心血管疾病和心理障礙已成為威脅人類身心健康的兩大主要問題。盡管基于心電圖信號的研究為解決這些問題提供了重要契機,但在心電特征的理解以及跨任務知識遷移方面,現有方法仍面臨性能瓶頸和適用性不足等挑戰。為此,本文設計了一種基于殘差網絡的多分辨率特征編碼網絡,能夠有效提取心電信號的局部形態特征與全局節律特征,增強特征表達能力。此外,提出的基于模型壓縮的持續學習方法通過將簡單任務中的結構化知識逐步傳遞到復雜任務,可有效提升下游任務性能。多分辨率學習模型在心電QRS波群檢測、心律失常分類和情緒分類等五個數據庫上取得了超越或與當前先進算法相當的性能。持續學習方法在跨領域、跨任務和數據增量的場景下都取得了相較于常規訓練方法的顯著提升,證明了所提出方法對于心電跨任務知識遷移的能力,為心電多任務學習提供了新路徑。
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
0 引言
個體健康不僅包括身體機能的正常運作,更體現在精神狀態的健全與良好。情感作為個體情緒和個性的重要組成部分,兼具生理和心理雙重特性。近年來,隨著人工智能算法的進步,結合傳感技術的可穿戴設備被廣泛用于生理信號分析,以分類或量化個體的生理與情感狀態[1]。本文聚焦心電信號(electrocardiogram,ECG)在心血管健康監測與情緒識別中的應用,分別提出ECG多分辨率(multi-resolution,MR)特征提取模型并設計了用于跨任務持續學習(continual learning,CL)的多任務訓練方法。
ECG在心血管疾病的異常事件檢測中已展現出成熟的應用價值[2–8],近年基于ECG信號的情緒識別也引起了越來越多的關注,特別是通過心率變異性(heart rate variability,HRV)分析自主神經活性[9],以評估個體情緒和壓力的波動。過往研究揭示了ECG波形和HRV與情感屬性之間存在顯著的相關性[10],并探討了使用ECG信號進行情感檢測的可行性和潛在限制[11]。
ECG分析的重點在于對關鍵波形(如QRS復合波、P波、T波)的精準分割,以及基于特定形態學和節律特性的任務分析[12]。早期研究集中于首先利用QRS復合波的形態、節律和幅度特征進行QRS定位[3]。這些方法有效地結合了QRS復合波的形態細節與RR間期變化規律,為ECG分類任務構建了與臨床知識高度一致的算法框架。基于QRS的形態和節律屬性的改變,結合臨床先驗知識指導,實現對心律失常等事件的分類,這一類方法被認為是基于規則的算法。近些年,深度學習算法的引入顯著減少了在ECG事件分類前對QRS復合波分割的需求,這些算法在分割和分類任務中分別采用獨立模型,并在多種應用中表現出卓越的性能[13-14]。
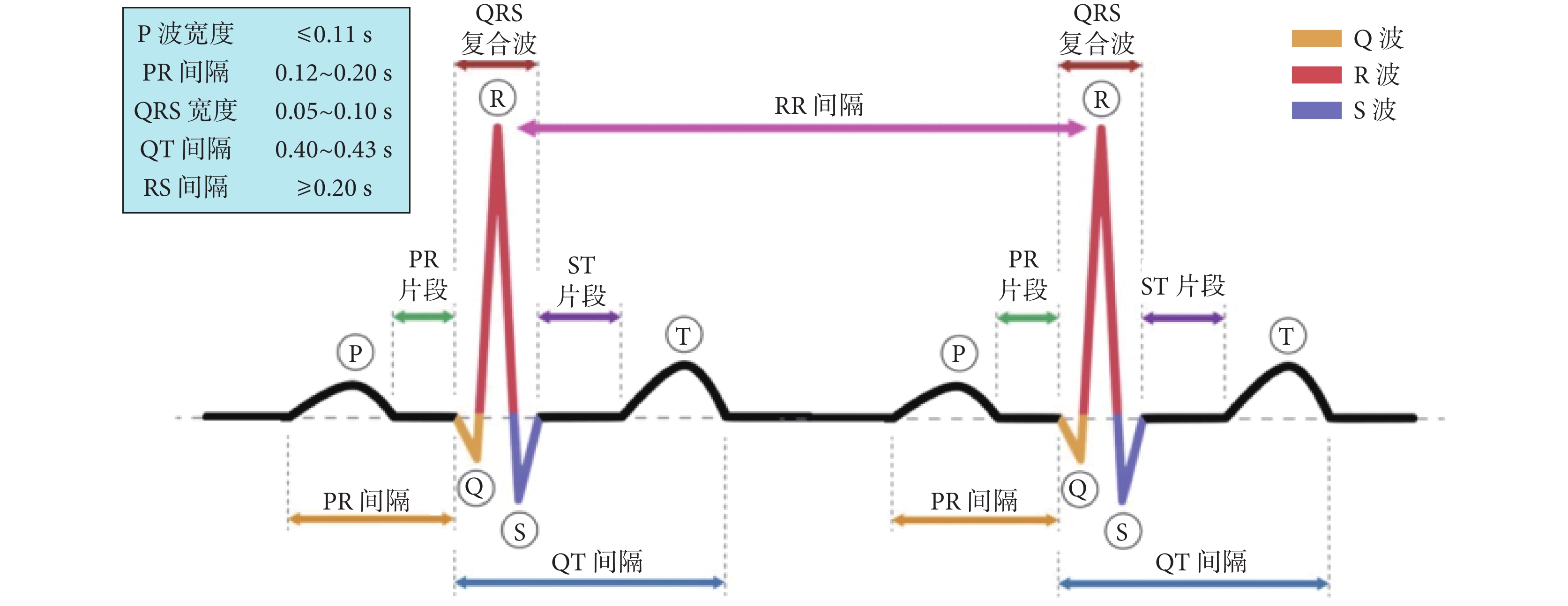
然而,針對可穿戴設備的廣泛應用,仍面臨兩大挑戰:① 決策過程中未能有效地利用低分辨率與高分辨率信息;② QRS復合波的形態與節律特性對于精確的QRS定位顯得尤為關鍵,這同樣對于準確的分類至關重要(如圖1所示)。但目前,在這一背景下的知識遷移機制仍顯不足,而解決這些挑戰是推進可穿戴設備在ECG監測和臨床解讀中普及的關鍵路徑。
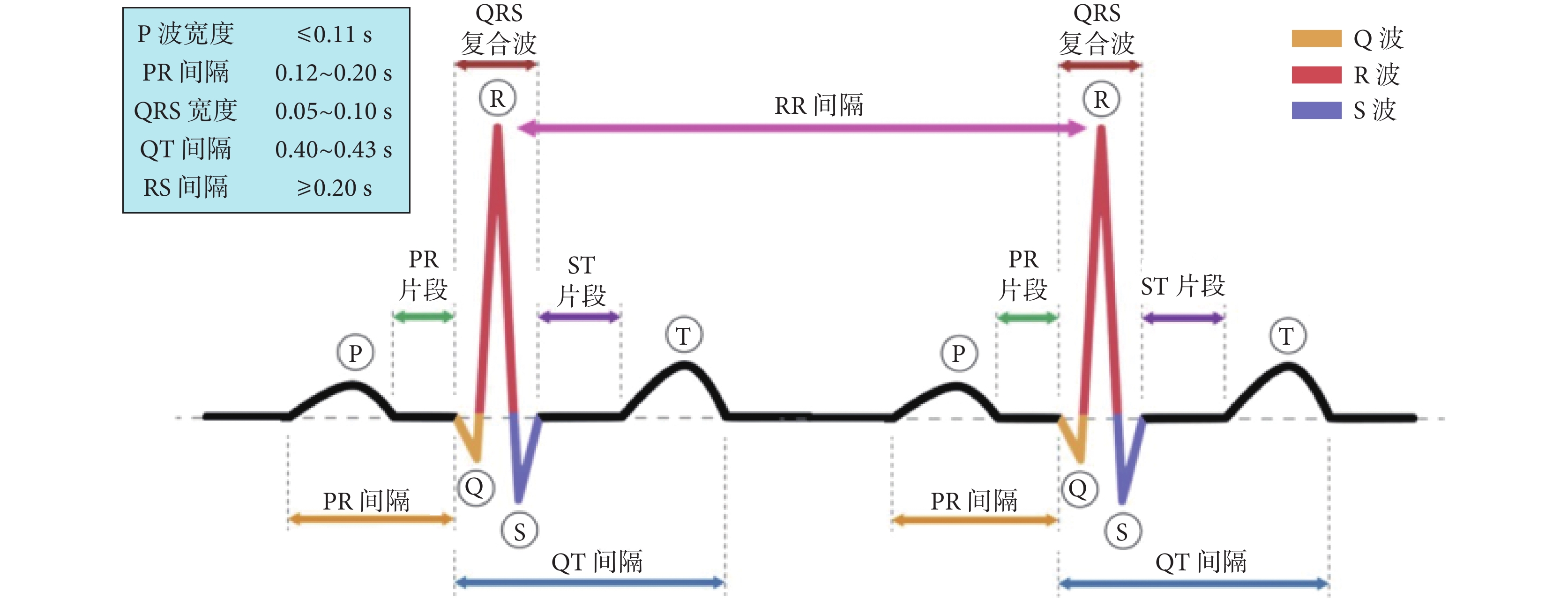 圖1
心電圖形態和節律屬性分析示意圖
Figure1.
