乳腺腫瘤的精準分割是病變判定的重要前提,現有的分割方法存在參數量大、推理速度慢、內存資源消耗大等問題。針對上述問題,本文在Attention U-Net的基礎上提出一種融合雙路徑聯合蒸餾的乳腺癌超聲影像輕量化語義分割模型T2KD Attention U-Net。首先,根據良惡性乳腺病灶不同的特征表示和上下文語義信息設計兩個教師模型來學習每一類圖像的細粒度特征;其次,采用聯合蒸餾的方法訓練輕量化的學生模型;最后,構造權重損失均衡函數來聚焦小目標的語義特征表示,解決數據前景和背景像素不平衡問題。該模型在Dataset BUSI和Dataset B兩個數據集上取得了良好的性能,Dataset BUSI上的準確率、召回率、精確度、Dice系數和mIoU分別為95.26%、86.23%、85.09%、83.59%和77.78%;在Dataset B上分別為97.95%、92.80%、88.33%、88.40%和82.42%,模型的整體性能有顯著提升。相比教師模型,學生模型參數量、模型大小和計算復雜度顯著降低(2.2×106 vs. 106.1×106,8.4 MB vs. 414 MB,16.59 GFLOPs vs. 205.98 GFLOPs)。總體而言,該模型在保證精度的同時大幅降低了計算量,對臨床醫學場景的部署提供了新的思路。
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
乳腺癌是全球發病率最高的癌癥[1]。乳腺癌超聲影像檢查是乳腺癌診斷的重要手段,但是一般的超聲影像需要專業醫師耗費大量時間和精力才能完成診斷,存在人為主觀性強、測量結果準確性差、可再現性差等問題,常常導致疾病的漏診或誤診[2]。在對精準度高要求的同時,醫學診斷對時效性要求也較高。所以,設計一種高效輕量化的模型來自動分割乳腺腫瘤病變區域就顯得尤為重要。
近幾年,隨著深度學習理論的發展,它在核磁影像、病理學圖像、計算機斷層掃描影像和多模態醫學影像等方面被廣泛研究[3-10]。在乳腺癌超聲圖像分割任務中,一些研究采用卷積神經網絡(convolutional neural network,CNN)、U-Net模型和注意力機制等方法[11-12],提高了分割精度。Zhang等[13]提出一種全卷積網絡的多目標語義分割方法,將乳腺超聲圖像分割成不同的目標組織區域。貢榮麟等[14]提出混合監督雙通道反饋U-Net模型,提升了乳腺癌超聲影像的病灶分割精度。Wang等[15]提出了一種從粗到細的融合卷積神經網絡對乳腺癌圖像進行分割,在三個數據集上均達到了良好的分割精度。Chen等[16]提出了一個新的雙向感知制導網絡(bidirectional aware guidance network,BAGNet)以分割惡性乳腺癌數據。Chen等[17]提出了一個強大的嵌入式U-Net(nested U-net,NU-Net)以精準分割乳腺腫瘤。Vakanski等[18]將顯著性注意力機制引入到深度學習模型中,通過U-Net網絡對乳腺癌超聲圖像進行分割,證明了注意力機制對乳腺癌圖像分割具有積極作用。Lei等[19]將自注意力機制引入乳腺癌圖像分割,同時開發了協同注意力機制提高兩個連續切片之間分割的一致性。Xue等[20]融合通道注意力和空間注意力來處理乳腺癌超聲圖像中不規則的邊界。Punn等[21]設計了一種基于跨空間注意力引導的inception U-Net,顯著提高了乳腺超聲圖像的分割能力。
