


癲癇腦電的自動分類對于癲癇的診斷和治療具有重要意義。本文提出了一種基于小波多尺度分析和極限學習機的癲癇腦電分類方法。首先,利用小波多尺度分析對原始腦電信號進行多尺度分解,提取出不同頻段的腦電信號。然后采用Hurst指數和樣本熵兩種非線性方法對原始腦電信號和小波多尺度分解得到的不同頻段腦電信號進行特征提取。最后,將得到的特征向量輸入到極限學習機中,實現癲癇腦電分類的目的。本文采用的方法在區分癲癇發作期和發作間期時取得了99.5%的分類準確率。結果表明,本方法在癲癇的診斷和治療中具有很好的應用前景。
引用本文: 崔剛強, 夏良斌, 梁建峰, 涂敏. 基于小波多尺度分析和極限學習機的癲癇腦電分類算法. 生物醫學工程學雜志, 2016, 33(6): 1025-1030,1038. doi: 10.7507/1001-5515.20160165 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
癲癇是一種由多種病因引起的慢性腦功能障礙疾病,其典型特征是大腦局部神經元反復地、突然地過度放電,導致中樞神經系統功能失常[1]。全世界有1%~2%的人口患有癲癇[2]。癲癇患者臨床表現為肌肉抽搐、意識喪失等,頻繁的癲癇發作往往會給患者的身體帶來極大的傷害,甚至危及生命,而且給患者家庭和社會帶來沉重的負擔。因此,加強癲癇疾病的前期診斷和后期治療工作,具有極其重要的意義。
腦電在臨床癲癇疾病的診斷、病灶定位、療效評估中有著不可替代的作用。癲癇發作表現為高幅同步節律波,包括棘波、尖波、棘慢復合波和尖慢復合波等[3]。目前,癲癇疾病的診斷工作主要由經驗豐富的醫生肉眼觀察長時間的腦電信號來完成,工作量巨大,而且受主觀因素影響較大,不同醫生給出的診斷結果有可能并不相同。因此,有必要開發一種癲癇腦電自動分類的方法。
癲癇腦電分類任務可以分為特征提取和分類兩部分工作。非線性動力學相關方法已經在癲癇腦電信號的非線性特征提取工作中有了很好的應用。已有研究者將Lyapunov指數[4]、Hurst指數[5]、近似熵[6]、分形維數[7]、樣本熵[8]、功率譜熵[9]、Lempel-Ziv復雜度[8]等非線性方法用于癲癇腦電信號的特征提取中。目前,癲癇腦電分類中使用較多的是K-最鄰近分類器[10]、貝葉斯分類器[11]、決策樹[12]、人工神經網絡(artificial neural network,ANN)[11]、支持向量機(support vector machine,SVM)[13-15]等,并且已經取得了一定的成果。文獻[14]比較了SVM、貝葉斯分類器、線性判別分析、K-最鄰近分類器、ANN等幾種分類方法在同一數據集上的分類效果,最終ANN取得了最高的97.7%的分類準確率。
Huang等[16]提出了一種新穎的單隱層前饋神經網絡的機器學習算法,即極限學習機(extreme learning machine,ELM),在學習機訓練開始時,就隨機給定它的隱藏層偏置和輸入權值,且無需在訓練過程中調整。與反向傳播(back propagation,BP)神經網絡相比,極限學習機既防止了學習過程中陷入局部最優解,又具有泛化能力強、訓練速度快的優點,有較好的應用前景。
本文提出了一種基于小波多尺度分析和極限學習機的癲癇腦電分類算法。首先,對原始腦電信號進行小波多尺度分解,提取出不同頻帶的腦電信號;然后,利用Hurst指數和樣本熵兩種方法進行非線性特征提取;最后,應用極限學習機分類器對癲癇腦電進行分類,并在波恩大學的癲癇腦電數據庫上測試分類器的性能。
1 基于小波多尺度分析的特征提取方法
1.1 小波多尺度分析
小波多尺度分析是一種將信號分解到多個尺度上的子空間的方法,分解后的信號在各個子空間同時具有時域和頻域的分辨率,可以方便地分析信號的時頻特性,在生物醫學信號處理中有很好的應用。
對于信號S來說,就是將其分解為尺度空間的A1近似部分和細節空間的D1細節部分,然后對A1部分再次進行尺度和細節的分解,得到A2和D2兩部分,再對A2進行如此分解。這里的近似信號對應于信號的低頻部分,而細節信號對應于信號的高頻部分。與傅里葉分析不同的是,高頻部分是分層次的,是在不同分辨率下逐步產生的。圖 1所示為信號S經過小波3層分解的示意圖。
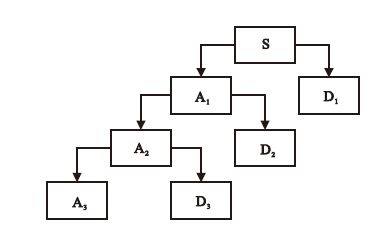 圖1
小波3層分解示意圖
Figure1.