Schematic diagram of electrocardiogram morphological and rhythmic attribute analysis
圖1
心電圖形態和節律屬性分析示意圖
Figure1.
Schematic diagram of electrocardiogram morphological and rhythmic attribute analysis
1 模型和方法
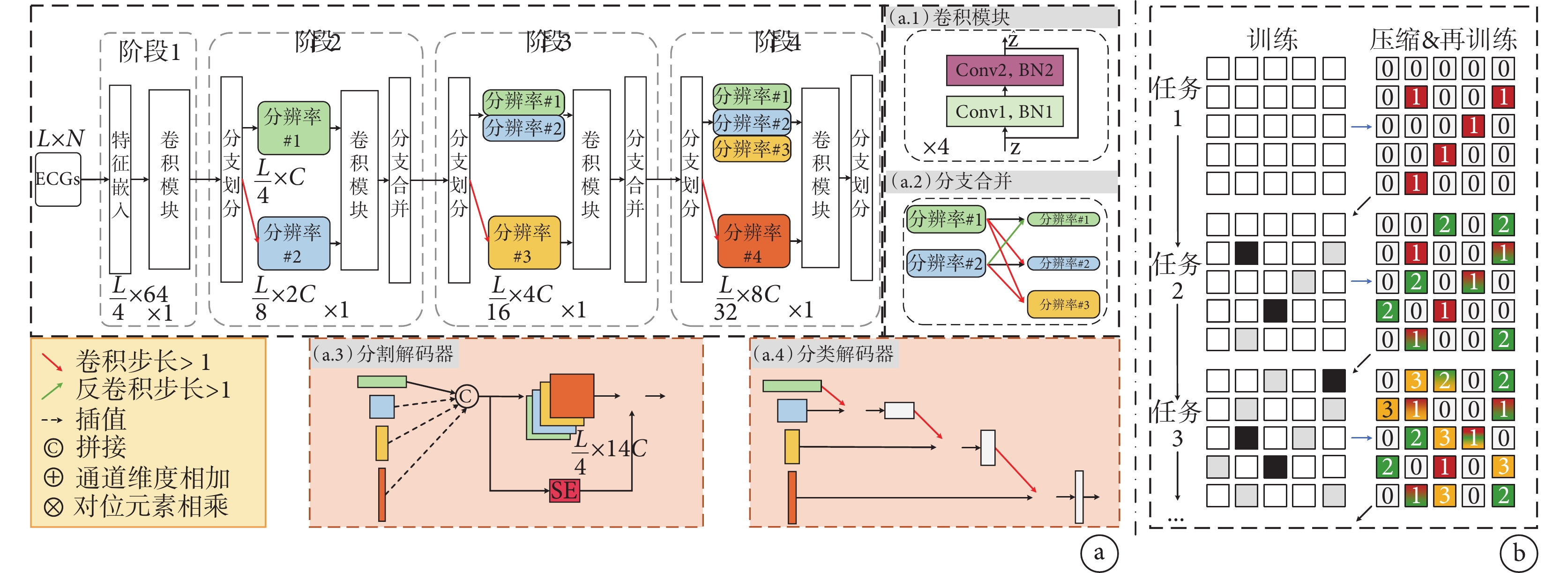
本節將詳細介紹為解決上述ECG多尺度特征提取挑戰而設計的心電多分辨率(ECG multi-resolution,ECG-MR)編碼器模型(見圖2a)以及從心臟健康到情緒健康的ECG持續學習(ECG continual learning,ECG-CL)策略(見圖2b)。
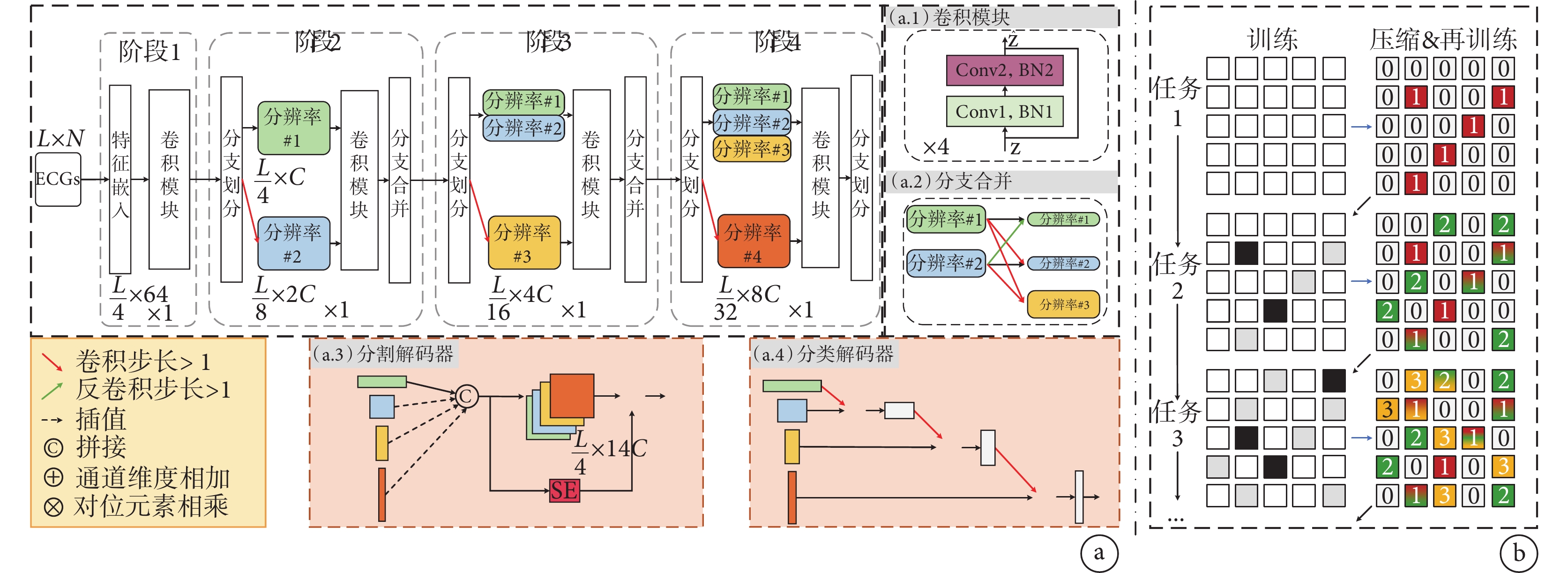 圖2
算法整體框架
圖2
算法整體框架
a. ECG 多分辨率模型骨干框架及分割/分類器設計;b. ECG 持續學習參數更新示意圖
Figure2. Overall algorithm frameworka. multi-resolution ECG framework and segmentation/classifier design; b. diagram of parameter updates for ECG continual learning
1.1 多分辨率編碼器
在圖2a中,本文詳細展示了為深入分析ECG信號而設計的多分辨率架構。對于任意輸入信號 ,長度為
,長度為 ,導聯數量為
,導聯數量為 。為了適應不同采集設備的ECG信號,并確保兼容多種輸入類型,所有信號均通過一個初始
。為了適應不同采集設備的ECG信號,并確保兼容多種輸入類型,所有信號均通過一個初始 卷積層,將通道數統一為標準的12導聯格式,即
卷積層,將通道數統一為標準的12導聯格式,即 = 12。接下來,使用一個卷積編碼層將原始ECG信號投射到高維特征空間,同時將信號長度縮短至原始長度的四分之一,即
= 12。接下來,使用一個卷積編碼層將原始ECG信號投射到高維特征空間,同時將信號長度縮短至原始長度的四分之一,即 。嵌入后的特征接著通過一系列卷積模塊進行處理,如圖2a.1所示,這些卷積模塊在保持信號原始分辨率的同時提取其特征。卷積編碼層和后續的卷積模塊共同組成了整個網絡架構的“第一階段”。
。嵌入后的特征接著通過一系列卷積模塊進行處理,如圖2a.1所示,這些卷積模塊在保持信號原始分辨率的同時提取其特征。卷積編碼層和后續的卷積模塊共同組成了整個網絡架構的“第一階段”。
為了精準捕獲ECG中不同尺度的特征,本文設計了一個分支層次網絡架構,該架構在深度增加時會進行特征分化。在第一分支中,網絡保持輸入特征的原始結構,通過跨步卷積提取更高級別的抽象特征表示。此操作使每個通道的特征維度減小,分辨率降至原始長度的八分之一,同時特征維度翻倍,提升到 。隨后,這些特征通過更深層的卷積塊進一步轉換。
。隨后,這些特征通過更深層的卷積塊進一步轉換。
如圖2a.2所示,為了有效整合不同層級的特征,引入了一個“分支合并模塊”。這一模塊通過將不同分辨率的特征進行整合,增強了模型的語義理解能力。該過程包括“分支劃分”、特征轉換及特征融合,共同構成了“第二階段”。此流程在“第三階段”和“第四階段”中重復進行,將分辨率逐步降低至 與
與 。
。
綜上所述,該多分辨率架構可分為四個獨立的階段,每個階段均由專門的模塊組成。在“分支劃分”模塊中,當前特征通過濾波器進行均等拆分,一半保持原有分辨率,另一半用于較低分辨率的特征處理。通過一系列殘差卷積塊,模型能夠精細地處理特征,而“分支合并”模塊則采用步進卷積或反卷積技術整合多種分辨率的特征,確保了信息的完整性和豐富性。四個階段協同作用,構建了一個能夠捕獲復雜語義信息并保留高分辨率細節的分層特征表示架構。
1.2 ECG分割解碼器
為了實現高精度的QRS波群分割任務,本研究進一步提出了基于MR特征提取器的QRS定位解碼器,該方法采用了將低分辨率信息插值到最高分辨率信息的方法,并結合了SE-Net模塊[15]以增強對心律失常相關ECG表現的注意力,如圖2a.3所示。
QRS定位解碼器的數學表示為:
 |
 |
 |
其中, ,
, 。串聯的特征表示為
。串聯的特征表示為 ,
, 表示插值函數,
表示插值函數, 表示SE-Net模塊,
表示SE-Net模塊, 表示逐元素乘法,
表示逐元素乘法, 和
和 是全連接層的參數,
是全連接層的參數, 表示自適應平均池化函數。最后,輸出的邏輯值
