


腦電圖(EEG)分析已被廣泛應用于疾病的診斷,針對癲癇患者的腦電檢測可及時對患者的發病情況作出判斷,具有很強的實用價值,因此急需癲癇腦電自動檢測、診斷分類技術。為實現患者正常期、癲癇發作間期和發作期各時段腦電的快速、高精度自動檢測分類,本文提出一種基于樣本熵(SampEn)與小波包能量特征提取結合糾錯編碼(ECOC)Real AdaBoost算法的腦電自動分類識別方法。將輸入信號的樣本熵值和4層小波包分解后的部分頻段能量作為特征,并用糾錯編碼和Real AdaBoost算法相結合的方式對其進行分類。本文采用德國波恩大學癲癇數據庫實驗數據(含正常人清醒、睜眼與清醒、閉眼,癲癇患者間歇期致癇灶外與致癇灶內及癲癇發作期5組腦電信號)進行了方法有效性檢驗。研究結果表明,該方法有較強的腦電特征分類識別能力,尤其對癲癇間歇期腦電信號識別率提升顯著,上述5組3個時期不同特征腦電信號的平均識別率可達96.78%,優于文獻已報道的多種算法且有較好穩定性與運算速度及實時應用潛力,可在臨床上對癲癇疾病的預報及檢測起到良好的輔助決策作用。
引用本文: 張健釗, 姜威, 賁晛燁. 基于樣本熵與小波包能量特征提取和Real AdaBoost算法的正常期、癲癇間歇與發作期的腦電自動檢測. 生物醫學工程學雜志, 2016, 33(6): 1031-1038. doi: 10.7507/1001-5515.20160166 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
癲癇(epilepsy)是由于大腦神經元異常放電所導致的短暫大腦功能障礙。癲癇患者在間歇期和發作期的腦電圖(electroencephalogram,EEG)會有較為明顯的異常表現,出現棘波、尖波及棘慢復合波等特征波形,因而腦電圖作為一項重要手段已廣泛應用于癲癇檢測中。醫學專家可以對腦電儀采集的腦電信號采取人工判讀的方法,從中找出癲癇的特征波形,從而實現對癲癇的診斷。但這種方法耗時耗力,而且不同專家對同一段波形的判斷也不盡一致,因此針對癲癇信號的自動檢測和識別分類顯得尤為必要。
近年來,眾多學者對癲癇腦電的自動診斷與分類展開了多項研究。小波變換[1]、經驗模態分解(empirical mode decomposition,EMD)[2]、熵[3-4]等常用信號分析方法均被應用于癲癇腦電的特征提取上;而目前流行的分類算法如人工神經網絡(artificial neural network,ANN)[4]、支持向量機(support vector machine,SVM)[5]、Boosting[6]等被廣泛用于腦電信號分類問題中,并達到了較高的分類精度。近年來廣受關注的極限學習機(extreme learning machine,ELM)因其訓練快速、分類性能出色等優點也受到了研究者們的青睞[7-8]。雖然這一領域的研究已取得了較為顯著的成果,但是仍面臨很多問題。在特征提取方面,僅局限于時、頻域或非線性方法用于描述腦電信號會顯得過于單一,使得分類器訓練不夠充分導致最終分類結果識別率不高,泛化能力不強,因此部分研究者嘗試將多種特征應用于腦電信號的判別上[8-9]。在模式識別方面,基于支持向量機的分類方法雖然對于小樣本問題有著較強的泛化能力,但對于規模較大的樣本訓練速度緩慢。而極限學習機雖然針對傳統神經網絡方法作了改進,但其初始輸入參數隨機產生,無法保證參數最優,使得最終分類效果受到一定影響。另外,目前的多數研究集中于腦電信號的二分類問題上,對信號的多時期分類的研究仍然較少。本文在此基礎上,結合集成學習算法不依賴參數、運算速度快的優點提出一種對癲癇各時期腦電信號檢測的方案。首先對截取的信號片段進行濾波處理去除相應高頻成分,并將改進的快速樣本熵(sample entropy,SampEn)計算方法引入其中,將樣本熵值與部分節點的小波包能量組成特征向量送入基于糾錯編碼(error-correcting output codes,ECOC)的Real AdaBoost多類分類器中,并采用累計置信度作為判決依據,最終實現了對正常期、發作間期和發作期腦電信號的分類。本文所述方案的基本流程如圖 1所示。
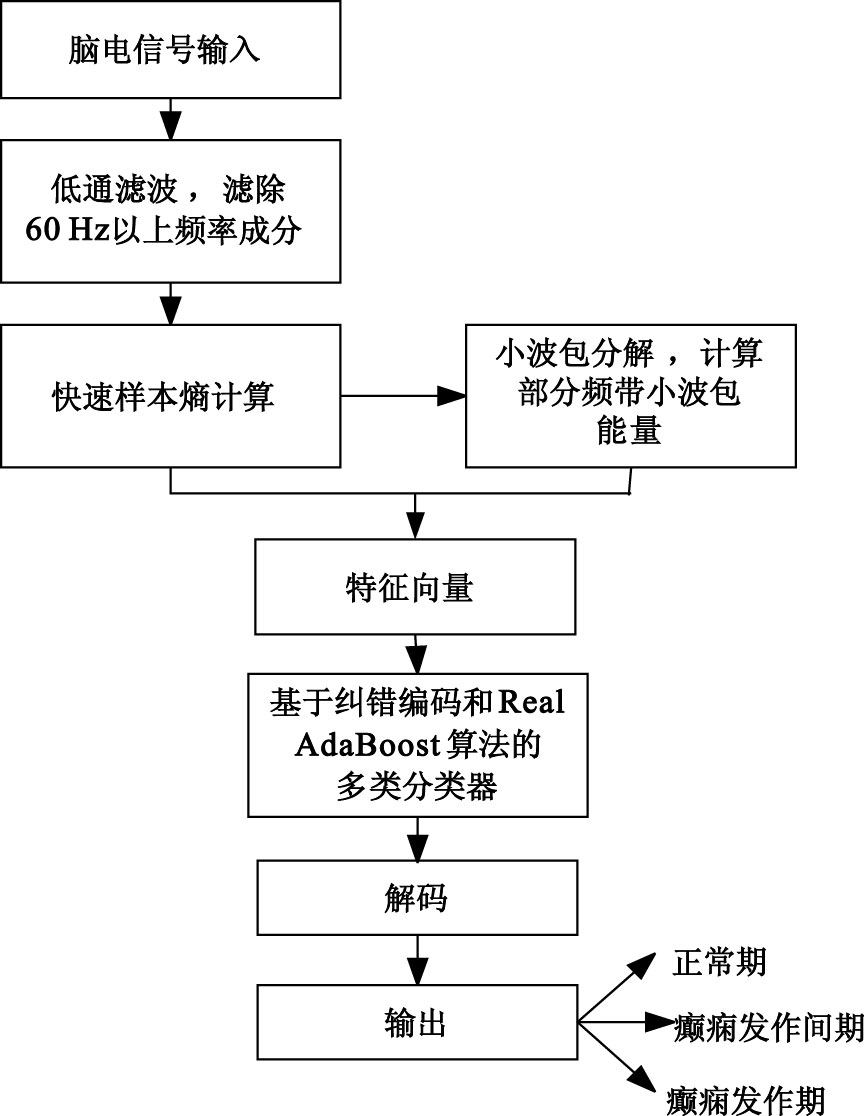 圖1
腦電信號識別流程
Figure1.
