隨著心電圖數據量快速增長,計算機輔助心電圖分析也有著越來越廣闊的應用需求。本文在基于導聯卷積神經網絡的臨床心電圖分類算法上提出多種策略,進一步提升其在實際應用中的性能。首先用不同的預處理方法和訓練方法獲得兩個不同的分類器,接著用多重輸出預測法來增強每個分類器的性能,最后用貝葉斯方法進行融合。測試了超過15萬條心電圖記錄,所提方法的準確率和受試者工作特征曲線下面積(AUC)分別為85.04%和0.918 5,明顯優于基于特征提取的傳統方法。
引用本文: 金林鵬, 董軍. 基于集成學習的臨床心電圖分類算法研究. 生物醫學工程學雜志, 2016, 33(5): 825-833. doi: 10.7507/1001-5515.20160134 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
心電圖(electrocardiogram, ECG)作為一種簡便、廉價、無損的心臟相關疾病診斷手段,自20世紀以來已廣泛應用于臨床。然而,在用心電圖進行長期監護的情形下,人工檢查非常耗時和枯燥;在每天產生大量數據的體檢中心,醫生大部分時間都在區分正常和異常心電圖,并非集中精力判讀異常心電圖。與此同時,隨著可穿戴設備興起,具有心電圖分析功能的產品越來越具有市場競爭力。所有這些使得計算機輔助心電圖分析得到廣泛而深入的研究,也取得了長足進步[1-3]。
一條心電圖記錄由多個心拍周期組成,因此,在過去的幾十年內,大量關于心拍分類的算法被提出,其主要做法是先提取臨床診斷特征[4-5]或數理特征[6-7],然后再配合規則推理[8-9]或統計學習[10-13]對心拍進行分類。根據所采取的評估準則,相關文獻可分為“個體內分類模式”和“個體間分類模式”兩大類[14-15]。個體內分類模式被多數文獻采用,其特點是訓練集和測試集均包含同一個體的心拍。由于個體心拍可用于身份識別[16],所以這種分類模式的準確率往往很高,但不符合臨床應用。de Chazal等[14]提出一種基于AAMI標準[17]和MIT-BIH Arrhythmias(MIT-BIH-AR)數據庫[18]的個體間分類模式,其特點是訓練集和測試集均由來自22條不同記錄的心拍組成,一定程度上考慮了個體差異。新近發表的文獻[4-5, 10, 12, 15]均采用這種分類模式,相對有效地評估了算法在臨床環境下的性能。然而,基于MIT-BIH-AR數據庫進行性能評估存在一定的局限性:整個數據集僅由48條時長約30 min的2導聯心電圖記錄組成,且并非所有記錄均包含相同的導聯;在數據規模很小且導聯不一致性的情形下,即使性能“很好”的心拍分類算法,也很難應用于實際環境。此外,在臨床診斷中更重要的是給出整條心電圖記錄的結論,并非心拍結論。
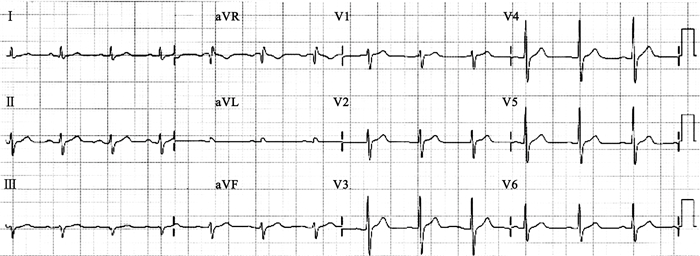
我們的研究工作面向遠程醫療和體檢中心,給定一條10 s左右的12導聯心電圖記錄(如圖 1所示),先由記錄分類算法進行篩選,若為異常心電圖,則再交由醫生進行判讀,即正異常記錄分類[19]。鑒于現有數據庫的局限性,我們構建了中國心血管疾病數據庫(Chinese Cardiovascular Disease Database, CCDD)[20],并開展相關研究工作:文獻[21]重現了在MIT-BIH-AR數據庫上具有高性能的心拍分類算法[6-7],并利用平均心拍技術進行正異常記錄分類,測試了11 760個樣本,準確率僅略高于70%;文獻[4]提出一種特定疾病特征選擇的心拍分類算法,采用de Chazal等建議的評估準則,其性能在相關文獻[5, 10, 12, 14-15]對比中具有優勢,但將其用于正異常記錄分類時,準確率明顯下降,僅略高于50%;文獻[22]提出一種融合領域知識的正異常記錄分類算法,測試了超過14萬條記錄,準確率為72%左右;文獻[23]提出一種基于導聯卷積神經網絡(Lead Convolutional Neural Network, LCNN),并結合顯性訓練法和直接預測法的正異常記錄分類算法,測試了超過15萬條記錄,準確率和受試者工作特征曲線下面積(area under receiver operating characteristic curve, AUC)分別為83.66%和0.908 6,是目前公開發表的最好結果。
 圖1
用于臨床診斷的12導聯心電圖
Figure1.
Twelve lead ECG for clinical diagnosis
圖1
用于臨床診斷的12導聯心電圖
Figure1.
Twelve lead ECG for clinical diagnosis
本文在已有工作的基礎上[23],首先提出一種新的監督訓練方法(即隱性訓練法),然后將其與傳統訓練方法(即顯性訓練法)相結合,訓練出兩個有差異的LCNN模型,最后用貝葉斯方法進行融合。在測試方面,提出比直接預測法效果更好的多點輸出預測法,以進一步提升LCNN的分類性能。
1 方法
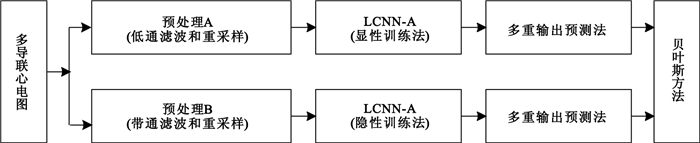
圖 2描述了心電圖記錄分類算法的整體框架:原始心電圖分為兩路,一路先經過低通濾波和下采樣,再輸入到由顯性訓練法所得的LCNN-A模型中,采用多重輸出預測法輸出決策概率值;另一路則先經過帶通濾波和下采樣,再輸入到由隱性訓練法所得的LCNN-B模型中,同樣采用多重輸出預測法輸出決策概率值;最后用貝葉斯方法融合兩路輸出。
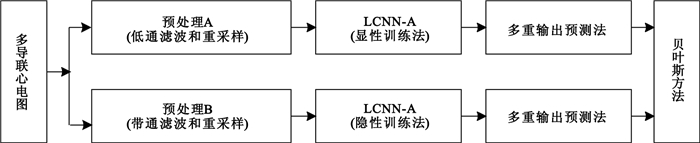 圖2
心電圖記錄分類框架
Figure2.
