引用本文: 田園, 林志浩, 李瑞, 汪貫龍, 李紅霞, 何磊. 基于組合優化的機器學習模型預測胃癌術后感染性并發癥的診斷性研究. 中國循證醫學雜志, 2024, 24(9): 993-1003. doi: 10.7507/1672-2531.202310069 復制
版權信息: ?四川大學華西醫院華西期刊社《中國循證醫學雜志》版權所有,未經授權不得轉載、改編
目前全球范圍內胃癌的發病率及死亡率在各類惡性腫瘤中排名高居第五位及第四位[1]。盡早行根治性手術是治療胃癌最主要的方法[2]。由于手術切除的范圍廣及時間長、機體免疫力降低、淋巴結清掃難度大等因素常導致胃癌術后感染性并發癥發生。研究表明術后感染性并發癥是胃癌患者的獨立預后因素[3],由于長期的炎癥會影響宿主的免疫抑制,導致微轉移灶的增長以及其他原因從而導致死亡[4]。同時術后感染會延長患者的住院時間,推遲輔助治療開始時機,嚴重影響手術效果。目前感染通常根據患者的臨床癥狀來懷疑,常導致診斷延遲。而常規的影像學檢查性價比較低,且有輻射的缺點。因此有必要確定特異性的生物標志物進行早期診斷,以便及時干預治療,改善患者的預后。研究表明持續的炎癥環境會促進癌細胞的增殖、侵襲和腫瘤血管生成等[5]。因此近年來,越來越多的研究集中在術前預后營養指數(prognostic nutritional index,PNI)、外周血中性粒細胞與外周血淋巴細胞比值(peripheral blood neutrophil/peripheral blood lymphocyte,NLR)、淋巴細胞絕對數與C-反應蛋白比值(lymphocyte/C-reactive protein,LCR)等綜合性炎癥指標作為預后生物標志物[6-8],他們計算簡單方便更易進行臨床指導。有研究表明以上指標有作為術后感染性疾病的生物標志物的潛力,甚至比單獨的C-反應蛋白(C-reactive protein,CRP)和白細胞表現出更好的預測能力[9,10]。
目前隨著人工智能的發展越來越多的應用于醫學,機器學習作為一種根據給定數據自動構建的數學人工智能算法,能夠捕捉大數據中復雜的非線性關系,更深入的挖掘臨床數據中隱藏的關系。研究表明,機器學習相比傳統的統計方法可以顯著提高疾病發生和術后預后預測的準確性[11]。但是大部分現有研究中的機器學習常常無法避免過擬合的問題,造成模型預測精度較低。本文提出一種組合預測方法,基于適度貪心算法(greedy algorithm,GA)改進優化XGBoost算法,以期改善過擬合問題提高預測模型精度。因此,本研究旨在探究以上炎癥指標是否是胃癌術后感染早期診斷的可靠生物標志物,并利用傳統與改進的機器學習構建一個準確性較高的模型來評估胃癌術后感染的風險。
1 資料和方法
1.1 資料收集
回顧性收集2018年5月至2023年4月安徽醫科大學第三附屬醫院胃腸外科為胃惡性腫瘤,行根治性手術的患者為研究對象。納入標準:① 術后病理學檢查診斷為原發性胃癌;② 美國麻醉師協會(American Society of Aneshesiologists,ASA)手術危險性分級1~3級;③ 術后病理分期為Ⅰ、Ⅱ和Ⅲ期。排除標準:① 術前合并急性、慢性感染性疾病、長期服用免疫抑制劑者;② 因出血或穿孔行急癥手術;③ 術前接受過放療、化療或免疫治療等輔助治療或伴遠端轉移;④ 合并其他惡性腫瘤。收集符合研究標準的胃癌根治性手術患者的基本信息:性別、年齡、體重指數、ASA分級、既往共病(高血壓、貧血、慢性肺部疾病、糖尿病)、手術方式、圍手術期輸血、手術范圍、聯合切除;實驗室檢查資料:術前7天內的淋巴細胞、中性粒細胞、CRP、血小板、單核細胞、癌胚抗原、前白蛋白、膽固醇、血清白蛋白、白細胞;腫瘤信息:術前TNM分期、細胞分化、腫瘤大小;手術信息:術中失血量、手術時間。本研究通過安徽醫科大學第三附屬醫院倫理委員會批準(批準號:2023-45號),本研究中使用數據不包含個人身份信息。
1.2 診斷標準
術后感染并發癥定義為:在術后30天內發生的手術導致的相關感染,包括:肺部感染、切口感染、吻合口漏、腹腔膿腫、泌尿系感染、十二指腸殘端瘺等,感染的診斷標準參照相應指南[12]。簡述如下:① 切口感染:皮膚和皮下組織術后30天內的感染,手術切口出現紅、腫、熱、痛,局部切口引流出血性或膿性的滲出物;② 吻合口瘺:臨床出現壓痛、反跳痛、肌緊張等腹膜炎體征,上消化道造影可見造影劑外溢,彩超提示吻合口周圍出現氣體、液體;③ 腹腔膿腫:術后30天內出現腹部癥狀,表現為腹痛、持續發熱等癥狀,經穿刺或影像學檢查證實,經手術引流或抗感染治療后好轉;④ 泌尿系感染:術后30天內出現的膀胱炎和尿道炎,臨床出現尿頻、尿急、尿痛等膀胱刺激癥狀,尿常規檢查可有膿尿和血尿,尿液培養出致病菌;⑤ 肺部感染:患者體溫大于38.5℃,白細胞計數升高,伴隨呼吸道癥狀或痰液培養陽性,在肺部聞及干、濕啰音,胸片提示新的浸潤性病變;⑥ 十二指腸殘端瘺表現為上腹部壓痛及肌緊張,引流管引流出渾濁樣或膽汁樣液體,并經影像學檢查證實。采用Clavien-Dindo標準評估其嚴重程度并以此進行分級,將Ⅱ級及以上的感染性并發癥作為本研究的感染性并發癥組。在同一名患者發生兩種或以上不同感染性并發癥時,采用更高級別的并發癥。并以此將納入患者分為感染性并發癥組及無感染性并發癥組。
1.3 模型構建
1.3.1 傳統機器學習模型構建
