近年來,采用腦電波進行癲癇發作檢測得到了學術界的廣泛關注,而用于癲癇發作檢測的腦電波數據存在數據采集困難、發作樣本少等問題,在訓練樣本量不足的情況下采用深度學習容易產生過擬合現象。為了解決此問題,本文以美國波士頓兒童醫院的癲癇腦電數據集為研究對象,將小波變換用于數據增強,通過設置不同的小波變換尺度因子來生成相應的數據,達到成倍增加訓練樣本的目的;另外,在模型設計方面,本文結合深度學習、集成學習和遷移學習等方法,提出在訓練樣本量不足的情況下針對特定癲癇患者的具有較高檢測準確率的癲癇檢測方法。在測試中,本文分析了以小波變換尺度因子為2、4、8時的癲癇發作檢測實驗結果,在小波尺度因子為8時,平均準確率、平均敏感度、平均特異性分別為95.47%、93.89%和96.48%;另外,通過與近期相關文獻進行對比,驗證了本文方法具有一定的優越性。本研究結果可為癲癇檢測的臨床應用提供借鑒。
引用本文: 楊涌, 秦小林, 林小光, 文含, 彭云聰. 基于數據增強和深度學習的特定患者癲癇檢測分析方法. 生物醫學工程學雜志, 2022, 39(2): 293-300. doi: 10.7507/1001-5515.202107060 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
癲癇(epilepsy)俗稱“羊角風”或“羊癲風”,是由大腦神經元突發性異常放電導致短暫大腦功能障礙的一種慢性疾病。癲癇患者分布廣泛,在全球范圍內大約有6 500萬患者;據中國最新流行病學資料顯示,中國有900萬左右癲癇患者,國內癲癇的總體患病率為7.0‰,年發病率為28.8/10萬,1年內有發作的活動性癲癇患病率占國內癲癇總量的4.6‰,癲癇已經成為僅次于頭痛的第二大神經系統疾病。癲癇發作的臨床表現復雜多樣,可表現為意識障礙、四肢痙攣、大小便失禁、吐白沫等癥狀,雖然癲癇發作短期內對患者沒有多大的影響,但是長期頻繁的發作會對患者的身心和智力產生嚴重影響[1-3]。
腦電圖(electroencephalogram,EEG)[4]是一種使用電生理指標記錄大腦活動的方法。它記錄大腦活動時的電波變化,是腦神經細胞的電生理活動在大腦皮層或頭皮表面的總體反映。近年來,采用EEG進行癲癇發作檢測得到了學術界的廣泛關注,研究方法主要包括機器學習和深度學習。其中,機器學習是對EEG信號進行特征提取(包括時域特征、頻域特征、時頻域特征、非線性特征等),然后采用支持向量機(support vector machine,SVM)[5]、線性判別分析(linear discriminant analysis,LDA)[6]、樸素貝葉斯(Naive Bayes,NB)[7]、邏輯回歸(logistic regression,LR)[8]、隨機森林(random forest,RF)[9]等方法進行分類,該類方法依賴先驗知識進行特征設計和提取,計算量較大。深度學習是將大量的數據輸入到深度神經網絡中進行訓練,然后用訓練好的神經網絡模型對新數據進行分類和預測,該方法在訓練樣本量相對較少的情況下,由于模型提取訓練樣本數據特征過于精確,導致該模型在測試集上效果差,容易產生過擬合現象。為了消除或緩解模型過擬合,科研工作者借鑒了圖像識別任務中通用的數據增強方法[10-11]和遷移學習,取得了一定的效果。但在癲癇檢測任務中,由于癲癇腦電數據具有時變性和患者間數據差異較大,導致直接采用應用于圖像處理的數據增強和遷移學習方法達不到預期消除過擬合問題的效果。
