基于CBCT生成的合成CT(sCT)能夠有效抑制偽影并提高CT值準確性,借此可精確計算放射劑量。然而,sCT圖像不同組織區域的生成質量嚴重不均衡,軟組織區域與其他區域相比生成質量較差。為此,本文提出了一種基于VGG-16的多任務注意力網絡(MuTA-Net),重點提升sCT軟組織區域的圖像質量。首先,引入多任務學習策略將sCT生成任務分為全局圖像生成、軟組織區域生成和骨區域分割三個子任務,保證全局圖像生成質量的同時,強化網絡對軟組織區域特征提取和生成的關注程度,并利用骨區域分割任務引導后續結果融合;然后,設計注意力模塊進一步優化網絡的特征提取能力,引導網絡從全局特征中提取子任務特征;最后,借助結果融合模塊整合各個子任務的生成結果,實現高質量的sCT圖像生成。在頭頸部CBCT上的實驗結果顯示,與ResNet、U-Net和U-Net++三種對比方法中的最優結果相比,基于本文所提方法生成的sCT圖像在軟組織區域的平均絕對誤差下降了12.52%。MuTA-Net在CBCT引導的自適應放療領域具有潛在的應用價值。
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
錐束計算機斷層掃描(cone beam computed tomography,CBCT)具有輻射劑量低、成像速度快、輕量便攜等優勢,是圖像引導放療(image guided radiation therapy,IGRT)中患者擺位驗證的關鍵工具[1-2]。自適應放療(adaptive radiation therapy,ART)作為IGRT的延伸,旨在借助CBCT監測解剖結構的變化,繼而調整放療計劃以確保放療的精準度[3-4]。個體化的精準放療能夠有效提高腫瘤局部控制率,降低正常組織并發癥的發生率。如果能夠直接基于CBCT圖像調整放療計劃,可以避免重新掃描計劃CT[5](planning CT,pCT),減少劑量損傷,提高治療效率。然而,錐束X線存在很強的散射信號[6-7],導致CBCT重建圖像質量不佳[8-11],如軟組織密度分辨率低、偽影嚴重、CT值失真。因此,CBCT圖像無法用于放射劑量的精確計算,難以支持自適應放療的引導[12-13]。
偽CT圖像合成技術有望解決上述CBCT圖像在放療中的局限性[14],該技術主要有兩種實現思路:一是通過醫學圖像配準獲得形變的計劃CT(deformed planning CT,dpCT)[15-16],二是通過深度學習生成合成CT(synthetic CT,sCT)[17-18]。醫學圖像配準方法通過尋找最佳空間變換參數對pCT圖像進行形變,獲取與CBCT解剖結構一致的dpCT,但當兩者解剖結構差異較大時,會降低配準精度,進而影響放射劑量計算精度,且該方法依賴人工設定參數,可重復性差,極大地限制了臨床應用[19]。深度學習方法具有特征自動提取能力,減少人為設計特征造成的不完備性,可以同時進行偽影抑制和CT值校正,提高了圖像合成效率和準確性。Yang等[20]定量比較了基于pCT形變配準的dpCT和基于CBCT生成的sCT,結論是當解剖結構變化較大時,sCT的精度要明顯優于dpCT的精度。研究人員將有監督網絡U-Net[21]和無監督網絡循環一致生成對抗網絡(cycle-consistent generative adversarial network,CycleGAN)[22]應用到sCT圖像生成,取得了不錯的效果[23-24]。后續又涌現出諸多改進方法,如Yuan等[25]提出U-Net++,引入密集連接整合不同層次的特征,提高了生成精度;Liu等[26]提出TranSE-cycleGAN,將卷積神經網絡和通道注意力引導的Transformer網絡結合,保留CBCT圖像結構的同時,提高了圖像CT值的精度。然而,骨、軟組織、空氣等不同區域的組織吸收率差異顯著,CBCT密度分辨率呈現明顯的區域不一致性,其中,CBCT圖像軟組織區域的密度分辨率低且CT值范圍小。現有方法采用單任務學習架構提取CBCT圖像的特征信息,未對軟組織區域做針對性處理,導致網絡對該區域的生成能力不足,常被過度平滑,相較于其他結構區域,生成質量較差。
針對目前sCT圖像不同組織區域的生成質量不均衡,特別是軟組織區域生成效果不理想的問題,本文提出了一種由CBCT生成sCT的多任務注意力網絡(Multi-Task Attention Network,MuTA-Net),重點提升sCT軟組織區域的圖像質量。首先,引入多任務學習策略[27]將sCT生成任務分為全局圖像生成、軟組織區域生成和骨區域分割三個子任務;然后,設計注意力模塊優化網絡的特征提取能力,引導網絡從全局特征中提取子任務特征,提高子任務的生成質量;最后,借助結果融合模塊整合各個子任務的生成結果,生成高質量的sCT圖像。鑒于多任務學習方法是一種典型的有監督學習方法,本文利用頭頸部CBCT數據對MuTA-Net和幾種先進的有監督學習方法(ResNet[28]、U-Net[23]和U-Net++[25])進行對比分析,定性和定量評估網絡的sCT生成性能。
1 方法
1.1 多任務學習策略
本文引入多任務學習策略,設計了一種多任務注意力網絡MuTA-Net,將sCT生成任務分為全局圖像生成Isct、軟組織區域生成Itissue和骨區域分割Ibone三個嵌套遞進的子任務,利用結果融合模塊整合子任務結果,生成高質量的sCT圖像。子任務功能如下:① Isct:學習CBCT圖像到pCT圖像的全局映射關系,保證全局圖像的生成質量。② Itissue:作為Isct的關鍵補充,強化網絡對軟組織區域特征提取和生成的關注程度,重點提升軟組織區域的圖像質量。③ Ibone:明確與軟組織區域差異明顯的骨區域的邊界,保證骨區域CT值的生成精度。理想情況下,Itissue的生成結果在軟組織區域存在CT值,骨區域的像素值為0,然而其在骨區域也會生成CT值,且該值準確性不高,這將極大干擾骨區域的生成精度。所以,Ibone用于骨區域的精準分割,在結果融合時利用分割結果強制將Itissue生成結果中的骨區域置0,保證骨區域內部CT值精度不受影響。
1.2 MuTA-Net
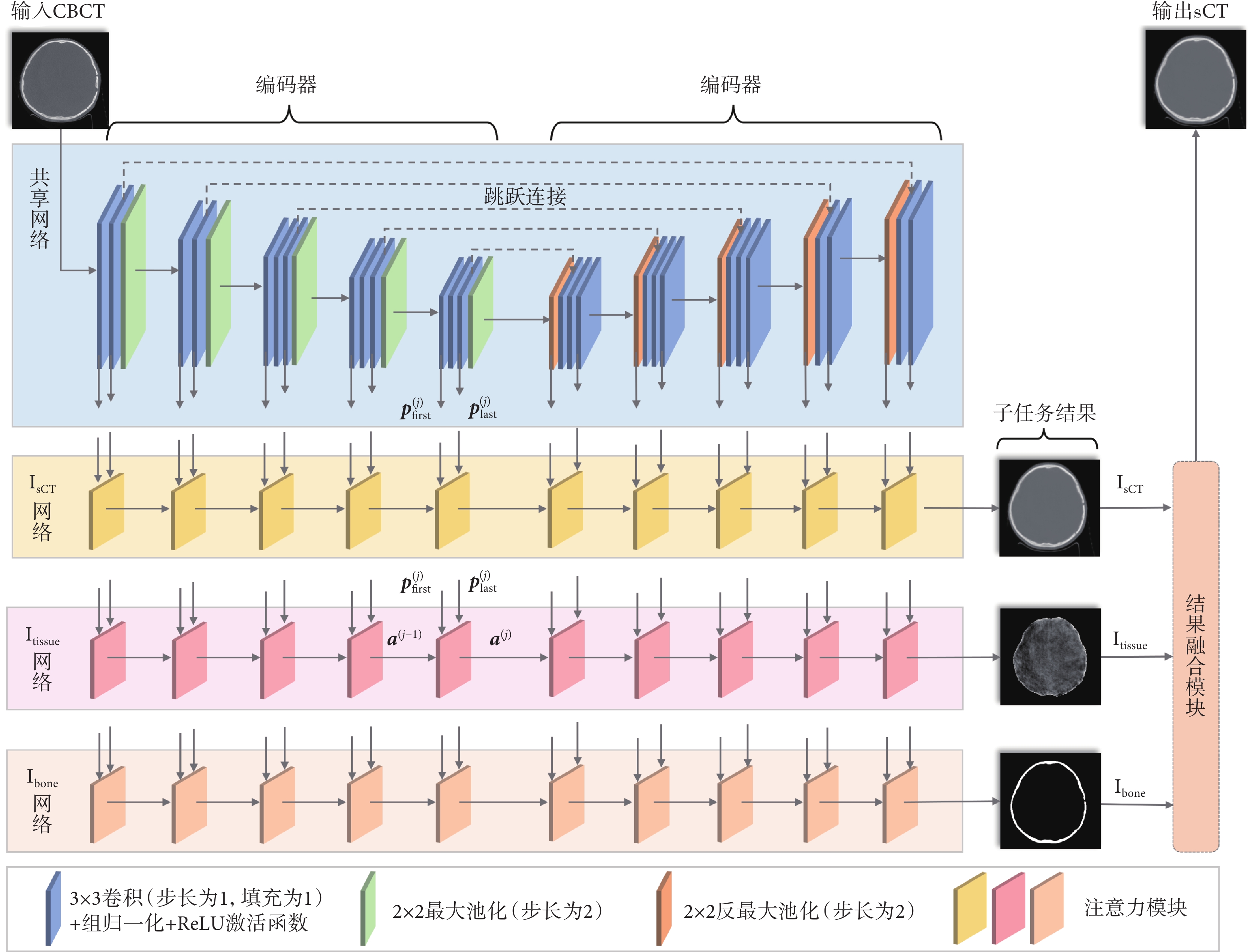
本文所提MuTA-Net如圖1所示,包含一個共享網絡和三個并行且結構相同的子任務網絡,每個網絡均由編碼器和解碼器組成。首先,CBCT圖像輸入到共享網絡提取多尺度全局特征。然后,三個子任務網絡針對各自任務從多尺度全局特征中進一步深化特征提取,獲取子任務特征。最后,子任務網絡末端輸出的三個子任務結果(Isct、Itissue和Ibone)經結果融合模塊融合,在Ibone區域外部,使用Itissue的生成結果,而在Ibone區域的內部,使用Isct的生成結果,從而輸出高質量sCT圖像,具體融合方式見附件1。
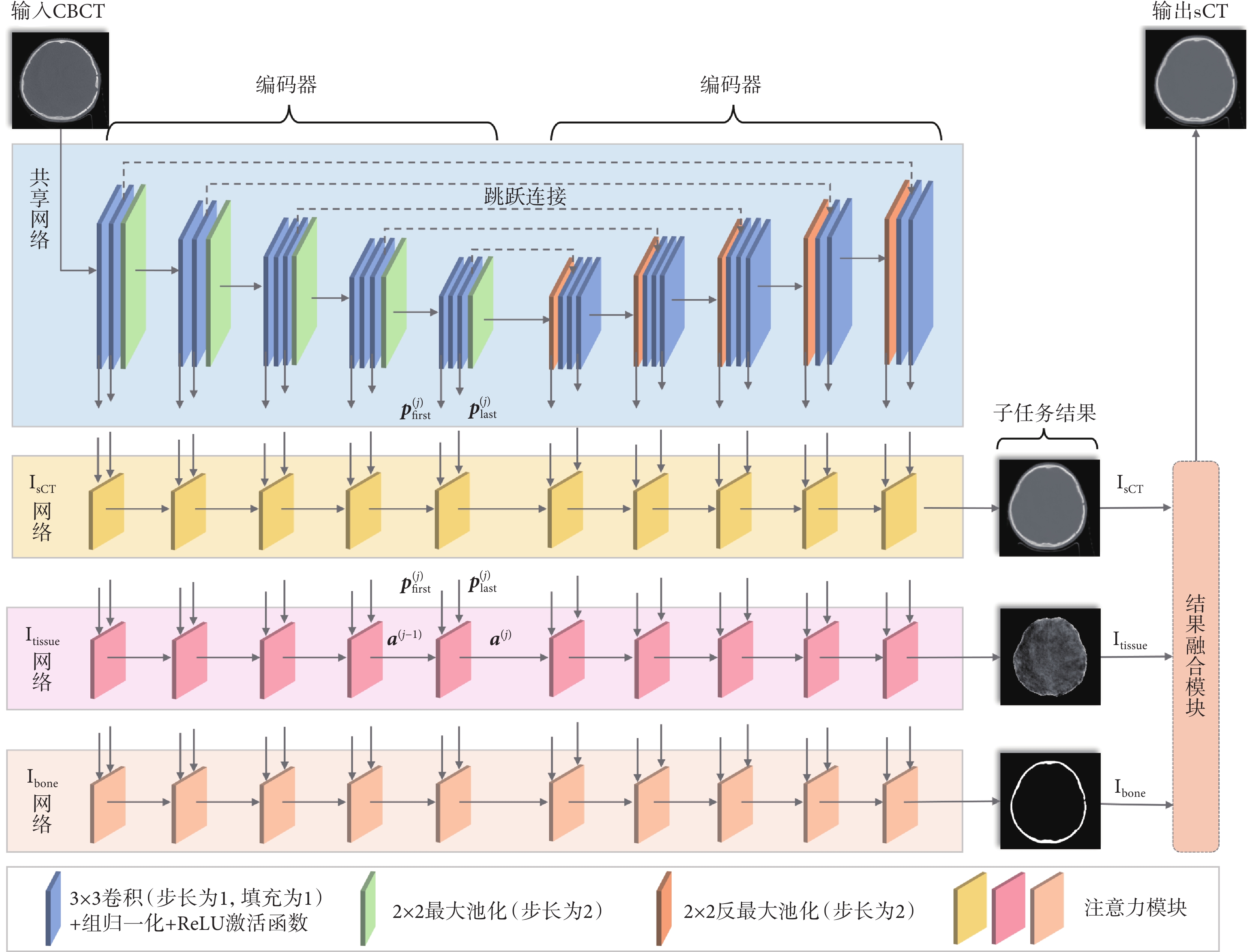 圖1
MuTA-Net 示意圖
Figure1.