Process of EEG signal recognition
圖1
腦電信號識別流程
Figure1.
Process of EEG signal recognition
1 實驗數據
本文使用的實驗數據來源于德國波恩大學癲癇研究中心數據庫[10],共分為5組數據集,編號分別為A和B(正常人清醒、睜眼時腦電數據和清醒、閉眼時腦電數據)、C和D(癲癇發作間期致癇灶外和致癇灶內腦電數據)及E(癲癇發作期腦電數據)。每組共有100段腦電信號,采樣頻率為173.6 Hz,每段共計4 097點數據,本文采用A~E組數據進行三個時期分類。將A、B組標記為正常時期信號數據,C、D組標記為發作間期信號數據,E組標記為發作期信號數據。由于原始數據段較長,實驗前先將每段數據最后一個點舍棄,并等分為4段,每段1 024點數據,每個數據集得到400段腦電信號樣本,共計2 000個樣本。
2 特征提取方法
2.1 樣本熵及其優化
樣本熵是由Richman等[11]提出的度量時間序列信號自我相似程度及復雜度的方法,是對于近似熵(approximate entropy,ApEn)的改進。較近似熵而言,樣本熵對數據長度及丟失數據不敏感,只需要較短的時間序列即可得到較為準確的估計。其基本思想是通過改變嵌入維度以計算序列產生新信息概率的大小。樣本熵可以用參數m、 r、 N表示,m為嵌入維度,r為相似容限,N為時間序列長度。對于同一個序列,構造包含m個和m+1個矢量的新序列,分別計算矢量之間距離小于r的平均數量Bm(r)和Bm+1(r),最終結果表示為$-\ln \left( \frac{{{B}^{m+1}}\left( r \right)}{{{B}^{m}}\left( r \right)} \right)$。通常情況下,m=1或2,r=0.1×std~0.25×std(std為序列標準差)。時間序列越復雜,自我相似程度越低,熵值越大。腦電信號作為一種有代表性的非平穩信號,其非線性特征的提取對于識別往往具有良好的效果,目前樣本熵理論也被廣泛應用于腦電信號分析中。實驗表明,癲癇發作間期和發作期信號成分復雜度減小,樣本熵值較正常時期明顯降低,如圖 2所示,為其中一組參數下(m=2,r=0.2×std,N=1 024)的兩個時期樣本熵分布規律比較。可見,發作期、發作間期與正常時期樣本熵區分效果較好,適合作為分類特征。
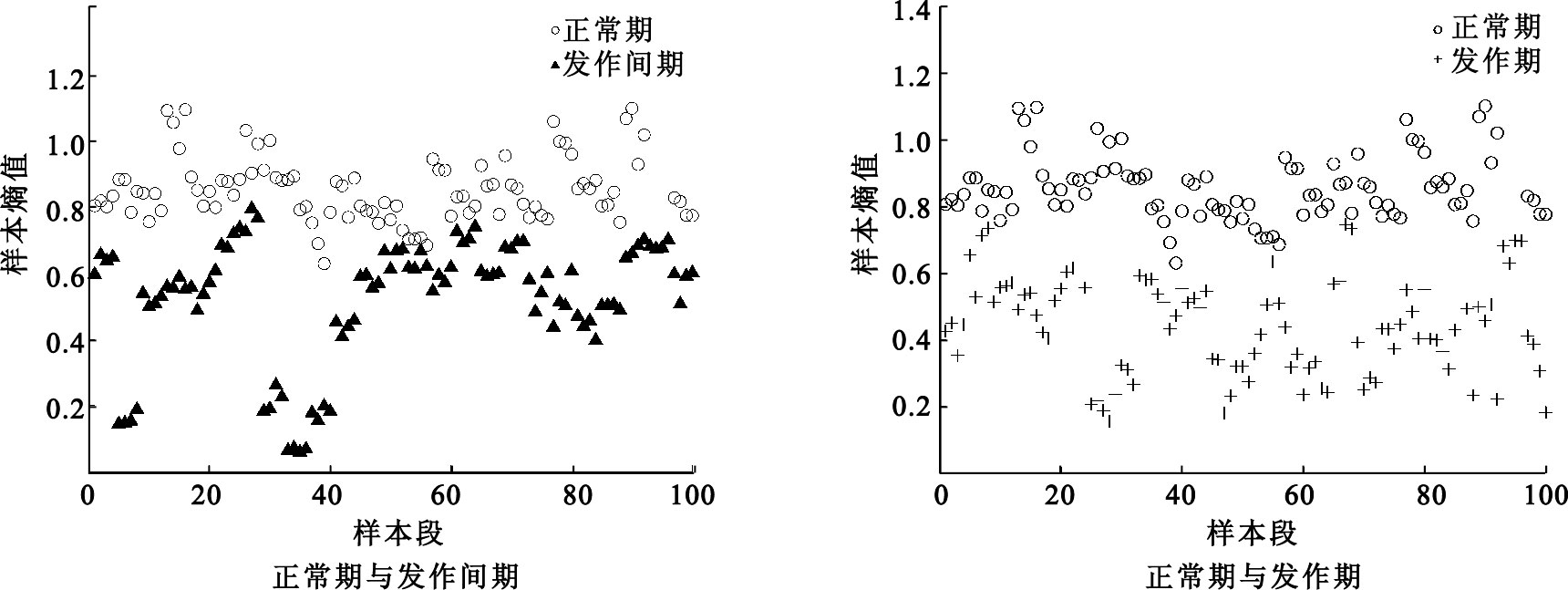 圖2
樣本熵在兩個時期的分布規律
Figure2.
Distribution of the sample entropy during the two periods
圖2
樣本熵在兩個時期的分布規律
Figure2.