目前,采用數據增強來改進和優化癲癇檢測方法的文獻相對較少,本文分析的文獻范圍擴展到采用EEG腦電信號進行情感識別、運動想象等相近文獻。Wang等[12]在情感識別任務中,對原始EEG數據進行隨機加噪,以達到增加訓練樣本量的目的,提高了網絡的準確率和魯棒性;Fahimi等[13]采用生成對抗網絡產生人工數據,在運動想象任務中將測試結果提升了7.32%;Krell等[14]在腦機接口任務中將EEG數據進行旋轉形成新樣本,提升了模型性能;Wei等[15]在癲癇檢測任務中采用生成對抗網絡生成訓練樣本數據,采用卷積神經網絡取得了72.11%的平均敏感度、95.89%的平均特異性和84%的平均準確率;Zhang等[16]采用遷移學習,將預先訓練好的ImageNet網絡參數遷移到VGG16、VGG19和ResNet50網絡中,在美國波士頓兒童醫院的癲癇數據集上實現VGG16網絡97.95%的準確率、VGG19網絡98.26%的準確率和ResNet50網絡96.17%的準確率;Jiang等[17]采用遷移學習、半監督學習等方法,在標注樣本數不足的情況下,在德國波恩癲癇數據集上取得了很好的效果。綜上所述,以上文獻中所報道的工作在訓練樣本量較少時模型性能取得了一定提升,但由于EEG信號具有時變性和不穩定性,單純借鑒圖像領域中的數據增強方法生成的數據與原數據不相關,借鑒圖像領域中的遷移學習思想存在訓練數據集選擇困難等問題,因此,在訓練樣本數量有限的情況下,為了避免過擬合現象,提高網絡檢測精度,需要探索新的數據增強方法。
1 本文提出的方法
1.1 方法概述
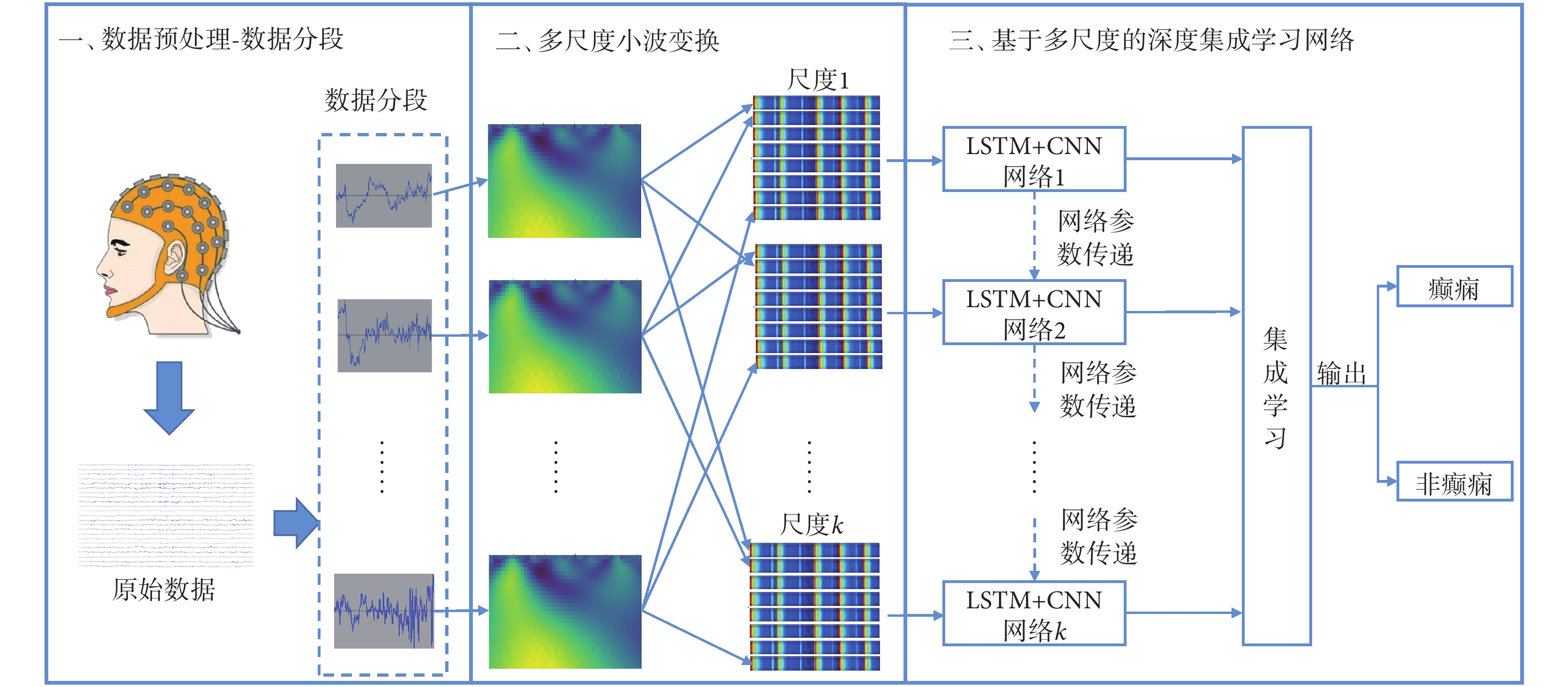
為了在訓練樣本有限的條件下實現高精度的癲癇檢測,本文提出的方法采用連續小波變換對訓練樣本進行數據增強。該方法包括3個組成部分:數據預處理、多尺度小波變換和基于多尺度的深度集成學習網絡。其中,在數據預處理中,對數據采用正則化進行處理,并以固定長度進行數據分段,以便于后期數據處理;在多尺度小波變換中,采用連續小波變換,分別對每個分段數據中的每個通道數據進行連續小波變換,然后將變換后的數據按小波變換尺度對數據進行整合;在基于多尺度的深度集成學習網絡中,采用長短時記憶網絡(long short-term memory,LSTM)和卷積神經網絡(convolutional neural networks,CNN)相結合的網絡結構,并借鑒遷移學習、集成學習等方法,實現癲癇發作和正常數據的分類。整個算法的執行流程如圖1所示。
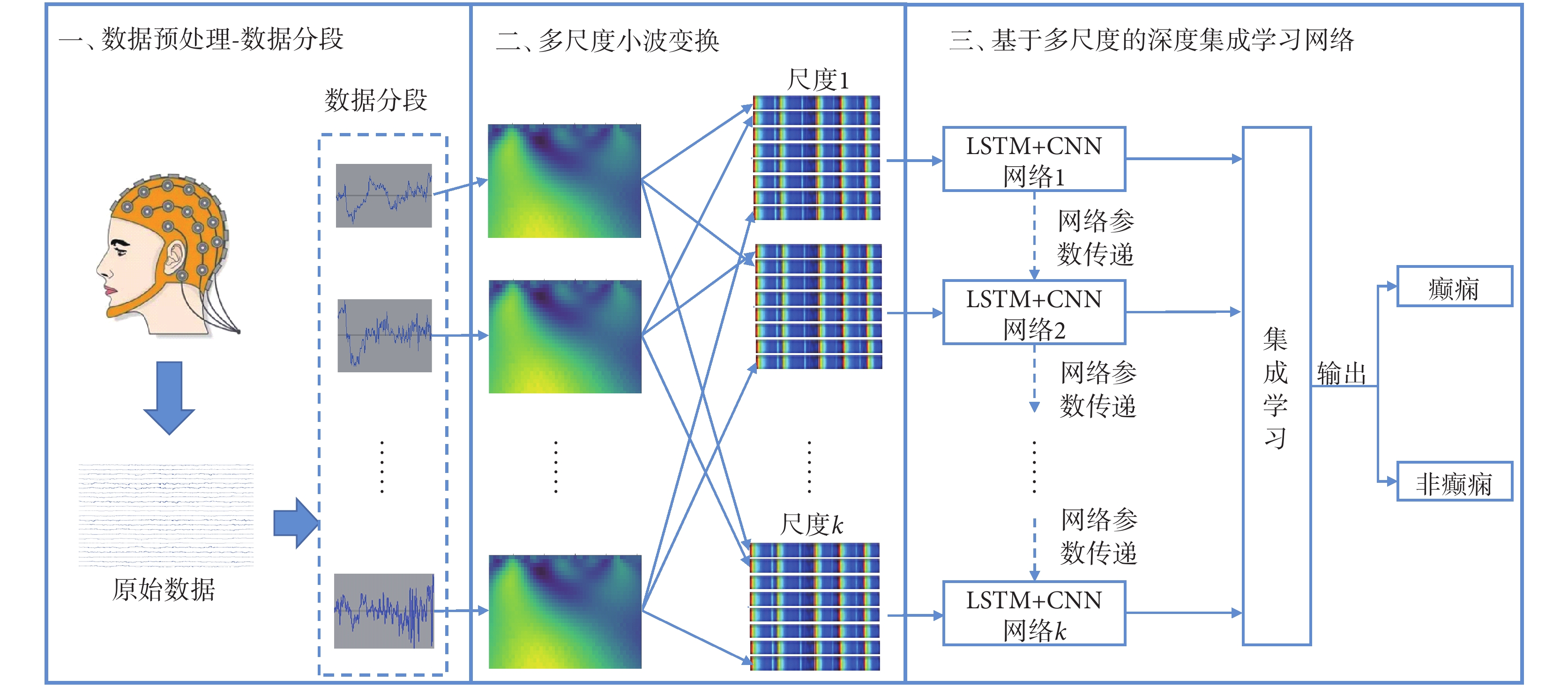 圖1
基于數據增強和深度集成學習的癲癇檢測模型流程圖
Figure1.
Flow chart of epilepsy detection model based on data augmentation and deep ensemble learning
圖1
基于數據增強和深度集成學習的癲癇檢測模型流程圖
Figure1.
Flow chart of epilepsy detection model based on data augmentation and deep ensemble learning
1.2 數據預處理
為了提高算法檢測準確率,本文采用min-max正則化技術[18]對腦電數據進行正則化處理,被正則化處理后的數據為0 ~ 1之間。min-max正則化方法如下式所示:
 |
其中, 為原始數據,
為原始數據, 為數據正則化后的數據,
為數據正則化后的數據, 和
和  為原始數據中的最小值和最大值。
為原始數據中的最小值和最大值。
對腦電數據正則化后,為了便于提取EEG數據特征,對腦電數據進行分段處理。在處理過程中,所有通道數據都被選取,在時間維度上,按照1 s為一個數據分段長度對數據進行分段,取完一段數據后滑動1 s取下一個數據段,當最后一段數據中采樣點不足256個點時,該分段數據被舍棄。對于數據段的標注,當截取的數據段在癲癇發作數據中,此分段數據標注為1,當截取的數據段在正常數據中,此分段數據標注為0。
1.3 小波變換與數據整合
由于連續小波變換具有多分辨特性,本文提出的方法選擇適當的小波尺度與母小波對截取的數據段按通道分別進行連續小波變換,從而獲得原始信號在時頻域上的有效表征信號[19],連續小波變換如下式所示:
 |
式中,WT表示小波變換, 為原始信號;a(a > 0)、b分別為尺度參數和位移參數;
為原始信號;a(a > 0)、b分別為尺度參數和位移參數; 為子波,是對母小波的縮放和位移。
為子波,是對母小波的縮放和位移。
通過對原始信號 作連續小波變換,相當于將
作連續小波變換,相當于將 投影到二維的時間-尺度平面上,在小波變換中,尺度類似于地圖中的比例尺,大的比例對應信號的全局概略描述,小的比例則對應信號的細節性描述。本文提出的方法考慮到連續小波變換中不同尺度對應的分辨率,通過對連續小波變換后的數據按小波尺度進行整合,產生多個與變換前相似但也存在一定差異的數據。具體而言,選取合適小波尺度和小波基函數,將包含23個通道的時域信號按通道分別進行連續小波變換,得到23個時間-尺度上的2維數據,然后將23個2維矩陣按小波尺度進行重構,相同尺度對應的數據合并得到新的2維矩陣。通過選擇不同的小波變換尺度k,可將原始數據量通過連續小波變換和重組操作后擴大k倍,達到數據增強的目的,從而緩解訓練樣本量不足的問題。
投影到二維的時間-尺度平面上,在小波變換中,尺度類似于地圖中的比例尺,大的比例對應信號的全局概略描述,小的比例則對應信號的細節性描述。本文提出的方法考慮到連續小波變換中不同尺度對應的分辨率,通過對連續小波變換后的數據按小波尺度進行整合,產生多個與變換前相似但也存在一定差異的數據。具體而言,選取合適小波尺度和小波基函數,將包含23個通道的時域信號按通道分別進行連續小波變換,得到23個時間-尺度上的2維數據,然后將23個2維矩陣按小波尺度進行重構,相同尺度對應的數據合并得到新的2維矩陣。通過選擇不同的小波變換尺度k,可將原始數據量通過連續小波變換和重組操作后擴大k倍,達到數據增強的目的,從而緩解訓練樣本量不足的問題。
1.4 運用遷移學習的LSTM+CNN網絡
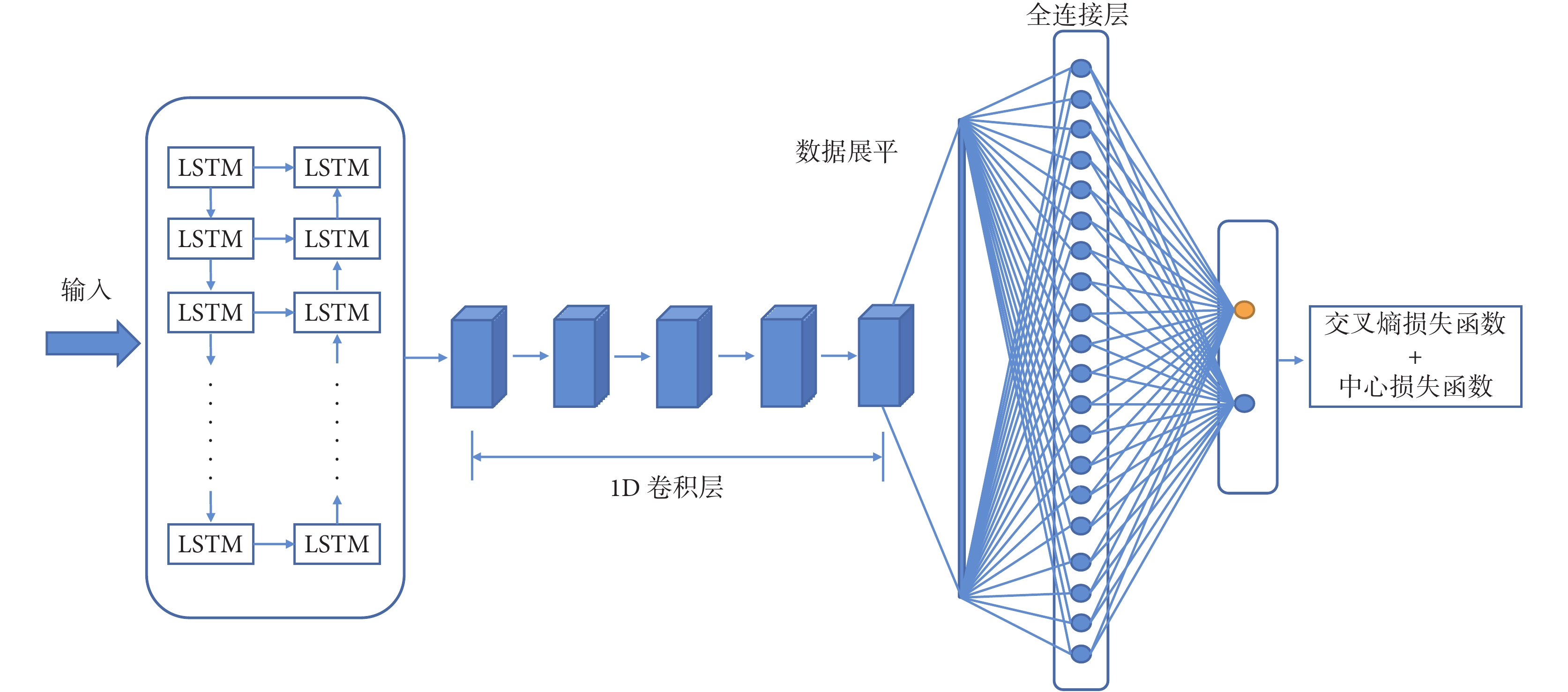
為了實現對癲癇發作數據和正常數據的分類,考慮到變換后的數據為2維矩陣,可看成圖像進行處理,且該數據仍然具有時間特性,因此,采用在時間序列數據表現優異的LSTM網絡和擅長圖像特征識別的CNN網絡。其中,LSTM網絡采用2層LSTM網絡充分提取時間序列的特征信息,網絡結構采取LSTM + CNN混合網絡結構,如圖2所示。
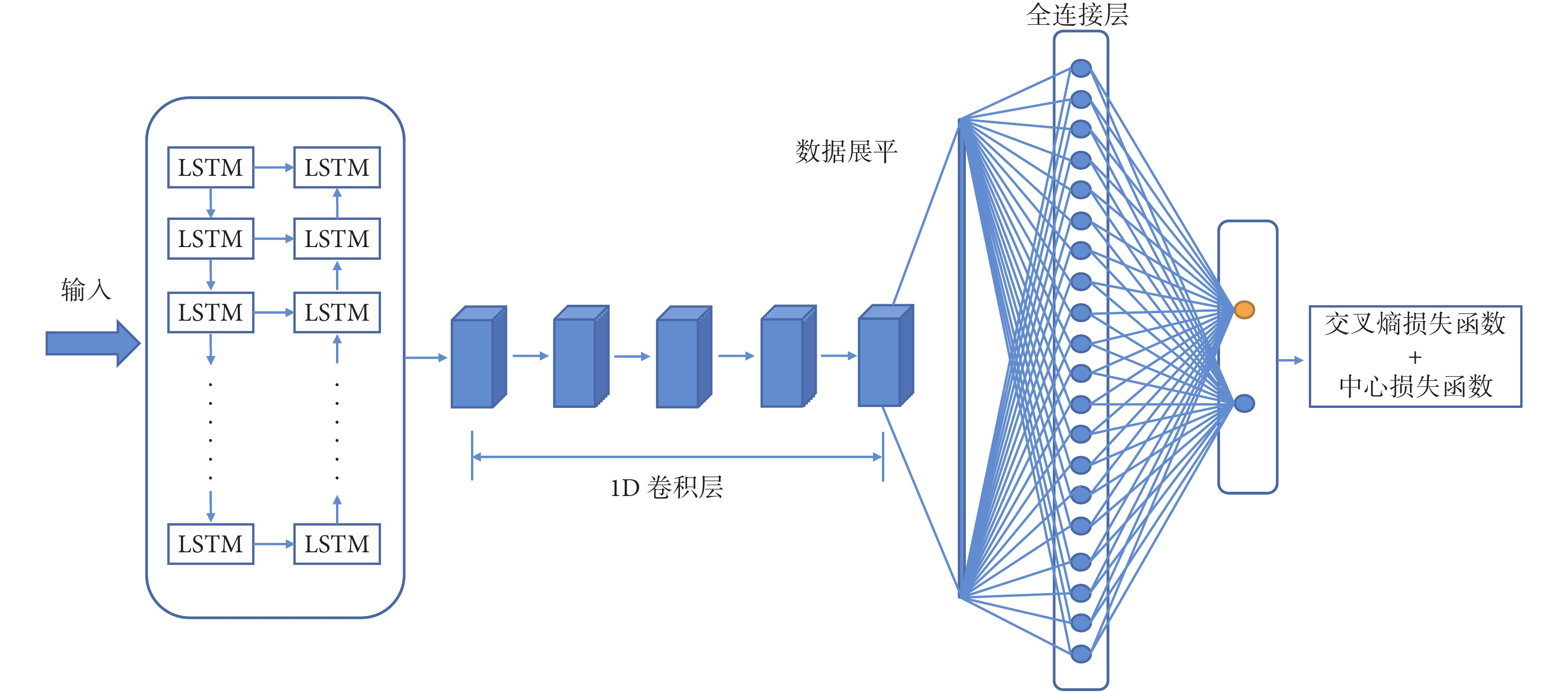 圖2
LSTM+CNN網絡
Figure2.
LSTM+CNN network
圖2
LSTM+CNN網絡
Figure2.