Framework of ECG recording classification
圖2
心電圖記錄分類框架
Figure2.
Framework of ECG recording classification
1.1 預處理
為了獲得兩個性能差異的LCNN模型,一個有效策略是使輸入數據有所差異。為此,我們首先采用兩種濾波方法對同一條心電圖記錄進行處理,分別為低通濾波和0.5~40 Hz的帶通濾波[24]。在圖 2中,若預處理A采用帶通濾波,而預處理B采用低通濾波,也同樣可行,這里是為了使第1路和文獻[23]保持一致。接著將濾波處理后的心電圖記錄重采樣到200 Hz[25]。考慮到開始采集時的不穩定信號,我們以0.125 s為起始點截取之后9.5s數據(原始心電圖記錄的時長不能短于9.625 s)。另外,12個導聯中僅有Ⅱ、Ⅲ、Ⅴ1、Ⅴ2、Ⅴ3、Ⅴ4、Ⅴ5、Ⅴ6是正交的,而剩余導聯可由它們線性推導,因此我們僅保留這8個正交導聯。最后每條心電圖記錄的采樣點數為8×1 900(=8×200×9.5),單位為mV。
1.2 導聯卷積神經網絡
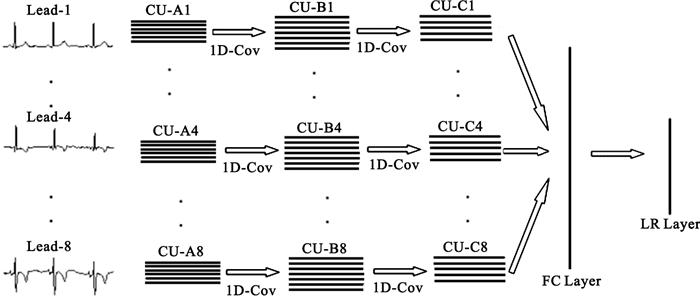
導聯內數據(水平方向)是內容相關的,而導聯間數據(垂直方向)是獨立的,這是多導聯心電圖與二維數字圖像最大的區別。基于這種特殊的結構和卷積神經網絡[26]的特點,LCNN[23]應運而生,其完整結構圖如圖 3所示。
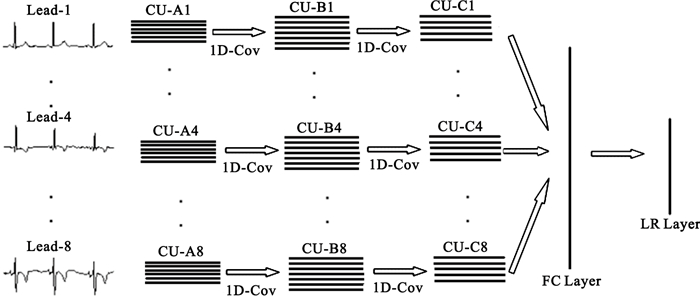 圖3
LCNN結構示意圖
Figure3.
Architecture sketch of LCNN
圖3
LCNN結構示意圖
Figure3.
Architecture sketch of LCNN
在圖 3中,1D-Cov表示1維卷積計算,CU表示卷積單元(包括一個卷積層和一個取樣層),每個導聯均有3個CU,且不同導聯間的CU互不相干,總共有24(=8×3)個CU。LCNN前向計算過程為:每個導聯的心電圖數據依次通過最適合自己的3個CU,之后匯總所有導聯的信息到全連接(fully connected,FC)層,最后交由Logistic回歸(LR)層輸出決策概率值。在實際應用中,每個導聯的CU個數可根據需要做相應調整。
本文在數值實驗中采用的LCNN,其相關參數設定如下[23]:三個卷積核尺寸分別為1×21、1×13和1×9,三個取樣核尺寸分別為1×7、1×6和1×6,三個特征面數分別為6、7和5;全連接層和Logistic回歸層的神經元數分別為50和1;輸入層的神經元數為8×1 700。
