醫療大數據的分析利用離不開高質量的臨床數據庫,我國在急救數據庫建設方面尚處于起步和探索階段。本文介紹了多參數急救數據庫的構建思路和關鍵技術,參考麻省理工學院(MIT)計算生理學實驗室創建的重癥監護醫學信息數據庫(MIMIC-III)的架構設計,并結合急診業務流和信息流,設計了急診數據整合模型,完成了高質量急救數據庫的建設。該數據庫目前涵蓋了 2015 年 5 月至 2017 年 10 月共 19 814 名不同患者的 22 941 次搶救醫療數據,包含相對完整的生理、生化、治療、檢查、護理等信息,并基于該數據庫開展了首屆急救大數據 Datathon 活動,全國有 13 個隊伍參賽。急救數據庫的建設為國內臨床數據庫的構建和應用提供了參考,為科學研究、臨床決策和改善醫療服務質量提供了有力的數據支撐,將進一步推動我國臨床數據的二次分析利用工作。
引用本文: 王俊梅, 劉同波, 孫瑜堯, 李沛堯, 趙宇卓, 張政波, 薛萬國, 黎檀實, 曹德森. 多參數急救數據庫建設及初步應用研究. 生物醫學工程學雜志, 2019, 36(5): 818-826, 833. doi: 10.7507/1001-5515.201809032 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
目前醫療行業已經迅速實現了計算機化及數字化,大部分醫療機構都直接或間接地使用信息技術提供醫療服務。現代醫療信息系統能夠產生并存儲海量的數據,這些數據涉及詳細的患者信息和臨床診療過程,但是來自真實世界的患者數據卻很少能被用于醫學研究,推動醫療領域的創新和發展,其主要障礙在于研究人員很難獲取和使用這些數據。若是能夠整合并開放醫療機構內部以及不同醫療機構間的患者數據,就會吸引更多的、具有不同背景的研究人員,通過多學科協作共同解決目前臨床醫學中所面臨的各類基礎問題。
傳統的醫學研究收集數據的方法大多是依靠臨床試驗注冊數據庫或慢病管理系統,建立專病數據集。專病數據庫中記錄的數據往往局限于某一特定的研究任務,通常只針對某一特定的疾病,其數據或結論不能用于其他疾病,并且其數據經常是來自某一地區的特定人群,往往導致基于這些數據庫的研究結論普適性較差。
第一個電子健康檔案(Electronic Health Records,EHR)于 20 世紀 60 年代問世。EHR 的建立最初是為了歸檔整理患者的醫療記錄,后來又增加了計費和質量改進的功能。之后 EHR 數據庫不斷發展,越來越全面,能夠動態更新,并且信息相互關聯。EHR 為建設更完整的醫療數據庫提供了數據基礎,進而為醫療大數據分析提供了機遇。它可以收集多維度的醫療數據,這使得臨床醫生、信息學家、數據工程師可以使用大型醫療信息數據庫研究解答各種問題。在信息技術不斷發展的今天,我們使用大數據挖掘理論和技術來分析和理解數據的能力都取得了巨大的進步,醫療數據挖掘分析在疾病風險評估、臨床決策支持、疾病發展預測、合理用藥指導、醫療管理和循證醫學等領域發揮了重要作用[1]。未來的臨床研究將依賴于大數據技術來改善患者的診療,以期為患者提供更好的服務。
目前國外已有不少成熟的大型醫療數據庫,可供全球研究人員開放使用。如:重癥監護醫學信息數據庫(Medical Information Mart for Intensive Care,MIMIC),包含了超過 6 萬的重癥加強護理病房(Intensive Care Unit,ICU)診療數據[2];還有飛利浦的 eICU 數據庫,囊括了 2014 年到 2015 年間美國本土各地區十多萬患者的 ICU 臨床數據。這兩個數據庫都可以通過
在急診救治過程中,會產生大量的動態醫療數據,其信息量豐富,價值密度大,建立大樣本多參數急救數據庫,可以為急救醫學研究提供來自“真實世界”的數據,提高救治的時效性和準確性,進而發展基于數據驅動的輔助決策支持系統。目前已有很多基于急診數據展開的研究,如美國俄勒岡州建立了全州范圍內的急診醫療服務數據庫,增強了基于結局的急診醫療服務研究,為提高醫療服務質量提供了有力的數據支持[4];Heldeweg 等[5]使用研究型數據庫(REDCap)中的急救數據,基于心電圖(electrocardiogram,ECG)和心率變異性(heart rate variability,HRV)參數為急診胸痛患者建立了性能優于心肌梗死溶栓治療(The Thrombolysis in Myocardial Infarction,TIMI)危險評分的心血管危險分層模型,為臨床決策提供了參考;Horng 等[6]基于急診數據,使用機器學習方法建立了可以識別膿毒血癥感染患者的模型,為臨床醫生提供了良好的決策支持。
目前我國的臨床數據庫建設和應用尚處于起步階段,目前存在的很多數據庫是因課題需要而建設的小型數據集或者專科數據庫[7-11],這些數據庫的數據來源較單一,共享性差,且質量良莠不齊[12];國家人口健康科學數據共享平臺提供了 200 多個科學數據集(
1 數據庫架構分析與數據整合
1.1 MIMIC-III 數據庫架構分析
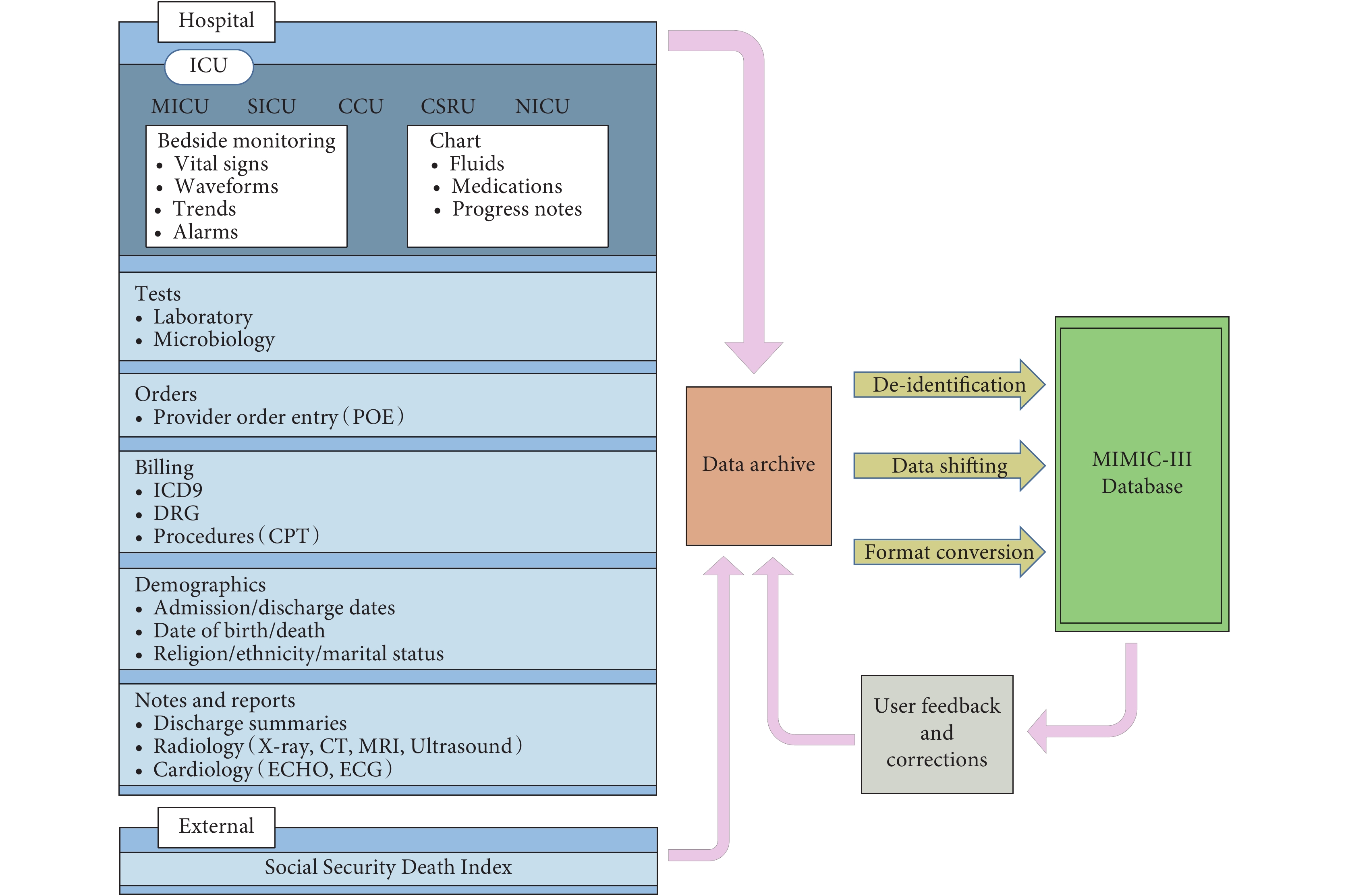
自 2003 年以來,麻省理工學院(Massachusetts Institute of Technology,MIT)計算生理學實驗室、貝斯以色列女執事醫學中心和飛利浦醫療共同合作,在美國國立衛生研究所資助下,一起開發和維護了 MIMIC 數據庫。該數據庫收集了醫院信息系統和 ICU 信息系統中存儲的臨床數據、床旁監護儀中的高精度波形數據以及來自社會保障總署的死亡信息。MIT 計算生理學實驗室團隊在 2015 年發布了重癥監護醫療數據倉庫 MIMIC-III[13],包含了 2001 年到 2012 年共 38 597 名去隱私化的成人入院患者數據,共計 53 423 人次的 ICU 記錄(每名患者會有多次入院以及多次進出 ICU 的記錄),數據主要來源于內科重癥監護室(Medical Intensive Care Unit,MICU)、外科重癥監護室(Surgical Intensive Care Unit,SICU)、心內科監護室(Cardiac/Coronary Care Unit,CCU)和心臟外科監護室(Cardiac Surgery Intensive Care Unit,CSRU)這四個監護室。目前,最新版 MIMIC-III v1.4 共包含 26 張數據表,主要分為四類:① 定義和追蹤患者,如患者入院信息(admissions)、患者入 ICU 信息(icustays);② ICU 內產生的患者數據,如 ICU 所有記錄觀察結果(chartevents)、患者入量(inputevents_cv)等;③ 醫院信息系統數據,如實驗室檢查結果(labevents)、診斷(diagnoses_icd)等;④ 字典表,如生化檢查字典表(d_labitems)、診斷字典表(d_icd_diagnoses)等。這些數據涵蓋了患者進入 ICU、ICU 轉換和出院的所有病程記錄數據,且數據經過日期 shift、格式轉換等去隱私化處理,最終形成該數據庫,其數據類型和整合流程如圖 1 所示[13]。
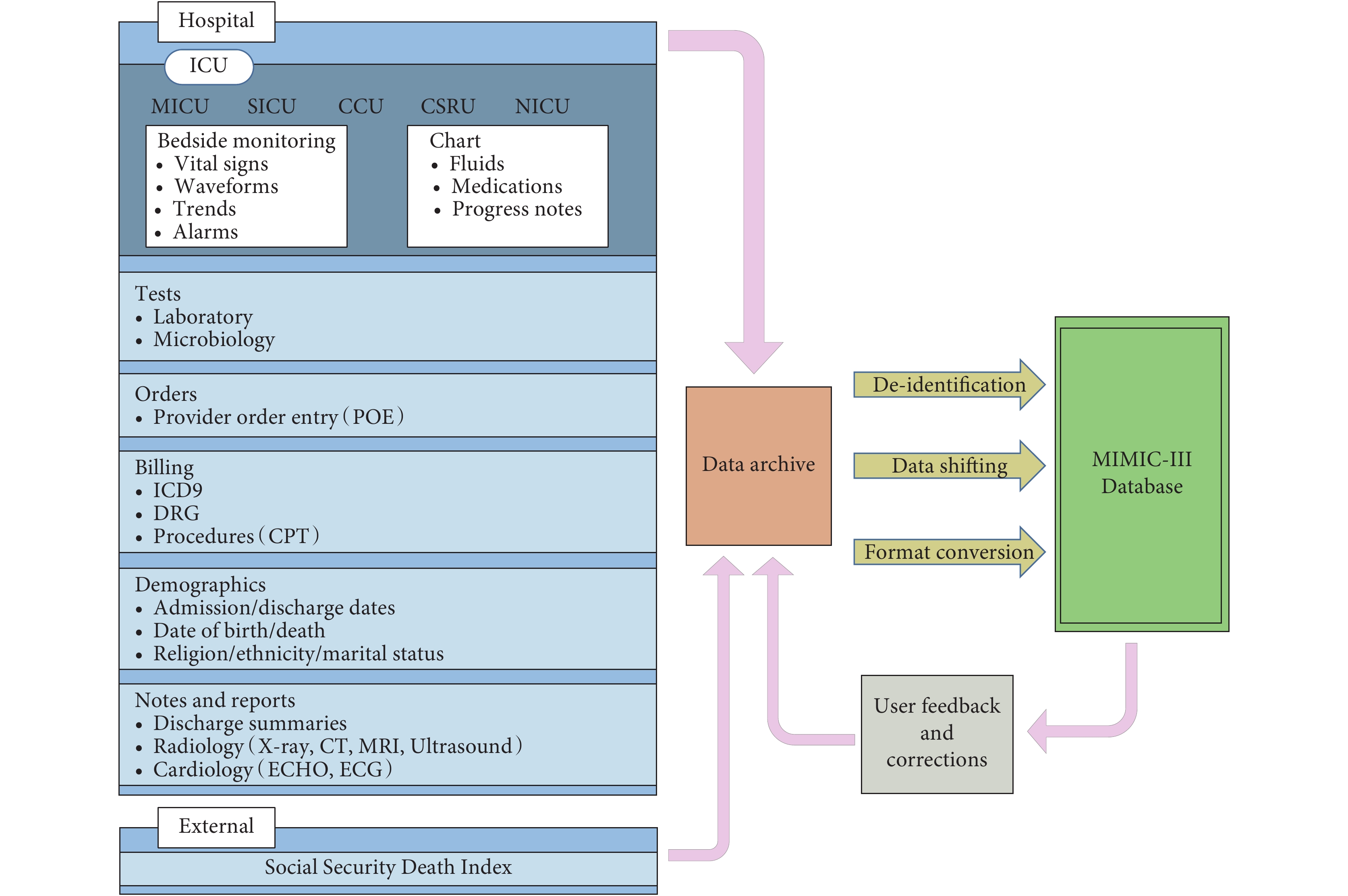 圖1
MIMIC-III 重癥數據庫概覽
Figure1.
