睡眠中如果癲癇發作會增加患者并發癥發作和猝死的概率,有效預測患者睡眠中的癲癇發作可讓醫患及時采取措施,降低上述概率。現有癲癇發作預測方法多是基于腦電信號設計的,但并未在睡眠時期進行針對性研究,而該時期腦電信號相比其他時期有其特殊性,因此為提高靈敏度、降低錯誤報警率,本文將挖掘睡眠腦電信號的特點,研究睡眠中癲癇發作的預測方法。本文提出的方法中首先構建特征向量,包括不同波段的絕對功率譜、相對功率譜和功率譜比值;其次應用分離性判據和分支定界法進行特征選擇;最后訓練支持向量機分類器并實現預測。相比于不針對睡眠腦電信號特點的癲癇預測方法(靈敏度 91.67%,錯誤報警率 9.19%),本文方法的靈敏度(100%)有所提高,而錯誤報警率(2.11%)則有所降低。本文方法是對現有癲癇預測方法的補充,具有一定的臨床價值。
引用本文: 劉偉楠, 劉燕, 佟寶同, 趙凌霄, 楊瑩雪, 王玉平, 戴亞康. 基于功率譜的睡眠中癲癇發作預測. 生物醫學工程學雜志, 2018, 35(3): 329-336. doi: 10.7507/1001-5515.201708062 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
癲癇(epilepsy)是腦部神經元突發性異常放電從而導致短暫大腦功能障礙的一種慢性疾病。患者在癲癇發作時如果得不到及時的救治,并發癥發病率和猝死率都將相對增大。如果能對癲癇發作進行準確預測,可使醫生或者家庭成員提前做好準備,及時救治,有效降低并發癥發病率和猝死率[1]。目前臨床上通常采取兩類措施應對癲癇發作:一方面通過視頻或者傳感器監測患者的運動狀況,從而判斷癲癇是否發作[2-4],原理上該類方法目前只能進行檢測而非預測;另一方面通過腦電信號可預測癲癇發作,其原理為癲癇發作癥狀滯后于腦電信號的改變[5],但現有基于腦電信號的癲癇預測方法并未在睡眠時期進行針對性研究,而睡眠狀態下的腦電信號與清醒狀態下的腦電信號有很大區別[6]。因此,應用現有不針對睡眠腦電信號特點的方法對睡眠中癲癇發作進行預測,會導致特征冗余、計算量增加,并會影響預測精度。綜上所述,有必要根據睡眠中腦電信號的特點研究癲癇發作的預測方法,提升睡眠中癲癇發作的預測精度。
現有基于腦電信號預測癲癇發作的方法大部分是基于“特征提取與分類”的模式進行的[7]。目前,特征提取的方法包括如:小波變換(wavelet transform)相關特征[8]、功率譜密度(power spectrum density,PSD)相關特征[9-11]、樣本熵(sample entropy)[12]、幅度頻率調制信號(amplitude-frequency modulation signal,AM-FM)[13]等。而癲癇腦電信號具有頻率變化大、非平穩的特點,因此選擇時頻特征相關的特征提取方法能夠比較好地反映癲癇腦電信號的特點。功率譜是腦電信號分析最常用的特征,表示信號功率隨頻率的變化情況,因此本文選擇功率譜相關的特征用于癲癇發作的預測。支持向量機(support vector machine,SVM)能夠較好地解決小樣本、非線性、高維數等問題,在分類問題中具有廣泛的應用基礎,因此本文采用支持向量機作為分類器。
腦電信號中 δ 波段因頻率過低,且在清醒狀態下不出現,因此現有不針對睡眠腦電信號特點的方法中一般不加入 δ 波段的相關特征[6]。但睡眠狀態下腦電信號呈現 δ 波加強,α 波減少甚至消失的趨勢,因此本文中加入 δ 波段的相關特征作為研究指標。本文方法具體的步驟為:首先分離頭皮腦電信號中包括 δ 波段在內的不同頻段信號;其次提取不同頻段下腦電信號的絕對功率譜(absolute power spectrum,APS)、相對功率譜(relative power spectrum,RPS)和功率譜比值(power spectrum ratio,PSR)3 種特征,組成混合特征;利用分離性判據和分支定界法(branch and bound,BAB)進行特征選擇,構建出表征個體癲癇的特征向量,最后將分類標簽(標簽由有經驗的醫生進行分類打標)放入支持向量機訓練分類器,利用分類器判斷實時腦電信號的狀態,如果可以判斷為癲癇發作前期,即完成對睡眠中的癲癇發作的預測。最終期望通過本文的研究結果,實現對現有癲癇預測方法的補充,以提升睡眠中癲癇發作的預測精度。
1 實驗數據