表示自適應平均池化函數。最后,輸出的邏輯值 ,大于0.5的數值表示在QRS定位任務中的潛在關注點。
,大于0.5的數值表示在QRS定位任務中的潛在關注點。
1.3 ECG分類解碼器
ECG分類任務的目標是基于多分辨率特性將ECG準確地劃分到預先設定的類別,這些類別包括但不限于心律失常類別和情感狀態(積極/消極)。本文提出的方法采用跨步卷積操作與通道維度上的求和策略,以此實現將ECG中的高分辨率細節信息有效地整合到低分辨率表示中,該過程如圖2a.4所示。
ECG分類解碼器的數學描述為:
 |
 |
 |
其中, 表示跨步卷積,
表示跨步卷積, 表示通道維度求和,
表示通道維度求和, 表示全局平均池化層,
表示全局平均池化層, 和
和 代表全連接層的參數。
代表全連接層的參數。 表示具有
表示具有 個類別的多標簽分類的邏輯值,同樣以0.5為閾值區分類別的置信度。
個類別的多標簽分類的邏輯值,同樣以0.5為閾值區分類別的置信度。
2 ECG多任務持續學習
ECG的處理在深度學習領域正受到廣泛關注,其跨設備和領域的一致性為知識遷移提供了堅實基礎,如圖1所示。然而,現有方法在應對多任務學習和模型適應性方面仍存在局限。為此,本文提出了一種基于自適應權重優化與權重剪枝的ECG持續學習方法——ECG-CL,旨在提升信號處理效率與準確性,并實現跨任務知識遷移。
2.1 持續學習訓練過程
假定集合 涵蓋所有ECG任務,且
涵蓋所有ECG任務,且 與
與 分別代表分割與分類任務的子集合,可以得出
分別代表分割與分類任務的子集合,可以得出 。這里,索引
。這里,索引 分別代表全部任務集、分割任務集合以及分類任務集合中當前的任務,且滿足
分別代表全部任務集、分割任務集合以及分類任務集合中當前的任務,且滿足 。基于此描述ECG-CL的具體流程如下所述。
。基于此描述ECG-CL的具體流程如下所述。
(1)任務 :如圖2b第一行所示,以第1節中提出的ECG-MR為骨干網絡,在任務
:如圖2b第一行所示,以第1節中提出的ECG-MR為骨干網絡,在任務 對應的數據集上從零開始訓練。隨后將執行第一次權重剪枝至特定的稀疏度水平。激進的權重修剪可能會損害性能,為補償這一損失,執行一輪低學習率的微調。對于第一個任務,保留下來的編碼器權重標記為
對應的數據集上從零開始訓練。隨后將執行第一次權重剪枝至特定的稀疏度水平。激進的權重修剪可能會損害性能,為補償這一損失,執行一輪低學習率的微調。對于第一個任務,保留下來的編碼器權重標記為 ,而被釋放的權重標記為
,而被釋放的權重標記為 。這一邏輯同樣適用于解碼器,分割任務的保留與釋放權重分別為
。這一邏輯同樣適用于解碼器,分割任務的保留與釋放權重分別為 和
和 ,分類任務亦然,保留與釋放權重分別標記為
,分類任務亦然,保留與釋放權重分別標記為 和
和 。
。
(2)任務 :假設已經完成了任務
:假設已經完成了任務 的學習,包括
的學習,包括 個分割任務和
個分割任務和 個分類任務。則至此為止的分割任務
個分類任務。則至此為止的分割任務 保留模型權重表示為
保留模型權重表示為 ,分類任務
,分類任務 的保留模型權重表示為
的保留模型權重表示為 。在這些保留權重的基礎上,進一步訓練權重選擇掩碼矩陣
。在這些保留權重的基礎上,進一步訓練權重選擇掩碼矩陣 和
和 ,以便挑選出對后續任務有益的通用特征,從而有助于將有利的知識遷移到下游任務。
,以便挑選出對后續任務有益的通用特征,從而有助于將有利的知識遷移到下游任務。
(3)面向新任務 :以分類任務為例,本文首先用選擇掩碼過濾后的保留權重
:以分類任務為例,本文首先用選擇掩碼過濾后的保留權重 來訓練網絡,以此作為通用知識基礎。之后,使用被釋放的權重
來訓練網絡,以此作為通用知識基礎。之后,使用被釋放的權重 來強化特定于任務
來強化特定于任務 的權重。重要的是,為了維持先前任務的性能,這些被挑選的權重在訓練過程中會被凍結。最后,通過一輪剪枝和再訓練,優化模型以適應新任務,同時盡可能地維持當前任務的表現。整個過程將按照這一策略循環進行,直到所有任務學習完畢。圖2b可視化了這一參數更新策略,訓練矩陣的空白單元表示可訓練的參數,灰色單元代表只參與前向傳播的權重,而黑色單元格內的參數則被凍結,不參與訓練。在“剪枝與重訓”矩陣中,標記為
的權重。重要的是,為了維持先前任務的性能,這些被挑選的權重在訓練過程中會被凍結。最后,通過一輪剪枝和再訓練,優化模型以適應新任務,同時盡可能地維持當前任務的表現。整個過程將按照這一策略循環進行,直到所有任務學習完畢。圖2b可視化了這一參數更新策略,訓練矩陣的空白單元表示可訓練的參數,灰色單元代表只參與前向傳播的權重,而黑色單元格內的參數則被凍結,不參與訓練。在“剪枝與重訓”矩陣中,標記為 的單元格代表了與任務
