心臟瓣膜病作為第3大心血管疾病,發病率僅次于冠狀動脈粥樣硬化性心臟病和高血壓,嚴重時可導致心室肥厚或心力衰竭。因此,早期檢測心臟瓣膜病具有重要意義。近年來,深度學習在心臟瓣膜病輔助診斷中的應用取得顯著進展,大幅提高了檢測準確率。本文針對深度學習在心臟瓣膜病輔助診斷中的研究展開綜述,首先介紹常見心臟瓣膜病的病因、病理機制與影響,然后探討心電信號、心音信號及多模態數據在心臟瓣膜病檢測中的優勢與局限性。對比傳統風險預測方法與大語言模型預測方法在心血管疾病風險預測中的應用,指出大語言模型在風險預測中的潛力。最后指出當前深度學習在該領域面臨的主要挑戰,并對未來的研究方向進行展望。
版權信息: ?四川大學華西醫院華西期刊社《中國胸心血管外科臨床雜志》版權所有,未經授權不得轉載、改編
根據《中國心血管健康與疾病報告2023概要》[1],心血管疾病(cardiovascular disease,CVD)在我國城鄉居民疾病死亡構成比中占首位,每5例死亡病例就有2例死于CVD。估算我國CVD現患病人數3.3億,預估到2030年,將有
近年來,深度學習在VHD的輔助診斷中嶄露頭角。通過對醫療數據的分析處理,可以輔助醫師對患者的疾病情況進行精準識別。此外,深度學習還可實現早期和低成本的VHD檢測,能克服傳統檢測方式需要專業技能的缺點,為中低收入地區的VHD早期診斷提供一種可行的替代方案。
當前,輔助VHD進行診斷的深度學習技術已經有所應用,本文將從VHD檢測和VHD風險預測兩個方面,探討深度學習技術的最新應用進展,旨在為后續研究提供新思路。
1 心臟瓣膜病概述
VHD指原發或繼發病因引起的單個或多個瓣膜結構或功能異常致其狹窄或反流,使心臟前負荷或后負荷增加引發心室結構改變,最終導致心功能不全的心血管疾病[7]。左側VHD主要涉及二尖瓣和主動脈瓣的病理變化,其發病原理包括瓣膜結構改變和瓣膜功能障礙等[8]。每種類型的瓣膜病在病理機制、臨床表現上各有不同。最常見的主動脈瓣和二尖瓣疾病的病因、病理機制、癥狀與影響[9-12]見表1。
當前,檢測VHD的方式包括Echo[13]、心臟磁共振成像(cardiac magnetic resonance imaging,CMR)[14]、計算機斷層掃描(computed tomography,CT)[15]、心電圖(electrocardiogram,ECG)[16]、心音圖(phonocardiogram,PCG)[17]等多種手段。但對心血管醫學中關于人工智能、機器學習、深度學習的研究進行檢索我們發現,只有不到3%的研究應用上述方法于VHD檢測且多數集中在機器學習領域[18]。隨著心血管醫療越來越數字化,電子健康記錄(electronic health record,EHR)在臨床中被廣泛集成,數據的標準化加上計算性能的提高將有利于深度學習在該領域的蓬勃發展,以改善VHD的檢測和疾病風險預測情況。
2 深度學習在心臟瓣膜病輔助診斷中的應用
深度學習是一種利用多層神經網絡模擬人腦工作方式的機器學習方法,能夠自動提取特征并處理復雜數據[19]。深度學習于2017年開始被廣泛應用于醫學圖像處理、信號處理領域[20]并展現出卓越性能。僅在中國,VHD就影響了約3.8%的人口,高達11%~13%的75歲以上老人存在中重度瓣膜病,多數患者直到癥狀發作之后才會接受檢查,嚴重延緩早期檢測和治療的進度[21]。深度學習能夠實時分析心音、心電信號并能與Echo等臨床檢測方式進行結合,降低對專業醫師的依賴并提高診斷準確性,正逐漸改變VHD的檢測格局。
2.1 心電信號在心臟瓣膜病檢測中的應用
心電信號通過記錄心臟電活動反映VHD對整體心臟功能的影響。VHD通常會影響心臟的機械功能,這些變化會間接導致心臟的電活動發生異常,如心房顫動、左心室肥大等[22]。分析心電信號不僅能夠檢測心臟電活動的異常,還能輔助診斷VHD。如Elias等[23]使用從3個醫院獲取的