Illustration of MuTA-Net
圖1
MuTA-Net 示意圖
Figure1.
Illustration of MuTA-Net
1.2.1 共享網絡
共享網絡基于VGG-16[29]搭建,編碼器共有五層,每層由兩到三個3 × 3卷積、組歸一化[30]、ReLU激活函數和一個最大池化級聯組成,解碼器結構則與編碼器對稱設計。為了防止池化丟失細節信息,本文在對稱的卷積層處引入跳躍連接[31]。共享網絡在每一層均輸出兩個全局特征,記為 和
和 ,其中j為網絡的層數。具體而言,在編碼器中,
,其中j為網絡的層數。具體而言,在編碼器中, 和
和 分別表示第j層首個3 × 3卷積和最后一個3 × 3卷積提取的全局特征,而在解碼器中,則分別表示第j層首步反最大池化和最后一個3 × 3卷積提取的全局特征。各層提取的全局特征并行傳輸到三個子任務網絡對應層的注意力模塊,以針對三個不同子任務進一步挖掘和提煉子任務特征。
分別表示第j層首個3 × 3卷積和最后一個3 × 3卷積提取的全局特征,而在解碼器中,則分別表示第j層首步反最大池化和最后一個3 × 3卷積提取的全局特征。各層提取的全局特征并行傳輸到三個子任務網絡對應層的注意力模塊,以針對三個不同子任務進一步挖掘和提煉子任務特征。
1.2.2 子任務網絡
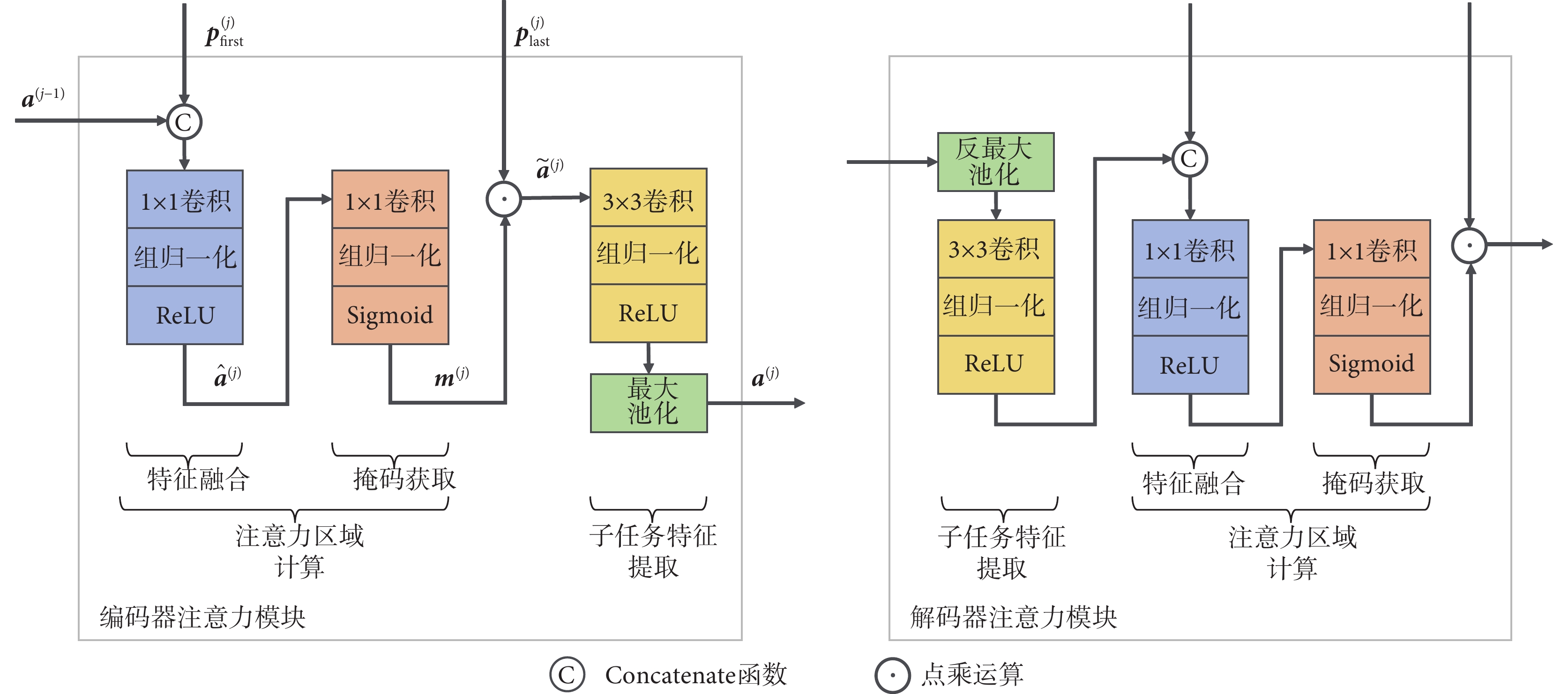
三個并行的子任務網絡具有與共享網絡相同的層數,每層由一個注意力模塊構成。注意力模塊的結構細節如圖2所示,分為編碼器注意力模塊與解碼器注意力模塊兩種類型,兩者結構對稱,均包含注意力區域計算和子任務特征提取兩個核心部分。注意力區域計算分為兩步:第一步為特征融合,由Concatenate函數、1 × 1卷積、組歸一化和ReLU激活函數級聯而成;第二步為掩碼獲取,由1 × 1卷積、組歸一化和Sigmoid激活函數級聯而成。子任務特征提取由3 × 3卷積、組歸一化、ReLU激活函數和(反)最大池化組成。
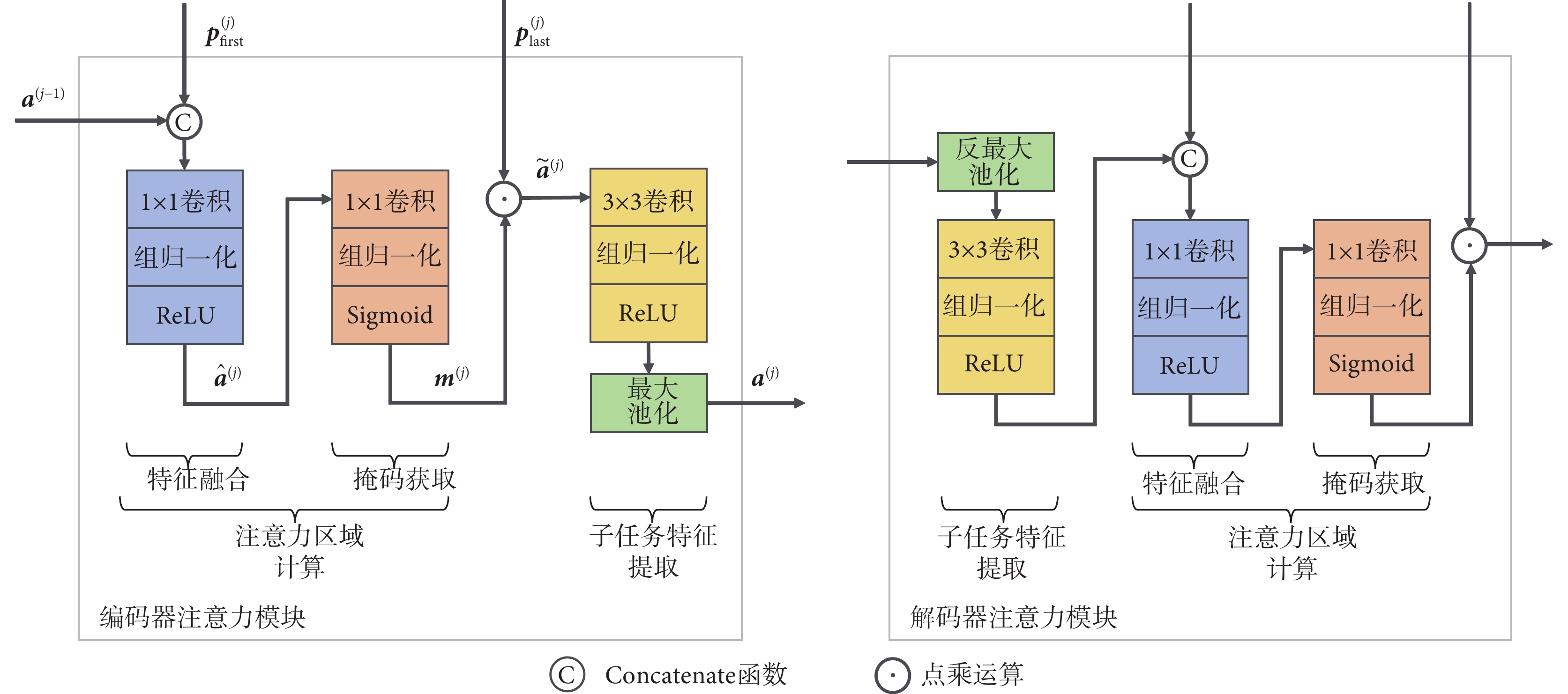 圖2
注意力模塊
Figure2.
