青光眼是全球排名首位的不可逆致盲眼病,定期的視野檢查是青光眼診斷和治療過程中的必要監測手段,提前預測患者未來視野將有利于臨床醫生對病情進展進行及時干預。為了聯合利用患者過去視野檢查結果中的時間和空間特征,以提高視野預測效果,本文采用卷積長短期記憶(ConvLSTM)網絡構建預測模型,并使用來自華盛頓大學漢弗瑞視野分析儀的視野測試數據集(UWHVF)的數據,對ConvLSTM模型與其他方法進行預測性能驗證與比較。研究結果顯示,相較于傳統方法,ConvLSTM模型具有更高的預測精度;同時,探究視野序列長度與預測性能的變化關系發現,當采用過去1.5~6.0年內的3次視野結果預測時,ConvLSTM模型的預測性能更好,預測結果的平均絕對誤差為2.255 dB,均方根誤差為3.457 dB,決定系數為0.960。實驗結果表明,本文所提方法僅使用既往視野檢測結果,即實現了較準確的未來0.5~2.0年內的視野預測,因此該方法有望用于輔助臨床醫生對視野進展進行評估并治療。
引用本文: 王握, 鄭秀娟, 呂智清, 李妮, 陳俊. 基于時空特征學習的視野預測研究. 生物醫學工程學雜志, 2024, 41(5): 1003-1011. doi: 10.7507/1001-5515.202310072 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
青光眼是一種進展緩慢、損害視神經及視覺通路并最終導致視覺功能損害的疾病,是全球首位的不可逆性致盲病因[1]。目前中國青光眼患者超過2 100萬,約占全世界青光眼患者的四分之一[2-3]。青光眼的特征是視網膜神經節細胞的丟失、視網膜神經纖維層(retinal nerve fiber layer,RNFL)變薄,并出現特征性視神經萎縮,而這些改變在功能上表現為特征性視野(visual field,VF)缺損[4]。視野改變是診斷青光眼的“金標準”,定期的視野隨訪檢查是青光眼診斷和監測病情進展的重要手段,且該監測往往是終身持續的。由于青光眼患者的視野變化波動比正常人更嚴重[5],視野惡化速度因個體而異,其中穩定型患者惡化速度通常小于0.5 dB/a,而快速進展型患者則超過1.5 dB/a[6]。并且隨著時間的推移,患者的視野進展模式存在明顯不同[7],再加上患者常常無法保證定期檢查,因此提前預測未來視野變化對青光眼診斷和治療具有重要意義。特別是預測未來0.5~2.0年內視野變化,對醫生盡早發現快速進展型患者,及時調整治療方案,具有重要臨床價值[8]。
目前,視野預測還主要聚焦于對視野進展評估研究,以期直接輔助臨床醫生提前做出治療決策。視野進展評估是一種分類任務,但是對于青光眼的視野進展的定義目前缺乏一種公認的“金標準”。常用的視野進展定義大致有4類:第一類是基于專家經驗的定義,即有經驗的臨床醫生判斷視野進展[9-10];第二類是基于隨機臨床試驗中采用的分級評分系統的定義,即根據視野評分進行進展分類[11-12];第三類是基于事件的定義,以視野隨訪與基線檢測的對比結果作為進展標準[9, 13];第四類是基于視野參數變化趨勢的定義,一般通過參數變化斜率及其統計學指標P值來判斷視野是否進展[14-15]。這些視野進展的定義方法各有不同,多種定義方法的比較研究結果表明:不同定義得到的視野進展的分類結果存在較大差異[16-18]。
由于各類視野進展定義方法本質上都是基于視野各點敏感度數值的計算,如果能直接對未來視野的逐點敏感度進行預測,預測結果將不受臨床醫生選擇視野進展定義的限制。目前對視野逐點敏感度進行預測的研究工作較少。Kamalipour等[19]采用一種卷積神經網絡(convolutional neural network,CNN)模型,利用譜域光學相干斷層掃描,將得到的患者RNFL厚度值作為輸入,預測視野的逐點敏感度。Taketani等[20]采用了多種傳統回歸模型,如普通最小二乘線性回歸(linear regression,LR)、二次回歸和指數回歸等,對視野逐點敏感度進行預測,最終發現要達到精確預測未來視野結果,所需的最少視野檢查結果數目大約為10。Wen等[21]開發了一種CNN模型5層級聯網絡(CascadeNet5),該模型僅使用單個視野結果作為輸入,即可預測青光眼患眼未來5.5年內的視野逐點敏感度。但是這種模型僅利用單個視野結果中的空間信息,而未充分利用患者過去隨訪結果中的時間信息。與Wen等[21]的工作不同,Park等[22]的工作更關注于視野隨訪結果中的時序信息,他們建立了一種遞歸神經網絡(recurrent neural network,RNN)模型,該模型以一系列5個連續的視野結果作為輸入,來預測第6個視野結果,該研究預測的是未來視野的總偏差(total deviation,TD)值,而不是逐點敏感度。
對于視野逐點敏感度預測而言,僅基于時間或空間單因素的預測方法可能造成過去視野檢查結果中有效信息的浪費,而卷積長短期記憶(convolutional long-short term memory,ConvLSTM)網絡是基于長短期記憶(long-short term memory,LSTM)網絡的一種改進模型,它可以同時利用數據中的時間信息以及空間信息[23]。已有多項研究證明,在時空序列預測問題上,ConvLSTM模型可表現出相當好的性能[24-26]。因此,為實現更高精度的未來視野預測,本研究采用ConvLSTM網絡作為預測模型。本文僅以患者過去視野的隨訪結果序列作為輸入,而無需其它生理結構信息,并將未來0.5~2.0年內視野的逐點敏感度預測作為輸出;另外,以樣本中包含視野結果的數目作為視野序列長度,對不同長度視野序列對預測結果產生的影響進行了探究,以期找到預測效果最好的視野序列長度。
1 方法
1.1 ConvLSTM網絡
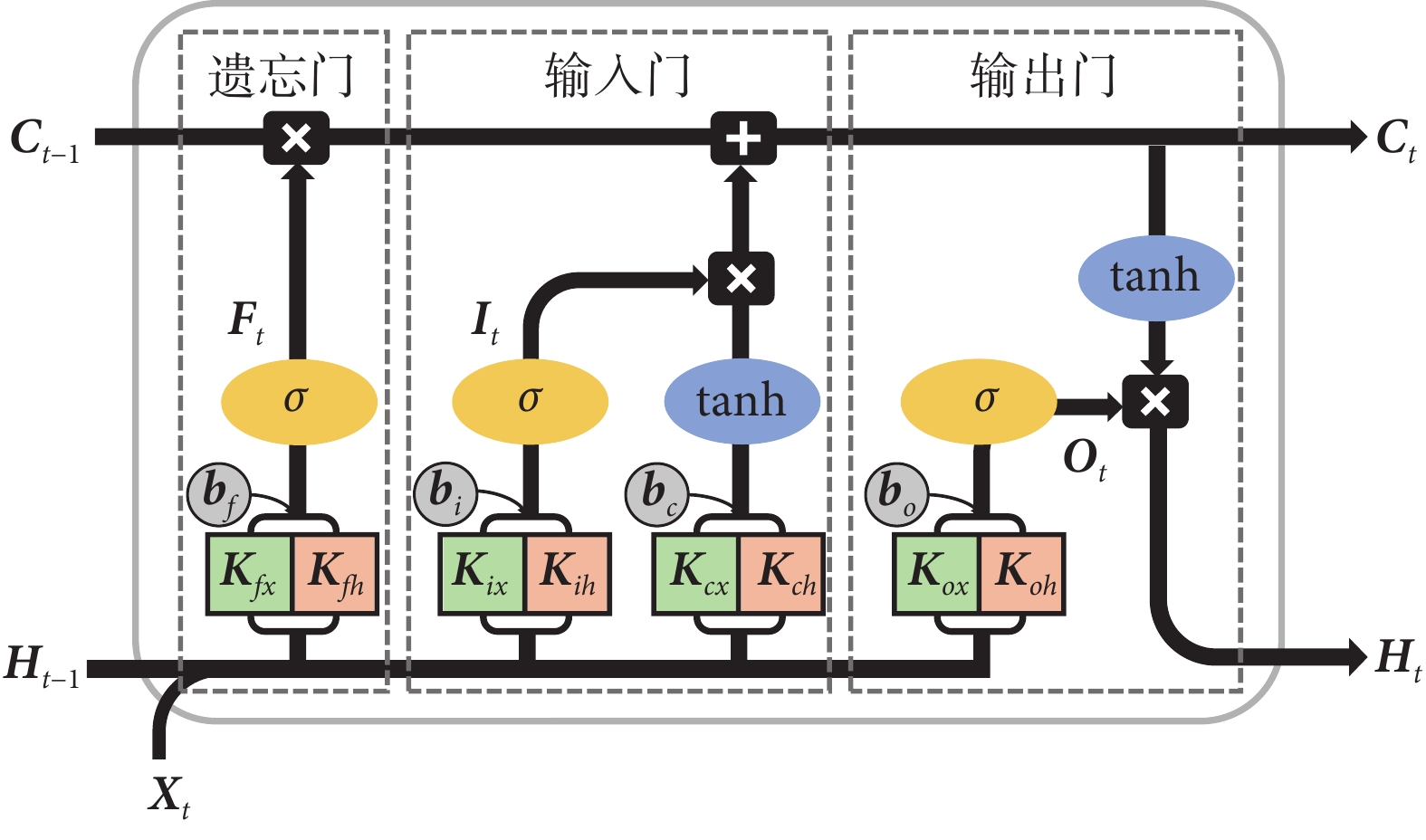
本研究旨在聯合利用患者過去視野序列的時序特征以及單個視野結果中各點敏感度的空間分布特征,實現對未來視野隨訪的預測。傳統LSTM在輸入到狀態、狀態到狀態的轉換中采用了全連接結構,無法有效提取空間信息[27]。然而,ConvLSTM將LSTM與卷積操作相結合,將LSTM中的轉換結構改進為卷積結構,使得網絡具備了對空間結構特征的提取能力,這種方法更適用于兼具長短程時間特性和空間結構特性的視野逐點敏感度預測任務。而且,ConvLSTM在每個時間步都使用相同的卷積核進行卷積操作,實現了參數共享和稀疏連接,相較于全連接結構其參數規模更小,運算效率更高。
ConvLSTM的結構與傳統的LSTM基本相似,同樣包括遺忘門(F)、輸入門(I)、細胞狀態(C)和輸出門(O)。ConvLSTM的細胞結構示意如圖1所示,各部分之間的關系如下:
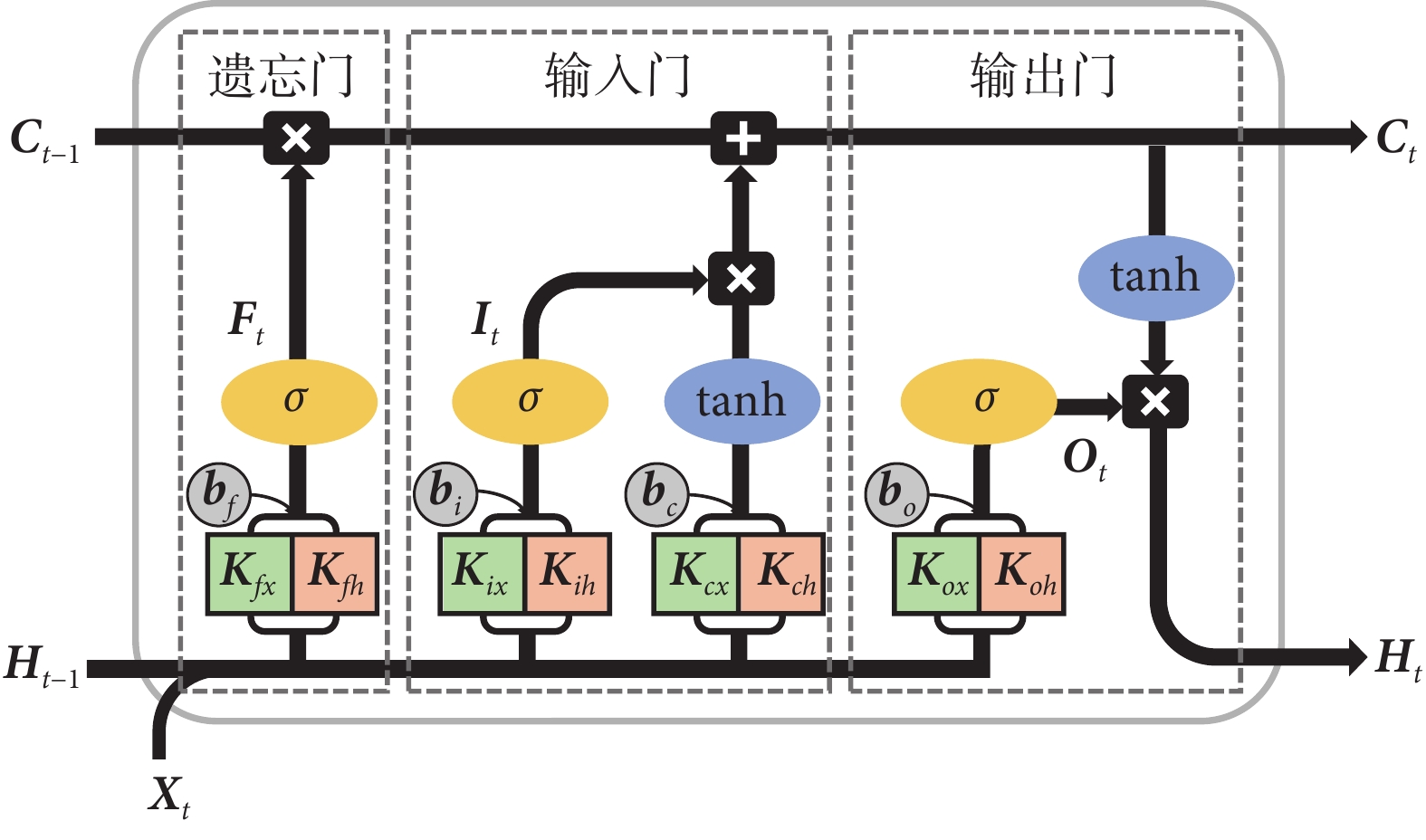 圖1
ConvLSTM細胞結構
Figure1.