VHD往往表現為心臟機械功能的改變,ECG雖能檢測心律失常和電活動異常,但在早期病變中對心肌功能障礙的評估有限。且其檢測性能受個體差異影響,在復雜病變中的診斷準確性較低[29]。此外,ECG對VHD的檢測多數以機器學習為主,深度學習模型多數限于CNN,不完全適用于VHD檢測是阻礙ECG在此領域發展的關鍵問題。
2.2 心音信號在心臟瓣膜病檢測中的應用
為更有效地評估心臟泵血能力和心室機械問題,對VHD檢測的深度學習研究大多聚焦于心音信號,心音信號能夠直接捕捉心臟瓣膜關閉時的聲音變化,不同的VHD會產生特定的心音變化,這些特征可以幫助醫師做出初步診斷[30]。通過心音信號的時頻特征轉換,如梅爾頻譜(mel-frequency cepstral coefficients,MFCC)、短時傅里葉變換、小波變換等,網絡模型可以從心音中提取與瓣膜病相關的特征,從而實現自動檢測。
當前,該領域的研究大多集中在公開心音數據集yaseen21[31],包含AS、MS、MR、二尖瓣脫垂(mitral valve prolapse,MVP)和正常各200條數據,所有數據以8 kHz采樣并采用單通道WAV形式存儲,瓣膜病類型的多樣和數據的平衡是該數據集受到青睞的關鍵原因。圍繞該數據集,Al-Issa等[32]通過時間拉伸、時間移位和添加噪聲的數據增強方式來擴充樣本,訓練了一個CNN+長短期記憶網絡(long short-term memory,LSTM)的混合模型,CNN層提取局部時頻特征后輸入LSTM層以進一步處理信號的時間序列特征。經過十折交叉驗證的實驗結果表明,該模型對于上述五分類問題,達到了98.48%的準確率。進一步的研究表明,不需要對模型進行復雜混合,特征提取方式的改進也可以提升檢測性能。Torre-Cruz等[17]提出一種結合正交非負矩陣分解(orthogonal non-negative matrix factorization,ONMF)與CNN的新方法,ONMF能有效分解心音的時頻特征并減少特征冗余,增強模型對關鍵信息的捕捉能力。通過引入ONMF,使用GoogLeNet的準確率達到98%,展現了改進特征提取方式在VHD檢測中的潛力。上述研究檢測準確率雖然較高,但無法解釋模型的識別過程。為了解決“黑盒”問題,Bhardwaj等[33]使用敏感性圖和夢境圖兩種可視化技術對結果進行解釋。夢境圖的結果表明,出現橢圓形的紅黃通道圖像表明識別了與AS相關的特征、具有多個紅藍通道的圓形特征表示對MR的精準識別、生成的圖像以藍綠通道為主顯示了MS的不同模式、生成多條延長的藍色通道圖像則解釋了與MVP相關的特殊形態特征。可視化技術的應用增強了醫療人員對AI模型的信賴,為個性化治療方案的制定提供依據。
隨著Transformer[34]模型的發展,研究人員開始將注意力機制引入心音分析。Transformer的全局注意力機制使其能夠捕捉心音中的長程依賴關系并有效提取信號的全局特征。相比傳統的CNN和循環神經網絡,Transformer在處理序列數據時具有更高的靈活性和準確性。Abbas等[35]將Transformer與CNN相結合,提出了CVT VHD檢測模型。使用連續小波變換將心音轉換為時頻圖像,通過CVT提取局部和全局特征。該模型在五類VHD識別中達到了99%的準確率,顯著提高了檢測性能,并且在處理含噪聲心音時依然保持較高的魯棒性。為簡化特征選擇方式并保持檢測精準度,Jamil等[36]首次將vision transformer(ViT)引入到VHD檢測中并提出了3種框架:對于一維信號,提取MFCC和線性預測編碼系數(LPCC)特征;對于二維信號,使用連續小波變換提取二維時頻表示,以使用ResNet50、AlexNet、Inception v3提取各種特征;使用自然/生物啟發算法(NIA/BIA),如粒子群優化和遺傳算法[37],以高效選擇最重要的特征。所提框架無需對心音進行任何預處理(如分割、濾波、降噪等),ViT的性能超過了目前的SOTA模型。上述關于Transformer模型的實驗雖然已經取得了接近100%的五分類檢測準確率,但模型性能提升的同時極大地增加了計算復雜度和資源消耗,不利于部署到醫療條件相對落后的地區。為了解決實驗室成果過渡到臨床應用的難題,Makimoto等[38]的研究進一步提高了模型的可解釋性和可用性,開發了一個輕量級CNN模型并使用來自556例患者的3個聽診位置的
