基于電子計算機斷層掃描(CT)影像的肺結節自動檢測可以有效輔助肺癌診治,但當前缺乏有效的交互工具將放射科醫生的判讀結果實時記錄并反饋,以優化后臺算法模型。本文設計并研發了一個支持CT圖像肺結節輔助診斷的在線交互審查系統,通過預置模型檢測出肺結節展示給醫生,醫生利用專業知識對檢測的肺結節進行標注,然后根據標注結果采用主動學習策略對內置模型進行迭代優化,以持續提高模型的準確性。本文以開源肺結節數據集——肺結節分析2016(LUNA16)的5~9號子集進行迭代實驗,隨著迭代次數的增加,模型的準確率、調和分數和交并比指標穩定提升,準確率從0.213 9提高至0.565 6。本文研究結果表明,該系統能在使用深度分割模型輔助醫生診斷的同時,最大程度地利用醫生的反饋信息來優化模型,迭代提高模型的準確性,從而更好地輔助醫生工作。
引用本文: 譚雙平, 李俊, 張曉娟, 嚴馨月, 張彤, 吳下里, 劉自強, 李莉莉, 馮娟, 韓海斌, 唐國英, 韓俊洲, 鄧友鋒. 基于主動學習的肺結節計算機輔助診斷交互審查技術. 生物醫學工程學雜志, 2024, 41(3): 503-510. doi: 10.7507/1001-5515.202310044 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
肺癌是一種臨床常見的惡性腫瘤,在全球范圍內都具有較高發病率和死亡率[1]。若能在早期進行檢測并治療,患者的五年存活率將得到大幅提高[2]。早期肺癌在計算機斷層掃描(computed tomography,CT)圖像中表現為肺結節,呈圓形不透明或不規則陰影。隨著醫學成像技術的迅猛發展,CT圖像分辨率不斷提高,能夠捕捉到更小尺寸的肺部病灶,這為肺結節的精準診斷提供了可能。
在龐大的CT圖像中判讀各類復雜肺結節,且保持較高的準確率和效率,對臨床醫生來說是一個較大挑戰。計算機輔助診斷(computer aided diagnosis,CAD)通過人工智能(artificial intelligence,AI)算法實現診斷過程的自動化,可有效提高診斷結果的準確率和放射科醫生的工作效率[3]。近年來,隨著深度學習的應用,針對CT影像的CAD進展迅速,涵蓋了數據預處理、肺實質分割、肺結節檢測、假陽性降低、肺結節分割、分類和檢索等各方面[4-9]。同時,許多醫療設備制造商和軟件公司也開始開發商業化肺結節CAD系統,具備智能化的肺結節檢測和診斷功能[10]。CAD系統的性能高度依賴于訓練數據集,但是獲取高質量的標注數據集需要有經驗的放射科醫生投入大量的時間和精力,而且現有的依托已標注數據集的模型泛化能力普遍較弱。雖然,已有文獻提出了融合深度主動學習的半自動化標注方法,可通過主動選取策略將最具價值的樣本提供給用戶人工標注,但這種方法沒有考慮到用戶標注的主動性[11-12]。研究發現,現階段CT圖像肺結節分割存在兩個問題:① 肺結節目標小,且具有準確像素級結節標簽的數據集獲取困難,常見的通用深度分割模型表現欠佳;② 不能有效地集成醫生的反饋,無法充分利用醫生的專業知識。
