本文提出了一種基于深度學習方法的慢性阻塞性肺疾病危重程度自動分類算法,并以大樣本臨床數據為輸入特征,分析各特征在分類中所占的權重。研究通過特征選擇、模型訓練、參數優化、模型測試,建立了基于深信度網絡架構的分類預測模型,通過對 2007 年、2011 年兩個版本的慢性阻塞性肺疾病全球倡議組織(GOLD)危重程度標準進行自動分類與測試,分類準確率均達到 90% 以上。同時,通過分析模型系數矩陣得出輸入特征的貢獻度排序,并通過該排序發現,貢獻度較大的輸入特征與臨床診斷先驗知識之間存在較好的吻合性,證明了深信度網絡分類模型的有效性。通過本文研究,期望能為深度學習方法在疾病診斷輔助決策中的應用提供有效解決方案。
引用本文: 應俊, 楊策源, 李全政, 薛萬國, 黎檀實, 曹文哲. 基于深度學習方法的慢性阻塞性肺疾病危重度分類研究. 生物醫學工程學雜志, 2017, 34(6): 842-849. doi: 10.7507/1001-5515.201604061 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
慢性阻塞性肺疾病(chronic obstructive pulmonary disease,COPD)是呼吸系統常見的慢性疾病,主要表現為呼吸道氣流阻塞,是由有害氣體及有害顆粒引起的呼吸道異常炎癥反應,如果不進行及時的干預治療,COPD 將進一步發展為肺心病和呼吸衰竭等危重程度很高的慢性疾病[1]。該病發病率、致殘率和病死率很高,全球 40 歲以上成人的發病率高達 9%~10%,根據世界衛生組織(World Health Organization,WHO)預測,到 2030 年 COPD 將成為全球第三大高致死率的疾病[2]。COPD 患者的危重程度分類評估是臨床診療過程中的基礎工作,是疾病治療的關鍵指針。如何有效又準確地對 COPD 的危重程度進行分類評估還存在一定難度,學術界先后推出多個分類標準作為臨床工作的實踐指南。2007 年,慢性阻塞性肺疾病全球倡議組織(The Global Initiative for Chronic Obstructive Lung Disease,GOLD)發布了首個針對該疾病危重程度的分類標準(GOLD2007),該標準主要是以肺功能參數的檢測值—— 一秒用力呼氣容積(forced expiratory volume in one second,FEV1)與用力肺活量(forced vital capacity,FVC)作為危重程度分類的依據。但是通過大量人群的臨床驗證與研究分析表明,僅僅參照肺功能參數無法有效地區分所有 COPD 患者的危重程度,而患者的身體狀況、急性加重程度同樣與 COPD 的危重程度有較大的相關性[3]。2011 年,英國國家衛生與臨床技術優化研究所(National institute for health and clinical excellence,NICE)重新修改完善了 GOLD 分類標準,將肺功能、急性加重次數和多種臨床評估量表,如改良的醫學研究理事會呼吸困難量表(modified medical study council,mMRC)、COPD 評估量表(COPD assessment test,CAT)、圣喬治呼吸問卷(St George's respiratory questionnaire,SGRQ)等共同納入評估因素,形成多因素、多維度的 GOLD2011 分類標準。醫學研究中,建立 GOLD 的分類標準實質上是尋找與疾病危重程度相關的主要因素,建立起多因素相關的綜合評價方法,以方便在臨床實踐中提供疾病危重程度的量化結果。