2.3 多模態數據融合在心臟瓣膜病檢測中的應用
VHD的檢測不僅僅局限于單一生理信號,還可以通過多模態數據融合來獲得更加全面的結果。隨著醫療數據多元化發展,越來越多的研究嘗試將ECG、PCG、Echo等多模態數據進行融合,以增強模型對不同病理特征的感知能力,提高診斷準確性。Lee等[39]首先提出了通過同步采集的心音和心電信號來檢測VHD的方法,利用心電信號中的R波峰值來標定心音中的S1和S2。這種同步方式能夠精確區分心音信號中的收縮期和舒張期,為心臟雜音檢測提供基礎。Shiraga等[40]也使用心音和心電信號進行特征融合來檢測嚴重AS、MR和左心室功能障礙。兩個實驗都通過CNN模型進行訓練,通過多模態特征融合,模型能夠更全面地捕捉心臟活動的各個維度,提升檢測性能。除了心音信號和心電信號的融合,研究[41]也提出Echo和ECG融合以檢測由AS引起的左心室肥厚,該研究使用經過濾除基線漂移和電源線干擾預處理的
2.4 其他方法在心臟瓣膜病檢測中的應用
隨著深度學習的不斷發展,其他模型如圖神經網絡(graph neural network,GNN)[43]和生成對抗網絡(generative adversarial network,GAN)[44]也展現出獨特的優勢和潛力。GNN能夠有效處理圖結構數據,在建模復雜生物網絡和病理關系方面具有顯著優勢。GAN則在數據增強和樣本生成方面展現出卓越的能力,能克服數據不足問題。如Ivantsits等[45]提出了一種基于GNN的幾何深度學習模型MV-GNN,通過三維經食管Echo數據生成連續的二尖瓣表面模型。結合CNN和GNN架構重建瓣膜網格,避免了傳統體素轉換誤差并支持時間連續的瓣膜運動分析。但模型依賴于預定義的拓撲網絡,可能無法準確重建復雜病變。為降低對網絡結構的適應性要求,Thomas等[46]使用圖卷積神經網絡(graph convolutional network,GCN)結合三維心臟網格重建實現對心臟結構的定位識別,使用合成的超聲數據進行訓練,在彌補臨床三維標注數據不足的同時還能完成結構定位和姿態估計。
雖然GNN和GCN在建模生物網絡結構方面展現顯著優勢,但在處理小樣本或缺少標注數據的問題上,GAN能通過生成多樣性和逼真度更高的合成數據有效提升在小樣本條件下的泛化能力。如Rayavarapu等[47]使用LSGAN和Cycle GAN進行ECG和PCG信號的生成以實現數據增強。Vinay等[48]使用多決策GAN生成并分類心音信號,結合雙向長短期記憶網絡(Bi-LSTM)捕獲時序特征,與Rayavarapu等[47]的研究類似,該研究采用的多決策GAN同樣生成逼真的合成數據來豐富數據量,兩者均顯示了GAN在醫學數據生成和疾病檢測中的潛力。此外,SCG[28,49]、陀螺心動圖(gyrocardiogram,GCG)[50]等非侵入性檢測技術在VHD檢測中也展現了較高的可靠性,在不依賴傳統ECG的情況下,可以通過多維振動信號捕獲心臟功能信息,為VHD的連續、無創監測提供新途徑。VHD檢測方法總結見表2。
3 心臟瓣膜病的風險預測
心血管疾病的發展過程復雜且動態,患者的癥狀可能隨時發生變化。因此,模型不僅需要準確識別當前癥狀,還需具備持續監測能力,追蹤癥狀的變化趨勢并預測潛在風險,以便及時調整治療方案[51]。風險預測模型是使用患者風險因素來估計醫療保健結果概率的方程。比較出名的風險預測模型有肺栓塞的Well標準[52]和識別危重患者膿毒癥高風險死亡率的SOFA評分[53]。近年來,預測嚴重AS患者未來病情的發展情況逐漸受到關注,因為在不經歷瓣膜置換的情況下,該疾病1年內的死亡率達到40%~50%。Namasivayam等[54]分析了