ConvLSTM cell structures
圖1
ConvLSTM細胞結構
Figure1.
ConvLSTM cell structures
(1)遺忘門:它決定了細胞狀態中有多少部分被遺忘或保持,其計算過程如式(1)所示:
 |
其中, 表示卷積;σ(?)表示S型生長曲線(sigmoid)映射函數;Xt、Ft分別代表第t時間步的輸入和遺忘門輸出;Ht?1代表第t ? 1時間步的隱藏狀態輸出;Kfx、Kfh分別代表遺忘門在隱藏狀態和輸入上的卷積核參數,bf為遺忘門對應的偏置參數。
表示卷積;σ(?)表示S型生長曲線(sigmoid)映射函數;Xt、Ft分別代表第t時間步的輸入和遺忘門輸出;Ht?1代表第t ? 1時間步的隱藏狀態輸出;Kfx、Kfh分別代表遺忘門在隱藏狀態和輸入上的卷積核參數,bf為遺忘門對應的偏置參數。
(2)輸入門:它決定了當前時間步的新信息有多少部分用于更新細胞狀態,其計算過程如式(2)所示:
 |
其中,It代表第t時間步的輸入門輸出,Kix、Kih分別代表輸入門在隱藏狀態和輸入上的卷積核參數,bi為輸入門對應的偏置參數。
(3)細胞狀態:它結合遺忘門輸出和輸入門輸出來更新自身,其計算過程如式(3)所示:
 |
其中, 表示哈達瑪(Hadamard)積,tanh(?)為雙曲正切函數;Ct ? 1、Ct分別代表第t ? 1和第t時間步的細胞狀態;Kcx、Kch分別代表細胞狀態在隱藏狀態和輸入上的卷積核參數,bc為細胞狀態對應的偏置參數。
表示哈達瑪(Hadamard)積,tanh(?)為雙曲正切函數;Ct ? 1、Ct分別代表第t ? 1和第t時間步的細胞狀態;Kcx、Kch分別代表細胞狀態在隱藏狀態和輸入上的卷積核參數,bc為細胞狀態對應的偏置參數。
(4)輸出門:它決定細胞狀態的哪一部分將作為當前時間步的隱藏狀態輸出,其計算過程如式(4)~式(5)所示:
 |
 |
其中,Ot、Ht分別代表第t時間步的輸出門輸出和隱藏狀態輸出;Kox、Koh分別代表輸出門在隱藏狀態和輸入上的卷積核參數,bo為輸出門對應的偏置參數。
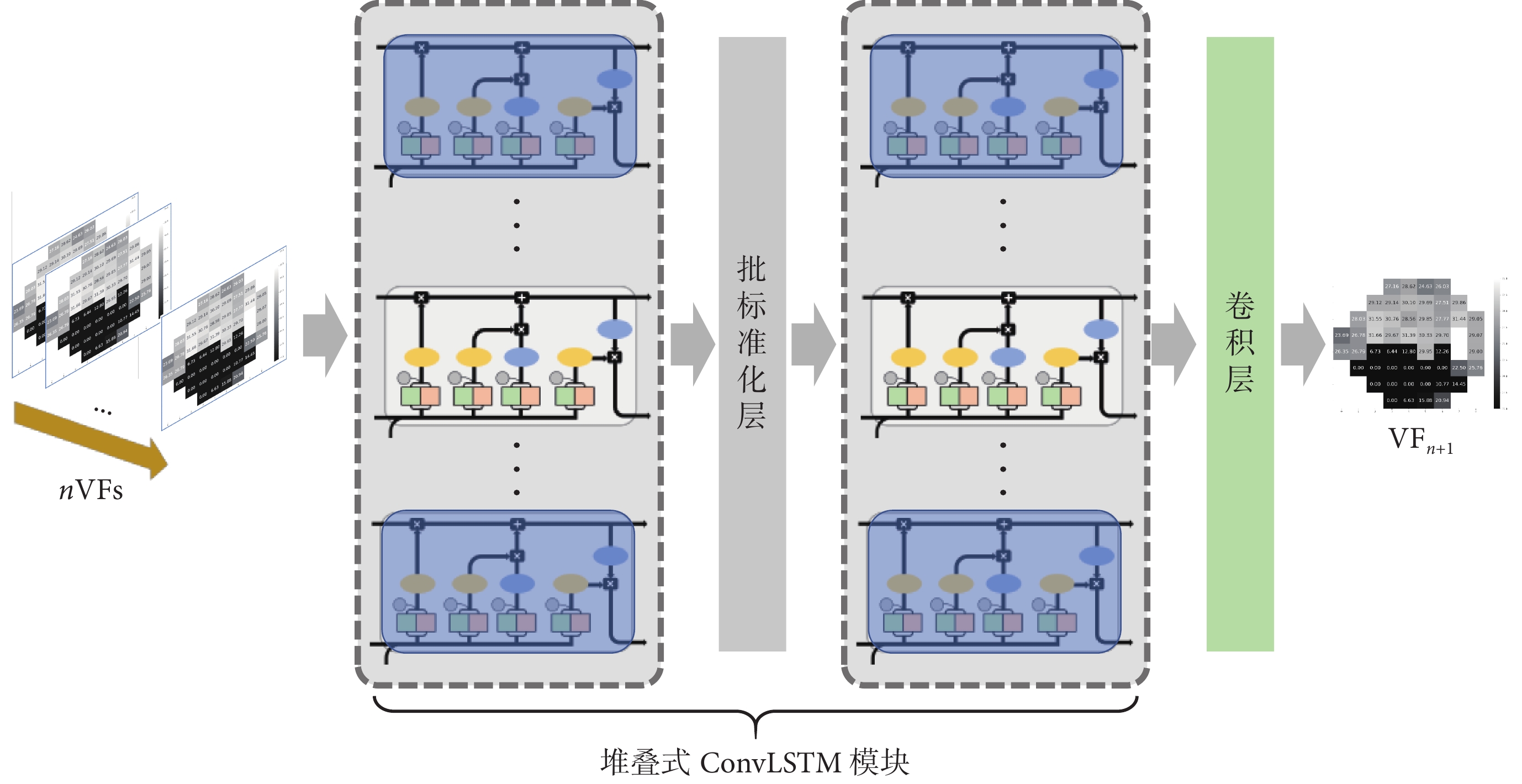
神經網絡在廣泛的具有挑戰性的預測問題上取得成功的原因通常歸結于其深度[28]。因此,本研究采用堆疊式ConvLSTM模塊,以增加網絡深度,從而獲得視野序列在不同時間尺度上的特征表示。本研究所采用模型的網絡結構包括1個堆疊式ConvLSTM模塊和1個卷積層。其中,堆疊式ConvLSTM模塊僅包含2個ConvLSTM單元,并且為避免梯度消失,在2個ConvLSTM單元之間添加了1個批標準化(batch normalization,BN)層,對前1個ConvLSTM單元所提取特征的分布進行調整。該模型結構圖如圖2所示,其中,nVFs表示長度為n的視野序列輸入,VFn+1表示模型的預測輸出為第n+1個視野結果。同時,n也與ConvLSTM的時間步數對應。由于以時序圖表示的單個視野結果尺寸較小,選擇較小的卷積核尺寸更適合用于提取視野特征,故設置2個ConvLSTM單元的卷積核大小為3×3,數目為32。最后的卷積層亦選擇卷積核大小為3×3,數目為1,以減少通道數目,進而輸出視野預測結果。
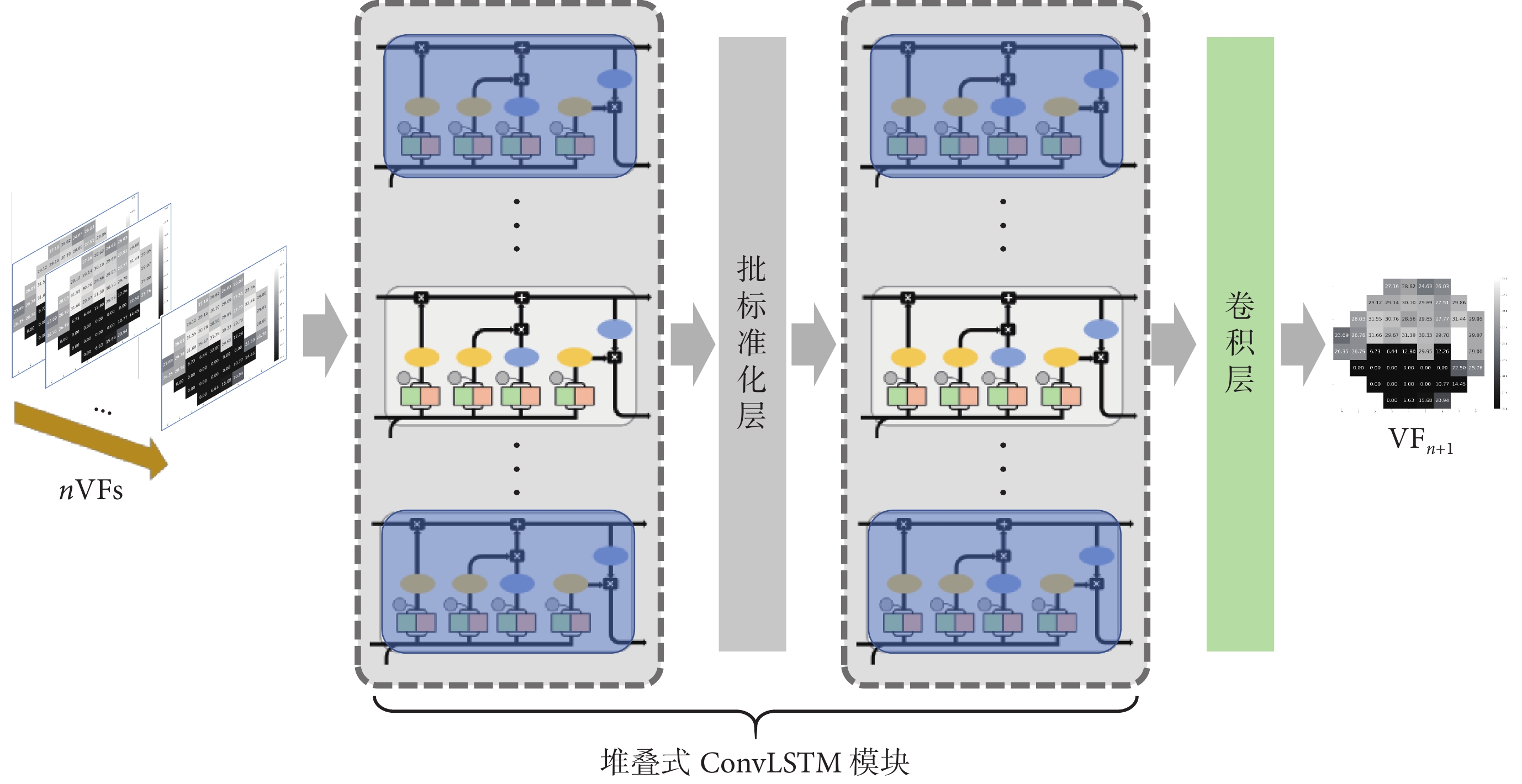 圖2
ConvLSTM網絡模型
Figure2.