本文利用python 3.9構建各種機器學習模型:linear regression、random forest、支持向量機(support vector machine,SVM)、梯度反向傳播(back propagation,BP)、LGBM、XGBoost,預測胃癌術后感染性并發癥的發生情況。除XGBoost外其余5種模型通過python 3.9安裝scikit-learn包構建。將患者的完整數據按照分層隨機化分組法分為70%訓練集和30%驗證集。訓練集數據用于預測模型的開發,驗證集數據用于驗證模型的性能。通過受試者工作特征(receiver operating characteristic,ROC)曲線下面積(area under curve,AUC)、準確率、召回率、F1分數、精確率來評估模型性能。
1.3.2 組合優化機器學習模型構建
XGBoost模型使用中面臨兩個問題:① 模型進行預測時調參較多,調參過程繁瑣,最優參數的選取難;② 模型應用gradient boosting思想,存在過擬合風險。因此本文采用GA來進行調參;然而使用GA算法當上一次迭代結果直接影響下一次迭代結果且出現謬誤時,會對最終結果造成較大誤差。故本文提出一種適度貪心(modified greedy algorithm,MGA)算法來進行歸正。通過約束貪心幅度,避免過度貪心而導致誤差累積,造成最終結果誤差較大的情況。最終得到最優結果,并引入加權集成學習的方法來增加模型穩健性。
本文采用MGA算法對參數進行分組后分步調優,并且每次并不是只依賴于最優的參數子集,而是選取若干個最優的參數子集,主要調整XGBoost中的max_depth、min_child_weight、gamma、subsample、colsample_bytree、reg_alpha、reg_lambda參數。見表1。參數調整的取值范圍見表2。
基于GA思想,本文將XGBoost的調參過程分為6個步驟,在每一步調參后取得的局部最優參數條件下,再對其他參數調優;以此類推,直至調整完所有參數。
盡管XGBoost表現一直很優越,但由于boosting算法的思想是追求“低偏差”而接受“高偏差”的特點,所以如果用單一的XGBoost將在建模上表現不好。為了避免因“數據分布不一致”“數據樣本量小”和過擬合的風險較大的問題。本文利用XGBoost的集成來增加模型的穩健性。在調參的過程中采用不是僅僅選取最優的一組參數,而是選取較優的幾組參數模型。調參步驟是:① 先調整max_depth和min_child_weight兩組參數,選擇得分最優的2組參數;② 其次再調整gamma參數,保留最優的2組數據;③ 然后調整subsample和colsample_bytree這兩組參數,選擇最優的2組數據;④ 接著對兩組正則系數reg_alpha,reg_lambda進行參數調整,選取最優一組數據;⑤ 因此現在共有2×2×2×1=8組數據;⑥ 調整learning_rate和num_boost_round的參數,選取最優的一組參數。
將調參過程隨機分為不同的幾個步驟,并且在每一次的步驟中調整一個或者兩個參數,例如上面的六步調整可以作為一種步驟組:① max_depth;② min_child_weight;③ gamma;④ subsample,colsample_bytree;⑤ reg_alpha,reg_lambda;⑥ learning_rate,num_boost_round。綜上所述,最終本文得到共8組最靠前的XGBoost參數模型見表3。
通過以上方法調參后得到的8組XGBoost參數模型,根據調參時參數的最優和次優進行比較排序從而加權集成學習。最優的分配權重2/3,次優的分配權重1/3。迭代次數設置為500次。故所獲得的8組參數模型比重分別為:0.296、0.148、0.148、0.074、0.148、0.074、0.074、0.038。
因此最終MGA-XGBoost模型為:Model=0.296×model 1+0.148×model 2+0.148×model 3+0.074×model 4+0.148×model 5+0.074×model 6+0.074×model 7+0.038×model 8。
1.4 統計分析
采用SPSS 24.0軟件對數據進行處理與特征分析,通過ROC計算NLR、外周血血小板與外周血淋巴細胞比值(peripheral blood platelet/peripheral blood lymphocyte,PLR)、PNI、LCR及外周血淋巴細胞與單核細胞比值(peripheral blood lymphocyte/peripheral monocytes,LMR)的最佳截斷值,見表4。在單因素分析中,連續變量[體重指數、手術時間、術中失血量、術前白細胞、術前中性粒細胞、術前淋巴細胞、術前CRP、癌胚抗原(carcinoembryonic antigen,CEA)、術前白蛋白、術前前白蛋白、術前膽固醇、腫瘤大小]以 ±s表示,并使用U檢驗進行分析,以評估感染組與非感染組之間的顯著性水平。單因素分析中的計數資料(性別、年齡、ASA分級、高血壓、糖尿病、慢性肺部疾病、貧血、手術方式、手術范圍、圍手術期輸血、聯合切除、細胞分化、分期、NLR、PLR、PNI、LCR、LMR)以病例數表示,組間采用χ2檢驗。根據訓練集的均值和標準差對連續變量進行歸一化。分類變量被編碼為二分類變量,1表示有事件,0表示沒有事件;性別也被編碼,1代表男性,0代表女性。P<0.05為差異有統計學意義。