Scheme of 3 layer wavelet decomposition
圖1
小波3層分解示意圖
Figure1.
Scheme of 3 layer wavelet decomposition
1.2 Hurst指數
Hurst指數是英國科學家H. E. Hurst在20世紀中葉提出的一種判斷時間序列是否具有時間依賴性的參數,現在也用于研究混沌時間序列的預測問題[17]。本文采用R/S法,即重標極差方法(rescaled range analysis)。步驟如下:
對于給定的時間序列xi(i=1,2,…,N),假定計算長度n,將時間序列劃分為長度為n的M個子序列,第m個子序列的第t個數據記為xt,m(t=1,…,n,m=1,…,M) ,第m個子序列的重標極差比為
| ${{\left( R/S \right)}_{n,m}}=\frac{{{R}_{n,m}}}{{{S}_{n,m}}}$ |
式中,Rn,m為第m個子序列的極差,Sn,m為第m個子序列的標準差:
| ${{R}_{n,m}}=\underset{1\le k\le n}{\mathop{\max }}\,\sum\limits_{t=1}^{k}{k({{x}_{t,m}}-\overline{{{x}_{n,m}}})}-\underset{1\le k\le n}{\mathop{\min }}\,\sum\limits_{t=1}^{k}{k({{x}_{t,m}}-\overline{{{x}_{n,m}}})}$ |
| ${{S}_{n,m}}=\sqrt{\frac{1}{n}\sum\limits_{t=1}^{k}{{{({{x}_{t,m}}-\overline{{{x}_{n,m}}})}^{2}}}}$ |
式中,xn,m為第m個子序列。時間序列xi對應于計算長度n的重標極差為
| ${{\left( R/S \right)}_{n}}=\frac{1}{M}\sum\limits_{m=1}^{M}{{{\left( R/S \right)}_{n,m}}}$ |
改變計算長度n,重新計算重標極差比,可以得到一組計算長度與重標極差的序列。Hurst認為,重標極差序列(R/S)n與計算長度n之間存在指數關系如下:
| ${{\left( R/S \right)}_{n}}=C\times {{n}^{H}}$ |
式中,C為常數,H即為Hurst指數。通過取雙對數:
| $\lg \left( R/S \right)=\lg \left( C \right)+H\lg \left( n \right)$ |
采用最小二乘法擬合公式(6),可以估算出Hurst指數。
1.3 樣本熵
Richman等[18]提出了一種評價給定時間序列復雜度的新方法,即樣本熵(sample entropy,SamEn),它是近似熵的一種改進方法。它是條件概率(conditional probability,CP)嚴格的自然對數,可用SamEn(m,r,N)來表示。其中,N為長度,r為相似容限,維數為m及m+1。樣本熵的具體算法如下:
將序列x(1),x(2),…,x(N)按順序組成m維矢量,其中1≤i≤N-m+1,即
| ${{X}_{m\left( i \right)}}=\left[ x\left( i \right),x\left( i+1 \right),\ldots ,x\left( i+m-1 \right) \right]$ |
定義矢量Xm(i)和矢量Xm(j)之間的距離為d[Xm(i),Xm(j)],即
| $d[{{X}_{m}}\left( i \right),{{X}_{m}}\left( j \right)]=\max x\left( i+k \right)-x\left( j+k \right)$ |
式中,1≤k≤m-1,1≤i,j≤N-m+1,i≠j。
給定相似容限r(r≥0),對于每一個1≤i≤N-m,統計出d[Xm(i),Xm(j)]≤r的數目與矢量總數N-m-1的比值,記作
| ${{B}^{m}}_{i}\left( r \right)=\frac{1}{N-m-1}num\{d[{{X}_{m}}\left( i \right),{{X}_{m}}\left( j \right)]\le r\}$ |