針對上述問題,本文設計并研發了一個支持CT圖像肺結節輔助診斷的在線交互審查方法和系統,提出“交互標記-標簽傳播-樣本集擴展-分割模型更新”的技術路線。其創新點包括:① 對肺結節像素級標簽難以獲取問題,設計了基于三維方向的梯度直方圖(three dimensional histogram of oriented gradients,3D-HOG)提取特征相似的標簽傳播策略,顧及不確定性和多樣性,擴展用于主動學習樣本選擇的候選樣本集;② 提出了基于交互圖形界面的醫生審查系統的設計與實現方法。
本文設計系統首先將檢測出的肺結節展示給醫生,醫生利用專業知識對系統檢測出的肺結節進行標注或糾正,然后根據標注結果采用標簽傳播的主動學習策略對內置模型進行迭代優化,以持續提高模型的準確性。本系統將肺結節檢測、醫生審查標注、模型優化等功能集于一體,在使用AI模型輔助醫生診斷的同時,又最大程度利用醫生的反饋信息來優化模型。本文設計的損失函數和主動學習優化方法,可作為任何一個肺結節分割模型及系統設計的有效參考,以迭代提高模型的準確性,更好地輔助醫生工作。
1 基于主動學習的肺結節輔助診斷交互審查系統設計
1.1 系統整體設計
本文介紹的肺結節CAD交互審查系統,是基于主動學習驅動的診斷方法。主動學習是通過假設樣本池中每個樣本對模型性能的提高貢獻不同,每次迭代訓練時選取信息量最大、價值最高的樣本,以盡可能少的樣本數量來提高模型性能[13]。系統首先通過內置模型檢測出肺結節,提供圖形化界面讓多位醫生對模型的初步檢測結果進行標注或糾正,然后從訓練數據集和待診斷數據集中同時篩選信息量較高的樣本對模型進行更新訓練,直至分割模型達到精度要求或不再提升。本文主動學習中使用的選擇策略是人工引導的樣本選取策略,其綜合多位醫生的投票得分和模型表現來設定各樣本的信息量,以提高分割模型在特定類型結節的檢測敏感度,改善肺結節多樣性和類別不平衡帶來的假陽性問題。該方法在原有樣本數據基礎上,每次逐漸增加主動學習樣本(約占原樣本數據1/4到1/5),以便在訓練過程中保留對舊數據的記憶,同時為了避免新數據對模型產生過大影響,算法會適當降低學習率使模型對舊知識的保留更穩定。
本文介紹的交互性包括兩方面:① 用戶可對模型檢測出的肺結節結果進行審查標注,并返回樣本,返回的樣本通過主動學習持續改進后臺模型。② 多用戶可同步或異步進行審查標注,算法會利用多用戶交互標注信息進行用戶不確定度計算,幫助篩選更有價值的樣本進行模型優化。
1.2 功能和流程設計
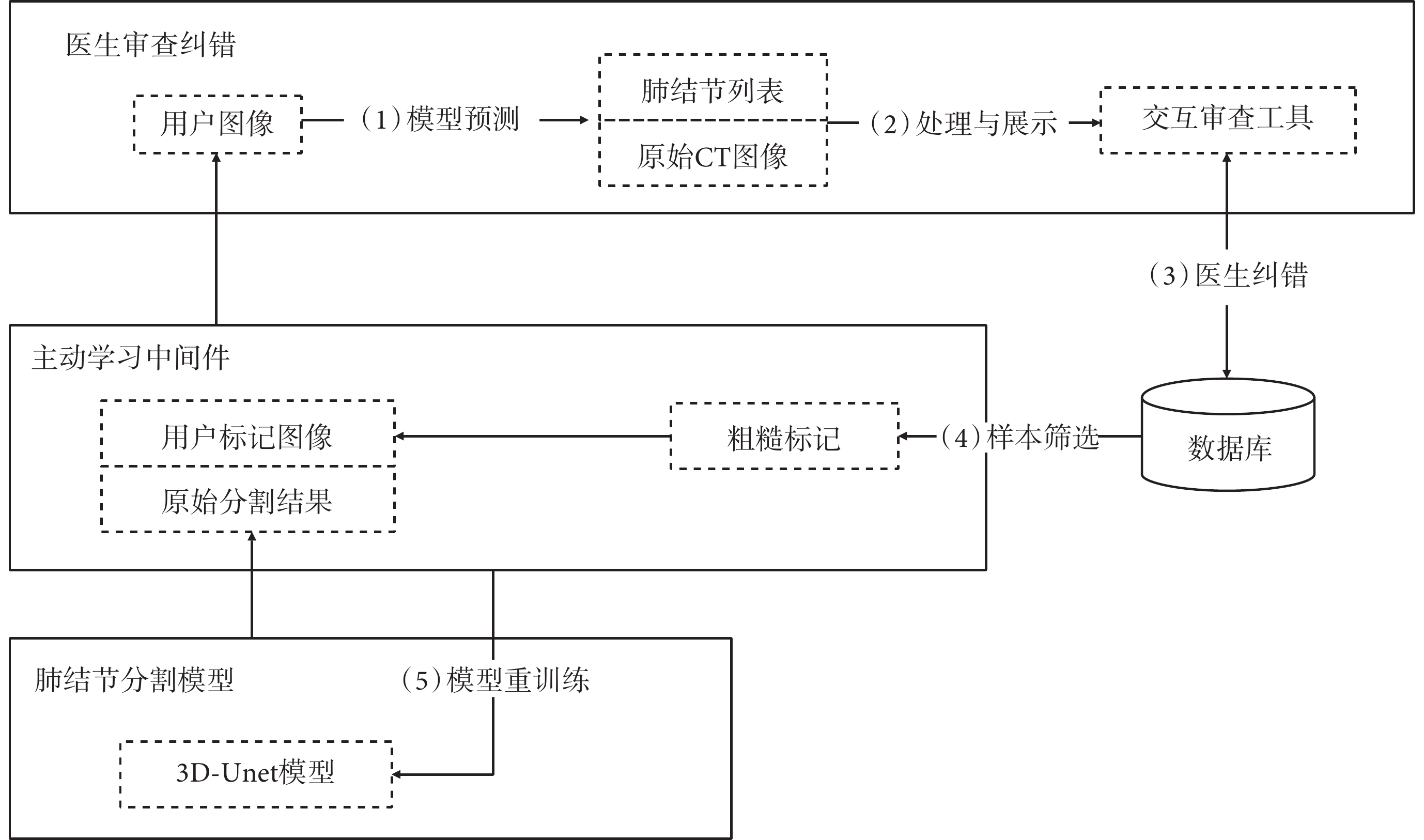
如圖1所示,本系統主要包括肺結節分割模型、主動學習中間件和醫生審查糾錯3個模塊,分別完成基于主動學習模型的肺結節分割、分割模型重訓練、基于網頁瀏覽器(web browser,web)的原始圖像和檢測結果可視化展示及用戶交互。各模塊按順序進行的主要功能如下:
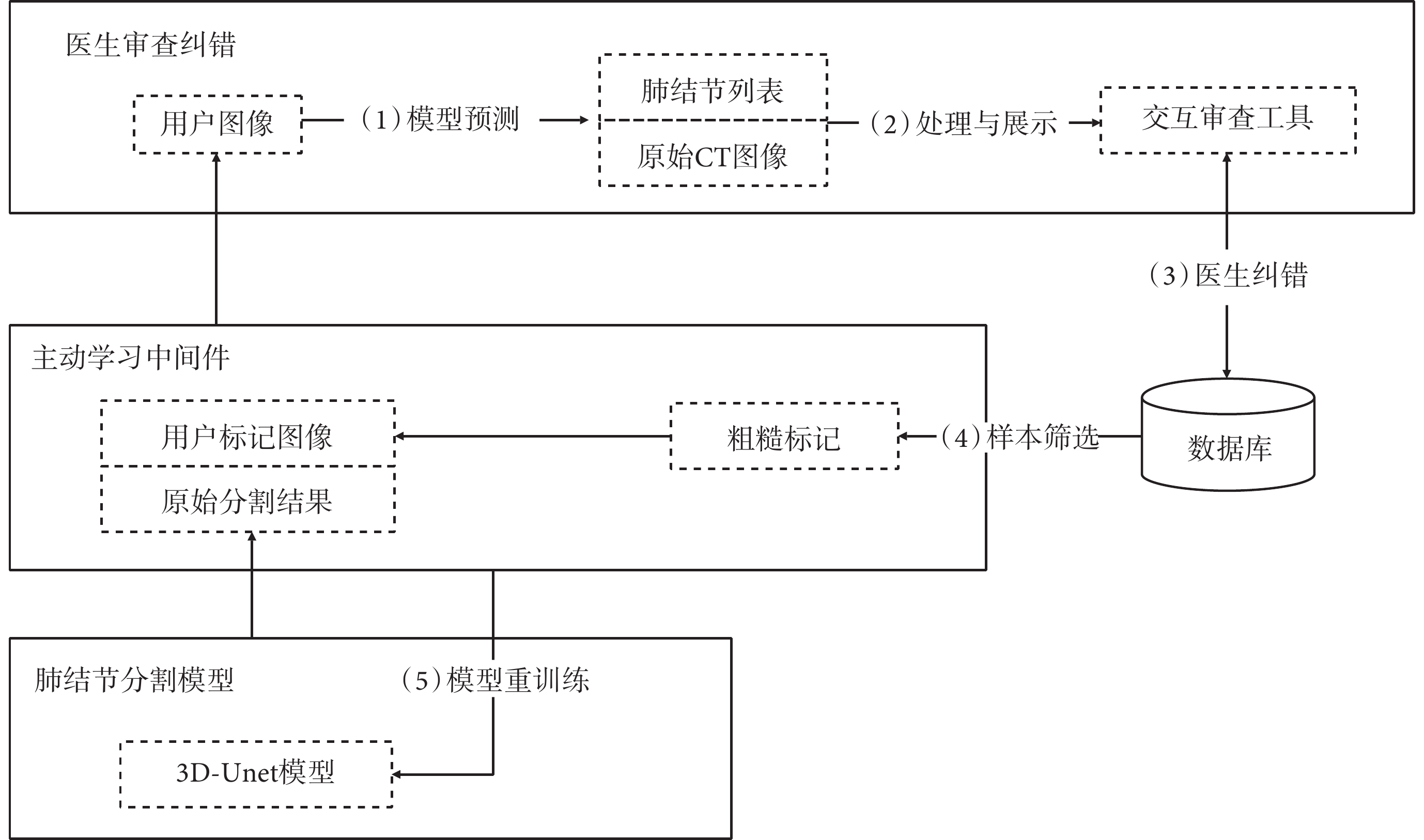 圖1
系統功能模塊和流程
Figure1.
System function modules and processes
圖1
系統功能模塊和流程
Figure1.
