針對多模態醫學圖像融合中的重要特征丟失、細節表現不突出和紋理不清晰等問題,提出一種圖像增強下使用生成對抗網絡(GAN)和卷積神經網絡(CNN)進行電子計算機斷層掃描(CT)圖像與磁共振成像(MRI)圖像融合的方法。生成器針對高頻特征圖像,雙鑒別器針對逆變換后的融合圖像;高頻特征圖像通過GAN模型進行特征融合,低頻特征圖像通過基于遷移學習的CNN預訓練模型進行特征融合。實驗結果表明,與當前先進融合算法相比,所提方法在主觀表現上紋理細節特征更加豐富,輪廓邊緣信息更加清晰突出;在客觀指標評估中,融合質量評價指標(QAB/F)、信息熵(IE)、空間頻率(SF)、結構相似性(SSIM)、互信息(MI)和融合視覺信息保真度(VIFF)等關鍵指標比其他最佳測試結果分別提高了2.0%、6.3%、7.0%、5.5%、9.0%和3.3%。融合后圖像可以有效地應用于醫學診斷,進一步提高診斷效率。
引用本文: 劉云鵬, 李瑾, 王宇, 蔡文立, 陳飛, 劉文潔, 毛顯昊, 干開豐, 王仁芳, 孫德超, 邱虹, 劉邦權. 圖像增強下基于生成對抗網絡和卷積神經網絡的CT與MRI融合方法. 生物醫學工程學雜志, 2023, 40(2): 208-216. doi: 10.7507/1001-5515.202209050 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
為了避免重復多次讀取和觀察相同部位下多種模態醫學影像,一種有效的解決方案是將多模態的醫學影像進行融合,同時最大限度地保留原來每個模態下的圖像特征。針對電子計算機斷層掃描(computed tomography,CT)與磁共振成像(magnetic resonance imaging,MRI)醫學圖像融合的研究,主要包括傳統空域方法、傳統變換域方法和完全深度學習的方法。傳統空域方法[1-6]的核心思想是以圖像原有的像素、像素塊或指定區域為計算單元,通過權重的方法控制不同圖像融合的比例與強度。該方法簡單快速,但是對比度信息、亮度信息和特征細節容易丟失。傳統空域融合方法的缺陷和不足可以使用變換域的方法[7-19]進行彌補,該方法對原始多模態圖像進行頻域或者其他相關類型分解,不同分解域上可以使用相同或不同的方法分別進行融合,比如不同分解域中可以使用相同或不同的深度學習方法,然后通過分解域的逆操作合成最終的融合圖像。
在深度學習應用領域,一方面可以直接使用卷積神經網絡(convolutional neural network,CNN)來獲取醫學圖像的特征用于融合,另一方面也可以使用生成對抗網絡(generative adversarial network,GAN)的思想來直接融合,由于GAN模型[20-27]需要的訓練數據更少,表達能力更為強大,在醫學圖像融合領域受到了極大的關注。CNN和GAN的方法既可以直接用于原始數據圖像,也可以用于分解后的特征圖像。
如前所述,在變換域的融合方法中,不同分解域可以使用不同的方法,例如在其中一個分解域中使用傳統的空域或變換域算法,而在另一個分解域中使用深度學習的方法。但在目前已知的研究范圍內,還沒有在高頻和低頻域中使用兩種不同的深度學習方法將CT和MRI進行融合的論文和技術。本研究使用變分模態分解(variational mode decomposition,VMD)方法進行變換,可以獲取更加豐富和精準的高頻特征圖像與低頻特征圖像,并且創新性地提出基于GAN的生成器與鑒別器不在同一個變換域中的端到端訓練模型,生成器針對高頻特征圖像,而鑒別器針對逆變換后的融合圖像,對于細節和紋理豐富的高頻圖像使用訓練后GAN模型的生成器進行融合,而對于低頻圖像,由于特征相對較少,通過基于遷移學習的CNN預訓練模型進行融合。同時結合圖像銳化、濾波、亮度調節和對比度調節方法,通過一種多參數搜索的方法進行圖像增強,用于訓練圖像和融合后圖像處理兩個方面。
1 研究方法
1.1 系統概述
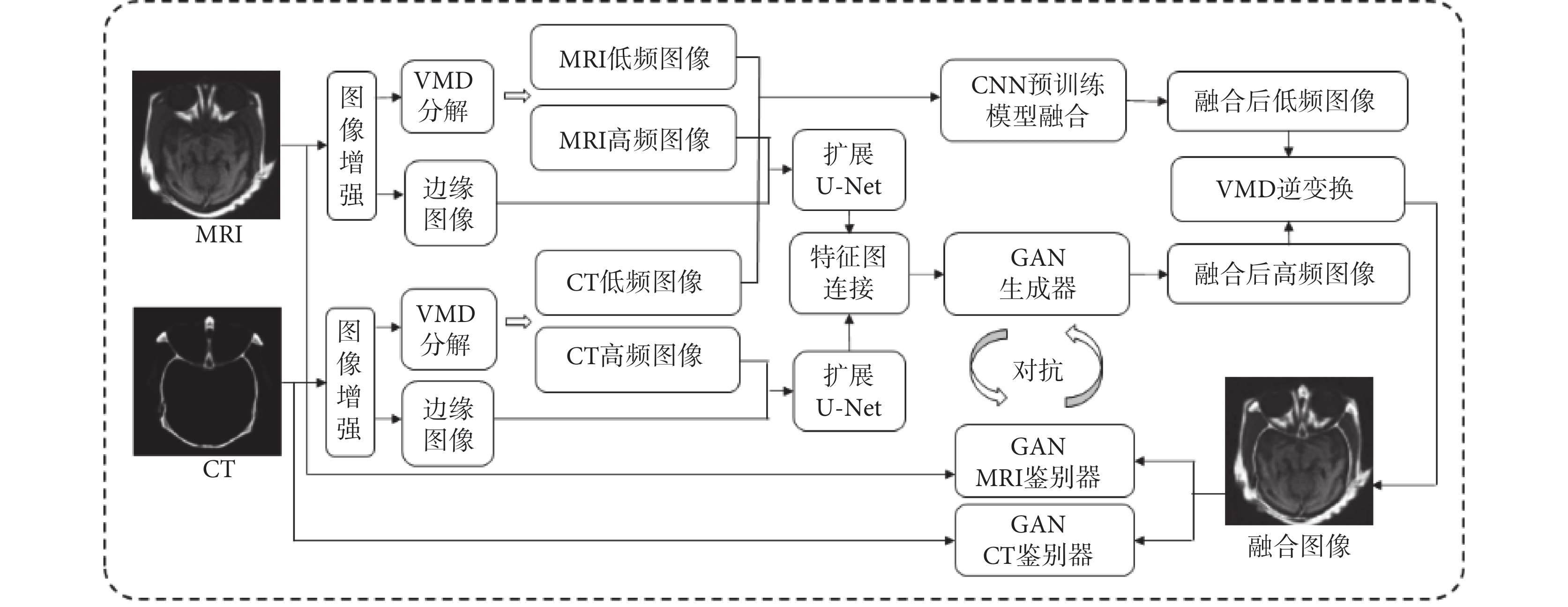
整個研究過程包括訓練和融合生成兩個基本過程,如圖1和圖2所示。在訓練過程中,首先對輸入的MRI和CT分別進行圖像增強,然后使用VMD方法對MRI和CT進行分解同時生成增強后的邊緣圖像,對于分解產生的低頻圖像使用CNN預訓練模型進行融合。對于分解產生的高頻圖像和邊緣圖像,則作為擴展U-Net網絡模型的輸入,然后對形成的特征圖連接后再輸入到GAN的生成器中進行訓練。這是因為,CT和MRI這樣的醫學圖像大多用于腫瘤等病變的診斷,所以在圖像中往往會有一些需要識別的小目標,這些區域是醫學圖像中最重要和關鍵的部分,而U-Net結構的網絡模型對于最大程度地獲取微小目標組織和結構的紋理特征與邊緣輪廓信息有著很好的效果。
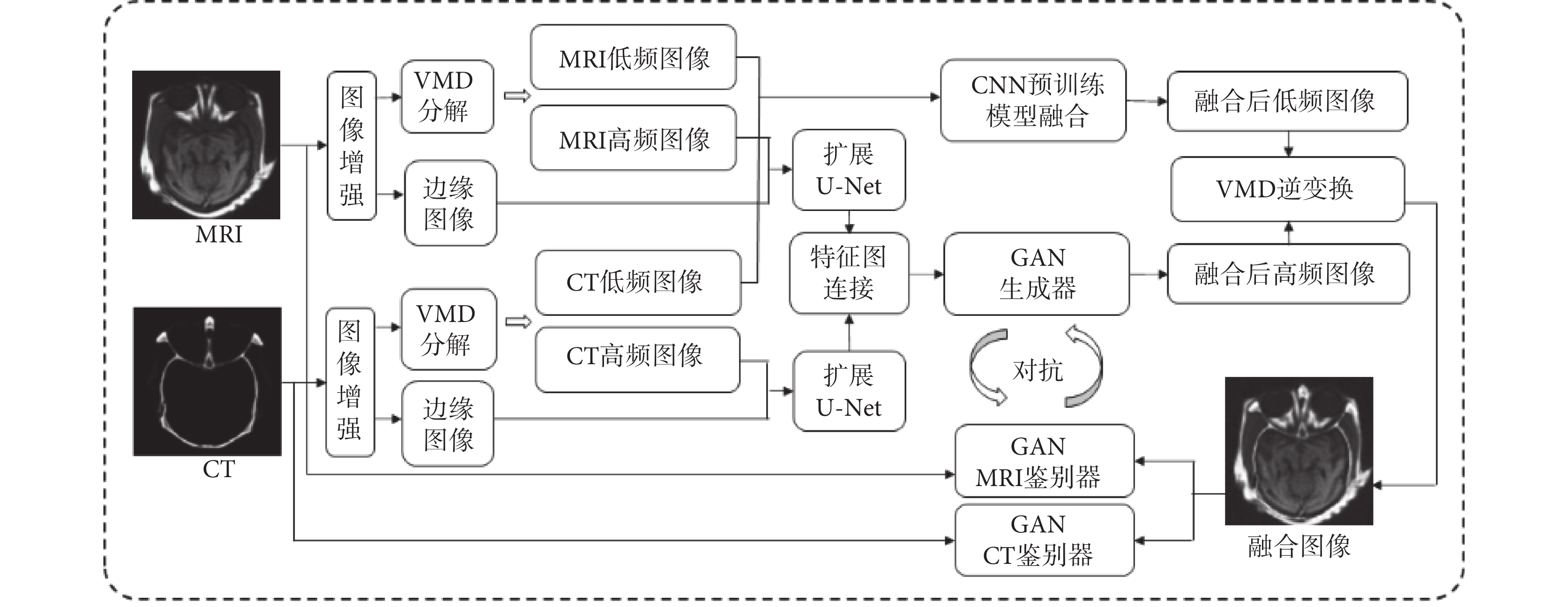 圖1
訓練基本過程
Figure1.
