精神分裂癥和抑郁癥患者的臨床表現不僅有一定的相似性,而且會隨著患者情緒的變化而變化,因此容易導致臨床診斷出現誤診。腦電圖 (EEG) 分析為準確區分和診斷精神分裂癥與抑郁癥患者提供了重要的參考和客觀依據。為了解決精神分裂癥與抑郁癥患者之間誤診的問題,提高區分和診斷這兩類疾病的準確率,本研究提取了 100 名抑郁癥患者和 100 名精神分裂癥患者的靜息態 EEG 信號特征,包括:① 信息熵、樣本熵、近似熵;② 統計學屬性;③ 各節律相對功率譜密度(rPSD)。然后,利用這些特征組成特征向量,結合支持向量機(SVM)和樸素貝葉斯(NB)分類器對精神分裂癥和抑郁癥患者進行分類研究。實驗結果表明:① 以各節律的 rPSD 組成的特征向量 P 的分類效果最好,平均準確率可達 84.2 %,最高達 86.3%;② SVM 的分類效果明顯優于 NB;③ β 節律的可分性最好,準確率最高,可達 76%;④ 特征權重較大的電極主要集中在額葉和頂葉。本研究結果表明,SVM 結合各節律 rPSD 組成的特征向量 P 組成的分類模型,對精神分裂癥和抑郁癥患者的區分具有較好的效果,或可對相關的臨床診斷起到一定的輔助作用。
引用本文: 賴虹宇, 馮靜雯, 王毅, 鄧偉, 曾金坤, 李濤, 張軍鵬, 劉凱. 抑郁癥和精神分裂癥患者靜息態腦電信號的分類研究. 生物醫學工程學雜志, 2019, 36(6): 916-923. doi: 10.7507/1001-5515.201812041 復制
版權信息: ?四川大學華西醫院華西期刊社《生物醫學工程學雜志》版權所有,未經授權不得轉載、改編
引言
精神分裂癥(schizophrenia,SCZ)和抑郁癥(depression,DP)是現今高發且危害較大的精神疾病,及時準確的診斷將有助于此類疾病的治療。腦電圖(electroencephalogram,EEG)記錄的是大腦神經細胞的電活動信號。研究表明,SCZ 和 DP 患者的 EEG 信號在節律、波幅和功率等方面均與正常人存在差異,因此對 EEG 信號進行深入研究,有助于精確區分和診斷這兩種疾病。
EEG 信號的分析方法主要包括時域、頻域、時頻域分析和非線性動力學分析等。Begi?等[1]通過量化 EEG 信號對 SCZ、DP 患者和正常人進行比較研究,發現 SCZ 患者和 DP 患者 EEG 信號的不同節律在各電極分布的情況存在明顯差異。當前,EEG 信號的時頻域分析方法已被廣泛應用 [2-4],如 Boashash 等[3]通過綜合分析時頻域的統計量特征、時頻域圖像特征和時頻域信號特征,對新生兒 EEG 信號癲癇病例進行分類識別,最高準確率達到 86.61%。另一方面,非線性動力學分析方法主要包括信號的樣本熵、近似熵、信息熵和 Lempel-Ziv 復雜度等度量分析[2-7],在分類研究中常與時頻域的特征相結合。例如,Sabeti 等[5]將樣本熵、近似熵和 Lempel-Ziv 復雜度等組成的特征向量用于 SCZ 患者和正常人的 EEG 信號分類,準確率達到了 91.26%。Li 等[6]用 Lempel-Ziv 復雜度研究 SCZ、DP 患者和正常人的 EEG 數據,發現 SCZ 組患者和 DP 組患者 EEG 信號的 Lempel-Ziv 復雜度有明顯的差異,且都高于正常人組。而在分類方法方面,Faust 等[7]利用非線性動力學分析方法提取 DP 患者和正常人的 EEG 信號特征向量進行多種分類器比較研究,發現概率神經網絡要優于其他方法。通過以上研究分析發現,目前的研究主要集中在患者和正常人之間的分類與識別,直接針對 SCZ 和 DP 患者的相關分類研究非常少。在 EEG 信號的特征選擇和特征提取方面,雖然有多種方法的結合應用,但是這些方法沒有充分考慮到不同頻段的 EEG 信號對特征選擇和特征提取有不同影響。
針對以上問題,本研究在頻域上結合非線性動力學分析方法和時域統計學分析的方法,提取不同的特征向量,利用不同的分類器對 SCZ 患者和 DP 患者的 EEG 信號進行分類研究。本研究整體流程如圖 1 所示,首先將采集的靜息態 EEG 信號進行預處理,并將其轉換成頻域信號,求得每段信號的功率譜密度(power spectral density,PSD)。然后,提取 PSD 的特征向量,即統計量特征、非線性動力學特征以及不同頻段的相對功率譜密度(relative power spectral density,rPSD),并且利用單變量特征選擇方法和基于懲罰項的特征選擇方法對 PSD 數據進行特征選擇和降維,再將得到的特征向量輸入到支持向量機(support vector machine,SVM)和樸素貝葉斯(naive Bayes,NB)分類器中進行分類研究。最后,利用查準率、查全率和準確率進行模型評估,比較不同的特征向量結合不同分類器的分類效果,檢驗不同特征的識別度,為精確區分 SCZ 患者和 DP 患者提供參考。此外,本研究利用以上特征選擇方法對特征屬性進行打分評估,計算每個電極的特征權重,找到了權重較大的腦區,以期為患者的臨床診斷和區分提供相關參考。
 圖1
整體流程圖
Figure1.
The overall flow chart
圖1
整體流程圖
Figure1.
The overall flow chart
1 材料和方法
1.1 數據來源和采集
本研究的數據來自于四川大學華西醫院第二門診部心理衛生中心,本課題組和該中心簽署了合作協議和保密協議,得到了數據的使用授權許可,且所有參與數據采集的患者都簽署了患者知情同意書。本課題組從符合國際疾病分類(international classification of diseases,ICD)確診的 SCZ 患者和 DP 患者中,按照 1∶1 匹配篩選出 SCZ 患者和 DP 患者各 100 例,其中:SCZ 患者男女各 50 名,平均年齡為(41.5 ± 4.37)歲;DP 患者男女各 50 名,平均年齡為(41.5 ± 4.35)歲,所有患者的年齡均在 32~51 歲之間,且服從正態分布,兩種患者的年齡、性別差異均無統計學意義(P > 0.05)。
本研究 EEG 信號的采集使用的是動態 EEG 儀(NATION8128W,上海諾誠電氣有限公司,中國),采樣頻率為 128 Hz,信號采集使用的是 16 通道的腦電帽,電極安置的方法遵循國際 10-20 導聯標準,電極的分布如圖 2 所示。信號采集全程在安靜封閉的室內進行,患者需閉眼,并保持安靜、清醒、放松的狀態。提示患者開始后,記錄 EEG 信號。首先,患者先閉眼做深呼吸 3 min,深呼吸結束后睜眼,給予 10 s 左右的緩和時間。然后,閉眼保持 7 s,緊接著睜眼保持 7 s,以此為一個閉、睜眼采集周期,連續采集三個這樣的閉、睜眼周期之后結束采集。但在實際采集過程存在操作誤差,所以閉、睜眼保持的時間實際是在 5~10 s 之間。
 圖2
電極分布圖
Figure2.
Electrodes distribution map
圖2
電極分布圖
Figure2.