式中,1≤j≤N-m,i≠j。求其對所有i的平均值
| ${{B}^{m}}\left( r \right)=\frac{1}{N-m}\sum\limits_{i-1}^{N-m}{{{B}^{m}}_{i}\left( r \right)}$ |
將維數加1,即對于m+1點矢量,得到Bm+1(r)。
理論上此序列的樣本熵為
| $\text{SamEn}\left( m,r \right)=\underset{N\to \infty }{\mathop{\lim }}\,\{-\ln ({{B}^{m+1}}\left( r \right)/{{B}^{m}}\left( r \right))\}$ |
當N取有限值時,上式表示為
| $\text{SamEn}\left( m,r \right)=-\ln \{{{B}^{m+1}}\left( r \right)/{{B}^{m}}\left( r \right)\}$ |
SamEn的值隨嵌入維數m和相似容限r的變化而變化,在特定的研究環境下,參數是一定的。一般情況下,m=1或2,r=0.1SD~0.25SD(SD是給定時間序列的標準差)。
2 基于極限學習機的癲癇腦電分類算法
2.1 極限學習機
假設有N個訓練樣本為(xi,yi)∈RN×Rm,其中,xi∈RN為輸入,yi∈Rm為輸出。具有M個隱藏層節點的標準單隱層前饋神經網絡的數學模型為
| $\sum\limits_{j-1}^{M}{{{\beta }_{j}}g({{\omega }_{j}}{{x}_{i}}+{{b}_{j}})={{o}_{i}},i=1,2,\ldots ,N}$ |
其中,ωj為連接輸入神經元與第j個隱藏層神經元的輸入權值向量,βj為連接第j個隱藏層神經元與輸出神經元的輸出權值向量,oi為實際輸出向量,bj為隱藏層神經元的偏置,g(·)是隱藏層神經元的激活函數。
如果該模型能夠零誤差地逼近訓練樣本的輸出yi,即$\sum\limits_{i-1}^{M}{{{o}_{i}}-{{y}_{i}}=0}$,則存在βj,ωj,bj使下式成立:
| $\sum\limits_{j=1}^{M}{{{\beta }_{j}}g({{\omega }_{j}}{{x}_{i}}+{{b}_{j}})={{y}_{i}},i=1,2,\ldots ,N}$ |
將上式簡化成緊湊的矩陣形式:
| $H\beta =Y$ |
其中H被稱為神經網絡隱藏層的輸出矩陣。
Huang等[16]的研究表明,當神經元的激活函數任意可微時,單隱層前饋神經網絡的訓練誤差可以接近無限小的正數ε,此時極限學習機的輸入權值向量ωj和隱藏層偏置bj在訓練過程中可保持不變,且可以隨機分配。因此,訓練過程等價為求線性系統的最小二乘解${\hat{\beta }}$,即
| $\left\| H\hat{\beta }-T \right\|=\underset{\beta }{\mathop{\min }}\,\left\| H\beta -T \right\|$ |
其解$\hat{\beta }\text{=}{{H}^{+}}Y$,H+是隱藏層輸出矩陣H的Moore-Penrose廣義逆。
2.2 癲癇腦電分類方法
本研究提出了一種基于小波多尺度分析和極限學習機的癲癇腦電分類算法。首先,利用小波多尺度分析對原始腦電信號進行5層多尺度分解,從中提取出4個不同頻段的腦電信號。其次,利用兩種非線性方法Hurst指數和樣本熵分別對原始腦電信號和提取出的4個不同頻段的腦電信號進行特征提取,得到了10維特征向量。最后,將非線性特征提取得到的10維特征向量作為極限學習機的輸入,實現癲癇腦電分類的目的。詳細流程圖如圖 2所示。
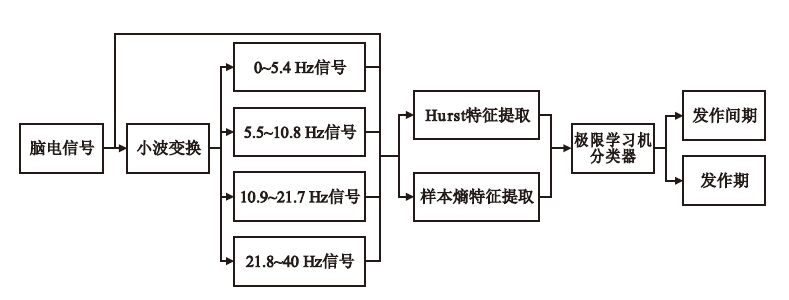 圖2
癲癇腦電分類方法流程圖
Figure2.
Flowchart of classification algorithm for epileptic EEG
圖2
癲癇腦電分類方法流程圖
Figure2.
