陣發性心房顫動(PAF)的風險預測是生物醫學工程領域的難題。本研究綜合了機器學習特征工程和深度學習端到端建模的優勢,提出了基于多模態特征融合的PAF風險預測方法。同時,本研究使用了四種不同的特征排序方法和Pearson相關性分析來確定最優的多模態特征集合,并使用隨機森林進行PAF的風險判斷。本研究的方法在公開數據中達到了(92.3 ± 2.1)%的準確率和(91.6 ± 2.9)%的F1分數。在臨床數據中達到了(91.4 ± 2.0)%的準確率和(90.8 ± 2.4)%的F1分數。提出的方法實現了多中心數據集的泛化并具有良好的臨床應用前景。
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
心房顫動(atrial fibrillation,AF)是導致中風、腦卒中和猝死的重要原因[1]。AF早期表現為具有陣發性與偶發性特點的陣發性房顫(paroxysmal atrial fibrillation,PAF),僅有極少數患者被發現而進入臨床干預階段[2]。PAF得不到及時的干預,將演變為持續性AF或永久性AF[3-4]。由于PAF具有陣發性與偶發性,使用常規的心電信號(electrocardiogram,ECG)難以預測。隨著穿戴式的長程心電監護設備在臨床上得到應用,長程ECG為PAF的預測提供了數據基礎。同時,臨床上探索出了許多與PAF發生相關的潛在指標[5-7]。
在機器學習(machine learning,ML)領域中,許多研究從ECG中提取時域、頻域和非線性域等特征來預測PAF發生的風險[8-9]。Thong等[10-11]綜合分析了房性早搏的數量、心動過速的節拍數量和早發性心房復合體的特征。Hickey等[12]在房性早搏的基礎上引入了功率譜密度(power spectral density,PSD)。De Chazal等[13]則是將RR間期的PSD和P波的PSD作為PAF風險的潛在特征。隨著心率變異性(heart rate variability,HRV)表現出顯著的重要性,Boon等[14-15]分別在單一時間尺度和多時間尺度上分析了ECG的HRV特征。Mohebbi等[16]和Narin等[17]將HRV的線性特征和非線性特征相結合。蘭天杰等[18]對HRV特征進行了PSD、近似熵和樣本熵等分析。
在深度學習(deep learning,DL)研究領域,Sutton等[19]借助長短時記憶網絡(long and short-term memory networks,LSTM)獲取了ECG的時序信息。Mendez等[20]使用二維卷積神經網絡(two-dimensional convolutional neural network,2D CNN)對特征矩陣進行學習以探究龐加萊圖的空間信息。Erdenebayar等[21]利用一維卷積神經網絡(1D CNN)和全連接對多個時間尺度下的ECG片段進行分析。Attia等[22]利用由10個殘差模塊構成的CNN對12導聯的竇性ECG記錄進行同步分析。楊萍等[23]基于CNN與LSTM提出了一種多路徑的復合型神經網絡。
基于特征工程的ML算法具有明確的臨床意義和可解釋性,但是難以全面獲取ECG中的PAF隱式信息[24]。基于端到端建模的DL算法省略了預處理和人工提取特征的過程,但是它獲取的特征受限于特定的數據集,難以實現多中心數據的泛化[25-26]。
本研究綜合了ML的特征工程和DL端到端建模的優勢,提出了多模態特征融合的PAF風險預測方法。本研究的優勢為:機器學習特征(machine learning feature,MF)為DL模型增加了可解釋性,DL模型的應用則增強了ML中ECG信息的多層次表示,兩者結合強化了整體方法對非線性的高維數據的擬合能力并提高了PAF風險預測的泛化性。同時,本研究采用多種重要性排序和相關性分析實現結果投票,從而增強特征排序和選擇的可靠性。
1 材料和方法
1.1 數據集
本研究使用了陣發性房顫預測挑戰賽數據集(PAF Prediction Challenge Database,AFPDB)[8]和山東省立醫院的臨床數據庫(Shandong Provincial Hospital Database,SPHDB)。AFPDB包含了50位正常人的ECG數據和25位PAF患者的ECG數據。所有記錄的時長均為30 min,采樣率均為128 Hz。將正常人的片段視為無PAF發生風險的ECG片段,記為NR片段;將PAF患者的記錄均視為有PAF發生風險的ECG片段,記為R片段。
本研究以AFPDB的數據處理方式為標準,從山東省立醫院收集了100條臨床數據構建了SPHDB。其中50條記錄來自正常人,50條記錄來自PAF患者,兩組記錄分別被標記為NR片段和R片段。所有的記錄時長為30 min,采樣率為200 Hz。實驗方案已經獲得山東省立醫院倫理委員會的批準。
1.2 預處理
首先,使用截止頻率為80 Hz的低通濾波器對肌電干擾進行去除[27]。然后,使用陷波器對工頻干擾進行去除(針對AFPDB和SPHDB,諧振頻率分別設置為60 Hz和50 Hz)。最后,使用db6小波對所有的ECG進行9階分解,刪除D1、D2和A9分量以去除基線漂移[28]。去噪后的ECG統一重采樣為200 Hz并分割為無重疊的1 min的片段。
1.3 機器學習特征提取
PAF發生時ECG的基本特征表現為:P波消失或異常不規則、F波出現、RR間期絕對不整、基線消失、心室波形不規則或無法確定電極軸等。ECG是由心肌細胞的電活動產生的,心肌細胞一旦發生壞死或病變則無法再生與修復。本研究假設:在PAF發生之前,部分心肌細胞的壞死或病變已經導致ECG出現異常。對此,本研究提取了32個人工特征,具體內容參見附件1。
部分頻域特征如下:若連續ECG的函數表達式為 ,其離散傅里葉變換如式(1)所示,
,其離散傅里葉變換如式(1)所示,
 |
則 的PSD計算過程如式(2)所示,
的PSD計算過程如式(2)所示,
 |
其中, 為傅里葉系數,
為傅里葉系數, 為信號采樣頻率,N為信號采樣點數目。由PSD可得總功率(total power,TP)、主頻值(main frequency values,MFV)、高頻能量(high frequency energy,HF)、低頻能量(low frequency energy,LF)和超低頻能量(very low frequency energy,VLF)。對于原始信號