Distribution of the sample entropy during the two periods
為滿足實時計算的要求,洪波等[12]提出了一種快速近似熵算法,引入二值矩陣,通過矩陣元素間簡單的邏輯運算簡化了運算過程,本文在此基礎上進一步優化了樣本熵的運算過程。由于通常情況下取m=2,因此以下方法在m=2的情況下進行計算,具體步驟如下:
(1) 對給定的N點序列{u(i)}、閾值r及嵌入維度m,初始化(N-1)×(N-1)的二值矩陣M,定義第i行第j列的元素為aij,則:
| ${{a}_{ij}}=\left\{ \begin{array}{*{35}{l}} 1 & u\left( i \right)-u\left( j+1 \right)r且j\ge i \\ 0 & 其他 \\ \end{array} \right.$ |
其中0<i,j<N;
(2) 初始化N-m+1維的行向量V,定義其中每個元素為vk且vk =0(1≤k≤N-m+1)。對矩陣M的每一行i(1≤i≤N-m),初始化si=0,則:
| ${{v}_{j+1}}\text{=}\left\{ \begin{array}{*{35}{l}} {{v}_{j+1}}+1 & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}=1 \\ {{v}_{j+1}} & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}=0 \\ \end{array} \right.$ |
| ${{s}_{i}}\text{=}\left\{ \begin{array}{*{35}{l}} {{s}_{i}}+1 & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}=1 \\ {{s}_{i}} & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}=0 \\ \end{array} \right.$ |
其中i≤j≤N-m。則兩矢量間最大距離的平均值為:
| ${{B}^{m}}_{i}\left( r \right)=\frac{{{s}_{i}}+{{v}_{i}}}{N-m}$ |
(3)對所有的Bmi(r)求平均,結果記為Bm(r),則:
| ${{B}^{m}}\left( r \right)=\frac{\sum\limits_{i=1}^{N-m}{{{B}^{m}}_{i}\left( r \right)+{{v}_{N-m+1}}/\left( N-m \right)}}{N-m+1}$ |
(4) 令m=m+1,重復執行第(2)(3)步,其中式(2)和式(3)修改為:
| ${{v}_{j+1}}\text{=}\left\{ \begin{array}{*{35}{l}} {{v}_{j+1}}+1 & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}\cap {{a}_{\left( i+2 \right)(j+2)}}=1 \\ {{v}_{j+1}} & ~{{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}\cap {{a}_{\left( i+2 \right)(j+2)}}=0 \\ \end{array} \right.$ |
| ${{s}_{i}}\text{=}\left\{ \begin{array}{*{35}{l}} {{s}_{i}}+1 & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}\cap {{a}_{\left( i+2 \right)(j+2)}}=1 \\ {{s}_{i}} & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}\cap {{a}_{\left( i+2 \right)(j+2)}}=0 \\ \end{array} \right.$ |
其余步驟不變,得到Bm+1(r);
(5) 由于序列長度N為有限值,所以根據以下公式計算樣本熵:
| $\text{SampEn}\left( m,r \right)=-\ln \frac{{{B}^{m+1}}\left( r \right)}{{{B}^{m}}\left( r \right)}$ |
由以上步驟可知,該方法省去了矩陣中重復部分的構造,并且通過引入向量V,避免了重復計算。原始算法和改進后快速算法的耗時如表 1所示。可見對于較長的序列,運算也可在1 s左右的時間完成,運算速度提高9倍以上。
2.2 小波包分解
小波分析作為一種時頻分析的主要工具已被廣泛應用于各個領域。相比于傅里葉變換和短時傅里葉變換,小波分析具有多分辨率分析的優點,可以在多個尺度上反映信號的局部細節。但傳統的小波變換只對每一次分解后信號的低頻成分做進一步分解而忽略了高頻成分,因而不能充分地反映信號細節。小波包分解是一種能夠繼續將高頻細節進一步分解的方法,因此對信號的描述更為精細。本文為提取腦電特征,采用Mallet快速算法對原始信號進行分解,并對相應節點的小波包系數進行重構得到最終系數。如圖 3所示為三層小波包分解所得到的小波包分解樹。腦電圖出現異常時,出現大量特征波(棘波、尖波、慢波),相應頻帶能量顯著增強,兩種狀態下腦電節律有很大差異。因此,小波包頻帶能量可以有效表征正常與異常兩種狀態。頻帶j的小波包能量為:
| ${{E}_{j}}=\sum\limits_{i=1}^{N}{\|{{n}_{i}}{{\|}^{2}}}$ |
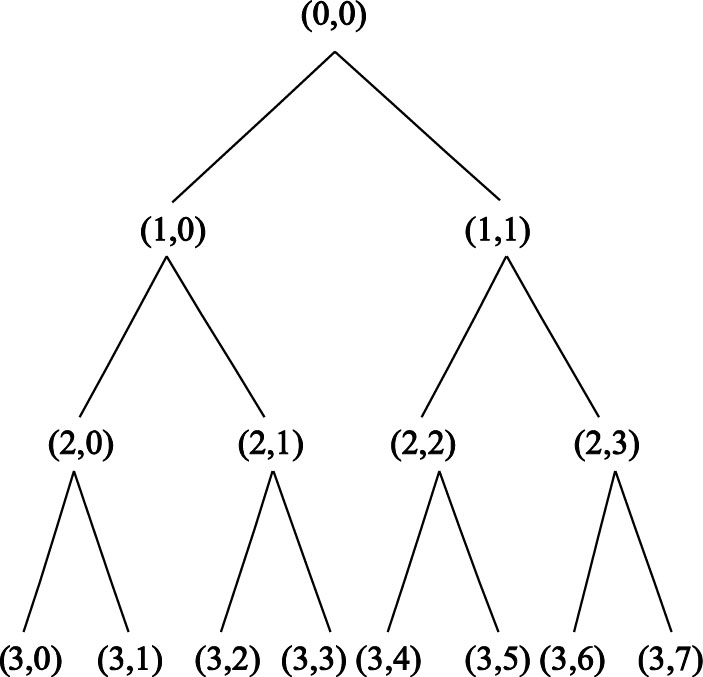 圖3
三層小波包分解的小波包樹
Figure3.
Wavelet packet tree of the three layer wavelet packet decomposition
圖3
三層小波包分解的小波包樹
Figure3.
