肺癌是對人類健康威脅最大的腫瘤疾病,早期發現對于患者的生存和康復至關重要。現有方法采用二維多視角框架學習肺結節特征并簡單集成多個視角特征實現肺結節良惡性分類。然而,這些方法存在不能有效捕捉空間特性和忽略了多個視角的差異性問題。因此,本文提出三維(3D)多視角卷積神經網絡(MVCNN)框架,為進一步解決多視角模型中各視角的差異性問題,在特征融合階段引入擠壓激勵(SE)模塊,構建了3D多視角擠壓激勵卷積神經網絡(MVSECNN)模型。最后,采用統計學方法對模型預測與醫生注釋結果進行分析。在獨立測試集中,模型的分類準確率和靈敏度分別為96.04%和98.59%,均高于目前已有方法;模型預測與病理診斷的一致性分數為0.948,顯著高于醫生注釋結果與病理診斷的一致性。本文所提方法可以有效地學習結節空間異質性和解決多視角差異性問題,同時實現了肺結節良惡性分類,對于輔助醫生進行臨床診斷具有重要意義。
引用本文: 楊楊, 李曉琴, 韓振波, 付繼鵬, 高斌. 基于三維多視角擠壓激勵卷積神經網絡的肺結節良惡性分類研究. 生物醫學工程學雜志, 2022, 39(3): 452-461. doi: 10.7507/1001-5515.202110059 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
肺癌是最常見的惡性腫瘤之一,由國際癌癥研究中心(international agency for research on cancer,IARC)發布的全球癌癥(global cancer,GLOBOCAN)統計報告2020年版顯示,肺癌死亡及發病人數均位于前三[1]。最新研究表明,通過低劑量計算機斷層掃描(computed tomography,CT)進行肺癌早期篩查,可使男性肺癌死亡率降低24%,女性肺癌死亡率降低33%[2],早期篩查對于肺癌的早發現、早治療、降低死亡率等具有重要價值。另一方面,隨著肺癌早期篩查的普及,醫生的閱片壓力激增,診斷過程中可能會造成誤診及漏診。肺癌與肺結節有著錯綜復雜的關系,因此早期的肺結節良惡性診斷是提高肺癌診斷率和延長患者生存期的關鍵步驟。現如今借助計算機技術的快速發展、醫療設備的完善與成熟的醫學圖像處理技術,計算機輔助診斷(computer aided diagnosis,CAD)系統應運而生。基于深度學習的肺結節良惡性分類方法,通過深層架構自動學習當前數據的抽象層次特征,能夠以圖像特征的識別和分類來訓練模型,并利用模型的準確率(accuracy,Acc)、損失值等多重評價指標來反向指導特征的提取[3]。例如,Hua等[4]在2015年首次提出將二維(two-dimensional,2D)卷積神經網絡(convolutional neural network,CNN)應用于肺結節分類。2D CNN雖然訓練速度快、占用資源少,但是會丟失肺結節的立體信息,為解決此問題,Liu等[5]在2017年提出將三維(three-dimensional,3D)CNN應用于肺結節分類。Marques等[6]從CT圖像和結節語義特征出發,提出了多任務3D CNN,結節的良惡性預測由CT圖像特征和語義特征共同決定。Astaraki等[7]為使3D CNN有效捕捉結節內部特征以及上下文信息,提出了雙路徑結構模型,將分割后的結節圖像與未經分割的結節圖像共同作為模型的輸入。Tang等[8]提出多分辨率3D雙路徑擠壓激勵聚合網絡(dual path squeeze excitation converged network,DPSECN)模型,多分辨率主要體現在將肺結節按其直徑尺寸進行三分類,然后通過線性插值將其轉化為另外兩種不同級別分辨率的數據,每個樣本獲得相應的三種不同分辨率的數據,作為模型的輸入來訓練模型。
Setio等[9]提出2D多視角(multi-view,MV)CNN(MVCNN),通過2D MVCNN實現3D特征的捕捉,對于每個結節數據,提取9個固定方向的2D圖像作為輸入,每個方向都進行特征提取。Roth等[10]將一個病灶的三個方向視圖(橫切、矢狀、冠狀)分別作為彩色圖像的三個通道,稱這樣的組合為2.5維表示,然后輸入到CNN網絡,進行特征提取。Zhai等[11]利用多任務學習,實現肺結節的良惡性分類,在模型的輸入方面同樣選擇了結節的9個固定方向2D視圖,與Setio等[9]研究的不同在于其增加了圖像重建的輔助任務。Xie等[12]提出基于知識的協同深度學習框架,將病灶的9個方向的2D視圖作為輸入,首先對每個病灶的每個方向視圖進行分割,獲得每個病灶的每個方向視圖的三種外觀視圖,然后對這三個外觀視圖提取特征并進行融合。這些研究在對多個視角進行特征融合時都是簡單集成融合,沒有考慮到多個視角的差異性[9-12]。
目前對于肺結節良惡性分類的研究,基于開源數據庫肺部圖像數據庫聯盟和圖像數據庫資源倡議(lung image database consortium and image database resource initiative,LIDC-IDRI)(網址為:https://wiki.cancerimagingarchive.net/display/Public/LIDC-IDRI)[13]中具有醫生注釋的數據進行建模的研究較多,采用病理診斷數據構建模型的研究較少,并且當前臨床醫學界公認病理診斷為“金標準”,因此本文認為基于“金標準”——病理診斷數據構建的模型具有更好的臨床價值;對于模仿醫生通過多方位觀察CT圖像進行診斷的研究目前僅僅局限于2D網絡,此類研究希望可以通過學習多個特定方向的2D視圖達到學習3D特征的目的,但是考慮到肺結節的空間異質性等特點,3D網絡比2D網絡能夠更充分且有效地提取3D特征,捕獲更豐富的空間信息;對于多視角特征融合,多數研究采用的都是簡單集成融合,或通過各個視角的模型表現手動計算權值,在本研究中為自動學習多視角特征的差異性,在特征融合階段引入擠壓激勵(squeeze excitation,SE)模塊;目前多數研究對于模型的評估僅僅基于模型級別進行對比評估,沒有與醫生注釋結果進行比較,本研究基于既擁有病理診斷又擁有醫生注釋的數據開展了一致性分析。基于以上問題,本文利用開源數據庫LIDC-IDRI中具有病理診斷的數據,首次提出了3D MV-SE-CNN(MVSECNN)模型,然后在具有病理診斷的數據上進行了驗證,為探索模型的臨床價值,進一步分析了模型預測與醫生注釋結果的一致性。因此,本文所提方法可以有效地學習結節空間異質性和解決多視角差異性問題,同時實現了肺結節良惡性分類,對于輔助醫生進行臨床診斷具有重要意義。