1.3 顯性訓練法
誤差反向傳播(back propagation, BP)算法[27]是最常用的神經網絡訓練方法,但由于它是一種局部搜索算法,因此要想獲得泛化能力強的分類模型,需要有足量的訓練樣本。然而,無限制地增加心電圖記錄的數目不現實;同時正常心電圖總是大量存在,而某種疾病的心電圖則相對要少,即類不平衡問題是普遍存在的。
從心電圖記錄中截取的一段局部數據,我們稱之為子記錄。顯然,若起始點不同,則對應的子記錄在數據空間中具有不同的分布。因此,我們通過平移起始點,從一條心電圖記錄中截取多條子記錄,并根據每類的樣本數確定每類的子記錄數,這樣既可以增加訓練樣本數,又解決了類不平衡問題。另外,我們還疊加正常情況下不影響醫生判讀的隨機信號,進一步增加訓練樣本數。
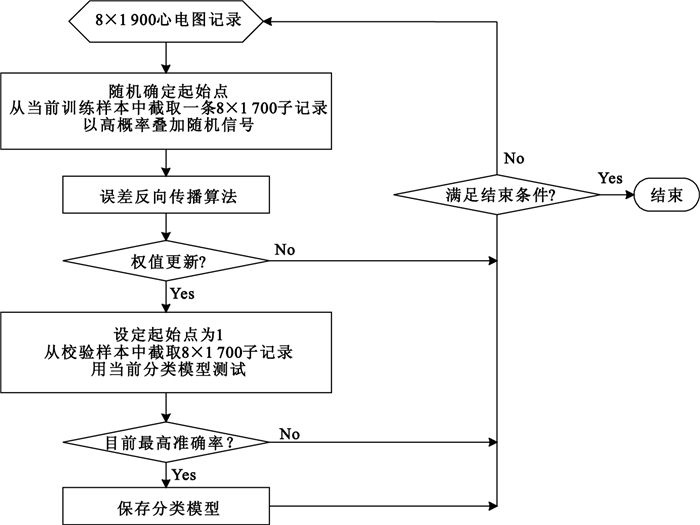
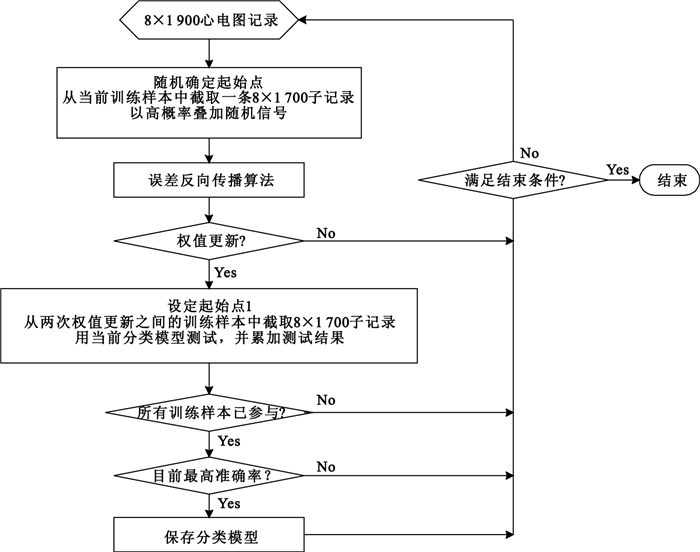
文獻[23]基于mini-batch[28],并結合以上兩種策略設計了顯性訓練法,其完整描述為:對于采樣點數為8×1 900的心電圖記錄,首先隨機確定起始點(取值為1~201間的任意整數),并截取一條8×1 700的子記錄(每導聯的起始點保持一致),然后以高概率疊加最大幅值不超過0.15 mV的隨機信號,這樣處理后再輸入到LCNN中進行誤差反向傳播;當已有560個樣本參與訓練,就更新網絡權值,再從每個校驗樣本中截取一條8×1 700的子記錄(起始點為1),用當前分類模型測試;若此時準確率是當前最高,則保存該模型;重復以上過程,直到滿足結束條件。圖 4給出了完整的顯性訓練過程。
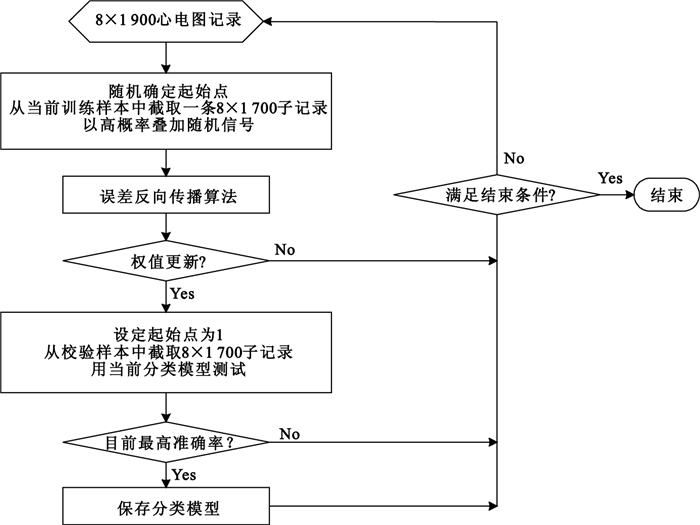 圖4
顯性訓練法
Figure4.
Explicit training method
圖4
顯性訓練法
Figure4.
Explicit training method
1.4 隱性訓練法
心電圖在個體間存在差異,但在某些個體間又有相似性。若校驗樣本不典型,即不包含全部有差異的個體,那么采用顯性訓練法所得的分類模型會存在一定的偏差,因為該方法是基于校驗樣本的測試結果來確定是否保存當前分類模型。然而,通過手工選擇代表性的心電圖記錄作為校驗樣本并不容易,受限于各種現實條件。為此,我們設計一種新的監督訓練方法,即隱性訓練法,如圖 5所示。
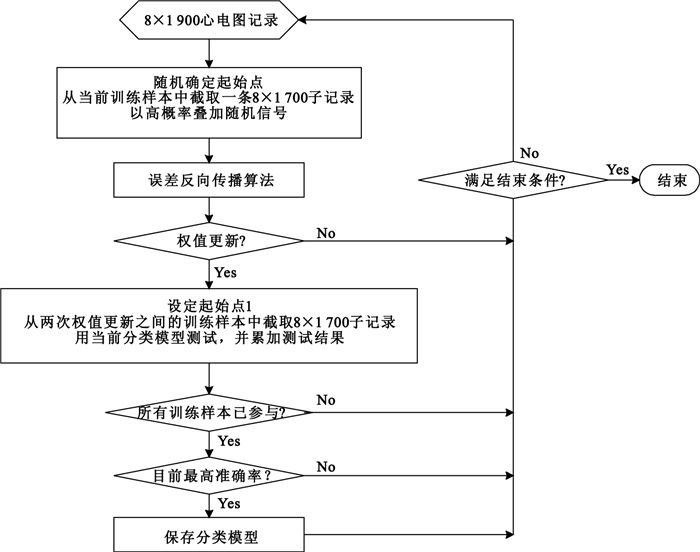 圖5
隱性訓練
Figure5.
Implicit training method
圖5
隱性訓練
Figure5.