System function modules and processes
(1)肺結節分割:對用戶傳入的原始CT圖像進行肺結節檢測,并將分割結果同時傳輸給前端可視化界面和中間件樣本選擇算法。
(2)分割結果處理與展示:后端通過連通域計算,獲得已分割的肺結節實例列表,并與原始CT圖像一起呈現給用戶。
(3)醫生審查:結合原始CT圖像,多位醫生通過交互界面對分割出的肺結節進行審查,對漏檢或錯檢的肺結節切片以畫圈的方式進行粗糙標記和糾正。
(4)基于主動學習的樣本篩選:當新增或修改的肺結節標記達到一定數量時,后端將醫生的審查標注結果和原始分割結果一同傳輸給在線樣本選擇模型,應用于三維U型網絡(3D-Unet)模型的更新訓練。
(5)模型重訓練與更新:在構建的訓練集基礎上,以增量方式優化當前模型。
(6)循環執行步驟(1)~步驟(5),直至分割模型達到精度要求或不再提升,在此過程中用戶可持續輸入未診斷的CT圖像。通過不斷迭代,使后臺分割模型不斷收到醫生的反饋,從而有效地融合醫生專業知識,提高模型的泛化能力和分割性能。
1.2.1 肺結節分割模型
3D-UNet模型是一種經典的卷積神經網絡結構,能夠同時捕獲圖像中的局部細節和全局上下文信息,因此常用于醫學影像分割領域[14-18]。為更好地支持分割模型重訓練,本文綜合了醫學圖像分割常用的戴斯(Dice)損失和交叉熵損失來設計損失函數。考慮到醫生提供的標注數量有限,在模型重訓練過程中,對醫生未標記的區域進行相對粗糙的樣本擴展。然后根據3D-HOG提取紋理特征向量,計算未標記樣本和具有精細標簽的本地訓練集的相似性來獲取未標記樣本的偽標簽,并將相似距離加入到加權Dice 損失函數的設計中[19],如式(1)所示:
 |
其中,Dp和Dn分別表示肺結節像素和背景像素的戴斯系數(以符號dice表示),超參數α由最小傳播距離計算,具體細節如式(2)~式(4)所示:
 |
 |
 |
Xp、Xn、Yp、Yn分別表示實際標注為結節、預測結果為結節、實際標注為背景、預測結果為背景的概率矩陣。rneg和rpos分別表示根據最小相似距離計算的背景和結節像素數所占的比值,其計算公式如式(5)~式(8)所示:
 |
 |
 |
 |
其中,mindistance為最小相似距離,nneg和npos分別表示標簽傳播后具有粗糙標簽的切塊中結節和背景的像素數,pneg和ppos分別表示標簽傳播后根據最小相似距離加權得到的背景和結節像素數。
此外,基于交叉熵損失函數的梯度穩定性,添加了結節和背景像素的對數懲罰項penp和penn,如式(9)~式(10)所示:
 |
 |
其中,yi表示預測結果像素為肺結節的概率,ε為一個極小值,防止對數的真數為0造成錯誤。通過多次實驗驗證,設置超參數ω = 2,λ = 0.2,最終損失函數(以符號loss表示)如式(11)所示:
 |
1.2.2 主動學習中間件
在模型構建過程中,本文使用肺結節正樣本作為初始訓練集,并在此基礎上訓練3D-Unet模型作為初始化模型,使其具有一定的基礎分割能力。但該初始訓練集只含有正樣本且數量較少,使得模型負樣本表現較差,泛化能力低,會帶來較多的假陽性結果。故在處理復雜任務或大規模數據集時需要調整模型以適應新的數據分布。因此,本文設計了主動學習中間件,一方面,對接收到的分割結果進行后處理,即對分割結果和原始CT圖像進行合成,并展示肺結節列表,以支持前端可視化;另一方面,分析已有的肺結節分割結果和用戶審查標注信息,自動選擇具有代表性和關鍵特征的樣本,用于模型訓練和優化。
在初始分割模型的基礎上,獲取醫生粗糙標簽并使用主動學習來實現分割模型的訓練優化與更新。主動學習的核心是選取重訓練的樣本,而樣本的信息量是選取的關鍵。現有度量數據信息量的方式較多,常用的有不確定度采樣、信息增益采樣、基于委員會查詢、不確定性和多樣性權衡等[14]。本文基于已有的度量標準,設計了一種綜合考慮醫生用戶和后臺算法的主動學習策略。
在醫生用戶方,要考慮多用戶反饋信息,可采用多人投票的方式計算正負樣本的不確定度,以對應樣本的投票者數量(以符號count表示)與參與總人數n的比值表示投票得分,投票得分越高,不確定度越高,如式(12)所示:
 |
其中,Sp即為根據用戶不確定度度量得到的高價值樣本。在后臺算法角度,可以綜合考慮正樣本的不確定性和負樣本的多樣性,該算法的不確定度Sm,采用最小值置信度選出分割模型不善識別的正樣本,如式(13)所示:
 |
其中,x表示輸入,yi表示類別,i代表類別數,P(yi|x)表示將x輸入分類為yi的概率。負樣本采用多樣性策略,基于3D-HOG特征向量,使用K均值聚類算法將用戶標注數據集劃分為K簇,通過計算每個樣本到類中心點的距離進行多樣性采樣,得到代表性樣本。同樣地,對本地訓練集的樣本篩選也采用了K均值聚類的選擇策略以保證結節類型的多樣性和代表性。最后,設定醫生與分割模型度量信息量的權重α,該值隨分割模型的性能變化。通常情況下,根據醫生反饋信息所度量的信息量更具有參考性,即α>0.5,綜合用戶不確定度Sp和算法不確定度Sm得到有價值樣本Stotal,如式(14)所示:
 |
1.2.3 基于交互界面的醫生審查
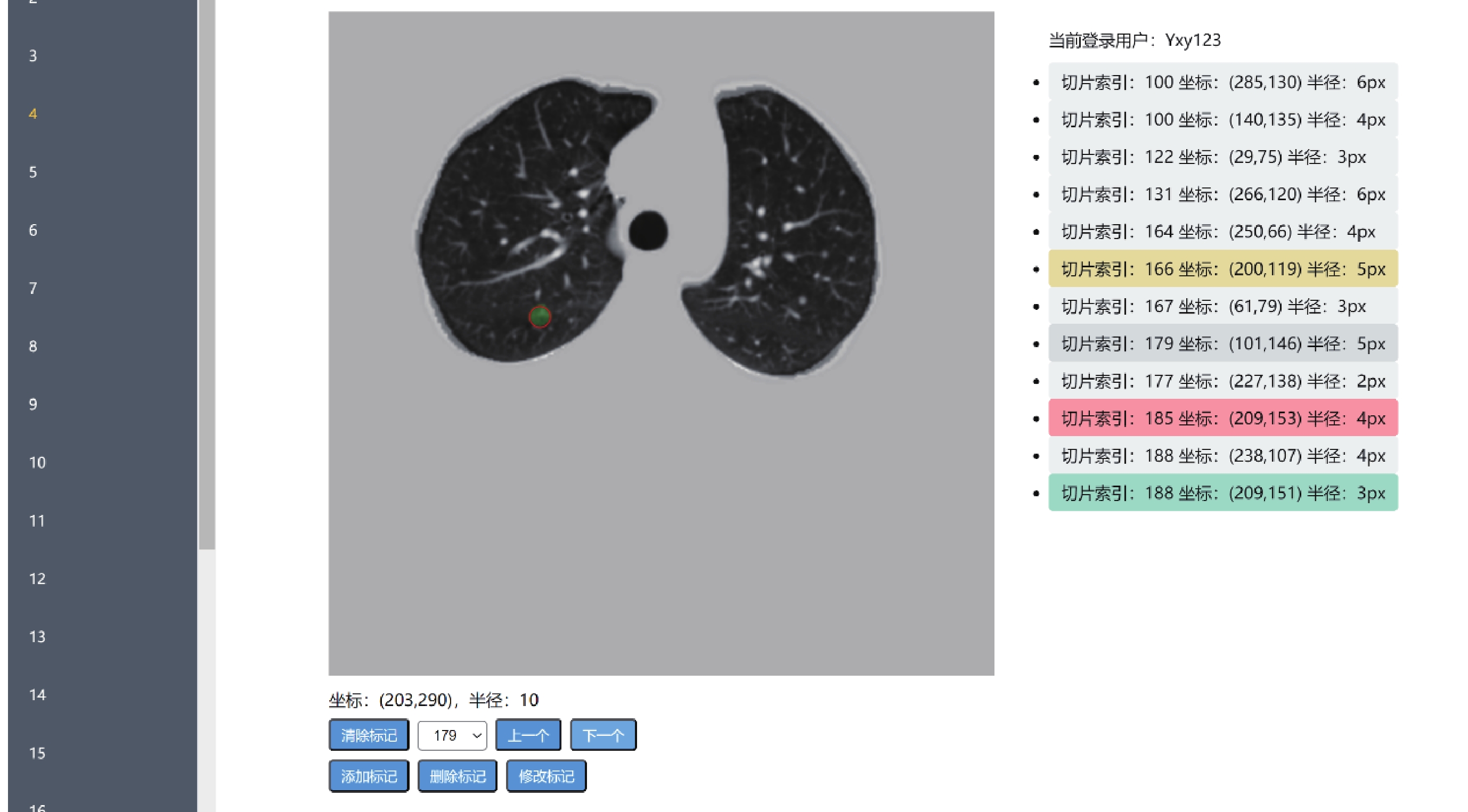
醫生審查糾錯模塊主要包括兩方面功能:用戶閱片和交互糾錯。閱片功能包括原始肺部圖像和肺結節分割結果展示。如圖2所示,左側,為肺部CT圖像切片列表,點擊任一切片,即可在中間畫布區域加載對應CT圖像文件的分割結果,系統檢測出的肺結節將會以綠色覆蓋顯示。右側列表框,展示3D-Unet模型執行分割任務檢出的所有肺結節實例,每個實例項包含:結節的坐標位置和半徑信息。閱片功能,可為醫生提供多種閱片方式,包括上下切片切換、切片索引值選取和肺結節快速定位。此外,系統還提供了肺結節快速定位功能,當用戶點擊右側已檢出肺結節時,系統會迅速切換至模型檢測到的對應肺結節中心位置,方便用戶重點關注模型檢出部分,從而提高閱片效率。
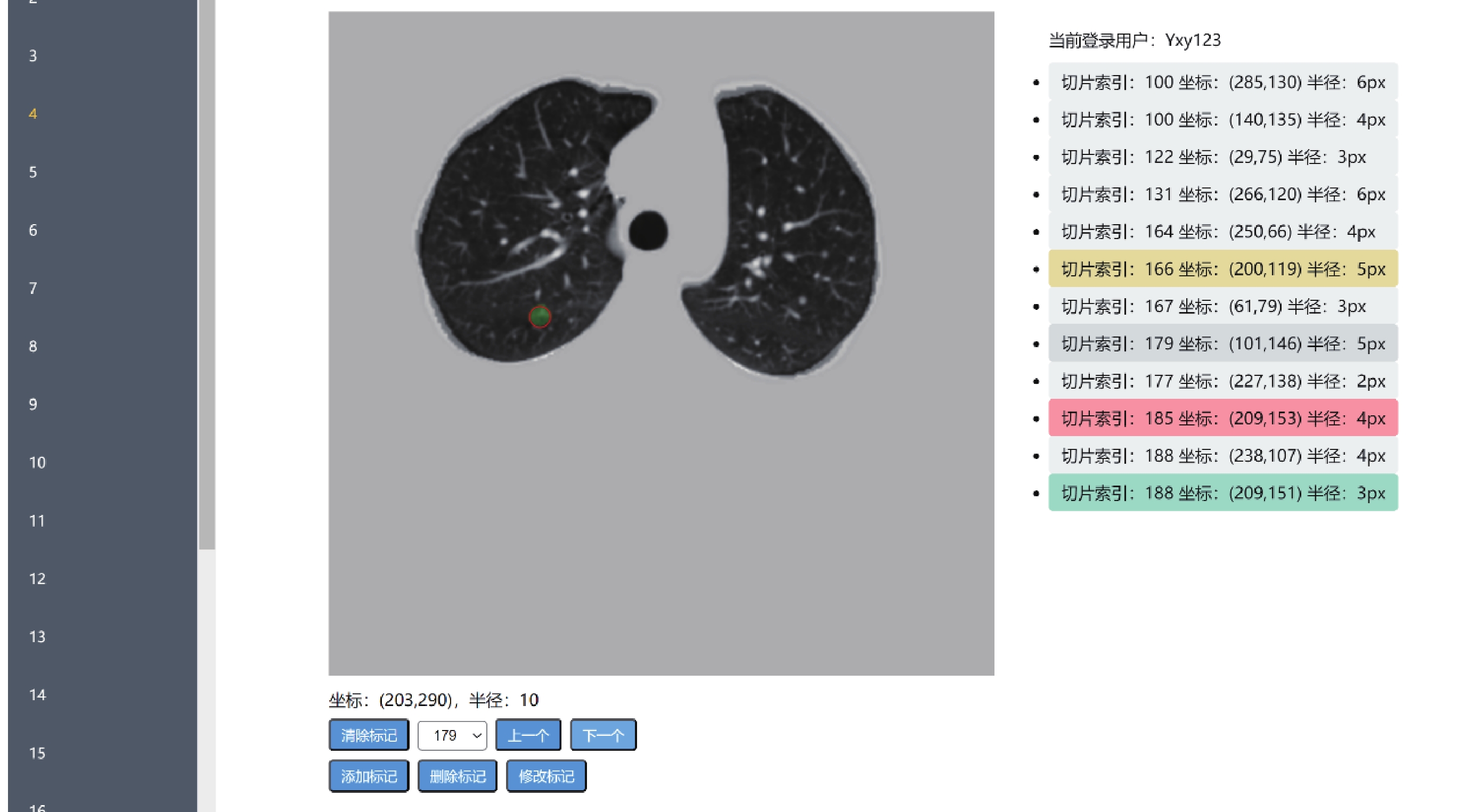 圖2
可視化頁面截圖
Figure2.
Visual page screenshot (color)
圖2
可視化頁面截圖
Figure2.
Visual page screenshot (color)
交互糾錯是本系統的核心功能。醫生在閱片時,可結合自己的經驗,通過刪除、修改和新增按鈕分別執行刪除、修改和增加肺結節操作。對刪除和修改操作,用戶點擊右側列表項的某一具體肺結節即可修改。對漏檢的肺結節,可直接在切片圖像中圈出漏檢的結節中心坐標和半徑。同時,不同的操作會以不同的顏色在肺結節列表中顯示,無色、紅色、綠色和黃色分別代表了用戶的無操作、刪除、新增和修改。當糾錯的肺結節達到一定數量時,后臺將操作記錄存入數據庫中,用于主動學習篩選樣本。
2 交互審查系統的開發與實現
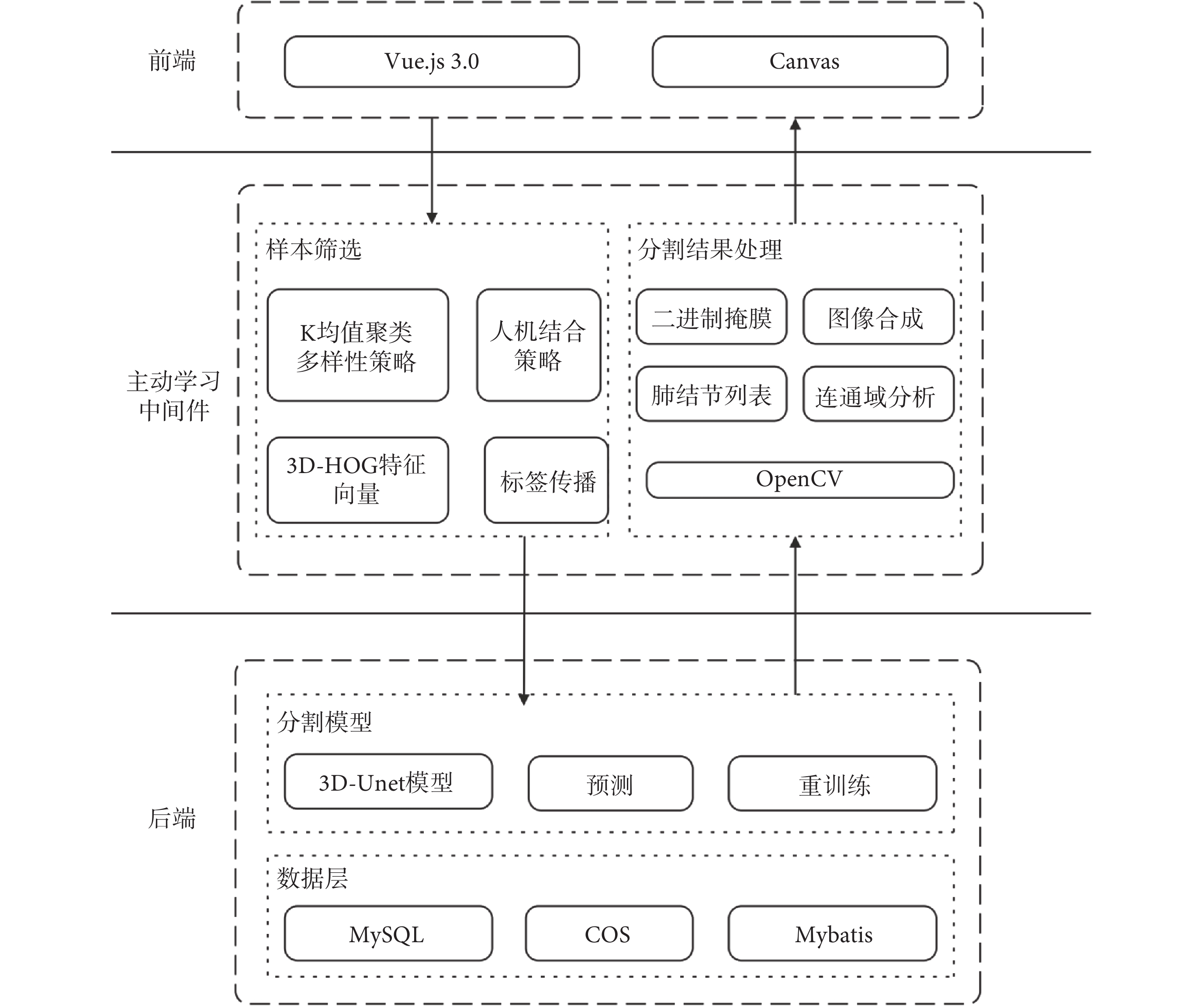
為便于多用戶分布式使用,本系統采用瀏覽器/服務器(B/S)架構進行開發,具體包括前端、后端(分割模型、數據層)和主動學習中間件等四部分,系統整體架構如圖3所示。
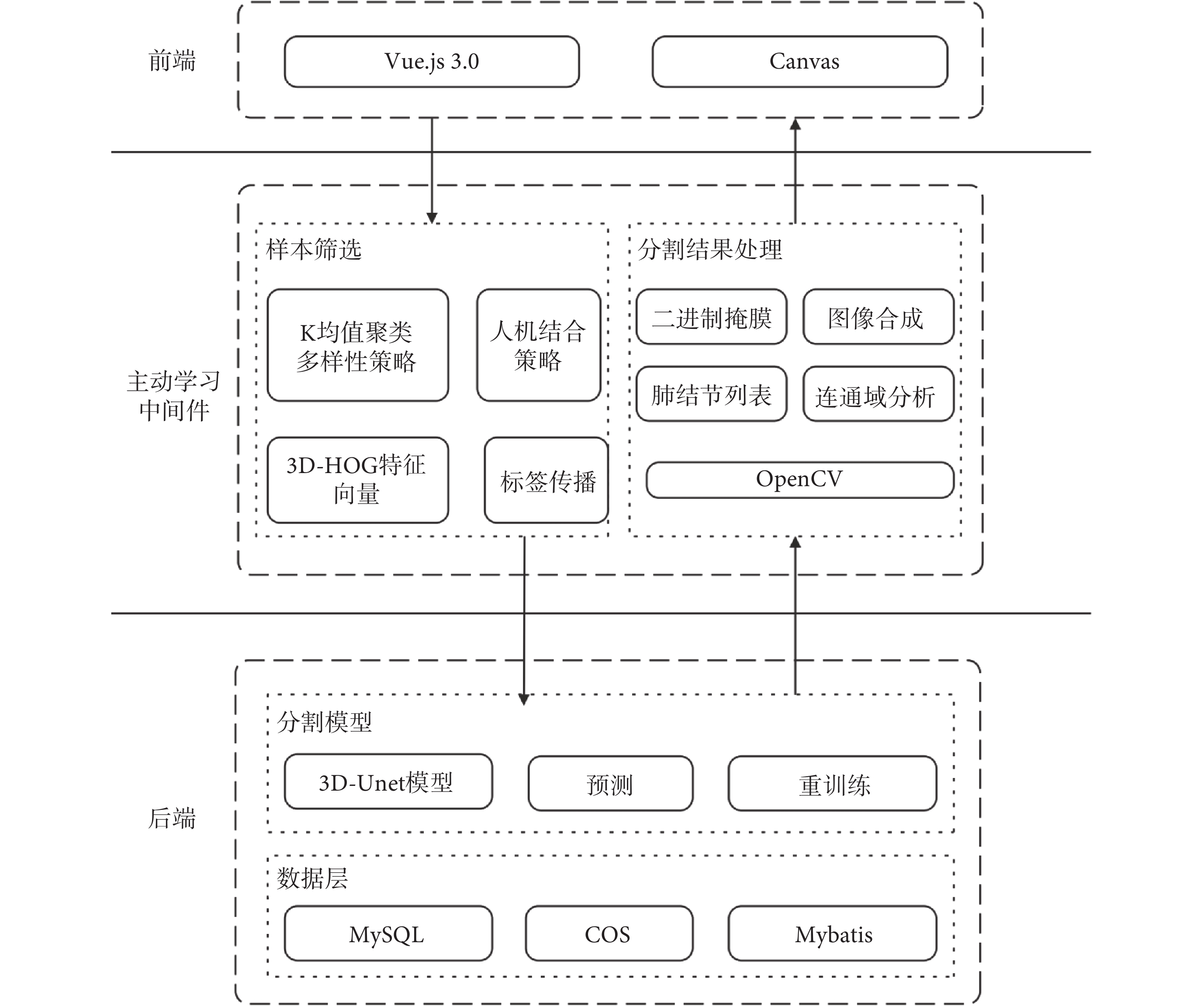 圖3
系統架構
Figure3.
System structure
圖3
系統架構
Figure3.
System structure
2.1 前端實現
交互審查診斷系統基于瀏覽器運行,前端選擇即時編譯語言JavaScript(Netscape Communications Co. Ltd.,美國)進行開發。系統界面設計選用Vue.js 3.0開發,它提供了一套聲明式的、組件化的編程模型,可高效地開發用戶界面。為支持CT圖像和用戶標注,本文借助繪圖工具Canvas(Netscape Communications Co. Ltd.,美國)實現用戶標注功能。它提供一個類似于畫布的區域,可通過JavaScript代碼在其中進行繪制,從而創建各種圖形、動畫和交互效果。另外,為實現用戶在本地瀏覽器中持久地存儲和快速訪問數據,前端將用戶信息記錄在本地存儲中,以降低頻繁查詢數據庫帶來的運行壓力。
2.2 后端設計與實現
2.2.1 后端架構
服務端使用面向對象語言Java(Oracle Co. Ltd.,美國)開發。在數據庫管理方面,通過定義實體類和數據持久性的開源框架Mybatis(Apache Co.,美國)進行數據庫交互,實現數據的增刪改查操作,尤其是用戶標注記錄的持久化存儲。為確保后端系統的安全性和權限安全管理,在用戶通過身份驗證后,利用會話管理跟蹤用戶在網站上的活動狀態,記錄登錄狀態并設置超時時間。若用戶未在系統中進行任何操作且登錄超時,則系統自動退出。
2.2.2 數據庫
本系統數據庫采用開源關系型數據庫MySQL(MySQL AB Co.,瑞典),借助騰訊云對象存儲(cloud object storage,COS)存儲肺實例數據,以降低下載資源時延,提高頁面渲染速度。本系統數據庫設計涉及三類實體,分別是醫生操作、肺結節操作記錄和肺部CT圖像實例。
2.2.3 肺結節分割模型
本系統3D-Unet模型采用基于面向對象語言Python 3.6(Python Software Foundation,荷蘭)的機器學習庫PyTorch(Python Software Foundation,荷蘭)作為深度學習框架,它提供了豐富的工具和庫,支持各種神經網絡模型的構建和訓練。當用戶的標注數量達到閾值時,服務會自動調用Python腳本,將導出的標注數據傳輸給模型以進行優化,并替換優化后的模型權重文件,以用于后續的肺結節檢測。
2.3 主動學習中間件的設計與實現
主動學習中間件,通過Python語言實現樣本篩選和肺結節分割結果的處理。對1.2.2小節中所述的主動學習查詢策略,系統通過計算3D-HOG特征向量、對未標記區域進行標簽傳播,使用人機結合和K均值聚類的多樣性查詢策略,分別在本地訓練集與用戶標記圖像中篩選樣本,構建新的訓練集用于模型優化。
