2019 年底暴發的新型冠狀病毒肺炎(COVID-19)疫情是人類史上一次重大突發公共衛生事件。中國醫學工作者在短時間內,經歷了對該未知病毒的逐步認識、證據積累和臨床實踐。截至目前,中國國家衛生健康委員會在數十天內密集發布了七個版本的《新型冠狀病毒感染的肺炎診療方案》(簡稱《診療方案》)。然而,快速準確地比較各版本的異同和掌握新版本的重點對臨床醫護人員和非專業人員來說存在一定困難。本文提出一種基于機器學習的計算機輔助智能分析方法,對文本主題進行無監督學習,自動分析不同版本《診療方案》的異同,主動給醫護人員推送新版本的關注重點,降低《診療方案》解讀的專業難度,提高非專業人員對診療方案的認識水平。實驗證明,與人工解讀方式相比較,本文方法能自動計算文本主題,實現主題的精準匹配,準確率達 100%,并可自動生成關鍵詞和語句級別的解讀報告,實現《診療方案》的計算機自動智能解讀。
引用本文: 蒲曉蓉, 陳柯成, 劉軍池, 文進, 鄭尚維, 李鴻浩. COVID-19 中國診療方案的機器學習智能分析方法. 生物醫學工程學雜志, 2020, 37(3): 365-372. doi: 10.7507/1001-5515.202003045 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
自 2019 年底以來全球相繼暴發新型冠狀病毒肺炎(COVID-19),其感染速度之快、范圍之廣屬歷史罕見。中國醫學工作者在短時間內,經歷了對該未知病毒的逐步認識、證據積累和臨床實踐。截至目前,中國國家衛生健康委員會組織相關專家研究、制定并發布了七個《新型冠狀病毒感染的肺炎診療方案》(以下簡稱《診療方案》)試行版本[1-7]。該系列版本內容差異較大,主要內容涵蓋冠狀病毒病原學特點、臨床特點、病例定義、鑒別診斷、病例的發現與報告、治療、解除隔離和出院標準、轉運原則和醫院感染控制等項目。《診療方案》是全國各醫療機構醫務人員對新型冠狀病毒肺炎患者進行診斷和救治的指導性文件。該系列診療方案的高度專業性和不同版本之間存在的諸多差異,導致臨床醫護人員和非專業人員在短時間內快速、準確解讀并掌握相關信息存在一定困難。因此,有必要研制計算機輔助的智能文本理解方法,自動區分不同版本的差異,并標識新版本的關注重點。
本課題針對國家衛生健康委員會正式發布的《診療方案》七個版本,基于認知計算理論[8],提出一種基于機器學習的隱狄利克雷分配(latent Dirichlet allocation,LDA)模型[9]的無監督聚類方法,自動挖掘不同版本《診療方案》的主題,進行版本間異同分析比較。
1 方法
1.1 總體架構