Implicit training method
整個訓練過程可描述為:對于采樣點數為8×1 900的心電圖記錄,首先隨機確定起始點(取值為1~201間的任意整數),并截取一條8×1 700子記錄,然后以高概率疊加最大幅值不超過0.15 mV的隨機信號,這樣處理后再輸入到LCNN進行誤差反向傳播;當已有560個樣本參與訓練,就更新網絡權值,再從兩次權值更新之間的每個訓練樣本中截取一條8×1 700的子記錄(起始點為1),用當前分類模型測試,并累加測試結果;當所有樣本都已參與訓練,若此時準確率是當前最高,則保存當前模型;重復以上過程,直到滿足結束條件。
對比圖 4和圖 5可知,相比顯性訓練法,隱性訓練法沒有獨立的校驗樣本,而是從整個訓練樣本中選出一部分樣本用于校驗。雖然訓練樣本和校驗樣本均從相同的心電圖記錄中截取子記錄,但前者的起始點隨機確定,且以高概率疊加隨機信號,而后者的起始點為1,且不疊加隨機信號。因此,這兩部分樣本重合的概率很小。
本文在數值實驗中,不論顯性訓練法還是隱性訓練法,均采用慣性量和變步長的反向傳播算法[29],最大訓練周期為500,初始步長為0.02,步長衰減率第2、3周期為0.940 5,其余為0.99,訓練目標是最大化校驗集準確率。
1.5 多重輸出預測法
文獻[23]所采用的直接預測法是指從8×1 900心電圖記錄中截取一條8×1 700子記錄,并直接交由LCNN進行分類。為了提高分類結果的置信度,本文提出一種新的測試方法,即多重輸出預測法,如圖 6所示。
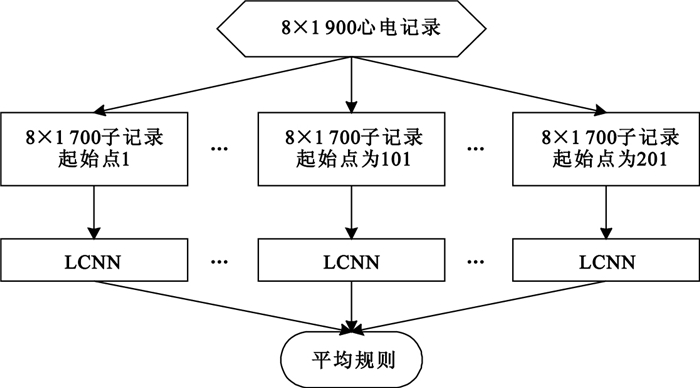 圖6
多重輸出預測法
Figure6.
Multiple output prediction method
圖6
多重輸出預測法
Figure6.
Multiple output prediction method
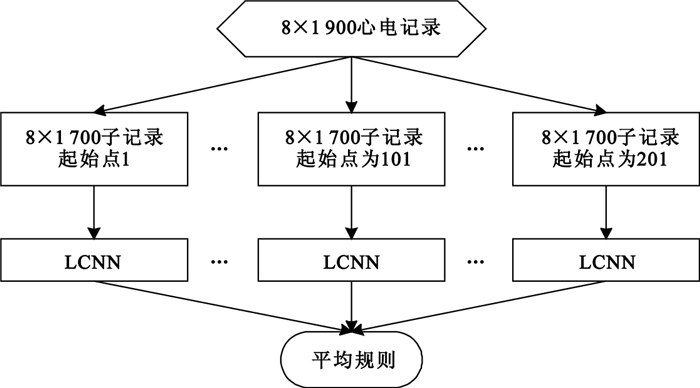
整個測試過程可描述為:對于采樣點數為8×1 900的心電圖記錄,首先截取9條8×1 700子記錄(起始點分別為1、26、51、76、101、126、151、176和201),然后交由LCNN進行測試,輸出9個決策概率值,最后采用平均規則求得輸出值。此外,我們還可采用加權等更有效的其他計算方法。
1.6 貝葉斯方法
在本文中,我們采用貝葉斯方法[30]融合兩個LCNN模型,以增強最終的分類性能:給定二分類的數據,假設兩個分類器的輸出可以組合,那么決策類別m可由式(1)確定
| $ \left\{ \begin{array}{l} P\left( {y = j|{c_1},{c_2}} \right) = \frac{1}{2}\sum\limits_{i = 1}^2 {P\left( {y = j|{c_i}} \right)} \\ m = \mathop {\arg }\limits_{1 \le j \le M} \max \left\{ {P\left( {y = j|{c_1},{c_2}} \right)} \right\} \end{array} \right. $ |
其中P(y=j|ci)是第i個分類器ci給出屬于類別j的概率值。
2 心電圖數據
CCDD(http://58.210.56.164:88/ccdd)中的每條心電圖記錄均來自臨床,標準12導聯,持續時間為10~20 s,采樣頻率為500 Hz,診斷結論由心臟科醫生給出。目前,該數據庫共有179 130條心電圖記錄,其中CCDD[data1-943]數據集中的每條記錄既有心拍結論,又有記錄結論;而CCDD[data944-179130]數據集中的每條記錄則僅有記錄結論。
為了驗證所提方法的有效性,我們按照文獻[23]的做法選定訓練樣本和測試樣本:首先去除時長不足9.625 s以及記錄結論為空或無效的心電圖,然后將記錄結論為“0x0101”或“0x020101”或“0x020102”的心電圖標注為正常樣本,其他均為異常樣本;接著將CCDD[data944-25693]數據集劃分為訓練樣本、校驗樣本和小規模測試集,而CCDD[data25694-179130]數據集則為大規模測試集。表 1顯示了整個數據集的樣本分布情況。
訓練樣本和校驗樣本是針對顯性訓練法而言,在隱性訓練法中,兩者會合并。分類算法在小規模測試集上的性能僅作為參考,我們更關注其在大規模測試集上的表現。
3 數值實驗
3.1 評價指標
按照醫學診斷的定義,正常心電圖和異常心電圖分別為陰性和陽性結果。表 2描述了真實類別與決策類別的可能關系。
診斷指標包括特異性Sp、靈敏度Se、陰性預測值NPV和正確率Acc;除此以外,我們還使用AUC、約登指數r、幾何平均GM數和自適應幾何平均數AGM數[31]來評估算法的整體性能,計算公式如下:
| $ \left\{ \begin{array}{l} {\rm{Sp = }}\frac{{{\rm{TN}}}}{{{\rm{TN + FP}}}}\\ {\rm{Se = }}\frac{{{\rm{TP}}}}{{{\rm{TP + FN}}}}\\ {\rm{NPV = }}\frac{{{\rm{TN}}}}{{{\rm{TN + FN}}}}\\ {\rm{Acc = }}\frac{{{\rm{TN + TP}}}}{{{\rm{TN + FP + FN + TP}}}} \end{array} \right. $ |