1 數據處理
1.1 數據來源
本文采用開源數據庫LIDC-IDRI,此數據庫共包含1 018個案例,1 010名受試者,每名受試者的數據均包括醫學數字成像和通信(digital imaging and communications in medicine,DICOM)圖像格式的CT數據和相應的可擴展標示語言(extensive markup language,XML)文件;其中的XML文件記錄了四名經驗豐富的胸部放射科醫生的注釋結果,注釋過程將結節類型分為大結節(直徑 ≥ 3 mm)、小結節(直徑 < 3 mm)和非結節,且放射科醫生對大結節進行了特征注釋以及坐標輪廓標記,相應的惡性等級評級注釋如表1所示,而小結節和非結節只進行了質心坐標注釋。
1.2 數據清洗
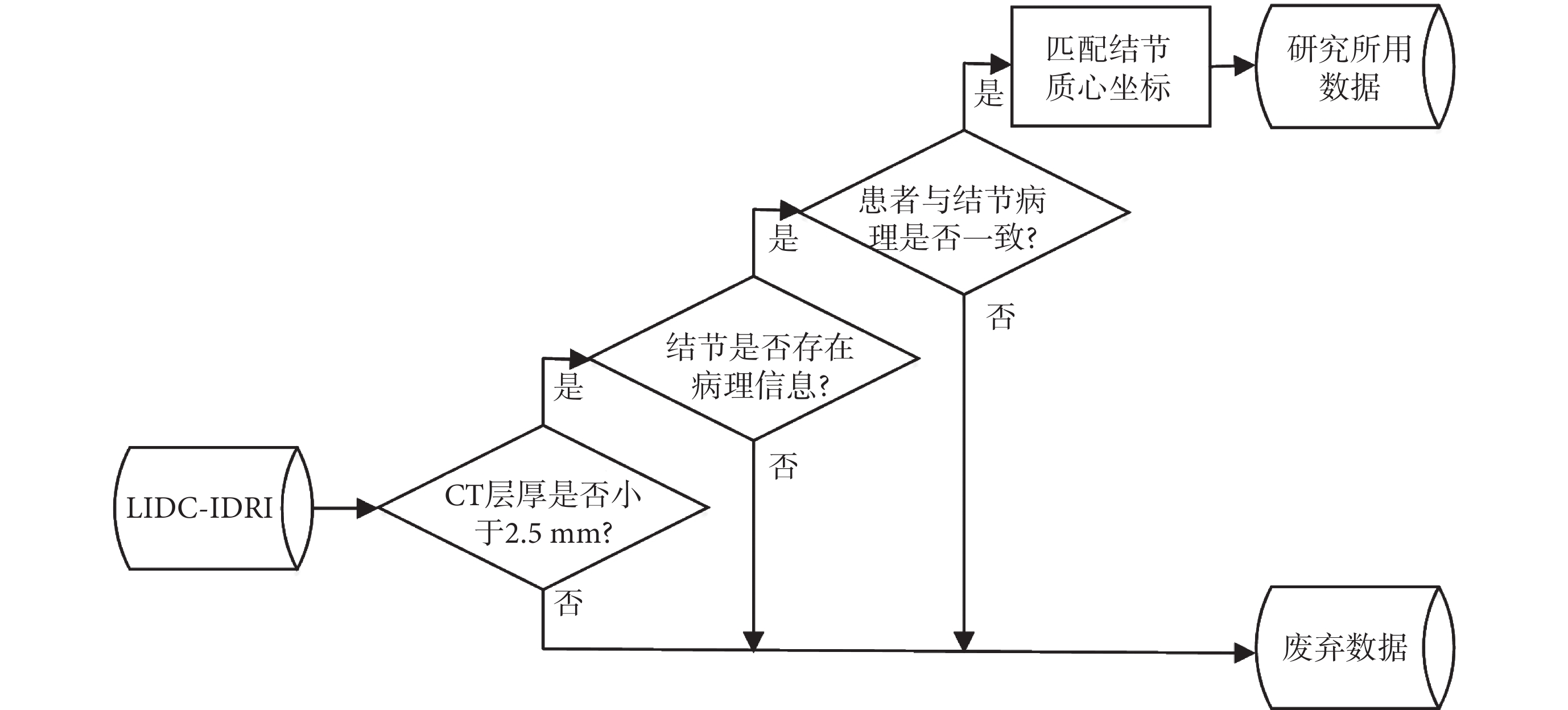
數據清洗的流程如圖1所示,在構建模型階段時只使用“金標準”數據,即具有病理診斷信息的數據,在評估模型預測與醫生注釋結果一致性時,將多名放射科醫生注釋與具有病理診斷信息的結節數據進行了對應。
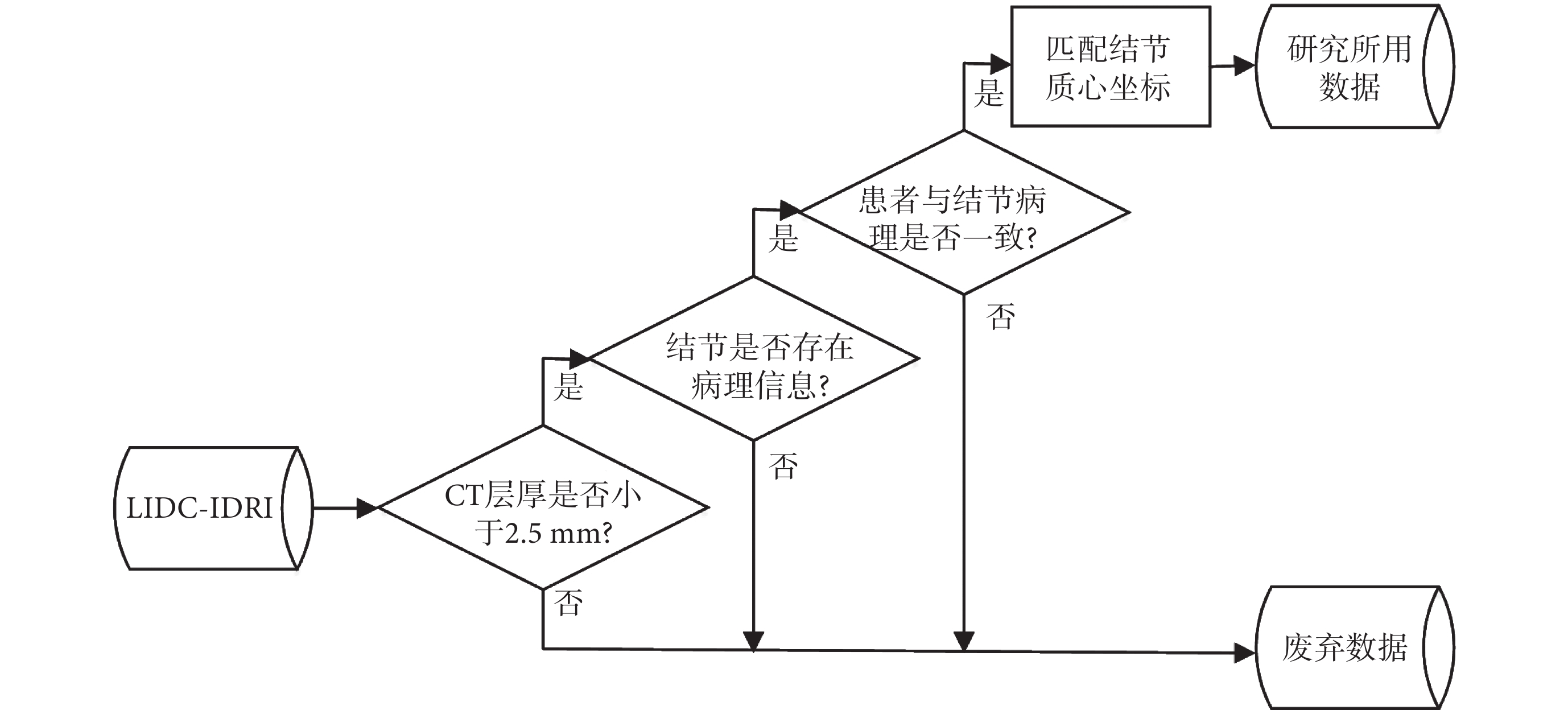 圖1
數據清洗流程圖
Figure1.
Data cleaning flow chart
圖1
數據清洗流程圖
Figure1.
Data cleaning flow chart
LIDC-IDRI數據庫中共有157名受試者擁有病理診斷信息,診斷信息分為患者層面和結節層面,各層面的診斷結果以及診斷方法如表2所示,其中患者層面和結節層面病理診斷結果相同的有138名。有研究表明CT層厚 ≤ 2.5 mm對于肺結節的診斷更有意義[14],最終CT層厚 ≤ 2.5 mm且診斷結果一致的受試者為125名,其中的結節尺寸分布以及醫生注釋情況如表3所示。
1.3 數據預處理
研究將具有病理診斷信息的數據作為訓練及測試模型的數據集,良惡性數據分別按照9:1的比例劃分為訓練集與測試集,如表4所示。
使用線性變換,將CT切片中CT值在?1 000~400亨氏單位(hounsfield units,HU)歸一化至0~1,如式(1)所示:
 |
其中,Hmax = 400 HU,為最大亨氏單位;Hmin = 1 000 HU,為最小亨氏單位。Ph是歸一化前的CT值,P為歸一化后在0~1范圍的值。
數據庫中的CT是由不同的掃描設備掃描得到,分辨率不同,本研究使用的125名患者CT的x與y方向的分辨率在0.46~0.98 mm之間,z方向的層厚在0.6~2.5 mm之間,為消除分辨率的差異,使用重采樣的方法將CT圖像x、y和z三個方向重采樣為1 mm×1 mm×1 mm。
對于具有診斷信息的數據,一部分為大結節數據,一部分為小結節數據,大結節的質心坐標采用Reeves等[15]的研究,小結節的質心坐標通過讀取XML文件獲得。所有獲得的質心坐標,都是距離每張圖像中心掃描點的距離信息,并不是坐標信息,無法直接定位到CT圖像上,因此需要先進行坐標轉換,大結節質心坐標轉換,如式(2)~式(4)所示;小結節質心坐標轉換,如式(2)、(3)、(5)所示:
 '/> '/> |
 '/> '/> |
 '/> '/> |
 '/> '/> |
其中, 、
、 和
和  是經過坐標轉換后的在每張CT圖像中的體素坐標,Coordx、Coordy和Coordz是原始的距離信息,OrigSpax、OrigSpay和OrigSpaz分別為CT圖像重采樣前x、y和z三個方向的像素分辨率,Origz為CT圖像在z方向的原點坐標,ResSpaz為CT圖像重采樣后z方向的像素分辨率,OrigSizez為CT圖像重采樣前z方向的的大小。
是經過坐標轉換后的在每張CT圖像中的體素坐標,Coordx、Coordy和Coordz是原始的距離信息,OrigSpax、OrigSpay和OrigSpaz分別為CT圖像重采樣前x、y和z三個方向的像素分辨率,Origz為CT圖像在z方向的原點坐標,ResSpaz為CT圖像重采樣后z方向的像素分辨率,OrigSizez為CT圖像重采樣前z方向的的大小。
樣本大小選擇對于研究本身也是一個關鍵因素,樣本大小為層數×長×寬,由于大結節的直徑在3.14~30.82 mm之間,因此樣本的長和寬需要大于結節的最大直徑,如表5所示,基于相同結構的3D CNN,采用Acc、靈敏度(sensitivity,Sen)和特異度(specificity,Spe)作為評判指標,進行多次實驗后,最終研究采用的樣本長 × 寬為40 mm × 40 mm,同時3D樣本的層數也受到了圖形處理器以及運算時間的限制,最終樣本的層數設置為9,即高為9 mm。
在模型訓練中,良惡性結節的類別不平衡可能會造成模型學習偏向數據量更大的一類,為克服此問題,本研究在數據平衡階段采用隨機平移技術來平衡數據。在數據集樣本較少時,為防止模型過擬合,可以通過數據增強來擴增樣本量,避免模型訓練過擬合。本文采用隨機平移、旋轉和翻轉對原始數據進行擴增,擴增后的良惡性肺結節數據總量為76 260例?