Basic training process
圖1
訓練基本過程
Figure1.
Basic training process
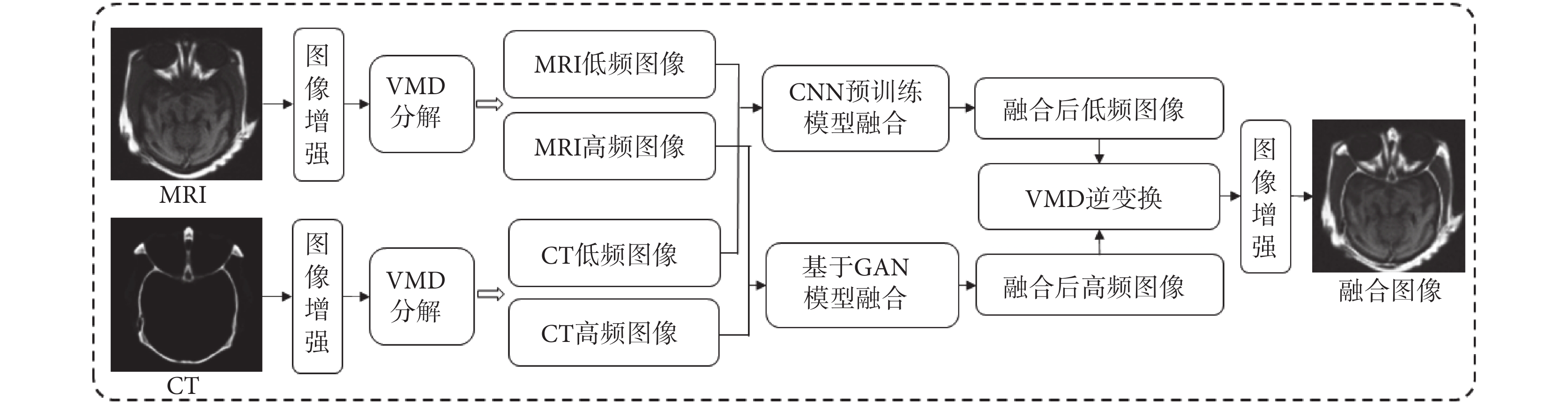
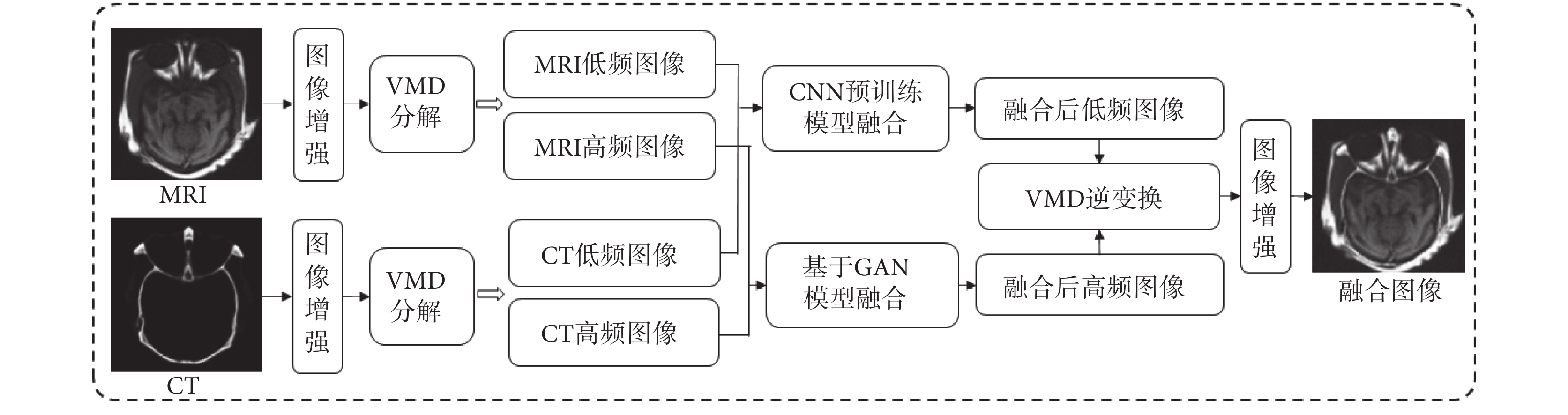 圖2
融合基本過程
Figure2.
Basic process of fusion
圖2
融合基本過程
Figure2.
Basic process of fusion
接著對GAN生成的高頻圖像和融合的低頻圖像進行VMD逆變換合并,生成訓練后的融合生成圖像,再將融合生成圖像分別與原始CT和MRI分別輸入到GAN CT鑒別器和GAN MRI鑒別器,與GAN生成器形成對抗訓練。這里的特別之處在于生成器只針對高頻圖像,而鑒別器是針對逆變換合并后的融合圖像。由于雙鑒別器的使用,此處無需人工構建融合標簽圖像。在融合生成過程中,對于輸入圖像同樣需要進行增強處理,與訓練相比,無需邊緣圖像的生成,對于分解產生的高頻圖像直接使用訓練好的GAN模型生成器進行融合,再與低頻融合圖像進行逆變換。為了進一步突出融合后的紋理細節特征,在逆變換后的融合圖像中再進行一次增強處理。
1.2 圖像融合
CT與MRI圖像融合包括VMD分解后的高頻特征圖像融合與低頻特征圖像融合兩個部分,由于低頻特征圖像以平坦區域和變化緩慢紋理為主,所以通過基于遷移學習的CNN預訓練模型可以得到很好的特征融合。對于高頻特征圖像,從本文系統概述的圖1中可以看出,在分解后的高頻域通過擴展U-Net獲取特征并進行連接后,再通過訓練GAN的生成器來對特征進行融合,而在逆變換后的高頻與低頻合成圖像中使用GAN的兩個鑒別器與高頻域的生成器進行對抗。
1.2.1 高頻圖像融合
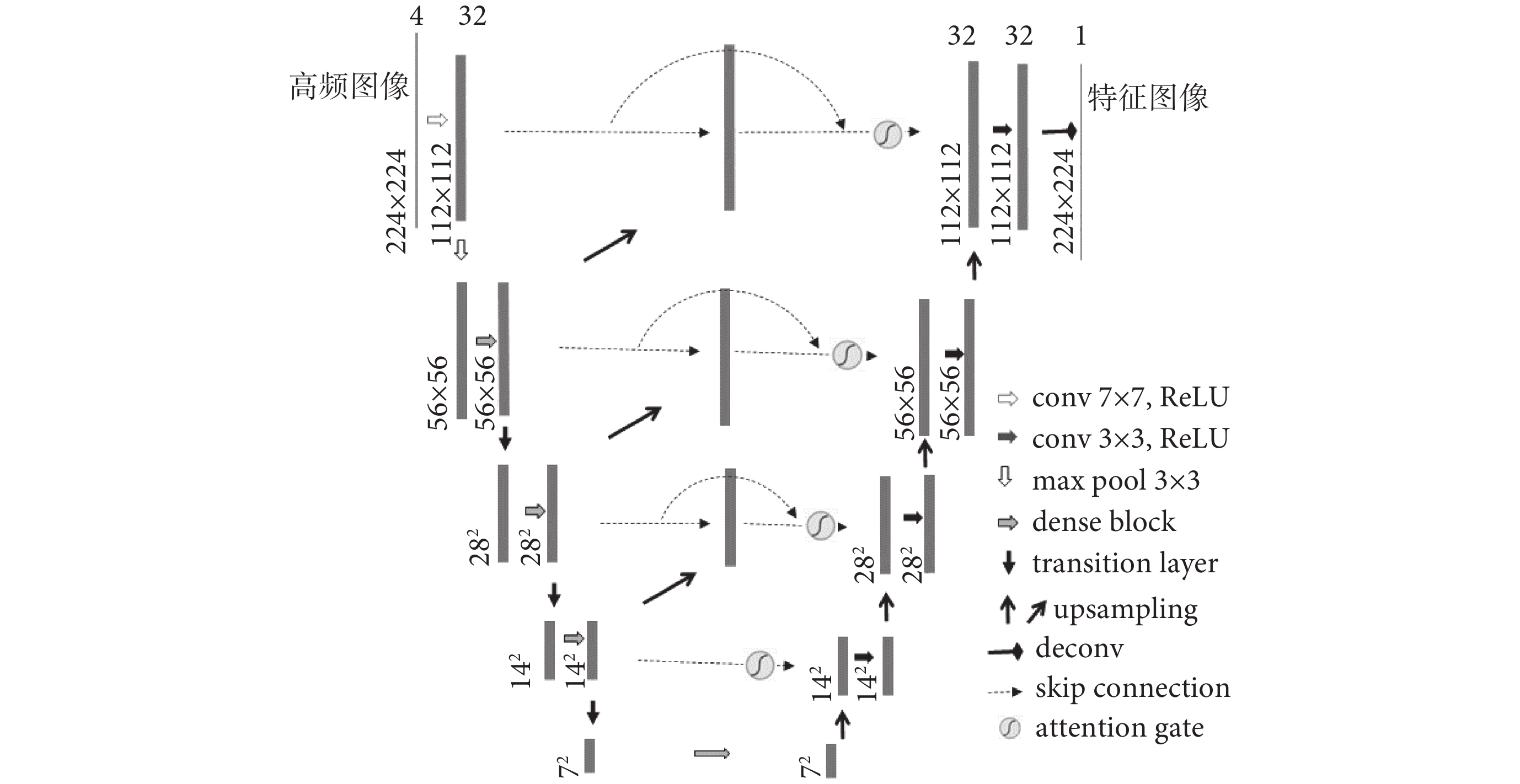