±s表示,并使用U檢驗進行分析,以評估感染組與非感染組之間的顯著性水平。單因素分析中的計數資料(性別、年齡、ASA分級、高血壓、糖尿病、慢性肺部疾病、貧血、手術方式、手術范圍、圍手術期輸血、聯合切除、細胞分化、分期、NLR、PLR、PNI、LCR、LMR)以病例數表示,組間采用χ2檢驗。根據訓練集的均值和標準差對連續變量進行歸一化。分類變量被編碼為二分類變量,1表示有事件,0表示沒有事件;性別也被編碼,1代表男性,0代表女性。P<0.05為差異有統計學意義。
2 結果
2.1 患者基本特征
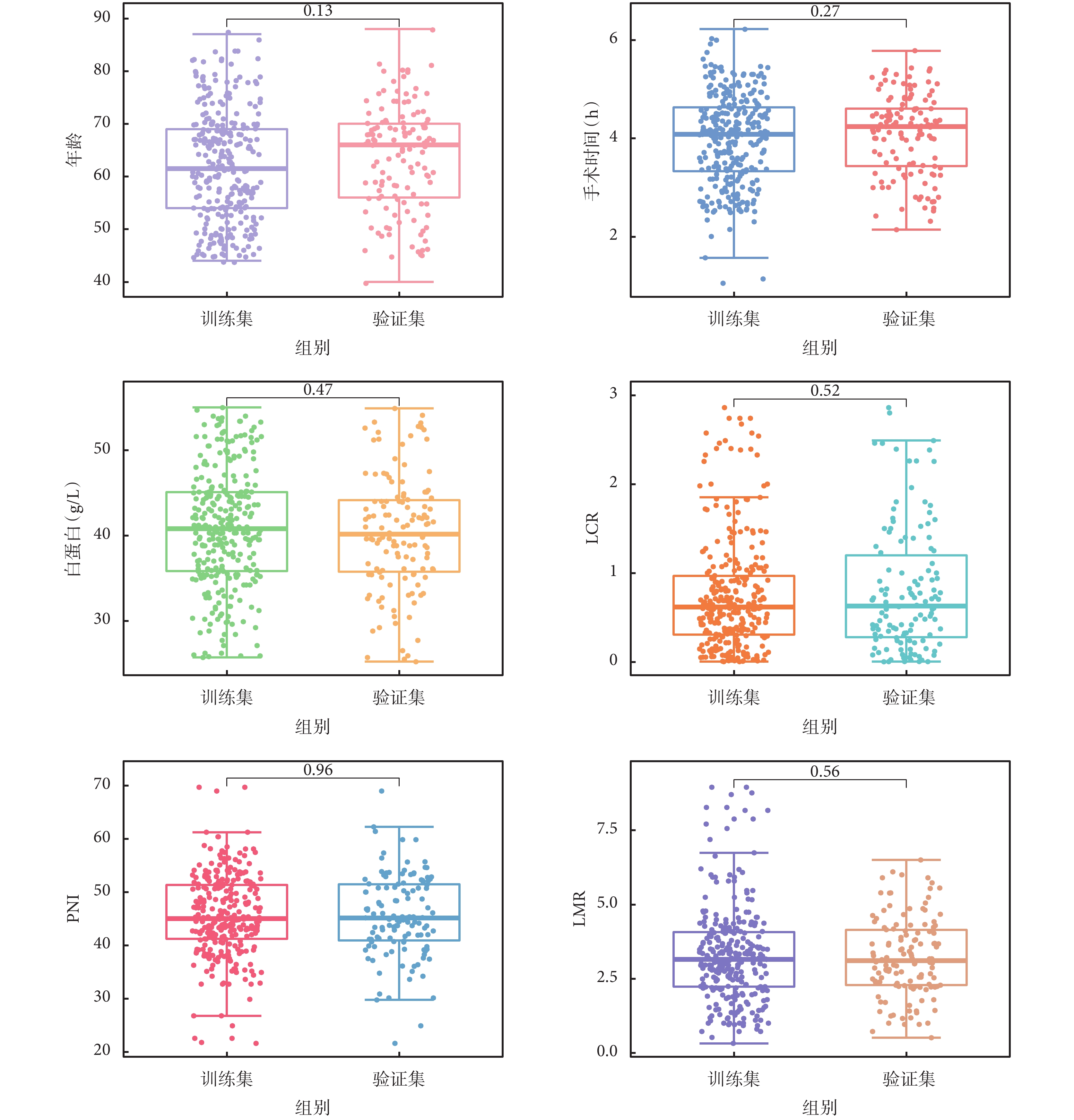
2018年5月至2023年4月期間有452例患者在我院胃腸外科行胃癌根治術。根據納入與排除標準,最終納入420例患者,其中男性172例(41%);女性248例(59%);年齡≥65歲237例(56%);<65歲183例(44%);納入的420例患者中術后感染性并發癥共84例,發生率20%。分層隨機化分組后訓練組占70%(n=294),測試組占30%(n=126)。為了更好地了解模型的數據特征,將患者依據訓練集和驗證集分為感染組和非感染兩組。其中主要指標術前LCR、PNI、LMR、年齡、手術時間、術前白蛋白數據分布情況見圖1。差異無統計學意義(P>0.05)。
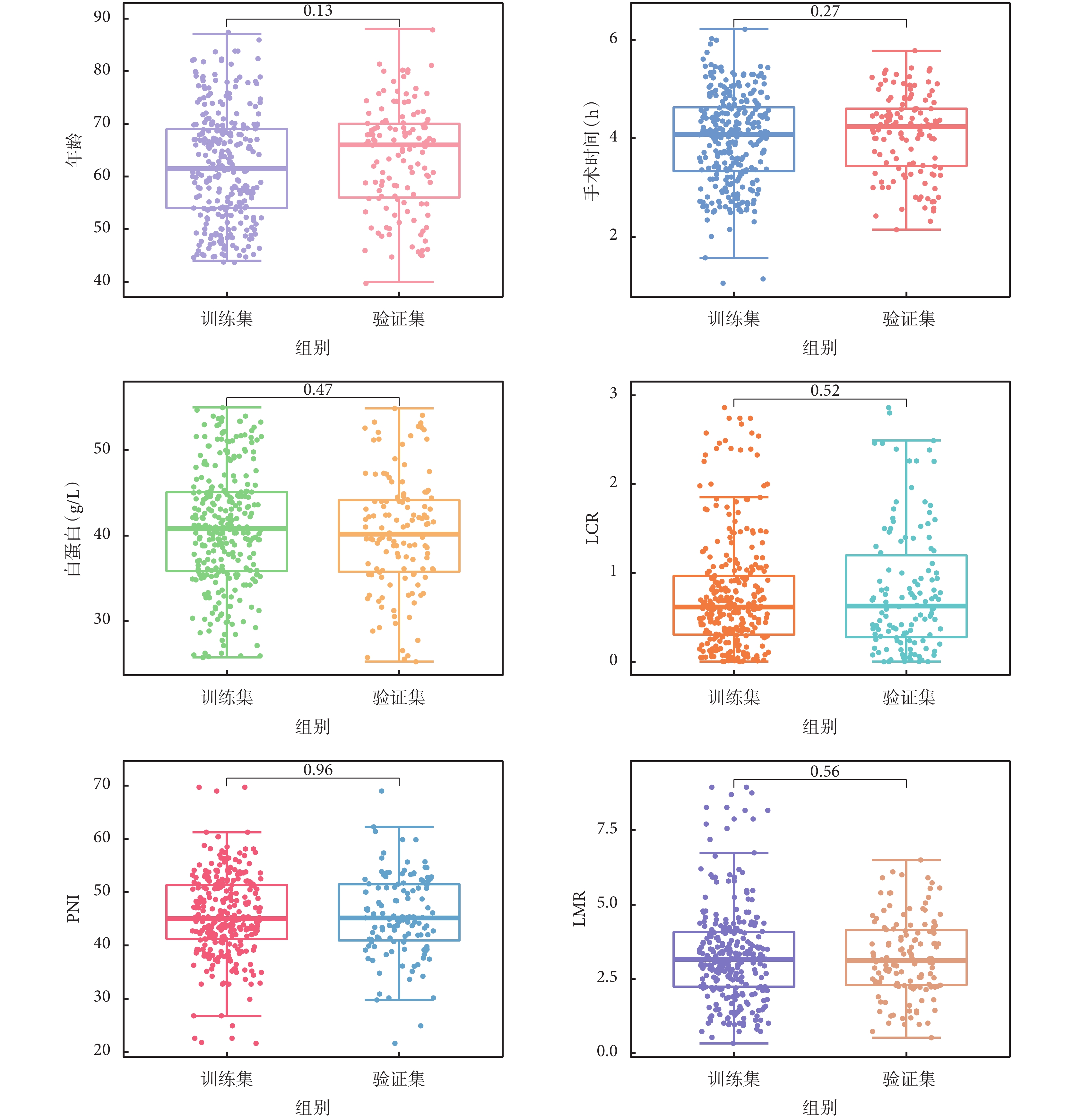 圖1
患者主要指標數據分布情況
圖1
患者主要指標數據分布情況
2.2 胃癌術后感染性并發癥的單因素分析結果
單因素分析結果顯示:年齡、手術時間、糖尿病、手術切除范圍、聯合切除、分期、術前白蛋白、圍手術期輸血、術前PNI、LCR及LMR等方面差異有統計學意義(P<0.05),見表5。
2.3 機器學習模型效能預測
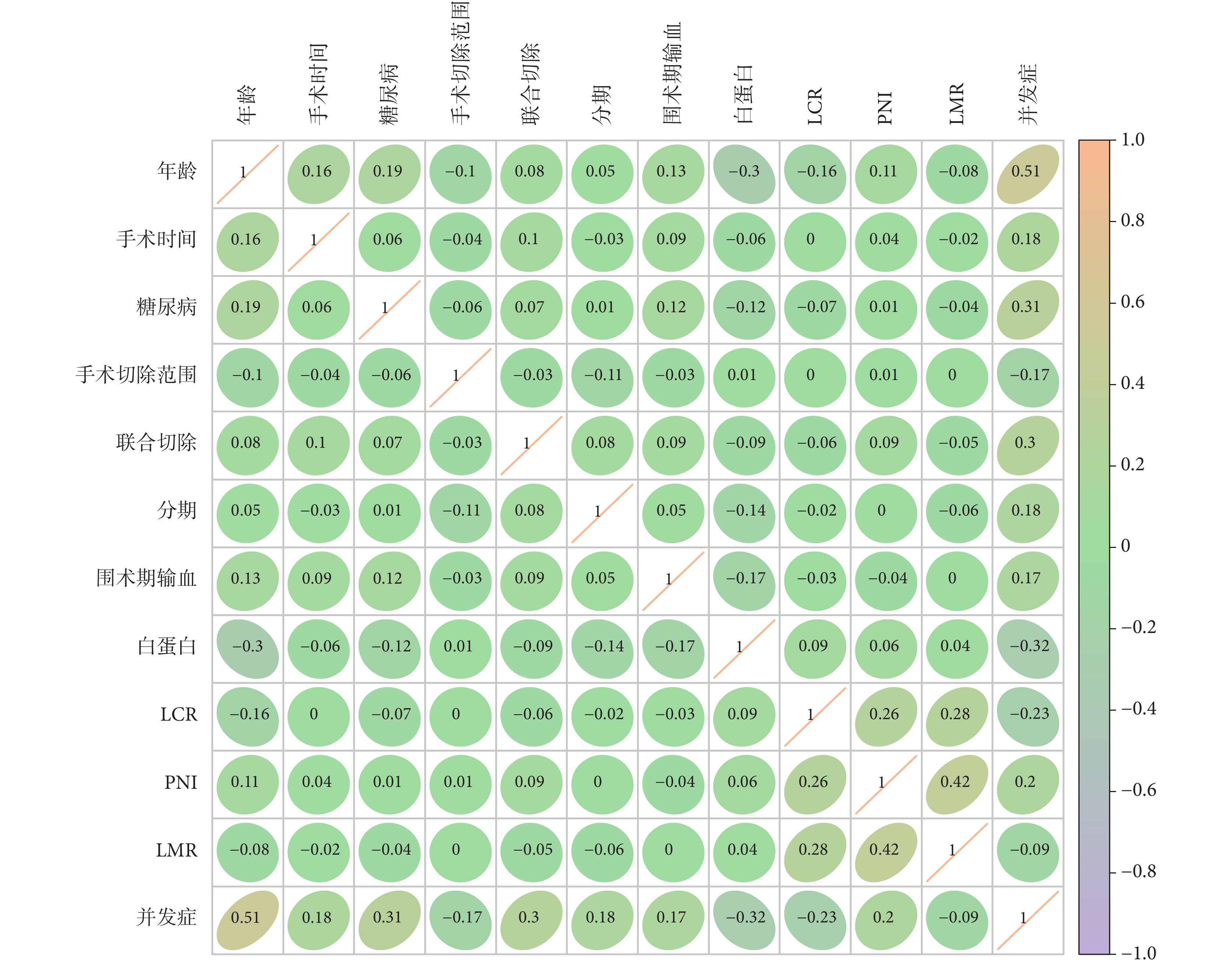
相關性分析展示了年齡、手術時間、糖尿病、手術切除范圍、聯合切除、分期、術前白蛋白、圍手術期輸血、術前PNI、LCR及LMR之間的關聯性,同時展示術后感染性并發癥與各個預測因素之間的關系。其中術后感染性并發癥與年齡(0.51)、糖尿病(0.31)表現出強關聯性,與LMR、LCR、術前白蛋白以及手術切除范圍呈現出負相關。此外PNI和LMR(0.42)之間具有相關性。見圖2。
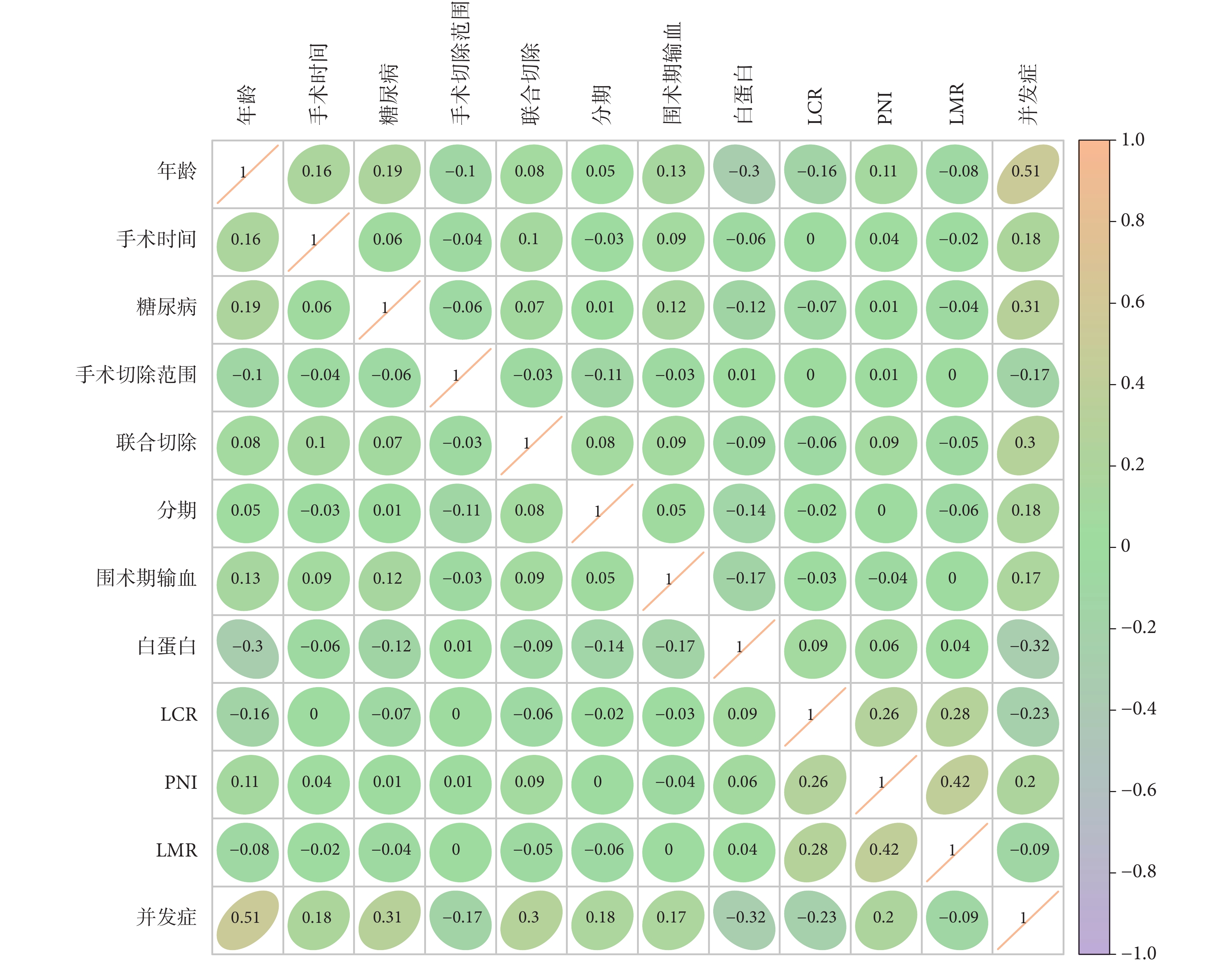 圖2
術后感染并發癥風險之間的相關性分析
圖2
術后感染并發癥風險之間的相關性分析
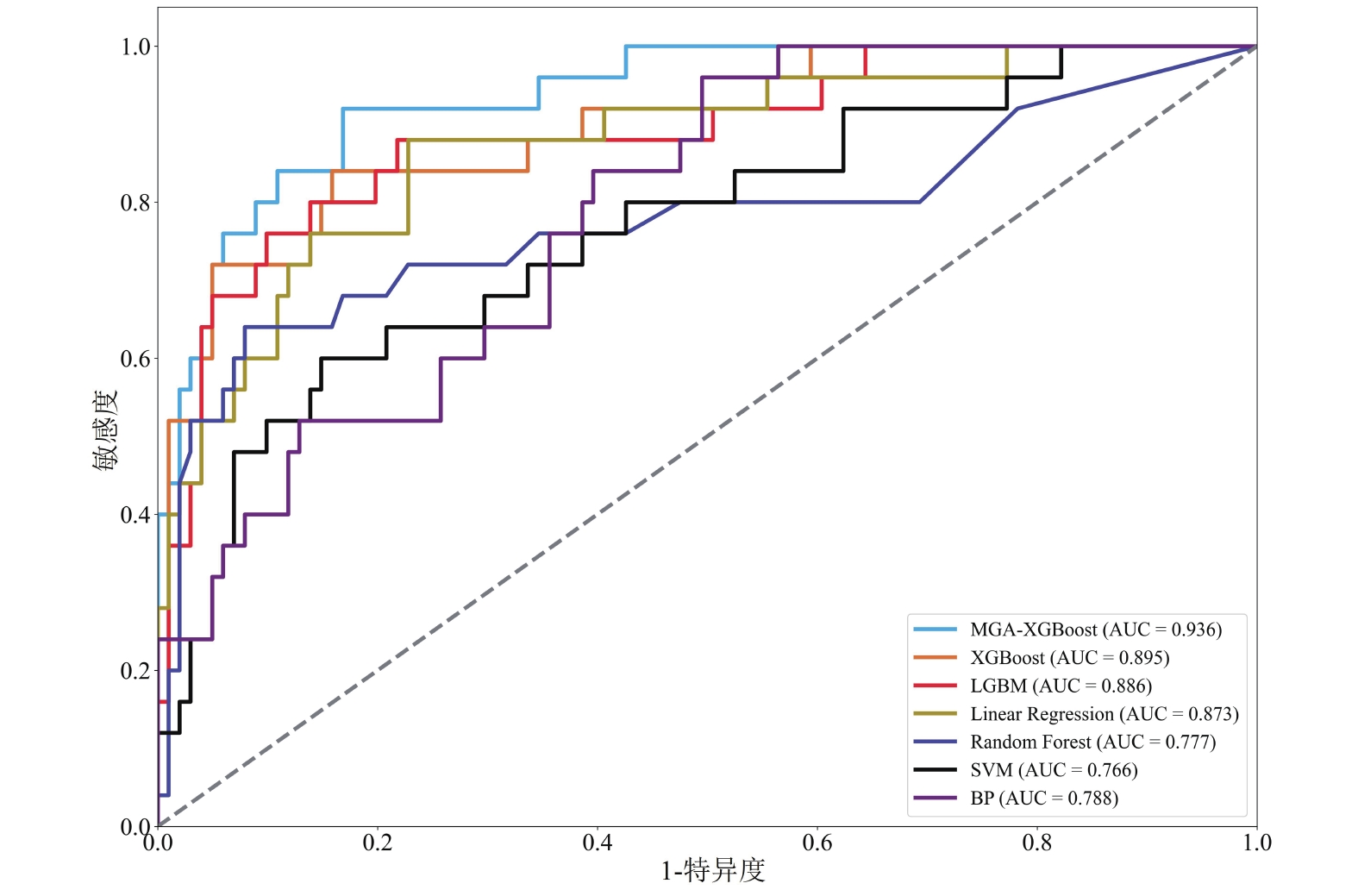
圖3展示了linear regression、random forest、SVM、BP、LGBM、XGBoost及改進后的MGA-XGBoost七個機器學習模型對胃癌術后感染性并發癥的預測性能。結果表明MGA-XGBoost預測模型的AUC值最高(0.936),random forest、SVM和BP均表現出一般的預測能力(AUC范圍為0.76~0.79)。
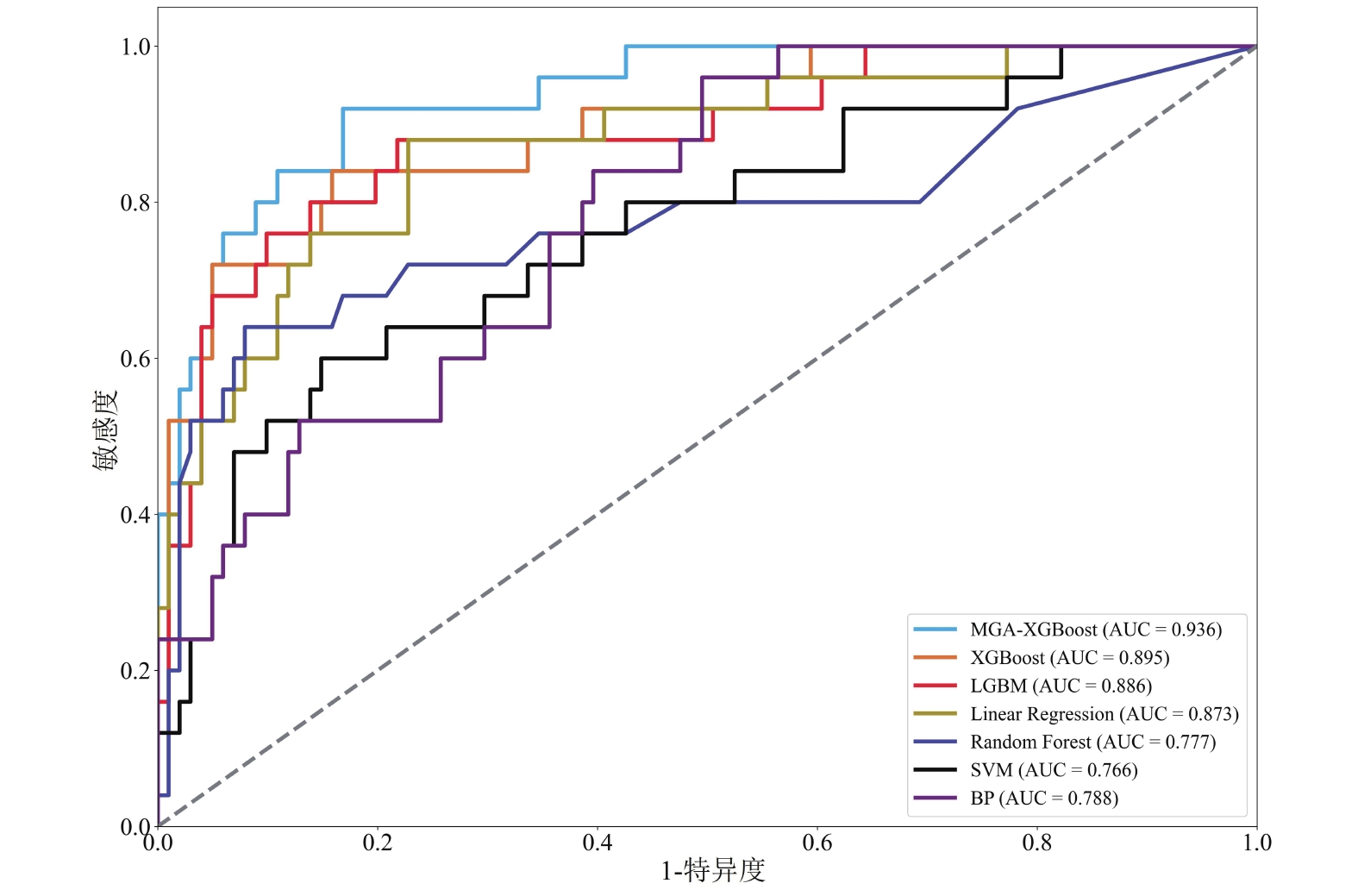 圖3
術后感染并發癥預測模型的ROC曲線
圖3
術后感染并發癥預測模型的ROC曲線
除了AUC外,本文還引入了準確率、召回率、F1分數、精確率來評估各種預測模型性能,見表6。可以看出MGA-XGBoost(準確率為0.889,精確率為0.79)、XGBoost(準確率為0.881,精確率為0.75)、LGBM(準確率為0.881,精確率為0.778)都表現出較好的精確率和準確率。BP的召回率(0.48)、F1分數(0.522)、精確率(0.571)均不理想。
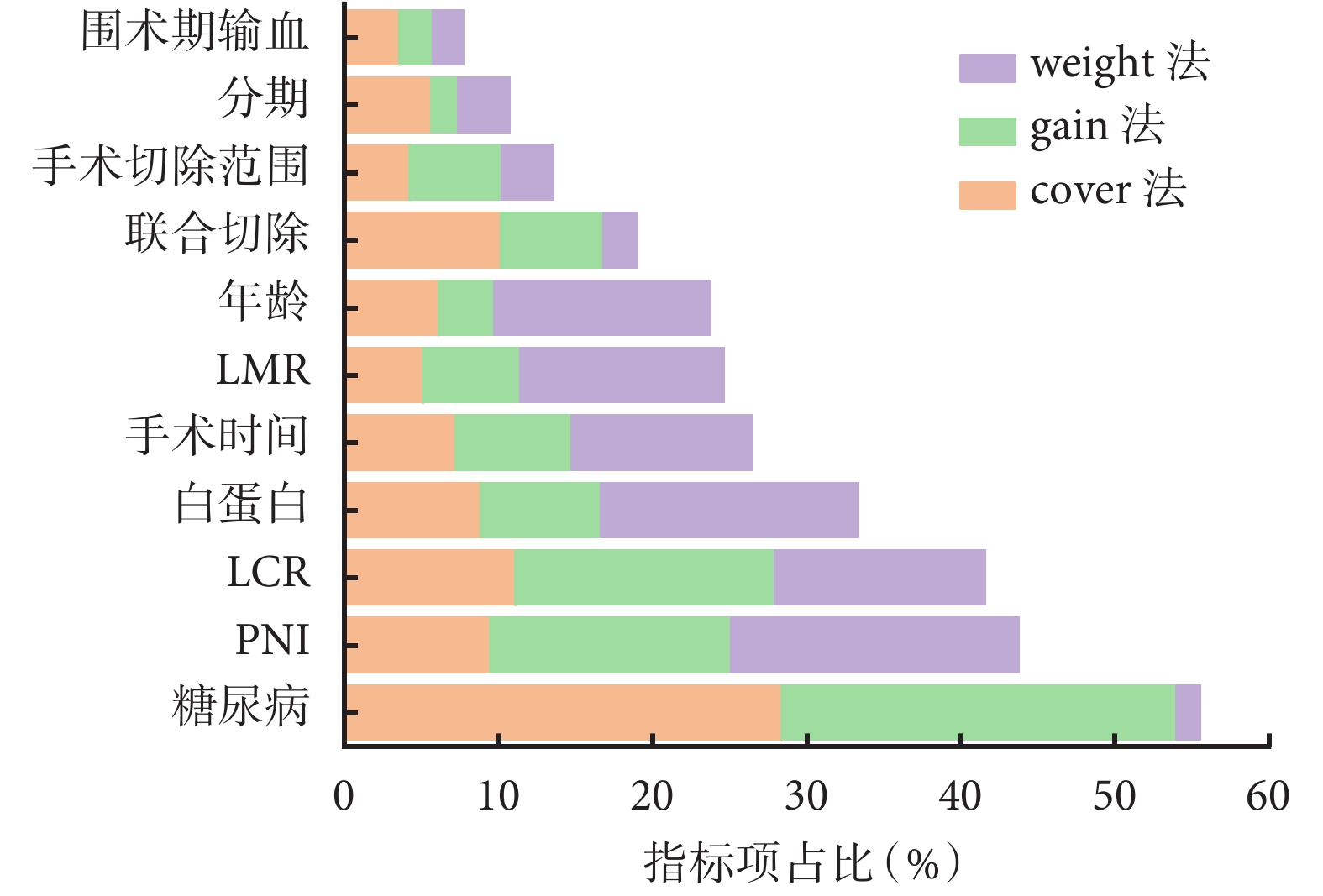
同時本研究對準確性最高的MGA-XGBoost預測模型內部特征重要性進行可視化顯示,結果見圖4。糖尿病、PNI和LCR分別排名第一、第二和第三。結合與術后感染性并發癥的相關性分析以及其在MGA-XGBoost算法中重要性分析的結果,將糖尿病和PNI視為重要的預測因素。
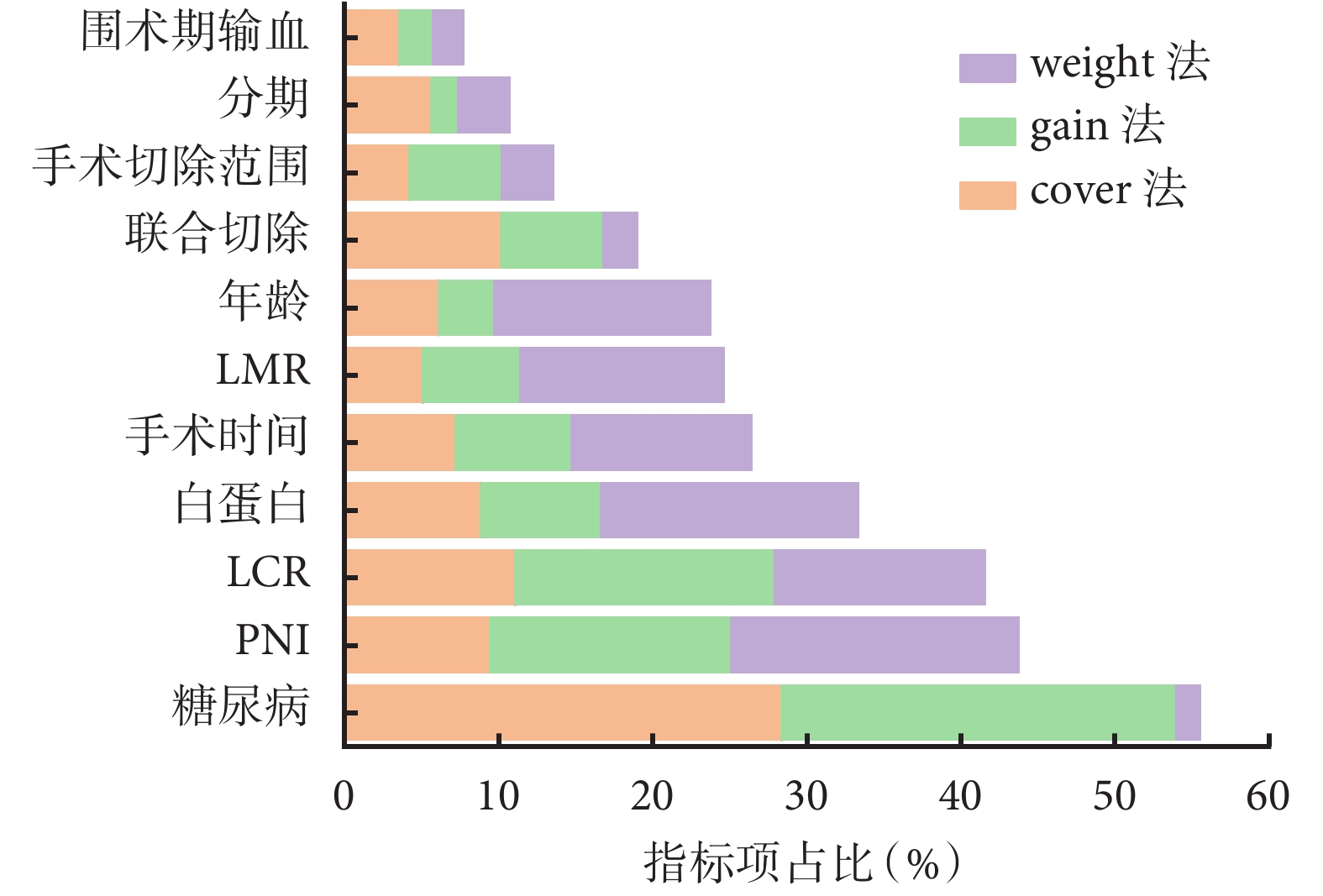 圖4
MGA-XGBoost模型特征重要性分析
圖4
MGA-XGBoost模型特征重要性分析
3 討論
目前機器學習在外科領域的研究中仍處于初級階段,但過往的研究表明其在風險預測方面有巨大潛力[13]。不同的研究之間存在著較大的異質性,主要表現為不同模型的選擇及樣本量的差異。目前存在著成千上萬的機器學習算法,對待不同的問題采用哪種算法最合適是需要深思熟慮的。因此本研究比較了六種常規機器學習算法,其中XGBoost的表現最優,AUC值為0.895。XGBoost是通過迭代構建、測試和調整一系列決策模型以校正結果,最終產生針對分類任務優化的決策樹算法[14]。因此在處理結構化數據和非結構化數據方面表現出色,通常可以獲得比其他算法更高的準確性。研究者為了開發機器學習模型通常會使用大量的樣本進行訓練。如,Tey等[15]的研究包括21 892多名患者和17個不同的變量。在他們的研究中,人工神經網絡在預測肺炎患者14天再次入院的早期檢測方面優于卷積神經網絡。然而,Ma等[16]利用XGBoost成功構建急性呼吸衰竭的預測模型中僅納入312名患者,與本研究樣本量類似。目前不同研究中的樣本量從73例[17]到111 888例[18]不等,也表明樣本量不是成功的機器學習模型的唯一因素。但是數據不足及模型復雜度過高,常常會導致機器學習中最常見的過擬合問題。因此針對這個問題本文進行組合優化。在本研究中,改進過的MGA-XGBoost在感染性術后并發癥風險預測方面表現最好。與其他六個模型相比, AUC、準確率和召回率在測試數據集中最高,對預測胃癌患者的術后感染性并發癥展現出巨大的優越性。