綜合分析,目前對乳腺癌病變的組織分割存在以下難點:① 在注意力機制和U-Net融合的過程中,模型對圖像淺層信息的提取不夠充分;② 在醫學圖像分割中,利用病灶分類這一先驗知識來驅動病灶精準分割還鮮有研究;③ 復雜的深度學習模型一味追求分割精度,卻忽略了模型的參數量和計算代價,限制了模型在醫學場景中的應用。為解決以上問題,本文在注意力U-Net(Attention U-Net)的基礎上提出一種雙教師聯合蒸餾的Attention U-Net模型(dual-teacher knowledge distillation Attention U-Net,T2KD Attention U-Net),該模型中的雙教師模型利用先驗知識實施輔助決策,增大模型訓練的樣本空間,并通過知識蒸餾的方法將知識遷移給學生模型。
1 本文方法
1.1 T2KD Attention U-Net模型整體流程
知識蒸餾本質上屬于遷移學習的范疇,Hinton等[22]首先提出知識蒸餾的方法,主要思想是將已經訓練好的高效的模型作為教師模型,然后從教師模型的輸出結果中“蒸餾”出“知識”用于學生模型的訓練,使輕量化的學生模型能夠接近甚至超越教師模型的性能表現[23]。
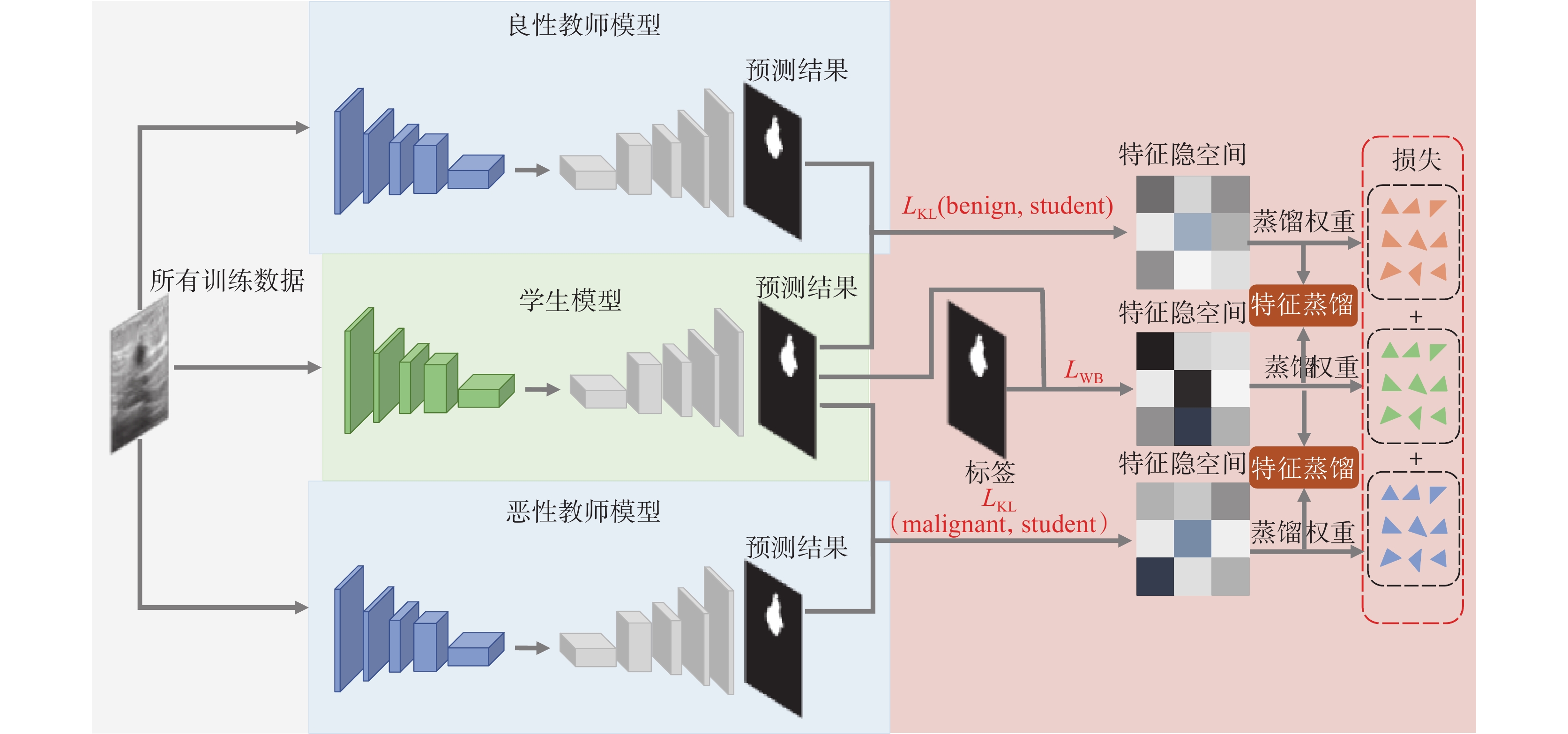
本文提出的T2KD Attention U-Net網絡模型,結構如圖1所示,包含兩個教師模型和一個學生模型。首先針對良性圖像和惡性圖像其語義特征的差異性,設計雙路徑聯合知識蒸餾模塊。具體地,利用病灶分類這一先驗知識實施輔助決策,將訓練數據中的良性圖像和惡性圖像分別輸入良性教師模型(benign)和惡性教師模型(malignant)兩個支路教師網絡,教師網絡從不同形態的數據中提取良性和惡性腫瘤的細粒度特征和上下文語義信息,最終訓練出高性能的良性教師模型和惡性教師模型。良性教師模型和惡性教師模型的預測結果分別與學生模型(student)的預測結果對比并計算損失函數: 和
和 ,并將特征映射到新的特征隱空間;學生模型的預測結果與真實標簽對比計算權重均衡損失函數(weight balance loss,
,并將特征映射到新的特征隱空間;學生模型的預測結果與真實標簽對比計算權重均衡損失函數(weight balance loss, ),也將特征映射到新的特征隱空間。通過模型學習不斷優化特征隱空間的概率分布,將最優的權重參數利用特征蒸餾傳輸給學生模型,使學生模型擁有和教師模型相近的良好性能。
),也將特征映射到新的特征隱空間。通過模型學習不斷優化特征隱空間的概率分布,將最優的權重參數利用特征蒸餾傳輸給學生模型,使學生模型擁有和教師模型相近的良好性能。
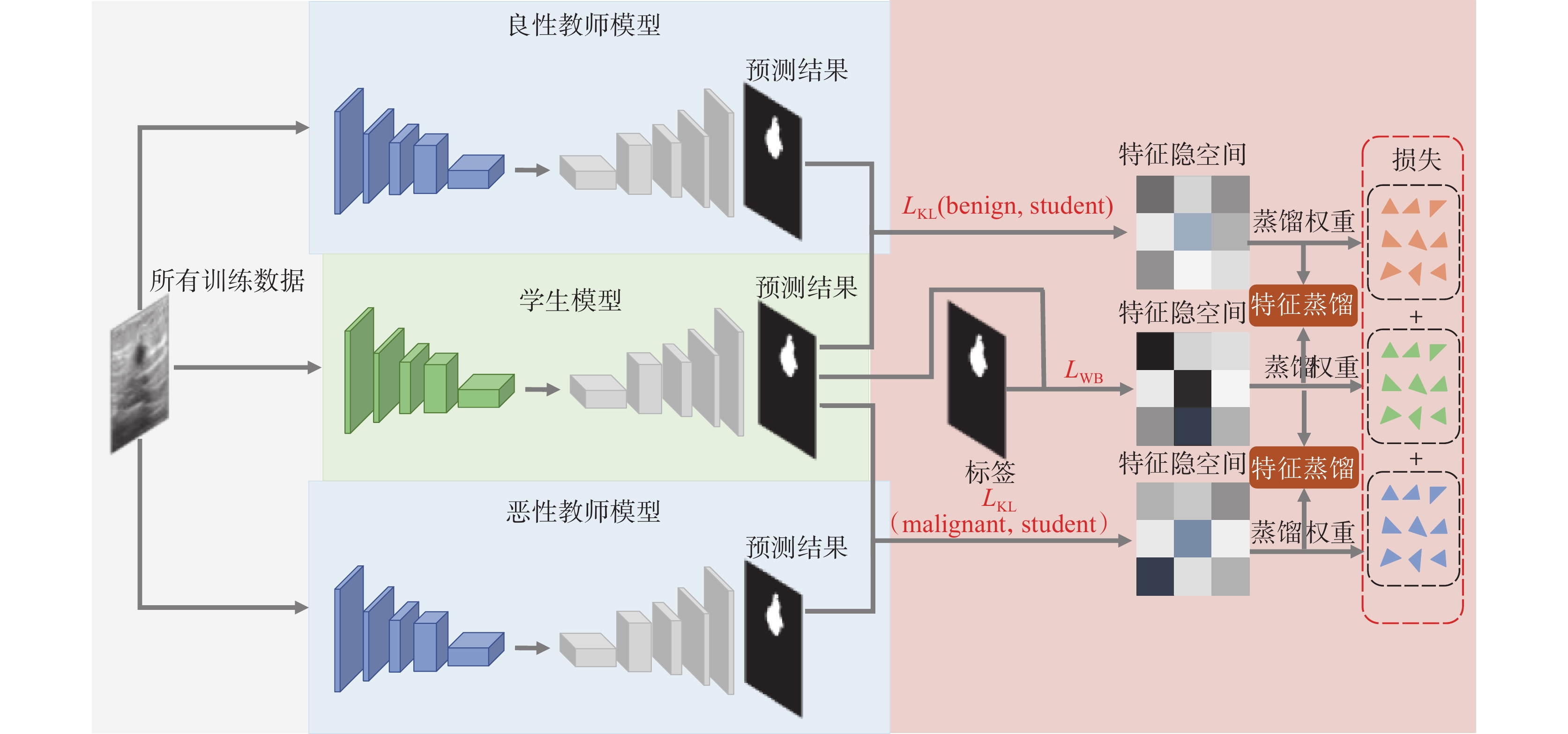 圖1
T2KD Attention U-Net網絡結構
Figure1.
The network architecture of T2KD Attention U-Net
圖1
T2KD Attention U-Net網絡結構
Figure1.