(1)擴展U-Net:如前所述,高頻圖像在進入GAN生成器訓練之前需要使用擴展U-Net進行特征提取與合并,圖1中所描述的擴展U-Net如圖3所示。與傳統U-Net不同的是,擴展U-Net的Dense連接與Skip連接在編碼端的卷積層、上層與下層的連接以及編碼與解碼的同層之間都有存在,這種交叉融合的Dense和Skip連接可以在訓練中獲得和傳遞更豐富的語義與特征信息,使得整體梯度流得以有效增強,同時全局最優解更加容易被找到。
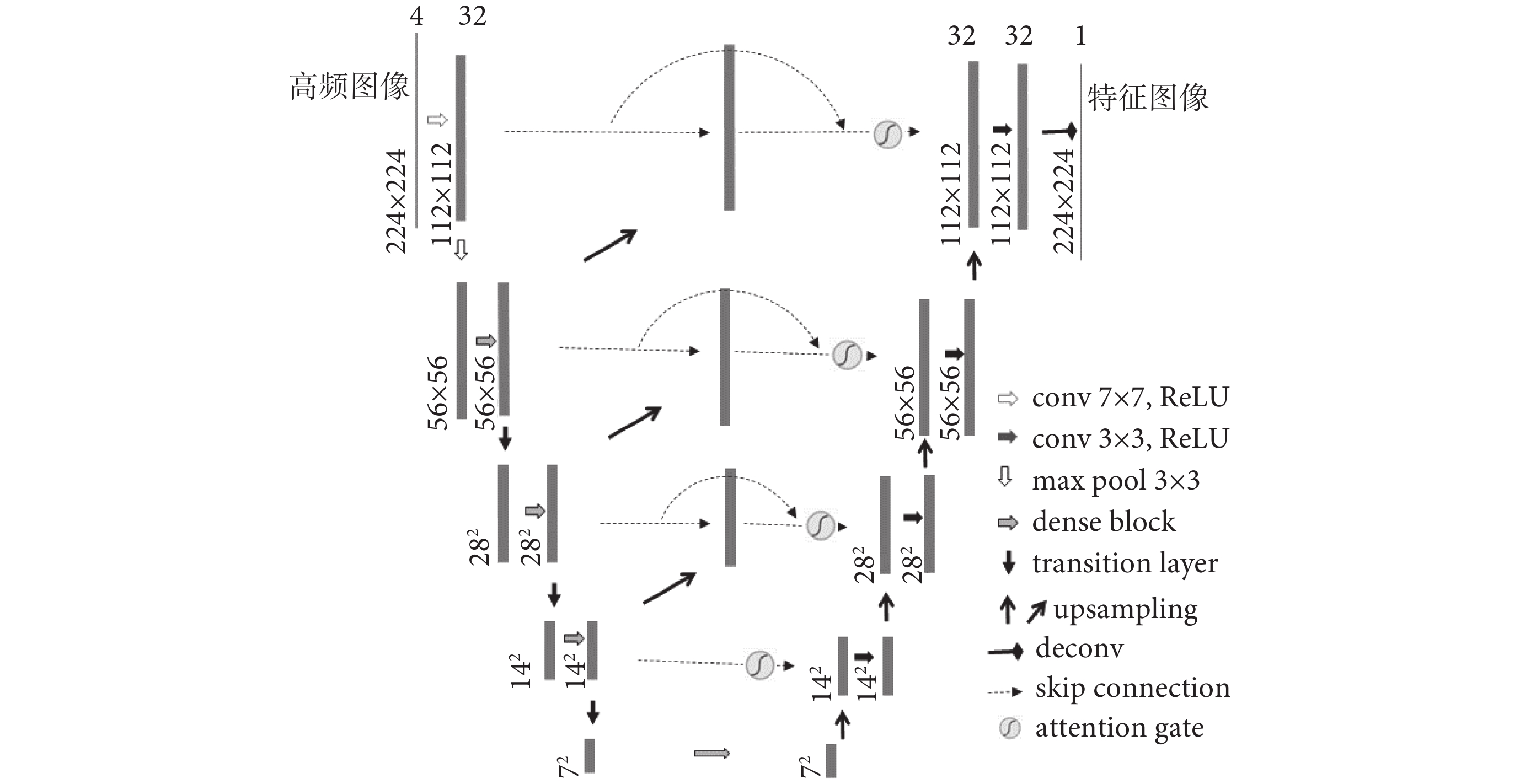 圖3
擴展U-Net結構圖
Figure3.
Extended U-Net network diagram
圖3
擴展U-Net結構圖
Figure3.
Extended U-Net network diagram
解碼層采用Isola等[28]提出的上采樣方法。為了避免上采樣過程中過多紋理細節的損失,使用子像素卷積模式[29],該方法可以將多個低分辨率特征圖像通過打亂像素次序(pixel shuffle)的方式來生成更高分辨率的圖像。在圖3的擴展U-Net結構中可以看到每一層的連接中都包含一個注意門(attention gate,AG),這里使用了一種醫學影像模式下的AG[30],該AG不僅可以關注形態差異較大的組織結構,還可以對卷積中特征容易弱化和消失的小目標進行有效的性能提升。
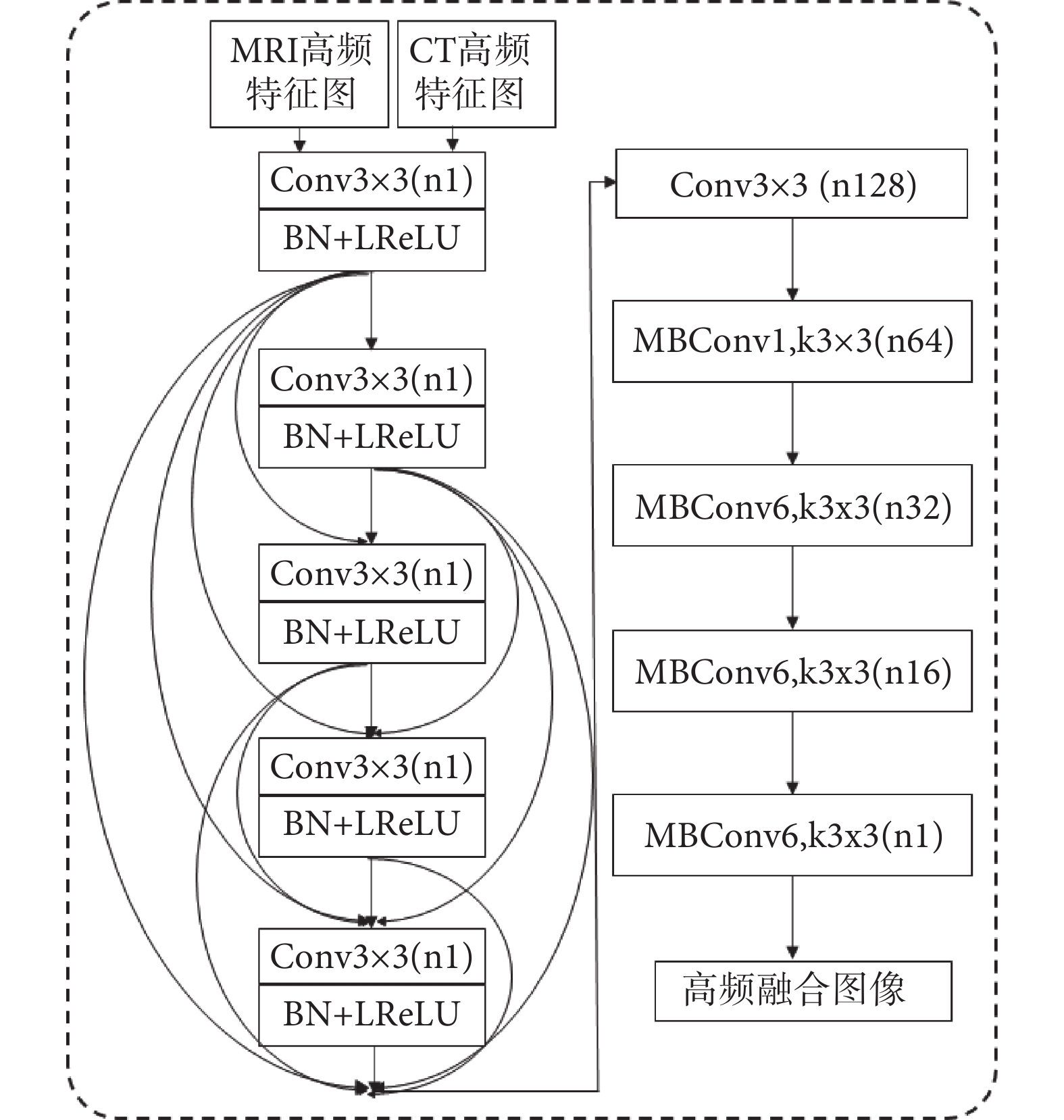
(2)生成器結構:生成器的基本結構如圖4所示,輸入通道為擴展U-Net輸出的MRI與CT高頻特征圖,都是單通道的灰度圖像。此處設計的生成器將DenseNet與EfficientNet的優勢進行結合,多路徑短連接、多目標神經架構搜索和因子分層化搜索空間技術的使用,將網絡容量與特征提取能力進行了很好的平衡,在圖像分辨率不是很高而且網絡寬度與深度都不是很大的情況下可以進一步減輕梯度消失問題,同時加強了特征的利用與有效傳遞。
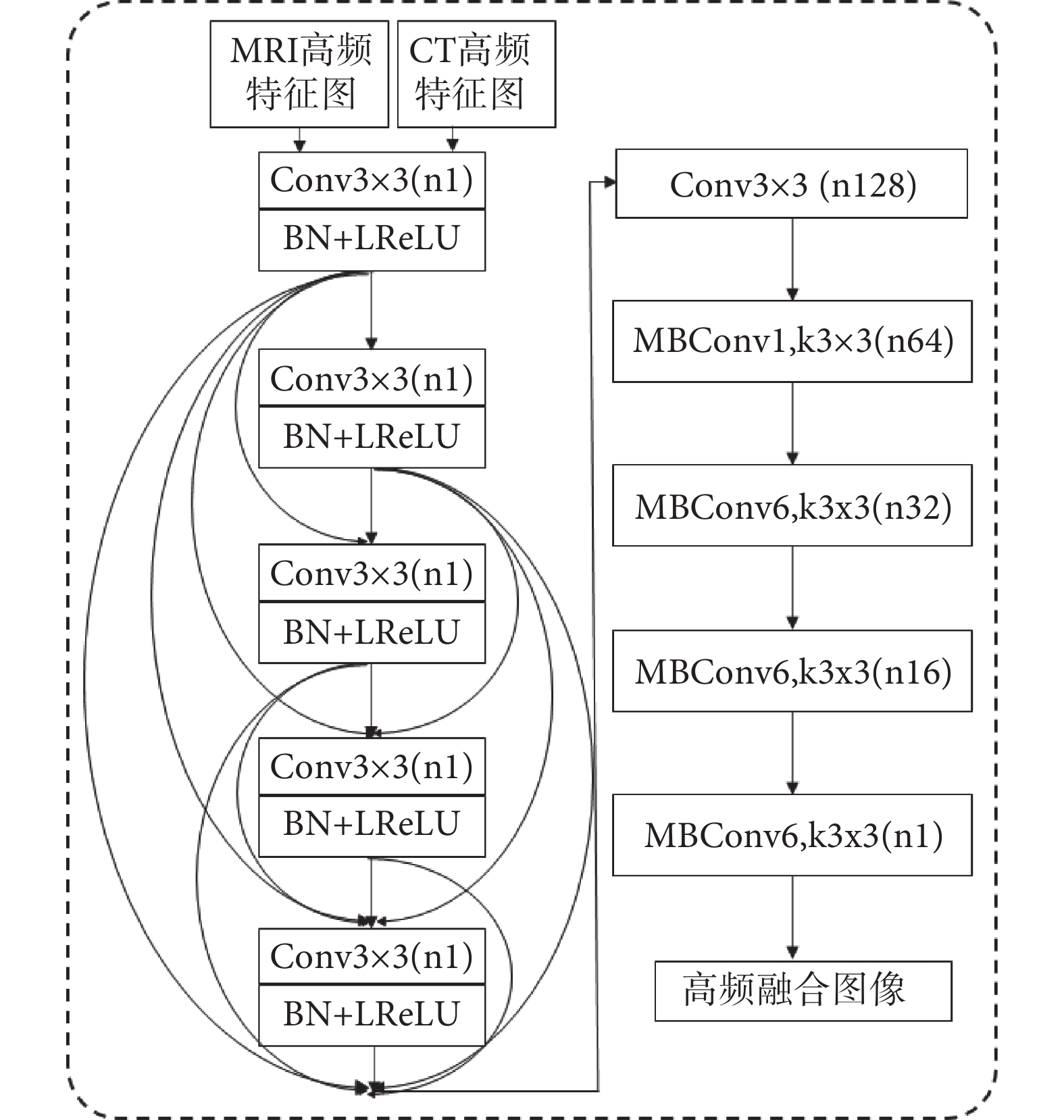 圖4
生成器結構
Figure4.
