最近,深度學習在醫學圖像任務中取得了令人矚目的成果。然而,這種方法通常需要大規模的標注數據,而醫學圖像的標注成本較高,因此如何從有限的標注數據中進行高效學習是一個難題。目前,常用的兩種方法是遷移學習和自監督學習,然而這兩種方法在多模態醫學圖像中的研究卻很少,因此本研究提出了一種多模態醫學圖像對比學習方法。該方法將同一患者不同模態的圖像作為正樣本,有效增加訓練過程中的正樣本數量,有助于模型充分學習病灶在不同模態圖像上的相似性和差異性,從而提高模型對醫學圖像的理解能力和診斷準確率。常用的數據增強方法并不適合多模態圖像,因此本文提出了一種域自適應反標準化方法,借助目標域的統計信息對源域圖像進行轉換。本研究以兩個不同的多模態醫學圖像分類任務對本文方法展開驗證:在微血管浸潤識別任務中,本文方法獲得了(74.79 ± 0.74)%的準確率和(78.37 ± 1.94)%的F1分數,相比其它較為熟知的學習方法有所提升;對于腦腫瘤病理分級任務,本文方法也取得了明顯的改進。結果表明,本文方法在多模態醫學圖像數據上取得了良好的結果,可為多模態醫學圖像的預訓練提供一種參考方案。
引用本文: 文含, 趙瑩, 蔡秀定, 劉愛連, 姚宇, 付忠良. 一種具有域自適應反標準化的多模態醫學圖像對比學習算法. 生物醫學工程學雜志, 2023, 40(3): 482-491. doi: 10.7507/1001-5515.202302050 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
最近,深度學習在各種醫學圖像任務中表現出良好的性能,如病灶分割、疾病診斷和療效預測[1]。然而,深度學習在醫學圖像中的應用也面臨一些挑戰,其中一個主要問題就是缺乏充足的標注數據。醫學圖像的標注通常需要專業醫生才能完成,任務難度較大且成本較高,因此如何從有限的標注數據中學習有代表性的特征成為一個迫切需要解決的問題。
目前,從有限的標注數據集中學習有代表性的特征主要有兩種常見的方法:一種方法是在大規模公共數據集上進行有監督的預訓練[2-4];另一種方法是在沒有標注的數據集上使用自監督學習進行自監督預訓練,然后在目標數據集上對預訓練的模型進行有監督的微調[5-6]。然而,這些方法在應用于醫學圖像任務時,存在一些局限性。對于第一種方法,將公共數據集上訓練的模型直接遷移到醫學圖像任務上,似乎沒有考慮到由于自然圖像和醫學圖像之間的分布差異而可能導致的模型性能下降的問題。這種方法是次優的,因為醫學圖像理解通常需要細粒度的視覺特征,這些特征與識別自然圖像中物體所需的特征完全不同。例如,Raghu等[7]研究發現,與簡單的隨機初始化相比,大規模視覺識別挑戰賽數據集(ImageNet)預訓練對模型性能的提升幾乎沒有效果。對于第二種方法,雖然自監督學習已經在一些醫學影像任務中取得了成果,如心臟磁共振成像(magnetic resonance imaging,MRI)分割[8]、視網膜疾病診斷[9]和新型冠狀病毒感染(corona virus disease 2019,COVID-19)診斷[10],但是每種醫學圖像都有其自身的噪聲和缺陷,這可能導致自監督學習方法的性能受到限制。而多模態醫學圖像可以提供互補信息[11],例如電子計算機斷層掃描(computed tomography,CT)可以提供組織密度信息,MRI可以提供組織構造信息等。通過聯合使用多模態醫學圖像進行自監督學習,可以獲得更全面和更準確的信息,從而提高對疾病的理解和診斷,因此研究多模態醫學圖像的自監督學習具有重要的意義。
多模態醫學圖像是患者在不同的醫療設備或同一設備的不同參數下獲得的,可以為醫學圖像診斷提供更豐富的信息。在這項研究中,本文提出了一個多模態對比學習框架,可以有效地利用每個患者的多模態醫學圖像來學習共有的特征表達。本文方法是從一個小批量數據中隨機選擇兩個模態圖像,如果這兩個模態圖像屬于一個患者,那么就被視為正樣本對。如果這兩個模態圖像不屬于同一個患者,那么就被視為負樣本對。然后,將這兩個模態的圖像分別輸入到對應特征編碼網絡中提取圖像特征,并通過投影網絡將獲得的特征映射到一個特征空間。接下來,通過對比損失使正樣本對在特征空間中盡可能地接近,而負樣本對則盡可能地遠離。最后,將預訓練好的特征編碼網絡遷移到目標任務上進行監督微調,以提高模型在目標數據集上的性能。
有研究表明,使用合理的數據增強方法可以改善自監督學習[12]。目前使用的數據增強方法(裁剪、調整大小、旋轉等)通常不能很好地考慮多模態醫學圖像的特點。由于數據集的統計信息包含分類任務的相關信息,因此本文提出了一種域自適應反標準化方法。該方法利用多模態數據集中各模態的統計信息對其它模態的數據進行數據轉換,可以有效擴大各模態樣本的數據量,從而提高模型對各模態數據的適應能力。具體而言,首先從多模態醫學圖像數據集中隨機選擇兩種模態作為源域和目標域,然后對源域和目標域的圖像進行標準化,最后利用目標域的統計信息對源域進行反標準化,從而得到轉換后的圖像。域自適應反標準化方法可以合理地利用各個模態圖像的統計信息實現有效地數據擴充。
為了公平地比較有監督預訓練、對比學習和本文方法,在兩個不同的醫學圖像數據集上進行了對比實驗:①基于肝細胞癌(hepatocellular carcinoma,HCC)多期相MRI的微血管浸潤(microvascular infiltration,MVI)識別;②基于腦膠質瘤多模態MRI的病理分級。此外,由于兩個數據集的數據量較小,本文在多模態對比學習階段使用域自適應反標準化方法來擴大數據量。綜上,通過本文提出的多模態對比學習算法在兩個數據集上進行驗證,以期獲得良好的性能,或可為多模態醫學圖像的預訓練提供一種參考方案。
1 相關工作
1.1 對比學習
對比學習作為自監督學習中一個非常重要的部分,被廣泛應用于計算機視覺、自然語言處理等領域。在對比學習中,通常會將兩個樣本輸入到模型中,并使用某種度量函數來計算它們之間的相似度或距離。這個度量函數可以是歐式距離、余弦相似度等。如果兩個樣本屬于同一類別,則目標是使它們的相似度盡可能高;如果屬于不同類別,則目標是使它們的相似度盡可能低。在計算機視覺領域,基于對比學習的方法已經在大規模公共數據集上取得了最先進的性能。例如,簡明對比學習(simple contrastive learning of representations,SimCLR)框架[12]、動量對比學習(momentum contrastive learning,MOCO)框架[13]、自舉潛變量學習(bootstrap your own latent learning,BYOL)框架[14]和孿生表示學習(simple siamese representation learning,SimSiam)框架[15]。
