胎心宮縮監護圖(CTG)是一種無侵入式的產前胎兒窘迫診斷的重要工具。面向基于深度學習的智能胎心監護需求,本文提出了基于三支決策理論(TWD)和多目標優化主動學習(MOAL)的深度主動學習算法(TWD-MOAL)。在卷積神經網絡(CNN)分類模型的訓練周期過程中,該算法結合TWD理論,在粒度批處理模式下選擇高質信度樣本作為偽標記樣本,同時參考由產科專家標注的低置信度樣本,在課題組整理的16 355條產前CTG信號數據集上進行驗證。實驗結果顯示,本文所提算法僅利用40%的已標注樣本,就已經達到80.63%的準確率;從各項指標綜合來看,都優于其他框架下的主動學習算法。研究表明,本文所提出的基于TWD-MOAL的智能胎心監護模型合理可行,明顯減少產科專家標注樣本所耗費的時間和精力,有效解決了臨床CTG信號數據不平衡問題,這對于輔助臨床醫師判讀以及實現胎心監護模型的智能化具有重要意義。
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
近年來,隨著輔助生育技術的進步以及“三胎”政策的正式落地,新生兒的出生質量以及孕產婦的孕育安全成為臨床上備受關注的焦點[1]。胎心宮縮監護圖(cardiotocography,CTG)可以無侵入性地應用在產前胎兒窘迫診斷中[2],它記錄了胎心率(fetal heart rate,FHR)信號和子宮收縮(uterine contraction,UC)隨時間變化的關系。FHR是胎兒心臟跳動的電信號,數值在110~160 beat/min之間為正常;UC是指在懷孕、分娩和生產過程中子宮肌肉有節奏地收緊和放松,通常以其頻率、持續時間和強度來描述。CTG作為評估胎兒健康狀況的一種方法,可協助產科醫生預測妊娠期間可能出現的并發癥,進而有效降低胎兒及母親的發病率和死亡率[3]。
臨床實踐中,視覺CTG利用國際描述性標準,從視覺的角度對CTG進行主觀性評估[2]。眾多國際組織,如美國婦產科醫師學會、國際婦產科聯盟[4],為了規范胎兒監護方法,分別制定了不同的胎兒監護指南,記錄了FHR基線、基線變異和加減速等FHR信號的基本形態學特征。臨床醫生根據等級評價方法,將處理后的FHR信號劃分為“正常”、“可疑”和“異常”三類,從而進一步評估胎兒健康狀況。目前,已有相關實驗驗證了機器學習(machine learning,ML)和人工智能方法能協助產科醫生做出更明確的醫療決策[5-7]。
近年來,深度學習(deep learning,DL)方法在實現端到端CTG信號分類任務上也取得了重大進展。例如,Zhou等[8]利用捷克技術大學及布爾諾大學醫院的產時公共數據集,通過基于長卷積的DL法針對胎兒狀態獲得了較高的分類精度以及參數調整速度。這種端到端智能判讀的形式,有效學習了臨床醫師人工判讀方式,進一步提高了分類準確率,可大大減少醫護人員的工作量。另一方面,采用DL方法需要大量的標注數據供應來優化海量參數,大量高質量的標注數據集會消耗高昂的人力和財力成本,在專業知識水平需求較高的領域難以實現[9-10]。但通過將 DL 與主動學習(active learning,AL)處理過程結合[11],可有效解決上述問題。
目前,有研究在中文電子病歷命名實體識別的應用中,結合深度AL算法( deep AL,DAL)使模型精度有效提升,F1分數(F1-score)提高幅度較大[12]。El-Hasnony 等[13]提出基于多標簽AL選擇策略的DL方法 ,并通過迭代選擇最相關的數據對其標簽進行查詢,以此來降低標簽成本。Xie等[14]提出了一種稱為主動領域適應的AL策略來協助目標領域的知識遷移,該方法在基準測試中超越了最先進方法。近年來,有研究將卷積神經網絡(convolutional neural network,CNN)運用于信號分類處理,取得了良好的分類結果[15-16]。例如,Hemmer 等[17]結合CNN提出一種新穎的AL算法,該算法通過捕獲高預測不確定性,能夠有效地從無標記數據中進行學習,且已在肺炎相關真實醫學用例中得到驗證。
