帕金森病患者早期存在聲帶損傷,其聲紋特征與健康人存在明顯差異,可以利用該差異識別帕金森病,但帕金森病患者聲紋數據樣本不足,因此本文提出雙自注意力深度卷積生成對抗網絡模型進行樣本增強,生成高分辨率的語譜圖,進而采用深度學習方法進行帕金森病識別。該模型通過增加網絡深度并結合梯度懲罰、頻譜歸一化技術改進樣本的紋理清晰度,并且構建一個基于遷移學習的純粹的卷積神經網絡家族(ConvNeXt)作為分類網絡,以此提取聲紋特征并進行分類,提升了帕金森病識別準確率。在帕金森病語音數據集上進行本文算法有效性驗證實驗,對比樣本增強前,本文所提模型生成的樣本清晰度以及弗雷謝起始距離(FID)均得到提高,并且本文網絡模型能夠獲得98.8%的準確率。本文研究結果表明,基于雙自注意力深度卷積生成對抗網絡樣本增強的帕金森病識別算法能夠準確區分健康人和帕金森病患者,有助于解決帕金森病早期識別聲紋數據樣本不足的問題。綜上,本文方法有效提高小樣本帕金森病語音數據集分類準確率,為早期帕金森病語音診斷提供了一種有效的解決思路。
引用本文: 張子豪, 趙德春, 王子瓊, 韋莉. 基于樣本增強的帕金森病識別算法研究. 生物醫學工程學雜志, 2024, 41(1): 17-25, 33. doi: 10.7507/1001-5515.202304011 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
帕金森病(Parkinson’s disease,PD)是一種神經退行性疾病,多發病于中老年人群。據預測,到2025年,中國帕金森病患者人數將增加到38.85萬人[1]。大約90%的帕金森病患者早期存在聲帶損傷,表現為嘴唇和下巴運動的幅度和速度降低、語音質量下降,發音呈單音和單色[2-3]、高振幅微擾、低信噪比和低基頻等特點[4-5]。在帕金森病早期檢測中,基于聲學特征的分析技術起到了重要作用,通過分析持續元音能及早地檢測帕金森病[6-8],該方法高效、便捷,已為廣大民眾所接受。
目前,機器學習方法已廣泛應用于帕金森病的早期檢測中。例如,Almeida等[9]使用通過多層感知機、最優路徑森林、支持向量機(support vector machines,SVM)結合持續發聲的語音信號檢測帕金森病。Benba等[10]對提取的梅爾頻率倒譜系數(Mel frequency cepstrum coefficient,MFCC)、人因子倒譜系數(human factor cepstral coefficients,HFCC)聲紋特征用支持向量機進行特征分類,區分帕金森病患者和健康人群。但使用機器學習技術分析聲紋特征參數,存在特征冗余、特征參數選擇復雜等問題。此外,機器學習分類器(如支持向量機、隨機森林等)容易發生過擬合、調參困難且計算量大等問題[11],所以尚需進一步開發新的算法提升分類結果。
近年來,深度學習在病理檢測中的成功應用,為利用聲紋差異進行帕金森病識別奠定了堅實的基礎。例如,王娟等[5]、Xu等[12]分別利用視覺幾何組16(visual geometry group 16,VGG16)網絡、殘差網絡50(residual network 50,ResNet50)來提取相關的聲紋特征進行圖像分類,獲得86.68%、91.25%的準確率,上述兩種方法解決了直接從時域特征上分析語音信號特征不連續性和冗余等問題,從而實現較高的帕金森病識別準確率。目前,一種純粹的卷積神經網絡家族(a family of pure convolutional neural networks,ConvNeXt)模型[13]由于浮點運算次數小、參數量少和準確率高,在圖像識別和分類領域具有較強競爭力。然而,訓練ConvNeXt模型依賴大量的樣本,樣本數量少容易導致過擬合,因此在使用該網絡模型進行帕金森病識別時,樣本擴充是一個亟待解決的問題。已有一些研究提出可采用樣本擴充的方法,例如:Karani等[14]在分割腦部和前列腺磁共振成像(magnetic resonance imaging,MRI)圖像時,使用基于幾何變換擴充樣本的方法,將骰子相似系數(dice similarity coefficient,DSC)分別提升2.31%、6.91%。Chen等[15]在心臟分割中提出空間圖像擴充方法,將DSC提高了15%。
生成對抗網絡(generative adversarial networks,GAN)自Goodfellow等[16]提出以來,衍生許多變體并廣泛應用于醫學領域的圖像處理和合成工作中,醫學圖像數據集稀缺問題得到改善[17]。Frid-Adar等[18]基于深度卷積GAN(deep convolutional GAN,DCGAN)構建深度學習框架,并運用于肝臟病變電子計算機斷層掃描(computed tomography,CT)圖像分類任務中。Chuquicusma等[19]使用DCGAN對肺結節CT圖像進行擴充,極大地改善結節圖像不足的問題。然而,在生成高分辨率圖像時,DCGAN容易出現模型特征提取能力不足、訓練不穩定和梯度消失等問題。為解決上述問題,研究人員提出一些改進措施。黃宏宇等[20]引入了自注意力機制,以克服傳統卷積算法僅能處理部分像素間相關信息的局限,從而提高圖像的清晰度。李秋麗等[21]提出在DCGAN網絡中引入頻譜歸一化(spectral normalization,SN)、自注意力機制的方法,實驗證明該模型能提高訓練穩定性并增強圖像質量。甘嵐等[22]使用沃瑟斯坦(Wasserstein)距離損失函數,頻譜歸一化穩定生成網絡和判別網絡,提高生成樣本的質量和多樣性。祝俊輝等[23]在生成器和判別器引入頻譜歸一化的殘差網絡,并使用帶梯度懲罰(gradient penalty,GP)的Wasserstein距離進行樣本擴充,從而提升分類網絡的識別準確率。Xie等[24]提出多頭相互自注意力機制GAN模型,以解決紋理合成中分辨率低和細節不足等質量問題。基于以上分析,本文提出基于梯度懲罰和頻譜歸一化的雙自注意力DCGAN (double self-attention DCGAN,DoubleSA-DCGAN)模型。通過梯度懲罰、頻譜歸一化技術使訓練過程變得更加穩定,而雙自注意力機制可提高紋理細節特征和全局特征的提取能力,從而實現樣本增強。綜上,本文提出一種擴充數據集方法,可以有效地擴充帕金森病語音數據集并應用到帕金森病患者的識別工作中,以期提高小樣本下帕金森病患者識別準確率,為早期帕金森病的診斷提供有益參考。
1 小樣本帕金森病識別模型
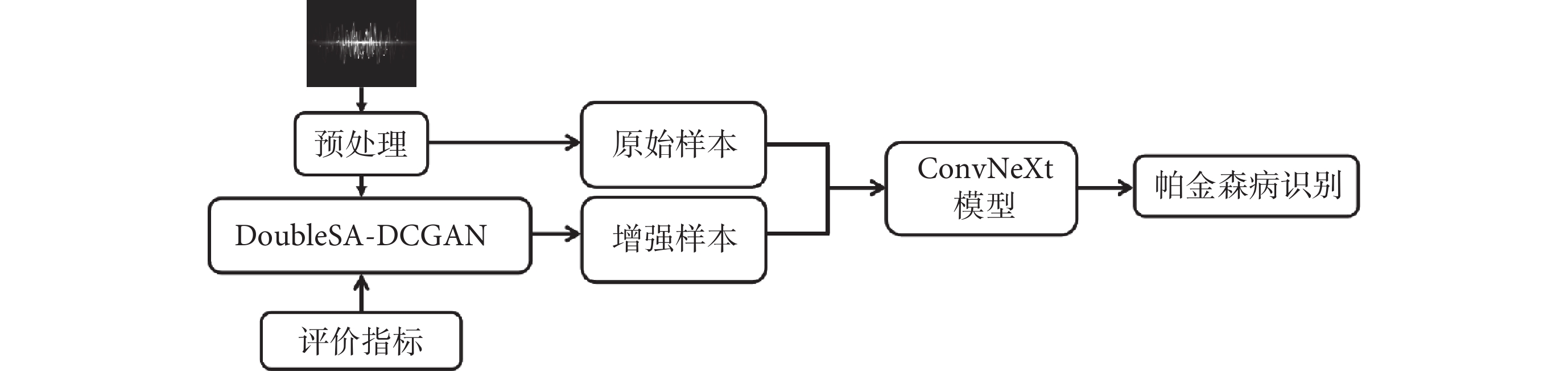
基于樣本增強的帕金森病識別模型如圖1所示,首先將原始的語音信號經過預處理后輸入DoubleSA-DCGAN模型,使用評價指標對生成的語譜圖進行評估,并挑選出質量較高的語譜圖。將原始樣本與增強樣本合并,用基于遷移學習的ConvNeXt模型進行分類,從而實現帕金森病識別。
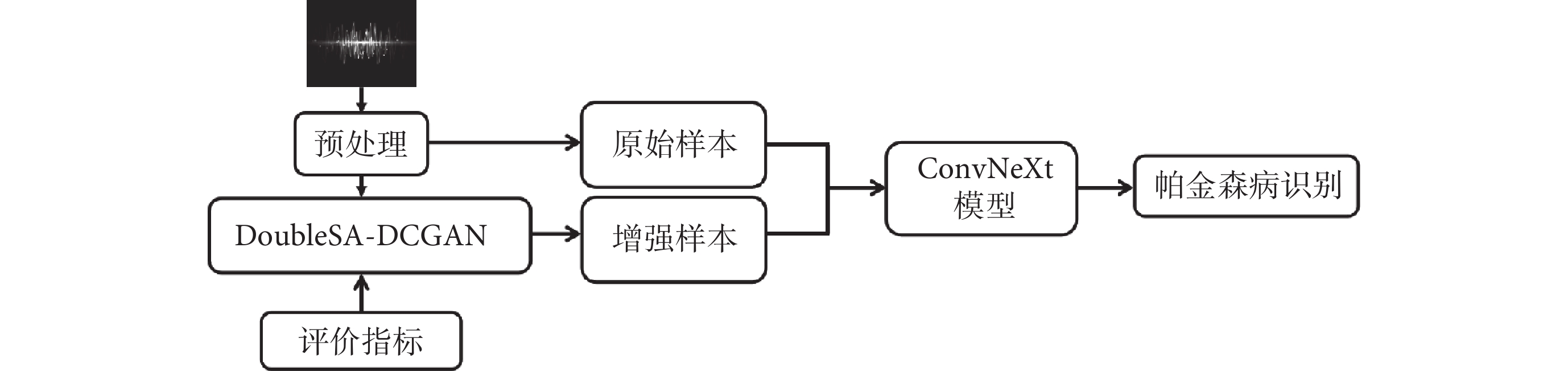 圖1
樣本增強的帕金森病識別模型
Figure1.
Sample enhanced Parkinson's disease recognition model
圖1
樣本增強的帕金森病識別模型
Figure1.