為信號采樣頻率,N為信號采樣點數目。由PSD可得總功率(total power,TP)、主頻值(main frequency values,MFV)、高頻能量(high frequency energy,HF)、低頻能量(low frequency energy,LF)和超低頻能量(very low frequency energy,VLF)。對于原始信號 ,它在高通濾波器與低通濾波器中的第
,它在高通濾波器與低通濾波器中的第 階小波節點(j,n)的系數分別為
階小波節點(j,n)的系數分別為 和
和 ,計算過程如式(3)所示:
,計算過程如式(3)所示:
 |
式中, 和
和 分別代表高通濾波器與低通濾波器的系數。假設由
分別代表高通濾波器與低通濾波器的系數。假設由 和
和 重構后的頻帶分量為
重構后的頻帶分量為 ,本研究選取
,本研究選取 隨時間的積分作為小波的能量,第j個頻帶的能量
隨時間的積分作為小波的能量,第j個頻帶的能量 計算過程如式(4)所示,
計算過程如式(4)所示,
 |
由 可得所有頻帶能量的疊加小波能量(wavelet energy,WEn)。
可得所有頻帶能量的疊加小波能量(wavelet energy,WEn)。
部分時頻域特征如下:頻譜中心(spectral center feature of time-frequency map,Centroid)和頻譜寬度(spectral width of time-frequency map,SWidth)的計算過程分別如式(5)和(6)所示,
 |
 |
其中, 和
和 分別是第k個頻率成分和能量,Nf是頻率成分的總數。
分別是第k個頻率成分和能量,Nf是頻率成分的總數。
部分非線性域特征如下:對于任意一段離散的ECG序列 ,通過如下步驟計算樣本熵(sample entropy,SampleEn):
,通過如下步驟計算樣本熵(sample entropy,SampleEn):
(1)選取合適的嵌入維度m,構造向量 :
:
 |
(2)設定容限閾值大小為r,計算兩向量間的距離d和函數 :
:
 |
 |
其中, ,SD為ECG序列的標準差,
,SD為ECG序列的標準差, 為滿足要求的樣本數量。
為滿足要求的樣本數量。
(3)函數 的均值為:
的均值為:
 |
(4)SampleEn為:
 |
1.4 深度學習特征提取
本研究針對一維ECG序列與二維時頻圖分別設計了輕量化的1D CNN和2D CNN,用于獲取時序信息和空間信息[28]。兩者的深度均為4層,卷積的步長均為2,卷積核的數量均為64。1D CNN的卷積核尺寸設置為,前兩層為1 × 11,后兩層為1 × 7;2D CNN的卷積核尺寸設置為,前兩層為5 × 5,后兩層為3 × 3。每層卷積之后依次添加批歸一化層、RELU激活函數和最大池化層(1D CNN和2D CNN中池化窗口分別為1 × 2和2 × 2,步長均為2)。1D CNN和2D CNN的分類層均包含兩層全連接層,第一層的神經元個數為16,第二層的神經元個數為2。其中1D CNN和2D CNN中第一層全連接層的輸出分別為 和
和 ,將
,將 視為ECG的時序特征,記為
視為ECG的時序特征,記為 ~
~ ,將
,將 視為時頻圖的空間特征,記為
視為時頻圖的空間特征,記為 ~
~ 。訓練過程的優化器為Adam,學習率設置為0.001,損失函數為二元交叉熵損失。
。訓練過程的優化器為Adam,學習率設置為0.001,損失函數為二元交叉熵損失。
1.5 特征篩選與預測
本研究基于4種特征排序算法,即最大相關性-最小冗余度(max-relevance and min-redundancy,MRMR)[29]、Chi2[30]、ReliefF[31]和Kruskal-Wallis(KW)[32],以及Pearson相關性分析對多模態特征集合進行特征選擇(feature selection,FS),具體過程參見附件2。首先,分別使用4種特征排序方法對64個特征值進行特征重要性評分 ,并將不同特征排序算法給出的重要性分數進行歸一化
,并將不同特征排序算法給出的重要性分數進行歸一化 。然后,將4種方法對同一個特征的分數相加并取平均值,得到該特征的最終重要性得分
。然后,將4種方法對同一個特征的分數相加并取平均值,得到該特征的最終重要性得分 。接著,設置閾值分數
。接著,設置閾值分數 ,并刪除
,并刪除 小于
小于 的特征。最后,對
的特征。最后,對 大于
大于 的特征進行Pearson相關性分析,保留強相關特征中
的特征進行Pearson相關性分析,保留強相關特征中 最高的特征,并輸入RF進行PAF風險預測。
最高的特征,并輸入RF進行PAF風險預測。
2 結果
2.1 評價指標
本研究基于準確率(accuracy,Acc)[(TP + TN)/(TP + TN + FP + FN)]、特異性(specificity,Spe)[TN/(TN + FP)]、靈敏度(sensitivity,Sen)[TP/(TP + FN)]、精度(precision,Pre)[TP/(TP + FP)]和F1分數(F1 score,F1)評估所提方法的性能。TP為真陽性,TN為真陰性,FN為假陰性,FP為假陽性。
2.2 特征選擇結果
人工提取的32個特征按照附件1中的順序依次編為1~32號,1D CNN的特征 ~
~ 依次編為33~48號,2D CNN的特征
依次編為33~48號,2D CNN的特征 ~
~ 依次編為49~64號。64個特征值的排序結果如圖1所示,結果表明特征重要性排名最高的特征為頻域的VLF,特征重要性排名最低的特征為DL的時頻域特征
依次編為49~64號。64個特征值的排序結果如圖1所示,結果表明特征重要性排名最高的特征為頻域的VLF,特征重要性排名最低的特征為DL的時頻域特征 。經過特征排序之后,本研究將閾值分數
。經過特征排序之后,本研究將閾值分數 設為0.2,并對
設為0.2,并對 大于
大于 的特征(即
的特征(即 較高的前42個特征)進行了相關性分析,只保留了Pearson相關系數小于0.8的非強相關性特征。最終,本研究共選擇了34個特征。其中MF有20個,DL的時域特征有6個,DL的時頻域特征有8個。
較高的前42個特征)進行了相關性分析,只保留了Pearson相關系數小于0.8的非強相關性特征。最終,本研究共選擇了34個特征。其中MF有20個,DL的時域特征有6個,DL的時頻域特征有8個。
 圖1
多模態特征值的排序結果
Figure1.