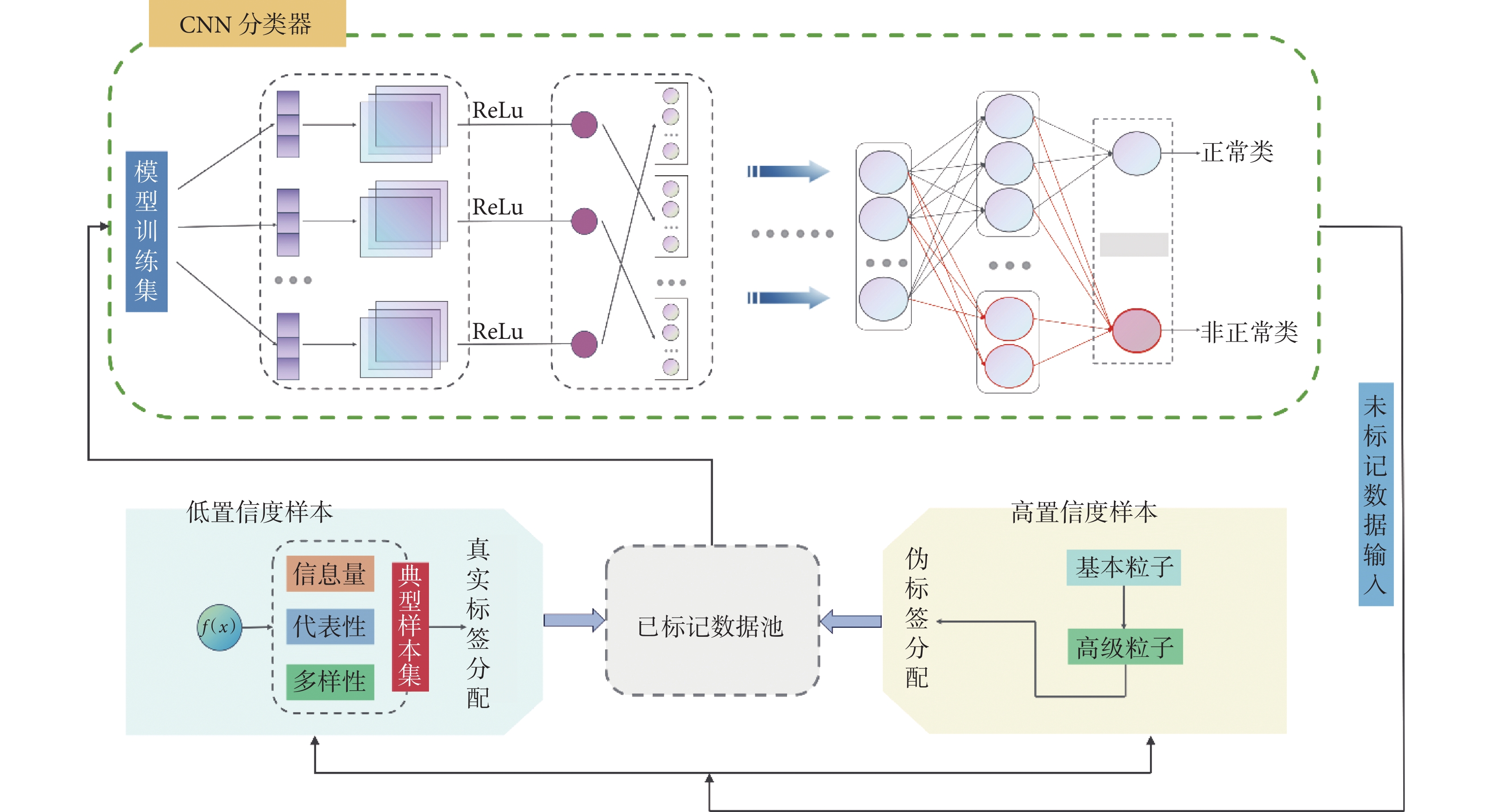
有鑒于此,本文提出了基于CNN和AL的框架。該框架能夠從無標簽樣本池中周期性地按批次篩選高、低置信度互補樣本,從而為CNN提供信息量盡可能大的數據。利用典型數據訓練網絡,可使模型迅速收斂,并且最大限度地提升模型的泛化能力和魯棒性。在這個過程中,對于待分配真實標簽的低置信度樣本,通過多目標優化主動學習( multi-objective optimization active learning,MOAL)方法,綜合考量樣本的信息量、代表性和多樣性來選擇給予標簽。對于待分配偽標簽的高置信度樣本,在粒度批處理模式下引入三支決策理論(three-way decision,TWD)[18],以此確定最終符合要求的偽標記樣本,本文將該算法簡稱為 TWD-MOAL。該模型處理流程如圖1 所示。該框架綜合考慮DL和AL的處理流程,可以顯著降低產科專家對數據標注的代價,并有效解決CTG信號數據不平衡問題,這對輔助臨床醫師判讀以及實現胎心監護模型的智能化具有重要意義。
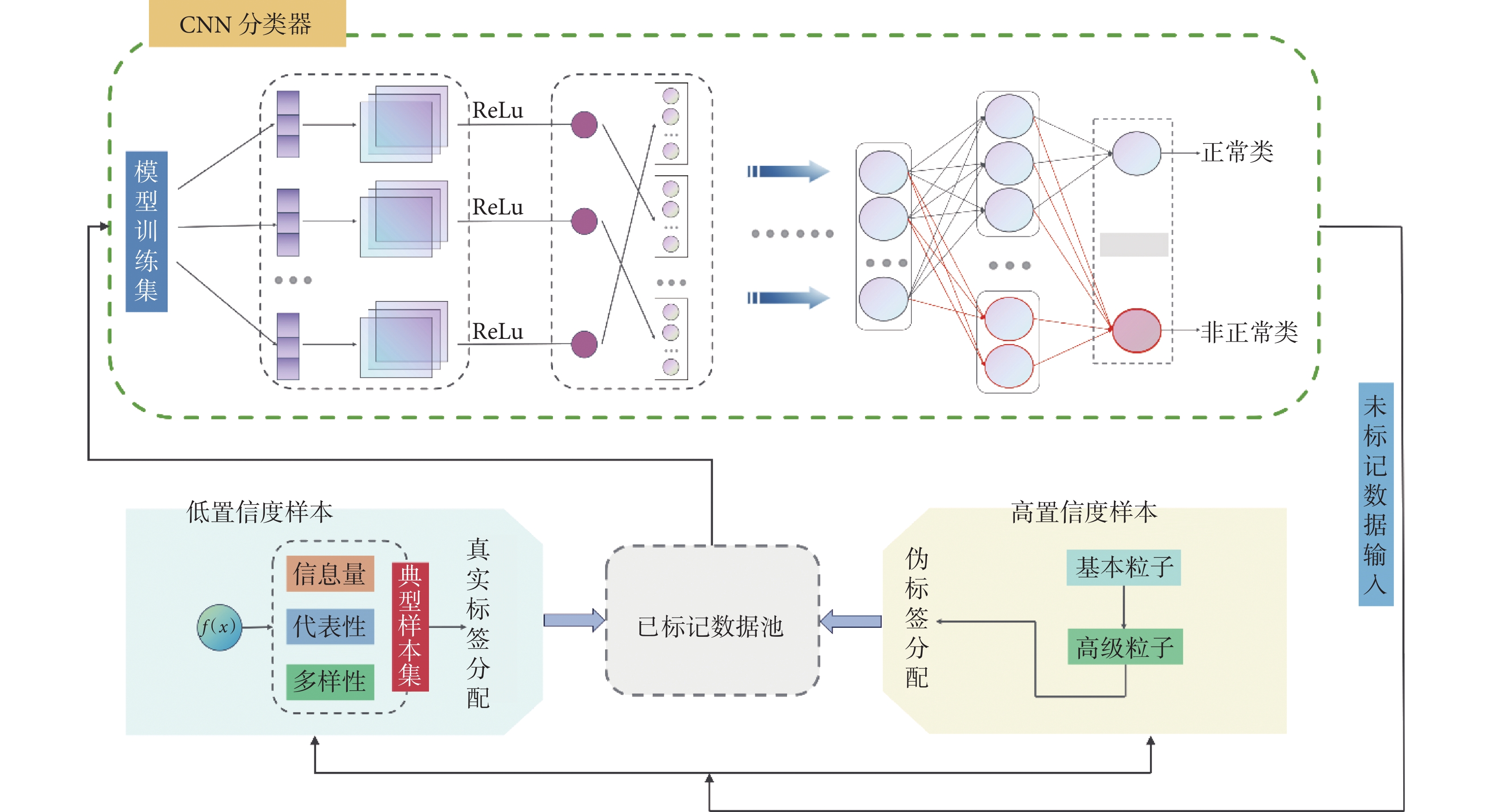 圖1
DAL模型總流程圖
Figure1.
Total flow diagram of DAL model
圖1
DAL模型總流程圖
Figure1.
Total flow diagram of DAL model
1 數據和方法
1.1 數據采集與處理
本文數據采于廣州醫科大學附屬第二醫院、廣州醫科大學附屬第三醫院和中山大學附屬第五醫院,共采集了1. 935 5萬例年齡范圍20~45 歲[平均年齡(27.27 ± 4.80)歲]的孕婦懷孕28周至分娩前[平均(36.35 ± 2.89)孕周]的CTG信號數據。本文研究通過了廣州醫科大學附屬第二醫院臨床試驗倫理委員會(編號:Q2018-06-02)、廣州醫科的大學附屬第三醫院藥物臨床試驗倫理委員會(編號:藥倫審器[2018]第020號)以及中山大學附屬第五醫院醫學倫理委員會(編號:中大五院[2018]倫字第(Q07-1)號)的審批,參與者均已簽署知情同意書,并已獲得相關數據使用授權。
本文信號采集儀器為分娩檢測系統(LP,廣州三瑞醫療器械有限公司,中國),采樣頻率為1.25 Hz,從信號提取的常見特征見附表1。采集得到的CTG信號由3位產科專家醫師依據產前胎兒監護指南進行判讀[19],判讀結果一致的信號被納入為本研究的數據集。最終,數據集共包含16 355條樣本記錄,其中正常類有11 998例,可疑類有4 326例,異常類有31例。鑒于數據存在嚴重不平衡現象以及本研究旨在輔助醫師初步篩選異常情況,本文將數據集中的異常類和可疑類案例合并為非正常類。
CTG 信號采集過程中,由于會受到各種因素的干擾,數據可能出現缺失、異常值,并帶有明顯的噪聲。為提高FHR、UC信號的DL建模性能,本文利用信號處理方法對 FHR和UC 信號進行處理,包括對異常值(持續時間大于15 s且值為0的信號)的處理、濾波平滑降噪以及標準化等操作。對于原始FHR信號中的不穩定部分,即相鄰兩個采樣點之間幅值相差絕對值大于20 beat/min的信號,采用線性插值法進行處理。濾波降噪選取的濾波器為巴特沃斯濾波器[20] 。本文使用分析FHR的開放訪問軟件 CTG-OAS(Elsevier Ltd.,土耳其) 進行FHR基線提取[21],然后將濾波處理前后的信號與FHR基線相減,得到FHR的標準化結果。
1.2 互補樣本選擇
1.2.1 MOAL算法