Generator structure
圖4
生成器結構
Figure4.
Generator structure
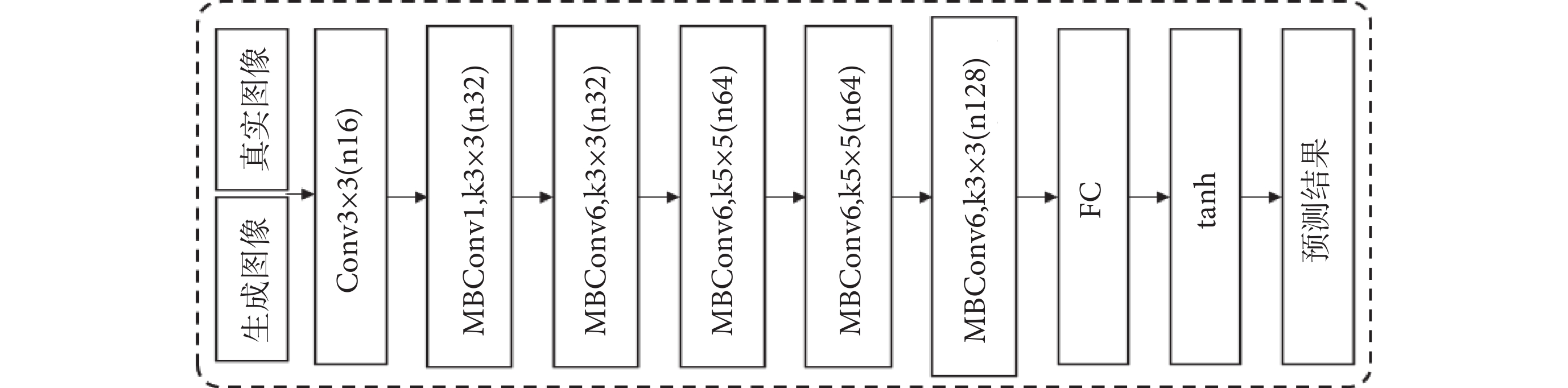
(3)鑒別器結構:鑒別器在訓練中是與生成器進行對抗。本文中兩個鑒別器DMRI和DCT分別將生成融合圖像與真實的MRI和CT進行區分,由于CT與MRI圖像紋理明顯不同,訓練中必須考慮兩種不同的數據分布在與生成器G對抗中的沖突,所以不僅要考慮對抗訓練還要顧及DMRI和DCT的平衡處理,在本文損失函數部分進行了平衡處理的損失設計方法描述。鑒別器DMRI和DCT的網絡結構相同,與生成器相比結構相對簡單,其基本結構如圖5所示,由于EfficientNet強大的特征提取與分類能力,依然使用了其核心網絡結構。
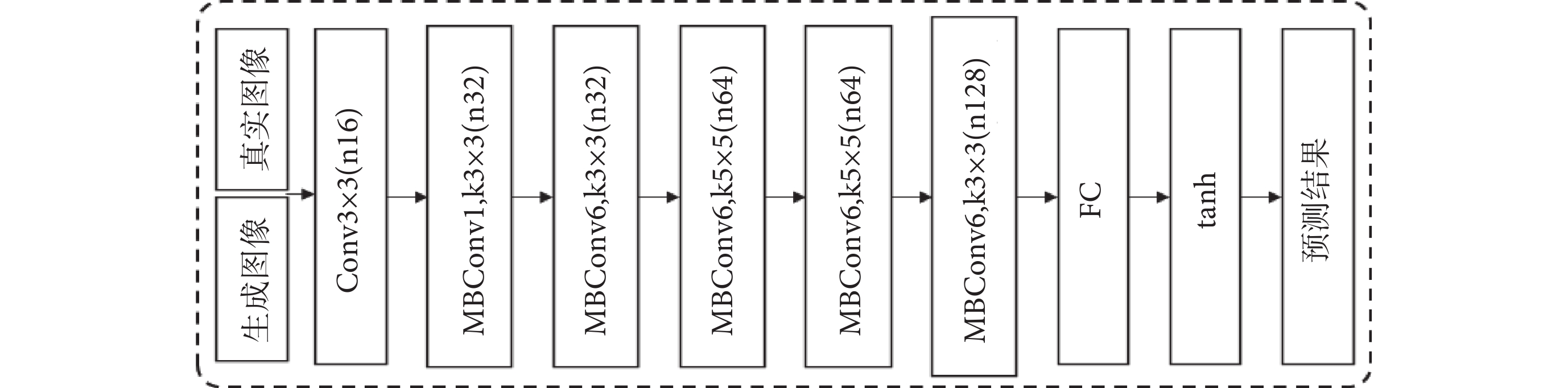 圖5
鑒別器結構
Figure5.
Discriminator structure
圖5
鑒別器結構
Figure5.
Discriminator structure
1.2.2 低頻圖像融合
具體描述如下:生成VMD分解的CT低頻特征圖像與MRI低頻特征圖像,將圖像都轉為單通道的灰度圖像,再對低頻灰度圖像進行0-1歸一化,通過像素值直接除以255實現。載入ImageNet數據集上的預訓練CNN模型EfficientNet及權重參數,去除預訓練模型的全連接層與分類層,保留用于特征提取的卷積層。CNN模型分別讀入歸一化的CT與MRI低頻圖像,并生成相應的特征圖。從CNN的淺層到深層,分別處理CT與MRI的每一個特征圖,對特征圖的每一行元素求和生成一個行特征值,從而生成一個新的特征圖,CT與MRI則分別對應一組新的特征圖組合。使用最近鄰插值方法將新的特征圖組合采樣到圖像大小,通過softmax函數根據特征圖計算CT與MRI像素的概率權重值,根據權重對CT與MRI空間上對應的像素值進行加權求和,得到融合后數據。將融合后數據轉為0-255的灰度像素空間,像素值直接乘以255取整實現。
2 實驗與分析
2.1 實驗環境與數據
GAN對抗訓練主要使用的硬件環境為NVIDIA Tesla P100顯卡,顯存16 GB。軟件環境包括Ubuntu16.04的操作系統和tensorflow1.12.0 + keras 2.2.5的深度學習平臺,加速對應庫為cudnn7.1.4,使用python3.6.12版本進行所有實驗與開發。實驗使用的CT與MRI數據來自美國哈佛醫學院的全腦圖譜數據庫(Whole Brain Atlas),每組CT與MRI前期都已經成功配準,本文研究中不涉及配準工作。
2.2 定量分析與討論
2.2.1 與當前先進方法整體對比
將本文方法與當前在空域融合、變換域融合和基于GAN融合的6種先進方法進行比較,所有方法都是在本文所提圖像增強方法的基礎上進行實驗。空域融合方法包括GM[5]和GC[6],變換域融合方法包括PS[18]和HID[17],基于GAN融合方法包括FusionGAN [25]和DDcGAN [27]。為了對所提方法的圖像融合性能進行評價,本研究使用融合質量評價指標(QAB/F)、信息熵(information entropy,IE)、空間頻率(spatial frequency,SF)、結構相似性(structural similarity,SSIM)、互信息(mutual information,MI)和融合視覺信息保真度(visual information fidelity for fusion,VIFF)等圖像融合領域的客觀評價指標對整個測試集數據進行定量分析,結果如表1所示。在使用的6個評價指標中,本文所提方法在所有實驗方法中的結果都是最優的。對于測試集所有數據的平均值,本文方法的QAB/F、IE、SF、SSIM、MI和VIFF比最差結果分別高出35.8%、27.8%、25.5%、22.8%、37.8%和32.5%,比次優結果分別高出2.0%、6.3%、7.0%、5.5%、9.0%和3.3%。可以看出,本文方法性能的提高是非常顯著的。
