針對構音障礙語音識別率難以提升的問題,本文提出一種多尺度梅爾域特征圖譜提取算法。該算法采用經驗模態分解方法分解語音信號,分別對三個有效分量提取Fbank特征及其一階差分,從而構成能夠捕捉頻域細節信息的新特征圖譜。其次,由于單路神經網絡在訓練過程中,存在有效特征丟失及計算復雜度高的問題,本文提出一種語音識別網絡模型。最后,在公開UA-Speech數據集上進行訓練和解碼。實驗結果表明,本文方法的語音識別模型準確率達到了92.77%,因此,本文所提算法能有效提高構音障礙語音識別率。
引用本文: 趙建星, 薛珮蕓, 白靜, 師晨康, 袁博, 師同同. 一種用于構音障礙語音識別的多尺度特征提取算法. 生物醫學工程學雜志, 2023, 40(1): 44-50. doi: 10.7507/1001-5515.202205049 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
構音障礙是一種發音相關肌肉或神經病變所導致的語言障礙,近年來針對構音障礙患者病理語音的研究受到廣泛關注[1-5],由于他們的言語肌肉受損,導致患者發音含糊不清,言語難以讓人理解[6]。構音障礙的類型與嚴重程度取決于受影響的神經系統區域[7],大多數情況下是由大腦損傷引起的,如腦癱或肌營養不良等先天性疾病,或者受到某些后天因素影響而造成的中風、腦損傷或帕金森病[8]等。由于構音障礙患者發音遲鈍、不清晰或語速波動較大,與人交流困難[9],因此標準的自動語音識別系統對于構音障礙的語音識別效果不佳[10-11]。
目前常用于語音識別的聲學特征[12]主要有:梅爾倒譜系數(mel frequency cepstral coefficents,MFCC)、韻律特征、線性預測倒譜系數(linear prediction cepstrum coefficient,LPCC)、頻譜圖[13]等。近年來,采用神經網絡搭建的語音識別聲學模型[14-15]普遍具有很好的泛化能力,深度神經網絡(deep neural networks,DNN)模型旨在通過使用病理語音數據來更好地訓練聲學模型[16],能有效地改善構音障礙語音識別的性能。王晴等[17]分析聽障患者語音的聲學及運動學特征,探討其不同特征之間的差異和聯系,能進一步幫助患者提高發音準確率。Zaidi等[18]提取不同聲學特征送入神經網絡模型中進行訓練,同時在DNN模型研究基礎上,嘗試使用卷積神經網絡(convolutional neural networks,CNN)和長短期記憶(long short-term memory,LSTM)神經網絡來提升構音障礙語音識別率。Mohammed等[19]采用經驗模態分解(empirical mode decomposition,EMD)和基于Hurst的模式選擇進行語音增強,之后提取MFCC特征作為CNN的輸入特征來實現構音障礙語音識別系統。雖然該方法提升了語音信號質量,但是提取的聲學特征精度難以保證,可能會影響語音識別效果。Joy等[20]提出基于DNN的自動語音識別系統,并在TORGO構音障礙語音數據庫上評估該系統的識別效果,文中針對DNN模型中隱藏節點和神經元的數量進行了相應調整,并通過隨機丟棄和序列判別訓練進一步優化模型,但對聲學特征維數處理相對較少。Rajeswari等[21]提出一種生成模型驅動的特征學習判別框架,但由于構音障礙患者發音缺乏一致性,提取的聲學特征存在相應的誤差。Yue等[22]提出的多流模型由卷積層、循環層和全連接層組成,能對各種信息流進行預處理,并在最佳抽象級別進行融合,可以更好地處理構音障礙語音。
針對構音障礙語音信號在提取梅爾域特征過程中頻域精度不夠準確、低頻有效特征易丟失及語音識別率難以提升的問題,筆者從頻域特征出發,首先采用EMD對濾波器組(filter banks,Fbank)特征進行改進,提出一種多尺度梅爾域特征圖譜提取算法,該算法結合EMD和Fbank特征兩者的優勢,能夠捕獲到構音障礙語音信號時變信息和相鄰幀信息之間的聯系,并通過捕捉語音信號低頻細節信息,表現出更佳的語音識別效果;其次,為了減少網絡模型的參數量和降低特征信息之間計算的復雜度,提出一種構音障礙語音識別網絡模型;最后,對本文模型進行訓練和解碼,并設計了不同聲學特征及網絡模型性能的對比實驗,來驗證本文所提算法的有效性。
1 基于EMD的多尺度梅爾域特征圖譜提取算法
EMD是一種處理非平穩和非線性信號的時頻分析方法,該方法可以自適應地將構音障礙語音信號分解為一組本征模函數(intrinsic mode function,IMF)的有限振蕩分量[23],從而有效地提取語音信號中出現的低頻振蕩信息。本文采用EMD對Fbank特征進行改進,提出一種多尺度梅爾域特征圖譜提取算法,該算法采用EMD對構音障礙語音信號進行分解,對分解后的IMF分量進行相關系數分析來篩選三個有效IMF分量,對有效IMF分量分別提取Fbank特征及其一階差分,再將各幀特征拼接在一起構成多尺度濾波器組(multiscale filter banks,MFbank)特征圖譜。MFbank特征圖譜結合了EMD和Fbank特征兩者的優勢,采用EMD方法篩選出三個有效表達語音信息的IMF分量,能夠有效彌補遺漏掉的語音低頻細節特征,更全面地表達語音信號信息;對三個有效IMF分量分別提取Fbank特征及其差分特征,考慮到了人耳的結構特性,保留語音信號數據之間的相關性,能夠捕獲到語音信號時變信息和相鄰幀信息之間的聯系,有利于語音識別網絡模型利用更加全面的語音細節特征來學習更加深層次的聲學特征信息。MFbank特征圖譜提取過程如圖1所示。
 圖1
MFbank特征圖譜提取流程圖
Figure1.
Flow chart of MFbank feature map extraction
圖1
MFbank特征圖譜提取流程圖
Figure1.
Flow chart of MFbank feature map extraction
MFbank特征圖譜具體提取過程如下:
(1)構音障礙語音信號經過預處理后,采用EMD方法分解出n個IMF分量,假設輸入的語音信號為y(t),則經過EMD方法分解后可以表示為
 |
其中, 為第i個IMF分量,
為第i個IMF分量, 為分解后剩余的殘余信號,t代表幀同步時間。
為分解后剩余的殘余信號,t代表幀同步時間。
(2)從n個IMF分量中找出能夠有效表達語音信息的IMF分量,采用Spearman Rank相關系數[24]來判斷每個IMF分量與原輸入構音障礙語音信號之間相關系數的大小,假設某IMF分量為x(t),計算y(t)與x(t)之間Spearman Rank相關系數的公式為
 |
其中, 、
、 分別為第n幀的y(t)、x(t)值,
分別為第n幀的y(t)、x(t)值, 、
、 分別為
分別為  、
、 的平均值,
的平均值, 為原輸入語音信號與分解后IMF之間的Spearman Rank相關系數值,N為分幀總數。一般認為
為原輸入語音信號與分解后IMF之間的Spearman Rank相關系數值,N為分幀總數。一般認為  > 0.1時,代表兩者之間具有相關性,本文選取相關系數最大的三個作為有效IMF分量。
> 0.1時,代表兩者之間具有相關性,本文選取相關系數最大的三個作為有效IMF分量。
(3)對三個有效IMF分量分別提取Fbank特征,Fbank特征提取過程[25]如圖2所示。
 圖2
Fbank特征提取流程圖
Figure2.