根據AL的基本步驟以及多目標優化理論,綜合考慮樣本的信息量、代表性和多樣性。首先定義如下目標約束優化問題,如式(1)所示:
 |
其中,Du為未標記樣本池的數據, f(x)表示信息量,p(x)表示樣本代表性,g(x)表示差異, β0表示初始差異閾值,取值0.35。
樣本信息量可用于減少模型的不確定性,本文使用信息熵來衡量Du的信息量;樣本代表性可作為所有未標記數據的整體特征表達,可用概率密度函數進行代表性估計,本文使用非參數方法獲得概率密度函數p(x);樣本集的多樣性是通過當前選擇的關鍵實例之間的差異來衡量的,并且它由多樣性評價函數的距離度量、約束函數和樣本多樣性三個方面組成。
(1)距離度量:本文使用向量的范數來計算樣本之間的距離。
(2)約束函數:AL算法是一個周期過程,已被查詢過的關鍵實例會確定 g(x)的計算,故設s為已查詢的最后一個關鍵實例,定義g(x) = dist(x, s),根據公式(1)可知,只有當g(x) = dist(x, s) > β時,實例才能被查詢。差異閾值可以設計為如式(2)所示:
 |
其中,?系數通常取0.5,n代表樣本個數,dist(i, j)代表樣本xi與樣本xj之間的歐氏距離,max表示取最大值。
(3)樣本多樣性:為確保關鍵樣本集合之間存在一定的多樣性,每個選定的關鍵實例都要滿足差異約束。設UI 為典型樣本集,閾值β的顯著差異集Nβ和多樣性評估函數div(UI)可表示為如式(3)~(4)所示:
 |
 |
其中,C2 |UI|為組合公式,l代表UI中的樣本對xi與xj。
1.2.2 TWD與粒計算
在粒度批處理模式下,對于高置信度樣本,在其注釋難度、樣本與標簽相關性適應度以及樣本得分方面,在基本粒子層面進行了一定的約束和計算;而高級粒子主要是基于基本粒子對樣本的分配標記優先級予以確定。本研究利用TWD針對樣本與標簽相關性的適應度設計了一個基于三向的加權模式,具體的TWD方法設計如下:
在評估樣本的重要性方面,本研究采用計算標簽與樣本的相關性的方式實現。其中,標簽與樣本以及樣本之間的相關性通過皮爾遜相關系數計算得到[22]。由于分配偽標簽的難度與標簽、樣本之間的相關性呈負相關,因此將分配正類、負類偽標簽上正相關標注的難度表示為如(5)所示:
 |
其中, 、
、 和
和 分別表示樣本
分別表示樣本 、正類樣本
、正類樣本 與負類樣本
與負類樣本 構成的特征向量矩陣,
構成的特征向量矩陣, 表示
表示 與
與 的相關系數,
的相關系數, 表示樣
表示樣 和
和 的相關系數,Diff0+、Diff0?分別表示分配正類、負類偽標簽正相關標注的難度。
的相關系數,Diff0+、Diff0?分別表示分配正類、負類偽標簽正相關標注的難度。
通過定義粒度算子gH獲得未標記樣本xi 的分數,進而評估樣本優先級。該分數與樣本水平得分Si相關;在本文中,令樣本水平得分與其標簽的相關性等價,gH如式(6)所示:
 |
其中,λ1和λ2為加權系數, 表示樣本x1構成的向量矩陣,
表示樣本x1構成的向量矩陣, 表示為樣本xi與
表示為樣本xi與  的相關系數 ,
的相關系數 , 表示為樣本xi與
表示為樣本xi與  的相關系數。 Si的值越大,則 xi的標記優先級越高。樣本的優先級通過對樣本與正標簽、負標簽的相關性進行加權求和確定。
的相關系數。 Si的值越大,則 xi的標記優先級越高。樣本的優先級通過對樣本與正標簽、負標簽的相關性進行加權求和確定。
以大多數正/負的標簽相關性為基線,可將相應標簽特定系數相關性的適合度分為三種情況,即高相關、適當相關和欠相關。本文針對樣本與標簽相關性的適應度設計了一個基于三向的加權模式。本文用tf + 0來表示模型對正常類別的適應度評估,該適應度是基于兩個相關性指標的比較,如式(7)所示:
 |