| $ r = {\rm{Se + Sp}} - 1 $ |
| $ GM = \sqrt {{\rm{Se \times Sp}}} $ |
| $ \left\{ \begin{array}{l} {{\rm{N}}_{\rm{n}}} = \frac{{{\rm{TN + FP}}}}{{{\rm{TN + FP + FN + TP}}}}\\ AGM = \frac{{GM + {\rm{Sp \times }}{{\rm{N}}_{\rm{n}}}}}{{{\rm{1 + }}{{\rm{N}}_{\rm{n}}}}} \end{array} \right. $ |
3.2 算法評估
我們首先用兩種方法訓練得到兩個LCNN模型,再對每個模型用兩種方法進行測試。表 3和表 4給出了相應的實驗結果,可知無論在哪個數據集上測試,多重輸出預測法可提高每個LCNN模型的性能指標。此外,我們還發現由顯性訓練法和隱性訓練法所得的LCNN模型各具優勢,如前者擁有高AUC,而后者則有高準確率。表 5給出了兩個LCNN模型的融合結果。
由表 5可知,相比單個模型,融合模型在小規模測試集和大規模測試集均取得了更好的分類性能。正異常記錄分類的關鍵技術是盡可能提高NPV為95%前提下的Sp指標[32];由表 3和表 5可知,相比顯性模型、隱性模型和文獻[23],融合模型在大規模測試集上分別使這個指標提高了4.3%、9.6%和21.6%。由此驗證了所提出方法的有效性。
3.3 與其他文獻對比
為了進一步評估所提出方法的性能,我們將其與已公開發表的正異常記錄分類算法做對比。文獻[22]提出一種融合RR間期分析、QRS波群相似性分析、基于數值特征和形態特征的統計分類器、心電圖典型特征(P波、T波、R波、PR間期等)分析的ECG-MTHC,可給出心電圖記錄的正異常結論。另外,鑒于目前相關研究工作不多,本文同樣基于現有的心拍分類技術構建一個正異常記錄分類器。文獻[15]提出一種融合小波變換、獨立成分分析、主成分分析、RR間期特征、支持向量機和多導聯融合的心拍分類算法,在MIT-BIH-AR數據庫上進行評估,其個體內分類模式和個體間分類模式的準確率分別為99.3%和86.4%,是迄今為止最好的結果之一。我們首先利用人工標注從CCDD[data1-943]數據集中截取每條心電圖記錄上的心拍,然后按照文獻[15]所提方法訓練一個心拍分類器。在測試階段,首先利用文獻[33]所提方法檢測一條心電圖記錄上的所有R波,然后截取心拍并進行測試,最后采用平均心拍法(計算所有心拍的平均決策概率值,以此確定記錄結論)[21]和異常優先法(若存在異常心拍,則整條記錄即為異常)[34]確定當前記錄的正異常結論。這兩種測試模型分別記為YeC[Avg]和YeC[Bias]。
表 6給出了不同分類模型在大規模測試集上的實驗結果,其中11 176條心電圖記錄由于無法提取出ECG-MTHC所需要的特征,故無法給出記錄結論。為了公平比較,我們給出其他分類模型在相同數據集上的測試結果。由表 6可知,YeC[Avg]和YeC[Bias]表現欠佳,其準確率均不超過50%,同文獻[4]的測試結果類似;ECG-MTHC表現相對不錯,其準確率為72.49%。相比而言,本文所提方法除了Se稍低外,其他所有性能指標均比其他模型要高,準確率更是達到了85.08%。
事實上,文獻[15]所提方法的不少步驟并不符合臨床實際,如經過5~12 Hz帶通濾波,心電圖記錄中的P波、T波等重要的臨床診斷信息均被去除,顯然不利于后續診斷。這個問題在僅有48條記錄的MIT-BIH-AR數據庫上被掩蓋,但在擁有十幾萬條記錄的CCDD數據庫上暴露無遺。另外,該方法所涉及的不少參數針對MIT-BIH-AR數據庫進行調整,顯然并不適用于所有的數據集。這也是不少公開發表論文的共同問題:高分類性能僅限于標準數據庫,而不能推廣到實際應用[21]。
2012年Hakacova等[35]對市場上心電圖設備的自動診斷結果進行統計分析,總共統計了576例心電圖,發現Philips Medical Systems準確率僅有80%,Draeger Medical Systems準確率僅有75%,而3名普通醫生的平均判讀準確率為85%。本文所提方法在超過15萬條心電圖記錄上的準確率為85.04%,具有一定的參考和應用價值。
4 結論
本文在基于LCNN的臨床心電圖分類算法上融入集成學習思想,包括不同的預處理方法、不同的訓練方法以及多重輸出預測法。通過測試超過15萬條心電圖記錄,所提方法的準確率和AUC分別為85.04%和0.918 5。
除了濾波方法外,小波變換、傅立葉變換等均可用于數據預處理;除了不同的校驗方法,不同的網絡結構、錯分代價等均能使訓練所得的LCNN模型有所差異。這些都是我們下一步要開展的研究工作。
引言
心電圖(electrocardiogram, ECG)作為一種簡便、廉價、無損的心臟相關疾病診斷手段,自20世紀以來已廣泛應用于臨床。然而,在用心電圖進行長期監護的情形下,人工檢查非常耗時和枯燥;在每天產生大量數據的體檢中心,醫生大部分時間都在區分正常和異常心電圖,并非集中精力判讀異常心電圖。與此同時,隨著可穿戴設備興起,具有心電圖分析功能的產品越來越具有市場競爭力。所有這些使得計算機輔助心電圖分析得到廣泛而深入的研究,也取得了長足進步[1-3]。