本文選取的數據集為波士頓兒童醫院與麻省理工大學的頭皮腦電信號開源數據庫(網址為:http://www.physionet.org/pn6/chbmit)[14]。該頭皮腦電數據以國際標準的 10-20 導聯系統收集于波士頓兒童醫院,所有患者均確診為難治性癲癇,所有數據的采樣頻率均為 256 Hz (fs = 256 Hz)。對于該數據集腦電信號狀態本文分類如下:發作前 60 min 作為發作前期(preictal)(以符號 C1 表示),發作時作為發作期(ictal,)(以符號 C2 表示),發作后 30 min 作為發作后期(postictal)(以符號 C3 表示),其余的時間作為發作間期(interictal)(以符號 C0 表示)。本文采用該數據集中有睡眠中癲癇發作的 3、10、12、15、16、20 號患者數據,對他們在睡眠狀態下發作前期和發作間期的腦電信號數據進行實驗分析。為盡量保持平衡,發作間期和發作前期的數據量要相適應,因此對于發作間期數據,本文通過隨機采樣挑選發作間期的樣本,使發作間期數據和發作前期數據在數據量上保持平衡。
2 方法
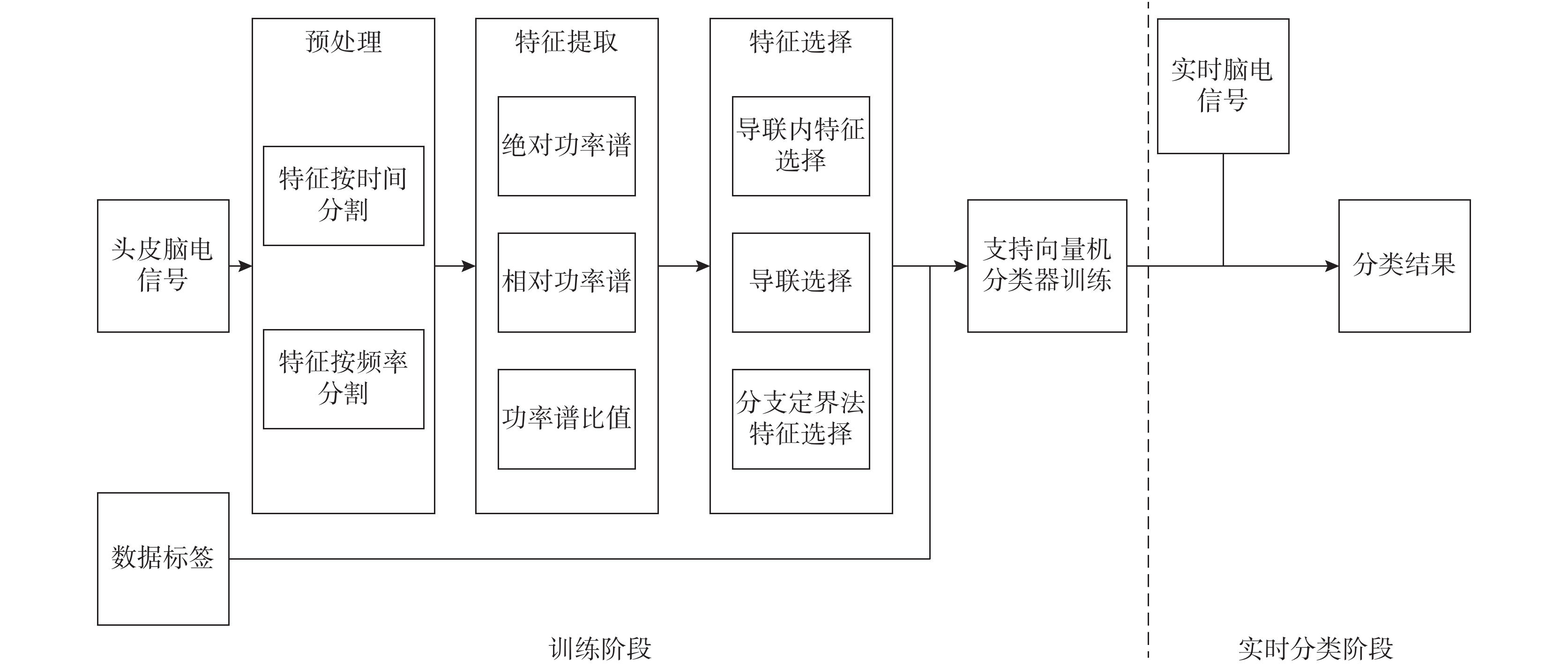
為實現預測睡眠中癲癇的發作,本文提出一種基于功率譜相關特征的分類方法,其方法流程如圖 1 所示。① 分類器訓練階段:首先對個體腦電信號數據進行預處理,將數據根據時間和頻率進行分段;其次提取絕對功率譜、相對功率譜和功率譜比值 3 種特征,組成混合特征;再次針對混合特征進行優化選擇,降低特征向量的維數,去掉冗余特征,構建出能有效表征個性癲癇的低維特征向量;最后結合數據標簽放入支持向量機訓練分類器。② 實時分類階段:將實時腦電信號通過分類器分類,觀察其狀態是否為發作前期,從而完成癲癇發作的預測。
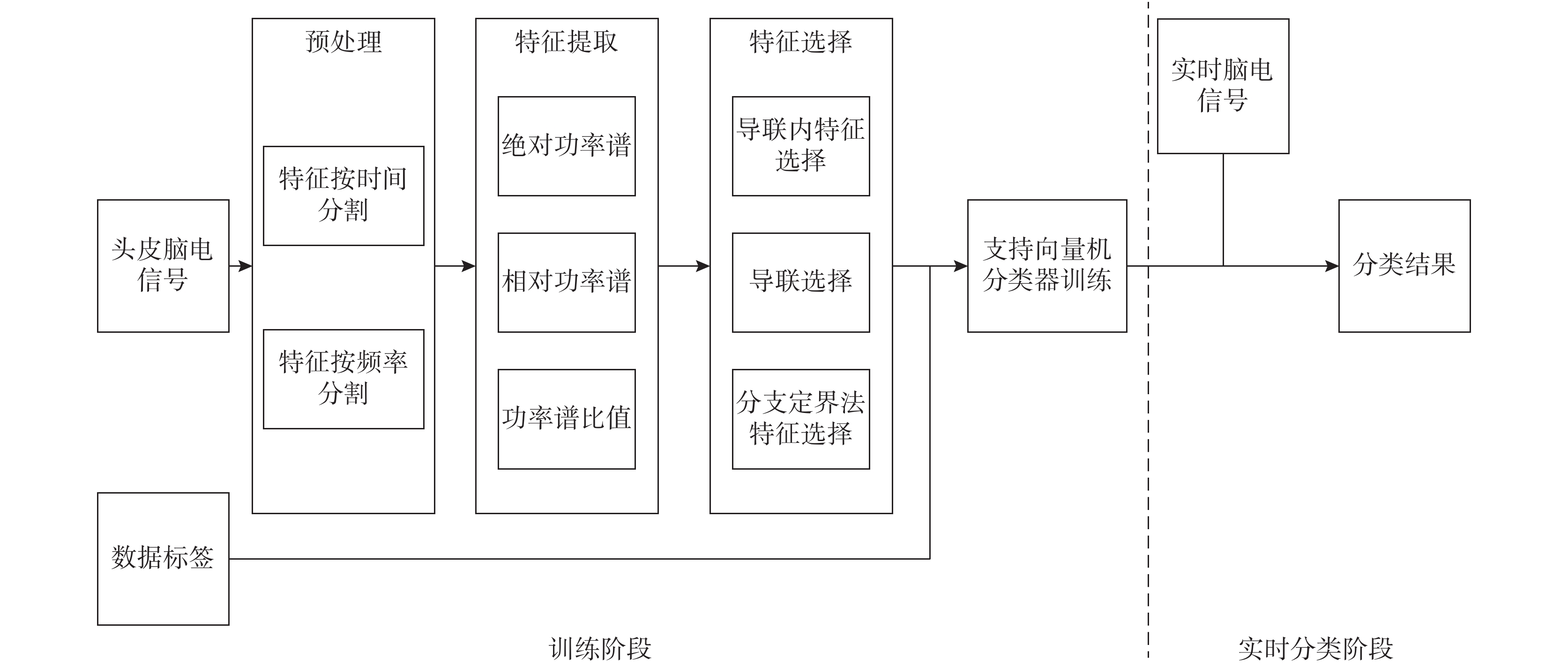 圖1
方法流程圖
Figure1.
Flowchart of the proposed method
圖1
方法流程圖
Figure1.
Flowchart of the proposed method
2.1 預處理
2.1.1 信號按時間分割
在信號預處理階段,為了減少計算復雜度和加快計算速度,需要對腦電信號進行分割,形成數據處理的基本單位。每個時間窗口數據的構成如式(1)所示:
 |
其中,S 為信號序列,M 為每個時間窗的樣本長度,L 為時間窗的總數。相鄰的 2 個窗口數據有 50% 的重疊部分,則本文中時間窗的長度為 4 s(即 M = 4 × fS)。
2.1.2 信號按頻域分解
本文所要提取的特征為時頻特征,因此需要將信號進行頻率分解。基于 2.1.1 節的窗口信號,本文首先將信號分解成 9 個波段(分界點頻率分到上波段),分別為 δ(1~4 Hz)、θ(4~8 Hz)、α(8~13 Hz)、β(13~30 Hz)、γ1(30~50 Hz)、γ2(50~70 Hz)、γ3(70~90 Hz)、γ4(90~110 Hz)、γ5(110~128 Hz)波段,其中 δ 波段為只在睡眠期間出現的波段,θ、α、β 波段為清醒狀態下腦電信號出現的波段,γ 波段則為高頻腦電波,主要出現在癲癇發作狀態下[15]。
2.2 特征提取
基于 2.1.2 節的信號數據,提取如下 3 種特征:絕對功率譜、相對功率譜、功率譜比值。這些特征在文獻[9, 11, 16]中已經驗證可以用于癲癇預測。其中相對功率譜和功率譜比值在錯誤報警率(false alarm rate,FAR)(以符號 FAR 表示)方面表現較好,但是在靈敏度(sensitivity,SS)(以符號 SS 表示)方面略差,絕對功率譜則相反,在靈敏度方面表現較好,錯誤報警率方面表現較差。為了得到更好的效果,本文同時對 3 種特征進行提取,并組成混合特征。
2.2.1 絕對功率譜
絕對功率譜為第 i 個頻段中所有功率譜總和的對數。其計算公式如式(2)所示:
 |
其中,Pi(l)為窗口數據 l 在頻段 i 的絕對功率譜。
2.2.2 相對功率譜
相對功率譜衡量的是第 i 個頻段的功率譜之和與全部頻段的功率譜之和的比值的對數,如式(3)所示:
 |
其中,Qi(l)為窗口數據 l 在頻段 i 的相對功率譜。
2.2.3 功率譜比值
功率譜比值定義如式(4)所示:
 |
其中,Ri,j(l)表示窗口數據 l 的頻段 i 相對于頻段 j 的功率譜比值。功率譜比值表示不同頻段之間的能量分布變化。對于每個導聯,都有
 = 36 個功率譜比值特征。
= 36 個功率譜比值特征。
2.2.4 混合特征