其中,ε→0+,w0、w0+分別表示模型初始參數與具有最大正相關樣本對應的模型參數, 表示 w0與w0+的相關系數。標簽的優先級由相關性強弱決定,即欠相關時優先級為 e,適度相關時為1,過相關時為1/e。類似地,可以定義tf – 0來表示具有最大負相關樣本的負常類標簽的相關性。
表示 w0與w0+的相關系數。標簽的優先級由相關性強弱決定,即欠相關時優先級為 e,適度相關時為1,過相關時為1/e。類似地,可以定義tf – 0來表示具有最大負相關樣本的負常類標簽的相關性。
1.3 DAL框架
本文所提出的DAL框架的處理流程如圖1所示,首先利用標記樣本集對CNN模型參數進行初始化。在訓練過程中,批次選擇高置信度樣本作為待分配偽標簽的樣本集,然后結合 Rizve等[23]所提出的偽標簽子集選擇框架,運用基于置信閾值的偽標簽方法進行標記。經 MOAL 算法篩選出低置信度樣本,在為低置信度樣本分配真實標簽后,將其與偽標記樣本共同構成已標記樣本池,作為CNN分類器的模型訓練集。每完成一次訓練,便對高置信度樣本的閾值進行更新,未標記的數據重新進行訓練,持續此過程,直至達到最大迭代次數,閾值更新如式(8)所示:
 |
其中,δ0是初始閾值,取值0.7;dr控制閾值變化率,取值0.05,t代表迭代次數。
2 實驗設計
2.1 參數設計及評價指標
本文將CTG信號數據集以訓練集:驗證集:測試集 = 6:2:2的比例劃分;使用的CNN架構配置為:以1 125 × 1 × 2信號作為輸入,在訓練期間將其隨機轉換為45 × 50 × 1的形式,并生成用于類別預測的歸一化指數函數(Softmax)輸出,初始學習率為0.000 1,批大小設置為256,優化器選擇自適應距估計(adaptive moment estimation,Adam)[24]。其中,激活函數為修正線性單元(rectified linear unit,ReLu)[25]。在DAL框架中,最大迭代次數設計為20,具體參數選擇見附表2。
為了驗證本文提出的算法在CTG信號數據的性能表現,選擇準確率(accuracy,Acc)、精確率(precision,Pre)、召回率(recall,Rec)、F1分數作為評價指標,各評價指標的計算公式如式(9)~式(13)所示:
 |
 |
 |
 |
式中,真陽性(true positive,TP)表示正類別中正確分類樣本的數量;真陰性(true negative,TN)表示負類別中正確分類樣本的數量;假陽性(false positive,FP)表示正類別中錯誤分類樣本的數量;假陰性(false negative,FN)是負類別中錯誤分類樣本的數量。
2.2 對比實驗
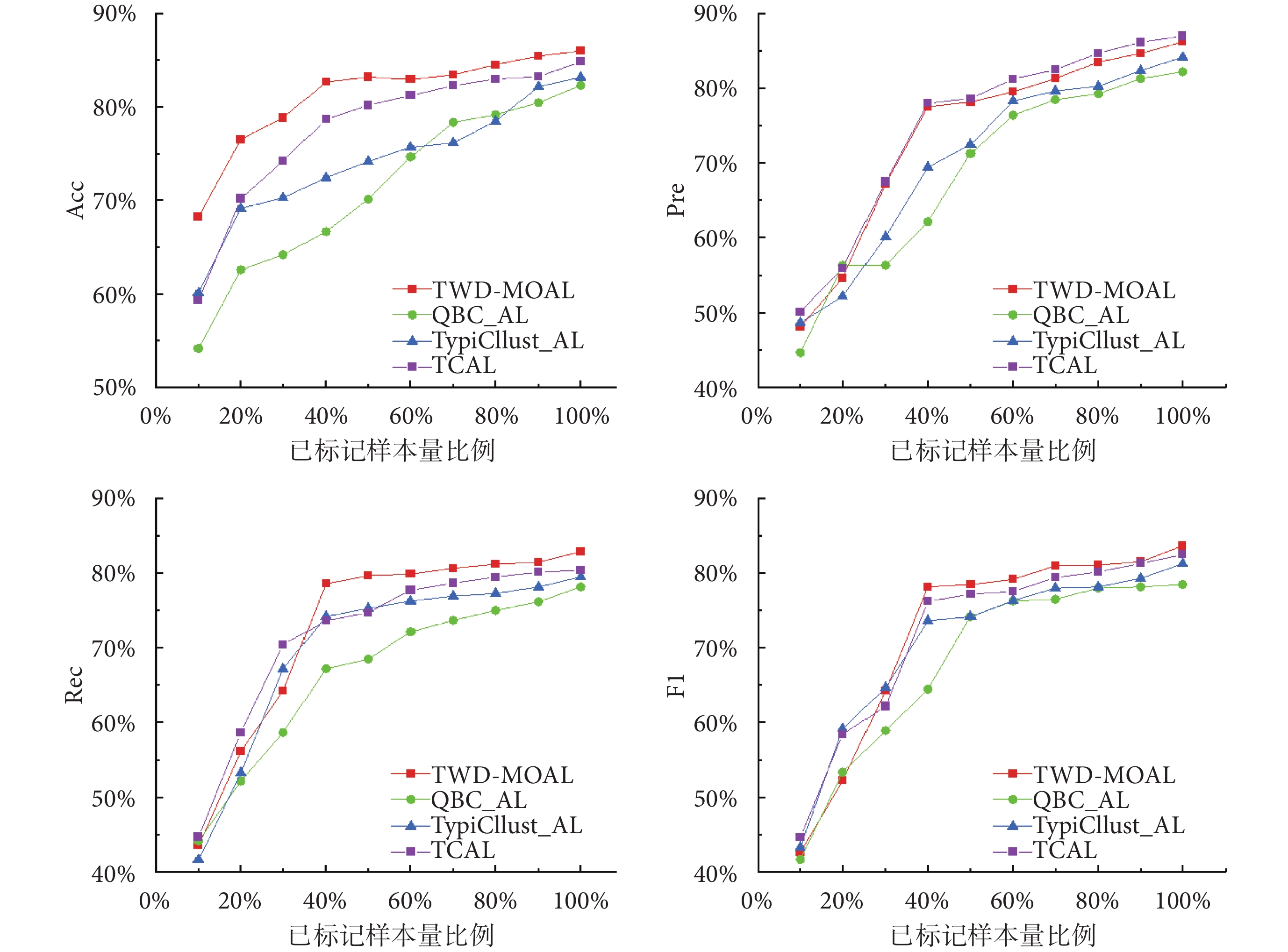
為了證明本文提出的DAL可以用較少的標記數據提高分類性能,本文將 TWD-MOAL 算法與主流的AL算法進行對比,主流AL算法有:基于委員會查詢的AL方法(query based committee AL,QBC_AL)、典型樣本聚類AL方法(typical samples clustering AL,TypiClust_AL)[11]、三重標準AL方法(triple criteria AL,TCAL)[26]。由于TWD-MOAL 算法結合了偽標簽自動分配方法,為避免混淆,下文所提及的已標注樣本量均為供專家標注的樣本量。該實驗通過折線圖對比Acc、Pre、Rec以及 F1 分數性能指標,結果如圖2所示。
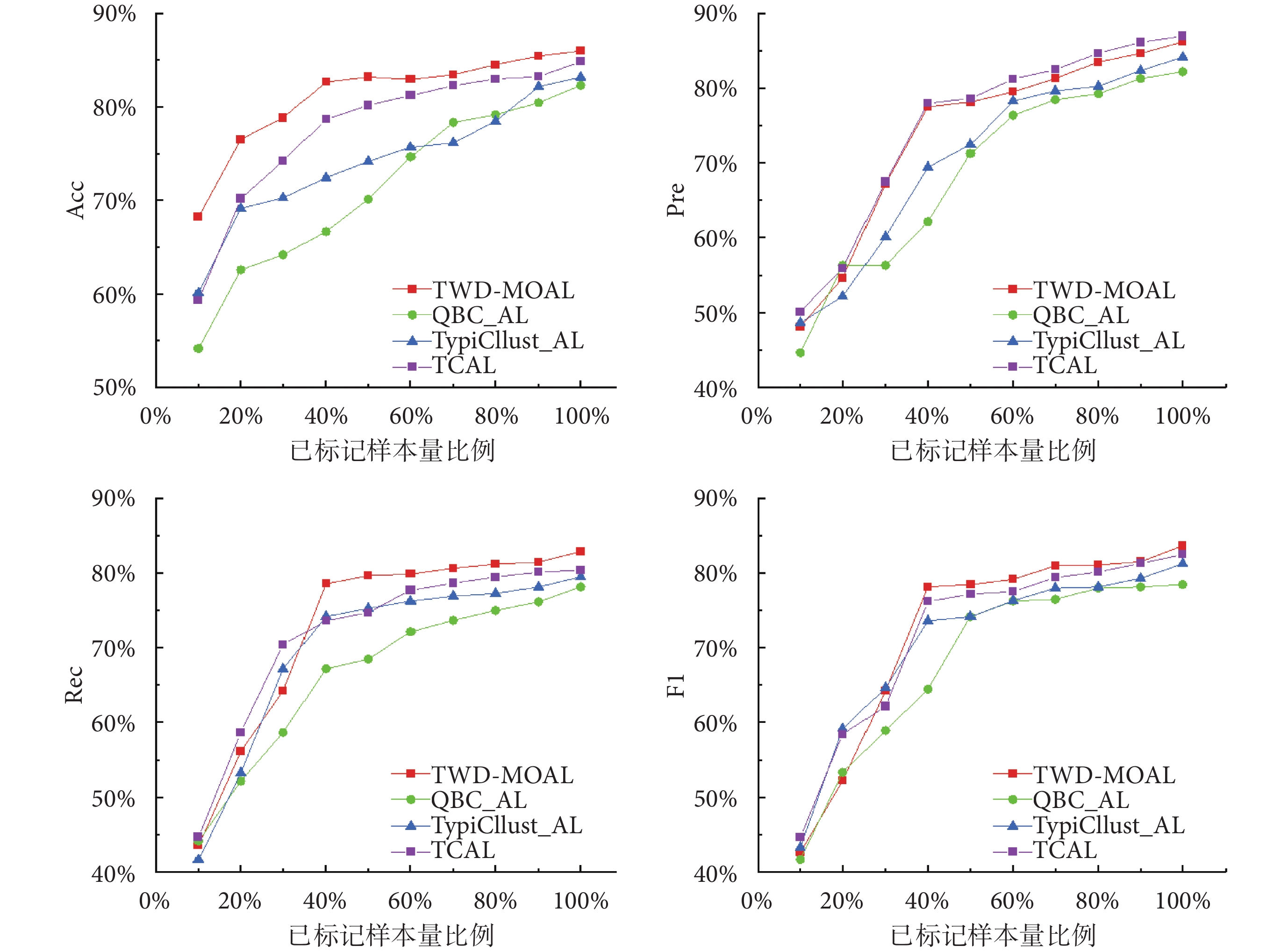 圖2
不同框架下的AL算法性能對比
Figure2.
Performance comparison of AL algorithms under different frameworks
圖2
不同框架下的AL算法性能對比
Figure2.
