性和靈敏性均高于 CPPDD 數據集的各項分類指標精度。這是由于漢語發音采用的是口腔前部發音體系,該體系主要特點是利用口腔前部運動發音,漢語發音對肌肉的控制力要求比較強,與 SPDD 數據集中的土耳其語相比,漢語發音的帕金森病患者的梯度統計特征變化的隨機性更強,因此,CPPDD 數據集的分類準確率要低于 SPDD 數據集。
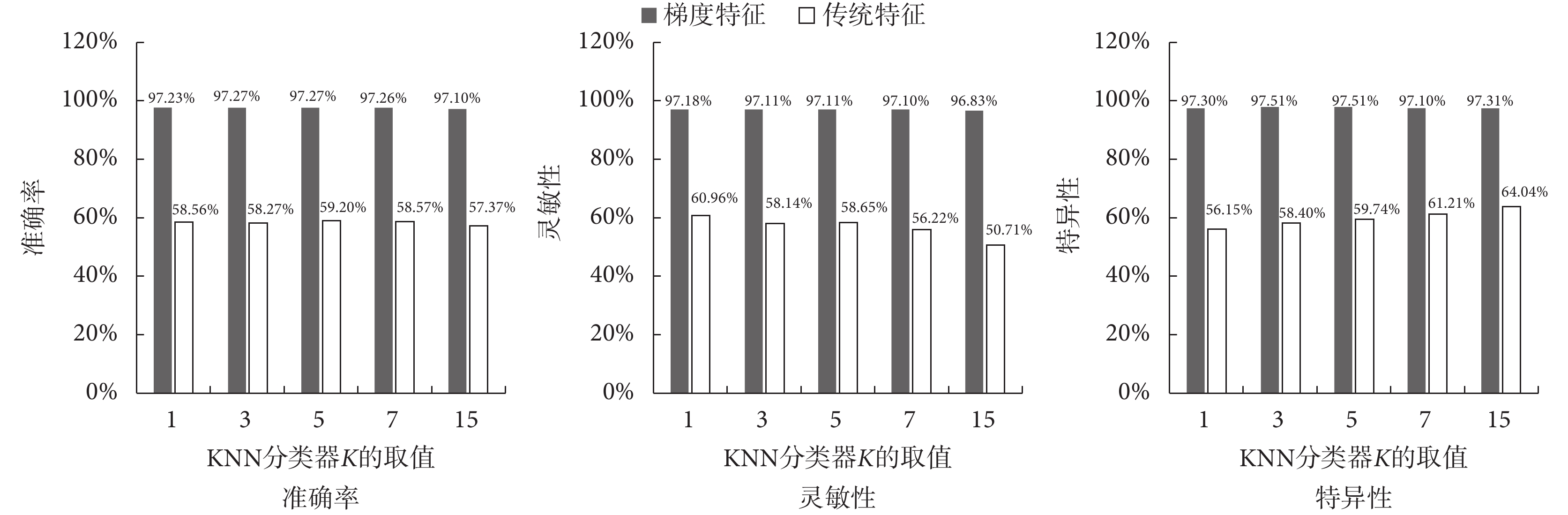
為了比較本文提取的梯度統計特征與傳統的特征的分類結果,圖7 繪制了 SPDD 數據集下,利用 KNN 分類器對梯度統計特征與傳統特征各項分類指標的整體均值對比柱狀圖。
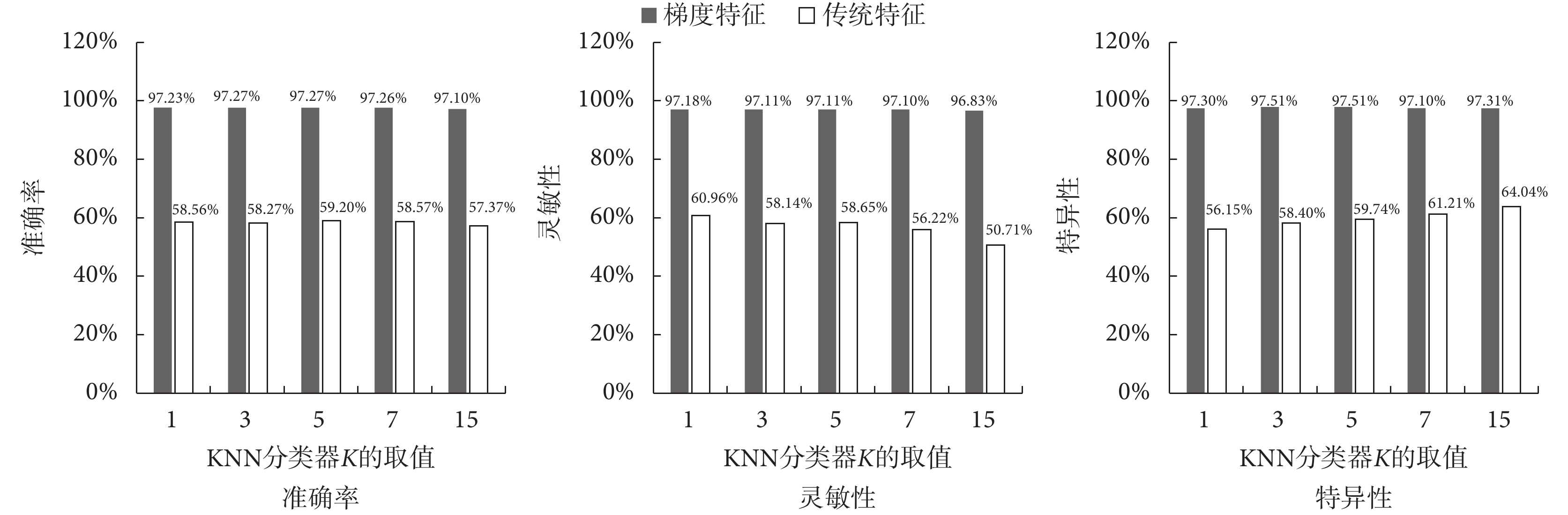 圖7
SPDD 數據集梯度統計特征與傳統特征各項分類指標的均值對比圖
Figure7.
Comparison of the mean values of the classification features of the gradient features and traditional features on SPDD dataset
圖7
SPDD 數據集梯度統計特征與傳統特征各項分類指標的均值對比圖
Figure7.
Comparison of the mean values of the classification features of the gradient features and traditional features on SPDD dataset
圖7 中通過對 SPDD 數據集中提取的梯度統計特征和傳統特征的準確率、靈敏性和特異性三個指標均值進行對比,結果表明在同一數據集、同一分類器中,基于梯度統計特征的各項分類指標精度相對于傳統特征各項分類指標的精度約有 30% 的提高,遠遠高于傳統特征的分類精度。
2.2 與其他方法的性能比較
本文從相同數據集、不同研究方法的角度出發,在 SPDD 數據集上,分別選取了文獻[15]、文獻[19]報告的結果與本文方法進行分類結果對比。其中,文獻[15]中所使用的傳統特征方法是由 SPDD 數據集的收集者 Sakar 教授提出,文獻[19]中所使用的方法是深度學習上最常用的三種深度學習網絡;在 CPPDD 數據集上,分別選取了文獻[20]和文獻[25]與本文方法進行分類結果對比,這兩個文獻是目前基于 CPPDD 數據集研究的最新文獻。
表4 比較了本文方法與上述文獻使用的特征提取方法的分類結果。其中,表4 中本文方法(梯度統計特征方法)中的數值選用的是整體均值的最優值,在 SPDD 中,選取的是K=3(或 5)時的整體均值的最優值;在 CPPDD 中,選取的是K=1 時的整體均值的最優值。根據實驗對比條件相同原則,表4 中的選取的各項指標的數據均為不同方法下的最優值。