Sample enhanced Parkinson's disease recognition model
1.1 語譜圖
語譜圖,由時頻分析方法獲得,包含基音、共振峰和相鄰幀間的相關性等聲紋特征信息;其生成步驟包括預加重、分幀、加窗、短時傅里葉變換、取短時功率譜。它能展示不同頻段的語音信號強度隨時間變化的情況。
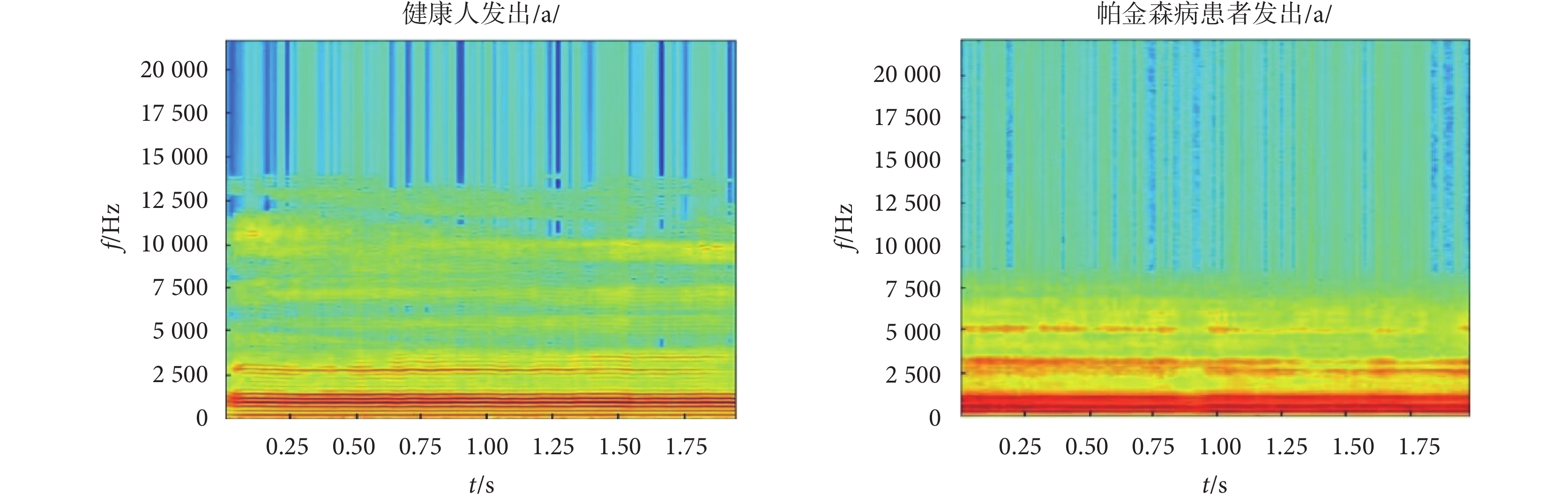
語譜圖能夠反映聲音在不同頻段上的強度變化,揭示聲音的特征和結構,如圖2所示。圖2中,左圖為健康人發出元音/a/的語譜圖,其顯示聲紋諧波范圍集中在0~15 000 Hz,包括基頻和中高頻區域的共振峰,并且紋理清晰;而右圖為帕金森病患者發出元音/a/的語譜圖,其顯示聲紋諧波范圍較窄,僅為0~7 500 Hz,且在高于2 500 Hz的中高頻區域紋理模糊、不規則,聲紋諧波信號消失。這些變化可能與帕金森病患者的聲帶損傷和聲音質量下降有關,因此可以通過分析語譜圖來識別帕金森病患者。
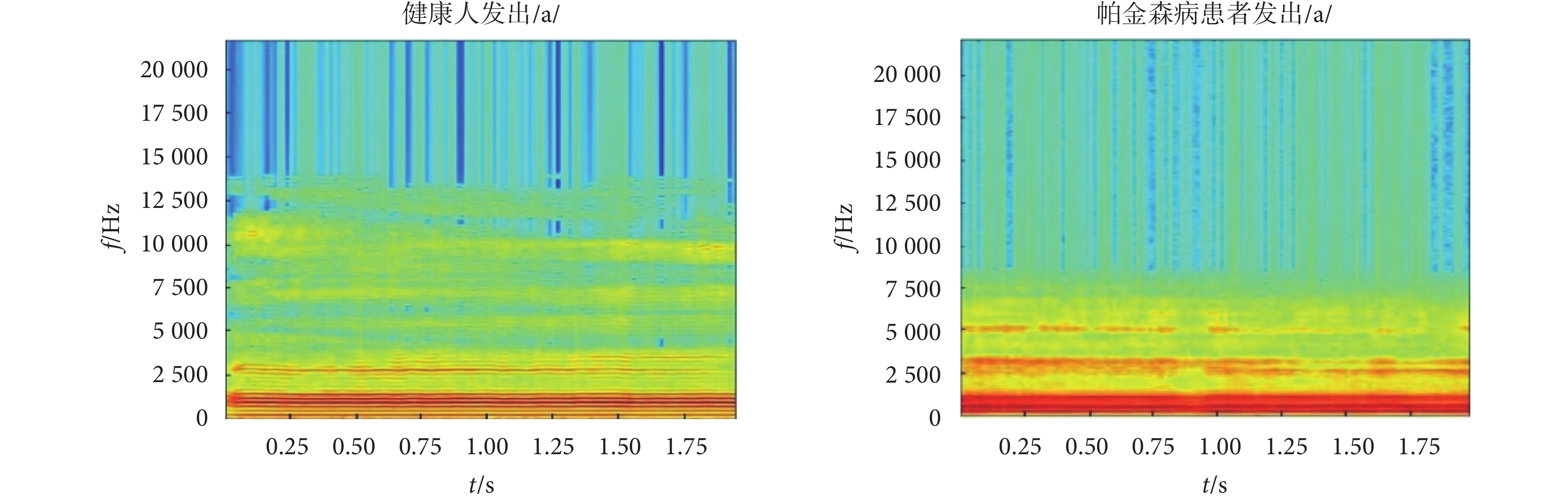 圖2
健康人和帕金森病患者的語譜圖
Figure2.
Spectrogram of healthy people and Parkinson's disease patients
圖2
健康人和帕金森病患者的語譜圖
Figure2.
Spectrogram of healthy people and Parkinson's disease patients
1.2 網絡結構
1.2.1 GAN原理
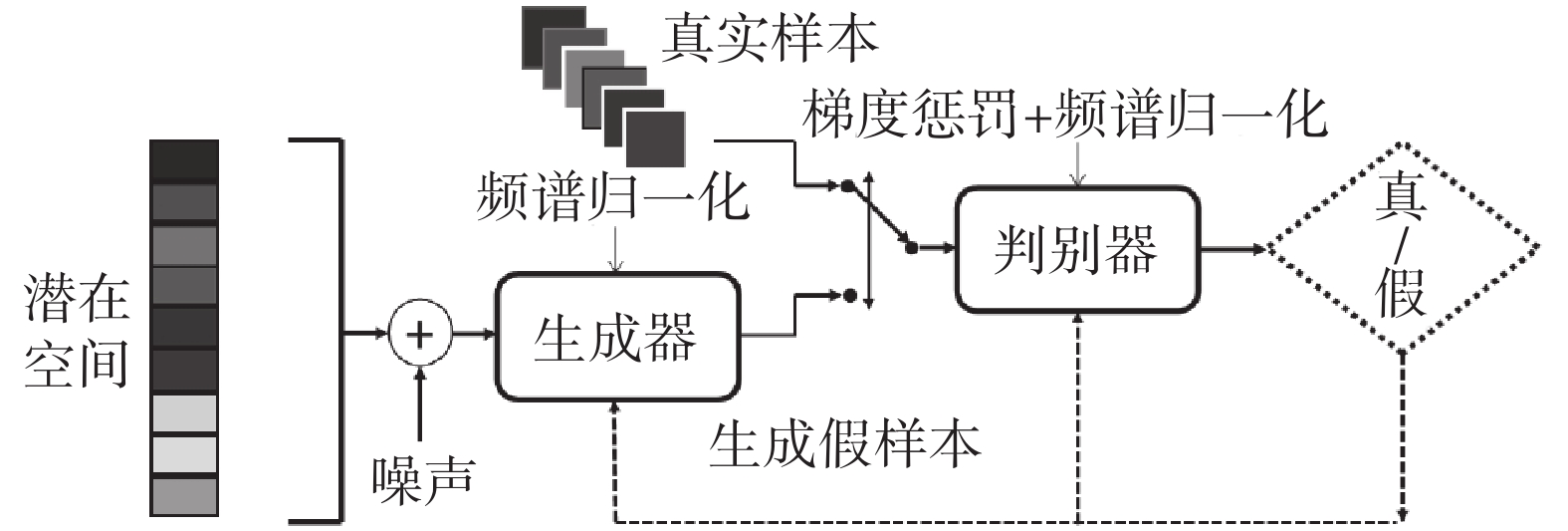
如圖3所示,GAN主要由生成器和判別器兩部分組成,訓練過程中生成器和判別器相互欺騙對方、相互對抗、相互博弈,使生成器能夠生成無限接近真實樣本的圖片。GAN的損失函數如式(1)所示:
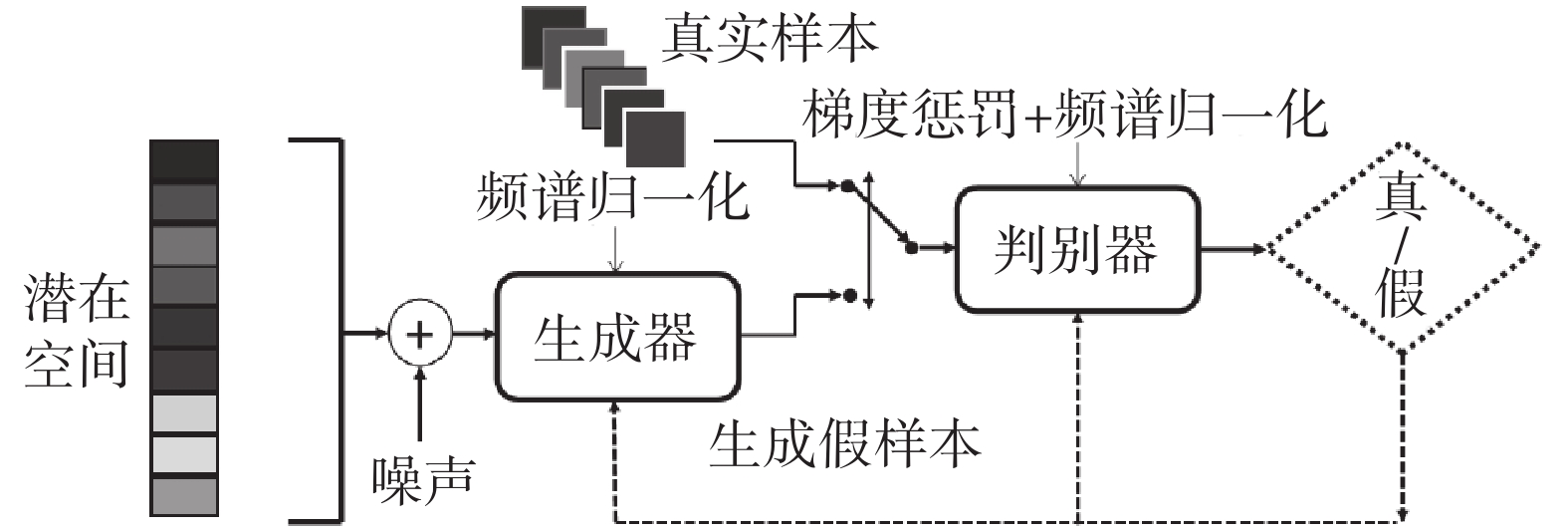 圖3
GAN網絡模型結構
Figure3.
Overview of GAN network structure
圖3
GAN網絡模型結構
Figure3.