Performance comparison of AL algorithms under different frameworks
從上述結果可以看出,當樣本數量在 20%~40%之間時,TWD-MOAL 算法適用性更好。基于此,本文根據過往經驗,針對AL的終止條件采用以下兩種不同方式:其一,限定標注成本只能維持到訓練集的40%,觀察不同框架下的AL算法性能如何表現;其二,設定當模型的各項評估指標達到75%時,終止模型訓練,觀察所需的標注量。
2.3 消融實驗
消融實驗一:在基準模型同為CNN(參數相同)且為DAL框架的條件下,將隨機采樣的AL算法(Random_AL)與文本所提出的方法進行模型性能對比。
消融實驗二:偽標簽方法對減少樣本標注量的重要性驗證。驗證方法為:基準模型和框架不變,模型中去除基于TWD的偽標簽自動分配方法,將MOAL方法與TWD-MOAL方法進行對比。
消融實驗三:數據不平衡性驗證。若去除AL采樣方式,改為對數據進行隨機采樣,這樣在數據輸入的前、中期會有很大不確定性,導致CNN訓練不充分。本文在數據處理過程中,輕微地對非正常類進行增強,增強方法為:利用濾波平滑前后的CTG信號參與模型的訓練過程。同時,為了驗證模型的篩選方法在一定程度上傾向于將樣本維持分布平衡狀態,在采樣數量逐漸增加的過程中,對CTG正常類樣本及非正常類樣本在總訓練數據中的占比情況進行分析。
3 結果
3.1 對比實驗結果
對比實驗中,實驗結果如表1、表2所示,粗體字代表相應指標的最優值。
上述結果表明,在利用40%已標注樣本時,TWD-MOAL已達到80.63%的準確率。從各項指標綜合來看,該算法都優于其他框架下的AL算法,這也進一步說明該模型可通過互補置信度樣本學習數據的特征,從而提高模型的分類性能。
綜上所述,本文所提出的基于 CNN的TWD-MOAL算法模型在CTG數據集上,與當前表現優秀的不同框架進行相比,具備顯著的優勢。本課題通過調研發現,這種運用AL的端到端的智能判讀方式可為產前胎心宮縮監護模型的構建提供一定的借鑒。
3.2 消融實驗結果
消融實驗一,隨著樣本訓練數量的增加,各評估指標值變化如表3所示,粗體字代表相應指標最優值。結果顯示,TWD-MOAL無論是在何種評估指標下,其分類性能都優于Random_AL。其中,在樣本量已標注40%時,模型準確率提升幅度明顯。這可能是針對不平衡的CTG數據,隨機采樣的方法并沒有對各類數據有所偏重。值得注意的是,由于模型的不確定因素以及數據的批量輸入,即便消耗了所有訓練集,兩種算法最終的分類性能仍然具有差異。
消融實驗二,結果如表4所示。經過實驗發現,盡管分配的偽標簽存在著近乎極小的錯誤率,但依舊能大量減少標簽量。從表4中可以觀察到,在加入偽標簽自動標注方法的情況下,所用到的標注量僅占使用MOAL方法標注量的約2/3,即可達到同樣的訓練結果(模型準確率達到75%)。這也進一步驗證了TWD-MOAL能顯著降低標注CTG數據所耗費的人力和時間成本。
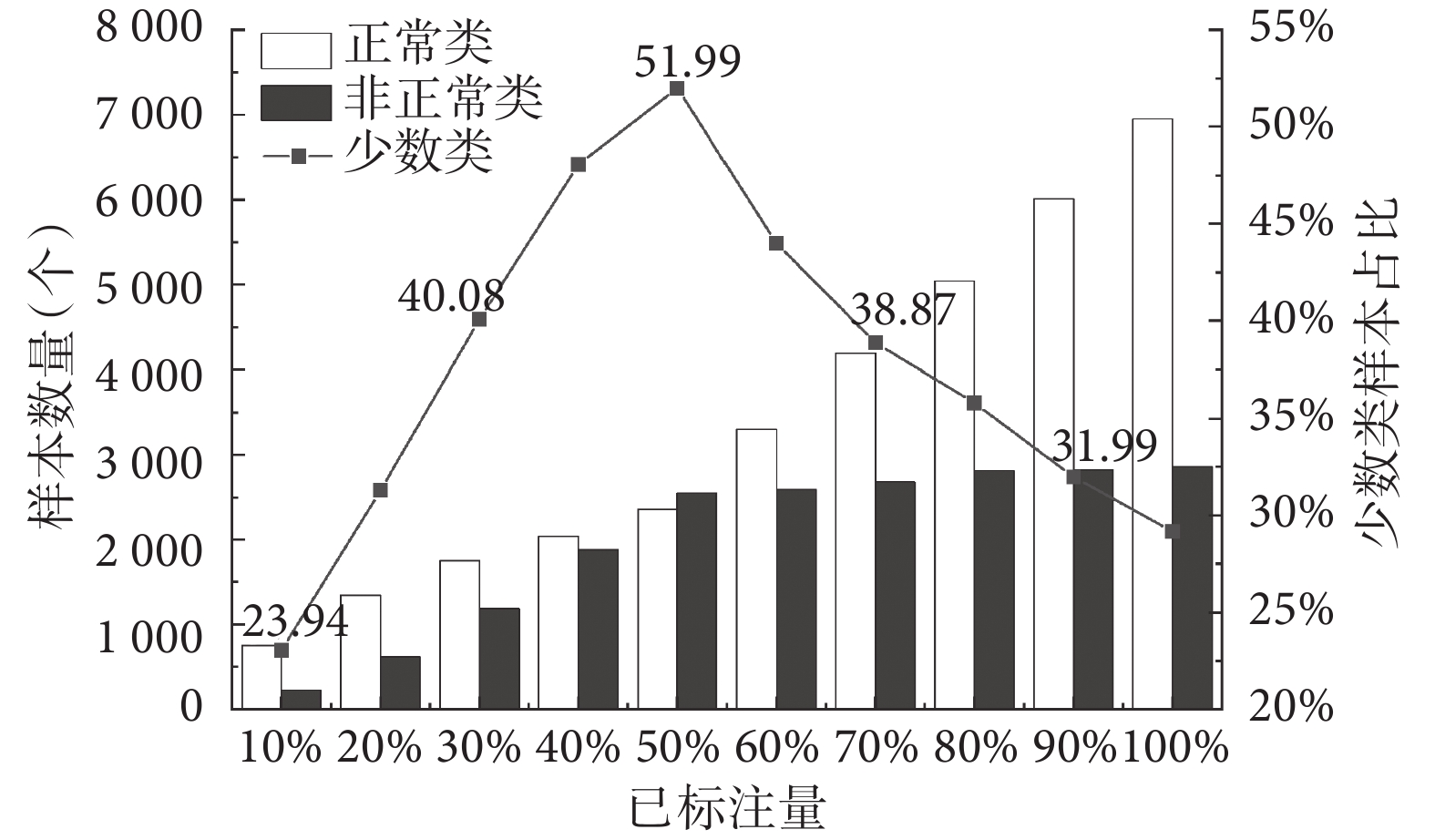
消融實驗三,利用AL方法進行采樣時,正常類、非正常類樣本占比情況如圖3所示。
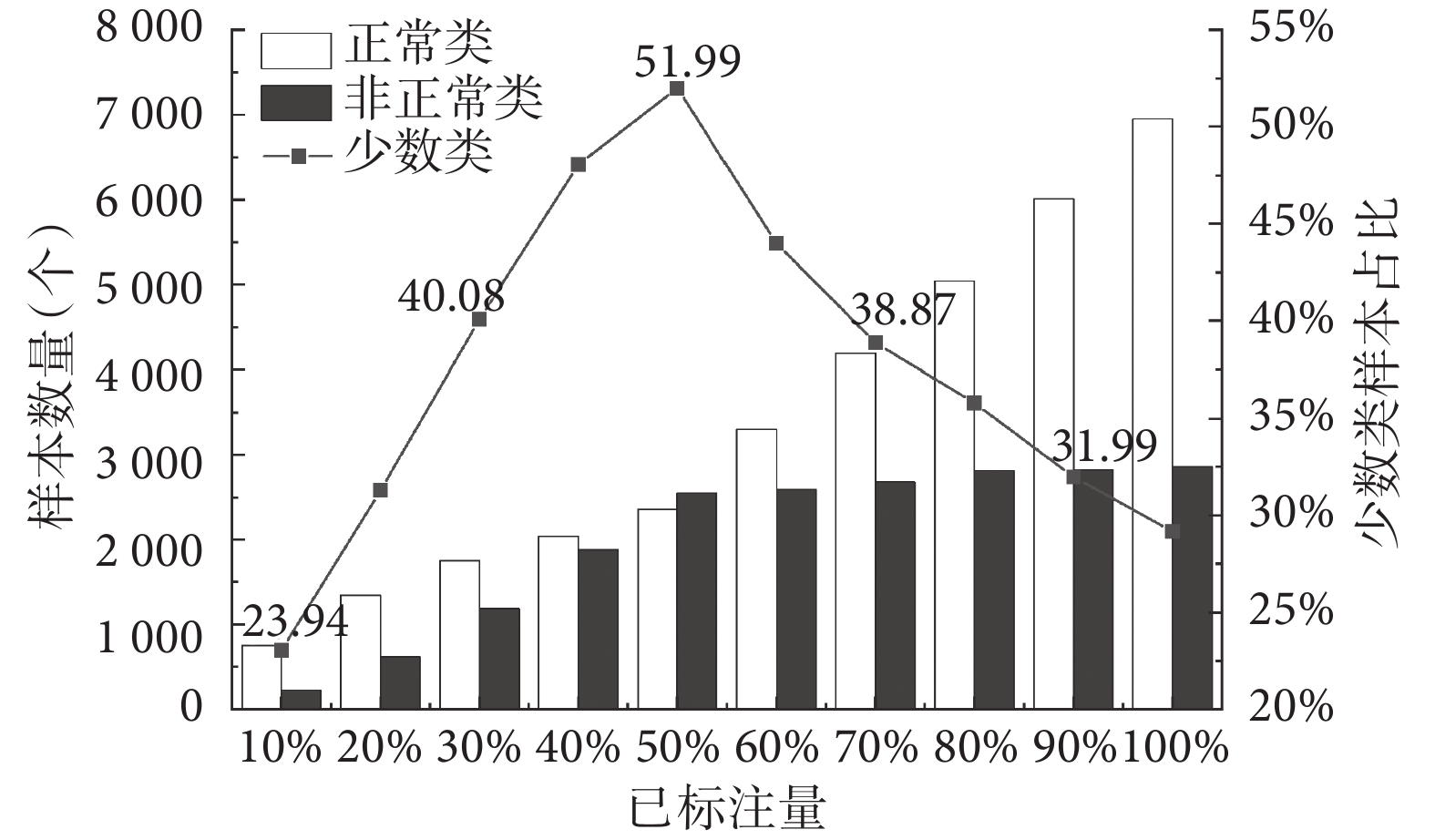 圖3
采樣過程中正常類、非正常類樣本占比情況
Figure3.