Flow chart of Fbank feature extraction
圖2
Fbank特征提取流程圖
Figure2.
Flow chart of Fbank feature extraction
① 假設IMF分量經過預處理后得到語音信號的序列幀為  ,對
,對  進行短時傅里葉變換,得出語音序列頻譜
進行短時傅里葉變換,得出語音序列頻譜  。
。
②  經過Mel三角濾波器組
經過Mel三角濾波器組  ,得到濾波之后的能量譜,
,得到濾波之后的能量譜, 的傳遞函數為
的傳遞函數為
 |
其中  為選用第m個Mel三角濾波器的中心頻率。
為選用第m個Mel三角濾波器的中心頻率。
③ 對經過步驟 ② 得到的能量譜,再進行對數變換得到Fbank特征 ,計算公式為
,計算公式為
 |
其中  為選用第m個Mel三角濾波器的傳遞函數,M為濾波器個數。
為選用第m個Mel三角濾波器的傳遞函數,M為濾波器個數。
(4)對有效IMF分量的Fbank特征進一步求取一階差分,得到差分特征 ,可以表示為
,可以表示為
 |
其中  表示第k個有效IMF分量的Fbank特征,
表示第k個有效IMF分量的Fbank特征, 表示第k個有效IMF分量Fbank特征的一階差分,j為語音信號分幀操作的第j幀,m為特征維度大小。
表示第k個有效IMF分量Fbank特征的一階差分,j為語音信號分幀操作的第j幀,m為特征維度大小。
(5)將得到的第j幀有效分量的Fbank特征及其一階差分進行拼接,得到語音信號第j幀組合特征  ,可以表示為
,可以表示為
 |
其中d = 6*m表示特征維度大小。
(6)將各幀組合特征拼接在一起,得到MFbank特征圖譜。
2 構音障礙語音識別網絡模型
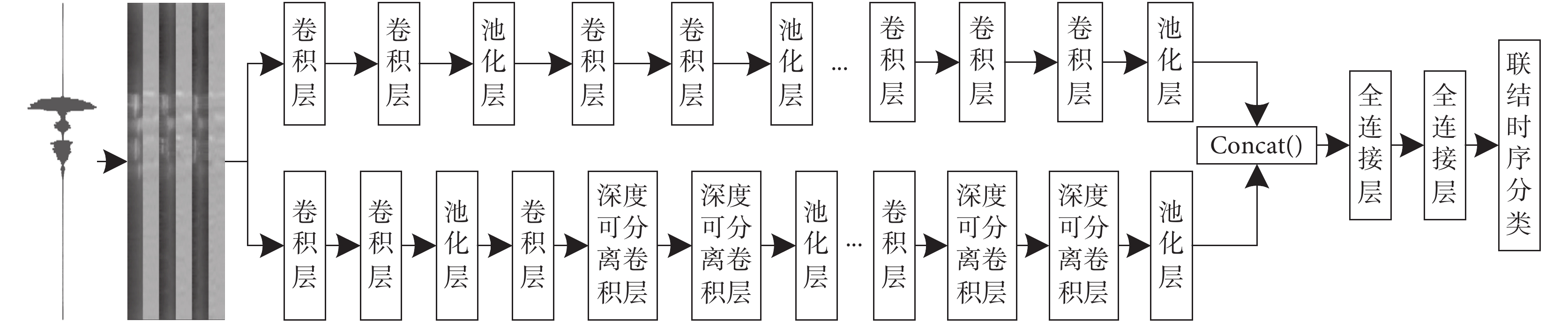
近年來,大多數的單路神經網絡在深度方向進行優化,在提取特征過程中會遺漏部分有效特征,因此本文提出一種構音障礙語音識別網絡模型,采用兩條不同的支路分別提取構音障礙語音特征,彌補了單條支路在提取特征時遺漏掉有效特征的缺陷,同時采用深度可分離卷積(depthwise separable convolution,DSC)對網絡模型進行優化,能夠減少網絡模型的參數量和計算復雜度。本文采用DSC和CNN在深度和寬度兩個不同維度上對語音信號的聲學模型進行建模,一條支路采用傳統CNN,另一條在模型前部分先使用傳統CNN,然后讓CNN與DSC兩者交替使用;再采用Concat( )函數將兩條支路提取的語音特征進行拼接得到特征圖,送入充當分類器的全連接層,最后采用聯結時序分類算法以單詞為建模單元進行訓練和解碼。構音障礙語音識別網絡模型的總體結構如圖3所示。
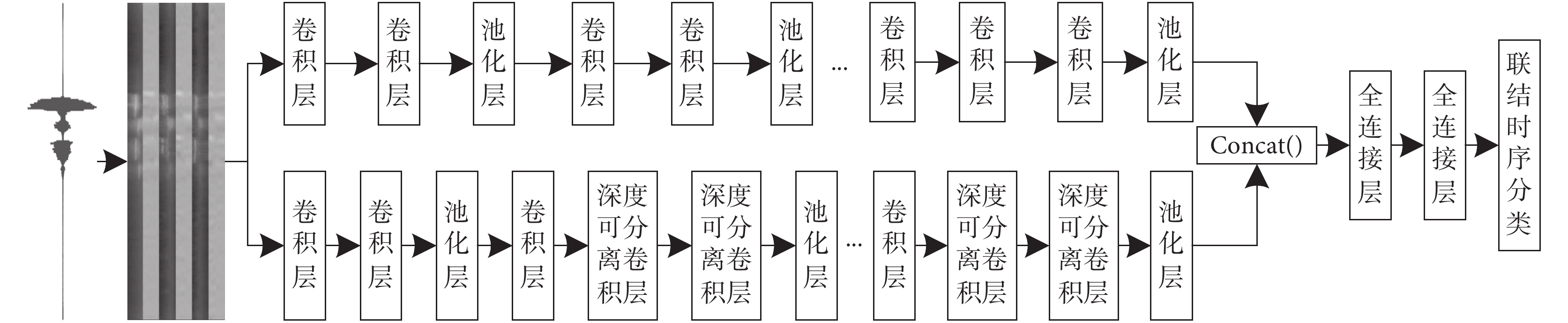 圖3
構音障礙語音識別網絡模型
Figure3.
