針對深度學習網絡應用于心臟核磁共振成像(MRI)圖像分割時網絡參數量以及浮點運算量較大的問題,本文提出一種輕量化的空洞并行卷積網絡(DPU-Net)以減少網絡參數的數量以及浮點運算數,進而通過多尺度自適應向量引導的知識蒸餾(MAVKD)訓練策略用于提取教師網絡的暗知識,以提高DPU-Net的分割精度。本文所提網絡采用獨特的卷積通道變化方式來減少參數量,并搭配殘差塊以及空洞卷積緩解因參數減少可能導致的梯度爆炸問題和空間信息丟失問題。研究結果顯示,該網絡在減少參數量以及提高浮點運算效率方面獲得大幅提升,并且將該網絡應用于自動心臟診斷挑戰賽(ACDC)公共數據集,所得骰子(dice)系數達到91.26%。該研究結果證實了本文所提出的輕量化網絡以及知識蒸餾策略的有效性,為深度學習在醫學圖像分割領域提供了可靠的網絡輕量化思路。
引用本文: 劉澤奇, 王寧, 張沖, 魏國輝. 基于輕量化網絡與知識蒸餾策略的心臟核磁共振圖像分割. 生物醫學工程學雜志, 2024, 41(6): 1204-1212. doi: 10.7507/1001-5515.202312015 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
隨著醫學成像技術的不斷進步,諸如計算機斷層掃描(computed tomography,CT)、磁共振成像(magnetic resonance imaging,MRI)、X射線和超聲波等技術已經成為現代醫學診斷的重要工具。然而,經上述設備采集的圖像數據尚需花費大量的時間精力進行判讀,以找尋準確的診斷依據。特別是在心臟疾病的診斷和治療中,準確分割心臟MRI圖像中的病灶,是診斷與治療心臟疾病的重要一環。近年來,深度學習的快速發展,使計算機智能輔助醫學圖像分割技術得到了廣泛關注[1]。雖然這些先進的分割技術顯著提高了分割的準確性,但由于網絡參數量和網絡浮點運算量的大幅增加,使得許多現有設備因硬件限制難以有效運行[2]。因此,如何在減輕醫學圖像分割網絡對計算機性能依賴的同時,確保其分割精度不受影響,仍然是當前研究領域的一個挑戰。
深度學習已經在醫學圖像分割領域取得了引人矚目的成果。自Ronneberger等[3]提出U型網絡(U-Net)架構以來,該架構迅速成為該領域的標桿,引發了對其多種變體的探索。例如:為克服U-Net在長程依賴關系上的局限,Chen等[4]提出構建轉換器(Transformer[5])與U-Net結合網絡(Transformer U-Net,TransU-Net),可有效學習全局與長距離依賴,從而顯著增強了分割效果;Cao等[6]提出了結合窗口Transformer(Swin-Transformer)[7]與U-Net的網絡(Swin-Transformer U-Net,SwinU-Net),利用Swin-Transformer的優勢,在減少計算負擔的同時提高了效率;此外,Zhou等[8]創新性地提出了僅依賴注意力機制的U-Net架構(not-another Transformer,NNFormer),使用長短距離體積Transformer與跳躍注意力連接,同樣在醫學圖像分割領域取得顯著成果。這些研究不斷推動深度學習在醫學圖像分割領域的前沿發展。
通過上述網絡可以看出,在U-Net中引用注意力機制,是有效提升網絡性能表現的方式,但是注意力機制同樣有著一個顯著的缺點,浮點運算量和參數量過大,如表1所示。
盡管表1中提及的網絡在心臟MRI圖像分割任務上表現出色,平均骰子系數(average dice coefficient,avg dice)均較高,但實際部署過程中,尤其是在面對大體積空間的醫學圖像時,這些網絡常常面臨設備限制[2]。因此,在保證模型性能的同時,實現網絡的輕量化是實際應用中重要的目標。
深度學習模型的輕量化研究一直是該領域的研究熱點。Zhang等[9]將通道重排與逐點分組卷積相結合,提出了重排網絡(suffle network,ShuffleNet),使網絡的參數量顯著減少。Howard等[10]采用深度可分離卷積搭配獨特的網絡結構,提出了用于移動設備的深度學習網絡——移動網絡(mobile network,MobileNet),同樣使網絡參數量明顯下降。此外,對注意力機制的輕量化同樣獲得了研究人員的關注,例如:Swin-Transformer和軸注意力機制(axial attention)等[11-12],均獲得不菲成果。但注意力機制所帶來的浮點運算量遠高于卷積操作,所以在輕量化網絡中引進注意力機制并不總是理想選擇。沈瑜等[13]提出一種輕量卷積U-Net(lightweight convolutional U-Net,LCU-Net)的輕量化網絡模型,該模型在設計上側重于腦部MRI圖像的配準任務,通過引入并行處理的輕量化卷積模塊以提高全局信息提取能力,最終在該領域取得了較好結果,但是該網絡在圖像分割任務中的效果尚未得到充分研究。Celaya等[2]提出了一種口袋網絡(pocket-network,PocketNet),通過抑制通道增長實現網絡的輕量化,在分割與分類任務中性能優異,媲美傳統網絡,但現有研究多聚焦單標簽分割,其在多標簽分割任務中的效果尚需進一步驗證與明確。
