睡眠分期是解決睡眠問題的基礎。針對現階段單通道腦電(EEG)數據和特征決定自動睡眠分期模型分類精度的上限問題,本文提出一種將深度卷積神經網絡(DCNN)和雙向長短期記憶神經網絡(BiLSTM)混合的自動睡眠分期模型。模型使用DCNN自動學習EEG信號的時頻域特征,使用BiLSTM提取數據之間的時序特征,充分挖掘數據包含的特征信息,以提高自動睡眠分期的準確率。同時,使用降噪技術與自適應合成采樣技術減少信號噪聲和不平衡數據集對模型性能的影響。本文采用歐洲數據格式存儲的睡眠數據集拓展版和上海精神衛生中心收集的睡眠數據集進行實驗,分別取得了86.9%和88.9%的整體準確率。與基礎網絡模型進行對比分析,實驗結果均優于基礎網絡,進一步證明了本文模型的有效性,可為構建基于單通道EEG信號的家庭睡眠監測系統提供借鑒。
引用本文: 章浩偉, 許哲, 苑成梅, 季曹珺, 劉穎. 基于單通道腦電信號的自動睡眠分期模型研究. 生物醫學工程學雜志, 2023, 40(3): 458-464. doi: 10.7507/1001-5515.202210072 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
睡眠在人類的健康中起著至關重要的作用。良好的睡眠質量、充足的睡眠時間和完整的睡眠結構有利于調節機體免疫功能,維持各系統功能處于穩定狀態[1]。臨床上使用多導睡眠圖(polysomnography,PSG)收集患者整晚腦電(electroencephalogram,EEG)、眼電(electrooculogram,EOG)、肌電(electromyogram,EMG)等生理信號[2],根據美國睡眠醫學學會(American Academy of Sleep Medicine,AASM)提供的睡眠評分標準[3],由專家依次將每30 s的信號標記為清醒期(wake,W)、快速眼動期(rapid eye moment,REM)和非快速眼動期(non-rapid eye moment,NREM),并將NREM細分為N1、N2和N3階段。每晚PSG記錄時長平均約為8 h,采用人工分期常出現分期效率低、錯誤率高等情況,阻礙了其在較大數據集上的應用,進而限制了該領域的相關研究。因此,怎樣利用計算機技術使睡眠分期更加精確、高效,是一個重要的研究內容。
隨著深度學習技術的不斷發展,卷積神經網絡(convolutional neural network,CNN)[4-7]、循環神經網絡(recurrent neural network,RNN)[8-9]相繼被用于構建自動睡眠分期模型。傳統RNN容易產生梯度消失等問題,無法學習長期依賴關系,且訓練效率低下,所以研究者們大多使用RNN變體網絡,如長短期記憶網絡(long short-term memory network,LSTM)和雙向長短期記憶網絡(bi-directional long short-term memory network,BiLSTM)等開展相關研究[10-11]。但這些網絡模型結構單一,無法同時考慮數據內的時頻域特征和時序特征,存在關鍵特征丟失、準確率不高等問題。因此,為了充分利用CNN在特征選擇、提取方面的良好性能以及RNN在處理具有時序信息數據時的獨特優勢,有研究者提出了將兩者相結合的深度學習模型,以提高自動睡眠分期模型性能,這也是最近研究的熱點[12-14]。Casciola等[15]構建了包含三個CNN層和兩個 LSTM 層的深度學習模型,對低質量雙通道EEG數據的驗證準確率為(74±10)%,在黃金標準PSG上實現了(77±10)%的驗證準確率。但該模型卷積層(convolutional layer,Conv)設計較為簡單,不能有效提取EEG數據的時頻域特征,且專家在手動分期過程中,不僅要考慮這一幀的數據信息,還要考慮前后幀對其的影響[9],因此僅使用LSTM不能有效地利用數據的前后時間序列信息。
在上述研究的基礎上,本文提出一種基于單通道EEG信號混合神經網絡模型。通過構建三條并行的CNN,依次設置不同大小的卷積核(convolutional kernel,Kernel)充分提取EEG數據的時頻域特征,結合空洞CNN更全面地捕捉特征信息,加快時域和頻域特征融合速度,接著使用三層BiLSTM提取前后時序特征,最后將上述混合特征輸入分類判別網絡實現更高準確率的自動分期。同時,提前對數據進行降噪和增強處理,以降低噪聲和樣本失衡對模型帶來的影響。最終,通過在兩個數據集上與基線模型進行的對比實驗,以驗證本文模型的有效性。綜上所述,期望本文模型能充分挖掘捕捉用于睡眠分期的EEG數據特征,能夠最大程度地貼合專家手動分期結果,實現有效地提高自動分期效率與準確率,今后能對人工智能與睡眠醫學領域的有效結合奠定基礎。