ConvLSTM network model
圖2
ConvLSTM網絡模型
Figure2.
ConvLSTM network model
1.2 對比模型
為了驗證ConvLSTM模型在視野逐點敏感度預測方面的優勢,本研究首先構建了4個基線模型,以提供基線預測性能。
本研究選取了2種高斯分布模型(Gaussian distribution model,GDM)和2種LR方法作為基線模型用于后續模型性能比對。其中,第一種GDM模型(記為GDM1)是基于Heijl等[29]工作中的視野進展速率的平均值和標準差。具體而言,本研究使用早期明顯青光眼的視野敏感度進展速率數據,即均值為?0.36 dB/a,標準差為0.60 dB/a,將視野序列中逐視野預測結果取平均作為未來視野的最終預測。第二種GDM模型(記為GDM2)則是基于由訓練集中統計得到的視野進展速率的平均值和標準差,之后按與GDM1相同步驟進行視野預測[21]。第一種LR模型(記為LR1)針對于患者群體,對視野各點敏感度進行LR操作,得到一組回歸系數,以之預測視野。第二種LR模型(記為LR2)則針對于患者個體的逐點敏感度,以患者之前的隨訪數據預測其未來視野[22]。然后,本研究以ConvLSTM模型結構為基礎,構建CNN模型和LSTM模型作為對比模型。CNN模型以單個視野結果作為輸入,僅利用視野逐點敏感度的空間位置信息對未來視野進行預測。而LSTM模型則以視野序列為輸入,利用序列中的時序信息預測未來視野。CNN模型的結構與ConvLSTM模型基本一致,它由3個卷積層組成,前2個卷積層的卷積核大小、卷積核數目等參數設置與ConvLSTM單元的參數設置基本相同,最后一層卷積層與ConvLSTM模型的最后一層卷積層完全相同。而LSTM模型中同樣僅包含2個LSTM單元,并且它以全連接層代替最后的卷積層。
2 實驗
本研究使用的開源數據集為來自華盛頓大學漢弗瑞視野分析儀的視野測試數據集(a dataset of perimetry tests from the Humphrey field analyzer at the University of Washington,UWHVF)[30],在此基礎上開展研究工作,以ConvLSTM模型與其他幾種對比方法進行預測性能驗證與比較。
2.1 數據集
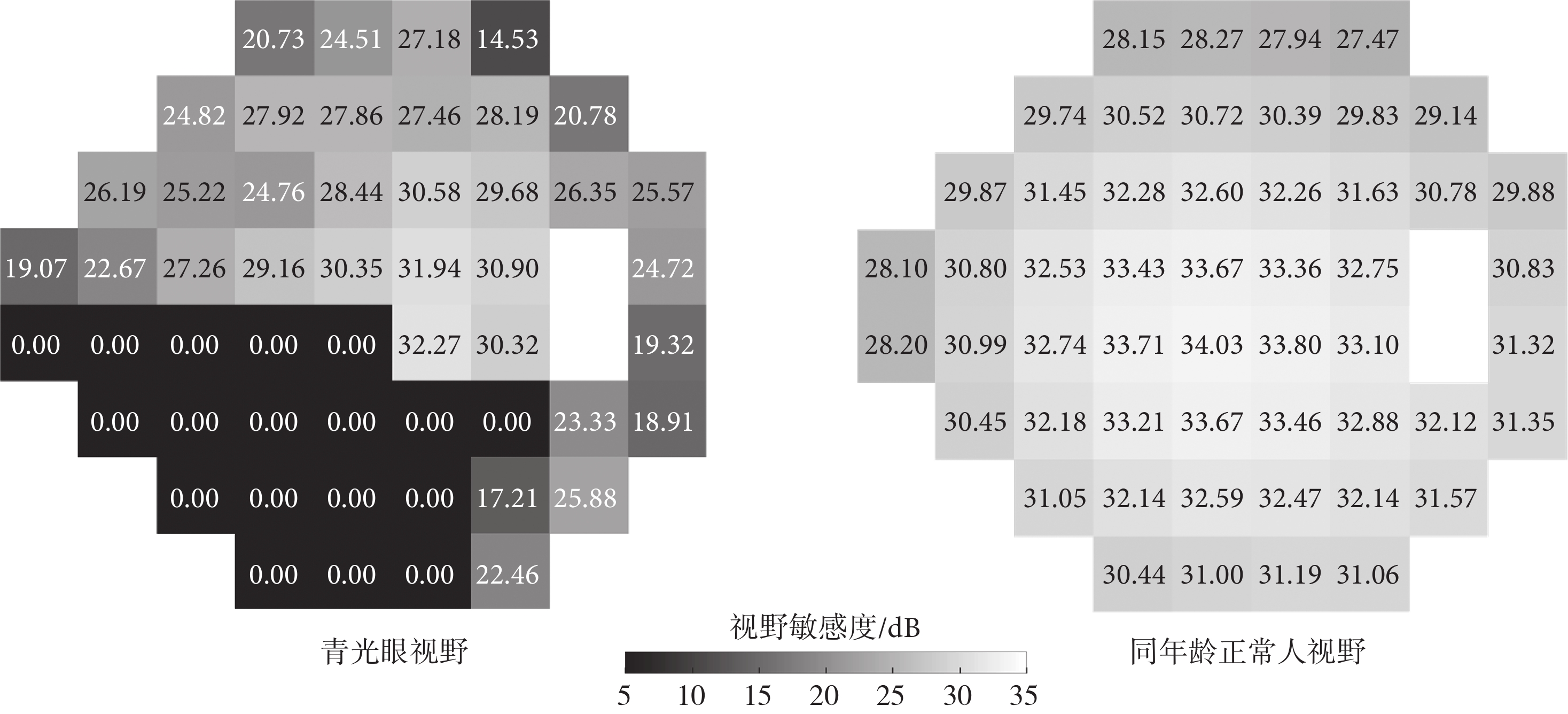
UWHVF數據集中所有患者都接受了視野測量與評估軟件漢弗瑞視野分析儀24-2程序模式(Humphrey Field Analyzer,24-2 Program)(Carl Zeiss Meditec Inc.,美國)的視野分析,使用瑞典交互式閾值算法(標準或快速)或全閾值策略執行。數據集包含了3 871位患者的7 428只眼睛的視野數據,共計28 943個視野,所有視野數據均采集自1998年—2018年。每只眼睛的每個視野在時間上進行了對齊,第1個視野被視為每只眼睛的基線視野。對所有納入數據集的患者進行統計,以“中值[四分位范圍]”形式顯示:年齡為64[54, 73] 歲;隨訪的時間為2.49[1.11, 5.03] 年;基線視野的平均總偏差(mean total deviation,MTD)為?4.51[?8.01, ?2.65] dB;模式標準差(pattern standard deviation,PSD)為2.41[1.70, 5.34] dB。UWHVF數據集中患者視野示例如圖3所示,逐點敏感度精確到百分位,灰度淺深與敏感度大小對應[30]。目前在UWHVF數據集上開展的視野相關的研究較少,尤其在視野敏感度預測方面仍無相關工作發表。
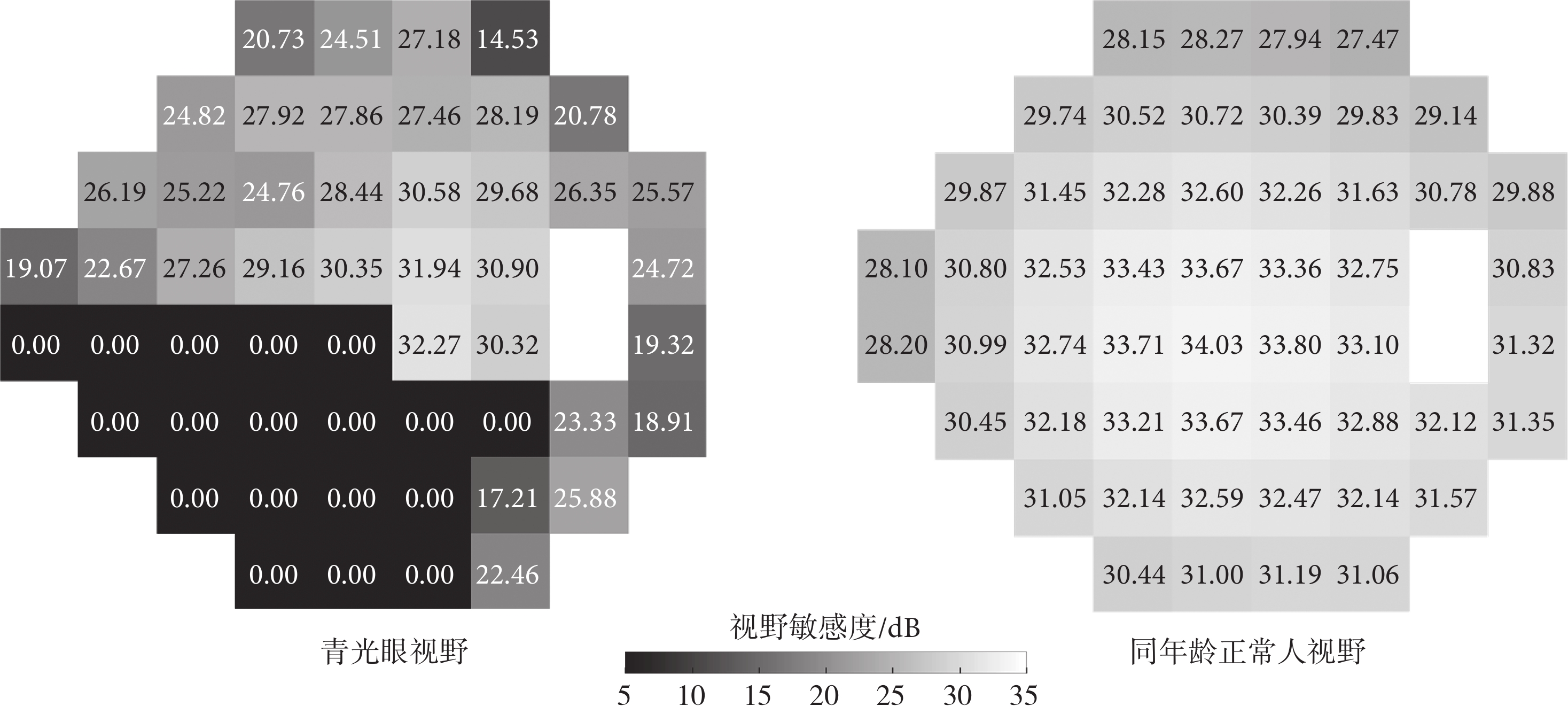 圖3
青光眼患者視野與正常視野對比示例
Figure3.