表4 中對比兩個數據集上對梯度統計特征與原始傳統特征的分類結果,可知在 SPDD 數據集中,文獻[15]對傳統特征使用 KNN 分類器進行分類,得到的最好結果為準確率 82.50%、靈敏性 85.00%、特異性 80.00%;在 CPPDD 數據集中,文獻[25]同樣對傳統特征使用 KNN 分類器分類,得到的準確率為 74.87%。其結果均低于基于梯度統計特征的分類精度。其原因在于原始的帕金森病語音特征提取方法是通過分別提取時域特征、頻域特征來表現帕金森病患者與正常人的語音差別,而本文提出的語音特征提取方法是綜合提取語音時域、頻域差分值的突變情況,并通過梯度值反映差分值的大小。本文方法的優點體現在以下兩個方面:一方面,正常人由于自身的控制能力較強,其各個域的梯度值變化具有一定的規律性,而帕金森病患者由于控制發音的能力相對減弱,導致其各個域的梯度值變化雜亂而沒有規律;另一方面,由于采集時會存在噪聲,在傳統的語音特征提取方法中噪聲會對其具有一定的影響,而本文提出的梯度統計方法中,通過統計各個方向的能量變化值,各個方向的噪聲能量相互抵消,在一定程度上抑制了噪聲,因此本文提出的特征提取方法相對原始的特征提取方法而言,具有更好的結果。
同樣,表4 中對本文的梯度統計特征方法與深度學習特征方法的分類結果做比較,本文的分類精度高于深度學習方法。分析主要原因為以下兩個方面:一方面,深度學習方法提取語音特征時,通過將語音轉化為聲譜圖,再將聲譜圖經過壓縮和截取后放入神經網絡,圖像的壓縮和截取會損失聲譜圖的部分信息,導致神經網絡在訓練學習時只能學習到語音的部分信息使分類精度降低;另一方面,深度學習網絡在訓練的時候需要大量的數據,而現有的帕金森病語音數據集相對來說數量較少,對神經網絡的適用性較低。
3 結論
本文針對帕金森病語音診斷問題,提出了一種基于時頻混合域局部統計的帕金森病語音障礙分析方法,該方法根據語音時頻化表示方法對語音信號的時域與頻域進行同窗表示,并用梯度統計方法提取帕金森病語音不同時頻混合程度的梯度統計特征,最后用 KNN 分類器對提取的特征進行分類診斷。本文通過局部梯度統計特征反映局部能量點與周圍能量之間的變化關系,并通過統計這種變化關系描述局部能量的變化特點,為帕金森病語音診斷提供了一種新的思路。實驗結果表明,通過本文方法所提取的梯度統計特征的分類精度要遠遠高于傳統語音特征和深度學習特征的分類精度。同時也要看到,特征維度較大是本文方法的不足之處,因此提取對分類精度影響較大的特征是下一步重點研究的內容。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
