胰腺形狀和輪廓多變,其分割是醫學圖像任務中公認的難點。基于卷積網絡(CNN)或轉換器(Transformer)的網絡在醫學圖像分割任務中表現出色,但CNN感受野窄,Transformer利用特征不充分,因此仍需改進。本文提出一種改進的胰腺分割方法,結合CNN和Transformer,在階段式編碼器中引入逐點可分離卷積,用更少參數提取更多特征。利用密集連接的集成解碼器融合多尺度特征,解決跳躍連接對結構的非必要限制。在深度監督中引入一致性項和對比損失,以保證模型的最終精度。為驗證方法的有效性,在長海胰腺數據集和美國國立衛生研究院(NIH)胰腺公開數據集上進行了大量對比實驗,分別取得了76.32%和86.78%的最高Dice相似性系數(DSC)值,同時多項其他指標占優。消融實驗驗證了網絡各組成部分對提升性能和減少參數均有重要貢獻。實驗說明本文改進的損失函數最能平滑訓練過程,使模型性能最佳。最終結果證實,本文方法性能表現優于其他先進方法,能夠有效提升胰腺分割效果,可輔助專業醫師診斷,為后續研究應用提供了可靠參考。
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
胰腺分割對醫學影像的研究有重要意義。由于在腹腔中胰腺的位置相對可變,沒有固定形狀和尺寸,因此相較于其他器官,胰腺分割更為困難。胰腺癌的病變通常伴隨著胰腺的形態改變,這種情況下,深度學習方法能夠協助醫生更好地進行臨床影像診斷。基于卷積神經網絡(convolutional nerual network,CNN)的模型在醫學圖像分割領域取得了顯著進展。從U型網絡(U-net)到殘差連接的U型網絡、巢穴U型網絡(U-net++),以及自適應U型網絡(nnU-net)[1-4],這些模型在十項全能挑戰和公開數據集中表現出色。但是,CNN難以捕捉輸入圖像中相距較遠的關聯特征[5]。為解決該問題,研究者引入自然語言處理領域的轉換器(Transformer)以捕捉全局依賴關系計算每個圖像塊之間的相關性,將得到的結果作為注意力掩碼[6]。進一步地,Liu等[7]提出了一種窗口滑動視覺轉換器(shifted windows vision Transformer,SwinViT)以處理變化尺度和大量像素輸入。得益于處理多尺度信息的能力和全局感受野,以SwinViT為編碼器的滑動窗口轉換器U型網絡(shifted window Transformer U-net,SwinUNETR)在圖像分割任務中表現出顯著的性能提升[8]。然而在醫學圖像分割任務中,目標區域通常是連續的,這意味著捕捉局部依賴關系有助于獲得更好結果。因此,最近的研究重新討論卷積網絡[9]。CNN和Transformer相結合是一種實用的方法,許多研究已經提出了若干結合方式[10]。He等[11]提出分階段引入卷積模塊到SwinUNETR的編碼器部分,顯著提高了其在三維(three-dimensional,3D)醫學圖像分割中的能力。為解決樣本不均衡的問題,Oktay[12]提出了注意力U型網絡,將U-Net和注意力機制相結合以應對胰腺分割問題。首先,卷積編碼器提取特征圖,再由注意力門從提取到的特征圖中學習局部語義信息,將注意力機制的作用區域縮小并集中到目標區域。
Transformer模塊中通道數目眾多,與卷積結合會極大增加參數數量。Zeng等[13]提出了整體分解卷積,在網絡的同一層中學習多個卷積核的參數。Chollet[14]提出的深度可分離卷積能夠減少網絡參數。它包括兩個步驟:深度卷積,對每個輸入通道應用單個濾波器;逐點卷積,與值為1的單位卷積核進行卷積,組合深度卷積的輸出。這種方法可以在輕量化網絡的同時維持其性能。
將CNN和Transformer骨干網絡相結合的方法主要分為兩類:① 修改多頭注意力機制,賦予其類似卷積的特性。在金字塔視覺Transformer中,Transformer被構建成金字塔形式,通過每個子塊階段中的嵌入層在不同尺度下生成特征圖[15]。相反地,一些研究者嘗試將Transformer架構整合到卷積運算中。Lee等[16]認為Transformer結構取得成功的原因在于很大的感受野和大量參數,進而主張使用由大尺寸卷積核構成的U型3D分割網絡(3D segmentation U-net,3DUXNet)替代自注意力機制實現較大的感受野,同時增加網絡的通道數,最終在多個數據集上取得了超越SwinUNETR的性能指標。② 將CNN與Transformer架構整合,但不改變各自骨干網絡的行為。腦腫瘤分割轉換器(Brain Tumor Segmentation Transformer,TransBTS)中,考慮到局部和全局信息同等重要,Transformer被引入CNN作為瓶頸層,用于提取全局信息并恢復局部特征,卷積解碼器將Transformer產生的特征圖逐步上采樣,還原至原始分辨率的預測輸出[17]。Zhou等[18]主張由Transformer實現特征提取的主要功能,進而提出了自適應轉換器(no new Transformer,nnFromer)網絡,將局部和全局自注意力由淺至深排布成U型網絡,并通過注意力跳躍連接,在解碼路徑進行特征融合。為了使Transformer和CNN的特征能夠相通,Li等[19]提出了Transfomer&CNN特征校準塊,其中來自CNN和Transformer的特征按維度進行校準,而后融合。Wu等[20]在層次化Transformer中合并了CNN實現的嵌入層和投影層,以應對多尺度和全局上下文信息。
密集連接的概念最先在密集連接網絡中被提出[21]。這種方式確保每層都接收到來自前面所有層的特征圖,并將輸出傳遞給所有后續層。Li等[22]將包含3個卷積模塊和2個最大池化模塊的DenseNet模型應用于胰腺囊腫的輔助診斷,通過密集鏈接網絡從完整的圖像中學習胰腺的高級語義特征,并將圖形特征與不同的胰腺囊腫病理型相關聯。Zhang等[23]進一步發展了該理論,引入了三個密集連接塊,分別是編碼器、解碼器和連接二者的部分,從而構成一個密集連接的U-net架構。全尺度U型網絡(U-net3+)進一步拓展了密集鏈接的應用,其編碼器也用一系列密集連接的卷積模塊組成,這種方式有效增強了特征融合傳播[24]。
為了緩解梯度消失和優化訓練過程,Lee等[25]提出了深度監督。深度監督在網絡的中間層引入輔助損失函數,這些輔助損失函數和目標函數同時優化。Arrastia等[26]提出將深度監督應用于多尺度層級以生成注意力圖并繼續向后傳播。Zhou等[27]提出在胰腺囊腫分割中引入深度監督,借由對胰腺的分割輔助對囊腫區域的分割。
1 方法
1.1 階段式多通道卷積SwinViT
本文提出的網絡結構如圖1所示。階段式編碼器中,多通道卷積后接SwinViT,構成一個階段。每個階段的輸出傳入下一階段,且傳入由兩次卷積正交化組成的殘差編碼器 。計算過程可以表示為:
。計算過程可以表示為:
 圖1
網絡的總體結構圖
Figure1.