傳統風險預測模型雖然表現出良好的效果,但通常依賴于手動選擇特征,此外,傳統模型只能處理結構化數據,缺乏從非結構化文本數據中提取有效特征的能力,如醫師的診斷筆記、住院記錄等無法直接用于訓練。隨著大語言模型(large language model,LLM)和大型視覺語言模型(large vision language model,LVLM)的推出,這一格局發生了改變,代表模型是由OpenAI開發的GPT[55]和Google開發的BERT[56]。這些LLM通常由數十億甚至上百億個參數組成,能夠理解和生成自然語言文本,執行各種語言相關任務。可以利用其處理序列數據的能力,提高心音狀態識別模型的整體性能并一定程度解決困擾深度學習的“黑盒”問題,提高模型可解釋性,增加臨床應用中的可信度[57]。
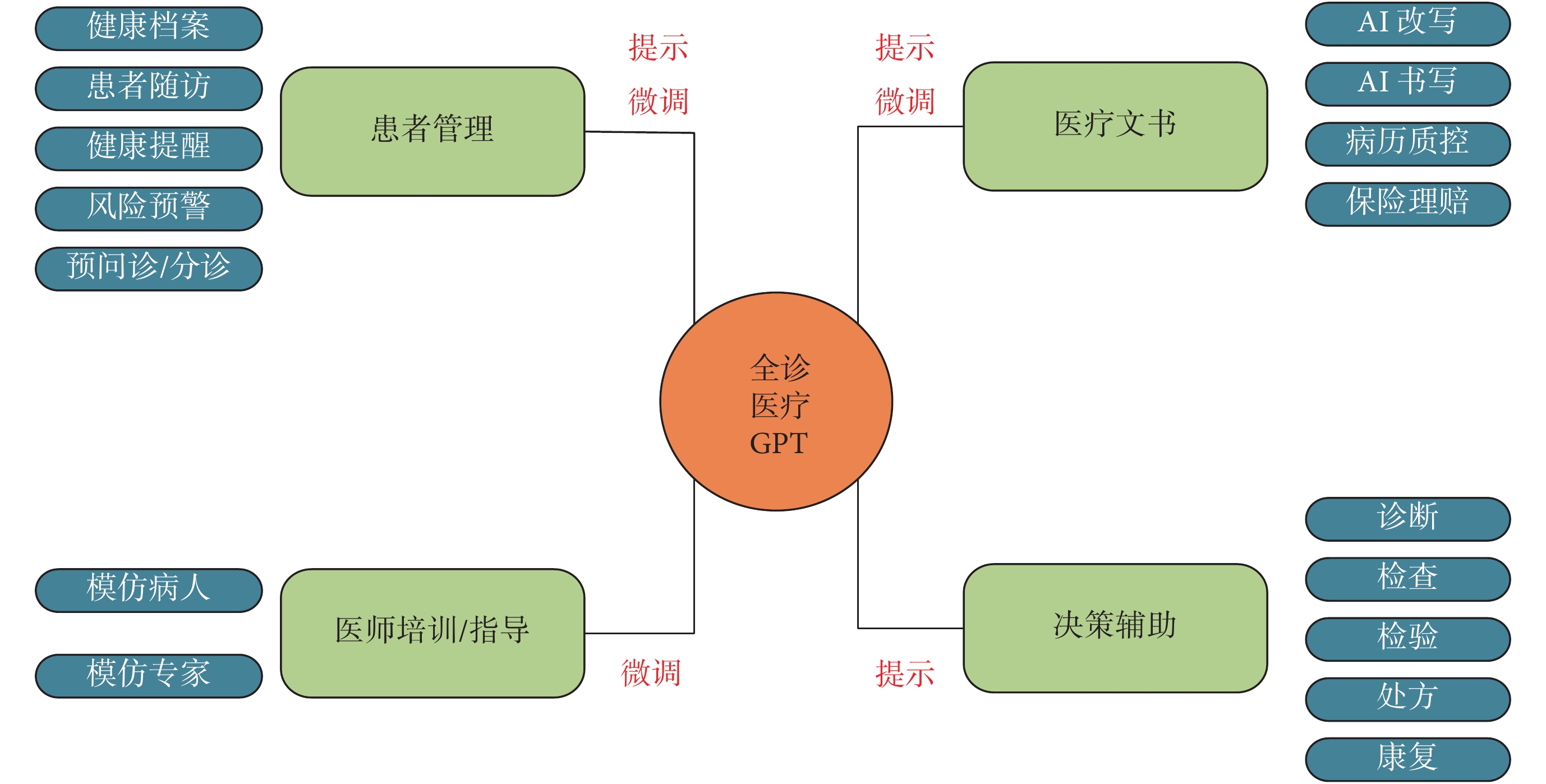
對VHD進行風險預測的LLM應用還在探索階段,但已經有研究將LLM用于心血管疾病的風險預測。如Vaid等[58]利用一個開源LLM(LLaMA-2 70B模型)來提取和總結患者的Echo歷史數據以簡化數據分析過程并提高臨床決策效率,分析了432個報告并生成了100個問題-答案對。其中時間關系的正確回答率為83%,病情嚴重程度評估的正確回答率為93%,對干預措施的識別準確率為84%,診斷檢索的準確率為100%,顯示出其在提升臨床決策和研究效率方面的潛力。Kwon等[59]認為LLM是全能臨床推理者,并提出了一個即時生成的推理感知診斷框架。為診斷心臟疾病和討論藥物治療方案,Novak等[60]評估了3種LLM,即Google Bard、GPT-3.5 Turbo和GPT-4.0在心臟病領域的潛在應用。結果表明GPT-4.0在所有測試場景中表現最佳,尤其是在復雜的臨床決策中,能夠準確理解醫學術語并提供符合當前臨床指南的答案。在討論藥物治療方案時,GPT-4.0能夠依據患者的低密度脂蛋白膽固醇水平推薦合理的降脂藥物,并遵守2018 AHA/ACC指南。而Google Bard則錯誤地推薦了不適當的藥物且對藥物相互作用的理解存在誤差。雖然LLM展示了變革醫學的潛力,但也存在一定的挑戰。一篇發表在The Lancet的文章[61]客觀評估了LLM的局限性,如存在社會偏見和無法保證數據的隱私與安全問題等,呼吁LLM在進入臨床應用前,需進行嚴格的臨床驗證,規避潛在風險。全診醫療GPT框架如圖1所示。
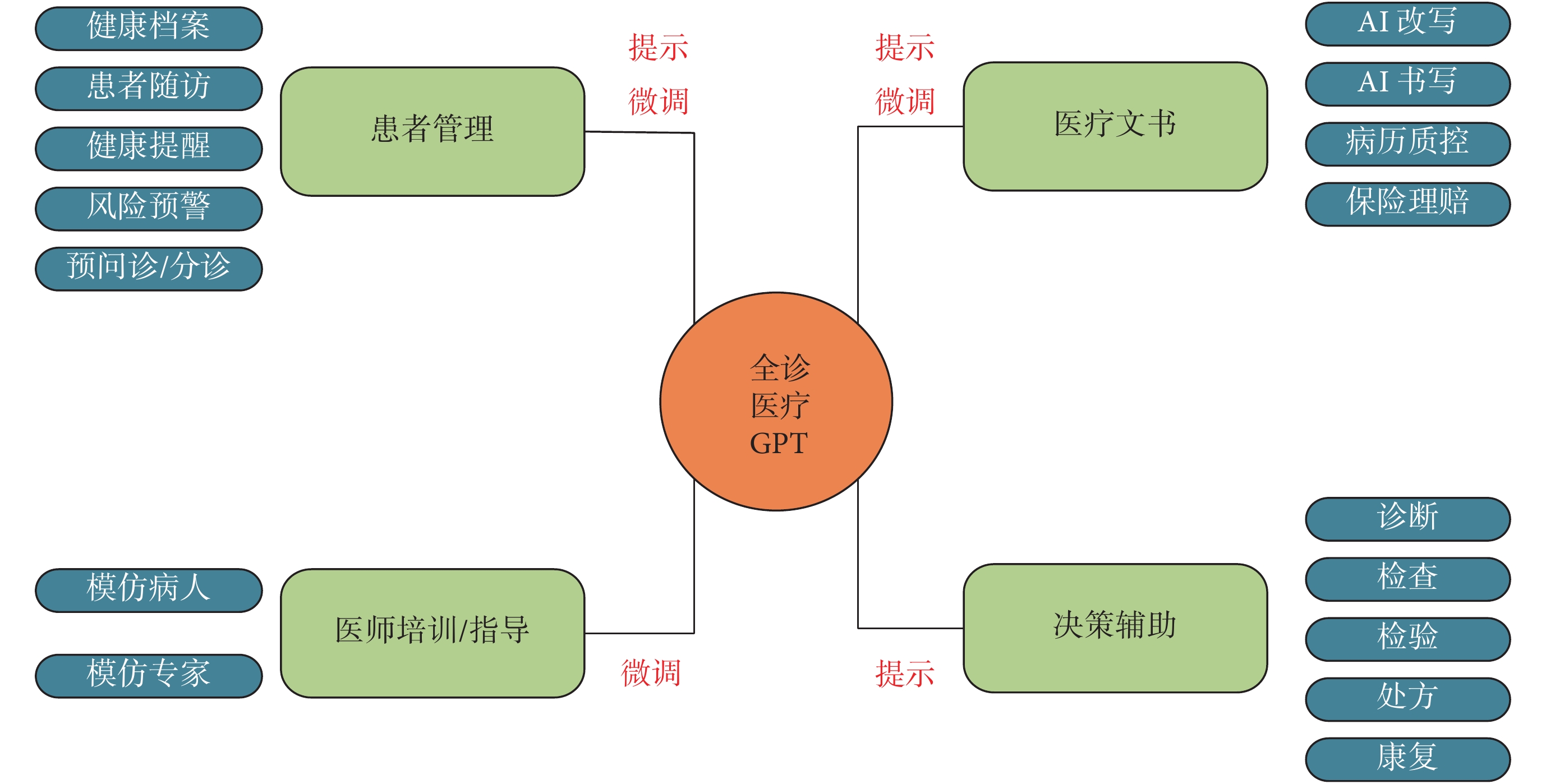 圖1
全診醫療GPT
圖1
全診醫療GPT
4 總結與展望
將深度學習引入VHD檢測中,不僅極大提高了醫療診斷的精確度,還有效避免了因醫師主觀因素可能引起的誤診風險。在輔助醫師進行術前診斷及臨床手術治療中發揮了不可替代的作用。盡管基于深度學習的VHD診斷方法取得了有效進展,但仍面臨諸多挑戰:
(1)VHD特異性數據的獲取。VHD患者的病理特征因病癥類型、個體差異而不同,獲取全面且具有代表性的特異性數據非常困難。采集此類數據不僅需要專門的醫療設備,還需在嚴格的臨床條件下,由專業醫務人員進行標注。高昂的時間經濟成本和嚴格的倫理與隱私保護要求,使得VHD特異性數據的獲取成為當前研究中的重大挑戰。未來應建立更加標準化和多樣化的數據收集體系。結合醫院和研究機構的資源,建立覆蓋不同年齡、性別和病癥的VHD數據集。
(2)VHD發展的多變性與動態性。VHD的進展過程復雜且動態,患者的癥狀可能隨時變化。所設計的模型不僅需要準確識別當前的癥狀,還必須追蹤癥狀的變化趨勢,預測潛在風險。未來可以結合能夠從醫療記錄、醫師報告中提取關鍵信息的LLM和可以結合圖像、信號等多模態信息,形成更全面的診斷支持的LVLM來提升綜合分析能力,持續完善長期監測系統。
(3)深度學習在臨床應用中的推廣挑戰。盡管基于深度學習的VHD診斷方法已取得顯著進展,但在推廣其應用于標準化流程和臨床指南方面仍面臨一些挑戰,未來需建立標準化的工作流程以確保深度學習技術的可信性。同時更新臨床指南并納入深度學習的最新研究成果,促使醫務人員對新技術的接受與應用。此外,開展相關培訓與教育項目,確保臨床醫務人員熟練運行深度學習工具,這對深度學習技術在VHD中的推廣至關重要。