在醫療大數據分析領域,應用機器學習分類方法模擬臨床決策規則,對疾病危重程度進行自動判斷一直是研究熱點。深度學習方法(deep learning)是近年來新興的一種復雜的機器學習算法,在語言和圖像識別方面取得的效果遠遠超過以前相關的其他技術[4-5]。它在搜索技術、數據挖掘、機器學習、機器翻譯、自然語言處理、多媒體學習、語音、推薦和個性化技術,以及其它相關領域都取得了很多成果[6]。該類算法是一種結構復雜的非線性特征提取器,能夠發現高維度數據結構之間潛在的代表性特征,能夠對高維度向量進行壓縮提煉。深度學習方法能夠構建含有多隱層的機器學習架構模型,通過對大規模數據進行訓練,可以得到大量更具代表性的特征信息。該算法通過對原始信號進行逐層特征變換,將樣本在原空間的特征表示變換到新的特征空間,自動地學習得到層次化的特征表示,并將無監督與監督相結合進行訓練,實現兩種方法優勢互補,解決克服多層神經網絡很難訓練達到最優的問題。
本研究應用深度學習方法按照 GOLD 分類標準的原則對 COPD 的危重程度進行分類,同時研究多種特征因素與 GOLD 分類之間潛在的相關性。研究基于深度學習方法中的深信度網絡(deep belief network,DBN)方法,建立面向疾病危重程度分類評估的數據模型,模擬人腦開展 GOLD 危重程度評估的臨床決策活動過程[7]。本文希望通過基于深度學習方法的分析以解決以下問題:
(1)按照 GOLD 分類標準原則開展 COPD 危重程度的自動分類,并分析深度學習方法中分類算法的效率;
(2)從全文分析數據對象中尋找到對 GOLD 分類標準的關鍵性影響因素,并研究影響因素對應的臨床意義。
1 材料與方法
1.1 數據
本文研究數據來自美國國家心臟、肺與血液研究機構(National Heart,Lung,and Blood Institute,NHLBI)主持建設的 COPD 臨床數據與基因信息數據庫(COPDGene),包括 10 300 名受試者連續 5 年的健康與醫療數據,其中 2/3 為白人,1/3 為黑人,每位受試者的數據項總計為 362 項,其中包括人口學信息、臨床評估量表、病史、電子病歷、檢驗結果、醫學影像、體格檢查、隨訪等數據,全部數據經過清洗、標準化、數字化、代碼化等預處理,成為完全結構化的數據集(網址為:www.COPDGene.org)[8]。所有受試者均標明了 GOLD2007 與 GOLD2011 分類后的結果,上述兩個分類結果主要由臨床專家依據國際組織提出的 GOLD 分類標準,結合患者病情診斷給出[9]。基本原則如下:GOLD2007 基于 FEV1 與 FVC 將受試者分為 1~4 級,其中 1 級為最輕,4 級為最危重。GOLD2011 分類標準是在 GOLD2007 的基礎上,重點考慮 mMRC、CAT、SGRQ 以及急性加重次數等因素,從癥狀與風險的輕重程度分為 A、B、C、D 四個級別,其中 A 級表示癥狀與風險均低;B 級表示癥狀重、風險低;C 級表示癥狀輕、風險高;D 級表示癥狀重、風險高[10]。同時在此基礎上,對高風險患者進行了進一步細分,如果 C、D 兩類患者只達到 FEV1 的閾值,則被分類為 C1、D1,如果只達到急性加重頻率的閾值,則被分類為 C2、D2,如果達到上述兩個參數的閾值,則被分類為 C3、D3。
1.2 特征選擇
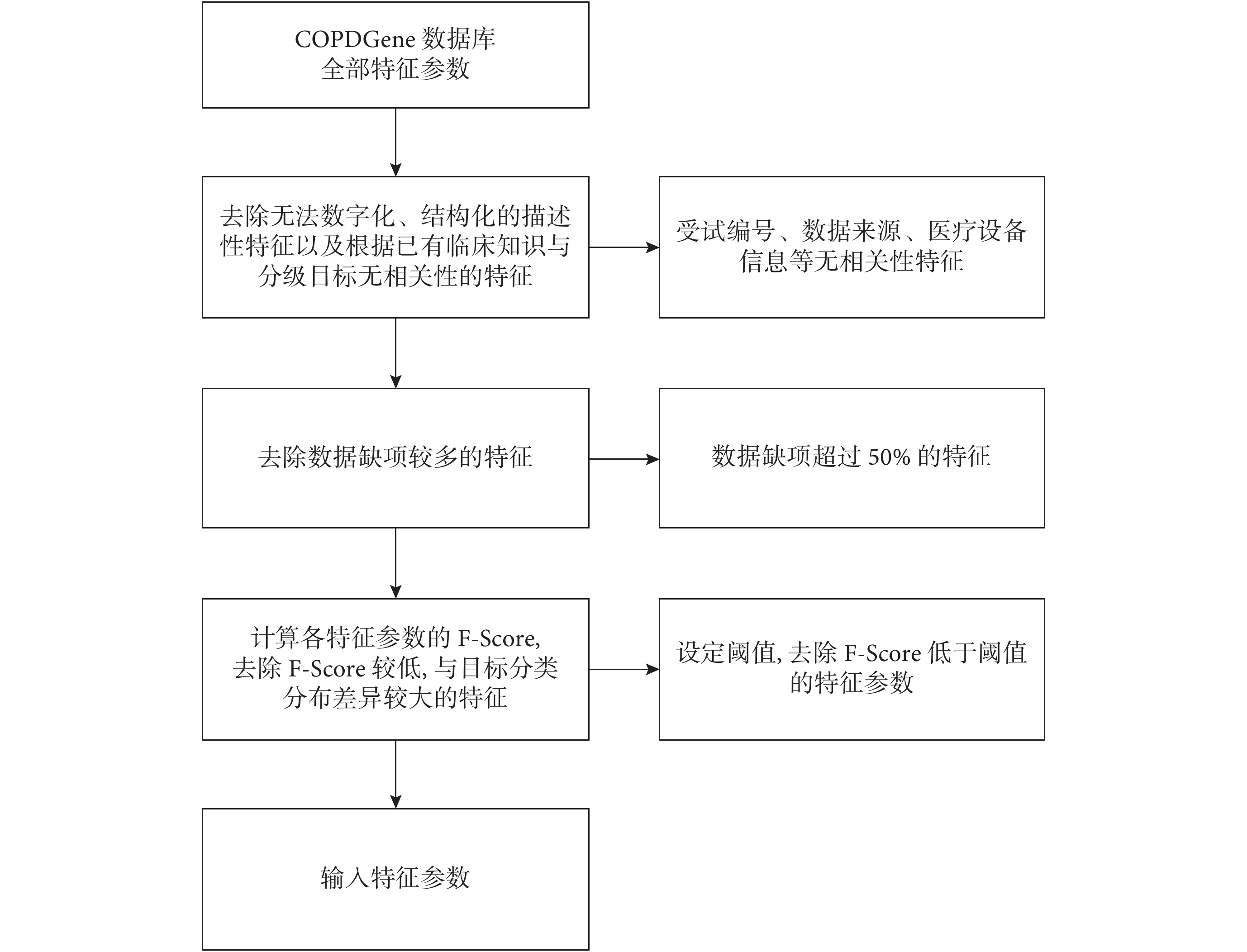