Overview of MIMIC-III Critical Database
圖1
MIMIC-III 重癥數據庫概覽
Figure1.
Overview of MIMIC-III Critical Database
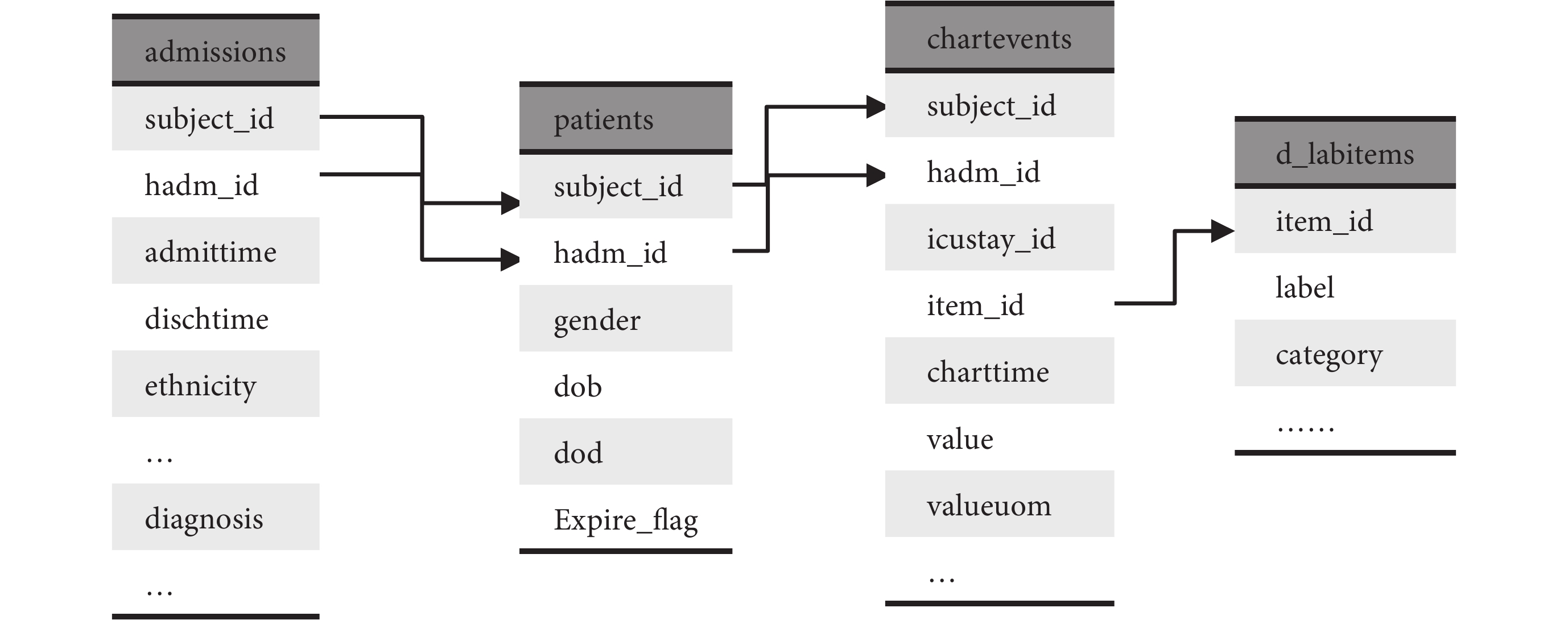
本文的急救數據庫架構設計參考了 MIMIC-III v1.4 版本,如圖 2 所示,不同類型信息存儲在不同的數據表,如 admissions 表存儲了患者入院基本信息,包括入出院時間、入院診斷和入院時基本狀態等;patients 表存儲了患者基本統計學信息,包括性別、出生日期等;chartevents 表存儲了患者生理生化等結果;d_labitems 以字典的形式存儲生理生化等指標名稱與 itemid 的映射關系。其中 subject_id 字段表示患者 id,即對應唯一的患者,hadm_id 表示患者不同的入院記錄 id,患者入院信息、基本統計學信息和其他臨床診療信息通過這些 id 進行關聯。另外,要獲得患者的生理生化值需要先從 d_labitems 這樣的字典表通過映射找到對應名稱的 itemid,并進一步查詢獲得結果。
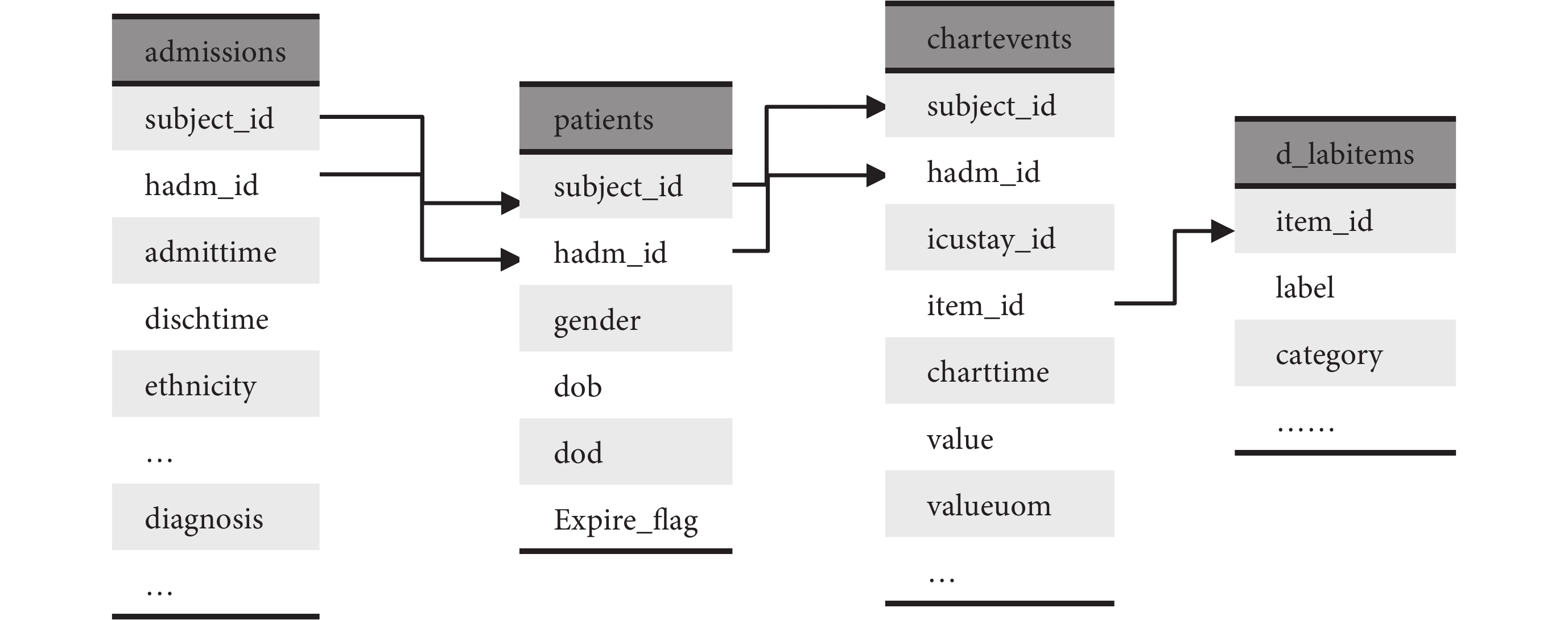 圖2
MIMIC-III 數據庫表結構
Figure2.
Table structure of MIMIC-III Database
圖2
MIMIC-III 數據庫表結構
Figure2.
