為了更加簡單、高效并準確地識別定位經蘇木精-伊紅(HE)染色切片圖像中的細胞核,本文提出了一種基于距離的細胞核標記方法,這種方法為在細胞核叢聚圖像中提取細胞核單體提供了一種新的處理思路。與目前主流的基于凹度分析的方法不同,本文所述方法避免了對圖像中細胞核叢聚和細胞核單體的分類預處理,可以對含有細胞核叢聚的完整圖像進行直接處理。該方法使用了一種被稱為距離評估矩陣序列(MSDRE)的矩陣集對叢聚細胞核中的點到區域邊界的距離進行快速估算,結合凸區域的中心點距邊界最遠這一客觀事實,它可以快速準確地定位、標記出圖像中所有的細胞核單體。在實驗中,本標記方法獲得了 95.26% 的標記準確率和每 1 000 個目標物平均耗時 1.54 s 的標記效率,較目前的主流方法具有更好的識別準確率和執行效率。本文所述方法在保持標記準確率不降低的前提下,大幅提高了識別標記的效率,提升了 HE 染色切片圖像分析系統的實時性,有利于相關成果的實施和應用。
引用本文: 孫文灝, 陸福相, 馬義德. 基于距離估計的細胞核標記法. 生物醫學工程學雜志, 2018, 35(3): 435-442. doi: 10.7507/1001-5515.201708041 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
蘇木精-伊紅(hematoxylin-eosin,HE)染色切片作為一種歷經百年的病理學工具,在醫學診斷中扮演著非常重要的角色。細胞核作為 HE 染色切片的主要信息攜帶者,被一種獨特的紫色(或藍色)顏料標記。病理學家們通過分析細胞核的分布、形態、大小以及細胞核與其他細胞核或其他組織之間的聯系進行疾病診斷及預后判斷。高效、準確地識別 HE 圖像細胞核的分布,是醫學輔助診斷系統的重要工作內容。在 HE 圖像中,細胞核除了以獨立形式存在外,還會通過相互間的接觸、粘連、重合等方式組合成細胞核叢聚。由于圖像中獨立和叢聚的細胞核數量巨大、分布無規律,再加上噪聲的干擾,使得此類圖像的處理難度很高。此外,除了提到的細胞核叢聚,叢聚現象也會出現在其他含有龐大數量的目標物圖像之中。如:生物培養基上的菌落叢聚、衛星遙感叢聚[1]和工業碎料叢聚[2]等。
為了解決包括細胞核在內的叢聚現象對圖像分析造成的不利影響。多年來,研究人員提出了許多方法來分離叢聚,如:形態學腐蝕法[3]、分水嶺法[4]、基于活動輪廓模型的方法[5-6]和基于凹度分析的方法[7-13]等。形態學腐蝕法是最早被用于分離叢聚目標物的方法之一,它可以很好地解決簡單的叢聚,但對于重度重合的復雜叢聚無法得到滿意的結果。分水嶺法是一種被廣泛認可的基于圖像灰度的拓撲表面的方法[7],但容易造成過度分割,影響特征提取。活動輪廓模型提取目標物方法早先較為流行,該方法很容易幾何建模,并在細胞圖像分割等方面取得了很好的效果[14],但這種方法需要人工調參、計算開銷較高,實時性不強。
基于凹度分析的方法是效果較好且目前使用較多的方法。早在 1994 年,Yeo 等[15]就利用叢聚外包絡與內凹邊界間的關系以及內凹邊界中像素間的距離來推測宮頸癌細胞叢聚中細胞單體的邊界。在隨后的 20 多年里,此類方法快速發展,并有多種改進方案被提出,如:Wang 等[7]利用瓶頸檢測和形狀分類,分別進行匹配點檢測和最優分離路徑獲取;Kumar 等[12]利用凹面點的深度、凹點顯著性(由凹點深度與凹點間距離所描述的特性)以及矯正手段來選擇分離路徑;Samsi 等[10]利用圖劃分進行凹面匹配尋找匹配點;Ulle 等[11]和 Wen 等[16]利用曲率、邊緣剪枝和邊緣推測的方法來搜索分離路徑等。這些方法分別在酵母細胞、血液細胞、彎孢菌細胞、油砂礦、腎蕨、阿拉伯樹膠等叢聚的分離實驗中取得了較好的效果,并被廣泛應用于農業、工業、醫學[9-11, 16-17]以及漫畫[18]等領域。盡管凹度分析方法在應用領域已經較為成功,但其依然存在如下缺點:
(1)基于凹度分析方法的目標是要找到叢聚中單體間的邊界。但在實際情況下,單體可能受重疊、擠壓、破裂、噪聲以及染色劑污染等因素的影響,導致真實的邊界信息丟失,甚至出現偽“邊界”。所以凹度分析類方法提取的“邊界”未必是完全可靠的。
(2)凹度分析方法只能處理獨立叢聚,不能直接對全局圖像進行處理。在處理實際問題時,需要事先提取出所有的叢聚,然后再單獨處理每一個叢聚。如 Wang 等[7]專門訓練了一個支持向量機來識別提取叢聚目標。這樣在處理含有大量目標物的實際圖像時,方法需要被反復調用,整體效率低下。
(3)“凹度”這一概念非常依賴于圖像的分辨率和叢聚以及單體輪廓的完整度。當構成叢聚的像素數量較少,或圖像含有較強的噪聲時,如圖 1 所示,很多基于凹度分析的方法無法正常工作。例如 Ulle 等[11]、Kumar 等[12]、Janssens 等[13]以及 Yeo 等[15]提出的方法在處理低分辨率的目標區域時,會產生曲率計算不準確、叢聚邊緣和外包絡差別過小而無法判斷內凹邊界等問題。如圖 1 所示,圖中的白色和黑色分別代表值為 1 和 0 的區域,白色為叢聚。紅線標記了兩個目標單體大致的分界,橙色框體標記了單體的中心區域。白色像素點上的數字代表該像素到區域邊緣的像素距離。
 圖1
一個含有噪聲的叢聚樣本圖像
Figure1.
A clump sample image with noise
圖1
一個含有噪聲的叢聚樣本圖像
Figure1.