在大多數情況下,輕量級網絡難以達到與重量級網絡相媲美的分割效果。為了提高輕量化網絡的性能,Hinton等[14]提出一種名為知識蒸餾(knowledge distillation,KD)的訓練策略,讓表現較差的網絡學習表現較好的教師網絡輸出的軟標簽,從而有效提升自身的性能,進而達到提高輕量化網絡效率的目的。為了提高KD策略的效果,研究者們提出多種改進方案,例如:Xu等[15]提出了解決KD參數設置問題的特征歸一化KD(feature normalized KD,FNKD);Tung等[16]揭示了類別之間的相似性關系,并據此提出保持相似性KD(similarity-preserving KD,SPKD);Tian等[17]通過為每個單獨的數據樣本建立自適應的學習視角,提出自適應視角KD(adaptive perspective KD,AKD)。
近幾年,將KD策略運用到醫學圖像上的研究逐漸興起,但是多數研究都聚集于多模態[18-20]、自監督學習[21]以及半監督學習[22],而對于醫學圖像的多類分割使其提升至和教師網絡相當的性能,仍然有待深入研究。
為了應對上述挑戰,本文創新性地提出了多尺度自適應向量引導KD(multi-scale adaptation vector KD,MAVKD)策略,該方法通過引入多尺度特征和自適應向量來指導輕量化網絡學習,從而更有效地從教師網絡中提取知識。并在口袋U-Net(PocketU-Net)[2]基礎上,設計了一種空洞并行卷積(dilated parallel convolution,DP)的U-Net(DPU-Net),該網絡利用空洞卷積來擴大感受野,并捕捉更多的上下文信息,同時采用并行卷積結構來平衡計算復雜度和性能。將MAVKD與DPU-Net相結合進行訓練,并以一系列實驗驗證其有效性,以期讓該方法在輕量化網絡的基礎上達到目前心臟MRI圖像分割任務的先進水平。
1 方法
1.1 DPU-Net網絡
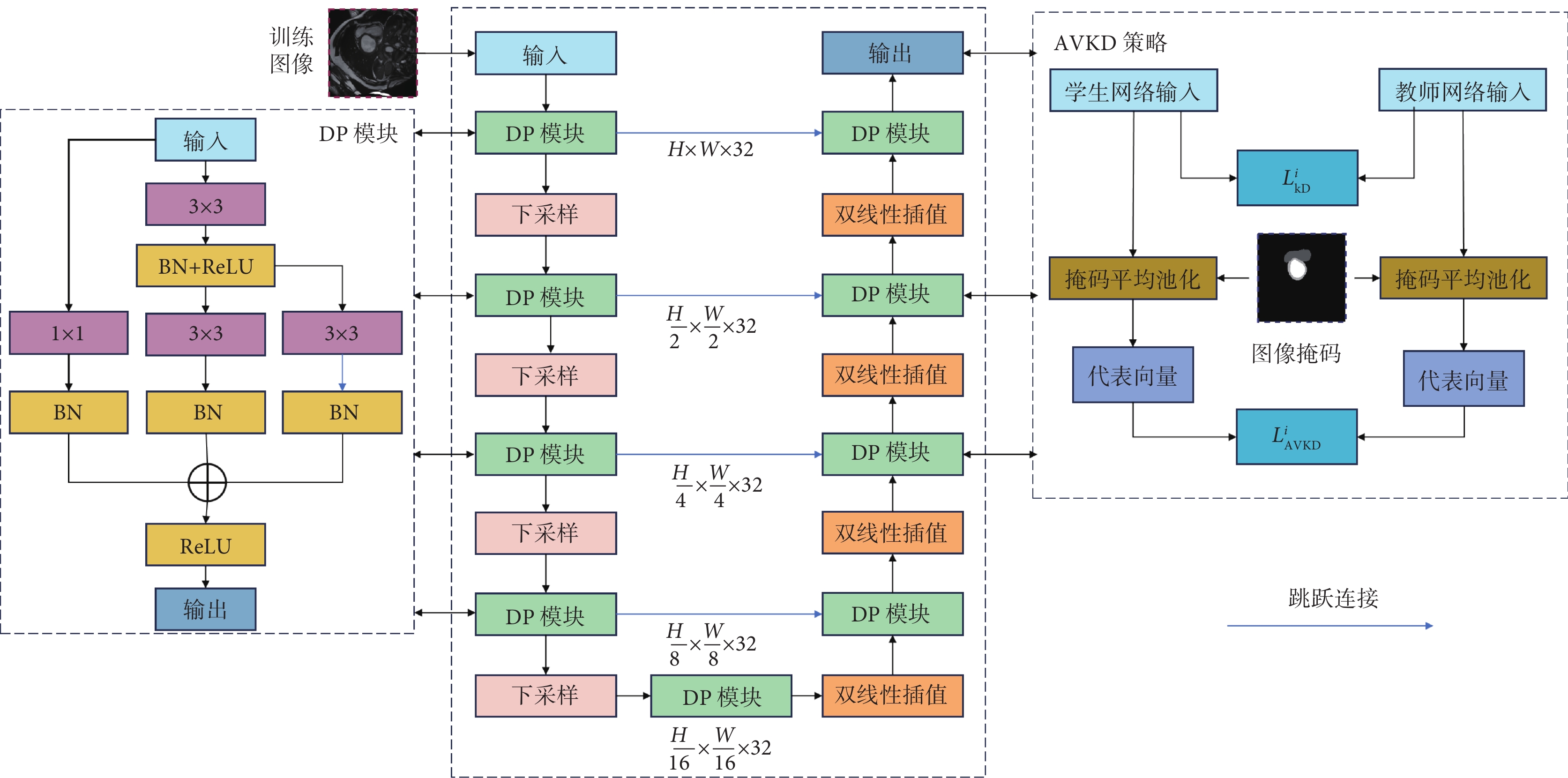
DPU-Net網絡模型結構如圖1所示。首先,將預處理后的訓練圖像作為輸入,通過一個1 × 1卷積映射層來調整通道數量。隨后,訓練圖像經過修正線性單元(rectified linear unit,ReLU)激活函數進行非線性變換,輸入到網絡中。在網絡的編碼階段,特征圖連續經過4個特征提取模塊,每個模塊包括一個DP模塊和一個下采樣層。特征圖經過每個下采樣層時,訓練數據通道數量不發生變化,以控制模型的大小。在網絡的解碼階段,每層通過雙線性插值得到的解碼特征數據與相同尺度下的編碼階段特征數據進行跳躍連接融合。融合后的特征數據經過DP模塊進一步處理和優化,最終將該層數據輸出,以供后續MAVKD和深度監督策略使用。
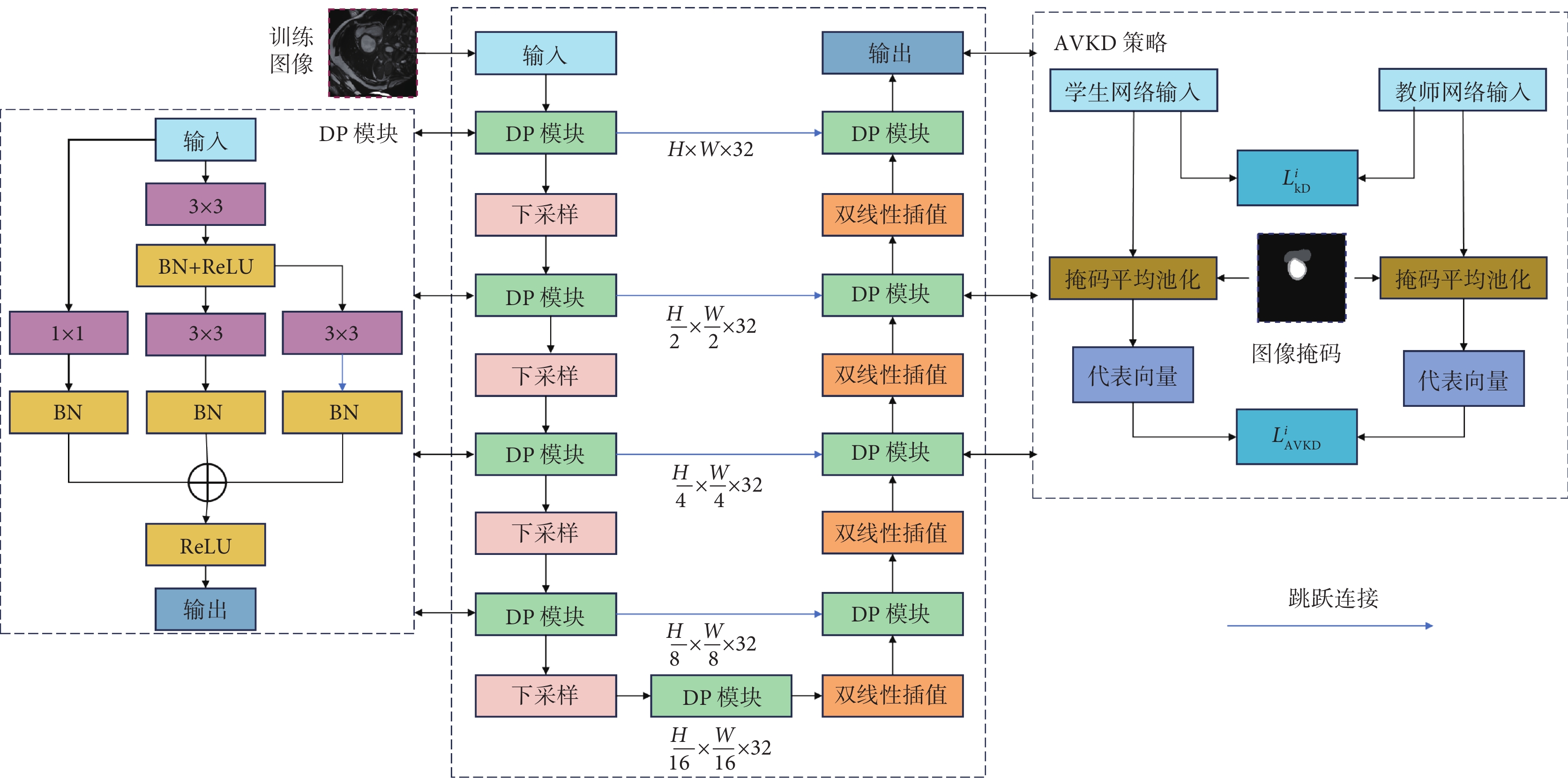 圖1
DPU-Net網絡模型與MAVKD策略
Figure1.
DPU-Net network model and MAVKD strategy
圖1
DPU-Net網絡模型與MAVKD策略
Figure1.
DPU-Net network model and MAVKD strategy
1.2 DP模塊
PocketU-Net由于追求輕量級設計,通道數量遠遠少于U-Net網絡,在心臟MRI圖像分割任務中,其對于心室、心肌等結構邊界分割效果模糊,甚至難以識別部分類別。此外,在訓練過程中還發現梯度爆炸問題,這些問題不僅影響了分割的精確度,還可能導致模型在測試集上的泛化能力下降。
為了解決上述問題,本文參考全卷積Transformer(full convolution Transformer,FCT)[23],提出DP模塊,如圖1所示。該模塊主要包括3 × 3卷積層、1 × 1卷積層、批規范化(batch normalization,BN)層、ReLU激活層。首先,圖像數據通過3 × 3卷積模塊,有助于組織和編輯圖像信息;其次,采用3 × 3空洞卷積與3 × 3普通卷積并行相加的模塊設計,可以有效緩解在不同分辨率等級下因通道數量減少而可能導致的信息丟失問題;最后,在該分辨率等級下,添加1 × 1卷積作為殘差模塊[24],用于解決梯度爆炸問題。BN層用于改善模型的穩定性和收斂速度;ReLU層用于實現非線性變換,從而加速網絡的訓練速度。
1.3 MAVKD模塊
本文在多尺度KD(multi-scale KD,MSKD)[25]的基礎上,引入了自適應向量KD(adaptation vector KD,AVKD),該技術能夠捕捉教師網絡執行心臟MRI圖像分割任務時所輸出的分割掩碼中不同類別代表向量的差異性信息。
首先,為滿足各分辨率層級下的輸出需求,將真實掩碼(Ground Truth)下采樣至不同分辨率層級,計算過程如式(1)所示:
 |
其中,i為當前網絡的分辨率層級,K代表網絡的最深層級,j為當前所處理的分割類別,N為圖像的分割類別總數,mi, j代表當前類別j的二進制掩碼下采樣至第i層的掩碼值,mpi代表第i層的最大池化操作,Mj為當前類別j真實的二進制掩碼值。
隨后,將教師網絡在不同尺度下的輸出通過額外的1 × 1卷積層進行處理,目的是將教師網絡與學生網絡的通道數量調整至相同,以作為AVKD模塊的輸入,計算過程如式(2)所示:
 |
其中, Ii, t、Ii, s分別代表教師網絡與學生網絡不同分辨率等級i下的輸出數據,Xi, t、Xi, s分別代表教師網絡與學生網絡不同分辨率等級i下的AVKD模塊輸入數據,f(?)代表1 × 1卷積映射,作用是將學生網絡與教師網絡各層的通道個數映射為相同數量,W、H為圖像數據的寬和高,C代表圖像數據的通道數量。
對不同尺度下的AVKD模塊輸入數據進行掩碼平均池化,從而輸出各尺度下不同類別的代表向量。結合式(1)和式(2),代表向量計算公式如式(3)所示:
 |
其中,x代表像素點的位置,mxi, j代表mi, j在位于像素點位置x時的值,Xxi, t與Xxi, s分別代表Xi,t、Xi,s在位于像素點位置x時的值, 、