Electrodes distribution map
1.2 數據預處理
本研究的數據參照文獻[8]進行預處理,具體的處理步驟包括:① 電極重定位;② 剔除無用電極;③ 濾波處理,帶通濾波器的頻段為 0.5~45 Hz,陷波為 50 Hz;④ 根據睜、閉眼的標記將數據分段;⑤ 用獨立成分分析方法去除偽跡;⑥ 用所有電極的平均電位進行電位重參考。
通過以上預處理后,得到長度在 5~10 s 之間的數據段。再分別計算睜、閉眼狀態下每段數據的 PSD。其中睜眼狀態下的數據共有 580 段,包含 DP 患者的 292 段、SCZ 患者的 288 段;閉眼狀態下的數據共有 585 段,包含 DP 患者的 295 段、SCZ 患者的 290 段。
1.3 特征向量
1.3.1 PSD 的特征
信息熵(information entropy,InEn)(以符號InEn表示)由 Shannon 提出,是系統不確定性和信息量大小的度量,也是整個系統不確定性的期望。當一個系統越有序,信息熵就越低;越混亂,信息熵就越高。其定義公式如式(1)所示[9-10]:
 |
其中,pi 表示事件發生的概率,i 表示樣本數量。
本研究中 PSD 的頻率為 1~55 Hz,故可以把每個電極的信號看成是一個頻率的固定序列,每個頻率點對應的 PSD 值為Pi,且 ,通過歸一化后表示為PNi,且
,通過歸一化后表示為PNi,且 。則求 PSD 數據的某一個電極的信息熵公式如式(2)所示:
。則求 PSD 數據的某一個電極的信息熵公式如式(2)所示:
 |
其中, ,且
,且 。
。
近似熵(approximate entropy,ApEn)(以符號ApEn表示)是一種用于量化時間序列變化的非線性動力學非負參數,表示一個時間序列的復雜性,反映了時間序列中新信息發生的可能性,越復雜的時間序列其近似熵就越大[5, 10],算法步驟表述如下:
(1)對于等時間間隔的N維時間序列
 ,定義相關參數m,r;其中m表示重構向量的長度,r是相似系數,用于重構向量間相似度的度量。
,定義相關參數m,r;其中m表示重構向量的長度,r是相似系數,用于重構向量間相似度的度量。
(2)定義 表示重構向量之間的距離。其中,
表示重構向量之間的距離。其中, 、
、 表示重構向量
表示重構向量 、
、 對應位置的元素,
對應位置的元素, 、
、 。
。
(3)對于上述序列,重構 m 維向量
 ,其中
,其中
 。
。
(4)計算重構向量 、
、 間的距離。當
間的距離。當 時,兩重構向量相似。
時,兩重構向量相似。 表示相似重構向量個數。計算相似的重構向量所占比例為:
表示相似重構向量個數。計算相似的重構向量所占比例為: 。
。
(5)定義公式: 
 。
。
(6)最后定義近似熵為: 
 。
。
樣本熵(sample entropy,SaEn)(以符號SaEn表示)也是表征時間序列復雜度的指標[4]。與近似熵比較,樣本熵優點在于其算法需要的數據量更小,所用時間少[5],不同點在于相較于前述近似熵算法中的(2)、(4)步中,樣本熵的步驟中多了 的條件,且第(4)步中相似度量的條件是
的條件,且第(4)步中相似度量的條件是 。由于步驟(1)~(4)與近似熵一樣,故不再贅述,步驟(5)、(6)的具體算法表述如下:
。由于步驟(1)~(4)與近似熵一樣,故不再贅述,步驟(5)、(6)的具體算法表述如下:
(5)定義公式: 
 ,即計算
,即計算 的均值。
的均值。
(6)定義樣本熵為:  。
。
本研究把頻率序列等效成時間序列,分別計算每個電極的近似熵和樣本熵,參數設置為 m = 2,r = 0.2·std。其中,符號std表示序列的標準差(standard deviation)。
統計學變量能反映數據本身的特性,本研究計算了每個電極 PSD 數據Pi的均值m、方差v、偏度s和峰度k來描述該數據。此外,將 PSD 分成 δ(1~3 Hz)、θ(4~7 Hz)、α(8~13 Hz)、β(14~30 Hz)四段節律,分別求每段節律的 rPSD。δ 的 rPSD 計算公式如式(3)所示:
 |
其中,Pi表示 PSD 值,i表示頻率點,j表示電極, ,同理可得Pθ(j),Pα(j),Pβ(j)。
,同理可得Pθ(j),Pα(j),Pβ(j)。
1.3.2 多通道特征提取和融合
本研究先計算每個電極上的數據特征,再將其組成一個特征向量,以此來描述每一段 PSD 數據。具體的方法如下:
(1)將睜、閉眼狀態下的每一段 PSD 數據看成一個樣本,分別計算每個樣本中每一個電極的信息熵、近似熵和樣本熵,組成 3 個 16 維的熵向量,
 ,
,
 ,
,
 。
。
(2)將步驟(1)中的 3 個 16 維的向量融合成一個 48 維的熵特征向量 。同理,可得到 64 維的統計量特征向量
。同理,可得到 64 維的統計量特征向量 ,其中
,其中
 ,
,
 ,
, ,
, 。64 維的 rPSD 特征向量
。64 維的 rPSD 特征向量 ,其中
,其中 ,
,
 ,
, ,
,
 。
。
通過以上的處理方法,特征向量的維數會成倍增加。因此,本研究除了對特征做標準化處理之外,還利用了單變量特征選擇方法和基于懲罰項的特征選擇方法進行特征選擇[11]。
1.3.3 特征選擇
對于預處理好的數據,為了減少數據的特征數量,防止過擬合現象,使模型泛化能力更強,需要選擇最有利于分類的特征進行模型訓練和分類識別,通常從特征的發散程度和特征與目標變量的相關性兩方面的統計指標去考慮。
單變量特征選擇方法是通過計算每一個特征的某個統計指標,以此來評價該特征的重要性。本研究使用了卡方檢驗(chi-square test,CT)和互信息檢驗(mutual information test,MT)兩個指標對應的算法來做特征選擇。CT 用來度量特征與目標變量之間的獨立性,MT 則是評價特征與目標變量間的相關性。最終,選擇前K個最重要的特征用于分類識別[11]。該特征選擇方法的優點是原理簡單易懂,利于數據理解,缺點是沒有考慮特征之間的獨立性和相關性,會丟失特征之間相關的信息。
基于懲罰項的特征選擇方法是利用算法本身的打分機制,通過訓練得到各個特征的權值系數,再根據權值系數從大到小排列,選擇權值系數較高的特征。本研究使用了基于 L1 范數作為懲罰項的線性支持分類機(linear support vector classify,LS)和邏輯回歸(logistic regression,LR)兩種算法作為對比來進行特征選擇。此類方法的特點是特征選擇過程和模型訓練過程是同時進行的,可以減少訓練時間,且引入 L1 范數可以有效地降低過擬合的風險。
本研究也利用以上的特征選擇方法,對每個電極的特征權重進行評估,篩選出了特征權重最大的電極及相應的腦區。
1.3.4 分類器
本研究使用了 NB 和 SVM 兩種分類器。NB 算法的核心是貝葉斯公式,即利用貝葉斯公式計算待分樣本屬于每一個類別的概率,最終將待分樣本歸為概率最大的那一類別。NB 邏輯簡單易于實現,但是其假設樣本特征之間相互獨立,會降低模型的泛化性能。
SVM 的主要思想是將特征通過核函數映射到一個高維空間,在這個高維空間中尋找一個最優決策超平面,使得該超平面不僅可以將兩個樣本分開,而且使該超平面距其兩側最近的樣本之間的距離最大化,從而使其具有良好的泛化能力。其中距超平面最近的樣本被定義為支持向量。實際中會根據數據的特性,選用相應的核函數。
本研究數據集的 80% 用于訓練,20% 用于測試。在訓練過程中,本研究使用K折交叉驗證法(K = 10)無重復抽樣地劃分訓練數據為訓練集和驗證集,訓練集用來訓練模型,驗證集用來評估模型性能,這樣能充分降低模型過擬合現象,提高模型的穩定性和泛化能力。本研究也使用了網格化搜索函數來優化模型[12]。
1.3.5 分類結果評估
