在實際應用中的腦-機接口系統要求腦電信號采集通道越少越好,然而當減少到只有一個通道時,其眼電偽跡去除比較困難。因此,本文提出一種基于小波變換和集合經驗模態分解的眼電偽跡去除算法,首先將單通道腦電信號進行小波變換,選擇包含眼電偽跡的小波成分進行集合經驗模態分解,進一步通過設置自相關系數閾值自動去除以眼電偽跡成分為主的固有模態函數,最后重構得到“干凈”的腦電信號。在仿真數據和真實數據上的對比實驗表明,本文所提算法解決了單通道腦電信號中眼電偽跡的自動去除問題,能夠在有效去除眼電偽跡的同時,造成較小的腦電信號失真,同時具有較低的算法復雜度,有助于推動腦-機接口技術走出實驗室,走向商業化應用。
引用本文: 張銳, 劉家俊, 陳明明, 張利朋, 胡玉霞. 基于小波變換—集合經驗模態分解的單通道腦電信號眼電偽跡自動去除研究. 生物醫學工程學雜志, 2021, 38(3): 473-482. doi: 10.7507/1001-5515.202012017 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
腦—機接口(brain-computer interface,BCI)通過解碼包含大腦意識狀態的腦功能信號與外界進行通訊,進而控制外部設備,它是由大腦和外部設備構成的閉環系統[1-2]。腦電(electroencephalogram,EEG)信號是 BCI 系統中常用的腦功能信號,其在采集過程中極易受到眼電(electrooculogram,EOG)偽跡的干擾,從而導致 BCI 解碼準確率下降。由于眼電偽跡與腦電信號的低頻段重疊,導致其去除較為困難[3]。對于多通道的腦電信號中眼電偽跡的去除已有很多研究,而且技術也比較成熟。近年來,隨著 BCI 技術不斷投入實際應用,要求腦電信號采集設備更加便攜易用,通道數目越少越好,特別是在一些特殊應用場景中只需要一個通道[4-5],這就給眼電偽跡去除算法提出了更高的要求。
盲源分離(blind source separation,BSS)是多通道腦電信號中眼電偽跡去除常用的算法,其原理是假設每個導聯的信號都是由特定的源產生的,經過行變化之后得到若干線性無關的行向量,然后將眼電偽跡相關的行向量置零就去除了眼電偽跡的源,最后經過反向行變換就得到了純凈的腦電信號[6]。例如,Mammone 等[7]提出了一種基于小波變換(wavelet transform,WT)和獨立成分分析(independent component analysis,ICA)的眼電偽跡去除算法(WT-ICA),對于多通道腦電信號具有較好的效果,但是這種算法對于單通道腦電信號卻不適用,這是因為 BSS 算法的先驗條件要求通道的數量必須不少于源的數量,而單通道信號卻同時有腦電源和眼電源。于是將單通道腦電信號進行分解以提高其對于 BSS 算法的適用性,是最直接的解決方案。例如,Cheng 等[8]提出了一種基于奇異譜分析(singular spectrum analysis,SSA)和二階盲辨識(second order blind identification,SOBI)的單通道腦電信號中眼電偽跡去除算法(SSA-SOBI),首先對單通道腦電信號進行 SSA 分解得到多維信號,然后再使用 SOBI 算法進行盲源分離,最后通過人工去除眼電偽跡相關源,再重構出沒有眼電偽跡的腦電信號。羅志增等[9]提出了一種基于自適應噪聲完備經驗模態分解(complete ensemble empirical mode decomposition with adaptive noise,CEEMDAN)和 ICA 的單通道腦電信號中眼電偽跡自動去除算法,先通過 CEEMDAN 分解得到多維信號,然后通過 ICA 算法進行盲源分離,最后通過模糊熵閾值自動去除眼電偽跡。雖然這些方法將單通道腦電信號分解為多維數據滿足了 BSS 算法的先驗條件,但是腦電信號和眼電偽跡都是通過一個傳感器采集的,在行變換的過程中可能將腦電信息和眼電信息一起集中到一個或幾個行向量中,也就是沒有將兩種生理電信號完全分離開,導致去除了很多有用的腦電信息。
WT 通過將信號進行特定母波的時間變換和尺度變換,得到若干組對應不同頻段的小波成分(wavelet components,WCs)[10]。由于眼電偽跡以低頻為主,因此單通道腦電信號經過 WT 之后可將眼電偽跡集中到低頻的幾個 WCs 中。經驗模態分解(empirical mode decomposition,EMD)是 Huang 等[11]在 1998 年提出的一種非線性非平穩信號分解技術。通過該方法,任何復雜的數據集都可以分解為數量有限的固有模態函數(intrinsic mode functions,IMFs)。EMD 是數據驅動的、自適應的,可以在不需要任何先驗知識的條件下對信號進行分解,在處理腦電等非平穩信號方面具有突出的性能[12-14]。但是 EMD 算法對噪聲非常敏感,容易造成模態混疊問題。為了解決這個問題,Wu 等[15]又提出了集合 EMD(ensemble EMD,EEMD)算法,并在腦電信號偽跡去除方面進行了成功的應用[16-17]。
為了更有效地去除單通道腦電信號中的眼電偽跡,并且最大限度地保留腦電信號成分,本文提出了一種 WT-EEMD 算法。先使用 WT 將單通道腦電信號分解成若干 WCs,接著將以眼電成分為主的 WCs 進行 EEMD 分解得到若干 IMFs,然后通過自相關系數(autocorrelation coefficient,AutoCC)閾值自動去除包含眼電偽跡的 IMFs,最后重構出“干凈”的腦電信號。WT-EEMD 算法使用兩步分解的策略,克服了盲源分離算法無法將腦電成分和眼電成分有效分離的問題。
1 方法
1.1 小波變換
WT 是繼傅里葉變換之后出現的又一個重要的信號處理理論,解決了時間信息丟失問題,在許多工程領域中都得到了廣泛的應用[18]。WT 在時頻平面上的局部化特征使得其在電生理信號的處理方面占有優勢,早在 1996 年就已用于腦電信號的去噪處理[19]。WT 是將一個信號經過特定母波的時間變換和尺度變換,得到了若干組對應于該尺度下信號與母波相似性的尺度系數(W),如式(1)所示:
 |
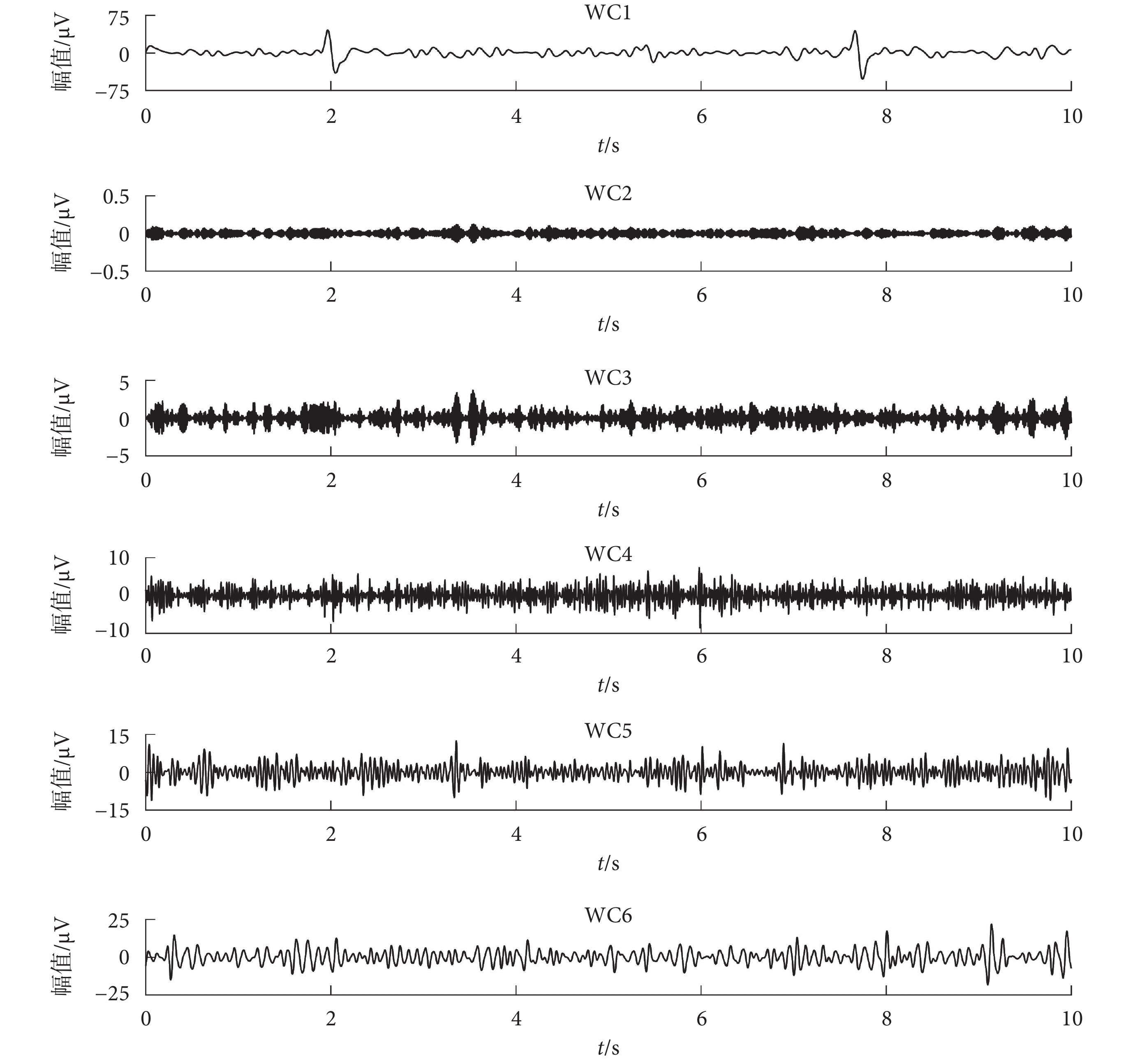
其中,a 為尺度變換,τ 為時間變換。WT 的關鍵參數為母波和分解層數:本文選擇 sym7 母波,進行 5 層小波分解。如圖 1 所示,為仿真數據進行 WT 分解得到的 WCs。
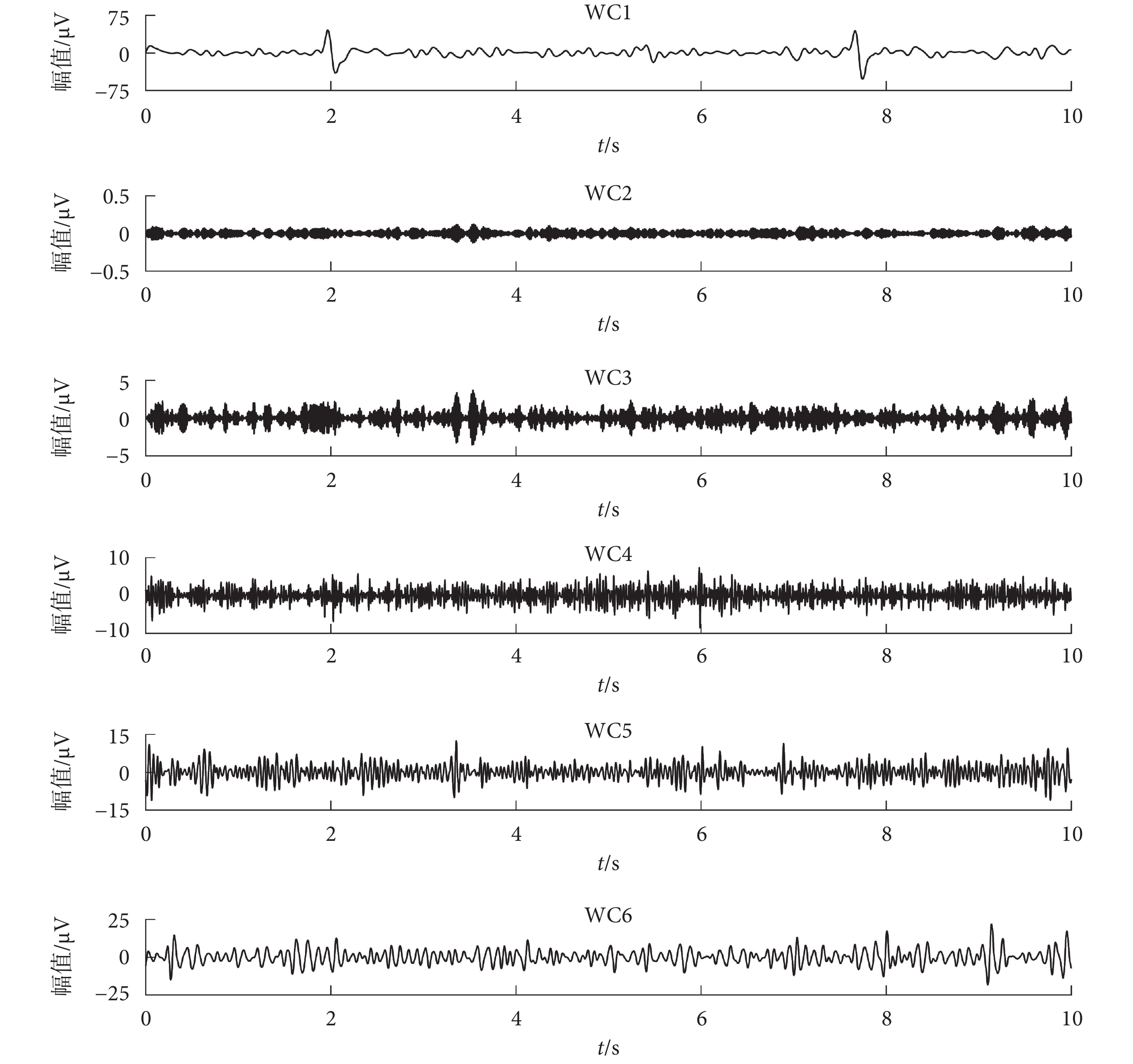 圖1
仿真數據進行 WT 得到的 WCs
Figure1.