Overall architecture of the network
圖1
網絡的總體結構圖
Figure1.
Overall architecture of the network
 |
其中 表示第n階段的輸入,UPWC(up point-wise convolution)和DPWC(down point-wise convolution)分別表示上采樣和下采樣逐點卷積,W-MSA(windows multihead self-attention)和SW-MSA(shift windows multihead self-attention)分別表示滑窗操作前后的多頭注意力機制,LN(linear normalization)表示規范化層。
表示第n階段的輸入,UPWC(up point-wise convolution)和DPWC(down point-wise convolution)分別表示上采樣和下采樣逐點卷積,W-MSA(windows multihead self-attention)和SW-MSA(shift windows multihead self-attention)分別表示滑窗操作前后的多頭注意力機制,LN(linear normalization)表示規范化層。
3D圖像輸入到網絡,被劃分成小圖像塊,拉平成小圖像塊序列,通過一個投影層將它們投影到更高的維度。投影層的輸出傳給編碼器。在多通道卷積模塊中,首先通過卷積層生成初步的特征圖,學習部分細節特征。然后,上采樣逐點卷積將特征圖投影到更高的隱藏維度,通道數擴展至4倍,用更多參數學習胰腺的周圍特征。隨后,采用下采樣逐點卷積將通道維度收縮至初始大小,以便下一步操作。與傳統卷積相比,這種方法可以有效保留重要的特征信息,同時不產生過多參數。
多通道卷積模塊的輸出送入SwinViT,它由兩個Transformer模塊構成,如圖1所示。借助窗口化方法將輸入特征圖劃分為更小的圖像塊,計算每個小塊之間的依賴關系,得到注意力掩碼并將它作為權重加到特征圖上。隨后,移動窗格重新計算注意力掩碼。在每個MSA和SW-MSA之后,特征圖被投影到更高的維度,實現進一步的特征學習。
1.2 集成解碼器
針對胰腺的多變性,本文設計了多路徑的集成解碼器,由密集連接的解碼單元組成。將殘差編碼器組的輸出作為輸入,通過密集連接網絡解碼,得到最終輸出。在圖1中,其結構類似上三角矩陣,每行解碼單元都是其各自深度的解碼路徑,每個矩形代表一個解碼單元,由轉置卷積和上采樣組成。每條解碼路徑都會產生一個預測結果:中間層的解碼路徑產生中間層輸出,而最后一個解碼路徑產生網絡的最終輸出。密集連接可以表示為:
 |
其中 表示轉置卷積操作,[ ]表示拼接,
表示轉置卷積操作,[ ]表示拼接, 表示上采樣操作,
表示上采樣操作, 是第i個殘差卷積模塊的輸出,
是第i個殘差卷積模塊的輸出, 是解碼單元的輸出。在每個解碼單元中,先拼接所有先前同深度單元的輸出,再對解碼路徑上前單元的輸出上采樣,最后與殘差編碼器的輸出拼接在一起,送入卷積層。解碼單元之間的密集連接有助于融合多尺度特征,更好地進行高級語義識別。
是解碼單元的輸出。在每個解碼單元中,先拼接所有先前同深度單元的輸出,再對解碼路徑上前單元的輸出上采樣,最后與殘差編碼器的輸出拼接在一起,送入卷積層。解碼單元之間的密集連接有助于融合多尺度特征,更好地進行高級語義識別。
1.3 對比損失
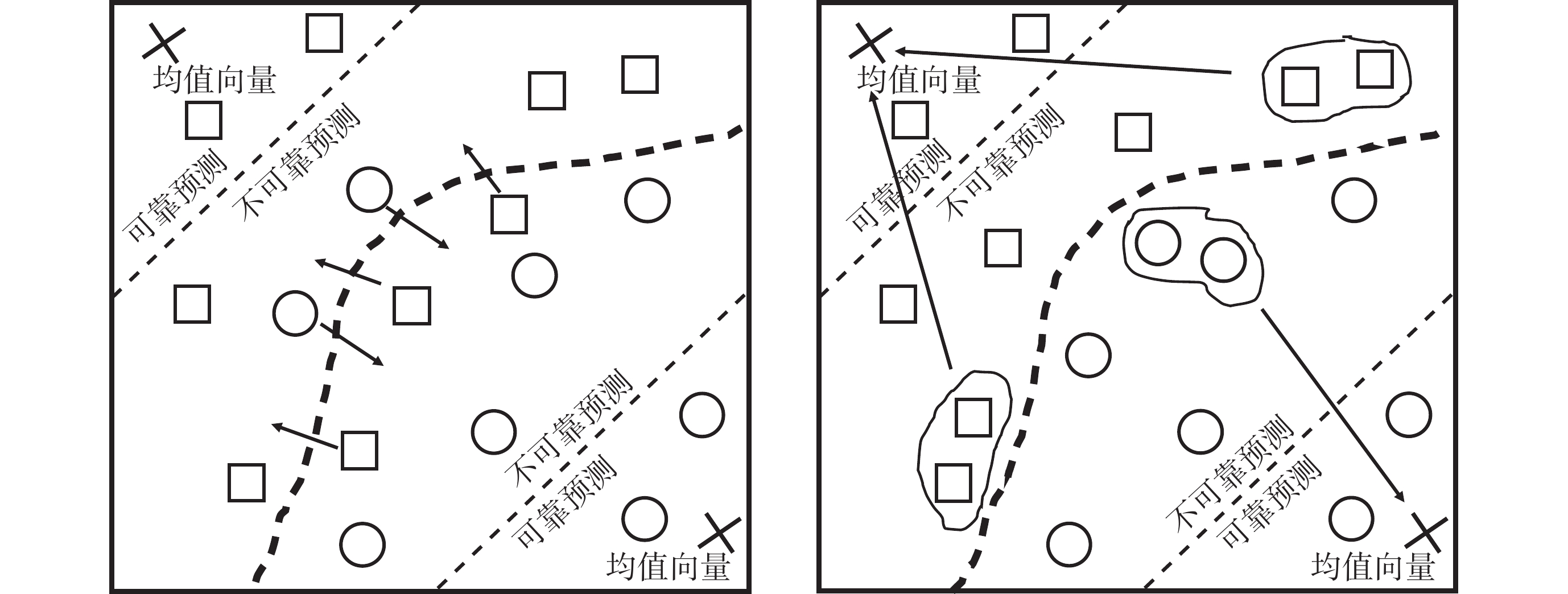
局部特征信息的缺失導致胰腺的預測區域斷續,為緩解這一問題,引入對比損失以監督包含高級語義信息的輸出。將輸出中的每個體素映射到特征嵌入空間。基于置信度分為可靠或不可靠,引導不可靠體素朝向其對應的可靠區域移動。所有的可靠體素作為一個集合,取該集合的均值向量 作為相應標簽區域的向量原型,表示嵌入空間中的相應標簽區域:
作為相應標簽區域的向量原型,表示嵌入空間中的相應標簽區域:
 |
 表示可靠的預測體素,f表示投影層的映射函數,
表示可靠的預測體素,f表示投影層的映射函數, 表示第k個標簽對應的目標區域。計算不可靠體素
表示第k個標簽對應的目標區域。計算不可靠體素 和向量原型
和向量原型 在特征空間中的距離作為二者的差異值,計算softmax得到概率分布:
在特征空間中的距離作為二者的差異值,計算softmax得到概率分布:
 |
其中 表示標簽類別數目,
表示標簽類別數目, 表示距離函數。如圖2所示,最小化距離的概率分布函數,不可靠體素就會被推向其對應的可靠標簽區域。
表示距離函數。如圖2所示,最小化距離的概率分布函數,不可靠體素就會被推向其對應的可靠標簽區域。
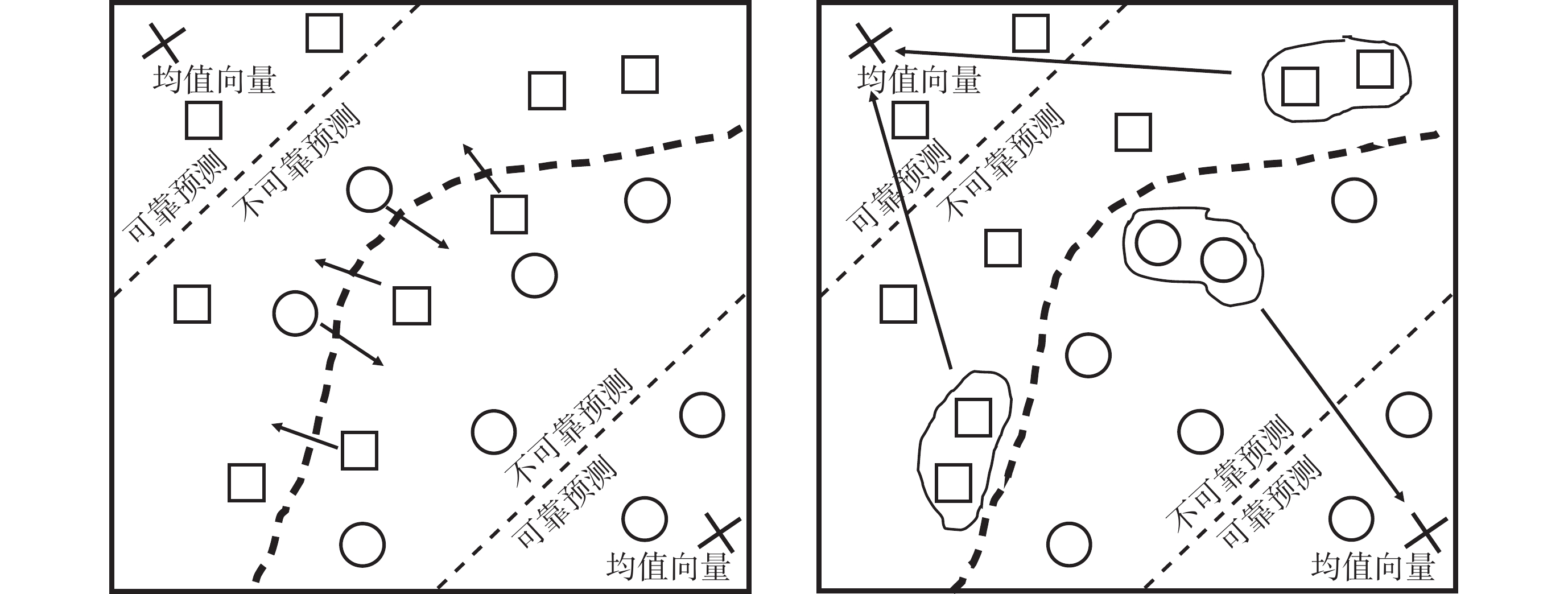 圖2
對比損失監督示意圖
Figure2.
Illustration of contrastive loss supervision
圖2
對比損失監督示意圖
Figure2.
