阿爾茨海默癥(AD)分類模型通常會將整張大腦影像分割為體素塊,并為之賦予與整張影像一致的標簽,但并非每個體素塊都與疾病密切相關。為此,本研究提出了基于弱監督多示例學習(MIL)和多尺度特征融合的AD輔助診斷框架,并從體素塊內部、體素塊之間以及高置信度體素塊三個方面設計框架。首先利用三維卷積神經網絡并融入多視角網絡,提取體素塊內部的深層次特征;再通過位置編碼和注意力機制捕捉體素塊間的空間關聯信息;最后篩選高置信度體素塊并結合多尺度信息融合策略,整合關鍵特征用于分類決策。模型分別在AD神經成像倡議(ADNI)數據集和開放獲取系列成像研究(OASIS)數據集上進行性能評估。實驗結果表明,所提框架在AD分類以及輕度認知障礙轉化分類兩項任務中,相較于其他主流框架,ACC及AUC分別平均提升了3%和4%,且可尋找到觸發疾病的關鍵體素塊,為AD輔助診斷提供了有效依據。
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
阿爾茨海默癥(Alzheimer’s disease,AD)是一種漸進式神經退行性變疾病,主要特征是記憶衰退和認知功能障礙。由于尚無能夠完全治愈AD的藥物,因此研究重心轉移至AD早期診斷[1],及時發現病癥并采取相應的治療措施,以減緩記憶衰退和認知功能障礙的進展。
AD患者的大腦結構易發生變化[2-3],而結構磁共振成像(structural magnetic resonance imaging,sMRI)有助于捕捉腦組織的細微結構變化[4-5],且具有空間分辨率高、非侵入性、無需對比劑、床易獲得等優勢,已成為AD研究中的主流影像技術之一。為了輔助醫生進行診斷決策和從sMRI的角度分析AD的成因和進展,研究者使用機器學習和深度學習分析AD患者疾病進展并對患者的健康狀況評估,彌補醫生在大量病理數據前主觀預測的不足和其他神經心理測試的不穩定性[6]。
基于體素塊級的sMRI診斷方法,作為體素級[7]與腦區級[8-10]分析的中間尺度,能夠更有效地捕捉sMRI圖像中的局部結構變化[11-15]。文獻[12]采用層級全卷積神經網絡(hierarchical fully convolutional network,H-FCN)為每個體素塊生成概率圖,具有良好的可解釋性;本團隊同時也基于體素塊級的三維卷積神經網絡(3-dimensional convolutional neural network,3D-CNN)模型推導發現了AD的大腦神經退化進展[14]。但由于大腦影像僅由單一標簽(例如:患者/正常)或粗略給出感興趣區域(region of interest,ROI)來描述,上述多種方法直接將標簽賦予整張影像分割后的體素塊,忽略了患者大腦中同樣存在正常區域[16],并非所有體素塊都發生病變。為此研究者將多示例學習(multiple instance learning,MIL)應用于AD診斷任務。文獻[17]提出的多示例模型通過提取高置信度體素塊特征,進行分類和輕度認知障礙轉化預測,但未考慮體素塊間的關聯性,忽略了大腦整體結構信息。文獻[18]提出一種雙注意多示例深度學習網絡,通過空間注意機制提取單個體素塊的判別特征,并以得分作為權重。然而,該方法僅關注單個體素塊特征,未充分利用體素塊的空間位置信息。此外,上述方法主要聚焦較大病變區域,對微小但關鍵病變的識別和細粒度信息的有效聚合能力不足。