Attention module
圖2
注意力模塊
Figure2.
Attention module
以任意一個子任務網絡編碼器中的第j層注意力模塊為例,對于其輸入而言,除了來自共享網絡對應層(第j層)提取的兩個全局特征( 和
和 )外,還有前一層(第
)外,還有前一層(第 層)注意力模塊輸出的子任務特征
層)注意力模塊輸出的子任務特征 。基于以上三個輸入,第j層注意力模塊最終輸出該層的子任務特征
。基于以上三個輸入,第j層注意力模塊最終輸出該層的子任務特征 。令
。令 表示1 × 1卷積,
表示1 × 1卷積, 表示3 × 3卷積,Norm表示組歸一化,P表示最大池化操作,則第j層編碼器注意力模塊的計算過程如下。
表示3 × 3卷積,Norm表示組歸一化,P表示最大池化操作,則第j層編碼器注意力模塊的計算過程如下。
首先,注意力模塊使用Concatenate函數將第一個全局特征 和前一層的子任務特征
和前一層的子任務特征 進行拼接,并利用1 × 1卷積進行特征融合,得到融合特征
進行拼接,并利用1 × 1卷積進行特征融合,得到融合特征 。需要注意的是,首層(
。需要注意的是,首層( )注意力模塊無需輸入前一層的子任務特征。公式如式(1)所示。
)注意力模塊無需輸入前一層的子任務特征。公式如式(1)所示。
 |
其中,?表示Concatenate函數。
然后,融合特征 依次經過1 × 1卷積和組歸一化后,由Sigmoid激活函數映射到[0,1],從而得到掩碼
依次經過1 × 1卷積和組歸一化后,由Sigmoid激活函數映射到[0,1],從而得到掩碼 ,如式(2)所示。
,如式(2)所示。
 |
最后,將掩碼 與第二個全局特征
與第二個全局特征 進行點乘運算,提取初步的子任務特征
進行點乘運算,提取初步的子任務特征 ,再借助3 × 3卷積進一步提取特征,并利用最大池化對特征圖進行下采樣,得到該層子任務特征
,再借助3 × 3卷積進一步提取特征,并利用最大池化對特征圖進行下采樣,得到該層子任務特征 。公式如式(3)所示。
。公式如式(3)所示。
 |
其中,⊙表示點乘運算。
由于結構對稱性,解碼器注意力模塊的計算過程與以上編碼器注意力模塊的計算過程相反。
1.3 損失函數
多任務學習的損失函數由三個子任務的損失函數線性加權獲得,如式(4)所示。
 |
其中, 、
、 和
和 為三個子任務的權重系數。
為三個子任務的權重系數。
對于Isct和Itissue兩個生成任務,采用平均絕對誤差(mean absolute error,MAE)構建損失函數,衡量生成圖像和標簽圖像之間的像素級差異。此外,為了增強網絡保留軟組織區域結構的能力,Itissue的損失函數還引入結構相似性指數(structural similarity index measure,SSIM),用于評估生成圖像和標簽圖像之間的結構相似性,這種聯合損失能夠有效監督軟組織區域像素級和結構級的訓練過程。
 |
 |
其中, 和
和 為Itissue的損失權重系數。
為Itissue的損失權重系數。
對于分割任務Ibone,在輸出進行Softmax激活處理后,使用交叉熵(cross entropy,CE)計算損失。
 |
各項指標的具體公式如式(8)、(9)、(10)所示。
 |
 |
 |
其中,X表示生成圖像,Y表示標簽圖像, 、
、 分別表示圖像X和Y中的單個像素,N表示圖像的像素數,
分別表示圖像X和Y中的單個像素,N表示圖像的像素數, 和
和 分別表示圖像X和Y的均值,
分別表示圖像X和Y的均值, 和
和 分別表示圖像X和Y的方差,
分別表示圖像X和Y的方差, 表示圖像X和Y的協方差。
表示圖像X和Y的協方差。 和
和 為常數項,避免分母為0。
為常數項,避免分母為0。
2 實驗與結果分析
2.1 數據與預處理
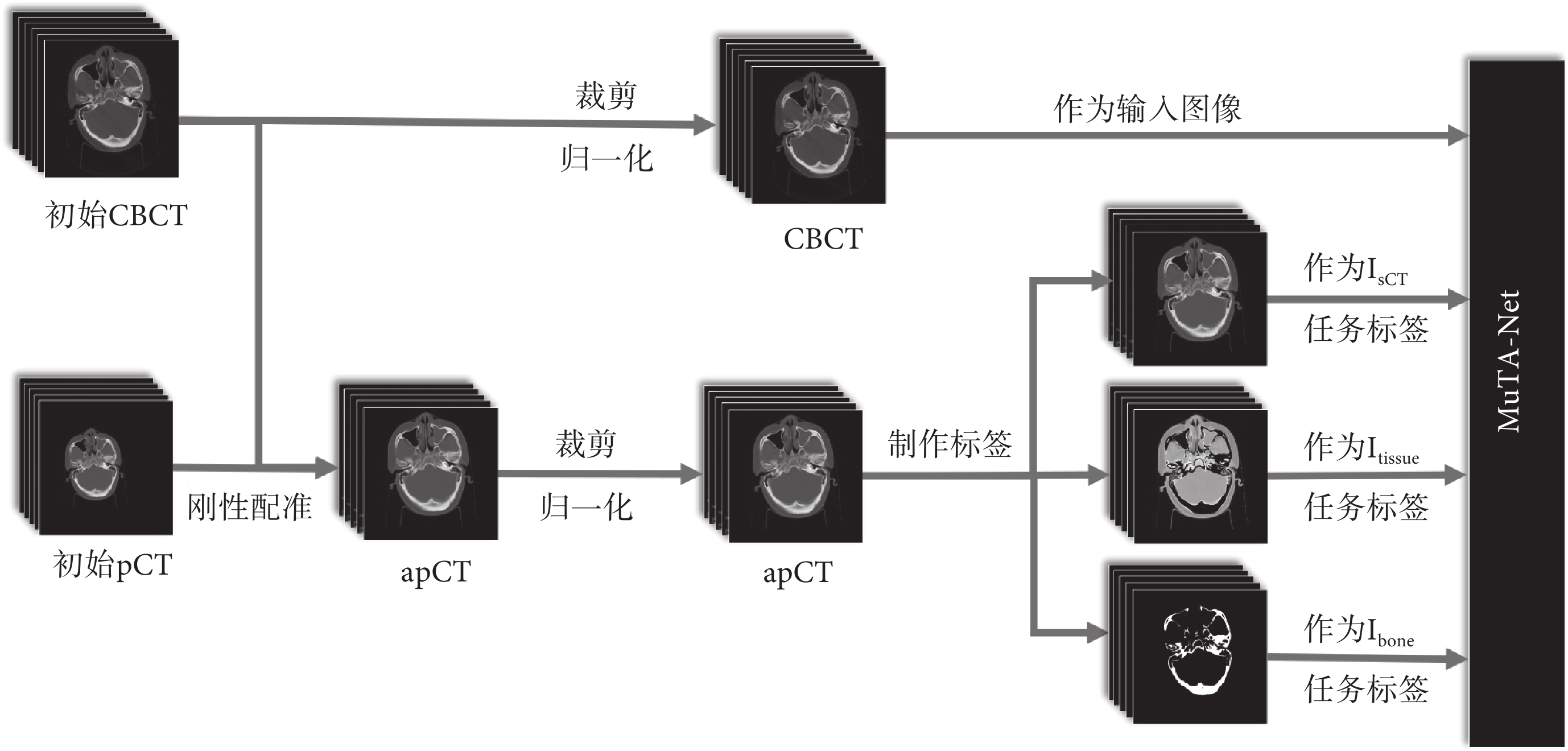
本文回顧性收集了2020年至2021年間中南大學湘雅醫院40例頭頸部癌癥患者的pCT圖像和CBCT圖像,所有納入研究的患者均在模擬定位階段接受標準化的pCT掃描,并在IGRT中以相同體位接受CBCT掃描。pCT圖像由Philips Brilliance大孔徑螺旋CT掃描儀獲取,管電壓為120 kV,管電流為285 mA到483 mA不等,重建體素尺寸為0.78~1.17 mm不等,層厚為3 mm。CBCT圖像采用Varian TrueBeam機載CBCT掃描儀獲取,管電壓為100 kV,管電流為20 mA,重建體素尺寸為0.51 mm,層厚為3 mm。pCT和CBCT的圖像尺寸均為512像素×512像素。其中,34例患者的pCT和CBCT用于訓練,其余6例患者的pCT和CBCT用于測試,掃描間隔均不超過1周。由于掃描間隔短,放療引發的解剖結構差異(特別是腫瘤大小差異)可忽略不計。本文使用臨床商用軟件MIM Maestro 6.7.10(MIM Software Inc.,美國)進行醫學圖像剛性配準。配準過程中,pCT圖像作為浮動圖像,CBCT圖像作為固定圖像,最終獲得對齊的pCT(aligned planning CT,apCT)圖像(與dpCT不同),該圖像具有與CBCT一致的解剖結構,確保二者可以構成嚴格配對的數據集。去除不含人體組織的切片后,最終獲得869張配對切片用于訓練,402張配對切片用于測試。
數據預處理流程如圖3所示。首先,進行剛性配準,獲得apCT圖像。其次,將圖像CT值裁剪至[–1 000,3 095] HU,去除無關背景信息,提高網絡的訓練效率。然后,將圖像像素值歸一化至[0,1],保留原始圖像特征信息,同時提高網絡訓練的收斂速度[32]。最后,基于apCT圖像制作各子任務訓練標簽。Isct標簽即apCT圖像,Itissue和Ibone標簽則通過閾值分割法制作。本文定義500 HU為軟組織區域與骨區域的界限,即CT值范圍在[–1 000,500] HU的為軟組織區域,在[500,3 095] HU的為骨區域,分別制作軟組織區域和骨區域的二值掩膜(區域內為1,其他區域為0)。Itissue標簽由apCT圖像與軟組織區域掩膜相乘獲得,Ibone標簽即骨區域掩膜。
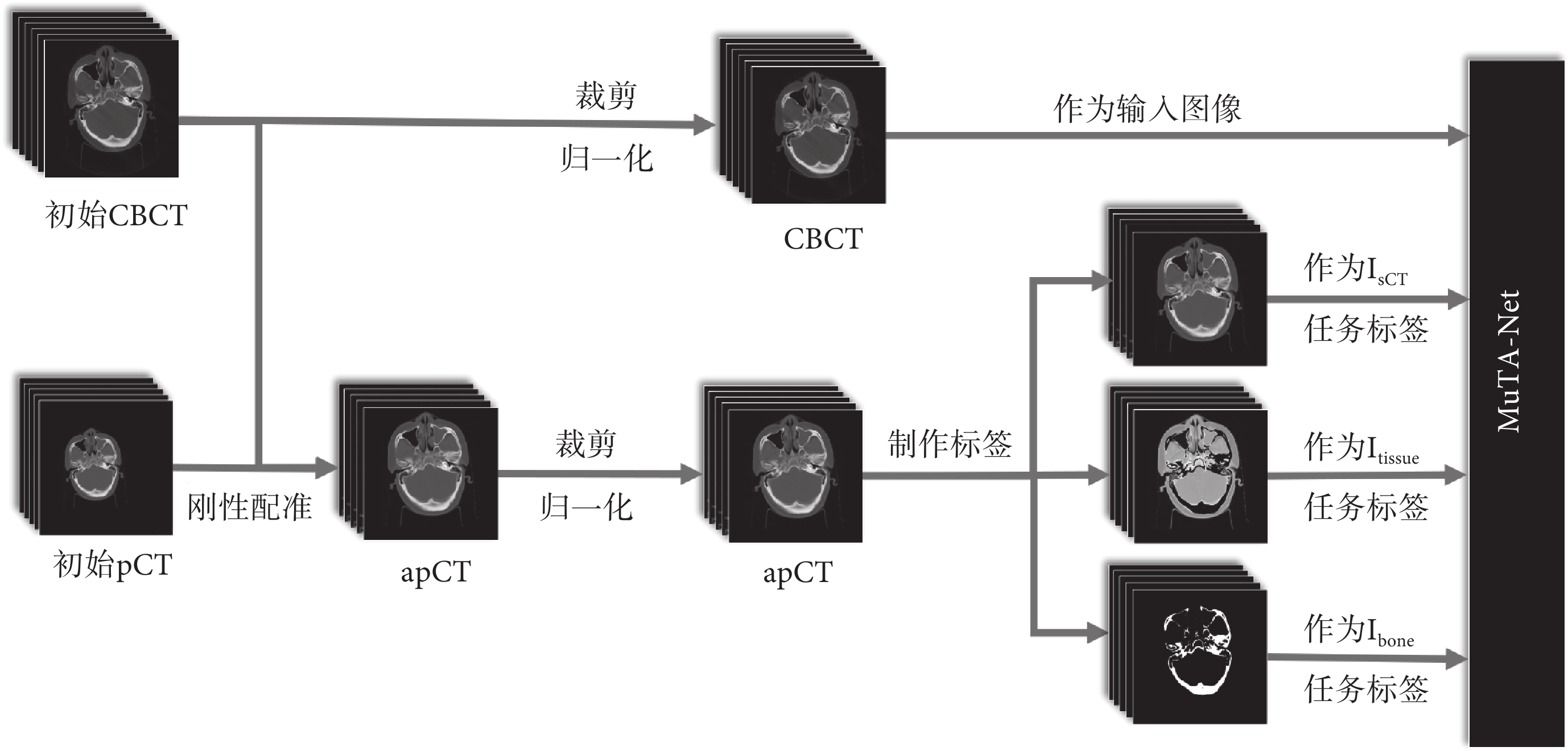 圖3
數據預處理流程
Figure3.