本研究用查準率(precision)(以符號Pr表示)、查全率(recall)(以符號Re表示)、準確率(accuracy)(以符號Acc表示)來評價模型的性能[12-13]。以 DP 患者的度量為例,查準率、查全率、準確率的定義公式如式(4)~(6)所示:
 |
 |
 |
其中,真陽性(true positive,TP)(符號記為:TP)表示本來是 DP 患者被預測為 DP 患者的個數;假陽性(false positive,FP)(符號記為:FP)表示本來是 SCZ 患者被預測為 DP 患者的個數;真陰性(true negative,TN)(符號記為:TN)表示本來是 SCZ 患者被預測為 SCZ 患者的個數;假陰性(false negative,FN)(符號記為:FN)表示本來 DP 患者被預測為 SCZ 患者的個數。為了便于表達,以符號 mPr 表示兩種疾病的平均查準率,以符號 mRe 表示兩種疾病的平均查全率。
2 結果
本研究在實驗初期將患者的睜、閉眼狀態下的 EEG 信號各自組成數據集和聯合組成數據集進行二分類。實驗結果發現,睜眼狀態下的最高準確率是 76%,兩種狀態聯合情況下的最高準確率是 77%,都沒有閉眼狀態下的分類效果好,且睜眼狀態數據集的加入反而降低了閉眼狀態數據集的分類效果。所以本研究選擇了閉眼狀態下的數據進行深入的分類研究。
本研究分別利用閉眼狀態 PSD 的三種特征向量 、
、 、
、
 作為 SVM 和 NB 分類器的輸入,利用單變量特征選擇方法和基于懲罰項的特征選擇方法進行特征選擇和降維。實驗結果如表 1 所示,其中效果最好的是 P + LS + SVM 的組合模型,即以 P 作為特征向量,以 LS 算法進行特征選擇,以 SVM 作為分類器,此時兩種疾病的平均查準率和平均查全率最高,都達到 85%。根據表 1 中的結果主要得到以下結論:
作為 SVM 和 NB 分類器的輸入,利用單變量特征選擇方法和基于懲罰項的特征選擇方法進行特征選擇和降維。實驗結果如表 1 所示,其中效果最好的是 P + LS + SVM 的組合模型,即以 P 作為特征向量,以 LS 算法進行特征選擇,以 SVM 作為分類器,此時兩種疾病的平均查準率和平均查全率最高,都達到 85%。根據表 1 中的結果主要得到以下結論:
(1)SVM 的分類效果優于 NB。
(2)三種特征向量中,rPSD 組成的特征向量P的分類效果最好。
(3)基于懲罰項的特征選擇方法處理的特征向量分類效果比單變量特征選擇方法的更好。
為了驗證表 1中最優組合模型的泛化性能,本研究將 P + LS + SVM 的組合模型結合 K 折交叉驗證法進行 10 次實驗,記錄最低、最高和平均準確率。同時,為了進一步驗證 rPSD 的識別度,再以 P + LS + SVM 的組合模型結合留出法[13]進行 10 次實驗,記錄相應的結果。實驗結果如表 2 所示,其中最優組合模型結合K折交叉驗證法得到的準確率最高為 84.6%、最低為 81.2%、平均為 83.1%;結合留出法得到的準確率最高為 86.3%、最低為 82.0%、平均為 84.2%。
如表 3 所示,比較了以各個節律的 rPSD 分別作為特征向量進行分類的結果。其中 β 節律 rPSD 組成的特征向量Pβ 的平均查準率和平均查全率最高,都可達 76%。
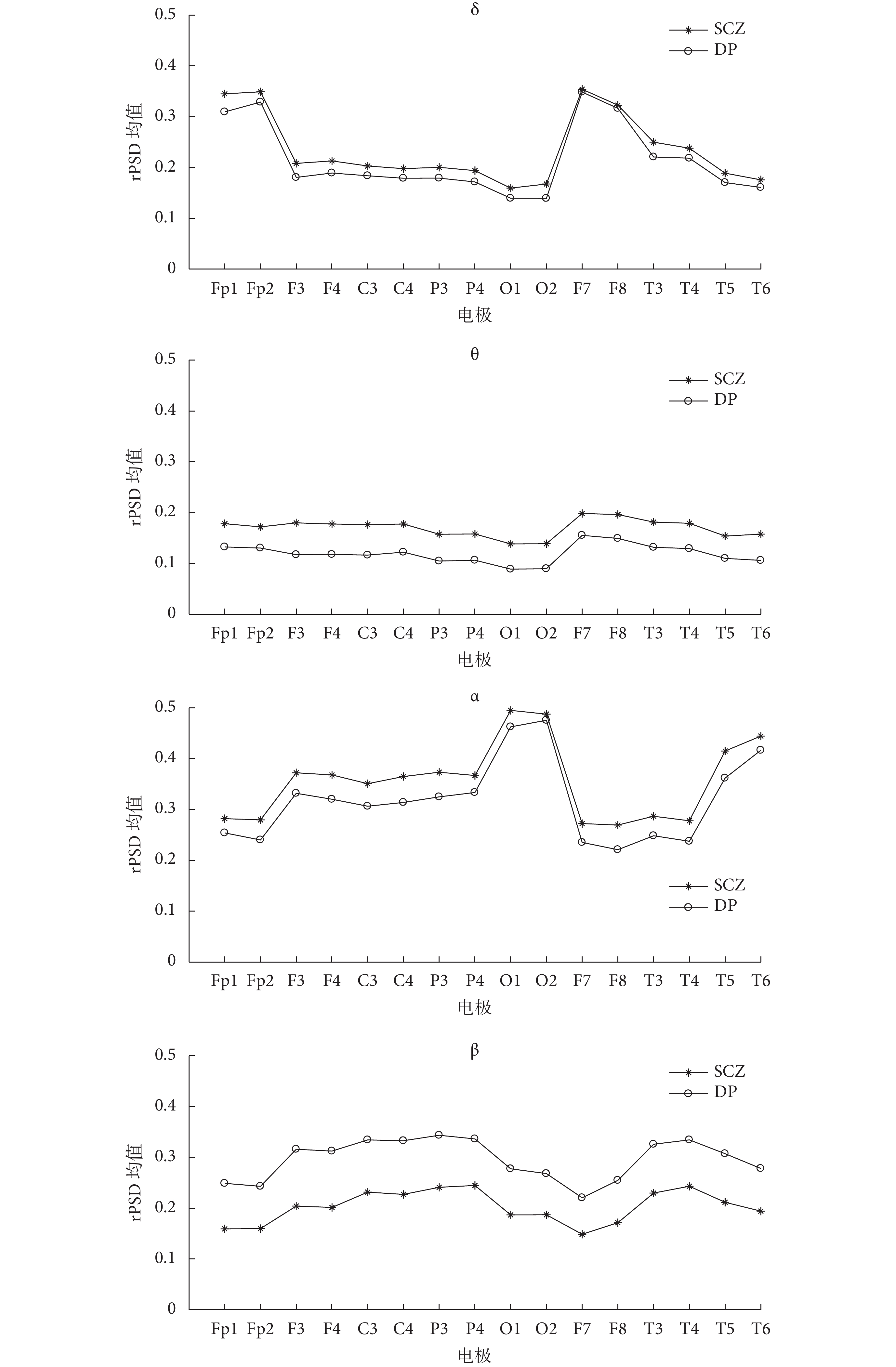
此外,各電極不同節律的 rPSD 的均值對比情況如圖 3 所示,可以發現同一節律 rPSD 的均值在各電極上的變化趨勢一致。
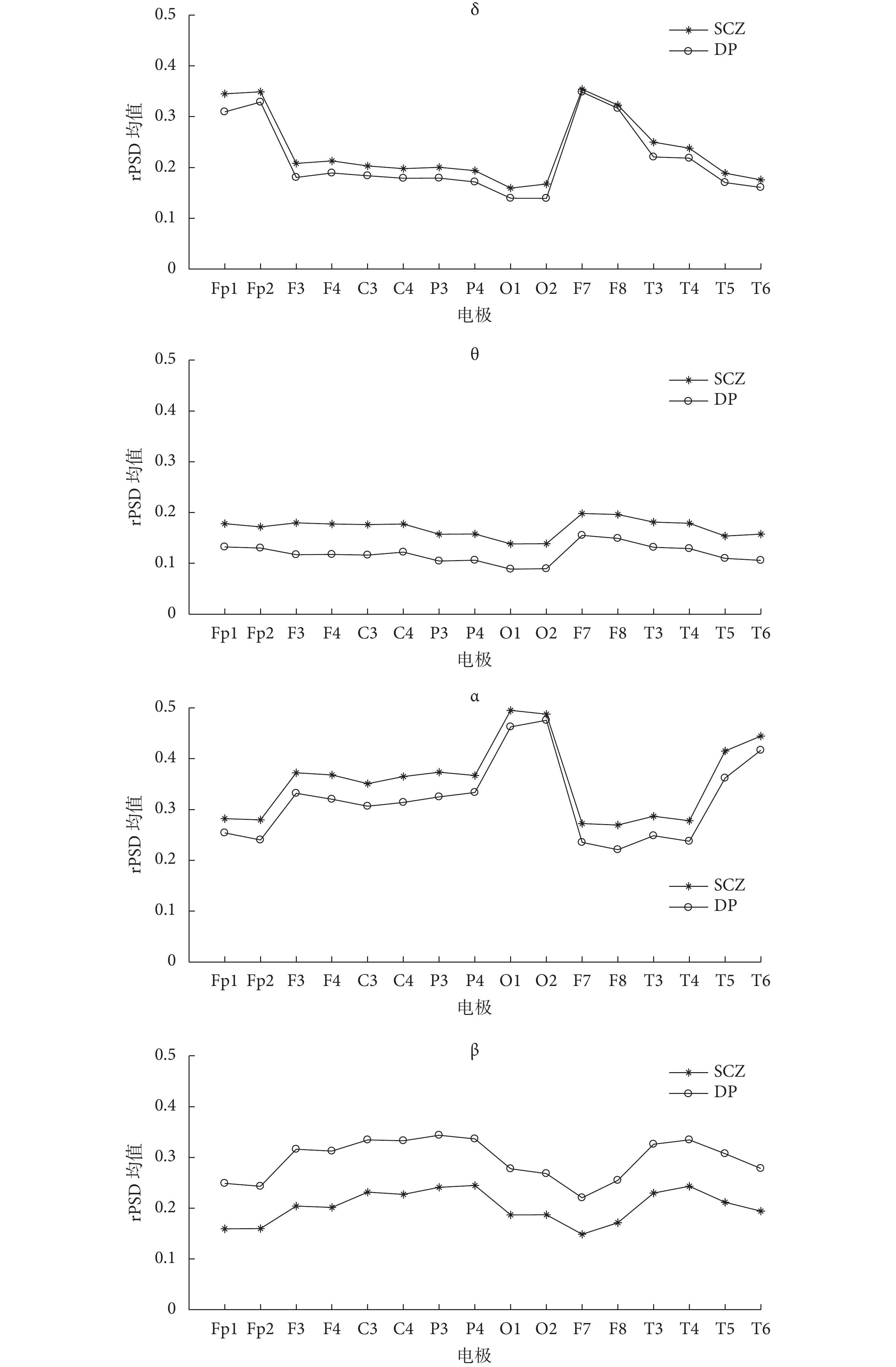 圖3
各個節律的 rPSD 均值在兩種疾病中各個電極的分布情況對比圖
Figure3.
Comparison of the distribution of rPSD mean of each rhythm in each electrode of two diseases
圖3
各個節律的 rPSD 均值在兩種疾病中各個電極的分布情況對比圖
Figure3.