Overview of GAN network structure
 |
其中,E代表目標函數,真實數據為x,Pdata(x)為數據空間x中定義的真實數據概率分布,真實數據符合Pdata(x)分布;輸入為噪聲信號z,Pz(z)為潛在空間z上定義的潛在變量z概率分布,噪聲信號符合Pz(z)分布,該噪聲信號經生成器映射函數得到生成數據G(z),將通過判別映射函數的真實數據D(x)與生成數據G(z)作為判別器的輸入。V(D,G)表示生成樣本和真實樣本的差異度, 代表交替訓練生成器G和判別器D,使其互相博弈尋找平衡點,讓V(D,G)的值最大,最終得到最優生成器。
代表交替訓練生成器G和判別器D,使其互相博弈尋找平衡點,讓V(D,G)的值最大,最終得到最優生成器。
頻譜歸一化是通過限制譜范數來限制李普希茨(Lipschitz)常數,以符號L表示,滿足 L=1的約束條件[25],如式(2)所示:
 |
其中, 為最大奇異值,是權重W的二范式;生成器和判別器的每層權重W都用式(2)進行頻譜歸一化,每次更新權重矩陣
為最大奇異值,是權重W的二范式;生成器和判別器的每層權重W都用式(2)進行頻譜歸一化,每次更新權重矩陣 中的參數,通過限制卷積濾波器的L < 1,來穩定生成器和判別器的訓練,有效地降低訓練的計算量。
中的參數,通過限制卷積濾波器的L < 1,來穩定生成器和判別器的訓練,有效地降低訓練的計算量。
Wasserstein距離損失函數結合GAN(Wasserstein-GAN,WGAN)[26]以權重裁剪迫使網絡僅學習簡單特征,所以常使用梯度懲罰來代替權重裁剪以強制實施Lipschitz約束[27],要求原始輸入的梯度的L2范數約束在1附近,從而避免梯度爆炸和消失問題,并提高網絡穩定性;帶梯度懲罰WGAN的最終目標函數(以符號P表示),如式(3)所示:
 |
其中,E為期望函數,
 為原始判別器損失項,
為原始判別器損失項, 為梯度懲罰項,
為梯度懲罰項, 為生成數據,x為真實數據,判別器D(·)的目標是迫使生成器的分布Pg和真實分布Pr的原始判別器損失項盡可能大 ,梯度懲罰項接近于1。
為生成數據,x為真實數據,判別器D(·)的目標是迫使生成器的分布Pg和真實分布Pr的原始判別器損失項盡可能大 ,梯度懲罰項接近于1。 是真實圖像和偽圖像之間的逐點插值,
是真實圖像和偽圖像之間的逐點插值, 是Pg、Pr之間的空間采樣,
是Pg、Pr之間的空間采樣, 是判別器輸出相對于插值的梯度,
是判別器輸出相對于插值的梯度, 是L2范數,
是L2范數, 是損失比率,一般設置為10。
是損失比率,一般設置為10。
1.2.2 雙自注意力機制
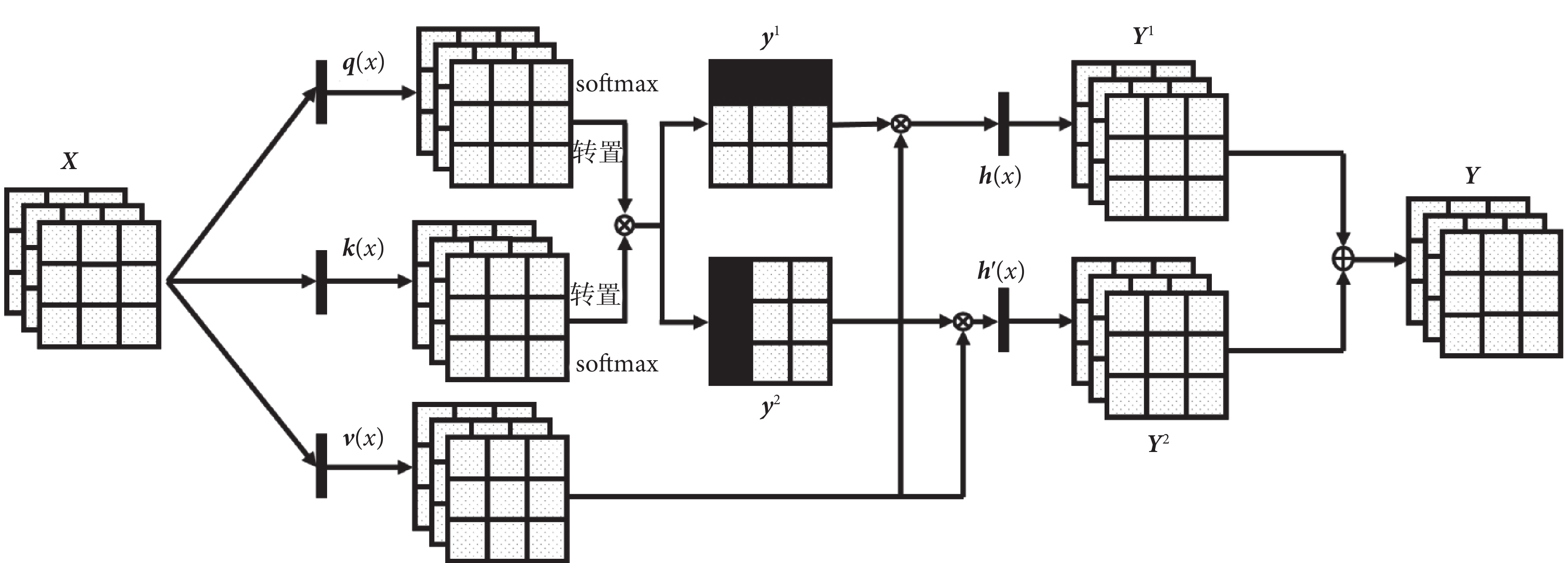
雙自注意力機制的計算過程如圖4所示, 表示兩個特征圖相乘,特征圖的第i行的各元素與另一個特征圖的第j列對應元素相乘后求和,
表示兩個特征圖相乘,特征圖的第i行的各元素與另一個特征圖的第j列對應元素相乘后求和, 表示兩個特征圖把其相對應位置元素相加融合成新的特征圖。卷積特征圖X通過三個1×1的卷積變換為三個特征空間q(x)、k(x)、v(x),其中
表示兩個特征圖把其相對應位置元素相加融合成新的特征圖。卷積特征圖X通過三個1×1的卷積變換為三個特征空間q(x)、k(x)、v(x),其中  ,c為輸入通道數,n為特征圖高和寬的乘積。
,c為輸入通道數,n為特征圖高和寬的乘積。 ,
, ,
, ,其中
,其中 ,
, ,
, ,
, 為輸出通道數,
為輸出通道數, 。
。
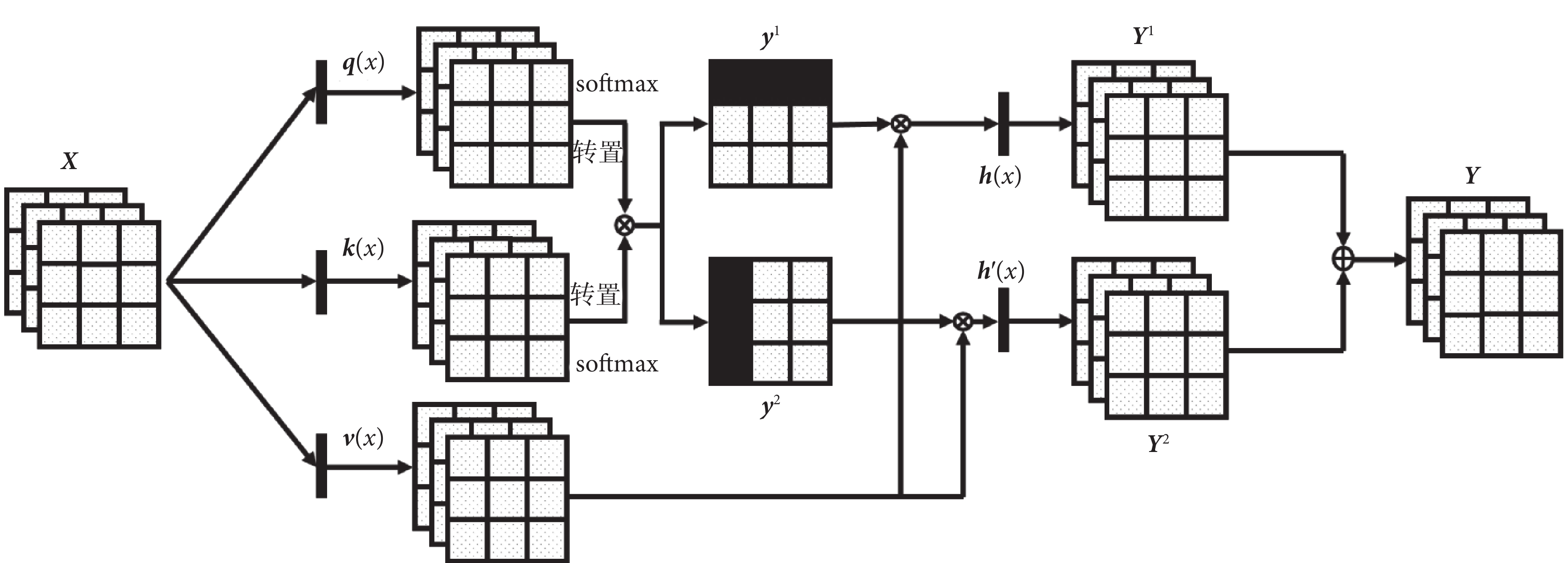 圖4
雙自注意力機制模型
Figure4.
Double self-attention mechanism model
圖4
雙自注意力機制模型
Figure4.
Double self-attention mechanism model
 表示合成第j個區域時,模型對第i個位置的關注程度;
表示合成第j個區域時,模型對第i個位置的關注程度; 表示當合成第i個區域時,模型對第j個位置的關注程度,從而實現任意兩個元素之間的依賴關系[28],如式(4)~式(5)所示:
表示當合成第i個區域時,模型對第j個位置的關注程度,從而實現任意兩個元素之間的依賴關系[28],如式(4)~式(5)所示:
 |
 |
其中,exp(·)代表e的幾次方, ,
, ,通過歸一化指數函數(softmax)分別對行列進行歸一化,計算得到注意力圖y1和y2,再分別與特征空間v(x)像素點相乘后通過一個1 × 1的卷積層得到自注意力特征圖Y1和Y2,如式(6)~式(7)所示:
,通過歸一化指數函數(softmax)分別對行列進行歸一化,計算得到注意力圖y1和y2,再分別與特征空間v(x)像素點相乘后通過一個1 × 1的卷積層得到自注意力特征圖Y1和Y2,如式(6)~式(7)所示:
 |
 '/> '/> |
將自注意力特征圖相加得到  ,輸出為
,輸出為  ,如式(8)所示:
,如式(8)所示:
 |
其中, ,
, ,
, ,在上述等式中
,在上述等式中  ,
, ,
, 。因此,最終輸出以符號yi表示,如式(9)所示:
。因此,最終輸出以符號yi表示,如式(9)所示:
 |
其中,γ為尺度參數,初始值為0; xi為原始的特征圖。
傳統GAN通過計算像素間的權重來建立依賴關系模型,從而捕捉圖像的全局結構。然而,卷積核的感受野是局部的,這種方法只能計算單一方向的像素之間的關注度。為處理圖像中的長距離依賴關系,將自注意力機制引入到GAN中,它能建立像素之間的遠距離關系[29]。DoubleSA-DCGAN將雙自注意力機制與DCGAN模型相結合,雙自注意力模塊能夠分析兩個注意力圖之間的相互關系,并生成詳細的特征位置線索信息,嵌入雙自注意力模塊可以幫助模型提高細節特性和全局特性,從而提高生成樣本的質量。
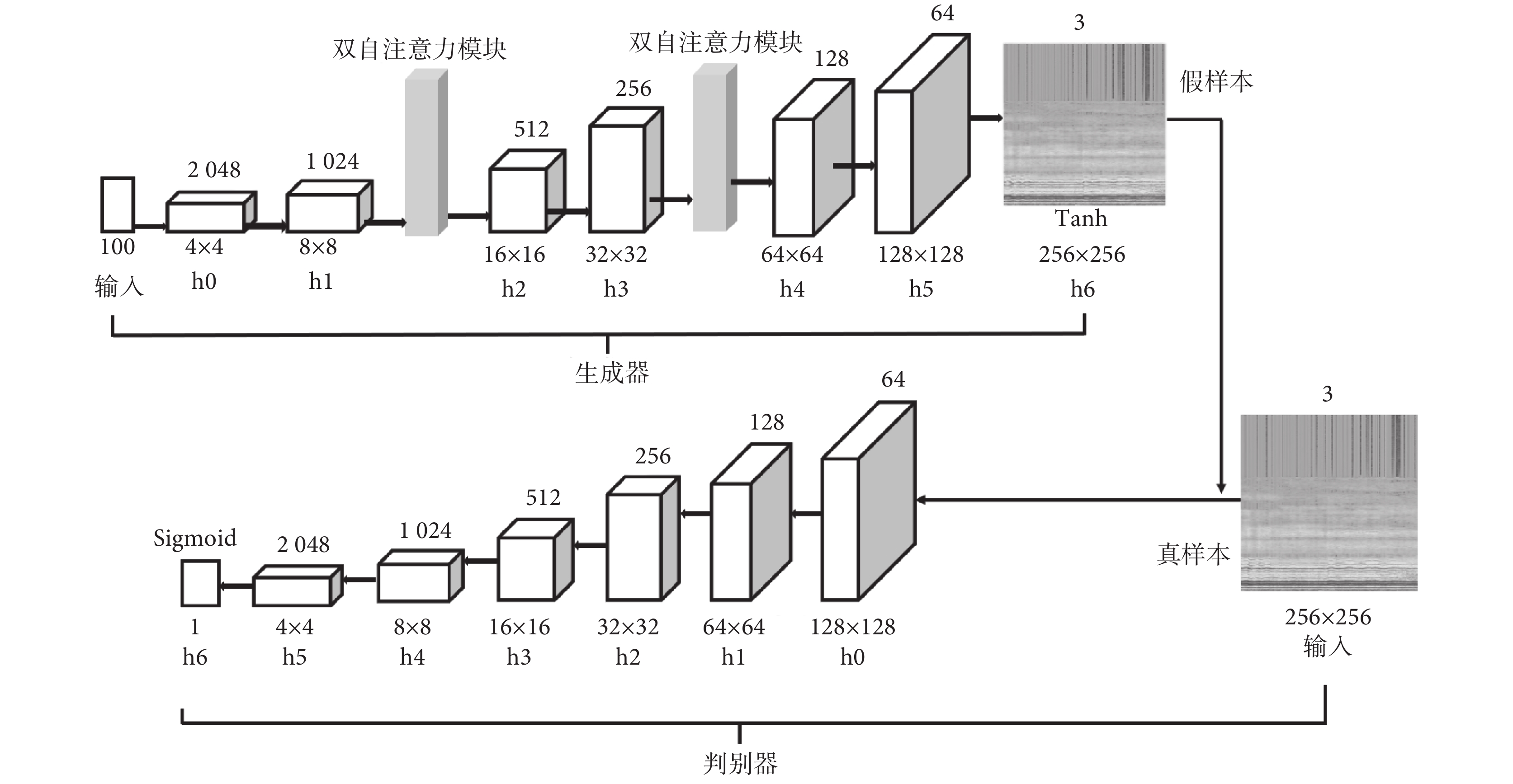
1.2.3 DoubleSA-DCGAN模型網絡結構
DoubleSA-DCGAN模型網絡結構如圖5所示,生成器網絡中h0~h5是4×4卷積核,步長為2,填充為1的微步幅卷積層。在微步幅卷積層后加入批量歸一化層(batch normalization,BN)幫助減緩初始化不當而導致的訓練困難,可以讓梯度在更深層傳播。生成器中各層均使用頻譜歸一化,每通過一個微步幅卷積層通道數減半,長寬變為原來一倍,h0~h5層都使用線性整流函數(rectified linear unit,ReLU),h6層使用雙曲正切函數Tanh(·)將生成的語譜圖映射到[?1, 1]的范圍,最后生成256 × 256 × 3語譜圖。
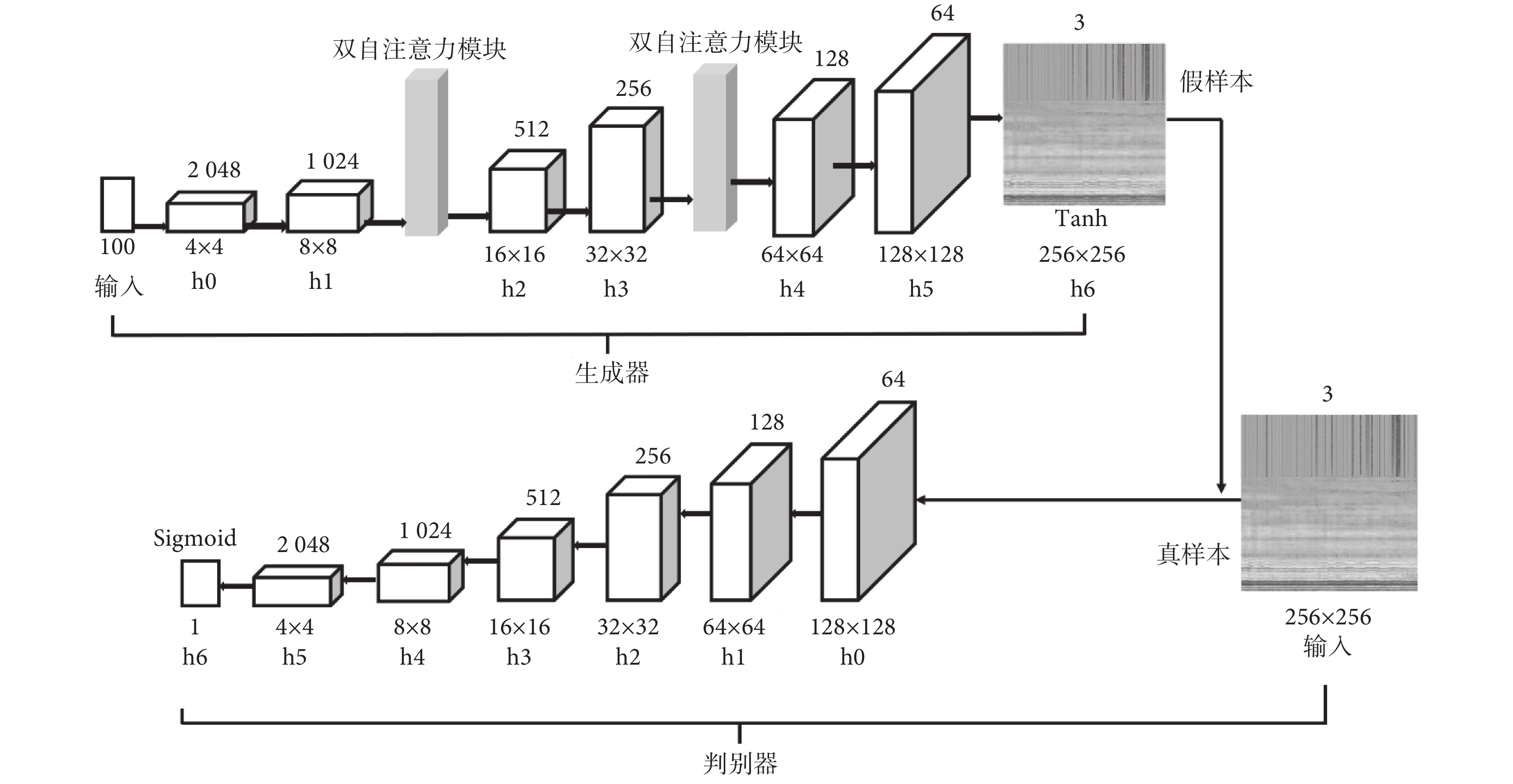 圖5
DoubleSA-DCGAN模型的網絡結構
Figure5.
Network structure of DoubleSA-DCGAN
圖5
DoubleSA-DCGAN模型的網絡結構
Figure5.
Network structure of DoubleSA-DCGAN
判別器下采樣卷積中,特征圖變化過程與生成器相反。判別器網絡中,h0~h5是4 × 4卷積核,步長為2,填充為1的卷積層,且各層也使用頻譜歸一化,通過卷積層進行下采樣,通道數增加一倍,長寬減少一半。h0~h5層都使用帶泄露ReLU(leaky ReLU,Leaky ReLU),h6層采用 S 型生長曲線(Sigmoid)激活函數判別其輸出結果表示輸入語譜圖來自真實樣本的概率。
為解決特征提取能力低、紋理合成中分辨率低和細節不足等問題,本文在生成器結構的8 × 8 × 1 024子層和32 × 32 × 256子層后加入雙自注意力模塊,雙自注意力模塊可以幫助建立像素之間的遠距離依賴關系,從而提高生成器在紋理合成任務中的性能。
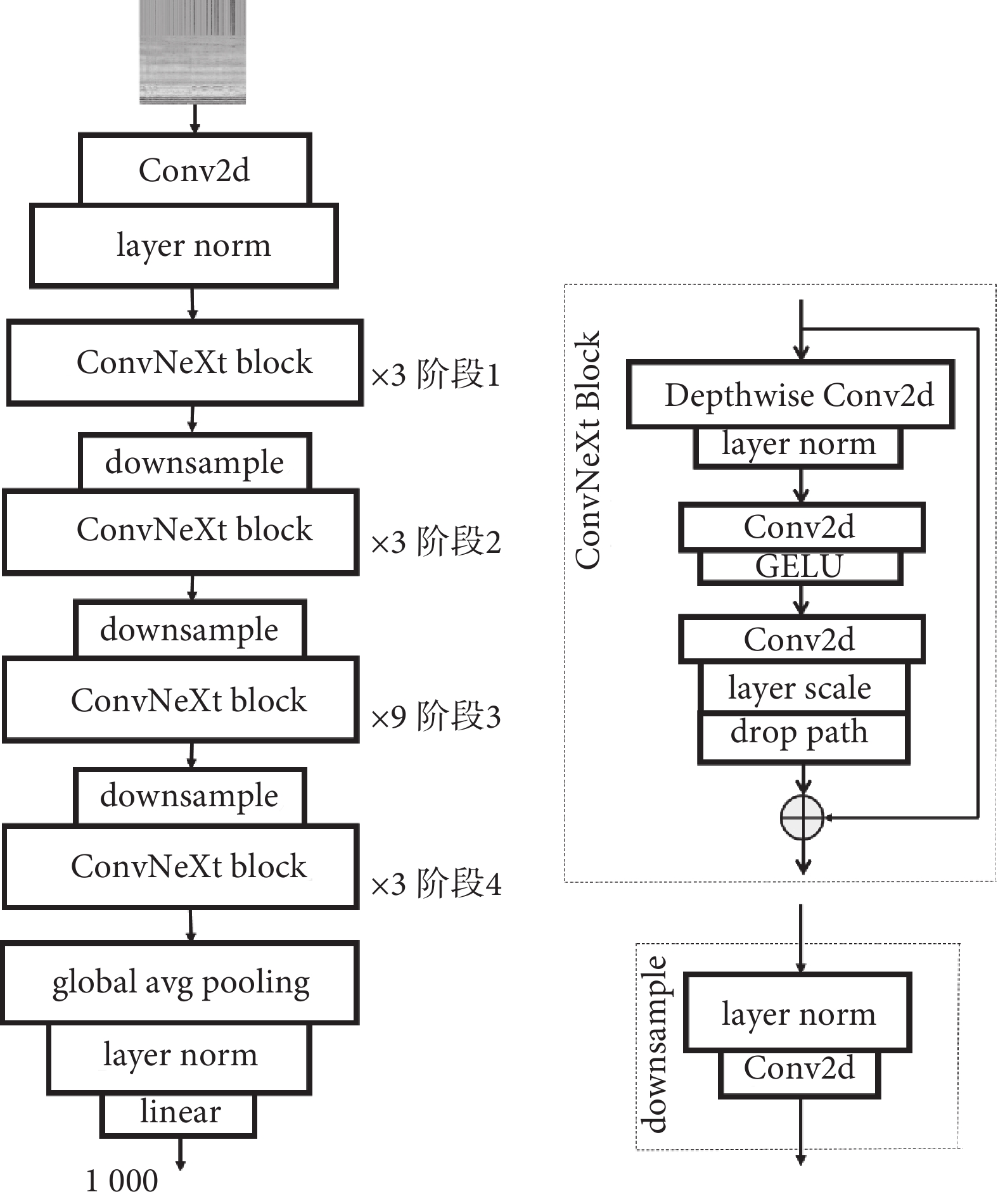
1.2.4 ConvNeXt模型的網絡結構
ConvNeXt網絡模型結構如圖6所示,在卷積過程中有4個階段(階段1~階段4),其中“× 3、× 3、× 9、× 3”代表每個階段堆疊塊重復的次數。對于局部的卷積結構(ConvNeXt Block),依次經過卷積核大小為7 × 7,步長為1,填充為3的深度可分離卷積層(Depthwise Conv2d)、歸一化層(layer norm)、二維卷積層(two-dimensional convolution,Conv2d)、高斯誤差線性單元層(Gaussian error linear units,GELU)、Conv2d、縮放輸入歸一化層(layer scale),再通過正則化手段(drop path)使其輸入和輸出維度一致。對于局部的下采樣結構(downsample)由歸一化層和卷積核大小為2 × 2,步長為2的卷積層組成。最后,利用殘差結構將輸入和輸出相加作為最后的輸出結果。ConvNeXt模型網絡通過卷積核大小為4 × 4,步長為4的卷積層對圖像進行下采樣,圖像的高和寬都減少為原來的四分之一,然后再通過四個局部卷積結構和三個局部下采樣結構分別將圖像的高和寬都依次減少為原來的二分之一,最后經過全局平均池化層(global avg pooling)、歸一化層和線性變換(linear),得到網絡輸出結果。
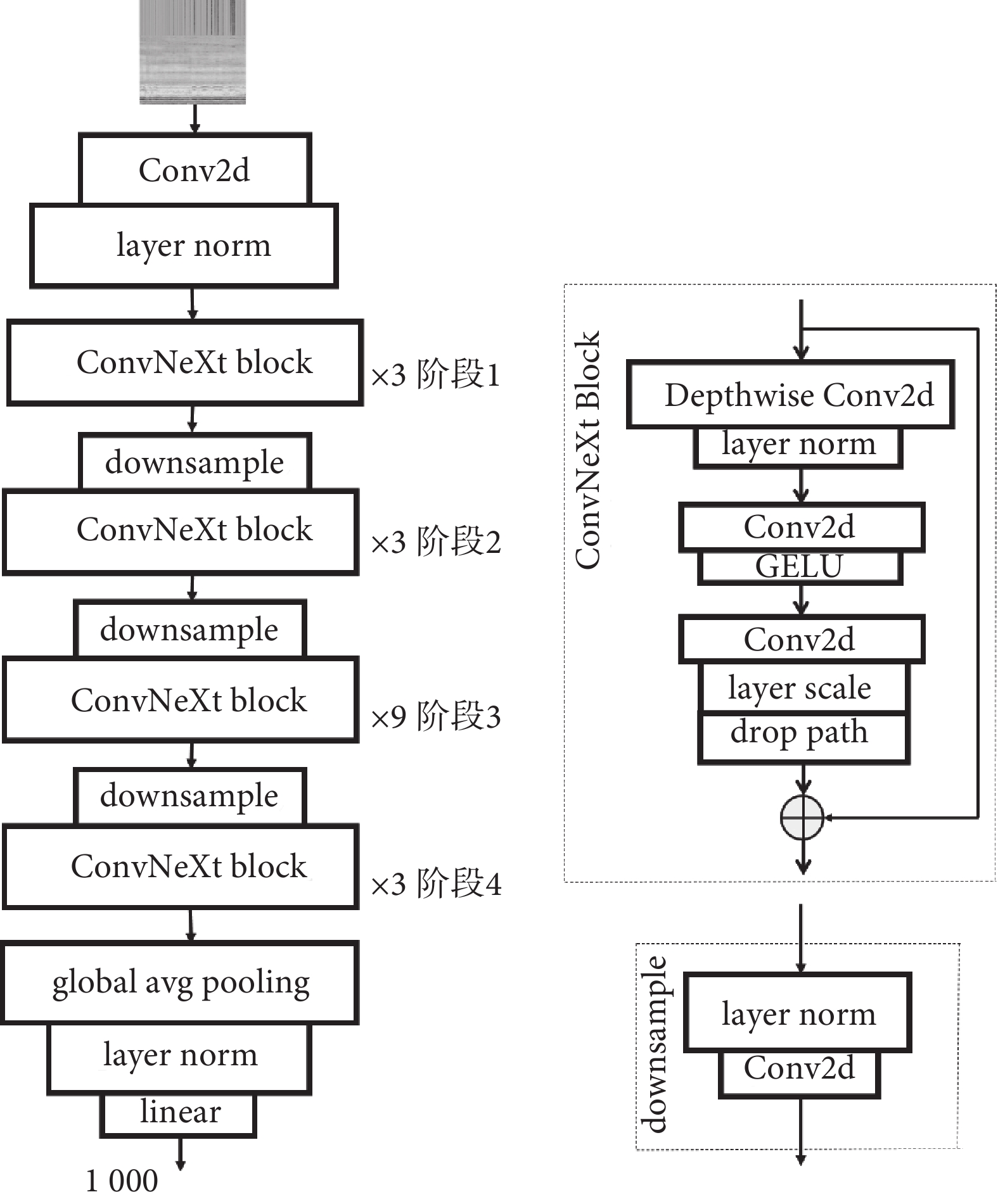 圖6
ConvNeXt模型的網絡結構
Figure6.