本文所提出的基于機器學習的計算機輔助智能分析方法的整體架構如圖 1 所示。其中,對文本主題分布的學習使用若干已有診療方案,作為訓練集,用于訓練 LDA 模型。將待分析診療方案作為測試樣本,基于訓練好的 LDA 模型,預測和匹配文本主題。最后,進行文本差異性分析,標注文本之間存在的差異。
 圖1
文本解析的架構
Figure1.
The framework of the text interpretation
圖1
文本解析的架構
Figure1.
The framework of the text interpretation
1.2 診療方案主題生成的 LDA 模型
首先,假設每一版《診療方案》由  個單詞組成,每一個詞可以表示成 one-hot 的向量形式,則一個版本的《診療方案》可以表示為:
個單詞組成,每一個詞可以表示成 one-hot 的向量形式,則一個版本的《診療方案》可以表示為:
 |
其中  是《診療方案》中的第
是《診療方案》中的第  個詞的向量表示。假設已有
個詞的向量表示。假設已有  個版本的《診療方案》,這些文本可以看作是進行主題分析的語料庫 D,可表示為:
個版本的《診療方案》,這些文本可以看作是進行主題分析的語料庫 D,可表示為:
 |
《診療方案》的文本可表示為潛在的  個主題上的隨機混合,每個主題又被單詞的分布所表征。LDA 假設語料庫
個主題上的隨機混合,每個主題又被單詞的分布所表征。LDA 假設語料庫  中的每個文本
中的每個文本  都有以下生成過程:
都有以下生成過程:
(1)對于每一版《診療方案》 ,得到方案
,得到方案  的主題分布參數
的主題分布參數  。
。
(2)對于每個主題  ,得到主題
,得到主題  上詞的多項式分布 φk。
上詞的多項式分布 φk。
(3)對于語料庫 D 中的第 i 個單詞  ,根據多項式分布
,根據多項式分布  得到主題
得到主題  ;根據多項式分布
;根據多項式分布  ,得到詞
,得到詞  。
。
實際應用中,一般使用 Gibbs 抽樣算法對 LDA 模型進行參數估計[10]。其中,潛在的主題個數是一個先驗數據,需要手動設置。主題數的設定一定程度上會影響主題生成的準確性。由于《診療方案》文本具有明顯的主題分段結構,每個段落對應一個相對獨立的主題,所以,《診療方案》的主題生成具備先驗基礎。基于此,本研究將《診療方案》按一級標題劃分為  個主題。
個主題。
1.3 診療方案文本主題匹配
對于一個待分析的《診療方案》,需要基于訓練好的 LDA 模型預測每一段落所屬主題分布的概率,即通過待分析的《診療方案》 及其組成單詞
及其組成單詞  ,推測潛在的主題
,推測潛在的主題  。由于
。由于  和
和  已知,所以可計算出
已知,所以可計算出  。基于 LDA 模型和《診療方案》已知的文本-單詞概率