An example of patient's visual field with glaucoma compared to normal person's visual field
圖3
青光眼患者視野與正常視野對比示例
Figure3.
An example of patient's visual field with glaucoma compared to normal person's visual field
2.2 數據預處理
首先,在患者水平上,本研究將UWHVF數據集劃分為兩部分:80%作為訓練集,用于訓練和驗證階段;20%作為測試集。兩個數據集中患者的統計信息如表1所示(表格僅統計信息完整的數據),可以發現,除性別信息部分缺失導致的差異以外,兩個數據集中的數據分布基本相近。為了探究不同長度的視野序列對未來視野的預測性能,本研究將兩個集合當中的視野按照時間間距與序列長度分別做了篩選,以得到不同長度的視野序列數據集。具體而言,篩選的標準為:在同一視野序列樣本中,相鄰視野檢查的時間間隔必須在0.5~2.0年內。此區間的選定是考慮到青光眼視野進展較緩慢,時間間距小于0.5年視野變化可能不明顯,不利于捕捉其變化規律,而當時間間距大于2.0年,則可認為是視野檢測失訪,不宜納入時序研究。此外,為了盡可能多地獲得樣本,允許視野序列部分重復。例如,某患者的一只眼睛有7個視野測試結果,分別在33.75、34.21、35.00、36.52、37.43、38.65、41.02歲,現可將其分為2個序列長度為4的視野樣本:(34.21、35.00、36.52、37.43歲)和(35.00、36.52、37.43、38.65歲),或者1個序列長度為5的樣本:(34.21、35.00、36.52、37.43、38.65歲)。并且,部分樣本的視野序列中包含全零視野,說明該患者已經造成不可逆致盲,無需納入研究而予以剔除。
最終,訓練集和測試集中樣本數目統計如表2所示。由于當序列長度大于7時,數據集中符合篩選條件的樣本數目過少,故研究僅針對長度為3~7的視野序列樣本(3VFs~7VFs)。對于序列長度為n+1的數據集,實驗將以前n個視野結果作為輸入序列預測第n+1個視野,記為nVFs→VFn+1,其中n=2, 3 …, 6。
在視野測量與評估軟件漢弗瑞視野分析儀24-2程序模式(Carl Zeiss Meditec Inc.,美國)測量下,共獲得54個視野測試點。剔除2個生理盲點后,僅使用剩下的52個測試點。每個視野被表示為8×9的矩陣,以保持其空間關系。對所有輸入特征采用零均值化方法,將其標準化成均值為0,標準差為1。
2.3 實驗參數與評價指標
研究實驗平臺采用64位Windows10操作系統(Microsoft Corp.,美國),編程語言為Python 3.6.0(Python Software Foundation,美國),而Python中的深度學習算法在TensorFlow 1.7.0(Google Inc.,美國)上使用開源神經網絡平臺Keras 2.2.0(Francois Chollet et al.,美國)實現。訓練深度學習模型的迭代次數均設置為25,批大小為32,選擇自適應矩估計(adaptive moment estimation,Adam)作為優化器,損失函數均采用均方誤差(mean squared error,MSE)損失。采用5折交叉驗證方式對這些模型進行訓練,選用交叉驗證中表現最優的模型參與后續在測試集上的預測性能對比。
預測模型的評價標準采用平均絕對誤差(mean absolute error,MAE)、均方根誤差(root mean squared error,RMSE)和決定系數R2,以避免不同評價標準本身存在的局限性。它們對應的計算如式(6)~式(8)所示:
 |
 |
 |
其中, 為第i個視野點的真實敏感度,
為第i個視野點的真實敏感度, 為模型預測第i個視野點的敏感度,
為模型預測第i個視野點的敏感度, 為真實敏感度均值,m為預測逐點敏感度的數目。
為真實敏感度均值,m為預測逐點敏感度的數目。