進一步分析表1,QAB/F為融合質量評價指標,利用局部度量輸入圖像顯著信息在融合圖像中的表現程度,重點度量邊緣信息的轉移情況,即圖像融合后原始圖像邊緣信息是否被保存。可以看出,GC與HID取得了不錯的效果,但是基本已經達到了傳統空域與變換域融合的極限,對邊緣融合效果較差。IE為信息熵,基于信息學理論測量一張融合圖像中信息量的大小,通常情況下該值越大,說明融合圖像中包含有價值的信息越多,融合表現就越好。可以看出,傳統變換域方法要好于傳統空域方法。SF為空間頻率,基于梯度的評價指標,反映圖像灰度變化率,度量圖像細節與紋理的清晰度,一般來說,SF越高則圖像越清晰。分析得知,GC為代表的傳統空域融合方法可以較好地保留梯度信息。SSIM為結構相似性,用于比較原始圖像和融合圖像之間的相似度,從圖像組成的角度將結構信息定義為獨立于亮度和對比度的屬性,反映場景中物體結構的特征,其值越接近1,表示融合效果越好。分析得知,空域變換由于是針對像素級別操作,容易造成對結構信息的破壞,所以效果最差。MI為互信息,度量原始圖像傳入到融合圖像中的信息量,表達兩張圖像的關聯程度,其值越大意味著來自原始圖像的信息越多。可以看到,傳統空域方法與傳統變換域方法差異并不明顯。VIFF為融合視覺信息保真度,采用人眼視覺系統的特性作為指標,是基于多種圖像特征的綜合評估,包括顏色、亮度、對比度等,可以更準確地評估融合結果的視覺質量。分析得知,傳統變換域方法要略好于傳統空域方法,但提升并不突出。再從整體統計結果分析來看,盡管FusionGAN使用了深度學習,但是性能提升并不突出,因為并沒有把變換域和深度學習的優勢進行結合。
2.2.2 消融實驗
本文的核心技術與創新在于在所提圖像增強方法的基礎上,使用變換效果更佳的VMD分解,同時在高頻和低頻域中使用兩種不同的深度學習方法進行融合。為了觀察核心技術點的貢獻,設計如下實驗:方案1:只是不使用圖像增強,使用原圖進行融合;方案2:只是不使用VMD分解,使用非下采樣剪切波變換(nonsubsampled shearlet transform,NSST)分解;方案3:只是低頻域不使用遷移學習方法,使用加權融合;方案4:只是高頻域不使用本文所設計的基于GAN的生成器與鑒別器不在同一個變換域中的端到端訓練模型,使用鑒別器直接與生成的高頻圖像進行對抗的GAN。測試集所有圖像的平均分析結果如表2所示。
從表2測試集整體結果來看,對于分析方案1中的圖像增強技術因素,使用圖像增強技術后,QAB/F、IE、SF、SSIM、MI和VIFF分別增加6.1%、7.1%、58.9%、6.7%、36.5%和50.4%,可以看出QAB/F、IE和SSIM的提升并不明顯,多在6%~7%,而SF、MI和VIFF的性能增加顯著,SF高達58.9%。對于方案2中的VMD分解技術因素,QAB/F、IE、SF、SSIM、MI和VIFF分別增加18.3%、9.0%、8.3%、14.3%、8.5%和54.6%,其中VIFF最為顯著,高達54.6%。對于方案3中的低頻融合技術因素,QAB/F、IE、SF、SSIM、MI和VIFF分別增加1.6%、0.1%、1.8%、1.0%、2.0%和4.2%,性能的提升相對較弱,個別圖像中部分性能指標值在使用低頻融合技術后還會有微弱的下降,但整體平均性能還是有了少量提高。對于方案4中的高頻融合技術因素,QAB/F、IE、SF、SSIM、MI和VIFF分別增加17.0%、7.2%、10.3%、19.6%、12.2%和49.0%,可以看出每個指標都有相當不錯的性能提升。