的單元格代表了與任務 相關的權重;而標記為‘0’的單元格則表示這些參數已經被釋放;漸變色的單元格則這表示些權重在多個任務中被共享使用。
相關的權重;而標記為‘0’的單元格則表示這些參數已經被釋放;漸變色的單元格則這表示些權重在多個任務中被共享使用。
2.2 持續學習推理過程
在深度學習模型的推理階段,確定任務標識符以便使用預保留的二進制掩碼來提取任務特定的參數變得尤為關鍵。本文提出的持續學習策略中,不論是單任務還是序列多任務場景,模型只需在推理開始時加載一次。這種高效的順序推斷是通過利用任務標識符確定的二進制掩碼來實現的。
考慮到實際的ECG解釋場景,可以設想一個已經訓練好的持續學習模型,其中包括四個任務:單導聯分割、多導聯分割、有限類別分類和多類別分類。通過融合ECG的分割與分類,根據輸入數據的特性,可以構建一個靈活的ECG解釋系統。對于給定的ECG片段,系統能夠智能地選擇適合的分割模型,并默認使用最全面的分類模型進行類別判斷。此外,為了滿足特定的診斷需求,任務屬性序列可以被手動調整,從而為ECG解釋提供個性化設置。為了適應持續學習的環境,在模型訓練過程中,需要反復進行訓練、修剪和重新訓練的步驟,以確保在引入新任務時舊任務的知識不被遺忘。
3 實驗設置
本節首先介紹ECG分割、分類和情緒分類的數據庫及數據劃分方式,隨后描述具體的實驗實施細節。
3.1 數據集描述
本文一共采用五個數據庫,如表1所示。
(1)ECG分割數據庫:
① MIT-BIH[16]:涵蓋48段各30 min的記錄,每段記錄的采樣率為360 Hz。
② CPSC2019 QRS[5]:第二屆中國生理測量挑戰賽(China Physiological Signal Challenge,CPSC)期間發布,專為可穿戴動態ECG的QRS檢測而設計。它包含5 252段具有各種偽差、沖擊、強烈噪聲和異常形態的單導聯ECG記錄,被視為QRS檢測任務中最具有挑戰性的數據集。
(2)ECG分類數據庫:
③ ICBEB 2018:在2018年的首屆CPSC期間發布的該數據庫[6],包含了來自六家醫院的6 877段12導聯ECG記錄,涵蓋了八種心律失常類型。
④ PTBXL:作為迄今為止最全面的開源ECG分類數據庫[7],涵蓋了21 873段來自18 885名患者的臨床12導聯ECG記錄。數據庫符合SCP-ECG標準ISO
(3)ECG情緒識別數據庫:
⑤ MAHNOB-HCI:該數據庫包含24位受試者共計440次實驗記錄。持續時長從35~117 s不等[17],包含1個通道,采樣率為256 Hz。標注了9個情緒效價值。
3.2 數據預處理
本研究提取了10 s長度的ECG記錄,采用0.5~45 Hz的5階巴特沃斯帶通濾波器來消除基線漂移和工頻干擾。信號均被歸一化為均值為零、標準差為1。對于未指定訓練和測試比例的數據庫(如MIT-BIH數據庫[16]),本研究采納了5折交叉驗證法,每折都依據患者信息來分配,確保了個體數據間的隔離,防止了信息泄露。針對CPSC2019數據庫[5],本研究的實驗嚴格按照競賽主辦方指定的數據劃分方式進行。
在分類任務中,本研究采納了文獻[7,18]中的數據切分方法,以保證實驗的公平性和可比性。分類實驗也遵從了PhysioNet/CinC-2020競賽針對PTBXL數據庫所提出的預定義切分準則。對于情緒識別任務,本文進行了效價值(0~8)的回歸任務和按效價值的2分類實驗,并采用留一驗證法來評估模型性能。
3.3 模型訓練參數
在本項研究中,模型訓練使用顯卡為雙路NVIDIA Tesla A100,主要深度學習開發框架采用PyTorch。為實現超參數的最優化,實驗進行了一系列的參數搜索,搜尋范圍分別為:① 初始學習率設定在1e-4至5e-2之間;② 批次大小設置為32、64、128或256;③ 隱藏層特征維度在4、8、12或18之間進行選擇。分割與分類任務的邏輯輸出決策閾值被設為0.5。在訓練的初期階段,即前五個周期內,采用了漸進增長的學習率預熱策略,初始學習率為1e-6。此后,隨著訓練周期數增加,每經過30個周期,學習率將減半。在模型剪枝過程中,學習率穩定在0.000 5,剪枝比例取決于具體任務需求。
3.4 評估指標
