將深度學習算法應用于核磁共振(MR)圖像分割時,必需以大量經標注后圖像作為訓練集的數據支撐。然而,MR圖像的特殊性導致采集大量的圖像數據較困難,制作大量的標注數據成本高。為降低MR圖像分割對大量標注數據的依賴,本文提出了一種用于小樣本MR圖像分割的元U型網絡(Meta-UNet),能夠利用少量的圖像標注數據完成MR圖像分割任務,并獲得良好的分割結果。其具體操作為:通過引入空洞卷積對U型網絡(U-Net)進行改進,增加網絡模型感受野從而提高模型對不同尺度目標的靈敏度;通過引入注意力機制提高模型對不同尺度目標的適應性;通過引入元學習機制,并采用復合損失函數對模型訓練進行良好的監督和有效的引導。本文利用提出的Meta-UNet模型,在不同分割任務上進行訓練,然后用訓練好的模型在全新的分割任務上進行評估,實現了目標圖像的高精度分割。新的分割方法比起常用的無監督醫學圖像配準分割方法——體素變形網絡(VoxelMorph)、數據增強醫學圖像分割方法——轉換學習數據增強模型(DataAug)和基于標簽轉移的醫學圖像分割方法——標簽轉移網絡(LT-Net)三種模型平均戴斯相似性系數(DSC)有一定提高。實驗結果顯示,本文所提方法利用少量樣本即可有效地進行MR圖像分割,今后可為臨床診斷和治療提供可靠輔助。
引用本文: 陳曉清, 付忠良, 姚宇. 一種基于元學習的小樣本核磁共振圖像分割方法. 生物醫學工程學雜志, 2023, 40(2): 193-201. doi: 10.7507/1001-5515.202208004 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
隨著深度學習在圖像識別、自然語言處理、視頻分析等任務上都取得越來越多的重大突破,深度學習也越來越多地應用于醫學圖像分析領域,尤其是在醫學圖像分割任務中應用更為廣泛。核磁共振(magnetic resonance,MR)圖像是采用核磁共振成像(magnetic resonance imaging,MRI)技術得到人體組織的圖像。MRI作為重要的醫學影像學手段在許多疾病的診斷、評估和管理中發揮著關鍵作用。圖像分割是MR圖像分析中至關重要的一步,通過對MR圖像精準分割來勾畫出身體的解剖結構和異常組織,是進行圖像引導干預、輔助放射診斷和制定放射治療計劃等影像相關工作的重要基礎。
當前MR圖像分割的方法主要都是利用編碼—解碼方法。Ronneberger等[1]提出的U型網絡(U-Net)模型是最著名的采用編碼—解碼結構的醫學圖像分割模型,該模型既提高了模型的精度又解決了梯度消失的問題。Zeng等[2]基于三維U-Net解決了MR圖像中股骨近端分割的問題。在U-Net基礎上,Milletari等[3]提出了V型網絡(V-Net)模型在MR圖像上對前列腺進行分割并獲得了較好的分割結果。Bouget等[4]利用輕量級三維U-Net完成了MR圖像上的腦膜瘤分割。Ren等[5]設計了多任務學習U-Net框架實現了MR圖像上心室和心肌的分割。由此可見,以U-Net為基本網絡進行改進來解決MR圖像分割問題是當前比較常規的選擇。但是U-Net相關方法在訓練樣本較少時效果不太理想[6],在面對小樣本任務時問題較明顯,因此在設計模型的時候盡量降低參數數量使得模型更加容易訓練是當前一種解決問題的思路。
小樣本學習的提出,早期主要是用于圖像分類問題[7],其利用先前學習到的知識來輔助預測只有少量樣本的新類別。經過多年的發展,小樣本學習已經用于機器學習和計算機視覺的各個方面。當前主要的方法主要包括元學習(meta-learning)、數據增強、遷移學習、度量學習等方法[8]。近年來小樣本學習也運用到了MR圖像分割。Zhao等[9]提出了數據增強算法(data augmentation,DataAug),該算法對于分割精度的提高起到間接的作用,卻需要額外的開銷完成訓練網絡學習轉換。Chartsias等[10]提出了一種通過學習MR圖像其他模態的分割信息實現小樣本MR圖像分割的方法,然而該方法需要其他模態的標注信息,在實際應用中很難展開。Guo等[11]使用級聯卷積神經網絡實現了小樣本腎臟MR圖像的分割。Wang等[12]提出了標簽遷移網絡(label transfer net,LT-Net),預測從圖集到目標圖像的對應變換,將變換運用到分割標簽,分割標簽就可以轉移到具有對應關系的未標記目標圖像上。
模型無關meta-learning(model-agnostic meta-learning,MAML)是一種重要的meta-learning方法[13]。它能夠為模型學習到一組適合的初始化參數。在訓練時,對模型參數進行訓練,面對新的任務只需要少量的數據訓練和少量的梯度下降步驟就能夠產生良好的泛化性。MAML最顯著的優點是,它與任何用梯度下降法訓練的模型兼容,并且適用于各種不同的學習問題;而傳統的模型都是進行隨機初始化,這樣參數需要很多步更新后才能夠達到比較好的結果。
上文介紹的小樣本MR圖像分割方法雖在實驗研究中有不錯的表現,但是其中很多的小樣本分割方法需要訓練額外的轉換網絡,或需要額外的標注信息和數據。由于MR圖像分割任務中各種器官組織的大小差異巨大,模型對不同器官分割任務的魯棒性也較差,同時目前利用meta-learning方法進行小樣本MR圖像分割的研究較少。因此本文將meta-learning和U-Net方法結合提出一種元U-Net模型(Meta-Unet),并利用空洞卷積和注意力機制對模型進行改進,在模型訓練時使用MAML和復合的損失函數,力求解決在小樣本MR圖像分割時需要額外數據信息和訓練額外中間網絡,以及在面對不同尺度的分割任務時效果不理想的問題。綜上所述,通過本文研究,以期能為臨床醫生在小樣本情況下提供較準確的分割結果,輔助后續的診斷和治療。
1 Meta-UNet小樣本分割算法
1.1 損失函數的改進
Meta-UNet采用了基于戴斯損失函數LD和平衡交叉熵損失函數LB設計的復合損失函數L,它們三者的關系及計算公式,如式(1)~式(3)所示:
 |
 |
 |
式(2)中,y和?分別表示真實標注和預測結果。戴斯損失函數可以衡量兩個樣本之間的相似度,用于樣本極度不平衡的情況。如果一般情況下使用戴斯損失函數會使得訓練不穩定。式(3)中,N為樣本數量。yi代表樣本i的標簽,正類為1而負類為0,pi表示樣本i預測為正類的概率。在交叉熵的基礎上增加了一個參數α,α = Y?/Y。Y代表所有樣本的真實標注數量,Y?是Y中負樣本的數量。α可以增大數量少的樣本的權重,對不平衡的樣本有良好的改善作用,可使得網絡的訓練結果表現更好。將戴斯損失函數和平衡交叉熵損失函數結合,解決了MR圖像分割時樣本不平衡問題,經實驗證明復合損失函數提高了模型的精確度和收斂速度。
1.2 網絡結構的改進
不同的MR圖像分割任務中需要分割的目標尺度往往差距非常大。尺度的差異極大地影響了小樣本MR圖像分割在面對新任務時的泛化能力。因此本文提出了一種級聯的空洞卷積結構,該結構可以提取不同感受野的特征,并且模型參數的數量增加不多,能夠有效地適應小樣本任務的需求。
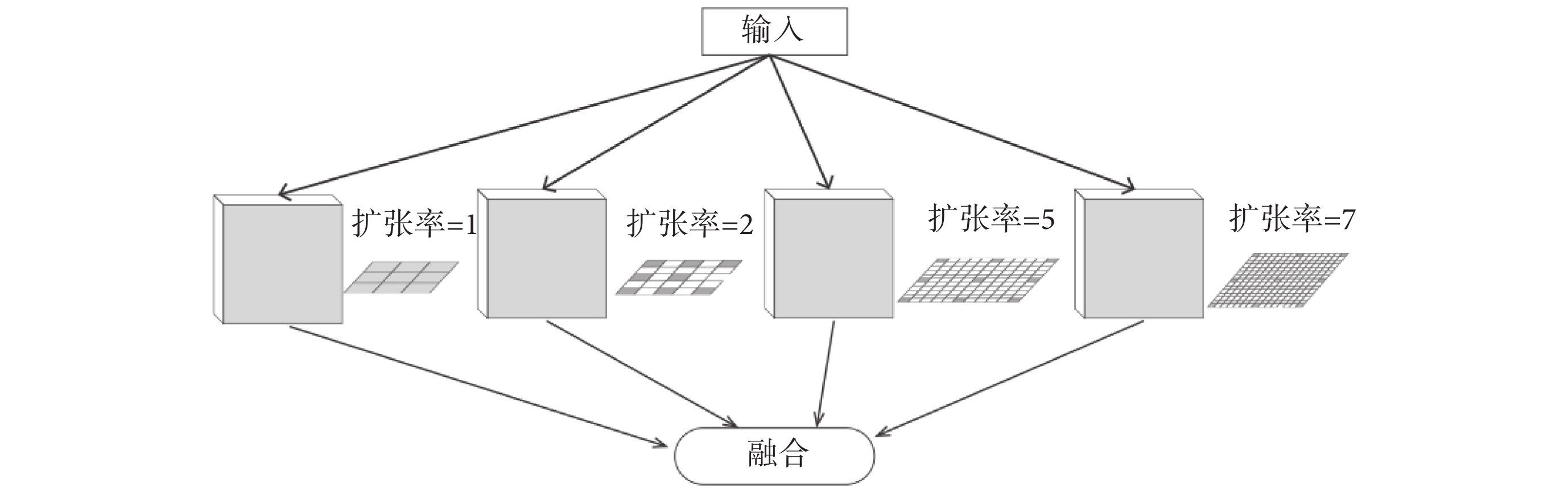
提高感受野的最直接方法是使用更大的卷積核,然而更大的卷積核卻導致模型有更多的參數需要訓練。因此本文為了減少需要訓練的參數使用了空洞卷積,在增加感受野的同時壓縮了參數數量。空洞卷積是一種稀疏的采樣方式,當多個空洞卷積疊加時,會損失信息的連續性與相關性,產生網格效應。Wang等[14]指出選擇鋸齒狀的空洞卷積可以有效避免網格效應提高特征利用率。因此本文采用1、2、5、7四種不同擴張率的空洞卷積進行級聯。每個分支將提取不同感受野的特征圖,再將提取到的特征圖進行融合,生成新的特征圖。空洞卷積模塊結構如圖1所示。
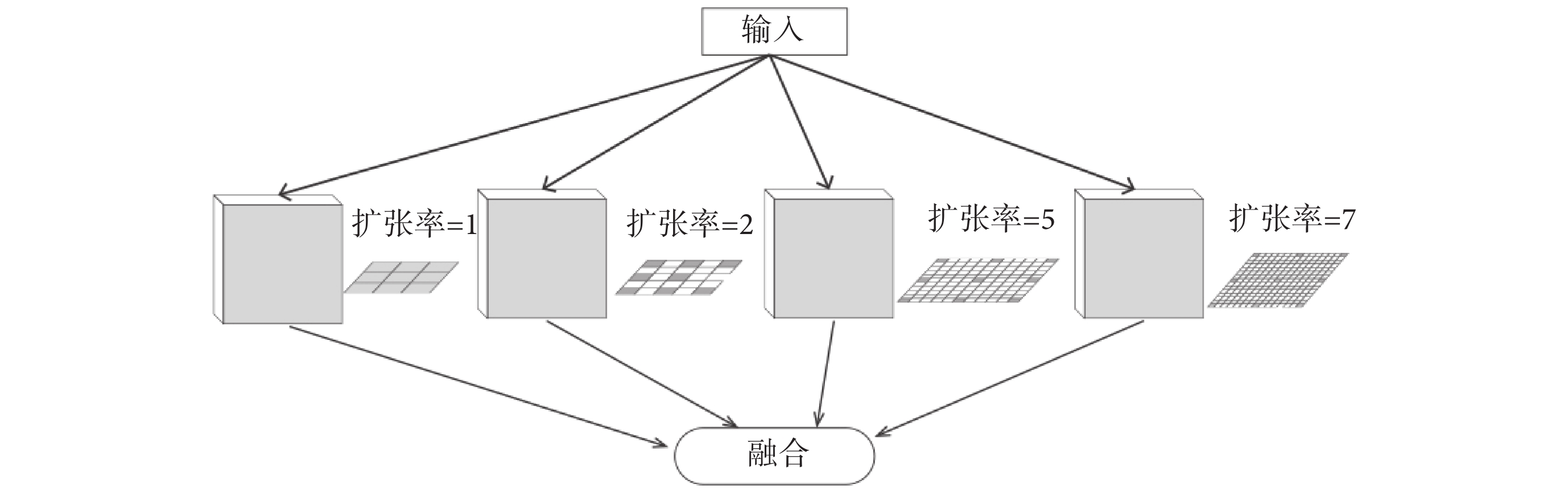 圖1
空洞卷積模塊
Figure1.