Wavelet packet tree of the three layer wavelet packet decomposition
其中N為相應頻帶系數個數,ni為小波包系數。
3 分類方法
AdaBoost算法是由Freund等[13]在20世紀90年代提出的集成學習算法。它的核心思想是對于同一訓練集訓練若干個弱分類器,并最終將弱分類器組合成強分類器。該算法通過每次迭代更新樣本權重,用將錯分的樣本權重增大的方式讓分類器更聚焦于難以被正確分類的樣本上。但AdaBoost算法弱分類器的輸出區間被限制在{+1,-1}之內,略顯粗糙。Schapire等[14]提出的Real AdaBoost算法對此進行了改進,引入置信度的概念,弱分類器輸出從原來的+1和-1拓展到了實數的范圍,以反映某樣本屬于某個類別的可能性大小。二分類問題的Real AdaBoost算法步驟如下:
(1) 已知訓練集集合S={(x1,y1),(x2,y2),…,(xn,yn)},弱分類器集合為H。其中xi為特征向量,yi∈{+1,-1}。初始化樣本權重D1(i)=1/n,i=1,2,3,…,n;
(2) 循環執行① ~④ 步,t為循環輪數,且t=1,2,3,…,T。
① 對樣本劃分為若干個互不相交的子空間,劃分后區間個數為m。對劃分后的每一區間計算+1和-1類的累計樣本權重,記為W+1jt和WW-1jt,1≤j≤m;
② 計算歸一化因子${{Z}_{t}}=\sum\limits_{j=1}^{m}{\sqrt{W_{+1}^{jt}W_{-1}^{jt}}}$,定義弱分類器函數ht(x),對任意屬于某區間的x有${{h}_{t}}\left( x \right)=\frac{1}{2}\text{ln}(W_{+1}^{jt}+\varepsilon )/(W_{-1}^{jt}+\varepsilon )$,其中1≤j≤m,ε為一很小的正數,選取${{h}_{t}}\left( x \right)=\arg \underset{h\in H}{\mathop{\min }}\,{{Z}_{t}}$;
③ 更新樣本權重:${{D}_{t+1}}\left( i \right)=\frac{{{D}_{t}}\left( i \right)}{{{Z}_{t}}}{{e}^{-{{y}_{i}}{{h}_{t}}({{x}_{i}})}}$;
④ 當達到初始設定條件時停止迭代,執行第(3)步,否則繼續執行循環體。
(3) 輸出強分類器$H\left( x \right)=sign(\sum\limits_{t=1}^{T}{{{h}_{t}}\left( x \right)+b})$。b為平滑因子,默認情況下為0。
基于糾錯編碼的分類方法是一種能將多類問題轉化成多個二類問題的方法[15]。其基本思想是對于一個K類問題,對每個類別均進行長度為L的二進制編碼(log2K<L≤2K-1-1)并生成一個K行L列的編碼表,在碼字的每一位上均進行二類分類并輸出一個類別標簽。經過L次分類之后生成一個碼字并與表中的K個碼字進行比較,最終的輸出類別被判為與表中漢明距離(Hamming distance)最小的碼字所對應的類別,此過程稱為解碼(decoding)。如表 2所示,是一個三類問題的編碼方案,其中ci代表類別,fi為每個二分類問題的分類器函數。通常情況下,二分類器可選用決策樹(decision tree,DT)、支持向量機等。但是當類別數目較少或碼長較短時,最后的分類結果往往會出現多種可能性,也就是生成的編碼表對該情況不具備糾錯能力。如表 2所示的編碼方案,當生成的碼字為“100”時,可以對應c1或c3兩個類別(漢明距離相等),這將對最終的分類帶來干擾,導致樣本被錯分的可能性增大。
由于Real AdaBoost算法的輸出值衡量了樣本屬于某類的可能性大小,即置信度的累計量,所以可采用累計置信度作為解碼規則。具體步驟為:
(1) 生成一個K行N列編碼表,對每個碼位均采用Real AdaBoost算法訓練一個二類分類器,分類器個數為N,類別標簽分別用+1、-1表示;
(2) 輸入一個樣本x并通過分類器輸出累計置信度yi(x),1≤i≤N;
(3) 給定一個碼字{cj1,cj2,…,cjN} (1≤j≤K,cji∈{-1,+1}),對于所有的j,計算某個碼字的累計置信度,即:
| ${{Y}_{j}}\left( x \right)=\sum\limits_{i=1}^{N}{{{c}_{ji}}{{y}_{i}}\left( x \right)}$ |
(4)取Yj(x)最大值所對應的類別為樣本最終所屬類別,即:
| $K\left( x \right)=\arg \underset{j}{\mathop{\max }}\,{{Y}_{j}}\left( x \right)$ |
利用置信度作為解碼依據可改善傳統基于漢明距離解碼所存在的缺陷,對結果的描述更為精細。分類效果較好的分類器往往在最后的決策中占據主要地位,彌補了某些分類器在分類效果上的不足,因而具備一定的糾錯能力,有效提高了預測精度。
4 數據處理及結果分析
首先對每段腦電信號進行低通濾波處理。根據采樣定理,信號最大頻率約為86.8 Hz。為減弱噪聲等因素干擾,濾除高頻成分,保留60 Hz以下的頻段范圍,如圖 4所示,顯示為處理后的各數據集波形。其中A和B分別為正常人清醒、睜眼時腦電數據和清醒、閉眼時腦電數據;C和D分別為癲癇發作間期致癇灶外和致癇灶內腦電數據;E為癲癇發作期腦電數據。
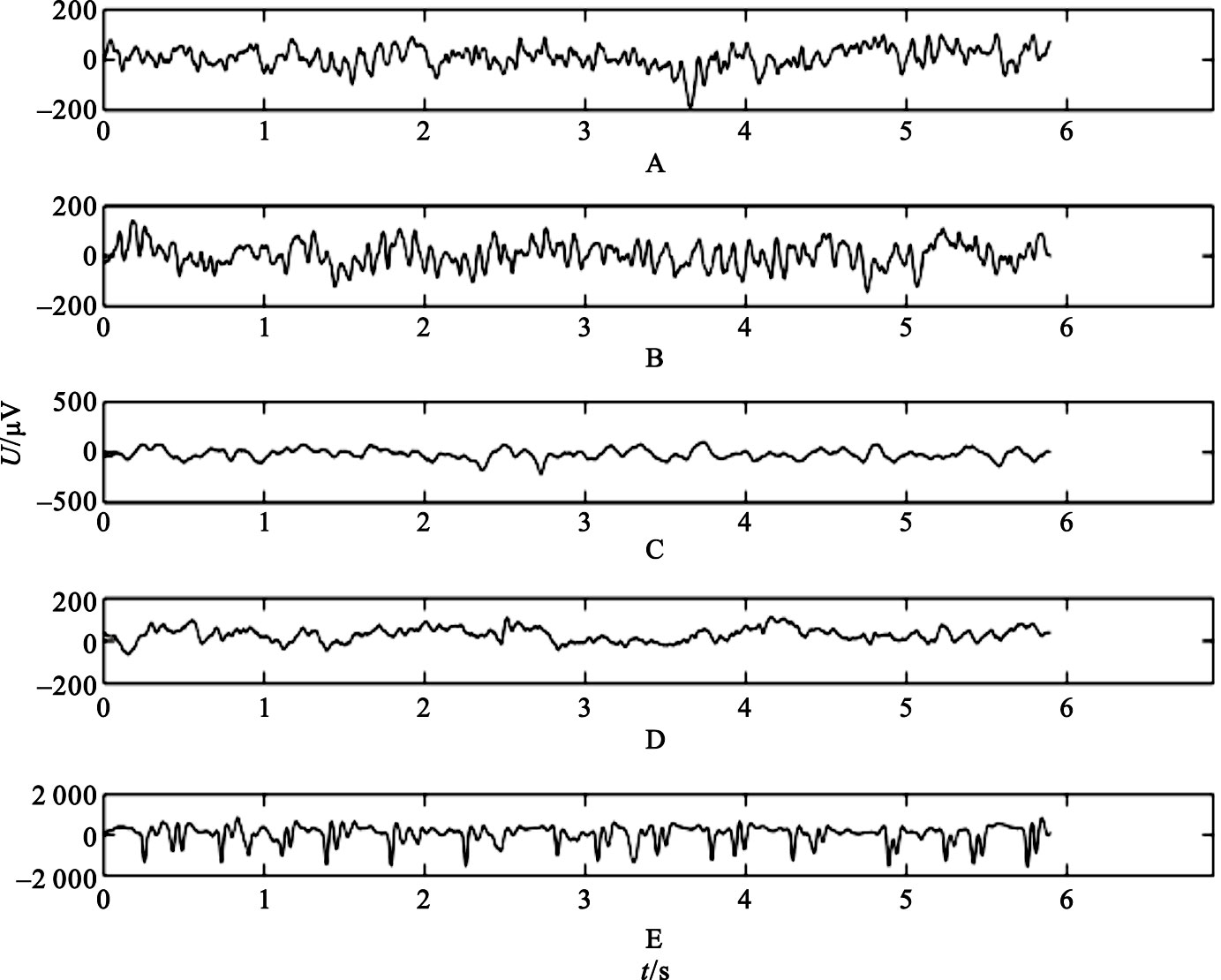 圖4
處理后的各數據集腦電信號波形
Figure4.