1 混合神經網絡模型
本文模型研究的整體思路為:首先對EEG信號進行數據降噪、增強處理,建立用于實驗的數據集,然后使用深度CNN(deep CNN,DCNN)和時序信息學習網絡提取信號的時頻域特征和時間序列特征,最后通過分類判別網絡實現自動睡眠分期。
1.1 數據預處理
1.1.1 數據降噪處理
為了降低噪聲對EEG信號的干擾,數據降噪是進行特征提取前十分重要的一步[16]。小波包降噪算法比小波變換更為細化,通過自適應選擇頻帶,將信號高頻分量和低頻分量都進行分解,經小波分解后,有用信號的小波分解系數較大,噪聲的小波分解系數較小。通過設置合適的閾值函數,大于閾值的分解系數保留下來,而小于閾值的分解系數則通過置零操作予以消除,由此達到降低噪聲的影響,從而提高信號的時頻分辨率[17]。小波包降噪算法包括4個步驟,描述如下:
(1)確定小波基函數 (t),根據輸入信號x(t)的類型選擇合適的
(t),根據輸入信號x(t)的類型選擇合適的 (t);
(t);
(2)確定要分解的層數N;
(3)確定分解閾值,對x(t)進行基于 (t)小波包N層分解;
(t)小波包N層分解;
(4)信號重構,對低頻系數和經過處理后的高頻系數進行小波包重構,實現降噪。
本文使用多貝西(Daubechies,Db)小波函數族的Db10小波基函數進行3層分解的降噪方案,提高降噪精度。睡眠分期使用的EEG信號的能量主要集中在0~35 Hz,因此本文使用數字濾波器對數據進行濾波處理,將信號頻率降到35 Hz以下。
1.1.2 數據增強處理
為了解決數據集中存在的樣本類失衡問題,本文采用自適應合成采樣(adaptive synthetic sampling,ADASYN)技術對樣本較少的數據進行增強處理[18-19]。ADASYN最大的優點在于會根據整個數據集的樣本分布自動決定少數樣本的合成樣本數量及分布。該算法生成少量樣本公式如式(1)所示:
 '/> '/> |
其中,di表示第i個少數類樣本;rand(0,1)表示0~1之間的隨機數;dki表示從di的k個最近鄰樣本中隨機選擇的一個樣本, 表示生成的合成樣本。
表示生成的合成樣本。
1.2 深度卷積神經網絡
1.2.1 特征提取模塊
基于深度學習技術的CNN模型,一般會在網絡的第一部分構建多個具有不同大小尺寸Kernel的Conv作為特征提取模塊,如式(2)~式(4)所示。通過不同大小Kernel的結合使用,可以讓Conv更加全面地捕捉EEG信號的時頻域信息,高效利用數據的局部和全局特征[20]。
 |
 |
 |
其中, 代表使用的不同大小的Kernel尺寸;
代表使用的不同大小的Kernel尺寸; 代表樣本中第
代表樣本中第 幀的單通道EEG信號片段;CNNx(?)代表卷積操作;
幀的單通道EEG信號片段;CNNx(?)代表卷積操作; 和
和 分別代表通過Conv之后對
分別代表通過Conv之后對 提取出的時域特征和頻域特征;
提取出的時域特征和頻域特征; 代表時域特征和頻域特征的拼接。
代表時域特征和頻域特征的拼接。
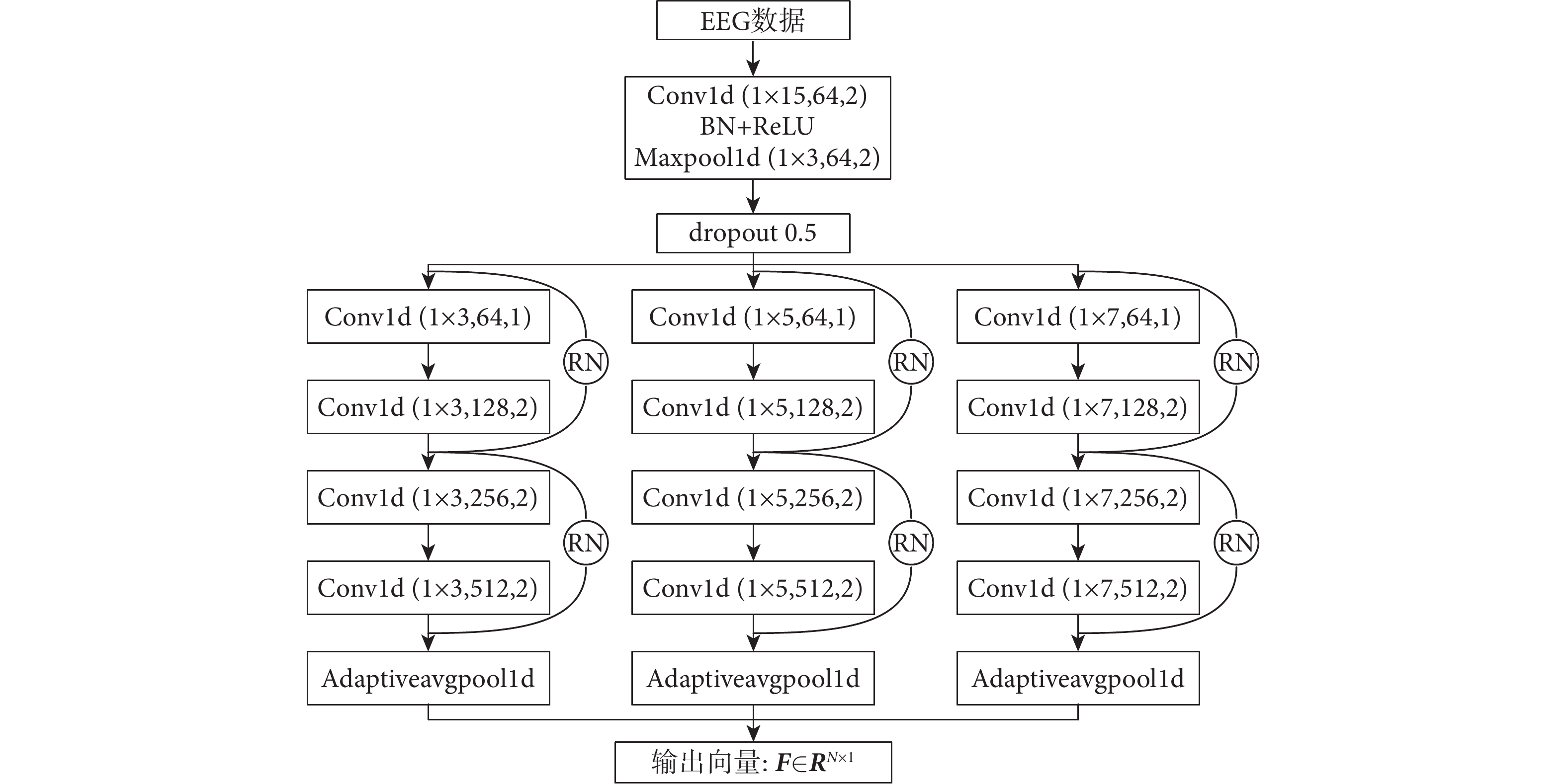
本文構建的特征提取模塊結構如圖1所示。應用三個并行的CNN,Kernel大小依次設置為3、5、7。三個并行CNN中的每一個分支由四個 Conv和一個一維自適應平均池化層(one dimensional adaptiveavgpool,Adaptiveavgpool1d)組成。每個Conv顯示了Kernel大小、通道尺寸以及步長。每個Conv都包含一維卷積運算(one dimensional convolution operation,Conv1d)、批量歸一化(batch normalization,BN)、線性整流函數(rectified linear unit,ReLU)和一維最大池化(one dimensional maxpool,Maxpool1d)。將預處理過的EEG數據送入模塊進行特征選擇與提取,最后拼接并行網絡提取的時域和頻域特征,得到輸出向量F∈RN×1,其中N表示特征向量長度。
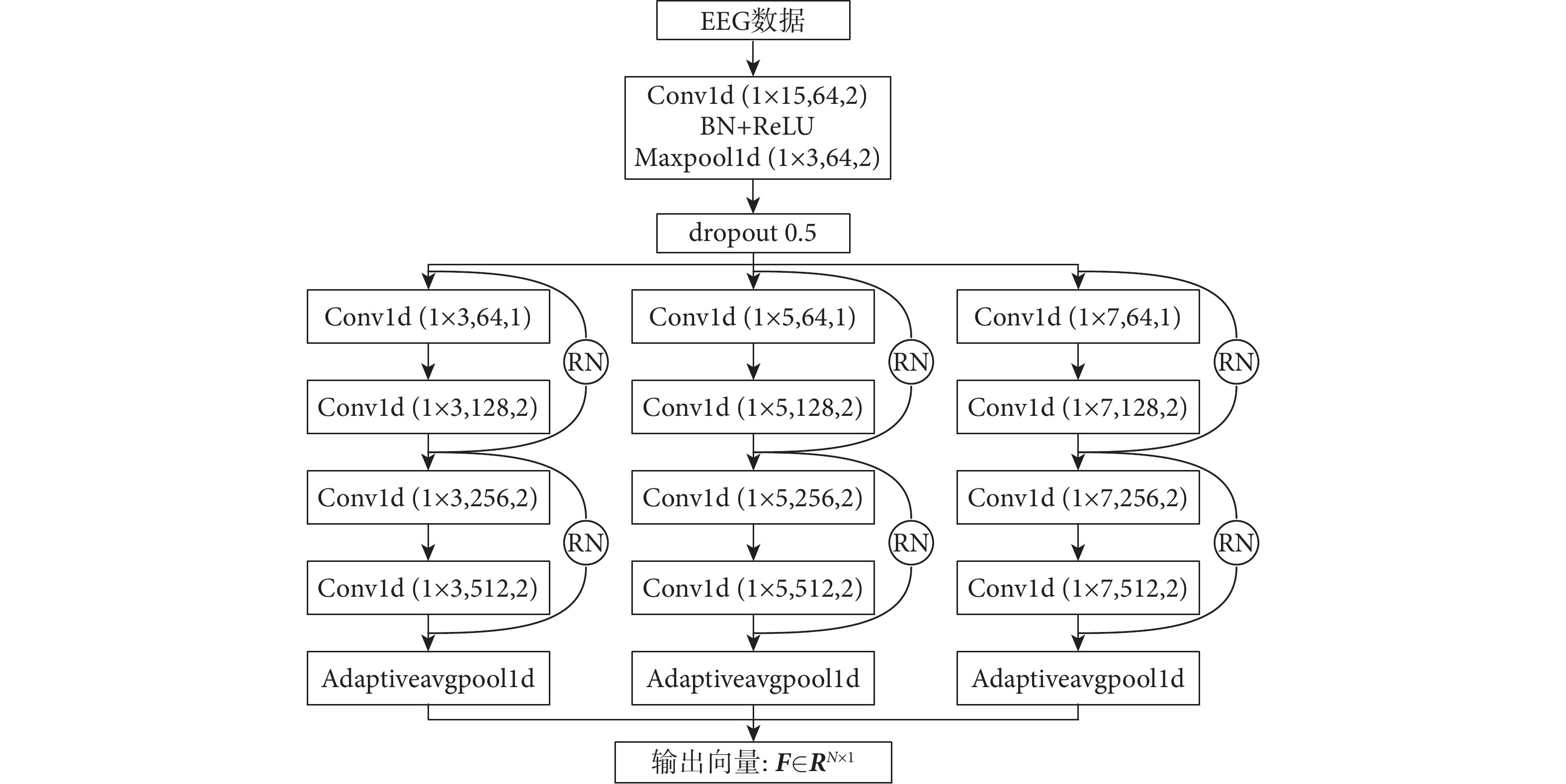 圖1
特征提取模塊
Figure1.
Feature extraction module
圖1
特征提取模塊
Figure1.