Speech recognition network model for dysarthria
圖3
構音障礙語音識別網絡模型
Figure3.
Speech recognition network model for dysarthria
CNN能夠很好地處理語音信號中包含不同聲學特征之間的高維數據,利用核函數從輸入語音信號中提取特征映射,內核矩陣充當滑動窗口,對每張特征圖執行卷積運算,其中卷積層可以通過局部感受野來發現不同聲學特征之間的相關性,池化層能夠過濾掉一些不相關的語音信息[26]。
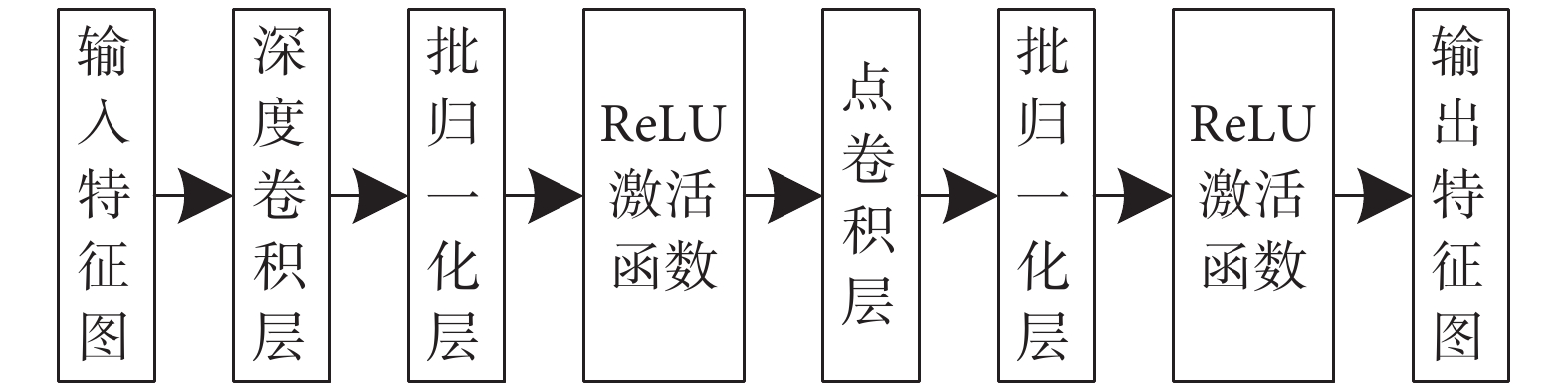
DSC能夠對神經網絡模型性能進行優化,其中先對每個不同通道的特征進行卷積運算,再采用1*1卷積形式拼接不同通道上的所有特征信息,以此搭建的輕量級模型[27]能夠在很大程度上減少網絡模型參數的數量以及降低特征信息之間計算的復雜度。DSC結構如圖4所示。
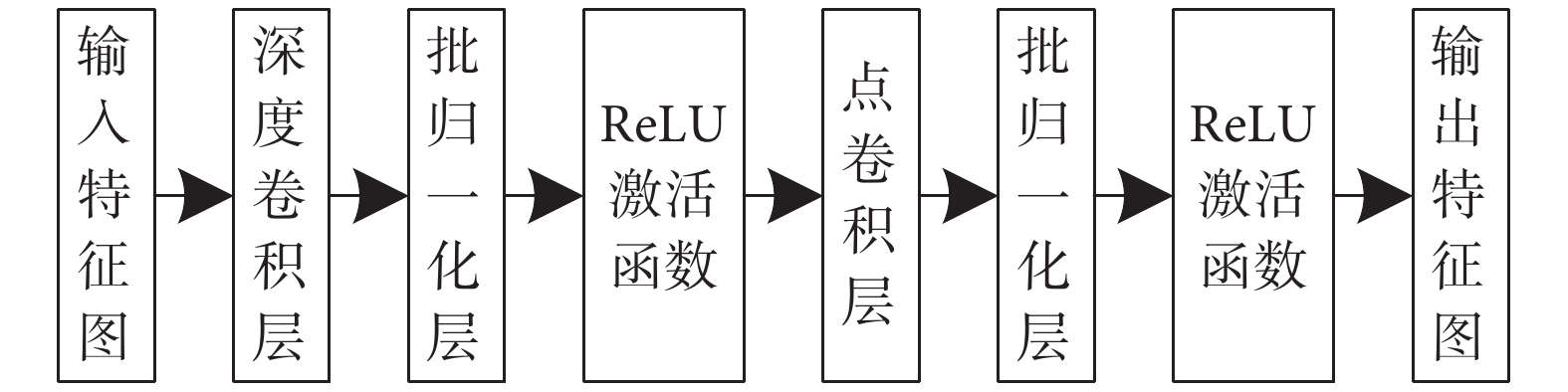 圖4
深度可分離卷積結構
Figure4.
Depthwise separable convolution structure
圖4
深度可分離卷積結構
Figure4.