Dilated convolution block
圖1
空洞卷積模塊
Figure1.
Dilated convolution block
面對四個不同的特征圖,本文考慮了兩種融合方式:將四個特征圖直接相加或將四個特征圖進行連接。相加融合特征圖會導致部分特征的丟失,而連接融合特征圖卻可以保留不同尺度特征,還可以使得不同尺度的特征在網絡的跳躍連接后能夠得到更好地復用,因此使用連接融合有望取得更好的效果。通過實驗也證明了使用連接融合更有利于提高模型的精度。
本文在模型中引入了注意力機制進一步提高模型的分割精度。注意力機制通常作為一個模塊用于編碼—解碼結構的網絡中提高網絡精度[15]。本文將注意力機制引入到模型當中,不但提高了分割精度,還有利于可視化解釋輸入和輸出數據之間的對應關系。
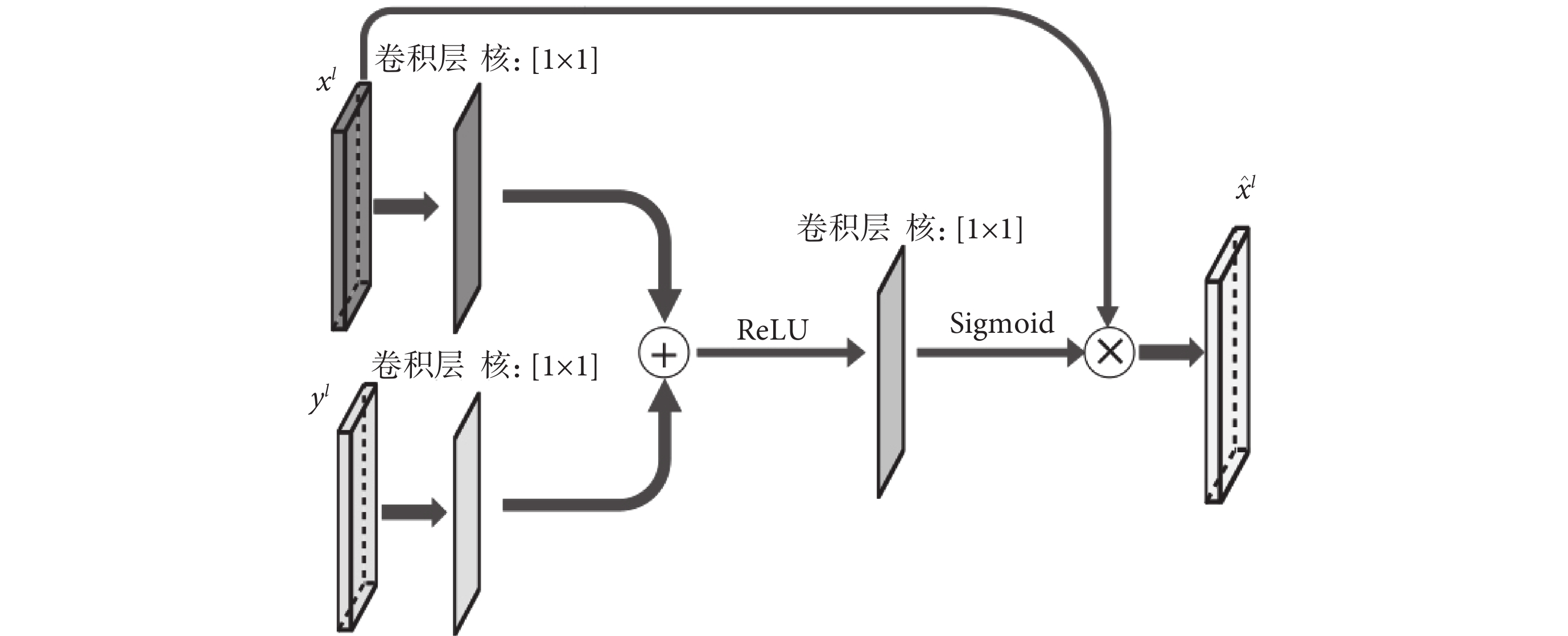
注意力模塊結構設計如圖2所示。xl和yl分別表示第l層U-Net結構的跳躍連接輸出和模型上一層的輸出,xl和yl通過一個1 × 1的卷積后相加,再經過線性整流函數(rectified linear unit,ReLU)、1 × 1卷積、S型生長曲線(Sigmoid)函數處理后與xl計算哈達瑪積,獲得最后的輸出  。注意力模塊在模型推理過程中會自動關注有顯著特征的區域并且不會引入大量參數,通過抑制無關區域的信號提高模型靈敏度和準確性。同時,注意力模塊還起到了類似分割前器官定位的作用。
。注意力模塊在模型推理過程中會自動關注有顯著特征的區域并且不會引入大量參數,通過抑制無關區域的信號提高模型靈敏度和準確性。同時,注意力模塊還起到了類似分割前器官定位的作用。 的計算如式(4)所示:
的計算如式(4)所示:
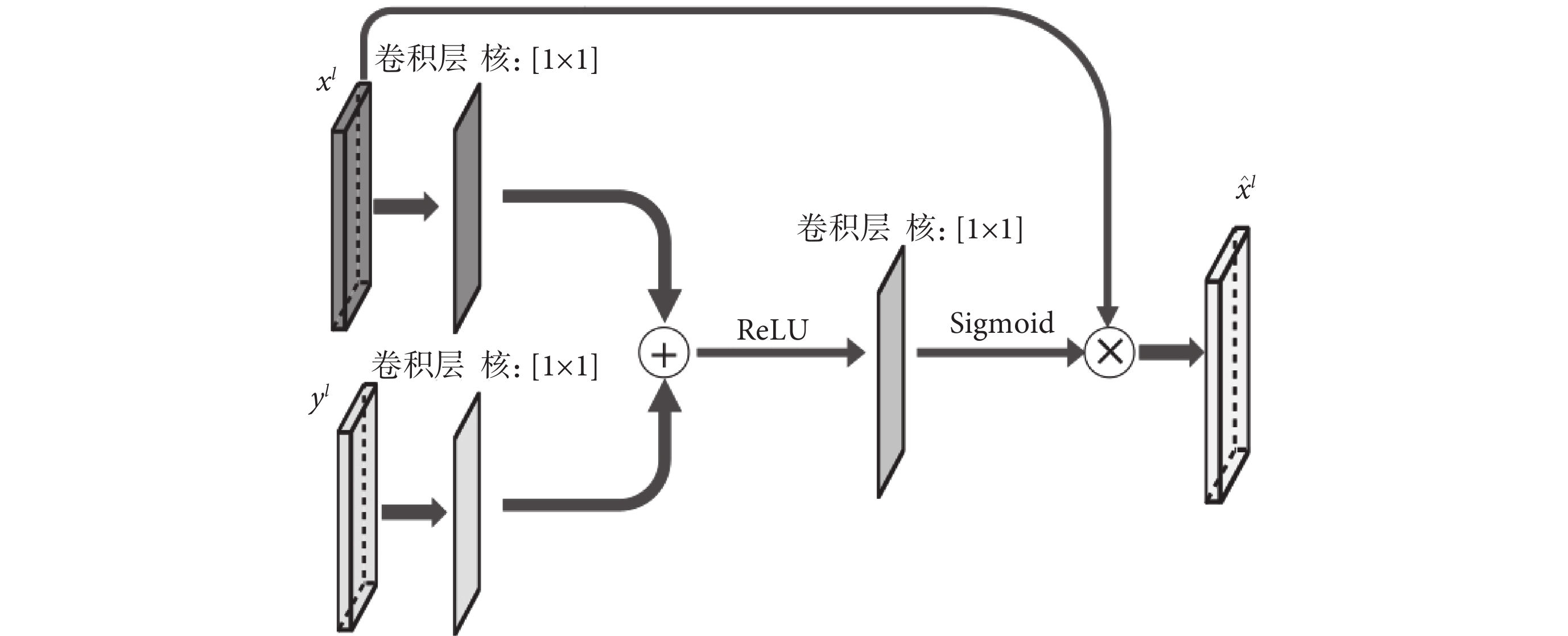 圖2
注意力模塊結構
Figure2.
The Structure of attention block
圖2
注意力模塊結構
Figure2.