Ranking results of multimodal feature values
圖1
多模態特征值的排序結果
Figure1.
Ranking results of multimodal feature values
2.3 單中心數據集的患者間結果
本研究分別在AFPDB和SPHDB上驗證了提出的方法在PAF風險預測任務中的性能。在確定了最優特征集后,本研究使用隨機森林(random forest,RF)完成預測。結果發現,當樹的數量為40時,預測的錯誤率達到最低且隨著樹的增加不再發生明顯的改變,所以本研究確定RF樹的數量為40。預測的錯誤率與樹的個數之間關系的完整數據參見附件3。
本研究在單中心數據集的患者間結果如表1所示。在AFPDB中的結果表明,Spe和Sen較為接近并且取得了較好的F1,這說明本研究的方法對PAF風險預測具有較好的泛化性,其應用過程中的誤報率和漏報率均較低。在SPHDB中的結果表明,本研究的方法應用于臨床數據集時保持了與公開數據集幾乎一致的水平,這說明研究方法在PAF風險預測任務中受測試環境、受試者Spe和ECG采集設備差異性的影響較低。綜上所述,本研究的算法在兩個數據集上均表現出了較好的PAF風險預測性能且具有良好的穩定性。
2.4 多中心數據集的患者間結果
本研究進行了跨數據集的患者間實驗,AFPDB和SPHDB輪流作為訓練集和測試集以驗證算法在多中心數據中的泛化性。結果如表2所示,本研究的算法在多中心數據集中具有較好的泛化性。表2的混淆矩陣顯示NR樣本被錯分為R樣本的數量明顯高于R樣本被錯分為NR樣本的數量,這是因為部分NR樣本受噪聲污染較為嚴重從而被誤診為R樣本。PAF的發生主要體現在HRV的變化,噪聲的存在可能會遮蓋微弱的ECG活動,使得HRV的分析變得困難。同時,HRV的計算依賴于準確識別RR間期,噪聲容易導致錯誤識別心跳并且出現錯誤的RR間期數據。
2.5 消融實驗
為了證明多個模態的特征具有相互輔助的作用和FS有助于提高算法的準確性,本研究通過一組消融實驗探討了 、
、 、MF和FS的作用。考慮到不同的分類器適用于不同的特征,本研究在RF的基礎上引入了支持向量機(support vector machine,SVM)和K-最近鄰(K-nearest neighbor,KNN)來提高消融實驗的可信度。消融實驗的結果如圖2所示。結果發現:
、MF和FS的作用。考慮到不同的分類器適用于不同的特征,本研究在RF的基礎上引入了支持向量機(support vector machine,SVM)和K-最近鄰(K-nearest neighbor,KNN)來提高消融實驗的可信度。消融實驗的結果如圖2所示。結果發現:
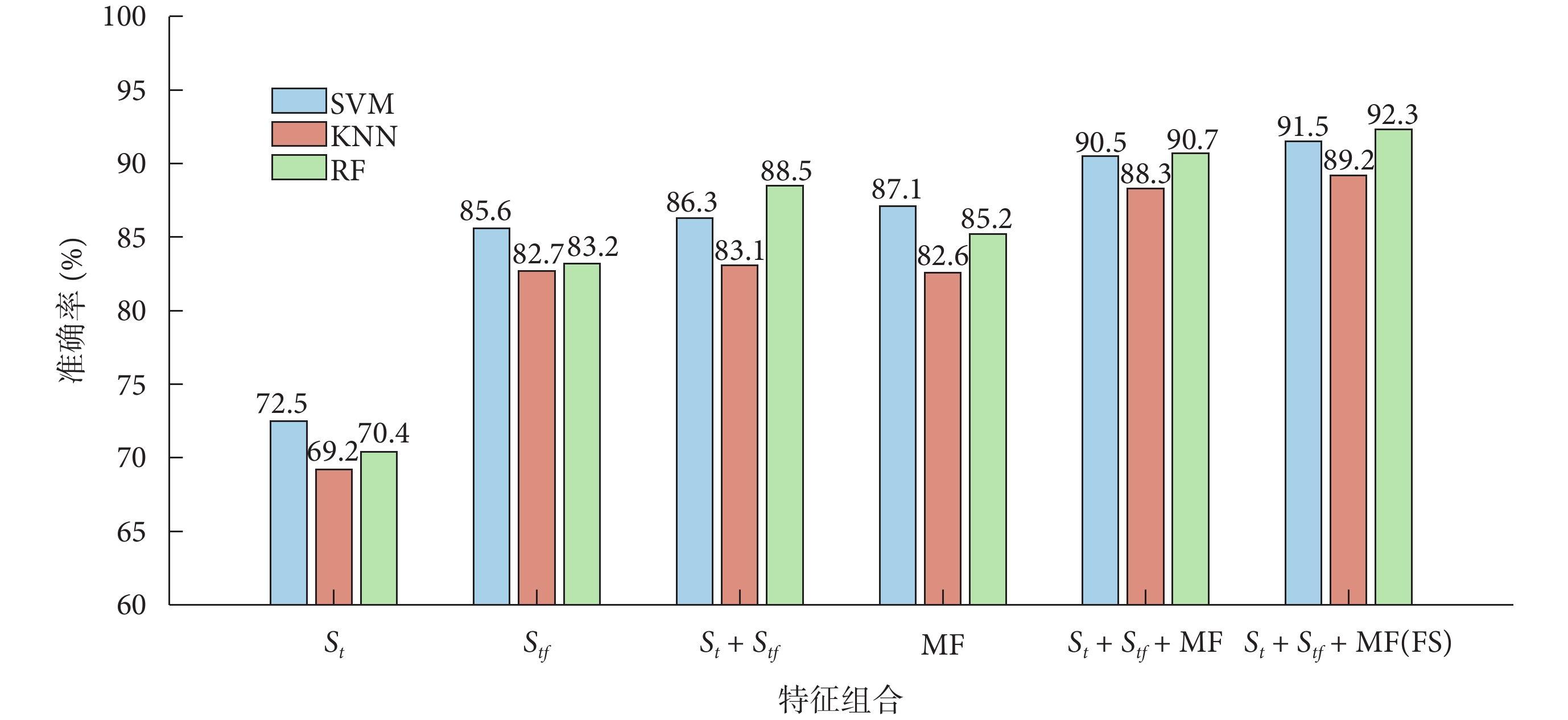
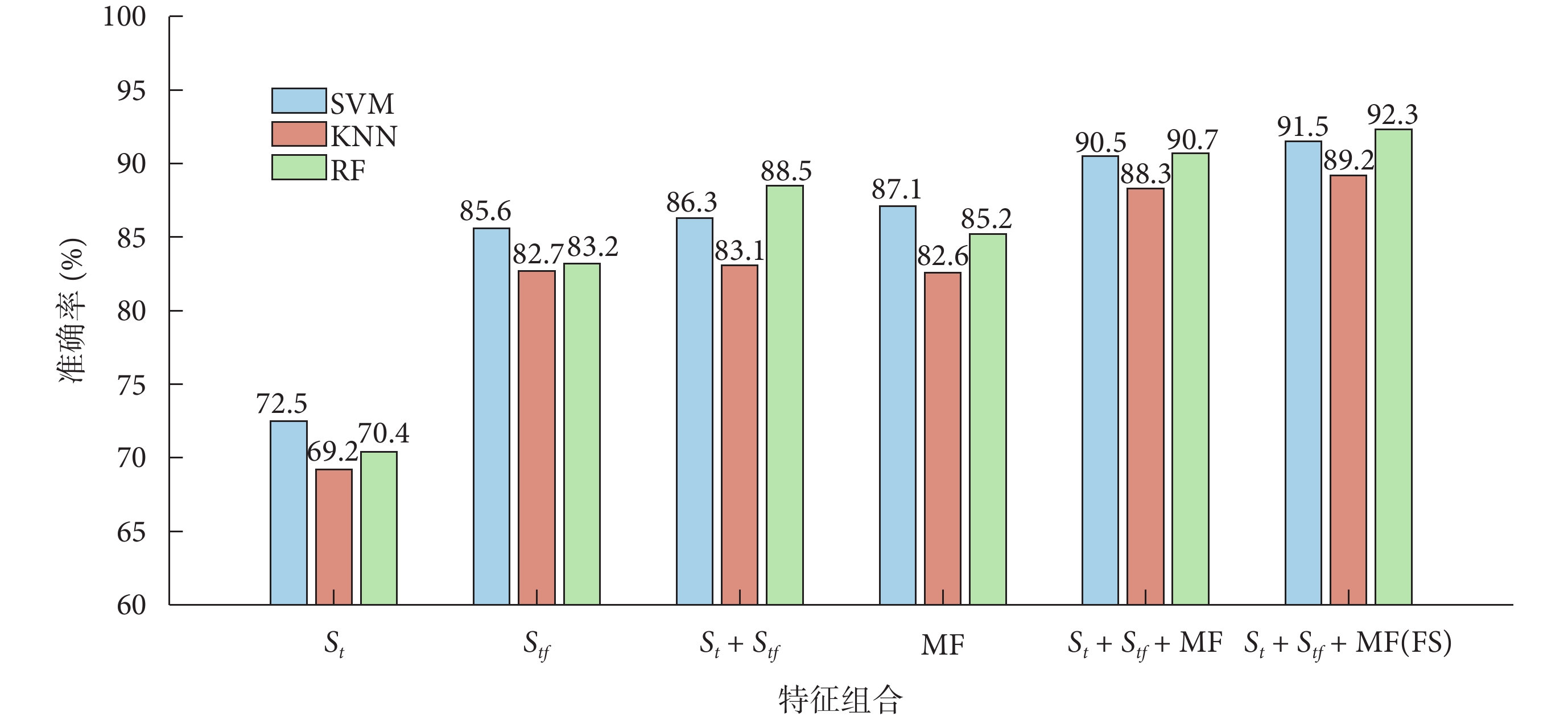 圖2
消融實驗結果
Figure2.
Results of ablation experiments
圖2
消融實驗結果
Figure2.