Flowchart of classification algorithm for epileptic EEG
3 實驗結果與分析
本文實驗數據來自德國波恩大學癲癇研究中心的腦電數據庫。腦電信號采集系統采樣頻率為173.61 Hz,濾波帶寬為0.53~40 Hz,腦電數據已通過人工去除偽跡。該數據集包含5個子集(記為Z、O、N、F和S),其中,數據子集Z和O分別是健康人睜眼、閉眼時的正常腦電信號;數據子集N和F分別是癲癇患者發作間期病灶外和病灶區的腦電信號;數據子集S為癲癇患者發作期的腦電信號。數據集N、F和S均是由帶狀電極植入顱內,貼在海馬結構表面記錄得到的,其中癲癇發作期腦電信號(S)和癲癇發作間期的病灶區腦電信號(F)均是由帶狀電極貼在海馬結構病灶區記錄得到的,而癲癇發作間期的病灶外腦電信號(N)是帶狀電極貼在病灶區之外的另一個大腦半球海馬結構處得到的。每個子集包含100段腦電信號,每段4 096點。將每段數據平均分為4小段,分別求每一小段的特征值,再對得到的4個特征值求均值,作為該段數據的特征值。本文中小波多尺度分析采用的是db3小波基函數。樣本熵分析中,m=2,r=0.20SD。表 1為本文中涉及到的縮寫及其含義。
利用Hurst和樣本熵分別對癲癇發作期和發作間期的原始腦電信號和提取出的各頻段腦電信號進行特征提取。為了方便比較癲癇發作期和發作間期腦電信號S兩種特征值的差異,繪制了原始腦電信號發作期和發作間期特征值的分布序列和箱圖,如圖 3和圖 4所示。由于篇幅所限,本文中僅展示了原始腦電信號發作期和發作間期特征值的分布序列和箱圖,并未展示其他子頻段信號特征值的對比情況。圖 3是癲癇發作期和發作間期腦電信號特征值Hurst_S的分布序列和箱圖。從圖 3(a)可以看出,對大多數樣本,發作間期的Hurst特征值明顯大于發作期的Hurst特征值。從圖 3(b)可以看出,發作間期的Hurst特征值的均值明顯大于發作期的Hurst特征值均值。Hurst特征值對比結果表明,癲癇腦電發作期和發作間期均為持續穩定序列,發作間期的持續穩定性更強。圖 4是癲癇發作期和發作間期腦電信號特征值SamEn_S的分布序列和箱圖,對大多數樣本,發作間期的樣本熵特征值明顯大于發作期的樣本熵特征值,發作間期的樣本熵特征值的均值也明顯大于發作期的樣本熵特征值的均值。樣本熵特征值對比結果表明,發作間期的癲癇腦電比發作期的癲癇腦電更加不規則、更加復雜,產生新模式的概率也更高。
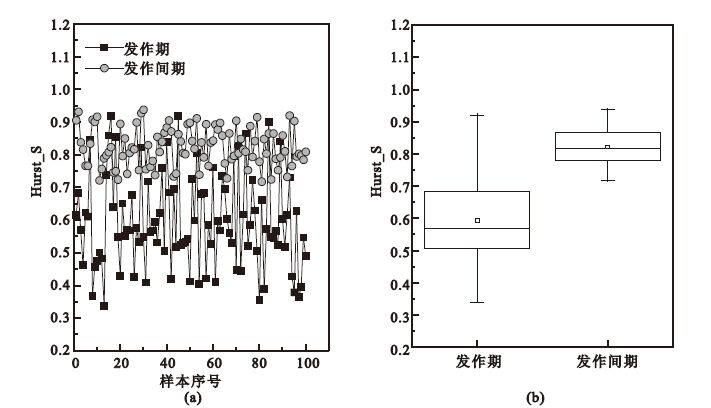 圖3
癲癇發作期和發作間期腦電信號特征值Hurst_S的分布序列和箱圖
圖3
癲癇發作期和發作間期腦電信號特征值Hurst_S的分布序列和箱圖
(a)Hurst_S的分布序列;(b)Hurst _S的箱圖
Figure3. Distribution series and box graphs of Hurst_S between epileptic ictal and interictal EEG(a) distribution series of Hurst_S; (b) box graphs of Hurst_S
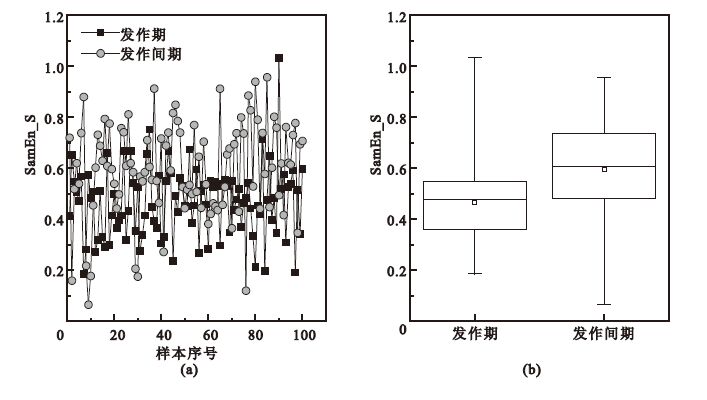 圖4
癲癇發作期和發作間期腦電信號特征值SamEn_S的分布序列和箱圖
圖4
癲癇發作期和發作間期腦電信號特征值SamEn_S的分布序列和箱圖
(a) SamEn_S的分布序列;(b)SamEn_S的箱圖
Figure4. Distribution series and box graphs of SamEn_S between epileptic ictal and interictal EEG(a) distribution series of SamEn_S; (b) box graphs of SamEn_S
表 2是對癲癇腦電10個特征值的單一特征值分類能力的評價結果。從表中可以得到以下結論:① 任意一個特征值對癲癇腦電的分類準確率均大于50%;② Hurst_S獲得了單一特征值的最高分類準確率89.5%;③ 利用原始腦電信號特征值得到的分類準確率大于從原始腦電信號提取出的各頻段腦電信號特征值的分類準確率;④ 總體來看,腦電信號的Hurst特征值的分類性能優于樣本熵特征值的分類性能。結果表明,本文提取的非線性特征能夠較好地反映大腦在發作期和發作間期時的非線性動力學特性。
按照上述特征提取方法,可以得到100個癲癇患者發作期的樣本,以及100個癲癇患者發作間期的樣本,其中每個樣本均包含一個10維特征向量。將10維特征向量作為極限學習機的輸入,采用交叉留一法(假設有N個樣本,將其中一個樣本作為測試集,其它N-1個樣本作為訓練集,這個步驟一直持續到每個樣本都被當作一次測試集為止,這樣得到N個分類器和N個測試結果,用這N個測試結果的平均值來評價分類器的性能),先訓練極限學習機分類模型,然后測試極限學習機的分類性能。本文中極限學習機的隱藏層節點均為50個。表 3是基于不同核函數的癲癇腦電發作期和發作間期分類結果,結果表明基于sig和radbas核函數的極限學習機均能達到很好的分類結果,其中訓練集上分類準確率均為100%,測試集上分類準確率為99.5%。