3 實驗結果及分析
3.1 模型對比結果
為了分析ConvLSTM模型在視野預測任務中的表現,使用相同的數據集訓練6種對比模型以及來自文獻[21]和文獻[22]的2種算法模型。其中,文獻[22]提出的算法模型是一種RNN模型,因此無需修改模型結構即可接受不同長度視野序列輸入。隨后,利用各模型在測試階段的預測結果計算不同的評價指標。結果統計如表3所示,最優值以加粗形式表示。
通過表3中各個模型的對比結果可以發現:① 從3項評價指標來看,5種深度學習方法的性能顯著優于各基線模型,表明它們對視野敏感度變化規律的刻畫能力更強,其中,性能最好的是ConvLSTM模型。與僅考慮視野空間或時間單因素信息的CNN和LSTM模型相比,ConvLSTM模型通過聯合考慮兩種信息,有效提高了視野預測的精度;② 兩種GDM模型的性能基本優于兩種LR模型,說明使用線性方式難以準確刻畫視野敏感度的變化,因此在表現上不如基于數據分布的方法;③ GDM1模型相較于GDM2模型表現更佳,這表明僅依靠訓練集得到的統計特征不足以全面描述患者群體特征,因此GDM1在測試集上的預測效果更好;④ LR2模型的表現優于LR1模型,后者的決定系數皆小于0.1,這表明不同患者個體的視野變化差異較大,基于患者整體的LR方法并不適用于視野預測。⑤ 來自文獻[21]的CascadeNet5模型與構建的CNN模型相比性能更好,這可能是因為前者的模型結構更加復雜,并且在輸入中加入了年齡信息。然而,ConvLSTM模型參數規模遠小于CascadeNet5模型,卻取得了更好的預測結果,說明時空特征的考慮比增加模型復雜度更加重要。⑥ 來自文獻[22]的RNN模型在5種深度學習模型中表現最差,這可能是由于它最初設計用于預測視野的總偏差值而非逐點敏感度。此外,在輸入的視野序列數據中人為加入了空白數據,增加了噪聲,進一步提升了模型的學習難度。
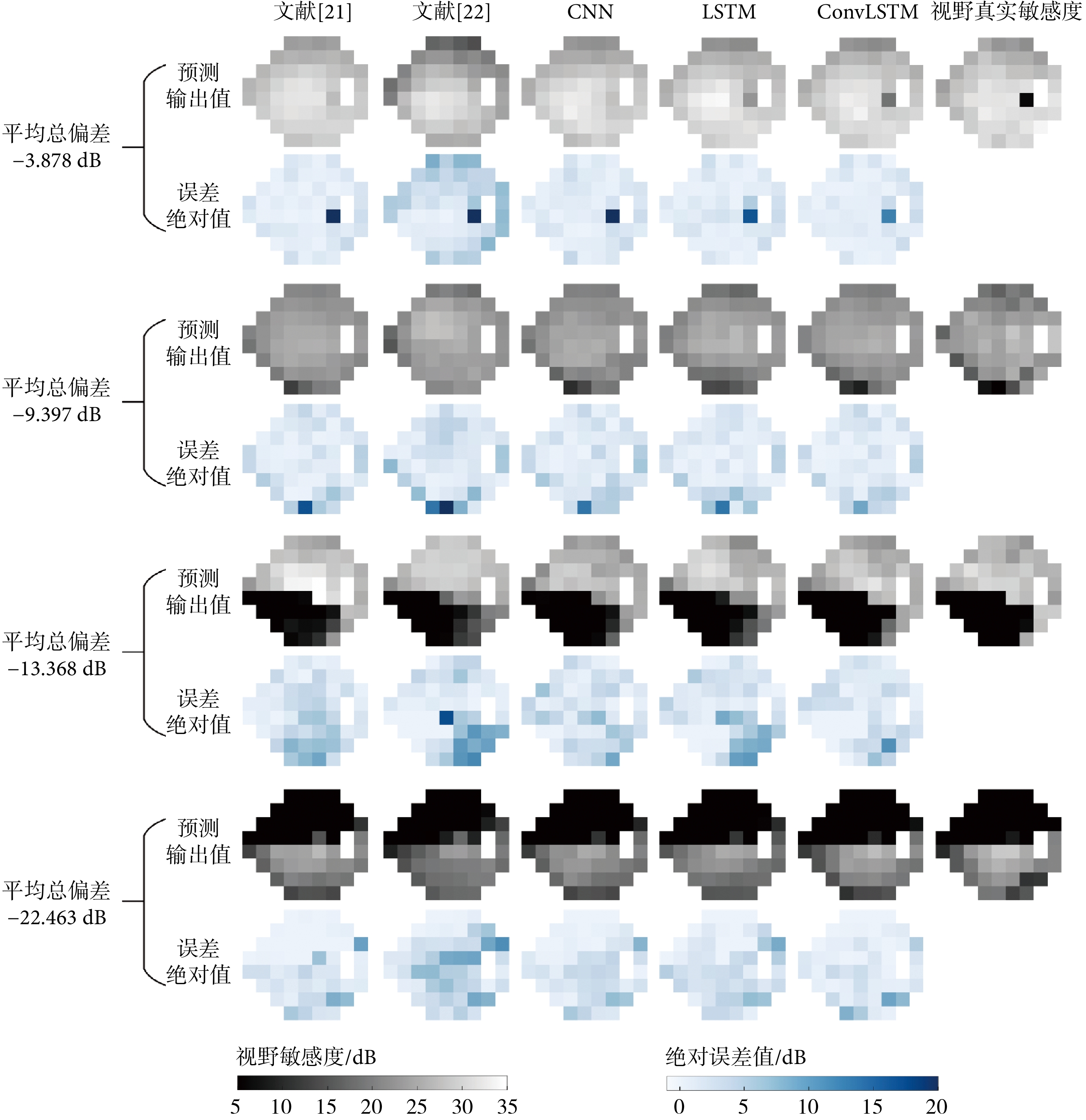
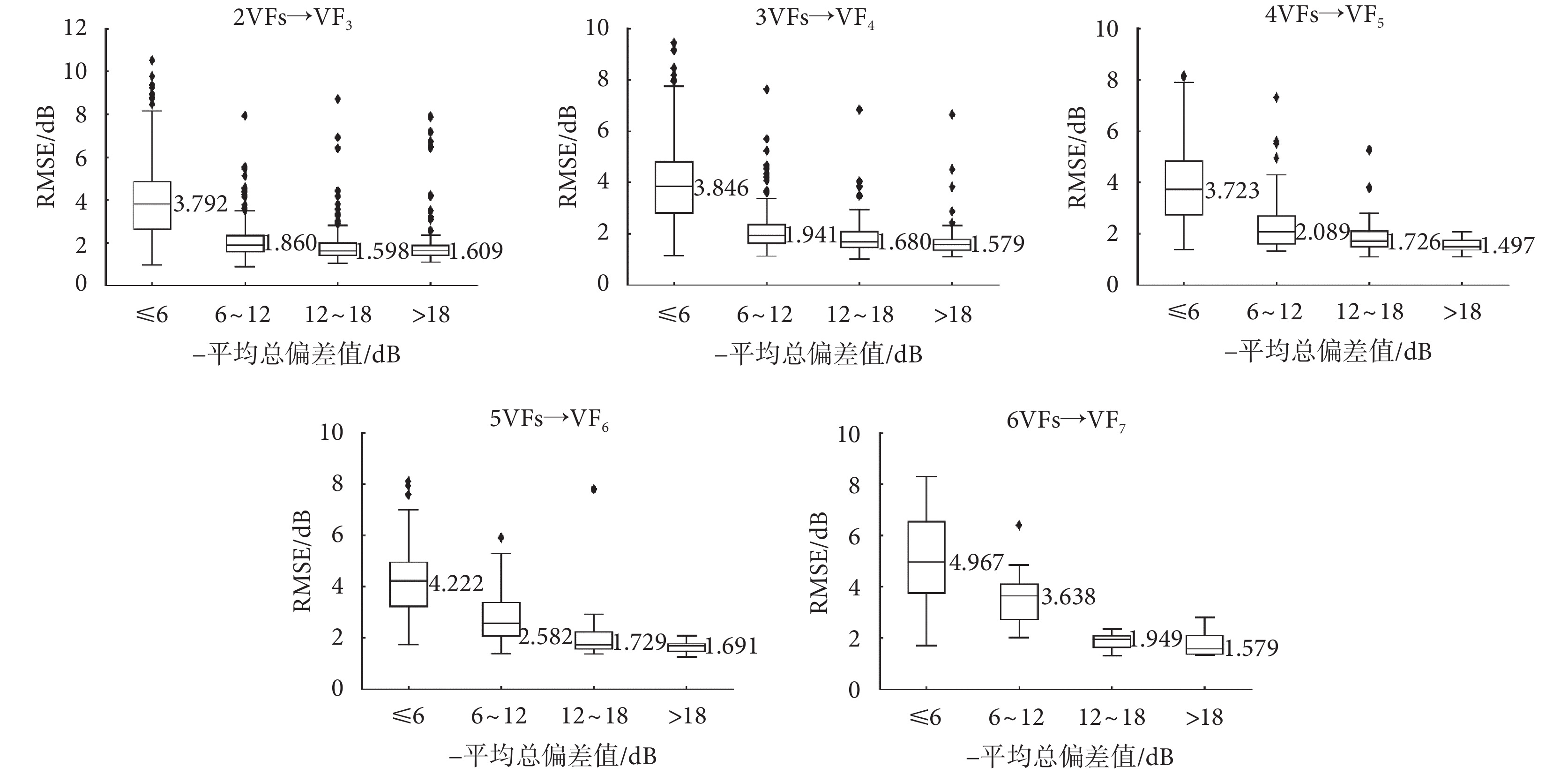
對于不同缺損程度的視野序列,各深度學習模型的預測性能可能會受到不同程度的影響。本研究將5種深度學習模型應用于不同缺損程度的視野序列進行預測,如圖4所示為代表性預測示例,其中包含預測輸出值及其誤差絕對值兩種圖像,缺損程度由平均總偏差確定。從圖4中示例可以看出,ConvLSTM模型受到視野缺損程度影響相對其他模型更小,主要的預測偏差出現在敏感度數值“分界線”上。進一步地,對ConvLSTM模型在各測試集上的預測結果按照平均總偏差值分段進行統計,采用RMSE指標,并以箱線圖方式表達,如圖5所示。從圖5中的對比結果可以看出,模型對于平均總偏差值較大的測試樣本,預測結果基本較好且相對穩定。這表明,對于視野缺損嚴重的患者,模型能更好地預測其視野敏感度變化,有助于醫生對病情發展進行及時干預。此外,由于各測試集中包含的樣本數目差距較大,箱線圖中“異常值”數目也與之相關,3VFs測試集上的“異常值”最多,7VFs測試集上最少。7VFs測試集中平均總偏差值為“>18 dB”的樣本RMSE分布較分散,也是由于樣本數目較少所導致。
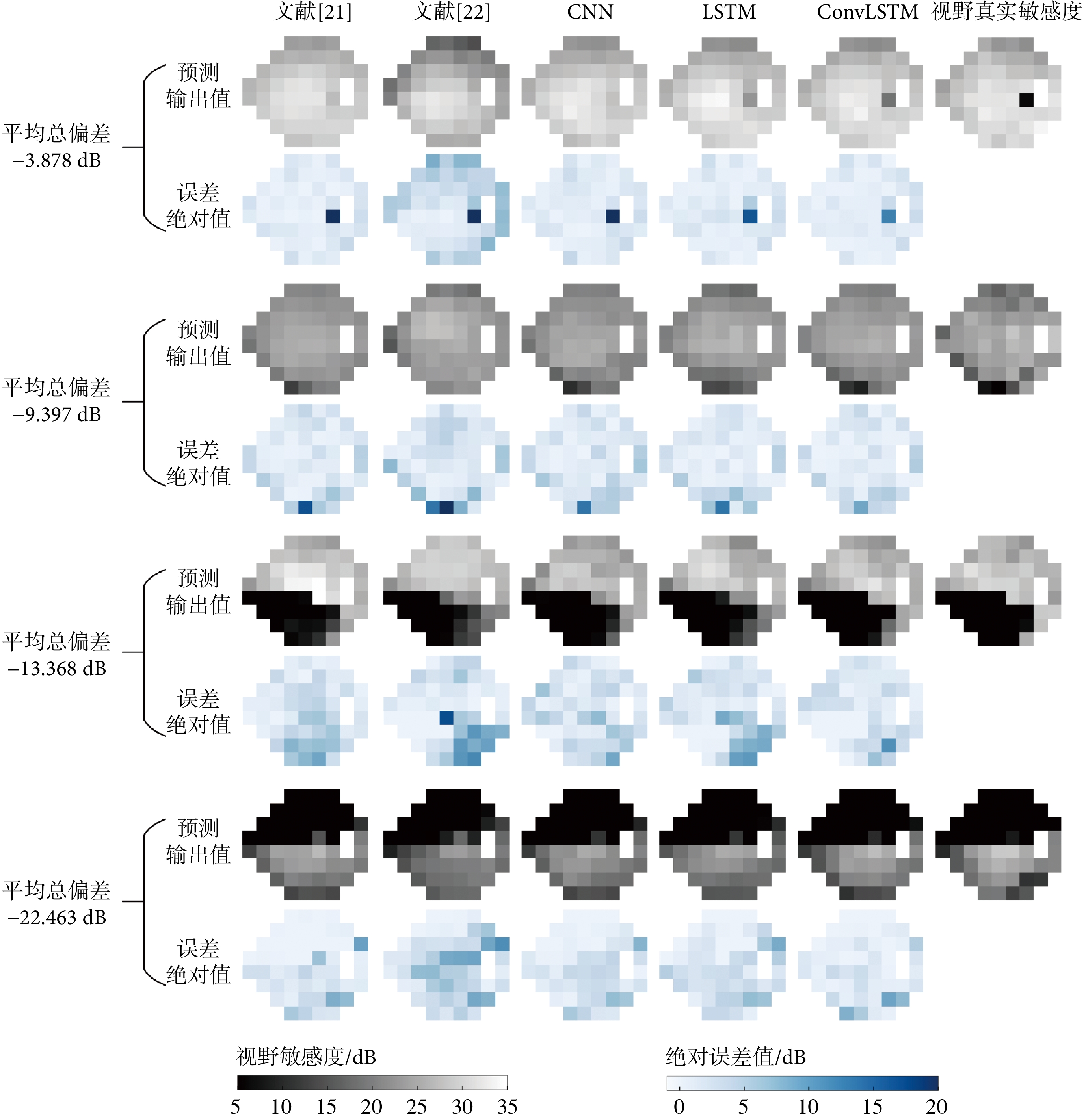 圖4
各模型對不同缺損程度視野的預測代表性示例
Figure4.
Representative examples of predicted visual fields with different defect degrees by different models
圖4
各模型對不同缺損程度視野的預測代表性示例
Figure4.
Representative examples of predicted visual fields with different defect degrees by different models
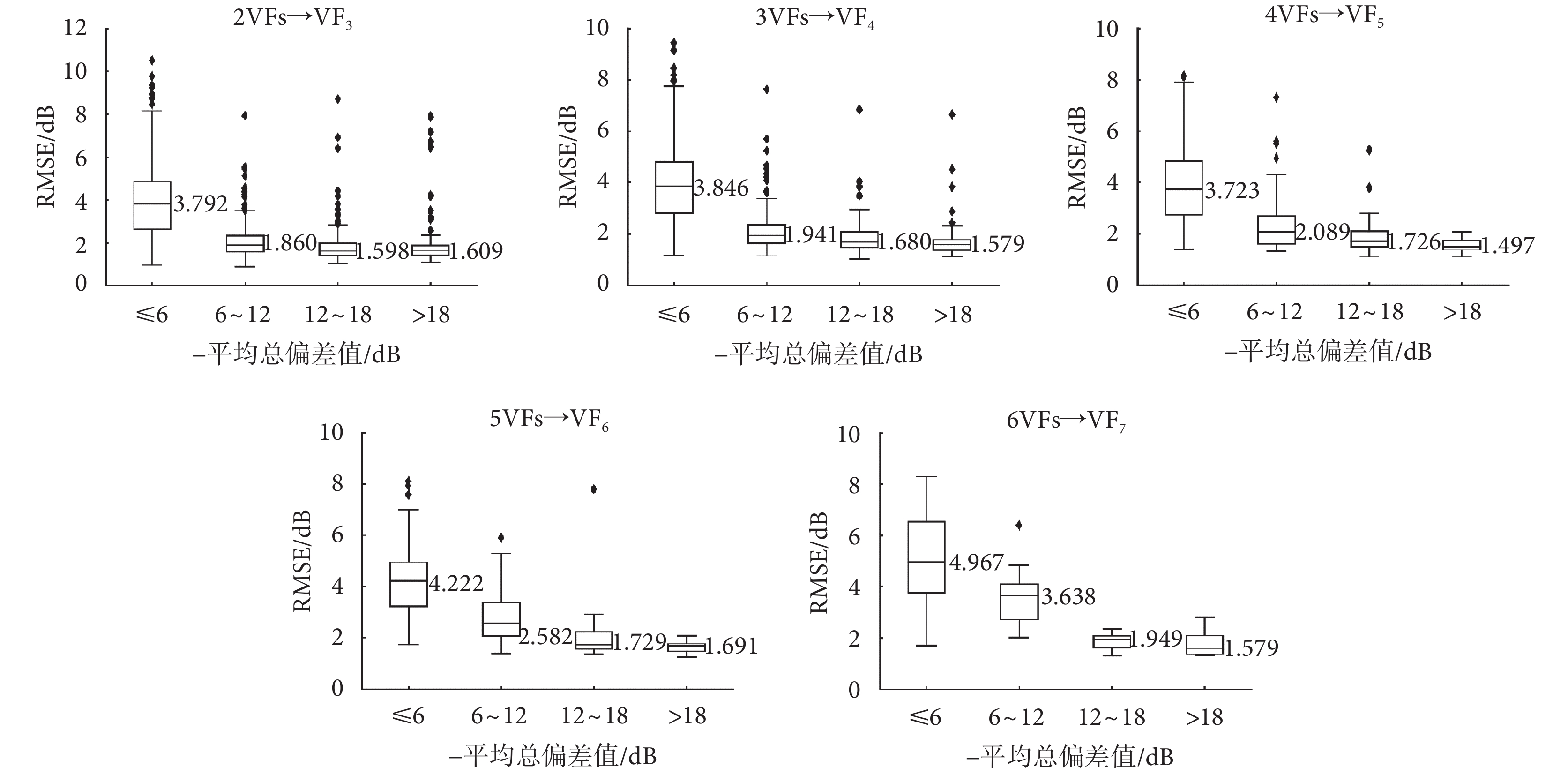 圖5
ConvLSTM模型在不同序列長度測試集上的預測結果統計(按平均總偏差分段)
Figure5.