很多機器學習算法的性能在一定程度上受到無關特征和冗余特征的不良影響,選出好的特征子集不但可以減輕后續運算的復雜度,提高后續運算的準確率,也減少了訓練樣本的需求量,利于找出更易理解的算法模型。特征空間的維數不宜過高,這在機器學習領域是一條公認的經驗性準則,依據該準則特征選擇即可以達到降低高維數據維數的目的。為提高算法效能,本研究在模型訓練前先對輸入特征進行優選,特征選擇的算法流程如圖 1 所示。首先去除數據不完整的特征,刪除缺失數據大于總量 50% 的特征,然后采用 Fisher 分類器算法對于特征進行優選。Fisher 分類器算法是一種性能較好的線性特征選擇算法,可以通過衡量特征在兩種類別之間的分辨能力,確定最佳線性分界面,實現最有效的特征選擇。研究表明該方法具有獨立于學習算法、計算代價小和效率高等優點,非常適合對大樣本數據進行特征選擇。Fisher 分類器算法根據數據點的分布特征得出 Fisher 評分(Fisher score,F-score)[11]。某個特征的 F-score 越高,表明其數據分布具有異類數據點分布越分散,而同類數據點分布越聚集的特征,表明該特征具有最有效的區分程度。因此本研究根據 F-score 值的大小對所有的輸入特征進行排序,選擇適當的閾值,去除 F-score 值較小的特征。在此過程中閾值的選擇是關鍵,直接決定了特征選擇的效果。本研究采用閾值優選的方法以獲得最佳的效果,即從大到小選擇一組閾值,生成一系列的特征子集,分別計算特征子集的分類準確率,從而確定最高準確率下的最優閾值。經過特征選擇過程,從高維的特征數據中篩除一些無關的或冗余的特征分量來達到降維的目的。
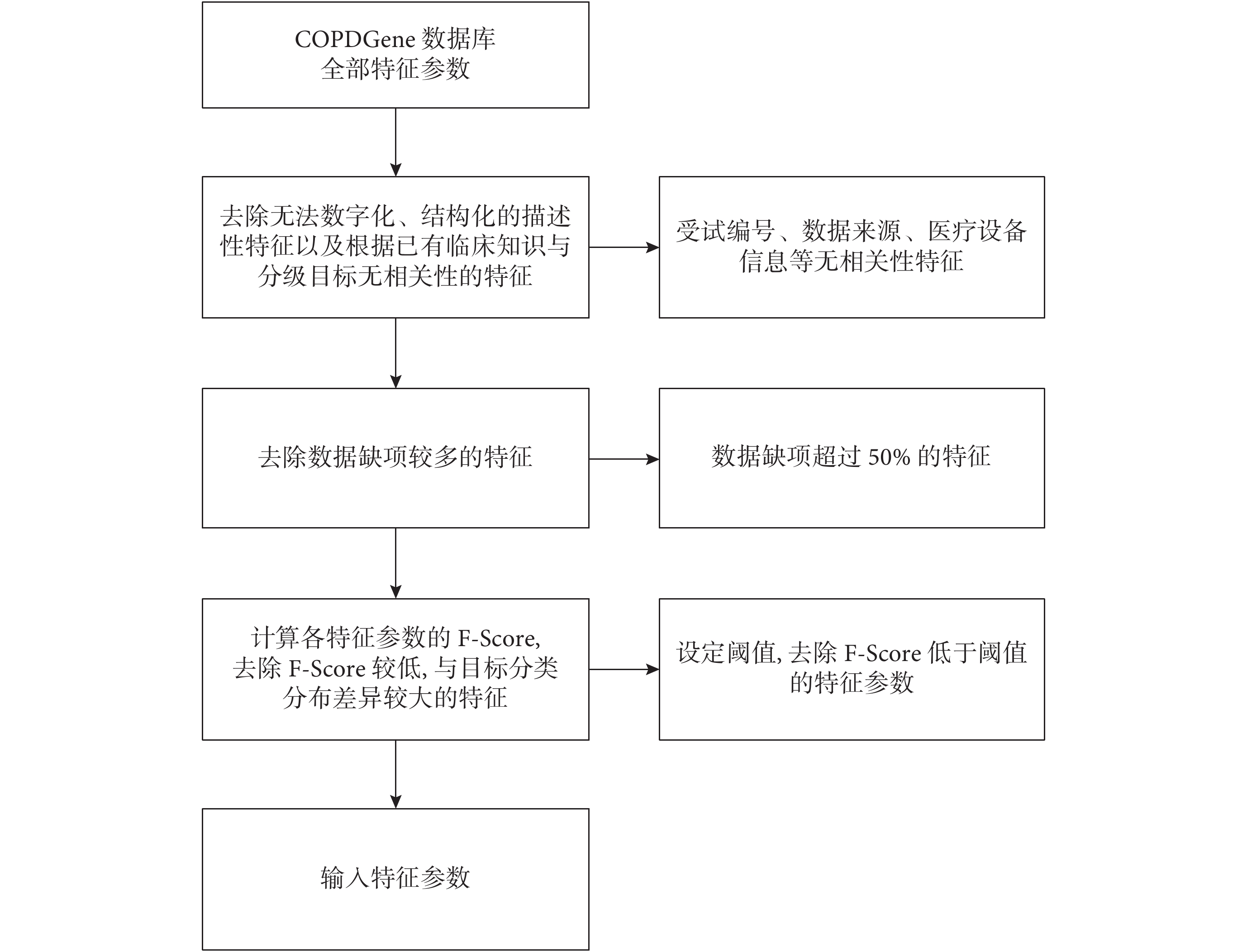 圖1
GOLD2007 分類分析的特征選擇流程圖
Figure1.
Flow chart describing the feature selection process of GOLD2007 classification analysis
圖1
GOLD2007 分類分析的特征選擇流程圖
Figure1.
Flow chart describing the feature selection process of GOLD2007 classification analysis
1.3 DBN 方法
DBN 方法是一種真正意義上的多層深度神經網絡分析方法,能夠對特征進行非線性分析[12]。DBN 方法是通過堆疊多個受限的玻爾茲曼機(restricted Boltzmann machine,RBM)生成。每一層 RBM 實質上是兩層神經元網絡,分為顯元(visible units)和隱元(hidden units)[13-14]。顯元主要是接受系統輸入或者前級神經網絡的輸入,隱元則是系統經過特征循環迭代、降維、抽象后的輸出特征。DBN 最底層是數據向量(data vectors),每一個神經元代表輸入數據向量的一個維度,最頂層是特征向量,表示最終的輸出的特征。
DBN 方法的訓練過程體現了無監督和有監督算法聯合運算的特點,訓練所得的模型兼具無監督學習與有監督學習的優點,能夠獲得更高的判斷準確率。在機器學習領域中,想要全局優化具有多層的 DBN 是比較困難的。Hinton 等[15]在 2006 年引入了 DBN 并給出了一種訓練該網絡的逐層貪婪訓練方法(greedy layer-wise pre training)。該方法主要訓練過程如下:首先是自底層向上的非監督學習,采用無標簽數據分層訓練各層參數,這是一個無監督訓練的過程,是 DBN 方法和傳統神經網絡方法區別最大的環節[16]。DBN 采用對比散度算法(contrastive divergence,CD)去逐層預訓練每層 RBM 的權值,CD 算法核心思想是使用估計的概率分布與真實概率分布之間的相對熵(relative entropy)的差異性作為度量準則,在近似的概率分布差異度量函數上求解最小化作為訓練參數的標準[17]。具體是用無標簽數據去訓練第一層,這樣就可以學習到第一層 RBM 的參數,然后固定第一層參數,將第一層 RBM 的輸出作為上一層 RBM 的輸入,去訓練上一個隱層的 RBM,通過逐層學習來獲得全局最優的網絡參數,這種訓練方法已經被證明是有效的[18]。