Table structure of MIMIC-III Database
MIMIC 數據庫經過多個版本的更迭,在應用方面相當成熟,目前已有大量學者、研究員使用該數據庫進行研究。同時,與數據庫相關的問題會在 Github(
1.2 急診業務流程
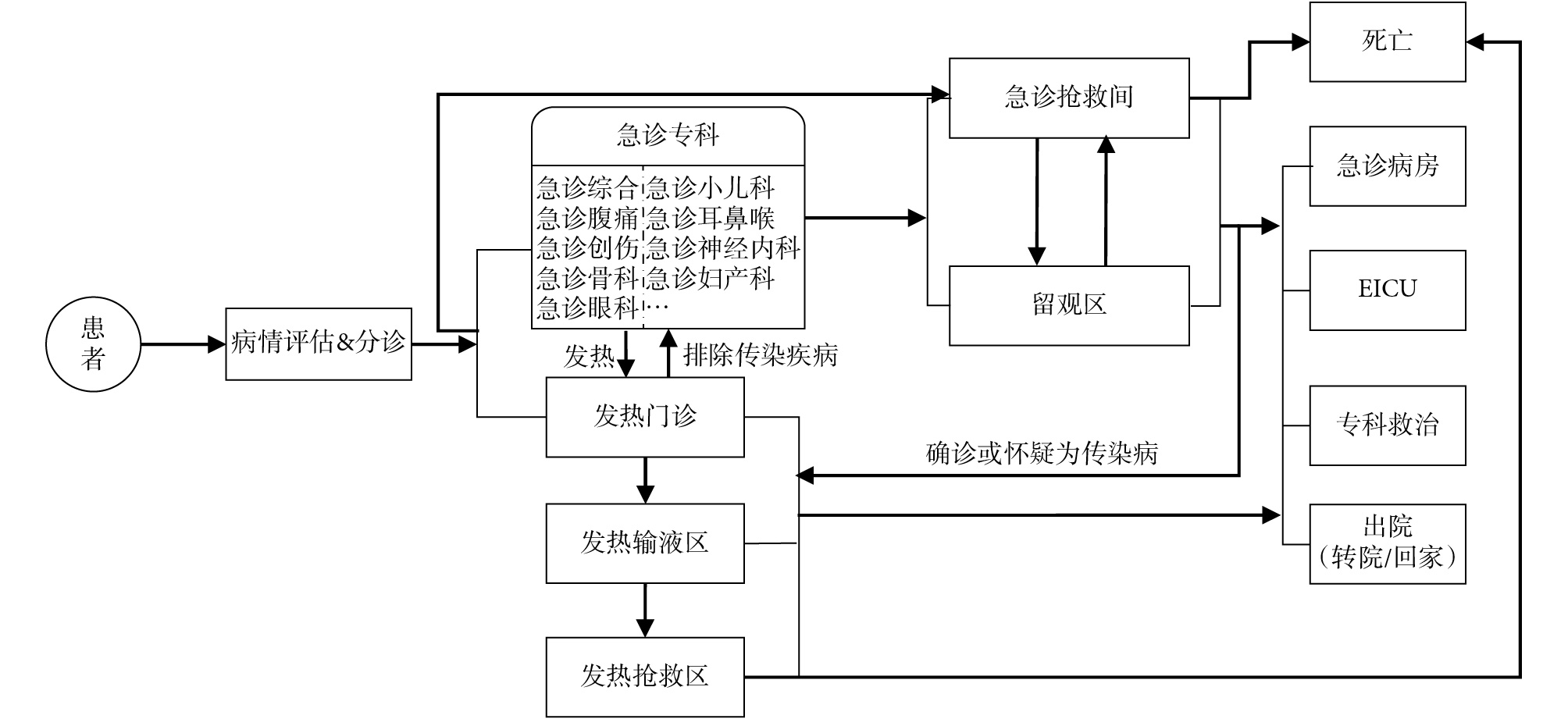
為了建立合理的數據庫架構,了解信息源,課題組對急診業務流程進行了深入調研,總結出急危重癥患者從入院到出院的急診業務流程,如圖 3 所示。患者在急診分診臺接受病情評估并被分診到急診相關科室,如急診腹痛、急診骨科、急診婦產科等,如果患者有發熱情況則會被分診到發熱門診進行救治,若患者已排除患有傳染病,可轉入相應急診科室就診。病情比較危急的患者會進入急診搶救室接受及時的救治,相應的,需要留院觀察的患者會進入留觀區,隨著病情發展,患者可能進入專科、急診病房、急診重癥監護室(Emergency Intensive Care Unit,EICU)以及轉入其他醫院繼續接受治療,或者宣布死亡。
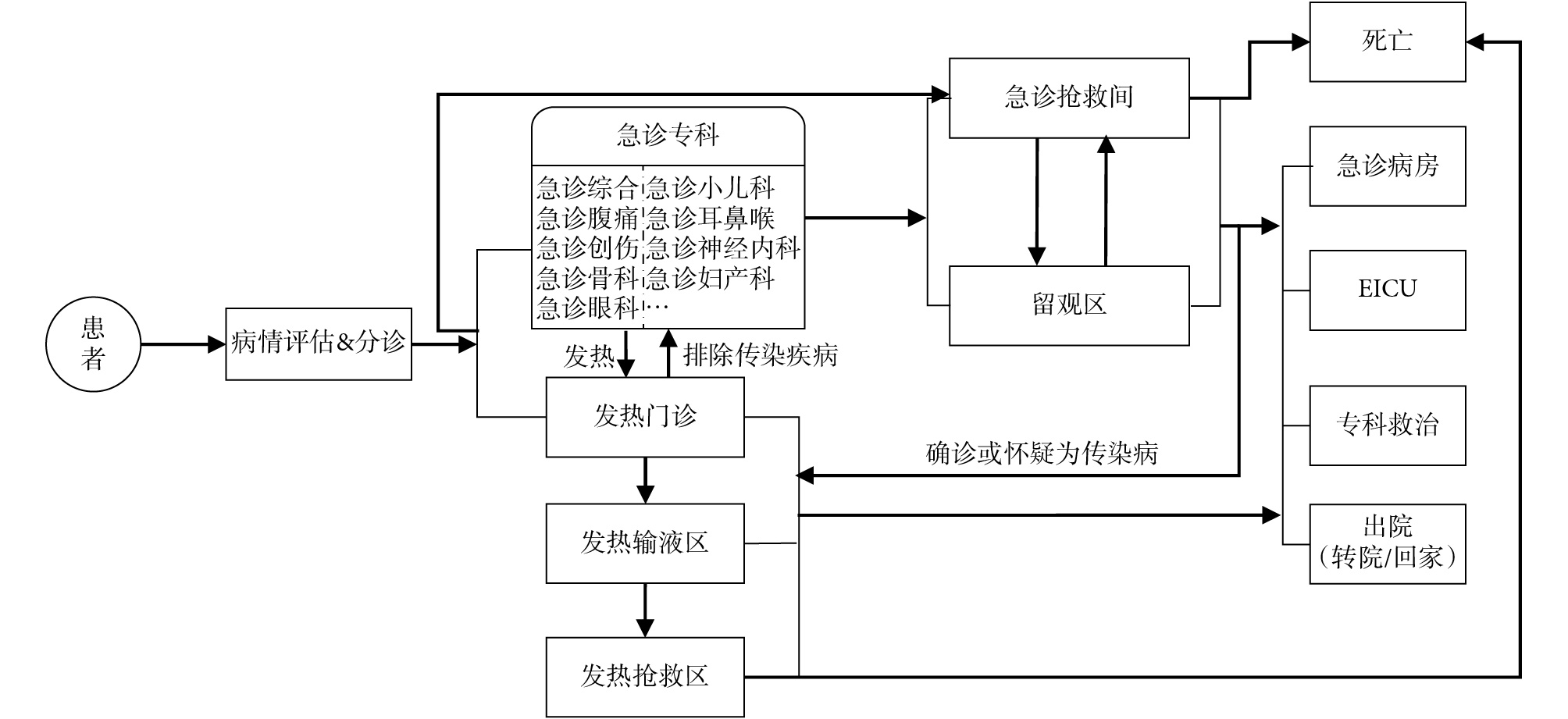 圖3
急診患者就診流程圖
Figure3.
Treatment flow of emergency patients
圖3
急診患者就診流程圖
Figure3.
Treatment flow of emergency patients
要建設一個高質量的臨床數據庫,對急診就診業務流和信息流進行深入分析十分重要。急診業務流和信息流涵蓋了患者在就診過程中產生的臨床信息、信息類別以及信息之間的關聯,有助于合理地設計數據庫架構。患者在接受分診時系統會記錄其基本信息如就診號、性別等,病情評估后患者被分診到相應的科室或進入搶救室就診,急診搶救系統會記錄患者在接受搶救的過程中的一系列數據,如床旁監護數據、生化檢查、醫囑、護理和報告等數值和文本信息。
1.3 急救數據庫數據整合
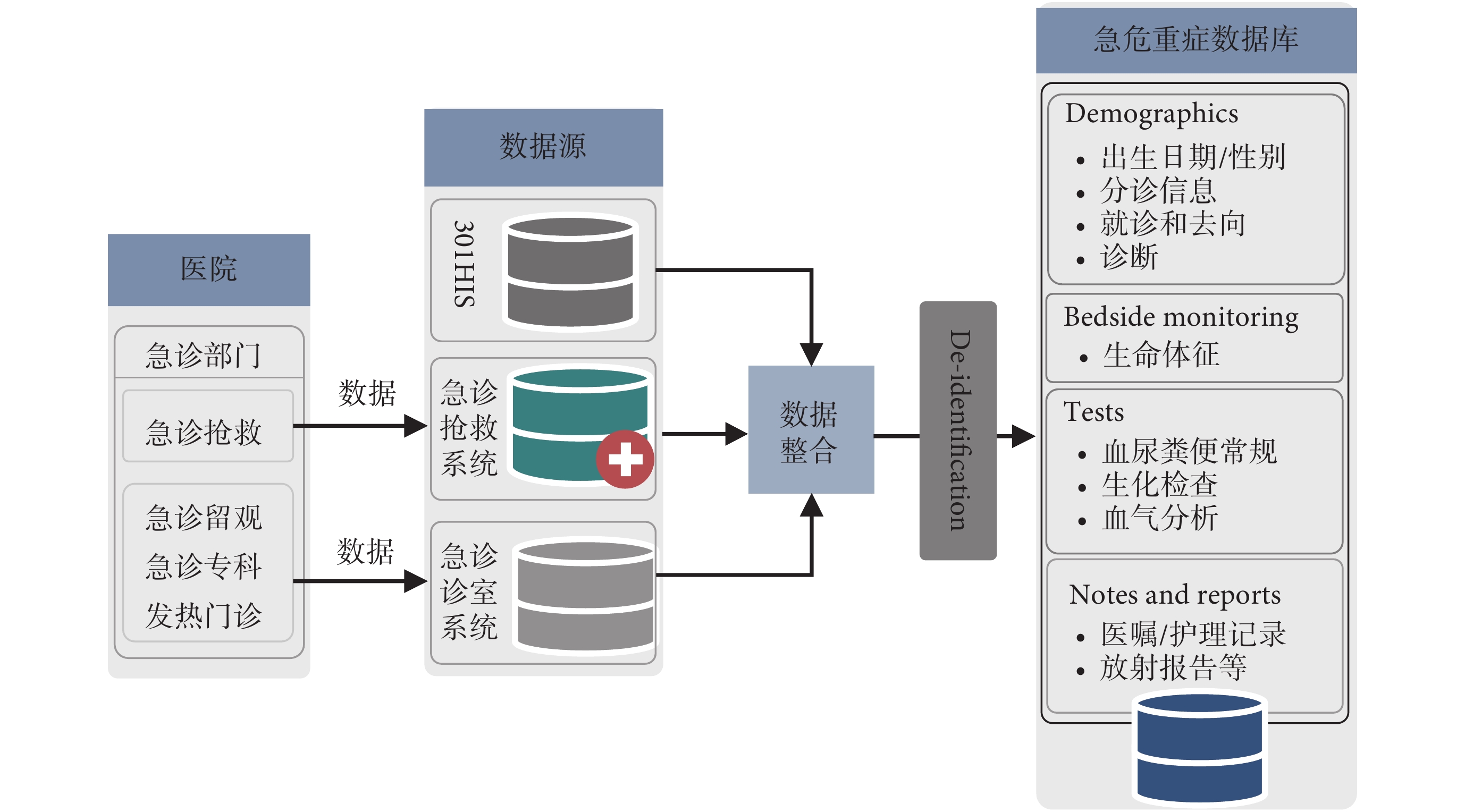
急救數據庫數據主要來源于解放軍總醫院的醫院信息系統(Hospital Information System,HIS)、急診搶救系統和急診專科診室系統。急診搶救系統和急診專科診室系統數據分別屬于不同的醫療系統,從急診專科診室信息系統獲得患者基本信息、分診信息、就診區域以及床旁監護數據;從急診搶救系統獲取患者就診過程中的醫囑、用藥和護理記錄等信息。最后從醫院 HIS 系統獲得患者的生化檢查數據,根據急診患者的就診流程,將患者從登記掛號到院內急救和轉出這一過程中產生的一系列數據進行有效關聯,數據整合流程如圖 4 所示。患者可能有多次就診記錄,在該數據庫中,患者的身份 ID 保持唯一,不同的就診記錄會分配有不同的就診 ID 從而區別患者的多次就診過程中產生的醫療信息。