表 4給出了本文采用的方法與其他幾種方法關于癲癇腦電發作期和發作間期的分類結果,表明本文采用的小波多尺度分析聯合非線性特征提取和極限學習機得到的分類結果,優于其他非線性特征和ANN、SVM等的分類結果。
4 結論
非線性動力學理論在腦電信號分析中有著很高的研究價值。Hurst和樣本熵兩種非線性方法均可使用較短的數據進行分析,有很好的抗噪能力,可用于生理信號的分析。本文利用Hurst和樣本熵兩種非線性方法對發作期和發作間期的腦電信號及由小波多尺度分解得到的各頻段腦電信號進行了特征提取,結果表明所有的非線性特征值都能達到50%以上的分類準確率,說明本文使用的非線性特征提取方法能夠反映發作期和發作間期的腦電信號的非線性動力學差異。將特征提取的10維特征向量作為輸入,比較了基于不同核函數的極限學習機的分類性能,發現基于sig和radbas核函數的極限學習機均能達到很好的分類結果,其中訓練集上分類準確率均為100%,測試集上分類準確率為99.5%。本文取得的分類結果優于其他研究中的結果,表明由小波多尺度分析聯合非線性特征構建的極限學習機分類器能夠很好地完成癲癇腦電分類任務,而且極限學習機分類器具有很好的泛化能力。
引言
癲癇是一種由多種病因引起的慢性腦功能障礙疾病,其典型特征是大腦局部神經元反復地、突然地過度放電,導致中樞神經系統功能失常[1]。全世界有1%~2%的人口患有癲癇[2]。癲癇患者臨床表現為肌肉抽搐、意識喪失等,頻繁的癲癇發作往往會給患者的身體帶來極大的傷害,甚至危及生命,而且給患者家庭和社會帶來沉重的負擔。因此,加強癲癇疾病的前期診斷和后期治療工作,具有極其重要的意義。
腦電在臨床癲癇疾病的診斷、病灶定位、療效評估中有著不可替代的作用。癲癇發作表現為高幅同步節律波,包括棘波、尖波、棘慢復合波和尖慢復合波等[3]。目前,癲癇疾病的診斷工作主要由經驗豐富的醫生肉眼觀察長時間的腦電信號來完成,工作量巨大,而且受主觀因素影響較大,不同醫生給出的診斷結果有可能并不相同。因此,有必要開發一種癲癇腦電自動分類的方法。
癲癇腦電分類任務可以分為特征提取和分類兩部分工作。非線性動力學相關方法已經在癲癇腦電信號的非線性特征提取工作中有了很好的應用。已有研究者將Lyapunov指數[4]、Hurst指數[5]、近似熵[6]、分形維數[7]、樣本熵[8]、功率譜熵[9]、Lempel-Ziv復雜度[8]等非線性方法用于癲癇腦電信號的特征提取中。目前,癲癇腦電分類中使用較多的是K-最鄰近分類器[10]、貝葉斯分類器[11]、決策樹[12]、人工神經網絡(artificial neural network,ANN)[11]、支持向量機(support vector machine,SVM)[13-15]等,并且已經取得了一定的成果。文獻[14]比較了SVM、貝葉斯分類器、線性判別分析、K-最鄰近分類器、ANN等幾種分類方法在同一數據集上的分類效果,最終ANN取得了最高的97.7%的分類準確率。
Huang等[16]提出了一種新穎的單隱層前饋神經網絡的機器學習算法,即極限學習機(extreme learning machine,ELM),在學習機訓練開始時,就隨機給定它的隱藏層偏置和輸入權值,且無需在訓練過程中調整。與反向傳播(back propagation,BP)神經網絡相比,極限學習機既防止了學習過程中陷入局部最優解,又具有泛化能力強、訓練速度快的優點,有較好的應用前景。
本文提出了一種基于小波多尺度分析和極限學習機的癲癇腦電分類算法。首先,對原始腦電信號進行小波多尺度分解,提取出不同頻帶的腦電信號;然后,利用Hurst指數和樣本熵兩種方法進行非線性特征提取;最后,應用極限學習機分類器對癲癇腦電進行分類,并在波恩大學的癲癇腦電數據庫上測試分類器的性能。
1 基于小波多尺度分析的特征提取方法
1.1 小波多尺度分析
小波多尺度分析是一種將信號分解到多個尺度上的子空間的方法,分解后的信號在各個子空間同時具有時域和頻域的分辨率,可以方便地分析信號的時頻特性,在生物醫學信號處理中有很好的應用。
對于信號S來說,就是將其分解為尺度空間的A1近似部分和細節空間的D1細節部分,然后對A1部分再次進行尺度和細節的分解,得到A2和D2兩部分,再對A2進行如此分解。這里的近似信號對應于信號的低頻部分,而細節信號對應于信號的高頻部分。與傅里葉分析不同的是,高頻部分是分層次的,是在不同分辨率下逐步產生的。圖 1所示為信號S經過小波3層分解的示意圖。
圖1
小波3層分解示意圖
Figure1.