最近,對比學習在醫學圖像任務中已經取得了一些成果。例如,Chaitanya等[16]引入了一個基于混合對比損失的自監督學習分割模型,該模型能夠學習局部和全局圖像表征。Sowrirajan等[17]使用MOCO在大型X光胸片數據集(chest expert,CheXpert)[18]上進行預訓練,然后對模型的分類性能進行評估。He等[10]提出了一種自我遷移對比學習框架(self-supervised learning and transfer learning,Self-Trans),以提高CT影像中COVID-19的分類準確率。Aziz等[19]提出了一種多實例對比學習方法(multi-instance contrastive learning,MICLe),以提高數碼相機圖像中皮膚病的分類精度。這些工作都表明在醫學圖像上采用對比學習方法可以提取到有代表性的特征,這些特征有助于模型對醫學圖像的理解,從而提高模型對疾病的診斷能力。
1.2 醫學多模態學習
與單模態醫學圖像相比,多模態醫學圖像通常由不同的醫學成像模態組成,例如CT、MRI和正電子發射斷層(positron emission tomography,PET)等,這些模態之間存在著豐富的信息交叉和相互依賴關系。研究人員已經開始關注多模態醫學圖像的應用,例如,Hervella等[9]提出了一個基于自監督多模態重建(self-supervised multimodal reconstruction,SMR)的視網膜計算機輔助診斷(computer-aided diagnosis,CAD)系統,該系統利用互補成像模態之間的多模態重建實現,并取得了比單模態更好的實驗結果。Windsor等[20]介紹了一個基于對比學習的多模態醫學圖像配準框架,該框架可以精確地配準同一患者的不同模態的醫學圖像。Taleb等[21]提出了一種自監督學習方法,它可以用來匹配無標簽的醫學圖像和遺傳數據,以揭示圖像和遺傳數據之間的關系。這些工作表明,采用多模態數據進行學習可以取得比單模態更好的效果。本文采用對比學習方法在多模態醫學圖像數據集上進行實驗,旨在學習不同模態圖像之間病灶的相似性,以獲得更全面、準確的信息,從而提高對疾病檢測和診斷的能力。
1.3 數據增強
常用的數據增強方法可以分為兩類:一類是標簽保持的數據增強方法,例如:對圖像進行幾何變換,包括翻轉、旋轉、移動、裁剪、扭曲、縮放等各種操作;或者對圖像的顏色進行變換,常見的有添加噪聲、模糊、擦除、填充等。然而,這類方法并不是專門為多模態醫學圖像設計的。另一類是標簽擾動的數據增強方法,例如,Zhang等[22]通過將訓練集中的圖像和標簽都按一定比例融合,生成新的數據。Yun等[23]通過隨機刪除一個圖像中的矩形區域,并用另一個圖像相同位置的像素值填充的方式進行數據擴充,同時根據像素的比例份額分配標簽。雖然標簽擾動的數據增強方法可以用于多模態醫學圖像數據,但是它們改變了數據的分布,可能會引入噪聲和誤差,從而影響模型的性能和穩定[23]。本研究針對多模態數據專門設計了一種域自適應反標準化方法,該方法能夠有效地使用不同模態數據的統計信息對圖像進行轉換,從而在不改變整個數據分布的情況下實現數據擴展。這是一種新型的多模態數據增強方法,可用于提高多模態醫學圖像分類的性能。
2 方法
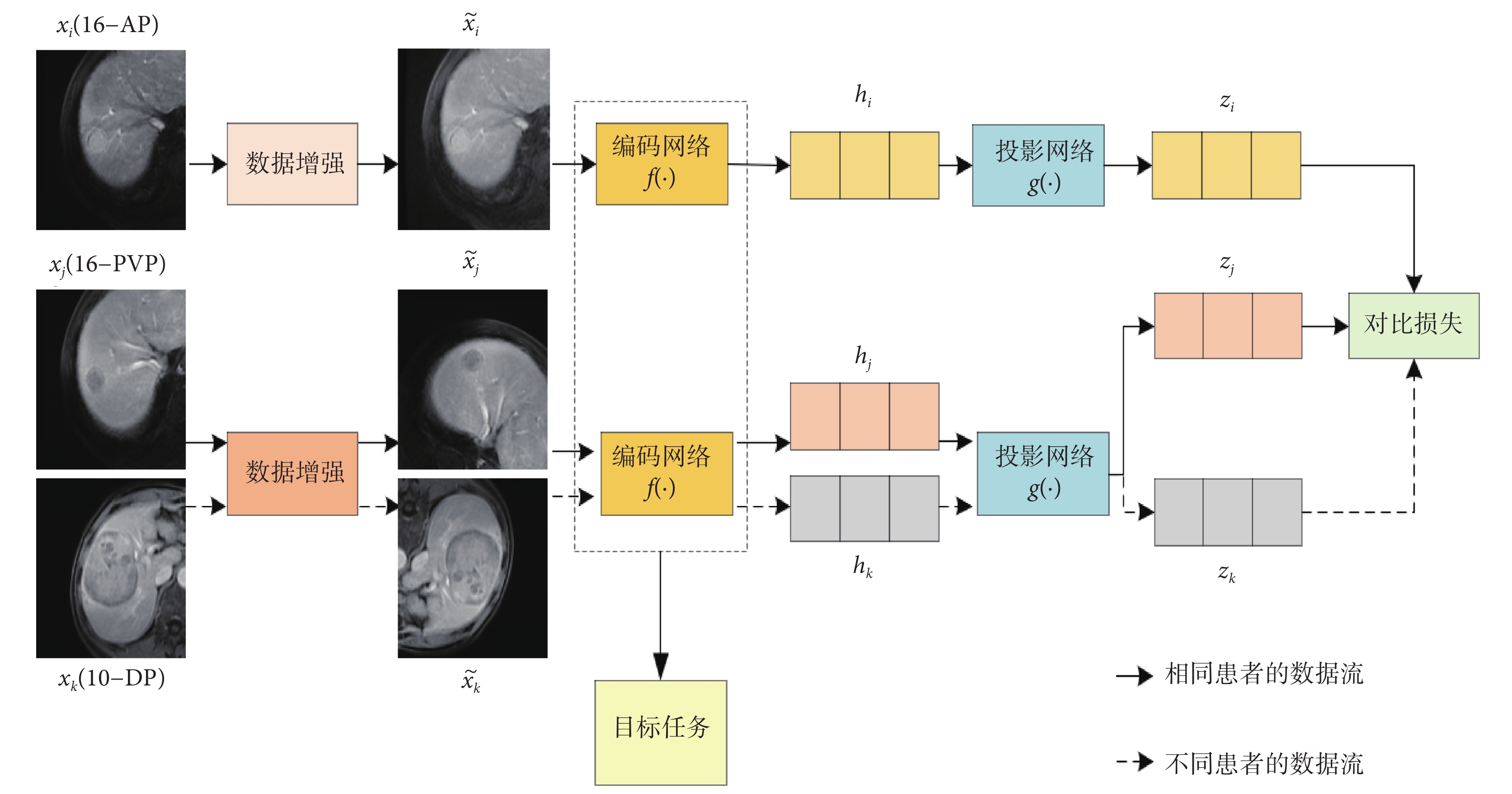
本文提出的方法主要包括兩個階段,如圖1所示。在多模態對比學習階段,使用提出的多模態對比學習方法對多個模態的圖像進行預訓練。在監督微調階段,將訓練好的模型遷移到目標數據集上進行有監督微調。接下來,在以下章節詳細描述本文方法。
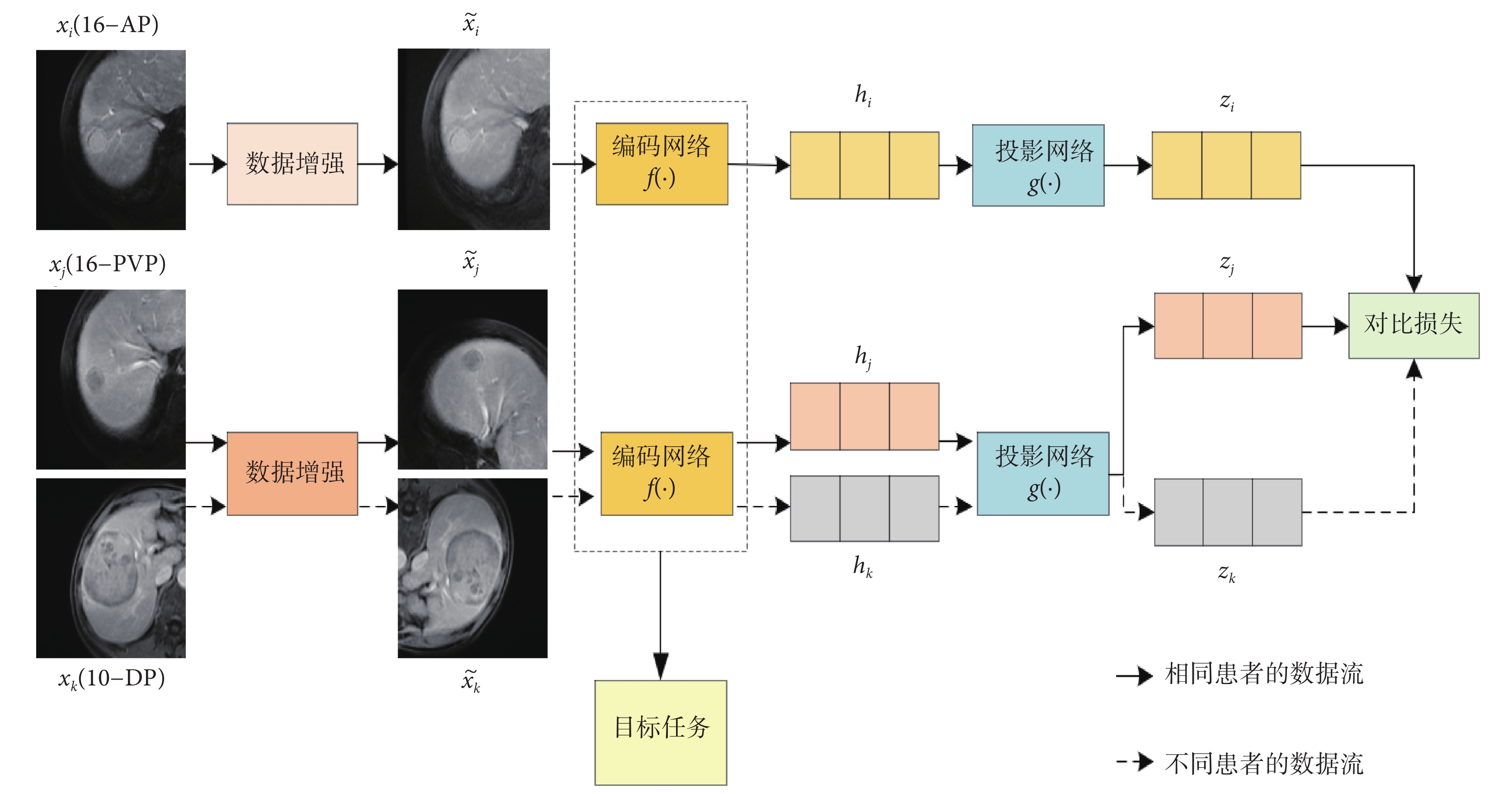 圖1
多模態對比學習方法的框架圖
Figure1.
Framework diagram of multimodal contrastive learning method
圖1
多模態對比學習方法的框架圖
Figure1.
Framework diagram of multimodal contrastive learning method
2.1 多模態對比學習
在對多模態醫學圖像數據集進行訓練時,隨機選擇一個有N個患者的小批次數據,其中每個患者X={x1, x2, ..., xm}可能包含多個模態醫學圖像。假設,由于患者的不同,m可能是不同的。在多模態對比學習階段,從N個患者的小批次數據中隨機選擇兩個模態的圖像,如果這兩個模態的圖像屬于同一個患者,如圖1中xi和xj分別屬于數據集中第16號患者的動脈期(arterial phase,AP)(16-AP)和靜脈期(portal venous phase,PVP)(16-PVP),那么xi和xj就構成一個正樣本對。如果這兩個模態的圖像屬于不同患者,如圖1中xi和xk分別屬于數據集中16-AP和第10號患者的延遲期(delayed phase,DP)(10-DP),那么xi和xk就構成一個負樣本對。其次,將這兩個模態的圖像xi和xj(或xk)輸入數據增強模塊,對它們分別進行隨機的圖像增強操作,得到增強后的圖像  和
和  (或
(或  )。然后,將
)。然后,將  和
和  (或
(或  )分別輸入對應的特征編碼網絡f(?),以提取圖像特征hi和hj(或hk)。接著,將這兩個特征hi和hj(或hk)分別輸入到投影網絡g(?),它們被映射到同一特征空間,并生成兩個特征向量zi和zj(或zk)。最后,采用對比損失來縮短zi和zj之間的距離,同時擴大zi和zk之間的距離。通過這種隱式的多模態融合方法使模型學習病灶在不同模態之間的相似性和差異性,有助于更好地理解不同模態之間的關系,從而提高模型對醫學圖像的理解能力和診斷準確率。