為了在保留大腦影像整體結構位置信息的同時,更精確地定位和分析微小病變區域,本文提出了基于多示例學習和多尺度特征融合(multi-scale feature fusion,MSFF)的AD診斷框架。首先,對sMRI數據進行預處理并提取體素塊內部特征。再針對體素塊空間位置關聯信息,使用位置編碼與注意力機制捕捉。最后基于高權重體素塊采用多尺度特征融合策略,以期從細微層次上提取更為精確的信息來完成分類任務。
1 實驗方法
1.1 數據預處理
sMRI圖像預處理:本文使用SPM12軟件的CAT12工具箱對圖像進行預處理,包括空間分割、去顱骨、配準到標準的蒙特利爾神經學研究所空間。預處理后的圖像尺寸為121 × 145 × 121(X × Y × Z),空間分辨率為2 mm × 2 mm × 2 mm/體素。同時在預處理的影像基礎上進行不重疊切割(N × N × N)分為若干體素塊,并去除掉背景部分,以及對所有切割后的體素塊嚴格熵篩選,最終組成模型所需輸入。
1.2 多示例學習
本研究基于多示例學習并遵循文獻[16]設計,將整張大腦影像視為一個包,體素塊作為示例。若任一體素塊的標簽為1(病變區域),則影像標簽為1;若所有體素塊標簽為0(正常),則影像標簽為0,見式(1)。盡管無法直接獲取體素塊的真實標簽,但若某體素塊對診斷結果影響顯著,可推測它為病變區域。
 |
上式中的 表示包標簽,
表示包標簽, 表示示例標簽。
表示示例標簽。
1.3 整體框架
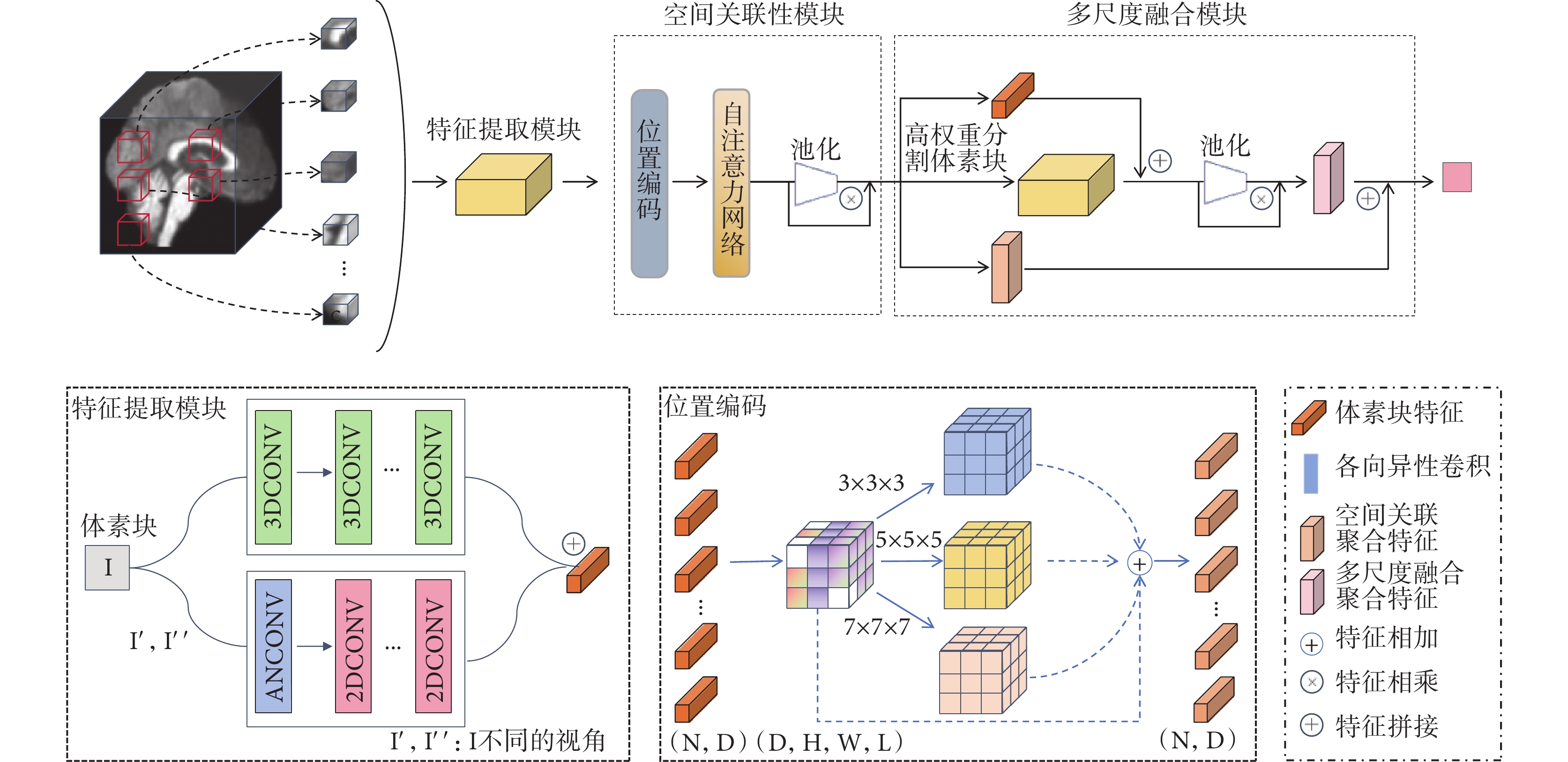
本文旨在構建基于sMRI數據的輔助診斷分類框架,如圖1所示。該框架涵蓋三個關鍵模塊:融入多視角特征提取模塊-體素塊內部、空間關聯性模塊-體素塊間、多尺度融合模塊-高置信度體素塊。框架模型遵循式(2)設計[19-20],研究重點聚焦于這三個模塊的組合,融入多視角特征提取模塊 和空間關聯性模塊與多尺度融合模塊組成的函數
和空間關聯性模塊與多尺度融合模塊組成的函數 。具體而言,優化
。具體而言,優化 以深入提取體素塊內部特征,增強
以深入提取體素塊內部特征,增強 捕捉體素塊空間位置關聯能力,同時通過多尺度機制整合關鍵體素塊信息,生成用于
捕捉體素塊空間位置關聯能力,同時通過多尺度機制整合關鍵體素塊信息,生成用于 分類的最終特征表示。
分類的最終特征表示。
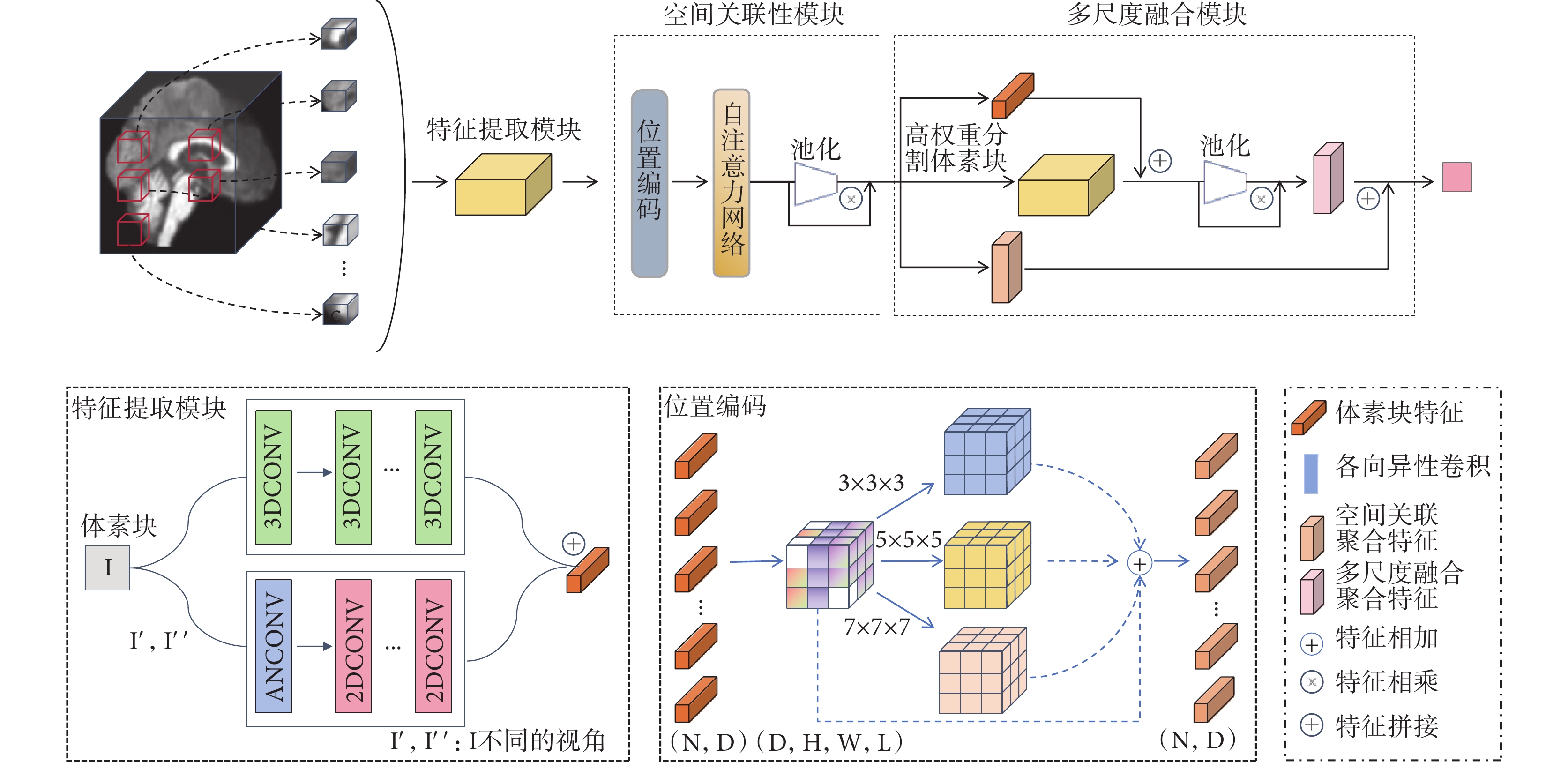 圖1
整體框架
Figure1.
Overall framework
圖1
整體框架
Figure1.