Depthwise separable convolution structure
深度卷積相比傳統卷積,能有效提取模型中不同通道上的特征得到空間維度上的特征信息。輸入特征圖先經過深度卷積層,再采用1*1卷積核改變特征圖個數得到每個點上的特征信息,在深度上加權組合得到新的輸出特征圖。
3 UA-Speech數據庫
3.1 數據庫概況
伊利諾伊大學公布UA-Speech數據庫[28],旨在促進構音障礙患者的用戶界面開發。該數據庫是由16名構音障礙患者和13名正常對照者的平行單詞語音記錄(包含10個數字、26個無線電字母、19個計算機命令和100個常見單詞)組成。所有語音樣本都是使用一個由八個麥克風組成的陣列錄音,采樣頻率為16 kHz,并將每個單詞錄音保存為單獨的wav文件。語料庫中構音障礙患者的語音清晰度從2%到95%不等,例如“非常低(0~25%)”、“低(25%~50%)”、“中等(50%~75%)”和“高(75%~100%)”。
3.2 數據集篩選
本文實驗采用公開UA-Speech語料庫中計算機命令單詞及數字單詞錄音,其中含有12名男性和3名女性受試者的語音。實驗過程中總共使用了6 264個構音障礙語音樣本,語音識別29個類的孤立單詞,每一類中包含216個語音樣本。其中4 640個語音樣本用于本文模型訓練,每一類平均分配160個語音樣本;1 273個語音樣本用于本文模型測試,每一類平均分配語音樣本;351個語音樣本用于本文模型驗證。本文實驗劃分的訓練、測試、驗證數據集中的每個語音樣本是互不相交且隨機選擇的。
4 實驗結果分析
4.1 實驗準備
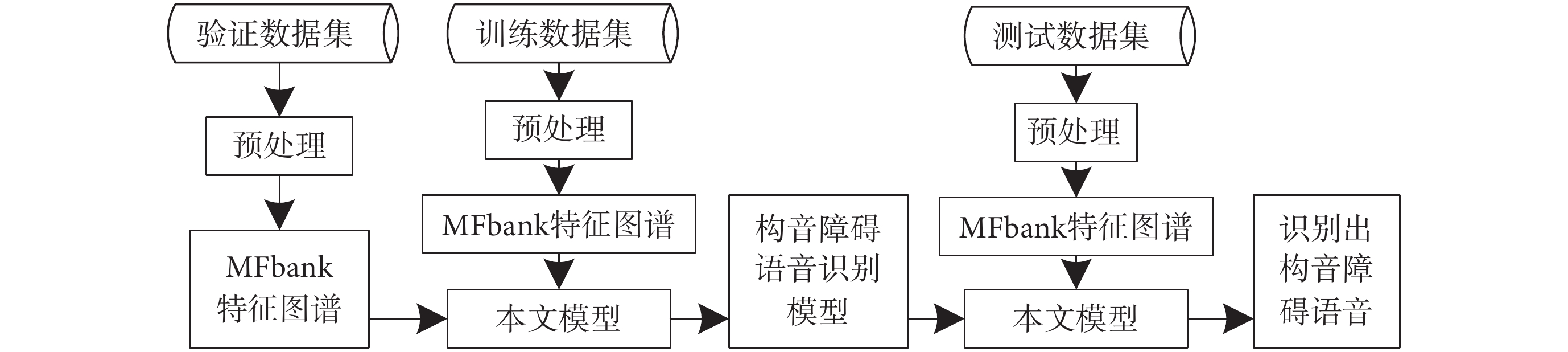
本文實驗使用電腦配置為i3-10 105F CPU、16GB機帶RAM和NVIDIA GeForce GTX 1 050Ti顯卡,采用Keras + Tensorflow深度學習框架來搭建構音障礙語音識別網絡模型,如圖3所示。本文進行的構音障礙語音識別實驗分為訓練和測試兩個部分,具體流程如圖5所示。
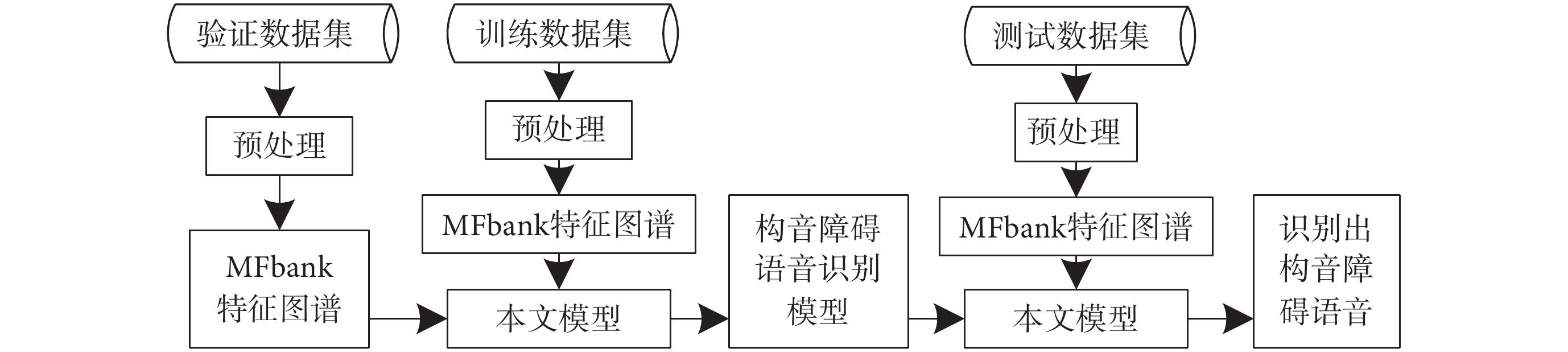 圖5
實驗流程圖
Figure5.
Experimental flow chart
圖5
實驗流程圖
Figure5.
Experimental flow chart
4.2 實驗參數及評價指標
本文對16 kHz構音障礙語音信號提取120維MFbank特征圖譜,采用適應性動量估計法(adaptive moment estimation,Adam)作為本文模型優化器,適用于非平穩目標訓練,學習率設為0.001。該模型添加批量歸一化(batch normalization,BN),以此提升該模型的泛化能力。在全連接層后使用Dropout,設置參數為0.3和0.5。卷積層中filters設置為8、16、32和64,池化層中pool_size設為2。本文模型采用ReLU函數作為激活函數,來解決訓練過程中出現梯度消失、爆炸的問題[29]。