EEG waveforms of each data set after being processed
圖4
處理后的各數據集腦電信號波形
Figure4.
EEG waveforms of each data set after being processed
樣本熵在宏觀上對非線性序列有較強的表征能力而無法對細節進行描述,而小波包分解則在細節上具有出色的描述能力,因此本文將兩者結合作為特征向量,對輸入腦電信號進行樣本熵計算及4層小波包分解。文獻[7]曾通過實驗指出,樣本熵參數選擇m=2,r=0.2×std時分類效果較佳,因此本文采取上述參數進行計算。小波基函數選擇Daubechies4小波。人類腦電活動范圍在0.5~30 Hz之間,為消除腦電記錄過程中出現的偽差干擾,同時需要盡可能包含腦電的各節律成分,選取(4,1)~(4,7)節點對應頻帶(層次結構如圖 3所示)的小波包系數進行重構并計算每個節點的能量的十萬分之一,與樣本熵值共同組成8維特征向量送入分類器進行檢測。如表 3所示,列出了各數據集隨機抽取300個樣本的特征平均值和小波包分解后各節點頻率范圍。其中E1~E7依次代表(4,1)~(4,7)節點對應頻帶能量的十萬分之一。
該分類問題采用的編碼表如表 4所示。為盡量保證訓練集各類別數量的平衡,將正負樣本按照適當比例進行隨機抽取,并從每個數據集剩余樣本中各隨機抽取100個樣本作為測試集,最終識別率取20次實驗平均值。如表 5所示,顯示了訓練樣本的具體分配情況。其中,Real AdaBoost算法采用單層決策樹作為每次樣本劃分的弱分類器,并規定當訓練誤差收斂或達到最大迭代次數時即停止訓練。
采用傳統基于漢明距離的解碼方法和本文方法所得到的各時期識別率和平均識別率的比較如圖 5所示,結果用條形圖和多次實驗的結果標準差表示。可以看出,對于正常時期腦電信號,兩者差距不大,但對于發作間期和發作期的分類,分類準確度分別提高2%和3%以上,且識別率的上下浮動較小,三個時期的綜合識別率最高可達到97.50%。說明從整體分類效果而言,利用置信度作為解碼規則可充分利用集成學習算法包含的信息,將輸出值而不是簡單的類別標簽輸出作為判別依據,有效提高了多分類問題中的識別率并具有更佳的穩定性。
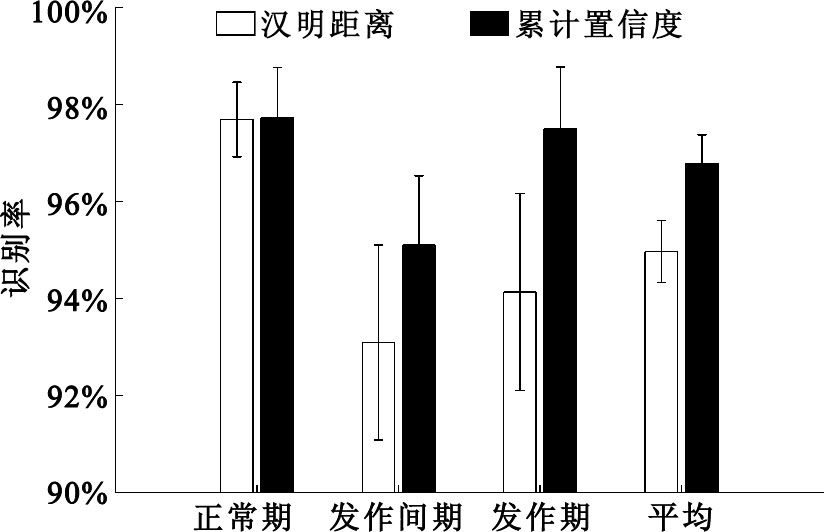 圖5
不同解碼方法識別率比較
Figure5.
Comparison of the accuracy between different decoding methods
圖5
不同解碼方法識別率比較
Figure5.
Comparison of the accuracy between different decoding methods
為了進一步顯示采用多特征的優勢,我們列出了采用不同特征提取方法所得出的三個時期的識別率及標準差,如圖 6所示。從兩者的比較中可以看出,兩種特征提取方法均可以有效表征三個時期的腦電信號,但僅采用小波包分解后各頻帶能量作為特征的識別率明顯低于小波包分解與樣本熵相結合作為特征的平均識別率,三個時期的識別率分別為93.55%、89.60%、95.50%和97.73%、95.10%、97.50%。對三個時期的分類精度分別提升了4.2%、5.5%和2.0%,尤其對發作間期信號識別率有明顯提升。這是因為樣本熵對正常期及異常期(發作間期與發作期)的區分度較好,作為補充特征對最終效果影響較大。由此可見,信號的非線性特征和時頻信息相結合的特征提取方案更為有效準確。
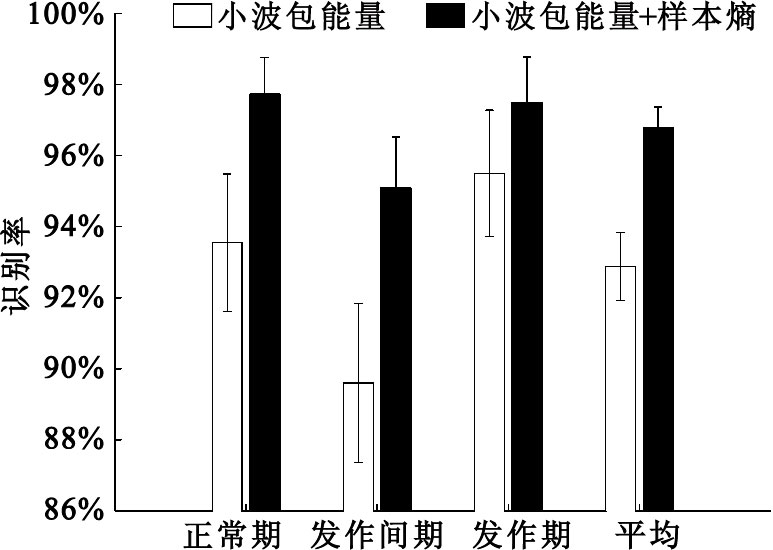 圖6
不同特征提取方法識別率比較
Figure6.
Comparison of the accuracy between different feature extraction methods
圖6
不同特征提取方法識別率比較
Figure6.