基于 2.2.1~2.2.3 小節所計算的特征向量,構建混合特征。其中每個導聯有 54 個特征,包括 9 個絕對功率譜、9 個相對功率譜和 36 個功率譜比值,最終特征向量為F = [P1(l),P2(l),
 ,P9(l),Q1(l),Q2(l),
,P9(l),Q1(l),Q2(l),
 ,Q9(l),R1(l),R2(l),
,Q9(l),R1(l),R2(l),
 ,R36(l)]T。
,R36(l)]T。
2.3 特征選擇
為了減少冗余特征,并防止分類器過擬合,需要從混合特征中挑選最具有統計意義的特征子集。本文特征選擇的方法主要分為 3 步:① 導聯內特征選擇:利用特征值分析找出每個導聯中線性獨立的特征子集。② 導聯選擇:根據可分離性判據 J,選擇能夠表征癲癇的導聯。③ 根據分支定界法進一步對特征進行優化選擇。特征選擇的標準采用可分離性判據。
可分離性判據是特征選擇中重要的選擇依據。可分離性判據的計算包含以下步驟:
(1)定義類內距離 Sw 和類間距離 Sb,如式(5)、(6)所示:
 |
 |
其中 c 代表類的數量,本文中 c 分為發作前期和發作間期兩種類別。E{ (f - μi) [ (f - μi)]T}為類別 i 的協方差矩陣,Pi 代表類別 i 的發生概率,μ0 為全部特征向量的平均向量,μi 為類別 i 的特征向量的平均向量。
(2)通過 Sw 和 Sb,得到可分離性判據 J,如式(7)所示:
 |
|A|代表矩陣 A 的跡。類內的數據聚類得越集中或者不同類的數據分開得越分散,則 J 值越大;相反,如果類內距離不能很好地集中聚類,或者不同類的數據不能很好地分開,則 J 值變小。對于特征向量來說,特征 J 越大,則表示該特征表征能力越強,越容易被選擇。
2.3.1 導聯內特征選擇
導聯內特征選擇可以快速地減少每個導聯內的無關特征,是導聯選擇和利用分支定界法優化特征選擇之前必不可少的一步。本文利用分離性判據及特征值分析法,從每個導聯的 54 個特征中選擇出 R 個特征。
特征值分析法被用來確定 R 的數量,本文對每個導聯的特征的協方差矩陣進行特征值分析,并找出其貢獻率大于 99% 的特征數量,即為 R 的值。如 3 號患者,貢獻率超過 99% 的特征數量為 10,則 R = 10。
確定 R 數量后,本文采取貪婪算法和分離性判據選擇出具體的特征。具體步驟為從空集開始,依次添加未被選擇的特征中可分離性判據 J 最大的特征,直到選擇出 R 個特征。值得注意的是,當特征向量線性相關時,J 可能會出現無限大的情況,這是由于 Sw 虧秩造成的。因此當選擇特征線性相關時,即 J 為無限大的時候,將該特征的 J 值設為 0。這種順序選擇方案將產生線性獨立的特征向量子集。
2.3.2 導聯選擇
導聯選擇可以根據實際情況,進一步限制特征的數量,避免了過多的計算。在實際情況中,癲癇發作往往只在 1 個或幾個腦區中進行,其余腦區對應的導聯對于癲癇發作預測來說,只能提供很少的信息量。本文中使用的導聯選擇標準和特征標準選擇一樣,具體描述為:從所有導聯中選擇 k 個導聯,如果選出的 k 個導聯的混合特征向量的可分離性判據 J 為所有混合特征向量中最大的,即選擇這 k 個導聯。例如,k = 2,計算導聯中所有兩個導聯組合成的特征向量的可分離性判據 J,選擇其中 J 值最大的組合,即為選擇的導聯。
2.3.3 基于分支定界法的優化特征選擇
為了使特征向量達到最好的分類效果或者說達到最大的可分離性判據 J,本文在特征基礎選擇和導聯選擇之后,運用分支定界法從原有的 R × k 個特征中選出最優的 r 個特征。分支定界法是一種常見的優化特征選擇方法,其基本思想為將所有可能的特征組合構建成一個樹狀結構,按照某種特定的規律對樹進行搜索,使搜索過程盡可能早地達到最優解而不必遍歷整棵樹的所有節點。
在文獻[17]中,開發了一種有效針對全局最優變量選擇的分支定界算法。該法能夠有效地選擇全局最優的特征向量子集,從而使回歸誤差最小。f(l) = [f1(l),f2(l),
 ,fR(l)]T 表示為根據窗口數據 l 經過導聯內特征選擇和導聯選擇計算得出的特征向量。yl 代表窗口數據 l 的標簽。y = [y1,y2,
,fR(l)]T 表示為根據窗口數據 l 經過導聯內特征選擇和導聯選擇計算得出的特征向量。yl 代表窗口數據 l 的標簽。y = [y1,y2,
 ,yL]T 為類標簽向量,F 為特征矩陣,如式(8)所示:
,yL]T 為類標簽向量,F 為特征矩陣,如式(8)所示:
 |