總之,深度學習在VHD診斷中的應用具有無窮潛力,通過進一步提升數據獲取的標準化與多樣性,推動合成數據生成技術的應用,優化模型的實時監測與處理能力,并探索LLM在VHD風險預測中的潛力。這不僅有望為臨床應用提供更加精準和有效的解決方案,還將推動醫工交叉融合,開辟更廣闊的智能醫療新領域。
利益沖突:無。
作者貢獻:馬志明負責收集和分析文獻資料及論文初稿撰寫;徐洪洋、邱鵬負責分析和整理文獻資料以及論文修改;劉兵、姜良負責論文的總體構思并指導論文寫作;曹慧負責論文總體設計及修訂。
根據《中國心血管健康與疾病報告2023概要》[1],心血管疾病(cardiovascular disease,CVD)在我國城鄉居民疾病死亡構成比中占首位,每5例死亡病例就有2例死于CVD。估算我國CVD現患病人數3.3億,預估到2030年,將有
近年來,深度學習在VHD的輔助診斷中嶄露頭角。通過對醫療數據的分析處理,可以輔助醫師對患者的疾病情況進行精準識別。此外,深度學習還可實現早期和低成本的VHD檢測,能克服傳統檢測方式需要專業技能的缺點,為中低收入地區的VHD早期診斷提供一種可行的替代方案。
當前,輔助VHD進行診斷的深度學習技術已經有所應用,本文將從VHD檢測和VHD風險預測兩個方面,探討深度學習技術的最新應用進展,旨在為后續研究提供新思路。
1 心臟瓣膜病概述
VHD指原發或繼發病因引起的單個或多個瓣膜結構或功能異常致其狹窄或反流,使心臟前負荷或后負荷增加引發心室結構改變,最終導致心功能不全的心血管疾病[7]。左側VHD主要涉及二尖瓣和主動脈瓣的病理變化,其發病原理包括瓣膜結構改變和瓣膜功能障礙等[8]。每種類型的瓣膜病在病理機制、臨床表現上各有不同。最常見的主動脈瓣和二尖瓣疾病的病因、病理機制、癥狀與影響[9-12]見表1。
當前,檢測VHD的方式包括Echo[13]、心臟磁共振成像(cardiac magnetic resonance imaging,CMR)[14]、計算機斷層掃描(computed tomography,CT)[15]、心電圖(electrocardiogram,ECG)[16]、心音圖(phonocardiogram,PCG)[17]等多種手段。但對心血管醫學中關于人工智能、機器學習、深度學習的研究進行檢索我們發現,只有不到3%的研究應用上述方法于VHD檢測且多數集中在機器學習領域[18]。隨著心血管醫療越來越數字化,電子健康記錄(electronic health record,EHR)在臨床中被廣泛集成,數據的標準化加上計算性能的提高將有利于深度學習在該領域的蓬勃發展,以改善VHD的檢測和疾病風險預測情況。
2 深度學習在心臟瓣膜病輔助診斷中的應用
深度學習是一種利用多層神經網絡模擬人腦工作方式的機器學習方法,能夠自動提取特征并處理復雜數據[19]。深度學習于2017年開始被廣泛應用于醫學圖像處理、信號處理領域[20]并展現出卓越性能。僅在中國,VHD就影響了約3.8%的人口,高達11%~13%的75歲以上老人存在中重度瓣膜病,多數患者直到癥狀發作之后才會接受檢查,嚴重延緩早期檢測和治療的進度[21]。深度學習能夠實時分析心音、心電信號并能與Echo等臨床檢測方式進行結合,降低對專業醫師的依賴并提高診斷準確性,正逐漸改變VHD的檢測格局。
2.1 心電信號在心臟瓣膜病檢測中的應用
心電信號通過記錄心臟電活動反映VHD對整體心臟功能的影響。VHD通常會影響心臟的機械功能,這些變化會間接導致心臟的電活動發生異常,如心房顫動、左心室肥大等[22]。分析心電信號不僅能夠檢測心臟電活動的異常,還能輔助診斷VHD。如Elias等[23]使用從3個醫院獲取的
VHD往往表現為心臟機械功能的改變,ECG雖能檢測心律失常和電活動異常,但在早期病變中對心肌功能障礙的評估有限。且其檢測性能受個體差異影響,在復雜病變中的診斷準確性較低[29]。此外,ECG對VHD的檢測多數以機器學習為主,深度學習模型多數限于CNN,不完全適用于VHD檢測是阻礙ECG在此領域發展的關鍵問題。
2.2 心音信號在心臟瓣膜病檢測中的應用