Feature extraction module
為緩解因更有效地捕捉特征而增加網絡深度引起的梯度消失問題,在每兩個Conv之間引入了殘差網絡(residual network,RN)。同時使用以下兩種技術防止模型過擬合:①是引入隨機失活(dropout)技術,以一定的概率隨機地刪除網絡中的神經元,有助于提高模型的泛化能力;②是L2正則化技術,通過降低損失函數中的權重數值大小來降低模型復雜度,防止模型中可能出現的梯度不穩定、網格退化等問題。
1.2.2 特征融合模塊
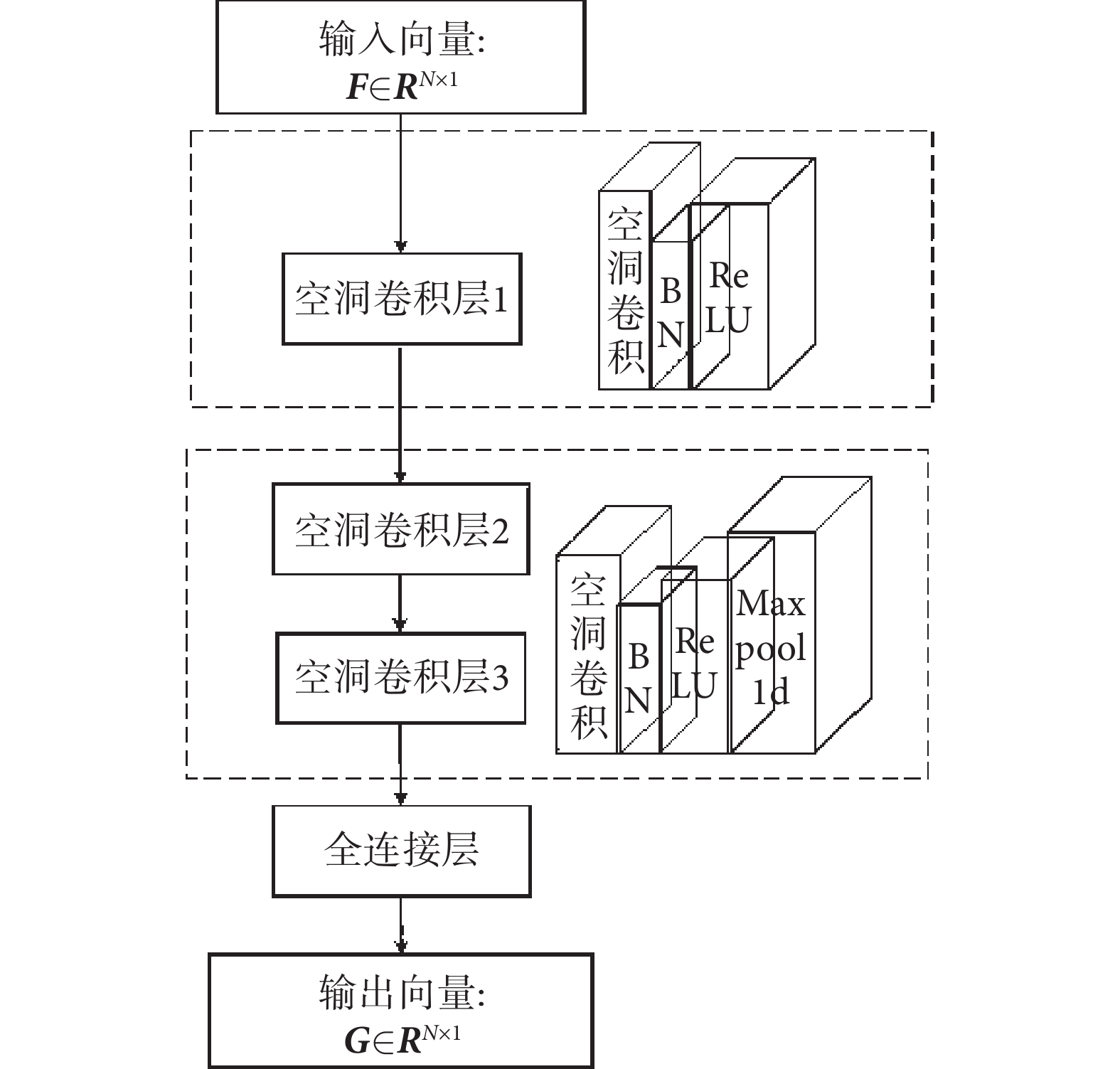
空洞CNN是一種特殊的DCNN,通過使用擴張系數,可以在不引入其他參數的前提下擴大網絡的感受野[21],在加快時域和頻域特征融合速度的同時,也使得每一層的卷積輸出都包含更加詳細的特征信息。本文設計的由三層空洞卷積層組成的特征融合網絡模塊如圖2所示。擴張系數依次設置為1、2、4,每層都包含空洞卷積、BN和ReLU,且第二層和第三層網絡增加Maxpool1d,以盡可能地減少參數并保留主要特征,提高模型泛化能力。F∈RN×1表示輸入特征融合模塊的特征向量,G∈RN×1表示經過模塊融合后輸出的特征向量。
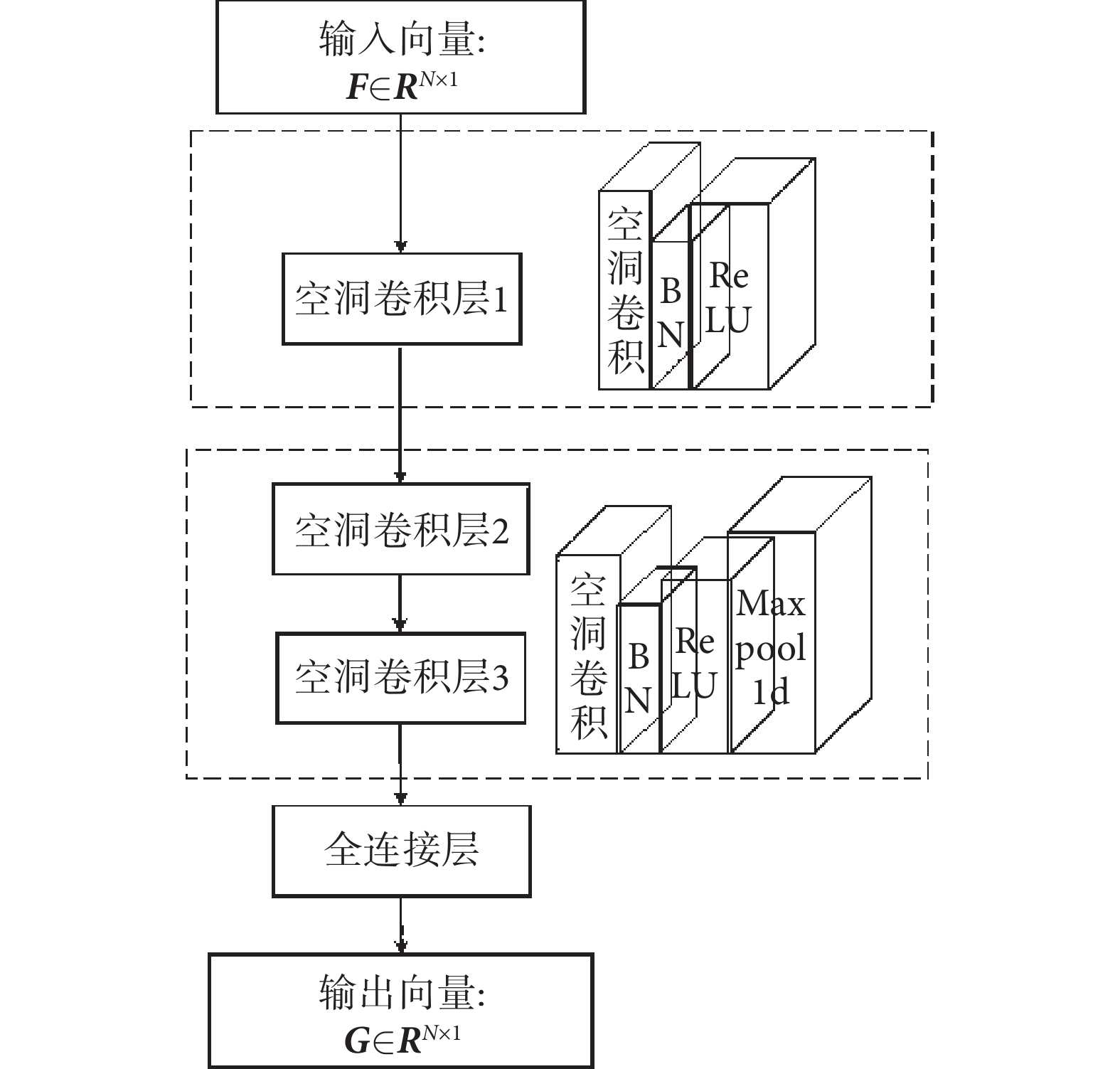 圖2
特征融合模塊
Figure2.
Feature fusion module
圖2
特征融合模塊
Figure2.