Statistics of prediction results of ConvLSTM model on different series length testing sets (segmented by mean total deviation)
圖5
ConvLSTM模型在不同序列長度測試集上的預測結果統計(按平均總偏差分段)
Figure5.
Statistics of prediction results of ConvLSTM model on different series length testing sets (segmented by mean total deviation)
3.2 不同序列長度結果
對于時序深度學習模型而言,其輸入時間序列的時間步數可能影響最終的預測性能。為了探究不同長度的視野序列輸入的影響,本研究對ConvLSTM模型在各測試集上的預測性能進行了比較分析。
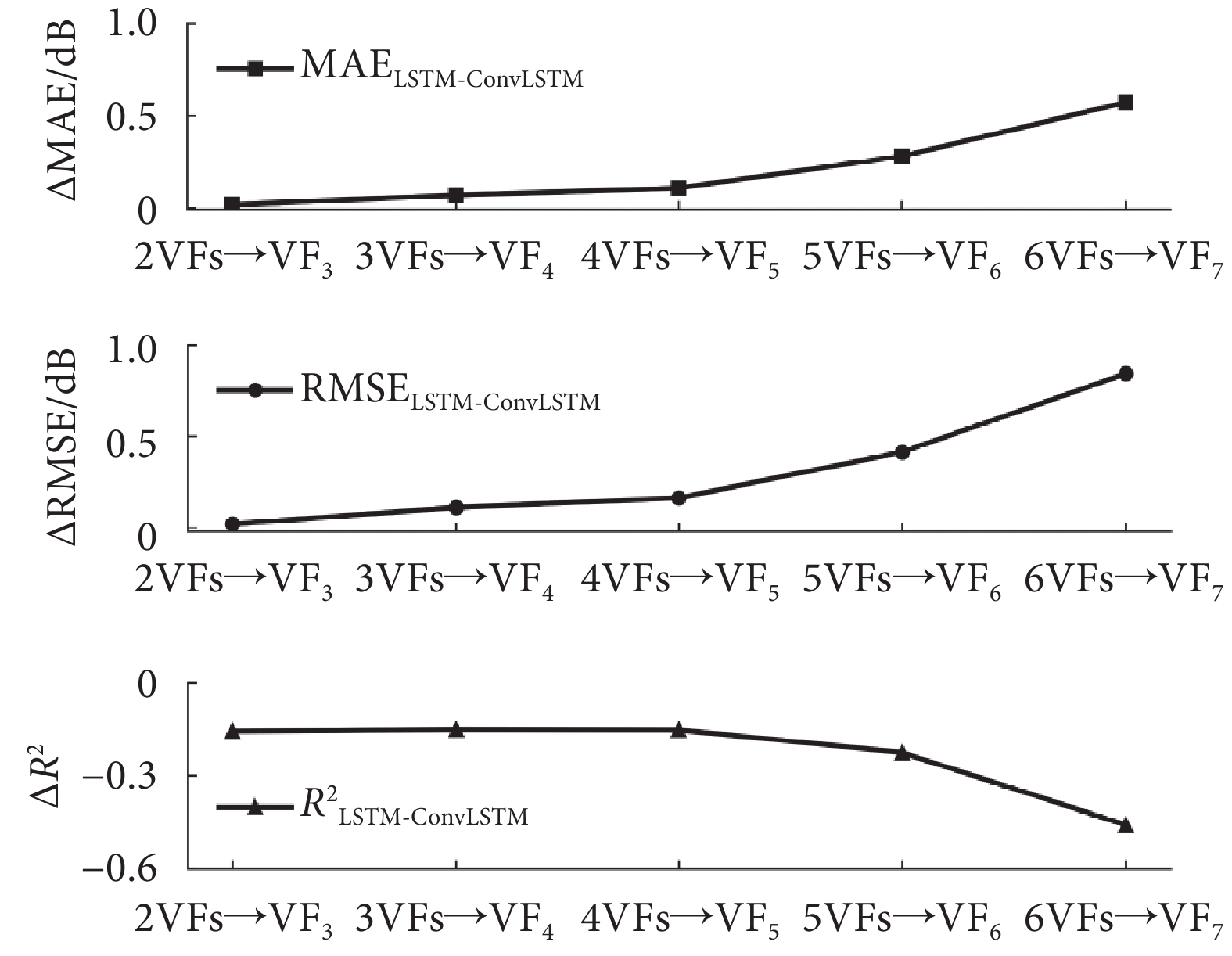
由表3中的統計結果可以看出,視野序列長度與模型預測性能之間存在關系。對于ConvLSTM模型而言,結果顯示視野序列長度并不是越長或越短預測性能越好,而是長度為3(即3VFs→VF4)的視野序列預測效果最佳。將LSTM和ConvLSTM兩種時序深度學習模型的評價指標差值以折線圖表示,如圖6所示,其中Δ表示差值。可以看到,隨著輸入視野序列長度變化,MAE、RMSE和R2等指標的差值不斷增大,說明二者性能差距在逐步拉開,而且LSTM模型預測指標原值是一直下降的,這表明視野序列中的時序信息的作用在減弱,而空間信息的作用則有所增強。原因在于,隨著視野序列長度的增加,視野檢測時間跨度增大,帶來的時間冗余信息隨之不斷增多,因此空間信息在視野預測中所占比重上升。在6VFs→VF7的預測中,CNN模型和文獻[21]模型預測結果的MAE值反而小于ConvLSTM模型,而其余指標均與后者相差不大,這說明在時間冗余信息的影響下,空間信息所起的作用在逐步凸顯。
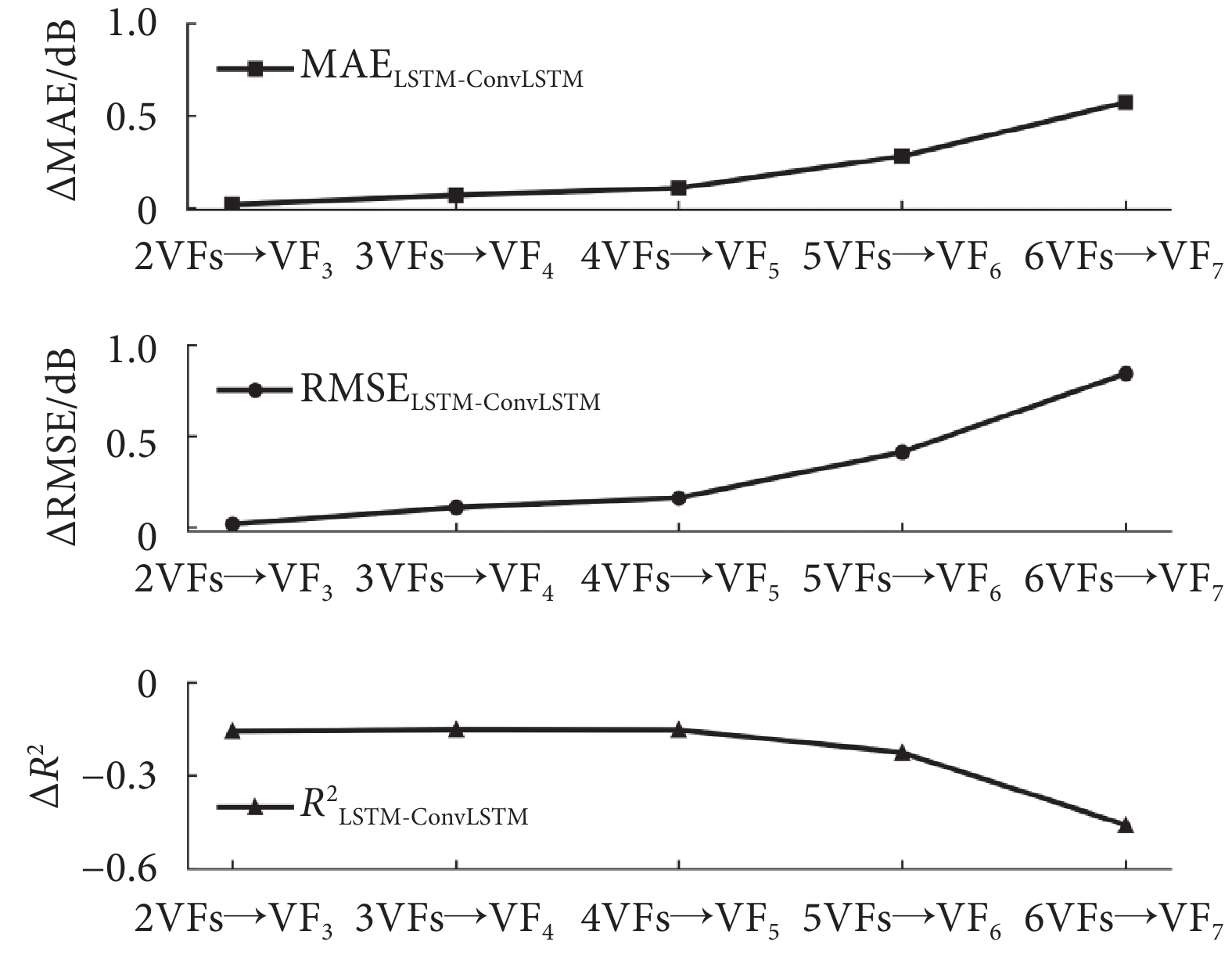 圖6
LSTM和ConvLSTM模型的預測性能差距
Figure6.
Predictive performance gap between LSTM and ConvLSTM models
圖6
LSTM和ConvLSTM模型的預測性能差距
Figure6.
