為了解決目前肝臟腫瘤病理分級主要依靠穿刺活檢、手術病理取材等侵入式方法的問題,提出了一種在非增強核磁共振圖像(MRI)上進行肝臟腫瘤病理分級的定量分析方法。首先對采集到的 MRI 圖像,由醫生在專業軟件中人工分割出病灶部位,對這些病灶部位提取高通量的 328 維圖像特征,包括灰度、形狀、紋理、小波等特征,利用最小絕對收縮和選擇運算符(LASSO)和交叉驗證方法從中挑選出對病理分級最有價值的特征,組成影像組學模型并融合臨床信息實現對腫瘤高、低分化分類的定量分析。在 170 位肝臟腫瘤患者的 MRI 圖像(T1 加權圖像和 T2 加權圖像)上進行實驗,通過計算接收者操作特征(ROC)曲線下面積(AUC)來衡量模型的預測性能。結果表明,基于高通量圖像特征的 LASSO 回歸定量分析方法,在訓練集上獲得 AUC 為 0.909,在測試集上 AUC 為 0.800。挑選出來的圖像特征組成的影像學標簽可以對高、低分化進行自動分類,從而為醫生提供了一種非侵入的輔助診斷方法,有助于預后判斷和治療方案的制定。
引用本文: 高飛, 閆鑌, 曾磊, 武明輝, 譚紅娜, 海金金, 寧培鋼, 史大鵬. 非增強核磁共振圖像中肝臟腫瘤病理分級的定量分析方法. 生物醫學工程學雜志, 2019, 36(4): 581-589. doi: 10.7507/1001-5515.201803014 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
肝臟腫瘤的早期診斷對制定治療方案有著重要意義,對于已進展為中晚期的腫瘤,盡可能在治療前明確腫瘤的分子生物學分型、分級等腫瘤異質性信息,可根據腫瘤的異質性選擇合理的治療方案,即精準治療。臨床實踐表明腫瘤的病理分級信息與患者的療效、預后密切相關,但依賴于穿刺活檢、手術病理取材的病理分級方法并不適合于所有腫瘤人群的治療前診斷。磁共振成像(magnetic resonance imaging,MRI)是一種常見的影像學診斷方法,但肉眼上對早期肝臟腫瘤的診斷仍存在局限性,對腫瘤異質性評估的價值并沒有被完全挖掘出來。2012 年荷蘭學者 Lambin 等[1]提出了放射組學的概念,同年 Kumar 等[2]將放射組學的定義擴展為影像組學。影像組學是以定量成像為基礎的新興技術,指的是高通量地從計算機斷層掃描成像(computed tomography,CT)、MRI 等醫學影像中提取影像特征,將傳統的影像轉換為可發掘的數據信息,通過定量分析來預測病理分級、分子生物學分型等。Doroshow 等[3]指出影像組學是轉化醫學未來發展方向之一。2014 年 Aerts 等[4]在《Nature》雜志上發布了一項根據定量的影像組學特征進行腫瘤分型的研究,結果顯示大量的影像特征與患者預后有顯著的聯系,影像組學特征能夠捕捉到腫瘤內部的異質性,并與基因表達的模式相關,并且某些特征在肺癌和頭頸部腫瘤都存在。最近兩三年基于影像組學的相關研究在對腫瘤的診斷、療效評估、預后判斷等方面已經顯示出巨大的臨床應用價值[5-7]。
影像組學的關鍵技術是提取高通量影像特征后的特征降維,可以利用各種機器學習算法來進行特征選擇和分類模型構建。對于“高維”數據(特征變量數目遠大于數據樣本數量)而言,常見的方法比如支持向量機(support vector machine,SVM)、隨機森林(random forest,RF)等,進行特征選擇時無法同時滿足模型的準確性、模型穩定性以及模型計算復雜度的要求[8],嶺回歸雖然可以解決變量之間的多重共線性問題,但是它得到的解是非稀疏的,不能有效地降低特征變量的維度。Tibshirani[9-10]提出了一種稱為最小絕對收縮和選擇運算符(least absolute shrinkage and selection operator,LASSO)的變量選擇方法,該方法在最小二乘估計的基礎上加入 L1 正則化項,使用模型系數的絕對值函數作為懲罰策略來壓縮模型系數,使一些與輸出結果效應非常弱的回歸系數變小,甚至變為零,因此 LASSO 可以提供一個稀疏解,很好地克服了傳統方法的不足。王金甲等[11]提出采用 LASSO 模型用于肝病的分類,其分類正確率優于傳統的模式識別方法;李靜等[12]提出基于廣義交互 LASSO 模型用于肝臟疾病分類;Liang 等[13]基于 LASSO 和影像組學對結直腸腫瘤的病理分級進行了預測;Guo 等[14]使用影像組學與基因組學聯合基于 LASSO 模型預測浸潤性乳腺癌的病理分級,取得了一些成果。
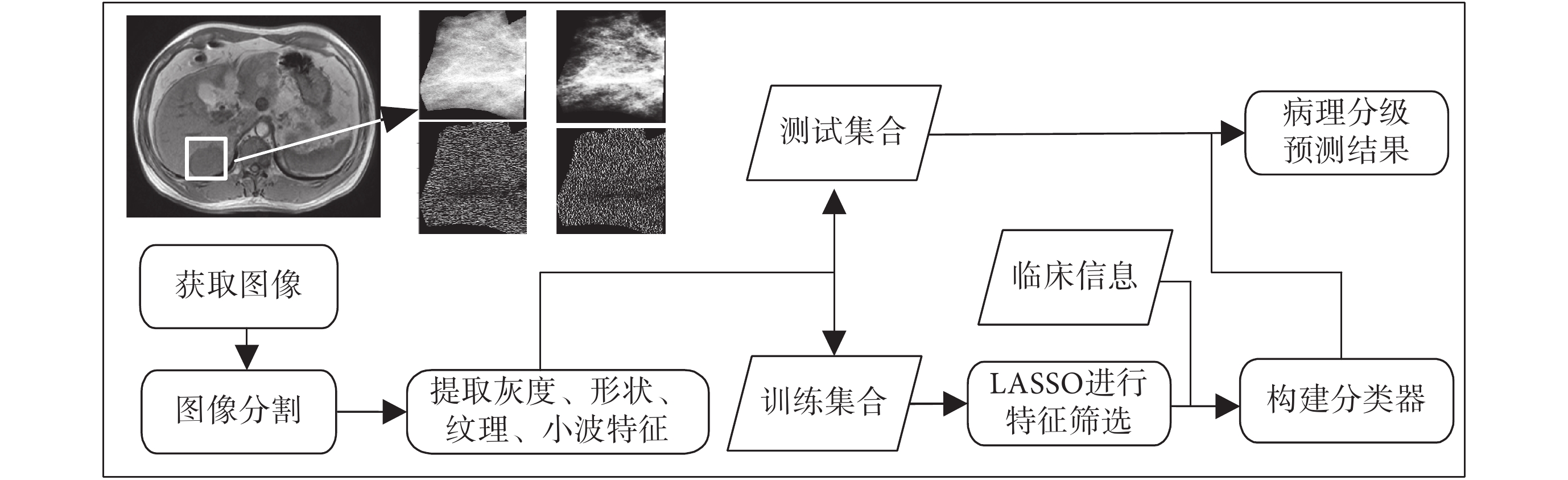
本文提出的肝臟腫瘤病理分級的定量分析方法主要是在非增強 T1 加權圖像(T1 weighted MRI,T1WI)和 T2 加權圖像(T2 weighted MRI,T2WI)上,采用手動方式將病灶部位分割出來,對分割出來的圖像提取高通量的影像特征,通過 LASSO 算法,經過交叉驗證從中篩選對病理分級最有關聯的影像特征,并融合臨床信息,構建分類器,對肝臟腫瘤的病理分級進行預測。圖 1 給出了該方法的流程圖。
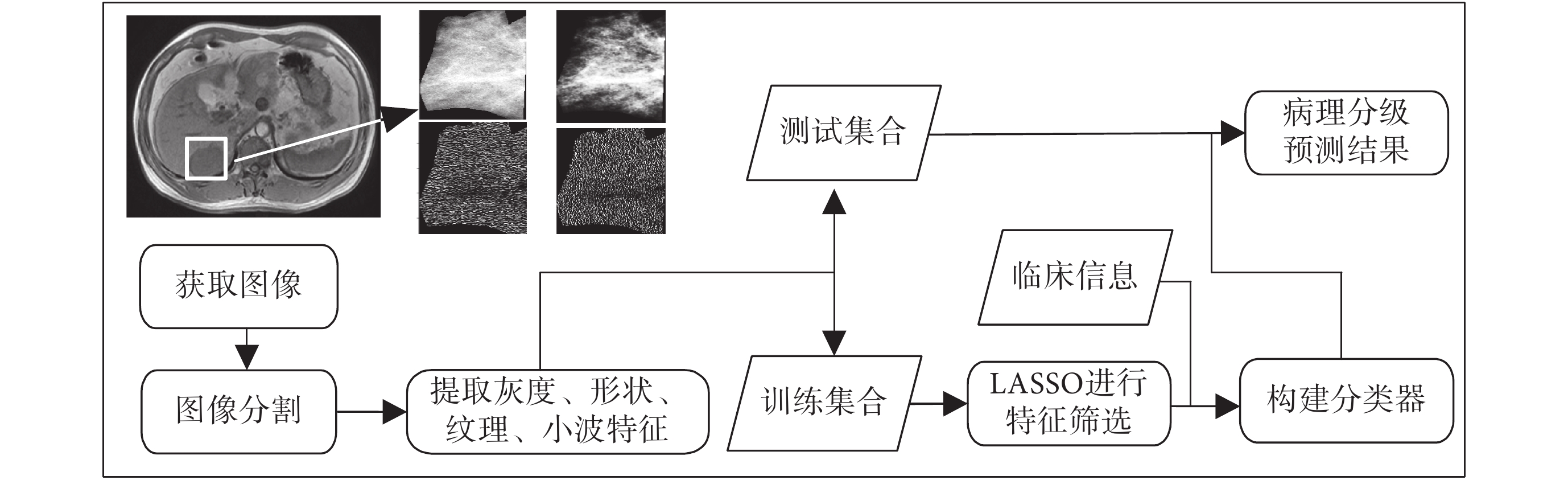 圖1
病理分級圖像處理流程
Figure1.
Flow chart of image processing for pathological grading
圖1
病理分級圖像處理流程
Figure1.
Flow chart of image processing for pathological grading