)分別輸入對應的特征編碼網絡f(?),以提取圖像特征hi和hj(或hk)。接著,將這兩個特征hi和hj(或hk)分別輸入到投影網絡g(?),它們被映射到同一特征空間,并生成兩個特征向量zi和zj(或zk)。最后,采用對比損失來縮短zi和zj之間的距離,同時擴大zi和zk之間的距離。通過這種隱式的多模態融合方法使模型學習病灶在不同模態之間的相似性和差異性,有助于更好地理解不同模態之間的關系,從而提高模型對醫學圖像的理解能力和診斷準確率。
本文提出的多模態對比學習框架由以下幾部分組成:
(1)數據增強。數據增強的作用是將輸入圖像對xi和xj隨機轉化為增強的圖像對  和
和  。本研究中使用的數據增強操作包括隨機縮放裁剪、隨機顏色失真,以及旋轉90 o、180 o和270 o。
。本研究中使用的數據增強操作包括隨機縮放裁剪、隨機顏色失真,以及旋轉90 o、180 o和270 o。
(2)編碼網絡。編碼網絡的作用是將增強的圖像對  和
和  映射成一對特征向量hi和hj。在實驗過程中,使用不同結構的網絡進行實驗,包括通道改組神經網絡(shuffle neural network,ShuffleNet)[24]、殘差神經網絡(residual neural network,ResNet)[25]和帶移動窗口的轉換器(shifted windows transformer,Swin Transformer)[26],以驗證本文方法的有效性。
映射成一對特征向量hi和hj。在實驗過程中,使用不同結構的網絡進行實驗,包括通道改組神經網絡(shuffle neural network,ShuffleNet)[24]、殘差神經網絡(residual neural network,ResNet)[25]和帶移動窗口的轉換器(shifted windows transformer,Swin Transformer)[26],以驗證本文方法的有效性。
(3)投影網絡。投影網絡的作用是將編碼的特征對hi和hj投影到一個向量空間中,然后使用對比損失來評估投影特征對zi和zj的相似度。在實驗中,使用兩個全連接層來組成投影網絡,投影網絡的隱藏層和輸出層的維度分別為256和128。
(4)對比損失。對比損失的作用是縮短正樣本對特征zi和zj之間的距離,同時擴大負樣本對zi和zk之間的距離。這樣可以使模型學習到腫瘤在不同模態圖像之間共同的特征,從而提高模型的表達能力和準確性。本文中對比損失Li, j的定義如式(1)所示:
 |
其中,sim(?, ?)是兩個向量zi和zj之間的余弦相似度; ,當k和i相等時為0,不等時為1;τ是一個溫度標量。
,當k和i相等時為0,不等時為1;τ是一個溫度標量。
2.2 監督微調
將多模態醫學圖像數據集上使用對比學習訓練的模型遷移到目標任務上進行監督微調,以提高模型在目標任務上的表現。在實驗中,凍結了在多模態對比學習階段訓練的特征編碼網絡的權重,并在特征編碼網絡之后添加了一個目標任務的分類網絡。該分類網絡由兩個全連接層組成,中間是批量歸一化(batch normalization,BN)和帶泄漏修正線性單元(leaky rectified linear unit,Leaky ReLU)激活函數。這兩個全連接層的維度為256和2。它們的初始化參數是由愷明(kaiming)[27]初始化方法產生的。
2.3 域自適應反標準化
在本節中,將仔細介紹域自適應反標準化方法。具體而言,將每一個模態視為一個域,并對每個域的圖像進行標準化處理,然后利用其它域的統計信息對當前域的標準化數據進行反標準化處理,從而實現不同域數據之間的適應。
本文使用目標域數據的統計信息來擴展源域數據,對于任何多模態數據集,將任意兩個模態作為源域Ds和目標域Dt,分別用M和N表示Ds和Dt的樣本數量。整個域自適應反標準化方法的詳細描述如下:
步驟(1):分別統計源域Ds中每張圖像 的平均值μs和標準差σs,以及目標域Dt中每張圖像
的平均值μs和標準差σs,以及目標域Dt中每張圖像 的平均值μt和標準差σt,其定義如式(2)和式(3)所示:
的平均值μt和標準差σt,其定義如式(2)和式(3)所示:
 |
 |
步驟(2):根據步驟(1)中計算的平均值μs和標準差σs對源域Ds中每張圖像 進行標準化處理,得到標準化后的圖像
進行標準化處理,得到標準化后的圖像 。同樣,對目標域Dt中每張圖像
。同樣,對目標域Dt中每張圖像 采取同樣的標準化處理,得到標準化后的圖像
采取同樣的標準化處理,得到標準化后的圖像 。標準化的計算如式(4)所示:
。標準化的計算如式(4)所示:
 |
步驟(3):將源域Ds中每張標準化的圖像 乘以目標域的標準差σt,再加上目標域的平均值μt,這樣就可以得到反標準化的圖像
乘以目標域的標準差σt,再加上目標域的平均值μt,這樣就可以得到反標準化的圖像 。同樣,對目標域Dt中每張標準化的圖像
。同樣,對目標域Dt中每張標準化的圖像 進行同樣的反標準化處理,就可以得到反標準化的圖像
進行同樣的反標準化處理,就可以得到反標準化的圖像 。反標準化的計算如式(5)所示:
。反標準化的計算如式(5)所示:
 |
3 實驗數據和設置
3.1 數據和預處理
本文方法在兩個不同的醫學圖像任務上進行了實驗。第一個任務是在三個期相的MRI上診斷HCC的MVI。第二個任務是在四個模態的MRI上對腦腫瘤進行病理分級。
對于MVI識別任務,實驗數據集由大連醫科大學第一附屬醫院放射科提供,并且數據集中的所有患者都經組織病理學證實為MVI。該數據集包含了261名HCC患者三種期相的MRI,分別為AP、PVP、DP。其中182名患者為陰性,79名患者為陽性。整個數據集由兩位具有10年MRI診斷經驗的放射科醫生進行注釋,并由另一位具有20年經驗的資深放射科醫生進行校準。該研究經大連醫科大學附屬第一醫院醫學倫理委員會審查獲得批準,并授權可以使用數據集中所有影像資料數據(批文編號:PJ-KS-KY-2019-167)。
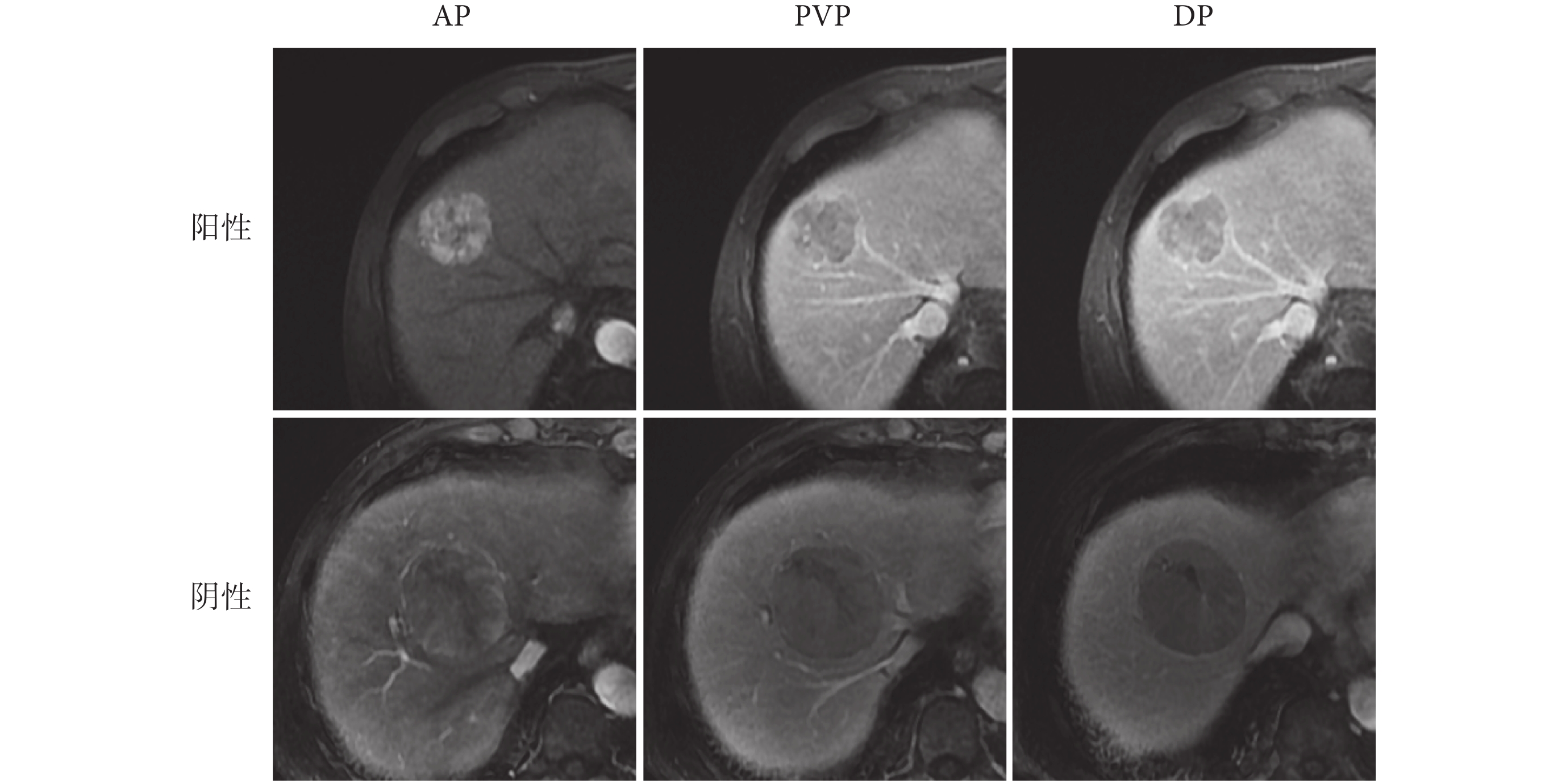
在實驗中,將數據集按照8:2的比例隨機劃分為訓練集和測試集。在多模態對比學習和監督微調兩個階段,訓練集有1 881張圖像,包括567張陽性圖像和1 314張陰性圖像;測試集有468張圖像,包括144張陽性圖像和324張陰性圖像。對于模型的輸入,從每個患者的三個期相MRI中選擇腫瘤面積最大的切片及其上下兩片。如圖2所示,可以看到MVI數據集中陰性和陽性的多期相MRI。
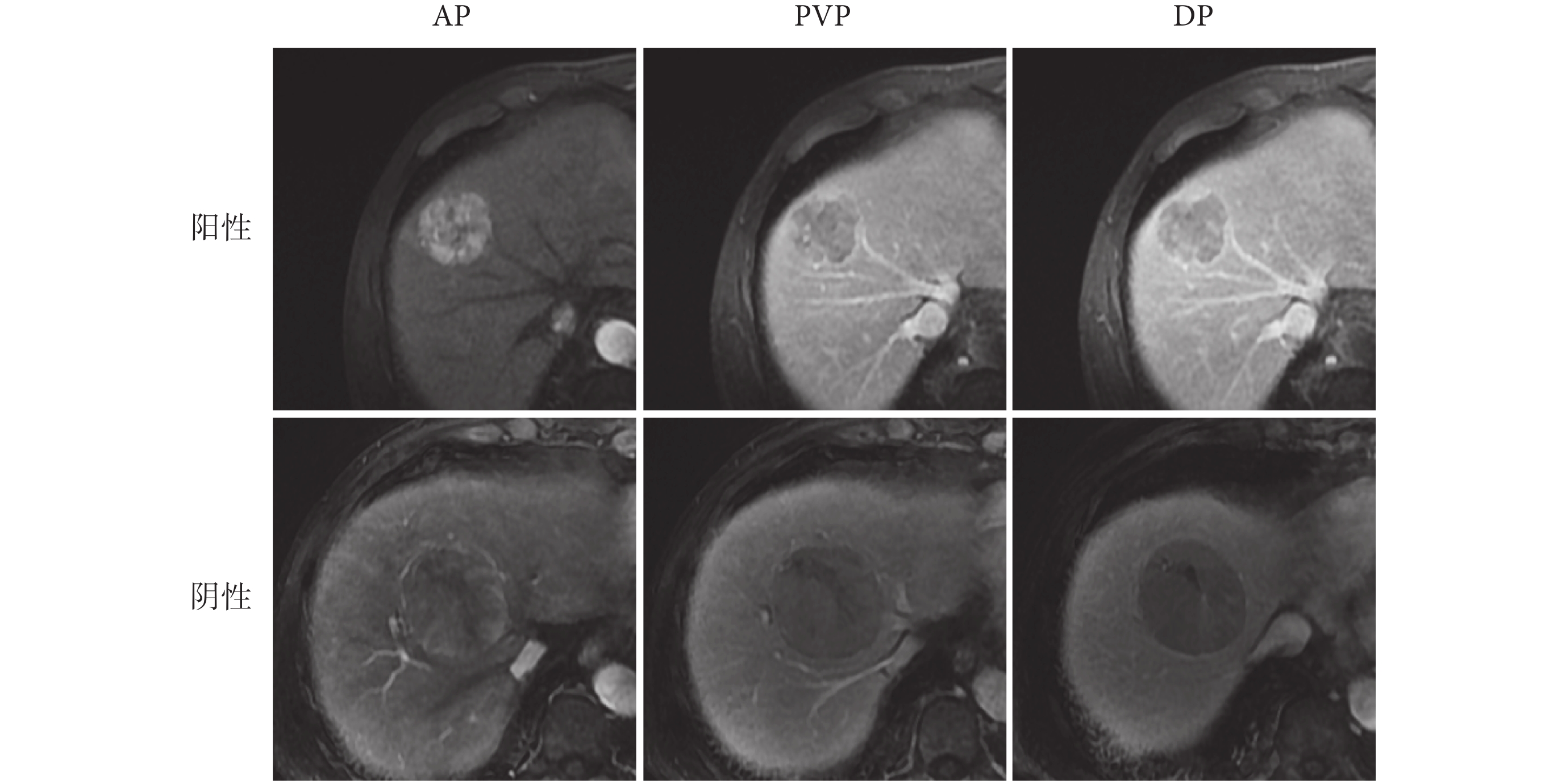 圖2
MVI數據集中多期相MRI示例圖
Figure2.