The Structure of attention block
 |
其中,σ1是ReLU函數,σ2是Sigmoid函數,ψ、ψx、ψy都是卷積操作,b、by是對應卷積的偏置項,運算符o代表哈達瑪積。將  與上一層的輸出yl進行連接后繼續進行后面的運算。
與上一層的輸出yl進行連接后繼續進行后面的運算。
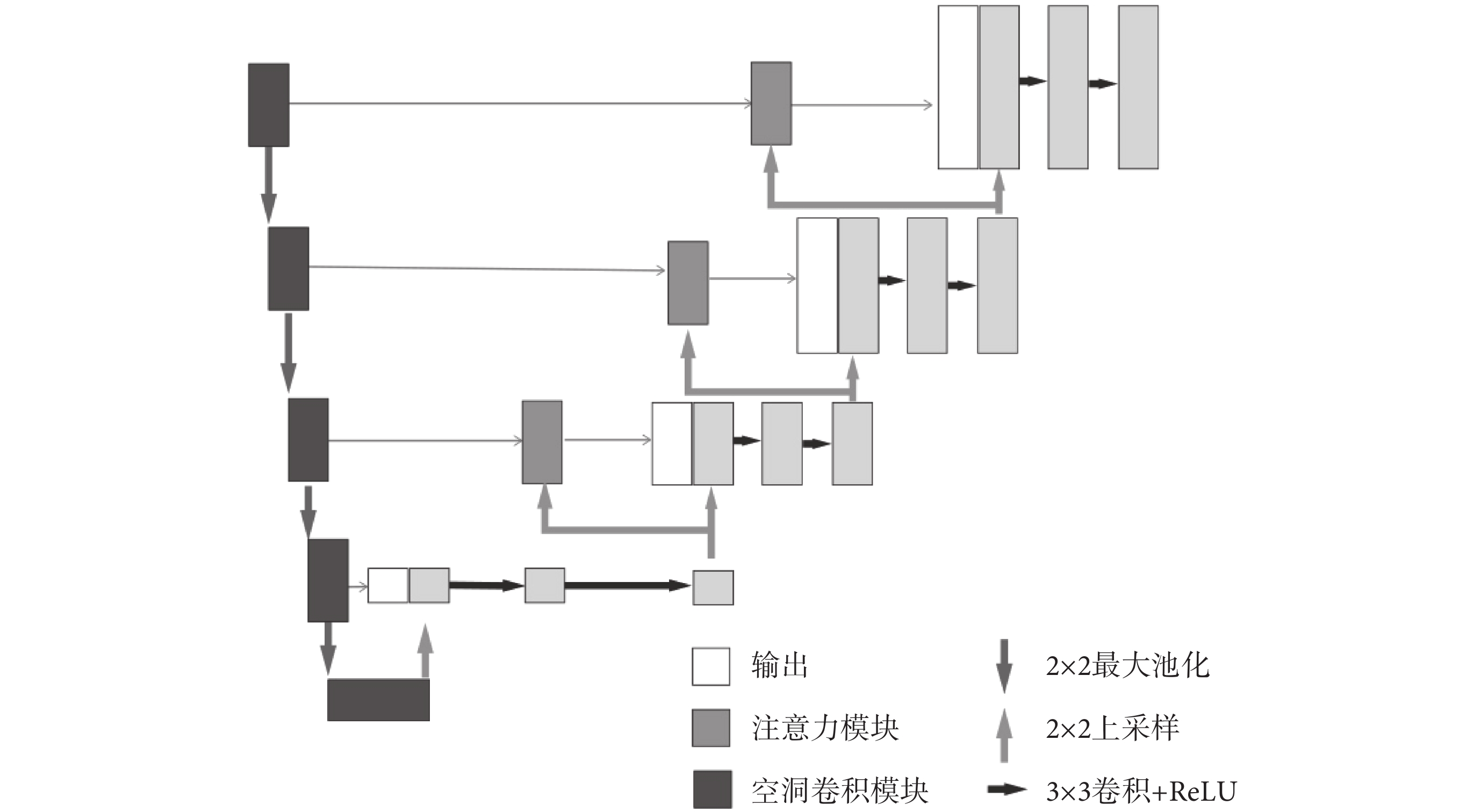
最終模型網絡結構如圖3所示。模型的編碼部分使用了5個空洞卷積模塊進行串連,每一個空洞卷積模塊的輸出將作為下一個空洞卷積模塊的輸入。同時,空洞卷積模塊的輸出還通過跳躍連接與解碼部分相連接,本文在前三個跳躍連接中添加了注意力模塊。解碼部分使用了5個將ReLU作為激活函數、核大小為3 × 3的卷積層,每一個卷積層后跟一個上采樣層。解碼部分卷積層的輸入是模型前一層網絡的輸出以及對應編碼部分輸出連接后的向量。通過以上模塊構成類U-Net結構,使網絡能有效適應不同尺度的目標,提取到的特征也得到有效地復用,提高了網絡分割精度。
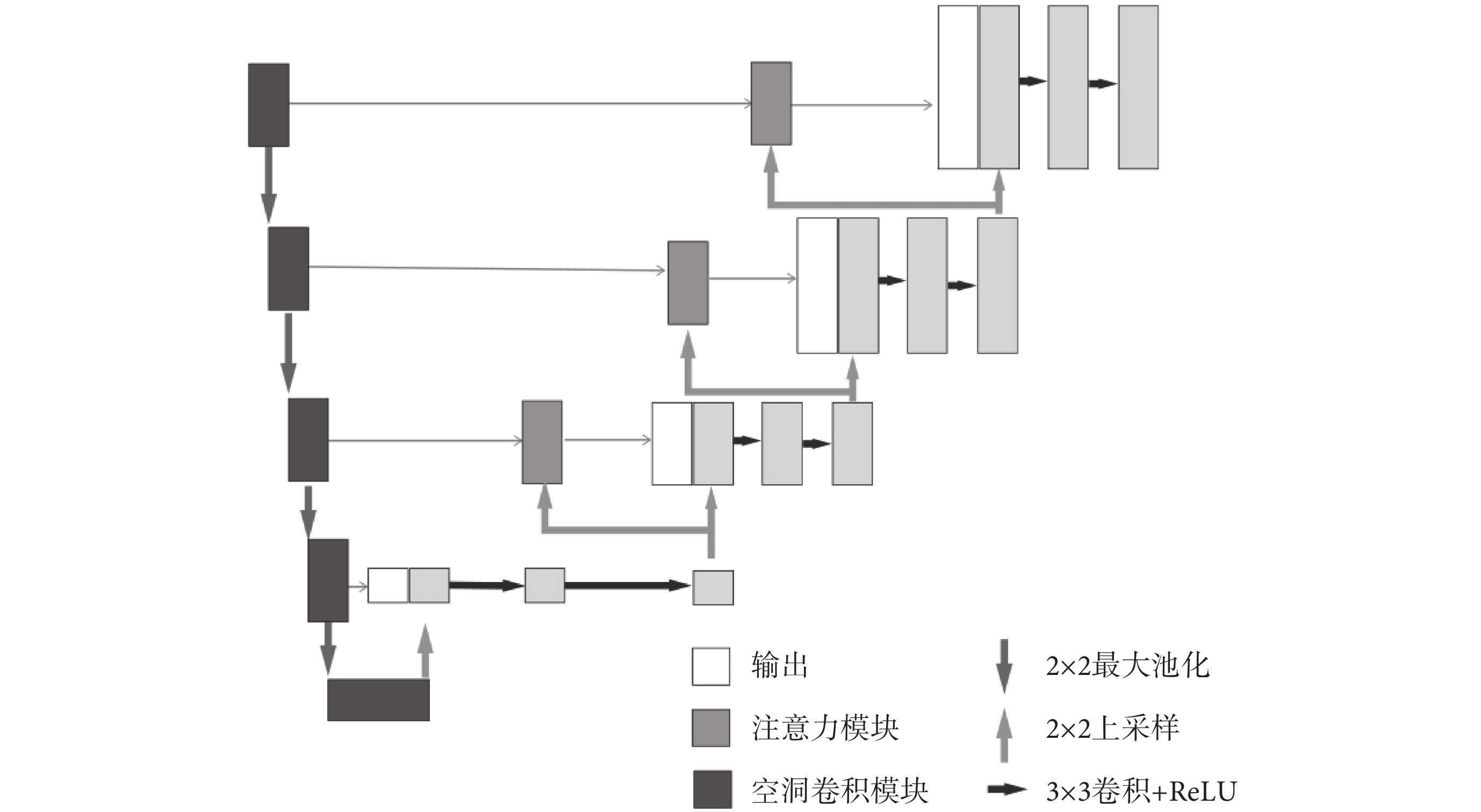 圖3
帶注意力機制的空洞卷積U-Net
Figure3.
Dilated convolution U-net with attention block
圖3
帶注意力機制的空洞卷積U-Net
Figure3.