Illustration of contrastive loss supervision
1.4 聯合深度監督
將集成解碼器的輸出分為兩類,分別是淺層解碼路徑輸出的粗略預測和深層解碼路徑輸出的精細預測。深度監督中,集成解碼器的每個輸出都與真實標簽進行比較,計算交叉熵損失和Dice損失:
 |
不同于深層網絡,淺層網絡的作用并不著重于學習高度語義信息。因此,引入一個一致性項,用精細預測得到的結果指導粗略預測。
 |
其中 是粗略預測,
是粗略預測, 是精細預測。精細預測中,可靠預測的體素更為密集地聚集在一起,呈現出更加豐富的語義信息,對它施加先前提及的對比損失
是精細預測。精細預測中,可靠預測的體素更為密集地聚集在一起,呈現出更加豐富的語義信息,對它施加先前提及的對比損失 ,能夠更準確地計算原型向量。
,能夠更準確地計算原型向量。
根據上述,得出粗略預測和精細預測的損失函數 和
和 :
:
 |
2 實驗
2.1 性能指標
應用以下指標評估所提出模塊的性能:Dice相似系數(Dice similarity coefficient,DSC)、精度(Precision)、召回率(Recall)、交并比(intersection of union,IoU)、平均對稱距離(average symmetric distance,ASD)和95%的豪斯多夫距離(Hausdorff distance,HD)。在本文任務中約定胰腺區域為前景,其他區域為背景。TP(true positive)表示正確預測的前景,TN(true negative)表示正確預測的背景,FN(false negative)表示預測為背景的前景,FP(false positive)表示被預測為前景的背景。根據上述約定,給出性能指標的定義如下:
DSC:衡量兩個集合之間重疊程度的指標。表達式為
 |
Precision:衡量模型所作的正預測的準確率。表達式為
 |
Recall:衡量正樣本被正確預測的概率。表達式為
 |
IoU:衡量模型分割結果與真實標簽的重合程度。表達式為
 |
ASD:衡量模型預測的分割邊界與真實標簽的分割邊界的相近程度。表達式為
 |
其中 代表真實標簽的分割邊界,
代表真實標簽的分割邊界, 代表預測的分割邊界。
代表預測的分割邊界。 表示體素z到Sgt的最小歐式距離。
表示體素z到Sgt的最小歐式距離。
95%HD:與ASD類似,同樣衡量預測邊界與真實邊界的相近程度。計算兩個邊界所有對應點之間的距離,然后舍棄最大的5%以減小異常值的影響。值越小表示兩個邊界更接近,更相似。表達式為:
 |
2.2 模型實現
實驗在NVIDIA GTX 4060ti(NVIDIA Inc.,美國)上進行,使用PyTorch 2.1(Facebook AI Research,美國)框架。應用仿射變換、旋轉和翻轉作為主要的數據增強方式。選擇Adam(OpenAI,美國)作為優化器,初始學習率為4e-4,每訓練50輪減半一次。除依照實驗設計應用本文提出的損失函數外,將Dice損失作為訓練過程中的損失函數。