Workflow of the image pre-processing
圖3
數據預處理流程
Figure3.
Workflow of the image pre-processing
2.2 實驗環境與超參設定
本文基于開源的Python 3.8.18機器學習庫PyTorch 1.8.1與英偉達GeForce RTX 3090Ti GPU環境構建多任務注意力網絡MuTA-Net。訓練的批大小設定為2,訓練輪次為200。采用Adam優化器,初始學習率設定為1e–5,訓練100輪后,學習率以0.1的衰減系數進行下降。本文利用隨機正態初始化,將所有權重按照均值為0,標準差為0.02的標準進行初始化。實驗表明,在當前環境條件下,三個子任務權重系數 、
、 和
和 分別取1.4、1.8、1.0,損失權重系數
分別取1.4、1.8、1.0,損失權重系數 和
和 分別取0.4、0.6,網絡效果達到最佳,具體實驗結果見附件2。輸入CBCT圖像和輸出sCT圖像的尺寸均為512像素×512像素。網絡的訓練時間約17 h,平均完成一位患者的sCT圖像生成約為20 s。所有對比網絡和消融實驗網絡均在相同的環境下進行訓練,具有完全相同的訓練參數。
分別取0.4、0.6,網絡效果達到最佳,具體實驗結果見附件2。輸入CBCT圖像和輸出sCT圖像的尺寸均為512像素×512像素。網絡的訓練時間約17 h,平均完成一位患者的sCT圖像生成約為20 s。所有對比網絡和消融實驗網絡均在相同的環境下進行訓練,具有完全相同的訓練參數。
2.3 網絡評估
本文采用MAE、均方根誤差(root mean square error,RMSE)、峰值信噪比(peak signal-to-noise ratio,PSNR)和SSIM四個指標評估MuTA-Net的性能。令X表示生成的sCT圖像,Y表示apCT圖像, 、
、 分別表示圖像中的單個像素,N表示圖像的像素數,則各項指標的定義與公式如下:
分別表示圖像中的單個像素,N表示圖像的像素數,則各項指標的定義與公式如下:
(1)MAE:值越小,表示sCT與apCT的像素值越接近,公式如前文式(8)所示。
(2)RMSE:與MAE相比,對異常值更敏感。RMSE值越小,表明sCT和apCT之間的像素值差異越小,公式如式(11)所示;
 |
(3)PSNR:值越大,表示sCT的噪聲水平越低,失真越小,公式如式(12)所示;
 |
其中, 表示圖像
表示圖像 的像素最大值與最小值之差。
的像素最大值與最小值之差。
(4)SSIM:值越接近1,表明sCT與apCT越相似,網絡的結構特征保留的能力越強,公式如前文式(9)所示。
此外,本文還通過CT值剖視圖、差異圖和直方圖對sCT圖像進行定性分析。剖視圖顯示了圖像沿著某一直線的像素強度分布,比較了圖像像素在同一方向的變化趨勢。差異圖將sCT圖像和apCT圖像相減并進行偽彩映射,直觀展現了圖像對應位置的CT值差異,越接近白色,表示該區域的CT值差異越小,說明網絡的CT值校正效果越好。直方圖則統計了圖像上每個CT值出現的頻次。
2.4 對比實驗結果
為了驗證MuTA-Net的有效性,本文將它與基礎的卷積神經網絡(ResNet[28])和常用的sCT生成網絡(U-Net[23])及其變體(U-Net++[25])進行對比,采用MAE、RMSE、PSNR和SSIM定量比較上述方法生成的sCT圖像(sCTResNet、sCTU-Net、sCTU-Net++、sCTMuTA-Net),結果如表1所示。