The proportion of normal and abnormal samples in the sampling process
圖3
采樣過程中正常類、非正常類樣本占比情況
Figure3.
The proportion of normal and abnormal samples in the sampling process
分析圖3可知,當樣本數較少時,樣本集中正常類樣本所占比例較高,利于獲取較多非正常類樣本。隨著樣本標注數量的增加,正常類樣本在樣本集中的比例逐漸降低,但由于整體樣本數量的增加,非正常類樣本數仍然在增加,這使得CTG樣本集趨向平衡,減少了后續模型的誤判概率,有效地解決了CTG數據不平衡問題。
4 討論
本文通過研究AL和DL相結合的處理流程,提出基于TWD和MOAL的深度神經網絡模型,致力于降低DL在CTG智能判讀中所需的標注成本。本文所提TWD-MOAL算法設計了基于偽標簽自動標注策略的DAL框架,在CNN的訓練周期過程中,結合TWD理論,在粒度批處理模式下選擇高置信度樣本作為偽標記樣本,同時參考有產科專家標注的低置信度樣本。其中,低置信度樣本由MOAL算法篩選得到,綜合衡量了樣本的信息量、代表性和多樣性。另外,考慮到平滑濾波會對信號產生較大衰減,在模型訓練過程中加入了未經過濾波平滑處理的數據,從而在一定程度上實現了數據增強,并經過消融實驗驗證了該方法能有效地解決數據分布不平衡問題,減少了后續模型的誤判率。實驗表明,加入偽標簽自動標注方法后,僅需用到MOAL方法的3/2的標注量,即可達到同樣的訓練結果(模型準確率達到75%)。并且,與隨機采樣的方法相比,本文提出的方法在各種不同模型評估指標下均展現了更為優異的模型性能。值得一提的是,在CTG數據集上,TWD-MOAL算法僅利用40%的已標注樣本,便能達到80.63%的準確率,且從各項指標綜合評估的角度出發,其性能表現全面優于其他框架下的AL算法。
綜上所述,本研究認為基于TWD-MOAL的智能胎心監護模型是合理可行的。該模型有效解決了DL與AL處理流程不一致以及CTG數據分布不平衡等關鍵問題,明顯減少了產科專家標注樣本所耗費的時間和精力,展現出了良好的應用前景與實際價值。
在未來的工作中,本研究將致力于采用更為精細且性能卓越的CNN基線模型,以進一步提高分類性能,同時對偽標簽的自動分配錯誤率進行具體分析,進一步探索模型的不確定性,為模型的持續優化提供有力依據。此外,鑒于AL算法在查詢階段復雜度往往較高,本課題組計劃實施一系列優化策略,來降低整個模型訓練的時間成本,從而提升整體效率與實用性,使其能夠更好地服務于臨床實踐等相關應用場景。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:全斌主要負責算法程序設計與實現、實驗結果分析;黃雅靜主要負責論文撰寫與修訂;李艷芳負責研究設計和評估模型的臨床有效性;李麗負責數據采集整理和模型評估;劉桂清主要負責評估模型的臨床有效性;陳沁群、張洪來主要負責算法咨詢與建議;魏航主要負責研究設計、算法設計指導,論文審閱及修訂,整體工作組織和監督。
倫理聲明:本研究通過廣州醫科大學附屬第二醫院臨床試驗倫理委員會(編號:Q2018-06-02)、廣州醫科的大學附屬第三醫院藥物臨床試驗倫理委員會(編號:藥倫審器[2018]第020號)以及中山大學附屬第五醫院醫學倫理委員會(編號:中大五院[2018]倫字第(Q07-1)號)的審批。
0 引言
近年來,隨著輔助生育技術的進步以及“三胎”政策的正式落地,新生兒的出生質量以及孕產婦的孕育安全成為臨床上備受關注的焦點[1]。胎心宮縮監護圖(cardiotocography,CTG)可以無侵入性地應用在產前胎兒窘迫診斷中[2],它記錄了胎心率(fetal heart rate,FHR)信號和子宮收縮(uterine contraction,UC)隨時間變化的關系。FHR是胎兒心臟跳動的電信號,數值在110~160 beat/min之間為正常;UC是指在懷孕、分娩和生產過程中子宮肌肉有節奏地收緊和放松,通常以其頻率、持續時間和強度來描述。CTG作為評估胎兒健康狀況的一種方法,可協助產科醫生預測妊娠期間可能出現的并發癥,進而有效降低胎兒及母親的發病率和死亡率[3]。
臨床實踐中,視覺CTG利用國際描述性標準,從視覺的角度對CTG進行主觀性評估[2]。眾多國際組織,如美國婦產科醫師學會、國際婦產科聯盟[4],為了規范胎兒監護方法,分別制定了不同的胎兒監護指南,記錄了FHR基線、基線變異和加減速等FHR信號的基本形態學特征。臨床醫生根據等級評價方法,將處理后的FHR信號劃分為“正常”、“可疑”和“異常”三類,從而進一步評估胎兒健康狀況。目前,已有相關實驗驗證了機器學習(machine learning,ML)和人工智能方法能協助產科醫生做出更明確的醫療決策[5-7]。
近年來,深度學習(deep learning,DL)方法在實現端到端CTG信號分類任務上也取得了重大進展。例如,Zhou等[8]利用捷克技術大學及布爾諾大學醫院的產時公共數據集,通過基于長卷積的DL法針對胎兒狀態獲得了較高的分類精度以及參數調整速度。這種端到端智能判讀的形式,有效學習了臨床醫師人工判讀方式,進一步提高了分類準確率,可大大減少醫護人員的工作量。另一方面,采用DL方法需要大量的標注數據供應來優化海量參數,大量高質量的標注數據集會消耗高昂的人力和財力成本,在專業知識水平需求較高的領域難以實現[9-10]。但通過將 DL 與主動學習(active learning,AL)處理過程結合[11],可有效解決上述問題。
目前,有研究在中文電子病歷命名實體識別的應用中,結合深度AL算法( deep AL,DAL)使模型精度有效提升,F1分數(F1-score)提高幅度較大[12]。El-Hasnony 等[13]提出基于多標簽AL選擇策略的DL方法 ,并通過迭代選擇最相關的數據對其標簽進行查詢,以此來降低標簽成本。Xie等[14]提出了一種稱為主動領域適應的AL策略來協助目標領域的知識遷移,該方法在基準測試中超越了最先進方法。近年來,有研究將卷積神經網絡(convolutional neural network,CNN)運用于信號分類處理,取得了良好的分類結果[15-16]。例如,Hemmer 等[17]結合CNN提出一種新穎的AL算法,該算法通過捕獲高預測不確定性,能夠有效地從無標記數據中進行學習,且已在肺炎相關真實醫學用例中得到驗證。
有鑒于此,本文提出了基于CNN和AL的框架。該框架能夠從無標簽樣本池中周期性地按批次篩選高、低置信度互補樣本,從而為CNN提供信息量盡可能大的數據。利用典型數據訓練網絡,可使模型迅速收斂,并且最大限度地提升模型的泛化能力和魯棒性。在這個過程中,對于待分配真實標簽的低置信度樣本,通過多目標優化主動學習( multi-objective optimization active learning,MOAL)方法,綜合考量樣本的信息量、代表性和多樣性來選擇給予標簽。對于待分配偽標簽的高置信度樣本,在粒度批處理模式下引入三支決策理論(three-way decision,TWD)[18],以此確定最終符合要求的偽標記樣本,本文將該算法簡稱為 TWD-MOAL。該模型處理流程如圖1 所示。該框架綜合考慮DL和AL的處理流程,可以顯著降低產科專家對數據標注的代價,并有效解決CTG信號數據不平衡問題,這對輔助臨床醫師判讀以及實現胎心監護模型的智能化具有重要意義。
圖1
DAL模型總流程圖
Figure1.