1 特征提取
對分割出來的病灶部位圖像進行特征提取,特征主要分為四類:① 強度特征;② 形狀和大小特征;③ 紋理特征;④ 小波特征。具體的特征描述見表 1 所示。
一階統計特征用來描述腫瘤的強度特性,是描述 MRI 圖像中腫瘤體素強度分布的通用和基礎指標。形狀和大小特征描述了病變區域的三維尺寸大小和形狀,用于描述球形或者細長形狀的腫瘤的特點。紋理特征主要基于 GLCM、GLRLM 進行計算和分析得到,由圖像中體素強度值進行離散化得到相應的紋理統計矩陣,可以量化腫瘤內異質差異,由于在全部三維方向上計算這些特征,提供了圖像中不同灰度級相對的位置信息,這個離散步驟不僅可以減少圖像噪聲,而且使所有腫瘤體素強度標準化,允許直接比較所計算的三維空間特征。三維小波特征是小波分解原圖后計算每個分量的強度和點奇異性特征,關注圖像內不同頻域的特征。本文采用的是一種離散的、非抽取的三維小波變換,對于任何一幅 MRI 圖像,原始圖像 X 可以分解為 8 個分量,假設 L 表示低通濾波,H 表示高通濾波,8 個分量分別是 XLLL、XLLH、XLHL、XLHH、XHLL、XHLH、XHHL、XHHH。比如 XLLH 就是高通子帶,它是沿 X 方向進行低通濾波、沿 Y 方向進行低通濾波、沿 Z 方向進行高通濾波得到的,可以表示如下:
 |
其中 NL 表示低通濾波器的長度,NH 表示高通濾波器的長度。
上述提到的高通量特征是在 Matlab R2014b(Mathworks,Natick,美國)下編碼完成的。
2 模型與方法
經過對病灶部位圖像進行特征提取,共提取了四大類共 328 維影像特征,但并非所有特征對于病理分級都是有用的,因此特征維度的降低十分必要。下面介紹特征選擇的方法 LASSO 模型,LASSO 模型是在多元分析時,通過對變量系數的壓縮,挑選出系數不為零的變量。
2.1 LASSO 的基本概念
假設已知數據  ,其中 xij 是預測變量,yi 是響應變量。同一般的回歸方程一樣,假設個體間是相互獨立的,或者在給定預測變量 xij 的條件下,yi 是相互獨立的。假設 xij 是標準化的,那么
,其中 xij 是預測變量,yi 是響應變量。同一般的回歸方程一樣,假設個體間是相互獨立的,或者在給定預測變量 xij 的條件下,yi 是相互獨立的。假設 xij 是標準化的,那么
 |
 ,則LASSO估計
,則LASSO估計  可定義為:
可定義為:
 |
同時滿足  的約束條件。其中 t ≥ 0 為懲罰參數,參數 t 在估計時用來控制收縮量,設
的約束條件。其中 t ≥ 0 為懲罰參數,參數 t 在估計時用來控制收縮量,設  為普通最小二乘估計值,記
為普通最小二乘估計值,記  ,當 0 < t <
,當 0 < t <  ,可以使一些回歸系數收縮并趨向于 0,并且一些回歸系數的估計值就等于 0,則 LASSO 估計就演變為下面的式子:
,可以使一些回歸系數收縮并趨向于 0,并且一些回歸系數的估計值就等于 0,則 LASSO 估計就演變為下面的式子:
 |
其中  > 0,參數
> 0,參數  和參數 t 是對應的,也即是參數
和參數 t 是對應的,也即是參數  對應的是模型的懲罰系數,當參數
對應的是模型的懲罰系數,當參數  越小時,模型的壓縮程度越低,提取的特征越多,當參數
越小時,模型的壓縮程度越低,提取的特征越多,當參數  越大時,對模型的壓縮程度越大,提取的特征越少。例如當
越大時,對模型的壓縮程度越大,提取的特征越少。例如當  時,效果會大致類似于尋找大小為
時,效果會大致類似于尋找大小為  的最優特征子集,也就是說變量集中一些變量的作用減小了,而且起作用的變量個數也僅大致為原來的二分之一。LASSO 模型的求解使用循環坐標下降法。
的最優特征子集,也就是說變量集中一些變量的作用減小了,而且起作用的變量個數也僅大致為原來的二分之一。LASSO 模型的求解使用循環坐標下降法。
2.2 LASSO 參數 t 的估計
LASSO 估計中懲罰參數 t 的估計有兩種方法:交叉驗證法和廣義交叉驗證法。
假設  ,其中
,其中  ,
, 。
。 估計的均方誤差MSE定義如下:
估計的均方誤差MSE定義如下:
 |
MSE 的求解比較困難,預測誤差 PSE 比較容易計算,并且和 MSE 是相關的。
 |
最小化 PSE 相當于最小化 MSE。
懲罰參數 t 也叫做 LASSO 參數,它相當于是 LASSO 的收縮邊界, ,這里定義與參數 t 相關的另一個參數 s 作為歸一化的 LASSO 參數,
,這里定義與參數 t 相關的另一個參數 s 作為歸一化的 LASSO 參數,
 |
2.2.1 交叉驗證
交叉驗證的基本思想是把樣本集分為兩大類——訓練集和驗證集用來估計模型參數,其中訓練集和驗證集的角色不斷地變換。 表示最優的參數 s,比如一個 10 折交叉驗證,樣本集共分為 10 份,一份作為驗證集,其余為訓練集,然后不停地變換驗證集,依次訓練模型,在歸一化參數 s 的條件下檢索 LASSO,并且預測誤差是由 s 從 0 到 1 不斷變化估計出來的,選擇產生最低預測誤差估計值 PSE 所對應的
表示最優的參數 s,比如一個 10 折交叉驗證,樣本集共分為 10 份,一份作為驗證集,其余為訓練集,然后不停地變換驗證集,依次訓練模型,在歸一化參數 s 的條件下檢索 LASSO,并且預測誤差是由 s 從 0 到 1 不斷變化估計出來的,選擇產生最低預測誤差估計值 PSE 所對應的  作為最優解。
作為最優解。
一個 N 折交叉驗證的算法流程如下:
步驟 1:將全部數據樣本 N 分為子樣本集  ;
;
步驟 2: ,選擇訓練集
,選擇訓練集  訓練模型,并用驗證集 Sv 計算
訓練模型,并用驗證集 Sv 計算 

 ;
;
步驟 3:在所有的  中選擇最小的 d(s)作為參數 s 的最優估計。
中選擇最小的 d(s)作為參數 s 的最優估計。
2.2.2 廣義交叉驗證
 的約束下,參數 s 的提出實際等價于在殘差和或者殘差平方上增加一個拉格朗日懲罰
的約束下,參數 s 的提出實際等價于在殘差和或者殘差平方上增加一個拉格朗日懲罰  ,其中
,其中  取決于 t,因此在式(4)的基礎上矩陣的表達形式為:
取決于 t,因此在式(4)的基礎上矩陣的表達形式為:
 |
在約束條件中適合  的有效參數量 d(λ)可以用下面的式子進行近似:
的有效參數量 d(λ)可以用下面的式子進行近似:
 |
可以構建廣義交叉驗證模型的統計方式:
 |
LASSO 回歸算法是由 R 語言編碼完成,并在 R Version3.4.2(R Foundation for Statistical Computing)中實現的。
2.3 病理分級分類模型構建
對手動分割出來的病灶部位圖像進行高維特征提取,利用 LASSO 算法對肝臟腫瘤病理分級進行多元回歸分析,挑選出對病理分級最有價值的影像特征。根據挑選出來的特征及其系數計算對病理分級進行預測的影像組學標簽 Rad-score,根據影像組學標簽進行分類測試。為了提高分類結果的準確率,將臨床信息和影像組學標簽進行融合,對病理分級進行分類預測。
臨床模型指的是僅僅利用臨床信息進行 Logistic 回歸分析;影像組學模型是指提取高通量影像特征后,基于 LASSO 算法篩選特征后進行分類預測;融合模型指的是將影像組學模型得到的影像組學標簽 Rad-score 和臨床信息融合后進行 Logistic 回歸分析。
2.4 統計學方法介紹
患者樣本數據在訓練集和測試集上的分布對比情況,性別和高低分化情況對比使用卡方檢驗 Chi-squared test,年齡對比使用 Mann-Whitney U 檢驗。
通過三種模型得到的高分化和低分化患者的預測分數差異比較使用 Mann-Whitney U 檢驗,并且給出了四分位距(interquartile range,IQR)和中位值。
用接收者操作特征(receiver operating characteristic,ROC)曲線下面積(area under the curve,AUC)來衡量預測模型的性能,基于訓練集設置最佳的分類閾值來計算 AUC,包括敏感性(sensitivity,SENS)、特異性(specificity,SPEC)、準確率(accuracy,ACC),然后將此閾值應用到測試集上,計算各個指標。AUC 大小的比較使用 Delong 測試,AUC 越大意味著分類的準確率越高,并給出了 AUC 的 95% 置信區間(confidence interval,CI)。
臨床模型包含患者的年齡、性別、病灶大小、脈管癌栓、乙肝、血甲胎蛋白、假包膜、門脈癌栓、肝硬化、門脈高壓等,利用 Logistic 回歸進行多元因素分析,從中挑選與病理分級關聯性最強的因素。臨床模型加入影像組學標簽 Rad-score 后,利用 Logistic 回歸再一次進行多元因素分析,并給出了比值比 Odds Ratios。
統計分析使用 MedCalc16.2.0 軟件完成(MedCalc software,http://www.medcalc.org),P < 0.05 表示差異有統計學意義。
3 實驗結果與分析
3.1 實驗數據
收集了 2012 年 1 月到 2016 年 12 月在河南省人民醫院治療過的肝臟腫瘤患者信息共 170 例,包含患者的 MRI 圖像和臨床信息,患者都已知曉本研究情況,合作醫院也批準了本課題的研究,所有的數據都經過了數字化處理并對個人隱私進行了隱藏。患者樣本入選實驗的標準是:① 病理學診斷為肝細胞癌并具有明確的病理分級(Edmondson 分級);② 在手術前一周行 MRI 檢查,圖像質量滿足實驗要求;③ 患者在手術之前沒有經過治療。高分化患者包括 Edmondson 等級為Ⅰ、Ⅰ-Ⅱ和Ⅱ的患者,低分化患者包括 Edmondson 等級為Ⅱ-Ⅲ、Ⅲ、Ⅲ-Ⅳ和Ⅳ的患者,進行高分化和低分化的二分類判別實驗。采集圖像使用的機器是通用醫療設備的 GE750 3.0T,原始圖像格式為 DICOM 格式,圖像分辨率為 512 * 512,掃描層厚為 7 mm,滿足實驗要求。由兩位超過 10 年讀片經驗的放射科醫師使用專業軟件 ITK-SNAP3.0(http://www.itk-snap.org)對腫瘤病灶部位進行手動分割。患者臨床信息主要包括患者的年齡、性別、病灶大小、脈管癌栓(有和無)、乙肝(有和無)、血甲胎蛋白(正常和升高)、假包膜(有、不完整、無)、門脈癌栓(有和無)、肝硬化(有、輕度、無)、門脈高壓(有和無)等,臨床信息取自于患者的病歷管理系統。
通過程序將 170 例患者隨機劃分為訓練集(125 例)和測試集(45 例),患者的情況描述如表 2 所示,訓練集和測試集分布基本一致(P值均 > 0.05)。圖 2 顯示了不同病理分級的肝臟腫瘤患者 T1WI 圖像和 T2WI 圖像,紅色曲線標注區域為腫瘤區域。
 圖2
肝臟腫瘤患者的 MRI 圖像
Figure2.
MRI images of patients with hepatocellular carcinoma
圖2
肝臟腫瘤患者的 MRI 圖像
Figure2.