以ResNet為代表的傳統卷積神經網絡在圖像生成任務上存在一定的局限性,sCTResNet的各項指標仍有提升空間;U-Net憑借其精巧的編解碼器架構設計,在特征提取的方面具有一定的優勢,然而在處理小尺寸目標時存在局限性;U-Net++在U-Net的基礎上引入了密集連接,可有效整合不同層次的特征,更好地捕獲上下文信息和細節特征;而本研究所提方法MuTA-Net通過引入多任務學習策略進一步提高了軟組織區域的圖像質量,并借助注意力模塊優化了網絡的特征提取能力。同CBCT圖像相比,sCTMuTA-Net圖像MAE下降了47.68%,RMSE下降了40.51%,PSNR上升了13.40%,SSIM上升了6.26%;與次優結果相比,sCTMuTA-Net圖像MAE下降了11.55%,RMSE下降了5.79%,PSNR上升了1.47%,SSIM上升了0.74%。這表明,MuTA-Net在CT值校正、噪聲抑制和結構細節保留等方面表現最佳,具有最優的sCT生成能力。
為了驗證MuTA-Net在軟組織區域生成方面的優勢,本文通過掩膜分離出CBCT圖像和sCT圖像中的軟組織區域,并采用MAE、RMSE、PSNR和SSIM比較sCT圖像軟組織區域的生成效果,如表2所示。與CBCT圖像相比,sCTMuTA-Net圖像軟組織區域的MAE下降了45.44%,RMSE下降了33.84%,PSNR上升了13.45%,SSIM上升了11.57%;與次優結果相比,sCTMuTA-Net圖像軟組織區域的MAE下降了12.52%,RMSE下降了5.25%,PSNR上升了1.65%,SSIM上升了0.99%。以上結果表明,MuTA-Net具有最好的軟組織區域生成性能,證實了它在提升CBCT圖像軟組織區域的生成質量方面具有優勢。同時,本文進一步分析了sCT圖像骨區域的生成效果,如表3所示,可知sCTMuTA-Net圖像骨區域的指標均達到最優,表明MuTA-Net在骨區域生成方面同樣表現出色。
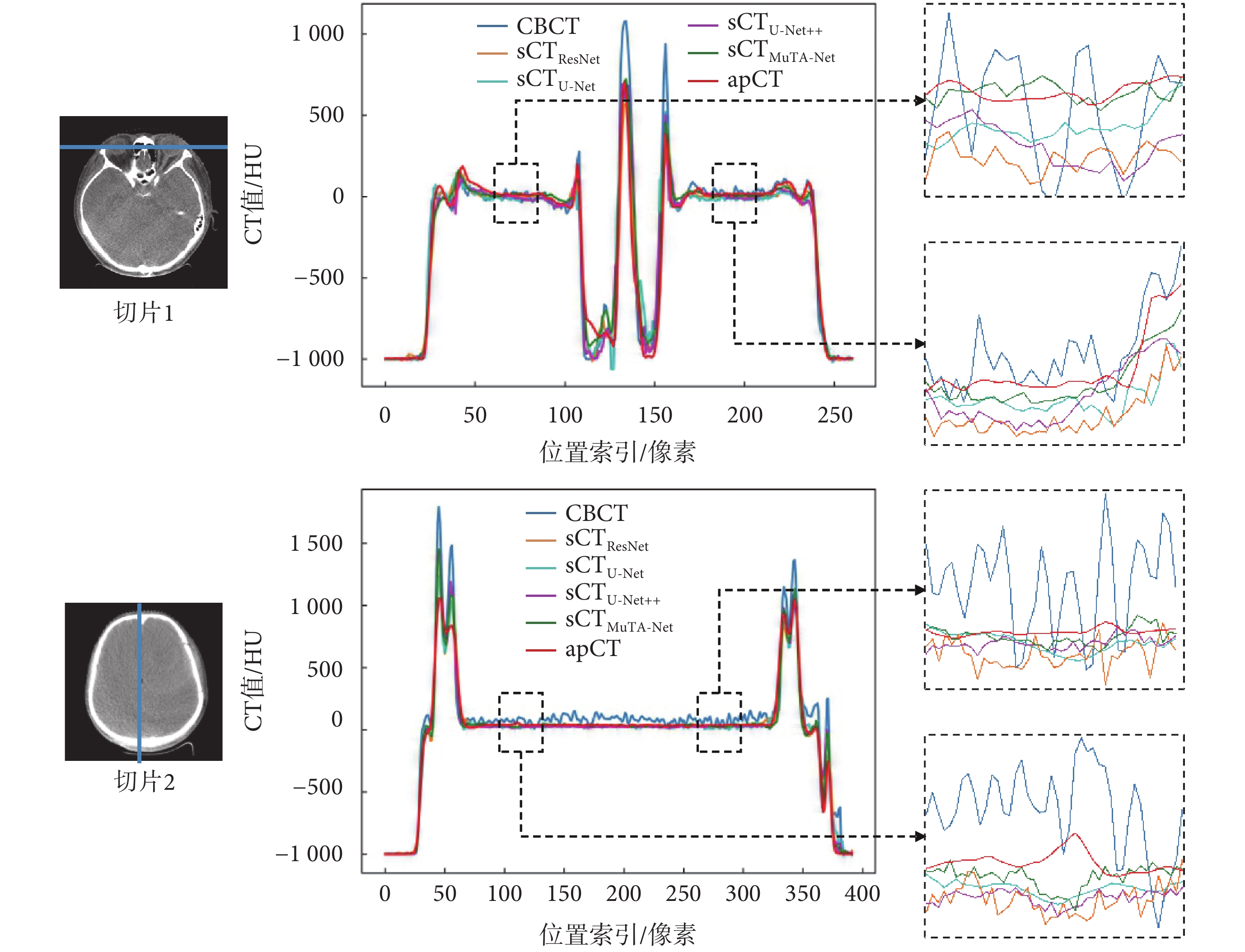
本文隨機選取了兩張切片,并繪制了橫向和縱向(藍色直線)上的CT值剖視圖,如圖4所示。CBCT圖像因受噪聲和偽影的影響,表現出較大的CT值波動。相比之下,每種sCT圖像剖視圖曲線呈現出更為平滑的曲線。其中,sCTMuTA-Net(綠色曲線)與apCT(紅色曲線)之間的差距最小,且變化趨勢保持一致,尤其是在眼球和腦部的軟組織區域(黑色方框)更為明顯,表示兩者CT值分布最為接近,這說明相較于對比方法,MuTA-Net具有最好的偽影抑制和CT值校正能力,特別是在軟組織區域的生成能力最佳。
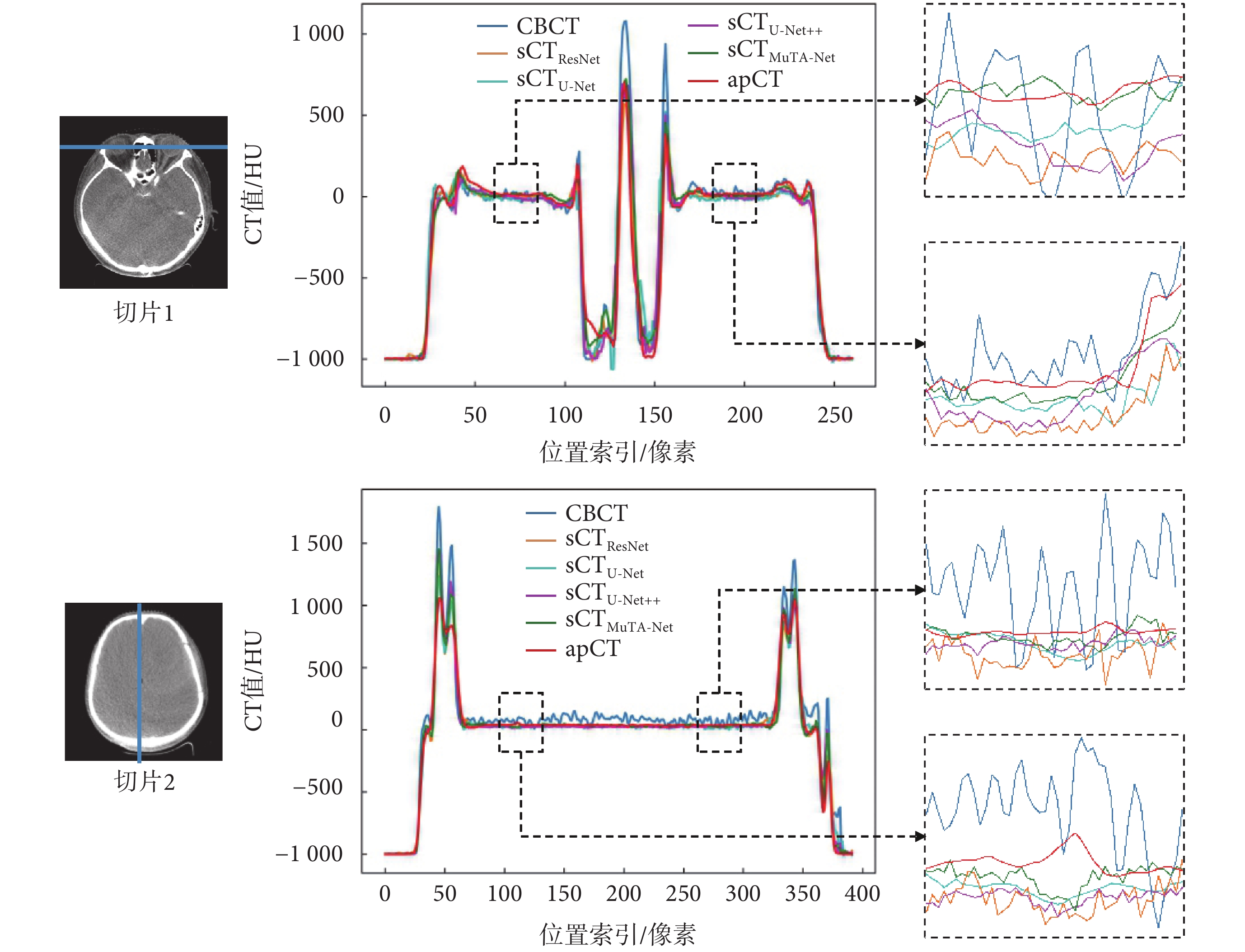 圖4
CT 值剖視圖
Figure4.
CT value profile
圖4
CT 值剖視圖
Figure4.
CT value profile
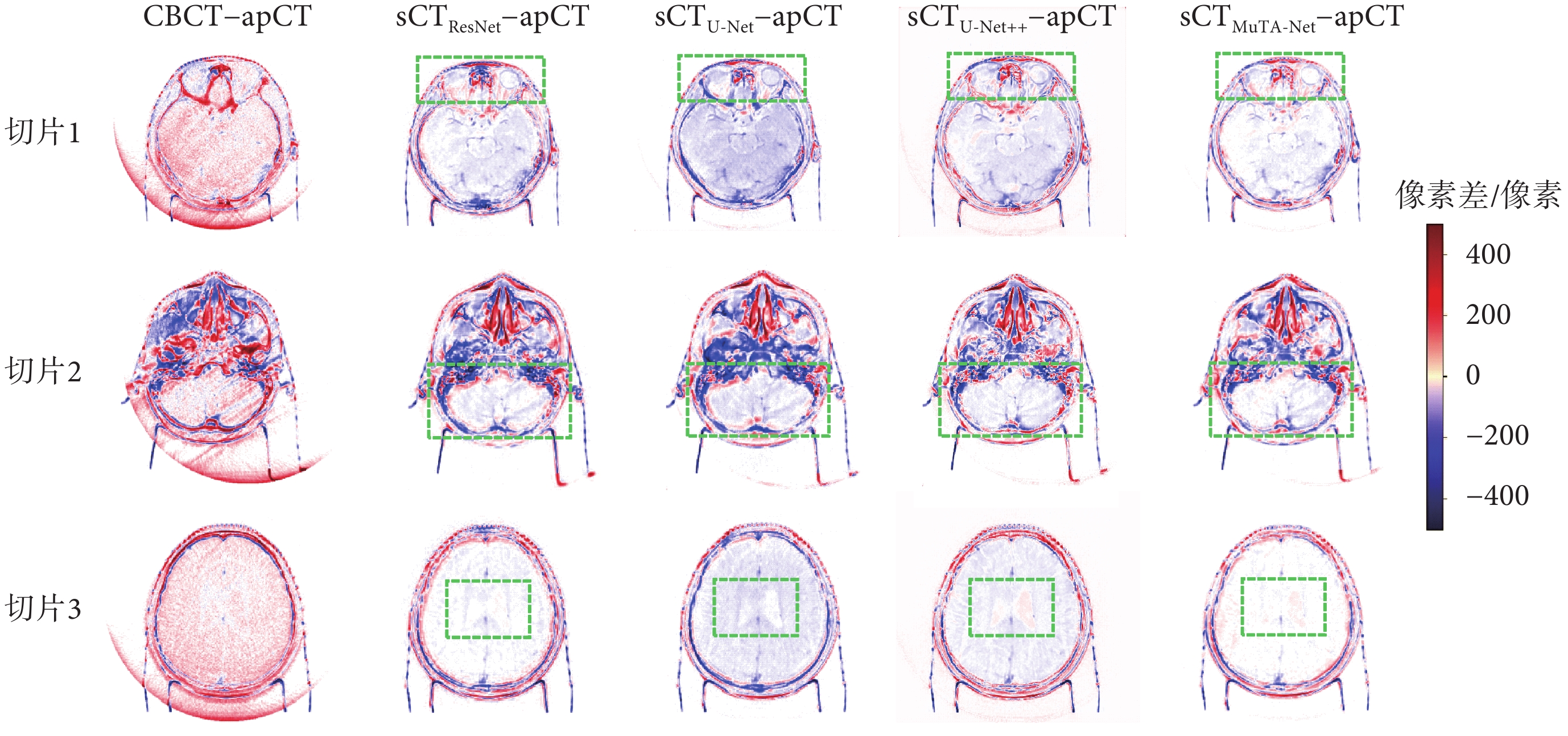
本文隨機選取了反映頭部不同組織的三張切片,并繪制了CT值差異圖,如圖5所示。從圖中可以看出,后四列sCT–apCT的顏色比第一列CBCT–apCT有了明顯淡化,其中sCTMuTA-Net?apCT的全局顏色最淺,體現了MuTA-Net具有最優的CT值校正能力。對比感興趣的軟組織區域(綠色方框)可以發現,sCTMuTA-Net?apCT在眼球(切片1)、小腦半球(切片2)和腦室(切片3)區域均近乎白色,表明了MuTA-Net在軟組織區域生成效果最佳。此外,sCTU-Net?apCT的腦組織區域相對偏向于藍色,這種偏色現象表明U-Net方法會引入大量噪聲,導致腦組織區域的CT值發生偏移,而sCTMuTA-Net?apCT并無這種偏色現象,說明MuTA-Net有效克服了U-Net中CT值偏移問題,凸顯了MuTA-Net在軟組織區域噪聲抑制方面的優勢。
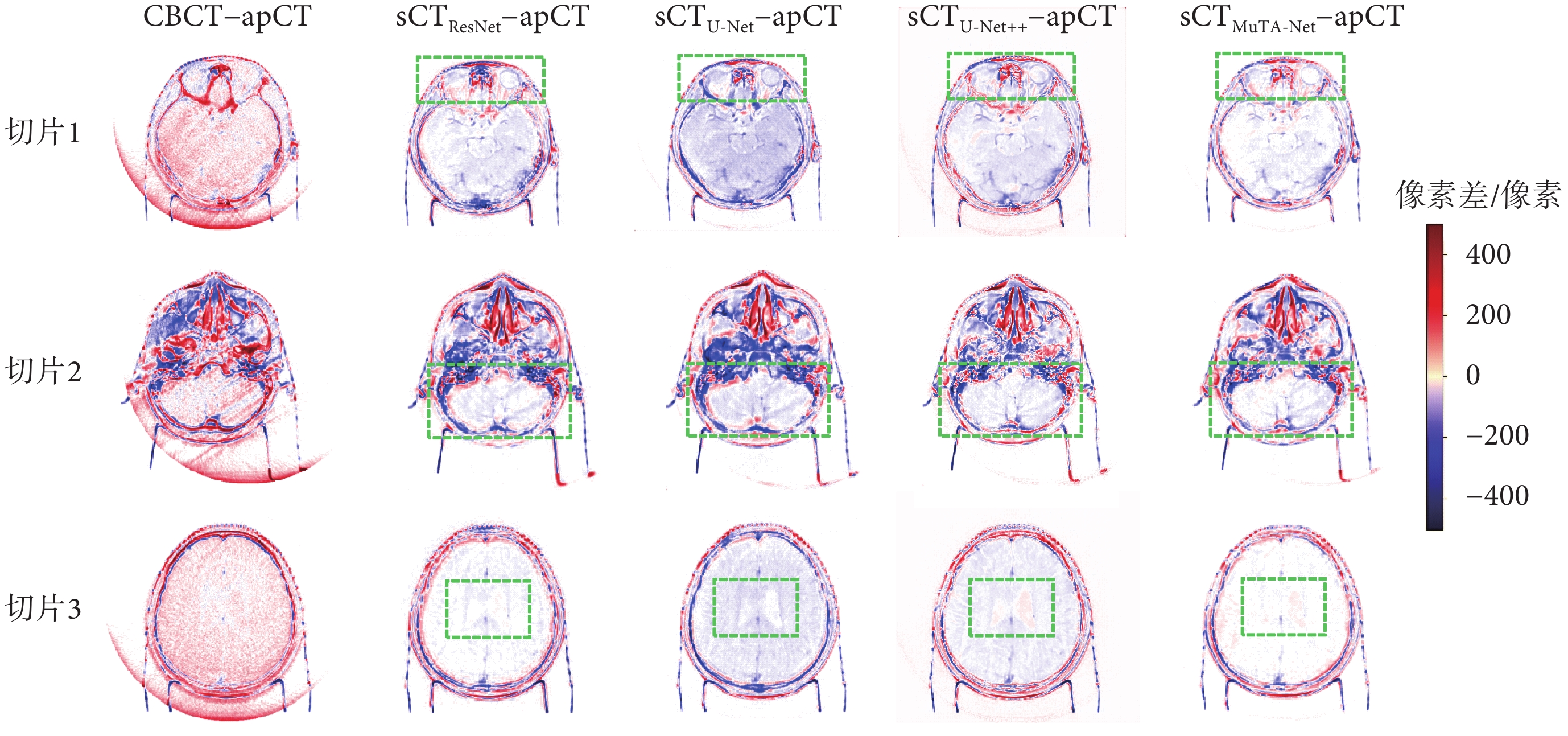 圖5
CT 值差異圖
Figure5.