Comparison of the distribution of rPSD mean of each rhythm in each electrode of two diseases
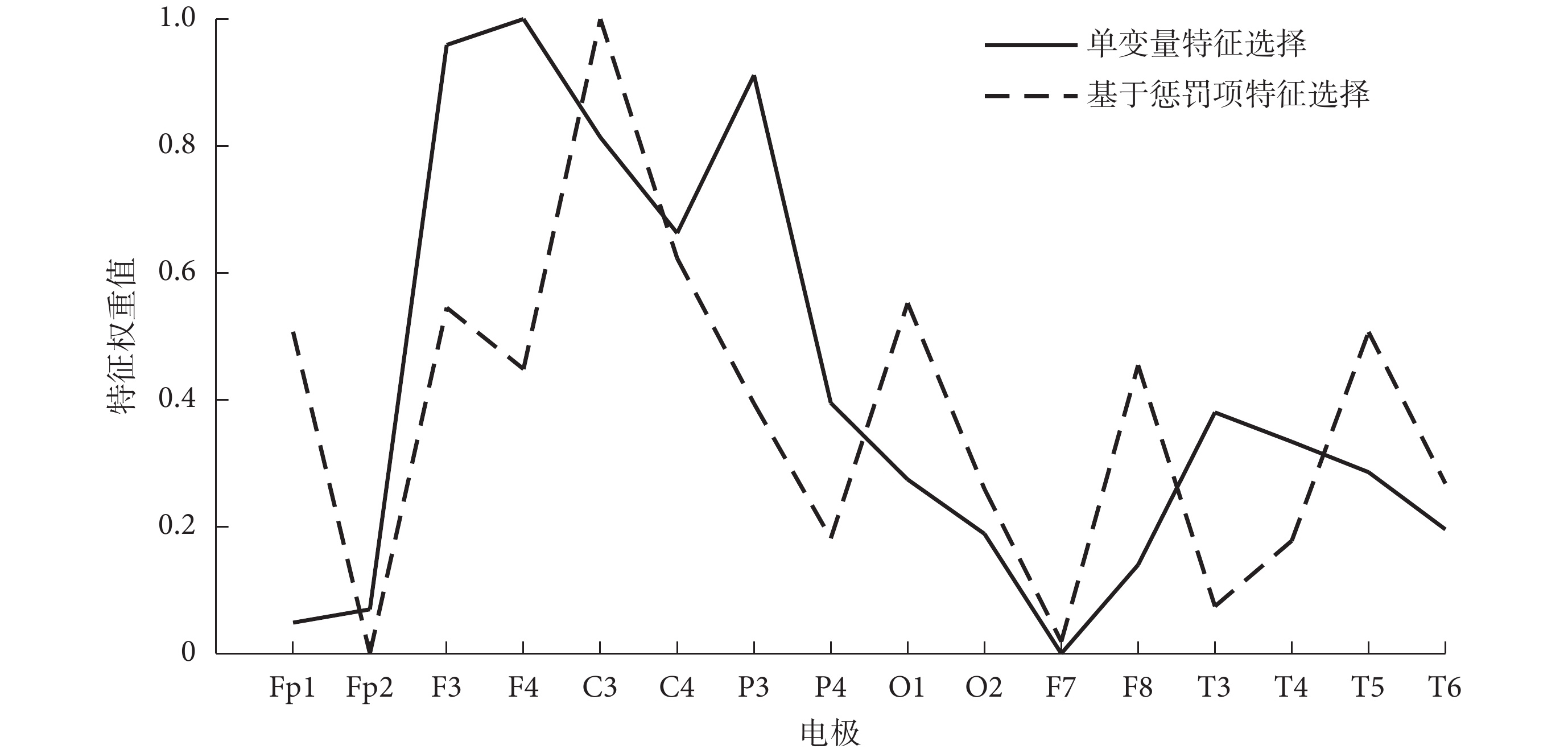
根據前文可知,特征向量P具有更高的識別度。所以,本研究在特征向量P的基礎上,分別利用 CT 和 MT 算法給各個電極打分,將 CT 算法對各個電極所打分數歸一化處理后以符號Sci表示,將 MT 算法對各個電極所打分數歸一化處理后以符號Smi表示,其中i表示電極,再將各個電極Sci、Smi分別求和后歸一化處理,得到各個電極的單變量特征選擇特征權重;利用 LS 和 LR 算法經過相同的處理,得到各個電極基于懲罰項的特征選擇特征權重。最終,各個電極的特征權重結果如圖 4 所示。
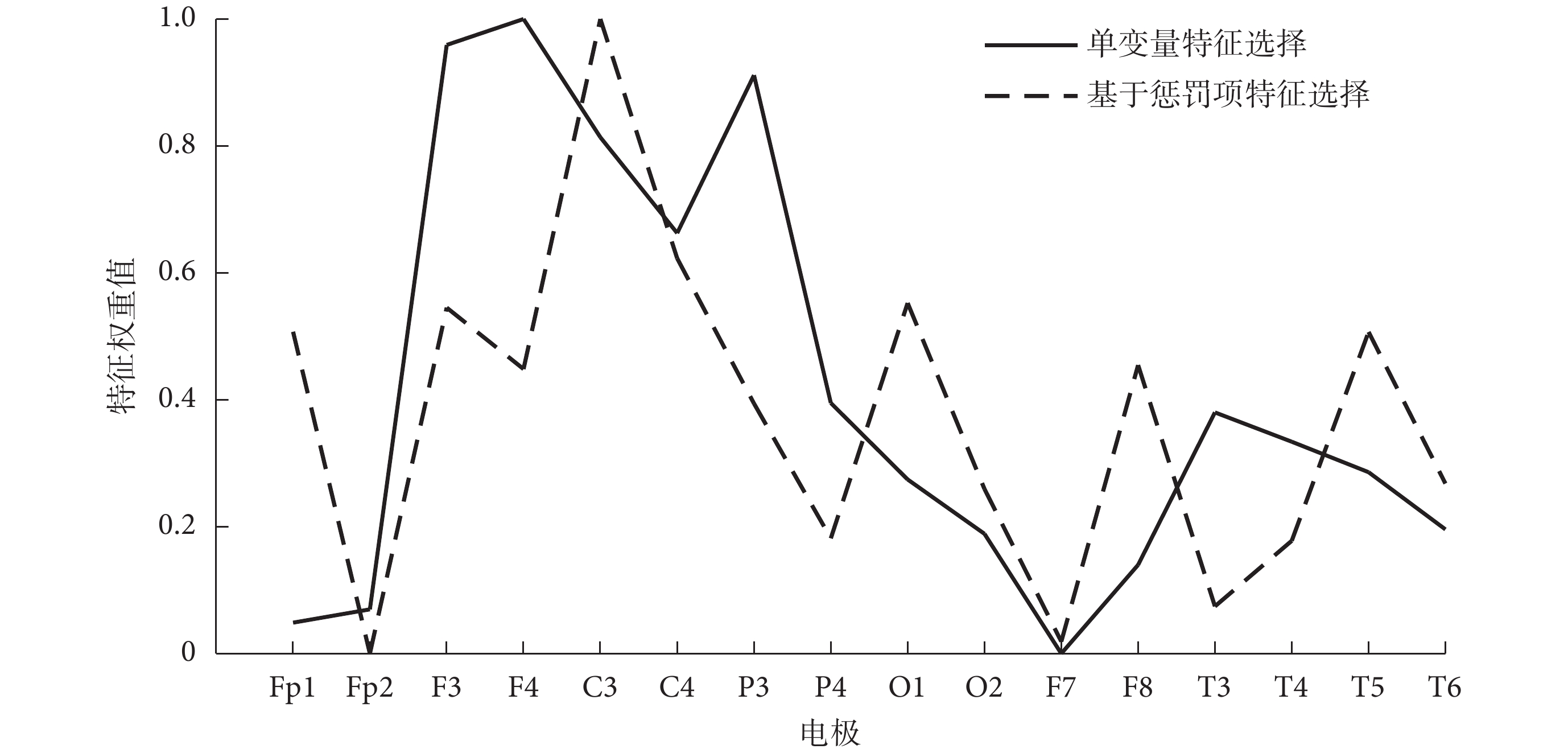 圖4
各個電極的特征權重值
Figure4.
Characteristic weight value of each electrode
圖4
各個電極的特征權重值
Figure4.