The network architecture of T2KD Attention U-Net
1.2 T2KD Attention U-Net網絡結構
1.2.1 教師網絡
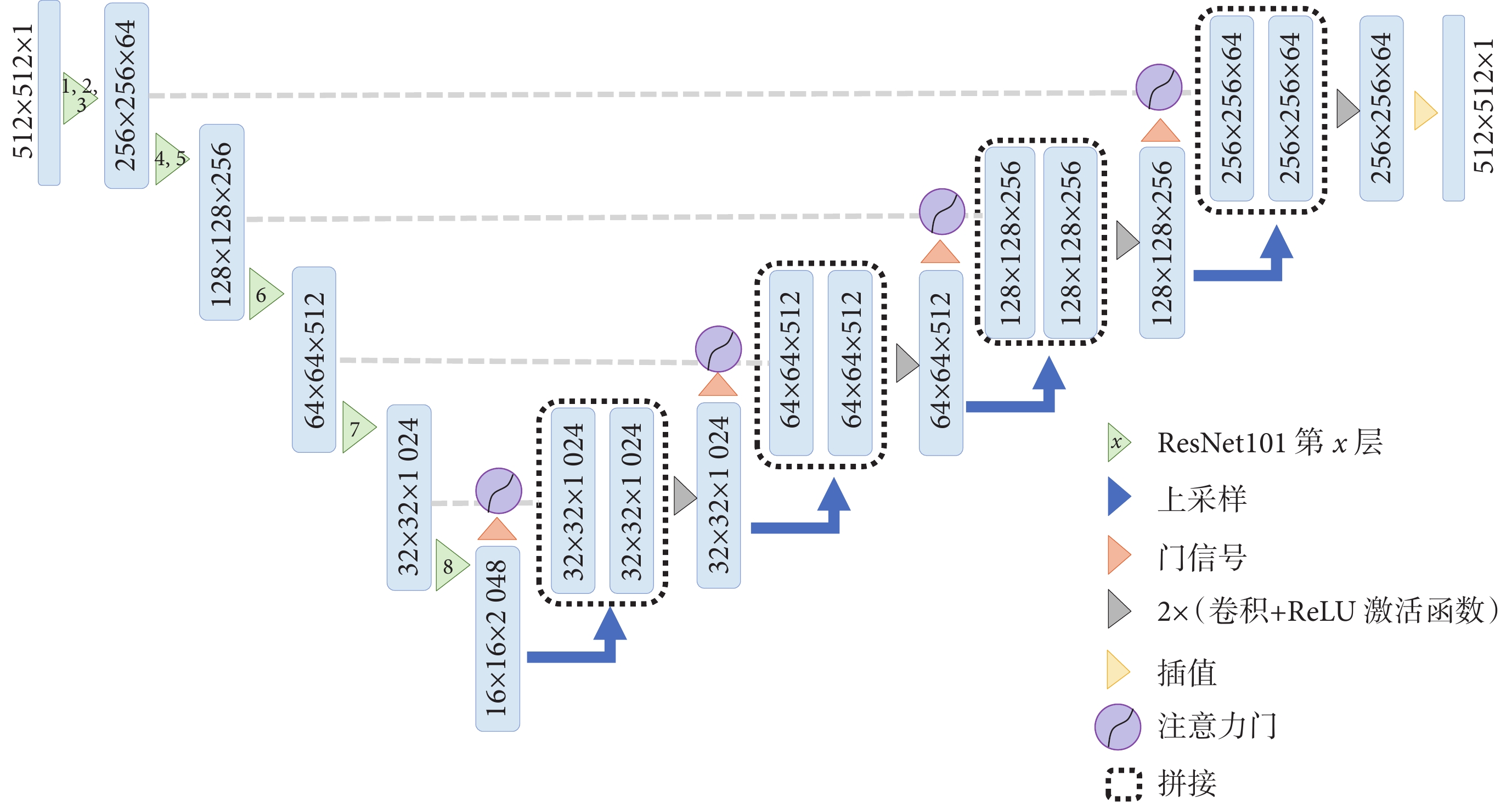
教師模型的網絡結構如圖2所示。教師模型采用改進的Attention U-Net網絡結構,編碼器部分采用ResNet101前8層作為特征編碼[24],共進行5次下采樣,分別使用ResNet101第1~3層、第4~5層、第6層、第7層、第8層。每次下采樣都會使用一個或多個瓶頸結構,以提取更高級別的特征。解碼器由上采樣層和卷積層組成,通過反卷積實現上采樣,在卷積層中提取特征信息。此外,解碼器使用注意力機制調整不同位置的特征圖權重,以便更好地捕捉圖像的語義信息,從而提高語義分割準確性。
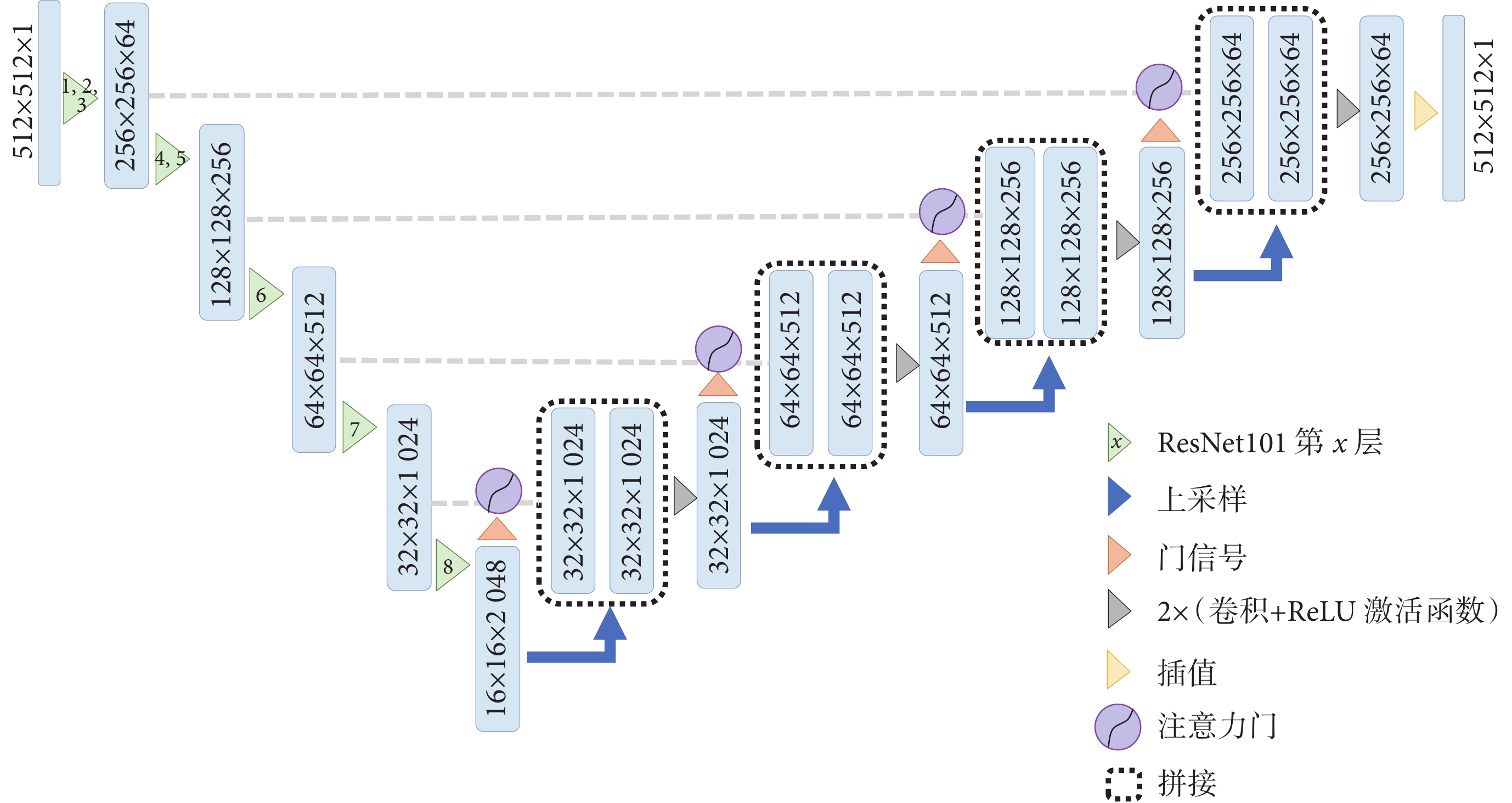 圖2
教師模型網絡結構
Figure2.
The network of teacher model
圖2
教師模型網絡結構
Figure2.