The WCs obtained by WT of simulation data
圖1
仿真數據進行 WT 得到的 WCs
Figure1.
The WCs obtained by WT of simulation data
1.2 集合經驗模態分解
EMD 分解是一種數據驅動的算法,能夠根據信號自身的特征自適應地將信號分解為若干具有物理意義的 IMFs 分量[20]。這些 IMFs 需要滿足以下兩個條件:
(1)極值的個數和過零點的個數必須相等或相差一個;
(2)在任何一點上,由局部極大值定義的上包絡線和由局部極小值定義的下包絡線的平均值為零。
其分解過程如下:
(1)求 x(t)所有的極大值和極小值。然后,用三次樣條函數連接所有極大值形成上包絡線 u(t),連接所有極小值形成下包絡線 b(t);
(2)計算上包絡線和下包絡線的平均值 m(t),然后從原始信號 x(t)中減去 m(t)得到新的信號  ,如式(2)~(3)所示:
,如式(2)~(3)所示:
 |
 |
(3)這個剩余的 h(t)被當作新的原始信號,重復上述兩個步驟,直到 h(t)滿足 IMFs 的兩個條件,就得到了第一個經驗模態函數 IMF1;
(4)重復上述步驟,直到殘差信號  是一個單調函數,篩選過程就會停止,這時原始信號 x(t)可以用于表示所有 IMFs 與殘差信號之和,如式(4)所示:
是一個單調函數,篩選過程就會停止,這時原始信號 x(t)可以用于表示所有 IMFs 與殘差信號之和,如式(4)所示:
 |
其中,n 為 IMFs 的個數, 為殘差信號。
為殘差信號。
EEMD 是一種噪聲輔助的方法,通過向原始信號中添加正態分布的、一定幅度的白噪聲,利用白噪聲均勻的頻譜特性,使得原始信號均勻地填充整個時頻空間,在不同尺度上具有連續性,從而降低了模態混疊問題[21]。添加白噪聲的原始信號進行 EMD 分解得到的 IMFs 都由信號和白噪聲組成的。通過多次添加白噪聲并進行分解,再將多次分解得到的 IMFs 進行平均,由于每次添加的白噪聲都是相互獨立的,所以平均之后 IMFs 中的白噪聲都相互抵消了,如式(5)所示:
 |
其中,N 為向 x(t)添加白噪聲的次數,這樣就可以得到第 j 個 IMFs 分量。EEMD 算法相當于進行了 N 次 EMD 分解,并將每一層上的 N 個 IMFs 分量進行平均。
EEMD 算法需要設置兩個參數,添加的白噪聲的幅度和次數。白噪聲的幅度用標準差來衡量,根據 Wu 等[15]的建議,本文中添加白噪聲的標準差為 0.2,添加白噪聲的次數設為 20。如式(6)所示,為分解得到的 IMFs 個數計算方法:
 |
其中,fix(x)表示取整,n 為采樣點數。本文所使用仿真數據的采樣點數為 5 120(數據長度為 10 s,采樣率為 512 Hz),因此根據式(6)計算可得 IMFs 的個數為 12,再加上殘差信號,共得到了 13 個分量。
1.3 小波變換-集合經驗模態分解
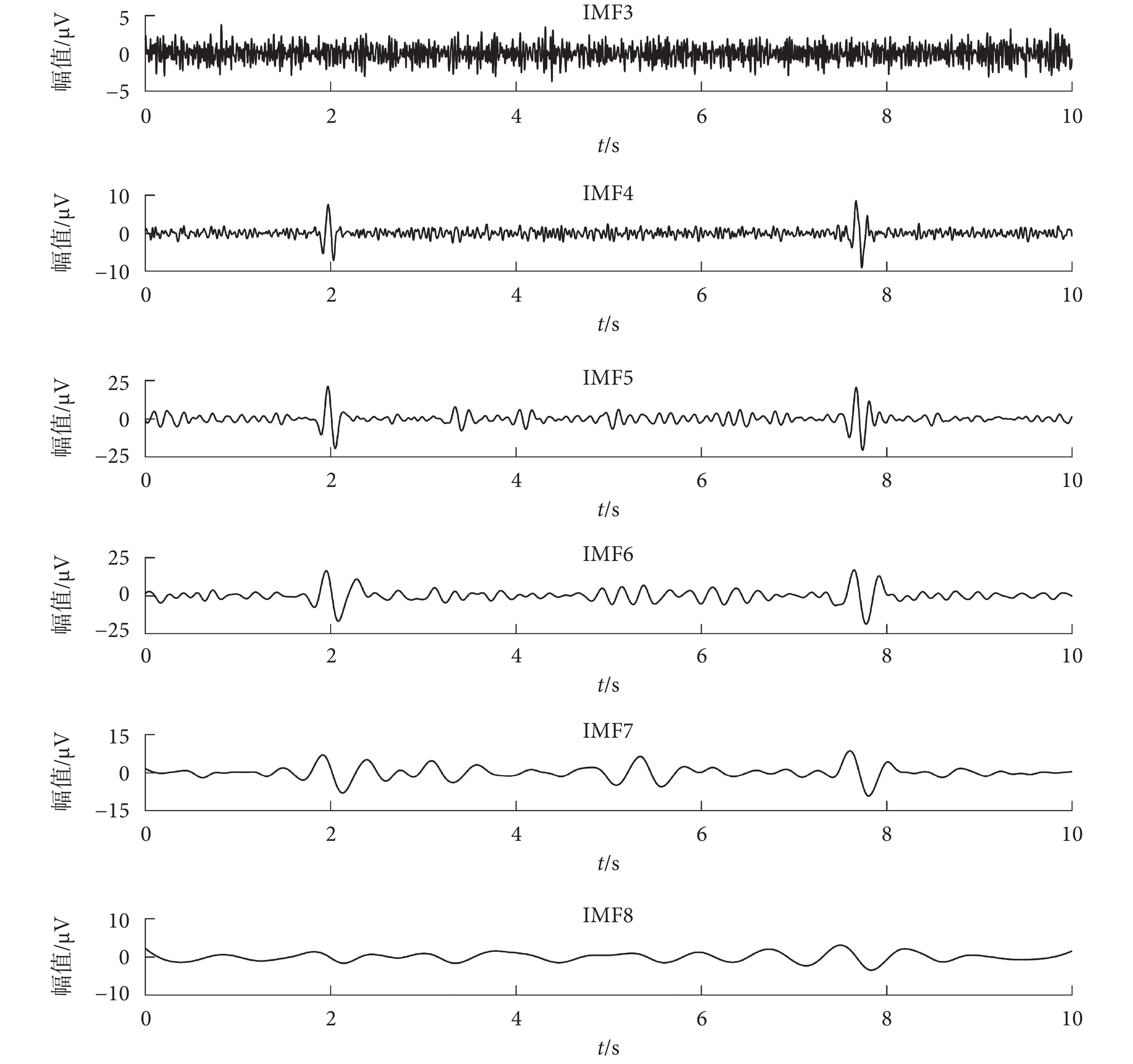
對于記錄得到的單通道腦電信號,先進行 WT 分解得到 6 個 WCs。由于眼電偽跡與腦電信號的低頻段在時域和頻域重疊,如果直接去除眼電偽跡相關的 WCs,會造成腦電信號的失真。所以本文選擇第 1 個和第 6 個 WCs,即低頻成分進行 EEMD 分解,可以更大程度地將腦電信號和眼電偽跡分離開。如圖 2 所示,為 WC1 進行 EEMD 分解得到的部分 IMFs,可以看出 IMF4、IMF5、IMF6、IMF7 中有眼電波動。
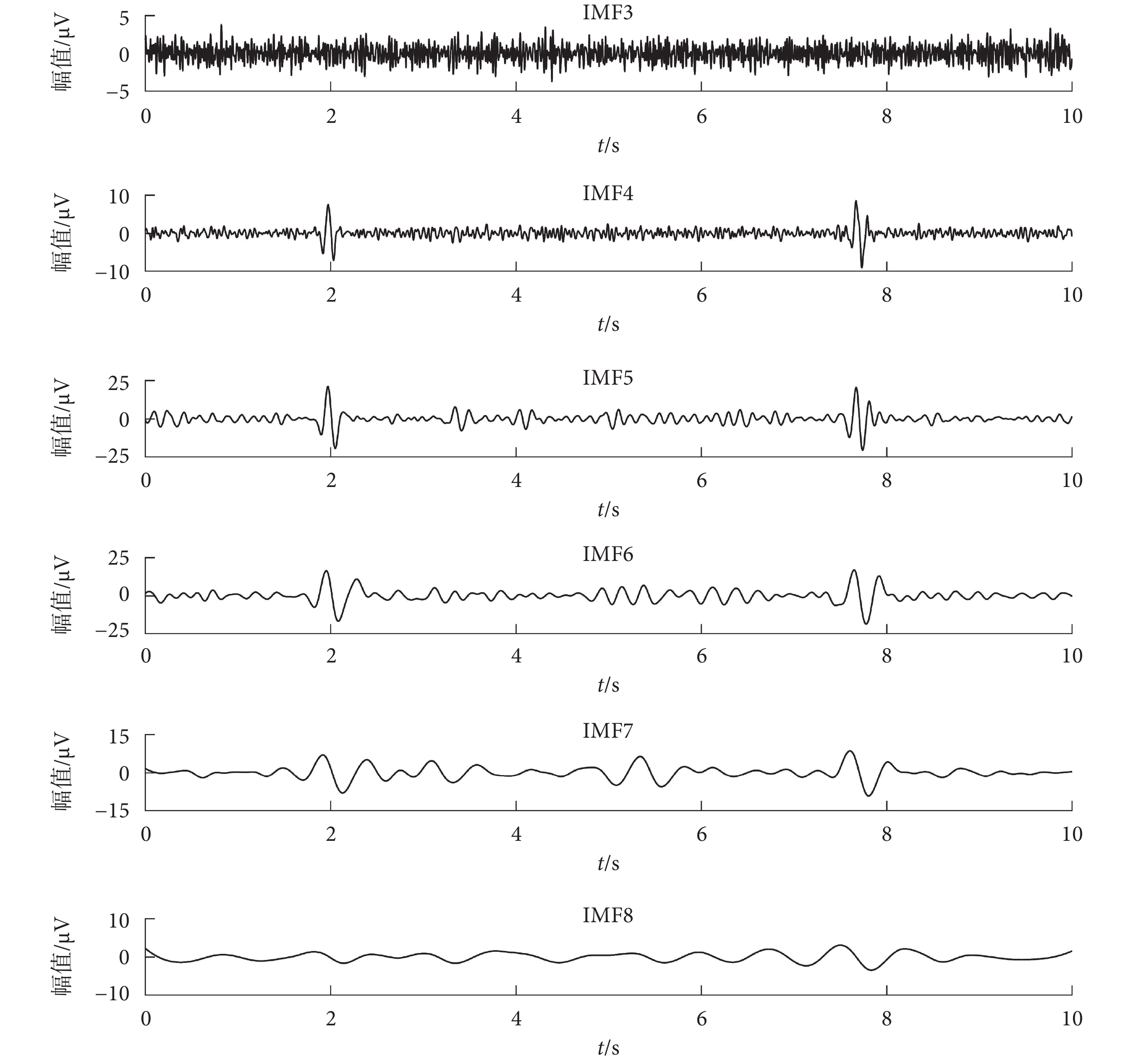 圖2
WC1 進行 EEMD 得到的 IMFs 分量
Figure2.
The IMFs obtained by EEMD of WC1
圖2
WC1 進行 EEMD 得到的 IMFs 分量
Figure2.