。基于 LDA 模型和《診療方案》已知的文本-單詞概率  ,可以訓練《診療方案》的文本-主題概率
,可以訓練《診療方案》的文本-主題概率  和主題-單詞概率
和主題-單詞概率  :
:
 |
計算文本中每個詞的生成概率:
 |
再利用最大期望算法(expectation-maximization,EM)[11]估計主題概率 
 ,即待分析《診療方案》
,即待分析《診療方案》 的第
的第  段屬于語料庫 D 中 H 個預設主題內的哪個主題的概率。本文取預測概率最高(即相關度最高的預設主題)的主題
段屬于語料庫 D 中 H 個預設主題內的哪個主題的概率。本文取預測概率最高(即相關度最高的預設主題)的主題  與待分析的《診療方案》
與待分析的《診療方案》 的第
的第  段
段  相匹配。
相匹配。
1.4 差異性挖掘
計算獲得《診療方案》 和與之主題分布最相似的文本
和與之主題分布最相似的文本  以后,就可以對某《診療方案》版本
以后,就可以對某《診療方案》版本  與
與  進行對應主題的差異性挖掘。
進行對應主題的差異性挖掘。
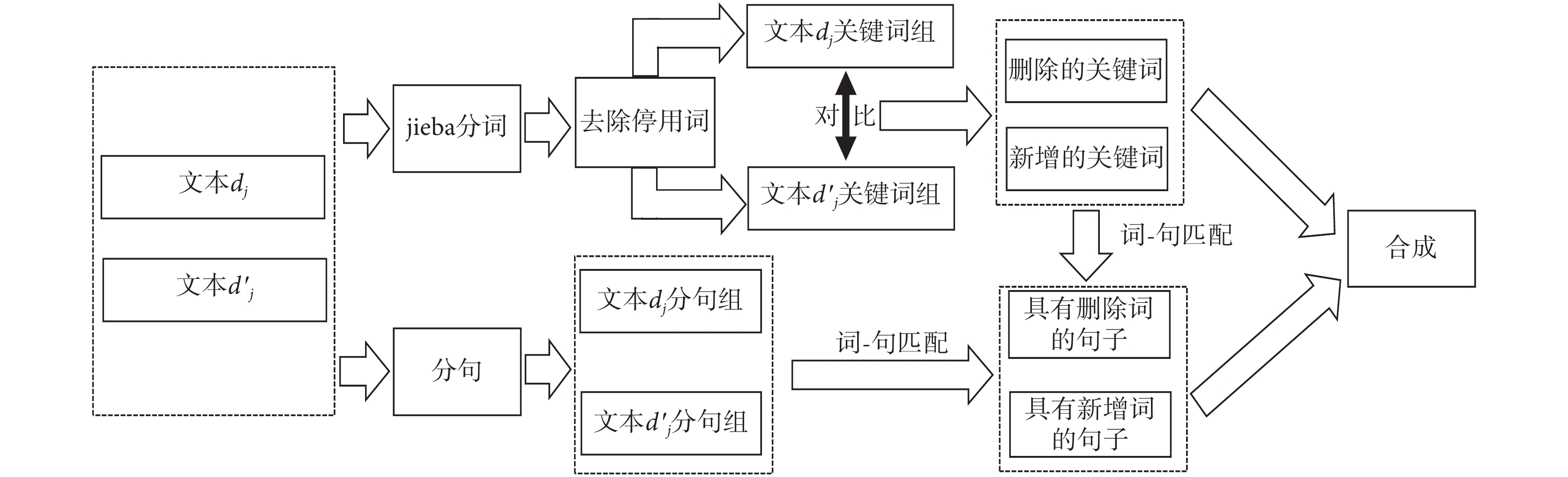
文本差異性挖掘的整體架構如圖 2 所示。基于文本關鍵詞級別的差異性挖掘,可以進一步挖掘語句級別的差異,從而最終獲得關鍵詞和語句一致性的《診療方案》解讀結論。特別指出:
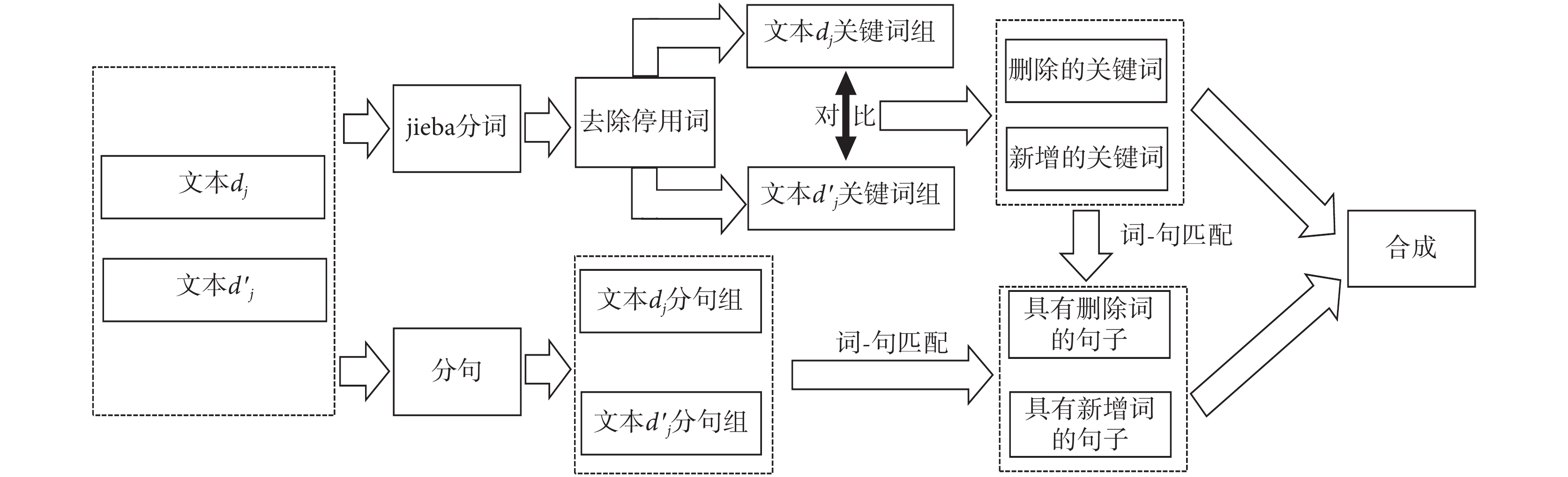 圖2
文本差異性挖掘架構
Figure2.
The framework of the text difference mining
圖2
文本差異性挖掘架構
Figure2.
The framework of the text difference mining
(1)《診療方案》比一般通用文本具有更強的專業性和特殊用途。所以,需要將一些自適應的停用詞添加到停用詞表。
(2)如果某語句存在刪除和新增的關鍵詞,該語句會被重復匹配,所以需要進行去重操作。
(3)對于新增的主題文本,LDA 模型的主題預測結果一般會呈現主題概率的多峰性特點(見后文實驗),可結合此屬性進行差異性挖掘。
2 實驗
2.1 數據集和實驗設計
數據集:本課題使用《診療方案》第一至第六版本作為訓練集,第七版本作為測試集。實驗主要解讀了《診療方案》的第七版和第六版。特別地,本文方法適合其他任何版本間的對比解讀。
實驗設計:訓練集的所有《診療方案》被合并成一個文本。首先需要對訓練集進行預實驗,以消除噪聲干擾(第一版本除外)和超參數設置。LDA 模型中,一級標題主題數設置為 9,訓練迭代數為 800,passes 設置為 40,訓練集的特征數目(單詞類型數量)為 965,文本數目(文本段落)為 43。LDA 模型的主題偏差指數收斂后停止訓練。