帕金森病是人類常見的中老年人神經系統變性疾病,其主要癥狀表現為震顫、肌肉僵直和行為緩慢等。目前雖然有輔酶 Q10[1]、5-羥胺再攝取抑制劑[2]和雷沙吉蘭[3]等方法治療帕金森病,但由于病因尚未完全明確,疾病無法完全治愈,所以對帕金森病的早期診斷顯得尤為重要。在帕金森病的早期檢測研究中,研究人員根據帕金森病的癥狀表現提出了一些檢測方法,其中包括步態分析[4]、可穿戴傳感器[5]、腦電信號分析[6]、生理信號分析[7]、語音信號分析[8]等。研究表明,在 200 名帕金森病患者實驗研究中,發現 74.00% 的帕金森病患者受到不同程度的言語障礙影響[9-11],因此,帕金森病的語音信號檢測分析引起了人們極大的關注[10-13]。
目前在帕金森病的語音研究中,主要集中在特征提取、特征選擇和分類三個方面。在特征提取領域,主要包括傳統的時域或頻域特征以及時頻混合域特征。傳統特征提取的方法主要是從語音信號中提取時域和頻域中的各種特征,在此方面有大量的研究者做出了巨大的貢獻。Little 等[14]根據語音的時頻和頻域分別提出了基本頻率變化測量 Jitter 和振幅變化測量 Shimmer,同時也提出了諧波噪聲比(harmonics to noise ratio,HNR)來顯示語音信號的噪聲特征,還研究了語音信號中的幾種非線性測量特征包括動態復雜度和基頻變化測量等。Sakar 等[15]增加了不同的音調特征、周期特征和無聲中斷的特征。提取時域信息或者頻域信息的傳統方法,在帕金森病語音研究中取得了一定的成就,但是由于只針對時域或者頻域提取特征,因而忽略了語音中其他因素帶來的直接影響。近年來,越來越多的學者開始關注時域與頻域的聯合特征描述,促進了以時頻混合分析為代表的變換域特征提取的研究。時頻混合域是描述信號在時間、頻率方面特性時用到的一種二維坐標系。Sakar 等[16]提取了時頻特征梅爾頻率倒譜系數(Mel-frequency cepstral coefficients,MFCC)、基于小波變換的特征聲音折疊特征和可調 Q 因子小波變換特征(tunable Q-factor wavelet transform,TQWT)。Naranjo 等[17-18]增加了不同階數的 MFCC。這些報道顯示越來越多的學者開始關注時頻混合域。此外,有些學者在時頻混合域中用深度學習的方法來解決帕金森病分類問題,以時頻混合域為基礎通過神經網絡進行訓練,該類方法取得了很好的分類效果[19-20]。