Dilated convolution U-net with attention block
2 Meta-UNet網絡訓練
2.1 使用MAML學習分割器
本文使用MAML訓練網絡以獲得適用于小樣本任務的優秀分割器。下面重點介紹使用MAML學習分割器實例的方法。在學習過程中,訓練數據是帶有分割目標真實標記的圖像。給定一個患者(記為Pi),收集一組訓練樣本(記為 ),即是meta-learning中的支持集(support set)。分割器表示為f(x; θ0),其中x是輸入圖像,而θ0表示分割器的初始化參數。使用梯度下降更新分割器k次后的參數記為θk,如式(5)所示:
),即是meta-learning中的支持集(support set)。分割器表示為f(x; θ0),其中x是輸入圖像,而θ0表示分割器的初始化參數。使用梯度下降更新分割器k次后的參數記為θk,如式(5)所示:
 |
其中,L是損失函數,y是輸入圖像x所對應的標簽,Nts為當前支持集中的樣本數量,α是內部優化的學習率。如式(5)所示的迭代過程稱為內部優化過程,內部優化后,還需要驗證優化后分割器的泛化能力。在同一個患者Pi上產生另一個樣本集  ,即meta-learning中的查詢集(query set),
,即meta-learning中的查詢集(query set), 包含的樣本數量為Nit。計算當前分割器在查詢集上的的平均損失Lmean,如式(6)所示:
包含的樣本數量為Nit。計算當前分割器在查詢集上的的平均損失Lmean,如式(6)所示:
 |
其中,y是輸入圖像x的標簽。計算迭代一輪后的損失,更新初始化參數θ0的方式如式(7)所示:
 |
其中,N表示病例的數量,β是外部循環的學習率, 表示更新后的參數。如式(7)所示過程為外部優化過程。外部優化的梯度通過內部優化的梯度進行反向傳播。通過以上步驟利用梯度下降方法即可獲得所需的分割器。
表示更新后的參數。如式(7)所示過程為外部優化過程。外部優化的梯度通過內部優化的梯度進行反向傳播。通過以上步驟利用梯度下降方法即可獲得所需的分割器。
2.2 Meta-UNet網絡訓練
Meta-UNet網絡訓練結構由內循環和外循環兩個部分組成。從內部循環開始到外部循環結束為一輪完整的訓練過程。網絡fA(θ)和網絡fB(?)是結構相同的兩個網絡,使用梯度下降法來優化網絡。將已標記數據集D按照分割目標分為支持集、驗證集、測試集三個數據集,分別記為Ds、Dv、Dt。Ds和Dv中只有部分分類目標相同,Dt與另兩個數據集分割目標完全不相同。根據小樣本訓練任務中的類別數N以及任務數量Ns、Nv對支持集和驗證集進行采樣,獲得不同的任務集合Ts和Tv。α和β分別是內外循環的學習率。首先使用隨機初始化方法初始化網絡fA(θ)的參數。每一輪訓練開始時,將fA(θ)的參數賦值給網絡fB(?),即? = θ,同時在任務集  和
和  上隨機采樣獲得一批數據記為
上隨機采樣獲得一批數據記為  和
和  。進行內循環訓練,對于
。進行內循環訓練,對于  中的每一個樣本計算損失梯度同時更新fB(?)的參數?,如式(8)所示:
中的每一個樣本計算損失梯度同時更新fB(?)的參數?,如式(8)所示:
 '/> '/> |
其中, 為?更新后的模型參數。完成內循環訓練后利用驗證集
為?更新后的模型參數。完成內循環訓練后利用驗證集  中的樣本開始外部循環,更新fA(θ)的參數θ,如式(9)所示:
中的樣本開始外部循環,更新fA(θ)的參數θ,如式(9)所示:
 '/> '/> |
其中, 為?更新后的模型參數。通過多輪以上的訓練步驟后就可以得到需要的模型fA(
為?更新后的模型參數。通過多輪以上的訓練步驟后就可以得到需要的模型fA( )。
)。
3 實驗及分析
3.1 實驗數據及性能度量指標
本文實驗數據來源于馬薩諸塞大學醫學院兒童和青少年神經發育計劃(child and adolescent neuro development initiative,CANDI)(網址為:https://www.nitrc.org/projects/candi_share/)提供的公開數據集[16]。數據集包含103個患者的MR的T1加權圖像,采集自57名男性和46名女性,圖像的大小為256 × 256,并且提供了39個大腦解剖結構的標注。為了計算效率本文通過減小輸入大小以降低計算量,將MR圖像裁剪成以原圖像中心為中心的160 × 160大小。裁剪后通過檢查,該大小圖像依然足以容納整個大腦。
本文性能度量指標選取戴斯相似性系數(Dice similarity coefficient,DSC)以及交并比(intersection over union,IoU)評估每個模型的分割精度,它們可以衡量手動注釋和預測結果之間的重疊程度。
3.2 實驗結果
實驗環境:中央處理器(Xeon 8369B @2.9GHz,Intel,美國),獨立顯卡(Tesla V100 32GB,Nvidia,美國)。深度學習框架為PyTorch 1.12.1(Linux Foundation,美國),編程語言為Python 3.10.5(Python Software Foundation,美國)。
3.2.1 損失函數有效性實驗
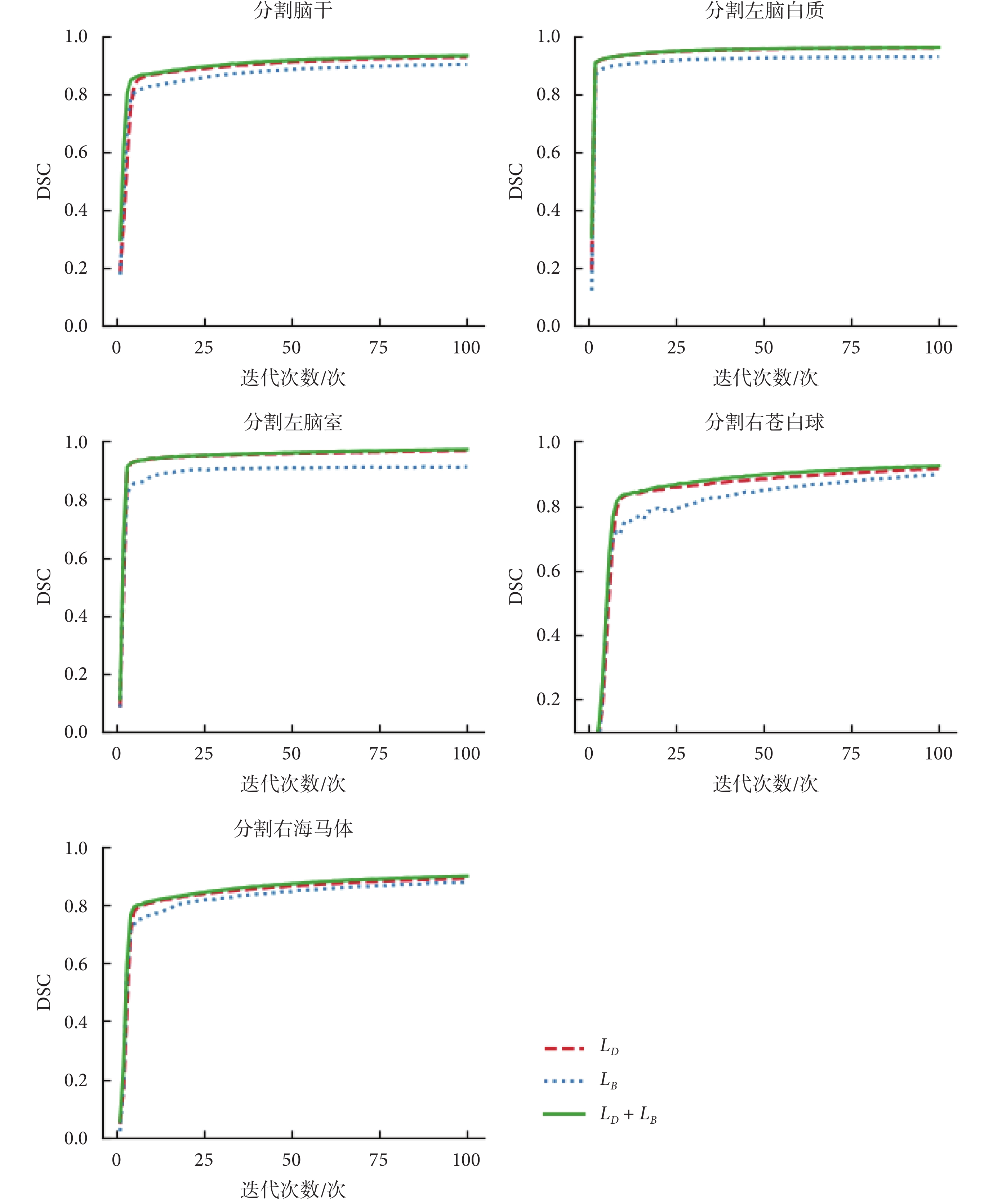
在CANDI數據集上,本文將U-Net作為基礎網絡,進行不同損失函數對模型性能影響的對比。實驗選擇腦干、左腦白質、左腦室、右蒼白球、右海馬體的分割任務對不同的損失函數進行比較。這些大腦結構覆蓋了大腦中尺度不同的不同結構,能夠有效說明損失函數選擇的有效性。實驗中將數據按照4:1的比例分為訓練集和測試集,利用不同的損失函數在訓練集上對模型進行訓練后在測試集上進行驗證。實驗結果如表1所示。本文繪制了選用復合損失函數以及單獨使用戴斯損失函數LD和平衡交叉熵損失函數LB在分割腦干、左腦白質、左腦室、右蒼白球和右海馬體時模型精度和訓練輪數的比較,如圖4所示。可見使用復合損失函數模型精度提高的同時收斂速度也得到了提高。
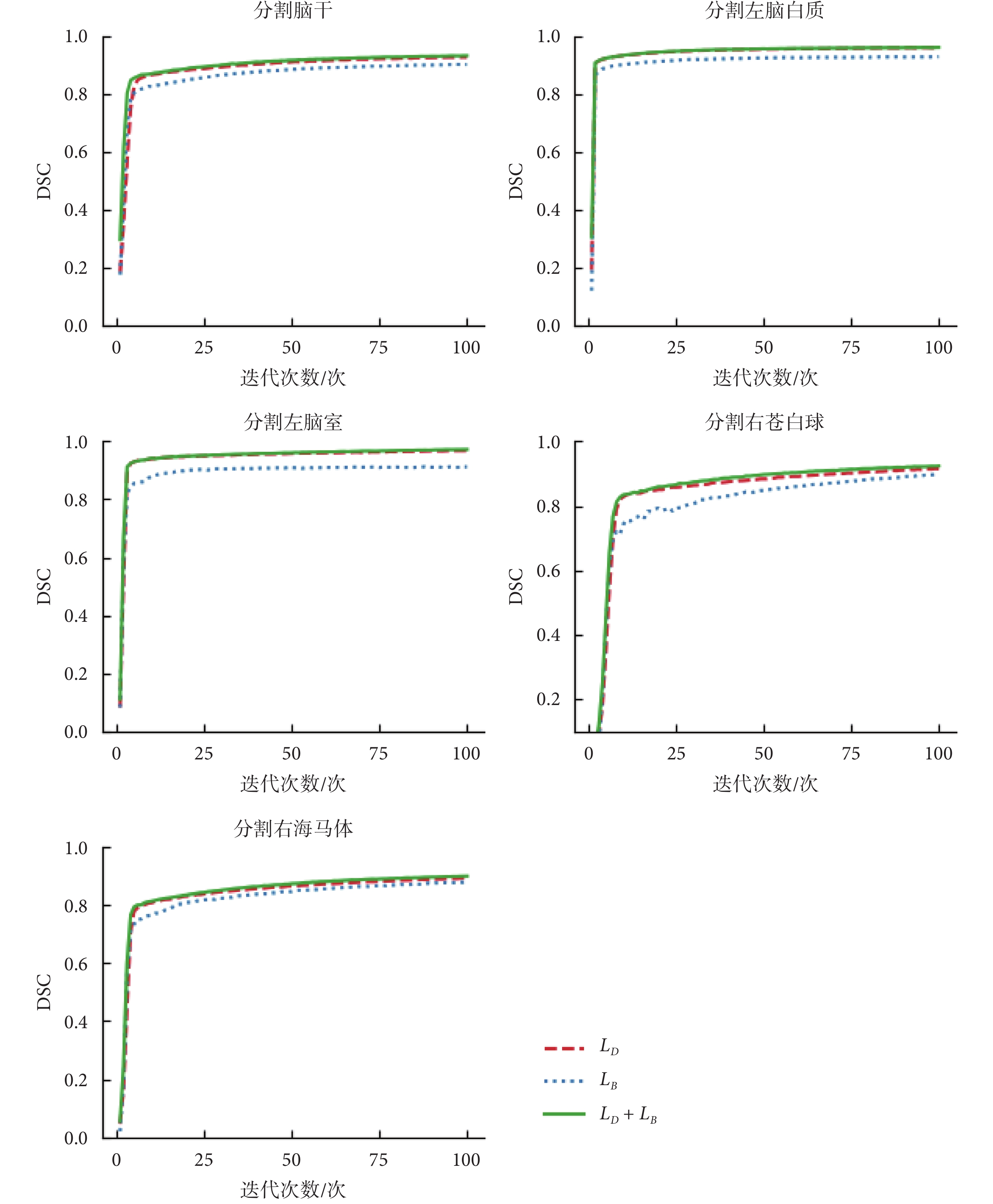 圖4
使用不同損失函數的模型精度在不同分割任務上的比較
Figure4.