2 方法
2.1 三維卷積神經網絡
CNN一般由輸入層、卷積層、池化層、全連接(fully connected,FC)層及輸出層構成,其借鑒生物分層理解圖像的原理,提取圖像的抽象表示。
CT以切片序列的形式存在,出現了時間維度上物體運動的信息,為提取3D空間信息,本研究使用3D卷積(convolution,Conv)操作。然后采用線性整流函數(rectified linear unit,ReLU)作為激活函數,增強網絡的學習能力和非線性表達能力。為降低特征映射的維數,引入3D最大池化(max pooling),其不僅能降低圖像維度,還帶來了一定程度的平移、旋轉不變性。在CNN中起到“分類器”作用的是FC層,在模型訓練的過程中80%的參數都來自于FC層,因此在FC層后加入丟棄(dropout)層[16],提高了網絡的泛化能力。為加快網絡的訓練過程,網絡中加入了批量歸一化(batch normalization,BN)層[17],其可以對前一層輸入數據進行批量歸一化處理,然后送入下一層。為進一步避免過擬合,研究采用了L2正則化。
2.2 擠壓激勵模塊
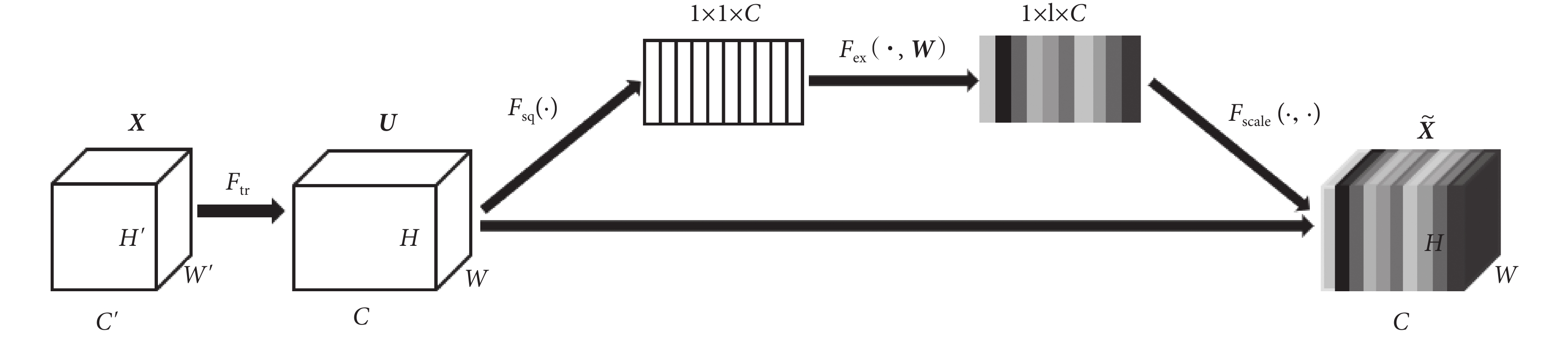
為使模型可以在學習的過程中關注不同視角之間的差異性,自動學習到不同視角特征的重要程度,在模型中引入了SE模塊[18],SE模塊本質上實現了通道的自注意功能,它能夠重新校準通道特征響應,并通過抑制非有用特征和強調信息特征來學習全局信息,同時,通過SE模塊可以積累特征再校準。Hu等[18]的研究已經證明SE模塊可以有效地提高CNN的表現,SE模塊的結構如圖2所示,其計算過程如式(6)~式(9)所示:
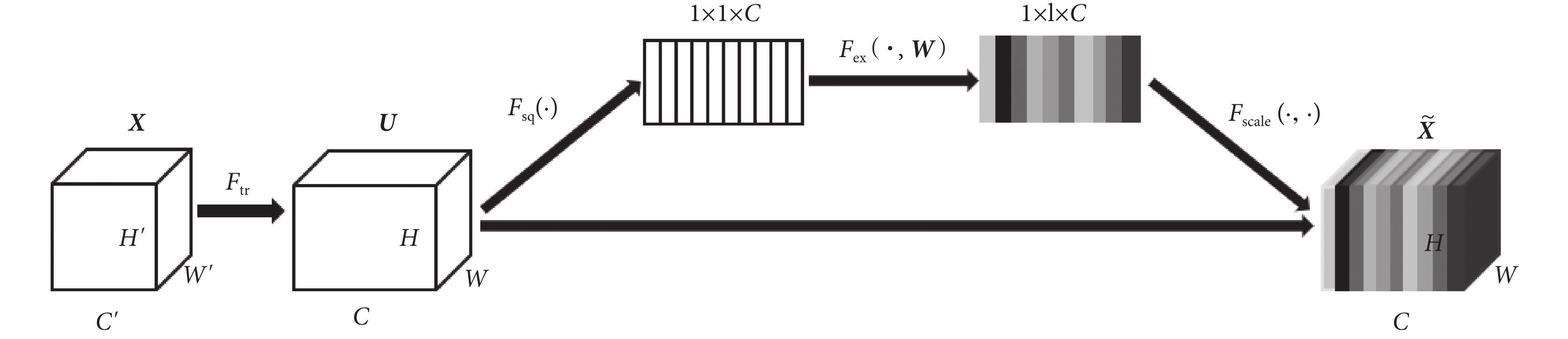 圖2
SE模塊結構
Figure2.
SE module structure
圖2
SE模塊結構
Figure2.
SE module structure
 '/> '/> |
 |
 |
 |
首先通過卷積操作Ftr,將通道數為  、長為
、長為  和寬為
和寬為  維度的輸入 X = [x1, x2,
維度的輸入 X = [x1, x2,  , xc']變換為通道數為C、長為H和寬為W維度的特征映射U= [u1, u2,
, xc']變換為通道數為C、長為H和寬為W維度的特征映射U= [u1, u2,  , uc],如式(6)所示,*代表卷積操作,vc為第c個卷積核參數,uc為第c個特征映射,xn為第n個通道映射,
, uc],如式(6)所示,*代表卷積操作,vc為第c個卷積核參數,uc為第c個特征映射,xn為第n個通道映射, 為對應第n個通道映射的第c個卷積核參數。為學習到每個特征通道的重要程度,基于全局平均池化操作Fsq將U變換為維度1 × 1 × C的特征映射Z = [z1, z2,
為對應第n個通道映射的第c個卷積核參數。為學習到每個特征通道的重要程度,基于全局平均池化操作Fsq將U變換為維度1 × 1 × C的特征映射Z = [z1, z2,  , zc],此時全局空間信息被壓縮到通道描述符中,生成了面向通道的統計信息,如式(7)所示,zc為第c個通道的統計信息。為能夠利用通道統計信息,SE模塊在激勵過程中先通過FC層和ReLU激活函數學習通道之間的非線性相互作用,然后采用FC層與S型生長曲線(sigmoid)函數學習非互斥的關系,確保允許多個通道被強調,以上這兩步操作被定義為Fex,如式(8)所示,其中δ代表了ReLU激活函數,σ代表了sigmoid激活函數,W為學習過程中的權重參數,S = [s1, s2,
, zc],此時全局空間信息被壓縮到通道描述符中,生成了面向通道的統計信息,如式(7)所示,zc為第c個通道的統計信息。為能夠利用通道統計信息,SE模塊在激勵過程中先通過FC層和ReLU激活函數學習通道之間的非線性相互作用,然后采用FC層與S型生長曲線(sigmoid)函數學習非互斥的關系,確保允許多個通道被強調,以上這兩步操作被定義為Fex,如式(8)所示,其中δ代表了ReLU激活函數,σ代表了sigmoid激活函數,W為學習過程中的權重參數,S = [s1, s2,  , sc]為學習到各個通道的激活值。最后,將U與激活值S通過通道乘法Fscale輸出維度為C × H × W的
, sc]為學習到各個通道的激活值。最后,將U與激活值S通過通道乘法Fscale輸出維度為C × H × W的  , 如式(9)所示,sc為第c個通道的激活值,
, 如式(9)所示,sc為第c個通道的激活值, 為第c個通道的輸出值。
為第c個通道的輸出值。
2.3 三維多視角擠壓激勵卷積神經網絡模型
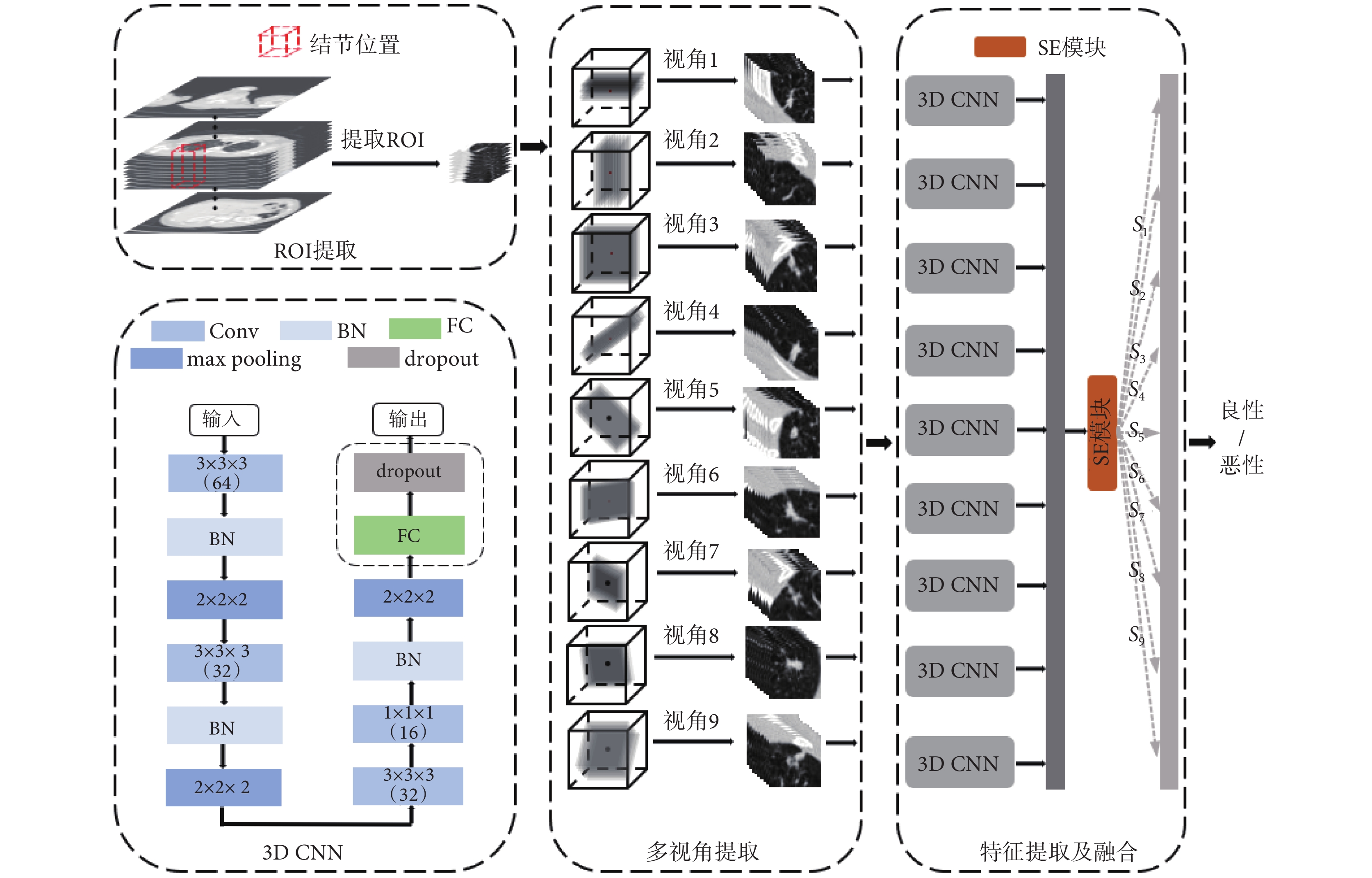
肺結節的形狀通常是球形的,多個方位觀察的形狀趨于相近,但是當被血管等包圍時,形狀很復雜,因此只從單個視角觀察肺結節不能夠充分掌握其特點,需結合多個視角進行觀察,通常醫生對于可疑性結節會對其進行一次靶掃描,以獲得結節所在部位更高分辨率以及全方位的影像資料,然后從多角度觀察病灶,結合多個視角的觀察對可疑性結節進一步診斷。