A clump sample image with noise
為解決凹度分析方法的上述缺陷,本文提出了一種新的基于距離的叢聚細胞核標記方法。此方法拋棄了凹度分析法尋找邊界的思路,轉而在全局圖像中直接對目標物進行標記,因而避免了“邊界”信息的缺失、損壞和噪聲干擾帶來的影響,也避免了提取叢聚目標物和反復調用算法帶來的耗時問題。另外,為解決歐式距離計算量較大的問題,本文還提出了一種基于圖像卷積的距離估算算法,較顯著地提高了本文方法的效率。本文方法在保持標記、識別準確率不降低的前提下,大幅提升了標記的效率,提高了 HE 染色切片圖像分析系統的實時性,有利于相關成果的實施和應用。
1 圖像資料的來源及授權情況
本文所用的所有細胞核圖像均由蘭州大學第一醫院病理研究所授權提供。圖像采集自常規病理診斷所用 HE 染色切片,并已在病理診斷申請單中獲得了患者認可切片圖像用于科學研究的授權。圖像捕獲所用設備為光學顯微鏡(BX51,奧林巴斯)和圖像采集器(DP71,奧林巴斯)。
2 基于距離估計的細胞核標記方法
2.1 待標記圖像的預處理
本文所述方法需要對 HE 染色細胞圖像進行預處理,獲取預處理后的二值化的細胞核圖像作為處理對象。由于現有細胞核二值化分割的預處理方法數量眾多,不再贅述,僅給出本文所采用的方式,如下所示。
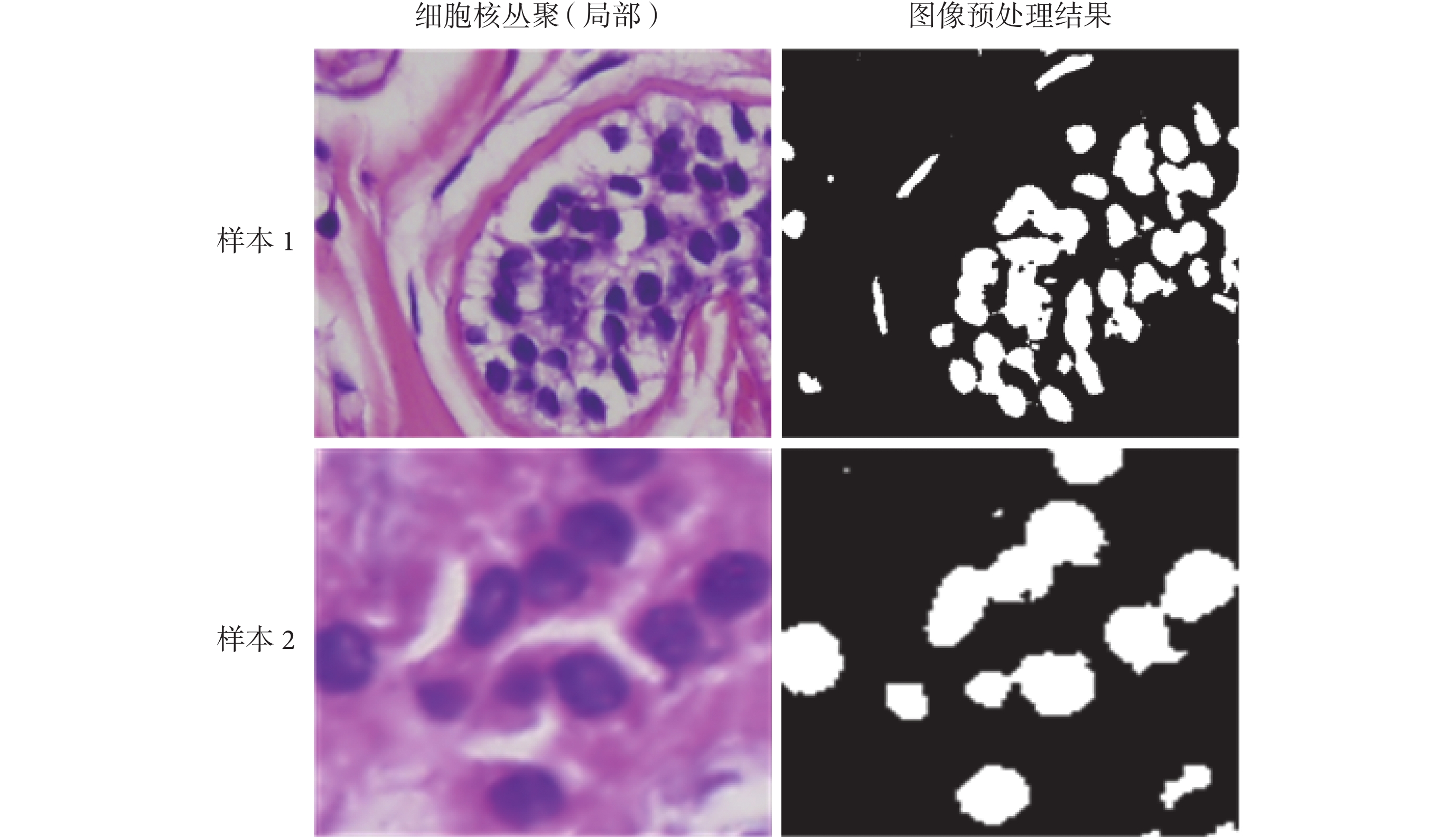
首先,采用 Macenko 等[19]的方法對 HE 染色細胞圖像進行圖像顏色的歸一化調整,降低 HE 染色圖片的染色多樣性帶來的影響。然后,采用 Cosatto 等[20]的方法對歸一化圖像在 H、E 分量進行顏色分解,進一步減少染色對分割的影響。最后,對圖像的 H 分量進行閾值處理,得到相對準確、穩定的細胞核二值化圖像,隨機選取的樣本圖如圖 2 所示。
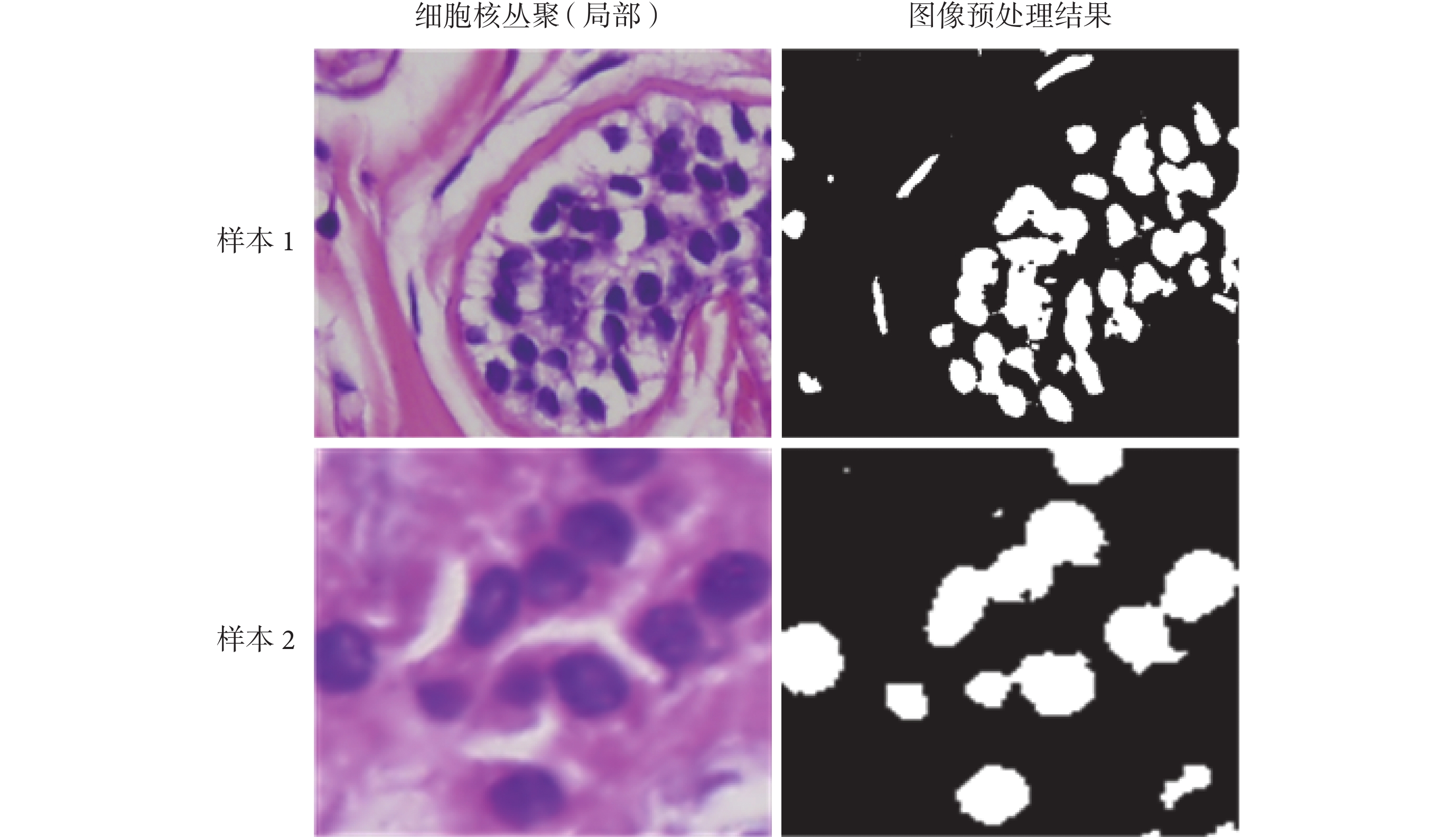 圖2
細胞核叢聚圖像的預處理結果示例
Figure2.
Sample results of nuclei clump image preprocessing
圖2
細胞核叢聚圖像的預處理結果示例
Figure2.