LSTM+CNN network
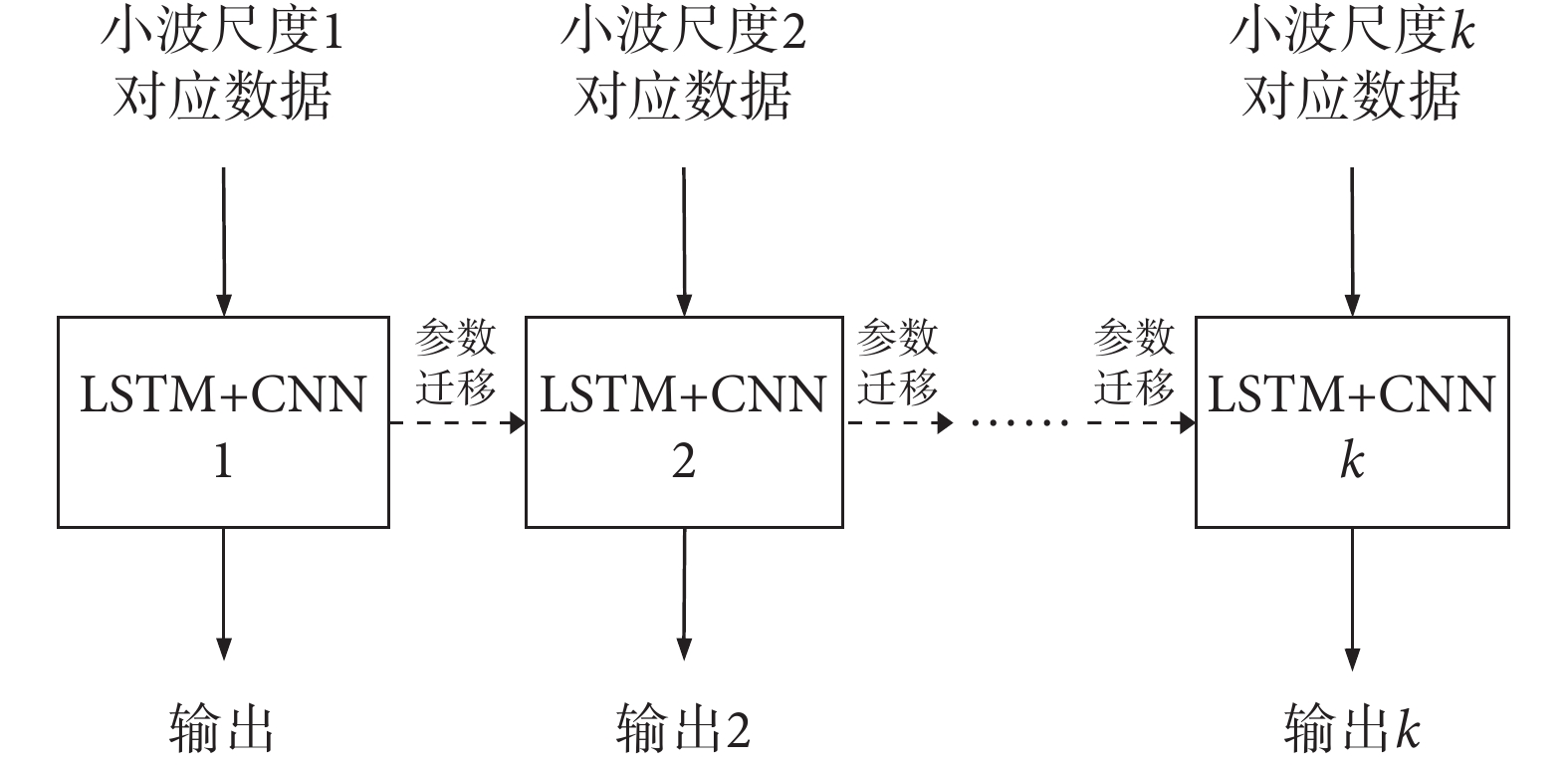
為了充分挖掘數據特性,本文提出的方法以數據增強為基礎,采用遷移學習思想,提升網絡整體性能。具體如下:經過連續小波變換和數據重構后為k路數據(k為小波變換尺度),分別輸入到k路神經網絡中進行訓練,小波變換尺度1對應的第1路數據輸入LSTM + CNN網絡1進行訓練,并將LSTM + CNN網絡1的網絡參數傳遞給LSTM + CNN網絡2,小波變換尺度2對應的第2路數據輸入LSTM + CNN網絡2中進行訓練,并將LSTM + CNN網絡2的網絡參數傳遞到下一級網絡,依次類推,完成整個訓練過程。遷移學習工作流程如圖3所示。
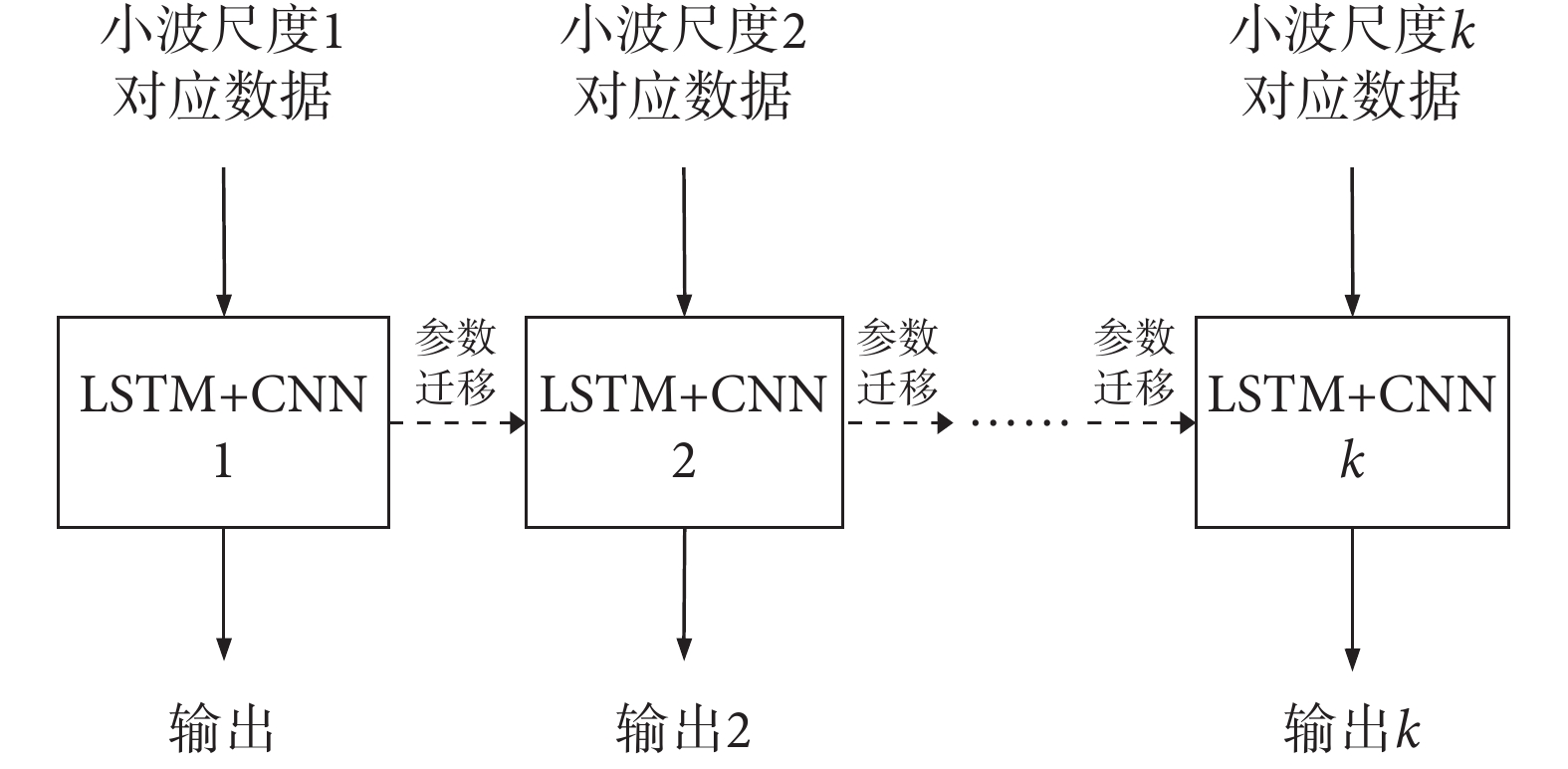 圖3
遷移學習工作流程
Figure3.
Workflow of transfer learning
圖3
遷移學習工作流程
Figure3.