本研究通過單因素回歸分析的方法探索了胃癌根治術后感染性并發癥的危險因素,包括:年齡、手術時間、糖尿病、手術切除范圍、聯合切除、分期、術前白蛋白、圍手術期輸血、術前PNI、LCR及LMR。以上危險因素都在既往不同文獻中報道過與術后感染性并發癥有關[19,20]。Kunisaki等[21]研究顯示,術中聯合臟器切除是胃癌根治術后發生腹腔感染的影響因素,可能由于聯合臟器切除擴大了手術切除范圍,延長了手術時間,從而發生術后感染的風險增大。本研究中手術時間也是術后感染的獨立危險因素,手術時間越長則反映了手術的復雜性,不僅會導致增加切口暴露的污染風險,同時對患者造成的創傷也會增大[22]。本研究的創新在于納入更多以往模型構建研究中未包括的綜合性炎癥指標,如PNI、LCR、LMR。此外術前NLR、PLR在本研究中都不是胃癌術后感染的獨立風險因素。
雖然XGBoost、LGBM和隨機森林等復雜算法在預測建模中展現出強大的性能,但它們是基于“黑盒”設計的,不透明性使得其很難在臨床環境中解釋和應用。其次臨床工作中大部分醫生都能識別出導致術后并發癥的因素,但難以判斷如何優先考慮這些特征。因此本研究探索了MGA-XGBoost預測模型通過結構分數的增益情況計算出選擇特征作為分割點,并通過weight、gain、cover聯合判斷重要性。這種方法改進了既往大部分研究發布的不透明的機器學習模型,同時我們還提出了簡潔實用的臨床建議。在本研究中排名前三的主要危險因素包括:糖尿病、PNI和LCR,提示醫生在臨床工作中優先對這三個因素給予重點關注。然而值得注意的是,在本研究的相關性分析中LCR與術后感染性并發癥呈負相關,表明在常規分析中往往可能會遺漏某些重要因素。
本研究結果顯示,術前合并糖尿病的患者術后發生感染性并發癥的風險顯著高于無糖尿病史的患者。罹患糖尿病的患者固有免疫和獲得性免疫功能均不同程度受損,對病原體的侵襲抵抗能力不足[23]。同時合并糖尿病的患者手術應激反應更明顯,劇烈的應激反應會使血糖迅速升高且不易控制[24]。有研究表明糖尿病并不是術后感染的絕對危險因素,術后血糖控制不良才是引起術后感染的高危險因素[25]。高血糖水平為細菌繁殖創造了有利環境,而醫院聚集各種病原菌,因此患者的住院時間越長,術后感染的發生概率越高。對于合并糖尿病患者,在術前、術后應嚴格控制血糖水平,及時調整降糖藥物用量和使用頻率,加強術后護理,盡早出院。
PNI最初用于評估胃腸道腫瘤患者的營養、免疫狀況及手術風險,根據血清白蛋白和淋巴細胞計數而得來。低白蛋白提示機體營養狀態較差,會導致負氮平衡使得體內堆積大量代謝物,更容易發生術后感染[26]。本研究中低蛋白血癥也是導致患者術后感染發生的獨立危險因素。淋巴細胞值是反映機體免疫狀態的指標,通過介導細胞毒性死亡與腫瘤細胞的發展和凋亡密切相關[27]。而感染和炎癥反應程度是否進一步加重是由機體的營養和免疫狀態決定。研究表明PNI對多種腫瘤的短期并發癥和長期預后有一定的預測價值[28,29]。Matsuda等[30]研究發現各種術前免疫營養指數中PNI為嚴重并發癥提供最高的預測值,其中與高PNI組相比,低PNI組表現出更高的兩種主要并發癥發生率(27.0% vs. 13.4%)和感染性并發癥(14.9% vs. 3.5%)。Lee等[31]研究中提示低PNI是胃切除術后總體并發癥的獨立危險因素。與本研究結果一致,結果提示低PNI患者術后發生感染性并發癥風險較高。因此對于術前低PNI患者可以給予以營養制劑干預,從而提高總淋巴細胞計數和免疫功能,降低術后感染的發生。
CRP水平可以反映全身炎癥反應的水平,其升高早于中性粒細胞增多或淋巴細胞減少,在炎癥過程中其血液水平更穩定[32]。基于以上因素LCR在早期炎癥及反應中可能會更加敏感。Okugawa等[8]分析術前九種血液炎癥指標的預后價值時,首次將LCR確定為結直腸癌的預后生物標志物。同時他們的另一項研究[33]表明術前低LCR水平是胃癌患者術后手術感染總生存率和無病生存期的獨立預測因素。Cheng等[34]研究也表明LCR可有效預測胃癌根治術后胃癌患者的術后并發癥和長期預后,且其預測值明顯優于其他基于炎癥的評分。與這些研究一致,本研究結果表明,術前低LCR患者表明癌癥患者的免疫反應受損和全身炎癥反應增強,易發生術后感染。
本研究中建立的MGA-XGBoost模型有助于臨床醫生對術后感染進行早期預測,從而盡早進行最佳干預和治療,并最終改善患者的護理。對高風險患者預防性應用廣譜抗生素以減少術后感染的發生率,根據抗生素的藥代動力學特點和用藥途徑判斷應用抗生素的時機。同時近年來過度使用抗生素,院內感染的發生率越來越高,導致多藥耐藥菌的高患病率。因此本模型可以避免低風險患者不必要或過度使用抗生素;同時指導醫生采取術前干預措施糾正或改善并發癥的預測因素(如低白蛋白和合并糖尿病)。如術前積極控制患者血糖,加強對老年患者管理,予以營養制劑提高患者免疫力。同時,對于高危患者的術后護理應加強管理,例如積極鼓勵患者活動,促進排痰咳嗽等。此外,模型中所有預測指標都是在臨床工作中簡單易得的,以便減少患者的治療費用和額外的檢查操作。