Example of multi-phase MRI in MVI dataset
圖2
MVI數據集中多期相MRI示例圖
Figure2.
Example of multi-phase MRI in MVI dataset
對于腦腫瘤病理分級任務,本文采用2019年多模態腦瘤分割挑戰賽(multimodal brain tumor segmentation challenge 2019, Brats2019)數據庫作為實驗數據來源。該數據庫共包含626個腦瘤患者,其中訓練集有335個患者,驗證集有125個患者,測試集有166個患者。由于驗證集和測試集沒有公開發布,在實驗中只使用訓練集中335個患者的多模態MRI,其中259名患者為高級別膠質瘤(high-grade glioma,HGG),76名患者為低級別膠質瘤(low-grade glioma,LGG)。每個患者都有四個模態的MRI,分別為T1、T2、液體衰減反轉恢復(fluid-attenuated inversion recovery,FLAIR)序列和對比增強T1加權(contrast-enhanced T1-weighted, T1ce)序列。每個模態的MRI有155張切片圖像,每張切片圖像的大小為240×240。本研究已得到Brats2019數據庫創建機構的授權,并可免費使用數據庫中所有數據資料。
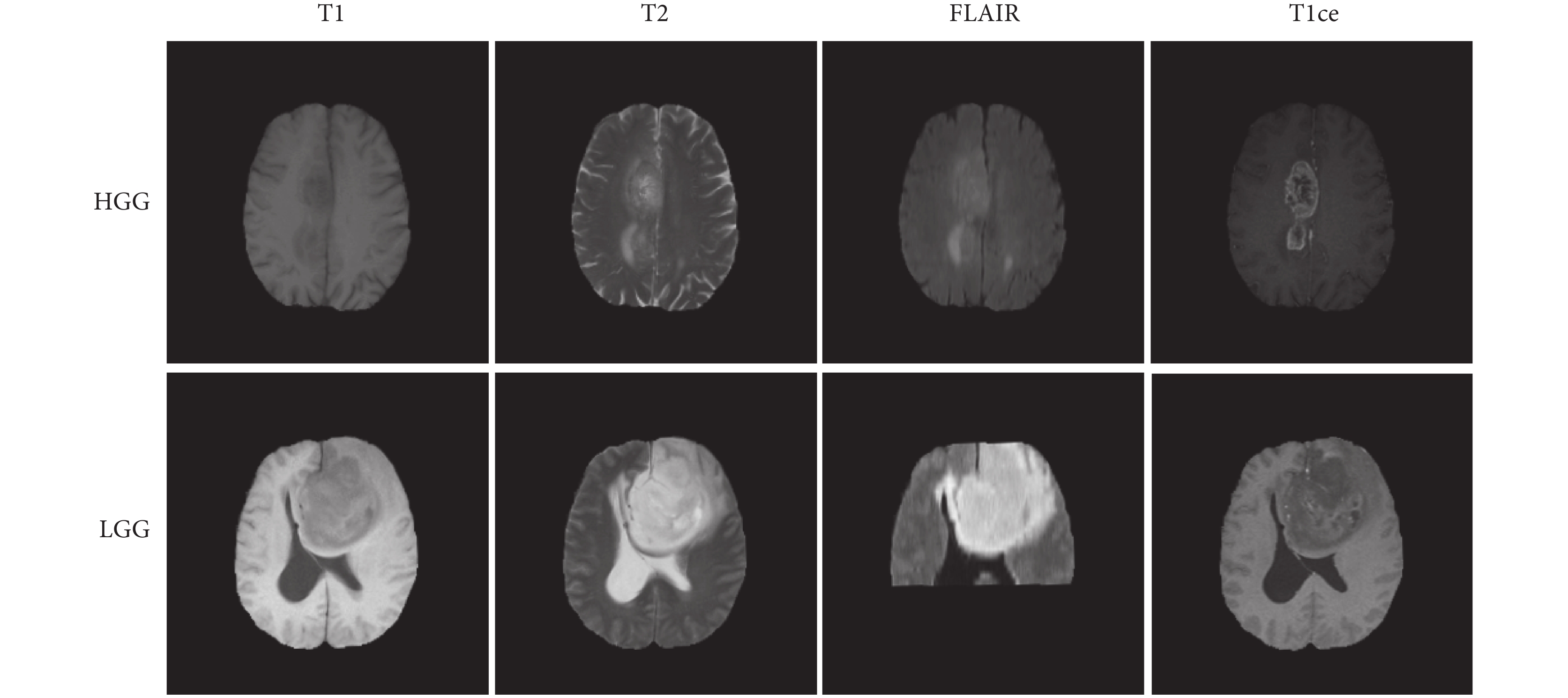
在實驗中,將Brats2019訓練集中335個患者以8:2的比例隨機劃分為訓練集和測試集,其中訓練集有267個患者,測試集有68個患者。在多模態對比學習和監督微調兩個階段,訓練集有3 204張圖像,包括2 484張HGG圖像和720張LGG圖像;測試集有816張圖像,包括624張HGG圖像和192張LGG圖像。對于模型的輸入,與MVI一樣,選擇腫瘤面積最大的切片及其上下兩片。如圖3所示,可以看到Brats2019數據集中HGG和LGG的多模態MRI。
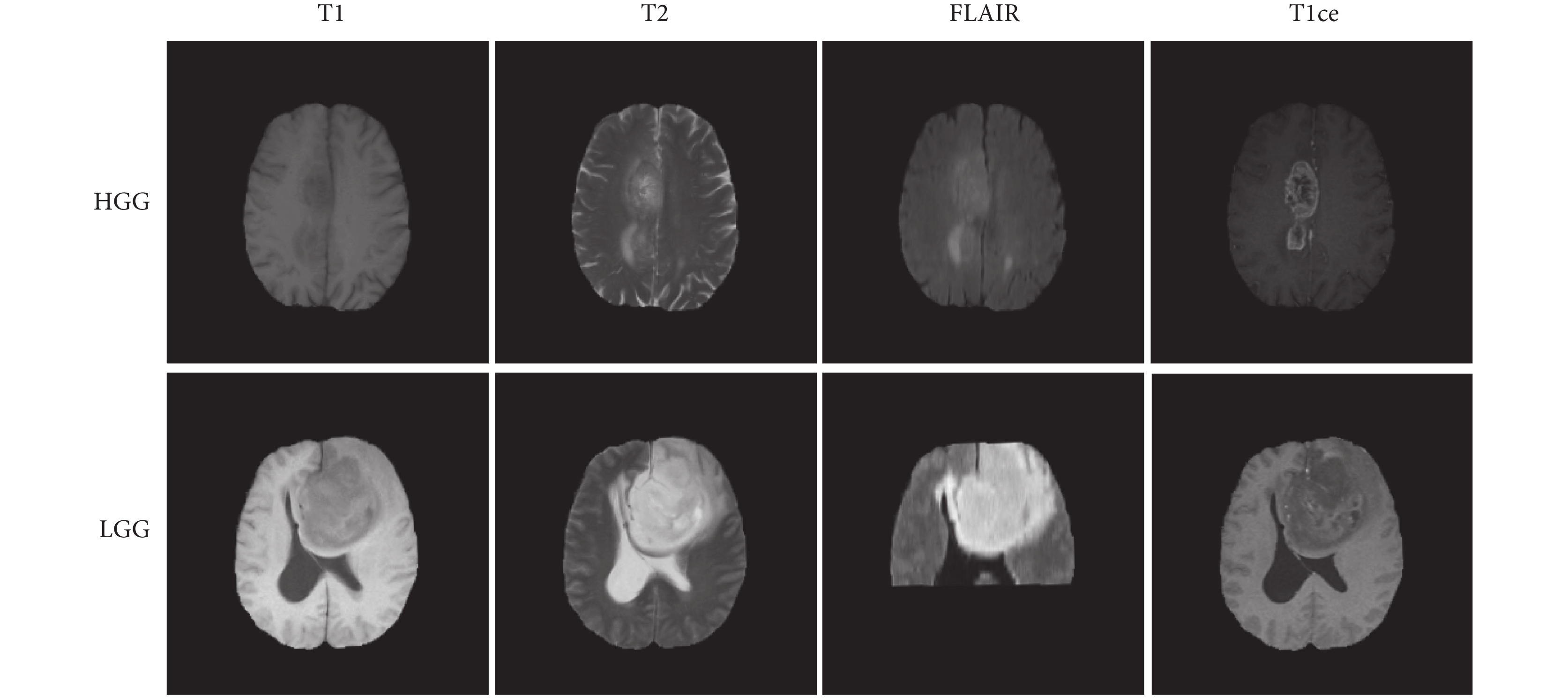 圖3
Brats2019數據集中多模態MRI示例圖
Figure3.
Example of multimodal MRI in Brats2019 dataset
圖3
Brats2019數據集中多模態MRI示例圖
Figure3.