本實驗采用了以下指標來評估ECG分割任務的性能:敏感性(sensitivity,SEN)、陽性預測值(positive predictive value,PP)以及F1分數。針對多標簽分類任務,本研究所采納的評價標準是宏觀平均受試者操作特征曲線下面積(area under macro-average receiver operating characteristic curve,Macro-AUC)。此外,對于情緒分類任務,本研究報告了二分類準確率(accuracy-2,Acc-2);對于情緒效價值回歸任務,則使用平均絕對誤差(mean absolute error,MAE)作為性能評價指標。
4 實驗結果與分析
4.1 方法對照實驗
本節在前文提到的數據庫上詳盡地對比了ECG-MR和ECG-CL與當前領先的各類算法。對照模型涵蓋了基于ECG先驗規則的傳統算法[3, 14, 19–21],以及最新的基于深度學習的ECG分割方法[2, 22]和分類方法[23–27]。
表2展示了分割實驗的對比結果。在傳統ECG數據庫MIT-BIH上,各種方法均表現出較高的準確性。然而,在噪聲干擾和心律失常較為嚴重的CPSC2019數據庫中,檢測精度普遍有所下降。相比之下,本研究提出的ECG-MR算法表現出卓越的性能,在大多數情況下均優于現有方法,或至少達到同等水平。表3展示了心律失常分類實驗的對比結果。本研究提出的方法在該任務中表現出卓越的性能,進一步體現了模型設計的有效性。表4結果顯示,在基于MAHNOB-HCI數據庫的情緒9維度回歸和正負向分類任務中,ECG-MR模型超越了基線模型,顯示出更強的特征捕捉能力,而ECG-CL在完成基本分割和簡單分類任務后,進一步增強了情緒的分類性能。
4.2 持續學習的性能評估
本研究結合深度學習與ECG專業知識,設計并執行了一系列持續學習實驗,模擬實際醫療應用場景中的連續任務學習過程。作為對照實驗,本研究選用ResNet_Wang[4]作為基線模型。該模型在ECG異常檢測任務中表現優異[7],且能夠高效利用模型參數,因此被用于對比ECG分割與分類任務的實驗。
持續學習具有兩大優勢:避免災難性遺忘和促進知識轉移。為驗證這兩點,本研究首先進行了“微調”實驗,將模型在一個任務上訓練至穩定性能后,在新任務上微調并評估每項任務的表現,以模擬持續學習過程。此外,為探索知識轉移效果,本研究設計了“從零開始”的實驗方案,通過為每個任務訓練獨立模型并獨立評估性能,進一步驗證持續學習在知識積累和轉移中的潛在優勢。
4.2.1 跨域持續學習的全面探討
本文的目標是構建一個全面的ECG解讀方法,該方法在四個連續的任務上實施持續學習。遵循從低級到高級、從簡單到復雜任務的原則,本文設定了以下的任務順序和相應的數據庫:① 單導聯分割:CPSC2019數據庫;② 少類別分類:ICBEB2018數據庫;③ 多類別分類:PTBXL數據庫。此設計策略旨在確保模型在從簡單到復雜的任務過渡中平穩地積累和傳遞知識。在這種安排中,每個下游任務都會生成任務特定的特征,同時利用從前一個任務中學到的通用特征。因此,本文預期性能會超過從零開始訓練的模型。
表5展示了提出的持續學習方法在不同骨干網絡上的對比結果。這些結果表明,與從頭開始訓練的模型相比,持續學習方法在下游任務中的性能更好,從而進一步支持了前文的斷言:提出的模型可以有效地從前序任務中轉移通用知識。值得注意的是,從頭開始訓練多個模型所需的存儲要求比單一持續學習模型的要求要多幾倍。在新任務上的微調雖然對最后兩個分類任務給出了相似的結果,但它無法保留來自前兩個任務的獨特知識,從而導致了災難性的遺忘。
4.2.2 基于ECG三大類別的持續學習
從臨床角度看,ECG報告通常基于P-QRS-T形態和波長信息來解釋。PTBXL數據庫被分類為三種非互斥類型:diag(診斷聲明,例如“前壁心肌梗死”,共44類)、form(與ECG的特定段內的顯著變化有關,例如“異常的QRS復合波”,共12類)和rhythm(與特定的節律變化有關,例如“房顫”,共19類)。
PTBXL是目前最全面的ECG異常事件數據庫,因此合理地認為,任何現有的、未列出的或未來可能被識別的ECG異常都可能歸入這三個類別之一。因此,本文在PTBXL數據庫的形態、節律和診斷類別上訓練了持續學習模型。下面描述了三種任務及對應的數據庫:① 形態:PTBXL-form;② 節律:PTBXL-rhythm;③ 診斷:PTBXL-diag。
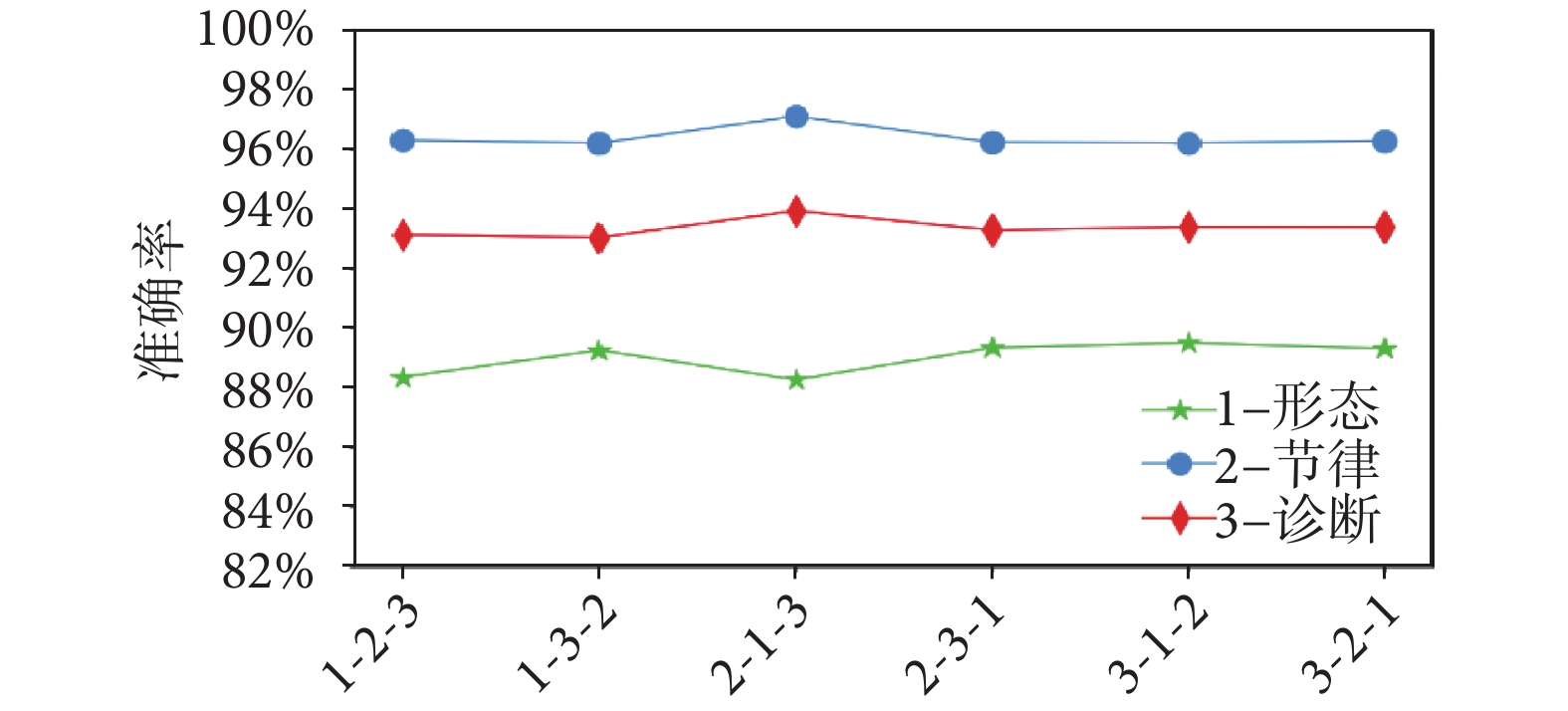
鑒于這三個任務之間沒有明確的層次關系,本文按照上述順序在表6中展示了它們的性能結果。此外,本文在圖3中探索了六種不同的任務輸入次序對持續學習方法性能的影響,發現任務的順序可能會稍微影響整體性能。這種效果可能歸因于分類任務的相似性。
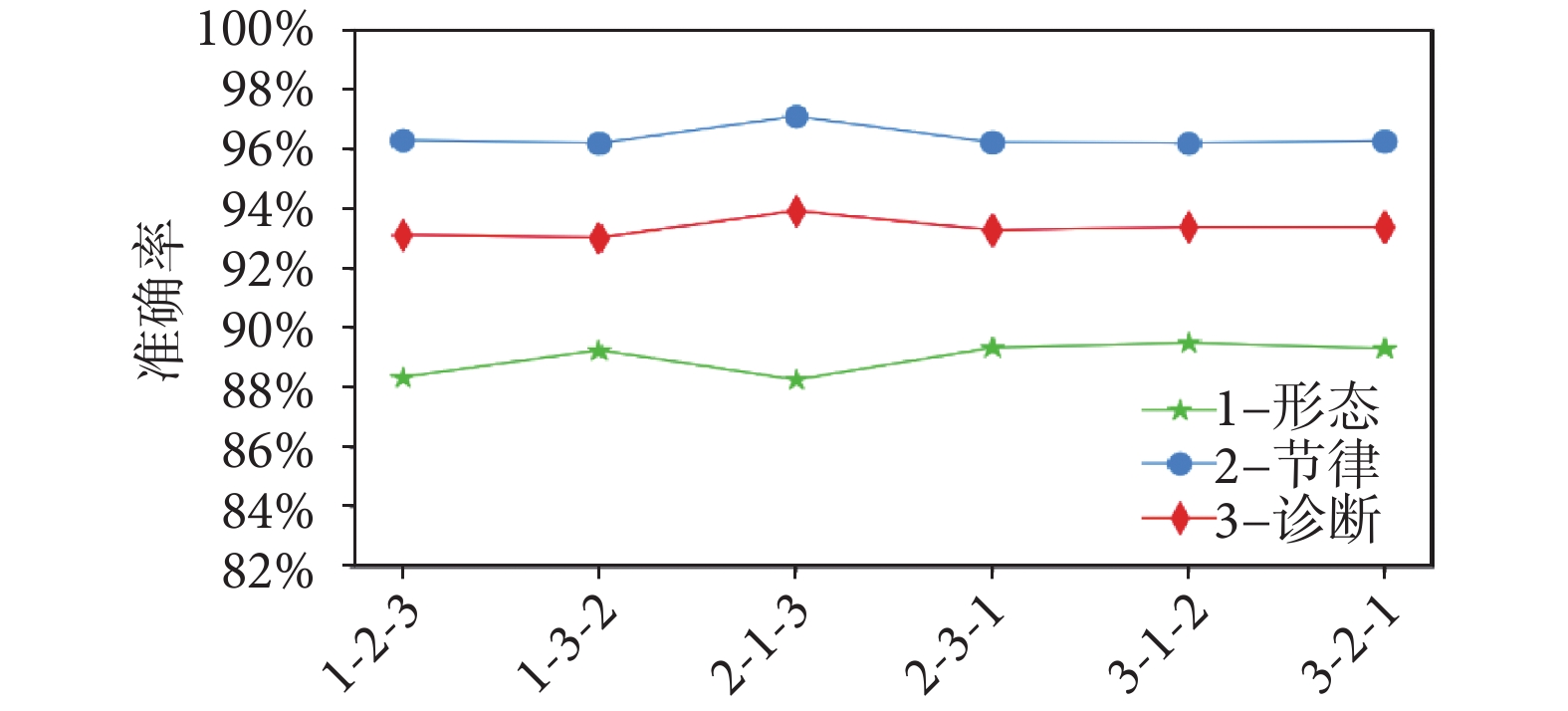 圖3
不同輸入序列下 ECG-CL 算法的性能表現
Figure3.