Sample results of nuclei clump image preprocessing
2.2 基于距離的細胞核標記原理
在 HE 染色的醫學切片圖像中,細胞核大多近似橢圓,如圖 2 所示,所以無論細胞核如何組成叢聚,“凸”的形態不會發生太大變化。對于一個凸區域來說,中心點到最近邊界的距離最遠。將細胞核視為一個凸區域,即可利用叢聚中點與邊界的距離,來估計叢聚中的細胞核的中心位置了。
由于傳統的距離計算方法(如:歐氏距離等)在計算凸區域中所有像素的間距時,計算量過大,所以本文提出了一種新的區域內點到區域邊界的距離估算算法。其原理可由平面點集理論中聚點的定義引出:設 E 為一個二維平面上的一個點集,對任意給定的距離 d > 0,如果點 p 的去心鄰域 U(p,d)內總有屬于集合 E 的點,則 p 稱為 E 的聚點。對于聚點中的內點,當 E 是“凸”的時候,隨著 d 的不斷增大,總會有一個最小距離值 DT(p),使得 d ≤ DT(p)時 U(p,d)內所有的點都屬于集合 E。當 d ≥ DT(p)時 U(p,d)內至少會含有一個不屬于 E 的點。定義邊界點的 DT(p)= 0,則有:如果位置 p0 是一個凸區域的中心點,那么它的 DT(p)必然是其所在凸區域內的最大值。也就是說點 p0 是二維平面內一個凸區域的中心點的必要條件為:
 |
利用聚點 p 到最近凸區域邊界的距離 DT(p)來尋找叢聚中滿足中心要求的點 p0,再經過篩選即可得到目標物單體的中心位置。
2.3 基于距離的細胞核的標記方法
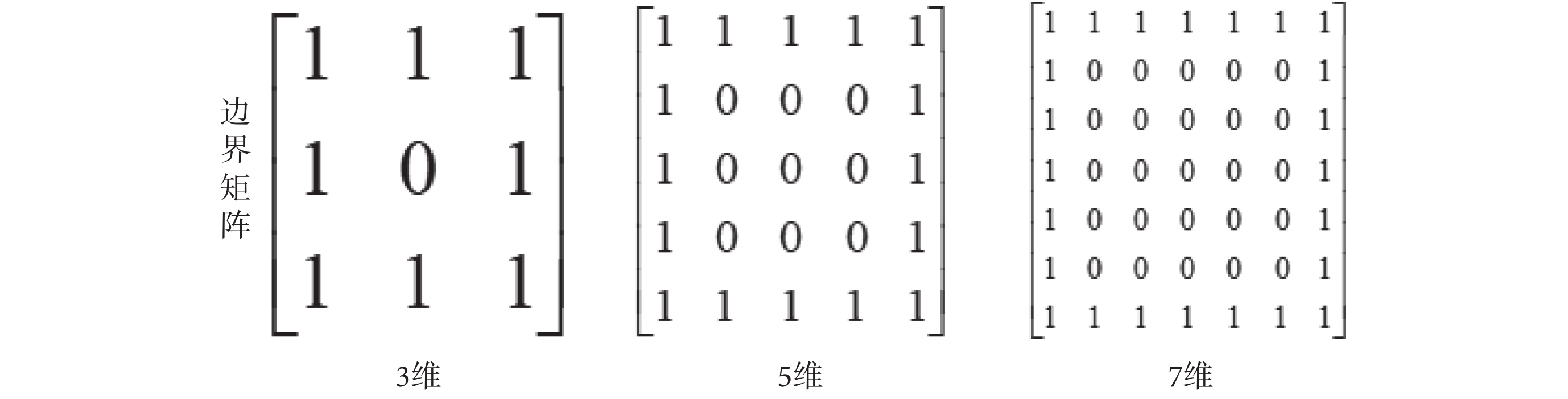
本文采用一種被稱為邊界矩陣(boundary matrix,BM)的特殊矩陣對最小距離 DT(p)進行估計。邊界矩陣被定義為所有的邊界點為 1,其他點均為 0 的奇方陣,如圖 3 所示。
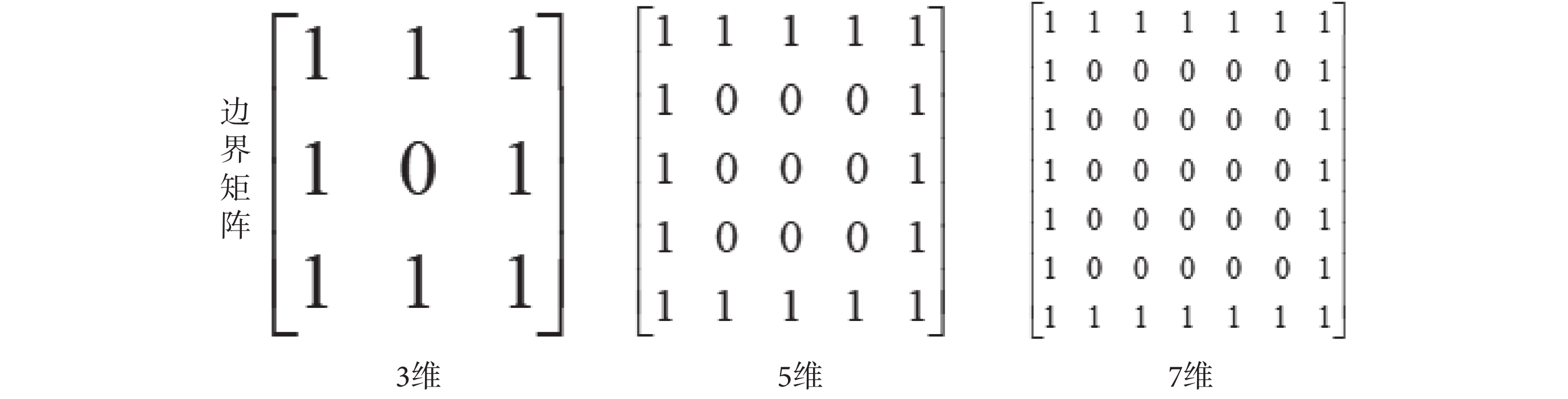 圖3
3 至 7 維的邊界矩陣示例
Figure3.
The boundary matrix with the dimension of three to seven
圖3
3 至 7 維的邊界矩陣示例
Figure3.
The boundary matrix with the dimension of three to seven
這些邊界矩陣依尺寸維度,依次排列所組成的集合被稱作邊界矩陣序列。當邊界矩陣作為核與二值圖像進行卷積時,輸出的值正好等于該點 p 的某個矩形鄰域邊界上的值為“1”的點的數量。如果卷積輸出值正好等于卷積核中“1”的數量(也就是說這個點在這個維度下的鄰域邊界是完整的),那么可以知道這個點的鄰域內的其它點都是這個區域 U(p,d)的聚點。如果卷積輸出值小于卷積核中“1”的數量,則認為這個鄰域包含了凸區域 U(p,d)的邊界或外點。這樣就可以估算某個區域中的點 p 距其邊界的最小距離 DT(p)了。
為便于計算,實際應用中使用距離估算圖(distance graph,DG)(以符號 DG 表示)來快速估算距離。DG 是一個與輸入圖像大小相同的矩陣,其中的非零元素表示輸入圖像中對應像素點到凸區域邊緣距離的最小值 DT(p)(近似值),零元素表示對應像素點不屬于某個凸區域。
 |
Bi 是一個與輸入圖像大小相同的矩陣,其元素值 Bixy 表示與輸入圖像對應像素點的某個鄰域邊界上的點是否全為聚點。Bixy 的計算如下:
 |
 |
其中,I 為二值化的叢聚圖像矩陣,BMi 為邊界矩陣(卷積核),c 為 I 與 BMi 的卷積結果。i 為邊界矩陣(卷積核)的尺寸維度,cxy 和 Bixy 分別表示 c 和 Bi 中的元素,x 和 y 表示像素的坐標位置,Sum()表示矩陣中所有元素之和,
 為卷積操作。如果卷積結果和卷積核中“1”的數量相等,則 Bixy 值為 1,否則將輸出為 0。
為卷積操作。如果卷積結果和卷積核中“1”的數量相等,則 Bixy 值為 1,否則將輸出為 0。
從圖 1 可以直觀地看出,叢聚圖像與 DG(由 3 維和 5 維的邊界矩陣為卷積核計算得出)之間的關系。由于叢聚中目標物單體的中心往往位于 DG 中的極大值區域內或孤立的極大值點上,所以計算這些區域的重心位置(或篩選出孤立的極大值點),即可得到近似的目標物中心坐標。
 |
pj 表示 DG 中屬于第 j 個目標物單體的點,pj0 表示第 j 個目標物中心的近似坐標。由于本文所述方法是標記出細胞核叢聚的坐標,所以這樣的精度是滿足要求的。
在某些應用中,圖像會含有大量、微小的目標物。在對目標物的形態、位置精度的要求不高的情況下,可在標記點處使用半徑為對應 DT(p)的圓來替代目標物。進而估算目標物的數量、大小、位置分布等特征。
另外,由于標記過程中最多的操作為卷積。由于卷積操作對圖像所包涵內容、信息以及圖像的分辨率沒有特殊要求,這使得方法的計算量取決于輸入圖像的大小,并可以處理一些由于分辨率過低而無法獲取“凹度”信息的圖像(本文方法可標記的最小目標為 3 × 3 的矩形區域)。在應用中,可適度降低目標物圖像分辨率,以換取更廣闊的圖像視野。此特性使本方法非常適于處理目標物數量眾多、體積細小且分布廣泛的叢聚圖像。
本節最后給出本文方法各處理階段圖像,如圖 4 所示。
 圖4
本文方法對細胞核叢聚樣本的標記過程
Figure4.
The label process of proposed method on nuclei clump sample
圖4
本文方法對細胞核叢聚樣本的標記過程
Figure4.