CT value difference
圖5
CT 值差異圖
Figure5.
CT value difference
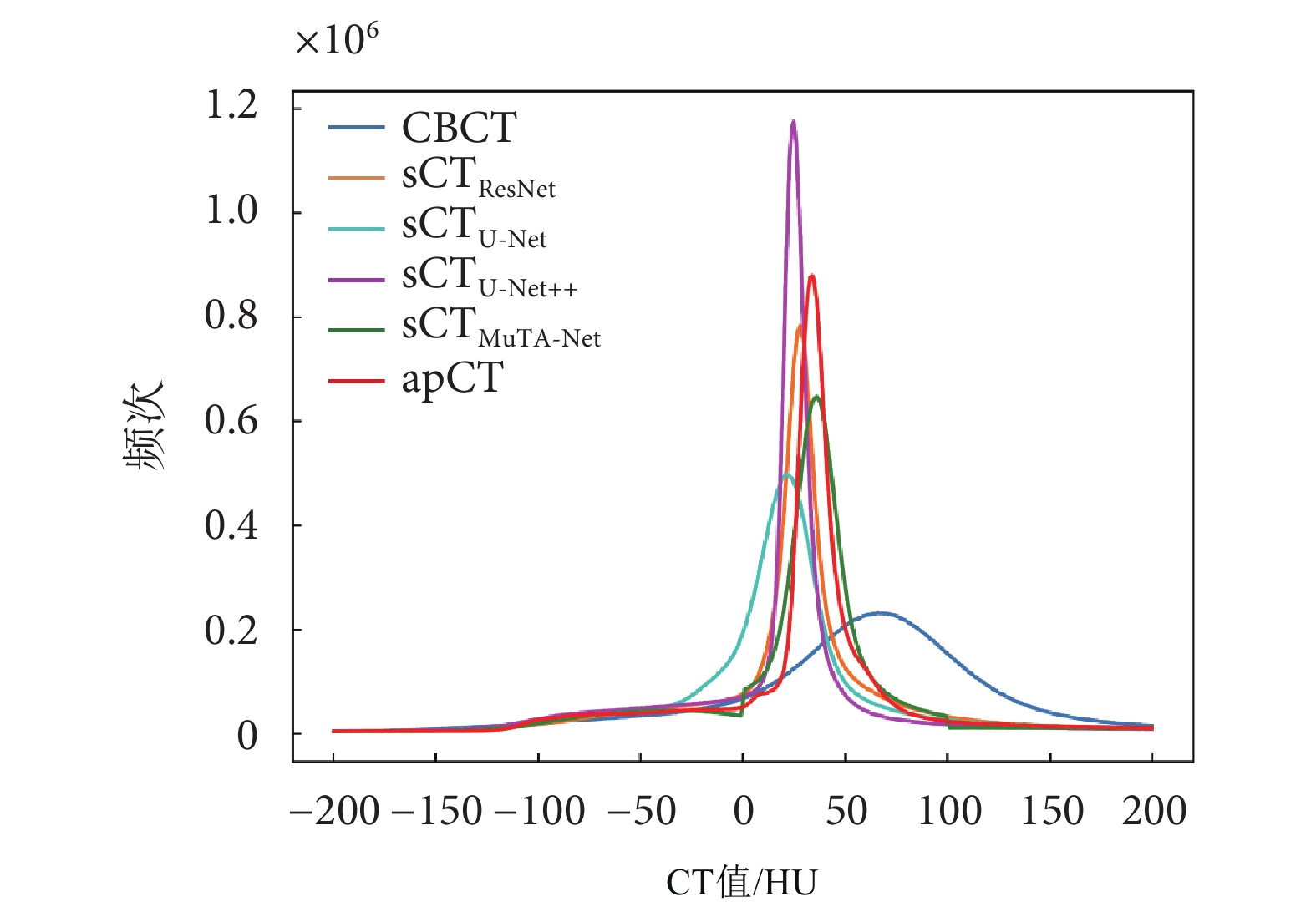
本文統計了所有測試集圖像CT值在[–200,200] HU之間出現的頻次,并繪制了CT值直方圖,如圖6所示。CBCT的直方圖曲線相較于apCT存在明顯的偏離,說明CBCT圖像CT值的不精確性。與CBCT相比,所有sCT圖像的直方圖曲線更好地擬合了apCT的直方圖曲線,其中sCTMuTA-Net最為接近,說明MuTA-Net對CT值的校正效果最佳。
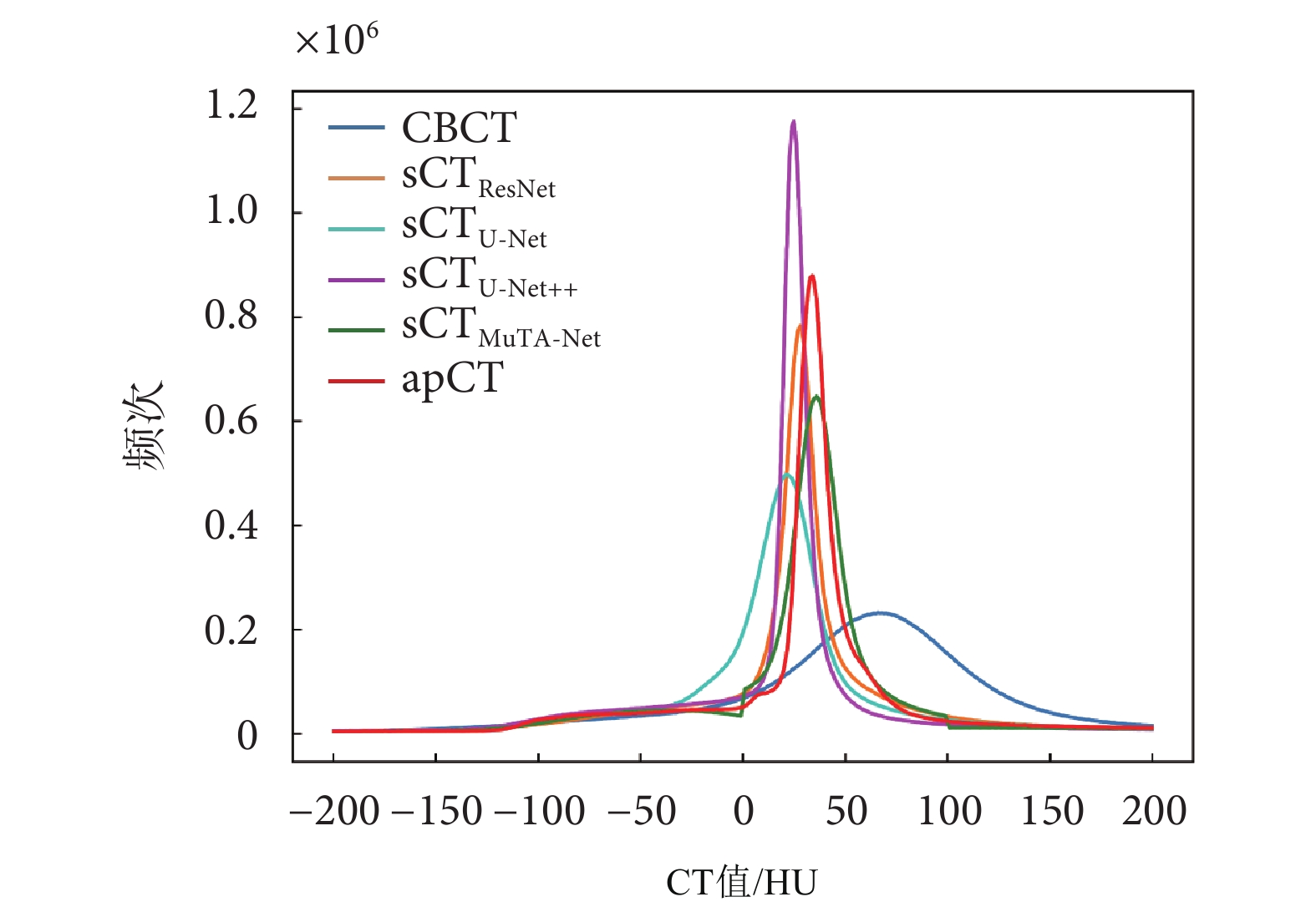 圖6
CT 值直方圖
Figure6.
Histogram line of CT value
圖6
CT 值直方圖
Figure6.