2.2 預實驗
預實驗對訓練集的所有《診療方案》進行初步分析,包括《診療方案》的總體分析和各方案的特征分析,預實驗為 LDA 模型的訓練提供基礎。
2.2.1 文本總體相似度分析
為了對不同版本的《診療方案》進行初步分析,本文將余弦相似度作為評價指標來度量《診療方案》之間的差異度,從而初步評估各個方案的變化程度。余弦相似度是基于語義的關鍵字的字向量之間的相似度評價指標,可定義為:
 |
其中, 、
、 表示詞
表示詞  和
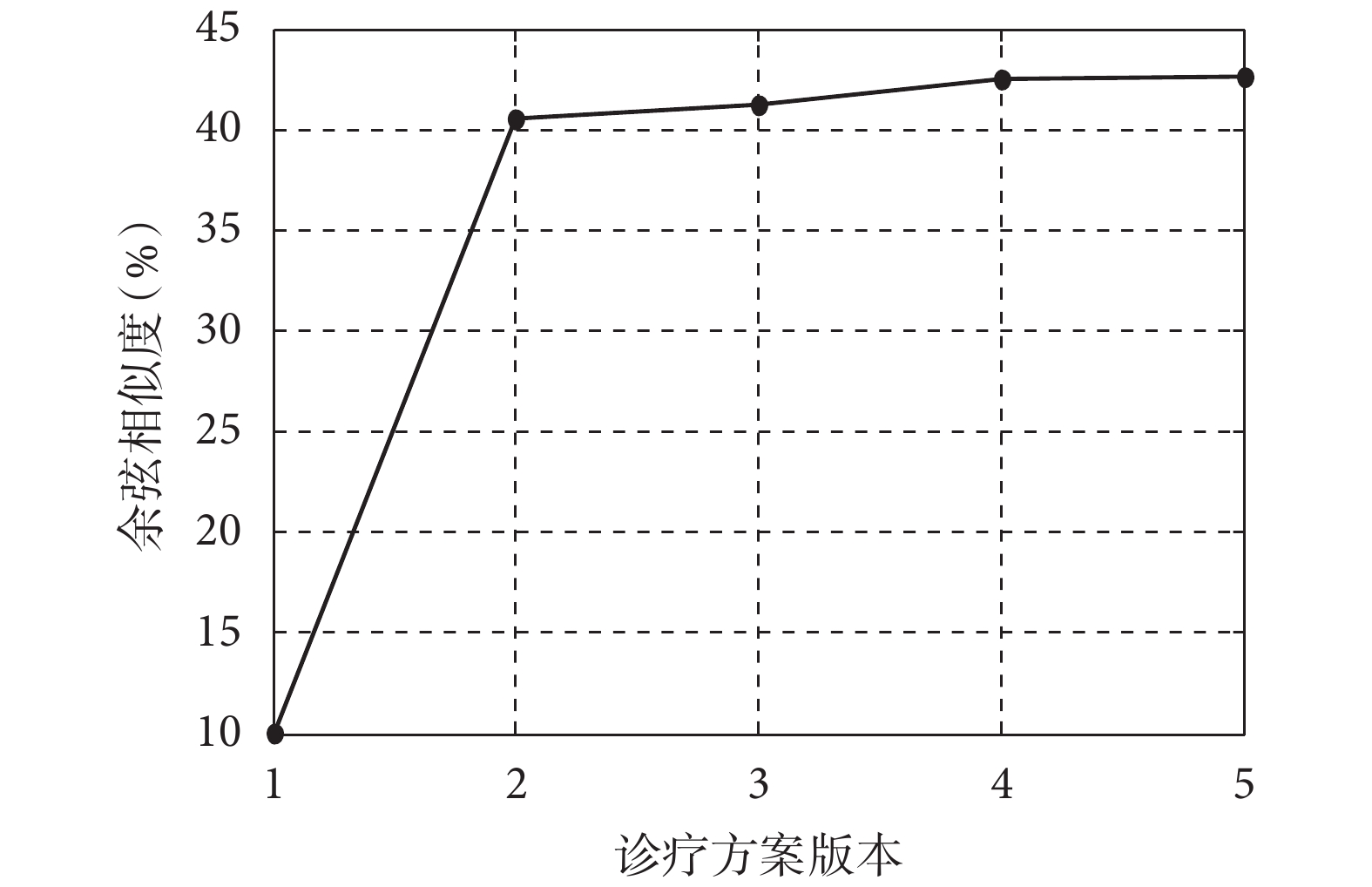
和  的詞向量表征,本文詞向量采用 one-hot 編碼形式。由圖 3 可見:
的詞向量表征,本文詞向量采用 one-hot 編碼形式。由圖 3 可見:
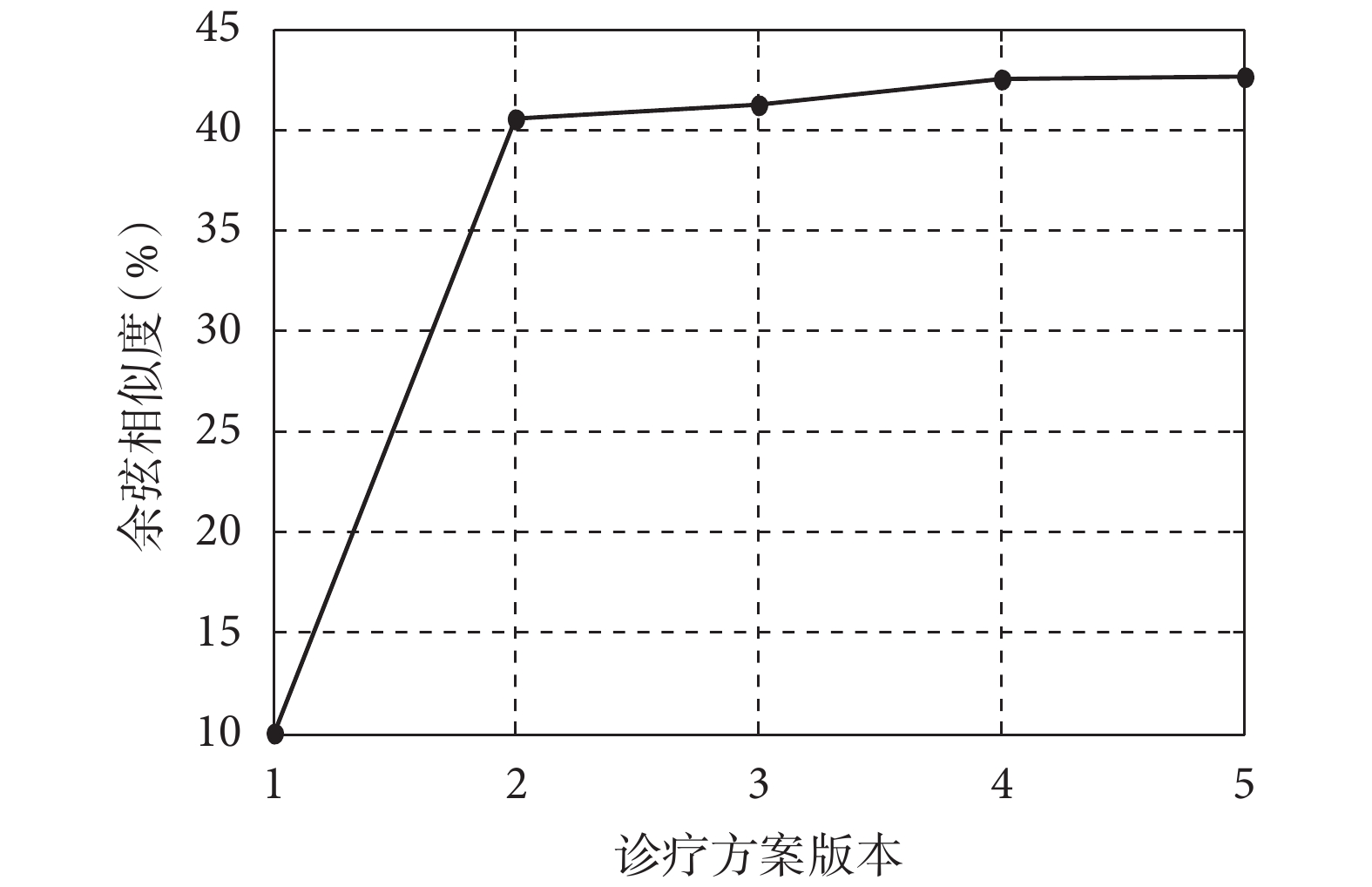 圖3
不同版本《診療方案》的總體相似度變化(第 6 版分 別與第 1 至第 5 版比較)
Figure3.
The variation of the overall similarity between the 6th and 1st to 5th version
圖3
不同版本《診療方案》的總體相似度變化(第 6 版分 別與第 1 至第 5 版比較)
Figure3.
The variation of the overall similarity between the 6th and 1st to 5th version
(1)《診療方案》第一版相比之后各版本,存在顯著的差異。
(2)《診療方案》第二版至第五版的內容總體趨近穩定。特別指出,實驗使用《診療方案》各版本對應的余弦相似度都是與第六版進行比較的結果。
2.2.2 《診療方案》各版本的特征分析
不同版本《診療方案》的總體相似度一定程度上反映了不同方案的相似性,但是無法精準刻畫每個方案的特征。本研究進一步基于關鍵詞的頻率統計對不同版本《診療方案》的總體特征進行刻畫。
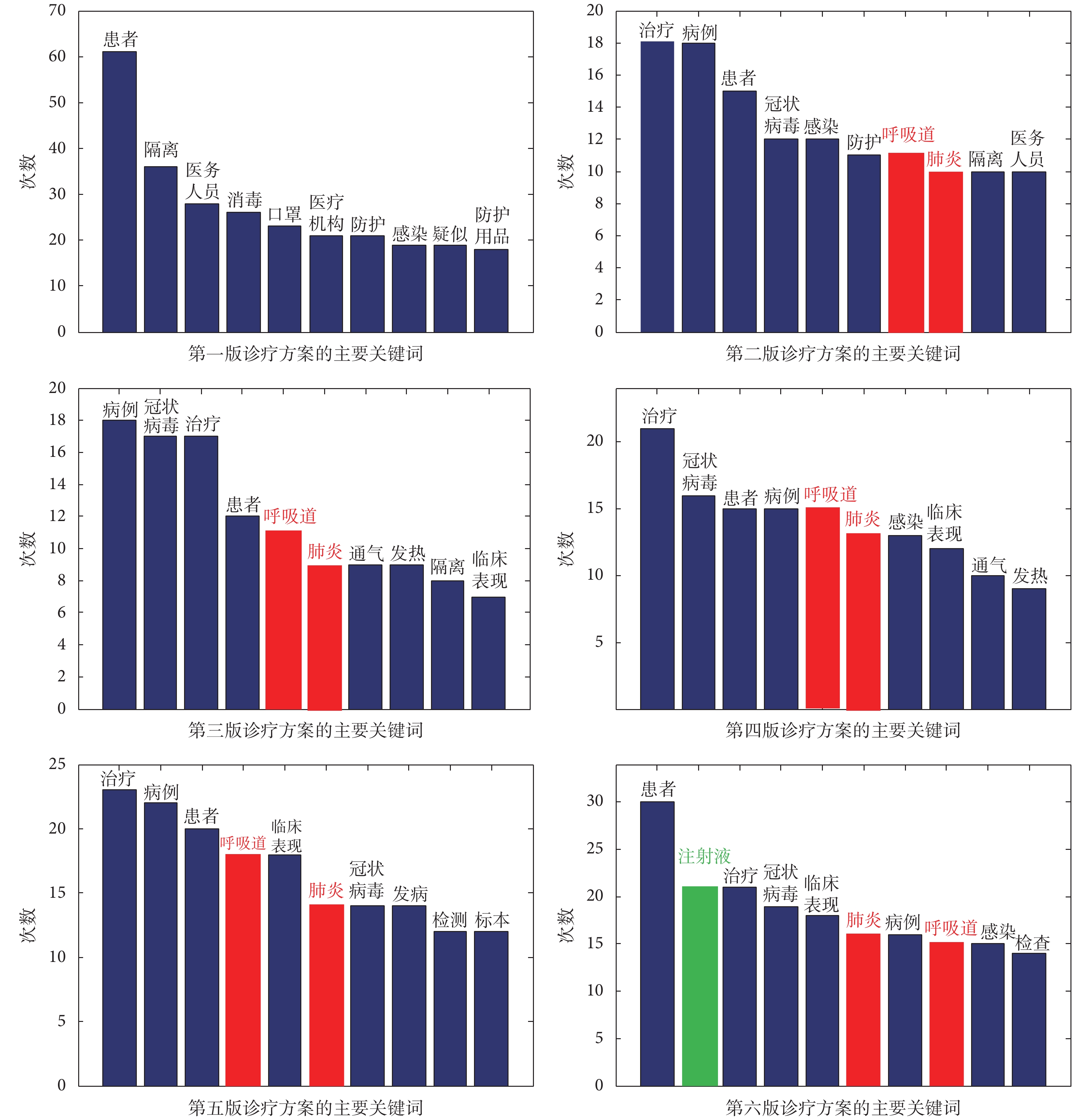
針對《診療方案》進行分詞、去除停用詞等預處理以后,得到各方案主要關鍵詞的統計數據,見圖 4 所示。分析發現:
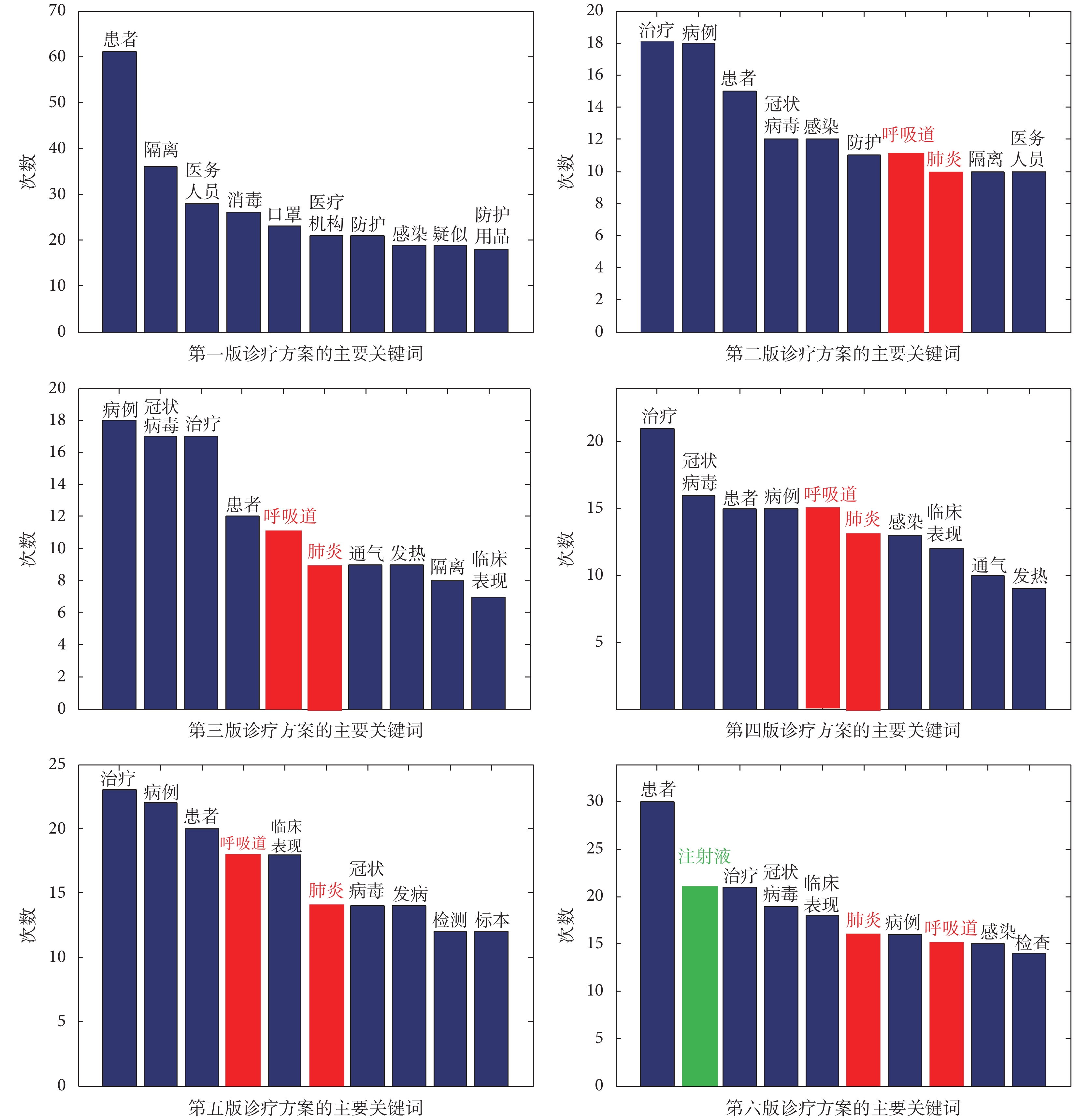 圖4
第一版至第六版診療方案排名前 10 的高頻關鍵詞統計圖
Figure4.
Statistics of the top 10 high-frequency keywords from the 1st to 6th version
圖4
第一版至第六版診療方案排名前 10 的高頻關鍵詞統計圖
Figure4.