近年來針對時頻混合域的研究逐步增多,提示我們在時頻混合域進行帕金森病檢測可能會有新的突破。因此本文提出了一種基于時頻混合域局部統計的帕金森病語音障礙分析方法,該方法基于時頻混合域,從能量突變的角度出發,提取了時頻混合域能量的梯度統計特征,全面提取了帕金森病語音的時頻域能量突變信息,并將提取的梯度統計特征通過 KNN 分類器進行分類,以期實現帕金森病的檢測。
1 材料和方法
1.1 數據集描述
在帕金森病語音分析中,大多數學者的研究數據均源于 Little 和 Sakar 提取的語音特征數據[21-24]。但是根據目前國際上對帕金森病原始語音障礙數據的公開情況,Little 并沒有公開帕金森語音數據集,因此本文采用的數據集為 Sakar 團隊[15]采集的土耳其語帕金森病語音數據集(Sakar’s Parkinson Detection Dataset,SPDD)和本團隊[25]采集的漢語發音的帕金森病語音數據集(Chinese Pronunciation Parkinson Detection Dataset,CPPDD)。
SPDD 數據集包括原始語音數據與提取的傳統特征數據兩部分。該數據集中包括 20 例帕金森病患者(6 例女性,14 例男性)和 20 例健康人(10 例男性,10 例女性),每例受試者分別采集 6 例語音片段(持續元音“a”與持續元音“o”的發音各三遍)。為了確保語音數據的一致性與平穩性,本文將原始語音信號截取 1.5 s 的平穩語音信號作為樣本,并對截取的語音信號作進一步篩選,最終得到符合實驗標準的語音樣本數 411 例。SPDD 數據集中包含原始語音聲學特征 Jitter、Shimmer、HNR 等 26 個傳統特征[15]如表1 所示,共包含傳統特征樣本數 1 040 例。
CPPDD 數據集中包含 36 例帕金森病患者(19 例男性,17 例女性)和 32 例健康人(16 例男性,16 例女性)的原始語音數據。其母語均為漢語,對每個受試者采集漢語發音(“a”和“o”),每個音節發音 3 次,每次持續發音 3 s。同樣截取 1.5 s 的平穩語音,并對信號進一步篩選,得到的 CPPDD 數據集共包含符合實驗標準的語音樣本數為 821 例。
1.2 方法
本文通過對語音數據進行時頻化表示,將語音數據的時域信息、頻域信息、時頻混合域信息進行同窗可視化,把語音的時域信號轉化到時頻混合域,然后通過局部梯度統計方法提取時頻混合域能量數據的時域特征、頻域特征以及時頻混合域特征。最后通過分類器將提取的特征進行訓練,將訓練好的分類器用于帕金森病語音檢測。該算法的整體流程圖如圖1 所示。
圖1
算法整體流程圖
Figure1.