The label process of proposed method on nuclei clump sample
2.4 距離評估矩陣序列
為便于解釋原理,本文 2.3 小節中使用了邊界矩陣作為卷積核來估算距離。但經實驗發現,使用距離評估矩陣序列(matrix sequence of distance rough estimating,MSDRE)作為卷積核會使結果更加穩定、有效。距離評估矩陣序列由若干個依尺度從小到大排列的距離評估矩陣組成。一個尺度為 n 維的距離評估矩陣由一個尺度為 n 維的菱形矩陣和一個尺度為(n – 2)維的邊界矩陣相加得到。菱形矩陣被定義為各邊中點及其連線值為 1,其余元素全部為 0 的奇方陣。尺度為 3 至 5 維的距離評估矩陣,如圖 5 所示。
 圖5
3 至 7 維的距離評估矩陣示例
Figure5.
The matrix sequence of distance rough estimating with the dimension of three to seven
圖5
3 至 7 維的距離評估矩陣示例
Figure5.
The matrix sequence of distance rough estimating with the dimension of three to seven
實質上,邊界矩陣和菱形矩陣是從不同的方向上對距離進行估計的。這種組合方式為距離的估算提供了方向性和計算上的冗余,從而控制了計算誤差、提高了穩定性。
2.5 標記方法的優化
不同分辨率的圖像采集設備捕獲的細胞核圖像中,細胞核叢聚及單體的大小會有很大的差異。捕獲圖像也會因混有雜質或是受到噪聲的影響,從而引入一些體積遠大于或遠小于目標單體的區塊。為此,可以利用先驗知識,選擇性地使用卷積核來解決這個問題。對于小雜質和噪聲,使用維度不低于 imin 的卷積核進行計算,以避免干擾。imin 的計算如式(6)所示:
 |
rmin 為目標物單體的合理的最小半徑,u 為冗余范圍系數,其取值范圍為 [0,1],{x} 表示對 x 取整。同理,利用同一類叢聚圖像中的目標物的合理的尺寸信息,可以設置距離評估矩陣序列的最大維度如式(7)所示:
 |
rmax 為合理的目標物的最大半徑。
如果由噪聲或其它原因產生的干擾點正好落在了叢聚的邊界上,本文方法的精度將會受到較大影響。這種干擾點通常是孤立的,使用半徑為 1 的結構元對每一副 Bi 進行一次膨脹操作,即可較好地解決這一問題。
當叢聚中的單體較為密集時,一些間隙或孔洞在高維度的卷積計算中會被誤認為是聚點。可通過比對距離估計圖 Bi,以避免這種情況的發生:若低維 Bi 中的某個點值為 0,則直接將所有高維 Bi 相應點的值置為 0。
3 實驗結果
由于本文方法可直接處理叢聚圖像,而凹度分析方法只能處理單獨叢聚,所以最終實驗被分為兩部分。第一部分為本文方法與人工標記在整幅圖像上的對比實驗,第二部分為本文方法與凹度分析方法在叢聚樣本上的對比實驗。實驗所有數據均采集自同一硬件平臺,其配置為中央處理器(i5-4590@3.30 GHz,英特爾)和主存(DDR3-8.00 GB,宇瞻)。
3.1 人工標記對比實驗
人工標記對比實驗的對象為 10 張分辨率為 1024 × 1360 的 40 倍顯微實驗圖像。經預處理,形成了含有超過 3 000 個細胞核的叢聚圖像樣本集。在此放大倍數和分辨率條件下,細胞核的大致合理的半徑約為 6~10 像素。所以實驗使用的距離評估矩陣序列的最小起始維度和最大截止維度分別為 7 和 31(冗余范圍系數 u 取 0.5)。
本實驗認為人工標記的目標為真實細胞核。通過人工和本文所述方法兩種手段分別對樣本圖像進行標記,實驗的結果和相關數據,如表 1 所示。其中的標記準確率和假陽(陰)性占比公式分別為:
 |
 |
這里的假陽性表示目標被本方法標記但未被人工標記,即被標記的目標不是細胞核。假陰性表示目標被人工標記但未被本方法標記,即漏標了真的細胞核。
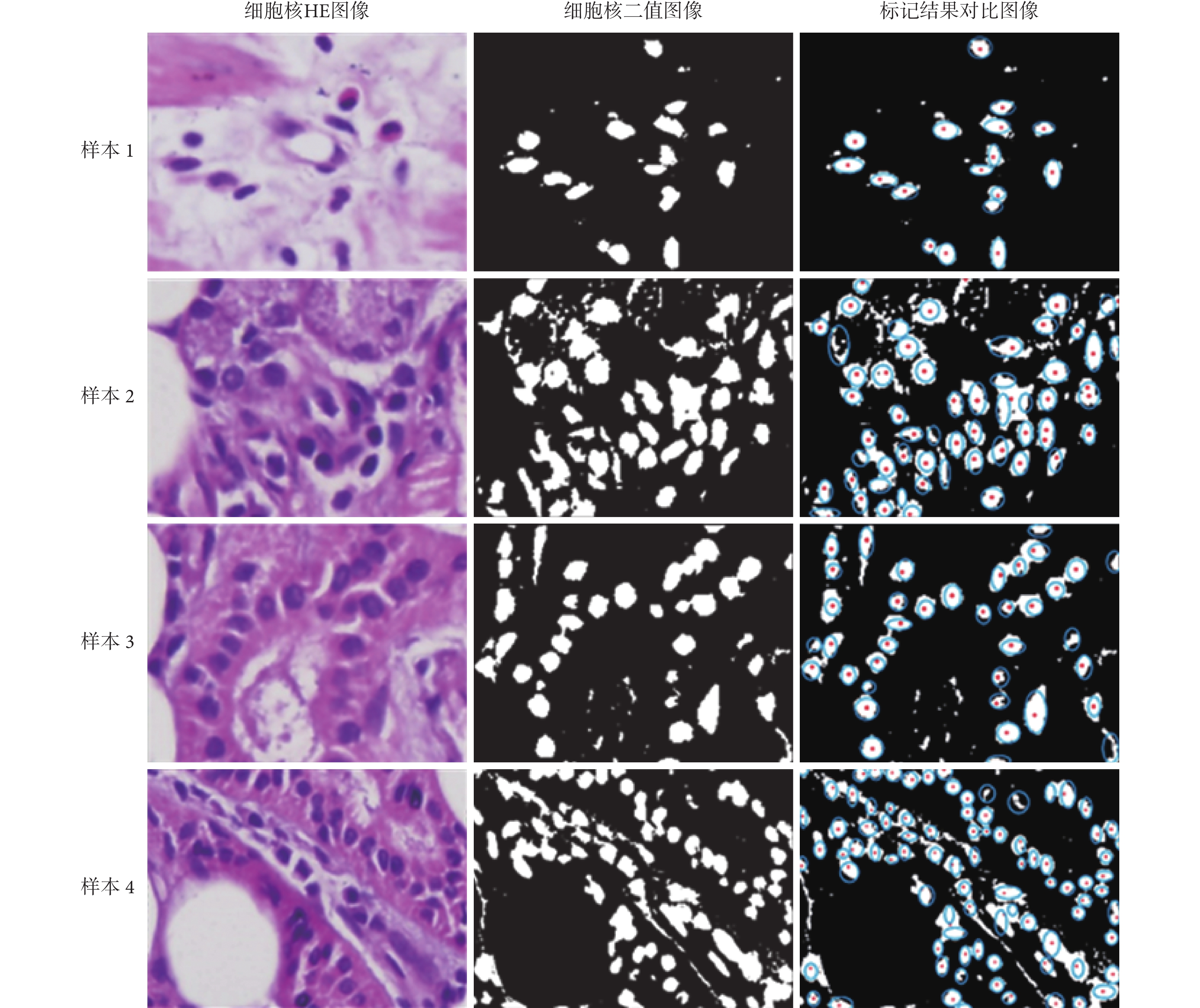