The IMFs obtained by EEMD of WC1
本文提出的 WT-EEMD 算法通過設置 AutoCC 閾值來挑選與眼電偽跡相關的 IMFs。AutoCC 是一個信號與其自身在不同時間點的互相關系數,它是信號與延遲后信號之間相似性的度量[22]。如式(7)所示,為 AutoCC(符號記為:aCC)的計算公式:
 |
其中,x(t)為原始腦電信號,x(t-τ)為延遲為 τ 的腦電信號,Cov(·)表示協方差,Var(·)表示方差。
腦電信號中包含有大量的信息,復雜度更高,所以具有更強的隨機性,AutoCC 就會較低。然而眼電偽跡是由眨眼或眼球活動產生的,呈現出低頻率、高振幅的特點,所以其 AutoCC 會更高。
本文分別計算了 10 個純凈的腦電信號和 10 個眼電信號在延遲為 1 情況下的 AutoCC,并對這兩組數據進行 t 檢驗,結果顯示兩組數據的差異具有統計學意義(P < 0.05)。分別使用這兩組數據對于假設均值 0.99 進行 t 檢驗,結果顯示兩組數據與假設均值 0.99 的差異均具有統計學意義(P < 0.05),所以將 AutoCC 閾值設置為 0.99 可以將腦電成分和眼電成分分離開。
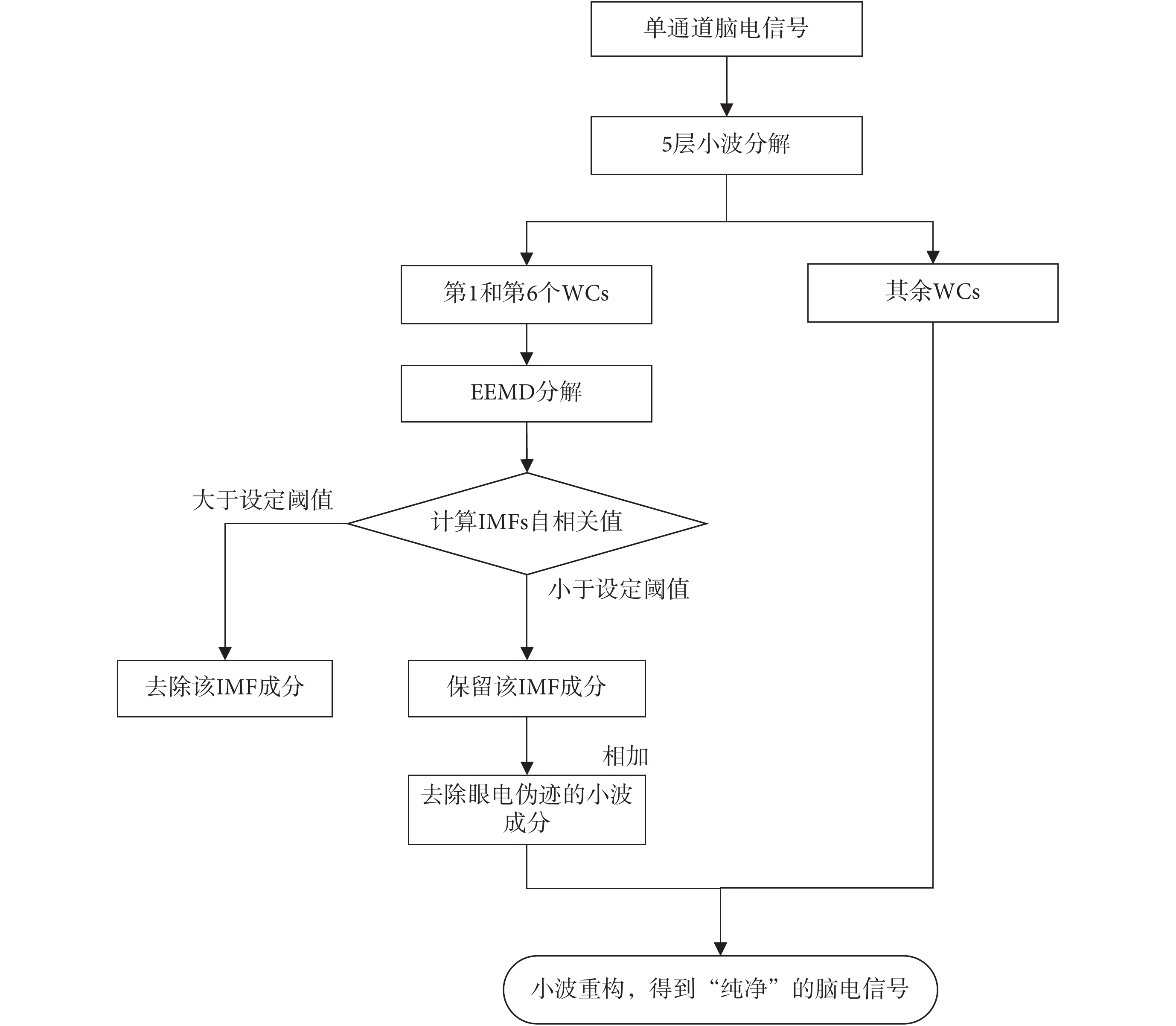
通過設置合適的 AutoCC 閾值,可以挑選出眼電偽跡相關的 IMFs 并去除。將剩余的 IMFs 相加就得到了沒有眼電偽跡的 WCs,再進行小波重構就得到了純凈的單通道腦電信號。如圖 3 所示,為 WT-EEMD 算法的流程。
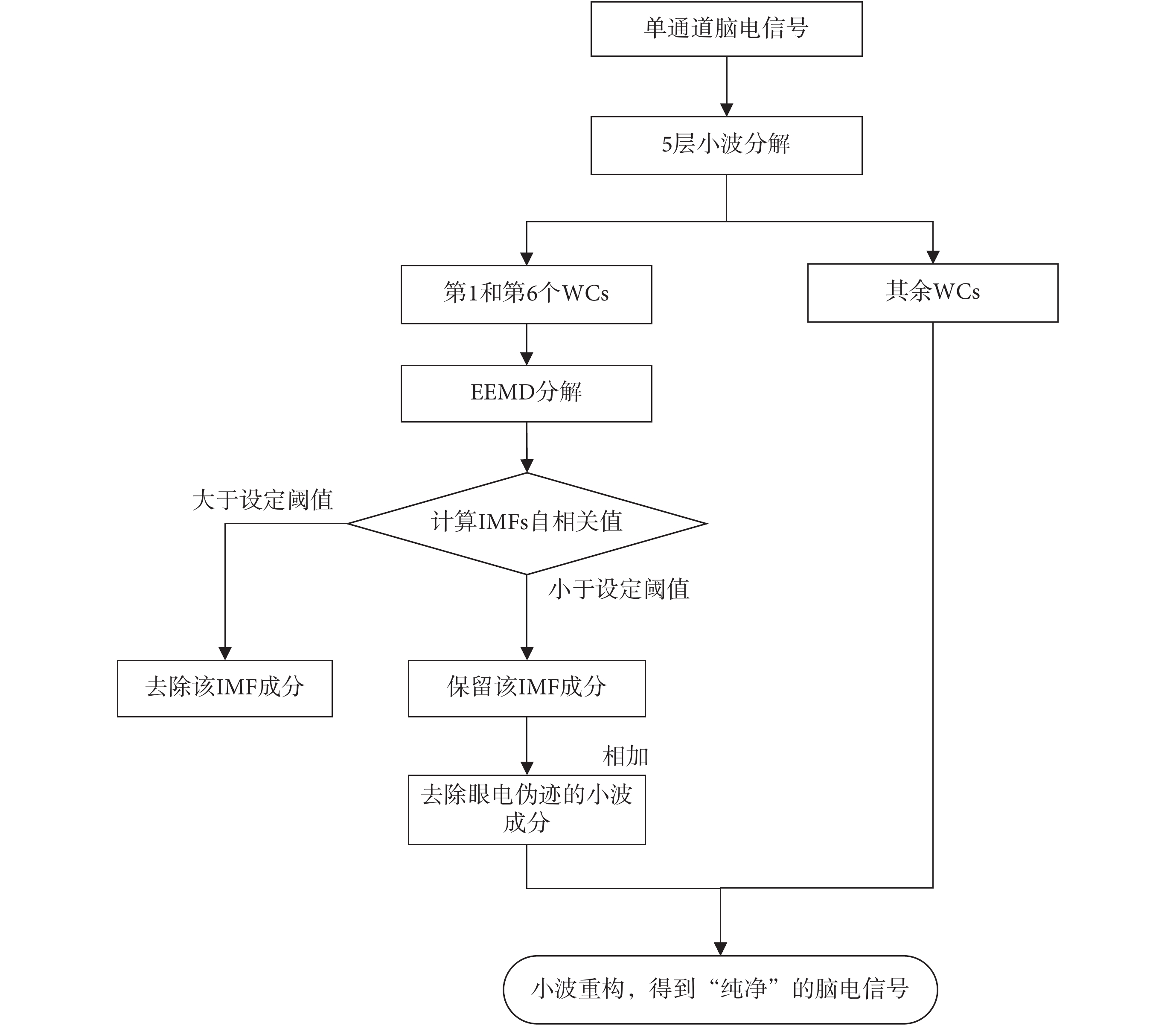 圖3
WT-EEMD 算法流程圖
Figure3.
The flow chart of WT-EEMD algorithm
圖3
WT-EEMD 算法流程圖
Figure3.
The flow chart of WT-EEMD algorithm
2 試驗
2.1 數據獲取
為了驗證本文提出的 WT-EEMD 算法的有效性,分別使用了仿真數據和真實數據進行測試。仿真數據是分別采集人的腦電信號和眼電信號按照混合模型生成。真實數據是采集人的帶有眼電偽跡的腦電信號。本試驗研究已通過鄭州大學生命科學倫理審查委員會批準,且受試者在試驗前簽署了知情同意書。采集設備使用腦立方耳機(Mindwave,NeuroSky,美國),采樣率為 512 Hz,能夠采集人前額 Fp1 通道的腦電信號。由于 Fp1 通道極易受到眼電偽跡的干擾,所以該采集器能夠捕獲到眼電偽跡。采集前要先清潔前額的皮膚,去除油脂和角質,降低電極片與頭皮之間的阻抗。采集過程中,試驗對象在安靜的房間內,并保持平靜。
2.1.1 仿真數據
仿真數據獲取的對象為一名成年健康男性,年齡為 25 歲。為了避免眼電偽跡的影響,腦電信號在閉眼的情況下采集,然后挑選出 10 段數據,每段數據 10 s,最后進行 1~70 Hz 的帶通濾波,保留了 Delta、Theta、Alpha 和 Beta 四個頻段的腦電數據[8],得到純凈的腦電信號。如圖 4 所示為純凈的腦電信號,可以觀察到腦電信號的幅值在?25~25 μV 之間,有輕微波動。
 圖4
純凈的腦電信號
Figure4.
The clean EEG signal
圖4
純凈的腦電信號
Figure4.
The clean EEG signal
眼電信號在睜眼的情況下采集,采集過程中先眨眼一次,然后眼球左右轉,最后再眨眼一次,每段數據長度為 10 s。因為眼電偽跡主要是低頻成分,所以對眼電信號進行 0.5~10 Hz 的帶通濾波,僅保留眼電偽跡相關的頻帶[8]。如圖 5 所示為濾出的眼電信號,可以觀察到在 2 s 和 8 s 時刻附近都有較明顯的垂直眼電偽跡,幅值在?110~110 μV 之間。在兩個垂直眼電信號之間也有較明顯的波動,這是眼球左右轉動形成的水平眼電偽跡。
 圖5
經過 0.5~10 Hz 濾波的眼電信號
Figure5.
The EOG signal filtered by 0.5~10 Hz
圖5
經過 0.5~10 Hz 濾波的眼電信號
Figure5.