為仿照醫生對可疑性肺結節的診斷方法,本研究提出3D MVCNN框架,基準模型的結構如圖3所示,在3D CNN 框中Conv層的核大小為3 × 3 × 3或1 × 1 × 1,核的個數分別為64、32、32和16,max pooling層的核大小為2 × 2 × 2,在3D CNN模型基礎上,將單視角增加至9個視角。首先對預處理后的樣本根據結節位置進行3D感興趣區域(region of interest,ROI)采樣,采樣至50 mm × 50 mm × 50 mm,見圖3中ROI提取區域。然后,對ROI使用空間采樣技術,如圖3中的ROI的提取和多視角圖像的提取所示,并與3D CNN模型進行對比,研究中設計的所有模型輸入均采樣為40 mm× 40 mm×9 mm。Setio等[9]研究表明,當9個視圖全部作為輸入時模型效果最優,如圖3 特征提取及融合所示,本研究將基于CT方位的9個3D視圖全部作為模型的輸入,每個視角的3D視圖由一個獨立的3D CNN(如圖3中3D CNN去除虛線框后的結構所示)處理,學習各個視角肺結節特征,充分地挖掘肺結節多方位信息。為使模型能夠自動學習9個視角的特征差異性,在特征提取及融合階段引入SE模塊,如式(10)所示,S = [s1, s2,  , s9]為SE模塊中學習到的各個視角的權重組合,F = [f1, f2,
, s9]為SE模塊中學習到的各個視角的權重組合,F = [f1, f2,  , f9]為9個視角經過3D CNN特征提取后的深度特征映射集合,M = [m1, m2,
, f9]為9個視角經過3D CNN特征提取后的深度特征映射集合,M = [m1, m2,  , m9]為通過SE模塊后的具有差異性的9個視角深度特征映射組合。最后,模型通過FC層和歸一化指數函數(softmax)計算類別得分。
, m9]為通過SE模塊后的具有差異性的9個視角深度特征映射組合。最后,模型通過FC層和歸一化指數函數(softmax)計算類別得分。
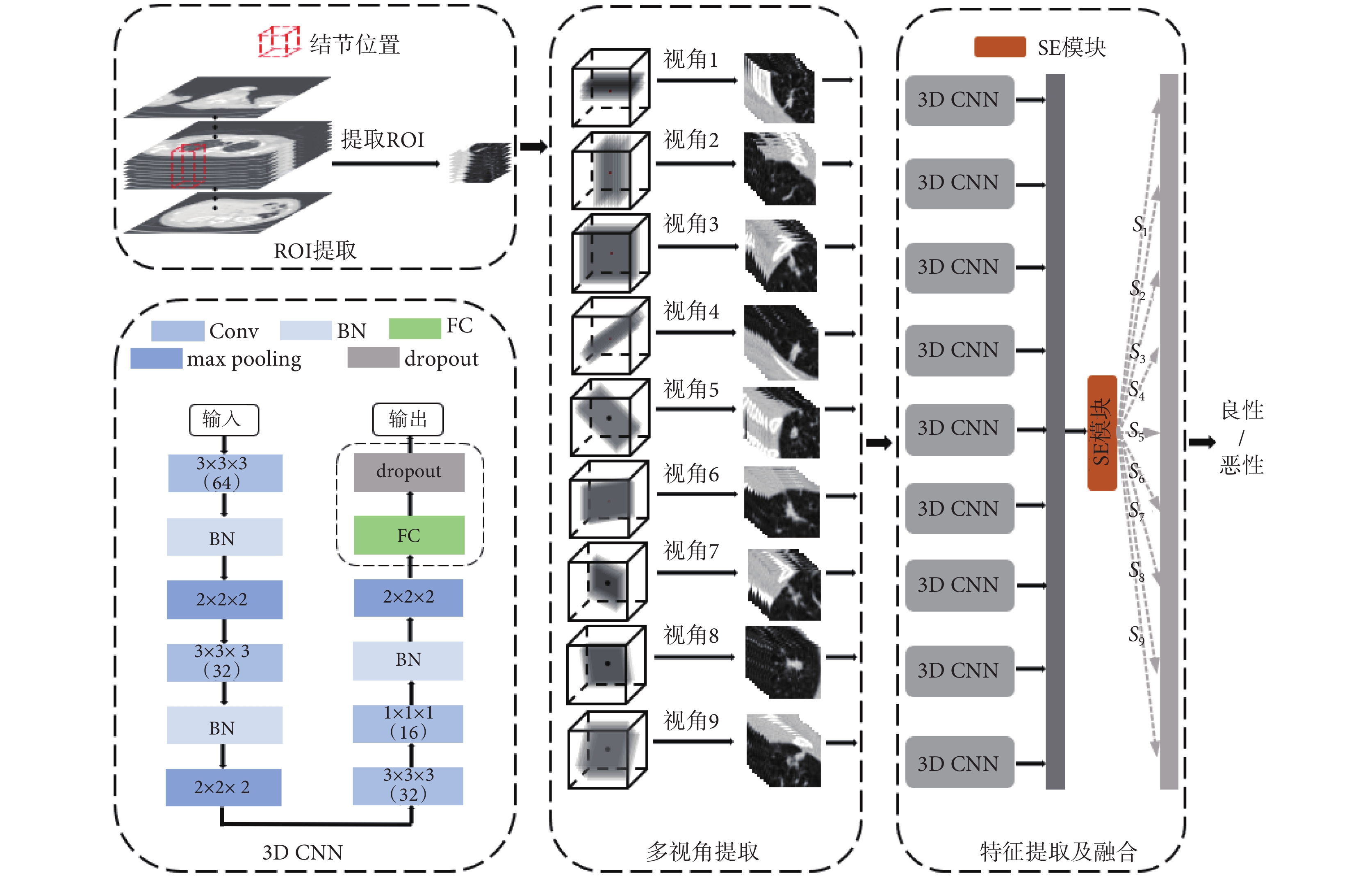 圖3
3D MVSECNN模型結構
Figure3.
3D MVSECNN model structure
圖3
3D MVSECNN模型結構
Figure3.
3D MVSECNN model structure
 |
3 結果
3.1 評價標準
研究通過計算Acc、Sen、Spe、馬修斯相關系數(Matthews correlation coefficient,MCC)和接收者操作特征(receiver operating characteristic,ROC)曲線下面積(area under curve,AUC)來評估模型的性能,如式(11)~式(14)所示:
 |
 |
 |
 |
其中,真陽性(true positive,TP)表示正樣本被正確分類的個數,真陰性(true negative,TN)表示負樣本被正確分類的個數,假陽性(false positive,FP)表示負樣本被錯誤分類為正樣本的個數,假陰性(false negative,FN)表示正樣本被錯誤分類為負樣個數。
MCC作為二分類問題的最佳度量指標,綜合考量了TP、TN、FP及 FN四個基礎評價指標,在樣本類別平衡與不平衡時都能作為有效的評價指標。ROC是反映Sen和Spe連續變量的綜合指標,AUC可以評估該二元分類器的可信度,AUC值越大說明其可信度越高。
為分析模型預測與醫生注釋結果一致性,研究引入了科恩卡帕系數(Cohen’s Kappa)[19]、加權卡帕系數(Weighted Kappa) [20]、弗萊斯卡帕系數(Fleiss’ Kappa)[21]和肯德爾和諧系數 (Kendall’s coefficient of concordance,Kendall’s W)[22]這四個一致性評價系數。
3.2 實驗設置
研究在操作系統Windows10(Microsoft,美國)和圖形處理器NVIDIA TITAN RTX(NVIDIA,美國)進行深度學習環境的搭建,利用機器學習庫Tensorflow 1.9.0(Google,美國)以及神經網絡庫Keras 2.1.6(Google,美國)構建模型,模型訓練過程中使用自適應矩估計(adaptive moment estimation,Adam)優化器,設置初始學習率為0.01,最小學習率為0.000 001;采用類交叉熵損失(categorical-crossentropy loss)函數進行參數的優化與迭代;使用回調函數與早停(early stopping)策略來優化學習率以及防止模型過擬合;利用統計分析軟件SPSS 25.0(IBM,美國)進行模型預測與醫生注釋結果的一致性分析。
3.3 三維多視角擠壓激勵卷積神經網絡模型結果
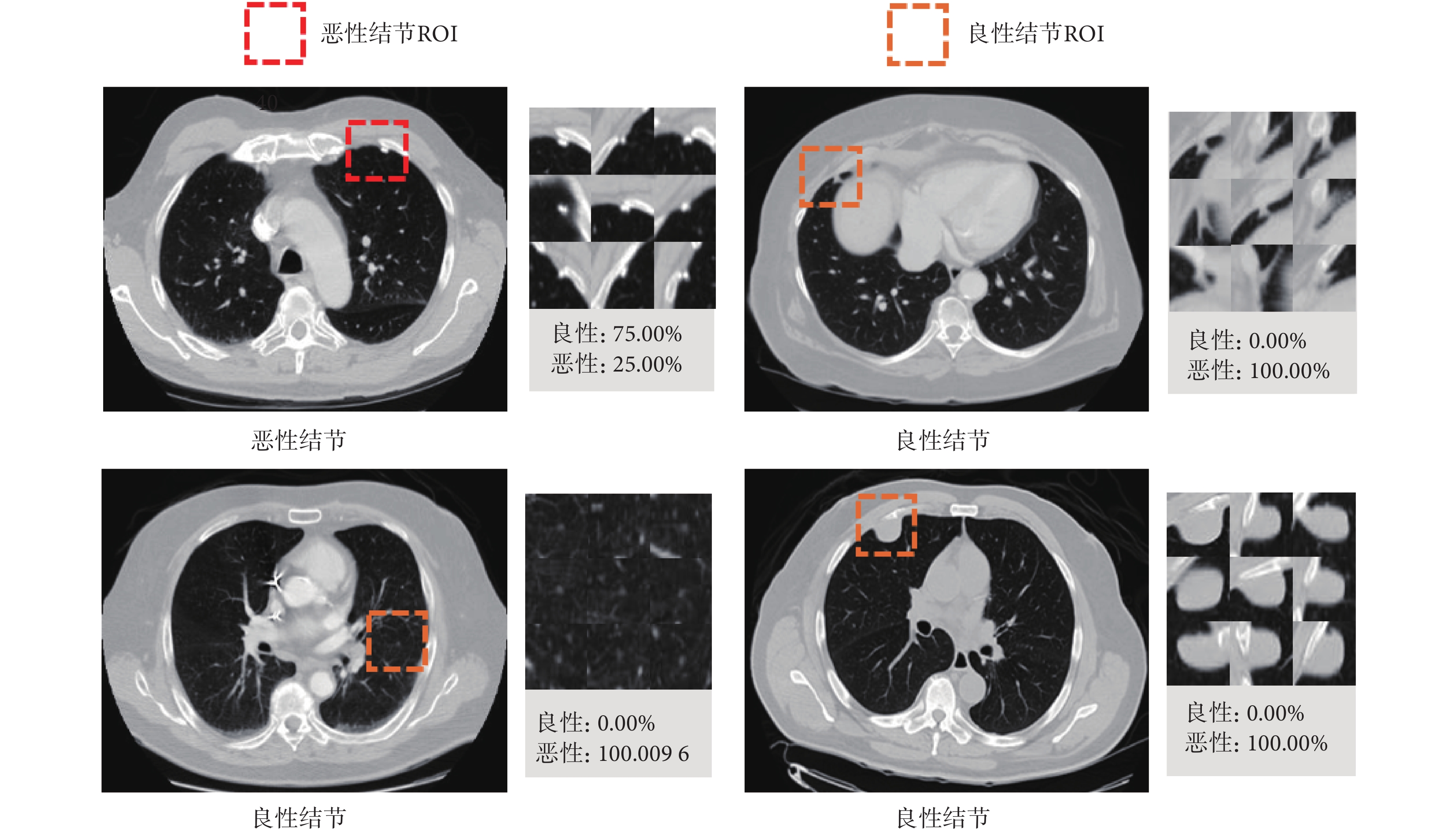
本研究提出的3D MVSECNN模型結合了3D MVCNN框架和SE模塊,并探討了3D MVCNN和SE模塊在肺結節良惡性分類中的能力,以說明3D MVSECNN模型的潛在優勢。3D CNN、3D MVCNN和3D MVSECNN模型層數都為10層,三個模型的性能比較如表6所示。如圖4所示,展示了部分肺結節正確分類結果。
 圖4
3D MVSECNN模型測試結果展示
Figure4.