肺結節分割結果,包括肺部CT圖像合成和肺結節列表獲取等步驟。CT圖像合成需要融合原始CT圖像和二進制掩膜圖像。使用開源計算機視覺和機器學習軟件庫OpenCV(Intel Co.,美國),將掩膜圖像的前景(肺結節區域)疊加在原始CT圖像上,并將融合后的圖像轉換為紅綠藍(red,green,blue,RGB)色彩格式,以綠色突出顯示檢測到的肺結節,方便用戶閱片。在肺結節列表獲取的過程中,本文通過三維組件庫對二進制掩膜圖像進行連通域分析,提取每個結節的中心點和坐標,并過濾半徑小于1 mm的肺結節,從而獲得肺結節列表。
3 實驗
3.1 基于LUNA16的交互診斷實驗
本文使用的影像數據來自于開源肺結節數據集——肺結節分析2016(the lung nodule analysis 2016,LUNA16)。該數據集共分為10個數據子集,子集編號為0~9,包含切片厚度一致且大于3 mm,并完整無缺失的888張CT圖像[5]。為量化評價本文所述模型的性能,本文選取醫學圖像領域常用的評價指標,包括:召回率(recall),反應漏檢情況;準確度(precision),衡量真正例與模型預測為正例的樣本比例;調和分數(F1-score),是準確度和召回率的調和平均值;交并比(mean intersection over union,MIoU),衡量預測結果的準確度和完整性。
實驗使用子集0~4作為訓練集,訓練建立初始模型3D-Unet(0~4),隨后在子集5~9進行五次檢測測試。如表1所示,可見3D-Unet(0~4)初始模型在數據集5~9的表現各不相同,但基本都表現為召回率高而準確率低,即假陽性高。
隨后在數據集5~9,模擬醫生進行簡單標記。根據主動學習多樣性策略,本文在初始訓練集中選取80個正樣本切塊和40個負樣本切塊,在每次迭代交互的數據集中選取40個具有粗糙標簽的正樣本切塊和80個負樣本切塊進行模型更新。初始3D-Unet與更新后的模型在數據集5~9上的表現如表2所示。經過交互標記和模型更新后,與初始分割模型相比,召回率降低,其余指標都有一定程度的提升。如表2所示,縱向對比準確率,第一次迭代后在數據集5的準確率為0.213 9,經過5次迭代后提升到0.565 6。另外,將表1和表2中的同一數據集進行對比,對比3D-Unet(0~4)訓練建立的初始模型與模型更新后在同一數據集上的表現,初始模型在數據集5的準確率為0.074 0,第一次迭代后提高到0.213 9。測試結果說明,本文提出的主動學習多樣性策略能夠根據模型在對應數據的表現情況,提取出不易識別、具有代表性、類別平衡的訓練樣本;同時也證實了重訓練損失函數對假陽性降低的有效性。
本文的實驗目的并非與已有的分割模型對比,而是可以依托任何一個分割模型,通過迭代改善該模型。實驗表明,與初始3D-Unet分割模型對比,本文提出的方法可以通過多次迭代提升分割精度。
3.2 運行測試
為測試系統運行效率,本文還對系統的運行速度進行了測試。測試環境使用64位Windows 10操作系統(Microsoft Co.,美國),處理器為至強金牌系列6133(Intel Co.,美國),內存為2 G,存儲為250 G,顯卡為RTX 2080 ti(NVIDIA Co.,美國)。運行測試的對象包括:主動學習樣本查詢、模型重訓練以及單張肺部CT圖像的預測速度。由于每輪迭代使用的測試數據集和用戶標注數量不同,為表征更普遍的運行情況,本文通過多次實驗后得到前述3個測試對象的預測平均時間分別為156 9 s、2.5 h、7 s。時長較長的主要原因是圖像數量較多、尺寸較大、非高性能運算服務器。隨著樣本的逐步增加,訓練所需時間也更長。但由于增加的規模有限,因此每次迭代學習由于新引入樣本導致訓練時間的增加幅度并不明顯。因此,如何在引入新樣本時,在盡可能保留必要知識的情況下去除舊樣本,從而提升迭代訓練效率,以及算法涉及特征向量的計算、標簽傳播、兩階段的肺結節預測等,是未來需改進的方向。
4 結束語
本文提出的支持醫生反饋信息的肺結節交互審查方法,在參考系統檢出肺結節結果的同時,又可及時采集醫生審查信息進行模型更新,可有效改善正負樣本不平衡問題,降低假陽性率,提高肺結節檢測準確性。值得一提的是,本文的研究重點不在于檢測和分割方法,而在于使用醫生標記和標簽傳播獲取粗糙標簽樣本集,利用主動學習實現對肺結節分割模型的迭代優化。任何一個肺結節分割模型,都可參考本文設計的損失函數和主動學習優化方法。但作為一個在線實時系統,主動學習樣本查詢和模型重訓練時間較長,難以快速響應用戶的下一步檢測需求,故優化系統運行效率是本文未來的重點研究方向之一,如圖像特征向量的計算優化、標簽傳播方法或改進網絡層級結構等。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:譚雙平主要負責項目主持、框架搭建、計劃安排及論文撰寫;張彤、鄧有鋒、李俊等主要負責項目實驗計劃、算法設計、程序設計指導及論文修改;張曉娟、嚴馨月主要負責實驗、算法設計及程序開發及論文撰寫;吳下里等其他人主要負責實驗指導、程序測試、數據分析及指導等工作。