其中,fi(j)為窗口 j 的第 i 個特征。F 中的每一列都為對應窗口 l 的特征向量,F 中的每一行都為對應特征的時間序列。定義 Gr = [fi1,fi2,
 ,fir]為含有 r 變量的 F 矩陣子集,其中 i1,i2,
,fir]為含有 r 變量的 F 矩陣子集,其中 i1,i2,
 ,ir 為特征的序號。本文選擇子集的標準是,當子集 Gr 用最小二乘法計算時,可以達到最小的誤差,則該子集即為選擇的子集。實際上就是選擇一組 i1,i2,
,ir 為特征的序號。本文選擇子集的標準是,當子集 Gr 用最小二乘法計算時,可以達到最小的誤差,則該子集即為選擇的子集。實際上就是選擇一組 i1,i2,
 ,ir,使式(9)達到最小。
,ir,使式(9)達到最小。
 |
其中,q = (GTG)–1GTy 為最佳投影向量。
在實際應用中,r 是非先驗的、未知的。所以需要對 r 進行選擇,選擇步驟如下:
(1)對每個可能的 r 值(r ∈ {1,2,
 ,R × k}),分別通過分支定界算法選出最優的特征向量子集。
,R × k}),分別通過分支定界算法選出最優的特征向量子集。
(2)對步驟(1)算出的每個特征向量子集,計算它們的 J 值。
(3)對于其中可分離性判據 J 大于閾值的特征向量子集,選出其中最小的 r 值,該 r 值即為最終選擇出的 r。
其中,閾值取 0.9 × Jmax,Jmax 為步驟(2)中計算的可分離性判據 J 中的最大值。
通過特征基本選擇、導聯選擇和基于分支定界法的特征優化算法,得出含有 r 個特征的特征向量。
2.4 基于支持向量機的分類器訓練
將上述處理結果通過機器學習的方法進行分類訓練,從而判斷某個時刻屬于癲癇發作前期還是屬于癲癇發作間期,如果為前期即進行報警。本文將發作間期數據 C0 編碼為–1,發作前期數據 C1 編碼為 1。針對每個人的數據集,利用留一法對數據進行訓練和測試。本文采用支持向量機中的支持向量分類機(support vector clustering,SVC),核心函數為徑向基函數(radial basis function,RBF)。SVC 要解決的優化問題如式(10)所示:
 |
約束于

 。其中 xi 代表 r 維的特征向量,N 代表用來訓練的樣本數量,ω 為超平面的方向,ω0 為初始的平面偏移,yi 為訓練的標簽,ξi 為松弛變量,C+、C– 為懲罰系數。懲罰系數 C+、C– 在如下數組中進行選擇(2–3,2–2,
。其中 xi 代表 r 維的特征向量,N 代表用來訓練的樣本數量,ω 為超平面的方向,ω0 為初始的平面偏移,yi 為訓練的標簽,ξi 為松弛變量,C+、C– 為懲罰系數。懲罰系數 C+、C– 在如下數組中進行選擇(2–3,2–2,
 ,22,23)。
,22,23)。
為了解決訓練樣本非線性問題,引入核函數 Kn,將數據映射到高維空間,以解決原本空間下的線性不可分問題。本文采用的核函數 Kn 為徑向基函數,其函數如式(11)所示:
 |
2.5 腦電信號實時分類
腦電信號經過預處理、特征提取、特征選擇,最后利用支持向量機訓練得到分類器。此時將實時腦電信號放入分類器中,判斷其狀態是否為發作前期。如果為發作前期,則進行報警。
3 實驗結果與分析
本文兩個重要的評價指標分別為靈敏度、錯誤報警率。靈敏度和錯誤報警率定義如式(12)、(13)所示:
 |
 |
其中,Nsuccess alarm 為成功報警次數,Nseizure 為癲癇發作總次數;Salarm 為在間期進行報警的時間窗數量,SC0 為間期所有時間窗的數量;其中靈敏度越高越好,而錯誤報警率則越低越好。
3.1 本文方法的結果
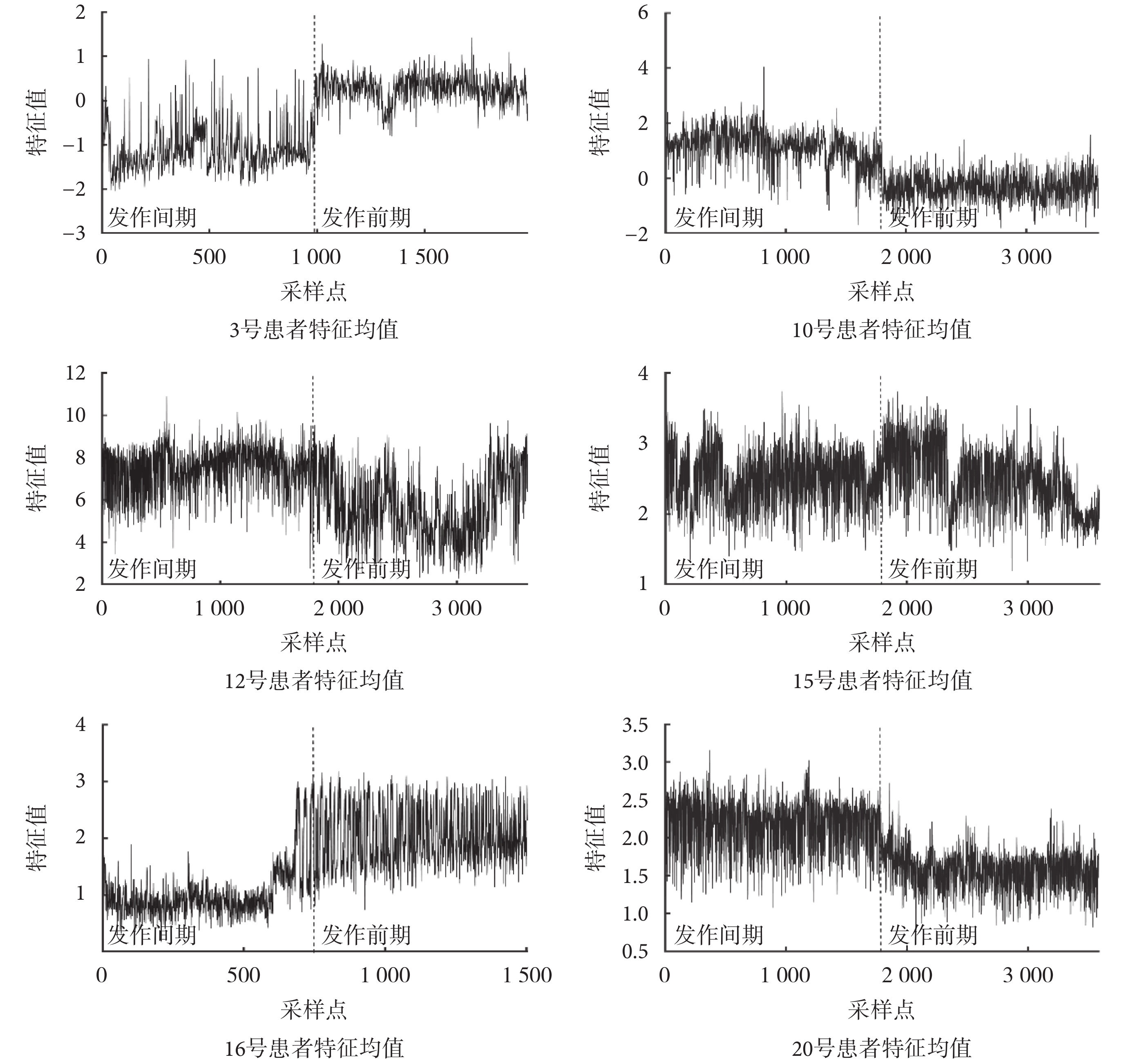
不同患者因致癇區不同等原因,癲癇腦電信號差異過大,故本文采取個性化處理,即每位患者的分類器都單獨進行訓練,最終得到的分類器采用留一法進行驗證得到分類結果,并利用靈敏度與錯誤報警率對該分類結果進行評價。各組患者發作間期和發作前期特征值變化如圖 2 所示,通過特征選擇得出的特征及分類結果評價如表 1 所示
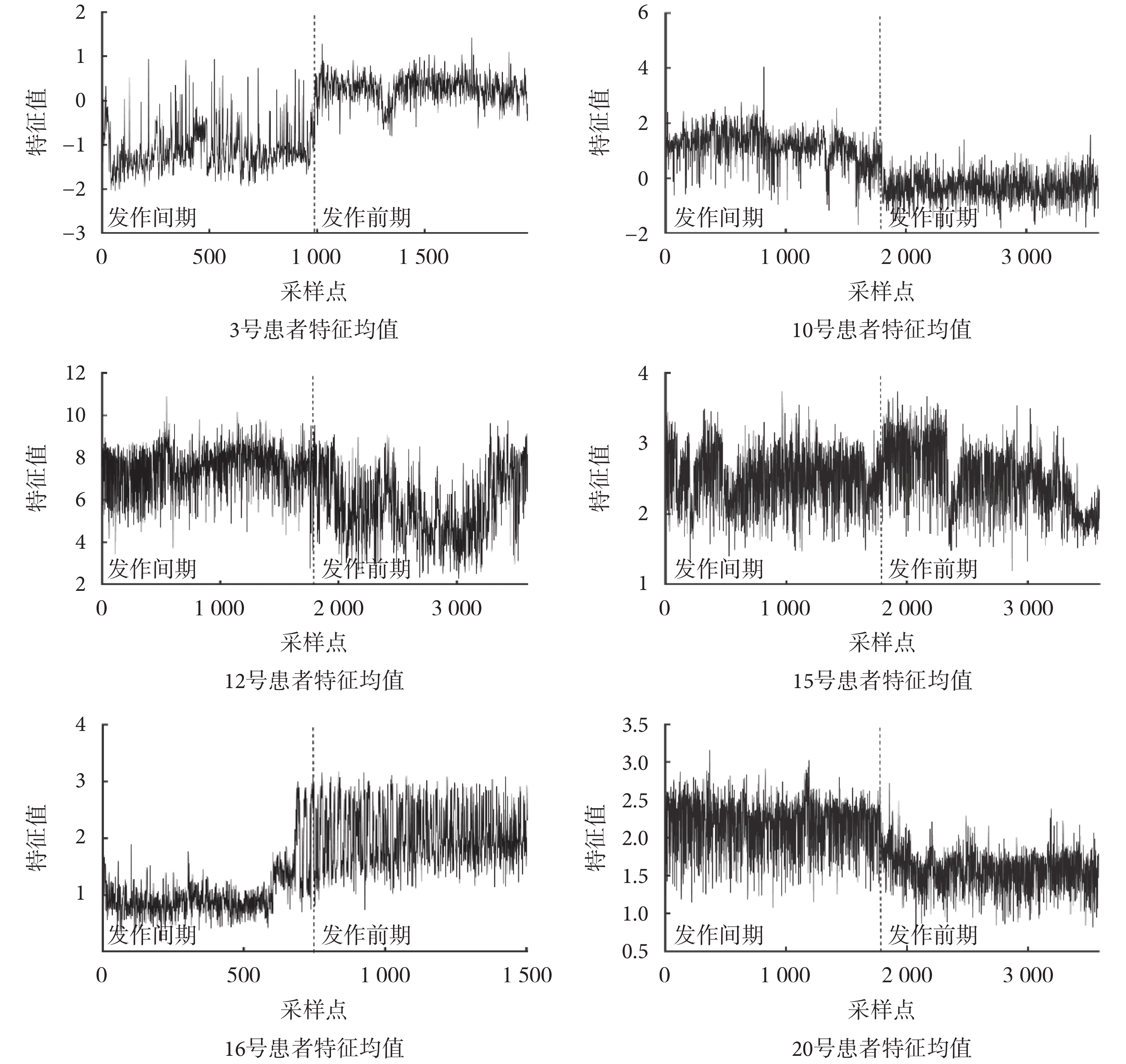 圖2
癲癇發作間期與發作前期的特征均值變化
Figure2.
The mean feature value change between interictal and ictal
圖2
癲癇發作間期與發作前期的特征均值變化
Figure2.