Statistics of the top 10 high-frequency keywords from the 1st to 6th version
(1)相比其他診療方案,《診療方案》第一版的主要關鍵詞頻率差異顯著。《診療方案》第一版主要關注疫情的防護,出現的高頻包括“消毒”“口罩”“防護”“防護用品”等關鍵詞。該結論與圖 3 的文本整體相似度的結論一致。
(2)《診療方案》第二版至第六版中,“呼吸道”“肺炎”(圖 4 中紅色標注)兩個關鍵詞出現的頻率逐步提高。由此可以推斷,臨床現象和相關研究確定了新冠病毒主要造成呼吸道和肺部感染。因此,在后續多個迭代的版本中逐步增加了這些關鍵詞的權重。
(3)《診療方案》第六版中的高頻詞與此前各版本相似,但是第二至第五版的高頻詞主要包括“治療”“患者”“病例”“冠狀病毒”等,而第六版出現了關鍵詞“注射液”(見圖 4 中綠色標注)。通過查閱《診療方案》發現“注射液”與中藥相對應,即《診療方案》第六版出現了中藥注射液推薦治療方案。
結合上述兩部分的預實驗可以發現,《診療方案》第一版的總體相似度和主要關鍵詞都與其他版本存在顯著差異。因此,本研究的 LDA 訓練數據不采用第一版,而只使用《診療方案》第二至第六版。
2.3 模型特點
表 1 展示了 LDA 主題生成模型的訓練結果,包括對訓練集中所有診療方案相似的主題進行聚類,并產生主題對應的權重值前 10 的關鍵詞和相應權重。從表 1 可見:
(1)每個主題對應的關鍵詞都與某特定主題具有較強的相關性。觀察表 1 中加粗的關鍵詞可以發現這些關鍵詞與主題的相關性,如“流行病學”主題的“傳播”“途徑”關鍵詞,“治療”主題的“注射液”“療程”關鍵詞,以及“鑒別診斷”主題的“鑒別”“腺病毒”和“合胞病毒”關鍵詞等。