0 引言
肺癌是一種臨床常見的惡性腫瘤,在全球范圍內都具有較高發病率和死亡率[1]。若能在早期進行檢測并治療,患者的五年存活率將得到大幅提高[2]。早期肺癌在計算機斷層掃描(computed tomography,CT)圖像中表現為肺結節,呈圓形不透明或不規則陰影。隨著醫學成像技術的迅猛發展,CT圖像分辨率不斷提高,能夠捕捉到更小尺寸的肺部病灶,這為肺結節的精準診斷提供了可能。
在龐大的CT圖像中判讀各類復雜肺結節,且保持較高的準確率和效率,對臨床醫生來說是一個較大挑戰。計算機輔助診斷(computer aided diagnosis,CAD)通過人工智能(artificial intelligence,AI)算法實現診斷過程的自動化,可有效提高診斷結果的準確率和放射科醫生的工作效率[3]。近年來,隨著深度學習的應用,針對CT影像的CAD進展迅速,涵蓋了數據預處理、肺實質分割、肺結節檢測、假陽性降低、肺結節分割、分類和檢索等各方面[4-9]。同時,許多醫療設備制造商和軟件公司也開始開發商業化肺結節CAD系統,具備智能化的肺結節檢測和診斷功能[10]。CAD系統的性能高度依賴于訓練數據集,但是獲取高質量的標注數據集需要有經驗的放射科醫生投入大量的時間和精力,而且現有的依托已標注數據集的模型泛化能力普遍較弱。雖然,已有文獻提出了融合深度主動學習的半自動化標注方法,可通過主動選取策略將最具價值的樣本提供給用戶人工標注,但這種方法沒有考慮到用戶標注的主動性[11-12]。研究發現,現階段CT圖像肺結節分割存在兩個問題:① 肺結節目標小,且具有準確像素級結節標簽的數據集獲取困難,常見的通用深度分割模型表現欠佳;② 不能有效地集成醫生的反饋,無法充分利用醫生的專業知識。
針對上述問題,本文設計并研發了一個支持CT圖像肺結節輔助診斷的在線交互審查方法和系統,提出“交互標記-標簽傳播-樣本集擴展-分割模型更新”的技術路線。其創新點包括:① 對肺結節像素級標簽難以獲取問題,設計了基于三維方向的梯度直方圖(three dimensional histogram of oriented gradients,3D-HOG)提取特征相似的標簽傳播策略,顧及不確定性和多樣性,擴展用于主動學習樣本選擇的候選樣本集;② 提出了基于交互圖形界面的醫生審查系統的設計與實現方法。
本文設計系統首先將檢測出的肺結節展示給醫生,醫生利用專業知識對系統檢測出的肺結節進行標注或糾正,然后根據標注結果采用標簽傳播的主動學習策略對內置模型進行迭代優化,以持續提高模型的準確性。本系統將肺結節檢測、醫生審查標注、模型優化等功能集于一體,在使用AI模型輔助醫生診斷的同時,又最大程度利用醫生的反饋信息來優化模型。本文設計的損失函數和主動學習優化方法,可作為任何一個肺結節分割模型及系統設計的有效參考,以迭代提高模型的準確性,更好地輔助醫生工作。
1 基于主動學習的肺結節輔助診斷交互審查系統設計
1.1 系統整體設計
本文介紹的肺結節CAD交互審查系統,是基于主動學習驅動的診斷方法。主動學習是通過假設樣本池中每個樣本對模型性能的提高貢獻不同,每次迭代訓練時選取信息量最大、價值最高的樣本,以盡可能少的樣本數量來提高模型性能[13]。系統首先通過內置模型檢測出肺結節,提供圖形化界面讓多位醫生對模型的初步檢測結果進行標注或糾正,然后從訓練數據集和待診斷數據集中同時篩選信息量較高的樣本對模型進行更新訓練,直至分割模型達到精度要求或不再提升。本文主動學習中使用的選擇策略是人工引導的樣本選取策略,其綜合多位醫生的投票得分和模型表現來設定各樣本的信息量,以提高分割模型在特定類型結節的檢測敏感度,改善肺結節多樣性和類別不平衡帶來的假陽性問題。該方法在原有樣本數據基礎上,每次逐漸增加主動學習樣本(約占原樣本數據1/4到1/5),以便在訓練過程中保留對舊數據的記憶,同時為了避免新數據對模型產生過大影響,算法會適當降低學習率使模型對舊知識的保留更穩定。
本文介紹的交互性包括兩方面:① 用戶可對模型檢測出的肺結節結果進行審查標注,并返回樣本,返回的樣本通過主動學習持續改進后臺模型。② 多用戶可同步或異步進行審查標注,算法會利用多用戶交互標注信息進行用戶不確定度計算,幫助篩選更有價值的樣本進行模型優化。
1.2 功能和流程設計
如圖1所示,本系統主要包括肺結節分割模型、主動學習中間件和醫生審查糾錯3個模塊,分別完成基于主動學習模型的肺結節分割、分割模型重訓練、基于網頁瀏覽器(web browser,web)的原始圖像和檢測結果可視化展示及用戶交互。各模塊按順序進行的主要功能如下:
圖1
系統功能模塊和流程
Figure1.