Network structure of ConvNeXt model
圖6
ConvNeXt模型的網絡結構
Figure6.
Network structure of ConvNeXt model
1.3 樣本擴充的選取標準
弗雷謝起始距離(Fréchet inception distance,FID)使用統計特征來衡量兩組圖像的相似度[28],以符號FID表示,最理想情況下FID的得分為0,定義如式(10)所示:
 |
其中,x和g表示真實圖片和生成圖片, 和
和  分別是生成圖像和真實圖像的特征向量均值,
分別是生成圖像和真實圖像的特征向量均值, 和
和  分別為它們的協方差矩陣均值,Tr表示矩陣的跡,
分別為它們的協方差矩陣均值,Tr表示矩陣的跡, 表示L2范數。
表示L2范數。
在無參考圖像的質量評價中,圖像的清晰度不高會造成圖像失真、圖像模糊,導致圖像分析和解譯困難,降低圖像的實際應用價值。本文選擇三種無參考圖像質量評價方法去評估圖像清晰度。
(1)灰度方差(sum of modulus of gray difference,SMD)函數,當圖像完全聚焦時高頻分量最多,即圖像最清晰,故可將灰度變化作為聚焦評價的依據[30],SMD函數定義如式(11)所示:
 |
其中,D(f)代表灰度值大小,f(x, y)表示圖像對應像素點(x, y)的灰度值。
(2)無參考圖像清晰度評價函數(Tenengrad),可以用來評估圖像的清晰度[30],其值越大,表示圖像越清晰,定義如式(12)所示:
 |
其中,D(I)表示圖像的清晰度,x和y是圖像對應像素點,T是給定的邊緣檢測閾值,G(x,y)是索貝爾(Sobel)算子提取水平和垂直方向的梯度值,如式(13)所示:
 |
其中,Gx和Gy分別是像素點(x, y)處索貝爾算子水平和垂直方向邊緣檢測算子的卷積。Tenengrad 函數中索貝爾算子定義如式(14)所示:
 |
其中,ix為水平方向上的算子矩陣,iy為垂直方向上的算子矩陣。
(3)拉普拉斯(Laplacian)梯度函數與Tenengrad函數基本一致,Laplacian函數將Laplacian算子作為邊緣檢測的方法,該算子矩陣L定義如式(15)所示:
 |
2 實驗
2.1 實驗設備
實驗環境:操作系統為Ubuntu18.04.6(Canonical Ltd.,英國),獨立顯卡(RTX3090, Nvidia Inc.,美國)。深度學習框架為Pytorch1.10(Linux Foundation,美國),編程語言為Python 3.9(Python Software Foundation,美國)。
2.2 數據集介紹及預處理
本文實驗使用的帕金森病語音數據集來自美國加利福尼亞大學歐文分校(University of California Irvine,UCI)構建的公開數據庫[7],簡稱UCI數據庫,該數據集分為訓練集和測試集。其中,訓練集包含的受試者數據為:446個健康人和399個帕金森病患者發出/a/、/o/和/u/三種元音語音信號片段;測試集包含的受試者數據為:60個健康人和60個帕金森病患者發出/a/、/o/二種元音語音信號片段。對每個語音進行預處理,并生成256 × 256分辨率的語譜圖,預處理的參數設置如表1所示。由于UCI數據庫原始數據集樣本的數量少,不利于DoubleSA-DCGAN模型收斂,故對原始的語譜圖進行隨機的水平、垂直翻轉,調整圖片明暗程度,微調圖片的對比度、飽和度,添加噪聲等操作,將數據集擴大到原來的5倍。同時將健康人圖片的標簽設為0,帕金森病患者圖片標簽設為1。
2.3 DoubleSA-DCGAN模型訓練
噪聲向量維度為100,使用自適應矩估計優化器(adaptive moment estimation,Adam)調節超參數,學習率設為0.000 2,動量1設為0.5,動量2設為0.999,批量大小設為64,梯度懲罰系數設為10,判別器與生成器訓練次數之比設為5,迭代數目設為2 000。
2.4 ConvNeXt模型訓練
使用FID、SMD函數、Laplacian梯度函數和Tenengrad函數作為選擇標準,將語譜圖添加標簽后,按6∶2∶2的比例劃分為訓練集、驗證集和測試集,迭代數目設置為1 000,學習率為0.000 5,批量大小設置為8,權重衰減參數為0.05。使用遷移學習的方法,利用訓練好的預訓練權重去訓練ConvNeXt模型。
3 實驗結果與分析
3.1 可視化DoubleSA-DCGAN模型生成結果
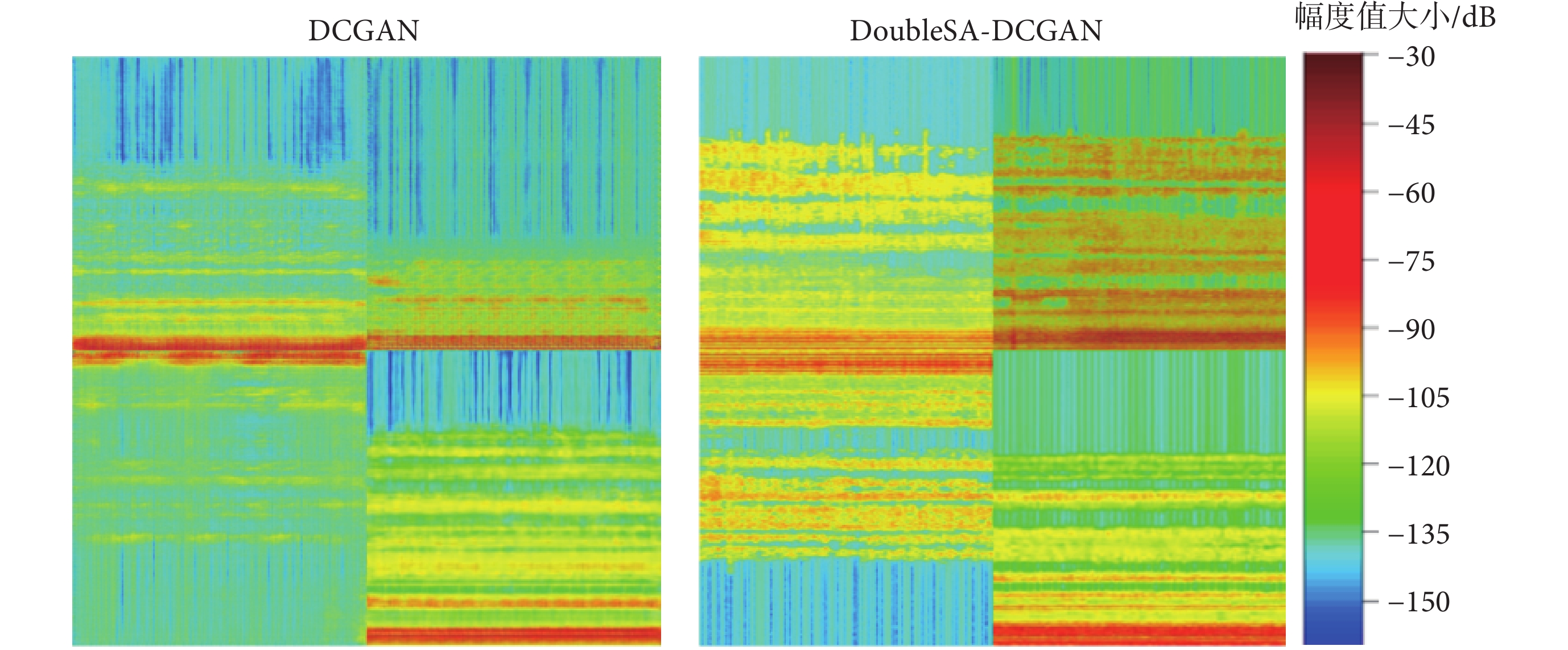
本文使用公共數據集UCI數據庫,分別進行原始DCGAN模型和DoubleSA-DCGAN模型實驗。實驗結果如圖7所示,原始DCGAN模型生成的樣本模糊,學習到的圖片特征少,可能出現模式坍塌現象。DoubleSA-DCGAN模型生成的樣本具有清晰的輪廓和紋理、并且辨識度較高。這表明雙自注意力機制在解決模式坍塌、生成樣本紋理不清晰和學習特征不足等問題方面起到了有效的改善作用,進一步說明DoubleSA-DCGAN生成的樣本具有更高的圖像質量。
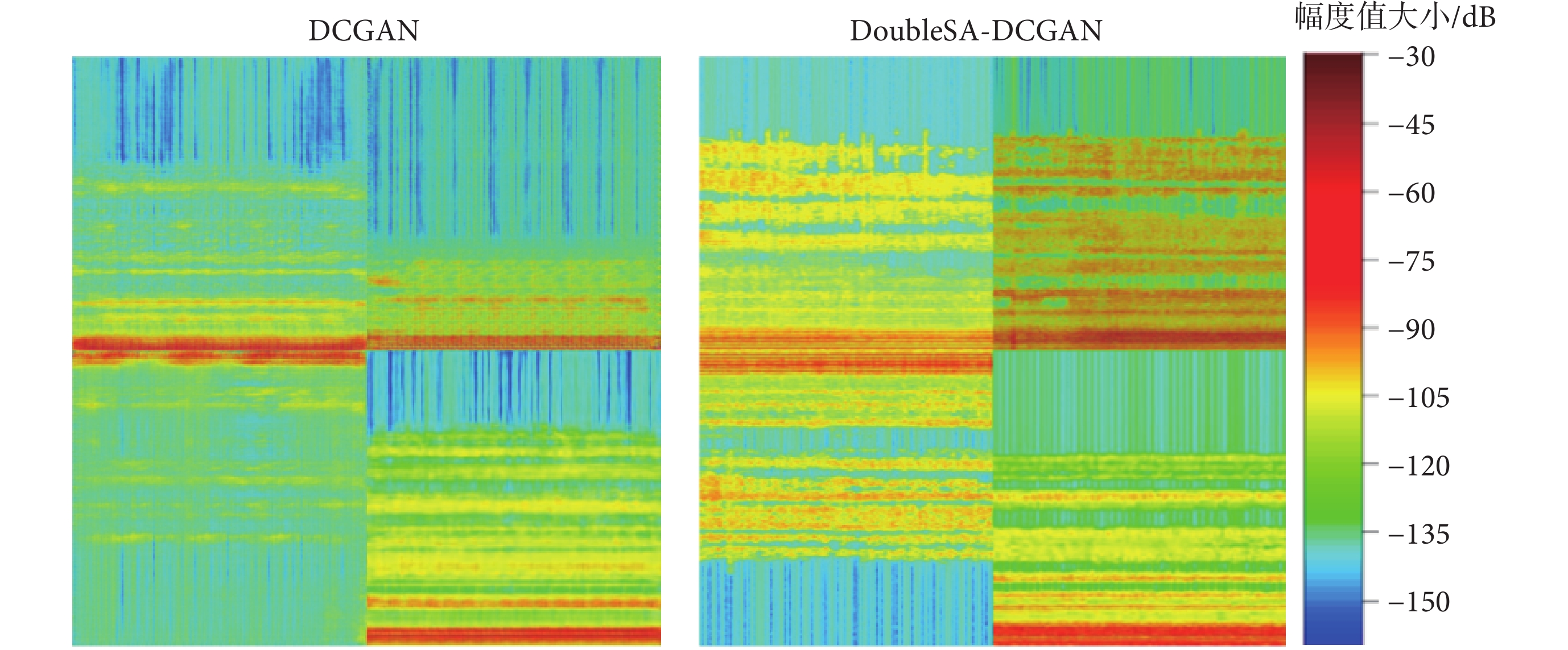 圖7
網絡訓練生成圖像對比
Figure7.