、 分別表示教師網絡和學生網絡輸出的各類別代表向量的集合,這些向量具有自適應性,不同圖像在同一網絡中生成的各類別代表向量可能存在明顯差異。通過讓學生網絡生成類似的代表向量,可以學習到不同圖像間的相異性,從而幫助AVKD產生積極的輔助效果。
分別表示教師網絡和學生網絡輸出的各類別代表向量的集合,這些向量具有自適應性,不同圖像在同一網絡中生成的各類別代表向量可能存在明顯差異。通過讓學生網絡生成類似的代表向量,可以學習到不同圖像間的相異性,從而幫助AVKD產生積極的輔助效果。
使用余弦相似度損失來鼓勵學生網絡生成類似于教師網絡的代表向量。余弦相似度越接近于1,兩個向量就越相似。單一分辨率等級上的AVKD損失定義如式(4)所示:
 |
其中, 表示第i層的AVKD損失,它鼓勵學生網絡生成同教師網絡相似的代表向量,從而增強學生網絡對教師網絡的學習能力。結合式(4),整個模型的損失定義如式(5)所示:
表示第i層的AVKD損失,它鼓勵學生網絡生成同教師網絡相似的代表向量,從而增強學生網絡對教師網絡的學習能力。結合式(4),整個模型的損失定義如式(5)所示:
 |
其中,L為網絡的整體損失, 為當前分辨率等級對網絡整體的損失占比,
為當前分辨率等級對網絡整體的損失占比, 和
和 為超參數,
為超參數, 表示標準KD損失,
表示標準KD損失, 為當前分辨率尺度下的輸出與經過下采樣后的二進制掩碼經計算所得到的真實損失。
為當前分辨率尺度下的輸出與經過下采樣后的二進制掩碼經計算所得到的真實損失。
2 實驗
2.1 實驗數據來源
為了證明本文所提出的模型與MAVKD的有效性,本文使用來自國際醫學圖像計算和計算機輔助干預協會(Medical Image Computing and Computer Assisted Intervention Society,MICCAI)2017年舉辦的自動心臟診斷挑戰賽(automatic cardiac diagnosis challenge,ACDC)[26]的公開數據集進行醫學圖像分割任務。ACDC數據集共包括100名患者的信息,其中包括100張心臟MRI圖像,分割標簽為左心室(left ventricle,LV)、右心室(right ventricle,RV)以及心肌(myocardium,MYO)的真實數據。本文將這100名患者按照80: 20的比例劃分為訓練數據和測試數據,其中訓練數據中70個用于訓練集,10用于為驗證集。數據集的數據增廣策略如下:隨機旋轉(0~90 °),隨機垂直翻轉,隨機水平翻轉,隨機仿射變換(0~20 °),最大偏移量(0.2),尺寸調整為(224,224)。
2.2 實驗環境及教師網絡的選擇
本文實驗使用計算機視覺和深度學習框架PyTorch 2.0(Meta Inc,美國)運行實驗,使用圖像增強庫Albumentations 1.0.3(ByteDance,美國)進行數據增強,使用自適應神經網絡框架nnU-Net 1.6.6(University of Heidelberg,德國)[27]以及醫學圖像處理庫Pymic 0.2.0(Xiangde Luo,中國)[28]處理數據,實驗在配備RTX
對于教師網絡的選擇,本文選擇了在數據集上表現極為優異的自適應非新U-Net框架(no new U-Net,nnU-Net)。由于是分割任務,教師網絡的損失函數選擇了交叉熵損失與骰子(dice)損失的結合。為實現MAVKD,本文選擇深度監督策略來控制網絡的輸出。使用自適應矩估計(adaptive moment estimation,Adam)優化器,初始學習率設置為1.0 × 10?5,批處理大小設置為24,訓練迭代次數設置為300。
2.3 評測指標
本文使用dice系數以及平均交并比(mean intersection over union,MIOU)來評價網絡的分割能力,并通過95%豪斯多夫距離(95% Hausdorff distance,HD95)來度量分割邊界的效果。
dice系數是圖像分割常用評價指標,值越大表示分割效果越好,其計算公式如式(6)所示:
 |
其中,P為網絡對像素的預測輸出,T為像素的真實標簽。
MIOU計算預測像素與真實像素之間的交集與并集之比,值越大表示分割效果越好,其計算公式如式(7)所示:
 |
其中,Pi為網絡對某類別的像素預測輸出,Ti為某類別的像素真實標簽,n為分割的總類別數。
HD95常用于計算兩個集合之間的距離,一般認為,HD95值越小,兩個集合之間的距離越近,相似度越高,從而分割效果也越好,其計算公式如式(8)所示:
 |
其中,dTP是預測像素到真實像素的單向豪斯多夫(Hausdorff)距離,該距離只關注到距離分布的第95百分位數;dPT是真實像素與預測像素的單向Hausdorff距離,該距離只關注到距離分布的第95百分位數。
3 結果
3.1 輕量化網絡對比實驗與消融實驗分析
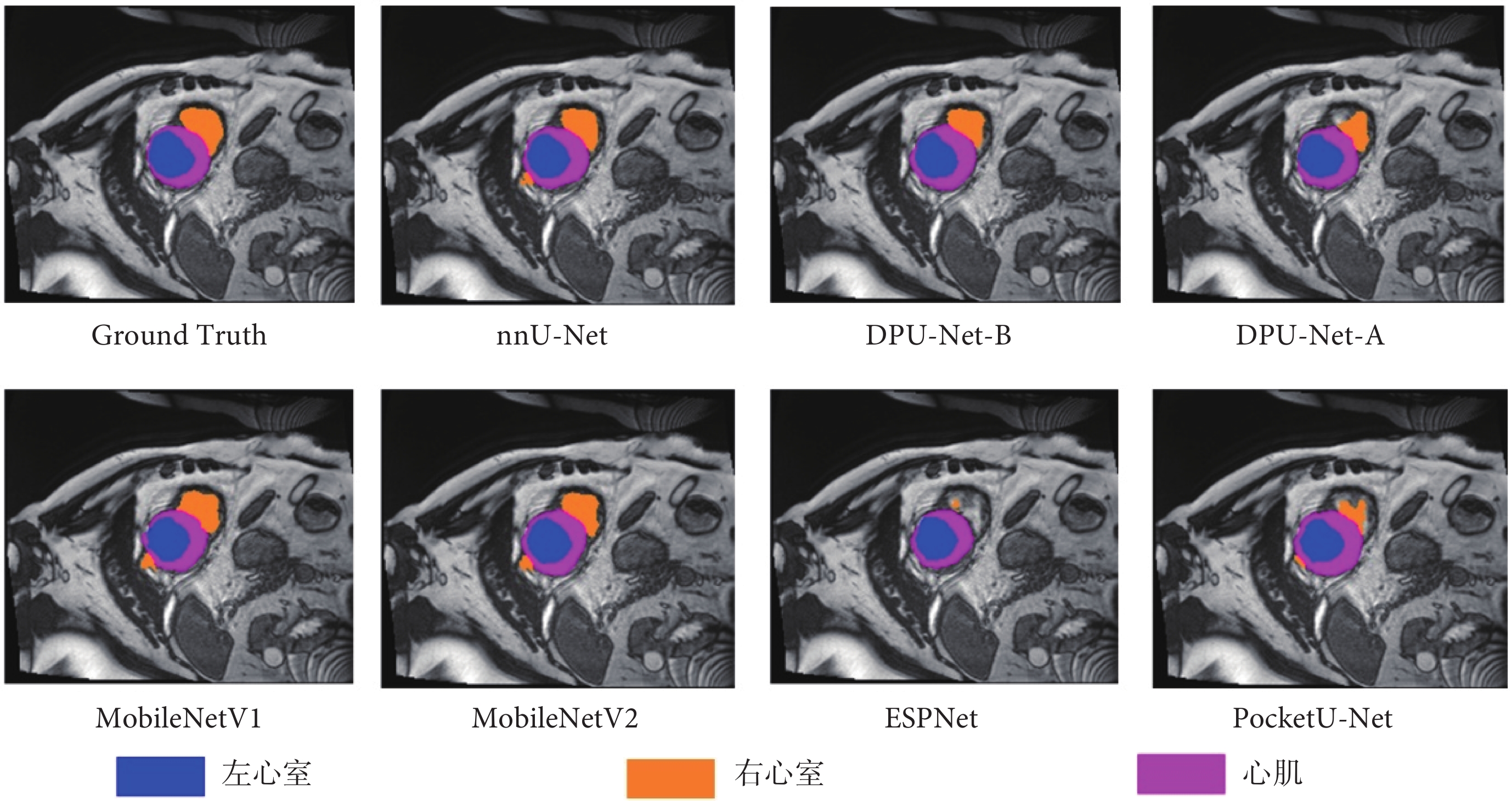
本文選擇的輕量化對比網絡包括在語義分割方面極為優秀的空洞卷積高效空間金字塔網絡(efficient spatial pyramid of dilated convolutions,ESPNet)[29],以及使用深度可分離卷積的MobileNet第1代版本(MobileNet version 1,MobileNetV1)和MobileNet第2代版本(MobileNet version 2,MobileNetV2)[30],還有簡化通道映射方式的PocketU-Net。為了全面比較輕量化網絡與重量級網絡在分割性能上的差距,本文使用nnU-Net作為基準,對所有輕量化網絡進行了對比實驗。對比實驗結果如表2所示,分割可視化結果如圖2所示。