Comparison of model accuracy on different segmentation tasks using different loss functions
圖4
使用不同損失函數的模型精度在不同分割任務上的比較
Figure4.
Comparison of model accuracy on different segmentation tasks using different loss functions
3.2.2 特征圖融合實驗
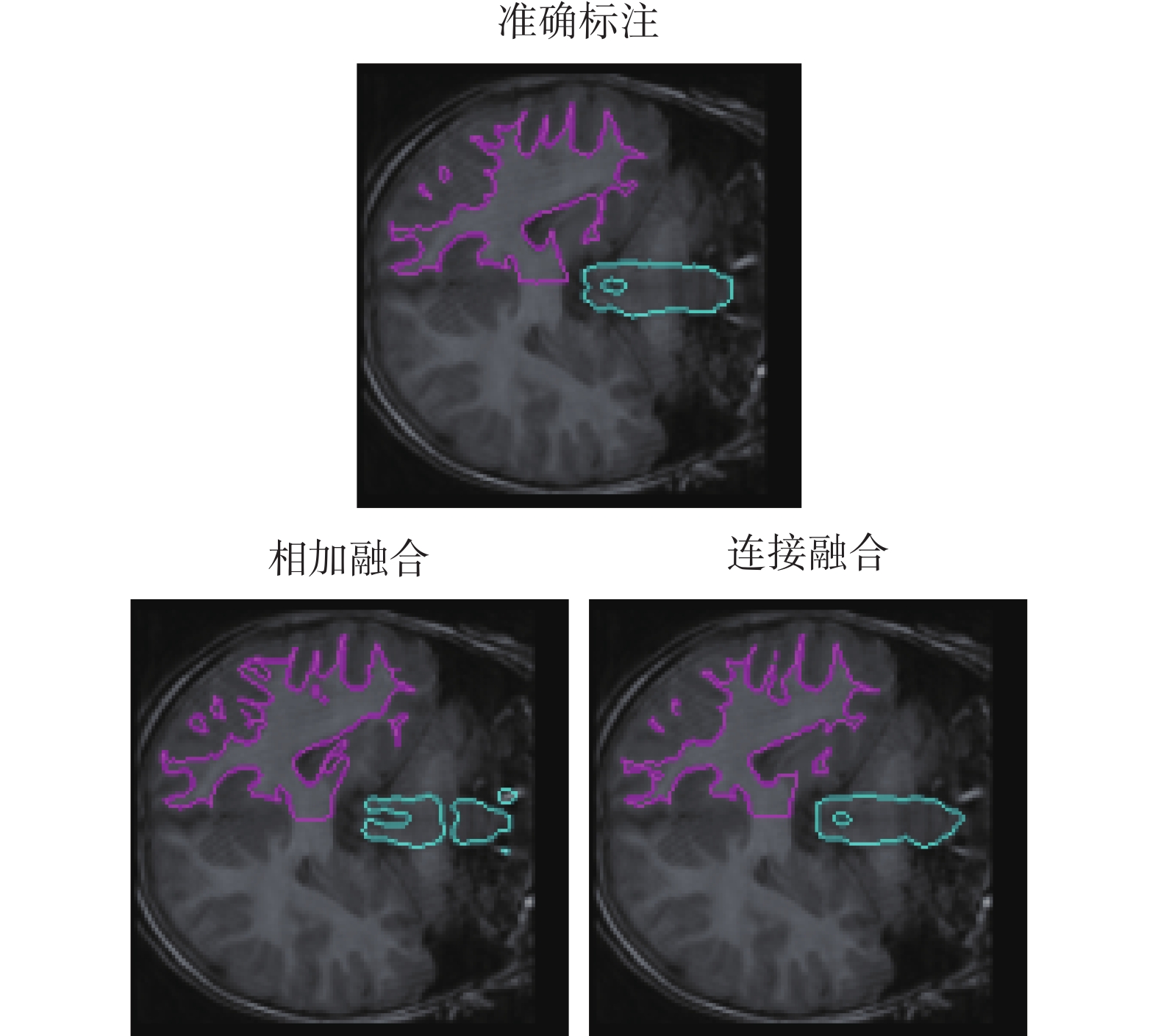
對特征圖的融合方式進行實驗。利用本文提出的Meta-Unet網絡使用特征圖相加和連接兩種方式進行實驗。內部循環學習率采用0.01,外部循環采用0.001的學習率。訓練好的模型面對新的右腦白質和腦干的分割任務,僅使用一個帶標記的病例數據訓練迭代100次,進行分割測試。得到的實驗結果如表2所示。同時分割結果的可視化對比如圖5所示,不同顏色線條分別表示腦干和右腦白質的分割結果,第一行為準確標注的標準分割結果,第二行依次為采用相加融合與連接融合的結果。從實驗結果可以看出,使用連接的方式進行特征圖融合可以使模型獲得更高的分割精度。
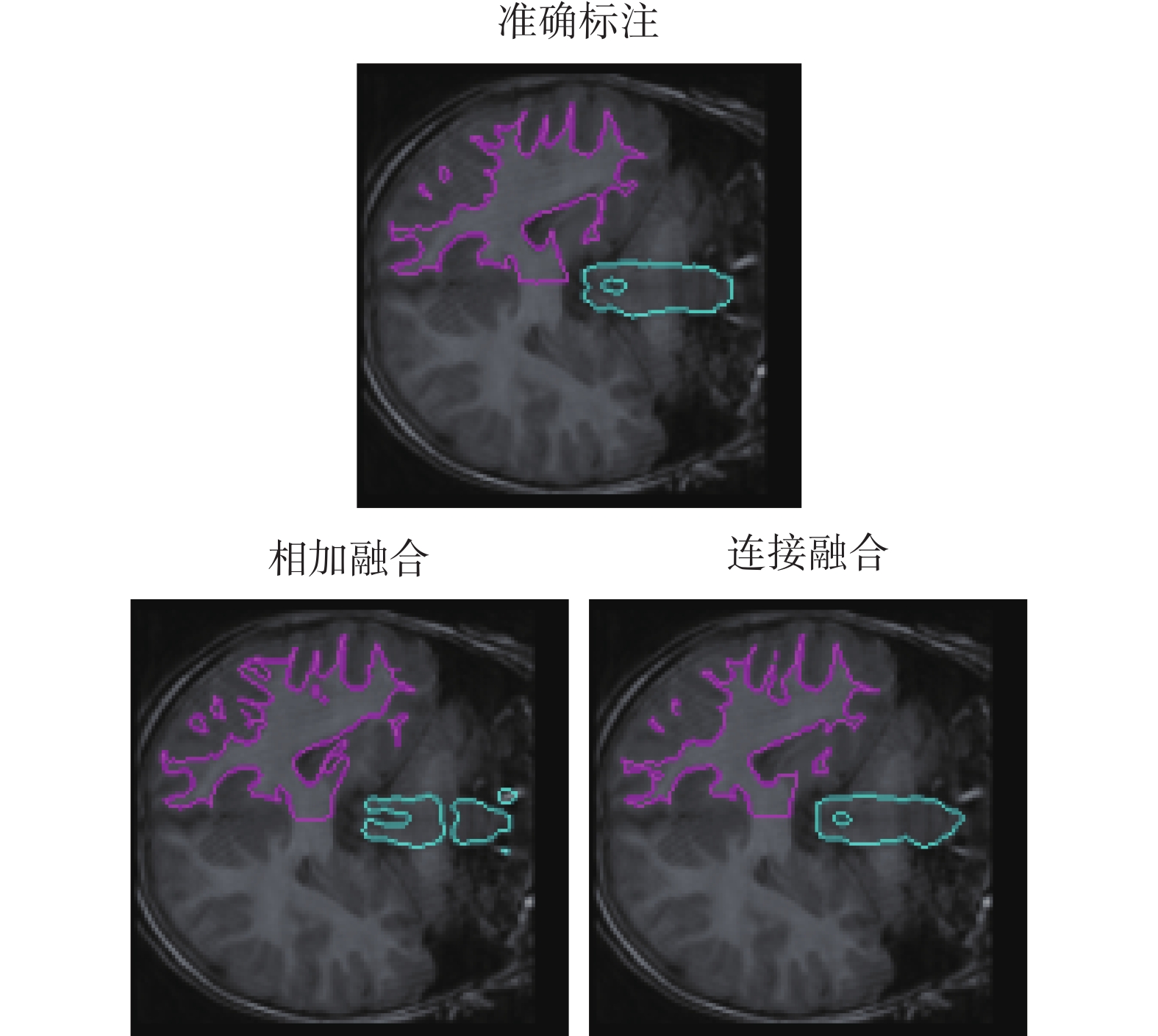 圖5
使用不同特征圖融合方式分割結果比較
Figure5.
Comparison of segmentation results using different feature map fusion methods
圖5
使用不同特征圖融合方式分割結果比較
Figure5.