Comparison of images generated during network training
圖7
網絡訓練生成圖像對比
Figure7.
Comparison of images generated during network training
3.2 樣本增強效果分析
圖像的清晰度是衡量數字圖像質量優劣的重要指標。隨機選取2 000張生成的樣本圖片,計算其三種無參考圖像清晰平均值作為量化評價指標。如表2所示,DoubleSA-DCGAN模型的評價指標SMD函數、Laplacian梯度函數、Tenengrad函數值都有明顯的提高。這表明梯度懲罰、頻譜歸一化以及雙自注意力機制在網絡訓練和圖像生成過程中起到了穩定和提升生成圖像質量的作用。
本文研究結果顯示,DoubleSA-DCGAN模型生成圖像的FID值為56.2,DCGAN模型生成圖像的FID值為113.5,DoubleSA-DCGAN模型相比改進前DCGAN模型的FID值有明顯的降低,表明DoubleSA-DCGAN生成的樣本與真實圖像的分布更加接近,質量和紋理更好。
3.3 樣本增強在分類識別性能上的分析
根據生成樣本在上述評價指標得分較高的表現,本文從生成樣本中分別選取920張語譜圖作為訓練集、280張語譜圖作為驗證集進行樣本增強。為了更好地測試該模型,從原始數據集各選取200張帕金森病患者和健康人語譜圖作為測試集。最后,訓練集包括1 200張語譜圖,驗證集包括400張語譜圖,測試集包括400張語譜圖,按照6∶2∶2的比例進行實驗。經過樣本增強后,各種模型網絡在小樣本帕金森病識別任務中的分類識別率均得到提高,VGG16網絡模型提高10.4%;殘差網絡34(residual network 34,ResNet34)模型提高10.7%;亞歷克斯網絡(AlexNet)模型提高5.73%;谷歌網絡(GoogLeNet)模型提高4.03%;ConvNeXt網絡模型提高4.52%,如表3所示,這說明樣本增強對于改善分類性能具有積極的影響。本文實驗結果表明,在小樣本帕金森病識別任務中ConvNeXt網絡的性能最佳。
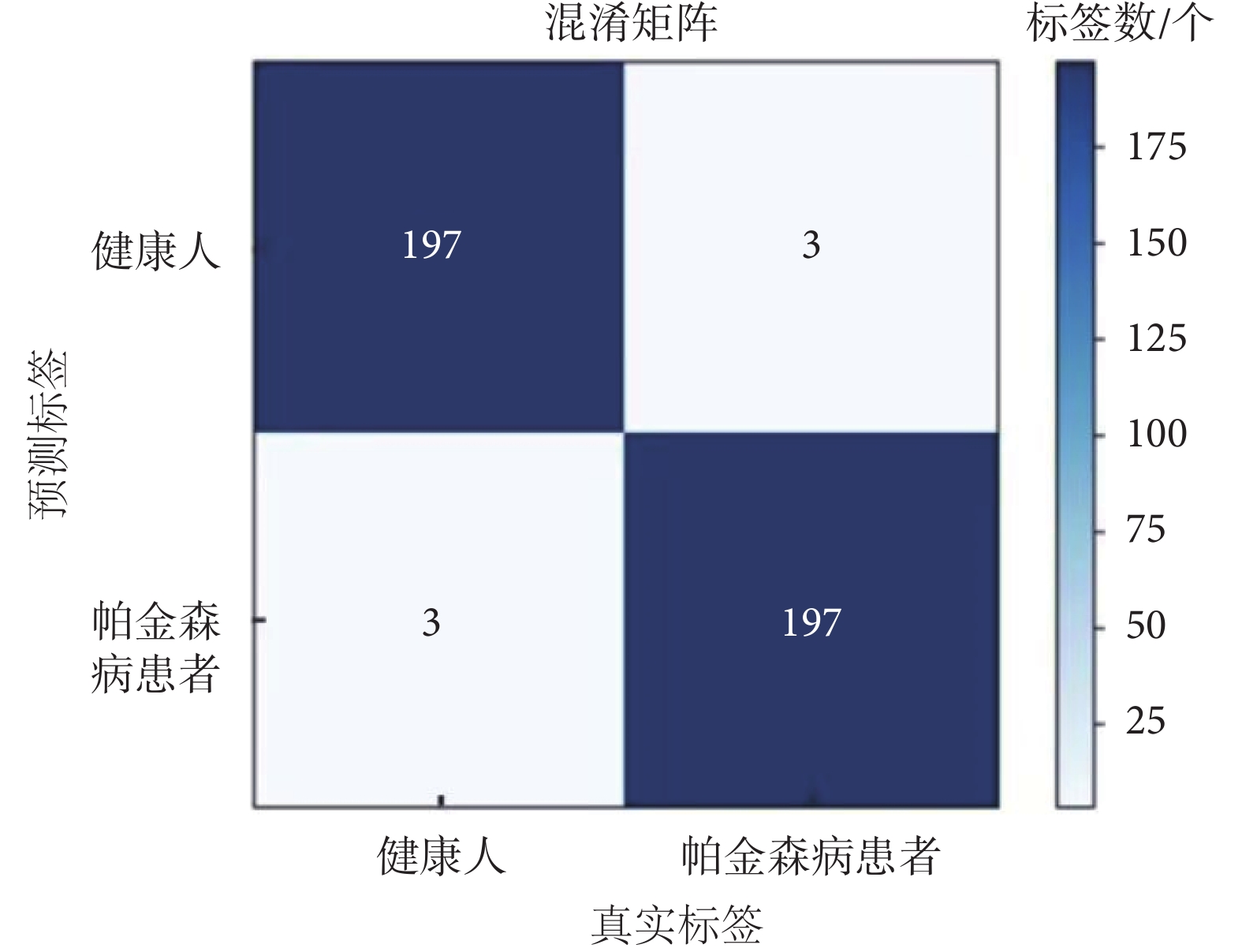
將訓練好的ConvNeXt模型的權重加載到混淆矩陣中,如圖8所示。
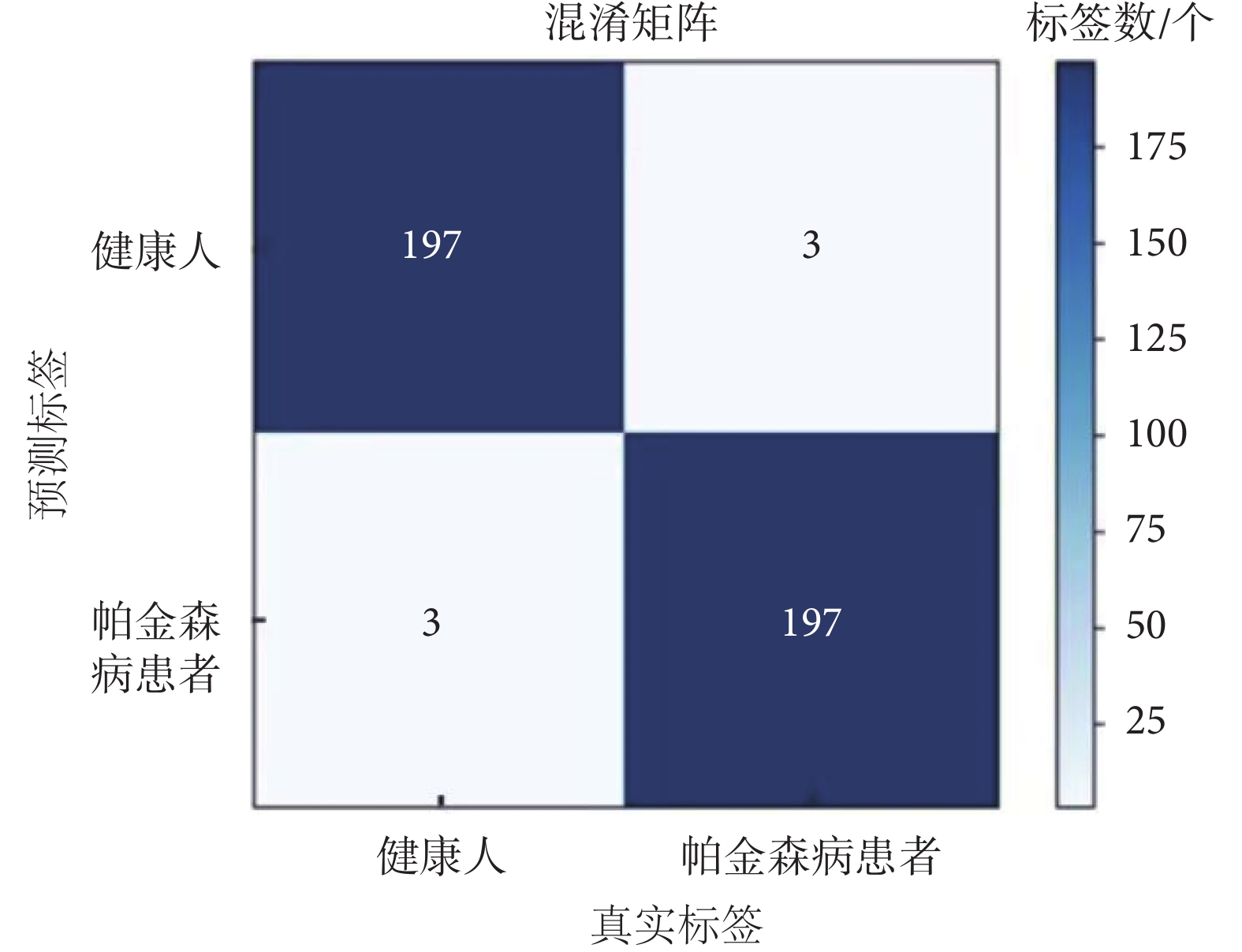 圖8
ConvNeXt分類模型的混淆矩陣
Figure8.