為更有效地評估心臟泵血能力和心室機械問題,對VHD檢測的深度學習研究大多聚焦于心音信號,心音信號能夠直接捕捉心臟瓣膜關閉時的聲音變化,不同的VHD會產生特定的心音變化,這些特征可以幫助醫師做出初步診斷[30]。通過心音信號的時頻特征轉換,如梅爾頻譜(mel-frequency cepstral coefficients,MFCC)、短時傅里葉變換、小波變換等,網絡模型可以從心音中提取與瓣膜病相關的特征,從而實現自動檢測。
當前,該領域的研究大多集中在公開心音數據集yaseen21[31],包含AS、MS、MR、二尖瓣脫垂(mitral valve prolapse,MVP)和正常各200條數據,所有數據以8 kHz采樣并采用單通道WAV形式存儲,瓣膜病類型的多樣和數據的平衡是該數據集受到青睞的關鍵原因。圍繞該數據集,Al-Issa等[32]通過時間拉伸、時間移位和添加噪聲的數據增強方式來擴充樣本,訓練了一個CNN+長短期記憶網絡(long short-term memory,LSTM)的混合模型,CNN層提取局部時頻特征后輸入LSTM層以進一步處理信號的時間序列特征。經過十折交叉驗證的實驗結果表明,該模型對于上述五分類問題,達到了98.48%的準確率。進一步的研究表明,不需要對模型進行復雜混合,特征提取方式的改進也可以提升檢測性能。Torre-Cruz等[17]提出一種結合正交非負矩陣分解(orthogonal non-negative matrix factorization,ONMF)與CNN的新方法,ONMF能有效分解心音的時頻特征并減少特征冗余,增強模型對關鍵信息的捕捉能力。通過引入ONMF,使用GoogLeNet的準確率達到98%,展現了改進特征提取方式在VHD檢測中的潛力。上述研究檢測準確率雖然較高,但無法解釋模型的識別過程。為了解決“黑盒”問題,Bhardwaj等[33]使用敏感性圖和夢境圖兩種可視化技術對結果進行解釋。夢境圖的結果表明,出現橢圓形的紅黃通道圖像表明識別了與AS相關的特征、具有多個紅藍通道的圓形特征表示對MR的精準識別、生成的圖像以藍綠通道為主顯示了MS的不同模式、生成多條延長的藍色通道圖像則解釋了與MVP相關的特殊形態特征。可視化技術的應用增強了醫療人員對AI模型的信賴,為個性化治療方案的制定提供依據。
隨著Transformer[34]模型的發展,研究人員開始將注意力機制引入心音分析。Transformer的全局注意力機制使其能夠捕捉心音中的長程依賴關系并有效提取信號的全局特征。相比傳統的CNN和循環神經網絡,Transformer在處理序列數據時具有更高的靈活性和準確性。Abbas等[35]將Transformer與CNN相結合,提出了CVT VHD檢測模型。使用連續小波變換將心音轉換為時頻圖像,通過CVT提取局部和全局特征。該模型在五類VHD識別中達到了99%的準確率,顯著提高了檢測性能,并且在處理含噪聲心音時依然保持較高的魯棒性。為簡化特征選擇方式并保持檢測精準度,Jamil等[36]首次將vision transformer(ViT)引入到VHD檢測中并提出了3種框架:對于一維信號,提取MFCC和線性預測編碼系數(LPCC)特征;對于二維信號,使用連續小波變換提取二維時頻表示,以使用ResNet50、AlexNet、Inception v3提取各種特征;使用自然/生物啟發算法(NIA/BIA),如粒子群優化和遺傳算法[37],以高效選擇最重要的特征。所提框架無需對心音進行任何預處理(如分割、濾波、降噪等),ViT的性能超過了目前的SOTA模型。上述關于Transformer模型的實驗雖然已經取得了接近100%的五分類檢測準確率,但模型性能提升的同時極大地增加了計算復雜度和資源消耗,不利于部署到醫療條件相對落后的地區。為了解決實驗室成果過渡到臨床應用的難題,Makimoto等[38]的研究進一步提高了模型的可解釋性和可用性,開發了一個輕量級CNN模型并使用來自556例患者的3個聽診位置的
2.3 多模態數據融合在心臟瓣膜病檢測中的應用