Histogram line of CT value
2.5 消融實驗結果
為了進一步驗證本文所提網絡各項任務的有效性,分別對Isct、Itissue和Ibone進行消融實驗。由于以上三個任務需依次增加,因此,本消融實驗中將MuTA-Net中的共享網絡記為Base;在此基礎上增加一個由多個注意力模塊構成的Isct網絡,記為Base + Isct;再加入Itissue網絡,記為Base + Isct+Itissue;最后加入Ibone網絡,記為Base+Isct + Itissue + Ibone(即本文所提網絡MuTA-Net)。表4展示了各組實驗的評價指標結果。
與Base相比,Base+Isct的生成結果在各項指標上均得到提升,MAE降低了5.62%,RMSE降低了10.09%,PSNR增加了2.17%,SSIM增加了0.75%,證實了注意力模塊在強化網絡的特征提取和圖像生成能力的積極作用。Base + Isct + Itissue的生成結果在各項指標上又有了大幅提升,表明通過增加Itissue,進一步增強了網絡對軟組織區域的特征保留能力,提升了軟組織區域的生成質量。Base + Isct + Itissue + Ibone的生成結果在所有指標上都表現出最佳的性能,新增的Ibone有效避免了結果融合對骨區域生成精度的影響,進一步提升了sCT圖像的生成質量。以上實驗結果充分驗證了MuTA-Net中各項任務的有效性。
3 結論
針對目前sCT圖像不同組織區域的生成質量不均衡,特別是軟組織區域生成效果不理想的問題,本文提出了一種由CBCT生成sCT的多任務注意力網絡MuTA-Net,引入的多任務學習策略能夠深入挖掘軟組織區域的特征信息,有效提升了軟組織區域的圖像質量,網絡中的注意力模塊可以高效地提取全局特征中的子任務特征,增強了網絡的特征挖掘能力,從而提高網絡的生成質量。實驗結果顯示,MuTA-Net生成的sCT圖像在MAE、RMSE、PSNR和SSIM四項指標上均優于對比方法(ResNet、U-Net、U-Net++),特別在軟組織區域的生成效果提升顯著。MuTA-Net生成的sCT圖像不僅具有與CBCT圖像一致的最新解剖結構,還兼具與pCT圖像同樣的高精確CT值。本文所提的sCT生成方法在CBCT引導的自適應放療領域具有潛在的應用價值。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:付紫維負責本文算法程序設計、結果記錄分析以及論文撰寫;朱葉晨負責提供實驗指導、數據分析指導和論文審閱修訂;張子健負責本文工作的臨床指導;高欣承擔論文審閱修訂與總體指導。
倫理聲明:本研究通過了中南大學湘雅醫院倫理委員會的審批(批文編號:202202037)。
本文附件見本刊網站的電子版本(biomedeng.cn)。
0 引言
錐束計算機斷層掃描(cone beam computed tomography,CBCT)具有輻射劑量低、成像速度快、輕量便攜等優勢,是圖像引導放療(image guided radiation therapy,IGRT)中患者擺位驗證的關鍵工具[1-2]。自適應放療(adaptive radiation therapy,ART)作為IGRT的延伸,旨在借助CBCT監測解剖結構的變化,繼而調整放療計劃以確保放療的精準度[3-4]。個體化的精準放療能夠有效提高腫瘤局部控制率,降低正常組織并發癥的發生率。如果能夠直接基于CBCT圖像調整放療計劃,可以避免重新掃描計劃CT[5](planning CT,pCT),減少劑量損傷,提高治療效率。然而,錐束X線存在很強的散射信號[6-7],導致CBCT重建圖像質量不佳[8-11],如軟組織密度分辨率低、偽影嚴重、CT值失真。因此,CBCT圖像無法用于放射劑量的精確計算,難以支持自適應放療的引導[12-13]。
偽CT圖像合成技術有望解決上述CBCT圖像在放療中的局限性[14],該技術主要有兩種實現思路:一是通過醫學圖像配準獲得形變的計劃CT(deformed planning CT,dpCT)[15-16],二是通過深度學習生成合成CT(synthetic CT,sCT)[17-18]。醫學圖像配準方法通過尋找最佳空間變換參數對pCT圖像進行形變,獲取與CBCT解剖結構一致的dpCT,但當兩者解剖結構差異較大時,會降低配準精度,進而影響放射劑量計算精度,且該方法依賴人工設定參數,可重復性差,極大地限制了臨床應用[19]。深度學習方法具有特征自動提取能力,減少人為設計特征造成的不完備性,可以同時進行偽影抑制和CT值校正,提高了圖像合成效率和準確性。Yang等[20]定量比較了基于pCT形變配準的dpCT和基于CBCT生成的sCT,結論是當解剖結構變化較大時,sCT的精度要明顯優于dpCT的精度。研究人員將有監督網絡U-Net[21]和無監督網絡循環一致生成對抗網絡(cycle-consistent generative adversarial network,CycleGAN)[22]應用到sCT圖像生成,取得了不錯的效果[23-24]。后續又涌現出諸多改進方法,如Yuan等[25]提出U-Net++,引入密集連接整合不同層次的特征,提高了生成精度;Liu等[26]提出TranSE-cycleGAN,將卷積神經網絡和通道注意力引導的Transformer網絡結合,保留CBCT圖像結構的同時,提高了圖像CT值的精度。然而,骨、軟組織、空氣等不同區域的組織吸收率差異顯著,CBCT密度分辨率呈現明顯的區域不一致性,其中,CBCT圖像軟組織區域的密度分辨率低且CT值范圍小。現有方法采用單任務學習架構提取CBCT圖像的特征信息,未對軟組織區域做針對性處理,導致網絡對該區域的生成能力不足,常被過度平滑,相較于其他結構區域,生成質量較差。
針對目前sCT圖像不同組織區域的生成質量不均衡,特別是軟組織區域生成效果不理想的問題,本文提出了一種由CBCT生成sCT的多任務注意力網絡(Multi-Task Attention Network,MuTA-Net),重點提升sCT軟組織區域的圖像質量。首先,引入多任務學習策略[27]將sCT生成任務分為全局圖像生成、軟組織區域生成和骨區域分割三個子任務;然后,設計注意力模塊優化網絡的特征提取能力,引導網絡從全局特征中提取子任務特征,提高子任務的生成質量;最后,借助結果融合模塊整合各個子任務的生成結果,生成高質量的sCT圖像。鑒于多任務學習方法是一種典型的有監督學習方法,本文利用頭頸部CBCT數據對MuTA-Net和幾種先進的有監督學習方法(ResNet[28]、U-Net[23]和U-Net++[25])進行對比分析,定性和定量評估網絡的sCT生成性能。
1 方法
1.1 多任務學習策略
本文引入多任務學習策略,設計了一種多任務注意力網絡MuTA-Net,將sCT生成任務分為全局圖像生成Isct、軟組織區域生成Itissue和骨區域分割Ibone三個嵌套遞進的子任務,利用結果融合模塊整合子任務結果,生成高質量的sCT圖像。子任務功能如下:① Isct:學習CBCT圖像到pCT圖像的全局映射關系,保證全局圖像的生成質量。② Itissue:作為Isct的關鍵補充,強化網絡對軟組織區域特征提取和生成的關注程度,重點提升軟組織區域的圖像質量。③ Ibone:明確與軟組織區域差異明顯的骨區域的邊界,保證骨區域CT值的生成精度。理想情況下,Itissue的生成結果在軟組織區域存在CT值,骨區域的像素值為0,然而其在骨區域也會生成CT值,且該值準確性不高,這將極大干擾骨區域的生成精度。所以,Ibone用于骨區域的精準分割,在結果融合時利用分割結果強制將Itissue生成結果中的骨區域置0,保證骨區域內部CT值精度不受影響。
1.2 MuTA-Net
本文所提MuTA-Net如圖1所示,包含一個共享網絡和三個并行且結構相同的子任務網絡,每個網絡均由編碼器和解碼器組成。首先,CBCT圖像輸入到共享網絡提取多尺度全局特征。然后,三個子任務網絡針對各自任務從多尺度全局特征中進一步深化特征提取,獲取子任務特征。最后,子任務網絡末端輸出的三個子任務結果(Isct、Itissue和Ibone)經結果融合模塊融合,在Ibone區域外部,使用Itissue的生成結果,而在Ibone區域的內部,使用Isct的生成結果,從而輸出高質量sCT圖像,具體融合方式見附件1。
圖1
MuTA-Net 示意圖
Figure1.
Illustration of MuTA-Net
1.2.1 共享網絡
共享網絡基于VGG-16[29]搭建,編碼器共有五層,每層由兩到三個3 × 3卷積、組歸一化[30]、ReLU激活函數和一個最大池化級聯組成,解碼器結構則與編碼器對稱設計。為了防止池化丟失細節信息,本文在對稱的卷積層處引入跳躍連接[31]。共享網絡在每一層均輸出兩個全局特征,記為和,其中j為網絡的層數。具體而言,在編碼器中,和分別表示第j層首個3 × 3卷積和最后一個3 × 3卷積提取的全局特征,而在解碼器中,則分別表示第j層首步反最大池化和最后一個3 × 3卷積提取的全局特征。各層提取的全局特征并行傳輸到三個子任務網絡對應層的注意力模塊,以針對三個不同子任務進一步挖掘和提煉子任務特征。
1.2.2 子任務網絡
三個并行的子任務網絡具有與共享網絡相同的層數,每層由一個注意力模塊構成。注意力模塊的結構細節如圖2所示,分為編碼器注意力模塊與解碼器注意力模塊兩種類型,兩者結構對稱,均包含注意力區域計算和子任務特征提取兩個核心部分。注意力區域計算分為兩步:第一步為特征融合,由Concatenate函數、1 × 1卷積、組歸一化和ReLU激活函數級聯而成;第二步為掩碼獲取,由1 × 1卷積、組歸一化和Sigmoid激活函數級聯而成。子任務特征提取由3 × 3卷積、組歸一化、ReLU激活函數和(反)最大池化組成。
圖2
注意力模塊
Figure2.
Attention module
以任意一個子任務網絡編碼器中的第j層注意力模塊為例,對于其輸入而言,除了來自共享網絡對應層(第j層)提取的兩個全局特征(和)外,還有前一層(第層)注意力模塊輸出的子任務特征。基于以上三個輸入,第j層注意力模塊最終輸出該層的子任務特征。令表示1 × 1卷積,表示3 × 3卷積,Norm表示組歸一化,P表示最大池化操作,則第j層編碼器注意力模塊的計算過程如下。
首先,注意力模塊使用Concatenate函數將第一個全局特征和前一層的子任務特征進行拼接,并利用1 × 1卷積進行特征融合,得到融合特征。需要注意的是,首層()注意力模塊無需輸入前一層的子任務特征。公式如式(1)所示。
|
其中,?表示Concatenate函數。
然后,融合特征依次經過1 × 1卷積和組歸一化后,由Sigmoid激活函數映射到[0,1],從而得到掩碼,如式(2)所示。
|
最后,將掩碼與第二個全局特征進行點乘運算,提取初步的子任務特征,再借助3 × 3卷積進一步提取特征,并利用最大池化對特征圖進行下采樣,得到該層子任務特征。公式如式(3)所示。
|
其中,⊙表示點乘運算。
由于結構對稱性,解碼器注意力模塊的計算過程與以上編碼器注意力模塊的計算過程相反。
1.3 損失函數
多任務學習的損失函數由三個子任務的損失函數線性加權獲得,如式(4)所示。
|
其中,、和為三個子任務的權重系數。
對于Isct和Itissue兩個生成任務,采用平均絕對誤差(mean absolute error,MAE)構建損失函數,衡量生成圖像和標簽圖像之間的像素級差異。此外,為了增強網絡保留軟組織區域結構的能力,Itissue的損失函數還引入結構相似性指數(structural similarity index measure,SSIM),用于評估生成圖像和標簽圖像之間的結構相似性,這種聯合損失能夠有效監督軟組織區域像素級和結構級的訓練過程。
|
|
其中,和為Itissue的損失權重系數。
對于分割任務Ibone,在輸出進行Softmax激活處理后,使用交叉熵(cross entropy,CE)計算損失。
|
各項指標的具體公式如式(8)、(9)、(10)所示。
|
|
|
其中,X表示生成圖像,Y表示標簽圖像,、分別表示圖像X和Y中的單個像素,N表示圖像的像素數,和分別表示圖像X和Y的均值,和分別表示圖像X和Y的方差,表示圖像X和Y的協方差。和為常數項,避免分母為0。
2 實驗與結果分析
2.1 數據與預處理
本文回顧性收集了2020年至2021年間中南大學湘雅醫院40例頭頸部癌癥患者的pCT圖像和CBCT圖像,所有納入研究的患者均在模擬定位階段接受標準化的pCT掃描,并在IGRT中以相同體位接受CBCT掃描。pCT圖像由Philips Brilliance大孔徑螺旋CT掃描儀獲取,管電壓為120 kV,管電流為285 mA到483 mA不等,重建體素尺寸為0.78~1.17 mm不等,層厚為3 mm。CBCT圖像采用Varian TrueBeam機載CBCT掃描儀獲取,管電壓為100 kV,管電流為20 mA,重建體素尺寸為0.51 mm,層厚為3 mm。pCT和CBCT的圖像尺寸均為512像素×512像素。其中,34例患者的pCT和CBCT用于訓練,其余6例患者的pCT和CBCT用于測試,掃描間隔均不超過1周。由于掃描間隔短,放療引發的解剖結構差異(特別是腫瘤大小差異)可忽略不計。本文使用臨床商用軟件MIM Maestro 6.7.10(MIM Software Inc.,美國)進行醫學圖像剛性配準。配準過程中,pCT圖像作為浮動圖像,CBCT圖像作為固定圖像,最終獲得對齊的pCT(aligned planning CT,apCT)圖像(與dpCT不同),該圖像具有與CBCT一致的解剖結構,確保二者可以構成嚴格配對的數據集。去除不含人體組織的切片后,最終獲得869張配對切片用于訓練,402張配對切片用于測試。
數據預處理流程如圖3所示。首先,進行剛性配準,獲得apCT圖像。其次,將圖像CT值裁剪至[–1 000,3 095] HU,去除無關背景信息,提高網絡的訓練效率。然后,將圖像像素值歸一化至[0,1],保留原始圖像特征信息,同時提高網絡訓練的收斂速度[32]。最后,基于apCT圖像制作各子任務訓練標簽。Isct標簽即apCT圖像,Itissue和Ibone標簽則通過閾值分割法制作。本文定義500 HU為軟組織區域與骨區域的界限,即CT值范圍在[–1 000,500] HU的為軟組織區域,在[500,3 095] HU的為骨區域,分別制作軟組織區域和骨區域的二值掩膜(區域內為1,其他區域為0)。Itissue標簽由apCT圖像與軟組織區域掩膜相乘獲得,Ibone標簽即骨區域掩膜。
圖3
數據預處理流程
Figure3.