MRI images of patients with hepatocellular carcinoma
3.2 實驗結果
LASSO 模型訓練時采用 10 折交叉驗證,選擇 AUC 作為優化的目標,此時選出的模型作為病理分級的最優影像組學模型,利用模型篩選出來的特征及其系數計算基于影像組學的預測分數 Rad-score,進行肝臟腫瘤的病理分級。
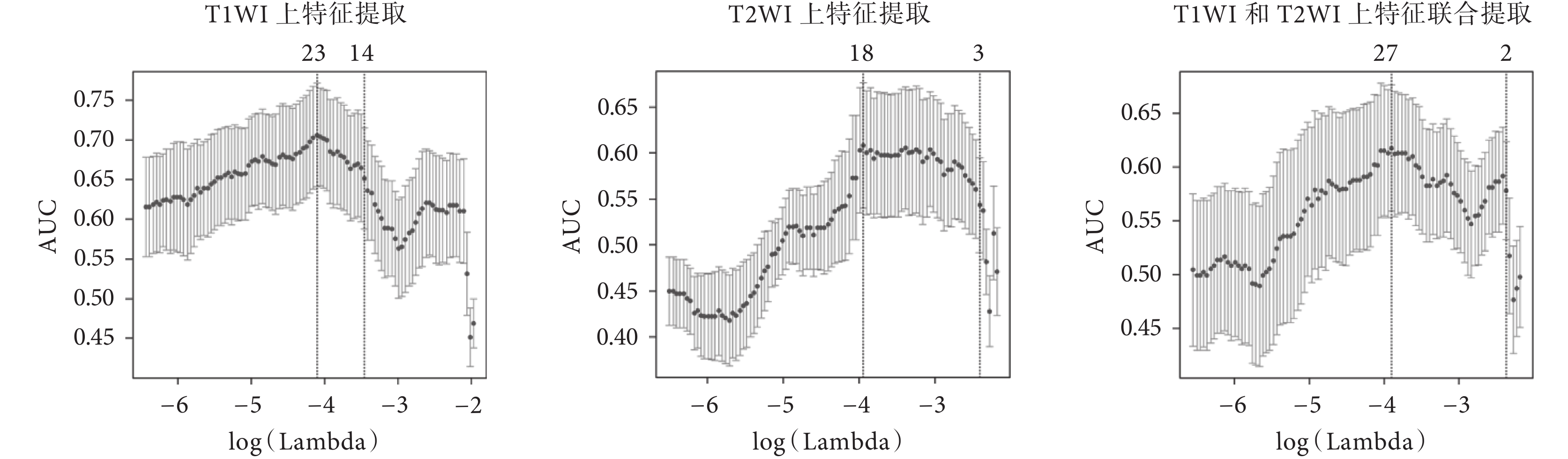
實驗中使用了肝臟腫瘤患者的 T1WI 和 T2WI 圖像,利用 LASSO 算法進行特征提取,構建分類模型,分別進行了 T1WI 特征篩選、T2WI 特征篩選以及 T1WI 和 T2WI 圖像特征聯合篩選三種實驗,特征提取的結果如圖 3 所示。橫坐標表示參數 λ 的變化情況,縱坐標 AUC 表示模型的輸出情況,曲線上方的數字表示模型提取特征的數量,從圖中可看出,當參數 λ 逐漸變大時,模型的 AUC 在變化,特征數量在減少,即模型的壓縮程度在增加。圖中左側虛線表示 AUC 最大時對應的取值和提取特征的數量,右側虛線表示在 AUC 一倍標準誤差時的特征提取情況,此時特征數量減少。選擇左側虛線對應的參數可以得到正確率最高的模型,選擇右側虛線對應的參數在保證一定準確率的同時可以精簡模型,減少提取特征的數量,提高模型的計算效率。從圖 3 可見,通過參數 λ,分別從 T1WI 的 328 維特征、T2WI 的 328 維特征以及 T1WI 和 T2WI 聯合的 656 維特征中提取了 23、18、27 個特征。
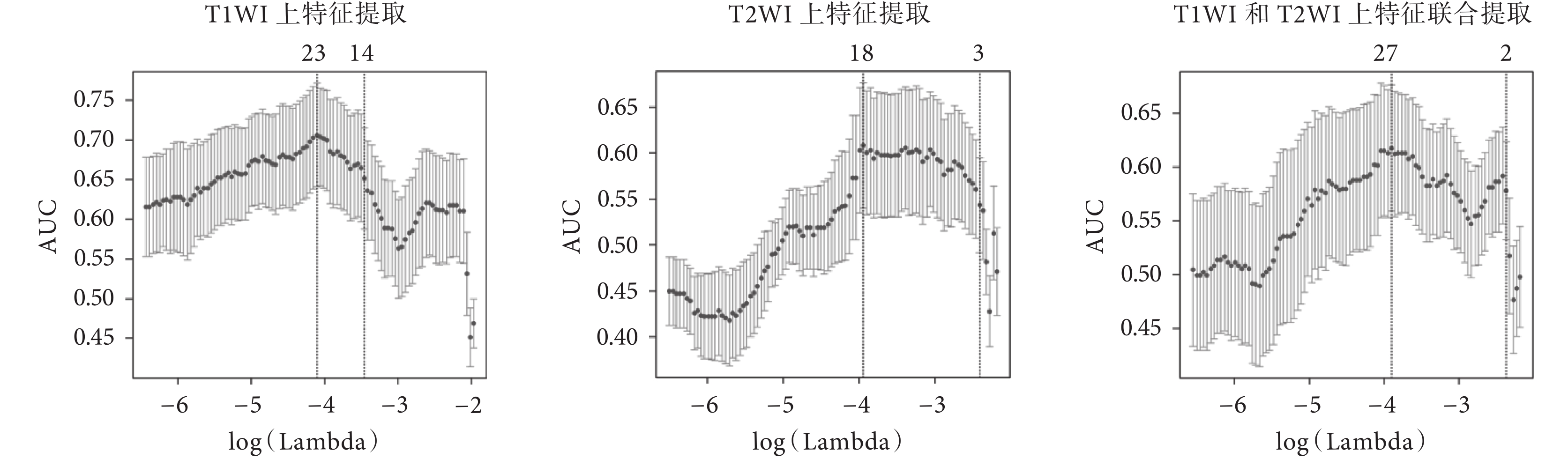 圖3