Results of ablation experiments
(1)僅使用 特征或
特征或 特征時,最高Acc分別達到了72.5%和85.6%,這說明在PAF風險預測任務中僅僅依靠時域信息或者頻域信息難以體現心臟電活動的漸進變換趨勢。
特征時,最高Acc分別達到了72.5%和85.6%,這說明在PAF風險預測任務中僅僅依靠時域信息或者頻域信息難以體現心臟電活動的漸進變換趨勢。
(2)僅使用MF時取得了優于 特征和
特征和 特征的結果,Acc最高達到了87.1%,這說明本研究提取的MF在PAF風險預測中占據主導地位,因此本研究的方法具有良好的可解釋性。
特征的結果,Acc最高達到了87.1%,這說明本研究提取的MF在PAF風險預測中占據主導地位,因此本研究的方法具有良好的可解釋性。
(3)將 特征與
特征與 特征相結合后,Acc最高達到了88.5%,結果要優于僅使用
特征相結合后,Acc最高達到了88.5%,結果要優于僅使用 特征、
特征、 特征或MF,這說明將一維ECG序列的時序特征與二維時頻圖的空間特征相結合有助于提高PAF風險預測的效果。
特征或MF,這說明將一維ECG序列的時序特征與二維時頻圖的空間特征相結合有助于提高PAF風險預測的效果。
(4)在MF的基礎上添加 特征與
特征與 特征后結果最高提升了5.7%,這說明MF與DL特征之間具有信息補充和相互輔助的作用。
特征后結果最高提升了5.7%,這說明MF與DL特征之間具有信息補充和相互輔助的作用。
(5)對多模態特征進行FS之后,Acc最高達到了92.3%。與未經過FS時相比,Acc提升了1.6%,這說明本研究設計的FS方案有助于降低多模態特征的信息冗余并提高算法的泛化性。
3 討論
本研究收集了部分PAF風險預測的文獻作為對比,對比結果如表3所示。文獻[18]中,遞歸分析達到的分類效果最佳,功率譜分析方法次之,近似熵和樣本熵分析、時間序列符號化的效果則不夠理想。其中近似熵和樣本熵的預測效果欠佳,可能是由于采用的數據庫中數據長度有限,得到的估計值和實際情況存在偏差。本研究的準確度和Sen分別比文獻[18]低3.6%和8.3%,Spe比文獻[18]高1.0%,這歸因于本研究基于1 min的ECG片段分析特征,從而確保具有更好的實時性。
文獻[19]通過消息隊列管理ECG數據流,并且考慮了水平部署的可擴展性因素以滿足不斷增長的ECG分析需求。同時,他們使用概率符號模式識別方法提取和分析ECG信號以實現PAF風險預測。本研究的Acc和Sen分別比文獻[19]低2.4%和8.3%,但是Spe比文獻[19]高4.3%。
文獻[23]同樣采用概率符號化模式識別方法,并提出CNN和LSTM的混合模型,用于提取模式轉移特征內隱含的局部空間特征和時間依賴特征。為了提升模型泛化能力,構建了基于混合模型的集成分類器。相比之下,本研究的Spe比文獻[23]低4.8%,但是準確度和Sen分別比文獻[23]高1.0%和10.6%,這說明同樣采用1 min的ECG片段預測PAF時,本研究的性能優于文獻[23]。
另外,本研究對FS后的MF進行了分析。結果發現,重要性排名前10的特征分別為VLF、LF、SEn、Ku、LFPR、Epmean、pNN50、Sk、MRR、SDRRD。重要性最高的特征主要來自頻域,這表明隨著心肌細胞壞死或病變程度的積累,在PAF發生之前,心臟電活動的頻率成分和頻率分布已經發生了改變。在所有的頻域特征中,成分相對穩定且不容易受到外界干擾和噪聲影響的低頻特征表現出最高的重要性。時頻域和非線性域中的熵特征也表現出較高的重要性,這說明了在PAF發生之前,心肌細胞的壞死和病變已經導致心臟電活動的復雜程度、不規則性和混沌行為發生潛在的改變。在心肌細胞的興奮-傳導過程中,竇房結會自發地產生電沖動并引發心房肌肉興奮和收縮,當心肌細胞發生不可逆的壞死與病變時,該過程的電信號將會趨向于復雜和不規則,即熵特征值升高。
本研究尚存在一定的局限性。第一,本研究雖然采用機器學習特征與深度學習特征相結合的方式提高了預測的性能,但是受限于深度學習的“黑盒”機制,未能給出深度學習特征的具體物理意義。第二,本研究的算法對于存在嚴重噪聲干擾的NR片段會出現一定的誤診情況。第三,本研究雖然實現了7種模態的特征融合,但是受數據庫的限制,未能探究患者的臨床信息(病史、用藥記錄和生理指標等)在PAF風險預測中的作用。
4 結論
本研究在ML的時域、頻域、時頻域、非線性域和形態學特征的基礎上,引入了DL提取的時序信息和空間信息,解決了ML先驗知識不足所導致的信息遺漏問題和DL在多中心數據中泛化性較低的問題。本研究將MRMR、Chi2、ReliefF和KW四種特征排序方式和Pearson相關性分析相結合,通過實現多模態特征的選擇降低了信息冗余問題造成的過擬合現象。本研究使用較短的ECG序列實現了可靠的PAF風險預測,并在多中心數據中表現出良好的泛化性。另外,本研究構建了一個用于PAF預測的臨床數據集以供其他研究者使用。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:李永建是本研究數學模型構建、實驗方案的設計人和執行人,完成數據分析以及論文初稿的寫作和修改;劉磊和魏守水是模型構建和實驗設計參與人,以及實驗數據的提供人;陳蒙、李逸學、王雨辰、魏守水指導論文寫作,提出修改意見。
倫理聲明:本研究通過了山東省立醫院倫理委員會的審批(批文編號:SZRJJ:NO.2022-0.38)。
本文附件見本刊網站的電子版本(biomedeng.cn)。
0 引言