Overall algorithm flowchart
1.2.1 時頻化表示方法
時域分析和頻域分析是語音信號分析的兩種重要方法,但這兩種方法均具有局限性:在進行時域分析時,無法直觀地展示語音信號的頻域特性;在進行頻域分析時,語音信號隨時間的變換關系也無從展現,因此將時域、頻域同時進行展示顯得尤為重要。本文通過使用短時傅里葉變換,將語音的時域信息和頻域信息同時轉換到時頻混合域,從而實現時頻化表示,如圖2 所示。
圖2
健康人與帕金森病患者語音時域、頻域及時頻混合域比較
兩組在時域圖中信號周期、頻域中頻譜分布及時頻混合域圖中能量分布均勻性與分布范圍表現出明顯差異
Figure2. Comparison of speech in time domain, frequency domain and time-frequency domain between healthy and patients with Parkinson’s diseasethere are significant differences in signal period, spectrum distribution and energy distribution uniformity and distribution range in the time domain
由圖2 可知,健康人和帕金森病患者的語音信號在時域波形和頻譜圖上均存在差異。在時域上,二者語音信號波形的周期不同,振幅的相對變化也不同;在頻域上,二者的頻譜在高頻和低頻的分布也存在差異。故本文綜合語音信號的時域和頻域信息,在時頻混合域分析信號的時頻能量譜。從圖2 中可直觀看出,健康人語音信號的能量分布與帕金森病患者相比,能量分布更加均勻,更具規律性;從語音信號主要能量的分布范圍來看,與帕金森病患者相比,健康人語音信號能量分布的范圍更加集中。
1.2.2 局部梯度統計
針對時頻混合域中的能量分布情況,本文采用局部梯度統計方法進行分析。該方法通過滑動窗口選擇局部數據,并對其進行差分化梯度統計處理,從而得到局部數據的統計信息。最后按照滑動窗口的滑動順序對每個窗口的梯度特征進行統計,得到時頻混合域的梯度統計特征。梯度統計特征的具體提取方法如圖3 所示。
圖3
局部梯度統計流程圖
Figure3.
Local gradient statistical flowchart
在圖3 局部梯度統計方法中,首先將時頻混合域能量數據進行滑窗處理,得到其局部數據,然后對該數據進行規范化處理。處理方法如式(1)所示。
|
在式(1)中,表示時頻混合域能量數據指數化的值,、表示窗口的頂點位置,,。其中l和w分別表示窗口的長度與寬度。表示頂點為的窗口內的局部數據。窗移與窗口大小相同。在局部能量數據內進行差分化梯度統計,其統計步驟如下所示:
步驟 1:計算滑動窗口內每個能量數據點在軸時間分量和軸頻率分量的差分值,分別為、,其計算方法如式(2)、式(3)所示。為了能夠提取邊界的時頻混合域能量數據點的差分值,本文在時頻混合域能量數據的外圍補充數值為 0 的能量數據。
|
|
步驟 2:計算滑動窗口內每個能量數據的梯度值大小,其梯度值用周邊能量點差分值的模值大小來表示,梯度值的計算方法如式(4)所示。表示坐標位置為的數據點的梯度值。
|
步驟 3:能量數據點的時域分量與頻域分量的比值表示該能量點時域與頻域信息的混合程度,即用角度表示不同程度的時頻混合程度。時頻混合程度的計算方法如式(5)所示。
|
步驟 4:根據局部能量數據的梯度值和時頻混合程度統計局部窗口內能量的梯度,構建包含時頻信息的局部梯度統計特征。將時頻混合程度進行量化,如式(6)所示。根據能量數據時頻化混合程度對應的量化級別統計能量數據的梯度值。