(2)各主題的高權重關鍵詞與該主題的語義之間存在較強的關聯性,如主題“病原學特點”與關鍵詞“病毒”(權重為 0.04)存在較強的語義關聯。
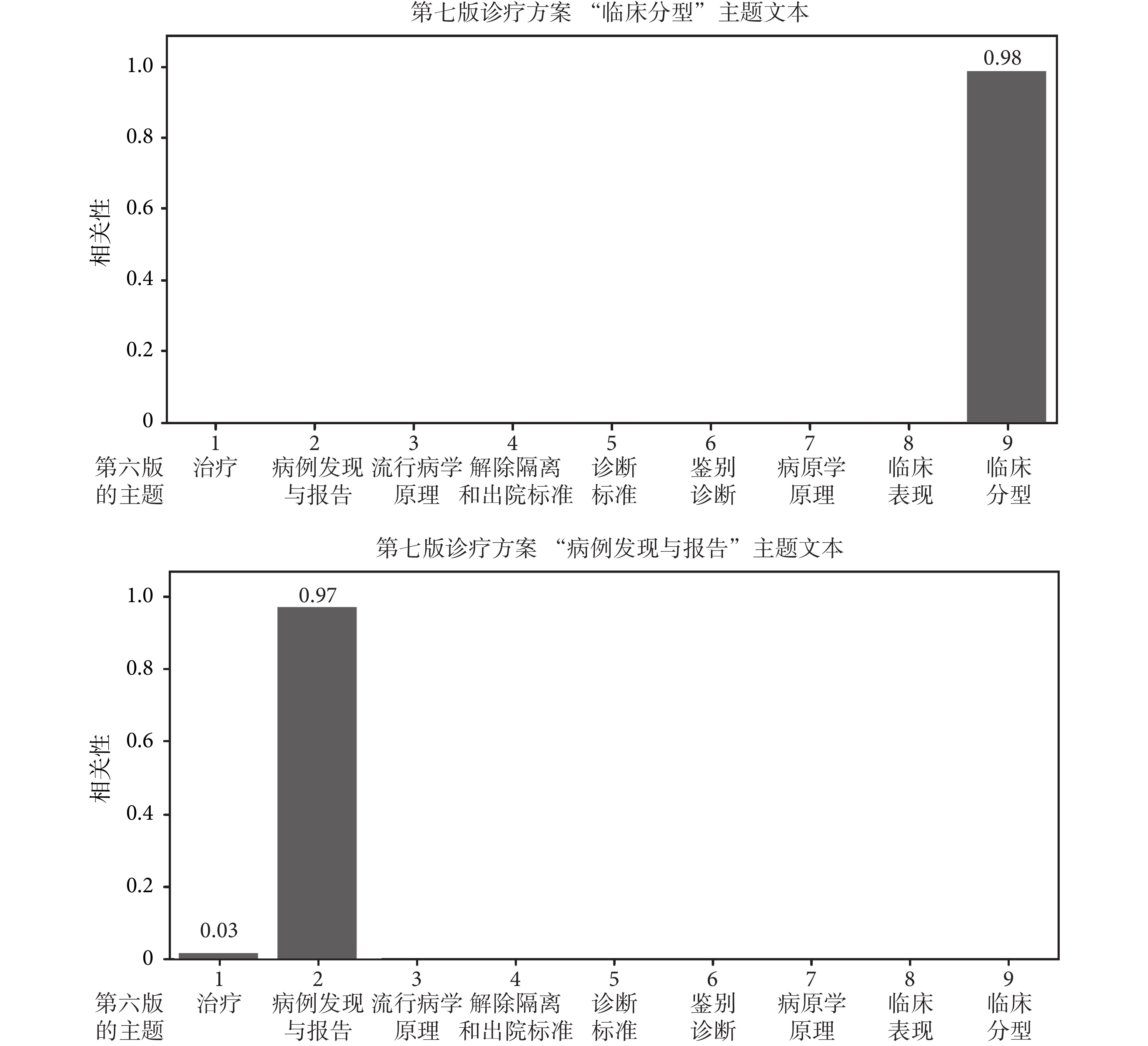
基于《診療方案》第二至第六版訓練 LDA 模型以后,將《診療方案》第七版用于驗證本文所提的整體架構。眾所周知,《診療方案》的版本越高其內容越翔實,解讀難度越大。本實驗選用《診療方案》第六版與第七版進行對比解讀,例如,使用 LDA 模型能將第七版的主題“臨床分型”和“病例發現與報告”,與第六版相應的主題進行精準匹配。
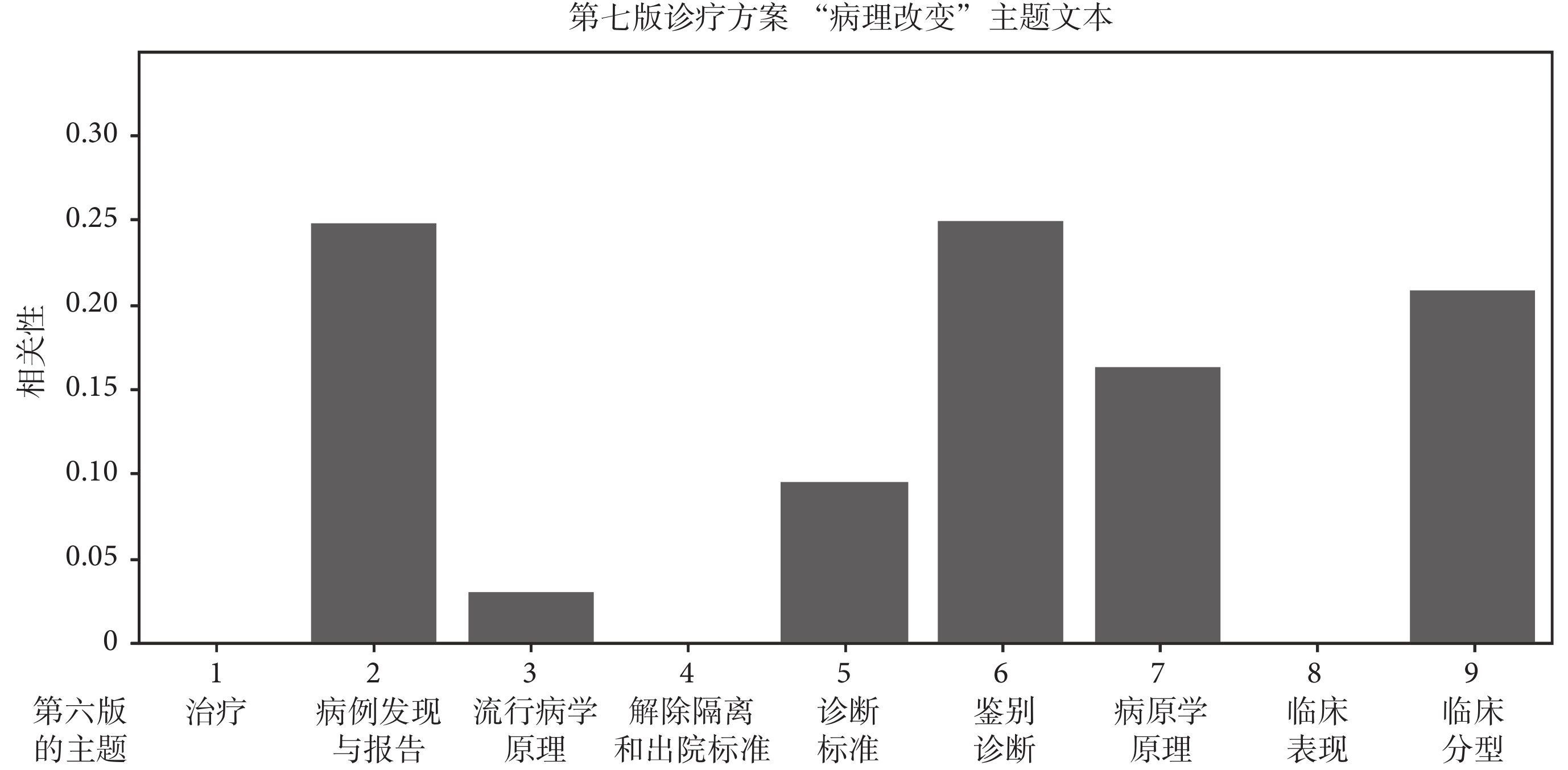
研究顯示,本文方法能精準識別任意兩個《診療方案》之間的不變主題和新增主題。圖 5 示意了不變主題的情況,即第七版《診療方案》中的“臨床分型”和“病例發現與報告”主題精準匹配了第六版的對應主題,兩個對應主題之間的相關性接近 1,即匹配準確度接近 100%。實驗證明,任意兩個《診療方案》版本之間,只要主題保持不變,都能準確匹配。圖 6 示意了版本之間新增主題情況下的實驗結果,即《診療方案》第七版新增了主題“病理改變”,用 LDA 模型進行主題匹配時,發現文本整體主題相關性呈現多峰性特點,且都具有較低的相關性。利用這兩個特點,可以識別出哪個是新增主題。
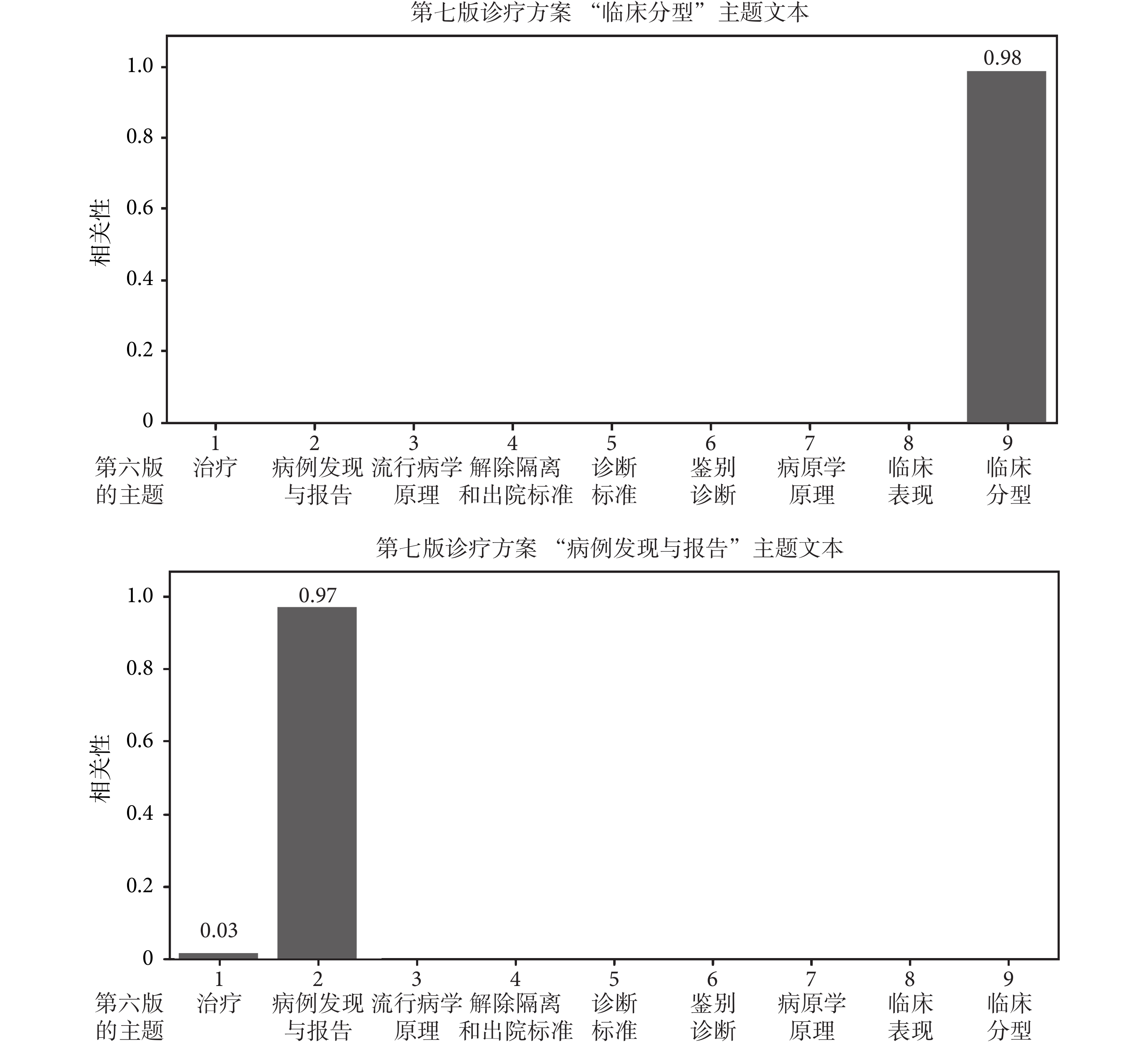 圖5
文本主題預測與匹配
Figure5.
Text topic prediction and match
圖5
文本主題預測與匹配
Figure5.
Text topic prediction and match
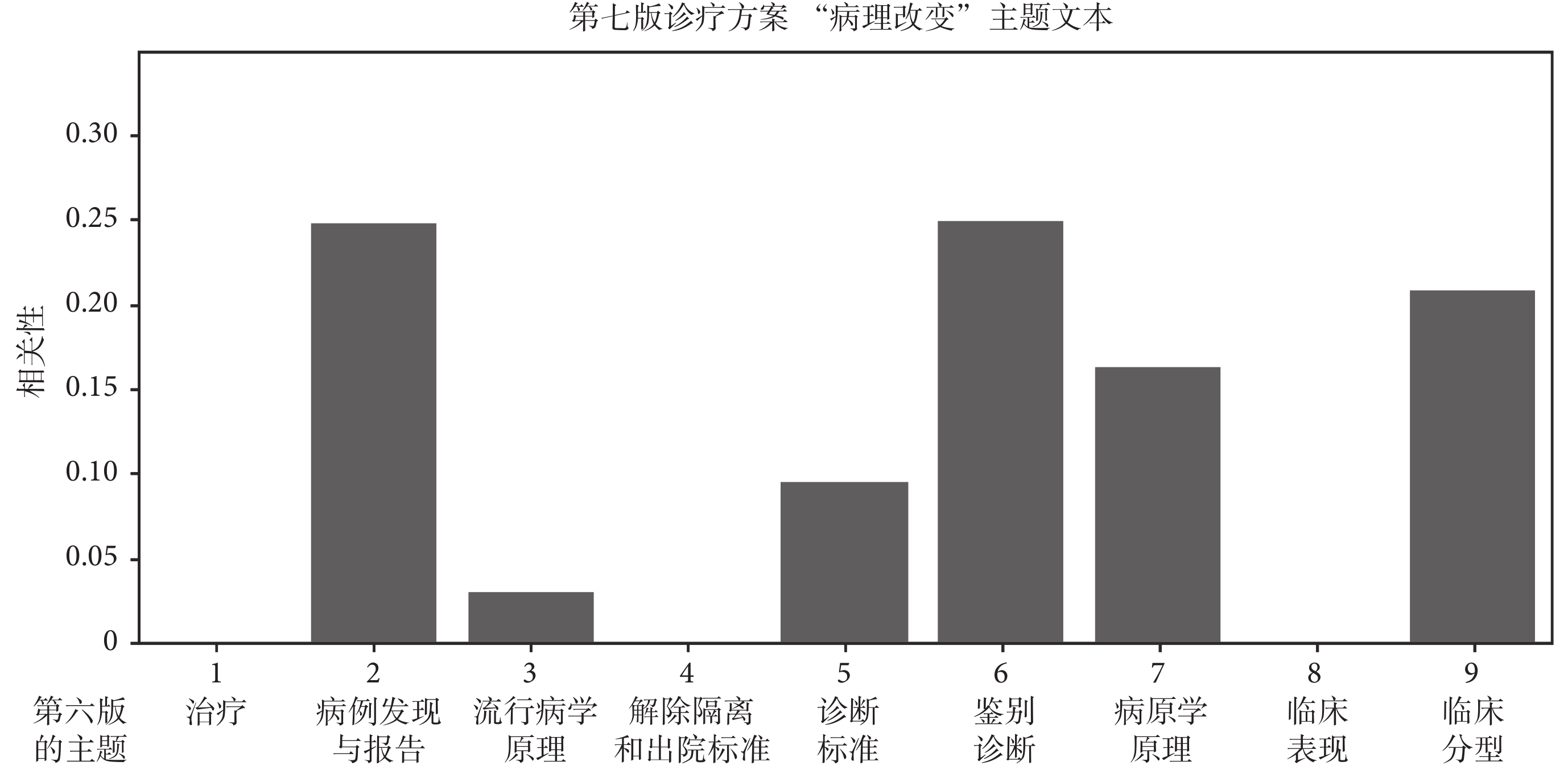 圖6
主題“病理改變”的相關性匹配結果
Figure6.