The EOG signal filtered by 0.5~10 Hz
仿真數據是通過將純凈的腦電信號與眼電信號進行混合得到的,如式(8)所示,為混合模型:
 |
其中  表示混合之后得到的仿真數據,
表示混合之后得到的仿真數據, 為純凈的腦電信號,
為純凈的腦電信號, 為眼電偽跡,
為眼電偽跡, 為眼電信號所占的權重。通過調整參 數
為眼電信號所占的權重。通過調整參 數 能夠調整仿真數據的信噪比(signal noise ratio,SNR),如式(9)所示:
能夠調整仿真數據的信噪比(signal noise ratio,SNR),如式(9)所示:
 |
其中,RMS(·)表示均方根值(root mean square,RMS),定義如式(10)所示:
 |
其中,T 為數據點數,x 為信號。
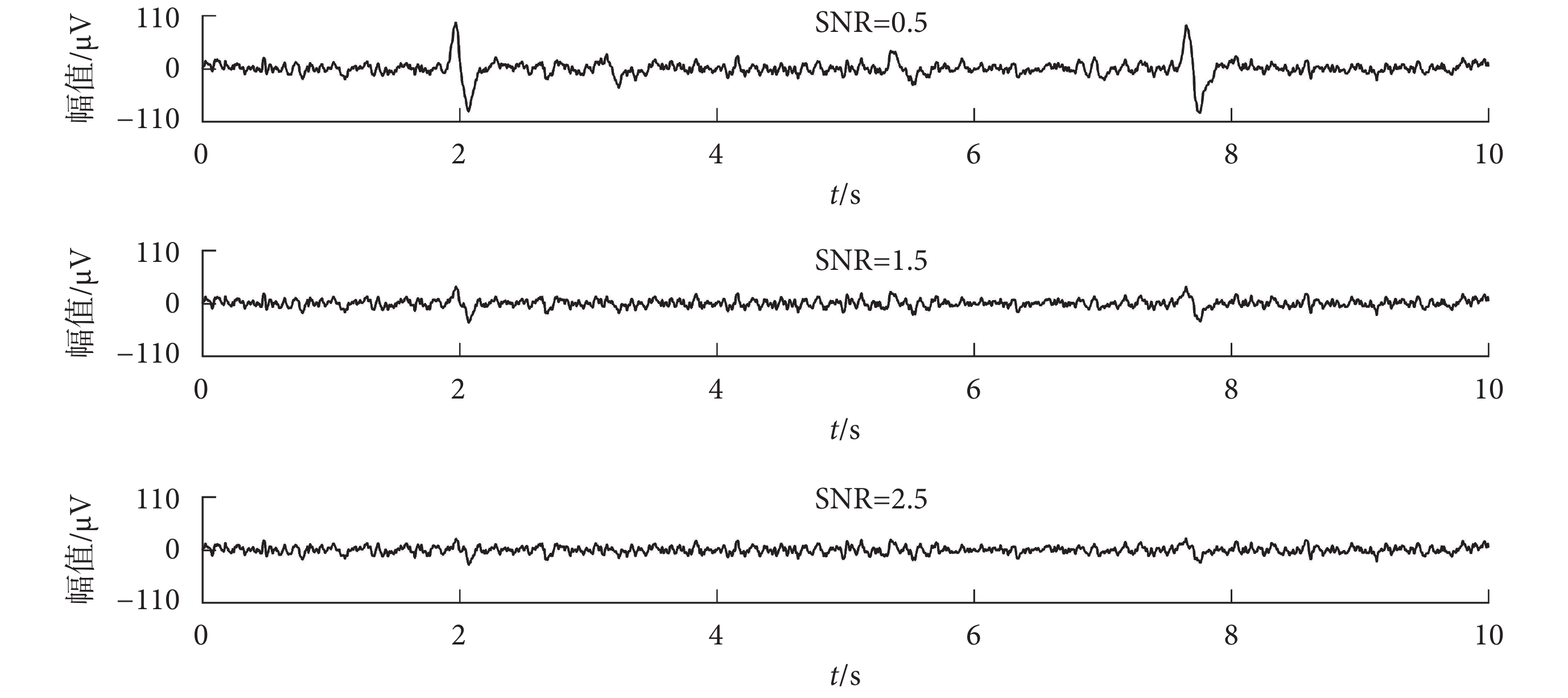
在本文中,選擇了 1 段眼電偽跡,按照不同的 SNR 分別與 10 段純凈的腦電信號進行混合。本文選擇的 SNR 范圍是 0.5~2.5,步長為 0.1。所以每個 SNR 值對應的都有 10 段仿真數據。如圖 6 所示,為同一個純凈的腦電信號與眼電信號按照不同 SNR 值進行混合得到的仿真數據,信噪比分別為 0.5、1.5 和 2.5。
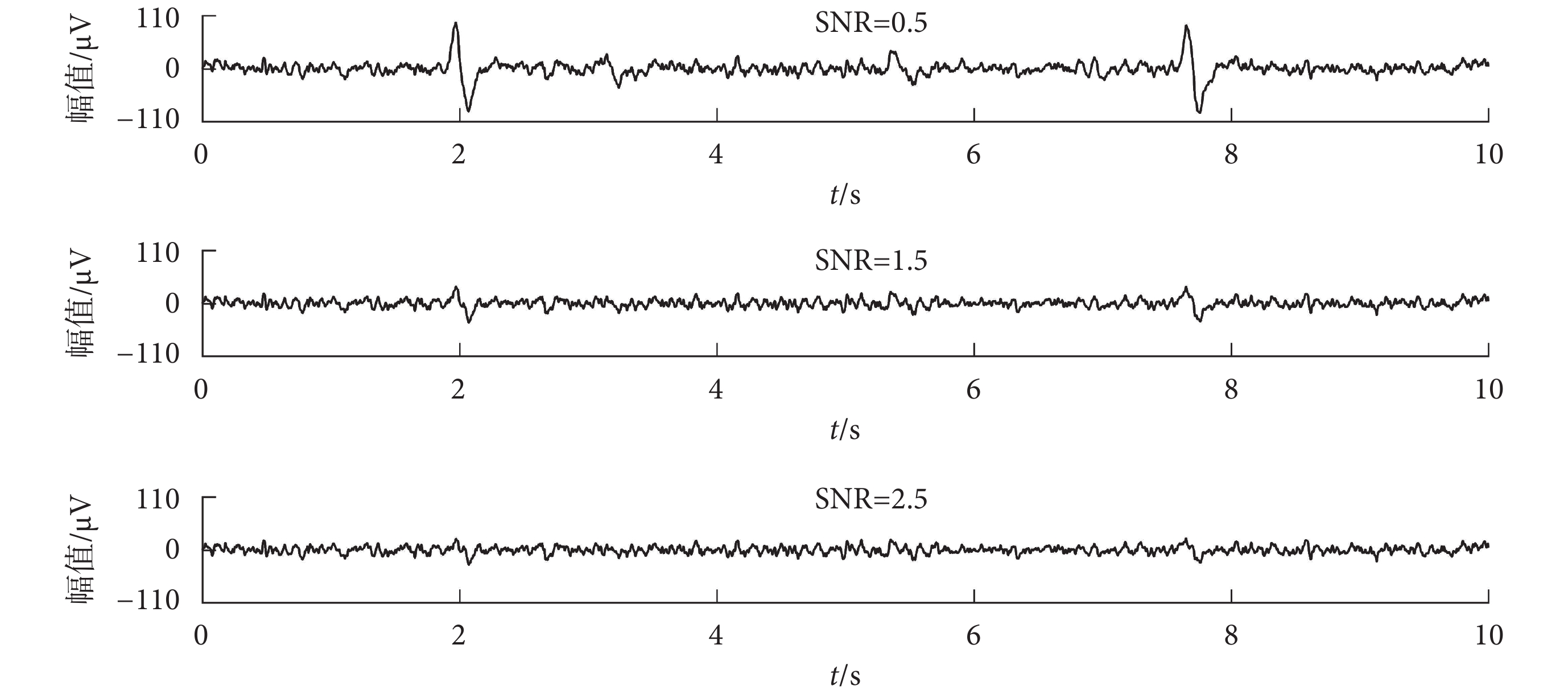 圖6
不同信噪比的仿真數據
Figure6.
The simulation data with different SNRs
圖6
不同信噪比的仿真數據
Figure6.
The simulation data with different SNRs
2.1.2 真實數據
仿真數據中的眼電偽跡是通過 0.5~10 Hz 的帶通濾波之后,按照一定的 SNR 添加到腦電信號中的,而真實腦電信號中眼電偽跡的頻帶范圍可能超出 0.5~10 Hz。而且,為了進一步驗證本文提出的 WT-EEMD 眼電偽跡去除算法對于不同受試者的適用性,有必要進一步使用該算法對真實腦電數據進行處理。真實數據采集 10 名受試者(6 名男性,4 名女性)在睜眼情況下的腦電信號,每個數據段長度為 6 s,然后從每名受試者的數據中挑選出 10 段包含有眼電偽跡的腦電信號,并對其進行 1~70 Hz 的帶通濾波,共得到 100 段數據。
2.2 眼電偽跡去除效果評價
2.2.1 仿真數據評價方法
本文將去除眼電偽跡之后的仿真數據與對應的純凈腦電信號進行定量分析,并以此來評價眼電偽跡去除算法的有效性。其評價標準分為兩個方面:能夠將眼電偽跡有效地去除;同時能夠最大限度減小腦電信號失真。本文采用相對均方根誤差(relative root-mean-squared error,RRMSE)和相關系數(correlation coefficient,CC)作為評價標準[16]。如式(11)所示,為 RRMSE 的定義:
 |
其中, 為去除眼電偽跡之后的仿真數據。
為去除眼電偽跡之后的仿真數據。
如式(12)所示,為 CC 的定義:
 |
RRMSE 的值越小,表示去除眼電偽跡之后的仿真數據與構造該仿真數據的純凈腦電信號越接近,眼電偽跡的去除越完全;CC 定量地評價了構造該仿真數據的純凈腦電信號和去除眼電偽跡之后的仿真數據之間的相關性,CC 的值越大,表示去除眼電偽跡之后的腦電信息保留越完整,失真越小。同時,本文還使用了算法運行時間這一指標,來測試眼電偽跡去除算法能否滿足實時在線 BCI 系統的需求。
2.2.2 真實數據評價方法
真實數據無法提取出純凈的腦電信號,所以不能計算 RRMSE 和 CC 來對眼電偽跡去除效果進行定量評價。對于眼電偽跡的有效去除方面,通過眼電偽跡去除前后的信號波形對比可以很直觀地展現,對于腦電信號失真方面,通過計算去除眼電偽跡后腦電信號高頻段的功率失真情況來進行對比(?P),如式(13)所示[23]:
 |
其中, 表示眼電偽跡去除前的功率,
表示眼電偽跡去除前的功率, 表示眼電偽跡去除后的功率。
表示眼電偽跡去除后的功率。
3 結果和討論
3.1 仿真數據測試結果
本文的仿真數據集中,每一個 SNR 的值都對應有 10 段數據,對每一段數據都使用 WT-EEMD、SSA-SOBI 和 WT-ICA 三種算法進行眼電偽跡去除處理。因此每一種算法針對每一個 SNR 都在不同的數據上運行了 10 次。通過計算這 10 次的 RRMSE、CC 和運行時間這三個指標的平均值,來評價算法對于不同 SNR 數據的眼電去除效果。并且,本文還統計了 RRMSE 和 CC 的標準差,用于評價算法的穩定性。
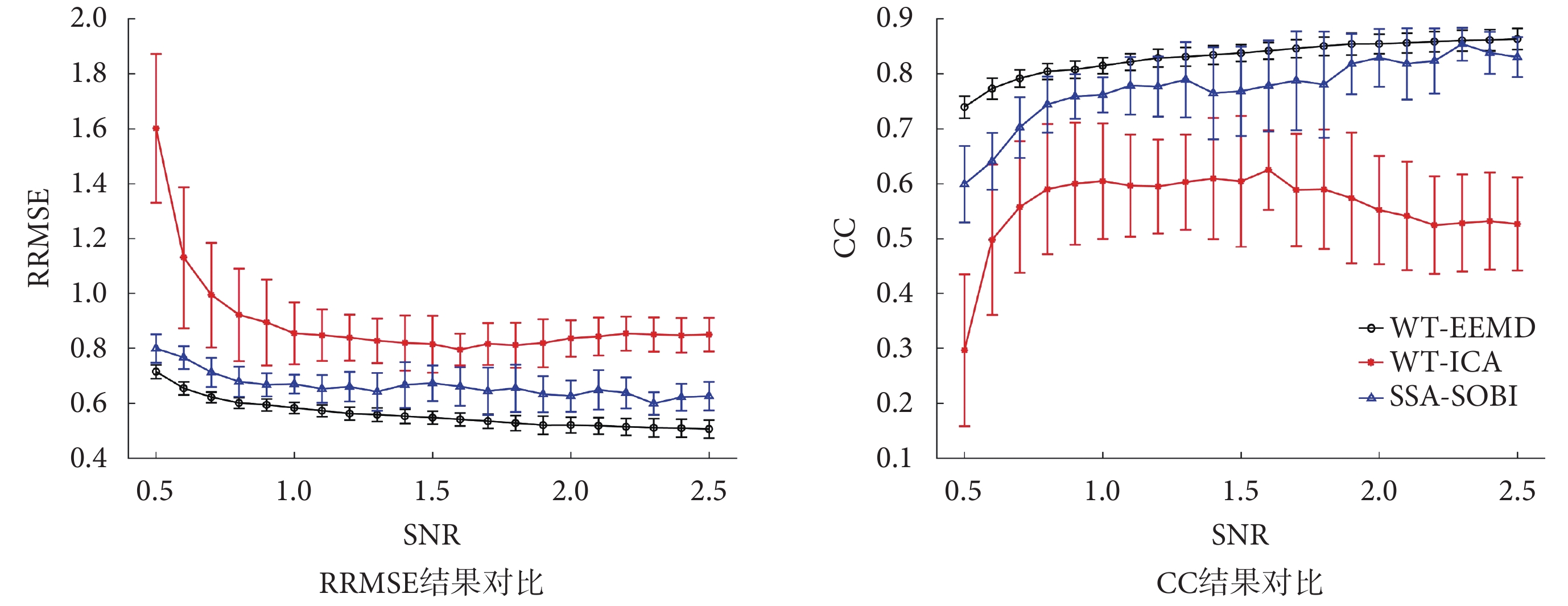
如圖 7 所示,為 WT-EEMD、WT-ICA 和 SSA-SOBI 三種算法的 RRMSE 和 CC 結果對比。RRMSE 的值越小,表示眼電偽跡的去除越完全。可以看出,隨著 SNR 值的增加,三種算法的 RRMSE 值都逐漸降低,本文提出的 WT-EEMD 算法在所有 SNR 下的 RRMSE 均值和標準差都低于另外兩種算法。CC 值越大,表示在去除眼電偽跡的同時,腦電信號失真越小。隨著 SNR 值的增加,WT-EEMD 和 SSA-SOBI 兩種算法對應的 CC 值都有緩慢的上升趨勢,而 WT-ICA 算法在信噪比 1.6 之后,CC 值逐漸下降。對比三種算法,WT-EEMD 算法去除眼電偽跡后的腦電信號失真明顯小于 SSA-SOBI、WT-ICA 兩種算法。
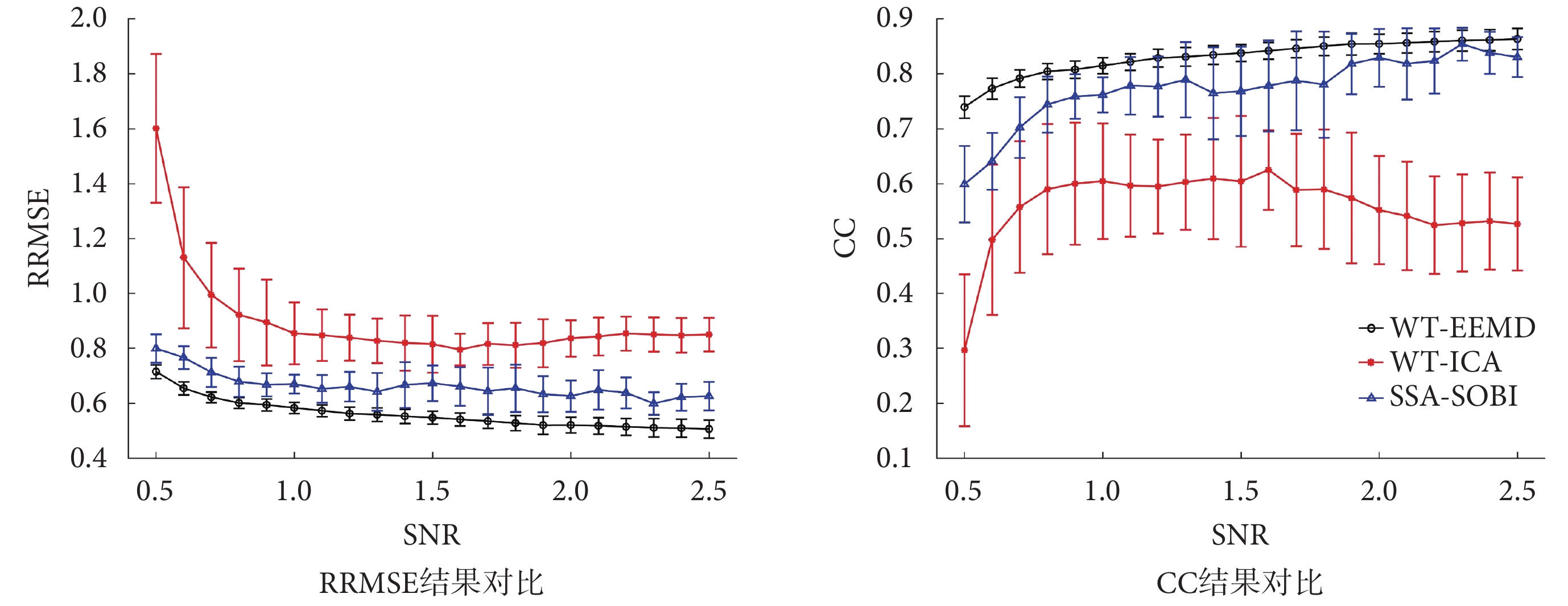 圖7
三種算法的 RRMSE 和 CC 結果對比
Figure7.