Feature fusion module
1.3 時序信息學習網絡
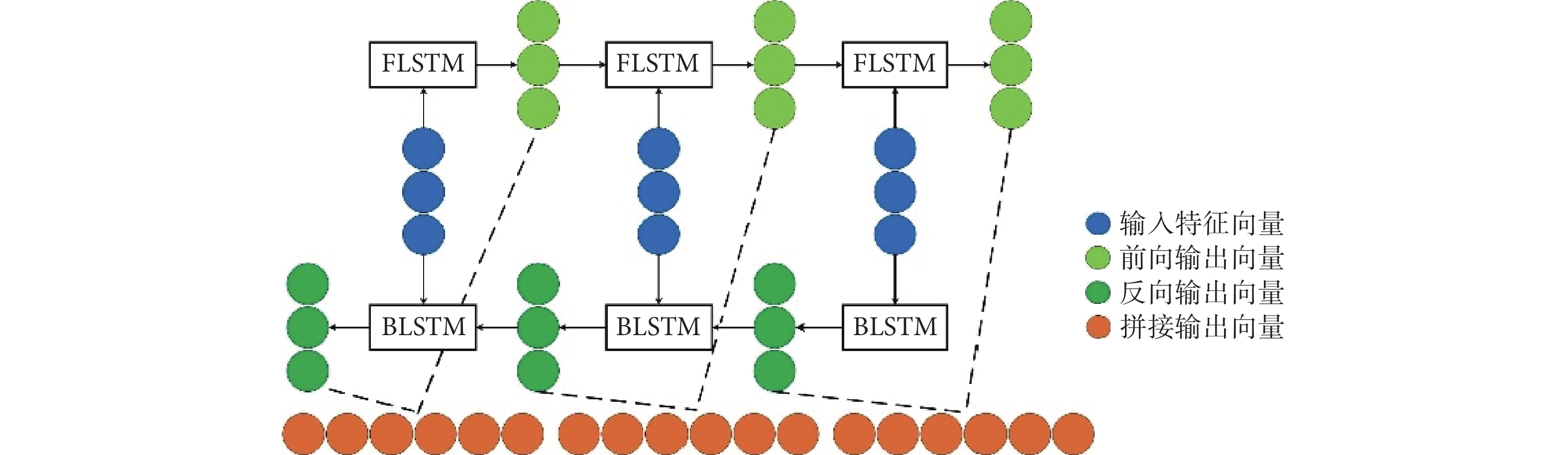
為了充分利用EEG信號之間的時間序列相關性,本文在DCNN后加入了由三層BiLSTM組成的時序信息學習網絡。如圖3所示,每層BiLSTM由前向的LSTM(forward LSTM,FLSTM)和反向的LSTM(back LSTM,BLSTM)組成,以幫助模型進行上下文信息的學習訓練。在同一時刻,FLSTM依次輸入特征向量G∈RN×1得到前向輸出向量HF∈RN×1,BLSTM 依次反向輸入特征向量G∈RN×1得到反向輸出向量HB∈RN×1,最后將前向與反向的向量進行拼接得到向量H∈RN×1。
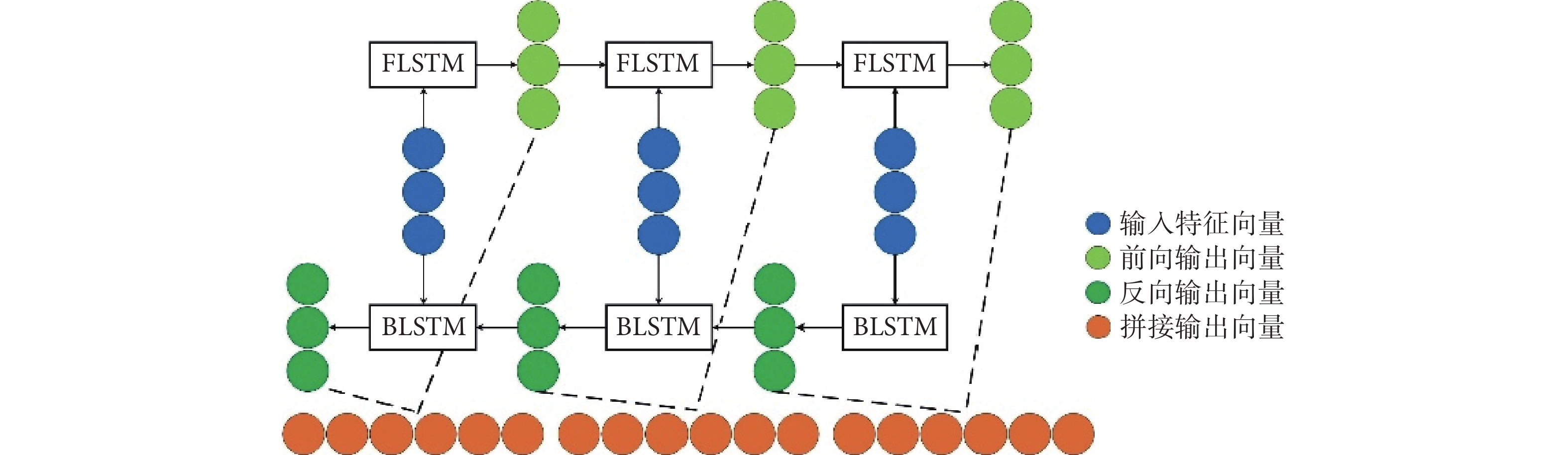 圖3
時序信息學習網絡
Figure3.
Timing information learning network
圖3
時序信息學習網絡
Figure3.
Timing information learning network
1.4 分類判別網絡
分類判別網絡是整個模型的最后一部分,主要由歸一化指數函數(Softmax)層組成。通過輸入包含EEG信號時頻域特征及時序信息的混合特征向量H∈RN×1,由Softmax函數將多分類結果以概率的形式展現出來,得到預測分期結果。Softmax函數表達式如式(5)所示:
 |
其中,zi為第i個節點的輸出值;C為輸出節點的個數,即樣本的分類標簽;e為指數函數;Softmax(?)為對輸入數據進行Softmax操作。
2 實驗與結果對比
2.1 實驗數據
本文使用兩個數據集來評估構建的模型,分別是歐洲數據格式存儲的睡眠數據集拓展版(Sleep-European Data Format Database Expanded,Sleep-EDFx)(網址為:www.physionet.org)[22]和上海精神衛生中心收集創建的公開睡眠數據集(Shanghai Mental Health Center Sleep Database,SMHCSD),本研究已獲準授權可以使用其數據。
Sleep-EDFx:該數據集包含197個整晚PSG記錄。153個健康人的睡眠磁帶數據(sleep cassette,SC)文件是對沒有服用過任何與睡眠相關藥物的健康人睡眠監測獲得的記錄,44個輕度入睡障礙患者的睡眠遙感數據(sleep telemetry,ST)文件是對服用過替馬西泮的睡眠障礙患者監測獲得的記錄。每個PSG記錄都包含2個通道EEG信號(Fpz-Cz、Pz-Cz)、EOG信號和EMG信號。EEG信號的采樣頻率為100 Hz。