The mean feature value change between interictal and ictal
3.2 本文方法與預測時不加入 δ 波段的方法結果對比
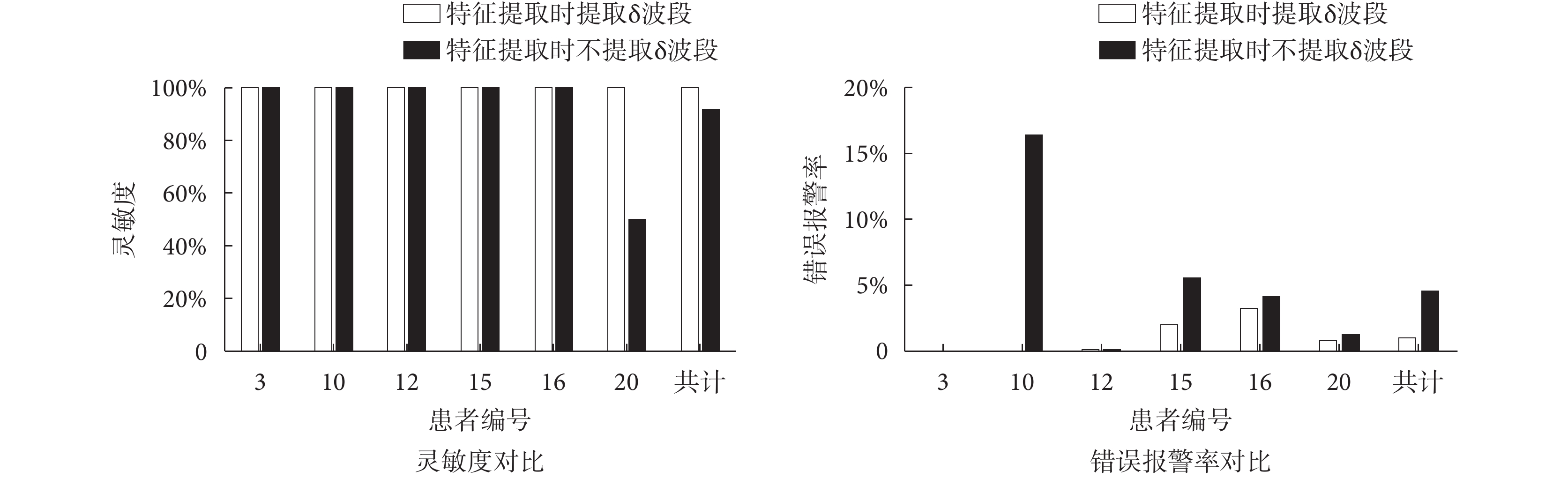
人在清醒狀態下腦電信號中不出現 δ 波段,現有癲癇預測或檢測算法中在進行頻域分割時,不考慮 δ 波段。但 δ 波段是睡眠期間的主要波段,因此本文方法在特征提取階段加入了 δ 波段。為了體現 δ 波段的效果,對比方法在頻域分解階段,腦電信號不在 δ 波段上進行分解。將對比方法的結果評價與在本文方法的結果評價進行對比。其結果評價對比如圖 3 所示。
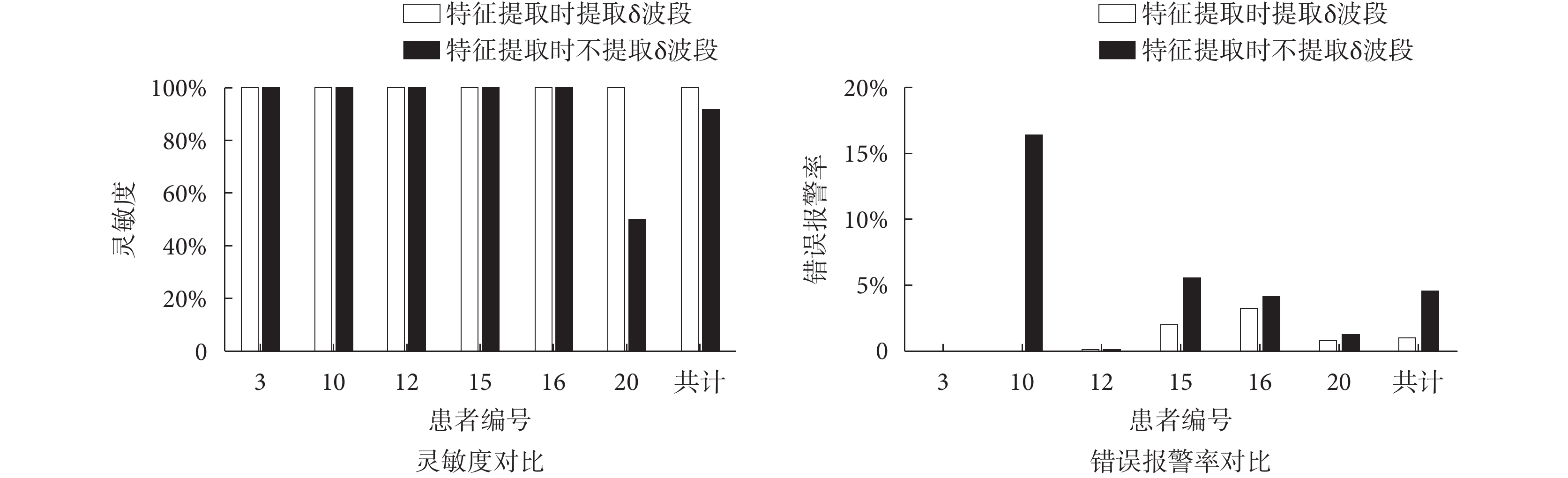 圖3
特征提取階段提取 δ 波段與不提取 δ 波段的結果評價對比
Figure3.
Comparison of results with or without δ band in feature extraction
圖3
特征提取階段提取 δ 波段與不提取 δ 波段的結果評價對比
Figure3.
Comparison of results with or without δ band in feature extraction
3.3 本文方法與使用單獨功率譜相關特征的方法對比
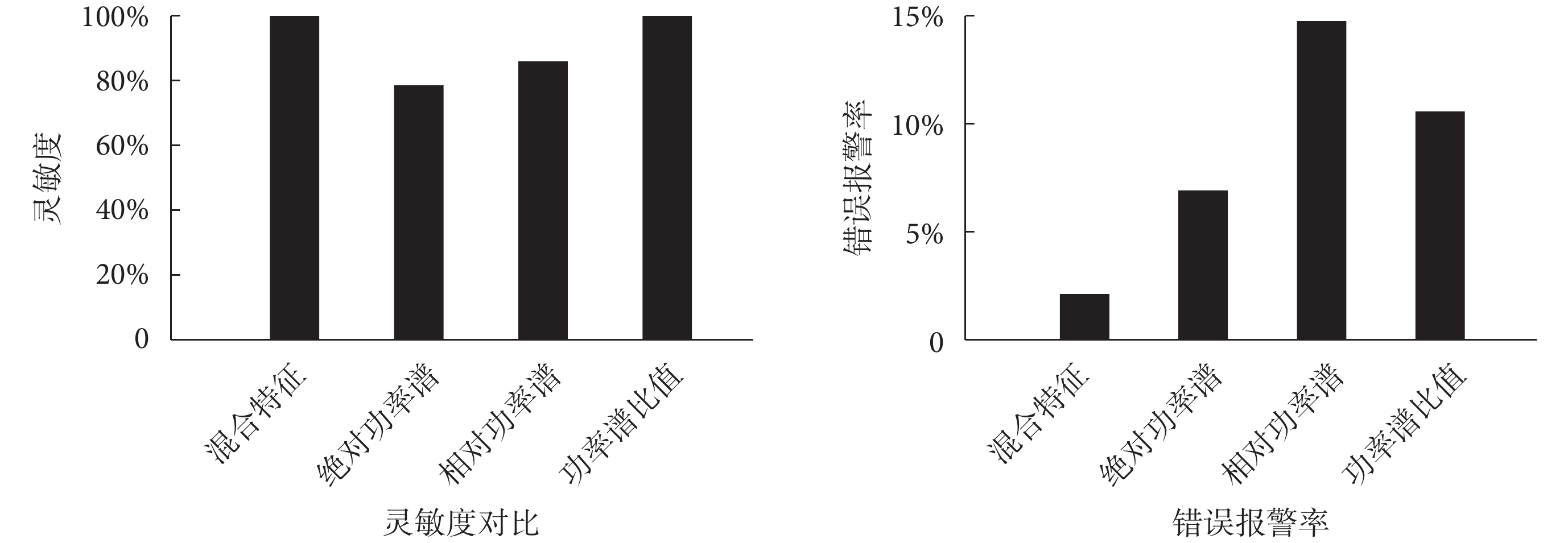
雖然文獻[9, 11, 16]證明絕對功率譜、相對功率譜和功率譜比值可以用來預測癲癇發作,但是每個特征單獨用來進行分類器訓練都有自己的劣勢。為了證明混合特征在預測睡眠中癲癇發作的應用方面的優勢,在特征提取階段,分別提取單獨的絕對功率譜、相對功率譜和功率譜比值特征。用這 3 種特征向量分別進行特征選擇和分類器訓練,得到分類結果,并對結果進行評價。其結果與本文方法即特征提取階段使用混合特征的結果評價進行對比,對比結果如圖 4 所示。
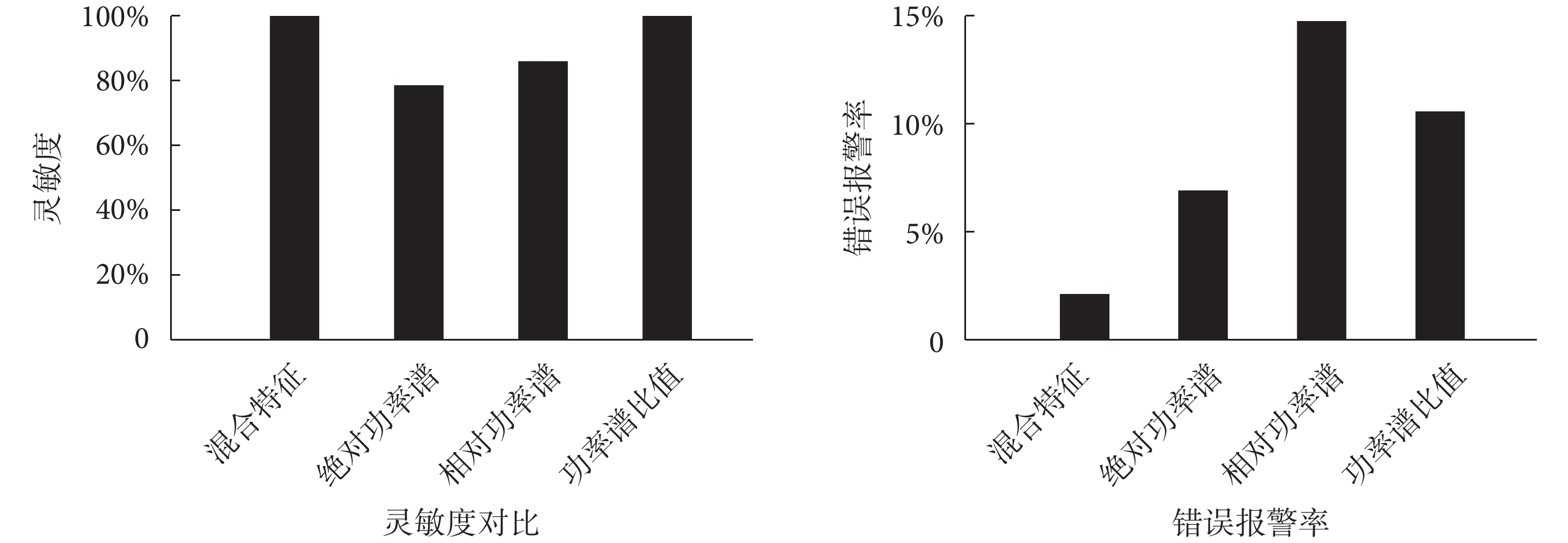 圖4
特征提取階段提取混合特征、絕對功率譜、相對功率譜與功率譜比值進行預測的結果評價對比
Figure4.