為了便于觀察,如圖 6 所示,給出了實驗結果中隨機截取的部分樣本局部圖像。圖 6 每一行的左側為 HE 染色的細胞核圖像,中間為二值化后的被測試圖像,右側為兩種標記方式疊加的實驗結果圖像。結果圖像中的淡藍色的小圈為人工標記結果,紅色的點為本文提出方法的標記結果。
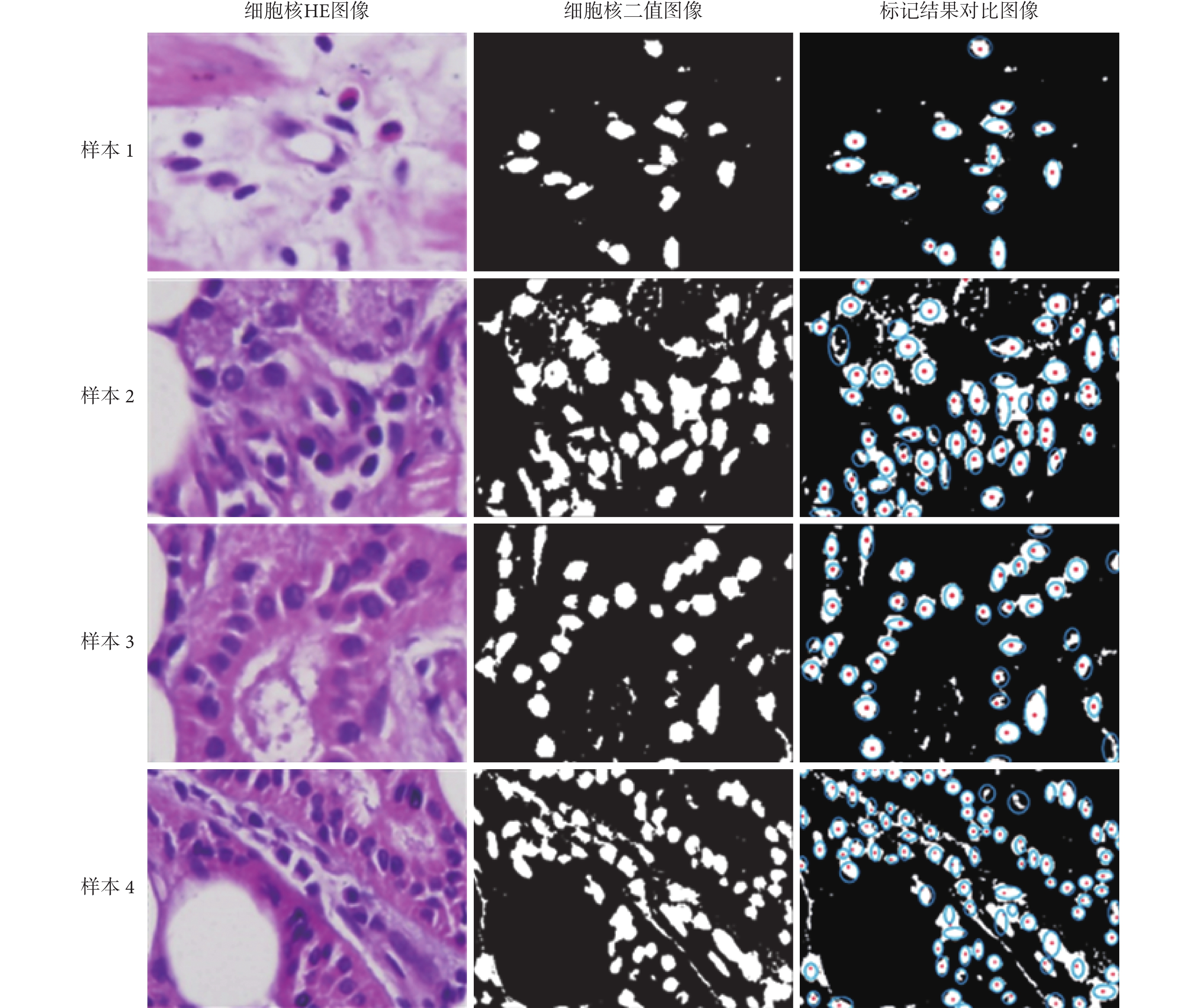 圖6
隨機截取的局部實驗圖像
Figure6.
Randomly captured local images in experiment
圖6
隨機截取的局部實驗圖像
Figure6.
Randomly captured local images in experiment
通過本次人工標記對比實驗表明,本文提出的方法具有很高的標記準確度與效率。本文方法在 10 張 HE 染色的叢聚圖像樣本集(共計包含 3 368 個細胞核)上對目標單體標記的準確率達到了 95.26% ± 2.72%。10 張圖像的平均標記時間為(0.518 ± 0.001 3)s,換算為每千個細胞核的平均標記時間約為 1.54 s。這種執行效率和精度足以滿足實際應用的需要。
本文所述方法對 5 不同種尺寸類型的圖像在相同實驗平臺下的計算耗時統計,如表 2 所示。每種尺寸類型中都含有 20 張隨機截取自實驗數據集的包含有 1~6 個單體細胞核或叢聚的圖像。從結果中可以看出,隨著圖像尺寸增大,算法的耗時也隨之增長,而耗時的標準差則保持幾乎為零。這證明本文算法的效率僅與圖像的尺寸相關而與圖像中包含的細胞核的單體或叢聚數量無關。
3.2 與凹度分析方法的對比實驗
為避免凹度分析法不能直接應用于整幅圖像,難以同本文方法進行比較的問題。我們在第一部分實驗的樣本集中,提取了部分細胞核叢聚圖像,組成新的樣本集,作為實驗的目標。新樣本集包含 50 張叢聚細胞核圖像,每幅圖像含若干細胞核組成的叢聚(共計 166 個細胞核)。
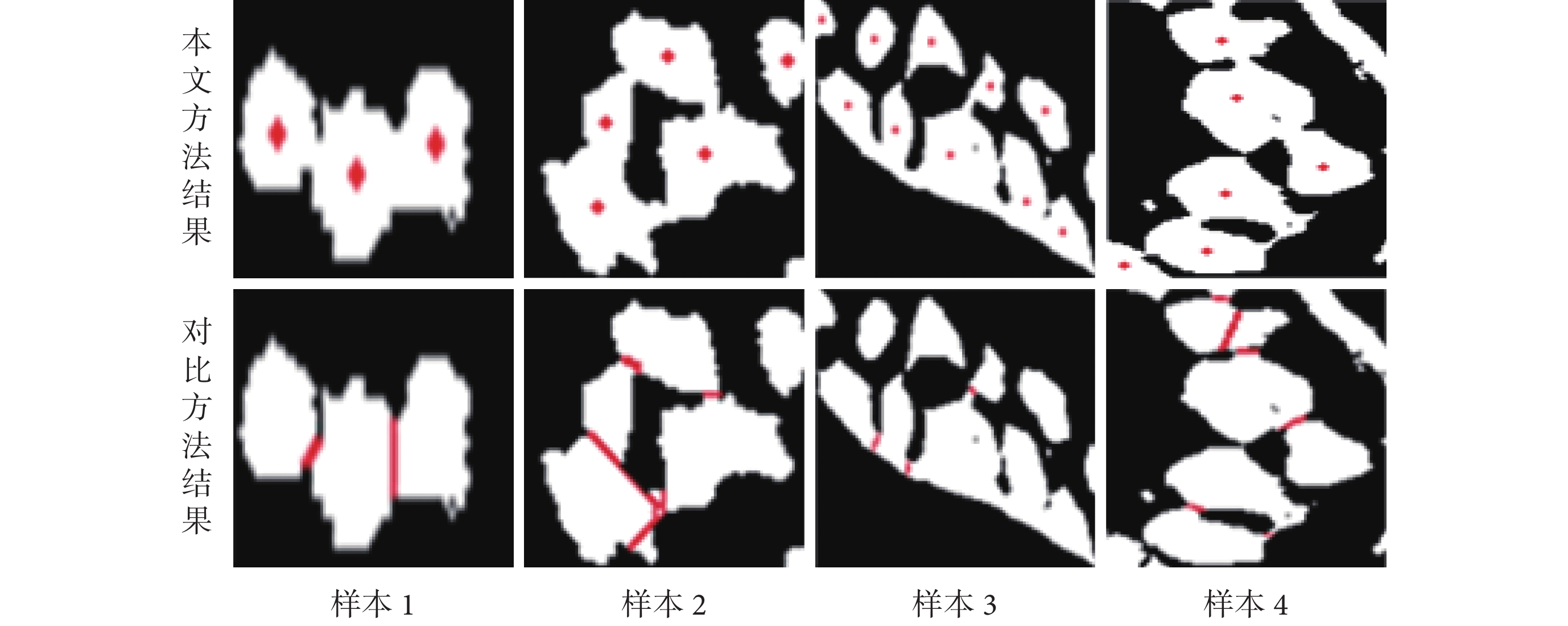
此實驗部分的對比方法為瓶頸分析法[7],它是目前凹度分析類方法中為數不多的在理論上可處理低分辨率細胞核叢聚的方法。最終的實驗結果如圖 7 和表 3 所示。
如圖 7 所示,圖中的第一行圖像為本文所述方法的標記結果,第二行為對比方法的分離結果。從圖中可知,對于如樣本 1 所示的簡單細胞核叢聚,兩種方法都有著很好的效果。但是對于如樣本 2~樣本 4 所示一些較為復雜的叢聚來說,本文所述方法的識別準確率更高。另外,如表 3 所示,其中的誤識別包括了假陰性和假陽性兩種情況,表中的總耗時為處理全部 50 個樣本的總體時間花費。實驗結果表明,本方法在準確率和處理速度兩方面均優于瓶頸分析法。
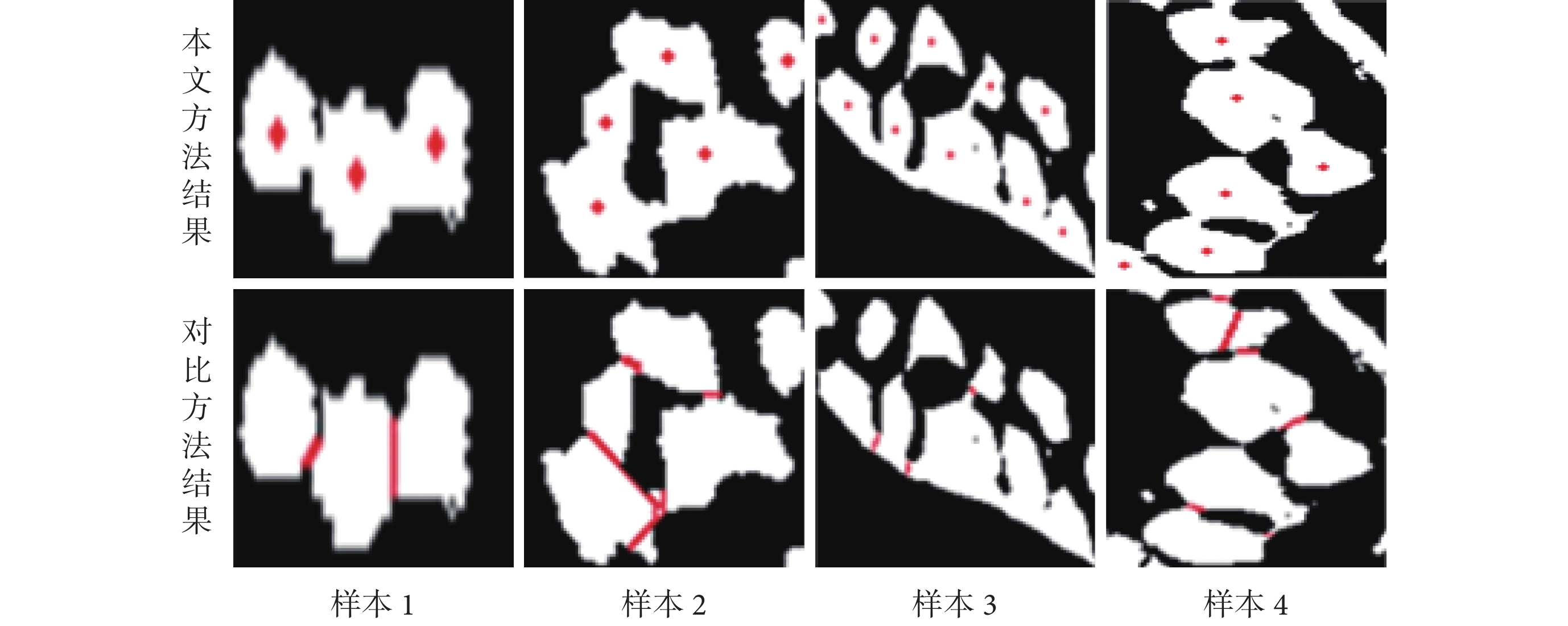 圖7
對比實驗的部分結果
Figure7.
A part of comparison of experimental results
圖7
對比實驗的部分結果
Figure7.
A part of comparison of experimental results
4 總結和討論
在細胞核叢聚的識別標記方面,基于凹度分析的方法實現起來較為復雜,計算耗時較長,且存在著因目標叢聚細胞核間的“邊界”圖像信息不完整(或不存在),易造成誤分割、誤識別等問題。為此,本文提出了一種簡單、實用的叢聚細胞核提取方法。本方法的優點在于:① 拋棄了尋找叢聚中細胞核之間的“邊界”的思路,轉而直接在整幅圖像中進行細胞核標記。這樣不僅避免了細胞核“邊界”信息缺失對細胞核辨識的影響,還避免了凹度分析方法中,逐個剔除圖像中非叢聚細胞核的預處理步驟,降低了方法的復雜度,并使本文方法的耗時僅依賴于輸入圖像的尺寸大小,而與圖像中包含的細胞核叢聚數量無關。② 通過建立基于卷積的距離估算算法,解決了圖像像素間距的快速計算問題。此算法所采用的卷積操作還使本文所述方法能夠處理一些由于分辨率過低而無法獲取“凹度”和“曲率”等信息的圖像。這些特性表明了本文方法具有較高的實用價值。