心房顫動(atrial fibrillation,AF)是導致中風、腦卒中和猝死的重要原因[1]。AF早期表現為具有陣發性與偶發性特點的陣發性房顫(paroxysmal atrial fibrillation,PAF),僅有極少數患者被發現而進入臨床干預階段[2]。PAF得不到及時的干預,將演變為持續性AF或永久性AF[3-4]。由于PAF具有陣發性與偶發性,使用常規的心電信號(electrocardiogram,ECG)難以預測。隨著穿戴式的長程心電監護設備在臨床上得到應用,長程ECG為PAF的預測提供了數據基礎。同時,臨床上探索出了許多與PAF發生相關的潛在指標[5-7]。
在機器學習(machine learning,ML)領域中,許多研究從ECG中提取時域、頻域和非線性域等特征來預測PAF發生的風險[8-9]。Thong等[10-11]綜合分析了房性早搏的數量、心動過速的節拍數量和早發性心房復合體的特征。Hickey等[12]在房性早搏的基礎上引入了功率譜密度(power spectral density,PSD)。De Chazal等[13]則是將RR間期的PSD和P波的PSD作為PAF風險的潛在特征。隨著心率變異性(heart rate variability,HRV)表現出顯著的重要性,Boon等[14-15]分別在單一時間尺度和多時間尺度上分析了ECG的HRV特征。Mohebbi等[16]和Narin等[17]將HRV的線性特征和非線性特征相結合。蘭天杰等[18]對HRV特征進行了PSD、近似熵和樣本熵等分析。
在深度學習(deep learning,DL)研究領域,Sutton等[19]借助長短時記憶網絡(long and short-term memory networks,LSTM)獲取了ECG的時序信息。Mendez等[20]使用二維卷積神經網絡(two-dimensional convolutional neural network,2D CNN)對特征矩陣進行學習以探究龐加萊圖的空間信息。Erdenebayar等[21]利用一維卷積神經網絡(1D CNN)和全連接對多個時間尺度下的ECG片段進行分析。Attia等[22]利用由10個殘差模塊構成的CNN對12導聯的竇性ECG記錄進行同步分析。楊萍等[23]基于CNN與LSTM提出了一種多路徑的復合型神經網絡。
基于特征工程的ML算法具有明確的臨床意義和可解釋性,但是難以全面獲取ECG中的PAF隱式信息[24]。基于端到端建模的DL算法省略了預處理和人工提取特征的過程,但是它獲取的特征受限于特定的數據集,難以實現多中心數據的泛化[25-26]。
本研究綜合了ML的特征工程和DL端到端建模的優勢,提出了多模態特征融合的PAF風險預測方法。本研究的優勢為:機器學習特征(machine learning feature,MF)為DL模型增加了可解釋性,DL模型的應用則增強了ML中ECG信息的多層次表示,兩者結合強化了整體方法對非線性的高維數據的擬合能力并提高了PAF風險預測的泛化性。同時,本研究采用多種重要性排序和相關性分析實現結果投票,從而增強特征排序和選擇的可靠性。
1 材料和方法
1.1 數據集
本研究使用了陣發性房顫預測挑戰賽數據集(PAF Prediction Challenge Database,AFPDB)[8]和山東省立醫院的臨床數據庫(Shandong Provincial Hospital Database,SPHDB)。AFPDB包含了50位正常人的ECG數據和25位PAF患者的ECG數據。所有記錄的時長均為30 min,采樣率均為128 Hz。將正常人的片段視為無PAF發生風險的ECG片段,記為NR片段;將PAF患者的記錄均視為有PAF發生風險的ECG片段,記為R片段。
本研究以AFPDB的數據處理方式為標準,從山東省立醫院收集了100條臨床數據構建了SPHDB。其中50條記錄來自正常人,50條記錄來自PAF患者,兩組記錄分別被標記為NR片段和R片段。所有的記錄時長為30 min,采樣率為200 Hz。實驗方案已經獲得山東省立醫院倫理委員會的批準。
1.2 預處理
首先,使用截止頻率為80 Hz的低通濾波器對肌電干擾進行去除[27]。然后,使用陷波器對工頻干擾進行去除(針對AFPDB和SPHDB,諧振頻率分別設置為60 Hz和50 Hz)。最后,使用db6小波對所有的ECG進行9階分解,刪除D1、D2和A9分量以去除基線漂移[28]。去噪后的ECG統一重采樣為200 Hz并分割為無重疊的1 min的片段。
1.3 機器學習特征提取
PAF發生時ECG的基本特征表現為:P波消失或異常不規則、F波出現、RR間期絕對不整、基線消失、心室波形不規則或無法確定電極軸等。ECG是由心肌細胞的電活動產生的,心肌細胞一旦發生壞死或病變則無法再生與修復。本研究假設:在PAF發生之前,部分心肌細胞的壞死或病變已經導致ECG出現異常。對此,本研究提取了32個人工特征,具體內容參見附件1。
部分頻域特征如下:若連續ECG的函數表達式為,其離散傅里葉變換如式(1)所示,
|
則的PSD計算過程如式(2)所示,
|
其中,為傅里葉系數,為信號采樣頻率,N為信號采樣點數目。由PSD可得總功率(total power,TP)、主頻值(main frequency values,MFV)、高頻能量(high frequency energy,HF)、低頻能量(low frequency energy,LF)和超低頻能量(very low frequency energy,VLF)。對于原始信號,它在高通濾波器與低通濾波器中的第階小波節點(j,n)的系數分別為和,計算過程如式(3)所示:
|
式中,和分別代表高通濾波器與低通濾波器的系數。假設由和重構后的頻帶分量為,本研究選取隨時間的積分作為小波的能量,第j個頻帶的能量計算過程如式(4)所示,
|
由可得所有頻帶能量的疊加小波能量(wavelet energy,WEn)。
部分時頻域特征如下:頻譜中心(spectral center feature of time-frequency map,Centroid)和頻譜寬度(spectral width of time-frequency map,SWidth)的計算過程分別如式(5)和(6)所示,