Overall framework
 |
上式中 表示整張影像,
表示整張影像, 表示體素塊。
表示體素塊。
1.3.1 融入多視角特征提取
在文獻[11-15]中,3D-CNN已廣泛應用于提取體素塊特征。在多示例學習框架下,所有體素塊特征提取共享同一套網絡參數,這要求網絡具備更強的泛化能力和魯棒性。為此,本文基于3D-CNN并結合多視角特征提取網絡,如圖1所示的特征提取模塊,通過深度挖掘體素塊特征,進一步提升模型的特征表達能力和分類性能。
具體來說,3DCNN由三個卷積塊、兩個中間最大池化層以及一個全連接層組成。卷積塊包含兩個卷積層,并添加歸一化層和ReLU激活函數,以加速訓練防止梯度爆炸。多視角網絡結構受文獻[21-22]啟發,將三維體素塊旋轉翻轉后經過三層各向異性卷積層(即在不同方向上具有不同尺寸的卷積核)投影到二維空間。每個視角獲取的二維投影送入二維特征提取網絡,以捕獲體素塊在不同視角和維度下的特征信息,并與三維特征融合,形成最終特征表示。
1.3.2 空間關聯性模塊
在多示例研究中,關于包中示例與整個包之間關系的假設有兩種觀點:一是包中示例獨立同分布,彼此之間沒有關聯[20];二是示例之間存在相關性,尤其在病理學研究中更為顯著[21, 23]。本文基于sMRI構建AD診斷框架,且腦組織萎縮區域在空間上存在關聯性[14, 23],因此遵循第二種假設。
因此,本文設計了基于位置編碼和注意力網絡的空間關聯性模塊,如圖1所示。首先將所有體素塊特征表示還原至原始大腦影像空間位置,這依賴于體素塊最初選取時的有序性。隨之運用不同尺寸的卷積核執行分組卷積,為每個體素塊嵌入空間位置信息。最后,將嵌入位置信息的特征與原始特征進行殘差連接以保留原始特征。
本文在實驗中考慮了絕對位置和相對位置兩種編碼方式。絕對位置編碼[24]將體素特征完全還原至原空間位置,未選中的位置用0填充;相對位置編碼[21]則僅建立被選中體素塊間的位置關系。鑒于多示例網絡的輸入為長度不固定的序列,本文實驗采用了相對位置編碼,并在后續實驗章節中對兩種編碼方式的性能進行了比較。
嵌入位置編碼信息后,使用自注意力網絡[24-25]實現體素塊間信息交匯,捕獲示例間的關聯關系。選擇自注意力網絡的原因在于它能夠根據特征之間的相似性,動態調整各體素塊的重要性,更有效地捕獲全局上下文關系,提高體素塊間的關聯建模能力。
最終需要聚合所有體素塊特征生成整張影像的特征表示。平均池化和最大池化雖然是常用的聚合方法,但由于它們參數固定無法通過網絡自身進行優化,也無法有效捕捉各示例貢獻,因此,本文采用基于注意力的池化聚合函數[20],通過可學習的注意力網絡為每個體素塊分配權重,且保證權重總和為1,確保對不同大小的特征包具有不變性。聚合特征通過體素塊特征與相應權重進行矩陣乘法得到。
1.3.3 多尺度融合模塊
空間關聯性模塊已初步實現式(2)中的 函數,但為了進一步精確定位和分析微小病變區域,本文設計了多尺度融合模塊。受文獻[19, 26]啟發,本文通過選擇高權重示例及其特征構建多尺度融合模塊,以排除低貢獻體素塊,從而獲得更具代表性的影像特征,提升模型置信度與性能。如圖1多尺度融合模塊所示,與傳統多尺度方法相比,并未在數據輸入階段處理多個支路的不同尺寸數據流,從而有效地避免了額外的計算開銷[27-28]。
函數,但為了進一步精確定位和分析微小病變區域,本文設計了多尺度融合模塊。受文獻[19, 26]啟發,本文通過選擇高權重示例及其特征構建多尺度融合模塊,以排除低貢獻體素塊,從而獲得更具代表性的影像特征,提升模型置信度與性能。如圖1多尺度融合模塊所示,與傳統多尺度方法相比,并未在數據輸入階段處理多個支路的不同尺寸數據流,從而有效地避免了額外的計算開銷[27-28]。
具體來說,基于空間關聯性模塊獲取的權重信息,引入超參數Top-K,選擇權重值前K的體素塊(N × N × N)。每個體素塊被切割成尺寸更小的子體素塊(N / 2 × N / 2 × N / 2),特征提取流程與父體素塊一致,最后將所有子體素塊特征與父體素塊特征融合。融合后的特征不僅用于構建代表影像的聚合特征,還用于計算每個融合特征的權重貢獻值。該方法旨在通過更細粒度的區域劃分,提供新的診斷依據,從而顯著提升模型對陽性樣本的識別能力。