根據上述分析,將四個方案中的技術因素重要性進行對比,可以看出對于QAB/F,VMD分解和高頻系數融合更為重要,對質量有較大提升。對于IE,低頻系數融合幾乎沒有任何提升,VMD分解提升最多。對于SF,圖像增強的貢獻是非常顯著的。對于SSIM,高頻系數融合對性能提升最為明顯,VMD分解也帶來較大提高。對于MI,圖像增強提升效果幅度最高。對于VIFF,除了低頻系數融合數帶來了少量提升外,圖像增強、VMD分解和高頻系數融合都有很大程度的性能提升貢獻。總體來看,圖像增強可以較大幅度地提升圖像融合效果的大部分性能指標;VMD分解對所有性能指標都有不同程度的提升,個別指標提升幅度較為明顯;低頻系數融合盡管對所有指標都有提升,但是程度較低甚至不明顯;高頻系數融合對所有指標都有較大幅度的提升。
2.3 典型圖片展示
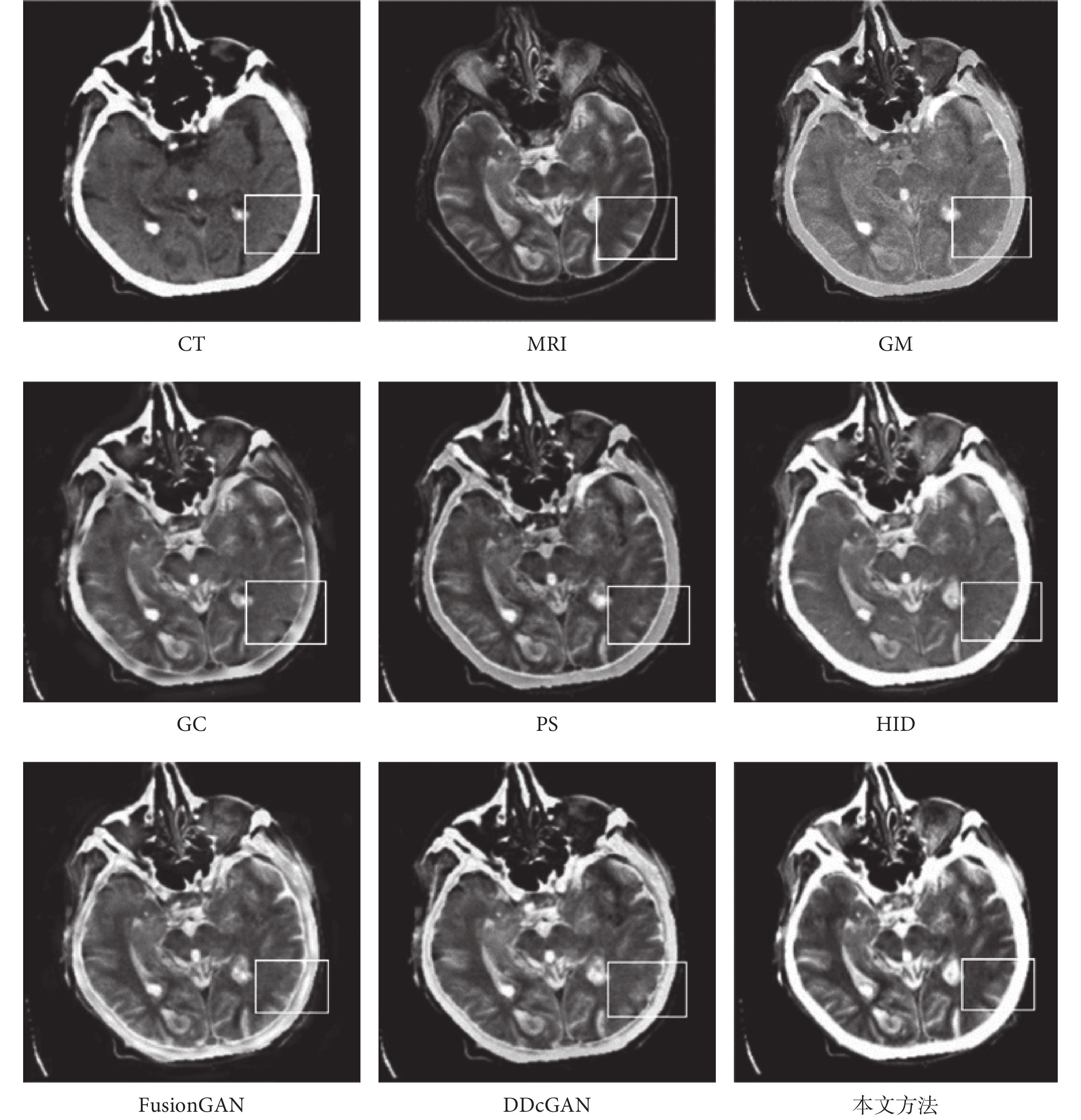
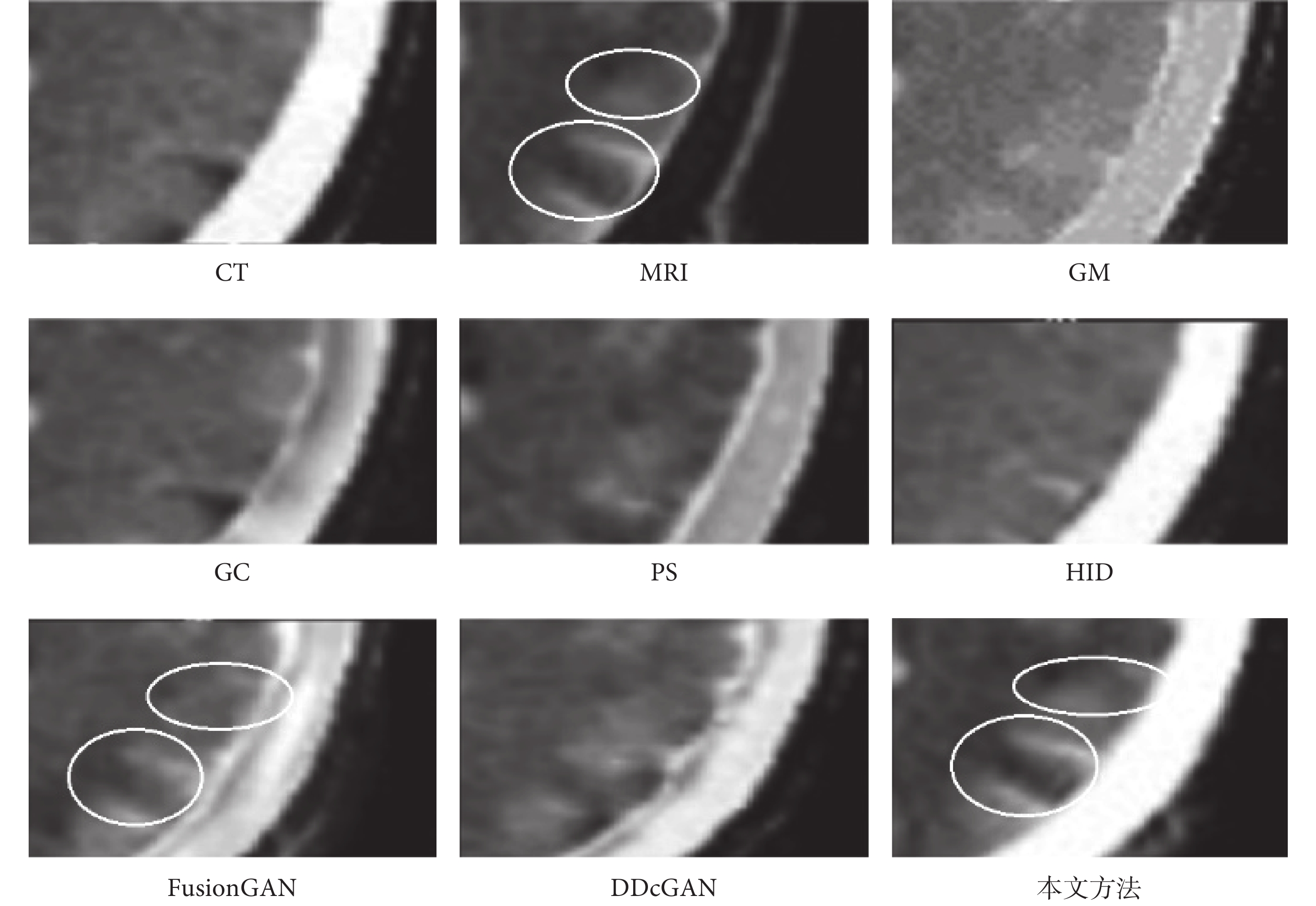
為了進一步說明本文方法優于其他算法,選擇典型圖片進行展示分析。整體融合效果如圖6所示,圖6中所標注的局部細節區域在圖7中進行放大展示,同時在圖7中用橢圓標注進一步突出本文算法效果的細節優勢。CT主要表現骨骼邊緣和組織結構的低頻數據,MRI則突出紋理細節和高頻特征數據,MRI表現的細節與紋理結構會更加豐富,也是圖像融合的關鍵。首先從圖6中的整體比較中可以看出,本文所提算法生成的圖像是CT骨骼特征和MRI紋理細節特征融合效果最好的,明顯優于其他6種方法。進一步分析來看,GM和HID是融合效果最差的兩個,紋理細節較為模糊,不能很好地獲取MRI的高頻特征數據,但是與GM相比,HID在骨骼邊緣獲取方面卻效果很好,與CT原有的骨骼特征以及本文方法獲取的結果基本一致。GC、PS、FusionGAN和DDcGAN的融合效果整體上看較為相似,但是通過圖7中細節放大觀察,與原始的MRI紋理對比,就會發現FusionGAN的效果最好,其次是DDcGAN、PS和GC,可以看出GC在紋理融合中效果最差,并不能很好地獲取MRI的高頻細節特征。再將FusionGAN與本文方法結果進行對比,從圖7的放大細節中可以看出,不管是CT中的骨骼邊緣特征,還是MRI中的輪廓與結構上的清晰度,以及紋理內部的對比度和微小的梯度變化,本文方法的融合效果都較為明顯地優于FusionGAN。同時從圖7的兩處橢圓標記中可以看出,本文算法融合的紋理高頻細節特征結果與MRI更為一致,進一步證實了本文算法的優越性。
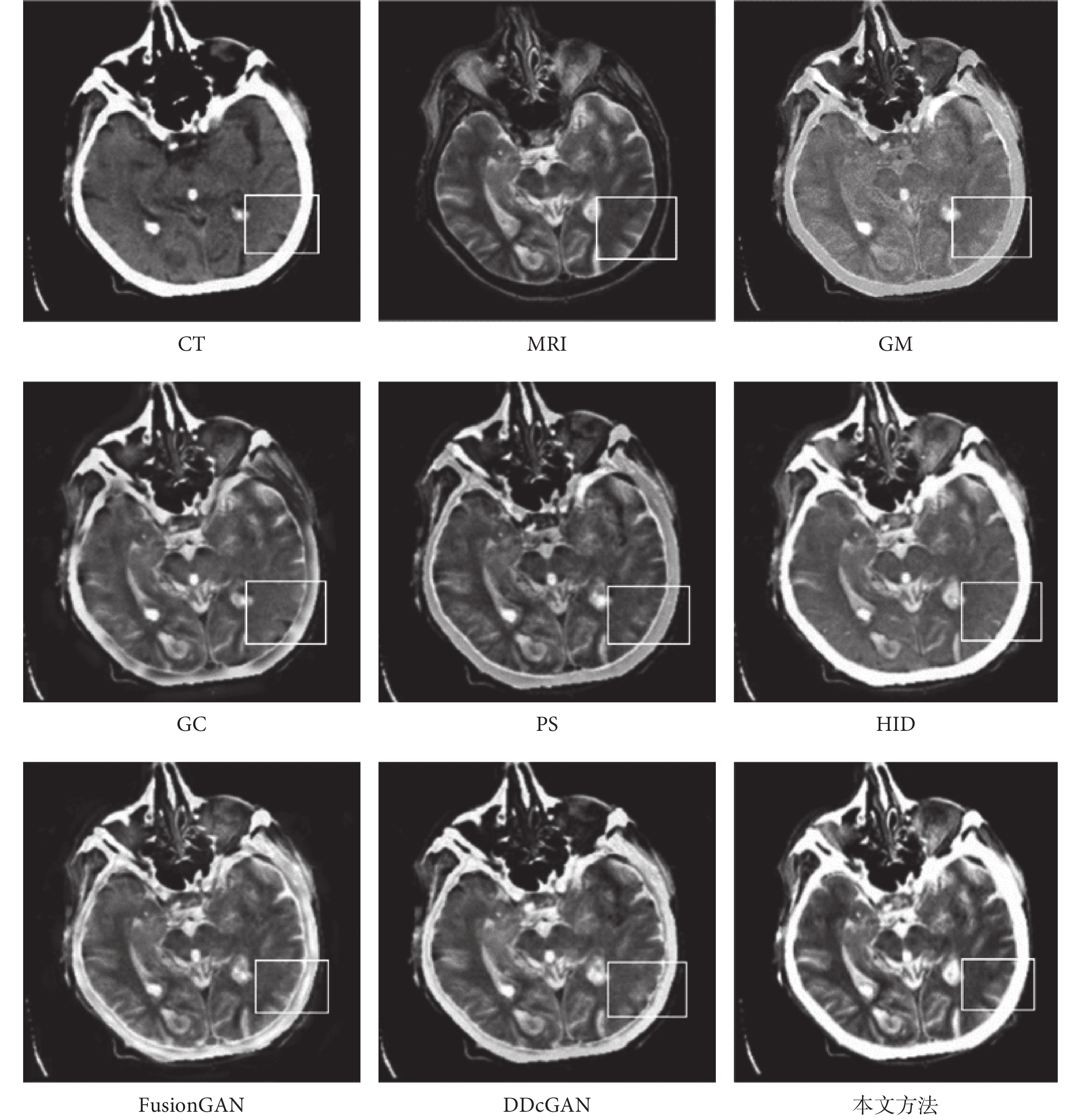 圖6
典型圖像整體融合效果展示
Figure6.
Display of overall fusion results of typical image
圖6
典型圖像整體融合效果展示
Figure6.
Display of overall fusion results of typical image
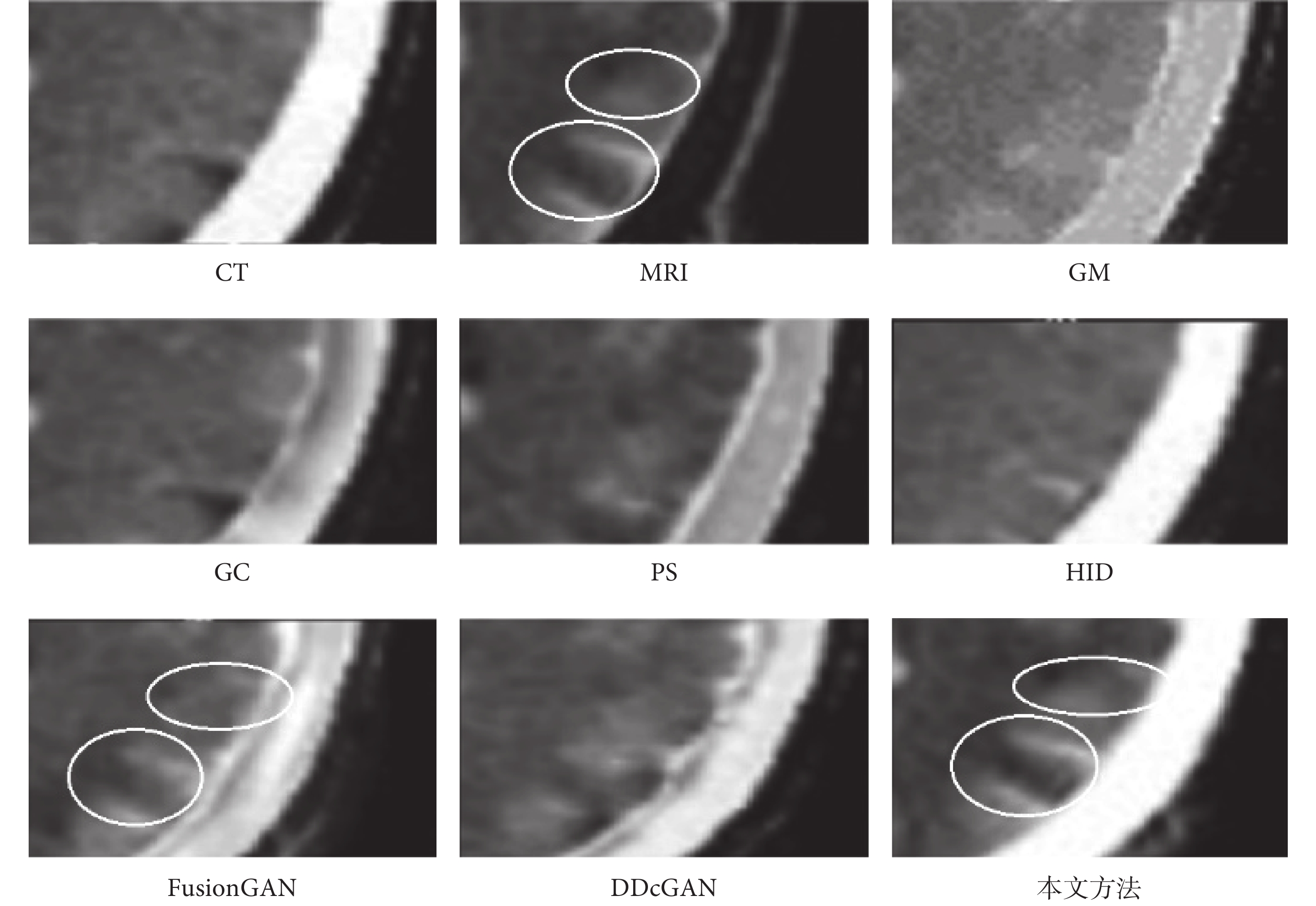 圖7
典型圖像局部融合細節展示
Figure7.