Comparison of segmentation results using different feature map fusion methods
3.2.3 模型比較實驗
在進行模型訓練時本文隨機選取其中25個結構作為訓練數據,12個結構作為測試數據。為了找到對于每個任務都相對最優的初始參數,必須使用相對較大的學習率,而優化真正模型參數的學習率應該是相對較小的。所以實驗中內部循環學習率采用0.01,外部循環采用0.001的學習率。利用MAML方法訓練模型的迭代次數為500次。選取無監督醫學圖像配準分割方法體素變形網絡(voxel morph network,VoxelMorph)[17]、基于數據增強醫學圖像分割方法轉換學習數據增強模型(data augmentation using learned transformations,DataAug)和標簽轉移網絡(label transfer network,LT-Net)醫學圖像分割方法三種當前已獲認可的方法和本文提出的新方法比較,僅僅使用一個帶標記的病例數據迭代訓練100次,本文提出的模型即獲得了更高的平均DSC。以用全部病例數據全監督學習的U-Net網絡作為基線進行對比,僅使用一個帶標注的病例數據進行訓練,本文方法在不同任務中獲得了最高91.8%的DSC,標準差與其他模型比較也明顯更小。實驗結果如表3所示,列出了不同模型在不同分割任務上的平均DSC和標準差,本文方法的平均DSC比起VoxelMorph、DataAug、LT-Net都有一定提高。如表4和表5所示,對比了不同模型在不同分割任務上的DSC和IoU。
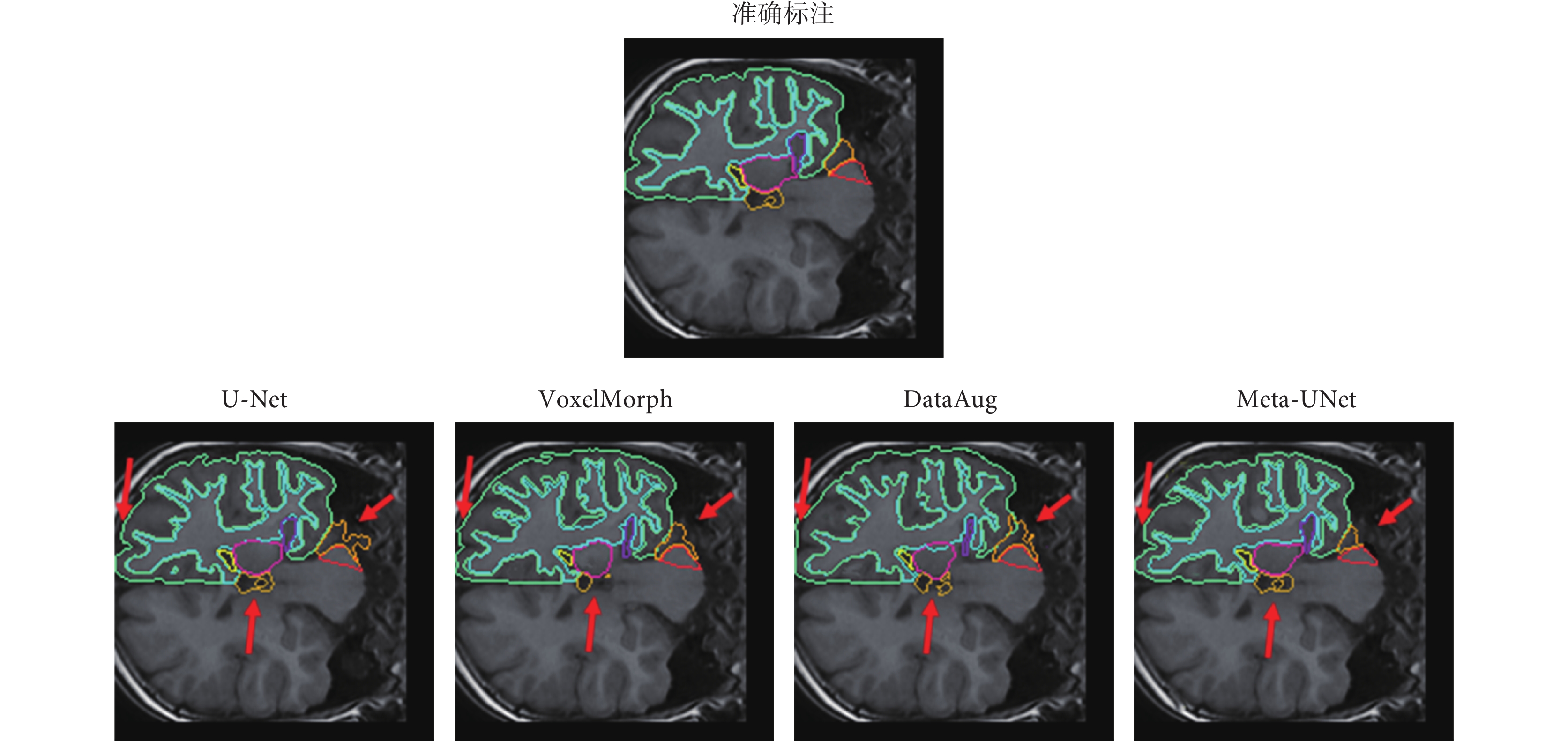
本文對U-Net、VoxelMorph、DataAug和本文提出的Meta-UNet四種模型對大腦結構進行分割的結果切面進行可視化,如圖6所示。圖6中,不同顏色線條分別展示了對右腦白質、右大腦皮質、右側腦室、右小腦白質、右小腦皮質、右丘腦、右海馬體、腦脊液的分割結果,第一行為準確標注,第二行依次為U-Net、VoxelMorph、DataAug以及本文提出的Meta-Unet的分割結果。其中紅色箭頭指示了與其它方法相比Meta-UNet分割的優勢,可以看出,本文的Meta-UNet分割出的大腦結構更符合醫學解剖學意義。
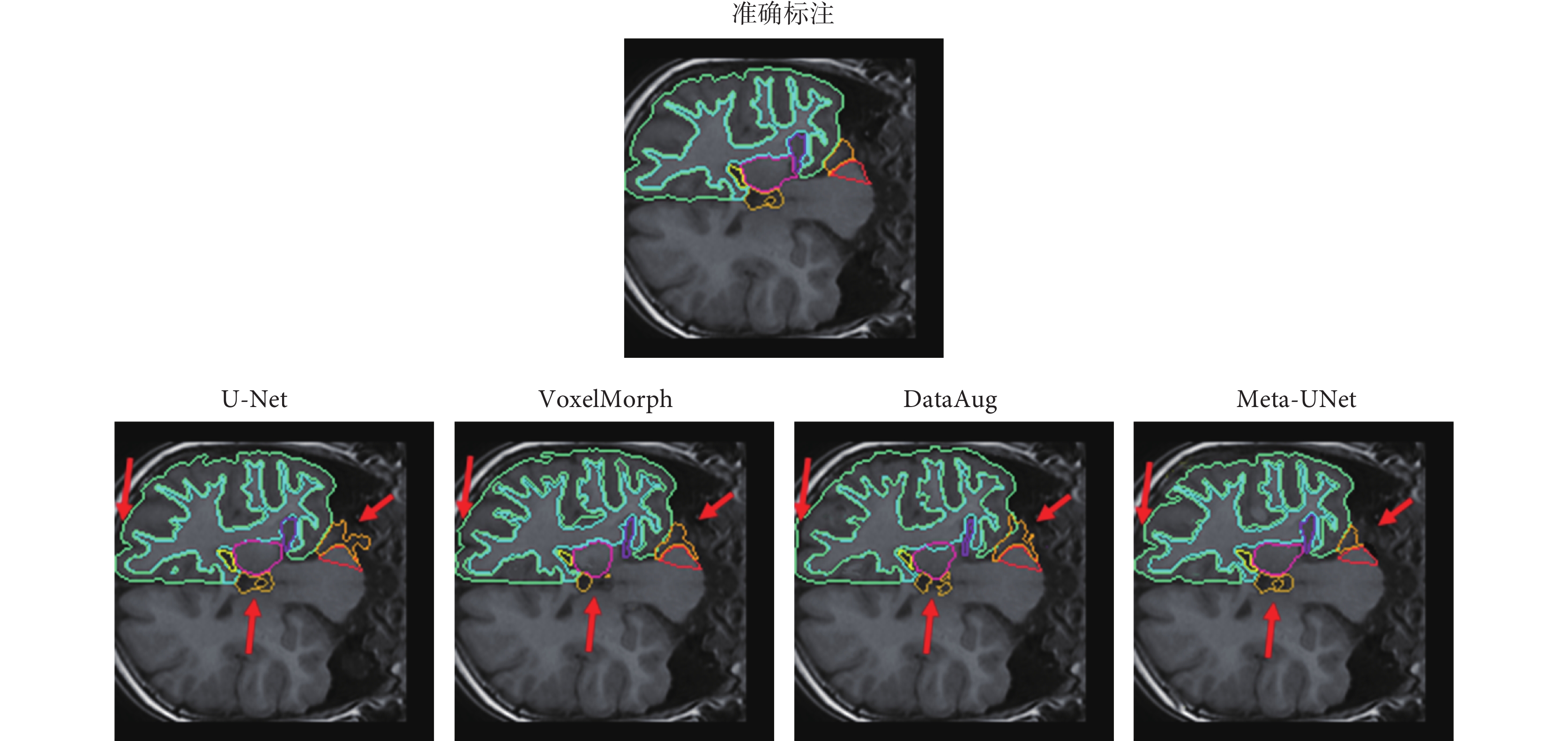 圖6
不同模型的大腦結構分割結果
Figure6.
Results of brain structure segmentation for different models
圖6
不同模型的大腦結構分割結果
Figure6.