其次是自頂層向下的監督學習,在對多層進行初始化后,用監督學習算法對整個神經網絡進行微調,得到的學習性能在很大程度上得到提高。在預訓練后,采用有標簽的數據作為訓練集來對網絡進行有監督學習訓練,此時誤差自頂向下傳輸。這種預訓練的方法類似傳統神經網絡的隨機初始化,但由于深度學習方法的第一步不是隨機初始化而是通過學習無標簽數據得到的,因此這個初值比較接近全局最優,所以深度學習方法效果好很多,程序上歸功于第一步的特征學習過程。本研究中,采用 3 層 RBM 結構的 DBN,其中包括 2 層隱層與 1 層顯層,每個隱層具有 100×100 個隱元。
2 結果
2.1 分類效果
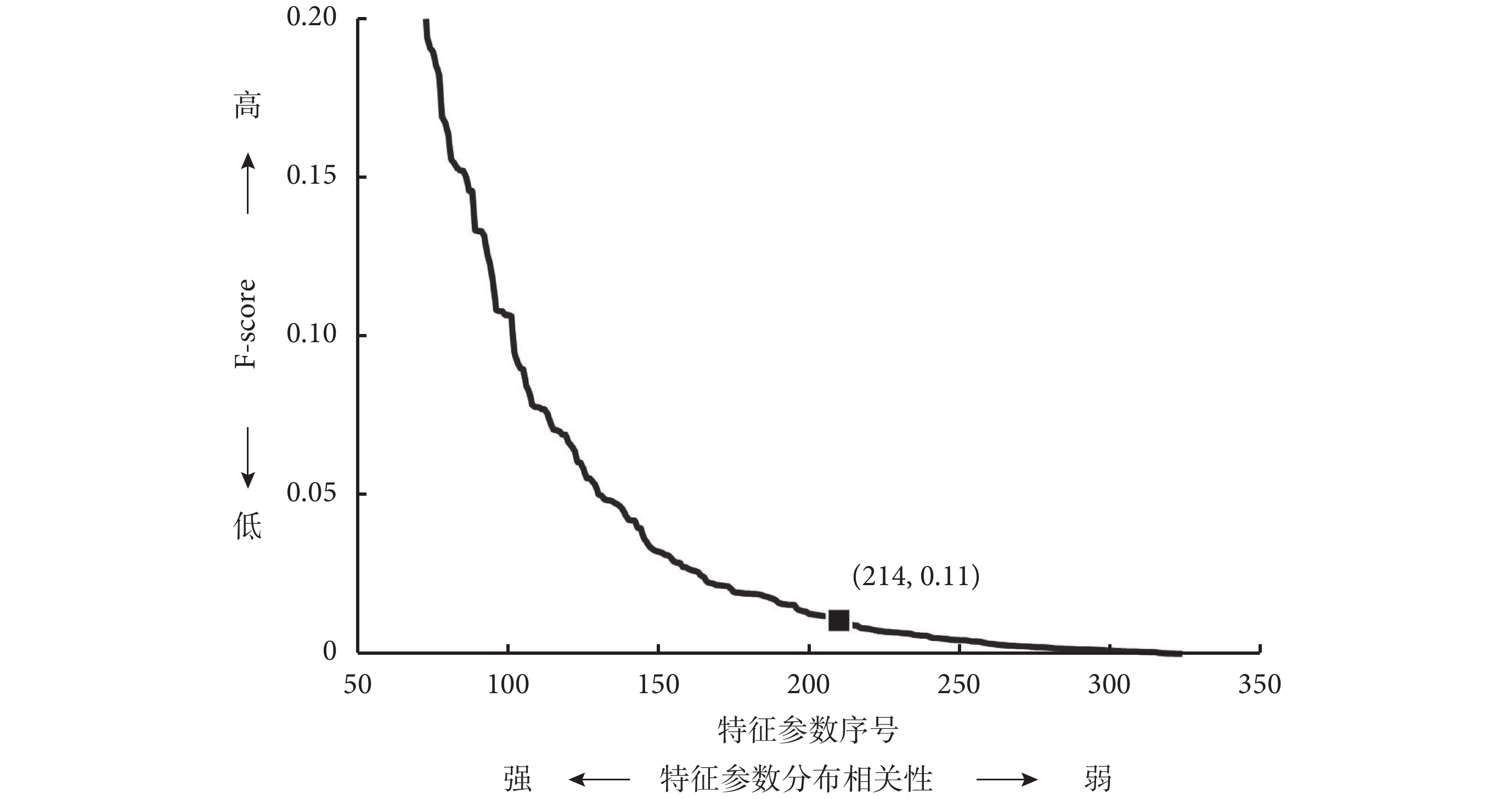
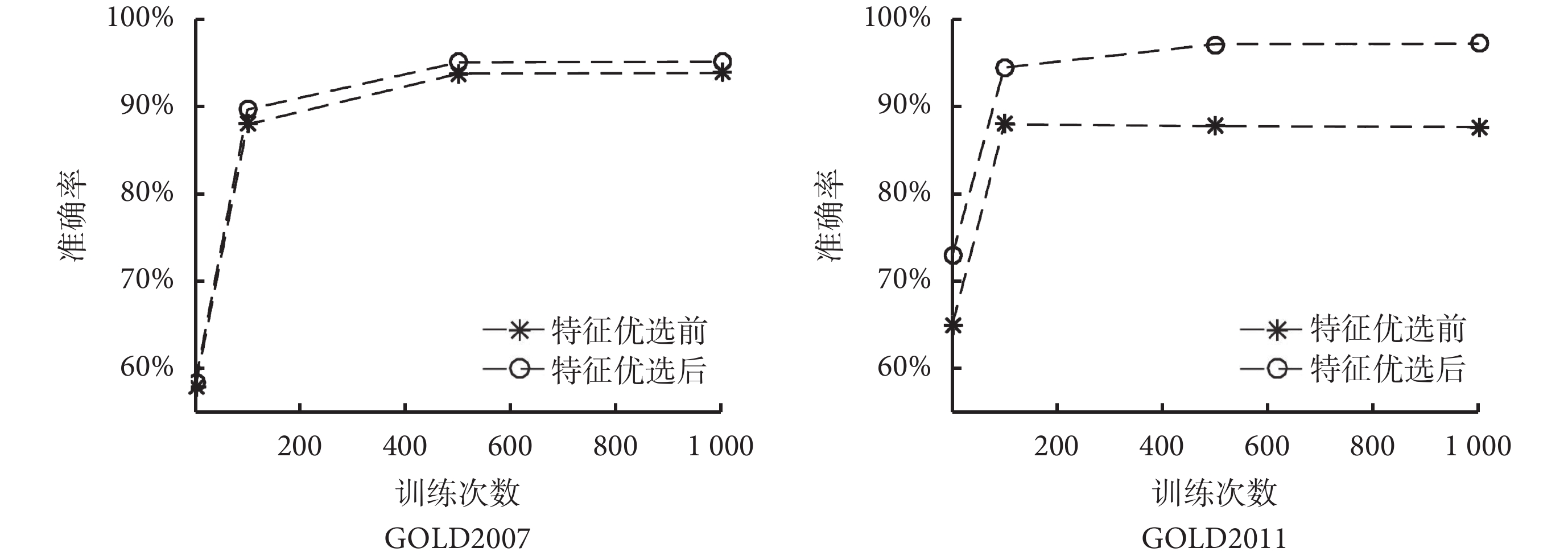
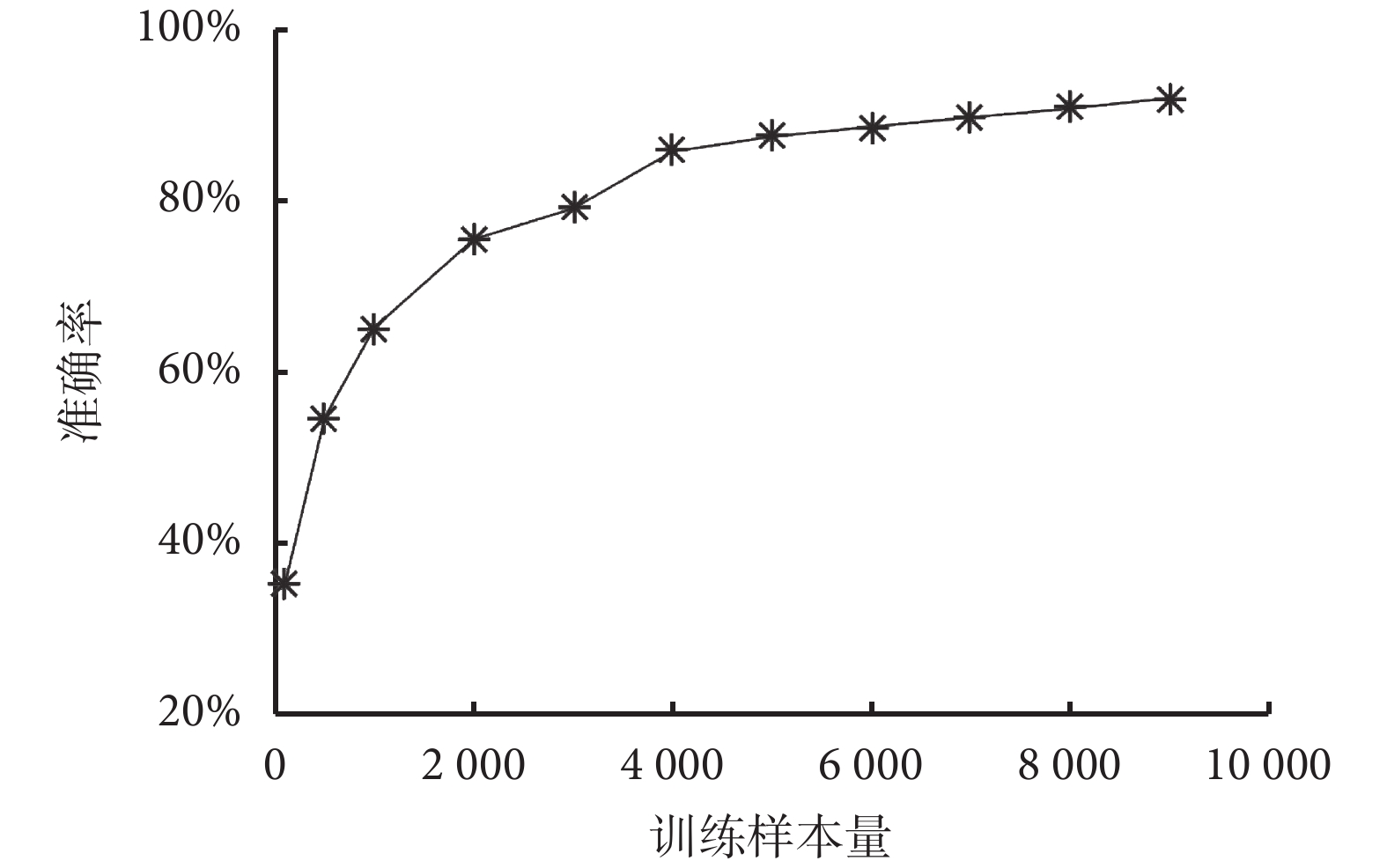
為提高模型測試的準確性,本研究采用十折交叉驗證法來提高判斷模型測試的精度。在特征選擇環節對于 F-score 值低于閾值的特征,不作為 DBN 模型訓練的輸入參數。在兩種分類下,輸入特征參數的 F-score 值,結果會隨著分類目標不同而變化。如圖 2 所示,我們對輸入特征按照 F-score 值的大小進行排序,在按照 GOLD2007 分類標準原則的分類算法中,經過閾值優選的方法獲得最佳閾值為 0.011,特征刪選后保留 F-score 值高于閾值的 214 個特征參數。通過對比特征選擇前后的結果發現,經過 Fisher 分類器算法對特征進行選擇后,后續深度學習方法的特征分類準確率明顯提高,如圖 3 所示,在同樣的 1 000 次迭代擬合下,GOLD2007 的分類準確率從 93% 提高到 95%,而 GOLD2011 的準確率從 88% 提高到 97%。通過分析輸入模型訓練的樣本數與準確率的關系發現,深度學習的特征分類準確率與投入訓練的樣本量相關。如圖 4 所示,以 GOLD2011 分類預測為例,當輸入樣本數達到 3 000 時,判斷的準確率達到 80% 以上,當訓練樣本量進一步擴大時,判斷的準確率也隨著提高,最終穩定于 97% 上下。
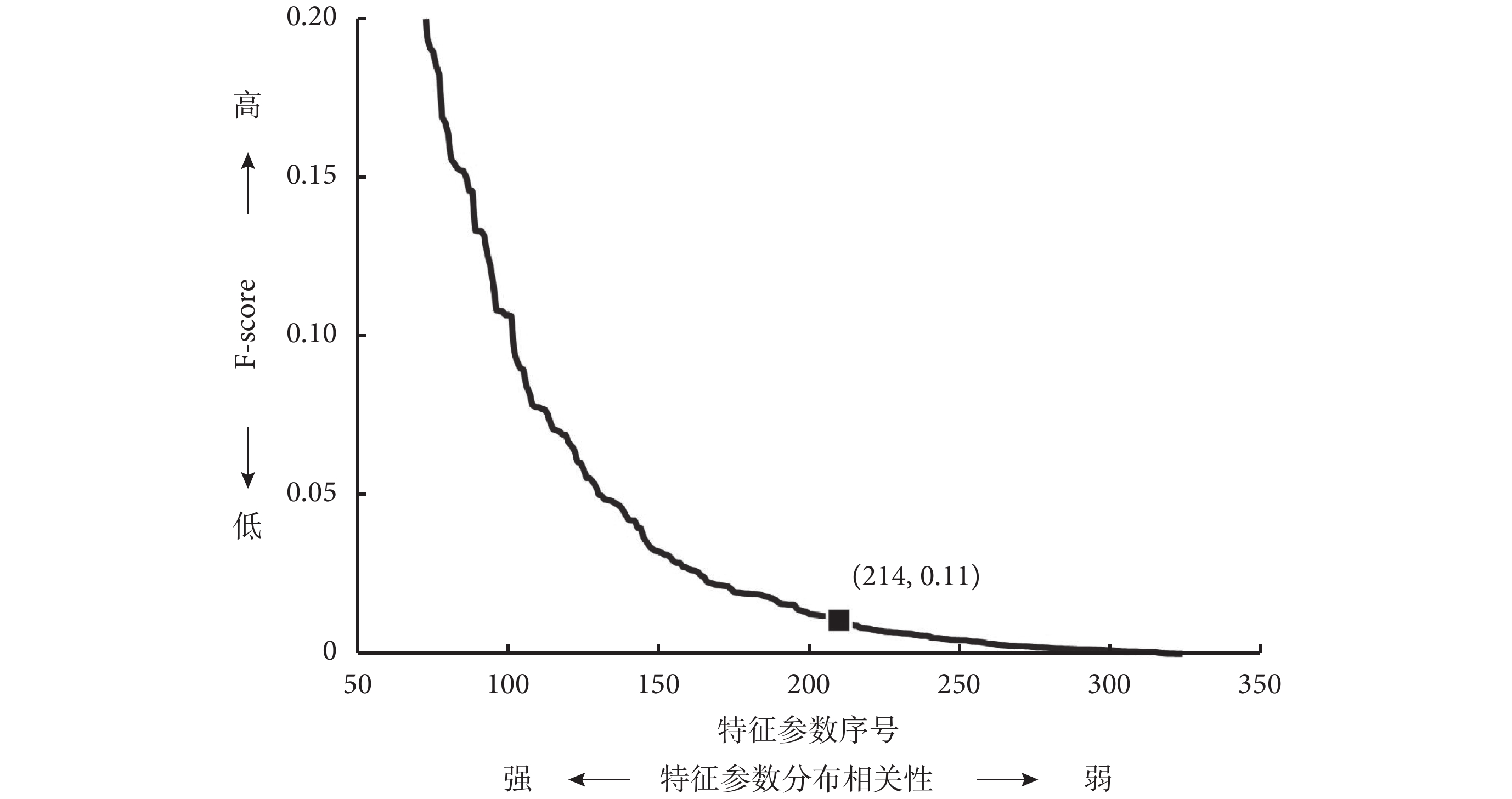 圖2
GOLD2007 分類分析的 F-score 排序
Figure2.
F-score order and screening of GOLD2007 classification analysis
圖2
GOLD2007 分類分析的 F-score 排序
Figure2.
F-score order and screening of GOLD2007 classification analysis
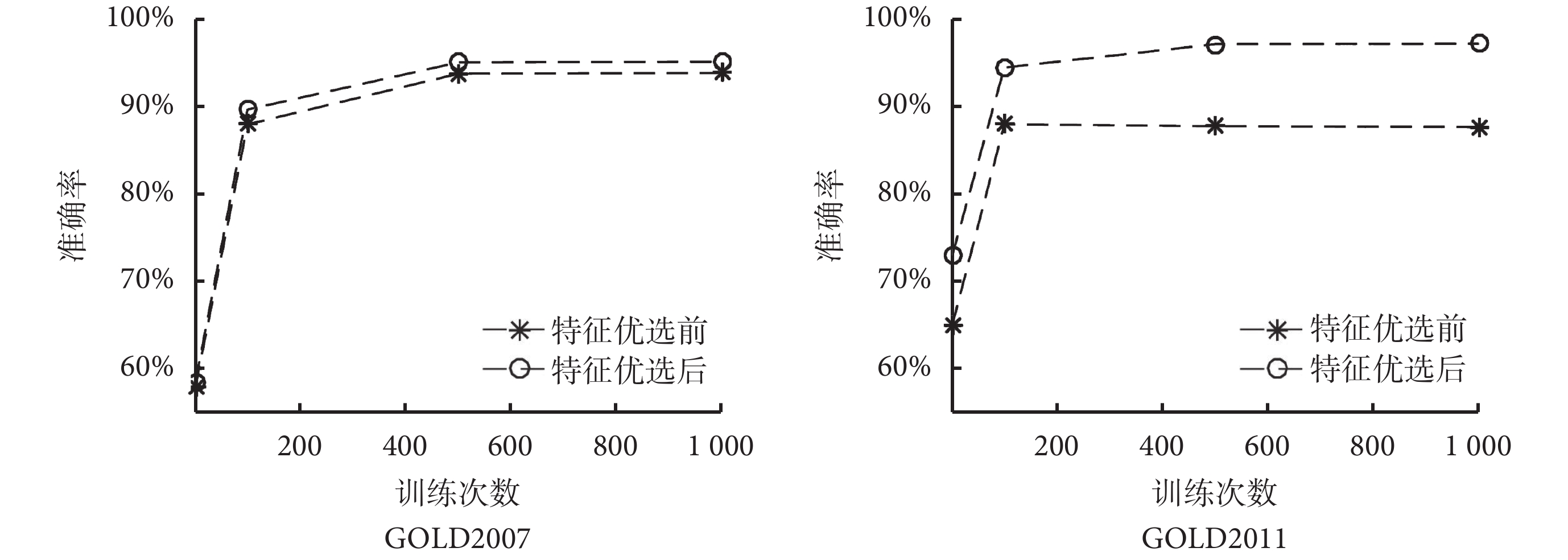 圖3
GOLD 分類準確率與模型訓練次數關系圖
Figure3.
Relationship between accuracy of GOLD classification and different training iterations
圖3
GOLD 分類準確率與模型訓練次數關系圖
Figure3.
Relationship between accuracy of GOLD classification and different training iterations
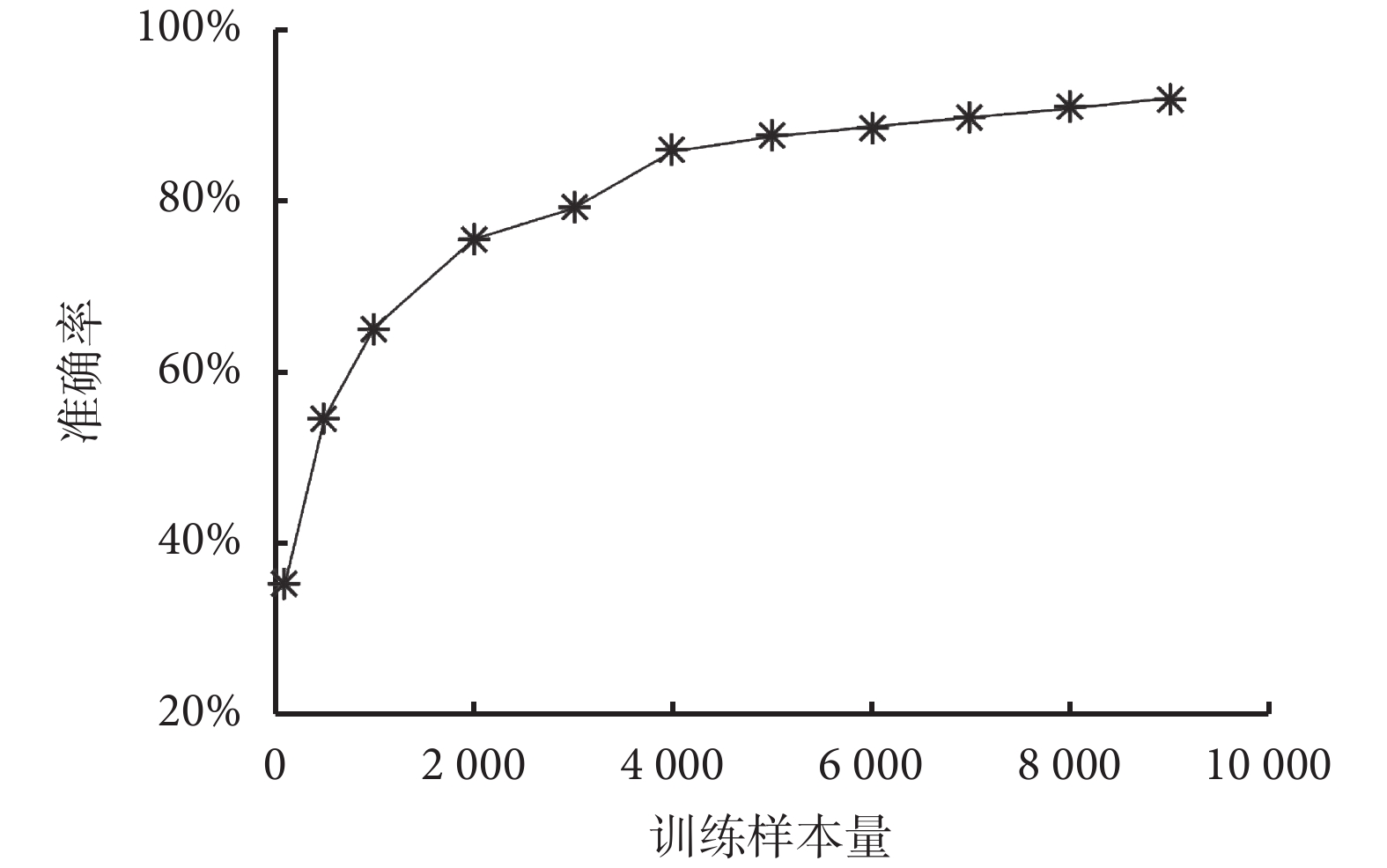 圖4
模型訓練樣本量與 GOLD2011 分類準確率關系圖
Figure4.