Workflow of transfer learning
1.5 集成學習
為了進一步提升深度學習模型的性能,Akyol[20]和楊澤鑫[21]將集成學習思想應用于癲癇發作檢測中,取得了不錯的應用效果。由于本文方法中提到的深度學習網絡有k個分支,各分支網絡為獨立的同質網絡,因此,為了提升網絡性能,本文借鑒集成學習思想,將各分支的輸出結果進行加權平均,如式(3)所示:
 |
其中, 為權重,
為權重, 為第i個分支網絡的預測結果,
為第i個分支網絡的預測結果, 為所有分支網絡的參數。
為所有分支網絡的參數。
通過將各分支網絡的輸出進行加權平均,從而得到性能更優、泛化能力更強、穩定性更高的網絡模型。
2 實驗設計
2.1 實驗數據集
本文使用美國波士頓兒童醫院的癲癇頭皮腦電圖數據集(https://physionet.org/content/chbmit/1.0.0/)[22],此數據集包含23名患者的24個連續頭皮腦電記錄。其中第1個和第21個記錄來自同一名患者,第24個記錄未提供個人相關信息。該數據集采用國際通用的10-20 EEG電極位置和命名系統,信號采樣頻率為256 Hz,分辨率為每秒16比特。在數據集中,大多數記錄采用23個通道,為便于研究,本文只保留包含23個通道的腦電數據,通道數小于或大于23的記錄將被舍棄,第12、15記錄的通道數量不滿足本實驗要求,因此,第12、15記錄的數據被舍棄。
表1為美國波士頓兒童醫院的癲癇頭皮腦電圖數據集中所有記錄的個人信息、發作次數,以及按實驗設置最終生成的癲癇發作樣本數量。
因每個記錄文件所包含的癲癇發作次數和時長不同,在實驗樣本選取時,采用256個采樣點為截取窗口,滑動截取步長為256,在癲癇發作數據中截取后生成的數據段作為正樣本,在發作數據前截取與正樣本數據長度一致的數據作為正常數據,并滑動截取后生成負樣本,最終形成樣本集。在訓練過程中,樣本集按80%∶10%∶10%分為訓練集、驗證集和測試集。
2.2 實驗環境
本文的實驗環境為:CentOS 7.8操作系統,編程語言采用的是Python3.7.4,深度學習框架為Pytorch(其版本為11.1)。顯卡為:GeForce RTX 2080 Ti。
2.3 實驗參數
本實驗采用LSTM+CNN網絡結構,訓練輪次設置為50次,數據批處理大小設置為32。使用交叉熵損失函數和中心損失函數聯合作為損失函數,模型使用Adam優化器,學習率設置為0.001,中心損失函數使用隨機梯度下降(stochastic gradient descent,SGD)優化器進行優化,學習率設置為0.05。輸入神經網絡的數據為(32,23,256),LSTM設置為雙層LSTM網絡,CNN網絡卷積層卷積核尺寸設置為(3,1),dropout為0.3。另外,在集成學習中,各分支權重設置為1。
2.4 評估指標
實驗使用準確率(accuracy,ACC)、敏感性(sensitivity,SN)和特異性(specificity,SP)對算法的性能進行量化分析。
準確率ACC定義為分類正確的樣本占所有樣本的比例,計算公式為:
 |
敏感性SN定義為分類正確的正樣本占所有正樣本的比例,即正確判斷為患病的比例,計算公式為:
 |
特異性SP定義為分類正確的負樣本占所有負樣本的比例,即正確判斷為非患病的比例,計算公式為:
 |
其中,TP(true positive,真正值):樣本被判定為正樣本,事實上也是正樣本;TN(true negative,真負值):樣本被判定為負樣本,事實上是負樣本;FP(false positive,假正值):樣本被判定為正樣本,但事實上是負樣本;FN(false negative,假負值):樣本被判定為負樣本,但事實上是正樣本。
3 測試結果和分析
本文在訓練樣本數量有限的前提下,采用連續小波變換對原始數據進行數據增強處理,并以小波尺度值來控制數據增強的數量,以減少深度學習網絡模型在訓練和測試過程中的過擬合現象,實現提高檢測精度和網絡穩定性的目的,因此,有必要研究分析不同的尺度因子對實驗結果的影響。在實驗中,本文選擇小波尺度因子為2、4、8進行數據增強,并對各個患者在不同小波尺度因子情況下的結果進行對比分析,測試結果如表2所示。
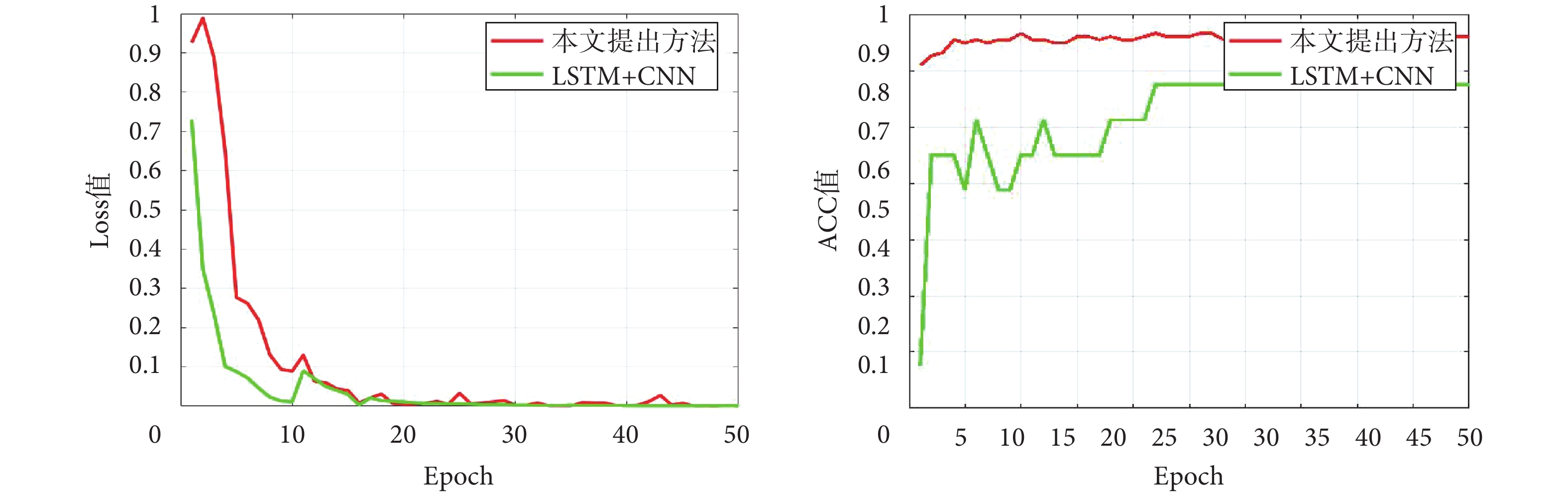
從測試結果對比上看,當小波尺度增加時,訓練樣本數量增加,平均準確率、平均敏感度和平均特異性逐漸增加。另外,為了驗證采用本文提出方法的效果,在美國波士頓兒童醫院的癲癇頭皮腦電圖數據集中對各個記錄數據進行50輪訓練和測試對比,對比方法為不采用數據增強時的LSTM + CNN網絡。圖4為記錄1采用兩種方法時的損失(Loss)值和準確率(ACC)值對比圖,從圖中Loss值可以看出,在訓練初期,本文提出方法Loss值大于對比方法LSTM + CNN網絡,其原因在于本文提出方法采用了數據增強,提高了訓練樣本的數量和多樣性;在ACC值對比上,本文提出方法明顯優于對比方法LSTM + CNN網絡。
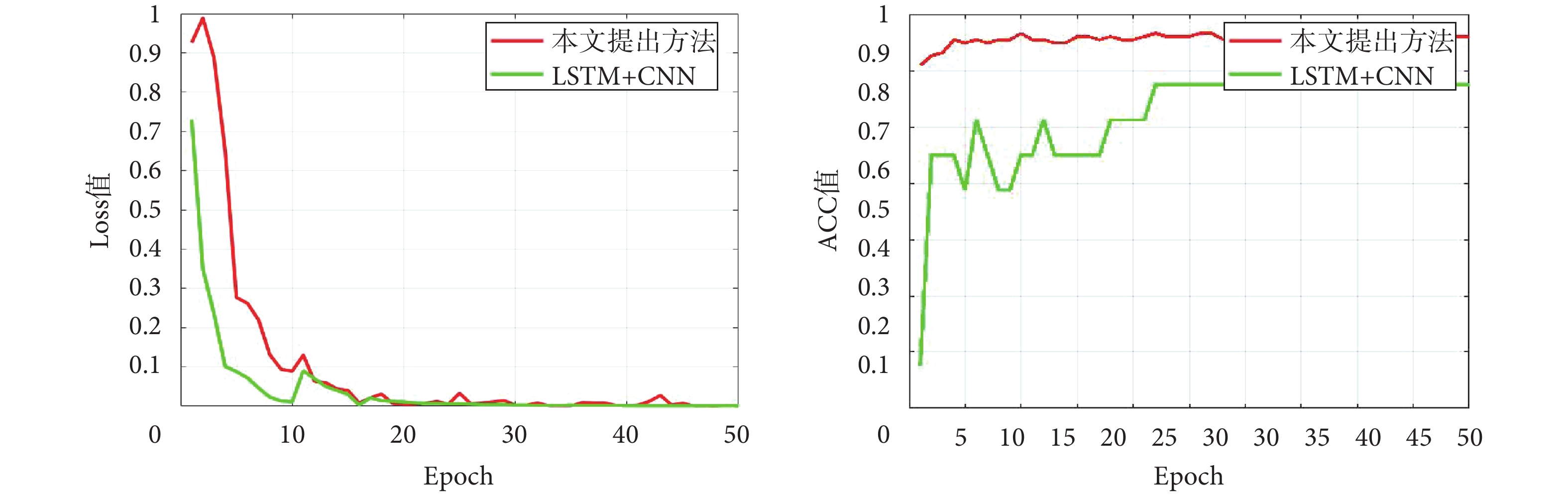 圖4
兩種方法Loss和ACC對比圖
Figure4.