基于上述方法,框架能夠提取兩類影像聚合特征:一類由空間關聯性模塊生成,另一類通過多尺度融合模塊獲得。兩種特征相結合,構成完整的影像特征表示,用于最終分類任務。
2 實驗數據與結果分析
2.1 數據集介紹
本研究從阿爾茨海默癥神經影像倡議(Alzheimer’s Disease Neuroimaging Initiative,ADNI)數據庫收集了1 531名年齡在55~90歲受試者的sMRI影像,將影像分為AD患者、正常對照組(healthy controls,HC)、輕度認知障礙者轉化為AD(progressive mild cognitive impairment,pMCI)以及輕度認知障礙者未轉化為AD(stable mild cognitive impairment,sMCI),具體細節見表1。針對每名受試者,選取約三個時間點的影像用于訓練和驗證。為避免數據泄露,實驗以受試者為單位進行數據集劃分,即同一受試者的影像只能出現在訓練集、驗證集或測試集中的一個。采用五折交叉驗證策略進行超參數選擇和模型訓練測試,并在開放獲取系列成像研究(Open Access Series of Imaging Studies,OASIS)數據集上評估模型的多中心泛化能力。
2.2 參數設置和評價指標
在實驗參數中學習率設定為0.5e-6并結合調度器動態調整。Dropout為0.5,權重衰減系數為0.000 5,損失函數采用交叉熵,優化器為Adam。父體素塊尺寸為30,Top-K初始化為20。模型性能評價采用四項指標:準確率(accuracy,ACC)、靈敏度(sensitive,SEN)、特異性(specificity,SPE)和曲線下面積(area under curve,AUC)。
2.3 對比實驗
為驗證本文方法的有效性,將提出的網絡模型與以下方法進行對比:① 3DCNN+ROI[29]:利用3DCNN結合ROI進行AD計算機輔助診斷。② 3DCNN+EL+GA[8]:基于3DCNN和ROI,并結合遺傳算法(genetic algorithm,GA)識別對分類有顯著貢獻的腦區。③ HFCN[28]:采用H-FCN自動識別局部判別性體素塊,并結合多尺度特征進行分類。④ DMIL[19]:基于嚴格多示例框架的端到端模型,以體素塊為示例,同時獲取其權重。⑤ DA-MIDL[18]:通過體素塊的全局最大池化、平均池化及多示例池化等操作,獲取體素塊貢獻度并構建分類模型。⑥ 本文方法(Ours):基于多示例學習框架,融合體素塊的多視角特征、位置信息,利用多示例池化和多尺度融合等機制,提升分類性能并優化權重貢獻度計算。
2.4 實驗結果
表2展示了本文方法與其他主流方法在AD分類和輕度認知障礙患者轉化預測任務中的性能對比。與現有方法相比,本文方法顯著提升了SEN,有效降低了漏診率,表明它對疾病相關大腦結構變化更具敏感性。
為評估模型泛化能力,本文在OASIS數據集上進行了AD分類實驗,結果如表3所示。盡管在OASIS測試集上的性能略有下降,但整體表現依然良好。
2.5 高權重的可鑒別性體素塊
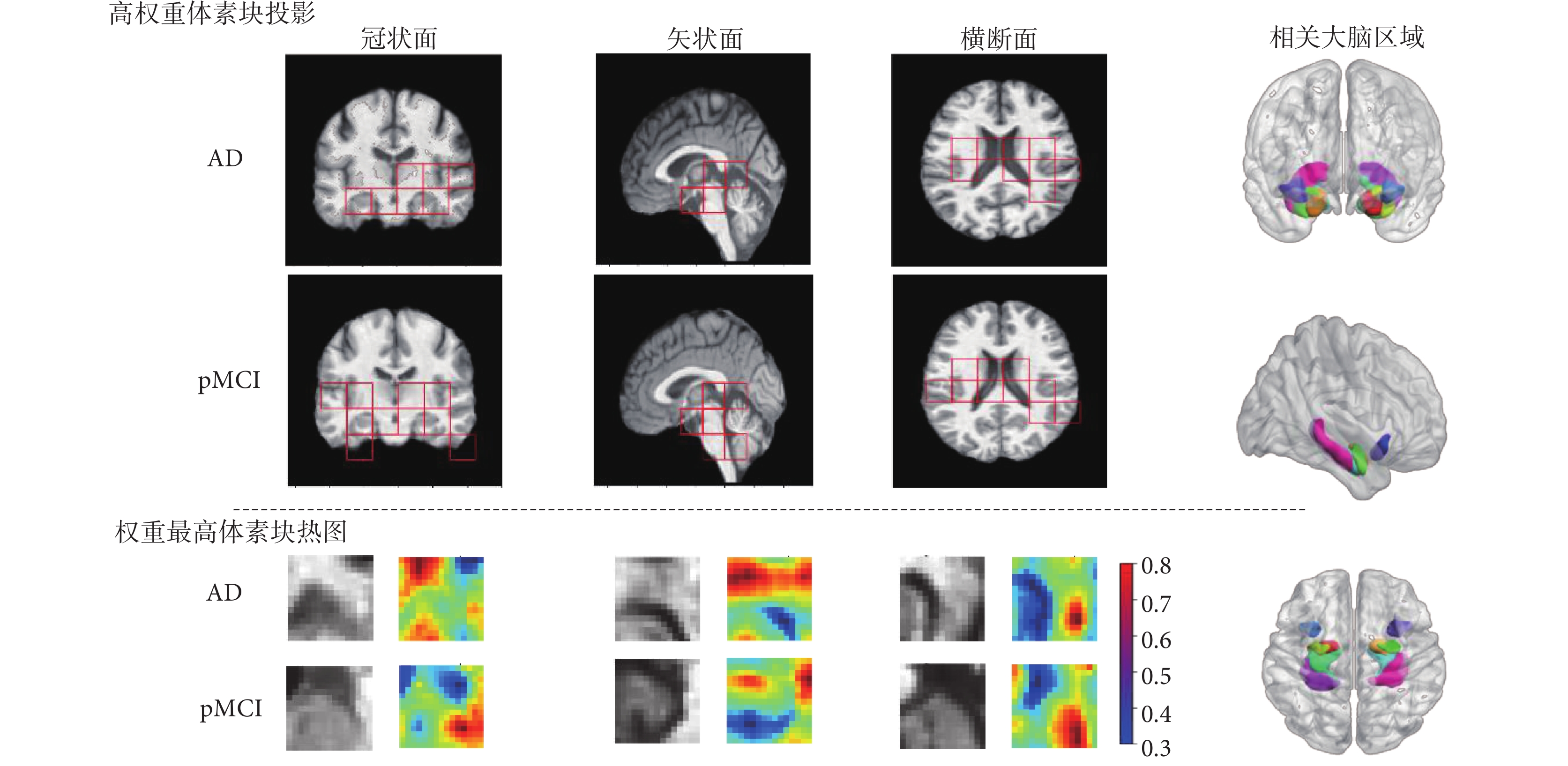
相關受試者通過式(3)以及在空間關聯性模塊、多尺度融合模塊獲得的權重生成最終的鑒別權重信息,選擇權重值大于平均值且排名前十的體素塊,具體位置詳見圖2。同時利用類激活圖[30]技術(class activation map,CAM)生成熱力圖,進一步識別體素塊內部對分類決策至關重要的區域,提供更精確的體素塊內部信息。實驗發現,不同影像中高貢獻體素塊呈現高度連通性并聚集,進一步支持腦組織萎縮區域在空間上具有一定聚集性的假設。
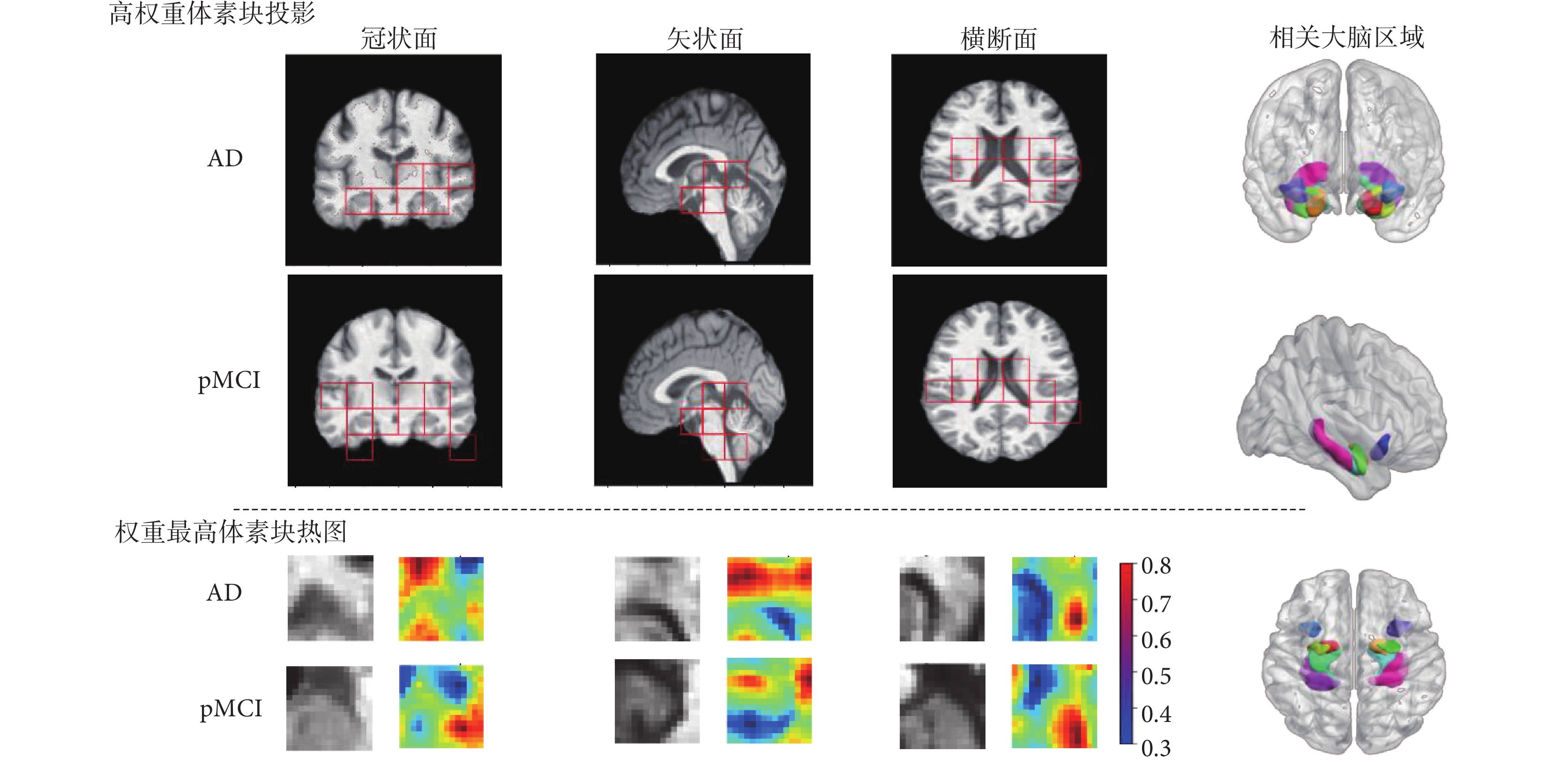 圖2
相關受試者高權重體素塊及最顯著體素塊熱力圖
Figure2.
High-weight voxel blocks and heatmap of prominent voxel blocks in relevant subjects
圖2
相關受試者高權重體素塊及最顯著體素塊熱力圖
Figure2.