Total flow diagram of DAL model
1 數據和方法
1.1 數據采集與處理
本文數據采于廣州醫科大學附屬第二醫院、廣州醫科大學附屬第三醫院和中山大學附屬第五醫院,共采集了1. 935 5萬例年齡范圍20~45 歲[平均年齡(27.27 ± 4.80)歲]的孕婦懷孕28周至分娩前[平均(36.35 ± 2.89)孕周]的CTG信號數據。本文研究通過了廣州醫科大學附屬第二醫院臨床試驗倫理委員會(編號:Q2018-06-02)、廣州醫科的大學附屬第三醫院藥物臨床試驗倫理委員會(編號:藥倫審器[2018]第020號)以及中山大學附屬第五醫院醫學倫理委員會(編號:中大五院[2018]倫字第(Q07-1)號)的審批,參與者均已簽署知情同意書,并已獲得相關數據使用授權。
本文信號采集儀器為分娩檢測系統(LP,廣州三瑞醫療器械有限公司,中國),采樣頻率為1.25 Hz,從信號提取的常見特征見附表1。采集得到的CTG信號由3位產科專家醫師依據產前胎兒監護指南進行判讀[19],判讀結果一致的信號被納入為本研究的數據集。最終,數據集共包含16 355條樣本記錄,其中正常類有11 998例,可疑類有4 326例,異常類有31例。鑒于數據存在嚴重不平衡現象以及本研究旨在輔助醫師初步篩選異常情況,本文將數據集中的異常類和可疑類案例合并為非正常類。
CTG 信號采集過程中,由于會受到各種因素的干擾,數據可能出現缺失、異常值,并帶有明顯的噪聲。為提高FHR、UC信號的DL建模性能,本文利用信號處理方法對 FHR和UC 信號進行處理,包括對異常值(持續時間大于15 s且值為0的信號)的處理、濾波平滑降噪以及標準化等操作。對于原始FHR信號中的不穩定部分,即相鄰兩個采樣點之間幅值相差絕對值大于20 beat/min的信號,采用線性插值法進行處理。濾波降噪選取的濾波器為巴特沃斯濾波器[20] 。本文使用分析FHR的開放訪問軟件 CTG-OAS(Elsevier Ltd.,土耳其) 進行FHR基線提取[21],然后將濾波處理前后的信號與FHR基線相減,得到FHR的標準化結果。
1.2 互補樣本選擇
1.2.1 MOAL算法
根據AL的基本步驟以及多目標優化理論,綜合考慮樣本的信息量、代表性和多樣性。首先定義如下目標約束優化問題,如式(1)所示:
|
其中,Du為未標記樣本池的數據, f(x)表示信息量,p(x)表示樣本代表性,g(x)表示差異, β0表示初始差異閾值,取值0.35。
樣本信息量可用于減少模型的不確定性,本文使用信息熵來衡量Du的信息量;樣本代表性可作為所有未標記數據的整體特征表達,可用概率密度函數進行代表性估計,本文使用非參數方法獲得概率密度函數p(x);樣本集的多樣性是通過當前選擇的關鍵實例之間的差異來衡量的,并且它由多樣性評價函數的距離度量、約束函數和樣本多樣性三個方面組成。
(1)距離度量:本文使用向量的范數來計算樣本之間的距離。
(2)約束函數:AL算法是一個周期過程,已被查詢過的關鍵實例會確定 g(x)的計算,故設s為已查詢的最后一個關鍵實例,定義g(x) = dist(x, s),根據公式(1)可知,只有當g(x) = dist(x, s) > β時,實例才能被查詢。差異閾值可以設計為如式(2)所示:
|
其中,?系數通常取0.5,n代表樣本個數,dist(i, j)代表樣本xi與樣本xj之間的歐氏距離,max表示取最大值。
(3)樣本多樣性:為確保關鍵樣本集合之間存在一定的多樣性,每個選定的關鍵實例都要滿足差異約束。設UI 為典型樣本集,閾值β的顯著差異集Nβ和多樣性評估函數div(UI)可表示為如式(3)~(4)所示:
|
|
其中,C2 |UI|為組合公式,l代表UI中的樣本對xi與xj。
1.2.2 TWD與粒計算
在粒度批處理模式下,對于高置信度樣本,在其注釋難度、樣本與標簽相關性適應度以及樣本得分方面,在基本粒子層面進行了一定的約束和計算;而高級粒子主要是基于基本粒子對樣本的分配標記優先級予以確定。本研究利用TWD針對樣本與標簽相關性的適應度設計了一個基于三向的加權模式,具體的TWD方法設計如下:
在評估樣本的重要性方面,本研究采用計算標簽與樣本的相關性的方式實現。其中,標簽與樣本以及樣本之間的相關性通過皮爾遜相關系數計算得到[22]。由于分配偽標簽的難度與標簽、樣本之間的相關性呈負相關,因此將分配正類、負類偽標簽上正相關標注的難度表示為如(5)所示:
|
其中,、和分別表示樣本、正類樣本與負類樣本構成的特征向量矩陣,表示與的相關系數,表示樣和的相關系數,Diff0+、Diff0?分別表示分配正類、負類偽標簽正相關標注的難度。
通過定義粒度算子gH獲得未標記樣本xi 的分數,進而評估樣本優先級。該分數與樣本水平得分Si相關;在本文中,令樣本水平得分與其標簽的相關性等價,gH如式(6)所示:
|
其中,λ1和λ2為加權系數,表示樣本x1構成的向量矩陣,表示為樣本xi與 的相關系數 ,表示為樣本xi與 的相關系數。 Si的值越大,則 xi的標記優先級越高。樣本的優先級通過對樣本與正標簽、負標簽的相關性進行加權求和確定。
以大多數正/負的標簽相關性為基線,可將相應標簽特定系數相關性的適合度分為三種情況,即高相關、適當相關和欠相關。本文針對樣本與標簽相關性的適應度設計了一個基于三向的加權模式。本文用tf + 0來表示模型對正常類別的適應度評估,該適應度是基于兩個相關性指標的比較,如式(7)所示:
|
其中,ε→0+,w0、w0+分別表示模型初始參數與具有最大正相關樣本對應的模型參數,表示 w0與w0+的相關系數。標簽的優先級由相關性強弱決定,即欠相關時優先級為 e,適度相關時為1,過相關時為1/e。類似地,可以定義tf – 0來表示具有最大負相關樣本的負常類標簽的相關性。
1.3 DAL框架
本文所提出的DAL框架的處理流程如圖1所示,首先利用標記樣本集對CNN模型參數進行初始化。在訓練過程中,批次選擇高置信度樣本作為待分配偽標簽的樣本集,然后結合 Rizve等[23]所提出的偽標簽子集選擇框架,運用基于置信閾值的偽標簽方法進行標記。經 MOAL 算法篩選出低置信度樣本,在為低置信度樣本分配真實標簽后,將其與偽標記樣本共同構成已標記樣本池,作為CNN分類器的模型訓練集。每完成一次訓練,便對高置信度樣本的閾值進行更新,未標記的數據重新進行訓練,持續此過程,直至達到最大迭代次數,閾值更新如式(8)所示:
|
其中,δ0是初始閾值,取值0.7;dr控制閾值變化率,取值0.05,t代表迭代次數。
2 實驗設計
2.1 參數設計及評價指標
本文將CTG信號數據集以訓練集:驗證集:測試集 = 6:2:2的比例劃分;使用的CNN架構配置為:以1 125 × 1 × 2信號作為輸入,在訓練期間將其隨機轉換為45 × 50 × 1的形式,并生成用于類別預測的歸一化指數函數(Softmax)輸出,初始學習率為0.000 1,批大小設置為256,優化器選擇自適應距估計(adaptive moment estimation,Adam)[24]。其中,激活函數為修正線性單元(rectified linear unit,ReLu)[25]。在DAL框架中,最大迭代次數設計為20,具體參數選擇見附表2。
為了驗證本文提出的算法在CTG信號數據的性能表現,選擇準確率(accuracy,Acc)、精確率(precision,Pre)、召回率(recall,Rec)、F1分數作為評價指標,各評價指標的計算公式如式(9)~式(13)所示:
|
|
|
|
式中,真陽性(true positive,TP)表示正類別中正確分類樣本的數量;真陰性(true negative,TN)表示負類別中正確分類樣本的數量;假陽性(false positive,FP)表示正類別中錯誤分類樣本的數量;假陰性(false negative,FN)是負類別中錯誤分類樣本的數量。
2.2 對比實驗
為了證明本文提出的DAL可以用較少的標記數據提高分類性能,本文將 TWD-MOAL 算法與主流的AL算法進行對比,主流AL算法有:基于委員會查詢的AL方法(query based committee AL,QBC_AL)、典型樣本聚類AL方法(typical samples clustering AL,TypiClust_AL)[11]、三重標準AL方法(triple criteria AL,TCAL)[26]。由于TWD-MOAL 算法結合了偽標簽自動分配方法,為避免混淆,下文所提及的已標注樣本量均為供專家標注的樣本量。該實驗通過折線圖對比Acc、Pre、Rec以及 F1 分數性能指標,結果如圖2所示。
圖2
不同框架下的AL算法性能對比
Figure2.