|
|
式(6)、式(7)表示滑窗內局部梯度統計特征的統計方法,表示量化的單位,表示量化級別,表示不同量化級別的梯度統計特征。對梯度統計特征進行歸一化,歸一化方法如式(8)所示。為一個極小且不為零的常數,表示 1 范數。即為一個滑動窗口內歸一化后的梯度統計特征。
| '/> |
設實驗中所用語音對應的時頻混合域的時間長度為、頻率長度為,則時頻混合域對應的窗口數量如式(9)所示。
|
通過統計每個窗口內的梯度統計特征可得到時頻混合域能量數據的梯度統計特征,如式(10)所示。
| '/> |
因此,的時頻混合域梯度統計特征的維數為。
時頻混合域梯度統計特征包含了不同時頻混合程度的梯度統計特征值。圖4 為梯度統計特征示意圖。以一個可視化窗口內的梯度統計特征為例,圖中每條線段的長度表示梯度統計值的大小,線段與水平線的夾角表示時域頻域的混合程度。
圖4
梯度統計特征示意圖特征
a 和 d. 時頻混合域能量可視化圖;b 和 e. 時頻混合域梯度統計特征圖;c 和 f. 四個可視化窗口內的梯度統計
Figure4. Sketch of gradient statistical featuresa & d. visualization of time-frequency domain energy; b & e. gradient statistical features charts in time-frequency domain; c & f. gradient statistical features charts in time-frequency domain in four visual windows
1.3 評估指標
為了說明分類器的分類性能,本文使用準確率(accuracy)、靈敏性(sensitivity)、特異性(specificity)三個指標對分類器進行評估。準確率的計算公式如式(11)所示。
|
其中 TP 是真陽性的數量,TN 為真陰性的數量,FP 是假陽性的數量,FN 為假陰性的數量。靈敏性和特異性分別為正確分類的陽性和陰性結果的統計測量值,如式(12)、(13)所示。
|
|
2 實驗結果與分析
為了證明本文方法所提特征的可行性與可靠性,分別在國際公開數據集 SPDD 和 CPPDD 數據集上,按照 1.2 所述的方法進行特征提取,并將提取的梯度統計特征輸入 KNN 分類器進行帕金森病分類診斷。在本文的實驗中,1.2.2 中各參數的選取如下:滑動窗口的大小為,即,,窗移為 8,量化的級別 ,。
在 KNN 分類器中,本文使用歐氏距離進行度量,K 使用的參數為 1、3、5、7、15。由于在數據集的采集過程中,對每個受試者的語音記錄有多條,為了避免不同樣本之間帶來的誤差,在實驗方法上,采用N折交叉驗證與留一樣本法交叉驗證相結合的方法進行測試。其中N折交叉驗證的思路為將全部數據集樣本劃分為N份,每份互不相交,且每份包含的樣本數量相同,輪流將其中的N-1 份做訓練集,1 份做測試集;留一樣本法交叉驗證的思路為輪流將數據集中的 1 個樣本作為測試集,其余樣本作為訓練集。本文在 SPDD、CPPDD 兩個數據集上分別采用 5 折交叉(N=5)、10 折交叉(N=10)和留一樣本法進行交叉驗證。
由于 5 折交叉驗證和 10 折交叉驗證的結果會因數據集的劃分不同而不同,因此本文實驗采用多次交叉驗證求均值,分別記錄了準確率、靈敏性和特異性的均值及標準差,以確保結果的可信度。同時,由于留一樣本法交叉驗證為無偏估計[19],因此無標準差和最優值。
2.1 本文實驗結果及對比分析