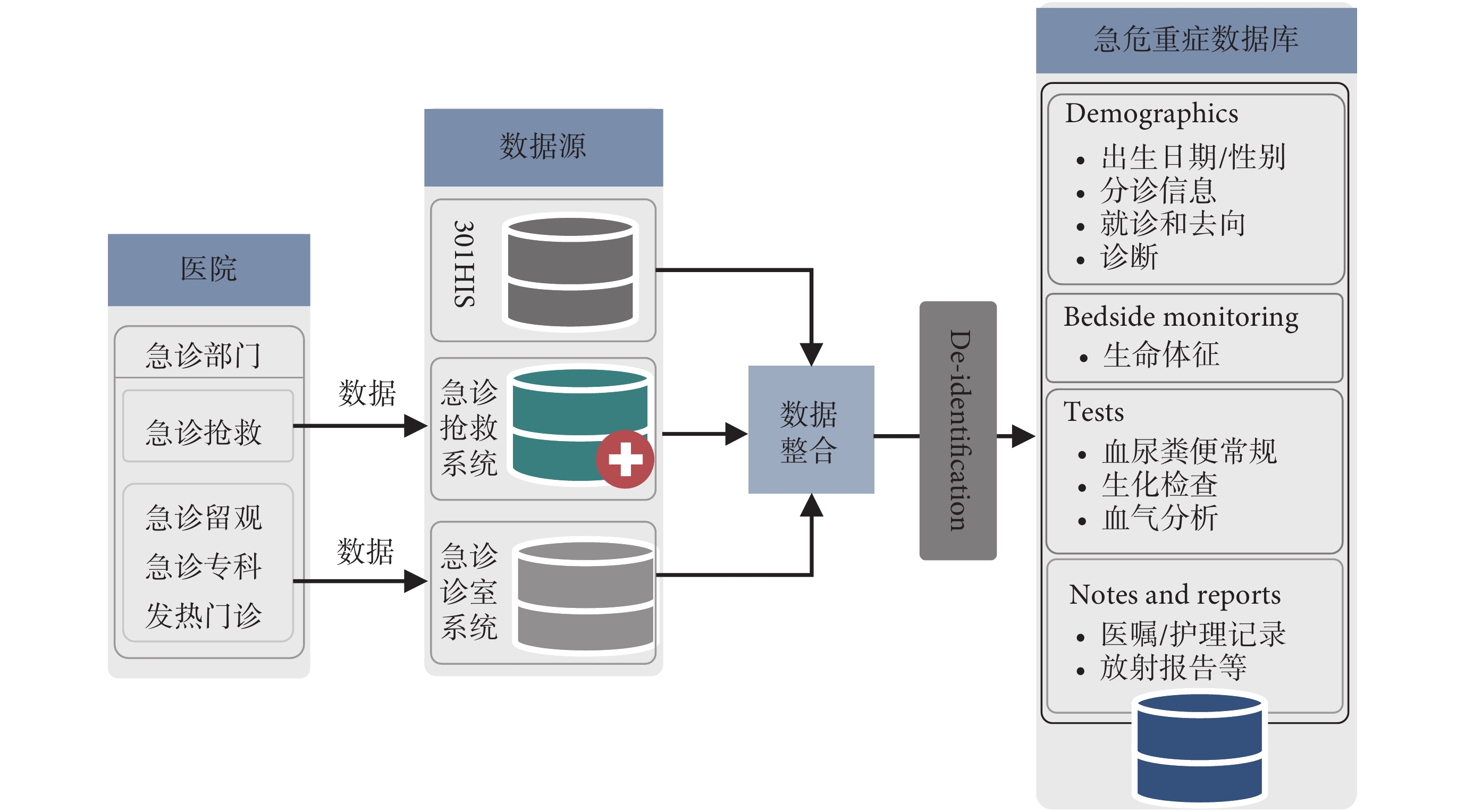 圖4
急救數據整合流程示意圖
Figure4.
Schematic diagram of the emergency data integration process
圖4
急救數據整合流程示意圖
Figure4.
Schematic diagram of the emergency data integration process
1.4 數據預處理
在將患者基本信息及診療相關信息錄入數據庫前,需要對數據進行一定的處理,主要包括以下過程。
1.4.1 數據去隱私化
患者姓名、身份證號、家庭住址和家人信息等屬于患者個人敏感信息,若這些信息發生丟失或泄露,不僅會給患者帶來麻煩并造成經濟損失,同時會給醫院的聲譽帶來負面影響。因此將與患者真實信息相關的患者姓名和就診的相關 ID(如 patientid、visitid 等)進行去隱私化處理。患者相關的就診 ID,一般由一位字母和一系列數字組成,去識別化后的 ID 同樣由字母和數字組成,因此首先獲得所有患者原始 ID,對原始 ID 中首字母用其他字母如‘S’替代,然后以隨機數的形式抽取數字部分并與某些數字做加減處理,產生的新數字與字母 S 組合產生新 ID,原始 ID 和新 ID 之間同時形成映射關系,因此可直接通過 ID 關聯將新 ID 與患者就診記錄進行一致關聯;患者姓名也借助算法產生新的名字,身份證和家庭住址等信息則去掉,不存儲在該數據庫中。對數據進行變換后,可避免直接或間接指向特定患者的信息出現在數據庫中,同時保持原始數據相關特征和業務處理流程不變,即保持患者診療過程中所產生的其他一系列就診相關信息不變。
1.4.2 數據清洗
解放軍總醫院急診信息系統于 2014 年 11 月在急診部門試運行,于 2015 年 5 月正式使用,而系統在試運行期間錄入了一些測試數據,這些數據在正式運行之前并未清除,導致數據庫中存在有歧義的數據:
(1)信息不一致。存在一部分數據,同一個患者 ID(patientid)對應的患者基本信息不一致,例如 patientID=1234321,在患者多次就診記錄中,存在出生日期不同或/和性別不一致的情況,即同一患者 ID 兩次或多次就診時記錄的性別(男/女)或者出生日期不同,這樣的信息會影響后續研究中的數據分析,統計發現這樣的數據約占總就診量的 0.34%,因此在數據中找出所有的患者 ID 相同但性別或出生日期不一致的數據,然后刪除以確保數據的一致性。
(2)數據重復。由于護士操作或者系統卡頓原因,數據庫中存在對同一患者同一次就診的重復分診信息,即在患者某一次就診時,除了分診時間間隔相當短,其他信息完全相同。在數據庫建設過程中,找出此類原因導致的多次重復分診患者,并去除患者的重復分診記錄。