Comparison of Loss and ACC between the two methods
圖4
兩種方法Loss和ACC對比圖
Figure4.
Comparison of Loss and ACC between the two methods
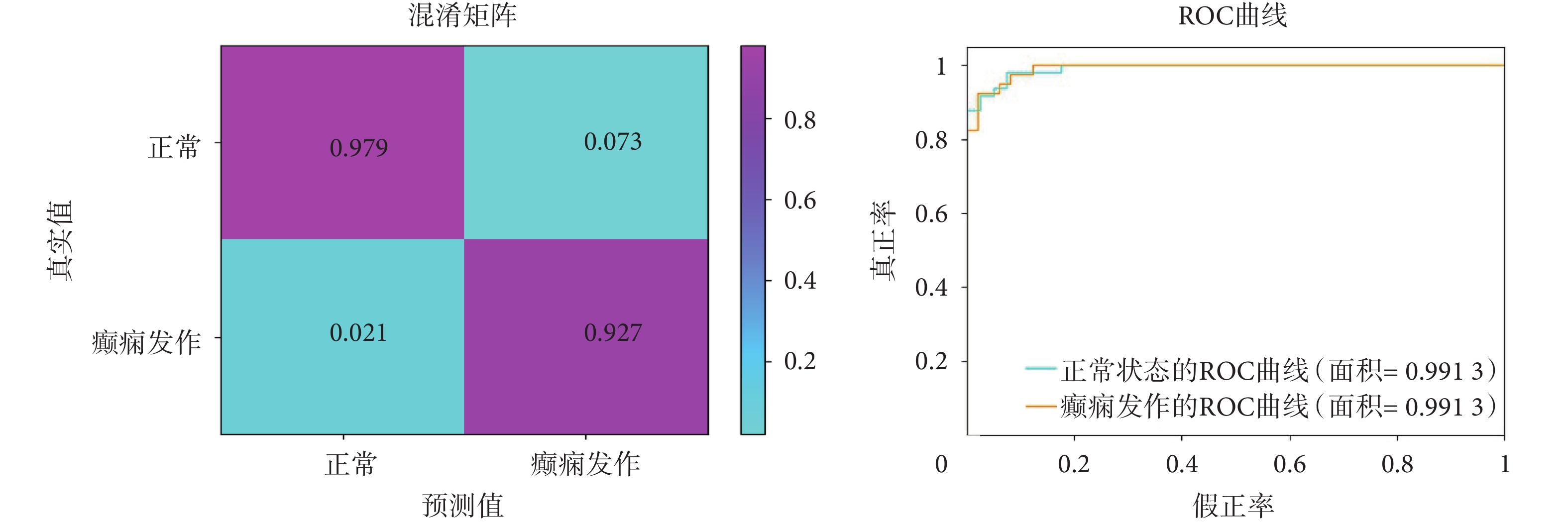
此外,為了對測試結果進行更仔細的分析,我們為每個患者的記錄數據繪制了混淆矩陣和接受者操作特征曲線(receiver operating characteristic curve,ROC)。圖5為記錄1的混淆矩陣和ROC曲線結果,從混淆矩陣中可以觀察到,本文提出的方法達到了97.9%的靈敏度和92.7%的特異性;從ROC曲線可以觀察到,正常和癲癇發作的曲線下面積(area under curve,AUC)都達到0.991 3,測試性能具有一定競爭性。
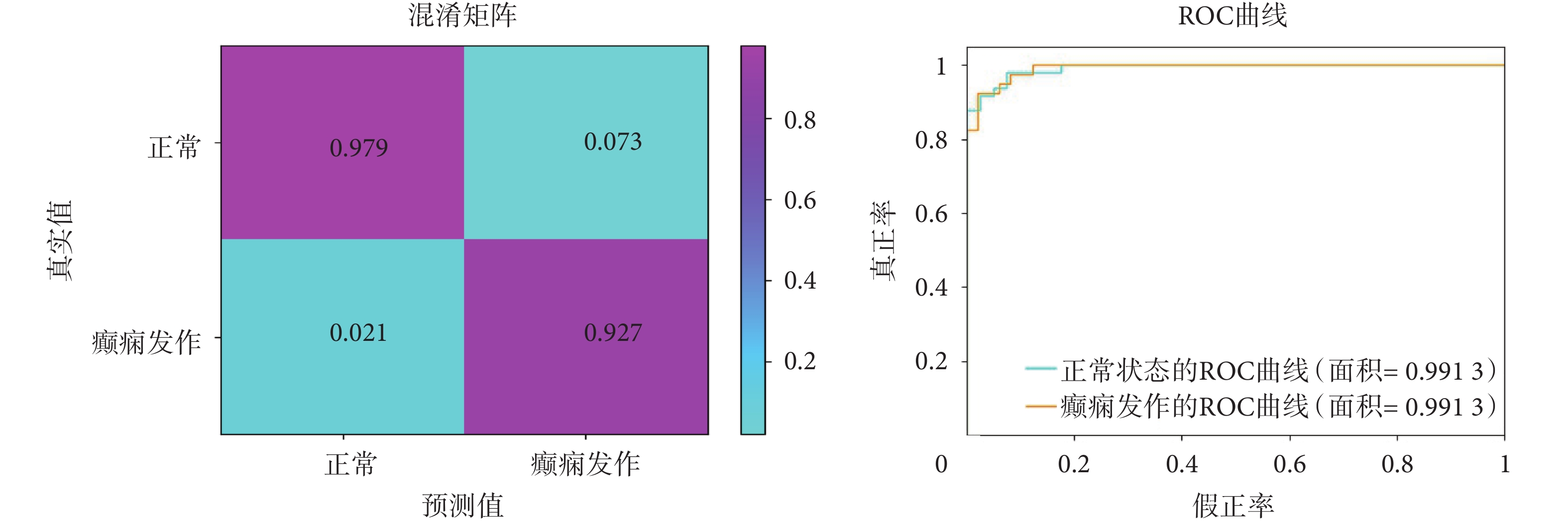 圖5
混淆矩陣和ROC曲線
Figure5.
Confusion matrix and ROC curves
圖5
混淆矩陣和ROC曲線
Figure5.