構音障礙語音識別網絡模型的評價指標采用單詞識別準確率(word recognition accuracy,WRA),可以表示為
 |
其中,C代表正確識別單詞個數,N代表嘗試識別單詞總個數。
4.3 實驗結果及分析
為了驗證本文所提多尺度梅爾域特征圖譜算法以及構音障礙語音識別網絡模型的有效性,本文設計了4組對比實驗進行討論:實驗一:使用MFCC特征來訓練本文模型;實驗二:使用Fbank特征來訓練本文模型;實驗三:使用MFbank特征圖譜剔除一階差分部分來訓練本文模型;實驗四:使用MFbank特征圖譜來訓練本文模型。采取上述四組實驗分別對測試集1 273條語音進行語音識別實驗,不同聲學特征的識別結果對比如表1所示,每個說話人的語音識別結果對比如表2所示。
由表1可得,本文方法的構音障礙語音識別率達到了92.77%,實驗四相比實驗一、實驗二和實驗三分別提高了20.89%、7.30%和2.59%。由于對MFCC特征進行改進,在計算過程中剔除離散余弦變換得到Fbank特征,能夠保留語音信號數據之間的相關性,實驗二的識別率比實驗一提高了13.59%。由于采用EMD方法能有效地分析語音信號中出現的低頻振蕩信息,彌補了遺漏掉的語音低頻細節特征,實驗三的識別率比實驗二提高了4.71%。由于采用差分特征能夠捕獲到語音信號時變信息和相鄰幀信息之間的聯系,實驗四的識別率比實驗三提高了2.59%。
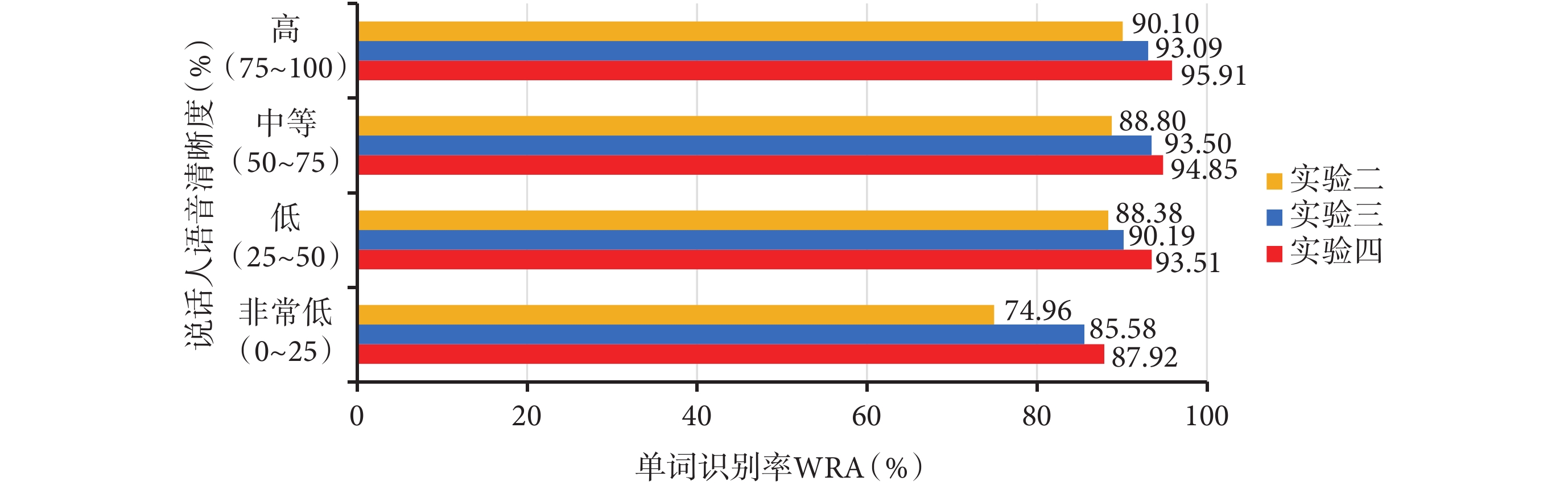
由表2可得,對于每個說話人來說,實驗四采用MFbank特征圖譜的識別效果優于實驗二采用Fbank特征和實驗三采用剔除一階差分的MFbank特征的識別效果。圖6給出說話人不同語音清晰度的語音識別結果對比,可以看出語音清晰度越高語音識別率越高,在語音清晰度非常低時,實驗四、實驗三和實驗二的語音識別率達到了87.92%、85.58%、74.96%;在語音清晰度高時,實驗四、實驗三和實驗二的語音識別率達到了95.91%、93.09%、90.10%。通過對表1、表2和圖6的分析,MFbank特征圖譜進行構音障礙語音識別時的識別率最高,該圖譜能夠有效地彌補遺漏掉的語音低頻細節特征,并捕獲到語音時變信息和相鄰幀信息之間的聯系,使得本文模型能夠利用更加全面的語音特征來學習更加深層次的特征信息,驗證了本文所提方法的有效性。
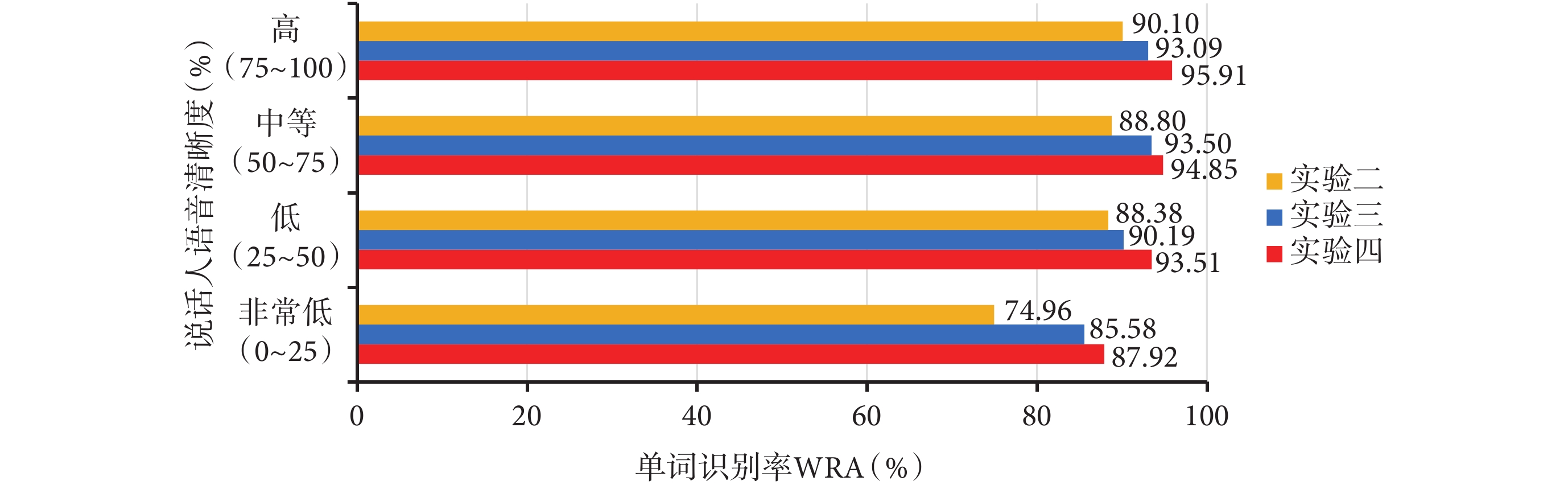 圖6
不同語音清晰度在實驗二、實驗三、實驗四中的識別結果
Figure6.
Recognition results of different speech intelligibility in Experiment 2, Experiment 3 and Experiment 4
圖6
不同語音清晰度在實驗二、實驗三、實驗四中的識別結果
Figure6.