Relationship between accuracy of GOLD2011 classification and different numbers of training data points
圖4
模型訓練樣本量與 GOLD2011 分類準確率關系圖
Figure4.
Relationship between accuracy of GOLD2011 classification and different numbers of training data points
2.2 系數矩陣
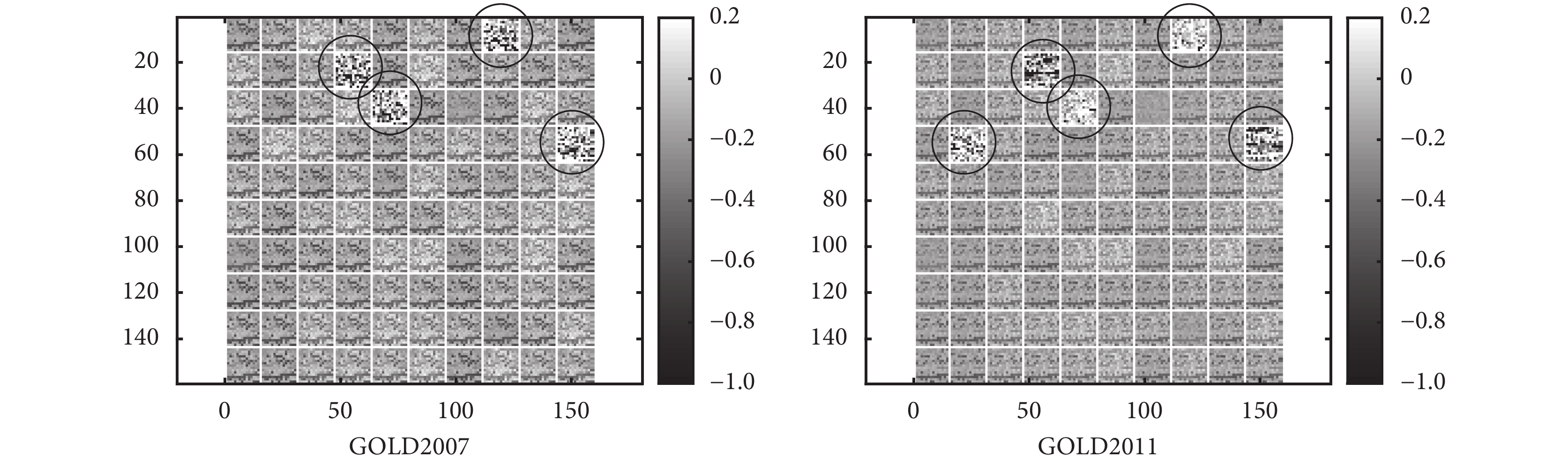
本研究建立的三層 DBN 模型由三個系數矩陣組成,三層系數矩陣共同參與模型運算。在機器學習領域,第一層系數矩陣能夠直接反映出輸入向量對分類結果的影響程度,如圖 5 所示,在第一層系數矩陣的色塊圖中,GOLD2007 分類明顯地出現 4 個與其他特征不同的系數組,表明經過第一層 RBM 系數矩陣降維后,分類模型自動抽象出 4 個特征,GOLD2011 分類則出現 5 個明顯的系數組,這些特征與分類結果密切相關。關于深度學習模型系數矩陣的物理意義還是研究的難點之一,特別是結合臨床問題解釋其在醫學上的意義還有待進一步深入研究。
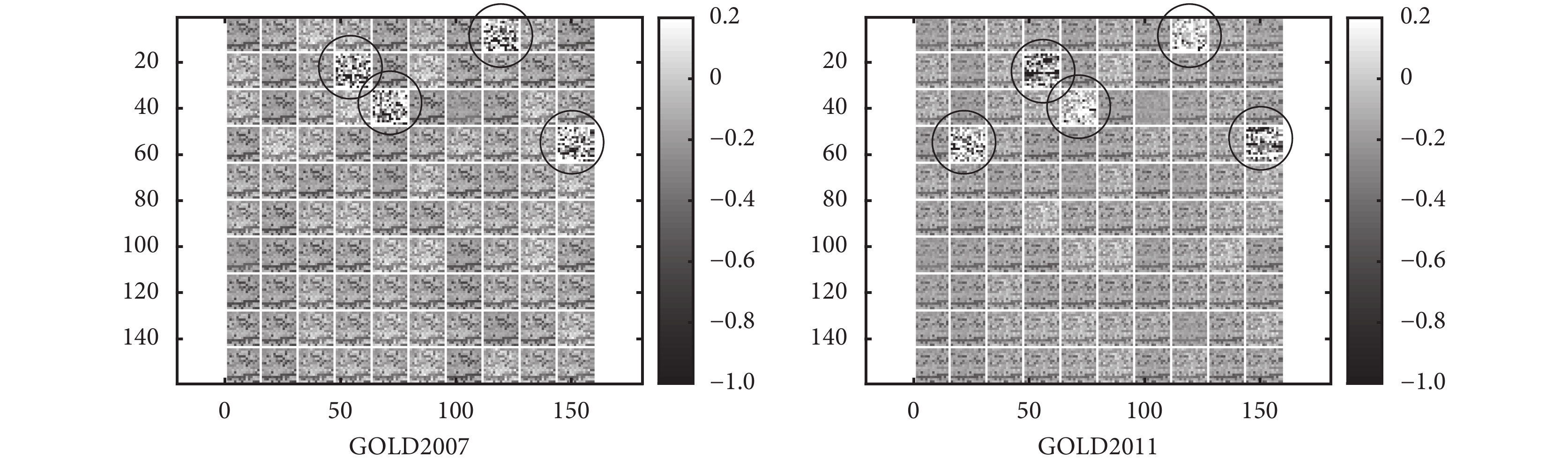 圖5
GOLD2007 與 GOLD2011 分類模型的第一層 RBM 系數矩陣灰度圖
Figure5.
Color chart of coefficient matrix in the first RBM layer for GOLD2007 and GOLD2011 classification model
圖5
GOLD2007 與 GOLD2011 分類模型的第一層 RBM 系數矩陣灰度圖
Figure5.