System function modules and processes
(1)肺結節分割:對用戶傳入的原始CT圖像進行肺結節檢測,并將分割結果同時傳輸給前端可視化界面和中間件樣本選擇算法。
(2)分割結果處理與展示:后端通過連通域計算,獲得已分割的肺結節實例列表,并與原始CT圖像一起呈現給用戶。
(3)醫生審查:結合原始CT圖像,多位醫生通過交互界面對分割出的肺結節進行審查,對漏檢或錯檢的肺結節切片以畫圈的方式進行粗糙標記和糾正。
(4)基于主動學習的樣本篩選:當新增或修改的肺結節標記達到一定數量時,后端將醫生的審查標注結果和原始分割結果一同傳輸給在線樣本選擇模型,應用于三維U型網絡(3D-Unet)模型的更新訓練。
(5)模型重訓練與更新:在構建的訓練集基礎上,以增量方式優化當前模型。
(6)循環執行步驟(1)~步驟(5),直至分割模型達到精度要求或不再提升,在此過程中用戶可持續輸入未診斷的CT圖像。通過不斷迭代,使后臺分割模型不斷收到醫生的反饋,從而有效地融合醫生專業知識,提高模型的泛化能力和分割性能。
1.2.1 肺結節分割模型
3D-UNet模型是一種經典的卷積神經網絡結構,能夠同時捕獲圖像中的局部細節和全局上下文信息,因此常用于醫學影像分割領域[14-18]。為更好地支持分割模型重訓練,本文綜合了醫學圖像分割常用的戴斯(Dice)損失和交叉熵損失來設計損失函數。考慮到醫生提供的標注數量有限,在模型重訓練過程中,對醫生未標記的區域進行相對粗糙的樣本擴展。然后根據3D-HOG提取紋理特征向量,計算未標記樣本和具有精細標簽的本地訓練集的相似性來獲取未標記樣本的偽標簽,并將相似距離加入到加權Dice 損失函數的設計中[19],如式(1)所示:
|
其中,Dp和Dn分別表示肺結節像素和背景像素的戴斯系數(以符號dice表示),超參數α由最小傳播距離計算,具體細節如式(2)~式(4)所示:
|
|
|
Xp、Xn、Yp、Yn分別表示實際標注為結節、預測結果為結節、實際標注為背景、預測結果為背景的概率矩陣。rneg和rpos分別表示根據最小相似距離計算的背景和結節像素數所占的比值,其計算公式如式(5)~式(8)所示:
|
|
|
|
其中,mindistance為最小相似距離,nneg和npos分別表示標簽傳播后具有粗糙標簽的切塊中結節和背景的像素數,pneg和ppos分別表示標簽傳播后根據最小相似距離加權得到的背景和結節像素數。
此外,基于交叉熵損失函數的梯度穩定性,添加了結節和背景像素的對數懲罰項penp和penn,如式(9)~式(10)所示:
|
|
其中,yi表示預測結果像素為肺結節的概率,ε為一個極小值,防止對數的真數為0造成錯誤。通過多次實驗驗證,設置超參數ω = 2,λ = 0.2,最終損失函數(以符號loss表示)如式(11)所示:
|
1.2.2 主動學習中間件
在模型構建過程中,本文使用肺結節正樣本作為初始訓練集,并在此基礎上訓練3D-Unet模型作為初始化模型,使其具有一定的基礎分割能力。但該初始訓練集只含有正樣本且數量較少,使得模型負樣本表現較差,泛化能力低,會帶來較多的假陽性結果。故在處理復雜任務或大規模數據集時需要調整模型以適應新的數據分布。因此,本文設計了主動學習中間件,一方面,對接收到的分割結果進行后處理,即對分割結果和原始CT圖像進行合成,并展示肺結節列表,以支持前端可視化;另一方面,分析已有的肺結節分割結果和用戶審查標注信息,自動選擇具有代表性和關鍵特征的樣本,用于模型訓練和優化。
在初始分割模型的基礎上,獲取醫生粗糙標簽并使用主動學習來實現分割模型的訓練優化與更新。主動學習的核心是選取重訓練的樣本,而樣本的信息量是選取的關鍵。現有度量數據信息量的方式較多,常用的有不確定度采樣、信息增益采樣、基于委員會查詢、不確定性和多樣性權衡等[14]。本文基于已有的度量標準,設計了一種綜合考慮醫生用戶和后臺算法的主動學習策略。
在醫生用戶方,要考慮多用戶反饋信息,可采用多人投票的方式計算正負樣本的不確定度,以對應樣本的投票者數量(以符號count表示)與參與總人數n的比值表示投票得分,投票得分越高,不確定度越高,如式(12)所示:
|
其中,Sp即為根據用戶不確定度度量得到的高價值樣本。在后臺算法角度,可以綜合考慮正樣本的不確定性和負樣本的多樣性,該算法的不確定度Sm,采用最小值置信度選出分割模型不善識別的正樣本,如式(13)所示:
|
其中,x表示輸入,yi表示類別,i代表類別數,P(yi|x)表示將x輸入分類為yi的概率。負樣本采用多樣性策略,基于3D-HOG特征向量,使用K均值聚類算法將用戶標注數據集劃分為K簇,通過計算每個樣本到類中心點的距離進行多樣性采樣,得到代表性樣本。同樣地,對本地訓練集的樣本篩選也采用了K均值聚類的選擇策略以保證結節類型的多樣性和代表性。最后,設定醫生與分割模型度量信息量的權重α,該值隨分割模型的性能變化。通常情況下,根據醫生反饋信息所度量的信息量更具有參考性,即α>0.5,綜合用戶不確定度Sp和算法不確定度Sm得到有價值樣本Stotal,如式(14)所示:
|
1.2.3 基于交互界面的醫生審查
醫生審查糾錯模塊主要包括兩方面功能:用戶閱片和交互糾錯。閱片功能包括原始肺部圖像和肺結節分割結果展示。如圖2所示,左側,為肺部CT圖像切片列表,點擊任一切片,即可在中間畫布區域加載對應CT圖像文件的分割結果,系統檢測出的肺結節將會以綠色覆蓋顯示。右側列表框,展示3D-Unet模型執行分割任務檢出的所有肺結節實例,每個實例項包含:結節的坐標位置和半徑信息。閱片功能,可為醫生提供多種閱片方式,包括上下切片切換、切片索引值選取和肺結節快速定位。此外,系統還提供了肺結節快速定位功能,當用戶點擊右側已檢出肺結節時,系統會迅速切換至模型檢測到的對應肺結節中心位置,方便用戶重點關注模型檢出部分,從而提高閱片效率。
圖2
可視化頁面截圖
Figure2.
Visual page screenshot (color)
交互糾錯是本系統的核心功能。醫生在閱片時,可結合自己的經驗,通過刪除、修改和新增按鈕分別執行刪除、修改和增加肺結節操作。對刪除和修改操作,用戶點擊右側列表項的某一具體肺結節即可修改。對漏檢的肺結節,可直接在切片圖像中圈出漏檢的結節中心坐標和半徑。同時,不同的操作會以不同的顏色在肺結節列表中顯示,無色、紅色、綠色和黃色分別代表了用戶的無操作、刪除、新增和修改。當糾錯的肺結節達到一定數量時,后臺將操作記錄存入數據庫中,用于主動學習篩選樣本。
2 交互審查系統的開發與實現
為便于多用戶分布式使用,本系統采用瀏覽器/服務器(B/S)架構進行開發,具體包括前端、后端(分割模型、數據層)和主動學習中間件等四部分,系統整體架構如圖3所示。
圖3
系統架構
Figure3.