SMHCSD:該數據集由上海精神衛生中心收集的2017—2021年148個整晚PSG記錄。每個PSG記錄都包含6個通道的EEG信號(F4-M1、F3-M2、C4-M1、C3-M2、O2-M1、O1-M2)、兩個EOG信號(EOG-L、EOG-R)、EMG信號、心電圖、左右腿電信號。EEG信號的采樣頻率為200 Hz。
以上數據集都包含由醫師手動劃分的睡眠分期結果標簽文件,本文將Sleep-EDFx中的N3期和N4期合并為N3期,并剔除了兩個數據集中與睡眠分期無關的數據及標簽。這兩個數據集每個睡眠階段的樣本數如表1所示。由數量可以看出,數據集中存在樣本類失衡問題,故采用1.1.2小節中的數據增強處理方法對少數類樣本進行數據增強,以構建類平衡數據集。
2.2 訓練設計
為了得到最優的訓練參數,使用網格搜索法探究學習率、批大小和迭代次數的最優參數值。結果表明上述參數分別設置為0.001、64、120時,模型表現最好。
本文使用兩個數據集中EEG信號的Fpz-Cz通道和C3-M2通道分別訓練和測試所構建的模型。在模型訓練時,使用自適應矩估計優化器(adaptive moment estimationadam, Adam)對網絡權重值進行更新優化,加快模型收斂速度。為了使模型得到的睡眠分期結果與實際分期結果盡可能相近,使用與分類判別網絡中的Softmax層相對應的多類交叉熵作為損失函數實現五分類任務。實驗使用十折交叉驗證的方法來測試該模型的準確性,將數據集分成10份,模型隨機選擇其中的9份作為訓練數據,1份作為測試數據,共進行十次實驗。
2.3 評價指標
本文實驗的評價指標包括準確度(accuracy,Acc)、科恩卡帕系數(Cohen's Kappa,Kappa)、精度(precision,PR)、召回率(recall,RE)、微觀F1得分(micro-F1,F1)以及宏觀F1得分(macro-F1,MF1)。
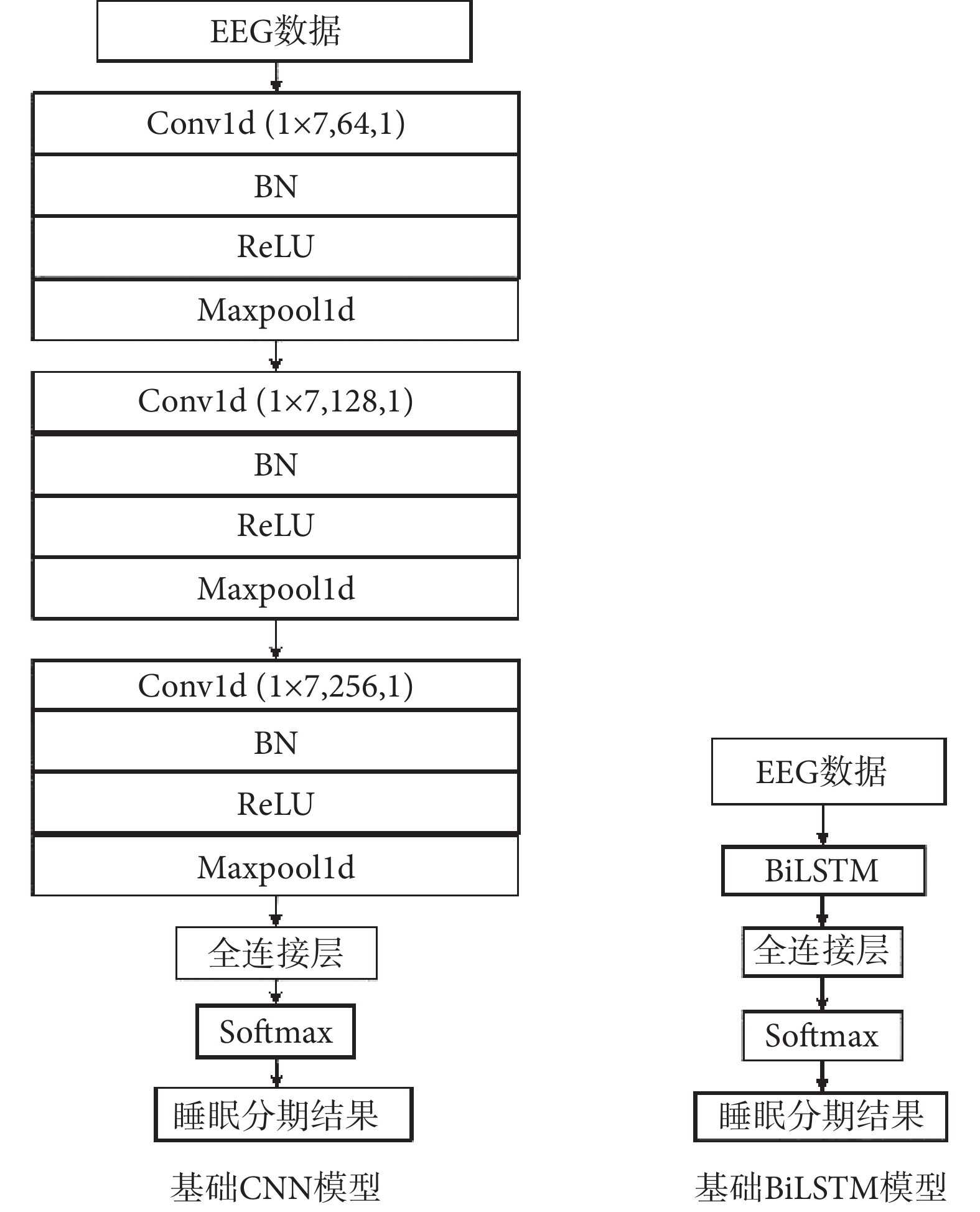
2.4 基礎網絡模型
本文構建了兩個單一基礎網絡模型用作對比實驗,分別是CNN和BiLSTM。結構如圖4所示。CNN主要由三個Conv組成,BiLSTM是將Conv替換為BiLSTM層,其他結構與CNN相同。
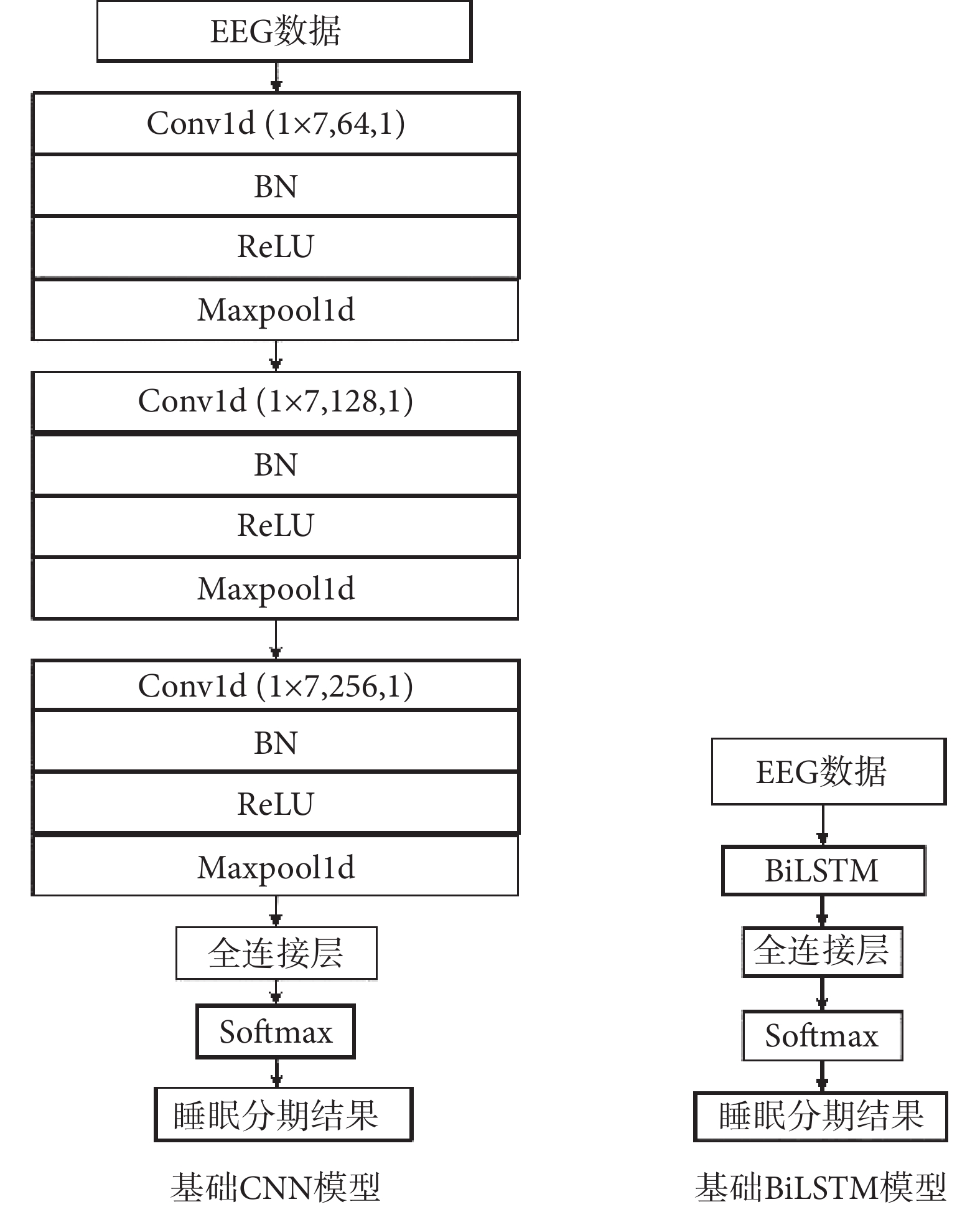 圖4
基礎網絡模型
Figure4.
Basic network model
圖4
基礎網絡模型
Figure4.