基于 LASSO 算法提取特征的結果
Figure3.
Feature selection using the LASSO logistic model
圖3
基于 LASSO 算法提取特征的結果
Figure3.
Feature selection using the LASSO logistic model
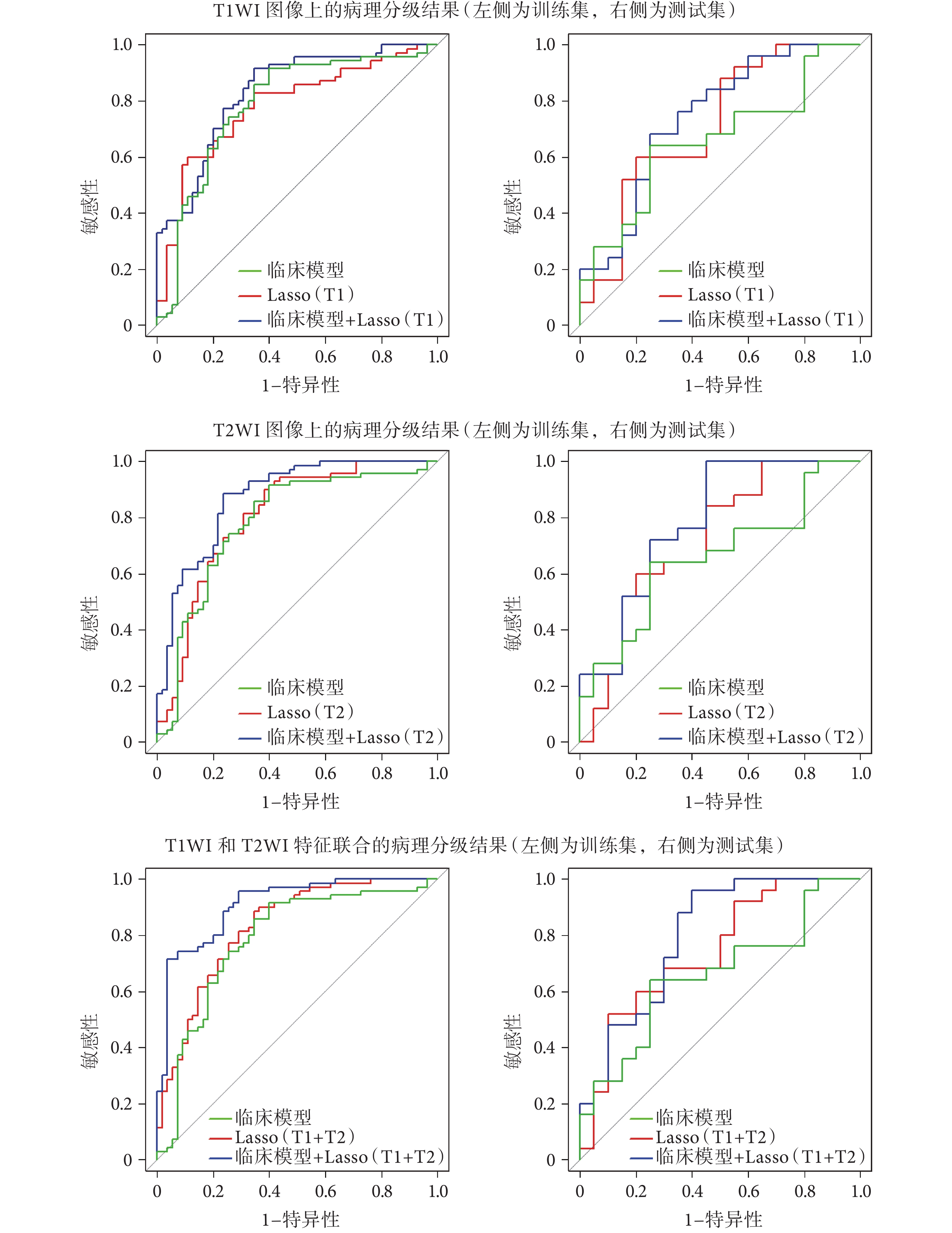
利用挑選出來的特征計算基于影像組學的預測標簽 Rad-score,在臨床模型、影像組學模型以及融合模型上進行了病理分級實驗,結果如表 3 所示。在分類閾值為 ? 0.868 8 時,融合模型取得了最高的分類結果,AUC 在訓練集上為 0.909(敏感性 95.71%,特異性 70.91%,準確率 84.40%),在測試集上為 0.800(敏感性 85.00%,特異性 65.00%,準確率 76.11%)。圖 4 分別給出了在 T1WI 圖像、T2WI 圖像、T1WI 和 T2WI 圖像特征聯合上基于 LASSO 回歸的影像組學模型病理分級結果以及融合臨床信息的病理分級結果,可以看到,融合模型均比沒有融合臨床信息的影像組學模型準確率有一定的提升。
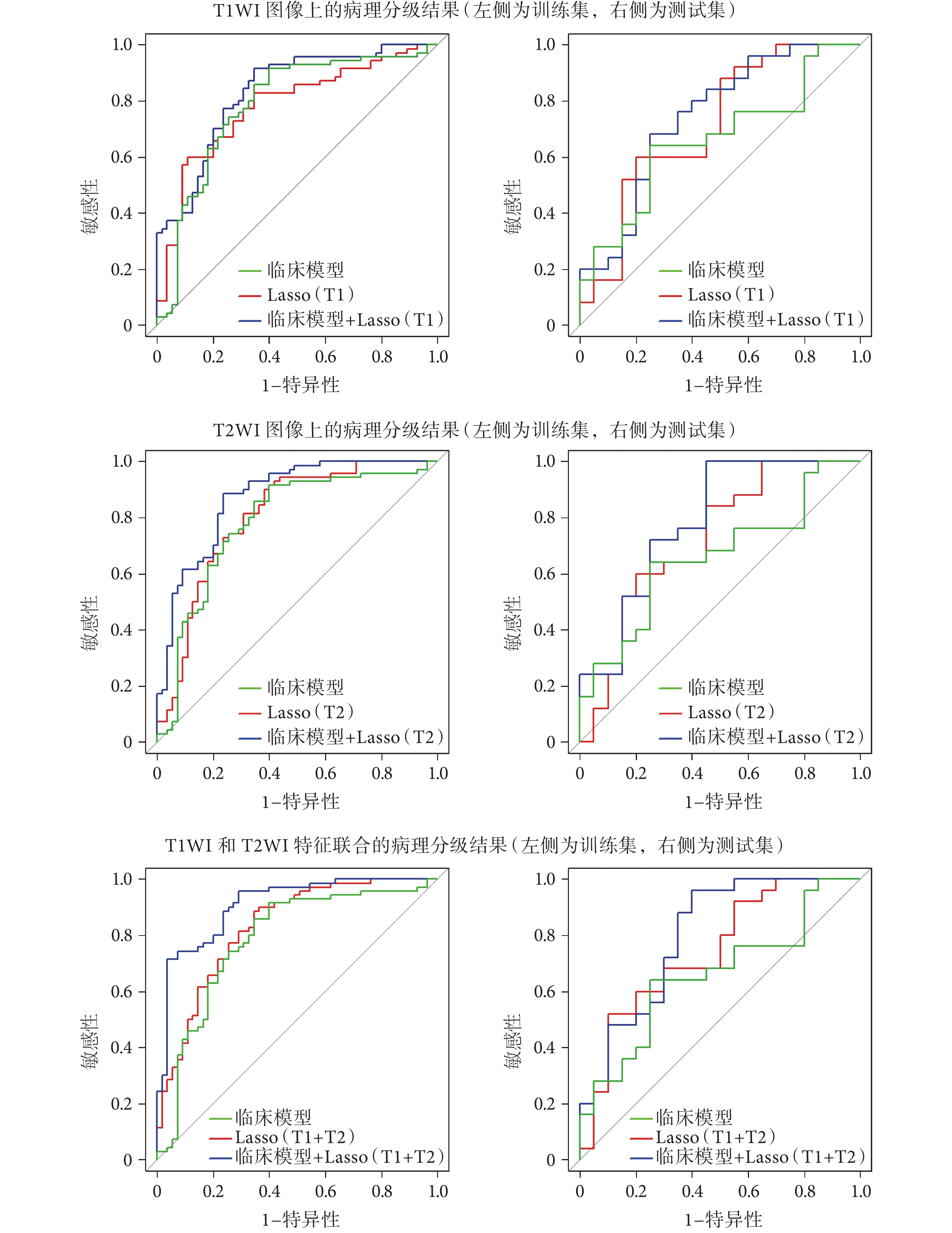 圖4
三種實驗的病理分級結果 ROC 曲線
Figure4.
The ROC curves of pathological grading results on the three experiments
圖4
三種實驗的病理分級結果 ROC 曲線
Figure4.