Scheme of 3 layer wavelet decomposition
1.2 Hurst指數
Hurst指數是英國科學家H. E. Hurst在20世紀中葉提出的一種判斷時間序列是否具有時間依賴性的參數,現在也用于研究混沌時間序列的預測問題[17]。本文采用R/S法,即重標極差方法(rescaled range analysis)。步驟如下:
對于給定的時間序列xi(i=1,2,…,N),假定計算長度n,將時間序列劃分為長度為n的M個子序列,第m個子序列的第t個數據記為xt,m(t=1,…,n,m=1,…,M) ,第m個子序列的重標極差比為
| ${{\left( R/S \right)}_{n,m}}=\frac{{{R}_{n,m}}}{{{S}_{n,m}}}$ |
式中,Rn,m為第m個子序列的極差,Sn,m為第m個子序列的標準差:
| ${{R}_{n,m}}=\underset{1\le k\le n}{\mathop{\max }}\,\sum\limits_{t=1}^{k}{k({{x}_{t,m}}-\overline{{{x}_{n,m}}})}-\underset{1\le k\le n}{\mathop{\min }}\,\sum\limits_{t=1}^{k}{k({{x}_{t,m}}-\overline{{{x}_{n,m}}})}$ |
| ${{S}_{n,m}}=\sqrt{\frac{1}{n}\sum\limits_{t=1}^{k}{{{({{x}_{t,m}}-\overline{{{x}_{n,m}}})}^{2}}}}$ |
式中,xn,m為第m個子序列。時間序列xi對應于計算長度n的重標極差為
| ${{\left( R/S \right)}_{n}}=\frac{1}{M}\sum\limits_{m=1}^{M}{{{\left( R/S \right)}_{n,m}}}$ |
改變計算長度n,重新計算重標極差比,可以得到一組計算長度與重標極差的序列。Hurst認為,重標極差序列(R/S)n與計算長度n之間存在指數關系如下:
| ${{\left( R/S \right)}_{n}}=C\times {{n}^{H}}$ |
式中,C為常數,H即為Hurst指數。通過取雙對數:
| $\lg \left( R/S \right)=\lg \left( C \right)+H\lg \left( n \right)$ |
采用最小二乘法擬合公式(6),可以估算出Hurst指數。
1.3 樣本熵
Richman等[18]提出了一種評價給定時間序列復雜度的新方法,即樣本熵(sample entropy,SamEn),它是近似熵的一種改進方法。它是條件概率(conditional probability,CP)嚴格的自然對數,可用SamEn(m,r,N)來表示。其中,N為長度,r為相似容限,維數為m及m+1。樣本熵的具體算法如下:
將序列x(1),x(2),…,x(N)按順序組成m維矢量,其中1≤i≤N-m+1,即
| ${{X}_{m\left( i \right)}}=\left[ x\left( i \right),x\left( i+1 \right),\ldots ,x\left( i+m-1 \right) \right]$ |
定義矢量Xm(i)和矢量Xm(j)之間的距離為d[Xm(i),Xm(j)],即
| $d[{{X}_{m}}\left( i \right),{{X}_{m}}\left( j \right)]=\max x\left( i+k \right)-x\left( j+k \right)$ |
式中,1≤k≤m-1,1≤i,j≤N-m+1,i≠j。
給定相似容限r(r≥0),對于每一個1≤i≤N-m,統計出d[Xm(i),Xm(j)]≤r的數目與矢量總數N-m-1的比值,記作