表2 為使用 KNN 分類器采用本文的梯度提取方法對國際公開數據集 SPDD 和 CPPDD 中的原始語音信號提取梯度統計特征的分類結果。5 折交叉驗證和 10 折交叉驗證記錄了各項指標的均值和標準差;留一樣本法交叉驗證記錄了各項指標的結果值。
由表2 可知,在 SPDD 數據集上,使用 KNN 對梯度統計特征分類時,得到的最優分類準確率為 97.27%,所對應的 K 值為 3;在 CPPDD 數據集上,使用 KNN 分類器對梯度統計特征分類時,得到的最優分類準確率為 90.81%,所對應的 K 值為 1。
表3 為利用文獻[15]所提的方法,將 SPDD 數據集中所提供的如表1 所示的傳統特征輸入 KNN 分類器進行分類診斷得到的分類結果。5 折交叉驗證和 10 折交叉驗證記錄了準確率、靈敏性和特異性的均值、標準差和最優值;留一樣本法交叉驗證記錄了各項指標的結果值。
由表3 可知,使用 KNN 分類器對 SPDD 數據集中的傳統特征分類時,得到的準確率的最優值為 83.45%,整體均值的最優值為 59.20%;而在文獻[15]中,采用 KNN 分類器對 SPDD 數據集中所提供的傳統特征分類,得到的準確率的最優值為 82.50%,得到的整體均值的最優值為 50.61%。可見,本文得到的實驗結果與文獻[15]的結果基本相當。
為了更清晰直觀地顯示 KNN 分類器的分類性能,圖5 繪制了表2 中 SPDD 和 CPPDD 數據集下的不同K值的準確率、靈敏性和特異性整體均值分布的折線圖。
圖5
SPDD 數據集與 CPPDD 數據集基于梯度統計特征的 KNN 分類結果
Figure5.
KNN classification results based on gradient statistical features of SPDD and CPPDD datasets
由圖5 可知,隨著 K 的增加,在兩個數據集上,分類器的評價指標前期變化幅度較小,當 K=7 時,分類器的評價指標下降幅度增加。說明利用本文所提取的梯度統計特征,有很強的聚類性。
為了比較不同語種發音對分類精度的影響,圖6 繪制了分別基于 SPDD 數據集與 CPPDD 數據集對梯度統計特征進行分類,分類器取不同 K 值時,準確率、靈敏性和特異性整體均值的折線對比圖。
圖6
SPDD 數據集與 CPPDD 數據集梯度統計特征各項分類指標的均值對比圖
Figure6.
Comparison of the mean values of the classification indexes of the gradient features of SPDD and CPDDD dataset
從圖6 中可以直觀地看出,對 SPDD 數據集上的梯度統計特征進行分類,其準確率、靈敏性和特異性的精度均高于 96.00%,而 CPPDD 數據集上的梯度統計特征分類,三個分類指標均低于 96.00%。從相同方法不同數據集的角度分析,對提取的梯度統計特征進行分類時,SPDD 數據集中的分類準確率、特異性和靈敏性均高于 CPPDD 數據集的各項分類指標精度。這是由于漢語發音采用的是口腔前部發音體系,該體系主要特點是利用口腔前部運動發音,漢語發音對肌肉的控制力要求比較強,與 SPDD 數據集中的土耳其語相比,漢語發音的帕金森病患者的梯度統計特征變化的隨機性更強,因此,CPPDD 數據集的分類準確率要低于 SPDD 數據集。
為了比較本文提取的梯度統計特征與傳統的特征的分類結果,圖7 繪制了 SPDD 數據集下,利用 KNN 分類器對梯度統計特征與傳統特征各項分類指標的整體均值對比柱狀圖。
圖7
SPDD 數據集梯度統計特征與傳統特征各項分類指標的均值對比圖
Figure7.