Performance of the ECG-CL algorithm with different input sequences
圖3
不同輸入序列下 ECG-CL 算法的性能表現
Figure3.
Performance of the ECG-CL algorithm with different input sequences
4.2.3 針對可穿戴設備的持續學習
智能手表和便攜式ECG監測器等可穿戴設備逐漸流行,主要用于實時監測心臟健康狀況并及時發現如心房顫動這樣的心律失常事件。單導聯ECG具備檢測多種常見心律失常的能力,例如心房早搏、室性早搏、心房顫動和個體情緒識別。本研究從單導聯ECG的分割開始,進一步利用持續學習算法完成對心律失常和情緒的分類。心律失常實驗基于ICBEB2018數據庫,將其中8類心律失常事件劃分為節律性異常(如房性早搏、室性早搏和房顫)和形態性異常(ST-T改變、左/右束支傳導阻滯)。考慮到左/右束支傳導阻滯在第一導聯中的明顯異常,本研究選擇了第一導聯進行實驗。
研究的順序和數據庫如下:① 單導聯ECG分割:CPSC 2019-分割;② 單導聯節律分類:ICBEB2018-節律;③ 單導聯形態分類:ICBEB2018-形態;④ 單導聯情緒2分類:MAHNOB-HCI-情緒。表7為持續學習在單導聯ECG上的應用表現,結果證明了持續學習方法在可穿戴設備上的有效性和實用性,以及學習基礎任務對情緒識別能力的提升。持續學習方法有效地實現了從心臟健康任務的診斷知識到情緒健康識別的遷移。
5 結論
本文針對ECG的局部和全局屬性聯合分析和跨ECG任務的有效知識遷移難題,分別設計了一個多分辨率ECG特征提取骨干網絡和基于參數隔離的持續學習策略。在此基礎上,本文進一步設計了不同類型的持續學習實驗:包括領域的增量學習(由心律失常任務向情緒識別任務的過渡)、任務的增量學習(從基礎到高級任務的逐步進展)以及類別的增量學習(從較少的類別向多類別任務的擴展)。實驗結果證明,本文提出的ECG-CL方法明顯勝過了傳統的“從零開始”訓練方法以及基于預訓練的模型微調方法,實現了有效的ECG任務的順向知識傳遞。這為實現對于未知ECG診斷任務的泛化和實現個性化心血管健康及情緒健康任務提供了堅實的基礎。通過對單導聯數據的進一步研究,證明了本文提出的算法在智能可穿戴設備上潛在的實用性,為日常生理健康監測和情緒健康檢測提供了更深入的視角。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:高鴻祥負責全文內容編排和撰寫,蔡志鵬負責全文材料整理和格式調整,李建清和劉澄玉負責論文指導工作。
0 引言
個體健康不僅包括身體機能的正常運作,更體現在精神狀態的健全與良好。情感作為個體情緒和個性的重要組成部分,兼具生理和心理雙重特性。近年來,隨著人工智能算法的進步,結合傳感技術的可穿戴設備被廣泛用于生理信號分析,以分類或量化個體的生理與情感狀態[1]。本文聚焦心電信號(electrocardiogram,ECG)在心血管健康監測與情緒識別中的應用,分別提出ECG多分辨率(multi-resolution,MR)特征提取模型并設計了用于跨任務持續學習(continual learning,CL)的多任務訓練方法。
ECG在心血管疾病的異常事件檢測中已展現出成熟的應用價值[2–8],近年基于ECG信號的情緒識別也引起了越來越多的關注,特別是通過心率變異性(heart rate variability,HRV)分析自主神經活性[9],以評估個體情緒和壓力的波動。過往研究揭示了ECG波形和HRV與情感屬性之間存在顯著的相關性[10],并探討了使用ECG信號進行情感檢測的可行性和潛在限制[11]。
ECG分析的重點在于對關鍵波形(如QRS復合波、P波、T波)的精準分割,以及基于特定形態學和節律特性的任務分析[12]。早期研究集中于首先利用QRS復合波的形態、節律和幅度特征進行QRS定位[3]。這些方法有效地結合了QRS復合波的形態細節與RR間期變化規律,為ECG分類任務構建了與臨床知識高度一致的算法框架。基于QRS的形態和節律屬性的改變,結合臨床先驗知識指導,實現對心律失常等事件的分類,這一類方法被認為是基于規則的算法。近些年,深度學習算法的引入顯著減少了在ECG事件分類前對QRS復合波分割的需求,這些算法在分割和分類任務中分別采用獨立模型,并在多種應用中表現出卓越的性能[13-14]。
然而,針對可穿戴設備的廣泛應用,仍面臨兩大挑戰:① 決策過程中未能有效地利用低分辨率與高分辨率信息;② QRS復合波的形態與節律特性對于精確的QRS定位顯得尤為關鍵,這同樣對于準確的分類至關重要(如圖1所示)。但目前,在這一背景下的知識遷移機制仍顯不足,而解決這些挑戰是推進可穿戴設備在ECG監測和臨床解讀中普及的關鍵路徑。
圖1
心電圖形態和節律屬性分析示意圖
Figure1.