The network of teacher model
1.2.2 學生網絡
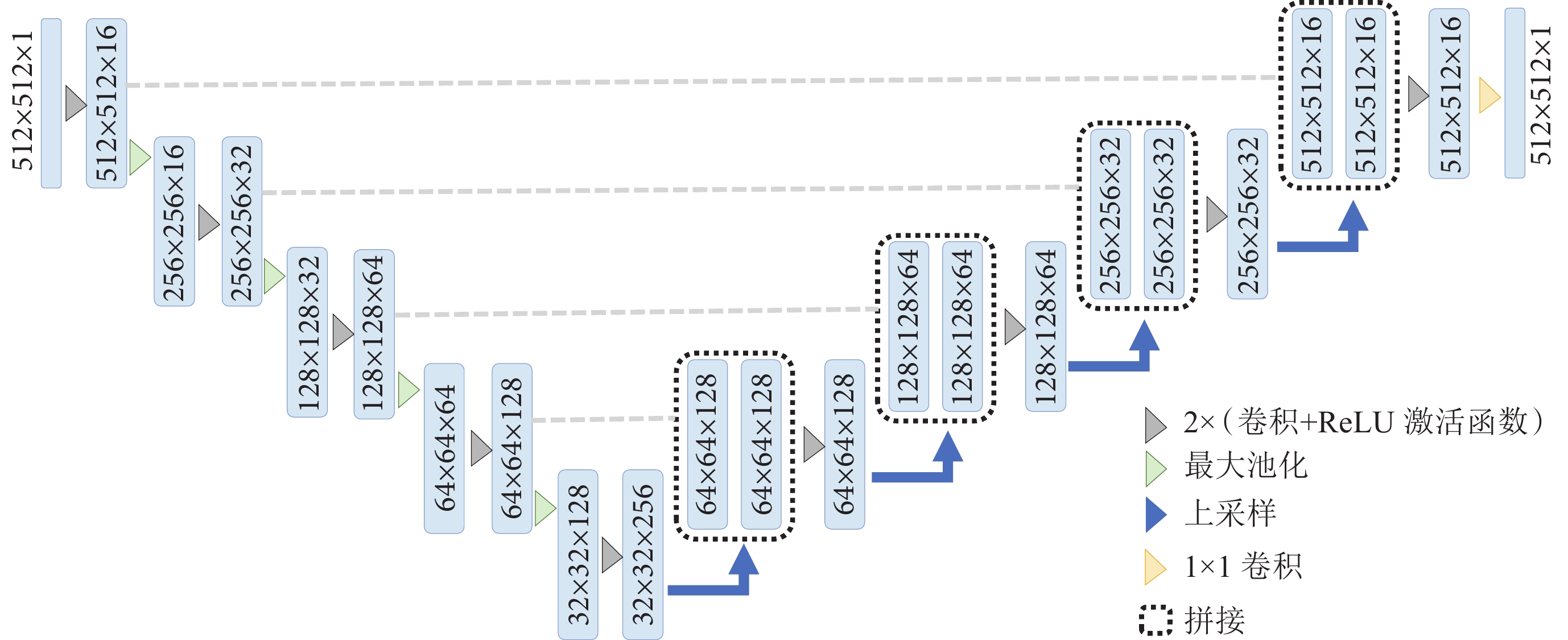
學生模型采用輕量化的U-Net(Simplified U-Net)的網絡結構(如圖3所示)。Simplified U-Net是在U-Net的基礎上減少通道數組成的,僅用了256個通道,相比于標準的U-Net模型,Simplified U-Net的參數數量大大減少,運行速度更快。
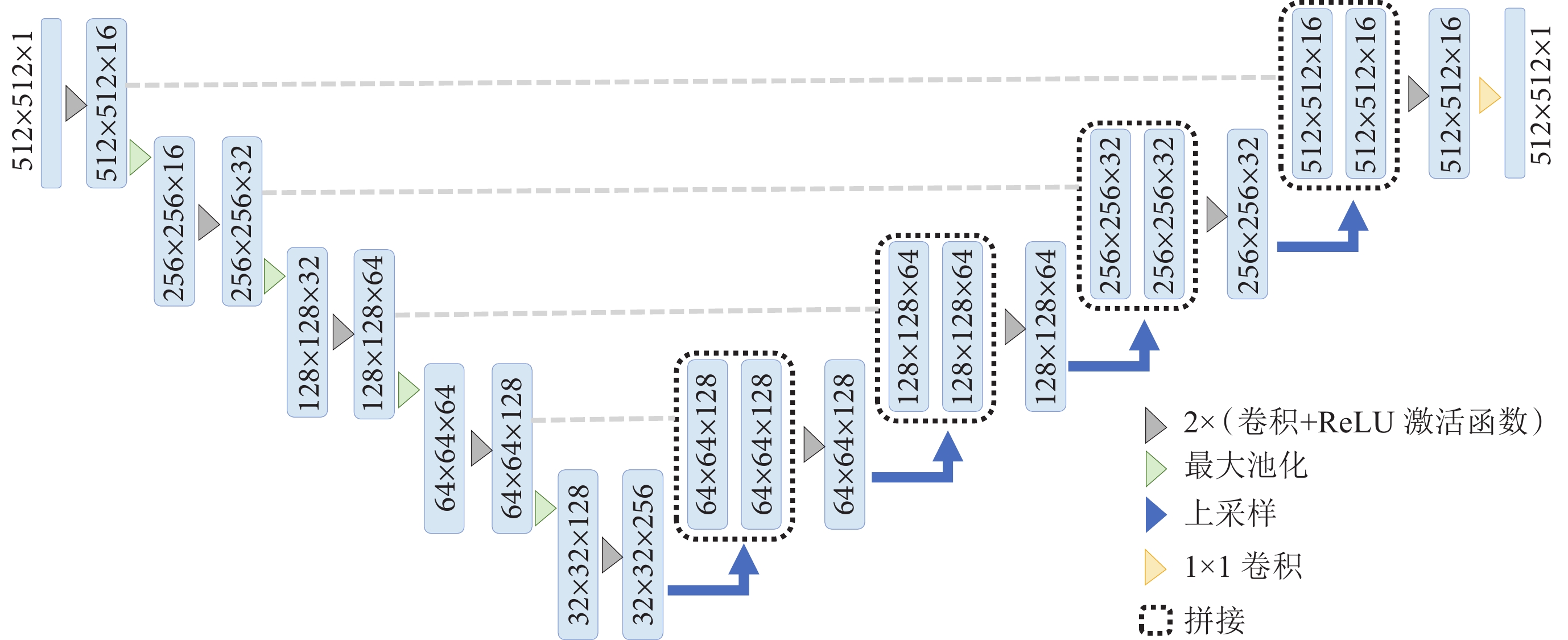 圖3
學生模型網絡結構
Figure3.
The architecture of student model
圖3
學生模型網絡結構
Figure3.
The architecture of student model
1.3 損失函數
知識蒸餾的損失通常包括兩部分:第一部分是學生網絡和真實標簽之間的硬損失,第二部分是學生網絡和教師網絡之間的軟損失。本文采用雙教師模型進行知識蒸餾,損失分為三部分:學生模型和真實標簽之間的硬損失;良性教師模型和學生模型之間的軟損失;惡性教師模型和學生模型之間的軟損失。
圖像分割本質是一個二分類問題,即預測每一個像素點是前景還是背景。交叉熵(cross entropy,CE)損失函數、戴斯相似系數(Dice)損失函數和交并比(intersection over union,IoU)損失函數都被廣泛應用于圖像分割,其中,CE損失函數通常用于預測每個像素的類別,而Dice損失函數和IoU損失函數則更加關注兩個分割結果之間的相似度。為了兼顧分類精度和分割精度,有效解決數據前景和背景像素不平衡問題,本文的硬損失設計了權重均衡損失函數 來進行算法優化,由CE損失函數、Dice損失函數和IoU損失函數共同組成,分別如式(1)~(3)所示,式(4)是由式(1)~(3)共同組成的
來進行算法優化,由CE損失函數、Dice損失函數和IoU損失函數共同組成,分別如式(1)~(3)所示,式(4)是由式(1)~(3)共同組成的 。另外,由于KL散度(Kullback-Leibler divergence)能夠較好地測量丟失的信息量,所以使用KL散度表示軟損失,如式(5)所示。最終的蒸餾損失函數如式(6)所示,由硬損失和軟損失共同組成。
。另外,由于KL散度(Kullback-Leibler divergence)能夠較好地測量丟失的信息量,所以使用KL散度表示軟損失,如式(5)所示。最終的蒸餾損失函數如式(6)所示,由硬損失和軟損失共同組成。
 |
 |
 |
其中,CE損失函數中 表示樣本的真實分布,
表示樣本的真實分布, 表示樣本的預測分布。Dice損失中
表示樣本的預測分布。Dice損失中 為像素類別數,
為像素類別數, 、
、 分別表示
分別表示 類的預測概率值和真實標簽值,
類的預測概率值和真實標簽值, 是類別數量,
是類別數量, 為第
為第 類的權重。IoU損失中
類的權重。IoU損失中 表示預測值,
表示預測值, 表示真實值。
表示真實值。
 |
 |
 |
蒸餾損失函數中, 是樣本
是樣本 的真實標簽,
的真實標簽, 是學生模型在樣本
是學生模型在樣本 上的對數歸一化指數函數(Log Softmax)輸出,
上的對數歸一化指數函數(Log Softmax)輸出, 和
和 是良性和惡性教師模型在樣本
是良性和惡性教師模型在樣本 上的歸一化指數函數(Softmax)輸出,
上的歸一化指數函數(Softmax)輸出, 、
、 和
和 是控制學生模型和教師模型權重的超參數。
是控制學生模型和教師模型權重的超參數。
1.4 聯合蒸餾策略
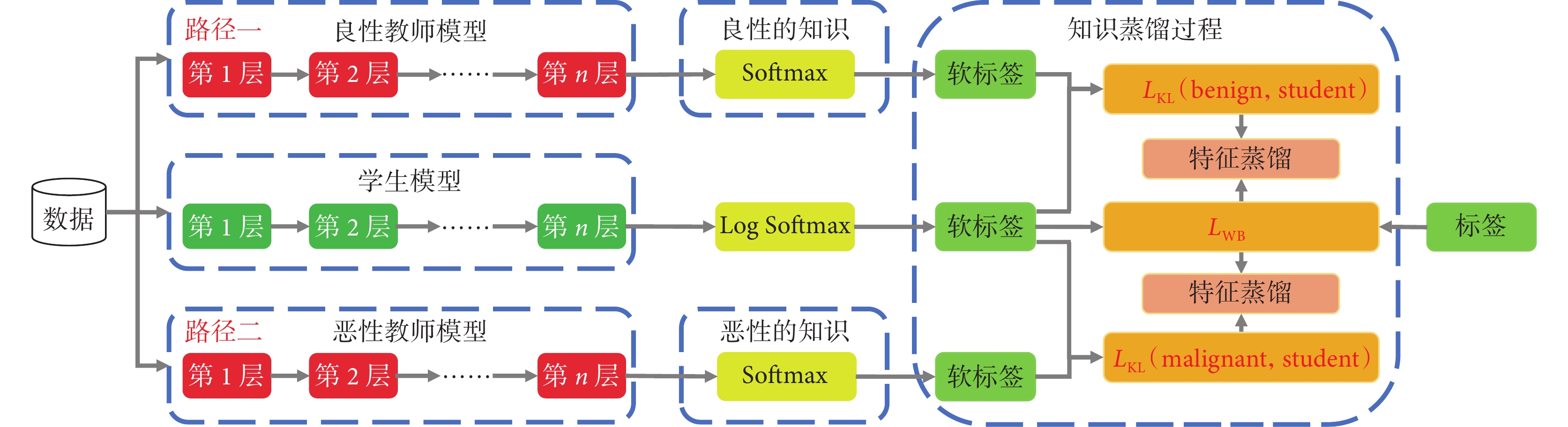
圖4詳細地描述了雙路徑聯合知識蒸餾模型的具體的“蒸餾”過程。具體而言,將圖像同時輸入訓練后的兩個教師模型和學生模型,對教師模型的預測值進行Softmax處理,對學生模型的預測值進行Log Softmax處理,生成它們對應的軟標簽,教師模型的軟標簽與學生模型的軟標簽之間形成軟損失( ),并通過特征蒸餾將知識傳遞給學生模型;另外,學生模型的軟標簽與真實標簽之間形成硬損失(
),并通過特征蒸餾將知識傳遞給學生模型;另外,學生模型的軟標簽與真實標簽之間形成硬損失( ),三個損失函數的加權和被用作整個模型的損失。在整個蒸餾過程中,良性教師模型提供了良性圖像的分割知識,而惡性教師模型提供了惡性圖像的分割知識,學生模型通過學習教師模型的預測行為來獲得充足的分割知識,實現良好的分割性能。