Recognition results of different speech intelligibility in Experiment 2, Experiment 3 and Experiment 4
為驗證本文提取MFbank特征圖譜以及本文模型所做貢獻的有效性,進行消融實驗,采用EMD方法分解語音信號,分別對三個有效IMF分量提取Fbank特征進行拼接得到EMD + Fbank特征;再增加一階差分處理得到EMD + Fbank + 一階差分特征。采用Concat( )函數將單路傳統CNN和單路傳統CNN + DSC進行拼接得到本文模型。將上述兩種特征及Fbank特征分別在單路傳統CNN、單路傳統CNN + DSC和本文模型上進行消融實驗對比,結果如表3所示。
由表3可知,EMD+Fbank特征相比Fbank特征在單路傳統CNN、單路傳統CNN+DSC、本文模型上的WRA分別提高了4.79%、4.71%、4.71%;EMD + Fbank + 一階差分特征相比EMD + Fbank特征在單路傳統CNN、單路傳統CNN + DSC、本文模型上的WRA分別提高了2.59%、2.51%、2.59%。相比單路傳統CNN和單路傳統CNN + DSC模型,EMD + Fbank特征在本文模型上的WRA分別提高了1.65%、1.02%,EMD + Fbank + 一階差分特征在本文模型上的WRA分別提高了1.65%、1.10%。由此可以得出,MFbank特征圖譜相對Fbank特征的優越性,能夠有效彌補遺漏掉的語音低頻細節特征,同時考慮到了人耳的結構特性,能夠捕獲到語音信號時變信息和相鄰幀信息之間的聯系;本文模型相對單路網絡模型的優越性,能夠在深度和寬度兩個不同維度上提取語音特征,彌補了單條支路遺漏掉的有效特征,進一步提升了語音識別率。
在公開UA-Speech數據集上,選取文獻[21]、[30]、[31]的研究方法與本文方法進行語音識別效果對比,如表4所示。其中,文獻[21]把MFCC向量映射到生成器模型誘導的固定維度向量空間里,在生成模型誘導似然向量空間(LL-SVM)和轉移向量空間(TP-SVM)中構建判別分類器;文獻[30]采用MFCC特征,作為神經網絡ANN和MLP的輸入特征;文獻[31]提出一種語音視覺系統(speech vision,SV),該系統能夠提取一種新的語音視覺特征,送入S-CNN模型進行訓練。觀察表4可以得出,本文方法的構音障礙語音識別率相比于ANN+MLP[30]、TP-SVM[21]、LL-SVM[21]和SV+S-CNN[31]分別提升了23.89%、19.09%、4.86%和3.23%。對比識別結果表明,本文方法的識別結果表現更佳,能夠有效地提升構音障礙語音識別率。
5 結束語
針對構音障礙語音識別率難以提升的問題,筆者從頻域特征入手,提出了一種多尺度梅爾域特征圖譜提取算法,該算法提取的MFbank特征圖譜能夠有效彌補遺漏掉的語音低頻細節特征,更全面地表達語音信號信息。本文采用DSC優化CNN,對語音信號的聲學模型進行建模,得到最佳的構音障礙語音識別網絡模型。在公開數據集上設計語音識別對比實驗,實驗結果表明,筆者所提方法的構音障礙語音識別率達到了92.77%,相比其他主流方法表現更佳,能有效提升語音識別率。在未來的工作中,將進一步優化構音障礙語音聲學特征提取算法,并改進構音障礙語音識別網絡模型結構來訓練更加穩健的語音識別模型。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:趙建星主要負責本研究算法的設計以及論文編寫、修訂;薛珮蕓和白靜老師主要負責實驗指導、研究計劃的安排;師晨康和袁博主要負責算法的平臺搭建、程序設計;師同同主要負責實驗數據的記錄分析。
倫理聲明:文中使用實驗數據來自公開數據庫,不涉及倫理問題。
0 引言
構音障礙是一種發音相關肌肉或神經病變所導致的語言障礙,近年來針對構音障礙患者病理語音的研究受到廣泛關注[1-5],由于他們的言語肌肉受損,導致患者發音含糊不清,言語難以讓人理解[6]。構音障礙的類型與嚴重程度取決于受影響的神經系統區域[7],大多數情況下是由大腦損傷引起的,如腦癱或肌營養不良等先天性疾病,或者受到某些后天因素影響而造成的中風、腦損傷或帕金森病[8]等。由于構音障礙患者發音遲鈍、不清晰或語速波動較大,與人交流困難[9],因此標準的自動語音識別系統對于構音障礙的語音識別效果不佳[10-11]。
目前常用于語音識別的聲學特征[12]主要有:梅爾倒譜系數(mel frequency cepstral coefficents,MFCC)、韻律特征、線性預測倒譜系數(linear prediction cepstrum coefficient,LPCC)、頻譜圖[13]等。近年來,采用神經網絡搭建的語音識別聲學模型[14-15]普遍具有很好的泛化能力,深度神經網絡(deep neural networks,DNN)模型旨在通過使用病理語音數據來更好地訓練聲學模型[16],能有效地改善構音障礙語音識別的性能。王晴等[17]分析聽障患者語音的聲學及運動學特征,探討其不同特征之間的差異和聯系,能進一步幫助患者提高發音準確率。Zaidi等[18]提取不同聲學特征送入神經網絡模型中進行訓練,同時在DNN模型研究基礎上,嘗試使用卷積神經網絡(convolutional neural networks,CNN)和長短期記憶(long short-term memory,LSTM)神經網絡來提升構音障礙語音識別率。Mohammed等[19]采用經驗模態分解(empirical mode decomposition,EMD)和基于Hurst的模式選擇進行語音增強,之后提取MFCC特征作為CNN的輸入特征來實現構音障礙語音識別系統。雖然該方法提升了語音信號質量,但是提取的聲學特征精度難以保證,可能會影響語音識別效果。Joy等[20]提出基于DNN的自動語音識別系統,并在TORGO構音障礙語音數據庫上評估該系統的識別效果,文中針對DNN模型中隱藏節點和神經元的數量進行了相應調整,并通過隨機丟棄和序列判別訓練進一步優化模型,但對聲學特征維數處理相對較少。Rajeswari等[21]提出一種生成模型驅動的特征學習判別框架,但由于構音障礙患者發音缺乏一致性,提取的聲學特征存在相應的誤差。Yue等[22]提出的多流模型由卷積層、循環層和全連接層組成,能對各種信息流進行預處理,并在最佳抽象級別進行融合,可以更好地處理構音障礙語音。
針對構音障礙語音信號在提取梅爾域特征過程中頻域精度不夠準確、低頻有效特征易丟失及語音識別率難以提升的問題,筆者從頻域特征出發,首先采用EMD對濾波器組(filter banks,Fbank)特征進行改進,提出一種多尺度梅爾域特征圖譜提取算法,該算法結合EMD和Fbank特征兩者的優勢,能夠捕獲到構音障礙語音信號時變信息和相鄰幀信息之間的聯系,并通過捕捉語音信號低頻細節信息,表現出更佳的語音識別效果;其次,為了減少網絡模型的參數量和降低特征信息之間計算的復雜度,提出一種構音障礙語音識別網絡模型;最后,對本文模型進行訓練和解碼,并設計了不同聲學特征及網絡模型性能的對比實驗,來驗證本文所提算法的有效性。
1 基于EMD的多尺度梅爾域特征圖譜提取算法
EMD是一種處理非平穩和非線性信號的時頻分析方法,該方法可以自適應地將構音障礙語音信號分解為一組本征模函數(intrinsic mode function,IMF)的有限振蕩分量[23],從而有效地提取語音信號中出現的低頻振蕩信息。本文采用EMD對Fbank特征進行改進,提出一種多尺度梅爾域特征圖譜提取算法,該算法采用EMD對構音障礙語音信號進行分解,對分解后的IMF分量進行相關系數分析來篩選三個有效IMF分量,對有效IMF分量分別提取Fbank特征及其一階差分,再將各幀特征拼接在一起構成多尺度濾波器組(multiscale filter banks,MFbank)特征圖譜。MFbank特征圖譜結合了EMD和Fbank特征兩者的優勢,采用EMD方法篩選出三個有效表達語音信息的IMF分量,能夠有效彌補遺漏掉的語音低頻細節特征,更全面地表達語音信號信息;對三個有效IMF分量分別提取Fbank特征及其差分特征,考慮到了人耳的結構特性,保留語音信號數據之間的相關性,能夠捕獲到語音信號時變信息和相鄰幀信息之間的聯系,有利于語音識別網絡模型利用更加全面的語音細節特征來學習更加深層次的聲學特征信息。MFbank特征圖譜提取過程如圖1所示。
圖1
MFbank特征圖譜提取流程圖
Figure1.