High-weight voxel blocks and heatmap of prominent voxel blocks in relevant subjects
 |
上式中 是空間關聯模塊第
是空間關聯模塊第 塊體素塊的權重,
塊體素塊的權重, 表示空間關聯模塊中第
表示空間關聯模塊中第 塊體素塊與分割后第
塊體素塊與分割后第 子體素塊的多尺度融合特征權重。
子體素塊的多尺度融合特征權重。
表4根據式(3)統計了ADNI測試集中AD患者的高權重體素塊中心(Z × Y × X)的出現頻率,并將之映射至Brainnetome Atlas的246個細粒度區域,獲取高權重體素塊在大腦結構中的分布情況。
為驗證高權重體素塊對模型診斷性能的影響,屏蔽每位患者首次預測結果中權重前五位的體素塊,并重新送入模型,記錄新的預測得分。結果顯示,多數患者的預測得分顯著下降。表5總結了分別屏蔽單個及所有前五高權重體素塊后,模型預測得分變化的具體結果。通過對比不同屏蔽條件下的預測得分變化,進一步體現了不同權重體素塊對模型性能的貢獻。
2.6 消融實驗
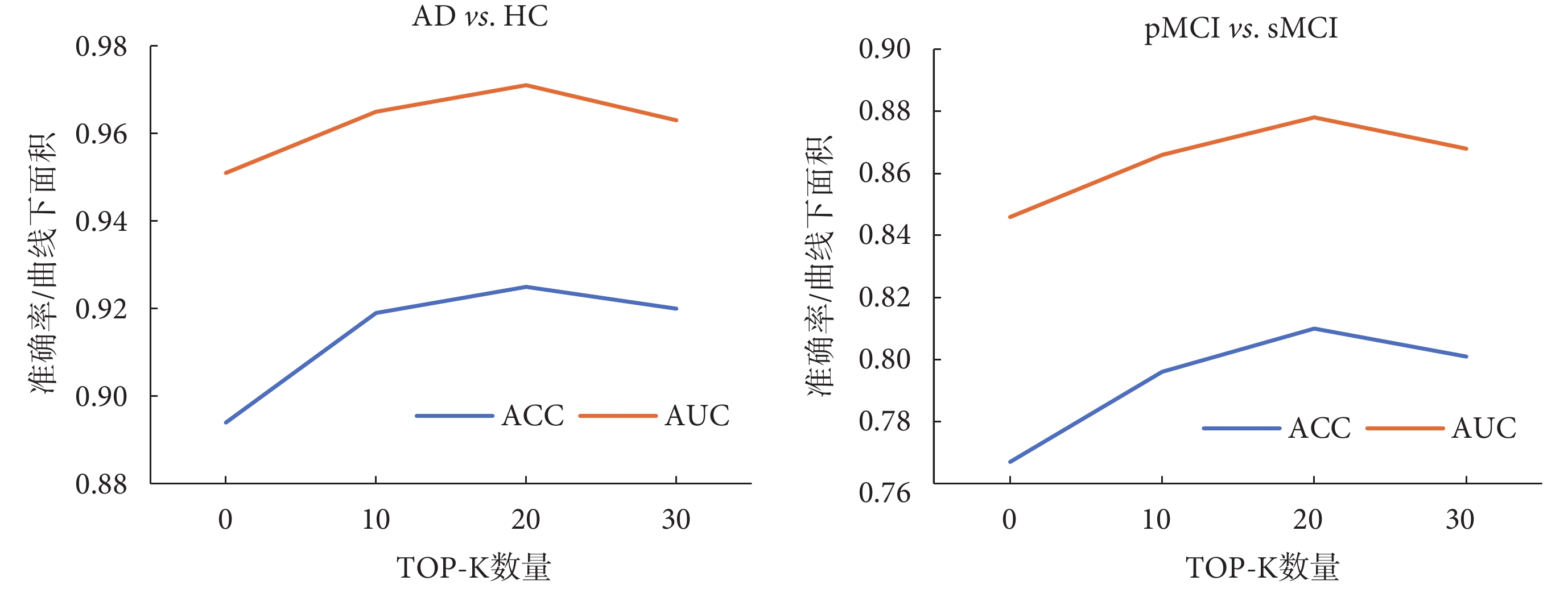
為驗證多尺度融合模塊的有效性及Top-K參數的影響,本文在AD分類和輕度認知障礙患者轉換任務上進行了實驗對比。圖3結果表明,當Top-K大于0(多尺度融合模塊參與訓練)時,模型的ACC和AUC均優于Top-K為0(多尺度融合模塊未參與訓練)的情況。然而,Top-K并非越大越優,過高的Top-K值可能引入干擾信息,降低模型判斷性能,增加計算開銷并延長訓練時間。
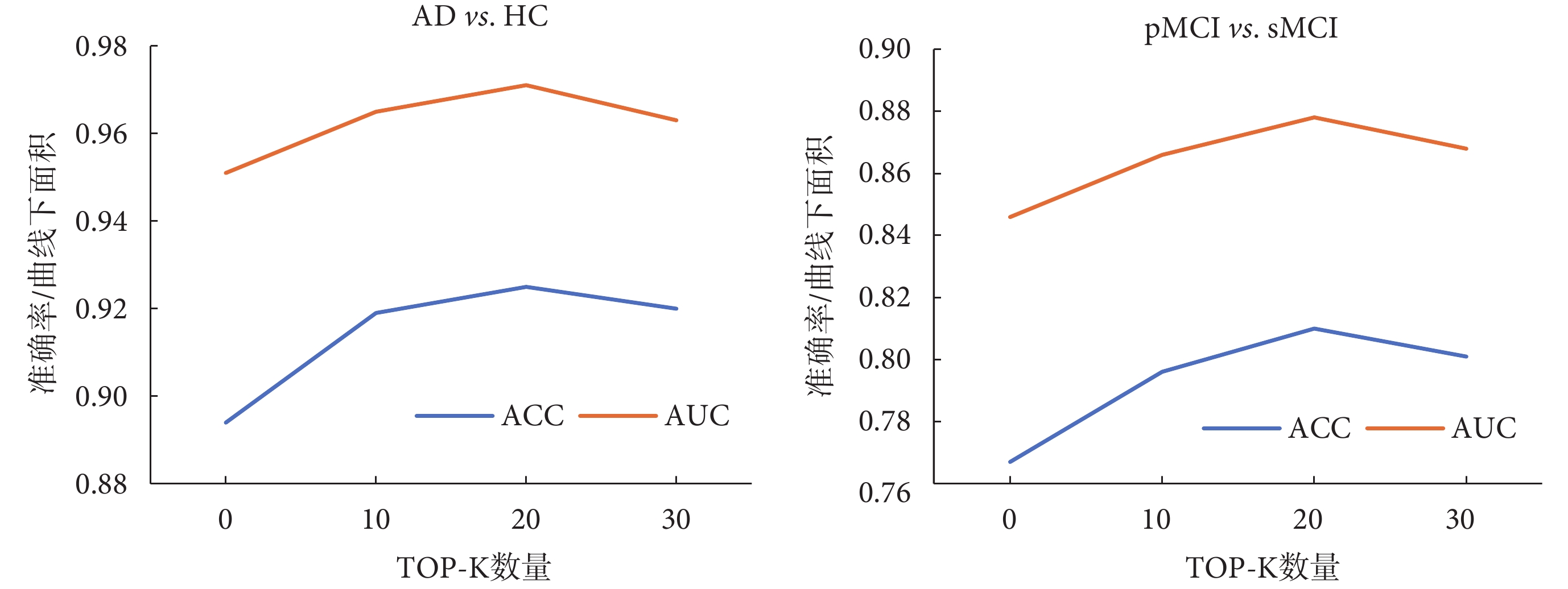 圖3
op-K數量對分類性能的影響
Figure3.
The impact of Top-K quantity on classification performance
圖3
op-K數量對分類性能的影響
Figure3.