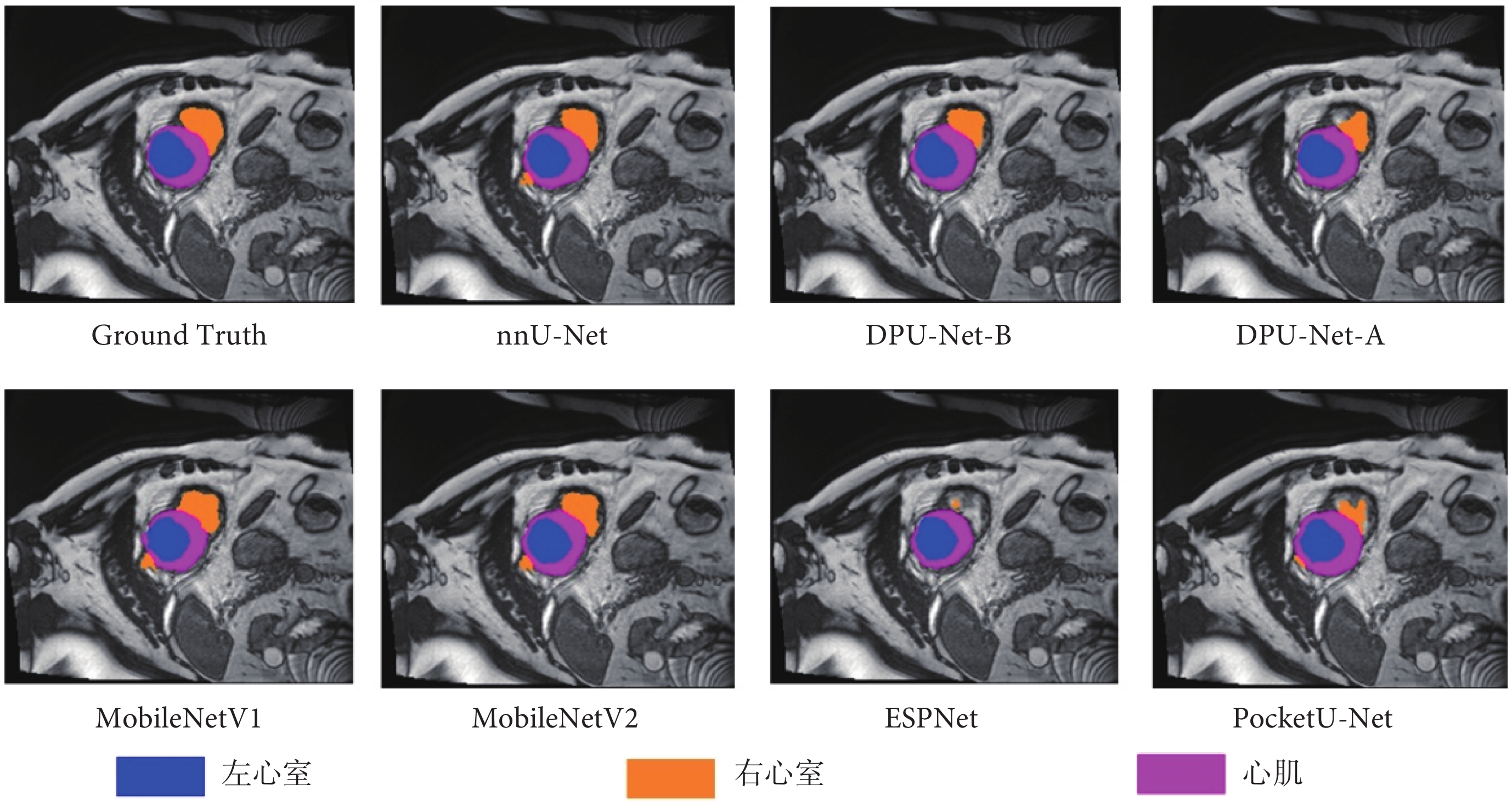 圖2
網絡分割效果可視化
Figure2.
Visualization of network segmentation results
圖2
網絡分割效果可視化
Figure2.
Visualization of network segmentation results
從實驗結果來看,雖然MobileNetV1通過深度可分離卷積策略,顯著減少了模型參數量與浮點運算量。然而,與nnU-Net相比,其分割性能仍存在明顯差距。MobileNetV2通過其獨特的線性瓶頸結構和倒置殘差模塊,在ACDC數據集上的分割性能相較于MobileNetV1有了顯著提升。ESPNet的設計初衷主要是面向現實場景中的應用,但現實場景與醫學圖像分割任務在圖像特征和細節要求上存在明顯不同,導致ESPNet在處理醫學圖像時無法準確捕捉關鍵信息,進而影響到分割結果的精度。
與當前頂尖的輕量化網絡MobileNetV2相比,本文創新提出的DPU-Net模型在性能上取得了顯著提升,在ACDC數據集分割任務中avg dice從89.08%提升至89.76%,同時在HD95評估標準上縮減了0.63個單位。在左心室、右心室及心肌的精細分割任務中,DPU-Net都表現出極具競爭力的結果。這一系列成果有力證明DPU-Net在心臟MRI醫學圖像分割任務中,相較于其他輕量化網絡,擁有更高的準確性。
為了深入探究DPU-Net模型中不同組件的貢獻,本文設計了系列消融實驗。通過這些實驗可以確定各個組件對模型的影響,并驗證其有效性,消融實驗結果如表2所示。
本文使用PocketU-Net作為基礎模型,以評估各個組件的影響。在此模型的基礎上,引入了DP模塊中的卷積并行模塊,命名為:DPU-Net-A,結果顯示avg dice從88.49%提升至88.83%,驗證了DP模塊對模型性能的貢獻。在DPU-Net-A的基礎上,再增加殘差模塊,命名為:DPU-Net-B,實驗結果表明,DPU-Net-B的avg dice從88.83%提升至89.76%,同樣證明在網絡中引入殘差模塊是有效的。
消融實驗結果表明,DP模塊和殘差模塊均對模型性能有顯著提升。DP模塊能夠有效地捕捉圖像的細節信息,殘差模塊能夠幫助提升模型的學習特征能力。盡管這些模塊均提高了模型的性能,但是與nnU-Net相比,DPU-Net仍有一定的差距,這表明輕量化模型要達到重量級模型的效果仍需面對挑戰。
為解決上述問題,本文提出將DPU-Net與MAVKD搭配訓練,以期達到重量級網絡的性能。
3.2 KD對比實驗分析
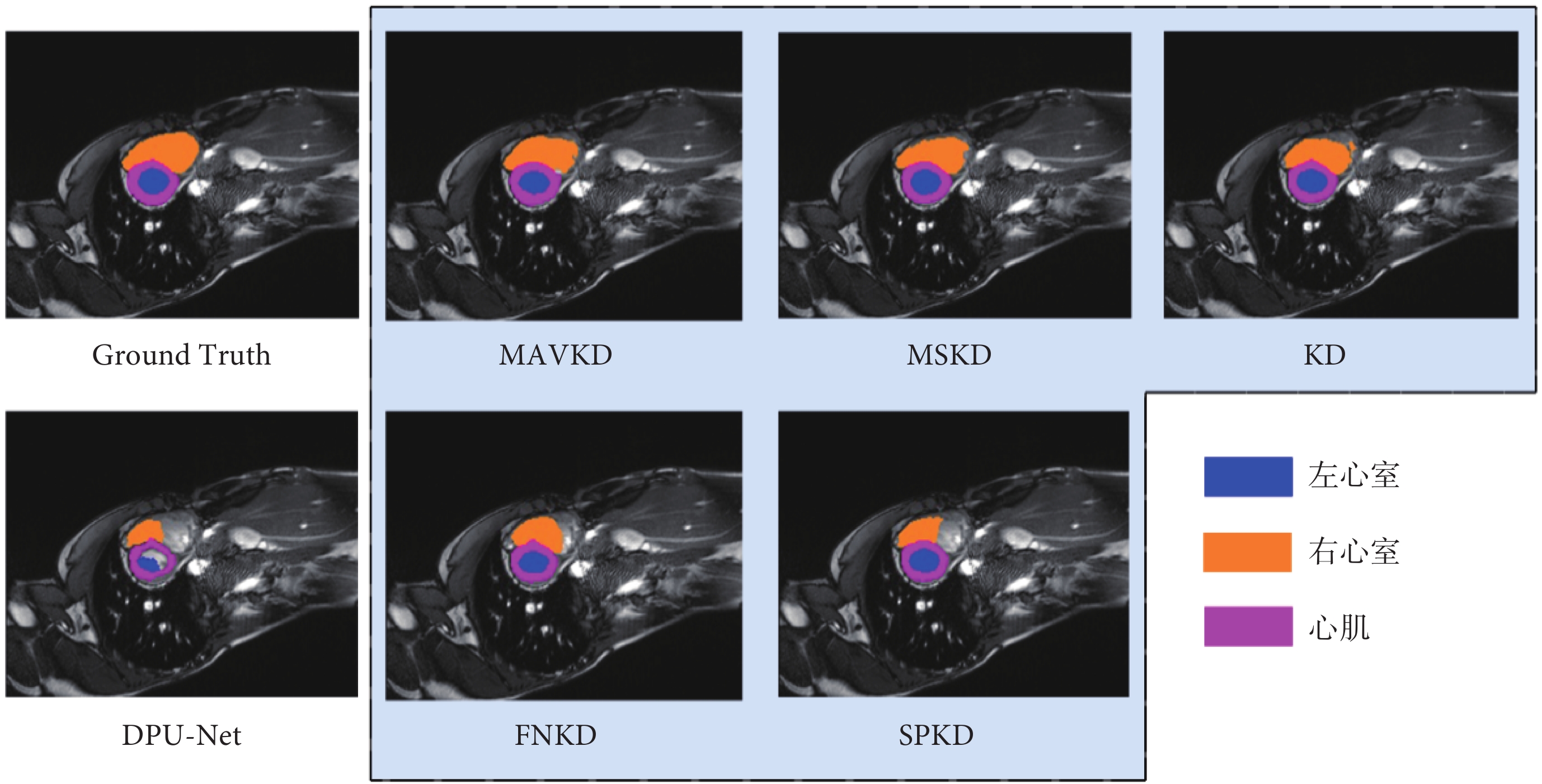
本文選擇的教師網絡為nnU-Net,并將其作為對比重量級網絡。為進一步開展MAVKD對比實驗,本文對比KD策略包括:使用柔性最大化(softmax)函數的標準KD策略、解決KD過程中參數設置問題的FNKD、可以捕捉不同樣本間相似性的SPKD,以及能夠通過多尺度輸出指導學生網絡的MSKD,實驗結果如表3所示,分割效果如圖3所示。
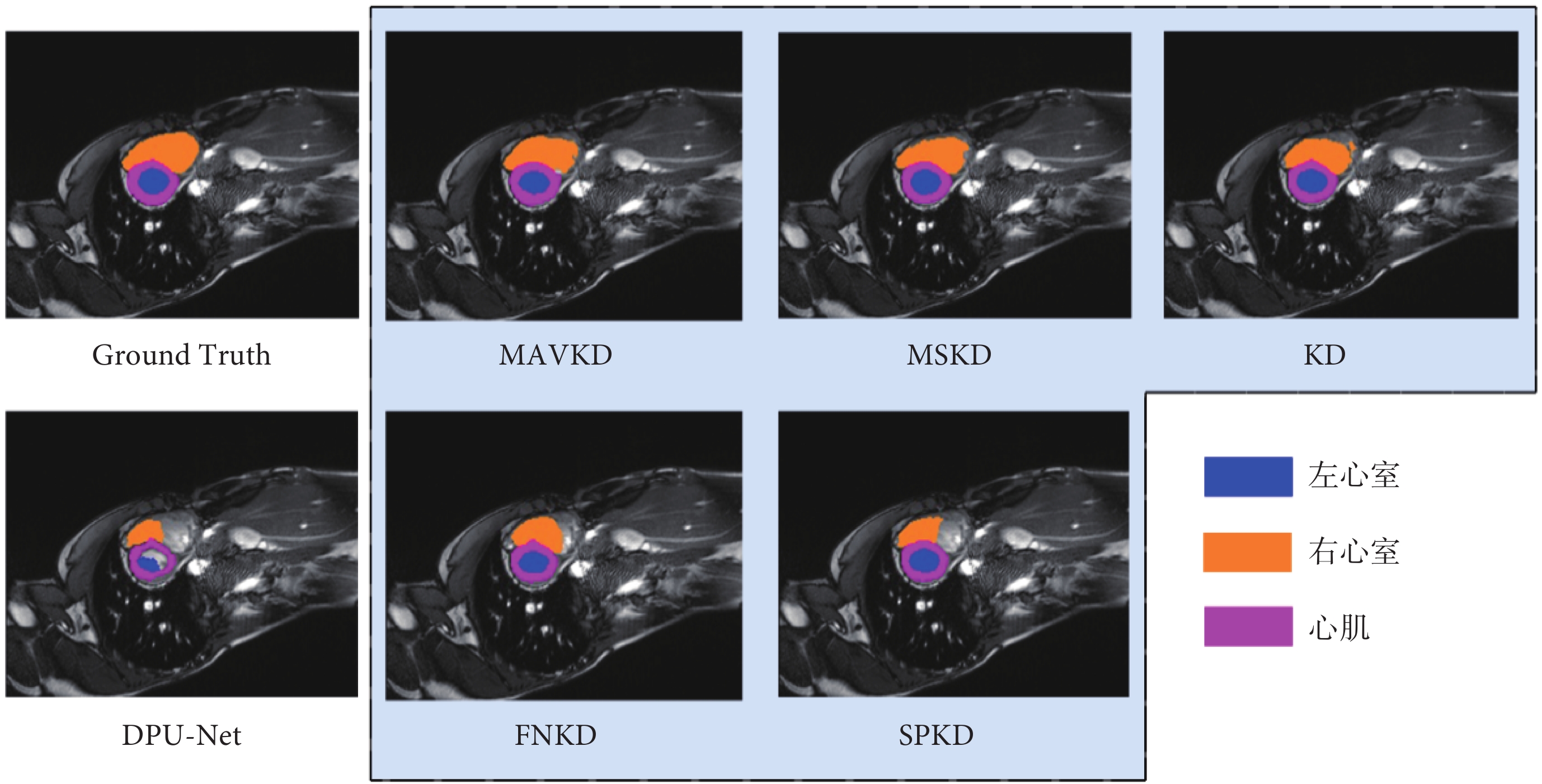 圖3
KD分割效果可視化
Figure3.
Visualization of KD segmentation results
圖3
KD分割效果可視化
Figure3.
Visualization of KD segmentation results
通過實驗結果分析,上述KD策略均顯著提高了DPU-Net的分割能力。相較于其他KD策略對DPU-Net的提升,MAVKD在心肌分割任務中dice系數從87.32%提升至89.45%,在左心室分割任務中dice系數從92.57%提升至94.12%,皆高于其他KD策略的提升效果。總體上,MAVKD策略使avg dice從89.76%提升至91.26%,并在HD95評估標準上縮減了0.38個單位,在所有KD策略中表現最佳。
這些結果表明,MAVKD策略在提升DPU-Net的分割性能方面優于其他KD策略。MAVKD的主要優勢在于它能夠通過捕捉教師網絡在處理不同圖像時所生成的代表向量,并將這些向量傳遞給學生網絡,從而幫助學生網絡更好地理解和學習圖像之間的差異。這種方法顯著增強了學生網絡在測試集上的泛化能力,使其在分割任務中表現更加出色。
綜上所述,MAVKD策略在DPU-Net模型中的應用,顯著提升了分割任務的精度和穩定性,并驗證了其作為有效KD策略的優勢。
3.3 模型泛化實驗
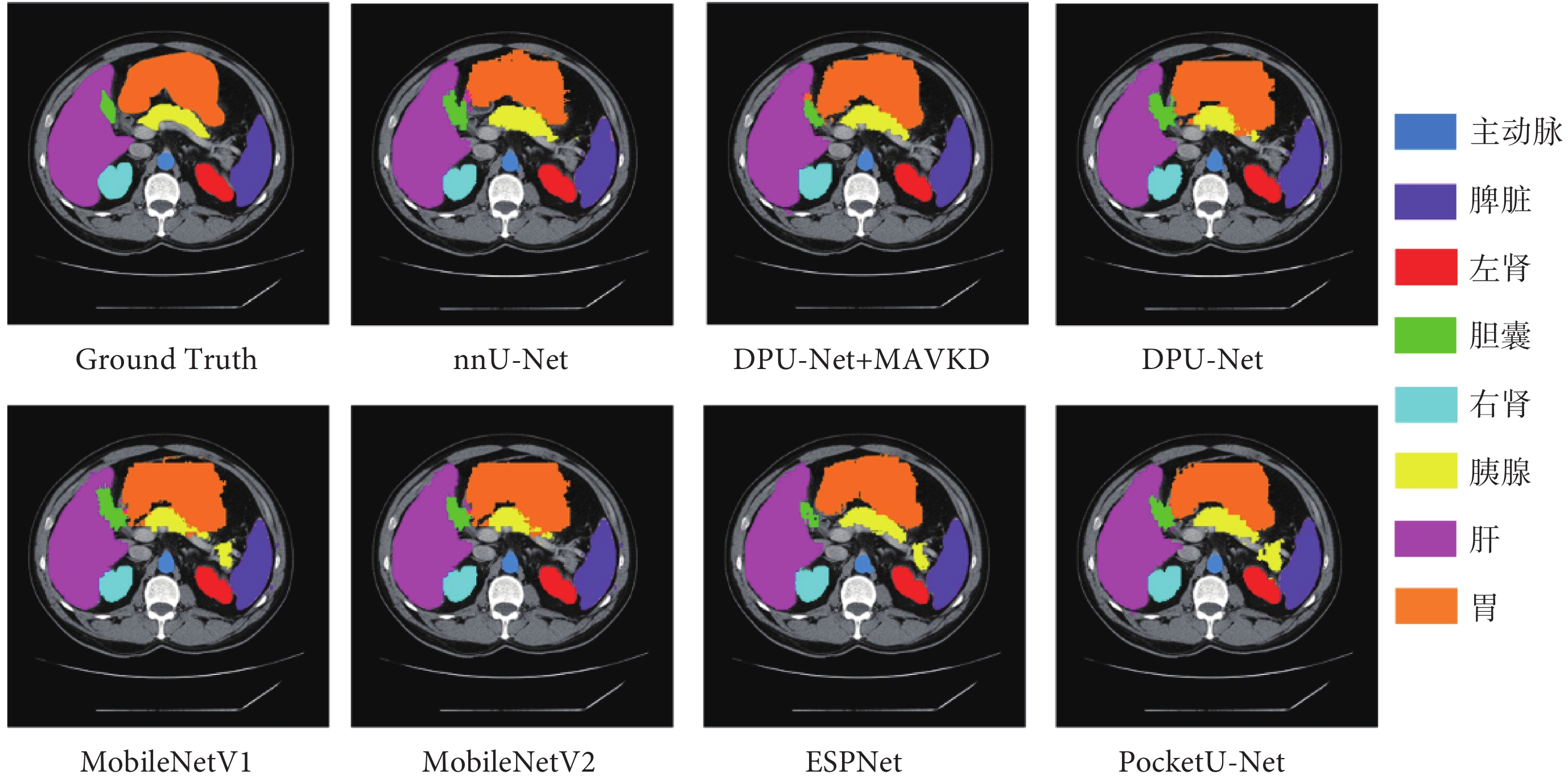
為了驗證DPU-Net的泛化能力,本文使用來自MICCAI 2015年舉辦的多圖譜標記超越顱穹窿挑戰(multi-atlas labeling beyond the cranial vault challenge,MALBCV)中突觸(Synapse)多器官醫學分割公開數據集進行測試。該數據集包含了30名受檢者的腹部CT圖像,覆蓋了8個腹部器官,共計3 779張腹部臨床CT醫學圖像。數據集中20例樣本被劃分為訓練集,10例樣本被劃分為測試集。數據增廣策略與ACDC數據集相同。實驗結果如表4所示,分割效果如圖4所示。
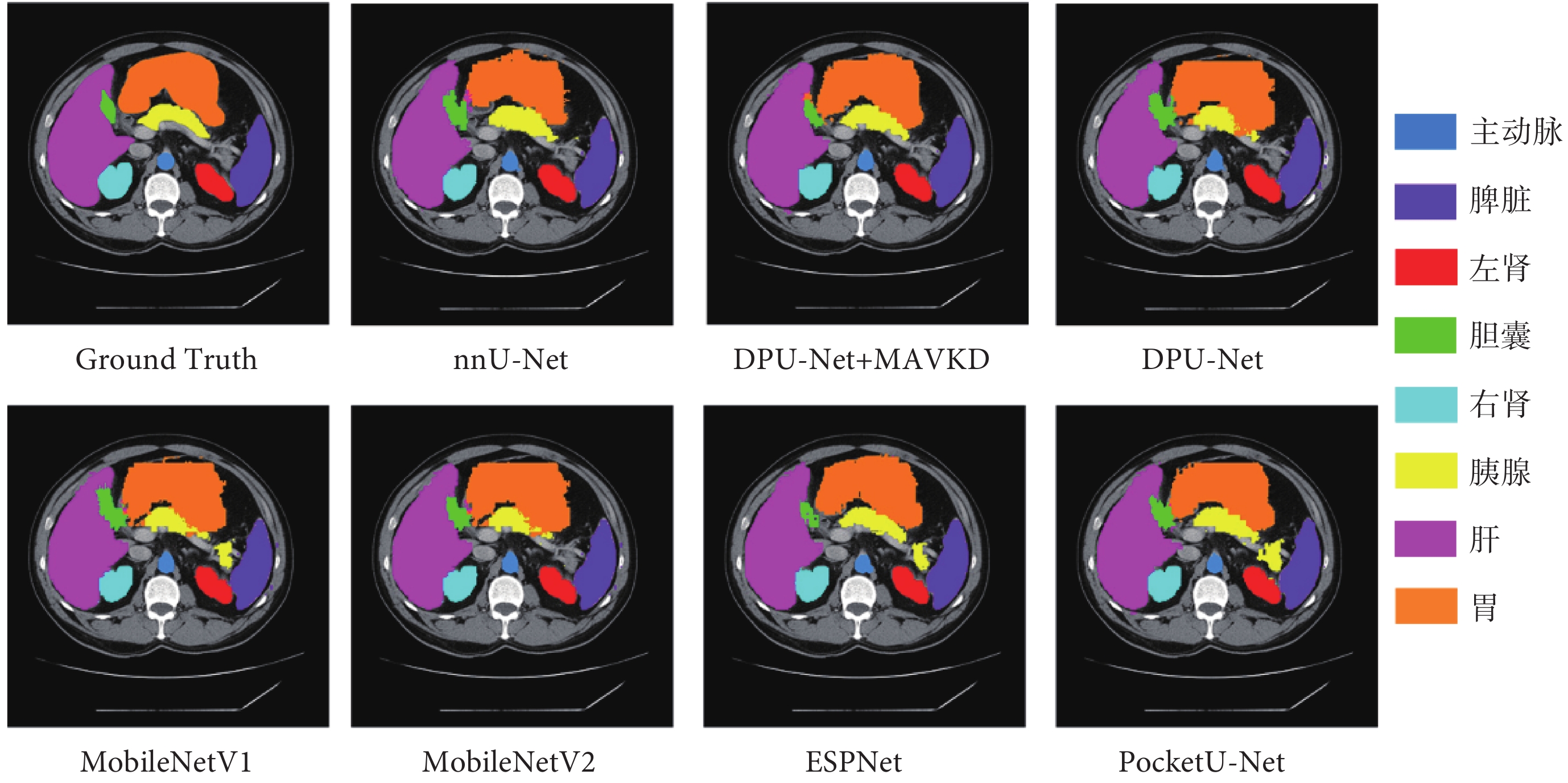 圖4
網絡泛化實驗分割效果可視化
Figure4.
Visualization of segmentation results in network generalization experiment