Flow chart of MFbank feature map extraction
MFbank特征圖譜具體提取過程如下:
(1)構音障礙語音信號經過預處理后,采用EMD方法分解出n個IMF分量,假設輸入的語音信號為y(t),則經過EMD方法分解后可以表示為
|
其中, 為第i個IMF分量, 為分解后剩余的殘余信號,t代表幀同步時間。
(2)從n個IMF分量中找出能夠有效表達語音信息的IMF分量,采用Spearman Rank相關系數[24]來判斷每個IMF分量與原輸入構音障礙語音信號之間相關系數的大小,假設某IMF分量為x(t),計算y(t)與x(t)之間Spearman Rank相關系數的公式為
|
其中,、 分別為第n幀的y(t)、x(t)值,、 分別為 、 的平均值, 為原輸入語音信號與分解后IMF之間的Spearman Rank相關系數值,N為分幀總數。一般認為 > 0.1時,代表兩者之間具有相關性,本文選取相關系數最大的三個作為有效IMF分量。
(3)對三個有效IMF分量分別提取Fbank特征,Fbank特征提取過程[25]如圖2所示。
圖2
Fbank特征提取流程圖
Figure2.
Flow chart of Fbank feature extraction
① 假設IMF分量經過預處理后得到語音信號的序列幀為 ,對 進行短時傅里葉變換,得出語音序列頻譜 。
② 經過Mel三角濾波器組 ,得到濾波之后的能量譜, 的傳遞函數為
|
其中 為選用第m個Mel三角濾波器的中心頻率。
③ 對經過步驟 ② 得到的能量譜,再進行對數變換得到Fbank特征,計算公式為
|
其中 為選用第m個Mel三角濾波器的傳遞函數,M為濾波器個數。
(4)對有效IMF分量的Fbank特征進一步求取一階差分,得到差分特征,可以表示為
|
其中 表示第k個有效IMF分量的Fbank特征, 表示第k個有效IMF分量Fbank特征的一階差分,j為語音信號分幀操作的第j幀,m為特征維度大小。
(5)將得到的第j幀有效分量的Fbank特征及其一階差分進行拼接,得到語音信號第j幀組合特征 ,可以表示為
|
其中d = 6*m表示特征維度大小。
(6)將各幀組合特征拼接在一起,得到MFbank特征圖譜。
2 構音障礙語音識別網絡模型
近年來,大多數的單路神經網絡在深度方向進行優化,在提取特征過程中會遺漏部分有效特征,因此本文提出一種構音障礙語音識別網絡模型,采用兩條不同的支路分別提取構音障礙語音特征,彌補了單條支路在提取特征時遺漏掉有效特征的缺陷,同時采用深度可分離卷積(depthwise separable convolution,DSC)對網絡模型進行優化,能夠減少網絡模型的參數量和計算復雜度。本文采用DSC和CNN在深度和寬度兩個不同維度上對語音信號的聲學模型進行建模,一條支路采用傳統CNN,另一條在模型前部分先使用傳統CNN,然后讓CNN與DSC兩者交替使用;再采用Concat( )函數將兩條支路提取的語音特征進行拼接得到特征圖,送入充當分類器的全連接層,最后采用聯結時序分類算法以單詞為建模單元進行訓練和解碼。構音障礙語音識別網絡模型的總體結構如圖3所示。
圖3
構音障礙語音識別網絡模型
Figure3.
Speech recognition network model for dysarthria
CNN能夠很好地處理語音信號中包含不同聲學特征之間的高維數據,利用核函數從輸入語音信號中提取特征映射,內核矩陣充當滑動窗口,對每張特征圖執行卷積運算,其中卷積層可以通過局部感受野來發現不同聲學特征之間的相關性,池化層能夠過濾掉一些不相關的語音信息[26]。
DSC能夠對神經網絡模型性能進行優化,其中先對每個不同通道的特征進行卷積運算,再采用1*1卷積形式拼接不同通道上的所有特征信息,以此搭建的輕量級模型[27]能夠在很大程度上減少網絡模型參數的數量以及降低特征信息之間計算的復雜度。DSC結構如圖4所示。
圖4
深度可分離卷積結構
Figure4.
Depthwise separable convolution structure
深度卷積相比傳統卷積,能有效提取模型中不同通道上的特征得到空間維度上的特征信息。輸入特征圖先經過深度卷積層,再采用1*1卷積核改變特征圖個數得到每個點上的特征信息,在深度上加權組合得到新的輸出特征圖。
3 UA-Speech數據庫
3.1 數據庫概況
伊利諾伊大學公布UA-Speech數據庫[28],旨在促進構音障礙患者的用戶界面開發。該數據庫是由16名構音障礙患者和13名正常對照者的平行單詞語音記錄(包含10個數字、26個無線電字母、19個計算機命令和100個常見單詞)組成。所有語音樣本都是使用一個由八個麥克風組成的陣列錄音,采樣頻率為16 kHz,并將每個單詞錄音保存為單獨的wav文件。語料庫中構音障礙患者的語音清晰度從2%到95%不等,例如“非常低(0~25%)”、“低(25%~50%)”、“中等(50%~75%)”和“高(75%~100%)”。
3.2 數據集篩選
本文實驗采用公開UA-Speech語料庫中計算機命令單詞及數字單詞錄音,其中含有12名男性和3名女性受試者的語音。實驗過程中總共使用了6 264個構音障礙語音樣本,語音識別29個類的孤立單詞,每一類中包含216個語音樣本。其中4 640個語音樣本用于本文模型訓練,每一類平均分配160個語音樣本;1 273個語音樣本用于本文模型測試,每一類平均分配語音樣本;351個語音樣本用于本文模型驗證。本文實驗劃分的訓練、測試、驗證數據集中的每個語音樣本是互不相交且隨機選擇的。
4 實驗結果分析
4.1 實驗準備
本文實驗使用電腦配置為i3-10 105F CPU、16GB機帶RAM和NVIDIA GeForce GTX 1 050Ti顯卡,采用Keras + Tensorflow深度學習框架來搭建構音障礙語音識別網絡模型,如圖3所示。本文進行的構音障礙語音識別實驗分為訓練和測試兩個部分,具體流程如圖5所示。
圖5
實驗流程圖
Figure5.