Basic network model
2.5 實驗結果與分析
本文模型使用Sleep-EDFx中的Fpz-Cz通道和SMHCSD中的C3-M2通道經過十折交叉驗證后的混淆矩陣,如表2和表3所示,總體性能如表4所示。混淆矩陣中的每行代表的是睡眠專家標注的分類結果,每列代表的是本模型自動分類結果,主對角線表示模型正確分類的樣本個數。表格的最后三列分別顯示了模型對于每個類別的預測性能。
從表2和表3可以看出,模型在兩個數據集上都達到了較好的睡眠分期結果。表現較差的N1階段的PR也分別達到了59.9%和58.6%,總體Acc達到了86.9%和88.9%。在混淆矩陣中,主對角線兩側的數據幾乎是對稱的,且SMHCSD中的N3階段同樣達到了較好的PR,這表明一些錯誤分期不是因為數據不均衡造成的[23],證明本文使用的ADASYN技術能在一定程度上解決數據類失衡問題。在較難分期的N1階段,PR雖達到了60%左右,但仍遠低于其他類的分期水平,可能原因是N1期與其它睡眠階段的EEG特征相似性較大,結合其他生理信號可能會實現更好的判別。
為了進一步評估所提模型的性能,將混合神經網絡與基礎網絡進行對比實驗。實驗結果如表5和表6所示。混合神經網絡每類的性能表現均優于單一網絡,且整體性能均得到了不同程度的提高。相較于基礎網絡,模型在Sleep-EDFx上Acc分別提升了11.9%和11.3%,Kappa分別提升了0.12和0.13,MF1分別提升了13.6%和11.4%;在SMHCSD上Acc分別提升了8.9%和8.1%,Kappa分別提升了0.12和0.11,MF1分別提升了7.8%和8.6%。這些指標數值的提升有效地說明了本文提出混合神經網絡模型的整體優越性。
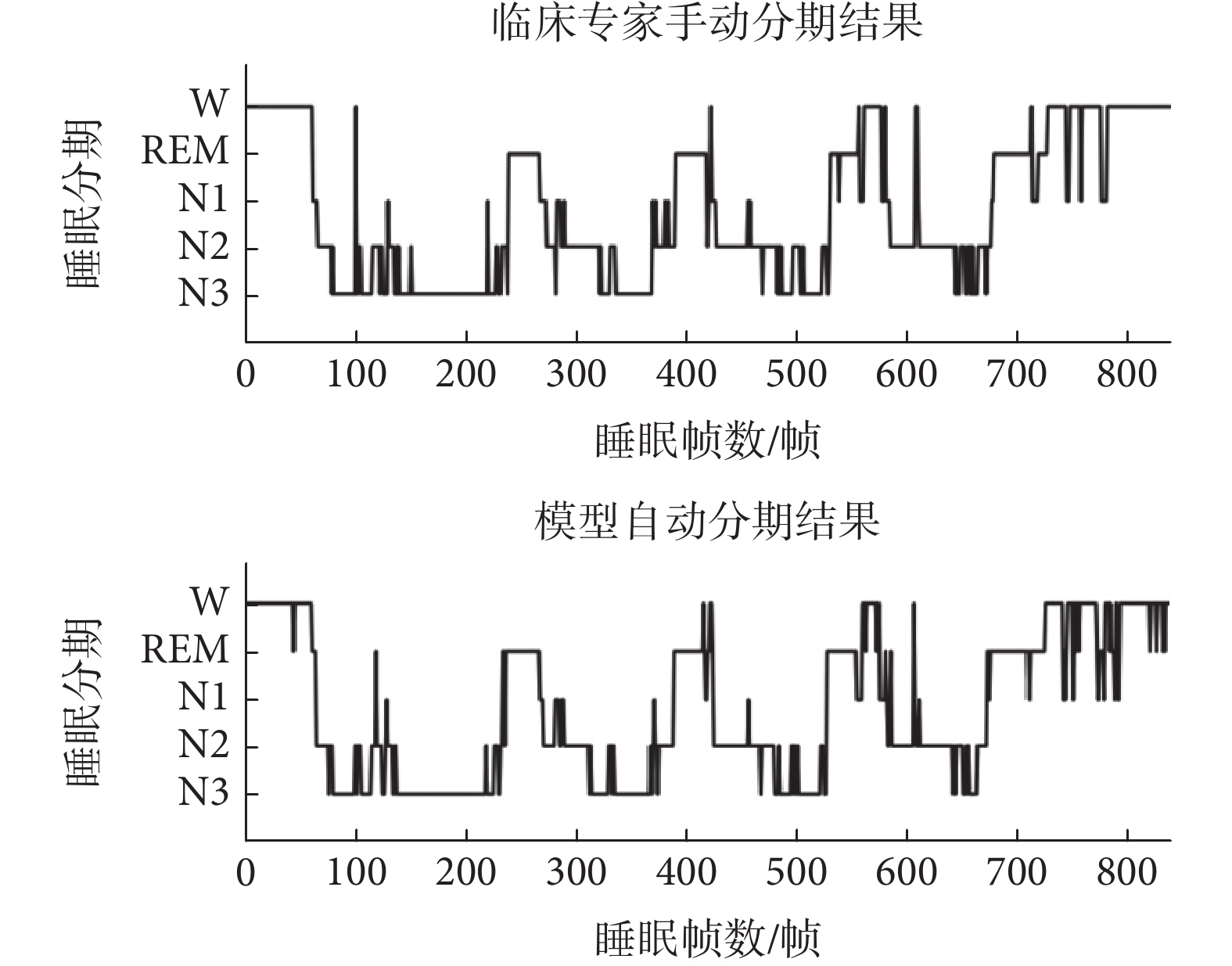
為了更加清晰地展示本文所提模型的準確性,選取了Sleep-EDFx中同一位受試者的臨床專家手動分期結果與本文模型自動分期結果對比圖,如圖5所示。縱坐標代表分期種類,橫坐標代表睡眠幀數。由圖5可以看出,該模型對于持續的睡眠狀態有著較好的分類效果,大多數錯誤分類是在一個階段過渡到另一個階段的過程中產生,可能原因是處于過渡階段的睡眠EEG信號具有不同時期的特征。總體上看,通過本文模型得到的自動睡眠分期結果與由臨床專家手動劃分標簽高度重合,進一步說明該模型的準確性較高。
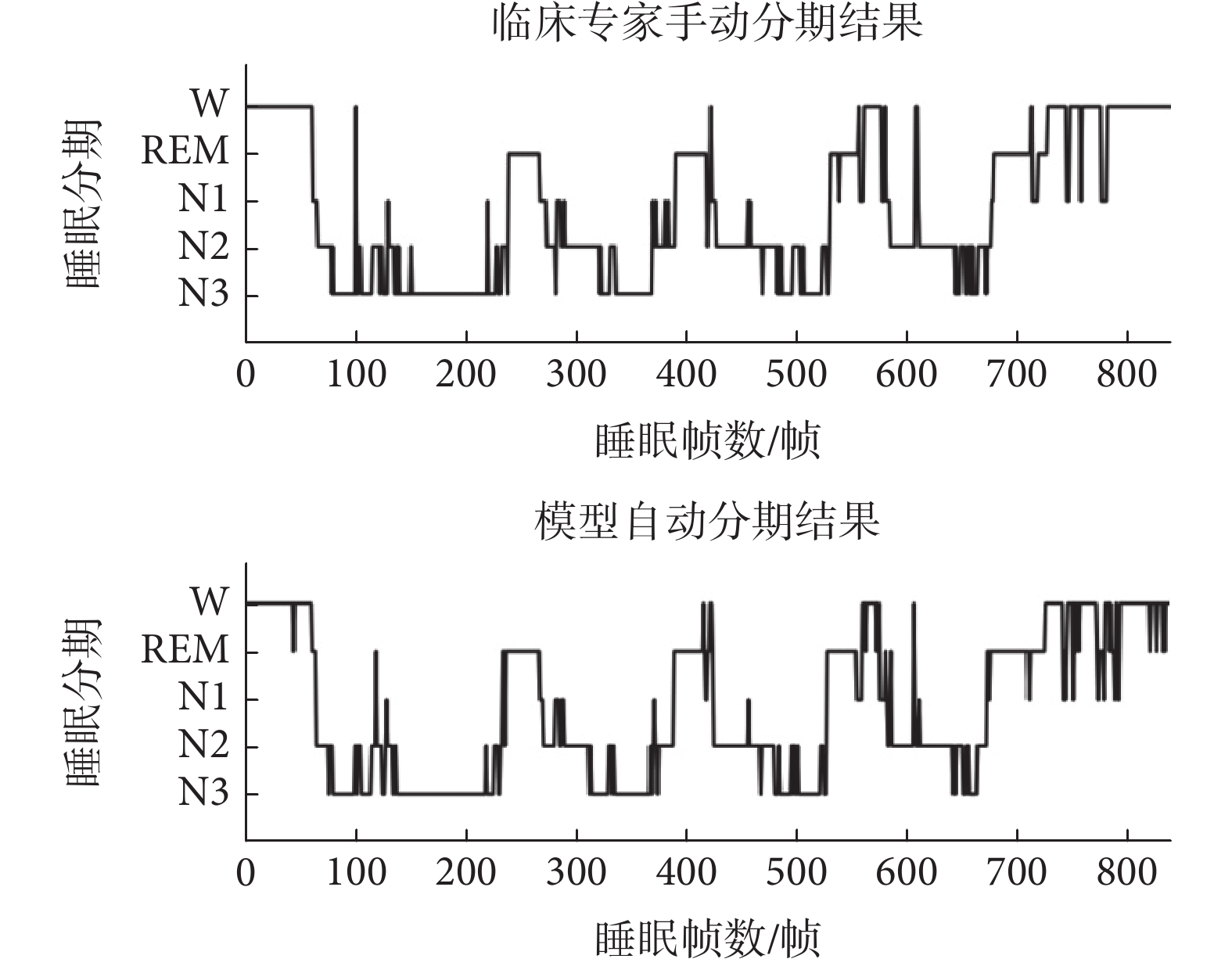 圖5
臨床專家手動標記的睡眠分期與模型自動睡眠分期結果對比圖
Figure5.
Comparison of sleep staging manually marked by clinical experts and automatic sleep staging by the model
圖5
臨床專家手動標記的睡眠分期與模型自動睡眠分期結果對比圖
Figure5.