本研究的局限性:① 樣本量較小,因為所有數據都是從一個中心獲得的。未來需要進行多中心研究進行訓練和驗證。② 機器學習算法的性能和可推廣性取決于分析的數據質量,本研究是回顧性研究,存在不可避免的選擇偏差。例如,在我們的中心,很少有患者患有吻合口瘺。此外本研究涉及的變量可能不足。當前算法中未測量的其他術前術中因素可能是患者風險的更重要的預測因素。未來的研究需評估引入新的預測因子是否可以提高模型的預測準確性。③ 本研究中術后感染性并發癥的總體發生率為20%,這被認為是相對較低的。由于術后感染性并發癥的發生率較低,未來應該進行包括大量胃癌患者在內的研究來克服這一限制。
綜上所述,本研究證明了具有11個風險因素的MGA-XGBoost模型可用于預測胃癌患者術后感染性并發癥,具有較高的準確性。同時,將風險預測與特征重要性分析相結合,幫助臨床醫生掌握術前干預相關指標,從而降低術后感染的風險。
目前全球范圍內胃癌的發病率及死亡率在各類惡性腫瘤中排名高居第五位及第四位[1]。盡早行根治性手術是治療胃癌最主要的方法[2]。由于手術切除的范圍廣及時間長、機體免疫力降低、淋巴結清掃難度大等因素常導致胃癌術后感染性并發癥發生。研究表明術后感染性并發癥是胃癌患者的獨立預后因素[3],由于長期的炎癥會影響宿主的免疫抑制,導致微轉移灶的增長以及其他原因從而導致死亡[4]。同時術后感染會延長患者的住院時間,推遲輔助治療開始時機,嚴重影響手術效果。目前感染通常根據患者的臨床癥狀來懷疑,常導致診斷延遲。而常規的影像學檢查性價比較低,且有輻射的缺點。因此有必要確定特異性的生物標志物進行早期診斷,以便及時干預治療,改善患者的預后。研究表明持續的炎癥環境會促進癌細胞的增殖、侵襲和腫瘤血管生成等[5]。因此近年來,越來越多的研究集中在術前預后營養指數(prognostic nutritional index,PNI)、外周血中性粒細胞與外周血淋巴細胞比值(peripheral blood neutrophil/peripheral blood lymphocyte,NLR)、淋巴細胞絕對數與C-反應蛋白比值(lymphocyte/C-reactive protein,LCR)等綜合性炎癥指標作為預后生物標志物[6-8],他們計算簡單方便更易進行臨床指導。有研究表明以上指標有作為術后感染性疾病的生物標志物的潛力,甚至比單獨的C-反應蛋白(C-reactive protein,CRP)和白細胞表現出更好的預測能力[9,10]。
目前隨著人工智能的發展越來越多的應用于醫學,機器學習作為一種根據給定數據自動構建的數學人工智能算法,能夠捕捉大數據中復雜的非線性關系,更深入的挖掘臨床數據中隱藏的關系。研究表明,機器學習相比傳統的統計方法可以顯著提高疾病發生和術后預后預測的準確性[11]。但是大部分現有研究中的機器學習常常無法避免過擬合的問題,造成模型預測精度較低。本文提出一種組合預測方法,基于適度貪心算法(greedy algorithm,GA)改進優化XGBoost算法,以期改善過擬合問題提高預測模型精度。因此,本研究旨在探究以上炎癥指標是否是胃癌術后感染早期診斷的可靠生物標志物,并利用傳統與改進的機器學習構建一個準確性較高的模型來評估胃癌術后感染的風險。
1 資料和方法
1.1 資料收集
回顧性收集2018年5月至2023年4月安徽醫科大學第三附屬醫院胃腸外科為胃惡性腫瘤,行根治性手術的患者為研究對象。納入標準:① 術后病理學檢查診斷為原發性胃癌;② 美國麻醉師協會(American Society of Aneshesiologists,ASA)手術危險性分級1~3級;③ 術后病理分期為Ⅰ、Ⅱ和Ⅲ期。排除標準:① 術前合并急性、慢性感染性疾病、長期服用免疫抑制劑者;② 因出血或穿孔行急癥手術;③ 術前接受過放療、化療或免疫治療等輔助治療或伴遠端轉移;④ 合并其他惡性腫瘤。收集符合研究標準的胃癌根治性手術患者的基本信息:性別、年齡、體重指數、ASA分級、既往共病(高血壓、貧血、慢性肺部疾病、糖尿病)、手術方式、圍手術期輸血、手術范圍、聯合切除;實驗室檢查資料:術前7天內的淋巴細胞、中性粒細胞、CRP、血小板、單核細胞、癌胚抗原、前白蛋白、膽固醇、血清白蛋白、白細胞;腫瘤信息:術前TNM分期、細胞分化、腫瘤大小;手術信息:術中失血量、手術時間。本研究通過安徽醫科大學第三附屬醫院倫理委員會批準(批準號:2023-45號),本研究中使用數據不包含個人身份信息。
1.2 診斷標準
術后感染并發癥定義為:在術后30天內發生的手術導致的相關感染,包括:肺部感染、切口感染、吻合口漏、腹腔膿腫、泌尿系感染、十二指腸殘端瘺等,感染的診斷標準參照相應指南[12]。簡述如下:① 切口感染:皮膚和皮下組織術后30天內的感染,手術切口出現紅、腫、熱、痛,局部切口引流出血性或膿性的滲出物;② 吻合口瘺:臨床出現壓痛、反跳痛、肌緊張等腹膜炎體征,上消化道造影可見造影劑外溢,彩超提示吻合口周圍出現氣體、液體;③ 腹腔膿腫:術后30天內出現腹部癥狀,表現為腹痛、持續發熱等癥狀,經穿刺或影像學檢查證實,經手術引流或抗感染治療后好轉;④ 泌尿系感染:術后30天內出現的膀胱炎和尿道炎,臨床出現尿頻、尿急、尿痛等膀胱刺激癥狀,尿常規檢查可有膿尿和血尿,尿液培養出致病菌;⑤ 肺部感染:患者體溫大于38.5℃,白細胞計數升高,伴隨呼吸道癥狀或痰液培養陽性,在肺部聞及干、濕啰音,胸片提示新的浸潤性病變;⑥ 十二指腸殘端瘺表現為上腹部壓痛及肌緊張,引流管引流出渾濁樣或膽汁樣液體,并經影像學檢查證實。采用Clavien-Dindo標準評估其嚴重程度并以此進行分級,將Ⅱ級及以上的感染性并發癥作為本研究的感染性并發癥組。在同一名患者發生兩種或以上不同感染性并發癥時,采用更高級別的并發癥。并以此將納入患者分為感染性并發癥組及無感染性并發癥組。