Test results display of 3D MVSECNN model
圖4
3D MVSECNN模型測試結果展示
Figure4.
Test results display of 3D MVSECNN model
3.4 模型預測與醫生注釋結果一致性分析
為評估所提出的模型臨床適用性,以病理診斷為媒介,基于有病理診斷和醫生注釋的數據(既擁有病理診斷且擁有4位醫生注釋,在等級注釋中沒有不確定等級注釋的結節數據),對病理診斷與模型預測以及病理診斷與醫生注釋結果分別進行了一致性分析。
病理診斷與醫生注釋結果的一致性分析方法及結果為:① 對四名醫生的注釋結果分別與病理診斷進行一致性分析,通過Cohen’s Kappa一致性分數以及P值表明單名醫生注釋結果與病理診斷無一致性(P > 0.05)或一致性較差(Cohen’s Kappa= 0.308,P = 0.027);② 四名醫生注釋結果之間進行一致性分析,發現四名醫生的注釋結果之間無一致性(P > 0.05),兩名或三名醫生的注釋結果一致性較好,因此將一致性分數最高的兩名醫生的注釋結果(Cohen’s Kappa = 0.671,P < 0.05)和三名醫生的注釋結果(Kendall’s W = 0.786,P < 0.05)分別與病理診斷做一致性分析,結果表明:兩名醫生的注釋結果與病理診斷一致性一般(Fleiss’ Kappa = 0.438,P < 0.05),三名醫生的注釋結果與病理診斷一致性一般(Fleiss’ Kappa = 0.477,P < 0.05)。
對于病理診斷與模型預測的一致性分析,利用 Cohen’s Kappa一致性分析,模型預測與病理診斷的一致性好(Cohen’s Kappa = 0.948,P < 0.05),表明模型預測與病理診斷的一致性明顯高于醫生注釋結果與病理診斷的一致性。
4 討論
本研究提出了一種新的基于CT圖像的肺結節良惡性分類方法,該方法利用3D MVSECNN模型學習肺結節良惡性分類的高分辨特征,在開源數據庫LIDC-IDRI上進行驗證,AUC為0.943[95% 置信區間(confidence interval,CI): 0.879,0.979],Acc為 96.04%,結果表明該方法具有良好的肺結節良惡性分類性能。
如表7所示,基于開源數據庫LIDC-IDRI中擁有病理診斷的數據,比較了本文提出的方法與其他研究方法的性能。Shewaye等[23]采用基于影像組學的傳統方法進行肺結節良惡性分類,但是這種方法在提取影像組學特征時其過程既復雜又費時;Kumar等[24-25]與Kang等[26]的研究利用深度學習方法進行建模,只是Kumar等[24-25]的兩個研究都是利用深度學習模型進行特征提取,然后基于提取的深度特征訓練分類器,采用的是“兩步走”模式,而Kang等[26]采用的是端到端的模式,更方便快捷,本研究在構建模型時也選擇了端到端的方式。Kang等[26]的研究雖然AUC值高于本研究,但是Acc以及Sen都低于本研究,這可能是由于其選擇的模型架構更復雜,且采用的數據是肺部圖像數據庫聯盟(lung image database consortium,LIDC)2圖像工具包(image toolbox)[27]自動提取的96名患者病理診斷數據,沒有將全部病理診斷數據用于研究。
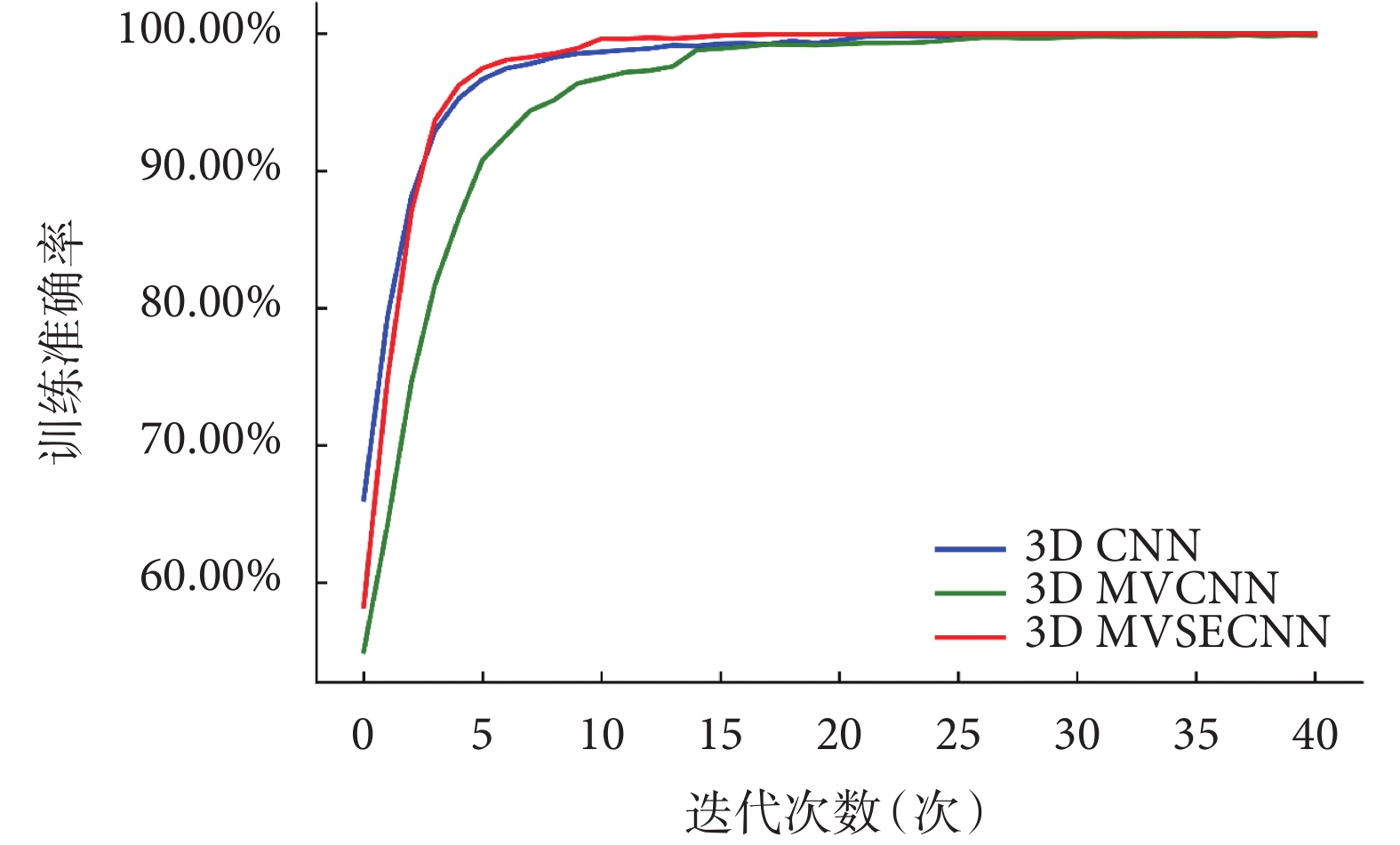
研究提出的3D MVCNN框架和SE模塊的組合是一種有效的肺結節良惡性分類方法。3D MVSECNN綜合了3D MVCNN框架的多視角特征融合特性和SE模塊用于特征重新校準的優點,在肺結節良惡性分類中顯示出良好的性能。如圖5所示,在模型訓練時,3D MVCNN比3D CNN收斂慢,這是由于模型需要考慮更多的數據以及參數,但是當在特征融合階段引入SE模塊后,3D MVSECNN模型在訓練過程中的收斂速度要快于其他兩個模型。
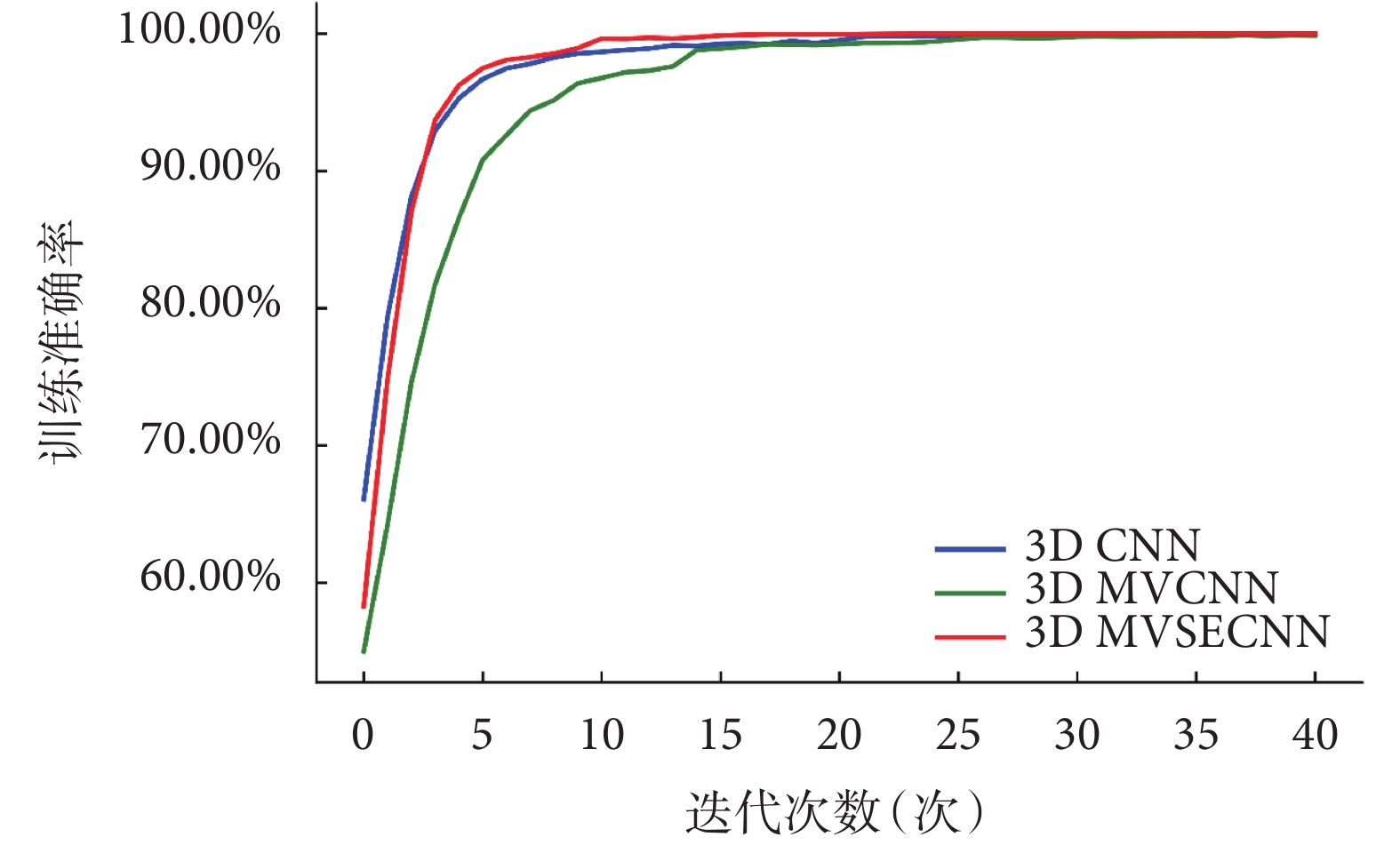 圖5
三個模型在模型訓練階段的Acc變化曲線
Figure5.