The comparison of RRMSE and CC results of the three algorithms
圖7
三種算法的 RRMSE 和 CC 結果對比
Figure7.
The comparison of RRMSE and CC results of the three algorithms
在 SSA-SOBI、WT-ICA 兩種方法中,都使用了 BSS 算法,通常假設腦電信號中有兩個源:腦電源、眼電源,雖然使用 SSA 或 WT 能夠將單通道的數據分解為多維數據,滿足了使用 BSS 算法的先驗條件,但圖 7 的結果顯示,這兩種方法可能并沒有將腦電源和眼電源完全分離,導致眼電偽跡去除性能不佳。
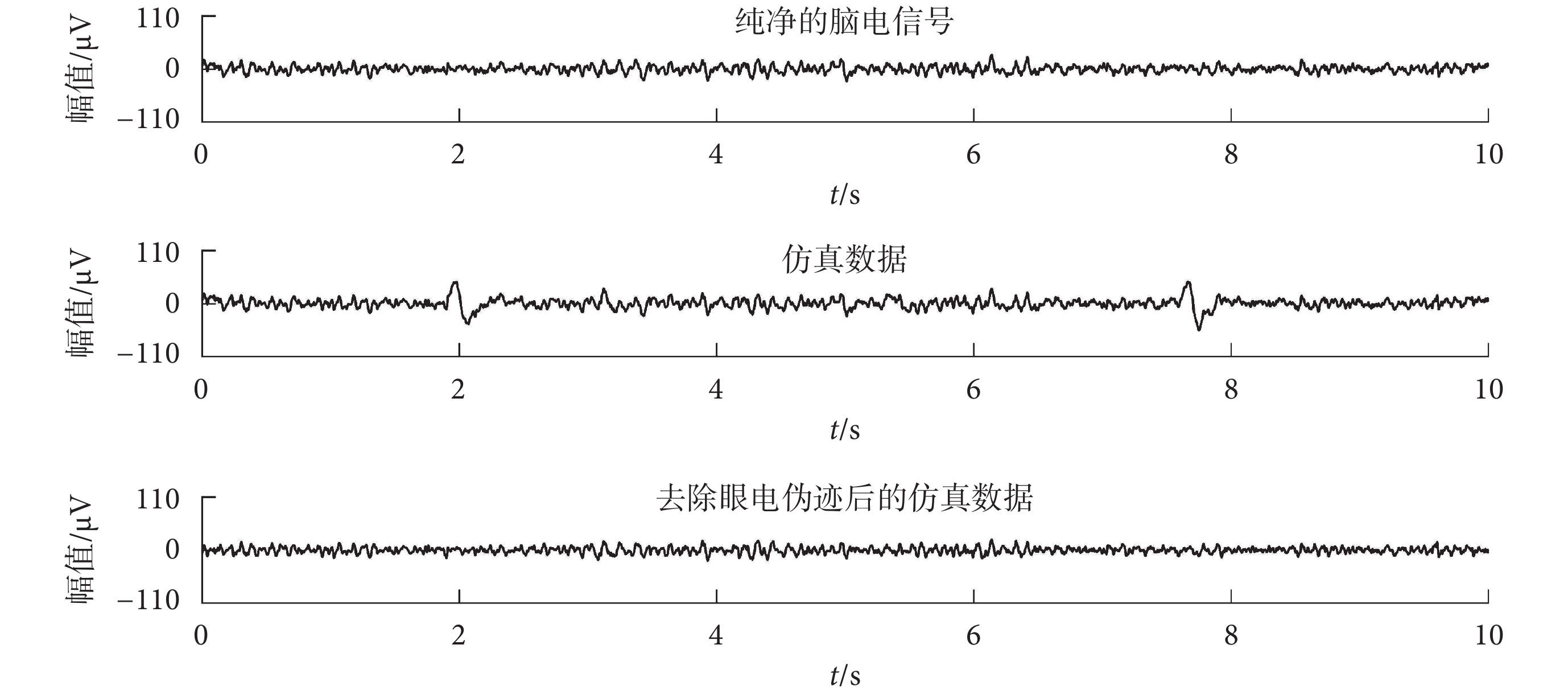
如圖 8 所示,為 WT-EEMD 算法對仿真數據進行眼電偽跡去除,其中的仿真數據為純凈的腦電信號與眼電信號以 SNR=1 為標準進行混合得到的。可以看出使用 WT-EEMD 算法能夠將眼電偽跡去除,且去除眼電偽跡后的仿真數據與構造該仿真數據的純凈腦電信號具有較高的相似性。
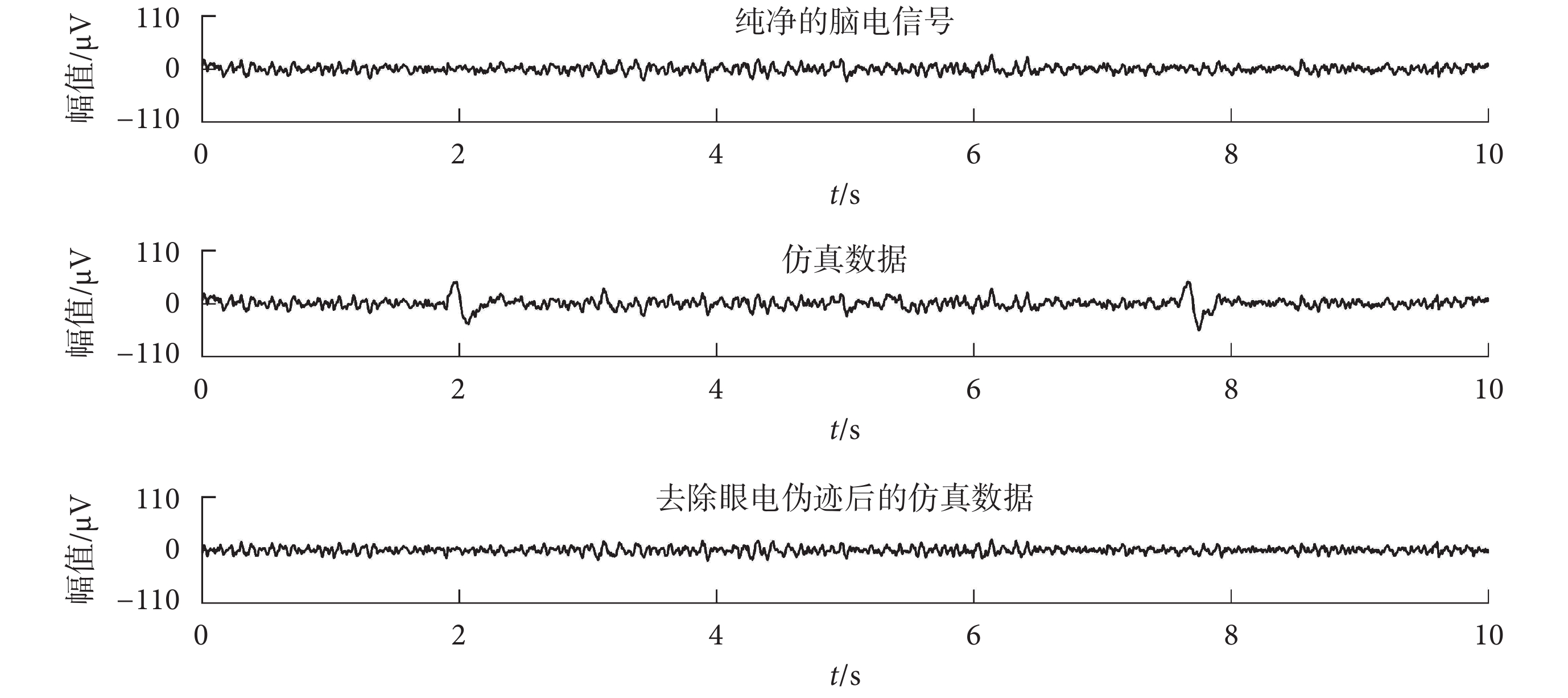 圖8
WT-EEMD 算法對仿真數據進行眼電偽跡去除
Figure8.
WT-EEMD algorithm for electrooculogram artifact removal from simulation data
圖8
WT-EEMD 算法對仿真數據進行眼電偽跡去除
Figure8.