The impact of Top-K quantity on classification performance
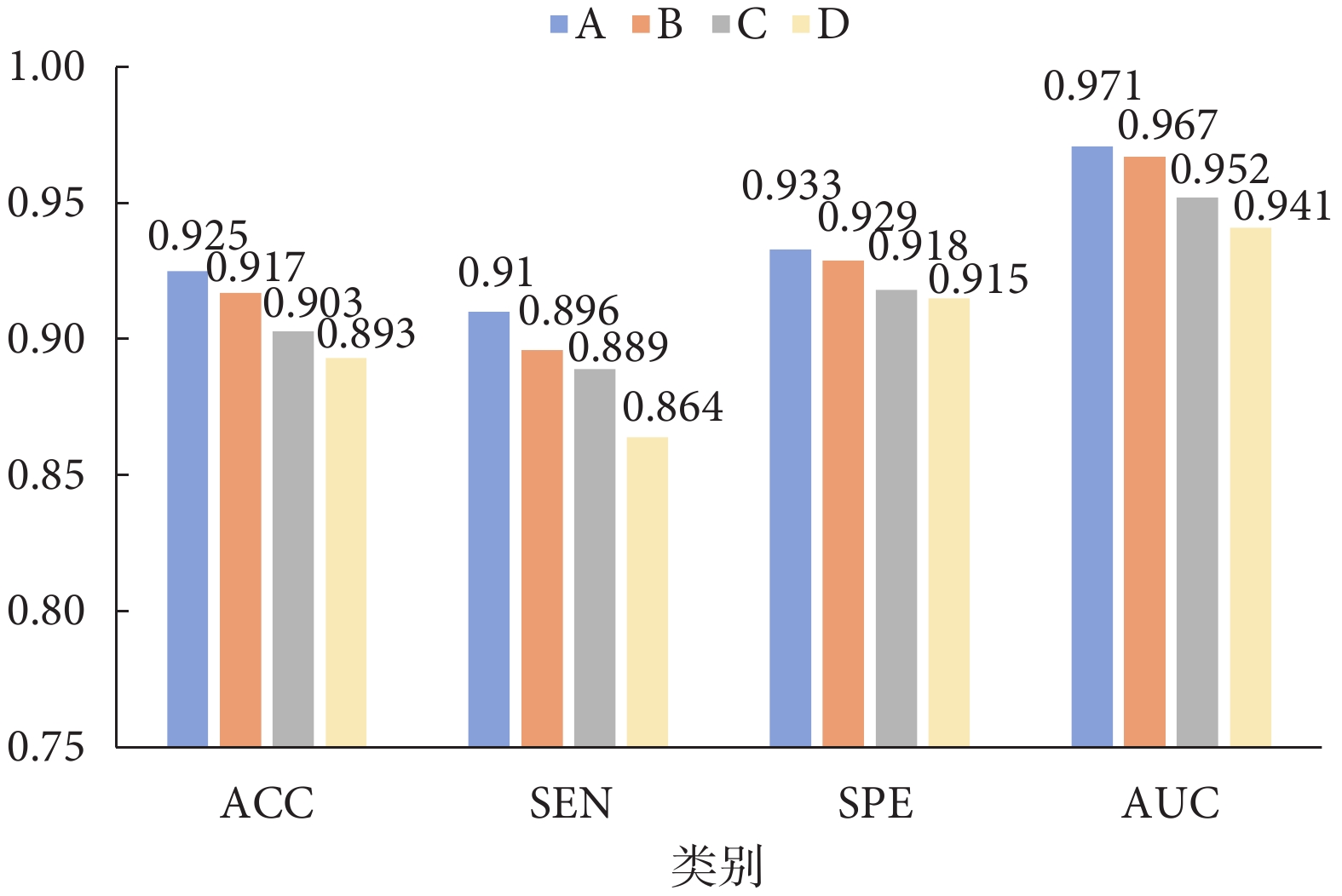
此外,為評估位置編碼模塊與多視角網絡的有效性,本文方法(A)在AD分類任務上與以下對照模型進行消融比較:(B)使用絕對位置編碼;(C)不含位置編碼;(D)不含位置編碼和多視角網絡。實驗結果如圖4所示,本文所提出的方法在各項指標上均取得了更為出色的表現,進一步驗證了所提方法的合理性。
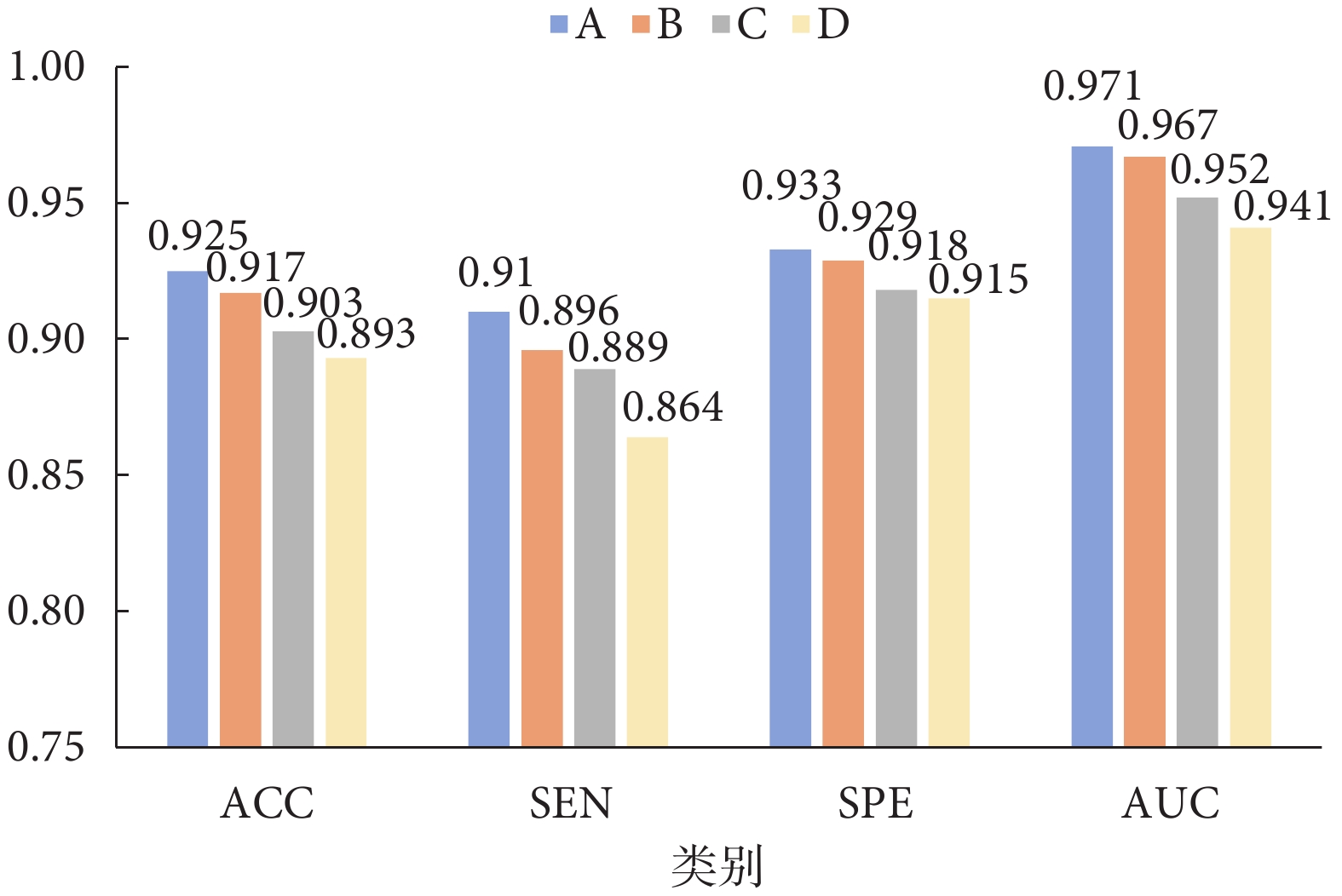 圖4
位置編碼與多視角網絡消融實驗
Figure4.
Ablation experiment on positional encoding and multi-view network
圖4
位置編碼與多視角網絡消融實驗
Figure4.