Predictive performance gap between LSTM and ConvLSTM models
4 結語
目前,針對視野逐點敏感度預測方面開展的工作還很有限,而現有研究方法仍存在諸多不足,如預測精度低、視野序列中的時空信息利用不充分等。本研究采用ConvLSTM模型對未來0.5~2.0年內視野的逐點敏感度進行預測,以青光眼患者既往視野隨訪結果作為輸入序列,而無需利用其他眼科特檢檢查或眼部解剖特征,實現了較高精度的預測。主要研究結論如下:① 相較于作為基線的傳統模型,深度學習模型在刻畫視野逐點敏感度變化方面的能力更強;② ConvLSTM模型充分考慮了視野敏感度隨時間變化規律以及各位置點之間的空間關系,因此其預測精度高于CNN模型和LSTM模型;③ 輸入預測模型的視野序列長度并非越長越好,時間序列過長可能帶來更多冗余信息,實驗發現適宜于ConvLSTM模型的輸入序列長度為3,即采用過去1.5~6.0年內的3次視野檢查結果預測效果更好。
當然,本研究在數據集選用方面存在一定局限性,由于目前開源的視野數據少,研究僅采用了UWHVF數據集,而缺少了其他人群的視野數據。同時,本研究工作是統計學意義上的改進,對于其能否在臨床上進行應用,需要結合臨床進一步評估,這也將是后續研究需要開展的工作。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:王握負責模型算法的設計和論文的撰寫;鄭秀娟負責指導方法理論和算法設計,以及指導論文的撰寫;呂智清負責資料收集和論文修改;李妮和陳俊負責指導醫學基礎和分析方法。
0 引言
青光眼是一種進展緩慢、損害視神經及視覺通路并最終導致視覺功能損害的疾病,是全球首位的不可逆性致盲病因[1]。目前中國青光眼患者超過2 100萬,約占全世界青光眼患者的四分之一[2-3]。青光眼的特征是視網膜神經節細胞的丟失、視網膜神經纖維層(retinal nerve fiber layer,RNFL)變薄,并出現特征性視神經萎縮,而這些改變在功能上表現為特征性視野(visual field,VF)缺損[4]。視野改變是診斷青光眼的“金標準”,定期的視野隨訪檢查是青光眼診斷和監測病情進展的重要手段,且該監測往往是終身持續的。由于青光眼患者的視野變化波動比正常人更嚴重[5],視野惡化速度因個體而異,其中穩定型患者惡化速度通常小于0.5 dB/a,而快速進展型患者則超過1.5 dB/a[6]。并且隨著時間的推移,患者的視野進展模式存在明顯不同[7],再加上患者常常無法保證定期檢查,因此提前預測未來視野變化對青光眼診斷和治療具有重要意義。特別是預測未來0.5~2.0年內視野變化,對醫生盡早發現快速進展型患者,及時調整治療方案,具有重要臨床價值[8]。
目前,視野預測還主要聚焦于對視野進展評估研究,以期直接輔助臨床醫生提前做出治療決策。視野進展評估是一種分類任務,但是對于青光眼的視野進展的定義目前缺乏一種公認的“金標準”。常用的視野進展定義大致有4類:第一類是基于專家經驗的定義,即有經驗的臨床醫生判斷視野進展[9-10];第二類是基于隨機臨床試驗中采用的分級評分系統的定義,即根據視野評分進行進展分類[11-12];第三類是基于事件的定義,以視野隨訪與基線檢測的對比結果作為進展標準[9, 13];第四類是基于視野參數變化趨勢的定義,一般通過參數變化斜率及其統計學指標P值來判斷視野是否進展[14-15]。這些視野進展的定義方法各有不同,多種定義方法的比較研究結果表明:不同定義得到的視野進展的分類結果存在較大差異[16-18]。
由于各類視野進展定義方法本質上都是基于視野各點敏感度數值的計算,如果能直接對未來視野的逐點敏感度進行預測,預測結果將不受臨床醫生選擇視野進展定義的限制。目前對視野逐點敏感度進行預測的研究工作較少。Kamalipour等[19]采用一種卷積神經網絡(convolutional neural network,CNN)模型,利用譜域光學相干斷層掃描,將得到的患者RNFL厚度值作為輸入,預測視野的逐點敏感度。Taketani等[20]采用了多種傳統回歸模型,如普通最小二乘線性回歸(linear regression,LR)、二次回歸和指數回歸等,對視野逐點敏感度進行預測,最終發現要達到精確預測未來視野結果,所需的最少視野檢查結果數目大約為10。Wen等[21]開發了一種CNN模型5層級聯網絡(CascadeNet5),該模型僅使用單個視野結果作為輸入,即可預測青光眼患眼未來5.5年內的視野逐點敏感度。但是這種模型僅利用單個視野結果中的空間信息,而未充分利用患者過去隨訪結果中的時間信息。與Wen等[21]的工作不同,Park等[22]的工作更關注于視野隨訪結果中的時序信息,他們建立了一種遞歸神經網絡(recurrent neural network,RNN)模型,該模型以一系列5個連續的視野結果作為輸入,來預測第6個視野結果,該研究預測的是未來視野的總偏差(total deviation,TD)值,而不是逐點敏感度。
對于視野逐點敏感度預測而言,僅基于時間或空間單因素的預測方法可能造成過去視野檢查結果中有效信息的浪費,而卷積長短期記憶(convolutional long-short term memory,ConvLSTM)網絡是基于長短期記憶(long-short term memory,LSTM)網絡的一種改進模型,它可以同時利用數據中的時間信息以及空間信息[23]。已有多項研究證明,在時空序列預測問題上,ConvLSTM模型可表現出相當好的性能[24-26]。因此,為實現更高精度的未來視野預測,本研究采用ConvLSTM網絡作為預測模型。本文僅以患者過去視野的隨訪結果序列作為輸入,而無需其它生理結構信息,并將未來0.5~2.0年內視野的逐點敏感度預測作為輸出;另外,以樣本中包含視野結果的數目作為視野序列長度,對不同長度視野序列對預測結果產生的影響進行了探究,以期找到預測效果最好的視野序列長度。
1 方法
1.1 ConvLSTM網絡
本研究旨在聯合利用患者過去視野序列的時序特征以及單個視野結果中各點敏感度的空間分布特征,實現對未來視野隨訪的預測。傳統LSTM在輸入到狀態、狀態到狀態的轉換中采用了全連接結構,無法有效提取空間信息[27]。然而,ConvLSTM將LSTM與卷積操作相結合,將LSTM中的轉換結構改進為卷積結構,使得網絡具備了對空間結構特征的提取能力,這種方法更適用于兼具長短程時間特性和空間結構特性的視野逐點敏感度預測任務。而且,ConvLSTM在每個時間步都使用相同的卷積核進行卷積操作,實現了參數共享和稀疏連接,相較于全連接結構其參數規模更小,運算效率更高。
ConvLSTM的結構與傳統的LSTM基本相似,同樣包括遺忘門(F)、輸入門(I)、細胞狀態(C)和輸出門(O)。ConvLSTM的細胞結構示意如圖1所示,各部分之間的關系如下:
圖1
ConvLSTM細胞結構
Figure1.
ConvLSTM cell structures
(1)遺忘門:它決定了細胞狀態中有多少部分被遺忘或保持,其計算過程如式(1)所示:
|
其中,表示卷積;σ(?)表示S型生長曲線(sigmoid)映射函數;Xt、Ft分別代表第t時間步的輸入和遺忘門輸出;Ht?1代表第t ? 1時間步的隱藏狀態輸出;Kfx、Kfh分別代表遺忘門在隱藏狀態和輸入上的卷積核參數,bf為遺忘門對應的偏置參數。
(2)輸入門:它決定了當前時間步的新信息有多少部分用于更新細胞狀態,其計算過程如式(2)所示:
|
其中,It代表第t時間步的輸入門輸出,Kix、Kih分別代表輸入門在隱藏狀態和輸入上的卷積核參數,bi為輸入門對應的偏置參數。
(3)細胞狀態:它結合遺忘門輸出和輸入門輸出來更新自身,其計算過程如式(3)所示:
|
其中,表示哈達瑪(Hadamard)積,tanh(?)為雙曲正切函數;Ct ? 1、Ct分別代表第t ? 1和第t時間步的細胞狀態;Kcx、Kch分別代表細胞狀態在隱藏狀態和輸入上的卷積核參數,bc為細胞狀態對應的偏置參數。
(4)輸出門:它決定細胞狀態的哪一部分將作為當前時間步的隱藏狀態輸出,其計算過程如式(4)~式(5)所示:
|
|
其中,Ot、Ht分別代表第t時間步的輸出門輸出和隱藏狀態輸出;Kox、Koh分別代表輸出門在隱藏狀態和輸入上的卷積核參數,bo為輸出門對應的偏置參數。
神經網絡在廣泛的具有挑戰性的預測問題上取得成功的原因通常歸結于其深度[28]。因此,本研究采用堆疊式ConvLSTM模塊,以增加網絡深度,從而獲得視野序列在不同時間尺度上的特征表示。本研究所采用模型的網絡結構包括1個堆疊式ConvLSTM模塊和1個卷積層。其中,堆疊式ConvLSTM模塊僅包含2個ConvLSTM單元,并且為避免梯度消失,在2個ConvLSTM單元之間添加了1個批標準化(batch normalization,BN)層,對前1個ConvLSTM單元所提取特征的分布進行調整。該模型結構圖如圖2所示,其中,nVFs表示長度為n的視野序列輸入,VFn+1表示模型的預測輸出為第n+1個視野結果。同時,n也與ConvLSTM的時間步數對應。由于以時序圖表示的單個視野結果尺寸較小,選擇較小的卷積核尺寸更適合用于提取視野特征,故設置2個ConvLSTM單元的卷積核大小為3×3,數目為32。最后的卷積層亦選擇卷積核大小為3×3,數目為1,以減少通道數目,進而輸出視野預測結果。
圖2
ConvLSTM網絡模型
Figure2.
ConvLSTM network model
1.2 對比模型
為了驗證ConvLSTM模型在視野逐點敏感度預測方面的優勢,本研究首先構建了4個基線模型,以提供基線預測性能。
本研究選取了2種高斯分布模型(Gaussian distribution model,GDM)和2種LR方法作為基線模型用于后續模型性能比對。其中,第一種GDM模型(記為GDM1)是基于Heijl等[29]工作中的視野進展速率的平均值和標準差。具體而言,本研究使用早期明顯青光眼的視野敏感度進展速率數據,即均值為?0.36 dB/a,標準差為0.60 dB/a,將視野序列中逐視野預測結果取平均作為未來視野的最終預測。第二種GDM模型(記為GDM2)則是基于由訓練集中統計得到的視野進展速率的平均值和標準差,之后按與GDM1相同步驟進行視野預測[21]。第一種LR模型(記為LR1)針對于患者群體,對視野各點敏感度進行LR操作,得到一組回歸系數,以之預測視野。第二種LR模型(記為LR2)則針對于患者個體的逐點敏感度,以患者之前的隨訪數據預測其未來視野[22]。然后,本研究以ConvLSTM模型結構為基礎,構建CNN模型和LSTM模型作為對比模型。CNN模型以單個視野結果作為輸入,僅利用視野逐點敏感度的空間位置信息對未來視野進行預測。而LSTM模型則以視野序列為輸入,利用序列中的時序信息預測未來視野。CNN模型的結構與ConvLSTM模型基本一致,它由3個卷積層組成,前2個卷積層的卷積核大小、卷積核數目等參數設置與ConvLSTM單元的參數設置基本相同,最后一層卷積層與ConvLSTM模型的最后一層卷積層完全相同。而LSTM模型中同樣僅包含2個LSTM單元,并且它以全連接層代替最后的卷積層。
2 實驗
本研究使用的開源數據集為來自華盛頓大學漢弗瑞視野分析儀的視野測試數據集(a dataset of perimetry tests from the Humphrey field analyzer at the University of Washington,UWHVF)[30],在此基礎上開展研究工作,以ConvLSTM模型與其他幾種對比方法進行預測性能驗證與比較。
2.1 數據集
UWHVF數據集中所有患者都接受了視野測量與評估軟件漢弗瑞視野分析儀24-2程序模式(Humphrey Field Analyzer,24-2 Program)(Carl Zeiss Meditec Inc.,美國)的視野分析,使用瑞典交互式閾值算法(標準或快速)或全閾值策略執行。數據集包含了3 871位患者的7 428只眼睛的視野數據,共計28 943個視野,所有視野數據均采集自1998年—2018年。每只眼睛的每個視野在時間上進行了對齊,第1個視野被視為每只眼睛的基線視野。對所有納入數據集的患者進行統計,以“中值[四分位范圍]”形式顯示:年齡為64[54, 73] 歲;隨訪的時間為2.49[1.11, 5.03] 年;基線視野的平均總偏差(mean total deviation,MTD)為?4.51[?8.01, ?2.65] dB;模式標準差(pattern standard deviation,PSD)為2.41[1.70, 5.34] dB。UWHVF數據集中患者視野示例如圖3所示,逐點敏感度精確到百分位,灰度淺深與敏感度大小對應[30]。目前在UWHVF數據集上開展的視野相關的研究較少,尤其在視野敏感度預測方面仍無相關工作發表。
圖3
青光眼患者視野與正常視野對比示例
Figure3.