Comparison of results obtained by extraction of mixed features, absolute power spectrum, relative power spectrum or power spectrum ratio in feature extraction
圖4
特征提取階段提取混合特征、絕對功率譜、相對功率譜與功率譜比值進行預測的結果評價對比
Figure4.
Comparison of results obtained by extraction of mixed features, absolute power spectrum, relative power spectrum or power spectrum ratio in feature extraction
3.4 實驗結果分析
在靈敏度上,本文方法的靈敏度為 100%,特征提取階段不加入 δ 波段的方法靈敏度為 91.67%,特征提取階段使用絕對功率譜的靈敏度為 78.6%,使用相對功率譜的靈敏度為 86.1%,使用功率譜比值的靈敏度為 100%。本文方法和使用功率譜比值的方法都達到了 100% 的靈敏度,特征提取階段不提取 δ 波段、單獨使用絕對功率譜和相對功率譜的方法的靈敏度均低于 100%。因此在靈敏度方面本文方法與單獨使用功率譜比值的方法均有較好的效果。
在錯誤報警率上,本文方法的平均錯誤報警率為 2.11%,特征提取階段不加入 δ 波段的方法錯誤報警率為 9.19%,特征提取階段使用絕對功率譜的錯誤報警率為 6.92%,使用相對功率譜的錯誤報警率為 14.75%,使用功率譜比值的錯誤報警率為 10.58%。本文方法的錯誤報警率最低。而在靈敏度方面表現較好的功率譜比值方法,其錯誤報警率則高達 14.75%。通過靈敏度和錯誤報警率的對比,體現出本文方法具有良好的預測能力。
4 結論
現有基于腦電信號的癲癇預測方法中,很少專門研究如何對睡眠中發作的癲癇進行預測。睡眠中發作的癲癇相對于在人體清醒狀態時發作的癲癇更難進行及時的救助,且有很大幾率會導致多種并發癥甚至導致癲癇猝死[1]。對于睡眠腦電信號來說,其特征與清醒時有明顯不同。睡眠腦電信號呈現低頻率、δ 波段增強、α 波段減弱等特點。如果不針對睡眠腦電信號的特點進行特殊處理就進行預測,很可能造成靈敏度下降或者錯誤報警率增加。
本文提出了一種基于腦電信號的個性化預測睡眠中癲癇發作的方法,該方法基于腦電信號,提取不同波段的絕對功率譜,相對功率譜和功率譜比值組成混合特征,并根據睡眠腦電信號的特殊性加入了 δ 波段的功率譜相關特征,應用分離性判據和分支定界法方法進行特征選擇,最后運用支持向量機對腦電信號進行分類,判斷實時輸入的腦電信號數據是否為癲癇前期,從而達到預測的結果。對比實驗得出,不加入 δ 波段特征方法的靈敏度為 91.67%,錯誤報警率為 9.19%。本文方法相對于上述方法在敏感度和錯誤報警率方面都得到提升,得到了 100% 的敏感度和 2.11% 的錯誤報警率。本方法得到了較好的預測效果,也證明了功率譜特征對于睡眠中的癲癇發作有一定的預測能力。
本文方法對于腦電信號只去除了機器噪聲,未進行進一步的去噪處理,這導致一些無關信息也被加入進來,從而降低了運算速度和預測效果。同時本文方法得到的錯誤報警率,雖然相較不針對睡眠腦電信號特點的方法得到提升,但 2.11% 的錯誤報警率還不能達到臨床級別。因此在以后的工作中,將在降低錯誤報警率方面和研究快速去噪方法方面繼續深入研究,以期使預測更加準確。
引言
癲癇(epilepsy)是腦部神經元突發性異常放電從而導致短暫大腦功能障礙的一種慢性疾病。患者在癲癇發作時如果得不到及時的救治,并發癥發病率和猝死率都將相對增大。如果能對癲癇發作進行準確預測,可使醫生或者家庭成員提前做好準備,及時救治,有效降低并發癥發病率和猝死率[1]。目前臨床上通常采取兩類措施應對癲癇發作:一方面通過視頻或者傳感器監測患者的運動狀況,從而判斷癲癇是否發作[2-4],原理上該類方法目前只能進行檢測而非預測;另一方面通過腦電信號可預測癲癇發作,其原理為癲癇發作癥狀滯后于腦電信號的改變[5],但現有基于腦電信號的癲癇預測方法并未在睡眠時期進行針對性研究,而睡眠狀態下的腦電信號與清醒狀態下的腦電信號有很大區別[6]。因此,應用現有不針對睡眠腦電信號特點的方法對睡眠中癲癇發作進行預測,會導致特征冗余、計算量增加,并會影響預測精度。綜上所述,有必要根據睡眠中腦電信號的特點研究癲癇發作的預測方法,提升睡眠中癲癇發作的預測精度。
現有基于腦電信號預測癲癇發作的方法大部分是基于“特征提取與分類”的模式進行的[7]。目前,特征提取的方法包括如:小波變換(wavelet transform)相關特征[8]、功率譜密度(power spectrum density,PSD)相關特征[9-11]、樣本熵(sample entropy)[12]、幅度頻率調制信號(amplitude-frequency modulation signal,AM-FM)[13]等。而癲癇腦電信號具有頻率變化大、非平穩的特點,因此選擇時頻特征相關的特征提取方法能夠比較好地反映癲癇腦電信號的特點。功率譜是腦電信號分析最常用的特征,表示信號功率隨頻率的變化情況,因此本文選擇功率譜相關的特征用于癲癇發作的預測。支持向量機(support vector machine,SVM)能夠較好地解決小樣本、非線性、高維數等問題,在分類問題中具有廣泛的應用基礎,因此本文采用支持向量機作為分類器。
腦電信號中 δ 波段因頻率過低,且在清醒狀態下不出現,因此現有不針對睡眠腦電信號特點的方法中一般不加入 δ 波段的相關特征[6]。但睡眠狀態下腦電信號呈現 δ 波加強,α 波減少甚至消失的趨勢,因此本文中加入 δ 波段的相關特征作為研究指標。本文方法具體的步驟為:首先分離頭皮腦電信號中包括 δ 波段在內的不同頻段信號;其次提取不同頻段下腦電信號的絕對功率譜(absolute power spectrum,APS)、相對功率譜(relative power spectrum,RPS)和功率譜比值(power spectrum ratio,PSR)3 種特征,組成混合特征;利用分離性判據和分支定界法(branch and bound,BAB)進行特征選擇,構建出表征個體癲癇的特征向量,最后將分類標簽(標簽由有經驗的醫生進行分類打標)放入支持向量機訓練分類器,利用分類器判斷實時腦電信號的狀態,如果可以判斷為癲癇發作前期,即完成對睡眠中的癲癇發作的預測。最終期望通過本文的研究結果,實現對現有癲癇預測方法的補充,以提升睡眠中癲癇發作的預測精度。
1 實驗數據
本文選取的數據集為波士頓兒童醫院與麻省理工大學的頭皮腦電信號開源數據庫(網址為:http://www.physionet.org/pn6/chbmit)[14]。該頭皮腦電數據以國際標準的 10-20 導聯系統收集于波士頓兒童醫院,所有患者均確診為難治性癲癇,所有數據的采樣頻率均為 256 Hz (fs = 256 Hz)。對于該數據集腦電信號狀態本文分類如下:發作前 60 min 作為發作前期(preictal)(以符號 C1 表示),發作時作為發作期(ictal,)(以符號 C2 表示),發作后 30 min 作為發作后期(postictal)(以符號 C3 表示),其余的時間作為發作間期(interictal)(以符號 C0 表示)。本文采用該數據集中有睡眠中癲癇發作的 3、10、12、15、16、20 號患者數據,對他們在睡眠狀態下發作前期和發作間期的腦電信號數據進行實驗分析。為盡量保持平衡,發作間期和發作前期的數據量要相適應,因此對于發作間期數據,本文通過隨機采樣挑選發作間期的樣本,使發作間期數據和發作前期數據在數據量上保持平衡。
2 方法
為實現預測睡眠中癲癇的發作,本文提出一種基于功率譜相關特征的分類方法,其方法流程如圖 1 所示。① 分類器訓練階段:首先對個體腦電信號數據進行預處理,將數據根據時間和頻率進行分段;其次提取絕對功率譜、相對功率譜和功率譜比值 3 種特征,組成混合特征;再次針對混合特征進行優化選擇,降低特征向量的維數,去掉冗余特征,構建出能有效表征個性癲癇的低維特征向量;最后結合數據標簽放入支持向量機訓練分類器。② 實時分類階段:將實時腦電信號通過分類器分類,觀察其狀態是否為發作前期,從而完成癲癇發作的預測。
圖1
方法流程圖
Figure1.