Example of multimodal MRI in Brats2019 dataset
3.2 實驗環境及參數設置
在實驗過程中,所有模型都是使用開源機器學習庫PyTorch 1.8.1(Facebook Inc.,美國)實現,這些模型在兩塊顯存為11 G的英偉達顯卡(RTX 2080 Ti,NVIDIA Inc.,美國)上并行訓練。在多模態對比學習階段,初始學習率為0.001,批大小為64,訓練周期為500個迭代次數(epoch)。在訓練過程中,使用自適應邊界優化(adaptive bound optimization,adabound[28])方法來優化模型參數,并使用自適應的學習率更新策略:當訓練集上的損失在20個epoch中沒有減少時,學習率被減小到原來的0.5倍。在監督微調階段,由于分類網絡只有兩個全連接層,所以將初始學習率值設定更小,并以較小的epoch進行訓練,以防止模型過擬合。具體而言,分類網絡初始化的學習率為0.000 3,批大小為64,訓練周期為200個epoch,優化器為adabound,還使用了與多模態對比學習階段相同的學習率自適應更新策略。由于實驗數據存在一定程度上的不確定性,因此在課題研究中進行了三次實驗并取平均值來提高結果的可靠性。
在多模態對比學習階段和監督微調階段都使用了在線數據增強方法,它包括隨機縮放裁剪、旋轉和顏色失真。具體而言,在兩個數據集上進行隨機縮放裁剪的裁剪框大小為224×224,對訓練集中的所有圖像進行90 o、180 o和270 o旋轉,還將訓練集中的圖像以0.8的概率進行顏色轉換,其中亮度、對比度和飽和度變為原來的0.4倍,色調變為原來的0.2倍。此外,對數據集中的所有圖像都進行標準化處理,即每張圖像都進行減均值和除以標準差。在多模態對比學習階段,不僅使用在線數據增強方法(其中包括縮放裁剪、旋轉和顏色失真)對原始數據進行實時變換來擴展訓練集,以使模型具有更好的魯棒性和泛化能力;還使用離線數據增強方法(域自適應反標準化)在模型訓練之前,通過對原始數據進行一系列的處理,生成新的虛擬數據集,并將其添加到原始數據集中,從而擴大數據量和多樣性。
3.3 評價標準
本文采用以下五個指標來評估模型的性能:①準確率(accuracy,ACC),表示正確預測的樣本占總樣本的比例;②受試者工作特征(receiver operating characteristic,ROC)曲線下面積(area under ROC curve,AUC);③精準率(precision, PRE),表示所有預測為正類的樣本中實際為正類樣本所占的比例;④召回率(recall,REC),表示實際為正類的樣本中預測為正類樣本所占的比例;⑤F1分數(F1 score, F1)綜合考慮PRE和REC,是兩者的諧波平均值。
4 實驗結果與分析
本文方法在MVI和Brats2019兩個數據集上進行了一系列實驗,并與基線模型進行了比較,其中包括隨機初始化(random)、遷移學習(transfer)、SimCLR、BYOL、SimSiam、MICLe、Self-Trans和SMR。其中,random和transfer屬于監督學習,SimCLR、BYOL、SimSiam、MICLe和Self-Trans屬于單模態對比學習,而SMR屬于多模態對比學習。同時,在三個不同結構的網絡上驗證了域自適應反標準化方法的有效性。
4.1 本文方法的表現
為了驗證本文方法的有效性,在MVI數據集上進行了一系列實驗,量化實驗結果如表1所示。可以看出,本文方法的實驗結果不僅比單模態自監督學習方法要好,而且相較于多模態自監督學習方法也有一定的優勢。具體而言,和其它對比學習方法相比,本文方法在ACC、AUC、REC和F1上均有所提升。這表明本文提出的多模態對比學習方法可以有效地提高模型分類性能。此外,還可以發現SimCLR、BYOL、SimSiam、MICLe、Self-Trans、SMR以及本文方法都取得了比radom和transfer更好的結果,這說明對比學習的訓練策略是有效的,對比學習方法能夠從圖像中學習有意義的特征表達,從而提高模型在MVI診斷任務上的表現。
為了進一步驗證本文方法的有效性,本文還在Brats2019數據集上進行了一系列對比實驗,量化實驗結果如表2所示。可以看出,與其它方法相比,本文方法在ACC,REC,PRE和F1四個評價指標上均有所提升。實驗結果表明,本文方法對HGG患者和LGG患者的分類更加準確,從而說明本文方法的分類結果是穩定可靠的。此外,在Brats2019數據集上,基于對比預訓練的方法和基于遷移學習的方法的性能是相當的,而本文方法比前兩者有明顯優勢。這一結果歸功于多模態對比學習策略,它將同一患者的多個模態視為正樣本,因此可以充分學習各個模態之間的共有特征,從而改善疾病診斷的性能。實驗結果表明,本文方法還可以更好地應用于其它多模態醫學圖像中的疾病診斷任務,并取得有競爭力的結果。
4.2 多模態對比學習策略消融實驗
為了驗證多模態對比學習策略的有效性,在MVI數據集上使用不同結構的網絡進行了消融實驗,包括ShuffleNet、ResNet和Swin Transformer。實驗結果如表3所示,ResNet*、ShuffleNet*和Swin Transformer*表示采用多模態對比學習訓練策略,而ResNet、ShuffleNet和Swin Transformer表示采用普通的對比學習訓練策略。可以看到,在三種不同結構的網絡上采用多模態對比學習訓練策略取得了明顯的提升。具體而言,在MVI數據集上采用多模態對比學習的ResNet*在ACC、AUC、REC、PRE和F1上分別比沒有采用多模態對比學習的ResNet有所提升。同樣,相較于ShuffleNet和Swin Transformer,采用多模態對比學習策略的ShuffleNet*和Swin Transformer*結果也有所改進。實驗結果表明,在多模態醫學圖像數據集上采用提出的多模態對比學習方法進行預訓練有助于提高模型的性能。同時,本文方法具有良好的通用性和可擴展性,可以應用于各種不同結構的網絡。
4.3 域自適應反標準化方法消融實驗
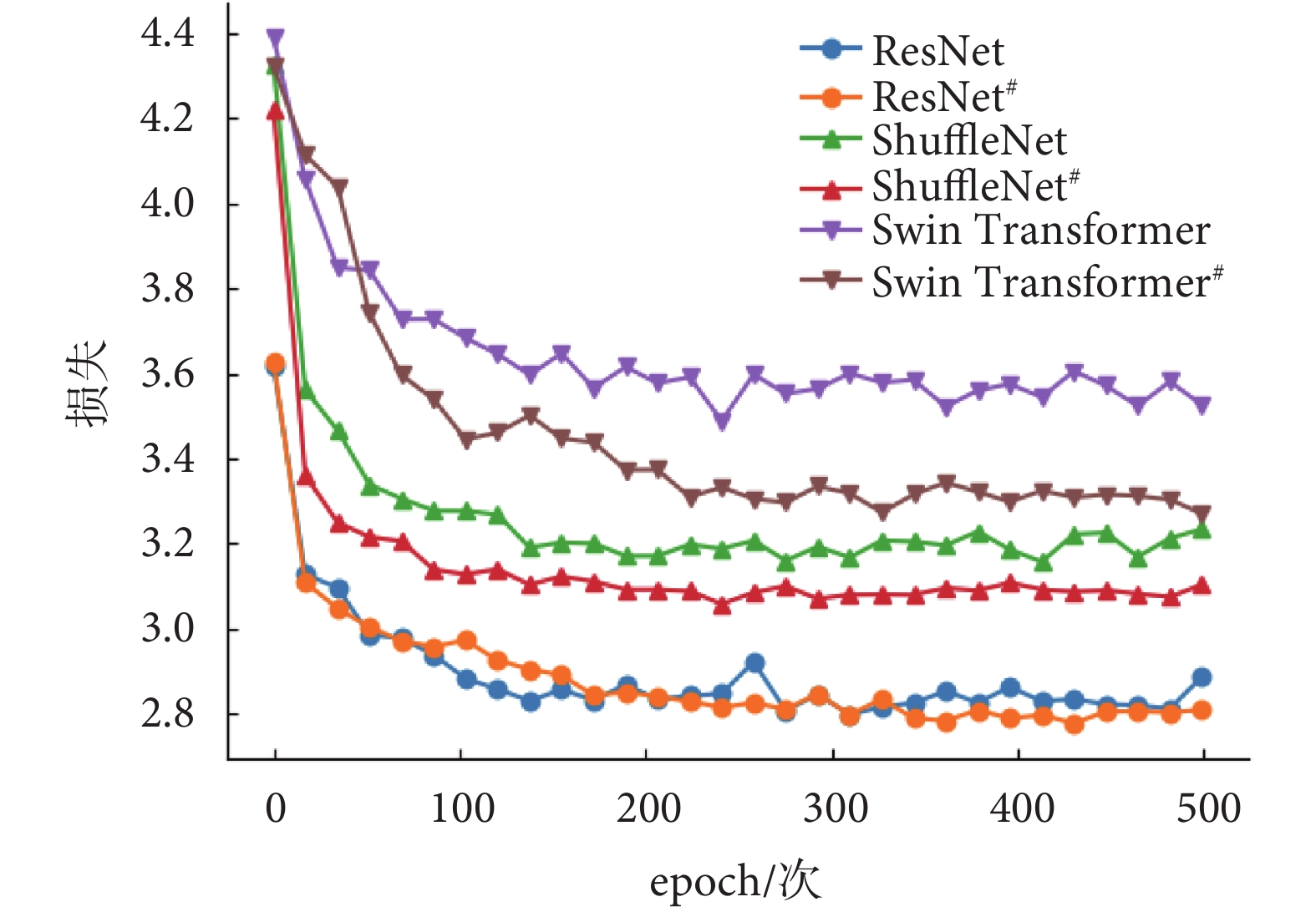
在MVI數據集上驗證本文提出的域自適應反標準化方法的消融實驗結果如圖4所示。ResNet#、ShuffleNet#和Swin Transformer#表示采用域自適應反標準化方法訓練,ResNet、ShuffleNet和Swin Transformer表示沒有采用域自適應反標準化方法訓練。在MVI數據集上使用域自適應反標準化方法訓練的ResNet#、ShuffleNet#和Swin Transformer#的損失曲線都低于沒有使用的ResNet、ShuffleNet和Swin Transformer的損失曲線。因此,這表明提出的域自適應反標準化方法可以提高模型在對比學習階段的學習能力。此外,使用ResNet作為特征編碼網絡的損失收斂最低,其次是ShuffleNet和Swin Transformer。因此,實驗結果表明在MVI數據集上使用ResNet可以更好地提取圖像特征。
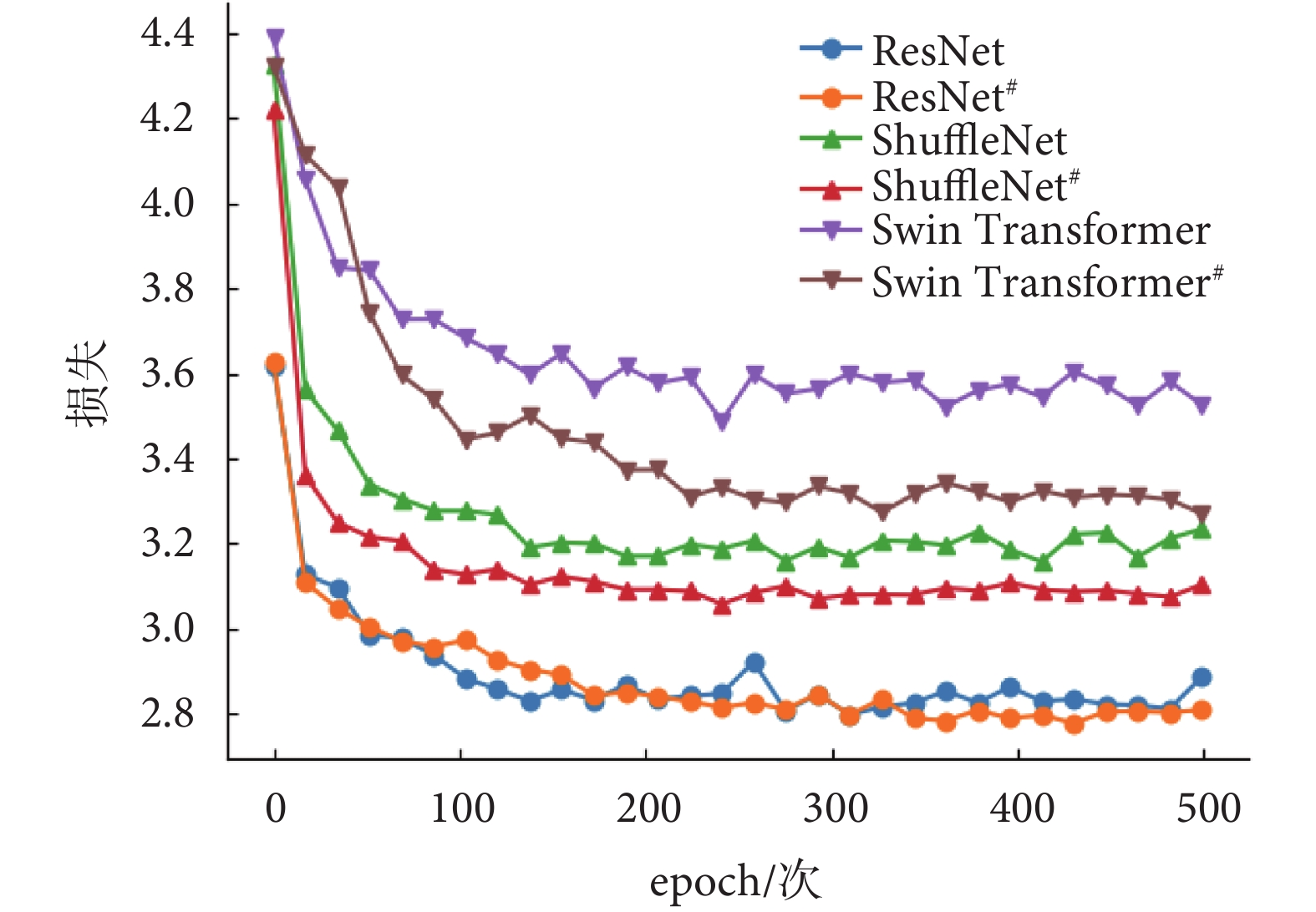 圖4
在MVI訓練集上使用域自適應反標準化的損失曲線的比較
Figure4.