An example of patient's visual field with glaucoma compared to normal person's visual field
2.2 數據預處理
首先,在患者水平上,本研究將UWHVF數據集劃分為兩部分:80%作為訓練集,用于訓練和驗證階段;20%作為測試集。兩個數據集中患者的統計信息如表1所示(表格僅統計信息完整的數據),可以發現,除性別信息部分缺失導致的差異以外,兩個數據集中的數據分布基本相近。為了探究不同長度的視野序列對未來視野的預測性能,本研究將兩個集合當中的視野按照時間間距與序列長度分別做了篩選,以得到不同長度的視野序列數據集。具體而言,篩選的標準為:在同一視野序列樣本中,相鄰視野檢查的時間間隔必須在0.5~2.0年內。此區間的選定是考慮到青光眼視野進展較緩慢,時間間距小于0.5年視野變化可能不明顯,不利于捕捉其變化規律,而當時間間距大于2.0年,則可認為是視野檢測失訪,不宜納入時序研究。此外,為了盡可能多地獲得樣本,允許視野序列部分重復。例如,某患者的一只眼睛有7個視野測試結果,分別在33.75、34.21、35.00、36.52、37.43、38.65、41.02歲,現可將其分為2個序列長度為4的視野樣本:(34.21、35.00、36.52、37.43歲)和(35.00、36.52、37.43、38.65歲),或者1個序列長度為5的樣本:(34.21、35.00、36.52、37.43、38.65歲)。并且,部分樣本的視野序列中包含全零視野,說明該患者已經造成不可逆致盲,無需納入研究而予以剔除。
最終,訓練集和測試集中樣本數目統計如表2所示。由于當序列長度大于7時,數據集中符合篩選條件的樣本數目過少,故研究僅針對長度為3~7的視野序列樣本(3VFs~7VFs)。對于序列長度為n+1的數據集,實驗將以前n個視野結果作為輸入序列預測第n+1個視野,記為nVFs→VFn+1,其中n=2, 3 …, 6。
在視野測量與評估軟件漢弗瑞視野分析儀24-2程序模式(Carl Zeiss Meditec Inc.,美國)測量下,共獲得54個視野測試點。剔除2個生理盲點后,僅使用剩下的52個測試點。每個視野被表示為8×9的矩陣,以保持其空間關系。對所有輸入特征采用零均值化方法,將其標準化成均值為0,標準差為1。
2.3 實驗參數與評價指標
研究實驗平臺采用64位Windows10操作系統(Microsoft Corp.,美國),編程語言為Python 3.6.0(Python Software Foundation,美國),而Python中的深度學習算法在TensorFlow 1.7.0(Google Inc.,美國)上使用開源神經網絡平臺Keras 2.2.0(Francois Chollet et al.,美國)實現。訓練深度學習模型的迭代次數均設置為25,批大小為32,選擇自適應矩估計(adaptive moment estimation,Adam)作為優化器,損失函數均采用均方誤差(mean squared error,MSE)損失。采用5折交叉驗證方式對這些模型進行訓練,選用交叉驗證中表現最優的模型參與后續在測試集上的預測性能對比。
預測模型的評價標準采用平均絕對誤差(mean absolute error,MAE)、均方根誤差(root mean squared error,RMSE)和決定系數R2,以避免不同評價標準本身存在的局限性。它們對應的計算如式(6)~式(8)所示:
|
|
|
其中,為第i個視野點的真實敏感度,為模型預測第i個視野點的敏感度,為真實敏感度均值,m為預測逐點敏感度的數目。
3 實驗結果及分析
3.1 模型對比結果
為了分析ConvLSTM模型在視野預測任務中的表現,使用相同的數據集訓練6種對比模型以及來自文獻[21]和文獻[22]的2種算法模型。其中,文獻[22]提出的算法模型是一種RNN模型,因此無需修改模型結構即可接受不同長度視野序列輸入。隨后,利用各模型在測試階段的預測結果計算不同的評價指標。結果統計如表3所示,最優值以加粗形式表示。
通過表3中各個模型的對比結果可以發現:① 從3項評價指標來看,5種深度學習方法的性能顯著優于各基線模型,表明它們對視野敏感度變化規律的刻畫能力更強,其中,性能最好的是ConvLSTM模型。與僅考慮視野空間或時間單因素信息的CNN和LSTM模型相比,ConvLSTM模型通過聯合考慮兩種信息,有效提高了視野預測的精度;② 兩種GDM模型的性能基本優于兩種LR模型,說明使用線性方式難以準確刻畫視野敏感度的變化,因此在表現上不如基于數據分布的方法;③ GDM1模型相較于GDM2模型表現更佳,這表明僅依靠訓練集得到的統計特征不足以全面描述患者群體特征,因此GDM1在測試集上的預測效果更好;④ LR2模型的表現優于LR1模型,后者的決定系數皆小于0.1,這表明不同患者個體的視野變化差異較大,基于患者整體的LR方法并不適用于視野預測。⑤ 來自文獻[21]的CascadeNet5模型與構建的CNN模型相比性能更好,這可能是因為前者的模型結構更加復雜,并且在輸入中加入了年齡信息。然而,ConvLSTM模型參數規模遠小于CascadeNet5模型,卻取得了更好的預測結果,說明時空特征的考慮比增加模型復雜度更加重要。⑥ 來自文獻[22]的RNN模型在5種深度學習模型中表現最差,這可能是由于它最初設計用于預測視野的總偏差值而非逐點敏感度。此外,在輸入的視野序列數據中人為加入了空白數據,增加了噪聲,進一步提升了模型的學習難度。
對于不同缺損程度的視野序列,各深度學習模型的預測性能可能會受到不同程度的影響。本研究將5種深度學習模型應用于不同缺損程度的視野序列進行預測,如圖4所示為代表性預測示例,其中包含預測輸出值及其誤差絕對值兩種圖像,缺損程度由平均總偏差確定。從圖4中示例可以看出,ConvLSTM模型受到視野缺損程度影響相對其他模型更小,主要的預測偏差出現在敏感度數值“分界線”上。進一步地,對ConvLSTM模型在各測試集上的預測結果按照平均總偏差值分段進行統計,采用RMSE指標,并以箱線圖方式表達,如圖5所示。從圖5中的對比結果可以看出,模型對于平均總偏差值較大的測試樣本,預測結果基本較好且相對穩定。這表明,對于視野缺損嚴重的患者,模型能更好地預測其視野敏感度變化,有助于醫生對病情發展進行及時干預。此外,由于各測試集中包含的樣本數目差距較大,箱線圖中“異常值”數目也與之相關,3VFs測試集上的“異常值”最多,7VFs測試集上最少。7VFs測試集中平均總偏差值為“>18 dB”的樣本RMSE分布較分散,也是由于樣本數目較少所導致。
圖4
各模型對不同缺損程度視野的預測代表性示例
Figure4.
Representative examples of predicted visual fields with different defect degrees by different models
圖5
ConvLSTM模型在不同序列長度測試集上的預測結果統計(按平均總偏差分段)
Figure5.
Statistics of prediction results of ConvLSTM model on different series length testing sets (segmented by mean total deviation)
3.2 不同序列長度結果
對于時序深度學習模型而言,其輸入時間序列的時間步數可能影響最終的預測性能。為了探究不同長度的視野序列輸入的影響,本研究對ConvLSTM模型在各測試集上的預測性能進行了比較分析。
由表3中的統計結果可以看出,視野序列長度與模型預測性能之間存在關系。對于ConvLSTM模型而言,結果顯示視野序列長度并不是越長或越短預測性能越好,而是長度為3(即3VFs→VF4)的視野序列預測效果最佳。將LSTM和ConvLSTM兩種時序深度學習模型的評價指標差值以折線圖表示,如圖6所示,其中Δ表示差值。可以看到,隨著輸入視野序列長度變化,MAE、RMSE和R2等指標的差值不斷增大,說明二者性能差距在逐步拉開,而且LSTM模型預測指標原值是一直下降的,這表明視野序列中的時序信息的作用在減弱,而空間信息的作用則有所增強。原因在于,隨著視野序列長度的增加,視野檢測時間跨度增大,帶來的時間冗余信息隨之不斷增多,因此空間信息在視野預測中所占比重上升。在6VFs→VF7的預測中,CNN模型和文獻[21]模型預測結果的MAE值反而小于ConvLSTM模型,而其余指標均與后者相差不大,這說明在時間冗余信息的影響下,空間信息所起的作用在逐步凸顯。
圖6
LSTM和ConvLSTM模型的預測性能差距
Figure6.
Predictive performance gap between LSTM and ConvLSTM models
4 結語
目前,針對視野逐點敏感度預測方面開展的工作還很有限,而現有研究方法仍存在諸多不足,如預測精度低、視野序列中的時空信息利用不充分等。本研究采用ConvLSTM模型對未來0.5~2.0年內視野的逐點敏感度進行預測,以青光眼患者既往視野隨訪結果作為輸入序列,而無需利用其他眼科特檢檢查或眼部解剖特征,實現了較高精度的預測。主要研究結論如下:① 相較于作為基線的傳統模型,深度學習模型在刻畫視野逐點敏感度變化方面的能力更強;② ConvLSTM模型充分考慮了視野敏感度隨時間變化規律以及各位置點之間的空間關系,因此其預測精度高于CNN模型和LSTM模型;③ 輸入預測模型的視野序列長度并非越長越好,時間序列過長可能帶來更多冗余信息,實驗發現適宜于ConvLSTM模型的輸入序列長度為3,即采用過去1.5~6.0年內的3次視野檢查結果預測效果更好。
當然,本研究在數據集選用方面存在一定局限性,由于目前開源的視野數據少,研究僅采用了UWHVF數據集,而缺少了其他人群的視野數據。同時,本研究工作是統計學意義上的改進,對于其能否在臨床上進行應用,需要結合臨床進一步評估,這也將是后續研究需要開展的工作。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:王握負責模型算法的設計和論文的撰寫;鄭秀娟負責指導方法理論和算法設計,以及指導論文的撰寫;呂智清負責資料收集和論文修改;李妮和陳俊負責指導醫學基礎和分析方法。