Flowchart of the proposed method
2.1 預處理
2.1.1 信號按時間分割
在信號預處理階段,為了減少計算復雜度和加快計算速度,需要對腦電信號進行分割,形成數據處理的基本單位。每個時間窗口數據的構成如式(1)所示:
|
其中,S 為信號序列,M 為每個時間窗的樣本長度,L 為時間窗的總數。相鄰的 2 個窗口數據有 50% 的重疊部分,則本文中時間窗的長度為 4 s(即 M = 4 × fS)。
2.1.2 信號按頻域分解
本文所要提取的特征為時頻特征,因此需要將信號進行頻率分解。基于 2.1.1 節的窗口信號,本文首先將信號分解成 9 個波段(分界點頻率分到上波段),分別為 δ(1~4 Hz)、θ(4~8 Hz)、α(8~13 Hz)、β(13~30 Hz)、γ1(30~50 Hz)、γ2(50~70 Hz)、γ3(70~90 Hz)、γ4(90~110 Hz)、γ5(110~128 Hz)波段,其中 δ 波段為只在睡眠期間出現的波段,θ、α、β 波段為清醒狀態下腦電信號出現的波段,γ 波段則為高頻腦電波,主要出現在癲癇發作狀態下[15]。
2.2 特征提取
基于 2.1.2 節的信號數據,提取如下 3 種特征:絕對功率譜、相對功率譜、功率譜比值。這些特征在文獻[9, 11, 16]中已經驗證可以用于癲癇預測。其中相對功率譜和功率譜比值在錯誤報警率(false alarm rate,FAR)(以符號 FAR 表示)方面表現較好,但是在靈敏度(sensitivity,SS)(以符號 SS 表示)方面略差,絕對功率譜則相反,在靈敏度方面表現較好,錯誤報警率方面表現較差。為了得到更好的效果,本文同時對 3 種特征進行提取,并組成混合特征。
2.2.1 絕對功率譜
絕對功率譜為第 i 個頻段中所有功率譜總和的對數。其計算公式如式(2)所示:
|
其中,Pi(l)為窗口數據 l 在頻段 i 的絕對功率譜。
2.2.2 相對功率譜
相對功率譜衡量的是第 i 個頻段的功率譜之和與全部頻段的功率譜之和的比值的對數,如式(3)所示:
|
其中,Qi(l)為窗口數據 l 在頻段 i 的相對功率譜。
2.2.3 功率譜比值
功率譜比值定義如式(4)所示:
|
其中,Ri,j(l)表示窗口數據 l 的頻段 i 相對于頻段 j 的功率譜比值。功率譜比值表示不同頻段之間的能量分布變化。對于每個導聯,都有
= 36 個功率譜比值特征。
2.2.4 混合特征
基于 2.2.1~2.2.3 小節所計算的特征向量,構建混合特征。其中每個導聯有 54 個特征,包括 9 個絕對功率譜、9 個相對功率譜和 36 個功率譜比值,最終特征向量為F = [P1(l),P2(l),
,P9(l),Q1(l),Q2(l),
,Q9(l),R1(l),R2(l),
,R36(l)]T。
2.3 特征選擇
為了減少冗余特征,并防止分類器過擬合,需要從混合特征中挑選最具有統計意義的特征子集。本文特征選擇的方法主要分為 3 步:① 導聯內特征選擇:利用特征值分析找出每個導聯中線性獨立的特征子集。② 導聯選擇:根據可分離性判據 J,選擇能夠表征癲癇的導聯。③ 根據分支定界法進一步對特征進行優化選擇。特征選擇的標準采用可分離性判據。
可分離性判據是特征選擇中重要的選擇依據。可分離性判據的計算包含以下步驟:
(1)定義類內距離 Sw 和類間距離 Sb,如式(5)、(6)所示:
|
|
其中 c 代表類的數量,本文中 c 分為發作前期和發作間期兩種類別。E{ (f - μi) [ (f - μi)]T}為類別 i 的協方差矩陣,Pi 代表類別 i 的發生概率,μ0 為全部特征向量的平均向量,μi 為類別 i 的特征向量的平均向量。
(2)通過 Sw 和 Sb,得到可分離性判據 J,如式(7)所示:
|
|A|代表矩陣 A 的跡。類內的數據聚類得越集中或者不同類的數據分開得越分散,則 J 值越大;相反,如果類內距離不能很好地集中聚類,或者不同類的數據不能很好地分開,則 J 值變小。對于特征向量來說,特征 J 越大,則表示該特征表征能力越強,越容易被選擇。
2.3.1 導聯內特征選擇
導聯內特征選擇可以快速地減少每個導聯內的無關特征,是導聯選擇和利用分支定界法優化特征選擇之前必不可少的一步。本文利用分離性判據及特征值分析法,從每個導聯的 54 個特征中選擇出 R 個特征。
特征值分析法被用來確定 R 的數量,本文對每個導聯的特征的協方差矩陣進行特征值分析,并找出其貢獻率大于 99% 的特征數量,即為 R 的值。如 3 號患者,貢獻率超過 99% 的特征數量為 10,則 R = 10。
確定 R 數量后,本文采取貪婪算法和分離性判據選擇出具體的特征。具體步驟為從空集開始,依次添加未被選擇的特征中可分離性判據 J 最大的特征,直到選擇出 R 個特征。值得注意的是,當特征向量線性相關時,J 可能會出現無限大的情況,這是由于 Sw 虧秩造成的。因此當選擇特征線性相關時,即 J 為無限大的時候,將該特征的 J 值設為 0。這種順序選擇方案將產生線性獨立的特征向量子集。
2.3.2 導聯選擇
導聯選擇可以根據實際情況,進一步限制特征的數量,避免了過多的計算。在實際情況中,癲癇發作往往只在 1 個或幾個腦區中進行,其余腦區對應的導聯對于癲癇發作預測來說,只能提供很少的信息量。本文中使用的導聯選擇標準和特征標準選擇一樣,具體描述為:從所有導聯中選擇 k 個導聯,如果選出的 k 個導聯的混合特征向量的可分離性判據 J 為所有混合特征向量中最大的,即選擇這 k 個導聯。例如,k = 2,計算導聯中所有兩個導聯組合成的特征向量的可分離性判據 J,選擇其中 J 值最大的組合,即為選擇的導聯。
2.3.3 基于分支定界法的優化特征選擇
為了使特征向量達到最好的分類效果或者說達到最大的可分離性判據 J,本文在特征基礎選擇和導聯選擇之后,運用分支定界法從原有的 R × k 個特征中選出最優的 r 個特征。分支定界法是一種常見的優化特征選擇方法,其基本思想為將所有可能的特征組合構建成一個樹狀結構,按照某種特定的規律對樹進行搜索,使搜索過程盡可能早地達到最優解而不必遍歷整棵樹的所有節點。
在文獻[17]中,開發了一種有效針對全局最優變量選擇的分支定界算法。該法能夠有效地選擇全局最優的特征向量子集,從而使回歸誤差最小。f(l) = [f1(l),f2(l),
,fR(l)]T 表示為根據窗口數據 l 經過導聯內特征選擇和導聯選擇計算得出的特征向量。yl 代表窗口數據 l 的標簽。y = [y1,y2,
,yL]T 為類標簽向量,F 為特征矩陣,如式(8)所示:
|
其中,fi(j)為窗口 j 的第 i 個特征。F 中的每一列都為對應窗口 l 的特征向量,F 中的每一行都為對應特征的時間序列。定義 Gr = [fi1,fi2,
,fir]為含有 r 變量的 F 矩陣子集,其中 i1,i2,
,ir 為特征的序號。本文選擇子集的標準是,當子集 Gr 用最小二乘法計算時,可以達到最小的誤差,則該子集即為選擇的子集。實際上就是選擇一組 i1,i2,
,ir,使式(9)達到最小。
|
其中,q = (GTG)–1GTy 為最佳投影向量。
在實際應用中,r 是非先驗的、未知的。所以需要對 r 進行選擇,選擇步驟如下:
(1)對每個可能的 r 值(r ∈ {1,2,