System structure
2.1 前端實現
交互審查診斷系統基于瀏覽器運行,前端選擇即時編譯語言JavaScript(Netscape Communications Co. Ltd.,美國)進行開發。系統界面設計選用Vue.js 3.0開發,它提供了一套聲明式的、組件化的編程模型,可高效地開發用戶界面。為支持CT圖像和用戶標注,本文借助繪圖工具Canvas(Netscape Communications Co. Ltd.,美國)實現用戶標注功能。它提供一個類似于畫布的區域,可通過JavaScript代碼在其中進行繪制,從而創建各種圖形、動畫和交互效果。另外,為實現用戶在本地瀏覽器中持久地存儲和快速訪問數據,前端將用戶信息記錄在本地存儲中,以降低頻繁查詢數據庫帶來的運行壓力。
2.2 后端設計與實現
2.2.1 后端架構
服務端使用面向對象語言Java(Oracle Co. Ltd.,美國)開發。在數據庫管理方面,通過定義實體類和數據持久性的開源框架Mybatis(Apache Co.,美國)進行數據庫交互,實現數據的增刪改查操作,尤其是用戶標注記錄的持久化存儲。為確保后端系統的安全性和權限安全管理,在用戶通過身份驗證后,利用會話管理跟蹤用戶在網站上的活動狀態,記錄登錄狀態并設置超時時間。若用戶未在系統中進行任何操作且登錄超時,則系統自動退出。
2.2.2 數據庫
本系統數據庫采用開源關系型數據庫MySQL(MySQL AB Co.,瑞典),借助騰訊云對象存儲(cloud object storage,COS)存儲肺實例數據,以降低下載資源時延,提高頁面渲染速度。本系統數據庫設計涉及三類實體,分別是醫生操作、肺結節操作記錄和肺部CT圖像實例。
2.2.3 肺結節分割模型
本系統3D-Unet模型采用基于面向對象語言Python 3.6(Python Software Foundation,荷蘭)的機器學習庫PyTorch(Python Software Foundation,荷蘭)作為深度學習框架,它提供了豐富的工具和庫,支持各種神經網絡模型的構建和訓練。當用戶的標注數量達到閾值時,服務會自動調用Python腳本,將導出的標注數據傳輸給模型以進行優化,并替換優化后的模型權重文件,以用于后續的肺結節檢測。
2.3 主動學習中間件的設計與實現
主動學習中間件,通過Python語言實現樣本篩選和肺結節分割結果的處理。對1.2.2小節中所述的主動學習查詢策略,系統通過計算3D-HOG特征向量、對未標記區域進行標簽傳播,使用人機結合和K均值聚類的多樣性查詢策略,分別在本地訓練集與用戶標記圖像中篩選樣本,構建新的訓練集用于模型優化。
肺結節分割結果,包括肺部CT圖像合成和肺結節列表獲取等步驟。CT圖像合成需要融合原始CT圖像和二進制掩膜圖像。使用開源計算機視覺和機器學習軟件庫OpenCV(Intel Co.,美國),將掩膜圖像的前景(肺結節區域)疊加在原始CT圖像上,并將融合后的圖像轉換為紅綠藍(red,green,blue,RGB)色彩格式,以綠色突出顯示檢測到的肺結節,方便用戶閱片。在肺結節列表獲取的過程中,本文通過三維組件庫對二進制掩膜圖像進行連通域分析,提取每個結節的中心點和坐標,并過濾半徑小于1 mm的肺結節,從而獲得肺結節列表。
3 實驗
3.1 基于LUNA16的交互診斷實驗
本文使用的影像數據來自于開源肺結節數據集——肺結節分析2016(the lung nodule analysis 2016,LUNA16)。該數據集共分為10個數據子集,子集編號為0~9,包含切片厚度一致且大于3 mm,并完整無缺失的888張CT圖像[5]。為量化評價本文所述模型的性能,本文選取醫學圖像領域常用的評價指標,包括:召回率(recall),反應漏檢情況;準確度(precision),衡量真正例與模型預測為正例的樣本比例;調和分數(F1-score),是準確度和召回率的調和平均值;交并比(mean intersection over union,MIoU),衡量預測結果的準確度和完整性。
實驗使用子集0~4作為訓練集,訓練建立初始模型3D-Unet(0~4),隨后在子集5~9進行五次檢測測試。如表1所示,可見3D-Unet(0~4)初始模型在數據集5~9的表現各不相同,但基本都表現為召回率高而準確率低,即假陽性高。
隨后在數據集5~9,模擬醫生進行簡單標記。根據主動學習多樣性策略,本文在初始訓練集中選取80個正樣本切塊和40個負樣本切塊,在每次迭代交互的數據集中選取40個具有粗糙標簽的正樣本切塊和80個負樣本切塊進行模型更新。初始3D-Unet與更新后的模型在數據集5~9上的表現如表2所示。經過交互標記和模型更新后,與初始分割模型相比,召回率降低,其余指標都有一定程度的提升。如表2所示,縱向對比準確率,第一次迭代后在數據集5的準確率為0.213 9,經過5次迭代后提升到0.565 6。另外,將表1和表2中的同一數據集進行對比,對比3D-Unet(0~4)訓練建立的初始模型與模型更新后在同一數據集上的表現,初始模型在數據集5的準確率為0.074 0,第一次迭代后提高到0.213 9。測試結果說明,本文提出的主動學習多樣性策略能夠根據模型在對應數據的表現情況,提取出不易識別、具有代表性、類別平衡的訓練樣本;同時也證實了重訓練損失函數對假陽性降低的有效性。
本文的實驗目的并非與已有的分割模型對比,而是可以依托任何一個分割模型,通過迭代改善該模型。實驗表明,與初始3D-Unet分割模型對比,本文提出的方法可以通過多次迭代提升分割精度。
3.2 運行測試
為測試系統運行效率,本文還對系統的運行速度進行了測試。測試環境使用64位Windows 10操作系統(Microsoft Co.,美國),處理器為至強金牌系列6133(Intel Co.,美國),內存為2 G,存儲為250 G,顯卡為RTX 2080 ti(NVIDIA Co.,美國)。運行測試的對象包括:主動學習樣本查詢、模型重訓練以及單張肺部CT圖像的預測速度。由于每輪迭代使用的測試數據集和用戶標注數量不同,為表征更普遍的運行情況,本文通過多次實驗后得到前述3個測試對象的預測平均時間分別為156 9 s、2.5 h、7 s。時長較長的主要原因是圖像數量較多、尺寸較大、非高性能運算服務器。隨著樣本的逐步增加,訓練所需時間也更長。但由于增加的規模有限,因此每次迭代學習由于新引入樣本導致訓練時間的增加幅度并不明顯。因此,如何在引入新樣本時,在盡可能保留必要知識的情況下去除舊樣本,從而提升迭代訓練效率,以及算法涉及特征向量的計算、標簽傳播、兩階段的肺結節預測等,是未來需改進的方向。
4 結束語
本文提出的支持醫生反饋信息的肺結節交互審查方法,在參考系統檢出肺結節結果的同時,又可及時采集醫生審查信息進行模型更新,可有效改善正負樣本不平衡問題,降低假陽性率,提高肺結節檢測準確性。值得一提的是,本文的研究重點不在于檢測和分割方法,而在于使用醫生標記和標簽傳播獲取粗糙標簽樣本集,利用主動學習實現對肺結節分割模型的迭代優化。任何一個肺結節分割模型,都可參考本文設計的損失函數和主動學習優化方法。但作為一個在線實時系統,主動學習樣本查詢和模型重訓練時間較長,難以快速響應用戶的下一步檢測需求,故優化系統運行效率是本文未來的重點研究方向之一,如圖像特征向量的計算優化、標簽傳播方法或改進網絡層級結構等。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:譚雙平主要負責項目主持、框架搭建、計劃安排及論文撰寫;張彤、鄧有鋒、李俊等主要負責項目實驗計劃、算法設計、程序設計指導及論文修改;張曉娟、嚴馨月主要負責實驗、算法設計及程序開發及論文撰寫;吳下里等其他人主要負責實驗指導、程序測試、數據分析及指導等工作。