WT-EEMD algorithm for electrooculogram artifact removal from simulation data
另外,在 Intel(R)Core(TM)i7-4790 CPU @ 3.60 GHz,16 G 內存配置的計算機上測試了這三種算法在 10 段仿真數據上的運行時間,并取平均值。WT-EEMD、SSA-SOBI 和 WT-ICA 三種算法的平均運行時間分別為:0.20、0.34、0.15 s。測試所用數據的長度是 10 s,而一般的在線 BCI 系統為了滿足實時性的需求,不會取這么長的數據。所以本文提出的 WT-EEMD 算法的平均運行時間完全能夠滿足實時在線 BCI 系統的要求。
3.2 真實數據測試結果
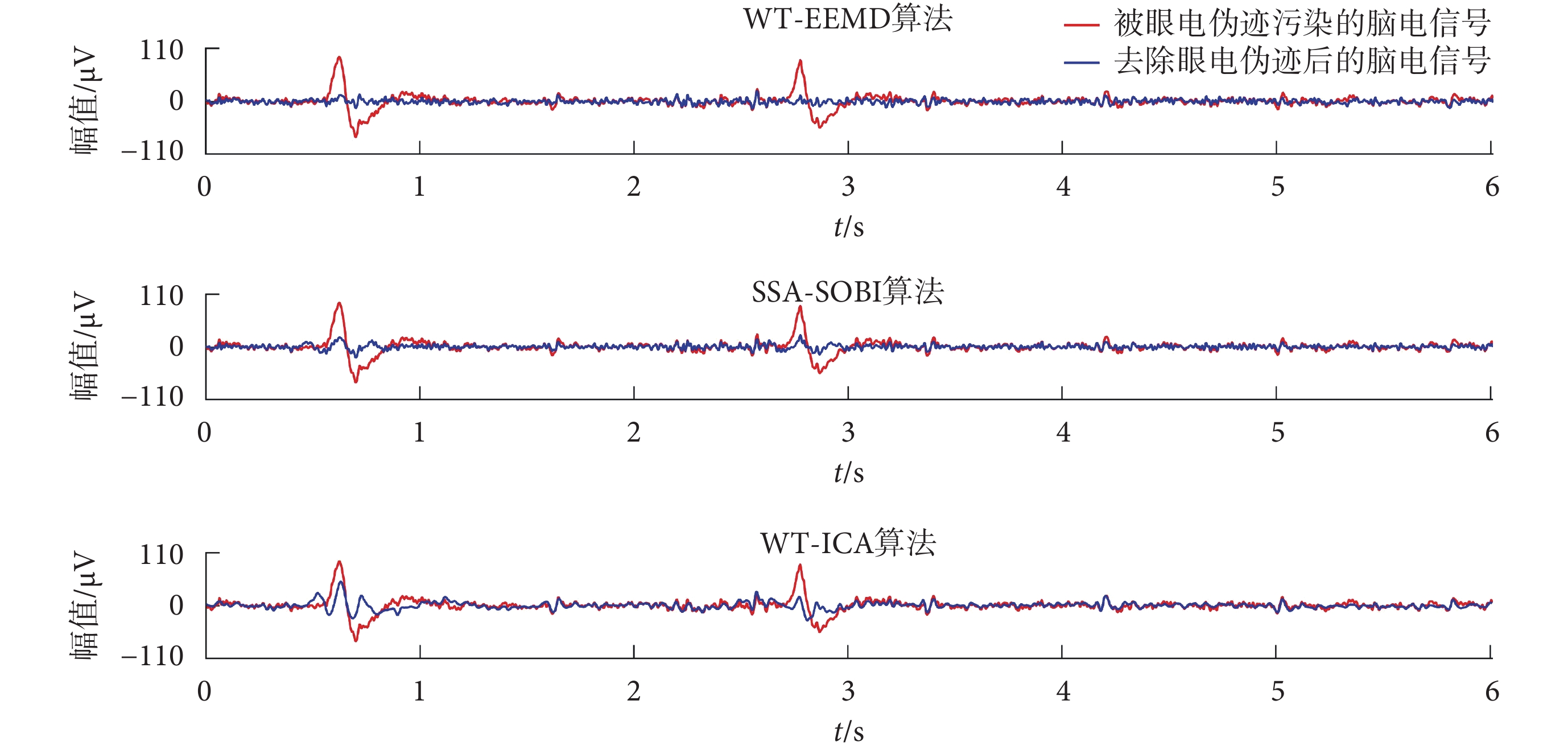
由于眼電偽跡高振幅、低頻率的特征,可以很直觀通過波形圖觀察到,因此可用觀察法評價眼電偽跡是否完全去除。如圖 9 所示,為 WT-EEMD、WT-ICA 和 SSA-SOBI 三種算法分別對同一段包含有眼電偽跡的腦電信號處理前后的波形對比。可以看出,本文提出的 WT-EEMD 算法去除眼電偽跡后,在原眼電偽跡位置不存在眼電波動,SSA-SOBI 算法僅剩余較少波動,而 WT-ICA 算法處理后剩余較多波動。所以,WT-EEMD 算法對于真實數據眼電偽跡去除有效性方面表現最好。
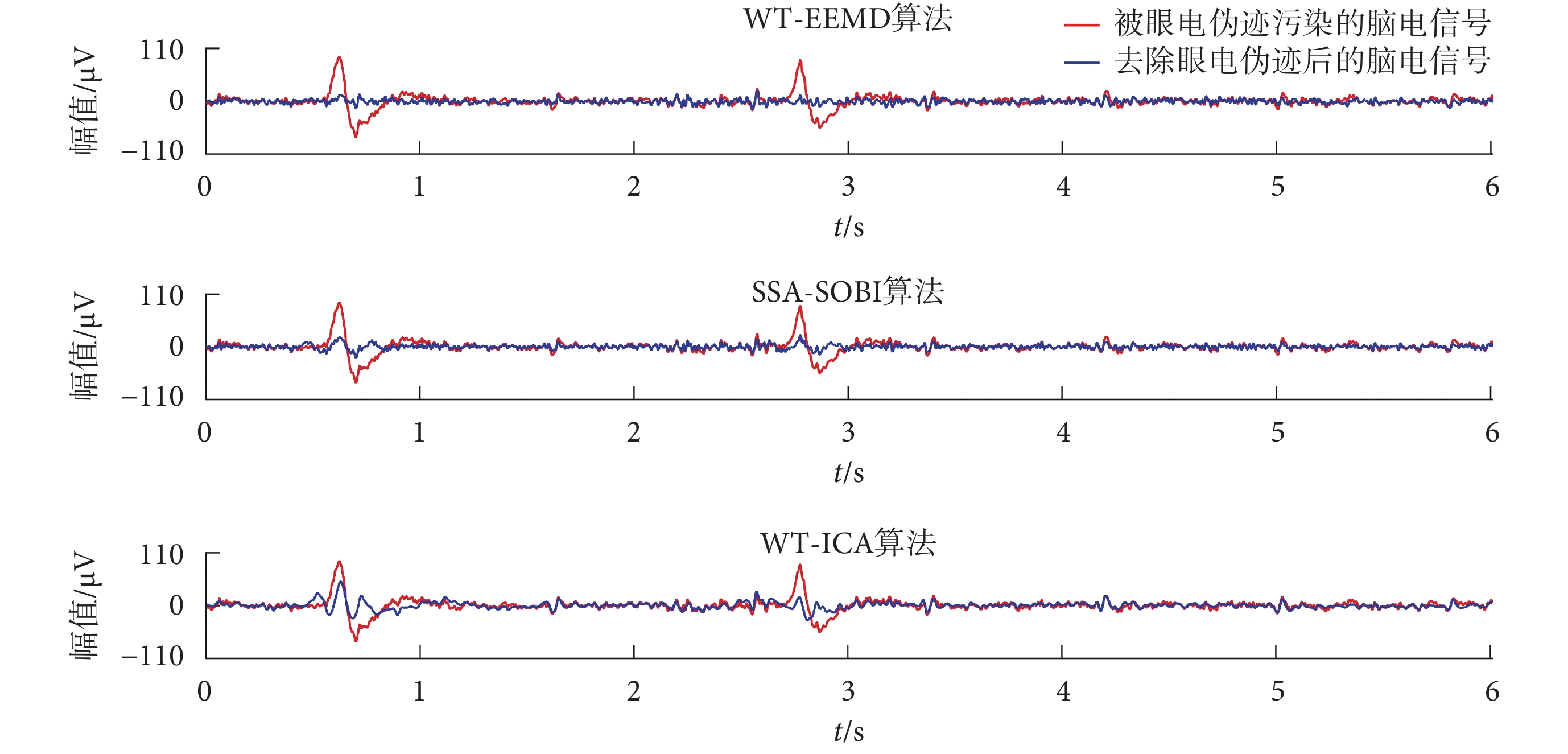 圖9
三種算法對同一段真實數據的眼電偽跡去除效果
Figure9.
The effect of three algorithms on the removal of electrooculogram artifacts from the same real data
圖9
三種算法對同一段真實數據的眼電偽跡去除效果
Figure9.
The effect of three algorithms on the removal of electrooculogram artifacts from the same real data
本文的真實數據集中,每名受試者都有 10 段包含有眼電偽跡的腦電數據,對每一段數據都使用 WT-EEMD、SSA-SOBI 和 WT-ICA 三種算法進行眼電偽跡去除處理。因此每一種眼電偽跡去除算法,針對每一名受試者都在不同的數據上運行了 10 次。因為眼電偽跡是以低頻段為主的干擾,Delta、Theta 等低頻段的功率失真不能體現腦電數據失真情況,所以計算這 10 次 Alpha、Beta 頻段功率失真的平均值,來評價眼電偽跡去除算法對該受試者真實數據進行處理的腦電數據失真情況。最后,統計了 10 名受試者功率失真的標準差,用于評價算法對于不同受試者數據的穩定性。
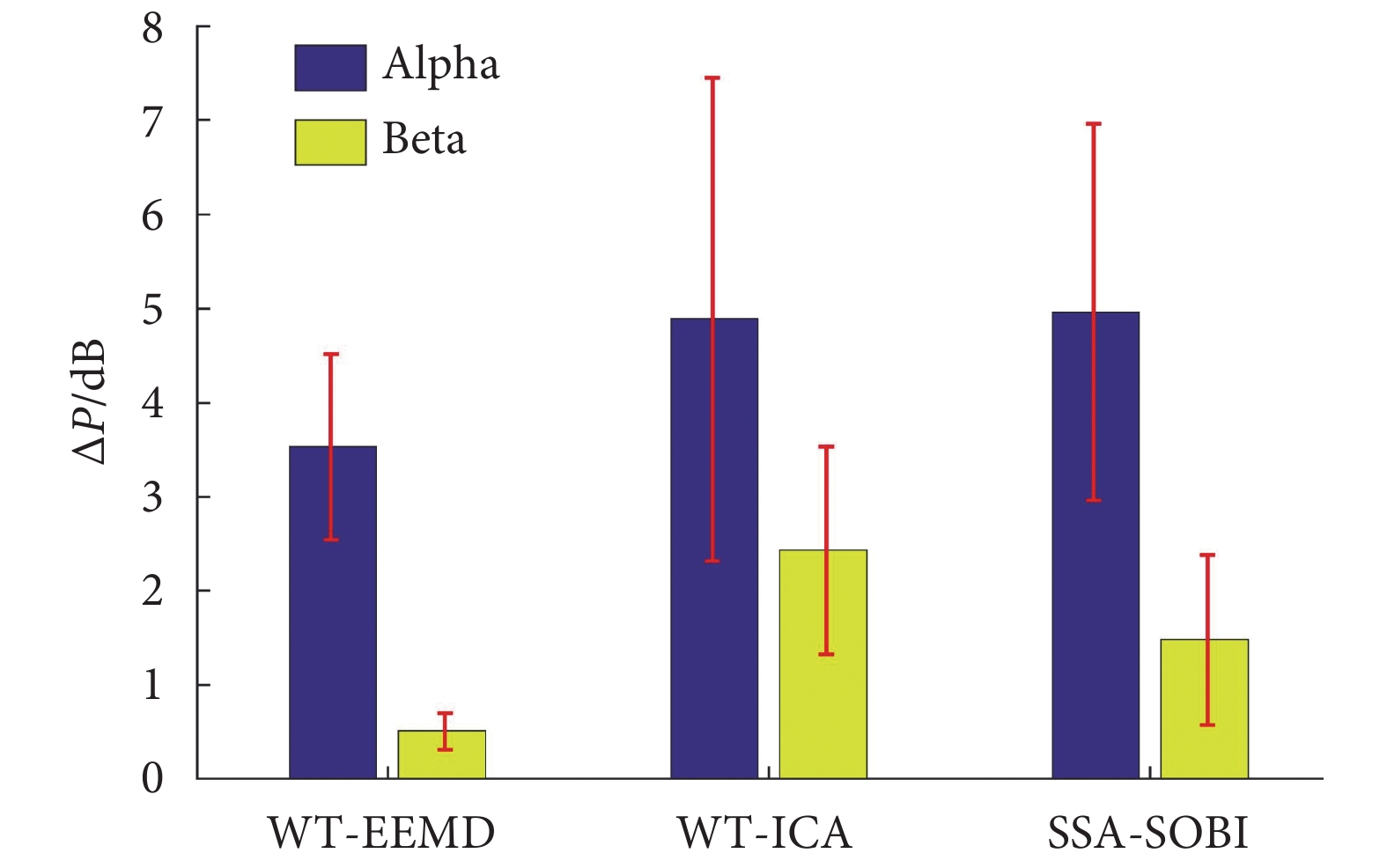
如圖 10 所示,為 WT-EEMD、WT-ICA 和 SSA-SOBI 三種算法去除眼電偽跡后分別在 Alpha、Beta 頻段的失真情況。可以看出,WT-EEMD 算法在兩個頻段的失真情況均小于另外兩種算法,并且具有較小的標準差,在對于不同受試者的穩定性上也優于另外兩種算法。
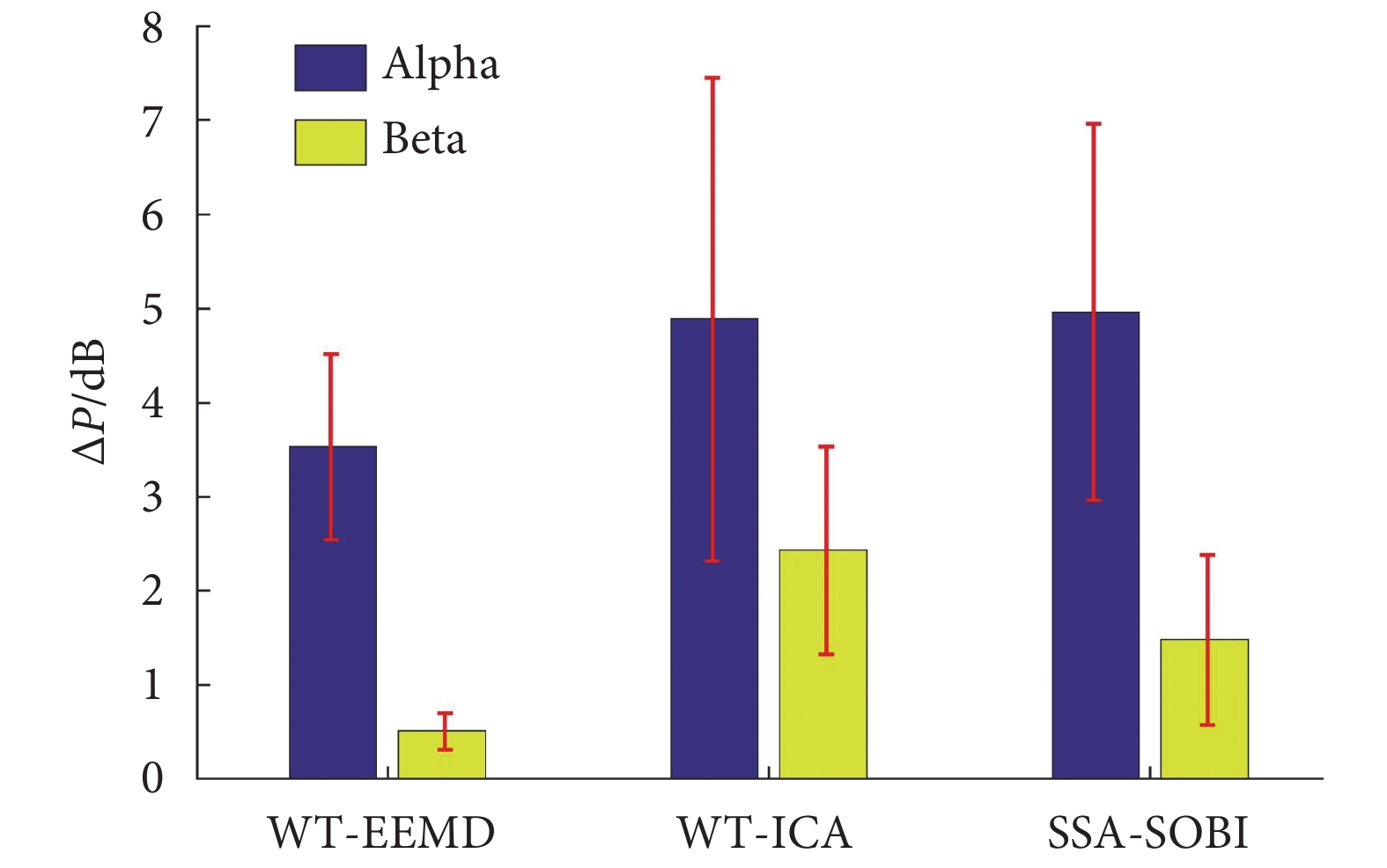 圖10
WT-EEMD、WT-ICA 和 SSA-SOBI 的功率失真對比
Figure10.