2.3 對比實驗
表1展示了多種先進模型在長海醫院數據集上取得的胰腺分割性能指標,表2展示了在美國國立衛生研究院(National Institutes of Health,NIH)胰腺公開數據集上獲得的性能指標。對長海數據集,提出的模型在DSC(76.32%)、Precision(74.40%)、Recall(78.35%)、IoU(60.94%)和ASD(8.26)五個指標中取得了最優的表現;對NIH數據集,本文的模型與其他先進方法相比優勢顯著,得到最高的DSC(86.78%),以及最高的Recall(89.56%)、ASD(11.76)和95%HD(0.99)。將各個模型在NIH數據集上的預測結果可視化為二值特征圖和三維立體圖,與真實標簽比較,如圖3所示。不難看出本文模型對前景位置的預測更加準確,對整體形狀輪廓的預測更為貼合。
 圖3
不同模型生成的預測輸出對比
Figure3.
Comparison of predictions generated by different models
圖3
不同模型生成的預測輸出對比
Figure3.
Comparison of predictions generated by different models
2.4 消融實驗
為了評估階段式卷積SwinViT、集成解碼器和聯合深度監督三個部分的貢獻,在NIH數據集上進行消融實驗。將SwinUNETR作為基準,它由SwinViT和U-net中的解碼部分組成。
如表3所示,基準模型的DSC為84.92%,單獨加入階段式卷積SwinViT后得到的DSC為85.06%,單獨加入集成解碼器后得到的DSC為85.34%,由此可見,兩個模塊對模型均有改進作用。將二者同時加入,觀察到DSC提高至86.41%。在此基礎上再引入本文提出的損失函數,能夠使DSC指標提高0.37%,達到86.78%。消融實驗驗證了每個組成部分的有效性,三者結合使網絡取得了最高的性能指標提升。
2.5 訓練過程對比
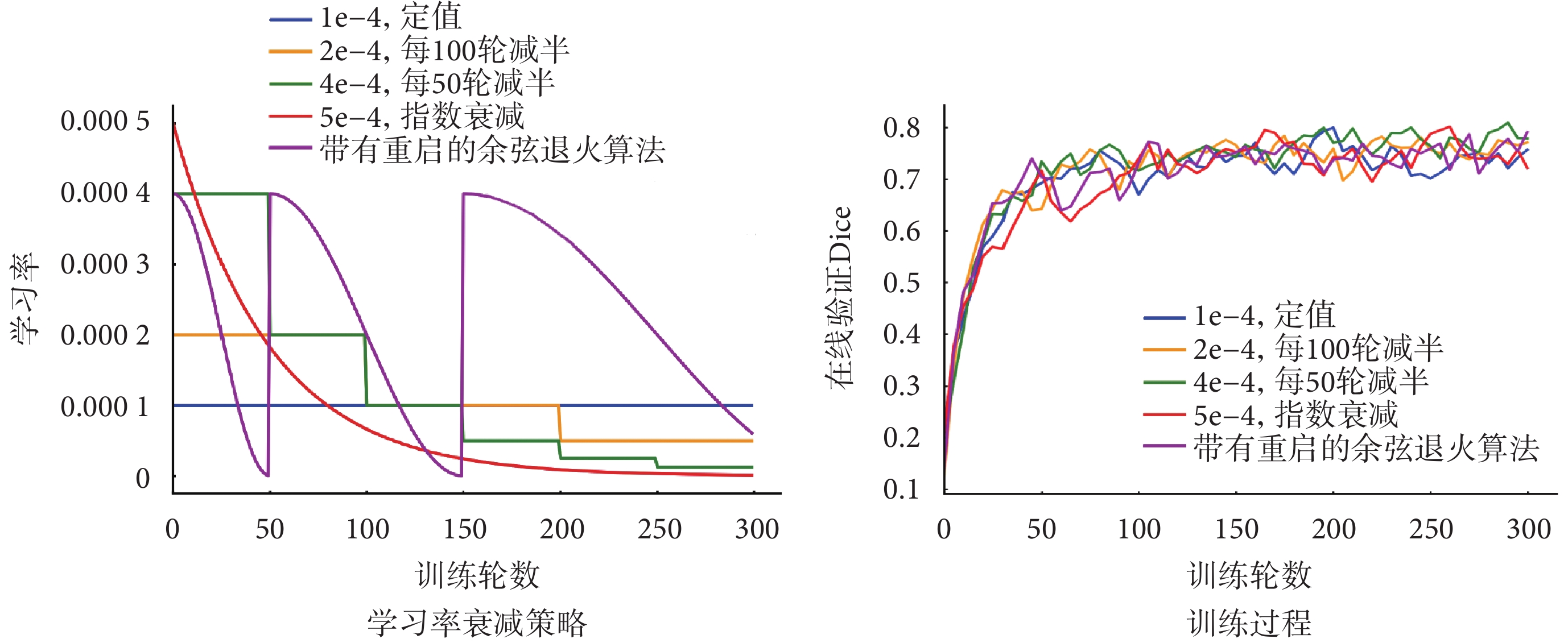
比較訓練過程,進一步驗證提出的損失函數對訓練過程的改進。分別以Dice損失、深度監督和聯合深度監督作為損失函數,訓練本文提出的模型,各訓練300輪,每五輪進行一次在線驗證。為了比較不同的學習率衰減策略,并得出最優結果,依據經驗選取五種常見的學習率衰減策略,通過實驗比較它們對訓練過程的影響。五種學習率衰減策略和對應的訓練過程如圖4所示。
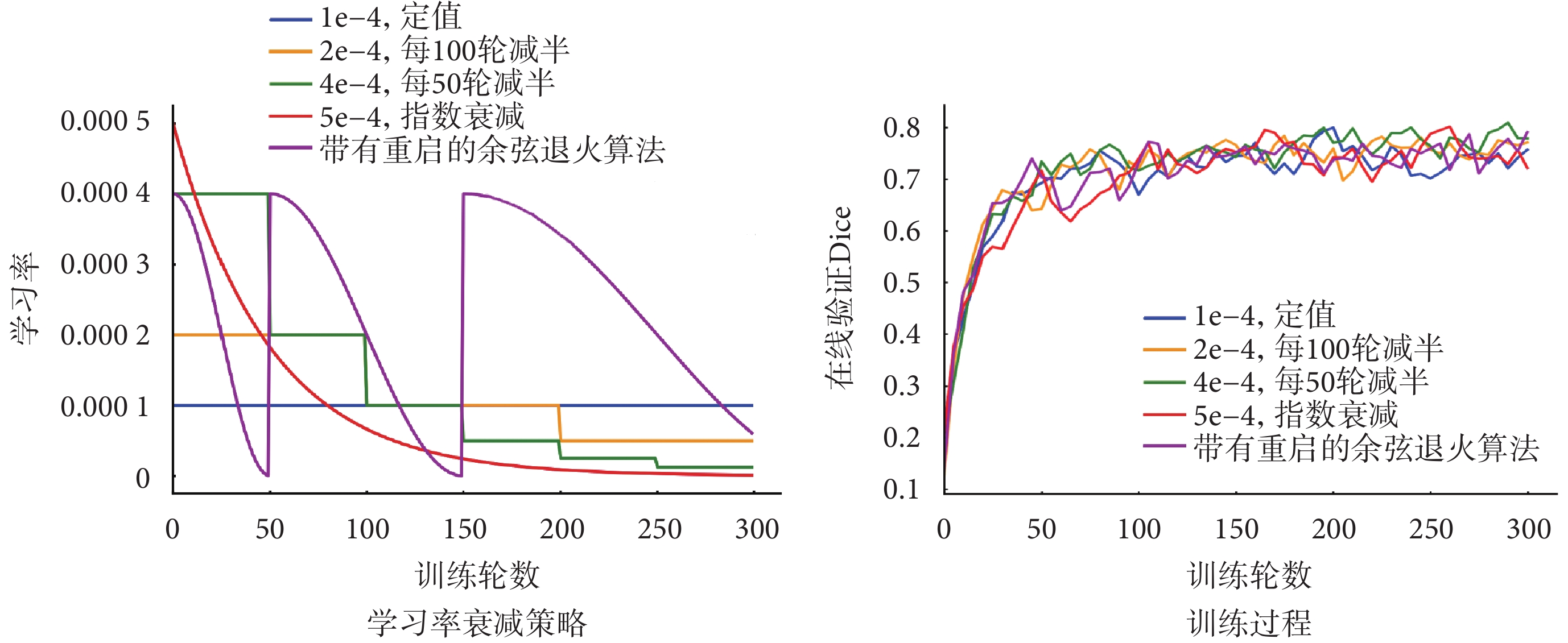 圖4
五種學習率衰減策略和對應訓練過程
Figure4.
Illustration of 5 learning rate decay strategies and corresponding training process
圖4
五種學習率衰減策略和對應訓練過程
Figure4.