一條心電圖記錄由多個心拍周期組成,因此,在過去的幾十年內,大量關于心拍分類的算法被提出,其主要做法是先提取臨床診斷特征[4-5]或數理特征[6-7],然后再配合規則推理[8-9]或統計學習[10-13]對心拍進行分類。根據所采取的評估準則,相關文獻可分為“個體內分類模式”和“個體間分類模式”兩大類[14-15]。個體內分類模式被多數文獻采用,其特點是訓練集和測試集均包含同一個體的心拍。由于個體心拍可用于身份識別[16],所以這種分類模式的準確率往往很高,但不符合臨床應用。de Chazal等[14]提出一種基于AAMI標準[17]和MIT-BIH Arrhythmias(MIT-BIH-AR)數據庫[18]的個體間分類模式,其特點是訓練集和測試集均由來自22條不同記錄的心拍組成,一定程度上考慮了個體差異。新近發表的文獻[4-5, 10, 12, 15]均采用這種分類模式,相對有效地評估了算法在臨床環境下的性能。然而,基于MIT-BIH-AR數據庫進行性能評估存在一定的局限性:整個數據集僅由48條時長約30 min的2導聯心電圖記錄組成,且并非所有記錄均包含相同的導聯;在數據規模很小且導聯不一致性的情形下,即使性能“很好”的心拍分類算法,也很難應用于實際環境。此外,在臨床診斷中更重要的是給出整條心電圖記錄的結論,并非心拍結論。
我們的研究工作面向遠程醫療和體檢中心,給定一條10 s左右的12導聯心電圖記錄(如圖 1所示),先由記錄分類算法進行篩選,若為異常心電圖,則再交由醫生進行判讀,即正異常記錄分類[19]。鑒于現有數據庫的局限性,我們構建了中國心血管疾病數據庫(Chinese Cardiovascular Disease Database, CCDD)[20],并開展相關研究工作:文獻[21]重現了在MIT-BIH-AR數據庫上具有高性能的心拍分類算法[6-7],并利用平均心拍技術進行正異常記錄分類,測試了11 760個樣本,準確率僅略高于70%;文獻[4]提出一種特定疾病特征選擇的心拍分類算法,采用de Chazal等建議的評估準則,其性能在相關文獻[5, 10, 12, 14-15]對比中具有優勢,但將其用于正異常記錄分類時,準確率明顯下降,僅略高于50%;文獻[22]提出一種融合領域知識的正異常記錄分類算法,測試了超過14萬條記錄,準確率為72%左右;文獻[23]提出一種基于導聯卷積神經網絡(Lead Convolutional Neural Network, LCNN),并結合顯性訓練法和直接預測法的正異常記錄分類算法,測試了超過15萬條記錄,準確率和受試者工作特征曲線下面積(area under receiver operating characteristic curve, AUC)分別為83.66%和0.908 6,是目前公開發表的最好結果。
圖1
用于臨床診斷的12導聯心電圖
Figure1.
Twelve lead ECG for clinical diagnosis
本文在已有工作的基礎上[23],首先提出一種新的監督訓練方法(即隱性訓練法),然后將其與傳統訓練方法(即顯性訓練法)相結合,訓練出兩個有差異的LCNN模型,最后用貝葉斯方法進行融合。在測試方面,提出比直接預測法效果更好的多點輸出預測法,以進一步提升LCNN的分類性能。
1 方法
圖 2描述了心電圖記錄分類算法的整體框架:原始心電圖分為兩路,一路先經過低通濾波和下采樣,再輸入到由顯性訓練法所得的LCNN-A模型中,采用多重輸出預測法輸出決策概率值;另一路則先經過帶通濾波和下采樣,再輸入到由隱性訓練法所得的LCNN-B模型中,同樣采用多重輸出預測法輸出決策概率值;最后用貝葉斯方法融合兩路輸出。
圖2
心電圖記錄分類框架
Figure2.
Framework of ECG recording classification
1.1 預處理
為了獲得兩個性能差異的LCNN模型,一個有效策略是使輸入數據有所差異。為此,我們首先采用兩種濾波方法對同一條心電圖記錄進行處理,分別為低通濾波和0.5~40 Hz的帶通濾波[24]。在圖 2中,若預處理A采用帶通濾波,而預處理B采用低通濾波,也同樣可行,這里是為了使第1路和文獻[23]保持一致。接著將濾波處理后的心電圖記錄重采樣到200 Hz[25]。考慮到開始采集時的不穩定信號,我們以0.125 s為起始點截取之后9.5s數據(原始心電圖記錄的時長不能短于9.625 s)。另外,12個導聯中僅有Ⅱ、Ⅲ、Ⅴ1、Ⅴ2、Ⅴ3、Ⅴ4、Ⅴ5、Ⅴ6是正交的,而剩余導聯可由它們線性推導,因此我們僅保留這8個正交導聯。最后每條心電圖記錄的采樣點數為8×1 900(=8×200×9.5),單位為mV。
1.2 導聯卷積神經網絡
導聯內數據(水平方向)是內容相關的,而導聯間數據(垂直方向)是獨立的,這是多導聯心電圖與二維數字圖像最大的區別。基于這種特殊的結構和卷積神經網絡[26]的特點,LCNN[23]應運而生,其完整結構圖如圖 3所示。
圖3
LCNN結構示意圖
Figure3.