The comparison of power distortion of WT-EEMD, WT-ICA and SSA-SOBI
圖10
WT-EEMD、WT-ICA 和 SSA-SOBI 的功率失真對比
Figure10.
The comparison of power distortion of WT-EEMD, WT-ICA and SSA-SOBI
4 結論
隨著 BCI 技術的發展,腦電信號采集設備也設計得越來越便攜,在許多實時在線的 BCI 系統中,往往只需要一個通道,這增加了腦電信號中眼電偽跡的去除難度。本文提出了一種基于 WT-EEMD 的單通道腦電信號中眼電偽跡去除算法,并使用仿真數據和真實數據進行測試,相較于 WT-ICA 和 SSA-SOBI 兩種算法具有較小的 RRMSE、較大的 CC、較短的運行時間以及較小的 Alpha、Beta 頻段功率失真。驗證了該算法能夠在去除眼電偽跡的同時,最大限度地保留腦電信息,并且該算法的運行時間能夠滿足實時在線 BCI 系統的需求。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
腦—機接口(brain-computer interface,BCI)通過解碼包含大腦意識狀態的腦功能信號與外界進行通訊,進而控制外部設備,它是由大腦和外部設備構成的閉環系統[1-2]。腦電(electroencephalogram,EEG)信號是 BCI 系統中常用的腦功能信號,其在采集過程中極易受到眼電(electrooculogram,EOG)偽跡的干擾,從而導致 BCI 解碼準確率下降。由于眼電偽跡與腦電信號的低頻段重疊,導致其去除較為困難[3]。對于多通道的腦電信號中眼電偽跡的去除已有很多研究,而且技術也比較成熟。近年來,隨著 BCI 技術不斷投入實際應用,要求腦電信號采集設備更加便攜易用,通道數目越少越好,特別是在一些特殊應用場景中只需要一個通道[4-5],這就給眼電偽跡去除算法提出了更高的要求。
盲源分離(blind source separation,BSS)是多通道腦電信號中眼電偽跡去除常用的算法,其原理是假設每個導聯的信號都是由特定的源產生的,經過行變化之后得到若干線性無關的行向量,然后將眼電偽跡相關的行向量置零就去除了眼電偽跡的源,最后經過反向行變換就得到了純凈的腦電信號[6]。例如,Mammone 等[7]提出了一種基于小波變換(wavelet transform,WT)和獨立成分分析(independent component analysis,ICA)的眼電偽跡去除算法(WT-ICA),對于多通道腦電信號具有較好的效果,但是這種算法對于單通道腦電信號卻不適用,這是因為 BSS 算法的先驗條件要求通道的數量必須不少于源的數量,而單通道信號卻同時有腦電源和眼電源。于是將單通道腦電信號進行分解以提高其對于 BSS 算法的適用性,是最直接的解決方案。例如,Cheng 等[8]提出了一種基于奇異譜分析(singular spectrum analysis,SSA)和二階盲辨識(second order blind identification,SOBI)的單通道腦電信號中眼電偽跡去除算法(SSA-SOBI),首先對單通道腦電信號進行 SSA 分解得到多維信號,然后再使用 SOBI 算法進行盲源分離,最后通過人工去除眼電偽跡相關源,再重構出沒有眼電偽跡的腦電信號。羅志增等[9]提出了一種基于自適應噪聲完備經驗模態分解(complete ensemble empirical mode decomposition with adaptive noise,CEEMDAN)和 ICA 的單通道腦電信號中眼電偽跡自動去除算法,先通過 CEEMDAN 分解得到多維信號,然后通過 ICA 算法進行盲源分離,最后通過模糊熵閾值自動去除眼電偽跡。雖然這些方法將單通道腦電信號分解為多維數據滿足了 BSS 算法的先驗條件,但是腦電信號和眼電偽跡都是通過一個傳感器采集的,在行變換的過程中可能將腦電信息和眼電信息一起集中到一個或幾個行向量中,也就是沒有將兩種生理電信號完全分離開,導致去除了很多有用的腦電信息。
WT 通過將信號進行特定母波的時間變換和尺度變換,得到若干組對應不同頻段的小波成分(wavelet components,WCs)[10]。由于眼電偽跡以低頻為主,因此單通道腦電信號經過 WT 之后可將眼電偽跡集中到低頻的幾個 WCs 中。經驗模態分解(empirical mode decomposition,EMD)是 Huang 等[11]在 1998 年提出的一種非線性非平穩信號分解技術。通過該方法,任何復雜的數據集都可以分解為數量有限的固有模態函數(intrinsic mode functions,IMFs)。EMD 是數據驅動的、自適應的,可以在不需要任何先驗知識的條件下對信號進行分解,在處理腦電等非平穩信號方面具有突出的性能[12-14]。但是 EMD 算法對噪聲非常敏感,容易造成模態混疊問題。為了解決這個問題,Wu 等[15]又提出了集合 EMD(ensemble EMD,EEMD)算法,并在腦電信號偽跡去除方面進行了成功的應用[16-17]。
為了更有效地去除單通道腦電信號中的眼電偽跡,并且最大限度地保留腦電信號成分,本文提出了一種 WT-EEMD 算法。先使用 WT 將單通道腦電信號分解成若干 WCs,接著將以眼電成分為主的 WCs 進行 EEMD 分解得到若干 IMFs,然后通過自相關系數(autocorrelation coefficient,AutoCC)閾值自動去除包含眼電偽跡的 IMFs,最后重構出“干凈”的腦電信號。WT-EEMD 算法使用兩步分解的策略,克服了盲源分離算法無法將腦電成分和眼電成分有效分離的問題。
1 方法
1.1 小波變換
WT 是繼傅里葉變換之后出現的又一個重要的信號處理理論,解決了時間信息丟失問題,在許多工程領域中都得到了廣泛的應用[18]。WT 在時頻平面上的局部化特征使得其在電生理信號的處理方面占有優勢,早在 1996 年就已用于腦電信號的去噪處理[19]。WT 是將一個信號經過特定母波的時間變換和尺度變換,得到了若干組對應于該尺度下信號與母波相似性的尺度系數(W),如式(1)所示:
|
其中,a 為尺度變換,τ 為時間變換。WT 的關鍵參數為母波和分解層數:本文選擇 sym7 母波,進行 5 層小波分解。如圖 1 所示,為仿真數據進行 WT 分解得到的 WCs。
圖1
仿真數據進行 WT 得到的 WCs
Figure1.
The WCs obtained by WT of simulation data
1.2 集合經驗模態分解
EMD 分解是一種數據驅動的算法,能夠根據信號自身的特征自適應地將信號分解為若干具有物理意義的 IMFs 分量[20]。這些 IMFs 需要滿足以下兩個條件:
(1)極值的個數和過零點的個數必須相等或相差一個;
(2)在任何一點上,由局部極大值定義的上包絡線和由局部極小值定義的下包絡線的平均值為零。
其分解過程如下:
(1)求 x(t)所有的極大值和極小值。然后,用三次樣條函數連接所有極大值形成上包絡線 u(t),連接所有極小值形成下包絡線 b(t);
(2)計算上包絡線和下包絡線的平均值 m(t),然后從原始信號 x(t)中減去 m(t)得到新的信號 ,如式(2)~(3)所示:
|
|
(3)這個剩余的 h(t)被當作新的原始信號,重復上述兩個步驟,直到 h(t)滿足 IMFs 的兩個條件,就得到了第一個經驗模態函數 IMF1;
(4)重復上述步驟,直到殘差信號 是一個單調函數,篩選過程就會停止,這時原始信號 x(t)可以用于表示所有 IMFs 與殘差信號之和,如式(4)所示:
|
其中,n 為 IMFs 的個數,為殘差信號。
EEMD 是一種噪聲輔助的方法,通過向原始信號中添加正態分布的、一定幅度的白噪聲,利用白噪聲均勻的頻譜特性,使得原始信號均勻地填充整個時頻空間,在不同尺度上具有連續性,從而降低了模態混疊問題[21]。添加白噪聲的原始信號進行 EMD 分解得到的 IMFs 都由信號和白噪聲組成的。通過多次添加白噪聲并進行分解,再將多次分解得到的 IMFs 進行平均,由于每次添加的白噪聲都是相互獨立的,所以平均之后 IMFs 中的白噪聲都相互抵消了,如式(5)所示:
|
其中,N 為向 x(t)添加白噪聲的次數,這樣就可以得到第 j 個 IMFs 分量。EEMD 算法相當于進行了 N 次 EMD 分解,并將每一層上的 N 個 IMFs 分量進行平均。
EEMD 算法需要設置兩個參數,添加的白噪聲的幅度和次數。白噪聲的幅度用標準差來衡量,根據 Wu 等[15]的建議,本文中添加白噪聲的標準差為 0.2,添加白噪聲的次數設為 20。如式(6)所示,為分解得到的 IMFs 個數計算方法:
|
其中,fix(x)表示取整,n 為采樣點數。本文所使用仿真數據的采樣點數為 5 120(數據長度為 10 s,采樣率為 512 Hz),因此根據式(6)計算可得 IMFs 的個數為 12,再加上殘差信號,共得到了 13 個分量。
1.3 小波變換-集合經驗模態分解
對于記錄得到的單通道腦電信號,先進行 WT 分解得到 6 個 WCs。由于眼電偽跡與腦電信號的低頻段在時域和頻域重疊,如果直接去除眼電偽跡相關的 WCs,會造成腦電信號的失真。所以本文選擇第 1 個和第 6 個 WCs,即低頻成分進行 EEMD 分解,可以更大程度地將腦電信號和眼電偽跡分離開。如圖 2 所示,為 WC1 進行 EEMD 分解得到的部分 IMFs,可以看出 IMF4、IMF5、IMF6、IMF7 中有眼電波動。
圖2
WC1 進行 EEMD 得到的 IMFs 分量
Figure2.