Illustration of 5 learning rate decay strategies and corresponding training process
可見,對本任務而言,策略3(即初始值4e-4,每50輪減半)得到的在線驗證曲線更為平穩且取得了最高的DSC,因此選為訓練所提出模型的學習率下降策略。
為了確保比較的一致性,將三個損失函數的值域歸一化到區間[0, 1]。每一輪和每一步的訓練損失曲線如圖5所示。可以看出,使用Dice損失時,訓練過程呈現出大幅度的振蕩抖動,而深度監督可以相對減輕這種情況。本文提出的聯合監督方法使振蕩幅度降至最小,訓練過程最平穩。
 圖5
不同監督方式下的訓練過程對比
Figure5.
Comparison of training process under different supervision methods
圖5
不同監督方式下的訓練過程對比
Figure5.
Comparison of training process under different supervision methods
2.6 參數量對比
比較本文模型和其他方法的參數量、浮點運算總量(floating point operations per second,FLOPs)和推理時間,結果見表4。本文模型性能出色,且能夠降低參數量至44.12M。盡管與輕量模型相比,所需的計算量較大,但與性能相近的方法相比,浮點運算量和預測時間都有一定改善。
3 結論
本文提出了一個基于CNN和Transformer骨干網絡,應用密集連接解碼器和聯合深度監督方法的胰腺分割模型。兩種骨干網絡相結合,更有利于捕捉胰腺的位置及其輪廓邊緣特征;逐點卷積使網絡輕量化;密集連接的集成解碼器融合多尺度胰腺特征,同時將卷積層分散到多個解碼單元,從而進一步輕量化模型同時保持良好性能。帶有一致性項和對比損失的深度監督可以顯著地平滑優化過程,并提高性能指標。本文模型在對比試驗中表現出顯著優勢,在NIH數據集下取得了86.78%的DSC值。消融實驗驗證了模型各組成部分的有效性。所提出的模型只需學習較少的參數就可以取得較好的表現。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:楊越負責實驗設計、代碼設計、實驗分析和論文寫作;秦辰棟負責數據分析和數據收集;王永雄負責提出研究的內容和意義、實驗可行性分析、基金支持和論文修訂
0 引言
胰腺分割對醫學影像的研究有重要意義。由于在腹腔中胰腺的位置相對可變,沒有固定形狀和尺寸,因此相較于其他器官,胰腺分割更為困難。胰腺癌的病變通常伴隨著胰腺的形態改變,這種情況下,深度學習方法能夠協助醫生更好地進行臨床影像診斷。基于卷積神經網絡(convolutional nerual network,CNN)的模型在醫學圖像分割領域取得了顯著進展。從U型網絡(U-net)到殘差連接的U型網絡、巢穴U型網絡(U-net++),以及自適應U型網絡(nnU-net)[1-4],這些模型在十項全能挑戰和公開數據集中表現出色。但是,CNN難以捕捉輸入圖像中相距較遠的關聯特征[5]。為解決該問題,研究者引入自然語言處理領域的轉換器(Transformer)以捕捉全局依賴關系計算每個圖像塊之間的相關性,將得到的結果作為注意力掩碼[6]。進一步地,Liu等[7]提出了一種窗口滑動視覺轉換器(shifted windows vision Transformer,SwinViT)以處理變化尺度和大量像素輸入。得益于處理多尺度信息的能力和全局感受野,以SwinViT為編碼器的滑動窗口轉換器U型網絡(shifted window Transformer U-net,SwinUNETR)在圖像分割任務中表現出顯著的性能提升[8]。然而在醫學圖像分割任務中,目標區域通常是連續的,這意味著捕捉局部依賴關系有助于獲得更好結果。因此,最近的研究重新討論卷積網絡[9]。CNN和Transformer相結合是一種實用的方法,許多研究已經提出了若干結合方式[10]。He等[11]提出分階段引入卷積模塊到SwinUNETR的編碼器部分,顯著提高了其在三維(three-dimensional,3D)醫學圖像分割中的能力。為解決樣本不均衡的問題,Oktay[12]提出了注意力U型網絡,將U-Net和注意力機制相結合以應對胰腺分割問題。首先,卷積編碼器提取特征圖,再由注意力門從提取到的特征圖中學習局部語義信息,將注意力機制的作用區域縮小并集中到目標區域。
Transformer模塊中通道數目眾多,與卷積結合會極大增加參數數量。Zeng等[13]提出了整體分解卷積,在網絡的同一層中學習多個卷積核的參數。Chollet[14]提出的深度可分離卷積能夠減少網絡參數。它包括兩個步驟:深度卷積,對每個輸入通道應用單個濾波器;逐點卷積,與值為1的單位卷積核進行卷積,組合深度卷積的輸出。這種方法可以在輕量化網絡的同時維持其性能。