Comparison of loss curves using domain adaptive denormalization on the MVI train set
圖4
在MVI訓練集上使用域自適應反標準化的損失曲線的比較
Figure4.
Comparison of loss curves using domain adaptive denormalization on the MVI train set
在MVI數據集上不同編碼網絡使用域自適應反標準化方法進行的消融實驗結果如表4所示。可以看到,采用域自適應反標準化的ResNet#、ShuffleNet#和Swin Transformer#比沒有使用域自適應反標準化的ResNet、ShuffleNet和Swin Transformer有一定的提升。實驗結果進一步表明在多模態醫學圖像數據集上采用提出的域自適應反標準化方法對訓練集進行擴充,有助于提升模型的性能。
4.4 編碼網絡特征維度消融實驗
本文探究了多模態對比學習階段特征編碼網絡的維度對實驗結果的影響。實驗中,在MVI數據集上采用ResNet作為特征編碼網絡,將特征維度分別設置為64、128、256和512進行消融實驗。實驗結果如表5所示,當特征維度為128時,模型預測的AUC和PRE達到最大值;當特征維度為256時,模型預測的ACC、REC和F1達到最大值,并且REC和F1相比其它維度有明顯的優勢。綜合比較而言,將特診編碼維度設置為256,可以取得更好的實驗結果。
5 結論
針對大規模醫學圖像標注數據難以獲取的問題,以及遷移學習和自監督學習在多模態醫學圖像任務中少有研究的現狀,本文提出了一種多模態對比學習方法。該方法將同一患者多模態的醫學圖像作為正樣本,不同患者的多模態醫學圖像作為負樣本,這樣可以有效增強訓練過程中的正樣本數量,使模型盡可能充分地學習多模態醫學圖像上病灶的相似性,從而提升模型對疾病的分類準確率。此外,由于實驗數據規模較小,而傳統的數據增強方法并不適用于多模態醫學圖像,因此本文提出了一種域自適應反標準化方法。該方法采用目標域的統計信息對源域進行數據擴增,從而在不改變整個數據集分布的情況下有效地擴充數據量。最后,在兩個數據集(MVI、Brats2019)上進行了廣泛的實驗,實驗結果表明,本文提出的多模態對比學習方法可以在兩個數據集上實現良好的性能。該方法為多模態醫學圖像數據集的預訓練提供了一個可行的參考方案,推動了深度學習在多模態醫學圖像領域的進一步發展。
在未來的工作中,計劃將患者的臨床數據融入本文提出的多模態對比學習方法中,以高效利用患者的多模態數據進行融合來提升疾病的診斷能力。此外,本文提出的域自適應反標準化方法是一種通用算法,很容易推廣到其它的多模態數據集中。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻說明:文含主要負責數據處理、算法設計與實現以及撰寫論文,趙瑩主要負責數據的收集和整理工作,蔡秀定主要負責算法設計和提出修改意見,付忠良參與了算法設計和指導論文寫作,劉愛連和姚宇提供了基金支持和提出修改意見。
倫理聲明:本研究通過了大連醫科大學附屬第一醫院倫理委員會的審批(批文編號:PJ-KS-KY-2019-167)
0 引言
最近,深度學習在各種醫學圖像任務中表現出良好的性能,如病灶分割、疾病診斷和療效預測[1]。然而,深度學習在醫學圖像中的應用也面臨一些挑戰,其中一個主要問題就是缺乏充足的標注數據。醫學圖像的標注通常需要專業醫生才能完成,任務難度較大且成本較高,因此如何從有限的標注數據中學習有代表性的特征成為一個迫切需要解決的問題。
目前,從有限的標注數據集中學習有代表性的特征主要有兩種常見的方法:一種方法是在大規模公共數據集上進行有監督的預訓練[2-4];另一種方法是在沒有標注的數據集上使用自監督學習進行自監督預訓練,然后在目標數據集上對預訓練的模型進行有監督的微調[5-6]。然而,這些方法在應用于醫學圖像任務時,存在一些局限性。對于第一種方法,將公共數據集上訓練的模型直接遷移到醫學圖像任務上,似乎沒有考慮到由于自然圖像和醫學圖像之間的分布差異而可能導致的模型性能下降的問題。這種方法是次優的,因為醫學圖像理解通常需要細粒度的視覺特征,這些特征與識別自然圖像中物體所需的特征完全不同。例如,Raghu等[7]研究發現,與簡單的隨機初始化相比,大規模視覺識別挑戰賽數據集(ImageNet)預訓練對模型性能的提升幾乎沒有效果。對于第二種方法,雖然自監督學習已經在一些醫學影像任務中取得了成果,如心臟磁共振成像(magnetic resonance imaging,MRI)分割[8]、視網膜疾病診斷[9]和新型冠狀病毒感染(corona virus disease 2019,COVID-19)診斷[10],但是每種醫學圖像都有其自身的噪聲和缺陷,這可能導致自監督學習方法的性能受到限制。而多模態醫學圖像可以提供互補信息[11],例如電子計算機斷層掃描(computed tomography,CT)可以提供組織密度信息,MRI可以提供組織構造信息等。通過聯合使用多模態醫學圖像進行自監督學習,可以獲得更全面和更準確的信息,從而提高對疾病的理解和診斷,因此研究多模態醫學圖像的自監督學習具有重要的意義。
多模態醫學圖像是患者在不同的醫療設備或同一設備的不同參數下獲得的,可以為醫學圖像診斷提供更豐富的信息。在這項研究中,本文提出了一個多模態對比學習框架,可以有效地利用每個患者的多模態醫學圖像來學習共有的特征表達。本文方法是從一個小批量數據中隨機選擇兩個模態圖像,如果這兩個模態圖像屬于一個患者,那么就被視為正樣本對。如果這兩個模態圖像不屬于同一個患者,那么就被視為負樣本對。然后,將這兩個模態的圖像分別輸入到對應特征編碼網絡中提取圖像特征,并通過投影網絡將獲得的特征映射到一個特征空間。接下來,通過對比損失使正樣本對在特征空間中盡可能地接近,而負樣本對則盡可能地遠離。最后,將預訓練好的特征編碼網絡遷移到目標任務上進行監督微調,以提高模型在目標數據集上的性能。
有研究表明,使用合理的數據增強方法可以改善自監督學習[12]。目前使用的數據增強方法(裁剪、調整大小、旋轉等)通常不能很好地考慮多模態醫學圖像的特點。由于數據集的統計信息包含分類任務的相關信息,因此本文提出了一種域自適應反標準化方法。該方法利用多模態數據集中各模態的統計信息對其它模態的數據進行數據轉換,可以有效擴大各模態樣本的數據量,從而提高模型對各模態數據的適應能力。具體而言,首先從多模態醫學圖像數據集中隨機選擇兩種模態作為源域和目標域,然后對源域和目標域的圖像進行標準化,最后利用目標域的統計信息對源域進行反標準化,從而得到轉換后的圖像。域自適應反標準化方法可以合理地利用各個模態圖像的統計信息實現有效地數據擴充。
為了公平地比較有監督預訓練、對比學習和本文方法,在兩個不同的醫學圖像數據集上進行了對比實驗:①基于肝細胞癌(hepatocellular carcinoma,HCC)多期相MRI的微血管浸潤(microvascular infiltration,MVI)識別;②基于腦膠質瘤多模態MRI的病理分級。此外,由于兩個數據集的數據量較小,本文在多模態對比學習階段使用域自適應反標準化方法來擴大數據量。綜上,通過本文提出的多模態對比學習算法在兩個數據集上進行驗證,以期獲得良好的性能,或可為多模態醫學圖像的預訓練提供一種參考方案。
1 相關工作
1.1 對比學習
對比學習作為自監督學習中一個非常重要的部分,被廣泛應用于計算機視覺、自然語言處理等領域。在對比學習中,通常會將兩個樣本輸入到模型中,并使用某種度量函數來計算它們之間的相似度或距離。這個度量函數可以是歐式距離、余弦相似度等。如果兩個樣本屬于同一類別,則目標是使它們的相似度盡可能高;如果屬于不同類別,則目標是使它們的相似度盡可能低。在計算機視覺領域,基于對比學習的方法已經在大規模公共數據集上取得了最先進的性能。例如,簡明對比學習(simple contrastive learning of representations,SimCLR)框架[12]、動量對比學習(momentum contrastive learning,MOCO)框架[13]、自舉潛變量學習(bootstrap your own latent learning,BYOL)框架[14]和孿生表示學習(simple siamese representation learning,SimSiam)框架[15]。
最近,對比學習在醫學圖像任務中已經取得了一些成果。例如,Chaitanya等[16]引入了一個基于混合對比損失的自監督學習分割模型,該模型能夠學習局部和全局圖像表征。Sowrirajan等[17]使用MOCO在大型X光胸片數據集(chest expert,CheXpert)[18]上進行預訓練,然后對模型的分類性能進行評估。He等[10]提出了一種自我遷移對比學習框架(self-supervised learning and transfer learning,Self-Trans),以提高CT影像中COVID-19的分類準確率。Aziz等[19]提出了一種多實例對比學習方法(multi-instance contrastive learning,MICLe),以提高數碼相機圖像中皮膚病的分類精度。這些工作都表明在醫學圖像上采用對比學習方法可以提取到有代表性的特征,這些特征有助于模型對醫學圖像的理解,從而提高模型對疾病的診斷能力。