The IMFs obtained by EEMD of WC1
本文提出的 WT-EEMD 算法通過設置 AutoCC 閾值來挑選與眼電偽跡相關的 IMFs。AutoCC 是一個信號與其自身在不同時間點的互相關系數,它是信號與延遲后信號之間相似性的度量[22]。如式(7)所示,為 AutoCC(符號記為:aCC)的計算公式:
|
其中,x(t)為原始腦電信號,x(t-τ)為延遲為 τ 的腦電信號,Cov(·)表示協方差,Var(·)表示方差。
腦電信號中包含有大量的信息,復雜度更高,所以具有更強的隨機性,AutoCC 就會較低。然而眼電偽跡是由眨眼或眼球活動產生的,呈現出低頻率、高振幅的特點,所以其 AutoCC 會更高。
本文分別計算了 10 個純凈的腦電信號和 10 個眼電信號在延遲為 1 情況下的 AutoCC,并對這兩組數據進行 t 檢驗,結果顯示兩組數據的差異具有統計學意義(P < 0.05)。分別使用這兩組數據對于假設均值 0.99 進行 t 檢驗,結果顯示兩組數據與假設均值 0.99 的差異均具有統計學意義(P < 0.05),所以將 AutoCC 閾值設置為 0.99 可以將腦電成分和眼電成分分離開。
通過設置合適的 AutoCC 閾值,可以挑選出眼電偽跡相關的 IMFs 并去除。將剩余的 IMFs 相加就得到了沒有眼電偽跡的 WCs,再進行小波重構就得到了純凈的單通道腦電信號。如圖 3 所示,為 WT-EEMD 算法的流程。
圖3
WT-EEMD 算法流程圖
Figure3.
The flow chart of WT-EEMD algorithm
2 試驗
2.1 數據獲取
為了驗證本文提出的 WT-EEMD 算法的有效性,分別使用了仿真數據和真實數據進行測試。仿真數據是分別采集人的腦電信號和眼電信號按照混合模型生成。真實數據是采集人的帶有眼電偽跡的腦電信號。本試驗研究已通過鄭州大學生命科學倫理審查委員會批準,且受試者在試驗前簽署了知情同意書。采集設備使用腦立方耳機(Mindwave,NeuroSky,美國),采樣率為 512 Hz,能夠采集人前額 Fp1 通道的腦電信號。由于 Fp1 通道極易受到眼電偽跡的干擾,所以該采集器能夠捕獲到眼電偽跡。采集前要先清潔前額的皮膚,去除油脂和角質,降低電極片與頭皮之間的阻抗。采集過程中,試驗對象在安靜的房間內,并保持平靜。
2.1.1 仿真數據
仿真數據獲取的對象為一名成年健康男性,年齡為 25 歲。為了避免眼電偽跡的影響,腦電信號在閉眼的情況下采集,然后挑選出 10 段數據,每段數據 10 s,最后進行 1~70 Hz 的帶通濾波,保留了 Delta、Theta、Alpha 和 Beta 四個頻段的腦電數據[8],得到純凈的腦電信號。如圖 4 所示為純凈的腦電信號,可以觀察到腦電信號的幅值在?25~25 μV 之間,有輕微波動。
圖4
純凈的腦電信號
Figure4.
The clean EEG signal
眼電信號在睜眼的情況下采集,采集過程中先眨眼一次,然后眼球左右轉,最后再眨眼一次,每段數據長度為 10 s。因為眼電偽跡主要是低頻成分,所以對眼電信號進行 0.5~10 Hz 的帶通濾波,僅保留眼電偽跡相關的頻帶[8]。如圖 5 所示為濾出的眼電信號,可以觀察到在 2 s 和 8 s 時刻附近都有較明顯的垂直眼電偽跡,幅值在?110~110 μV 之間。在兩個垂直眼電信號之間也有較明顯的波動,這是眼球左右轉動形成的水平眼電偽跡。
圖5
經過 0.5~10 Hz 濾波的眼電信號
Figure5.
The EOG signal filtered by 0.5~10 Hz
仿真數據是通過將純凈的腦電信號與眼電信號進行混合得到的,如式(8)所示,為混合模型:
|
其中 表示混合之后得到的仿真數據, 為純凈的腦電信號, 為眼電偽跡, 為眼電信號所占的權重。通過調整參 數 能夠調整仿真數據的信噪比(signal noise ratio,SNR),如式(9)所示:
|
其中,RMS(·)表示均方根值(root mean square,RMS),定義如式(10)所示:
|
其中,T 為數據點數,x 為信號。
在本文中,選擇了 1 段眼電偽跡,按照不同的 SNR 分別與 10 段純凈的腦電信號進行混合。本文選擇的 SNR 范圍是 0.5~2.5,步長為 0.1。所以每個 SNR 值對應的都有 10 段仿真數據。如圖 6 所示,為同一個純凈的腦電信號與眼電信號按照不同 SNR 值進行混合得到的仿真數據,信噪比分別為 0.5、1.5 和 2.5。
圖6
不同信噪比的仿真數據
Figure6.
The simulation data with different SNRs
2.1.2 真實數據
仿真數據中的眼電偽跡是通過 0.5~10 Hz 的帶通濾波之后,按照一定的 SNR 添加到腦電信號中的,而真實腦電信號中眼電偽跡的頻帶范圍可能超出 0.5~10 Hz。而且,為了進一步驗證本文提出的 WT-EEMD 眼電偽跡去除算法對于不同受試者的適用性,有必要進一步使用該算法對真實腦電數據進行處理。真實數據采集 10 名受試者(6 名男性,4 名女性)在睜眼情況下的腦電信號,每個數據段長度為 6 s,然后從每名受試者的數據中挑選出 10 段包含有眼電偽跡的腦電信號,并對其進行 1~70 Hz 的帶通濾波,共得到 100 段數據。
2.2 眼電偽跡去除效果評價
2.2.1 仿真數據評價方法
本文將去除眼電偽跡之后的仿真數據與對應的純凈腦電信號進行定量分析,并以此來評價眼電偽跡去除算法的有效性。其評價標準分為兩個方面:能夠將眼電偽跡有效地去除;同時能夠最大限度減小腦電信號失真。本文采用相對均方根誤差(relative root-mean-squared error,RRMSE)和相關系數(correlation coefficient,CC)作為評價標準[16]。如式(11)所示,為 RRMSE 的定義:
|
其中, 為去除眼電偽跡之后的仿真數據。
如式(12)所示,為 CC 的定義:
|
RRMSE 的值越小,表示去除眼電偽跡之后的仿真數據與構造該仿真數據的純凈腦電信號越接近,眼電偽跡的去除越完全;CC 定量地評價了構造該仿真數據的純凈腦電信號和去除眼電偽跡之后的仿真數據之間的相關性,CC 的值越大,表示去除眼電偽跡之后的腦電信息保留越完整,失真越小。同時,本文還使用了算法運行時間這一指標,來測試眼電偽跡去除算法能否滿足實時在線 BCI 系統的需求。
2.2.2 真實數據評價方法
真實數據無法提取出純凈的腦電信號,所以不能計算 RRMSE 和 CC 來對眼電偽跡去除效果進行定量評價。對于眼電偽跡的有效去除方面,通過眼電偽跡去除前后的信號波形對比可以很直觀地展現,對于腦電信號失真方面,通過計算去除眼電偽跡后腦電信號高頻段的功率失真情況來進行對比(?P),如式(13)所示[23]:
|
其中, 表示眼電偽跡去除前的功率, 表示眼電偽跡去除后的功率。
3 結果和討論
3.1 仿真數據測試結果
本文的仿真數據集中,每一個 SNR 的值都對應有 10 段數據,對每一段數據都使用 WT-EEMD、SSA-SOBI 和 WT-ICA 三種算法進行眼電偽跡去除處理。因此每一種算法針對每一個 SNR 都在不同的數據上運行了 10 次。通過計算這 10 次的 RRMSE、CC 和運行時間這三個指標的平均值,來評價算法對于不同 SNR 數據的眼電去除效果。并且,本文還統計了 RRMSE 和 CC 的標準差,用于評價算法的穩定性。
如圖 7 所示,為 WT-EEMD、WT-ICA 和 SSA-SOBI 三種算法的 RRMSE 和 CC 結果對比。RRMSE 的值越小,表示眼電偽跡的去除越完全。可以看出,隨著 SNR 值的增加,三種算法的 RRMSE 值都逐漸降低,本文提出的 WT-EEMD 算法在所有 SNR 下的 RRMSE 均值和標準差都低于另外兩種算法。CC 值越大,表示在去除眼電偽跡的同時,腦電信號失真越小。隨著 SNR 值的增加,WT-EEMD 和 SSA-SOBI 兩種算法對應的 CC 值都有緩慢的上升趨勢,而 WT-ICA 算法在信噪比 1.6 之后,CC 值逐漸下降。對比三種算法,WT-EEMD 算法去除眼電偽跡后的腦電信號失真明顯小于 SSA-SOBI、WT-ICA 兩種算法。
圖7
三種算法的 RRMSE 和 CC 結果對比
Figure7.
The comparison of RRMSE and CC results of the three algorithms
在 SSA-SOBI、WT-ICA 兩種方法中,都使用了 BSS 算法,通常假設腦電信號中有兩個源:腦電源、眼電源,雖然使用 SSA 或 WT 能夠將單通道的數據分解為多維數據,滿足了使用 BSS 算法的先驗條件,但圖 7 的結果顯示,這兩種方法可能并沒有將腦電源和眼電源完全分離,導致眼電偽跡去除性能不佳。
如圖 8 所示,為 WT-EEMD 算法對仿真數據進行眼電偽跡去除,其中的仿真數據為純凈的腦電信號與眼電信號以 SNR=1 為標準進行混合得到的。可以看出使用 WT-EEMD 算法能夠將眼電偽跡去除,且去除眼電偽跡后的仿真數據與構造該仿真數據的純凈腦電信號具有較高的相似性。
圖8
WT-EEMD 算法對仿真數據進行眼電偽跡去除
Figure8.
WT-EEMD algorithm for electrooculogram artifact removal from simulation data
另外,在 Intel(R)Core(TM)i7-4790 CPU @ 3.60 GHz,16 G 內存配置的計算機上測試了這三種算法在 10 段仿真數據上的運行時間,并取平均值。WT-EEMD、SSA-SOBI 和 WT-ICA 三種算法的平均運行時間分別為:0.20、0.34、0.15 s。測試所用數據的長度是 10 s,而一般的在線 BCI 系統為了滿足實時性的需求,不會取這么長的數據。所以本文提出的 WT-EEMD 算法的平均運行時間完全能夠滿足實時在線 BCI 系統的要求。
3.2 真實數據測試結果
由于眼電偽跡高振幅、低頻率的特征,可以很直觀通過波形圖觀察到,因此可用觀察法評價眼電偽跡是否完全去除。如圖 9 所示,為 WT-EEMD、WT-ICA 和 SSA-SOBI 三種算法分別對同一段包含有眼電偽跡的腦電信號處理前后的波形對比。可以看出,本文提出的 WT-EEMD 算法去除眼電偽跡后,在原眼電偽跡位置不存在眼電波動,SSA-SOBI 算法僅剩余較少波動,而 WT-ICA 算法處理后剩余較多波動。所以,WT-EEMD 算法對于真實數據眼電偽跡去除有效性方面表現最好。
圖9
三種算法對同一段真實數據的眼電偽跡去除效果
Figure9.
The effect of three algorithms on the removal of electrooculogram artifacts from the same real data
本文的真實數據集中,每名受試者都有 10 段包含有眼電偽跡的腦電數據,對每一段數據都使用 WT-EEMD、SSA-SOBI 和 WT-ICA 三種算法進行眼電偽跡去除處理。因此每一種眼電偽跡去除算法,針對每一名受試者都在不同的數據上運行了 10 次。因為眼電偽跡是以低頻段為主的干擾,Delta、Theta 等低頻段的功率失真不能體現腦電數據失真情況,所以計算這 10 次 Alpha、Beta 頻段功率失真的平均值,來評價眼電偽跡去除算法對該受試者真實數據進行處理的腦電數據失真情況。最后,統計了 10 名受試者功率失真的標準差,用于評價算法對于不同受試者數據的穩定性。
如圖 10 所示,為 WT-EEMD、WT-ICA 和 SSA-SOBI 三種算法去除眼電偽跡后分別在 Alpha、Beta 頻段的失真情況。可以看出,WT-EEMD 算法在兩個頻段的失真情況均小于另外兩種算法,并且具有較小的標準差,在對于不同受試者的穩定性上也優于另外兩種算法。
圖10
WT-EEMD、WT-ICA 和 SSA-SOBI 的功率失真對比
Figure10.
The comparison of power distortion of WT-EEMD, WT-ICA and SSA-SOBI
4 結論
隨著 BCI 技術的發展,腦電信號采集設備也設計得越來越便攜,在許多實時在線的 BCI 系統中,往往只需要一個通道,這增加了腦電信號中眼電偽跡的去除難度。本文提出了一種基于 WT-EEMD 的單通道腦電信號中眼電偽跡去除算法,并使用仿真數據和真實數據進行測試,相較于 WT-ICA 和 SSA-SOBI 兩種算法具有較小的 RRMSE、較大的 CC、較短的運行時間以及較小的 Alpha、Beta 頻段功率失真。驗證了該算法能夠在去除眼電偽跡的同時,最大限度地保留腦電信息,并且該算法的運行時間能夠滿足實時在線 BCI 系統的需求。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。