Comparison of the accuracy between different feature extraction methods
其它同類型的研究在各數據集上的分類效果如表 6所示。可見在類似的問題上,所采用的特征提取方法和分類方法均對最終的分類效果有影響,而多特征結合則具有更大優勢,結合時域和頻域等信息共同表征腦電信號將是類似問題研究的重點。另外,對于較復雜的分類問題,分類算法的選取及優化往往對最終結果產生不可忽視的影響。綜合來看,本文所采取的方法即使是在多種數據集的情況下也可達到可觀的分類準確度,對癲癇各時期診斷有較強的參考價值。
5 結論
為解決癲癇多時期腦電分類問題,本文將Real AdaBoost算法與糾錯編碼相結合,并將樣本熵和小波包能量作為特征,實現了對正常、發作間期和發作期腦電信號的有效識別。實驗表明,采用多種特征可有效解決單一特征識別率不高的問題,且利用快速樣本熵算法可滿足實時性檢測的要求。另外,用累計置信度代替漢明距離作為解碼規則可充分利用每個二類分類器輸出所包含的信息,并成功地把二類問題推廣到多類問題上,因此本文提出的方法對癲癇腦電檢測較為有效,在實際中有較強的應用價值,也為其它腦電分類問題,例如運動想象腦電分類、情緒分類等多分類問題提供了有效的解決方案。但是同樣可以看到在多類問題中,發作間期腦電信號的識別率仍然略低于正常時期和發作期。在今后的工作中,我們將嘗試其它的特征提取方法,提高發作間期腦電信號的識別率,以達到與其他兩個時期識別率相當的水平。
引言
癲癇(epilepsy)是由于大腦神經元異常放電所導致的短暫大腦功能障礙。癲癇患者在間歇期和發作期的腦電圖(electroencephalogram,EEG)會有較為明顯的異常表現,出現棘波、尖波及棘慢復合波等特征波形,因而腦電圖作為一項重要手段已廣泛應用于癲癇檢測中。醫學專家可以對腦電儀采集的腦電信號采取人工判讀的方法,從中找出癲癇的特征波形,從而實現對癲癇的診斷。但這種方法耗時耗力,而且不同專家對同一段波形的判斷也不盡一致,因此針對癲癇信號的自動檢測和識別分類顯得尤為必要。
近年來,眾多學者對癲癇腦電的自動診斷與分類展開了多項研究。小波變換[1]、經驗模態分解(empirical mode decomposition,EMD)[2]、熵[3-4]等常用信號分析方法均被應用于癲癇腦電的特征提取上;而目前流行的分類算法如人工神經網絡(artificial neural network,ANN)[4]、支持向量機(support vector machine,SVM)[5]、Boosting[6]等被廣泛用于腦電信號分類問題中,并達到了較高的分類精度。近年來廣受關注的極限學習機(extreme learning machine,ELM)因其訓練快速、分類性能出色等優點也受到了研究者們的青睞[7-8]。雖然這一領域的研究已取得了較為顯著的成果,但是仍面臨很多問題。在特征提取方面,僅局限于時、頻域或非線性方法用于描述腦電信號會顯得過于單一,使得分類器訓練不夠充分導致最終分類結果識別率不高,泛化能力不強,因此部分研究者嘗試將多種特征應用于腦電信號的判別上[8-9]。在模式識別方面,基于支持向量機的分類方法雖然對于小樣本問題有著較強的泛化能力,但對于規模較大的樣本訓練速度緩慢。而極限學習機雖然針對傳統神經網絡方法作了改進,但其初始輸入參數隨機產生,無法保證參數最優,使得最終分類效果受到一定影響。另外,目前的多數研究集中于腦電信號的二分類問題上,對信號的多時期分類的研究仍然較少。本文在此基礎上,結合集成學習算法不依賴參數、運算速度快的優點提出一種對癲癇各時期腦電信號檢測的方案。首先對截取的信號片段進行濾波處理去除相應高頻成分,并將改進的快速樣本熵(sample entropy,SampEn)計算方法引入其中,將樣本熵值與部分節點的小波包能量組成特征向量送入基于糾錯編碼(error-correcting output codes,ECOC)的Real AdaBoost多類分類器中,并采用累計置信度作為判決依據,最終實現了對正常期、發作間期和發作期腦電信號的分類。本文所述方案的基本流程如圖 1所示。
圖1
腦電信號識別流程
Figure1.
Process of EEG signal recognition
1 實驗數據
本文使用的實驗數據來源于德國波恩大學癲癇研究中心數據庫[10],共分為5組數據集,編號分別為A和B(正常人清醒、睜眼時腦電數據和清醒、閉眼時腦電數據)、C和D(癲癇發作間期致癇灶外和致癇灶內腦電數據)及E(癲癇發作期腦電數據)。每組共有100段腦電信號,采樣頻率為173.6 Hz,每段共計4 097點數據,本文采用A~E組數據進行三個時期分類。將A、B組標記為正常時期信號數據,C、D組標記為發作間期信號數據,E組標記為發作期信號數據。由于原始數據段較長,實驗前先將每段數據最后一個點舍棄,并等分為4段,每段1 024點數據,每個數據集得到400段腦電信號樣本,共計2 000個樣本。
2 特征提取方法
2.1 樣本熵及其優化
樣本熵是由Richman等[11]提出的度量時間序列信號自我相似程度及復雜度的方法,是對于近似熵(approximate entropy,ApEn)的改進。較近似熵而言,樣本熵對數據長度及丟失數據不敏感,只需要較短的時間序列即可得到較為準確的估計。其基本思想是通過改變嵌入維度以計算序列產生新信息概率的大小。樣本熵可以用參數m、 r、 N表示,m為嵌入維度,r為相似容限,N為時間序列長度。對于同一個序列,構造包含m個和m+1個矢量的新序列,分別計算矢量之間距離小于r的平均數量Bm(r)和Bm+1(r),最終結果表示為$-\ln \left( \frac{{{B}^{m+1}}\left( r \right)}{{{B}^{m}}\left( r \right)} \right)$。通常情況下,m=1或2,r=0.1×std~0.25×std(std為序列標準差)。時間序列越復雜,自我相似程度越低,熵值越大。腦電信號作為一種有代表性的非平穩信號,其非線性特征的提取對于識別往往具有良好的效果,目前樣本熵理論也被廣泛應用于腦電信號分析中。實驗表明,癲癇發作間期和發作期信號成分復雜度減小,樣本熵值較正常時期明顯降低,如圖 2所示,為其中一組參數下(m=2,r=0.2×std,N=1 024)的兩個時期樣本熵分布規律比較。可見,發作期、發作間期與正常時期樣本熵區分效果較好,適合作為分類特征。
圖2
樣本熵在兩個時期的分布規律
Figure2.