Architecture sketch of LCNN
在圖 3中,1D-Cov表示1維卷積計算,CU表示卷積單元(包括一個卷積層和一個取樣層),每個導聯均有3個CU,且不同導聯間的CU互不相干,總共有24(=8×3)個CU。LCNN前向計算過程為:每個導聯的心電圖數據依次通過最適合自己的3個CU,之后匯總所有導聯的信息到全連接(fully connected,FC)層,最后交由Logistic回歸(LR)層輸出決策概率值。在實際應用中,每個導聯的CU個數可根據需要做相應調整。
本文在數值實驗中采用的LCNN,其相關參數設定如下[23]:三個卷積核尺寸分別為1×21、1×13和1×9,三個取樣核尺寸分別為1×7、1×6和1×6,三個特征面數分別為6、7和5;全連接層和Logistic回歸層的神經元數分別為50和1;輸入層的神經元數為8×1 700。
1.3 顯性訓練法
誤差反向傳播(back propagation, BP)算法[27]是最常用的神經網絡訓練方法,但由于它是一種局部搜索算法,因此要想獲得泛化能力強的分類模型,需要有足量的訓練樣本。然而,無限制地增加心電圖記錄的數目不現實;同時正常心電圖總是大量存在,而某種疾病的心電圖則相對要少,即類不平衡問題是普遍存在的。
從心電圖記錄中截取的一段局部數據,我們稱之為子記錄。顯然,若起始點不同,則對應的子記錄在數據空間中具有不同的分布。因此,我們通過平移起始點,從一條心電圖記錄中截取多條子記錄,并根據每類的樣本數確定每類的子記錄數,這樣既可以增加訓練樣本數,又解決了類不平衡問題。另外,我們還疊加正常情況下不影響醫生判讀的隨機信號,進一步增加訓練樣本數。
文獻[23]基于mini-batch[28],并結合以上兩種策略設計了顯性訓練法,其完整描述為:對于采樣點數為8×1 900的心電圖記錄,首先隨機確定起始點(取值為1~201間的任意整數),并截取一條8×1 700的子記錄(每導聯的起始點保持一致),然后以高概率疊加最大幅值不超過0.15 mV的隨機信號,這樣處理后再輸入到LCNN中進行誤差反向傳播;當已有560個樣本參與訓練,就更新網絡權值,再從每個校驗樣本中截取一條8×1 700的子記錄(起始點為1),用當前分類模型測試;若此時準確率是當前最高,則保存該模型;重復以上過程,直到滿足結束條件。圖 4給出了完整的顯性訓練過程。
圖4
顯性訓練法
Figure4.
Explicit training method
1.4 隱性訓練法
心電圖在個體間存在差異,但在某些個體間又有相似性。若校驗樣本不典型,即不包含全部有差異的個體,那么采用顯性訓練法所得的分類模型會存在一定的偏差,因為該方法是基于校驗樣本的測試結果來確定是否保存當前分類模型。然而,通過手工選擇代表性的心電圖記錄作為校驗樣本并不容易,受限于各種現實條件。為此,我們設計一種新的監督訓練方法,即隱性訓練法,如圖 5所示。
圖5
隱性訓練
Figure5.
Implicit training method
整個訓練過程可描述為:對于采樣點數為8×1 900的心電圖記錄,首先隨機確定起始點(取值為1~201間的任意整數),并截取一條8×1 700子記錄,然后以高概率疊加最大幅值不超過0.15 mV的隨機信號,這樣處理后再輸入到LCNN進行誤差反向傳播;當已有560個樣本參與訓練,就更新網絡權值,再從兩次權值更新之間的每個訓練樣本中截取一條8×1 700的子記錄(起始點為1),用當前分類模型測試,并累加測試結果;當所有樣本都已參與訓練,若此時準確率是當前最高,則保存當前模型;重復以上過程,直到滿足結束條件。
對比圖 4和圖 5可知,相比顯性訓練法,隱性訓練法沒有獨立的校驗樣本,而是從整個訓練樣本中選出一部分樣本用于校驗。雖然訓練樣本和校驗樣本均從相同的心電圖記錄中截取子記錄,但前者的起始點隨機確定,且以高概率疊加隨機信號,而后者的起始點為1,且不疊加隨機信號。因此,這兩部分樣本重合的概率很小。
本文在數值實驗中,不論顯性訓練法還是隱性訓練法,均采用慣性量和變步長的反向傳播算法[29],最大訓練周期為500,初始步長為0.02,步長衰減率第2、3周期為0.940 5,其余為0.99,訓練目標是最大化校驗集準確率。
1.5 多重輸出預測法
文獻[23]所采用的直接預測法是指從8×1 900心電圖記錄中截取一條8×1 700子記錄,并直接交由LCNN進行分類。為了提高分類結果的置信度,本文提出一種新的測試方法,即多重輸出預測法,如圖 6所示。
圖6
多重輸出預測法
Figure6.
Multiple output prediction method
整個測試過程可描述為:對于采樣點數為8×1 900的心電圖記錄,首先截取9條8×1 700子記錄(起始點分別為1、26、51、76、101、126、151、176和201),然后交由LCNN進行測試,輸出9個決策概率值,最后采用平均規則求得輸出值。此外,我們還可采用加權等更有效的其他計算方法。
1.6 貝葉斯方法
在本文中,我們采用貝葉斯方法[30]融合兩個LCNN模型,以增強最終的分類性能:給定二分類的數據,假設兩個分類器的輸出可以組合,那么決策類別m可由式(1)確定
| $ \left\{ \begin{array}{l} P\left( {y = j|{c_1},{c_2}} \right) = \frac{1}{2}\sum\limits_{i = 1}^2 {P\left( {y = j|{c_i}} \right)} \\ m = \mathop {\arg }\limits_{1 \le j \le M} \max \left\{ {P\left( {y = j|{c_1},{c_2}} \right)} \right\} \end{array} \right. $ |
其中P(y=j|ci)是第i個分類器ci給出屬于類別j的概率值。
2 心電圖數據
CCDD(http://58.210.56.164:88/ccdd)中的每條心電圖記錄均來自臨床,標準12導聯,持續時間為10~20 s,采樣頻率為500 Hz,診斷結論由心臟科醫生給出。目前,該數據庫共有179 130條心電圖記錄,其中CCDD[data1-943]數據集中的每條記錄既有心拍結論,又有記錄結論;而CCDD[data944-179130]數據集中的每條記錄則僅有記錄結論。