1.2 醫學多模態學習
與單模態醫學圖像相比,多模態醫學圖像通常由不同的醫學成像模態組成,例如CT、MRI和正電子發射斷層(positron emission tomography,PET)等,這些模態之間存在著豐富的信息交叉和相互依賴關系。研究人員已經開始關注多模態醫學圖像的應用,例如,Hervella等[9]提出了一個基于自監督多模態重建(self-supervised multimodal reconstruction,SMR)的視網膜計算機輔助診斷(computer-aided diagnosis,CAD)系統,該系統利用互補成像模態之間的多模態重建實現,并取得了比單模態更好的實驗結果。Windsor等[20]介紹了一個基于對比學習的多模態醫學圖像配準框架,該框架可以精確地配準同一患者的不同模態的醫學圖像。Taleb等[21]提出了一種自監督學習方法,它可以用來匹配無標簽的醫學圖像和遺傳數據,以揭示圖像和遺傳數據之間的關系。這些工作表明,采用多模態數據進行學習可以取得比單模態更好的效果。本文采用對比學習方法在多模態醫學圖像數據集上進行實驗,旨在學習不同模態圖像之間病灶的相似性,以獲得更全面、準確的信息,從而提高對疾病檢測和診斷的能力。
1.3 數據增強
常用的數據增強方法可以分為兩類:一類是標簽保持的數據增強方法,例如:對圖像進行幾何變換,包括翻轉、旋轉、移動、裁剪、扭曲、縮放等各種操作;或者對圖像的顏色進行變換,常見的有添加噪聲、模糊、擦除、填充等。然而,這類方法并不是專門為多模態醫學圖像設計的。另一類是標簽擾動的數據增強方法,例如,Zhang等[22]通過將訓練集中的圖像和標簽都按一定比例融合,生成新的數據。Yun等[23]通過隨機刪除一個圖像中的矩形區域,并用另一個圖像相同位置的像素值填充的方式進行數據擴充,同時根據像素的比例份額分配標簽。雖然標簽擾動的數據增強方法可以用于多模態醫學圖像數據,但是它們改變了數據的分布,可能會引入噪聲和誤差,從而影響模型的性能和穩定[23]。本研究針對多模態數據專門設計了一種域自適應反標準化方法,該方法能夠有效地使用不同模態數據的統計信息對圖像進行轉換,從而在不改變整個數據分布的情況下實現數據擴展。這是一種新型的多模態數據增強方法,可用于提高多模態醫學圖像分類的性能。
2 方法
本文提出的方法主要包括兩個階段,如圖1所示。在多模態對比學習階段,使用提出的多模態對比學習方法對多個模態的圖像進行預訓練。在監督微調階段,將訓練好的模型遷移到目標數據集上進行有監督微調。接下來,在以下章節詳細描述本文方法。
圖1
多模態對比學習方法的框架圖
Figure1.
Framework diagram of multimodal contrastive learning method
2.1 多模態對比學習
在對多模態醫學圖像數據集進行訓練時,隨機選擇一個有N個患者的小批次數據,其中每個患者X={x1, x2, ..., xm}可能包含多個模態醫學圖像。假設,由于患者的不同,m可能是不同的。在多模態對比學習階段,從N個患者的小批次數據中隨機選擇兩個模態的圖像,如果這兩個模態的圖像屬于同一個患者,如圖1中xi和xj分別屬于數據集中第16號患者的動脈期(arterial phase,AP)(16-AP)和靜脈期(portal venous phase,PVP)(16-PVP),那么xi和xj就構成一個正樣本對。如果這兩個模態的圖像屬于不同患者,如圖1中xi和xk分別屬于數據集中16-AP和第10號患者的延遲期(delayed phase,DP)(10-DP),那么xi和xk就構成一個負樣本對。其次,將這兩個模態的圖像xi和xj(或xk)輸入數據增強模塊,對它們分別進行隨機的圖像增強操作,得到增強后的圖像 和 (或 )。然后,將 和 (或 )分別輸入對應的特征編碼網絡f(?),以提取圖像特征hi和hj(或hk)。接著,將這兩個特征hi和hj(或hk)分別輸入到投影網絡g(?),它們被映射到同一特征空間,并生成兩個特征向量zi和zj(或zk)。最后,采用對比損失來縮短zi和zj之間的距離,同時擴大zi和zk之間的距離。通過這種隱式的多模態融合方法使模型學習病灶在不同模態之間的相似性和差異性,有助于更好地理解不同模態之間的關系,從而提高模型對醫學圖像的理解能力和診斷準確率。
本文提出的多模態對比學習框架由以下幾部分組成:
(1)數據增強。數據增強的作用是將輸入圖像對xi和xj隨機轉化為增強的圖像對 和 。本研究中使用的數據增強操作包括隨機縮放裁剪、隨機顏色失真,以及旋轉90 o、180 o和270 o。
(2)編碼網絡。編碼網絡的作用是將增強的圖像對 和 映射成一對特征向量hi和hj。在實驗過程中,使用不同結構的網絡進行實驗,包括通道改組神經網絡(shuffle neural network,ShuffleNet)[24]、殘差神經網絡(residual neural network,ResNet)[25]和帶移動窗口的轉換器(shifted windows transformer,Swin Transformer)[26],以驗證本文方法的有效性。
(3)投影網絡。投影網絡的作用是將編碼的特征對hi和hj投影到一個向量空間中,然后使用對比損失來評估投影特征對zi和zj的相似度。在實驗中,使用兩個全連接層來組成投影網絡,投影網絡的隱藏層和輸出層的維度分別為256和128。
(4)對比損失。對比損失的作用是縮短正樣本對特征zi和zj之間的距離,同時擴大負樣本對zi和zk之間的距離。這樣可以使模型學習到腫瘤在不同模態圖像之間共同的特征,從而提高模型的表達能力和準確性。本文中對比損失Li, j的定義如式(1)所示:
|
其中,sim(?, ?)是兩個向量zi和zj之間的余弦相似度;,當k和i相等時為0,不等時為1;τ是一個溫度標量。
2.2 監督微調
將多模態醫學圖像數據集上使用對比學習訓練的模型遷移到目標任務上進行監督微調,以提高模型在目標任務上的表現。在實驗中,凍結了在多模態對比學習階段訓練的特征編碼網絡的權重,并在特征編碼網絡之后添加了一個目標任務的分類網絡。該分類網絡由兩個全連接層組成,中間是批量歸一化(batch normalization,BN)和帶泄漏修正線性單元(leaky rectified linear unit,Leaky ReLU)激活函數。這兩個全連接層的維度為256和2。它們的初始化參數是由愷明(kaiming)[27]初始化方法產生的。
2.3 域自適應反標準化
在本節中,將仔細介紹域自適應反標準化方法。具體而言,將每一個模態視為一個域,并對每個域的圖像進行標準化處理,然后利用其它域的統計信息對當前域的標準化數據進行反標準化處理,從而實現不同域數據之間的適應。
本文使用目標域數據的統計信息來擴展源域數據,對于任何多模態數據集,將任意兩個模態作為源域Ds和目標域Dt,分別用M和N表示Ds和Dt的樣本數量。整個域自適應反標準化方法的詳細描述如下:
步驟(1):分別統計源域Ds中每張圖像的平均值μs和標準差σs,以及目標域Dt中每張圖像的平均值μt和標準差σt,其定義如式(2)和式(3)所示:
|
|
步驟(2):根據步驟(1)中計算的平均值μs和標準差σs對源域Ds中每張圖像進行標準化處理,得到標準化后的圖像。同樣,對目標域Dt中每張圖像采取同樣的標準化處理,得到標準化后的圖像。標準化的計算如式(4)所示:
|
步驟(3):將源域Ds中每張標準化的圖像乘以目標域的標準差σt,再加上目標域的平均值μt,這樣就可以得到反標準化的圖像。同樣,對目標域Dt中每張標準化的圖像進行同樣的反標準化處理,就可以得到反標準化的圖像。反標準化的計算如式(5)所示:
|
3 實驗數據和設置
3.1 數據和預處理
本文方法在兩個不同的醫學圖像任務上進行了實驗。第一個任務是在三個期相的MRI上診斷HCC的MVI。第二個任務是在四個模態的MRI上對腦腫瘤進行病理分級。
對于MVI識別任務,實驗數據集由大連醫科大學第一附屬醫院放射科提供,并且數據集中的所有患者都經組織病理學證實為MVI。該數據集包含了261名HCC患者三種期相的MRI,分別為AP、PVP、DP。其中182名患者為陰性,79名患者為陽性。整個數據集由兩位具有10年MRI診斷經驗的放射科醫生進行注釋,并由另一位具有20年經驗的資深放射科醫生進行校準。該研究經大連醫科大學附屬第一醫院醫學倫理委員會審查獲得批準,并授權可以使用數據集中所有影像資料數據(批文編號:PJ-KS-KY-2019-167)。
在實驗中,將數據集按照8:2的比例隨機劃分為訓練集和測試集。在多模態對比學習和監督微調兩個階段,訓練集有1 881張圖像,包括567張陽性圖像和1 314張陰性圖像;測試集有468張圖像,包括144張陽性圖像和324張陰性圖像。對于模型的輸入,從每個患者的三個期相MRI中選擇腫瘤面積最大的切片及其上下兩片。如圖2所示,可以看到MVI數據集中陰性和陽性的多期相MRI。
圖2
MVI數據集中多期相MRI示例圖
Figure2.