Display of local fusion details of typical image
圖7
典型圖像局部融合細節展示
Figure7.
Display of local fusion details of typical image
3 結論
本文針對CT與MRI的圖像融合進行研究,針對現有融合方法中重要特征丟失、細節表現不突出和紋理不清晰等問題,提出一種圖像增強下使用GAN和CNN進行CT與MRI融合的方法。結合圖像銳化、濾波、亮度調節和對比度調節方法,通過一種多參數搜索的方法進行圖像增強。本文創新性提出基于GAN的生成器與鑒別器不在同一個變換域中的端到端訓練模型,生成器針對高頻特征圖像,而鑒別器針對逆變換后的融合圖像。同時基于變換域中高頻與低頻數據的不同特點,提出高頻特征圖像通過訓練的GAN模型進行特征融合、低頻特征圖像通過基于遷移學習的CNN預訓練模型進行特征融合的方法。該方法可以在融合圖像中更好地保留每個模式圖像獨有的細節特征。本文圖像增強方法與圖像融合方法不僅適用于多模態的醫學圖像,同樣也適用于其他領域的圖像增強與圖像融合應用場景。在未來下一步的研究中,將研究MRI與正電子發射計算機斷層掃描(positron emission tomography,PET)圖像的融合,由于PET圖像并非單通道的灰度圖像,所以在圖像預處理與訓練上會有所調整。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:劉云鵬、李瑾負責整體設計與核心算法分析;王宇、蔡文立、王仁芳負責算法技術指導;干開豐負責醫學知識指導;孫德超、邱虹、劉邦權負責編碼與實驗分析;陳飛、劉文潔、毛顯昊負責數據整理與圖表繪制。
0 引言
為了避免重復多次讀取和觀察相同部位下多種模態醫學影像,一種有效的解決方案是將多模態的醫學影像進行融合,同時最大限度地保留原來每個模態下的圖像特征。針對電子計算機斷層掃描(computed tomography,CT)與磁共振成像(magnetic resonance imaging,MRI)醫學圖像融合的研究,主要包括傳統空域方法、傳統變換域方法和完全深度學習的方法。傳統空域方法[1-6]的核心思想是以圖像原有的像素、像素塊或指定區域為計算單元,通過權重的方法控制不同圖像融合的比例與強度。該方法簡單快速,但是對比度信息、亮度信息和特征細節容易丟失。傳統空域融合方法的缺陷和不足可以使用變換域的方法[7-19]進行彌補,該方法對原始多模態圖像進行頻域或者其他相關類型分解,不同分解域上可以使用相同或不同的方法分別進行融合,比如不同分解域中可以使用相同或不同的深度學習方法,然后通過分解域的逆操作合成最終的融合圖像。
在深度學習應用領域,一方面可以直接使用卷積神經網絡(convolutional neural network,CNN)來獲取醫學圖像的特征用于融合,另一方面也可以使用生成對抗網絡(generative adversarial network,GAN)的思想來直接融合,由于GAN模型[20-27]需要的訓練數據更少,表達能力更為強大,在醫學圖像融合領域受到了極大的關注。CNN和GAN的方法既可以直接用于原始數據圖像,也可以用于分解后的特征圖像。
如前所述,在變換域的融合方法中,不同分解域可以使用不同的方法,例如在其中一個分解域中使用傳統的空域或變換域算法,而在另一個分解域中使用深度學習的方法。但在目前已知的研究范圍內,還沒有在高頻和低頻域中使用兩種不同的深度學習方法將CT和MRI進行融合的論文和技術。本研究使用變分模態分解(variational mode decomposition,VMD)方法進行變換,可以獲取更加豐富和精準的高頻特征圖像與低頻特征圖像,并且創新性地提出基于GAN的生成器與鑒別器不在同一個變換域中的端到端訓練模型,生成器針對高頻特征圖像,而鑒別器針對逆變換后的融合圖像,對于細節和紋理豐富的高頻圖像使用訓練后GAN模型的生成器進行融合,而對于低頻圖像,由于特征相對較少,通過基于遷移學習的CNN預訓練模型進行融合。同時結合圖像銳化、濾波、亮度調節和對比度調節方法,通過一種多參數搜索的方法進行圖像增強,用于訓練圖像和融合后圖像處理兩個方面。
1 研究方法
1.1 系統概述
整個研究過程包括訓練和融合生成兩個基本過程,如圖1和圖2所示。在訓練過程中,首先對輸入的MRI和CT分別進行圖像增強,然后使用VMD方法對MRI和CT進行分解同時生成增強后的邊緣圖像,對于分解產生的低頻圖像使用CNN預訓練模型進行融合。對于分解產生的高頻圖像和邊緣圖像,則作為擴展U-Net網絡模型的輸入,然后對形成的特征圖連接后再輸入到GAN的生成器中進行訓練。這是因為,CT和MRI這樣的醫學圖像大多用于腫瘤等病變的診斷,所以在圖像中往往會有一些需要識別的小目標,這些區域是醫學圖像中最重要和關鍵的部分,而U-Net結構的網絡模型對于最大程度地獲取微小目標組織和結構的紋理特征與邊緣輪廓信息有著很好的效果。
圖1
訓練基本過程
Figure1.
Basic training process
圖2
融合基本過程
Figure2.
Basic process of fusion
接著對GAN生成的高頻圖像和融合的低頻圖像進行VMD逆變換合并,生成訓練后的融合生成圖像,再將融合生成圖像分別與原始CT和MRI分別輸入到GAN CT鑒別器和GAN MRI鑒別器,與GAN生成器形成對抗訓練。這里的特別之處在于生成器只針對高頻圖像,而鑒別器是針對逆變換合并后的融合圖像。由于雙鑒別器的使用,此處無需人工構建融合標簽圖像。在融合生成過程中,對于輸入圖像同樣需要進行增強處理,與訓練相比,無需邊緣圖像的生成,對于分解產生的高頻圖像直接使用訓練好的GAN模型生成器進行融合,再與低頻融合圖像進行逆變換。為了進一步突出融合后的紋理細節特征,在逆變換后的融合圖像中再進行一次增強處理。
1.2 圖像融合
CT與MRI圖像融合包括VMD分解后的高頻特征圖像融合與低頻特征圖像融合兩個部分,由于低頻特征圖像以平坦區域和變化緩慢紋理為主,所以通過基于遷移學習的CNN預訓練模型可以得到很好的特征融合。對于高頻特征圖像,從本文系統概述的圖1中可以看出,在分解后的高頻域通過擴展U-Net獲取特征并進行連接后,再通過訓練GAN的生成器來對特征進行融合,而在逆變換后的高頻與低頻合成圖像中使用GAN的兩個鑒別器與高頻域的生成器進行對抗。
1.2.1 高頻圖像融合
(1)擴展U-Net:如前所述,高頻圖像在進入GAN生成器訓練之前需要使用擴展U-Net進行特征提取與合并,圖1中所描述的擴展U-Net如圖3所示。與傳統U-Net不同的是,擴展U-Net的Dense連接與Skip連接在編碼端的卷積層、上層與下層的連接以及編碼與解碼的同層之間都有存在,這種交叉融合的Dense和Skip連接可以在訓練中獲得和傳遞更豐富的語義與特征信息,使得整體梯度流得以有效增強,同時全局最優解更加容易被找到。
圖3
擴展U-Net結構圖
Figure3.
Extended U-Net network diagram
解碼層采用Isola等[28]提出的上采樣方法。為了避免上采樣過程中過多紋理細節的損失,使用子像素卷積模式[29],該方法可以將多個低分辨率特征圖像通過打亂像素次序(pixel shuffle)的方式來生成更高分辨率的圖像。在圖3的擴展U-Net結構中可以看到每一層的連接中都包含一個注意門(attention gate,AG),這里使用了一種醫學影像模式下的AG[30],該AG不僅可以關注形態差異較大的組織結構,還可以對卷積中特征容易弱化和消失的小目標進行有效的性能提升。
(2)生成器結構:生成器的基本結構如圖4所示,輸入通道為擴展U-Net輸出的MRI與CT高頻特征圖,都是單通道的灰度圖像。此處設計的生成器將DenseNet與EfficientNet的優勢進行結合,多路徑短連接、多目標神經架構搜索和因子分層化搜索空間技術的使用,將網絡容量與特征提取能力進行了很好的平衡,在圖像分辨率不是很高而且網絡寬度與深度都不是很大的情況下可以進一步減輕梯度消失問題,同時加強了特征的利用與有效傳遞。
圖4
生成器結構
Figure4.
Generator structure
(3)鑒別器結構:鑒別器在訓練中是與生成器進行對抗。本文中兩個鑒別器DMRI和DCT分別將生成融合圖像與真實的MRI和CT進行區分,由于CT與MRI圖像紋理明顯不同,訓練中必須考慮兩種不同的數據分布在與生成器G對抗中的沖突,所以不僅要考慮對抗訓練還要顧及DMRI和DCT的平衡處理,在本文損失函數部分進行了平衡處理的損失設計方法描述。鑒別器DMRI和DCT的網絡結構相同,與生成器相比結構相對簡單,其基本結構如圖5所示,由于EfficientNet強大的特征提取與分類能力,依然使用了其核心網絡結構。
圖5
鑒別器結構
Figure5.