圖4
網絡泛化實驗分割效果可視化
Figure4.
Visualization of segmentation results in network generalization experiment
DPU-Net在Synapse數據集的表現未能達到ACDC數據集上的優異水平。實驗結果顯示,DPU-Net的avg dice要比MobileNetV2稍低,表明DPU-Net在處理包含更多分類標簽和圖像噪聲的復雜數據時,難以捕捉細節信息,從而導致分割能力的不足,也說明該模型的泛化能力較目前先進的輕量化網絡仍有不足。
然而,通過應用MAVKD策略訓練之后,DPU-Net的性能顯著提升。這表明MAVKD能夠有效改善模型在復雜的數據集上的表現,增強模型的泛化能力。實驗結果證明,MAVKD不僅能提升了DPU-Net在ACDC數據集上的分割精度,還展示了其在不同數據集上提高DPU-Net性能的能力。
綜上所述,本實驗驗證了DPU-Net與MAVKD在不同數據集上的泛化能力。雖然DPU-Net在ACDC數據集上表現優異,但在處理復雜數據時仍有改進空間,這些發現為模型的進一步優化和實際應用提供了重要參考。同時,MAVKD在面對不同數據集時,提升了DPU-Net的分割能力,充分證明該KD策略的良好泛化性。
4 結論
本文提出的輕量化網絡模型DPU-Net及其配套的MAVKD訓練策略,在ACDC和Synapse數據集上均展現了卓越的分割效果。DPU-Net在MAVKD訓練策略的支持下,不僅在ACDC心臟MRI數據集上達到了與重量級網絡相當的分割水平,還在Synapse數據集上表現出目前輕量化網絡中最優秀的分割能力。上述成果表明,DPU-Net與MAVKD策略結合的輕量化網絡方案在保持高性能的同時有效減少了模型復雜度,為實際應用中的心臟MRI醫學圖像分割乃至其他醫學圖像分割場景提供了有力支持。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:劉澤奇負責整體解決方案的設計、實驗規劃、論文撰寫、程序設計,王寧與張沖負責文獻資料的收集、分析以及論文初稿的撰寫,魏國輝負責論文寫作思路的制定及論文審閱修訂。
0 引言
隨著醫學成像技術的不斷進步,諸如計算機斷層掃描(computed tomography,CT)、磁共振成像(magnetic resonance imaging,MRI)、X射線和超聲波等技術已經成為現代醫學診斷的重要工具。然而,經上述設備采集的圖像數據尚需花費大量的時間精力進行判讀,以找尋準確的診斷依據。特別是在心臟疾病的診斷和治療中,準確分割心臟MRI圖像中的病灶,是診斷與治療心臟疾病的重要一環。近年來,深度學習的快速發展,使計算機智能輔助醫學圖像分割技術得到了廣泛關注[1]。雖然這些先進的分割技術顯著提高了分割的準確性,但由于網絡參數量和網絡浮點運算量的大幅增加,使得許多現有設備因硬件限制難以有效運行[2]。因此,如何在減輕醫學圖像分割網絡對計算機性能依賴的同時,確保其分割精度不受影響,仍然是當前研究領域的一個挑戰。
深度學習已經在醫學圖像分割領域取得了引人矚目的成果。自Ronneberger等[3]提出U型網絡(U-Net)架構以來,該架構迅速成為該領域的標桿,引發了對其多種變體的探索。例如:為克服U-Net在長程依賴關系上的局限,Chen等[4]提出構建轉換器(Transformer[5])與U-Net結合網絡(Transformer U-Net,TransU-Net),可有效學習全局與長距離依賴,從而顯著增強了分割效果;Cao等[6]提出了結合窗口Transformer(Swin-Transformer)[7]與U-Net的網絡(Swin-Transformer U-Net,SwinU-Net),利用Swin-Transformer的優勢,在減少計算負擔的同時提高了效率;此外,Zhou等[8]創新性地提出了僅依賴注意力機制的U-Net架構(not-another Transformer,NNFormer),使用長短距離體積Transformer與跳躍注意力連接,同樣在醫學圖像分割領域取得顯著成果。這些研究不斷推動深度學習在醫學圖像分割領域的前沿發展。
通過上述網絡可以看出,在U-Net中引用注意力機制,是有效提升網絡性能表現的方式,但是注意力機制同樣有著一個顯著的缺點,浮點運算量和參數量過大,如表1所示。
盡管表1中提及的網絡在心臟MRI圖像分割任務上表現出色,平均骰子系數(average dice coefficient,avg dice)均較高,但實際部署過程中,尤其是在面對大體積空間的醫學圖像時,這些網絡常常面臨設備限制[2]。因此,在保證模型性能的同時,實現網絡的輕量化是實際應用中重要的目標。
深度學習模型的輕量化研究一直是該領域的研究熱點。Zhang等[9]將通道重排與逐點分組卷積相結合,提出了重排網絡(suffle network,ShuffleNet),使網絡的參數量顯著減少。Howard等[10]采用深度可分離卷積搭配獨特的網絡結構,提出了用于移動設備的深度學習網絡——移動網絡(mobile network,MobileNet),同樣使網絡參數量明顯下降。此外,對注意力機制的輕量化同樣獲得了研究人員的關注,例如:Swin-Transformer和軸注意力機制(axial attention)等[11-12],均獲得不菲成果。但注意力機制所帶來的浮點運算量遠高于卷積操作,所以在輕量化網絡中引進注意力機制并不總是理想選擇。沈瑜等[13]提出一種輕量卷積U-Net(lightweight convolutional U-Net,LCU-Net)的輕量化網絡模型,該模型在設計上側重于腦部MRI圖像的配準任務,通過引入并行處理的輕量化卷積模塊以提高全局信息提取能力,最終在該領域取得了較好結果,但是該網絡在圖像分割任務中的效果尚未得到充分研究。Celaya等[2]提出了一種口袋網絡(pocket-network,PocketNet),通過抑制通道增長實現網絡的輕量化,在分割與分類任務中性能優異,媲美傳統網絡,但現有研究多聚焦單標簽分割,其在多標簽分割任務中的效果尚需進一步驗證與明確。