),三個損失函數的加權和被用作整個模型的損失。在整個蒸餾過程中,良性教師模型提供了良性圖像的分割知識,而惡性教師模型提供了惡性圖像的分割知識,學生模型通過學習教師模型的預測行為來獲得充足的分割知識,實現良好的分割性能。
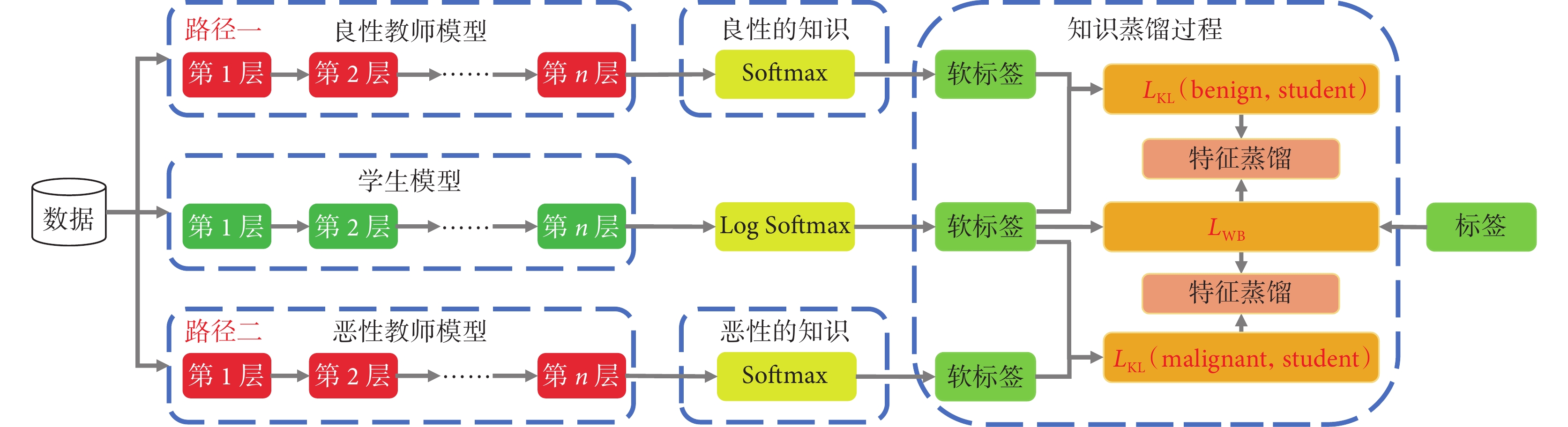 圖4
雙路徑聯合知識蒸餾學習框架結構
Figure4.
The architecture of double-path joint knowledge distillation framework
圖4
雙路徑聯合知識蒸餾學習框架結構
Figure4.
The architecture of double-path joint knowledge distillation framework
2 實驗結果與分析
2.1 數據集
本文實驗數據來源于兩個中心的臨床公開數據集,均獲得授權可以使用。第一中心的臨床數據集為乳腺超聲圖像數據集(breast ultrasound images dataset,Dataset BUSI)[25],是來自埃及開羅Bahey婦女(年齡25~75歲)癌癥早期檢測和治療醫院的臨床數據,由LOGIQ E9和LOGIQ E9 Agile兩套美國彩色多普勒超聲診斷系統共同采集,包含780張女性乳腺超聲圖像,平均圖像大小為500像素×500像素,圖像格式為PNG格式,圖像被分為三類,包括正常133張、良性437張、惡性210張,每張腫瘤圖像對應一張或多張病灶分割結果。這一數據集主要用于模型的訓練和測試。第二中心的臨床數據集為乳腺數據集B(breast ultrasound dataset B,Dataset B)[26],該數據集是來自西班牙薩瓦德爾帕洛阿爾托研究中心醫院的臨床數據,由美國西門子公司的ACUSON Sequoia C512多普勒超聲診斷系統采集,包含163張來自不同女性的乳腺超聲影像,平均圖像大小為760像素 × 570像素,每張圖像上存在1處或多處乳腺病變,其中54例是惡性病變,109例是良性病變。這一數據集有兩方面的作用:一是用于訓練和測試;二是用于模型的外部驗證實驗。
2.2 實驗環境及參數設置
本文模型基于Pytorch實現,實驗環境為Ubuntu20.04系統,12核2.50GHz Intel(R) Xeon(R) Platinum 8255C CPU,50 GB內存,一塊NVIDIA GeForce RTX
2.3 評價指標
為了評估圖像分割算法模型的性能,本實驗選擇使用Dice系數、平均交并比(mean intersection over union,mIoU)、準確率(accuracy,ACC)、精確度(precision,PRE)、召回率(recall,REC)五個性能評價值指標。其具體計算公式分別為:
 |
 |
 |
 |
 |
其中, 表示真實的分割標簽,
表示真實的分割標簽, 表示網絡模型輸出的預測結果,
表示網絡模型輸出的預測結果, 表示像素類別總數,
表示像素類別總數, 表示真實類別為
表示真實類別為 ,且預測類別也為
,且預測類別也為 的像素總數,
的像素總數, 表示真實類別為
表示真實類別為 ,但預測類別為
,但預測類別為 的像素總數。
的像素總數。 、
、 、
、 、
、 分別表示真陽性、真陰性、假陽性、假陰性的像素點數目。
分別表示真陽性、真陰性、假陽性、假陰性的像素點數目。
2.4 實驗結果與分析
2.4.1 對比分析實驗
首先,實驗驗證了T2KD Attention U-Net中教師模型的性能優勢。具體地,本文通過與包含U-Net和Attention U-Net在內的5個模型進行對比實驗,以驗證T2KD Attention U-Net作為教師模型的優秀性能表現,詳細的量化結果如下表1[11-12, 27-28]所示,從表中可以觀察到,本文提出的T2KD Attention U-Net的教師模型在各個指標上均優于其他模型。
具體的可視化分割結果如圖5所示。通過實驗結果可以觀測到T2KD Attention U-Net整體分割性能較其他分割方法更加優越,對乳腺病變區域的分割更加精細和完整。更多可視化結果參見附件1。
 圖5
乳腺超聲圖像在先進模型的分割對比結果
Figure5.