1.3 模型構建
1.3.1 傳統機器學習模型構建
本文利用python 3.9構建各種機器學習模型:linear regression、random forest、支持向量機(support vector machine,SVM)、梯度反向傳播(back propagation,BP)、LGBM、XGBoost,預測胃癌術后感染性并發癥的發生情況。除XGBoost外其余5種模型通過python 3.9安裝scikit-learn包構建。將患者的完整數據按照分層隨機化分組法分為70%訓練集和30%驗證集。訓練集數據用于預測模型的開發,驗證集數據用于驗證模型的性能。通過受試者工作特征(receiver operating characteristic,ROC)曲線下面積(area under curve,AUC)、準確率、召回率、F1分數、精確率來評估模型性能。
1.3.2 組合優化機器學習模型構建
XGBoost模型使用中面臨兩個問題:① 模型進行預測時調參較多,調參過程繁瑣,最優參數的選取難;② 模型應用gradient boosting思想,存在過擬合風險。因此本文采用GA來進行調參;然而使用GA算法當上一次迭代結果直接影響下一次迭代結果且出現謬誤時,會對最終結果造成較大誤差。故本文提出一種適度貪心(modified greedy algorithm,MGA)算法來進行歸正。通過約束貪心幅度,避免過度貪心而導致誤差累積,造成最終結果誤差較大的情況。最終得到最優結果,并引入加權集成學習的方法來增加模型穩健性。
本文采用MGA算法對參數進行分組后分步調優,并且每次并不是只依賴于最優的參數子集,而是選取若干個最優的參數子集,主要調整XGBoost中的max_depth、min_child_weight、gamma、subsample、colsample_bytree、reg_alpha、reg_lambda參數。見表1。參數調整的取值范圍見表2。
基于GA思想,本文將XGBoost的調參過程分為6個步驟,在每一步調參后取得的局部最優參數條件下,再對其他參數調優;以此類推,直至調整完所有參數。
盡管XGBoost表現一直很優越,但由于boosting算法的思想是追求“低偏差”而接受“高偏差”的特點,所以如果用單一的XGBoost將在建模上表現不好。為了避免因“數據分布不一致”“數據樣本量小”和過擬合的風險較大的問題。本文利用XGBoost的集成來增加模型的穩健性。在調參的過程中采用不是僅僅選取最優的一組參數,而是選取較優的幾組參數模型。調參步驟是:① 先調整max_depth和min_child_weight兩組參數,選擇得分最優的2組參數;② 其次再調整gamma參數,保留最優的2組數據;③ 然后調整subsample和colsample_bytree這兩組參數,選擇最優的2組數據;④ 接著對兩組正則系數reg_alpha,reg_lambda進行參數調整,選取最優一組數據;⑤ 因此現在共有2×2×2×1=8組數據;⑥ 調整learning_rate和num_boost_round的參數,選取最優的一組參數。
將調參過程隨機分為不同的幾個步驟,并且在每一次的步驟中調整一個或者兩個參數,例如上面的六步調整可以作為一種步驟組:① max_depth;② min_child_weight;③ gamma;④ subsample,colsample_bytree;⑤ reg_alpha,reg_lambda;⑥ learning_rate,num_boost_round。綜上所述,最終本文得到共8組最靠前的XGBoost參數模型見表3。
通過以上方法調參后得到的8組XGBoost參數模型,根據調參時參數的最優和次優進行比較排序從而加權集成學習。最優的分配權重2/3,次優的分配權重1/3。迭代次數設置為500次。故所獲得的8組參數模型比重分別為:0.296、0.148、0.148、0.074、0.148、0.074、0.074、0.038。
因此最終MGA-XGBoost模型為:Model=0.296×model 1+0.148×model 2+0.148×model 3+0.074×model 4+0.148×model 5+0.074×model 6+0.074×model 7+0.038×model 8。
1.4 統計分析
采用SPSS 24.0軟件對數據進行處理與特征分析,通過ROC計算NLR、外周血血小板與外周血淋巴細胞比值(peripheral blood platelet/peripheral blood lymphocyte,PLR)、PNI、LCR及外周血淋巴細胞與單核細胞比值(peripheral blood lymphocyte/peripheral monocytes,LMR)的最佳截斷值,見表4。在單因素分析中,連續變量[體重指數、手術時間、術中失血量、術前白細胞、術前中性粒細胞、術前淋巴細胞、術前CRP、癌胚抗原(carcinoembryonic antigen,CEA)、術前白蛋白、術前前白蛋白、術前膽固醇、腫瘤大小]以±s表示,并使用U檢驗進行分析,以評估感染組與非感染組之間的顯著性水平。單因素分析中的計數資料(性別、年齡、ASA分級、高血壓、糖尿病、慢性肺部疾病、貧血、手術方式、手術范圍、圍手術期輸血、聯合切除、細胞分化、分期、NLR、PLR、PNI、LCR、LMR)以病例數表示,組間采用χ2檢驗。根據訓練集的均值和標準差對連續變量進行歸一化。分類變量被編碼為二分類變量,1表示有事件,0表示沒有事件;性別也被編碼,1代表男性,0代表女性。P<0.05為差異有統計學意義。