(3)無效數據。如患者的化驗結果數據中存儲了不可解讀的錯誤信息,例如化驗結果“白細胞數”記錄為“------”,在建庫過程中通過正則表達式或者字符串匹配等方法,找出所有存儲結果無效的類似錯誤信息并予以去除。
2 數據庫概述
急救數據庫在國家自然科學基金面上項目(No.61471398)的資助下于 2017 年 7 月開始建設,并在同年 12 月份測試完成。該數據庫涵蓋了解放軍總醫院 2015 年 5 月至 2017 年 10 月的急救患者診療數據,由 19 814 名不同患者共 22 491 次的搶救醫療數據組成(很多患者會有多次入院以及多次進出搶救室的記錄)。該數據庫整合了患者在接受救治過程中產生的存儲在多個醫療信息系統的臨床相關數據,共有 12 個數據表,主要分為三類:(1)定義、追蹤患者,如患者基本信息表(emg_patients)、患者分診信息(emg_triagePatients)等;(2)搶救室內數據,如床旁監護數據(emg_vitalSign)、醫囑信息(emg_medical_order)等;(3)醫院信息系統數據,如輔助檢查項目(exam_master、exam_report)、實驗室檢查(lab_test_master、lab_result)。表 1 給出了急救數據庫中具體的表結構和內容。
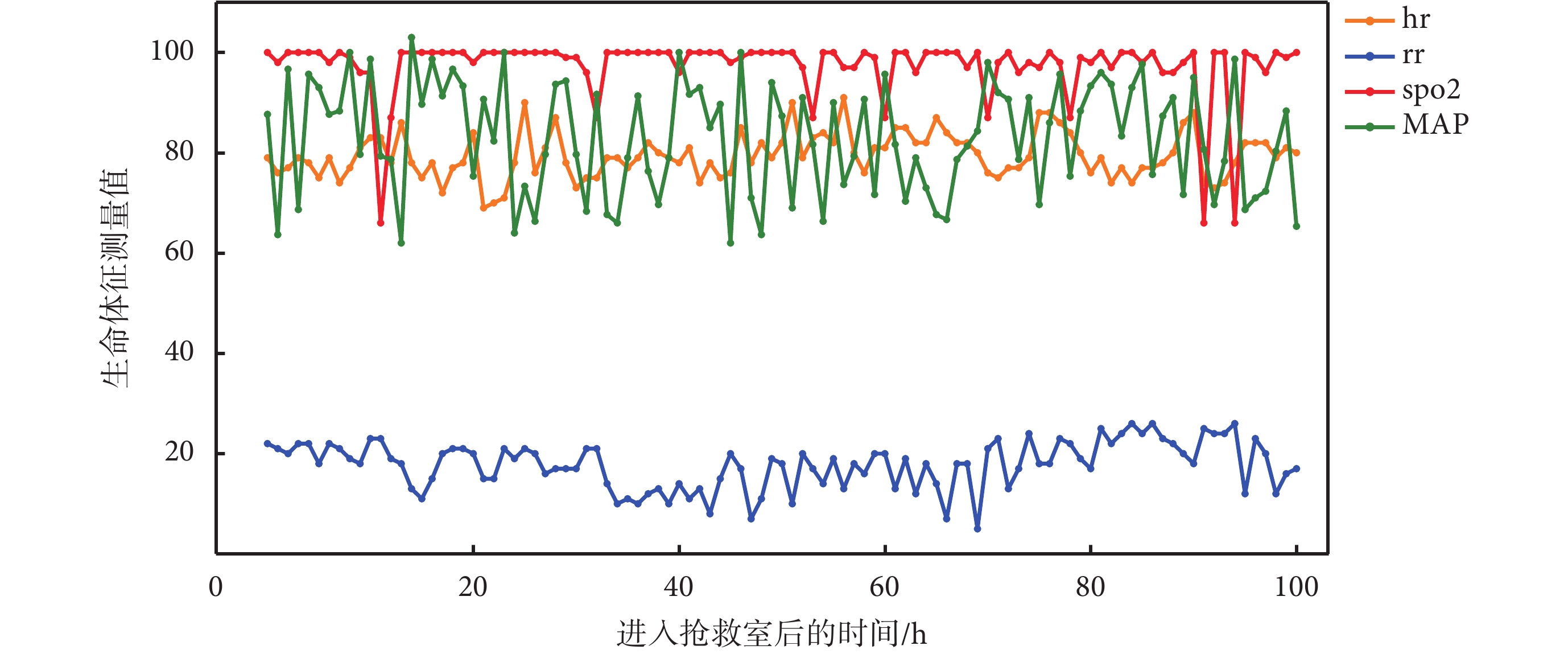
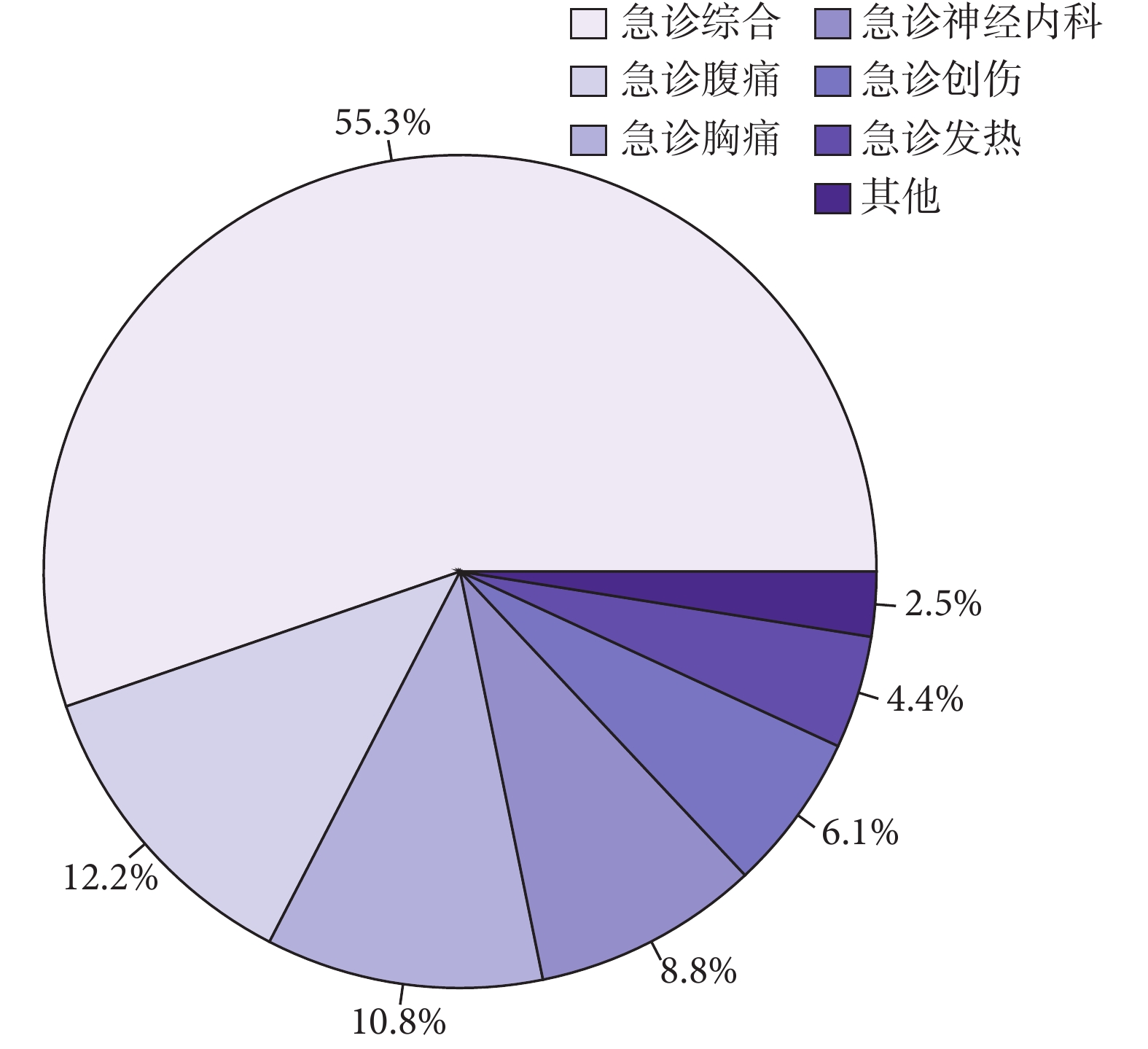
圖 5 為某一患者入搶救室后的床旁監護數據,該患者診斷為骨髓增生異常綜合征和心房顫動,床旁監護數據展示了數據庫的高粒度特性和豐富的數據特征。表 2 給出了數據庫中患者基本信息的統計。圖 6 顯示了急救數據庫中患者分診至各科室的統計分布,其中急診綜合接收患者量最多,急診腹痛次之。表 3 描述了急救數據庫中包含的常見急癥,其中消化系統急癥、心血管系統急癥和呼吸系統急癥較為普遍。
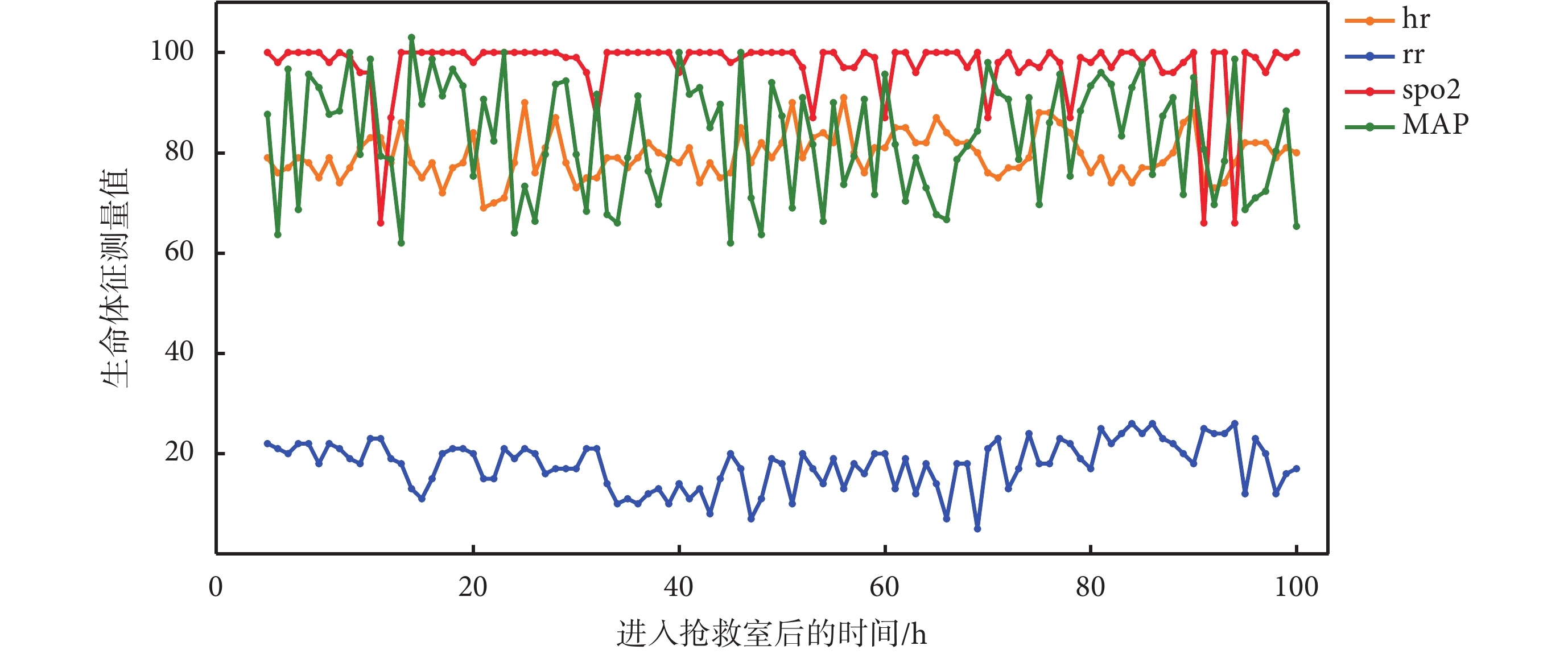 圖5
某一患者在搶救室的床旁監護數據
圖5
某一患者在搶救室的床旁監護數據
hr:心率;rr:呼吸率;spo2:血氧飽和度;MAP:平均動脈壓
Figure5. Bedside monitoring data for a patient in the rescue roomhr: heart rate; rr: respiratory rate; spo2: blood oxygen saturation; MAP: mean arterial pressure
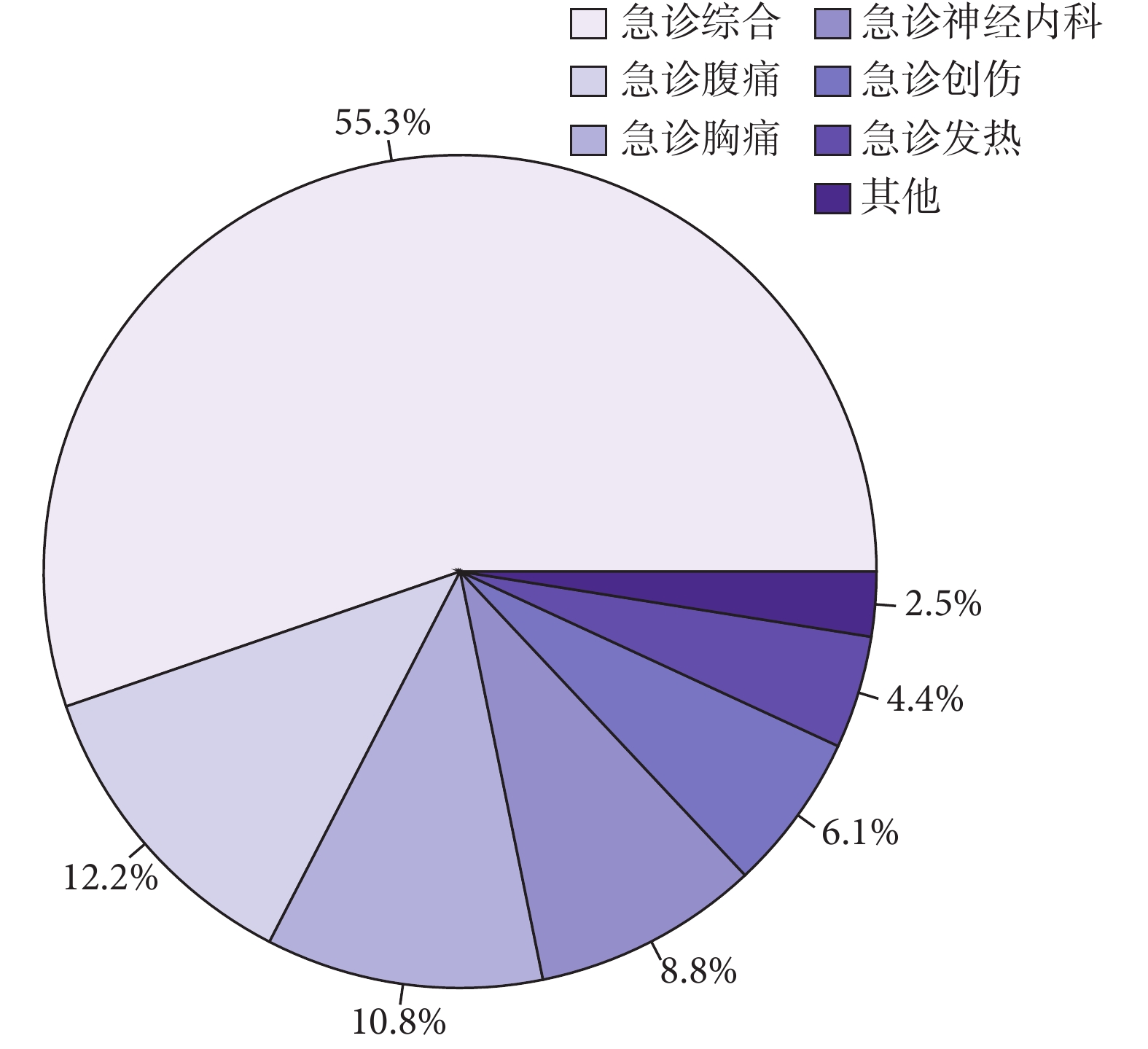 圖6
急診各專科急救患者就診比例
Figure6.
Proportion of emergency patients in emergency departments
圖6
急診各專科急救患者就診比例
Figure6.