The ROC curves of pathological grading results on the three experiments
表 4 給出了融合模型得出的預測分數在訓練集和測試集上、不同年齡和性別的分布對比情況。表中給出了中位值和四分位距(P值均小于 0.05)。可以看到在訓練集和測試集、男性和女性、年齡在 57 歲以上及 57 歲以下等范圍內,低分化患者的預測分數高于高分化患者的預測分數,且高分化患者與低分化患者的分數差異較為明顯,說明了本文提出的定量分析方法的有效性。
表 5 給出了臨床模型和融合模型進行病理分級時,多因素 Logistic 回歸各個變量的系數、比值比 Odds Ratios 及 95% 置信區間,P 值小于 0.05 的變量被挑選出來組成回歸方程。
3.3 實驗分析與討論
本研究提出了一種利用影像組學的肝臟腫瘤病理分級定量分析方法,在建立的模型中,設定定量的分類閾值后,通過肝臟腫瘤 MRI 圖像可以預測病理分級情況。本文主要利用 LASSO 算法進行影像學特征的篩選,組成預測方程計算病理分級的影像學標簽 Rad-score。實驗結果證明這種方法可以很好地進行肝臟腫瘤的高、低分化二分類。
從表 3 可以看出,臨床模型預測肝臟腫瘤病理分級的能力較差,說明臨床信息對病理分級的貢獻有限;表 5 中從臨床模型的各個因素變量來看,挑選出了甲胎蛋白(P = 0.001)水平和不完整包膜情況(P = 0.013),前期也有相關文獻[15]討論了甲胎蛋白和肝臟腫瘤分期的關系。
在一些相關的研究中,使用圖像紋理特征進行疾病預測的研究較多,如在結直腸癌 CT 圖像上進行生存期預測[16],以及在肺癌 CT 圖像中進行分期預測[17],都是單獨使用紋理特征,并取得了不錯的效果。本文提出的基于影像組學的病理分級方法,提取的特征不僅僅限于紋理特征,還有形狀、灰度、小波等特征,特征的使用更全面更豐富,采用多種特征的聯合分析,分類效果更好。從表 3 可以看出,基于影像組學的模型分類性能有了較大提升,說明影像組學對肝臟腫瘤病理分級的作用較為明顯,MRI 圖像內部蘊含的一些肉眼無法觀察到的特征與肝臟腫瘤的病理分級有關聯。Liang 等[13]提出基于影像組學模型的結直腸癌 CT 圖像上的病理分級,在訓練集上 AUC = 0.792,測試集上 AUC = 0.708,也說明了影像組學方法的有效性。陳舒婷[18]進行了基于影像組學模型的肝癌 CT 圖像上 Edmondson 等級的預測,文章在進行高通量特征篩選時,只使用了簡單的 U 檢測方法,最終的分類結果 AUC 在訓練集上為 0.765 6(n = 285),測試集上為 0.673 3(n = 127)。
傳統的分析中臨床信息和影像學特征是分開討論的,將基于影像組學模型得到的影像學標簽加入到臨床信息中,進行病理分級的分析,可以形成很好的互補。從圖 4 可以看出,在 T1WI、T2WI、T1WI 融合 T2WI 三組實驗上,影像組學標簽加入臨床信息后,分類性能都有了提升。從表 3 可以看出,融合模型在 T1WI 融合 T2WI 實驗上分類性能達到了最高。從表 5 可以看出,融合模型中挑選出來的因素是影像組學標簽(P < 0.000 1)、AFP(P = 0.016)和門脈高壓(P = 0.038),說明將臨床信息中甲胎蛋白等指標的檢測與影像組學的結果融合在一起,可以提升基于影像組學的病理分級結果的準確性。
本文的研究方法是基于非增強 MRI 圖像進行的,該方法也可以在其他模態的圖像上進行分析,比如 CT 等。本文進行的是病理分級的研究,其他諸如病理分期、復發預測、生存期預測、療效評估等都可以采用類似的方法。
4 結束語
隨著基因數據、圖像數據等醫療大數據的出現,利用大數據進行腫瘤疾病診斷的價值還沒有完全挖掘出來,影像組學為解決精準醫學需求提供了新的思路。影像組學用到的關鍵技術是高通量特征提取后的降維方法,由于數據樣本維度較高,當多個自變量有些相關時,模型計算可能出現多重共線性問題,當多重共線性嚴重時,模型的微小變化會造成系數估計的較大變化,使模型結果很不穩定,求解高度的多重共線性問題會造成計算困難,傳統的回歸無法正常地解決這類多重共線性問題,LASSO 回歸算法則可以很好地解決這類問題,在盡量減少模型參數的同時還可以保持較高的識別準確率,很適合在影像組學中使用。本文采用 LASSO 回歸算法,通過交叉驗證可以很好地提取出對病理分級最有價值的特征,計算高、低分化二分類的影像組學標簽,結合臨床信息構造分類器,可實現對肝臟腫瘤病理分級的定量分析,結果表明影像組學特征可以很好地預測肝臟腫瘤患者的病理分級,該方法進一步挖掘了 MRI 圖像中對診斷有意義的數據,提升了基于 MRI 圖像的輔助診斷水平。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
肝臟腫瘤的早期診斷對制定治療方案有著重要意義,對于已進展為中晚期的腫瘤,盡可能在治療前明確腫瘤的分子生物學分型、分級等腫瘤異質性信息,可根據腫瘤的異質性選擇合理的治療方案,即精準治療。臨床實踐表明腫瘤的病理分級信息與患者的療效、預后密切相關,但依賴于穿刺活檢、手術病理取材的病理分級方法并不適合于所有腫瘤人群的治療前診斷。磁共振成像(magnetic resonance imaging,MRI)是一種常見的影像學診斷方法,但肉眼上對早期肝臟腫瘤的診斷仍存在局限性,對腫瘤異質性評估的價值并沒有被完全挖掘出來。2012 年荷蘭學者 Lambin 等[1]提出了放射組學的概念,同年 Kumar 等[2]將放射組學的定義擴展為影像組學。影像組學是以定量成像為基礎的新興技術,指的是高通量地從計算機斷層掃描成像(computed tomography,CT)、MRI 等醫學影像中提取影像特征,將傳統的影像轉換為可發掘的數據信息,通過定量分析來預測病理分級、分子生物學分型等。Doroshow 等[3]指出影像組學是轉化醫學未來發展方向之一。2014 年 Aerts 等[4]在《Nature》雜志上發布了一項根據定量的影像組學特征進行腫瘤分型的研究,結果顯示大量的影像特征與患者預后有顯著的聯系,影像組學特征能夠捕捉到腫瘤內部的異質性,并與基因表達的模式相關,并且某些特征在肺癌和頭頸部腫瘤都存在。最近兩三年基于影像組學的相關研究在對腫瘤的診斷、療效評估、預后判斷等方面已經顯示出巨大的臨床應用價值[5-7]。
影像組學的關鍵技術是提取高通量影像特征后的特征降維,可以利用各種機器學習算法來進行特征選擇和分類模型構建。對于“高維”數據(特征變量數目遠大于數據樣本數量)而言,常見的方法比如支持向量機(support vector machine,SVM)、隨機森林(random forest,RF)等,進行特征選擇時無法同時滿足模型的準確性、模型穩定性以及模型計算復雜度的要求[8],嶺回歸雖然可以解決變量之間的多重共線性問題,但是它得到的解是非稀疏的,不能有效地降低特征變量的維度。Tibshirani[9-10]提出了一種稱為最小絕對收縮和選擇運算符(least absolute shrinkage and selection operator,LASSO)的變量選擇方法,該方法在最小二乘估計的基礎上加入 L1 正則化項,使用模型系數的絕對值函數作為懲罰策略來壓縮模型系數,使一些與輸出結果效應非常弱的回歸系數變小,甚至變為零,因此 LASSO 可以提供一個稀疏解,很好地克服了傳統方法的不足。王金甲等[11]提出采用 LASSO 模型用于肝病的分類,其分類正確率優于傳統的模式識別方法;李靜等[12]提出基于廣義交互 LASSO 模型用于肝臟疾病分類;Liang 等[13]基于 LASSO 和影像組學對結直腸腫瘤的病理分級進行了預測;Guo 等[14]使用影像組學與基因組學聯合基于 LASSO 模型預測浸潤性乳腺癌的病理分級,取得了一些成果。
本文提出的肝臟腫瘤病理分級的定量分析方法主要是在非增強 T1 加權圖像(T1 weighted MRI,T1WI)和 T2 加權圖像(T2 weighted MRI,T2WI)上,采用手動方式將病灶部位分割出來,對分割出來的圖像提取高通量的影像特征,通過 LASSO 算法,經過交叉驗證從中篩選對病理分級最有關聯的影像特征,并融合臨床信息,構建分類器,對肝臟腫瘤的病理分級進行預測。圖 1 給出了該方法的流程圖。
圖1
病理分級圖像處理流程
Figure1.