Ablation experiment on positional encoding and multi-view network
3 結論
為了提高基于sMRI的計算機輔助診斷AD的性能并定位觸發病癥的關鍵之處,本文提出了一種基于多示例學習和多尺度特征融合的sMRI輔助診斷框架,通過體素塊內部、體素塊間及高置信度體素塊進行多尺度特征提取。相比現有主流方法,框架在整體性能和關鍵特征捕捉方面表現良好。然而,本研究仍存在一些局限性,在跨數據集和臨床環境下的泛化能力尚需進一步驗證,且框架可解釋性不足。這些局限性為未來的研究提供了重要方向。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:帥志富主要負責數據記錄與分析、算法程序與設計以及論文撰寫;曾安、潘丹主要負責實驗流程、協調溝通、計劃安排、提供實驗指導以及論文審閱修訂,林勁芝主要負責論文審閱修訂。
0 引言
阿爾茨海默癥(Alzheimer’s disease,AD)是一種漸進式神經退行性變疾病,主要特征是記憶衰退和認知功能障礙。由于尚無能夠完全治愈AD的藥物,因此研究重心轉移至AD早期診斷[1],及時發現病癥并采取相應的治療措施,以減緩記憶衰退和認知功能障礙的進展。
AD患者的大腦結構易發生變化[2-3],而結構磁共振成像(structural magnetic resonance imaging,sMRI)有助于捕捉腦組織的細微結構變化[4-5],且具有空間分辨率高、非侵入性、無需對比劑、床易獲得等優勢,已成為AD研究中的主流影像技術之一。為了輔助醫生進行診斷決策和從sMRI的角度分析AD的成因和進展,研究者使用機器學習和深度學習分析AD患者疾病進展并對患者的健康狀況評估,彌補醫生在大量病理數據前主觀預測的不足和其他神經心理測試的不穩定性[6]。
基于體素塊級的sMRI診斷方法,作為體素級[7]與腦區級[8-10]分析的中間尺度,能夠更有效地捕捉sMRI圖像中的局部結構變化[11-15]。文獻[12]采用層級全卷積神經網絡(hierarchical fully convolutional network,H-FCN)為每個體素塊生成概率圖,具有良好的可解釋性;本團隊同時也基于體素塊級的三維卷積神經網絡(3-dimensional convolutional neural network,3D-CNN)模型推導發現了AD的大腦神經退化進展[14]。但由于大腦影像僅由單一標簽(例如:患者/正常)或粗略給出感興趣區域(region of interest,ROI)來描述,上述多種方法直接將標簽賦予整張影像分割后的體素塊,忽略了患者大腦中同樣存在正常區域[16],并非所有體素塊都發生病變。為此研究者將多示例學習(multiple instance learning,MIL)應用于AD診斷任務。文獻[17]提出的多示例模型通過提取高置信度體素塊特征,進行分類和輕度認知障礙轉化預測,但未考慮體素塊間的關聯性,忽略了大腦整體結構信息。文獻[18]提出一種雙注意多示例深度學習網絡,通過空間注意機制提取單個體素塊的判別特征,并以得分作為權重。然而,該方法僅關注單個體素塊特征,未充分利用體素塊的空間位置信息。此外,上述方法主要聚焦較大病變區域,對微小但關鍵病變的識別和細粒度信息的有效聚合能力不足。
為了在保留大腦影像整體結構位置信息的同時,更精確地定位和分析微小病變區域,本文提出了基于多示例學習和多尺度特征融合(multi-scale feature fusion,MSFF)的AD診斷框架。首先,對sMRI數據進行預處理并提取體素塊內部特征。再針對體素塊空間位置關聯信息,使用位置編碼與注意力機制捕捉。最后基于高權重體素塊采用多尺度特征融合策略,以期從細微層次上提取更為精確的信息來完成分類任務。
1 實驗方法
1.1 數據預處理
sMRI圖像預處理:本文使用SPM12軟件的CAT12工具箱對圖像進行預處理,包括空間分割、去顱骨、配準到標準的蒙特利爾神經學研究所空間。預處理后的圖像尺寸為121 × 145 × 121(X × Y × Z),空間分辨率為2 mm × 2 mm × 2 mm/體素。同時在預處理的影像基礎上進行不重疊切割(N × N × N)分為若干體素塊,并去除掉背景部分,以及對所有切割后的體素塊嚴格熵篩選,最終組成模型所需輸入。
1.2 多示例學習
本研究基于多示例學習并遵循文獻[16]設計,將整張大腦影像視為一個包,體素塊作為示例。若任一體素塊的標簽為1(病變區域),則影像標簽為1;若所有體素塊標簽為0(正常),則影像標簽為0,見式(1)。盡管無法直接獲取體素塊的真實標簽,但若某體素塊對診斷結果影響顯著,可推測它為病變區域。
|
上式中的表示包標簽,表示示例標簽。
1.3 整體框架
本文旨在構建基于sMRI數據的輔助診斷分類框架,如圖1所示。該框架涵蓋三個關鍵模塊:融入多視角特征提取模塊-體素塊內部、空間關聯性模塊-體素塊間、多尺度融合模塊-高置信度體素塊。框架模型遵循式(2)設計[19-20],研究重點聚焦于這三個模塊的組合,融入多視角特征提取模塊和空間關聯性模塊與多尺度融合模塊組成的函數。具體而言,優化以深入提取體素塊內部特征,增強捕捉體素塊空間位置關聯能力,同時通過多尺度機制整合關鍵體素塊信息,生成用于分類的最終特征表示。
圖1
整體框架
Figure1.
Overall framework
|
上式中表示整張影像,表示體素塊。
1.3.1 融入多視角特征提取
在文獻[11-15]中,3D-CNN已廣泛應用于提取體素塊特征。在多示例學習框架下,所有體素塊特征提取共享同一套網絡參數,這要求網絡具備更強的泛化能力和魯棒性。為此,本文基于3D-CNN并結合多視角特征提取網絡,如圖1所示的特征提取模塊,通過深度挖掘體素塊特征,進一步提升模型的特征表達能力和分類性能。
具體來說,3DCNN由三個卷積塊、兩個中間最大池化層以及一個全連接層組成。卷積塊包含兩個卷積層,并添加歸一化層和ReLU激活函數,以加速訓練防止梯度爆炸。多視角網絡結構受文獻[21-22]啟發,將三維體素塊旋轉翻轉后經過三層各向異性卷積層(即在不同方向上具有不同尺寸的卷積核)投影到二維空間。每個視角獲取的二維投影送入二維特征提取網絡,以捕獲體素塊在不同視角和維度下的特征信息,并與三維特征融合,形成最終特征表示。
1.3.2 空間關聯性模塊
在多示例研究中,關于包中示例與整個包之間關系的假設有兩種觀點:一是包中示例獨立同分布,彼此之間沒有關聯[20];二是示例之間存在相關性,尤其在病理學研究中更為顯著[21, 23]。本文基于sMRI構建AD診斷框架,且腦組織萎縮區域在空間上存在關聯性[14, 23],因此遵循第二種假設。
因此,本文設計了基于位置編碼和注意力網絡的空間關聯性模塊,如圖1所示。首先將所有體素塊特征表示還原至原始大腦影像空間位置,這依賴于體素塊最初選取時的有序性。隨之運用不同尺寸的卷積核執行分組卷積,為每個體素塊嵌入空間位置信息。最后,將嵌入位置信息的特征與原始特征進行殘差連接以保留原始特征。
本文在實驗中考慮了絕對位置和相對位置兩種編碼方式。絕對位置編碼[24]將體素特征完全還原至原空間位置,未選中的位置用0填充;相對位置編碼[21]則僅建立被選中體素塊間的位置關系。鑒于多示例網絡的輸入為長度不固定的序列,本文實驗采用了相對位置編碼,并在后續實驗章節中對兩種編碼方式的性能進行了比較。
嵌入位置編碼信息后,使用自注意力網絡[24-25]實現體素塊間信息交匯,捕獲示例間的關聯關系。選擇自注意力網絡的原因在于它能夠根據特征之間的相似性,動態調整各體素塊的重要性,更有效地捕獲全局上下文關系,提高體素塊間的關聯建模能力。