Discriminator structure
1.2.2 低頻圖像融合
具體描述如下:生成VMD分解的CT低頻特征圖像與MRI低頻特征圖像,將圖像都轉為單通道的灰度圖像,再對低頻灰度圖像進行0-1歸一化,通過像素值直接除以255實現。載入ImageNet數據集上的預訓練CNN模型EfficientNet及權重參數,去除預訓練模型的全連接層與分類層,保留用于特征提取的卷積層。CNN模型分別讀入歸一化的CT與MRI低頻圖像,并生成相應的特征圖。從CNN的淺層到深層,分別處理CT與MRI的每一個特征圖,對特征圖的每一行元素求和生成一個行特征值,從而生成一個新的特征圖,CT與MRI則分別對應一組新的特征圖組合。使用最近鄰插值方法將新的特征圖組合采樣到圖像大小,通過softmax函數根據特征圖計算CT與MRI像素的概率權重值,根據權重對CT與MRI空間上對應的像素值進行加權求和,得到融合后數據。將融合后數據轉為0-255的灰度像素空間,像素值直接乘以255取整實現。
2 實驗與分析
2.1 實驗環境與數據
GAN對抗訓練主要使用的硬件環境為NVIDIA Tesla P100顯卡,顯存16 GB。軟件環境包括Ubuntu16.04的操作系統和tensorflow1.12.0 + keras 2.2.5的深度學習平臺,加速對應庫為cudnn7.1.4,使用python3.6.12版本進行所有實驗與開發。實驗使用的CT與MRI數據來自美國哈佛醫學院的全腦圖譜數據庫(Whole Brain Atlas),每組CT與MRI前期都已經成功配準,本文研究中不涉及配準工作。
2.2 定量分析與討論
2.2.1 與當前先進方法整體對比
將本文方法與當前在空域融合、變換域融合和基于GAN融合的6種先進方法進行比較,所有方法都是在本文所提圖像增強方法的基礎上進行實驗。空域融合方法包括GM[5]和GC[6],變換域融合方法包括PS[18]和HID[17],基于GAN融合方法包括FusionGAN [25]和DDcGAN [27]。為了對所提方法的圖像融合性能進行評價,本研究使用融合質量評價指標(QAB/F)、信息熵(information entropy,IE)、空間頻率(spatial frequency,SF)、結構相似性(structural similarity,SSIM)、互信息(mutual information,MI)和融合視覺信息保真度(visual information fidelity for fusion,VIFF)等圖像融合領域的客觀評價指標對整個測試集數據進行定量分析,結果如表1所示。在使用的6個評價指標中,本文所提方法在所有實驗方法中的結果都是最優的。對于測試集所有數據的平均值,本文方法的QAB/F、IE、SF、SSIM、MI和VIFF比最差結果分別高出35.8%、27.8%、25.5%、22.8%、37.8%和32.5%,比次優結果分別高出2.0%、6.3%、7.0%、5.5%、9.0%和3.3%。可以看出,本文方法性能的提高是非常顯著的。
進一步分析表1,QAB/F為融合質量評價指標,利用局部度量輸入圖像顯著信息在融合圖像中的表現程度,重點度量邊緣信息的轉移情況,即圖像融合后原始圖像邊緣信息是否被保存。可以看出,GC與HID取得了不錯的效果,但是基本已經達到了傳統空域與變換域融合的極限,對邊緣融合效果較差。IE為信息熵,基于信息學理論測量一張融合圖像中信息量的大小,通常情況下該值越大,說明融合圖像中包含有價值的信息越多,融合表現就越好。可以看出,傳統變換域方法要好于傳統空域方法。SF為空間頻率,基于梯度的評價指標,反映圖像灰度變化率,度量圖像細節與紋理的清晰度,一般來說,SF越高則圖像越清晰。分析得知,GC為代表的傳統空域融合方法可以較好地保留梯度信息。SSIM為結構相似性,用于比較原始圖像和融合圖像之間的相似度,從圖像組成的角度將結構信息定義為獨立于亮度和對比度的屬性,反映場景中物體結構的特征,其值越接近1,表示融合效果越好。分析得知,空域變換由于是針對像素級別操作,容易造成對結構信息的破壞,所以效果最差。MI為互信息,度量原始圖像傳入到融合圖像中的信息量,表達兩張圖像的關聯程度,其值越大意味著來自原始圖像的信息越多。可以看到,傳統空域方法與傳統變換域方法差異并不明顯。VIFF為融合視覺信息保真度,采用人眼視覺系統的特性作為指標,是基于多種圖像特征的綜合評估,包括顏色、亮度、對比度等,可以更準確地評估融合結果的視覺質量。分析得知,傳統變換域方法要略好于傳統空域方法,但提升并不突出。再從整體統計結果分析來看,盡管FusionGAN使用了深度學習,但是性能提升并不突出,因為并沒有把變換域和深度學習的優勢進行結合。
2.2.2 消融實驗
本文的核心技術與創新在于在所提圖像增強方法的基礎上,使用變換效果更佳的VMD分解,同時在高頻和低頻域中使用兩種不同的深度學習方法進行融合。為了觀察核心技術點的貢獻,設計如下實驗:方案1:只是不使用圖像增強,使用原圖進行融合;方案2:只是不使用VMD分解,使用非下采樣剪切波變換(nonsubsampled shearlet transform,NSST)分解;方案3:只是低頻域不使用遷移學習方法,使用加權融合;方案4:只是高頻域不使用本文所設計的基于GAN的生成器與鑒別器不在同一個變換域中的端到端訓練模型,使用鑒別器直接與生成的高頻圖像進行對抗的GAN。測試集所有圖像的平均分析結果如表2所示。
從表2測試集整體結果來看,對于分析方案1中的圖像增強技術因素,使用圖像增強技術后,QAB/F、IE、SF、SSIM、MI和VIFF分別增加6.1%、7.1%、58.9%、6.7%、36.5%和50.4%,可以看出QAB/F、IE和SSIM的提升并不明顯,多在6%~7%,而SF、MI和VIFF的性能增加顯著,SF高達58.9%。對于方案2中的VMD分解技術因素,QAB/F、IE、SF、SSIM、MI和VIFF分別增加18.3%、9.0%、8.3%、14.3%、8.5%和54.6%,其中VIFF最為顯著,高達54.6%。對于方案3中的低頻融合技術因素,QAB/F、IE、SF、SSIM、MI和VIFF分別增加1.6%、0.1%、1.8%、1.0%、2.0%和4.2%,性能的提升相對較弱,個別圖像中部分性能指標值在使用低頻融合技術后還會有微弱的下降,但整體平均性能還是有了少量提高。對于方案4中的高頻融合技術因素,QAB/F、IE、SF、SSIM、MI和VIFF分別增加17.0%、7.2%、10.3%、19.6%、12.2%和49.0%,可以看出每個指標都有相當不錯的性能提升。
根據上述分析,將四個方案中的技術因素重要性進行對比,可以看出對于QAB/F,VMD分解和高頻系數融合更為重要,對質量有較大提升。對于IE,低頻系數融合幾乎沒有任何提升,VMD分解提升最多。對于SF,圖像增強的貢獻是非常顯著的。對于SSIM,高頻系數融合對性能提升最為明顯,VMD分解也帶來較大提高。對于MI,圖像增強提升效果幅度最高。對于VIFF,除了低頻系數融合數帶來了少量提升外,圖像增強、VMD分解和高頻系數融合都有很大程度的性能提升貢獻。總體來看,圖像增強可以較大幅度地提升圖像融合效果的大部分性能指標;VMD分解對所有性能指標都有不同程度的提升,個別指標提升幅度較為明顯;低頻系數融合盡管對所有指標都有提升,但是程度較低甚至不明顯;高頻系數融合對所有指標都有較大幅度的提升。
2.3 典型圖片展示
為了進一步說明本文方法優于其他算法,選擇典型圖片進行展示分析。整體融合效果如圖6所示,圖6中所標注的局部細節區域在圖7中進行放大展示,同時在圖7中用橢圓標注進一步突出本文算法效果的細節優勢。CT主要表現骨骼邊緣和組織結構的低頻數據,MRI則突出紋理細節和高頻特征數據,MRI表現的細節與紋理結構會更加豐富,也是圖像融合的關鍵。首先從圖6中的整體比較中可以看出,本文所提算法生成的圖像是CT骨骼特征和MRI紋理細節特征融合效果最好的,明顯優于其他6種方法。進一步分析來看,GM和HID是融合效果最差的兩個,紋理細節較為模糊,不能很好地獲取MRI的高頻特征數據,但是與GM相比,HID在骨骼邊緣獲取方面卻效果很好,與CT原有的骨骼特征以及本文方法獲取的結果基本一致。GC、PS、FusionGAN和DDcGAN的融合效果整體上看較為相似,但是通過圖7中細節放大觀察,與原始的MRI紋理對比,就會發現FusionGAN的效果最好,其次是DDcGAN、PS和GC,可以看出GC在紋理融合中效果最差,并不能很好地獲取MRI的高頻細節特征。再將FusionGAN與本文方法結果進行對比,從圖7的放大細節中可以看出,不管是CT中的骨骼邊緣特征,還是MRI中的輪廓與結構上的清晰度,以及紋理內部的對比度和微小的梯度變化,本文方法的融合效果都較為明顯地優于FusionGAN。同時從圖7的兩處橢圓標記中可以看出,本文算法融合的紋理高頻細節特征結果與MRI更為一致,進一步證實了本文算法的優越性。
圖6
典型圖像整體融合效果展示
Figure6.
Display of overall fusion results of typical image
圖7
典型圖像局部融合細節展示
Figure7.
Display of local fusion details of typical image
3 結論
本文針對CT與MRI的圖像融合進行研究,針對現有融合方法中重要特征丟失、細節表現不突出和紋理不清晰等問題,提出一種圖像增強下使用GAN和CNN進行CT與MRI融合的方法。結合圖像銳化、濾波、亮度調節和對比度調節方法,通過一種多參數搜索的方法進行圖像增強。本文創新性提出基于GAN的生成器與鑒別器不在同一個變換域中的端到端訓練模型,生成器針對高頻特征圖像,而鑒別器針對逆變換后的融合圖像。同時基于變換域中高頻與低頻數據的不同特點,提出高頻特征圖像通過訓練的GAN模型進行特征融合、低頻特征圖像通過基于遷移學習的CNN預訓練模型進行特征融合的方法。該方法可以在融合圖像中更好地保留每個模式圖像獨有的細節特征。本文圖像增強方法與圖像融合方法不僅適用于多模態的醫學圖像,同樣也適用于其他領域的圖像增強與圖像融合應用場景。在未來下一步的研究中,將研究MRI與正電子發射計算機斷層掃描(positron emission tomography,PET)圖像的融合,由于PET圖像并非單通道的灰度圖像,所以在圖像預處理與訓練上會有所調整。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:劉云鵬、李瑾負責整體設計與核心算法分析;王宇、蔡文立、王仁芳負責算法技術指導;干開豐負責醫學知識指導;孫德超、邱虹、劉邦權負責編碼與實驗分析;陳飛、劉文潔、毛顯昊負責數據整理與圖表繪制。