Acc change curve of the three models in the model training
圖5
三個模型在模型訓練階段的Acc變化曲線
Figure5.
Acc change curve of the three models in the model training
如圖6所示,3D MVSECNN模型在獨立測試集上預測錯誤的樣本共四個,一個為惡性樣本,三個為良性樣本。對于惡性樣本,模型預測時將其預測為良性結節,可能是由于多視角觀察其形狀都為光滑的類圓形;右上角的良性結節被錯誤分類可能是由于多視角觀察肺結節的形狀較為復雜,與別的肺部結構有牽連;左下角的良性結節可能是由于其周圍有多條血管;右下角的良性結節被錯誤分類最大可能性是由于結節直徑較大,因為肺結節的良惡性診斷很大一部分原因取決于結節直徑大小。
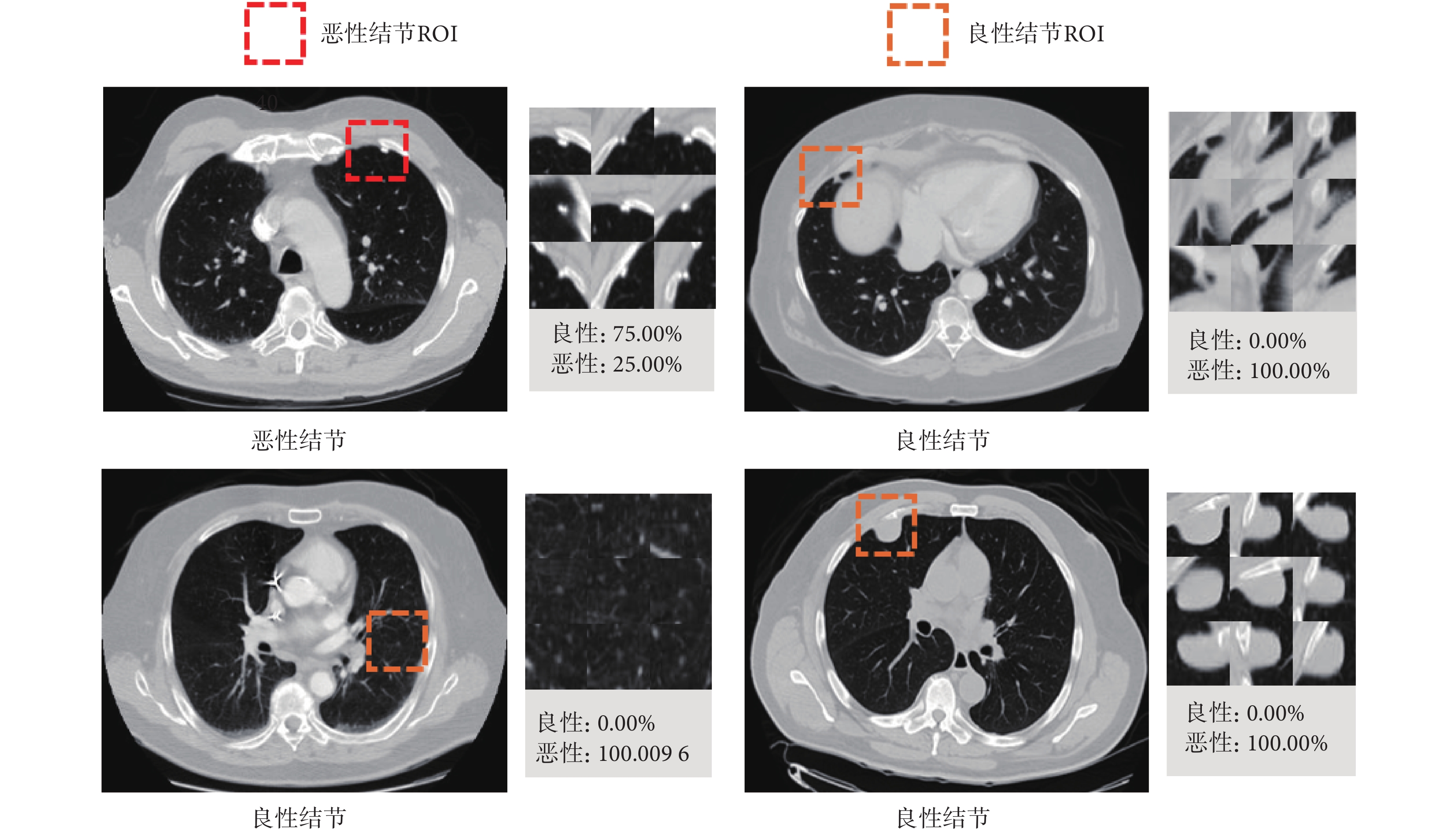 圖6
3D MVSECNN模型預測錯誤樣本展示
Figure6.
Sample display of prediction error of 3D MVSECNN model
圖6
3D MVSECNN模型預測錯誤樣本展示
Figure6.