VHD的檢測不僅僅局限于單一生理信號,還可以通過多模態數據融合來獲得更加全面的結果。隨著醫療數據多元化發展,越來越多的研究嘗試將ECG、PCG、Echo等多模態數據進行融合,以增強模型對不同病理特征的感知能力,提高診斷準確性。Lee等[39]首先提出了通過同步采集的心音和心電信號來檢測VHD的方法,利用心電信號中的R波峰值來標定心音中的S1和S2。這種同步方式能夠精確區分心音信號中的收縮期和舒張期,為心臟雜音檢測提供基礎。Shiraga等[40]也使用心音和心電信號進行特征融合來檢測嚴重AS、MR和左心室功能障礙。兩個實驗都通過CNN模型進行訓練,通過多模態特征融合,模型能夠更全面地捕捉心臟活動的各個維度,提升檢測性能。除了心音信號和心電信號的融合,研究[41]也提出Echo和ECG融合以檢測由AS引起的左心室肥厚,該研究使用經過濾除基線漂移和電源線干擾預處理的
2.4 其他方法在心臟瓣膜病檢測中的應用
隨著深度學習的不斷發展,其他模型如圖神經網絡(graph neural network,GNN)[43]和生成對抗網絡(generative adversarial network,GAN)[44]也展現出獨特的優勢和潛力。GNN能夠有效處理圖結構數據,在建模復雜生物網絡和病理關系方面具有顯著優勢。GAN則在數據增強和樣本生成方面展現出卓越的能力,能克服數據不足問題。如Ivantsits等[45]提出了一種基于GNN的幾何深度學習模型MV-GNN,通過三維經食管Echo數據生成連續的二尖瓣表面模型。結合CNN和GNN架構重建瓣膜網格,避免了傳統體素轉換誤差并支持時間連續的瓣膜運動分析。但模型依賴于預定義的拓撲網絡,可能無法準確重建復雜病變。為降低對網絡結構的適應性要求,Thomas等[46]使用圖卷積神經網絡(graph convolutional network,GCN)結合三維心臟網格重建實現對心臟結構的定位識別,使用合成的超聲數據進行訓練,在彌補臨床三維標注數據不足的同時還能完成結構定位和姿態估計。
雖然GNN和GCN在建模生物網絡結構方面展現顯著優勢,但在處理小樣本或缺少標注數據的問題上,GAN能通過生成多樣性和逼真度更高的合成數據有效提升在小樣本條件下的泛化能力。如Rayavarapu等[47]使用LSGAN和Cycle GAN進行ECG和PCG信號的生成以實現數據增強。Vinay等[48]使用多決策GAN生成并分類心音信號,結合雙向長短期記憶網絡(Bi-LSTM)捕獲時序特征,與Rayavarapu等[47]的研究類似,該研究采用的多決策GAN同樣生成逼真的合成數據來豐富數據量,兩者均顯示了GAN在醫學數據生成和疾病檢測中的潛力。此外,SCG[28,49]、陀螺心動圖(gyrocardiogram,GCG)[50]等非侵入性檢測技術在VHD檢測中也展現了較高的可靠性,在不依賴傳統ECG的情況下,可以通過多維振動信號捕獲心臟功能信息,為VHD的連續、無創監測提供新途徑。VHD檢測方法總結見表2。
3 心臟瓣膜病的風險預測
心血管疾病的發展過程復雜且動態,患者的癥狀可能隨時發生變化。因此,模型不僅需要準確識別當前癥狀,還需具備持續監測能力,追蹤癥狀的變化趨勢并預測潛在風險,以便及時調整治療方案[51]。風險預測模型是使用患者風險因素來估計醫療保健結果概率的方程。比較出名的風險預測模型有肺栓塞的Well標準[52]和識別危重患者膿毒癥高風險死亡率的SOFA評分[53]。近年來,預測嚴重AS患者未來病情的發展情況逐漸受到關注,因為在不經歷瓣膜置換的情況下,該疾病1年內的死亡率達到40%~50%。Namasivayam等[54]分析了
傳統風險預測模型雖然表現出良好的效果,但通常依賴于手動選擇特征,此外,傳統模型只能處理結構化數據,缺乏從非結構化文本數據中提取有效特征的能力,如醫師的診斷筆記、住院記錄等無法直接用于訓練。隨著大語言模型(large language model,LLM)和大型視覺語言模型(large vision language model,LVLM)的推出,這一格局發生了改變,代表模型是由OpenAI開發的GPT[55]和Google開發的BERT[56]。這些LLM通常由數十億甚至上百億個參數組成,能夠理解和生成自然語言文本,執行各種語言相關任務。可以利用其處理序列數據的能力,提高心音狀態識別模型的整體性能并一定程度解決困擾深度學習的“黑盒”問題,提高模型可解釋性,增加臨床應用中的可信度[57]。