經實驗發現,本文提出的方法還存在一定的局限性,例如:對近似于餅、團狀的細胞核組成聚落的識別效果較好,但對長條狀的細胞核組成的聚落的識別效果不夠理想;如果叢聚中的細胞核由于光照等原因在二值化圖像的白色區域內部出現黑色噪點,也可能發生誤判。我們將對這些問題進行更深入的研究,并逐步引入細胞核圖像的灰度、顏色等信息和其他先驗知識等,盡可能提高基于距離標記方法的準確率,以獲得更好的細胞核辨識效果。
引言
蘇木精-伊紅(hematoxylin-eosin,HE)染色切片作為一種歷經百年的病理學工具,在醫學診斷中扮演著非常重要的角色。細胞核作為 HE 染色切片的主要信息攜帶者,被一種獨特的紫色(或藍色)顏料標記。病理學家們通過分析細胞核的分布、形態、大小以及細胞核與其他細胞核或其他組織之間的聯系進行疾病診斷及預后判斷。高效、準確地識別 HE 圖像細胞核的分布,是醫學輔助診斷系統的重要工作內容。在 HE 圖像中,細胞核除了以獨立形式存在外,還會通過相互間的接觸、粘連、重合等方式組合成細胞核叢聚。由于圖像中獨立和叢聚的細胞核數量巨大、分布無規律,再加上噪聲的干擾,使得此類圖像的處理難度很高。此外,除了提到的細胞核叢聚,叢聚現象也會出現在其他含有龐大數量的目標物圖像之中。如:生物培養基上的菌落叢聚、衛星遙感叢聚[1]和工業碎料叢聚[2]等。
為了解決包括細胞核在內的叢聚現象對圖像分析造成的不利影響。多年來,研究人員提出了許多方法來分離叢聚,如:形態學腐蝕法[3]、分水嶺法[4]、基于活動輪廓模型的方法[5-6]和基于凹度分析的方法[7-13]等。形態學腐蝕法是最早被用于分離叢聚目標物的方法之一,它可以很好地解決簡單的叢聚,但對于重度重合的復雜叢聚無法得到滿意的結果。分水嶺法是一種被廣泛認可的基于圖像灰度的拓撲表面的方法[7],但容易造成過度分割,影響特征提取。活動輪廓模型提取目標物方法早先較為流行,該方法很容易幾何建模,并在細胞圖像分割等方面取得了很好的效果[14],但這種方法需要人工調參、計算開銷較高,實時性不強。
基于凹度分析的方法是效果較好且目前使用較多的方法。早在 1994 年,Yeo 等[15]就利用叢聚外包絡與內凹邊界間的關系以及內凹邊界中像素間的距離來推測宮頸癌細胞叢聚中細胞單體的邊界。在隨后的 20 多年里,此類方法快速發展,并有多種改進方案被提出,如:Wang 等[7]利用瓶頸檢測和形狀分類,分別進行匹配點檢測和最優分離路徑獲取;Kumar 等[12]利用凹面點的深度、凹點顯著性(由凹點深度與凹點間距離所描述的特性)以及矯正手段來選擇分離路徑;Samsi 等[10]利用圖劃分進行凹面匹配尋找匹配點;Ulle 等[11]和 Wen 等[16]利用曲率、邊緣剪枝和邊緣推測的方法來搜索分離路徑等。這些方法分別在酵母細胞、血液細胞、彎孢菌細胞、油砂礦、腎蕨、阿拉伯樹膠等叢聚的分離實驗中取得了較好的效果,并被廣泛應用于農業、工業、醫學[9-11, 16-17]以及漫畫[18]等領域。盡管凹度分析方法在應用領域已經較為成功,但其依然存在如下缺點:
(1)基于凹度分析方法的目標是要找到叢聚中單體間的邊界。但在實際情況下,單體可能受重疊、擠壓、破裂、噪聲以及染色劑污染等因素的影響,導致真實的邊界信息丟失,甚至出現偽“邊界”。所以凹度分析類方法提取的“邊界”未必是完全可靠的。
(2)凹度分析方法只能處理獨立叢聚,不能直接對全局圖像進行處理。在處理實際問題時,需要事先提取出所有的叢聚,然后再單獨處理每一個叢聚。如 Wang 等[7]專門訓練了一個支持向量機來識別提取叢聚目標。這樣在處理含有大量目標物的實際圖像時,方法需要被反復調用,整體效率低下。
(3)“凹度”這一概念非常依賴于圖像的分辨率和叢聚以及單體輪廓的完整度。當構成叢聚的像素數量較少,或圖像含有較強的噪聲時,如圖 1 所示,很多基于凹度分析的方法無法正常工作。例如 Ulle 等[11]、Kumar 等[12]、Janssens 等[13]以及 Yeo 等[15]提出的方法在處理低分辨率的目標區域時,會產生曲率計算不準確、叢聚邊緣和外包絡差別過小而無法判斷內凹邊界等問題。如圖 1 所示,圖中的白色和黑色分別代表值為 1 和 0 的區域,白色為叢聚。紅線標記了兩個目標單體大致的分界,橙色框體標記了單體的中心區域。白色像素點上的數字代表該像素到區域邊緣的像素距離。
圖1
一個含有噪聲的叢聚樣本圖像
Figure1.