Schematic diagram of electrocardiogram morphological and rhythmic attribute analysis
1 模型和方法
本節將詳細介紹為解決上述ECG多尺度特征提取挑戰而設計的心電多分辨率(ECG multi-resolution,ECG-MR)編碼器模型(見圖2a)以及從心臟健康到情緒健康的ECG持續學習(ECG continual learning,ECG-CL)策略(見圖2b)。
圖2
算法整體框架
a. ECG 多分辨率模型骨干框架及分割/分類器設計;b. ECG 持續學習參數更新示意圖
Figure2. Overall algorithm frameworka. multi-resolution ECG framework and segmentation/classifier design; b. diagram of parameter updates for ECG continual learning
1.1 多分辨率編碼器
在圖2a中,本文詳細展示了為深入分析ECG信號而設計的多分辨率架構。對于任意輸入信號,長度為,導聯數量為。為了適應不同采集設備的ECG信號,并確保兼容多種輸入類型,所有信號均通過一個初始卷積層,將通道數統一為標準的12導聯格式,即 = 12。接下來,使用一個卷積編碼層將原始ECG信號投射到高維特征空間,同時將信號長度縮短至原始長度的四分之一,即。嵌入后的特征接著通過一系列卷積模塊進行處理,如圖2a.1所示,這些卷積模塊在保持信號原始分辨率的同時提取其特征。卷積編碼層和后續的卷積模塊共同組成了整個網絡架構的“第一階段”。
為了精準捕獲ECG中不同尺度的特征,本文設計了一個分支層次網絡架構,該架構在深度增加時會進行特征分化。在第一分支中,網絡保持輸入特征的原始結構,通過跨步卷積提取更高級別的抽象特征表示。此操作使每個通道的特征維度減小,分辨率降至原始長度的八分之一,同時特征維度翻倍,提升到。隨后,這些特征通過更深層的卷積塊進一步轉換。
如圖2a.2所示,為了有效整合不同層級的特征,引入了一個“分支合并模塊”。這一模塊通過將不同分辨率的特征進行整合,增強了模型的語義理解能力。該過程包括“分支劃分”、特征轉換及特征融合,共同構成了“第二階段”。此流程在“第三階段”和“第四階段”中重復進行,將分辨率逐步降低至與。
綜上所述,該多分辨率架構可分為四個獨立的階段,每個階段均由專門的模塊組成。在“分支劃分”模塊中,當前特征通過濾波器進行均等拆分,一半保持原有分辨率,另一半用于較低分辨率的特征處理。通過一系列殘差卷積塊,模型能夠精細地處理特征,而“分支合并”模塊則采用步進卷積或反卷積技術整合多種分辨率的特征,確保了信息的完整性和豐富性。四個階段協同作用,構建了一個能夠捕獲復雜語義信息并保留高分辨率細節的分層特征表示架構。
1.2 ECG分割解碼器
為了實現高精度的QRS波群分割任務,本研究進一步提出了基于MR特征提取器的QRS定位解碼器,該方法采用了將低分辨率信息插值到最高分辨率信息的方法,并結合了SE-Net模塊[15]以增強對心律失常相關ECG表現的注意力,如圖2a.3所示。
QRS定位解碼器的數學表示為:
|
|
|
其中,,。串聯的特征表示為,表示插值函數,表示SE-Net模塊,表示逐元素乘法,和是全連接層的參數,表示自適應平均池化函數。最后,輸出的邏輯值,大于0.5的數值表示在QRS定位任務中的潛在關注點。
1.3 ECG分類解碼器
ECG分類任務的目標是基于多分辨率特性將ECG準確地劃分到預先設定的類別,這些類別包括但不限于心律失常類別和情感狀態(積極/消極)。本文提出的方法采用跨步卷積操作與通道維度上的求和策略,以此實現將ECG中的高分辨率細節信息有效地整合到低分辨率表示中,該過程如圖2a.4所示。
ECG分類解碼器的數學描述為:
|
|
|
其中,表示跨步卷積,表示通道維度求和,表示全局平均池化層,和代表全連接層的參數。表示具有個類別的多標簽分類的邏輯值,同樣以0.5為閾值區分類別的置信度。
2 ECG多任務持續學習
ECG的處理在深度學習領域正受到廣泛關注,其跨設備和領域的一致性為知識遷移提供了堅實基礎,如圖1所示。然而,現有方法在應對多任務學習和模型適應性方面仍存在局限。為此,本文提出了一種基于自適應權重優化與權重剪枝的ECG持續學習方法——ECG-CL,旨在提升信號處理效率與準確性,并實現跨任務知識遷移。
2.1 持續學習訓練過程
假定集合涵蓋所有ECG任務,且與分別代表分割與分類任務的子集合,可以得出。這里,索引分別代表全部任務集、分割任務集合以及分類任務集合中當前的任務,且滿足。基于此描述ECG-CL的具體流程如下所述。
(1)任務:如圖2b第一行所示,以第1節中提出的ECG-MR為骨干網絡,在任務對應的數據集上從零開始訓練。隨后將執行第一次權重剪枝至特定的稀疏度水平。激進的權重修剪可能會損害性能,為補償這一損失,執行一輪低學習率的微調。對于第一個任務,保留下來的編碼器權重標記為,而被釋放的權重標記為。這一邏輯同樣適用于解碼器,分割任務的保留與釋放權重分別為和,分類任務亦然,保留與釋放權重分別標記為和。
(2)任務:假設已經完成了任務的學習,包括個分割任務和個分類任務。則至此為止的分割任務保留模型權重表示為,分類任務的保留模型權重表示為。在這些保留權重的基礎上,進一步訓練權重選擇掩碼矩陣和,以便挑選出對后續任務有益的通用特征,從而有助于將有利的知識遷移到下游任務。
(3)面向新任務:以分類任務為例,本文首先用選擇掩碼過濾后的保留權重來訓練網絡,以此作為通用知識基礎。之后,使用被釋放的權重來強化特定于任務的權重。重要的是,為了維持先前任務的性能,這些被挑選的權重在訓練過程中會被凍結。最后,通過一輪剪枝和再訓練,優化模型以適應新任務,同時盡可能地維持當前任務的表現。整個過程將按照這一策略循環進行,直到所有任務學習完畢。圖2b可視化了這一參數更新策略,訓練矩陣的空白單元表示可訓練的參數,灰色單元代表只參與前向傳播的權重,而黑色單元格內的參數則被凍結,不參與訓練。在“剪枝與重訓”矩陣中,標記為的單元格代表了與任務相關的權重;而標記為‘0’的單元格則表示這些參數已經被釋放;漸變色的單元格則這表示些權重在多個任務中被共享使用。
2.2 持續學習推理過程
在深度學習模型的推理階段,確定任務標識符以便使用預保留的二進制掩碼來提取任務特定的參數變得尤為關鍵。本文提出的持續學習策略中,不論是單任務還是序列多任務場景,模型只需在推理開始時加載一次。這種高效的順序推斷是通過利用任務標識符確定的二進制掩碼來實現的。
考慮到實際的ECG解釋場景,可以設想一個已經訓練好的持續學習模型,其中包括四個任務:單導聯分割、多導聯分割、有限類別分類和多類別分類。通過融合ECG的分割與分類,根據輸入數據的特性,可以構建一個靈活的ECG解釋系統。對于給定的ECG片段,系統能夠智能地選擇適合的分割模型,并默認使用最全面的分類模型進行類別判斷。此外,為了滿足特定的診斷需求,任務屬性序列可以被手動調整,從而為ECG解釋提供個性化設置。為了適應持續學習的環境,在模型訓練過程中,需要反復進行訓練、修剪和重新訓練的步驟,以確保在引入新任務時舊任務的知識不被遺忘。
3 實驗設置
本節首先介紹ECG分割、分類和情緒分類的數據庫及數據劃分方式,隨后描述具體的實驗實施細節。
3.1 數據集描述
本文一共采用五個數據庫,如表1所示。
(1)ECG分割數據庫:
① MIT-BIH[16]:涵蓋48段各30 min的記錄,每段記錄的采樣率為360 Hz。
② CPSC2019 QRS[5]:第二屆中國生理測量挑戰賽(China Physiological Signal Challenge,CPSC)期間發布,專為可穿戴動態ECG的QRS檢測而設計。它包含5 252段具有各種偽差、沖擊、強烈噪聲和異常形態的單導聯ECG記錄,被視為QRS檢測任務中最具有挑戰性的數據集。
(2)ECG分類數據庫:
③ ICBEB 2018:在2018年的首屆CPSC期間發布的該數據庫[6],包含了來自六家醫院的6 877段12導聯ECG記錄,涵蓋了八種心律失常類型。
④ PTBXL:作為迄今為止最全面的開源ECG分類數據庫[7],涵蓋了21 873段來自18 885名患者的臨床12導聯ECG記錄。數據庫符合SCP-ECG標準ISO
(3)ECG情緒識別數據庫:
⑤ MAHNOB-HCI:該數據庫包含24位受試者共計440次實驗記錄。持續時長從35~117 s不等[17],包含1個通道,采樣率為256 Hz。標注了9個情緒效價值。
3.2 數據預處理