在大多數情況下,輕量級網絡難以達到與重量級網絡相媲美的分割效果。為了提高輕量化網絡的性能,Hinton等[14]提出一種名為知識蒸餾(knowledge distillation,KD)的訓練策略,讓表現較差的網絡學習表現較好的教師網絡輸出的軟標簽,從而有效提升自身的性能,進而達到提高輕量化網絡效率的目的。為了提高KD策略的效果,研究者們提出多種改進方案,例如:Xu等[15]提出了解決KD參數設置問題的特征歸一化KD(feature normalized KD,FNKD);Tung等[16]揭示了類別之間的相似性關系,并據此提出保持相似性KD(similarity-preserving KD,SPKD);Tian等[17]通過為每個單獨的數據樣本建立自適應的學習視角,提出自適應視角KD(adaptive perspective KD,AKD)。
近幾年,將KD策略運用到醫學圖像上的研究逐漸興起,但是多數研究都聚集于多模態[18-20]、自監督學習[21]以及半監督學習[22],而對于醫學圖像的多類分割使其提升至和教師網絡相當的性能,仍然有待深入研究。
為了應對上述挑戰,本文創新性地提出了多尺度自適應向量引導KD(multi-scale adaptation vector KD,MAVKD)策略,該方法通過引入多尺度特征和自適應向量來指導輕量化網絡學習,從而更有效地從教師網絡中提取知識。并在口袋U-Net(PocketU-Net)[2]基礎上,設計了一種空洞并行卷積(dilated parallel convolution,DP)的U-Net(DPU-Net),該網絡利用空洞卷積來擴大感受野,并捕捉更多的上下文信息,同時采用并行卷積結構來平衡計算復雜度和性能。將MAVKD與DPU-Net相結合進行訓練,并以一系列實驗驗證其有效性,以期讓該方法在輕量化網絡的基礎上達到目前心臟MRI圖像分割任務的先進水平。
1 方法
1.1 DPU-Net網絡
DPU-Net網絡模型結構如圖1所示。首先,將預處理后的訓練圖像作為輸入,通過一個1 × 1卷積映射層來調整通道數量。隨后,訓練圖像經過修正線性單元(rectified linear unit,ReLU)激活函數進行非線性變換,輸入到網絡中。在網絡的編碼階段,特征圖連續經過4個特征提取模塊,每個模塊包括一個DP模塊和一個下采樣層。特征圖經過每個下采樣層時,訓練數據通道數量不發生變化,以控制模型的大小。在網絡的解碼階段,每層通過雙線性插值得到的解碼特征數據與相同尺度下的編碼階段特征數據進行跳躍連接融合。融合后的特征數據經過DP模塊進一步處理和優化,最終將該層數據輸出,以供后續MAVKD和深度監督策略使用。
圖1
DPU-Net網絡模型與MAVKD策略
Figure1.
DPU-Net network model and MAVKD strategy
1.2 DP模塊
PocketU-Net由于追求輕量級設計,通道數量遠遠少于U-Net網絡,在心臟MRI圖像分割任務中,其對于心室、心肌等結構邊界分割效果模糊,甚至難以識別部分類別。此外,在訓練過程中還發現梯度爆炸問題,這些問題不僅影響了分割的精確度,還可能導致模型在測試集上的泛化能力下降。
為了解決上述問題,本文參考全卷積Transformer(full convolution Transformer,FCT)[23],提出DP模塊,如圖1所示。該模塊主要包括3 × 3卷積層、1 × 1卷積層、批規范化(batch normalization,BN)層、ReLU激活層。首先,圖像數據通過3 × 3卷積模塊,有助于組織和編輯圖像信息;其次,采用3 × 3空洞卷積與3 × 3普通卷積并行相加的模塊設計,可以有效緩解在不同分辨率等級下因通道數量減少而可能導致的信息丟失問題;最后,在該分辨率等級下,添加1 × 1卷積作為殘差模塊[24],用于解決梯度爆炸問題。BN層用于改善模型的穩定性和收斂速度;ReLU層用于實現非線性變換,從而加速網絡的訓練速度。
1.3 MAVKD模塊
本文在多尺度KD(multi-scale KD,MSKD)[25]的基礎上,引入了自適應向量KD(adaptation vector KD,AVKD),該技術能夠捕捉教師網絡執行心臟MRI圖像分割任務時所輸出的分割掩碼中不同類別代表向量的差異性信息。
首先,為滿足各分辨率層級下的輸出需求,將真實掩碼(Ground Truth)下采樣至不同分辨率層級,計算過程如式(1)所示:
|
其中,i為當前網絡的分辨率層級,K代表網絡的最深層級,j為當前所處理的分割類別,N為圖像的分割類別總數,mi, j代表當前類別j的二進制掩碼下采樣至第i層的掩碼值,mpi代表第i層的最大池化操作,Mj為當前類別j真實的二進制掩碼值。
隨后,將教師網絡在不同尺度下的輸出通過額外的1 × 1卷積層進行處理,目的是將教師網絡與學生網絡的通道數量調整至相同,以作為AVKD模塊的輸入,計算過程如式(2)所示:
|