Proportion of emergency patients in emergency departments
3 數據庫初步應用
數據庫建設基本完成后,我們對數據庫的開放應用進行了探索。2018 年 3 月 16 日至 3 月 18 日,解放軍總醫院急診科聯合清華大學、北京交通大學等國內 20 多家高校、科研院所,并邀請來自國內外知名的臨床和信息工程專家,舉辦了第一屆急救大數據 Datathon(
4 討論與結論
本文詳細介紹了多參數急救數據庫的建設過程,對數據庫的結構和內容作了詳細描述。數據庫在架構設計方面參考了 MIMIC-III[13]數據庫結構,內容上整合了來自解放軍總醫院急診和部分專科系統的數據。在數據整合過程中,我們對患者臨床數據進行了數據清洗以確保數據信息完整性和一致性并避免數據冗余。完成數據庫建設后,我們進一步分析了數據庫中存儲數據的概況并對數據庫的應用進行了初步探索。
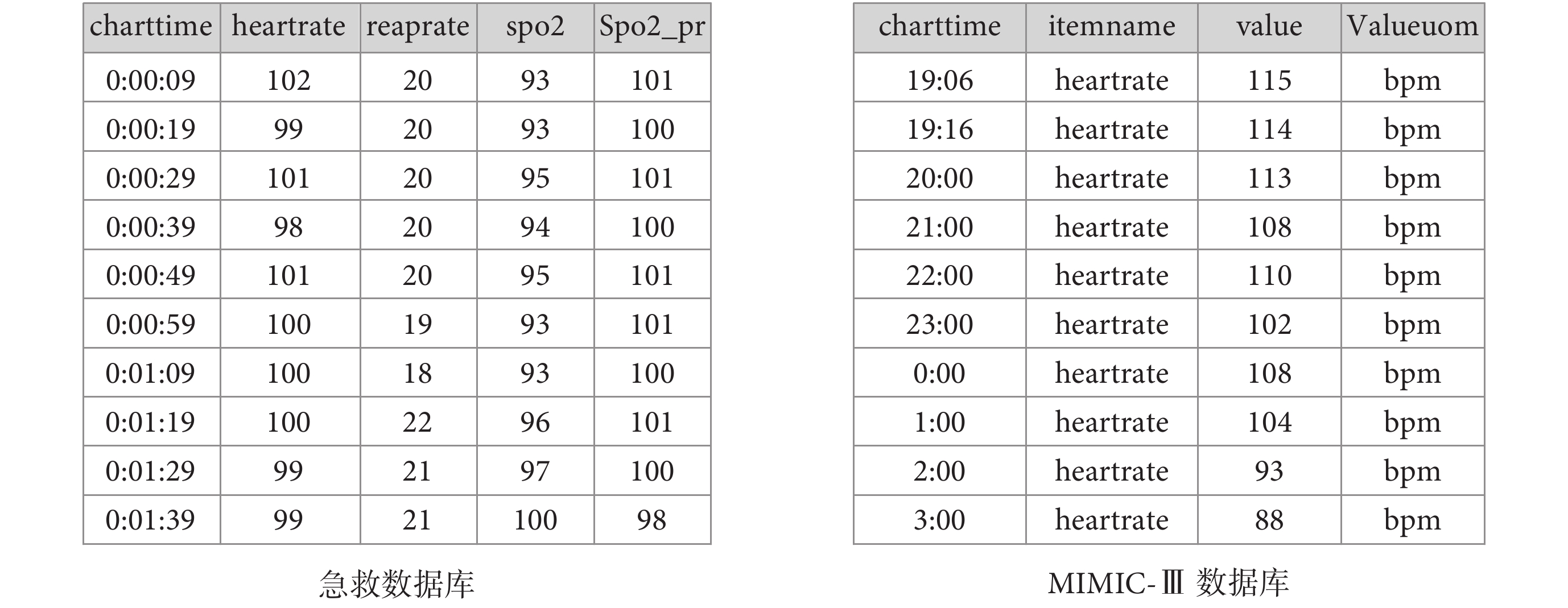
MIMIC 數據庫經過 10 多年的持續優化和更新,數據庫結構合理,易用性強,為全球急危重癥數據庫建設提供了參考標準。本文介紹的雖然是一個單中心(解放軍總醫院)臨床數據庫,但由于其參考了 MIMIC 數據庫結構,結合了我院急診救治的業務流和信息流,并對部分數據存儲結構進行了改進,可以為建設我國高質量臨床數據庫提供有效的參考。如圖 7 所示,床旁監護數據如心率(heartrate)、呼吸率(resprate)和氧飽和度(spo2)等不同生理指標會在同一時間被存儲,圖 7 右圖展示了 MIMIC-III 數據庫采用的行記錄方式,即每一行記錄一個時間對應的單個生理指標值,圖 7 左圖展示了本研究的數據庫根據各個指標采樣頻率使用列存儲的形式,每一行記錄一個時間點對應的所有生命體征數據。一般研究者會同時使用所有的生命體征數據,本研究中的數據結構不僅便于使用者查詢和使用數據,提高查詢效率,也有助于節省存儲空間,因此對國內急危重癥數據庫的建設具有一定的參考價值。
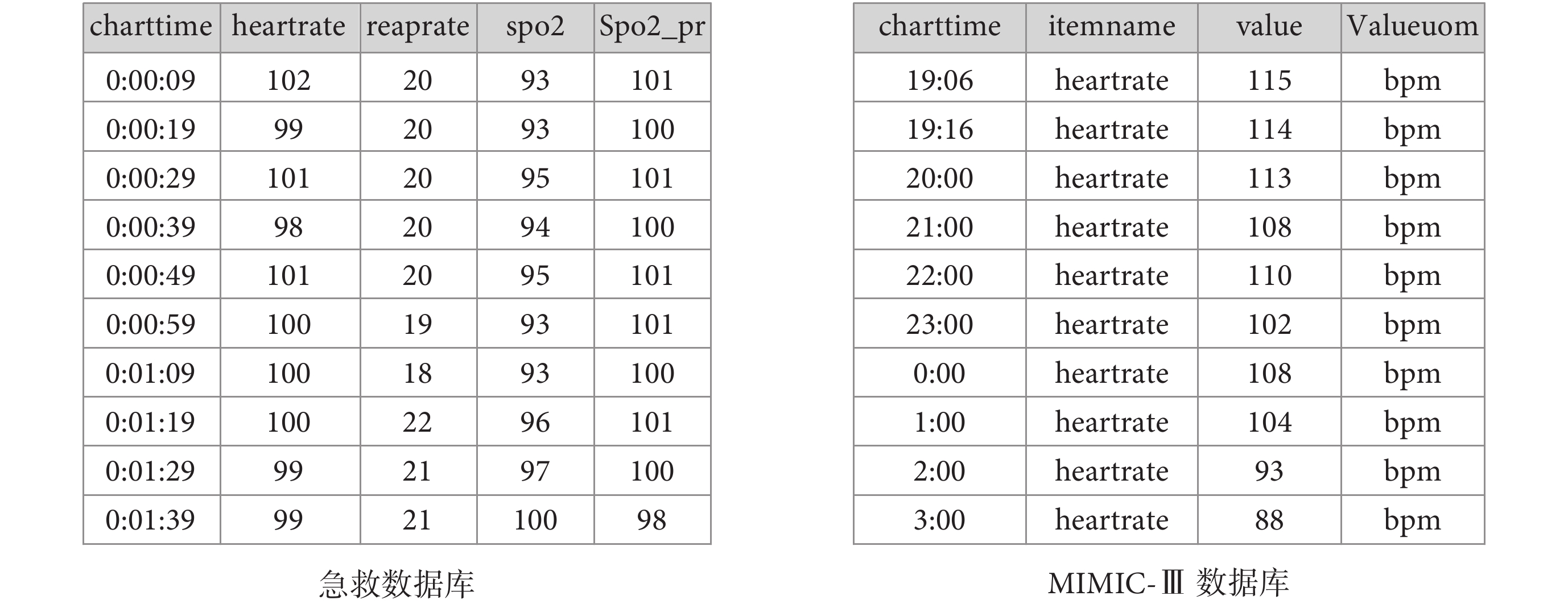 圖7
數據庫床旁監護數據存儲結構示例圖
Figure7.
Storage structure of the database bedside monitoring data
圖7
數據庫床旁監護數據存儲結構示例圖
Figure7.