Flow chart of image processing for pathological grading
1 特征提取
對分割出來的病灶部位圖像進行特征提取,特征主要分為四類:① 強度特征;② 形狀和大小特征;③ 紋理特征;④ 小波特征。具體的特征描述見表 1 所示。
一階統計特征用來描述腫瘤的強度特性,是描述 MRI 圖像中腫瘤體素強度分布的通用和基礎指標。形狀和大小特征描述了病變區域的三維尺寸大小和形狀,用于描述球形或者細長形狀的腫瘤的特點。紋理特征主要基于 GLCM、GLRLM 進行計算和分析得到,由圖像中體素強度值進行離散化得到相應的紋理統計矩陣,可以量化腫瘤內異質差異,由于在全部三維方向上計算這些特征,提供了圖像中不同灰度級相對的位置信息,這個離散步驟不僅可以減少圖像噪聲,而且使所有腫瘤體素強度標準化,允許直接比較所計算的三維空間特征。三維小波特征是小波分解原圖后計算每個分量的強度和點奇異性特征,關注圖像內不同頻域的特征。本文采用的是一種離散的、非抽取的三維小波變換,對于任何一幅 MRI 圖像,原始圖像 X 可以分解為 8 個分量,假設 L 表示低通濾波,H 表示高通濾波,8 個分量分別是 XLLL、XLLH、XLHL、XLHH、XHLL、XHLH、XHHL、XHHH。比如 XLLH 就是高通子帶,它是沿 X 方向進行低通濾波、沿 Y 方向進行低通濾波、沿 Z 方向進行高通濾波得到的,可以表示如下:
|
其中 NL 表示低通濾波器的長度,NH 表示高通濾波器的長度。
上述提到的高通量特征是在 Matlab R2014b(Mathworks,Natick,美國)下編碼完成的。
2 模型與方法
經過對病灶部位圖像進行特征提取,共提取了四大類共 328 維影像特征,但并非所有特征對于病理分級都是有用的,因此特征維度的降低十分必要。下面介紹特征選擇的方法 LASSO 模型,LASSO 模型是在多元分析時,通過對變量系數的壓縮,挑選出系數不為零的變量。
2.1 LASSO 的基本概念
假設已知數據 ,其中 xij 是預測變量,yi 是響應變量。同一般的回歸方程一樣,假設個體間是相互獨立的,或者在給定預測變量 xij 的條件下,yi 是相互獨立的。假設 xij 是標準化的,那么
|
,則LASSO估計 可定義為:
|
同時滿足 的約束條件。其中 t ≥ 0 為懲罰參數,參數 t 在估計時用來控制收縮量,設 為普通最小二乘估計值,記 ,當 0 < t < ,可以使一些回歸系數收縮并趨向于 0,并且一些回歸系數的估計值就等于 0,則 LASSO 估計就演變為下面的式子:
|
其中 > 0,參數 和參數 t 是對應的,也即是參數 對應的是模型的懲罰系數,當參數 越小時,模型的壓縮程度越低,提取的特征越多,當參數 越大時,對模型的壓縮程度越大,提取的特征越少。例如當 時,效果會大致類似于尋找大小為 的最優特征子集,也就是說變量集中一些變量的作用減小了,而且起作用的變量個數也僅大致為原來的二分之一。LASSO 模型的求解使用循環坐標下降法。
2.2 LASSO 參數 t 的估計
LASSO 估計中懲罰參數 t 的估計有兩種方法:交叉驗證法和廣義交叉驗證法。
假設 ,其中 ,。 估計的均方誤差MSE定義如下:
|
MSE 的求解比較困難,預測誤差 PSE 比較容易計算,并且和 MSE 是相關的。
|
最小化 PSE 相當于最小化 MSE。
懲罰參數 t 也叫做 LASSO 參數,它相當于是 LASSO 的收縮邊界,,這里定義與參數 t 相關的另一個參數 s 作為歸一化的 LASSO 參數,
|
2.2.1 交叉驗證
交叉驗證的基本思想是把樣本集分為兩大類——訓練集和驗證集用來估計模型參數,其中訓練集和驗證集的角色不斷地變換。 表示最優的參數 s,比如一個 10 折交叉驗證,樣本集共分為 10 份,一份作為驗證集,其余為訓練集,然后不停地變換驗證集,依次訓練模型,在歸一化參數 s 的條件下檢索 LASSO,并且預測誤差是由 s 從 0 到 1 不斷變化估計出來的,選擇產生最低預測誤差估計值 PSE 所對應的 作為最優解。
一個 N 折交叉驗證的算法流程如下:
步驟 1:將全部數據樣本 N 分為子樣本集 ;
步驟 2:,選擇訓練集 訓練模型,并用驗證集 Sv 計算 ;
步驟 3:在所有的 中選擇最小的 d(s)作為參數 s 的最優估計。
2.2.2 廣義交叉驗證
的約束下,參數 s 的提出實際等價于在殘差和或者殘差平方上增加一個拉格朗日懲罰 ,其中 取決于 t,因此在式(4)的基礎上矩陣的表達形式為:
|
在約束條件中適合 的有效參數量 d(λ)可以用下面的式子進行近似:
|
可以構建廣義交叉驗證模型的統計方式:
|
LASSO 回歸算法是由 R 語言編碼完成,并在 R Version3.4.2(R Foundation for Statistical Computing)中實現的。
2.3 病理分級分類模型構建
對手動分割出來的病灶部位圖像進行高維特征提取,利用 LASSO 算法對肝臟腫瘤病理分級進行多元回歸分析,挑選出對病理分級最有價值的影像特征。根據挑選出來的特征及其系數計算對病理分級進行預測的影像組學標簽 Rad-score,根據影像組學標簽進行分類測試。為了提高分類結果的準確率,將臨床信息和影像組學標簽進行融合,對病理分級進行分類預測。
臨床模型指的是僅僅利用臨床信息進行 Logistic 回歸分析;影像組學模型是指提取高通量影像特征后,基于 LASSO 算法篩選特征后進行分類預測;融合模型指的是將影像組學模型得到的影像組學標簽 Rad-score 和臨床信息融合后進行 Logistic 回歸分析。
2.4 統計學方法介紹
患者樣本數據在訓練集和測試集上的分布對比情況,性別和高低分化情況對比使用卡方檢驗 Chi-squared test,年齡對比使用 Mann-Whitney U 檢驗。
通過三種模型得到的高分化和低分化患者的預測分數差異比較使用 Mann-Whitney U 檢驗,并且給出了四分位距(interquartile range,IQR)和中位值。
用接收者操作特征(receiver operating characteristic,ROC)曲線下面積(area under the curve,AUC)來衡量預測模型的性能,基于訓練集設置最佳的分類閾值來計算 AUC,包括敏感性(sensitivity,SENS)、特異性(specificity,SPEC)、準確率(accuracy,ACC),然后將此閾值應用到測試集上,計算各個指標。AUC 大小的比較使用 Delong 測試,AUC 越大意味著分類的準確率越高,并給出了 AUC 的 95% 置信區間(confidence interval,CI)。
臨床模型包含患者的年齡、性別、病灶大小、脈管癌栓、乙肝、血甲胎蛋白、假包膜、門脈癌栓、肝硬化、門脈高壓等,利用 Logistic 回歸進行多元因素分析,從中挑選與病理分級關聯性最強的因素。臨床模型加入影像組學標簽 Rad-score 后,利用 Logistic 回歸再一次進行多元因素分析,并給出了比值比 Odds Ratios。
統計分析使用 MedCalc16.2.0 軟件完成(MedCalc software,http://www.medcalc.org),P < 0.05 表示差異有統計學意義。
3 實驗結果與分析
3.1 實驗數據
收集了 2012 年 1 月到 2016 年 12 月在河南省人民醫院治療過的肝臟腫瘤患者信息共 170 例,包含患者的 MRI 圖像和臨床信息,患者都已知曉本研究情況,合作醫院也批準了本課題的研究,所有的數據都經過了數字化處理并對個人隱私進行了隱藏。患者樣本入選實驗的標準是:① 病理學診斷為肝細胞癌并具有明確的病理分級(Edmondson 分級);② 在手術前一周行 MRI 檢查,圖像質量滿足實驗要求;③ 患者在手術之前沒有經過治療。高分化患者包括 Edmondson 等級為Ⅰ、Ⅰ-Ⅱ和Ⅱ的患者,低分化患者包括 Edmondson 等級為Ⅱ-Ⅲ、Ⅲ、Ⅲ-Ⅳ和Ⅳ的患者,進行高分化和低分化的二分類判別實驗。采集圖像使用的機器是通用醫療設備的 GE750 3.0T,原始圖像格式為 DICOM 格式,圖像分辨率為 512 * 512,掃描層厚為 7 mm,滿足實驗要求。由兩位超過 10 年讀片經驗的放射科醫師使用專業軟件 ITK-SNAP3.0(http://www.itk-snap.org)對腫瘤病灶部位進行手動分割。患者臨床信息主要包括患者的年齡、性別、病灶大小、脈管癌栓(有和無)、乙肝(有和無)、血甲胎蛋白(正常和升高)、假包膜(有、不完整、無)、門脈癌栓(有和無)、肝硬化(有、輕度、無)、門脈高壓(有和無)等,臨床信息取自于患者的病歷管理系統。
通過程序將 170 例患者隨機劃分為訓練集(125 例)和測試集(45 例),患者的情況描述如表 2 所示,訓練集和測試集分布基本一致(P值均 > 0.05)。圖 2 顯示了不同病理分級的肝臟腫瘤患者 T1WI 圖像和 T2WI 圖像,紅色曲線標注區域為腫瘤區域。
圖2
肝臟腫瘤患者的 MRI 圖像
Figure2.