Confusion matrix and ROC curves
分析其原因在于:一是充分利用了連續小波變換的性質和特點,將小波變換應用于數據增強,提高了訓練數據量;二是借鑒遷移學習的思想,將數據增強后的數據串行輸入到k個獨立網絡中進行訓練,網絡模型參數逐級遷移,保留了多個分支網絡的多樣性;三是結合集成學習思想,將各個子網絡的訓練結果進行綜合處理,提高了網絡的準確率和穩定性。
在對比文獻的選擇方面,文獻[15,23-25]以美國波士頓兒童醫院的癲癇頭皮腦電圖數據集為測試驗證對象,采用了與本文模型結構較為接近的網絡結構,因此,本文方法將與這些文獻進行對比,以驗證本文方法的優越性。為了保證實驗結果的可比性,采用了相同的美國波士頓兒童醫院的癲癇頭皮腦電圖數據集,實驗對比結果如表3所示。
在對比實驗中,本文提出的方法以小波變換尺度值為8時的測試結果與對比文獻進行比較分析,結果可見:本文提出的方法在準確率和敏感度方面結果最優,在特異性方面,文獻[15]采用CNN達到96.94%,為對比方法中最高;文獻[24]采用CNN和循環神經網絡(recurrent neural network,RNN)相結合的網絡結構,該網絡測試結果與本文提出的方法最接近;另外,單獨采用CNN[15]、RNN[23]、LSTM[25]則測試性能不理想。分析本文所提出方法的優越性,有以下3個方面:① 采用小波變換進行數據增強;② 通過設置不同的小波變換尺度因子實現生成數據量的控制;③ 采用遷移學習、集成學習思想,提出了綜合考慮遷移學習、集成學習的LSTM+CNN網絡。
4 結論
本文基于EEG的癲癇腦電檢測任務,在訓練樣本數量有限的條件下,為了提高網絡的檢測精度和魯棒性,利用連續小波變換的多尺度特性對癲癇腦電數據進行數據增強,并以此為基礎提出了一種基于數據增強和深度學習的癲癇檢測方法,在美國波士頓兒童醫院的癲癇頭皮腦電圖數據集上進行了充分測試,驗證了本方法在不同小波尺度上的平均準確率、平均敏感性和平均特異性,并與相關文獻進行對比,達到了具有一定競爭力的測試結果。另外,關于將來的研究方向,還需要采用領域自適應和領域泛化等技術解決患者間測試差異的問題,研究更具普適性的方法,進一步提升模型檢測性能,為癲癇檢測的臨床應用探索可用的高精度、高適應性、高可靠性的算法。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:楊涌主要負責數據的預處理和算法的設計與實現工作,秦小林和林小光參與了算法設計工作,文含參與了實驗程序編寫和調試工作,彭云聰參與了數據收集和前期數據處理工作。
引言
癲癇(epilepsy)俗稱“羊角風”或“羊癲風”,是由大腦神經元突發性異常放電導致短暫大腦功能障礙的一種慢性疾病。癲癇患者分布廣泛,在全球范圍內大約有6 500萬患者;據中國最新流行病學資料顯示,中國有900萬左右癲癇患者,國內癲癇的總體患病率為7.0‰,年發病率為28.8/10萬,1年內有發作的活動性癲癇患病率占國內癲癇總量的4.6‰,癲癇已經成為僅次于頭痛的第二大神經系統疾病。癲癇發作的臨床表現復雜多樣,可表現為意識障礙、四肢痙攣、大小便失禁、吐白沫等癥狀,雖然癲癇發作短期內對患者沒有多大的影響,但是長期頻繁的發作會對患者的身心和智力產生嚴重影響[1-3]。
腦電圖(electroencephalogram,EEG)[4]是一種使用電生理指標記錄大腦活動的方法。它記錄大腦活動時的電波變化,是腦神經細胞的電生理活動在大腦皮層或頭皮表面的總體反映。近年來,采用EEG進行癲癇發作檢測得到了學術界的廣泛關注,研究方法主要包括機器學習和深度學習。其中,機器學習是對EEG信號進行特征提取(包括時域特征、頻域特征、時頻域特征、非線性特征等),然后采用支持向量機(support vector machine,SVM)[5]、線性判別分析(linear discriminant analysis,LDA)[6]、樸素貝葉斯(Naive Bayes,NB)[7]、邏輯回歸(logistic regression,LR)[8]、隨機森林(random forest,RF)[9]等方法進行分類,該類方法依賴先驗知識進行特征設計和提取,計算量較大。深度學習是將大量的數據輸入到深度神經網絡中進行訓練,然后用訓練好的神經網絡模型對新數據進行分類和預測,該方法在訓練樣本量相對較少的情況下,由于模型提取訓練樣本數據特征過于精確,導致該模型在測試集上效果差,容易產生過擬合現象。為了消除或緩解模型過擬合,科研工作者借鑒了圖像識別任務中通用的數據增強方法[10-11]和遷移學習,取得了一定的效果。但在癲癇檢測任務中,由于癲癇腦電數據具有時變性和患者間數據差異較大,導致直接采用應用于圖像處理的數據增強和遷移學習方法達不到預期消除過擬合問題的效果。
目前,采用數據增強來改進和優化癲癇檢測方法的文獻相對較少,本文分析的文獻范圍擴展到采用EEG腦電信號進行情感識別、運動想象等相近文獻。Wang等[12]在情感識別任務中,對原始EEG數據進行隨機加噪,以達到增加訓練樣本量的目的,提高了網絡的準確率和魯棒性;Fahimi等[13]采用生成對抗網絡產生人工數據,在運動想象任務中將測試結果提升了7.32%;Krell等[14]在腦機接口任務中將EEG數據進行旋轉形成新樣本,提升了模型性能;Wei等[15]在癲癇檢測任務中采用生成對抗網絡生成訓練樣本數據,采用卷積神經網絡取得了72.11%的平均敏感度、95.89%的平均特異性和84%的平均準確率;Zhang等[16]采用遷移學習,將預先訓練好的ImageNet網絡參數遷移到VGG16、VGG19和ResNet50網絡中,在美國波士頓兒童醫院的癲癇數據集上實現VGG16網絡97.95%的準確率、VGG19網絡98.26%的準確率和ResNet50網絡96.17%的準確率;Jiang等[17]采用遷移學習、半監督學習等方法,在標注樣本數不足的情況下,在德國波恩癲癇數據集上取得了很好的效果。綜上所述,以上文獻中所報道的工作在訓練樣本量較少時模型性能取得了一定提升,但由于EEG信號具有時變性和不穩定性,單純借鑒圖像領域中的數據增強方法生成的數據與原數據不相關,借鑒圖像領域中的遷移學習思想存在訓練數據集選擇困難等問題,因此,在訓練樣本數量有限的情況下,為了避免過擬合現象,提高網絡檢測精度,需要探索新的數據增強方法。
1 本文提出的方法
1.1 方法概述
為了在訓練樣本有限的條件下實現高精度的癲癇檢測,本文提出的方法采用連續小波變換對訓練樣本進行數據增強。該方法包括3個組成部分:數據預處理、多尺度小波變換和基于多尺度的深度集成學習網絡。其中,在數據預處理中,對數據采用正則化進行處理,并以固定長度進行數據分段,以便于后期數據處理;在多尺度小波變換中,采用連續小波變換,分別對每個分段數據中的每個通道數據進行連續小波變換,然后將變換后的數據按小波變換尺度對數據進行整合;在基于多尺度的深度集成學習網絡中,采用長短時記憶網絡(long short-term memory,LSTM)和卷積神經網絡(convolutional neural networks,CNN)相結合的網絡結構,并借鑒遷移學習、集成學習等方法,實現癲癇發作和正常數據的分類。整個算法的執行流程如圖1所示。
圖1
基于數據增強和深度集成學習的癲癇檢測模型流程圖
Figure1.
Flow chart of epilepsy detection model based on data augmentation and deep ensemble learning
1.2 數據預處理
為了提高算法檢測準確率,本文采用min-max正則化技術[18]對腦電數據進行正則化處理,被正則化處理后的數據為0 ~ 1之間。min-max正則化方法如下式所示:
|
其中, 為原始數據, 為數據正則化后的數據, 和 為原始數據中的最小值和最大值。
對腦電數據正則化后,為了便于提取EEG數據特征,對腦電數據進行分段處理。在處理過程中,所有通道數據都被選取,在時間維度上,按照1 s為一個數據分段長度對數據進行分段,取完一段數據后滑動1 s取下一個數據段,當最后一段數據中采樣點不足256個點時,該分段數據被舍棄。對于數據段的標注,當截取的數據段在癲癇發作數據中,此分段數據標注為1,當截取的數據段在正常數據中,此分段數據標注為0。
1.3 小波變換與數據整合
由于連續小波變換具有多分辨特性,本文提出的方法選擇適當的小波尺度與母小波對截取的數據段按通道分別進行連續小波變換,從而獲得原始信號在時頻域上的有效表征信號[19],連續小波變換如下式所示:
|
式中,WT表示小波變換, 為原始信號;a(a > 0)、b分別為尺度參數和位移參數; 為子波,是對母小波的縮放和位移。
通過對原始信號作連續小波變換,相當于將投影到二維的時間-尺度平面上,在小波變換中,尺度類似于地圖中的比例尺,大的比例對應信號的全局概略描述,小的比例則對應信號的細節性描述。本文提出的方法考慮到連續小波變換中不同尺度對應的分辨率,通過對連續小波變換后的數據按小波尺度進行整合,產生多個與變換前相似但也存在一定差異的數據。具體而言,選取合適小波尺度和小波基函數,將包含23個通道的時域信號按通道分別進行連續小波變換,得到23個時間-尺度上的2維數據,然后將23個2維矩陣按小波尺度進行重構,相同尺度對應的數據合并得到新的2維矩陣。通過選擇不同的小波變換尺度k,可將原始數據量通過連續小波變換和重組操作后擴大k倍,達到數據增強的目的,從而緩解訓練樣本量不足的問題。
1.4 運用遷移學習的LSTM+CNN網絡
為了實現對癲癇發作數據和正常數據的分類,考慮到變換后的數據為2維矩陣,可看成圖像進行處理,且該數據仍然具有時間特性,因此,采用在時間序列數據表現優異的LSTM網絡和擅長圖像特征識別的CNN網絡。其中,LSTM網絡采用2層LSTM網絡充分提取時間序列的特征信息,網絡結構采取LSTM + CNN混合網絡結構,如圖2所示。
圖2
LSTM+CNN網絡
Figure2.
LSTM+CNN network
為了充分挖掘數據特性,本文提出的方法以數據增強為基礎,采用遷移學習思想,提升網絡整體性能。具體如下:經過連續小波變換和數據重構后為k路數據(k為小波變換尺度),分別輸入到k路神經網絡中進行訓練,小波變換尺度1對應的第1路數據輸入LSTM + CNN網絡1進行訓練,并將LSTM + CNN網絡1的網絡參數傳遞給LSTM + CNN網絡2,小波變換尺度2對應的第2路數據輸入LSTM + CNN網絡2中進行訓練,并將LSTM + CNN網絡2的網絡參數傳遞到下一級網絡,依次類推,完成整個訓練過程。遷移學習工作流程如圖3所示。
圖3
遷移學習工作流程
Figure3.