2 結果
2.1 患者基本特征
2018年5月至2023年4月期間有452例患者在我院胃腸外科行胃癌根治術。根據納入與排除標準,最終納入420例患者,其中男性172例(41%);女性248例(59%);年齡≥65歲237例(56%);<65歲183例(44%);納入的420例患者中術后感染性并發癥共84例,發生率20%。分層隨機化分組后訓練組占70%(n=294),測試組占30%(n=126)。為了更好地了解模型的數據特征,將患者依據訓練集和驗證集分為感染組和非感染兩組。其中主要指標術前LCR、PNI、LMR、年齡、手術時間、術前白蛋白數據分布情況見圖1。差異無統計學意義(P>0.05)。
圖1
患者主要指標數據分布情況
2.2 胃癌術后感染性并發癥的單因素分析結果
單因素分析結果顯示:年齡、手術時間、糖尿病、手術切除范圍、聯合切除、分期、術前白蛋白、圍手術期輸血、術前PNI、LCR及LMR等方面差異有統計學意義(P<0.05),見表5。
2.3 機器學習模型效能預測
相關性分析展示了年齡、手術時間、糖尿病、手術切除范圍、聯合切除、分期、術前白蛋白、圍手術期輸血、術前PNI、LCR及LMR之間的關聯性,同時展示術后感染性并發癥與各個預測因素之間的關系。其中術后感染性并發癥與年齡(0.51)、糖尿病(0.31)表現出強關聯性,與LMR、LCR、術前白蛋白以及手術切除范圍呈現出負相關。此外PNI和LMR(0.42)之間具有相關性。見圖2。
圖2
術后感染并發癥風險之間的相關性分析
圖3展示了linear regression、random forest、SVM、BP、LGBM、XGBoost及改進后的MGA-XGBoost七個機器學習模型對胃癌術后感染性并發癥的預測性能。結果表明MGA-XGBoost預測模型的AUC值最高(0.936),random forest、SVM和BP均表現出一般的預測能力(AUC范圍為0.76~0.79)。
圖3
術后感染并發癥預測模型的ROC曲線
除了AUC外,本文還引入了準確率、召回率、F1分數、精確率來評估各種預測模型性能,見表6。可以看出MGA-XGBoost(準確率為0.889,精確率為0.79)、XGBoost(準確率為0.881,精確率為0.75)、LGBM(準確率為0.881,精確率為0.778)都表現出較好的精確率和準確率。BP的召回率(0.48)、F1分數(0.522)、精確率(0.571)均不理想。
同時本研究對準確性最高的MGA-XGBoost預測模型內部特征重要性進行可視化顯示,結果見圖4。糖尿病、PNI和LCR分別排名第一、第二和第三。結合與術后感染性并發癥的相關性分析以及其在MGA-XGBoost算法中重要性分析的結果,將糖尿病和PNI視為重要的預測因素。
圖4
MGA-XGBoost模型特征重要性分析
3 討論
目前機器學習在外科領域的研究中仍處于初級階段,但過往的研究表明其在風險預測方面有巨大潛力[13]。不同的研究之間存在著較大的異質性,主要表現為不同模型的選擇及樣本量的差異。目前存在著成千上萬的機器學習算法,對待不同的問題采用哪種算法最合適是需要深思熟慮的。因此本研究比較了六種常規機器學習算法,其中XGBoost的表現最優,AUC值為0.895。XGBoost是通過迭代構建、測試和調整一系列決策模型以校正結果,最終產生針對分類任務優化的決策樹算法[14]。因此在處理結構化數據和非結構化數據方面表現出色,通常可以獲得比其他算法更高的準確性。研究者為了開發機器學習模型通常會使用大量的樣本進行訓練。如,Tey等[15]的研究包括21 892多名患者和17個不同的變量。在他們的研究中,人工神經網絡在預測肺炎患者14天再次入院的早期檢測方面優于卷積神經網絡。然而,Ma等[16]利用XGBoost成功構建急性呼吸衰竭的預測模型中僅納入312名患者,與本研究樣本量類似。目前不同研究中的樣本量從73例[17]到111 888例[18]不等,也表明樣本量不是成功的機器學習模型的唯一因素。但是數據不足及模型復雜度過高,常常會導致機器學習中最常見的過擬合問題。因此針對這個問題本文進行組合優化。在本研究中,改進過的MGA-XGBoost在感染性術后并發癥風險預測方面表現最好。與其他六個模型相比, AUC、準確率和召回率在測試數據集中最高,對預測胃癌患者的術后感染性并發癥展現出巨大的優越性。
本研究通過單因素回歸分析的方法探索了胃癌根治術后感染性并發癥的危險因素,包括:年齡、手術時間、糖尿病、手術切除范圍、聯合切除、分期、術前白蛋白、圍手術期輸血、術前PNI、LCR及LMR。以上危險因素都在既往不同文獻中報道過與術后感染性并發癥有關[19,20]。Kunisaki等[21]研究顯示,術中聯合臟器切除是胃癌根治術后發生腹腔感染的影響因素,可能由于聯合臟器切除擴大了手術切除范圍,延長了手術時間,從而發生術后感染的風險增大。本研究中手術時間也是術后感染的獨立危險因素,手術時間越長則反映了手術的復雜性,不僅會導致增加切口暴露的污染風險,同時對患者造成的創傷也會增大[22]。本研究的創新在于納入更多以往模型構建研究中未包括的綜合性炎癥指標,如PNI、LCR、LMR。此外術前NLR、PLR在本研究中都不是胃癌術后感染的獨立風險因素。