Storage structure of the database bedside monitoring data
另一方面,數據庫建設的目的在于分析利用,本文介紹的急救數據庫也是國內首個可以向社會開放使用的高質量臨床數據庫,依托該數據庫已經成功舉辦了第一屆急救大數據和 Datathon 活動,有力推動了我國急救領域的臨床數據資源建設和分析利用工作。目前該數據庫依托于醫療大數據應用技術國家工程實驗室和解放軍總醫院醫療大數據中心,向研究人員開放。經過審批后,研究人員可以在解放軍總醫院醫療大數據中心操作和使用該數據庫,就感興趣的臨床問題開展研究。相信該工作將進一步推動我國臨床數據庫的建設和共享利用。
我國目前也存在很多醫療數據庫[14-16],是針對課題研究需要而建設的小型數據集或者專科數據庫,這些數據庫存儲的是預先收集的患者數據,通常只包含某些特定的疾病,很少包含同一地區其他相關患者的數據,因此用這些數據庫進行的研究普適性須進一步驗證。而且由于國內很多 ICU 沒有現代化的專科業務系統,無法獲得更多的醫療設備數據,使得數據庫中存儲的生理數據缺失或較稀疏。急救患者有較高的惡化風險,如會發生感染、充血性心力衰竭[17]、急性心肌梗死等嚴重病癥,而生理數據在急危重癥評估中有重要價值。因此要建設高質量的急危重癥數據庫,離不開現代化的專科業務系統和醫療設備物聯網技術的支持。
我們的多參數急救數據庫得益于急診專科信息系統和醫療設備物聯網的支持,可以采集到豐富的生理數據。與 MIMIC 數據庫相比,該數據庫還有一個特點是記錄了更豐富完整的生化數據,如腦尿鈉肽(brain natriuretic peptide,BNP)、C-反應蛋白(C-reactive protein,CRP)和白細胞介素 6(interleukin 6,IL-6)等生化指標。其中 BNP 是急性冠脈綜合征患者死亡的強關聯指標,CRP 廣泛用于急性感染性疾病的診斷和術后感染的監測,IL-6 能很好地評估急性胰腺炎的嚴重程度等,而 MIMIC 中這類重要的生化指標存在缺失或記錄值較少。其中,在 MIMIC-III 數據庫 61 532 次患者 ICU 就診記錄中,僅有 998 條 BNP 測量記錄,即人均測量次數為 0.016,CRP 為 0.010,而 IL-6 無數據;在我們的急救數據庫中,17 107 條不同就診記錄中,BNP 的人均測量次數為 1.367,CRP 為 0.861,IL-6 為 0.499。我們的數據庫具有豐富完整的臨床數據,可以支持研究者開展很多基于患者生理數據預測疾病發展趨勢和疾病評估等的研究,有助于早期發現并干預有惡化風險的臨床事件進而改善患者的預后,并節約醫療資源[18-19],在以后的臨床隊列研究和改善醫療質量方面可起到重要作用,為臨床研究提供數據支持進而改善急診救治的效率和水平。
但是,在數據庫建設過程中仍存在一些問題,該急救數據庫仍需進一步完善,大致有以下幾個方面:
(1)數據庫整合時,患者的實驗室檢查數據來源于院內 HIS 系統,而患者基本信息和就診信息來自急診診室系統和急診搶救系統,急診信息系統和院內 HIS 系統之間的實驗室檢查數據關聯較弱,是通過時間區間關聯患者對應的數據,這導致患者的化驗檢查數據與患者的搶救記錄(患者某一次入院記錄中,存在多次時間間隔很短的搶救記錄)無法直接匹配;
(2)目前數據庫僅包含患者在急診部門的數據,而院內其他專科數據尚未錄入數據庫,無法追蹤患者從急診科轉出至其他科室的醫療數據,無法獲得患者在院內就診的完整流程;
(3)由于我們的數據庫尚處于起步階段,目前還未能與死亡登記數據庫、國家醫療保險信息數據庫等進行對接,所以與國際較成熟的醫療數據庫相比存在一定不足。
接下來我們將從以下幾個方面完善急救數據庫:
(1)進一步完善急診信息系統,建立與院內 HIS 系統較強的關聯,使得實驗室檢查數據能夠與患者的某一次搶救室記錄一一對應;
(2)進一步整合院內其他科室的臨床數據,使得患者從入院到出院過程中所有的臨床數據被納入數據庫,形成完整的臨床數據鏈;
(3)完善數據庫架構,為國內醫療數據庫的建設提供參考。
隨著院內更多高質量數據的整合,數據完整度不斷提升,急救數據庫將為大型臨床研究的實施提供重要的平臺,促進數據中潛藏信息的深度挖掘,進而為我國急危重癥患者救治提供有力的數據支撐。
EHR 研究為研究者們提供了更多臨床證據,研究者們可以使用大型臨床數據庫中的信息研究解答各種問題。EHR 為研究者們帶來了研究模式的轉變,利用 EHR 能幫助我們建立可持續學習的系統。與傳統的隨機對照試驗(randomized controlled trial,RCT)相比,EHR 包含的變量更豐富,信息更詳細完整,使用 EHR 可以完成許多 RCT 不能進行的研究,而且大大降低了成本和難度,是研究復雜的臨床決策過程的理想工具。使用 EHR 還可以幫助臨床醫師精準地評估診斷結果,以及高效快捷地發現藥品和其他醫療干預所導致的不良反應事件等[5]。因此,臨床醫生和研究者們需要不斷發掘海量 EHR 數據所蘊含的潛力,從而為臨床提供更好的決策支持。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
目前醫療行業已經迅速實現了計算機化及數字化,大部分醫療機構都直接或間接地使用信息技術提供醫療服務。現代醫療信息系統能夠產生并存儲海量的數據,這些數據涉及詳細的患者信息和臨床診療過程,但是來自真實世界的患者數據卻很少能被用于醫學研究,推動醫療領域的創新和發展,其主要障礙在于研究人員很難獲取和使用這些數據。若是能夠整合并開放醫療機構內部以及不同醫療機構間的患者數據,就會吸引更多的、具有不同背景的研究人員,通過多學科協作共同解決目前臨床醫學中所面臨的各類基礎問題。
傳統的醫學研究收集數據的方法大多是依靠臨床試驗注冊數據庫或慢病管理系統,建立專病數據集。專病數據庫中記錄的數據往往局限于某一特定的研究任務,通常只針對某一特定的疾病,其數據或結論不能用于其他疾病,并且其數據經常是來自某一地區的特定人群,往往導致基于這些數據庫的研究結論普適性較差。
第一個電子健康檔案(Electronic Health Records,EHR)于 20 世紀 60 年代問世。EHR 的建立最初是為了歸檔整理患者的醫療記錄,后來又增加了計費和質量改進的功能。之后 EHR 數據庫不斷發展,越來越全面,能夠動態更新,并且信息相互關聯。EHR 為建設更完整的醫療數據庫提供了數據基礎,進而為醫療大數據分析提供了機遇。它可以收集多維度的醫療數據,這使得臨床醫生、信息學家、數據工程師可以使用大型醫療信息數據庫研究解答各種問題。在信息技術不斷發展的今天,我們使用大數據挖掘理論和技術來分析和理解數據的能力都取得了巨大的進步,醫療數據挖掘分析在疾病風險評估、臨床決策支持、疾病發展預測、合理用藥指導、醫療管理和循證醫學等領域發揮了重要作用[1]。未來的臨床研究將依賴于大數據技術來改善患者的診療,以期為患者提供更好的服務。
目前國外已有不少成熟的大型醫療數據庫,可供全球研究人員開放使用。如:重癥監護醫學信息數據庫(Medical Information Mart for Intensive Care,MIMIC),包含了超過 6 萬的重癥加強護理病房(Intensive Care Unit,ICU)診療數據[2];還有飛利浦的 eICU 數據庫,囊括了 2014 年到 2015 年間美國本土各地區十多萬患者的 ICU 臨床數據。這兩個數據庫都可以通過
在急診救治過程中,會產生大量的動態醫療數據,其信息量豐富,價值密度大,建立大樣本多參數急救數據庫,可以為急救醫學研究提供來自“真實世界”的數據,提高救治的時效性和準確性,進而發展基于數據驅動的輔助決策支持系統。目前已有很多基于急診數據展開的研究,如美國俄勒岡州建立了全州范圍內的急診醫療服務數據庫,增強了基于結局的急診醫療服務研究,為提高醫療服務質量提供了有力的數據支持[4];Heldeweg 等[5]使用研究型數據庫(REDCap)中的急救數據,基于心電圖(electrocardiogram,ECG)和心率變異性(heart rate variability,HRV)參數為急診胸痛患者建立了性能優于心肌梗死溶栓治療(The Thrombolysis in Myocardial Infarction,TIMI)危險評分的心血管危險分層模型,為臨床決策提供了參考;Horng 等[6]基于急診數據,使用機器學習方法建立了可以識別膿毒血癥感染患者的模型,為臨床醫生提供了良好的決策支持。
目前我國的臨床數據庫建設和應用尚處于起步階段,目前存在的很多數據庫是因課題需要而建設的小型數據集或者專科數據庫[7-11],這些數據庫的數據來源較單一,共享性差,且質量良莠不齊[12];國家人口健康科學數據共享平臺提供了 200 多個科學數據集(
1 數據庫架構分析與數據整合
1.1 MIMIC-III 數據庫架構分析
自 2003 年以來,麻省理工學院(Massachusetts Institute of Technology,MIT)計算生理學實驗室、貝斯以色列女執事醫學中心和飛利浦醫療共同合作,在美國國立衛生研究所資助下,一起開發和維護了 MIMIC 數據庫。該數據庫收集了醫院信息系統和 ICU 信息系統中存儲的臨床數據、床旁監護儀中的高精度波形數據以及來自社會保障總署的死亡信息。MIT 計算生理學實驗室團隊在 2015 年發布了重癥監護醫療數據倉庫 MIMIC-III[13],包含了 2001 年到 2012 年共 38 597 名去隱私化的成人入院患者數據,共計 53 423 人次的 ICU 記錄(每名患者會有多次入院以及多次進出 ICU 的記錄),數據主要來源于內科重癥監護室(Medical Intensive Care Unit,MICU)、外科重癥監護室(Surgical Intensive Care Unit,SICU)、心內科監護室(Cardiac/Coronary Care Unit,CCU)和心臟外科監護室(Cardiac Surgery Intensive Care Unit,CSRU)這四個監護室。目前,最新版 MIMIC-III v1.4 共包含 26 張數據表,主要分為四類:① 定義和追蹤患者,如患者入院信息(admissions)、患者入 ICU 信息(icustays);② ICU 內產生的患者數據,如 ICU 所有記錄觀察結果(chartevents)、患者入量(inputevents_cv)等;③ 醫院信息系統數據,如實驗室檢查結果(labevents)、診斷(diagnoses_icd)等;④ 字典表,如生化檢查字典表(d_labitems)、診斷字典表(d_icd_diagnoses)等。這些數據涵蓋了患者進入 ICU、ICU 轉換和出院的所有病程記錄數據,且數據經過日期 shift、格式轉換等去隱私化處理,最終形成該數據庫,其數據類型和整合流程如圖 1 所示[13]。
圖1
MIMIC-III 重癥數據庫概覽
Figure1.
Overview of MIMIC-III Critical Database
本文的急救數據庫架構設計參考了 MIMIC-III v1.4 版本,如圖 2 所示,不同類型信息存儲在不同的數據表,如 admissions 表存儲了患者入院基本信息,包括入出院時間、入院診斷和入院時基本狀態等;patients 表存儲了患者基本統計學信息,包括性別、出生日期等;chartevents 表存儲了患者生理生化等結果;d_labitems 以字典的形式存儲生理生化等指標名稱與 itemid 的映射關系。其中 subject_id 字段表示患者 id,即對應唯一的患者,hadm_id 表示患者不同的入院記錄 id,患者入院信息、基本統計學信息和其他臨床診療信息通過這些 id 進行關聯。另外,要獲得患者的生理生化值需要先從 d_labitems 這樣的字典表通過映射找到對應名稱的 itemid,并進一步查詢獲得結果。
圖2
MIMIC-III 數據庫表結構
Figure2.
Table structure of MIMIC-III Database
MIMIC 數據庫經過多個版本的更迭,在應用方面相當成熟,目前已有大量學者、研究員使用該數據庫進行研究。同時,與數據庫相關的問題會在 Github(
1.2 急診業務流程
為了建立合理的數據庫架構,了解信息源,課題組對急診業務流程進行了深入調研,總結出急危重癥患者從入院到出院的急診業務流程,如圖 3 所示。患者在急診分診臺接受病情評估并被分診到急診相關科室,如急診腹痛、急診骨科、急診婦產科等,如果患者有發熱情況則會被分診到發熱門診進行救治,若患者已排除患有傳染病,可轉入相應急診科室就診。病情比較危急的患者會進入急診搶救室接受及時的救治,相應的,需要留院觀察的患者會進入留觀區,隨著病情發展,患者可能進入專科、急診病房、急診重癥監護室(Emergency Intensive Care Unit,EICU)以及轉入其他醫院繼續接受治療,或者宣布死亡。
圖3
急診患者就診流程圖
Figure3.
Treatment flow of emergency patients
要建設一個高質量的臨床數據庫,對急診就診業務流和信息流進行深入分析十分重要。急診業務流和信息流涵蓋了患者在就診過程中產生的臨床信息、信息類別以及信息之間的關聯,有助于合理地設計數據庫架構。患者在接受分診時系統會記錄其基本信息如就診號、性別等,病情評估后患者被分診到相應的科室或進入搶救室就診,急診搶救系統會記錄患者在接受搶救的過程中的一系列數據,如床旁監護數據、生化檢查、醫囑、護理和報告等數值和文本信息。
1.3 急救數據庫數據整合
急救數據庫數據主要來源于解放軍總醫院的醫院信息系統(Hospital Information System,HIS)、急診搶救系統和急診專科診室系統。急診搶救系統和急診專科診室系統數據分別屬于不同的醫療系統,從急診專科診室信息系統獲得患者基本信息、分診信息、就診區域以及床旁監護數據;從急診搶救系統獲取患者就診過程中的醫囑、用藥和護理記錄等信息。最后從醫院 HIS 系統獲得患者的生化檢查數據,根據急診患者的就診流程,將患者從登記掛號到院內急救和轉出這一過程中產生的一系列數據進行有效關聯,數據整合流程如圖 4 所示。患者可能有多次就診記錄,在該數據庫中,患者的身份 ID 保持唯一,不同的就診記錄會分配有不同的就診 ID 從而區別患者的多次就診過程中產生的醫療信息。
圖4
急救數據整合流程示意圖
Figure4.