Example of multi-phase MRI in MVI dataset
對于腦腫瘤病理分級任務,本文采用2019年多模態腦瘤分割挑戰賽(multimodal brain tumor segmentation challenge 2019, Brats2019)數據庫作為實驗數據來源。該數據庫共包含626個腦瘤患者,其中訓練集有335個患者,驗證集有125個患者,測試集有166個患者。由于驗證集和測試集沒有公開發布,在實驗中只使用訓練集中335個患者的多模態MRI,其中259名患者為高級別膠質瘤(high-grade glioma,HGG),76名患者為低級別膠質瘤(low-grade glioma,LGG)。每個患者都有四個模態的MRI,分別為T1、T2、液體衰減反轉恢復(fluid-attenuated inversion recovery,FLAIR)序列和對比增強T1加權(contrast-enhanced T1-weighted, T1ce)序列。每個模態的MRI有155張切片圖像,每張切片圖像的大小為240×240。本研究已得到Brats2019數據庫創建機構的授權,并可免費使用數據庫中所有數據資料。
在實驗中,將Brats2019訓練集中335個患者以8:2的比例隨機劃分為訓練集和測試集,其中訓練集有267個患者,測試集有68個患者。在多模態對比學習和監督微調兩個階段,訓練集有3 204張圖像,包括2 484張HGG圖像和720張LGG圖像;測試集有816張圖像,包括624張HGG圖像和192張LGG圖像。對于模型的輸入,與MVI一樣,選擇腫瘤面積最大的切片及其上下兩片。如圖3所示,可以看到Brats2019數據集中HGG和LGG的多模態MRI。
圖3
Brats2019數據集中多模態MRI示例圖
Figure3.
Example of multimodal MRI in Brats2019 dataset
3.2 實驗環境及參數設置
在實驗過程中,所有模型都是使用開源機器學習庫PyTorch 1.8.1(Facebook Inc.,美國)實現,這些模型在兩塊顯存為11 G的英偉達顯卡(RTX 2080 Ti,NVIDIA Inc.,美國)上并行訓練。在多模態對比學習階段,初始學習率為0.001,批大小為64,訓練周期為500個迭代次數(epoch)。在訓練過程中,使用自適應邊界優化(adaptive bound optimization,adabound[28])方法來優化模型參數,并使用自適應的學習率更新策略:當訓練集上的損失在20個epoch中沒有減少時,學習率被減小到原來的0.5倍。在監督微調階段,由于分類網絡只有兩個全連接層,所以將初始學習率值設定更小,并以較小的epoch進行訓練,以防止模型過擬合。具體而言,分類網絡初始化的學習率為0.000 3,批大小為64,訓練周期為200個epoch,優化器為adabound,還使用了與多模態對比學習階段相同的學習率自適應更新策略。由于實驗數據存在一定程度上的不確定性,因此在課題研究中進行了三次實驗并取平均值來提高結果的可靠性。
在多模態對比學習階段和監督微調階段都使用了在線數據增強方法,它包括隨機縮放裁剪、旋轉和顏色失真。具體而言,在兩個數據集上進行隨機縮放裁剪的裁剪框大小為224×224,對訓練集中的所有圖像進行90 o、180 o和270 o旋轉,還將訓練集中的圖像以0.8的概率進行顏色轉換,其中亮度、對比度和飽和度變為原來的0.4倍,色調變為原來的0.2倍。此外,對數據集中的所有圖像都進行標準化處理,即每張圖像都進行減均值和除以標準差。在多模態對比學習階段,不僅使用在線數據增強方法(其中包括縮放裁剪、旋轉和顏色失真)對原始數據進行實時變換來擴展訓練集,以使模型具有更好的魯棒性和泛化能力;還使用離線數據增強方法(域自適應反標準化)在模型訓練之前,通過對原始數據進行一系列的處理,生成新的虛擬數據集,并將其添加到原始數據集中,從而擴大數據量和多樣性。
3.3 評價標準
本文采用以下五個指標來評估模型的性能:①準確率(accuracy,ACC),表示正確預測的樣本占總樣本的比例;②受試者工作特征(receiver operating characteristic,ROC)曲線下面積(area under ROC curve,AUC);③精準率(precision, PRE),表示所有預測為正類的樣本中實際為正類樣本所占的比例;④召回率(recall,REC),表示實際為正類的樣本中預測為正類樣本所占的比例;⑤F1分數(F1 score, F1)綜合考慮PRE和REC,是兩者的諧波平均值。
4 實驗結果與分析
本文方法在MVI和Brats2019兩個數據集上進行了一系列實驗,并與基線模型進行了比較,其中包括隨機初始化(random)、遷移學習(transfer)、SimCLR、BYOL、SimSiam、MICLe、Self-Trans和SMR。其中,random和transfer屬于監督學習,SimCLR、BYOL、SimSiam、MICLe和Self-Trans屬于單模態對比學習,而SMR屬于多模態對比學習。同時,在三個不同結構的網絡上驗證了域自適應反標準化方法的有效性。
4.1 本文方法的表現
為了驗證本文方法的有效性,在MVI數據集上進行了一系列實驗,量化實驗結果如表1所示。可以看出,本文方法的實驗結果不僅比單模態自監督學習方法要好,而且相較于多模態自監督學習方法也有一定的優勢。具體而言,和其它對比學習方法相比,本文方法在ACC、AUC、REC和F1上均有所提升。這表明本文提出的多模態對比學習方法可以有效地提高模型分類性能。此外,還可以發現SimCLR、BYOL、SimSiam、MICLe、Self-Trans、SMR以及本文方法都取得了比radom和transfer更好的結果,這說明對比學習的訓練策略是有效的,對比學習方法能夠從圖像中學習有意義的特征表達,從而提高模型在MVI診斷任務上的表現。
為了進一步驗證本文方法的有效性,本文還在Brats2019數據集上進行了一系列對比實驗,量化實驗結果如表2所示。可以看出,與其它方法相比,本文方法在ACC,REC,PRE和F1四個評價指標上均有所提升。實驗結果表明,本文方法對HGG患者和LGG患者的分類更加準確,從而說明本文方法的分類結果是穩定可靠的。此外,在Brats2019數據集上,基于對比預訓練的方法和基于遷移學習的方法的性能是相當的,而本文方法比前兩者有明顯優勢。這一結果歸功于多模態對比學習策略,它將同一患者的多個模態視為正樣本,因此可以充分學習各個模態之間的共有特征,從而改善疾病診斷的性能。實驗結果表明,本文方法還可以更好地應用于其它多模態醫學圖像中的疾病診斷任務,并取得有競爭力的結果。
4.2 多模態對比學習策略消融實驗
為了驗證多模態對比學習策略的有效性,在MVI數據集上使用不同結構的網絡進行了消融實驗,包括ShuffleNet、ResNet和Swin Transformer。實驗結果如表3所示,ResNet*、ShuffleNet*和Swin Transformer*表示采用多模態對比學習訓練策略,而ResNet、ShuffleNet和Swin Transformer表示采用普通的對比學習訓練策略。可以看到,在三種不同結構的網絡上采用多模態對比學習訓練策略取得了明顯的提升。具體而言,在MVI數據集上采用多模態對比學習的ResNet*在ACC、AUC、REC、PRE和F1上分別比沒有采用多模態對比學習的ResNet有所提升。同樣,相較于ShuffleNet和Swin Transformer,采用多模態對比學習策略的ShuffleNet*和Swin Transformer*結果也有所改進。實驗結果表明,在多模態醫學圖像數據集上采用提出的多模態對比學習方法進行預訓練有助于提高模型的性能。同時,本文方法具有良好的通用性和可擴展性,可以應用于各種不同結構的網絡。
4.3 域自適應反標準化方法消融實驗
在MVI數據集上驗證本文提出的域自適應反標準化方法的消融實驗結果如圖4所示。ResNet#、ShuffleNet#和Swin Transformer#表示采用域自適應反標準化方法訓練,ResNet、ShuffleNet和Swin Transformer表示沒有采用域自適應反標準化方法訓練。在MVI數據集上使用域自適應反標準化方法訓練的ResNet#、ShuffleNet#和Swin Transformer#的損失曲線都低于沒有使用的ResNet、ShuffleNet和Swin Transformer的損失曲線。因此,這表明提出的域自適應反標準化方法可以提高模型在對比學習階段的學習能力。此外,使用ResNet作為特征編碼網絡的損失收斂最低,其次是ShuffleNet和Swin Transformer。因此,實驗結果表明在MVI數據集上使用ResNet可以更好地提取圖像特征。
圖4
在MVI訓練集上使用域自適應反標準化的損失曲線的比較
Figure4.
Comparison of loss curves using domain adaptive denormalization on the MVI train set
在MVI數據集上不同編碼網絡使用域自適應反標準化方法進行的消融實驗結果如表4所示。可以看到,采用域自適應反標準化的ResNet#、ShuffleNet#和Swin Transformer#比沒有使用域自適應反標準化的ResNet、ShuffleNet和Swin Transformer有一定的提升。實驗結果進一步表明在多模態醫學圖像數據集上采用提出的域自適應反標準化方法對訓練集進行擴充,有助于提升模型的性能。
4.4 編碼網絡特征維度消融實驗
本文探究了多模態對比學習階段特征編碼網絡的維度對實驗結果的影響。實驗中,在MVI數據集上采用ResNet作為特征編碼網絡,將特征維度分別設置為64、128、256和512進行消融實驗。實驗結果如表5所示,當特征維度為128時,模型預測的AUC和PRE達到最大值;當特征維度為256時,模型預測的ACC、REC和F1達到最大值,并且REC和F1相比其它維度有明顯的優勢。綜合比較而言,將特診編碼維度設置為256,可以取得更好的實驗結果。
5 結論
針對大規模醫學圖像標注數據難以獲取的問題,以及遷移學習和自監督學習在多模態醫學圖像任務中少有研究的現狀,本文提出了一種多模態對比學習方法。該方法將同一患者多模態的醫學圖像作為正樣本,不同患者的多模態醫學圖像作為負樣本,這樣可以有效增強訓練過程中的正樣本數量,使模型盡可能充分地學習多模態醫學圖像上病灶的相似性,從而提升模型對疾病的分類準確率。此外,由于實驗數據規模較小,而傳統的數據增強方法并不適用于多模態醫學圖像,因此本文提出了一種域自適應反標準化方法。該方法采用目標域的統計信息對源域進行數據擴增,從而在不改變整個數據集分布的情況下有效地擴充數據量。最后,在兩個數據集(MVI、Brats2019)上進行了廣泛的實驗,實驗結果表明,本文提出的多模態對比學習方法可以在兩個數據集上實現良好的性能。該方法為多模態醫學圖像數據集的預訓練提供了一個可行的參考方案,推動了深度學習在多模態醫學圖像領域的進一步發展。
在未來的工作中,計劃將患者的臨床數據融入本文提出的多模態對比學習方法中,以高效利用患者的多模態數據進行融合來提升疾病的診斷能力。此外,本文提出的域自適應反標準化方法是一種通用算法,很容易推廣到其它的多模態數據集中。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻說明:文含主要負責數據處理、算法設計與實現以及撰寫論文,趙瑩主要負責數據的收集和整理工作,蔡秀定主要負責算法設計和提出修改意見,付忠良參與了算法設計和指導論文寫作,劉愛連和姚宇提供了基金支持和提出修改意見。
倫理聲明:本研究通過了大連醫科大學附屬第一醫院倫理委員會的審批(批文編號:PJ-KS-KY-2019-167)