其中, Ii, t、Ii, s分別代表教師網絡與學生網絡不同分辨率等級i下的輸出數據,Xi, t、Xi, s分別代表教師網絡與學生網絡不同分辨率等級i下的AVKD模塊輸入數據,f(?)代表1 × 1卷積映射,作用是將學生網絡與教師網絡各層的通道個數映射為相同數量,W、H為圖像數據的寬和高,C代表圖像數據的通道數量。
對不同尺度下的AVKD模塊輸入數據進行掩碼平均池化,從而輸出各尺度下不同類別的代表向量。結合式(1)和式(2),代表向量計算公式如式(3)所示:
|
其中,x代表像素點的位置,mxi, j代表mi, j在位于像素點位置x時的值,Xxi, t與Xxi, s分別代表Xi,t、Xi,s在位于像素點位置x時的值,、分別表示教師網絡和學生網絡輸出的各類別代表向量的集合,這些向量具有自適應性,不同圖像在同一網絡中生成的各類別代表向量可能存在明顯差異。通過讓學生網絡生成類似的代表向量,可以學習到不同圖像間的相異性,從而幫助AVKD產生積極的輔助效果。
使用余弦相似度損失來鼓勵學生網絡生成類似于教師網絡的代表向量。余弦相似度越接近于1,兩個向量就越相似。單一分辨率等級上的AVKD損失定義如式(4)所示:
|
其中,表示第i層的AVKD損失,它鼓勵學生網絡生成同教師網絡相似的代表向量,從而增強學生網絡對教師網絡的學習能力。結合式(4),整個模型的損失定義如式(5)所示:
|
其中,L為網絡的整體損失,為當前分辨率等級對網絡整體的損失占比,和為超參數,表示標準KD損失,為當前分辨率尺度下的輸出與經過下采樣后的二進制掩碼經計算所得到的真實損失。
2 實驗
2.1 實驗數據來源
為了證明本文所提出的模型與MAVKD的有效性,本文使用來自國際醫學圖像計算和計算機輔助干預協會(Medical Image Computing and Computer Assisted Intervention Society,MICCAI)2017年舉辦的自動心臟診斷挑戰賽(automatic cardiac diagnosis challenge,ACDC)[26]的公開數據集進行醫學圖像分割任務。ACDC數據集共包括100名患者的信息,其中包括100張心臟MRI圖像,分割標簽為左心室(left ventricle,LV)、右心室(right ventricle,RV)以及心肌(myocardium,MYO)的真實數據。本文將這100名患者按照80: 20的比例劃分為訓練數據和測試數據,其中訓練數據中70個用于訓練集,10用于為驗證集。數據集的數據增廣策略如下:隨機旋轉(0~90 °),隨機垂直翻轉,隨機水平翻轉,隨機仿射變換(0~20 °),最大偏移量(0.2),尺寸調整為(224,224)。
2.2 實驗環境及教師網絡的選擇
本文實驗使用計算機視覺和深度學習框架PyTorch 2.0(Meta Inc,美國)運行實驗,使用圖像增強庫Albumentations 1.0.3(ByteDance,美國)進行數據增強,使用自適應神經網絡框架nnU-Net 1.6.6(University of Heidelberg,德國)[27]以及醫學圖像處理庫Pymic 0.2.0(Xiangde Luo,中國)[28]處理數據,實驗在配備RTX
對于教師網絡的選擇,本文選擇了在數據集上表現極為優異的自適應非新U-Net框架(no new U-Net,nnU-Net)。由于是分割任務,教師網絡的損失函數選擇了交叉熵損失與骰子(dice)損失的結合。為實現MAVKD,本文選擇深度監督策略來控制網絡的輸出。使用自適應矩估計(adaptive moment estimation,Adam)優化器,初始學習率設置為1.0 × 10?5,批處理大小設置為24,訓練迭代次數設置為300。
2.3 評測指標
本文使用dice系數以及平均交并比(mean intersection over union,MIOU)來評價網絡的分割能力,并通過95%豪斯多夫距離(95% Hausdorff distance,HD95)來度量分割邊界的效果。
dice系數是圖像分割常用評價指標,值越大表示分割效果越好,其計算公式如式(6)所示:
|
其中,P為網絡對像素的預測輸出,T為像素的真實標簽。
MIOU計算預測像素與真實像素之間的交集與并集之比,值越大表示分割效果越好,其計算公式如式(7)所示:
|
其中,Pi為網絡對某類別的像素預測輸出,Ti為某類別的像素真實標簽,n為分割的總類別數。
HD95常用于計算兩個集合之間的距離,一般認為,HD95值越小,兩個集合之間的距離越近,相似度越高,從而分割效果也越好,其計算公式如式(8)所示:
|
其中,dTP是預測像素到真實像素的單向豪斯多夫(Hausdorff)距離,該距離只關注到距離分布的第95百分位數;dPT是真實像素與預測像素的單向Hausdorff距離,該距離只關注到距離分布的第95百分位數。
3 結果
3.1 輕量化網絡對比實驗與消融實驗分析
本文選擇的輕量化對比網絡包括在語義分割方面極為優秀的空洞卷積高效空間金字塔網絡(efficient spatial pyramid of dilated convolutions,ESPNet)[29],以及使用深度可分離卷積的MobileNet第1代版本(MobileNet version 1,MobileNetV1)和MobileNet第2代版本(MobileNet version 2,MobileNetV2)[30],還有簡化通道映射方式的PocketU-Net。為了全面比較輕量化網絡與重量級網絡在分割性能上的差距,本文使用nnU-Net作為基準,對所有輕量化網絡進行了對比實驗。對比實驗結果如表2所示,分割可視化結果如圖2所示。
圖2
網絡分割效果可視化
Figure2.