Workflow of transfer learning
1.5 集成學習
為了進一步提升深度學習模型的性能,Akyol[20]和楊澤鑫[21]將集成學習思想應用于癲癇發作檢測中,取得了不錯的應用效果。由于本文方法中提到的深度學習網絡有k個分支,各分支網絡為獨立的同質網絡,因此,為了提升網絡性能,本文借鑒集成學習思想,將各分支的輸出結果進行加權平均,如式(3)所示:
|
其中, 為權重, 為第i個分支網絡的預測結果, 為所有分支網絡的參數。
通過將各分支網絡的輸出進行加權平均,從而得到性能更優、泛化能力更強、穩定性更高的網絡模型。
2 實驗設計
2.1 實驗數據集
本文使用美國波士頓兒童醫院的癲癇頭皮腦電圖數據集(https://physionet.org/content/chbmit/1.0.0/)[22],此數據集包含23名患者的24個連續頭皮腦電記錄。其中第1個和第21個記錄來自同一名患者,第24個記錄未提供個人相關信息。該數據集采用國際通用的10-20 EEG電極位置和命名系統,信號采樣頻率為256 Hz,分辨率為每秒16比特。在數據集中,大多數記錄采用23個通道,為便于研究,本文只保留包含23個通道的腦電數據,通道數小于或大于23的記錄將被舍棄,第12、15記錄的通道數量不滿足本實驗要求,因此,第12、15記錄的數據被舍棄。
表1為美國波士頓兒童醫院的癲癇頭皮腦電圖數據集中所有記錄的個人信息、發作次數,以及按實驗設置最終生成的癲癇發作樣本數量。
因每個記錄文件所包含的癲癇發作次數和時長不同,在實驗樣本選取時,采用256個采樣點為截取窗口,滑動截取步長為256,在癲癇發作數據中截取后生成的數據段作為正樣本,在發作數據前截取與正樣本數據長度一致的數據作為正常數據,并滑動截取后生成負樣本,最終形成樣本集。在訓練過程中,樣本集按80%∶10%∶10%分為訓練集、驗證集和測試集。
2.2 實驗環境
本文的實驗環境為:CentOS 7.8操作系統,編程語言采用的是Python3.7.4,深度學習框架為Pytorch(其版本為11.1)。顯卡為:GeForce RTX 2080 Ti。
2.3 實驗參數
本實驗采用LSTM+CNN網絡結構,訓練輪次設置為50次,數據批處理大小設置為32。使用交叉熵損失函數和中心損失函數聯合作為損失函數,模型使用Adam優化器,學習率設置為0.001,中心損失函數使用隨機梯度下降(stochastic gradient descent,SGD)優化器進行優化,學習率設置為0.05。輸入神經網絡的數據為(32,23,256),LSTM設置為雙層LSTM網絡,CNN網絡卷積層卷積核尺寸設置為(3,1),dropout為0.3。另外,在集成學習中,各分支權重設置為1。
2.4 評估指標
實驗使用準確率(accuracy,ACC)、敏感性(sensitivity,SN)和特異性(specificity,SP)對算法的性能進行量化分析。
準確率ACC定義為分類正確的樣本占所有樣本的比例,計算公式為:
|
敏感性SN定義為分類正確的正樣本占所有正樣本的比例,即正確判斷為患病的比例,計算公式為:
|
特異性SP定義為分類正確的負樣本占所有負樣本的比例,即正確判斷為非患病的比例,計算公式為:
|
其中,TP(true positive,真正值):樣本被判定為正樣本,事實上也是正樣本;TN(true negative,真負值):樣本被判定為負樣本,事實上是負樣本;FP(false positive,假正值):樣本被判定為正樣本,但事實上是負樣本;FN(false negative,假負值):樣本被判定為負樣本,但事實上是正樣本。
3 測試結果和分析
本文在訓練樣本數量有限的前提下,采用連續小波變換對原始數據進行數據增強處理,并以小波尺度值來控制數據增強的數量,以減少深度學習網絡模型在訓練和測試過程中的過擬合現象,實現提高檢測精度和網絡穩定性的目的,因此,有必要研究分析不同的尺度因子對實驗結果的影響。在實驗中,本文選擇小波尺度因子為2、4、8進行數據增強,并對各個患者在不同小波尺度因子情況下的結果進行對比分析,測試結果如表2所示。
從測試結果對比上看,當小波尺度增加時,訓練樣本數量增加,平均準確率、平均敏感度和平均特異性逐漸增加。另外,為了驗證采用本文提出方法的效果,在美國波士頓兒童醫院的癲癇頭皮腦電圖數據集中對各個記錄數據進行50輪訓練和測試對比,對比方法為不采用數據增強時的LSTM + CNN網絡。圖4為記錄1采用兩種方法時的損失(Loss)值和準確率(ACC)值對比圖,從圖中Loss值可以看出,在訓練初期,本文提出方法Loss值大于對比方法LSTM + CNN網絡,其原因在于本文提出方法采用了數據增強,提高了訓練樣本的數量和多樣性;在ACC值對比上,本文提出方法明顯優于對比方法LSTM + CNN網絡。
圖4
兩種方法Loss和ACC對比圖
Figure4.
Comparison of Loss and ACC between the two methods
此外,為了對測試結果進行更仔細的分析,我們為每個患者的記錄數據繪制了混淆矩陣和接受者操作特征曲線(receiver operating characteristic curve,ROC)。圖5為記錄1的混淆矩陣和ROC曲線結果,從混淆矩陣中可以觀察到,本文提出的方法達到了97.9%的靈敏度和92.7%的特異性;從ROC曲線可以觀察到,正常和癲癇發作的曲線下面積(area under curve,AUC)都達到0.991 3,測試性能具有一定競爭性。
圖5
混淆矩陣和ROC曲線
Figure5.
Confusion matrix and ROC curves
分析其原因在于:一是充分利用了連續小波變換的性質和特點,將小波變換應用于數據增強,提高了訓練數據量;二是借鑒遷移學習的思想,將數據增強后的數據串行輸入到k個獨立網絡中進行訓練,網絡模型參數逐級遷移,保留了多個分支網絡的多樣性;三是結合集成學習思想,將各個子網絡的訓練結果進行綜合處理,提高了網絡的準確率和穩定性。
在對比文獻的選擇方面,文獻[15,23-25]以美國波士頓兒童醫院的癲癇頭皮腦電圖數據集為測試驗證對象,采用了與本文模型結構較為接近的網絡結構,因此,本文方法將與這些文獻進行對比,以驗證本文方法的優越性。為了保證實驗結果的可比性,采用了相同的美國波士頓兒童醫院的癲癇頭皮腦電圖數據集,實驗對比結果如表3所示。
在對比實驗中,本文提出的方法以小波變換尺度值為8時的測試結果與對比文獻進行比較分析,結果可見:本文提出的方法在準確率和敏感度方面結果最優,在特異性方面,文獻[15]采用CNN達到96.94%,為對比方法中最高;文獻[24]采用CNN和循環神經網絡(recurrent neural network,RNN)相結合的網絡結構,該網絡測試結果與本文提出的方法最接近;另外,單獨采用CNN[15]、RNN[23]、LSTM[25]則測試性能不理想。分析本文所提出方法的優越性,有以下3個方面:① 采用小波變換進行數據增強;② 通過設置不同的小波變換尺度因子實現生成數據量的控制;③ 采用遷移學習、集成學習思想,提出了綜合考慮遷移學習、集成學習的LSTM+CNN網絡。
4 結論
本文基于EEG的癲癇腦電檢測任務,在訓練樣本數量有限的條件下,為了提高網絡的檢測精度和魯棒性,利用連續小波變換的多尺度特性對癲癇腦電數據進行數據增強,并以此為基礎提出了一種基于數據增強和深度學習的癲癇檢測方法,在美國波士頓兒童醫院的癲癇頭皮腦電圖數據集上進行了充分測試,驗證了本方法在不同小波尺度上的平均準確率、平均敏感性和平均特異性,并與相關文獻進行對比,達到了具有一定競爭力的測試結果。另外,關于將來的研究方向,還需要采用領域自適應和領域泛化等技術解決患者間測試差異的問題,研究更具普適性的方法,進一步提升模型檢測性能,為癲癇檢測的臨床應用探索可用的高精度、高適應性、高可靠性的算法。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:楊涌主要負責數據的預處理和算法的設計與實現工作,秦小林和林小光參與了算法設計工作,文含參與了實驗程序編寫和調試工作,彭云聰參與了數據收集和前期數據處理工作。