| ${{B}^{m}}_{i}\left( r \right)=\frac{1}{N-m-1}num\{d[{{X}_{m}}\left( i \right),{{X}_{m}}\left( j \right)]\le r\}$ |
式中,1≤j≤N-m,i≠j。求其對所有i的平均值
| ${{B}^{m}}\left( r \right)=\frac{1}{N-m}\sum\limits_{i-1}^{N-m}{{{B}^{m}}_{i}\left( r \right)}$ |
將維數加1,即對于m+1點矢量,得到Bm+1(r)。
理論上此序列的樣本熵為
| $\text{SamEn}\left( m,r \right)=\underset{N\to \infty }{\mathop{\lim }}\,\{-\ln ({{B}^{m+1}}\left( r \right)/{{B}^{m}}\left( r \right))\}$ |
當N取有限值時,上式表示為
| $\text{SamEn}\left( m,r \right)=-\ln \{{{B}^{m+1}}\left( r \right)/{{B}^{m}}\left( r \right)\}$ |
SamEn的值隨嵌入維數m和相似容限r的變化而變化,在特定的研究環境下,參數是一定的。一般情況下,m=1或2,r=0.1SD~0.25SD(SD是給定時間序列的標準差)。
2 基于極限學習機的癲癇腦電分類算法
2.1 極限學習機
假設有N個訓練樣本為(xi,yi)∈RN×Rm,其中,xi∈RN為輸入,yi∈Rm為輸出。具有M個隱藏層節點的標準單隱層前饋神經網絡的數學模型為
| $\sum\limits_{j-1}^{M}{{{\beta }_{j}}g({{\omega }_{j}}{{x}_{i}}+{{b}_{j}})={{o}_{i}},i=1,2,\ldots ,N}$ |
其中,ωj為連接輸入神經元與第j個隱藏層神經元的輸入權值向量,βj為連接第j個隱藏層神經元與輸出神經元的輸出權值向量,oi為實際輸出向量,bj為隱藏層神經元的偏置,g(·)是隱藏層神經元的激活函數。
如果該模型能夠零誤差地逼近訓練樣本的輸出yi,即$\sum\limits_{i-1}^{M}{{{o}_{i}}-{{y}_{i}}=0}$,則存在βj,ωj,bj使下式成立:
| $\sum\limits_{j=1}^{M}{{{\beta }_{j}}g({{\omega }_{j}}{{x}_{i}}+{{b}_{j}})={{y}_{i}},i=1,2,\ldots ,N}$ |
將上式簡化成緊湊的矩陣形式:
| $H\beta =Y$ |
其中H被稱為神經網絡隱藏層的輸出矩陣。
Huang等[16]的研究表明,當神經元的激活函數任意可微時,單隱層前饋神經網絡的訓練誤差可以接近無限小的正數ε,此時極限學習機的輸入權值向量ωj和隱藏層偏置bj在訓練過程中可保持不變,且可以隨機分配。因此,訓練過程等價為求線性系統的最小二乘解${\hat{\beta }}$,即
| $\left\| H\hat{\beta }-T \right\|=\underset{\beta }{\mathop{\min }}\,\left\| H\beta -T \right\|$ |
其解$\hat{\beta }\text{=}{{H}^{+}}Y$,H+是隱藏層輸出矩陣H的Moore-Penrose廣義逆。
2.2 癲癇腦電分類方法
本研究提出了一種基于小波多尺度分析和極限學習機的癲癇腦電分類算法。首先,利用小波多尺度分析對原始腦電信號進行5層多尺度分解,從中提取出4個不同頻段的腦電信號。其次,利用兩種非線性方法Hurst指數和樣本熵分別對原始腦電信號和提取出的4個不同頻段的腦電信號進行特征提取,得到了10維特征向量。最后,將非線性特征提取得到的10維特征向量作為極限學習機的輸入,實現癲癇腦電分類的目的。詳細流程圖如圖 2所示。
圖2
癲癇腦電分類方法流程圖
Figure2.