Sample display of prediction error of 3D MVSECNN model
5 結論
本文提出了一種新的基于CT圖像的肺結節良惡性分類方法。該方法使用3D MVSECNN學習高分辨特征來分類惡性和良性肺結節。在開源數據庫LIDC-IDRI進行驗證,實驗結果表明:該方法的Acc和Sen比現有的基于傳統特征和深度特征的方法的更高,惡性肺結節預測結果的逃逸率小于1.5%;與病理診斷的一致性分析表明:模型預測與病理診斷的一致性明顯高于醫生注釋結果與病理診斷的一致性,模型分類結果對輔助臨床醫生診斷具有重要作用。本研究將進一步收集肺結節良惡性病理診斷數據用于現有模型優化和驗證,繼而開發深度學習技術對肺結節進行分類。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:楊楊負責研究算法程序設計,文章構思,實驗數據處理,論文撰寫;韓振波和付繼鵬負責論文修改和圖表繪制;李曉琴,高斌負責實驗指導,數據分析指導,論文審閱修訂。
引言
肺癌是最常見的惡性腫瘤之一,由國際癌癥研究中心(international agency for research on cancer,IARC)發布的全球癌癥(global cancer,GLOBOCAN)統計報告2020年版顯示,肺癌死亡及發病人數均位于前三[1]。最新研究表明,通過低劑量計算機斷層掃描(computed tomography,CT)進行肺癌早期篩查,可使男性肺癌死亡率降低24%,女性肺癌死亡率降低33%[2],早期篩查對于肺癌的早發現、早治療、降低死亡率等具有重要價值。另一方面,隨著肺癌早期篩查的普及,醫生的閱片壓力激增,診斷過程中可能會造成誤診及漏診。肺癌與肺結節有著錯綜復雜的關系,因此早期的肺結節良惡性診斷是提高肺癌診斷率和延長患者生存期的關鍵步驟。現如今借助計算機技術的快速發展、醫療設備的完善與成熟的醫學圖像處理技術,計算機輔助診斷(computer aided diagnosis,CAD)系統應運而生。基于深度學習的肺結節良惡性分類方法,通過深層架構自動學習當前數據的抽象層次特征,能夠以圖像特征的識別和分類來訓練模型,并利用模型的準確率(accuracy,Acc)、損失值等多重評價指標來反向指導特征的提取[3]。例如,Hua等[4]在2015年首次提出將二維(two-dimensional,2D)卷積神經網絡(convolutional neural network,CNN)應用于肺結節分類。2D CNN雖然訓練速度快、占用資源少,但是會丟失肺結節的立體信息,為解決此問題,Liu等[5]在2017年提出將三維(three-dimensional,3D)CNN應用于肺結節分類。Marques等[6]從CT圖像和結節語義特征出發,提出了多任務3D CNN,結節的良惡性預測由CT圖像特征和語義特征共同決定。Astaraki等[7]為使3D CNN有效捕捉結節內部特征以及上下文信息,提出了雙路徑結構模型,將分割后的結節圖像與未經分割的結節圖像共同作為模型的輸入。Tang等[8]提出多分辨率3D雙路徑擠壓激勵聚合網絡(dual path squeeze excitation converged network,DPSECN)模型,多分辨率主要體現在將肺結節按其直徑尺寸進行三分類,然后通過線性插值將其轉化為另外兩種不同級別分辨率的數據,每個樣本獲得相應的三種不同分辨率的數據,作為模型的輸入來訓練模型。
Setio等[9]提出2D多視角(multi-view,MV)CNN(MVCNN),通過2D MVCNN實現3D特征的捕捉,對于每個結節數據,提取9個固定方向的2D圖像作為輸入,每個方向都進行特征提取。Roth等[10]將一個病灶的三個方向視圖(橫切、矢狀、冠狀)分別作為彩色圖像的三個通道,稱這樣的組合為2.5維表示,然后輸入到CNN網絡,進行特征提取。Zhai等[11]利用多任務學習,實現肺結節的良惡性分類,在模型的輸入方面同樣選擇了結節的9個固定方向2D視圖,與Setio等[9]研究的不同在于其增加了圖像重建的輔助任務。Xie等[12]提出基于知識的協同深度學習框架,將病灶的9個方向的2D視圖作為輸入,首先對每個病灶的每個方向視圖進行分割,獲得每個病灶的每個方向視圖的三種外觀視圖,然后對這三個外觀視圖提取特征并進行融合。這些研究在對多個視角進行特征融合時都是簡單集成融合,沒有考慮到多個視角的差異性[9-12]。
目前對于肺結節良惡性分類的研究,基于開源數據庫肺部圖像數據庫聯盟和圖像數據庫資源倡議(lung image database consortium and image database resource initiative,LIDC-IDRI)(網址為:https://wiki.cancerimagingarchive.net/display/Public/LIDC-IDRI)[13]中具有醫生注釋的數據進行建模的研究較多,采用病理診斷數據構建模型的研究較少,并且當前臨床醫學界公認病理診斷為“金標準”,因此本文認為基于“金標準”——病理診斷數據構建的模型具有更好的臨床價值;對于模仿醫生通過多方位觀察CT圖像進行診斷的研究目前僅僅局限于2D網絡,此類研究希望可以通過學習多個特定方向的2D視圖達到學習3D特征的目的,但是考慮到肺結節的空間異質性等特點,3D網絡比2D網絡能夠更充分且有效地提取3D特征,捕獲更豐富的空間信息;對于多視角特征融合,多數研究采用的都是簡單集成融合,或通過各個視角的模型表現手動計算權值,在本研究中為自動學習多視角特征的差異性,在特征融合階段引入擠壓激勵(squeeze excitation,SE)模塊;目前多數研究對于模型的評估僅僅基于模型級別進行對比評估,沒有與醫生注釋結果進行比較,本研究基于既擁有病理診斷又擁有醫生注釋的數據開展了一致性分析。基于以上問題,本文利用開源數據庫LIDC-IDRI中具有病理診斷的數據,首次提出了3D MV-SE-CNN(MVSECNN)模型,然后在具有病理診斷的數據上進行了驗證,為探索模型的臨床價值,進一步分析了模型預測與醫生注釋結果的一致性。因此,本文所提方法可以有效地學習結節空間異質性和解決多視角差異性問題,同時實現了肺結節良惡性分類,對于輔助醫生進行臨床診斷具有重要意義。
1 數據處理
1.1 數據來源
本文采用開源數據庫LIDC-IDRI,此數據庫共包含1 018個案例,1 010名受試者,每名受試者的數據均包括醫學數字成像和通信(digital imaging and communications in medicine,DICOM)圖像格式的CT數據和相應的可擴展標示語言(extensive markup language,XML)文件;其中的XML文件記錄了四名經驗豐富的胸部放射科醫生的注釋結果,注釋過程將結節類型分為大結節(直徑 ≥ 3 mm)、小結節(直徑 < 3 mm)和非結節,且放射科醫生對大結節進行了特征注釋以及坐標輪廓標記,相應的惡性等級評級注釋如表1所示,而小結節和非結節只進行了質心坐標注釋。
1.2 數據清洗
數據清洗的流程如圖1所示,在構建模型階段時只使用“金標準”數據,即具有病理診斷信息的數據,在評估模型預測與醫生注釋結果一致性時,將多名放射科醫生注釋與具有病理診斷信息的結節數據進行了對應。
圖1
數據清洗流程圖
Figure1.
Data cleaning flow chart
LIDC-IDRI數據庫中共有157名受試者擁有病理診斷信息,診斷信息分為患者層面和結節層面,各層面的診斷結果以及診斷方法如表2所示,其中患者層面和結節層面病理診斷結果相同的有138名。有研究表明CT層厚 ≤ 2.5 mm對于肺結節的診斷更有意義[14],最終CT層厚 ≤ 2.5 mm且診斷結果一致的受試者為125名,其中的結節尺寸分布以及醫生注釋情況如表3所示。
1.3 數據預處理
研究將具有病理診斷信息的數據作為訓練及測試模型的數據集,良惡性數據分別按照9:1的比例劃分為訓練集與測試集,如表4所示。
使用線性變換,將CT切片中CT值在?1 000~400亨氏單位(hounsfield units,HU)歸一化至0~1,如式(1)所示:
|
其中,Hmax = 400 HU,為最大亨氏單位;Hmin = 1 000 HU,為最小亨氏單位。Ph是歸一化前的CT值,P為歸一化后在0~1范圍的值。
數據庫中的CT是由不同的掃描設備掃描得到,分辨率不同,本研究使用的125名患者CT的x與y方向的分辨率在0.46~0.98 mm之間,z方向的層厚在0.6~2.5 mm之間,為消除分辨率的差異,使用重采樣的方法將CT圖像x、y和z三個方向重采樣為1 mm×1 mm×1 mm。
對于具有診斷信息的數據,一部分為大結節數據,一部分為小結節數據,大結節的質心坐標采用Reeves等[15]的研究,小結節的質心坐標通過讀取XML文件獲得。所有獲得的質心坐標,都是距離每張圖像中心掃描點的距離信息,并不是坐標信息,無法直接定位到CT圖像上,因此需要先進行坐標轉換,大結節質心坐標轉換,如式(2)~式(4)所示;小結節質心坐標轉換,如式(2)、(3)、(5)所示:
| '/> |
| '/> |
| '/> |
| '/> |
其中,、 和 是經過坐標轉換后的在每張CT圖像中的體素坐標,Coordx、Coordy和Coordz是原始的距離信息,OrigSpax、OrigSpay和OrigSpaz分別為CT圖像重采樣前x、y和z三個方向的像素分辨率,Origz為CT圖像在z方向的原點坐標,ResSpaz為CT圖像重采樣后z方向的像素分辨率,OrigSizez為CT圖像重采樣前z方向的的大小。
樣本大小選擇對于研究本身也是一個關鍵因素,樣本大小為層數×長×寬,由于大結節的直徑在3.14~30.82 mm之間,因此樣本的長和寬需要大于結節的最大直徑,如表5所示,基于相同結構的3D CNN,采用Acc、靈敏度(sensitivity,Sen)和特異度(specificity,Spe)作為評判指標,進行多次實驗后,最終研究采用的樣本長 × 寬為40 mm × 40 mm,同時3D樣本的層數也受到了圖形處理器以及運算時間的限制,最終樣本的層數設置為9,即高為9 mm。
在模型訓練中,良惡性結節的類別不平衡可能會造成模型學習偏向數據量更大的一類,為克服此問題,本研究在數據平衡階段采用隨機平移技術來平衡數據。在數據集樣本較少時,為防止模型過擬合,可以通過數據增強來擴增樣本量,避免模型訓練過擬合。本文采用隨機平移、旋轉和翻轉對原始數據進行擴增,擴增后的良惡性肺結節數據總量為76 260例?
2 方法
2.1 三維卷積神經網絡
CNN一般由輸入層、卷積層、池化層、全連接(fully connected,FC)層及輸出層構成,其借鑒生物分層理解圖像的原理,提取圖像的抽象表示。
CT以切片序列的形式存在,出現了時間維度上物體運動的信息,為提取3D空間信息,本研究使用3D卷積(convolution,Conv)操作。然后采用線性整流函數(rectified linear unit,ReLU)作為激活函數,增強網絡的學習能力和非線性表達能力。為降低特征映射的維數,引入3D最大池化(max pooling),其不僅能降低圖像維度,還帶來了一定程度的平移、旋轉不變性。在CNN中起到“分類器”作用的是FC層,在模型訓練的過程中80%的參數都來自于FC層,因此在FC層后加入丟棄(dropout)層[16],提高了網絡的泛化能力。為加快網絡的訓練過程,網絡中加入了批量歸一化(batch normalization,BN)層[17],其可以對前一層輸入數據進行批量歸一化處理,然后送入下一層。為進一步避免過擬合,研究采用了L2正則化。
2.2 擠壓激勵模塊
為使模型可以在學習的過程中關注不同視角之間的差異性,自動學習到不同視角特征的重要程度,在模型中引入了SE模塊[18],SE模塊本質上實現了通道的自注意功能,它能夠重新校準通道特征響應,并通過抑制非有用特征和強調信息特征來學習全局信息,同時,通過SE模塊可以積累特征再校準。Hu等[18]的研究已經證明SE模塊可以有效地提高CNN的表現,SE模塊的結構如圖2所示,其計算過程如式(6)~式(9)所示:
圖2
SE模塊結構
Figure2.