Comparison of the mean values of the classification features of the gradient features and traditional features on SPDD dataset
圖7 中通過對 SPDD 數據集中提取的梯度統計特征和傳統特征的準確率、靈敏性和特異性三個指標均值進行對比,結果表明在同一數據集、同一分類器中,基于梯度統計特征的各項分類指標精度相對于傳統特征各項分類指標的精度約有 30% 的提高,遠遠高于傳統特征的分類精度。
2.2 與其他方法的性能比較
本文從相同數據集、不同研究方法的角度出發,在 SPDD 數據集上,分別選取了文獻[15]、文獻[19]報告的結果與本文方法進行分類結果對比。其中,文獻[15]中所使用的傳統特征方法是由 SPDD 數據集的收集者 Sakar 教授提出,文獻[19]中所使用的方法是深度學習上最常用的三種深度學習網絡;在 CPPDD 數據集上,分別選取了文獻[20]和文獻[25]與本文方法進行分類結果對比,這兩個文獻是目前基于 CPPDD 數據集研究的最新文獻。
表4 比較了本文方法與上述文獻使用的特征提取方法的分類結果。其中,表4 中本文方法(梯度統計特征方法)中的數值選用的是整體均值的最優值,在 SPDD 中,選取的是K=3(或 5)時的整體均值的最優值;在 CPPDD 中,選取的是K=1 時的整體均值的最優值。根據實驗對比條件相同原則,表4 中的選取的各項指標的數據均為不同方法下的最優值。
表4 中對比兩個數據集上對梯度統計特征與原始傳統特征的分類結果,可知在 SPDD 數據集中,文獻[15]對傳統特征使用 KNN 分類器進行分類,得到的最好結果為準確率 82.50%、靈敏性 85.00%、特異性 80.00%;在 CPPDD 數據集中,文獻[25]同樣對傳統特征使用 KNN 分類器分類,得到的準確率為 74.87%。其結果均低于基于梯度統計特征的分類精度。其原因在于原始的帕金森病語音特征提取方法是通過分別提取時域特征、頻域特征來表現帕金森病患者與正常人的語音差別,而本文提出的語音特征提取方法是綜合提取語音時域、頻域差分值的突變情況,并通過梯度值反映差分值的大小。本文方法的優點體現在以下兩個方面:一方面,正常人由于自身的控制能力較強,其各個域的梯度值變化具有一定的規律性,而帕金森病患者由于控制發音的能力相對減弱,導致其各個域的梯度值變化雜亂而沒有規律;另一方面,由于采集時會存在噪聲,在傳統的語音特征提取方法中噪聲會對其具有一定的影響,而本文提出的梯度統計方法中,通過統計各個方向的能量變化值,各個方向的噪聲能量相互抵消,在一定程度上抑制了噪聲,因此本文提出的特征提取方法相對原始的特征提取方法而言,具有更好的結果。
同樣,表4 中對本文的梯度統計特征方法與深度學習特征方法的分類結果做比較,本文的分類精度高于深度學習方法。分析主要原因為以下兩個方面:一方面,深度學習方法提取語音特征時,通過將語音轉化為聲譜圖,再將聲譜圖經過壓縮和截取后放入神經網絡,圖像的壓縮和截取會損失聲譜圖的部分信息,導致神經網絡在訓練學習時只能學習到語音的部分信息使分類精度降低;另一方面,深度學習網絡在訓練的時候需要大量的數據,而現有的帕金森病語音數據集相對來說數量較少,對神經網絡的適用性較低。
3 結論
本文針對帕金森病語音診斷問題,提出了一種基于時頻混合域局部統計的帕金森病語音障礙分析方法,該方法根據語音時頻化表示方法對語音信號的時域與頻域進行同窗表示,并用梯度統計方法提取帕金森病語音不同時頻混合程度的梯度統計特征,最后用 KNN 分類器對提取的特征進行分類診斷。本文通過局部梯度統計特征反映局部能量點與周圍能量之間的變化關系,并通過統計這種變化關系描述局部能量的變化特點,為帕金森病語音診斷提供了一種新的思路。實驗結果表明,通過本文方法所提取的梯度統計特征的分類精度要遠遠高于傳統語音特征和深度學習特征的分類精度。同時也要看到,特征維度較大是本文方法的不足之處,因此提取對分類精度影響較大的特征是下一步重點研究的內容。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。