Workflow of the image pre-processing
2.2 實驗環境與超參設定
本文基于開源的Python 3.8.18機器學習庫PyTorch 1.8.1與英偉達GeForce RTX 3090Ti GPU環境構建多任務注意力網絡MuTA-Net。訓練的批大小設定為2,訓練輪次為200。采用Adam優化器,初始學習率設定為1e–5,訓練100輪后,學習率以0.1的衰減系數進行下降。本文利用隨機正態初始化,將所有權重按照均值為0,標準差為0.02的標準進行初始化。實驗表明,在當前環境條件下,三個子任務權重系數、和分別取1.4、1.8、1.0,損失權重系數和分別取0.4、0.6,網絡效果達到最佳,具體實驗結果見附件2。輸入CBCT圖像和輸出sCT圖像的尺寸均為512像素×512像素。網絡的訓練時間約17 h,平均完成一位患者的sCT圖像生成約為20 s。所有對比網絡和消融實驗網絡均在相同的環境下進行訓練,具有完全相同的訓練參數。
2.3 網絡評估
本文采用MAE、均方根誤差(root mean square error,RMSE)、峰值信噪比(peak signal-to-noise ratio,PSNR)和SSIM四個指標評估MuTA-Net的性能。令X表示生成的sCT圖像,Y表示apCT圖像,、分別表示圖像中的單個像素,N表示圖像的像素數,則各項指標的定義與公式如下:
(1)MAE:值越小,表示sCT與apCT的像素值越接近,公式如前文式(8)所示。
(2)RMSE:與MAE相比,對異常值更敏感。RMSE值越小,表明sCT和apCT之間的像素值差異越小,公式如式(11)所示;
|
(3)PSNR:值越大,表示sCT的噪聲水平越低,失真越小,公式如式(12)所示;
|
其中,表示圖像的像素最大值與最小值之差。
(4)SSIM:值越接近1,表明sCT與apCT越相似,網絡的結構特征保留的能力越強,公式如前文式(9)所示。
此外,本文還通過CT值剖視圖、差異圖和直方圖對sCT圖像進行定性分析。剖視圖顯示了圖像沿著某一直線的像素強度分布,比較了圖像像素在同一方向的變化趨勢。差異圖將sCT圖像和apCT圖像相減并進行偽彩映射,直觀展現了圖像對應位置的CT值差異,越接近白色,表示該區域的CT值差異越小,說明網絡的CT值校正效果越好。直方圖則統計了圖像上每個CT值出現的頻次。
2.4 對比實驗結果
為了驗證MuTA-Net的有效性,本文將它與基礎的卷積神經網絡(ResNet[28])和常用的sCT生成網絡(U-Net[23])及其變體(U-Net++[25])進行對比,采用MAE、RMSE、PSNR和SSIM定量比較上述方法生成的sCT圖像(sCTResNet、sCTU-Net、sCTU-Net++、sCTMuTA-Net),結果如表1所示。以ResNet為代表的傳統卷積神經網絡在圖像生成任務上存在一定的局限性,sCTResNet的各項指標仍有提升空間;U-Net憑借其精巧的編解碼器架構設計,在特征提取的方面具有一定的優勢,然而在處理小尺寸目標時存在局限性;U-Net++在U-Net的基礎上引入了密集連接,可有效整合不同層次的特征,更好地捕獲上下文信息和細節特征;而本研究所提方法MuTA-Net通過引入多任務學習策略進一步提高了軟組織區域的圖像質量,并借助注意力模塊優化了網絡的特征提取能力。同CBCT圖像相比,sCTMuTA-Net圖像MAE下降了47.68%,RMSE下降了40.51%,PSNR上升了13.40%,SSIM上升了6.26%;與次優結果相比,sCTMuTA-Net圖像MAE下降了11.55%,RMSE下降了5.79%,PSNR上升了1.47%,SSIM上升了0.74%。這表明,MuTA-Net在CT值校正、噪聲抑制和結構細節保留等方面表現最佳,具有最優的sCT生成能力。
為了驗證MuTA-Net在軟組織區域生成方面的優勢,本文通過掩膜分離出CBCT圖像和sCT圖像中的軟組織區域,并采用MAE、RMSE、PSNR和SSIM比較sCT圖像軟組織區域的生成效果,如表2所示。與CBCT圖像相比,sCTMuTA-Net圖像軟組織區域的MAE下降了45.44%,RMSE下降了33.84%,PSNR上升了13.45%,SSIM上升了11.57%;與次優結果相比,sCTMuTA-Net圖像軟組織區域的MAE下降了12.52%,RMSE下降了5.25%,PSNR上升了1.65%,SSIM上升了0.99%。以上結果表明,MuTA-Net具有最好的軟組織區域生成性能,證實了它在提升CBCT圖像軟組織區域的生成質量方面具有優勢。同時,本文進一步分析了sCT圖像骨區域的生成效果,如表3所示,可知sCTMuTA-Net圖像骨區域的指標均達到最優,表明MuTA-Net在骨區域生成方面同樣表現出色。
本文隨機選取了兩張切片,并繪制了橫向和縱向(藍色直線)上的CT值剖視圖,如圖4所示。CBCT圖像因受噪聲和偽影的影響,表現出較大的CT值波動。相比之下,每種sCT圖像剖視圖曲線呈現出更為平滑的曲線。其中,sCTMuTA-Net(綠色曲線)與apCT(紅色曲線)之間的差距最小,且變化趨勢保持一致,尤其是在眼球和腦部的軟組織區域(黑色方框)更為明顯,表示兩者CT值分布最為接近,這說明相較于對比方法,MuTA-Net具有最好的偽影抑制和CT值校正能力,特別是在軟組織區域的生成能力最佳。
圖4
CT 值剖視圖
Figure4.
CT value profile
本文隨機選取了反映頭部不同組織的三張切片,并繪制了CT值差異圖,如圖5所示。從圖中可以看出,后四列sCT–apCT的顏色比第一列CBCT–apCT有了明顯淡化,其中sCTMuTA-Net?apCT的全局顏色最淺,體現了MuTA-Net具有最優的CT值校正能力。對比感興趣的軟組織區域(綠色方框)可以發現,sCTMuTA-Net?apCT在眼球(切片1)、小腦半球(切片2)和腦室(切片3)區域均近乎白色,表明了MuTA-Net在軟組織區域生成效果最佳。此外,sCTU-Net?apCT的腦組織區域相對偏向于藍色,這種偏色現象表明U-Net方法會引入大量噪聲,導致腦組織區域的CT值發生偏移,而sCTMuTA-Net?apCT并無這種偏色現象,說明MuTA-Net有效克服了U-Net中CT值偏移問題,凸顯了MuTA-Net在軟組織區域噪聲抑制方面的優勢。
圖5
CT 值差異圖
Figure5.
CT value difference
本文統計了所有測試集圖像CT值在[–200,200] HU之間出現的頻次,并繪制了CT值直方圖,如圖6所示。CBCT的直方圖曲線相較于apCT存在明顯的偏離,說明CBCT圖像CT值的不精確性。與CBCT相比,所有sCT圖像的直方圖曲線更好地擬合了apCT的直方圖曲線,其中sCTMuTA-Net最為接近,說明MuTA-Net對CT值的校正效果最佳。
圖6
CT 值直方圖
Figure6.
Histogram line of CT value
2.5 消融實驗結果
為了進一步驗證本文所提網絡各項任務的有效性,分別對Isct、Itissue和Ibone進行消融實驗。由于以上三個任務需依次增加,因此,本消融實驗中將MuTA-Net中的共享網絡記為Base;在此基礎上增加一個由多個注意力模塊構成的Isct網絡,記為Base + Isct;再加入Itissue網絡,記為Base + Isct+Itissue;最后加入Ibone網絡,記為Base+Isct + Itissue + Ibone(即本文所提網絡MuTA-Net)。表4展示了各組實驗的評價指標結果。
與Base相比,Base+Isct的生成結果在各項指標上均得到提升,MAE降低了5.62%,RMSE降低了10.09%,PSNR增加了2.17%,SSIM增加了0.75%,證實了注意力模塊在強化網絡的特征提取和圖像生成能力的積極作用。Base + Isct + Itissue的生成結果在各項指標上又有了大幅提升,表明通過增加Itissue,進一步增強了網絡對軟組織區域的特征保留能力,提升了軟組織區域的生成質量。Base + Isct + Itissue + Ibone的生成結果在所有指標上都表現出最佳的性能,新增的Ibone有效避免了結果融合對骨區域生成精度的影響,進一步提升了sCT圖像的生成質量。以上實驗結果充分驗證了MuTA-Net中各項任務的有效性。
3 結論
針對目前sCT圖像不同組織區域的生成質量不均衡,特別是軟組織區域生成效果不理想的問題,本文提出了一種由CBCT生成sCT的多任務注意力網絡MuTA-Net,引入的多任務學習策略能夠深入挖掘軟組織區域的特征信息,有效提升了軟組織區域的圖像質量,網絡中的注意力模塊可以高效地提取全局特征中的子任務特征,增強了網絡的特征挖掘能力,從而提高網絡的生成質量。實驗結果顯示,MuTA-Net生成的sCT圖像在MAE、RMSE、PSNR和SSIM四項指標上均優于對比方法(ResNet、U-Net、U-Net++),特別在軟組織區域的生成效果提升顯著。MuTA-Net生成的sCT圖像不僅具有與CBCT圖像一致的最新解剖結構,還兼具與pCT圖像同樣的高精確CT值。本文所提的sCT生成方法在CBCT引導的自適應放療領域具有潛在的應用價值。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:付紫維負責本文算法程序設計、結果記錄分析以及論文撰寫;朱葉晨負責提供實驗指導、數據分析指導和論文審閱修訂;張子健負責本文工作的臨床指導;高欣承擔論文審閱修訂與總體指導。
倫理聲明:本研究通過了中南大學湘雅醫院倫理委員會的審批(批文編號:202202037)。
本文附件見本刊網站的電子版本(biomedeng.cn)。