Visualization of network segmentation results
從實驗結果來看,雖然MobileNetV1通過深度可分離卷積策略,顯著減少了模型參數量與浮點運算量。然而,與nnU-Net相比,其分割性能仍存在明顯差距。MobileNetV2通過其獨特的線性瓶頸結構和倒置殘差模塊,在ACDC數據集上的分割性能相較于MobileNetV1有了顯著提升。ESPNet的設計初衷主要是面向現實場景中的應用,但現實場景與醫學圖像分割任務在圖像特征和細節要求上存在明顯不同,導致ESPNet在處理醫學圖像時無法準確捕捉關鍵信息,進而影響到分割結果的精度。
與當前頂尖的輕量化網絡MobileNetV2相比,本文創新提出的DPU-Net模型在性能上取得了顯著提升,在ACDC數據集分割任務中avg dice從89.08%提升至89.76%,同時在HD95評估標準上縮減了0.63個單位。在左心室、右心室及心肌的精細分割任務中,DPU-Net都表現出極具競爭力的結果。這一系列成果有力證明DPU-Net在心臟MRI醫學圖像分割任務中,相較于其他輕量化網絡,擁有更高的準確性。
為了深入探究DPU-Net模型中不同組件的貢獻,本文設計了系列消融實驗。通過這些實驗可以確定各個組件對模型的影響,并驗證其有效性,消融實驗結果如表2所示。
本文使用PocketU-Net作為基礎模型,以評估各個組件的影響。在此模型的基礎上,引入了DP模塊中的卷積并行模塊,命名為:DPU-Net-A,結果顯示avg dice從88.49%提升至88.83%,驗證了DP模塊對模型性能的貢獻。在DPU-Net-A的基礎上,再增加殘差模塊,命名為:DPU-Net-B,實驗結果表明,DPU-Net-B的avg dice從88.83%提升至89.76%,同樣證明在網絡中引入殘差模塊是有效的。
消融實驗結果表明,DP模塊和殘差模塊均對模型性能有顯著提升。DP模塊能夠有效地捕捉圖像的細節信息,殘差模塊能夠幫助提升模型的學習特征能力。盡管這些模塊均提高了模型的性能,但是與nnU-Net相比,DPU-Net仍有一定的差距,這表明輕量化模型要達到重量級模型的效果仍需面對挑戰。
為解決上述問題,本文提出將DPU-Net與MAVKD搭配訓練,以期達到重量級網絡的性能。
3.2 KD對比實驗分析
本文選擇的教師網絡為nnU-Net,并將其作為對比重量級網絡。為進一步開展MAVKD對比實驗,本文對比KD策略包括:使用柔性最大化(softmax)函數的標準KD策略、解決KD過程中參數設置問題的FNKD、可以捕捉不同樣本間相似性的SPKD,以及能夠通過多尺度輸出指導學生網絡的MSKD,實驗結果如表3所示,分割效果如圖3所示。
圖3
KD分割效果可視化
Figure3.
Visualization of KD segmentation results
通過實驗結果分析,上述KD策略均顯著提高了DPU-Net的分割能力。相較于其他KD策略對DPU-Net的提升,MAVKD在心肌分割任務中dice系數從87.32%提升至89.45%,在左心室分割任務中dice系數從92.57%提升至94.12%,皆高于其他KD策略的提升效果。總體上,MAVKD策略使avg dice從89.76%提升至91.26%,并在HD95評估標準上縮減了0.38個單位,在所有KD策略中表現最佳。
這些結果表明,MAVKD策略在提升DPU-Net的分割性能方面優于其他KD策略。MAVKD的主要優勢在于它能夠通過捕捉教師網絡在處理不同圖像時所生成的代表向量,并將這些向量傳遞給學生網絡,從而幫助學生網絡更好地理解和學習圖像之間的差異。這種方法顯著增強了學生網絡在測試集上的泛化能力,使其在分割任務中表現更加出色。
綜上所述,MAVKD策略在DPU-Net模型中的應用,顯著提升了分割任務的精度和穩定性,并驗證了其作為有效KD策略的優勢。
3.3 模型泛化實驗
為了驗證DPU-Net的泛化能力,本文使用來自MICCAI 2015年舉辦的多圖譜標記超越顱穹窿挑戰(multi-atlas labeling beyond the cranial vault challenge,MALBCV)中突觸(Synapse)多器官醫學分割公開數據集進行測試。該數據集包含了30名受檢者的腹部CT圖像,覆蓋了8個腹部器官,共計3 779張腹部臨床CT醫學圖像。數據集中20例樣本被劃分為訓練集,10例樣本被劃分為測試集。數據增廣策略與ACDC數據集相同。實驗結果如表4所示,分割效果如圖4所示。
圖4
網絡泛化實驗分割效果可視化
Figure4.
Visualization of segmentation results in network generalization experiment
DPU-Net在Synapse數據集的表現未能達到ACDC數據集上的優異水平。實驗結果顯示,DPU-Net的avg dice要比MobileNetV2稍低,表明DPU-Net在處理包含更多分類標簽和圖像噪聲的復雜數據時,難以捕捉細節信息,從而導致分割能力的不足,也說明該模型的泛化能力較目前先進的輕量化網絡仍有不足。
然而,通過應用MAVKD策略訓練之后,DPU-Net的性能顯著提升。這表明MAVKD能夠有效改善模型在復雜的數據集上的表現,增強模型的泛化能力。實驗結果證明,MAVKD不僅能提升了DPU-Net在ACDC數據集上的分割精度,還展示了其在不同數據集上提高DPU-Net性能的能力。
綜上所述,本實驗驗證了DPU-Net與MAVKD在不同數據集上的泛化能力。雖然DPU-Net在ACDC數據集上表現優異,但在處理復雜數據時仍有改進空間,這些發現為模型的進一步優化和實際應用提供了重要參考。同時,MAVKD在面對不同數據集時,提升了DPU-Net的分割能力,充分證明該KD策略的良好泛化性。
4 結論
本文提出的輕量化網絡模型DPU-Net及其配套的MAVKD訓練策略,在ACDC和Synapse數據集上均展現了卓越的分割效果。DPU-Net在MAVKD訓練策略的支持下,不僅在ACDC心臟MRI數據集上達到了與重量級網絡相當的分割水平,還在Synapse數據集上表現出目前輕量化網絡中最優秀的分割能力。上述成果表明,DPU-Net與MAVKD策略結合的輕量化網絡方案在保持高性能的同時有效減少了模型復雜度,為實際應用中的心臟MRI醫學圖像分割乃至其他醫學圖像分割場景提供了有力支持。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:劉澤奇負責整體解決方案的設計、實驗規劃、論文撰寫、程序設計,王寧與張沖負責文獻資料的收集、分析以及論文初稿的撰寫,魏國輝負責論文寫作思路的制定及論文審閱修訂。