為了驗證所提方法的有效性,我們按照文獻[23]的做法選定訓練樣本和測試樣本:首先去除時長不足9.625 s以及記錄結論為空或無效的心電圖,然后將記錄結論為“0x0101”或“0x020101”或“0x020102”的心電圖標注為正常樣本,其他均為異常樣本;接著將CCDD[data944-25693]數據集劃分為訓練樣本、校驗樣本和小規模測試集,而CCDD[data25694-179130]數據集則為大規模測試集。表 1顯示了整個數據集的樣本分布情況。
訓練樣本和校驗樣本是針對顯性訓練法而言,在隱性訓練法中,兩者會合并。分類算法在小規模測試集上的性能僅作為參考,我們更關注其在大規模測試集上的表現。
3 數值實驗
3.1 評價指標
按照醫學診斷的定義,正常心電圖和異常心電圖分別為陰性和陽性結果。表 2描述了真實類別與決策類別的可能關系。
診斷指標包括特異性Sp、靈敏度Se、陰性預測值NPV和正確率Acc;除此以外,我們還使用AUC、約登指數r、幾何平均GM數和自適應幾何平均數AGM數[31]來評估算法的整體性能,計算公式如下:
| $ \left\{ \begin{array}{l} {\rm{Sp = }}\frac{{{\rm{TN}}}}{{{\rm{TN + FP}}}}\\ {\rm{Se = }}\frac{{{\rm{TP}}}}{{{\rm{TP + FN}}}}\\ {\rm{NPV = }}\frac{{{\rm{TN}}}}{{{\rm{TN + FN}}}}\\ {\rm{Acc = }}\frac{{{\rm{TN + TP}}}}{{{\rm{TN + FP + FN + TP}}}} \end{array} \right. $ |
| $ r = {\rm{Se + Sp}} - 1 $ |
| $ GM = \sqrt {{\rm{Se \times Sp}}} $ |
| $ \left\{ \begin{array}{l} {{\rm{N}}_{\rm{n}}} = \frac{{{\rm{TN + FP}}}}{{{\rm{TN + FP + FN + TP}}}}\\ AGM = \frac{{GM + {\rm{Sp \times }}{{\rm{N}}_{\rm{n}}}}}{{{\rm{1 + }}{{\rm{N}}_{\rm{n}}}}} \end{array} \right. $ |
3.2 算法評估
我們首先用兩種方法訓練得到兩個LCNN模型,再對每個模型用兩種方法進行測試。表 3和表 4給出了相應的實驗結果,可知無論在哪個數據集上測試,多重輸出預測法可提高每個LCNN模型的性能指標。此外,我們還發現由顯性訓練法和隱性訓練法所得的LCNN模型各具優勢,如前者擁有高AUC,而后者則有高準確率。表 5給出了兩個LCNN模型的融合結果。
由表 5可知,相比單個模型,融合模型在小規模測試集和大規模測試集均取得了更好的分類性能。正異常記錄分類的關鍵技術是盡可能提高NPV為95%前提下的Sp指標[32];由表 3和表 5可知,相比顯性模型、隱性模型和文獻[23],融合模型在大規模測試集上分別使這個指標提高了4.3%、9.6%和21.6%。由此驗證了所提出方法的有效性。
3.3 與其他文獻對比
為了進一步評估所提出方法的性能,我們將其與已公開發表的正異常記錄分類算法做對比。文獻[22]提出一種融合RR間期分析、QRS波群相似性分析、基于數值特征和形態特征的統計分類器、心電圖典型特征(P波、T波、R波、PR間期等)分析的ECG-MTHC,可給出心電圖記錄的正異常結論。另外,鑒于目前相關研究工作不多,本文同樣基于現有的心拍分類技術構建一個正異常記錄分類器。文獻[15]提出一種融合小波變換、獨立成分分析、主成分分析、RR間期特征、支持向量機和多導聯融合的心拍分類算法,在MIT-BIH-AR數據庫上進行評估,其個體內分類模式和個體間分類模式的準確率分別為99.3%和86.4%,是迄今為止最好的結果之一。我們首先利用人工標注從CCDD[data1-943]數據集中截取每條心電圖記錄上的心拍,然后按照文獻[15]所提方法訓練一個心拍分類器。在測試階段,首先利用文獻[33]所提方法檢測一條心電圖記錄上的所有R波,然后截取心拍并進行測試,最后采用平均心拍法(計算所有心拍的平均決策概率值,以此確定記錄結論)[21]和異常優先法(若存在異常心拍,則整條記錄即為異常)[34]確定當前記錄的正異常結論。這兩種測試模型分別記為YeC[Avg]和YeC[Bias]。
表 6給出了不同分類模型在大規模測試集上的實驗結果,其中11 176條心電圖記錄由于無法提取出ECG-MTHC所需要的特征,故無法給出記錄結論。為了公平比較,我們給出其他分類模型在相同數據集上的測試結果。由表 6可知,YeC[Avg]和YeC[Bias]表現欠佳,其準確率均不超過50%,同文獻[4]的測試結果類似;ECG-MTHC表現相對不錯,其準確率為72.49%。相比而言,本文所提方法除了Se稍低外,其他所有性能指標均比其他模型要高,準確率更是達到了85.08%。
事實上,文獻[15]所提方法的不少步驟并不符合臨床實際,如經過5~12 Hz帶通濾波,心電圖記錄中的P波、T波等重要的臨床診斷信息均被去除,顯然不利于后續診斷。這個問題在僅有48條記錄的MIT-BIH-AR數據庫上被掩蓋,但在擁有十幾萬條記錄的CCDD數據庫上暴露無遺。另外,該方法所涉及的不少參數針對MIT-BIH-AR數據庫進行調整,顯然并不適用于所有的數據集。這也是不少公開發表論文的共同問題:高分類性能僅限于標準數據庫,而不能推廣到實際應用[21]。
2012年Hakacova等[35]對市場上心電圖設備的自動診斷結果進行統計分析,總共統計了576例心電圖,發現Philips Medical Systems準確率僅有80%,Draeger Medical Systems準確率僅有75%,而3名普通醫生的平均判讀準確率為85%。本文所提方法在超過15萬條心電圖記錄上的準確率為85.04%,具有一定的參考和應用價值。
4 結論
本文在基于LCNN的臨床心電圖分類算法上融入集成學習思想,包括不同的預處理方法、不同的訓練方法以及多重輸出預測法。通過測試超過15萬條心電圖記錄,所提方法的準確率和AUC分別為85.04%和0.918 5。
除了濾波方法外,小波變換、傅立葉變換等均可用于數據預處理;除了不同的校驗方法,不同的網絡結構、錯分代價等均能使訓練所得的LCNN模型有所差異。這些都是我們下一步要開展的研究工作。