Correlation match results of the topic "pathological changes"
圖6
主題“病理改變”的相關性匹配結果
Figure6.
Correlation match results of the topic "pathological changes"
2.4 實驗結果
利用本文所提的文本差異性挖掘方法,對比《診療方案》第六版和第七版,分別針對“臨床分型”“病例發現與報告”“治療”“解除隔離和出院標準”四個主題自動生成解讀報告,見表 2 到表 5。
由表 2 到表 5 可見,本文方法能以符合人類認知的角度自動解讀《診療方案》,自動區分不同版本之間的差異性語句和關鍵詞,幫助醫生和非醫學專業人士快速、精準識別不同版本的差異,掌握新版本的重點。
3 討論和結論
本文使用的 LDA 模型是一種基于貝葉斯概率的數學模型,可以廣泛用于文本聚類、主題劃分和預測。LDA 模型包含詞、主題、文本三層結構,可以通過詞向量對文本中的詞進行表征,以進行文本的相似性推測。LDA 是概率隱含語義分析(probabilistic latent semantic analysis,PLSA)模型[12]的一種改進方法,改進了 PLSA 模型參數隨訓練文本增加線性增長、產生的語義可定義性差等不足,為本文進行有效的主題聚類提供了保障。
本文的主要貢獻包括:
(1)提出一種基于 LDA 模型的無監督學習方法,對不同版本《診療方案》的文本主題進行無監督學習。相比基于頻率的匹配方法,如 TF-IDF[13],LDA 模型方法具有語義分析功能和更小計算復雜度的優勢[14],在實踐中往往具有更好的魯棒性。
(2)提出一種輕量級的相同主題文本內容差異化的挖掘方法。用于確定主題的文本,能自動搜索不同文本之間新增或刪減的關鍵詞,以及與之對應的語句。
本文提出的基于機器學習的計算機輔助智能分析方法,對文本主題進行無監督學習,自動計算文本主題,實現主題的精準匹配,準確率達 100%;自動分析不同版本《診療方案》的異同,主動給醫護人員推送新版本的關注重點;自動生成關鍵詞和語句級別的解讀報告,降低《診療方案》解讀的專業難度,提高非專業人員對診療方案的認識水平。本文方法能替代人工解讀,實現《診療方案》的計算機自動智能解讀。
實驗證明,相比于人工解讀,本文方法通過對現有《診療方案》多個版本的主題進行無監督學習,能夠實現目標版本的主題匹配,準確率達 100%。此外,本方法能夠自動生成語句級和關鍵詞級的《診療方案》解讀報告,有助于非專業人士理解醫學專業知識。下一步,我們會將《診療方案》與全國的 COVID-19 確診和治愈出院等數據相結合,循證研究二者之間的相關性和《診療方案》的效果,為醫護技術評價、醫院管理和衛生決策提供參考。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
自 2019 年底以來全球相繼暴發新型冠狀病毒肺炎(COVID-19),其感染速度之快、范圍之廣屬歷史罕見。中國醫學工作者在短時間內,經歷了對該未知病毒的逐步認識、證據積累和臨床實踐。截至目前,中國國家衛生健康委員會組織相關專家研究、制定并發布了七個《新型冠狀病毒感染的肺炎診療方案》(以下簡稱《診療方案》)試行版本[1-7]。該系列版本內容差異較大,主要內容涵蓋冠狀病毒病原學特點、臨床特點、病例定義、鑒別診斷、病例的發現與報告、治療、解除隔離和出院標準、轉運原則和醫院感染控制等項目。《診療方案》是全國各醫療機構醫務人員對新型冠狀病毒肺炎患者進行診斷和救治的指導性文件。該系列診療方案的高度專業性和不同版本之間存在的諸多差異,導致臨床醫護人員和非專業人員在短時間內快速、準確解讀并掌握相關信息存在一定困難。因此,有必要研制計算機輔助的智能文本理解方法,自動區分不同版本的差異,并標識新版本的關注重點。
本課題針對國家衛生健康委員會正式發布的《診療方案》七個版本,基于認知計算理論[8],提出一種基于機器學習的隱狄利克雷分配(latent Dirichlet allocation,LDA)模型[9]的無監督聚類方法,自動挖掘不同版本《診療方案》的主題,進行版本間異同分析比較。
1 方法
1.1 總體架構
本文所提出的基于機器學習的計算機輔助智能分析方法的整體架構如圖 1 所示。其中,對文本主題分布的學習使用若干已有診療方案,作為訓練集,用于訓練 LDA 模型。將待分析診療方案作為測試樣本,基于訓練好的 LDA 模型,預測和匹配文本主題。最后,進行文本差異性分析,標注文本之間存在的差異。
圖1
文本解析的架構
Figure1.
The framework of the text interpretation
1.2 診療方案主題生成的 LDA 模型
首先,假設每一版《診療方案》由 個單詞組成,每一個詞可以表示成 one-hot 的向量形式,則一個版本的《診療方案》可以表示為:
|
其中 是《診療方案》中的第 個詞的向量表示。假設已有 個版本的《診療方案》,這些文本可以看作是進行主題分析的語料庫 D,可表示為:
|
《診療方案》的文本可表示為潛在的 個主題上的隨機混合,每個主題又被單詞的分布所表征。LDA 假設語料庫 中的每個文本 都有以下生成過程:
(1)對于每一版《診療方案》,得到方案 的主題分布參數 。
(2)對于每個主題 ,得到主題 上詞的多項式分布 φk。
(3)對于語料庫 D 中的第 i 個單詞 ,根據多項式分布 得到主題 ;根據多項式分布 ,得到詞 。
實際應用中,一般使用 Gibbs 抽樣算法對 LDA 模型進行參數估計[10]。其中,潛在的主題個數是一個先驗數據,需要手動設置。主題數的設定一定程度上會影響主題生成的準確性。由于《診療方案》文本具有明顯的主題分段結構,每個段落對應一個相對獨立的主題,所以,《診療方案》的主題生成具備先驗基礎。基于此,本研究將《診療方案》按一級標題劃分為 個主題。
1.3 診療方案文本主題匹配
對于一個待分析的《診療方案》,需要基于訓練好的 LDA 模型預測每一段落所屬主題分布的概率,即通過待分析的《診療方案》 及其組成單詞 ,推測潛在的主題 。由于 和 已知,所以可計算出 。基于 LDA 模型和《診療方案》已知的文本-單詞概率 ,可以訓練《診療方案》的文本-主題概率 和主題-單詞概率 :
|
計算文本中每個詞的生成概率:
|
再利用最大期望算法(expectation-maximization,EM)[11]估計主題概率 ,即待分析《診療方案》 的第 段屬于語料庫 D 中 H 個預設主題內的哪個主題的概率。本文取預測概率最高(即相關度最高的預設主題)的主題 與待分析的《診療方案》 的第 段 相匹配。
1.4 差異性挖掘
計算獲得《診療方案》 和與之主題分布最相似的文本 以后,就可以對某《診療方案》版本 與 進行對應主題的差異性挖掘。
文本差異性挖掘的整體架構如圖 2 所示。基于文本關鍵詞級別的差異性挖掘,可以進一步挖掘語句級別的差異,從而最終獲得關鍵詞和語句一致性的《診療方案》解讀結論。特別指出:
圖2
文本差異性挖掘架構
Figure2.