對VHD進行風險預測的LLM應用還在探索階段,但已經有研究將LLM用于心血管疾病的風險預測。如Vaid等[58]利用一個開源LLM(LLaMA-2 70B模型)來提取和總結患者的Echo歷史數據以簡化數據分析過程并提高臨床決策效率,分析了432個報告并生成了100個問題-答案對。其中時間關系的正確回答率為83%,病情嚴重程度評估的正確回答率為93%,對干預措施的識別準確率為84%,診斷檢索的準確率為100%,顯示出其在提升臨床決策和研究效率方面的潛力。Kwon等[59]認為LLM是全能臨床推理者,并提出了一個即時生成的推理感知診斷框架。為診斷心臟疾病和討論藥物治療方案,Novak等[60]評估了3種LLM,即Google Bard、GPT-3.5 Turbo和GPT-4.0在心臟病領域的潛在應用。結果表明GPT-4.0在所有測試場景中表現最佳,尤其是在復雜的臨床決策中,能夠準確理解醫學術語并提供符合當前臨床指南的答案。在討論藥物治療方案時,GPT-4.0能夠依據患者的低密度脂蛋白膽固醇水平推薦合理的降脂藥物,并遵守2018 AHA/ACC指南。而Google Bard則錯誤地推薦了不適當的藥物且對藥物相互作用的理解存在誤差。雖然LLM展示了變革醫學的潛力,但也存在一定的挑戰。一篇發表在The Lancet的文章[61]客觀評估了LLM的局限性,如存在社會偏見和無法保證數據的隱私與安全問題等,呼吁LLM在進入臨床應用前,需進行嚴格的臨床驗證,規避潛在風險。全診醫療GPT框架如圖1所示。
圖1
全診醫療GPT
4 總結與展望
將深度學習引入VHD檢測中,不僅極大提高了醫療診斷的精確度,還有效避免了因醫師主觀因素可能引起的誤診風險。在輔助醫師進行術前診斷及臨床手術治療中發揮了不可替代的作用。盡管基于深度學習的VHD診斷方法取得了有效進展,但仍面臨諸多挑戰:
(1)VHD特異性數據的獲取。VHD患者的病理特征因病癥類型、個體差異而不同,獲取全面且具有代表性的特異性數據非常困難。采集此類數據不僅需要專門的醫療設備,還需在嚴格的臨床條件下,由專業醫務人員進行標注。高昂的時間經濟成本和嚴格的倫理與隱私保護要求,使得VHD特異性數據的獲取成為當前研究中的重大挑戰。未來應建立更加標準化和多樣化的數據收集體系。結合醫院和研究機構的資源,建立覆蓋不同年齡、性別和病癥的VHD數據集。
(2)VHD發展的多變性與動態性。VHD的進展過程復雜且動態,患者的癥狀可能隨時變化。所設計的模型不僅需要準確識別當前的癥狀,還必須追蹤癥狀的變化趨勢,預測潛在風險。未來可以結合能夠從醫療記錄、醫師報告中提取關鍵信息的LLM和可以結合圖像、信號等多模態信息,形成更全面的診斷支持的LVLM來提升綜合分析能力,持續完善長期監測系統。
(3)深度學習在臨床應用中的推廣挑戰。盡管基于深度學習的VHD診斷方法已取得顯著進展,但在推廣其應用于標準化流程和臨床指南方面仍面臨一些挑戰,未來需建立標準化的工作流程以確保深度學習技術的可信性。同時更新臨床指南并納入深度學習的最新研究成果,促使醫務人員對新技術的接受與應用。此外,開展相關培訓與教育項目,確保臨床醫務人員熟練運行深度學習工具,這對深度學習技術在VHD中的推廣至關重要。
總之,深度學習在VHD診斷中的應用具有無窮潛力,通過進一步提升數據獲取的標準化與多樣性,推動合成數據生成技術的應用,優化模型的實時監測與處理能力,并探索LLM在VHD風險預測中的潛力。這不僅有望為臨床應用提供更加精準和有效的解決方案,還將推動醫工交叉融合,開辟更廣闊的智能醫療新領域。
利益沖突:無。
作者貢獻:馬志明負責收集和分析文獻資料及論文初稿撰寫;徐洪洋、邱鵬負責分析和整理文獻資料以及論文修改;劉兵、姜良負責論文的總體構思并指導論文寫作;曹慧負責論文總體設計及修訂。