|
|
其中,和分別是第k個頻率成分和能量,Nf是頻率成分的總數。
部分非線性域特征如下:對于任意一段離散的ECG序列,通過如下步驟計算樣本熵(sample entropy,SampleEn):
(1)選取合適的嵌入維度m,構造向量:
|
(2)設定容限閾值大小為r,計算兩向量間的距離d和函數:
|
|
其中,,SD為ECG序列的標準差,為滿足要求的樣本數量。
(3)函數的均值為:
|
(4)SampleEn為:
|
1.4 深度學習特征提取
本研究針對一維ECG序列與二維時頻圖分別設計了輕量化的1D CNN和2D CNN,用于獲取時序信息和空間信息[28]。兩者的深度均為4層,卷積的步長均為2,卷積核的數量均為64。1D CNN的卷積核尺寸設置為,前兩層為1 × 11,后兩層為1 × 7;2D CNN的卷積核尺寸設置為,前兩層為5 × 5,后兩層為3 × 3。每層卷積之后依次添加批歸一化層、RELU激活函數和最大池化層(1D CNN和2D CNN中池化窗口分別為1 × 2和2 × 2,步長均為2)。1D CNN和2D CNN的分類層均包含兩層全連接層,第一層的神經元個數為16,第二層的神經元個數為2。其中1D CNN和2D CNN中第一層全連接層的輸出分別為和,將視為ECG的時序特征,記為~,將視為時頻圖的空間特征,記為~。訓練過程的優化器為Adam,學習率設置為0.001,損失函數為二元交叉熵損失。
1.5 特征篩選與預測
本研究基于4種特征排序算法,即最大相關性-最小冗余度(max-relevance and min-redundancy,MRMR)[29]、Chi2[30]、ReliefF[31]和Kruskal-Wallis(KW)[32],以及Pearson相關性分析對多模態特征集合進行特征選擇(feature selection,FS),具體過程參見附件2。首先,分別使用4種特征排序方法對64個特征值進行特征重要性評分,并將不同特征排序算法給出的重要性分數進行歸一化。然后,將4種方法對同一個特征的分數相加并取平均值,得到該特征的最終重要性得分。接著,設置閾值分數,并刪除小于的特征。最后,對大于的特征進行Pearson相關性分析,保留強相關特征中最高的特征,并輸入RF進行PAF風險預測。
2 結果
2.1 評價指標
本研究基于準確率(accuracy,Acc)[(TP + TN)/(TP + TN + FP + FN)]、特異性(specificity,Spe)[TN/(TN + FP)]、靈敏度(sensitivity,Sen)[TP/(TP + FN)]、精度(precision,Pre)[TP/(TP + FP)]和F1分數(F1 score,F1)評估所提方法的性能。TP為真陽性,TN為真陰性,FN為假陰性,FP為假陽性。
2.2 特征選擇結果
人工提取的32個特征按照附件1中的順序依次編為1~32號,1D CNN的特征~依次編為33~48號,2D CNN的特征~依次編為49~64號。64個特征值的排序結果如圖1所示,結果表明特征重要性排名最高的特征為頻域的VLF,特征重要性排名最低的特征為DL的時頻域特征。經過特征排序之后,本研究將閾值分數設為0.2,并對大于的特征(即較高的前42個特征)進行了相關性分析,只保留了Pearson相關系數小于0.8的非強相關性特征。最終,本研究共選擇了34個特征。其中MF有20個,DL的時域特征有6個,DL的時頻域特征有8個。
圖1
多模態特征值的排序結果
Figure1.
Ranking results of multimodal feature values
2.3 單中心數據集的患者間結果
本研究分別在AFPDB和SPHDB上驗證了提出的方法在PAF風險預測任務中的性能。在確定了最優特征集后,本研究使用隨機森林(random forest,RF)完成預測。結果發現,當樹的數量為40時,預測的錯誤率達到最低且隨著樹的增加不再發生明顯的改變,所以本研究確定RF樹的數量為40。預測的錯誤率與樹的個數之間關系的完整數據參見附件3。
本研究在單中心數據集的患者間結果如表1所示。在AFPDB中的結果表明,Spe和Sen較為接近并且取得了較好的F1,這說明本研究的方法對PAF風險預測具有較好的泛化性,其應用過程中的誤報率和漏報率均較低。在SPHDB中的結果表明,本研究的方法應用于臨床數據集時保持了與公開數據集幾乎一致的水平,這說明研究方法在PAF風險預測任務中受測試環境、受試者Spe和ECG采集設備差異性的影響較低。綜上所述,本研究的算法在兩個數據集上均表現出了較好的PAF風險預測性能且具有良好的穩定性。
2.4 多中心數據集的患者間結果
本研究進行了跨數據集的患者間實驗,AFPDB和SPHDB輪流作為訓練集和測試集以驗證算法在多中心數據中的泛化性。結果如表2所示,本研究的算法在多中心數據集中具有較好的泛化性。表2的混淆矩陣顯示NR樣本被錯分為R樣本的數量明顯高于R樣本被錯分為NR樣本的數量,這是因為部分NR樣本受噪聲污染較為嚴重從而被誤診為R樣本。PAF的發生主要體現在HRV的變化,噪聲的存在可能會遮蓋微弱的ECG活動,使得HRV的分析變得困難。同時,HRV的計算依賴于準確識別RR間期,噪聲容易導致錯誤識別心跳并且出現錯誤的RR間期數據。
2.5 消融實驗
為了證明多個模態的特征具有相互輔助的作用和FS有助于提高算法的準確性,本研究通過一組消融實驗探討了、、MF和FS的作用。考慮到不同的分類器適用于不同的特征,本研究在RF的基礎上引入了支持向量機(support vector machine,SVM)和K-最近鄰(K-nearest neighbor,KNN)來提高消融實驗的可信度。消融實驗的結果如圖2所示。結果發現:
圖2
消融實驗結果
Figure2.