The segmentation comparison results of SOTA models in Dataset BUSI
圖5
乳腺超聲圖像在先進模型的分割對比結果
Figure5.
The segmentation comparison results of SOTA models in Dataset BUSI
進一步,本文驗證了T2KD Attention U-Net中的輕量化學生模型的性能優勢。將學生模型與教師模型在內的6個模型進行對比分析,在兩個數據集上的結果如表2所示。在Dataset BUSI中,學生模型的Dice、PRE、REC、mIoU和ACC略低于U-Net及其變體模型,但學生模型的參數量少,模型體量小,且模型復雜度低,每秒10億次的浮點運算數(giga floating-point operations per second,GFLOPs)也相當低。在Dataset B中,學生模型的Dice、PRE和mIoU均高于其他模型,REC和ACC略低于最優模型。與良性教師和惡性教師模型相比,學生模型能夠接近甚至超越教師模型,同時學生模型的參數量、模型體量和模型計算復雜度分別僅有教師模型的2.07%、2.02%和8.05%,這充分體現了學生模型的輕量化特征。
2.4.2 消融性分析實驗
為了驗證良性和惡性雙路徑教師模型聯合蒸餾的效果優于單個教師模型,本文在兩個數據集上實施以下消融性實驗:首先,分別使用良性圖像數據、惡性圖像數據和混合圖像數據(包含良性和惡性圖像)單獨進行訓練,并分別使用這三種類型的數據集進行測試,實驗結果如表3所示。結果顯示,僅使用良性圖像數據進行訓練的模型在對良性和混合圖像數據進行測試時效果較好(第1、5和8、12行),但對惡性圖像數據進行測試時效果較差(第3、10行),這主要是因為整個數據集中良性圖像占比高,其特征分布相對較集中,更容易學習。
進一步分析,僅使用惡性圖像數據進行訓練的模型在對良性、惡性和混合圖像數據進行測試時效果都比較理想(第2、4、6和9、11、13行),這主要是因為良性圖像的病灶區域比較規則,邊界比較清晰,其語義特征信息相對單一,辨識度較高,特征表示代表性弱,而惡性圖像的病灶區域多呈不規則形狀,邊界相對模糊,其語義特征信息量大,辨識度較低,特征表示代表性強,這也充分驗證了用特征分布復雜的惡性圖像訓練的模型對于特征分布單一的良性圖像效果較好,體現了模型具有良好的魯棒性。
此外,進一步設計使用良性和惡性數據分別訓練模型并對混合數據進行測試,其大部分性能結果(第5、6行和12、13行)均高于80%,表明良性訓練模型和惡性訓練模型對最終圖像分割性能的提升具有較大的推動作用。另外,盡管使用良性和惡性數據訓練的模型在對混合數據進行測試時均取得了較好的性能結果,但與使用混合數據訓練的模型結果(第7行和第14行,均高于83%)相比仍然存在較大差距,因此,本文進一步設計了單教師和雙教師模型蒸餾對比實驗。實驗結果表明雙教師聯合蒸餾策略對于整個模型的性能提升具有重要作用(具體實驗數據參見附件2)。
2.4.3 外部驗證實驗
為了進一步驗證本文模型的魯棒性和泛化能力,本文設計了外部驗證實驗。在外部驗證過程中,僅利用Dataset BUSI數據集進行模型訓練,模型訓練完后在Dataset B數據集上進行外部驗證實驗,具體結果如表4所示,最終學生模型的ACC、PRE、REC、Dice和mIoU指標分別為97.01%、80.62%、76.96%、75.93%和71.88%,實驗結果表明本文教師模型和學生模型在新的數據集上依然具有較高的識別精度。
3 結論
針對復雜的深度學習模型參數量大,計算復雜度高,難以快速部署在醫療場景的問題,本文提出一種面向乳腺癌超聲影像輕量化的分割模型T2KD Attention U-Net。首先,將Bottleneck結構融入到Attention U-Net作為教師模型,構造輕量化的Simplified U-Net作為學生模型;其次,充分利用乳腺病灶良性和惡性兩種類別這一先驗知識實施輔助決策,設計雙路徑聯合知識蒸餾的教師網絡,將良性和惡性兩個教師模型的知識“蒸餾”給學生模型。
本文的主要貢獻如下:
(1)針對現有的深度學習模型參數量多,計算復雜度高的問題,本文提出了雙路徑聯合知識蒸餾模型T2KD Attention U-Net,實現了乳腺癌病灶的輕量化精準分割。
(2)針對良惡性圖像特征差異性大,上下文語義特征不穩定的問題,本文提出了利用病灶分類這一先驗知識實施輔助決策,以驅動病灶精準分割。
(3)本文設計了一種新的權重均衡損失函數來優化乳腺癌圖像數據前景和背景像素不平衡問題。
本文模型在Dataset BUSI和Dataset B多中心數據集上實施了對比分析實驗、消融性分析實驗、蒸餾對比實驗和外部驗證實驗,均以極低的參數量和輕量化的模型取得了較高的性能,模型具有較好的泛化性和魯棒性。總而言之,本文所用方法能夠在保證精度的同時降低模型復雜度,為將模型部署到移動設備提供了幫助。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:郭宏江負責實驗設計與實踐和論文寫作;丁優優、劉彤彤負責超聲數據整理;姚碩、侯代森負責圖表數據制作;張嵐、黨豪負責論文研究、論文潤色和論文寫作指導。
本文附件見本刊網站的電子版本(biomedeng.cn)。
0 引言
乳腺癌是全球發病率最高的癌癥[1]。乳腺癌超聲影像檢查是乳腺癌診斷的重要手段,但是一般的超聲影像需要專業醫師耗費大量時間和精力才能完成診斷,存在人為主觀性強、測量結果準確性差、可再現性差等問題,常常導致疾病的漏診或誤診[2]。在對精準度高要求的同時,醫學診斷對時效性要求也較高。所以,設計一種高效輕量化的模型來自動分割乳腺腫瘤病變區域就顯得尤為重要。
近幾年,隨著深度學習理論的發展,它在核磁影像、病理學圖像、計算機斷層掃描影像和多模態醫學影像等方面被廣泛研究[3-10]。在乳腺癌超聲圖像分割任務中,一些研究采用卷積神經網絡(convolutional neural network,CNN)、U-Net模型和注意力機制等方法[11-12],提高了分割精度。Zhang等[13]提出一種全卷積網絡的多目標語義分割方法,將乳腺超聲圖像分割成不同的目標組織區域。貢榮麟等[14]提出混合監督雙通道反饋U-Net模型,提升了乳腺癌超聲影像的病灶分割精度。Wang等[15]提出了一種從粗到細的融合卷積神經網絡對乳腺癌圖像進行分割,在三個數據集上均達到了良好的分割精度。Chen等[16]提出了一個新的雙向感知制導網絡(bidirectional aware guidance network,BAGNet)以分割惡性乳腺癌數據。Chen等[17]提出了一個強大的嵌入式U-Net(nested U-net,NU-Net)以精準分割乳腺腫瘤。Vakanski等[18]將顯著性注意力機制引入到深度學習模型中,通過U-Net網絡對乳腺癌超聲圖像進行分割,證明了注意力機制對乳腺癌圖像分割具有積極作用。Lei等[19]將自注意力機制引入乳腺癌圖像分割,同時開發了協同注意力機制提高兩個連續切片之間分割的一致性。Xue等[20]融合通道注意力和空間注意力來處理乳腺癌超聲圖像中不規則的邊界。Punn等[21]設計了一種基于跨空間注意力引導的inception U-Net,顯著提高了乳腺超聲圖像的分割能力。