Performance comparison of AL algorithms under different frameworks
從上述結果可以看出,當樣本數量在 20%~40%之間時,TWD-MOAL 算法適用性更好。基于此,本文根據過往經驗,針對AL的終止條件采用以下兩種不同方式:其一,限定標注成本只能維持到訓練集的40%,觀察不同框架下的AL算法性能如何表現;其二,設定當模型的各項評估指標達到75%時,終止模型訓練,觀察所需的標注量。
2.3 消融實驗
消融實驗一:在基準模型同為CNN(參數相同)且為DAL框架的條件下,將隨機采樣的AL算法(Random_AL)與文本所提出的方法進行模型性能對比。
消融實驗二:偽標簽方法對減少樣本標注量的重要性驗證。驗證方法為:基準模型和框架不變,模型中去除基于TWD的偽標簽自動分配方法,將MOAL方法與TWD-MOAL方法進行對比。
消融實驗三:數據不平衡性驗證。若去除AL采樣方式,改為對數據進行隨機采樣,這樣在數據輸入的前、中期會有很大不確定性,導致CNN訓練不充分。本文在數據處理過程中,輕微地對非正常類進行增強,增強方法為:利用濾波平滑前后的CTG信號參與模型的訓練過程。同時,為了驗證模型的篩選方法在一定程度上傾向于將樣本維持分布平衡狀態,在采樣數量逐漸增加的過程中,對CTG正常類樣本及非正常類樣本在總訓練數據中的占比情況進行分析。
3 結果
3.1 對比實驗結果
對比實驗中,實驗結果如表1、表2所示,粗體字代表相應指標的最優值。
上述結果表明,在利用40%已標注樣本時,TWD-MOAL已達到80.63%的準確率。從各項指標綜合來看,該算法都優于其他框架下的AL算法,這也進一步說明該模型可通過互補置信度樣本學習數據的特征,從而提高模型的分類性能。
綜上所述,本文所提出的基于 CNN的TWD-MOAL算法模型在CTG數據集上,與當前表現優秀的不同框架進行相比,具備顯著的優勢。本課題通過調研發現,這種運用AL的端到端的智能判讀方式可為產前胎心宮縮監護模型的構建提供一定的借鑒。
3.2 消融實驗結果
消融實驗一,隨著樣本訓練數量的增加,各評估指標值變化如表3所示,粗體字代表相應指標最優值。結果顯示,TWD-MOAL無論是在何種評估指標下,其分類性能都優于Random_AL。其中,在樣本量已標注40%時,模型準確率提升幅度明顯。這可能是針對不平衡的CTG數據,隨機采樣的方法并沒有對各類數據有所偏重。值得注意的是,由于模型的不確定因素以及數據的批量輸入,即便消耗了所有訓練集,兩種算法最終的分類性能仍然具有差異。
消融實驗二,結果如表4所示。經過實驗發現,盡管分配的偽標簽存在著近乎極小的錯誤率,但依舊能大量減少標簽量。從表4中可以觀察到,在加入偽標簽自動標注方法的情況下,所用到的標注量僅占使用MOAL方法標注量的約2/3,即可達到同樣的訓練結果(模型準確率達到75%)。這也進一步驗證了TWD-MOAL能顯著降低標注CTG數據所耗費的人力和時間成本。
消融實驗三,利用AL方法進行采樣時,正常類、非正常類樣本占比情況如圖3所示。
圖3
采樣過程中正常類、非正常類樣本占比情況
Figure3.
The proportion of normal and abnormal samples in the sampling process
分析圖3可知,當樣本數較少時,樣本集中正常類樣本所占比例較高,利于獲取較多非正常類樣本。隨著樣本標注數量的增加,正常類樣本在樣本集中的比例逐漸降低,但由于整體樣本數量的增加,非正常類樣本數仍然在增加,這使得CTG樣本集趨向平衡,減少了后續模型的誤判概率,有效地解決了CTG數據不平衡問題。
4 討論
本文通過研究AL和DL相結合的處理流程,提出基于TWD和MOAL的深度神經網絡模型,致力于降低DL在CTG智能判讀中所需的標注成本。本文所提TWD-MOAL算法設計了基于偽標簽自動標注策略的DAL框架,在CNN的訓練周期過程中,結合TWD理論,在粒度批處理模式下選擇高置信度樣本作為偽標記樣本,同時參考有產科專家標注的低置信度樣本。其中,低置信度樣本由MOAL算法篩選得到,綜合衡量了樣本的信息量、代表性和多樣性。另外,考慮到平滑濾波會對信號產生較大衰減,在模型訓練過程中加入了未經過濾波平滑處理的數據,從而在一定程度上實現了數據增強,并經過消融實驗驗證了該方法能有效地解決數據分布不平衡問題,減少了后續模型的誤判率。實驗表明,加入偽標簽自動標注方法后,僅需用到MOAL方法的3/2的標注量,即可達到同樣的訓練結果(模型準確率達到75%)。并且,與隨機采樣的方法相比,本文提出的方法在各種不同模型評估指標下均展現了更為優異的模型性能。值得一提的是,在CTG數據集上,TWD-MOAL算法僅利用40%的已標注樣本,便能達到80.63%的準確率,且從各項指標綜合評估的角度出發,其性能表現全面優于其他框架下的AL算法。
綜上所述,本研究認為基于TWD-MOAL的智能胎心監護模型是合理可行的。該模型有效解決了DL與AL處理流程不一致以及CTG數據分布不平衡等關鍵問題,明顯減少了產科專家標注樣本所耗費的時間和精力,展現出了良好的應用前景與實際價值。
在未來的工作中,本研究將致力于采用更為精細且性能卓越的CNN基線模型,以進一步提高分類性能,同時對偽標簽的自動分配錯誤率進行具體分析,進一步探索模型的不確定性,為模型的持續優化提供有力依據。此外,鑒于AL算法在查詢階段復雜度往往較高,本課題組計劃實施一系列優化策略,來降低整個模型訓練的時間成本,從而提升整體效率與實用性,使其能夠更好地服務于臨床實踐等相關應用場景。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:全斌主要負責算法程序設計與實現、實驗結果分析;黃雅靜主要負責論文撰寫與修訂;李艷芳負責研究設計和評估模型的臨床有效性;李麗負責數據采集整理和模型評估;劉桂清主要負責評估模型的臨床有效性;陳沁群、張洪來主要負責算法咨詢與建議;魏航主要負責研究設計、算法設計指導,論文審閱及修訂,整體工作組織和監督。
倫理聲明:本研究通過廣州醫科大學附屬第二醫院臨床試驗倫理委員會(編號:Q2018-06-02)、廣州醫科的大學附屬第三醫院藥物臨床試驗倫理委員會(編號:藥倫審器[2018]第020號)以及中山大學附屬第五醫院醫學倫理委員會(編號:中大五院[2018]倫字第(Q07-1)號)的審批。