Comparison of sleep staging manually marked by clinical experts and automatic sleep staging by the model
3 結論
針對提升自動睡眠模型分類精度問題,本文提出一種基于單通道EEG信號的自動睡眠分期模型。該模型使用數字濾波器、小波包降噪技術和ADASYN技術對EEG數據進行預處理,利用DCNN提取數據間的時頻域特征,結合BiLSTM提取數據間前后時間序列相關性信息特征,充分提取用于睡眠分期的EEG信號特征。模型通過不同數據集以及與基礎網絡進行對比實驗的方法,證明了本文模型在自動睡眠分期方面的優越性能,可減輕臨床醫生手動標注睡眠階段負擔,同時可為構建家庭睡眠監測系統提供方法支撐。
然而,該模型還存在一定缺陷,不能對睡眠中的過渡階段進行很好的分類,表明該模型的性能還有一定的優化空間,這也為進一步研究指明了方向。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:章浩偉、許哲、劉穎負責數據整理、實驗設計、模型的搭建與實驗及文章撰寫;苑成梅、季曹珺負責數據收集、指導性支持。
0 引言
睡眠在人類的健康中起著至關重要的作用。良好的睡眠質量、充足的睡眠時間和完整的睡眠結構有利于調節機體免疫功能,維持各系統功能處于穩定狀態[1]。臨床上使用多導睡眠圖(polysomnography,PSG)收集患者整晚腦電(electroencephalogram,EEG)、眼電(electrooculogram,EOG)、肌電(electromyogram,EMG)等生理信號[2],根據美國睡眠醫學學會(American Academy of Sleep Medicine,AASM)提供的睡眠評分標準[3],由專家依次將每30 s的信號標記為清醒期(wake,W)、快速眼動期(rapid eye moment,REM)和非快速眼動期(non-rapid eye moment,NREM),并將NREM細分為N1、N2和N3階段。每晚PSG記錄時長平均約為8 h,采用人工分期常出現分期效率低、錯誤率高等情況,阻礙了其在較大數據集上的應用,進而限制了該領域的相關研究。因此,怎樣利用計算機技術使睡眠分期更加精確、高效,是一個重要的研究內容。
隨著深度學習技術的不斷發展,卷積神經網絡(convolutional neural network,CNN)[4-7]、循環神經網絡(recurrent neural network,RNN)[8-9]相繼被用于構建自動睡眠分期模型。傳統RNN容易產生梯度消失等問題,無法學習長期依賴關系,且訓練效率低下,所以研究者們大多使用RNN變體網絡,如長短期記憶網絡(long short-term memory network,LSTM)和雙向長短期記憶網絡(bi-directional long short-term memory network,BiLSTM)等開展相關研究[10-11]。但這些網絡模型結構單一,無法同時考慮數據內的時頻域特征和時序特征,存在關鍵特征丟失、準確率不高等問題。因此,為了充分利用CNN在特征選擇、提取方面的良好性能以及RNN在處理具有時序信息數據時的獨特優勢,有研究者提出了將兩者相結合的深度學習模型,以提高自動睡眠分期模型性能,這也是最近研究的熱點[12-14]。Casciola等[15]構建了包含三個CNN層和兩個 LSTM 層的深度學習模型,對低質量雙通道EEG數據的驗證準確率為(74±10)%,在黃金標準PSG上實現了(77±10)%的驗證準確率。但該模型卷積層(convolutional layer,Conv)設計較為簡單,不能有效提取EEG數據的時頻域特征,且專家在手動分期過程中,不僅要考慮這一幀的數據信息,還要考慮前后幀對其的影響[9],因此僅使用LSTM不能有效地利用數據的前后時間序列信息。
在上述研究的基礎上,本文提出一種基于單通道EEG信號混合神經網絡模型。通過構建三條并行的CNN,依次設置不同大小的卷積核(convolutional kernel,Kernel)充分提取EEG數據的時頻域特征,結合空洞CNN更全面地捕捉特征信息,加快時域和頻域特征融合速度,接著使用三層BiLSTM提取前后時序特征,最后將上述混合特征輸入分類判別網絡實現更高準確率的自動分期。同時,提前對數據進行降噪和增強處理,以降低噪聲和樣本失衡對模型帶來的影響。最終,通過在兩個數據集上與基線模型進行的對比實驗,以驗證本文模型的有效性。綜上所述,期望本文模型能充分挖掘捕捉用于睡眠分期的EEG數據特征,能夠最大程度地貼合專家手動分期結果,實現有效地提高自動分期效率與準確率,今后能對人工智能與睡眠醫學領域的有效結合奠定基礎。
1 混合神經網絡模型
本文模型研究的整體思路為:首先對EEG信號進行數據降噪、增強處理,建立用于實驗的數據集,然后使用深度CNN(deep CNN,DCNN)和時序信息學習網絡提取信號的時頻域特征和時間序列特征,最后通過分類判別網絡實現自動睡眠分期。
1.1 數據預處理
1.1.1 數據降噪處理
為了降低噪聲對EEG信號的干擾,數據降噪是進行特征提取前十分重要的一步[16]。小波包降噪算法比小波變換更為細化,通過自適應選擇頻帶,將信號高頻分量和低頻分量都進行分解,經小波分解后,有用信號的小波分解系數較大,噪聲的小波分解系數較小。通過設置合適的閾值函數,大于閾值的分解系數保留下來,而小于閾值的分解系數則通過置零操作予以消除,由此達到降低噪聲的影響,從而提高信號的時頻分辨率[17]。小波包降噪算法包括4個步驟,描述如下:
(1)確定小波基函數(t),根據輸入信號x(t)的類型選擇合適的(t);
(2)確定要分解的層數N;
(3)確定分解閾值,對x(t)進行基于(t)小波包N層分解;
(4)信號重構,對低頻系數和經過處理后的高頻系數進行小波包重構,實現降噪。
本文使用多貝西(Daubechies,Db)小波函數族的Db10小波基函數進行3層分解的降噪方案,提高降噪精度。睡眠分期使用的EEG信號的能量主要集中在0~35 Hz,因此本文使用數字濾波器對數據進行濾波處理,將信號頻率降到35 Hz以下。
1.1.2 數據增強處理
為了解決數據集中存在的樣本類失衡問題,本文采用自適應合成采樣(adaptive synthetic sampling,ADASYN)技術對樣本較少的數據進行增強處理[18-19]。ADASYN最大的優點在于會根據整個數據集的樣本分布自動決定少數樣本的合成樣本數量及分布。該算法生成少量樣本公式如式(1)所示:
| '/> |
其中,di表示第i個少數類樣本;rand(0,1)表示0~1之間的隨機數;dki表示從di的k個最近鄰樣本中隨機選擇的一個樣本,表示生成的合成樣本。
1.2 深度卷積神經網絡
1.2.1 特征提取模塊
基于深度學習技術的CNN模型,一般會在網絡的第一部分構建多個具有不同大小尺寸Kernel的Conv作為特征提取模塊,如式(2)~式(4)所示。通過不同大小Kernel的結合使用,可以讓Conv更加全面地捕捉EEG信號的時頻域信息,高效利用數據的局部和全局特征[20]。
|
|
|
其中,代表使用的不同大小的Kernel尺寸;代表樣本中第幀的單通道EEG信號片段;CNNx(?)代表卷積操作;和分別代表通過Conv之后對提取出的時域特征和頻域特征;代表時域特征和頻域特征的拼接。
本文構建的特征提取模塊結構如圖1所示。應用三個并行的CNN,Kernel大小依次設置為3、5、7。三個并行CNN中的每一個分支由四個 Conv和一個一維自適應平均池化層(one dimensional adaptiveavgpool,Adaptiveavgpool1d)組成。每個Conv顯示了Kernel大小、通道尺寸以及步長。每個Conv都包含一維卷積運算(one dimensional convolution operation,Conv1d)、批量歸一化(batch normalization,BN)、線性整流函數(rectified linear unit,ReLU)和一維最大池化(one dimensional maxpool,Maxpool1d)。將預處理過的EEG數據送入模塊進行特征選擇與提取,最后拼接并行網絡提取的時域和頻域特征,得到輸出向量F∈RN×1,其中N表示特征向量長度。
圖1
特征提取模塊
Figure1.
Feature extraction module
為緩解因更有效地捕捉特征而增加網絡深度引起的梯度消失問題,在每兩個Conv之間引入了殘差網絡(residual network,RN)。同時使用以下兩種技術防止模型過擬合:①是引入隨機失活(dropout)技術,以一定的概率隨機地刪除網絡中的神經元,有助于提高模型的泛化能力;②是L2正則化技術,通過降低損失函數中的權重數值大小來降低模型復雜度,防止模型中可能出現的梯度不穩定、網格退化等問題。
1.2.2 特征融合模塊
空洞CNN是一種特殊的DCNN,通過使用擴張系數,可以在不引入其他參數的前提下擴大網絡的感受野[21],在加快時域和頻域特征融合速度的同時,也使得每一層的卷積輸出都包含更加詳細的特征信息。本文設計的由三層空洞卷積層組成的特征融合網絡模塊如圖2所示。擴張系數依次設置為1、2、4,每層都包含空洞卷積、BN和ReLU,且第二層和第三層網絡增加Maxpool1d,以盡可能地減少參數并保留主要特征,提高模型泛化能力。F∈RN×1表示輸入特征融合模塊的特征向量,G∈RN×1表示經過模塊融合后輸出的特征向量。
圖2
特征融合模塊
Figure2.