綜合分析,目前對乳腺癌病變的組織分割存在以下難點:① 在注意力機制和U-Net融合的過程中,模型對圖像淺層信息的提取不夠充分;② 在醫學圖像分割中,利用病灶分類這一先驗知識來驅動病灶精準分割還鮮有研究;③ 復雜的深度學習模型一味追求分割精度,卻忽略了模型的參數量和計算代價,限制了模型在醫學場景中的應用。為解決以上問題,本文在注意力U-Net(Attention U-Net)的基礎上提出一種雙教師聯合蒸餾的Attention U-Net模型(dual-teacher knowledge distillation Attention U-Net,T2KD Attention U-Net),該模型中的雙教師模型利用先驗知識實施輔助決策,增大模型訓練的樣本空間,并通過知識蒸餾的方法將知識遷移給學生模型。
1 本文方法
1.1 T2KD Attention U-Net模型整體流程
知識蒸餾本質上屬于遷移學習的范疇,Hinton等[22]首先提出知識蒸餾的方法,主要思想是將已經訓練好的高效的模型作為教師模型,然后從教師模型的輸出結果中“蒸餾”出“知識”用于學生模型的訓練,使輕量化的學生模型能夠接近甚至超越教師模型的性能表現[23]。
本文提出的T2KD Attention U-Net網絡模型,結構如圖1所示,包含兩個教師模型和一個學生模型。首先針對良性圖像和惡性圖像其語義特征的差異性,設計雙路徑聯合知識蒸餾模塊。具體地,利用病灶分類這一先驗知識實施輔助決策,將訓練數據中的良性圖像和惡性圖像分別輸入良性教師模型(benign)和惡性教師模型(malignant)兩個支路教師網絡,教師網絡從不同形態的數據中提取良性和惡性腫瘤的細粒度特征和上下文語義信息,最終訓練出高性能的良性教師模型和惡性教師模型。良性教師模型和惡性教師模型的預測結果分別與學生模型(student)的預測結果對比并計算損失函數:和,并將特征映射到新的特征隱空間;學生模型的預測結果與真實標簽對比計算權重均衡損失函數(weight balance loss,),也將特征映射到新的特征隱空間。通過模型學習不斷優化特征隱空間的概率分布,將最優的權重參數利用特征蒸餾傳輸給學生模型,使學生模型擁有和教師模型相近的良好性能。
圖1
T2KD Attention U-Net網絡結構
Figure1.
The network architecture of T2KD Attention U-Net
1.2 T2KD Attention U-Net網絡結構
1.2.1 教師網絡
教師模型的網絡結構如圖2所示。教師模型采用改進的Attention U-Net網絡結構,編碼器部分采用ResNet101前8層作為特征編碼[24],共進行5次下采樣,分別使用ResNet101第1~3層、第4~5層、第6層、第7層、第8層。每次下采樣都會使用一個或多個瓶頸結構,以提取更高級別的特征。解碼器由上采樣層和卷積層組成,通過反卷積實現上采樣,在卷積層中提取特征信息。此外,解碼器使用注意力機制調整不同位置的特征圖權重,以便更好地捕捉圖像的語義信息,從而提高語義分割準確性。
圖2
教師模型網絡結構
Figure2.
The network of teacher model
1.2.2 學生網絡
學生模型采用輕量化的U-Net(Simplified U-Net)的網絡結構(如圖3所示)。Simplified U-Net是在U-Net的基礎上減少通道數組成的,僅用了256個通道,相比于標準的U-Net模型,Simplified U-Net的參數數量大大減少,運行速度更快。
圖3
學生模型網絡結構
Figure3.
The architecture of student model
1.3 損失函數
知識蒸餾的損失通常包括兩部分:第一部分是學生網絡和真實標簽之間的硬損失,第二部分是學生網絡和教師網絡之間的軟損失。本文采用雙教師模型進行知識蒸餾,損失分為三部分:學生模型和真實標簽之間的硬損失;良性教師模型和學生模型之間的軟損失;惡性教師模型和學生模型之間的軟損失。
圖像分割本質是一個二分類問題,即預測每一個像素點是前景還是背景。交叉熵(cross entropy,CE)損失函數、戴斯相似系數(Dice)損失函數和交并比(intersection over union,IoU)損失函數都被廣泛應用于圖像分割,其中,CE損失函數通常用于預測每個像素的類別,而Dice損失函數和IoU損失函數則更加關注兩個分割結果之間的相似度。為了兼顧分類精度和分割精度,有效解決數據前景和背景像素不平衡問題,本文的硬損失設計了權重均衡損失函數來進行算法優化,由CE損失函數、Dice損失函數和IoU損失函數共同組成,分別如式(1)~(3)所示,式(4)是由式(1)~(3)共同組成的。另外,由于KL散度(Kullback-Leibler divergence)能夠較好地測量丟失的信息量,所以使用KL散度表示軟損失,如式(5)所示。最終的蒸餾損失函數如式(6)所示,由硬損失和軟損失共同組成。
|
|
|
其中,CE損失函數中表示樣本的真實分布,表示樣本的預測分布。Dice損失中為像素類別數,、分別表示類的預測概率值和真實標簽值,是類別數量,為第類的權重。IoU損失中表示預測值,表示真實值。
|
|
|
蒸餾損失函數中,是樣本的真實標簽,是學生模型在樣本上的對數歸一化指數函數(Log Softmax)輸出,和是良性和惡性教師模型在樣本上的歸一化指數函數(Softmax)輸出,、和是控制學生模型和教師模型權重的超參數。
1.4 聯合蒸餾策略
圖4詳細地描述了雙路徑聯合知識蒸餾模型的具體的“蒸餾”過程。具體而言,將圖像同時輸入訓練后的兩個教師模型和學生模型,對教師模型的預測值進行Softmax處理,對學生模型的預測值進行Log Softmax處理,生成它們對應的軟標簽,教師模型的軟標簽與學生模型的軟標簽之間形成軟損失(),并通過特征蒸餾將知識傳遞給學生模型;另外,學生模型的軟標簽與真實標簽之間形成硬損失(),三個損失函數的加權和被用作整個模型的損失。在整個蒸餾過程中,良性教師模型提供了良性圖像的分割知識,而惡性教師模型提供了惡性圖像的分割知識,學生模型通過學習教師模型的預測行為來獲得充足的分割知識,實現良好的分割性能。
圖4
雙路徑聯合知識蒸餾學習框架結構
Figure4.