Distribution of the sample entropy during the two periods
為滿足實時計算的要求,洪波等[12]提出了一種快速近似熵算法,引入二值矩陣,通過矩陣元素間簡單的邏輯運算簡化了運算過程,本文在此基礎上進一步優化了樣本熵的運算過程。由于通常情況下取m=2,因此以下方法在m=2的情況下進行計算,具體步驟如下:
(1) 對給定的N點序列{u(i)}、閾值r及嵌入維度m,初始化(N-1)×(N-1)的二值矩陣M,定義第i行第j列的元素為aij,則:
| ${{a}_{ij}}=\left\{ \begin{array}{*{35}{l}} 1 & u\left( i \right)-u\left( j+1 \right)r且j\ge i \\ 0 & 其他 \\ \end{array} \right.$ |
其中0<i,j<N;
(2) 初始化N-m+1維的行向量V,定義其中每個元素為vk且vk =0(1≤k≤N-m+1)。對矩陣M的每一行i(1≤i≤N-m),初始化si=0,則:
| ${{v}_{j+1}}\text{=}\left\{ \begin{array}{*{35}{l}} {{v}_{j+1}}+1 & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}=1 \\ {{v}_{j+1}} & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}=0 \\ \end{array} \right.$ |
| ${{s}_{i}}\text{=}\left\{ \begin{array}{*{35}{l}} {{s}_{i}}+1 & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}=1 \\ {{s}_{i}} & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}=0 \\ \end{array} \right.$ |
其中i≤j≤N-m。則兩矢量間最大距離的平均值為:
| ${{B}^{m}}_{i}\left( r \right)=\frac{{{s}_{i}}+{{v}_{i}}}{N-m}$ |
(3)對所有的Bmi(r)求平均,結果記為Bm(r),則:
| ${{B}^{m}}\left( r \right)=\frac{\sum\limits_{i=1}^{N-m}{{{B}^{m}}_{i}\left( r \right)+{{v}_{N-m+1}}/\left( N-m \right)}}{N-m+1}$ |
(4) 令m=m+1,重復執行第(2)(3)步,其中式(2)和式(3)修改為:
| ${{v}_{j+1}}\text{=}\left\{ \begin{array}{*{35}{l}} {{v}_{j+1}}+1 & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}\cap {{a}_{\left( i+2 \right)(j+2)}}=1 \\ {{v}_{j+1}} & ~{{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}\cap {{a}_{\left( i+2 \right)(j+2)}}=0 \\ \end{array} \right.$ |
| ${{s}_{i}}\text{=}\left\{ \begin{array}{*{35}{l}} {{s}_{i}}+1 & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}\cap {{a}_{\left( i+2 \right)(j+2)}}=1 \\ {{s}_{i}} & {{a}_{ij}}\cap {{a}_{\left( i+1 \right)(j+1)}}\cap {{a}_{\left( i+2 \right)(j+2)}}=0 \\ \end{array} \right.$ |
其余步驟不變,得到Bm+1(r);
(5) 由于序列長度N為有限值,所以根據以下公式計算樣本熵:
| $\text{SampEn}\left( m,r \right)=-\ln \frac{{{B}^{m+1}}\left( r \right)}{{{B}^{m}}\left( r \right)}$ |
由以上步驟可知,該方法省去了矩陣中重復部分的構造,并且通過引入向量V,避免了重復計算。原始算法和改進后快速算法的耗時如表 1所示。可見對于較長的序列,運算也可在1 s左右的時間完成,運算速度提高9倍以上。
2.2 小波包分解
小波分析作為一種時頻分析的主要工具已被廣泛應用于各個領域。相比于傅里葉變換和短時傅里葉變換,小波分析具有多分辨率分析的優點,可以在多個尺度上反映信號的局部細節。但傳統的小波變換只對每一次分解后信號的低頻成分做進一步分解而忽略了高頻成分,因而不能充分地反映信號細節。小波包分解是一種能夠繼續將高頻細節進一步分解的方法,因此對信號的描述更為精細。本文為提取腦電特征,采用Mallet快速算法對原始信號進行分解,并對相應節點的小波包系數進行重構得到最終系數。如圖 3所示為三層小波包分解所得到的小波包分解樹。腦電圖出現異常時,出現大量特征波(棘波、尖波、慢波),相應頻帶能量顯著增強,兩種狀態下腦電節律有很大差異。因此,小波包頻帶能量可以有效表征正常與異常兩種狀態。頻帶j的小波包能量為:
| ${{E}_{j}}=\sum\limits_{i=1}^{N}{\|{{n}_{i}}{{\|}^{2}}}$ |
圖3
三層小波包分解的小波包樹
Figure3.
Wavelet packet tree of the three layer wavelet packet decomposition
其中N為相應頻帶系數個數,ni為小波包系數。
3 分類方法
AdaBoost算法是由Freund等[13]在20世紀90年代提出的集成學習算法。它的核心思想是對于同一訓練集訓練若干個弱分類器,并最終將弱分類器組合成強分類器。該算法通過每次迭代更新樣本權重,用將錯分的樣本權重增大的方式讓分類器更聚焦于難以被正確分類的樣本上。但AdaBoost算法弱分類器的輸出區間被限制在{+1,-1}之內,略顯粗糙。Schapire等[14]提出的Real AdaBoost算法對此進行了改進,引入置信度的概念,弱分類器輸出從原來的+1和-1拓展到了實數的范圍,以反映某樣本屬于某個類別的可能性大小。二分類問題的Real AdaBoost算法步驟如下:
(1) 已知訓練集集合S={(x1,y1),(x2,y2),…,(xn,yn)},弱分類器集合為H。其中xi為特征向量,yi∈{+1,-1}。初始化樣本權重D1(i)=1/n,i=1,2,3,…,n;
(2) 循環執行① ~④ 步,t為循環輪數,且t=1,2,3,…,T。
① 對樣本劃分為若干個互不相交的子空間,劃分后區間個數為m。對劃分后的每一區間計算+1和-1類的累計樣本權重,記為W+1jt和WW-1jt,1≤j≤m;
② 計算歸一化因子${{Z}_{t}}=\sum\limits_{j=1}^{m}{\sqrt{W_{+1}^{jt}W_{-1}^{jt}}}$,定義弱分類器函數ht(x),對任意屬于某區間的x有${{h}_{t}}\left( x \right)=\frac{1}{2}\text{ln}(W_{+1}^{jt}+\varepsilon )/(W_{-1}^{jt}+\varepsilon )$,其中1≤j≤m,ε為一很小的正數,選取${{h}_{t}}\left( x \right)=\arg \underset{h\in H}{\mathop{\min }}\,{{Z}_{t}}$;