Color chart of coefficient matrix in the first RBM layer for GOLD2007 and GOLD2011 classification model
2.3 特征分析
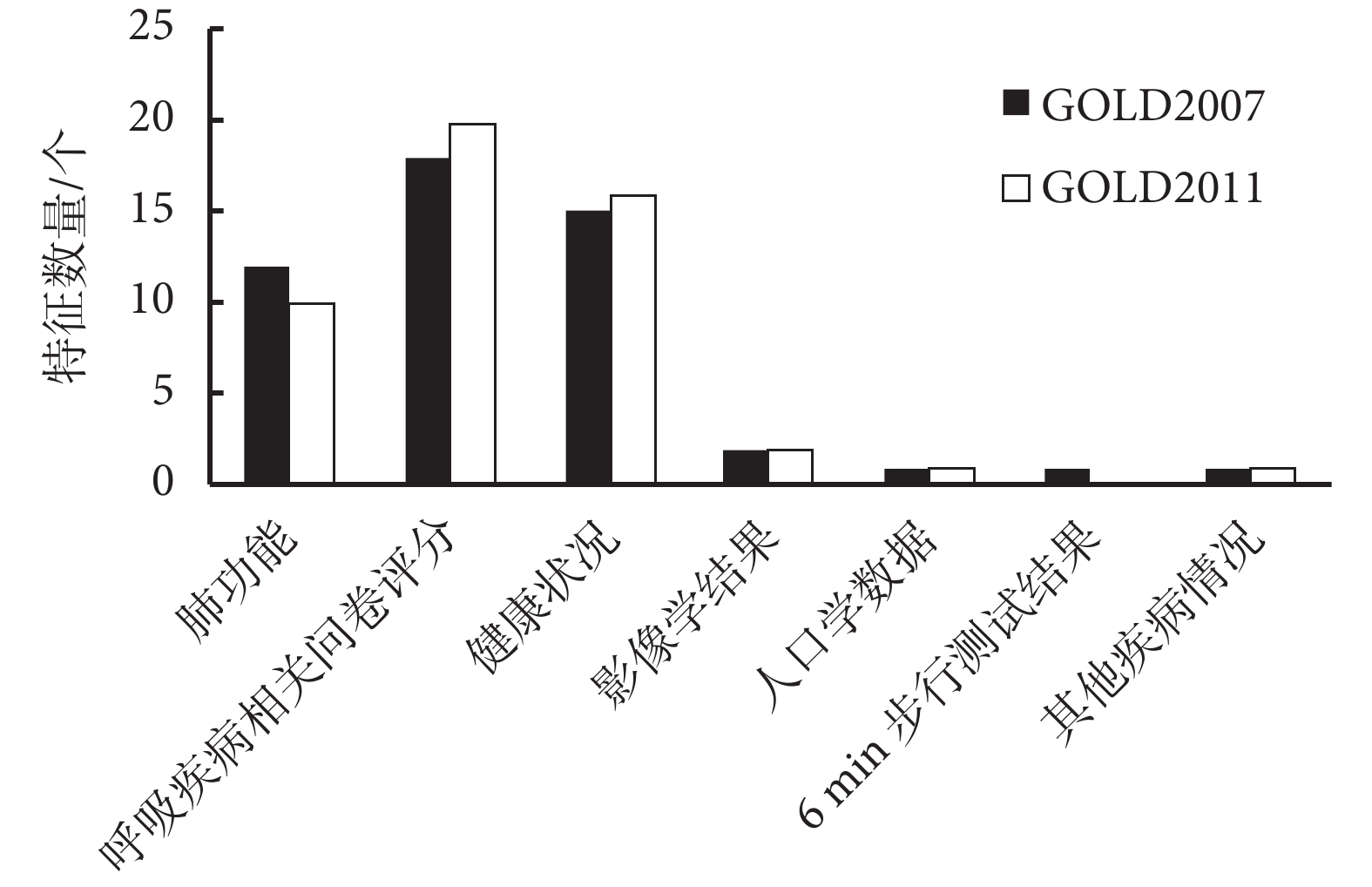
DBN 模型的系數矩陣明確了各層網絡節點之間的關系,因此要分析輸入特征相對于輸出特征的真實關系,需要對輸入特征相對于所有節點之間權重系數進行綜合評估。我們以第一層矩陣中輸入特征對應權重的絕對值和作為該特征在 DBN 模型中的綜合權重值,該權重值反映出該輸入特征參數對分類結果的影響程度。根據權重值的大小,我們得到輸入特征的影響力排序,如圖 6 所示,我們對前 50 個高權重的重要特征進行歸納分類,無論是 GOLD2007 還是 GOLD2011 分類預測中,90% 的重要特征主要集中在肺功能參數、呼吸系統疾病的相關評分以及健康狀況三個子類。如表 1、表 2 所示,在 GOLD2007 與 GOLD2011 分類的前 10 個重要特征中,發現 FEV1、FEV1/FVC 等肺功能參數對 GOLD2007 分類具有首要的影響,其他屬于前 10 的影響特征還包括健康調查簡表(the MOS item short from health survey,SF-36)、爬山時是否呼吸短促以及吸煙年齡等。對于 GOLD2011 分類標準,SGRQ 評分是首要特征,其余特征包括哮喘用藥、是否哮喘、爬山時是否呼吸短促、COPD 患病時間、SF-36 評分、FEV1、急性加重頻率以及吸煙狀況。
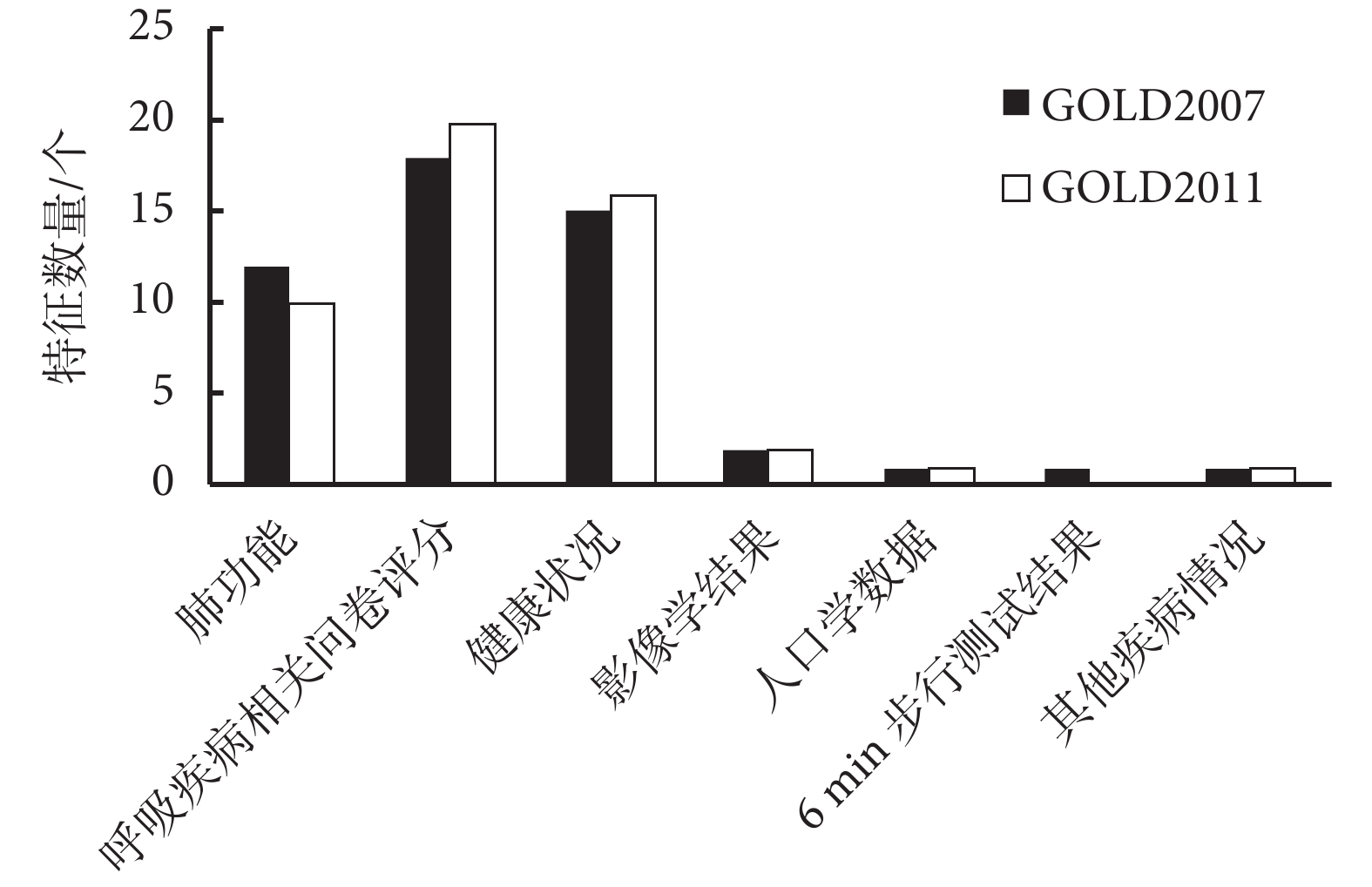 圖6
前 50 個敏感特征的分類數量分布
Figure6.
Classification quantity distribution of the top 50 sensitive features
圖6
前 50 個敏感特征的分類數量分布
Figure6.
Classification quantity distribution of the top 50 sensitive features
3 討論
本文將深度學習分類算法應用于 COPD 危重程度的分類評估,通過對大量高維度、無規則、含噪聲的數據進行降維與抽象,得出 GOLD 分類預測模型以及輸入特征與分類之間的潛在相關性。該方法探索了深度學習方法對 COPD 危重程度分類預測的有效性與可行性。通過研究結果表明,深度學習方法中的 DBN 能夠有效區分 90% 以上 COPD 患者的危重分類問題。
在大數據的機器學習過程中,由于輸入特征向量較多,經常涉及降維的問題,不是所有的特征參數都能夠對最終分類的結果有益,甚至還存在反作用[19]。因此,特征選擇方法能夠提前去除一些干擾以及與分類結果相關性較差的特征,而保留具有較強相關性的特征[20]。Fisher 分類器的結果反映的是每個輸入參數與最后所需分類結果之間空間分布的相關性,評分較低的參數,被認為是對分類結果無益的,因此需要進行舍棄。分析結果表明,經過 Fisher 分類器進行特征選擇后,測試的準確率明顯提高,DBN 集成 Fisher 特征選擇方法可以提高 DBN 的分類效果。
在臨床診療過程中,對疾病危重分類的診斷可抽象為人腦通過大量特征參數按照已有經驗以及復雜邏輯關系進行聯合判斷的思維過程[21]。本研究用建立 DBN 嘗試將這個復雜思維過程進行模型化與工程化,經過 500 次迭代優化后,預測模型逐漸趨向固定可重復,預測準確率保持相對穩定。本研究中,最終依據 GOLD2007 分類標準進行分類的最高準確率達到 94.9%,GOLD2011 準確率達到 97.2%。相同的分析算法下,對應 GOLD2011 分類的建模獲得出更高的預測準確率。在臨床上 GOLD2011 是 GOLD2007 的完善版本,GOLD2007 作為早期版本,主要是以患者肺功能單個參數作為判斷的依據,其在臨床上存在局限性,而 GOLD2011 版則在此基礎上將多種臨床評估量表(mMRC、CAT、SGRQ 等)、急性加重次數也納入到評估標準,形成多維度、綜合性的分類評估,使得臨床診斷更加準確,危重分類也更加細化,文獻研究表明,GOLD2011 分類標準更加符合 COPD 危重程度的真實情況,具備更好的適應性[22-23]。在本文的 DBN 分類過程中 GOLD2011 分類標準獲得了更高的準確性,符合臨床判斷標準的完善過程,表明 DBN 方法能夠反映出疾病危重程度分類標準的改進情況。
從 DBN 第一層系數矩陣的分布特征來看,部分輸入特征值對應的系數具有較大的綜合權重值,反映出此類敏感特征在特征抽象的過程中具有較大的貢獻度與影響性。通過對 GOLD2007、GOLD2011 分類標準預測所得到的前 50 個敏感因素進行分類分析發現,具有影響力的特征類型較為集中,主要可歸納為肺功能參數、呼吸疾病問卷評分以及健康狀況三類。此三類評分與 GOLD2011 分類依據完全相符[24]。通過對前 10 個敏感因素進行分析發現,GOLD2007 分類標準的敏感特征分布集中,前 10 個敏感特征中有 6 個是肺功能檢測結果相關的,反映出肺功能參數是 GOLD2007 分類標準的主要生理依據。在 GOLD2011 分類標準中,敏感特征包括了肺功能參數、SGRQ 健康評估、急性加重頻率等,這些特征符合臨床實際分類所依據的主要參數指標[25],上述結果表明通過 DBN 方法找到的敏感特征與臨床的分類決策依據具有較好的一致性。前 10 位的參數中,肺功能參數 FEV1、SF-36 量表-軀體健康評分、急行或上坡時是否氣短以及吸煙相關的 4 個參數均出現在兩個分類的影響因素中。根據臨床已有的研究,前三個參數均是 COPD 的主要表現特征,特別是吸煙相關參數是造成 COPD 病情變化與有效控制的重要影響因素[26]。這一結果反映出 DBN 分析獲得的敏感因素與臨床的先驗知識保持了一定的一致性,DBN 能夠從大量特征中找出部分敏感特征與分類結果之間潛在的相關性。
基于機器學習的臨床診療決策方法研究一直是醫療大數據領域的熱點,深度學習方法在醫療大數據分析中的應用在國內目前還是較新的方向。本研究探索將新興的深度學習方法應用于臨床疾病危重程度自動分類,雖然研究所用的數據規模有限,但數據結構、格式化程度、質量均符合機器學習的要求,但結果表明基于深度學習的分類分析可以有效地模擬臨床對疾病的診斷決策,能夠實現較高的判斷準確率,本研究為醫療大數據分析在疾病診斷中的應用提供了思路與案例。
引言