,R × k}),分別通過分支定界算法選出最優的特征向量子集。
(2)對步驟(1)算出的每個特征向量子集,計算它們的 J 值。
(3)對于其中可分離性判據 J 大于閾值的特征向量子集,選出其中最小的 r 值,該 r 值即為最終選擇出的 r。
其中,閾值取 0.9 × Jmax,Jmax 為步驟(2)中計算的可分離性判據 J 中的最大值。
通過特征基本選擇、導聯選擇和基于分支定界法的特征優化算法,得出含有 r 個特征的特征向量。
2.4 基于支持向量機的分類器訓練
將上述處理結果通過機器學習的方法進行分類訓練,從而判斷某個時刻屬于癲癇發作前期還是屬于癲癇發作間期,如果為前期即進行報警。本文將發作間期數據 C0 編碼為–1,發作前期數據 C1 編碼為 1。針對每個人的數據集,利用留一法對數據進行訓練和測試。本文采用支持向量機中的支持向量分類機(support vector clustering,SVC),核心函數為徑向基函數(radial basis function,RBF)。SVC 要解決的優化問題如式(10)所示:
|
約束于
。其中 xi 代表 r 維的特征向量,N 代表用來訓練的樣本數量,ω 為超平面的方向,ω0 為初始的平面偏移,yi 為訓練的標簽,ξi 為松弛變量,C+、C– 為懲罰系數。懲罰系數 C+、C– 在如下數組中進行選擇(2–3,2–2,
,22,23)。
為了解決訓練樣本非線性問題,引入核函數 Kn,將數據映射到高維空間,以解決原本空間下的線性不可分問題。本文采用的核函數 Kn 為徑向基函數,其函數如式(11)所示:
|
2.5 腦電信號實時分類
腦電信號經過預處理、特征提取、特征選擇,最后利用支持向量機訓練得到分類器。此時將實時腦電信號放入分類器中,判斷其狀態是否為發作前期。如果為發作前期,則進行報警。
3 實驗結果與分析
本文兩個重要的評價指標分別為靈敏度、錯誤報警率。靈敏度和錯誤報警率定義如式(12)、(13)所示:
|
|
其中,Nsuccess alarm 為成功報警次數,Nseizure 為癲癇發作總次數;Salarm 為在間期進行報警的時間窗數量,SC0 為間期所有時間窗的數量;其中靈敏度越高越好,而錯誤報警率則越低越好。
3.1 本文方法的結果
不同患者因致癇區不同等原因,癲癇腦電信號差異過大,故本文采取個性化處理,即每位患者的分類器都單獨進行訓練,最終得到的分類器采用留一法進行驗證得到分類結果,并利用靈敏度與錯誤報警率對該分類結果進行評價。各組患者發作間期和發作前期特征值變化如圖 2 所示,通過特征選擇得出的特征及分類結果評價如表 1 所示
圖2
癲癇發作間期與發作前期的特征均值變化
Figure2.
The mean feature value change between interictal and ictal
3.2 本文方法與預測時不加入 δ 波段的方法結果對比
人在清醒狀態下腦電信號中不出現 δ 波段,現有癲癇預測或檢測算法中在進行頻域分割時,不考慮 δ 波段。但 δ 波段是睡眠期間的主要波段,因此本文方法在特征提取階段加入了 δ 波段。為了體現 δ 波段的效果,對比方法在頻域分解階段,腦電信號不在 δ 波段上進行分解。將對比方法的結果評價與在本文方法的結果評價進行對比。其結果評價對比如圖 3 所示。
圖3
特征提取階段提取 δ 波段與不提取 δ 波段的結果評價對比
Figure3.
Comparison of results with or without δ band in feature extraction
3.3 本文方法與使用單獨功率譜相關特征的方法對比
雖然文獻[9, 11, 16]證明絕對功率譜、相對功率譜和功率譜比值可以用來預測癲癇發作,但是每個特征單獨用來進行分類器訓練都有自己的劣勢。為了證明混合特征在預測睡眠中癲癇發作的應用方面的優勢,在特征提取階段,分別提取單獨的絕對功率譜、相對功率譜和功率譜比值特征。用這 3 種特征向量分別進行特征選擇和分類器訓練,得到分類結果,并對結果進行評價。其結果與本文方法即特征提取階段使用混合特征的結果評價進行對比,對比結果如圖 4 所示。
圖4
特征提取階段提取混合特征、絕對功率譜、相對功率譜與功率譜比值進行預測的結果評價對比
Figure4.
Comparison of results obtained by extraction of mixed features, absolute power spectrum, relative power spectrum or power spectrum ratio in feature extraction
3.4 實驗結果分析
在靈敏度上,本文方法的靈敏度為 100%,特征提取階段不加入 δ 波段的方法靈敏度為 91.67%,特征提取階段使用絕對功率譜的靈敏度為 78.6%,使用相對功率譜的靈敏度為 86.1%,使用功率譜比值的靈敏度為 100%。本文方法和使用功率譜比值的方法都達到了 100% 的靈敏度,特征提取階段不提取 δ 波段、單獨使用絕對功率譜和相對功率譜的方法的靈敏度均低于 100%。因此在靈敏度方面本文方法與單獨使用功率譜比值的方法均有較好的效果。
在錯誤報警率上,本文方法的平均錯誤報警率為 2.11%,特征提取階段不加入 δ 波段的方法錯誤報警率為 9.19%,特征提取階段使用絕對功率譜的錯誤報警率為 6.92%,使用相對功率譜的錯誤報警率為 14.75%,使用功率譜比值的錯誤報警率為 10.58%。本文方法的錯誤報警率最低。而在靈敏度方面表現較好的功率譜比值方法,其錯誤報警率則高達 14.75%。通過靈敏度和錯誤報警率的對比,體現出本文方法具有良好的預測能力。
4 結論
現有基于腦電信號的癲癇預測方法中,很少專門研究如何對睡眠中發作的癲癇進行預測。睡眠中發作的癲癇相對于在人體清醒狀態時發作的癲癇更難進行及時的救助,且有很大幾率會導致多種并發癥甚至導致癲癇猝死[1]。對于睡眠腦電信號來說,其特征與清醒時有明顯不同。睡眠腦電信號呈現低頻率、δ 波段增強、α 波段減弱等特點。如果不針對睡眠腦電信號的特點進行特殊處理就進行預測,很可能造成靈敏度下降或者錯誤報警率增加。
本文提出了一種基于腦電信號的個性化預測睡眠中癲癇發作的方法,該方法基于腦電信號,提取不同波段的絕對功率譜,相對功率譜和功率譜比值組成混合特征,并根據睡眠腦電信號的特殊性加入了 δ 波段的功率譜相關特征,應用分離性判據和分支定界法方法進行特征選擇,最后運用支持向量機對腦電信號進行分類,判斷實時輸入的腦電信號數據是否為癲癇前期,從而達到預測的結果。對比實驗得出,不加入 δ 波段特征方法的靈敏度為 91.67%,錯誤報警率為 9.19%。本文方法相對于上述方法在敏感度和錯誤報警率方面都得到提升,得到了 100% 的敏感度和 2.11% 的錯誤報警率。本方法得到了較好的預測效果,也證明了功率譜特征對于睡眠中的癲癇發作有一定的預測能力。
本文方法對于腦電信號只去除了機器噪聲,未進行進一步的去噪處理,這導致一些無關信息也被加入進來,從而降低了運算速度和預測效果。同時本文方法得到的錯誤報警率,雖然相較不針對睡眠腦電信號特點的方法得到提升,但 2.11% 的錯誤報警率還不能達到臨床級別。因此在以后的工作中,將在降低錯誤報警率方面和研究快速去噪方法方面繼續深入研究,以期使預測更加準確。