將CNN和Transformer骨干網絡相結合的方法主要分為兩類:① 修改多頭注意力機制,賦予其類似卷積的特性。在金字塔視覺Transformer中,Transformer被構建成金字塔形式,通過每個子塊階段中的嵌入層在不同尺度下生成特征圖[15]。相反地,一些研究者嘗試將Transformer架構整合到卷積運算中。Lee等[16]認為Transformer結構取得成功的原因在于很大的感受野和大量參數,進而主張使用由大尺寸卷積核構成的U型3D分割網絡(3D segmentation U-net,3DUXNet)替代自注意力機制實現較大的感受野,同時增加網絡的通道數,最終在多個數據集上取得了超越SwinUNETR的性能指標。② 將CNN與Transformer架構整合,但不改變各自骨干網絡的行為。腦腫瘤分割轉換器(Brain Tumor Segmentation Transformer,TransBTS)中,考慮到局部和全局信息同等重要,Transformer被引入CNN作為瓶頸層,用于提取全局信息并恢復局部特征,卷積解碼器將Transformer產生的特征圖逐步上采樣,還原至原始分辨率的預測輸出[17]。Zhou等[18]主張由Transformer實現特征提取的主要功能,進而提出了自適應轉換器(no new Transformer,nnFromer)網絡,將局部和全局自注意力由淺至深排布成U型網絡,并通過注意力跳躍連接,在解碼路徑進行特征融合。為了使Transformer和CNN的特征能夠相通,Li等[19]提出了Transfomer&CNN特征校準塊,其中來自CNN和Transformer的特征按維度進行校準,而后融合。Wu等[20]在層次化Transformer中合并了CNN實現的嵌入層和投影層,以應對多尺度和全局上下文信息。
密集連接的概念最先在密集連接網絡中被提出[21]。這種方式確保每層都接收到來自前面所有層的特征圖,并將輸出傳遞給所有后續層。Li等[22]將包含3個卷積模塊和2個最大池化模塊的DenseNet模型應用于胰腺囊腫的輔助診斷,通過密集鏈接網絡從完整的圖像中學習胰腺的高級語義特征,并將圖形特征與不同的胰腺囊腫病理型相關聯。Zhang等[23]進一步發展了該理論,引入了三個密集連接塊,分別是編碼器、解碼器和連接二者的部分,從而構成一個密集連接的U-net架構。全尺度U型網絡(U-net3+)進一步拓展了密集鏈接的應用,其編碼器也用一系列密集連接的卷積模塊組成,這種方式有效增強了特征融合傳播[24]。
為了緩解梯度消失和優化訓練過程,Lee等[25]提出了深度監督。深度監督在網絡的中間層引入輔助損失函數,這些輔助損失函數和目標函數同時優化。Arrastia等[26]提出將深度監督應用于多尺度層級以生成注意力圖并繼續向后傳播。Zhou等[27]提出在胰腺囊腫分割中引入深度監督,借由對胰腺的分割輔助對囊腫區域的分割。
1 方法
1.1 階段式多通道卷積SwinViT
本文提出的網絡結構如圖1所示。階段式編碼器中,多通道卷積后接SwinViT,構成一個階段。每個階段的輸出傳入下一階段,且傳入由兩次卷積正交化組成的殘差編碼器。計算過程可以表示為:
圖1
網絡的總體結構圖
Figure1.
Overall architecture of the network
|
其中表示第n階段的輸入,UPWC(up point-wise convolution)和DPWC(down point-wise convolution)分別表示上采樣和下采樣逐點卷積,W-MSA(windows multihead self-attention)和SW-MSA(shift windows multihead self-attention)分別表示滑窗操作前后的多頭注意力機制,LN(linear normalization)表示規范化層。
3D圖像輸入到網絡,被劃分成小圖像塊,拉平成小圖像塊序列,通過一個投影層將它們投影到更高的維度。投影層的輸出傳給編碼器。在多通道卷積模塊中,首先通過卷積層生成初步的特征圖,學習部分細節特征。然后,上采樣逐點卷積將特征圖投影到更高的隱藏維度,通道數擴展至4倍,用更多參數學習胰腺的周圍特征。隨后,采用下采樣逐點卷積將通道維度收縮至初始大小,以便下一步操作。與傳統卷積相比,這種方法可以有效保留重要的特征信息,同時不產生過多參數。
多通道卷積模塊的輸出送入SwinViT,它由兩個Transformer模塊構成,如圖1所示。借助窗口化方法將輸入特征圖劃分為更小的圖像塊,計算每個小塊之間的依賴關系,得到注意力掩碼并將它作為權重加到特征圖上。隨后,移動窗格重新計算注意力掩碼。在每個MSA和SW-MSA之后,特征圖被投影到更高的維度,實現進一步的特征學習。
1.2 集成解碼器
針對胰腺的多變性,本文設計了多路徑的集成解碼器,由密集連接的解碼單元組成。將殘差編碼器組的輸出作為輸入,通過密集連接網絡解碼,得到最終輸出。在圖1中,其結構類似上三角矩陣,每行解碼單元都是其各自深度的解碼路徑,每個矩形代表一個解碼單元,由轉置卷積和上采樣組成。每條解碼路徑都會產生一個預測結果:中間層的解碼路徑產生中間層輸出,而最后一個解碼路徑產生網絡的最終輸出。密集連接可以表示為:
|
其中表示轉置卷積操作,[ ]表示拼接,表示上采樣操作,是第i個殘差卷積模塊的輸出,是解碼單元的輸出。在每個解碼單元中,先拼接所有先前同深度單元的輸出,再對解碼路徑上前單元的輸出上采樣,最后與殘差編碼器的輸出拼接在一起,送入卷積層。解碼單元之間的密集連接有助于融合多尺度特征,更好地進行高級語義識別。
1.3 對比損失
局部特征信息的缺失導致胰腺的預測區域斷續,為緩解這一問題,引入對比損失以監督包含高級語義信息的輸出。將輸出中的每個體素映射到特征嵌入空間。基于置信度分為可靠或不可靠,引導不可靠體素朝向其對應的可靠區域移動。所有的可靠體素作為一個集合,取該集合的均值向量作為相應標簽區域的向量原型,表示嵌入空間中的相應標簽區域:
|
表示可靠的預測體素,f表示投影層的映射函數,表示第k個標簽對應的目標區域。計算不可靠體素和向量原型在特征空間中的距離作為二者的差異值,計算softmax得到概率分布:
|
其中表示標簽類別數目,表示距離函數。如圖2所示,最小化距離的概率分布函數,不可靠體素就會被推向其對應的可靠標簽區域。
圖2
對比損失監督示意圖
Figure2.