③ 更新樣本權重:${{D}_{t+1}}\left( i \right)=\frac{{{D}_{t}}\left( i \right)}{{{Z}_{t}}}{{e}^{-{{y}_{i}}{{h}_{t}}({{x}_{i}})}}$;
④ 當達到初始設定條件時停止迭代,執行第(3)步,否則繼續執行循環體。
(3) 輸出強分類器$H\left( x \right)=sign(\sum\limits_{t=1}^{T}{{{h}_{t}}\left( x \right)+b})$。b為平滑因子,默認情況下為0。
基于糾錯編碼的分類方法是一種能將多類問題轉化成多個二類問題的方法[15]。其基本思想是對于一個K類問題,對每個類別均進行長度為L的二進制編碼(log2K<L≤2K-1-1)并生成一個K行L列的編碼表,在碼字的每一位上均進行二類分類并輸出一個類別標簽。經過L次分類之后生成一個碼字并與表中的K個碼字進行比較,最終的輸出類別被判為與表中漢明距離(Hamming distance)最小的碼字所對應的類別,此過程稱為解碼(decoding)。如表 2所示,是一個三類問題的編碼方案,其中ci代表類別,fi為每個二分類問題的分類器函數。通常情況下,二分類器可選用決策樹(decision tree,DT)、支持向量機等。但是當類別數目較少或碼長較短時,最后的分類結果往往會出現多種可能性,也就是生成的編碼表對該情況不具備糾錯能力。如表 2所示的編碼方案,當生成的碼字為“100”時,可以對應c1或c3兩個類別(漢明距離相等),這將對最終的分類帶來干擾,導致樣本被錯分的可能性增大。
由于Real AdaBoost算法的輸出值衡量了樣本屬于某類的可能性大小,即置信度的累計量,所以可采用累計置信度作為解碼規則。具體步驟為:
(1) 生成一個K行N列編碼表,對每個碼位均采用Real AdaBoost算法訓練一個二類分類器,分類器個數為N,類別標簽分別用+1、-1表示;
(2) 輸入一個樣本x并通過分類器輸出累計置信度yi(x),1≤i≤N;
(3) 給定一個碼字{cj1,cj2,…,cjN} (1≤j≤K,cji∈{-1,+1}),對于所有的j,計算某個碼字的累計置信度,即:
| ${{Y}_{j}}\left( x \right)=\sum\limits_{i=1}^{N}{{{c}_{ji}}{{y}_{i}}\left( x \right)}$ |
(4)取Yj(x)最大值所對應的類別為樣本最終所屬類別,即:
| $K\left( x \right)=\arg \underset{j}{\mathop{\max }}\,{{Y}_{j}}\left( x \right)$ |
利用置信度作為解碼依據可改善傳統基于漢明距離解碼所存在的缺陷,對結果的描述更為精細。分類效果較好的分類器往往在最后的決策中占據主要地位,彌補了某些分類器在分類效果上的不足,因而具備一定的糾錯能力,有效提高了預測精度。
4 數據處理及結果分析
首先對每段腦電信號進行低通濾波處理。根據采樣定理,信號最大頻率約為86.8 Hz。為減弱噪聲等因素干擾,濾除高頻成分,保留60 Hz以下的頻段范圍,如圖 4所示,顯示為處理后的各數據集波形。其中A和B分別為正常人清醒、睜眼時腦電數據和清醒、閉眼時腦電數據;C和D分別為癲癇發作間期致癇灶外和致癇灶內腦電數據;E為癲癇發作期腦電數據。
圖4
處理后的各數據集腦電信號波形
Figure4.
EEG waveforms of each data set after being processed
樣本熵在宏觀上對非線性序列有較強的表征能力而無法對細節進行描述,而小波包分解則在細節上具有出色的描述能力,因此本文將兩者結合作為特征向量,對輸入腦電信號進行樣本熵計算及4層小波包分解。文獻[7]曾通過實驗指出,樣本熵參數選擇m=2,r=0.2×std時分類效果較佳,因此本文采取上述參數進行計算。小波基函數選擇Daubechies4小波。人類腦電活動范圍在0.5~30 Hz之間,為消除腦電記錄過程中出現的偽差干擾,同時需要盡可能包含腦電的各節律成分,選取(4,1)~(4,7)節點對應頻帶(層次結構如圖 3所示)的小波包系數進行重構并計算每個節點的能量的十萬分之一,與樣本熵值共同組成8維特征向量送入分類器進行檢測。如表 3所示,列出了各數據集隨機抽取300個樣本的特征平均值和小波包分解后各節點頻率范圍。其中E1~E7依次代表(4,1)~(4,7)節點對應頻帶能量的十萬分之一。
該分類問題采用的編碼表如表 4所示。為盡量保證訓練集各類別數量的平衡,將正負樣本按照適當比例進行隨機抽取,并從每個數據集剩余樣本中各隨機抽取100個樣本作為測試集,最終識別率取20次實驗平均值。如表 5所示,顯示了訓練樣本的具體分配情況。其中,Real AdaBoost算法采用單層決策樹作為每次樣本劃分的弱分類器,并規定當訓練誤差收斂或達到最大迭代次數時即停止訓練。
采用傳統基于漢明距離的解碼方法和本文方法所得到的各時期識別率和平均識別率的比較如圖 5所示,結果用條形圖和多次實驗的結果標準差表示。可以看出,對于正常時期腦電信號,兩者差距不大,但對于發作間期和發作期的分類,分類準確度分別提高2%和3%以上,且識別率的上下浮動較小,三個時期的綜合識別率最高可達到97.50%。說明從整體分類效果而言,利用置信度作為解碼規則可充分利用集成學習算法包含的信息,將輸出值而不是簡單的類別標簽輸出作為判別依據,有效提高了多分類問題中的識別率并具有更佳的穩定性。
圖5
不同解碼方法識別率比較
Figure5.
Comparison of the accuracy between different decoding methods
為了進一步顯示采用多特征的優勢,我們列出了采用不同特征提取方法所得出的三個時期的識別率及標準差,如圖 6所示。從兩者的比較中可以看出,兩種特征提取方法均可以有效表征三個時期的腦電信號,但僅采用小波包分解后各頻帶能量作為特征的識別率明顯低于小波包分解與樣本熵相結合作為特征的平均識別率,三個時期的識別率分別為93.55%、89.60%、95.50%和97.73%、95.10%、97.50%。對三個時期的分類精度分別提升了4.2%、5.5%和2.0%,尤其對發作間期信號識別率有明顯提升。這是因為樣本熵對正常期及異常期(發作間期與發作期)的區分度較好,作為補充特征對最終效果影響較大。由此可見,信號的非線性特征和時頻信息相結合的特征提取方案更為有效準確。
圖6
不同特征提取方法識別率比較
Figure6.
Comparison of the accuracy between different feature extraction methods
其它同類型的研究在各數據集上的分類效果如表 6所示。可見在類似的問題上,所采用的特征提取方法和分類方法均對最終的分類效果有影響,而多特征結合則具有更大優勢,結合時域和頻域等信息共同表征腦電信號將是類似問題研究的重點。另外,對于較復雜的分類問題,分類算法的選取及優化往往對最終結果產生不可忽視的影響。綜合來看,本文所采取的方法即使是在多種數據集的情況下也可達到可觀的分類準確度,對癲癇各時期診斷有較強的參考價值。
5 結論
為解決癲癇多時期腦電分類問題,本文將Real AdaBoost算法與糾錯編碼相結合,并將樣本熵和小波包能量作為特征,實現了對正常、發作間期和發作期腦電信號的有效識別。實驗表明,采用多種特征可有效解決單一特征識別率不高的問題,且利用快速樣本熵算法可滿足實時性檢測的要求。另外,用累計置信度代替漢明距離作為解碼規則可充分利用每個二類分類器輸出所包含的信息,并成功地把二類問題推廣到多類問題上,因此本文提出的方法對癲癇腦電檢測較為有效,在實際中有較強的應用價值,也為其它腦電分類問題,例如運動想象腦電分類、情緒分類等多分類問題提供了有效的解決方案。但是同樣可以看到在多類問題中,發作間期腦電信號的識別率仍然略低于正常時期和發作期。在今后的工作中,我們將嘗試其它的特征提取方法,提高發作間期腦電信號的識別率,以達到與其他兩個時期識別率相當的水平。