MRI images of patients with hepatocellular carcinoma
3.2 實驗結果
LASSO 模型訓練時采用 10 折交叉驗證,選擇 AUC 作為優化的目標,此時選出的模型作為病理分級的最優影像組學模型,利用模型篩選出來的特征及其系數計算基于影像組學的預測分數 Rad-score,進行肝臟腫瘤的病理分級。
實驗中使用了肝臟腫瘤患者的 T1WI 和 T2WI 圖像,利用 LASSO 算法進行特征提取,構建分類模型,分別進行了 T1WI 特征篩選、T2WI 特征篩選以及 T1WI 和 T2WI 圖像特征聯合篩選三種實驗,特征提取的結果如圖 3 所示。橫坐標表示參數 λ 的變化情況,縱坐標 AUC 表示模型的輸出情況,曲線上方的數字表示模型提取特征的數量,從圖中可看出,當參數 λ 逐漸變大時,模型的 AUC 在變化,特征數量在減少,即模型的壓縮程度在增加。圖中左側虛線表示 AUC 最大時對應的取值和提取特征的數量,右側虛線表示在 AUC 一倍標準誤差時的特征提取情況,此時特征數量減少。選擇左側虛線對應的參數可以得到正確率最高的模型,選擇右側虛線對應的參數在保證一定準確率的同時可以精簡模型,減少提取特征的數量,提高模型的計算效率。從圖 3 可見,通過參數 λ,分別從 T1WI 的 328 維特征、T2WI 的 328 維特征以及 T1WI 和 T2WI 聯合的 656 維特征中提取了 23、18、27 個特征。
圖3
基于 LASSO 算法提取特征的結果
Figure3.
Feature selection using the LASSO logistic model
利用挑選出來的特征計算基于影像組學的預測標簽 Rad-score,在臨床模型、影像組學模型以及融合模型上進行了病理分級實驗,結果如表 3 所示。在分類閾值為 ? 0.868 8 時,融合模型取得了最高的分類結果,AUC 在訓練集上為 0.909(敏感性 95.71%,特異性 70.91%,準確率 84.40%),在測試集上為 0.800(敏感性 85.00%,特異性 65.00%,準確率 76.11%)。圖 4 分別給出了在 T1WI 圖像、T2WI 圖像、T1WI 和 T2WI 圖像特征聯合上基于 LASSO 回歸的影像組學模型病理分級結果以及融合臨床信息的病理分級結果,可以看到,融合模型均比沒有融合臨床信息的影像組學模型準確率有一定的提升。
圖4
三種實驗的病理分級結果 ROC 曲線
Figure4.
The ROC curves of pathological grading results on the three experiments
表 4 給出了融合模型得出的預測分數在訓練集和測試集上、不同年齡和性別的分布對比情況。表中給出了中位值和四分位距(P值均小于 0.05)。可以看到在訓練集和測試集、男性和女性、年齡在 57 歲以上及 57 歲以下等范圍內,低分化患者的預測分數高于高分化患者的預測分數,且高分化患者與低分化患者的分數差異較為明顯,說明了本文提出的定量分析方法的有效性。
表 5 給出了臨床模型和融合模型進行病理分級時,多因素 Logistic 回歸各個變量的系數、比值比 Odds Ratios 及 95% 置信區間,P 值小于 0.05 的變量被挑選出來組成回歸方程。
3.3 實驗分析與討論
本研究提出了一種利用影像組學的肝臟腫瘤病理分級定量分析方法,在建立的模型中,設定定量的分類閾值后,通過肝臟腫瘤 MRI 圖像可以預測病理分級情況。本文主要利用 LASSO 算法進行影像學特征的篩選,組成預測方程計算病理分級的影像學標簽 Rad-score。實驗結果證明這種方法可以很好地進行肝臟腫瘤的高、低分化二分類。
從表 3 可以看出,臨床模型預測肝臟腫瘤病理分級的能力較差,說明臨床信息對病理分級的貢獻有限;表 5 中從臨床模型的各個因素變量來看,挑選出了甲胎蛋白(P = 0.001)水平和不完整包膜情況(P = 0.013),前期也有相關文獻[15]討論了甲胎蛋白和肝臟腫瘤分期的關系。
在一些相關的研究中,使用圖像紋理特征進行疾病預測的研究較多,如在結直腸癌 CT 圖像上進行生存期預測[16],以及在肺癌 CT 圖像中進行分期預測[17],都是單獨使用紋理特征,并取得了不錯的效果。本文提出的基于影像組學的病理分級方法,提取的特征不僅僅限于紋理特征,還有形狀、灰度、小波等特征,特征的使用更全面更豐富,采用多種特征的聯合分析,分類效果更好。從表 3 可以看出,基于影像組學的模型分類性能有了較大提升,說明影像組學對肝臟腫瘤病理分級的作用較為明顯,MRI 圖像內部蘊含的一些肉眼無法觀察到的特征與肝臟腫瘤的病理分級有關聯。Liang 等[13]提出基于影像組學模型的結直腸癌 CT 圖像上的病理分級,在訓練集上 AUC = 0.792,測試集上 AUC = 0.708,也說明了影像組學方法的有效性。陳舒婷[18]進行了基于影像組學模型的肝癌 CT 圖像上 Edmondson 等級的預測,文章在進行高通量特征篩選時,只使用了簡單的 U 檢測方法,最終的分類結果 AUC 在訓練集上為 0.765 6(n = 285),測試集上為 0.673 3(n = 127)。
傳統的分析中臨床信息和影像學特征是分開討論的,將基于影像組學模型得到的影像學標簽加入到臨床信息中,進行病理分級的分析,可以形成很好的互補。從圖 4 可以看出,在 T1WI、T2WI、T1WI 融合 T2WI 三組實驗上,影像組學標簽加入臨床信息后,分類性能都有了提升。從表 3 可以看出,融合模型在 T1WI 融合 T2WI 實驗上分類性能達到了最高。從表 5 可以看出,融合模型中挑選出來的因素是影像組學標簽(P < 0.000 1)、AFP(P = 0.016)和門脈高壓(P = 0.038),說明將臨床信息中甲胎蛋白等指標的檢測與影像組學的結果融合在一起,可以提升基于影像組學的病理分級結果的準確性。
本文的研究方法是基于非增強 MRI 圖像進行的,該方法也可以在其他模態的圖像上進行分析,比如 CT 等。本文進行的是病理分級的研究,其他諸如病理分期、復發預測、生存期預測、療效評估等都可以采用類似的方法。
4 結束語
隨著基因數據、圖像數據等醫療大數據的出現,利用大數據進行腫瘤疾病診斷的價值還沒有完全挖掘出來,影像組學為解決精準醫學需求提供了新的思路。影像組學用到的關鍵技術是高通量特征提取后的降維方法,由于數據樣本維度較高,當多個自變量有些相關時,模型計算可能出現多重共線性問題,當多重共線性嚴重時,模型的微小變化會造成系數估計的較大變化,使模型結果很不穩定,求解高度的多重共線性問題會造成計算困難,傳統的回歸無法正常地解決這類多重共線性問題,LASSO 回歸算法則可以很好地解決這類問題,在盡量減少模型參數的同時還可以保持較高的識別準確率,很適合在影像組學中使用。本文采用 LASSO 回歸算法,通過交叉驗證可以很好地提取出對病理分級最有價值的特征,計算高、低分化二分類的影像組學標簽,結合臨床信息構造分類器,可實現對肝臟腫瘤病理分級的定量分析,結果表明影像組學特征可以很好地預測肝臟腫瘤患者的病理分級,該方法進一步挖掘了 MRI 圖像中對診斷有意義的數據,提升了基于 MRI 圖像的輔助診斷水平。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。