Results of ablation experiments
(1)僅使用特征或特征時,最高Acc分別達到了72.5%和85.6%,這說明在PAF風險預測任務中僅僅依靠時域信息或者頻域信息難以體現心臟電活動的漸進變換趨勢。
(2)僅使用MF時取得了優于特征和特征的結果,Acc最高達到了87.1%,這說明本研究提取的MF在PAF風險預測中占據主導地位,因此本研究的方法具有良好的可解釋性。
(3)將特征與特征相結合后,Acc最高達到了88.5%,結果要優于僅使用特征、特征或MF,這說明將一維ECG序列的時序特征與二維時頻圖的空間特征相結合有助于提高PAF風險預測的效果。
(4)在MF的基礎上添加特征與特征后結果最高提升了5.7%,這說明MF與DL特征之間具有信息補充和相互輔助的作用。
(5)對多模態特征進行FS之后,Acc最高達到了92.3%。與未經過FS時相比,Acc提升了1.6%,這說明本研究設計的FS方案有助于降低多模態特征的信息冗余并提高算法的泛化性。
3 討論
本研究收集了部分PAF風險預測的文獻作為對比,對比結果如表3所示。文獻[18]中,遞歸分析達到的分類效果最佳,功率譜分析方法次之,近似熵和樣本熵分析、時間序列符號化的效果則不夠理想。其中近似熵和樣本熵的預測效果欠佳,可能是由于采用的數據庫中數據長度有限,得到的估計值和實際情況存在偏差。本研究的準確度和Sen分別比文獻[18]低3.6%和8.3%,Spe比文獻[18]高1.0%,這歸因于本研究基于1 min的ECG片段分析特征,從而確保具有更好的實時性。
文獻[19]通過消息隊列管理ECG數據流,并且考慮了水平部署的可擴展性因素以滿足不斷增長的ECG分析需求。同時,他們使用概率符號模式識別方法提取和分析ECG信號以實現PAF風險預測。本研究的Acc和Sen分別比文獻[19]低2.4%和8.3%,但是Spe比文獻[19]高4.3%。
文獻[23]同樣采用概率符號化模式識別方法,并提出CNN和LSTM的混合模型,用于提取模式轉移特征內隱含的局部空間特征和時間依賴特征。為了提升模型泛化能力,構建了基于混合模型的集成分類器。相比之下,本研究的Spe比文獻[23]低4.8%,但是準確度和Sen分別比文獻[23]高1.0%和10.6%,這說明同樣采用1 min的ECG片段預測PAF時,本研究的性能優于文獻[23]。
另外,本研究對FS后的MF進行了分析。結果發現,重要性排名前10的特征分別為VLF、LF、SEn、Ku、LFPR、Epmean、pNN50、Sk、MRR、SDRRD。重要性最高的特征主要來自頻域,這表明隨著心肌細胞壞死或病變程度的積累,在PAF發生之前,心臟電活動的頻率成分和頻率分布已經發生了改變。在所有的頻域特征中,成分相對穩定且不容易受到外界干擾和噪聲影響的低頻特征表現出最高的重要性。時頻域和非線性域中的熵特征也表現出較高的重要性,這說明了在PAF發生之前,心肌細胞的壞死和病變已經導致心臟電活動的復雜程度、不規則性和混沌行為發生潛在的改變。在心肌細胞的興奮-傳導過程中,竇房結會自發地產生電沖動并引發心房肌肉興奮和收縮,當心肌細胞發生不可逆的壞死與病變時,該過程的電信號將會趨向于復雜和不規則,即熵特征值升高。
本研究尚存在一定的局限性。第一,本研究雖然采用機器學習特征與深度學習特征相結合的方式提高了預測的性能,但是受限于深度學習的“黑盒”機制,未能給出深度學習特征的具體物理意義。第二,本研究的算法對于存在嚴重噪聲干擾的NR片段會出現一定的誤診情況。第三,本研究雖然實現了7種模態的特征融合,但是受數據庫的限制,未能探究患者的臨床信息(病史、用藥記錄和生理指標等)在PAF風險預測中的作用。
4 結論
本研究在ML的時域、頻域、時頻域、非線性域和形態學特征的基礎上,引入了DL提取的時序信息和空間信息,解決了ML先驗知識不足所導致的信息遺漏問題和DL在多中心數據中泛化性較低的問題。本研究將MRMR、Chi2、ReliefF和KW四種特征排序方式和Pearson相關性分析相結合,通過實現多模態特征的選擇降低了信息冗余問題造成的過擬合現象。本研究使用較短的ECG序列實現了可靠的PAF風險預測,并在多中心數據中表現出良好的泛化性。另外,本研究構建了一個用于PAF預測的臨床數據集以供其他研究者使用。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:李永建是本研究數學模型構建、實驗方案的設計人和執行人,完成數據分析以及論文初稿的寫作和修改;劉磊和魏守水是模型構建和實驗設計參與人,以及實驗數據的提供人;陳蒙、李逸學、王雨辰、魏守水指導論文寫作,提出修改意見。
倫理聲明:本研究通過了山東省立醫院倫理委員會的審批(批文編號:SZRJJ:NO.2022-0.38)。
本文附件見本刊網站的電子版本(biomedeng.cn)。