本研究提取了10 s長度的ECG記錄,采用0.5~45 Hz的5階巴特沃斯帶通濾波器來消除基線漂移和工頻干擾。信號均被歸一化為均值為零、標準差為1。對于未指定訓練和測試比例的數據庫(如MIT-BIH數據庫[16]),本研究采納了5折交叉驗證法,每折都依據患者信息來分配,確保了個體數據間的隔離,防止了信息泄露。針對CPSC2019數據庫[5],本研究的實驗嚴格按照競賽主辦方指定的數據劃分方式進行。
在分類任務中,本研究采納了文獻[7,18]中的數據切分方法,以保證實驗的公平性和可比性。分類實驗也遵從了PhysioNet/CinC-2020競賽針對PTBXL數據庫所提出的預定義切分準則。對于情緒識別任務,本文進行了效價值(0~8)的回歸任務和按效價值的2分類實驗,并采用留一驗證法來評估模型性能。
3.3 模型訓練參數
在本項研究中,模型訓練使用顯卡為雙路NVIDIA Tesla A100,主要深度學習開發框架采用PyTorch。為實現超參數的最優化,實驗進行了一系列的參數搜索,搜尋范圍分別為:① 初始學習率設定在1e-4至5e-2之間;② 批次大小設置為32、64、128或256;③ 隱藏層特征維度在4、8、12或18之間進行選擇。分割與分類任務的邏輯輸出決策閾值被設為0.5。在訓練的初期階段,即前五個周期內,采用了漸進增長的學習率預熱策略,初始學習率為1e-6。此后,隨著訓練周期數增加,每經過30個周期,學習率將減半。在模型剪枝過程中,學習率穩定在0.000 5,剪枝比例取決于具體任務需求。
3.4 評估指標
本實驗采用了以下指標來評估ECG分割任務的性能:敏感性(sensitivity,SEN)、陽性預測值(positive predictive value,PP)以及F1分數。針對多標簽分類任務,本研究所采納的評價標準是宏觀平均受試者操作特征曲線下面積(area under macro-average receiver operating characteristic curve,Macro-AUC)。此外,對于情緒分類任務,本研究報告了二分類準確率(accuracy-2,Acc-2);對于情緒效價值回歸任務,則使用平均絕對誤差(mean absolute error,MAE)作為性能評價指標。
4 實驗結果與分析
4.1 方法對照實驗
本節在前文提到的數據庫上詳盡地對比了ECG-MR和ECG-CL與當前領先的各類算法。對照模型涵蓋了基于ECG先驗規則的傳統算法[3, 14, 19–21],以及最新的基于深度學習的ECG分割方法[2, 22]和分類方法[23–27]。
表2展示了分割實驗的對比結果。在傳統ECG數據庫MIT-BIH上,各種方法均表現出較高的準確性。然而,在噪聲干擾和心律失常較為嚴重的CPSC2019數據庫中,檢測精度普遍有所下降。相比之下,本研究提出的ECG-MR算法表現出卓越的性能,在大多數情況下均優于現有方法,或至少達到同等水平。表3展示了心律失常分類實驗的對比結果。本研究提出的方法在該任務中表現出卓越的性能,進一步體現了模型設計的有效性。表4結果顯示,在基于MAHNOB-HCI數據庫的情緒9維度回歸和正負向分類任務中,ECG-MR模型超越了基線模型,顯示出更強的特征捕捉能力,而ECG-CL在完成基本分割和簡單分類任務后,進一步增強了情緒的分類性能。
4.2 持續學習的性能評估
本研究結合深度學習與ECG專業知識,設計并執行了一系列持續學習實驗,模擬實際醫療應用場景中的連續任務學習過程。作為對照實驗,本研究選用ResNet_Wang[4]作為基線模型。該模型在ECG異常檢測任務中表現優異[7],且能夠高效利用模型參數,因此被用于對比ECG分割與分類任務的實驗。
持續學習具有兩大優勢:避免災難性遺忘和促進知識轉移。為驗證這兩點,本研究首先進行了“微調”實驗,將模型在一個任務上訓練至穩定性能后,在新任務上微調并評估每項任務的表現,以模擬持續學習過程。此外,為探索知識轉移效果,本研究設計了“從零開始”的實驗方案,通過為每個任務訓練獨立模型并獨立評估性能,進一步驗證持續學習在知識積累和轉移中的潛在優勢。
4.2.1 跨域持續學習的全面探討
本文的目標是構建一個全面的ECG解讀方法,該方法在四個連續的任務上實施持續學習。遵循從低級到高級、從簡單到復雜任務的原則,本文設定了以下的任務順序和相應的數據庫:① 單導聯分割:CPSC2019數據庫;② 少類別分類:ICBEB2018數據庫;③ 多類別分類:PTBXL數據庫。此設計策略旨在確保模型在從簡單到復雜的任務過渡中平穩地積累和傳遞知識。在這種安排中,每個下游任務都會生成任務特定的特征,同時利用從前一個任務中學到的通用特征。因此,本文預期性能會超過從零開始訓練的模型。
表5展示了提出的持續學習方法在不同骨干網絡上的對比結果。這些結果表明,與從頭開始訓練的模型相比,持續學習方法在下游任務中的性能更好,從而進一步支持了前文的斷言:提出的模型可以有效地從前序任務中轉移通用知識。值得注意的是,從頭開始訓練多個模型所需的存儲要求比單一持續學習模型的要求要多幾倍。在新任務上的微調雖然對最后兩個分類任務給出了相似的結果,但它無法保留來自前兩個任務的獨特知識,從而導致了災難性的遺忘。
4.2.2 基于ECG三大類別的持續學習
從臨床角度看,ECG報告通常基于P-QRS-T形態和波長信息來解釋。PTBXL數據庫被分類為三種非互斥類型:diag(診斷聲明,例如“前壁心肌梗死”,共44類)、form(與ECG的特定段內的顯著變化有關,例如“異常的QRS復合波”,共12類)和rhythm(與特定的節律變化有關,例如“房顫”,共19類)。
PTBXL是目前最全面的ECG異常事件數據庫,因此合理地認為,任何現有的、未列出的或未來可能被識別的ECG異常都可能歸入這三個類別之一。因此,本文在PTBXL數據庫的形態、節律和診斷類別上訓練了持續學習模型。下面描述了三種任務及對應的數據庫:① 形態:PTBXL-form;② 節律:PTBXL-rhythm;③ 診斷:PTBXL-diag。
鑒于這三個任務之間沒有明確的層次關系,本文按照上述順序在表6中展示了它們的性能結果。此外,本文在圖3中探索了六種不同的任務輸入次序對持續學習方法性能的影響,發現任務的順序可能會稍微影響整體性能。這種效果可能歸因于分類任務的相似性。
圖3
不同輸入序列下 ECG-CL 算法的性能表現
Figure3.
Performance of the ECG-CL algorithm with different input sequences
4.2.3 針對可穿戴設備的持續學習
智能手表和便攜式ECG監測器等可穿戴設備逐漸流行,主要用于實時監測心臟健康狀況并及時發現如心房顫動這樣的心律失常事件。單導聯ECG具備檢測多種常見心律失常的能力,例如心房早搏、室性早搏、心房顫動和個體情緒識別。本研究從單導聯ECG的分割開始,進一步利用持續學習算法完成對心律失常和情緒的分類。心律失常實驗基于ICBEB2018數據庫,將其中8類心律失常事件劃分為節律性異常(如房性早搏、室性早搏和房顫)和形態性異常(ST-T改變、左/右束支傳導阻滯)。考慮到左/右束支傳導阻滯在第一導聯中的明顯異常,本研究選擇了第一導聯進行實驗。
研究的順序和數據庫如下:① 單導聯ECG分割:CPSC 2019-分割;② 單導聯節律分類:ICBEB2018-節律;③ 單導聯形態分類:ICBEB2018-形態;④ 單導聯情緒2分類:MAHNOB-HCI-情緒。表7為持續學習在單導聯ECG上的應用表現,結果證明了持續學習方法在可穿戴設備上的有效性和實用性,以及學習基礎任務對情緒識別能力的提升。持續學習方法有效地實現了從心臟健康任務的診斷知識到情緒健康識別的遷移。
5 結論
本文針對ECG的局部和全局屬性聯合分析和跨ECG任務的有效知識遷移難題,分別設計了一個多分辨率ECG特征提取骨干網絡和基于參數隔離的持續學習策略。在此基礎上,本文進一步設計了不同類型的持續學習實驗:包括領域的增量學習(由心律失常任務向情緒識別任務的過渡)、任務的增量學習(從基礎到高級任務的逐步進展)以及類別的增量學習(從較少的類別向多類別任務的擴展)。實驗結果證明,本文提出的ECG-CL方法明顯勝過了傳統的“從零開始”訓練方法以及基于預訓練的模型微調方法,實現了有效的ECG任務的順向知識傳遞。這為實現對于未知ECG診斷任務的泛化和實現個性化心血管健康及情緒健康任務提供了堅實的基礎。通過對單導聯數據的進一步研究,證明了本文提出的算法在智能可穿戴設備上潛在的實用性,為日常生理健康監測和情緒健康檢測提供了更深入的視角。
重要聲明
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
作者貢獻聲明:高鴻祥負責全文內容編排和撰寫,蔡志鵬負責全文材料整理和格式調整,李建清和劉澄玉負責論文指導工作。