Characteristic weight value of each electrode
3 討論與分析
本研究主要利用靜息態 EEG 信號的不同特征向量,結合 SVM 和 NB 分類器,對 SCZ 患者和 DP 患者進行分類識別。如表 1所示,非線性動力學的相關特征即信息熵、近似熵和樣本熵組成的特征向量的分類準確率最高為 76%,而文獻[5]以近似熵、信息熵、譜熵和 Lempel-Ziv 復雜度等組成特征向量結合 Adaboost 算法對 SCZ 患者和正常人進行分類,最高準確率為 90%,出現這種差距的原因可能是 SCZ 患者和 DP 患者的 EEG 信號復雜度的差異程度沒有 SCZ 患者和正常人之間的高[6]。此外,表 1中P + LS + SVM 的組合模型的分類效果最好,結合表 2 中的驗證結果可知,此組合模型具有良好的泛化性能且各節律 rPSD 組成的特征向量P具有良好的識別度。各節律在 SCZ 患者和 DP 患者腦區中的分布情況存在明顯的差別[1, 6],結合表 3 和圖 3 的結果可知,本研究中 β 節律的 rPSD 識別度最高,且其 rPSD 均值在 DP 患者中更高,在 SCZ 患者中更低,而其他節律的 rPSD 均值則在 SCZ 患者中更高,在 DP 患者中更低。另外,β 節律的 rPSD 均值在兩種疾病間的差值最大,這與其分類準確率最高的結果保持一致。所以類似的研究中 β 節律更值得關注。相較于單獨節律,各個節律組合在一起的分類效果明顯提高,說明各節律之間存在較強的相關性。統計量特征屬性是對數據宏觀上的刻畫和描述,但在分類研究中樣本個性的描述更有利于分類,故表 1 中統計量的特征向量 T 的分類效果最差。
如圖 4 所示,各電極的兩種特征權重并非完全一致,權重都比較大的電極主要包括 F3、F4、C3、C4 和 P3,集中在額葉和頂葉,且呈現出半球間對稱性分布的特點;權重都最小的電極是 Fp1 和 F7,分布在左前額葉;O1、F8、T5 則是其他基于懲罰項特征選擇特征權重較大的電極,分布在右前額葉和左枕葉。額葉異常與 SCZ 患者的主要癥狀相關[14];頂葉與人體的空間記憶認知能力密切相關;枕葉在聽覺和視覺功能處理上起著重要作用,與精神障礙患者的幻覺和錯覺等癥狀密切相關;以上區域的異常變化對診斷此類疾病有著重要的參考意義。
本研究表明 SVM 的分類效果優于 NB,與相關研究有 SVM 分類效果普遍優于其他分類器的結論一致[3, 7]。此外,以 Pβ 為特征向量進行分類時,NB 的分類效果有明顯提升,原因可能是 Pβ 數據間的相關性更小,因為 NB 的前提條件是假設屬性之間相互獨立。
綜上所述,本研究發現 rPSD 組成的特征向量具有很好的識別度,最高準確率可達 86.3%,并發現權重大的特征主要集中在額葉、頂葉和左枕葉,該研究結果可為 SCZ 和 DP 的準確區分和診斷提供有力的參考。目前本研究只在頻域提取特征,下一步將嘗試結合腦網絡特征進一步研究精神障礙疾病的分類,為此類疾病的臨床診斷提供更加可靠的參考。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。
引言
精神分裂癥(schizophrenia,SCZ)和抑郁癥(depression,DP)是現今高發且危害較大的精神疾病,及時準確的診斷將有助于此類疾病的治療。腦電圖(electroencephalogram,EEG)記錄的是大腦神經細胞的電活動信號。研究表明,SCZ 和 DP 患者的 EEG 信號在節律、波幅和功率等方面均與正常人存在差異,因此對 EEG 信號進行深入研究,有助于精確區分和診斷這兩種疾病。
EEG 信號的分析方法主要包括時域、頻域、時頻域分析和非線性動力學分析等。Begi?等[1]通過量化 EEG 信號對 SCZ、DP 患者和正常人進行比較研究,發現 SCZ 患者和 DP 患者 EEG 信號的不同節律在各電極分布的情況存在明顯差異。當前,EEG 信號的時頻域分析方法已被廣泛應用 [2-4],如 Boashash 等[3]通過綜合分析時頻域的統計量特征、時頻域圖像特征和時頻域信號特征,對新生兒 EEG 信號癲癇病例進行分類識別,最高準確率達到 86.61%。另一方面,非線性動力學分析方法主要包括信號的樣本熵、近似熵、信息熵和 Lempel-Ziv 復雜度等度量分析[2-7],在分類研究中常與時頻域的特征相結合。例如,Sabeti 等[5]將樣本熵、近似熵和 Lempel-Ziv 復雜度等組成的特征向量用于 SCZ 患者和正常人的 EEG 信號分類,準確率達到了 91.26%。Li 等[6]用 Lempel-Ziv 復雜度研究 SCZ、DP 患者和正常人的 EEG 數據,發現 SCZ 組患者和 DP 組患者 EEG 信號的 Lempel-Ziv 復雜度有明顯的差異,且都高于正常人組。而在分類方法方面,Faust 等[7]利用非線性動力學分析方法提取 DP 患者和正常人的 EEG 信號特征向量進行多種分類器比較研究,發現概率神經網絡要優于其他方法。通過以上研究分析發現,目前的研究主要集中在患者和正常人之間的分類與識別,直接針對 SCZ 和 DP 患者的相關分類研究非常少。在 EEG 信號的特征選擇和特征提取方面,雖然有多種方法的結合應用,但是這些方法沒有充分考慮到不同頻段的 EEG 信號對特征選擇和特征提取有不同影響。
針對以上問題,本研究在頻域上結合非線性動力學分析方法和時域統計學分析的方法,提取不同的特征向量,利用不同的分類器對 SCZ 患者和 DP 患者的 EEG 信號進行分類研究。本研究整體流程如圖 1 所示,首先將采集的靜息態 EEG 信號進行預處理,并將其轉換成頻域信號,求得每段信號的功率譜密度(power spectral density,PSD)。然后,提取 PSD 的特征向量,即統計量特征、非線性動力學特征以及不同頻段的相對功率譜密度(relative power spectral density,rPSD),并且利用單變量特征選擇方法和基于懲罰項的特征選擇方法對 PSD 數據進行特征選擇和降維,再將得到的特征向量輸入到支持向量機(support vector machine,SVM)和樸素貝葉斯(naive Bayes,NB)分類器中進行分類研究。最后,利用查準率、查全率和準確率進行模型評估,比較不同的特征向量結合不同分類器的分類效果,檢驗不同特征的識別度,為精確區分 SCZ 患者和 DP 患者提供參考。此外,本研究利用以上特征選擇方法對特征屬性進行打分評估,計算每個電極的特征權重,找到了權重較大的腦區,以期為患者的臨床診斷和區分提供相關參考。
圖1
整體流程圖
Figure1.
The overall flow chart
1 材料和方法
1.1 數據來源和采集
本研究的數據來自于四川大學華西醫院第二門診部心理衛生中心,本課題組和該中心簽署了合作協議和保密協議,得到了數據的使用授權許可,且所有參與數據采集的患者都簽署了患者知情同意書。本課題組從符合國際疾病分類(international classification of diseases,ICD)確診的 SCZ 患者和 DP 患者中,按照 1∶1 匹配篩選出 SCZ 患者和 DP 患者各 100 例,其中:SCZ 患者男女各 50 名,平均年齡為(41.5 ± 4.37)歲;DP 患者男女各 50 名,平均年齡為(41.5 ± 4.35)歲,所有患者的年齡均在 32~51 歲之間,且服從正態分布,兩種患者的年齡、性別差異均無統計學意義(P > 0.05)。
本研究 EEG 信號的采集使用的是動態 EEG 儀(NATION8128W,上海諾誠電氣有限公司,中國),采樣頻率為 128 Hz,信號采集使用的是 16 通道的腦電帽,電極安置的方法遵循國際 10-20 導聯標準,電極的分布如圖 2 所示。信號采集全程在安靜封閉的室內進行,患者需閉眼,并保持安靜、清醒、放松的狀態。提示患者開始后,記錄 EEG 信號。首先,患者先閉眼做深呼吸 3 min,深呼吸結束后睜眼,給予 10 s 左右的緩和時間。然后,閉眼保持 7 s,緊接著睜眼保持 7 s,以此為一個閉、睜眼采集周期,連續采集三個這樣的閉、睜眼周期之后結束采集。但在實際采集過程存在操作誤差,所以閉、睜眼保持的時間實際是在 5~10 s 之間。
圖2
電極分布圖
Figure2.