慢性阻塞性肺疾病(chronic obstructive pulmonary disease,COPD)是呼吸系統常見的慢性疾病,主要表現為呼吸道氣流阻塞,是由有害氣體及有害顆粒引起的呼吸道異常炎癥反應,如果不進行及時的干預治療,COPD 將進一步發展為肺心病和呼吸衰竭等危重程度很高的慢性疾病[1]。該病發病率、致殘率和病死率很高,全球 40 歲以上成人的發病率高達 9%~10%,根據世界衛生組織(World Health Organization,WHO)預測,到 2030 年 COPD 將成為全球第三大高致死率的疾病[2]。COPD 患者的危重程度分類評估是臨床診療過程中的基礎工作,是疾病治療的關鍵指針。如何有效又準確地對 COPD 的危重程度進行分類評估還存在一定難度,學術界先后推出多個分類標準作為臨床工作的實踐指南。2007 年,慢性阻塞性肺疾病全球倡議組織(The Global Initiative for Chronic Obstructive Lung Disease,GOLD)發布了首個針對該疾病危重程度的分類標準(GOLD2007),該標準主要是以肺功能參數的檢測值—— 一秒用力呼氣容積(forced expiratory volume in one second,FEV1)與用力肺活量(forced vital capacity,FVC)作為危重程度分類的依據。但是通過大量人群的臨床驗證與研究分析表明,僅僅參照肺功能參數無法有效地區分所有 COPD 患者的危重程度,而患者的身體狀況、急性加重程度同樣與 COPD 的危重程度有較大的相關性[3]。2011 年,英國國家衛生與臨床技術優化研究所(National institute for health and clinical excellence,NICE)重新修改完善了 GOLD 分類標準,將肺功能、急性加重次數和多種臨床評估量表,如改良的醫學研究理事會呼吸困難量表(modified medical study council,mMRC)、COPD 評估量表(COPD assessment test,CAT)、圣喬治呼吸問卷(St George's respiratory questionnaire,SGRQ)等共同納入評估因素,形成多因素、多維度的 GOLD2011 分類標準。醫學研究中,建立 GOLD 的分類標準實質上是尋找與疾病危重程度相關的主要因素,建立起多因素相關的綜合評價方法,以方便在臨床實踐中提供疾病危重程度的量化結果。
在醫療大數據分析領域,應用機器學習分類方法模擬臨床決策規則,對疾病危重程度進行自動判斷一直是研究熱點。深度學習方法(deep learning)是近年來新興的一種復雜的機器學習算法,在語言和圖像識別方面取得的效果遠遠超過以前相關的其他技術[4-5]。它在搜索技術、數據挖掘、機器學習、機器翻譯、自然語言處理、多媒體學習、語音、推薦和個性化技術,以及其它相關領域都取得了很多成果[6]。該類算法是一種結構復雜的非線性特征提取器,能夠發現高維度數據結構之間潛在的代表性特征,能夠對高維度向量進行壓縮提煉。深度學習方法能夠構建含有多隱層的機器學習架構模型,通過對大規模數據進行訓練,可以得到大量更具代表性的特征信息。該算法通過對原始信號進行逐層特征變換,將樣本在原空間的特征表示變換到新的特征空間,自動地學習得到層次化的特征表示,并將無監督與監督相結合進行訓練,實現兩種方法優勢互補,解決克服多層神經網絡很難訓練達到最優的問題。
本研究應用深度學習方法按照 GOLD 分類標準的原則對 COPD 的危重程度進行分類,同時研究多種特征因素與 GOLD 分類之間潛在的相關性。研究基于深度學習方法中的深信度網絡(deep belief network,DBN)方法,建立面向疾病危重程度分類評估的數據模型,模擬人腦開展 GOLD 危重程度評估的臨床決策活動過程[7]。本文希望通過基于深度學習方法的分析以解決以下問題:
(1)按照 GOLD 分類標準原則開展 COPD 危重程度的自動分類,并分析深度學習方法中分類算法的效率;
(2)從全文分析數據對象中尋找到對 GOLD 分類標準的關鍵性影響因素,并研究影響因素對應的臨床意義。
1 材料與方法
1.1 數據
本文研究數據來自美國國家心臟、肺與血液研究機構(National Heart,Lung,and Blood Institute,NHLBI)主持建設的 COPD 臨床數據與基因信息數據庫(COPDGene),包括 10 300 名受試者連續 5 年的健康與醫療數據,其中 2/3 為白人,1/3 為黑人,每位受試者的數據項總計為 362 項,其中包括人口學信息、臨床評估量表、病史、電子病歷、檢驗結果、醫學影像、體格檢查、隨訪等數據,全部數據經過清洗、標準化、數字化、代碼化等預處理,成為完全結構化的數據集(網址為:www.COPDGene.org)[8]。所有受試者均標明了 GOLD2007 與 GOLD2011 分類后的結果,上述兩個分類結果主要由臨床專家依據國際組織提出的 GOLD 分類標準,結合患者病情診斷給出[9]。基本原則如下:GOLD2007 基于 FEV1 與 FVC 將受試者分為 1~4 級,其中 1 級為最輕,4 級為最危重。GOLD2011 分類標準是在 GOLD2007 的基礎上,重點考慮 mMRC、CAT、SGRQ 以及急性加重次數等因素,從癥狀與風險的輕重程度分為 A、B、C、D 四個級別,其中 A 級表示癥狀與風險均低;B 級表示癥狀重、風險低;C 級表示癥狀輕、風險高;D 級表示癥狀重、風險高[10]。同時在此基礎上,對高風險患者進行了進一步細分,如果 C、D 兩類患者只達到 FEV1 的閾值,則被分類為 C1、D1,如果只達到急性加重頻率的閾值,則被分類為 C2、D2,如果達到上述兩個參數的閾值,則被分類為 C3、D3。
1.2 特征選擇
很多機器學習算法的性能在一定程度上受到無關特征和冗余特征的不良影響,選出好的特征子集不但可以減輕后續運算的復雜度,提高后續運算的準確率,也減少了訓練樣本的需求量,利于找出更易理解的算法模型。特征空間的維數不宜過高,這在機器學習領域是一條公認的經驗性準則,依據該準則特征選擇即可以達到降低高維數據維數的目的。為提高算法效能,本研究在模型訓練前先對輸入特征進行優選,特征選擇的算法流程如圖 1 所示。首先去除數據不完整的特征,刪除缺失數據大于總量 50% 的特征,然后采用 Fisher 分類器算法對于特征進行優選。Fisher 分類器算法是一種性能較好的線性特征選擇算法,可以通過衡量特征在兩種類別之間的分辨能力,確定最佳線性分界面,實現最有效的特征選擇。研究表明該方法具有獨立于學習算法、計算代價小和效率高等優點,非常適合對大樣本數據進行特征選擇。Fisher 分類器算法根據數據點的分布特征得出 Fisher 評分(Fisher score,F-score)[11]。某個特征的 F-score 越高,表明其數據分布具有異類數據點分布越分散,而同類數據點分布越聚集的特征,表明該特征具有最有效的區分程度。因此本研究根據 F-score 值的大小對所有的輸入特征進行排序,選擇適當的閾值,去除 F-score 值較小的特征。在此過程中閾值的選擇是關鍵,直接決定了特征選擇的效果。本研究采用閾值優選的方法以獲得最佳的效果,即從大到小選擇一組閾值,生成一系列的特征子集,分別計算特征子集的分類準確率,從而確定最高準確率下的最優閾值。經過特征選擇過程,從高維的特征數據中篩除一些無關的或冗余的特征分量來達到降維的目的。
圖1
GOLD2007 分類分析的特征選擇流程圖
Figure1.