A clump sample image with noise
為解決凹度分析方法的上述缺陷,本文提出了一種新的基于距離的叢聚細胞核標記方法。此方法拋棄了凹度分析法尋找邊界的思路,轉而在全局圖像中直接對目標物進行標記,因而避免了“邊界”信息的缺失、損壞和噪聲干擾帶來的影響,也避免了提取叢聚目標物和反復調用算法帶來的耗時問題。另外,為解決歐式距離計算量較大的問題,本文還提出了一種基于圖像卷積的距離估算算法,較顯著地提高了本文方法的效率。本文方法在保持標記、識別準確率不降低的前提下,大幅提升了標記的效率,提高了 HE 染色切片圖像分析系統的實時性,有利于相關成果的實施和應用。
1 圖像資料的來源及授權情況
本文所用的所有細胞核圖像均由蘭州大學第一醫院病理研究所授權提供。圖像采集自常規病理診斷所用 HE 染色切片,并已在病理診斷申請單中獲得了患者認可切片圖像用于科學研究的授權。圖像捕獲所用設備為光學顯微鏡(BX51,奧林巴斯)和圖像采集器(DP71,奧林巴斯)。
2 基于距離估計的細胞核標記方法
2.1 待標記圖像的預處理
本文所述方法需要對 HE 染色細胞圖像進行預處理,獲取預處理后的二值化的細胞核圖像作為處理對象。由于現有細胞核二值化分割的預處理方法數量眾多,不再贅述,僅給出本文所采用的方式,如下所示。
首先,采用 Macenko 等[19]的方法對 HE 染色細胞圖像進行圖像顏色的歸一化調整,降低 HE 染色圖片的染色多樣性帶來的影響。然后,采用 Cosatto 等[20]的方法對歸一化圖像在 H、E 分量進行顏色分解,進一步減少染色對分割的影響。最后,對圖像的 H 分量進行閾值處理,得到相對準確、穩定的細胞核二值化圖像,隨機選取的樣本圖如圖 2 所示。
圖2
細胞核叢聚圖像的預處理結果示例
Figure2.
Sample results of nuclei clump image preprocessing
2.2 基于距離的細胞核標記原理
在 HE 染色的醫學切片圖像中,細胞核大多近似橢圓,如圖 2 所示,所以無論細胞核如何組成叢聚,“凸”的形態不會發生太大變化。對于一個凸區域來說,中心點到最近邊界的距離最遠。將細胞核視為一個凸區域,即可利用叢聚中點與邊界的距離,來估計叢聚中的細胞核的中心位置了。
由于傳統的距離計算方法(如:歐氏距離等)在計算凸區域中所有像素的間距時,計算量過大,所以本文提出了一種新的區域內點到區域邊界的距離估算算法。其原理可由平面點集理論中聚點的定義引出:設 E 為一個二維平面上的一個點集,對任意給定的距離 d > 0,如果點 p 的去心鄰域 U(p,d)內總有屬于集合 E 的點,則 p 稱為 E 的聚點。對于聚點中的內點,當 E 是“凸”的時候,隨著 d 的不斷增大,總會有一個最小距離值 DT(p),使得 d ≤ DT(p)時 U(p,d)內所有的點都屬于集合 E。當 d ≥ DT(p)時 U(p,d)內至少會含有一個不屬于 E 的點。定義邊界點的 DT(p)= 0,則有:如果位置 p0 是一個凸區域的中心點,那么它的 DT(p)必然是其所在凸區域內的最大值。也就是說點 p0 是二維平面內一個凸區域的中心點的必要條件為:
|
利用聚點 p 到最近凸區域邊界的距離 DT(p)來尋找叢聚中滿足中心要求的點 p0,再經過篩選即可得到目標物單體的中心位置。
2.3 基于距離的細胞核的標記方法
本文采用一種被稱為邊界矩陣(boundary matrix,BM)的特殊矩陣對最小距離 DT(p)進行估計。邊界矩陣被定義為所有的邊界點為 1,其他點均為 0 的奇方陣,如圖 3 所示。
圖3
3 至 7 維的邊界矩陣示例
Figure3.
The boundary matrix with the dimension of three to seven
這些邊界矩陣依尺寸維度,依次排列所組成的集合被稱作邊界矩陣序列。當邊界矩陣作為核與二值圖像進行卷積時,輸出的值正好等于該點 p 的某個矩形鄰域邊界上的值為“1”的點的數量。如果卷積輸出值正好等于卷積核中“1”的數量(也就是說這個點在這個維度下的鄰域邊界是完整的),那么可以知道這個點的鄰域內的其它點都是這個區域 U(p,d)的聚點。如果卷積輸出值小于卷積核中“1”的數量,則認為這個鄰域包含了凸區域 U(p,d)的邊界或外點。這樣就可以估算某個區域中的點 p 距其邊界的最小距離 DT(p)了。
為便于計算,實際應用中使用距離估算圖(distance graph,DG)(以符號 DG 表示)來快速估算距離。DG 是一個與輸入圖像大小相同的矩陣,其中的非零元素表示輸入圖像中對應像素點到凸區域邊緣距離的最小值 DT(p)(近似值),零元素表示對應像素點不屬于某個凸區域。
|
Bi 是一個與輸入圖像大小相同的矩陣,其元素值 Bixy 表示與輸入圖像對應像素點的某個鄰域邊界上的點是否全為聚點。Bixy 的計算如下:
|
|
其中,I 為二值化的叢聚圖像矩陣,BMi 為邊界矩陣(卷積核),c 為 I 與 BMi 的卷積結果。i 為邊界矩陣(卷積核)的尺寸維度,cxy 和 Bixy 分別表示 c 和 Bi 中的元素,x 和 y 表示像素的坐標位置,Sum()表示矩陣中所有元素之和,
為卷積操作。如果卷積結果和卷積核中“1”的數量相等,則 Bixy 值為 1,否則將輸出為 0。
從圖 1 可以直觀地看出,叢聚圖像與 DG(由 3 維和 5 維的邊界矩陣為卷積核計算得出)之間的關系。由于叢聚中目標物單體的中心往往位于 DG 中的極大值區域內或孤立的極大值點上,所以計算這些區域的重心位置(或篩選出孤立的極大值點),即可得到近似的目標物中心坐標。
|
pj 表示 DG 中屬于第 j 個目標物單體的點,pj0 表示第 j 個目標物中心的近似坐標。由于本文所述方法是標記出細胞核叢聚的坐標,所以這樣的精度是滿足要求的。
在某些應用中,圖像會含有大量、微小的目標物。在對目標物的形態、位置精度的要求不高的情況下,可在標記點處使用半徑為對應 DT(p)的圓來替代目標物。進而估算目標物的數量、大小、位置分布等特征。
另外,由于標記過程中最多的操作為卷積。由于卷積操作對圖像所包涵內容、信息以及圖像的分辨率沒有特殊要求,這使得方法的計算量取決于輸入圖像的大小,并可以處理一些由于分辨率過低而無法獲取“凹度”信息的圖像(本文方法可標記的最小目標為 3 × 3 的矩形區域)。在應用中,可適度降低目標物圖像分辨率,以換取更廣闊的圖像視野。此特性使本方法非常適于處理目標物數量眾多、體積細小且分布廣泛的叢聚圖像。
本節最后給出本文方法各處理階段圖像,如圖 4 所示。
圖4
本文方法對細胞核叢聚樣本的標記過程
Figure4.