Electrodes distribution map
1.2 數據預處理
本研究的數據參照文獻[8]進行預處理,具體的處理步驟包括:① 電極重定位;② 剔除無用電極;③ 濾波處理,帶通濾波器的頻段為 0.5~45 Hz,陷波為 50 Hz;④ 根據睜、閉眼的標記將數據分段;⑤ 用獨立成分分析方法去除偽跡;⑥ 用所有電極的平均電位進行電位重參考。
通過以上預處理后,得到長度在 5~10 s 之間的數據段。再分別計算睜、閉眼狀態下每段數據的 PSD。其中睜眼狀態下的數據共有 580 段,包含 DP 患者的 292 段、SCZ 患者的 288 段;閉眼狀態下的數據共有 585 段,包含 DP 患者的 295 段、SCZ 患者的 290 段。
1.3 特征向量
1.3.1 PSD 的特征
信息熵(information entropy,InEn)(以符號InEn表示)由 Shannon 提出,是系統不確定性和信息量大小的度量,也是整個系統不確定性的期望。當一個系統越有序,信息熵就越低;越混亂,信息熵就越高。其定義公式如式(1)所示[9-10]:
|
其中,pi 表示事件發生的概率,i 表示樣本數量。
本研究中 PSD 的頻率為 1~55 Hz,故可以把每個電極的信號看成是一個頻率的固定序列,每個頻率點對應的 PSD 值為Pi,且,通過歸一化后表示為PNi,且。則求 PSD 數據的某一個電極的信息熵公式如式(2)所示:
|
其中,,且。
近似熵(approximate entropy,ApEn)(以符號ApEn表示)是一種用于量化時間序列變化的非線性動力學非負參數,表示一個時間序列的復雜性,反映了時間序列中新信息發生的可能性,越復雜的時間序列其近似熵就越大[5, 10],算法步驟表述如下:
(1)對于等時間間隔的N維時間序列,定義相關參數m,r;其中m表示重構向量的長度,r是相似系數,用于重構向量間相似度的度量。
(2)定義表示重構向量之間的距離。其中,、表示重構向量、對應位置的元素,、。
(3)對于上述序列,重構 m 維向量,其中。
(4)計算重構向量、間的距離。當時,兩重構向量相似。表示相似重構向量個數。計算相似的重構向量所占比例為:。
(5)定義公式: 。
(6)最后定義近似熵為: 。
樣本熵(sample entropy,SaEn)(以符號SaEn表示)也是表征時間序列復雜度的指標[4]。與近似熵比較,樣本熵優點在于其算法需要的數據量更小,所用時間少[5],不同點在于相較于前述近似熵算法中的(2)、(4)步中,樣本熵的步驟中多了的條件,且第(4)步中相似度量的條件是。由于步驟(1)~(4)與近似熵一樣,故不再贅述,步驟(5)、(6)的具體算法表述如下:
(5)定義公式: ,即計算的均值。
(6)定義樣本熵為: 。
本研究把頻率序列等效成時間序列,分別計算每個電極的近似熵和樣本熵,參數設置為 m = 2,r = 0.2·std。其中,符號std表示序列的標準差(standard deviation)。
統計學變量能反映數據本身的特性,本研究計算了每個電極 PSD 數據Pi的均值m、方差v、偏度s和峰度k來描述該數據。此外,將 PSD 分成 δ(1~3 Hz)、θ(4~7 Hz)、α(8~13 Hz)、β(14~30 Hz)四段節律,分別求每段節律的 rPSD。δ 的 rPSD 計算公式如式(3)所示:
|
其中,Pi表示 PSD 值,i表示頻率點,j表示電極,,同理可得Pθ(j),Pα(j),Pβ(j)。
1.3.2 多通道特征提取和融合
本研究先計算每個電極上的數據特征,再將其組成一個特征向量,以此來描述每一段 PSD 數據。具體的方法如下:
(1)將睜、閉眼狀態下的每一段 PSD 數據看成一個樣本,分別計算每個樣本中每一個電極的信息熵、近似熵和樣本熵,組成 3 個 16 維的熵向量,,,。
(2)將步驟(1)中的 3 個 16 維的向量融合成一個 48 維的熵特征向量。同理,可得到 64 維的統計量特征向量,其中,,,。64 維的 rPSD 特征向量,其中,,,。
通過以上的處理方法,特征向量的維數會成倍增加。因此,本研究除了對特征做標準化處理之外,還利用了單變量特征選擇方法和基于懲罰項的特征選擇方法進行特征選擇[11]。
1.3.3 特征選擇
對于預處理好的數據,為了減少數據的特征數量,防止過擬合現象,使模型泛化能力更強,需要選擇最有利于分類的特征進行模型訓練和分類識別,通常從特征的發散程度和特征與目標變量的相關性兩方面的統計指標去考慮。
單變量特征選擇方法是通過計算每一個特征的某個統計指標,以此來評價該特征的重要性。本研究使用了卡方檢驗(chi-square test,CT)和互信息檢驗(mutual information test,MT)兩個指標對應的算法來做特征選擇。CT 用來度量特征與目標變量之間的獨立性,MT 則是評價特征與目標變量間的相關性。最終,選擇前K個最重要的特征用于分類識別[11]。該特征選擇方法的優點是原理簡單易懂,利于數據理解,缺點是沒有考慮特征之間的獨立性和相關性,會丟失特征之間相關的信息。
基于懲罰項的特征選擇方法是利用算法本身的打分機制,通過訓練得到各個特征的權值系數,再根據權值系數從大到小排列,選擇權值系數較高的特征。本研究使用了基于 L1 范數作為懲罰項的線性支持分類機(linear support vector classify,LS)和邏輯回歸(logistic regression,LR)兩種算法作為對比來進行特征選擇。此類方法的特點是特征選擇過程和模型訓練過程是同時進行的,可以減少訓練時間,且引入 L1 范數可以有效地降低過擬合的風險。
本研究也利用以上的特征選擇方法,對每個電極的特征權重進行評估,篩選出了特征權重最大的電極及相應的腦區。
1.3.4 分類器
本研究使用了 NB 和 SVM 兩種分類器。NB 算法的核心是貝葉斯公式,即利用貝葉斯公式計算待分樣本屬于每一個類別的概率,最終將待分樣本歸為概率最大的那一類別。NB 邏輯簡單易于實現,但是其假設樣本特征之間相互獨立,會降低模型的泛化性能。
SVM 的主要思想是將特征通過核函數映射到一個高維空間,在這個高維空間中尋找一個最優決策超平面,使得該超平面不僅可以將兩個樣本分開,而且使該超平面距其兩側最近的樣本之間的距離最大化,從而使其具有良好的泛化能力。其中距超平面最近的樣本被定義為支持向量。實際中會根據數據的特性,選用相應的核函數。
本研究數據集的 80% 用于訓練,20% 用于測試。在訓練過程中,本研究使用K折交叉驗證法(K = 10)無重復抽樣地劃分訓練數據為訓練集和驗證集,訓練集用來訓練模型,驗證集用來評估模型性能,這樣能充分降低模型過擬合現象,提高模型的穩定性和泛化能力。本研究也使用了網格化搜索函數來優化模型[12]。
1.3.5 分類結果評估