Flow chart describing the feature selection process of GOLD2007 classification analysis
1.3 DBN 方法
DBN 方法是一種真正意義上的多層深度神經網絡分析方法,能夠對特征進行非線性分析[12]。DBN 方法是通過堆疊多個受限的玻爾茲曼機(restricted Boltzmann machine,RBM)生成。每一層 RBM 實質上是兩層神經元網絡,分為顯元(visible units)和隱元(hidden units)[13-14]。顯元主要是接受系統輸入或者前級神經網絡的輸入,隱元則是系統經過特征循環迭代、降維、抽象后的輸出特征。DBN 最底層是數據向量(data vectors),每一個神經元代表輸入數據向量的一個維度,最頂層是特征向量,表示最終的輸出的特征。
DBN 方法的訓練過程體現了無監督和有監督算法聯合運算的特點,訓練所得的模型兼具無監督學習與有監督學習的優點,能夠獲得更高的判斷準確率。在機器學習領域中,想要全局優化具有多層的 DBN 是比較困難的。Hinton 等[15]在 2006 年引入了 DBN 并給出了一種訓練該網絡的逐層貪婪訓練方法(greedy layer-wise pre training)。該方法主要訓練過程如下:首先是自底層向上的非監督學習,采用無標簽數據分層訓練各層參數,這是一個無監督訓練的過程,是 DBN 方法和傳統神經網絡方法區別最大的環節[16]。DBN 采用對比散度算法(contrastive divergence,CD)去逐層預訓練每層 RBM 的權值,CD 算法核心思想是使用估計的概率分布與真實概率分布之間的相對熵(relative entropy)的差異性作為度量準則,在近似的概率分布差異度量函數上求解最小化作為訓練參數的標準[17]。具體是用無標簽數據去訓練第一層,這樣就可以學習到第一層 RBM 的參數,然后固定第一層參數,將第一層 RBM 的輸出作為上一層 RBM 的輸入,去訓練上一個隱層的 RBM,通過逐層學習來獲得全局最優的網絡參數,這種訓練方法已經被證明是有效的[18]。其次是自頂層向下的監督學習,在對多層進行初始化后,用監督學習算法對整個神經網絡進行微調,得到的學習性能在很大程度上得到提高。在預訓練后,采用有標簽的數據作為訓練集來對網絡進行有監督學習訓練,此時誤差自頂向下傳輸。這種預訓練的方法類似傳統神經網絡的隨機初始化,但由于深度學習方法的第一步不是隨機初始化而是通過學習無標簽數據得到的,因此這個初值比較接近全局最優,所以深度學習方法效果好很多,程序上歸功于第一步的特征學習過程。本研究中,采用 3 層 RBM 結構的 DBN,其中包括 2 層隱層與 1 層顯層,每個隱層具有 100×100 個隱元。
2 結果
2.1 分類效果
為提高模型測試的準確性,本研究采用十折交叉驗證法來提高判斷模型測試的精度。在特征選擇環節對于 F-score 值低于閾值的特征,不作為 DBN 模型訓練的輸入參數。在兩種分類下,輸入特征參數的 F-score 值,結果會隨著分類目標不同而變化。如圖 2 所示,我們對輸入特征按照 F-score 值的大小進行排序,在按照 GOLD2007 分類標準原則的分類算法中,經過閾值優選的方法獲得最佳閾值為 0.011,特征刪選后保留 F-score 值高于閾值的 214 個特征參數。通過對比特征選擇前后的結果發現,經過 Fisher 分類器算法對特征進行選擇后,后續深度學習方法的特征分類準確率明顯提高,如圖 3 所示,在同樣的 1 000 次迭代擬合下,GOLD2007 的分類準確率從 93% 提高到 95%,而 GOLD2011 的準確率從 88% 提高到 97%。通過分析輸入模型訓練的樣本數與準確率的關系發現,深度學習的特征分類準確率與投入訓練的樣本量相關。如圖 4 所示,以 GOLD2011 分類預測為例,當輸入樣本數達到 3 000 時,判斷的準確率達到 80% 以上,當訓練樣本量進一步擴大時,判斷的準確率也隨著提高,最終穩定于 97% 上下。
圖2
GOLD2007 分類分析的 F-score 排序
Figure2.
F-score order and screening of GOLD2007 classification analysis
圖3
GOLD 分類準確率與模型訓練次數關系圖
Figure3.
Relationship between accuracy of GOLD classification and different training iterations
圖4
模型訓練樣本量與 GOLD2011 分類準確率關系圖
Figure4.
Relationship between accuracy of GOLD2011 classification and different numbers of training data points
2.2 系數矩陣
本研究建立的三層 DBN 模型由三個系數矩陣組成,三層系數矩陣共同參與模型運算。在機器學習領域,第一層系數矩陣能夠直接反映出輸入向量對分類結果的影響程度,如圖 5 所示,在第一層系數矩陣的色塊圖中,GOLD2007 分類明顯地出現 4 個與其他特征不同的系數組,表明經過第一層 RBM 系數矩陣降維后,分類模型自動抽象出 4 個特征,GOLD2011 分類則出現 5 個明顯的系數組,這些特征與分類結果密切相關。關于深度學習模型系數矩陣的物理意義還是研究的難點之一,特別是結合臨床問題解釋其在醫學上的意義還有待進一步深入研究。
圖5
GOLD2007 與 GOLD2011 分類模型的第一層 RBM 系數矩陣灰度圖
Figure5.
Color chart of coefficient matrix in the first RBM layer for GOLD2007 and GOLD2011 classification model
2.3 特征分析
DBN 模型的系數矩陣明確了各層網絡節點之間的關系,因此要分析輸入特征相對于輸出特征的真實關系,需要對輸入特征相對于所有節點之間權重系數進行綜合評估。我們以第一層矩陣中輸入特征對應權重的絕對值和作為該特征在 DBN 模型中的綜合權重值,該權重值反映出該輸入特征參數對分類結果的影響程度。根據權重值的大小,我們得到輸入特征的影響力排序,如圖 6 所示,我們對前 50 個高權重的重要特征進行歸納分類,無論是 GOLD2007 還是 GOLD2011 分類預測中,90% 的重要特征主要集中在肺功能參數、呼吸系統疾病的相關評分以及健康狀況三個子類。如表 1、表 2 所示,在 GOLD2007 與 GOLD2011 分類的前 10 個重要特征中,發現 FEV1、FEV1/FVC 等肺功能參數對 GOLD2007 分類具有首要的影響,其他屬于前 10 的影響特征還包括健康調查簡表(the MOS item short from health survey,SF-36)、爬山時是否呼吸短促以及吸煙年齡等。對于 GOLD2011 分類標準,SGRQ 評分是首要特征,其余特征包括哮喘用藥、是否哮喘、爬山時是否呼吸短促、COPD 患病時間、SF-36 評分、FEV1、急性加重頻率以及吸煙狀況。
圖6
前 50 個敏感特征的分類數量分布
Figure6.
Classification quantity distribution of the top 50 sensitive features
3 討論
本文將深度學習分類算法應用于 COPD 危重程度的分類評估,通過對大量高維度、無規則、含噪聲的數據進行降維與抽象,得出 GOLD 分類預測模型以及輸入特征與分類之間的潛在相關性。該方法探索了深度學習方法對 COPD 危重程度分類預測的有效性與可行性。通過研究結果表明,深度學習方法中的 DBN 能夠有效區分 90% 以上 COPD 患者的危重分類問題。
在大數據的機器學習過程中,由于輸入特征向量較多,經常涉及降維的問題,不是所有的特征參數都能夠對最終分類的結果有益,甚至還存在反作用[19]。因此,特征選擇方法能夠提前去除一些干擾以及與分類結果相關性較差的特征,而保留具有較強相關性的特征[20]。Fisher 分類器的結果反映的是每個輸入參數與最后所需分類結果之間空間分布的相關性,評分較低的參數,被認為是對分類結果無益的,因此需要進行舍棄。分析結果表明,經過 Fisher 分類器進行特征選擇后,測試的準確率明顯提高,DBN 集成 Fisher 特征選擇方法可以提高 DBN 的分類效果。
在臨床診療過程中,對疾病危重分類的診斷可抽象為人腦通過大量特征參數按照已有經驗以及復雜邏輯關系進行聯合判斷的思維過程[21]。本研究用建立 DBN 嘗試將這個復雜思維過程進行模型化與工程化,經過 500 次迭代優化后,預測模型逐漸趨向固定可重復,預測準確率保持相對穩定。本研究中,最終依據 GOLD2007 分類標準進行分類的最高準確率達到 94.9%,GOLD2011 準確率達到 97.2%。相同的分析算法下,對應 GOLD2011 分類的建模獲得出更高的預測準確率。在臨床上 GOLD2011 是 GOLD2007 的完善版本,GOLD2007 作為早期版本,主要是以患者肺功能單個參數作為判斷的依據,其在臨床上存在局限性,而 GOLD2011 版則在此基礎上將多種臨床評估量表(mMRC、CAT、SGRQ 等)、急性加重次數也納入到評估標準,形成多維度、綜合性的分類評估,使得臨床診斷更加準確,危重分類也更加細化,文獻研究表明,GOLD2011 分類標準更加符合 COPD 危重程度的真實情況,具備更好的適應性[22-23]。在本文的 DBN 分類過程中 GOLD2011 分類標準獲得了更高的準確性,符合臨床判斷標準的完善過程,表明 DBN 方法能夠反映出疾病危重程度分類標準的改進情況。
從 DBN 第一層系數矩陣的分布特征來看,部分輸入特征值對應的系數具有較大的綜合權重值,反映出此類敏感特征在特征抽象的過程中具有較大的貢獻度與影響性。通過對 GOLD2007、GOLD2011 分類標準預測所得到的前 50 個敏感因素進行分類分析發現,具有影響力的特征類型較為集中,主要可歸納為肺功能參數、呼吸疾病問卷評分以及健康狀況三類。此三類評分與 GOLD2011 分類依據完全相符[24]。通過對前 10 個敏感因素進行分析發現,GOLD2007 分類標準的敏感特征分布集中,前 10 個敏感特征中有 6 個是肺功能檢測結果相關的,反映出肺功能參數是 GOLD2007 分類標準的主要生理依據。在 GOLD2011 分類標準中,敏感特征包括了肺功能參數、SGRQ 健康評估、急性加重頻率等,這些特征符合臨床實際分類所依據的主要參數指標[25],上述結果表明通過 DBN 方法找到的敏感特征與臨床的分類決策依據具有較好的一致性。前 10 位的參數中,肺功能參數 FEV1、SF-36 量表-軀體健康評分、急行或上坡時是否氣短以及吸煙相關的 4 個參數均出現在兩個分類的影響因素中。根據臨床已有的研究,前三個參數均是 COPD 的主要表現特征,特別是吸煙相關參數是造成 COPD 病情變化與有效控制的重要影響因素[26]。這一結果反映出 DBN 分析獲得的敏感因素與臨床的先驗知識保持了一定的一致性,DBN 能夠從大量特征中找出部分敏感特征與分類結果之間潛在的相關性。
基于機器學習的臨床診療決策方法研究一直是醫療大數據領域的熱點,深度學習方法在醫療大數據分析中的應用在國內目前還是較新的方向。本研究探索將新興的深度學習方法應用于臨床疾病危重程度自動分類,雖然研究所用的數據規模有限,但數據結構、格式化程度、質量均符合機器學習的要求,但結果表明基于深度學習的分類分析可以有效地模擬臨床對疾病的診斷決策,能夠實現較高的判斷準確率,本研究為醫療大數據分析在疾病診斷中的應用提供了思路與案例。