The label process of proposed method on nuclei clump sample
2.4 距離評估矩陣序列
為便于解釋原理,本文 2.3 小節中使用了邊界矩陣作為卷積核來估算距離。但經實驗發現,使用距離評估矩陣序列(matrix sequence of distance rough estimating,MSDRE)作為卷積核會使結果更加穩定、有效。距離評估矩陣序列由若干個依尺度從小到大排列的距離評估矩陣組成。一個尺度為 n 維的距離評估矩陣由一個尺度為 n 維的菱形矩陣和一個尺度為(n – 2)維的邊界矩陣相加得到。菱形矩陣被定義為各邊中點及其連線值為 1,其余元素全部為 0 的奇方陣。尺度為 3 至 5 維的距離評估矩陣,如圖 5 所示。
圖5
3 至 7 維的距離評估矩陣示例
Figure5.
The matrix sequence of distance rough estimating with the dimension of three to seven
實質上,邊界矩陣和菱形矩陣是從不同的方向上對距離進行估計的。這種組合方式為距離的估算提供了方向性和計算上的冗余,從而控制了計算誤差、提高了穩定性。
2.5 標記方法的優化
不同分辨率的圖像采集設備捕獲的細胞核圖像中,細胞核叢聚及單體的大小會有很大的差異。捕獲圖像也會因混有雜質或是受到噪聲的影響,從而引入一些體積遠大于或遠小于目標單體的區塊。為此,可以利用先驗知識,選擇性地使用卷積核來解決這個問題。對于小雜質和噪聲,使用維度不低于 imin 的卷積核進行計算,以避免干擾。imin 的計算如式(6)所示:
|
rmin 為目標物單體的合理的最小半徑,u 為冗余范圍系數,其取值范圍為 [0,1],{x} 表示對 x 取整。同理,利用同一類叢聚圖像中的目標物的合理的尺寸信息,可以設置距離評估矩陣序列的最大維度如式(7)所示:
|
rmax 為合理的目標物的最大半徑。
如果由噪聲或其它原因產生的干擾點正好落在了叢聚的邊界上,本文方法的精度將會受到較大影響。這種干擾點通常是孤立的,使用半徑為 1 的結構元對每一副 Bi 進行一次膨脹操作,即可較好地解決這一問題。
當叢聚中的單體較為密集時,一些間隙或孔洞在高維度的卷積計算中會被誤認為是聚點。可通過比對距離估計圖 Bi,以避免這種情況的發生:若低維 Bi 中的某個點值為 0,則直接將所有高維 Bi 相應點的值置為 0。
3 實驗結果
由于本文方法可直接處理叢聚圖像,而凹度分析方法只能處理單獨叢聚,所以最終實驗被分為兩部分。第一部分為本文方法與人工標記在整幅圖像上的對比實驗,第二部分為本文方法與凹度分析方法在叢聚樣本上的對比實驗。實驗所有數據均采集自同一硬件平臺,其配置為中央處理器(i5-4590@3.30 GHz,英特爾)和主存(DDR3-8.00 GB,宇瞻)。
3.1 人工標記對比實驗
人工標記對比實驗的對象為 10 張分辨率為 1024 × 1360 的 40 倍顯微實驗圖像。經預處理,形成了含有超過 3 000 個細胞核的叢聚圖像樣本集。在此放大倍數和分辨率條件下,細胞核的大致合理的半徑約為 6~10 像素。所以實驗使用的距離評估矩陣序列的最小起始維度和最大截止維度分別為 7 和 31(冗余范圍系數 u 取 0.5)。
本實驗認為人工標記的目標為真實細胞核。通過人工和本文所述方法兩種手段分別對樣本圖像進行標記,實驗的結果和相關數據,如表 1 所示。其中的標記準確率和假陽(陰)性占比公式分別為:
|
|
這里的假陽性表示目標被本方法標記但未被人工標記,即被標記的目標不是細胞核。假陰性表示目標被人工標記但未被本方法標記,即漏標了真的細胞核。
為了便于觀察,如圖 6 所示,給出了實驗結果中隨機截取的部分樣本局部圖像。圖 6 每一行的左側為 HE 染色的細胞核圖像,中間為二值化后的被測試圖像,右側為兩種標記方式疊加的實驗結果圖像。結果圖像中的淡藍色的小圈為人工標記結果,紅色的點為本文提出方法的標記結果。
圖6
隨機截取的局部實驗圖像
Figure6.
Randomly captured local images in experiment
通過本次人工標記對比實驗表明,本文提出的方法具有很高的標記準確度與效率。本文方法在 10 張 HE 染色的叢聚圖像樣本集(共計包含 3 368 個細胞核)上對目標單體標記的準確率達到了 95.26% ± 2.72%。10 張圖像的平均標記時間為(0.518 ± 0.001 3)s,換算為每千個細胞核的平均標記時間約為 1.54 s。這種執行效率和精度足以滿足實際應用的需要。
本文所述方法對 5 不同種尺寸類型的圖像在相同實驗平臺下的計算耗時統計,如表 2 所示。每種尺寸類型中都含有 20 張隨機截取自實驗數據集的包含有 1~6 個單體細胞核或叢聚的圖像。從結果中可以看出,隨著圖像尺寸增大,算法的耗時也隨之增長,而耗時的標準差則保持幾乎為零。這證明本文算法的效率僅與圖像的尺寸相關而與圖像中包含的細胞核的單體或叢聚數量無關。
3.2 與凹度分析方法的對比實驗
為避免凹度分析法不能直接應用于整幅圖像,難以同本文方法進行比較的問題。我們在第一部分實驗的樣本集中,提取了部分細胞核叢聚圖像,組成新的樣本集,作為實驗的目標。新樣本集包含 50 張叢聚細胞核圖像,每幅圖像含若干細胞核組成的叢聚(共計 166 個細胞核)。
此實驗部分的對比方法為瓶頸分析法[7],它是目前凹度分析類方法中為數不多的在理論上可處理低分辨率細胞核叢聚的方法。最終的實驗結果如圖 7 和表 3 所示。
如圖 7 所示,圖中的第一行圖像為本文所述方法的標記結果,第二行為對比方法的分離結果。從圖中可知,對于如樣本 1 所示的簡單細胞核叢聚,兩種方法都有著很好的效果。但是對于如樣本 2~樣本 4 所示一些較為復雜的叢聚來說,本文所述方法的識別準確率更高。另外,如表 3 所示,其中的誤識別包括了假陰性和假陽性兩種情況,表中的總耗時為處理全部 50 個樣本的總體時間花費。實驗結果表明,本方法在準確率和處理速度兩方面均優于瓶頸分析法。
圖7
對比實驗的部分結果
Figure7.
A part of comparison of experimental results
4 總結和討論
在細胞核叢聚的識別標記方面,基于凹度分析的方法實現起來較為復雜,計算耗時較長,且存在著因目標叢聚細胞核間的“邊界”圖像信息不完整(或不存在),易造成誤分割、誤識別等問題。為此,本文提出了一種簡單、實用的叢聚細胞核提取方法。本方法的優點在于:① 拋棄了尋找叢聚中細胞核之間的“邊界”的思路,轉而直接在整幅圖像中進行細胞核標記。這樣不僅避免了細胞核“邊界”信息缺失對細胞核辨識的影響,還避免了凹度分析方法中,逐個剔除圖像中非叢聚細胞核的預處理步驟,降低了方法的復雜度,并使本文方法的耗時僅依賴于輸入圖像的尺寸大小,而與圖像中包含的細胞核叢聚數量無關。② 通過建立基于卷積的距離估算算法,解決了圖像像素間距的快速計算問題。此算法所采用的卷積操作還使本文所述方法能夠處理一些由于分辨率過低而無法獲取“凹度”和“曲率”等信息的圖像。這些特性表明了本文方法具有較高的實用價值。
經實驗發現,本文提出的方法還存在一定的局限性,例如:對近似于餅、團狀的細胞核組成聚落的識別效果較好,但對長條狀的細胞核組成的聚落的識別效果不夠理想;如果叢聚中的細胞核由于光照等原因在二值化圖像的白色區域內部出現黑色噪點,也可能發生誤判。我們將對這些問題進行更深入的研究,并逐步引入細胞核圖像的灰度、顏色等信息和其他先驗知識等,盡可能提高基于距離標記方法的準確率,以獲得更好的細胞核辨識效果。