Results of brain structure segmentation for different models
3.3 實驗結果討論
(1)損失函數有效性實驗:實驗結果如表1所示,使用復合損失函數的分割模型對腦干、左腦白質、左腦室、右蒼白球和右海馬體進行分割的精度都提高了。如圖4所示,也證明了使用復合損失函數的情況下模型精度提高的同時收斂速度也得到了提高。分析其原因主要是利用新的復合損失函數進行訓練使得模型有效適應樣本均衡和不均衡的情況。
(2)特征圖融合實驗:使用不同融合方式進行圖像分割的DSC和IoU結果如表2所示。圖5可視化了分割結果的對比。從以上結果都可以看出,使用連接融合特征圖的方式要優于直接相加。直接相加操作會帶來信息損失,且直接相加的融合方式默認幾個特征圖的權重一致,然而不同的特征圖對于最終模型的影響效果卻不一定是等權重的。使用連接的方式進行特征圖的融合,則避免了上面的問題。
(3)模型比較實驗:從表4和表5可以看到本文方法在對腦白質、大腦皮質、腦室、小腦白質、小腦皮質、丘腦這些相對較大的目標分割上的表現和現有方法相當,而在尾狀核、第三腦室、第四腦室、海馬體、腦脊液、主動脈這些相對較小的目標分割時表現出更好的結果。實驗結果證明了Meta-UNet在腦MR圖像小樣本分割任務上的優越性。正如前面分析指出的,本文方法引入空洞卷積和注意力機制對不同尺度的目標分割具有良好的適應性,而引入MAML則可以利用額外有意義的監督信號來推動小樣本學習過程朝著更穩健和解剖學上更有意義的方向發展。從實驗中還可以發現DataAug方法在腦白質、大腦皮質、腦室、小腦白質、小腦皮質、丘腦這些相對較大的目標分割任務中的表現較本文提出的Meta-Unet方法好。分析其原因,DataAug方法是對一個帶標簽的圖像和一組無標簽的圖像之間的空間和外觀轉換進行建模,學習帶標簽圖像和無標簽圖像之間的非線性變形和成像強度的多種變化。然后,使用這些變換模型隨機作用在有標簽的示例上來合成新的帶標簽的示例,從而達到擴充帶標簽數據集的目的。最后,把這些新合成的帶標簽數據用于訓練有監督的分割網絡模型。DataAug在生成擴充帶標簽數據集時使用了無標簽的測試數據,因此測試數據也參與到了模型的訓練過程,使得DataAug的表現相對較好。但面對相對較小的目標時,通過對空間和外觀轉換建模的方法進行DataAug效果不理想。因此在小目標分割時本文提出的方法得到了更好的效果。
4 結論
本文將meta-learning、注意力機制和空洞卷積這三個機器學習經典思想應用到MR圖像分割中,提出了一種結合meta-learning、注意力機制和空洞卷積的Meta-UNet網絡,并利用該網絡實現了MR圖像的小樣本分割。本文模型對U-Net網絡進行了改進,首先引入了空洞卷積,使網絡模型的感受野增加,在小幅增加計算量的前提下提高了模型對不同尺度目標的靈敏度。其次,引入了注意力機制,進一步提高模型對不同尺度分割目標的適應性。最后,引入了MAML機制,使用復合損失函數對模型訓練進行良好的監督和有效的引導,使得模型能夠更好地適應小樣本分割任務。實驗結果表明,在不同尺度目標的小樣本分割任務中,Meta-UNet的分割結果更加符合臨床醫學解剖學要求。將本文研究思路和方法應用于圖像質量差、圖像差別大、圖像分割困難的超聲心動圖小樣本分割上,將是本課題組下一步研究重點。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:陳曉清是本研究的實驗設計和執行人,完成數據分析,論文初稿的寫作與修改;付忠良和姚宇指導論文寫作,提出修改意見。
引言
隨著深度學習在圖像識別、自然語言處理、視頻分析等任務上都取得越來越多的重大突破,深度學習也越來越多地應用于醫學圖像分析領域,尤其是在醫學圖像分割任務中應用更為廣泛。核磁共振(magnetic resonance,MR)圖像是采用核磁共振成像(magnetic resonance imaging,MRI)技術得到人體組織的圖像。MRI作為重要的醫學影像學手段在許多疾病的診斷、評估和管理中發揮著關鍵作用。圖像分割是MR圖像分析中至關重要的一步,通過對MR圖像精準分割來勾畫出身體的解剖結構和異常組織,是進行圖像引導干預、輔助放射診斷和制定放射治療計劃等影像相關工作的重要基礎。
當前MR圖像分割的方法主要都是利用編碼—解碼方法。Ronneberger等[1]提出的U型網絡(U-Net)模型是最著名的采用編碼—解碼結構的醫學圖像分割模型,該模型既提高了模型的精度又解決了梯度消失的問題。Zeng等[2]基于三維U-Net解決了MR圖像中股骨近端分割的問題。在U-Net基礎上,Milletari等[3]提出了V型網絡(V-Net)模型在MR圖像上對前列腺進行分割并獲得了較好的分割結果。Bouget等[4]利用輕量級三維U-Net完成了MR圖像上的腦膜瘤分割。Ren等[5]設計了多任務學習U-Net框架實現了MR圖像上心室和心肌的分割。由此可見,以U-Net為基本網絡進行改進來解決MR圖像分割問題是當前比較常規的選擇。但是U-Net相關方法在訓練樣本較少時效果不太理想[6],在面對小樣本任務時問題較明顯,因此在設計模型的時候盡量降低參數數量使得模型更加容易訓練是當前一種解決問題的思路。
小樣本學習的提出,早期主要是用于圖像分類問題[7],其利用先前學習到的知識來輔助預測只有少量樣本的新類別。經過多年的發展,小樣本學習已經用于機器學習和計算機視覺的各個方面。當前主要的方法主要包括元學習(meta-learning)、數據增強、遷移學習、度量學習等方法[8]。近年來小樣本學習也運用到了MR圖像分割。Zhao等[9]提出了數據增強算法(data augmentation,DataAug),該算法對于分割精度的提高起到間接的作用,卻需要額外的開銷完成訓練網絡學習轉換。Chartsias等[10]提出了一種通過學習MR圖像其他模態的分割信息實現小樣本MR圖像分割的方法,然而該方法需要其他模態的標注信息,在實際應用中很難展開。Guo等[11]使用級聯卷積神經網絡實現了小樣本腎臟MR圖像的分割。Wang等[12]提出了標簽遷移網絡(label transfer net,LT-Net),預測從圖集到目標圖像的對應變換,將變換運用到分割標簽,分割標簽就可以轉移到具有對應關系的未標記目標圖像上。
模型無關meta-learning(model-agnostic meta-learning,MAML)是一種重要的meta-learning方法[13]。它能夠為模型學習到一組適合的初始化參數。在訓練時,對模型參數進行訓練,面對新的任務只需要少量的數據訓練和少量的梯度下降步驟就能夠產生良好的泛化性。MAML最顯著的優點是,它與任何用梯度下降法訓練的模型兼容,并且適用于各種不同的學習問題;而傳統的模型都是進行隨機初始化,這樣參數需要很多步更新后才能夠達到比較好的結果。
上文介紹的小樣本MR圖像分割方法雖在實驗研究中有不錯的表現,但是其中很多的小樣本分割方法需要訓練額外的轉換網絡,或需要額外的標注信息和數據。由于MR圖像分割任務中各種器官組織的大小差異巨大,模型對不同器官分割任務的魯棒性也較差,同時目前利用meta-learning方法進行小樣本MR圖像分割的研究較少。因此本文將meta-learning和U-Net方法結合提出一種元U-Net模型(Meta-Unet),并利用空洞卷積和注意力機制對模型進行改進,在模型訓練時使用MAML和復合的損失函數,力求解決在小樣本MR圖像分割時需要額外數據信息和訓練額外中間網絡,以及在面對不同尺度的分割任務時效果不理想的問題。綜上所述,通過本文研究,以期能為臨床醫生在小樣本情況下提供較準確的分割結果,輔助后續的診斷和治療。
1 Meta-UNet小樣本分割算法
1.1 損失函數的改進
Meta-UNet采用了基于戴斯損失函數LD和平衡交叉熵損失函數LB設計的復合損失函數L,它們三者的關系及計算公式,如式(1)~式(3)所示:
|
|
|
式(2)中,y和?分別表示真實標注和預測結果。戴斯損失函數可以衡量兩個樣本之間的相似度,用于樣本極度不平衡的情況。如果一般情況下使用戴斯損失函數會使得訓練不穩定。式(3)中,N為樣本數量。yi代表樣本i的標簽,正類為1而負類為0,pi表示樣本i預測為正類的概率。在交叉熵的基礎上增加了一個參數α,α = Y?/Y。Y代表所有樣本的真實標注數量,Y?是Y中負樣本的數量。α可以增大數量少的樣本的權重,對不平衡的樣本有良好的改善作用,可使得網絡的訓練結果表現更好。將戴斯損失函數和平衡交叉熵損失函數結合,解決了MR圖像分割時樣本不平衡問題,經實驗證明復合損失函數提高了模型的精確度和收斂速度。
1.2 網絡結構的改進
不同的MR圖像分割任務中需要分割的目標尺度往往差距非常大。尺度的差異極大地影響了小樣本MR圖像分割在面對新任務時的泛化能力。因此本文提出了一種級聯的空洞卷積結構,該結構可以提取不同感受野的特征,并且模型參數的數量增加不多,能夠有效地適應小樣本任務的需求。
提高感受野的最直接方法是使用更大的卷積核,然而更大的卷積核卻導致模型有更多的參數需要訓練。因此本文為了減少需要訓練的參數使用了空洞卷積,在增加感受野的同時壓縮了參數數量。空洞卷積是一種稀疏的采樣方式,當多個空洞卷積疊加時,會損失信息的連續性與相關性,產生網格效應。Wang等[14]指出選擇鋸齒狀的空洞卷積可以有效避免網格效應提高特征利用率。因此本文采用1、2、5、7四種不同擴張率的空洞卷積進行級聯。每個分支將提取不同感受野的特征圖,再將提取到的特征圖進行融合,生成新的特征圖。空洞卷積模塊結構如圖1所示。
圖1
空洞卷積模塊
Figure1.
Dilated convolution block
面對四個不同的特征圖,本文考慮了兩種融合方式:將四個特征圖直接相加或將四個特征圖進行連接。相加融合特征圖會導致部分特征的丟失,而連接融合特征圖卻可以保留不同尺度特征,還可以使得不同尺度的特征在網絡的跳躍連接后能夠得到更好地復用,因此使用連接融合有望取得更好的效果。通過實驗也證明了使用連接融合更有利于提高模型的精度。
本文在模型中引入了注意力機制進一步提高模型的分割精度。注意力機制通常作為一個模塊用于編碼—解碼結構的網絡中提高網絡精度[15]。本文將注意力機制引入到模型當中,不但提高了分割精度,還有利于可視化解釋輸入和輸出數據之間的對應關系。
注意力模塊結構設計如圖2所示。xl和yl分別表示第l層U-Net結構的跳躍連接輸出和模型上一層的輸出,xl和yl通過一個1 × 1的卷積后相加,再經過線性整流函數(rectified linear unit,ReLU)、1 × 1卷積、S型生長曲線(Sigmoid)函數處理后與xl計算哈達瑪積,獲得最后的輸出 。注意力模塊在模型推理過程中會自動關注有顯著特征的區域并且不會引入大量參數,通過抑制無關區域的信號提高模型靈敏度和準確性。同時,注意力模塊還起到了類似分割前器官定位的作用。 的計算如式(4)所示:
圖2
注意力模塊結構
Figure2.
The Structure of attention block
|
其中,σ1是ReLU函數,σ2是Sigmoid函數,ψ、ψx、ψy都是卷積操作,b、by是對應卷積的偏置項,運算符o代表哈達瑪積。將 與上一層的輸出yl進行連接后繼續進行后面的運算。
最終模型網絡結構如圖3所示。模型的編碼部分使用了5個空洞卷積模塊進行串連,每一個空洞卷積模塊的輸出將作為下一個空洞卷積模塊的輸入。同時,空洞卷積模塊的輸出還通過跳躍連接與解碼部分相連接,本文在前三個跳躍連接中添加了注意力模塊。解碼部分使用了5個將ReLU作為激活函數、核大小為3 × 3的卷積層,每一個卷積層后跟一個上采樣層。解碼部分卷積層的輸入是模型前一層網絡的輸出以及對應編碼部分輸出連接后的向量。通過以上模塊構成類U-Net結構,使網絡能有效適應不同尺度的目標,提取到的特征也得到有效地復用,提高了網絡分割精度。
圖3
帶注意力機制的空洞卷積U-Net
Figure3.