本研究用查準率(precision)(以符號Pr表示)、查全率(recall)(以符號Re表示)、準確率(accuracy)(以符號Acc表示)來評價模型的性能[12-13]。以 DP 患者的度量為例,查準率、查全率、準確率的定義公式如式(4)~(6)所示:
|
|
|
其中,真陽性(true positive,TP)(符號記為:TP)表示本來是 DP 患者被預測為 DP 患者的個數;假陽性(false positive,FP)(符號記為:FP)表示本來是 SCZ 患者被預測為 DP 患者的個數;真陰性(true negative,TN)(符號記為:TN)表示本來是 SCZ 患者被預測為 SCZ 患者的個數;假陰性(false negative,FN)(符號記為:FN)表示本來 DP 患者被預測為 SCZ 患者的個數。為了便于表達,以符號 mPr 表示兩種疾病的平均查準率,以符號 mRe 表示兩種疾病的平均查全率。
2 結果
本研究在實驗初期將患者的睜、閉眼狀態下的 EEG 信號各自組成數據集和聯合組成數據集進行二分類。實驗結果發現,睜眼狀態下的最高準確率是 76%,兩種狀態聯合情況下的最高準確率是 77%,都沒有閉眼狀態下的分類效果好,且睜眼狀態數據集的加入反而降低了閉眼狀態數據集的分類效果。所以本研究選擇了閉眼狀態下的數據進行深入的分類研究。
本研究分別利用閉眼狀態 PSD 的三種特征向量、、 作為 SVM 和 NB 分類器的輸入,利用單變量特征選擇方法和基于懲罰項的特征選擇方法進行特征選擇和降維。實驗結果如表 1 所示,其中效果最好的是 P + LS + SVM 的組合模型,即以 P 作為特征向量,以 LS 算法進行特征選擇,以 SVM 作為分類器,此時兩種疾病的平均查準率和平均查全率最高,都達到 85%。根據表 1 中的結果主要得到以下結論:
(1)SVM 的分類效果優于 NB。
(2)三種特征向量中,rPSD 組成的特征向量P的分類效果最好。
(3)基于懲罰項的特征選擇方法處理的特征向量分類效果比單變量特征選擇方法的更好。
為了驗證表 1中最優組合模型的泛化性能,本研究將 P + LS + SVM 的組合模型結合 K 折交叉驗證法進行 10 次實驗,記錄最低、最高和平均準確率。同時,為了進一步驗證 rPSD 的識別度,再以 P + LS + SVM 的組合模型結合留出法[13]進行 10 次實驗,記錄相應的結果。實驗結果如表 2 所示,其中最優組合模型結合K折交叉驗證法得到的準確率最高為 84.6%、最低為 81.2%、平均為 83.1%;結合留出法得到的準確率最高為 86.3%、最低為 82.0%、平均為 84.2%。
如表 3 所示,比較了以各個節律的 rPSD 分別作為特征向量進行分類的結果。其中 β 節律 rPSD 組成的特征向量Pβ 的平均查準率和平均查全率最高,都可達 76%。
此外,各電極不同節律的 rPSD 的均值對比情況如圖 3 所示,可以發現同一節律 rPSD 的均值在各電極上的變化趨勢一致。
圖3
各個節律的 rPSD 均值在兩種疾病中各個電極的分布情況對比圖
Figure3.
Comparison of the distribution of rPSD mean of each rhythm in each electrode of two diseases
根據前文可知,特征向量P具有更高的識別度。所以,本研究在特征向量P的基礎上,分別利用 CT 和 MT 算法給各個電極打分,將 CT 算法對各個電極所打分數歸一化處理后以符號Sci表示,將 MT 算法對各個電極所打分數歸一化處理后以符號Smi表示,其中i表示電極,再將各個電極Sci、Smi分別求和后歸一化處理,得到各個電極的單變量特征選擇特征權重;利用 LS 和 LR 算法經過相同的處理,得到各個電極基于懲罰項的特征選擇特征權重。最終,各個電極的特征權重結果如圖 4 所示。
圖4
各個電極的特征權重值
Figure4.
Characteristic weight value of each electrode
3 討論與分析
本研究主要利用靜息態 EEG 信號的不同特征向量,結合 SVM 和 NB 分類器,對 SCZ 患者和 DP 患者進行分類識別。如表 1所示,非線性動力學的相關特征即信息熵、近似熵和樣本熵組成的特征向量的分類準確率最高為 76%,而文獻[5]以近似熵、信息熵、譜熵和 Lempel-Ziv 復雜度等組成特征向量結合 Adaboost 算法對 SCZ 患者和正常人進行分類,最高準確率為 90%,出現這種差距的原因可能是 SCZ 患者和 DP 患者的 EEG 信號復雜度的差異程度沒有 SCZ 患者和正常人之間的高[6]。此外,表 1中P + LS + SVM 的組合模型的分類效果最好,結合表 2 中的驗證結果可知,此組合模型具有良好的泛化性能且各節律 rPSD 組成的特征向量P具有良好的識別度。各節律在 SCZ 患者和 DP 患者腦區中的分布情況存在明顯的差別[1, 6],結合表 3 和圖 3 的結果可知,本研究中 β 節律的 rPSD 識別度最高,且其 rPSD 均值在 DP 患者中更高,在 SCZ 患者中更低,而其他節律的 rPSD 均值則在 SCZ 患者中更高,在 DP 患者中更低。另外,β 節律的 rPSD 均值在兩種疾病間的差值最大,這與其分類準確率最高的結果保持一致。所以類似的研究中 β 節律更值得關注。相較于單獨節律,各個節律組合在一起的分類效果明顯提高,說明各節律之間存在較強的相關性。統計量特征屬性是對數據宏觀上的刻畫和描述,但在分類研究中樣本個性的描述更有利于分類,故表 1 中統計量的特征向量 T 的分類效果最差。
如圖 4 所示,各電極的兩種特征權重并非完全一致,權重都比較大的電極主要包括 F3、F4、C3、C4 和 P3,集中在額葉和頂葉,且呈現出半球間對稱性分布的特點;權重都最小的電極是 Fp1 和 F7,分布在左前額葉;O1、F8、T5 則是其他基于懲罰項特征選擇特征權重較大的電極,分布在右前額葉和左枕葉。額葉異常與 SCZ 患者的主要癥狀相關[14];頂葉與人體的空間記憶認知能力密切相關;枕葉在聽覺和視覺功能處理上起著重要作用,與精神障礙患者的幻覺和錯覺等癥狀密切相關;以上區域的異常變化對診斷此類疾病有著重要的參考意義。
本研究表明 SVM 的分類效果優于 NB,與相關研究有 SVM 分類效果普遍優于其他分類器的結論一致[3, 7]。此外,以 Pβ 為特征向量進行分類時,NB 的分類效果有明顯提升,原因可能是 Pβ 數據間的相關性更小,因為 NB 的前提條件是假設屬性之間相互獨立。
綜上所述,本研究發現 rPSD 組成的特征向量具有很好的識別度,最高準確率可達 86.3%,并發現權重大的特征主要集中在額葉、頂葉和左枕葉,該研究結果可為 SCZ 和 DP 的準確區分和診斷提供有力的參考。目前本研究只在頻域提取特征,下一步將嘗試結合腦網絡特征進一步研究精神障礙疾病的分類,為此類疾病的臨床診斷提供更加可靠的參考。
利益沖突聲明:本文全體作者均聲明不存在利益沖突。