Confusion matrix of ConvNeXt classification model
圖8
ConvNeXt分類模型的混淆矩陣
Figure8.
Confusion matrix of ConvNeXt classification model
本文采用精確率(precision)、召回率(recall)和特異度(specificity)作為二分類算法評價指標。通過混淆矩陣的分析,計算出健康人和帕金森病患者的精確率、召回率和特異度均為0.985,如表4所示。
實驗結果表明,DoubleSA-DCGAN模型可實現對語譜圖質量紋理以及樣本數量增強。同時,ConvNeXt分類模型對語譜圖進行特征提取和分類時表現出色,達到了98.8%的帕金森病識別準確率。針對帕金森病研究的音頻數據稀缺下采用DoubleSA-DCGAN結合ConvNeXt的深度學習方法進行帕金森病識別是可行且有效的。
4 結論
本文提出一種針對帕金森病研究中音頻數據稀缺并且獲取困難等問題的樣本擴充方法,稱為DoubleSA-DCGAN。該方法通過引入雙自注意力機制建立長距離依賴關系,以幫助模型提高細節特性和全局特性,從而提高生成樣本的質量,同時還引入梯度懲罰和頻譜歸一化技術提高DoubleSA-DCGAN模型的穩定性。實驗結果表明,在小樣本條件下,使用GAN對帕金森病數據集樣本量進行擴充是可行且有效的。本文提出的DoubleSA-DCGAN和ConvNeXt混合模型在小樣本條件下能夠提高帕金森病的識別率。這為帕金森病相關研究提供了一種有效的解決方案,并有望應用于臨床實踐。雖然本文提出的方法在早期帕金森病識別研究中取得良好的結果,但相關細節仍然需要進一步驗證和探索,此外還應意識到樣本擴充只是帕金森病相關研究中的某一方面,未來還需要綜合考慮其他更多相關因素。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:張子豪是本研究的實驗設計人和執行人,負責數據分析,總結實驗結果。王子瓊和韋莉負責論文初稿的寫作與修改;趙德春指導論文寫作,提出修改意見。
0 引言
帕金森病(Parkinson’s disease,PD)是一種神經退行性疾病,多發病于中老年人群。據預測,到2025年,中國帕金森病患者人數將增加到38.85萬人[1]。大約90%的帕金森病患者早期存在聲帶損傷,表現為嘴唇和下巴運動的幅度和速度降低、語音質量下降,發音呈單音和單色[2-3]、高振幅微擾、低信噪比和低基頻等特點[4-5]。在帕金森病早期檢測中,基于聲學特征的分析技術起到了重要作用,通過分析持續元音能及早地檢測帕金森病[6-8],該方法高效、便捷,已為廣大民眾所接受。
目前,機器學習方法已廣泛應用于帕金森病的早期檢測中。例如,Almeida等[9]使用通過多層感知機、最優路徑森林、支持向量機(support vector machines,SVM)結合持續發聲的語音信號檢測帕金森病。Benba等[10]對提取的梅爾頻率倒譜系數(Mel frequency cepstrum coefficient,MFCC)、人因子倒譜系數(human factor cepstral coefficients,HFCC)聲紋特征用支持向量機進行特征分類,區分帕金森病患者和健康人群。但使用機器學習技術分析聲紋特征參數,存在特征冗余、特征參數選擇復雜等問題。此外,機器學習分類器(如支持向量機、隨機森林等)容易發生過擬合、調參困難且計算量大等問題[11],所以尚需進一步開發新的算法提升分類結果。
近年來,深度學習在病理檢測中的成功應用,為利用聲紋差異進行帕金森病識別奠定了堅實的基礎。例如,王娟等[5]、Xu等[12]分別利用視覺幾何組16(visual geometry group 16,VGG16)網絡、殘差網絡50(residual network 50,ResNet50)來提取相關的聲紋特征進行圖像分類,獲得86.68%、91.25%的準確率,上述兩種方法解決了直接從時域特征上分析語音信號特征不連續性和冗余等問題,從而實現較高的帕金森病識別準確率。目前,一種純粹的卷積神經網絡家族(a family of pure convolutional neural networks,ConvNeXt)模型[13]由于浮點運算次數小、參數量少和準確率高,在圖像識別和分類領域具有較強競爭力。然而,訓練ConvNeXt模型依賴大量的樣本,樣本數量少容易導致過擬合,因此在使用該網絡模型進行帕金森病識別時,樣本擴充是一個亟待解決的問題。已有一些研究提出可采用樣本擴充的方法,例如:Karani等[14]在分割腦部和前列腺磁共振成像(magnetic resonance imaging,MRI)圖像時,使用基于幾何變換擴充樣本的方法,將骰子相似系數(dice similarity coefficient,DSC)分別提升2.31%、6.91%。Chen等[15]在心臟分割中提出空間圖像擴充方法,將DSC提高了15%。
生成對抗網絡(generative adversarial networks,GAN)自Goodfellow等[16]提出以來,衍生許多變體并廣泛應用于醫學領域的圖像處理和合成工作中,醫學圖像數據集稀缺問題得到改善[17]。Frid-Adar等[18]基于深度卷積GAN(deep convolutional GAN,DCGAN)構建深度學習框架,并運用于肝臟病變電子計算機斷層掃描(computed tomography,CT)圖像分類任務中。Chuquicusma等[19]使用DCGAN對肺結節CT圖像進行擴充,極大地改善結節圖像不足的問題。然而,在生成高分辨率圖像時,DCGAN容易出現模型特征提取能力不足、訓練不穩定和梯度消失等問題。為解決上述問題,研究人員提出一些改進措施。黃宏宇等[20]引入了自注意力機制,以克服傳統卷積算法僅能處理部分像素間相關信息的局限,從而提高圖像的清晰度。李秋麗等[21]提出在DCGAN網絡中引入頻譜歸一化(spectral normalization,SN)、自注意力機制的方法,實驗證明該模型能提高訓練穩定性并增強圖像質量。甘嵐等[22]使用沃瑟斯坦(Wasserstein)距離損失函數,頻譜歸一化穩定生成網絡和判別網絡,提高生成樣本的質量和多樣性。祝俊輝等[23]在生成器和判別器引入頻譜歸一化的殘差網絡,并使用帶梯度懲罰(gradient penalty,GP)的Wasserstein距離進行樣本擴充,從而提升分類網絡的識別準確率。Xie等[24]提出多頭相互自注意力機制GAN模型,以解決紋理合成中分辨率低和細節不足等質量問題。基于以上分析,本文提出基于梯度懲罰和頻譜歸一化的雙自注意力DCGAN (double self-attention DCGAN,DoubleSA-DCGAN)模型。通過梯度懲罰、頻譜歸一化技術使訓練過程變得更加穩定,而雙自注意力機制可提高紋理細節特征和全局特征的提取能力,從而實現樣本增強。綜上,本文提出一種擴充數據集方法,可以有效地擴充帕金森病語音數據集并應用到帕金森病患者的識別工作中,以期提高小樣本下帕金森病患者識別準確率,為早期帕金森病的診斷提供有益參考。
1 小樣本帕金森病識別模型
基于樣本增強的帕金森病識別模型如圖1所示,首先將原始的語音信號經過預處理后輸入DoubleSA-DCGAN模型,使用評價指標對生成的語譜圖進行評估,并挑選出質量較高的語譜圖。將原始樣本與增強樣本合并,用基于遷移學習的ConvNeXt模型進行分類,從而實現帕金森病識別。
圖1
樣本增強的帕金森病識別模型
Figure1.
Sample enhanced Parkinson's disease recognition model
1.1 語譜圖
語譜圖,由時頻分析方法獲得,包含基音、共振峰和相鄰幀間的相關性等聲紋特征信息;其生成步驟包括預加重、分幀、加窗、短時傅里葉變換、取短時功率譜。它能展示不同頻段的語音信號強度隨時間變化的情況。
語譜圖能夠反映聲音在不同頻段上的強度變化,揭示聲音的特征和結構,如圖2所示。圖2中,左圖為健康人發出元音/a/的語譜圖,其顯示聲紋諧波范圍集中在0~15 000 Hz,包括基頻和中高頻區域的共振峰,并且紋理清晰;而右圖為帕金森病患者發出元音/a/的語譜圖,其顯示聲紋諧波范圍較窄,僅為0~7 500 Hz,且在高于2 500 Hz的中高頻區域紋理模糊、不規則,聲紋諧波信號消失。這些變化可能與帕金森病患者的聲帶損傷和聲音質量下降有關,因此可以通過分析語譜圖來識別帕金森病患者。
圖2
健康人和帕金森病患者的語譜圖
Figure2.
Spectrogram of healthy people and Parkinson's disease patients
1.2 網絡結構
1.2.1 GAN原理
如圖3所示,GAN主要由生成器和判別器兩部分組成,訓練過程中生成器和判別器相互欺騙對方、相互對抗、相互博弈,使生成器能夠生成無限接近真實樣本的圖片。GAN的損失函數如式(1)所示:
圖3
GAN網絡模型結構
Figure3.
Overview of GAN network structure
|
其中,E代表目標函數,真實數據為x,Pdata(x)為數據空間x中定義的真實數據概率分布,真實數據符合Pdata(x)分布;輸入為噪聲信號z,Pz(z)為潛在空間z上定義的潛在變量z概率分布,噪聲信號符合Pz(z)分布,該噪聲信號經生成器映射函數得到生成數據G(z),將通過判別映射函數的真實數據D(x)與生成數據G(z)作為判別器的輸入。V(D,G)表示生成樣本和真實樣本的差異度, 代表交替訓練生成器G和判別器D,使其互相博弈尋找平衡點,讓V(D,G)的值最大,最終得到最優生成器。
頻譜歸一化是通過限制譜范數來限制李普希茨(Lipschitz)常數,以符號L表示,滿足 L=1的約束條件[25],如式(2)所示:
|
其中,為最大奇異值,是權重W的二范式;生成器和判別器的每層權重W都用式(2)進行頻譜歸一化,每次更新權重矩陣中的參數,通過限制卷積濾波器的L < 1,來穩定生成器和判別器的訓練,有效地降低訓練的計算量。
Wasserstein距離損失函數結合GAN(Wasserstein-GAN,WGAN)[26]以權重裁剪迫使網絡僅學習簡單特征,所以常使用梯度懲罰來代替權重裁剪以強制實施Lipschitz約束[27],要求原始輸入的梯度的L2范數約束在1附近,從而避免梯度爆炸和消失問題,并提高網絡穩定性;帶梯度懲罰WGAN的最終目標函數(以符號P表示),如式(3)所示:
|
其中,E為期望函數, 為原始判別器損失項,為梯度懲罰項, 為生成數據,x為真實數據,判別器D(·)的目標是迫使生成器的分布Pg和真實分布Pr的原始判別器損失項盡可能大 ,梯度懲罰項接近于1。 是真實圖像和偽圖像之間的逐點插值, 是Pg、Pr之間的空間采樣, 是判別器輸出相對于插值的梯度, 是L2范數, 是損失比率,一般設置為10。
1.2.2 雙自注意力機制
雙自注意力機制的計算過程如圖4所示,表示兩個特征圖相乘,特征圖的第i行的各元素與另一個特征圖的第j列對應元素相乘后求和,表示兩個特征圖把其相對應位置元素相加融合成新的特征圖。卷積特征圖X通過三個1×1的卷積變換為三個特征空間q(x)、k(x)、v(x),其中 ,c為輸入通道數,n為特征圖高和寬的乘積。,,,其中,,, 為輸出通道數,。
圖4
雙自注意力機制模型
Figure4.