Dilated convolution U-net with attention block
2 Meta-UNet網絡訓練
2.1 使用MAML學習分割器
本文使用MAML訓練網絡以獲得適用于小樣本任務的優秀分割器。下面重點介紹使用MAML學習分割器實例的方法。在學習過程中,訓練數據是帶有分割目標真實標記的圖像。給定一個患者(記為Pi),收集一組訓練樣本(記為),即是meta-learning中的支持集(support set)。分割器表示為f(x; θ0),其中x是輸入圖像,而θ0表示分割器的初始化參數。使用梯度下降更新分割器k次后的參數記為θk,如式(5)所示:
|
其中,L是損失函數,y是輸入圖像x所對應的標簽,Nts為當前支持集中的樣本數量,α是內部優化的學習率。如式(5)所示的迭代過程稱為內部優化過程,內部優化后,還需要驗證優化后分割器的泛化能力。在同一個患者Pi上產生另一個樣本集 ,即meta-learning中的查詢集(query set), 包含的樣本數量為Nit。計算當前分割器在查詢集上的的平均損失Lmean,如式(6)所示:
|
其中,y是輸入圖像x的標簽。計算迭代一輪后的損失,更新初始化參數θ0的方式如式(7)所示:
|
其中,N表示病例的數量,β是外部循環的學習率, 表示更新后的參數。如式(7)所示過程為外部優化過程。外部優化的梯度通過內部優化的梯度進行反向傳播。通過以上步驟利用梯度下降方法即可獲得所需的分割器。
2.2 Meta-UNet網絡訓練
Meta-UNet網絡訓練結構由內循環和外循環兩個部分組成。從內部循環開始到外部循環結束為一輪完整的訓練過程。網絡fA(θ)和網絡fB(?)是結構相同的兩個網絡,使用梯度下降法來優化網絡。將已標記數據集D按照分割目標分為支持集、驗證集、測試集三個數據集,分別記為Ds、Dv、Dt。Ds和Dv中只有部分分類目標相同,Dt與另兩個數據集分割目標完全不相同。根據小樣本訓練任務中的類別數N以及任務數量Ns、Nv對支持集和驗證集進行采樣,獲得不同的任務集合Ts和Tv。α和β分別是內外循環的學習率。首先使用隨機初始化方法初始化網絡fA(θ)的參數。每一輪訓練開始時,將fA(θ)的參數賦值給網絡fB(?),即? = θ,同時在任務集 和 上隨機采樣獲得一批數據記為 和 。進行內循環訓練,對于 中的每一個樣本計算損失梯度同時更新fB(?)的參數?,如式(8)所示:
| '/> |
其中, 為?更新后的模型參數。完成內循環訓練后利用驗證集 中的樣本開始外部循環,更新fA(θ)的參數θ,如式(9)所示:
| '/> |
其中, 為?更新后的模型參數。通過多輪以上的訓練步驟后就可以得到需要的模型fA()。
3 實驗及分析
3.1 實驗數據及性能度量指標
本文實驗數據來源于馬薩諸塞大學醫學院兒童和青少年神經發育計劃(child and adolescent neuro development initiative,CANDI)(網址為:https://www.nitrc.org/projects/candi_share/)提供的公開數據集[16]。數據集包含103個患者的MR的T1加權圖像,采集自57名男性和46名女性,圖像的大小為256 × 256,并且提供了39個大腦解剖結構的標注。為了計算效率本文通過減小輸入大小以降低計算量,將MR圖像裁剪成以原圖像中心為中心的160 × 160大小。裁剪后通過檢查,該大小圖像依然足以容納整個大腦。
本文性能度量指標選取戴斯相似性系數(Dice similarity coefficient,DSC)以及交并比(intersection over union,IoU)評估每個模型的分割精度,它們可以衡量手動注釋和預測結果之間的重疊程度。
3.2 實驗結果
實驗環境:中央處理器(Xeon 8369B @2.9GHz,Intel,美國),獨立顯卡(Tesla V100 32GB,Nvidia,美國)。深度學習框架為PyTorch 1.12.1(Linux Foundation,美國),編程語言為Python 3.10.5(Python Software Foundation,美國)。
3.2.1 損失函數有效性實驗
在CANDI數據集上,本文將U-Net作為基礎網絡,進行不同損失函數對模型性能影響的對比。實驗選擇腦干、左腦白質、左腦室、右蒼白球、右海馬體的分割任務對不同的損失函數進行比較。這些大腦結構覆蓋了大腦中尺度不同的不同結構,能夠有效說明損失函數選擇的有效性。實驗中將數據按照4:1的比例分為訓練集和測試集,利用不同的損失函數在訓練集上對模型進行訓練后在測試集上進行驗證。實驗結果如表1所示。本文繪制了選用復合損失函數以及單獨使用戴斯損失函數LD和平衡交叉熵損失函數LB在分割腦干、左腦白質、左腦室、右蒼白球和右海馬體時模型精度和訓練輪數的比較,如圖4所示。可見使用復合損失函數模型精度提高的同時收斂速度也得到了提高。
圖4
使用不同損失函數的模型精度在不同分割任務上的比較
Figure4.
Comparison of model accuracy on different segmentation tasks using different loss functions
3.2.2 特征圖融合實驗
對特征圖的融合方式進行實驗。利用本文提出的Meta-Unet網絡使用特征圖相加和連接兩種方式進行實驗。內部循環學習率采用0.01,外部循環采用0.001的學習率。訓練好的模型面對新的右腦白質和腦干的分割任務,僅使用一個帶標記的病例數據訓練迭代100次,進行分割測試。得到的實驗結果如表2所示。同時分割結果的可視化對比如圖5所示,不同顏色線條分別表示腦干和右腦白質的分割結果,第一行為準確標注的標準分割結果,第二行依次為采用相加融合與連接融合的結果。從實驗結果可以看出,使用連接的方式進行特征圖融合可以使模型獲得更高的分割精度。
圖5
使用不同特征圖融合方式分割結果比較
Figure5.
Comparison of segmentation results using different feature map fusion methods
3.2.3 模型比較實驗
在進行模型訓練時本文隨機選取其中25個結構作為訓練數據,12個結構作為測試數據。為了找到對于每個任務都相對最優的初始參數,必須使用相對較大的學習率,而優化真正模型參數的學習率應該是相對較小的。所以實驗中內部循環學習率采用0.01,外部循環采用0.001的學習率。利用MAML方法訓練模型的迭代次數為500次。選取無監督醫學圖像配準分割方法體素變形網絡(voxel morph network,VoxelMorph)[17]、基于數據增強醫學圖像分割方法轉換學習數據增強模型(data augmentation using learned transformations,DataAug)和標簽轉移網絡(label transfer network,LT-Net)醫學圖像分割方法三種當前已獲認可的方法和本文提出的新方法比較,僅僅使用一個帶標記的病例數據迭代訓練100次,本文提出的模型即獲得了更高的平均DSC。以用全部病例數據全監督學習的U-Net網絡作為基線進行對比,僅使用一個帶標注的病例數據進行訓練,本文方法在不同任務中獲得了最高91.8%的DSC,標準差與其他模型比較也明顯更小。實驗結果如表3所示,列出了不同模型在不同分割任務上的平均DSC和標準差,本文方法的平均DSC比起VoxelMorph、DataAug、LT-Net都有一定提高。如表4和表5所示,對比了不同模型在不同分割任務上的DSC和IoU。
本文對U-Net、VoxelMorph、DataAug和本文提出的Meta-UNet四種模型對大腦結構進行分割的結果切面進行可視化,如圖6所示。圖6中,不同顏色線條分別展示了對右腦白質、右大腦皮質、右側腦室、右小腦白質、右小腦皮質、右丘腦、右海馬體、腦脊液的分割結果,第一行為準確標注,第二行依次為U-Net、VoxelMorph、DataAug以及本文提出的Meta-Unet的分割結果。其中紅色箭頭指示了與其它方法相比Meta-UNet分割的優勢,可以看出,本文的Meta-UNet分割出的大腦結構更符合醫學解剖學意義。
圖6
不同模型的大腦結構分割結果
Figure6.
Results of brain structure segmentation for different models
3.3 實驗結果討論
(1)損失函數有效性實驗:實驗結果如表1所示,使用復合損失函數的分割模型對腦干、左腦白質、左腦室、右蒼白球和右海馬體進行分割的精度都提高了。如圖4所示,也證明了使用復合損失函數的情況下模型精度提高的同時收斂速度也得到了提高。分析其原因主要是利用新的復合損失函數進行訓練使得模型有效適應樣本均衡和不均衡的情況。
(2)特征圖融合實驗:使用不同融合方式進行圖像分割的DSC和IoU結果如表2所示。圖5可視化了分割結果的對比。從以上結果都可以看出,使用連接融合特征圖的方式要優于直接相加。直接相加操作會帶來信息損失,且直接相加的融合方式默認幾個特征圖的權重一致,然而不同的特征圖對于最終模型的影響效果卻不一定是等權重的。使用連接的方式進行特征圖的融合,則避免了上面的問題。
(3)模型比較實驗:從表4和表5可以看到本文方法在對腦白質、大腦皮質、腦室、小腦白質、小腦皮質、丘腦這些相對較大的目標分割上的表現和現有方法相當,而在尾狀核、第三腦室、第四腦室、海馬體、腦脊液、主動脈這些相對較小的目標分割時表現出更好的結果。實驗結果證明了Meta-UNet在腦MR圖像小樣本分割任務上的優越性。正如前面分析指出的,本文方法引入空洞卷積和注意力機制對不同尺度的目標分割具有良好的適應性,而引入MAML則可以利用額外有意義的監督信號來推動小樣本學習過程朝著更穩健和解剖學上更有意義的方向發展。從實驗中還可以發現DataAug方法在腦白質、大腦皮質、腦室、小腦白質、小腦皮質、丘腦這些相對較大的目標分割任務中的表現較本文提出的Meta-Unet方法好。分析其原因,DataAug方法是對一個帶標簽的圖像和一組無標簽的圖像之間的空間和外觀轉換進行建模,學習帶標簽圖像和無標簽圖像之間的非線性變形和成像強度的多種變化。然后,使用這些變換模型隨機作用在有標簽的示例上來合成新的帶標簽的示例,從而達到擴充帶標簽數據集的目的。最后,把這些新合成的帶標簽數據用于訓練有監督的分割網絡模型。DataAug在生成擴充帶標簽數據集時使用了無標簽的測試數據,因此測試數據也參與到了模型的訓練過程,使得DataAug的表現相對較好。但面對相對較小的目標時,通過對空間和外觀轉換建模的方法進行DataAug效果不理想。因此在小目標分割時本文提出的方法得到了更好的效果。
4 結論
本文將meta-learning、注意力機制和空洞卷積這三個機器學習經典思想應用到MR圖像分割中,提出了一種結合meta-learning、注意力機制和空洞卷積的Meta-UNet網絡,并利用該網絡實現了MR圖像的小樣本分割。本文模型對U-Net網絡進行了改進,首先引入了空洞卷積,使網絡模型的感受野增加,在小幅增加計算量的前提下提高了模型對不同尺度目標的靈敏度。其次,引入了注意力機制,進一步提高模型對不同尺度分割目標的適應性。最后,引入了MAML機制,使用復合損失函數對模型訓練進行良好的監督和有效的引導,使得模型能夠更好地適應小樣本分割任務。實驗結果表明,在不同尺度目標的小樣本分割任務中,Meta-UNet的分割結果更加符合臨床醫學解剖學要求。將本文研究思路和方法應用于圖像質量差、圖像差別大、圖像分割困難的超聲心動圖小樣本分割上,將是本課題組下一步研究重點。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:陳曉清是本研究的實驗設計和執行人,完成數據分析,論文初稿的寫作與修改;付忠良和姚宇指導論文寫作,提出修改意見。