Feature fusion module
1.3 時序信息學習網絡
為了充分利用EEG信號之間的時間序列相關性,本文在DCNN后加入了由三層BiLSTM組成的時序信息學習網絡。如圖3所示,每層BiLSTM由前向的LSTM(forward LSTM,FLSTM)和反向的LSTM(back LSTM,BLSTM)組成,以幫助模型進行上下文信息的學習訓練。在同一時刻,FLSTM依次輸入特征向量G∈RN×1得到前向輸出向量HF∈RN×1,BLSTM 依次反向輸入特征向量G∈RN×1得到反向輸出向量HB∈RN×1,最后將前向與反向的向量進行拼接得到向量H∈RN×1。
圖3
時序信息學習網絡
Figure3.
Timing information learning network
1.4 分類判別網絡
分類判別網絡是整個模型的最后一部分,主要由歸一化指數函數(Softmax)層組成。通過輸入包含EEG信號時頻域特征及時序信息的混合特征向量H∈RN×1,由Softmax函數將多分類結果以概率的形式展現出來,得到預測分期結果。Softmax函數表達式如式(5)所示:
|
其中,zi為第i個節點的輸出值;C為輸出節點的個數,即樣本的分類標簽;e為指數函數;Softmax(?)為對輸入數據進行Softmax操作。
2 實驗與結果對比
2.1 實驗數據
本文使用兩個數據集來評估構建的模型,分別是歐洲數據格式存儲的睡眠數據集拓展版(Sleep-European Data Format Database Expanded,Sleep-EDFx)(網址為:www.physionet.org)[22]和上海精神衛生中心收集創建的公開睡眠數據集(Shanghai Mental Health Center Sleep Database,SMHCSD),本研究已獲準授權可以使用其數據。
Sleep-EDFx:該數據集包含197個整晚PSG記錄。153個健康人的睡眠磁帶數據(sleep cassette,SC)文件是對沒有服用過任何與睡眠相關藥物的健康人睡眠監測獲得的記錄,44個輕度入睡障礙患者的睡眠遙感數據(sleep telemetry,ST)文件是對服用過替馬西泮的睡眠障礙患者監測獲得的記錄。每個PSG記錄都包含2個通道EEG信號(Fpz-Cz、Pz-Cz)、EOG信號和EMG信號。EEG信號的采樣頻率為100 Hz。
SMHCSD:該數據集由上海精神衛生中心收集的2017—2021年148個整晚PSG記錄。每個PSG記錄都包含6個通道的EEG信號(F4-M1、F3-M2、C4-M1、C3-M2、O2-M1、O1-M2)、兩個EOG信號(EOG-L、EOG-R)、EMG信號、心電圖、左右腿電信號。EEG信號的采樣頻率為200 Hz。
以上數據集都包含由醫師手動劃分的睡眠分期結果標簽文件,本文將Sleep-EDFx中的N3期和N4期合并為N3期,并剔除了兩個數據集中與睡眠分期無關的數據及標簽。這兩個數據集每個睡眠階段的樣本數如表1所示。由數量可以看出,數據集中存在樣本類失衡問題,故采用1.1.2小節中的數據增強處理方法對少數類樣本進行數據增強,以構建類平衡數據集。
2.2 訓練設計
為了得到最優的訓練參數,使用網格搜索法探究學習率、批大小和迭代次數的最優參數值。結果表明上述參數分別設置為0.001、64、120時,模型表現最好。
本文使用兩個數據集中EEG信號的Fpz-Cz通道和C3-M2通道分別訓練和測試所構建的模型。在模型訓練時,使用自適應矩估計優化器(adaptive moment estimationadam, Adam)對網絡權重值進行更新優化,加快模型收斂速度。為了使模型得到的睡眠分期結果與實際分期結果盡可能相近,使用與分類判別網絡中的Softmax層相對應的多類交叉熵作為損失函數實現五分類任務。實驗使用十折交叉驗證的方法來測試該模型的準確性,將數據集分成10份,模型隨機選擇其中的9份作為訓練數據,1份作為測試數據,共進行十次實驗。
2.3 評價指標
本文實驗的評價指標包括準確度(accuracy,Acc)、科恩卡帕系數(Cohen's Kappa,Kappa)、精度(precision,PR)、召回率(recall,RE)、微觀F1得分(micro-F1,F1)以及宏觀F1得分(macro-F1,MF1)。
2.4 基礎網絡模型
本文構建了兩個單一基礎網絡模型用作對比實驗,分別是CNN和BiLSTM。結構如圖4所示。CNN主要由三個Conv組成,BiLSTM是將Conv替換為BiLSTM層,其他結構與CNN相同。
圖4
基礎網絡模型
Figure4.
Basic network model
2.5 實驗結果與分析
本文模型使用Sleep-EDFx中的Fpz-Cz通道和SMHCSD中的C3-M2通道經過十折交叉驗證后的混淆矩陣,如表2和表3所示,總體性能如表4所示。混淆矩陣中的每行代表的是睡眠專家標注的分類結果,每列代表的是本模型自動分類結果,主對角線表示模型正確分類的樣本個數。表格的最后三列分別顯示了模型對于每個類別的預測性能。
從表2和表3可以看出,模型在兩個數據集上都達到了較好的睡眠分期結果。表現較差的N1階段的PR也分別達到了59.9%和58.6%,總體Acc達到了86.9%和88.9%。在混淆矩陣中,主對角線兩側的數據幾乎是對稱的,且SMHCSD中的N3階段同樣達到了較好的PR,這表明一些錯誤分期不是因為數據不均衡造成的[23],證明本文使用的ADASYN技術能在一定程度上解決數據類失衡問題。在較難分期的N1階段,PR雖達到了60%左右,但仍遠低于其他類的分期水平,可能原因是N1期與其它睡眠階段的EEG特征相似性較大,結合其他生理信號可能會實現更好的判別。
為了進一步評估所提模型的性能,將混合神經網絡與基礎網絡進行對比實驗。實驗結果如表5和表6所示。混合神經網絡每類的性能表現均優于單一網絡,且整體性能均得到了不同程度的提高。相較于基礎網絡,模型在Sleep-EDFx上Acc分別提升了11.9%和11.3%,Kappa分別提升了0.12和0.13,MF1分別提升了13.6%和11.4%;在SMHCSD上Acc分別提升了8.9%和8.1%,Kappa分別提升了0.12和0.11,MF1分別提升了7.8%和8.6%。這些指標數值的提升有效地說明了本文提出混合神經網絡模型的整體優越性。
為了更加清晰地展示本文所提模型的準確性,選取了Sleep-EDFx中同一位受試者的臨床專家手動分期結果與本文模型自動分期結果對比圖,如圖5所示。縱坐標代表分期種類,橫坐標代表睡眠幀數。由圖5可以看出,該模型對于持續的睡眠狀態有著較好的分類效果,大多數錯誤分類是在一個階段過渡到另一個階段的過程中產生,可能原因是處于過渡階段的睡眠EEG信號具有不同時期的特征。總體上看,通過本文模型得到的自動睡眠分期結果與由臨床專家手動劃分標簽高度重合,進一步說明該模型的準確性較高。
圖5
臨床專家手動標記的睡眠分期與模型自動睡眠分期結果對比圖
Figure5.
Comparison of sleep staging manually marked by clinical experts and automatic sleep staging by the model
3 結論
針對提升自動睡眠模型分類精度問題,本文提出一種基于單通道EEG信號的自動睡眠分期模型。該模型使用數字濾波器、小波包降噪技術和ADASYN技術對EEG數據進行預處理,利用DCNN提取數據間的時頻域特征,結合BiLSTM提取數據間前后時間序列相關性信息特征,充分提取用于睡眠分期的EEG信號特征。模型通過不同數據集以及與基礎網絡進行對比實驗的方法,證明了本文模型在自動睡眠分期方面的優越性能,可減輕臨床醫生手動標注睡眠階段負擔,同時可為構建家庭睡眠監測系統提供方法支撐。
然而,該模型還存在一定缺陷,不能對睡眠中的過渡階段進行很好的分類,表明該模型的性能還有一定的優化空間,這也為進一步研究指明了方向。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:章浩偉、許哲、劉穎負責數據整理、實驗設計、模型的搭建與實驗及文章撰寫;苑成梅、季曹珺負責數據收集、指導性支持。