Double self-attention mechanism model
表示合成第j個區域時,模型對第i個位置的關注程度; 表示當合成第i個區域時,模型對第j個位置的關注程度,從而實現任意兩個元素之間的依賴關系[28],如式(4)~式(5)所示:
|
|
其中,exp(·)代表e的幾次方,,,通過歸一化指數函數(softmax)分別對行列進行歸一化,計算得到注意力圖y1和y2,再分別與特征空間v(x)像素點相乘后通過一個1 × 1的卷積層得到自注意力特征圖Y1和Y2,如式(6)~式(7)所示:
|
| '/> |
將自注意力特征圖相加得到 ,輸出為 ,如式(8)所示:
|
其中,,,,在上述等式中 ,,。因此,最終輸出以符號yi表示,如式(9)所示:
|
其中,γ為尺度參數,初始值為0; xi為原始的特征圖。
傳統GAN通過計算像素間的權重來建立依賴關系模型,從而捕捉圖像的全局結構。然而,卷積核的感受野是局部的,這種方法只能計算單一方向的像素之間的關注度。為處理圖像中的長距離依賴關系,將自注意力機制引入到GAN中,它能建立像素之間的遠距離關系[29]。DoubleSA-DCGAN將雙自注意力機制與DCGAN模型相結合,雙自注意力模塊能夠分析兩個注意力圖之間的相互關系,并生成詳細的特征位置線索信息,嵌入雙自注意力模塊可以幫助模型提高細節特性和全局特性,從而提高生成樣本的質量。
1.2.3 DoubleSA-DCGAN模型網絡結構
DoubleSA-DCGAN模型網絡結構如圖5所示,生成器網絡中h0~h5是4×4卷積核,步長為2,填充為1的微步幅卷積層。在微步幅卷積層后加入批量歸一化層(batch normalization,BN)幫助減緩初始化不當而導致的訓練困難,可以讓梯度在更深層傳播。生成器中各層均使用頻譜歸一化,每通過一個微步幅卷積層通道數減半,長寬變為原來一倍,h0~h5層都使用線性整流函數(rectified linear unit,ReLU),h6層使用雙曲正切函數Tanh(·)將生成的語譜圖映射到[?1, 1]的范圍,最后生成256 × 256 × 3語譜圖。
圖5
DoubleSA-DCGAN模型的網絡結構
Figure5.
Network structure of DoubleSA-DCGAN
判別器下采樣卷積中,特征圖變化過程與生成器相反。判別器網絡中,h0~h5是4 × 4卷積核,步長為2,填充為1的卷積層,且各層也使用頻譜歸一化,通過卷積層進行下采樣,通道數增加一倍,長寬減少一半。h0~h5層都使用帶泄露ReLU(leaky ReLU,Leaky ReLU),h6層采用 S 型生長曲線(Sigmoid)激活函數判別其輸出結果表示輸入語譜圖來自真實樣本的概率。
為解決特征提取能力低、紋理合成中分辨率低和細節不足等問題,本文在生成器結構的8 × 8 × 1 024子層和32 × 32 × 256子層后加入雙自注意力模塊,雙自注意力模塊可以幫助建立像素之間的遠距離依賴關系,從而提高生成器在紋理合成任務中的性能。
1.2.4 ConvNeXt模型的網絡結構
ConvNeXt網絡模型結構如圖6所示,在卷積過程中有4個階段(階段1~階段4),其中“× 3、× 3、× 9、× 3”代表每個階段堆疊塊重復的次數。對于局部的卷積結構(ConvNeXt Block),依次經過卷積核大小為7 × 7,步長為1,填充為3的深度可分離卷積層(Depthwise Conv2d)、歸一化層(layer norm)、二維卷積層(two-dimensional convolution,Conv2d)、高斯誤差線性單元層(Gaussian error linear units,GELU)、Conv2d、縮放輸入歸一化層(layer scale),再通過正則化手段(drop path)使其輸入和輸出維度一致。對于局部的下采樣結構(downsample)由歸一化層和卷積核大小為2 × 2,步長為2的卷積層組成。最后,利用殘差結構將輸入和輸出相加作為最后的輸出結果。ConvNeXt模型網絡通過卷積核大小為4 × 4,步長為4的卷積層對圖像進行下采樣,圖像的高和寬都減少為原來的四分之一,然后再通過四個局部卷積結構和三個局部下采樣結構分別將圖像的高和寬都依次減少為原來的二分之一,最后經過全局平均池化層(global avg pooling)、歸一化層和線性變換(linear),得到網絡輸出結果。
圖6
ConvNeXt模型的網絡結構
Figure6.
Network structure of ConvNeXt model
1.3 樣本擴充的選取標準
弗雷謝起始距離(Fréchet inception distance,FID)使用統計特征來衡量兩組圖像的相似度[28],以符號FID表示,最理想情況下FID的得分為0,定義如式(10)所示:
|
其中,x和g表示真實圖片和生成圖片, 和 分別是生成圖像和真實圖像的特征向量均值, 和 分別為它們的協方差矩陣均值,Tr表示矩陣的跡, 表示L2范數。
在無參考圖像的質量評價中,圖像的清晰度不高會造成圖像失真、圖像模糊,導致圖像分析和解譯困難,降低圖像的實際應用價值。本文選擇三種無參考圖像質量評價方法去評估圖像清晰度。
(1)灰度方差(sum of modulus of gray difference,SMD)函數,當圖像完全聚焦時高頻分量最多,即圖像最清晰,故可將灰度變化作為聚焦評價的依據[30],SMD函數定義如式(11)所示:
|
其中,D(f)代表灰度值大小,f(x, y)表示圖像對應像素點(x, y)的灰度值。
(2)無參考圖像清晰度評價函數(Tenengrad),可以用來評估圖像的清晰度[30],其值越大,表示圖像越清晰,定義如式(12)所示:
|
其中,D(I)表示圖像的清晰度,x和y是圖像對應像素點,T是給定的邊緣檢測閾值,G(x,y)是索貝爾(Sobel)算子提取水平和垂直方向的梯度值,如式(13)所示:
|
其中,Gx和Gy分別是像素點(x, y)處索貝爾算子水平和垂直方向邊緣檢測算子的卷積。Tenengrad 函數中索貝爾算子定義如式(14)所示:
|
其中,ix為水平方向上的算子矩陣,iy為垂直方向上的算子矩陣。
(3)拉普拉斯(Laplacian)梯度函數與Tenengrad函數基本一致,Laplacian函數將Laplacian算子作為邊緣檢測的方法,該算子矩陣L定義如式(15)所示:
|
2 實驗
2.1 實驗設備
實驗環境:操作系統為Ubuntu18.04.6(Canonical Ltd.,英國),獨立顯卡(RTX3090, Nvidia Inc.,美國)。深度學習框架為Pytorch1.10(Linux Foundation,美國),編程語言為Python 3.9(Python Software Foundation,美國)。
2.2 數據集介紹及預處理
本文實驗使用的帕金森病語音數據集來自美國加利福尼亞大學歐文分校(University of California Irvine,UCI)構建的公開數據庫[7],簡稱UCI數據庫,該數據集分為訓練集和測試集。其中,訓練集包含的受試者數據為:446個健康人和399個帕金森病患者發出/a/、/o/和/u/三種元音語音信號片段;測試集包含的受試者數據為:60個健康人和60個帕金森病患者發出/a/、/o/二種元音語音信號片段。對每個語音進行預處理,并生成256 × 256分辨率的語譜圖,預處理的參數設置如表1所示。由于UCI數據庫原始數據集樣本的數量少,不利于DoubleSA-DCGAN模型收斂,故對原始的語譜圖進行隨機的水平、垂直翻轉,調整圖片明暗程度,微調圖片的對比度、飽和度,添加噪聲等操作,將數據集擴大到原來的5倍。同時將健康人圖片的標簽設為0,帕金森病患者圖片標簽設為1。
2.3 DoubleSA-DCGAN模型訓練
噪聲向量維度為100,使用自適應矩估計優化器(adaptive moment estimation,Adam)調節超參數,學習率設為0.000 2,動量1設為0.5,動量2設為0.999,批量大小設為64,梯度懲罰系數設為10,判別器與生成器訓練次數之比設為5,迭代數目設為2 000。
2.4 ConvNeXt模型訓練
使用FID、SMD函數、Laplacian梯度函數和Tenengrad函數作為選擇標準,將語譜圖添加標簽后,按6∶2∶2的比例劃分為訓練集、驗證集和測試集,迭代數目設置為1 000,學習率為0.000 5,批量大小設置為8,權重衰減參數為0.05。使用遷移學習的方法,利用訓練好的預訓練權重去訓練ConvNeXt模型。
3 實驗結果與分析
3.1 可視化DoubleSA-DCGAN模型生成結果
本文使用公共數據集UCI數據庫,分別進行原始DCGAN模型和DoubleSA-DCGAN模型實驗。實驗結果如圖7所示,原始DCGAN模型生成的樣本模糊,學習到的圖片特征少,可能出現模式坍塌現象。DoubleSA-DCGAN模型生成的樣本具有清晰的輪廓和紋理、并且辨識度較高。這表明雙自注意力機制在解決模式坍塌、生成樣本紋理不清晰和學習特征不足等問題方面起到了有效的改善作用,進一步說明DoubleSA-DCGAN生成的樣本具有更高的圖像質量。
圖7
網絡訓練生成圖像對比
Figure7.
Comparison of images generated during network training
3.2 樣本增強效果分析
圖像的清晰度是衡量數字圖像質量優劣的重要指標。隨機選取2 000張生成的樣本圖片,計算其三種無參考圖像清晰平均值作為量化評價指標。如表2所示,DoubleSA-DCGAN模型的評價指標SMD函數、Laplacian梯度函數、Tenengrad函數值都有明顯的提高。這表明梯度懲罰、頻譜歸一化以及雙自注意力機制在網絡訓練和圖像生成過程中起到了穩定和提升生成圖像質量的作用。
本文研究結果顯示,DoubleSA-DCGAN模型生成圖像的FID值為56.2,DCGAN模型生成圖像的FID值為113.5,DoubleSA-DCGAN模型相比改進前DCGAN模型的FID值有明顯的降低,表明DoubleSA-DCGAN生成的樣本與真實圖像的分布更加接近,質量和紋理更好。
3.3 樣本增強在分類識別性能上的分析
根據生成樣本在上述評價指標得分較高的表現,本文從生成樣本中分別選取920張語譜圖作為訓練集、280張語譜圖作為驗證集進行樣本增強。為了更好地測試該模型,從原始數據集各選取200張帕金森病患者和健康人語譜圖作為測試集。最后,訓練集包括1 200張語譜圖,驗證集包括400張語譜圖,測試集包括400張語譜圖,按照6∶2∶2的比例進行實驗。經過樣本增強后,各種模型網絡在小樣本帕金森病識別任務中的分類識別率均得到提高,VGG16網絡模型提高10.4%;殘差網絡34(residual network 34,ResNet34)模型提高10.7%;亞歷克斯網絡(AlexNet)模型提高5.73%;谷歌網絡(GoogLeNet)模型提高4.03%;ConvNeXt網絡模型提高4.52%,如表3所示,這說明樣本增強對于改善分類性能具有積極的影響。本文實驗結果表明,在小樣本帕金森病識別任務中ConvNeXt網絡的性能最佳。
將訓練好的ConvNeXt模型的權重加載到混淆矩陣中,如圖8所示。
圖8
ConvNeXt分類模型的混淆矩陣
Figure8.
Confusion matrix of ConvNeXt classification model
本文采用精確率(precision)、召回率(recall)和特異度(specificity)作為二分類算法評價指標。通過混淆矩陣的分析,計算出健康人和帕金森病患者的精確率、召回率和特異度均為0.985,如表4所示。
實驗結果表明,DoubleSA-DCGAN模型可實現對語譜圖質量紋理以及樣本數量增強。同時,ConvNeXt分類模型對語譜圖進行特征提取和分類時表現出色,達到了98.8%的帕金森病識別準確率。針對帕金森病研究的音頻數據稀缺下采用DoubleSA-DCGAN結合ConvNeXt的深度學習方法進行帕金森病識別是可行且有效的。
4 結論
本文提出一種針對帕金森病研究中音頻數據稀缺并且獲取困難等問題的樣本擴充方法,稱為DoubleSA-DCGAN。該方法通過引入雙自注意力機制建立長距離依賴關系,以幫助模型提高細節特性和全局特性,從而提高生成樣本的質量,同時還引入梯度懲罰和頻譜歸一化技術提高DoubleSA-DCGAN模型的穩定性。實驗結果表明,在小樣本條件下,使用GAN對帕金森病數據集樣本量進行擴充是可行且有效的。本文提出的DoubleSA-DCGAN和ConvNeXt混合模型在小樣本條件下能夠提高帕金森病的識別率。這為帕金森病相關研究提供了一種有效的解決方案,并有望應用于臨床實踐。雖然本文提出的方法在早期帕金森病識別研究中取得良好的結果,但相關細節仍然需要進一步驗證和探索,此外還應意識到樣本擴充只是帕金森病相關研究中的某一方面,未來還需要綜合考慮其他更多相關因素。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:張子豪是本研究的實驗設計人和執行人,負責數據分析,總結實驗結果。王子瓊和韋莉負責論文初稿的寫作與修改;趙德春指導論文寫作,提出修改意見。