Flowchart of classification algorithm for epileptic EEG
3 實驗結果與分析
本文實驗數據來自德國波恩大學癲癇研究中心的腦電數據庫。腦電信號采集系統采樣頻率為173.61 Hz,濾波帶寬為0.53~40 Hz,腦電數據已通過人工去除偽跡。該數據集包含5個子集(記為Z、O、N、F和S),其中,數據子集Z和O分別是健康人睜眼、閉眼時的正常腦電信號;數據子集N和F分別是癲癇患者發作間期病灶外和病灶區的腦電信號;數據子集S為癲癇患者發作期的腦電信號。數據集N、F和S均是由帶狀電極植入顱內,貼在海馬結構表面記錄得到的,其中癲癇發作期腦電信號(S)和癲癇發作間期的病灶區腦電信號(F)均是由帶狀電極貼在海馬結構病灶區記錄得到的,而癲癇發作間期的病灶外腦電信號(N)是帶狀電極貼在病灶區之外的另一個大腦半球海馬結構處得到的。每個子集包含100段腦電信號,每段4 096點。將每段數據平均分為4小段,分別求每一小段的特征值,再對得到的4個特征值求均值,作為該段數據的特征值。本文中小波多尺度分析采用的是db3小波基函數。樣本熵分析中,m=2,r=0.20SD。表 1為本文中涉及到的縮寫及其含義。
利用Hurst和樣本熵分別對癲癇發作期和發作間期的原始腦電信號和提取出的各頻段腦電信號進行特征提取。為了方便比較癲癇發作期和發作間期腦電信號S兩種特征值的差異,繪制了原始腦電信號發作期和發作間期特征值的分布序列和箱圖,如圖 3和圖 4所示。由于篇幅所限,本文中僅展示了原始腦電信號發作期和發作間期特征值的分布序列和箱圖,并未展示其他子頻段信號特征值的對比情況。圖 3是癲癇發作期和發作間期腦電信號特征值Hurst_S的分布序列和箱圖。從圖 3(a)可以看出,對大多數樣本,發作間期的Hurst特征值明顯大于發作期的Hurst特征值。從圖 3(b)可以看出,發作間期的Hurst特征值的均值明顯大于發作期的Hurst特征值均值。Hurst特征值對比結果表明,癲癇腦電發作期和發作間期均為持續穩定序列,發作間期的持續穩定性更強。圖 4是癲癇發作期和發作間期腦電信號特征值SamEn_S的分布序列和箱圖,對大多數樣本,發作間期的樣本熵特征值明顯大于發作期的樣本熵特征值,發作間期的樣本熵特征值的均值也明顯大于發作期的樣本熵特征值的均值。樣本熵特征值對比結果表明,發作間期的癲癇腦電比發作期的癲癇腦電更加不規則、更加復雜,產生新模式的概率也更高。
圖3
癲癇發作期和發作間期腦電信號特征值Hurst_S的分布序列和箱圖
(a)Hurst_S的分布序列;(b)Hurst _S的箱圖
Figure3. Distribution series and box graphs of Hurst_S between epileptic ictal and interictal EEG(a) distribution series of Hurst_S; (b) box graphs of Hurst_S
圖4
癲癇發作期和發作間期腦電信號特征值SamEn_S的分布序列和箱圖
(a) SamEn_S的分布序列;(b)SamEn_S的箱圖
Figure4. Distribution series and box graphs of SamEn_S between epileptic ictal and interictal EEG(a) distribution series of SamEn_S; (b) box graphs of SamEn_S
表 2是對癲癇腦電10個特征值的單一特征值分類能力的評價結果。從表中可以得到以下結論:① 任意一個特征值對癲癇腦電的分類準確率均大于50%;② Hurst_S獲得了單一特征值的最高分類準確率89.5%;③ 利用原始腦電信號特征值得到的分類準確率大于從原始腦電信號提取出的各頻段腦電信號特征值的分類準確率;④ 總體來看,腦電信號的Hurst特征值的分類性能優于樣本熵特征值的分類性能。結果表明,本文提取的非線性特征能夠較好地反映大腦在發作期和發作間期時的非線性動力學特性。
按照上述特征提取方法,可以得到100個癲癇患者發作期的樣本,以及100個癲癇患者發作間期的樣本,其中每個樣本均包含一個10維特征向量。將10維特征向量作為極限學習機的輸入,采用交叉留一法(假設有N個樣本,將其中一個樣本作為測試集,其它N-1個樣本作為訓練集,這個步驟一直持續到每個樣本都被當作一次測試集為止,這樣得到N個分類器和N個測試結果,用這N個測試結果的平均值來評價分類器的性能),先訓練極限學習機分類模型,然后測試極限學習機的分類性能。本文中極限學習機的隱藏層節點均為50個。表 3是基于不同核函數的癲癇腦電發作期和發作間期分類結果,結果表明基于sig和radbas核函數的極限學習機均能達到很好的分類結果,其中訓練集上分類準確率均為100%,測試集上分類準確率為99.5%。
表 4給出了本文采用的方法與其他幾種方法關于癲癇腦電發作期和發作間期的分類結果,表明本文采用的小波多尺度分析聯合非線性特征提取和極限學習機得到的分類結果,優于其他非線性特征和ANN、SVM等的分類結果。
4 結論
非線性動力學理論在腦電信號分析中有著很高的研究價值。Hurst和樣本熵兩種非線性方法均可使用較短的數據進行分析,有很好的抗噪能力,可用于生理信號的分析。本文利用Hurst和樣本熵兩種非線性方法對發作期和發作間期的腦電信號及由小波多尺度分解得到的各頻段腦電信號進行了特征提取,結果表明所有的非線性特征值都能達到50%以上的分類準確率,說明本文使用的非線性特征提取方法能夠反映發作期和發作間期的腦電信號的非線性動力學差異。將特征提取的10維特征向量作為輸入,比較了基于不同核函數的極限學習機的分類性能,發現基于sig和radbas核函數的極限學習機均能達到很好的分類結果,其中訓練集上分類準確率均為100%,測試集上分類準確率為99.5%。本文取得的分類結果優于其他研究中的結果,表明由小波多尺度分析聯合非線性特征構建的極限學習機分類器能夠很好地完成癲癇腦電分類任務,而且極限學習機分類器具有很好的泛化能力。