雖然XGBoost、LGBM和隨機森林等復雜算法在預測建模中展現出強大的性能,但它們是基于“黑盒”設計的,不透明性使得其很難在臨床環境中解釋和應用。其次臨床工作中大部分醫生都能識別出導致術后并發癥的因素,但難以判斷如何優先考慮這些特征。因此本研究探索了MGA-XGBoost預測模型通過結構分數的增益情況計算出選擇特征作為分割點,并通過weight、gain、cover聯合判斷重要性。這種方法改進了既往大部分研究發布的不透明的機器學習模型,同時我們還提出了簡潔實用的臨床建議。在本研究中排名前三的主要危險因素包括:糖尿病、PNI和LCR,提示醫生在臨床工作中優先對這三個因素給予重點關注。然而值得注意的是,在本研究的相關性分析中LCR與術后感染性并發癥呈負相關,表明在常規分析中往往可能會遺漏某些重要因素。
本研究結果顯示,術前合并糖尿病的患者術后發生感染性并發癥的風險顯著高于無糖尿病史的患者。罹患糖尿病的患者固有免疫和獲得性免疫功能均不同程度受損,對病原體的侵襲抵抗能力不足[23]。同時合并糖尿病的患者手術應激反應更明顯,劇烈的應激反應會使血糖迅速升高且不易控制[24]。有研究表明糖尿病并不是術后感染的絕對危險因素,術后血糖控制不良才是引起術后感染的高危險因素[25]。高血糖水平為細菌繁殖創造了有利環境,而醫院聚集各種病原菌,因此患者的住院時間越長,術后感染的發生概率越高。對于合并糖尿病患者,在術前、術后應嚴格控制血糖水平,及時調整降糖藥物用量和使用頻率,加強術后護理,盡早出院。
PNI最初用于評估胃腸道腫瘤患者的營養、免疫狀況及手術風險,根據血清白蛋白和淋巴細胞計數而得來。低白蛋白提示機體營養狀態較差,會導致負氮平衡使得體內堆積大量代謝物,更容易發生術后感染[26]。本研究中低蛋白血癥也是導致患者術后感染發生的獨立危險因素。淋巴細胞值是反映機體免疫狀態的指標,通過介導細胞毒性死亡與腫瘤細胞的發展和凋亡密切相關[27]。而感染和炎癥反應程度是否進一步加重是由機體的營養和免疫狀態決定。研究表明PNI對多種腫瘤的短期并發癥和長期預后有一定的預測價值[28,29]。Matsuda等[30]研究發現各種術前免疫營養指數中PNI為嚴重并發癥提供最高的預測值,其中與高PNI組相比,低PNI組表現出更高的兩種主要并發癥發生率(27.0% vs. 13.4%)和感染性并發癥(14.9% vs. 3.5%)。Lee等[31]研究中提示低PNI是胃切除術后總體并發癥的獨立危險因素。與本研究結果一致,結果提示低PNI患者術后發生感染性并發癥風險較高。因此對于術前低PNI患者可以給予以營養制劑干預,從而提高總淋巴細胞計數和免疫功能,降低術后感染的發生。
CRP水平可以反映全身炎癥反應的水平,其升高早于中性粒細胞增多或淋巴細胞減少,在炎癥過程中其血液水平更穩定[32]。基于以上因素LCR在早期炎癥及反應中可能會更加敏感。Okugawa等[8]分析術前九種血液炎癥指標的預后價值時,首次將LCR確定為結直腸癌的預后生物標志物。同時他們的另一項研究[33]表明術前低LCR水平是胃癌患者術后手術感染總生存率和無病生存期的獨立預測因素。Cheng等[34]研究也表明LCR可有效預測胃癌根治術后胃癌患者的術后并發癥和長期預后,且其預測值明顯優于其他基于炎癥的評分。與這些研究一致,本研究結果表明,術前低LCR患者表明癌癥患者的免疫反應受損和全身炎癥反應增強,易發生術后感染。
本研究中建立的MGA-XGBoost模型有助于臨床醫生對術后感染進行早期預測,從而盡早進行最佳干預和治療,并最終改善患者的護理。對高風險患者預防性應用廣譜抗生素以減少術后感染的發生率,根據抗生素的藥代動力學特點和用藥途徑判斷應用抗生素的時機。同時近年來過度使用抗生素,院內感染的發生率越來越高,導致多藥耐藥菌的高患病率。因此本模型可以避免低風險患者不必要或過度使用抗生素;同時指導醫生采取術前干預措施糾正或改善并發癥的預測因素(如低白蛋白和合并糖尿病)。如術前積極控制患者血糖,加強對老年患者管理,予以營養制劑提高患者免疫力。同時,對于高危患者的術后護理應加強管理,例如積極鼓勵患者活動,促進排痰咳嗽等。此外,模型中所有預測指標都是在臨床工作中簡單易得的,以便減少患者的治療費用和額外的檢查操作。
本研究的局限性:① 樣本量較小,因為所有數據都是從一個中心獲得的。未來需要進行多中心研究進行訓練和驗證。② 機器學習算法的性能和可推廣性取決于分析的數據質量,本研究是回顧性研究,存在不可避免的選擇偏差。例如,在我們的中心,很少有患者患有吻合口瘺。此外本研究涉及的變量可能不足。當前算法中未測量的其他術前術中因素可能是患者風險的更重要的預測因素。未來的研究需評估引入新的預測因子是否可以提高模型的預測準確性。③ 本研究中術后感染性并發癥的總體發生率為20%,這被認為是相對較低的。由于術后感染性并發癥的發生率較低,未來應該進行包括大量胃癌患者在內的研究來克服這一限制。
綜上所述,本研究證明了具有11個風險因素的MGA-XGBoost模型可用于預測胃癌患者術后感染性并發癥,具有較高的準確性。同時,將風險預測與特征重要性分析相結合,幫助臨床醫生掌握術前干預相關指標,從而降低術后感染的風險。