最終需要聚合所有體素塊特征生成整張影像的特征表示。平均池化和最大池化雖然是常用的聚合方法,但由于它們參數固定無法通過網絡自身進行優化,也無法有效捕捉各示例貢獻,因此,本文采用基于注意力的池化聚合函數[20],通過可學習的注意力網絡為每個體素塊分配權重,且保證權重總和為1,確保對不同大小的特征包具有不變性。聚合特征通過體素塊特征與相應權重進行矩陣乘法得到。
1.3.3 多尺度融合模塊
空間關聯性模塊已初步實現式(2)中的函數,但為了進一步精確定位和分析微小病變區域,本文設計了多尺度融合模塊。受文獻[19, 26]啟發,本文通過選擇高權重示例及其特征構建多尺度融合模塊,以排除低貢獻體素塊,從而獲得更具代表性的影像特征,提升模型置信度與性能。如圖1多尺度融合模塊所示,與傳統多尺度方法相比,并未在數據輸入階段處理多個支路的不同尺寸數據流,從而有效地避免了額外的計算開銷[27-28]。
具體來說,基于空間關聯性模塊獲取的權重信息,引入超參數Top-K,選擇權重值前K的體素塊(N × N × N)。每個體素塊被切割成尺寸更小的子體素塊(N / 2 × N / 2 × N / 2),特征提取流程與父體素塊一致,最后將所有子體素塊特征與父體素塊特征融合。融合后的特征不僅用于構建代表影像的聚合特征,還用于計算每個融合特征的權重貢獻值。該方法旨在通過更細粒度的區域劃分,提供新的診斷依據,從而顯著提升模型對陽性樣本的識別能力。
基于上述方法,框架能夠提取兩類影像聚合特征:一類由空間關聯性模塊生成,另一類通過多尺度融合模塊獲得。兩種特征相結合,構成完整的影像特征表示,用于最終分類任務。
2 實驗數據與結果分析
2.1 數據集介紹
本研究從阿爾茨海默癥神經影像倡議(Alzheimer’s Disease Neuroimaging Initiative,ADNI)數據庫收集了1 531名年齡在55~90歲受試者的sMRI影像,將影像分為AD患者、正常對照組(healthy controls,HC)、輕度認知障礙者轉化為AD(progressive mild cognitive impairment,pMCI)以及輕度認知障礙者未轉化為AD(stable mild cognitive impairment,sMCI),具體細節見表1。針對每名受試者,選取約三個時間點的影像用于訓練和驗證。為避免數據泄露,實驗以受試者為單位進行數據集劃分,即同一受試者的影像只能出現在訓練集、驗證集或測試集中的一個。采用五折交叉驗證策略進行超參數選擇和模型訓練測試,并在開放獲取系列成像研究(Open Access Series of Imaging Studies,OASIS)數據集上評估模型的多中心泛化能力。
2.2 參數設置和評價指標
在實驗參數中學習率設定為0.5e-6并結合調度器動態調整。Dropout為0.5,權重衰減系數為0.000 5,損失函數采用交叉熵,優化器為Adam。父體素塊尺寸為30,Top-K初始化為20。模型性能評價采用四項指標:準確率(accuracy,ACC)、靈敏度(sensitive,SEN)、特異性(specificity,SPE)和曲線下面積(area under curve,AUC)。
2.3 對比實驗
為驗證本文方法的有效性,將提出的網絡模型與以下方法進行對比:① 3DCNN+ROI[29]:利用3DCNN結合ROI進行AD計算機輔助診斷。② 3DCNN+EL+GA[8]:基于3DCNN和ROI,并結合遺傳算法(genetic algorithm,GA)識別對分類有顯著貢獻的腦區。③ HFCN[28]:采用H-FCN自動識別局部判別性體素塊,并結合多尺度特征進行分類。④ DMIL[19]:基于嚴格多示例框架的端到端模型,以體素塊為示例,同時獲取其權重。⑤ DA-MIDL[18]:通過體素塊的全局最大池化、平均池化及多示例池化等操作,獲取體素塊貢獻度并構建分類模型。⑥ 本文方法(Ours):基于多示例學習框架,融合體素塊的多視角特征、位置信息,利用多示例池化和多尺度融合等機制,提升分類性能并優化權重貢獻度計算。
2.4 實驗結果
表2展示了本文方法與其他主流方法在AD分類和輕度認知障礙患者轉化預測任務中的性能對比。與現有方法相比,本文方法顯著提升了SEN,有效降低了漏診率,表明它對疾病相關大腦結構變化更具敏感性。
為評估模型泛化能力,本文在OASIS數據集上進行了AD分類實驗,結果如表3所示。盡管在OASIS測試集上的性能略有下降,但整體表現依然良好。
2.5 高權重的可鑒別性體素塊
相關受試者通過式(3)以及在空間關聯性模塊、多尺度融合模塊獲得的權重生成最終的鑒別權重信息,選擇權重值大于平均值且排名前十的體素塊,具體位置詳見圖2。同時利用類激活圖[30]技術(class activation map,CAM)生成熱力圖,進一步識別體素塊內部對分類決策至關重要的區域,提供更精確的體素塊內部信息。實驗發現,不同影像中高貢獻體素塊呈現高度連通性并聚集,進一步支持腦組織萎縮區域在空間上具有一定聚集性的假設。
圖2
相關受試者高權重體素塊及最顯著體素塊熱力圖
Figure2.
High-weight voxel blocks and heatmap of prominent voxel blocks in relevant subjects
|
上式中是空間關聯模塊第塊體素塊的權重,表示空間關聯模塊中第塊體素塊與分割后第子體素塊的多尺度融合特征權重。
表4根據式(3)統計了ADNI測試集中AD患者的高權重體素塊中心(Z × Y × X)的出現頻率,并將之映射至Brainnetome Atlas的246個細粒度區域,獲取高權重體素塊在大腦結構中的分布情況。
為驗證高權重體素塊對模型診斷性能的影響,屏蔽每位患者首次預測結果中權重前五位的體素塊,并重新送入模型,記錄新的預測得分。結果顯示,多數患者的預測得分顯著下降。表5總結了分別屏蔽單個及所有前五高權重體素塊后,模型預測得分變化的具體結果。通過對比不同屏蔽條件下的預測得分變化,進一步體現了不同權重體素塊對模型性能的貢獻。
2.6 消融實驗
為驗證多尺度融合模塊的有效性及Top-K參數的影響,本文在AD分類和輕度認知障礙患者轉換任務上進行了實驗對比。圖3結果表明,當Top-K大于0(多尺度融合模塊參與訓練)時,模型的ACC和AUC均優于Top-K為0(多尺度融合模塊未參與訓練)的情況。然而,Top-K并非越大越優,過高的Top-K值可能引入干擾信息,降低模型判斷性能,增加計算開銷并延長訓練時間。
圖3
op-K數量對分類性能的影響
Figure3.
The impact of Top-K quantity on classification performance
此外,為評估位置編碼模塊與多視角網絡的有效性,本文方法(A)在AD分類任務上與以下對照模型進行消融比較:(B)使用絕對位置編碼;(C)不含位置編碼;(D)不含位置編碼和多視角網絡。實驗結果如圖4所示,本文所提出的方法在各項指標上均取得了更為出色的表現,進一步驗證了所提方法的合理性。
圖4
位置編碼與多視角網絡消融實驗
Figure4.
Ablation experiment on positional encoding and multi-view network
3 結論
為了提高基于sMRI的計算機輔助診斷AD的性能并定位觸發病癥的關鍵之處,本文提出了一種基于多示例學習和多尺度特征融合的sMRI輔助診斷框架,通過體素塊內部、體素塊間及高置信度體素塊進行多尺度特征提取。相比現有主流方法,框架在整體性能和關鍵特征捕捉方面表現良好。然而,本研究仍存在一些局限性,在跨數據集和臨床環境下的泛化能力尚需進一步驗證,且框架可解釋性不足。這些局限性為未來的研究提供了重要方向。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:帥志富主要負責數據記錄與分析、算法程序與設計以及論文撰寫;曾安、潘丹主要負責實驗流程、協調溝通、計劃安排、提供實驗指導以及論文審閱修訂,林勁芝主要負責論文審閱修訂。