Experimental flow chart
4.2 實驗參數及評價指標
本文對16 kHz構音障礙語音信號提取120維MFbank特征圖譜,采用適應性動量估計法(adaptive moment estimation,Adam)作為本文模型優化器,適用于非平穩目標訓練,學習率設為0.001。該模型添加批量歸一化(batch normalization,BN),以此提升該模型的泛化能力。在全連接層后使用Dropout,設置參數為0.3和0.5。卷積層中filters設置為8、16、32和64,池化層中pool_size設為2。本文模型采用ReLU函數作為激活函數,來解決訓練過程中出現梯度消失、爆炸的問題[29]。
構音障礙語音識別網絡模型的評價指標采用單詞識別準確率(word recognition accuracy,WRA),可以表示為
|
其中,C代表正確識別單詞個數,N代表嘗試識別單詞總個數。
4.3 實驗結果及分析
為了驗證本文所提多尺度梅爾域特征圖譜算法以及構音障礙語音識別網絡模型的有效性,本文設計了4組對比實驗進行討論:實驗一:使用MFCC特征來訓練本文模型;實驗二:使用Fbank特征來訓練本文模型;實驗三:使用MFbank特征圖譜剔除一階差分部分來訓練本文模型;實驗四:使用MFbank特征圖譜來訓練本文模型。采取上述四組實驗分別對測試集1 273條語音進行語音識別實驗,不同聲學特征的識別結果對比如表1所示,每個說話人的語音識別結果對比如表2所示。
由表1可得,本文方法的構音障礙語音識別率達到了92.77%,實驗四相比實驗一、實驗二和實驗三分別提高了20.89%、7.30%和2.59%。由于對MFCC特征進行改進,在計算過程中剔除離散余弦變換得到Fbank特征,能夠保留語音信號數據之間的相關性,實驗二的識別率比實驗一提高了13.59%。由于采用EMD方法能有效地分析語音信號中出現的低頻振蕩信息,彌補了遺漏掉的語音低頻細節特征,實驗三的識別率比實驗二提高了4.71%。由于采用差分特征能夠捕獲到語音信號時變信息和相鄰幀信息之間的聯系,實驗四的識別率比實驗三提高了2.59%。
由表2可得,對于每個說話人來說,實驗四采用MFbank特征圖譜的識別效果優于實驗二采用Fbank特征和實驗三采用剔除一階差分的MFbank特征的識別效果。圖6給出說話人不同語音清晰度的語音識別結果對比,可以看出語音清晰度越高語音識別率越高,在語音清晰度非常低時,實驗四、實驗三和實驗二的語音識別率達到了87.92%、85.58%、74.96%;在語音清晰度高時,實驗四、實驗三和實驗二的語音識別率達到了95.91%、93.09%、90.10%。通過對表1、表2和圖6的分析,MFbank特征圖譜進行構音障礙語音識別時的識別率最高,該圖譜能夠有效地彌補遺漏掉的語音低頻細節特征,并捕獲到語音時變信息和相鄰幀信息之間的聯系,使得本文模型能夠利用更加全面的語音特征來學習更加深層次的特征信息,驗證了本文所提方法的有效性。
圖6
不同語音清晰度在實驗二、實驗三、實驗四中的識別結果
Figure6.
Recognition results of different speech intelligibility in Experiment 2, Experiment 3 and Experiment 4
為驗證本文提取MFbank特征圖譜以及本文模型所做貢獻的有效性,進行消融實驗,采用EMD方法分解語音信號,分別對三個有效IMF分量提取Fbank特征進行拼接得到EMD + Fbank特征;再增加一階差分處理得到EMD + Fbank + 一階差分特征。采用Concat( )函數將單路傳統CNN和單路傳統CNN + DSC進行拼接得到本文模型。將上述兩種特征及Fbank特征分別在單路傳統CNN、單路傳統CNN + DSC和本文模型上進行消融實驗對比,結果如表3所示。
由表3可知,EMD+Fbank特征相比Fbank特征在單路傳統CNN、單路傳統CNN+DSC、本文模型上的WRA分別提高了4.79%、4.71%、4.71%;EMD + Fbank + 一階差分特征相比EMD + Fbank特征在單路傳統CNN、單路傳統CNN + DSC、本文模型上的WRA分別提高了2.59%、2.51%、2.59%。相比單路傳統CNN和單路傳統CNN + DSC模型,EMD + Fbank特征在本文模型上的WRA分別提高了1.65%、1.02%,EMD + Fbank + 一階差分特征在本文模型上的WRA分別提高了1.65%、1.10%。由此可以得出,MFbank特征圖譜相對Fbank特征的優越性,能夠有效彌補遺漏掉的語音低頻細節特征,同時考慮到了人耳的結構特性,能夠捕獲到語音信號時變信息和相鄰幀信息之間的聯系;本文模型相對單路網絡模型的優越性,能夠在深度和寬度兩個不同維度上提取語音特征,彌補了單條支路遺漏掉的有效特征,進一步提升了語音識別率。
在公開UA-Speech數據集上,選取文獻[21]、[30]、[31]的研究方法與本文方法進行語音識別效果對比,如表4所示。其中,文獻[21]把MFCC向量映射到生成器模型誘導的固定維度向量空間里,在生成模型誘導似然向量空間(LL-SVM)和轉移向量空間(TP-SVM)中構建判別分類器;文獻[30]采用MFCC特征,作為神經網絡ANN和MLP的輸入特征;文獻[31]提出一種語音視覺系統(speech vision,SV),該系統能夠提取一種新的語音視覺特征,送入S-CNN模型進行訓練。觀察表4可以得出,本文方法的構音障礙語音識別率相比于ANN+MLP[30]、TP-SVM[21]、LL-SVM[21]和SV+S-CNN[31]分別提升了23.89%、19.09%、4.86%和3.23%。對比識別結果表明,本文方法的識別結果表現更佳,能夠有效地提升構音障礙語音識別率。
5 結束語
針對構音障礙語音識別率難以提升的問題,筆者從頻域特征入手,提出了一種多尺度梅爾域特征圖譜提取算法,該算法提取的MFbank特征圖譜能夠有效彌補遺漏掉的語音低頻細節特征,更全面地表達語音信號信息。本文采用DSC優化CNN,對語音信號的聲學模型進行建模,得到最佳的構音障礙語音識別網絡模型。在公開數據集上設計語音識別對比實驗,實驗結果表明,筆者所提方法的構音障礙語音識別率達到了92.77%,相比其他主流方法表現更佳,能有效提升語音識別率。在未來的工作中,將進一步優化構音障礙語音聲學特征提取算法,并改進構音障礙語音識別網絡模型結構來訓練更加穩健的語音識別模型。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:趙建星主要負責本研究算法的設計以及論文編寫、修訂;薛珮蕓和白靜老師主要負責實驗指導、研究計劃的安排;師晨康和袁博主要負責算法的平臺搭建、程序設計;師同同主要負責實驗數據的記錄分析。
倫理聲明:文中使用實驗數據來自公開數據庫,不涉及倫理問題。