The framework of the text difference mining
(1)《診療方案》比一般通用文本具有更強的專業性和特殊用途。所以,需要將一些自適應的停用詞添加到停用詞表。
(2)如果某語句存在刪除和新增的關鍵詞,該語句會被重復匹配,所以需要進行去重操作。
(3)對于新增的主題文本,LDA 模型的主題預測結果一般會呈現主題概率的多峰性特點(見后文實驗),可結合此屬性進行差異性挖掘。
2 實驗
2.1 數據集和實驗設計
數據集:本課題使用《診療方案》第一至第六版本作為訓練集,第七版本作為測試集。實驗主要解讀了《診療方案》的第七版和第六版。特別地,本文方法適合其他任何版本間的對比解讀。
實驗設計:訓練集的所有《診療方案》被合并成一個文本。首先需要對訓練集進行預實驗,以消除噪聲干擾(第一版本除外)和超參數設置。LDA 模型中,一級標題主題數設置為 9,訓練迭代數為 800,passes 設置為 40,訓練集的特征數目(單詞類型數量)為 965,文本數目(文本段落)為 43。LDA 模型的主題偏差指數收斂后停止訓練。
2.2 預實驗
預實驗對訓練集的所有《診療方案》進行初步分析,包括《診療方案》的總體分析和各方案的特征分析,預實驗為 LDA 模型的訓練提供基礎。
2.2.1 文本總體相似度分析
為了對不同版本的《診療方案》進行初步分析,本文將余弦相似度作為評價指標來度量《診療方案》之間的差異度,從而初步評估各個方案的變化程度。余弦相似度是基于語義的關鍵字的字向量之間的相似度評價指標,可定義為:
|
其中,、 表示詞 和 的詞向量表征,本文詞向量采用 one-hot 編碼形式。由圖 3 可見:
圖3
不同版本《診療方案》的總體相似度變化(第 6 版分 別與第 1 至第 5 版比較)
Figure3.
The variation of the overall similarity between the 6th and 1st to 5th version
(1)《診療方案》第一版相比之后各版本,存在顯著的差異。
(2)《診療方案》第二版至第五版的內容總體趨近穩定。特別指出,實驗使用《診療方案》各版本對應的余弦相似度都是與第六版進行比較的結果。
2.2.2 《診療方案》各版本的特征分析
不同版本《診療方案》的總體相似度一定程度上反映了不同方案的相似性,但是無法精準刻畫每個方案的特征。本研究進一步基于關鍵詞的頻率統計對不同版本《診療方案》的總體特征進行刻畫。
針對《診療方案》進行分詞、去除停用詞等預處理以后,得到各方案主要關鍵詞的統計數據,見圖 4 所示。分析發現:
圖4
第一版至第六版診療方案排名前 10 的高頻關鍵詞統計圖
Figure4.
Statistics of the top 10 high-frequency keywords from the 1st to 6th version
(1)相比其他診療方案,《診療方案》第一版的主要關鍵詞頻率差異顯著。《診療方案》第一版主要關注疫情的防護,出現的高頻包括“消毒”“口罩”“防護”“防護用品”等關鍵詞。該結論與圖 3 的文本整體相似度的結論一致。
(2)《診療方案》第二版至第六版中,“呼吸道”“肺炎”(圖 4 中紅色標注)兩個關鍵詞出現的頻率逐步提高。由此可以推斷,臨床現象和相關研究確定了新冠病毒主要造成呼吸道和肺部感染。因此,在后續多個迭代的版本中逐步增加了這些關鍵詞的權重。
(3)《診療方案》第六版中的高頻詞與此前各版本相似,但是第二至第五版的高頻詞主要包括“治療”“患者”“病例”“冠狀病毒”等,而第六版出現了關鍵詞“注射液”(見圖 4 中綠色標注)。通過查閱《診療方案》發現“注射液”與中藥相對應,即《診療方案》第六版出現了中藥注射液推薦治療方案。
結合上述兩部分的預實驗可以發現,《診療方案》第一版的總體相似度和主要關鍵詞都與其他版本存在顯著差異。因此,本研究的 LDA 訓練數據不采用第一版,而只使用《診療方案》第二至第六版。
2.3 模型特點
表 1 展示了 LDA 主題生成模型的訓練結果,包括對訓練集中所有診療方案相似的主題進行聚類,并產生主題對應的權重值前 10 的關鍵詞和相應權重。從表 1 可見:
(1)每個主題對應的關鍵詞都與某特定主題具有較強的相關性。觀察表 1 中加粗的關鍵詞可以發現這些關鍵詞與主題的相關性,如“流行病學”主題的“傳播”“途徑”關鍵詞,“治療”主題的“注射液”“療程”關鍵詞,以及“鑒別診斷”主題的“鑒別”“腺病毒”和“合胞病毒”關鍵詞等。
(2)各主題的高權重關鍵詞與該主題的語義之間存在較強的關聯性,如主題“病原學特點”與關鍵詞“病毒”(權重為 0.04)存在較強的語義關聯。
基于《診療方案》第二至第六版訓練 LDA 模型以后,將《診療方案》第七版用于驗證本文所提的整體架構。眾所周知,《診療方案》的版本越高其內容越翔實,解讀難度越大。本實驗選用《診療方案》第六版與第七版進行對比解讀,例如,使用 LDA 模型能將第七版的主題“臨床分型”和“病例發現與報告”,與第六版相應的主題進行精準匹配。
研究顯示,本文方法能精準識別任意兩個《診療方案》之間的不變主題和新增主題。圖 5 示意了不變主題的情況,即第七版《診療方案》中的“臨床分型”和“病例發現與報告”主題精準匹配了第六版的對應主題,兩個對應主題之間的相關性接近 1,即匹配準確度接近 100%。實驗證明,任意兩個《診療方案》版本之間,只要主題保持不變,都能準確匹配。圖 6 示意了版本之間新增主題情況下的實驗結果,即《診療方案》第七版新增了主題“病理改變”,用 LDA 模型進行主題匹配時,發現文本整體主題相關性呈現多峰性特點,且都具有較低的相關性。利用這兩個特點,可以識別出哪個是新增主題。
圖5
文本主題預測與匹配
Figure5.
Text topic prediction and match
圖6
主題“病理改變”的相關性匹配結果
Figure6.
Correlation match results of the topic "pathological changes"
2.4 實驗結果
利用本文所提的文本差異性挖掘方法,對比《診療方案》第六版和第七版,分別針對“臨床分型”“病例發現與報告”“治療”“解除隔離和出院標準”四個主題自動生成解讀報告,見表 2 到表 5。
由表 2 到表 5 可見,本文方法能以符合人類認知的角度自動解讀《診療方案》,自動區分不同版本之間的差異性語句和關鍵詞,幫助醫生和非醫學專業人士快速、精準識別不同版本的差異,掌握新版本的重點。
3 討論和結論
本文使用的 LDA 模型是一種基于貝葉斯概率的數學模型,可以廣泛用于文本聚類、主題劃分和預測。LDA 模型包含詞、主題、文本三層結構,可以通過詞向量對文本中的詞進行表征,以進行文本的相似性推測。LDA 是概率隱含語義分析(probabilistic latent semantic analysis,PLSA)模型[12]的一種改進方法,改進了 PLSA 模型參數隨訓練文本增加線性增長、產生的語義可定義性差等不足,為本文進行有效的主題聚類提供了保障。
本文的主要貢獻包括:
(1)提出一種基于 LDA 模型的無監督學習方法,對不同版本《診療方案》的文本主題進行無監督學習。相比基于頻率的匹配方法,如 TF-IDF[13],LDA 模型方法具有語義分析功能和更小計算復雜度的優勢[14],在實踐中往往具有更好的魯棒性。
(2)提出一種輕量級的相同主題文本內容差異化的挖掘方法。用于確定主題的文本,能自動搜索不同文本之間新增或刪減的關鍵詞,以及與之對應的語句。
本文提出的基于機器學習的計算機輔助智能分析方法,對文本主題進行無監督學習,自動計算文本主題,實現主題的精準匹配,準確率達 100%;自動分析不同版本《診療方案》的異同,主動給醫護人員推送新版本的關注重點;自動生成關鍵詞和語句級別的解讀報告,降低《診療方案》解讀的專業難度,提高非專業人員對診療方案的認識水平。本文方法能替代人工解讀,實現《診療方案》的計算機自動智能解讀。
實驗證明,相比于人工解讀,本文方法通過對現有《診療方案》多個版本的主題進行無監督學習,能夠實現目標版本的主題匹配,準確率達 100%。此外,本方法能夠自動生成語句級和關鍵詞級的《診療方案》解讀報告,有助于非專業人士理解醫學專業知識。下一步,我們會將《診療方案》與全國的 COVID-19 確診和治愈出院等數據相結合,循證研究二者之間的相關性和《診療方案》的效果,為醫護技術評價、醫院管理和衛生決策提供參考。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。