The architecture of double-path joint knowledge distillation framework
2 實驗結果與分析
2.1 數據集
本文實驗數據來源于兩個中心的臨床公開數據集,均獲得授權可以使用。第一中心的臨床數據集為乳腺超聲圖像數據集(breast ultrasound images dataset,Dataset BUSI)[25],是來自埃及開羅Bahey婦女(年齡25~75歲)癌癥早期檢測和治療醫院的臨床數據,由LOGIQ E9和LOGIQ E9 Agile兩套美國彩色多普勒超聲診斷系統共同采集,包含780張女性乳腺超聲圖像,平均圖像大小為500像素×500像素,圖像格式為PNG格式,圖像被分為三類,包括正常133張、良性437張、惡性210張,每張腫瘤圖像對應一張或多張病灶分割結果。這一數據集主要用于模型的訓練和測試。第二中心的臨床數據集為乳腺數據集B(breast ultrasound dataset B,Dataset B)[26],該數據集是來自西班牙薩瓦德爾帕洛阿爾托研究中心醫院的臨床數據,由美國西門子公司的ACUSON Sequoia C512多普勒超聲診斷系統采集,包含163張來自不同女性的乳腺超聲影像,平均圖像大小為760像素 × 570像素,每張圖像上存在1處或多處乳腺病變,其中54例是惡性病變,109例是良性病變。這一數據集有兩方面的作用:一是用于訓練和測試;二是用于模型的外部驗證實驗。
2.2 實驗環境及參數設置
本文模型基于Pytorch實現,實驗環境為Ubuntu20.04系統,12核2.50GHz Intel(R) Xeon(R) Platinum 8255C CPU,50 GB內存,一塊NVIDIA GeForce RTX
2.3 評價指標
為了評估圖像分割算法模型的性能,本實驗選擇使用Dice系數、平均交并比(mean intersection over union,mIoU)、準確率(accuracy,ACC)、精確度(precision,PRE)、召回率(recall,REC)五個性能評價值指標。其具體計算公式分別為:
|
|
|
|
|
其中,表示真實的分割標簽,表示網絡模型輸出的預測結果,表示像素類別總數,表示真實類別為,且預測類別也為的像素總數,表示真實類別為,但預測類別為的像素總數。、、、分別表示真陽性、真陰性、假陽性、假陰性的像素點數目。
2.4 實驗結果與分析
2.4.1 對比分析實驗
首先,實驗驗證了T2KD Attention U-Net中教師模型的性能優勢。具體地,本文通過與包含U-Net和Attention U-Net在內的5個模型進行對比實驗,以驗證T2KD Attention U-Net作為教師模型的優秀性能表現,詳細的量化結果如下表1[11-12, 27-28]所示,從表中可以觀察到,本文提出的T2KD Attention U-Net的教師模型在各個指標上均優于其他模型。
具體的可視化分割結果如圖5所示。通過實驗結果可以觀測到T2KD Attention U-Net整體分割性能較其他分割方法更加優越,對乳腺病變區域的分割更加精細和完整。更多可視化結果參見附件1。
圖5
乳腺超聲圖像在先進模型的分割對比結果
Figure5.
The segmentation comparison results of SOTA models in Dataset BUSI
進一步,本文驗證了T2KD Attention U-Net中的輕量化學生模型的性能優勢。將學生模型與教師模型在內的6個模型進行對比分析,在兩個數據集上的結果如表2所示。在Dataset BUSI中,學生模型的Dice、PRE、REC、mIoU和ACC略低于U-Net及其變體模型,但學生模型的參數量少,模型體量小,且模型復雜度低,每秒10億次的浮點運算數(giga floating-point operations per second,GFLOPs)也相當低。在Dataset B中,學生模型的Dice、PRE和mIoU均高于其他模型,REC和ACC略低于最優模型。與良性教師和惡性教師模型相比,學生模型能夠接近甚至超越教師模型,同時學生模型的參數量、模型體量和模型計算復雜度分別僅有教師模型的2.07%、2.02%和8.05%,這充分體現了學生模型的輕量化特征。
2.4.2 消融性分析實驗
為了驗證良性和惡性雙路徑教師模型聯合蒸餾的效果優于單個教師模型,本文在兩個數據集上實施以下消融性實驗:首先,分別使用良性圖像數據、惡性圖像數據和混合圖像數據(包含良性和惡性圖像)單獨進行訓練,并分別使用這三種類型的數據集進行測試,實驗結果如表3所示。結果顯示,僅使用良性圖像數據進行訓練的模型在對良性和混合圖像數據進行測試時效果較好(第1、5和8、12行),但對惡性圖像數據進行測試時效果較差(第3、10行),這主要是因為整個數據集中良性圖像占比高,其特征分布相對較集中,更容易學習。
進一步分析,僅使用惡性圖像數據進行訓練的模型在對良性、惡性和混合圖像數據進行測試時效果都比較理想(第2、4、6和9、11、13行),這主要是因為良性圖像的病灶區域比較規則,邊界比較清晰,其語義特征信息相對單一,辨識度較高,特征表示代表性弱,而惡性圖像的病灶區域多呈不規則形狀,邊界相對模糊,其語義特征信息量大,辨識度較低,特征表示代表性強,這也充分驗證了用特征分布復雜的惡性圖像訓練的模型對于特征分布單一的良性圖像效果較好,體現了模型具有良好的魯棒性。
此外,進一步設計使用良性和惡性數據分別訓練模型并對混合數據進行測試,其大部分性能結果(第5、6行和12、13行)均高于80%,表明良性訓練模型和惡性訓練模型對最終圖像分割性能的提升具有較大的推動作用。另外,盡管使用良性和惡性數據訓練的模型在對混合數據進行測試時均取得了較好的性能結果,但與使用混合數據訓練的模型結果(第7行和第14行,均高于83%)相比仍然存在較大差距,因此,本文進一步設計了單教師和雙教師模型蒸餾對比實驗。實驗結果表明雙教師聯合蒸餾策略對于整個模型的性能提升具有重要作用(具體實驗數據參見附件2)。
2.4.3 外部驗證實驗
為了進一步驗證本文模型的魯棒性和泛化能力,本文設計了外部驗證實驗。在外部驗證過程中,僅利用Dataset BUSI數據集進行模型訓練,模型訓練完后在Dataset B數據集上進行外部驗證實驗,具體結果如表4所示,最終學生模型的ACC、PRE、REC、Dice和mIoU指標分別為97.01%、80.62%、76.96%、75.93%和71.88%,實驗結果表明本文教師模型和學生模型在新的數據集上依然具有較高的識別精度。
3 結論
針對復雜的深度學習模型參數量大,計算復雜度高,難以快速部署在醫療場景的問題,本文提出一種面向乳腺癌超聲影像輕量化的分割模型T2KD Attention U-Net。首先,將Bottleneck結構融入到Attention U-Net作為教師模型,構造輕量化的Simplified U-Net作為學生模型;其次,充分利用乳腺病灶良性和惡性兩種類別這一先驗知識實施輔助決策,設計雙路徑聯合知識蒸餾的教師網絡,將良性和惡性兩個教師模型的知識“蒸餾”給學生模型。
本文的主要貢獻如下:
(1)針對現有的深度學習模型參數量多,計算復雜度高的問題,本文提出了雙路徑聯合知識蒸餾模型T2KD Attention U-Net,實現了乳腺癌病灶的輕量化精準分割。
(2)針對良惡性圖像特征差異性大,上下文語義特征不穩定的問題,本文提出了利用病灶分類這一先驗知識實施輔助決策,以驅動病灶精準分割。
(3)本文設計了一種新的權重均衡損失函數來優化乳腺癌圖像數據前景和背景像素不平衡問題。
本文模型在Dataset BUSI和Dataset B多中心數據集上實施了對比分析實驗、消融性分析實驗、蒸餾對比實驗和外部驗證實驗,均以極低的參數量和輕量化的模型取得了較高的性能,模型具有較好的泛化性和魯棒性。總而言之,本文所用方法能夠在保證精度的同時降低模型復雜度,為將模型部署到移動設備提供了幫助。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:郭宏江負責實驗設計與實踐和論文寫作;丁優優、劉彤彤負責超聲數據整理;姚碩、侯代森負責圖表數據制作;張嵐、黨豪負責論文研究、論文潤色和論文寫作指導。
本文附件見本刊網站的電子版本(biomedeng.cn)。