Illustration of contrastive loss supervision
1.4 聯合深度監督
將集成解碼器的輸出分為兩類,分別是淺層解碼路徑輸出的粗略預測和深層解碼路徑輸出的精細預測。深度監督中,集成解碼器的每個輸出都與真實標簽進行比較,計算交叉熵損失和Dice損失:
|
不同于深層網絡,淺層網絡的作用并不著重于學習高度語義信息。因此,引入一個一致性項,用精細預測得到的結果指導粗略預測。
|
其中是粗略預測,是精細預測。精細預測中,可靠預測的體素更為密集地聚集在一起,呈現出更加豐富的語義信息,對它施加先前提及的對比損失,能夠更準確地計算原型向量。
根據上述,得出粗略預測和精細預測的損失函數和:
|
2 實驗
2.1 性能指標
應用以下指標評估所提出模塊的性能:Dice相似系數(Dice similarity coefficient,DSC)、精度(Precision)、召回率(Recall)、交并比(intersection of union,IoU)、平均對稱距離(average symmetric distance,ASD)和95%的豪斯多夫距離(Hausdorff distance,HD)。在本文任務中約定胰腺區域為前景,其他區域為背景。TP(true positive)表示正確預測的前景,TN(true negative)表示正確預測的背景,FN(false negative)表示預測為背景的前景,FP(false positive)表示被預測為前景的背景。根據上述約定,給出性能指標的定義如下:
DSC:衡量兩個集合之間重疊程度的指標。表達式為
|
Precision:衡量模型所作的正預測的準確率。表達式為
|
Recall:衡量正樣本被正確預測的概率。表達式為
|
IoU:衡量模型分割結果與真實標簽的重合程度。表達式為
|
ASD:衡量模型預測的分割邊界與真實標簽的分割邊界的相近程度。表達式為
|
其中代表真實標簽的分割邊界,代表預測的分割邊界。表示體素z到Sgt的最小歐式距離。
95%HD:與ASD類似,同樣衡量預測邊界與真實邊界的相近程度。計算兩個邊界所有對應點之間的距離,然后舍棄最大的5%以減小異常值的影響。值越小表示兩個邊界更接近,更相似。表達式為:
|
2.2 模型實現
實驗在NVIDIA GTX 4060ti(NVIDIA Inc.,美國)上進行,使用PyTorch 2.1(Facebook AI Research,美國)框架。應用仿射變換、旋轉和翻轉作為主要的數據增強方式。選擇Adam(OpenAI,美國)作為優化器,初始學習率為4e-4,每訓練50輪減半一次。除依照實驗設計應用本文提出的損失函數外,將Dice損失作為訓練過程中的損失函數。
2.3 對比實驗
表1展示了多種先進模型在長海醫院數據集上取得的胰腺分割性能指標,表2展示了在美國國立衛生研究院(National Institutes of Health,NIH)胰腺公開數據集上獲得的性能指標。對長海數據集,提出的模型在DSC(76.32%)、Precision(74.40%)、Recall(78.35%)、IoU(60.94%)和ASD(8.26)五個指標中取得了最優的表現;對NIH數據集,本文的模型與其他先進方法相比優勢顯著,得到最高的DSC(86.78%),以及最高的Recall(89.56%)、ASD(11.76)和95%HD(0.99)。將各個模型在NIH數據集上的預測結果可視化為二值特征圖和三維立體圖,與真實標簽比較,如圖3所示。不難看出本文模型對前景位置的預測更加準確,對整體形狀輪廓的預測更為貼合。
圖3
不同模型生成的預測輸出對比
Figure3.
Comparison of predictions generated by different models
2.4 消融實驗
為了評估階段式卷積SwinViT、集成解碼器和聯合深度監督三個部分的貢獻,在NIH數據集上進行消融實驗。將SwinUNETR作為基準,它由SwinViT和U-net中的解碼部分組成。
如表3所示,基準模型的DSC為84.92%,單獨加入階段式卷積SwinViT后得到的DSC為85.06%,單獨加入集成解碼器后得到的DSC為85.34%,由此可見,兩個模塊對模型均有改進作用。將二者同時加入,觀察到DSC提高至86.41%。在此基礎上再引入本文提出的損失函數,能夠使DSC指標提高0.37%,達到86.78%。消融實驗驗證了每個組成部分的有效性,三者結合使網絡取得了最高的性能指標提升。
2.5 訓練過程對比
比較訓練過程,進一步驗證提出的損失函數對訓練過程的改進。分別以Dice損失、深度監督和聯合深度監督作為損失函數,訓練本文提出的模型,各訓練300輪,每五輪進行一次在線驗證。為了比較不同的學習率衰減策略,并得出最優結果,依據經驗選取五種常見的學習率衰減策略,通過實驗比較它們對訓練過程的影響。五種學習率衰減策略和對應的訓練過程如圖4所示。
圖4
五種學習率衰減策略和對應訓練過程
Figure4.
Illustration of 5 learning rate decay strategies and corresponding training process
可見,對本任務而言,策略3(即初始值4e-4,每50輪減半)得到的在線驗證曲線更為平穩且取得了最高的DSC,因此選為訓練所提出模型的學習率下降策略。
為了確保比較的一致性,將三個損失函數的值域歸一化到區間[0, 1]。每一輪和每一步的訓練損失曲線如圖5所示。可以看出,使用Dice損失時,訓練過程呈現出大幅度的振蕩抖動,而深度監督可以相對減輕這種情況。本文提出的聯合監督方法使振蕩幅度降至最小,訓練過程最平穩。
圖5
不同監督方式下的訓練過程對比
Figure5.
Comparison of training process under different supervision methods
2.6 參數量對比
比較本文模型和其他方法的參數量、浮點運算總量(floating point operations per second,FLOPs)和推理時間,結果見表4。本文模型性能出色,且能夠降低參數量至44.12M。盡管與輕量模型相比,所需的計算量較大,但與性能相近的方法相比,浮點運算量和預測時間都有一定改善。
3 結論
本文提出了一個基于CNN和Transformer骨干網絡,應用密集連接解碼器和聯合深度監督方法的胰腺分割模型。兩種骨干網絡相結合,更有利于捕捉胰腺的位置及其輪廓邊緣特征;逐點卷積使網絡輕量化;密集連接的集成解碼器融合多尺度胰腺特征,同時將卷積層分散到多個解碼單元,從而進一步輕量化模型同時保持良好性能。帶有一致性項和對比損失的深度監督可以顯著地平滑優化過程,并提高性能指標。本文模型在對比試驗中表現出顯著優勢,在NIH數據集下取得了86.78%的DSC值。消融實驗驗證了模型各組成部分的有效性。所提出的模型只需學習較少的參數就可以取得較好的表現。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:楊越負責實驗設計、代碼設計、實驗分析和論文寫作;秦辰棟負責數據分析和數據收集;王永雄負責提出研究的內容和意義、實驗可行性分析、基金支持和論文修訂