Schematic diagram of the emergency data integration process
1.4 數據預處理
在將患者基本信息及診療相關信息錄入數據庫前,需要對數據進行一定的處理,主要包括以下過程。
1.4.1 數據去隱私化
患者姓名、身份證號、家庭住址和家人信息等屬于患者個人敏感信息,若這些信息發生丟失或泄露,不僅會給患者帶來麻煩并造成經濟損失,同時會給醫院的聲譽帶來負面影響。因此將與患者真實信息相關的患者姓名和就診的相關 ID(如 patientid、visitid 等)進行去隱私化處理。患者相關的就診 ID,一般由一位字母和一系列數字組成,去識別化后的 ID 同樣由字母和數字組成,因此首先獲得所有患者原始 ID,對原始 ID 中首字母用其他字母如‘S’替代,然后以隨機數的形式抽取數字部分并與某些數字做加減處理,產生的新數字與字母 S 組合產生新 ID,原始 ID 和新 ID 之間同時形成映射關系,因此可直接通過 ID 關聯將新 ID 與患者就診記錄進行一致關聯;患者姓名也借助算法產生新的名字,身份證和家庭住址等信息則去掉,不存儲在該數據庫中。對數據進行變換后,可避免直接或間接指向特定患者的信息出現在數據庫中,同時保持原始數據相關特征和業務處理流程不變,即保持患者診療過程中所產生的其他一系列就診相關信息不變。
1.4.2 數據清洗
解放軍總醫院急診信息系統于 2014 年 11 月在急診部門試運行,于 2015 年 5 月正式使用,而系統在試運行期間錄入了一些測試數據,這些數據在正式運行之前并未清除,導致數據庫中存在有歧義的數據:
(1)信息不一致。存在一部分數據,同一個患者 ID(patientid)對應的患者基本信息不一致,例如 patientID=1234321,在患者多次就診記錄中,存在出生日期不同或/和性別不一致的情況,即同一患者 ID 兩次或多次就診時記錄的性別(男/女)或者出生日期不同,這樣的信息會影響后續研究中的數據分析,統計發現這樣的數據約占總就診量的 0.34%,因此在數據中找出所有的患者 ID 相同但性別或出生日期不一致的數據,然后刪除以確保數據的一致性。
(2)數據重復。由于護士操作或者系統卡頓原因,數據庫中存在對同一患者同一次就診的重復分診信息,即在患者某一次就診時,除了分診時間間隔相當短,其他信息完全相同。在數據庫建設過程中,找出此類原因導致的多次重復分診患者,并去除患者的重復分診記錄。
(3)無效數據。如患者的化驗結果數據中存儲了不可解讀的錯誤信息,例如化驗結果“白細胞數”記錄為“------”,在建庫過程中通過正則表達式或者字符串匹配等方法,找出所有存儲結果無效的類似錯誤信息并予以去除。
2 數據庫概述
急救數據庫在國家自然科學基金面上項目(No.61471398)的資助下于 2017 年 7 月開始建設,并在同年 12 月份測試完成。該數據庫涵蓋了解放軍總醫院 2015 年 5 月至 2017 年 10 月的急救患者診療數據,由 19 814 名不同患者共 22 491 次的搶救醫療數據組成(很多患者會有多次入院以及多次進出搶救室的記錄)。該數據庫整合了患者在接受救治過程中產生的存儲在多個醫療信息系統的臨床相關數據,共有 12 個數據表,主要分為三類:(1)定義、追蹤患者,如患者基本信息表(emg_patients)、患者分診信息(emg_triagePatients)等;(2)搶救室內數據,如床旁監護數據(emg_vitalSign)、醫囑信息(emg_medical_order)等;(3)醫院信息系統數據,如輔助檢查項目(exam_master、exam_report)、實驗室檢查(lab_test_master、lab_result)。表 1 給出了急救數據庫中具體的表結構和內容。
圖 5 為某一患者入搶救室后的床旁監護數據,該患者診斷為骨髓增生異常綜合征和心房顫動,床旁監護數據展示了數據庫的高粒度特性和豐富的數據特征。表 2 給出了數據庫中患者基本信息的統計。圖 6 顯示了急救數據庫中患者分診至各科室的統計分布,其中急診綜合接收患者量最多,急診腹痛次之。表 3 描述了急救數據庫中包含的常見急癥,其中消化系統急癥、心血管系統急癥和呼吸系統急癥較為普遍。
圖5
某一患者在搶救室的床旁監護數據
hr:心率;rr:呼吸率;spo2:血氧飽和度;MAP:平均動脈壓
Figure5. Bedside monitoring data for a patient in the rescue roomhr: heart rate; rr: respiratory rate; spo2: blood oxygen saturation; MAP: mean arterial pressure
圖6
急診各專科急救患者就診比例
Figure6.
Proportion of emergency patients in emergency departments
3 數據庫初步應用
數據庫建設基本完成后,我們對數據庫的開放應用進行了探索。2018 年 3 月 16 日至 3 月 18 日,解放軍總醫院急診科聯合清華大學、北京交通大學等國內 20 多家高校、科研院所,并邀請來自國內外知名的臨床和信息工程專家,舉辦了第一屆急救大數據 Datathon(
4 討論與結論
本文詳細介紹了多參數急救數據庫的建設過程,對數據庫的結構和內容作了詳細描述。數據庫在架構設計方面參考了 MIMIC-III[13]數據庫結構,內容上整合了來自解放軍總醫院急診和部分專科系統的數據。在數據整合過程中,我們對患者臨床數據進行了數據清洗以確保數據信息完整性和一致性并避免數據冗余。完成數據庫建設后,我們進一步分析了數據庫中存儲數據的概況并對數據庫的應用進行了初步探索。
MIMIC 數據庫經過 10 多年的持續優化和更新,數據庫結構合理,易用性強,為全球急危重癥數據庫建設提供了參考標準。本文介紹的雖然是一個單中心(解放軍總醫院)臨床數據庫,但由于其參考了 MIMIC 數據庫結構,結合了我院急診救治的業務流和信息流,并對部分數據存儲結構進行了改進,可以為建設我國高質量臨床數據庫提供有效的參考。如圖 7 所示,床旁監護數據如心率(heartrate)、呼吸率(resprate)和氧飽和度(spo2)等不同生理指標會在同一時間被存儲,圖 7 右圖展示了 MIMIC-III 數據庫采用的行記錄方式,即每一行記錄一個時間對應的單個生理指標值,圖 7 左圖展示了本研究的數據庫根據各個指標采樣頻率使用列存儲的形式,每一行記錄一個時間點對應的所有生命體征數據。一般研究者會同時使用所有的生命體征數據,本研究中的數據結構不僅便于使用者查詢和使用數據,提高查詢效率,也有助于節省存儲空間,因此對國內急危重癥數據庫的建設具有一定的參考價值。
圖7
數據庫床旁監護數據存儲結構示例圖
Figure7.
Storage structure of the database bedside monitoring data
另一方面,數據庫建設的目的在于分析利用,本文介紹的急救數據庫也是國內首個可以向社會開放使用的高質量臨床數據庫,依托該數據庫已經成功舉辦了第一屆急救大數據和 Datathon 活動,有力推動了我國急救領域的臨床數據資源建設和分析利用工作。目前該數據庫依托于醫療大數據應用技術國家工程實驗室和解放軍總醫院醫療大數據中心,向研究人員開放。經過審批后,研究人員可以在解放軍總醫院醫療大數據中心操作和使用該數據庫,就感興趣的臨床問題開展研究。相信該工作將進一步推動我國臨床數據庫的建設和共享利用。
我國目前也存在很多醫療數據庫[14-16],是針對課題研究需要而建設的小型數據集或者專科數據庫,這些數據庫存儲的是預先收集的患者數據,通常只包含某些特定的疾病,很少包含同一地區其他相關患者的數據,因此用這些數據庫進行的研究普適性須進一步驗證。而且由于國內很多 ICU 沒有現代化的專科業務系統,無法獲得更多的醫療設備數據,使得數據庫中存儲的生理數據缺失或較稀疏。急救患者有較高的惡化風險,如會發生感染、充血性心力衰竭[17]、急性心肌梗死等嚴重病癥,而生理數據在急危重癥評估中有重要價值。因此要建設高質量的急危重癥數據庫,離不開現代化的專科業務系統和醫療設備物聯網技術的支持。
我們的多參數急救數據庫得益于急診專科信息系統和醫療設備物聯網的支持,可以采集到豐富的生理數據。與 MIMIC 數據庫相比,該數據庫還有一個特點是記錄了更豐富完整的生化數據,如腦尿鈉肽(brain natriuretic peptide,BNP)、C-反應蛋白(C-reactive protein,CRP)和白細胞介素 6(interleukin 6,IL-6)等生化指標。其中 BNP 是急性冠脈綜合征患者死亡的強關聯指標,CRP 廣泛用于急性感染性疾病的診斷和術后感染的監測,IL-6 能很好地評估急性胰腺炎的嚴重程度等,而 MIMIC 中這類重要的生化指標存在缺失或記錄值較少。其中,在 MIMIC-III 數據庫 61 532 次患者 ICU 就診記錄中,僅有 998 條 BNP 測量記錄,即人均測量次數為 0.016,CRP 為 0.010,而 IL-6 無數據;在我們的急救數據庫中,17 107 條不同就診記錄中,BNP 的人均測量次數為 1.367,CRP 為 0.861,IL-6 為 0.499。我們的數據庫具有豐富完整的臨床數據,可以支持研究者開展很多基于患者生理數據預測疾病發展趨勢和疾病評估等的研究,有助于早期發現并干預有惡化風險的臨床事件進而改善患者的預后,并節約醫療資源[18-19],在以后的臨床隊列研究和改善醫療質量方面可起到重要作用,為臨床研究提供數據支持進而改善急診救治的效率和水平。
但是,在數據庫建設過程中仍存在一些問題,該急救數據庫仍需進一步完善,大致有以下幾個方面:
(1)數據庫整合時,患者的實驗室檢查數據來源于院內 HIS 系統,而患者基本信息和就診信息來自急診診室系統和急診搶救系統,急診信息系統和院內 HIS 系統之間的實驗室檢查數據關聯較弱,是通過時間區間關聯患者對應的數據,這導致患者的化驗檢查數據與患者的搶救記錄(患者某一次入院記錄中,存在多次時間間隔很短的搶救記錄)無法直接匹配;
(2)目前數據庫僅包含患者在急診部門的數據,而院內其他專科數據尚未錄入數據庫,無法追蹤患者從急診科轉出至其他科室的醫療數據,無法獲得患者在院內就診的完整流程;
(3)由于我們的數據庫尚處于起步階段,目前還未能與死亡登記數據庫、國家醫療保險信息數據庫等進行對接,所以與國際較成熟的醫療數據庫相比存在一定不足。
接下來我們將從以下幾個方面完善急救數據庫:
(1)進一步完善急診信息系統,建立與院內 HIS 系統較強的關聯,使得實驗室檢查數據能夠與患者的某一次搶救室記錄一一對應;
(2)進一步整合院內其他科室的臨床數據,使得患者從入院到出院過程中所有的臨床數據被納入數據庫,形成完整的臨床數據鏈;
(3)完善數據庫架構,為國內醫療數據庫的建設提供參考。
隨著院內更多高質量數據的整合,數據完整度不斷提升,急救數據庫將為大型臨床研究的實施提供重要的平臺,促進數據中潛藏信息的深度挖掘,進而為我國急危重癥患者救治提供有力的數據支撐。
EHR 研究為研究者們提供了更多臨床證據,研究者們可以使用大型臨床數據庫中的信息研究解答各種問題。EHR 為研究者們帶來了研究模式的轉變,利用 EHR 能幫助我們建立可持續學習的系統。與傳統的隨機對照試驗(randomized controlled trial,RCT)相比,EHR 包含的變量更豐富,信息更詳細完整,使用 EHR 可以完成許多 RCT 不能進行的研究,而且大大降低了成本和難度,是研究復雜的臨床決策過程的理想工具。使用 EHR 還可以幫助臨床醫師精準地評估診斷結果,以及高效快捷地發現藥品和其他醫療干預所導致的不良反應事件等[5]。因此,臨床醫生和研究者們需要不斷發掘海量 EHR 數據所蘊含的潛力,從而為臨床提供更好的決策支持。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。