SE module structure
| '/> |
|
|
|
首先通過卷積操作Ftr,將通道數為 、長為 和寬為 維度的輸入 X = [x1, x2, , xc']變換為通道數為C、長為H和寬為W維度的特征映射U= [u1, u2, , uc],如式(6)所示,*代表卷積操作,vc為第c個卷積核參數,uc為第c個特征映射,xn為第n個通道映射, 為對應第n個通道映射的第c個卷積核參數。為學習到每個特征通道的重要程度,基于全局平均池化操作Fsq將U變換為維度1 × 1 × C的特征映射Z = [z1, z2, , zc],此時全局空間信息被壓縮到通道描述符中,生成了面向通道的統計信息,如式(7)所示,zc為第c個通道的統計信息。為能夠利用通道統計信息,SE模塊在激勵過程中先通過FC層和ReLU激活函數學習通道之間的非線性相互作用,然后采用FC層與S型生長曲線(sigmoid)函數學習非互斥的關系,確保允許多個通道被強調,以上這兩步操作被定義為Fex,如式(8)所示,其中δ代表了ReLU激活函數,σ代表了sigmoid激活函數,W為學習過程中的權重參數,S = [s1, s2, , sc]為學習到各個通道的激活值。最后,將U與激活值S通過通道乘法Fscale輸出維度為C × H × W的 , 如式(9)所示,sc為第c個通道的激活值, 為第c個通道的輸出值。
2.3 三維多視角擠壓激勵卷積神經網絡模型
肺結節的形狀通常是球形的,多個方位觀察的形狀趨于相近,但是當被血管等包圍時,形狀很復雜,因此只從單個視角觀察肺結節不能夠充分掌握其特點,需結合多個視角進行觀察,通常醫生對于可疑性結節會對其進行一次靶掃描,以獲得結節所在部位更高分辨率以及全方位的影像資料,然后從多角度觀察病灶,結合多個視角的觀察對可疑性結節進一步診斷。
為仿照醫生對可疑性肺結節的診斷方法,本研究提出3D MVCNN框架,基準模型的結構如圖3所示,在3D CNN 框中Conv層的核大小為3 × 3 × 3或1 × 1 × 1,核的個數分別為64、32、32和16,max pooling層的核大小為2 × 2 × 2,在3D CNN模型基礎上,將單視角增加至9個視角。首先對預處理后的樣本根據結節位置進行3D感興趣區域(region of interest,ROI)采樣,采樣至50 mm × 50 mm × 50 mm,見圖3中ROI提取區域。然后,對ROI使用空間采樣技術,如圖3中的ROI的提取和多視角圖像的提取所示,并與3D CNN模型進行對比,研究中設計的所有模型輸入均采樣為40 mm× 40 mm×9 mm。Setio等[9]研究表明,當9個視圖全部作為輸入時模型效果最優,如圖3 特征提取及融合所示,本研究將基于CT方位的9個3D視圖全部作為模型的輸入,每個視角的3D視圖由一個獨立的3D CNN(如圖3中3D CNN去除虛線框后的結構所示)處理,學習各個視角肺結節特征,充分地挖掘肺結節多方位信息。為使模型能夠自動學習9個視角的特征差異性,在特征提取及融合階段引入SE模塊,如式(10)所示,S = [s1, s2, , s9]為SE模塊中學習到的各個視角的權重組合,F = [f1, f2, , f9]為9個視角經過3D CNN特征提取后的深度特征映射集合,M = [m1, m2, , m9]為通過SE模塊后的具有差異性的9個視角深度特征映射組合。最后,模型通過FC層和歸一化指數函數(softmax)計算類別得分。
圖3
3D MVSECNN模型結構
Figure3.
3D MVSECNN model structure
|
3 結果
3.1 評價標準
研究通過計算Acc、Sen、Spe、馬修斯相關系數(Matthews correlation coefficient,MCC)和接收者操作特征(receiver operating characteristic,ROC)曲線下面積(area under curve,AUC)來評估模型的性能,如式(11)~式(14)所示:
|
|
|
|
其中,真陽性(true positive,TP)表示正樣本被正確分類的個數,真陰性(true negative,TN)表示負樣本被正確分類的個數,假陽性(false positive,FP)表示負樣本被錯誤分類為正樣本的個數,假陰性(false negative,FN)表示正樣本被錯誤分類為負樣個數。
MCC作為二分類問題的最佳度量指標,綜合考量了TP、TN、FP及 FN四個基礎評價指標,在樣本類別平衡與不平衡時都能作為有效的評價指標。ROC是反映Sen和Spe連續變量的綜合指標,AUC可以評估該二元分類器的可信度,AUC值越大說明其可信度越高。
為分析模型預測與醫生注釋結果一致性,研究引入了科恩卡帕系數(Cohen’s Kappa)[19]、加權卡帕系數(Weighted Kappa) [20]、弗萊斯卡帕系數(Fleiss’ Kappa)[21]和肯德爾和諧系數 (Kendall’s coefficient of concordance,Kendall’s W)[22]這四個一致性評價系數。
3.2 實驗設置
研究在操作系統Windows10(Microsoft,美國)和圖形處理器NVIDIA TITAN RTX(NVIDIA,美國)進行深度學習環境的搭建,利用機器學習庫Tensorflow 1.9.0(Google,美國)以及神經網絡庫Keras 2.1.6(Google,美國)構建模型,模型訓練過程中使用自適應矩估計(adaptive moment estimation,Adam)優化器,設置初始學習率為0.01,最小學習率為0.000 001;采用類交叉熵損失(categorical-crossentropy loss)函數進行參數的優化與迭代;使用回調函數與早停(early stopping)策略來優化學習率以及防止模型過擬合;利用統計分析軟件SPSS 25.0(IBM,美國)進行模型預測與醫生注釋結果的一致性分析。
3.3 三維多視角擠壓激勵卷積神經網絡模型結果
本研究提出的3D MVSECNN模型結合了3D MVCNN框架和SE模塊,并探討了3D MVCNN和SE模塊在肺結節良惡性分類中的能力,以說明3D MVSECNN模型的潛在優勢。3D CNN、3D MVCNN和3D MVSECNN模型層數都為10層,三個模型的性能比較如表6所示。如圖4所示,展示了部分肺結節正確分類結果。
圖4
3D MVSECNN模型測試結果展示
Figure4.
Test results display of 3D MVSECNN model
3.4 模型預測與醫生注釋結果一致性分析
為評估所提出的模型臨床適用性,以病理診斷為媒介,基于有病理診斷和醫生注釋的數據(既擁有病理診斷且擁有4位醫生注釋,在等級注釋中沒有不確定等級注釋的結節數據),對病理診斷與模型預測以及病理診斷與醫生注釋結果分別進行了一致性分析。
病理診斷與醫生注釋結果的一致性分析方法及結果為:① 對四名醫生的注釋結果分別與病理診斷進行一致性分析,通過Cohen’s Kappa一致性分數以及P值表明單名醫生注釋結果與病理診斷無一致性(P > 0.05)或一致性較差(Cohen’s Kappa= 0.308,P = 0.027);② 四名醫生注釋結果之間進行一致性分析,發現四名醫生的注釋結果之間無一致性(P > 0.05),兩名或三名醫生的注釋結果一致性較好,因此將一致性分數最高的兩名醫生的注釋結果(Cohen’s Kappa = 0.671,P < 0.05)和三名醫生的注釋結果(Kendall’s W = 0.786,P < 0.05)分別與病理診斷做一致性分析,結果表明:兩名醫生的注釋結果與病理診斷一致性一般(Fleiss’ Kappa = 0.438,P < 0.05),三名醫生的注釋結果與病理診斷一致性一般(Fleiss’ Kappa = 0.477,P < 0.05)。
對于病理診斷與模型預測的一致性分析,利用 Cohen’s Kappa一致性分析,模型預測與病理診斷的一致性好(Cohen’s Kappa = 0.948,P < 0.05),表明模型預測與病理診斷的一致性明顯高于醫生注釋結果與病理診斷的一致性。
4 討論
本研究提出了一種新的基于CT圖像的肺結節良惡性分類方法,該方法利用3D MVSECNN模型學習肺結節良惡性分類的高分辨特征,在開源數據庫LIDC-IDRI上進行驗證,AUC為0.943[95% 置信區間(confidence interval,CI): 0.879,0.979],Acc為 96.04%,結果表明該方法具有良好的肺結節良惡性分類性能。
如表7所示,基于開源數據庫LIDC-IDRI中擁有病理診斷的數據,比較了本文提出的方法與其他研究方法的性能。Shewaye等[23]采用基于影像組學的傳統方法進行肺結節良惡性分類,但是這種方法在提取影像組學特征時其過程既復雜又費時;Kumar等[24-25]與Kang等[26]的研究利用深度學習方法進行建模,只是Kumar等[24-25]的兩個研究都是利用深度學習模型進行特征提取,然后基于提取的深度特征訓練分類器,采用的是“兩步走”模式,而Kang等[26]采用的是端到端的模式,更方便快捷,本研究在構建模型時也選擇了端到端的方式。Kang等[26]的研究雖然AUC值高于本研究,但是Acc以及Sen都低于本研究,這可能是由于其選擇的模型架構更復雜,且采用的數據是肺部圖像數據庫聯盟(lung image database consortium,LIDC)2圖像工具包(image toolbox)[27]自動提取的96名患者病理診斷數據,沒有將全部病理診斷數據用于研究。
研究提出的3D MVCNN框架和SE模塊的組合是一種有效的肺結節良惡性分類方法。3D MVSECNN綜合了3D MVCNN框架的多視角特征融合特性和SE模塊用于特征重新校準的優點,在肺結節良惡性分類中顯示出良好的性能。如圖5所示,在模型訓練時,3D MVCNN比3D CNN收斂慢,這是由于模型需要考慮更多的數據以及參數,但是當在特征融合階段引入SE模塊后,3D MVSECNN模型在訓練過程中的收斂速度要快于其他兩個模型。
圖5
三個模型在模型訓練階段的Acc變化曲線
Figure5.
Acc change curve of the three models in the model training
如圖6所示,3D MVSECNN模型在獨立測試集上預測錯誤的樣本共四個,一個為惡性樣本,三個為良性樣本。對于惡性樣本,模型預測時將其預測為良性結節,可能是由于多視角觀察其形狀都為光滑的類圓形;右上角的良性結節被錯誤分類可能是由于多視角觀察肺結節的形狀較為復雜,與別的肺部結構有牽連;左下角的良性結節可能是由于其周圍有多條血管;右下角的良性結節被錯誤分類最大可能性是由于結節直徑較大,因為肺結節的良惡性診斷很大一部分原因取決于結節直徑大小。
圖6
3D MVSECNN模型預測錯誤樣本展示
Figure6.
Sample display of prediction error of 3D MVSECNN model
5 結論
本文提出了一種新的基于CT圖像的肺結節良惡性分類方法。該方法使用3D MVSECNN學習高分辨特征來分類惡性和良性肺結節。在開源數據庫LIDC-IDRI進行驗證,實驗結果表明:該方法的Acc和Sen比現有的基于傳統特征和深度特征的方法的更高,惡性肺結節預測結果的逃逸率小于1.5%;與病理診斷的一致性分析表明:模型預測與病理診斷的一致性明顯高于醫生注釋結果與病理診斷的一致性,模型分類結果對輔助臨床醫生診斷具有重要作用。本研究將進一步收集肺結節良惡性病理診斷數據用于現有模型優化和驗證,繼而開發深度學習技術對肺結節進行分類。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:楊楊負責研究算法程序設計,文章構思,實驗數據處理,論文撰寫;韓振波和付繼鵬負責論文修改和圖表繪制;李曉琴,高斌負責實驗指導,數據分析指導,論文審閱修訂。